Отправить асинхронный HTTP-запрос к развернутой модели — документация AI Cloud ML Space. Руководство пользователя
Отправить асинхронный вызов используя ключ
Асинхронные HTTP-запросы позволяют:
С помощью таймаутов можно устанавливать ограничения на время обработки асинхронного запроса.
При отправке асинхронных вызовов возможно задать три вида таймаутов (через заголовок):
X-Health-Timeout— ограничение на проверку работоспособности сервиса с моделью, созданного при асинхронном запросе (значение устанавливается в секундах, по умолчанию — 120).X-Request-Timeout— ограничение на время обработки асинхронного запроса (значение устанавливается в секундах, по умолчанию — 300).X-Full-Live-Timeout— ограничение на общее время жизни сервиса с моделью, созданного при асинхронном запросе (значение устанавливается в секундах, по умолчанию —None).
В случае неуспешного выполнения вызова, он повторяется до превышения пяти попыток, либо до превышения  После превышения одного из этих лимитов вызов помечается завершенным с ошибкой и повторная отправка больше не производится.
После превышения одного из этих лимитов вызов помечается завершенным с ошибкой и повторная отправка больше не производится.
Общее время жизни равно сумме времени на проверку работоспособности и времени на обработку асинхронного запроса.
Асинхронному вызову присваивается уникальный идентификатор Request ID —
c05541b6-882a-4c25-8bba-865907e60c69. Request ID нужно использовать для получения статуса асинхронного вызова.Для получения списка асинхронных вызовов используйте метод Get Async Inferences.
Для проверки статуса асинхронного вызова используйте метод Get Async Inference Status.
Для отправки асинхронного вызова не нужна авторизация. Не требуется получать Long API Keys.
Возможно отправлять вызовы с использованием ключа из вкладки Управление ключами.
Для асинхронных запросов создаются отдельные асинхронные экземпляры деплоя.
Отсутствуют ограничения на количество асинхронных экземпляров деплоя, обрабатывающих асинхронные вызовы.

Временно недоступен просмотр логов для асинхронных запросов и их мониторинг.

Получите ключ во вкладке Управление ключами.
Добавьте к запросу заголовок вида —
X-Async-Request: truecurl --location --request POST 'https://api.aicloud.sbercloud.ru/public/v2/async_inferences/v1/{cluster}/{inference_name}/{predict}' \ --header 'x-workspace-id: {workspace_id}' \ --header 'x-api-key: {ключ, полученный из вкладки "Управление ключами"}' \ --header 'X-Async-Request: true' \ --header 'Content-Type: application/json' \ --data-raw '{"key": "value"}'Отправьте запрос.
Проверьте результаты выполнения запроса одним из двух способов.
Была ли эта статья полезной?
Как я писал асинхронные веб-запросы на Python, или почему провайдер считает, что я бандит / Хабр
На днях по работе потребовалось сделать утилиту, которая прямо вот из консоли ходит в апи нашего клауд сервиса и берет оттуда кое-какую информацию. Подробности что и зачем — вне этого рассказа. Принципиальный вопрос здесь другой — скорость. Скорость реально важна (порядок количества запросов — десятки и сотни). Потому что ждать — не кайф.
Подробности что и зачем — вне этого рассказа. Принципиальный вопрос здесь другой — скорость. Скорость реально важна (порядок количества запросов — десятки и сотни). Потому что ждать — не кайф.
Здесь я хочу поделиться своим ресёрчем на тему запросов, как делать круто, а как нет. С примерами кода конечно. А так же рассказать, как я тупил.
Начнем, пожалуй, с классики
Последовательные синхронные запросы. Будем использовать всем известную либу https://catfact.ninja/. Метрикой качества будет RPS (Request per second). Чем выше — тем соотвественно лучше.
import time
import requests
from tqdm import tqdm
URL = 'https://catfact.ninja/'
class Api:
def __init__(self, url: str):
self.url = url
def http_get(self, path: str, times: int):
content = []
for _ in tqdm(range(times), desc='Fetching data. ..', colour='GREEN'):
response = requests.get(self.url + path)
content.append(response.json())
return content
if __name__ == '__main__':
N = 10
api = Api(URL)
start_timestamp = time.time()
print(api.http_get(path='fact/', times=N))
task_time = round(time.time() - start_timestamp, 2)
rps = round(N / task_time, 1)
print(
f"| Requests: {N}; Total time: {task_time} s; RPS: {rps}. |\n"
) ..', colour='GREEN'):
response = requests.get(self.url + path)
content.append(response.json())
return content
if __name__ == '__main__':
N = 10
api = Api(URL)
start_timestamp = time.time()
print(api.http_get(path='fact/', times=N))
task_time = round(time.time() - start_timestamp, 2)
rps = round(N / task_time, 1)
print(
f"| Requests: {N}; Total time: {task_time} s; RPS: {rps}. |\n"
)
..', colour='GREEN'):
response = requests.get(self.url + path)
content.append(response.json())
return content
if __name__ == '__main__':
N = 10
api = Api(URL)
start_timestamp = time.time()
print(api.http_get(path='fact/', times=N))
task_time = round(time.time() - start_timestamp, 2)
rps = round(N / task_time, 1)
print(
f"| Requests: {N}; Total time: {task_time} s; RPS: {rps}. |\n"
)Получаем следующий вывод в терминале:
Fetching data...: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:06<00:00, 1.52it/s]
[{'fact': 'Despite imagery of cats happily drinking milk from saucers, studies indicate that cats are actually lactose intolerant and should avoid it entirely.', 'length': 148}, {'fact': 'The smallest pedigreed cat is a Singapura, which can weigh just 4 lbs (1.8 kg), or about five large cans of cat food. The largest pedigreed cats are Maine Coon cats, which can weigh 25 lbs (11.3 kg), or nearly twice as much as an average cat weighs.', 'length': 249}, {'fact': 'A cat has 230 bones in its body. A human has 206. A cat has no collarbone, so it can fit through any opening the size of its head.', 'length': 130}, {'fact': "Cats' hearing is much more sensitive than humans and dogs.", 'length': 58}, {'fact': 'The first formal cat show was held in England in 1871; in America, in 1895.', 'length': 75}, {'fact': 'In contrast to dogs, cats have not undergone major changes during their domestication process.', 'length': 94}, {'fact': 'Ginger tabby cats can have freckles around their mouths and on their eyelids!', 'length': 77}, {'fact': 'Cats bury their feces to cover their trails from predators.', 'length': 59}, {'fact': 'While it is commonly thought that the ancient Egyptians were the first to domesticate cats, the oldest known pet cat was recently found in a 9,500-year-old grave on the Mediterranean island of Cyprus. This grave predates early Egyptian art depicting cats by 4,000 years or more.', 'length': 278}, {'fact': 'Relative to its body size, the clouded leopard has the biggest canines of all animals’ canines. Its dagger-like teeth can be as long as 1.8 inches (4.5 cm).', 'length': 156}]
| Requests: 10; Total time: 6.61 s; RPS: 1.5. |
RPS — 1.5. Очень грустно. У меня еще и интернет не самый быстрый сейчас дома. Ну тут добавить нечего.
Что можно оптимизировать уже сейчас? Ответ: использовать requests.Session
Eсли делать несколько запросов к одному и тому же хосту, базовое TCP-соединение будет использоваться повторно, что приводит к значительному увеличению производительности. (цитата из документации
Используем сессию
def http_get_with_session(self, path: str, times: int):
content = []
with requests.session() as session:
for _ in tqdm(range(times), desc='Fetching data...', colour='GREEN'):
response = session. get(self.url + path)
content.append(response.json())
return content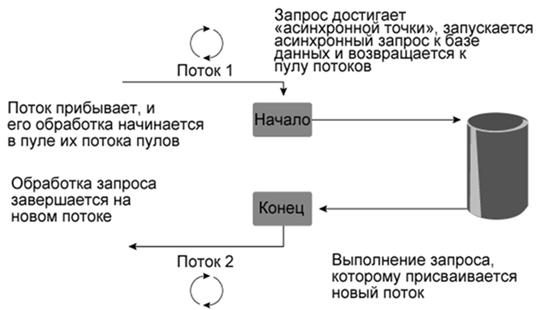 get(self.url + path)
content.append(response.json())
return content
get(self.url + path)
content.append(response.json())
return contentНемного изменив метод, и вызвав его, видим следующее:
Fetching data...: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 10/10 [00:02<00:00, 3.88it/s]
[{'fact': 'Cats purr at the same frequency as an idling diesel engine, about 26 cycles per second.', 'length': 87}, {'fact': 'Cats eat grass to aid their digestion and to help them get rid of any fur in their stomachs.', 'length': 92}, {'fact': 'A cat’s heart beats nearly twice as fast as a human heart, at 110 to 140 beats a minute.', 'length': 88}, {'fact': 'The world’s rarest coffee, Kopi Luwak, comes from Indonesia where a wildcat known as the luwak lives. The cat eats coffee berries and the coffee beans inside pass through the stomach. The beans are harvested from the cat’s dung heaps and then cleaned and roasted. Kopi Luwak sells for about $500 for a 450 g (1 lb) bag. 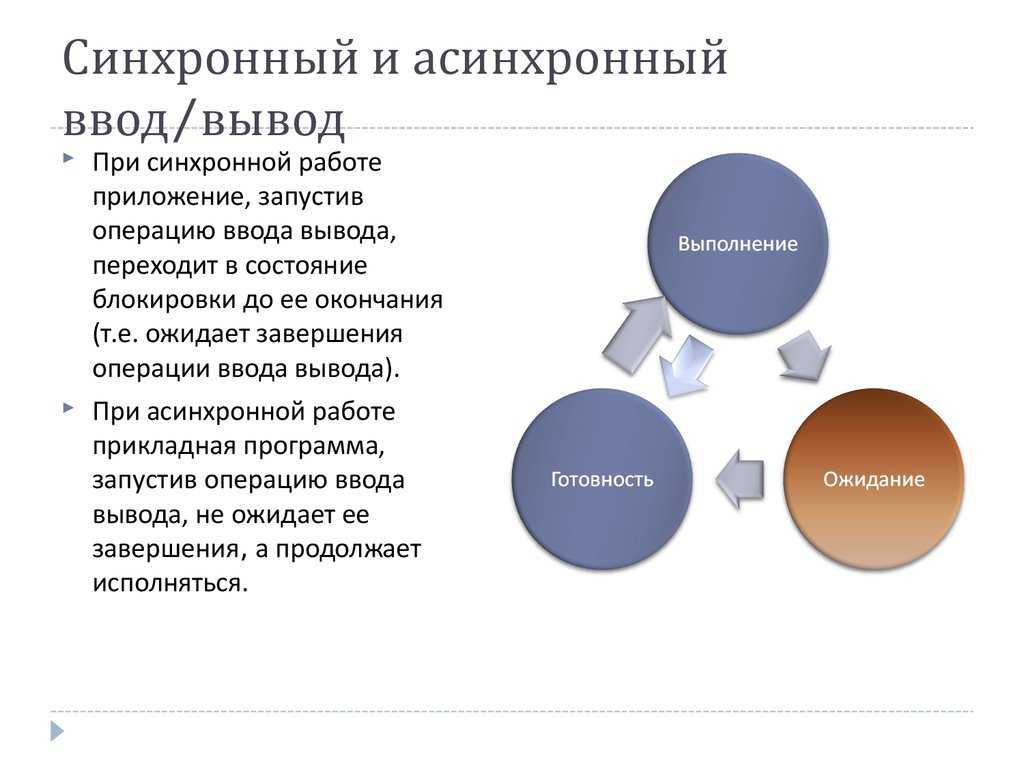
Почти 4 RPS, в сравнении с 1.5 уже прорыв.
Но не секрет, что для сокращения i/o time есть практика использования асихнронных/многопоточных программ. Это как раз такой случай, потому что во время ожидания ответа от сервера наша программа ничего не делает, хотя могла бы отправлять уже другой запрос, а потом другой и т.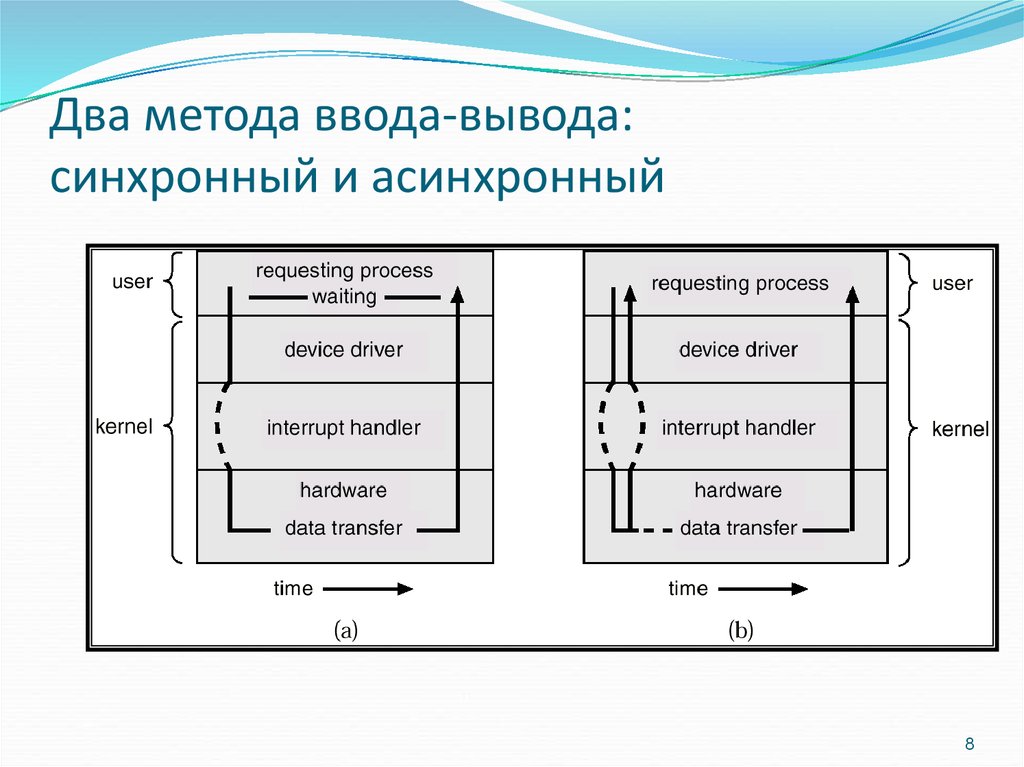 д. Попробуем реализовать асинхронный подход к решению кейса.
д. Попробуем реализовать асинхронный подход к решению кейса.
async / await
Для удобства вызовов сделаем функцию-оболочку:
def run_case(func, path, times):
start_timestamp = time.time()
asyncio.run(func(path, times))
task_time = round(time.time() - start_timestamp, 2)
rps = round(times / task_time, 1)
print(
f"| Requests: {times}; Total time: {task_time} s; RPS: {rps}. |\n"
)И собственно сама реализация метода (не забудьте поставить aiohttp, обычные реквесты не работают в асинхронной парадигме):
async def async_http_get(self, path: str, times: int):
async with aiohttp.ClientSession() as session:
content = []
for _ in tqdm(range(times), desc='Async fetching data...', colour='GREEN'):
response = await session.get(url=self.url + path)
content.append(await response.text(encoding='UTF-8'))
return contentif __name__ == '__main__':
N = 50
api = Api(URL)
run_case(api. async_http_get, path='fact/', times=N) async_http_get, path='fact/', times=N)
async_http_get, path='fact/', times=N)Видим:
Async fetching data...: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:12<00:00, 3.99it/s] | Requests: 50; Total time: 12.55 s; RPS: 4.0. |
Удивительно, но разницы с предыдущим случаем особо нет. Я думаю выигрыш в i/o тайме компенсируется издержками на передачу управления потоком функциями друг другу (слышал что очень ругают эти моменты в python). Как на самом деле не знаю.
На словах такой подход можно объяснить так.
— В цикле создается корутина, которая отправляет запрос.
— Не дожидаясь ответа, управление потоком отдается снова event loop’у, который создает следующую по «for циклу» корутину, которая тоже отправляет запрос.
— Но теперь прежде чем отдать управление эвент лупу проверяется статус ответа первой корутины. Если она может быть продолжена (получила ответ на запрос), то управление потоком возвращается ей, если нет, то см. пункт 2.
пункт 2.
— И так далее
В итоге код-то впринципе асихнронный, но запросы не отправляются «разом». Принципиально иначе подойти к этой ситуации поможет asyncio.gather.
Используем asyncio.gather
Gather — как ни банально с английского собирать. Метод gather собирает коллекцию корутин и запускает их разом (тоже условно конечно). То есть, в отличии от предыдущего случая, мы в цикле создаем корутины, а потом их запускаем.
Было:
[cоздали корутину] -> [запустили корутину] -> [cоздали корутину] -> [запустили корутину] ->
[cоздали корутину] -> [запустили корутину] ->[cоздали корутину] -> [запустили корутину]
А стало:
[cоздали корутину] -> [создали корутину] ->[cоздали корутину] -> [создали корутину] ->
[запустили корутину] -> [запустили корутину] -> [запустили корутину] -> [запустили корутину]
async def async_gather_http_get(self, path: str, times: int):
async with aiohttp. ClientSession() as session:
tasks = []
for _ in tqdm(range(times), desc='Async gather fetching data...', colour='GREEN'):
tasks.append(asyncio.create_task(session.get(self.url + path)))
responses = await asyncio.gather(*tasks)
return [await r.json() for r in responses] ClientSession() as session:
tasks = []
for _ in tqdm(range(times), desc='Async gather fetching data...', colour='GREEN'):
tasks.append(asyncio.create_task(session.get(self.url + path)))
responses = await asyncio.gather(*tasks)
return [await r.json() for r in responses]
ClientSession() as session:
tasks = []
for _ in tqdm(range(times), desc='Async gather fetching data...', colour='GREEN'):
tasks.append(asyncio.create_task(session.get(self.url + path)))
responses = await asyncio.gather(*tasks)
return [await r.json() for r in responses]if __name__ == '__main__':
N = 50
api = Api(URL)
run_case(api.async_gather_http_get, path='fact/', times=N)И получаем… получаем… ничего не получаем. Курсор продолжает многозначительно мигать в окне терминала. Не работает — подумал Штирлиц.
Путем мучительного дебага и попыток понять, почему мой код не работает, я понял — причина в моем VPN. Его узлы находятся где-то в юрисдикции Cloudflare. А они такое поведение не поощряют, считая, что я бот. Нормальный человек столько запросов в секунду делать не будет, поэтому мои запросы…теряются где-то в пучинах интернета. Ответа на них не будет. Никогда. Корутины просто не заканчиваются.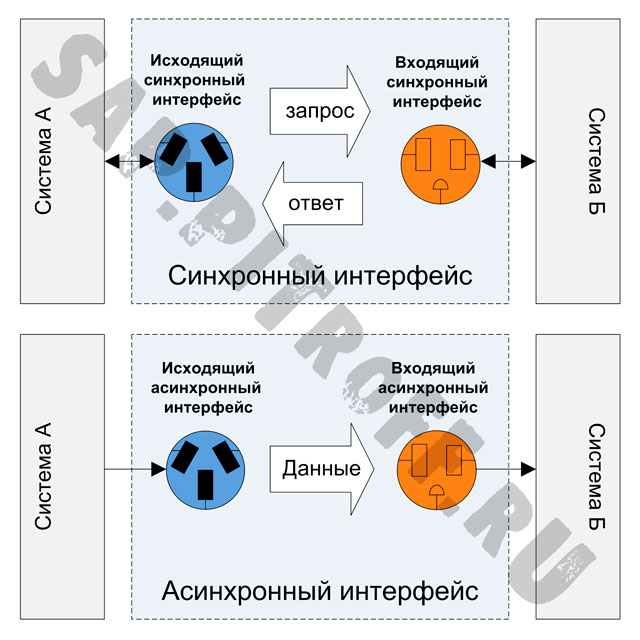
Окей, поняв откуда ноги растут, запускаем код:
Async gather fetching data...: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:00<00:00, 106834.03it/s] | Requests: 50; Total time: 2.38 s; RPS: 21.0. |
Цифры выросли, круто, 21 не 1.5 — это уж точно.
Однако же есть какой-то предел, увеличим N (число запросов) до 200.
| Requests: 200; Total time: 2.97 s; RPS: 67.3. |
Это что же получается, можно и так? На самом деле нет. Если внимательно рассмотреть, что же все-таки нам отвечает сервер, то заметим, что большая часть ответов это {'message': 'Rate Limit Exceeded', 'code': 429}
Конкретный лимит запросв, который я установил в ходе эксперимента с этим сервисом — это около 60 ответов за раз, остальное он не переваривает. Так что если будете так ходить в сервисы, которые не хотите перегрузить или вообще положить, то подходите к этом вопросу обдуманно, не превышайте определенных рамок.
Что там с threading?
Тут особо смысла нет — практический эксперимент показал, что threading показывает такие же результаты (плюс — минус), как асихнронный код из пункта 3.
multiprocessing
Не буду врать, просто посмотрел как нечто похожее делал какой-то индус с Ютуба. Результаты сильно хуже, чем у предыдущих способов. Да и писать такой код — это насилие над своей психикой. А я свою психику берегу.
Подведу итоги:
На днях упал Cloudlfare — извините, это из-за меня, больше не буду.
Хотите быть чемпионом по запросам — используйте asyncio.gather, но с тщательно подобранными лимитами. Если вы ходите не на один хост, а в разные источники, то вообще не стестяйтесь.
. В чем разница между асинхронным и синхронным HTTP-запросом?
спросил
Изменено 6 месяцев назад
Просмотрено 98 тысяч раз
В чем разница между асинхронным и синхронным HTTP-запросом?
- веб-сервер
3
Синхронный :
Синхронный запрос блокирует клиент до завершения операции. В таком случае движок javascript браузера блокируется.
В таком случае движок javascript браузера блокируется.
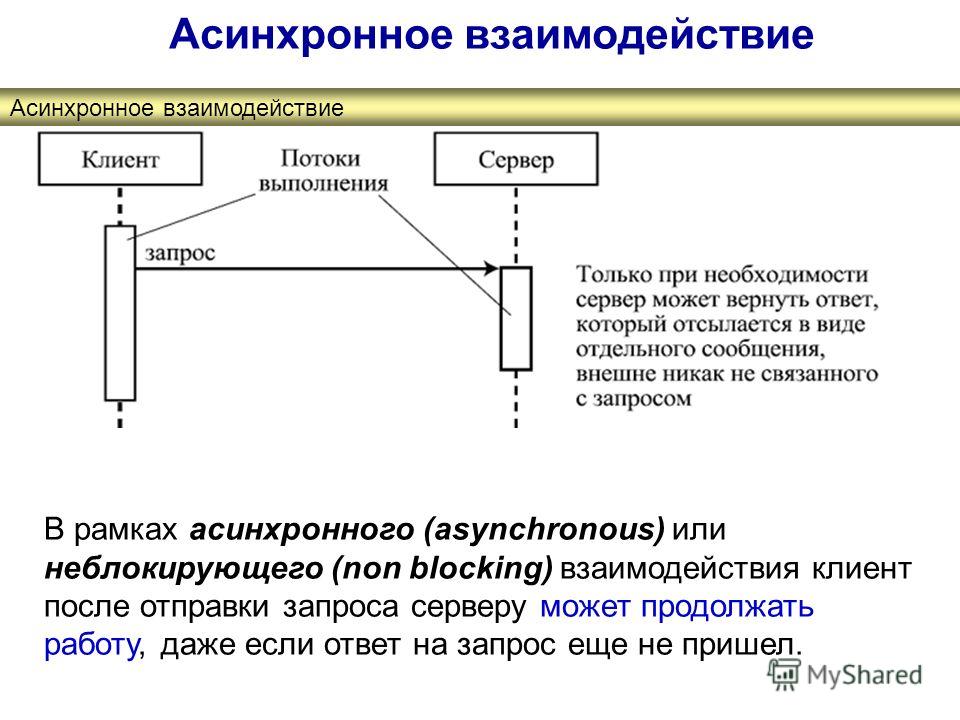
Асинхронный Асинхронный запрос не блокирует клиента, т. е. браузер отвечает. В это время пользователь также может выполнять другие операции. В этом случае движок javascript браузера не блокируется.
3
Ознакомьтесь с разделом Определение синхронности и асинхронности в веб-приложениях для предыдущего обсуждения. Короче:
Асинхронные API не блокируются. Каждый синхронный вызов ожидает и блокирует ваши результаты > для возврата. Это просто спящий поток и потраченные впустую вычисления.
0
Асинхронные API не блокируются. Каждый синхронный вызов ожидает и блокирует ваши результаты. Это просто спящий поток и потраченные впустую вычисления.
Если вам нужно, чтобы что-то произошло, отправьте асинхронный запрос и выполните дальнейшие вычисления, когда запрос вернется. Это означает, что ваш поток простаивает и может взять на себя другую работу.
Это означает, что ваш поток простаивает и может взять на себя другую работу.
Асинхронные запросы — это способ масштабирования до тысяч одновременных пользователей.
Ответ Сачина Гандвани очень хорошо объяснен простыми словами. Если вы все еще не уверены в разнице между асинхронным HTTP-запросом и синхронным HTTP-запросом, вы можете прочитать это — https://developer.mozilla.org/en-US/docs/Web/API/XMLHttpRequest/Synchronous_and_Asynchronous_Requests
1
Синхронный клиент создает структуру HTTP, отправляет запрос и ожидает ответа. Асинхронный клиент создает структуру HTTP, отправляет запрос и движется дальше. В этом случае клиент уведомляется, когда приходит ответ. Исходный поток или другой поток может затем обработать ответ. Хотя асинхронное поведение может привести к более быстрому общему выполнению, синхронное поведение может быть предпочтительным в некоторых случаях, когда необходим более упрощенный код.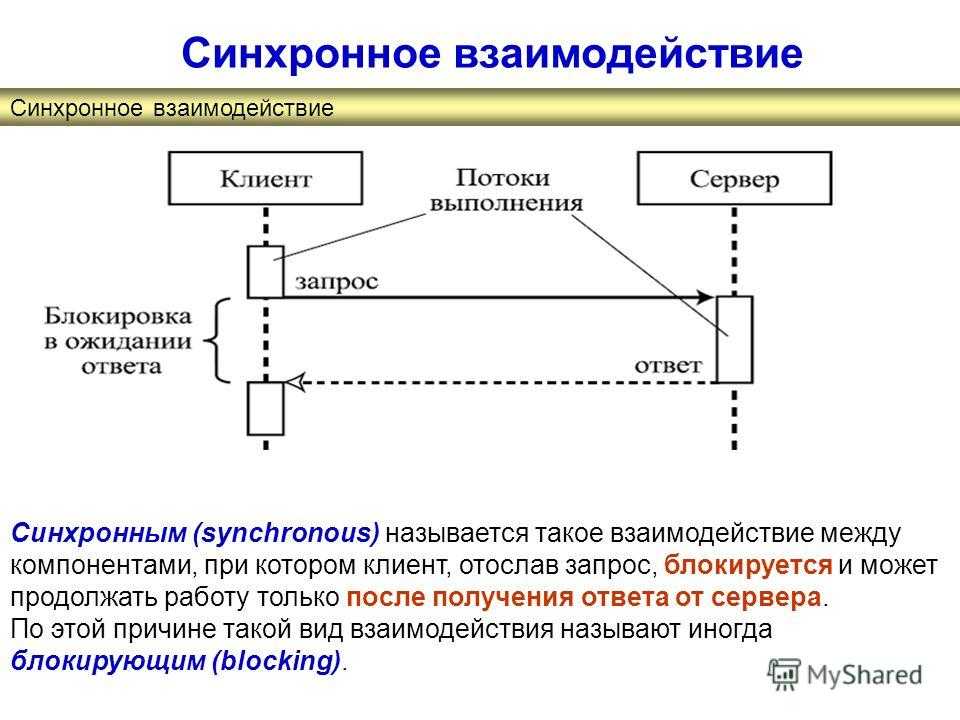
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
асинхронных запросов Python Ru Python спросил
Изменено 1 месяц назад
Просмотрено 6к раз
Итак, у меня есть список URL-адресов изображений, которые я хочу перебрать с помощью библиотеки запросов и загрузить все изображения в каталог.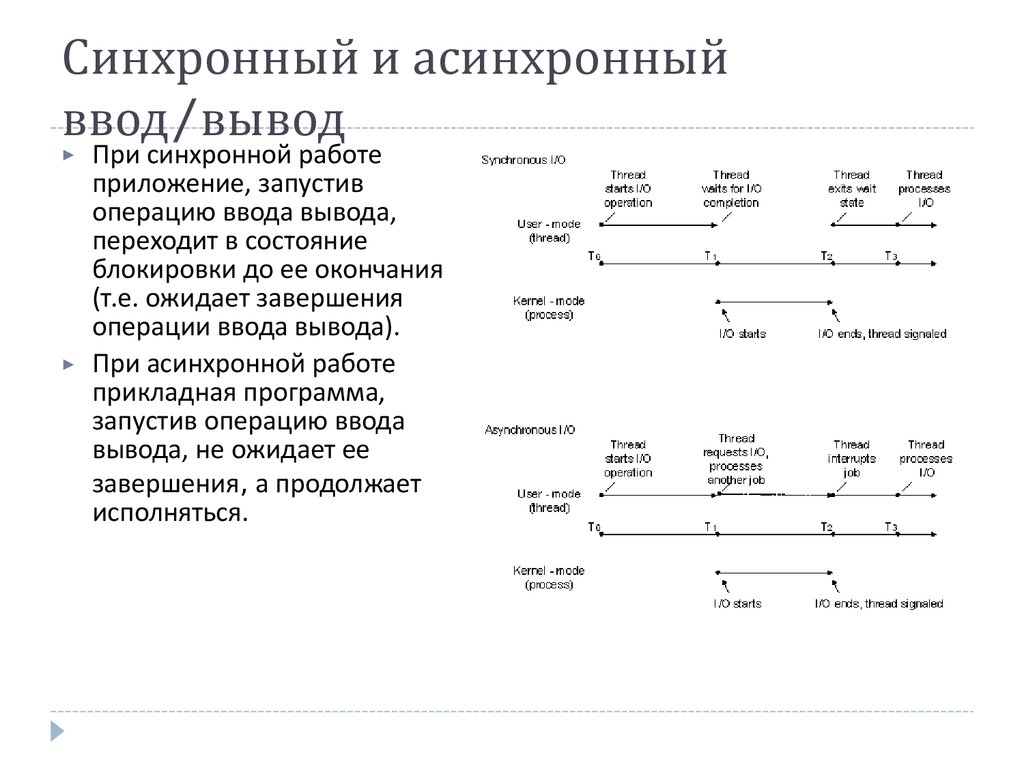
определение get_image (url, image_name):
path = pathlib.Path('/path/to/some/directory')
ответ = запросы.получить (url, поток = Истина)
с open('{}/{}.png'.format(path, image_name), 'wb') в качестве файла:
для блока в response.iter_content(1024):
файл.запись(блок)
для URL в URL:
get_image(url,имя_изображения)
Теперь, нельзя ли создать декоратор, чтобы сделать функцию обратным вызовом, которая будет запускаться после получения ответа на конкретный асинхронный запрос?
- python
- python-запросы
- python-asyncio
1
Если вам нужно несколько одновременных запросов + обратные вызовы, вы можете использовать такой модуль, как grequests. Это не имеет ничего общего с asyncio .
asyncio — это все, чтобы избежать использования обратных вызовов (чтобы избежать ада обратных вызовов) и сделать написание асинхронного кода таким же простым, как и синхронный.
Если вы решите попробовать asyncio , вам следует либо использовать клиент aiohttp вместо запросов (это предпочтительнее), либо запустить запросы в пуле потоков, управляемом asyncio. Пример обоих способов можно найти здесь.
Рекомендуемые grequests теперь рекомендуют:
Примечание. Возможно, вместо этого вам следует использовать запросы-потоки или запросы-фьючерсы.
Пример использования запросов-фьючерсов:
из request_futures.sessions импортирует FuturesSession
сеанс = фьючерссессион()
# первый запрос запускается в фоновом режиме
future_one = session.get('http://httpbin.org/get')
# второй запрос запускается сразу
future_two = session.get('http://httpbin.org/get?foo=bar')
# ждем завершения первого запроса, если он еще не завершен
response_one = future_one.result()
print('Статус ответа один: {0}'.format(response_one.status_code))
печать (response_one.