Как задать кодировку utf 8 в html
Автор статьи: Сергей Каминский
При создании сайта у начинающих веб-мастеров часто появляются вопросы: в какой кодировке делать сайт, чем отличается UTF-8 от windows-1251 и как ее прописывать в META Charset HTML-страницы сайта. Ответы на все эти вопросы в данной статье.
Что такое кодировка сайта и как она работает
Кодировку можно представить в виде таблицы, состоящей из разных букв, цифр и других символов понятных человеку, которые закодированы определенным образом. Когда вы открываете текстовый файл, к которым относятся в том числе HTML-страницы, то компьютер считывает из заголовка файла в какой кодировке он был сохранен и выводит текст в соответствующей кодировке преобразовывая компьютерные данные в вид понятный человеку сопоставляя эти данные с таблицей кодировки. Если информация о кодировке из заголовка файла совпадает с кодировкой в которой сохранены данные в HTML-странице, то пользователь видит привычные ему буквы, цифры и другие символы. Если же есть несовпадение, то в результате пользователю выводится непонятный набор символов, особенно часто это происходит в старых почтовых программах. Если пользователь получил письмо с непонятными крякозябрами, то просто перебирая разные кодировки, обычно получается угадать и выбрать ту, в которой написано письмо, и в результате непонятный набор символов превращается в понятный человеку текст.
Если же есть несовпадение, то в результате пользователю выводится непонятный набор символов, особенно часто это происходит в старых почтовых программах. Если пользователь получил письмо с непонятными крякозябрами, то просто перебирая разные кодировки, обычно получается угадать и выбрать ту, в которой написано письмо, и в результате непонятный набор символов превращается в понятный человеку текст.
То же самое происходит и с HTML-страницами сайта. Если документ был сохранен, например, в кодировке UTF-8, а в самом документе прописан META-тег указывающий что это кодировка windows-1251, то браузер опять же будет сопоставлять сохраненные в файле данные с таблицей указанной ему кодировки и так как символы закодированы по-разному, то браузер выведет вместо привычного текста непонятный набор символов или же часть букв может быть в нормальном виде, а другие буквы или символы могут выводиться, например, в виде знаков вопроса. Все выше сказанное относится в том числе и к отображению имен файлов.
Создавая новый документ в текстовом редакторе лучше сразу убедиться что выбрана нужная кодировка. Современные редакторы позволяют преобразовать текст открытого документа из одной кодировки в другую, а стандартный Блокнот позволяет выбрать кодировку только при сохранении файла.
Самые распространенные кодировки
Из предыдущего пункта вы уже знаете что такое кодировка и почему настолько важно правильно прописать ее в коде страниц сайта. Давайте теперь выясним какую из множества кодировок лучше выбрать для будущего сайта. Поскольку самой распространенной и наиболее понятной в освоении всегда была операционная система Windows, то большинство веб-разработчиков создавали HTML-страницы в кодировке windows-1251 (ANSI), которая использовалась по-умолчанию. Но windows-1251 поддерживает не очень большое количество букв и символов, а разработчики хотят использовать в своих текстах различные стрелочки, сердечки, квадратики и другие символы, в том числе есть необходимость совмещать слова из разных языков в одном документе, поэтому на смену ей уже давно пришла более расширенная UTF-8 и большинство разработчиков используют именно эту кодировку.
Проблемы с кодировкой не только в HTML-странице
Сайт, независимо от того является ли он просто набором статических HTML-документов или сложных динамических скриптов генерирующих страницы на лету, размещается на веб-сервере, который также работает с определенной кодировкой. И если сервер выдает информацию в одной кодировке, а ваши страницы или скрипты сохранены в другой кодировке, то опять же могут быть проблемы с отображением страниц в браузере пользователя. Многие хостинги позволяют менять настройки и выбрать кодировку в соответствии с той, которая используется в файлах сайта, через панель управления или же прописать ее в файле .htaccess, если на хостинге используется популярный веб-сервер Apache.
Практически ни один современный сайт не обходится без использования базы данных MySQL и она также может стать источником проблем с кодировкой. Если файлы сайта сохранены в одной кодировке, а информация в базе данных в другой, то на странице та часть информации, которая выводится из базы данных может отображаться в виде все тех же знаков вопросов или других непонятных символов. Чтобы избежать проблем с кодировкой она должна быть одинаковой для веб-сервера, базы данных MySQL, в скриптах, в HTML-страницах сайта и в META-теге, который прописывается в HTML-коде. Если есть проблемы с отображением текста, то проверяйте на наличие проблемы все выше перечисленное.
Чтобы избежать проблем с кодировкой она должна быть одинаковой для веб-сервера, базы данных MySQL, в скриптах, в HTML-страницах сайта и в META-теге, который прописывается в HTML-коде. Если есть проблемы с отображением текста, то проверяйте на наличие проблемы все выше перечисленное.
META Charset HTML-документа
Чтобы сообщить браузеру и поисковым системам в какой кодировке сохранены страницы сайта в их коде прописывается META Charset.
Для кодировки windows-1251:
Для кодировки UTF-8:
Теперь вы знаете что такое кодировка сайта и где искать проблемы если в какой-либо части сайта неправильно отображается текст.
Другие записи по теме в разделе статьи по HTML и CSS
Это задание архивной главы. Перейдите по ссылке, чтобы пройти задание в актуальной главе.
Кодировку HTML-страницы нужно указывать для того, чтобы веб-браузер мог правильно отображать текст на странице. Если браузер неправильно угадает кодировку, то вместо текста будут отображаться иероглифы.
Чтобы сообщить браузеру кодировку HTML-страницы, необходимо внутри тега использовать тег:
Самая распространённая современная кодировка — utf-8 . Используйте её во всех своих проектах.
Для кириллицы в Windows charset часто задавали как windows-1251 . Но сейчас это считается плохой практикой.
Хотите досконально разбираться в разметке, знать о доступности, строить сетки на флексбоксах? Записывайтесь на профессиональный курс по вёрстке первого уровня, проходящий c 20 января по 22 марта 2020. До 26 ноября цена 13 900 14 900
- index.html Сплит-режим
- style.css Сплит-режим
Когда кодировка документа задана неверно, некоторые символы отображаются как «иероглифы», а некоторые нет.
Метатеги используются для хранения информации предназначенной для браузеров и поисковых систем. Например, механизмы поисковых систем обращаются к метатегам для получения описания сайта, ключевых слов и других данных.
Метатеги для поисковых механизмов
Среди разработчиков сайтов существует мнение, что правильно написанные метатеги позволяют подняться к верхним строчкам поисковых серверов.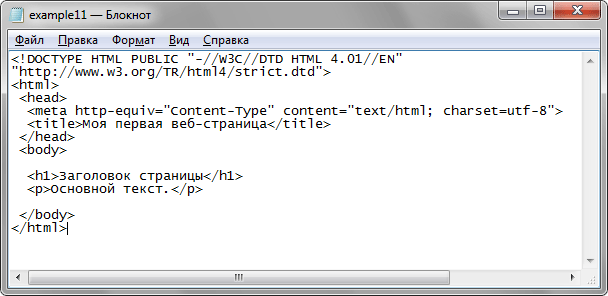 На самом деле это не так, на одних метатегах высоко не поднимешься, но и неудачно выполненное содержимое метатегов может ухудшить рейтинг сайта.
На самом деле это не так, на одних метатегах высоко не поднимешься, но и неудачно выполненное содержимое метатегов может ухудшить рейтинг сайта.
Два метатега предназначены специально для поисковых серверов: description (описание) и keywords (ключевые слова). Некоторые вебмастера добавляли в раздел keywords ключевые слова, которые не имеют никакого отношения к теме сайта, но зато пользовались определенным успехом среди посетителей поисковиков. Однако, через некоторое время, поисковые системы научились бороться с таким явлением и проверяют содержимое веб-страницы на соответствие заявленным ключевым словам.
Некоторые принципы, относящиеся к метатегам:
- не включайте ключевые слова, которые не содержатся на ваших страницах;
- не повторяйте ключевые слова;
- используйте метатеги по их прямому назначению;
- делайте описание и список ключевых слов различными для каждой страницы сайта с учетом содержимого.
description
Большинство поисковых серверов отображают содержимое поля description (пример 1) при выводе результатов поиска. Если этого тега нет на странице, то поисковый движок просто перечислит первые встречающиеся слова на странице, которые, как правило, оказываются не очень-то и в тему.
Если этого тега нет на странице, то поисковый движок просто перечислит первые встречающиеся слова на странице, которые, как правило, оказываются не очень-то и в тему.
Пример 1. Использование Description
keywords
Этот метатег был предназначен для описания ключевых слов, встречающихся на странице (пример 2). Но в результате действия людей, желающих попасть в верхние строчки поисковых систем любыми средствами, теперь дискредитирован. Поэтому многие поисковики пропускают этот параметр.
Пример 2. Использование Keywords
Ключевые слова можно перечислять через пробел или запятую. Поисковые системы сами приведут запись к виду, который они используют.
Автозагрузка страниц
Чтобы автоматически загружать новый документ через определенный промежуток времени используется инструкция http-equiv=»refresh» (пример 3).
Пример 3. Автозагрузка страницы
Браузер поймет эту запись, как ожидать 5 секунд, а затем загрузить новую страницу, указанную в параметре URL , в данном случае это переход на сайт htmlbook. ru.
ru.
Этот метатег позволяет создавать перенаправление (редирект) на другой сайт. Если URL не указан, произойдет автоматическое обновление текущей страницы через количество секунд, заданных в атрибуте content .
Кодировка
Чтобы сообщить браузеру, в какой кодировке находятся символы веб-страницы, необходимо установить параметр . Для операционной системы Windows и кириллицы charset обычно принимает значение utf-8 или windows-1251 (пример 4).
Пример 4. Выбор текущей кодировки
Если указание кодировки отсутствует, браузер пытается сам определить, какой тип символов используется в документе и выбирает необходимую кодировку автоматически. Браузер не всегда может точно распознать язык веб-страницы и в некоторых случаях предлагает вьетнамскую кодировку вместо кириллицы. По этой причине лучше всегда указывать приведенную строчку. Тем не менее, возникают обстоятельства, когда указание кодировки может принести определенный вред. Например, веб-сервер автоматически использует перекодирование данных в KOI-8, а браузер, встретив параметр charset=windows-1251 , переводит текст в кодировку Windows.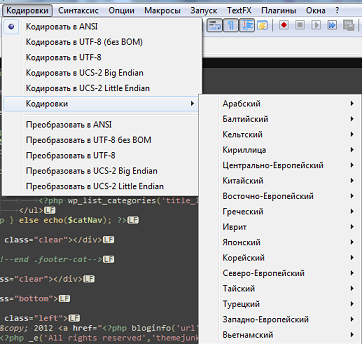 Получается двойное изменение символов, прочитать такой текст не просто. К счастью, подобная проблема уже отходит в прошлое, во всяком случае, ее легко можно выявить и нейтрализовать на уровне сервера.
Получается двойное изменение символов, прочитать такой текст не просто. К счастью, подобная проблема уже отходит в прошлое, во всяком случае, ее легко можно выявить и нейтрализовать на уровне сервера.
Проблема кодировки на сайте ▷ Как изменить кодировку сайта на utf 8 и Что значит слетела кодировка?
Ситуация, когда в результате открытия сайта вместо необходимого нам содержания выводятся различные не читаемые символы, возникает, когда кодировка документа не совпадает с кодировкой, которую устанавливает сайту сервер. Главным принципом отсутствия проблем с кодировкой является уникальность кодировки во всем вашем проекте.
Как же это проследить и устранить проблему с кодировкой на сайте?
Содержание
Кодировка в meta-теге
Пункт первый
Очень просто. Начните с самого документа. При создании любого html-документа его кодировка указывается в блоке head в meta-теге. Этот самый meta-тег выглядит следующим образом:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
Данный тег говорит о том, что документ использует кодировку UTF-8, или так называемый Юникод. Наиболее распространенными кодировками являются UTF-8 и
Наиболее распространенными кодировками являются UTF-8 и
Кодировка документа
Пункт второй
Далее. Когда ваш документ готов, и вы определились с его кодировкой, указав её в meta-теге, важно чтобы и сам документ был сохранен в этой кодировке.
Кодировка в .htaccess
Пункт третий
Если при открытии данного документа в браузере перед вами все равно появляются некорректные символы, здесь уже причина в настройках сервера. Тем не менее, решить эту проблему также не сложно.
AddDefaultCharset UTF-8
Разумеется, если вы используете Windows-1251, то вместо UTF-8 следует прописать WINDOWS-1251. Затем файл .htaccess нужно сохранить. Перезапускать сервер после этого не обязательно.
Кодировка в базе данных MySQL
Пункт четвертый
После этого некорректные символы с сайта должны исчезнуть. Однако не отовсюду. Кроме файлов сайт держится еще на базах данных, таблицы и поля которых тоже имеют свою кодировку. Кодировка таблиц и полей базы данных должна также совпадать с кодировкой всех файлов сайта и самого сервера. Если же после выставления правильной кодировки в базе данных перед вами все равно возникают непонятные символы, то проблема в кодировке подключения к базе данных. Для решения данной проблемы подключитесь к серверу баз данных с правами mysql root пользователя.
Для решения данной проблемы подключитесь к серверу баз данных с правами mysql root пользователя.
mysql -u root -p
выберите необходимую вам БД
USE имя_базы;
и выполните следующий запрос:
SET NAMES 'utf8’;
Если вы используете кодировку Windows-1251, то вместо utf-8 следует прописать cp1251. Так данную кодировку называет сервер MySQL.
Наиболее рекомендуемой кодировкой является UTF-8, так как она поддерживает наибольшее количество символов и является практически универсальной для всех языков, однако, выбор всегда остается за вами.
На этом всё. Ваш сайт должен отображаться как надо.
Примечание
Часто возникают ситуации, связанные с тем, что файл .htaccess не работает. Это связано с настройками Apache для вашего сервера или же для отдельного виртуального хоста, на котором содержится Ваш сайт. За опции данного файла отвечает директива
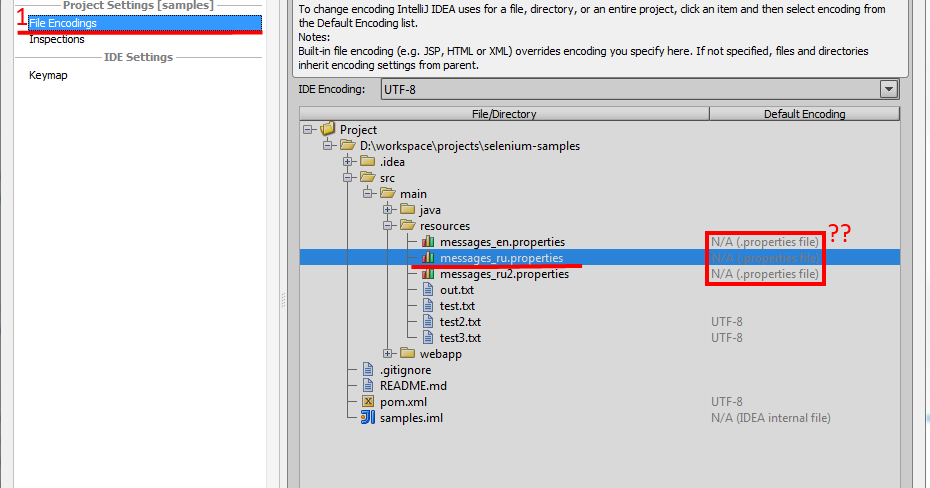 conf. Если данная директива выглядит так: AllowOverride None, то сервер будет игнорировать файлы .htaccess. Для решения этой проблемы следует заменить None на All. Это даст вам возможность переопределять все допустимые настройки с помощью файла .htaccess. После внесения изменений в файл httpd.conf необходимо либо перезапустить веб-сервер (лучше), либо выполнить команду
conf. Если данная директива выглядит так: AllowOverride None, то сервер будет игнорировать файлы .htaccess. Для решения этой проблемы следует заменить None на All. Это даст вам возможность переопределять все допустимые настройки с помощью файла .htaccess. После внесения изменений в файл httpd.conf необходимо либо перезапустить веб-сервер (лучше), либо выполнить команду Подробнее о виртуальных хостах вы можете прочитать в статье Настройка виртуальных хостов в Apache.
Как подключить utf 8 html
Нужно правильно раскодировать сигналы, которые наш мозг получает из окружающей среды. Проще говоря, следует правильно « настроить » свой взгляд на жизнь. Ну, вроде не полупустой кошелек, а наполовину полный. То есть, требуется использовать нужную кодировку. Для интернета чаще всего правильной является кодировка utf :
Немного о кодировках
Наверное, не является секретом тот факт, что основным типом содержимого во всемирном веб-пространстве является текст.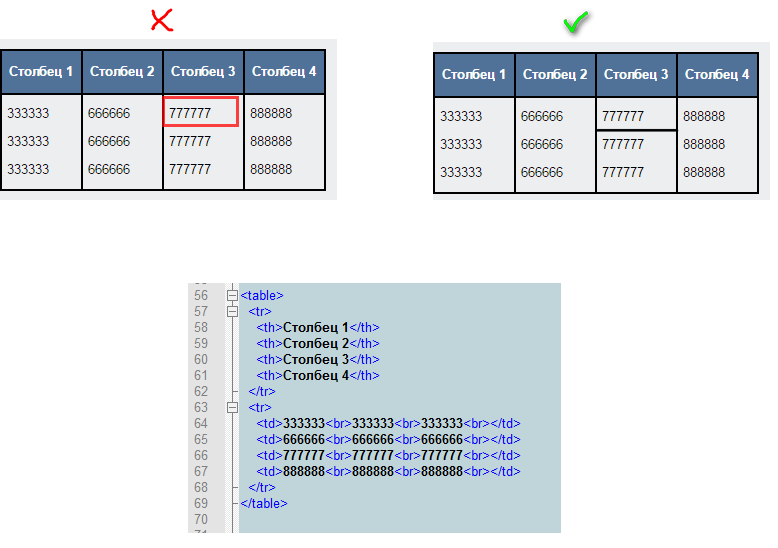
Но передача текста в цифровом формате происходит совсем иначе, чем у нас на экране. Для перевода текста в машинный код используется двоичная система исчисления, состоящая лишь из 0 и 1.
Следующим этапом передачи текста в виртуальном пространстве является его отображение на клиентских машинах с помощью браузера, интерпретирующего html . Вот тут и начинается самое интересное, когда браузер клиента и веб-страница содержат в себе текстовые данные в разных кодировках. Тогда пользователь на своем мониторе видит не текст, а какие-то непонятные ( нечитаемые ) символы:
Чаще всего нужно всего лишь поменять кодировку веб-страницы на кодировку utf8. Ведь она является наиболее распространенной во всем интернете.
Кодировка UTF-8
Наиболее распространенная среди стандартизированных и общепринятых текстовых кодировок. Расшифровывается как « восьмибитный формат преобразования Юникода » или « Unicode Transformation Format ».
Стандарт был разработан еще в 1992 году. В настоящее время он широко применяется не только во всемирной паутине, но и на прикладном уровне ( локальные машины и операционные системы ). Основным достоинством кодировки является ее совместимость с ASCII:
ASCII («American standard code for information interchange») еще одна (но более старая) кодировка представления текстовых данных. В ее таблице символов значения печатных и непечатных знаков заданы с помощью чисел в шестнадцатеричной системе исчисления.
При использовании UTF-8 для передачи данных в формате ASCII используются 7 первых битов. Последний ( восьмой ) служит для вывода « мусора » ( некорректно раскодированных данных ). Что при использовании кодировки для латинских символов существенно уменьшает объем текстовых данных.
Как уже говорилось, часто для корректного отображения текста достаточно лишь поменять кодировку документа. Рассмотрим, как это можно сделать в различных дисциплинах, применяемых для построения веб-пространства.
Как установить кодировку в HTML и PHP
Для установки utf 8 кодировки в html используется специальный тег . Он объединяет в себе в форме атрибутов значение метатегов.
Метатеги используются для передачи и хранения информации, предназначенной для браузеров и поисковиков. Одним из атрибутов тега является charset . Он служит для установки кодировки веб-страницы. Пример использования:
Также можно установить кодировку некоторым элементам страницы. Например, ссылке. Для этого также используется атрибут charset , значением которого выступает нужная кодировка:
Кроме этого можно присваивать значения непосредственно заголовкам http , которые передаются вместе с ответом на запрос от браузера к серверу. В таком случае кодировка сайта utf 8 , переданная через заголовок, будет доминирующей над значением, заданным внутри веб-страницы.
Многие из страниц ресурсов не являются статическими, а динамически создаются благодаря использованию серверных языков программирования. Чаще всего для построения сайтов применяют PHP . Поэтому важно знать о его средствах, позволяющих «на лету» поменять кодировку генерируемой веб-страницы.
Чаще всего для построения сайтов применяют PHP . Поэтому важно знать о его средствах, позволяющих «на лету» поменять кодировку генерируемой веб-страницы.
Для установки и модификации значений заголовка используется функция header() . Ее синтаксис:
Чтобы корректно задать в php кодировку utf 8 , вызов функции header() в коде должен находиться выше всех тегов html .
Глобальные настройки кодировки
Описанные выше методы могут использоваться для отдельных веб-страниц или небольших сайтов. Но что делать, если вы имеете дело с ресурсом, состоящим из нескольких сотен страниц и десятка разделов? Давайте разберемся, как установить кодировку utf 8 для всего сайта.
Для этого нужно вносить изменения в дополнительный файл конфигурации ресурса. Он носит название .htaccess . Сначала его нужно открыть в любом текстовом редакторе, а затем добавить туда строку:
В качестве более глобального способа изменения кодировки стоит рассмотреть пример на основе любого локального сервера. Для большей наглядности мы возьмем Denwer , который довольно широко распространен в наших краях.
Для большей наглядности мы возьмем Denwer , который довольно широко распространен в наших краях.
Чтобы изменить кодировку всех ресурсов, размещенных на нашем сервере Apache , нужно отредактировать содержимое конфигурационного файла httpd.conf . Он находится по пути:
Как и в предыдущем примере, в нем нужно заменить значение AddDefaultCharset на нужное. В нашем случае это utf-8 :
Изменение кодировки базы данных
Изменение кодировки рассмотрим на примере MySQL . Так как это одна из самых востребованных и распространенных СУБД, применяемых в сайтостроении. Все изменения можно произвести в файле my.ini . В Денвере он находится по пути:
Здесь нужно поменять значение нескольких полей на utf-8 :
- default-character-set ;
- character-set-server ;
- init-connect = «set names» ;
- default-character-set .
И затем добавить строку skip-character-set-client-handshake :
Подобные изменения можно внести не только для всех баз данных на сервере, но и для отдельно взятой в php базы mysql . Сделать это можно через пользовательский интерфейс оболочки PHPMyAdmin .
Сделать это можно через пользовательский интерфейс оболочки PHPMyAdmin .
Сначала узнаем, какие кодировки установлены по умолчанию в нашей базе данных. Для этого вводим запрос SQL :
Вот какой ответ мы должны получить:
Если какие-либо значения нас не удовлетворяют, то нужно их изменить. Воспользуемся для этого запросом к ядру сервера СУБД:
В результате мы получим новые значения переменных character_set_connection , character_set_results и character_set_client.
К сожалению, не все так просто обстоит с изменением кодировки в таблицах Excel . Для этого придется воспользоваться сторонней программой для перекодирования файлов. Или обработать данные с помощью громоздких функций.
Мы рассмотрели все основные способы изменения веб-документов на кодировку utf . Надеемся, что этот материал поможет вам не только выбрать правильную кодировку текста, но и « установить » правильный взгляд на жизнь.
На сколько бы это глупо не казалось, но для удачного выставления кодировки необходимо выполнить целых 11(!) правил.
Хочу зарание предупредить, если какая-то из настроек в .htaccess повлечет за собой ошибку 500, это значит, что хостинг запретил менять этот параметр на сервере. В таком случае проверьте тот факт, что у Вас UTF-8 и в случае чего обратитесь к админам хостинга.
И для тех, кто попал на эту страницу с вопросами об Ajax: Ajax работает в кодировке UTF-8.
Правило №1: Указываем в HTML верстке в теге первой строчкой, кроме случаев, где мы будем использовать тег , так как он так же как и кодировка имеет приоритет над расположением, следующий код:
Правило №2: Указываем кодировку для PHP и самого файла, для этого нам необходимо выставить заголовок функцией header(). Выставляем его в самом начале нашего файла (абсолютно в самом начале), сразу после указания уровня вывода ошибок:
Правило №3: Кодировка для подключения к к БД MySQL. Устанавливается после подключения к БД и выбора бд (mysql_connect, mysql_select_db). Если у нас модуль mysql:
или улучшенный модуль mysqli:
Правило №4: Кодировка в . htaccess:
htaccess:
Правило №5: Кодировка для библиотеки mb, начиная с версии php 5.4 можно не указывать, так как по умолчанию будет использоваться именно UTF-8. Ну а пока прописываем её в файле .htaccess:
Либо в самом PHP, что в итоге выполнит одни и те же действия:
Правило №6: При сохранении файлов (обязательно ВСЕХ!) выбрать кодировку UTF-8 without BOM, повторюсь, without BOM — это необходимая настройка, в противном случае Ваш сайт не будет работать как надо. Для тех, кто пользуется удобной программой DreamWeaver:
Modify => Page Properties => Title/Encoding и выставляем «Encoding: UTF-8», после чего нажимаем ReLoad, убираем галочку с BOM «Include Unicode Signature (BOM)». Apply + OK.
Модификации => Свойства страницы => Заголовок/Кодировка и выставляем кодировку UTF-8. Нажимаем «перезагрузить», убрали галочку с Подключить Юникод Сигнатуры (BOM). Применить и OK.
Правило №7: если на данный момент какой-то из текстов был введён на странице или в БД — его необходимо перенабрать.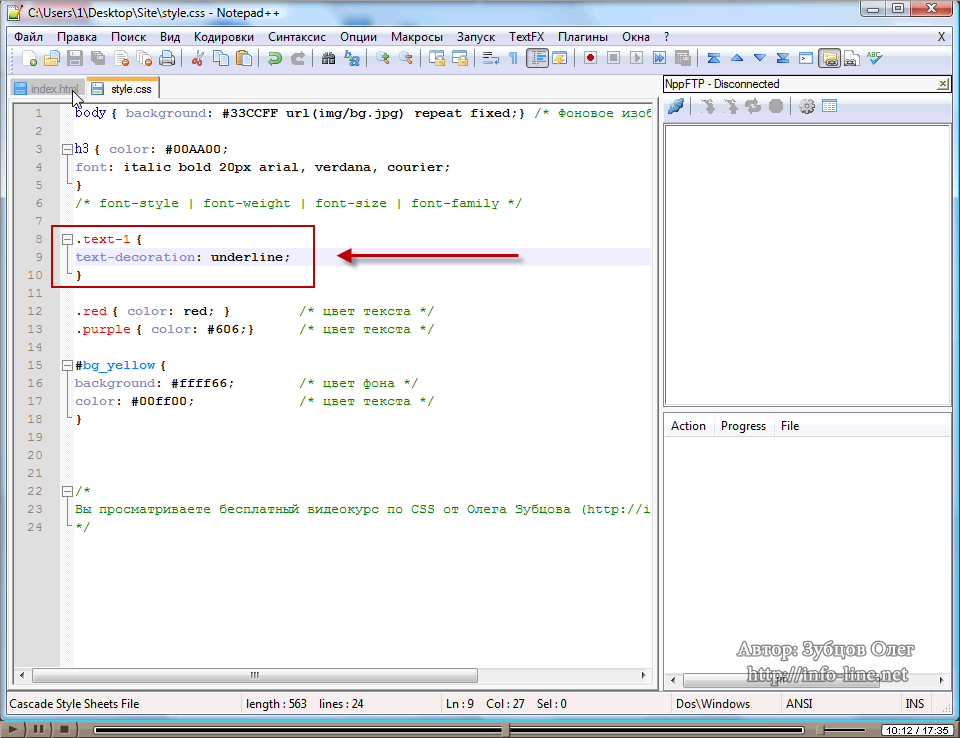 Дело в том, что символ в одной кодировке представляет один набор бит для русских символов, а в другой — другой. Именно поэтому необходимо его либо перенабрать, либо перекодировать. Современные программы имеют возможность перевести текст из одной кодировки в другую. Об этой возможности интересуйтесь в мануалах Ваших программ.
Дело в том, что символ в одной кодировке представляет один набор бит для русских символов, а в другой — другой. Именно поэтому необходимо его либо перенабрать, либо перекодировать. Современные программы имеют возможность перевести текст из одной кодировки в другую. Об этой возможности интересуйтесь в мануалах Ваших программ.
Правило №8: Есть исключение, когда текст приходит к Вам на страницу с другого сайта в другой кодировке. Тогда на PHP есть удобная функция для перевода из одной кодировки в другую:
Правило №9: Для строковых функций strlen, substr, необходимо использовать их аналоги на библиотеке mb_, а именно: mb_strlen, mb_substr, то есть к функции дописываем mb_ .
Правило №10: Для работы с регулярными выражениями необходимо указывать модификатор u . Это обязательный параметр!
Правило №11: Для CSS файлов указывается кодировка так:
В заключение скажу, что символы в кодировке WIN-1251 состоят из 1 байта, то есть 8 бит, а в свою очередь в кодировке UTF-8 символы могут состоять от 1 до 4 байт, всё дело в том, что кодировка UTF-8 позволяет создавать мультиязычные сайты, так как все существующие в мире символы в ней присутствуют.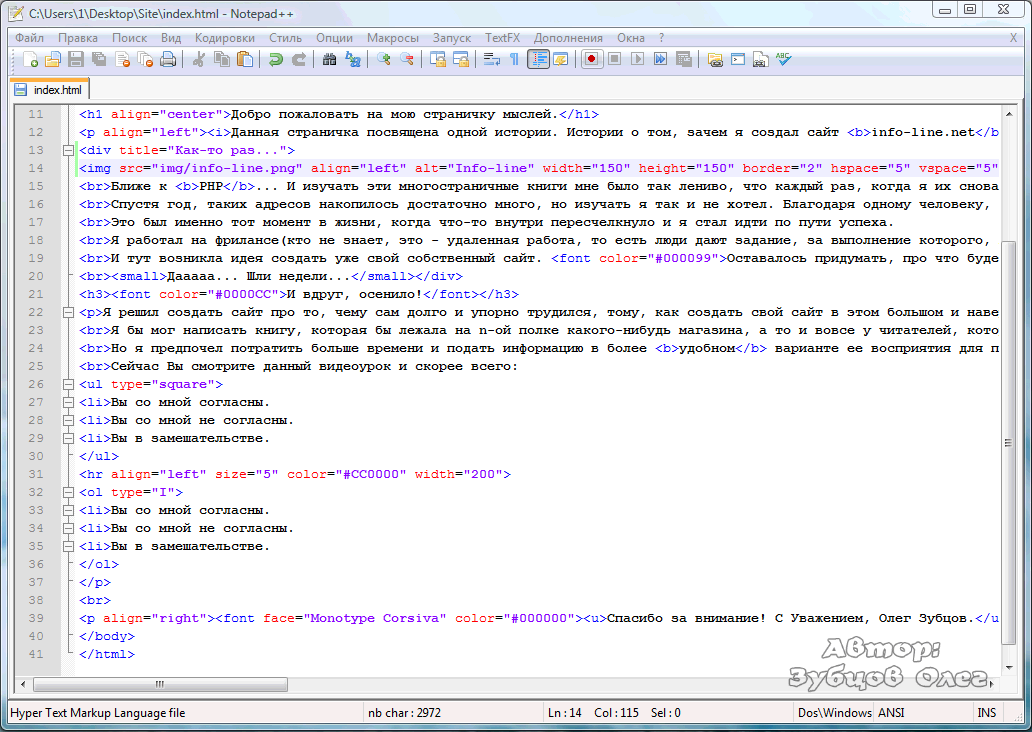
Ради любопытства русская буква в кодировке UTF-8 занимает 2 байта, именно поэтому за 1 символ функция strlen возвращает длину 2, то есть 2 байта, а mb_strlen возвращает уже правильную длину в 1 символ.
Автор статьи: Сергей Каминский
При создании сайта у начинающих веб-мастеров часто появляются вопросы: в какой кодировке делать сайт, чем отличается UTF-8 от windows-1251 и как ее прописывать в META Charset HTML-страницы сайта. Ответы на все эти вопросы в данной статье.
Что такое кодировка сайта и как она работает
Кодировку можно представить в виде таблицы, состоящей из разных букв, цифр и других символов понятных человеку, которые закодированы определенным образом. Когда вы открываете текстовый файл, к которым относятся в том числе HTML-страницы, то компьютер считывает из заголовка файла в какой кодировке он был сохранен и выводит текст в соответствующей кодировке преобразовывая компьютерные данные в вид понятный человеку сопоставляя эти данные с таблицей кодировки. Если информация о кодировке из заголовка файла совпадает с кодировкой в которой сохранены данные в HTML-странице, то пользователь видит привычные ему буквы, цифры и другие символы. Если же есть несовпадение, то в результате пользователю выводится непонятный набор символов, особенно часто это происходит в старых почтовых программах. Если пользователь получил письмо с непонятными крякозябрами, то просто перебирая разные кодировки, обычно получается угадать и выбрать ту, в которой написано письмо, и в результате непонятный набор символов превращается в понятный человеку текст.
Если информация о кодировке из заголовка файла совпадает с кодировкой в которой сохранены данные в HTML-странице, то пользователь видит привычные ему буквы, цифры и другие символы. Если же есть несовпадение, то в результате пользователю выводится непонятный набор символов, особенно часто это происходит в старых почтовых программах. Если пользователь получил письмо с непонятными крякозябрами, то просто перебирая разные кодировки, обычно получается угадать и выбрать ту, в которой написано письмо, и в результате непонятный набор символов превращается в понятный человеку текст.
То же самое происходит и с HTML-страницами сайта. Если документ был сохранен, например, в кодировке UTF-8, а в самом документе прописан META-тег указывающий что это кодировка windows-1251, то браузер опять же будет сопоставлять сохраненные в файле данные с таблицей указанной ему кодировки и так как символы закодированы по-разному, то браузер выведет вместо привычного текста непонятный набор символов или же часть букв может быть в нормальном виде, а другие буквы или символы могут выводиться, например, в виде знаков вопроса. Все выше сказанное относится в том числе и к отображению имен файлов.
Все выше сказанное относится в том числе и к отображению имен файлов.
Создавая новый документ в текстовом редакторе лучше сразу убедиться что выбрана нужная кодировка. Современные редакторы позволяют преобразовать текст открытого документа из одной кодировки в другую, а стандартный Блокнот позволяет выбрать кодировку только при сохранении файла.
Самые распространенные кодировки
Из предыдущего пункта вы уже знаете что такое кодировка и почему настолько важно правильно прописать ее в коде страниц сайта. Давайте теперь выясним какую из множества кодировок лучше выбрать для будущего сайта. Поскольку самой распространенной и наиболее понятной в освоении всегда была операционная система Windows, то большинство веб-разработчиков создавали HTML-страницы в кодировке windows-1251 (ANSI), которая использовалась по-умолчанию. Но windows-1251 поддерживает не очень большое количество букв и символов, а разработчики хотят использовать в своих текстах различные стрелочки, сердечки, квадратики и другие символы, в том числе есть необходимость совмещать слова из разных языков в одном документе, поэтому на смену ей уже давно пришла более расширенная UTF-8 и большинство разработчиков используют именно эту кодировку.
Проблемы с кодировкой не только в HTML-странице
Сайт, независимо от того является ли он просто набором статических HTML-документов или сложных динамических скриптов генерирующих страницы на лету, размещается на веб-сервере, который также работает с определенной кодировкой. И если сервер выдает информацию в одной кодировке, а ваши страницы или скрипты сохранены в другой кодировке, то опять же могут быть проблемы с отображением страниц в браузере пользователя. Многие хостинги позволяют менять настройки и выбрать кодировку в соответствии с той, которая используется в файлах сайта, через панель управления или же прописать ее в файле .htaccess, если на хостинге используется популярный веб-сервер Apache.
Практически ни один современный сайт не обходится без использования базы данных MySQL и она также может стать источником проблем с кодировкой. Если файлы сайта сохранены в одной кодировке, а информация в базе данных в другой, то на странице та часть информации, которая выводится из базы данных может отображаться в виде все тех же знаков вопросов или других непонятных символов. Чтобы избежать проблем с кодировкой она должна быть одинаковой для веб-сервера, базы данных MySQL, в скриптах, в HTML-страницах сайта и в META-теге, который прописывается в HTML-коде. Если есть проблемы с отображением текста, то проверяйте на наличие проблемы все выше перечисленное.
META Charset HTML-документа
Чтобы сообщить браузеру и поисковым системам в какой кодировке сохранены страницы сайта в их коде прописывается META Charset.
Для кодировки windows-1251:
Для кодировки UTF-8:
Теперь вы знаете что такое кодировка сайта и где искать проблемы если в какой-либо части сайта неправильно отображается текст.
Другие записи по теме в разделе статьи по HTML и CSS
Тег HTML — мета теги страницы description, keywords, viewport
Мета тег <meta> HTML определяет информацию о веб странице. Теги группы meta называют мета тегами, а содержимое мета тега — метаданными. Метаданные указывают различную техническую информацию о документе, в основном для браузеров и поисковых систем и не видны пользователю на сайте.
Часто используются meta-теги: author, description, keywords, viewport, charset.
Мета теги находятся в области <head> HTML документа (подробнее про <head>). Вставить или, как говорят, прописать мета теги можно в любом порядке и количестве.
Использовать meta теги не обязательно, но мы рекомендуем заполнять хотя бы мета теги description, viewport, charset. Это будет плюсом для внутренней оптимизации сайта.
Синтаксис
<meta атрибут="значение" атрибут="значение">Примеры использования <meta> в HTML коде
<html>
<head>
<meta charset="UTF-8">
<meta name="description" content="Мета теги в HTML документе. Описание популярных мета тегов, примеры использования на веб странице">
<meta name="author" content="Ivan Ivanov">
</head>
</html>Основные мета теги
Ниже приведены несколько основных тегов <meta> с комментариями по применению и примерами использования.
Meta-тег description
Краткое описание документа (страницы сайта). Поисковые системы могут использовать содержимое мета тега description для вывода в сниппете поисковой выдачи.
Пример использования мета тега description
<meta name="description" content="Краткое описание страницы">Meta-тег keywords
Ключевые слова страницы. Ранее использовался для указания поисковым системам основные смысловые фразы веб-страницы. На данный момент существуют разные мнения как правильно и стоит ли заполнять мета тег keywords.
Пример заполнения мета тега keywords
<meta name="keywords" content="ключевое слово 1, ключевое слово 2, ключевое слово 3">Meta-тег viewport
Задает некоторые параметры окна просмотра в браузере. Атрибут width указывает ширину окна просмотра (вьюпорта), initial-scale — коэффициент масштабирования при первом открытии страницы.
Пример использования мета тега viewport
Мета тег для адаптивного сайта: указывает, что ширина вьюпорта подгоняется под размеры устройства:
<meta name="viewport" content="width=device-width, initial-scale=1.0">Meta-тег charset
Кодировка веб страницы. Наиболее частое значение: «UTF-8».
Пример использования мета тега кодировки charset
<meta charset="UTF-8">Meta тег refresh
Мета тег с атрибутом http-equiv=»refresh» указывает время автоматического обновления страницы. Страница будет автоматически перезагружаться с интервалом указанным в content атрибуте. Значение указывается в секундах.
Пример использования meta http refresh
<meta http-equiv="refresh" content="45"> <!-- Обновление страницы каждые 45 секунд -->Поддержка браузерами
Атрибуты
| Атрибут | Значения | Описание |
|---|---|---|
| charset |
character_set |
Указывает кодировку HTML документа. |
| content |
тестовое значение |
Основное содержимое мета тега. Зависит от других атрибутов. Используется вместе с http-equiv или name. |
| http-equiv |
content-type |
Устанавливает HTTP заголовок для атрибута content. Сontent-type — Кодировка. Устаревшее значение, в HTML5 используйте charset (см. пример выше). |
| name |
application-name |
Имя мета тега. Как и http-equiv определяет суть мета тега. Application-name — имя веб приложения, которое представляет страница. |
Кодировка — Проблемы с кодировкой — utf-8 — windows-1251
В этой статье я постараюсь поставить все точки над «и» (а так же над «i») в вопросе выбора кодировки для создаваемой HTML-страницы.
Когда я только начинал заниматься сайтостроительством у меня постоянно возникали проблемы из-за этих кодировок. Сохранишь HTML-страницу, выгрузишь на сервер, открываешь, бах, а там кракозябры. Ну вот и здравствуйте, приехали.
Или в среде отладки (например, локальная среда разработки «Денвер») все нормально, а с хостинга опять они, кракозябры проклятые, нагло на меня смотрят.
С движками сколько мучений было. Вдруг, непонятно почему, родные русские буквы превращаются в …
Сейчас мы с этим делом подробно разберемся и вы будете четко знать в какую кодировку сохранять HTML-страницу и посредством каких инструментов.
Для укрепления нашего взаимопонимания определимся с понятием кодировка. Так вот, кодировка — это таблица соответствия машинных кодов и символов алфавита. Есть какая-то последовательность машинных символов, которую умный компьютер, в соответствии с выбранной кодовой таблицей, заменяет на понятные нам буквы.
В 90-е годы прошлого века (древность какая, а я как сейчас помню календарь 1991 года на стене) существовало 4-е кодировки для PC и еще одна, своя собственная, для Мака. Ирония судьбы заключается в том, что во всех этих кодировках символы латиницы ставились в соответствие машинным кодам по одному и тому же алгоритму, а вот по поводу кирилицы каждая из кодировок имела свое собственное мнение.
Вся эта путаница и привела к появлению кракозябров. Например, если слово «Вопрос», набранное в кодировке windows-1251, отобразить кодировкой KOI8-R, получится слово «бНОПНЯ».
Слава Богу, 90-е годы уже далеко позади и из пяти бредокодировок осталось всего 2-е нормальных.. А еще в utf-8 есть знак «евро»; а еще utf-8 позволяет в одном HTML-файле совмещать кучу разнообразных специфических символов, используемых в таких языках как грузинский, иврит, китайский, японский; а еще utf-8 в кодировках HTML — это правило хорошего тона.
Надеюсь я вас убедил и вы будете использовать Юникод (кстати «utf-8» и «Юникод» — это синонимы или, если быть более точным, utf-8 — это одна из кодировок семейства Юникод, которая снискала популярность в среде веб-разработчиков).
Теперь пристально посмотрим на инструменты перекодирования файлов, которые я рекомендую вам использовать, уважаемый читатель.
Инструменты для работы с кодировками HTML файлов
Собственно, их всего три:
- PSPad. Бесплатный текстовый редактор, мой любимый.
- Notepad++. Еще один хороший текстовый редактор и тоже бесплатный.
- Dreamweaver. Ну с Dreamweaver-ом вы с вами знакомы из моих видеоуроков по верстке сайта.
Загружаем какой-то HTML-файл в PSPad. И как же нам понять, что за кодировка у загруженного подопытного? Очень просто в строке состояния (внизу) все четко написано.
Кодировка открытого HTML-файла windows-1251
А у этого файла HTML кодировка utf-8
А теперь, создавая новый HTML-документ, позаботимся о его кодировке.
Идем в меню моего любимого PSPad-а. Нас интересует пункт Формат. В нем-то мы и поставим галку напротив кодировки utf-8.
Кодировка будущего HTML-файла будет utf-8
А так кодировка будующего файла — windows-1251
Теперь о том как изменить кодировку файла HTML. Да оказывается очень просто:
Пример перекодирования файла из кодировки windows-1251 в utf-8
Нужно кликнуть по требуемой кодировке в пункте меню Формат и кодировка сменится. После этого сохраняйте файл, он перекодирован, дело сделано.
Что касается Notepad++ все очень похоже на вышеописанную ситуацию. Только для работы с кодировками нужно использовать пункт меню Кодировки.
Вся разница заключается в том, что в случае Notepad++ появляются, специально разработанные для преобразования кодировок, пункты меню Преобразовать... (лишние на мой взгляд, в PSPad все проще и поэтому я им пользуюсь). Соответственно, именно по ним и нужно кликать при желании поменять кодировки у нашего HTML-файла.
Кроме всего прочего, при сохранении в utf-8 у нас есть выбор: без BOM или с BOM. Нам, как веб-мастерам, нужно использовать кодировку UTF-8 (без BOM).
Вот что нам ответит Википедия на вопрос «что такое BOM»
Для определения формата представления Юникода в текстовом файле используется приём, по которому в начале текста записывается символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый меткой порядка байтов (англ. Byte Order Mark, BOM). Этот способ позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует. Также он иногда применяется для обозначения формата UTF-8, хотя к этому формату и неприменимо понятие порядка байтов.
Если прочитать приведенный текст 10 раз, почесать затылок, то становится понятно: для utf-8 BOM нам НЕ нужен. Кроме того, если сохранить файл с php-скриптом в кодировку utf-8 с BOM, то он не будет работать, потому что обработчик не поймет, что это за ерунда такая написана в начале файла-скрипта (я имею ввиду тот самый неразрывный пробел с нулевой шириной).
Так-так, осталось пристально взглянуть на Dreamweaver.
Создавая новый файл, обращайте внимание на то, в какой кодировке он будет создан. Для этого в окне создания нового документа File → New (Ctrl+N) воспользуйтесь кнопкой Preferences…
И посмотрите, что задано в качестве кодировки по умолчанию:
Кодировка создаваемого HTML-файла по умолчанию в Dreamweaver
Перекодировать открытый HTML-файл в Dreamweaver можно в диалоге Page Properties, который запускается из меню Modify → Page Properties (Ctrl + J).
Выбирайте требуемую кодировку, нажимайте ОК и все, задача по перекодированию выполнена (а вот BOM все так же ненужен, не ставьте галку).
Определение кодировки браузерами
Итак, наш HTML-файл сохранен в выбранную нами кодировку. Теперь давайте разберемся с вопросом: каким образом браузер узнает о применяемой в данном HTML-файле кодировке?
Здесь есть три варианта:
1. Мы сами сообщаем браузеру о том, какая кодировка установлена для данного HTML файла. Делается это посредством META-тега
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
В приведенном примере браузеру дается указание, что загруженный HTML-файл сохранен в кодировке utf-8.
Если HTML-файл сохранен в кодировку windows-1251, то:
<meta http-equiv="Content-Type" content="text/html; charset=windows-1251">
Кстати, при перекодировке файлов не забывайте изменять директивы в META-теге на актуальные. Dreamweaver, при изменении кодировки, делает это автоматически, а в других текстовых редакторах вам нужно самим ставить в соответствие примененную кодировку и директиву META-тега.
Полный HTML выглядит следующим образом (привожу его для понимания вопроса «в каком месте указывается META-тег с директивой кодировки» внимание на 4-ю строку):
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd"> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <title>Untitled Document</title> </head> <body> Ну и т.д.
2. При помощи файла .htaccess. Иногда сервер насильно передает заголовки для загружаемых HTML-файлов и сообщает браузеру кодировку по умолчанию. В этом случае браузер не обращает внимания на директивы в META-теге, а отображает HTML-файл в той кодировки, которую сообщил сервер. Чтобы файл загружалсяв той кодировке, которая нужна вам (часто хостинг насильно указывает кодировку windows-1251), в корне хостинг-директории создается файл с именем «.htaccess».
Файл этот предназначен для дополнительной конфигурации сервера. Действие .htaccess-директив распространяется на все файлы и подкаталоги, которые находятся в том каталоге, куда вы сохранили файл .htaccess.
Создать этот файл можно, например, в Total Commander-е, нажав горячее сочетание клавиш Shift+F4 и указав имя создаваемому файлу .htaccess. Далее в текстовом редакторе указываются директивы дополнительных настроек кодировки по умолчанию.
Для HTML-файлов в кодировке utf-8 в .htaccess нужно написать одну строку:
AddDefaultCharset UTF-8
Для HTML-файлов в кодировке Windows-1251:
AddDefaultCharset Windows-1251
Если ваш хостинг хитро-мудрый и не обращает внимания на эти директивы, то можно попробовать:
charsetdisable on
AddDefaultCharset Off
Если и это не дало результата, то просто спросите у своего хостера, чего вам делать, чтобы отключить кодировку по умолчанию :). Все это зависит от конкретных настроек сервера у хостинг-провайдера.
3. PHP-инструкция, указывающая кодировку по умолчанию. В файле, который нужно отобразить в желаемой кодировке, не смотря на настройки сервера хостинг-провайдера, в самом начале указывается директива с php-кодом:
<?php header('Content-type: text/html; charset=utf-8')?>Этот php-код отправит заголовок сервера с указанием кодировки по умолчанию для браузера. В приведенном примере, для отображения страницы, будет применяться кодировка utf-8.
Против такого лома, обычно, приемов в настройках сервера хостинг-провайдера не остается.
Хочу заметить, что для обработки php-инструкций сервером, html-файл должен иметь расширение .php (например index.php).
Есть еще вопросы по кодировкам? Пишите в комментарии. Нужно решить эти проблемы раз и на всегда 🙂
С уважением, Андрей Морковин.
HTML Meta Charset – прописываем кодировку сайта
При создании сайта у начинающих веб-мастеров часто появляются вопросы: в какой кодировке делать сайт, чем отличается UTF-8 от windows-1251 и как ее прописывать в META Charset HTML-страницы сайта. Ответы на все эти вопросы в данной статье.
Что такое кодировка сайта и как она работает
Кодировку можно представить в виде таблицы, состоящей из разных букв, цифр и других символов понятных человеку, которые закодированы определенным образом. Когда вы открываете текстовый файл, к которым относятся в том числе HTML-страницы, то компьютер считывает из заголовка файла в какой кодировке он был сохранен и выводит текст в соответствующей кодировке преобразовывая компьютерные данные в вид понятный человеку сопоставляя эти данные с таблицей кодировки. Если информация о кодировке из заголовка файла совпадает с кодировкой в которой сохранены данные в HTML-странице, то пользователь видит привычные ему буквы, цифры и другие символы. Если же есть несовпадение, то в результате пользователю выводится непонятный набор символов, особенно часто это происходит в старых почтовых программах. Если пользователь получил письмо с непонятными крякозябрами, то просто перебирая разные кодировки, обычно получается угадать и выбрать ту, в которой написано письмо, и в результате непонятный набор символов превращается в понятный человеку текст.
То же самое происходит и с HTML-страницами сайта. Если документ был сохранен, например, в кодировке UTF-8, а в самом документе прописан META-тег указывающий что это кодировка windows-1251, то браузер опять же будет сопоставлять сохраненные в файле данные с таблицей указанной ему кодировки и так как символы закодированы по-разному, то браузер выведет вместо привычного текста непонятный набор символов или же часть букв может быть в нормальном виде, а другие буквы или символы могут выводиться, например, в виде знаков вопроса. Все выше сказанное относится в том числе и к отображению имен файлов.
Создавая новый документ в текстовом редакторе лучше сразу убедиться что выбрана нужная кодировка. Современные редакторы позволяют преобразовать текст открытого документа из одной кодировки в другую, а стандартный Блокнот позволяет выбрать кодировку только при сохранении файла.
Самые распространенные кодировки
Из предыдущего пункта вы уже знаете что такое кодировка и почему настолько важно правильно прописать ее в коде страниц сайта. Давайте теперь выясним какую из множества кодировок лучше выбрать для будущего сайта. Поскольку самой распространенной и наиболее понятной в освоении всегда была операционная система Windows, то большинство веб-разработчиков создавали HTML-страницы в кодировке windows-1251 (ANSI), которая использовалась по-умолчанию. Но windows-1251 поддерживает не очень большое количество букв и символов, а разработчики хотят использовать в своих текстах различные стрелочки, сердечки, квадратики и другие символы, в том числе есть необходимость совмещать слова из разных языков в одном документе, поэтому на смену ей уже давно пришла более расширенная UTF-8 и большинство разработчиков используют именно эту кодировку.
Проблемы с кодировкой не только в HTML-странице
Сайт, независимо от того является ли он просто набором статических HTML-документов или сложных динамических скриптов генерирующих страницы на лету, размещается на веб-сервере, который также работает с определенной кодировкой. И если сервер выдает информацию в одной кодировке, а ваши страницы или скрипты сохранены в другой кодировке, то опять же могут быть проблемы с отображением страниц в браузере пользователя. Многие хостинги позволяют менять настройки и выбрать кодировку в соответствии с той, которая используется в файлах сайта, через панель управления или же прописать ее в файле .htaccess, если на хостинге используется популярный веб-сервер Apache.
Практически ни один современный сайт не обходится без использования базы данных MySQL и она также может стать источником проблем с кодировкой. Если файлы сайта сохранены в одной кодировке, а информация в базе данных в другой, то на странице та часть информации, которая выводится из базы данных может отображаться в виде все тех же знаков вопросов или других непонятных символов. Чтобы избежать проблем с кодировкой она должна быть одинаковой для веб-сервера, базы данных MySQL, в скриптах, в HTML-страницах сайта и в META-теге, который прописывается в HTML-коде. Если есть проблемы с отображением текста, то проверяйте на наличие проблемы все выше перечисленное.
META Charset HTML-документа
Чтобы сообщить браузеру и поисковым системам в какой кодировке сохранены страницы сайта в их коде прописывается META Charset.
Для кодировки windows-1251:
<!DOCTYPE html>
<html lang="ru">
<head>
<title>Заголовок страницы</title>
<meta http-equiv="content-type" content="text/html; charset=windows-1251" />
</head>
<body>
<p>Текст страницы</p>
</body>
</html>
Для кодировки UTF-8:
<!DOCTYPE html>
<html lang="ru">
<head>
<title>Заголовок страницы</title>
<meta http-equiv="content-type" content="text/html; charset=UTF-8" />
</head>
<body>
<p>Текст страницы</p>
</body>
</html>
Теперь вы знаете что такое кодировка сайта и где искать проблемы если в какой-либо части сайта неправильно отображается текст.
Источник: kaminskiy-web.com
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Загрузка…1 июля 202086 просмотров Вернуться на главную| Номер | Описание эффекта | Номер | Описание эффекта |
|---|---|---|---|
| 0 | Прямоугольники внутрь | 12 | Растворение |
| 1 | Прямоугольники наружу | 13 | Вертикальная панорама внутрь |
| 2 | Круг внутрь | 14 | Вертикальная панорама наружу |
| 3 | Круг наружу | 15 | Горизонтальная панорама внутрь |
| 4 | Наплыв наверх | 16 | Горизонтальная панорама наружу |
| 5 | Наплыв вниз | 17 | Уголки влево — вниз |
| 6 | Наплыв вправо | 18 | Уголки влево — вверх |
| 7 | Наплыв влево | 19 | Уголки вправо – вниз |
| 8 | Вертикальные жалюзи | 20 | Уголки вправо – вверх |
| 9 | Горизонтальные жалюзи | 21 | Случайные горизонтальные полосы |
| 10 | Шажки горизонтальные | 22 | Случайные вертикальные полосы |
| 11 | Шажки вертикальные | 23 | Случайный выбор эффекта |
Файл page1.html
Эффекты перехода страниц
На заметку:
Эффекты перехода с одной страницы на другую работают не во всех браузерах.
«Перейти»
Файл page2.html
Эффекты перехода страниц
На заметку:
Эффекты открытия и закрытия веб-страниц будут видны только при переходе
от одной страницы к другой или же при помощи кнопок «назад» «вперёд».
При первом открыти страницы, а также во время перезагрузки
эффекты перехода видны не будут.
Нажмите на «Перейти» чтобы перейти к следующей странице
и оценить эффект перехода от одной странице к другой.
«Перейти»
Ещё раз напомню о том что мета теги стоит применять умело и грамотно особенно это касается команд для робота и кодировки символов, иначе весь Ваш труд может пойти насмарку..
Заголовок Refresh (автоматический переход на другую страницу) можно использовать не совсем стандартно.. Некоторые авторы используют его для создания своего рода «презентации» слайд шоу, где сменяющиеся страницы и есть кадры презентации. Представьте заходит человек на такой сайт а тут ему «Откинетесь на спинку кресла и расслабьтесь..»:) а далее сами по себе пошли картинки, графики, тексты.. а последняя страница тупиковая где пользователь берёт сайт «в свои руки» или же может замыкаться на первую. Только всегда помните о золотом правиле веб-мастера: Главное не переборщить!
Одна из самых частых проблем сайта — это его кодировка. И несмотря на это многие Web-мастера продолжают утверждать, что браузер сам выбирает кодировку. Действительно, он выбирает кодировку сам, но делает это не всегда правильно. Вот это и есть самая распространнёная ошибка с кодировкой: сайт в кодировке, допустим, UTF-8 , а браузер настойчиво выбирает windows-1251 . Вот как задать жёстко кодировку через файл htaccess , я расскажу в этой небольшой статье.
Для того, чтобы задать кодировку файла в htaccess достаточно написать в нём всего одну строчку:
AddDefaultCharset UTF-8
Если Вам нужна windows-1251 , то тогда так:
AddDefaultCharset WINDOWS-1251
Всего одна строчка и теперь браузер, независимо от своего предпочтения, будет выбирать указанную кодировку. Сразу говорю, данный способ — это действительно мощный. Вы должны понимать, что раз браузер неправильно распознаёт кодировку Вашего сайта (игнорируя даже мета-тег «ContentType «), значит, на то есть свои причины, поэтому внимательно проверьте: везде ли всё хорошо отображается.
Надеюсь, что этой статьей я помог Вам решить проблему с кодировкой. А в следующей статье я расскажу о проблеме, связанной с кодировкой базы данных . Это тоже весьма частая проблема, которую многие не могут решить.
15.03.2016
Пока нет
Всем привет!
Продолжаем изучать основы HTML. В этом уроке мы разберем, как указать HTML кодировку для сайта (веб-страницы).
Этот урок очень важен, так как незнание того, как указать кодировку для веб-страницы может привести к тому, что вашу страницу не смогут прочитать. Вы спросите: «Это как так, не смогут?».
Давайте я покажу, как выглядит мой блог с неправильной кодировкой:
Итак, HTML кодировка – это таблицы соответствия кодов и символов алфавита. То есть, наш компьютер по кодировке поменяет код на понятные читабельные буквы .
Чтобы сообщить браузеру, в какой кодировке находятся символы веб-страницы, необходимо прописать между тегами
вот такой мета тег:Обратите внимание, в коде есть слово «имя кодировки». Здесь нужно указать HTML кодировку.
Обычно это utf-8
или windows-1251
.
Кодировка для utf-8 :
Кодировка для windows-1251 :
Если забыть указать браузеру, в какой кодировке сайт или веб-страница, то браузер попытается определить кодировку автоматически, но не всегда у него это выходит правильно. В итог результат будет такой, который я показал на картинке выше.
Переходим к практике.
Как создать HTML документ с
кодировкой utf-8
«Все программы» => «Стандартные» => «Блокнот» :
вот этот мета-тег: Моя первая HTML-страничка на StepkinBlog..Жмите в блокноте «Файл» => «Сохранит как…» :
Там, где пункт «Кодировка:»
укажите «UTF-8»
.
Жмите «Сохранить»
:
Увеличить изображение?
Как создать HTML документ с кодировкой windows-1251
Открывайте стандартный блокнот. «Все программы» => «Стандартные» => «Блокнот» .
Далее вставляете в блокнот стандартный код HTML:
Теперь указываем, в какой кодировке сохранена веб-страница. Для этого разместите между тегами
вот этот мета-тег:Вот так должно получиться (строка №4 ):
Моя первая HTML-страничка на StepkinBlog..Жмите в блокноте «Файл» => «Сохранит как…» :
Там, где пункт «Имя файла»
напишите название веб-страницы на латинице и с расширением «.html»
. Я думю, вы это помните еще с первых уроков.
Там, где пункт «Кодировка:»
укажите «ANSI»
.
Жмите «Сохранить»
:
Вот и все!
Большинство вебмастеров выбирают кодировку UTF-8 . Причины говорить не буду, так как боюсь нагрузить вас информацией, которая на вашем этапе познания HTML еще не нужна.
Для примера в блокнте установите код:
И укажите при сохранении «ANSI» :
Так как это неправильно, результат будет вот таким:
Сохраняйте правильно ваши веб-страници во избежание вот таких результатов
Предыдущая запись
Следующая запись
Здравствуйте, уважаемые читатели моего блога. Сегодня мы поговорим с вами про кодировку. Если вы читали мою статью о том, то знаете, что любой документ в интернете хранится не в том виде, в каком мы привыкли его видеть. Он записан при помощи непонятных человеку символов и знаков. С текстом все точно также.
Существует несколько кодировок, а потому, иногда увидев непонятные символы при открытии книги в мобильном приложении или запилив статью на сайт, вы, поменяв кое-какие значения в настройках, увидите привычный глазу алфавит.
Кодировка windows-1251 – что это такое, какое значение она имеет при создании сайта, какие символы будут доступны и является ли она лучшим решением на сегодняшний день? Обо всем этом в сегодняшней статье. Как всегда, простым языком, максимально понятно и с минимальным количеством терминов.
Немного теории
Любой документ на компьютере или в интернете, как я уже сказал, хранится в виде двоичного кода. К примеру, если вы используете кодировку ASCII, то буква «К» будет записана как 10001010, а windows 1251 под этим числом скрывается символ – Љ. В итоге, если браузер или программа обратится к другой таблице и считает вместо ASCII коды windows 1251, то читатель увидит совершенно непонятные ему символ.
Логичен вопрос, нафига было придумывать множество таблиц с кодами? Дело в том, что помимо русского алфавита существует еще и английский, немецкий, китайский. По некоторым подсчетам, существует около 200 000 символов. Хотя, я не очень доверяю этой статистике, вспоминая про японский.
Не забывайте, что для заглавной и строчной буквы нужно придумать свой код, есть запятые, тире и так далее.
Чем больше в таблице символов, тем длиннее код каждого из них, а значит и вес документа становится больше.
Представьте, если бы одна книга весила 4 Гб! Она бы очень долго загружалась, занимала все свободное место на компьютере. Решение о скачивании представлялось бы делом нелегким.
Если вспомнить о сайтах, то вообще страшно подумать, что бы произошло. Каждая страничка открывалась даже на скоростном оптоволокне по часу с лишним! Думаю, мобильные телефоны можно было бы смело выкидывать. Пользоваться ими на улице даже с 4G? Сомневаюсь.
По этим причинам каждый программист в свое время старался придумать свою таблицу символов. Чтобы было удобно для использования и вес сохранялся оптимальным.
Microsoft, к примеру, для русскоязычного сегмента создали windows-1251. В ней, конечно же, есть свои достоинства и недостатки. Как и у любого другого продукта.
Сейчас уже, лишь 2% всех страниц в интернете написано на 1251. Большинство веб-мастеров используют UTF-8. Почему так?
Недостатки и достоинства
UTF-8, в отличие от windows-1251 универсальная кодировка, в ней содержатся буквы различных алфавитов. Существует даже UTF-128, где есть вообще все языки – теулу, суахили, лаосский, мальтийский и так далее.
UTF-8 победнее, буквы занимают в разы меньше места и занимают всего один байт памяти, как и в 1251. В УТФ есть редкие символы из других языков или специальные символы. Они-то и весят по 5-6 байтов, но в документе используются крайне редко.
Эта кодировка более продумана, а потому ее использует большинство приложений по умолчанию. То есть, если вы не указываете программе, какую кодировку вы используете, то первым делом он проверит именно UTF-8 .
Когда вы создаете html документ для сайта, то указываете браузерам на какую таблицу им обращать внимание при расшифровке записей.
Для этого необходимо вставить в тег head следующие данные. После символов «charset=» идет либо утф, либо виндовс, как в примере ниже.
| meta http-equiv = «Content-Type» content = «text/html; charset=windows-1251» > |
Если в дальнейшем вы захотите что-то поменять и вставить фразу на албанском, используя эту таблицу расшифровок, то ничего не получится, ведь этого языка кодировка не поддерживает. UTF‑8 без проблем позволит вам это сделать.
Если вас заинтересовало правильное создание сайта, то я могу порекомендовать вам курс Михаила Русакова «Создание и Раскрутка сайта от А до Я ».
Он содержит в себе очень много – 256 уроков, затрагивающих , JavaScript, и XML. Помимо языков программирования вы сможете понять как монетизировать сайт, то есть скорее и больше получать прибыль. Один из немногих курсов, в котором было бы так подробно разъяснено все, что нужно.
Сам я вот уже год обучаюсь в школе блоггеров Александра Борисова . Это занимает в разы больше времени, конца и края пока не видно, но зато не менее исчерпывающе и дисциплинирует. Мотивирует продолжать разработку.
Ну а если возникают вопросы, не нужно искать по интернету. Всегда есть грамотный наставник.
Что-то я отошел от темы. Давайте вернемся к кодировкам.
Базы банных
Когда речь идет о php, все вообще страшно. Я уже рассказывал про базы данных, они используются для ускорения работы сайта. Обычно, вы к ним не обращаетесь, но когда появляется необходимость в переносе сайта становится не по себе.
Сложности случаются у всех, не важно какой у вас опыт работы, стаж и выслуга лет. Некоторые странички в базе могут содержать в себе все доступные символы для виндовс-1251, другие, к примеру, в шаблонах страниц, в другой кодировке.
Пока не нужен перенос все работает и функционирует, хоть и не совсем правильно. Но после переезда начинаются неприятности. В идеале вы должны использовать либо только УТФ, либо виндовс-1251, но по факту всегда и у всех случаются вот такие недочеты.
Чтобы расшифровка согласовалась необходимо вписать код mysql_query(«SET NAMES cp1251»). В этом случае преобразование будет осуществлять по другому протоколу – cp1251.
Htaccess
Если на сайте вы настойчиво решили использовать именно 1251, то вам следует найти или создать файл htaccess. Он отвечает за настройки конфигурации. В него придется добавить еще три строчки, чтобы все сошлось.
| DefaultLanguage ru; AddDefaultCharset windows-1251; php_value default_charset «cp1251» |
DefaultLanguage ru; AddDefaultCharset windows-1251; php_value default_charset «cp1251»
Я все же настоятельно рекомендую вам задумать о использовании UTF-8. Он более популярен, прост и богат. Какие бы решения вы не приняли сейчас, важно, чтобы впоследствии можно было все исправить. Добавить англоязычную версию сайта на этой кодировке будет в разы проще. Ничего не нужно исправлять.
Решение остается за вами. Подписывайтесь на рассылку, чтобы узнавать как можно быстрее , где учиться, чтобы не повторять чужих ошибок, а также какие блоггеры получают больше посетителей.
До новых встреч и удачи в ваших начинаниях.
Как задать кодировку сайта, что бы браузер верно мог её определить, и не показывать вам кракозяблы, типа:
Р-аказать сайт Сѓ нас — это создать сайт недорого Рё качественно
В HTML для указания кодировки используется тег:
Наиболее часто встречаются типы кодировки для русского языка передаваемые в заголовке документа:
Windows-1251 — Кириллица (Windows).
KOI8-r — Кириллица (КОИ8-Р)
cp866 — Кириллица (DOS).
Windows-1252 — Западная Европа (Windows).
Windows-1250 — Центральная Европа (Windows).
UTF-8 — двух байтовая кодировка
Теперь рассмотрим указание кодировки по умолчанию через файл.htaccess (если это файла нету, надо его создать, имя файла начинается с точки)
AddDefaultCharset задает дефолтную таблицу символов (кодировку) для всех выдаваемых страниц на веб-сервере Apache
Достаточно добавить 1 строку
AddDefaultCharset UTF-8
AddDefaultCharset WINDOWS-1251
Всего одна строчка, и браузер выдаст страницу пользователю, в правильной кодировке, независимо от своих предпочтений. Кодировка сайта будет одинакова для всех браузеров.
При загрузке файла на сервер возможна перекодировка. Указываем, что все получаемые файлы будут иметь кодировку windows-1251, для этого напишем.
Ссылка на кодировку URL-адресов HTML
URL — унифицированный указатель ресурсов
Веб-браузеры запрашивают страницы с веб-серверов, используя URL-адрес.
URL-адрес — это адрес веб-страницы, например: https://www.w3schools.com.
Кодировка URL (процентное кодирование)
КодировкаURL преобразует символы в формат, который можно передавать через Интернет.
URL-адресов можно отправлять только через Интернет с помощью Набор символов ASCII.
Поскольку URL-адреса часто содержат символы вне набора ASCII, URL-адрес должен быть преобразован в допустимый формат ASCII.
Кодировка URL заменяет небезопасные символы ASCII на «%», за которым следуют два
шестнадцатеричные цифры.
URL-адреса не могут содержать пробелов. Кодировка URL обычно заменяет пробел на знак плюса (+) или% 20.
Попробуйте сами
Если вы нажмете кнопку «Отправить» ниже, браузер закодирует введенный URL-адрес. перед отправкой на сервер.Страница на сервере будет отображать полученные Вход.
Попробуйте ввести другие данные и снова нажмите «Отправить».
Функции кодирования URL
В JavaScript, PHP и ASP есть функции, которые можно использовать для URL закодировать строку.
PHP имеет функцию rawurlencode (), а ASP — функцию Server.URLEncode ().
В JavaScript вы можете использовать функцию encodeURIComponent () .
Нажмите кнопку «Кодировать URL», чтобы увидеть, как функция JavaScript кодирует текст.
Примечание: Функция JavaScript кодирует пробел как% 20.
Ссылка на кодировку ASCII
Ваш браузер будет кодировать ввод в соответствии с набор символов, используемый на вашей странице.
Набор символов по умолчанию в HTML5 — UTF-8.
| Персонаж | из Windows-1252 | из UTF-8 |
|---|---|---|
| место | % 20 | % 20 |
| ! | % 21 | % 21 |
| « | % 22 | % 22 |
| # | % 23 | % 23 |
| $ | % 24 | % 24 |
| % | % 25 | % 25 |
| и | % 26 | % 26 |
| ‘ | % 27 | % 27 |
| ( | % 28 | % 28 |
| ) | % 29 | % 29 |
| * | % 2A | % 2A |
| + | % 2B | % 2B |
| , | % 2C | % 2C |
| – | % 2D | % 2D |
| . | % 2Э | % 2Э |
| / | % 2F | % 2F |
| 0 | % 30 | % 30 |
| 1 | % 31 | % 31 |
| 2 | % 32 | % 32 |
| 3 | % 33 | % 33 |
| 4 | % 34 | % 34 |
| 5 | % 35 | % 35 |
| 6 | % 36 | % 36 |
| 7 | % 37 | % 37 |
| 8 | % 38 | % 38 |
| 9 | % 39 | % 39 |
| : | % 3A | % 3A |
| ; | % 3B | % 3B |
| < | % 3C | % 3C |
| = | % 3D | % 3D |
| > | % 3Э | % 3Э |
| ? | % 3F | % 3F |
| @ | % 40 | % 40 |
| А | % 41 | % 41 |
| B | % 42 | % 42 |
| С | % 43 | % 43 |
| D | % 44 | % 44 |
| E | % 45 | % 45 |
| F | % 46 | % 46 |
| G | % 47 | % 47 |
| H | % 48 | % 48 |
| I | % 49 | % 49 |
| Дж | % 4A | % 4A |
| К | % 4B | % 4B |
| л | % 4C | % 4C |
| M | % 4D | % 4D |
| N | % 4Э | % 4Э |
| O | % 4 этаж | % 4 этаж |
| п. | % 50 | % 50 |
| Q | % 51 | % 51 |
| R | % 52 | % 52 |
| S | % 53 | % 53 |
| т | % 54 | % 54 |
| U | % 55 | % 55 |
| В | % 56 | % 56 |
| Вт | % 57 | % 57 |
| х | % 58 | % 58 |
| Y | % 59 | % 59 |
| Z | % 5A | % 5A |
| [ | % 5B | % 5B |
| \ | % 5C | % 5C |
| ] | % 5D | % 5D |
| ^ | % 5E | % 5E |
| _ | % 5F | % 5F |
| ` | % 60 | % 60 |
| a | % 61 | % 61 |
| б | % 62 | % 62 |
| с | % 63 | % 63 |
| г | % 64 | % 64 |
| e | % 65 | % 65 |
| f | % 66 | % 66 |
| г | % 67 | % 67 |
| ч | % 68 | % 68 |
| i | % 69 | % 69 |
| j | % 6A | % 6A |
| к | % 6Б | % 6B |
| л | % 6C | % 6C |
| м | % 6D | % 6D |
| n | % 6E | % 6E |
| или | % 6F | % 6F |
| p | % 70 | % 70 |
| q | % 71 | % 71 |
| r | % 72 | % 72 |
| с | % 73 | % 73 |
| т | % 74 | % 74 |
| u | % 75 | % 75 |
| в | % 76 | % 76 |
| Вт | % 77 | % 77 |
| х | % 78 | % 78 |
| y | % 79 | % 79 |
| z | % 7A | % 7A |
| { | % 7B | % 7B |
| | | % 7C | % 7C |
| } | % 7D | % 7D |
| ~ | % 7E | % 7E |
| % 7F | % 7F | |
| ` | % 80 | % E2% 82% AC |
| % 81 | % 81 | |
| ‚ | % 82 | % E2% 80% 9A |
| ƒ | % 83 | % C6% 92 |
| „ | % 84 | % E2% 80% 9E |
| … | % 85 | % E2% 80% A6 |
| † | % 86 | % E2% 80% A0 |
| ‡ | % 87 | % E2% 80% A1 |
| ˆ | % 88 | % CB% 86 |
| ‰ | % 89 | % E2% 80% B0 |
| Š | % 8A | % C5% A0 |
| ‹ | % 8B | % E2% 80% B9 |
| Π| % 8C | % C5% 92 |
| % 8D | % C5% 8D | |
| Ž | % 8E | % C5% BD |
| % 8F | % 8F | |
| % 90 | % C2% 90 | |
| ‘ | % 91 | % E2% 80% 98 |
| ’ | % 92 | % E2% 80% 99 |
| “ | % 93 | % E2% 80% 9C |
| ” | % 94 | % E2% 80% 9D |
| • | % 95 | % E2% 80% A2 |
| – | % 96 | % E2% 80% 93 |
| – | % 97 | % E2% 80% 94 |
| ˜ | % 98 | % CB% 9C |
| ™ | % 99 | % E2% 84 |
| š | % 9A | % C5% A1 |
| › | % 9В | % E2% 80 |
| œ | % 9C | % C5% 93 |
| % 9D | % 9D | |
| × | % 9E | % C5% BE |
| Ÿ | % 9F | % C5% B8 |
| % A0 | % C2% A0 | |
| ¡ | % A1 | % C2% A1 |
| ¢ | % A2 | % C2% A2 |
| £ | % A3 | % C2% A3 |
| ¤ | % A4 | % C2% A4 |
| ¥ | % A5 | % C2% A5 |
| ¦ | % A6 | % C2% A6 |
| § | % A7 | % C2% A7 |
| ¨ | % A8 | % C2% A8 |
| © | % A9 | % C2% A9 |
| ª | % AA | % C2% AA |
| « | % AB | % C2% AB |
| ¬ | % переменного тока | % C2% AC |
| % нашей эры | % C2% AD | |
| ® | % AE | % C2% AE |
| ¯ | % AF | % C2% AF |
| ° | % B0 | % C2% B0 |
| ± | % B1 | % C2% B1 |
| ² | % B2 | % C2% B2 |
| ³ | % B3 | % C2% B3 |
| ´ | % B4 | % C2% B4 |
| мкм | % B5 | % C2% B5 |
| ¶ | % B6 | % C2% B6 |
| · | % B7 | % C2% B7 |
| ¸ | % B8 | % C2% B8 |
| ¹ | % B9 | % C2% B9 |
| º | % BA | % C2% BA |
| » | % BB | % C2% BB |
| ¼ | % BC | % C2% BC |
| ½ | % BD | % C2% BD |
| ¾ | % БЫТЬ | % C2% BE |
| ¿ | % BF | % C2% BF |
| À | % C0 | % C3% 80 |
| Á | % C1 | % C3% 81 |
| Â | % C2 | % C3% 82 |
| Ã | % C3 | % C3% 83 |
| Ä | % C4 | % C3% 84 |
| Å | % C5 | % C3% 85 |
| Æ | % C6 | % C3% 86 |
| Ç | % C7 | % C3% 87 |
| È | % C8 | % C3% 88 |
| É | % C9 | % C3% 89 |
| Ê | % CA | % C3% 8A |
| Ë | % CB | % C3% 8B |
| Ì | % CC | % C3% 8C |
| Í | % CD | % C3% 8D |
| Î | % CE | % C3% 8E |
| Ï | % CF | % C3% 8F |
| ì | % D0 | % C3% 90 |
| Ñ | % D1 | % C3% 91 |
| Ò | % D2 | % C3% 92 |
| Ó | % D3 | % C3% 93 |
| Ô | % D4 | % C3% 94 |
| Õ | % D5 | % C3% 95 |
| Ö | % D6 | % C3% 96 |
| × | % D7 | % C3% 97 |
| Ø | % D8 | % C3% 98 |
| Ù | % D9 | % C3% 99 |
| Ú | % DA | % C3% 9A |
| Û | % DB | % C3% 9B |
| Ü | % ПВ | % C3% 9C |
| Ý | % DD | % C3% 9D |
| Þ | % DE | % C3% 9E |
| ß | % DF | % C3% 9F |
| до | % E0 | % C3% A0 |
| á | % E1 | % C3% A1 |
| â | % E2 | % C3% A2 |
| ã | % E3 | % C3% A3 |
| ä | % E4 | % C3% A4 |
| å | % E5 | % C3% A5 |
| æ | % E6 | % C3% A6 |
| ç | % E7 | % C3% A7 |
| и | % E8 | % C3% A8 |
| é | % E9 | % C3% A9 |
| ê | % EA | % C3% AA |
| ë | % EB | % C3% AB |
| мм | % EC | % C3% AC |
| до | % ПВ | % C3% AD |
| до | % EE | % C3% AE |
| • | % EF | % C3% AF |
| ð | % F0 | % C3% B0 |
| ñ | % F1 | % C3% B1 |
| шт | % F2 | % C3% B2 |
| ó | % F3 | % C3% B3 |
| ô | % F4 | % C3% B4 |
| х | % F5 | % C3% B5 |
| ö | % F6 | % C3% B6 |
| ÷ | % F7 | % C3% B7 |
| ø | % F8 | % C3% B8 |
| ù | % F9 | % C3% B9 |
| ú | % FA | % C3% BA |
| û | % FB | % C3% BB |
| ü | % FC | % C3% BC |
| ý | % FD | % C3% BD |
| þ | % FE | % C3% BE |
| ÿ | % FF | % C3% BF |
Ссылка на кодирование URL
Управляющие символы ASCII % 00-% 1F изначально были разработаны для аппаратные устройства управления.
Управляющие символы не имеют никакого отношения к URL-адресу.
| Символ ASCII | Описание | Кодировка URL |
|---|---|---|
| NUL | нулевой символ | % 00 |
| SOH | начало заголовка | % 01 |
| STX | начало текста | % 02 |
| ETX | конец текста | % 03 |
| EOT | конец передачи | % 04 |
| ENQ | запрос | % 05 |
| ACK | подтвердить | % 06 |
| БЕЛ | звонок (кольцо) | % 07 |
| BS | возврат | % 08 |
| HT | горизонтальный язычок | % 09 |
| LF | перевод строки | % 0A |
| VT | вертикальный язычок | % 0B |
| FF | подача формы | % 0C |
| CR | возврат каретки | % 0D |
| SO | сдвиг | % 0E |
| SI | смена | % 0F |
| DLE | выход канала передачи данных | % 10 |
| DC1 | устройство управления 1 | % 11 |
| DC2 | Устройство управления 2 | % 12 |
| DC3 | Устройство управления 3 | % 13 |
| DC4 | Устройство управления 4 | % 14 |
| НАК | отрицательное подтверждение | % 15 |
| SYN | синхронизировать | % 16 |
| ЭТБ | блок передачи конца | % 17 |
| CAN | отменить | % 18 |
| EM | конец среднего | % 19 |
| ПОД | заменить | % 1A |
| ESC | побег | % 1B |
| ФС | разделитель файлов | % 1С |
| GS | разделитель групп | % 1D |
| RS | разделитель записей | % 1Э |
| США | блок сепаратора | % 1 этаж |
Что такое кодировка UTF-8? Руководство для непрограммистов
Текст: его важность в Интернете само собой разумеется.Это первая буква «Т» в «HTTP», единственная буква «Т» в «HTML», и практически каждый веб-сайт так или иначе использует ее, будь то URL-адрес, часть маркетингового текста, обзор продукта, вирусный твит или Сообщение блога. (Привет!)
Но веб-текст на самом деле может быть не таким простым, как вы думаете. Рассмотрим тысячи языков, на которых сегодня говорят, или все знаки препинания и символы, которые мы можем добавить, чтобы улучшить их, или тот факт, что создаются новые смайлы, чтобы уловить каждую человеческую эмоцию. Как веб-сайты все это хранят и обрабатывают?По правде говоря, даже такая простая вещь, как текст, требует хорошо скоординированной, четко определенной системы для отображения в веб-браузерах.В этом посте я объясню основы одной технологии, которая имеет ключевое значение для текста в Интернете, UTF-8 . Мы изучим основы хранения и кодирования текста и обсудим, как это помогает разместить на вашем сайте привлекательные слова.
Прежде чем мы начнем, вы должны быть знакомы с основами HTML и готовы погрузиться в легкую информатику.
Что такое UTF-8?
UTF-8 означает «Формат преобразования Unicode — 8 бит». Пока это нам не помогает, так что давайте вернемся к основам.
Двоичный: как компьютеры хранят информацию
Для хранения информации компьютеры используют двоичную систему. В двоичном формате все данные представлены последовательностями из единиц и нулей. Самая основная двоичная единица — это бит , который представляет собой всего лишь единицу или 0. Следующая по величине двоичная единица, байт, состоит из 8 бит. Пример байта — «01101011».
Каждый цифровой актив, с которым вы когда-либо сталкивались, — от программного обеспечения до мобильных приложений, от веб-сайтов до историй в Instagram — построен на этой системе байтов, которые связаны друг с другом таким образом, чтобы они имели смысл для компьютеров.Когда мы говорим о размерах файлов, мы имеем в виду количество байтов. Например, килобайт — это примерно тысяча байт, а гигабайт — примерно миллиард байтов.
Текст — это один из многих ресурсов, которые компьютеры хранят и обрабатывают. Текст состоит из отдельных символов, каждый из которых представлен в компьютерах строкой битов. Эти строки собираются в цифровые слова, предложения, абзацы, любовные романы и т. Д.
ASCII: преобразование символов в двоичные
Американский стандартный код обмена информацией (ASCII) был ранней стандартизированной системой кодирования текста.Кодирование — это процесс преобразования символов человеческих языков в двоичные последовательности, которые могут обрабатывать компьютеры.
БиблиотекаASCII включает все прописные и строчные буквы латинского алфавита (A, B, C…), каждую цифру от 0 до 9 и некоторые общие символы (например, /,! И?). Он присваивает каждому из этих символов уникальный трехзначный код и уникальный байт.
В таблице ниже показаны примеры символов ASCII с соответствующими кодами и байтами.
| Знак | Код ASCII | БАЙТ |
| А | 065 | 01000001 |
| a | 097 | 01100001 |
| B | 066 | 01000010 |
| б | 098 | 01100010 |
| Z | 090 | 01011010 |
| z | 122 | 01111010 |
| 0 | 048 | 00110000 |
| 9 | 057 | 00111001 |
| ! | 033 | 00100001 |
| ? | 063 | 00111111 |
Подобно тому, как символы объединяются в слова и предложения на языке, двоичный код делает это в текстовых файлах.Итак, фраза «Быстрая коричневая лисица перепрыгивает через ленивого пса». в двоичном формате ASCII будет:
01010100 01101000 01100101 00100000 01110001
01110101 01101001 01100011 01101011 00100000
01100010 01110010 01101111 01110111 01101110
00100000 01100110 01101111 01111000 00100000
01101010 01110101 01101101 01110000 01110011
00100000 01101111 01110110 01100101 01110010
00100000 01110100 01101000 01100101 00100000
01101100 01100001 01111010 01111001 00100000
01100100 01101111 01100111 00101110
Это мало что значит для нас, людей, но это хлеб с маслом для компьютера.
Число символов, которые может представлять ASCII, ограничено числом доступных уникальных байтов, поскольку каждый символ получает один байт. Если вы посчитаете, то обнаружите, что существует 256 различных способов сгруппировать восемь единиц и нулей вместе. Это дает нам 256 различных байтов или 256 способов представления символа в ASCII. Когда в 1960 году был представлен ASCII, это было нормально, поскольку разработчикам требовалось всего 128 байт для представления всех необходимых им английских символов и символов.
Но по мере глобального распространения компьютерных технологий компьютерные системы начали хранить текст не только на английском, но и на других языках, многие из которых использовали символы, отличные от ASCII.Были созданы новые системы для сопоставления других языков с одним и тем же набором из 256 уникальных байтов, но использование нескольких систем кодирования было неэффективным и запутанным. Разработчикам требовался лучший способ кодирования всех возможных символов с помощью одной системы.
Unicode: способ сохранить каждый символ, когда-либо
Введите Unicode, систему кодирования, которая решает проблему пространства для ASCII. Как и ASCII, Unicode назначает уникальный код, называемый кодовой точкой , каждому символу. Однако более сложная система Unicode может генерировать более миллиона кодовых точек, чего более чем достаточно, чтобы учесть каждый символ на любом языке.
Unicode теперь является универсальным стандартом для кодирования всех человеческих языков. И да, он даже включает смайлики.
Ниже приведены несколько примеров текстовых символов и соответствующих им кодовых точек. Каждая кодовая точка начинается с буквы «U» для «Unicode», за которой следует уникальная строка символов, представляющая символ.
| Знак | Кодовая точка |
| А | U + 0041 |
| a | U + 0061 |
| 0 | U + 0030 |
| 9 | U + 0039 |
| ! | U + 0021 |
| Ø | U + 00D8 |
| ڃ | U + 0683 |
| ಚ | U + 0C9A |
| 𠜎 | U + 2070E |
| 😁 | U + 1F601 |
Если вы хотите узнать, как генерируются кодовые точки и что они означают в Unicode, ознакомьтесь с этим подробным объяснением.
Итак, теперь у нас есть стандартизированный способ представления каждого символа, используемого каждым человеческим языком, в одной библиотеке. Это решает проблему нескольких систем маркировки для разных языков — любой компьютер на Земле может использовать Unicode.
Но только Unicode не хранит слова в двоичном формате. Компьютерам нужен способ перевода Unicode в двоичный код, чтобы его символы можно было хранить в текстовых файлах. Вот где пригодится UTF-8.
UTF-8: последний фрагмент головоломки
UTF-8 — это система кодирования Unicode.Он может преобразовать любой символ Юникода в соответствующую уникальную двоичную строку, а также может преобразовать двоичную строку обратно в символ Юникода. Это значение «UTF» или «Формат преобразования Unicode».
Существуют и другие системы кодирования Unicode, помимо UTF-8, но UTF-8 уникален, поскольку представляет символы в однобайтовых единицах. Помните, что один байт состоит из восьми бит, отсюда и «-8» в его названии.
Более конкретно, UTF-8 преобразует кодовую точку (которая представляет один символ в Unicode) в набор от одного до четырех байтов.Первые 256 символов в библиотеке Unicode, которые включают символы, которые мы видели в ASCII, представлены как один байт. Символы, которые появляются позже в библиотеке Unicode, кодируются как двухбайтовые, трехбайтовые и, возможно, четырехбайтовые двоичные единицы.
Ниже приведена та же таблица символов сверху, с выводом UTF-8 для каждого добавленного символа. Обратите внимание, что некоторые символы представлены одним байтом, а другие используют больше.
| Знак | Кодовая точка | Двоичная кодировка UTF-8 |
| А | U + 0041 | 01000001 |
| a | U + 0061 | 01100001 |
| 0 | U + 0030 | 00110000 |
| 9 | U + 0039 | 00111001 |
| ! | U + 0021 | 00100001 |
| Ø | U + 00D8 | 11000011 10011000 |
| ڃ | U + 0683 | 11011010 10000011 |
| ಚ | U + 0C9A | 11100000 10110010 10011010 |
| 𠜎 | U + 2070E | 11110000 10100000 10011100 10001110 |
| 😁 | U + 1F601 | 11110000 10011111 10011000 10000001 |
Почему UTF-8 преобразовывает одни символы в один байт, а другие — в четыре байта? Короче для экономии памяти.Используя меньше места для представления более общих символов (например, символов ASCII), UTF-8 уменьшает размер файла, позволяя использовать гораздо большее количество менее распространенных символов. Эти менее распространенные символы кодируются в два или более байта, но это нормально, если они хранятся редко.
Пространственная эффективность — ключевое преимущество кодировки UTF-8. Если бы вместо этого каждый символ Unicode был представлен четырьмя байтами, текстовый файл, написанный на английском языке, был бы в четыре раза больше, чем тот же файл, закодированный с помощью UTF-8.
Еще одним преимуществом кодировки UTF-8 является ее обратная совместимость с ASCII. Первые 128 символов в библиотеке Unicode соответствуют символам в библиотеке ASCII, а UTF-8 переводит эти 128 символов Unicode в те же двоичные строки, что и ASCII. В результате UTF-8 может без проблем преобразовывать текстовый файл, отформатированный в ASCII, в читаемый человеком текст.
Символы UTF-8 в веб-разработке
UTF-8 — наиболее распространенный метод кодировки символов, используемый сегодня в Интернете, и набор символов по умолчанию для HTML5.Более 95% всех веб-сайтов, в том числе и ваш собственный, хранят персонажей таким образом. Кроме того, распространенные методы передачи данных через Интернет, такие как XML и JSON, кодируются стандартами UTF-8.
Поскольку в настоящее время это стандартный метод кодирования текста в Интернете, все страницы вашего сайта и базы данных должны использовать кодировку UTF-8. Система управления контентом или конструктор веб-сайтов по умолчанию сохранят ваши файлы в формате UTF-8, но все же рекомендуется следить за тем, чтобы вы придерживались этой передовой практики.
Текстовые файлы, закодированные с помощью UTF-8, должны указывать на это программному обеспечению, обрабатывающему их.В противном случае программа не сможет должным образом преобразовать двоичный код обратно в символы. В файлах HTML вы можете увидеть строку кода, подобную следующему, вверху:
Это сообщает браузеру, что файл HTML закодирован в UTF-8, чтобы браузер мог преобразовать его обратно в разборчивый текст.
UTF-8 по сравнению с UTF-16
Как я уже упоминал, UTF-8 — не единственный метод кодирования для символов Unicode — существует также UTF-16.Эти методы различаются количеством байтов, необходимых для хранения символа. UTF-8 кодирует символ в двоичную строку из одного, двух, трех или четырех байтов. UTF-16 кодирует символ Unicode в строку из двух или четырех байтов.
Это различие видно из их названий. В UTF-8 наименьшее двоичное представление символа — это один байт или восемь битов. В UTF-16 наименьшее двоичное представление символа составляет два байта или шестнадцать бит.
И UTF-8, и UTF-16 могут переводить символы Unicode в удобные для компьютера двоичные файлы и обратно.Однако они несовместимы друг с другом. Эти системы используют разные алгоритмы для сопоставления кодовых точек с двоичными строками, поэтому двоичный вывод для любого заданного символа будет отличаться от обоих методов:
| Знак | Двоичная кодировка UTF-8 | Двоичная кодировка UTF-16 |
| А | 01000001 | 01000001 11011000 00001110 11011111 |
| 𠜎 | 11110000 10100000 10011100 10001110 | 01000001 11011000 00001110 11011111 |
UTF-8 предпочтительнее UTF-16 на большинстве веб-сайтов, поскольку она использует меньше памяти.Напомним, что UTF-8 кодирует каждый символ ASCII всего одним байтом. UTF-16 должен кодировать эти же символы в двух или четырех байтах. Это означает, что текстовый файл на английском языке с кодировкой UTF-16 будет как минимум в два раза больше размера того же файла с кодировкой UTF-8.
UTF-16 эффективнее UTF-8 только на некоторых неанглоязычных сайтах. Если веб-сайт использует язык с символами, находящимися дальше в библиотеке Unicode, UTF-8 будет кодировать все символы как четыре байта, тогда как UTF-16 может кодировать многие из тех же символов только как два байта.Тем не менее, если ваши страницы заполнены буквами ABC и 123, придерживайтесь UTF-8.
Декодирование мира кодировки UTF-8
Это было много слов о словах, поэтому давайте резюмируем то, что мы рассмотрели:
- Компьютеры хранят данные, включая текстовые символы, как двоичные (единицы и нули).
- ASCII был ранним способом кодирования или отображения символов в двоичный код, чтобы компьютеры могли их хранить. Однако в ASCII не было достаточно места для представления нелатинских символов и чисел в двоичном формате.
- Unicode был решением этой проблемы. Unicode присваивает уникальный «код» каждому символу на каждом человеческом языке.
- UTF-8 — это метод кодировки символов Unicode. Это означает, что UTF-8 берет кодовую точку для данного символа Юникода и переводит ее в строку двоичного кода. Он также делает обратное, считывая двоичные цифры и преобразуя их обратно в символы.
- UTF-8 в настоящее время является самым популярным методом кодирования в Интернете, поскольку он может эффективно хранить текст, содержащий любые символы.
- UTF-16 — еще один метод кодирования, но он менее эффективен для хранения текстовых файлов (за исключением тех, которые написаны на некоторых неанглийских языках).
Перевод Unicode — это не то, о чем большинству из нас нужно думать при просмотре или разработке веб-сайтов, и именно в этом суть — создать бесшовную систему обработки текста, которая работает для всех языков и веб-браузеров. Если он работает хорошо, вы этого не заметите.
Но если вы обнаружите, что страницы вашего веб-сайта занимают чрезмерно много места или если ваш текст усеян буквами и, пора применить ваши новые знания о UTF-8.
На этой странице: open (), file.read (), file.readlines (), file.write (), file.writelines ().Открытие и закрытие «файлового объекта»Как показано в Учебниках №12 и №13, операции ввода-вывода файлов (ввода-вывода) выполняются через объект данных файла . Обычно это происходит следующим образом:
Чтение из файлаХорошо, мы знаем, как открывать и закрывать файловый объект. Но каковы фактические команды для чтения ? Есть несколько методов.Во-первых,.read () считывает все текстовое содержимое файла как , одну строку . Ниже файл считывается в переменную с именем marytxt, которая в конечном итоге становится объектом строкового типа. Скачайте mary-short.txt и попробуйте сами.
Запись в файлСпособы написания также входят в пару:.write () и .writelines (). Как и соответствующие методы чтения, .write () обрабатывает одну строку, а .writelines () обрабатывает список строк.Ниже .write () каждый раз записывает одну строку в указанный выходной файл:
Общие ловушкиФайловый ввод-вывод, как известно, чреват камнями преткновения для начинающих программистов. Ниже приведены самые распространенные.Ошибка «Нет такого файла или каталога»
Проблемы с кодировкой
Все содержимое файла можно прочитать только ОДИН РАЗ за открытие
Можно писать только строковый тип
Ваш выходной файл пуст Это происходит с , каждый : вы что-то записываете, открываете файл для просмотра, но обнаруживаете, что он пустой. В других случаях содержимое файла может быть неполным.Любопытно, правда? Что ж, причина проста: ВЫ ЗАБЫЛИ .close (). Запись происходит в буферов ; очистка последнего буфера записи не происходит, пока вы не закроете свой файловый объект. ВСЕГДА НЕ ЗАКРЫВАЙТЕ СВОЙ ФАЙЛ-ОБЪЕКТ. (Windows) Разрывы строк не отображаются |
Что такое кодирование URL в HTML
Из этого руководства вы узнаете, как кодировать URL-адрес для безопасной передачи данных через Интернет.
Что такое кодировка URL
Согласно RFC 3986, символы в URL ограничены только определенным набором зарезервированных и незарезервированных символов US-ASCII.В URL нельзя использовать любые другие символы. Но URL-адрес часто содержит символы вне набора символов US-ASCII, поэтому они должны быть преобразованы в допустимый формат US-ASCII для обеспечения совместимости во всем мире. Кодирование URL, также известное как процентное кодирование, — это процесс кодирования информации URL, чтобы ее можно было безопасно передавать через Интернет.
Чтобы отобразить широкий спектр символов, которые используются во всем мире, используется двухэтапный процесс:
- Сначала данные кодируются в соответствии с кодировкой символов UTF-8.
- Тогда только те байты, которые не соответствуют символам в незарезервированном наборе, должны быть закодированы в процентах, например% HH, где HH — шестнадцатеричное значение байта.
Например, строка: François будет закодирована как: Fran% C3% A7ois
Ç, ç (c-cedilla) — латинская буква.
Зарезервированные символы
Некоторые символы зарезервированы или ограничены для использования в URL-адресе, поскольку они могут (или не могут) определяться как разделители общим синтаксисом в конкретной схеме URL-адреса.Например, косая черта / символов используется для разделения разных частей URL-адреса.
Если данные для компонента URL-адреса содержат символ, который может конфликтовать с зарезервированным набором символов, который определен как разделитель в схеме URL-адреса, то перед формированием URL-адреса конфликтующий символ должен быть закодирован в процентах. Зарезервированные символы в URL-адресе:
! | # | $ | и | ' | ( | ) | * | + | , | / | : | ; | = | ? | @ | [ | ] |
% 21 | % 23 | % 24 | % 26 | % 27 | % 28 | % 29 | % 2A | % 2B | % 2C | % 2F | % 3A | % 3B | % 3D | % 3F | % 40 | % 5Б | % 5D |
Незарезервированные символы
Символы, которые разрешены в URL-адресе, но не имеют зарезервированного назначения, называются незарезервированными.К ним относятся прописные и строчные буквы, десятичные цифры, дефис, точка, подчеркивание и тильда. В следующей таблице перечислены все незарезервированные символы в URL-адресе:
А | Б | С | D | E | Ф | г | H | I | Дж | К | л | М | № | O | п. | К | R | S | т | U | В | Вт | X | Y | Z |
а | б | c | г | e | f | г | ч | и | дж | к | л | м | n | или | п | q | r | с | т | u | v | w | x | y | z |
0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | – | _ | . | ~ | ||||||||||||
Конвертер кодирования URL
Следующий преобразователь кодирует и декодирует символы в соответствии с RFC 3986.
Введите символ и нажмите кнопку кодирования или декодирования, чтобы увидеть результат.
Unicode в JavaScript
Кодировка Unicode исходных файлов
Если не указано иное, браузер предполагает, что исходный код любой программы написан в местной кодировке, которая зависит от страны и может вызвать непредвиденные проблемы.По этой причине важно установить кодировку для любого документа JavaScript.
Как указать другую кодировку, в частности UTF-8, наиболее распространенную кодировку файлов в Интернете?
Если файл содержит символ спецификации, который имеет приоритет при определении кодировки. Вы можете прочитать много разных мнений в Интернете, некоторые говорят, что спецификация в UTF-8 не приветствуется, а некоторые редакторы даже не добавляют ее.
Это то, что говорит стандарт Unicode:
… Использование спецификации не требуется и не рекомендуется для UTF-8, но может встречаться в контекстах, где данные UTF-8 преобразуются из других форм кодирования, которые используют спецификацию, или где спецификация используется в качестве подписи UTF-8.
Это то, что говорит W3C:
В HTML5 браузеры должны распознавать спецификацию UTF-8 и использовать ее для определения кодировки страницы, а последние версии основных браузеров обрабатывают спецификацию должным образом при использовании для страниц с кодировкой UTF-8. — https://www.w3.org/International/questions/qa-byte-order-mark
Если файл получен с использованием HTTP (или HTTPS), заголовок Content-Type может указывать кодировку:
Content-Type: application / javascript; charset = utf-8 Если этот параметр не установлен, резервным вариантом является проверка атрибута charset тега сценария :
<скрипт src = "./app.js "charset =" utf-8 "> Если этот параметр не установлен, используется метатег набора символов документа:
...
... Атрибут charset в обоих случаях нечувствителен к регистру (см. Спецификацию)
Все это определено в RFC 4329 «Scripting Media Types».
Публичным библиотекам, как правило, следует избегать использования символов вне набора ASCII в своем коде, чтобы избежать его загрузки пользователями с кодировкой, отличной от их исходной, и, таким образом, создания проблем.
Как JavaScript использует Unicode внутри себя
Хотя исходный файл JavaScript может иметь любую кодировку, JavaScript затем преобразует его внутренне в UTF-16 перед выполнением.
СтрокиJavaScript — это все последовательности UTF-16, как гласит стандарт ECMAScript:
Когда строка содержит фактические текстовые данные, каждый элемент считается одной единицей кода UTF-16.
Использование Unicode в строке
Последовательность Unicode может быть добавлена в любую строку, используя формат \ uXXXX :
Последовательность может быть создана путем объединения двух последовательностей Unicode:
const s2 = '\ u0065 \ u0301' // é
Обратите внимание, что хотя обе генерируют акцентированный e, это две разные строки, и s2 считается длиной 2 символа:
s1.длина // 1
s2.length // 2
И когда вы пытаетесь выбрать этот символ в текстовом редакторе, вам нужно пройти его 2 раза, так как при первом нажатии клавиши со стрелкой для его выбора он просто выбирает половину элемента.
Вы можете написать строку, объединяющую символ Юникода с простым char, поскольку внутренне это фактически одно и то же:
const s3 = 'e \ u0301' // é
s3.length === 2 // верно
s2 === s3 // правда
s1! == s3 // верно
Нормализация
Нормализация Unicode — это процесс устранения неоднозначности в способе представления символа, например, для облегчения сравнения строк.
Как в примере выше:
const s1 = '\ u00E9' // é
const s3 = 'e \ u0301' // é
s1! == s3
ES6 / ES2015 представил метод normalize () в прототипе String, поэтому мы можем:
s1.normalize () === s3.normalize () // верно
смайликов
Emojis — это весело, они являются символами Unicode, поэтому их можно использовать в строках:
Emojis являются частью астральных планов, за пределами первой базовой многоязычной плоскости (BMP), и поскольку эти точки за пределами BMP не могут быть представлены в 16-битном формате, JavaScript должен использовать комбинацию из 2 символов для их представления
Символ 🐶, который представляет собой U + 1F436 , традиционно кодируется как \ uD83D \ uDC36 (называемый суррогатной парой).Для этого есть формула, но это довольно сложная тема.
Некоторые смайлы также создаются путем объединения других смайлов. Вы можете найти их, просмотрев этот список https://unicode.org/emoji/charts/full-emoji-list.html и обратите внимание на те, которые имеют более одного элемента в столбце символов Юникода.
👩❤️👩 создается объединением 👩 ( \ uD83D \ uDC69 ), ❤️ ( \ u2764 \ uFE0F \ u200D ) и еще одного 👩 ( \ uD83D \ uDC69 ) в одну строку: \ uD83D \ uDC69 \ u2764 \ uE0F \ uD83D \ uDC69
Невозможно заставить этот смайлик засчитываться как 1 символ.
Получите правильную длину строки
При попытке выполнить
'👩❤️👩'. Длина
Вы получите 8 взамен, так как длина учитывает отдельные кодовые точки Unicode.
Кроме того, повторять это довольно забавно:
И что любопытно, вставив этот смайлик в поле пароля, он засчитывается 8 раз, что, возможно, делает его действующим паролем в некоторых системах.
Как получить «реальную» длину строки, содержащей символы Юникода?
Один из простых способов в ES6 + — использовать оператор распространения :
Вы также можете использовать библиотеку Punycode от Матиаса Биненса:
требуется ("punycode").ucs2.decode ('🐶'). length // 1
(Punycode также отлично подходит для преобразования Unicode в ASCII)
Обратите внимание, что смайлы, созданные путем объединения других смайликов, по-прежнему будут давать плохой счет:
require ('punycode'). Ucs2.decode ('👩❤️👩'). Length // 6
[... '👩❤️👩']. Длина // 6
Однако, если строка имеет объединяющих меток , это все равно не даст правильного подсчета. Посмотрите этот глюк https://glitch.com/edit/#!/node-unicode-ignore-marks-in-length в качестве примера.
(вы можете создать свой собственный странный текст с пометками здесь: https://lingojam.com/WeirdTextGenerator)
Длина — не единственное, на что следует обращать внимание. Кроме того, реверсирование строки подвержено ошибкам, если не обрабатывается правильно.
Экранирование кодовой точки Unicode ES6
ES6 / ES2015 представил способ представления точек Unicode в астральных планах (любой кодовой точки Unicode, требующей более 4 символов) путем заключения кода в круглые скобки на графике:
Символ собаки 🐶, который представляет собой U + 1F436 , может быть представлен как \ u {1F436} вместо того, чтобы объединять две несвязанные кодовые точки Unicode, как мы показали ранее: \ uD83D \ uDC36 .
Но длина Расчет по-прежнему работает некорректно, поскольку внутренне он преобразован в суррогатную пару, показанную выше.
Кодирование символов ASCII
Первые 128 символов можно закодировать с помощью специального escape-символа \ x , который принимает только 2 символа:
Это будет работать только с \ x00 до \ xFF , который представляет собой набор символов ASCII.
Поддержка Unicode в HTML, редакторах HTML и веб-браузерах
Создание многоязычных веб-страниц:
Поддержка Unicode в HTML, редакторах HTML и веб-браузерах
Введение
Unicode предназначен для того, чтобы отдельные документы могли содержать символы или текст из многих сценариев и языков, и чтобы эти документы можно было использовать на компьютерах с операционными системами на любом языке, оставаясь при этом понятными.Поэтому он идеально подходит для работы во всемирной паутине.
Спецификация HTML 4.0 сделала важный шаг на пути к интернационализации Всемирной паутины, приняв универсальный набор символов (как указано в ISO / IEC 10646 Информационные технологии — Универсальный многооктетный кодированный набор символов (UCS) ) в качестве набора символов документа. для HTML. UCS, как указано в ISO / IEC 10646-1: 2000, в точности эквивалентен стандарту Unicode 3.0.
RFC 2070 ( Интернационализация языка гипертекстовой разметки ) также был включен в HTML 4.0, который теперь включает положение для языков с написанием справа налево (таких как арабский и иврит), соответствующей пунктуации и сочетания букв и диакритических знаков. Последние версии Internet Explorer пошли еще дальше, с поддержкой монгольского языка, который пишется сверху вниз.
Добавление символов Unicode на веб-страницы
Если вы хотите использовать только несколько символов Юникода, которых нет на клавиатуре, например математические символы или несколько символов в другом скрипте, есть три способа ввести эти символы в текст.
- Ссылки на сущности символов
В HTML-файл можно включить 252 символа, введя символическое имя между амперсандом и точкой с запятой, например & mdash; для длинного тире (-). Эти ссылки на символьные сущности должны отображаться независимо от кодировки символов документа и поэтому должны работать в файлах HTML с любой кодировкой символов.
Индекс ссылок на символьные сущности
Netscape Communicator 4.x не может отображать большинство этих объектов, если они не присутствуют в кодировке символов документа. - Ссылки на числовые символы
Вы можете ввести любой символ Юникода в файл HTML, взяв его десятичную числовую ссылку на символ и добавив амперсанд и хэш в начале и точку с запятой в конце, например & # 8212; должен отображаться как длинное тире (-). Это метод, используемый на тестовых страницах Unicode.
Цифровые ссылки на символы должны отображаться независимо от кодировки символов документа и поэтому должны работать в файлах HTML с любой кодировкой символов.Netscape Communicator 4.x не может отображать большинство ссылок на числовые символы, если они не присутствуют в кодировке символов документа. - Ссылки на шестнадцатеричные символы
Если вы предпочитаете использовать шестнадцатеричные числа вместо десятичных, вы можете сделать это, добавив амперсанд, хэш и x спереди и точку с запятой в конце. Например, & # x2014; должен отображаться как длинное тире (-). С помощью этого метода можно ввести любой символ Юникода.
Коммуникатор Netscape 4.x распознает только несколько ссылок на шестнадцатеричные символы.
Использование нескольких сценариев на веб-страницах
Если вы хотите добавить текст в другие сценарии на свои HTML-страницы, очевидно, что ввод большого количества числовых ссылок на символы потребует много времени и подвержен ошибкам, поэтому вам нужно использовать либо редактор HTML с многоязычной поддержкой, либо текстовый процессор. с многоязычной поддержкой и возможностью сохранять файлы в формате HTML с кодировкой UTF-8.
Шрифты Unicode
ШрифтыUnicode позволяют хранить полные наборы символов для нескольких языков в одном файле шрифта, но они не обязательно должны содержать все символы Unicode. Шрифты для определенных языков, как правило, дают результаты, более приемлемые для носителей языка, чем шрифты, которые пытаются охватить многие языки и сценарии. В идеале редакторы должны иметь возможность использовать более одного шрифта для одного документа HTML.Веб-браузеры должны иметь возможность использовать более одного шрифта для отображения страницы, содержащей специальные символы или несколько сценариев, полагаясь на их значения по умолчанию или на предпочтения пользователя — автору страницы редко требуется указывать шрифты.
ПользователиWindows имеют увеличивающийся диапазон шрифтов Unicode, некоторые для определенных языков, а другие (такие как Arial Unicode MS, Bitstream CyberBit и Code2000), охватывающие многие языки и сценарии. Mac OS X 10 может использовать шрифты, предназначенные для Windows, и поставляется с растущим диапазоном шрифтов Mac Unicode, которые позволяют редактировать и отображать различные сценарии.
Хотя обычно в этом нет необходимости, вы можете использовать стили для указания предпочтительных шрифтов (и альтернатив) для разделов текста на определенном языке, определив класс в таблице стилей, подобной этой, в
вашего файла:
Затем вы можете применить стиль к любому тегу HTML в
, а также указать язык для раздела текста: Латинский текст, за которым следует тайский текст и другие латинские тексты.
По мере того, как веб-браузер поддерживает несколько языков, указание языков должно помочь обеспечить лучшее отображение диакритических знаков, комбинированных символов, знаков препинания и переноса в зависимости от языка.
Ни один из редакторов HTML или текстовых процессоров для Mac OS 9 не может использовать шрифты Unicode TrueType, даже если операционная система их поддерживает. Вместо этого они используют языковые наборы, в которых используются проприетарные наборы символов Apple для ввода, отображения и печати внешних и специальных символов, а затем преобразования в Unicode, когда файл сохраняется с кодировкой символов UTF-8.
Кодировки символов
Кодировка символов документа HTML определяет технические детали того, как символы в наборе символов документа должны быть представлены в виде битов при сохранении в компьютерном файле или передаче через Интернет. К счастью, вам не нужно разбираться в технических деталях, чтобы писать веб-страницы.
Единственная деталь о кодировках символов, которую необходимо знать писателю, — это то, что некоторые кодировки символов (например, UTF-8) позволяют включать любой из символов в наборе символов документа, в то время как другие (например, ISO-8859-1 или SHIFT_JIS) допускают только подмножества.Однако символы, которые не допускаются в кодировке символов, по-прежнему могут быть включены в документ HTML с помощью ссылок на символы. UTF-8 — это обычная кодировка символов для любого файла HTML, содержащего текст в двух или более нелатинских сценариях, но ее можно использовать для любого документа.
Кодировку символов можно указать в параметре charset метатега в
документа HTML, например:
Лучше указать кодировку символов в заголовке HTTP, передаваемом с веб-сервера, но это не контролируется большинством авторов.
Кодировка символов также упоминается другими именами, включая схему кодирования символов, кодировку символов, набор символов, набор кодированных символов, кодировку и набор символов передачи.
Проблемы с кодировкой
Хорошей практикой является использование одной и той же кодировки на всех этапах создания документа, от редактирования текста до отображения в веб-браузере. Если вы видите символы правильно в одной части процесса, но неправильно в другой части, то вы почти наверняка не используете одну и ту же кодировку во всем.
Текст отображается как задумано:
Текст в кодировке UTF-8, но отображается как ISO-8859-1:
Текст в кодировке ISO-8859-1, но отображается как UTF-8:
Редакторы HTML для Macintosh
Нет редакторов HTML, которые использовали бы встроенную поддержку Mac OS 9 для шрифтов Unicode TrueType, поэтому пользователи Mac могут печатать только на языках, для которых доступны языковые наборы.
Текстовые процессорыMicrosoft Word 98 и Word 2001, работающие под Mac OS 9, могут использовать один или несколько языковых наборов для создания многоязычных HTML-документов с кодировкой символов UTF-8. Эти документы включают указанные шрифты, но они по-прежнему правильно отображаются в браузерах Internet Explorer и Netscape в системах Windows, в которых есть альтернативные шрифты для соответствующих сценариев.
BBEdit 6 — это текстовый редактор со множеством возможностей для создания HTML-документов.На экране редактирования всегда отображаются HTML-теги, поэтому для предварительного просмотра страниц необходимо использовать веб-браузер. Его можно использовать для создания веб-страниц, содержащих любые алфавиты с написанием слева направо, для которых существуют языковые комплекты, но не арабский или иврит. Документы могут содержать несколько сценариев, но одновременно отображается только один сценарий. Он может открывать и сохранять файлы HTML с кодировкой символов UTF-8.
Netscape Composer 7 может создавать и редактировать файлы HTML на любом из языков и сценариев, для которых установлены языковые комплекты.Он может работать в WYSIWYG или текстовом режимах, а также может открывать и сохранять файлы с кодировкой символов UTF-8.
Muwse (ранее назывался Unisite) — это редактор HTML, который может одновременно отображать любой из языков и скриптов, для которых установлены языковые комплекты. Он использует веб-браузеры для предварительного просмотра страниц. Он может сохранять файлы HTML с кодировкой символов UTF-8.
Adobe GoLive 5 — это редактор HTML, который может одновременно отображать любые языки с написанием слева направо и сценарии, для которых установлены языковые комплекты.Он может работать в режимах WYSIWYG и code visible, а также открывать и сохранять файлы HTML с кодировкой UTF-8.
Adobe InDesign 1.5 может экспортировать файлы в формате HTML с кодировкой символов UTF-8, но не поддерживает шрифты или драйверы клавиатуры в языковых наборах. Он может использовать шрифты Unicode Macintosh TrueType (например, шрифт Tahoma, поставляемый с Office 98 и Word 98), но символы, отсутствующие в MacRoman, необходимо вводить из диалогового окна «Выбор символа …» в меню «Тип».
Другие редакторы WYSIWYG HTML (такие как Dreamweaver 4 и Freeway 3), работающие под Mac OS 9, не могут использовать кодировку символов UTF-8. Они действительно поддерживают некоторые кодировки для нелатинских сценариев, но они ограничивают вас вводом текста на латинице плюс еще один сценарий, такой как кириллица, китайский, японский или корейский. Они не поддерживают арабский или иврит. Многоязычный текстовый процессор Nisus Writer может сохранять файлы в формате HTML, но не в кодировке UTF-8.
Редакторы HTML для Windows
Windows 95, Windows 98, Windows ME, Windows NT, Windows 2000 и Windows XP поддерживают шрифты Unicode TrueType и поэтому могут отображать на экране практически любой символ.Они также позволяют вводить больше скриптов, чем Mac OS 9; В Windows XP больше всего драйверов для клавиатуры.
Существует четыре хорошо известных редактора WYSIWYG HTML для Windows, которые могут использовать кодировку символов UTF-8, Macromedia Dreamweaver MX, Adobe GoLive, Microsoft FrontPage и Namo WebEditor. Все четыре программы могут использовать любой драйвер клавиатуры, доступный в Windows. GoLive 5 может использовать визуальные клавиатуры (полезно, если вы не очень хорошо знакомы с конкретной раскладкой клавиатуры), но не глобальные редакторы текста, позволяющие вводить текст на китайском, японском и корейском языках.FrontPage 2003 и Namo WebEditor поддерживают глобальные редакторы IME и визуальные клавиатуры. Компонент Composer Mozilla также обеспечивает WYSIWYG-редактирование страниц с несколькими сценариями, поддерживает глобальные IME и визуальные клавиатуры и может сохранять файлы в кодировке UTF-8.
Microsoft Word 97 и Word 2000 позволяют вводить несколько сценариев и сохранять многоязычные документы в формате HTML с кодировкой UTF-8. Word 2000 (но не Word 97) поддерживает глобальные редакторы IME и визуальные клавиатуры.В Word 2002 доступна поддержка тайского и некоторых индийских языков. Если вы хотите использовать HTML-файлы из Word 2000 на веб-сайте, обязательно загрузите HTML-фильтр 2.0 в Центре загрузки Microsoft Office, чтобы удалить специфичные для Office теги разметки. ; Word 2002 имеет это встроенное.
Веб-браузеры Microsoft Internet Explorer 5, 5.5 и 6 могут преобразовывать HTML-документы в кодировку символов UTF-8 при условии, что исходный файл использует одну из кодировок в меню «Просмотр»> «Кодировка».Просто откройте файл, убедитесь, что кодировка и отображение верны, а затем выберите «Сохранить как» в меню «Файл».
HomeSite 5 может открывать и сохранять файлы с кодировкой символов UTF-8, но поддерживает только набор символов ANSI.
Веб-браузеры
После создания многоязычных веб-страниц вы должны протестировать их в максимально возможном количестве браузеров и операционных систем.Почти все современные веб-браузеры поддерживают Unicode и поэтому могут отображать текст одновременно на нескольких скриптах и языках при условии, что установлены подходящие шрифты и что браузер настроен на их использование. Более поздние браузеры могут использовать символы из более чем одного шрифта для правильного отображения многоязычной страницы.
Три основных веб-браузера для Windows включают поддержку шрифтов Unicode TrueType и поэтому могут отображать практически любой символ, который вы, вероятно, найдете на веб-странице.Браузер Mozilla, вероятно, имеет лучшую поддержку Unicode и может смешивать символы из нескольких шрифтов для отображения практически любого символа. Internet Explorer 6 и Opera 7 не так хорошо умеют выбирать символы из нескольких шрифтов.
Веб-браузерыдля Mac OS 9 не так хороши, как браузеры для Windows, в отображении многоязычных страниц; они не включают поддержку шрифтов Unicode и могут отображать только те символы, которые поддерживаются установленным Apple Language Kit.Internet Explorer 5 и Netscape 4.8 не поддерживают арабский, иврит или тайский язык. Mozilla 1.2 и Netscape 7 поддерживают арабский, иврит и тайский язык, а iCab 2 Preview поддерживает арабский, деванагари, гуджарати, гурмукхи, иврит и тайский язык. Opera 6 поддерживает большинство скриптов с написанием слева направо.
Для Mac OS X 10, Mozilla, Netscape 7, Safari и Opera 7.5 поддерживают большинство скриптов, включая арабский и иврит. Internet Explorer 5.2 имеет те же ограничения, что и версия OS 9.
Авторские права © 1999–2007 Алан Вуд
Создано 3 февраля 1999 г. Последнее обновление 18 января 2007 г.
Зачем кодировать (экранировать) специальные символы в HTML
Почему мне нужно писать сущность символа?
Вы можете спросить себя, почему нельзя просто скопировать весь символ? Зачем вам нужен HTML-код этого объекта? И я вам скажу почему.Потому что браузер может неправильно кодировать. Один символ может отображаться как другой или как неизвестный символ. Он может даже смешиваться с предыдущим символом, если браузер ошибается. Я уверен, что вам не понравится такой пользовательский опыт на вашем сайте.
Текстовые символы кодируются в некоторые числа, а затем интерпретируются браузерами как символы некоторой системы кодирования. Когда вы вводите специальные символы, выходящие за пределы стандартного 7-битного диапазона ASCII , прямо в HTML-код, необходимо учитывать некоторые моменты.Если вы просто вставите 3-байтовые символы некоторой кодировки прямо в свой HTML-код без « экранирования » (например, преобразования их в их коды сущностей символов), у вас могут возникнуть большие проблемы. Это потому, что код HTML должен быть написан и прочитан в кодировке ASCII. Если вы вставите символы из других систем кодирования, таких как Unicode или UTF-8, вы можете заставить браузеры обрабатывать ваши многобайтовые символы так же, как несколько разных символов. Так что не забудьте написать исходный код HTML просто в ASCII.Вместо того, чтобы писать символы, всегда пишите их сущности.
Вот почему вы также должны не забыть определить метатег типа содержимого, например . Он определяет кодировку. Подробнее об этом будет дальше.
Мета-тег набора символов
Набор символов (или charset ) метатег используется для указания кодировки данных, которые отправляет ваш сервер HTTP .Раньше я думал, что — это метаэлемент, предназначенный для интерпретации только браузером, как и обычный тег HTML. Согласно WWW Consortium, он помогает вашему HTTP-серверу генерировать соответствующий заголовок кодировки. Если в заголовке « Content-Type » отсутствует параметр « charset = » — браузеры обычно думают, что ваш исходный код написан в кодировке ISO-8859-1. А это может вызвать серьезные неприятности.
Кодировать символы в
URLПомните, что браузеры отправляют запросы на HTTP-серверы в кодировке ASCII.Вы всегда должны кодировать ( escape ) специальные текстовые символы в ваших URL путях. Это по той же причине, почему вы должны избегать их в HTML-коде.
Несколько дней назад я узнал, что вы также должны кодировать символ « & » как « & amp; », когда у вас есть бизнес с URL-ссылкой. Это потому, что все остальные экранированные символы начинаются с « & ». Итак, если вы напишете путь к вашему файлу php или что-то вроде этого: « // example.com /? a = 1 & b = 2 «, ваш браузер может подумать, что с помощью» & b «вы хотели выразить какой-то не-ASCII-символ.
Вот почему вам следует попытаться» экранировать «специальные символы в URL-адресах.
Итак, вкратце, вам нужно выработать следующие привычки:
- Всегда определяйте метатег типа содержимого.
- Всегда «экранируйте» символы, отличные от ASCII, в коде HTML.
- Всегда «экранируйте» символы, отличные от ASCII, и амперсанд (&) в URL .
В основном это инструмент JavaScript для веб-мастеров, которые хотят разместить некоторые символы или текст не на английском языке в html-кодах или скриптах своего веб-сайта. Но также любой, кто хочет узнать числовую или шестнадцатеричную сущность какого-либо персонажа, может использовать этот отличный инструмент.
Enty
Кнопки для объектов HTML
Введите текст со специальными символами, которые нужно преобразовать.
Если вам нужны теги типа быть преобразованным в & lt; b & gt; и коды символов, такие как & # 174; чтобы тоже были закодированы (& amp; # 174;), а также — Нажмите кнопка.
Если вы хотите сохранить теги и предыдущие коды символов — нажмите. Это сохранит такие вещи, как & # x266a; ♪ в & # x266a; & # x266a; ) .
Вы также можете использовать кнопку, чтобы преобразованные символы оставались такими же, как в примере, но при этом преобразовывали обозначения тегов «<» и «>» в их сущности.
Вы также можете переключиться с десятичных кодов сущностей на шестнадцатеричные (базовые 16) символьные коды.Установите для этого флажок «Десятичный / шестнадцатеричный».
Сущности JavaScript
Вы можете переключиться на преобразование символов в объекты Javascript, такие как «\ ufe31 \ &». Просто снимите для этого флажок «HTML / JavaScript». Я не уверен, но думаю, что это работает и для Adobe Flash ActionScript.
Извлечение кодов символов с помощью Enty
Вы можете использовать этот инструмент для извлечения десятичных или шестнадцатеричных кодов нужных вам символов. Есть несколько способов набирать символы с клавиатуры с этими кодами.Вы можете найти их в символах клавиатуры. Чтобы получить коды символов, вы должны скопировать эти символы в мой инструмент и нажать. В результате вы получите текст, заключенный внутри «& #» и «;», или «& # x» и «;» — десятичный и шестнадцатеричный код соответствующих символов. Я уверена, ты быстро все поймешь. 😉
Зачем это нужно веб-мастерам?
Поскольку в этом мире существует множество различных систем кодирования, вы не можете просто скопировать и вставить специальные текстовые символы в исходный HTML-код и быть довольным тем, как ваша страница отображает их.Вы помещаете его в кодировку номер один в текстовом редакторе, и браузер вашего пользователя думает, что это кодировка номер два, поэтому веб-мастера должны использовать только наиболее совместимые символы в своих HTML-кодах и скриптах.
С помощью этого инструмента вы можете преобразовать текстовые символы, отличные от ASCII, в совместимый текст ASCII с объектами html и кодами символов JavaScript этих специальных символов. И отныне нет необходимости в этих ужасно выглядящих ссылках на таблицы сущностей html. И вам не нужно в течение нескольких минут искать персонажа, которого вы хотите получить.И в большей части случаев я уверен, что этого даже не было, потому что эти ссылки всегда больше о каких-то греческих и компьютерных знаках, символы авторских прав и т. д. Я знаю, потому что некоторое время назад я сам сделал такую таблицу, но это бесполезно, если ты ищешь крутые символы (кстати в моей коллекции чертовски много syperb) символов Facebook. * Злой смех * Теперь пришло время для конвертера специальных символов. Просто скопируйте нужные символы в поле ввода и вуаля! Ну вот! Всего за несколько секунд — настоящая хватка для кунг-фу!
Вы даже можете скопировать весь текст, содержащий символы, и инструмент преобразует только специальные символы, чтобы вы могли преобразовать текст в UTF-8 в любой HTML или JavaScript.Вы даже можете скопировать результат и снова преобразовать его в получить код этого предыдущего результата (знаете, это иногда полезно в js). Не забудьте добавить его в закладки, если вы веб-разработчик, писатель javascript или если у вас есть какое-то хобби по созданию веб-сайтов, потому что я считаю это очень удобным сам. 😉 Я, правда, очень много этим пользуюсь.
.