HTTP соединение (HTTP Connections) | IT-блог о веб-технологиях, серверах, протоколах, базах данных, СУБД, SQL, компьютерных сетях, языках программирования и создание сайтов.
- 05.06.2016
- HTTP протокол, Сервера и протоколы
Привет, читатель блога ZametkiNaPolyah.ru! Продолжим знакомиться с протоколом HTTP в рубрике серверы и протоколы и ее разделе HTTP протокол. В данной записи мы с тобой поговорим про HTTP соединения и, в основном, о том, как они реализованы в HTTP протоколе версии 1.1. Для начала скажу, что на данный момент действуют постоянные HTTP соединения, это означает одну простую вещь: за одну TCP сессию можно отправить несколько HTTP запросов и получить столько же HTTP ответов, раньше это было далеко не так. Так же в этой записи мы затронем требования к передаче HTTP сообщений.
HTTP соединение (HTTP Connections)
Постоянные HTTP соединения (Persistent Connections HTTP)
Содержание статьи:
- Постоянные HTTP соединения (Persistent Connections HTTP)
- Требования к передаче сообщений и выбор HTTP соединений (HTTP Connections)
Если вы хотите узнать всё про протокол HTTP, обратитесь к навигации по рубрике HTTP протокол.
Давайте посмотрим, что дают постоянные HTTP соединения (HTTP Connections):
- Сейчас не требуется постоянно поднимать новое TCP соединение для запроса, поэтому существенно экономятся ресурсы серверов.
- HTTP запросы клиента и ответы сервера можно представить как непрерывно работающий конвейер, причем параллельный, в рамках одного TCP соединения.
- Для установки TCP соединения машине клиента и машине сервера обязательно нужно посылать пакеты, следовательно, третий уровень модели OSI был очень загружен, так было до появления постоянного HTTP соединения (HTTP Connections).

Поэтому на данный момент все HTTP клиенты и HTTP серверы разрабатываются с учетом того, чтобы работать, используя постоянные HTTP соединения между клиентом и сервером. В версии протокола HTTP 1.1 любой клиент по умолчанию считает, что ему нужно работать с сервером по постоянному HTTP соединению (Persistent Connection HTTP). Как только клиент и сервер прекратили общаться, им необходимо разорвать TCP соединение, делается это специальным полем в заголовке Connection (если не знаете, что такое заголовки и поля, то почитайте статью параметры HTTP). После того, как клиент получил сообщение о разрыве TCP соединения, он не должен (читай про требования HTTP) посылать серверу заголовки.
С учетом того, что HTTP соединение постоянное, клиент может посылать несколько HTTP запросов подряд, не ожидаю HTTP сообщений от сервера, но сервер должен посылать HTTP ответы на сообщения клиента в том порядке, в котором он получил запросы. С учетом того, что на данный момент используется постоянное HTTP соединение (HTTP Connections), сервера имеют определенные значения времени ожидания (конкретные цифры зависят непосредственно от настроек сервера), после которого они перестают поддерживать неактивные соединения.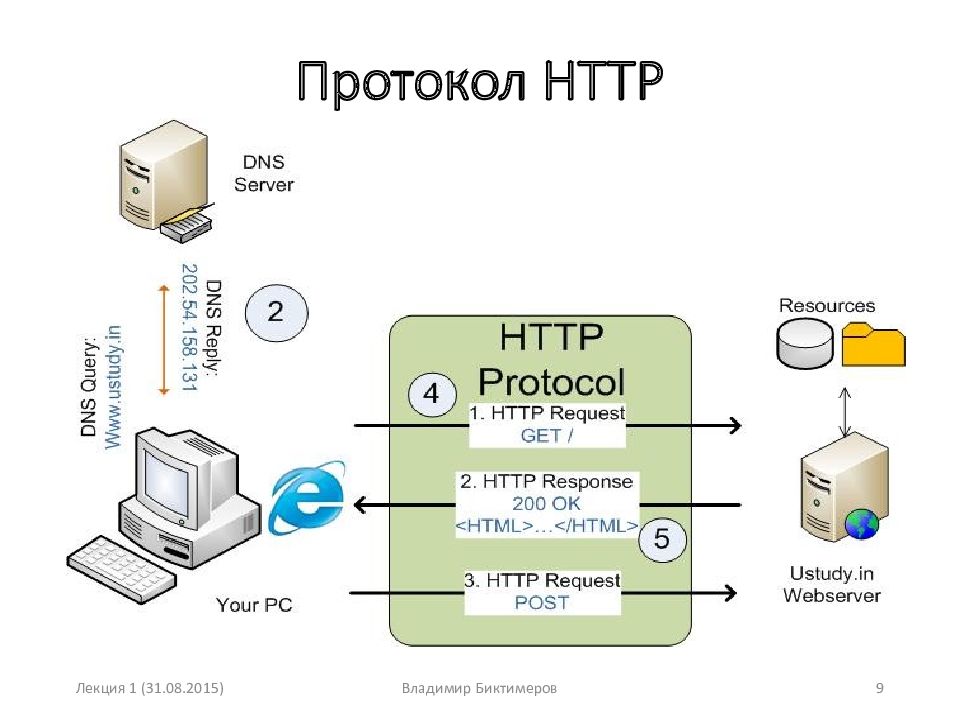
Хочу заметить, что при закрытии TCP соединения клиент и сервер могут работать асинхронно (хотя HTTP протокол по всем определениям синхронный). Например, мы имеем неактивное
В общем, суть данного поста в том, что на данный момент в HTTP поддерживается конвейерное постоянное HTTP соединение с возможностью асинхронной обработки события закрытия соединения.
Требования к передаче сообщений и выбор HTTP соединений (HTTP Connections)
Общие требования к передаче сообщений в стандарте HTTP:
- В HTTP 1.1 серверам следует поддерживать постоянные HTTP соединения.
- В HTTP1 клиентам следует во время отправки сообщения контролировать соединение на предмет ошибок. При обнаружении ошибки клиенту следует немедленно прекратить передачу. Если тело HTTP сообщения посылается с использованием кодирования по кускам, то кусок нулевой длины могут использоваться для индикации преждевременного конца сообщения.
- Протокол HTTP версии 1.1 предусматривает то, что клиент должен уметь работать с кодом состояния 100.
 При обнаружении ошибки клиенту следует немедленно прекратить передачу. Если тело HTTP сообщения посылается с использованием кодирования по кускам, то кусок нулевой длины могут использоваться для индикации преждевременного конца сообщения.
При обнаружении ошибки клиенту следует немедленно прекратить передачу. Если тело HTTP сообщения посылается с использованием кодирования по кускам, то кусок нулевой длины могут использоваться для индикации преждевременного конца сообщения.Сервера версии HTTP 1.1 должны уметь работать с клиентами 1.0 и ниже, при этом сервера не должны использовать сообщения с кодом состояния 100. Если клиент HTTP 1.1 взаимодействует с сервером 1.0 , то для корректной отправки повторного запроса он должен использовать следующий алгоритм:
- Инициализировать новое соединение с сервером.
- Передать заголовки запроса (request-headers).
- Инициализировать переменную R примерным временем передачи информации на сервер и обратно (например на основании времени установления соединения), или постоянным значение в 5 секунд, если время передачи не доступно.
- Вычислить T = R * (2**N), где N — число предыдущих повторов этого запроса.
- Либо дождаться от сервера ответа с кодом ошибки, либо просто выждать T секунд (смотря что произойдет раньше).
- Если ответа с кодом ошибки не получено, после T секунд передать тело запроса.
- Если клиент обнаруживает, что HTTP соединение было закрыто преждевременно, то ему нужно повторять начиная с шага 1, пока запрос не будет принят, либо пока не будет получен ошибочный ответ, либо пока у пользователя не кончится терпение и он не завершит процесс повторения.

Вот такие требования к передаче HTTP сообщений предъявляются стандартом HTTP. На этом мы закончим рассмотрение HTTP соединений, более полную информацию вы сможете узнать из стандарта HTTP 1.1.
Возможно, эти записи вам покажутся интересными
HTTP Протокол — Простым Языком для Начинающих
Когда протокол HTTP только появился, web был устроен достаточно просто. Там в основном размещались простые текстовые странички в формате HTML. Поэтому протокол HTTP версия 1.0 работал в режиме запрос-ответ. Клиент запрашивает web-страницу у сервера, сервер ему эту страницу передает, это позволило сделать протокол достаточно простым.
Поэтому протокол HTTP версия 1.0 работал в режиме запрос-ответ. Клиент запрашивает web-страницу у сервера, сервер ему эту страницу передает, это позволило сделать протокол достаточно простым.
Первую статью о протоколе HTTP читайте в статье HTTP для чайников.
Однако современный web устроен более сложно. Современные web-страницы включают большое количество других ресурсов. Кроме web-страницы, необходимо загрузить:
- целевой файл;
- файл, который содержит программы, которые будут выполняться на стороне браузера;
- картинки, которые являются составной частью web-страницы;
- возможно видео или аудио.
Кроме этого, некоторые страницы используют какие-то блоки передаваемые с других сайтов. Таким образом, по протоколу HTTP сейчас загружается ни одна страница, а большое количество ресурсов с web-сервера.
Загрузка нескольких ресурсовПосмотрим как это реализуется. Прежде чем, что-то загружать с web-сервера, клиенту необходимо установить TCP соединение.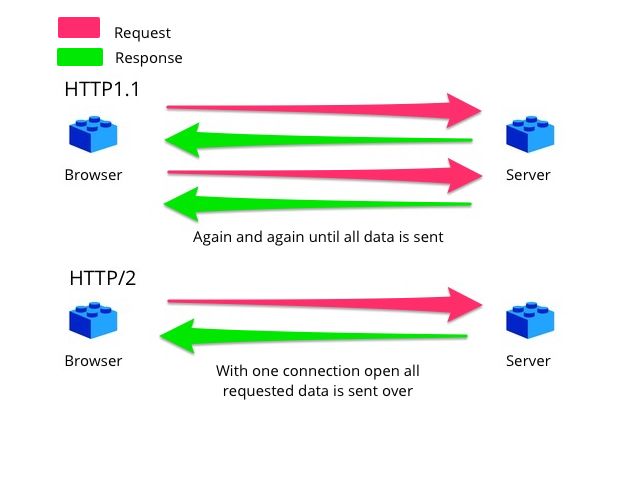
Затем выполняется запрос по протоколу HTTP.
GET возвращает web-страницу, после этого соединение закрывается.
Браузер анализирует содержимое web-страницы, видит, что необходимо загрузить целевой файл, большое количество картинок и другие элементы. Для того чтобы загрузить следующий ресурс, например стилевой файл необходимо открыть новое соединение.
После этого клиент передает запрос HTTP GET на загрузку стилевого файла.
Сервер в ответ передает этот файл.
После чего соединение снова закрывается. Таким образом, для того чтобы загрузить каждый элемент web-страницы, необходимо открыть отдельные tcp соединения.
Постоянное соединение в HTTPАльтернативный подход, который называется постоянное соединение, заключается в том что можно один раз установить соединение tcp и затем использовать его для загрузки различных ресурсов не только HTML страницы, но и стилевых файлов, javascript, картинок и всех связанных ресурсов. TCP соединения разрываются после того, как все ресурсы были загружены.
TCP соединения разрываются после того, как все ресурсы были загружены.
По-английски постоянное соединение называется HTTP persistent connection или HTTP keep-alive. Использование постоянного соединения позволяет повысить скорость загрузки web-страниц.
- Во-первых, нет необходимости каждый раз устанавливать HTTP соединения, то есть мы не проходим процедуру трехкратного рукопожатия.
- Во вторых, скорость передачи данных при установке нового соединения TCP низкая. Для того чтобы регулировать скорость передачи данных, TCP используют размер окна, чем больше размер окна тем больше скорость передачи данных. Так как при установке соединения, TCP ничего не знает про сеть, то используется маленький размер окна, который увеличивается при получении каждого подтверждения с помощью механизма slowstart, а затем аддитивного увеличения мультипликативного уменьшения. Если мы не открываем каждый раз новое соединение, а используем существующие, то нам не надо каждый раз начинать с маленького размера окна, и мы используем существующее TCP соединение, которое позволяет передавать данные на высокой скорости.
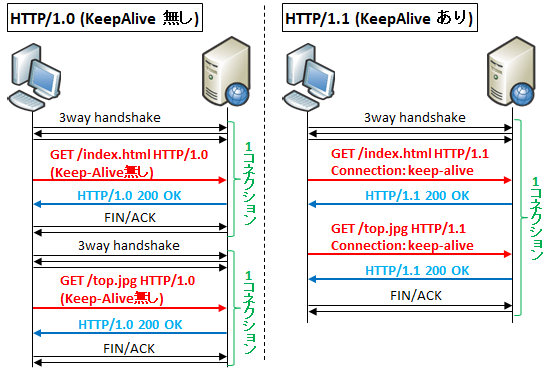
В стандарте HTTP 1.0 не было возможности использовать постоянное соединение. Уже после публикации стандарта был придуман специальный заголовок Connection: keep-alive. Клиент добавляет этот заголовок к запросу, для того чтобы попросить сервер не закрывать соединение после передачи ответа. Если сервер понимает этот заголовок и поддерживает постоянное соединение, он оставляет соединение открытым и добавляет этот заголовок к ответу.
В HTTP 1.0 нет гарантий, что соединение останется открытым, так как этот заголовок не является частью стандарта, то клиент и сервер могут его не поддерживать, а во-вторых у сервера просто может не хватить ресурсов для того чтобы оставить соединение открытым.
Рассмотрим пример использования заголовка
GET /tehnologii/protokoli HTTP 1.0
Host: www.zvondozvon.ru
Connection:keep-alive
Посылаем запрос http, используя метод GET, хотим получить страничку со статьями по протоколам (/tehnologii/protokoli), которые находятся на сайте (www.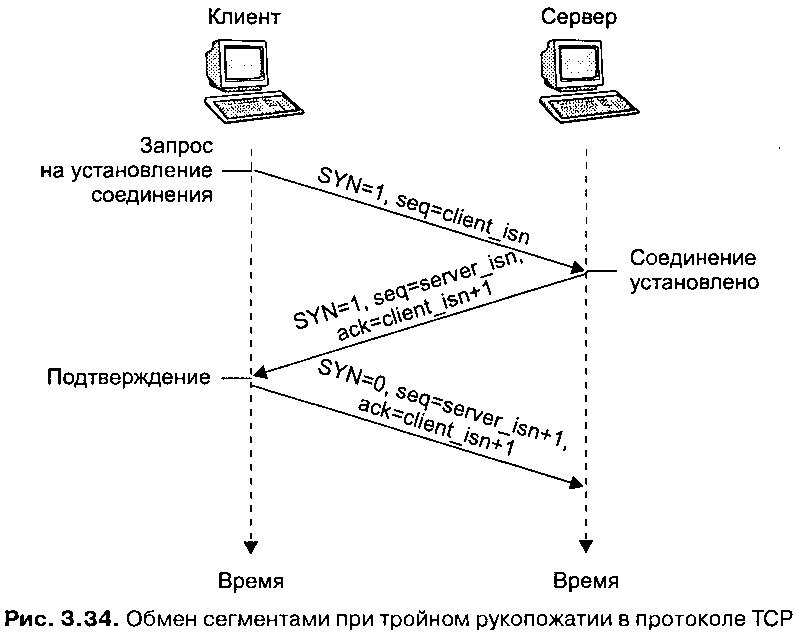 zvondozvon.ru) по протоколу HTTP/1.0.
zvondozvon.ru) по протоколу HTTP/1.0.
Добавляем заголовок Connection:keep-alive для того чтобы попросить сервер не разрывать соединение после того как он передаст нам web-страницу.
Сервер присылает нам ответ
HTTP/1.0 200 OK
Server: nginx
Content-Type: text/htm1; charset=UTF-8
Content-Length: 5161
Connection: keep-alive
Первая строчка статус 200 ОК, означает, что необходимая нам страница найдена. Дальше идут заголовки, и нужный нам заголовок Connection:keep-alive, который говорит о том, что сервер поддерживает постоянное соединение и он оставил соединение открытым для того чтобы можно было загружать следующие ресурсы.
Постоянное соединение в HTTP 1.1В версии протокола HTTP 1.1 все соединения по умолчанию считаются постоянными. Использовать заголовок Connection:keep-alive не обязательно, но многие браузеры и серверы до сих пор это делают. Однако, если клиент не вставим заголовок Connection:keep-alive в запрос, соединение все равно останется открытым. Если по каким-то причинам клиент считает, что соединение нужно разорвать, то он может использовать заголовок connection close.
Однако, если клиент не вставим заголовок Connection:keep-alive в запрос, соединение все равно останется открытым. Если по каким-то причинам клиент считает, что соединение нужно разорвать, то он может использовать заголовок connection close.
Хотя постоянные HTTP соединение позволяет увеличить скорость передачи данных от web сервера к клиенту, поддержание этого соединения требует ресурсов на сервере. Ресурсы сервера ограничены, и если клиент открыл соединения и его не использует, то этих ресурсов не хватит другим клиентам, особенно это плохо для высоконагруженных серверов, к которым поступают несколько сотен или тысяч запросов в секунду.
Поэтому современные web-серверы автоматически закрывают соединение, если оно не используется в течение какого-то времени, как правило от 5 до 15 или 20 секунд. Обычно этого времени достаточно для того чтобы загрузить web-страницу и все сопутствующие ей ресурсы.
Другая технология, которая позволяет увеличить скорость передачи данных HTTP, называется HTTP pipelining, по-русски конвейерная обработка. Она заключается в следующем, после того как сделали запрос на получение HTML странички, получили ответ, браузер проанализировал ответ и извлек перечень всех ресурсов которые нужно загрузить с сервера.
Конвейерная обработка позволяет передать от клиента серверу сразу несколько запросов для загрузки ресурсов не дожидаясь получения ответа.
Сервер получив несколько запросов, в ответ отправляют сразу все запрошенные ресурсы. Недостатком технологии является то, что ресурсы должны передаваться в том же порядке в котором пришли запросы.
Однако если с загрузкой какого-то ресурса возникли проблемы, то другие ресурсы передавать нельзя даже если они уже готовы к передачи. Это проблема решена в протоколе HTTP 2. 0, где можно нумеровать запросы и передавать ресурсы от сервера клиенту в любом порядке. К сожалению конвейерная обработка на практике используется достаточно редко.
0, где можно нумеровать запросы и передавать ресурсы от сервера клиенту в любом порядке. К сожалению конвейерная обработка на практике используется достаточно редко.
Еще один вариант, как можно увеличить скорость загрузки web-страниц это использовать несколько HTTP соединений. Клиент открывает несколько соединений с web сервер и каждое соединение используется для загрузки разных ресурсов.
Например, первое соединение для загрузки стилевого файла, следующие соединение для загрузки javascript и другие соединения для передачи различных картинок. Каждое такое соединение может быть постоянным и использоваться для загрузки нескольких ресурсов, а также внутри таких соединений можно использовать HTTP pipelining. Почти все современные браузеры используют несколько HTTP соединений как правило от 4 до 8.
Кэширование в HTTPРассмотрим другой механизм, созданный для увеличения скорости загрузки веб страниц с использованием постоянного соединения HTTP — кэширование. Сейчас многие современные web браузеры могут сохранить страницу на локальном диске, если она изменяется редко, и показывать страницу из каша на диске, а не загружать ее с сервера.
Сейчас многие современные web браузеры могут сохранить страницу на локальном диске, если она изменяется редко, и показывать страницу из каша на диске, а не загружать ее с сервера.
А также возможно кеширование не полностью web-страницы, а отдельных ресурсов, которые изменяются реже. К таким ресурсам относятся картинки, например, если на сайте есть логотип компании, то вряд ли он изменяется очень часто, это также могут быть таблицы стилей, библиотеки Java Script. Дополнительным преимуществом является то, что такие ресурсы используются ни одной страницей, а несколькими страницами на сайте.
Кэширование требует место на локальном диске компьютера, но сейчас это не составляет проблем. Поддержка кэширования ресурсов встроена прямо в протокол http. Основная проблема заключается в том, что браузеру необходимо определить можно ли брать страницу из кэша, или страница изменилась и необходимо обращаться за ней к web –серверу. В http для этой цели используется заголовок Expires. Этот заголовок web-сервер добавляет к ресурсу, когда передает http ответ и заголовок говорит о том, до какого времени можно хранить ресурс в кэше.
Заголовок Expires:
— Expires: Sun, 12 Jun 2016 10:35:18 GMT
— Указывает, до какого времени можно хранить ресурс в кэш
— Web-сервера навсегда устанавливают этот заголовок
В примере ресурс можно хранить до 12 июня, после этого ресурс устареет и необходимо снова обращаться к серверу. Однако не все web-серверы устанавливают этот заголовок. Если заголовок Expires не установлен, то браузер может использовать некоторые Эвристики. Например, он может использовать поле last-modified в котором указываются дата последнего изменения ресурса.
— Last-Modified: Wed, 25 May 2016 06:12:24 GMT
— Если страница долго не менялась, то скорее всего можно загрузить ее из кэша
— Возможны ошибки
В примере 25 мая 2016 года. Если страница долго не менялось, то можно предположить, что в ближайшее время она не изменится, и можно брать ее копию из кэша. С другой стороны при таком подходе возможны ошибки. Например, наша эвристика может заключаться в том, что мы берем из кэша те страницы, которые не менялись в течение двух недель, но страница может меняться 1 раз в месяц.
Протокол http содержит другой подход, который позволяет определить изменилась страница или нет. Для этого клиент должен отправить серверу запрос GET с условием, или по-английски Conditional GET. Клиент передает запрос GET с условиям, в ответ сервер может сказать, что страница не изменилась, тогда браузер берет версию страницы из кэша, а если страница поменялась, то web-сервер передаст измененную версию web-страниц.
Как работает запрос Conditional GET
При первом обращении к ресурсу, браузер посылает обычный запрос GET и сохраняет результат в кэш. Conditional GET можно использовать только если в http ответе установлен заголовок Last-modified, в котором указана дата последнего изменения ресурса.
В следующий раз, когда браузер будет обращаться к серверу за тем же самым ресурсом, он уже будет использовать запрос Conditional GET, в этом запросе используется дополнительный заголовок if-Modified-Since, в этом заголовки указывается дата изменения ресурсов, это дата как раз берется из значения заголовка last-modified, который передал нам сервер.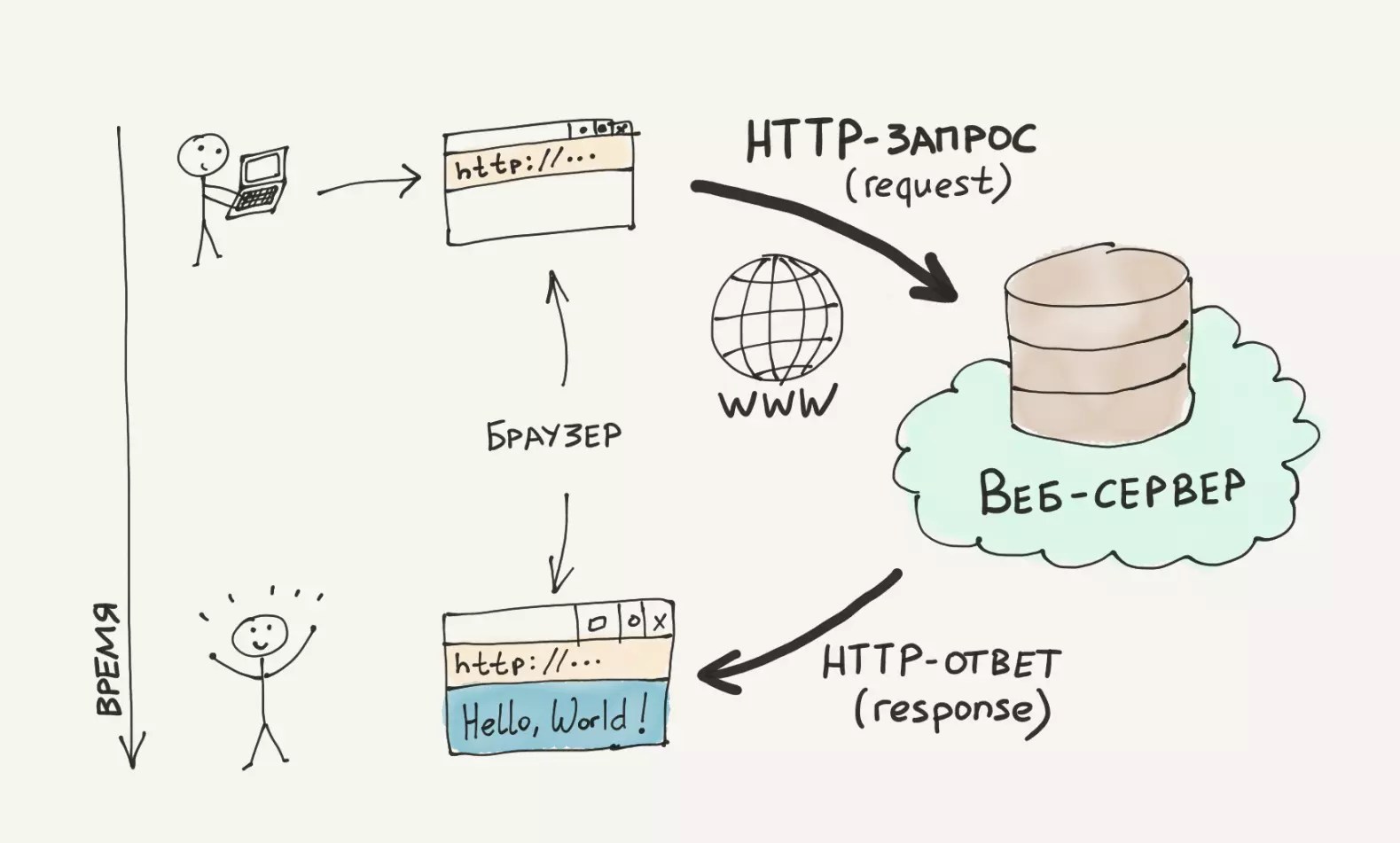
Сервер может передать два варианта ответа на Conditional GET запрос. Если ресурс не поменялся, то сервер передает короткое сообщение со статусом 304 Not Modified. Это сообщение, также может включать дополнительные заголовки по управлению кэша. Сам ресурс при этом не передается, так как актуальная копия есть в кэше браузера. Если же ресурс поменялся, то измененная версия ресурса передается полностью, при этом используется статус http ответа 200 OK.
ETag в запросах Get с условиемВ протоколе версия HTTP 1.1 появилась другая возможность проверить изменился ресурс или нет. Для этого используется entity tag или сокращенно ETag, это код который генерируется на основе содержимого ресурса? как правило это хэш-код или что-нибудь подобное.
Web-сервер при отправке ресурса, добавляет этот код в заголовок ETag, если ресурс изменился, то значение ETag также поменяются.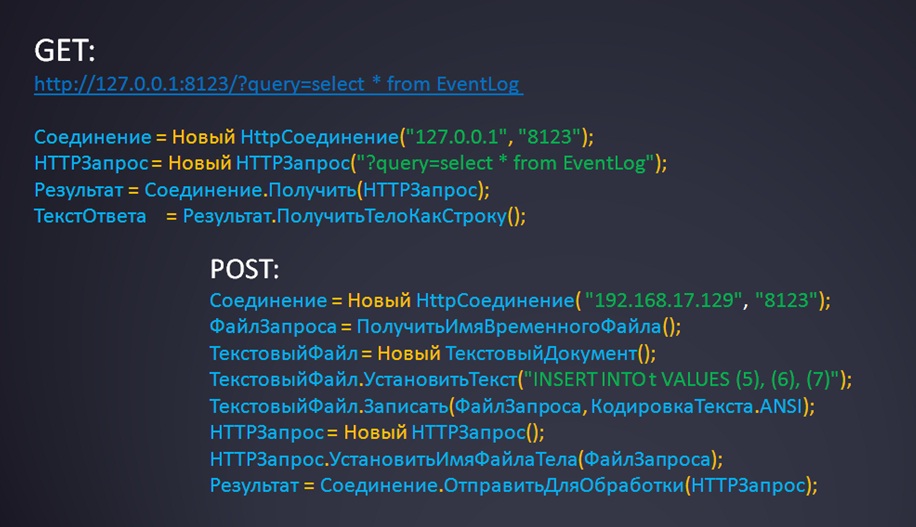 ETag удобно применять, если web-сервер может передавать различные варианты одной и той же страниц.
ETag удобно применять, если web-сервер может передавать различные варианты одной и той же страниц.
Например, на разных языках, в этом случае дату изменений использовать нельзя, так как страницы на разных языках могут быть изменены в одно и тоже время, а ETag вполне подходит. Если мы хотим использовать ETag в conditional GET то вместо заголовка if-Modified-Since мы должны указывать If-None-Match. Вот пример: If-None-Match: 57454284-3d8f
Заголовок Cache—ControlВ стандарте HTTP 1.1 появился новый заголовок Cache-Control с помощью которого можно более гибко управлять кэшированием. Заголовок Cache-Control может содержать несколько различных элементов.
Cache-Control: private, max-age=10. В этом примере используется два элемента private и max-age = 10 разделенное запятой.
Что можно использовать в заголовке Cache-Control
- значение no-store, говорит о том, что ресурс нельзя сохранять в кэш;
- no-cache, говорит о том, что и ресурсы сохранять в кэш можно, но для его использования необходимо выполнить запрос conditional GET, и загружать ресурс из кэша только в том случае если он не изменился на сервере;
- public, говорит о том, что информация может быть доступна всем и ее можно кэшировать, это значение удобно использовать совместно с http аутентификацией, так как по умолчанию при аутентификации кэширование не используется;
- private сообщает о том, что страница может быть сохранена только в частном кэша браузера, но не в разделяемых кэшах;
- max-age устанавливает время хранения ресурсов кэша в секундах, используется для замены заголовка expires.
Данные web могут быть закешированы не только на браузере, который установлен на персональный компьютере клиента, но также и в других местах. Например, может использоваться прокси-сервер. В этом случае клиенты обращаются к web-серверам не напрямую, а через прокси-сервер. Прокси-сервер сам подключается к web-серверам в интернет, получает ресурсы, сохраняет их в кэш и потом передает клиентам.
Если большое количество клиентов, которые работают с прокси часто обращаются на одни и те же сайты, то использование прокси-сервера позволяет значительно повысить скорость загрузки web-страниц. Так как необходимые ресурсы уже могут быть в разделяемом кэше, потому что их кто-то уже запрашивал.
С другой стороны пользователи, как правило заходят на большое количество разных сайтов, и все эти обращения также записываются в кэш прокси-сервера, хотя потом они используется очень редко или вообще не используются. Это значительно снижает эффективность работы прокси-серверов.
Это значительно снижает эффективность работы прокси-серверов.
Есть другой вариант прокси-сервера, который называется обратный прокси или reverse proxy. В отличии от обычного прокси, он устанавливается не со стороны клиентов, а со стороны web-серверов.
Обратный прокси-сервер принимает запросы от клиентов web-браузеров из интернета и передает их на web-сервера. При этом прокси-сервер, также кэширует ответы web-серверов, он кэширует не только статическую информацию, но и динамические страницы, которые получаются в результате работы программ на web-серверах. Эти программы часто обращаются к базам данных или к другим ресурсам, и работают достаточно медленно. Поэтому кэширование результатов работы этих программ в виде готовой страницы на обратном прокси-сервере существенно повышают скорость загрузки web-страниц.
Заключение о протоколе HTTP
Итак, постоянное соединение HTTP позволяет использовать одно и то же TCP соединение для загрузки нескольких ресурсов. Это позволяет сократить время на установку соединения TCP, нет необходимости каждый раз проходить процедуру трехкратного рукопожатия.
Это позволяет сократить время на установку соединения TCP, нет необходимости каждый раз проходить процедуру трехкратного рукопожатия.
В стандарте http 1.0 не было поддержки постоянного соединения, эта возможность была добавлена уже после публикации стандарта в виде заголовка connection: keep-alive. В стандарте http 1.1 все соединения по умолчанию постоянны и заголовок connection: keep-alive использовать не обязательно.
Мы рассмотрели кэширование web и его поддержку в протоколе http. Если в страницу, ввести какой-то ресурс из кэша, то загрузка происходит значительно быстрее, чем если мы обращаемся за тем же самым ресурсом в сеть. Необходимо иметь ввиду, что данные кэшируется не только в кэше web-браузера, это так называемый частный кэш, который является отдельным для каждого пользователя, но и данные могут быть закэшированные в других местах. Например, на прокси-серверах, на обратных прокси-серверах, которые копируют запросы большого количества пользователей и такой кэш называется разделяемый.
Типичный HTTP-сеанс — HTTP
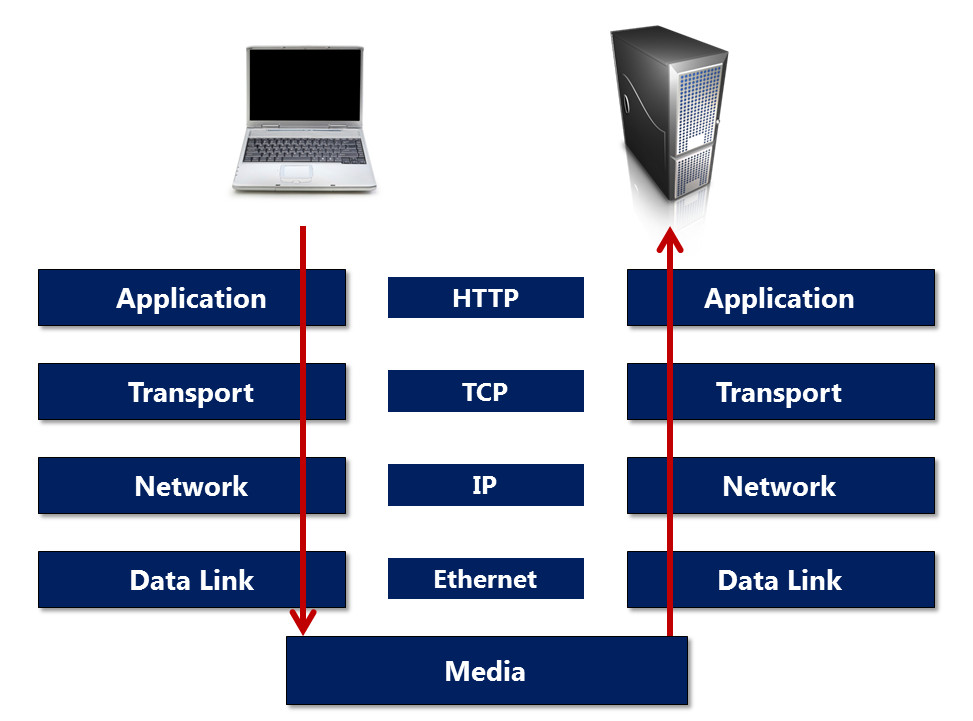
- Клиент устанавливает соединение TCP (или соответствующее соединение, если транспортный уровень не TCP).
- Клиент отправляет запрос и ожидает ответа.
- Сервер обрабатывает запрос, отправляет ответ, предоставляя код состояния и соответствующие данные.
Начиная с HTTP/1.1, соединение больше не закрывается после завершения третьей фазы, и теперь клиенту предоставляется дополнительный запрос: это означает, что вторую и третью фазы теперь можно выполнять любое количество раз.
В протоколах клиент-сервер соединение устанавливает клиент. Открытие соединения в HTTP означает инициирование соединения на нижележащем транспортном уровне, обычно это TCP.
При использовании TCP портом по умолчанию для HTTP-сервера на компьютере является порт 80. Также можно использовать другие порты, например, 8000 или 8080. URL-адрес страницы, которую нужно получить, содержит как имя домена, так и номер порта, хотя последнее можно опустить, если оно равно 80.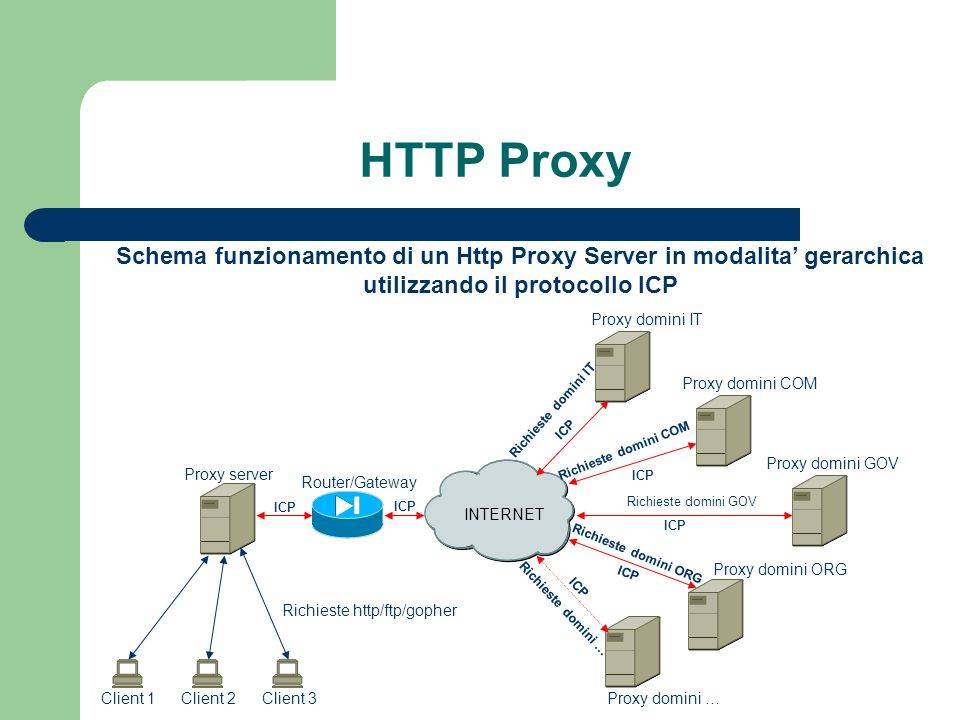 Подробнее см. в разделе Идентификация ресурсов в Интернете.
Подробнее см. в разделе Идентификация ресурсов в Интернете.
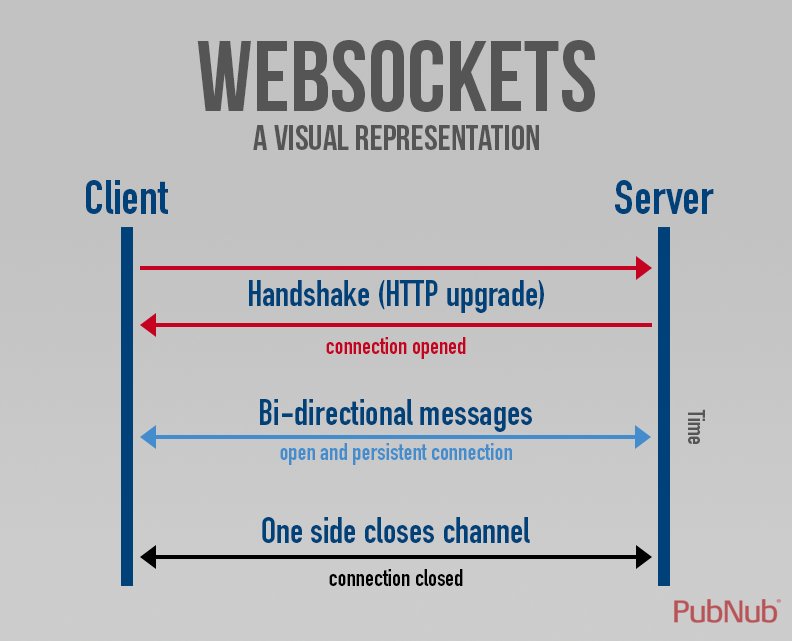
Примечание: Модель клиент-сервер не позволяет серверу отправлять данные клиенту без явного запроса на это. Чтобы обойти эту проблему, веб-разработчики используют несколько методов: периодически проверяют связь с сервером через API-интерфейсы fetch() , используя API WebSockets или аналогичные протоколы.
После установления соединения пользовательский агент может отправить запрос (пользовательский агент обычно представляет собой веб-браузер, но может быть и любым другим, например, сканером). Запрос клиента состоит из текстовых директив, разделенных CRLF (возврат каретки, за которым следует перевод строки), разделенных на три блока:
- Первая строка содержит метод запроса, за которым следуют его параметры:
- путь к документу в виде абсолютного URL без протокола или имени домена
- версия протокола HTTP
- Последующие строки представляют собой HTTP-заголовок, предоставляющий серверу информацию о том, какой тип данных подходит (например, какой язык, какие типы MIME) или другие данные, изменяющие его поведение (например, отказ от отправки ответа, если он уже кэширован). ). Эти заголовки HTTP образуют блок, который заканчивается пустой строкой.
- Последний блок — это необязательный блок данных, который может содержать дополнительные данные, в основном используемые методом POST.
 ). Эти заголовки HTTP образуют блок, который заканчивается пустой строкой.
). Эти заголовки HTTP образуют блок, который заканчивается пустой строкой.Примеры запросов
Получение корневой страницы developer.mozilla.org (
ПОЛУЧИТЬ / HTTP/1.1 Хост: developer.mozilla.org Accept-Language: fr
Обратите внимание на последнюю пустую строку, она отделяет блок данных от блока заголовка. Так как нет Content-Length предоставляется в заголовке HTTP, этот блок данных представляется пустым, отмечая конец заголовков, что позволяет серверу обрабатывать запрос в тот момент, когда он получает эту пустую строку.
Например, отправка результата формы:
POST /contact_form.php HTTP/1.1 Хост: developer.
 mozilla.org
Длина содержимого: 64
Content-Type: application/x-www-form-urlencoded
name=Joe%20User&request=Отправить%20me%20one%20of%20your%20catalogue
mozilla.org
Длина содержимого: 64
Content-Type: application/x-www-form-urlencoded
name=Joe%20User&request=Отправить%20me%20one%20of%20your%20catalogue
Способы запроса
HTTP определяет набор методов запроса, указывающих желаемое действие, которое должно быть выполнено над ресурсом. Хотя они также могут быть существительными, эти методы запросов иногда называют HTTP-глаголами. Наиболее распространенными запросами являются GET и POST :
- Метод
GETзапрашивает представление данных указанного ресурса. Запросы с использованиемGETдолжны извлекать только данные. - Метод
POSTотправляет данные на сервер, чтобы он мог изменить свое состояние. Этот метод часто используется для HTML-форм.
После того, как подключенный агент отправил свой запрос, веб-сервер обрабатывает его и в конечном итоге возвращает ответ. Подобно запросу клиента, ответ сервера состоит из текстовых директив, разделенных CRLF, хотя и разделенных на три блока:
- Первая строка, строка состояния , состоит из подтверждения используемой версии HTTP, за которой следует код состояния ответа (и его краткое значение в удобочитаемом тексте).
- Последующие строки представляют определенные заголовки HTTP, предоставляя клиенту информацию об отправленных данных (например, тип, размер данных, используемый алгоритм сжатия, подсказки о кэшировании). Подобно блоку заголовков HTTP для клиентского запроса, эти заголовки HTTP образуют блок, заканчивающийся пустой строкой.
- Последний блок — это блок данных, содержащий необязательные данные.

Примеры ответов
Успешный ответ веб-страницы:
HTTP/1.1 200 OK Тип содержимого: текст/html; кодировка = utf-8 Длина контента: 55743 Соединение: Keep-alive Cache-Control: s-maxage=300, public, max-age=0 Язык содержания: en-US Дата: Чт, 06 декабря 2018 г., 17:37:18 по Гринвичу ETag: "2e77ad1dc6ab0b53a2996dfd4653c1c3" Сервер: мейнхельд/0.6.1 Строгая транспортная безопасность: max-age=63072000 X-Content-Type-Options: nosniff Параметры X-Frame: ЗАПРЕТИТЬ X-XSS-защита: 1; режим = блок Варьировать: Accept-Encoding,Cookie Возраст: 7 лет <голова> <мета-кодировка="utf-8">Простая веб-страница <тело>Простая веб-страница HTML
Привет, мир!
Уведомление о том, что запрошенный ресурс перемещен навсегда:
HTTP/1.
 1 301 Перемещен навсегда
Сервер: Apache/2.4.37 (Red Hat)
Тип содержимого: текст/html; кодировка = utf-8
Дата: Чт, 06 декабря 2018 г., 17:33:08 по Гринвичу
Расположение: https://developer.mozilla.org/ (это новая ссылка на ресурс, ожидается, что юзер-агент ее получит)
Keep-Alive: таймаут=15, макс=98
Допустимые диапазоны: байты
Через: Moz-Cache-zlb05
Соединение: Keep-Alive
Content-Length: 325 (контент содержит страницу по умолчанию для отображения, если пользовательский агент не может перейти по ссылке)
… (содержит адаптированную для сайта страницу, помогающую пользователю найти недостающий ресурс)
1 301 Перемещен навсегда
Сервер: Apache/2.4.37 (Red Hat)
Тип содержимого: текст/html; кодировка = utf-8
Дата: Чт, 06 декабря 2018 г., 17:33:08 по Гринвичу
Расположение: https://developer.mozilla.org/ (это новая ссылка на ресурс, ожидается, что юзер-агент ее получит)
Keep-Alive: таймаут=15, макс=98
Допустимые диапазоны: байты
Через: Moz-Cache-zlb05
Соединение: Keep-Alive
Content-Length: 325 (контент содержит страницу по умолчанию для отображения, если пользовательский агент не может перейти по ссылке)
… (содержит адаптированную для сайта страницу, помогающую пользователю найти недостающий ресурс)
Уведомление о том, что запрошенный ресурс не существует:
HTTP/1.1 404 Не найдено Тип содержимого: текст/html; кодировка = utf-8 Длина содержимого: 38217 Соединение: Keep-alive Cache-Control: без кеша, без хранения, с обязательной повторной проверкой, max-age=0 Язык содержания: en-US Дата: Чт, 06 декабря 2018 г., 17:35:13 по Гринвичу Истекает: четверг, 06 декабря 2018 г.
 , 17:35:13 по Гринвичу
Сервер: мейнхельд/0.6.1
Строгая транспортная безопасность: max-age=63072000
X-Content-Type-Options: nosniff
Параметры X-Frame: ЗАПРЕТИТЬ
X-XSS-защита: 1; режим = блок
Варьировать: Accept-Encoding,Cookie
X-Cache: ошибка из облачного фронта
… (содержит адаптированную для сайта страницу, помогающую пользователю найти недостающий ресурс)
, 17:35:13 по Гринвичу
Сервер: мейнхельд/0.6.1
Строгая транспортная безопасность: max-age=63072000
X-Content-Type-Options: nosniff
Параметры X-Frame: ЗАПРЕТИТЬ
X-XSS-защита: 1; режим = блок
Варьировать: Accept-Encoding,Cookie
X-Cache: ошибка из облачного фронта
… (содержит адаптированную для сайта страницу, помогающую пользователю найти недостающий ресурс)
Коды состояния ответа
Коды состояния ответа HTTP указывают, был ли успешно выполнен конкретный HTTP-запрос. Ответы сгруппированы в пять классов: информационные ответы, успешные ответы, перенаправления, ошибки клиента и ошибки сервера.
-
200: ОК. Запрос выполнен. -
301: Перемещено навсегда. Этот код ответа означает, что URI запрошенного ресурса был изменен. -
404: Не найдено. Сервер не может найти запрошенный ресурс.
- Идентификация ресурсов в Интернете
- HTTP-заголовки
- Методы HTTP-запроса
- Коды состояния ответа HTTP
Обнаружили проблему с содержанием этой страницы?
- Отредактируйте страницу на GitHub.
- Сообщить о проблеме с содержимым.
- Посмотреть исходный код на GitHub.
Последний раз эта страница была изменена участниками MDN.
Объяснение HTTP-подключения
Управление HTTP-подключениями — важный процесс в HTTP. Тип соединения HTTP влияет на производительность, стабильность и общую работу веб-приложений и веб-сайтов. Типы и параметры подключения — это области, которые были обновлены между версиями HTTP либо для повышения производительности, либо для повышения надежности.
Содержание- Область соединения
- Типы соединения
- Постоянное соединение
- Конвейерная обработка
- Разделение домена
- Фреймы, потоки и мультиплексирование
- QUIC и HTTP/3
- Вывод
- См. также
Область соединения
HTTP соединения между клиентом и сервером не создаются сквозным образом. Скорее, они выполняются на основе hop-by-hop, что означает, что первое HTTP-соединение открывается между клиентом и первым посредником или прокси между ним и сервером. Между каждым посредником создается новое HTTP-соединение, и, наконец, создается новое соединение между конечным узлом-посредником и сервером.
Скорее, они выполняются на основе hop-by-hop, что означает, что первое HTTP-соединение открывается между клиентом и первым посредником или прокси между ним и сервером. Между каждым посредником создается новое HTTP-соединение, и, наконец, создается новое соединение между конечным узлом-посредником и сервером.
Это важно, потому что промежуточные узлы могут использовать свои собственные параметры для указания типов HTTP-соединений, а одна сквозная поездка может состоять из разных. Это может повлиять как на производительность, так и на стабильность.
Типы соединений
В HTTP/1.1, TCP используется для предоставления краткосрочных HTTP-соединений, постоянных HTTP-соединений и конвейерной обработки. До HTTP/1.0 для загрузки ресурсов на одной веб-странице требовалось множество HTTP-соединений. Все это были недолговечные HTTP-соединения, каждое из которых передавало ровно один ресурс, даже если каждый ресурс представлял собой просто одно изображение как часть более крупной мультимедийной веб-страницы. HTTP-соединения не выполнялись параллельно, а это означало, что каждое из них должно было быть закрыто до того, как будет установлено следующее.
HTTP-соединения не выполнялись параллельно, а это означало, что каждое из них должно было быть закрыто до того, как будет установлено следующее.
Постоянное соединение
Чтобы уменьшить количество необходимых HTTP-соединений, в HTTP/1.0 был введен постоянный тип HTTP-соединения. Это сокращает накладные расходы, поскольку несколько HTTP-запросов могут быть выполнены через одно HTTP-соединение, не требуя дополнительной пропускной способности, необходимой для удаления и повторного установления новых. Нетрудно понять, что на странице с множеством изображений, для каждого из которых изначально требовалось отдельное HTTP-соединение, постоянное HTTP-соединение экономило время и пропускную способность. В предыдущей модели сетевая задержка увеличивалась в первую очередь из-за дополнительных рукопожатий, для каждого из которых требовался как минимум один полный круговой обход сети.
Постоянное HTTP-соединение также известно как соединение keep-alive и является методом по умолчанию в HTTP/1. 1. Он имеет преимущество в производительности помимо устранения множественных рукопожатий. В частности, чем дольше HTTP-соединение остается открытым, тем дольше алгоритм управления перегрузкой TCP должен найти оптимальную пропускную способность. Это связано с тем, что каждое соединение TCP начинается в режиме с жестким ограничением скорости, чтобы смягчить влияние потерянных пакетов данных. Если HTTP-соединение поддерживает большую пропускную способность, она постепенно настраивается. Это иногда называют теплым HTTP-соединением. Когда HTTP-соединение разрывается, весь этот процесс необходимо сбросить.
1. Он имеет преимущество в производительности помимо устранения множественных рукопожатий. В частности, чем дольше HTTP-соединение остается открытым, тем дольше алгоритм управления перегрузкой TCP должен найти оптимальную пропускную способность. Это связано с тем, что каждое соединение TCP начинается в режиме с жестким ограничением скорости, чтобы смягчить влияние потерянных пакетов данных. Если HTTP-соединение поддерживает большую пропускную способность, она постепенно настраивается. Это иногда называют теплым HTTP-соединением. Когда HTTP-соединение разрывается, весь этот процесс необходимо сбросить.
Постоянные HTTP-соединения потребляют ресурсы, даже когда они простаивают, и в результате одно из них не поддерживается бесконечно. Бездействующее HTTP-соединение будет разорвано для экономии ресурсов сервера и повышения производительности.
Конвейерная обработка
Конвейерная обработка HTTP аналогична постоянному HTTP-соединению тем, что перед его закрытием можно выполнить несколько HTTP-запросов. Эти два типа HTTP-соединений различаются тем, что постоянное HTTP-соединение предназначено для набора полных пар HTTP-запрос/ответ. При выполнении каждого HTTP-запроса сервер генерирует и отправляет соответствующий HTTP-ответ. Одно последовательно следует за другим. С помощью конвейерной обработки можно выполнить несколько HTTP-запросов, не дожидаясь ответа HTTP, что в конечном итоге снижает задержку в сети.
Эти два типа HTTP-соединений различаются тем, что постоянное HTTP-соединение предназначено для набора полных пар HTTP-запрос/ответ. При выполнении каждого HTTP-запроса сервер генерирует и отправляет соответствующий HTTP-ответ. Одно последовательно следует за другим. С помощью конвейерной обработки можно выполнить несколько HTTP-запросов, не дожидаясь ответа HTTP, что в конечном итоге снижает задержку в сети.
Конвейерная обработка ограничена идемпотентными методами HTTP, включая HTTP GET, HEAD, PUT и DELETE. Причина этого в том, что если сообщение потеряно, то можно повторно отправить весь HTTP-запрос, не беспокоясь о побочных эффектах.
Существует несколько проблем с конвейерным методом соединения HTTP, поэтому он больше не используется в современных веб-браузерах. Первая проблема связана со сложностью реализации. Необходимо учитывать несколько факторов, в том числе размер ресурса, продолжительность времени, необходимого для полной передачи данных по сети, и пропускную способность.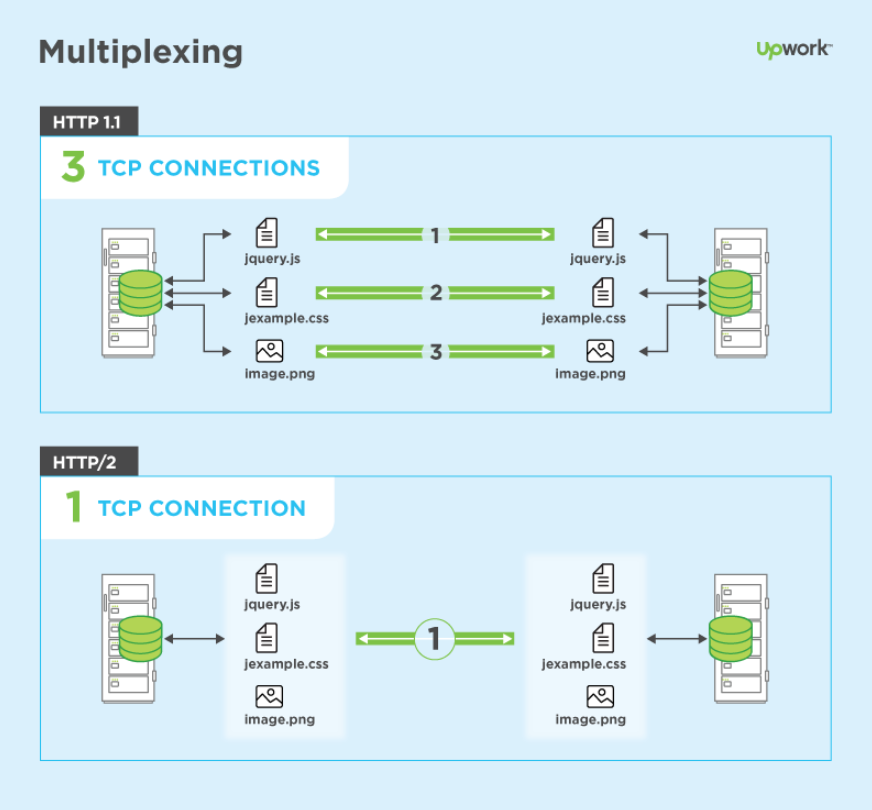 Без их видимости сообщения с более низким приоритетом могут поступать раньше критических, что в конечном итоге приводит к небольшому улучшению в большинстве случаев. Трудности с реализацией привели к проблемам с прокси, что до сих пор является проблемой, которую трудно объяснить. Наконец, конвейерная обработка подвержена проблеме начального этапа.
Без их видимости сообщения с более низким приоритетом могут поступать раньше критических, что в конечном итоге приводит к небольшому улучшению в большинстве случаев. Трудности с реализацией привели к проблемам с прокси, что до сих пор является проблемой, которую трудно объяснить. Наконец, конвейерная обработка подвержена проблеме начального этапа.
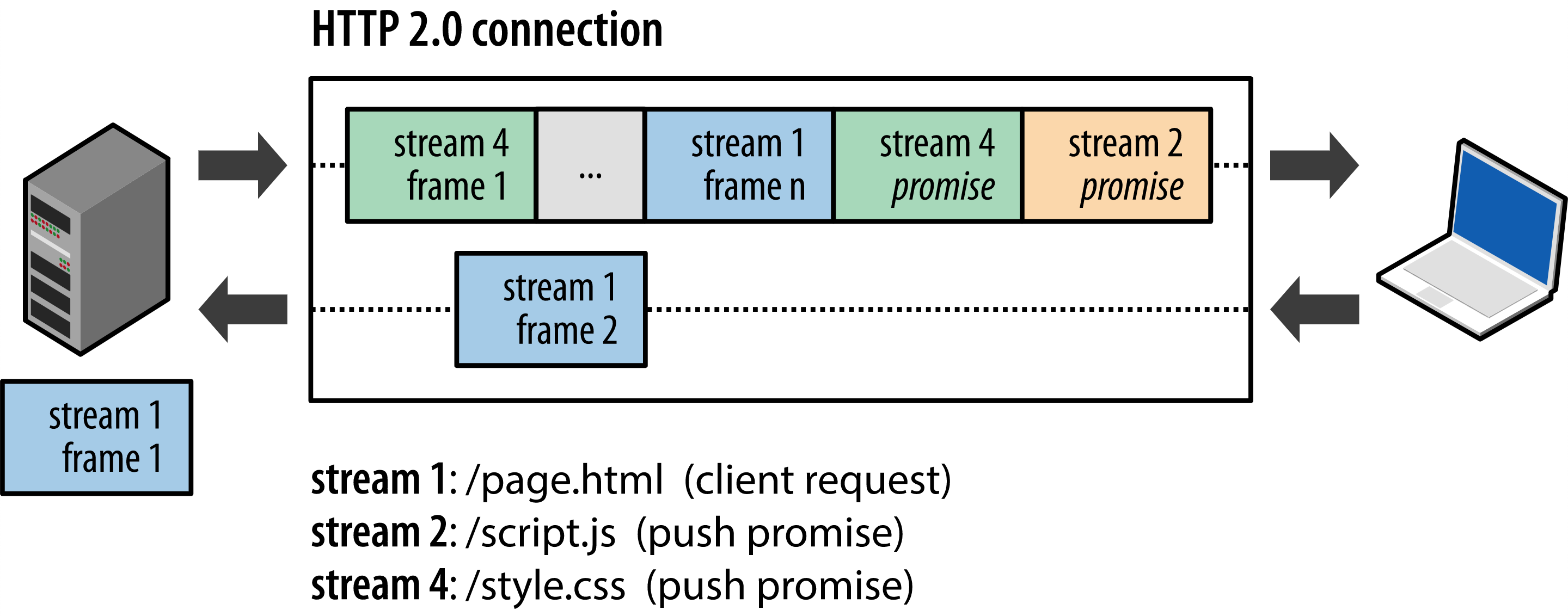
Заменой HTTP/2 конвейерной обработки является новый протокол, называемый мультиплексированием.
Разделение домена
Разделение домена — это метод, который использовался для повышения производительности загрузки страниц путем открытия нескольких одновременных HTTP-соединений. По сути, он позволяет одновременно извлекать больше ресурсов, чем обычно разрешено. Однако этот метод устарел и не нужен в HTTP/2. Это связано с тем, что HTTP/2 искусно обрабатывает несколько HTTP-запросов параллельно, что позволяет использовать концепцию и все преимущества сегментирования домена. Кроме того, в некоторых случаях сегментирование домена может отрицательно сказаться на производительности.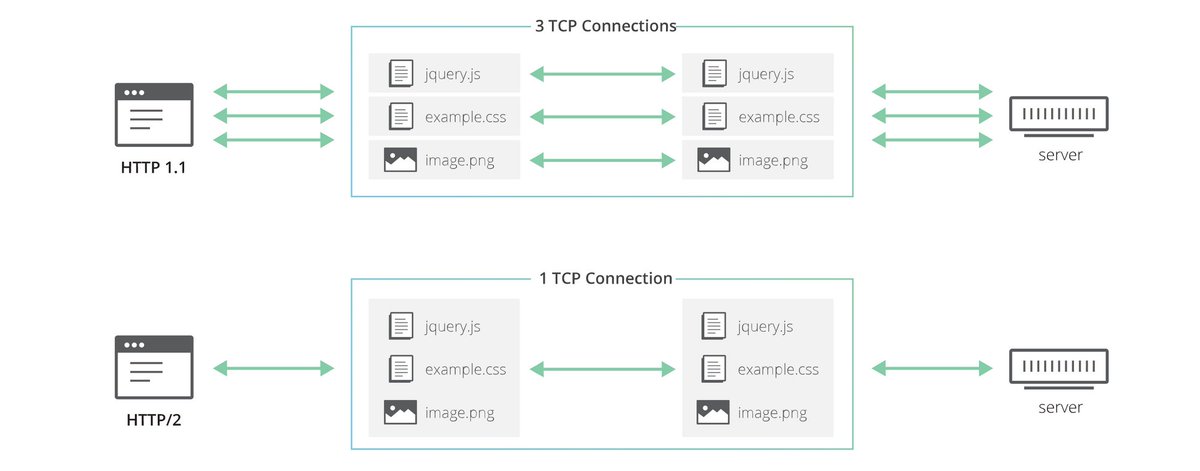
Кадры, потоки и мультиплексирование
HTTP/2 представляет концепцию фрейма, которая представляет собой двоичную замену разделов заголовка и тела сообщения HTTP. Проще говоря, фрейм — это базовая структура данных, которая отправляется во время HTTP-соединения, а несколько фреймов составляют сообщение. Существует несколько типов фреймов, включая фрейм заголовка, фрейм данных и т. д. Одно из преимуществ упаковки раздела заголовка HTTP в двоичный фрейм заключается в том, что его можно сжать, что опять же снижает требования к полосе пропускания и повышает производительность.
Сообщение или набор кадров затем упаковываются в поток. Поток — это двунаправленная последовательность кадров, которая может сосуществовать со многими потоками в одном и том же HTTP-соединении. Это то, что называется мультиплексированием. Потоки идентифицируются по идентификатору потока, чтобы избежать коллизий, а главное преимущество заключается в том, что для всех сообщений в обоих направлениях можно использовать одно HTTP-соединение. Мультиплексирование также решает проблему блокировки очереди, поскольку запросы, которые передаются по одному и тому же HTTP-соединению, могут отвечать не по порядку.
Мультиплексирование также решает проблему блокировки очереди, поскольку запросы, которые передаются по одному и тому же HTTP-соединению, могут отвечать не по порядку.
QUIC и HTTP/3
Хотя HTTP/2 является улучшением по сравнению с HTTP/1.1, одна из проблем заключается в том, что он просто смягчает проблему блокировки начала строки. Причина этого в том, что одно соединение TCP действительно может поддерживать несколько потоков, но в случае сбоя одного из них все потоки остаются заблокированными. По сути, трафик останавливается до тех пор, пока потерянные пакеты не будут успешно повторно переданы и приняты. Проблема присуща TCP и не может быть легко устранена. Следовательно, QUIC создан на основе UDP .
Поскольку QUIC не зависит от TCP , он не ограничен его ограничениями. Однако это требует значительных усилий, поскольку QUIC воспроизводит расширенный набор функций, предлагаемых TCP , но с использованием протокола UDP .