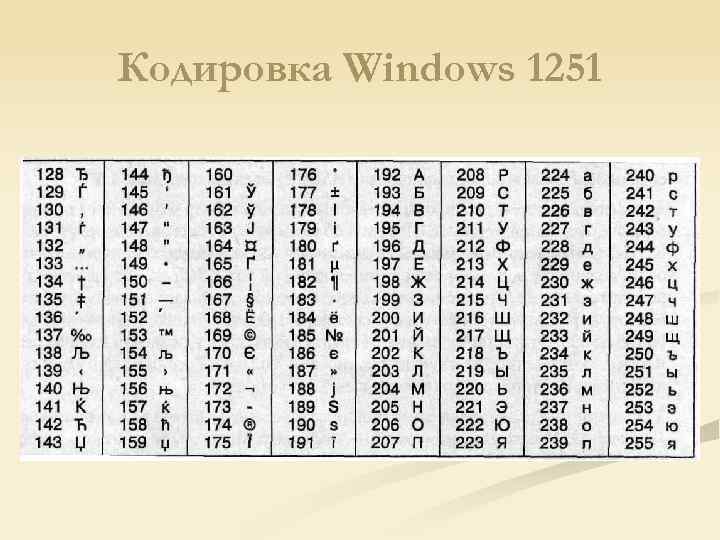
Порядок подготовки и конвертации OpenEdge базы данных для работы с кодировкой KZ-1048
KZ-1048 – аббревиатура для кодовой таблицы с символами казахского языка, основанной на стандарте СТ РК 1048-2002, которая используется в базах данных OpenEdge Progress.
Для примера будет использоваться база данных с кодировкой KOI8-R.
Предварительно, на компьютер пользователя, который будет работать с базой с поддержкой казахского языка, должны быть установлены казахские шрифты. Эти шрифты можно скачать здесь http://www.sci.kz/%7Esairan/kazwin95.html. Скачайте и установите их. После этого необходимо добавить казахскую консоль в Windows. Для этого щелкните право кнопкой на значке языка и выберите Settings
Далее всё как обычно, при добавлении языка в Windows.
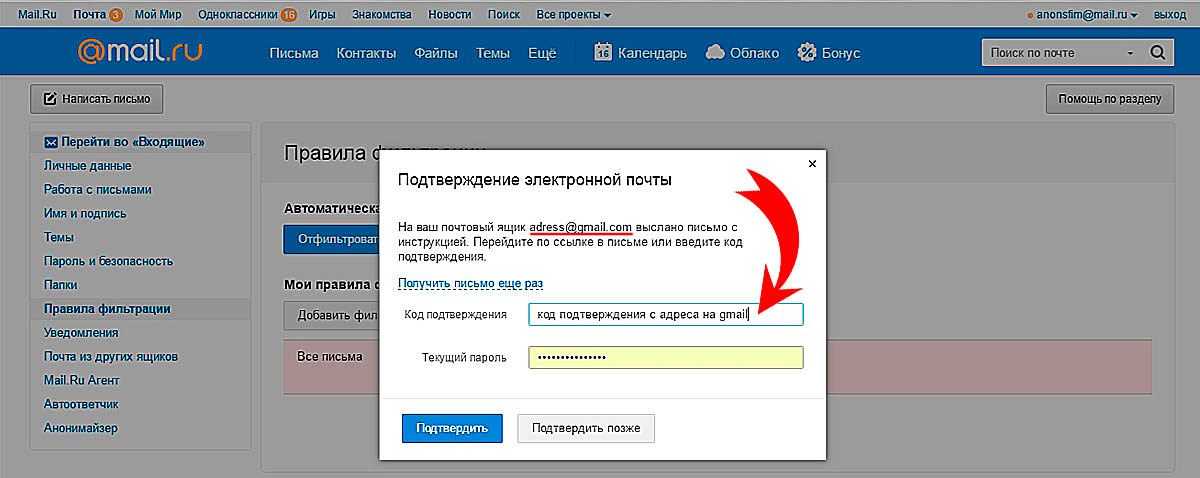
Еще одно. Терминалу PuTTY нужно указать, с какой кодировкой ему придется работать, чтобы корректно отображать казахские символы. Для этого в настройках терминала выставьте значение кодировки как показано на рисунке:
Выбор кодировки Win1251 (Cyrillic) обусловлен тем, что стандарт СТ РК 1048-2002 основан именно на кодировке 1251.
1. Подготовка файла convmap.cp
Необходимые файлы для кодировки KZ-1048 лежат здесь(Скачать):
convmap.dat – файл со списком кодировок, которые будут содержаться в convmap.cp
KZ-1048.dat – файл с кодировкой KZ-1048 и таблицей сопоставления с кодировкой UTF-8
KZ-1048.df – кодовая страница KZ-1048
utf-8.dat – файл с описанием кодировки UTF-8
undefine.dat – файл с описание undefined кодировки
ICU-ru.df – таблица сортировки для кириллицы
readme.txt – описание процесса создания нового файла convmap.cp
В дальнейшем, для работы базы данных с этой кодировкой необходимо использовать параметр –covnmap со значением, которое будет содержать полный путь к казахскому convmap.cp. Для удобства работы, по окончании конвертации этот файл можно будет поместить в установочный каталог Progress.
1. Подготовка к конвертации
1. 1 Подготовка файла для загрузки данных
1 Подготовка файла для загрузки данных
В нашем случае (смена кодовой таблицы базы) возможна только загрузка текстовых данных (текстовый дамп). Для быстрой загрузки текстовых данных существует утилита bulkload, которая для загрузки использует файл описания с расширением .fd. Для подготовки этого файла необходимо:
1. зайти в Tools -> Data Dictionary -> Admin -> Create Bulk Loader Description File…
2. Нажать F5
3. Ввести «*», Enter – будут выделены все таблицы
4. Нажать F1, откроется окно «Make Bulk Load Description File for Some Tables»
5. Ни чего не меняя, еще раз нажать F1, начнется формирование файла
По завершению формирования файла будет выдано сообщение «Making of bulk load description file completed.»
В текущем рабочем каталоге будет создан файл <dbname>.fd, который будет в дальнейшем использован для загрузки данных.

Внимание! В базе могут существовать поля в таблице с типом RECID, поля с этим типом игнорируются при формировании bulk loader файла. Поэтому, после создания файла, необходимо вручную добавить их в файл. В противном случае, в дальнейшем, при загрузке данных вы получите ошибку загрузки.
1.2 Выгрузить текущие значения сиквенций
Для сохранения текущих значений автоматических счетчиков (сиквенций) необходимо выгрузить эти значения. Для этого зайдите в Tools -> Data Dictionary -> Admin -> Dump Data and Definitions –> Sequences Current Values… и нажмите F1.
По завершению выгрузки будет выдано сообщение «Dump of sequence values completed.».
В текущем каталоге будет создан файл _seqvals.d.
1.3 Выгрузка содержимого таблицы _user
Выгрузка содержимого таблицы _user необходима для сохранения информации о пользователях. Для этого необходимо зайти в Tools -> Data Dictionary -> Admin -> Dump Data and Definitions –> User Table Contents.
По завершению выгрузки будет выдано сообщение «Dump of users completed.».
В текущем каталоге будет создан файл _user.d
1.4 Подготовка скриптов для выгрузки
Скрипты для выгрузки можно подготовить утилитой mkdump. Для этого перейдите в каталог базы данных и создайте в нем каталог /dump/. После чего зайдите в созданный каталог и запустите утилиту с указанием в качестве параметров полного пути к базе данных, логина и пароля пользователя
cd /data/10/kzmkdir dump
cd dump/
mkdump /data/10/kz/<dbname> –U <username> –P ********
Результатом работу утилиты будет создание в каталоге /dump/ следующих каталогов и файлов:
/ldprocs/ — каталог, содержащий программы для загрузки данных/dmpprocs/ — каталог, содержащий программы для выгрузки данных
fileload.
p – программа загрузки данных, использующая программы из каталога /ldprocs/
filedump.p – программа выгрузки данных, использующая программа из каталога /dmpprocs/
 p – программа загрузки данных, использующая программы из каталога /ldprocs/
p – программа загрузки данных, использующая программы из каталога /ldprocs/
1.5 Выгрузка данных
Для осуществления выгрузки лучше всего сначала запустить базу данных в многопользовательском режиме. Для этого сначала необходимо отключить репликацию и и after-imaging, если они включены:
proutil /data/10/kz/<dbname> -C disableSiteReplication sourceproutil /data/10/kz/<dbname> -C aimage end
proserve /data/10/kz/<dbname>
После этого можно будет запустить программу выгрузки данных. Хотелось бы предупредить. Запускаемая программа — filedump.p предназначена для последовательной выгрузки.
 Но при необходимости ускорения процесса, можно разделить содержимое программ на несколько небольших процессов.
Но при необходимости ускорения процесса, можно разделить содержимое программ на несколько небольших процессов.
Запустите программу как показано ниже:
mpro /data/10/kz/<dbname> -p filedump -U <username> –P ***********
Результатом работы программы будет создание текстовых файлов с расширением .d, содержащих данные таблиц базы. Файлы будут располагаться в текущем рабочем каталоге.
По окончанию выгрузки остановить базу данных командой:
proshut /data/10/kz/<dbname>
 DBANALYS
DBANALYS
Для анализа результатов конвертации базы данных до и после выгрузки необходимо сформировать dbanalys базы. Для этого выполните следующую команду для остановленной базы данных:
proutil /data/10/kz/<dbname> -C dbanalys > first-dbanalys.txt
Сохраните, полученный в результате работы утилиты, файл first-dbanalys.txt в отдельный каталог, он понадобится в будущем для сравнения.
3. Удаление существующей базы данных
Теперь, мы готовы к началу конвертации. И чтобы старая база нам не мешалась – мы ее удалим:
prodel /data/10/kz/<dbname>
Внимание! Перед удалением базы, убедитесь, что у Вас имеется резервная копия на случай необходимости восстановления.
4. Создание базы-пустышки с кодировкой KZ-1048
4. 1 Копирование empty базы
1 Копирование empty базы
Для создания пустой базы данных, необходимо скопировать «базу-пустышку», которая находится в установочном каталоге Progress /usr/dlc, и называется empty4. Цифра «4» указывает на размер блока базы данных, в нашем случае 4096 Kb.
Предварительно, советую в структурный файл добавить по одному тому к каждой области данных, за исключением “Schema Area”. Это необходимо, если по каким либо причинам базе данных понадобится дополнительное пространство для размещения данных. Если же этого пространства ей не хватит, то в момент загрузки данных произойдет аварийное завершение работы процесса загрузки – лучше подстраховаться, чем потом повторять всё заново.
И так, запустите следующую команду копирования:
procopy /usr/dlc/empty4 /data/10/kz/<dbname>
4.2 Загрузка кодовой таблицы KZ-1048
Процесс загрузки будет осуществляться через промежуточную кодовую таблицу UTF-8.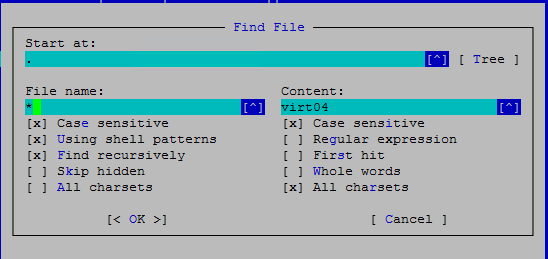 Причина тому то, что не существует прямой таблицы конвертации из KOI8-R в KZ-1048. Связанно это с отсутствием символов имеющихся в кодировке KZ-1048 у кодовой таблицы KOI8-R. Поэтому конвертация будет проходить по схеме KOI8-R -> UTF-8 -> KZ-1048.
Причина тому то, что не существует прямой таблицы конвертации из KOI8-R в KZ-1048. Связанно это с отсутствием символов имеющихся в кодировке KZ-1048 у кодовой таблицы KOI8-R. Поэтому конвертация будет проходить по схеме KOI8-R -> UTF-8 -> KZ-1048.
Файл с кодовой таблицей UTF-8 вы сможете найти в установочном каталоге Progressи называется он ICU-ru.df. Для его загрузки необходимо зайти в Tools -> Data Dictionary -> Admin -> Load Data and Definitions -> Data Definitions (.df file). Найдите файл кодовой таблицы с помощью кнопки «<Files…>». После чего нажмите F1. По завершению загрузки система попросит выполнить переиндексацию данных.
Выполните переиндексацию следующей командой, на данной стадии этот процесс займет не много времени, поскольку база данных пустая:
proutil /data/10/kz/<dbname> -C idxbuild ALL -pf mu_utf.pf
Обратите внимание на параметр «-pf mu_utf.
 pf» — в указанном файле содержится информация о кодировке используемой базой теперь, т.е UTF-8. В стандартном же файле параметров, который находится в /ust/dlc/startup/pf содержится информация для KOI8-R, и утилита idxbuild не будет работать с этой кодировкой в то время как база уже имеет кодировку UTF-8.
pf» — в указанном файле содержится информация о кодировке используемой базой теперь, т.е UTF-8. В стандартном же файле параметров, который находится в /ust/dlc/startup/pf содержится информация для KOI8-R, и утилита idxbuild не будет работать с этой кодировкой в то время как база уже имеет кодировку UTF-8.
Теперь, после переиндексации, необходимо выполнить те же шаги, но только для кодировки KZ-1048. Но подключаться к базе придется с указанием файла параметров для кодировки UTF-8.
pro bank -pf mu_utf.pf
При этом база данных выдаст сообщение о возможных проблемах при работе с базой данных с кодировкой UTF-8 в режиме TTY. На этой стадии для нас это сообщение значения не имеет.
Зайдите в Tools -> Data Dictionary -> Admin -> Load Data and Definitions -> Data Definitions (.df file). Найдите файл кодовой таблицы KZ-1048.df с помощью кнопки «<Files.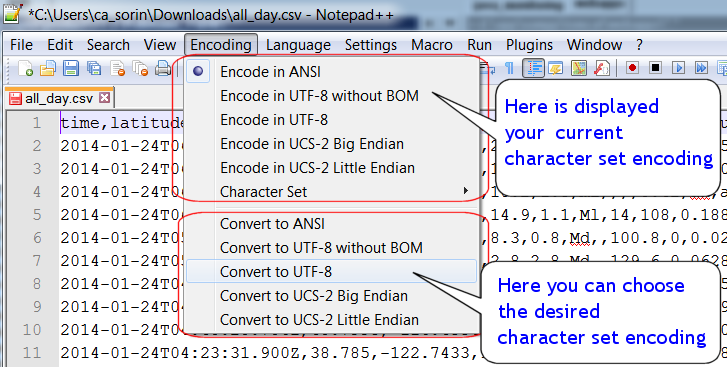 После чего нажмите F1. Система опять попросит переиндексацию, выполните ее с помощью следующей команды:
После чего нажмите F1. Система опять попросит переиндексацию, выполните ее с помощью следующей команды:
proutil /data/10/kz/<dbname> -C idxbuild ALL -pf my_kz.pf
Обратите внимание на файл параметров «my_kz.pf» в нём содержится информация по использованию кодировки KZ-1048.
После переиндексации мы имеем готовую базу данных, поддерживающую работу кодовой таблицы с символами казахского языка KZ-1048 основанную на стандарте СТ РК 1048-2002.
С целью безопасности и исключения необходимости повторного выполнения указанных действий, советую выполнить первую резервную копию базы данных.
probkup /data/10/kz/<dbname> /data/10/kz/backup/kz-first.bak
5. Подготовка данных к загрузке
5.1 Конвертация <dbname>. df.
df.
Файл описания схемы базы данных bank.df находится в кодировке KOI8-R, его нужно сконвертировать в кодировку KZ-1048. Для этого воспользуемся системной утилитой Linux, которая называется iconv:
iconv -c -f KOI8-R -t STRK1048-2002 <dbname>.df > kz<dbname>.df
Здесь параметры означают следующее:
-с, игнорирование возможных ошибок во время конвертации, нам он нужен, поскольку в базе встречаются символы, оставшиеся еще от латышской кодировки (разработчики Прагмы).
-f, указывает название кодовой таблицы, с которой происходит конвертация
-t, указывает название кодовой таблицы, в которую происходит конвертация, в нашем случае, стандарт СТ РК 1048-2002 встроен в Linux.
Теперь у нас есть файл kz<dbname>.df, содержащий описание схемы базы данных в кодировке KZ-1048.
Осталось только одно. Необходимо убрать упоминание о кодировке KOI8-R в конце файла, просто удалите следующие строки:
.PSC
cpstream=KOI8-R
.
0001886339
Либо замените KOI8-R на KZ-1048
Далее, таким же образом сконвертируйте выгруженные ранее файлы: _user.d, _seqvals.d, <dbname>.fd.
5.2 Конвертация содержимого таблиц
Перейдите в каталог /data/10/kz/dump/
cd /data/10/kz/dump/
Создайте каталог kzdump
mkdir kzdump
Берем скрипт conv.sh. Редактируем его, указав новые пути: откуда брать файлы в кодировке KOI8-R и куда сохранять файлы в кодировке KZ-1048. Установите права доступа на скрипт 700:
chmod 700 conv.
 sh
sh
Запустите скрипт на выполнение из каталога /data/10/kz/dump/ следующей командой:
(/data/10/kz/dump) ./conv.sh
Код скрипта conv.sh:
#!/bin/bash
pth=»/data/10/kzt/dump» # Path to the dir with the files
pth3=»/data/10/kz/dump/kzdump» # Path to the dir with the files
inp=»KOI8-R» # Input charset
otp=»STRK1048-2002″ # Output charset
suff=»kz» # Suffics
for fl in `ls -f $pth`
do
eval iconv -c -f $inp -t $otp $fl > «$pth3/$fl» 2>&1 /dev/null # converting files
done
Результатом работы скрипта будет появление в каталоге /kzdump/ файлов с содержимым таблиц в кодировке KZ-1048.
6. Загрузка описания схемы базы данных
Теперь необходимо загрузить описание схемы базы данных в кодировке KZ-1048. Для этого зайдите в базу следующей командой:
pro bank -pf my_kz.pf
Выберите Tools-> Data Dictionary -> Admin -> Load Data and Definitions-> Data Definitions (.df file). С помощью кнопки «<Files…>» найдите и выберите df-файл с кодировкой KZ-1048 – kz<dbname>.df. Нажмите F1. Система выдаст сообщение об отсутствии в файле описания его кодировки «There is no Code Page defined in this input file.» — ни чего страшного, нажмите “OK”. Будет предложено загрузить в файл в кодировке по умолчанию – KZ-1048. Нажмите F1. Начнется процесс загрузки. В случае успешной загрузки, будет выдано сообщение «Load completed.».
Теперь новая база имеет схему.
7. Загрузка данных в базу.
Перейдите в каталог с файлами выгрузки, сконвертированными в KZ-1048:
cd /data/10/kz/dump/kzdump
Запустите следующую команду загрузки:
time proutil /data/10/kz/bank -C bulkload kz<dbname>.
 fd -pf my_kz.pf < forbulk.txt
fd -pf my_kz.pf < forbulk.txt
По завершению загрузки, вы вернетесь в командную строку.
8. Переиндексация базы данных
Поскольку утилита bulkload для ускорения процесса загрузки деактивирует все индексы, то после завершения загрузки, чтобы данные стали доступны для использования, необходимо выполнить полную переиндексацию базы данных. Для этого выполните следующую команду:
proutil /data/10/kz/bank -C idxbuild ALL -pf my_kz.pf
По завершению работы утилиты, вы должны получить следующее сообщение: «Index rebuild complete. 0 error(s) encountered.»
9. Загрузить таблицу пользователей (_user)
Теперь мы должны загрузить в базу всех зарегистрированных в ней пользователей. Для этого зайдите в базу:
pro bank -pf my_kz.
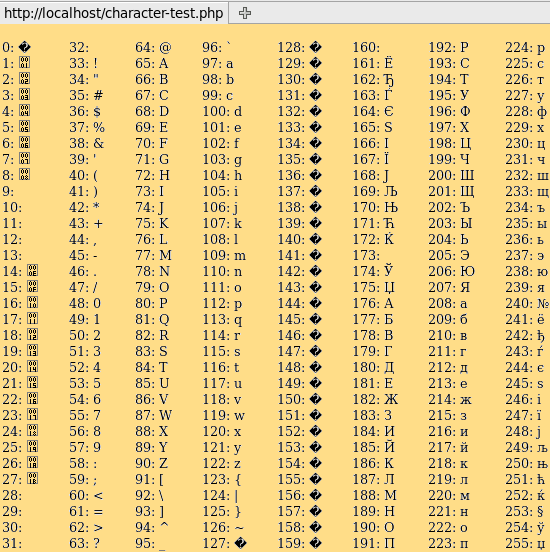 pf
pf
Затем выберите Tools -> Data Dictionary -> Admin -> Load Data and Definitions -> User Table Contents. С помощью кнопки «<Files…>» выберите скновертированный файл пользователей _kzuser.d. Нажмите F1. При успешной загрузки вы получите сообщение «User information loaded successfully.».
Теперь в базе имеются пользователи, и при следующем входе будет запрошен логин и пароль.
Не выходя из базы приступаем к выполнению следующего пункта.
10. Загрузка секвенций
Теперь загрузим значения счетчиков (секвенций). Выберите Tools -> Data Dictionary -> Admin -> Load Data and Definitions -> Sequences Current Values. С помощью кнопки «<Files…>» выберите скновертированный файл пользователей _kzseqvals.d. Нажмите F1. При успешной загрузки вы получите сообщение «Load of sequence values completed».
Теперь можно считать, что база полностью конвертирована!
11. Формирование и сверка dbanalys.
Формирование и сверка dbanalys.
Снова формируем dbanalys с помощью следующей команды:
proutil bank -C dbanalys > dbanalys-last.txt
По окончанию, необходимо сравнить количество записей в базе до и после конвертации, если оно одинаковое – значит, всё в порядке и конвертация прошла успешно.
Башкатов В.Г. 2008 г.
Как прочитать файлы в Python и решить проблему с кодировками
На практике в реальных проектах Data Science часто приходится сталкиваться с чтением датасетов, а также записывать добытую в ходе вычислений информацию в файлы. Сегодня мы расскажем о работе с файлами в Python: чтение и запись, проблема с кодировками, добавление значений в конец файла, временные папки и файлы.
Открываем, а затем читаем или записываем
Предположим, у нас имеется файл, который нужно прочитать в Python. Для этого можно воспользоваться функцией open внутри контекстного менеджера:
with open('file. txt') as f:
data = f.read() # содержимое файла
 txt') as f:
data = f.read() # содержимое файла
txt') as f:
data = f.read() # содержимое файла
Таким же образом можно записать информацию в файл, указав w в качестве аргумента:
text = 'Hello'
with open('file.txt', 'w') as f:
f.write(text)
Отметим некоторые особенности данной функции. Во-первых, для чтения файла мы не указывали никаких аргументов кроме имени файла, поскольку по умолчанию уже стоит режим чтения. Мы также не указывали явно, что это именно текстовый файл, а не бинарный, так как это тоже стоит по умолчанию. Для чтения и записи бинарных файлов добавляется b, например, rb или wb.
Во-вторых, мы использовали функцию open в контекстном менеджере. Можно обойтись и без него, но тогда после чтения или записи следует закрыть файл.
f = open('file.txt')
f.read()
f.close()
На открытие файла Python выделяет память, поэтому, чтобы избежать ее утечки, рекомендуется закрывать файлы.
Чтение файла с разной кодировкой
На многих операционных системах Python в качестве стандарта кодирования использует UTF-8, который также поддерживает кириллицу. Тем не менее, часто можно столкнуться с проблемами неправильной кодировки и получить распространенную ошибку вроде этой:
>>> f = open('somefile.txt', encoding='ascii')
>>> f.read()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/Python3.8/encodings/ascii.py", line 26, in decode
return codecs.ascii_decode(input, self.errors)[0]
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position
12: ordinal not in range(128))
В примере указана кодировка ASCII, но файл закодирован в другом формате, поэтому и возникает такая ошибка. Решить ее можно тремя способами:
- Указать
erorr=replace, который заменит нераспознанные символы знаком?:>>> f = open('somefile. txt', encoding='ascii', errors='replace')
>>> f.read()
'H?llo py?ho?-school!'
- Указать
erorr=ignore, который проигнорирует нераспознанные символы:>>> f = open('somefile.txt', encoding='ascii', errors='replace') >>> f.read() 'Hllo pyho-school!' - Указать правильную кодировку. Если текст на русском языке, то можно посмотреть кодировки с поддержкой кириллицы, которые есть в документации Python. Например, явно указать UTF-8 или cp1251:
f = open('somefile.txt', encoding='utf-8') # или cp1251 f = open('somefile.txt', encoding='cp1251')
 txt', encoding='ascii', errors='replace')
>>> f.read()
'H?llo py?ho?-school!'
txt', encoding='ascii', errors='replace')
>>> f.read()
'H?llo py?ho?-school!'
Добавление в конец и запрет открытия файлов
Как мы уже отметили ранее, для записи текстового файла добавляется аргумент w. Но если вызвать метод write, он перепишет весь файл. Во многих случаях требуется добавить данные в конец файла. Тогда используется
Тогда используется a вместо w:
text2 = 'world'
with open('file.txt', 'a') as f:
f.write(text)
# Helloworld
Если файла не существует, то при a и при w он будет создан. Но чтобы не трогать существующие файлы, а создать новый, передается параметр x:
# 'x' не даст возможности открыть файл, так как он существует
>>> with open('file.txt', 'x') as f:
... f.write(text2)
FileExistsError Traceback (most recent call last)
FileExistsError: [Errno 17] File exists: 'file.txt'
# Поскольку file2.txt не существует, все OK
>>> with open('file2.txt', 'x') as f:
... f.write(text2)
Временные файлы
Иногда бывает, что требуется создать файл или папку внутри Python-программы, а после ее закрытия их нужно удалить. Тогда пригодится стандартный модуль tempfile. Например, класс
Например, класс TemporaryFile создаст временный файл, который удалится после закрытия. Ниже пример в Python.
>>> from tempfile import TemporaryFile
>>> f = TemporaryFile("w+t")
>>> f.write("hello")
>>> f.seek(0)
>>> f.read()
'hello'
>>> f.close() # файл уничтожается
# либо в контекстном менеджере
f.write(text2)
Обратите внимание на 3 вещи. Первое, мы явно передаем "w+t", чтобы записать как текстовый файл, поскольку по умолчанию стоит "w+b" для бинарных файлов. Второе, метод seek(0) используется для перехода на самый первый символ, поскольку чтение происходит с текущего указателя, а он стоит в конце (после буквы ‘o’ в слове ‘hello’). Поэтому не стоит переживать, что мы можем стереть предыдущую запись:
>>> f.seek(5) # переходим в конец >>> f.
 read()
''
>>> f.write("world")
5
>>> f.seek(0) # переходим в начало
>>> f.read()
'helloworld'
read()
''
>>> f.write("world")
5
>>> f.seek(0) # переходим в начало
>>> f.read()
'helloworld'
Третье, файл TemporaryFile невидим для файловой системы, он используется только внутри Python, поэтому извне будет трудно его найти.
Именованные временные файлы
А вот объекты класса NamedTemporaryFile будут видны файловой системе, и найти месторасположение можно с помощью атрибута name:
>>> from tempfile import NamedTemporaryFile
>>> f = NamedTemporaryFile("w+t")
>>> f.name
'/tmp/tmp60djsgli'
>>> f.close()
Как можно заметить, файл называется tmp60djsgli. Для удобства можно явно указать его название и формат:
>>> f = NamedTemporaryFile("w+t", prefix="myfile", suffix=".txt")
>>> f.name
'/tmp/myfile7mxae0fi. txt'
 txt'
txt'
Временные папки
Кроме временных файлов можно создавать временные папки. Для этого используется класс TemporaryDirectory:
>>> from tempfile import TemporaryDirectory >>> d = TemporaryDirectory() >>> d.name '/tmp/tmp5eadqzz5'
Он также принимает в качестве аргументов prefix и suffix, а также может использоваться внутри контекстного менеджера Python.
В следующей статье поговорим о взаимодействии файловой системы и Python. А получить практические навыки работы с файлами на реальных проектах Data Science вы сможете на наших курсах по Python в лицензированном учебном центре обучения и повышения квалификации IT-специалистов в Москве.
Смотреть расписание
Записаться на курс
Источники
- https://docs.python.org/3/library/functions.html#open
- https://docs.python.org/3/library/tempfile.html
Out-File (Microsoft.
 PowerShell.Utility) — PowerShell | Microsoft Learn
PowerShell.Utility) — PowerShell | Microsoft Learn- Справочник
- Модуль:
- Microsoft.PowerShell.Утилита
Отправляет вывод в файл.
Синтаксис
Вне файла [-FilePath] <строка> [[-Кодировка] <Кодировка>] [-Добавить] [-Сила] [-NoClobber] [-Ширина <число>] [-NoNewline] [-InputObject] [-Что, если] [-Подтверждать] [<Общие параметры>]
Вне файла [[-Кодировка] <Кодировка>] -LiteralPath <строка> [-Добавить] [-Сила] [-NoClobber] [-Ширина <число>] [-NoNewline] [-InputObject] [-Что, если] [-Подтверждать] [ ]
Описание
Командлет Out-File отправляет выходные данные в файл. Он неявно использует систему форматирования PowerShell для
записать в файл. Файл получает то же представление на дисплее, что и терминал. Это означает
что вывод может быть не идеальным для программной обработки, если только все входные объекты не являются строками.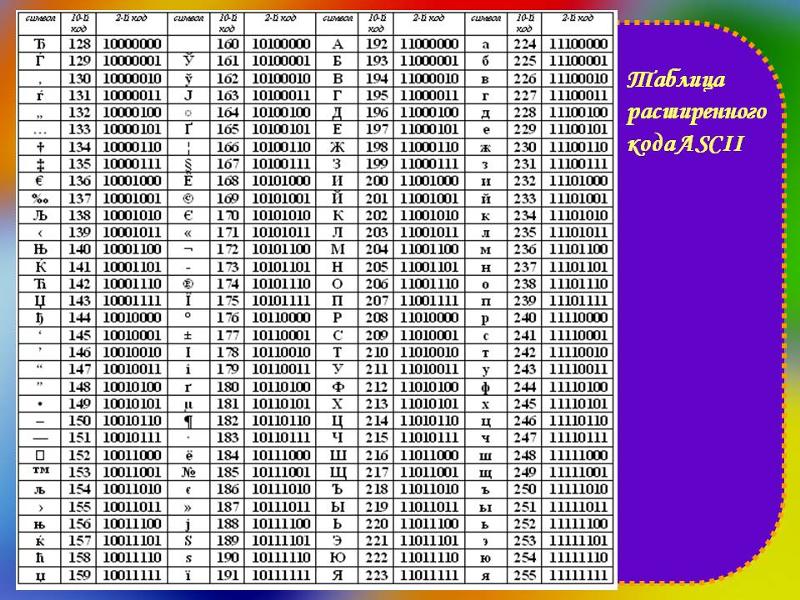 Когда вам нужно указать параметры для вывода, используйте
Когда вам нужно указать параметры для вывода, используйте Out-File вместо перенаправления
оператор ( > ). Дополнительные сведения о перенаправлении см.
about_Redirection.
Примеры
Пример 1. Отправка вывода и создание файла
В этом примере показано, как отправить список процессов локального компьютера в файл. Если файл делает
не существует, Out-File создает файл по указанному пути.
Процесс получения | Out-File -FilePath .\Process.txt
Get-Content -Путь .\Process.txt
NPM(K) PM(M) WS(M) CPU(s) Id SI ProcessName
------ ----- ----- ------ -- -- -----------
2922,39 35,40 10,98 42764 9 Применение
53 99,04 113,96 0,00 32664 0 CcmExec
27 96.62 112.43 113.00 17720 9 Код Командлет Get-Process получает список процессов, запущенных на локальном компьютере. Процесс объекты отправляются по конвейеру в командлет Out-File . Out-File использует FilePath параметр и создает файл в текущем каталоге с именем Process.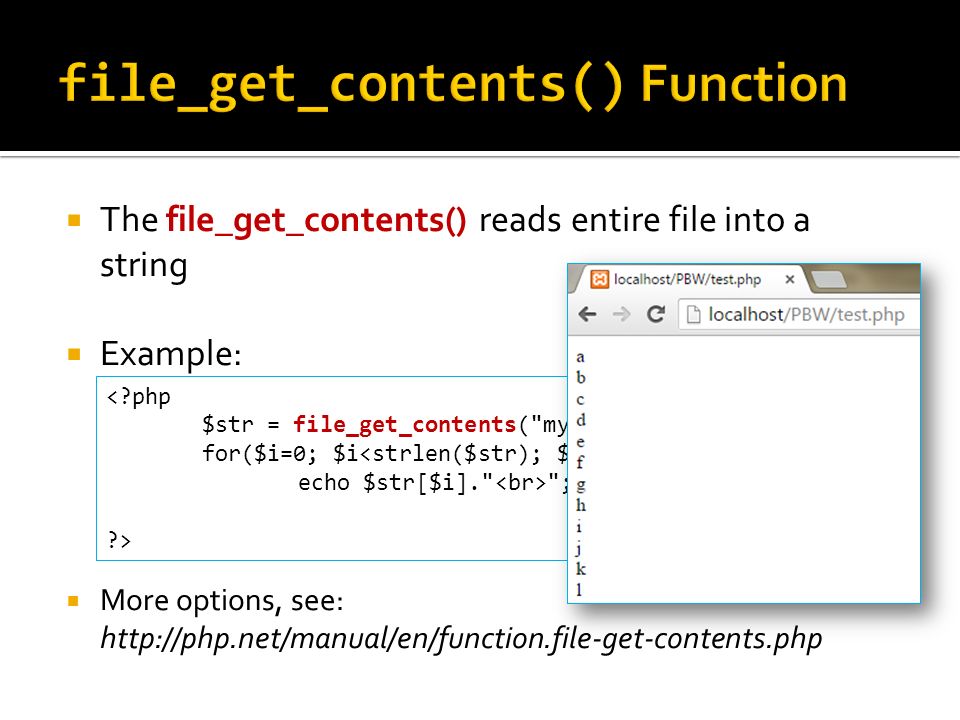 txt .
txt . Get-Content Команда получает содержимое из файла и отображает его в консоли PowerShell.
Пример 2. Предотвращение перезаписи существующего файла
В этом примере предотвращается перезапись существующего файла. По умолчанию Out-File перезаписывает
существующие файлы.
Процесс получения | Out-File -FilePath .\Process.txt -NoClobber Out-File: файл «C:\Test\Process.txt» уже существует. В строке:1 символ:15 + Получить-Процесс | Out-File -FilePath .\Process.txt -NoClobber + ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Командлет Get-Process получает список процессов, запущенных на локальном компьютере. Процесс объекты отправляются по конвейеру в командлет Out-File . Out-File использует FilePath параметр и пытается записать в файл в текущем каталоге с именем Process.txt . Параметр NoClobber предотвращает перезапись файла и отображает сообщение о том, что
Файл уже существует.
Пример 3: Отправка вывода в файл в формате ASCII
В этом примере показано, как закодировать вывод с помощью определенного типа кодирования.
$Procs = Get-Process Out-File -FilePath .\Process.txt -InputObject $Procs -Encoding ASCII -Width 50
Командлет Get-Process получает список процессов, запущенных на локальном компьютере. Процесс объекты хранятся в переменной $Procs . Out-File использует параметр FilePath и создает
файл в текущем каталоге с именем Процесс.txt . Параметр InputObject передает
обрабатывать объекты в $Procs в файл Process.txt . Параметр Encoding преобразует
вывод в формат ASCII . Параметр Width ограничивает длину каждой строки в файле 50 символами, поэтому
некоторые данные могут быть усечены.
Пример 4. Использование поставщика и отправка вывода в файл
В этом примере показано, как использовать командлет Out-File , когда вы не находитесь в Поставщик файловой системы водить машину. Используйте командлет
Используйте командлет Get-PSProvider для просмотра поставщиков на локальном компьютере. Для большего
информацию см. в разделе about_Providers.
PS> Set-Location-Псевдоним пути: PS> Получить-местоположение Путь ---- Псевдоним:\ PS> Получить-ChildItem | Out-File - FilePath C:\TestDir\AliasNames.txt PS> Get-Content -Path C:\TestDir\AliasNames.txt Имя типа команды ----------- ---- Псевдоним % -> ForEach-Object Псевдоним? -> Где-Объект Псевдоним ac -> Добавить контент Псевдоним cat -> Get-Content
Команда Set-Location использует параметр Path для установки текущего местоположения в реестр.
провайдер Псевдоним: . Командлет Get-Location отображает полный путь для Alias: . Get-ChildItem отправляет объекты по конвейеру в командлет Out-File . Out-File использует Параметр FilePath для указания полного пути и имени выходного файла, C:\TestDir\AliasNames. txt . Командлет
txt . Командлет Get-Content использует параметр Path и отображает
содержимое файла в консоли PowerShell.
Пример 5: Установка ширины выходного файла для всей области
В этом примере используется $PSDefaultParameterValues для установки параметра Ширина для всех вызовов Out-File и операторы перенаправления ( > и >> ) на 2000. Это гарантирует, что везде
в текущей области, в которой вы выводите данные в формате таблицы в файл, PowerShell использует ширину строки
2000 вместо ширины линии, определяемой шириной консоли хоста PowerShell.
функция DemoDefaultOutFileWidth() {
пытаться {
$PSDefaultParameterValues['out-file:width'] = 2000
$logFile = "$pwd\logfile.txt"
Get-ChildItem Env:\ > $logFile
Get-Service -ErrorAction Игнорировать | Формат-Таблица-Авторазмер | Выходной файл $logFile -Append
Get-процесс | Идентификатор таблицы форматов, SI, имя, путь, MainWindowTitle >> $logFile
}
окончательно {
$PSDefaultParameterValues. Remove('out-file:width')
}
}
DemoDefaultOutFileWidth  Remove('out-file:width')
}
}
DemoDefaultOutFileWidth
Remove('out-file:width')
}
}
DemoDefaultOutFileWidth Дополнительные сведения о $PSDefaultParameterValues , см.
about_Preference_Variables.
Parameters
-Append
-Confirm
-Encoding
-FilePath
-Force
-InputObject
-LiteralPath
-NoClobber
-NoNewline
-WhatIf
-Width
Inputs
PSObject
Вы можете передать любой объект этому командлету.
Выходы
Нет
Этот командлет не возвращает никаких результатов.
Примечания
Объекты ввода автоматически форматируются так же, как в терминале, но вы можете использовать Format-* Командлет для явного управления форматированием вывода в файл. Например, Дата получения | Список форматов | Out-File out.txt
Чтобы отправить выходные данные команды PowerShell в командлет Out-File , используйте конвейер.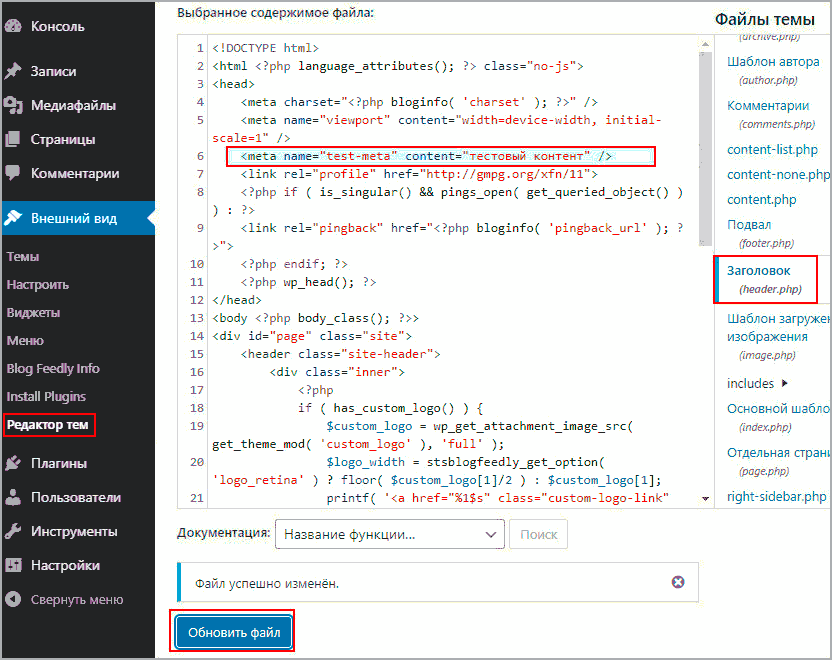 В качестве альтернативы вы
может хранить данные в переменной и использовать Параметр InputObject для передачи данных в
В качестве альтернативы вы
может хранить данные в переменной и использовать Параметр InputObject для передачи данных в Out-File командлет.
Out-File сохраняет данные в файл, но не создает никаких выходных объектов для конвейера.
В PowerShell 7.2 добавлена возможность управления визуализацией управляющих последовательностей ANSI. ANSI-украшенный
вывод, который передается в Out-File , может быть изменен в зависимости от настройки Свойство $PSStyle.OutputRendering . Для получения дополнительной информации см.
about_ANSI_терминалы.
- about_Providers
- about_Quoting_Rules
- Вне значения по умолчанию
- Внешний хост
- Out-Null
- Внешняя строка
- Тройник Объект
Кодирование содержимого — HTTP | МДН
В заголовке представления Content-Encoding перечислены все кодировки, которые были применены к представлению (полезная нагрузка сообщения), и в каком порядке. Это позволяет получателю узнать, как декодировать представление, чтобы получить исходный формат полезной нагрузки.
Кодирование содержимого в основном используется для сжатия данных сообщения без потери информации об исходном типе носителя.
Это позволяет получателю узнать, как декодировать представление, чтобы получить исходный формат полезной нагрузки.
Кодирование содержимого в основном используется для сжатия данных сообщения без потери информации об исходном типе носителя.
Обратите внимание, что исходный тип носителя/контента указывается в заголовке Content-Type , и что Content-Encoding применяется к представлению или «кодированной форме» данных. Если исходный носитель каким-либо образом закодирован (например, в виде zip-файла), эта информация не будет включена в заголовок Content-Encoding .
Серверам рекомендуется максимально сжимать данные и использовать кодировку содержимого, где это уместно. Сжатие сжатого типа носителя, такого как zip или jpeg, может быть неуместным, так как это может увеличить полезную нагрузку.
| Тип заголовка | Заголовок представления |
|---|---|
| Запрещенное имя заголовка | нет |
Кодировка содержимого: gzip Content-Encoding: сжать Content-Encoding: дефляция Кодировка содержимого: br // Несколько, в том порядке, в котором они были применены Content-Encoding: deflate, gzip
-
gzip Формат, использующий кодировку Лемпеля-Зива.
(LZ77) с 32-битной CRC. Это исходный формат UNIX 9.0295 gzip программа. Стандарт HTTP/1.1 также рекомендует, чтобы серверы, поддерживающие этот
content-encoding должен распознавать x-gzipкак псевдоним для совместимости целей.-
компресс Формат, использующий алгоритм Лемпеля-Зива-Велча (LZW). имя значения было взято из программы UNIX Compress , которая реализовала это алгоритм. Подобно программе сжатия, которая исчезла из большинства UNIX-систем. дистрибутивов, эта кодировка контента сегодня не используется многими браузерами, частично из-за выдачи патента (срок его действия истек в 2003 г.).
-
сдувание Использование zlib структура (определена в RFC 1950) со сжатием deflate алгоритм (определен в RFC 1951).
-
бр Check cross-browser support before using.»>
Нестандартный
Check cross-browser support before using.»>
Нестандартный Формат, использующий алгоритм Бротли.
 (LZ77) с 32-битной CRC. Это исходный формат UNIX 9.0295 gzip программа. Стандарт HTTP/1.1 также рекомендует, чтобы серверы, поддерживающие этот
content-encoding должен распознавать
(LZ77) с 32-битной CRC. Это исходный формат UNIX 9.0295 gzip программа. Стандарт HTTP/1.1 также рекомендует, чтобы серверы, поддерживающие этот
content-encoding должен распознавать Сжатие с помощью gzip
На стороне клиента вы можете объявить список схем сжатия, которые будут отправлены
вместе с HTTP-запросом. Заголовок Accept-Encoding используется для
согласование кодировки контента.
Accept-Encoding: gzip, deflate
Сервер отвечает используемой схемой, обозначенной Content-Encoding заголовок ответа.
Кодировка содержимого: gzip
Обратите внимание, что сервер не обязан использовать какой-либо метод сжатия. Сжатие высоко зависит от настроек сервера и используемых серверных модулей.
| Спецификация |
|---|
| Неизвестная спецификация # field.content-encoding |
Таблицы BCD загружаются только в браузере с включенным JavaScript.