Линейный поиск в JavaScript
В контексте компьютерных наук поиск — это процесс поиска определенного элемента в заданном списке / массиве. Если внимательно присмотреться, алгоритмы поиска можно найти везде.
Рассмотрим процесс входа на веб-сайт. Введенный адрес электронной почты и пароль ищутся по существующим парам ключ-значение в базе данных для проверки пользователя.
В этой статье давайте рассмотрим самый простой алгоритм поиска по заданному списку элементов — линейный поиск.
Что такое линейный поиск
Алгоритм линейного поиска — это набор инструкций для обхода данного списка и проверки каждого элемента в списке, пока мы не найдем тот элемент, который ищем. Технический термин для искомого элемента — ключевой.
Алгоритм переходит от самого левого (или начального) элемента и продолжает поиск, пока не найдет желаемый элемент или не пройдется по всем элементам в списке.
Если элемент найден, мы вернем позицию (или index) элемента. Если искомого элемента нет в списке, мы обычно возвращаемся
Если искомого элемента нет в списке, мы обычно возвращаемся -1.
Реализация линейного поиска в JavaScript
Мы можем перемещаться по заданному списку с помощью цикла for. Давайте посмотрим на реализацию линейного поиска:
function linearSearch(arr, key){
for(let i = 0; i < arr.length; i++){
if(arr[i] === key){
return i
}
}
return -1
}
Здесь мы просматриваем все элементы в массиве и сравниваем каждый элемент с ключом. Если мы находим совпадение, мы возвращаем индекс элемента. В нашем случае переменная i отслеживает, где мы находимся в массиве, и если мы находим совпадение, мы возвращаем текущее значение для
Если элемент не существует в нашем списке, функция linearSearch не вернет никакого значения i из цикла. Мы сразу после цикла устанавливаем return -1, чтобы показать, что функция не нашла нужный элемент.
Глобальный линейный поиск
В предыдущей реализации мы возвращаем значение после того, как встретим первое вхождение искомого элемента (key). Но что, если мы хотим получить индексы всех вхождений данного элемента?
Но что, если мы хотим получить индексы всех вхождений данного элемента?
Здесь на помощь приходит глобальный линейный поиск. Это вариант линейного поиска, в котором мы ищем несколько вхождений данного элемента.
Посмотрим на реализацию глобального линейного поиска:
function globalLinearSearch(arr, key){
let results = []
for(let i = 0; i < arr.length; i++){
if(arr[i] === key){
results.push(i)
}
}
// If results array is empty, return -1
if(!results){
return -1
}
return results
}
В этом случае вместо немедленного возврата индекса соответствующего элемента мы сохраняем его в массиве. В итоге мы возвращаем массив индексов.
Эффективность линейного поиска
Линейный поиск — классический пример алгоритма грубой силы. Это означает, что алгоритм не использует никакой логики, чтобы попытаться сделать то, что он должен делать быстро, или как-то уменьшить диапазон элементов, в которых он ищет key. Другие алгоритмы поиска стремятся сделать это более эффективно за счет какой-то предварительной обработки списка / массива, например, его сортировки.
Другие алгоритмы поиска стремятся сделать это более эффективно за счет какой-то предварительной обработки списка / массива, например, его сортировки.
Временная сложность линейного поиска составляет O(n), где n — количество элементов в списке, который мы ищем. Это потому, что при расчете временной сложности мы всегда учитываем наихудший случай. В случае линейного поиска (как и в случае с большинством поисковых алгоритмов) наихудший случай возникает, когда элемент не существует в списке. В этой ситуации нам нужно будет просмотреть все n элементов, чтобы определить, что этого элемента нет.
Вывод
В этой статье мы рассмотрели логику линейного поиска, а затем, используя эти знания, реализовали алгоритм на JavaScript. Мы также рассмотрели временную сложность алгоритма линейного поиска.
Это, безусловно, простой алгоритм поиска, который не использует никакой логики, чтобы попытаться отбросить определенный диапазон для поиска или с упором на скорость.
JavaScript Массив Ссылка
❮ Предыдущая Следующая Ссылка ❯
Массив объектов
Объект Массив используется для хранения нескольких значений в одной переменной:
var cars = [«Saab», «Volvo», «BMW»];
Массив индексов начинается с нуля: Первый элемент в массиве равно 0, второй 1, и так далее.
Для учебника о Массивы, читайте JavaScript массив Учебник .
Свойства массива
| Имущество | Описание |
|---|---|
| constructor | Возвращает функцию, которая создала прототип объекта массива |
| length | Устанавливает или возвращает количество элементов в массиве |
| prototype | Позволяет добавлять свойства и методы объекта Array, |
Методы массивов
| метод | Описание |
|---|---|
| concat() | Объединяет два или более массивов, и возвращает копию соединенных массивов |
| copyWithin() | Элементы копии массива внутри массива, и из указанных позиций |
| every() | Проверяет, является ли каждый элемент в массиве пройти тест |
| fill() | Заполните элементы массива со статическим значением |
| filter() | Создает новый массив с каждым элементом в массиве, которые проходят тест |
| find() | Возвращает значение первого элемента массива, которые проходят испытание |
| findIndex() | Возвращает индекс первого элемента массива, которые проходят тест |
| forEach() | Вызывает функцию для каждого элемента массива |
| indexOf() | Поиск массива для элемента и возвращает его позицию |
| isArray() | Проверяет, является ли объект массивом |
| join() | Объединяет все элементы массива в строку |
| lastIndexOf() | Поиск массива для элемента, начиная с конца, и возвращает его позицию |
| map() | Создает новый массив с результатом вызова функции для каждого элемента массива |
| pop() | Удаляет последний элемент массива и возвращает этот элемент |
| push() | Добавление новых элементов в конец массива и возвращает новую длину |
| reduce() | Уменьшение значения массива в одно значение (going left-to-right) |
| reduceRight() | Уменьшение значения массива в одно значение (going right-to-left) |
| reverse() | Меняет порядок элементов в массиве |
| shift() | Удаляет первый элемент массива и возвращает этот элемент |
| slice() | Выбирает часть массива и возвращает новый массив |
| some() | Проверяет, является ли какой-либо из элементов в массиве пройти тест |
| sort() | Сортирует элементы массива |
| splice() | Добавляет / Удаляет элементы из массива |
| toString() | Преобразует массив в строку и возвращает результат |
| unshift() | Добавление новых элементов в начало массива и возвращает новую длину |
| valueOf() | Возвращает примитивное значение массива |
❮ Предыдущая Следующая Ссылка ❯
5 методов поиска элементов в массивах JavaScript | Hicaro Adriano
Опубликовано в·
5 мин. Читать
Читать·
21 декабря 2020 г. Кредиты изображений: АвторНабор элемента в списке или массиве является общей задачей в разработке программного обеспечения. Цель состоит в том, чтобы либо найти местоположение данного элемента, либо определить, что элемент вообще не является частью коллекции.
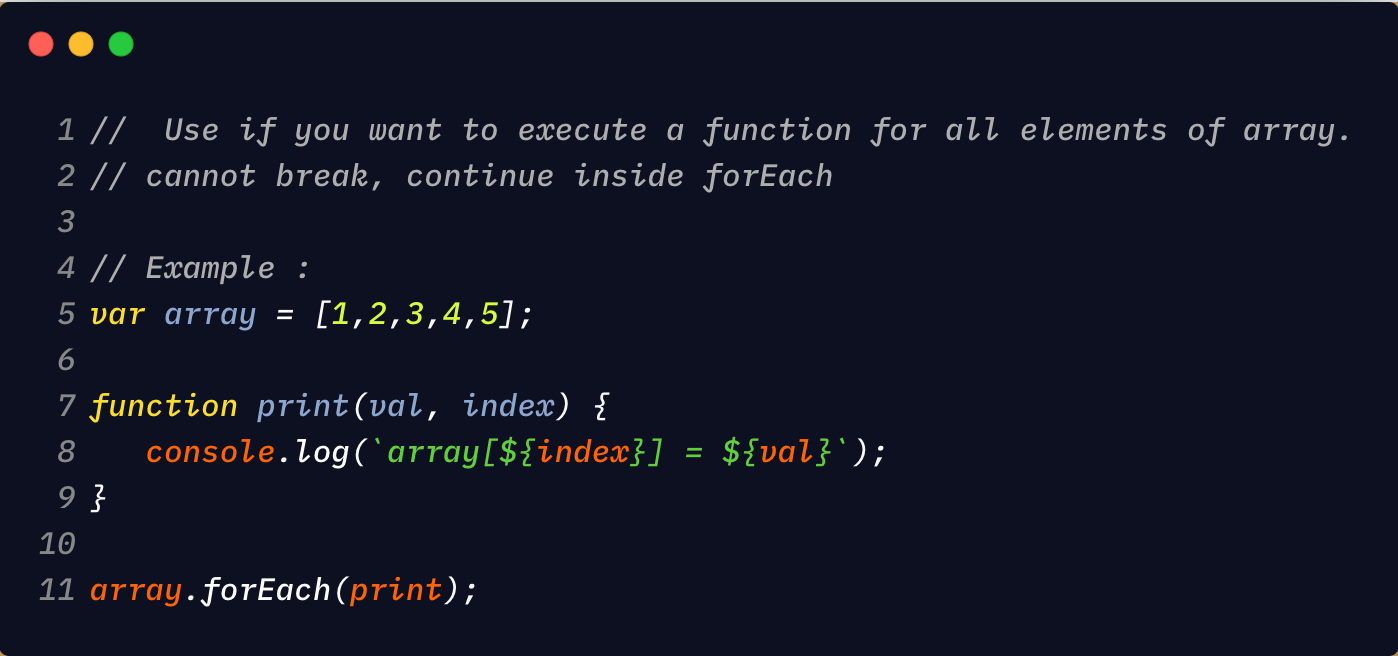
Ранние версии JavaScript предлагали ограниченный набор методов поиска в массиве. Обычно в этих версиях при выполнении поиска отображается 9Цикл 0015 for будет основным ресурсом для перебора элементов и проверки их по отдельности.
Нет ничего плохого в нашем старом добром цикле на . Это очень эффективный способ перебора набора элементов, который используется во многих языках программирования.
Однако в более поздних версиях JavaScript реализована улучшенная поддержка поиска в массиве. ECMAScript 5 (ES5) добавил методы indexOf и lastIndexOf , а ECMAScript 2015 (ES6) добавил find , findIndex и множество других отличных улучшений языка. Эти методы упрощают использование и делают ваш код более читабельным.
Эти методы упрощают использование и делают ваш код более читабельным.
Вы можете спросить себя, почему существует так много методов для выполнения одной и той же задачи. Ответ заключается в том, что эти методы не равны — у каждого есть свой вариант использования. Иногда вам нужно определить, существует ли элемент в массиве. В других случаях вам нужно получить сам элемент из массива. Независимо от того, каков ваш вариант использования, JavaScript прикроет вашу спину!
Пять методов, которые мы рассмотрим в этой статье: включает
некоторые Примечание : Несмотря на то, что существует множество типов и разновидностей поисковых алгоритмов , которые вы можете реализовать для повышения эффективности, эта статья призвана стать руководством по встроенным методам массива JavaScript и не будет вдаваться в подробности их реализации.
indexOf возвращает первый индекс, по которому предоставленный элемент может быть найден в массиве. Подобно
Подобно findIndex , он вернет -1 , если элемент не найден.
Этот метод сравнивает предоставленный элемент поиска с элементами массива, используя строгое равенство. Итак, если вы пытались найти индекс, в котором находится значение 3 , например, но вы предоставили этому методу '3' , элемент не будет найден, и метод вернет -1 .
Вы также можете предоставить этому методу необязательный второй аргумент, чтобы указать, с какого индекса вы хотите начать поиск.
Примечание. Массив JavaScript также предоставляет аналогичный метод с именем lastIndexOf . Он имеет ту же сигнатуру indexOf , но с той разницей, что он возвращает последний индекс, по которому был найден элемент, вместо первого.
Какой самый быстрый способ узнать, существует ли что-то в массиве в Javascript? | Тьяго Бертоло
В этом тесте я использовал массив JSON с 1 миллионом строк, каждая строка будет содержать 500 случайно сгенерированных символов.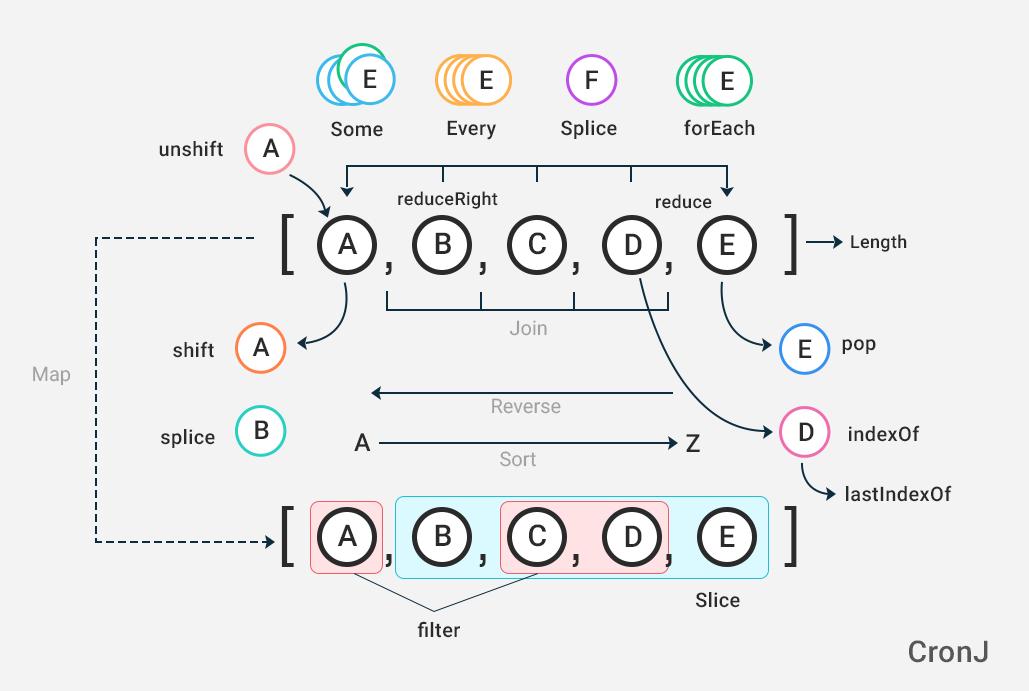
Я хочу измерить, сколько времени требуется тестируемой функции, чтобы определить, существует ли среднее значение массива (
Мы используем среднее значение массива, чтобы не наказывать методы, которые начинают с поиска последнего элемента массива.
Код, который измеряет, сколько времени требуется, чтобы найти элемент в середине массива.Каждая функция тестируется 25 раз для одного и того же массива. Окончательный результат представляет собой среднее значение измеренного времени (самое короткое и самое длинное время отбрасываются).
Используемый код можно найти здесь.
Время измеряется с помощью performance.now().
Это пример одной команды, которая использовалась для измерения временной сложности indexOf :
node --no-warnings src/bin/measure-time.mjs --file wordCount_1000000_wordSize_500 --function indexOf
Полный список используемых команд можно посмотреть здесь.
Для массива с 1 миллионом строк длиной 500 я получил следующие результаты:
Сколько времени требуется, чтобы найти значение в средней позиции массива с 1 миллионом записей по 500 символов? Предполагается, что функции одного цвета имеют одинаковую производительность.
Результаты не слишком точны, любое изменение ниже 15% считается неважным.
Два последовательных запуска могут в некоторой степени привести к различным результатам.
Например, проверка lodashIndexOf дважды:
> node --no-warnings src/bin/measure-time.mjs --file wordCount_1000000_wordSize_500 --function lodashIndexOfResult:
lodashIndexOf заняла в среднем 12. 226 миллисекунд. (25 прогонов)
lodashIndexOf заняло в среднем 10,873 миллисекунды. (25 прогонов)
Чтобы уменьшить вес сравнения строк в результатах, я повторил тест, но с 2 миллионами слов длины 20.
Были получены следующие результаты:
Сколько времени требуется, чтобы найти значение в средней позиции массива с 2 миллионами записей по 20 символов.Для массива из 2,5 миллионов слов длиной 9:
Сколько времени требуется, чтобы найти значение в средней позиции массива из 2,5 миллионов элементов по 9 символов?- find , некоторые и findIndex постоянно медленнее остальных.

- методы lodash почти так же быстры, как и лучшие, и их следует учитывать из-за дополнительной функциональности, которую они предоставляют
- включает и indexOf являются самыми быстрыми при работе с большими строками
- собственные циклы являются самыми быстрыми при работе с большими массивами при использовании родного циклы, сравниваемые с == , похоже, дают тот же результат, что и
Код, используемый для этого теста, можно найти здесь.
В этом тесте я использовал массив JSON с 1 миллионом строк, каждая строка будет содержать 500 случайно сгенерированных символов.
Я хочу измерить, сколько места в куче было выделено после того, как тестируемая функция успешно нашла значение в середине входного массива ( array[array.length/2] ).
Использование кучи было получено с помощью process.memoryUsage() .
Этот тест не очень надежен. Я не могу контролировать сборку мусора, я не знаю, что импортированные библиотеки делают с памятью нашей системы, но это может дать нам подсказку, если некоторые из методов не такие «бережливые», как другие.