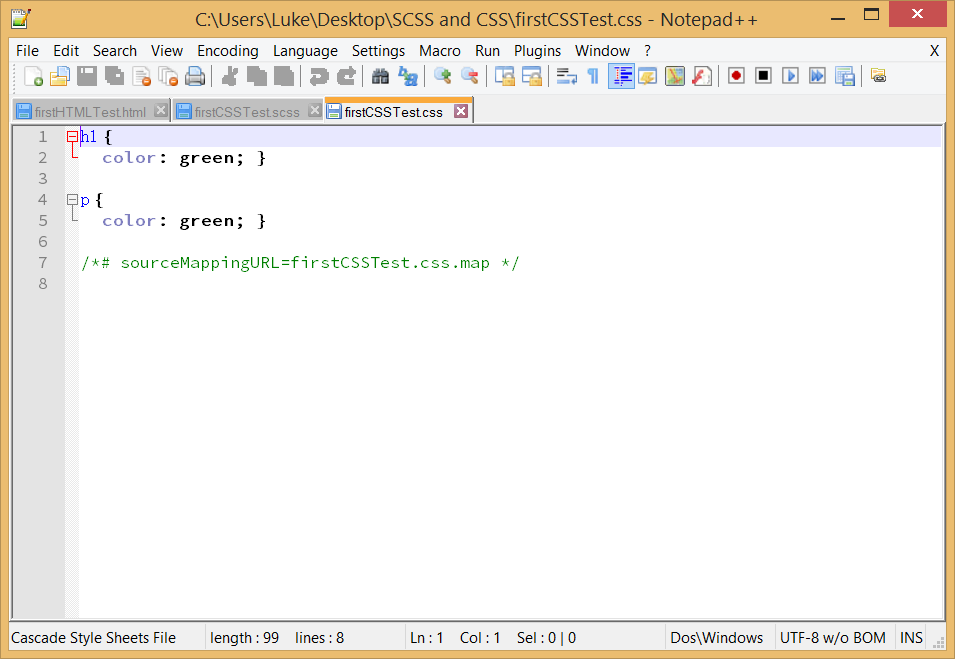
URL HTML
URL является веб-адрес.
URL может состоять из букв, таких как «W3CSchools.cc», или Интернет-протокола (IP) адрес: 192.68.20.50. Большинство войти на сайт, чтобы использовать доменные имена для доступа, поскольку имя проще запомнить, чем цифры.
URL — Uniform Resource Locator
Веб-браузер запрашивает страницу с URL-адрес веб-сервера.
При нажатии на ссылку в HTML-страницы, соответствующие теги указывает на адрес <a> World Wide Web.
Унифицированный указатель информационного ресурса (URL) используется для поиска документов на World Wide Web.
Экземпляр Адрес страницы Web: http://www.w3big.com/html/html-tutorial.html~~HEAD=pobj правила синтаксиса:
Схема: // host.domain: порт / путь / имя файла
Объяснение:
- Схема — определение типа Интернет-услуг. Наиболее распространенным типом является HTTP
- Host — хозяин домена (по умолчанию хоста HTTP WWW)
- Домен — это определение доменных имен в Интернете, такие w3big.com
- : Порт — определяет номер порта на хосте (HTTP по умолчанию номер порта 80)
- путь — путь для определения сервера (Если этот параметр опущен, то документ должен находиться в корневом каталоге вашего веб-сайта).
- имя файла — название пользовательского документа / ресурса
Общие URL Схемы
Вот некоторые схемы URL:
| Scheme | 访问 | 用于… |
|---|---|---|
| http | 超文本传输协议 | 以 http:// 开头的普通网页。不加密。 |
| https | 安全超文本传输协议 | 安全网页,加密所有信息交换。 |
| ftp | 文件传输协议 | 用于将文件下载或上传至网站。 |
| file | 您计算机上的文件。 |
Кодировка символов URL
URL можно использовать только набор символов ASCII .
Для того, чтобы быть отправлены через Интернет. Поскольку URL часто содержит символы вне набора ASCII, URL должен быть преобразован в допустимый формат ASCII.
Поскольку URL часто содержит символы вне набора ASCII, URL должен быть преобразован в допустимый формат ASCII.
URL-закодированы с использованием «%» следуют два шестнадцатеричных чисел, чтобы заменить символы не-ASCII.
URL не может содержать пробелы. кодирование URL обычно используют +, чтобы заменить пробелы.
Онлайн примеры
При нажатии на кнопку «Отправить», браузер будет URL кодируется перед отправкой ввод. Страница на сервере будет показывать принятого ввода.
Попробуйте ввести несколько символов, а затем нажмите кнопку Отправить еще раз.
URL примеры кодирования
| 字符 | URL 编码 |
|---|---|
| € | %80 |
| £ | %A3 |
| © | %A9 |
| ® | %AE |
| À | %C0 |
| Á | %C1 |
| Â | %C2 |
| Ã | %C3 |
| Ä | %C4 |
| A | %C5 |
Для получения полного URL закодированы ссылки, пожалуйста , посетите наш URL закодирован справочное руководство .
HTML URL — Унифицированные локаторы ресурсов
URL — это другое слово для веб-адреса.
URL может состоять из слов (w3schools.com) или IP-адреса. (192.68.20.50).
Большинство людей вводят название при серфинге, потому что названия легче запомнить, чем цифры.
URL — унифицированный указатель ресурса
Унифицированный указатель ресурса (URL) используется для адресации документа (или других данных) в Интернете.
Веб-адрес, например https://w3schoolsrus.github.io/html/index.htmlследует этим правилам синтаксиса:
scheme://prefix. domain:port/path/filename
domain:port/path/filename
Объяснение:
- scheme — определяет тип Интернет-сервиса (наиболее распространенным является http или https)
- prefix — определяет домен prefix
- domain — определяет Интернет доменное имя (например w3schools.com)
- port — определяет номер порта на хосте (по умолчанию для http является 80)
- path — определяет path на сервере (если не указан: корневой каталог сайта)
- filename — определяет название документа или ресурса
Общие схемы URL
В таблице ниже перечислены некоторые распространенные схемы:
| Схема | Короче для | Используется для |
|---|---|---|
| http | Протокол передачи гипертекста | Общие веб-страницы. Не зашифрованы |
| https | Безопасный протокол передачи гипертекста | Безопасные веб-страницы. Зашифрованные |
| ftp | Протокол передачи файлов | Скачивание или загрузка файлов |
| file | Файл на вашем компьютере |
URL Кодирование
URL-адреса могут быть отправлены только через Интернет с помощью ASCII набор символов. Если URL-адрес содержит символы вне набора ASCII, он должен быть преобразован.
Кодировка URL преобразует не-ASCII символы в формат, который может быть передан через Интернет.
Кодировка URL заменяет символы, не входящие в ASCII, на «%», за которым следуют шестнадцатеричные цифры.
URL не могут содержать пробелы. Кодировка URL обычно заменяет пробел знаком плюс (+) или %20.
Кодировка URL обычно заменяет пробел знаком плюс (+) или %20.
Попробуйте сами
Если вы нажмете «Отправить», браузер выполнит URL-кодирование ввода перед его отправкой на сервер.
На странице сервера отобразятся полученные данные.
Попробуйте ввести другие данные и снова нажмите «Отправить».
ASCII кодирование. Примеры
Ваш браузер будет кодировать ввод в соответствии с набором символов, используемым на вашей странице.
Набор символов по умолчанию в HTML5 — UTF-8.
| Символ | Из Windows-1252 | Из UTF-8 |
|---|---|---|
| € | %80 | %E2%82%AC |
| £ | %A3 | %C2%A3 |
| © | %A9 | %C2%A9 |
| ® | %AE | %C2%AE |
| À | %C0 | %C3%80 |
| Á | %C1 | %C3%81 |
| Â | %C2 | %C3%82 |
| Ã | %C3 | %C3%83 |
| Ä | %C4 | %C3%84 |
| Å | %C5 | %C3%85 |
Для получения полной справки на все кодировки URL, посетите URL кодирование. Справочник на нашем сайте W3Schools на русском.
HTML URL-кодировка | Как выполнить кодировку URL в HTML? (Пример)
Введение в HTML-кодирование URL
В этой статье мы подробно узнаем о кодировании URL-адресов HTML. HTML URL является аббревиатурой от Uniform Resource Locator для глобального или IP-адреса в World Wide Web. Веб-сервер получает страницу, используя URL для веб-браузера.
Веб-сервер получает страницу, используя URL для веб-браузера.
Пример: https://www.google.com является одним из URL.
Набор символов ASCII важен для HTML-кодирования URL. URL отправляется в Интернет с использованием набора символов ASCII. Не-ASCII-символы ограничены, поскольку они могут создавать конфликт при поиске пути к серверу. Из-за этой проблемы HTML использует URL-кодировку.
HTML URL Encoding, преобразуйте символ не ASCII в формат, который можно отправить в Интернет. Пользователи могут быть преобразованы с использованием «%», чтобы продолжить с двумя шестнадцатеричными цифрами.
Как выполнить кодировку URL в HTML?
- Язык HTML создает URL, используя теги и атрибуты href. Например . если вы создаете какой-либо сайт и хотите перейти с одной страницы на другую, напишите имя файла.,
- Некоторые символы ограничены именем веб-адреса из-за создания конфликта. Символ не-ASCII заменяется на «%», чтобы продолжить с двумя шестнадцатеричными цифрами.
- URL не содержит места. Он занимает место знака плюс (+) или% 20. В виде HTML-страницы в текстовом выводе «input» появилось пространство, после чего показывается знак плюс. Косвенно пробел произошел в имени URL, затем отображается% 20.
- Тег URL содержит заглавные буквы (A-Z) и строчные буквы (a-z), десятичные цифры (1-9) и некоторые специальные символы.
В форме, если я поставлю пробел, то кодировка URL будет выглядеть как HTML + CSS.
В любом URL, если мы дадим пробел, то кодировка URL будет выглядеть как мой% 20file.html.
- Зарезервированные символы: в URL-адресе есть некоторые символы, которые имеют некоторое значение, и мы можем использовать назначение имен. Мы можем использовать оба способа, такие как знак плюс (/), используемый для отдельной части URL-адреса, с другой стороны, мы можем / кодировать% 2f без значения в имени адреса.
- Небезопасные символы: Есть много символов, которые имеют много недоразумений в URL-адресе, например, пробел в имени URL-адреса.

3. Не-ASCII контрольный символ
Ниже приведена таблица, используемая для кодирования не-ASCII символов.
символ Кодирование URL символ Кодирование URL символ Кодирование URL символ Кодирование URL € % 80 ~ % 98 « % аб ¿ % Б.Ф. , % 82 ™ % 99 % переменный ток À % c0 ƒ % 83 š % 9a ª % аа Á % c1 « % 84 > % 9b ® % ае  % c2 … % 85 œ % 9c ¯ % аф à % c3 † % 86 % 9d ° % b0 Ä % c4 ‡ % 87 ž % 9e ± % b1 Å % c5 Ÿ % 9F ² %Би 2 Æ % v6 ‰ % 89 × % d7 ³ % b3 БЗ % c7 Š % 8а ¡ % a1 ‘ % b4 Э. % c8 < % 8b ¢ % a2 μ % b5 É % с9 О.Н % 8c £ % a3 ¶ % b6 Ê % ча Ž % 8e ¤ % a4 · % b7 Ë % центибар ‘ % 91 ¥ % a5 ¸ % b8 Я % куб. ‘ % 92 | % a6 ¹ % b9 Я %компакт диск « % 93 § % a7 º % ба Я % в.п. » % 94 ¨ % a8 » % бб Я % ср • % 95 © % a9 ¼ %До нашей эры Ð % d0 — % 96 — % 97 ½ % шд ЦТС % d1 ã % e3 Þ % от ¾ %быть Ò % d2 æ % e6 ß % Д.Ф. Ø % d8 Ó % d3 ä % e4 à % e0 Ý % дд Ф % d4 4. Управляющие символы ASCII
Ниже приведена таблица, используемая для кодирования символов Ascii.
ASCII персонаж URL-кодирование NUL — нулевой символ % 00 SOH — начало заголовка % 01 STX — начало текста % 02 ETX — конец текста % 03 EOT — конец передачи % 04 ENQ — запрос % 05 ACK — подтвердить % 06 БЕЛ — колокол (кольцо) % 07 БС — забой % 08 HT- горизонтальная вкладка % 09 LF- перевод строки % 0A VT- вертикальная вкладка % 0B FF- подача формы % 0C CR- возврат каретки % 0D SO- сдвиг % 0E SI- сдвиг в % 0F DLE- побег канала передачи данных % 10 DC1- устройство управления 1 % 11 DC2- устройство управления 2 % 12 DC3- устройство управления 3 % 13 DC4 — устройство управления 4 % 14 NAK- отрицательное подтверждение % 15 SYN- синхронизировать % 16 ETB- конец блока передачи % 17 МОЖЕТ отменить % 18 EM — конец среды % 19 SUB- заменитель % 1A ESC- побег % 1В FS — файловый разделитель % 1С GS- группа сепаратор % 1D RS- запись разделитель % 1E US- сепаратор % 1F Важность кодирования URL в HTML
Если URL-адрес зарезервирован, небезопасные и не ASCII-символы, тогда URL-адрес становится более сложным и непонятным.
Когда веб-браузер выполняет поиск по URL-адресам, веб-сервер выполняет поиск по имени или пути URL-адреса. Если имя URL-адреса не ASCII, то трудно найти URLImportance of URL Encoding в HTMLURL-адрес должен быть легкодоступным, общепринятым и понятным для всех веб-браузеров, а также для веб-сервера. некоторые символы создают недопонимание в URL, потому что они используются для каких-то целей, если они не используются ни для каких целей. этот конфликт времени мог произойти, и путь не дошел до пользователя.
Чтобы преодолеть все трудности и упростить использование не-ASCII-символов, преобразованных в ASCII-код, используйте%, чтобы получить два шестнадцатеричных числа.
Вывод
Кодирование URL в HTML знает, как преобразовать набор символов, не относящихся к ASCII, в допустимый набор форматов ASCII. Он общепринят, и веб-браузер работает без ошибок. URL кодирования может быть запущен легко и безопасно. Во избежание конфликта имен и назначения имен необходимо URL-кодирование.
Рекомендуемые статьи
Это руководство по кодированию URL HTML. Здесь мы обсудим введение URL-адреса HTML и как выполнить кодирование URL в HTML, а также его примеры и важность. Вы также можете посмотреть следующие статьи, чтобы узнать больше
- Различные типы фреймов в HTML
- Лучшие 3 атрибута текстовой ссылки в HTML
- HTML-команды (базовый, средний, расширенный)
- Элементы HTML5 — теги и примеры
- Продолжить работу над оператором в C # с примерами
Инновационные решения для ЦОД, Интернета вещей и ПК
Поиск на сайте Intel.com
Вы можете выполнять поиск по всему сайту Intel.com различными способами.
- Торговое наименование: Core i9
- Номер документа: 123456
- Кодовое название: Kaby Lake
- Специальные операторы: “Ice Lake”, Ice AND Lake, Ice OR Lake, Ice*
Ссылки по теме
Вы также можете воспользоваться быстрыми ссылками ниже, чтобы посмотреть результаты самых популярных поисковых запросов.
Недавние поисковые запросы
Начало работы с Google Fonts API | Разработчики Google
В этом руководстве объясняется, как использовать Google Fonts API для добавления шрифтов в ваш Интернет. страниц. Вам не нужно заниматься программированием; все, что вам нужно сделать, это добавить специальный Ссылка таблицы стилей на ваш HTML-документ, а затем ссылка на шрифт в стиле CSS.
Быстрый пример
Вот пример. Скопируйте и вставьте в файл следующий HTML-код:
<ссылка rel = "таблица стилей" href = "https: // шрифты.googleapis.com/css?family=Tangerine "> <стиль> тело { семейство шрифтов: «Мандарин», с засечками; размер шрифта: 48 пикселей; }Делаем Интернет красивой!Затем откройте файл в современном веб-браузере. Вы должны увидеть страницу с далее шрифтом Tangerine:
Делаем Интернет красивой!
Это предложение представляет собой обычный текст, поэтому вы можете изменить его внешний вид с помощью CSS.Пытаться добавление тени к стилю в предыдущем примере:
тело { семейство шрифтов: «Мандарин», с засечками; размер шрифта: 48 пикселей; тень текста: 4px 4px 4px #aaa; }Теперь вы должны увидеть тень под текстом:
Делаем Интернет красивой!
И это только начало того, что вы можете делать с Fonts API и CSS.
Обзор
Вы можете начать использовать Google Fonts API всего за два шага:
Добавьте ссылку на таблицу стилей для запроса желаемого веб-шрифта (ов):
<ссылка rel = "таблица стилей" href = "https: // шрифты.
googleapis.com/css?family= Шрифт + имя ">
Стиль элемента с помощью запрошенного веб-шрифта либо в таблице стилей:
.css-selector { семейство шрифтов: ' Font Name ', serif; }или со встроенным стилем самого элемента:
Название шрифта ', serif;"> Ваш текст


 Когда веб-браузер выполняет поиск по URL-адресам, веб-сервер выполняет поиск по имени или пути URL-адреса. Если имя URL-адреса не ASCII, то трудно найти URLImportance of URL Encoding в HTML
Когда веб-браузер выполняет поиск по URL-адресам, веб-сервер выполняет поиск по имени или пути URL-адреса. Если имя URL-адреса не ASCII, то трудно найти URLImportance of URL Encoding в HTML
 googleapis.com/css?family= Шрифт + имя ">
googleapis.com/css?family= Шрифт + имя ">
serif или sans-serif , в конец списка,
поэтому при необходимости браузер может вернуться к своим шрифтам по умолчанию.Список шрифтов, которые вы можете использовать, см. Google шрифты.
Указание семейств шрифтов и стилей в URL-адресе таблицы стилей
Чтобы определить, какой URL использовать в ссылке на таблицу стилей, начните с Google Базовый URL Fonts API:
https://fonts.googleapis.com/css
Затем добавьте параметр URL family = с одним или несколькими именами семейств шрифтов и
стили.
Например, чтобы запросить Шрифт Inconsolata:
https://fonts.googleapis.com/css?family=InconsolataПримечание. Замените любые пробелы в названии семейства шрифтов знаками «плюс» (
+ ). Чтобы запросить несколько семейств шрифтов, разделите имена вертикальной чертой
( | ).
Например, чтобы запросить шрифты Мандарин, Инконсолата и Droid Sans:
https://fonts.
 googleapis.com/css?family=Tangerine|Inconsolata|Droid+Sans
googleapis.com/css?family=Tangerine|Inconsolata|Droid+Sans
Запрос нескольких шрифтов позволяет использовать все эти шрифты на вашей странице.(Но не переусердствуйте; большинству страниц не нужно очень много шрифтов, а запрос большое количество шрифтов может замедлить загрузку ваших страниц.)
API Google Fonts предоставляет обычную версию запрошенных шрифтов от
дефолт. Чтобы запросить другие стили или веса, добавьте двоеточие (: ) к имени
шрифт, за которым следует список стилей или значений, разделенных запятыми (, ).
Например:
https://fonts.googleapis.com/css?family=Tangerine:bold,bolditalic|Inconsolata:italic|Droid+Sans
Чтобы узнать, какие стили и веса доступны для данного шрифта, см. список шрифтов в Google Fonts.
Для каждого запрашиваемого стиля вы можете указать полное название или сокращение; в качестве альтернативы можно указать числовой вес:
| Стиль | Спецификаторы |
|---|---|
| курсив | курсив или i |
| полужирный | жирный или b или числовой вес, например 700 |
| полужирный курсив | жирным шрифтом или bi |
Например, чтобы запросить курсив Cantarell и жирный шрифт Droid Serif, вы можете использовать любой из следующих URL-адресов:
https: // шрифты.googleapis.com/css?family=Cantarell:italic|Droid+Serif:bold https://fonts.googleapis.com/css?family=Cantarell:i|Droid+Serif:b https://fonts.googleapis.com/css?family=Cantarell:i|Droid+Serif:700
Использовать font-display
font-display позволяет управлять
что происходит, пока шрифт недоступен. Обычно уместно указывать значение, отличное от значения по умолчанию
Обычно уместно указывать значение, отличное от значения по умолчанию auto .
Передайте желаемое значение в строке запроса отобразите параметр :
https: // шрифты.googleapis.com/css?family=Roboto&display=swap
Определение подмножеств скриптов
Некоторые шрифты в каталоге шрифтов Google поддерживает несколько скриптов (например, латынь, кириллица и греческий язык). Чтобы чтобы указать, какие подмножества должны быть загружены, параметр подмножества должен быть добавлен к URL-адресу.
Например, чтобы запросить подмножество кириллицы в Шрифт Roboto Mono, URL будет:
https://fonts.googleapis.com/css?family=Roboto+Mono&subset=cyrillic
Для запроса греческого подмножества Шрифт Roboto Mono, URL будет:
https: // шрифты.googleapis.com/css?family=Roboto+Mono&subset=greek
Для запроса греческой и кириллической подмножеств Шрифт Roboto Mono, URL будет:
https://fonts.googleapis.com/css?family=Roboto+Mono&subset=greek,кирилловый
Латинское подмножество всегда включается, если доступно, и его не нужно указывать. Обратите внимание: если клиентский браузер поддерживает диапазон Unicode (http://caniuse.com/#feat=font-unicode-range) параметр подмножества игнорируется; браузер выберет из подмножеств поддерживается шрифтом, чтобы получить то, что необходимо для визуализации текста.
Полный список доступных шрифтов и подмножеств шрифтов см. Google шрифты.
Оптимизация запросов шрифтов
Часто, когда вы хотите использовать веб-шрифт на своем веб-сайте или в приложении, вы
заранее знайте, какие буквы вам понадобятся. Это часто происходит, когда вы используете
веб-шрифт в логотипе или заголовке.
В этих случаях вам следует подумать об указании значения text = в вашем шрифте.
URL-адрес запроса. Это позволяет Google возвращать файл шрифта, оптимизированный для вашего
запрос.В некоторых случаях это может уменьшить размер файла шрифта до 90%.
Чтобы использовать эту функцию, просто добавьте text = в свой Google Fonts API.
Запросы. Например, если вы используете Inconsolata только для названия своего
blog, вы можете поместить сам заголовок как значение text = . Вот что
запрос будет выглядеть так:
https://fonts.googleapis.com/css?family=Inconsolata&text=Hello
Как и все строки запроса, вы должны кодировать URL-адресом значение:
https: // шрифты.googleapis.com/css?family=Inconsolata&text=Hello%20World
Эта функция также работает для международных шрифтов, позволяя указать UTF-8. символы. Например, ¡Hola! представлен как:
https://fonts.googleapis.com/css?family=Inconsolata&text=%c2%a1Hola!Примечание: нет необходимости указывать параметр
subset = при использовании text = в качестве
он позволяет вам ссылаться на любой символ в исходном шрифте.Включение эффектов шрифта (бета)
При создании заголовков или отображении текста на своем веб-сайте вам часто нужно стилизуйте свой текст декоративным способом.Чтобы упростить вашу работу, в Google есть предоставил коллекцию эффектов шрифта, которые вы можете использовать с минимальными усилиями, чтобы производить красивый отображаемый текст. Например:
Это эффект шрифта!
Чтобы использовать эту бета-функцию, просто добавьте effect = в свой Google
Запрос Fonts API и добавление соответствующего имени класса в элемент (ы) HTML
на что вы хотите повлиять. В нашем примере выше мы использовали
В нашем примере выше мы использовали shadow-multiple эффект шрифта, поэтому запрос будет выглядеть так:
https: // шрифты.googleapis.com/css?family=Rancho&effect=shadow-multiple
Чтобы использовать эффект, добавьте соответствующее имя класса к своим элементам HTML. В
соответствующее имя класса всегда является именем эффекта с префиксом font-effect- ,
поэтому имя класса для shadow-multiple будет font-effect-shadow-multiple :
Это эффект шрифта!
Вы можете запросить несколько эффектов, разделив имена эффектов вертикальной чертой
персонаж ( | ).
https://fonts.googleapis.com/css?family=Rancho&effect=shadow-multiple|3d-float
Вот полный список всех эффектов шрифтов, которые мы предлагаем:
| Эффект | Название API | Название класса | Опора |
|---|---|---|---|
| Анаглиф | анаглиф | шрифт-эффект-анаглиф | Chrome, Firefox, Opera, Safari |
| Вывеска из кирпича | кирпичная вывеска | знак-эффект-шрифт-кирпич | Chrome, Safari |
| Холст с принтом | на холсте | шрифт-эффект-холст-принт | Chrome, Safari |
| Треск | треск | Эффект шрифта, треск | Chrome, Safari |
| Разлагающийся | распадается | Затухание эффекта шрифта | Chrome, Safari |
| Разрушение | разрушение | шрифт-эффект-разрушение | Chrome, Safari |
| Проблемные | проблемные | эффект шрифта проблемный | Chrome, Safari |
| Проблемная древесина | состаренная древесина | с эффектом шрифта, состаренное дерево | Chrome, Safari |
| Тиснение | тиснение | шрифт-эффект-тиснение | Chrome, Firefox, Opera, Safari |
| Пожар | пожар | шрифт-эффект-огонь | Chrome, Firefox, Opera, Safari |
| Анимация огня | огонь-анимация | шрифт-эффект-огонь-анимация | Chrome, Firefox, Opera, Safari |
| Хрупкий | хрупкий | шрифт-эффект-хрупкий | Chrome, Safari |
| трава | трава | шрифт-эффект-трава | Chrome, Safari |
| Лед | лед | шрифт-эффект-лед | Chrome, Safari |
| Митоз | митоз | шрифт-эффект-митоз | Chrome, Safari |
| Неон | неон | шрифт-эффект-неон | Chrome, Firefox, Opera, Safari |
| Контур | контур | шрифт-эффект-контур | Chrome, Firefox, Opera, Safari |
| Путь зеленый | паттинг-грин | шрифт-эффект-паттинг-зеленый | Chrome, Safari |
| Сталь с потертостями | стальная с потертостями | Сталь с потертостями с эффектом шрифта | Chrome, Safari |
| Множественные тени | теневое множественное | шрифт-эффект-тень-кратное | Chrome, Firefox, Opera, Safari |
| Расколотый | расколотый | разделенные эффектом шрифта | Chrome, Safari |
| Статический | статический | статический эффект шрифта | Chrome, Safari |
| Штрих | штукатурка | шрифт эффект stonewash | Chrome, Safari |
| Трехмерный | 3d | шрифт-эффект-3d | Chrome, Firefox, Opera, Safari |
| Трехмерный поплавок | 3d-поплавок | шрифт-эффект-3d-поплавок | Chrome, Firefox, Opera, Safari |
| Винтаж | марочный | шрифт-эффект-винтаж | Chrome, Safari |
| Обои | обои | шрифт-эффект-обои | Chrome, Safari |
 3d) не особенно хорошо масштабируются, и
как правило, лучше всего смотрятся при использовании шрифта большего размера. Кроме того, вы можете
хотите изменить стиль шрифтов, например изменить цвет текста, чтобы он соответствовал
твоя страница.
3d) не особенно хорошо масштабируются, и
как правило, лучше всего смотрятся при использовании шрифта большего размера. Кроме того, вы можете
хотите изменить стиль шрифтов, например изменить цвет текста, чтобы он соответствовал
твоя страница.Есть много других способов стилизовать ваши шрифты, и многие вещи возможны через CSS. Мы просто предлагаем вам несколько идей для начала. Для большего идеи, попробуйте поискать в Google «текстовые эффекты css» и просмотрите многие идеи, которые уже есть в сети!
Дополнительная литература
Указание базового URL-адреса документа с помощью элемента HTML
Веб-сайты состоят из серии ссылок, указывающих на страницы и источники, такие как изображения и таблицы стилей.Существует два способа указать URL, который ссылается на эти источники : либо использовать абсолютный путь, либо относительный путь.
Абсолютный путь относится к определенному месту назначения, обычно он начинается с имени домена (вместе с HTTP), например www.domain.com/destination/source.jpg . Относительный путь противоположен: место назначения ссылки зависит от корневого расположения или, в большинстве случаев, от доменного имени вашего веб-сайта.
Типичный относительный путь будет выглядеть следующим образом:

Если домен вашего веб-сайта, например, hongkiat.com , путь к изображению будет разрешен до hongkiat.com/assets/img/image.png . Вы должны понимать это, если разрабатываете сайт какое-то время.
Но большинство из вас, вероятно, не слышали об элементе
«Базовый элемент позволяет авторам указывать базовый URL-адрес документа для целей разрешения относительных URL-адресов, а имя — контекст просмотра по умолчанию для целей следующих гиперссылок.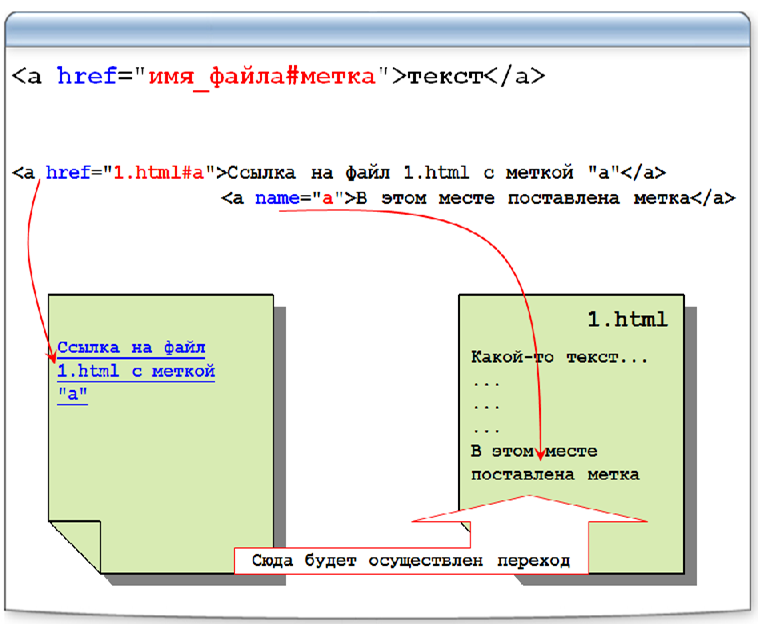 ”
”
Этот элемент
Использование базового элемента
и внутри .В следующем примере мы устанавливаем базовый URL-адрес на Google.
Эта спецификация повлияет на все пути в документе, включая тот, который указан в атрибуте href и src изображений. Итак, предполагая, что у нас есть таблица стилей, изображения и ссылки в документе, заданном относительным путем, например:
Ссылка привязки
Несмотря на то, что наша веб-страница находится под demo.hongkiat.com , относительный путь будет ссылаться на hongkiat.maxcdn.com , следуя базовому пути, указанному в теге
Все относительные пути в конечном итоге будут:
Ссылка привязки
Установка целевой ссылки по умолчанию
Помимо определения базового URL, тег target . Скажем, вы хотите, чтобы вся ссылка в документе открывала в новой вкладке браузера , установите для цели значение _blank , вот так.
Ограничения
Тег
Во-первых, браузер . Это может вызвать проблему иерархии в документе, если закрывающий тег не указан. Простой быстрый способ решить эту проблему — добавить , закрывающий в комментарии, .
Если вы используете # в сочетании с
Кроме того, пустой href приведет к базовому URL вместо ссылки на текущий каталог, в котором находится страница (это поведение браузера по умолчанию), что может вызвать непредвиденные проблемы со ссылками.
Заключение
URL-адресов HTML
HTML-ссылки
Когда вы щелкаете ссылку в документе HTML, например: Последний Page, базовый тег указывает на место (адрес) в Интернете. со значением атрибута href, например: Последняя Страница .
Ссылка «Последняя страница» в примере — это ссылка, относящаяся к веб-сайту. который вы просматриваете, и ваш браузер создаст полный веб-адрес, например http://www.w3schools.com/html/lastpage.htm для доступа к странице.
Унифицированные указатели ресурсов
Что-то, называемое унифицированным указателем ресурса (URL), используется для адресации
документ (или другие данные) на
Всемирная паутина.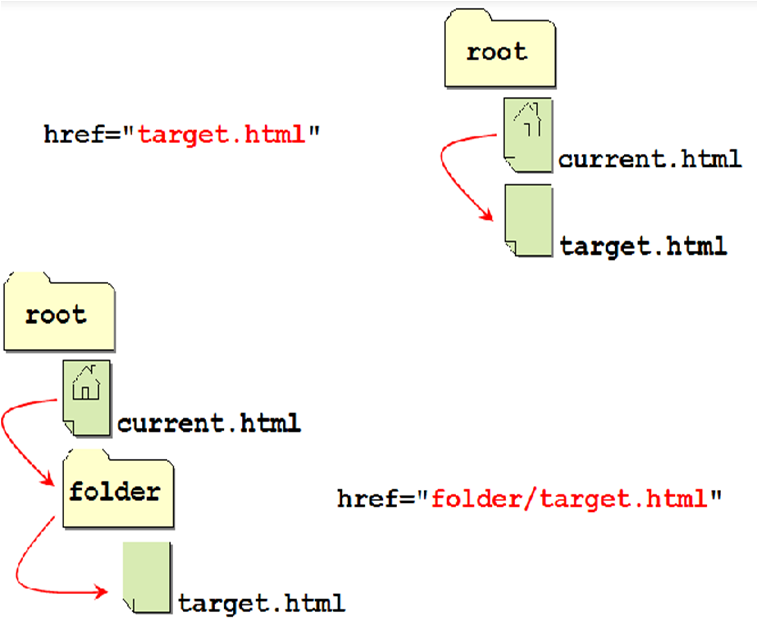 Полный веб-адрес вроде этого: http://www.w3schools.com/html/lastpage.htm
следует этим правилам синтаксиса:
Полный веб-адрес вроде этого: http://www.w3schools.com/html/lastpage.htm
следует этим правилам синтаксиса:
схема: //host.domain: порт / путь / имя файла
Схема определяет тип интернет-сервиса. Большинство общий тип — http .Домен определяет имя домена в Интернете как w3schools.com.
Хост определяет хост домена. Если не указано, хост по умолчанию для http — это www .
: порт определяет номер порта на хосте.Порт номер обычно опускается. Номер порта по умолчанию для http: 80 .
Путь определяет путь (подкаталог) на сервере. Если путь не указан, ресурс (документ) должен находиться в корне каталог веб-сайта.
Имя файла определяет имя документа. Имя файла по умолчанию может быть default.asp, index.html или что-то еще в зависимости от настроек веб-сервера.
Схемы URL
Некоторые примеры наиболее распространенных схем можно найти ниже:
| Схемы | Доступ |
|---|---|
| файл | файл на локальном ПК |
| ftp | файл на FTP-сервере |
| http | файл на сервере World Wide Web |
| суслик | файл на сервере Gopher |
| новости | группа новостей Usenet |
| телнет | Telnet-соединение |
| WAIS | файл на сервере WAIS |
Доступ к группе новостей
Следующий HTML-код:
создает ссылку на группу новостей, подобную этой группе новостей HTML.
Загрузка с FTP
Следующий HTML-код:
создает ссылку для загрузки такого файла:
Скачать
WinZip.
(Ссылка не работает. Не пытайтесь. Это просто пример. W3Schools не действительно есть каталог ftp.)
Ссылка на вашу почтовую систему
Следующий HTML-код:
создает ссылку на вашу собственную почтовую систему, например:
[адрес электронной почты защищен]
Надежный, доступный, многофункциональный веб-хостинг!
Избавьтесь от неуверенности в веб-хостинге и позвольте GoDaddy.com вернуть сервис, производительность и ценность. тип хостинга или план, который вы выбираете, ваш сайт получает 24/7 обслуживание и защита в нашем дата-центре мирового класса. Плюс, вы получите квалифицированное и вежливое обслуживание, которого вы заслуживаете, от крупнейший в мире провайдер имени хоста.
С тремя планами на выбор и цены начинаются всего с 4,99 доллара в месяц. , GoDaddy.com обязательно найдет план, который подходящего размера и по правильной цене именно для вас!
Все планы включают БЕСПЛАТНУЮ настройку 24×7, БЕСПЛАТНЫЙ круглосуточный мониторинг, лучший- высококлассные маршрутизаторы, брандмауэры и серверы, круглосуточная физическая безопасность на месте и доступ к нашему эксклюзивному подключению Go Daddy Hosting Connection, THE place установить более 30 БЕСПЛАТНЫХ приложений.Виртуальный выделенный и выделенный Также доступны серверные планы. Посетите GoDaddy.com сегодня .
Также доступны виртуальный выделенный, выделенный сервер и неограниченные планы.
Сэкономьте 10% на веб-хостинге — введите код w3tenoff при оформлении заказа
Телефонные ссылки
Схема URL-адреса tel используется для запуска приложения «Телефон» на устройствах iOS и начала набора указанного номера телефона. Когда пользователь нажимает на телефонную ссылку на веб-странице, iOS отображает предупреждение с вопросом, действительно ли пользователь хочет набрать номер телефона, и инициирует набор, если пользователь соглашается. Когда пользователь открывает URL-адрес со схемой
Когда пользователь открывает URL-адрес со схемой tel в собственном приложении, iOS 10.3 и более поздних версий отображает предупреждение и требует подтверждения пользователя перед набором номера. (Когда этот сценарий возникает в версиях iOS до 10.3, iOS инициирует набор номера без дальнейшего запроса пользователя и не отображает предупреждение, хотя собственное приложение может быть настроено для отображения собственного предупреждения.)
FaceTime в macOS 10.10 и более поздних версиях также можно использовать схему URL-адреса tel для запуска приложения «Телефон» на устройстве iOS с помощью Handoff.Этот сценарий работает, когда FaceTime настроен для набора телефонных номеров (конфигурация по умолчанию), а устройство iOS подключено к той же учетной записи iCloud, что и Mac.
Вы можете явно указать телефонные ссылки как в веб-приложениях, так и в собственных приложениях iOS, используя схему URL-адресов tel . В следующих примерах показаны строки, отформатированные для Safari и для собственного приложения:
HTML-ссылка:
1-408-555-5555
Строка URL-адреса собственного приложения:
Чтобы пользователи не злонамеренно перенаправляли телефонные звонки или изменяли поведение телефона или учетной записи, приложение «Телефон» поддерживает большинство, но не все, специальные символы в схеме tel .В частности, если URL-адрес содержит символы * или # , приложение «Телефон» не пытается набрать соответствующий номер телефона. Если ваше приложение получает строки URL-адреса от пользователя или из неизвестного источника, вы также должны убедиться, что любые специальные символы, которые могут не подходить для URL-адреса, экранированы должным образом. Для собственных приложений используйте метод stringByAddingPercentEscapesUsingEncoding: из NSString для экранирования символов, который возвращает правильно экранированную версию исходной строки.
В Safari на iOS определение номера телефона включено по умолчанию. Однако, если ваша веб-страница содержит номера, которые можно интерпретировать как номера телефонов, но не являются номерами телефонов, вы можете отключить определение номера телефона. Вы также можете отключить определение номера телефона, чтобы предотвратить изменение документа DOM при его анализе браузером. Чтобы отключить определение номера телефона в Safari на iOS, используйте метатег определения формата следующим образом:
В листинге 2-1 показана простая веб-страница, на которой отключено автоматическое определение номера телефона.При отображении в Safari на iOS телефонный номер 408-555-5555 не отображается в виде ссылки. Однако номер 1-408-555-5555 отображается как ссылка, потому что он находится в телефонной ссылке.
Листинг 2-1 Отключение определения номера телефона
"http: // www .w3.org / TR / xhtml1 / DTD / xhtml1-strict.dtd "> |
|
|
|
|
 ->
-> iOS Примечание: Если приложение «Телефон» не установлено на устройстве iOS, при открытии URL-адреса tel отображается соответствующее предупреждающее сообщение для пользователя.
Дополнительные сведения о схеме URL tel см. В RFC 2806 и RFC 2396.
sitemaps.org - Протокол
Перейти к:
Определения тегов XML
Преобразование объекта
Использование файлов индекса Sitemap
Другие форматы Sitemap
Местоположение файла Sitemap
Проверка вашего Sitemap
Расширение протокола Sitemaps
Информирование поисковых роботов
Этот документ описывает схему XML для протокола Sitemap.
Формат протокола Sitemap состоит из тегов XML. Все значения данных в файле Sitemap должны быть экранированным от сущности. Сам файл должен быть в кодировке UTF-8.
Карта сайта должна:
- Начните с открывающего тега
и заканчиваться закрывающим тегом . - Укажите пространство имен (стандарт протокола) в пределах
тег. - Включите запись
для каждого URL, как родительский тег XML. - Включите дочернюю запись
для каждого родительский тег.
Все остальные теги необязательны. Поддержка этих дополнительных тегов может различаться в зависимости от поиска. двигатели.За подробностями обращайтесь к документации каждой поисковой системы.
Кроме того, все URL-адреса в файле Sitemap должны быть с одного хоста, например www.example.com. или store.example.com. Для получения дополнительных сведений см. Файл Sitemap. расположение
Образец XML-карты сайта
В следующем примере показан файл Sitemap, содержащий только один URL и использующий все необязательные теги.Необязательные теги выделены курсивом.
http://www.example.com/
01.01.2005
ежемесячно
0,8
Также посмотрите наш пример с несколькими URL-адресами.
Определения тегов XML
Доступные теги XML описаны ниже.
Атрибут Описание требуется Инкапсулирует файл и ссылается на текущий стандарт протокола.
требуется Родительский тег для каждой записи URL. Остальные теги являются дочерними по отношению к этому тегу.
требуется URL страницы. Этот URL-адрес должен начинаться с протокола (например, http) и заканчиваться на косая черта в конце, если этого требует ваш веб-сервер.Это значение должно быть меньше 2048. символы.
необязательный Дата последней модификации файла.Эта дата должна быть в Формат даты и времени W3C. Этот формат позволяет опускать временную часть, если желаемый и используйте ГГГГ-ММ-ДД.
Обратите внимание, что этот тег отделен от заголовка If-Modified-Since (304) сервера могут возвращаться, а поисковые системы могут использовать информацию из обоих источников по-разному.
<частота смены> необязательный Как часто страница будет меняться. Это значение предоставляет общую информацию поисковым системам и может не соответствовать точно тому, как часто они сканируют страницу.Допустимые значения:
- всегда
- почасово
- ежедневно
- еженедельно
- ежемесячно
- годовой
- никогда
Значение «всегда» следует использовать для описания документов, которые меняются каждый раз, когда они доступны.Значение «никогда» следует использовать для описания заархивированных URL-адресов.
Обратите внимание, что значение этого тега считается подсказкой , а не командой. Даже если сканеры поисковых систем могут учитывать эту информацию при принятии решений, они могут сканировать страницы с пометкой "ежечасно" реже, чем это, и они могут сканировать страницы с пометкой «ежегодно» чаще, чем это.Поисковые роботы могут периодически сканировать страницы с пометкой «никогда», чтобы они могли обрабатывать неожиданные изменения на этих страницах.
<приоритет> необязательный Приоритет этого URL-адреса по отношению к другим URL-адресам на вашем сайте.Диапазон допустимых значений от 0,0 до 1,0. Это значение не влияет на то, как ваши страницы сравниваются со страницами. на других сайтах - он позволяет только поисковым системам узнать, какие страницы вы считаете наиболее важно для сканеров.
По умолчанию приоритет страницы равен 0,5.
Обратите внимание, что приоритет, который вы назначаете странице, вряд ли повлияет на положение ваших URL-адресов на страницах результатов поисковой системы.Поисковые системы могут использовать эта информация при выборе URL-адресов на одном сайте, поэтому вы можете использовать эту тег, чтобы увеличить вероятность того, что ваши самые важные страницы будут присутствовать в поиске. индекс.
Также обратите внимание, что присвоение высокого приоритета всем URL-адресам на вашем сайте вряд ли вам поможет.Поскольку приоритет относительный, он используется только для выбора между URL-адресами на вашем сайте.
Вернуться к началу
Сущность, убегающая
Ваш файл Sitemap должен иметь кодировку UTF-8 (обычно это можно сделать при сохранении файл).Как и во всех файлах XML, любые значения данных (включая URL-адреса) должны использовать сущность escape-коды для символов, перечисленных в таблице ниже.
Характер Код выхода Амперсанд & & amp; Одиночная цитата ' ' Двойная кавычка " & quot; Лучше чем > & gt; Меньше, чем < & lt;
Кроме того, все URL-адреса (включая URL-адрес вашего Sitemap) должны иметь экранирование URL-адресов и закодированы для удобства чтения веб-сервером, на котором они расположены. Однако если вы используете любой сценарий, инструмент или файл журнала для генерации ваших URL-адресов (что угодно кроме ввода вручную), обычно это уже сделано за вас. пожалуйста, проверьте чтобы убедиться, что ваши URL-адреса следуют RFC-3986 стандарт для URI, RFC-3987 стандарт для IRI и стандарт XML.
Ниже приведен пример URL-адреса, в котором используется символ, отличный от ASCII ( ü ), а также символ, который требует экранирования сущности ( и ):
http: // www.example.com/ümlat.php&q=name
Ниже приведен тот же URL-адрес в кодировке ISO-8859-1 (для размещения на сервере, который использует этот кодировка) и экранированный URL:
http://www.example.com/%FCmlat.php&q=name
Ниже приведен тот же URL-адрес в кодировке UTF-8 (для размещения на сервере, который использует эту кодировку). и экранированный URL:
http: // www.example.com/%C3%BCmlat.php&q=name
Ниже приведен тот же URL, но также экранированный объект:
http://www.example.com/%C3%BCmlat.php&q=name
Образец XML-карты сайта
В следующем примере показан файл Sitemap в формате XML. Карта сайта в примере содержит небольшое количество URL-адресов, каждый из которых использует свой набор необязательных параметров.
http://www.example.com/
1 января 2005 г.
ежемесячно
0,8
http: // www. example.com/catalog?item=12&desc=vacation_hawaii
еженедельно
http://www.example.com/catalog?item=73&desc=vacation_new_zealand
23 декабря 2004 г.
еженедельно
http: // www.example.com/catalog?item=74&desc=vacation_newfoundland
2004-12-23T18: 00: 15 + 00: 00
0,3
http://www.example.com/catalog?item=83&desc=vacation_usa
23 ноября 2004 г.
Вернуться к началу
Использование файлов индекса Sitemap (для группировки нескольких файлов Sitemap файлы)
Вы можете предоставить несколько файлов Sitemap, но каждый предоставленный файл Sitemap должен иметь не более 50 000 URL и не должен превышать 50 МБ (52 428 800 байт).При желании вы можете сжать файлы Sitemap с помощью gzip, чтобы уменьшить требования к пропускной способности; однако файл карты сайта после распаковки не должен быть больше чем 50 МБ. Если вы хотите указать более 50 000 URL-адресов, необходимо создать несколько файлов Sitemap. файлы.
Если вы предоставляете несколько файлов Sitemap, вам следует перечислить каждый файл Sitemap в Файл индекса Sitemap.Файлы индекса Sitemap не могут содержать более 50 000 файлов Sitemap и не должен превышать 50 МБ (52 428 800 байт) и может быть сжат. Вы можете иметь более одного файла индекса Sitemap. XML-формат файла индекса Sitemap очень аналогичен формату XML файла Sitemap.
Файл индекса Sitemap должен:
- Начать с открытия
и заканчиваться закрывающим тегом . - Включить запись
для каждого файла Sitemap в качестве родительского тега XML. - Включить дочернюю запись
для каждый родительский тег .
Необязательный тег также доступен для файлов индекса Sitemap.
Примечание. В файле индекса Sitemap можно указывать только найденные файлы Sitemap. на том же сайте, что и файл индекса Sitemap. Например, http://www.yoursite.com/sitemap_index.xml может включать файлы Sitemap на http://www.yoursite.com, но не на http://www.example.com или http://yourhost.yoursite.com. Как и в случае с файлами Sitemap, ваш файл индекса Sitemap должен быть в кодировке UTF-8.
Образец XML-файла Sitemap Индекс
В следующем примере показан индекс Sitemap, в котором перечислены два файла Sitemap:
<карта сайта>
http://www.example.com/sitemap1.xml.gz
2004-10-01T18: 23: 17 + 00: 00
<карта сайта>
http: // www.example.com/sitemap2.xml.gz
1 января 2005 г.
Примечание. URL-адреса файлов Sitemap , как и все значения в ваших файлах XML, должны быть сущность сбежала.
Карта сайта Индексировать определения тегов XML
Атрибут Описание требуется Инкапсулирует информацию обо всех файлах Sitemap в файле. <карта сайта> требуется Инкапсулирует информацию об отдельном файле Sitemap. требуется Определяет расположение Sitemap.
Этим расположением может быть файл Sitemap, файл Atom, файл RSS или простой текстовый файл.
необязательный Определяет время изменения соответствующего файла Sitemap.Это не соответствуют времени изменения любой из страниц, перечисленных в этом файле Sitemap. Значение тега lastmod должно быть в Формат даты и времени W3C.
Указав отметку времени последней модификации, вы активируете сканеры поисковых систем. для получения только части файлов Sitemap в индексе i.е. сканер может только получить Файлы Sitemap, которые были изменены с определенной даты. Эта инкрементальная загрузка файла Sitemap Механизм позволяет быстро обнаруживать новые URL-адреса на очень больших сайтах.
Вернуться к началу
Другие форматы файлов Sitemap
Протокол Sitemap позволяет вам предоставлять подробную информацию о ваших страницах поисковым системам, и мы поощряем его использование, так как вы можете предоставить дополнительную информацию о сайте страницы за пределами URL-адресов.Однако в дополнение к протоколу XML мы поддерживаем RSS-каналы и текстовые файлы, которые предоставляют более ограниченную информацию.
Канал синдикации
Вы можете предоставить канал RSS (Real Simple Syndication) 2.0 или Atom 0.3 или 1.0. В общем, вы можете использовать этот формат только в том случае, если на вашем сайте уже есть канал распространения. Примечание что этот метод может не позволить поисковым системам узнать обо всех URL-адресах на вашем сайте, поскольку фид может предоставлять информацию только о недавних URL-адресах, хотя поисковые системы все еще может использовать эту информацию, чтобы узнавать о других страницах вашего сайта во время их обычные процессы сканирования путем перехода по ссылкам на страницах фида.Делать убедитесь, что канал находится в каталоге самого высокого уровня, который вы хотите поисковыми системами. ползать. Поисковые системы извлекают информацию из фида следующим образом:
- <ссылка> поле - указывает URL
- поле даты изменения (поле
для RSS-каналов и дата для каналов Atom) - указывает, когда каждый URL был в последний раз изменен.Использование поле даты изменения не является обязательным.
Текстовый файл
Вы можете предоставить простой текстовый файл, содержащий по одному URL-адресу в каждой строке. Текстовый файл должен следовать этим правилам:
- Текстовый файл должен содержать по одному URL-адресу в строке. URL-адреса не могут содержать встроенные новые строки.
- Необходимо полностью указать URL-адреса, включая http.
- Каждый текстовый файл может содержать не более 50 000 URL и не должен превышать 50 МБ. (52 428 800 байт). Если на вашем сайте более 50 000 URL-адресов, вы можете разделить список в несколько текстовых файлов и добавлять каждый по отдельности.
- Текстовый файл должен использовать кодировку UTF-8. Вы можете указать это при сохранении файла (например, в Блокноте это указано в меню «Кодировка» диалогового окна «Сохранить как». коробка).
- Текстовый файл не должен содержать никакой информации, кроме списка URL-адресов.
- Текстовый файл не должен содержать информации верхнего или нижнего колонтитула.
- Если хотите, вы можете сжать текстовый файл Sitemap с помощью gzip, чтобы уменьшить ваши требования к пропускной способности.
- Вы можете назвать текстовый файл как хотите. Убедитесь, что ваш URL-адреса соответствуют стандарту RFC-3986 для URI стандарт RFC-3987 для IRI
- Вы должны загрузить текстовый файл в каталог самого высокого уровня, который вы хотите поисковыми системами. для сканирования и убедитесь, что вы не перечисляете URL-адреса в текстовом файле, которые находятся в каталоге более высокого уровня.
Примеры записей в текстовом файле показаны ниже.
http://www.example.com/catalog?item=1
http://www.example.com/catalog?item=11
Вернуться к началу
Расположение файла Sitemap
Расположение файла Sitemap определяет набор URL-адресов, которые можно включить в этот файл Sitemap.Файл Sitemap, расположенный по адресу http://example.com/catalog/sitemap.xml, может включать любые URL-адреса, начинающиеся с http://example.com/catalog/, но не могут включать URL-адреса начиная с http://example.com/images/.
Если у вас есть разрешение на изменение http://example.org/path/sitemap.xml, это предполагается, что у вас также есть разрешение на предоставление информации для URL-адресов с префиксом http: // пример.org / путь /. Примеры URL-адресов, считающихся действительными в http://example.com/catalog/sitemap.xml включают:
http://example.com/catalog/show?item=23
http://example.com/catalog/show?item=233&user=3453
URL-адреса, недопустимые в http://example.com/catalog/sitemap.xml, включают:
http://example.com/image/show?item=23
http: // пример.ru / image / show? item = 233 & user = 3453
https://example.com/catalog/page1.php
Обратите внимание: это означает, что все URL-адреса, перечисленные в файле Sitemap, должны использовать один и тот же протокол. (http, в этом примере) и находятся на том же хосте, что и Sitemap. Например, если файл Sitemap находится по адресу http://www.example.com/sitemap.xml, он не может включать URL-адреса из поддомена http: //.example.com.
URL-адреса, которые не считаются действительными, исключаются из дальнейшего рассмотрения. это настоятельно рекомендуется разместить файл Sitemap в корневом каталоге вашего веб-сайта. сервер. Например, если ваш веб-сервер находится по адресу example.com, то ваш индекс Sitemap файл будет по адресу http://example.com/sitemap.xml. В некоторых случаях вам может понадобиться для создания разных файлов Sitemap для разных путей (например,g., если разрешения безопасности в вашей организации разделите доступ на запись к разным каталогам).
Если вы отправляете Sitemap, используя путь с номером порта, вы должны указать этот порт. число как часть пути в каждом URL, указанном в файле Sitemap. Например, если ваш файл Sitemap находится по адресу http://www.example.com:100/sitemap.xml, то каждый URL-адрес, указанный в файле Sitemap, должен начинаться с http: // www.example.com:100.
Файлы Sitemap и Cross Подает
Чтобы отправить файлы Sitemap для нескольких хостов с одного хоста, вам необходимо «подтвердить» право собственности. хоста (ов), URL-адреса которых отправляются в Sitemap. Вот пример. Допустим, вы хотите отправить файлы Sitemap для 3 хостов:
www.host1.com с файлом Sitemap sitemap-host1.xml
www.host2.com с файлом Sitemap sitemap-host2.xml
www.host3.com с файлом Sitemap sitemap-host3.xml
Более того, вы хотите разместить все три файла Sitemap на одном хосте: www.sitemaphost.com. Таким образом, URL-адреса файлов Sitemap будут:
http://www.sitemaphost.com/sitemap-host1.xml
http: // www.sitemaphost.com/sitemap-host2.xml
http://www.sitemaphost.com/sitemap-host3.xml
По умолчанию это приведет к ошибке «перекрестной отправки», поскольку вы пытаетесь для отправки URL-адресов для www.host1.com через файл Sitemap, размещенный на www.sitemaphost.com (и то же самое для двух других хостов). Один из способов избежать ошибки - доказать, что вы владеете (т.е. имеют право изменять файлы) www.host1.com. Вы можете сделать это изменив файл robots.txt на www.host1.com так, чтобы он указывал на Sitemap на www.sitemaphost.com.
В этом примере файл robots.txt по адресу http://www.host1.com/robots.txt будет содержать строка «Карта сайта: http://www.sitemaphost.com/sitemap-host1.xml». Изменяя Файл robots.txt на www.host1.com и указав на файл Sitemap на www.sitemaphost.com, вы неявно доказали, что являетесь владельцем www.host1.com. Другими словами, тот, кто контролирует файл robots.txt на www.host1.com доверяет карте сайта http://www.sitemaphost.com/sitemap-host1.xml содержать URL-адреса для www.host1.com. Тот же процесс можно повторить для другого два хозяина.
Теперь вы можете отправить файлы Sitemap на сайте www.sitemaphost.com.
Когда файл robots.txt определенного хоста, скажем http://www.host1.com/robots.txt, указывает в файл Sitemap или индекс Sitemap на другом хосте; ожидается, что для каждого из целевые файлы Sitemap, такие как http://www.sitemaphost.com/sitemap-host1.xml, все URL-адреса принадлежат хосту, указывающему на него. Это связано с тем, что, как отмечалось ранее, файл Sitemap ожидается, что URL-адреса будут поступать только с одного хоста.
Вернуться к началу
Проверка вашего Sitemap
Следующие XML-схемы определяют элементы и атрибуты, которые могут появляться в ваш файл Sitemap. Вы можете скачать эту схему по ссылкам ниже:
Для файлов Sitemap: http: // www.sitemaps.org/schemas/sitemap/0.9/sitemap.xsd
Для файлов индекса Sitemap: http://www.sitemaps.org/schemas/sitemap/0.9/siteindex.xsd
Существует ряд инструментов, которые помогут вам проверить структуру вашего Карта сайта на основе этой схемы. Вы можете найти список инструментов, связанных с XML, на каждом из по следующим адресам:
http: // www.w3.org/XML/Schema#Tools
http://www.xml.com/pub/a/2000/12/13/schematools.html
Чтобы проверить ваш Sitemap или файл индекса Sitemap на соответствие схеме, XML файлу потребуются дополнительные заголовки, как показано ниже.
Карта сайта:
...
Индексный файл Sitemap:
<карта сайта>
...
Вернуться к началу
Расширение протокола Sitemaps
Вы можете расширить протокол Sitemap, используя собственное пространство имен.Просто укажите это пространство имен в корневом элементе. Например:
<пример: example_tag>
...
...
Вернуться к началу
Информирование поисковых роботов
После того, как вы создали файл Sitemap и разместили его на своем веб-сервере, вам потребуется чтобы проинформировать поисковые системы, поддерживающие этот протокол, о своем местонахождении.Вы можете сделать это:
Затем поисковые системы могут получить ваш файл Sitemap и сделать URL-адреса доступными для их краулеры.
Отправка файла Sitemap через поиск интерфейс подачи двигателя
Чтобы отправить файл Sitemap непосредственно в поисковую систему, которая позволит вам получать информацию о статусе и любых ошибках обработки см. в документации каждой поисковой системы.
Указание местоположения файла Sitemap в ваш файл robots.txt
Вы можете указать местоположение файла Sitemap с помощью файла robots.txt. Сделать это, просто добавьте следующую строку, включающую полный URL-адрес в карту сайта:
Карта сайта: http://www.example.com/sitemap.xml
Эта директива не зависит от строки пользовательского агента, поэтому не имеет значения, где вы помещаете его в свой файл.Если у вас есть файл индекса Sitemap, вы можете включить расположение только этого файла. Вам не нужно перечислять каждый отдельный файл Sitemap в списке. в индексном файле.
Вы можете указать несколько файлов Sitemap для каждого файла robots.txt.
Карта сайта: http://www.example.com/sitemap-host1.xml
Карта сайта: http://www.example.com/sitemap-host2.xml
Отправка файла Sitemap с помощью HTTP-запроса
Чтобы отправить файл Sitemap с помощью HTTP-запроса (замените на URL-адрес, предоставленный поисковой системой), отправьте запрос по следующему URL-адресу:
/ ping? Sitemap = sitemap_url
Например, если ваш файл Sitemap находится по адресу http: // www.example.com/sitemap.gz, ваш URL станет:
/ping?sitemap=http://www.example.com/sitemap.gz
URL-адрес кодирует все, что находится после / ping? Sitemap =:
/ping?sitemap=http%3A%2F%2Fwww.yoursite.com%2Fsitemap.gz
Вы можете отправить HTTP-запрос с помощью wget, curl или другого механизма по вашему выбору.Успешный запрос вернет код ответа HTTP 200; если вы получите другой ответ, вы должны повторно отправить свой запрос. Код ответа HTTP 200 указывает только что поисковая система получила ваш файл Sitemap, а не сам файл Sitemap или URL-адреса, содержащиеся в нем, были действительными. Самый простой способ сделать это - настроить автоматизированный работа по созданию и отправке файлов Sitemap на регулярной основе.
Примечание: Если вы предоставляете файл индекса Sitemap, вам нужно только для выдачи одного HTTP-запроса, который включает расположение файла индекса Sitemap; вам не нужно отправлять отдельные запросы для каждого файла Sitemap, указанного в индексе.
Вернуться к началу
Без содержания
Протокол Sitemaps позволяет сообщать поисковым системам, какой контент вы хотели бы вроде проиндексировано.Чтобы указать поисковым системам контент, который вы не хотите индексировать, используйте файл robots.txt. файл или метатег robots. См. Robotstxt.org для получения дополнительной информации о том, как исключить контент из поисковых систем.
Вернуться к началу
Последнее обновление: 21 ноября 2016 г.
urllib.parse - Разбор URL-адресов на компоненты - документация Python 3.9.2
Исходный код: Lib / urllib / parse.py
Этот модуль определяет стандартный интерфейс для взлома Uniform Resource Locator (URL)
строки в компонентах (схема адресации, сетевое расположение, путь и т. д.), чтобы
объединить компоненты обратно в строку URL и преобразовать «относительный URL»
на абсолютный URL-адрес, заданный «базовым URL-адресом».
Модуль был разработан в соответствии с RFC в Интернете по Relative Uniform.
Локаторы ресурсов.Он поддерживает следующие схемы URL: файл , ftp , gopher , hdl , http , https , imap , mailto , mms , новости , nntp , prospero , rsync , rtsp , rtspu , sftp , shttp , sip , sips , snews , svn , svn + ssh , telnet , wais , ws , wss .
Модуль urllib.parse определяет функции, которые делятся на два основных
категории: парсинг URL и цитирование URL. Они подробно описаны в
следующие разделы.
Разбор URL
Функции синтаксического анализа URL-адресов сосредоточены на разделении строки URL-адреса на ее компоненты,
или при объединении компонентов URL в строку URL.
-
urllib.parse. urlparse ( urlstring , scheme = '' , allow_fragments = True ) Разбирает URL-адрес на шесть компонентов, возвращая именованный кортеж из 6 элементов.Этот
соответствует общей структуре URL: схема: // netloc / путь; параметры? Запрос # фрагмент .
Каждый элемент кортежа представляет собой строку, возможно, пустую. Компоненты не разбиты
на более мелкие части (например, сетевое местоположение представляет собой одну строку), а%
побеги не расширяются. Указанные выше разделители не являются частью
результат, за исключением ведущей косой черты в компоненте пути , который сохраняется, если
настоящее время. Например:
>>> из urllib.анализировать импорт URL
>>> o = urlparse ('http://www.cwi.nl:80/%7Eguido/Python.html')
>>> о
ParseResult (scheme = 'http', netloc = 'www.cwi.nl: 80', path = '/% 7Eguido / Python.html',
params = '', query = '', фрагмент = '')
>>> o.scheme
'http'
>>> o.port
80
>>> o.geturl ()
'http://www.cwi.nl:80/%7Eguido/Python.html'
Следуя спецификациям синтаксиса в RFC 1808 , urlparse распознает
netloc, только если он правильно введен с помощью «//».В противном случае
предполагается, что ввод является относительным URL-адресом и, следовательно, должен начинаться с
компонент пути.
>>> из urllib.parse import urlparse
>>> urlparse ('// www.cwi.nl:80/%7Eguido/Python.html')
ParseResult (scheme = '', netloc = 'www.cwi.nl: 80', path = '/% 7Eguido / Python.html',
params = '', query = '', фрагмент = '')
>>> urlparse ('www.cwi.nl/%7Eguido/Python.html')
ParseResult (scheme = '', netloc = '', path = 'www.cwi.nl /% 7Eguido / Python.html',
params = '', query = '', фрагмент = '')
>>> urlparse ('справка / Python.html ')
ParseResult (scheme = '', netloc = '', path = 'help / Python.html', params = '',
запрос = '', фрагмент = '')
Схема Аргумент задает схему адресации по умолчанию, которая
используется только в том случае, если URL-адрес не указан. Он должен быть одного типа
(текст или байты) как urlstring , за исключением того, что значение по умолчанию '' равно
всегда разрешено и автоматически преобразуется в b '' , если необходимо.
Если аргумент allow_fragments false, идентификаторы фрагментов не
признал.Вместо этого они анализируются как часть пути, параметры
или компонент запроса, а фрагмент устанавливается на пустую строку в
возвращаемое значение.
Возвращаемое значение - именованный кортеж, что означает, что его элементы могут
доступны по индексу или как именованные атрибуты, а именно:
Атрибут
Индекс
Значение
Значение, если отсутствует
схема
0
Спецификатор схемы URL
схема параметр
netloc
1
Часть сетевого расположения
пустая строка
путь
2
Иерархический путь
пустая строка
параметры
3
Параметры последнего пути
элемент
пустая строка
запрос
4
Компонент запроса
пустая строка
фрагмент
5
Идентификатор фрагмента
пустая строка
имя пользователя
Имя пользователя
Нет
пароль
Пароль
Нет
имя хоста
Имя хоста (нижний регистр)
Нет
порт
Номер порта как целое число,
при наличии
Нет
Чтение атрибута порта вызовет ошибку ValueError , если
в URL указан недопустимый порт.См. Раздел
Структурированные результаты анализа для получения дополнительной информации об объекте результата.
Несовпадающие квадратные скобки в атрибуте netloc вызовут ValueError .
символов в атрибуте netloc , которые разлагаются под NFKC
нормализация (как используется кодировкой IDNA) в любой из /, ? , г. # , @ или : вызовет ValueError . Если URL-адрес
разложить перед синтаксическим анализом, ошибки не возникнет.
Как и в случае со всеми именованными кортежами, у подкласса есть несколько дополнительных методов
и атрибуты, которые особенно полезны. Один из таких методов - _replace () .
Метод _replace () вернет новый объект ParseResult, заменяющий указанный
поля с новыми значениями.
>>> из urllib.parse import urlparse
>>> u = urlparse ('// www.cwi.nl:80/%7Eguido/Python.html')
>>> ты
ParseResult (scheme = '', netloc = 'www.cwi.nl: 80', path = '/% 7Eguido / Python.html ',
params = '', query = '', фрагмент = '')
>>> u._replace (схема = 'http')
ParseResult (scheme = 'http', netloc = 'www.cwi.nl: 80', path = '/% 7Eguido / Python.html',
params = '', query = '', фрагмент = '')
Изменено в версии 3.2: Добавлены возможности синтаксического анализа URL-адресов IPv6.
Изменено в версии 3.3: фрагмент теперь анализируется для всех схем URL (если только не allow_fragment ).
false) в соответствии с RFC 3986 . Ранее белый список
схемы, поддерживающие фрагменты, существовали.
Изменено в версии 3.6: номера портов вне допустимого диапазона теперь вызывают ValueError вместо
возвращает Нет .
Изменено в версии 3.8: Символы, влияющие на синтаксический анализ netloc при нормализации NFKC, будут
теперь вызовите ValueError .
-
urllib.parse. parse_qs ( qs , keep_blank_values = False , strict_parsing = False , encoding = 'utf-8' , errors = 'replace' , max_num_fields = None max_num_fields = None 906 ') Анализировать строку запроса, заданную как строковый аргумент (данные типа application / x-www-form-urlencoded ).Данные возвращаются в виде
толковый словарь. Ключи словаря - это уникальные имена переменных запроса и
значения - это списки значений для каждого имени.
Необязательный аргумент keep_blank_values - это флаг, указывающий, пусто ли
значения в запросах с процентной кодировкой следует рассматривать как пустые строки. Истинная ценность
указывает, что пробелы должны быть оставлены как пустые строки. По умолчанию false
значение указывает, что пустые значения должны игнорироваться и обрабатываться так, как если бы они были
не включено.
Необязательный аргумент strict_parsing - это флаг, указывающий, что делать с
ошибки разбора. Если false (по умолчанию), ошибки игнорируются. Если правда,
ошибки вызывают исключение ValueError .
Необязательные параметры кодирования , ошибки и , параметры определяют способ декодирования
последовательности, закодированные в процентах, в символы Unicode, как это принято bytes.decode () метод.
Необязательный аргумент max_num_fields - максимальное количество полей для
читать.Если установлено, то выдает ValueError , если их больше max_num_fields прочитанных полей.
Необязательный аргумент разделитель - это символ, используемый для разделения
аргументы запроса. По умолчанию это и .
Используйте функцию urllib.parse.urlencode () (с функцией dosq параметр установлен на True ), чтобы преобразовать такие словари в запрос
струны.
Изменено в версии 3.2: добавлено кодирования и ошибок параметров.
Изменено в версии 3.8: Добавлен параметр max_num_fields .
Изменено в версии 3.9.2: Добавлен параметр разделителя со значением по умолчанию и . Python
версии до Python 3.9.2 позволяли использовать как ; и и как
разделитель параметров запроса. Это было изменено, чтобы разрешить только один
ключ-разделитель с и в качестве разделителя по умолчанию.
-
urllib.разобрать. parse_qsl ( qs , keep_blank_values = False , strict_parsing = False , encoding = 'utf-8' , errors = 'replace' , max_num_fields = None ') Анализировать строку запроса, заданную как строковый аргумент (данные типа application / x-www-form-urlencoded ). Данные возвращаются в виде списка
пары имя, значение.
Необязательный аргумент keep_blank_values - это флаг, указывающий, пусто ли
значения в запросах с процентной кодировкой следует рассматривать как пустые строки.Истинная ценность
указывает, что пробелы должны быть оставлены как пустые строки. По умолчанию false
значение указывает, что пустые значения должны игнорироваться и обрабатываться так, как если бы они были
не включено.
Необязательный аргумент strict_parsing - это флаг, указывающий, что делать с
ошибки разбора. Если false (по умолчанию), ошибки игнорируются. Если правда,
ошибки вызывают исключение ValueError .
Необязательные параметры кодирования , ошибки и , параметры определяют способ декодирования
последовательности, закодированные в процентах, в символы Unicode, как это принято байт.decode () метод.
Необязательный аргумент max_num_fields - максимальное количество полей для
читать. Если установлено, то выдает ValueError , если их больше max_num_fields прочитанных полей.
Необязательный аргумент разделитель - это символ, используемый для разделения аргументов запроса. По умолчанию это и .
Используйте функцию urllib.parse.urlencode () для преобразования таких списков пар в
строки запроса.
Изменено в версии 3.2: добавлено кодирования и ошибок параметров.
Изменено в версии 3.8: Добавлен параметр max_num_fields .
Изменено в версии 3.9.2: Добавлен параметр разделителя со значением по умолчанию и . Python
версии до Python 3.9.2 позволяли использовать как ; и и как
разделитель параметров запроса. Это было изменено, чтобы разрешить только один
ключ-разделитель с и в качестве разделителя по умолчанию.
-
urllib.parse. urlunparse ( части ) Создайте URL-адрес из кортежа, возвращенного функцией urlparse () . части Аргумент может быть любым итерируемым из шести пунктов. Это может привести к небольшому
другой, но эквивалентный URL-адрес, если изначально проанализированный URL-адрес содержал
ненужные разделители (например, ? с пустым запросом; RFC
заявляет, что они эквивалентны).
-
urllib.разобрать. urlsplit ( urlstring , scheme = '' , allow_fragments = True ) Это похоже на urlparse () , но не разделяет параметры из URL.
Обычно это следует использовать вместо urlparse () , если более свежий URL
синтаксис, позволяющий применять параметры к каждому сегменту участка пути URL-адреса (см. RFC 2396 ) требуется. Отдельная функция нужна для
разделите сегменты пути и параметры.Эта функция возвращает 5 элементов
именованный кортеж:
(схема адресации, сетевое расположение, путь, запрос, идентификатор фрагмента).
Возвращаемое значение - именованный кортеж, к его элементам можно получить доступ по индексу.
или как названные атрибуты:
Атрибут
Индекс
Значение
Значение, если отсутствует
схема
0
Спецификатор схемы URL
схема параметр
netloc
1
Часть сетевого расположения
пустая строка
путь
2
Иерархический путь
пустая строка
запрос
3
Компонент запроса
пустая строка
фрагмент
4
Идентификатор фрагмента
пустая строка
имя пользователя
Имя пользователя
Нет
пароль
Пароль
Нет
имя хоста
Имя хоста (нижний регистр)
Нет
порт
Номер порта как целое число,
при наличии
Нет
Чтение атрибута порта вызовет ошибку ValueError , если
в URL указан недопустимый порт.См. Раздел
Структурированные результаты анализа для получения дополнительной информации об объекте результата.
Несовпадающие квадратные скобки в атрибуте netloc вызовут ValueError .
символов в атрибуте netloc , которые разлагаются под NFKC
нормализация (как используется кодировкой IDNA) в любой из /, ? , г. # , @ или : вызовет ValueError . Если URL-адрес
разложить перед синтаксическим анализом, ошибки не возникнет.
Изменено в версии 3.6: номера портов вне допустимого диапазона теперь вызывают ValueError вместо
возвращает Нет .
Изменено в версии 3.8: Символы, влияющие на синтаксический анализ netloc при нормализации NFKC, будут
теперь вызовите ValueError .
-
urllib.parse. urlunsplit ( детали ) Объединить элементы кортежа, возвращенные функцией urlsplit () , в
полный URL-адрес в виде строки.Аргумент частей может быть любым из пяти элементов.
повторяемый. Это может привести к немного другому, но эквивалентному URL-адресу, если
Первоначально проанализированный URL-адрес содержал ненужные разделители (например, знак?
с пустым запросом; RFC утверждает, что они эквивалентны).
-
urllib.parse. urljoin ( base , url , allow_fragments = True ) Создайте полный («абсолютный») URL, объединив «базовый URL» (, базовый ) с
другой URL ( url ).Неформально здесь используются компоненты базового URL, в
в частности схему адресации, расположение в сети и (часть)
path, чтобы указать недостающие компоненты в относительном URL-адресе. Например:
>>> из urllib.parse import urljoin
>>> urljoin ('http://www.cwi.nl/%7Eguido/Python.html', 'FAQ.html')
'http://www.cwi.nl/%7Eguido/FAQ.html'
Аргумент allow_fragments имеет то же значение и значение по умолчанию, что и для urlparse () .
Примечание
Если url является абсолютным URL (то есть он начинается со схемы // или : // ),
URL-адрес Имя хоста и / или схема будут представлены в результате.Например:
>>> urljoin ('http://www.cwi.nl/%7Eguido/Python.html',
... '//www.python.org/%7Eguido')
'http://www.python.org/%7Eguido'
Если вы не хотите этого поведения, предварительно обработайте URL-адрес с помощью urlsplit () и urlunsplit () , удалив возможные части схемы и netloc .
Изменено в версии 3.5: Поведение обновлено в соответствии с семантикой, определенной в RFC 3986 .
-
urllib.разобрать. urldefrag ( url ) Если url содержит идентификатор фрагмента, вернуть измененную версию url без идентификатора фрагмента, а идентификатор фрагмента как отдельный
нить. Если в url нет идентификатора фрагмента, вернуть url без изменений
и пустая строка.
Возвращаемое значение - именованный кортеж, к его элементам можно получить доступ по индексу.
или как названные атрибуты:
Атрибут
Индекс
Значение
Значение, если отсутствует
URL
0
URL без фрагмента
пустая строка
фрагмент
1
Идентификатор фрагмента
пустая строка
См. Раздел «Результаты структурированного анализа» для получения дополнительной информации о результате.
объект.
Изменено в версии 3.2: Результатом является структурированный объект, а не простой кортеж из двух элементов.
-
urllib.parse. развернуть ( url ) Извлечь URL-адрес из обернутого URL-адреса (то есть строки, отформатированной как , , URL: scheme: // host / path или схема : // хост / путь ). Если url не является обернутым URL, он возвращается
без изменений.
Анализ байтов в кодировке ASCII
Функции синтаксического анализа URL-адресов были изначально разработаны для работы с символами.
только струны. На практике полезно уметь правильно манипулировать
цитируемые и закодированные URL-адреса как последовательности байтов ASCII. Соответственно,
Все функции синтаксического анализа URL в этом модуле работают с байтами, и объектов bytearray в дополнение к объектам str .
Если переданы данные str , результат также будет содержать только str data.Если байтов или байтов массив данных переданный результат будет содержать только байт и данных.
Попытка смешать данные str с байтами или bytearray в одном вызове функции приведет к TypeError возникает при попытке передать не-ASCII
байтовые значения вызовут UnicodeDecodeError .
Для упрощения преобразования объектов результата между str и байт , все возвращаемые значения из функций синтаксического анализа URL предоставляют
либо метод encode () (когда результат содержит str data) или decode () метод (когда результат содержит байтов данные).Сигнатуры этих методов соответствуют сигнатурам соответствующих str и bytes методы (за исключением того, что кодировка по умолчанию
это 'ascii' , а не 'utf-8' ). Каждый дает значение
соответствующий тип, содержащий либо байтов, либо данных (для encode () методов) или str data (для decode () методов).
Приложения, которые должны работать с потенциально неправильно цитируемыми URL-адресами
которые могут содержать данные, отличные от ASCII, должны будут выполнить собственное декодирование из
байты в символы перед вызовом методов синтаксического анализа URL.
Поведение, описанное в этом разделе, относится только к синтаксическому анализу URL-адресов.
функции. Функции цитирования URL-адресов используют свои собственные правила при создании
или потребляют байтовые последовательности, как описано в документации к
отдельные функции цитирования URL.
Изменено в версии 3.2: функции синтаксического анализа URL теперь принимают последовательности байтов в кодировке ASCII
Результаты структурированного анализа
Объекты результата из urlparse () , urlsplit () и
Функции urldefrag () являются подклассами кортежа типа .Эти подклассы добавляют атрибуты, перечисленные в документации для
эти функции, поддержка кодирования и декодирования, описанная в
предыдущий раздел, а также дополнительный метод:
-
urllib.parse.SplitResult. geturl () Вернуть повторно объединенную версию исходного URL-адреса в виде строки. Это может
отличается от исходного URL тем, что схема может быть нормализована до более низкой
корпус и пустые компоненты могут быть отброшены. В частности, пустые параметры,
запросы и идентификаторы фрагментов будут удалены.
Для результатов urldefrag () будут удалены только идентификаторы пустых фрагментов.
Для результатов urlsplit () и urlparse () все отмеченные изменения будут
сделано для URL-адреса, возвращаемого этим методом.
Результат этого метода остается неизменным, если он передается обратно через оригинал.
функция синтаксического анализа:
>>> из urllib.parse import urlsplit
>>> url = 'HTTP://www.Python.org/doc/#'
>>> r1 = urlsplit (url)
>>> r1.geturl ()
'http://www.Python.org/doc/'
>>> r2 = urlsplit (r1.geturl ())
>>> r2.geturl ()
'http://www.Python.org/doc/'
Следующие классы предоставляют реализации структурированного синтаксического анализа.
результатов при работе на ул. объектов:
- класс
urllib.parse. DefragResult ( url , фрагмент ) Конкретный класс для результатов urldefrag () , содержащих str данные.Метод encode () возвращает DefragResultBytes .
пример.
- класс
urllib.parse. ParseResult ( схема , netloc , путь , параметры , запрос , фрагмент ) Конкретный класс для результатов urlparse () , содержащих str данные. Метод encode () возвращает ParseResultBytes .
пример.
- класс
urllib.parse. SplitResult ( схема , netloc , путь , запрос , фрагмент ) Конкретный класс для результатов urlsplit () , содержащих str данные. Метод encode () возвращает SplitResultBytes пример.
Следующие классы обеспечивают реализацию результатов синтаксического анализа, когда
работает с байтами или байтами, массив объектов:
- класс
urllib.разобрать. DefragResultBytes ( URL , фрагмент ) Конкретный класс для результатов urldefrag () , содержащих байт данные. Метод decode () возвращает DefragResult .
пример.
- класс
urllib.parse. ParseResultBytes ( схема , netloc , путь , параметры , запрос , фрагмент ) Конкретный класс для результатов urlparse () , содержащих байт данные.Метод decode () возвращает ParseResult .
пример.
- класс
urllib.parse. SplitResultBytes ( схема , netloc , путь , запрос , фрагмент ) Конкретный класс для urlsplit () результатов, содержащих байт данные. Метод decode () возвращает SplitResult .
пример.
URL-адрес
Функции цитирования URL-адресов сосредоточены на получении данных программы и обеспечении их безопасности.
для использования в качестве компонентов URL-адреса путем заключения специальных символов в кавычки и соответственно
кодирование не-ASCII текста.Они также поддерживают обращение этих операций к
воссоздать исходные данные из содержимого компонента URL, если это
задача еще не охвачена функциями синтаксического анализа URL, описанными выше.
-
urllib.parse. цитата ( строка , safe = '/' , encoding = None , errors = None ) Заменить специальные символы в строке , используя escape-последовательность % xx . Буквы,
цифры и символы '_.- ~ ' никогда не котируются. По умолчанию это
Функция предназначена для цитирования раздела пути в URL-адресе. Необязательный безопасный параметр указывает дополнительные символы ASCII, которые не должны быть
цитируется - его значение по умолчанию '/' .
строка может быть либо str , либо байтовым объектом .
Изменено в версии 3.7: перенесено с RFC 2396 на RFC 3986 для цитирования строк URL. «~» Сейчас
входит в набор безоговорочных персонажей.
Необязательные параметры кодирования , ошибки и , параметры указывают, как поступать с
символы, отличные от ASCII, которые принимаются методом str.encode () .
Кодировка по умолчанию 'utf-8' . ошибки по умолчанию "строгий" , что означает, что неподдерживаемые символы вызывают Ошибка UnicodeEncodeError .
Кодировка Ошибки и не должны указываться, если строка является байт или TypeError .
Обратите внимание, что цитата (строка, безопасная, кодировка, ошибки) эквивалентна quote_from_bytes (string.encode (кодировка, ошибки), безопасно) .
Пример: котировка ('/ El Niño /') дает '/ El% 20Ni% C3% B1o /' .
-
urllib.parse. quote_plus ( строка , safe = '' , encoding = None , errors = None ) Аналогично quote () , но с заменой пробелов знаками плюс, как требуется для
цитирование значений формы HTML при построении строки запроса для перехода в URL.Знаки плюса в исходной строке экранируются, если они не включены в сейф . Он также не имеет безопасный по умолчанию на '/' .
Пример: quote_plus ('/ El Niño /') дает '% 2FEl + Ni% C3% B1o% 2F' .


 Это значение предоставляет общую информацию поисковым системам и может не соответствовать точно тому, как часто они сканируют страницу.Допустимые значения:
Это значение предоставляет общую информацию поисковым системам и может не соответствовать точно тому, как часто они сканируют страницу.Допустимые значения: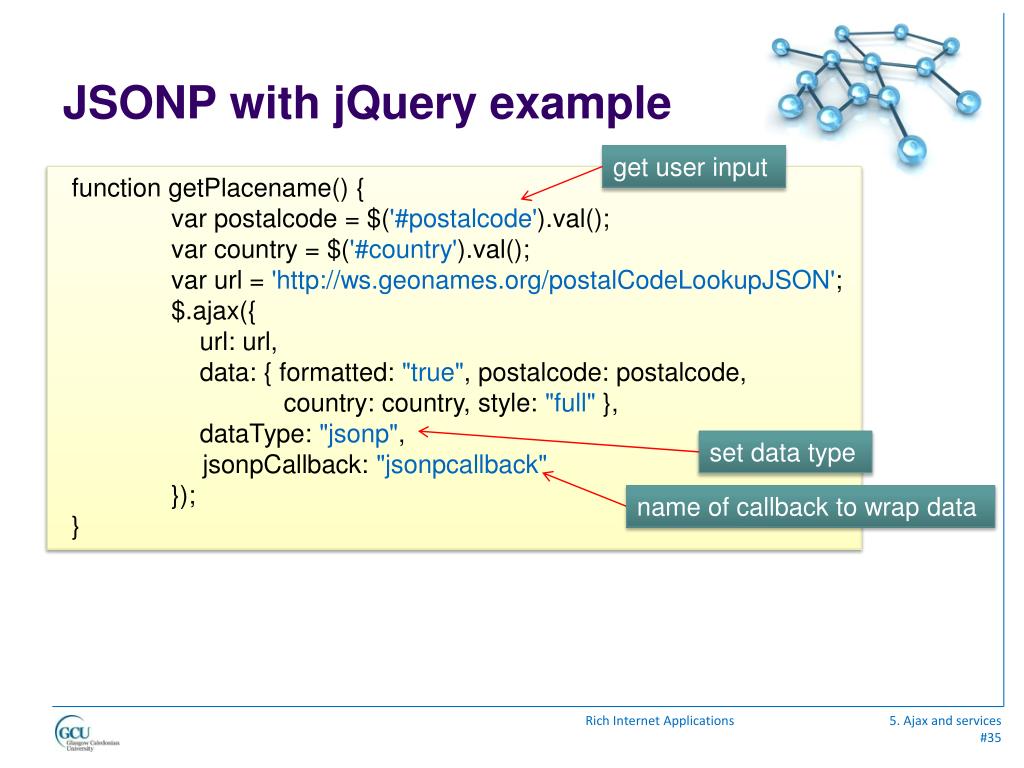 Это значение не влияет на то, как ваши страницы сравниваются со страницами. на других сайтах - он позволяет только поисковым системам узнать, какие страницы вы считаете наиболее важно для сканеров.
Это значение не влияет на то, как ваши страницы сравниваются со страницами. на других сайтах - он позволяет только поисковым системам узнать, какие страницы вы считаете наиболее важно для сканеров. example.com/catalog?item=12&desc=vacation_hawaii
example.com/catalog?item=12&desc=vacation_hawaii -
urllib.parse.quote_from_bytes( байта , safe = '/' ) Подобноразмеромquote (), но принимает объектбайт, а не объектstrи не выполняет кодирование строк в байты.Пример:quote_from_bytes (b'a & \ xef ')дает'a% 26% EF'.
urllib.parse.unquote( строка , кодировка = 'utf-8' , ошибки = 'заменить' )Заменить% xxescape-последовательностей их односимвольными эквивалентами. Необязательные параметры кодирования и ошибки указывают, как декодировать последовательности, закодированные в процентах, в символы Unicode, как это принятобайт.decode ()метод.строка может быть либоstr, либобайтовым объектом.кодировка по умолчанию'utf-8'. ошибок по умолчанию'заменить', что означает, что недопустимые последовательности заменяются символом-заполнителем.Пример:unquote ('/ El% 20Ni% C3% B1o /')дает'/ El Niño /'.Изменено в версии 3.9: строка Параметр поддерживает байты и объекты str (ранее только str).
urllib.parse.unquote_plus( строка , кодировка = 'utf-8' , ошибки = 'заменить' )Аналогичноunquote (), но при необходимости замените знаки плюса пробелами. для удаления кавычек из значений HTML-формы.строка должна бытьстрокой.Пример:unquote_plus ('/ El + Ni% C3% B1o /')дает'/ El Niño /'.
urllib.разобрать.unquote_to_bytes( строка )Заменить% xxescape-последовательности их однооктетным эквивалентом и вернутьбайтобъект.строка может быть либоstr, либобайтовым объектом.Если это строкаПример:unquote_to_bytes ('a% 26% EF')возвращаетb'a & \ xef '.
urllib.parse.urlencode( запрос , dosq = False , safe = '' , encoding = None , error = None , quote_via = quote_plus )Преобразование объекта сопоставления или последовательности двухэлементных кортежей, которые могут содержатьstrилибайтовобъектов, в кодированном в процентах ASCII текстовая строка. Если результирующая строка должна использоваться как данные для POST работа с функциейurlopen (), затем он должен быть закодирован в байтах, иначе это приведет кОшибка типа.Результирующая строка представляет собой серию изпар ключ = значение, разделенных'и'символы, где ключ и значение цитируются с использованием quote_via функция. По умолчаниюquote_plus ()используется для цитирования значений, которые означает, что пробелы заключаются в кавычки как'+'символов, а символы ‘/’ кодируется как% 2F, что соответствует стандарту для запросов GET (application / x-www-form-urlencoded).Альтернативная функция, которая может быть передается как quote_via isquote (), который будет кодировать пробелы как% 20и не кодировать символы «/». Для максимального контроля над тем, что цитируется, используйтеукажитеи укажите значение для safe .Когда последовательность двухэлементных кортежей используется в качестве запроса аргумент, первый элемент каждого кортежа является ключом, а второй - ценить. Элемент значения сам по себе может быть последовательностью, и в этом случае, если необязательный параметр доза оценивается какИстинный, индивидуальныйключ = значениепар, разделенных'&', генерируются для каждого элемента последовательность значений для ключа.Порядок параметров в закодированном строка будет соответствовать порядку кортежей параметров в последовательности.безопасные , кодирующие ошибки и параметры передаются в quote_via (кодировка ошибки и параметры передаются только когда элементом запроса являетсяstr).Чтобы отменить этот процесс кодирования, используютсяparse_qs ()иparse_qsl (). предоставляется в этом модуле для синтаксического анализа строк запроса в структурах данных Python.Обратитесь к примерам urllib, чтобы узнать, какurllib.parse.urlencode () Методможет использоваться для генерации запроса строка URL-адреса или данных для запроса POST.Изменено в версии 3.2: запрос поддерживает байты и строковые объекты.Новое в версии 3.5: параметр quote_via .
См. Также
RFC 3986 - унифицированные идентификаторы ресурсовЭто текущий стандарт (STD66).Любые изменения в модуле urllib.parse должен соответствовать этому. Могли наблюдаться определенные отклонения, которые в основном для целей обратной совместимости и для некоторых де-факто требования к синтаксическому анализу, которые обычно наблюдаются в основных браузерах.RFC 2732 - Формат буквальных адресов IPv6 в URL.Определяет требования к синтаксическому анализу URL-адресов IPv6.RFC 2396 - Uniform Resource Identifiers (URI): Generic SyntaxДокумент, описывающий общие синтаксические требования для Uniform Resource Имена (URN) и унифицированные указатели ресурсов (URL).RFC 2368 - схема URL mailto.Требования к синтаксическому анализу для схем URL mailto.RFC 1808 - Относительные унифицированные указатели ресурсовЭтот запрос комментариев включает правила для присоединения абсолютного и относительный URL, включая изрядное количество «аномальных примеров», которые определяют лечение пограничных случаев.RFC 1738 - унифицированные указатели ресурсов (URL)Это определяет формальный синтаксис и семантику абсолютных URL.
Имеет ссылку с URL-адресом LocalHost или 127.0.0.1
Критический Этот совет требует немедленного внимания, поскольку проблема может серьезно повлиять на сканирование, индексирование или ранжирование. Проблема Этот совет представляет собой ошибку или проблему, которую необходимо исправить.
Это означает, что рассматриваемый URL-адрес содержит по крайней мере одну исходящую ссылку привязки с URL-адресом, указывающим на LocalHost или 127.0.0.1.
Почему это важно?
LocalHost - это стандартное имя хоста, присвоенное адресу локального компьютера, а IP-адрес вашего localhost - 127.0.0.1. Локальный сервер не подключен к Интернету, но позволяет видеть ваш сайт в браузере, как если бы вы просматривали его в Интернете, поэтому адреса LocalHost могут использоваться во время разработки веб-сайта.
Поскольку эти файлы не являются общедоступными, при запуске веб-сайта имя хоста заменяется фактическим именем домена.
Этот совет касается случаев, когда остаются ссылки на адреса LocalHost, которые будут недоступны для публики и должны быть удалены / исправлены.
Что проверяет подсказка?
Этот совет будет запускаться для любого внутреннего URL-адреса, который содержит хотя бы одну исходящую ссылку привязки, где href ссылается на LocalHost или 127.0.0.1.
Примеры, запускающие этот намек:
Любой из приведенных ниже примеров ссылок вызовет подсказку.
Якорь со ссылкой на 127.0.0.1 с портом
Тест Якорь с URL-адресом 127.0.0.1 без порта
Якорь с URL-адресом, указывающим на LocalHost с портом
Якорь с URL-адресом, ссылающимся на LocalHost, без порта
Как решить эту проблему?
Этот совет помечен как «Критический», поскольку он представляет собой принципиально критическую проблему, которая может иметь серьезные негативные последствия для обычного поискового трафика.