Информационный ресурс о языке SQL
General information
Domain Name: | 2sql.ru |
Registration Date: | |
Expiration Date: | |
Registrar URL: | |
Registrar Contact: | |
Hosted In: | |
Safety: | Safe |
Domain Extension: | .ru |
IP address: |
Meta Data Analysis
Website Name:
2SQL.ru — Информационный ресурс о языке SQLWebsite Description:
2sql.ru – информационный ресурс о SQL, призванный помочь всем желающим разобраться и овладеть этим языком на хорошем уровне.Website Keywords:
SQL, Structured Quary Language, язык SQLRankings
Alexa Rank: | 0 |
OverAll Traffic Chart | Search-Engine Traffic Chart |
Security & Safety
Google Safe Browsing: | Safe |
WOT Trustworthiness: | # |
Siteadvisor Rating: | # |
Geographics
City: | |
Country Name: | |
Latitude: | |
Longitude: |
DNS Analysis
| Host | Type | Class | TTL | Target |
2sql. ru ru | A | IN | 3799 | |
| 2sql.ru | NS | IN | 3799 | ns.hostland.ru |
| 2sql.ru | NS | IN | 3799 | ns3.hostland.ru |
| 2sql.ru | SOA | IN | 3599 | |
| 2sql.ru | MX | IN | 3799 | mail.2sql.ru |
SEO Analysis
Site Status | Congratulations! Your site is alive. |
Title Tag | The meta title of your page has a length of 69 characters. Most search engines will truncate meta titles to 70 characters. |
Meta Description | The meta description of your page has a length of 220 characters. |
Google Search Results Preview | 2SQL.ru — Информационный ресурс о языке SQL |
Most Common Keywords Test | There is likely no optimal keyword density (search engine algorithms have evolved beyond
keyword density metrics as a significant ranking factor). It can be useful, however, to note which
keywords appear most often on your page and if they reflect the intended topic of your page. More
importantly, the keywords on your page should appear within natural sounding and grammatically
correct copy. -> sql — 10 -> joinsql — 5 -> sqlsql — 3 -> sqlru — 2 -> bysql — 2 |
Keyword Usage | Your page have common keywords from meta tags. |
h2 Headings Status | Your pages having these h2 headigs. |
h3 Headings Status | Your pages having these h3 headigs. |
Robots.txt Test | Congratulations! Your site uses a «robots.txt» file: https://2sql.ru/robots.txt |
Sitemap Test | Congratulations! We’ve found sitemap file for your website: https://2sql.ru/sitemap. |
Broken Links Test | Congratulations! Your page doesn’t have any broken links. |
Image Alt Test | 1 images found in your page and 1 images are without «ALT» text. |
Google Analytics | Congratulations! Your page is already submitted to Google Analytics. |
Favicon Test | Congratulations! Your website appears to have a favicon. |
Site Loading Speed Test | Your site loading time is around |
Flash Test | Congratulations! Your website does not include flash objects (an outdated technology that was sometimes used to deliver rich multimedia content). |
Frame Test | Congratulations! Your webpage does not use frames. |
CSS Minification | Your page having 4 external css files and out of them 1 css files are minified. |
JS Minification | Your page having 16 external js files and out of them 9 js files are minified.  com/pagead/js/adsbygoogle.js com/pagead/js/adsbygoogle.js//pagead2.googlesyndication.com/pagead/js/adsbygoogle.js http://yandex.st/share/share.js http://2sql.ru/wp-content/plugins/syntaxhighlighter/syntaxhighlighter3/scripts/shCore.js?ver=3.0.9 http://2sql.ru/wp-content/plugins/syntaxhighlighter/syntaxhighlighter3/scripts/shBrushSql.js?ver=3.0.9 |
 Most search engines will truncate meta descriptions to 160 characters.
Most search engines will truncate meta descriptions to 160 characters. 

 Flash content does not work well on mobile devices, and is difficult for crawlers to interpret.
Flash content does not work well on mobile devices, and is difficult for crawlers to interpret.Глава 2. SQL : ОБЗОР.. Понимание SQL
Глава 2. SQL : ОБЗОР.
ЭТА ГЛАВА ПОЗАКОМИТ ВАС СО СТРУКТУРОЙ SQL языка а также с определенными общими выводами, такими как тип данных которые эти поля могут содержать и некоторые области неоднозначностей которые существуют в SQL.
Она педназначена обеспечить связь с более конкретной информацией в последующих главах. Вы не должны запоминать каждую подробность упомянутую в этой главе. Краткий обзор представлен здесь в одной удобно размещеной области, многие подробности которой вы можете иметь чтобы в последствии ссылаться к ним по мере овладения языком. Мы поместили все это в начало книги чтобы ориентировать вас на мир SQL без упрощенного подхода к его проблемам и в тоже время дать Вам привычные в будущем места для ссылки к ним когда у Вас появятся вопросы. Этот материал может стать более понятным когда мы перейдем к описанию конкретных команд SQL, начинающихся с Главы 3.
Этот материал может стать более понятным когда мы перейдем к описанию конкретных команд SQL, начинающихся с Главы 3.
КАК РАБОТАЕТ SQL?
SQL это язык ориентированный специально на реляционные базы данных.
Он устраняет много работы которую вы должны были бы сделать если бы вы использовали универсальный язык программирования, напрмер C. Чтобы сформировать реляционную базу данных на C, вам необходимо было бы начать с самого начала. Вы должны были бы определить объект — называемый таблицей которая могла бы расти чтобы иметь любое число строк, а затем создавать постепенно процедуры для помещения значений в нее и извлечения из них. Если бы вы захотели найти некоторые определенные строки, вам необходимо было бы выполнить по шагам процедуру, подобную следующей :
* Рассмотрите строку таблицы.
* Выполните проверку — является ли эта строка одной из строк которая вам нужна.
* Если это так, сохраните ее где-нибудь пока вся таблица не будет проверена.
* Проверьте имеются ли другие строки в таблице.
* Если имеются, возвратитесь на шаг 1.
* Если строк больше нет, вывести все значения сохраненные в шаге 3.
( Конечно, это не фактический набор C команд, а только логика шагов которые должны были бы быть включены в реальную программу.) SQL сэкономит вам все это. Команды в SQL могут работать со всеми группами таблиц как с единым объектом и могут обрабатывать любое количество информации извлеченной или полученной из их, в виде единого модуля.
ЧТО ДЕЛАЕТ ANSI?
Как мы уже рассказывали в Введении, стандарт SQL определяется с помощью кода ANSI (Американский Национальный Институт Стандартов). ANSI не изобретал SQL. Это по существу изобретение IBM. Но другие компании подхватили SQL сразу же, по крайней мере одна компания (Oracle) отбила у IBM право на рыночную продажу SQL продуктов.
После того как появился ряд конкурирующих программ SQL на рынке, ANSI определил стандарт к которому они должны быть приведены (определение таких стандартов и является функцией ANSI ).
Однако после этого, появились некоторые проблемы. Возникли они в результате стандартизации ANSI ввиде некоторых ограничений. Так как не всегда ANSI определяет то что является наиболее полезным, то программы пытаются соответствовать стандарту ANSI не позволяя ему ограничивать их слишком сильно. Это, в свою очередь, ведет к случайным несогласованностям. Программы Баз Данных обычно дают ANSI SQL дополнительные особенности и часто ослабляют многие ограничения из большинства из них.
Следовательно, общие разновидности ANSI будут также рассмотрены. Хотя мы очевидно не сможем объять каждое исключение или разновидность, удачные идеи имеют тенденцию к внедрению и использованию в различных программах даже когда они не определены стандартом ANSI.
ANSI — это вид минимального стандарта и вы можете делать больше чем он позволяет, хотя и должны выполнять его указания при выполнении задач которые он определяет.
ИНТЕРАКТИВНЫЙ И ВЛОЖЕННЫЙ SQL
Имеются два SQL: Интерактивный и Вложенный. Большей частью, обе формы работают одинаково, но используются различно. Интерактивный SQL используется для функционирования непосредственно в базе данных чтобы производить вывод для использования его заказчиком. В этой форме SQL, когда вы введете команду, она сейчас же выполнится и вы сможете увидеть вывод (если он вообще получится) — немедленно.
Большей частью, обе формы работают одинаково, но используются различно. Интерактивный SQL используется для функционирования непосредственно в базе данных чтобы производить вывод для использования его заказчиком. В этой форме SQL, когда вы введете команду, она сейчас же выполнится и вы сможете увидеть вывод (если он вообще получится) — немедленно.
Вложенный SQL состоит из команд SQL помещенных внутри программ, которые обычно написаны на некотором другом языке (типа КОБОЛА или Паскаля).
Это делает эти программы более мощными и эффективным. Однако, допуская эти языки, приходится иметь дело с структурой SQL и стилем управления данных который требует некоторых расширений к интерактивному SQL. Передача SQL команд во вложенный SQL является выдаваемой («passed off») для переменных или параметров используемых программой в которую они были вложены.
В этой книге, мы будем представлять SQL в интерактивной форме. Это даст нам возможность обсуждать команды и их эффекты не заботясь о том как они связаны с помощью интерфейса с другими языками. Интерактивный SQL — это форма наиболее полезная непрограммистам. Все что вы узнаете относительно интерактивного SQL в основном применимо и к вложенной форме. Изменения необходимые для использования вложенной формы будут использованы в последней главе этой книги.
Интерактивный SQL — это форма наиболее полезная непрограммистам. Все что вы узнаете относительно интерактивного SQL в основном применимо и к вложенной форме. Изменения необходимые для использования вложенной формы будут использованы в последней главе этой книги.
СУБПОДРАЗДЕЛЕНИЯ SQL
И в интерактивной и во вложенной формах SQL, имеются многочисленные части, или субподразделения. Так как вы вероятно сталкнетесь с этой терминологией при чтении SQL, мы дадим некоторые пояснения.
К сожалению, эти термины не используются повсеместно во всех реализациях. Они подчеркиваются ANSI и полезны на концептуальном уровне, но большинство SQL программ практически не обрабатывают их отдельно, так что они по существу становятся функциональными категориями команд SQL.
DDL (Язык Определения Данных ) — так называемый Язык Описания Схемы в ANSI, состоит из команд которые создают объекты (таблицы, индексы, просмотры, и так далее ) в базе данных.
DML (Язык Манипулирования Данными) — это набор команд которые определяют какие значения представлены в таблицах в любой момент времени.
DCD (Язык Управления Данными) состоит из средств которые определяют, разрешить ли пользователю выполнять определенные действия или нет.
Они являются составными частями DDL в ANSI. Не забывайте эти имена.
Это не различные языки, а разделы команд SQL сгруппированных по их функциям.
РАЗЛИЧНЫЕ ТИПЫ ДАННЫХ
Не все типы значений которые могут занимать поля таблицы — логически одинаковые. Наиболее очевидное различие — между числами и текстом. Вы не можете помещать числа в алфавитном порядке или вычитать одно имя из другого. Так как системы с реляционной базой данных базируются на связях между фрагментами информации, различные типы данных должны понятно отличаться друга от друга, так чтобы соответствующие процессы и срав нения. могли быть в них выполнены.
В SQL, это делается с помощью назначения каждому полю — типа данных который укаазывает на тип значения которое это поле может содержать.
Все значения в данном поле должны иметь одинаковый тип. В таблице Заказчиков, например, cname и city — содержат строки текста для оценки, snum, и cnum — это уже номера. По этой причине, вы не можете ввести значение Highest(Наивысший) или значение None(Никакой) в поле rating, которое имеет числовой тип данных. Это ограничение удачно, так как оно налагает некоторую структурность на ваши данные. Вы часто будете сравнивать некоторые или все значения в данном поле, поэтому вы можете выполнять действие только на определенных строках а не на всех. Вы не могли бы сделать этого если бы значения полей имели смешанный тип данных.
По этой причине, вы не можете ввести значение Highest(Наивысший) или значение None(Никакой) в поле rating, которое имеет числовой тип данных. Это ограничение удачно, так как оно налагает некоторую структурность на ваши данные. Вы часто будете сравнивать некоторые или все значения в данном поле, поэтому вы можете выполнять действие только на определенных строках а не на всех. Вы не могли бы сделать этого если бы значения полей имели смешанный тип данных.
К сожалению, определение этих типов данных является основной областью в которой большинство коммерческих программ баз данных и официальный стандарт SQL, не всегда совпадают. ANSI SQL стандарт распознает только текст и тип номера, в то время как большинство коммерческих программ используют другие специальные типы. Такие как, DATA(ДАТА) и TIME(ВРЕМЯ) — фактически почти стандартные типы( хотя точный формат их меняется). Некоторые пакеты также поддерживают такие типы, как например MONEY(ДЕНЬГИ) и BINARY (ДВОИЧНЫЕ). (MONEY — это специальная система исчисления используемая компьютерами. Вся информация в компьютере передается двоичными числами и затем преобразовываются в другие системы, что бы мы могли легко использовать их и понимать.)
Вся информация в компьютере передается двоичными числами и затем преобразовываются в другие системы, что бы мы могли легко использовать их и понимать.)
ANSI определяет несколько различных типов значений чисел, различия между которыми — довольно тонки и иногда их путают. Разрешенные ANSI типы данных перечислены в Приложении B.
Сложность числовых типов ANSI можно, по крайней мере частично,объяснить усилием сделать вложенный SQL, совместимым с рядом других языков.
Два типа чисел ANSI, INTEGER(ЦЕЛОЕ ЧИСЛО) и DECIMAL (ДЕСЯТИЧНОЕ ЧИСЛО) (которые можно сокращать как INT и DEC, соответственно ), будут адекватны для наших целей, также как и для целей большинства практических деловых прикладных программ. Естественно, что тип ЦЕЛОЕ можно представить как ДЕСЯТИЧНОЕ ЧИСЛО которое не содержит никаких цифр справа от десятичной точки.
Тип для текста — CHAR (или СИМВОЛ ), который относится к строке текста. Поле типа CHAR имеет определенную длину, которая определяется максимальным числом символов которые могут быть введены в это поле.
Больше всего реализаций также имеют нестандартный тип называемый VARCHAR(ПЕРЕМЕННОЕ ЧИСЛО СИМВОЛОВ), который является текстовой строкой которая может иметь любую длину до определенного реализацией максимума (обычно 254 символа). CHARACTER и VARCHAR значения включаются в одиночные кавычки как «текст». Различие между CHAR и VARCHAR в том, что CHAR должен резервировать достаточное количество памяти для максимальной длины строки, а VARCHAR распределяет память так как это необходимо.
Символьные типы состоят из всех печатных символов, включая числа.
Однако, номер 1 не то же что символ «1». Символ «1» — только другой печатный фрагмент текста, не определяемый системой как наличие числового значения 1.
Например 1 + 1=2, но «1» + «1» не равняется «2».
Символьные значения сохраняются в компьютере как двоичные значения, но показываются пользователю как печатный текст. Преобразование следует за форматом определяемым системой которую вы используете. Этот формат преобразования будет одним из двух стандартных типов (возможно с расширениями) используемых в компьютерных системах: в ASCII коде (используемом во всех персональных и малых компьютерах ) и EBCDIC коде (Расширенном Двоично-Десятичном Коде Объмена Информации) (используемом в больших компьютерах). Определенные операции, такие как упорядочивание в алфавитном порядке значений поля, будет изменяться вместе с форматом. Применение этих двух форматов будет обсуждаться в Главе 4.
Определенные операции, такие как упорядочивание в алфавитном порядке значений поля, будет изменяться вместе с форматом. Применение этих двух форматов будет обсуждаться в Главе 4.
Мы должны следить за рынком, а не ANSI, в использовании типа называемого DATE(ДАТОЙ). (В системе, которая не распознает тип ДАТА, вы конечно можете обьявить дату как символьное или числовое поле, но это сделает большинство операций более трудоемкими. ) Вы должны смотреть свою документацию по пакету программ которые вы будете использовать, чтобы выяснить точно, какие типы данных она поддерживает.
SQL НЕСОГЛАСОВАННОСТИ
Вы можете понять из предшествующего обсуждения, что имеются самостоятельные несогласованности внутри продуктов мира SQL. SQL появился из коммерческого мира баз данных как инструмент, и был позже превращен в стандарт ANSI. К сожалению, ANSI не всегда определяет наибольшую пользу, поэтому программы пытаются соответствовать стандарту ANSI не позволяя ему ограничивать их слишком сильно. ANSI — вид минимального стандарта — вы можете делать больше чем он это позволяет, но вы должны быть способны получить те же самые результаты что и при выполнении той же самой задачи.
ANSI — вид минимального стандарта — вы можете делать больше чем он это позволяет, но вы должны быть способны получить те же самые результаты что и при выполнении той же самой задачи.
ЧТО ТАКОЕ — ПОЛЬЗОВАТЕЛЬ?
SQL обычно находится в компьютерных системах которые имеют больше чем одного пользователя, и следовательно должны делать различие между ними (ваше семейство PC может иметь любое число пользователей, но оно обычно не имеет способов чтобы отличвать одного от другого). Обычно, в такой системе, каждый пользователь имеет некий вид кода проверки прав который идентифицирует его или ее (терминология изменяется). В начале сеанса с компьютером, пользователь входит в систему (регистрируется), сообщая компьютеру кто этот пользователь, идентифицированный с помощью определенного ID(Идентификатора). Любое колличество людей использующих тот же самый ID доступа, являются отдельными пользователями; и аналогично, один человек может представлять большое количество пользователей (в разное время ), используя различные доступные Идентификаторы.
SQL следует этому примеру. Действия в большинстве сред SQL приведены к специальному доступному Идентификатору который точно соответствует определенному пользователю. Таблица или другой объект принадлежит пользователю, который имеет над ним полную власть. Пользователь может или не может иметь привилегии чтобы выполнять действие над объектом.
Для наших целей, мы договоримся, что любой пользователь имеет привилегии необходимые чтобы выполнять любое действие, пока мы не возвратимся специально к обсуждению привилегий в Главе 22.
Специальное значение — USER(ПОЛЬЗОВАТЕЛЬ) может использоваться как аргумент в команде. Оно указывает на доступный Идентификатор пользователя, выдавшего команду.
УСЛОВИЯ И ТЕРМИНОЛОГИЯ
Ключевые слова — это слова которые имеют специальное значение в SQL. Они могут быть командами, но не текстом и не именами объектов. Мы будем выделять ключевые слова печатая их ЗАГЛАВНЫМИ БУКВАМИ. Вы должны соблюдать осторожность чтобы не путать ключевые слова с терминами.
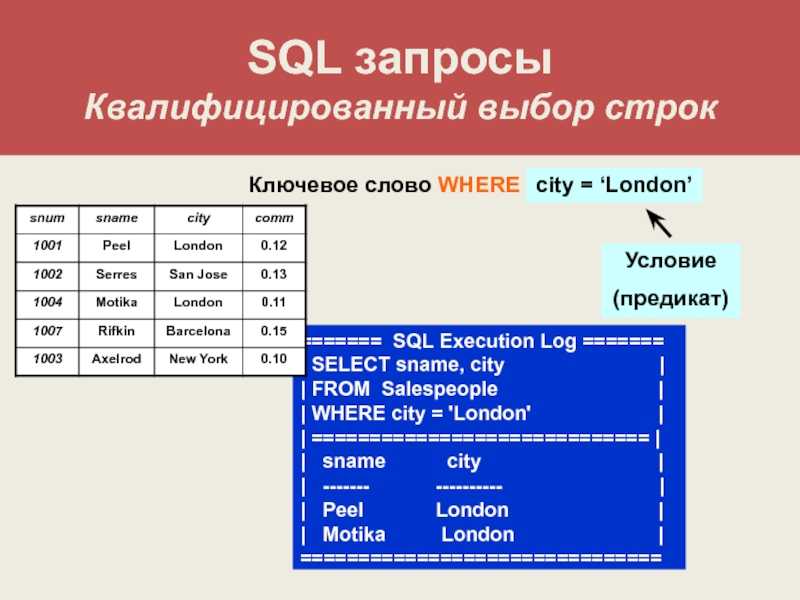
SQL имеет определенные специальные термины которые используются чтобы описывать его. Среди них — такие слова как запрос, предложение, и предикат, которые являются важнейшими в описании и понимании языка но не означают что-нибудь самостоятельное для SQL.
Команды, или предложения, являются инструкциями которыми Вы обращаетесь к SQL базе данных. Команды состоят из одной или более отдельных логических частей называемых предложениями. Предложения начинаются ключевым словом для которого они являются проименованными, и состоят из ключевых слов и аргументов. Например предложения с которыми вы можете сталкиваться — это » FROM Salespeope » и » WHERE city=»London».
Аргументы завершают или изменяют значение предложения. В примерах выше, Salespeople — аргумент, а FROM — ключевое слово предложения FROM.
Аналогично, » city=»London» » — агрумент предложения WHERE. Объекты — структуры в базе данных которым даны имена и сохраняются в памяти.
Они включают в себя базовые таблицы, представления (два типа таблиц), и индексы.
Чтобы показать Вам как формируются команды, мы будем делать это на примерах. Имеется, однако, более формальный метод описания команд использующих стандартизированные условные обозначения. Мы будем использовать его в более поздних главах, для удобства чтобы понимать эти условные обозначения в случае если вы столкнетесь с ним в других SQL документах. Квадратные скобки ([ ] ) будут указывать части которые могут неиспользоваться, а многоточия (… ) указывать что все предшествующее им может повторяться любое число раз. Слова обозначенные в угловых скобках (<>) — специальные термины которые объясняют что они собой представляют.
Мы упростили стандартную терминологию SQL значительно, но без ухудшения его понимания.
РЕЗЮМЕ
Мы быстро прошли основы в этой главе. Но нашим намерением и было — просто пролететь над основами SQL, так чтобы вы могли понять идею относительно всего объема. Когда мы возвратимся к основе в следующей главе, некоторые вещи станут более конкретными. Теперь вы знаете кое-что относительно SQL — какова его структура, как он используется, как он представляет данные, и как они определяются (и некоторые несогласованности появляющиеся при этом ), и некоторые условные обозначения и термины используемые чтобы описывать их. Все это — много информации для одной главы; мы не ожидаем что бы вы запомнили все эти подробности, но вы сможете вернуться позже к ним если понадобится. По Главе 3, мы будем идти, показывая конкретно, как формируются команды и что они делают. Мы представим вам команду SQL используемую чтобы извлекать информацию из таблиц, и которая является наиболее широко используемой командой в SQL. К концу этой главы, вы будете способны извлекать конкретную информацию из вашей базы данных с высокой степенью точности.
Теперь вы знаете кое-что относительно SQL — какова его структура, как он используется, как он представляет данные, и как они определяются (и некоторые несогласованности появляющиеся при этом ), и некоторые условные обозначения и термины используемые чтобы описывать их. Все это — много информации для одной главы; мы не ожидаем что бы вы запомнили все эти подробности, но вы сможете вернуться позже к ним если понадобится. По Главе 3, мы будем идти, показывая конкретно, как формируются команды и что они делают. Мы представим вам команду SQL используемую чтобы извлекать информацию из таблиц, и которая является наиболее широко используемой командой в SQL. К концу этой главы, вы будете способны извлекать конкретную информацию из вашей базы данных с высокой степенью точности.
Глава 14 Программы для обработки фото: краткий обзор, для чего могут пригодиться
Глава 14 Программы для обработки фото: краткий обзор, для чего могут пригодиться Любые фотокамеры, в том числе и самые дорогие модели, не всегда дают самый идеальный результат: красные глаза, низкая резкость, плохая освещенность или хроматические аберрации, вот лишь
Глава 15 Программы для обработки видео: краткий обзор для чего могут пригодиться
Глава 15
Программы для обработки видео: краткий обзор для чего могут пригодиться
Аналогично с фотографиями вы можете обрабатывать и видео на компьютере. Для этого также есть масса программ, которые позволят вам видоизменять видеофайлы. Если несколько лет назад
Для этого также есть масса программ, которые позволят вам видоизменять видеофайлы. Если несколько лет назад
ГЛАВА 1. ОБЩИЙ ОБЗОР ОСОБЕННОСТЕЙ СИСТЕМЫ
ГЛАВА 1. ОБЩИЙ ОБЗОР ОСОБЕННОСТЕЙ СИСТЕМЫ За время, прошедшее с момента ее появления в 1969 году, система UNIX стала довольно популярной и получила распространение на машинах с различной мощностью обработки, от микропроцессоров до больших ЭВМ, обеспечивая на них общие
Глава 2 Обзор служб набора протоколов TCP/IP
Глава 2 Обзор служб набора протоколов TCP/IP 2.1 Введение Почему семейство протоколов TCP/IP получило столь широкое распространение? Прежде всего, благодаря способности к взаимному объединению гетерогенных локальных и глобальных сетей. Не менее важной является способность
Глава 10 Обзор системы
Глава 10
Обзор системы
Начиная с этой главы я начну рассказывать собственно о работе в Ubuntu и об устройстве этой системы. Надеюсь, вы успешно справились с установкой и не испугались незнакомых операций и терминов, которыми она изобиловала.Итак, начнём знакомство с Ubuntu
Надеюсь, вы успешно справились с установкой и не испугались незнакомых операций и терминов, которыми она изобиловала.Итак, начнём знакомство с Ubuntu
ГЛАВА 1 Обзор средств взаимодействия процессов Unix
ГЛАВА 1 Обзор средств взаимодействия процессов Unix 1.1. Введение Аббревиатура IPC расшифровывается как interprocess communication, то есть взаимодействие процессов. Обычно под этим понимается передача сообщений различных видов между процессами в какой-либо операционной системе. При
R.1.1 Обзор
R.1.1 Обзор Это руководство содержит следующее:1. Введение.2. Соглашения о лексических понятиях.3. Основные понятия.4. Стандартные преобразования.5. Выражения.6. Операторы.7. Описания.8. Описатели.9. Классы.10. Производные классы.11. Контроль доступа к членам.12. Специальные
Глава 1.
 Обзор Ruby
Обзор RubyГлава 1. Обзор Ruby Язык формирует способ нашего мышления и определяет то, о чем мы можем размышлять. Бенджамин Ди Уорф Стоит напомнить, что в новом языке программирования иногда видят панацею, особенно его адепты. Но ни один язык не сможет заменить все остальные. Не
12.1.1. Обзор
12.1.1. Обзор В 2001 году Tk был, наверное, самым популярным графическим интерфейсом для Ruby. Он был первым и долгое время входил в состав стандартного дистрибутива Ruby. Сейчас он, пожалуй, не так распространен, но все еще широко применяется.Кто-то скажет, что Tk уже устарел. Те, кому
ГЛАВА 25. Обзор транзакций Firebird.
ГЛАВА 25. Обзор транзакций Firebird.
В базах данных клиент-сервер, таких как Firebird, клиентское приложение никогда не касается данных, которые физически хранятся в страницах базы данных. Вместо этого клиентские приложения ведут общение с системой управления базой данных — с
Вместо этого клиентские приложения ведут общение с системой управления базой данных — с
Глава 1 Общий обзор языка Пролог
Глава 1 Общий обзор языка Пролог В этой главе на примере конкретной программы рассматриваются основные механизмы Пролога. Несмотря на то, что материал излагается в основном неформально, здесь вводятся многие важные
Глава 17 Обзор автоматизированных средств оценки безопасности
Глава 17 Обзор автоматизированных средств оценки безопасности В этой главе обсуждаются следующие темы: • Краткие сведения об автоматизированных средствах оценки безопасности • Применение автоматизированных инструментальных средств для тестирования на проникновение
Глава 10. Краткий обзор
Глава 10.
Краткий обзор
Мы будем опираться на симбиоз взаимодействующих между собой методик. Методик, некоторые из которых были забыты десятилетия назад как непрактичные и наивные.Вот исходные материалы, из которых нам предстоит построить новую дисциплину разработки
Методик, некоторые из которых были забыты десятилетия назад как непрактичные и наивные.Вот исходные материалы, из которых нам предстоит построить новую дисциплину разработки
422196 — презентация онлайн
Министерство образования и науки Республики Казахстан
Семипалатинский Государственный Педагогический Институт
Физико-математический факультет
Кафедра информатики и информационных систем
Дисциплина : «Базы данных и информационных систем»
Специальность: 5В001110 – информатика
Тема: Язык SQL
Преподаватель: Батырока К.А.
Выпролинили: Шаяхметова А. Нурланкызы А.
2. План:
1. Введение2. SQL
3. Функции языка SQL
4. Стандарты SQL
5. SQL в компьютерной сети
6. Элементы языка SQL
7. Ключевые слова. Имена. Константы
8. Типы данных. Выражения.
9. Встроенные функции
10. Чтение данных.
Оператор Select. Предложение Select
3. Введение
Большинство современных СУБД построено на реляционной моделиданных.
 Для получения информации из отношений (таблиц) базы
Для получения информации из отношений (таблиц) базыданных в качестве языка манипулирования данными в
теоретическом плане используется язык SQL
4. SQL – структурированный язык запросов, предназначенный для работы с БД реляционного типа.
SQL является интерактивным языком запросов, которыйобеспечивает пользователю быстрый доступ к данным.
SQL является также языком программирования баз данных.
Программисты могут вставить SQL-запросы в свои программы,
чтобы получить доступ к базам данных
SQL – язык распределения базы данных, служит для распределения
данных взаимодействующих систем, для распределенной
обработки баз данных
5. Функции языка SQL:
Организация данных – создание и изменение структуры базданных
Чтение данных
Обработка данных – удаление, добавление и корректировка
данных
Управление доступа к данным – предоставление привилегий
(ограничение возможностей) пользователю для чтения и
изменения данных
Совместное использование данных- координация общего
пользования данных многими пользователями
Целостность данных – защита данных от разрушения при сбое
системы или других обстоятельствах
6.
 Стандарты SQLРазработка SQL началась в 1982 году Американским институтом
Стандарты SQLРазработка SQL началась в 1982 году Американским институтомнациональных стандартов ANSI (American National Standards
Institute). В 1986 SQL был официально утвержден как стандарт
ANSI, ф в 1987 году – в качестве стандарта ISO (International
Standards Organization) – международной организации по
стандартизации.
7. SQL в компьютерной сети
Сервер базы данных выполняет SQL – запрос и возвращаетпользователю только ту информацию из базы данных, которая
соответствует этому SQL — запросу
8. Элементы языка SQL
Ключевые словаИмена
Константы
Типы данных
Встроенные функции
выражения
9. Ключевые слова. Имена. Константы
Ключевые слова – это фиксированный набор английскихслов, которые определяют тип запроса и
необходимую информацию для выполнения этого
запроса
Имена используются для обозначения (присвоения
имени) таблиц, столбцов в таблице, а также
владельцев таблиц (баз данных)
Константы служат для явного указания величин –
чисел, строк, дату и время – в командах SQL
10.
 Типы данных. Выражения.Типы данных служат для представления информации в базах
Типы данных. Выражения.Типы данных служат для представления информации в базахданных. В SQL определен набор типов данных (char, varchar ,
integer, smallint…)
Выражения в SQL представляют собой имена, константы,
встроенные функции, связанные между собой знаками
арифметических операций. В сложных выражениях для
изменения порядка вычислений применяются круглые скобки.
11. Встроенные функции в основном предназначены для преобразования типов данных и для обработки строк
Некоторые встроенные функцииCurrent_date()- возвращает текущую дату
Current_time(точность) — возвращает текущее время
Char_length(строка) – возвращает длину строки
Extract – возвращает значение части day, hour и т.д. даты
Lower(строка) — возвращает строку, преобразованную к нижнему
регистру
Upper (строка) — возвращает строку, преобразованную к верхнему
регистру
Month(дата) – возвращает значение месяца из указанной даты в
виде целого числа
Year(дата) – возвращает значение года из указанной даты в виде
целого числа
12.
 Чтение данных. Оператор Select. Предложение SelectОператор Select читает данные из базы данных и возвращает их в виде таблицы результата
Чтение данных. Оператор Select. Предложение SelectОператор Select читает данные из базы данных и возвращает их в виде таблицы результатазапроса
Предложение Select, с которого начинается оператор Select, содержит элементы данных,
которые будут возвращены в виде результирующей таблицы. Указанные в предложении
Select элементы данных будут составлять столбцы возвращаемой таблицы. В качестве
возвращаемых столбцов могут быть указаны:
1)
Имя столбца некоторой таблицы базы данных;
2)
Константа, которая будет содержаться в соответствующем столбце возвращаемой
таблицы
3)
Выражение, которое будет вычисляться для каждой строки возвращаемой таблицы, и
помещаться в соответствующем столбце этой таблицы
13. Предложение FROM
Предложение FROM начинается с ключевого слова FROM, за которым следует в простом случаесписок спецификаций таблиц, разделенных запятыми. В общем случае за ключевым словом FROM
указывается операция соединения (JOIN) исходных таблиц.
Спецификатор таблицы определяет таблицу, из которой запрашиваются исходные данные
для формирования возвращаемой таблицы. Спецификатор таблицы представляет собой либо имя
исходной таблицы, либо имя исходной таблицы вместе с псевдонимом, указываемым после имени
через пробел. Синтаксическая диаграмма спецификатора таблицы следующая (рис 1).
Рис 1 Синтаксическая диаграмма спецификатора
таблицы.
Псевдоним может быть может быть использован в следующих предложениях оператора
SELECT вместо имени.
Примеры
1.
SELECT Sname, City
FROM salespeople
2.
SELECT Sname, salespeople. City, Customers.*
From Salespeople S, Customers
14. Предложение FROM
Операция соединения определена в стандарте SQL2 и имеет следующую синтаксическуюдиаграмму (рис 2).
Рис 2 Синтаксическая диаграмма
операции соединения
Операция CROSS JOIN дает декартово произведение двух таблиц, UNION JOIN дает сложение
двух таблиц. Ключевое слово INNER задает внутреннее объединение (по умолчанию), OUTER –
внешнее объединение (левое, правое и полное) ; NATURAL – естественное объединение
(равенство значений в одноименных столбцах, при этом предложения ON и USING не
обязательны).
15. Предложение WHERE
Предложение WHERE осуществляется отбор нужных строк из таблицы, получаемой впредложении FROM. Отбор строк производится в соответствии с условием поиска, которое
указывается в предложении за ключевым словом WHERE. Условие поиска представляет собой
выражение, которое вычисляется для каждой строки возвращаемой таблицы. При вычислении
выражения данные соответствующей строки берутся из столбцов, указанных в выражении. Для
каждой проверяемой строки условие поиска может иметь одно из трех значений – TRUE, FALSE
и NULL. Отбираются только те строки, для которой условие поиска имеют значение TRUE.
Условие поиска имеет следующую синтаксическую диаграмму (рис 3).
Рис 3 Синтаксическая диаграмма условии поиска
Из диаграммы видно, что условие поиска состоит из простых условий объединенных с помощью
логических операций NOT, AND и OR.
16. Предложение WHERE
В следующей таблице приведены результаты логических операций над значениями TRUE, FALSE иNULL.

В SQL существует пять простых условий поиска:
Сравнение;
Проверка на принадлежность диапазону;
Проверка на принадлежность множеству;
Проверка на соответствие шаблону;
Проверка на равенство значению NULL.
17. Предложение WHERE
Сравнение. При сравнении вычисляются и сравниваются значения двух выражений. Существуетшесть операций сравнения, которые показаны на следующей синтаксической диаграмме (рис 4)
Рис 4 Синтаксическая диаграмма операций сравнения
Результатом сравнения будет значения TRUE , если значения выражений сравниваются и
FALSE – если не сравниваются. В случае, если значение хотя бы одного выражения будет NULL,
то результат сравнения будет NULL.
18. Предложение WHERE
Проверка на принадлежность диапазону. Данная проверка определяет находится или нетзначение проверяемого выражения в диапазоне, указанном за ключевым словом BETWEEN, как
показано на следующей диаграмме (рис 5)
Рис 5 Синтаксическая диаграмма проверки
на принадлежность диапазону
Проверка на принадлежность диапазону эквивалента следующему логическому выражению
(A>=B) AND (A<=C), где А – проверяемое выражение, а В и С – соответственно нижнее и
верхнее границы диапазона.

19. Предложение WHERE
Проверка на принадлежность множеству. Данной проверке соответствует следующаясинтаксическая диаграмма (рис 6)
Рис 6 Синтаксическая диаграмма проверки
на принадлежность множеству
Проверка на принадлежность множеству определяет, равняется или нет значение проверяемого
выражения одному из констант, указанных за ключевым словом IN. Проверка на принадлежность
множеству эквивалентна следующему условию поиска сравнение
(А=С1) OR (A=C2)..(A=Cn) , где А – проверяемое выражение, а Сi – константы.
20. Предложение WHERE
Проверка на соответствие шаблону. Данная проверка выполняется над текстовыми данными.Данной проверке соответствует следующая синтаксическая диаграмма (рис 7)
Рис 7 Синтаксическая диаграмма проверки
на соответствие шаблону
С помощью этой проверки отбираются те строки, в которых данные, соответствующие
заданному столбцу, отвечают некоторому шаблону, следующему в предложении за ключевым
словом LIKE.
21. Предложение WHERE
Проверка на равенство значению NULL. Для проверки значения элемента столбца на равенствоNULL в SQL предусмотрена специальная проверка, называемая проверкой на равенство NULL.
Синтаксическая диаграмма этой проверки следующая (рис 8)
Рис 8 Синтаксическая диаграмма проверки
на равенство значению NULL
В соответствии с этой проверкой отбираются те строки, т.е. проверка имеет значение TRUE,
у которых данные в указанном столбце равны NULL.
22. Агрегатные функции
В SQL предусмотрены специальные функции, которые называются агрегатными(статистическими) функциями. В SQL имеются следующие агрегатные функции:
SUM() – вычисляют сумму значений, содержащих в аргументе;
AVG() – вычисляет среднее значение;
MIN(), MAX() – находит минимальное, максимальное значения;
COUNT() – подсчитывает в столбце количество не NULL-значений;
COUNT(*) – подсчитывает количество строк в запрашиваемой таблице.
Выражение должно содержать имена столбцов и определяет столбец, элементы которого
вычисляются с помощью соответствующих элементов этих столбцов.

Так как агрегатная функция возвращает одно значение, то она не может быть аргументом
другой агрегатной функции. Агрегатные функции используются в предложениях SELECT и
HAVING.
23. Предложение GROUP BY
Предложение GROUP BY позволяет запрашивать данные, которые являются итоговыми дляотдельных групп строк таблицы получаемой в предложении FROM. Если в запросе имеется
предложение GROUP BY , то строки запрашиваемой таблицы разбиваются на группы.
На запросы с применением предложения GROUP BY налагаются следующие ограничения –
возвращаемыми столбцами, указанными в предложении SELECT, могут быть:
Константа ;
Агрегатная функция;
Столбце группировки;
Выражение, включающее в себе перечисленные выше элементы.
24. Предложение HAVING
Для того, чтобы из групп строк, получаемых после предложения GROUP BY, выбрать требуемыегруппы, используется предложение HAVING. В это предложении за ключевым словом HAVING
следует условие поиска групп, аналогичное условию поиска в предложении WHERE.

Условию поиска применяется к группам строк, получаемых после предложения GROUP BY и
поэтому на элементы, входящие в условие поиска, налагаются те же ограничения, какие были
перечислены для возвращаемых столбцов при рассмотрении предложения GROUP BY. Таким
образом, в условие поиска могут входить константы , агрегатные функции, столбцы группировки
и выражение из них.
Предложение HAVING в основном используется вместе с предложением GROUP BY. Но язык SQL
допускает и отдельное применение предложения HAVING. В этом случае результат запроса
рассматривается как одна группа и предложение HAVING выполняет те же функции что и
предложение WHERE.
SQL — Функции
MySQL имеет множество встроенных функций: строковые, числовые, даты и расширенные функции.
Строковые функции
| Функция | Описание |
|
ASCII |
Возвращает числовой код, который представляет конкретный символ |
|
CHAR_LENGTH |
Возвращает длину указанной строки (в символах) |
|
CHARACTER_LENGTH |
Возвращает длину указанной строки (в символах) |
|
CONCAT |
Объединяет два или более выражения вместе |
|
CONCAT_WS |
Объединяет два или более выражения вместе и добавляет разделитель между ними |
|
FIELD |
Возвращает позицию значения в списке значений |
|
FIND_IN_SET |
Возвращает позицию строки в списке строк |
|
FORMAT |
Форматирует число как формат «#, ###. |
|
INSERT |
Вставляет подстроку в строку в указанной позиции для определенного количества символов |
|
INSTR |
Возвращает позицию первого вхождения строки в другую строку |
|
LCASE |
Преобразует строку в нижний регистр |
|
LEFT |
Извлекает подстроку из строки (начиная слева) |
|
LENGTH |
Возвращает длину указанной строки (в байтах) |
|
LOCATE |
Возвращает позицию первого вхождения подстроки в строку |
|
LOWER |
Преобразует строку в нижний регистр |
|
LPAD |
Возвращает строку, которая добавлена в левую сторону с указанной строкой до определенной длины |
|
LTRIM |
Удаляет ведущие пробелы из строки |
|
MID |
Извлекает подстроку из строки (начиная с любой позиции) |
|
POSITION |
Возвращает позицию первого вхождения подстроки в строку |
|
REPEAT |
Повторяет строку определенное количество раз |
|
REPLACE |
Заменяет все вхождения указанной строки |
|
REVERSE |
Отменяет строку и возвращает результат |
|
RIGHT |
Извлекает подстроку из строки (начиная справа) |
|
RPAD |
Возвращает строку с правой строкой с определенной строкой до определенной длины |
|
RTRIM |
Удаляет конечные пробелы из строки |
|
SPACE |
Возвращает строку с заданным количеством пробелов |
|
STRCMP |
Проверяет, одинаковы ли две строки |
|
SUBSTR |
Извлекает подстроку из строки (начиная с любой позиции) |
|
SUBSTRING |
Извлекает подстроку из строки (начиная с любой позиции) |
|
SUBSTRING_INDEX |
Возвращает подстроку string и перед integer вхождений delimiter |
|
TRIM |
Удаляет начальные и конечные пробелы из строки |
|
UCASE |
Преобразует строку в верхний регистр |
|
UPPER |
Преобразует строку в верхний регистр |
 ##», округляя его до определенного количества знаков после запятой
##», округляя его до определенного количества знаков после запятойЧисловые функции
| Функция | Описание |
|
ABS |
Возвращает абсолютное значение числа |
|
ACOS |
Возвращает косинус дуги числа |
|
ASIN |
Возвращает синус дуги числа |
|
ATAN |
Возвращает тангенс дуги числа или дуги касательной n и m |
|
ATAN2 |
Возвращает тангенс дуги n и m |
|
AVG |
Возвращает среднее значение выражения |
|
CEIL |
Возвращает наименьшее целочисленное значение, которое больше или равно числу |
|
CEILING |
Возвращает наименьшее целочисленное значение, которое больше или равно числу |
|
COS |
Возвращает косинус числа |
|
COT |
Возвращает котангенс числа |
|
COUNT |
Возвращает количество записей в выбранном запросе |
|
DEGREES |
Преобразует значение радиана в градусы |
|
DIV |
Используется для целочисленного деления |
|
EXP |
Возвращает e, поднятый до степени числа |
|
FLOOR |
Возвращает наибольшее целочисленное значение, которое меньше или равно числу |
|
GREATEST |
Возвращает наибольшее значение в списке выражений |
|
LEAST |
Возвращает наименьшее значение в списке выражений |
|
LN |
Возвращает натуральный логарифм числа |
|
LOG |
Возвращает натуральный логарифм числа или логарифм числа к заданной базе |
|
LOG10 |
Возвращает логарифм базы-10 числа |
|
LOG2 |
Возвращает логарифм базы-2 числа |
|
MAX |
Возвращает максимальное значение выражения |
|
MIN |
Возвращает минимальное значение выражения |
|
MOD |
Возвращает остаток n, деленный на m |
|
PI |
Возвращает значение PI, отображаемое с шестью знаками после запятой |
|
POW |
Возвращает m, поднятую до n-й степени |
|
POWER |
Возвращает m, поднятую до n-й степени |
|
RADIANS |
Преобразует значение в градусах в радианы |
|
RAND |
Возвращает случайное число или случайное число в пределах диапазона |
|
ROUND |
Возвращает число, округленное до определенного количества знаков после запятой |
|
SIGN |
Возвращает значение, обозначающее знак числа |
|
SIN |
Возвращает синус числа |
|
SQRT |
Возвращает квадратный корень из числа |
|
SUM |
Возвращает суммарное значение выражения |
|
TAN |
Возвращает тангенс числа |
|
TRUNCATE |
Возвращает число, усеченное до определенного количества знаков после запятой |
Функции даты
| Функция | Описание |
|
DATEDIFF |
Возвращает дату после добавления определенного интервала времени / даты |
|
DATE_ADD |
Возвращает время / дату-время после добавления определенного временного интервала |
|
DATE_FORMAT |
Возвращает текущую дату |
|
DATE_SUB |
Возвращает текущую дату |
|
DAY |
Возвращает текущее время |
|
DAYNAME |
Возвращает текущую дату и время |
|
DAYOFMONTH |
Возвращает текущее время |
|
DAYOFWEEK |
Извлекает значение даты из выражения даты или даты и времени |
|
DAYOFYEAR |
Возвращает разницу в днях между двумя значениями даты |
|
EXTRACT |
Возвращает дату после добавления определенного интервала времени / даты |
|
FROM_DAYS |
Форматирует дату, указанную маской формата |
|
HOUR |
Возвращает дату после вычитания определенного интервала времени / даты |
|
LAST_DAY |
Возвращает дневную часть значения даты |
|
LOCALTIME |
Возвращает имя дня недели для даты |
|
LOCALTIMESTAMP |
Возвращает дневную часть значения даты |
|
MAKEDATE |
Возвращает индекс недели недели для значения даты |
|
MAKETIME |
Возвращает день года для значения даты |
|
MICROSECOND |
Извлекает части с даты |
|
MINUTE |
Возвращает значение даты из числового представления дня |
|
MONTH |
Возвращает часовую часть значения даты |
|
MONTHNAME |
Возвращает последний день месяца на заданную дату |
|
NOW |
Возвращает текущую дату и время |
|
PERIOD_ADD |
Возвращает текущую дату и время |
|
PERIOD_DIFF |
Возвращает дату определенного годового и дневного значения |
|
QUARTER |
Возвращает время для определенного часа, минуты, второй комбинации |
|
SECOND |
Возвращает микросекундную часть значения даты |
|
SEC_TO_TIME |
Возвращает минутную часть значения даты |
|
STR_TO_DATE |
Возвращает месячную часть значения даты |
|
SUBDATE |
Возвращает полное название месяца для даты |
|
SUBTIME |
Возвращает текущую дату и время |
|
SYSDATE |
Принимает период и добавляет к нему определенное количество месяцев |
|
TIME |
Возвращает разницу в месяцах между двумя периодами |
|
TIME_FORMAT |
Возвращает четвертную часть значения даты |
|
TIME_TO_SEC |
Возвращает вторую часть значения даты |
|
TIMEDIFF |
Преобразует числовые секунды в значение времени |
|
TIMESTAMP |
Принимает строку и возвращает дату, заданную маской формата |
|
TO_DAYS |
Возвращает дату, после которой вычитается определенный интервал времени / даты |
|
WEEK |
Возвращает значение time / datetime после вычитания определенного временного интервала |
|
WEEKDAY |
Возвращает текущую дату и время |
|
WEEKOFYEAR |
Извлекает значение времени из выражения time / datetime |
|
YEAR |
Форматирует время, указанное маской формата |
|
YEARWEEK |
Преобразует значение времени в числовые секунды |
Расширенные функции
| Функция | Описание |
|
BIN |
Преобразует десятичное число в двоичное число |
|
BINARY |
Преобразует значение в двоичную строку |
|
CASE |
Позволяет вам оценить условия и вернуть значение при выполнении первого условия |
|
CAST |
Преобразует значение из одного типа данных в другой тип данных |
|
COALESCE |
Возвращает первое ненулевое выражение в списке |
|
CONNECTION_ID |
Возвращает уникальный идентификатор соединения для текущего соединения |
|
CONV |
Преобразует число из одной базы чисел в другую |
|
CONVERT |
Преобразует значение из одного типа данных в другой или один набор символов в другой |
|
CURRENT_USER |
Возвращает имя пользователя и имя хоста для учетной записи MySQL, используемой сервером, для проверки подлинности текущего клиента |
|
DATABASE |
Возвращает имя базы данных по умолчанию |
|
IF |
Возвращает одно значение, если условие TRUE или другое значение, если условие FALSE |
|
IFNULL |
Позволяет вернуть альтернативное значение, если выражение равно NULL |
|
ISNULL |
Проверяет, является ли выражение NULL |
|
LAST_INSERT_ID |
Возвращает первое значение AUTO_INCREMENT, заданное последним оператором INSERT или UPDATE |
|
NULLIF |
Сравнивает два выражения |
|
SESSION_USER |
Возвращает имя пользователя и имя хоста для текущего пользователя MySQL |
|
SYSTEM_USER |
Возвращает имя пользователя и имя хоста для текущего пользователя MySQL |
|
USER |
Возвращает имя пользователя и имя хоста для текущего пользователя MySQL |
|
VERSION |
Возвращает версию базы данных MySQL |
Глава 2.
 Язык SQL
Язык SQLФред Тусси
Группа разработчиков HSQL
$Revision: 6576 $
Copyright 2002-2022 Fred Toussi. Разрешение предоставляется на распространять этот документ без каких-либо изменений в соответствии с условиями Лицензия HSQLDB. Дополнительное разрешение предоставлено HSQL Development Группа для распространения этого документа с изменениями или без изменений под условия лицензии HSQLDB.
18.07.2022
Содержание
- Поддержка стандартов SQL
- Операторы определения (DDL и другие)
- Операторы обработки данных (DML)
- Операторы запроса данных (DQL)
- Вызов пользовательских процедур и функций
- Настройка свойств для базы данных и сеанса
- Общие операции с базой данных
- Заявления о транзакциях
- Комментарии в заявлениях
- Операторы в процедурах SQL
- SQL-данные и таблицы
- Чувствительность к регистру
- Постоянные таблицы
- Временные таблицы
- Краткое руководство по типам данных
- Типы данных и операции
- Числовые типы
- Логический тип
- Типы строк символов
- Двоичные строковые типы
- Типы битовых строк
- Лоб-данные
- Хранение и обработка объектов Java
- Введите длину, точность и масштаб
- Типы даты и времени
- Типы интервалов
- Массивы
- Определение массива
- Ссылка на массив
- Операции с массивами
Поддержка стандартов SQL
Язык SQL состоит из инструкций для различных операций. HyperSQL 2.x поддерживает диалект SQL, постепенно определяемый ISO.
(также ANSI) Стандарты SQL 92, 1999, 2003, 2008, 2011 и 2016. Это означает
синтаксис, указанный в стандартном тексте, принимается для любого поддерживаемого
операция. Почти все функции SQL-92 вплоть до Advanced Level доступны.
поддерживается, а также дополнительные функции, составляющие SQL:2016
основные и многие дополнительные функции этого стандарта.
HyperSQL 2.x поддерживает диалект SQL, постепенно определяемый ISO.
(также ANSI) Стандарты SQL 92, 1999, 2003, 2008, 2011 и 2016. Это означает
синтаксис, указанный в стандартном тексте, принимается для любого поддерживаемого
операция. Почти все функции SQL-92 вплоть до Advanced Level доступны.
поддерживается, а также дополнительные функции, составляющие SQL:2016
основные и многие дополнительные функции этого стандарта.
На момент выпуска этого выпуска HyperSQL поддерживает самый широкий диапазон Стандартные функции SQL среди всех СУБД с открытым исходным кодом.
В различных главах этого руководства перечислены поддерживаемые синтаксис. Когда запись или преобразование существующего SQL DDL (язык определения данных), DML (язык обработки данных) или DQL (язык запросов данных) для HSQLDB, вам следует ознакомиться с поддерживаемым синтаксисом и изменить операторы соответственно.
Более 300 слов зарезервированы стандартом и не должны использоваться
как имена таблиц или столбцов. Например, слово POSITION зарезервировано, поскольку оно
это функция, определенная Стандартами, с той же ролью, что и
Например, слово POSITION зарезервировано, поскольку оно
это функция, определенная Стандартами, с той же ролью, что и String::indexOf(String) в Java. По умолчанию,
HyperSQL не мешает вам использовать зарезервированное слово, если оно не
поддерживают его использование или могут отличить его. Например, CUBE является зарезервированным
слово для функции, которая поддерживается HyperSQL с версии 2.5.1.
До этой версии CUBE можно было использовать в качестве имени таблицы или столбца, но это
больше не разрешено. Вам следует избегать использования таких имен в качестве будущих версий
HyperSQL, скорее всего, будет поддерживать зарезервированные слова и может отклонить ваши
определения таблицы или запросы. Полный список зарезервированных слов SQL находится в
приложение Списки ключевых слов . Ты
можно установить свойство, чтобы запретить использование зарезервированных ключевых слов для имен
таблицы и другие объекты базы данных. Существует несколько других пользовательских
свойства для контроля строгого применения стандарта SQL в
разные области.
Если вам нужно использовать зарезервированное ключевое слово в качестве имени базы данных объект, вы можете заключить его в двойные кавычки.
HyperSQL также поддерживает расширения с ключевыми словами и выражениями
которые не являются частью стандарта SQL. Такие выражения, как SELECT
НАЧАЛО 5 ИЗ .. , ВЫБЕРИТЕ ПРЕДЕЛ 0 10 ИЗ ... или DROP TABLE mytable IF EXISTS входят в число таких
конструкции.
Многие книги посвящены синтаксису SQL Standard, и с ними можно ознакомиться.
В HyperSQL версии 2 все функции JDBC4, применимые к
возможности HSQLDB полностью поддерживаются. Соответствующие классы JDBC:
тщательно документированы с дополнительными разъяснениями и специфическими для HyperSQL
Комментарии. См. JavaDoc для org.hsqldb.jdbc.* классов.
В следующих разделах перечислены ключевые слова, запускающие различные SQL-запросы.
утверждения, сгруппированные по их функции.
Операторы определения (DDL и другие)
Операторы определения создают, изменяют или удаляют объекты базы данных. Таблицы и представления — это объекты, содержащие данные. Существуют и другие типы объекты, не содержащие данных. Эти заявления рассматриваются в Глава «Схемы и объекты базы данных».
СОЗДАТЬ
Далее следует {СХЕМА | ТАБЛИЦА | ПОСМОТРЕТЬ | ПОСЛЕДОВАТЕЛЬНОСТЬ | ПРОЦЕДУРА | ФУНКЦИЯ | ПОЛЬЗОВАТЕЛЬ | РОЛЬ | … } ключевое слово используется для создания объекты базы данных.
ALTER
За которым следуют те же ключевые слова, что и CREATE, это ключевое слово используется для изменить объект.
DROP
За которым следуют те же ключевые слова, что и выше, это ключевое слово используется для удалить объект. Если объект содержит данные, данные удаляются слишком.
GRANT
Ключевое слово, за которым следует имя роли или привилегии, назначает
роль или дает разрешения ПОЛЬЗОВАТЕЛЮ или роли.
REVOKE
REVOKE, за которым следует имя роли или привилегии, является напротив ГРАНТА.
КОММЕНТАРИЙ К
За которым следуют те же ключевые слова, что и СОЗДАТЬ, это ключевое слово используется для добавить текстовый комментарий к TABLE, VIEW, COLUMN, ROUTINE и TRIGGER объекты.
EXPLAIN REFERENCES
За этими ключевыми словами следует TO или FROM, чтобы перечислить другие объекты базы данных, которые ссылаются на данный объект, или наоборот.
DECLARE
Используется для объявления временных таблиц сеансов и переменные.
Операторы обработки данных (DML)
Операторы обработки данных добавляют, обновляют или удаляют данные в таблицах и взгляды. Эти заявления рассматриваются в разделе Доступ к данным и их изменение. глава.
INSERT
Вставляет одну или несколько строк в таблицу или представление.
UPDATE
Обновляет одну или несколько строк в таблице или представлении.
DELETE
Удаляет одну или несколько строк из таблицы или представления.
TRUNCATE
Удаляет все строки в таблице.
MERGE
Выполняет условную ВСТАВКУ, ОБНОВЛЕНИЕ или УДАЛЕНИЕ в таблице или представлении используя данные, указанные в заявлении.
Операторы запроса данных (DQL)
Операторы запроса данных извлекают и комбинируют данные из таблиц и представления и возвращать наборы результатов. Эти заявления рассматриваются в разделе Доступ к данным и их изменение. глава.
SELECT
Возвращает набор результатов, сформированный из подмножества строк и столбцов в одну или несколько таблиц или представлений.
ЗНАЧЕНИЯ
Возвращает набор результатов, сформированный из постоянных значений.
WITH …
Это ключевое слово запускает серию операторов SELECT, формирующих
запрос. Первые SELECT действуют как подзапросы для окончательного SELECT.
оператор в том же запросе.
EXPLAIN PLAN
За этими ключевыми словами следует полный текст любого DQL или DML утверждение. Набор результатов показывает анатомию данного DQL или DML. оператор, включая индексы, используемые для доступа к таблицам.
Вызов пользовательских процедур и функций
CALL
Вызов процедуры или функции. Вызов функции может вернуть набор результатов или значение, а вызов процедуры может вернуть один или несколько наборы результатов и значения одновременно. Это утверждение описано в подпрограммы, вызываемые SQL глава.
Установка свойств для базы данных и сеанса
SET
Оператор SET имеет множество вариантов и используется для установки значения общих свойств базы данных или текущего сеанса. Использование оператора SET для базы данных описано в главе «Управление системой». Использование сеанса описано в главе «Сеансы и транзакции».
Общие операции с базой данных
Общие операции с базой данных включают резервное копирование, контрольную точку и
другие операции. Эти утверждения подробно описаны в разделе «Управление системой».
глава.
Эти утверждения подробно описаны в разделе «Управление системой».
глава.
BACKUP
Создает резервную копию базы данных в целевом каталоге.
PERFORM
Включает команды для экспорта и импорта сценариев SQL из/в база данных. Также включает команду для проверки непротиворечивости индексы.
СЦЕНАРИЙ
Создает сценарий операторов SQL, который создает базу данных объекты и настройки.
КОНТРОЛЬНАЯ ТОЧКА
Сохраняет все изменения в базе данных до этого момента на диск файлы.
ВЫКЛЮЧЕНИЕ
Закрывает базу данных после сохранения всех изменений.
Операторы транзакции
Эти операторы используются в сеансе для запуска, завершения или управления транзакции. Они рассматриваются в главе «Сеансы и транзакции».
НАЧАТЬ ТРАНЗАКЦИЮ
Этот оператор инициирует новую транзакцию с заданным характеристики транзакции
SET TRANSACTION
Вводит одну или несколько характеристик для следующего
сделка.
COMMIT
Фиксирует изменения данных, сделанные в текущем сделка.
ROLLBACK
Откат изменений данных, сделанных в текущей транзакции. Это также возможен откат к точке сохранения.
SAVEPOINT
Записывает точку в текущей транзакции, чтобы будущие изменения можно откатиться к этому моменту.
RELEASE SAVEPOINT
Освобождает существующую точку сохранения.
LOCK
Блокирует набор таблиц для управления транзакциями.
ПОДКЛЮЧИТЬ
Запускает новый сеанс и продолжает операции в этом сессия.
ОТКЛЮЧИТЬ
Завершает текущий сеанс.
Комментарии в операторах
Любой оператор SQL может включать комментарии. Комментарии удалены до того, как оператор будет выполнен.
Строковые комментарии в стиле SQL начинаются с двух дефисов -- и продлить до конца строки.
Комментарии в стиле C могут охватывать часть строки или несколько строк. Они начинаются с
Они начинаются с /* и заканчиваться на */ .
Операторы в процедурах SQL
Основная часть определяемых пользователем процедур и функций SQL (вместе называемые подпрограммами) могут содержать несколько других типов операторы и ключевые слова в дополнение к операторам DML и DQL. Эти включить: BEGIN и END для блоков; циклы FOR, WHILE и REPEAT; ЕСЛИ ЕЩЕ и блоки ELSEIF; Операторы SIGNAL и RESIGNAL для обработки исключения.
Эти операторы подробно описаны в подпрограммах, вызываемых SQL. глава.
Данные и таблицы SQL
Все данные хранятся в таблицах. Поэтому создание базы данных требует определения таблиц и их столбцов. Стандарт SQL поддерживает временные таблицы, предназначенные для временных данных, управляемых каждым сеансом, и постоянные базовые таблицы, которые предназначены для постоянных данных, совместно используемых разные сеансы.
База данных HyperSQL может быть полностью в памяти mem: база данных без автоматического сохранения или
файловый, постоянный файл: база данных .
Чувствительность к регистру
Стандартный SQL не чувствителен к регистру, за исключением случаев, когда имена объектов
заключаются в двойные кавычки. Ключевые слова SQL можно писать в любом регистре;
например, sElect , SELECT и select разрешены и преобразованы в верхний регистр.
Идентификаторы, такие как имена таблиц, столбцов и других объектов, определенных
пользователем, также преобразуются в верхний регистр. Например, myTable , MyTable и MYTABLE все ссылаются на одну и ту же таблицу и хранятся в
база данных в регистронормальной форме, в которой для
идентификаторы без кавычек. Когда имя объекта заключено в двойной
кавычки при создании, точное имя используется в качестве нормального регистра
form, и на него должна ссылаться точно такая же строка в двойных кавычках.
Например, "myTable" и "MYTABLE" — разные таблицы.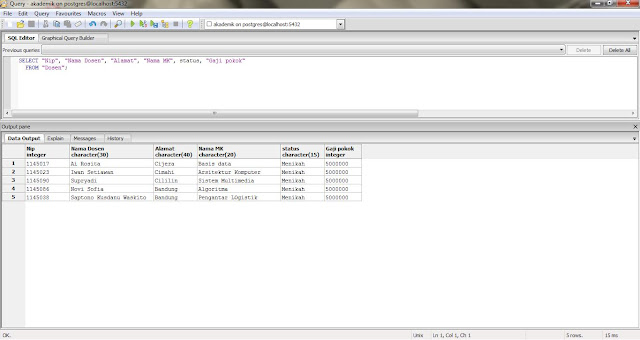 Когда
имя в двойных кавычках пишется в верхнем регистре, на него можно ссылаться в любом случае;
Когда
имя в двойных кавычках пишется в верхнем регистре, на него можно ссылаться в любом случае; "MYTABLE" совпадает с myTable и MyTable , потому что все они преобразованы в ТАБЛИЦА .
Постоянные таблицы
HyperSQL поддерживает стандартное определение постоянной базы table, но определяет три типа в зависимости от способа хранения данных. Это таблицы MEMORY, таблицы CACHED и таблицы TEXT.
Таблицы памяти являются типом по умолчанию, когда команда CREATE TABLE
используется. Их данные полностью хранятся в памяти. В файловых базах данных
Таблицы MEMORY являются постоянными, и любое изменение их структуры или
содержимое записывается в *.log и *.script файлов. *.скрипт файл и файл *.log читаются в следующий раз, когда
база данных открывается, а таблицы MEMORY пересоздаются со всеми
данные. Этот процесс может занять много времени, если размер базы данных превышает
десятки мегабайт. Когда база данных закрыта, все данные
сохранен.
Этот процесс может занять много времени, если размер базы данных превышает
десятки мегабайт. Когда база данных закрыта, все данные
сохранен.
Таблицы CACHED создаются с помощью команды CREATE CACHED TABLE. В памяти хранится только часть их данных или индексов, что позволяет таблицы, которые в противном случае заняли бы до нескольких сотен мегабайт Память. Еще одним преимуществом кэшированных таблиц является то, что механизм базы данных требуется меньше времени для запуска, когда кэшированная таблица используется для больших объемы данных. Недостатком кэшированных таблиц является уменьшение скорость. Не используйте кэшированные таблицы, если ваш набор данных относительно мал. В приложение с несколькими маленькими таблицами и несколькими большими, лучше использовать режим MEMORY по умолчанию для небольших таблиц.
Таблицы TEXT используют CSV (значения, разделенные запятыми) или другие файлы с разделителями.
текстовый файл в качестве источника своих данных. Вы можете указать существующий CSV
файл, например дамп из другой базы данных или программы, в качестве источника
ТЕКСТОВАЯ таблица. Кроме того, вы можете указать пустой файл для заполнения
с данными механизмом базы данных. Таблицы TEXT эффективны в памяти
использования, так как они кэшируют только часть текстовых данных и все индексы.
Источник данных текстовой таблицы всегда можно переназначить другому файлу.
если необходимо. Команды необходимы для настройки таблицы TEXT, как подробно описано
в текстовых таблицах
глава.
Вы можете указать существующий CSV
файл, например дамп из другой базы данных или программы, в качестве источника
ТЕКСТОВАЯ таблица. Кроме того, вы можете указать пустой файл для заполнения
с данными механизмом базы данных. Таблицы TEXT эффективны в памяти
использования, так как они кэшируют только часть текстовых данных и все индексы.
Источник данных текстовой таблицы всегда можно переназначить другому файлу.
если необходимо. Команды необходимы для настройки таблицы TEXT, как подробно описано
в текстовых таблицах
глава.
С памятью all-in-mem : баз данных, обе Объявления таблиц MEMORY и CACHED обрабатываются как объявления для таблиц MEMORY, которые существуют только на время процесса Java. В последних версиях HyperSQL разрешены объявления таблиц TEXT. в базах данных all-in-memory.
Тип таблиц по умолчанию в результате будущей CREATE TABLE можно указать с помощью команды SQL:
SET DATABASE DEFAULT TABLE TYPE { CACHED | ПАМЯТЬ }; тип существующей таблицы можно изменить с помощью команды SQL:
SET TABLE <имя таблицы> TYPE { CACHED | ПАМЯТЬ }; SQL
операторы, такие как INSERT или SELECT, обращаются к различным типам таблиц
равномерно. Для доступа к различным типам не требуется никаких изменений в операторах.
таблицы.
Для доступа к различным типам не требуется никаких изменений в операторах.
таблицы.
Временные таблицы
Данные во ВРЕМЕННЫХ таблицах не сохраняются и сохраняются только в течение время жизни сеанса. Содержимое каждой таблицы TEMP видно только из сеанса, который используется для его заполнения.
HyperSQL поддерживает два типа временных таблиц.
Тип GLOBAL TEMPORARY является объектом схемы.
Он создается с помощью команды CREATE GLOBAL TEMPORARY TABLE .
утверждение. Определение таблицы сохраняется, и каждый сеанс
доступ к таблице. Но каждый сеанс видит свою копию таблицы,
который пуст в начале сеанса.
Тип LOCAL TEMPORARY не является схемой
объект. Он создан с помощью ОБЪЯВИТЬ МЕСТНЫЙ ВРЕМЕННЫЙ
ТАБЛИЦА заявление. Определение таблицы длится только для
длительность сеанса и не сохраняется в базе данных. Таблица
может быть объявлен в середине транзакции без совершения
сделка. Если имя схемы необходимо для ссылки на эти таблицы в
данный оператор SQL, имя псевдосхемы
Если имя схемы необходимо для ссылки на эти таблицы в
данный оператор SQL, имя псевдосхемы SESSION может быть использован.
При фиксации сеанса содержимое всех временных таблиц
очищен по умолчанию. Если оператор определения таблицы включает ON COMMIT PRESERVE ROWS , тогда содержимое сохраняется
когда происходит коммит.
Строки во временных таблицах по умолчанию хранятся в памяти. Если
свойство hsqldb.result_max_memory_rows было
набор или SET SESSION RESULT MEMORY ROWS <строка
count> , таблицы с количеством строк выше
настройки хранятся на диске.
Краткое руководство по типам данных
Стандарт SQL строго типизирован и полностью типобезопасен. Это поддерживает следующие основные типы, которые все поддерживаются ГиперSQL.
Числовые типы TINYINT, SMALLINT, INTEGER и BIGINT являются типами с фиксированной двоичной точностью.
 Эти типы более эффективны для хранения
и получить. NUMERIC и DECIMAL — это типы с определяемым пользователем десятичным числом.
точность. Их можно использовать с нулевой шкалой для хранения очень больших
целые числа или с ненулевым масштабом для хранения десятичных дробей.
Тип DOUBLE является 64-битным, приближенным типом с плавающей запятой. ГиперSQL
даже позволяет хранить бесконечность в этом типе.
Эти типы более эффективны для хранения
и получить. NUMERIC и DECIMAL — это типы с определяемым пользователем десятичным числом.
точность. Их можно использовать с нулевой шкалой для хранения очень больших
целые числа или с ненулевым масштабом для хранения десятичных дробей.
Тип DOUBLE является 64-битным, приближенным типом с плавающей запятой. ГиперSQL
даже позволяет хранить бесконечность в этом типе.Тип BOOLEAN предназначен для логических значений и может содержать значение TRUE, FALSE. или НЕИЗВЕСТНО. Хотя HyperSQL позволяет использовать единицу и ноль в присвоение или сравнение, вы должны использовать стандартные значения для этого тип.
Типы строк символов: CHAR(L), VARCHAR(L) и CLOB (здесь L обозначает параметр длины, целое число). CHAR для фиксированной ширины строки, и любая строка, присвоенная этому типу, дополняется пробелы в конце. Если вы используете CHAR без длины L, то это интерпретируется как строка из одного символа.
Не используйте этот тип для
общее хранилище строк. Используйте VARCHAR(L) для общих строк. Там
являются только ограничения памяти и влияние на производительность для максимального
длина VARCHAR(L). Если строки больше нескольких килобайт,
рассмотрите возможность использования CLOB. Типы CLOB — лучший выбор для очень долгого
струны. Не используйте этот тип для коротких строк, так как
последствия для производительности. По умолчанию LONGVARCHAR является синонимом
длинный VARCHAR и может использоваться без указания размера. Вы можете установить
LONGVARCHAR для сопоставления с CLOB с sql.longvar_is_lobсвойство подключения или набор Оператор DATABASE SQL LONGVAR IS LOB TRUE.Типы двоичных строк: BINARY(L), VARBINARY(L) и BLOB. Не надо используйте BINARY(L), если вы не храните строки фиксированной длины, такие как UUID. Этот тип дополняет короткие двоичные строки нулевыми байтами.
ДВОИЧНЫЙ
без длины L означает один байт. Используйте VARBINARY(L) для общего
двоичные строки и BLOB для больших двоичных объектов. Вы должны подать заявку
те же соображения, что и с типами строк символов. По
по умолчанию LONGVARBINARY является синонимом длинного VARBINARY и может быть
используется без указания размера. Вы можете установить LONGVARBINARY для сопоставления с
BLOB, с sql.longvar_is_lobсоединение или оператор SET DATABASE SQL LONGVAR IS LOB TRUE.Типы BIT(L) и BITVARYING(L) предназначены для битовых карт. Не используй их для других типов данных. BIT без аргумента длины L означает один бит и иногда используется как логический тип. Использовать логическое значение вместо этого типа.
Тип UUID предназначен для значений UUID (также называемых GUID). Значение хранится как ДВОИЧНЫЙ. Строки символов UUID, а также BINARY строки, могут использоваться для вставки или сравнения.
Типы datetime DATE, TIME и TIMESTAMP вместе с доступны их варианты WITH TIME ZONE. Подробности читайте в в этой главе о том, как использовать эти типы.
Тип INTERVAL очень эффективен при использовании вместе с типы даты и времени. Это очень просто в использовании, но поддерживается в основном системы корпоративных баз данных. Обратите внимание, что функции, добавляющие дни или значения месяцев до даты и времени на самом деле не заменяют ИНТЕРВАЛ тип. Такие выражения, как
(датакол - 7 ДЕНЬ) > CURRENT_DATEоптимизированы для использования индексов, когда это возможен, в то время как эквивалентные вызовы функций не оптимизированный.Тип OTHER предназначен для хранения объектов Java. Если ваши объекты большие, сериализуйте их в своем приложении и сохраните как BLOB в базе данных.
Тип ARRAY поддерживает все базовые типы, кроме LOB и OTHER.
типы. Объекты данных ARRAY удерживаются в памяти во время обработки. Это
поэтому не рекомендуется хранить более тысячи
объекты в МАССИВЕ в обычных операциях с дисковыми базами данных.
Для специализированных приложений используйте МАССИВ с таким количеством элементов, сколько вам нужно.
выделение памяти может поддерживать.
 Эти типы более эффективны для хранения
и получить. NUMERIC и DECIMAL — это типы с определяемым пользователем десятичным числом.
точность. Их можно использовать с нулевой шкалой для хранения очень больших
целые числа или с ненулевым масштабом для хранения десятичных дробей.
Тип DOUBLE является 64-битным, приближенным типом с плавающей запятой. ГиперSQL
даже позволяет хранить бесконечность в этом типе.
Эти типы более эффективны для хранения
и получить. NUMERIC и DECIMAL — это типы с определяемым пользователем десятичным числом.
точность. Их можно использовать с нулевой шкалой для хранения очень больших
целые числа или с ненулевым масштабом для хранения десятичных дробей.
Тип DOUBLE является 64-битным, приближенным типом с плавающей запятой. ГиперSQL
даже позволяет хранить бесконечность в этом типе. Не используйте этот тип для
общее хранилище строк. Используйте VARCHAR(L) для общих строк. Там
являются только ограничения памяти и влияние на производительность для максимального
длина VARCHAR(L). Если строки больше нескольких килобайт,
рассмотрите возможность использования CLOB. Типы CLOB — лучший выбор для очень долгого
струны. Не используйте этот тип для коротких строк, так как
последствия для производительности. По умолчанию LONGVARCHAR является синонимом
длинный VARCHAR и может использоваться без указания размера. Вы можете установить
LONGVARCHAR для сопоставления с CLOB с
Не используйте этот тип для
общее хранилище строк. Используйте VARCHAR(L) для общих строк. Там
являются только ограничения памяти и влияние на производительность для максимального
длина VARCHAR(L). Если строки больше нескольких килобайт,
рассмотрите возможность использования CLOB. Типы CLOB — лучший выбор для очень долгого
струны. Не используйте этот тип для коротких строк, так как
последствия для производительности. По умолчанию LONGVARCHAR является синонимом
длинный VARCHAR и может использоваться без указания размера. Вы можете установить
LONGVARCHAR для сопоставления с CLOB с  ДВОИЧНЫЙ
без длины L означает один байт. Используйте VARBINARY(L) для общего
двоичные строки и BLOB для больших двоичных объектов. Вы должны подать заявку
те же соображения, что и с типами строк символов. По
по умолчанию LONGVARBINARY является синонимом длинного VARBINARY и может быть
используется без указания размера. Вы можете установить LONGVARBINARY для сопоставления с
BLOB, с
ДВОИЧНЫЙ
без длины L означает один байт. Используйте VARBINARY(L) для общего
двоичные строки и BLOB для больших двоичных объектов. Вы должны подать заявку
те же соображения, что и с типами строк символов. По
по умолчанию LONGVARBINARY является синонимом длинного VARBINARY и может быть
используется без указания размера. Вы можете установить LONGVARBINARY для сопоставления с
BLOB, с 
 типы. Объекты данных ARRAY удерживаются в памяти во время обработки. Это
поэтому не рекомендуется хранить более тысячи
объекты в МАССИВЕ в обычных операциях с дисковыми базами данных.
Для специализированных приложений используйте МАССИВ с таким количеством элементов, сколько вам нужно.
выделение памяти может поддерживать.
типы. Объекты данных ARRAY удерживаются в памяти во время обработки. Это
поэтому не рекомендуется хранить более тысячи
объекты в МАССИВЕ в обычных операциях с дисковыми базами данных.
Для специализированных приложений используйте МАССИВ с таким количеством элементов, сколько вам нужно.
выделение памяти может поддерживать.HyperSQL 2.7 имеет несколько режимов совместимости, которые позволяют использовать тип имена, которые используются другими СУБД, должны быть приняты и переведены в ближайший стандартный тип SQL. Например, тип TEXT, поддерживаемый MySQL и PostgreSQL переведен в эти режимы совместимости.
Таблица 2.1. Список типов SQL
| Тип | Описание |
|---|---|
| TINYINT, SMALLINT, INT или INTEGER, BIGNIT | двоичных типов чисел с точностью 8, 16, 32, 64 бита соответственно |
| DOUBLE или FLOAT | 64-битное число с плавающей запятой |
| DECIMAL(P,S), DEC(P,S) или NUMERIC(P,S) | идентичные типы для фиксированного числа точности (*) |
| BOOLEAN | логический тип поддерживает TRUE, FALSE и UNKNOWN |
| СИМВОЛ(L) или СИМВОЛ(L) | строковый тип UTF-16 фиксированной длины, дополненный пробелом длина L (**) |
| VARCHCHAR(L) или CHARACTER VARYING(L) | тип строки UTF-16 переменной длины (***) |
| CLOB(L) | тип длинной строки переменной длины UTF-16 (***) |
| LONGVARCHAR(L) | нестандартный синоним VARCHAR(L) (***) |
| BINARY(L) | тип двоичной строки фиксированной длины — дополняется нулями длина L (**) |
| VARBINARY(L) или BINARY VARYING(L) | тип двоичной строки переменной длины (***) |
| BLOB(L) | Тип двоичной строки переменной длины (***) |
| LONGVARBINARY(L) | нестандартный синоним для VARBINARY(L) (***) |
| BIT(L) | битовая карта фиксированной длины — дополняется 0 до длины L — максимальная значение L равно 1024 |
| BIT VARYING(L) | битовая карта переменной длины — максимальное значение L 1024 |
| UUID | 16-байтовый фиксированный двоичный тип, представленный как UUID строка |
| ДАТА | дата |
| ВРЕМЯ(S) | время суток (****) |
| ВРЕМЯ(S) С ЧАСОВЫМ ПОЯСОМ | время суток со значением смещения зоны (****) |
| TIMESTAMP(S) | дата и время суток (****) |
| TIMESTAMP(S) С ЧАСОВЫМ ПОЯСОМ | timestamp со значением смещения зоны (****) |
| ИНТЕРВАЛ | дата или временной интервал — имеет много вариантов |
| ПРОЧЕЕ | нестандартный тип для сериализуемого объекта Java |
| МАССИВ | массив базового типа |
В таблице выше: (*) Параметры являются необязательными.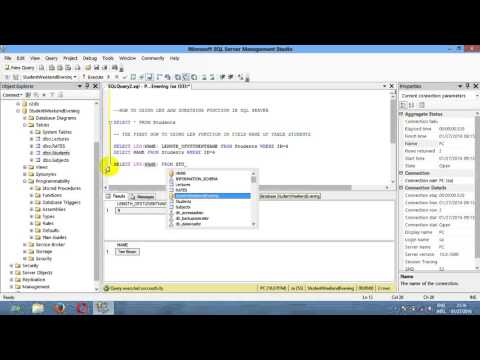 P используется для
максимальная точность и S для шкалы DECIMAL и NUMERIC. Если только П
используется, S по умолчанию равно 0. Если ничего не используется, P по умолчанию равно 128, а S по умолчанию
до 0. Максимальное значение каждого параметра не ограничено. (**) Параметр
L используется для фиксированной длины. Если не используется, по умолчанию используется 1. (***)
параметр L используется для максимальной длины. Требуется для VARCHAR(L) и
VARBINARY(L), но не является обязательным для других типов. Если не используется, по умолчанию
до 1G для BLOB или CLOB и 16M для LONGVARCHAR и LONGVARBINARY.
максимальное значение параметра не ограничено для CLOB и BLOB. Это 2 *
1024 *1024 *1024 для других типов строк. (****) Параметр S равен
необязательный и указывает точность времени до доли секунды (от 0 до 9).
Если не используется, по умолчанию 6.
P используется для
максимальная точность и S для шкалы DECIMAL и NUMERIC. Если только П
используется, S по умолчанию равно 0. Если ничего не используется, P по умолчанию равно 128, а S по умолчанию
до 0. Максимальное значение каждого параметра не ограничено. (**) Параметр
L используется для фиксированной длины. Если не используется, по умолчанию используется 1. (***)
параметр L используется для максимальной длины. Требуется для VARCHAR(L) и
VARBINARY(L), но не является обязательным для других типов. Если не используется, по умолчанию
до 1G для BLOB или CLOB и 16M для LONGVARCHAR и LONGVARBINARY.
максимальное значение параметра не ограничено для CLOB и BLOB. Это 2 *
1024 *1024 *1024 для других типов строк. (****) Параметр S равен
необязательный и указывает точность времени до доли секунды (от 0 до 9).
Если не используется, по умолчанию 6.
Типы данных и операции
HyperSQL поддерживает все типы, определенные в SQL-92, плюс BOOLEAN,
Типы BINARY, ARRAY и LOB, которые позже были добавлены в стандарт SQL. Это
также поддерживает нестандартный тип OTHER для хранения сериализуемой Java.
объекты.
Это
также поддерживает нестандартный тип OTHER для хранения сериализуемой Java.
объекты.
SQL является строго типизированным языком. Все данные, хранящиеся в определенных столбцы таблиц и другие объекты (например, генераторы последовательностей) имеют конкретные виды. Каждый элемент данных соответствует ограничениям типа, таким как точность и масштаб столбца. Он также соответствует любым дополнительным ограничения целостности, определенные как ограничения CHECK в доменах или столы. Типы могут быть явно преобразованы с помощью выражения CAST, но в большинстве выражений они преобразуются автоматически.
Данные возвращаются пользователю (или прикладной программе) в виде
результат выполнения операторов SQL, таких как выражения запроса или функция
звонки. Все операторы компилируются перед выполнением, а возвращаемый тип
данных известно после компиляции и до выполнения. Следовательно,
после подготовки оператора тип данных каждого столбца возвращаемого
результат известен, включая любое свойство точности или масштаба.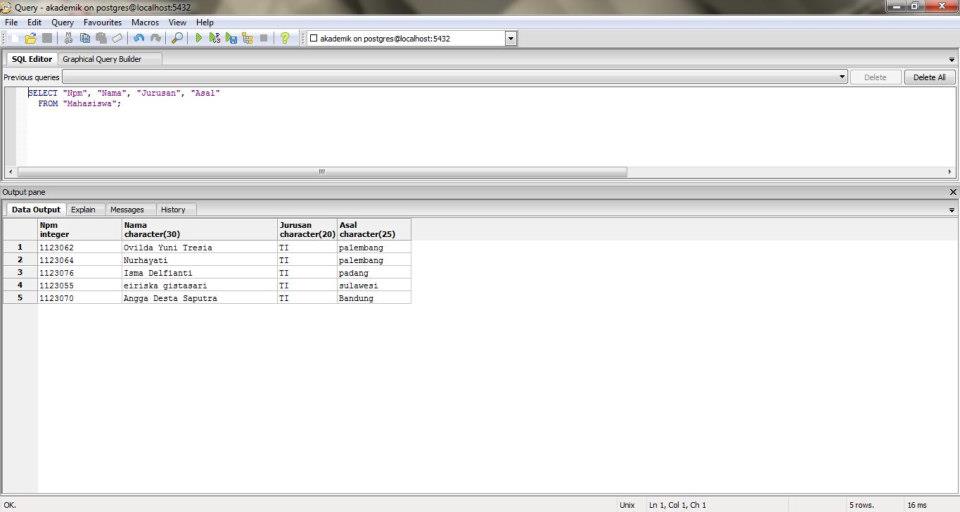 Тип делает
не изменится, когда тот же запрос, который вернул одну строку, возвращает много строк, как
в результате добавления дополнительных данных в таблицы.
Тип делает
не изменится, когда тот же запрос, который вернул одну строку, возвращает много строк, как
в результате добавления дополнительных данных в таблицы.
Некоторые функции SQL, используемые в операторах SQL, являются полиморфными, но точный тип аргумента и возвращаемое значение определяются в время компиляции.
При подготовке оператора с использованием JDBC PreparedStatement объект, компилируется движком
и тип столбцов его ResultSet и/или его параметров
доступным с помощью методов ПодготовленоОтчет .
Числовые типы
TINYINT, SMALLINT, INTEGER, BIGINT, NUMERIC и DECIMAL (без
десятичная точка) являются поддерживаемыми целочисленными типами. Они соответствуют
соответственно байт , короткий , инт , длинный , BigDecimal и BigDecimal Типы Java в диапазоне значений,
они могут представлять (NUMERIC и DECIMAL эквивалентны).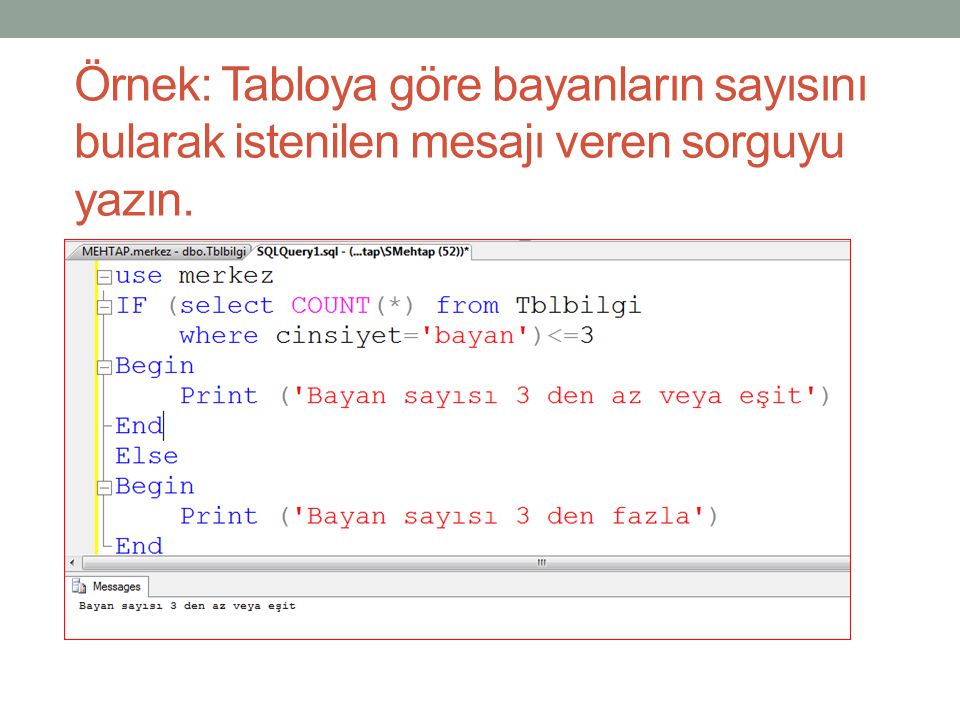 Тип
TINYINT — это расширение HSQLDB для стандарта SQL, в то время как другие
соответствуют стандартному определению. Тип SQL диктует максимальное
и минимальные значения, которые могут храниться в поле каждого типа. Например
диапазон значений для TINYINT составляет от -128 до +127. Битовая точность
TINYINT, SMALLINT, INTEGER и BIGINT равны соответственно 8, 16, 32 и 64.
Для NUMERIC и DECIMAL используется десятичная точность.
Тип
TINYINT — это расширение HSQLDB для стандарта SQL, в то время как другие
соответствуют стандартному определению. Тип SQL диктует максимальное
и минимальные значения, которые могут храниться в поле каждого типа. Например
диапазон значений для TINYINT составляет от -128 до +127. Битовая точность
TINYINT, SMALLINT, INTEGER и BIGINT равны соответственно 8, 16, 32 и 64.
Для NUMERIC и DECIMAL используется десятичная точность.
DECIMAL и NUMERIC с десятичными дробями отображаются в java.math.BigDecimal и может иметь очень большие
количество цифр. В HyperSQL эти два типа эквивалентны. Эти
типы вместе с целочисленными типами называются точными числовыми
типы.
В HyperSQL REAL, FLOAT и DOUBLE эквивалентны: все они
сопоставлен с двойным в Java. Эти типы определены
по стандарту SQL как приблизительные числовые типы. Битовая точность
все эти типы 64-битные.
Десятичная точность и масштаб типов NUMERIC и DECIMAL могут
быть факультативно определены. Например, DECIMAL(10,2) означает максимальную сумму
количество цифр равно 10 и после запятой всегда 2 цифры
точка, а DECIMAL(10) означает 10 цифр без десятичной точки.
битовая точность FLOAT может быть определена, но она игнорируется и по умолчанию
используется битовая точность 64. Точность по умолчанию NUMERIC и
DECIMAL (если не определено) равно 128.
Например, DECIMAL(10,2) означает максимальную сумму
количество цифр равно 10 и после запятой всегда 2 цифры
точка, а DECIMAL(10) означает 10 цифр без десятичной точки.
битовая точность FLOAT может быть определена, но она игнорируется и по умолчанию
используется битовая точность 64. Точность по умолчанию NUMERIC и
DECIMAL (если не определено) равно 128.
Примечание. Если для базы данных настроено игнорирование ограничений точности типов с помощью команды SET DATABASE SQL SIZE FALSE, затем определение типа DECIMAL без точности и масштаба обрабатывается как DECIMAL(128,32). В при нормальной работе он обрабатывается как DECIMAL(128).
Интегральные типы
В выражениях значения TINYINT, SMALLINT, INTEGER, BIGINT,
Типы NUMERIC и DECIMAL (без десятичной точки) могут быть свободно
объединены, и никакого сужения данных не происходит. Полученное значение равно
тип, который может поддерживать все возможные значения.
Если оператор SELECT ссылается на простой столбец или функцию, то возвращаемый тип — это тип, соответствующий столбцу или возвращаемый тип функции. Например:
вернет ResultSet , где тип
первый столбец — java.lang.Integer , а
второй столбец — java.lang.Long . Однако
вернет java.lang.Long и BigDecimal значений, сгенерированных в результате
продвижение универсального типа для всех возможных возвращаемых значений. Обратите внимание, что тип
повышение до BigDecimal обеспечивает правильное значение
возвращается, если MAX(b) оценивается как Длинн.MAX_VALUE .
Нет встроенного ограничения на размер промежуточного интеграла
значения в выражениях. В результате вы должны проверить тип ResultSet столбец и выберите соответствующий метод getXXXX() для его получения. Альтернативно,
вы можете использовать метод
Альтернативно,
вы можете использовать метод getObject() , а затем бросить
результат до java.lang.Number и используйте intValue() или longValue() , если значение не является экземпляром java.math.BigDecimal .
Когда результат выражения сохраняется в столбце
таблица базы данных, она должна соответствовать целевому столбцу, иначе ошибка
возвращается. Например, когда 12345678456789012/
123456874567890 оценивается, результат может быть сохранен в
любой столбец целочисленного типа, даже столбец TINYINT, так как это небольшой
ценность.
В операторах SQL целочисленный литерал рассматривается как INTEGER, если его значение не подходит. В этом случае он рассматривается как BIGINT или ДЕСЯТИЧНЫЙ, в зависимости от значения.
В зависимости от типов операндов результат
операция возвращается в JDBC ResultSet в любом
связанных типов Java: Integer , Long или BigDecimal .
Методы ResultSet.getXXXX() можно использовать для
извлекать значения, если возвращаемое значение может быть представлено
полученный тип. Этот тип детерминированно основан на запросе,
не в фактически возвращенных строках.
Другие числовые типы
В операторах SQL числовые литералы с десятичной точкой
обрабатываются как DECIMAL, если они не записаны с показателем степени. Таким образом 0,2 считается ДЕСЯТИЧНЫМ значением, но 0.2E0 считается значением DOUBLE.
При приближенном числовом типе REAL, FLOAT или DOUBLE (все
синонимичный) является частью выражения, включающего различные числовые типы,
тип результата DOUBLE. ДЕСЯТИЧНЫЕ значения могут быть преобразованы в
DOUBLE, если они не превышают Двойной.MIN_VALUE -
Диапазон Double.MAX_VALUE 90 107. Например, А*В, А/В, А+В и т.д.
вернет значение DOUBLE, если A или B является DOUBLE.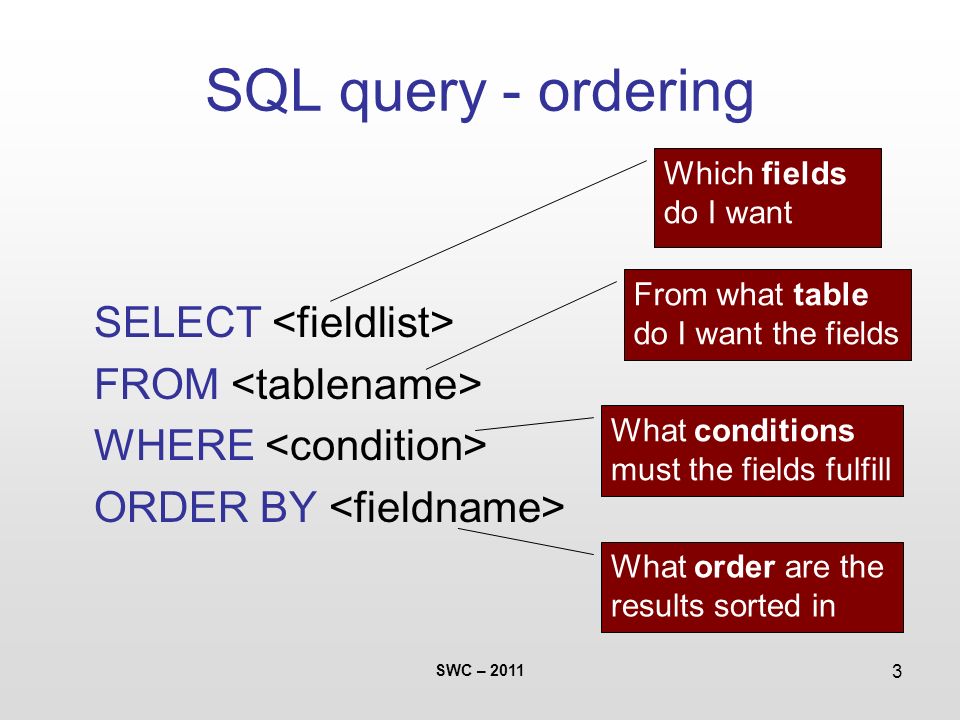
В противном случае, когда значение DOUBLE не существует, если DECIMAL или NUMERIC значение является частью выражения, тип результата - DECIMAL или ЦИФРОВОЙ. Подобно целочисленным значениям, когда результат выражения присвоено столбцу таблицы, значение должно соответствовать целевому столбцу, в противном случае возвращается ошибка. Это означает небольшое 4-значное значение Тип DECIMAL может быть присвоен столбцу SMALLINT или INTEGER, но значение с 15 цифрами не может.
Когда значение DECIMAL умножается на DECIMAL или целочисленный тип, результирующая шкала представляет собой сумму шкал двух терминов. Когда они делятся, результатом является значение со шкалой (количество цифр до справа от запятой) равно большей из шкал двух условия. Вычисляется точность для обеих операций (обычно увеличено), чтобы разрешить все возможные результаты.
Различие между DOUBLE и DECIMAL важно, когда
происходит деление. Например,
Например, 10,0/8,0 (ДЕСЯТИЧНЫЙ)
равно 1,2 , но 10.0E0/8.0E0 (ДВОЙНОЕ) равно 1,25 . Без операций деления,
ДЕСЯТИЧНЫЕ значения представляют точную арифметику.
Значения REAL, FLOAT и DOUBLE хранятся в базе данных как объектов java.lang.Double . Специальные значения, такие как
NaN и +-Infinity также сохраняются и поддерживаются. Эти значения могут быть
отправлено в базу данных через JDBC Подготовленное заявление методы и возвращаются в ResultSet объектов. Чтобы разрешить деление на
ноль значений DOUBLE в операторах SQL (которые возвращают NaN или
+-Infinity) вы должны установить свойство hsqldb.double_nan как false (SET
БАЗА ДАННЫХ SQL DOUBLE NAN FALSE). Двойные значения могут быть получены из ResultSet требуемого типа, если они
может быть представлен. Для установки значений, когда PreparedStatement. или  setDouble()
setDouble() setFloat() используется, значение обрабатывается как
УДВОИТЬ автоматически.
Короче говоря,
<числовой тип> ::= <точный числовой тип> | <приблизительный числовой тип>
<точный числовой тип> ::= NUMERIC [ <левый
paren> <точность> [ <запятая> <масштаб> ] <справа
парен > ] | { ДЕСЯТИЧНЫЙ | DEC } [ <левая скобка> <точность> [ <запятая> <масштаб> ] <правая скобка> ] | ТИНЬИНТ | МАЛЕНЬКИЙ
| ЦЕЛОЕ | ИНТ | БОЛЬШОЙ
<приблизительный числовой тип> ::= FLOAT [ <левый
paren> <точность> <правая скобка> ] | НАСТОЯЩИЙ | ДВОЙНОЙ
ТОЧНОСТЬ
<точность> ::= <без знака
целое>
<шкала> ::= <без знака
целое>
Boolean Type
Тип BOOLEAN соответствует стандарту SQL и представляет
значения ИСТИНА , ЛОЖЬ и НЕИЗВЕСТНО . Этот тип столбца может быть инициализирован с помощью
логические значения Java или с
Этот тип столбца может быть инициализирован с помощью
логические значения Java или с NULL для НЕИЗВЕСТНО значение.
Логика трех значений иногда понимается неправильно. Например, х IN (1, 2, NULL) не возвращает значение true, если x равно NULL.
В предыдущих версиях HyperSQL BIT был просто псевдонимом для БУЛЕВОЕ. В версии 2 BIT представляет собой однобитовую растровую карту.
<логический тип> ::= BOOLEAN
Стандарт SQL не поддерживает преобразование типов в BOOLEAN кроме из строк символов, состоящих из логических литералов. Поскольку Тип BOOLEAN относительно новый для Стандарта, несколько баз данных продукты использовали другие типы для представления логических значений. Для улучшения совместимости, HyperSQL допускает некоторые преобразования типов в логические.
Значения типов BIT и BIT VARYING длины 1 могут быть преобразованы
в БУЛЕВОЕ. Если бит установлен, результатом преобразования является TRUE. значение, в противном случае оно FALSE.
значение, в противном случае оно FALSE.
Значения типов TINYINT, SMALLINT, INTEGER и BIGINT могут быть преобразуется в BOOLEAN. Если значение равно нулю, результатом будет FALSE. значение, в противном случае оно TRUE.
Типы символьных строк
Типы CHARACTER, CHARACTER VARYING и CLOB являются
Стандартные типы строк символов. СИМВОЛ, ВАРЧАР и СИМВОЛ БОЛЬШОЙ
OBJECT являются синонимами этих типов. HyperSQL также поддерживает LONGVARCHAR.
как синоним VARCHAR. Если LONGVARCHAR используется без длины, то
назначена длина 16M. Вы можете установить LONGVARCHAR для сопоставления с CLOB,
с свойство соединения sql.longvar_is_lob или
оператор SET DATABASE SQL LONGVAR IS LOB TRUE..
Набор символов HyperSQL по умолчанию — Unicode, поэтому все возможные строки символов могут быть представлены этими типами.
Стандартное поведение SQL типа CHARACTER является остатком
устаревшие системы, в которых строки символов дополняются пробелами для заполнения
фиксированная ширина. Эти пробелы иногда являются значительными, в то время как в других
случаях они молча отбрасываются. Лучше всего было бы избегать
Тип CHARACTER вообще. Для остальных типов строки
не заполняется при назначении столбцам или переменным данного типа.
конечные пробелы по-прежнему считаются отбрасываемыми для всех символов
типы. Поэтому, если строка с завершающими пробелами слишком длинная для присвоения
к столбцу или переменной заданной длины, пробелы за типом
длина отбрасываются, и назначение выполняется успешно (при условии, что все
символы за пределами длины типа являются пробелами).
Эти пробелы иногда являются значительными, в то время как в других
случаях они молча отбрасываются. Лучше всего было бы избегать
Тип CHARACTER вообще. Для остальных типов строки
не заполняется при назначении столбцам или переменным данного типа.
конечные пробелы по-прежнему считаются отбрасываемыми для всех символов
типы. Поэтому, если строка с завершающими пробелами слишком длинная для присвоения
к столбцу или переменной заданной длины, пробелы за типом
длина отбрасываются, и назначение выполняется успешно (при условии, что все
символы за пределами длины типа являются пробелами).
Типы VARCHAR и CLOB имеют ограничения по длине, но строки не дополняется системой. Обратите внимание, что если вы используете большую длину для VARCHAR или CLOB, дополнительное пространство в базе данных не используется. Космос используемое для каждого сохраненного элемента, пропорционально его фактической длине.
Если CHARACTER используется без указания длины, длина
по умолчанию 1. Для типа CLOB ограничение длины может быть определено в
единицы килобайт (К, 1024), мегабайт (М, 1024 * 1024) или гигабайт (Г,
1024*1024*1024), используя
Для типа CLOB ограничение длины может быть определено в
единицы килобайт (К, 1024), мегабайт (М, 1024 * 1024) или гигабайт (Г,
1024*1024*1024), используя <множитель> . Если
CLOB используется без указания длины, длина по умолчанию равна
1 ГБ.
<тип строки символов> ::= { CHARACTER | СИМВОЛ }
[ <левая скобка> <длина символа> <правая скобка> ] | {
ХАРАКТЕР ИЗМЕНЯЕТСЯ | ИЗМЕНЕНИЕ СИМВОЛ | VARCHAR } <левая скобка> <длина символа> <правая скобка> | LONGVARCHAR [ <слева
paren> <длина символа> <правая скобка> ] | <символ
тип крупного объекта>
<тип большого символьного объекта> ::= { CHARACTER
БОЛЬШОЙ ОБЪЕКТ | КРУПНЫЙ ОБЪЕКТ | CLOB } [ <левая скобка> <длина большого объекта> <правая скобка> ]
<длина символа> ::= <целое без знака> [ <единицы длины символа> ]
<длина большого объекта> ::= <длина> [ <множитель> ] | <длина большого объекта
токен >
<длина большого символа> ::= <большой
длина объекта> [ <единицы длины символов>]
<маркер длины большого объекта> ::= <цифра>.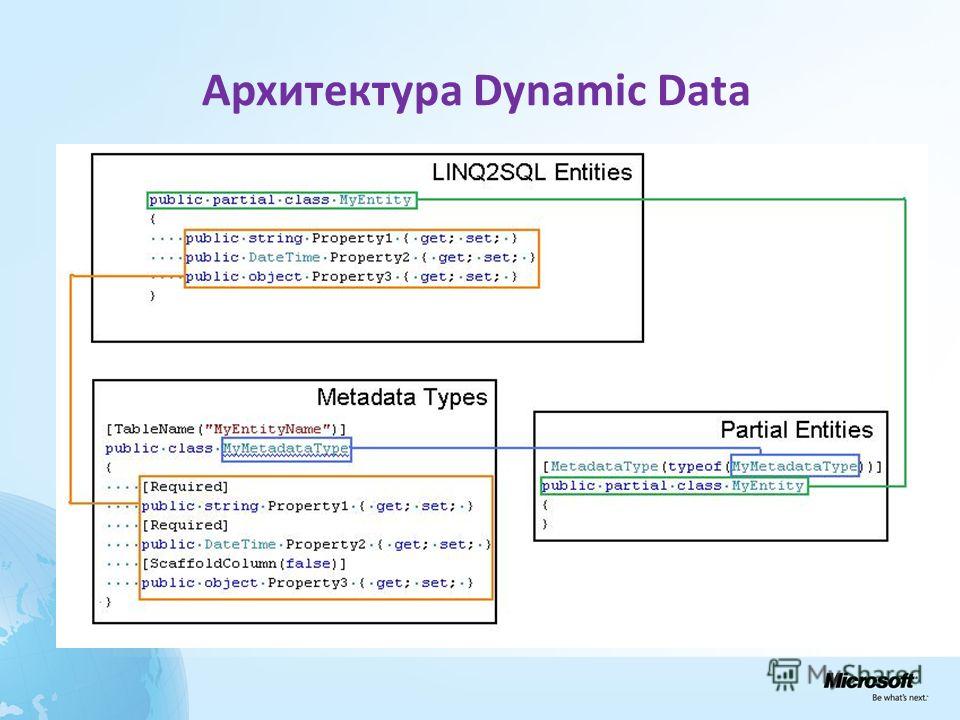 .. <множитель>
.. <множитель>
<множитель> ::= K | М | Г
<единицы длины символов> ::= СИМВОЛЫ |
ОКТЕТЫ
Каждый тип символов имеет сопоставление. Это либо по умолчанию сопоставления или указано явно с предложением COLLATE. Сопоставления обсуждается в главе «Схемы и объекты базы данных».
Типы двоичных строк
Типы BINARY, BINARY VARYING и BLOB являются стандартом SQL.
двоичные строковые типы. VARBINARY и BINARY LARGE OBJECT являются синонимами для
Типы BINARY VARYING и BLOB. HyperSQL также поддерживает LONGVARBINARY в качестве
синоним VARBINARY. Вы можете установить LONGVARBINARY для сопоставления с BLOB с помощью
свойство соединения sql.longvar_is_lob или SET
Оператор DATABASE SQL LONGVAR IS LOB TRUE.
Типы двоичных строк используются аналогично символьным строкам.
типы. Есть несколько встроенных функций, которые перегружены для
поддержка символьных, двоичных и битовых строк.
Тип BINARY представляет строку фиксированной ширины. Каждый короче строка дополняется нулями, чтобы заполнить фиксированную ширину. Подобно CHARACTER, конечные нули в строке BINARY просто отбрасывается при некоторых операциях. По той же причине лучше избегать этот конкретный тип и вместо этого используйте VARBINARY.
При сравнении двух двоичных значений, если одно из них имеет тип BINARY, затем выполняется заполнение нулями, чтобы увеличить длину более короткого строку на более длинную перед сравнением. Заполнение не выполняется с другие бинарные типы. Если байты равны концу более короткого значение, то более длинная строка считается больше, чем более короткая нить.
Если BINARY используется без указания длины, длина
по умолчанию 1. Для типа BLOB ограничение длины может быть определено в
единицы килобайт (К, 1024), мегабайт (М, 1024 * 1024) или гигабайт (Г,
1024 * 1024 * 1024), используя <множитель> . Если
BLOB используется без указания длины, длина по умолчанию равна
1 ГБ.
Если
BLOB используется без указания длины, длина по умолчанию равна
1 ГБ.
Тип UUID представляет строку UUID. Тип похож на
BINARY(16), но с дополнительными ограничениями, запрещающими присваивание,
приведение или сравнение с более короткими или более длинными строками. Строки, такие как
'24ff1824-01e8-4dac-8eb3-3fee32ad2b9с' или
'24ff182401e84dac8eb33fee32ad2b9c' разрешены. Когда значение UUID
преобразуется в тип CHARACTER, дефисы вставляются в
требуемые должности. Объекты Java UUID можно использовать с java.sql.PreparedStatement для вставки значений этого
тип. Метод getObject() ResultSet возвращает
Объект Java для данных столбца UUID.
<тип двоичной строки> ::= BINARY [
<двоичный тип строки большого объекта> ::= { BINARY
БОЛЬШОЙ ОБЪЕКТ | BLOB } [ <левая скобка> <длина большого объекта> <правая скобка> ]
<длина> ::= <без знака
целое>
Типы битовых строк
Типы BIT и BIT VARYING являются поддерживаемыми типами битовых строк. Эти типы были определены в SQL:1999, но позже были удалены из
Стандарт. Битовые типы представляют битовые карты заданной длины. Каждый бит равен 0
или 1. Тип BIT представляет строку фиксированной ширины. Каждая более короткая строка
дополняется нулями для заполнения фиксированного. Если BIT используется без
при указании длины длина по умолчанию равна 1. Тип BIT VARYING
имеет максимальную ширину, а более короткие строки не дополняются.
Эти типы были определены в SQL:1999, но позже были удалены из
Стандарт. Битовые типы представляют битовые карты заданной длины. Каждый бит равен 0
или 1. Тип BIT представляет строку фиксированной ширины. Каждая более короткая строка
дополняется нулями для заполнения фиксированного. Если BIT используется без
при указании длины длина по умолчанию равна 1. Тип BIT VARYING
имеет максимальную ширину, а более короткие строки не дополняются.
До введения типа BOOLEAN в стандарт SQL обычно использовалась однобитовая строка типа BIT(1). За совместимость с другими продуктами, которые не соответствуют или не расширяют Стандарт SQL, HyperSQL допускает значения типов BIT и BIT VARYING с длина 1 для преобразования в тип BOOLEAN и обратно. БУЛЕВОЕ ИСТИНА считается равным B'1', BOOLEAN FALSE считается равным Б'0'.
По той же причине столбцам и
переменные типа BIT(1). Для присваивания числовое значение ноль
преобразуются в B'0', а все остальные значения преобразуются в B'1'.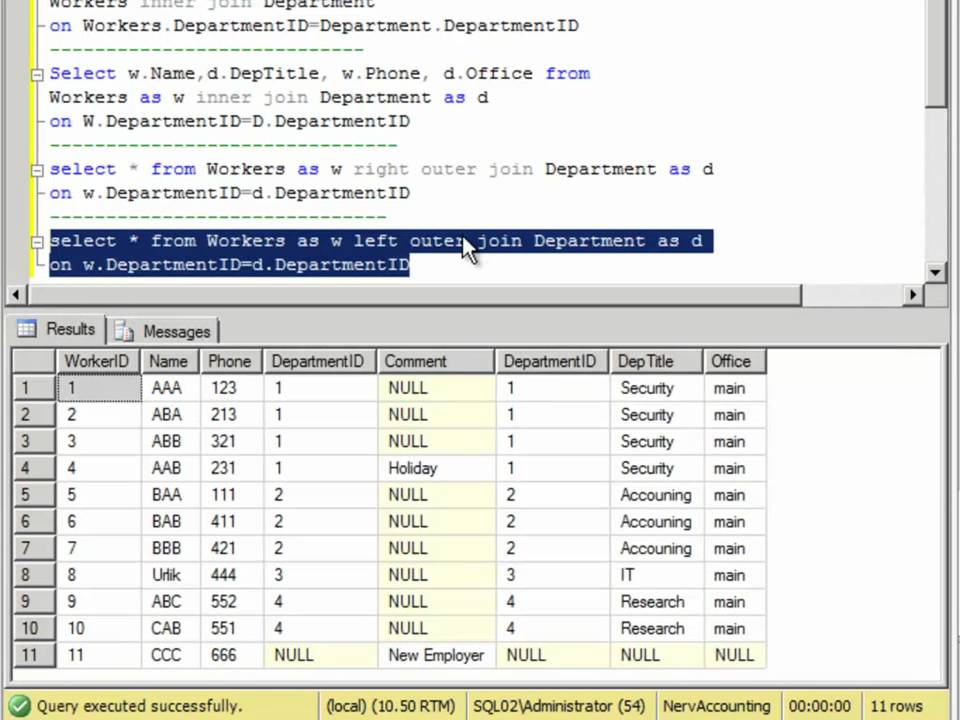 За
сравнения, числовые значения 1 считаются равными B'1', а числовые
нулевое значение считается равным B'0'.
За
сравнения, числовые значения 1 считаются равными B'1', а числовые
нулевое значение считается равным B'0'.
Не разрешено выполнять другие арифметические или логические операции операции с участием BIT(1) и BIT VARYING(1). Ребенок операций допустимые для битовых строк аналогичны тем, которые разрешены для BINARY и СИМВОЛЬНЫЕ строки. Несколько встроенных функций поддерживают все три типа нить.
<тип битовой строки> ::= BIT [ <левая скобка> <длина> <правая скобка> ] | БИТ ИЗМЕНЯЕТСЯ <левая скобка> <длина> <правая скобка>
Данные больших объектов
BLOB и CLOB являются типами больших объектов. Эти типы используются очень долго.
строки, которые не обязательно помещаются в памяти. Маленькие лобки, которые подходят
Доступ к памяти можно получить так же, как к данным столбца BINARY или VARCHAR. Но лоб
обычно намного больше, и поэтому доступ к ним осуществляется с помощью специального JDBC.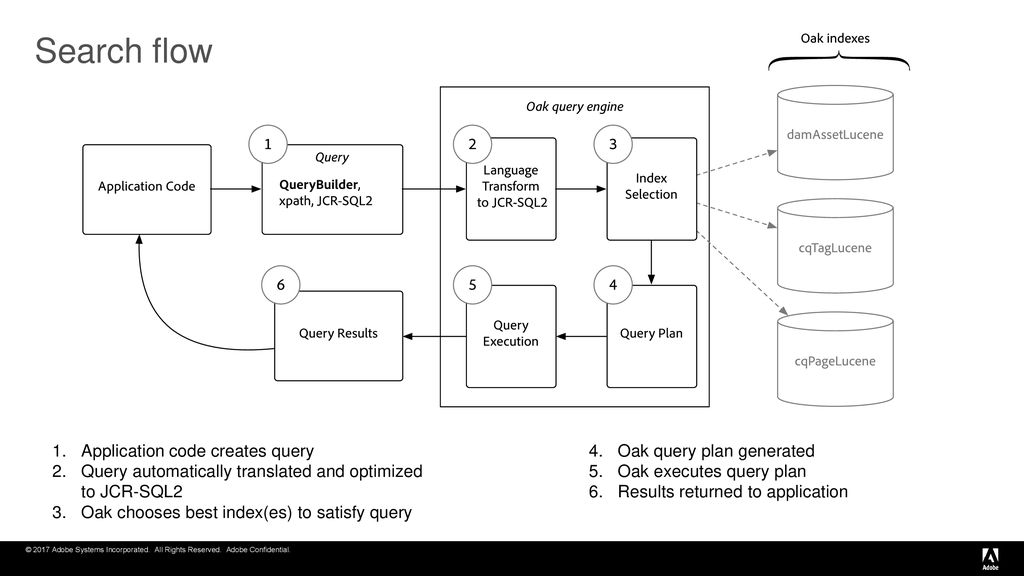 методы.
методы.
Для вставки LOB в таблицу или для обновления столбца типа LOB
с новым лобом вы можете использовать setBinaryStream() и setCharacterStream() методы JDBC java.sql.PreparedStatement . Это очень эффективно
методы для длинных лепестков. Поддерживаются и другие методы. Если данные для
BLOB или CLOB уже является объектом памяти, вы можете использовать setBytes() или setString() методов,
которые эффективны для данных памяти. Другой способ – получить лоб
с getBlob() и getClob() методы java.sql.Connection , заполните его данные,
затем используйте setBlob() или setClob() методов ПодготовленоОтчет . Еще один метод позволяет
создать экземпляры org.hsqldb.jdbc.JDBCBlobFile и org.hsqldb.jdbc.JDBCClobFile и создать большой
lob для использования с setBlob() и setClob() методов.
Большой объект извлекается из ResultSet с метод getBlob() или getClob() .
Затем для доступа к данным используются методы обработки больших объектов.
HyperSQL также обеспечивает эффективный доступ к частям больших объектов с методов getBytes() или getString() .
Кроме того, части BLOB или CLOB, уже сохраненные в таблице, могут быть
модифицированный. Обновляемый ResultSet используется для выбора
ряд из таблицы. getBlob() или получитьClob() методов ResultSet являются
используется для доступа к большому объекту как java.sql.Blob или объект java.sql.Clob . setBytes() и setString() методы
из этих объектов можно использовать для изменения lob. Наконец метод updateRow() ResultSet используется для обновления большого объекта в строке. Примечание
эти модификации не допускаются со сжатыми или зашифрованными
лоб.
Примечание
эти модификации не допускаются со сжатыми или зашифрованными
лоб.
Логически большие объекты хранятся в столбцах таблиц. Их физическое хранилище представляет собой отдельный файл *.lobs. Этот файл создается, как только BLOB или CLOB вставляется в базу данных. Файл будет расти как новый лобы вставляются в базу данных. В версии 2 файл *.lobs никогда не удаляются, даже если все большие объекты удаляются из базы данных. В этом В этом случае вы можете удалить файл *.lobs после ВЫКЛЮЧЕНИЯ. Когда контрольная точка случается, пространство, используемое для удаленных объектов, освобождается и повторно используется для будущие лобы. По умолчанию клобы хранятся без сжатия. Вы можете используйте настройку базы данных, чтобы включить сжатие clobs. Это может значительно уменьшить размер хранения клобов.
Хранение и обработка объектов Java
Начиная с версии 2.3.4 существует два варианта хранения Java
Объекты.
Параметр по умолчанию позволяет хранить объект Serializable. Объекты остаются сериализованными в базе данных до тех пор, пока они не будут извлечены. прикладная программа, извлекающая объект, должна включать в себя classpath класс Java для объекта, в противном случае он не может получить объект.
Любой сериализуемый объект Java может быть вставлен непосредственно в
столбец типа OTHER, использующий любую вариацию PreparedStatement.setObject() методов.
Альтернативный вариант живого объекта для mem: только базы данных и включается, когда
свойство базы данных sql.live_object=true добавляется к соединению
свойство, которое создает базу данных mem. Например 'jdbc:hsqldb:mem:mydb;sql.live_object=true' . С
с этой опцией любой объект Java может быть сохранен, так как он не сериализуется.
Оператор SQL SET DATABASE SQL LIVE OBJECT TRUE может
также использоваться. Обратите внимание, что оператор SQL должен выполняться в первый
подключение к базе данных до того, как будут вставлены какие-либо данные. Нет доступа к данным
должно быть сделано из этого соединения. Вместо этого должны быть новые связи.
используется для доступа к данным.
Обратите внимание, что оператор SQL должен выполняться в первый
подключение к базе данных до того, как будут вставлены какие-либо данные. Нет доступа к данным
должно быть сделано из этого соединения. Вместо этого должны быть новые связи.
используется для доступа к данным.
Для целей сравнения и в индексах любые два объекта Java считаются равными, если только один из них не равен NULL. Вы не можете искать определенного объекта или выполнить соединение столбца типа OTHER.
Объекты Java можно просто хранить внутри, и никакие операции не могут
выполняться над ними, кроме присваивания между столбцами типа OTHER
или проверка на NULL. Такие тесты, как ГДЕ объект1 = объект2 не означает, что вы могли бы ожидать, как и любой ненулевой объект
удовлетворил бы таким тестам. Но ГДЕ object1 НЕТ
NULL вполне приемлем.
Движок не позволяет назначать обычные значения столбца
Столбцы объекта Java (например, присвоение INTEGER или STRING таким
столбец с оператором SQL, например UPDATE mytable SET
objectcol = intcol ГДЕ . ).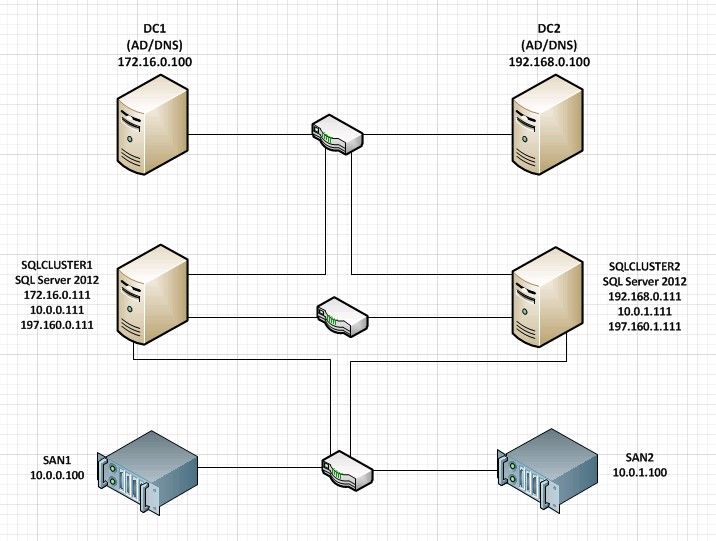 ..
..
<тип объекта Java> ::= ДРУГОЕ
Метод хранения по умолчанию используется, когда объекты и их состояние должно быть сохранено и восстановлено в будущем. Этот метод также используется, когда ресурсы памяти ограничены, а коллекции объектов сохраняются и извлекаются только при необходимости.
Параметр «Живой объект» использует таблицу базы данных как набор объекты. Это позволяет хранить некоторые атрибуты объектов в одном и том же таблице рядом с самим объектом и быстрый поиск и извлечение объекты по их атрибутам. Например, когда многие тысячи живых объекты содержат детали фильмов, название фильма и режиссера можно хранятся в таблице, и поиск фильмов может быть выполнен на этих атрибуты:
В любом случае должен храниться хотя бы один атрибут объекта
чтобы обеспечить эффективное извлечение объектов как из Live Object, так и из
Серийное хранилище. Идентификационный номер часто используется в качестве сохраненного столбца. атрибут.
атрибут.
Тип Длина, точность и масштаб
В HyperSQL квалификаторы длины столбца, точности и масштаба
обязательны и всегда соблюдаются. Типы VARCHAR и VARBINARY
требуют параметр размера и не имеют значения по умолчанию. Для совместимости
с операторами CREATE TABLE из других баз данных, которые не имеют размера
параметры для столбца VARCHAR, свойство URL hsqldb.enforce_size=false или инструкция SQL SET DATABASE SQL SIZE FALSE может использоваться для разрешения
создание таблицы и автоматически применить большое значение для максимального
размер столбца VARCHAR. Вы должны протестировать свое приложение, чтобы убедиться, что
длина, точность и масштаб, используемые для определений столбцов,
соответствующие данным приложения.
Все остальные типы имеют значения по умолчанию для параметров размера или точности.
Однако значения по умолчанию могут не соответствовать требованиям вашего приложения, и вы
возможно, придется указать параметры.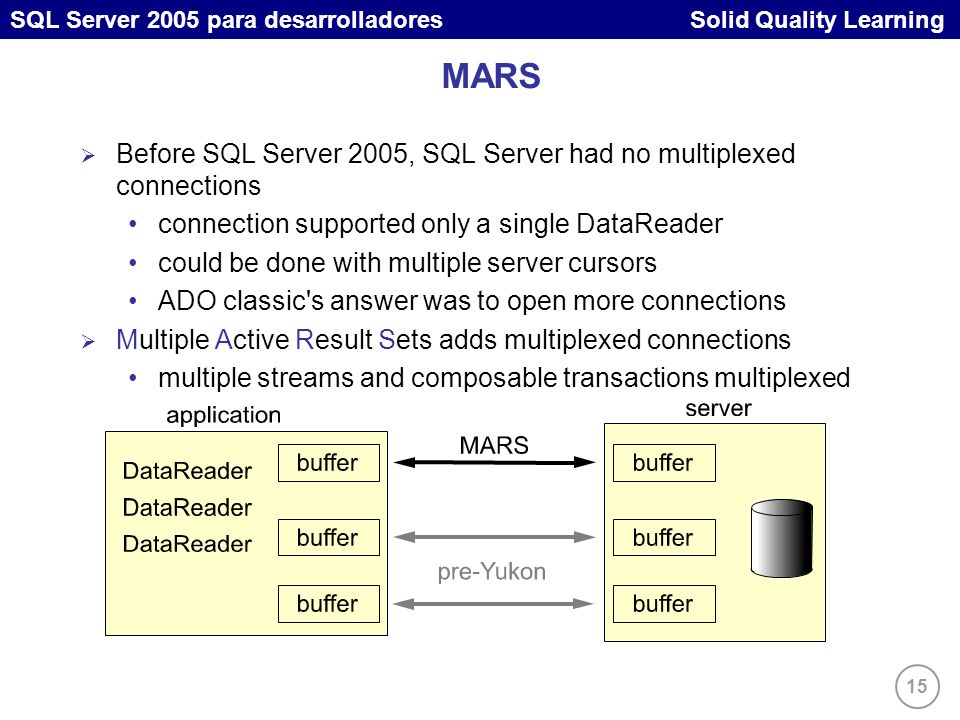
Типы строк, включая все типы строк BIT, BINARY и CHAR плюс CLOB и BLOB обычно определяются длиной. Если длина не указывается для BIT, BINARY и CHAR, длина по умолчанию равна 1. Для CLOB и BLOB используется определенная реализацией длина 1G.
Типы TIME и TIMESTAMP могут быть определены с долями секунды точность от 0 до 9. Определение типа INTERVAL может иметь точность и, в некоторых случаях, с точностью до доли секунды. Типы DECIMAL и NUMERIC могут быть определены с точностью и масштабом. Для всех этих типов используется значение точности или масштаба по умолчанию, если оно не указано. Масштаб по умолчанию равен 0. Дробная точность по умолчанию для ВРЕМЕНИ равна 0, в то время как это 6 для TIMESTAMP.
Значения могут быть преобразованы из одного типа в другой двумя разными способами.
способами: с помощью явного выражения CAST или с помощью неявного преобразования
в присваивании, сравнении и агрегировании.
Строковые значения не могут быть присвоены столбцам VARCHAR, если они длиннее определенной длины типа. Для столбцов CHARACTER длинный строка может быть присвоена (с усечением) только в том случае, если все символы после длины пробелы. Более короткие строки дополняются пробелом символ при вставке в столбец CHARACTER. Подобные правила применяется к столбцам VARBINARY и BINARY. Для столбцов BINARY заполнение и правила усечения применяются с нулевыми байтами вместо пространства.
Явное приведение значения к типу CHARACTER или VARCHAR будет
привести к принудительному усечению или дополнению. Итак тест типа CAST
(mycol AS VARCHAR(2)) = 'xy' найдет значения, начинающиеся
с «ху». Это эквивалент SUBSTRING(mycol FROM 1 FOR
2)= 'ху' .
Для всех числовых типов правила явного приведения и неявного приведения
конверсия одинаковая. Если приведение или преобразование приводит к тому, что какие-либо цифры
теряется от дробной части, оно может иметь место. Если не дробное
часть значения не может быть представлена в новом типе, приведении или
преобразование невозможно и приведет к исключению данных.
Если не дробное
часть значения не может быть представлена в новом типе, приведении или
преобразование невозможно и приведет к исключению данных.
Существуют специальные правила для DATE, TIME, TIMESTAMP и INTERVAL броски и преобразования.
Типы даты и времени
HSQLDB полностью поддерживает типы и операции даты и времени и интервала, включая все соответствующие дополнительные функции, как указано в стандарте SQL начиная с SQL-92. Две группы типов дополняют друг друга.
Тип ДАТА представляет календарную дату с ГОДОМ, МЕСЯЦОМ и ДНЕМ поля.
Тип TIME представляет время суток с ЧАСАМИ, МИНУТАМИ и СЕКУНДами. полей, а также необязательное поле SECOND FRACTION.
Тип TIMESTAMP представляет комбинацию DATE и TIME типы.
Типы TIME и TIMESTAMP могут включать WITH TIME ZONE или WITHOUT TIME
квалификаторы ZONE (по умолчанию). Они могут иметь дробные доли секунды. За
например, TIME(6) имеет шесть дробных цифр для второго поля.
Если точность долей секунды не указана, по умолчанию используется 0 для TIME и до 6 для TIMESTAMP.
<тип даты и времени> ::= ДАТА | ВРЕМЯ [ <слева
скобка> <точность времени> <правая скобка> ] [ <с или
без часового пояса> ] | TIMESTAMP [ <левая скобка> <отметка времени
точность> <правая скобка> ] [ <с часовым поясом или без него> ]
<с часовым поясом или без него> ::= С ЧАСОВЫМ ПОЯСОМ |
БЕЗ ЧАСОВОГО ПОЯСА
<точность времени> ::= <доля секунды времени
точность>
<точность метки времени> ::= <дробное время
точность секунд>
<точность долей секунды> ::= <беззнаковое целое>
Литералы TIME или TIMESTAMP, содержащие значение смещения зоны, С ЧАСОВЫМ ПОЯСОМ. Примеры строковых литералов, используемых для представления даты значения времени, некоторые с часовым поясом, некоторые без, ниже:
Часовой пояс
Значения DATE не учитывают часовые пояса. Например, Организация Объединенных Наций
объявляет 5 июня Всемирным днем окружающей среды, который отмечался ДАТА
'2008-06-05' в разных часовых поясах.
Например, Организация Объединенных Наций
объявляет 5 июня Всемирным днем окружающей среды, который отмечался ДАТА
'2008-06-05' в разных часовых поясах.
Значения TIME и TIMESTAMP без часового пояса, обычно имеют контекст это указывает на некоторый местный часовой пояс. Например, база данных для колледжа расписания курсов обычно хранят даты и время занятий без часовых поясов. Это работает, потому что местоположение колледжа фиксировано, а часовой пояс смещение одинаково для всех значений. Даже когда события принимают место в разных часовых поясах, например время международных рейсов, это можно хранить всю информацию о дате и времени как ссылки на единый часовой пояс, обычно GMT. Для некоторых баз данных может быть полезно сохраните смещение часового пояса вместе с каждым значением даты и времени. SQL Значения TIME WITH TIME ZONE и TIMESTAMP WITH TIME ZONE включают время значение смещения зоны.
Смещение часового пояса имеет тип INTERVAL HOUR TO MINUTE. Этот тип данных описан в следующем разделе. Юридические значения
между «–18:00» и «+18:00».
Этот тип данных описан в следующем разделе. Юридические значения
между «–18:00» и «+18:00».
Операции с датой и временем Типы
Выражение <выражение datetime> AT TIME ZONE { <первичный интервал> | <имя часового пояса> } оценивается как
значение даты и времени, представляющее точно такой же момент времени в
указано <смещение времени> или географический <имя часового пояса> . Выражение, В
МЕСТНОЕ эквивалентно AT TIME ZONE <местное время
водоизмещение > . Если используется В ЧАСОВОМ ПОЯСЕ с операндом даты и времени типа БЕЗ ЧАСОВОГО ПОЯСА операнд является первым
преобразуется в значение типа WITH TIME ZONE с использованием календаря сеанса,
затем для значения устанавливается указанное смещение часового пояса. Следовательно,
в этих случаях конечное значение зависит от часового пояса сеанса в
которой использовалась выписка, рассчитанная в точный момент времени (из
ввод) и учет летнего времени в этой точке
время.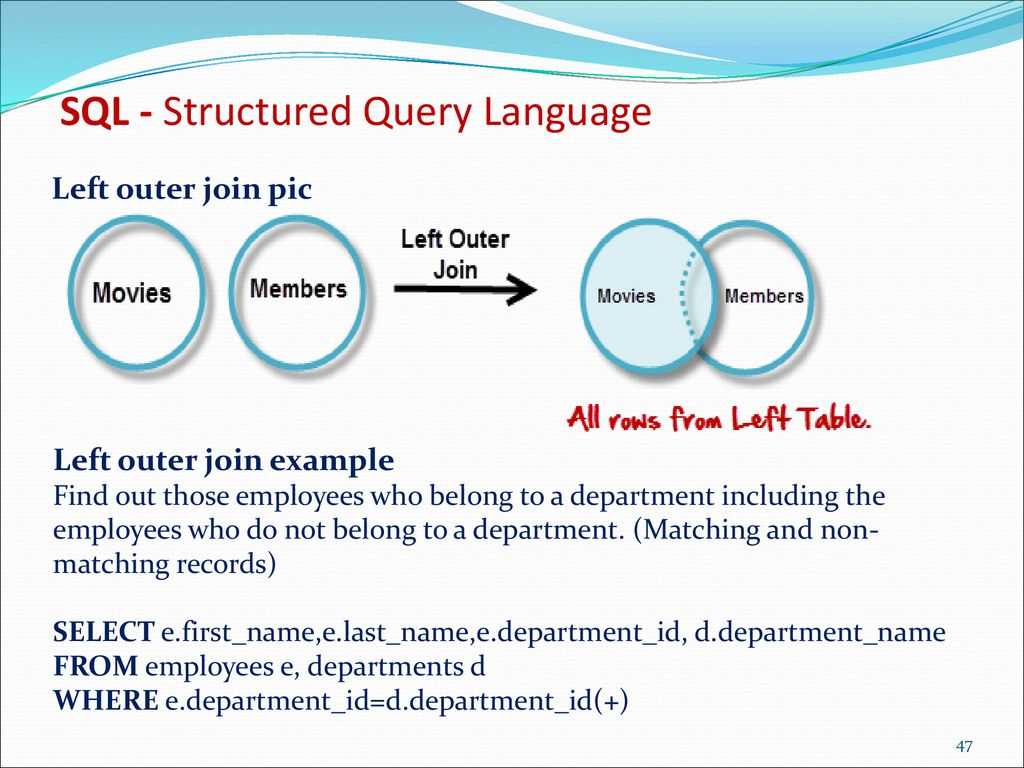
Начиная с версии 2.7.0 можно использовать региональные часовые пояса с AT ЧАСОВОЙ ПОЯС. Любое используемое имя зоны должно точно соответствовать поддерживаемому идентификатору TimeZone. с помощью JVM. К ним относятся такие имена, как «Америка/Нью-Йорк». Некоторые зоны включают периоды летнего времени, которые используются при преобразовании часовой пояс.
См. также функцию FROM_TZ, которая позволяет преобразовать время без изменения значений даты и времени, таких как часы и минуты.
В ЧАСОВОМ ПОЯСЕ изменяет значения поля операнда даты и времени. Это делается по следующей схеме:
определить соответствующую дату и время в UTC, используя сеанс календарь.
найти значение даты и времени в заданном часовом поясе, которое соответствует со значением UTC из шага 1.
Пример a:
В первом приведенном выше примере смещение часового пояса сеанса равно
'-8:00'.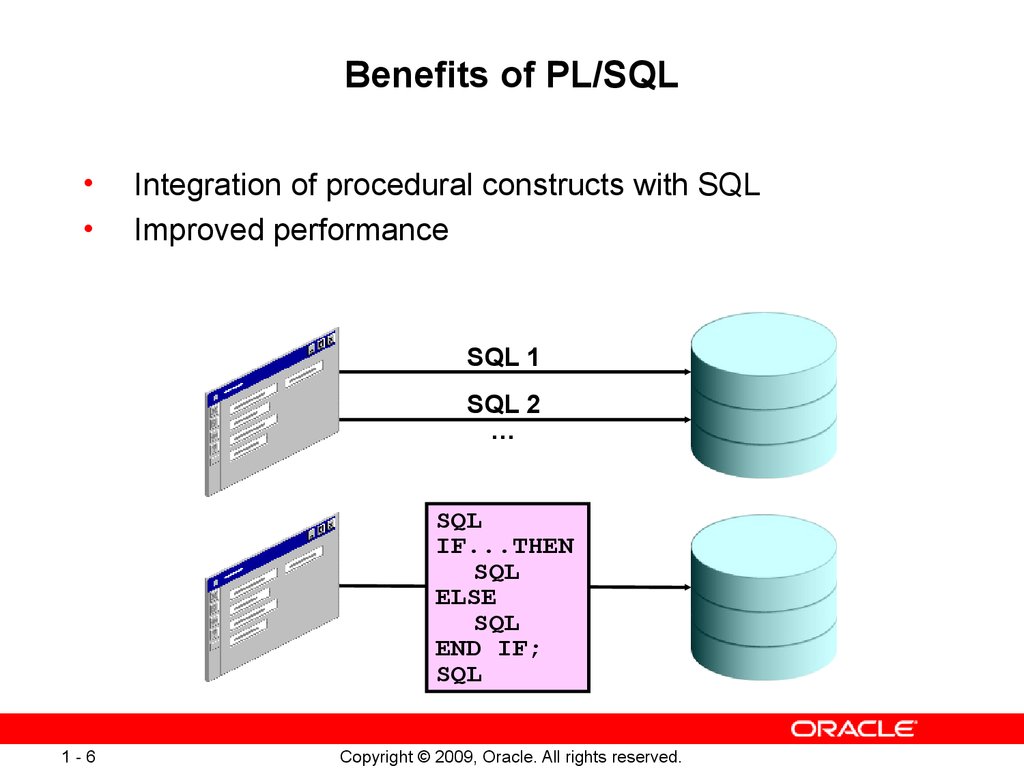 На шаге 1 время «11:00:00» преобразуется в UTC, т.е.
«19:00:00+0:00». На шаге 2 это значение выражается как время
«14:00:00-5:00» в целевой зоне.
На шаге 1 время «11:00:00» преобразуется в UTC, т.е.
«19:00:00+0:00». На шаге 2 это значение выражается как время
«14:00:00-5:00» в целевой зоне.
Во втором примере смещение часового пояса сеанса не считается. На шаге 1 время конвертируется в UTC, т.е. '07:00:00+0:00', на шаге 2 это значение выражается как время «02:00:00–5:00» в целевой зоне.
Пример b:
Поскольку операнд имеет часовой пояс, результат не зависит от смещение часового пояса сеанса. Шаг 1 приводит к ВРЕМЕНИ '17:00:00+0:00', а шаг 2 приводит к TIME '18:00:00+1:00'
Обратите внимание, что операнд не ограничен литералами даты и времени, используемыми в эти примеры. Любое допустимое выражение, результатом которого является значение даты и времени. может быть операндом.
Преобразование типа
CAST используется для всех остальных преобразований. Примеры:
В первом примере, если <значение> имеет время
компонент зоны, он просто удаляется. Например, ВРЕМЯ '12:00:00-5:00'
преобразуется в TIME '12:00:00'
Например, ВРЕМЯ '12:00:00-5:00'
преобразуется в TIME '12:00:00'
Во втором примере, если <значение> не имеет
компонент часового пояса, текущее смещение часового пояса сеанса
добавлен. Например, ВРЕМЯ «12:00:00» преобразуется в ВРЕМЯ «12:00:00-8:00».
когда смещение часового пояса сеанса равно «-8:00».
Преобразование между DATE и TIMESTAMP выполняется путем удаления Компонент TIME значения TIMESTAMP или путем установки часов, минут и второе поле в ноль. TIMESTAMP '2008-08-08 20:08:08+8:00' становится DATE «2008-08-08», а DATE «2008-08-22» становится TIMESTAMP «2008-08-22». 00:00:00».
Преобразование между TIME и TIMESTAMP выполняется путем удаления значения поля DATE значения TIMESTAMP или путем добавления полей значение TIME в поля текущего значения даты сеанса.
Задание
Когда значение присваивается цели даты и времени, например, используется значение
чтобы обновить строку таблицы, тип значения должен быть таким же, как
цель, но характеристики С ЧАСОВЫМ ПОЯСОМ или БЕЗ ЧАСОВОГО ПОЯСА могут быть
другой.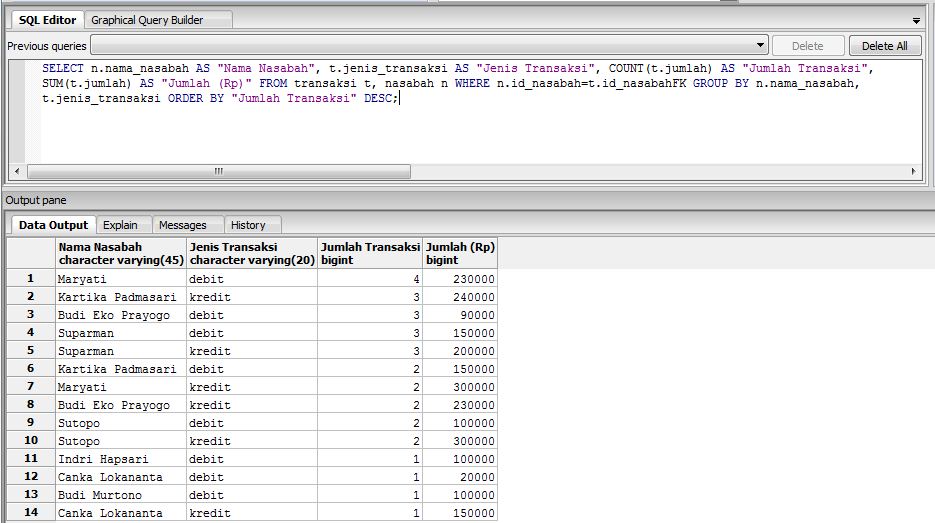 Если типы не совпадают, необходимо использовать явный CAST для
преобразовать значение в целевой тип.
Если типы не совпадают, необходимо использовать явный CAST для
преобразовать значение в целевой тип.
Сравнение
При сравнении значений С ЧАСОВЫМ ПОЯСОМ они преобразуются в формат UTC значения перед сравнением. Если значение WITH TIME ZONE сравнивается с другим БЕЗ ЧАСОВОГО ПОЯСА, то значение С ЧАСОВЫМ ПОЯСОМ преобразуется в В МЕСТНОМ, затем конвертируется в БЕЗ ЧАСОВОГО ПОЯСА перед сравнением.
Не рекомендуется разрабатывать приложения, которые полагаются на сравнения и преобразования между значениями ВРЕМЕНИ С ЧАСОВЫМ ПОЯСОМ. преобразования могут включать нормализацию значения времени, что приводит к неожиданные результаты. Например, выражение: МЕЖДУ(ВРЕМЯ «12:00:00–8:00», ВРЕМЯ «22:00:00–8:00») преобразуется в МЕЖДУ(ВРЕМЯ «20:00:00+0:00», ВРЕМЯ «06:00:00+0:00»), когда оно оценивается в формате UTC. зона, которая всегда FALSE.
Функции
Некоторые функции возвращают отметку времени текущего сеанса в разных типы даты и времени:
HyperSQL поддерживает очень широкий набор функций для
преобразование, извлечение и манипулирование значениями DATE и TIMESTAMP. Видеть
главу «Встроенные функции».
Часовой пояс сеанса Водоизмещение
При запуске сеанса SQL (с соединением JDBC) локальный часовой пояс клиентской JVM (включая любые сезонные корректировки времени, такие как как летнее время) используется как смещение часового пояса сеанса. В версия 2.7.0 объект календаря Java с местным часовым поясом создается и используется клиентская JVM. Поэтому, когда сезонная корректировка времени для перехода на летнее время производится, когда сессия открыта, SQL смещение зоны сеанса изменено. В некоторых старых версиях HyperSQL смещение времени сеанса SQL не изменилось, когда сезонное время произошла регулировка.
Чтобы изменить смещение часового пояса сеанса SQL, используйте следующее команды:
УСТАНОВИТЬ ЧАСОВОЙ ПОЯС <время
водоизмещение >
УСТАНОВИТЬ МЕСТНЫЙ ЧАСОВОЙ ПОЯС
Первая команда устанавливает заданное значение смещения. вторая команда восстанавливает исходное смещение часового пояса в реальном времени.
сессия.
Значения даты и времени и Ява
Когда значения даты и времени отправляются в базу данных с помощью PreparedStatement или CallableStatement интерфейсы, объект Java
преобразуется в тип параметра подготовленного или вызываемого оператора.
Этот тип может быть DATE, TIME или TIMESTAMP (с часовым поясом или без него).
смещение часового пояса — это часовой пояс сеанса JDBC.
Когда значения даты и времени извлекаются из базы данных с помощью ResultSet интерфейс, есть два представления. getString(…) методов Интерфейс ResultSet , вернуть точное представление
значения в типе SQL, так как оно хранится в базе данных. Этот
включает правильное количество цифр для дробного поля секунды, и
для значений со смещением часового пояса — смещение часового пояса. Поэтому, если в базе данных хранится ВРЕМЯ '12:00:00', все пользователи в
разные часовые пояса получат «12:00:00», когда они получат значение как
нить. getTime(…) и getTimestamp(…) методы Интерфейс ResultSet возвращает объекты Java,
исправлен часовой пояс сеанса. Значение миллисекунды UTC содержало java.sql.Time или объекты java.sql.Timestamp будут настроены на
часовой пояс сеанса, поэтому Метод toString() этих объектов возвращает
одинаковые значения в разных часовых поясах.
Если вы хотите сохранить и получить значения UTC, которые не зависят от
любой часовой пояс сеанса, вы можете использовать столбец TIMESTAMP WITH TIME ZONE. setTime(...) и setTimestamp(...) методов
Интерфейс PreparedStatement с параметром Calendar можно использовать для
присвоить значения. Часовой пояс данного аргумента Calendar используется как
часовой пояс. И наоборот, getTime(...) и getTimestamp(...) методов ResultSet
интерфейс, который имеет параметр Calendar, может использоваться с Calendar
аргумент для получения значений.
Расширения Java 8
JDBC 4 и JAVA6 не включали коды типов для типов даты и времени SQL которые имеют свойство TIME ZONE. Поэтому HyperSQL сообщил об этих типах по умолчанию как типы datetime без TIME ZONE.
JAVA 8 представила новые коды типов для TIMESTAMP WITH TIME ZONE и
ВРЕМЯ С ЧАСОВЫМ ПОЯСОМ. HyperSQL (кроме jar-файлов, скомпилированных с помощью JDK 1.6)
поддерживает это в ResultSet , PreparedStatement и CallableStatement .
Метод
getObject(int columnIndex)в столбце TIMESTAMP WITH TIME ZONE возвращаетобъект java.time.OffsetDateTime.Метод
getObject(int columnIndex)в столбце TIME WITH TIME ZONE возвращаетобъект java.. time.OffsetTime getObject(int columnIndex, Class type)для любой даты, времени и временной метки поддерживаетjava.timeтипы пакетов:LocalDate,LocalTime,локальная дата и время,Время смещения,OffsetDateTimeиЭкземпляр, а такжетипы пакетов java.sql,Дата,ВремяиОтметка времени.Методы
setObjectтакже поддерживают Java объекты вышеперечисленных типов.getObjectиметодов setObjectс параметрами имени столбца вести себя так же, как их аналоги с columnIndexe параметры.
Нестандартный Расширения
HyperSQL версии 2. 7 поддерживает некоторые расширения стандарта SQL
обработка типов datetime и interval. Например, Стандарт
выражение для добавления количества дней к дате имеет явный INTERVAL
значение, но HSQLDB также позволяет использовать целое число без указания ДНЯ.
Примеры некоторых стандартных выражений и их нестандартных альтернатив
приведены ниже:
Рекомендуется использовать синтаксис SQL Standard, т.к. точен и исключает двусмысленность.
Типы интервалов
Типы интервалов используются для представления различий между датой и временем.
ценности. Разницу между двумя значениями даты и времени можно измерить в
секунд или месяцев. Для измерений в месяцах единицы измерения ГОД и МЕСЯЦ
доступны, в то время как для измерений в секундах единицы ДЕНЬ, ЧАС,
МИНУТА, СЕКУНДА доступны. Устройства можно использовать по отдельности или в составе
диапазон. Тип интервала может указывать точность наиболее значимого
поле и цифры второй дроби ВТОРОГО поля (если оно имеет
ВТОРОЕ поле). Точность по умолчанию равна 2 в соответствии со стандартом.
вторая точность по умолчанию равна 0. Точность по умолчанию слишком мала для многих
приложений и должны быть переопределены.
<тип интервала> ::= ИНТЕРВАЛ <интервал
классификатор>
<спецификатор интервала> ::= <начальное поле> TO <конец поля> | <одно поле даты и времени>
<начальное поле> ::= <не вторая первичная дата и время
field> [ <левая скобка> <точность ведущего поля интервала> <правая скобка> ]
<конечное поле> ::= <не вторая первичная дата и время
поле> | SECOND [ <левая скобка> <интервал доли секунды
точность> <правая скобка> ]
<одно поле даты и времени> ::= <не второе первичное поле
поле даты и времени> [ <левая скобка> <начальное поле интервала
точность> <правая скобка> ] | ВТОРОЙ [ <левая скобка> <интервал точность начального поля> [ <запятая> <интервал
точность долей секунды> ] <правая скобка> ]
<основное поле даты и времени> ::= <не второе
основное поле даты и времени> | ВТОРОЙ
<не второе основное поле даты и времени> ::= YEAR |
МЕСЯЦ | ДЕНЬ | ЧАС | МИНУТА
<точность интервала в долях секунды> ::= <беззнаковое целое>
<интервал ведущего поля точности> ::= <беззнаковое целое>
Примеры определения типа INTERVAL:
Слово INTERVAL указывает общее имя типа. Остаток от
определение называется <спецификатор интервала> .
Это обозначение важно, так как в большинстве выражений <определитель интервала> используется без слова
ИНТЕРВАЛ.
Значения интервала
Значение интервала может быть отрицательным, положительным или нулевым. Интервал type имеет все поля даты и времени в указанном диапазоне. Эти поля аналогичны типам TIMESTAMP. Различия такие же следующим образом:
Первое поле значения интервала может содержать любое числовое значение. с заданной точностью. Например, поле часа в HOUR(2) TO SECOND может содержать значения выше 23 (до 99). Поля года и месяца могут удерживать ноль (в отличие от значения TIMESTAMP) и максимальное значение месяца поле, которое не является самым важным полем, равно 11.
Стандартная функция ABS(<значение интервала
выражение>) можно использовать для преобразования отрицательного значения интервала
к положительному.
Буквальное представление интервальных значений состоит из типа определение со строкой, представляющей значение интервала, вставленное после слово ИНТЕРВАЛ. Несколько примеров литерала интервала ниже:
Интервал значений типов, основанных на секундах, может быть приведен друг в друга. Точно так же те, которые основаны на месяцах, могут быть преобразованы друг в друга. Невозможно привести или преобразовать значение на основе секунд к единице в зависимости от месяцев или наоборот.
Когда выполняется приведение к типу с меньшим младшим значащим поле, ничего не теряется из значения интервала. В противном случае значения для отсутствующие наименее значимые поля отбрасываются. Примеры:
Числовое значение может быть приведено к интервальному типу. В этом случае
числовое значение сначала преобразуется в тип INTERVAL с одним полем с
то же поле, что и наименее значимое поле типа целевого интервала.
Затем это значение преобразуется в тип целевого интервала. Например, CAST(
22 КАК ИНТЕРВАЛ ГОД В МЕСЯЦ) оценивается как ИНТЕРВАЛ '22' МЕСЯЦ, а затем
ИНТЕРВАЛ '1 10' ГОД В МЕСЯЦ. Обратите внимание, что SQL Standard поддерживает только приведение
к типам INTERVAL с одним полем, в то время как HyperSQL допускает приведение к
также многопольные типы.
Значение интервала может быть приведено к числовому типу. В этом случае значение интервала сначала преобразуется в тип ИНТЕРВАЛ с одним полем с то же поле, что и наименее значимое поле значения интервала. Значение затем преобразуется в целевой тип. Например, CAST (ИНТЕРВАЛ '1-11' ГОД В МЕСЯЦ КАК ЦЕЛОЕ) оценивается как ИНТЕРВАЛ '23' МЕСЯЦ, а затем 23.
Значение интервала может быть приведено к символьному типу, в результате чего в литерале INTERVAL. Значение символа может быть преобразовано в INTERVAL тип, если это строка с форматом, совместимым с INTERVAL буквальный.
Два значения интервала могут быть добавлены или вычтены, пока типы
оба основаны на одном и том же поле, т. е. оба основаны на MONTH или
ВТОРОЙ. Оба значения преобразуются в тип интервала с одним полем с
то же поле, что и наименее значимое поле между двумя типами. После
сложения или вычитания, результат преобразуется в тип интервала, который
содержит все поля двух исходных типов.
Значение интервала можно умножить или разделить на числовое значение. Опять же, значение преобразуется в числовое, которое затем умножается или разделить, прежде чем преобразовать обратно в исходный тип интервала.
Значение интервала инвертируется простым префиксом с минусом знак.
Значения интервала, используемые в выражениях, являются либо типизированными значениями,
включая интервальные литералы, или интервальные приведения. Выражение: <выражение> <определитель интервала> — это приведение
результата <выражение> в
Тип INTERVAL, указанный в <спецификатор интервала>.
приведение может быть сформировано путем добавления ключевых слов и круглых скобок следующим образом: CAST
( <выражение> AS INTERVAL <спецификатор интервала> ).
В приведенных ниже примерах представлены различные формы выражения
которые представляют значение интервала, которое затем добавляется к заданной дате
буквальный.
Дата, время и интервал Операции
Интервал может быть добавлен или вычтен из значения даты и времени, поэтому пока у них есть некоторые общие поля. Например, ИНТЕРВАЛЬНЫЙ МЕСЯЦ нельзя добавить к значению TIME, в то время как INTERVAL HOUR TO SECOND можно. интервал сначала преобразуется в числовое значение, затем значение добавляется или вычитается из соответствующего поля datetime ценность.
Если результат сложения или вычитания выходит за пределы допустимого
диапазон для поля, значение поля нормализуется и переносится в
следующее значимое поле, пока все поля не будут нормализованы. Например,
добавление 20 минут к TIME '23:50:10' последовательно приведет к
«23:70:10», «24:10:10» и, наконец, ВРЕМЯ «00:10:10». Вычитание 20 минут
из результата выполняется так: '00:-10:10', '-1:50:10', наконец
ВРЕМЯ '23:50:10'. Обратите внимание, что если нормализация DATE или TIMESTAMP приводит к
значение поля YEAR вне диапазона (1,10000), затем исключение
состояние повышено.
Если значение интервала, основанное на МЕСЯЦЕ, прибавляется или вычитается из значение DATE или TIMESTAMP, результат может иметь недопустимый день (30 или 31) за данный результат месяц. В этом случае условием исключения является поднятый.
Результатом вычитания двух выражений datetime является интервал
ценность. Два выражения даты и времени должны быть одного типа. Тип
значение интервала должно быть указано в выражении, используя только
имена интервальных полей. Два выражения datetime заключены в
круглые скобки, за которыми следует <классификатор интервала> поля. В первом примере ниже COL1 и COL2 имеют одинаковую дату и время.
тип, а результат оценивается в типе INTERVAL YEAR TO MONTH.
Отдельные поля значений даты и времени и интервала могут быть извлекается с помощью функции EXTRACT. Эту же функцию можно использовать для извлечения полей смещения часового пояса значения даты и времени.
ВЫДЕРЖКА ({ГОД | МЕСЯЦ | ДЕНЬ | ЧАС | МИНУТА | СЕКУНД |
TIMEZONE_HOUR | ЧАСОВОЙ ПОЯС_МИНУТА | ДЕНЬ_НЕДЕЛИ | WEEK_OF_YEAR } ОТ
{<значение даты и времени> | <значение интервала>})
Дихотомия между типами интервалов, основанными на секундах, и теми,
по месяцам, связано с тем, что разные календарные месяцы
имеют разное количество дней. Например, выражение «девять месяцев
и девять дней с момента события» не является точным, когда дата события
неизвестный. Он может представлять собой период около 284 дней плюс-минус один.
Значения интервала SQL не зависят от даты или времени начала или окончания.
Однако, когда они добавляются или вычитаются из определенной даты или
значения временной метки, результат может быть недействительным и вызвать исключение (например,
прибавление одного месяца к 30 января приводит к 30 февраля, т. е.
инвалид).
JDBC имеет досадное ограничение и не включает коды типов
для типов SQL INTERVAL. Поэтому для совместимости с инструментами баз данных
которые ограничены кодами типов JDBC, HyperSQL сообщает об этих типах
по умолчанию как VARCHAR. Вы можете использовать свойство URL hsqldb.translate_dti_types=false , чтобы переопределить
поведение по умолчанию.
Расширения Java 8
JAVA 8 не имеет кодов типов SQL для типов INTERVAL. ГиперSQL
(кроме банок, скомпилированных с JDK 1.6) поддерживает java.time типов для типов INTERVAL в ResultSet , PreparedStatement и CallableStatement .
getObject(int columnIndex, Class тип)метод для INTERVAL поддерживаетjava.time.Periodтип для ГОД и МЕСЯЦ интервал и типjava.time.Durationдля другие типы интервалов, которые охватывают DAY до SECOND.метод setObject(int columnIndex)принимаетjava.time.Periodиобъектов java.time.Durationдля столбцов соответствующие типы INTERVAL.getObjectиметодов setObjectс параметрами имени столбца вести себя так же, как их аналоги с columnIndexe параметры.
Массивы
Массивы — это мощная функция SQL:2016, которая может помочь решить многие общие проблемы. Массивы не должны использоваться в качестве замены столы.
HyperSQL поддерживает массивы значений в соответствии со Стандартом.
Элементы массива имеют значение NULL или относятся к одному и тому же типу данных. Это
можно определить массивы всех поддерживаемых типов, включая типы
описанные в этой главе, и пользовательские типы, за исключением типов LOB. SQL
массив является одномерным и адресуется с позиции 1. Пустой массив
также может быть использован, который не имеет элемента.
Массивы могут храниться в базе данных, а также использоваться как временные контейнеры значений для упрощения операторов SQL. Они облегчить обмен данными между механизмом SQL и пользовательским заявление.
Полный диапазон поддерживаемого синтаксиса позволяет создавать массивы, использовать в SELECT или других операторах, объединенных со строками таблиц и используемых в рутинные звонки.
Определение массива
Тип столбца таблицы, параметр процедуры, переменная или возвращаемое значение функции может быть определено как массив.
<тип массива> ::= <тип данных> ARRAY [
Слово ARRAY добавляется к любому допустимому определению типа, кроме BLOB
и определения типа CLOB. Если дополнительный <максимум
кардинальность > не используется, значение по умолчанию 1024. размер массива не может быть расширен за пределы максимальной мощности.
В приведенном ниже примере таблица содержит столбец INTEGER
массивы и столбец массивов VARCHAR. Массив VARCHAR имеет явное
максимальный размер 10, что означает, что каждый массив может иметь от 0 до 10
элементы. Массив INTEGER имеет максимальный размер по умолчанию 1024.
столбец scores имеет предложение по умолчанию с пустым массивом. По умолчанию
пункт может быть определен только как ПО УМОЛЧАНИЮ НОЛЬ или МАССИВ ПО УМОЛЧАНИЮ[] и не допускает массивы, содержащие
элементы.
Массив может быть создан из выражений значений или запроса выражение.
<конструктор значений массива по перечислению> ::= МАССИВ <левая квадратная скобка или треугольник> <список элементов массива> <правая
скобка или триграф >
<список элементов массива> ::= <значение выражения> [
{ <запятая> <выражение-значение> }. .. ]
<конструктор значений массива по запросу> ::= МАССИВ <левая скобка> <выражение запроса> [ <порядок по предложению> ] <правая скобка>
В приведенных ниже примерах массивы состоят из значений, столбца ссылки или переменные, вызовы функций или выражения запросов.
Вставка и обновление таблицы со столбцом ARRAY может использовать массив конструкторы не только для обновленных значений столбца, но и для равенства условия поиска:
При использовании PreparedStatement с параметром ARRAY Java
массив или объект java.sql.Array может использоваться для установки
параметр.
В приведенном ниже примере подготовлены инструкции для INSERT и UPDATE. используются параметры массива.
В приведенном ниже примере используется java.sql.Array .
для обновления, используя те же данные, что и выше:
Триграф
Триграф заменяет <левая квадратная скобка> и <правая скобка>.
<триграф в левой скобке> ::= ??(
<триграф в правой скобке> ::= ??)
В приведенном ниже примере показано использование триграфов вместо скобки.
Ссылка на массив
Наиболее распространенными операциями над массивом являются ссылка на элемент и присваивание, которые используются при чтении или записи элемента множество. В отличие от Java и многих других языков, массивы расширяются, если элементу присваивается индекс за пределами текущей длины. Это может приводят к пробелам, содержащим элементы NULL. Длина массива не может превышать максимальная кардинальность.
Элементы всех массивов, включая те, которые являются результатом на вызовы функций или другие операции можно ссылаться для чтения.
<ссылка на элемент массива> ::= <значение массива
выражение> <левая квадратная скобка> <выражение числового значения> <правая скобка>
Элементы массивов, являющиеся столбцами таблицы или переменными подпрограммы, могут
ссылаться на написание. Это делается в операторе SET либо
внутри оператора UPDATE или как отдельный оператор в случае
стандартные переменные, параметры OUT и INOUT.
<спецификация элемента целевого массива> ::= <цель
ссылка на массив> <левая квадратная скобка или триграф> <простое значение
спецификация> <правая скобка или триграф>
<ссылка на целевой массив> ::= <параметр SQL
ссылка> | <ссылка на столбец>
Обратите внимание, что для индекс массива при выполнении присваивания. Примеры ниже продемонстрировать, как элементы массива упоминаются в SELECT и ОБНОВЛЕНИЕ заявлений.
Операции с массивами
Несколько операций и функций SQL могут использоваться с массивы.
ОБЪЕДИНЕНИЕ
Объединение массивов выполняется аналогично объединению строк. Все элементы массива справа добавляются к массиву на оставил.
<объединение массивов> ::= <значение массива
выражение 1> <оператор конкатенации> <значение массива
выражение 2>
<оператор конкатенации> ::= ||
ФУНКЦИИ
Функции, перечисленные ниже, работают с массивами. Подробности описаны в
главу «Встроенные функции».
ARRAY_AGG является агрегатной функцией и производит
массив, содержащий значения из разных строк оператора SELECT.
Подробности описаны в главе Доступ к данным и их изменение.
SEQUENCE_ARRAY создает массив с последовательным
элементы.
CARDINALITY <левая скобка> <значение массива
выражение> <правая скобка>
MAX_CARDINALITY <левая скобка> <значение массива
выражение> <правая скобка>
Количество элементов массива и максимальное количество элементов — это функции, которые возвращают целое число. CARDINALITY возвращает количество элементов, а MAX_CARDINALITY возвращает максимальное заявленное количество элементов массива.
POSITION_ARRAY <левая скобка> <значение
выражение> IN <выражение значения массива> [FROM <числовое значение
выражение>] <правая скобка>
Функция POSITION_ARRAY возвращает позицию первого
совпадение для <выражения-значения> с самого начала или с заданного
начальная позиция при использовании <выражения числового значения>.
TRIM_ARRAY <левая скобка> <значение массива
выражение> <запятая> <выражение числового значения> <право
парен >
Функция TRIM_ARRAY возвращает копию массива с
указанное количество элементов, удаленных с конца массива. <выражение значения массива> может быть любым выражением
который оценивается как массив.
SORT_ARRAY <левая скобка> <значение массива
выражение> [ { ASC | DESC } ] [ NULLS { FIRST | ПОСЛЕДНИЙ } ] <справа
парен >
Функция SORT_ARRAY возвращает отсортированную копию массива. НУЛЕВОЙ элементы появляются в начале нового массива. Вы можете изменить направление сортировки или положение элементов NULL с опцией ключевые слова.
ЛИТОЕ
Массив можно преобразовать в массив другого типа. Каждый элемент массива преобразуется в тип элемента целевого массива тип. Например:
НЕНЕСТ
Массивы могут быть преобразованы в ссылки на таблицы с помощью команды UNNEST
ключевое слово.
UNNEST(<выражение значения массива>) [ WITH ORDINALITY
]
<выражение значения массива> может быть любым
выражение, результатом которого является массив. Возвращается таблица, содержащая
один столбец, если WITH ORDINALITY не используется, или два столбца, если WITH
Используется ОРДИНАЛЬНОСТЬ. Первый столбец содержит элементы массива
(включая все нули). Если в таблице два столбца, второй
столбец содержит порядковый номер элемента в массиве. Когда
UNNEST используется в предложении FROM запроса, оно подразумевает LATERAL
ключевое слово, которое означает, что массив, который преобразуется в таблицу, может принадлежать
любая таблица, предшествующая UNNEST в предложении FROM. Это объясняется
в главе «Доступ к данным и их изменение».
ВСТРОЕННЫЙ КОНСТРУКТОР
Конструкторы массивов можно использовать в операторах SELECT и других. За
Например, конструктор массива с подзапросом может возвращать значения из
несколько строк как один массив.
В приведенном ниже примере показан конструктор ARRAY с коррелированным подзапрос для возврата списка значений заказов для каждого клиента. Таблица CUSTOMER, включенная для тестов в приложение DatabaseManager GUI. является источником данных.
СРАВНЕНИЕ
Массивы можно сравнивать на равенство. Можно определить
Ограничение UNIQUE для столбца типа ARRAY. Два массива равны, если
они имеют одинаковую длину, и значения в каждой позиции индекса равны
либо равно, либо оба NULL. Выражения массива нельзя использовать в
выражения сравнения, такие как GREATER THAN, но их можно использовать в
Предложение ORDER BY. Например, можно добавить ORDER BY
ORDERS к приведенному выше оператору SELECT,
ПОЛЬЗОВАТЕЛЬСКИЕ ФУНКЦИИ и ПРОЦЕДУРЫ
Параметры массива, переменные и возвращаемые значения могут быть указаны в
определяемые пользователем функции и процедуры, включая агрегатные функции. Ан
агрегатная функция может возвращать массив, содержащий все скалярные
значения, которые были агрегированы. Эти возможности позволяют расширить диапазон
приложений, которые будут покрыты определяемыми пользователем функциями и упрощенными данными
обмен между движком и приложением пользователя.
Глава 2. Структура языка SQL
Глава 2. Структура языка SQL
В этом справочнике описывается язык SQL, поддерживаемый Firebird.
2.1 Предыстория языка SQL Firebird
Для начала несколько замечаний о некоторых характеристиках, лежащих в основе реализации языка Firebird.
2.1.1 Варианты SQL
Различные подмножества SQL применяются к разным секторам деятельности. Подмножества SQL в языковой реализации Firebird:
Динамический SQL — это основная часть языка, соответствующая части 2 (SQL/Foundation) спецификации SQL.
DSQL представляет операторы, передаваемые клиентскими приложениями через общедоступный API Firebird и обрабатываемые ядром базы данных.
Процедурный SQL дополняет динамический SQL, позволяя использовать составные операторы, содержащие локальные переменные, присваивания, условия, циклы и другие процедурные конструкции. PSQL соответствует части 4 (SQL/PSM) спецификации SQL. Первоначально расширения PSQL были доступны только в постоянных хранимых модулях (процедуры и триггеры), но в более поздних версиях они появились и в Dynamic SQL (см.0106 ВЫПОЛНИТЬ БЛОК ).
Embedded SQL определяет подмножество DSQL, поддерживаемое Firebird gpre , приложение, которое позволяет вам встраивать конструкции SQL в ваш основной язык программирования (C, C++, Pascal, Cobol и т. д.) и предварительно обрабатывать эти встроенные конструкции в правильные вызовы API Firebird.
🛈︎
Примечание
В ESQL поддерживается только часть операторов и выражений, реализованных в DSQL.
Интерактивный ISQL относится к языку, который может быть выполнен с помощью Firebird isql , приложения командной строки для интерактивного доступа к базам данных. Как обычное клиентское приложение, его родным языком является DSQL.
Он также предлагает несколько дополнительных команд, которые недоступны за пределами его конкретной среды.
В этом справочнике полностью представлены подмножества DSQL и PSQL. Здесь не описываются разновидности ESQL и ISQL, если не указано иное.
2.1.2 Диалекты SQL
Диалект SQL — термин, определяющий специфические функции языка SQL, доступные при доступе к базе данных. Диалекты SQL могут быть определены на уровне базы данных и указаны на уровне соединения. Доступны три диалекта:
Диалект 1 предназначен исключительно для обеспечения обратной совместимости с устаревшими базами данных из очень старых версий InterBase, v.5 и ниже. Базы данных диалекта 1 сохраняют некоторые языковые функции, которые отличаются от диалекта 3, используемого по умолчанию для баз данных Firebird.
Информация о дате и времени хранится в типе данных
DATE. Также доступен тип данных TIMESTAMP, который идентичен этой реализацииDATE.В качестве альтернативы апострофам для разделения строковых данных можно использовать двойные кавычки. Это противоречит стандарту SQL — двойные кавычки зарезервированы для особой синтаксической цели как в стандартном SQL, так и в диалекте 3. Поэтому следует всячески избегать двойных кавычек.
Точность для типов данных
NUMERICиDECIMALменьше, чем в диалекте 3, и, если точность фиксированного десятичного числа больше 9, Firebird сохраняет его внутри как длинное значение с плавающей запятой.Тип данных
BIGINT(64-разрядное целое число) не поддерживается.Идентификаторы нечувствительны к регистру и всегда должны соответствовать правилам для обычных идентификаторов — см. раздел Раздел 2.3, Идентификаторы ниже.
Хотя значения генератора хранятся в виде 64-битных целых чисел, клиентский запрос диалекта 1, например,
SELECT GEN_ID (MyGen, 1), вернет значение генератора, усеченное до 32 бит.
Диалект 2 доступен только при подключении клиента Firebird и не может быть установлен в базе данных. Он предназначен для устранения возможных проблем с устаревшими данными при переносе базы данных с диалекта 1 на диалект 3.
В базах данных Dialect 3 числа
(типы данных
DECIMALиNUMERIC) хранятся внутри как длинные значения с фиксированной точкой (масштабированные целые числа), когда точность превышает 9.ВРЕМЯ Тип данныхдоступен только для хранения данных о времени суток.Тип данных
DATEхранит только информацию о дате.64-битный целочисленный тип данных
БОЛЬШОЙдоступен.Двойные кавычки зарезервированы для разграничения нерегулярных идентификаторов, включения имен объектов, которые чувствительны к регистру или которые не соответствуют требованиям для обычных идентификаторов в других отношениях.
Все строки должны быть заключены в одинарные кавычки (апострофы).
Значения генератора хранятся в виде 64-битных целых чисел.
☝︎
Важно
Использование Dialect 3 настоятельно рекомендуется для вновь разрабатываемых баз данных и приложений. Диалекты базы данных и соединения должны совпадать, за исключением условий миграции с диалектом 2.
В этом справочнике описывается семантика диалекта SQL 3, если не указано иное.
2.1.3 Состояния ошибок
Обработка каждого оператора SQL либо завершается успешно, либо завершается с ошибкой из-за определенного состояния ошибки. Обработка ошибок может производиться как в клиентском приложении, так и на стороне сервера с помощью PSQL.
S2SQL: внедрение синтаксиса в кодировщик графика взаимодействия вопрос-схема для парсеров преобразования текста в SQL
Binyuan Hui, Жуин Гэн, Лихан Ван, Боуэн Цинь, Яньян Ли, Боуэн Ли, Цзян Сун, Юнбин Ли
Abstract
Задача преобразования вопроса на естественном языке в исполняемый SQL-запрос, известная как преобразование текста в SQL, является важной ветвью семантического разбора. В этой задаче успешно используется современный кодировщик на основе графа, но он плохо моделирует синтаксис вопроса. В этой статье мы предлагаем S 2 SQL, внедряющий синтаксис в кодировщик графа схемы вопросов для парсеров преобразования текста в SQL, который эффективно использует информацию о синтаксической зависимости вопросов в преобразовании текста в SQL для повышения производительности. Мы также используем ограничение развязки, чтобы вызвать встраивание различных реляционных ребер, что еще больше повышает производительность сети. Эксперименты с Spider и параметром надежности Spider-Syn демонстрируют, что предложенный подход превосходит все существующие методы при использовании моделей предварительного обучения, в результате чего производительность занимает первое место в таблице лидеров Spider.- Anthology ID:
- 2022.findings-acl.99
- Volume:
- Findings of the Association for Computational Linguistics: ACL 2022
- Month:
- May
- Year:
- 2022
- Address:
- Дублин, Ирландия
- Места проведения:
- ACL | Выводы
- SIG:
- Издатель:
- Ассоциация компьютерной лингвистики
- Примечание:
- Страницы:
- 1254–1262
- Язык:
- URL:
- https://aclanthology. org/2022.findings-ACL.99
- DOI:
- 10.18653/V1/2022.Findings-ACLINTS-ACLININGS-ACLININGS-ACLININGS-ACLININGS-ai:
- 10.18653/V1/2022.FINDINGS-ACLINTINGS-ACLINTINGS-ACLINGS-ACLINTINGS-ACLINTINGS. :
- Ссылка (ACL):
- Биньюань Хуэй, Жуин Гэн, Лихан Ван, Боуэн Цинь, Яньян Ли, Боуэн Ли, Цзянь Сун и Юнбин Ли. 2022. S2SQL: внедрение синтаксиса в кодировщик графа взаимодействия вопрос-схема для парсеров преобразования текста в SQL. В г. Выводы Ассоциации компьютерной лингвистики: ACL 2022 , страницы 1254–1262, Дублин, Ирландия. Ассоциация компьютерной лингвистики.
- Процитируйте (неофициально):
- S2SQL: внедрение синтаксиса в кодировщик графа взаимодействия вопрос-схема для парсеров преобразования текста в SQL (Hui et al., Findings 2022)
- Копия цитирования:
- PDF:
- https://aclanthology.org/2022.findings-acl.99.pdf
- Программное обеспечение:
- 2022.findings-acl.99. software.zip
- Данные SPI 1
- 2${SQL}: внедрение синтаксиса в кодировщик графика взаимодействия вопрос-схема для синтаксических анализаторов текста в {SQL}»,
автор = «Хуэй, Биньюань и
Гэн, Жуин и
Ван, Лихан и
Цинь, Боуэн и
Ли, Яньян и
Ли, Боуэн и
Сун, Цзянь и
Ли, Юнбинь»,
booktitle = «Выводы Ассоциации компьютерной лингвистики: ACL 2022»,
месяц = май,
год = «2022»,
address = «Дублин, Ирландия»,
издатель = «Ассоциация вычислительной лингвистики»,
url = «https://aclanthology.org/2022.findings-acl.92$SQL, внедряющий синтаксис в кодировщик графа схемы вопросов для синтаксических анализаторов преобразования текста в SQL, который эффективно использует информацию о синтаксической зависимости вопросов в преобразовании текста в SQL для повышения производительности. Мы также используем ограничение развязки, чтобы вызвать встраивание различных реляционных ребер, что еще больше повышает производительность сети. Эксперименты с Spider и параметром надежности Spider-Syn демонстрируют, что предлагаемый подход превосходит все существующие методы при использовании моделей предварительного обучения, в результате чего производительность занимает первое место в таблице лидеров Spider.
}
<моды> <информация о заголовке> S²SQL: внедрение синтаксиса в кодировщик графика взаимодействия вопрос-схема для анализаторов преобразования текста в SQL <название типа="личное">Биньюань Хуэй <роль>автор <название типа="личное">Жуин Генг <роль>автор <название типа="личное">Лихан Ванг <роль>автор <название типа="личное">Боуэн Цинь <роль>автор <название типа="личное">Яньян Ли <роль>автор <название типа="личное">Боуэн Ли <роль>автор <название типа="личное">Цзян Вс <роль>автор <название типа="личное">Юнбинь Ли <роль>автор <информация о происхождении>2022-05 текст <информация о заголовке> Выводы Ассоциации компьютерной лингвистики: ACL 2022 <информация о происхождении>Ассоциация компьютерной лингвистики <место>Дублин, Ирландия публикация конференции Задача преобразования вопроса на естественном языке в исполняемый SQL-запрос, известная как преобразование текста в SQL, является важной ветвью семантического разбора. В этой задаче успешно используется современный кодировщик на основе графа, но он плохо моделирует синтаксис вопроса. В этой статье мы предлагаем S²SQL, внедряющий синтаксис в кодировщик графа схемы вопросов для парсеров преобразования текста в SQL, который эффективно использует информацию о синтаксической зависимости вопросов в преобразовании текста в SQL для повышения производительности. Мы также используем ограничение развязки, чтобы вызвать встраивание различных реляционных ребер, что еще больше повышает производительность сети. Эксперименты с Spider и параметром надежности Spider-Syn демонстрируют, что предлагаемый подход превосходит все существующие методы при использовании моделей предварительного обучения, в результате чего производительность занимает первое место в таблице лидеров Spider.hui-etal-2022-s2sql 10.18653/v1/2022.findings-acl.99 <местоположение> https://aclanthology. <часть> <дата>2022-05 <единица экстента="страница"> org/2022.findings-acl.991254 1262 %0 Материалы конференции %T S²SQL: внедрение синтаксиса в кодировщик графика взаимодействия вопрос-схема для парсеров преобразования текста в SQL %A Хуэй, Биньюань %A Гэн, Жуин %А Ван, Лихан %А Цинь, Боуэн %А Ли, Яньян %А Ли, Боуэн %A Сун, Цзянь %А Ли, Юнбинь %S Выводы Ассоциации компьютерной лингвистики: ACL 2022 %D 2022 %8 май %I Ассоциация компьютерной лингвистики %C Дублин, Ирландия %F хуи-etal-2022-s2sql %X Задача преобразования вопроса на естественном языке в исполняемый SQL-запрос, известная как преобразование текста в SQL, является важной ветвью семантического разбора. В этой задаче успешно используется современный кодировщик на основе графа, но он плохо моделирует синтаксис вопроса. В этой статье мы предлагаем S²SQL, внедряющий синтаксис в кодировщик графа схемы вопросов для парсеров преобразования текста в SQL, который эффективно использует информацию о синтаксической зависимости вопросов в преобразовании текста в SQL для повышения производительности.
Мы также используем ограничение развязки, чтобы вызвать встраивание различных реляционных ребер, что еще больше повышает производительность сети. Эксперименты с Spider и параметром надежности Spider-Syn демонстрируют, что предложенный подход превосходит все существующие методы при использовании моделей предварительного обучения, в результате чего производительность занимает первое место в таблице лидеров Spider.
%R 10.18653/v1/2022.findings-acl.99
%U https://aclanthology.org/2022.findings-acl.99
%U https://doi.org/10.18653/v1/2022.findings-acl.99
%Р 1254-1262
Уценка (неофициальная)
[S2SQL: внедрение синтаксиса в кодировщик графика взаимодействия вопросов и схем для парсеров преобразования текста в SQL] (https://aclanthology.org/2022.findings-acl.99) (Hui et al. , Результаты 2022)
- S2SQL: Внедрение синтаксиса в кодировщик графика взаимодействия вопросов и схем для парсеров преобразования текста в SQL (Hui et al., Результаты 2022)
ACL
- Binyuan Hui, Ruiying Geng, Lihan Wang, Bowen Qin, Yanyang Li, Bowen Li, Jian Sun и Yongbin Li. 2022. S2SQL: внедрение синтаксиса в кодировщик графа взаимодействия вопрос-схема для парсеров преобразования текста в SQL. В г. Выводы Ассоциации компьютерной лингвистики: ACL 2022 , стр. 1254–1262, Дублин, Ирландия. Ассоциация компьютерной лингвистики.
Основы баз данных № 2: SQL Server Management Studio
12 июня 2017 г., Грант Фричи 2 комментариев
Лучший способ изучить любую программу — начать ее использовать. В наборе инструментов SQL Server есть множество программных инструментов, но самым большим и важным является SQL Server Management Studio (SSMS). SSMS — это место, где вы будете проводить большую часть своего времени, когда начнете работать с SQL Server. Он предоставляет очень большой набор графических пользовательских интерфейсов для создания баз данных, настройки безопасности, чтения данных из базы данных и всевозможных других вещей в ваших экземплярах SQL Server, базах данных, хранящихся там, и всего прочего внутри этих баз данных.
Он также предоставляет вам интерфейс к основному языку сценариев SQL Server, с помощью которого вы можете делать с сервером практически все, что угодно. Язык сценариев называется Transact Structured Query Language, или Transact SQL, или просто T-SQL для краткости. Это ваш шанс, наконец, приступить к изучению инструмента, который позволит вам управлять своими собственными базами данных и серверами.Чтобы приступить к работе с SQL Server после его установки (см. раздел «Основы базы данных №1» для обзора установки SQL Server), вы открываете SQL Server Management Studio из меню «Пуск» на своем компьютере (и можете установить SQL Server Management Studio совершенно самостоятельно). Когда он откроется, вам сначала будет представлено окно подключения. В зависимости от того, как вы установили SQL Server, на данном этапе у вас есть выбор и решения. Установка могла быть установкой по умолчанию, что означает, что имя сервера — это все, что вам нужно для подключения к SQL Server. Если нет, то, возможно, было указано имя экземпляра с обратной косой чертой между именем сервера и именем экземпляра.
В дополнение к имени сервера и/или экземпляра вам также нужно беспокоиться о том, как была настроена безопасность. В большинстве установок будет использоваться встроенная безопасность Windows. Это означает, что ваш логин Windows дает вам доступ к SQL Server. В некоторых местах вам будет предоставлено имя пользователя и пароль, это известно как вход в SQL Server. При работе с Azure вы также можете использовать сертификаты или многофакторную авторизацию. Они выходят за рамки начального уровня, который мы здесь рассматриваем. В большинстве случаев ваше подключение к SQL Server будет выглядеть примерно так:После того, как вы правильно настроите соединение, вы можете нажать на кнопку Connect. Это соединит вас напрямую с SSMS. Если вы следовали всем инструкциям, теперь вы подключены к своему экземпляру SQL Server. Вы видите много нового для себя. Я расскажу о некоторых основных функциях различных окон, готовясь ко всей работе, которую вы будете выполнять с этим программным обеспечением в будущем.
Конфигурация SSMS по умолчанию имеет строку меню в верхней части экрана. В строке меню есть список пунктов меню, которые могут меняться в зависимости от того, какие другие окна или процессы у вас открыты. Меню — это один из способов доступа к командам и функциям в SQL Server. Под строкой меню находится панель инструментов. Панель инструментов, как и меню, может меняться в зависимости от того, что еще у вас открыто. Кнопки на панелях инструментов настраиваются. Эти кнопки представляют собой еще один способ доступа к командам и функциям в SQL Server. Оставшееся окно делится на две части. В левой части экрана находится окно Object Explorer. С правой стороны, когда вы впервые открываете сервер при установке по умолчанию, ничего не будет видно. В нижней части окна находится панель состояния и информации, которая показывает различную информацию в зависимости от того, что вы выбрали или открыли в окнах выше.
SSMS построена на основе среды программирования Microsoft, Visual Studio, и имеет много общих функций.
Окна очень настраиваемые. Вы можете сделать так, чтобы окна плавали независимо друг от друга, или вы можете монтировать их в разных местах на экране, создавая среды с вкладками, если вы предпочитаете это. Вы также можете закреплять и откреплять окна, заставляя их появляться и исчезать из поля зрения, когда указатель мыши приближается к ним, щелкнув значок канцелярской кнопки в окне. Попробуйте щелкнуть канцелярскую кнопку, видимую в окне обозревателя объектов. Окно должно исчезнуть, оставив маленькую вкладку в левой части экрана с надписью Object Explorer. Если вы наведете указатель мыши на эту вкладку и оставите его там, что называется наведением, окно Object Explorer снова выскочит. Щелкните значок канцелярской кнопки еще раз, и окно обозревателя объектов снова будет закреплено в левой части экрана, как и раньше.Теперь вам не нужно знать обо всех возможных комбинациях конфигураций. Достаточно знать, что вы можете настроить систему так, как вам больше всего хотелось бы, чтобы она работала лучше всего для вас.
Вы потратите много времени на работу с обозревателем объектов, поэтому имеет смысл сначала с ним ознакомиться. SSMS позволит вам подключаться к нескольким экземплярам SQL Server. При подключении к каждому экземпляру вы увидите их список в обозревателе объектов. Рядом с каждым сервером будет маленький значок плюса, который открывает дерево для этого сервера. Дерево представляет собой список различных типов объектов, которыми вы можете начать управлять из SSMS. При подключении к серверу имя сервера отображается в верхней части окна обозревателя объектов. Ниже представлены различные части дерева, как вы можете видеть ниже. Мой сервер — это имя виртуальной машины по умолчанию, WIN-MA9H6M2E1QF. Мой экземпляр SQL Server называется DOJO в честь всех тренировок по боевым искусствам. Вы можете увидеть их здесь:Изучение поведения инструмента SSMS будет непрерывным процессом из-за всех доступных вам опций. Начните работу, нажав на значок плюса рядом с папкой с надписью Databases.
Откроется список баз данных для вашего сервера. Поскольку по умолчанию базы данных не установлены и вы, вероятно, их не создавали, в дереве вы должны увидеть только еще две папки; Системные базы данных и моментальные снимки базы данных. Нажмите на плюс рядом с системными базами данных, и вы увидите четыре базы данных, которые SQL Server использует для управления своими собственными операциями: master, model msdb и tempdb. Пока не беспокойтесь о том, что они делают, и вам действительно не следует даже думать об изменении параметров или объектов внутри этих баз данных. Но вы можете посмотреть на них, чтобы увидеть, что там хранится. Щелкните знак «минус», который теперь находится рядом с меткой «Системные базы данных». Это закрывает этот список. Щелкните знак «минус» рядом с меткой «Базы данных», и вы также закроете этот список. Вот как можно получить доступ ко всем различным объектам через Object Explorer. Существуют и другие способы манипулирования объектами в обозревателе объектов.Щелкните правой кнопкой мыши метку Базы данных в обозревателе объектов.
Это действие открывает контекстное окно с другими функциями. Пункты меню, отмеченные многоточием, …, откроют другие окна. Пункты меню, отмеченные черной стрелкой вправо, откроют другие меню. Вы можете увидеть контекстное меню здесь:Действия, описанные в меню, вероятно, не требуют пояснений, как «Новая база данных», или загадочны, как «Запустить PowerShell». Вы будете использовать ряд этих функций на протяжении всей книги, и теперь у вас есть лучшее представление о том, как их отследить.
В верхней части проводника объектов находится ряд значков, позволяющих выполнять другие действия. Слева находится раскрывающееся меню, позволяющее подключиться к другому экземпляру SQL Server, помеченному как Database Engine, Analysis Services, Integration Services или Reporting Services. Рядом с ним находится ряд иконок. Первый предназначен для подключения к другому экземпляру SQL Server. Рядом с ним находится значок, который отключит вас от сервера, выбранного в данный момент в окне обозревателя объектов.
Попробуйте нажать на этот значок. Дерево в окне Обозревателя объектов исчезнет. Чтобы вернуть его, вам нужно снова подключиться к серверу, как вы делали это раньше. Но вы можете открыть окно подключения одним из двух описанных выше способов.Взгляните на верхнюю часть экрана, где находится строка меню. Здесь есть несколько вариантов, но тот, который должен беспокоить вас больше всего в данный момент, находится справа, «Помощь». Нажмите на меню «Справка», и вы увидите несколько различных вариантов. Самый важный на данный момент находится прямо вверху, View Help. Нажмите на этот пункт меню. Если вы впервые пытаетесь открыть справку, вам будет предложено выбрать, хотите ли вы подключиться к онлайн-справке или нет. Онлайн-справка более актуальна, чем любые файлы справки, установленные в вашей системе. Это означает, что вы получите гораздо более точные ответы, но он медленнее и с ним немного сложнее манипулировать, чем с локальным файлом справки, который называется Books Online. Производственные серверы в некоторых компаниях также не могут подключиться к Интернету, поэтому это решение зависит от вашей ситуации.
Самое важное, что нужно знать о SQL Server, это то, что всегда есть много способов добиться цели. Доступ к окну справки очень важен. Еще более важно получить правильный вид помощи. Вы можете щелкнуть меню, как мы сделали выше, но у вас также есть возможность открыть справку в контексте окна, в котором вы сейчас работаете. В любое время, когда вы хотите увидеть справку для окна, в котором вы находитесь, нажмите клавишу F1 на клавиатуре. Это откроет экран справки.
Меню в верхней части экрана могут меняться в зависимости от того, что вы делаете, и какие окна открыты на экране ниже. Не удивляйтесь, если вы увидите новые пункты меню, которые иногда появляются по мере того, как вы работаете с примерами из этой серии. Меню взяты из Visual Studio, поэтому они не всегда могут показаться применимыми к среде управления базами данных, но через эти меню вы получаете множество функциональных возможностей. Некоторые из них дублируют функции, которые вы уже видели. Например, если щелкнуть пункт меню «Файл», отобразится ряд пунктов меню.
Вверху есть возможность подключить обозреватель объектов с многоточием. Это откроет окно подключения, которое вы уже видели.Щелкните меню «Вид». Это показывает вам очень большое количество вещей, которые вы можете вывести на экран для просмотра или изменения. Единственное, что вас беспокоит в данный момент, — это второе, Детали обозревателя объектов. Нажмите на это, и вы должны увидеть второе окно, открытое справа от вашего окна Object Explorer. В зависимости от того, что в данный момент выбрано в обозревателе объектов, вы можете увидеть элементы, отображаемые в окне сведений обозревателя объектов. Вы заметите, что это окно немного отличается в самом верху. У него есть вкладка. Эта большая область в SSMS настроена для просмотра с вкладками по умолчанию. Как и другие окна, вы можете настроить это. Здесь будет отображаться несколько различных типов окон, и все они будут оставаться открытыми до тех пор, пока вы их не закроете, выстроившись в ряд вкладок в верхней части экрана.
Чтобы просмотреть сведения об обозревателе объектов в действии, щелкните имя сервера и экземпляра в верхней части окна обозревателя объектов.
Это вызовет список объектов в окне сведений обозревателя объектов, который выглядит в основном идентично древовидному списку в обозревателе объектов. Вы можете выбрать эти объекты в этом окне, но если вы дважды не щелкнете по ним, вы не откроете ни одну из папок. Пока не исследуйте. Если вы что-то выбрали в окне сведений обозревателя объектов, щелкните пустое пространство справа или под списком объектов. Посмотрите вниз в нижней части окна. Вы должны увидеть серую рамку, протянувшуюся через все окно сведений обозревателя объектов, которая выглядит примерно так, как показано ниже. Когда сервер и экземпляр выбраны в обозревателе объектов, а другие объекты не выбраны в сведениях обозревателя объектов, в этом сером поле должна отображаться информация о вашем сервере и экземпляре.Прокручивая страницу, вы можете увидеть различную информацию о вашем сервере, такую как текущая версия установленного на нем SQL Server, количество баз данных, которых, вероятно, четыре (у меня 23), и другую информацию, такую как Максимальная память сервера.
Вся эта и многое другое информация доступна вам, когда вы выбираете различные объекты в окне обозревателя объектов. Попробуйте выбрать несколько и посмотрите, как изменится информация, отображаемая в окне сведений обозревателя объектов.Как видите, в SQL Server доступно много информации в различных формах. Изучение всех различных способов просмотра этой информации и знание того, что она означает, — это лишь часть того, что вам нужно изучить, чтобы научиться хорошо манипулировать сервером.
Существует ряд других окон и представлений данных, которые будут рассмотрены в оставшейся части этой серии. Теперь у вас есть основы, позволяющие приступить к изучению вашей системы.
Заключение
Среда SQL Server Management Studio (SSMS) — это среда, в которой вы будете проводить большую часть своего времени при работе с SQL Server, поэтому знакомство с ней как можно раньше — отличный способ начать обучение. Когда вы работаете со своими собственными системами, вы будете лучше подготовлены к пониманию того, почему они хранят данные именно так, потому что вы знакомы как с реляционными моделями, так и с многомерными моделями и их использованием.
Джейкобс Джобс — Администратор базы данных уровня 2
Сегодня вызов. Изобретая завтра.
Мы заинтересованы в вас и вашем успехе. Все, что мы делаем, больше, чем просто проект. Это и наша проблема как человеческих существ. Вот почему мы привносим вдумчивый и совместный подход к каждому из наших партнерских отношений.
В Jacobs мы бросаем вызов статус-кво и заново определяем, как решать самые большие проблемы в мире, превращая большие идеи в интеллектуальные решения для более взаимосвязанного и устойчивого мира.
Планируйте свою карьеру в компании, которая вдохновляет и дает вам возможность делать свою работу наилучшим образом, чтобы вы могли развиваться, расти и добиваться успеха – сегодня и завтра нанимает в поддержку контракта USSOCOM SITEC II Enterprise Operations and Maintenance Contract! Этот контракт предусматривает поддержку классифицированных и несекретных ИТ-услуг. Наша миссия проста: предоставить полностью боеспособные силы специального назначения для защиты Соединенных Штатов.
Наша динамичная корпоративная группа занимается внутренним обслуживанием, обновлением и интеграцией инфраструктурных услуг и систем, предоставляемых силам специального назначения по всему миру. Эта высокоэффективная группа предоставляет возможность изучить с нуля поддержку сетей и систем в совершенно секретной среде. Если вы заинтересованы в практической работе в высоком темпе, необходимой для выполнения более крупной миссии, подайте заявку ниже!Описание работы
Сменная работа требуется для поддержки операций 24×7. Важно быть готовым работать в любую смену/назначенные часы, включая ночные часы, выходные и праздничные дни.
Администратор базы данных — для роли уровня 2 требуется прочная техническая база в отношении структуры базы данных, ее настройки, установки, эксплуатации и обслуживания. Должен иметь знания и опыт работы с основными языками и приложениями реляционных баз данных, такими как Microsoft Structured Query Language (SQL) Server, Oracle и IBM DB2.
Администратор базы данных — роль уровня 2 должна демонстрировать способность уделять пристальное внимание деталям, обладать сильной ориентацией на обслуживание клиентов и иметь способность работать в команде. Эта должность будет предоставлять услуги поддержки администрирования баз данных (DBA), в том числе опыт уровня 2, а также планирование, внедрение и мониторинг услуг по установке исправлений для физических и виртуальных решений.Типичные обязанности включают:
Мониторинг и обслуживание баз данных
Выполнение запрошенных изменений, обновлений и модификаций структуры и данных базы данных
Обеспечение того, чтобы технические модификации не оказывали неблагоприятного воздействия на целостность, стабильность и доступность базы данных
Внедрение решений для инфраструктуры резервного копирования и восстановления баз данных
Вот что вам понадобится:
Квалификация
Требования к очистке: TS/SCI
Требования к образованию:
Требования к сертификации:
9- 6.
И
Oracle Certified Associate (OCA) 11g * ИЛИ
MCSA: SQL Server 2012/2014 ИЛИ
MCSA: администратор базы данных SQL 2016 ИЛИ
Сертифицировано Microsoft: помощник администратора базы данных Azure
Требования к опыту:
Не менее 1 года опыта работы в роли администратора баз данных, выполняющего поддержку уровня 2, и не менее четырех лет работы с базами данных.
Моделирование и внедрение баз данных.
Разработка пользовательского интерфейса и взаимодействие с пользователем.
Способность производить визуализацию данных для принятия решений руководством.
Знание как минимум одного объектно-ориентированного языка программирования, такого как Java, C++ или .NET.
Навыки работы с приложениями Microsoft Office: желательно знание Microsoft Access.
Сильные устные и письменные коммуникативные навыки.
Желателен опыт интеграции базы данных Microsoft SharePoint.
Основные функции
Рабочая среда
Работа будет выполняться внутри большого объекта. Внутренняя среда может быть кабиной (соображения: тесные помещения, низкий или умеренный шум, яркое или тусклое освещение).
Рабочие задания различаются в зависимости от требований клиента.
Работа может включать поездки с военными для участия в учениях в суровых условиях
Работа на открытом воздухе может включать различные условия окружающей среды, включая жаркий, пыльный, холодный, ледяной и ветреный климат.
Физические требования
Сидеть за столом. Использование телефона и ПК или ноутбука. Требуется подача. Может потребоваться подъем и перенос коробок с расходными материалами или файлов весом до 25 фунтов.
Продолжительные периоды сидения за компьютером/ноутбуком или телефоном.Может потребоваться лазание, работа на высоте и в небольших замкнутых пространствах, например, под фальшполами, внутри шкафов и серверных стоек. Должен быть в состоянии долго сидеть, наклоняться, стоять на коленях или приседать. Работайте в шумных местах с более высокой и низкой температурой, чем стандартные офисные условия. Подъемно-транспортное оборудование до 50 фунтов.
Оборудование и машины
Общее офисное оборудование, которое включает: телефон, факсимильный аппарат, копировальный аппарат, ПК/ноутбук и другое разное офисное оборудование.
Серверы, коммутаторы, маршрутизаторы и другое компьютерное оборудование, поддерживающее сетевую среду.
Ручные инструменты, электроинструменты, лестницы и испытательное оборудование.
Может потребоваться управление транспортными средствами.
Присутствие
Регулярное посещение в соответствии с установленным графиком работы обязательно.
Важно иметь возможность работать в любую смену/назначенные часы.
Вас могут попросить продолжить работу в поддержку войны, чрезвычайных обстоятельств или учений
Вас могут попросить продолжить работу в ненастную погоду или в других условиях, когда другим не разрешается работать
Должность может требовать работы в ночное время и в выходные дни и может включать поездки с военными для участия в операциях/учениях в районах с полевыми условиями
Поездки
- Могут потребоваться континентальные и зарубежные поездки. Важно сохранить действующий паспорт.
Прочие основные функции
Прием на работу зависит от получения всех необходимых сертификатов в сроки, указанные в отказе от правительства (если применимо), и наличия необходимых сертификатов в течение срока действия контракта.
Неспособность получить/поддержать требуемые сертификаты приведет к дисквалификации на эту должность и может привести к увольнению.Кандидат должен демонстрировать профессиональное поведение, способствующее командной работе, развитию сотрудничества и повышению производительности на рабочем месте. Должен быть хорошо организован с возможностью координировать, расставлять приоритеты и выполнять несколько задач одновременно в условиях высокого давления. Способность общаться в устной и письменной форме для эффективной работы с различными государственными, военными и подрядчиками на всех уровнях.
Кандидат должен уметь эффективно взаимодействовать с людьми на всех уровнях организации.
Уход за собой и одежда обычно деловая, но зависит от стандартов клиента. Не должны представлять угрозу безопасности для сотрудников, работающих в одной и той же зоне.
Должность, на которую вы претендуете, требует допуска правительства США.
Это сделано для того, чтобы сообщить вам, что если вы получите предложение, если у вас есть двойное гражданство (т. Е. Гражданин США и другой страны), для получения разрешения вам потребуется отказаться от своего гражданства в другой стране.
#ANSDefense #MOIP #SITEC2 #li-kp2
Джейкобс является работодателем равных возможностей/положительных действий. Все квалифицированные кандидаты будут рассматриваться при приеме на работу независимо от расы, религии, вероисповедания, цвета кожи, национального происхождения, происхождения, пола (включая беременность, роды, грудное вскармливание или медицинские условия, связанные с беременностью, родами или грудным вскармливанием), возраста, состояния здоровья. , семейный или домашний статус партнера, сексуальная ориентация, пол, гендерная идентичность, гендерное выражение и трансгендерный статус, умственная отсталость или физическая инвалидность, генетическая информация, статус военного или ветерана, гражданство, статус с низким доходом или любой другой статус или характеристика, защищенная применимыми закон.
Узнайте больше о своих правах в соответствии с федеральными законами о EEO (https://www.dol.gov/ofccp/regs/compliance/posters/pdf/eeopost.pdf) и дополнительную информацию. (https://www1.eeoc.gov/employers/upload/eeoc_gina_supplement.pdf)Оператор SQL UNION
❮ Предыдущий Далее ❯
Оператор SQL UNION
Оператор
UNIONиспользуется для объединения набора результатов двух или болееВЫБЕРИТЕзаявления.- Каждая инструкция
SELECTвнутриСОЮЗдолжен иметь тот же номер колонн - Столбцы также должны иметь похожие типы данных
- Столбцы в
каждый оператор
SELECTтакже должен быть в том же порядке
Синтаксис UNION
SELECT имя_столбца(ов) FROM таблица1
UNION
SELECT имя_столбца(ов) FROM таблица2 ;UNION ALL Синтаксис
Оператор
UNIONпо умолчанию выбирает только отдельные значения. Позволять
повторяющиеся значения, используйте UNION ALL:SELECT имя_столбца FROM table1
UNION ALL
SELECT имя_столбца FROM таблица2 ;Примечание: Имена столбцов в результирующем наборе обычно равны имена столбцов в первом операторе
SELECT.Демонстрационная база данных
В этом руководстве мы будем использовать известную учебную базу данных Northwind.
Ниже представлена выборка из таблицы «Клиенты»:
CustomerID ИмяКлиента Контактное имя Адрес Город Почтовый индекс Страна 1 Альфред Футтеркисте Мария Андерс ул. Обере 57 Берлин 12209 Германия 2 Ана Трухильо Emparedados y helados Ана Трухильо Авда. Конститусьон 2222Мексика Д.Ф. 05021 Мексика 3 Антонио Морено Такерия Антонио Морено Матадерос 2312 Мексика Д.Ф. 05023 Мексика И выбор из таблицы «Поставщики»:
SupplierID Название Поставщика Контактное имя Адрес Город Почтовый индекс Страна 1 Экзотическая жидкость Шарлотта Купер ул. Гилберта, 49 Лондон ЭК1 4SD Великобритания 2 Новый Орлеан Cajun Delights Шелли Берк Почтовый индекс Коробка 78934 Новый Орлеан 70117 США 3 Усадьба бабушки Келли Регина Мерфи 707 Оксфорд Роуд. Анн-Арбор 48104 США SQL UNION Пример
Следующая инструкция SQL возвращает города (только разные значения) из таблиц «Клиенты» и «Поставщики»:
Пример
ВЫБРАТЬ Город ИЗ Заказчиков
ОБЪЕДИНЕНИЕ
ВЫБРАТЬ Город ИЗ Поставщиков
ORDER BY City;Попробуйте сами »
Примечание: Если некоторые клиенты или поставщики имеют один и тот же город, каждый город будет указан один раз, потому что
UNIONвыбирает только отдельные значения. ИспользоватьUNION ALLтакже выбрать повторяющиеся значения!SQL UNION ALL Пример
Следующая инструкция SQL возвращает города (также повторяющиеся значения) из таблиц «Клиенты» и «Поставщики»:
Пример
ВЫБЕРИТЕ Город ИЗ Заказчиков
ОБЪЕДИНЕНИЕ ВСЕ
ВЫБЕРИТЕ Город ИЗ Поставщиков
ЗАКАЗАТЬ ПО ГОРОДУ;Попробуйте сами »
SQL UNION With WHERE
Следующая инструкция SQL возвращает города Германии.
(только отдельные значения) из таблиц «Клиенты» и «Поставщики»:Пример
ВЫБЕРИТЕ город, страну ИЗ клиентов
ГДЕ Страна=’Германия’
СОЮЗ
ВЫБЕРИТЕ город, страну ИЗ поставщиков
ГДЕ Страна=’ Германия’
ЗАКАЗАТЬ ПО ГОРОДУ;Попробуйте сами »
SQL UNION ALL With WHERE
Следующая инструкция SQL возвращает города Германии (также повторяющиеся значения) из таблица «Клиенты» и «Поставщики»:
Пример
ВЫБЕРИТЕ Город, Страна ИЗ Заказчиков
ГДЕ Страна=’Германия’
ОБЪЕДИНЕНИЕ ВСЕ
ВЫБЕРИТЕ Город, Страна ИЗ Поставщиков
ГДЕ Страна=’Германия’
ЗАКАЗАТЬ ПО Город;Попробуйте сами »
Другой пример UNION
Следующая инструкция SQL перечисляет всех клиентов и поставщиков:
Пример
ВЫБЕРИТЕ ‘Клиент’ AS Type, ContactName, City, Country
FROM Customers
UNION
SELECT ‘Supplier’, ContactName, City, Country
FROM Поставщики;Попробуйте сами »
Обратите внимание на «Тип AS» выше — это псевдоним.
SQL
Псевдонимы используются для присвоения таблице или столбцу временного имени.
Псевдоним существует только на время выполнения запроса. Итак, вот мы создали
временный столбец с именем «Тип», в котором указано, является ли контактное лицо
«Заказчик» или «Поставщик».❮ Предыдущий Далее ❯
НОВИНКА
Мы только что запустили
Видео W3SchoolsУзнать
ВЫБОР ЦВЕТА
КОД ИГРЫ
Играть в игру
Top Tutorials
Учебное пособие по HTML
Учебное пособие по CSS
Учебное пособие по JavaScript
Учебное пособие
Учебное пособие по SQL
Учебное пособие по Python
Учебное пособие по W3.CSS
Учебное пособие по Bootstrap
Учебное пособие по PHP
Учебное пособие по Java
Учебное пособие по C++
Учебное пособие по jQueryОсновные ссылки
Справочник по HTML
Справочник по CSS
Справочник по JavaScript
Справочник по SQL
Справочник по Python
Справочник по W3.