Обзор протокола HTTP — HTTP
HTTP — это протокол, позволяющий получать различные ресурсы, например HTML-документы. Протокол HTTP лежит в основе обмена данными в Интернете. HTTP является протоколом клиент-серверного взаимодействия, что означает инициирование запросов к серверу самим получателем, обычно веб-браузером (web-browser). Полученный итоговый документ будет (может) состоять из различных поддокументов, являющихся частью итогового документа: например, из отдельно полученного текста, описания структуры документа, изображений, видео-файлов, скриптов и многого другого.
Клиенты и серверы взаимодействуют, обмениваясь одиночными сообщениями (а не потоком данных). Сообщения, отправленные клиентом, обычно веб-браузером, называются запросами, а сообщения, отправленные сервером, называются ответами.
Хотя HTTP был разработан ещё в начале 1990-х годов, за счёт своей расширяемости в дальнейшем он все время совершенствовался. HTTP является протоколом прикладного уровня, который чаще всего использует возможности другого протокола — TCP (или TLS — защищённый TCP) — для пересылки своих сообщений, однако любой другой надёжный транспортный протокол теоретически может быть использован для доставки таких сообщений. Благодаря своей расширяемости, он используется не только для получения клиентом гипертекстовых документов, изображений и видео, но и для передачи содержимого серверам, например, с помощью HTML-форм. HTTP также может быть использован для получения только частей документа с целью обновления веб-страницы по запросу (например, посредством AJAX запроса).
Благодаря своей расширяемости, он используется не только для получения клиентом гипертекстовых документов, изображений и видео, но и для передачи содержимого серверам, например, с помощью HTML-форм. HTTP также может быть использован для получения только частей документа с целью обновления веб-страницы по запросу (например, посредством AJAX запроса).
HTTP — это клиент-серверный протокол, то есть запросы отправляются какой-то одной стороной — участником обмена (user-agent) (либо прокси вместо него). Чаще всего в качестве участника выступает веб-браузер, но им может быть кто угодно, например, робот, путешествующий по Сети для пополнения и обновления данных индексации веб-страниц для поисковых систем.
Каждый запрос (англ. request) отправляется серверу, который обрабатывает его и возвращает ответ (англ. response). Между этими запросами и ответами как правило существуют многочисленные посредники, называемые прокси, которые выполняют различные операции и работают как шлюзы или кэш, например.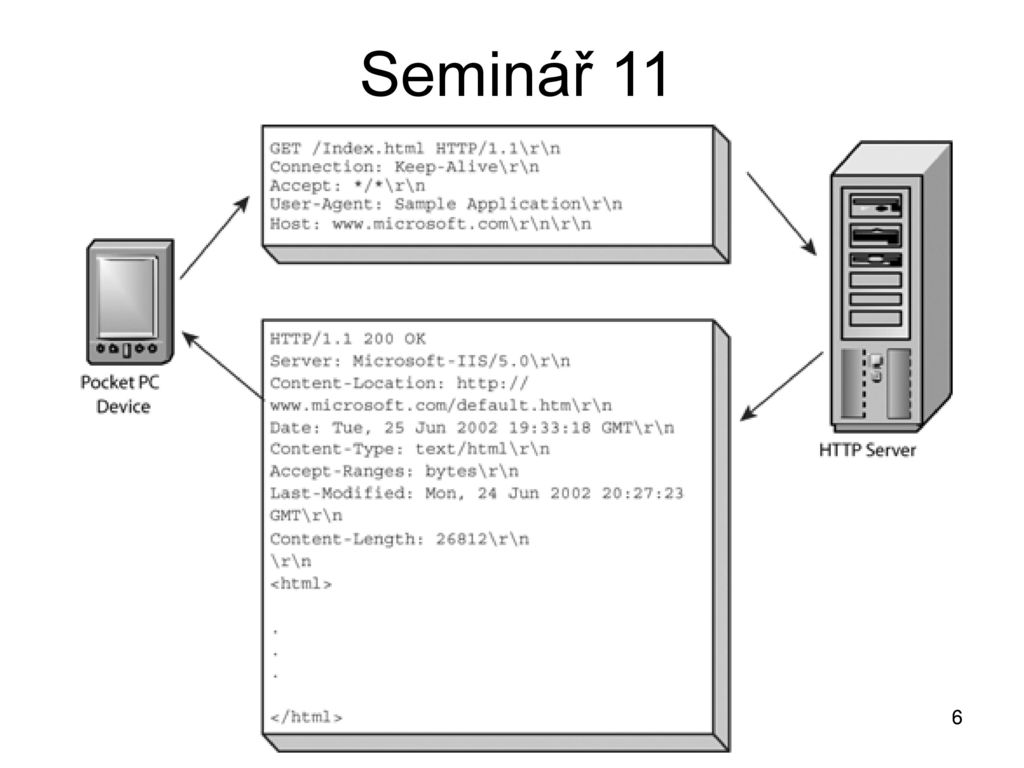
Обычно между браузером и сервером гораздо больше различных устройств-посредников, которые играют какую-либо роль в обработке запроса: маршрутизаторы, модемы и так далее. Благодаря тому, что Сеть построена на основе системы уровней (слоёв) взаимодействия, эти посредники «спрятаны» на сетевом и транспортном уровнях. В этой системе уровней HTTP занимает самый верхний уровень, который называется «прикладным» (или «уровнем приложений»). Знания об уровнях сети, таких как представительский, сеансовый, транспортный, сетевой, канальный и физический, имеют важное значение для понимания работы сети и диагностики возможных проблем, но не требуются для описания и понимания HTTP.
Клиент: участник обмена
Участник обмена (user agent) — это любой инструмент или устройство, действующие от лица пользователя. Эту задачу преимущественно выполняет веб-браузер; в некоторых случаях участниками выступают программы, которые используются инженерами и веб-разработчиками для отладки своих приложений.
Браузер всегда является той сущностью, которая создаёт запрос. Сервер обычно этого не делает, хотя за многие годы существования сети были придуманы способы, которые могут позволить выполнить запросы со стороны сервера.
Чтобы отобразить веб страницу, браузер отправляет начальный запрос для получения HTML-документа этой страницы. После этого браузер изучает этот документ и запрашивает дополнительные файлы, необходимые для отображения содержания веб-страницы (исполняемые скрипты, информацию о макете страницы — CSS таблицы стилей, дополнительные ресурсы в виде изображений и видео-файлов), которые непосредственно являются частью исходного документа, но расположены в других местах сети. Далее браузер соединяет все эти ресурсы для отображения их пользователю в виде единого документа — веб-страницы. Скрипты, выполняемые самим браузером, могут получать по сети дополнительные ресурсы на последующих этапах обработки веб-страницы, и браузер соответствующим образом обновляет отображение этой страницы для пользователя.
Веб-страница является гипертекстовым документом. Это означает, что некоторые части отображаемого текста являются ссылками, которые могут быть активированы (обычно нажатием кнопки мыши) с целью получения и соответственно отображения новой веб-страницы (переход по ссылке). Это позволяет пользователю «перемещаться» по страницам сети (Internet). Браузер преобразует эти гиперссылки в HTTP-запросы и в дальнейшем полученные HTTP-ответы отображает в понятном для пользователя виде.
Веб-сервер
На другой стороне коммуникационного канала расположен сервер, который обслуживает (англ. serve) пользователя, предоставляя ему документы по запросу. С точки зрения конечного пользователя, сервер всегда является некой одной виртуальной машиной, полностью или частично генерирующей документ, хотя фактически он может быть группой серверов, между которыми балансируется нагрузка, то есть перераспределяются запросы различных пользователей, либо сложным программным обеспечением, опрашивающим другие компьютеры (такие как кеширующие серверы, серверы баз данных, серверы приложений электронной коммерции и другие).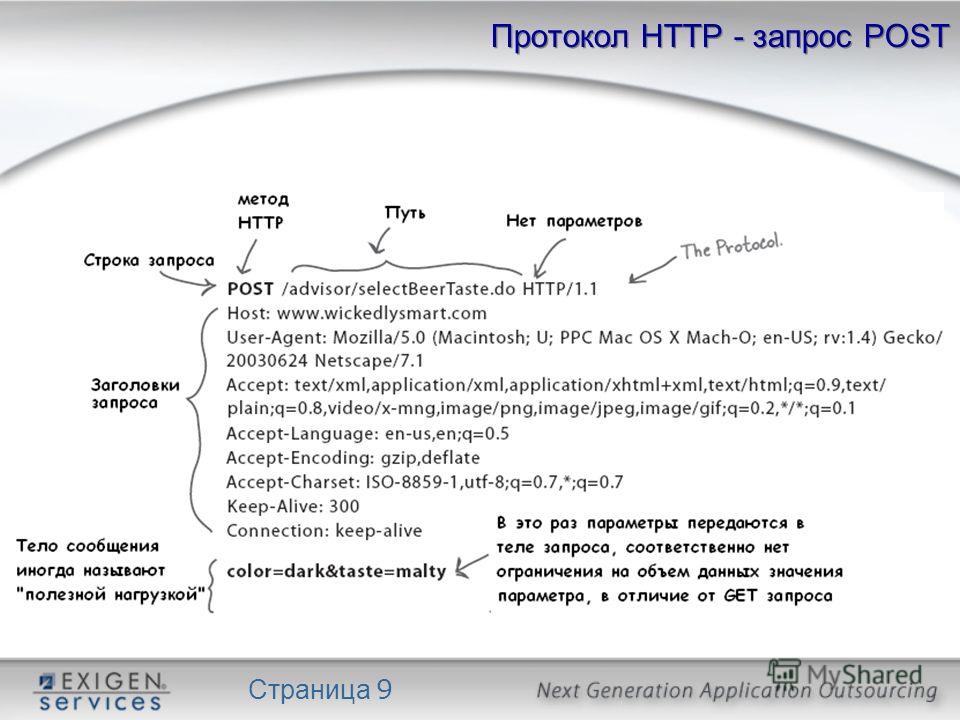
Сервер не обязательно расположен на одной машине, и наоборот — несколько серверов могут быть расположены (поститься) на одной и той же машине. В соответствии с версией HTTP/1.1 и имея Host заголовок, они даже могут делить тот же самый IP-адрес.
Прокси
Между веб-браузером и сервером находятся большое количество сетевых узлов, передающих HTTP сообщения. Из-за слоистой структуры большинство из них оперируют также на транспортном сетевом или физическом уровнях, становясь прозрачным на HTTP слое и потенциально снижая производительность. Эти операции на уровне приложений называются прокси. Они могут быть прозрачными или нет, (изменяющие запросы не пройдут через них), и способны исполнять множество функций:
- caching (кеш может быть публичным или приватными, как кеш браузера)
- фильтрация (как сканирование антивируса, родительский контроль, …)
- выравнивание нагрузки (позволить нескольким серверам обслуживать разные запросы)
- аутентификация (контролировать доступом к разным ресурсам)
- протоколирование (разрешение на хранение истории операций)
HTTP — прост
Даже с большей сложностью, введённой в HTTP/2 путём инкапсуляции HTTP-сообщений в фреймы, HTTP, как правило, прост и удобен для восприятия человеком. HTTP-сообщения могут читаться и пониматься людьми, обеспечивая более лёгкое тестирование разработчиков и уменьшенную сложность для новых пользователей.
HTTP-сообщения могут читаться и пониматься людьми, обеспечивая более лёгкое тестирование разработчиков и уменьшенную сложность для новых пользователей.
HTTP — расширяемый
Введённые в HTTP/1.0 HTTP-заголовки сделали этот протокол лёгким для расширения и экспериментирования. Новая функциональность может быть даже введена простым соглашением между клиентом и сервером о семантике нового заголовка.
HTTP не имеет состояния, но имеет сессию
HTTP не имеет состояния: не существует связи между двумя запросами, которые последовательно выполняются по одному соединению. Из этого немедленно следует возможность проблем для пользователя, пытающегося взаимодействовать с определённой страницей последовательно, например, при использовании корзины в электронном магазине. Но хотя ядро HTTP не имеет состояния, куки позволяют использовать сессии с сохранением состояния. Используя расширяемость заголовков, куки добавляются к рабочему потоку, позволяя сессии на каждом HTTP-запросе делиться некоторым контекстом или состоянием.
HTTP и соединения
Соединение управляется на транспортном уровне, и потому принципиально выходит за границы HTTP. Хотя HTTP не требует, чтобы базовый транспортного протокол был основан на соединениях, требуя только
HTTP/1.0 открывал TCP-соединение для каждого обмена запросом/ответом, имея два важных недостатка: открытие соединения требует нескольких обменов сообщениями, и потому медленно, хотя становится более эффективным при отправке нескольких сообщений, или при регулярной отправке сообщений: тёплые соединения более эффективны, чем
Для смягчения этих недостатков, HTTP/1.1 предоставил конвейерную обработку (которую оказалось трудно реализовать) и устойчивые соединения: лежащее в основе TCP соединение можно частично контролировать через заголовок Connection.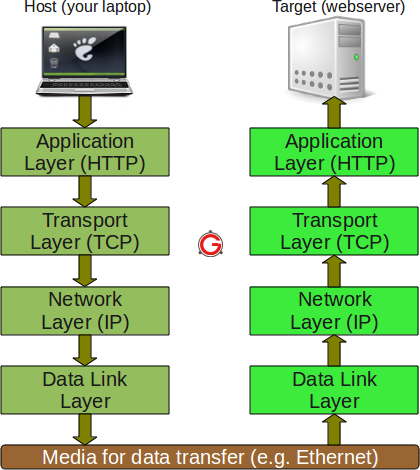 HTTP/2 сделал следующий шаг, добавив мультиплексирование сообщений через простое соединение, помогающее держать соединение тёплым и более эффективным.
HTTP/2 сделал следующий шаг, добавив мультиплексирование сообщений через простое соединение, помогающее держать соединение тёплым и более эффективным.
Проводятся эксперименты по разработке лучшего транспортного протокола, более подходящего для HTTP. Например, Google экспериментирует с QUIC (которая основана на UDP) для предоставления более надёжного и эффективного транспортного протокола.
Естественная расширяемость HTTP со временем позволила большее управление и функциональность Сети. Кеш и методы аутентификации были ранними функциями в истории HTTP. Способность ослабить первоначальные ограничения, напротив, была добавлена в 2010-е.
Ниже перечислены общие функции, управляемые с HTTP.
- Кеш
Сервер может инструктировать прокси и клиенты, указывая что и как долго кешировать. Клиент может инструктировать прокси промежуточных кешей игнорировать хранимые документы. - Ослабление ограничений источника
Для предотвращения шпионских и других нарушающих приватность вторжений, веб-браузер обеспечивает строгое разделение между веб-сайтами.
- Аутентификация
Некоторые страницы доступны только специальным пользователям. Базовая аутентификация может предоставляться через HTTP, либо через использование заголовка WWW-Authenticate (en-US) и подобных ему, либо с помощью настройки спецсессии, используя куки. - Прокси и туннелирование
Серверы и/или клиенты часто располагаются в интернете и скрывают свои истинные IP-адреса от других. HTTP запросы идут через прокси для пересечения этого сетевого барьера. Не все прокси — HTTP прокси. SOCKS-протокол, например, оперирует на более низком уровне. Другие, как, например, ftp, могут быть обработаны этими прокси. - Сессии
Использование HTTP кук позволяет связать запрос с состоянием на сервере. Это создаёт сессию, хотя ядро HTTP — протокол без состояния. Это полезно не только для корзин в интернет-магазинах, но также для любых сайтов, позволяющих пользователю настроить выход.

 Это создаёт сессию, хотя ядро HTTP — протокол без состояния. Это полезно не только для корзин в интернет-магазинах, но также для любых сайтов, позволяющих пользователю настроить выход.
Это создаёт сессию, хотя ядро HTTP — протокол без состояния. Это полезно не только для корзин в интернет-магазинах, но также для любых сайтов, позволяющих пользователю настроить выход.Когда клиент хочет взаимодействовать с сервером, являющимся конечным сервером или промежуточным прокси, он выполняет следующие шаги:
- Открытие TCP соединения: TCP-соединение будет использоваться для отправки запроса (или запросов) и получения ответа. Клиент может открыть новое соединение, переиспользовать существующее или открыть несколько TCP-соединений к серверу.
- Отправка HTTP-сообщения: HTTP-сообщения (до HTTP/2) являются человекочитаемыми. Начиная с HTTP/2, простые сообщения инкапсулируются во фреймы, делая невозможным их чтение напрямую, но принципиально остаются такими же.
- Читает ответ от сервера:
HTTP/1.1 200 OK Date: Sat, 09 Oct 2010 14:28:02 GMT Server: Apache Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT ETag: "51142bc1-7449-479b075b2891b" Accept-Ranges: bytes Content-Length: 29769 Content-Type: text/html <!DOCTYPE html.
.. (here comes the 29769 bytes of the requested web page) - Закрывает или переиспользует соединение для дальнейших запросов.
 .. (here comes the 29769 bytes of the requested web page)
.. (here comes the 29769 bytes of the requested web page)Если активирован HTTP-конвейер, несколько запросов могут быть отправлены без ожидания получения первого ответа целиком. HTTP-конвейер тяжело внедряется в существующие сети, где старые куски ПО сосуществуют с современными версиями. HTTP-конвейер был заменён в HTTP/2 на более надёжные мультиплексные запросы во фрейме.
Подробнее в отдельной статье «Сообщения HTTP»
HTTP/1.1 и более ранние HTTP сообщения человекочитаемые. В версии HTTP/2 эти сообщения встроены в новую бинарную структуру, фрейм, позволяющий оптимизации, такие как компрессия заголовков и мультиплексирование. Даже если часть оригинального HTTP сообщения отправлена в этой версии HTTP, семантика каждого сообщения не изменяется и клиент воссоздаёт (виртуально) оригинальный HTTP-запрос. Это также полезно для понимания HTTP/2 сообщений в формате HTTP/1.1.
Существует два типа HTTP сообщений, запросы и ответы, каждый в своём формате.
Запросы
Примеры HTTP запросов:
Запросы содержат следующие элементы:
- HTTP-метод, обычно глагол подобно
GET,POSTили существительное, какOPTIONSилиHEAD, определяющее операцию, которую клиент хочет выполнить. Обычно, клиент хочет получить ресурс (используяGET) или передать значения HTML-формы (используяPOST), хотя другие операция могут быть необходимы в других случаях. - Путь к ресурсу: URL ресурсы лишены элементов, которые очевидны из контекста, например без протокола (
http://), домена (здесьdeveloper.mozilla.org), или TCP порта (здесь80). - Версию HTTP-протокола.
- Заголовки (опционально), предоставляющие дополнительную информацию для сервера.
- Или тело, для некоторых методов, таких как
POST, которое содержит отправленный ресурс.
Ответы
Примеры ответов:
Ответы содержат следующие элементы:
- Версию HTTP-протокола.
- Сообщение состояния — краткое описание кода состояния.
- HTTP заголовки, подобно заголовкам в запросах.
- Опционально: тело, содержащее пересылаемый ресурс.
HTTP — лёгкий в использовании расширяемый протокол. Структура клиент-сервера, вместе со способностью к простому добавлению заголовков, позволяет HTTP продвигаться вместе с расширяющимися возможностями Сети.
Хотя HTTP/2 добавляет некоторую сложность, встраивая HTTP сообщения во фреймы для улучшения производительности, базовая структура сообщений осталась с HTTP/1.0. Сессионный поток остаётся простым, позволяя исследовать и отлаживать с простым монитором HTTP-сообщений.
Last modified: , by MDN contributors
что это такое, для чего служит протокол
Есть проблемы с ранжированием, проект не растет, хотите проверить работу своих специалистов по продвижению? Закажите профессиональный аудит в Семантике
Аудит и стратегия продвижения в Семантике
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
HTTP — это протокол, позволяющий передавать данные. Изначально он создавался для отправки и принятия документов, содержащих внутри ссылки для выполнения перехода на сторонние ресурсы.
Аббревиатура читается как «HyperText Transfer Protocol», что в переводе означает «протокол для передачи гипертекста». HTTP относится к группе прикладного уровня на основании специфики, использующейся OSI.
Чтобы лучше понять, что значит HTTP, разберем простую аналогию. Представим, что вы общаетесь с иностранцем в социальной сети. Он отправляет вам сообщение на английском языке, вы его получаете. Но понять содержимое вы не можете, так как не достаточно владеете языком. Чтобы расшифровать сообщение, воспользуетесь словарем. Поняв суть, вы отвечаете иностранцу на русском языке и отправляете ответ. Иностранец получает ответ и с помощью переводчика расшифровывает послание. Если упростить весь механизм, протоколы интернета HTTP выполняют функцию переводчика. С их помощью браузер может переводить зашифрованное содержимое веб-страниц и отображать их содержимое.
С их помощью браузер может переводить зашифрованное содержимое веб-страниц и отображать их содержимое.
Для чего нужен HTTP
Протокол HTTP служит для обмена информацией с помощью клиент-серверной модели. Клиент составляет и передает запрос на сервер, затем сервер обрабатывает и анализирует его, после этого создается ответ и отправляется пользователю. По окончании данного процесса клиент делает новую команду, и все повторяется.
Таким образом, протокол HTTP позволяет осуществлять обмен информацией между различными приложениями пользователей и специальными веб-серверами, а также подключаться к веб-ресурсам (как правило, браузерам). Сегодня описываемый протокол обеспечивает работу всей сети. Протокол передачи данных HTTP применяется и для передачи информации по другим протоколам более низкого уровня, например, WebDAV или SOAP. При этом протокол представляет собой средство для транспортировки. Многие программы также основываются на применении HTTP в качестве основного инструмента для обмена информацией. Данные представляются в различных форматах, к примеру, JSON или XML.
Данные представляются в различных форматах, к примеру, JSON или XML.
HTTP является протоколом для обмена информацией с помощью соединения IP/ ТСР. Как правило, для этого сервер использует порт 80 типа TCP. Если порт не прописан, программное обеспечение клиента будет использовать порт 80 типа TCP по умолчанию. В некоторых случаях могут использоваться и другие порты.
В протоколе HTTP используется симметричная схема шифрования, в его работе применяются симметричные криптосистемы. Симметричные криптосистемы предполагают использование одного и того же ключа для шифрования и расшифрования информации.
Чем отличается HTTP от HTTPS
Отличие можно обнаружить даже из расшифровок аббревиатур. HTTPS расшифровывается как «защита протокола передачи гипертекста». Таким образом, HTTP — самостоятельный протокол, а HTTPS — расширение для его защиты. По HTTP информация передается незащищенной, а HTTPS обеспечивает криптографическую защиту. Особенно актуально это для ресурсов с ответственной авторизацией. Это могут быть социальные сети или сайты платежных систем.
Это могут быть социальные сети или сайты платежных систем.
Чем опасна передача незащищенных данных? Программа-перехватчик может в любой момент передать их злоумышленникам. HTTPS имеет сложную техническую организацию, что позволяет надежно защищать информацию и исключить возможность несанкционированного доступа к ней. Отличие заключается и в портах. HTTPS, как правило, работает с портом 443.
Таким образом, HTTP применяется для передачи данных, а HTTPS позволяет осуществлять защищенную передачу данных с помощью шифрования и выполнять авторизацию на ресурсах с высоким уровнем безопасности.
Дополнительный функционал
HTTP отличается богатым функционалом, он совместим с различными расширениями. Используемая сегодня спецификация 1.1 позволяет применять заголовок Upgrade для переключения и работы через другие протоколы при обмене данными. Для этого пользователь должен отправить запрос серверу с данным заголовком. Если же сервер нуждается в переходе на специфичный обмен по иному протоколу, он возвращает клиенту запрос, в котором отображается статус «426 Upgrade Required».
Данная возможность особенно актуальна для обмена информацией через WebSocket (имеет спецификацию RFC 6455 , позволяет обмениваться данными в любой момент, без лишних HTTP-запросов). Для перехода на WebSocket один пользователь отправляет запрос с заголовком Upgrade и значением «websocket». Далее сервер отвечает «101 Switching Protocols». После этого момента начинается передача информация по WebSocket.
Протокол HTTP служит для передачи информации в сети Интернет.
Содержание
- Hyper Text Transfer Protocol
- Структура протокола HTTP
- Методы протокола
- Специфика HTTP
- Преимущества и недостатки протокола
- Достоинства
- Недостатки
- Как работает интернет? Протоколы HTTP/HTTPS
Hyper Text Transfer Protocol
Интернет протокол HTTP — Hyper Text Transfer Protocol является протоколом передачи гипертекста. Он предназначен для передачи различной информации между клиентом и сервером и является символьно-ориентированным клиент-серверным протоколом.
Это протокол прикладного уровня, не сохраняющий состояния и используется службой World Wide Web. В настоящее время HTTP в основном используется для получения данных с web -сайтов.
В основе протокола лежит технология «клиент-сервер». Это предполагает наличие потребителей – клиентов. Клиенты инициализируют соединение и посылают запрос и наличие поставщиков – серверов. Сервер ждет соединения чтобы получить запрос, производит нужные операции и возвращает клиенту сообщение с результатом.
Всего было четыре версии протокола. Самый первый вариант интернет протокола HTTP 0.9 был выпущен в 1991 году и впервые издан в январе 1992 года. Он привел к урегулированию норм и правил взаимосвязи между клиентами и серверами HTTP, а соответственно к точному разграничению функций между этими элементами. Были запротоколированы основные синтаксические и семантические принципы и положения.
В феврале 2015 года вышли последние редакции черновика очередной версии протокола. Протокол HTTP 2 отличает от предшествующих протоколов то, что он является бинарным. Его основные ключевые особенности: мультиплексирование запросов, последовательность приоритетов для запросов, уплотнение заголовков. Можно загружать несколько элементов параллельно, при помощи одного TCP-соединения, поддержка push-уведомлений серверной стороны.
Протокол HTTP 2 отличает от предшествующих протоколов то, что он является бинарным. Его основные ключевые особенности: мультиплексирование запросов, последовательность приоритетов для запросов, уплотнение заголовков. Можно загружать несколько элементов параллельно, при помощи одного TCP-соединения, поддержка push-уведомлений серверной стороны.
Структура протокола HTTP
Сообщение HTTP содержит три части, которые пересылаются в следующем порядке:
- Starting line — стартовая строка. Устанавливает тип передаваемого сообщения;
- Headers – заголовки. Дают характеристику телу сообщения, параметры его передачи и иные данные;
- Message Body — тело сообщения. Передает непосредственно информацию сообщения. Необходимо в обязательном порядке отделить тело сообщение от заголовков пустой строкой.
В этих трёх частях стартовая строка обязательно должна присутствовать. Заголовки и тело сообщения являются необязательными элементами. Это связано с тем, что собственно стартовая строка указывает на вид запроса — ответа. Исключением является интернет протокол HTTP версии 0.9. В ней сообщение запроса включает всего лишь стартовую строку, а сообщения ответа содержит только его тело.
Это связано с тем, что собственно стартовая строка указывает на вид запроса — ответа. Исключением является интернет протокол HTTP версии 0.9. В ней сообщение запроса включает всего лишь стартовую строку, а сообщения ответа содержит только его тело.
Методы протокола
Метод HTTP — последовательность из разных символов, кроме символов управления и разделителей, которые указывают на главное действие над ресурсом. Как правило метод представляет из себя короткое английское слово, написанное заголовочными буквами. Наименование метода является чувствительным к регистру.
Сервер может применять какие угодно методы. Для сервера или клиента нет методов являющихся обязательными. Если сервер не смог определить метод указанный клиентом, то он должен возвратить статус 501 – «Not Implemented». Если сервер определил метод, но его нельзя применить к конкретному ресурсу, то будет возвращено сообщение содержащее код 405 — «Method Not Allowed».
Во всех этих случаях сервер должен включить в ответное сообщение заголовок «Allow». Список включает в себя поддерживаемые методы. Все серверы обязаны поддерживать минимально методы GET и HEAD.
GET — применяется для запроса содержимого указанного источника. При помощи метода также можно начать какой-нибудь процесс. При этом в тело сообщения ответа нужно включить сведения о ходе реализации процесса. Клиент имеет возможность передать параметры исполнения запроса в URL целевого ресурса сразу после символа «?»: GET/path/resource?
HEAD – применяется аналогично методу GET. Отличие заключается в том, что в ответе сервера нет тела. Запрос HEAD как правило используется для извлечения метаданных, проверки существования ресурса, то есть валидация URL. Также этот запрос нужен для того, чтобы узнать, было ли изменение ресурса с момента предыдущего обращения. Еще одним часто используемым методом является метод POST.
Еще одним часто используемым методом является метод POST.
Специфика HTTP
Интернет протокол HTTP отличается от других протоколов тем, что создает отдельную TCP-сессию на любой запрос. В следующих версиях протокола было разрешено выполнять несколько запросов во время одной TCP-сессии. Но при этом браузеры, как правило, делают запрос только на страницу и находящиеся в ней объекты (изображения, таблицы стилей и так далее), а затем сразу прерывают TCP-сессию.
TCP/IPЧтобы поддерживать авторизованный доступ в протоколе HTTP используются файлы cookies, представляющие собой небольшие части данных, отосланные веб-сервером и сохраняемые на компьютере в браузере. Веб-клиент, пытаясь открыть страницу нужного сайта посылает этот фрагмент информации веб-серверу в виде HTTP-запроса.
Достоинства
- Интернет протокол HTTP дает возможность достаточно просто создавать нужные клиентские приложения.
- Первоначальные возможности протокола возможно расширить, внедрив свои персональные заголовки.
- Протокол поддерживается как клиент большим числом программ и есть возможность выбирать среди множества хостинговых компаний с серверами HTTP.
Недостатки
- Протокол HTTP не содержит в явном виде возможность навигации внутри ресурсов сервера.
- Отсутствует поддержка распределенности. Промышленное применение интернет протокола HTTP с использованием распределённых вычислений при больших нагрузках на сервер оказывается непригодным.
Как работает интернет? Протоколы HTTP/HTTPS
Простым языком об HTTP / Хабр
Вашему вниманию предлагается описание основных аспектов протокола HTTP — сетевого протокола, с начала 90-х и по сей день позволяющего вашему браузеру загружать веб-страницы. Данная статья написана для тех, кто только начинает работать с компьютерными сетями и заниматься разработкой сетевых приложений, и кому пока что сложно самостоятельно читать официальные спецификации.
HTTP — широко распространённый протокол передачи данных, изначально предназначенный для передачи гипертекстовых документов (то есть документов, которые могут содержать ссылки, позволяющие организовать переход к другим документам).
Аббревиатура HTTP расшифровывается как HyperText Transfer Protocol, «протокол передачи гипертекста». В соответствии со спецификацией OSI, HTTP является протоколом прикладного (верхнего, 7-го) уровня. Актуальная на данный момент версия протокола, HTTP 1.1, описана в спецификации RFC 2616.
Протокол HTTP предполагает использование клиент-серверной структуры передачи данных. Клиентское приложение формирует запрос и отправляет его на сервер, после чего серверное программное обеспечение обрабатывает данный запрос, формирует ответ и передаёт его обратно клиенту. После этого клиентское приложение может продолжить отправлять другие запросы, которые будут обработаны аналогичным образом.
Задача, которая традиционно решается с помощью протокола HTTP — обмен данными между пользовательским приложением, осуществляющим доступ к веб-ресурсам (обычно это веб-браузер) и веб-сервером. На данный момент именно благодаря протоколу HTTP обеспечивается работа Всемирной паутины.
Также HTTP часто используется как протокол передачи информации для других протоколов прикладного уровня, таких как SOAP, XML-RPC и WebDAV. В таком случае говорят, что протокол HTTP используется как «транспорт».
API многих программных продуктов также подразумевает использование HTTP для передачи данных — сами данные при этом могут иметь любой формат, например, XML или JSON.
Как правило, передача данных по протоколу HTTP осуществляется через TCP/IP-соединения. Серверное программное обеспечение при этом обычно использует TCP-порт 80 (и, если порт не указан явно, то обычно клиентское программное обеспечение по умолчанию использует именно 80-й порт для открываемых HTTP-соединений), хотя может использовать и любой другой.
Как отправить HTTP-запрос?
Самый простой способ разобраться с протоколом HTTP — это попробовать обратиться к какому-нибудь веб-ресурсу вручную. Представьте, что вы браузер, и у вас есть пользователь, который очень хочет прочитать статьи Анатолия Ализара.
Представьте, что вы браузер, и у вас есть пользователь, который очень хочет прочитать статьи Анатолия Ализара.
Предположим, что он ввёл в адресной строке следующее:
http://alizar.habrahabr.ru/
Соответственно вам, как веб-браузеру, теперь необходимо подключиться к веб-серверу по адресу alizar.habrahabr.ru.
Для этого вы можете воспользоваться любой подходящей утилитой командной строки. Например, telnet:
telnet alizar.habrahabr.ru 80
Сразу уточню, что если вы вдруг передумаете, то нажмите Ctrl + «]», и затем ввод — это позволит вам закрыть HTTP-соединение. Помимо telnet можете попробовать nc (или ncat) — по вкусу.
После того, как вы подключитесь к серверу, нужно отправить HTTP-запрос. Это, кстати, очень легко — HTTP-запросы могут состоять всего из двух строчек.
Для того, чтобы сформировать HTTP-запрос, необходимо составить стартовую строку, а также задать по крайней мере один заголовок — это заголовок Host, который является обязательным, и должен присутствовать в каждом запросе. Дело в том, что преобразование доменного имени в IP-адрес осуществляется на стороне клиента, и, соответственно, когда вы открываете TCP-соединение, то удалённый сервер не обладает никакой информацией о том, какой именно адрес использовался для соединения: это мог быть, например, адрес alizar.habrahabr.ru, habrahabr.ru или m.habrahabr.ru — и во всех этих случаях ответ может отличаться. Однако фактически сетевое соединение во всех случаях открывается с узлом 212.24.43.44, и даже если первоначально при открытии соединения был задан не этот IP-адрес, а какое-либо доменное имя, то сервер об этом никак не информируется — и именно поэтому этот адрес необходимо передать в заголовке Host.
Дело в том, что преобразование доменного имени в IP-адрес осуществляется на стороне клиента, и, соответственно, когда вы открываете TCP-соединение, то удалённый сервер не обладает никакой информацией о том, какой именно адрес использовался для соединения: это мог быть, например, адрес alizar.habrahabr.ru, habrahabr.ru или m.habrahabr.ru — и во всех этих случаях ответ может отличаться. Однако фактически сетевое соединение во всех случаях открывается с узлом 212.24.43.44, и даже если первоначально при открытии соединения был задан не этот IP-адрес, а какое-либо доменное имя, то сервер об этом никак не информируется — и именно поэтому этот адрес необходимо передать в заголовке Host.
Стартовая (начальная) строка запроса для HTTP 1.1 составляется по следующей схеме:
Метод URI HTTP/Версия
Например (такая стартовая строка может указывать на то, что запрашивается главная страница сайта):
GET / HTTP/1.1
Метод (в англоязычной тематической литературе используется слово method, а также иногда слово verb — «глагол») представляет собой последовательность из любых символов, кроме управляющих и разделителей, и определяет операцию, которую нужно осуществить с указанным ресурсом.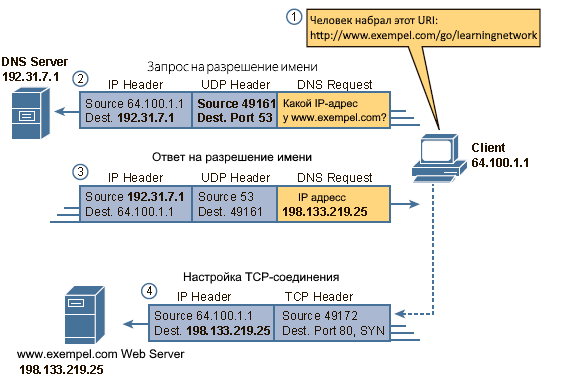 Спецификация HTTP 1.1 не ограничивает количество разных методов, которые могут быть использованы, однако в целях соответствия общим стандартам и сохранения совместимости с максимально широким спектром программного обеспечения как правило используются лишь некоторые, наиболее стандартные методы, смысл которых однозначно раскрыт в спецификации протокола.
Спецификация HTTP 1.1 не ограничивает количество разных методов, которые могут быть использованы, однако в целях соответствия общим стандартам и сохранения совместимости с максимально широким спектром программного обеспечения как правило используются лишь некоторые, наиболее стандартные методы, смысл которых однозначно раскрыт в спецификации протокола.
URI (Uniform Resource Identifier, унифицированный идентификатор ресурса) — путь до конкретного ресурса (например, документа), над которым необходимо осуществить операцию (например, в случае использования метода GET подразумевается получение ресурса). Некоторые запросы могут не относиться к какому-либо ресурсу, в этом случае вместо URI в стартовую строку может быть добавлена звёздочка (астериск, символ «*»). Например, это может быть запрос, который относится к самому веб-серверу, а не какому-либо конкретному ресурсу. В этом случае стартовая строка может выглядеть так:
OPTIONS * HTTP/1.1
Версия определяет, в соответствии с какой версией стандарта HTTP составлен запрос. Указывается как два числа, разделённых точкой (например 1.1).
Указывается как два числа, разделённых точкой (например 1.1).
Для того, чтобы обратиться к веб-странице по определённому адресу (в данном случае путь к ресурсу — это «/»), нам следует отправить следующий запрос:
GET / HTTP/1.1Host: alizar.habrahabr.ru
При этом учитывайте, что для переноса строки следует использовать символ возврата каретки (Carriage Return), за которым следует символ перевода строки (Line Feed). После объявления последнего заголовка последовательность символов для переноса строки добавляется дважды.
Впрочем, в спецификации HTTP рекомендуется программировать HTTP-сервер таким образом, чтобы при обработке запросов в качестве межстрочного разделителя воспринимался символ LF, а предшествующий символ CR, при наличии такового, игнорировался. Соответственно, на практике бо́льшая часть серверов корректно обработает и такой запрос, где заголовки отделены символом LF, и он же дважды добавлен после объявления последнего заголовка.
Если вы хотите отправить запрос в точном соответствии со спецификацией, можете воспользоваться управляющими последовательностями \r и \n:
echo -en "GET / HTTP/1.1\r\nHost: alizar.habrahabr.ru\r\n\r\n" | ncat alizar.habrahabr.ru 80
Как прочитать ответ?
Стартовая строка ответа имеет следующую структуру:
HTTP/Версия Код состояния Пояснение
Версия протокола здесь задаётся так же, как в запросе.
Код состояния (Status Code) — три цифры (первая из которых указывает на класс состояния), которые определяют результат совершения запроса. Например, в случае, если был использован метод GET, и сервер предоставляет ресурс с указанным идентификатором, то такое состояние задаётся с помощью кода 200. Если сервер сообщает о том, что такого ресурса не существует — 404. Если сервер сообщает о том, что не может предоставить доступ к данному ресурсу по причине отсутствия необходимых привилегий у клиента, то используется код 403.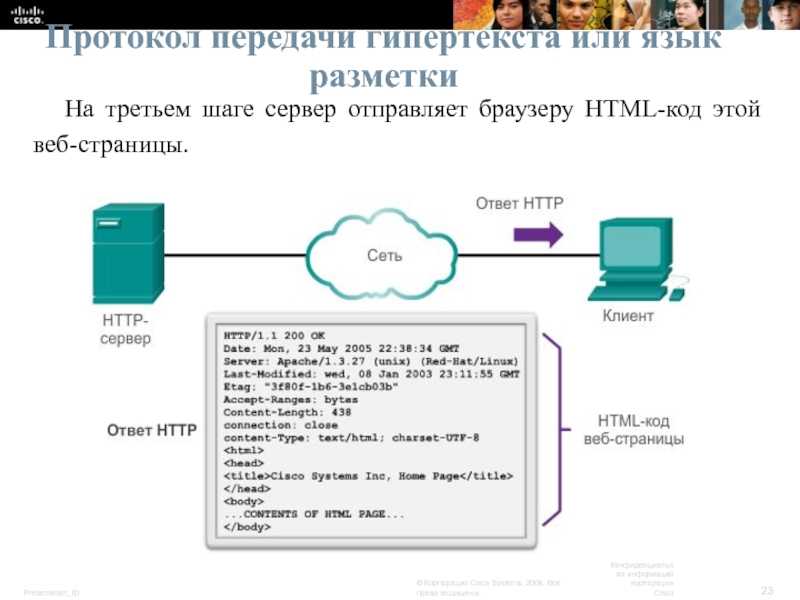 Спецификация HTTP 1.1 определяет 40 различных кодов HTTP, а также допускается расширение протокола и использование дополнительных кодов состояний.
Спецификация HTTP 1.1 определяет 40 различных кодов HTTP, а также допускается расширение протокола и использование дополнительных кодов состояний.
Пояснение к коду состояния (Reason Phrase) — текстовое (но не включающее символы CR и LF) пояснение к коду ответа, предназначено для упрощения чтения ответа человеком. Пояснение может не учитываться клиентским программным обеспечением, а также может отличаться от стандартного в некоторых реализациях серверного ПО.
После стартовой строки следуют заголовки, а также тело ответа. Например:
HTTP/1.1 200 OK Server: nginx/1.2.1 Date: Sat, 08 Mar 2014 22:53:46 GMT Content-Type: application/octet-stream Content-Length: 7 Last-Modified: Sat, 08 Mar 2014 22:53:30 GMT Connection: keep-alive Accept-Ranges: bytes Wisdom
Тело ответа следует через два переноса строки после последнего заголовка. Для определения окончания тела ответа используется значение заголовка Content-Length (в данном случае ответ содержит 7 восьмеричных байтов: слово «Wisdom» и символ переноса строки).
Но вот по тому запросу, который мы составили ранее, веб-сервер вернёт ответ не с кодом 200, а с кодом 302. Таким образом он сообщает клиенту о том, что обращаться к данному ресурсу на данный момент нужно по другому адресу.
Смотрите сами:
HTTP/1.1 302 Moved Temporarily Server: nginx Date: Sat, 08 Mar 2014 22:29:53 GMT Content-Type: text/html Content-Length: 154 Connection: keep-alive Keep-Alive: timeout=25 Location: http://habrahabr.ru/users/alizar/ <html> <head><title>302 Found</title></head> <body bgcolor="white"> <center><h2>302 Found</h2></center> <hr><center>nginx</center> </body> </html>
В заголовке Location передан новый адрес. Теперь URI (идентификатор ресурса) изменился на /users/alizar/, а обращаться нужно на этот раз к серверу по адресу habrahabr.ru (впрочем, в данном случае это тот же самый сервер), и его же указывать в заголовке Host.
То есть:
GET /users/alizar/ HTTP/1.1Host: habrahabr.ru
В ответ на этот запрос веб-сервер Хабрахабра уже выдаст ответ с кодом 200 и достаточно большой документ в формате HTML.
Если вы уже успели вжиться в роль, то можете теперь прочитать полученный от сервера HTML-код, взять карандаш и блокнот, и нарисовать профайл Ализара — в принципе, именно этим бы на вашем месте браузер сейчас и занялся.
А что с безопасностью?
Сам по себе протокол HTTP не предполагает использование шифрования для передачи информации. Тем не менее, для HTTP есть распространённое расширение, которое реализует упаковку передаваемых данных в криптографический протокол SSL или TLS.
Название этого расширения — HTTPS (HyperText Transfer Protocol Secure). Для HTTPS-соединений обычно используется TCP-порт 443. HTTPS широко используется для защиты информации от перехвата, а также, как правило, обеспечивает защиту от атак вида man-in-the-middle — в том случае, если сертификат проверяется на клиенте, и при этом приватный ключ сертификата не был скомпрометирован, пользователь не подтверждал использование неподписанного сертификата, и на компьютере пользователя не были внедрены сертификаты центра сертификации злоумышленника.
На данный момент HTTPS поддерживается всеми популярными веб-браузерами.
А есть дополнительные возможности?
Протокол HTTP предполагает достаточно большое количество возможностей для расширения. В частности, спецификация HTTP 1.1 предполагает возможность использования заголовка Upgrade для переключения на обмен данными по другому протоколу. Запрос с таким заголовком отправляется клиентом. Если серверу требуется произвести переход на обмен данными по другому протоколу, то он может вернуть клиенту ответ со статусом «426 Upgrade Required», и в этом случае клиент может отправить новый запрос, уже с заголовком Upgrade.
Такая возможность используется, в частности, для организации обмена данными по протоколу WebSocket (протокол, описанный в спецификации RFC 6455, позволяющий обеим сторонам передавать данные в нужный момент, без отправки дополнительных HTTP-запросов): стандартное «рукопожатие» (handshake) сводится к отправке HTTP-запроса с заголовком Upgrade, имеющим значение «websocket», на который сервер возвращает ответ с состоянием «101 Switching Protocols», и далее любая сторона может начать передавать данные уже по протоколу WebSocket.
Что-то ещё, кстати, используют?
На данный момент существуют и другие протоколы, предназначенные для передачи веб-содержимого. В частности, протокол SPDY (произносится как английское слово speedy, не является аббревиатурой) является модификацией протокола HTTP, цель которой — уменьшить задержки при загрузке веб-страниц, а также обеспечить дополнительную безопасность.
Увеличение скорости обеспечивается посредством сжатия, приоритизации и мультиплексирования дополнительных ресурсов, необходимых для веб-страницы, чтобы все данные можно было передать в рамках одного соединения.
Опубликованный в ноябре 2012 года черновик спецификации протокола HTTP 2.0 (следующая версия протокола HTTP после версии 1.1, окончательная спецификация для которой была опубликована в 1999) базируется на спецификации протокола SPDY.
Многие архитектурные решения, используемые в протоколе SPDY, а также в других предложенных реализациях, которые рабочая группа httpbis рассматривала в ходе подготовки черновика спецификации HTTP 2. 0, уже ранее были получены в ходе разработки протокола HTTP-NG, однако работы над протоколом HTTP-NG были прекращены в 1998.
На данный момент поддержка протокола SPDY есть в браузерах Firefox, Chromium/Chrome, Opera, Internet Exporer и Amazon Silk.
И что, всё?
В общем-то, да. Можно было бы описать конкретные методы и заголовки, но фактически эти знания нужны скорее в том случае, если вы пишете что-то конкретное (например, веб-сервер или какое-то клиентское программное обеспечение, которое связывается с серверами через HTTP), и для базового понимания принципа работы протокола не требуются. К тому же, всё это вы можете очень легко найти через Google — эта информация есть и в спецификациях, и в Википедии, и много где ещё.
Впрочем, если вы знаете английский и хотите углубиться в изучение не только самого HTTP, но и используемых для передачи пакетов TCP/IP, то рекомендую прочитать вот эту статью.
Ну и, конечно, не забывайте, что любая технология становится намного проще и понятнее тогда, когда вы фактически начинаете ей пользоваться.
Удачи и плодотворного обучения!
Какой принцип работы HTTP протокола?
Maria Kholodnitska 25.03.2020 7903 на прочтение 7 минут
Протокол HTTP (аббревиатура от анг. HyperText Transfer Protocol, протокол передачи гипертекста) является протоколом седьмого прикладного уровня модели OSI. HTTP есть основой системы World Wide Web, с помощью которого предоставляется возможность просмотра, доступа к веб-страницам в браузере и обеспечивается работа сети Интернет. В этот и состоит главная цель протокола. Также HTTP может служить в качестве транспорта для других протоколов прикладного уровня, например, SOAP.
Робота HTTP основана на клиент-серверной архитектуре. Где идет “общение” между клиентом и сервером посредством запросов и ответов. Об этом пройдемся более детально. Для этих целей использует протокол транспортного уровня TCP. Сервер работает на 80 порту, а для клиента номер порта генерируется автоматически операционной системой.
Клиенты (в большинстве случаев веб-браузеры, но могут быть и другим ПО) выполняют соединение, формируют и отправляют запрос к серверу. Эти запросы должны иметь стандартизованную структуру.
Сервер в свою очередь получает запрос от клиента, проверяет его, выполняет необходимые действия по полученному запросу, и возвращает ответ с сообщением с результатами выполнения назад клиенту. Аналогично имеет определенную установленную стандартную структуру.
Также между клиентом и сервером могут существовать посредники, такие как Proxy, для выполнения транспортных задач.
Структура HTTP запроса должна включать в себя:
- стартовую строку запроса с указанным методом, URL, и версией HTTP
Например,
GET /promotions HTTP/1.1
Host: hyperhost.ua
Методом задается само действие которое нужно выполнить на сервере с ресурсом указанным в URL. URL (Uniform Resource Locator, уникальное положение ресурса) — путь к запрашиваемому ресурсу. Коротко пройдемся по основным методах: GET, POST, HEAD, PUT, DELETE, TRACE, OPTIONS, CONNECT.
- GET — этот метод применяется, чтобы получить данные с сервера по заданном адресе.
- HEAD — работает по аналогии, как GET, и используется для получения запрашиваемого ресурса по указанному пути. А отличие в том, что в ответе сервер передает лишь заголовки и статусную строку, но без тела сообщения.
- POST — нужен уже наоборот для передачи необходимый данных от клиента на сервер. Например, при заполнении форм регистрации посетителем сайта, отправка введенных данных будет идти этим методом.
- PUT — с помощью метода осуществляется обновление ресурса по указанному пути.
- DELETE — служит для удаления ресурса указанного в URI.
- CONNECT — направляет существующее соединение через прокси.
- OPTIONS — чтобы получить характеристики, возможности текущего HTTP соединения для указанного ресурса.
- TRACE — позволяет проследить состояние ресурса, какие изменение, кем и когда вносились и т.д.
Есть несколько версий протокола, до недавнего времени чаще всего используется расширенная версия HTTP 1.1, так как без проблем поддерживается всеми браузерами и серверами, но при использовании было ряд нюансов касательно TCP соединений так называемого «медленного старта» (данные отправляются не сразу, а используется алгоритм для определения допустимого объема данных для передачи, чтобы не получить перегрузку сети, этот момент не дает использовать полностью пропускную способность сети), и спустя 10 лет был анонсирована новую версию HTTP/2, где главной особенностью было включение HTTP-потоков (позволяло выполнять несколько запросов через одно TCP-соединение). HTTP/2 частично решал вопрос, но не до конца. Потому с прошлого года внедрилась для тестирования версия HTTP/3, где уже вместо TCP используется QUIC (транспортный протокол разработан Google), для решения проблем с «медленным стартом».
- заголовки запросов и их значения
Содержит дополнительную информацию касательно системных параметрах, файлах cookie и другой служебной информации. Нужно обязательно включить заголовок Host c версии HTTP 1.1, где указывается доменное имя. Делается то для того, что на одной IP может располагаться несколько сайтов, а заголовок будет указывать на сайт, для нужно выполнить то или иное действия опираясь на указанный метод в стартовой строке.
Может иметь и другие заголовки, например, Content-Type указывает на тип передаваемого сообщения, а Content-Length на его длину. Поля что начинаются с Accept указывают серверу выдавать только указанные в заголовку форматы данных, которые потом сможет распознать и обработать при получении клиент. Например, Accept — задается список допустимых форматов, Accept-Charset — список поддерживаемых кодировок, Accept-Language — список естественных языков, Accept-Ranges — список единиц измерения. Также можно выделить заголовок User-Agent, где указано программное обеспечение клиента и его компоненты. Существует очень много заголовков. Обзор всех заголовков и их значений описаны в документации для необходимой версии HTTP здесь.
Заголовки от тела отделяются пустой строкой.
3) тело запроса. Является необязательным элементом и может отсутствовать. Содержит в себе данные, которые будут передаваться в сформированном запросе.
Синтаксис ответа сервера очень похож с структурой запроса и включает:
- строку состояния, с указанием версии протокола, кодом состояния и его кратким описанием.
Например,
HTTP/1.1 200 OK
Именно по коду состояние клиентское приложение узнаёт о результатах отправленного запроса, анализирует его и определяет какие действия следует совершить дальше. Уже по началу кода состояния можно судить об успешности запроса, так как первая цифра указывает на класс состояния. Чтобы было более понятные, после кода идет краткая фраза на английском языке с объяснением причины полученного ответа. В нас на блоге ГиперХост есть отдельная статья посвященная кодам состояние с их детальным описанием, ознакомится можно по ссылке здесь, поэтому не будем задерживаться на этом пункте, а перейдем к следующему.
- заголовок ответа
Также дополняет ответ сервера дополнительной информацией, которая необходима для осуществления “общения” между клиентом и сервером. Можно выделить такие заголовки: Vary — предоставлен список всех заголовков запроса, которые были приняты во внимание при обработке запроса и формирования ответа. Server — указаны веб-сервер и его компоненты, именно где был сформирован ответ. А заголовок Via — преподносит список версий протокола, названий и версий прокси-серверов, через которых прошло сообщение. Заголовок Age содержит время в секундах, в течение которого объект находился в прокси-кэше. Allow — указывает на доступные методы, которые могут применяться к ресурсу (такой заголовок отправляется если указанный в запросе метод был недоступен). Public — похож на Allow, но определяет допустимые методы уже на уровне всего сервера. Заголовок Date — дата когда сообщение с сервера было отправлено к клиенту. Last-Modified — определяет дату последний модификации ресурса. Retry-After — указывает на время после которого клиент может осуществить следующий запрос к серверу.
Аналогично с другими заголовками можно ознакомится в документации.
- тело ответа также не есть обязательным составляющим ответа, но как вариант, может предоставлять в себе содержание запрашиваемого ресурса.
Говорить об HTTP можно очень долго, в этой статье мы описали некоторые базовые моменты. Но будем и дальше продолжать обращать внимание и оповещать тему развития протокола.
что это за протокол передачи данных и как он работает
HTTP – это протокол передачи информации в интернете, который расшифровывается как «протокол передачи гипертекста» (HyperText Transfer Protocol). Например, браузер отправляет единичный запрос на сервер, который в свою очередь обрабатывает его, формирует ответ и делится с браузером этим ответом – ресурсами в виде данных.
Курс Уверенный старт в IT Поможем определить подходящую вам IT-профессию и освоить её с нуля. Вы на практике попробуете разные направления: разработку на разных языках, аналитику данных, Data Science, менеджмент в IT. Это самый подходящий курс для построения карьеры в IT в новой реальности. Хочу в IT!
Благодаря взаимодействию клиента (локального компьютера с браузером) и сервера (высокопроизводительного специального компьютера) в сети можно передавать данные. Изначально HTTP использовался только для гипертекстовых документов, но сейчас он может передавать любую информацию. Гипертекстовые документы также могут содержать гиперcсылки, при нажатии на которые формируется новый http-запрос, в ответе на который может содержаться другой гипертекстовый документ. Таким образом мы перемещаемся по страницам в интернете.
HTTP-запрос состоит из трех элементов:
- стартовой строки, которая задает параметры запроса или ответа,
- заголовка, который описывает сведения о передаче и другую служебную информацию.
- тело (его не всегда можно встретить в структуре). Обычно в нем как раз лежат передаваемые данные. От заголовка тело отделяется пустой строкой.
Важнейшим элементом структуры запроса является стартовая строка. Благодаря ей сервер понимает, что от него хотят. Вот как она устроена:
Метод + URL + HTTP/Версия
Метод (иногда его называют HTTP-глаголом) – описывает, какое именно действие нужно совершить со страницей. Можно придумать самые разные, но стандартных методов девять: GET, HEAD, POST, PUT, DELETE,CONNECT, OPTIONS, TRACE, PATCH. Их функциональность раскрывается в названии, они позволяют получить данные (GET), отправить данные на сервер (POST), удалить (DELETE) или заменить часть (PATCH).
Чаще всего используют GET и POST, они нужны для чтения и отправки данных на сервер. Например вы зашли в соцсеть, увидели пост и решили оставить комментарий. Или зашли в интернет-магазин, решили что-то купить и оставили данные карты.
URL (Uniform Resource Locator) – единообразный идентификатор ресурса, идентифицирует ресурс и определяет его точное местоположение. Именно с помощью URL записаны ссылки в интернете.
В отличие от него URN не ведет к конкретному адресу, а просто определяет ресурс во множестве терминов. Потенциально это удобно, чтобы не перегружать интернет устаревшими или пропавшими ссылками.
Версия показывает, какую версию протокола нужно использовать в ответе сервера.
HTTP-ответ строится примерно по тому же принципу, что и запрос:
HTTP/Версия + Код состояния + Пояснение
Версия совпадает с версией в запросе.
Код состояния показывает статус запроса. Это трехзначное число, благодаря которому можно узнать, получен ли запрос, обработан ли он, какие ошибки есть. Например, одна из самых известных ошибок – 404 – сообщает о том, что сервер не нашел ресурс по адресу. Возможно, в запросе опечатка, ошибка или он не соответствует протоколу.
В пояснении стоит краткое описание ответа, например, к той же ошибке 404 может добавляться Not Found, что и раскрывает суть статуса запроса.
Читайте также: Как стать программистом с нуля?
HTTPS – это расширение протокола HTTP, которое обеспечивает защиту передаваемых данных. Для сайта это важный параметр, так как шифрование позволяет ему обезопасить информацию, которую туда вводят люди (пароли, реквизиты кредитных карт), от хакерских атак. HTTP-протокол передает данные в открытую, поэтому их легко перехватить.
HTTPS защищен SSL-сертификатом. Благодаря ему уязвимые данные шифруются сначала на клиенте (браузере, например) в результате чего они становятся похожи на случайный набор символов и только потом отправляются на сервер. Каждый раз при HTTP-запросе шифр меняется, поэтому успеть подобрать ключ и украсть данные довольно трудно.
Сейчас защищенное соединение есть у большинства сайтов, причем многие браузеры по умолчанию уже работают только с https. Это легко проверить: в адресной строке браузера обычно стоит замок или она помечена зеленым цветом. Это показывает, что сайт подлинный и у него есть SSL-сертификат.
Специализация Frontend- разработчик PRO Получите перспективную творческую профессию и знания уровня middle. Вы изучите JavaScript и TypeScript. За время обучения вы выполните 5 проектов на JavaScript и получите 13 проектов в портфолио.
Посмотреть программу
HTTP | MDN
Протокол передачи гипертекста (HTTP) — это протокол прикладного уровня для передачи гипермедиа-документов, таких как HTML. Он был разработан для связи между веб-браузерами и веб-серверами, но может использоваться и для других целей. HTTP следует классической модели клиент-сервер, когда клиент открывает соединение для отправки запроса, а затем ждет, пока не получит ответ. HTTP — это протокол без сохранения состояния, что означает, что сервер не сохраняет никаких данных (состояния) между двумя запросами.
Узнайте, как использовать HTTP, с помощью руководств и руководств.
- Обзор HTTP
Основные характеристики протокола клиент-сервер: что он может делать и как его использовать.
- HTTP-кэш
Кэширование очень важно для быстрых веб-сайтов.
В этой статье описываются различные методы кэширования и способы управления ими с помощью заголовков HTTP.- Файлы cookie HTTP
Принцип работы файлов cookie определяется RFC 6265. При обслуживании HTTP-запроса сервер может отправить
Set-CookieЗаголовок HTTP с ответом. Затем клиент возвращает значение файла cookie с каждым запросом к одному и тому же серверу в виде заголовка запросаCookie. Срок действия файла cookie также может быть установлен на определенную дату или ограничен определенным доменом и путем.- Совместное использование ресурсов между источниками (CORS)
Межсайтовые HTTP-запросы — это HTTP-запросы для ресурсов из домена, отличного от домена ресурса, отправляющего запрос. Например, HTML-страница из домена А (
http://domain.example/) делает запрос изображения в домене B (http://domainb.foo/image.jpg) через элементimg. Сегодня веб-страницы очень часто загружают межсайтовые ресурсы, включая таблицы стилей CSS, изображения, сценарии и другие ресурсы. CORS позволяет веб-разработчикам контролировать, как их сайт реагирует на межсайтовые запросы.- Подсказки HTTP-клиента
Client Hints — это набор заголовков ответов, которые сервер может использовать для упреждающего запроса информации от клиента об устройстве, сети, пользователе и предпочтениях агента пользователя. Затем сервер может определить, какие ресурсы отправлять, на основе информации, которую клиент выбирает для предоставления.
- Эволюция HTTP
Краткое описание изменений между ранними версиями HTTP, современным HTTP/2, зарождающимся HTTP/3 и более поздними версиями.
- Руководство по веб-безопасности Mozilla
Сборник советов, которые помогут операционным группам создавать безопасные веб-приложения.
- HTTP-сообщения
Описывает тип и структуру различных типов сообщений HTTP/1.x и HTTP/2.
- Типичный сеанс HTTP
Показывает и объясняет ход обычного HTTP-сеанса.
- Управление соединением в HTTP/1.x
Описывает три модели управления соединениями, доступные в HTTP/1.x, их сильные и слабые стороны.
Просмотрите подробную справочную документацию по HTTP.
Заголовки сообщений HTTP используются для описания ресурса или поведения сервера или клиента. Поля заголовков хранятся в реестре IANA. IANA также ведет реестр предлагаемых новых заголовков HTTP-сообщений.
- Методы HTTP-запроса
Различные операции, которые можно выполнить с помощью HTTP:
GET,POST, а также менее распространенные запросы, такие какOPTIONS,DELETEилиTRACE.- Коды ответа состояния HTTP
Коды ответа HTTP указывают, был ли успешно выполнен конкретный HTTP-запрос. Ответы сгруппированы в пять классов: информационные ответы, успешные ответы, перенаправления, ошибки клиента и ошибки сервера.
- Директивы CSP
Поля заголовка ответа
Content-Security-Policyпозволяют администраторам веб-сайтов контролировать ресурсы, которые пользовательскому агенту разрешено загружать для данной страницы. За некоторыми исключениями, политики в основном включают указание источников серверов и конечных точек сценариев.
Полезные инструменты и ресурсы для понимания и отладки HTTP.
- Инструменты разработчика Firefox
Сетевой монитор
- Обсерватория Мозилла
Проект, призванный помочь разработчикам, системным администраторам и специалистам по безопасности настроить свои сайты безопасно и надежно.
- РедБот
Инструменты для проверки заголовков, связанных с кешем.
- Как работают браузеры (2011)
Очень подробная статья о внутреннем устройстве браузера и потоке запросов по протоколу HTTP. ОБЯЗАТЕЛЬНО ДЛЯ ПРОЧТЕНИЯ любому веб-разработчику.
Последнее изменение: , участниками MDN
Обзор HTTP — HTTP
HTTP — это протокол для получения ресурсов, таких как HTML-документы. Это основа любого обмена данными в Интернете, и это протокол клиент-сервер, что означает, что запросы инициируются получателем, обычно веб-браузером. Полный документ реконструируется из различных извлеченных вложенных документов, например, текста, описания макета, изображений, видео, сценариев и т. д.
Клиенты и серверы общаются, обмениваясь отдельными сообщениями (в отличие от потока данных). Сообщения, отправляемые клиентом, обычно веб-браузером, называются запросы , а сообщения, отправленные сервером в качестве ответа, называются отклики .
HTTP, разработанный в начале 1990-х годов, представляет собой расширяемый протокол, который со временем развивался. Это протокол прикладного уровня, который отправляется через TCP или через TCP-соединение с шифрованием TLS, хотя теоретически можно использовать любой надежный транспортный протокол. Благодаря своей расширяемости он используется не только для извлечения гипертекстовых документов, но также изображений и видео или для отправки контента на серверы, например, с результатами HTML-форм. HTTP также можно использовать для извлечения частей документов для обновления веб-страниц по запросу.
HTTP — это клиент-серверный протокол: запросы отправляются одним объектом — агентом пользователя (или прокси-сервером от его имени).
В большинстве случаев агентом пользователя является веб-браузер, но это может быть что угодно, например, робот, который просматривает Интернет для заполнения и поддержки индекса поисковой системы.
Каждый отдельный запрос отправляется на сервер, который обрабатывает его и предоставляет ответ, называемый ответом . Между клиентом и сервером существует множество объектов, которые в совокупности называются прокси, которые выполняют различные операции и действуют, например, как шлюзы или кэши.
На самом деле между браузером и сервером, обрабатывающим запрос, больше компьютеров: маршрутизаторы, модемы и прочее. Благодаря многоуровневой структуре Интернета они скрыты в сетевом и транспортном уровнях. HTTP находится сверху, на прикладном уровне. Хотя базовые уровни важны для диагностики сетевых проблем, они в основном не имеют отношения к описанию HTTP.
Клиент: пользовательский агент
Пользовательский агент — любой инструмент, который действует от имени пользователя.
Эту роль в основном выполняет веб-браузер, но ее также могут выполнять программы, используемые инженерами и веб-разработчиками для отладки своих приложений.
Браузер всегда объект, инициирующий запрос. Он никогда не является сервером (хотя с годами были добавлены некоторые механизмы для имитации сообщений, инициированных сервером).
Чтобы отобразить веб-страницу, браузер отправляет исходный запрос на получение HTML-документа, представляющего страницу. Затем он анализирует этот файл, делая дополнительные запросы, соответствующие сценариям выполнения, информации о макете (CSS) для отображения и подресурсам, содержащимся на странице (обычно изображения и видео). Затем веб-браузер объединяет эти ресурсы, чтобы представить полный документ, веб-страницу. Сценарии, выполняемые браузером, могут извлекать больше ресурсов на более поздних этапах, и браузер соответствующим образом обновляет веб-страницу.
Веб-страница представляет собой гипертекстовый документ.
Это означает, что некоторые части отображаемого контента представляют собой ссылки, которые можно активировать (обычно щелчком мыши) для получения новой веб-страницы, что позволяет пользователю направлять свой пользовательский агент и перемещаться по сети. Браузер переводит эти указания в HTTP-запросы и дополнительно интерпретирует HTTP-ответы, чтобы предоставить пользователю четкий ответ.
Веб-сервер
На противоположной стороне канала связи находится сервер, который подает документ по запросу клиента. Сервер виртуально выглядит как одна машина; но на самом деле это может быть набор серверов, разделяющих нагрузку (балансировка нагрузки), или сложная часть программного обеспечения, опрашивающая другие компьютеры (например, кеш, сервер БД или серверы электронной коммерции), полностью или частично генерирующая документ по запросу.
Сервер не обязательно представляет собой одну машину, но на одной машине может быть размещено несколько экземпляров серверного программного обеспечения.
С HTTP/1.1 и Заголовок узла , они могут даже иметь один и тот же IP-адрес.
Прокси
Между веб-браузером и сервером многочисленные компьютеры и машины передают HTTP-сообщения.
Из-за многоуровневой структуры веб-стека большинство из них работают на транспортном, сетевом или физическом уровнях, становясь прозрачными на уровне HTTP и потенциально оказывая значительное влияние на производительность. Те, которые работают на уровне приложений, обычно называются прокси .
Они могут быть прозрачными, пересылая запросы, которые они получают, не изменяя их каким-либо образом, или непрозрачными, и в этом случае они каким-то образом изменят запрос, прежде чем передать его на сервер.
Прокси могут выполнять множество функций:
- кэширование (кэш может быть общедоступным или частным, как и кеш браузера)
- фильтрация (например, антивирусное сканирование или родительский контроль)
- балансировка нагрузки (чтобы несколько серверов могли обслуживать разные запросы)
- аутентификация (для управления доступом к различным ресурсам)
- ведение журнала (позволяющее хранить историческую информацию)
Простой HTTP
HTTP, как правило, разработан таким образом, чтобы быть простым и понятным для человека, даже с добавленной сложностью, представленной в HTTP/2 за счет инкапсуляции сообщений HTTP в фреймы. Сообщения HTTP могут быть прочитаны и поняты людьми, что упрощает тестирование для разработчиков и снижает сложность для новичков.
HTTP является расширяемым
Представленные в HTTP/1.0 заголовки HTTP упрощают расширение этого протокола и экспериментирование с ним. Новая функциональность может быть введена даже простым соглашением между клиентом и сервером о семантике нового заголовка.
HTTP не имеет состояния, но не без сеанса
HTTP не имеет состояния: нет связи между двумя запросами, последовательно выполняемыми по одному и тому же соединению.
Это немедленно создает проблемы для пользователей, пытающихся последовательно взаимодействовать с определенными страницами, например, используя корзину для покупок в электронной коммерции.
Но хотя ядро самого HTTP не имеет состояния, файлы cookie HTTP позволяют использовать сеансы с отслеживанием состояния.
С помощью расширяемости заголовков в рабочий процесс добавляются файлы cookie HTTP, что позволяет создавать сеансы для каждого HTTP-запроса для совместного использования одного и того же контекста или одного и того же состояния.
HTTP и соединения
Соединение контролируется на транспортном уровне и, следовательно, принципиально выходит за рамки HTTP. HTTP не требует, чтобы базовый транспортный протокол был основан на соединении; требуется только, чтобы он был надежным или не терял сообщения (как минимум, в таких случаях выдавая ошибку). Среди двух наиболее распространенных транспортных протоколов в Интернете TCP является надежным, а UDP — нет. Таким образом, HTTP опирается на стандарт TCP, основанный на соединении.
Прежде чем клиент и сервер смогут обменяться парой HTTP-запрос/ответ, они должны установить TCP-соединение, процесс, для которого требуется несколько круговых обходов. По умолчанию HTTP/1.0 открывает отдельное TCP-соединение для каждой пары HTTP-запрос/ответ. Это менее эффективно, чем совместное использование одного TCP-соединения, когда несколько запросов отправляются друг за другом.
Чтобы смягчить этот недостаток, в HTTP/1.1 была введена конвейерная обработка (которая оказалась сложной для реализации) и постоянные соединения : базовое TCP-соединение можно частично контролировать с помощью заголовка Connection . HTTP/2 пошел еще дальше, мультиплексируя сообщения по одному соединению, помогая сохранять соединение теплым и более эффективным.
В настоящее время проводятся эксперименты по разработке лучшего транспортного протокола, более подходящего для HTTP. Например, Google экспериментирует с QUIC, который основан на UDP, чтобы обеспечить более надежный и эффективный транспортный протокол.
Эта расширяемая природа HTTP со временем позволила расширить возможности управления и функциональности Интернета. Методы кэширования и аутентификации были функциями, которые обрабатывались в начале истории HTTP. Напротив, возможность ослабить ограничение источника была добавлена только в 2010-х годах.
Вот список общих функций, которыми можно управлять с помощью HTTP:
- Кэширование Кэшированием документов можно управлять с помощью HTTP.
Сервер может указать прокси и клиентам, что кэшировать и как долго.
Клиент может указать прокси-серверам промежуточного кэша игнорировать сохраненный документ.
- Ослабление исходного ограничения Чтобы предотвратить отслеживание и другие вторжения в частную жизнь, веб-браузеры обеспечивают строгое разделение между веб-сайтами. Только страницы из того же источника могут получить доступ ко всей информации веб-страницы. Хотя такое ограничение является бременем для сервера, заголовки HTTP могут ослабить это строгое разделение на стороне сервера, позволяя документу стать лоскутным одеялом информации, полученной из разных доменов; для этого могут быть даже причины, связанные с безопасностью.
- Аутентификация Некоторые страницы могут быть защищены, чтобы доступ к ним могли получить только определенные пользователи.
Базовая аутентификация может быть обеспечена HTTP, либо с использованием
WWW-Authenticateи аналогичных заголовков, либо путем установки определенного сеанса с использованием файлов cookie HTTP. - Прокси и туннелирование Серверы или клиенты часто располагаются в интрасетях и скрывают свой истинный IP-адрес от других компьютеров. Затем HTTP-запросы проходят через прокси-серверы, чтобы преодолеть этот сетевой барьер.
Не все прокси являются HTTP-прокси.
Протокол SOCKS, например, работает на более низком уровне.
Другие протоколы, такие как ftp, могут обрабатываться этими прокси-серверами.
- сеансов Использование файлов cookie HTTP позволяет связать запросы с состоянием сервера. Это создает сеансы, несмотря на то, что базовый HTTP является протоколом без состояния. Это полезно не только для корзин покупок электронной коммерции, но и для любого сайта, позволяющего пользователю настраивать вывод.
Когда клиент хочет связаться с сервером, конечным сервером или промежуточным прокси, он выполняет следующие шаги:
- Откройте TCP-соединение: TCP-соединение используется для отправки запроса или нескольких и получения ответа.
Клиент может открыть новое соединение, повторно использовать существующее соединение или открыть несколько TCP-соединений с серверами.
- Отправить HTTP-сообщение: HTTP-сообщения (до HTTP/2) удобочитаемы.
В HTTP/2 эти простые сообщения инкапсулируются во фреймы, что делает невозможным их прямое чтение, но принцип остается прежним.
Например:
ПОЛУЧИТЬ/HTTP/1.1 Хост: developer.mozilla.org Accept-Language: fr
- Прочитайте ответ, отправленный сервером, например:
HTTP/1.1 200 ОК Дата: 09 октября 2010 г., 14:28:02 по Гринвичу Сервер: Апач Последнее изменение: Вт, 01 декабря 2009 г.20:18:22 по Гринвичу ETag: "51142bc1-7449-479b075b2891b" Допустимые диапазоны: байты Длина контента: 29769 Тип содержимого: текст/html … (здесь идут 29769 байт запрошенной веб-страницы)
- Закройте или повторно используйте соединение для дальнейших запросов.
Если активирована конвейерная обработка HTTP, можно отправить несколько запросов, не дожидаясь полного получения первого ответа.
Конвейерную обработку HTTP оказалось трудно реализовать в существующих сетях, где старые части программного обеспечения сосуществуют с современными версиями. Конвейерная обработка HTTP была заменена в HTTP/2 более надежным мультиплексированием запросов внутри кадра.
Сообщения HTTP, определенные в HTTP/1.1 и более ранних версиях, удобочитаемы. В HTTP/2 эти сообщения встроены в двоичную структуру, кадр , что позволяет выполнять такие оптимизации, как сжатие заголовков и мультиплексирование. Даже если в этой версии HTTP отправляется только часть исходного HTTP-сообщения, семантика каждого сообщения остается неизменной, и клиент воссоздает (виртуально) исходный запрос HTTP/1.1. Поэтому полезно понимать сообщения HTTP/2 в формате HTTP/1.1.
Существует два типа HTTP-сообщений: запросы и ответы, каждый из которых имеет собственный формат.
Запросы
Пример HTTP-запроса:
Запросы состоят из следующих элементов:
- HTTP-метод, обычно глагол типа
GET,POSTили существительное вродеOPTIONSилиHEAD, который определяет операцию, которую хочет выполнить клиент. Как правило, клиент хочет получить ресурс (используя GET) или отправить значение HTML-формы (используяPOST), хотя в других случаях может потребоваться больше операций. - Путь ресурса для выборки; URL-адрес ресурса, очищенный от очевидных из контекста элементов, например без протокола (
http://), домена (здесьdeveloper.mozilla.org) или TCP-порта (здесь80). - Версия протокола HTTP.
- Необязательные заголовки, передающие дополнительную информацию для серверов.
- Тело для некоторых методов, таких как
POST, аналогично ответам, которые содержат отправленный ресурс.
Ответы
Пример ответа:
Ответы состоят из следующих элементов:
- Версия протокола HTTP, которому они следуют.
- Код состояния, указывающий, был ли запрос успешным и почему.
- Сообщение о состоянии, неавторизованное краткое описание кода состояния.
- HTTP-заголовки, такие как для запросов.
- Необязательно тело, содержащее выбранный ресурс.
Наиболее часто используемым API на основе HTTP является API XMLHttpRequest , который можно использовать для обмена данными между агентом пользователя и сервером.
Современный Fetch API предоставляет те же функции с более мощным и гибким набором функций.
Другой API, события, отправленные сервером, представляет собой одностороннюю службу, которая позволяет серверу отправлять события клиенту, используя HTTP в качестве транспортного механизма.
Использование EventSource , клиент открывает соединение и устанавливает обработчики событий.
Браузер клиента автоматически преобразует сообщения, поступающие в потоке HTTP, в соответствующие объекты Event . Затем он доставляет их обработчикам событий, которые были зарегистрированы для событий типа , если они известны, или обработчику событий onmessage , если не был установлен обработчик событий конкретного типа.
HTTP — это расширяемый протокол, который прост в использовании. Структура клиент-сервер в сочетании с возможностью добавления заголовков позволяет HTTP развиваться вместе с расширенными возможностями Интернета.
Хотя HTTP/2 добавляет некоторую сложность за счет встраивания сообщений HTTP во фреймы для повышения производительности, базовая структура сообщений осталась неизменной со времен HTTP/1.0. Поток сеанса остается простым, что позволяет исследовать и отлаживать его с помощью простого монитора HTTP-сообщений.
Последнее изменение: , участниками MDN
Использование HTTP | Подробное руководство по использованию HTTP
HTTP (протокол передачи гипертекста) — это протокол прикладного уровня, используемый для передачи документов или файлов, таких как HTML. Этот протокол помогает установить защищенную и безопасную связь между веб-браузером и веб-серверами. Этот HTTP-протокол имеет много других применений, связанных с ним. HTTP проверяет и отслеживает архитектуру клиент-сервер, которая используется для создания запроса и, в свою очередь, ожидает ответа от сервера. HTTP включает в себя другие функции, такие как Evolution of HTTP-сообщения, поток типичного сеанса HTTP, управление соединениями HTTP / 1.x и склонность HTTP к веб-безопасности Mozilla.
Список применений HTTP
Хотя HTTP (протокол передачи гипертекста) действует как протокол для установления связи между клиентом и сервером, помимо этого существует множество других функций, которые используются как часть HTTP:
1. HTTP как протокол
HTTP считается протоколом, который действует в основном на прикладном уровне, который устанавливает связь как протокол и методы интерфейса, которые хосты в основном используют в любой коммуникационной сети. Модель OSI для работы в сети и связи также использует протокол HTTP.
2. Использование HTTP в качестве клиент-серверной архитектуры
HTTP постоянно следует модели клиент-сервер, которая разделяет рабочую нагрузку и полезную нагрузку между исходными пользователями, клиентом и конечным пользователем, сервером. Протокол связи HTTP широко использует протокол прикладного уровня, который включает взаимодействие процессоров между серверами. Когда дело доходит до балансировки нагрузки и шаблонов маршрутизации, он также использует протокол HTTP, что делает его вполне подходящим для глубокого обслуживания маршрутов.
3. Компоненты систем или архитектуры, связанных с HTTP
Поскольку HTTP следует архитектуре клиент-сервер, запросы сначала перенаправляются агенту пользователя; затем необходимо отправить весь запрос с помощью пользовательского агента, а затем подготовить его для сервера. Для представления веб-страницы и загрузки любой веб-страницы в системе обязательно использование протокола HTTP. Прокси-серверы в архитектуре играют важную роль, а уровень HTTP оказывает значительное влияние на производительность.
Прокси-серверы могут выполнять множество функций, таких как:
- Кэширование: Использует HTTP для завершения процесса, а кеш может быть общедоступным, частным или подобным кешу браузера.
- Фильтрация: Фильтрация в смысле HTTP относится к антивирусному сканированию или наличию некоторого родительского контроля.
- Балансировка нагрузки: Как только запросы попадают на сервер, он позволяет нескольким серверам подключаться и обмениваться данными.
- Аутентификация: Позволяет HTTP контролировать доступ к различным ресурсам.
- Ведение журнала: Ведение журнала также играет важную роль и в некоторой степени основано на протоколе HTTP, поскольку он загружает страницу или любую другую информацию после установления связи с сервером, отслеживание будет поддерживаться путем хранения исторической информации.
4. HTTP-кэширование как использование Функция
Технология кэширования сохраняет копию любого ресурса, а затем отправляет ответ по запросу. Частный кеш предназначен для пользователя, а затем кеш браузера, содержащий информацию о документе, легко загружается благодаря наличию протокола HTTP. Протокол HTTP не является обязательным для использования в этом сценарии, но часто рекомендуется использовать этот протокол, чтобы получить правильный ответ кэширования с использованием кода сообщения об ошибке получения и состояния.
5. Управление заголовком кэширования HTTP/1.1
Общий заголовок HTTP/1.1 cache-control используется для указания директив для выполнения различных механизмов кэширования, обеспечивающих правильную реакцию всего клиента и сервера с использованием этого протокола HTTP. Директива public указывает, что ответ может кэшироваться любым кэшем и может хранить ответы тем или иным способом.
6. Использование файлов cookie Функция HTTP
Файл cookie HTTP или веб-файл cookie или, скажем, файл cookie браузера — это небольшой набор информации или данных, которые отправляются через сервер в веб-браузер пользователя. Браузер в HTTP может использоваться для хранения данных, а затем он возвращается при последующих запросах к тому же серверу. Это помогает постоянно проверять информацию с отслеживанием состояния, на которую необходимо ссылаться, когда требуется получить некоторую важную информацию для HTTP без сохранения состояния. Все вопросы, связанные с управлением сессиями, отслеживанием и персонализацией, добросовестно используют протокол HTTP. Поскольку они обеспечивают легитимацию API, которые поддерживают большинство приложений или веб-страниц. Любой заголовок ответа HTTP, когда он отправляется как часть запроса, отправляется с использованием файла cookie, поддерживающего протокол HTTP.
7. Совместное использование ресурсов между источниками с использованием HTTP
Этот метод использует механизм, связанный с HTTP-заголовком для серверов, чтобы предоставить обзор и указать, что он связан с другими источниками, а не с собственным, что любой браузер должен разрешать при загрузке ресурса. Браузер отправляет фактическую информацию заголовка, которая будет использоваться при простой реализации; в противном случае было бы пустой тратой времени не поддерживать это. Как и любой API, связанный с Fetch, будет использоваться HTTP в соответствии с политикой того же источника.
8. Эволюция HTTP и его дальнейшее использование
HTTP — это первый протокол, используемый Всемирной паутиной, разработанный Тимом Бернерсом-Ли со многими эволюционными изменениями и дополнениями, с учетом гибкости и универсальности. Эта функция также использует другие версии HTTP с возможностью расширения до HTTP/1.0.
Представлена основная программа этого протокола, позволяющая передавать метаданные в конец заголовка путем передачи других документов, а не путем добавления простых HTML-файлов. Затем вошел в историю HTTP/1.1, который считается стандартизированным протоколом как часть HTTP, используемым для правильного использования фрагментированных ответов для большей части отправляемых данных. После того, как появились RFC2616, RFC7230 и RFC 7235, они стали более совершенными, что повысило безопасность.
9. Поддержка Mozilla Web Security в операционных группах
HTTP также позволяет многим другим оперативным группам оставаться на связи для предоставления веб-приложений.
Заключение – Использование HTTP
При использовании HTTP имеет множество применений. Это упрощает связь между клиентом и сервером без какого-либо вмешательства. Это делает общую отправку файлов и данных конфиденциальной благодаря функции защиты с использованием протокола HTTP. HTTP имеет множество преимуществ, связанных с его использованием. В то же время он может действовать и использоваться другим приложением во многих формах.
Рекомендуемые статьи
Это руководство по использованию HTTP. Здесь мы обсудим введение и список использования HTTP для лучшего понимания. Вы также можете ознакомиться со следующими статьями, чтобы узнать больше:
- Flask HTTPS
- XML HttpRequest
- Файлы cookie HTTP
- Методы HTTP
Что такое HTTP? Как это работает и связанные с этим проблемы безопасности
С момента своего появления в начале 1990-х годов Всемирная паутина стала центральной частью жизни большинства людей, предоставляя возможности для работы, исследований, торговли и социальных связей, а также бесконечный поток видео с кошками. Открыв веб-браузер на устройстве с доступом в Интернет, вы можете получить доступ к почти бесконечному миру информации.
Одним из принципов дизайна Интернета является открытость — раскрытие и стандартизация правил, по которым веб-приложения должны работать и взаимодействовать друг с другом. Эта открытость обеспечивает совместимость, позволяя веб-приложениям от разных поставщиков, которые придерживаются согласованных правил, корректно и надежно работать друг с другом.
Мультимедийные возможности, поддерживаемые современным Интернетом, развились из исходной текстовой концепции. Тем не менее, основной механизм извлечения информации с веб-сайта во многом такой же, как и задумывался изначально. Ключ к этой связи называется HTTP, простой протокол, который поддерживает Интернет.
Что такое HTTP и зачем он нам нужен?
HTTP означает протокол передачи гипертекста. Это формально определенный набор правил для связи между клиентом (сетевым ресурсом, запрашивающим данные или услуги) и сервером (ресурсом, который получает запрос и отвечает на него).
Другими словами: если Интернет — это инфраструктура, соединяющая веб-клиентов и серверы, то HTTP — это «язык», на котором они говорят друг с другом по этому соединению. Вот как мы заставляем веб-страницы загружаться и воспроизводить видео на YouTube.
Стандартизированные протоколы компьютерных сетей обеспечивают надежную совместную работу аппаратного и программного обеспечения, произведенного разными поставщиками. HTTP делает это для веб-коммуникаций. Протокол HTTP определяет правила для запросов ресурсов и ответов между веб-клиентами и серверами.
HTTP — это протокол прикладного уровня в семиуровневой сетевой модели OSI, который стандартизирует коммуникационные функции телекоммуникационных или вычислительных систем независимо от базовой внутренней структуры и технологии. За определение и постоянную разработку этого протокола теперь отвечает международная организация под названием Инженерная рабочая группа Интернета (IETF).
HTTP чаще всего используется с клиентом веб-браузера (например, Chrome, Safari или Edge) и веб-сервером, работающим в компьютерной системе, расположенной где-то в Интернете. HTTP также поддерживает множество других веб-приложений и сервисов.
Важная терминология
Некоторые термины, использованные в этом обсуждении, могут оказаться полезными, если дать им немного больше определений и обсуждений. Эти термины включают:
- Протокол: Согласованный набор правил, соглашений и структур данных, которые определяют, как ресурсы обмениваются данными.
- Сервер: Сетевой поставщик ресурсов или услуг для клиентов. Например, веб-сервер может доставлять содержимое веб-страницы вместе с другими службами веб-браузерам, запрашивающим эти службы.
- Клиент: Сетевой запросчик услуг с сервера. Например, веб-браузер (клиент) может запросить загрузку веб-страницы с веб-сервера или загрузку и отправку сообщения электронной почты через почтовый сервер.
- Доверенное лицо: За пределами Интернета доверенным лицом является лицо, имеющее полномочия действовать от имени другого лица. Например, лицо, имеющее доверенность, может выступать в качестве доверенного лица или представлять законные интересы другого лица. В цифровом мире прокси (или прокси-сервер) — это приложение, которое действует как посредник для клиентов, ищущих ресурсы с других серверов. Целью этого чаще всего является маскировка личности запрашивающего клиента — возможно, наиболее простыми примерами прокси-серверов являются платные прокси-сервисы, такие как iVPN, к которым пользователи подключаются за определенную плату, чтобы защитить свои данные и действия в Интернете.
- Запрос: Как правило, запрос представляет собой формальную просьбу о чем-либо. В контексте HTTP запрос — это сообщение, отправляемое клиентом на веб-сервер, в котором указывается действие, которое необходимо выполнить с ресурсом.
- URL: Унифицированный указатель ресурса или URL — это уникальный идентификатор веб-ресурса, указывающий его местоположение в сети и механизм, который следует использовать для его извлечения. URL-адреса иногда называют веб-адресами и обычно используются для связывания веб-страниц друг с другом.
- TLS/SSL: SSL относится к Secure Sockets Layer, протоколу для шифрования и защиты связи в компьютерной сети. SSL использовался до 2014 года, когда из-за уязвимостей он был заменен более безопасным криптографическим протоколом TLS. SSL и TLS используются для защиты HTTP-соединений в протоколе HTTPS.
- HTML: Язык гипертекстовой разметки используется для определения и форматирования документов, предназначенных для отображения в веб-браузерах. Это один из основных стандартов Всемирной паутины.
Как работает HTTP?
Всемирная паутина использует HTTP для связи между веб-клиентами и серверами — запросы на веб-страницы, обновления веб-ресурсов, состояние запросов и т. д. Протокол HTTP определяет, как веб-клиент и сервер взаимодействуют друг с другом. Он подробно определяет запросы, которые клиент может запрашивать у сервера, а также то, как сервер должен отвечать. Это включает в себя синтаксис разрешенных сообщений — по существу, разрешенные грамматические правила и семантику этих сообщений, а также предполагаемое значение запросов и ответов. Это также определяет возможности, доступные веб-клиентам при их взаимодействии с веб-серверами.
В модели клиент-сервер клиент всегда инициирует запросы к серверу. В веб-приложениях веб-браузер обычно является клиентом, а веб-сервер — сервером. Например, браузер может запросить «Отправьте мне веб-страницу http://neeva.com/learn». Затем сервер отправляет соответствующий ответ, например: «Вот HTML-код этой веб-страницы. Удачи!» или, альтернативно, «Эта страница не существует, извините». Запросы и ответы адресуются соответствующим ресурсам и передаются в виде HTML-документов по протоколу TCP/IP.
Протокол HTTP определяет восемь «глаголов», с помощью которых веб-клиент может запросить получение, обновление или управление содержимым ресурса веб-сервера. Эти восемь типов HTTP-запросов известны как методы HTTP-запросов и включают в себя:
Для получения ресурса (обычно веб-контента)
- HEAD
- GET
Для обновления ресурса 72 POST7
5
Для удаления ресурса
- DELETE
For debugging messages
- TRACE
For creating a network connection
- CONNECT
A user can request a web page by typing an HTTP URL into a browser’s address бар. Это заставляет браузер формировать запрос к веб-серверу для получения HTML-документа по указанному URL-адресу. Обычно для этого используется метод HTTP-запроса «GET». Если запрошенный документ существует и если пользователь клиента имеет разрешение на доступ к нему, его копия возвращается в браузер, который отвечает за синтаксический анализ и правильное отображение документа пользователю.
Здесь может быть несколько усложняющих факторов:
- Безопасность приложения может препятствовать доступу к запрошенному ресурсу.
- Каскадные таблицы стилей (CSS) могут повлиять на макет.
- Возможно, потребуется получить дополнительные связанные подстраницы.
- Встроенный код, такой как JavaScript, может быть извлечен и выполнен.
- Все это, вероятно, проходит через веб-прокси, которые передают запросы и ответы в обоих направлениях.
HTTP против HTTPS
Интернет не является частным каналом связи. HTTP-запросы и ответы передаются в виде простого текста. Они могут быть легко перехвачены и прочитаны людьми или программами, отличными от их предполагаемых получателей. Это может не иметь большого значения для ваших видео с кошками, но при работе с паролями, номерами кредитных карт или другой конфиденциальной информацией могут произойти плохие вещи. В частности, эволюция электронной коммерции создала раннюю потребность в более безопасном общении в Интернете.
Еще одна проблема с HTTP — «спуфинг», когда вредоносный веб-сайт выдает себя за адресный сайт и перехватывает сообщения. HTTP сам по себе не может гарантировать подлинность удаленного сервера, и клиент может быть обманут, заставив общаться с самозванцем без гарантированной аутентификации личности удаленного сервера.
HTTPS (аббревиатура от HTTP Secure) — это усовершенствование HTTP. Он обеспечивает безопасную аутентификацию удаленного сервера и зашифрованную передачу данных HTTP. HTTPS полагается на цифровой сертификат от доверенной третьей стороны (известной как «центр сертификации») для защиты соединения и подтверждения того, что сайт является тем, за кого себя выдает. Он также использует TLS для шифрования HTTP-запросов и ответов, предотвращая кражу конфиденциальной информации хитрыми мошенниками.
Сегодня обычно поддерживаются как HTTP, так и HTTPS. Ссылка, которую вы вводите или на которую нажимаете, может начинаться с http:// или https://, обозначая используемый протокол. Современные веб-браузеры отображают висячий замок в адресной строке при использовании безопасного соединения HTTPS. Они опускают это изображение при использовании менее безопасного HTTP.
Безопасен ли HTTP?
HTTP менее чем на 100% безопасен, и конфиденциальность нашей онлайн-активности становится все более приоритетной задачей для многих людей и компаний. Большая часть того, что мы делаем в Интернете, связана с личными, рабочими, финансовыми и другими конфиденциальными данными. HTTPS гарантирует, что вы подключаетесь к предполагаемой веб-службе, а обмен данными между вашим браузером и веб-службой не может быть прочитан перехватчиками.
Некоторые современные браузеры предупреждают пользователя при попытке доступа к веб-сайту с использованием протокола HTTP, называя его «небезопасным». Из-за этого все больше веб-сайтов специально поддерживают HTTPS и перенаправляют HTTP-запросы на более безопасный канал связи HTTPS.
Готовы защитить свою конфиденциальность в Интернете и использовать продукты, которые приносят пользу вам, а не мошенникам и рекламодателям? Попробуйте Neeva, первую в мире частную поисковую систему без рекламы. Мы никогда не будем продавать или передавать ваши данные никому, особенно рекламодателям, и мы стремимся показывать вам лучшие результаты для каждого поиска. Попробуйте Neeva сами на neeva.com.
Что такое протокол HTTP? Введение в HTTP для тестировщиков
Если вы тестируете веб-приложения, вам необходимо знать, какова цель протокола HTTP и как он работает. Собственно, в моем первом проекте мне не хватало этих знаний. Однако с тех пор я понял, насколько это важно, и именно поэтому я хочу поделиться этим с вами. В этой статье я покажу вам основы протокола HTTP. Например, как BE (внутренняя часть) и FE (внешняя часть) обмениваются данными, где вы можете увидеть данные и как вы можете использовать эти знания, чтобы добавить дополнительную информацию в свои сообщения об ошибках.
Надеюсь, немного потренировавшись, вы сможете определить, где лежит ошибка (BE или FE). За что ваши разработчики будут вам благодарны. Итак, без лишних слов – приступим!
Каково назначение протокола HTTP?
HTTP означает протокол передачи гипертекста. HTTP отвечает за то, как браузер (клиент) взаимодействует с сервером. Он точно определяет формат общения между ними. Современные браузеры обычно используют этот протокол. Например, чтобы прочитать эту статью, ваш браузер также использует HTTP.
Но HTTP — не единственный протокол, используемый для связи между клиентом и сервером. Есть намного больше. В модели OSI, концептуальной модели того, как информация перемещается по сети, протокол HTTP находится на последнем уровне — уровне приложений.
Однако в этой статье я пропущу другие протоколы и уровни модели OSI, так как это слишком расплывчатая тема. Тем не менее, стоит знать, где находится HTTP в этой модели.
Важно отметить, что HTTP является протоколом без сохранения состояния. Это означает, что сервер и клиент не хранят информацию о каких-либо предыдущих запросах к ним. Поэтому каждый запрос должен содержать всю необходимую информацию.
Вы, наверное, много слышали о файлах cookie. Именно благодаря им вы можете избежать отсутствия состояния HTTP. Но мы поговорим подробнее о том, как работают файлы cookie, позже в этой статье.
Как работает протокол HTTP
В основном связь между клиентом и сервером основана на HTTP-запросе и HTTP-ответе.
Сначала клиент отправляет запрос на сервер — например, дайте мне ресурс x. Затем сервер отправляет ответ клиенту — вот запрошенный вами ресурс x. Но если вы хотите увидеть любую веб-страницу, не будет одного запроса и одного ответа. Их будет много. Потому что каждый запрос связан с определенным ресурсом.
Например, чтобы показать главную страницу Scalac (www.scalac.io) клиент (мой браузер) сделал 83 запроса к серверу.
Как видите, каждая строка — это запрос на ресурс. Вы можете убедиться в этом сами на любой веб-странице. Если вы используете Windows, откройте браузер и нажмите клавишу F12. На Mac нажмите cmd+alt+i. Затем перейдите на вкладку сети и откройте любой веб-сайт.
Ресурсом может быть HTML-страница, файл CSS, шрифт, изображение или файл с кодом JavaScript.
Заголовки HTTP
К каждому запросу клиент прикрепляет заголовки HTTP. Сервер также делает то же самое для каждого ответа. Заголовки используются для отправки метаданных о ресурсах.
Заголовки имеют вид:
имя-заголовка: значение-заголовка
В приведенной ниже таблице я поместил наиболее распространенные заголовки, которые вы встретите, и их значение.
| Коллектор | Описание | Пример |
| Принять | В запросе клиент может указать, какой формат ответа он принимает. | Принять: приложение/json |
| Тип контента | Определяет тип отправляемых данных. | Тип содержимого: приложение/xml |
| Хост | Сообщает серверу, на какой домен мы хотим отправить запрос. | Хост : www.somewebsite.com |
| Сервер | Сервер сообщает клиентам, какое программное обеспечение они используют для обработки ответа | Сервер: nginx |
| Агент пользователя | Сообщает, какой клиент использовался для отправки запроса. | Агент пользователя: Mozilla/5.0 |
| Кэш-контроль | Этот заголовок используется для управления процессом кэширования. | Управление кэшем: без кэша |
| Печенье | В этом заголовке клиент отправляет файлы cookie на сервер. | Файл cookie: имя файла cookie = значение файла cookie |
| Набор печенья | В этом заголовке сервер отправляет файлы cookie клиенту. | Набор файлов cookie: имя файла cookie = значение файла cookie |
Что такое кэш?
Кэш — это механизм, позволяющий веб-страницам загружаться быстрее. Некоторые ресурсы хранятся в памяти вашего браузера. И эта память называется кэшем. Ниже приведен пример того, как это работает.
Вашему браузеру требуется img.jpg для отображения любого изображения на веб-странице. Таким образом, ваш браузер сначала должен запросить его с сервера, и сервер отвечает ресурсом. Здесь начинается роль кэша. Браузер сохраняет img.jpg в кеше для последующего использования. И когда вы снова посетите эту веб-страницу, вашему браузеру не нужно будет отправлять запрос на сервер для ресурса img.jpg. Потому что браузер сможет просто взять ресурс из своего кеша.
Однако для того, чтобы браузер кэшировал какие-либо данные, это должно быть запрограммировано в коде, иначе он сам не будет знать, что кэшировать.
Вот запрос к www.scalac.io с отключенным кешированием.
Вот запрос на www.scalac.io с включенным кешированием.
Как видите, при включенном кеше запросов на 9 меньше и страница загружается на 2,35 с быстрее.
Вы можете включить или отключить кеш в инструментах разработчика. Но это будет работать только с открытыми инструментами разработчика.
Помните!Если ваш разработчик развертывает новые функции или исправления ошибок в тестовой среде, рекомендуется очистить весь кеш браузера перед его тестированием. Это связано с тем, что ошибка все еще может появиться или новая функция может быть невидимой для вас. Конечно, другое решение — протестировать в режиме инкогнито. Лично я предпочитаю первое решение.
Ниже показано, как очистить кеш в инструментах разработчика.
Как работают файлы cookie
Как я упоминал ранее, HTTP — это протокол без сохранения состояния. Но файлы cookie являются обходным путем для решения этой проблемы.
С помощью файлов cookie сервер может связать запрос клиента в один пакет. Однако файлы cookie должны содержать только общедоступную информацию, поскольку они могут храниться в памяти браузера очень долго.
Предположим, вы вошли в свою учетную запись и установили флажок «Запомнить меня». Сервер отправляет заголовок (set-cookie: cookie-value) вашему браузеру в ответ с файлом cookie. Файл cookie назначается определенному домену. Это означает, что при следующем посещении этой страницы ваш браузер отправит запрос на этот домен с файлом cookie (cookie: значение файла cookie) . Затем сервер авторизует вас на основе этого файла cookie.
Почему вам необходимо знать эти 4 метода HTTP
Методы HTTP помогают различать запросы, отправленные на сервер. Это делается для того, чтобы мы знали, какие действия были выполнены на ресурсе. Вот наиболее распространенные методы, эквивалентные действиям CRUD (Create, Read, Update, Delete). На самом деле методов в протоколе HTTP больше, но вам не придется иметь с ними дело слишком часто. Ключ в том, чтобы помнить только эти четыре:
| Метод HTTP | Описание |
| ПОЛУЧИТЬ | метод GET является базовым запросом. Отвечает за отображение текущего представления ресурса. Например, метод HTTP GET используется для отображения веб-страниц или форм. Параметры передаются в URL-адресе. Так что все их видят. Вот почему GET следует использовать только для отображения, а не для сохранения конфиденциальных данных. |
| ПОЧТ | метод POST используется, когда вы хотите добавить новые ресурсы. Например, создание новой учетной записи или отправка файлов. Параметры передаются в теле. Метод POST безопаснее, чем GET, и его следует использовать для отправки конфиденциальных данных. |
| ПУТ | метод PUT используется, когда вы хотите обновить существующий ресурс. Например, вы хотите изменить адрес электронной почты в существующей учетной записи. |
| УДАЛИТЬ | метод DELETE отвечает за удаление ресурсов. Например, вы можете удалить свою учетную запись. |
5 основных групп статусов HTTP
Статус HTTP прикрепляется к каждому ответу. По сути, статус говорит нам, был ли запрос успешным или нет. Статусы состоят из 3 цифр. Я уверен, вы уже видели некоторые коды, такие как 404 — не найдено, 500 — внутренняя ошибка сервера. Есть много разных кодов состояния, но мы можем разделить их на 5 групп. Вот некоторые из наиболее распространенных статусов:
| Группы статусов HTTP | Описание | Пример |
| 1хх | Это информационные коды. Они очень редки. На самом деле, я еще не встречал ни одного. | 101 – Переключение протоколов |
| 2хх | Запрос успешно обработан. | 200 – ОК
201 – Создан 204 – Не содержание |
| 3хх | Коды перенаправления. Это означает, что запрос должен быть направлен на другой адрес или сервер. Например, если Scalac меняет адрес и вы вводите в URL этот старый, вы должны увидеть код из группы 3xx 9.0696 | 301 — переехал навсегда |
| 4xx | Коды ошибок клиента. Они появляются, когда проблема лежит на стороне клиента. Например, у вас нет прав на запрос ресурса или вы допустили опечатку в URL-адресе, и ресурс не существует. | 400 — Неверный запрос
401 — Неавторизованный 403 — Запрещено 404 – Не найдено |
| 5хх | Коды ошибок сервера. Эти коды представляют собой серьезную проблему. Потому что это может означать, что с сервером что-то не так и он не может обработать запрос от клиента. | 500 — Внутренняя ошибка сервера
502 — Плохой шлюз 503 — Услуга недоступна |
Если вас интересуют другие коды состояния HTTP, вы можете увидеть их все вместе с их значениями в Википедии .
Руководство по HTTP: Какова роль протокола HTTP в повседневной работе тестировщика
В видео ниже я хочу, чтобы вы рассмотрели случай из последнего проекта, над которым я работал. Надеюсь, вы найдете это хорошим примером того, как использовать знания из этой статьи. Я также хотел бы показать вам, какую еще информацию вы можете добавить в свой тикет, чтобы действительно помочь своим разработчикам.
Сводка
Уф! Это была длинная статья. Но я уверен, что вы многое узнали о HTTP. По сути, если вы понимаете большую часть этой статьи, то можете сказать, что теперь знаете протокол HTTP. Естественно, если у вас есть какие-либо вопросы, пожалуйста, не стесняйтесь задавать их в комментариях ниже.
См. также
Введение в HTTP: понимание основ HTTP
HTTP означает протокол передачи гипертекста и используется для передачи данных через Интернет.
Это важный протокол для понимания веб-разработчиками, и из-за его широкого распространения он также используется для передачи данных и команд в приложениях Интернета вещей.
В первой версии протокола был только один метод, а именно GET, который запрашивал страницу с сервера.
Ответ сервера всегда был HTML-страницей. Wiki
Чтобы дать вам представление о том, насколько простым был протокол HTTP, взгляните на исходную спецификацию, которая состояла всего из 1 страницы.
Существует несколько версий HTTP, начиная с исходной версии 0.9 .
Текущая версия 1.1, последний раз она была изменена в 2014 году. Дополнительные сведения см. на Wiki.
Как это работает
Как и большинство интернет-протоколов http это команда и ответ текстовый протокол с использованием модели связи клиент-сервер .
Клиент делает запрос, а сервер отвечает.
HTTP-протокол также является протоколом без сохранения состояния , что означает, что серверу не требуется хранить информацию о сеансе, и каждый запрос не зависит от другого. См. эту вики
Это означает:
- Все запросы исходить от клиента (вашего браузера)
- Сервер отвечает на запрос.
- Запросы (команды) и ответы имеют читаемый текст.
- Запросы не зависят друг от друга и от сервера не нужно отслеживать запросов.
Структура запроса и ответа
Запрос и ответ Структура сообщения s одинаковы и показаны ниже:
Запрос состоит из:
Команда или запрос + необязательный заголовок3 .
Ответ состоит из:
Код состояния + необязательных заголовков + необязательного основного содержимого .
Простая комбинация CRLF (возврат каретки и перевод строки) используется для разделения частей, а одна пустая строка ( CRLF ) указывает на конец заголовков.
Если запрос или ответ содержит тело сообщения , то это указано в заголовке .
Наличие тела сообщения в запросе сигнализируется полем заголовка Content-Length или Transfer-Encoding . Структура сообщения запроса не зависит от семантики метода, даже если метод не определяет никакого использования тела сообщения. – RFC 7230, раздел 3.3.
Примечание: за телом сообщения не следует CRLF. См. RFC 7230, раздел 3.5. более детально.
Стартовая строка является обязательной и структурирована следующим образом:
Метод + путь к ресурсу + версия протокола
Пример, если мы пытаемся получить доступ к веб-странице testpage.htm на www.testsite5.com
Стартовая строка запроса будет
GET /test.htm HTTP/1.1
Где
- GET — метод
- /testpage.htm — относительный путь к ресурсу.
- HTTP/1.1 — используемая нами версия протокола
Примечания:
- Относительный путь не включает имя домена.
- Веб-браузер использует введенный URL-адрес для создания относительный URI ресурса.
Примечание: URL (унифицированный локатор ресурсов) используется для веб-страниц. Это пример URI (унифицированный индикатор ресурсов).
Фактический HTTP-запрос не отображается в браузере и виден только с помощью специальных инструментов, таких как HTTP-заголовок в реальном времени (Firefox).
HTTP и URL
Большинство людей знакомы с вводом URL-адреса в веб-браузере. Обычно выглядит так.
URL-адрес также может включать порт, который обычно скрыт браузером, но вы можете указать его вручную, как показано ниже: получить этот ресурс (http) .
http — это протокол передачи, который передает ресурс (веб-страницу, изображение, видео и т. д.) с сервера клиенту.
Ответы HTTP и коды ответов
На каждый запрос есть ответ . Ответ состоит из кода СТАТУСА
- и описания .
- 1 или более дополнительных заголовков
- Дополнительное тело сообщения может состоять из нескольких строк, включая двоичные данные
Коды состояния ответа разделены на 5 групп, каждая группа имеет значение и трехзначный код .
- 1xx – Информационный
- 2xx – Успешно
- 3xx — Множественный выбор
- 4xx — Ошибка клиента
- 5xx — Ошибка сервера
Например, успешный запрос страницы вернет код ответа 200 , а неудачный — код ответа 400 .
Вы можете найти полный список и их значение здесь
Пример ответа на запрос
Мы собираемся изучить запросы и ответы при доступе к простой веб-странице (testpage.htm)
Вот что я ввожу в адресную строку браузера:
и это ответ, который отображает браузер:
и вот снимок экрана http запрос-ответ который происходит за кулисами .
Обратите внимание , заголовки запросов автоматически вставляются браузером, а заголовки ответов вставляются веб-сервером.
В запросе нет основного содержимого. Содержимое тела ответа представляет собой веб-страницу и отображается в браузере, а не Инструмент живых заголовков .
Типы запросов
До сих пор мы не упоминали типов запросов , но в наших примерах мы видели тип запроса GET.
Тип или метод GET request используется для запроса ресурса с веб-сервера.
GET — это наиболее часто используемый тип запроса и единственный тип запроса в исходной спецификации HTTP.
Типы запросов, методы или глаголы
Протокол HTTP теперь поддерживает 8 типов запросов, также называемых в документации методами или глаголами, а именно:
- GET — Запрос ресурса с сервера
- POST — отправка ресурса на сервер (например, загрузка файлов)
- PUT — как POST, но заменяет ресурс
- DELETE-Удалить ресурс с сервера
- HEAD — как GET, но возвращает только заголовки, а не содержимое
- ВАРИАНТЫ -Получить параметры ресурса
- ИСПРАВЛЕНИЕ — Применение модификаций к ресурсу
- TRACE — Выполняет возврат сообщения по шлейфу
В Интернете сегодня 9Чаще всего используются методы 0003 GET (получение веб-страниц) и POST (отправка веб-форм).