POST — Веб-технологии для разработчиков
HTTP-метод POST предназначен для отправки данных на сервер. Тип тела запроса указывается в заголовке Content-Type.
Разница между PUT и POST состоит в том, что PUT является идемпотентным: повторное его применение дает тот же результат, что и при первом применении (то есть у метода нет побочных эффектов), тогда как повторный вызов одного и того же метода POST может иметь такие эффекты, как например, оформление одного и того же заказа несколько раз.
Запрос POST обычно отправляется через форму HTML и приводит к изменению на сервере. В этом случае тип содержимого выбирается путем размещения соответствующей строки в атрибуте enctype элемента <form> или formenctype атрибута элементов <input> или <button>:
application/x-www-form-urlencoded'&', с'='между ключом и значением. Не буквенно-цифровые символы — percent encoded: это причина, по которой этот тип не подходит для использования с двоичными данными (вместо этого используйтеmultipart/form-data)multipart/form-data: каждое значение посылается как блок данных («body part»), с заданными пользовательским клиентом разделителем («boundary»), разделяющим каждую часть. Эти ключи даются в заголовкиContent-Dispositionкаждой частиtext/plain
Когда запрос POST отправляется с помощью метода, отличного от HTML-формы, — например, через POST предназначен для обеспечения единообразного метода для покрытия следующих функций:
- Аннотация существующих ресурсов
- Публикация сообщения на доске объявлений, в новостной группе, в списке рассылки или в аналогичной группе статей;
- Добавление нового пользователя посредством модальности регистрации;
- Предоставление блока данных, например, результата отправки формы, процессу обработки данных;
- Расширение базы данных с помощью операции добавления.
Синтаксис
POST /index.html
Пример
Простая форма запроса, используя стандартный
POST / HTTP/1.1 Host: foo.com Content-Type: application/x-www-form-urlencoded Content-Length: 13 say=Hi&to=Mom
Форма запроса, используя multipart/form-data content type:
POST /test.html HTTP/1.1 Host: example.org Content-Type: multipart/form-data;boundary="boundary" --boundary Content-Disposition: form-data; name="field1" value1 --boundary Content-Disposition: form-data; name="field2"; filename="example.txt" value2 --boundary--
Спецификация
Совместимость с браузерами
The compatibility table in this page is generated from structured data. If you’d like to contribute to the data, please check out https://github.com/mdn/browser-compat-data and send us a pull request.
| Компьютеры | Мобильные | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Chrome | Edge | Firefox | Internet Explorer | Opera | Safari | Android webview | Chrome для Android | Firefox для Android | Opera для Android | Safari on iOS | Samsung Internet | |
POST | Chrome Полная поддержка Да | Edge | Firefox Полная поддержка Да | IE Полная поддержка Да | Opera Полная поддержка Да | Safari Полная поддержка Да | WebView Android Полная поддержка Да | Chrome Android Полная поддержка | Firefox Android Полная поддержка Да | Opera Android Полная поддержка Да | Safari iOS Полная поддержка Да | Samsung Internet Android Полная поддержка Да |
Легенда
- Полная поддержка
- Полная поддержка
Смотрите также
Типы HTTP-запросов и философия REST / Хабр
Этот пост — ответ на вопрос, заданный в комментарии к одной из моих статей.В статье я хочу рассказать, что же из себя представляют HTTP-методы GET/POST/PUT/DELETE и другие, для чего они были придуманы и как их использовать в соответствии с REST.
Итак, что же представляет из себя один из основных протоколов интернета? Педантов отправлю к RFC2616, а остальным расскажу по-человечески 🙂
Этот протокол описывает взаимодействие между двумя компьютерами (клиентом и сервером), построенное на базе сообщений, называемых запрос (Request) и ответ (Response). Каждое сообщение состоит из трех частей: стартовая строка, заголовки и тело. При этом обязательной является только стартовая строка.
Стартовые строки для запроса и ответа имеют различный формат — нам интересна только стартовая строка запроса, которая выглядит так:
METHOD URI HTTP/VERSION,
где METHOD — это как раз метод HTTP-запроса, URI — идентификатор ресурса, VERSION — версия протокола (на данный момент актуальна версия 1.1).
Заголовки — это набор пар имя-значение, разделенных двоеточием. В заголовках передается различная служебная информация: кодировка сообщения, название и версия браузера, адрес, с которого пришел клиент (Referrer) и так далее.
Тело сообщения — это, собственно, передаваемые данные. В ответе передаваемыми данными, как правило, является html-страница, которую запросил браузер, а в запросе, например, в теле сообщения передается содержимое файлов, загружаемых на сервер. Но как правило, тело сообщения в запросе вообще отсутствует.
Рассмотрим пример.
Запрос:
GET /index.php HTTP/1.1 Host: example.com User-Agent: Mozilla/5.0 (X11; U; Linux i686; ru; rv:1.9b5) Gecko/2008050509 Firefox/3.0b5 Accept: text/html Connection: close
Первая строка — это строка запроса, остальные — заголовки; тело сообщения отсутствует
Ответ:
HTTP/1.0 200 OK Server: nginx/0.6.31 Content-Language: ru Content-Type: text/html; charset=utf-8 Content-Length: 1234 Connection: close ... САМА HTML-СТРАНИЦА ...
Вернемся к стартовой строке запроса и вспомним, что в ней присутствует такой параметр, как URI. Это расшифровывается, как Uniform Resource Identifier — единообразный идентификатор ресурса. Ресурс — это, как правило, файл на сервере (пример URI в данном случае ‘/styles.css’), но вообще ресурсом может являться и какой-либо абстрактный объект (‘/blogs/webdev/’ — указывает на блок «Веб-разработка», а не на конкретный файл).
Тип HTTP-запроса (также называемый HTTP-метод) указывает серверу на то, какое действие мы хотим произвести с ресурсом. Изначально (в начале 90-х) предполагалось, что клиент может хотеть от ресурса только одно — получить его, однако сейчас по протоколу HTTP можно создавать посты, редактировать профиль, удалять сообщения и многое другое. И эти действия сложно объединить термином «получение».
Для разграничения действий с ресурсами на уровне HTTP-методов и были придуманы следующие варианты:
- GET — получение ресурса
- POST — создание ресурса
- PUT — обновление ресурса
- DELETE — удаление ресурса
Обратите внимание на тот факт, что спецификация HTTP не обязывает сервер понимать все методы (которых на самом деле гораздо больше, чем 4) — обязателен только GET, а также не указывает серверу, что он должен делать при получении запроса с тем или иным методом. А это значит, что сервер в ответ на запрос DELETE /index.php HTTP/1.1
REST (REpresentational State Transfer) — это термин был введен в 2000-м году Роем Филдингом (Roy Fielding) — одним из разработчиков протокола HTTP — в качестве названия группы принципов построения веб-приложений. Вообще REST охватывает более широкую область, нежели HTTP — его можно применять и в других сетях с другими протоколами. REST описывает принципы взаимодействия клиента и сервера, основанные на понятиях «ресурса» и «глагола» (можно понимать их как подлежащее и сказуемое). В случае HTTP ресурс определяется своим URI, а глагол — это HTTP-метод.
REST дает программистам возможность писать стандартизованные и чуть более красивые веб-приложения, чем раньше. Используя REST, URI для добавления нового юзера будет не /user.php?action=create (метод GET/POST), а просто /user.php (метод строго POST).
В итоге, совместив имеющуюся спецификацию HTTP и REST-подход наконец-то обретают смысл различные HTTP-методы. GET — возвращает ресурс, POST — создает новый, PUT — обновляет существующий, DELETE — удаляет.
Да, есть небольшая проблема с применением REST на практике. Проблема эта называется HTML.
PUT/DELETE запросы можно отправлять посредством XMLHttpRequest, посредством обращения к серверу «вручную» (скажем, через curl или даже через telnet), но нельзя сделать HTML-форму, отправляющую полноценный PUT/DELETE-запрос.
Дело в том, спецификация HTML не позволяет создавать формы, отправляющие данные иначе, чем через GET или POST. Поэтому для нормальной работы с другими методами приходится имитировать их искусственно. Например, в Rack (механизм, на базе которого Ruby взаимодействует с веб-сервером; с применением Rack сделаны Rails, Merb и другие Ruby-фреймворки) в форму можно добавить hidden-поле с именем «_method», а в качестве значения указать название метода (например, «PUT») — в этом случае будет отправлен POST-запрос, но Rack сможет сделать вид, что получил PUT, а не POST.
Методы GET и POST. Использование и отличия
HTTP методы GET и POST используются для отправки данных на сервер.
Чаще всего методы используются в HTML формах, гиперссылках и AJAX запросах.
POST и GET запросы можно отправить на сервер с помощью любого программного обеспечения, работающего с протоколом HTTP.
Обработка запросов может отличаться в зависимости от типа сервера.
Большинство действующих сайтов работают с языком программирования PHP. В этом случае передаваемые данные попадают в суперглобальные массивы $_GET и $_POST.
Массивы $_GET и $_POST являются ассоциативными. Таким образом, переданный на сервер параметр с именем «user_name», будет доступен как $_GET[‘user_name’] или $_POST[‘user_name’] в зависимости от используемого метода.
Какой метод использовать GET или POST, чем отличаются методы
Основное отличие метода GET от POST в способе передачи данных.
Запрос GET передает данные в URL в виде пар «имя-значение» (другими словами, через ссылку), а запрос POST передает данные в теле запроса (подробно показано в примерах ниже). Это различие определяет свойства методов и ситуации, подходящие для использования того или иного HTTP метода.
Страница, созданная методом GET, может быть открыта повторно множество раз. Такая страница может быть кэширована браузерами, проиндексирована поисковыми системами и добавлена в закладки пользователем. Из этого следует, что метод GET следует использовать для получения данных от сервера и не желательно в запросах, предполагающих внесений изменений в ресурс.
Например, можно использовать метод GET в HTML форме фильтра товаров: когда нужно, исходя из данных введенных пользователем, переправить его на страницу с отфильтрованными товарами, соответствующими его выбору.
Запрос, выполненный методом POST, напротив следует использовать в случаях, когда нужно вносить изменение в ресурс (выполнить авторизацию, отправить форму оформления заказа, форму обратной связи, форму онлайн заявки). Повторный переход по конечной ссылке не вызовет повторную обработку запроса, так как не будет содержать переданных ранее параметров. Метод POST имеет большую степень защиты данных, чем GET: параметры запроса не видны пользователю без использования специального ПО, что дает методу преимущество при пересылке конфиденциальных данных, например в формах авторизации.
HTTP метод POST поддерживает тип кодирования данных multipart/form-data, что позволяет передавать файлы.
Также следует заметить, что методы можно комбинировать. То есть, при необходимости вы можете отправить POST запрос на URL, имеющий GET параметры.
В каких случаях использовать POST и когда нужно использовать GET
В таблице ниже показаны распространенные варианты использования HTTP запросов с объяснением в чем разница между GET и POST запросами в конкретной ситуации.
| Ситуация | GET | POST |
|---|---|---|
| Фильтр товаров |
Пользователь получит страницу с подходящими ему товарами, сможет сохранить ее в закладки, переслать ссылку на страницу с параметрами другим и вернуться к странице позже без повторного заполнения формы фильтра. |
Для повторного посещения страницы пользователь должен будет повторно заполнить форму фильтра, страницей с параметрами нельзя будет поделиться, сохранить в закладки и вернуться к странице позже без повторного заполнения формы фильтра. |
| Форма авторизации |
Отсутствует защита конфиденциальной информации. Введенный пароль будет виден в адресной строке браузера, будет сохранен в истории посещенных сайтов. |
Хотя данные могут передаваться в незашифрованном виде, увидеть их можно только через инструменты разработчика или с помощью другого специального программного обеспечения. |
|
Онлайн заявка Оформления заказа Форма обратной |
При повторном обращении по конечной ссылке на сервере будет произведена повторная обработка, например, будет создана повторная заявка, оформлен еще один заказ, создан еще один запрос на обратную связь. |
Повторное обращение по конечной ссылке не приведет к повторной обработке запроса с введенными ранее параметрами. |
| Через гиперссылку |
Переход по гиперссылке с параметрами равнозначен отправке запроса через HTML форму. |
Нет технической возможности поместить POST запрос в гиперссылку. |
| AJAX запросы | Используются оба метода. Выбор зависит от контекста. Принципы выбора метода такие же, как и для HTML форм. | |
Сравнительная таблица HTTP методов GET и POST
В таблице ниже приведены основные свойства и отличия GET и POST методов.
| Свойство | GET | POST |
|---|---|---|
| Способ передачи данных | Через URL | В теле HTTP запроса |
| Защита данных |
Данные видны всем в адресной строке браузера, истории браузера и т.п. |
Данные можно увидеть только с помощью инструментов разработчика, расширений браузера, специализированных программ. |
| Длина запроса |
Не более 2048 символов |
Не ограничена Примечание: ограничения могут быть установлены сервером. |
| Сохранение в закладки |
Страница с параметрами может быть добавлена в закладки |
Страница с параметрами не может быть добавлена в закладки. |
| Кэширование | Страница с параметрами может быть кэширована | Страница с параметрами не может быть кэширована |
| Индексирование поисковыми системами | Страница с параметрами может быть индексирована | Страница с параметрами не может быть индексирована |
| Возможность отправки файлов | Не поддерживается | Поддерживается |
| Поддерживаемые типы кодирования | application/x-www-form-urlencoded |
application/x-www-form-urlencoded multipart/form-data text/plain |
| Использование в гиперссылках <a> | Да | Нет |
| Использование в HTML формах | Да | Да |
| Использование в AJAX запросах | Да | Да |
Пример использования GET запроса
В примере показана простая HTML форма фильтра по нескольким параметрам.
HTML код формы, генерирующей GET запрос:
<form method="GET" name="filter" action="http://example.com/catalog/">
<p>Диагональ экрана</p>
<label><input type="radio" name="screen" value="4" checked> 4</label><br>
<label><input type="radio" name="screen" value="4.5"> 4.5</label><br>
<label><input type="radio" name="screen" value="5"> 5</label>
<p>Цвет</p>
<label><input type="checkbox" name="color_black" checked> Черный</label><br>
<label><input type="checkbox" name="color_white" checked> Белый</label><br>
<label><input type="checkbox" name="color_golden"> Золотой</label><br>
<input type="submit" value="Применить фильтр">
</form>После отправки формы браузер переведет пользователя по ссылке:
http://example.com/catalog/?screen=4&color_black=on&color_white=on
Ссылка содержит URL документа, отвечающего за обработку и блок параметров. Знак «?» отмечает начало блока параметров GET запроса. Далее находятся пары «имя-значение», разделенные знаком «&». Имена параметров отделены от значений знаком «=».
Переход по ссылке, приведенной выше, будет равнозначен отправке формы с указанными параметрами.
Пример использования POST запроса
В примере показана простая HTML форма авторизации.
HTML код формы, генерирующей POST запрос:
<form method="POST" name="authorization" action="http://example.com/profile.php">
Логин: <input type="text" name="username"><br>
Пароль: <input type="password" name="user_password"><br>
<input type="submit" value="Войти">
</form>После отправки формы браузер переведет пользователя по ссылке:
http://example.com/profile.php
Для того, чтобы увидеть переданные параметры, воспользуемся инструментами разработчика.
Запрос состоит из области заголовков и тела запроса.

В заголовках указана служебная информация: URL обработчика, тип кодирования, параметры браузера и т.д.
В теле запроса содержатся передаваемые параметры. Формат тела запроса может отличаться в зависимости от выбранного типа кодирования.
HTTP-запрос методом POST.
Кроме метода GET, который мы рассмотрели в предыдущей заметке, существует еще один метод отправки запроса по протоколу HTTP – метод POST. Метод POST тоже очень часто используется на практике.

Если, для того, чтобы обратиться к серверу методом GET, нам достаточно было набрать запрос в URL-адрес, то в методе POST все работает по другому принципу.
Для того, чтобы выполнить этот вид запроса, нам необходимо нажать на кнопку с атрибутом type=»submit», которая расположена на веб-странице. Обратите внимание, что эта кнопка расположена в элементе <form>, у которого установлен атрибут method со значением post.
Рассмотрим этот HTML-код:
<form name="form1" method="post" action="post.php"> Введите текст:<br /> <textarea name="text" cols="80" rows="10"></textarea> <input name="" type="submit" value="Отправить"/> </form>
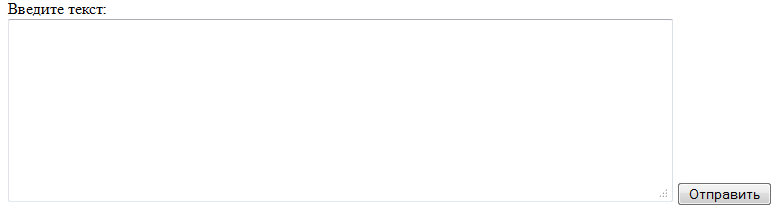
Если пользователь введет в текстовое поле какой-либо текст и нажмет на кнопку «Отправить», то на сервер будет отправлена переменная text со значением того содержимого, которое ввел пользователь. Эта переменная будет отправлена методом POST.
Если в форме написать так:
<form name="form1" method="get" action="post.php">
То данные будут отправляться методом GET.
Если, в случае с GET-запросом, объем данных, которые мы могли передать ограничивался длиной адресной строки браузера, то в случае с запросом POST, такого ограничения нет, и мы можем передавать значительные объемы информации.
Еще одно отличие метода POST от GET, метод POST скрывает все передаваемые им переменные и их значения, в своём теле (Entity-Body). В случае с методом GET они хранились в строке запроса (Request-URI).
Вот пример запроса, выполненного методом POST:
POST / HTTP/1.0\r\n Host: www.site.ru\r\n Referer: http://www.site.ru/index.html\r\n Cookie: income=1\r\n Content-Type: application/x-www-form-urlencoded\r\n Content-Length: 35\r\n \r\n login=Dima&password=12345
Таким образом, передавая данные методом POST, их будет намного труднее перехватить злоумышленнику, т.к. они скрыты от непосредственного просмотра, поэтому метод передачи данных методом POST считается более безопасным способом.
Кроме того, методом POST можно передавать не только текст, но и мультимедиа данные (картинки, аудио, видео). Существует специальный параметр Content-Type, который определяет тот вид информации, который необходимо передать.
Ну и, наконец, чтобы на сервере получить данные, которые были переданы этим методом, используется переменная POST.
Вот пример обработки на языке PHP:
<?php echo $_POST['text']; ?>
Все мои уроки по серверному программированию здесь.
редиректы, POST и GET запросы, и «потерянные» данные
![]() Имеется приложение, которое должно принимать данные через POST-запросы от клиентов.
Имеется приложение, которое должно принимать данные через POST-запросы от клиентов.
Перед этим приложением имеется некий прокси, не важно какой — AWS Application Load Balancer, NGINX или любой другой. Мы изначально столкнулись с проблемой на AWS ALB, потом я начал тестить на NGINX, что бы искючить влияение самого AWS-сервиса — воспроизводится везде, т.к. не зависит от проксирующей службы.
Прокси помимо проксирования трафика к приложению выполняет редирект с HTTP (80) на HTTPS (443).
Собственно, проблема возникает именно во время такого редиректа:
- клиент отправляет
POSTпо HTTP - прокси возвращает клиенту редирект 301 или 302 на HTTPS
- клиент отправляет запрос на HTTPS, но:
- либо запрос превращается в
GET - либо он остаётся
POST, но все данные после редиректа «пропадают»
- либо запрос превращается в
Setup — тестовая площадка
Для тестирования будем использовать следующий сетап:
- на входе API-запросы принимаются NGINX
- NGINX через
proxy_passпо HTTP передаёт запрос бекенду- в роли бекенда используем Go-приложение в Docker-контейнере, что бы воспроизвести проблему с
POST, который превращается вGET - и Python-приложение, что бы воспроизвести проблему с «потерянными» данными и пустым
Сontent-length
- в роли бекенда используем Go-приложение в Docker-контейнере, что бы воспроизвести проблему с
NGINX
Тут всё совершенно стандартно — обычный NGINX, который принимает соединения на порт 80, и редиректит их на HTTPS:
server {
listen 80;
server_name dev.poc.example.com;
location / {
return 302 https://dev.poc.example.com$request_uri;
}
}
...И server 443 {} — тоже стандартный, с proxy_pass на бекенд, тут для тестов используем 8081:
...
server {
listen 443 ssl;
server_name dev.poc.example.com;
...
location / {
proxy_pass http://localhost:8081;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
Go-app в Docker
Там на самом деле несколько контейнеров, нас интересует их проксирующий go-queue-consumer, в котором крутися стандартный NGINX (весь этот сетап ещё в Proof of Concept, потому не удивляйтесь количеству NGINX в этой схеме).
Нам от него интересны логи, в которых будет POST или GET.
Python web-server
И для тестирования HTTP message body — используем нагугленный Python-скрипт:
#!/usr/bin/env python3
"""
Very simple HTTP server in python for logging requests
Usage::
./server.py [<port>]
"""
from http.server import BaseHTTPRequestHandler, HTTPServer
import logging
class S(BaseHTTPRequestHandler):
def _set_response(self):
self.send_response(200)
self.send_header('Content-type', 'text/html')
self.end_headers()
def do_GET(self):
logging.info("GET request,\nPath: %s\nHeaders:\n%s\n", str(self.path), str(self.headers))
self._set_response()
self.wfile.write("GET request for {}".format(self.path).encode('utf-8'))
def do_POST(self):
content_length = int(self.headers['Content-Length']) # <--- Gets the size of data
post_data = self.rfile.read(content_length) # <--- Gets the data itself
logging.info("POST request,\nPath: %s\nHeaders:\n%s\n\nBody:\n%s\n",
str(self.path), str(self.headers), post_data.decode('utf-8'))
self._set_response()
self.wfile.write("POST request for {}".format(self.path).encode('utf-8'))
def run(server_class=HTTPServer, handler_class=S, port=8081):
logging.basicConfig(level=logging.INFO)
server_address = ('', port)
httpd = server_class(server_address, handler_class)
logging.info('Starting httpd...\n')
try:
httpd.serve_forever()
except KeyboardInterrupt:
pass
httpd.server_close()
logging.info('Stopping httpd...\n')
if __name__ == '__main__':
from sys import argv
if len(argv) == 2:
run(port=int(argv[1]))
else:
run()Примеры — воспроизводим проблему
POST теряет данные после редиректа
Первое, с чем столкнулись, и что вообще заставило углубиться в проблему — после выполнения редиректа с HTTP на HTTPS — POST-запрос терял данные.
Т.е, обратился бекенд-разработчик, который сказал, что после редиректа на бекенд не приходят данные.
Что бы воспроизвести проблему — используем Python-скрипт, приведённый выше.
Запускаем его на порту 8081:
root@ip-10-0-15-118:/home/admin# ./test_post.py 8081
INFO:root:Starting httpd…
Выполняем curl с POST с какими-то данными в --data:
curl -vL -X POST http://dev.poc.example.com/ -d «param1=value1¶m2=value2»
…
* Trying 52.***.***.224:80…
…
> Content-Length: 27
…
< HTTP/1.1 302 Moved Temporarily
…
< Content-Length: 161
< Connection: keep-alive
< Location: https://dev.poc.example.com/
…
> POST / HTTP/1.1
> Host: dev.poc.example.com
> User-Agent: curl/7.67.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 502 Bad Gateway
< Server: nginx/1.10.3
…
< Content-Type: text/html
< Content-Length: 173
Что тут происходит:
POST-запрос с данными на HTTP, Content-Length: 27- 302 редирект на HTTPS
POSTна HTTPS, Content-Length: 173
В логах NGINX видим нормальный HTTP POST:
…
==> /var/log/nginx/dev.poc.example.com-error.log <==
2019/11/23 09:52:41 [error] 19793#19793: *51100 upstream prematurely closed connection while reading response header from upstream, client: 194.***.***.26, server: dev.poc.example.com, request: «POST / HTTP/1.1», upstream: «http://127.0.0.1:8081/», host: «dev.poc.example.com»
==> /var/log/nginx/dev.poc.example.com-access.log <==
194.***.***.26 — — [23/Nov/2019:09:52:41 +0000] «POST / HTTP/1.1» 502 173 «-» «curl/7.67.0»
…
И посмотрим stderr нашего Python-сервера:
…
Exception happened during processing of request from (‘127.0.0.1’, 38224)
Traceback (most recent call last):
File «/usr/lib/python3.5/socketserver.py», line 313, in _handle_request_noblock
self.process_request(request, client_address)
File «/usr/lib/python3.5/socketserver.py», line 341, in process_request
self.finish_request(request, client_address)
File «/usr/lib/python3.5/socketserver.py», line 354, in finish_request
self.RequestHandlerClass(request, client_address, self)
File «/usr/lib/python3.5/socketserver.py», line 681, in __init__
self.handle()
File «/usr/lib/python3.5/http/server.py», line 422, in handle
self.handle_one_request()
File «/usr/lib/python3.5/http/server.py», line 410, in handle_one_request
method()
File «./test_post.py», line 22, in do_POST
content_length = int(self.headers[‘Content-Length’]) # <— Gets the size of data
TypeError: int() argument must be a string, a bytes-like object or a number, not ‘NoneType’
…
Нас тут интересуют вот эти строки:
…
content_length = int(self.headers[‘Content-Length‘])
TypeError: int() argument must be a string, a bytes-like object or a number, not ‘NoneType‘
Т.е. к приложению Content-Length пришёл совершенно пустой.
При этом, если выполнить прямой запрос на HTTP (с отключенным редиректом в NGINX) или HTTPS — всё работает, как ожидается:
curl -vL -X POST https://dev.poc.example.com/ -d «param1=value1¶m2=value2»
…
> POST / HTTP/1.1
> Host: dev.poc.example.com
> User-Agent: curl/7.67.0
> Accept: */*
> Content-Length: 27
> Content-Type: application/x-www-form-urlencoded
>
* upload completely sent off: 27 out of 27 bytes
* Mark bundle as not supporting multiuse
< HTTP/1.1 200 OK
< Server: nginx/1.10.3
< Date: Sat, 23 Nov 2019 09:55:07 GMT
< Content-Type: text/html
< Transfer-Encoding: chunked
< Connection: keep-alive
<
* Connection #0 to host dev.poc.example.com left intact
POST request for /
И stdout Python-приложения:
…
INFO:root:POST request,
Path: /
Headers:
Host: dev.poc.example.com
X-Real-IP: 194.***.***.26
X-Forwarded-For: 194.***.***.26
X-Forwarded-Proto: https
Connection: close
Content-Length: 27
User-Agent: curl/7.67.0
Accept: */*
Content-Type: application/x-www-form-urlencoded
Body:
param1=value1¶m2=value2
127.0.0.1 — — [23/Nov/2019 09:55:07] «POST / HTTP/1.0» 200 —
Теперь — посмотрим на вторую проблему.
POST становится GET
В процессе дебага описанной выше проблемы, когда на бекенд не доходили данные при POST, нашлось ещё одно интересное поведение запросов при HTTP-редиректах.
Теперь посмотрим, как POST превращается в …. GET 🙂
«Всё сложно». Детали поведения рассмотрим в конце этого поста, сейчас — давайте попробуем один и тот же запрос на один и тот же ендпоинт, но используя два разных клиента — curl, и Postman (в виде standalone-приложения на рабочей машине).
curl
Выполняем запрос с типом POST на HTTP, добавляем -L, что бы проследовать по редиректам на HTTPS.
Тут в роли бекенда уже используем не Python-скрипт, как в примерах выше, а наш реальный бекенд в Docker-контейнере, что бы продемонстрировать его нормальную и не очень работу.
Сами данные значения и ошибки сейчас не имеют — нам интересен только тип запроса в логах NGINX:
curl -vL -X POST http://dev.poc.example.com/skin/api/v1/receipt -d «{}»
…
> POST /skin/api/v1/receipt HTTP/1.1
> Host: dev.poc.example.com
> User-Agent: curl/7.67.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 400 Bad Request
< Server: nginx/1.10.3
< Date: Sat, 23 Nov 2019 10:07:37 GMT
< Content-Type: application/json; charset=utf-8
< Content-Length: 58
< Connection: keep-alive
<
* Connection #1 to host dev.poc.example.com left intact
{«message»:»Validation failed: unable to parse json body»}
Ещё раз — на ошибки не обращаем внимания, т.к. реальные данные к бекенду не отправили, нас сейчас интересует исключительно тип запроса в логах, давайте ещё глянем в логах NGINX:
==> /var/log/nginx/dev.poc.example.com-access.log <==
194.***.***.26 — — [23/Nov/2019:10:07:37 +0000] «POST /skin/api/v1/receipt HTTP/1.1» 400 58 «-» «curl/7.67.0»
Тут всё хорошо, да? POST отправили — POST приняли.
Если мы curl-ом отправим явный GET — ответ бекенда будет другим:
curl -L -X GET http://dev.poc.example.com/skin/api/v1/receipt -d «{}»
404 page not found
И вот этот же GET в логе NGINX:
==> /var/log/nginx/dev.poc.example.com-access.log <==
194.***.***.26 — — [23/Nov/2019:10:07:37 +0000] «POST /skin/api/v1/receipt HTTP/1.1» 400 58 «-» «curl/7.67.0»
194.***.***.26 — — [23/Nov/2019:10:09:57 +0000] «GET /skin/api/v1/receipt HTTP/1.1» 404 18 «-» «curl/7.67.0»
Всё правильно — всё логично, да?
Postman
А теперь — повторяем этот же запрос из Postman.
Нам важно отправить другим клиентом, QA-тима воспроизводила как раз в Postman, но должно быть и в прочих.
Выполняем такой же запрос — POST на HTTP, и сработает редирект на HTTPS:

И? 🙂
И теперь — смотрим лог NGINX снова, последняя запись:
==> /var/log/nginx/dev.poc.example.com-access.log <==
194.***.***.26 — — [23/Nov/2019:10:07:37 +0000] «POST /skin/api/v1/receipt HTTP/1.1» 400 58 «-» «curl/7.67.0»
194.***.***.26 — — [23/Nov/2019:10:09:57 +0000] «GET /skin/api/v1/receipt HTTP/1.1» 404 18 «-» «curl/7.67.0»
194.***.***.26 — — [23/Nov/2019:10:11:44 +0000] «GET /skin/api/v1/receipt HTTP/1.1» 404 18 «http://dev.poc.example.com/skin/api/v1/receipt» «PostmanRuntime/7.19.0»
Ээээ…
Шта?!?
Но я ведь отправил явный POST?
Ещё раз:
- выполняем запрос
curl, срабатывает редирект HTTP => HTTPS, видимPOST— всё отлично - выполняем запрос из Postman, срабатывает редирект HTTP => HTTPS, видим
GET— WTF???
POST, GET и «потерянные данные»
Зато теперь сновится понятно — куда «потерялись» наши данные из POST — потому что он превратился к GET.
Причина проблемы, 3xx redirects и HTTP RFC
Собственно, обе проблемы вызваны одной и той же причиной.
Начнём со чтения кода 301 в RFC 2616 — https://tools.ietf.org/html/rfc2616#section-10.3.2 — нас тут особенно интересует Note к описанию 301 редиректа:
Note: When automatically redirecting a POST request after
receiving a 301 status code, some existing HTTP/1.0 user agents
will erroneously change it into a GET request.
Т.е. некоторые существующие агенты HTTP/1.0 после выполнения POST и получения 301 — меняют его тип (хотя не должны, см. ниже), и выполняют GET.
Но это оказалось только вершиной айсберга.
Читаем дальше, про код 302, в том же RFC 2016 — https://tools.ietf.org/html/rfc2616#section-10.3.3 — и снова внимание на Note:
Note: RFC 1945 and RFC 2068 specify that the client is not allowed
to change the method on the redirected request. However, most
existing user agent implementations treat 302 as if it were a 303
response, performing a GET on the Location field-value regardless
of the original request method. The status codes 303 and 307 have
been added for servers that wish to make unambiguously clear which
kind of reaction is expected of the client.
RFC 1945 про 3хх редиректы — https://tools.ietf.org/html/rfc1945#section-9.3
RFC 2068 про 3хх редиректы — https://tools.ietf.org/html/rfc2068#section-10.3.2
Т.е. — RFC 1945 and RFC 2068 говорят, что клиент не должен менять метод для редиректнуого запроса, но при этом большинство считают код 302 как 303.
Идём ниже, и читаем описание кода 303 — https://tools.ietf.org/html/rfc2616#section-10.3.4:
The response to the request can be found under a different URI and
SHOULD be retrieved using a GET method on that resource.
Т.е., когда клиент считает, что он получил 303 код — он всегда выполняет GET.
Т.е, что мы видим в случае с Postman (и нашими мобильными клиентами, на которых проблема и проявилась изначально):
- клиент отправляет
POSTна HTTP - получает редирект на HTTPS с кодом 301 или 302
- воспринимает его, как редирект 303
- и меняет тип своего запроса уже к HTTPS на
GET, с «потерей» отправленных данных
Решение
Найти решение помогла документация от Mozilla (хотя подсказка была и в Notes RFC 2016 по 302), которая в своей документации к 301 и 302 явно говорит:
It is therefore recommended to set the 302 code only as a response for GET or HEAD methods and to use 307 Temporary Redirect instead, as the method change is explicitly prohibited in that case.
Идём в NGINX, меняем код редиректа с 302 на 307:
server {
listen 80;
...
location / {
# return 302 https://dev.poc.example.com$request_uri;
return 307 https://dev.poc.example.com$request_uri;
}
}
...Перечитываем конфиги NGINX и повторяем запрос с помощью curl:
curl -L -X POST http://dev.poc.example.com/skin/api/v1/receipt -d «{}»
{«message»:»Validation failed: fields ‘hardware_id’ and ‘receipt’ are mandatory»}
Теперь мы получили валидный ответ от бекенда, который просто хочет нормальных входных данных.
Редирект сработал, POST-запрос от нас пришёл.
Лог NGINX:
==> /var/log/nginx/dev.poc.example.com-access.log <==
194.***.***.26 — — [23/Nov/2019:10:07:37 +0000] «POST /skin/api/v1/receipt HTTP/1.1» 400 58 «-» «curl/7.67.0»
194.***.***.26 — — [23/Nov/2019:10:09:57 +0000] «GET /skin/api/v1/receipt HTTP/1.1» 404 18 «-» «curl/7.67.0»
194.***.***.26 — — [23/Nov/2019:10:11:44 +0000] «GET /skin/api/v1/receipt HTTP/1.1» 404 18 «http://dev.poc.example.com/skin/api/v1/receipt» «PostmanRuntime/7.19.0»
194.***.***.26 — — [23/Nov/2019:10:35:51 +0000] «POST /skin/api/v1/receipt HTTP/1.1» 422 81 «-» «curl/7.67.0»
194.***.***.26 — — [23/Nov/2019:10:36:00 +0000] «POST /skin/api/v1/receipt HTTP/1.1» 422 81 «-» «curl/7.67.0»
Повторяем запрос из Postman:

Лог NGINX:
==> /var/log/nginx/dev.poc.example.com-access.log <==
194.***.***.26 — — [23/Nov/2019:10:07:37 +0000] «POST /skin/api/v1/receipt HTTP/1.1» 400 58 «-» «curl/7.67.0»
194.***.***.26 — — [23/Nov/2019:10:09:57 +0000] «GET /skin/api/v1/receipt HTTP/1.1» 404 18 «-» «curl/7.67.0»
194.***.***.26 — — [23/Nov/2019:10:11:44 +0000] «GET /skin/api/v1/receipt HTTP/1.1» 404 18 «http://dev.poc.example.com/skin/api/v1/receipt» «PostmanRuntime/7.19.0»
194.***.***.26 — — [23/Nov/2019:10:35:51 +0000] «POST /skin/api/v1/receipt HTTP/1.1» 422 81 «-» «curl/7.67.0»
194.***.***.26 — — [23/Nov/2019:10:36:00 +0000] «POST /skin/api/v1/receipt HTTP/1.1» 422 81 «-» «curl/7.67.0»
194.***.***.26 — — [23/Nov/2019:10:37:57 +0000] «POST /skin/api/v1/receipt HTTP/1.1» 422 81 «http://dev.poc.example.com/skin/api/v1/receipt» «PostmanRuntime/7.19.0»
Всё работает, как ожидалось.
AWS Application Load Balancer redirects
Увы, при использовании редиректов на AWS ALB — он не позволяет задать другой код:

В целом — на этом всё.
Было интересно.
Ссылки по теме
Эта же проблема на других ресурсах
Помогло найти причину и решение
Простым языком об HTTP / Хабр
Вашему вниманию предлагается описание основных аспектов протокола HTTP — сетевого протокола, с начала 90-х и по сей день позволяющего вашему браузеру загружать веб-страницы. Данная статья написана для тех, кто только начинает работать с компьютерными сетями и заниматься разработкой сетевых приложений, и кому пока что сложно самостоятельно читать официальные спецификации.HTTP — широко распространённый протокол передачи данных, изначально предназначенный для передачи гипертекстовых документов (то есть документов, которые могут содержать ссылки, позволяющие организовать переход к другим документам).
Аббревиатура HTTP расшифровывается как HyperText Transfer Protocol, «протокол передачи гипертекста». В соответствии со спецификацией OSI, HTTP является протоколом прикладного (верхнего, 7-го) уровня. Актуальная на данный момент версия протокола, HTTP 1.1, описана в спецификации RFC 2616.
Протокол HTTP предполагает использование клиент-серверной структуры передачи данных. Клиентское приложение формирует запрос и отправляет его на сервер, после чего серверное программное обеспечение обрабатывает данный запрос, формирует ответ и передаёт его обратно клиенту. После этого клиентское приложение может продолжить отправлять другие запросы, которые будут обработаны аналогичным образом.
Задача, которая традиционно решается с помощью протокола HTTP — обмен данными между пользовательским приложением, осуществляющим доступ к веб-ресурсам (обычно это веб-браузер) и веб-сервером. На данный момент именно благодаря протоколу HTTP обеспечивается работа Всемирной паутины.
Также HTTP часто используется как протокол передачи информации для других протоколов прикладного уровня, таких как SOAP, XML-RPC и WebDAV. В таком случае говорят, что протокол HTTP используется как «транспорт».
API многих программных продуктов также подразумевает использование HTTP для передачи данных — сами данные при этом могут иметь любой формат, например, XML или JSON.
Как правило, передача данных по протоколу HTTP осуществляется через TCP/IP-соединения. Серверное программное обеспечение при этом обычно использует TCP-порт 80 (и, если порт не указан явно, то обычно клиентское программное обеспечение по умолчанию использует именно 80-й порт для открываемых HTTP-соединений), хотя может использовать и любой другой.
Как отправить HTTP-запрос?
Самый простой способ разобраться с протоколом HTTP — это попробовать обратиться к какому-нибудь веб-ресурсу вручную. Представьте, что вы браузер, и у вас есть пользователь, который очень хочет прочитать статьи Анатолия Ализара.
Предположим, что он ввёл в адресной строке следующее:
http://alizar.habrahabr.ru/
Соответственно вам, как веб-браузеру, теперь необходимо подключиться к веб-серверу по адресу alizar.habrahabr.ru.
Для этого вы можете воспользоваться любой подходящей утилитой командной строки. Например, telnet:
telnet alizar.habrahabr.ru 80
Сразу уточню, что если вы вдруг передумаете, то нажмите Ctrl + «]», и затем ввод — это позволит вам закрыть HTTP-соединение. Помимо telnet можете попробовать nc (или ncat) — по вкусу.
После того, как вы подключитесь к серверу, нужно отправить HTTP-запрос. Это, кстати, очень легко — HTTP-запросы могут состоять всего из двух строчек.
Для того, чтобы сформировать HTTP-запрос, необходимо составить стартовую строку, а также задать по крайней мере один заголовок — это заголовок Host, который является обязательным, и должен присутствовать в каждом запросе. Дело в том, что преобразование доменного имени в IP-адрес осуществляется на стороне клиента, и, соответственно, когда вы открываете TCP-соединение, то удалённый сервер не обладает никакой информацией о том, какой именно адрес использовался для соединения: это мог быть, например, адрес alizar.habrahabr.ru, habrahabr.ru или m.habrahabr.ru — и во всех этих случаях ответ может отличаться. Однако фактически сетевое соединение во всех случаях открывается с узлом 212.24.43.44, и даже если первоначально при открытии соединения был задан не этот IP-адрес, а какое-либо доменное имя, то сервер об этом никак не информируется — и именно поэтому этот адрес необходимо передать в заголовке Host.
Стартовая (начальная) строка запроса для HTTP 1.1 составляется по следующей схеме:
Метод URI HTTP/Версия
Например (такая стартовая строка может указывать на то, что запрашивается главная страница сайта):
GET / HTTP/1.1
Метод (в англоязычной тематической литературе используется слово method, а также иногда слово verb — «глагол») представляет собой последовательность из любых символов, кроме управляющих и разделителей, и определяет операцию, которую нужно осуществить с указанным ресурсом. Спецификация HTTP 1.1 не ограничивает количество разных методов, которые могут быть использованы, однако в целях соответствия общим стандартам и сохранения совместимости с максимально широким спектром программного обеспечения как правило используются лишь некоторые, наиболее стандартные методы, смысл которых однозначно раскрыт в спецификации протокола.
URI (Uniform Resource Identifier, унифицированный идентификатор ресурса) — путь до конкретного ресурса (например, документа), над которым необходимо осуществить операцию (например, в случае использования метода GET подразумевается получение ресурса). Некоторые запросы могут не относиться к какому-либо ресурсу, в этом случае вместо URI в стартовую строку может быть добавлена звёздочка (астериск, символ «*»). Например, это может быть запрос, который относится к самому веб-серверу, а не какому-либо конкретному ресурсу. В этом случае стартовая строка может выглядеть так:
OPTIONS * HTTP/1.1
Версия определяет, в соответствии с какой версией стандарта HTTP составлен запрос. Указывается как два числа, разделённых точкой (например 1.1).
Для того, чтобы обратиться к веб-странице по определённому адресу (в данном случае путь к ресурсу — это «/»), нам следует отправить следующий запрос:
GET / HTTP/1.1
Host: alizar.habrahabr.ru
При этом учитывайте, что для переноса строки следует использовать символ возврата каретки (Carriage Return), за которым следует символ перевода строки (Line Feed). После объявления последнего заголовка последовательность символов для переноса строки добавляется дважды.
Впрочем, в спецификации HTTP рекомендуется программировать HTTP-сервер таким образом, чтобы при обработке запросов в качестве межстрочного разделителя воспринимался символ LF, а предшествующий символ CR, при наличии такового, игнорировался. Соответственно, на практике бо́льшая часть серверов корректно обработает и такой запрос, где заголовки отделены символом LF, и он же дважды добавлен после объявления последнего заголовка.
Если вы хотите отправить запрос в точном соответствии со спецификацией, можете воспользоваться управляющими последовательностями \r и \n:
echo -en "GET / HTTP/1.1\r\nHost: alizar.habrahabr.ru\r\n\r\n" | ncat alizar.habrahabr.ru 80
Как прочитать ответ?
Стартовая строка ответа имеет следующую структуру:
HTTP/Версия Код состояния Пояснение
Версия протокола здесь задаётся так же, как в запросе.
Код состояния (Status Code) — три цифры (первая из которых указывает на класс состояния), которые определяют результат совершения запроса. Например, в случае, если был использован метод GET, и сервер предоставляет ресурс с указанным идентификатором, то такое состояние задаётся с помощью кода 200. Если сервер сообщает о том, что такого ресурса не существует — 404. Если сервер сообщает о том, что не может предоставить доступ к данному ресурсу по причине отсутствия необходимых привилегий у клиента, то используется код 403. Спецификация HTTP 1.1 определяет 40 различных кодов HTTP, а также допускается расширение протокола и использование дополнительных кодов состояний.
Пояснение к коду состояния (Reason Phrase) — текстовое (но не включающее символы CR и LF) пояснение к коду ответа, предназначено для упрощения чтения ответа человеком. Пояснение может не учитываться клиентским программным обеспечением, а также может отличаться от стандартного в некоторых реализациях серверного ПО.
После стартовой строки следуют заголовки, а также тело ответа. Например:
HTTP/1.1 200 OK
Server: nginx/1.2.1
Date: Sat, 08 Mar 2014 22:53:46 GMT
Content-Type: application/octet-stream
Content-Length: 7
Last-Modified: Sat, 08 Mar 2014 22:53:30 GMT
Connection: keep-alive
Accept-Ranges: bytes
Wisdom
Тело ответа следует через два переноса строки после последнего заголовка. Для определения окончания тела ответа используется значение заголовка Content-Length (в данном случае ответ содержит 7 восьмеричных байтов: слово «Wisdom» и символ переноса строки).
Но вот по тому запросу, который мы составили ранее, веб-сервер вернёт ответ не с кодом 200, а с кодом 302. Таким образом он сообщает клиенту о том, что обращаться к данному ресурсу на данный момент нужно по другому адресу.
Смотрите сами:
HTTP/1.1 302 Moved Temporarily
Server: nginx
Date: Sat, 08 Mar 2014 22:29:53 GMT
Content-Type: text/html
Content-Length: 154
Connection: keep-alive
Keep-Alive: timeout=25
Location: http://habrahabr.ru/users/alizar/
<html>
<head><title>302 Found</title></head>
<body bgcolor="white">
<center><h2>302 Found</h2></center>
<hr><center>nginx</center>
</body>
</html>
В заголовке Location передан новый адрес. Теперь URI (идентификатор ресурса) изменился на /users/alizar/, а обращаться нужно на этот раз к серверу по адресу habrahabr.ru (впрочем, в данном случае это тот же самый сервер), и его же указывать в заголовке Host.
То есть:
GET /users/alizar/ HTTP/1.1
Host: habrahabr.ru
В ответ на этот запрос веб-сервер Хабрахабра уже выдаст ответ с кодом 200 и достаточно большой документ в формате HTML.
Если вы уже успели вжиться в роль, то можете теперь прочитать полученный от сервера HTML-код, взять карандаш и блокнот, и нарисовать профайл Ализара — в принципе, именно этим бы на вашем месте браузер сейчас и занялся.
А что с безопасностью?
Сам по себе протокол HTTP не предполагает использование шифрования для передачи информации. Тем не менее, для HTTP есть распространённое расширение, которое реализует упаковку передаваемых данных в криптографический протокол SSL или TLS.
Название этого расширения — HTTPS (HyperText Transfer Protocol Secure). Для HTTPS-соединений обычно используется TCP-порт 443. HTTPS широко используется для защиты информации от перехвата, а также, как правило, обеспечивает защиту от атак вида man-in-the-middle — в том случае, если сертификат проверяется на клиенте, и при этом приватный ключ сертификата не был скомпрометирован, пользователь не подтверждал использование неподписанного сертификата, и на компьютере пользователя не были внедрены сертификаты центра сертификации злоумышленника.
На данный момент HTTPS поддерживается всеми популярными веб-браузерами.
А есть дополнительные возможности?
Протокол HTTP предполагает достаточно большое количество возможностей для расширения. В частности, спецификация HTTP 1.1 предполагает возможность использования заголовка Upgrade для переключения на обмен данными по другому протоколу. Запрос с таким заголовком отправляется клиентом. Если серверу требуется произвести переход на обмен данными по другому протоколу, то он может вернуть клиенту ответ со статусом «426 Upgrade Required», и в этом случае клиент может отправить новый запрос, уже с заголовком Upgrade.
Такая возможность используется, в частности, для организации обмена данными по протоколу WebSocket (протокол, описанный в спецификации RFC 6455, позволяющий обеим сторонам передавать данные в нужный момент, без отправки дополнительных HTTP-запросов): стандартное «рукопожатие» (handshake) сводится к отправке HTTP-запроса с заголовком Upgrade, имеющим значение «websocket», на который сервер возвращает ответ с состоянием «101 Switching Protocols», и далее любая сторона может начать передавать данные уже по протоколу WebSocket.
Что-то ещё, кстати, используют?
На данный момент существуют и другие протоколы, предназначенные для передачи веб-содержимого. В частности, протокол SPDY (произносится как английское слово speedy, не является аббревиатурой) является модификацией протокола HTTP, цель которой — уменьшить задержки при загрузке веб-страниц, а также обеспечить дополнительную безопасность.
Увеличение скорости обеспечивается посредством сжатия, приоритизации и мультиплексирования дополнительных ресурсов, необходимых для веб-страницы, чтобы все данные можно было передать в рамках одного соединения.
Опубликованный в ноябре 2012 года черновик спецификации протокола HTTP 2.0 (следующая версия протокола HTTP после версии 1.1, окончательная спецификация для которой была опубликована в 1999) базируется на спецификации протокола SPDY.
Многие архитектурные решения, используемые в протоколе SPDY, а также в других предложенных реализациях, которые рабочая группа httpbis рассматривала в ходе подготовки черновика спецификации HTTP 2.0, уже ранее были получены в ходе разработки протокола HTTP-NG, однако работы над протоколом HTTP-NG были прекращены в 1998.
На данный момент поддержка протокола SPDY есть в браузерах Firefox, Chromium/Chrome, Opera, Internet Exporer и Amazon Silk.
И что, всё?
В общем-то, да. Можно было бы описать конкретные методы и заголовки, но фактически эти знания нужны скорее в том случае, если вы пишете что-то конкретное (например, веб-сервер или какое-то клиентское программное обеспечение, которое связывается с серверами через HTTP), и для базового понимания принципа работы протокола не требуются. К тому же, всё это вы можете очень легко найти через Google — эта информация есть и в спецификациях, и в Википедии, и много где ещё.
Впрочем, если вы знаете английский и хотите углубиться в изучение не только самого HTTP, но и используемых для передачи пакетов TCP/IP, то рекомендую прочитать вот эту статью.
Ну и, конечно, не забывайте, что любая технология становится намного проще и понятнее тогда, когда вы фактически начинаете ей пользоваться.
Удачи и плодотворного обучения!
Поскольку основным способом взаимодействия с IPAM-системой будет RESTful API, я решил рассказать о нём отдельно.
Воздаю хвалы архитекторам современного мира — у нас есть стандартизированные интерфейсы. Да их много — это минус, но они есть — это плюс.
Эти интерфейсы взаимодействия обрели имя API — Application Programming Interface.
Одним из таких интерфейсов является RESTful API, который и используется для работы с NetBox.
Если очень просто, то API даёт клиенту набор инструментов, через которые тот может управлять сервером. А клиентом может выступать по сути что угодно: веб-браузер, командная консоль, разработанное производителем приложение, или вообще любое другое приложение, у которого есть доступ к API.
Например, в случае NetBox, добавить новое устройство в него можно следующими способами: через веб-браузер, отправив curl’ом запрос в консоли, использовать Postman, обратиться к библиотеке requests в питоне, воспользоваться SDK pynetbox или перейти в Swagger.
Таким образом, один раз написав единый интерфейс, производитель навсегда освобождает себя от необходимости с каждым новым клиентом договариваться как его подключать (хотя, это самую малость лукавство).
- REST, RESTful, API
- Структура сообщений HTTP
- Стартовая строка
- Заголовки
- Тело HTTP-сообщения
- Методы
- HTTP GET
- HTTP POST
- HTTP PUT
- HTTP PATCH
- HTTP DELETE
- Способы работы с RESTful API
- CURL
- Postman
- Python+Requests
- SDK Pynebtbox
- SWAGGER
- Критика REST и альтернативы
- Полезные ссылки
Ниже я дам очень упрощённое описание того, что такое REST.
Начнём с того, что RESTful API — это именно интерфейс взаимодействия, основанный на REST, в то время как сам REST (REpresentational State Transfer) — это набор ограничений, используемых для создания WEB-сервисов.
О каких именно ограничениях идёт речь, можно почитать в главе 5 диссертации Роя Филдинга Architectural Styles and the Design of Network-based Software Architectures. Мне же позвольте привести только три наиболее значимых (с моей точки зрения) из них:
- В REST-архитектуре используется модель взаимодействия Клиент-Сервер.
- Каждый REST-запрос содержит всю информацию, необходимую для его выполнения. То есть сервер не должен помнить ничего о предыдущих запросах клиента, что, как известно, характеризуется словом Stateless — не храним информацию о состоянии.
- Единый интерфейс. Реализация приложения отделена от сервиса, который оно предоставляет. То есть пользователь знает, что оно делает и как с ним взаимодействовать, но как именно оно это делает не имеет значения. При изменении приложения, интерфейс остаётся прежним, и клиентам не нужно подстраиваться.
WEB-сервисы, удовлетворяющие всем принципам REST, называются RESTful WEB-services.
А API, который предоставляют RESTful WEB-сервисы, называется RESTful API.
REST — не протокол, а, так называемый, стиль архитектуры (один из). Развиваемому вместе с HTTP Роем Филдингом, REST’у было предназначено использовать HTTP 1.1, в качестве транспорта.
Адрес назначения (или иным словом — объект, или ещё иным — эндпоинт) — это привычный нам URI.
Формат передаваемых данных — XML или JSON.
Для этой серии статей на linkmeup развёрнута read-only (для вас, дорогие, читатели) инсталляция NetBox: netbox.linkmeup.ru:45127.Давайте интереса ради сделаем один запрос:На чтение права не требуются, но если хочется попробовать читать с токеном, то можно воспользоваться этим: API Token: 90a22967d0bc4bdcd8ca47ec490bbf0b0cb2d9c8.
curl -X GET -H "Authorization: TOKEN 90a22967d0bc4bdcd8ca47ec490bbf0b0cb2d9c8" \
-H "Accept: application/json; indent=4" \
http://netbox.linkmeup.ru:45127/api/dcim/devices/1/То есть утилитой curl мы делаем GET объекта по адресу netbox.linkmeup.ru:45127/api/dcim/devices/1/ с ответом в формате JSON и отступом в 4 пробела.
Или чуть более академически: GET возвращает типизированный объект devices, являющийся параметром объекта DCIM.
Этот запрос можете выполнить и вы — просто скопируйте себе в терминал.
URL, к которому мы обращаемся в запросе, называется Endpoint. В некотором смысле это конечный объект, с которым мы будем взаимодействовать.
Например, в случае netbox’а список всех endpoint’ов можно получить тут.
И ещё обратите внимание на знак / в конце URL — он обязателен.Вот что мы получим в ответ:
{
"id": 1,
"name": "mlg-host-0",
"display_name": "mlg-host-0",
"device_type": {
"id": 4,
"url": "http://netbox.linkmeup.ru/api/dcim/device-types/4/",
"manufacturer": {
"id": 4,
"url": "http://netbox.linkmeup.ru/api/dcim/manufacturers/4/",
"name": "Hypermacro",
"slug": "hypermacro"
},
"model": "Server",
"slug": "server",
"display_name": "Hypermacro Server"
},
"device_role": {
"id": 1,
"url": "http://netbox.linkmeup.ru/api/dcim/device-roles/1/",
"name": "Server",
"slug": "server"
},
"tenant": null,
"platform": null,
"serial": "",
"asset_tag": null,
"site": {
"id": 6,
"url": "http://netbox.linkmeup.ru/api/dcim/sites/6/",
"name": "Малага",
"slug": "mlg"
},
"rack": {
"id": 1,
"url": "http://netbox.linkmeup.ru/api/dcim/racks/1/",
"name": "A",
"display_name": "A"
},
"position": 41,
"face": {
"value": "front",
"label": "Front",
"id": 0
},
"parent_device": null,
"status": {
"value": "active",
"label": "Active",
"id": 1
},
"primary_ip": null,
"primary_ip4": null,
"primary_ip6": null,
"cluster": null,
"virtual_chassis": null,
"vc_position": null,
"vc_priority": null,
"comments": "",
"local_context_data": null,
"tags": [],
"custom_fields": {},
"config_context": {},
"created": "2020-01-14",
"last_updated": "2020-01-14T18:39:01.288081Z"
}
Это JSON (как мы и просили), описывающий device с ID 1: как называется, с какой ролью, какой модели, где стоит итд.
Так будет выглядеть HTTP-запрос:
GET /api/dcim/devices/1/ HTTP/1.1
Host: netbox.linkmeup.ru:45127
User-Agent: curl/7.54.0
Accept: application/json; indent=4Так будет выглядеть ответ:
HTTP/1.1 200 OK
Server: nginx/1.14.0 (Ubuntu)
Date: Tue, 21 Jan 2020 15:14:22 GMT
Content-Type: application/json
Content-Length: 1638
Connection: keep-alive
DataДамп транзакции.
А теперь разберёмся, что же мы натворили.
HTTP-сообщение состоит из трёх частей, только первая из которых является обязательной.
- Стартовая строка
- Заголовки
- Тело сообщения
Стартовая строка
Стартовые строки HTTP-запроса и ответа выглядят по-разному.
HTTP-Запрос
METHOD URI HTTP_VERSIONМетод определяет, какое действие клиент хочет совершить: получить данные, создать объект, обновить его, удалить.Пример:
URI — идентификатор ресурса, куда клиент обращается или иными словами путь к ресурсу/документу.
HTTP_VERSION — соответственно версия HTTP. На сегодняшний день для REST это всегда 1.1.
GET /api/dcim/devices/1/ HTTP/1.1HTTP-Ответ
HTTP_VERSION STATUS_CODE REASON_PHRASEHTTP_VERSION — версия HTTP (1.1).
STATUS_CODE — три цифры кода состояния (200, 404, 502 итд)
REASON_PHRASE — Пояснение (OK, NOT FOUND, BAD GATEWAY итд)
Пример:
HTTP/1.1 200 OKЗаголовки
В заголовках передаются параметры данной HTTP-транзакции.
Например, в примере выше в HTTP-запросе это были:
Host: netbox.linkmeup.ru:45127
User-Agent: curl/7.54.0
Accept: application/json; indent=4В них указано, что
- Обращаемся к хосту netbox.linkmeup.ru:45127,
- Запрос был сгенерирован в curl,
- А принимаем данные в формате JSON с отступом 4.
А вот какие заголовки были в HTTP-ответе:
Server: nginx/1.14.0 (Ubuntu)
Date: Tue, 21 Jan 2020 15:14:22 GMT
Content-Type: application/json
Content-Length: 1638
Connection: keep-aliveВ них указано, что
- Тип сервера: nginx на Ubuntu,
- Время формирования ответа,
- Формат данных в ответе: JSON
- Длина данных в ответе: 1638 байтов
- Соединение не нужно закрывать — ещё будут данные.
Заголовки, как вы уже заметили, выглядят как пары имя: значение, разделённые знаком «:».
Полный список возможных заголовков.
Тело HTTP-сообщения
Тело используется для передачи собственно данных.
В HTTP-ответе это может быть HTML-страничка, или в нашем случае JSON-объект.
Между заголовками и телом должна быть как минимум одна пустая строка.
При использовании метода GET в HTTP-запросе обычно никакого тела нет, потому что передавать нечего. Но тело есть в HTTP-ответе.
А вот например, при POST уже и в запросе будет тело. Давайте о методах и поговорим теперь.
Как вы уже поняли, для работы с WEB-сервисами HTTP использует методы. То же самое касается и RESTful API.
Возможные сценарии в реальной жизни описываются термином CRUD — Create, Read, Update, Delete.
Вот список наиболее популярных методов HTTP, реализующих CRUD:
- HTTP GET
- HTTP POST
- HTTP PUT
- HTTP DELETE
- HTTP PATCH
Методы также называются глаголами, поскольку указывают на то, какое действие производится.
Полный список методов.
Давайте на примере NetBox разберёмся с каждым из них.
HTTP GET
Это метод для получения информации.
Так, например, мы забираем список устройств:
curl -H "Accept: application/json; indent=4" \
http://netbox.linkmeup.ru:45127/api/dcim/devices/ Метод GET безопасный (safe), поскольку не меняет данные, а только запрашивает.
Он идемпотентный с той точки зрения, что один и тот же запрос всегда возвращает одинаковый результат (до тех пор, пока сами данные не поменялись).
На GET сервер возвращает сообщение с HTTP-кодом и телом ответа (response code и response body).
То есть если всё OK, то код ответа — 200 (OK).
Если URL не найден — 404 (NOT FOUND).
Если что-то не так с самим сервером или компонентами, это может быть 500 (SERVER ERROR) или 502 (BAD GATEWAY).
Все возможные коды ответов.
Тело возвращается в формате JSON или XML.
Дамп транзакции.
Давайте ещё пару примеров. Теперь мы запросим информацию по конкретному устройству по его имени.
curl -X GET -H "Accept: application/json; indent=4" \
"http://netbox.linkmeup.ru:45127/api/dcim/devices/?name=mlg-leaf-0"Здесь, чтобы задать условия поиска в URI я ещё указал атритбут объекта (параметр name и его значение mlg-leaf-0). Как вы можете видеть, перед условием и после слэша идёт знак «?», а имя и значение разделяются знаком «=».
Так выглядит запрос.
GET /api/dcim/devices/?name=mlg-leaf-0 HTTP/1.1
Host: netbox.linkmeup.ru:45127
User-Agent: curl/7.54.0
Accept: application/json; indent=4Дамп транзакции.
Если нужно задать пару условий, то запрос будет выглядеть так:
curl -X GET -H "Accept: application/json; indent=4" \
"http://netbox.linkmeup.ru:45127/api/dcim/devices/?role=leaf&site=mlg"Здесь мы запросили все устройства с ролью leaf, расположенные на сайте mlg.
То есть два условия отделяются друг от друга знаком «&».
Дамп транзакции.
Из любопытного и приятного — если через «&» задать два условия с одним именем, то между ними будет на самом деле не логическое «И», а логическое «ИЛИ».
То есть вот такой запрос и в самом деле вернёт два объекта: mlg-leaf-0 и mlg-spine-0
curl -X GET -H "Accept: application/json; indent=4" \
"http://netbox.linkmeup.ru:45127/api/dcim/devices/?name=mlg-leaf-0&name=mlg-spine-0"Дамп транзакции.
Попробуем обратиться к несуществующему URL.
curl -X GET -H "Accept: application/json; indent=4" \
"http://netbox.linkmeup.ru:45127/api/dcim/IDGAF/"Дамп транзакции.
HTTP POST
POST используется для создания нового объекта в наборе объектов. Или более сложным языком: для создания нового подчинённого ресурса.
Уточнение от arthuriantech:
Включая, но не ограничиваясь. Метод POST предназначен для передачи данных на сервер с целью дальнейшей обработки — он используется для любых действий, которые не нужно стандартизировать в рамках HTTP. До RFC 5789 он был единственным легальным способом вносить частичные изменения.
roy.gbiv.com/untangled/2009/it-is-okay-to-use-post
tools.ietf.org/html/rfc7231#section-4.3.3
То есть, если есть набор devices, то POST позволяет создать новый объект device внутри devices.
Выберем тот же Endpoint и с помощью POST создадим новое устройство.
curl -X POST "http://netbox.linkmeup.ru:45127/api/dcim/devices/" \
-H "accept: application/json"\
-H "Content-Type: application/json" \
-H "Authorization: TOKEN a9aae70d65c928a554f9a038b9d4703a1583594f" \
-d "{ \"name\": \"just a simple russian girl\", \"device_type\": 1, \"device_role\": 1, \"site\": 3, \"rack\": 3, \"position\": 5, \"face\": \"front\"}"Здесь уже появляется заголовок Authorization, содержащий токен, который авторизует запрос на запись, а после директивы -d расположен JSON с параметрами создаваемого устройства:
{
"name": "just a simple russian girl",
"device_type": 1,
"device_role": 1,
"site": 3,
"rack": 3,
"position": 5,
"face": "front"}Запрос у вас не сработает, потому что Токен уже не валиден — не пытайтесь записать в NetBox.В ответ приходит HTTP-ответ с кодом 201 (CREATED) и JSON’ом в теле сообщения, где сервер возвращает все параметры о созданном устройстве.
HTTP/1.1 201 Created
Server: nginx/1.14.0 (Ubuntu)
Date: Sat, 18 Jan 2020 11:00:22 GMT
Content-Type: application/json
Content-Length: 1123
Connection: keep-alive
JSONДамп транзакции.
Теперь новым запросом с методом GET можно его увидеть в выдаче:
curl -X GET -H "Accept: application/json; indent=4" \
"http://netbox.linkmeup.ru:45127/api/dcim/devices/?q=russian"«q» в NetBox’е позволяет найти все объекты, содержащие в своём названии строку, идущую дальше.POST, очевидно, не является ни безопасным, ни идемпотентным — он наверняка меняет данные, и дважды выполненный запрос приведёт или к созданию второго такого же объекта, или к ошибке.
HTTP PUT
Это метод для изменения существующего объекта. Endpoint для PUT выглядит иначе, чем для POST — в нём теперь содержится конкретный объект.
PUT может возвращать коды 201 или 200.
Важный момент с этим методом: нужно передавать все обязательные атрибуты, поскольку PUT замещает собой старый объект.
Поэтому, если например, просто попытаться добавить атрибут asset_tag нашему новому устройству, то получим ошибку:
curl -X PUT "http://netbox.linkmeup.ru:45127/api/dcim/devices/18/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: TOKEN a9aae70d65c928a554f9a038b9d4703a1583594f" \
-d "{ \"asset_tag\": \"12345678\"}"{"device_type":["This field is required."],"device_role":["This field is required."],"site":["This field is required."]}Но если добавить недостающие поля, то всё сработает:
curl -X PUT "http://netbox.linkmeup.ru:45127/api/dcim/devices/18/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: TOKEN a9aae70d65c928a554f9a038b9d4703a1583594f" \
-d "{ \"name\": \"just a simple russian girl\", \"device_type\": 1, \"device_role\": 1, \"site\": 3, \"rack\": 3, \"position\": 5, \"face\": \"front\", \"asset_tag\": \"12345678\"}"Дамп транзакции.
Обратите внимание на URL здесь — теперь он включает ID устройства, которое мы хотим менять (18).
HTTP PATCH
Этот метод используется для частичного изменения ресурса.
WAT? Спросите вы, а как же PUT?
PUT — изначально существовавший в стандарте метод, предполагающий полную замену изменяемого объекта. Соответственно в методе PUT, как я и писал выше, придётся указать даже те атрибуты объекта, которые не меняются.
А PATCH был добавлен позже и позволяет указать только те атрибуты, которые действительно меняются.
Например:
curl -X PATCH "http://netbox.linkmeup.ru:45127/api/dcim/devices/18/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: TOKEN a9aae70d65c928a554f9a038b9d4703a1583594f" \
-d "{ \"serial\": \"BREAKINGBAD\"}"Здесь также в URL указан ID устройства, но для изменения только один атрибут serial.
Дамп транзакции.
HTTP DELETE
Очевидно, удаляет объект.
Пример.
curl -X DELETE "http://netbox.linkmeup.ru:45127/api/dcim/devices/21/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: TOKEN a9aae70d65c928a554f9a038b9d4703a1583594f"Метод DELETE идемпотентен с той точки зрения, что повторно выполненный запрос уже ничего не меняет в списке ресурсов (но вернёт код 404 (NOT FOUND).
curl -X DELETE "http://netbox.linkmeup.ru:45127/api/dcim/devices/21/" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-H "Authorization: TOKEN a9aae70d65c928a554f9a038b9d4703a1583594f"{"detail":"Not found."}Curl — это, конечно, очень удобно для доблестных воинов CLI, но есть инструменты получше.
Postman
Postman позволяет в графическом интерфейсе формировать запросы, выбирая методы, заголовки, тело, и отображает результат в удобочитаемом виде.
Кроме того запросы и URI можно сохранять и возвращаться к ним позже.
Скачать Postman на оф.сайте.
Так мы можем сделать GET:
Здесь указан Token в GET только для примера.
А так POST:
Postman служит только для работы с RESTful API.
Например, не пытайтесь через него отправить NETCONF XML, как это делал я на заре своей автоматизационной карьеры.Один из приятных бонусов специфицированного API в том, что вы можете в Postman импортировать все эндпоинты и их методы как коллекцию.
Для этого в окне Import (File->Import) выберите Import From Link и вставьте в окно URL netbox.linkmeup.ru:45127/api/docs/?format=openapi.
Далее, всё, что только можно, вы найдёте в коллекциях.
Python+requests
Но даже через Postman вы, скорее всего, не будете управлять своими Production-системами. Наверняка, у вас будут внешние приложения, которые захотят без вашего участия взаимодействовать с ними.
Например, система генерации конфигурации захочет забрать список IP-интерфейсов из NetBox.
В Python есть чудесная библиотека requests, которая реализует работу через HTTP.
Пример запроса списка всех устройств:
import requests
HEADERS = {'Content-Type': 'application/json', 'Accept': 'application/json'}
NB_URL = "http://netbox.linkmeup.ru:45127"
request_url = f"{NB_URL}/api/dcim/devices/"
devices = requests.get(request_url, headers = HEADERS)
print(devices.json())Снова добавим новое устройство:
import requests
API_TOKEN = "a9aae70d65c928a554f9a038b9d4703a1583594f"
HEADERS = {'Authorization': f'Token {API_TOKEN}', 'Content-Type': 'application/json', 'Accept': 'application/json'}
NB_URL = "http://netbox.linkmeup.ru:45127"
request_url = f"{NB_URL}/api/dcim/devices/"
device_parameters = {
"name": "just a simple REQUESTS girl",
"device_type": 1,
"device_role": 1,
"site": 3,
}
new_device = requests.post(request_url, headers = HEADERS, json=device_parameters)
print(new_device.json())Python+NetBox SDK
В случае NetBox есть также Python SDK — Pynetbox, который представляет все Endpoint’ы NetBox в виде объекта и его атрибутов, делая за вас всю грязную работу по формированию URI и парсингу ответа, хотя и не бесплатно, конечно.
Например, сделаем то же, что и выше, использую pynetbox.
Список всех устройств:
import pynetbox
NB_URL = "http://netbox.linkmeup.ru:45127"
nb = pynetbox.api(NB_URL)
devices = nb.dcim.devices.all()
print(devices)Добавить новое устройство:
import pynetbox
API_TOKEN = "a9aae70d65c928a554f9a038b9d4703a1583594f"
NB_URL = "http://netbox.linkmeup.ru:45127"
nb = pynetbox.api(NB_URL, token = API_TOKEN)
device_parameters = {
"name": "just a simple PYNETBOX girl",
"device_type": 1,
"device_role": 1,
"site": 3,
}
new_device = nb.dcim.devices.create(**device_parameters)
print(new_device)Документация по Pynetbox.
SWAGGER
За что ещё стоит поблагодарить ушедшее десятилетие, так это за спецификации API. Если вы перейдёте по этому пути, то попадёте в Swagger UI — документацию по API Netbox.
На этой странице перечислены все Endpoint’ы, методы работы с ними, возможные параметры и атрибуты и указано, какие из них обязательны. Кроме того описаны ожидаемые ответы.
На этой же странице можно выполнять интерактивные запросы, кликнув на Try it out.
По какой-от причине swagger в качестве Base URL берёт имя сервера без порта, поэтому функция Try it out не работает в моих примерах со Swagger’ом. Но вы можете попробовать это на собственной инсталляции.При нажатии на Execute Swagger UI сформирует строку curl, с помощью которой можно аналогичный запрос сделать из командной строки.
В Swagger UI можно даже создать объект:
Для этого достаточно быть авторизованным пользователем, обладающим нужными правами.
То, что мы видим на этой странице — это Swagger UI — документация, сгенерированная на основе спецификации API.
С трендами на микросервисную архитектуру всё более важным становится иметь стандартизированный API для взаимодействия между компонентами, эндпоинты и методы которого легко определить как человеку, так и приложению, не роясь в исходном коде или PDF-документации.
Поэтому разработчики сегодня всё чаще следуют парадигме API First, когда сначала задумываются об API, а уже потом о реализации.
В этом дизайне сначала специфицируется API, а затем из него генерируются документация, клиентское приложение, серверная часть и необходимы тесты.
Swagger — это фреймворк и язык спецификации (который ныне переименован в OpenAPI 2.0), позволяющие реализовать эту задачу.
Углубляться в него я не буду.
За бо́льшими деталями сюда:
Существует и такая, да. Не всё в том мире 2000-го года так уже радужно.
Не являясь экспертом, не берусь предметно раскрывать вопрос, но дам ссылку на небесспорную статью на Хабре.
Альтернативным интерфейсом взаимодействия компонентов системы сегодня является gRPC. Ему же пророчат большое будущее на ниве новых подходов к работе с сетевым оборудованием. Но о нём мы поговорим когда-то в будущем, когда придёт его черёд.
Можно также взглянуть на многообещающий GraphQL, но нам опять же нет нужды с ним работать пока, поэтому остаётся на самостоятельное изучение.
Важно
Токен a9aae70d65c928a554f9a038b9d4703a1583594f был использован только в демонстрационных целях и больше не работает.Прямое указание токенов в коде программы недопустимо и сделано здесь мной только в интересах упрощения примеров.
- Андрею Панфилову за вычитку и правки
- Александру Фатину за вычитку и правки
GET против POST
Что такое HTTP?
Протокол передачи гипертекста (HTTP) предназначен для включения связь между клиентами и серверами.
HTTP работает как протокол запрос-ответ между клиентом и сервером.
Пример: клиент (браузер) отправляет HTTP-запрос на сервер; тогда сервер возвращает ответ клиенту. Ответ содержит информацию о состоянии запрос и может также содержать запрошенный контент.
Методы HTTP
- GET
- ПОСТ
- PUT
- ГОЛОВА
- УДАЛИТЬ
- патч
- ВАРИАНТЫ
Два наиболее распространенных метода HTTP: GET и POST.
Метод GET
GET используется для запроса данных от указанного ресурс.
GET — один из самых распространенных методов HTTP.
Обратите внимание, что строка запроса (пары имя / значение) отправляется в URL запрос GET:
/test/demo_form.php?name1=value1&name2=value2
Некоторые другие примечания по запросам GET:
- GET запросов может быть кэшировано
- запросов GET остаются в истории браузера
- запросов GET можно добавить в закладки
- GET-запросы никогда не должны использоваться при работе с конфиденциальными данными
- GET-запросов имеют ограничения по длине
- GET-запросы используются только для запроса данных (не изменять)
Метод POST
POST используется для отправки данных на сервер для создания / обновления ресурса.
Данные, отправленные на сервер с POST, хранятся в теле запроса HTTP-запрос:
POST /test/demo_form.php HTTP / 1.1
Ведущий: w3schools.com
имя1 = значение1 & имя2 = значение2
POST — один из самых распространенных методов HTTP.
Некоторые другие замечания по запросам POST:
- запросов POST никогда не кэшируются
- POST-запросов не сохраняются в истории браузера
- POST-запросы не могут быть добавлены в закладки
- POST-запросов не имеют ограничений по длине данных
метод PUT
PUT используется для отправки данных на сервер для создания / обновления ресурса.
Разница между POST и PUT заключается в том, что PUT-запросы являются идемпотентными. Который вызов одного и того же запроса PUT несколько раз всегда приводит к результат. Напротив, вызов POST-запроса неоднократно имеет побочные эффекты создавая один и тот же ресурс несколько раз.
метод ГОЛОВА
HEAD практически идентична GET, но без тела ответа.
Другими словами, если GET / users возвращает список пользователей, то HEAD / users будет сделать тот же запрос, но не вернет список пользователей.
HEAD-запросы полезны для проверки того, что GET-запрос будет возвращать раньше фактически делает запрос GET — как перед загрузкой большого файла или ответа тело.
УДАЛИТЬ Метод
Метод DELETE удаляет указанный ресурс.
ОПЦИИ Метод
Метод OPTIONS описывает параметры связи для цели ресурс.
Сравнить GET иPOST
В следующей таблице сравниваются два метода HTTP: GET и POST.
| GET | ПОСТ | |
|---|---|---|
| Кнопка НАЗАД / Перезагрузка | Безвредный | Данные будут повторно отправлены (браузер должен предупредить пользователя о том, что данные должны быть повторно отправлены) |
| В закладки | Можно добавить в закладки | Нельзя добавить в закладки |
| Кэшированный | Можно кэшировать | Не кэшируется |
| Тип кодировки | заявка / x-www-form-urlencoded | application / x-www-form-urlencoded или multipart / form-data.Использовать многочастное кодирование для двоичных данных |
| История | Параметры остаются в истории браузера | Параметры не сохраняются в истории браузера |
| Ограничения на длину данных | Да, при отправке данных метод GET добавляет данные в URL; и длина URL-адреса ограничена (максимальная длина URL-адреса составляет 2048 символов) | Без ограничений |
| Ограничения на тип данных | Разрешены только символы ASCII | Без ограничений.Двоичные данные также допускаются |
| Безопасность | GET менее безопасен по сравнению с POST, поскольку отправленные данные являются частью URL-адреса Никогда не используйте GET при отправке паролей или другой конфиденциальной информации! | POST немного безопаснее, чем GET, поскольку параметры не сохраняются в истории браузера или в журналах веб-сервера. |
| Видимость | Данные видны всем в URL | Данные не отображаются в URL |
,
HTTP определяет набор методов запроса , чтобы указать желаемое действие, которое должно быть выполнено для данного ресурса. Хотя они также могут быть существительными, эти методы запроса иногда называются глаголами HTTP . Каждый из них реализует различную семантику, но некоторые общие черты разделяются их группой: например, Метод запроса может быть безопасным, идемпотентным или кэшируемым.
-
GET - Метод GET
запрашивает представление указанного ресурса.Запросы с использованиемGETдолжны только получать данные. -
ГОЛОВА - Метод
HEADзапрашивает ответ, идентичный ответу на запросGET, но без тела ответа. -
ПОСТ - Метод
POSTиспользуется для отправки объекта на указанный ресурс, что часто вызывает изменение состояния или побочные эффекты на сервере. -
PUT Метод
PUTзаменяет все текущие представления целевого ресурса полезной нагрузкой запроса.-
DELETE - Метод
УДАЛИТЬудаляет указанный ресурс. -
СОЕДИНИТЬ Метод
CONNECTустанавливает туннель к серверу, идентифицированному целевым ресурсом.-
ВАРИАНТЫ - Метод
ОПЦИИиспользуется для описания параметров связи для целевого ресурса. -
TRACE Метод
TRACEвыполняет проверку обратной связи по пути к целевому ресурсу.-
PATCH - Метод
PATCHиспользуется для применения частичных модификаций к ресурсу.
Технические характеристики
Совместимость браузера
Чтобы внести свой вклад в эти данные о совместимости, напишите запрос на извлечение этого файла: https://github.com/mdn/browser-compat-data/blob/master/http/methods.json.
Данные о совместимости не найдены. Пожалуйста, отправьте данные для "http / Methods" (глубина: 1) в хранилище данных совместимости MDN.
См. Также
,http - Как отправить запрос POST с PHP?
Переполнение стека- Товары
- Клиенты
- Случаи использования
- Переполнение стека Публичные вопросы и ответы
- Команды Частные вопросы и ответы для вашей команды
- предприятие Частные вопросы и ответы для вашего предприятия
- работы Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимать технический талант
- реклама Связаться с разработчиками по всему миру
Загрузка…
,POST - Tecnologia para desenvolvedores web
O метод HTTP POST envia dados ao servidor. Типовая информация Content-Type .
Разница между PUT и POST в очереди PUT в виде идемпотента Assim Como Passando Uma Ordem Várias Везес.
Uma solicitação POST geralmente и enviada por meio de um formulário HTML e resulta em uma alteração no servidor. Nesse caso, o типо де контекстуо и выделение колокандо строка адекватно без атрибута энтип до элемент <форма> или атрибут формат до элементов <вход> или <кнопка>
- заявка
/ x-www-form-urlencoded: в качестве единого счета,и,=.Признаки без изменений в коде: в процентах: в обязательном порядке и правильном подходе для использования в общепринятых данных (например, вmultipart / form-data) -
multipart / form-data -
текст / обычный
Quando a Requisição POST - Условия предоставления различных форм HTML - совместная информация XMLHttpRequest - корпоративное предложение.Соответствует требованиям HTTP 1.1, o POST и проектам, разрешенным для использования в качестве единого объекта:
- существующий рецензент
- Postar uma mensagem em um quadro de avisos, группа новостей, списки электронных писем или групп, аналогичных de artigos;
- год назад, когда дело дошло до нас;
- Fornecendo um bloco de dados, como o resultado do envio de um formulário, para um processo de манипулясан де дадос;
- Estendendo um Banco de dados por meio de uma operação de добавление .
Синтаксис
POST /index.html
Exemplo
Um упрощает использование формул тип контента application / x-www-form-urlencoded :
POST / HTTP / 1.1 Ведущий: foo.com Тип содержимого: application / x-www-form-urlencoded Длина контента: 13 сказать = Привет и = Мама
Um formulário utilizando o тип контента multipart / form-data :
POST /test.html HTTP / 1.1 Ведущий: пример.организация Content-Type: multipart / form-data; border = "border" --boundary Content-Disposition: форма-данные; имя = "field1" value1 --boundary Content-Disposition: форма-данные; Name = "поле2"; имя файла = "example.txt" значение2
Especificações
Таба де совместимости не имеет никакого отношения к партии. Чтобы узнать больше о ком-то дадосе, обратитесь к https://github.com/mdn/browser-compat-data e envie-nos um запрос на получение .
Обновление данных о совместимости на GitHub| Рабочий стол | Мобильный | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Chrome | Edge | Firefox | Интернет-обозреватель | Opera | Safari | Android-браузер 901 веб-браузер 901 Android 913 Android Android-браузер Веб-браузер 901 Android 913 Android 913 Android Android-браузер 901 веб-браузер 901 для Android AndroidOpera для Android | Safari на iOS | Samsung Интернет | ||||
POST | Chrome Полная поддержка Да | Край Полная поддержка 12 | Firefox Полная поддержка Да | IE Полная поддержка Да | Опера Полная поддержка Да | Safari Полная поддержка Да | WebView Android Полная поддержка Да | Chrome Android Полная поддержка Да | Firefox Android Полная поддержка Да | Opera Android Полная поддержка Да | Safari iOS Полная поддержка Да | Samsung Интернет Android Полная поддержка Да |
Легенда
- Полная поддержка
- Полная поддержка