Какие бывают базы данных
Базы данных — это способ упорядочить информацию так, чтобы компьютер мог с ней легко работать, а человек мог пользоваться этими данными как ему удобно. Мы уже писали о базах данных в общем, теперь углубимся.
👉 Это знания скорее из области информатики, чем прикладного программирования. Если вы просто делаете сайты или обслуживаете интернет-магазин, вероятнее всего, вам из этого понадобятся только реляционные базы данных. Но когда вы захотите сделать более сложные приложения — например рекомендации товаров, — вам потребуются знания о других типах баз.
Считайте, что эта статья для расширения кругозора.
Три основных типа
В зависимости от того, какие данные нужно в ней хранить и как с ними работать, базы делятся на реляционные и нереляционные:
Реляционные
Реляционные базы данных ещё называют табличными, потому что все данные в них можно представить в виде разных таблиц. Одни таблицы связаны с другими, а другие — с третьими. Например, база данных покупок в магазине может выглядеть так:
Одни таблицы связаны с другими, а другие — с третьими. Например, база данных покупок в магазине может выглядеть так:
Смотрите, у магазина есть две таблицы — с товарами и покупателями. Но когда один из них что-то покупает, то данные попадают в третью таблицу. В ней есть своя информация (количество купленных товаров) и ссылки на покупателя и сам товар. Если нужно, можно по этим связям попасть в нужную таблицу и узнать подробности о той или другой записи.
Если у покупателя поменяется номер телефона, то нам достаточно будет поменять это в одной таблице «Клиенты». Благодаря тому, что в «Покупки» записывается только код покупателя, нам не нужно менять имя больше нигде — данные сами обновятся автоматически, когда мы захотим посмотреть, кто именно купил табурет.
Сетевые
В отличие от реляционных баз, в сетевых между таблицами и записями может быть несколько разных связей, каждая из который отвечает за что-то своё.
Если мы возьмём базу данных с сайта Кинопоиска, то она может выглядеть так:
Особенность сетевой базы данных в том, что в ней запоминаются все связи и всё содержимое для каждой связи. Базе не нужно тратить время на поиск нужных данных, потому что вся информация об этом уже есть в специальных индексных файлах. Они показывают, какая запись с какой связана, и быстро выдают результат.
Например, вы посмотрели «Начало» Кристофера Нолана и вам понравился этот фильм. Когда вы перейдёте к списку фильмов, которые он ещё снял, база на сайте сделает так:
- возьмёт имя режиссёра;
- посмотрит, какие связи и с чем у него есть;
- выдаст список фильмов;
- к этим фильмам может сразу подгрузить список актёров, которые там играют;
- и сразу же показать постеры к каждому фильму.
А главное — база сделает это очень быстро, потому что ей не нужно просматривать всю базу в поисках нужных фильмов. Она сразу видит, какие фильмы с чем связаны, и выдаёт ответ.
Она сразу видит, какие фильмы с чем связаны, и выдаёт ответ.
Иерархические
Иерархия — это когда есть вышестоящий, а есть его подчинённые, кто ниже. У них могут быть свои подчинённые и так далее. Мы уже касались такой модели, когда говорили про деревья и бустинг.
В такой базе данных сразу видно, к чему относятся записи, где они лежат и как до них добраться. Самый простой пример такой базы данных — хранение файлов и папок на компьютере:
Видно, что на диске C: есть много папок: Dropbox, eSupport, GDrive и все те, которые не поместились на экране.
Внутри папки GDrive есть ###_Inbox и #_Альбатрос, а внутри #_Альбатроса — десятки других папок. Если мы посмотрим на скриншот, то увидим, то должностная инструкция бухгалтера лежит с остальными файлами внутри папки Должностные и охрана труда, которая лежит внутри папки Инструкции.
Иерархическая база данных знает, кто кому подчиняется, и поэтому может быстро находить нужную информацию. Но такие базы можно организовать только в том случае, когда у вас есть чёткое разделение в данных, что главнее, а что ему подчиняется.
Но такие базы можно организовать только в том случае, когда у вас есть чёткое разделение в данных, что главнее, а что ему подчиняется.
Главное о базах данных
- Чаще всего базы данных напоминают таблицы: в них одному параметру соответствует один набор данных. Например, один клиент — одно имя, один телефон, один адрес.
- Такие «табличные» базы данных называются реляционными.
- Чтобы строить сложные связи, разные таблицы в реляционных базах можно связывать между собой: ставить ссылки.
- Реляционная база — не единственный способ хранения данных. Есть ситуации, когда нам нужна большая гибкость в хранении.
- Бывают сетевые базы данных: когда нужно хранить много связей между множеством объектов. Например, каталог фильмов: в одном фильме может участвовать много человек, а каждый из них может участвовать во множестве фильмов.
- Бывают иерархические базы, или «деревья».
 Пример — наша файловая система.
Пример — наша файловая система. - Какую выбрать базу — зависит от задачи. Одна база не лучше другой, но они могут быть более или менее подходящими для определённых задач.
 Пример — наша файловая система.
Пример — наша файловая система.Текст и иллюстрации:
Миша Полянин
Редактор:
Максим Ильяхов
Корректор:
Ира Михеева
Иллюстратор:
Даня Берковский
Вёрстка:
Маша Дронова
Доставка:
Олег Вешкурцев
Что-то делает руками:
Паша Федоров
Во славу:
Практикума
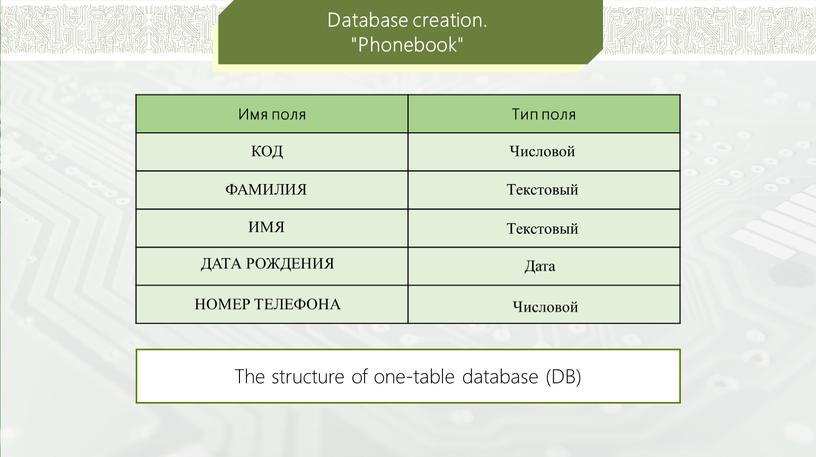
12.2. Типы баз данных. Основы информатики: Учебник для вузов
Читайте также
Типы данных
Типы данных
Приведенные в этой главе таблицы взяты непосредственно из оперативной справочной системы и представляют единую модель данных Windows (Windows Uniform Data Model). Определения типов можно найти в заголовочном файле BASETSD.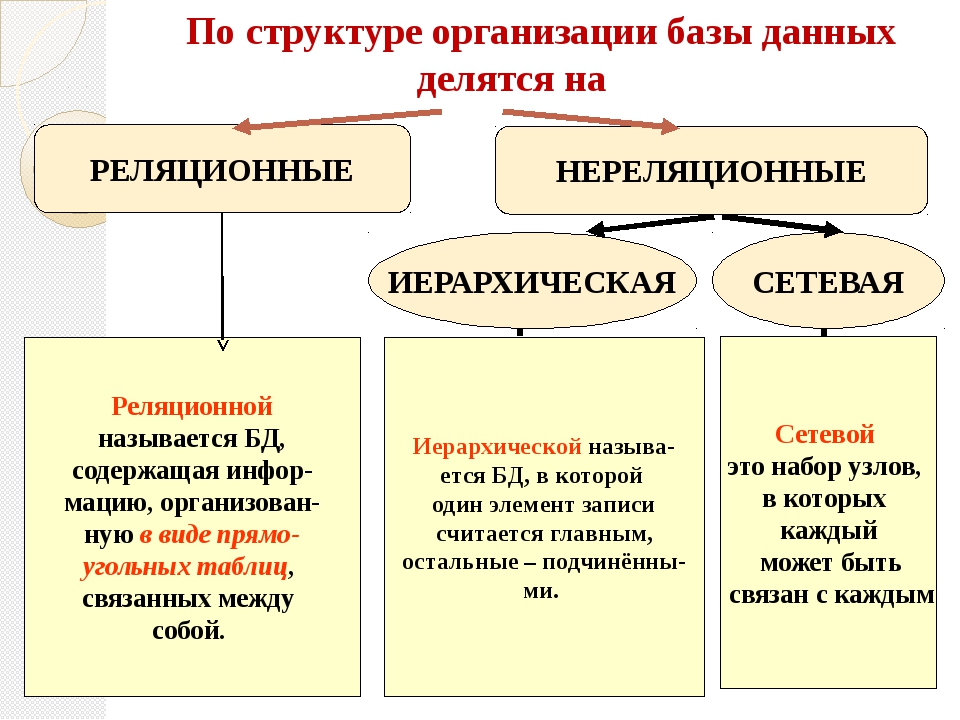 H, входящем в состав интегрированной среды разработки
H, входящем в состав интегрированной среды разработки
Типы данных
Типы данных В JScript поддерживаются шесть типов данных, главными из которых являются числа, строки, объекты и логические данные. Оставшиеся два типа — это null (пустой тип) и undefined (неопределенный
14.5.1 Типы данных
20.10.3 Типы данных MIB
20. 10.3 Типы данных MIB
Причиной широкого распространения SNMP стало то, что проектировщики придерживались правила «Будь проще!»? Все данные MIB состоят из простых скалярных переменных, хотя отдельные части MIB могут быть логически организованы в таблицы.? Только небольшое число
10.3 Типы данных MIB
Причиной широкого распространения SNMP стало то, что проектировщики придерживались правила «Будь проще!»? Все данные MIB состоят из простых скалярных переменных, хотя отдельные части MIB могут быть логически организованы в таблицы.? Только небольшое число
Типы данных
Типы данных Несмотря на то, что типы данных подробно описаны в документации (см. [1, гл. 4]), необходимо рассмотреть ряд понятий, которые будут часто использоваться в последующих главах книги. Помимо изложения сведений общего характера будут рассмотрены также примеры
Типы данных
Типы данных
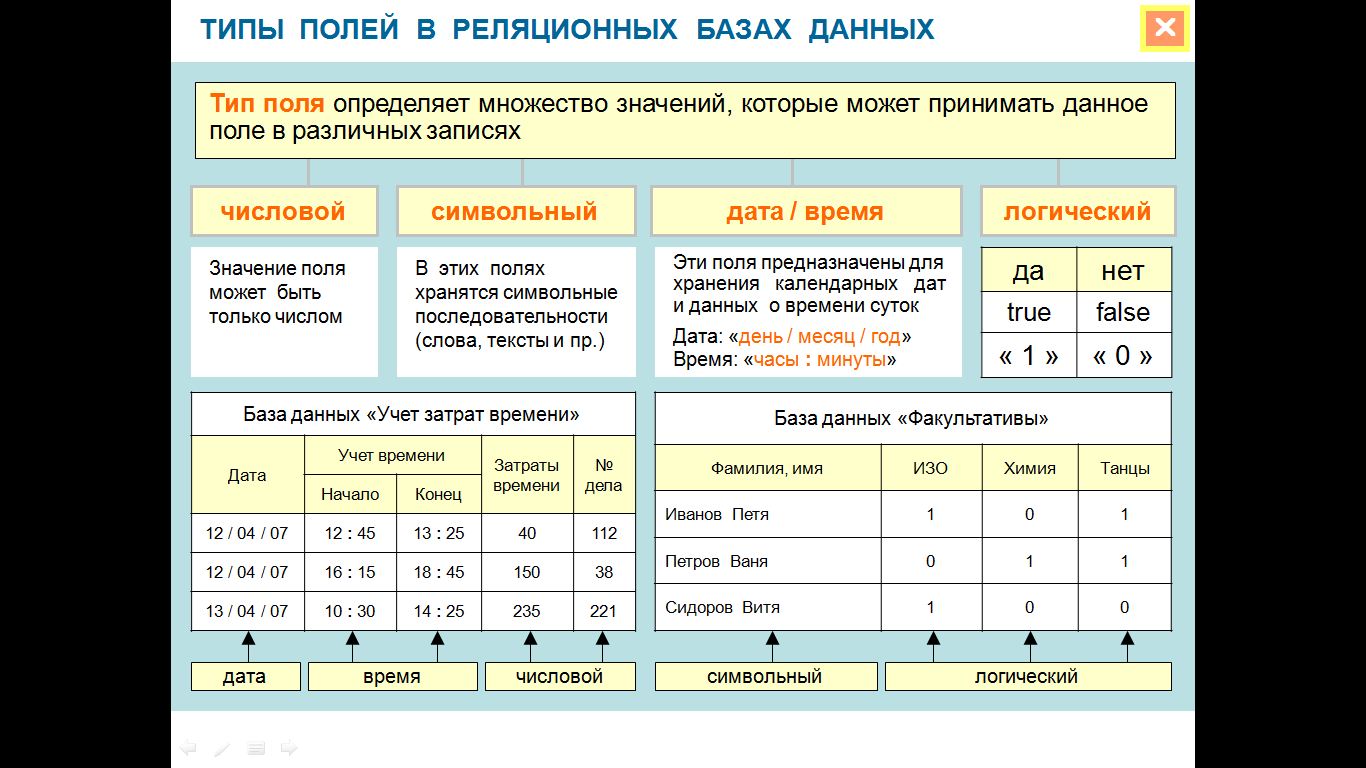
Один из этапов проектирования базы данных заключается в объявлении типа каждого поля, что позволяет процессору базы данных эффективно сохранять и извлекать данные.
Пользовательские типы данных
Пользовательские типы данных Для объявления пользовательских типов, используют конструкцию вида:type имя_типа = описание_типа;К примеру, таким образом можно объявлять типы множеств, перечислимые типы и
Основные типы данных
Основные типы данных Ключевые слова: Основные типы данных определяются с помощью следующих семи ключевых слов: int, long, short, unsigned, char, float, double Целые со знаком: Могут иметь положительные и отрицательные значения.int: основной тип целых чисел для конкретной системы.long или long int:
1.
 Базовые типы данных
Базовые типы данных
1. Базовые типы данных Типы данных, как и отношения, делятся на базовые и виртуальные.(О виртуальных типах данных мы поговорим чуть позже, посвятим этой теме отдельную главу.)Базовые типы данных – это любые типы данных, заданные в системах управления базами данных
Базовые типы данных
Базовые типы данных В языке Си реализован набор типов данных, называемых «базовыми» типами. Спецификации этих типов перечислены в таблице 3.1.Таблица 3.1. Базовые типы Спецификация типов Целые signed char знаковый символьный signed int знаковый целый signed short int знаковый
Типы данных
 Например, в языке Java кодint i = 15;объявит переменную целого типа int с именем i и присвоит ей значение 15. В этом случае тип данных ставится в
Например, в языке Java кодint i = 15;объявит переменную целого типа int с именем i и присвоит ей значение 15. В этом случае тип данных ставится в
Типы данных
Типы данных Обзор типов Типы в PascalABC.NET подразделяются на простые, строковые, структурированные, типы указателей, процедурные типы и классы.К простым относятся целые и вещественные типы, логический, символьный, перечислимый и диапазонный тип.К структурированным типам
12.2. Типы баз данных
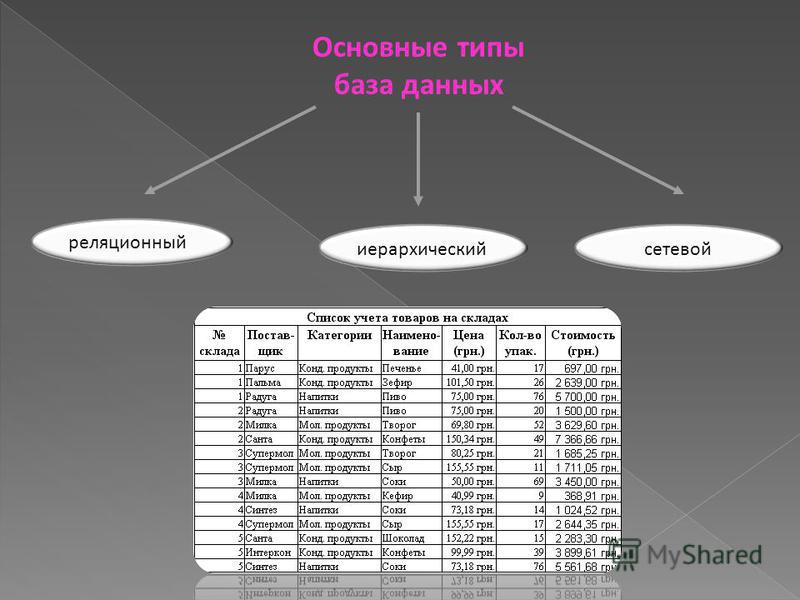
12.2. Типы баз данных Группу связанных между собой элементов данных называют обычно записью. Известны три основных типа организации данных и связей между ними: иерархический (в виде дерева), сетевой и реляционный.Иерархическая БДВ иерархической БД существует
5.
 2.4. Типы данных
2.4. Типы данных
5.2.4. Типы данных Мы можем вводить в ячейки следующие данные: текст, числа, даты, также приложение Numbers предоставляет возможность добавлять флажки, ползунки и другие элементы управления. Аналогично MS Excel для выравнивания чисел, дат и текстовых данных в Numbers существуют
большой обзор типов и подходов. Доклад Яндекса / Блог компании Яндекс / Хабр
Это конспект лекции Татьяны Денисовой tdenisova — бэкенд-разработчика в Яндекс.Учебнике. Вы узнаете, какие бывают базы данных, какие их особенности важно помнить, как в работе с данными учитывать характеристики системы и планы масштабирования, в какую из тем нужно углубиться для решения конкретной задачи. А также как при возникновении багов определить, является ли работа с БД источником проблемы (и если да, то в какую сторону копать).
— О чем именно мы будем говорить? Не о примитивных селектах и джойнах — о них, я думаю, большинство из вас уже знает.
Мы будем говорить о реальном применении баз, о том, с какими сложностями вы можете столкнуться и что вам как бэкенд-разработчику нужно знать. Информации будет много, вот содержание. Не нужно прямо досконально знать детали каждого из этих пунктов, но нужно знать, что этот пункт существует.
И нужно знать, как какие проблемы решаются, чтобы, когда у вас будет задача построить структуру, сохранить данные, вы знали, какую модель данных выбрать и как их сохранить. Или предположим, у вас проблема, вы видите, что база данных не работает, работает медленно, или возникли проблемы с данными, несогласованность. Тогда вы должны понимать, куда копать.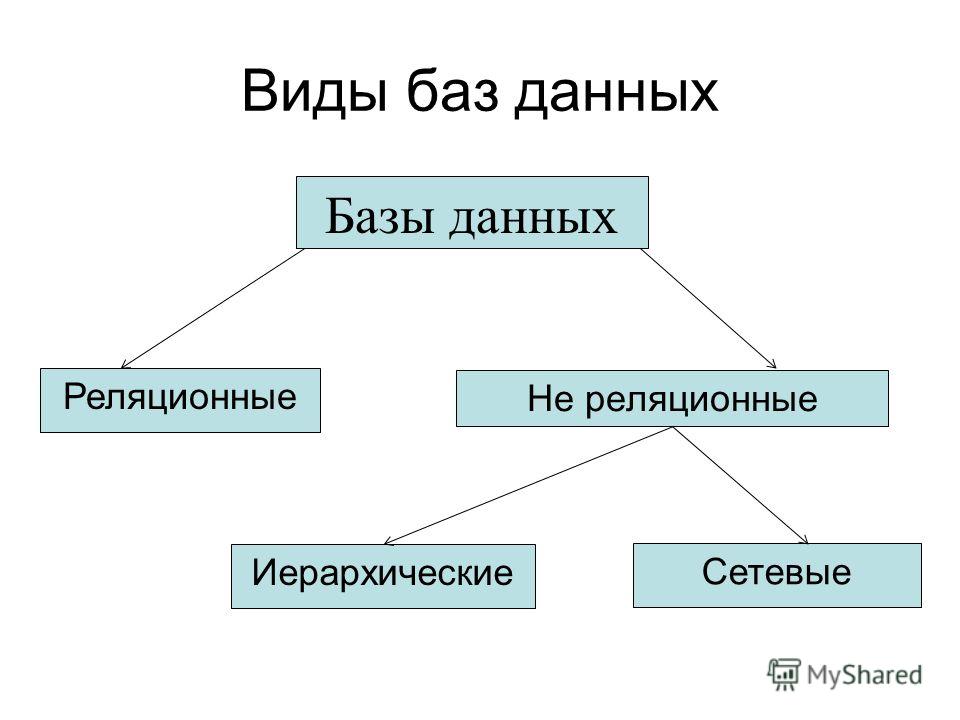 То есть нужно знать, какие понятия существуют и с какой стороны подойти к проблемам.
То есть нужно знать, какие понятия существуют и с какой стороны подойти к проблемам.
Сначала мы с вами поговорим о данных. Что это такое вообще? Вокруг нас много фактов, много сведений, но пока они никак не собраны, они для нас бесполезны. Мы их собираем, структурируем и сохраняем. И именно это сохраненное структурирование называется данными, а то, что их хранит, — базой данных. Но пока эти данные просто где-то лежат собранные, они для нас тоже в принципе бесполезны. Поэтому существует прослойка над базами данных — СУБД. Это то, что позволяет нам доставать данные, сохранять их и анализировать. Таким образом, данные, которые мы получаем, мы превращаем в информацию, которую уже можем вывести пользователю. Пользователь получает знания и применяет их.
Мы обсудим, как структурировать сведения и факты, хранить их, в каком виде данных, в какой модели. И как их достать так, чтобы много пользователей одновременно могли обращаться к данным и получить корректный результат, чтобы наши итоговые знания, которые мы будем применять, были правдивыми и верными.
Для начала мы с вами поговорим о реляционных базах данных. Думаю, реляционная модель многим из вас знакома. Это модель типа таблиц и отношений между таблицами. Представим, что у нас есть мессенджер, в который мы записываем данные и сообщения между пользователями. Мы можем их записать все в одну такую большую объемную таблицу, широкую, где у нас будет много повторяющихся данных — от кого, кто, кому, в какой чат. А можем всеэто записать в различные таблицы, то есть нормализовать наши данные, привести в третью нормальную форму.
На слайдах есть примечания и ссылочки. Мы не будем сейчас углубляться в каждое понятие. Я постараюсь технические понятия, которые могут быть вам незнакомы, не говорить. Но все, что я говорю, вы найдете в примечаниях к слайдам. В том числе по нормализации тоже будет ссылочка, вы сможете почитать, если это понятие вам не знакомо.
В общих словах, нормализация — это разбиение данных на таблицы с целью, чтобы эти данные стали более структурированы. Например, здесь есть теперь таблица юзера, чата мессенджера и сообщений. Такая структура обеспечивает, что сюда будут записаны сообщения именно тех пользователей, которых мы знаем, и из известных нам чатов. То есть мы обеспечиваем целостность данных. Мы обеспечиваем факт того, что мы всегда можем собрать общую картинку целиком. Но при этом мы храним, например, в таблице сообщений только айдишники, только идентификаторы. Таким образом мы сокращаем общий размер базы данных, делаем ее меньше. Соответственно, делаем проще запись в эту БД. Нам не нужно постоянно записывать во много таблиц. Мы просто записываем в одну таблицу с айдишником.
Например, здесь есть теперь таблица юзера, чата мессенджера и сообщений. Такая структура обеспечивает, что сюда будут записаны сообщения именно тех пользователей, которых мы знаем, и из известных нам чатов. То есть мы обеспечиваем целостность данных. Мы обеспечиваем факт того, что мы всегда можем собрать общую картинку целиком. Но при этом мы храним, например, в таблице сообщений только айдишники, только идентификаторы. Таким образом мы сокращаем общий размер базы данных, делаем ее меньше. Соответственно, делаем проще запись в эту БД. Нам не нужно постоянно записывать во много таблиц. Мы просто записываем в одну таблицу с айдишником.
Если говорить про нормализацию, она вообще очень упрощает видение системы, потому что очень графична, и нам сразу становится понятно, какие взаимоотношения между какими таблицами у нас есть.
Мы уменьшаем количество ошибок при записи данных, потому что если мы записываем сообщение в месседжере и такого пользователя у нас еще нет, то нам придется его завести. Но итоговая картина, общие данные у нас останутся целостными.
Но итоговая картина, общие данные у нас останутся целостными.
Про уменьшение размера базы данных я уже сказала. Нам в таблице сообщений не придется каждый раз писать все данные о пользователе. Чтобы посмотреть профиль, мы можем просто зайти в таблицу User.
О несогласованной зависимости также предупредила. Это как раз ссылки на айдишники других таблиц, идентификаторы являются уникальными значениями в рамках одной таблицы. По-другому они называются primary key, и когда у нас есть ссылка на эти primary key, то сама ссылка в другой таблице называется foreign key.
Такая структура также защищает наши данные от случайного удаления. Мы не можем удалить юзера, потому что, например, у него есть сообщение. Это такая небольшая, но подстраховка.
Казалось бы, мы сделали отличную структуру, все понятно, все зависимо, все цельно. С чем еще нужно работать?
Представим, что мы реально запустили это в эксплуатацию, у нас стало много пользователей и, соответственно, много сообщений.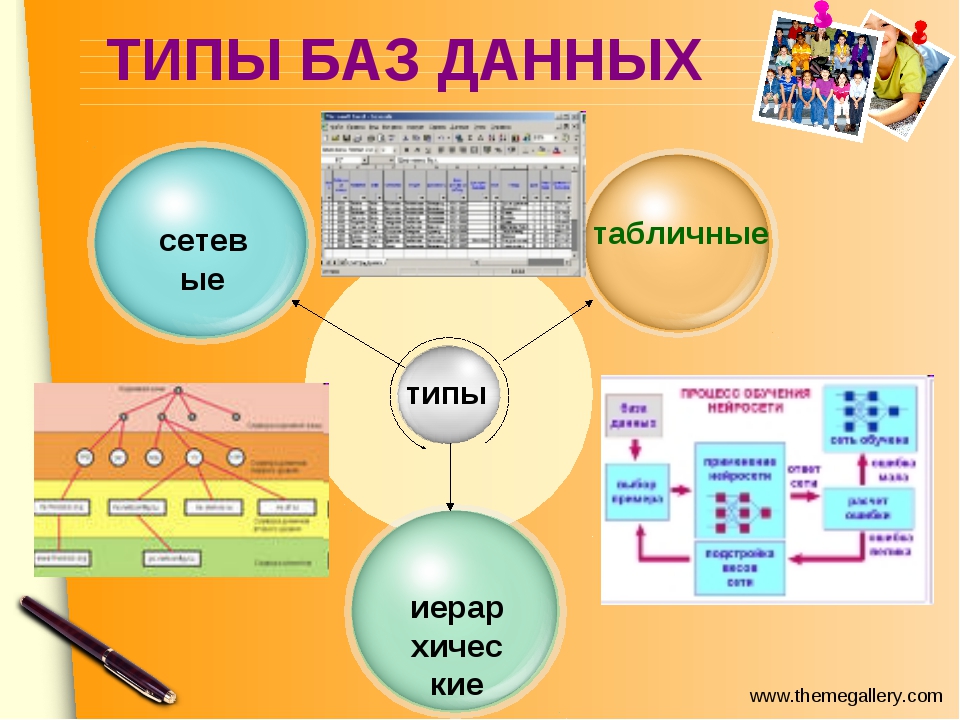 Они постоянно друг с другом общаются. Что происходит в нашей таблице сообщений? Она постоянно растет. И чтобы искать в не данные, нам нужно постоянно перебирать абсолютно все сообщения, проверять, от этого пользователя они или нет, в этом чате или нет, и только тогда их выводить.
Они постоянно друг с другом общаются. Что происходит в нашей таблице сообщений? Она постоянно растет. И чтобы искать в не данные, нам нужно постоянно перебирать абсолютно все сообщения, проверять, от этого пользователя они или нет, в этом чате или нет, и только тогда их выводить.
Естественно, чем больше пользователей, чем больше сообщений, тем дольше будут проходить запросы полного перебора. Нам нужно решение, которое позволит быстро искать сообщения в таблице.
Для такого случая, для ускорения поиска, используют индексы. Самая простая ассоциация с индексами — это содержание в книге. Если вам нужно в книге найти информацию, вы можете просто пролистать книгу, а можете зайти в оглавление. Индексы — это своего рода оглавление.
Есть еще хороший пример с телефонной книжкой. Вы можете нажать на букву на своем телефоне, и вас сразу перекинет ссылочно на фамилии, начинающиеся с этой буквы. Индексы баз данных работают по очень похожему принципу. Давайте посмотрим нашу таблицу с сообщениями и то, как мы эти данные будем доставать.
Прошу обратить внимание, как именно мы будем работать с данными. Не с тем, какие у нас есть строки в таблице, а вообще. Индексы строятся по принципу того, какие запросы вы делаете.
Представим, что мы делаем в основном запросы по чату, то есть узнаём, какие сообщения есть в этом чате. Построим индекс именно по столбцу чатов. Индексы в базе данных — это отдельная структура. Таблица от нее не зависима. То есть индекс вы можете в любой момент удалить и перестроить заново, и таблица от этого не пострадает.
Здесь видно, что мы выделили, поставили индекс на столбец, и у нас выделилась отдельная структурка, которая уже немножко сократила количество записей, потому что в 11 чате уже есть несколько сообщений. СУБД обеспечивает быстрый поиск по вот этой маленькой таблице чата. Как это делается? Естественно, поиск происходит не простым перебором. Есть много алгоритмов быстрого поиска, мы с вами рассмотрим один из самых популярных алгоритмов, которые используются по умолчанию в большинстве баз данных. Это сбалансированное дерево.
Это сбалансированное дерево.
Как оно работает? У нас есть номер чата, это целое значение, и дерево выстраивается по такому принципу: то, что слева от узла значений меньше, справа от узла значений больше. Что нам дает такая структура? Если посмотреть на итоговые листы этого дерева, то все значения внизу упорядочены. Это огромный плюс в приросте производительности. Сейчас покажу, почему.
Например, мы ищем значение. Одно значение искать очень просто. Мы проходим вниз по дереву или влево, вправо — в зависимости от того, больше это значение или меньше.
А если мы хотим найти, например, диапазон, то смотрите, как просто и быстро это получается. Мы доходим до значения и дальше по ссылкам в листьях уже по упорядоченным значениям просто идем до конца.
Если нам нужен диапазон, определенный от и до, — делаем абсолютно то же самое. Находим начальное значение и уже по ссылкам листьев идем до максимального значения. Мы по дереву прошли только один раз. Это очень удобно, очень быстро.
Это очень удобно, очень быстро.
Точно так же у нас будут искаться максимальные и минимальные значения. Пройти совсем влево, совсем вправо. Так же у нас будет происходит получение упорядоченного списка. То есть если нам нужно просто получить все чаты упорядоченно, мы доходим до первого и уже по листьям идем до самого правого значения, получаем упорядоченный список. Именно по такому принципу база данных очень быстро ищет в таблице индексов те строчки, которые нам нужны для выборки, и возвращает их.
Что тут важно знать? Казалось бы, классная структура — мы сейчас на каждый столбец построим по такому дереву и будем искать. Как вы думаете, почему это не сработает? Почему у нас не будет прироста скорости, если мы на каждый столбец построим по дереву? (…)
У нас действительно ускорятся селекты. Каждый раз, когда нам нужно пройти по какому-то значению, мы заходим в индекс, находим там ссылку на сами значения. Индексы, как правило, содержат именно ссылки на строки, а не сами строки. И для селектов это работает идеально. Но как только мы захотим задать данные таблицы, проапдейтить либо удалить данные, то все эти деревья придется перестраивать.
И для селектов это работает идеально. Но как только мы захотим задать данные таблицы, проапдейтить либо удалить данные, то все эти деревья придется перестраивать.
На самом деле удаление не перестроит, а просто фрагментирует это дерево, и у нас получатся много пустых значений. Будет огромное дерево с пустыми значениями. Но именно при update и при create эти деревья каждый раз будут перестраиваться. В итоге мы получим огромный overhead над всех этой структурой. И вместо того, чтобы быстренько достать данные и ускорить базу данных, мы будем замедлять наши запросы.
Что еще важно знать? Когда вы будете работать с базой, посмотрите, почитайте, какие индексы в ней существуют, потому что в каждой базе свои реализации, свои разные индексы. Есть индексы для ускорения, есть индексы для обеспечения целостности. Один из самых простых — как раз primary key. Это тоже индекс уникальности. И относительно вашей базы смотрите, как он устроен, как с ним работать, потому что это такие знания, которые вам помогут писать наиболее оптимальные запросы.
Мы обсудили, что нужно иметь в виду накладные расходы на поддержание индексов при вставке данных. Забыла сказать, что когда вы выстраиваете индекс, он должен обладать высокой селективностью. Что это значит?
Посмотрим на это дерево. Мы понимаем, что если стоит индекс на true false, то получается просто два огромных куска дерева слева и справа. И мы проходимся в лучшем случае по 50% таблицы, что на самом деле не очень эффективно. Лучше всего делать индекс именно на те столбцы, у которых наиболее разные значения. Таким образом мы ускорим наши выборки.
Про фрагментацию я сказала, при удалении данных ее нужно иметь в виду. Если у нас часто проходит удаление по данным, содержащимся в индексе, то его, возможно, придется дефрагментировать, и за этим тоже нужно следить. Также важно понимать, что вы строите индекс исходя не из того, какие у вас столбцы, а из того, как вы эти данные используете. И запросы, которые включают индексы, нужно писать очень аккуратно. Что значит аккуратно? Когда вы пишете запрос, отправляете его в базу данных, он отправляется не напрямую в базу, а в некую программную прослойку, которая называется планировщиком запросов.
Планировщик имеет у себя определенную таблицу соответствия того, какая операция сколько стоит и насколько она дорогая. В примере с PostgreSQL есть специальные технические таблицы, которые собирают информацию о ваших данных, о ваших таблицах. Планировщик смотрит, какой у вас запрос, какие данные хранятся в таблице pg_stat. Это как раз таблица, которая хранит общую информацию о том, сколько у вас данных и какие столбцы в вашей таблице, какие индексы на ней. Исходя из этого он смотрит планы выполнения вашего запроса, считает, сколько времени по какому плану уйдет на запрос, и выбирает самый оптимальный.
Если вы хотите посмотреть прогнозируемое время выполнения вашего запроса, можете использовать операцию Explain. Если хотите фактическое выполнение, можете использовать Explain analyze. Какая разница? Как я и говорила, планировщик изначально рассчитывает время выполнения, исходя из примерного времени на каждую операцию. Поэтому реальное время может отличаться в зависимости от машины и от особенностей ваших данных. Так что если вам нужно именно фактическое выполнение, то, конечно, лучше использовать Explain analyze.
Так что если вам нужно именно фактическое выполнение, то, конечно, лучше использовать Explain analyze.
На этом слайде вы можете посмотреть пример. Он показывает, что иногда запросы с учетом вашего столбца, на котором есть индексы, могут использовать не индекс scan, а просто full scan по всей таблице. Это происходит, если у нас невысокая селективность индекса и если планировщик считает, что запрос полным scan по таблице будет выгоднее.
Представим, что у нас есть наш мессенджер и мы хотим в списке чатов, например, показывать имя чата либо количество непрочитанных сообщений. Если мы каждый раз, открывая чатик, будем пересчитывать все данные по всем чатам, это будет очень невыгодно.
Есть такое понятие — денормализация. Это копирование наиболее горячих используемых данных либо предрасчет нужных данных и сохранение их в таблицу.
Так может выглядеть соотношение юзера с чатом. То есть помимо ID юзера и ID чата мы кратко туда сохраним имя чата, лог чата и количество непрочитанных сообщений. Таким образом нам каждый раз не нужно будет нагружать все наши таблицы, делать селект и все это пересчитывать.
Таким образом нам каждый раз не нужно будет нагружать все наши таблицы, делать селект и все это пересчитывать.
В чем плюс денормализации? Мы ускоряем процесс выборки данных. То есть наши селекты проходят максимально быстро, мы максимально быстро отдаем пользователям ответ.
Сложность в том, что каждый раз, когда мы добавляем новые данные, нам все эти столбцы нужно пересчитывать и очень велика вероятность ошибки. То есть если наши селекты становятся гораздо проще и нам не нужно все время джойнить, то наши update и create становятся очень громоздкими, потому что нам нужно повесить туда триггеры, пересчитать и ничего не забыть.
Поэтому денормализацию нужно использовать, только когда она вам действительно нужна. И как мы сейчас шли по вот этой всей логике, сначала нужно данные нормализовать, посмотреть, как вы их будете использовать, настроить индексы. Если у вас есть запросы, которые, как вы считаете, плохо работают, то перед денормализацией посмотрите Explain. Узнайте, как они реально выполняются, как планировщик их выполняет. И только потом, когда вы уже придете к тому, что денормализация все-таки нужна, тогда вы можете ее сделать. Но такая практика есть, и в реальных проектах денормализация данных достаточно часто используется.
И только потом, когда вы уже придете к тому, что денормализация все-таки нужна, тогда вы можете ее сделать. Но такая практика есть, и в реальных проектах денормализация данных достаточно часто используется.
Пойдем дальше. Даже если вы хорошо структурировали данные, выбрали модель данных, собрали, все денормализовали, придумали индексы, — все равно очень многое в IT-мире может пойти не так.
Может отказать ПО, может выключиться электроэнергия, может отказать аппаратное обеспечение или сеть. Есть и второй класс проблем: нашими базами данных одновременно пользуется очень много пользователей. Они могут одновременно обновлять одни и те же данные. Все эти проблемы мы должны уметь решать.
Давайте посмотрим на конкретных примерах, о чем идет речь.
Представим, что есть два пользователя, которые хотят забронировать переговорку. Пользователь 1 видит, что переговорка в это время свободна, и начинает ее бронировать. У него открывается окошко, и он думает, кого же из коллег я позову. Пока он думает, пользователь 2 тоже видит, что переговорка свободна, и открывает себе окошко редактирования.
Пока он думает, пользователь 2 тоже видит, что переговорка свободна, и открывает себе окошко редактирования.
В итоге, когда пользователь 1 сохранил эти данные, он ушел и думает, что все отлично, переговорка забронирована. Но в это время пользователь 2 перезаписывает его данные, и получается так, что переговорка закрепилась за пользователем 2. Это называется конфликтом данных. И мы должны уметь показывать эти конфликты людям и как-то их разрешать. Именно в этом месте у нас будет перезапись.
Как это сделать? Мы можем просто заблокировать переговорку на какое-то время, пока пользователь 1 думает. Если он сохранил данные, то пользователю 2 мы не разрешим это делать. Если он данные отпустил и не стал сохранять, то пользователь 2 сможет забронировать переговорку. Подобную картину вы могли видеть, когда покупаете билеты в кино. Вам дается 15 минут на то, чтобы оплатить билеты, иначе они вновь предоставляются другим людям, которые тоже могут их взять и оплатить.
Вот другой пример, который нам покажет, насколько важно следить, чтобы наши операции выполнялись полностью.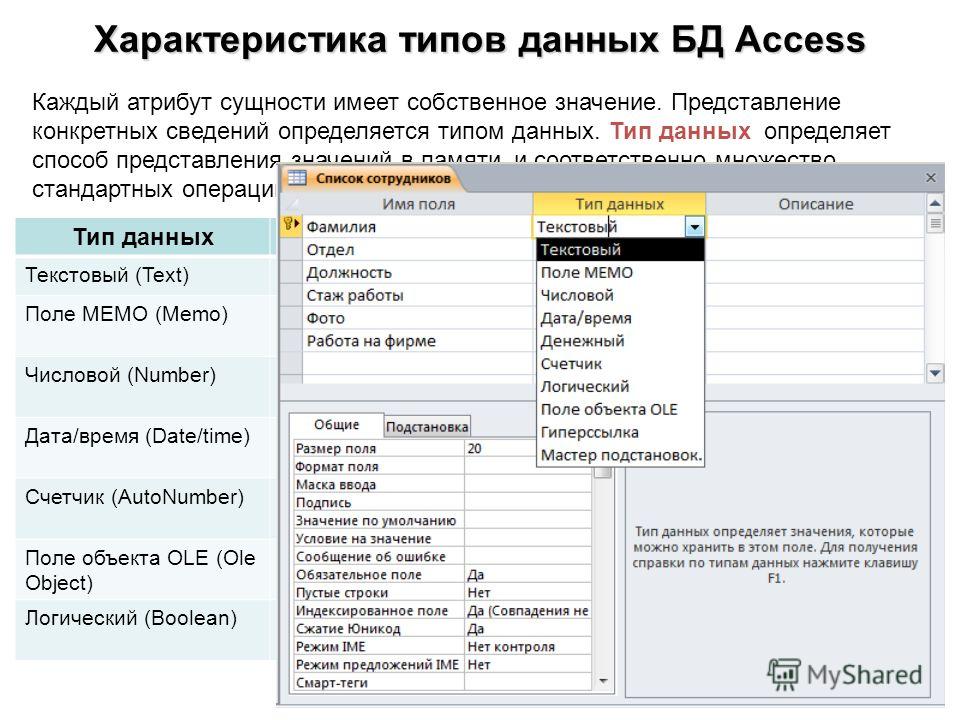 Допустим, я хочу с банковского счета 1 перекинуть деньги на счет 2. В этом моменте у меня есть три операции. Я проверяю, что у меня достаточно средств, вычитаю со своего первого счета средства и кидаю на второй счет. Понятное дело, что если в любой из этих моментов у меня произойдет сбой, то что-то пойдет не так.
Допустим, я хочу с банковского счета 1 перекинуть деньги на счет 2. В этом моменте у меня есть три операции. Я проверяю, что у меня достаточно средств, вычитаю со своего первого счета средства и кидаю на второй счет. Понятное дело, что если в любой из этих моментов у меня произойдет сбой, то что-то пойдет не так.
Например, если вот на этом этапе произойдет другая транзакция, которая считывает данные, то средств на моем счете будет уже недостаточно, я не смогу выполнить другие операции. Если на втором моменте произойдет проблема, то мы, например, сняли с одного счета деньги, а на второй не закинули. Получается, что в итоге на моем банковском счету, на всех моих счетах станет на какую-то сумму меньше. Эти деньги уже никак не вернуть.
Для решения таких проблем существует понятие транзакции — атомарного, целостного выполнения всех трех операций одновременно.
Как это делает база данных? Она записывает все эти изменения в определенный журнал и применяет их, только когда у нас транзакция коммитится. Таким образом мы гарантируем, что все вот эти операции будут выполнены как единое целое либо не будут выполнены вовсе.
Таким образом мы гарантируем, что все вот эти операции будут выполнены как единое целое либо не будут выполнены вовсе.
Если в любой момент этого времени у нас произойдет сбой, то с первого счета не будут вычтены деньги и, соответственно, мы их не потеряем.
У транзакций есть четыре свойства, четыре требования к ним. Это Atomicity, Consistency, Isolation и Durability — атомарность, согласованность, изоляция и сохраняемость данных. Что это за свойства?
- Atomicity или атомарность — гарантия того, что операция, которую вы выполняете, будет выполнена полностью, что она не будет выполнена частично. Таким образом мы гарантируем, что общая согласованность данных в нашей базе будет и до операции, и после.
- Consistency или согласованность — больше бизнес-правило, скорее не со стороны СУБД или самой базы данных. Согласованность не нужно путать с целостностью (Integrity). Если кто-то из вас работал с базами данных и передавал данные с айдишника, который не существует, то вы могли получать Integrity Error, ошибку целостности: система не понимала, что с ним делать. Именно наличие взаимосвязи отношений и уникальности ключей называется целостностью. А согласованность — то, что мы пишем в самой транзакции.
Например, в этом примере, когда мы пишем транзакцию, нужно с одного счета снимать столько же денег, сколько мы кидаем на второй счет. То есть в итоге у нас данные по общему балансу в начале и в конце должны быть одинаковыми. Это и есть согласованность.
- Isolation или изоляция — это как раз то, что мы с вами смотрели на примере переговорки. Ваша система должна вести себя предсказуемо и контролируемо относительно параллельного выполнения операций. Она должна гарантировать, что параллельно работающие пользователи не будут мешать друг другу и что не будет неожиданных изменений.
- Durability или сохраняемость — свойство транзакции, которое говорит о том, что если ответ пришел пользователю, то эти данные уже точно будут сохранены, что они не пропадут.
 Именно наличие взаимосвязи отношений и уникальности ключей называется целостностью. А согласованность — то, что мы пишем в самой транзакции.
Именно наличие взаимосвязи отношений и уникальности ключей называется целостностью. А согласованность — то, что мы пишем в самой транзакции.Поговорим побольше про изоляцию. Изолированность транзакций — очень дорогое свойство, на него тратится очень много ресурсов, из-за этого у нас в базах существует несколько уровней изоляции.
 Давайте посмотрим, какие проблемы могут быть, и исходя из этого уже обсудим, как их решать.
Давайте посмотрим, какие проблемы могут быть, и исходя из этого уже обсудим, как их решать.Существует четыре основных класса проблем — потерянное обновление, «грязное» чтение, неповторяющееся чтение и фантомное чтение. Рассмотрим подробнее.
Потерянное обновление — это как в примере с переговорками, когда у пользователя 1 перезаписались данные и он об этом не знает. То есть мы не блокировали данные, которые этот пользователь изменяет, и, соответственно, получили их перезапись.
Проблема «грязного» чтения возникает, когда пользователь видит временные изменения другого пользователя, которые потом могут быть откатаны или просто сделаны временно.
В данном случае пользователь 1 что-то записал в базу данных. Пользователь 2 в это время что-то оттуда считал и строит аналитику по этим данным. А пользователь 1 столкнулся с ошибкой, несоответствием и эти данные откатывает. Таким образом, аналитика, которую записал пользователь 2, будет ненастоящая, неверная, потому что уже нет тех данных, исходя из которых он ее рассчитывал.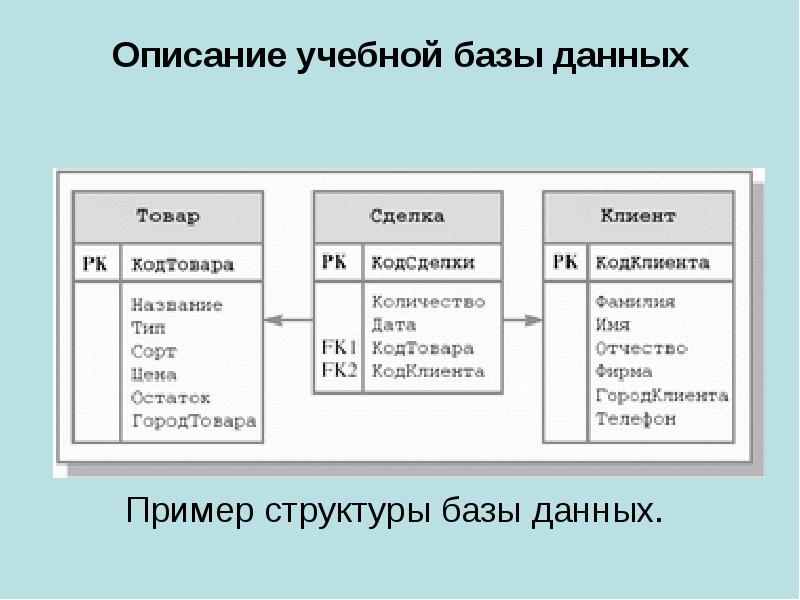 Такую проблему тоже нужно уметь решать.
Такую проблему тоже нужно уметь решать.
Неповторяемое чтение — это когда у нас у пользователя 1 долгая транзакция. Он выбирает данные из базы, а в это время пользователь 2 изменяет часть тех же самых данных.
В данном случае получается, что пользователь 1 не заблокировал изменения тех данных, которые у него есть. И несмотря на то, что он сам получил слепок данных, при повторном запросе на тот же самый селект он может получить другие значения в этих строках. Таким образом, у него будет конфликт, несоответствие данных, которые он записывает.
Похожая проблема может быть, если пользователь 2 добавил или удалил данные. То есть пользователь 1 сделал запрос, а потом при повторном запросе этих же самых данных у него появились или пропали строки. В этом случае в рамках транзакции очень сложно понять, что с ними делать, как их вообще обрабатывать.
Чтобы решать эти проблемы, есть четыре уровня изоляции. Первый, самый низкий уровень — Read uncommitted. Это то, что в PostgreSQL описывается как No lock. Когда мы читаем или пишем данные, мы не блокируем другим пользователям ни чтение, ни запись этих данных. Получается, что мы не блокируем никакие изменения. Все четыре перечисленные проблемы по-прежнему могут произойти. Но от чего защищает этот уровень изоляции? Он гарантирует, что все транзакции, которые пришли в базу данных, будут выполнены. Если два пользователя одновременно начали выполнять запросы с одними и теми же данными, то обе эти транзакции будут выполнены последовательно.
Это то, что в PostgreSQL описывается как No lock. Когда мы читаем или пишем данные, мы не блокируем другим пользователям ни чтение, ни запись этих данных. Получается, что мы не блокируем никакие изменения. Все четыре перечисленные проблемы по-прежнему могут произойти. Но от чего защищает этот уровень изоляции? Он гарантирует, что все транзакции, которые пришли в базу данных, будут выполнены. Если два пользователя одновременно начали выполнять запросы с одними и теми же данными, то обе эти транзакции будут выполнены последовательно.
Для чего это может быть полезно? Этот уровень изоляции очень редко используется в практике, но он может быть полезен, например, когда есть большой аналитический запрос и вы хотите во втором запросе почитать и посмотреть, на каком этапе находится ваша аналитика, какие данные уже записаны а какие нет. И тогда второй запрос — который для дебага, отладки, проверки — вы запускаете как раз в таком уровне изоляции. И он видит все изменения вашего первого аналитического запроса, которые в итоге могут быть откатаны.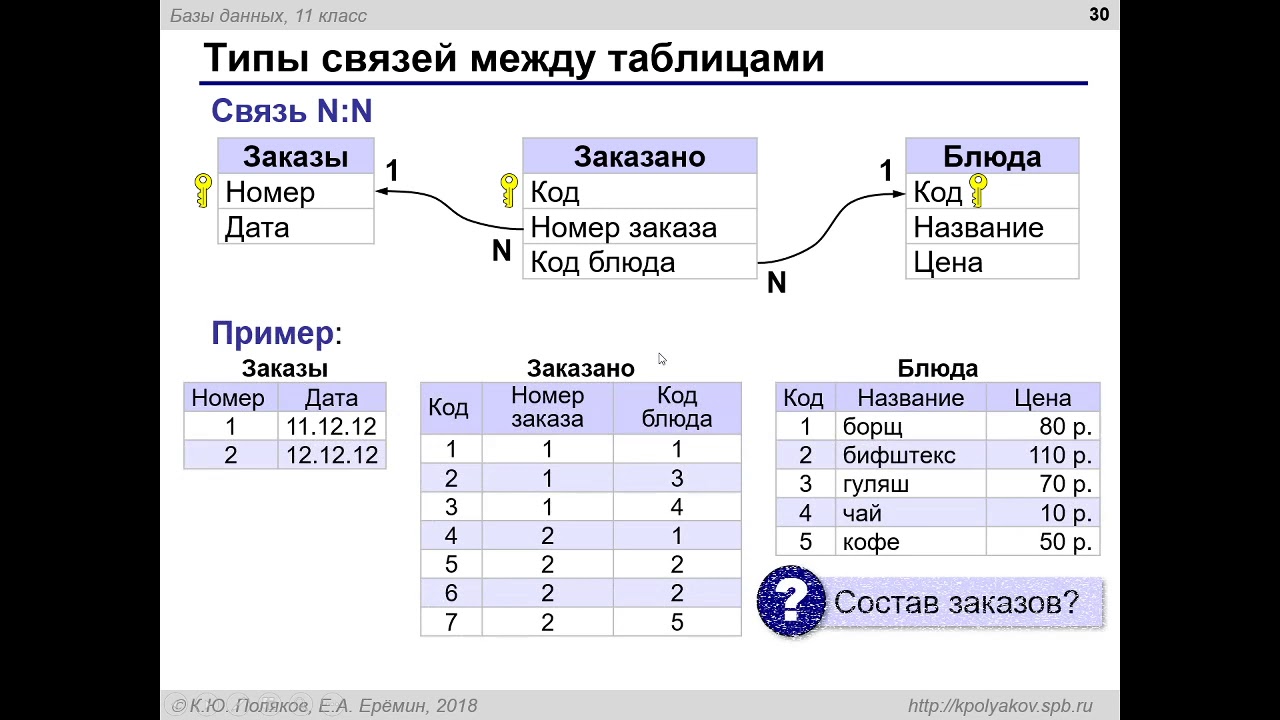 Или не откатаны, но в текущий момент вы можете посмотреть состояние системы.
Или не откатаны, но в текущий момент вы можете посмотреть состояние системы.
Read committed, чтение фиксированных данных. Этот уровень изоляции используется по умолчанию в большинстве реляционных баз, в том числе и в PostgreSQL, и в Oracle. Он гарантирует, что вы никогда не прочитаете «грязные» данные. То есть другая транзакция никогда не видит промежуточных этапов первой транзакции. Преимущество в том, что это очень хорошо подходит для маленьких коротких запросов. Мы гарантируем, что у нас никогда не будет ситуации, когда мы видим какие-то части данных, недописанные данные. Например, увеличиваем зарплату целому отделу и не видим, когда только часть людей получили прибавку, а вторая часть сидит с неиндексированной зарплатой. Потому что если у нас будет такая ситуация, логично, что наша аналитика сразу «поедет».
От чего не защищает этот уровень изоляции? Он не защищает от того, что данные, которые вы проселектили, могут быть изменены. В случае небольших запросов этого уровня изоляции вполне достаточно, но для больших, долгих запросов, сложной аналитики, естественно, можно использовать более сложные уровни, которые блокируют ваши таблицы.
Уровень изоляции Repeatable read защищает от первых трех проблем, которые мы с вами обсуждали. Это и потерянное обновление, когда перезаписали нашу переговорку; «грязное» чтение — чтение незафиксированных данных; и это неповторяющееся чтение — чтение данных, обновленных другими транзакциями.
Как оно обеспечивается? С помощью блокировки таблицы, то есть блокировки нашего селекта. Когда мы берем селект в нашу транзакцию, то получается как будто слепок данных. И мы в этот момент не видим изменений других пользователей, все время работаем именно с этим слепком данных. Минус в том, что мы блокируем данные и, соответственно, у нас меньше параллельных запросов, которые могут работать с данными. Это очень важный аспект. И вообще, почему этих уровней изоляции так много?
Чем выше уровень, тем больше блоков и меньше пользователей, которые параллельно могут работать с базой. Каждая транзакция видит определенный слепок данных, который не может меняться. Но могут появиться новые данные. Так что этот уровень изоляции нас не спасает от появления новых данных, которые подходят под селект.
Так что этот уровень изоляции нас не спасает от появления новых данных, которые подходят под селект.
Есть еще один уровень изоляции — сериализация. Часто ее называют упорядочиваемостью. Это полная блокировка данных в таблице. Она спасает от фантомного чтения, то есть от чтения как раз тех данных, которые у нас добавились или удалились, потому что мы блокируем таблицу, не разрешаем в нее писать. И выполняем наши запросы целостно.
Это очень полезно для сложных, больших аналитических запросов, в которых очень важна точность и целостность данных. Не получится так, что мы в какой-то момент считали данные пользователя, а потом в другой таблице появились новые статистики и получился рассинхрон.
Это самый высокий уровень изоляции. Здесь самое большое количество блокировок и самая маленькая возможность параллелизации запросов.
Что нужно знать о транзакциях? Что они нам упрощают жизнь, потому что реализованы на уровне СУБД и нам нужно только правильно делать наши запросы, правильно их формировать, так, чтобы данные в итоге были согласованы. И чтобы блокировать именно те данные, с которыми наши пользователи работают. Нужно иметь в виду, что плохо блокировать всё и везде. В зависимости от того, какая у вас система и кто сколько читает/пишет, у вас будет разный уровень изолированности. Если вам нужна максимально быстрая система, которая допускает какие-то ошибки, вы можете выбрать минимальный уровень изоляции. Если у вас банковская система, которая должна гарантировать, что данные согласованы, все выполнено и ничего не потерялось — тогда, конечно, нужно выбирать максимальный уровень изоляции.
И чтобы блокировать именно те данные, с которыми наши пользователи работают. Нужно иметь в виду, что плохо блокировать всё и везде. В зависимости от того, какая у вас система и кто сколько читает/пишет, у вас будет разный уровень изолированности. Если вам нужна максимально быстрая система, которая допускает какие-то ошибки, вы можете выбрать минимальный уровень изоляции. Если у вас банковская система, которая должна гарантировать, что данные согласованы, все выполнено и ничего не потерялось — тогда, конечно, нужно выбирать максимальный уровень изоляции.
Мы уже достаточно классно продвинулись в понимании того, как выстраивать структуру базы данных и что может произойти. Пойдем дальше.
Насколько безопасно хранить одну базу данных. Конечно, не безопасно. Если с ней что-то случается, мы теряем все данные. Если есть бекап, мы можем его накатить, но тогда возникнет время простоя системы. Если у нас ломается сеть или узел становится недоступен, система тоже будет какое-то время находиться в простое, в downtime.
Как это можно разрешить? Есть такое понятие — репликация. Это дублирование базы данных на другие узлы и серверы.
Это именно дублирование полностью, копия базы данных. Как мы можем этот механизм использовать?
Во-первых, если с БД что-то случилось, мы можем перенаправить запросы на другую копию базы данных, что в принципе логично. Это основное применение. Как еще мы можем это использовать?
Представим, что пользователь находится далеко от сервера. Мы можем распределить серверы так, чтобы покрывать максимальное количество пользователей и максимально быстро отдавать им запросы. На каждом из этих серверов будет одинаковая с другими копия, но запросы будут возвращаться пользователям быстрее.
Еще одно очень популярное использование — распределение нагрузки. Так как у нас одинаковые копии данных, мы можем читать не из головы, не из одной базы данных, а из разных. Таким образом мы разгружаем наш сервер.
Также у нас есть понятие OLTP-запросов и OLAP-запросов. Что это такое? OLTP — короткие транзакционные запросы. OLAP — долгая аналитика. Это когда мы берем огромный джойн, огромный селект, всё мёржим и нам очень важно, чтобы в этот момент все данные были залочены, чтобы не было никаких изменений и БД была целостна.
Что это такое? OLTP — короткие транзакционные запросы. OLAP — долгая аналитика. Это когда мы берем огромный джойн, огромный селект, всё мёржим и нам очень важно, чтобы в этот момент все данные были залочены, чтобы не было никаких изменений и БД была целостна.
Для таких ситуаций можно делать аналитику на отдельной копии базы данных. Так мы не будем аффектить наших пользователей, они смогут тоже делать записи в базу, просто потом эти записи придут и на нашу копию.
Чтобы грамотно распределить копии баз данных, вводится понятие ведущего узла и ведомого узла, Master и Slave. Slave очень часто называют репликой либо follower. Master — узел, в который наш пользователь, наше приложение пишет. Master применяет все изменения, ведет журнал изменений, и этот журнал отправляет на Slave. Slave не принимает изменения от пользователей, а применяет лишь изменения журнала от Master. Прошу заметить, что Master не отправляет каждый раз копию, а отправляет именно изменения. Slave накатывает эти изменения и получает такую же копию данных, как и в Master.
Очень важный параметр реплицируемой системы — синхронно или асинхронно выполняются запросы. Что такое синхронный запрос? Это когда Master отправляет запрос на синхронную реплику, на синхронный Slave, и ждет, когда Slave скажет: «Да, я принял», — и вернет Master подтверждение. Только тогда Master вернет пользователю ответ. Если же реплика асинхронная, то Master отправляет запрос на реплику, но сразу говорит пользователю, что «Всё, я записал». Давайте посмотрим, как это работает.
Есть юзер, который записал данные в Master. Master отправил их на две реплики, подождал ответа от синхронной реплики и сразу дал ответ пользователю. Асинхронная реплика записала и сказала Master: «Да, все окей, данные записаны».
С точки зрения такой иерархии, Master и Slave, у нас может быть одна голова или несколько. Если у нас один ведущих узел, в него очень удобно писать, а читать можно из синхронной реплики. Почему именно из синхронной? Потому что синхронная реплика с максимальной точностью гарантирует, что в ней актуальные данные.
Когда к данным применяется запрос, операция из журнала, это тоже требует времени. Поэтому, если вам важна стопроцентная точность данных, которые вы хотите получить, вы должны ходить за чтением, за селектом в Master. Если вам не критично, что данные могут прийти с небольшим опозданием, вы можете читать из синхронного Slave. Если вам абсолютно не критична актуальность данных, вы можете читать в том числе из асинхронной реплики, тем самым разгружая Master и синхронную реплику от запросов.
В репликации также может быть несколько ведущих узлов. Разные приложения могут писать в разные головы, и эти Master потом между собой разрешают конфликты.
Очень простой пример применения таких данных — всякие офлайн-приложения. Например, на вашем телефоне есть календарь. Вы отключились от сети и записали в календарь событие. В данном случае ваше локальное хранилище, ваш телефон, — это Master. Он сохранил в себе данные, и при появлении сети Master вашей локальной копии и копия, которая на сервере, разрешат конфликты, объединят эти данные.
Это очень простой пример такой репликации. Она часто применяется для совместного редактирования онлайн-документов, либо когда очень велика вероятность потери сети.
Также существуют репликации без ведущих узлов. Что это такое? Это репликация, при которой сам клиент отсылает данные на бóльшую часть реплик и читает их тоже из бóльшей части реплик. Здесь видно, что серединная реплика у нас является пересечением наших Read и update.
То есть мы гарантируем, что каждый раз, читая данные, мы попадем хотя бы в одну из реплик, в которой данные самые актуальные. А между собой у реплик выстраивается механизм обмена информаций с основным логом изменений и конфликтов между репликами. В данном случае очень часто реализовывают именно толстый клиент. Если он получил данные от реплики, в которой лежат более поздние изменения, чем в другой, то он просто отправляет данные на другую реплику либо разрешает конфликт.
Что важно знать про репликацию? Основной смысл репликации — отказоустойчивость системы, высокая доступность вашего сервера.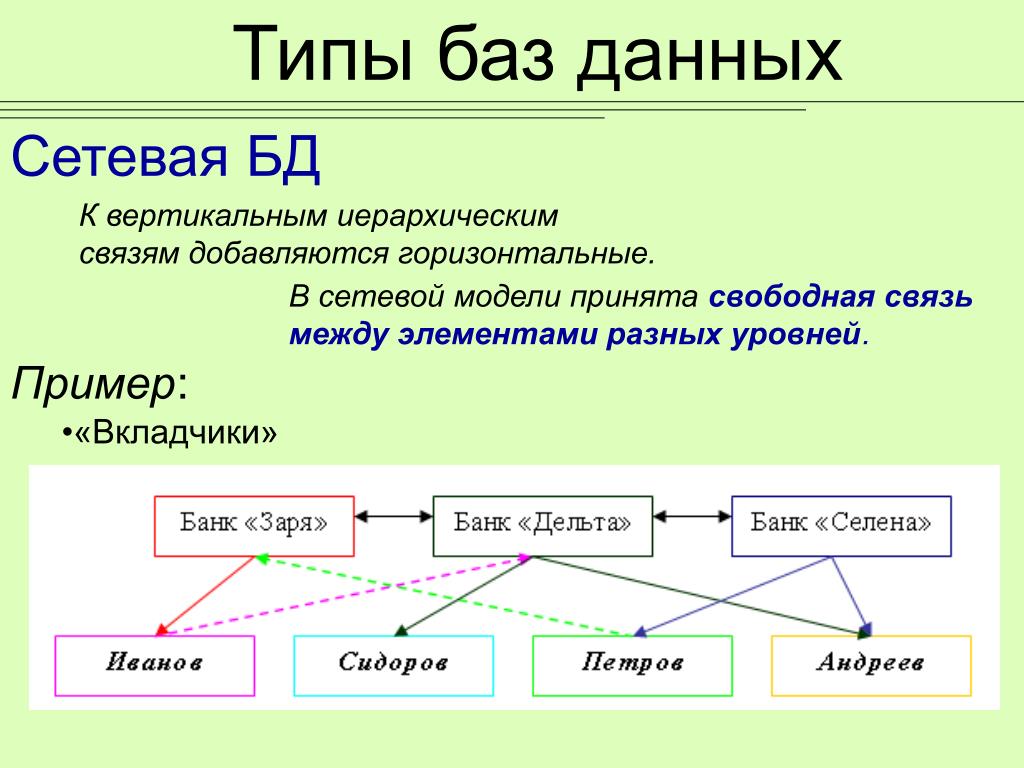 Что бы ни случилось с базой, система будет доступна, ваши пользователи смогут писать данные, и когда восстановится соединение с Master или с другой репликой, то все данные тоже будут восстановлены.
Что бы ни случилось с базой, система будет доступна, ваши пользователи смогут писать данные, и когда восстановится соединение с Master или с другой репликой, то все данные тоже будут восстановлены.
Репликация очень помогает разгрузке серверов и перераспределению запросов чтения с Master на реплики. Мы можем масштабировать это чтение, создавать больше реплик на чтение и делать нашу систему еще быстрее. Еще можно сделать реплику на сложные долгие аналитические запросы, которые требуют большого количества блокировок и могут повлиять на доступность системы.
На примере офлайн-приложений мы с вами посмотрели, как можно такие данные хранить и разруливать конфликты. В случае синхронной реплики может быть Replication lag, то есть отставание по времени. В случае асинхронной реплики он есть практически всегда. То есть когда вы читаете данные из асинхронной реплики, вы должны понимать, что они могут быть не актуальны.
По иерархии забыла сказать, что когда есть один Master, который ждет ответа от синхронной реплики, логично предположить, что если у нас все реплики синхронны, и какая-то вдруг стала недоступна, то наша система не сможет сохранить запрос. Тогда Master запишет нас в первый синхронный Slave, получит ответ, попросит второй Slave, ответа не получит, и в итоге придется откатывать всю транзакцию.
Тогда Master запишет нас в первый синхронный Slave, получит ответ, попросит второй Slave, ответа не получит, и в итоге придется откатывать всю транзакцию.
Поэтому в таких системах, как правило, делают одну реплику синхронной, а остальные асинхронными. Синхронная реплика гарантирует, что ваши данные сохранились еще где-то. То есть помимо Master, с которым может что-то произойти, мы гарантируем, что есть хотя бы еще один узел, который содержит полную копию абсолютно того же журнала транзакций, тех же самых данных.
Асинхронная реплика, с другой стороны, не гарантирует сохранность данных. Если у нас есть только асинхронные реплики и Master отключился, то они могут отставать, туда могли еще не прийти данные. В таких случаях, как правило, выстраивают такую иерархию, что либо у нас Master, одна синхронная реплика и остальные асинхронные, либо у нас Master и все реплики асинхронные, если нам не важна сохраняемость данных.
Есть одно «но»: все реплики должны иметь одинаковую конфигурацию. Если говорить на примере PostgreSQL, они должны иметь одинаковую версию самого PostgreSQL, потому что разные версии базы могут иметь и разный формат журнала операций. И если реплика поднимается из другой версии, она просто может не прочитать операции, которые записала другая база.
Если говорить на примере PostgreSQL, они должны иметь одинаковую версию самого PostgreSQL, потому что разные версии базы могут иметь и разный формат журнала операций. И если реплика поднимается из другой версии, она просто может не прочитать операции, которые записала другая база.
Что такое реплика? Это полная копия всех данных. Представим, что данных так много, что сервер не справляется. Какое первое решение?
Первое решение — купить более дорогую машину с большим количеством памяти, с большим CPU, с большим диском. Это решение будет по большей части правильным, пока вы не столкнетесь с проблемой дороговизны железа. Однажды покупать новую машину станет слишком дорого, либо будет уже просто некуда расти. Есть огромное количество данных, которые просто физически невозможно разместить на одной машине.
В таких случаях можно использовать горизонтальное масштабирование. То, что мы видели ранее, увеличение производительности одной машины, является вертикальным масштабированием. Увеличение количества машин — это горизонтальное масштабирование.
Увеличение количества машин — это горизонтальное масштабирование.
Чтобы разбить данные по машинам, используют шардинг или, по-другому, секционирование. То есть разбиение данных на секции и блоки по ключу, по айдишнику, по дате. Мы еще поговорим об этом дальше, это один из ключевых параметров, но смысл именно в том, чтобы по определенному признаку разделить данные и отправить их на разные машины. Таким образом, наши машины могут стать менее производительными, но система по-прежнему сможет функционировать и получать данные уже с разных машин.
Чтобы в целом понять, где какие данные лежат, нужна определенная таблица соответствий шарда, нашей копии и данных.
Бывают случаи, когда не используется специальное хранилище данных и клиент просто ходит по очереди на каждый шард и проверяет, есть ли там данные, которые соответствуют его запросу.
Бывает специальная программная прослойка, которая хранит в себе определенные знания о том, в каком шарде какой диапазон данных лежит.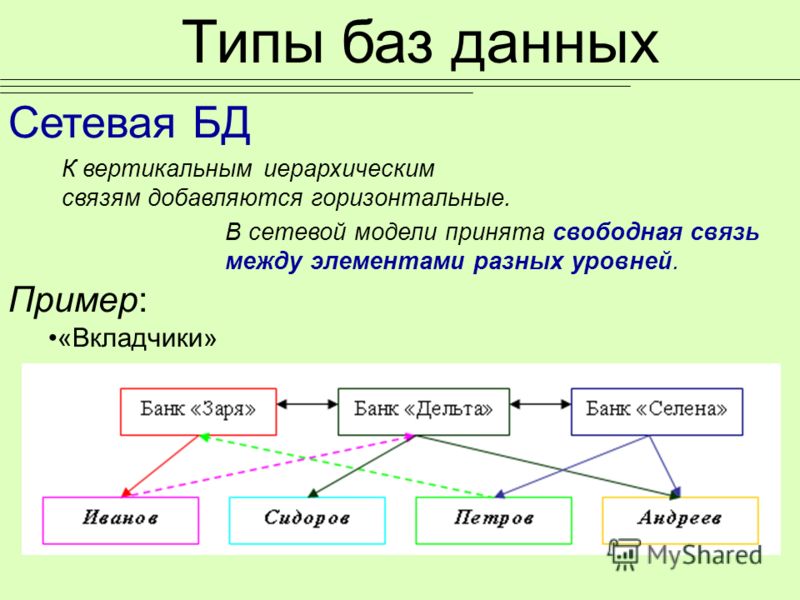 И, соответственно, идет уже именно туда, на тот самый узел, где лежат необходимые данные.
И, соответственно, идет уже именно туда, на тот самый узел, где лежат необходимые данные.
Бывает толстый клиент. Это когда мы не зашиваем сам клиент в отдельную прослойку, а зашиваем в него самого данные о том, как у нас шардированы данные.
Вот этот случай. Он, кстати, самый частоиспользуемый. Хорош тем, что наше приложение, наш клиент, даже тот код, который вы пишете, — он не знает о том, что таблица шардирована, хотя мы указываем это в config, в самой базе. Мы просто говорим ей — селект, и уже в самой БД идет разбиение на шарды и понимание, откуда селектить. Здесь же вы в самом коде определяете то, откуда читать данные.
Есть специальные сервисы, которые помогают структурировать и вообще апдейтить информаци. Сложно ее держать согласованной и актуальной. Мы что-то заселектили, записали новые данные. Или что-то изменилось, и нам нужно очень правильно маршрутизировать наши запросы. Есть специальные сервисы координации запросов. Один из них — Zookeper. Вы можете посмотреть, как они вообще работают.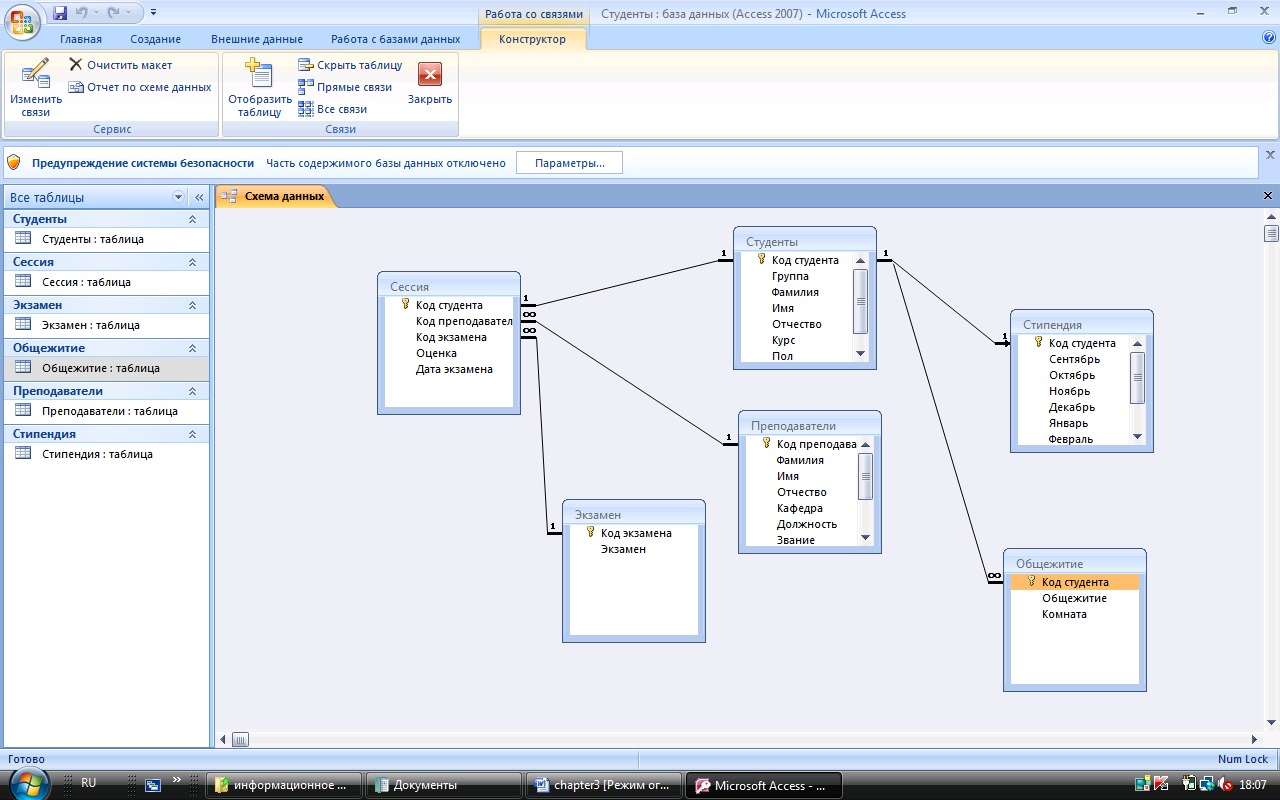 Очень интересная структура. Они сохранили очень много нервов и времени разработчикам.
Очень интересная структура. Они сохранили очень много нервов и времени разработчикам.
Что важно, какие аспекты нужно иметь в виду, когда вы секционируете? Важно понимать, по какому ключу мы будем делать разбиение на шарды. Пересобирать все эти данные достаточно дорого, поэтому очень важно не ошибаться с тем, как данные будут потенциально в будущем использоваться. Если мы хорошо и правильно сделали шардинг, то при наиболее частоиспользуемых запросах мы будем всегда знать, на какую реплику ходить.
Например, если мы по айдишникам пользователя храним все их данные на определенных репликах, тогда мы понимаем, что можем прийти на одну это реплику и все джойны сделать именно на ней. Но хранить именно по айдишнику — не самая крутая идея. Сейчас я расскажу, почему.
Если мы неправильно определили ключ в секционировании, если у нас очень сложный запрос, то нам и правда придется сходить на разные шарды, объединить все данные и только потом отдать их приложению. К счастью, большая часть СУБД делает это за нас. Но какие накладные расходы возникнут под плохо написанными запросами? Или под шардингом, который разбит по неправильному узлу?
Но какие накладные расходы возникнут под плохо написанными запросами? Или под шардингом, который разбит по неправильному узлу?
Про айдишники. Если система работает только с новыми пользователями и у нас по айдишникам увеличение, то все запросы будут идти в последний узел.
Что получится? Три других работающих машины будут стоять без дела. А эта машина будет просто гореть — так называемый hot spot. Это узкое место вашей потенциальной системы, то место, которое может даже отказать по коннектам.
Поэтому, когда мы определяем ключ шардирования, очень важно понимать, насколько сбалансированы будут эти узлы. Очень часто используются хэши, это такое более-менее нейтральное, сбалансированное расположение данных. Но если у вас хэш-функция на ключе, то вы не сможете выбирать, например, по диапазонам. Логично, потому что по диапазонам нельзя раскинуться в разные шарды.
По дате — то же самое. Если мы, например, аналитику раскидываем и сделаем шарды по дате, то, понятное дело, какой-нибудь один шард десятилетней давности вообще не будет использоваться.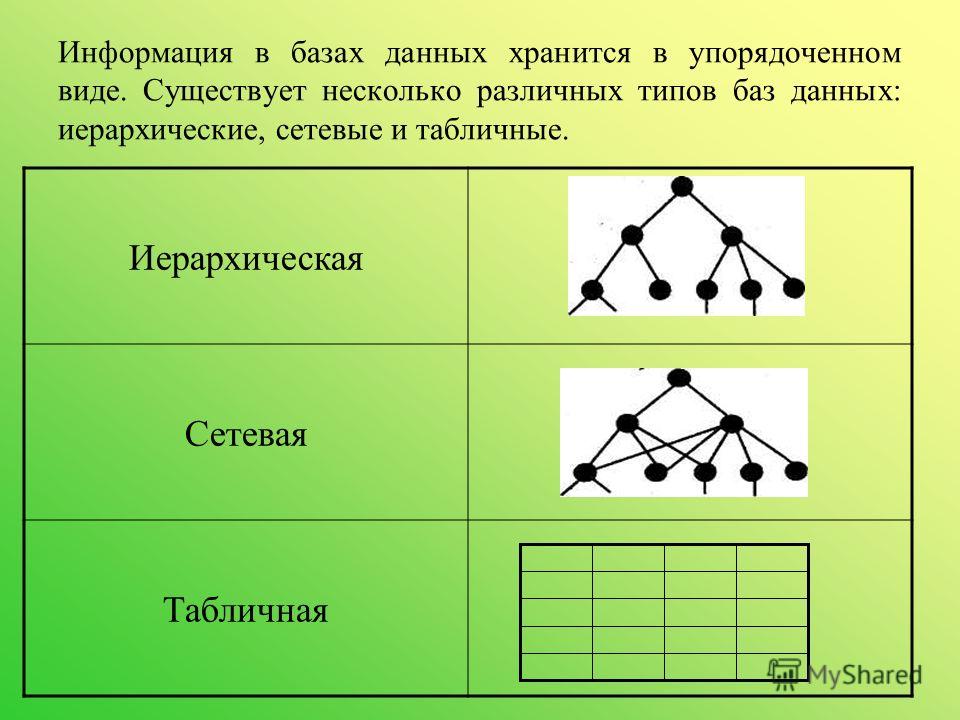 Нам это не выгодно. А пересобирать данные и перешардировать всегда очень дорого.
Нам это не выгодно. А пересобирать данные и перешардировать всегда очень дорого.
Отвечу на вопрос, который был до этого. Что лучше сделать — определить индексы или сделать шарды? Конечно, индексы.
Смотрите, шарды — это отдельные машины с целой поднятой инфраструктурой. И этот средний компонент содержит нечто похожее на индексы. Есть быстрый поиск по параметрам — где, куда ходить. Вот такое соотношение. Но если есть шардинг, итоговая картина будет вот такая:
Есть приложения, какая-то голова, которая знает, куда ходить. И есть шарды, на каждом из которых настроена реплика. Это реально очень большой overhead, если данных немного. То есть к шардингу нужно прибегать, только когда вы действительно достигли лимита вертикального масштабирования, когда покупать более дорогую машину не релевантно количеству ваших данных или доходам. Тогда можно купить несколько разных, более дешевых машин и выстроить на них вот такую архитектуру.
Для чего нужны реплики, я думаю, понятно: потому что шарды разбиваются, это куски баз данных, но они как бы уникальные. Они находятся только в этих местах. Мы их разбиваем еще и на копии, которые делают наши узлы отказоустойчивыми и подстраховывают на случай проблем.
Они находятся только в этих местах. Мы их разбиваем еще и на копии, которые делают наши узлы отказоустойчивыми и подстраховывают на случай проблем.
Самое главное: шардинг используется именно там, где вам не просто хочется разбить данные на классификацию, а именно там, где данных действительно много.
Теперь давайте подойдем больше к моделям данных и посмотрим, как данные можно хранить.
Реляционные БД, которые мы смотрели до этого, имеют огромное количество преимуществ, потому что они, в первую очередь, очень распространены и всем понятны. Они наглядно показывают отношение между объектами и обеспечивают целостность.
Но есть минус: они требуют четкой структуры. Есть таблица, в которую мы должны запихнуть все данные. Если посмотреть с точки зрения вообще всех сведений и фактов, которые мы собираем, они очень разные. То есть у нас может быть работа с продуктовыми данными, с данными пользователей, сообщений и так далее. Эти данные реально требуют четкой структуры, целостности. Для них идеально подходит реляционная база.
Для них идеально подходит реляционная база.
Но предположим, у нас есть, например, лог операций или описание объектов, где каждый объект имеет разные характеристики. Мы, конечно, можем это записать в джейсончик в реляционной БД и радоваться, что у нас он разрастается бесконечно.
А можем посмотреть на другие схемы, на другие системы хранения. NoSQL — очень кричащая аббревиатура, даже прямо провоцирующая — «нет SQL». Как она появилась?
Когда люди столкнулись с тем, что реляционные базы данных не везде успешны, они собрали конференцию, который нужен был хештег, — вот и придумали #NoSQL. Он прижился. Позже начали говорить не «нет SQL», а «не только SQL». Это просто все, что не реляционное: огромное семейство разных баз данных, которые не являются такими жестко структурированными, схематичными и табличными, как реляционные БД.
Семейство нереляционных моделей данных разделяют на четыре вида: ключ-значение, документоориентированные, столбцовые и графовые базы данных. Рассмотрим каждый из этих пунктов, узнаем, какие данные в каких из них лучше хранить и для чего они используются.
Ключ-значение. Это самое простое. Вот словарь, вот соотношение. Эта база данных, в которой данные хранятся по ключам, причем неважно, что лежит под конкретным ключом. У нас и сам ключ, и данные могут быть и простыми, и гораздо более сложными структурами. Такая база хороша тем, что она, подобно индексу, очень быстро ищет данные. Именно поэтому key-value очень часто используется для кэша. Преимущество в том, что наше value может быть разное в разных ключах.
Мы можем использовать ключ, например, для хранения сессий пользователя. Пользователь кликнул, мы записали это в value. Это такой schemaless, модель данных без определенной схемы, структуры значений. Благодаря тому, что это очень простая структура, она имеет высокую скорость и легко масштабируется. У нас уже есть ключи, и мы можем очень легко их шардировать, сделать их хэши. Это одна из самых высокомасштабируемых баз данных.
Примеры — Redis, Memcached, Amazon DynamoDB, Riak, LevelDB. Вы можете посмотреть особенности реализации именно key-value хранилищ.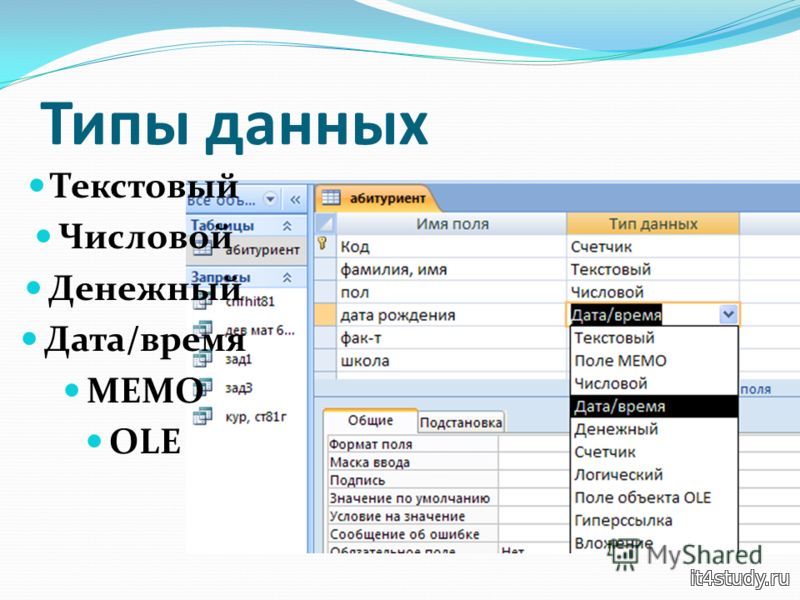
Документоориентированные базы данных очень похожи на key-value в какой-то из областей их применения. Но у них единицей является документ. Это такая сложная структура, по которой мы можем селектить определенные данные, делать балковые операции: Bulk insert, Bulk update.
Каждый документ может хранить в себе, как правило, XML, JSON или BSON — бинарно-сохраняемый JSON. Но сейчас это уже практически всегда JSON или BSON. Это тоже как бы пара ключ-значение, можно это себе представить как таблицу, в которой каждая строка имеет определенные характеристики, и мы по этим ключам можем из нее что-либо доставать.
Преимущество документоориентированных БД: они обладают очень высокой доступностью и гибкостью данных. В любой документ, в любой JSON вы можете записать абсолютно любой набор данных. И они очень часто применяются — например, когда нужно сделать какой-нибудь каталог и когда каждый продукт в каталоге может иметь разные характеристики.
Или, например, профили пользователей. Кто-то указал свой любимый фильм, кто-то — любимую еду. Чтобы не засовывать все в одно поле, которое будет хранить непонятно что, мы можем все записать в JSON документоориентированной базы.
Кто-то указал свой любимый фильм, кто-то — любимую еду. Чтобы не засовывать все в одно поле, которое будет хранить непонятно что, мы можем все записать в JSON документоориентированной базы.
Еще одна модель, в которой удобно хранить данные, — столбцовые БД. Их еще называют колоночными, column database.
Это очень интересная структура, которая используется, как мне кажется, практически во всех больших и сложных проектах. Такая база данных подразумевает, что мы храним данные на диске не строчками, а столбцами. Используется для очень быстрого поиска по огромному объему данных. Как правило — для аналитики, когда нужно проселектить значения только из определенных столбцов.
Представим, что у нас есть огромная таблица. И если бы мы хранили данные строчками, то было бы то, что внизу: огромное количество строчек. Для селекта даже по трем параметрам этой таблицы нам нужно пройти по всей таблице. А когда мы храним значения по столбцам, то при селекте по трем значениям нужно пройтись только по трем вот таким, грубо говоря, строчкам, потому что столбцы у нас записываются вот так. Проходя по этим трем строчкам, мы сразу получаем порядковый номер нужного нам значения и достаем его уже из других столбцов.
Проходя по этим трем строчкам, мы сразу получаем порядковый номер нужного нам значения и достаем его уже из других столбцов.
В чем преимущество таких баз данных? За счет того, что они ищут по маленькому объему данных, у них очень высокая скорость обработки запросов и большая гибкость данных, потому что мы можем добавлять любое количество столбцов, не меняя структуру. Здесь не как в реляционных БД, нам не нужно засовывать наши данные в определенные рамки.
Самые популярные столбцовые — это, наверное, Cassandra, HBase и ClickHouse. Испытайте их. Очень интересно инвертировать в голове отношение строк и столбцов. И это действительно эффективный и быстрый доступ к большому количеству данных.
Есть еще семейство графовых баз данных. Они также содержат узлы и ребра. Ребра используются, чтобы показать отношния, как и в реляционных базах. Но графовые базы могут расти бесконечно в разные стороны. Поэтому она более гибкая. У нее очень высокая скорость поиска, потому что не нужно селектить и джойнить по всем таблицам.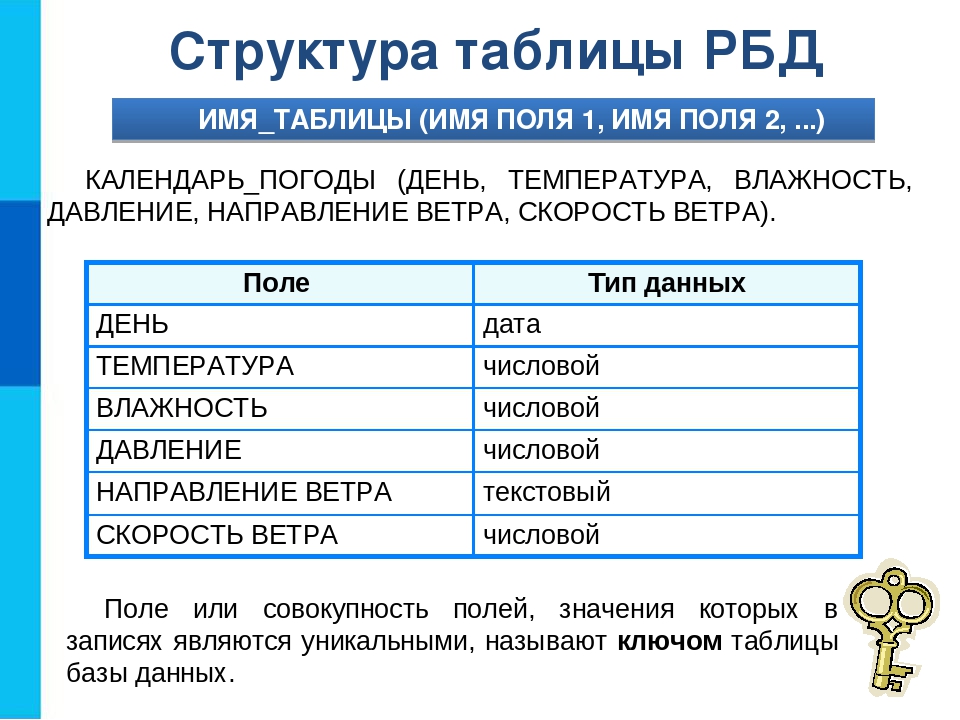 У нашего узла сразу есть ребра, которые показывают отношение ко всем разным объектам.
У нашего узла сразу есть ребра, которые показывают отношение ко всем разным объектам.
Для чего используются эти базы данных? Чаще всего — именно чтобы показать отношения. Например, в соцсетях можно ответить на вопрос, кто на кого подписан. У нас сразу есть линки на всех фолловеров нужного человека. Еще очень часто эти базы используются для определения схем мошенничества, потому что это тоже связано с демонстрацией связей операций друг с другом. Например, можно отследить, когда эта же банковская карта была использована в другом городе или когда с этого же айпишника заходили в аккаунт какого-нибудь другого пользователя.
Именно эти сложные отношения, которые помогают разрулить нестандартные ситуации, часто используются для анализа такого взаимодействия и взаимоотношения.
Нереляционные базы данных не заменяют реляционные. Они просто другие. Другой формат данных и другая логика их работы, не хуже и не лучше. Это просто другой подход к другим данным. И да, нереляционные базы используются очень часто. Их не нужно бояться, их нужно, наоборот, пробовать.
Их не нужно бояться, их нужно, наоборот, пробовать.
Если вы делаете кэш, то, естественно, берете какой-нибудь Redis, простое и быстрое key-value. Если у вас есть огромное количество логов для анализа, вы можете скинуть его в ClickHouse или в какую-нибудь колоночную базу, по которой потом будет очень удобно искать. Либо записать в документоориентированную базу, потому что там может быть разное значение документов. Это тоже может оказаться удобно для селекта.
Выбирайте модель данных в зависимости от того, какие данные вы будете использовать. Либо реляционная, либо нереляционная. Охарактеризуйте данные. Так вы сможете подобрать самое подходящее хранилище, которое в будущем сможете масштабировать.
Вы сегодня узнали очень много о самых разных проблемах и способах хранения данных. Еще раз повторю то, что я говорила в самом начале: не нужно знать прямо все досконально, не нужно копаться в чем-то одном. Если интересно — конечно, можно. Но важно знать о том, что это вообще существует, какие есть подходы и как вообще можно мыслить.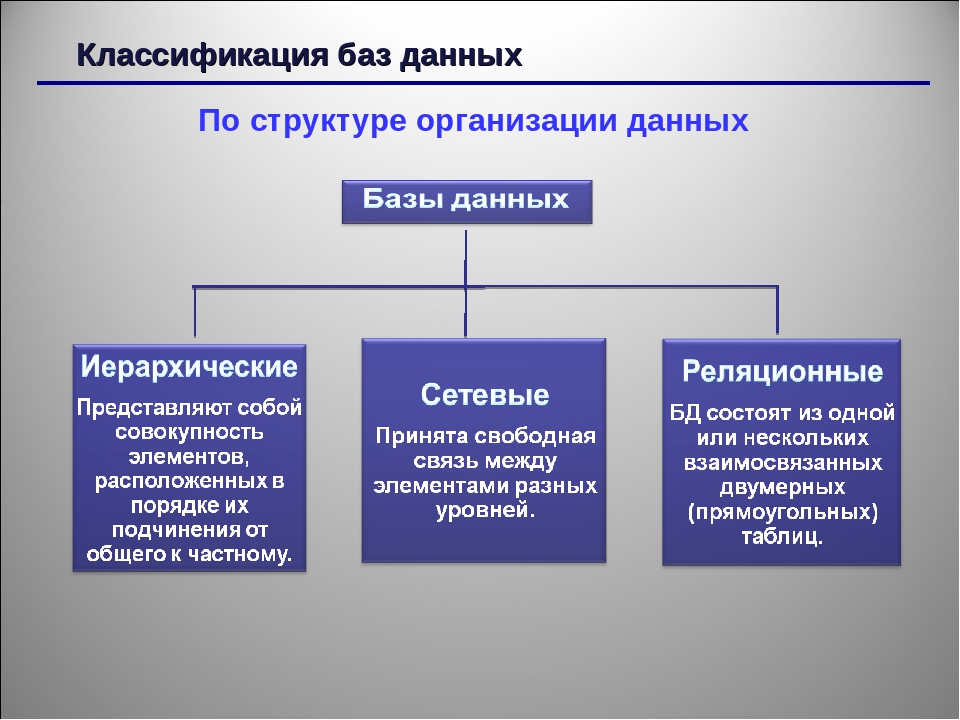 Если нужна отказоустойчивость, есть смысл сделать реплику. Предположим, я записала данные, но не увидела. Тогда, наверное, моя реплика дала лаг. Не нужно изобретать велосипеды — есть уже много готовых решений для разных задач. Расширяйте кругозор, а если появится баг или какая-нибудь другая проблема, вы по характеристикам бага поймете, где именно произошел сбой, сможете найти решение через поисковик. Спасибо за внимание.
Если нужна отказоустойчивость, есть смысл сделать реплику. Предположим, я записала данные, но не увидела. Тогда, наверное, моя реплика дала лаг. Не нужно изобретать велосипеды — есть уже много готовых решений для разных задач. Расширяйте кругозор, а если появится баг или какая-нибудь другая проблема, вы по характеристикам бага поймете, где именно произошел сбой, сможете найти решение через поисковик. Спасибо за внимание.
Типы данных в MS Access
Имена полей и тип данных в MS Access
Для определения поля таблицы обязательно задаются Имя поля (Field Name) и Тип данных (Data Type).
Имя поля (Field Name). Каждое поле в таблице должно иметь уникальное имя, удовлетворяющее соглашениям об именах объектов в Access. Оно является комбинацией из букв, цифр, пробелов и специальных символов, за исключением точки (.), восклицательного знака (!), надстрочного знака (`) и квадратных скобок ([ ]). Имя не может начинаться с пробела и содержать управляющие символы с кодами ASCII от 0 до 31. Максимальная длина имени 64 символа.
Максимальная длина имени 64 символа.
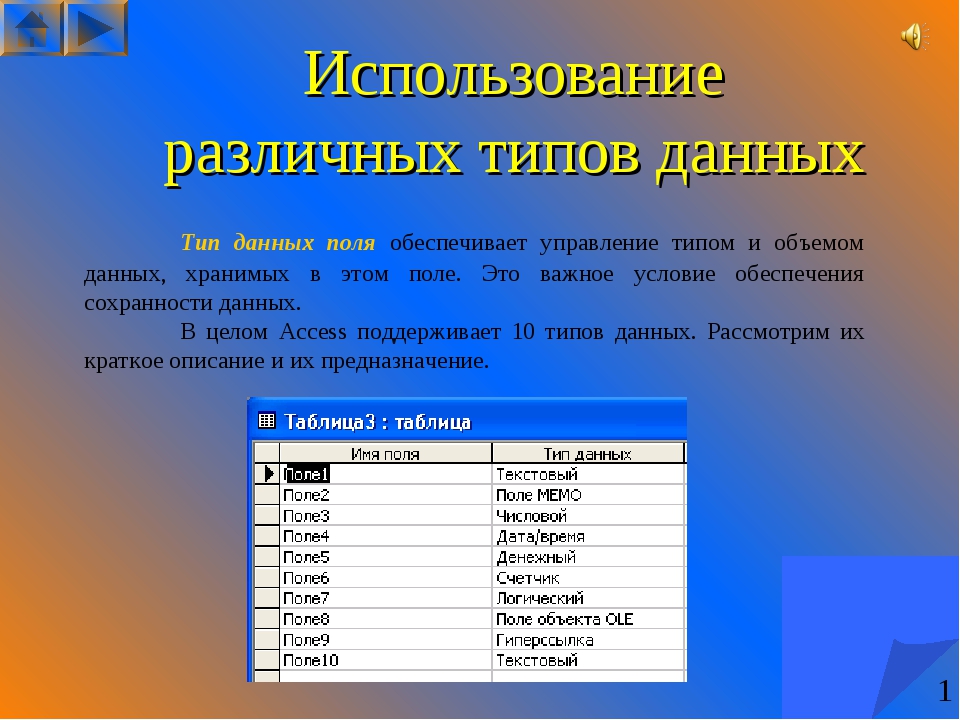
Тип данных в MS Access (Data Type). Тип данных определяется значениями, которые предполагается хранить в поле, и операциями, которые будут выполняться с этими значениями. В Access допускается использование двенадцати типов данных.
Рассмотрим вкратце типы данных в MS Access, виды, назначение и допустимый размер данных, которые могут назначаться полям таблицы в Access.
- Текстовый (Text) — используется для хранения текста или комбинаций алфавитно-цифровых знаков, не применяемых в расчетах (например, код товара). Максимальная длина поля 255 знаков.
- Поле МЕМО (Memo) — используется для хранения обычного текста или комбинаций алфавитно-цифровых знаков длиной более 255 знаков. Поля с этим типом данных в базах данных формата Access 2007 поддерживают также форматирование текста. Это единственный в Access тип данных, обеспечивающий встроенную поддержку отображения и хранения форматированного текста. Максимальный размер поля 1 Гбайт знаков или 2 Гбайт памяти (2 байта на знак) при программном заполнении полей, и 65 535 знаков при вводе данных вручную в поле и в любой элемент управления, связанный с этим полем.
- Числовой (Number) — служит для хранения числовых значений (целых или дробных), предназначенных для вычислений, исключением являются денежные значения, для которых используется тип данных Денежный (Currency). Размер поля 1, 2, 4 и 8 байтов, или 16 байтов (если используется для кода репликации) зависит от типа чисел, вводимых в поле.
- Дата/время (Date/Time) — используется для хранения значений даты и времени в виде 8-байтовых чисел двойной точности с плавающей запятой. Целая часть значения, расположенная слева от десятичной запятой, представляет собой дату. Дробная часть, расположенная справа от десятичной запятой, — это время. Хранение значений даты и времени в числовом формате позволяет выполнять различные вычисления с этими данными.
- Денежный (Currency) — используется для хранения денежных значений в виде 8-байтовых чисел с точностью до четырех знаков после запятой. Этот тип данных применяется для хранения финансовых данных и в тех случаях, когда значения не должны округляться.
- Счетчик (AutoNumber) — используется для уникальных числовых 4-байтовых значений, которые автоматически вводит Access при добавлении записи. Вводимые числа могут последовательно увеличиваться на указанное приращение или выбираться случайно. Обычно используются в первичных ключах.
- Логический (Yes/No) — применяется для хранения логических значений, которые могут содержать одно из двух значений: Да/Нет, Истина/Ложь или Вкл/Выкл. (8 битов = 1 байт). Используется 1 для значений Да и 0 для значений Нет. Размер равен 1 биту.
- Поле объекта OLE (OLE Object) — используется для хранения изображений, документов, диаграмм и других объектов из приложений MS Office и других программ Windows в виде растровых изображений, которые затем отображаются в элементах управления форм или отчетов, связанных с этим полем таблицы.
Чтобы в Access просматривать эти изображения, необходимо, чтобы на компьютере, использующем базу данных, был зарегистрирован OLE-сервер (про-грамма, поддерживающая этот тип файлов). Если для данного типа файлов OLE-сервер не зарегистрирован, отображается значок поврежденного изображения. - Гиперссылка (Hyperlink) — применяется для хранения ссылок на Web-узлы (URL-адреса), на узлы или файлы интрасети или локальной сети (UNC-адреса — стандартного формата записи пути), а также на узлы или файлы локального компьютера. Кроме того, можно использовать ссылку на объекты Access, хранящиеся в базе данных. Может хранить до 1 Гбайт данных.
- Вложение (Attachment) — используется для вложения в поле записи файлов изображений, электронных таблиц, документов, диаграмм и других файлов поддерживаемых типов точно так же, как в сообщения электронной почты. Вложенные файлы можно просматривать и редактировать в соответствии с заданными для поля параметрами. Эти поля не имеют ограничений, связанных с отсутствием зарегистрированных OLE-серверов. Более рационально используют место для хранения, чем поля с типом данных Поле объекта OLE (OLE Object), поскольку не создают растровые изображения исходного файла. Максимальная длина поля для сжатых вложений — 2 Гбайт, для несжатых — примерно 700 Кбайт в зависимости от степени возможного сжатия вложения.
- Вычисляемый (Calculated) — предназначен для создания вычисляемых полей: числовых, текстовых, денежных, дата/время, логических. Значение вычисляемого поля определяется выражением, записанным в поле и использующим другие поля текущей записи, некоторые встроенные функции и константы, связанные арифметическими, логическими или строковыми операторами.
- Мастер подстановок (Lookup Wizard) или Подстановка и отношения (Lookup & Relationship) — вызывает мастера подстановок, с помощью которого можно создать поле, позволяющее выбрать значения из списка, построенного на основе значений поля другой таблицы, запроса или фиксированного набора значений. Такое поле отображается как поле со списком. Если список построен на основе поля таблицы или запроса, тип данных и размер создаваемого поля определяется типом данных и размером привязанного столбца; если на основе набора значений — размером текстового поля, содержащего значение. Кроме того, мастер подстановок позволяет определить связь таблиц и включить проверку связной целостности данных.
 Максимальный размер поля 1 Гбайт знаков или 2 Гбайт памяти (2 байта на знак) при программном заполнении полей, и 65 535 знаков при вводе данных вручную в поле и в любой элемент управления, связанный с этим полем.
Максимальный размер поля 1 Гбайт знаков или 2 Гбайт памяти (2 байта на знак) при программном заполнении полей, и 65 535 знаков при вводе данных вручную в поле и в любой элемент управления, связанный с этим полем.

 Эти поля не имеют ограничений, связанных с отсутствием зарегистрированных OLE-серверов. Более рационально используют место для хранения, чем поля с типом данных Поле объекта OLE (OLE Object), поскольку не создают растровые изображения исходного файла. Максимальная длина поля для сжатых вложений — 2 Гбайт, для несжатых — примерно 700 Кбайт в зависимости от степени возможного сжатия вложения.
Эти поля не имеют ограничений, связанных с отсутствием зарегистрированных OLE-серверов. Более рационально используют место для хранения, чем поля с типом данных Поле объекта OLE (OLE Object), поскольку не создают растровые изображения исходного файла. Максимальная длина поля для сжатых вложений — 2 Гбайт, для несжатых — примерно 700 Кбайт в зависимости от степени возможного сжатия вложения.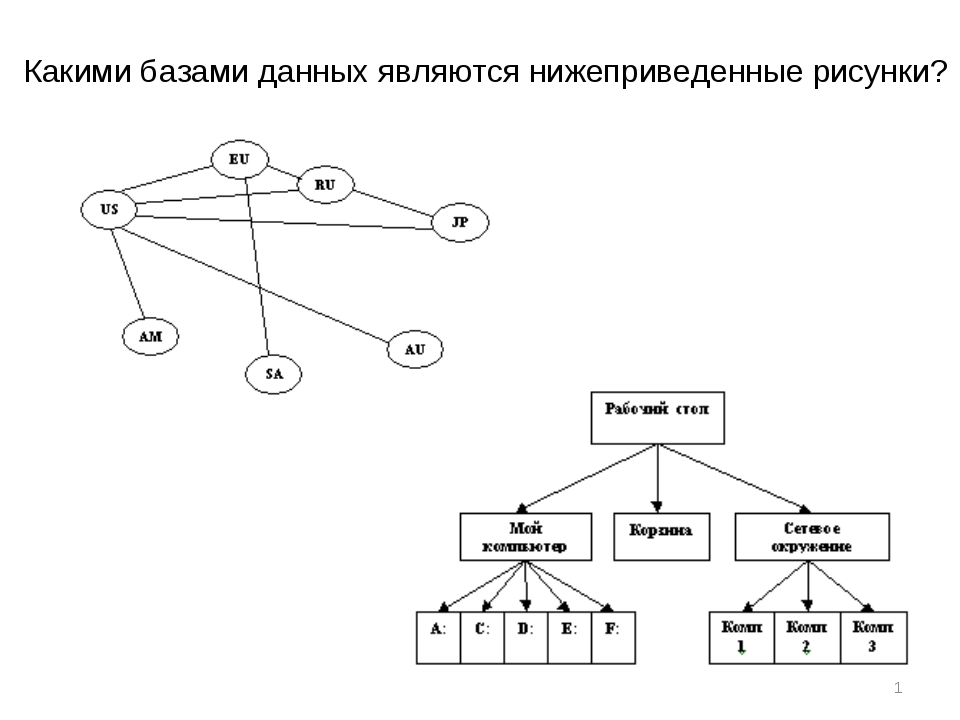 Такое поле отображается как поле со списком. Если список построен на основе поля таблицы или запроса, тип данных и размер создаваемого поля определяется типом данных и размером привязанного столбца; если на основе набора значений — размером текстового поля, содержащего значение. Кроме того, мастер подстановок позволяет определить связь таблиц и включить проверку связной целостности данных.
Такое поле отображается как поле со списком. Если список построен на основе поля таблицы или запроса, тип данных и размер создаваемого поля определяется типом данных и размером привязанного столбца; если на основе набора значений — размером текстового поля, содержащего значение. Кроме того, мастер подстановок позволяет определить связь таблиц и включить проверку связной целостности данных.Закрепим полученные знания просмотром видео:
Про основные свойства полей MS Access читаем тут.
Выбираем базу данных. Рассмотрим различные типы баз данных, а… | by Iuliia Averianova | NOP::Nuances of Programming
Опытный ли вы инженер-программист или студент, пишущий университетский проект, в какой-то момент вам нужно будет выбрать базу данных для ваших целей.
Если вы ранее уже использовали какую-то БД, вы можете просто сказать: “Я выберу эту базу, потому что знаком с ней”. Это вполне подходящее решение, когда производительность не критична для вашего проекта. В противном случае выбор неподходящей базы станет препятствием при расширении проекта. Исправить ошибку может быть довольно сложно. Даже если вы работаете в зрелом проекте, который использует конкретную БД, важно знать ее ограничения и понимать, когда стоит добавить базу другого типа к вашему стеку. Комбинирование нескольких баз данных довольно распространено.
В противном случае выбор неподходящей базы станет препятствием при расширении проекта. Исправить ошибку может быть довольно сложно. Даже если вы работаете в зрелом проекте, который использует конкретную БД, важно знать ее ограничения и понимать, когда стоит добавить базу другого типа к вашему стеку. Комбинирование нескольких баз данных довольно распространено.
Еще одна причина разобраться с базами данных и их свойствами: вопросы о БД очень распространены на собеседованиях. Когда вам будет нужна короткая шпаргалка, прокрутите в конец поста.
Эти базы состоят из связанных между собой таблиц. Каждая строка таблицы представляет собой запись. Почему такие базы называются реляционными? Потому, что они строятся на отношениях между объектами, описанными в БД.
Допустим, у вас есть таблица с информацией о студентах и таблица оценок курса (курс, оценка, идентификатор студента). Каждая строка с оценкой соотносится с записью о студенте. На диаграмме ниже значение в столбце Student ID указывает на строки в таблице Students по их значению в столбце ID.
Все данные из реляционных баз данных запрашиваются с помощью SQL-подобных языков, имеющих встроенную поддержку операции объединения. Реляционные базы позволяют индексировать столбцы для быстрых запросов. Из-за своей структурированной природы, схема реляционных баз данных определяется до ввода данных. Примеры таких баз:
- MySQL.
- PostgreSQL.
- Oracle.
- MS SQL Server.
В реляционных базах данных все структурировано по колонкам и столбцам. В свою очередь, в нереляционных базах нет общей структурированной схемы для записей. Большая часть NoSQL баз содержит JSON записи. Разные записи могут содержать разные поля.
Это семейство БД называется NoSQL (Not only SQL — не только SQL), так как многие NoSQL базы данных поддерживают SQL, но это не самый лучший вариант их использования. Cуществует 4 типа баз данных NoSQL.
Документные
Атомарной (неделимой) единицей таких БД является документ. Каждый документ — JSON, схема может различаться в разных документах и содержать разные поля.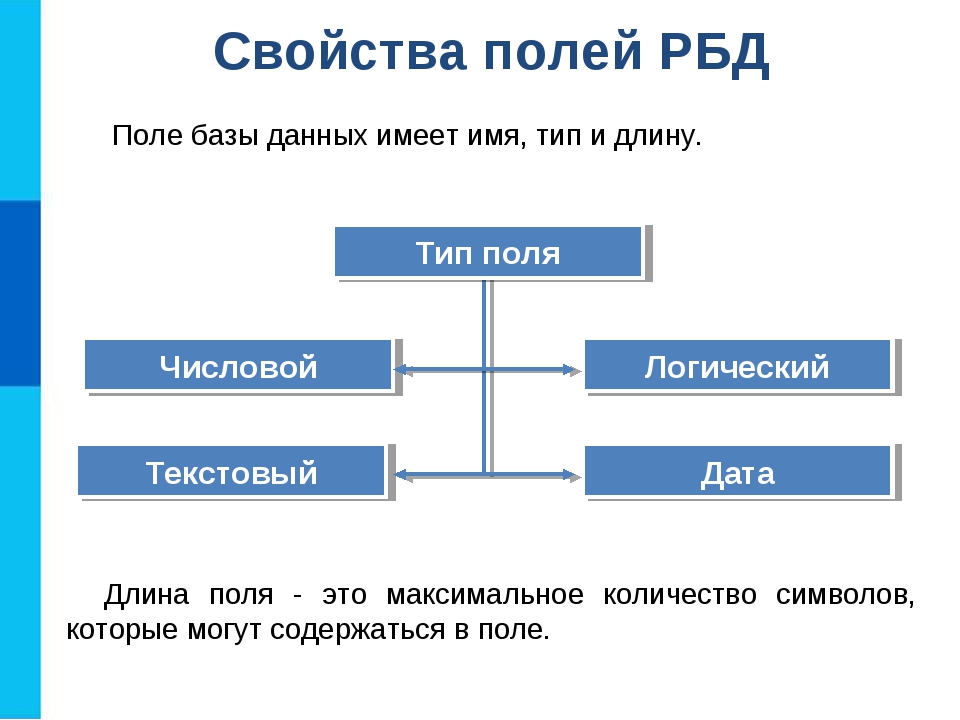 Документные БД позволяют индексировать некоторые поля документа для ускорения запросов на основе этих полей. Следовательно, во всех документах есть поля.
Документные БД позволяют индексировать некоторые поля документа для ускорения запросов на основе этих полей. Следовательно, во всех документах есть поля.
Использование
Поскольку различные записи независимы друг от друга (логически и структурно), эти базы данных поддерживают параллельные вычисления, что позволяет легко анализировать большой объём данных. Примеры:
Колоночные
Атомарная единица таких БД — колонка таблицы. Данные сохраняются столбец за столбцом, что делает колоночные запросы очень эффективными, и, поскольку данные в каждой колонке однородны, это позволяет лучше сжимать данные.
Использование
В тех случаях, когда удобно делать запросы к подмножеству столбцов (оно не обязательно должно быть одинаковым каждый раз!). Колоночные БД обрабатывают такие запросы очень быстро, так как читают только конкретные колонки (в то время как строчные БД должны читать строки полностью).
В науке о данных часто бывает, что каждая колонка представляет определенную характеристику. Как специалист по данным я часто тренирую свои модели на подмножествах характеристик и проверяю отношения между ними и оценками (корреляция, дисперсия, значимость). То же подходит и для логов— в них зачастую множество полей, но при каждом запросе используются только некоторые. Например:
Как специалист по данным я часто тренирую свои модели на подмножествах характеристик и проверяю отношения между ними и оценками (корреляция, дисперсия, значимость). То же подходит и для логов— в них зачастую множество полей, но при каждом запросе используются только некоторые. Например:
Ключ-значение
В этих БД запросы только на основе ключа — вы запрашиваете ключ и получаете его значение.
Такие БД не поддерживают запросы между различными значениями записей, вроде такого: выбрать все записи, где город — Нью-Йорк.
Полезное свойство этих БД — поле времени жизни (Time-to-Live, TTL), в котором можно задать отдельно для каждой записи и состояния, когда их нужно удалить из БД.
Достоинства
Это очень быстрые БД. Во-первых, потому что используют уникальные ключи, во-вторых, потому что большинство БД типа ключ-значение хранят данные в оперативной памяти, что обеспечивает быстрый доступ к данным.
Недостатки
Необходимо определять уникальные ключи, хорошие идентификаторы, основанные на заранее известных вам данных.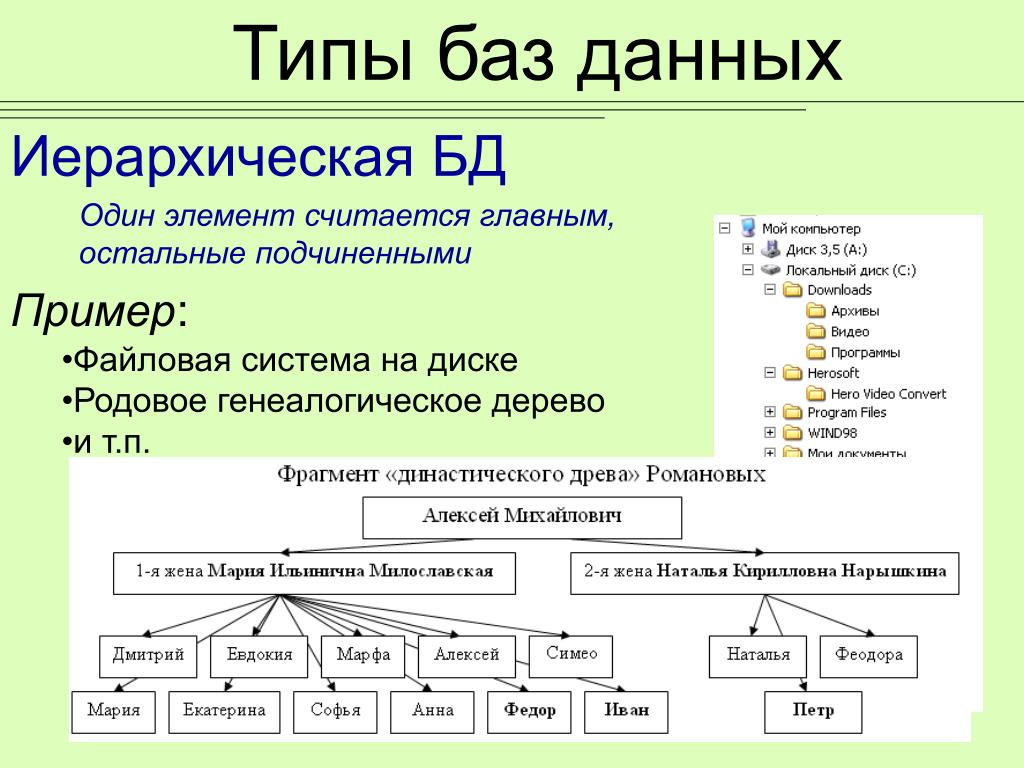 Зачастую они дороже, чем другие типы баз данных, так как используют оперативную память.
Зачастую они дороже, чем другие типы баз данных, так как используют оперативную память.
Использование
В основном используются для кэширования, потому что быстрые и не требуют сложных запросов. Поле времени жизни для кэширования также очень полезно. Такие БД могут использоваться для любых данных, которые требуют быстрых запросов и соответствуют формату ключ-значение. Примеры таких баз:
Графовые
Содержат узлы, отображающие объекты, а также ребра, отображающие отношения между ними.
Использование
Созданы для работы с графовыми данными, такими как сети знаний или социальные сети. Примеры баз:
Как вы уже догадались, универсального решения нет. Самые распространенные БД для регулярного использования — реляционные и документные. Давайте сравним их.
Достоинства реляционных баз- Имеют простую структуру, которая подходит к большинству типов данных.
- Используют SQL, который широко распространен и по умолчанию поддерживает операции объединения.
- Позволяют быстро обновлять данные. Вся БД хранится на одном компьютере, а отношения между записями используются как указатели, то есть вы можете обновить одну запись — и все связанные с ней записи немедленно обновятся.
- Реляционные БД также поддерживают атомарные транзакции. Что это? Предположим, я хочу перевести X долларов от Алисы к Бобу. Я хочу осуществить 3 действия: уменьшить баланс Алисы на X, увеличить баланс Боба на X и задокументировать транзакцию. Я могу назначить эти действия атомарной единицей БД — или произойдут все действия, или ни одно. Это защищает от ошибок при сбоях.

Недостатки реляционных баз
- Поскольку каждый запрос выполняется к целой таблице, время выполнения запроса зависит от размера таблицы. Это важное ограничение, которое заставляет нас сохранять таблицы относительно небольшими и проводить оптимизацию БД для ее масштабирования.
- Масштабирование осуществляется добавлением вычислительных мощностей к компьютеру, на котором установлена БД, этот метод называется вертикальное масштабирование. Почему это недостаток? Потому, что существует предел вычислительной мощности компьютера, добавление ресурсов провоцирует простой.
- Не поддерживаются объекты на основе ООП, даже представление простых списков очень сложно.
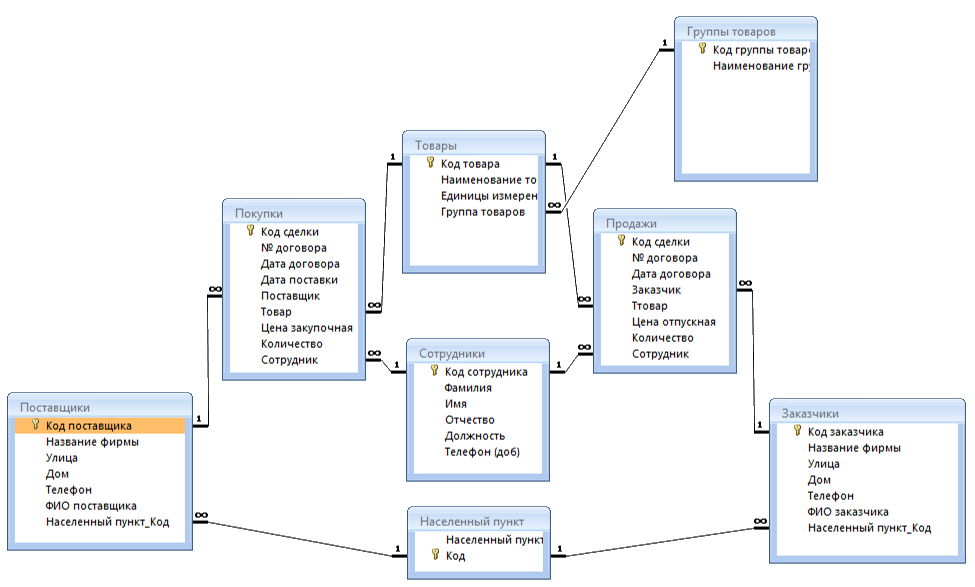 Почему это недостаток? Потому, что существует предел вычислительной мощности компьютера, добавление ресурсов провоцирует простой.
Почему это недостаток? Потому, что существует предел вычислительной мощности компьютера, добавление ресурсов провоцирует простой.Достоинства документных баз
- Позволяют хранить объекты с разной структурой.
- Могут отображать почти все структуры данных, включая объекты на основе ООП, списки и словари, используя старый добрый JSON.
- Несмотря на то, что NoSQL не схематичны по своей природе, они часто поддерживают проверку схемы. Это значит, что вы можете сделать коллекцию со схемой. Эта схема не будет простой, как таблица: это будет JSON схема со специфическими полями.
- Запросы к NoSQL очень быстрые — каждая запись независима и, следовательно, время запроса не зависит от размера базы. По той же причине эта БД поддерживает параллельность.
- В NoSQL масштабирование БД осуществляется добавлением компьютеров и распределением данных между ними, этот метод называется горизонтальное масштабирование. Оно позволяет автоматически добавлять ресурсы к БД, когда нам нужно, не провоцируя простои.
 Оно позволяет автоматически добавлять ресурсы к БД, когда нам нужно, не провоцируя простои.
Оно позволяет автоматически добавлять ресурсы к БД, когда нам нужно, не провоцируя простои.Недостатки документных баз
- Обновление данных —медленный процесс в документной БД, потому что данные могут быть распределены между компьютерами и могут дублироваться.
- Атомарные транзакции по умолчанию не поддерживаются. Вы можете сами добавить их в код, используя механизм проверки и возврата, но, поскольку записи распределены между компьютерами, транзакция не может быть атомарной единицей, а значит, может возникнуть состояние гонки.
- Для кэширования используем БД типа ключ-значение.
- Для графов— графовые БД.
- Если удобно делать запросы по колонкам или характеристикам — колоночные БД.
- Для всех остальных случаев реляционные или документные базы данных.
Читайте также:
Понятие базы данных (БД). Типы баз данных, их преимущества и недостатки. Понятие системы управления базами данных (СУБД)
База данных – совокупность взаимосвязанных данных, которые можно использовать для большого числа приложений, быстро получать и модифицировать необходимую информацию.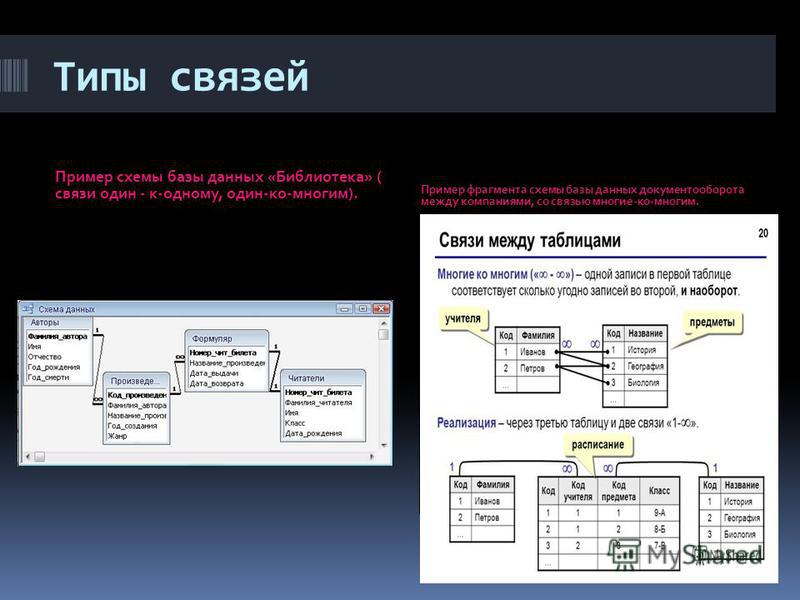
Модели базы данных базируются на современном подходе к обработке информации. Структура информации базы позволяет формировать логические записи их элементов и их взаимосвязи. Взаимосвязи могут быть: один к одному, один ко многому и многие ко многим.
Применение того или иного типа взаимосвязи определены тремя моделями базы данных: иерархической, сетевой, реляционной.
Иерархическая модель представлена в виде древовидного графа. Достоинство этой модели в том, что она позволяет описать структуру данных как на логическом, так и на физическом уровне. Ее недостаток – жесткая фиксированность взаимосвязи между элементами.
В связи с этим любые изменения связей требуют изменения ее структуры. Кроме того, быстрота доступа достигнута за счет потери информационной гибкости, т.е. за один проход по древу невозможно получить информацию, расположенную по другой ветви связи. Данная модель реализует тип связи один ко многим.
Сетевая модель базы данных представлена в виде диаграммы связей.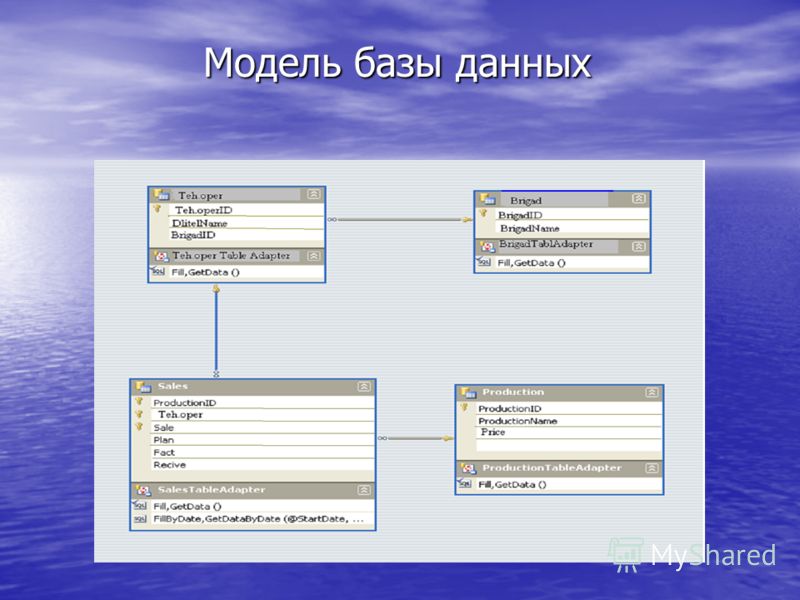 В сетевой модели допустимы любые виды связей между записями, отсутствуют ограничения на число обратных связей. Используется принцип многие ко многим. К достоинству этой модели относится большая информационная гибкость по сравнению с иерархической моделью, однако сохраняется недостаток – жесткость структуры.
В сетевой модели допустимы любые виды связей между записями, отсутствуют ограничения на число обратных связей. Используется принцип многие ко многим. К достоинству этой модели относится большая информационная гибкость по сравнению с иерархической моделью, однако сохраняется недостаток – жесткость структуры.
При необходимости частой реорганизации информационной базы применяют наиболее совершенную модель базы данных – реляционную, в которой отсутствуют отличия между объектами и взаимосвязями. Тип связи такой модели – один к одному. В этой модели связи между объектами представлены в виде двумерных таблиц – отношений.
Поскольку любую структуру данных можно преобразовать в простую двухмерную таблицу, а такое представление является наиболее удобным и для пользователя, и для машины, подавляющее большинство современных информационных систем работает именно с такими таблицами, т.е. с реляционными базами данных.
Отношения обладают следующими свойствами:
- каждый элемент – один элемент данных;
- повторяющиеся группы отсутствуют;
- элементы столбца имеют одинаковую природу;
- в таблице не повторяются строки;
- строки и столбцы можно просматривать в любом порядке.
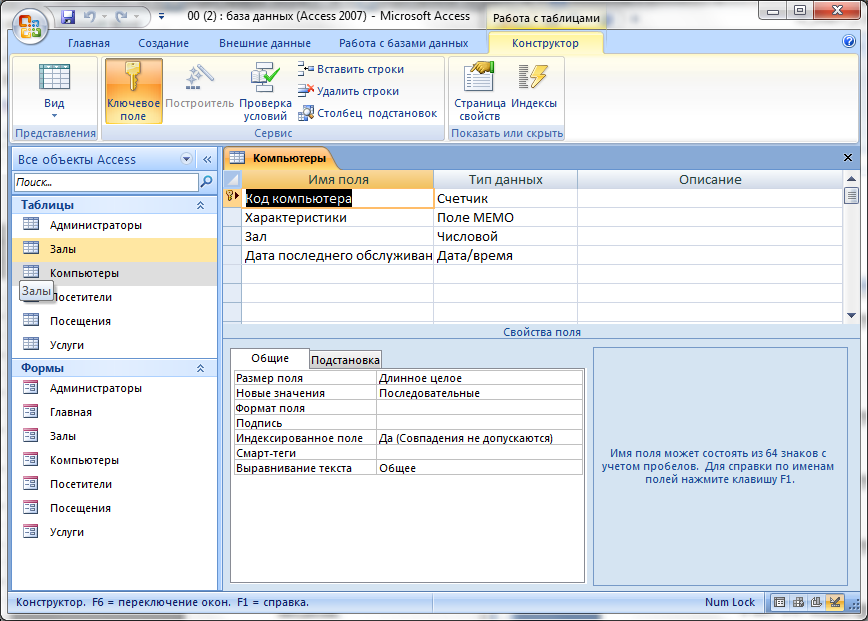
Преимущество данной модели:
- простота логической модели;
- гибкость системы;
- независимость данных;
- возможность построения простого языка манипулирования данными с помощью математической теории реляционной алгебры. Именно наличие строгого математического аппарата обусловило ее наибольшее распространение и перспективность в современных компьютерных технологиях.
Если прикладная информационная система опирается на некоторую систему управления данными, обладающую свойствами: поддержание логически согласованного набора файлов; обеспечение языка манипулирования данными; восстановление информации после разного рода сбоев; реально параллельная работа нескольких пользователей, то эта система управления данными является системой управления базами данных (СУБД).
Основные функции СУБД:
1. Непосредственное управление данными во внешней памяти
Эта функция включает обеспечение необходимых структур внешней памяти как для хранения данных, непосредственно входящих в БД, так и для служебных целей, например, для убыстрения доступа к данным. В некоторых реализациях СУБД активно используются возможности существующих файловых систем, в других работа производится вплоть до уровня устройств внешней памяти. В развитых СУБД пользователи в любом случае не обязаны знать, использует ли СУБД файловую систему, и если использует, то как организованы файлы. В частности, СУБД поддерживает собственную систему именования объектов БД.
В некоторых реализациях СУБД активно используются возможности существующих файловых систем, в других работа производится вплоть до уровня устройств внешней памяти. В развитых СУБД пользователи в любом случае не обязаны знать, использует ли СУБД файловую систему, и если использует, то как организованы файлы. В частности, СУБД поддерживает собственную систему именования объектов БД.
2. Управление буферами оперативной памяти
СУБД обычно работают с БД значительного размера; по крайней мере этот размер обычно существенно больше доступного объема оперативной памяти. Понятно, что если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся (система будет работать со скоростью устройства внешней памяти.
Практически единственным (способом реального увеличения этой скорости является буферизация данных в оперативной памяти. При этом, даже если операционная система производит общесистемную буферизацию (как в случае ОС UNIX), этого недостаточно для целей СУБД, которая располагает гораздо большей информацией о полезности буферизации той или иной части БД. Поэтому в развитых СУБД поддерживается собственный набор буферов оперативной памяти с собственной дисциплиной замены
Поэтому в развитых СУБД поддерживается собственный набор буферов оперативной памяти с собственной дисциплиной замены
буферов.
3. Управление транзакциями
Транзакция — это последовательность операций над БД, рассматриваемых СУБД как единое целое. Либо транзакция успешно выполняется и СУБД фиксирует изменения БД, произведенные этой транзакцией, во внешней памяти, либо ни одно из этих изменений никак не отражается на состоянии БД. Понятие транзакции необходимо для поддержания логической целостности БД.
Каждая транзакция начинается при целостном состоянии БД и оставляет это состояние целостным после своего завершения, делает очень удобным использование понятия транзакции как единицы активности пользователя по отношению к БД. При соответствующем управлении параллельно выполняющимися транзакциями со стороны СУБД каждый из пользователей может в принципе ощущать себя единственным пользователем СУБД.
4. Журнализация
Одним из основных требований к СУБД является надежность хранения данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. Обычно рассматриваются два возможных вида аппаратных сбоев: так называемые мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера (например, аварийное выключение питания), и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти.
Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. Обычно рассматриваются два возможных вида аппаратных сбоев: так называемые мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера (например, аварийное выключение питания), и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти.
Примерами программных сбоев могут быть: аварийное завершение работы СУБД (по причине ошибки в программе или в результате некоторого аппаратного сбоя) или аварийное завершение пользовательской программы, в результате чего некоторая транзакция остается незавершенной. Первую ситуацию можно рассматривать как особый вид мягкого аппаратного сбоя; при возникновении последней требуется ликвидировать последствия только одной транзакции.
Поддержание надежности хранения данных в БД требует избыточности хранения данных, причем та часть данных, которая используется для восстановления, должна храниться особо надежно.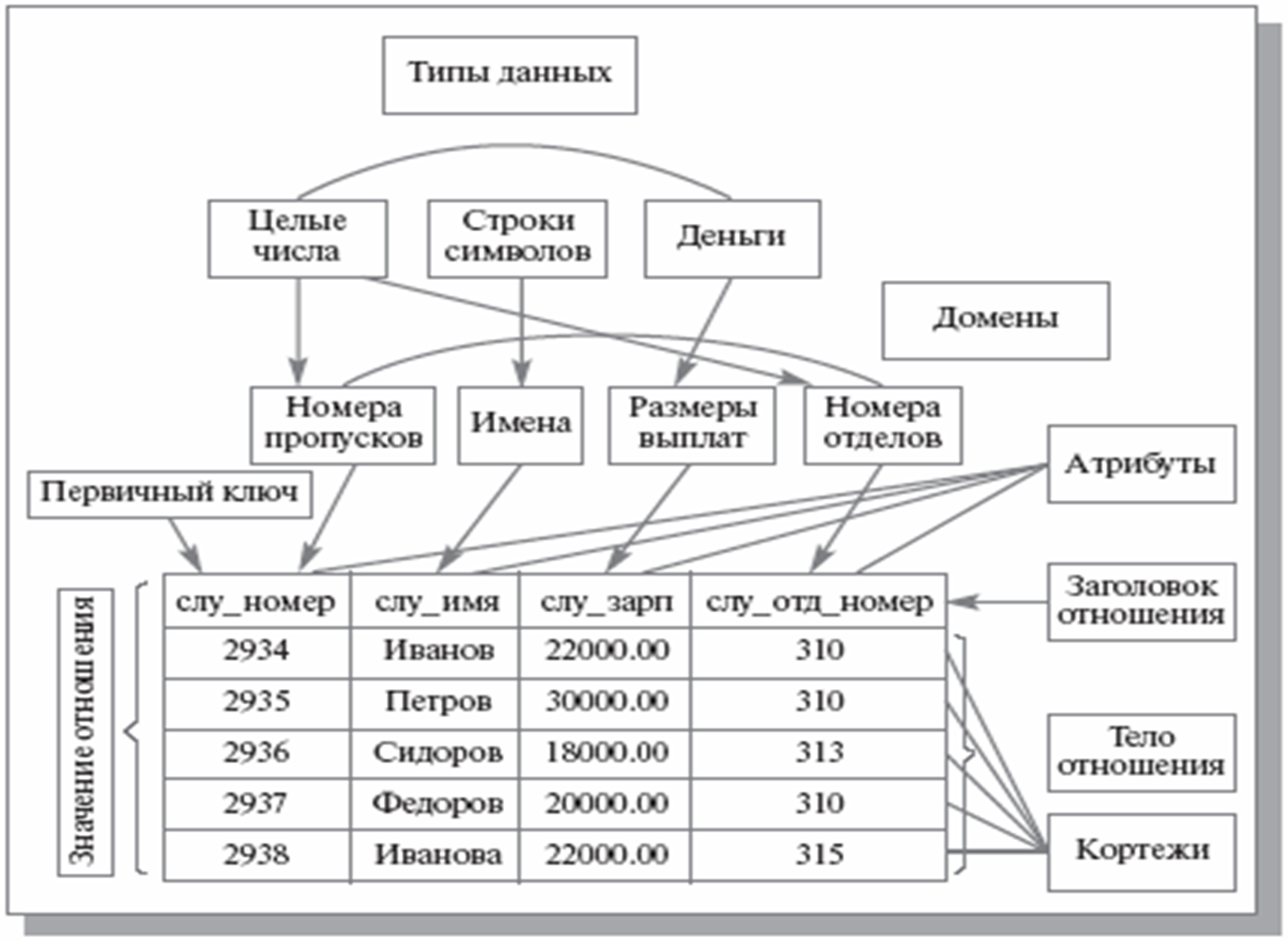 Наиболее распространенным методом поддержания такой избыточной информации является ведение журнала изменений БД.
Наиболее распространенным методом поддержания такой избыточной информации является ведение журнала изменений БД.
Журнал — это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью (иногда поддерживаются две копии журнала, располагаемые на разных физических дисках), в которую поступают записи обо всех изменениях основной части БД.
Для восстановления БД после жесткого сбоя используют журнал и архивную копию БД. Грубо говоря, архивная копия — это полная копия БД к моменту начала заполнения журнала (имеется много вариантов более гибкой трактовки смысла архивной копии). Конечно, для нормального восстановления БД после жесткого сбоя необходимо, чтобы журнал не пропал.
Восстановление БД состоит в том, что исходя из архивной копии по журналу воспроизводится работа всех транзакций, которые закончились к моменту сбоя. Можно даже воспроизвести работу незавершенных транзакций и продолжить их работу после завершения восстановления.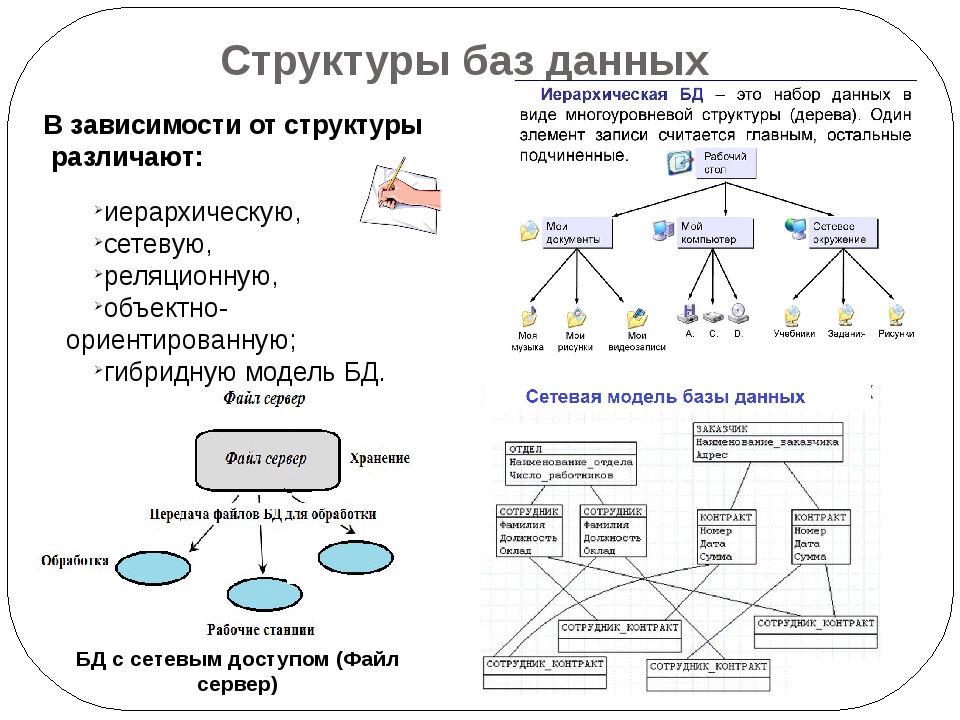 Однако в реальных системах это обычно не делается, поскольку процесс восстановления после жесткого сбоя является достаточно длительным.
Однако в реальных системах это обычно не делается, поскольку процесс восстановления после жесткого сбоя является достаточно длительным.
5. Поддержка языков БД
Для работы с базами данных используются специальные языки, в целом называемые языками баз данных. В ранних СУБД поддерживалось несколько специализированных по своим функциям языков. Чаще всего выделялись два языка — язык определения схемы БД (SDL) и язык манипулирования данными (DML). SDL служил главным образом для определения логической структуры БД, т.е. той структуры БД, какой она представляется пользователям. DML содержал набор операторов манипулирования данными, т.е. операторов, позволяющих заносить данные в БД, удалять, модифицировать или выбирать существующие данные.
В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с базами данных.
Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language), который сочетает средства SDL и DML, т. е. позволяет определять схему реляционной БД и манипулировать данными. Внутренняя часть СУБД (ядро) вообще не работает с именами таблиц и их столбцов.
е. позволяет определять схему реляционной БД и манипулировать данными. Внутренняя часть СУБД (ядро) вообще не работает с именами таблиц и их столбцов.
Классификация систем управления базами данных (самостоятельно).
Организация типичной СУБД и состав ее компонентов соответствует рассмотренному набору функций.
Логически в современной реляционной СУБД можно выделить наиболее внутреннюю часть — ядро СУБД (часто его называют Data Base Engine), компилятор языка БД (обычно SQL), подсистему поддержки времени выполнения, набор утилит. В некоторых системах эти части выделяются явно, в других — нет, но логически такое разделение можно провести во всех СУБД.
Ядро СУБД отвечает за управление данными во внешней памяти, управление буферами оперативной памяти, управление транзакциями и журнализацию. Соответственно, можно выделить такие компоненты ядра (по крайней мере, логически, хотя в некоторых системах эти компоненты выделяются явно), как менеджер данных, менеджер буферов, менеджер транзакций и менеджер журнала.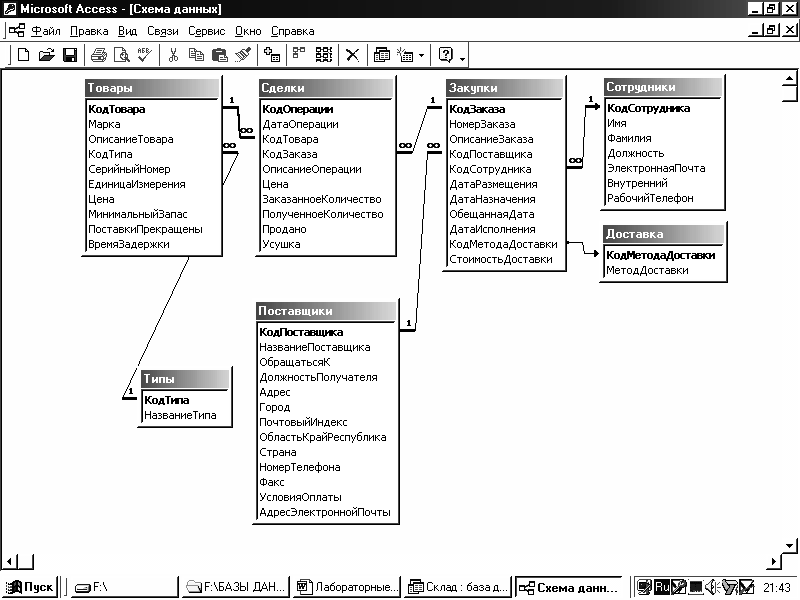
Функции этих компонентов взаимосвязаны, и для обеспечения корректной работы СУБД все эти компоненты должны взаимодействовать по тщательно продуманным и проверенным протоколам.
Основной функцией компилятора языка БД является компиляция операторов языка БД в некоторую выполняемую программу. Компилятор должен решить, каким образом выполнять оператор языка прежде, чем произвести программу. Применяются достаточно сложные методы оптимизации операторов.
В отдельные утилиты БД обычно выделяют такие процедуры, которые слишком накладно выполнять с использованием языка БД, например, загрузка и выгрузка БД, сбор статистики, глобальная проверка целостности БД и т.д. Утилиты программируются с использованием интерфейса ядра СУБД, а иногда даже с проникновением внутрь ядра.
Типы связей в реляционных базах данных
Практически всегда БД не ограничивается одной таблицей. Сложно представить себе какой-либо бизнес-процесс на предприятии, который мог бы сконцентрироваться только на одном предмете в плане информации.
Рассмотрим пример учебной базы данных. Имеется отдел, который занимается обработкой звонков, поступающих на различные линии. Линии обслуживаются конкретными операторами. Операторы состоят в разных группах под присмотром супервайзеров.
Только из данного краткого описания можно выделить несколько самостоятельных объектов:
- Телефонные линии обслуживания;
- Сотрудники отдела;
- Должности сотрудников;
- Группы, по которым распределены сотрудники;
- Звонки.
Ознакомившись с диаграммой базы данных, можно обратить внимание на то, что некоторая информация из одних таблиц присутствует в других, т.е. между ними имеются связи.
В нашем конкретном случае, все таблицы можно соединить между собой. Чтобы понять, как это правильно сделать, необходимо рассмотреть типы связей.
Логику соединения таблиц в БД важно понять с самого начала изучения SQL, так как наверняка Вы не будете писать запросы только к одной таблице.
Всего существует 3 типа связей:
Примечание:
В данном материале обозначения связей приводятся на примере MS SQL Server. В иных СУБД они могут обозначаться по-разному, но у Вас не должно возникнуть проблем с определением их типа, т.к. они либо очень похожи, либо интуитивно понятны.
Связь «Один к одному»
Связь один к одному образуется, когда ключевой столбец (идентификатор) присутствует в другой таблице, в которой тоже является ключом либо свойствами столбца задана его уникальность (одно и тоже значение не может повторяться в разных строках).
На практике связь «один к одному» наблюдается не часто. Например, она может возникнуть, когда требуется разделить данных одной таблицы на несколько отдельных таблиц с целью безопасности.
В учебной безе данных нет подходящего примера, но гипотетически могла бы существовать необходимость разделения таблицы сотрудников.
Пример:
Представьте, что базой данных пользуются несколько менеджеров и аналитиков, а таблица «Сотрудники» содержит те же столбцы, что и учебная база. Следовательно, доступ к персональным данным может получить любой из упомянутых работников.
Следовательно, доступ к персональным данным может получить любой из упомянутых работников.
Чтобы устранить возможность утечки конфиденциальной информации, принимается решение о переносе информации паспортных данных в отдельную таблицу, доступ к которой предоставляется ограниченному кругу лиц.
Связь «Один ко многим»
В типе связей один ко многим одной записи первой таблицы соответствует несколько записей в другой таблице.
Рассмотрим связь учебной базы данных между должностями и сотрудниками, которая относится к рассматриваемому типу.
Записи должностей в таблице «Должность» уникальны, так как нет смысла повторно создавать имеющуюся запись. Записи в таблице «Сотрудники» также уникальны, но несколько различных сотрудников могут находиться на одинаковой должностной позиции.
Символ ключа на конце связи указывает, что таблица, к которой этой конец прилегает, находится на стороне «один» (связанный столбец является первичным ключом), а символ бесконечности находится на стороне «многие» (такой столбец является внешним ключом).
Связь «Многие ко многим»
Если нескольким записям из одной таблицы соответствует несколько записей из другой таблицы, то такая связь называется «многие ко многим» и организовывается посредством связывающей таблицы.
В нашей базе подобное наблюдается только между таблицами с сотрудниками и линиями.
Из диаграммы видно, что имеются две связи «один ко многим» (один сотрудник может обрабатывать несколько телефонных линий, и одну линию могут обрабатывать несколько сотрудников), но в совокупности они образуют связь «многие ко многим».
Для чего все это нужно?
Связи выполняют более важную роль, чем просто информация размещения данных по таблицам. Прежде всего они требуются разработчикам для поддержания целостности баз данных.
Правильно настроив связи, можно быть уверенным, что ничего не потеряется.
Представьте, что Вы решили удалить одну из групп в таблице учебной базы данных. Если бы связи не было, то для тех сотрудников, которые к ней были определены, остался идентификатор несуществующей группы.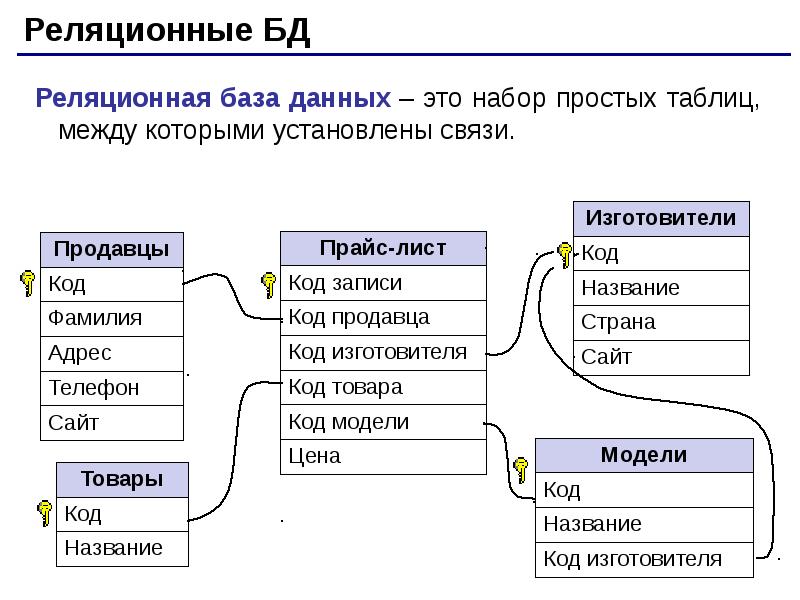 Связь не позволит удалить группу, пока она имеется во внешних ключах других таблиц. Для начала следовало определить сотрудников в другие имеющиеся или новые группы, а только затем удалить ненужную запись. Поэтому связи называют еще ограничениями.
Связь не позволит удалить группу, пока она имеется во внешних ключах других таблиц. Для начала следовало определить сотрудников в другие имеющиеся или новые группы, а только затем удалить ненужную запись. Поэтому связи называют еще ограничениями.
- < Назад
- Вперёд >
Если материалы office-menu.ru Вам помогли, то поддержите, пожалуйста, проект, чтобы я мог развивать его дальше.
Добавить комментарий
Краткий обзор различных типов баз данных
База данных — это набор данных, хранящихся в упорядоченном виде. Для эффективного управления системой вам потребуется эффективная память о прошлых и настоящих записях, которые вошли в эту конкретную систему и / или вышли из нее. То же самое относится к бизнесу или организации, которые потребуют совместных усилий нескольких людей. Для этой цели компании, большие и маленькие, а также такие организации, как больницы, школы и университеты, используют очень полезный метод сбора, сборки и обмена данными в систематизированных «объектах», которые хранятся в различных типах доступных баз данных.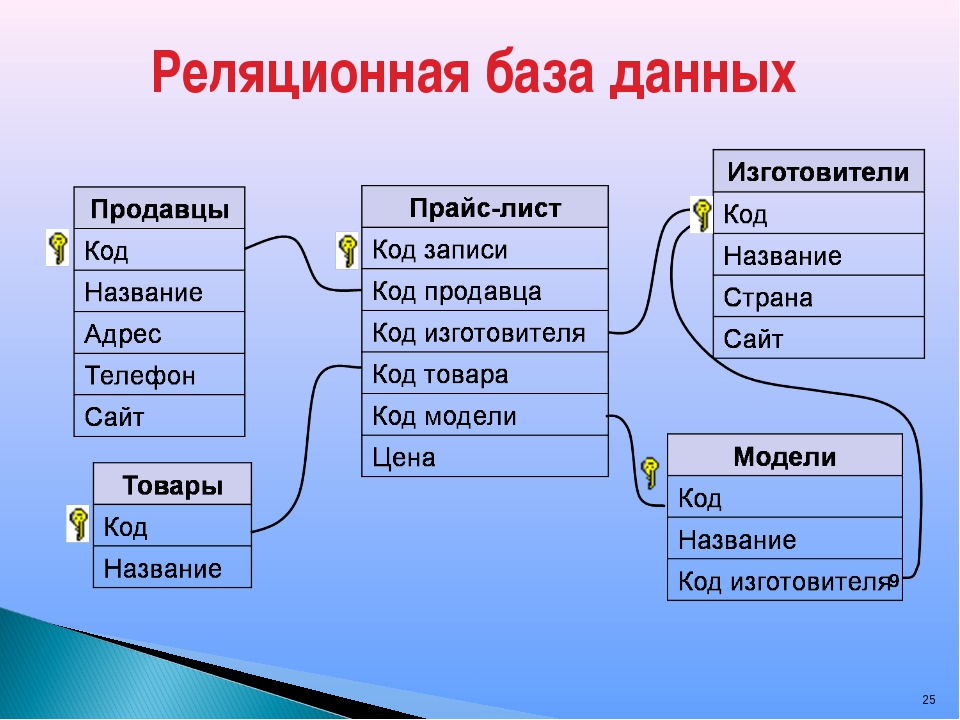
В блоге дается обзор СУБД, объясняется, что такое базы данных, для чего используются базы данных и, в частности, для чего используются базы данных в бизнесе, а также обсуждаются общие типы структур баз данных
Определение базы данныхБаза данных представляет собой «структурированный набор данных, хранящихся в компьютере, особенно тот, который доступен различными способами». Однако существуют различные типы баз данных, каждая из которых предоставляет своим пользователям разные функции.Например, база данных No SQL предлагает пользователям высокую масштабируемость, в то время как схемы реляционных баз данных более строгие по своей природе и обеспечивают большую согласованность и структуру.
Типы объектов базы данныхСуществует четыре различных типа объектов базы данных, которые помогают пользователям компилировать, вводить, хранить и анализировать важные данные:
- Таблицы
- Запросы
- Формы
- Отчеты
Базы данных используются для упорядоченного хранения огромного количества данных, собранных в легкодоступных для авторизованного пользователя.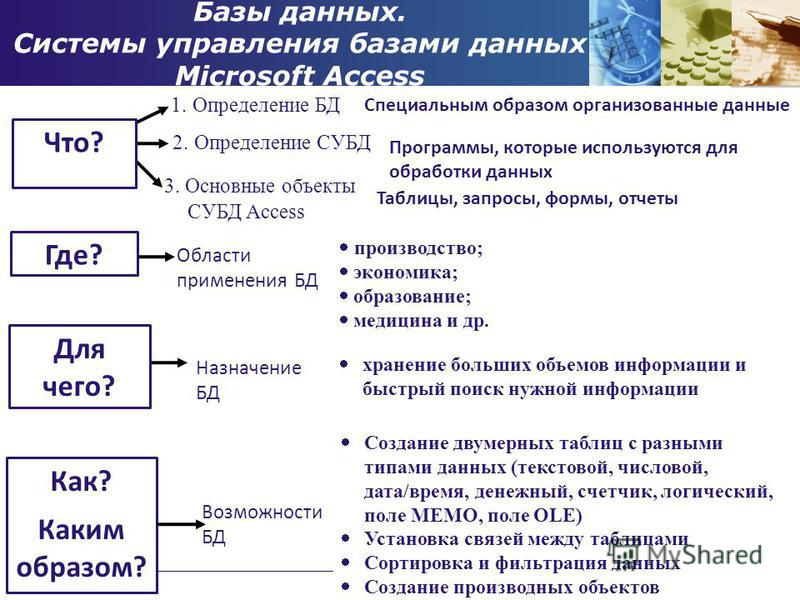 Они могут быть важны для роста бизнеса по-разному:
Они могут быть важны для роста бизнеса по-разному:
- Позволяет компании принимать более обоснованные бизнес-решения.
- Эффективное хранение и поиск связанной информации.
- Помогает анализировать и усугублять бизнес-данные.
- Собирайте и храните важные данные о клиентах из различных приложений.
- Предоставляет своевременные персонализированные приложения на основе данных и аналитику в реальном времени.
- Обеспечивает точный, надежный и немедленный доступ к важным бизнес-данным, которые могут использоваться различными бизнес-отделами для анализа шаблонов данных, создания отчетов и прогнозирования будущих тенденций.
- Часто данные отображаются через иерархические базы данных, используемые устаревшими системами, в реляционные базы данных, используемые в хранилищах данных.
Источник: Toptal
Объяснение типов баз данных
Существуют различные типы данных базы данных:
- Иерархическая база данных: Иерархическая база данных следует порядку ранжирования или родительско-дочерним отношениям для структурирования данных.
- Сетевая база данных: Сетевая база данных похожа на иерархическую базу данных, но с некоторыми изменениями.Сетевая база данных позволяет дочерней записи соединяться с различными родительскими записями, таким образом, обеспечивая двусторонние отношения.
- Объектно-ориентированная база данных: в объектно-ориентированной базе данных информация хранится в объектно-подобном виде.
- Реляционная база данных: Реляционная база данных ориентирована на таблицы, где каждый бит данных связан с каждым другим битом данных.
- Нереляционная база данных или база данных NoSQL: база данных без SQL использует различные форматы, такие как документы, графики, широкие столбцы и т. Д., Что обеспечивает большую гибкость и масштабируемость конструкции базы данных.

Однако базы данных широко делятся на два основных типа или категории, а именно: реляционных баз данных или баз данных последовательностей и нереляционных или непоследовательных баз данных или базы данных без SQL .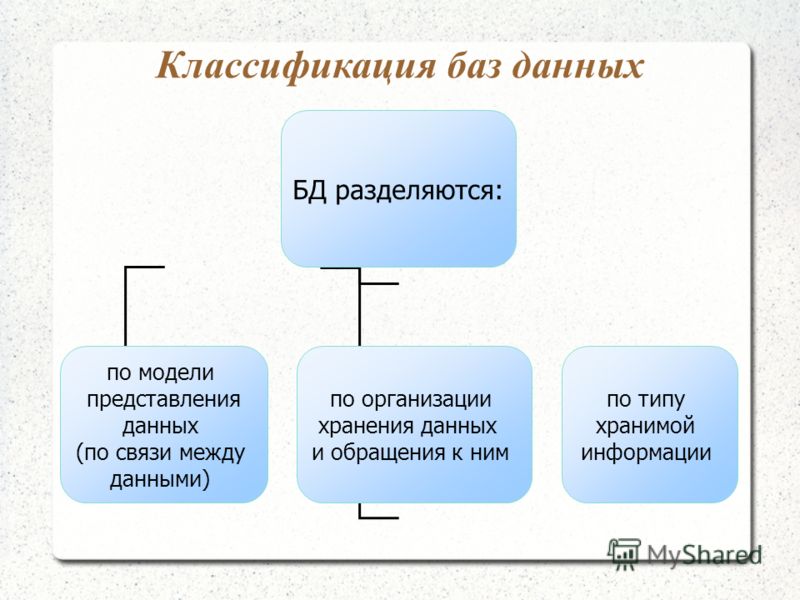 Они могут использоваться организацией по отдельности или вместе, в зависимости от характера данных и требуемых функций.
Они могут использоваться организацией по отдельности или вместе, в зависимости от характера данных и требуемых функций.
Реляционные базы данных
Люди часто спрашивают, какой тип базы данных является наиболее распространенным? Реляционная база данных — ответ на их вопрос.Этот тип СУБД системы управления базами данных использует схему, которая представляет собой шаблон, используемый для определения структуры данных, которые будут храниться в базе данных.
Как и для компании, продающей продукты своим клиентам, для них важно иметь некоторую форму хранимых знаний о том, куда эти продукты пошли, кому и в каком количестве.
Для каждого подхода могут использоваться разные таблицы и даже типы таблиц реляционной базы данных. Например, одну таблицу можно использовать для отображения основной информации о покупателях, вторую — для информации о проданных продуктах, а третью таблицу можно использовать для подсчета того, кто, сколько раз и где покупал этот продукт.
Есть ключи, связанные с таблицами в реляционной базе данных. Они помогают быстро получить сводку базы данных или получить доступ к конкретной строке или столбцу, которые вы, возможно, захотите проверить.
Они помогают быстро получить сводку базы данных или получить доступ к конкретной строке или столбцу, которые вы, возможно, захотите проверить.
Таблицы, которые также называются объектами, связаны друг с другом. Таблица с информацией о клиентах может предоставить конкретный идентификатор для каждого клиента, который может просто обозначать все, что нужно знать об этом клиенте, например, его адрес, имя и контактную информацию.Кроме того, в таблице с описанием продукта каждому продукту можно присвоить определенный идентификатор. Таблица, в которой записаны все заказы, просто должна будет записать эти идентификаторы и их количество. Любое изменение в любой из этих таблиц повлияет на все из них, но предсказуемым и систематическим образом.
Целостность данных обеспечивается ограничениями систем управления реляционными базами данных (СУБД). РСУБД гарантирует, что отображаемые данные точны и на них можно положиться. Однако существуют разные типы реляционных баз данных.Имена различных баз данных: Microsoft SQL Server, Oracle Database, MySQL и IBM DB2.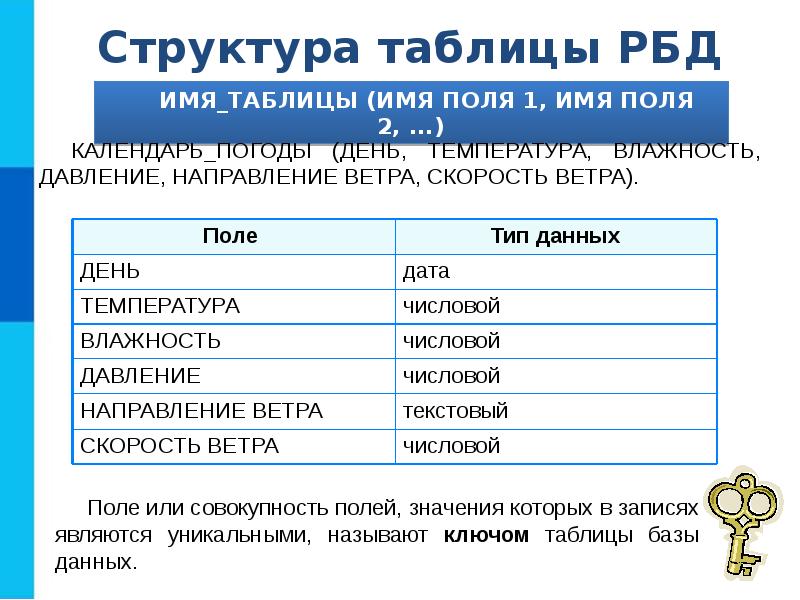
Существуют разные типы баз данных SQL. Вот некоторые примеры этих баз данных на языке структурированных запросов (SQL):
Oracle
Система баз данных Oracle, продукт корпорации Oracle, служит в качестве мультимодальной системы управления.
PostgreSQL
PostgreSQL, также называемый Postgre, подчеркивает соответствие стандартам наряду с расширяемостью и служит системой управления объектно-реляционной базой данных.
MySQL
Эта конкретная СУБД с открытым исходным кодом работает на всех доступных платформах, таких как Windows, Linux и UNIX.
SQL Server
Продукт Microsoft, SQL Server в основном используется для хранения и извлечения данных из программных прикладных систем и из них.
Достоинства и недостатки реляционных баз данных
Реляционные базы данных имеют свои достоинства и недостатки, которые стоит рассмотреть, прежде чем в них вкладывать средства:
Достоинства
- Реляционные базы данных представляют собой строгую схему, означающую, что каждая новая запись должна иметь различные компоненты, которые позволяют помещать его в предварительно сформированный шаблон. Это делает данные предсказуемыми и легко поддающимися оценке.
- Соответствие ACID является обязательным для всех баз данных РСУБД. Это означает, что они должны обеспечивать атомарность, согласованность, изоляцию и долговечность.
- Они хорошо структурированы и практически не оставляют места для каких-либо ошибок.
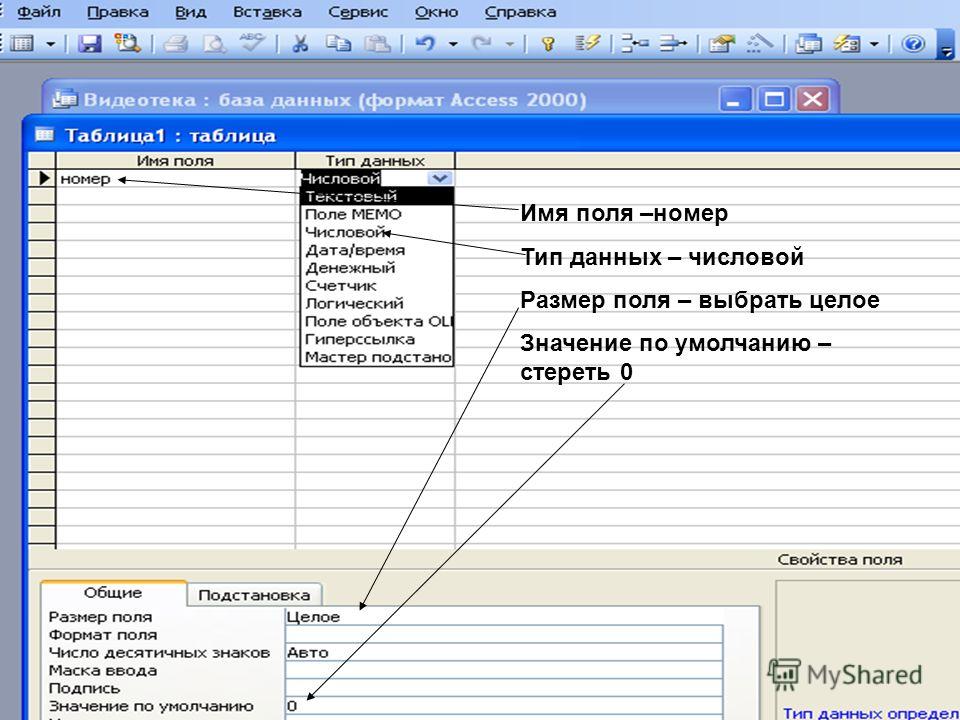 Это делает данные предсказуемыми и легко поддающимися оценке.
Это делает данные предсказуемыми и легко поддающимися оценке.Недостатки
- Скрупулезный характер, строгие схемы и ограничения реляционных баз данных делают практически невозможным хранение в числах, которые необходимы для сегодняшних гигантских данных в Интернете.
- Невозможно масштабировать по горизонтали, поскольку реляционные базы данных следуют определенной схеме. Хотя вертикальное масштабирование кажется очевидным ответом, это не так. Вертикальное масштабирование имеет предел, и в наше время и возраст данные, собираемые через Интернет ежедневно, просто слишком велики, чтобы представить, что вертикальное масштабирование будет работать долго.
- Ограничения схемы также препятствуют миграции данных в разные СУБД и из них. Они должны быть идентичными, иначе это просто не сработает.
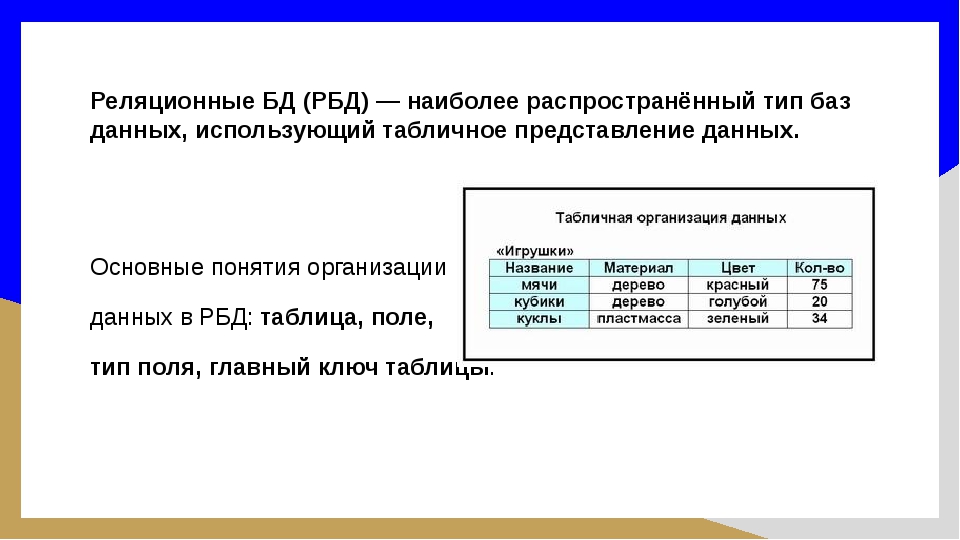 Они должны быть идентичными, иначе это просто не сработает.
Они должны быть идентичными, иначе это просто не сработает.Нереляционные базы данных
Эта нереляционная форма организации базы данных более снисходительна по своей структуре и форме, чем реляционные базы данных.Вместо таблиц со столбцами и строками у них есть коллекции разных категорий, например, пользователей и заказов. Эти коллекции иллюстрированы документами. Таким образом, в одной коллекции может быть несколько документов, и они могут или не могут следовать какому-либо конкретному шаблону или схеме.
Документ может иметь название, адрес и продукт в коллекции; в то же время другой документ может иметь только название и продукт в той же коллекции, поскольку для этих документов нет конкретной схемы.Кроме того, разные коллекции не обязательно могут иметь отношения между собой.
Существуют различные типы нереляционных баз данных:
Хранилища «ключ-значение»
Этот тип только хранит и предоставляет быстрые и простые сведения о парах «ключ-значение».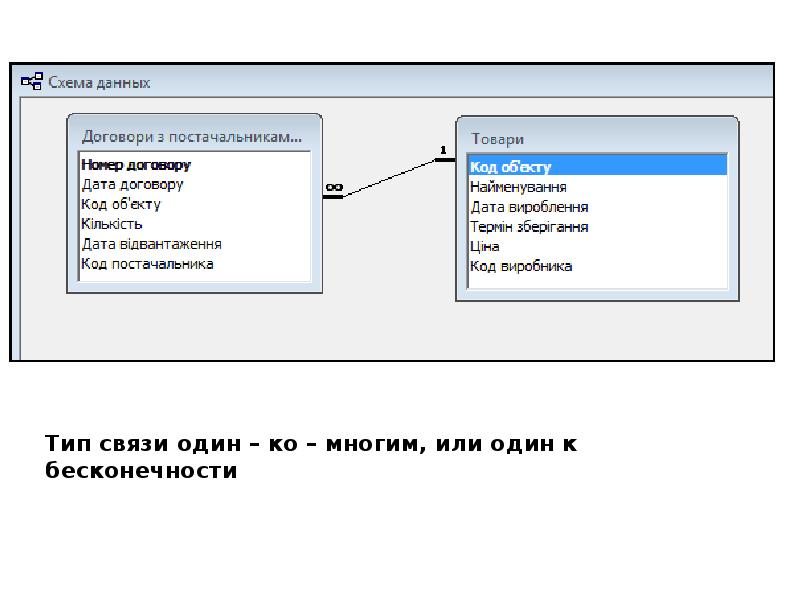 Это простой и легкий способ хранить данные и получать к ним доступ. Некоторые примеры — Amazon DynamoDB и Redis.
Это простой и легкий способ хранить данные и получать к ним доступ. Некоторые примеры — Amazon DynamoDB и Redis.
Хранилища с широкими столбцами
Этот тип также можно назвать многомерным хранилищем «ключ-значение», поскольку он хранит и управляет огромными объемами данных в таблицах или нескольких столбцах, каждый столбец которых может действовать как запись.Это помогает масштабировать несколько петабайт данных. Яркими примерами являются Scylla, HBase и Cassandra.
Хранилища документов
Здесь единообразная структура не является обязательной для записей. Они могут иметь широкий спектр типов и значений, и все они могут быть вложенными. Данные хранятся в документах JSON, и эти документы напоминают документы с ключом-значением и расширенным столбцом. Некоторые из самых известных баз данных NoSQL попадают в эту категорию, а именно Couchbase и MongoDB.
Поисковые системы
Они отличаются от хранилищ документов тем, что помогают сделать данные доступными с помощью простого текстового поиска. Некоторые примеры: Solr, Splunk и Exasticsearch.
Некоторые примеры: Solr, Splunk и Exasticsearch.
Графические базы данных
Графические базы данных показывают связи между различными точками данных. Они используются в основном, когда есть потребность в анализе различных типов данных и их взаимосвязи друг с другом. Они представлены в виде сети связанных объектов или узлов. Примерами являются Datastax Enterprise Graph и Neo4J.
Достоинства и недостатки нереляционных баз данных
Как и все остальное, нереляционные базы данных несовершенны и имеют некоторые преимущества, но также и некоторые ограничения.К ним относятся:
Merits
- Их свободный от схемы характер упрощает управление и хранение огромных объемов данных. Их также можно легко масштабировать по горизонтали.
- Данные не слишком сложны и могут быть распределены между несколькими выделенными узлами для большей доступности.
Недостатки
- Поскольку у них нет определенной структуры или схемы для хранимых данных, вы не можете полагаться на свои данные для определенного поля, потому что оно может не иметь их.
- Отсутствие связей очень затрудняет обновление данных, поскольку вам придется обновлять каждую деталь отдельно.
Типы пользователей базы данных
Существуют различные типы пользователей баз данных (СУБД), например:
- Администратор базы данных (DBA)
- Конечный пользователь
- Системный аналитик
- Программист
- Дизайнер баз данных
Типы современных баз данных
Храните ли вы данные с устройств IoT? Используете систему управления цифровым контентом? Как насчет обработки данных конфигурации, записи инвентаря или информации о транзакции? Или, может быть, иметь дело с любой другой системой, обрабатывающей или генерирующей данные? Если ваши данные необходимо хранить и получать к ним доступ, вам понадобится какая-то база данных.
Скорее всего, вы это уже знаете. Но если вы в последнее время не смотрели базы данных, вы можете быть удивлены тем, как изменился ландшафт. Это уже не просто битва между поставщиками монолитных реляционных баз данных. Фактически, популярность нереляционных баз данных растет, более чем вдвое за последние 5 лет; однако только один (MongoDB) входит в пятерку лучших (вместе реляционных и нереляционных).
Фактически, популярность нереляционных баз данных растет, более чем вдвое за последние 5 лет; однако только один (MongoDB) входит в пятерку лучших (вместе реляционных и нереляционных).
В зависимости от типа, структуры, модели данных, хранилища данных и предполагаемого варианта использования ваших данных, различные системы, вероятно, лучше подходят для ваших нужд.Требуемая схема или механизм запросов, ваши требования к согласованности или задержке или даже скорость транзакции (в том числе в реальном времени) также могут повлиять на ваше решение. Например, встроенная база данных для системы с локально хранящимися данными динамической конфигурации будет иметь совершенно другие требования, чем операционная реляционная база данных, предназначенная для отслеживания бронирований гостиничных номеров.
Итак, с чего начать при выборе базы данных? Мы рассмотрели как NoSQL (нереляционные), так и системы управления реляционными базами данных (РСУБД), чтобы получить представление об обеих экосистемах с высоты птичьего полета, чтобы вы могли начать работу.
SQL / СУБД / реляционные базы данных
СУБДболее широко известны и понятны, чем их собратья NoSQL. Реляционные базы данных появились в 70-х годах для хранения данных в соответствии со схемой, которая позволяет отображать данные в виде таблиц со строками и столбцами. Думайте о реляционной базе данных как о коллекции таблиц, каждая из которых имеет схему , которая представляет фиксированные атрибуты и типы данных, которые будут иметь элементы в таблице. Все СУБД предоставляют функциональные возможности для чтения, создания, обновления и удаления данных, обычно с помощью операторов языка структурированных запросов (SQL).
Таблицы в реляционной базе данных имеют ключей , связанных с ними, которые используются для идентификации определенных столбцов или строк таблицы и облегчения более быстрого доступа к конкретной таблице, строке или столбцу, представляющему интерес.
Целостность данных имеет особое значение в реляционных базах данных, и СУБД использует ряд ограничений для обеспечения надежности и точности данных, содержащихся в ваших таблицах.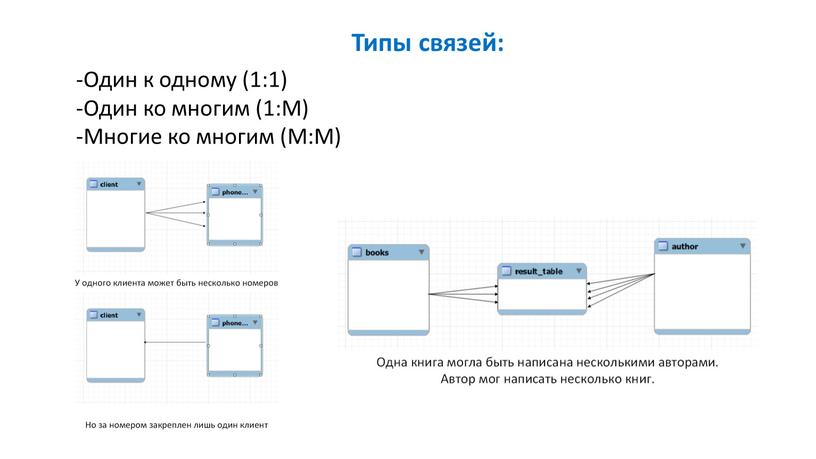
Хотя существует множество реляционных баз данных, со временем они стали самыми популярными:
- Oracle — Oracle Database (обычно называемая Oracle RDBMS или просто Oracle) — это многомодельная система управления базами данных, производимая и продаваемая Oracle Corporation.
- MySQL — MySQL — это СУБД с открытым исходным кодом, основанная на языке структурированных запросов (SQL). MySQL работает практически на всех платформах, включая Linux, UNIX и Windows.
- Microsoft SQL Server — Microsoft SQL Server — это СУБД, которая поддерживает широкий спектр приложений для обработки транзакций, бизнес-аналитики и аналитики в корпоративных ИТ-средах.
- PostgreSQL — PostgreSQL, часто просто Postgres, представляет собой систему управления объектно-реляционными базами данных (ORDBMS) с упором на расширяемость и соответствие стандартам.
- DB2 — DB2 — это СУБД, предназначенная для эффективного хранения, анализа и извлечения данных.
Преимущества
- Реляционные базы данных — это хорошо документированные и зрелые технологии, а СУБД продаются и обслуживаются рядом известных корпораций. Стандарты
- SQL четко определены и общеприняты.
- Большой пул квалифицированных разработчиков, имеющих опыт работы с SQL и СУБД.
- Все СУБД являются ACID-совместимыми, что означает, что они удовлетворяют требованиям атомарности, согласованности, изоляции и долговечности.

Недостатки
- РСУБД плохо работают — или вообще не работают — с неструктурированными или полуструктурированными данными из-за ограничений схемы и типа. Это делает их непригодными для большой аналитики или нагрузок на события Интернета вещей.
- Таблицы в вашей реляционной базе данных не обязательно будут взаимно однозначно отображаться с объектом или классом, представляющим те же данные.
- При миграции одной РСУБД в другую схемы и типы, как правило, должны быть идентичны между исходной и целевой таблицами, чтобы миграция работала (ограничение схемы).По многим из тех же причин чрезвычайно сложные наборы данных или те, которые содержат записи переменной длины, обычно трудно обрабатывать с помощью схемы СУБД.
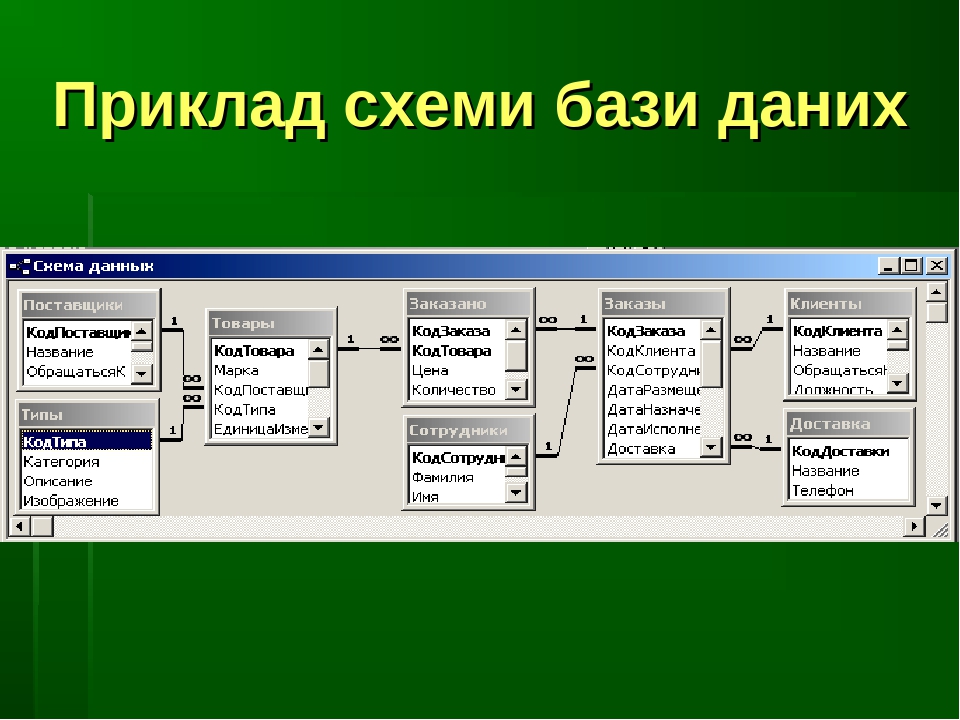
NoSQL / нереляционные базы данных
Базы данных NoSQL стали популярной альтернативой реляционным базам данных по мере того, как веб-приложения становились все более сложными. NoSQL / нереляционные базы данных могут принимать различные формы. Однако критическое различие между NoSQL и реляционными базами данных заключается в том, что схемы СУБД жестко определяют, как все данные, вставленные в базу данных, должны быть типизированы и составлены, тогда как базы данных NoSQL могут быть независимыми от схемы, что позволяет хранить и обрабатывать неструктурированные и полуструктурированные данные.
Типы
Обратите внимание, что некоторые продукты могут относиться к нескольким категориям. Например, Couchbase — это одновременно база данных документов и хранилище ключей.
Хранилища ключей и значений , такие как Redis и Amazon DynamoDB, представляют собой чрезвычайно простые системы управления базами данных, которые хранят только пары ключ-значение и предоставляют базовые функции для получения значения, связанного с известным ключом.
Простота хранилищ ключ-значение делает эти системы управления базами данных особенно подходящими для встроенных баз данных, где хранимые данные не особенно сложны, а скорость имеет первостепенное значение.
Хранилища с широкими столбцами , такие как Cassandra, Scylla и HBase, представляют собой системы, не зависящие от схемы, которые позволяют пользователям хранить данные в группах или таблицах из столбцов, одна строка которых может рассматриваться как запись — мульти -мерное хранилище ключей и значений.
Эти решения разработаны с целью обеспечения достаточного масштабирования для управления петабайтами данных на тысячах обычных серверов в массивной распределенной системе.
Хотя технически не требующие схемы, хранилища с широкими столбцами, такие как Scylla и Cassandra, используют вариант SQL, называемый CQL, для определения данных и управления ими, что делает их простыми для тех, кто уже знаком с СУБД.
Хранилища документов , включая MongoDB и Couchbase, — это системы без схемы, которые хранят данные в форме документов JSON. Хранилища документов аналогичны хранилищам «ключ-значение» или хранилищам с широкими столбцами, но имя документа является ключом, а содержимое документа, каким бы оно ни было, является значением.
Хранилища документов аналогичны хранилищам «ключ-значение» или хранилищам с широкими столбцами, но имя документа является ключом, а содержимое документа, каким бы оно ни было, является значением.
В хранилище документов отдельные записи не требуют единой структуры, могут содержать много разных типов значений и могут быть вложенными. Такая гибкость делает их особенно подходящими для управления полуструктурированными данными в распределенных системах.
Базы данных графиков , такие как Neo4J и Datastax Enterprise Graph, представляют данные как сеть связанных узлов или объектов для облегчения визуализации данных и анализа графиков.
Узел или объект в базе данных графа содержит данные произвольной формы, которые связаны отношениями и сгруппированы по меткам. Программное обеспечение графических систем управления базами данных (СУБД) разработано с акцентом на демонстрацию соединений между точками данных.
В результате графические базы данных обычно используются, когда конечной целью системы является анализ взаимосвязей между разнородными точками данных, например, при предотвращении мошенничества, расширенных корпоративных операциях или исходном графе друзей Facebook.
Поисковые системы , такие как Elasticsearch, Splunk и Solr, хранят данные с помощью документов JSON без схемы. Они похожи на хранилища документов, но с большим упором на то, чтобы ваши неструктурированные или полуструктурированные данные были легко доступны через текстовый поиск со строками различной сложности.
Преимущества
Поскольку существует так много типов и разнообразных приложений баз данных NoSQL, их сложно определить, но в целом:
- Модели данных без схемы более гибкие и простые в администрировании. Базы данных
- NoSQL обычно более горизонтально масштабируемы и отказоустойчивы.
- Данные можно легко распределить по разным узлам. Чтобы улучшить доступность и / или устойчивость к разделам, вы можете выбрать, чтобы данные на некоторых узлах были «в конечном итоге согласованными».
Недостатки
Они также зависят от типа базы данных. В основном:
- Базы данных NoSQL, как правило, менее широко распространены и развиты, чем решения РСУБД, поэтому часто требуется особый опыт.
- Существует ряд форматов и ограничений, специфичных для каждого типа базы данных.
Популярные реляционные и нереляционные базы данных
Какая база данных вам подходит?
В этом посте рассматриваются только самые популярные и самые известные примеры этих типов баз данных.Более полный список, включая описания, смотрите здесь.
- Если соответствие ACID (атомарность, долговечность, согласованность и долговечность) является вашим первым приоритетом, рассмотрите возможность использования СУБД.
- Если у вас массово распределенная система и вы можете согласиться на возможную согласованность на некоторых узлах / разделах, вы можете рассмотреть широкое хранилище столбцов, такое как Cassandra или Scylla.
- Если ваши входные данные особенно разнородны и их трудно инкапсулировать в соответствии со схемой нормализации, рассмотрите возможность использования СУБД NoSQL.
- Если ваша цель — вертикальное масштабирование, рассмотрите РСУБД; и наоборот, если вы хотите масштабировать по горизонтали, может быть предпочтительнее СУБД NoSQL.

К счастью, используете ли вы реляционные, нереляционные базы данных или смесь обоих типов баз данных, Alooma поможет вам!
Хотите узнать больше?
Alooma — это конвейер данных как сервис, который переносит все ваши источники данных (включая базы данных) в Google BigQuery, Amazon Redshift, Snowflake и другие. Если вы хотите узнать больше о том, как Alooma может помочь вам перенести и интегрировать ваши данные, не стесняйтесь обращаться к нам.
Типы систем управления базами данных
База данных — это совокупность данных или записей. Системы управления базами данных предназначены для управления базами данных. Система управления базами данных (СУБД) — это программная система, которая использует стандартный метод для хранения и организации данных. Данные можно добавлять, обновлять, удалять или просматривать с помощью различных стандартных алгоритмов и запросов.
Типы систем управления базами данных
Существует несколько типов систем управления базами данных. Вот список из семи распространенных систем управления базами данных:
Вот список из семи распространенных систем управления базами данных:
- Иерархические базы данных
- Сетевые базы данных
- Реляционные базы данных
- Объектно-ориентированные базы данных
- Графические базы данных
- Базы данных моделей ER
- Базы данных документов
- Базы данных NoSQL
Иерархические базы данных
В модели иерархической системы управления базами данных (иерархических СУБД) данные хранятся в узле отношений родитель-потомок.В иерархической базе данных, помимо фактических данных, записи также содержат информацию о своих группах родительских / дочерних отношений.
В иерархической модели базы данных данные организованы в древовидную структуру. Данные хранятся в виде набора полей, где каждое поле содержит только одно значение. Записи связаны друг с другом через связи в отношениях родитель-потомок. В иерархической модели базы данных каждая дочерняя запись имеет только одного родителя. Родитель может иметь несколько детей.
Родитель может иметь несколько детей.
Чтобы получить данные поля, нам нужно пройти через каждое дерево, пока не будет найдена запись.
Иерархическая структура системы баз данных была разработана IBM в начале 1960-х годов. Хотя иерархическая структура проста, она негибкая из-за отношения родитель-потомок «один ко многим». Иерархические базы данных широко используются для создания высокопроизводительных и доступных приложений, обычно в банковской и телекоммуникационной отраслях.
IBM Information Management System (IMS) и Windows Registry — два популярных примера иерархических баз данных.
Advantage
Доступ к иерархической базе данных и ее быстрое обновление. Как показано на рисунке выше, его структура модели похожа на дерево, а отношения между записями определены заранее. Эта особенность — палка о двух концах.
Недостаток Этот тип структуры базы данных состоит в том, что каждый дочерний элемент в дереве может иметь только одного родителя.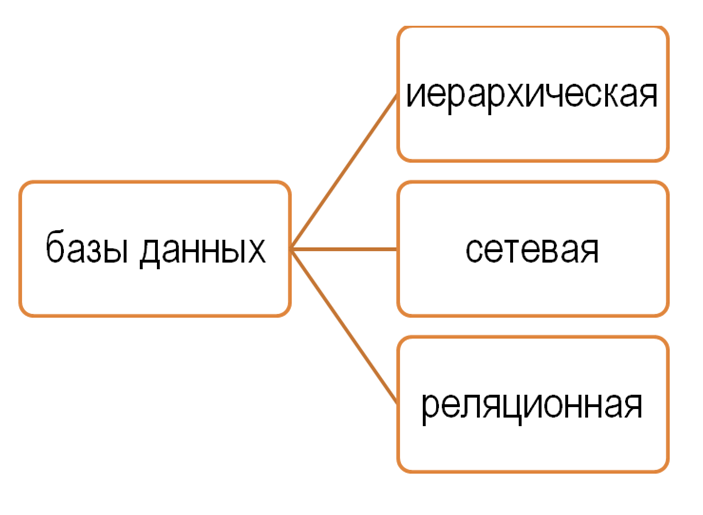 Отношения или связи между детьми недопустимы, даже если они имеют смысл с логической точки зрения. Иерархические базы данных имеют такой же дизайн. Добавление нового поля или записи требует переопределения всей базы данных.
Отношения или связи между детьми недопустимы, даже если они имеют смысл с логической точки зрения. Иерархические базы данных имеют такой же дизайн. Добавление нового поля или записи требует переопределения всей базы данных.Сетевые базы данных
Системы управления сетевыми базами данных (сетевые СУБД) используют сетевую структуру для создания отношений между объектами. Сетевые базы данных в основном используются на больших цифровых компьютерах. Сетевые базы данных представляют собой иерархические базы данных, но в отличие от иерархических баз данных, в которых один узел может иметь только одного родителя, сетевой узел может иметь связь с несколькими объектами.Сетевая база данных больше похожа на паутину или взаимосвязанную сеть записей.
В сетевых базах данных дети называются членами, а родители — оккупантами. Разница между каждым дочерним элементом или членом состоит в том, что у них может быть более одного родителя.
Утверждение сетевой модели данных аналогично иерархической модели данных.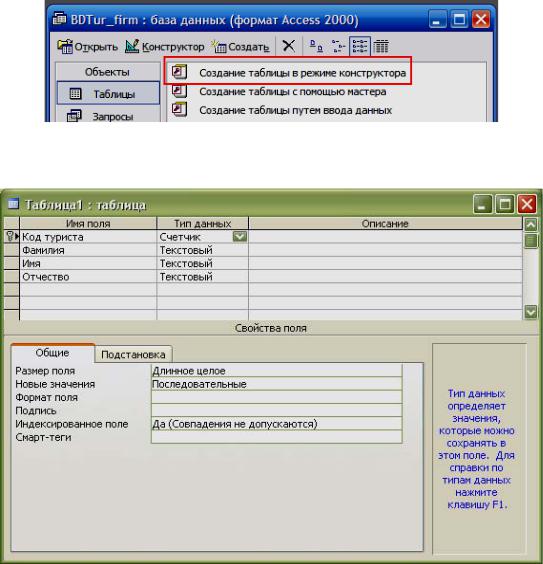 Данные в сетевой базе данных организованы по принципу «многие ко многим».
Данные в сетевой базе данных организованы по принципу «многие ко многим».
Структура сетевой базы данных была изобретена Чарльзом Бахманом.Некоторые из популярных сетевых баз данных — это интегрированное хранилище данных (IDS), IDMS (интегрированная система управления базами данных), Raima Database Manager, TurboIMAGE и Univac DMS-1100.
Реляционные базы данных
В системе управления реляционными базами данных (СУБД) отношения между данными являются реляционными, и данные хранятся в табличной форме столбцов и строк. Каждый столбец таблицы представляет атрибут, а каждая строка в таблице представляет собой запись.Каждое поле в таблице представляет собой значение данных.
Язык структурированных запросов (SQL) — это язык, используемый для запросов к СУБД, включая вставку, обновление, удаление и поиск записей. Реляционные базы данных работают с каждой таблицей, у которой есть ключевое поле, однозначно указывающее каждую строку. Эти ключевые поля можно использовать для соединения одной таблицы данных с другой.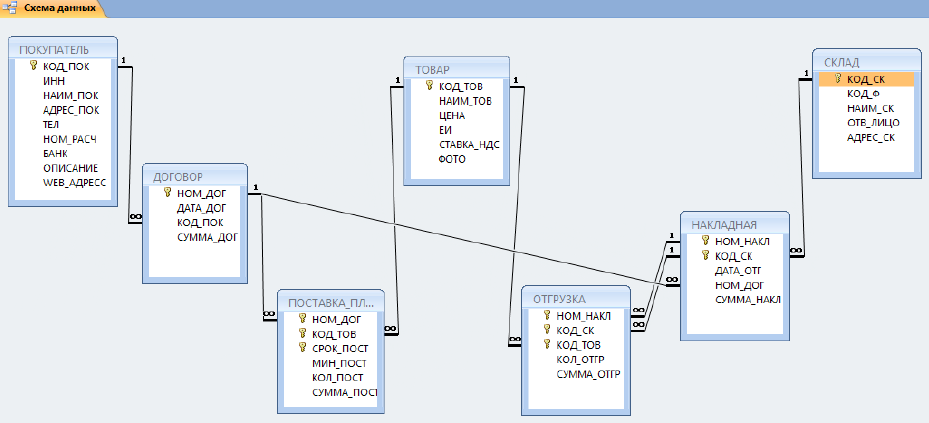
Реляционные базы данных — самые популярные и широко используемые базы данных. Некоторые из популярных DDBMS — это Oracle, SQL Server, MySQL, SQLite и IBM DB2.
Реляционная база данных имеет два основных преимущества:
- Реляционные базы данных можно использовать с минимальным обучением или без него.
- Записи в базе данных можно изменять без указания всего тела.
Свойства реляционных таблиц
В реляционной базе данных мы должны следовать свойствам, приведенным ниже:
- Значения атомарные
- Каждая строка отдельно.
- Значения столбца — одно и то же.
- Колонны без особенностей.
- Последовательность строк не важна.
- У каждого столбца есть общее имя.
Объектно-ориентированная модель
В этой модели мы должны обсудить функциональность объектно-ориентированного программирования. Это требует большего, чем просто хранение объектов языка программирования. Расширение семантики C ++ и Java объектных СУБД. Он предоставляет полнофункциональные возможности программирования баз данных, сохраняя при этом совместимость с родным языком.Он добавляет функциональность базы данных в языки объектного программирования. Этот подход аналогичен разработке приложений и баз данных в постоянной модели данных и языковой среде. Приложениям требуется меньше кода, они используют более естественное моделирование данных, а базы кода легче поддерживать. Разработчики объектов могут писать полные приложения для баз данных с приличным количеством дополнительных усилий.
Это требует большего, чем просто хранение объектов языка программирования. Расширение семантики C ++ и Java объектных СУБД. Он предоставляет полнофункциональные возможности программирования баз данных, сохраняя при этом совместимость с родным языком.Он добавляет функциональность базы данных в языки объектного программирования. Этот подход аналогичен разработке приложений и баз данных в постоянной модели данных и языковой среде. Приложениям требуется меньше кода, они используют более естественное моделирование данных, а базы кода легче поддерживать. Разработчики объектов могут писать полные приложения для баз данных с приличным количеством дополнительных усилий.
Объектно-ориентированная база данных представляет собой целостность систем объектно-ориентированного языка программирования и согласованных систем.Сила объектно-ориентированных баз данных проистекает из циклической обработки как согласованных данных, обнаруживаемых в базах данных, так и временных данных, обнаруживаемых при выполнении программ.
Объектно-ориентированные базы данных используют небольшие перерабатываемые объекты, отделенные от программного обеспечения, называемые объектами. Сами объекты хранятся в объектно-ориентированной базе данных.
Каждый объект содержит два элемента:
- Часть данных (например, звук, видео, текст или графика).
- Инструкции или программы, называемые методами, для того, что делать с данными.
Объектно-ориентированные системы управления базами данных (OODBM) были созданы в начале 1980-х годов. Некоторые OODBM были разработаны для работы с такими языками ООП, как Delphi, Ruby, C ++, Java и Python. Некоторые популярные OODBM: TORNADO, Gemstone, ObjectStore, GBase, VBase, InterSystems Cache, Versant Object Database, ODABA, ZODB, Poet. ДЖЕЙД и Информикс.
Недостатки объектно-ориентированных баз данных
- Объектно-ориентированные базы данных дороже в разработке.
- Большинство организаций не желают отказываться от этих баз данных и переходить от них.
Преимущества объектно-ориентированных баз данных
Преимущества объектно-ориентированных баз данных очевидны. Возможность смешивать и сопоставлять объекты многократного использования обеспечивает невероятные мультимедийные возможности.
Графические базы данных
Графические базы данных — это базы данных NoSQL, которые используют структуру графов для семантических запросов.Данные хранятся в виде узлов, ребер и свойств. В базе данных графа узел представляет собой объект или экземпляр, такой как покупатель, человек или автомобиль. Узел эквивалентен записи в системе реляционной базы данных. Край в базе данных графа представляет собой отношение, которое соединяет узлы. Свойства — это дополнительная информация, добавляемая к узлам.
Neo4j, Azure Cosmos DB, SAP HANA, Sparksee, Oracle Spatial and Graph, OrientDB, ArrangoDB и MarkLogic являются одними из популярных графических баз данных.Структура базы данных Graph также поддерживается некоторыми СУБД, включая Oracle и SQL Server 2017 и более поздние версии.
Базы данных моделей ER
Модель ER обычно реализуется как база данных. В простой реализации реляционной базы данных каждая строка таблицы представляет один экземпляр типа сущности, а каждое поле в таблице представляет тип атрибута. В реляционной базе данных связь между сущностями реализуется путем сохранения первичного ключа одной сущности в виде указателя или «внешнего ключа» в таблице другой сущности.
Модель сущность-связь была разработана Питером Ченом в 1976 году.
Базы данных документов
Базы данных документов (Document DB) также являются базами данных NoSQL, которые хранят данные в форме документов. Каждый документ представляет данные, их отношения между другими элементами данных и атрибуты данных. База данных документов хранит данные в форме «ключ-значение».
База данных документов стала популярной в последнее время из-за их хранения документов и свойств NoSQL.Хранилище данных NoSQL обеспечивает более быстрый механизм хранения и поиска документов.
Популярные базы данных NoSQL: Hadoop / Hbase, Cassandra, Hypertable, MapR, Hortonworks, Cloudera, Amazon SimpleDB, Apache Flink, IBM Informix, Elastic, MongoDB и Azure DocumentDB.
Базы данных NoSQL
Базы данных NoSQL — это базы данных, которые не используют SQL в качестве основного языка доступа к данным. База данных Graph, сетевая база данных, база данных объектов и базы данных документов являются общими базами данных NoSQL.Эта статья отвечает на вопрос, что такое база данных NoSQL.
База данных NoSQL не имеет предопределенных схем, что делает базы данных NoSQL идеальным кандидатом для быстро меняющихся сред разработки.
NoSQL позволяет разработчикам вносить изменения на лету, не затрагивая приложения.
Базы данных NoSQL можно разделить на следующие пять основных категорий: базы данных столбцов, документов, графиков, ключей и значений и объектов.
Вот список из 10 популярных баз данных NoSQL:
- Cosmos DB
- ArangoDB
- Couchbase Server
- CouchDB
- Amazon DocumentDB
- MongoDB, CouchBase
- Elasticsearch
- Informix19 SAP HAN Neo4j
Хотите больше?
Вот еще несколько статей, которые могут вас заинтересовать:
Резюме
Типы баз данных — GeeksforGeeks
Беглый обзор нынешней потребности в хранении больших объемов данных, относящихся к нескольким связанным или несвязанным категориям, показывает, что базы данных должны быть очень эффективными в том, для чего они предназначены.
Это происходит не только из-за того, что мы имеем дело с постоянно обновляемым или изменяемым объемом данных; динамика этого больше не представляет особого интереса. Это связано с социальной ценностью, которую каждый человек придает им: базы данных являются буквально основой образа жизни клиента или ценности бизнеса.
Проектирование различных типов баз данных лежит в основе функциональности, которую они предоставляют пользователям. Поскольку данные являются динамическими объектами, способы их хранения сильно различаются.Это также причина того, что компании создают собственные типы баз данных, соответствующие их потребностям.
В этой статье мы рассмотрим наиболее часто используемые базы данных. А именно:
- Иерархические базы данных
- Сетевые базы данных
- Объектно-ориентированные базы данных
- Реляционные базы данных
- Базы данных NoSQL
1. Иерархические базы данных :
Как и в любой иерархии, эта база данных следует за последовательностью данных, классифицируемых по рангам или уровням, при этом данные классифицируются на основе общей точки связи.В результате два объекта данных будут иметь более низкий ранг, а общность получит более высокий ранг. См. Схему ниже:
Обратите внимание на то, что кафедры и администрация полностью непохожи друг на друга, но при этом подпадают под сферу компетенции университета. Это элементы, образующие эту иерархию.
Другая перспектива советует визуализировать данные, организованные в виде родительско-дочерних отношений, которые при добавлении нескольких элементов данных будут напоминать дерево.Дочерние записи связаны с родительской записью с помощью поля, поэтому для родительской записи разрешено несколько дочерних записей. Однако наоборот невозможно.
Обратите внимание, что из-за такой структуры иерархические базы данных нелегко продать; добавление элементов данных требует длительного обхода базы данных.
2. Сетевые базы данных:
С точки зрения непрофессионала, сетевая база данных — это иерархическая база данных, но с серьезной настройкой. Дочерним записям предоставляется возможность связываться с несколькими родительскими записями.В результате наблюдается сеть или сеть файлов базы данных, связанных несколькими потоками. Обратите внимание, что у элементов Student, Faculty и Resources есть по две родительские записи: Departments и Clubs.
Конечно, в сложной структуре сетевые базы данных более способны представлять два направленных отношения. Кроме того, концептуальная простота способствует использованию более простого языка управления базами данных.
Недостаток заключается в невозможности изменить структуру из-за ее сложности, а также в ее сильной структурной зависимости.
3. Объектно-ориентированные базы данных :
Те, кто знаком с парадигмой объектно-ориентированного программирования, смогут легко понять эту модель баз данных. Информация, хранящаяся в базе данных, может быть представлена как объект, который отвечает как экземпляр модели базы данных. Следовательно, на объект можно без труда ссылаться и вызывать его. В результате нагрузка на базу данных существенно снижается.
На диаграмме выше у нас есть разные объекты, связанные друг с другом с помощью методов; можно получить адрес Person (представленный объектом Person) с помощью метода lifeAt ().Кроме того, эти объекты имеют атрибуты, которые фактически являются элементами данных, которые необходимо определить в базе данных.
Примером таких моделей является программная библиотека Berkeley DB, которая использует те же концептуальные основы для предоставления быстрых и высокоэффективных ответов на запросы к базе данных из встроенной базы данных.
4. Реляционные базы данных :
Считающиеся наиболее зрелыми из всех баз данных, эти базы данных лидируют в производственной линии вместе со своими системами управления.В этой базе данных каждая часть информации связана с любой другой информацией. Это связано с тем, что каждое значение данных в базе данных имеет уникальный идентификатор в форме записи.
Обратите внимание, что все данные в этой модели сведены в таблицу. Следовательно, каждая строка данных в базе данных связана с другой строкой с использованием первичного ключа. Точно так же каждая таблица связана с другой таблицей с помощью внешнего ключа.
Обратитесь к диаграмме ниже и обратите внимание, как концепция «ключей» используется для связи двух таблиц.
Благодаря введению таблиц для организации данных он стал чрезвычайно популярным. Как следствие, они широко интегрированы в интерфейсы Web-Ap и служат идеальными хранилищами пользовательских данных. Что делает его еще более интересным, так это простота его освоения, поскольку язык, используемый для взаимодействия с базой данных, прост (в данном случае SQL) и легок для понимания.
Также стоит помнить о том, что в реляционных базах данных масштабирование и перемещение по данным является довольно легкой задачей по сравнению с иерархическими базами данных.
5. Базы данных NoSQL :
NoSQL, изначально относящаяся к не-SQL или нереляционным, — это база данных, которая обеспечивает механизм для хранения и извлечения данных. Эти данные моделируются средствами, отличными от табличных отношений, используемых в реляционных базах данных.
База данных NoSQL отличается простотой конструкции, более простым горизонтальным масштабированием до кластеров машин и более точным контролем над доступностью. Структуры данных, используемые базами данных NoSQL, отличаются от структур данных, используемых по умолчанию в реляционных базах данных, что ускоряет некоторые операции в NoSQL.Пригодность данной базы данных NoSQL зависит от проблемы, которую она должна решить. Структуры данных, используемые базами данных NoSQL, иногда также считаются более гибкими, чем таблицы реляционных баз данных.
MongoDB относится к категории баз данных на основе документов NoSQL.
Преимущества NoSQL —
Есть много преимуществ работы с базами данных NoSQL, такими как MongoDB и Cassandra. Основные преимущества — высокая масштабируемость и доступность.
Недостатки NoSQL —
У NoSQL есть следующие недостатки.
- NoSQL — это база данных с открытым исходным кодом.
- Графический интерфейс недоступен
- Резервное копирование — слабое место для некоторых баз данных NoSQL, таких как MongoDB.
- Большой размер документа.
Это всего лишь несколько типов структур баз данных, которые представляют фундаментальные концепции, широко используемые в отрасли. Однако, как упоминалось ранее, клиенты, как правило, сосредотачиваются на создании баз данных, отвечающих их собственным потребностям; для хранения данных в схеме, которая демонстрирует функциональность переменной на основе ее чертежа.Следовательно, возможности для развития баз данных и систем управления базами данных очевидны.
Вниманию читателя! Не прекращайте учиться сейчас. Ознакомьтесь со всеми важными концепциями теории CS для собеседований SDE с помощью курса CS Theory Course по доступной для студентов цене и будьте готовы к отрасли.
Сравнить типы баз данных | Типы баз данных развиваются в соответствии с различными потребностями
Устаревшие базы данных: открывая путь для современных систем
Устаревшие типы баз данных представляют собой вехи на пути к современным базам данных.Они все еще могут найти точку опоры в определенных специализированных средах, но в основном были заменены более надежными альтернативами для производственных сред.
Этот раздел посвящен историческим типам баз данных, которые мало используются в современной разработке. Вы можете сразу перейти к разделу о реляционных базах данных, если вас это не интересует.
Плоские базы данных: простые структуры данных для организации небольших объемов локальных данных
Самый простой способ управлять данными на компьютере вне приложения — сохранить их в базовом формате файла.В первых решениях для управления данными использовался этот подход, и он до сих пор остается популярным вариантом для хранения небольших объемов информации без высоких требований.
Первые базы данных с плоскими файлами представляли информацию в файлах в виде обычных, машинно-анализируемых структур. Данные хранятся в виде обычного текста, что ограничивает тип контента, который может быть представлен в самой базе данных. Иногда для использования в качестве разделителя или маркера, указывающего, когда одно поле заканчивается и начинается следующее, выбирается специальный символ или другой индикатор.Например, запятая используется в файлах CSV (значения, разделенные запятыми), а двоеточие или пробелы используются во многих файлах данных в Unix-подобных системах. В других случаях разделитель не используется, вместо этого поля определяются с фиксированной длиной, которая может быть дополнена для более коротких значений.
/ etc / passwd в системах * nix:
9082 7root: x: 0: 0: root: / root: / bin / bash
daemon: x: 1: 1: daemon: / usr / sbin: / usr / sbin / nologin
bin: x: 2: 2: bin: / bin: / usr / sbin / nologin
sys: x: 3: 3: sys: / dev: / usr / sbin / nologin
sync: x: 4: 65534: sync: / bin: / bin / sync
games: x: 5: 60: games: / usr / games: / usr / sbin / nologin
man: x: 6: 12: man: / var / cache / man: / usr / sbin / nologin
lp: x: 7: 7: lp: / var / spool / lpd: / usr / sbin / nologin
mail: x: 8: 8: mail: / var / mail: / usr / sbin / nologin
news: x: 9: 9: news: / var / spool / news: / usr / sbin / nologin
backup: x: 34: 34: резервное копирование: / var / backups: / usr / sbin / nologin
список: x: 38: 38: менеджер списков рассылки: / var / list: / usr / sbin / nologin
никто: x: 65534: 65534: никто: / nonexistent: / usr / sbin / nologin
syslog: x: 102: 106 :: / home / syslog: / usr / sbin / nologin
bob: x: 1000: 1000: Боб Смит ,,,: / home / bob: / bin / bash
Файл
/ etc / passwdопределяет пользователей, по одному в каждой строке.У каждого пользователя есть такие атрибуты, как имя, идентификаторы пользователя и группы, домашний каталог и оболочка по умолчанию, каждый из которых разделен двоеточием.Хотя базы данных с плоскими файлами просты, они очень ограничены по уровню сложности, с которым они могут справиться. Система, которая считывает данные или манипулирует ими, не может легко устанавливать связи между представленными данными. Файловые системы обычно не имеют каких-либо функций одновременного доступа пользователей или данных. Базы данных с плоскими файлами обычно подходят только для систем с небольшими требованиями к чтению или записи.Например, многие операционные системы используют плоские файлы для хранения данных конфигурации.
Несмотря на эти ограничения, базы данных с плоскими файлами по-прежнему широко используются в сценариях, когда локальным процессам необходимо хранить и организовывать небольшие объемы данных. Хороший пример этого - данные конфигурации для многих приложений в Linux и других Unix-подобных системах. В этих случаях формат плоских файлов служит интерфейсом, который люди и приложения могут легко читать и управлять. Некоторые преимущества этого формата заключаются в том, что он имеет надежные и гибкие инструменты, легко управляется без специального программного обеспечения и прост для понимания и работы.
Примеры:
Иерархические базы данных: использование родительско-дочерних отношений для отображения данных в деревья
Первоначальное введение: 1960-е годы
Иерархические базы данных были следующей эволюцией в развитии управления базами данных. Они кодируют отношения между элементами, где каждая запись имеет единственного родителя. Это создает древовидную структуру, которую можно использовать для категоризации записей в соответствии с их родительской записью.
Это простое отображение отношений предоставляет пользователям возможность устанавливать отношения между элементами в древовидной структуре.Это очень полезно для определенных типов данных, но не позволяет управлять сложными отношениями. Более того, значение отношений родитель-потомок неявно. Одно родительско-дочернее соединение может быть между клиентом и его заказами, а другое может представлять сотрудника и оборудование, которое им было выделено. Сама структура данных не различает эти отношения.
Иерархические базы данных - это начало движения к более сложным представлениям об управлении данными.Траектория систем управления базами данных, которые были разработаны впоследствии, продолжает эту тенденцию.
Иерархические базы данных сегодня мало используются из-за их ограниченной способности организовывать большую часть данных и из-за накладных расходов на доступ к данным путем обхода иерархии. Однако несколько невероятно важных систем можно рассматривать как иерархические базы данных. Например, файловую систему можно рассматривать как специализированную иерархическую базу данных, поскольку система файлов и каталогов четко вписывается в парадигму с одним родителем / несколькими дочерними элементами.Аналогичным образом, системы DNS и LDAP действуют как базы данных для иерархических наборов данных.
Примеры:
Сетевые базы данных: отображение более гибких соединений с неиерархическими связями
Первоначальное введение: конец 1960-х годов
Сетевые базы данных, построенные на основе, предоставляемой иерархическими базами данных, с добавлением дополнительной гибкости. Вместо того, чтобы всегда иметь одного родителя, как в иерархических базах данных, записи сетевой базы данных могут иметь более одного родителя, что позволяет им эффективно моделировать более сложные отношения.Говоря о сетевых базах данных, важно понимать, что сеть используется для обозначения соединений между разными записями данных, а не соединений между разными компьютерами или программным обеспечением.
Сетевые базы данных могут быть представлены общим графом вместо дерева . Значение графа было определено схемой , в которой излагается, что представляет каждый узел данных и каждое отношение. Это придало данным структуру, которая раньше могла быть достигнута только через логический вывод.
Определение: Схема
Схема базы данных - это описание логической структуры базы данных или содержащихся в ней элементов. Схемы часто включают объявления структуры отдельных записей, групп записей и отдельных атрибутов, из которых состоят записи базы данных. Они также могут определять типы данных и дополнительные ограничения для управления типом данных, которые могут быть добавлены в структуру.
Сетевые базы данных стали огромным шагом вперед с точки зрения гибкости и способности отображать связи между информацией.Однако они все еще были ограничены теми же шаблонами доступа и конструктивным мышлением иерархических баз данных. Например, чтобы получить доступ к данным, вам все равно нужно было пройти по сетевым путям к рассматриваемой записи. Отношения «родитель-потомок», перенесенные из иерархических баз данных, также повлияли на способ соединения элементов друг с другом.
Современные примеры сетевых систем баз данных найти сложно. Настройка и работа с сетевыми базами данных требовали больших навыков и специальных знаний в предметной области.Большинство систем, которые можно было аппроксимировать с помощью сетевых баз данных, оказались более подходящими после появления реляционных баз данных.
Примеры:
Реляционные базы данных: работа с таблицами как стандартное решение для организации хорошо структурированных данных
Первоначальное введение: 1969
Реляционные базы данных являются старейшими типами баз данных общего назначения, которые все еще широко используются сегодня. Фактически, реляционные базы данных составляют большинство баз данных, используемых в настоящее время в производстве.
Реляционные базы данных организуют данные с помощью таблиц . Таблицы - это структуры, которые накладывают схему на содержащиеся в них записи. Каждый столбец в таблице имеет имя и тип данных . Каждая строка представляет собой отдельную запись или элемент данных в таблице, которая содержит значения для каждого из столбцов. Реляционные базы данных получили свое название от математических отношений, которые используют кортежи (например, строки в таблице) для представления упорядоченных наборов данных.
Специальные поля в таблицах, называемые внешними ключами , могут содержать ссылки на столбцы в других таблицах.Это позволяет базе данных соединять две таблицы по запросу для объединения различных типов данных.
Высокоорганизованная структура, обеспечиваемая жесткой структурой таблиц, в сочетании с гибкостью, обеспечиваемой связями между таблицами, делает реляционные базы данных очень мощными и адаптируемыми ко многим типам данных. Соответствие можно обеспечить на уровне таблицы, но операции с базой данных могут комбинировать эти данные и манипулировать ими по-новому.
Хотя язык запросов не является неотъемлемым элементом реляционных баз данных, он был создан для доступа и управления данными, хранящимися в этом формате.Он может запрашивать и объединять данные из нескольких таблиц в одном операторе. SQL также может фильтровать, агрегировать, суммировать и ограничивать данные, которые он возвращает. Таким образом, хотя SQL не является частью реляционной системы, он часто является фундаментальной частью работы с этими базами данных.
Определение: SQL
SQL, или язык структурированных запросов, - это семейство языков, используемое для запроса и обработки данных в реляционных базах данных. Он отлично подходит для объединения данных из нескольких таблиц и фильтрации на основе ограничений, которые позволяют использовать его для выражения сложных запросов.Варианты языка были приняты почти во всех реляционных базах данных из-за его гибкости, мощности и повсеместного распространения.
В общем, реляционные базы данных часто хорошо подходят для любых данных, которые являются регулярными, предсказуемыми и извлекают выгоду из способности гибко составлять информацию в различных форматах. Поскольку реляционные базы данных работают по схеме, может быть сложнее изменить структуру данных после того, как они окажутся в системе. Однако схема также помогает обеспечить целостность данных, обеспечивая соответствие значений ожидаемым форматам и включение необходимой информации.В целом реляционные базы данных - хороший выбор для многих приложений, поскольку приложения часто генерируют хорошо упорядоченные, структурированные данные.
Примеры:
Базы данных NoSQL: современные альтернативы для данных, которые не соответствуют реляционной парадигме
NoSQL - это термин для разнообразного набора современных типов баз данных, которые предлагают подходы, отличные от стандартного реляционного шаблона. Термин NoSQL в некоторой степени неверен, поскольку базы данных в этой категории являются скорее реакцией на реляционный архетип, чем на язык запросов SQL.Говорят, что NoSQL означает «не-SQL» или «не только SQL», чтобы иногда уточнить, что они иногда позволяют выполнять запросы, подобные SQL.
Базы данных "ключ-значение": простые поисковые запросы в стиле словаря для базового хранения и поиска
Первое введение: 1970-е | Рост популярности: 2000–2010 гг.
Базы данных «ключ-значение», или хранилища «ключ-значение», являются одними из простейших типов баз данных. Хранилища "ключ-значение" работают путем хранения произвольных данных, доступных через определенный ключ .Для хранения данных вы предоставляете ключ и большой двоичный объект данных, который хотите сохранить, например объект JSON, изображение или простой текст. Чтобы получить данные, вы указываете ключ, а затем получаете обратно большой двоичный объект данных. В большинстве базовых реализаций база данных не оценивает данные, которые она хранит, и допускает ограниченные способы взаимодействия с ними.
Если хранилища ключей и значений кажутся простыми, то это потому, что они таковы. Но эта простота часто является преимуществом в тех сценариях, в которых они чаще всего используются.Хранилища "ключ-значение" часто используются для хранения данных конфигурации, информации о состоянии и любых данных, которые могут быть представлены словарем или хэшем на языке программирования. Хранилища "ключ-значение" обеспечивают быстрый и несложный доступ к этому типу данных.
Некоторые реализации предоставляют более сложные действия поверх этой основы в соответствии с основным типом данных, хранящимся под каждым ключом. Например, они могут увеличивать числовые значения или выполнять срезы или другие операции со списками.Поскольку многие хранилища ключей и значений загружают свои наборы данных в память, эти операции могут выполняться очень эффективно.
Базы данных «ключ-значение» не предписывают никакой схемы для данных, которые они хранят, и поэтому часто используются для одновременного хранения многих различных типов данных. Пользователь несет ответственность за определение любой схемы именования ключей, которая поможет идентифицировать значения, и отвечает за обеспечение того, чтобы значение было соответствующего типа и формата. Хранилище «ключ-значение» наиболее полезно как легкое решение для хранения простых значений, с которыми можно работать извне после извлечения.
Одно из самых популярных применений баз данных «ключ-значение» - это хранение значений конфигурации, переменных и флагов приложений для веб-сайтов и веб-приложений. При запуске программы могут проверять конфигурацию хранилища ключей и значений, что обычно выполняется очень быстро. Это позволяет вам изменять поведение ваших сервисов во время выполнения, изменяя данные в хранилище "ключ-значение". Приложения также можно настроить на периодическую перепроверку или перезапуск при появлении изменений. Эти хранилища конфигурации часто сохраняются на диске периодически, чтобы предотвратить потерю данных в случае сбоя системы.
Примеры:
Базы данных документов: Хранение всех данных элемента в гибких структурах с самоописанием
Рост популярности: 2009
Базы данных документов, также известные как документно-ориентированные базы данных или хранилища документов, совместно используют базовые семантика доступа и поиска хранилищ "ключ-значение". Базы данных документов также используют ключ для однозначной идентификации данных в базе данных. Фактически, грань между расширенными хранилищами ключей и значений и базами данных документов может быть довольно нечеткой.Однако вместо хранения произвольных больших двоичных объектов базы данных документов хранят данные в структурированных форматах, называемых документами, часто с использованием таких форматов, как JSON, BSON или XML.
Хотя данные в документах организованы в рамках структуры, базы данных документов не предписывают какой-либо конкретный формат или схему. Каждый документ может иметь разную внутреннюю структуру, которую интерпретирует база данных. Таким образом, в отличие от хранилищ «ключ-значение», контент, хранящийся в базах данных документов, можно запрашивать и анализировать.
В некотором смысле базы данных документов располагаются между реляционными базами данных и хранилищами "ключ-значение". Они используют простую семантику «ключ-значение» и нестрогие требования к данным, которыми известны хранилища «ключ-значение», но они также предоставляют возможность наложить структуру, которую вы можете использовать для запроса и работы с данными в будущем.
Однако не следует преувеличивать сравнение с реляционными базами данных. Хотя базы данных документов предоставляют методы структурирования данных в документах и работы с наборами данных на основе этих структур, доступные гарантии, отношения и операции сильно отличаются от реляционных баз данных.
Базы данных документов - хороший выбор для быстрой разработки, потому что вы можете изменить свойства данных, которые хотите сохранить, в любой момент, не изменяя существующие структуры или данные. Вам нужно только заполнить записи, если вы хотите. Каждый документ в базе данных имеет свою собственную систему организации. Если вы все еще разбираетесь в своей структуре данных, и ваши данные в основном состоят из дискретных записей, которые не содержат большого количества перекрестных ссылок, база данных документов может быть хорошим местом для начала.Однако будьте осторожны, поскольку дополнительная гибкость означает, что вы несете ответственность за поддержание согласованности и структуры своих данных, что может быть чрезвычайно сложной задачей.
Примеры:
Графические базы данных: сопоставление отношений с акцентом на значимость связей между данными
Рост популярности: 2000-е годы
Графические базы данных - это тип базы данных NoSQL, в которой используется другой подход к установлению отношений между данными. Вместо того, чтобы отображать отношения с таблицами и внешними ключами, базы данных графов устанавливают соединения, используя концепции узлов , ребер и свойств .
Графические базы данных представляют данные как отдельные узлы, которые могут иметь любое количество связанных с ними свойств. Между этими узлами устанавливаются ребра (также называемые отношениями), представляющие различные типы соединений. Таким образом, база данных кодирует информацию об элементах данных в узлах и информацию об их отношениях на ребрах, которые соединяют узлы.
На первый взгляд графические базы данных выглядят похожими на более ранние сетевые базы данных.Оба типа сосредоточены на связях между элементами и позволяют явно отображать отношения между различными типами данных. Однако сетевые базы данных требуют пошагового обхода для перемещения между элементами и ограничены типами отношений, которые они могут представлять.
Графические базы данных наиболее полезны при работе с данными, где отношения или связи очень важны. Важно понимать, что, говоря о реляционных базах данных, слово «реляционные» относится к способности связывать информацию в разных таблицах вместе.С другой стороны, в графовых базах данных основной целью является определение самих отношений и управление ими.
Например, запрос соединения между двумя пользователями сайта социальной сети в реляционной базе данных, вероятно, потребует объединения нескольких таблиц и, следовательно, будет довольно ресурсоемким. Тот же самый запрос был бы простым в базе данных графа, которая напрямую отображает соединения. Основное внимание в графовых базах данных уделяется тому, чтобы сделать работу с этим типом данных интуитивно понятной и эффективной.
Базы данных семейства столбцов: базы данных с гибкими столбцами для преодоления разрыва между реляционными базами данных и базами данных документов
Рост популярности: 2000-е годы
Базы данных семейства столбцов, также называемые нереляционными хранилищами столбцов, базами данных с широкими столбцами или просто колоночные базы данных, возможно, относятся к типу NoSQL, который на первый взгляд больше всего похож на реляционные базы данных. Как и реляционные базы данных, базы данных с широкими столбцами хранят данные с использованием таких понятий, как строки и столбцы.Однако в базах данных с широкими столбцами связь между этими элементами сильно отличается от того, как их используют реляционные базы данных.
В реляционных базах данных схема определяет структуру столбцов в таблице, указывая, какие столбцы будут в таблице, соответствующие типы данных и другие критерии. Все строки в таблице должны соответствовать этой фиксированной схеме.
Вместо таблиц базы данных семейств столбцов имеют структуры, называемые семейств столбцов . Семейства столбцов содержат строки данных, каждая из которых определяет свой собственный формат.Строка состоит из уникального идентификатора строки, используемого для поиска строки, за которым следуют наборы имен столбцов и значений.
В этом дизайне каждая строка в семействе столбцов определяет свою собственную схему. Эту схему можно легко изменить, поскольку она влияет только на эту единственную строку данных. Каждая строка может иметь разное количество столбцов с разными типами данных. Иногда полезно думать о базах данных семейств столбцов как о базах данных «ключ-значение», где каждый ключ (идентификатор строки) возвращает словарь произвольных атрибутов и их значений (имена столбцов и их значения).
Базы данных семейства столбцов хороши при работе с приложениями, требующими высокой производительности для операций на основе строк и высокой масштабируемости. Поскольку все данные и метаданные для записи доступны с одним идентификатором строки, для поиска и извлечения информации не требуется дорогостоящих в вычислительном отношении соединений. Система базы данных также обычно обеспечивает размещение всех данных в строке на одном компьютере в кластере, что упрощает сегментирование и масштабирование данных.
Однако базы данных семейства столбцов работают не во всех сценариях. Если у вас есть высокореляционные данные, требующие объединений, это неподходящий тип базы данных для вашего приложения. Базы данных семейства столбцов твердо ориентированы на операции, основанные на строках. Это означает, что агрегированные запросы, такие как суммирование, усреднение и другие процессы, ориентированные на аналитику, могут быть трудными или невозможными. Это может иметь большое влияние на то, как вы разрабатываете свои приложения и какие типы шаблонов использования вы можете использовать.
Примеры:
Базы данных временных рядов: отслеживание изменений значений с течением времени
Рост популярности: 2010-е годы
Базы данных временных рядов - это хранилища данных, предназначенные для сбора и управления значениями, которые меняются с течением времени. Хотя иногда они рассматриваются как подмножество других типов баз данных, таких как хранилища ключей и значений, базы данных временных рядов широко распространены и достаточно уникальны, чтобы их учитывать.
Многие базы данных временных рядов организованы в структуры, в которых записываются значения для одного элемента с течением времени.Например, можно создать таблицу или аналогичную структуру для отслеживания температуры процессора. Внутри каждое значение будет состоять из отметки времени и значения температуры, чтобы отобразить, какая температура была в определенные моменты времени.
В других реализациях метки времени используются в качестве ключей для одновременного хранения значений нескольких показателей или столбцов. Например, эти структуры позволят вам сохранять и извлекать значения температуры процессора, загрузки системы и использования памяти с использованием единой временной метки.
С точки зрения характеристик чтения и записи базы данных временных рядов в значительной степени ориентированы на запись. Они предназначены для обработки постоянного потока входящих данных. В общем, базы данных временных рядов работают с регулярными последовательными потоками данных без множества всплесков, что упрощает планирование, чем некоторые другие типы данных. Производительность часто зависит от количества отслеживаемых элементов, интервала опроса между записью новых значений и фактической полезной нагрузки данных, которую необходимо сохранить.
Базы данных временных рядов по своей природе обычно предназначены только для добавления. Каждый входящий фрагмент данных сохраняется как новое значение, связанное с текущим моментом времени. Значения, уже присутствующие в базе данных, обычно не изменяются после приема. Поскольку наиболее ценные данные часто являются самыми последними, иногда более старые значения агрегируются, подвергаются пониженной выборке или суммируются с более низким разрешением, чтобы размер набора данных оставался управляемым.
Базы данных временных рядов часто используются для хранения информации мониторинга или производительности системы.Это делает их идеальным вариантом для управления инфраструктурой, особенно средами IoT (Интернет вещей), которые генерируют много данных. Любая система мониторинга или оповещения, которую вы можете использовать для наблюдения за средами развертывания, скорее всего, будет использовать какой-либо тип базы данных временных рядов.
Примеры:
Базы данных NewSQL: привнесение современной масштабируемости и производительности в традиционный реляционный шаблон
Рост популярности: 2010-е годы
Базы данных NoSQL - отличный вариант для ситуаций, когда ваши данные не вписываются в реляционный шаблон.Поскольку они были разработаны совсем недавно, системы NoSQL, как правило, разрабатываются с учетом требований к масштабируемости и производительности.
Однако до недавнего времени не существовало решения для простого масштабирования реляционных данных. Чтобы удовлетворить эту потребность, был разработан новый тип реляционных баз данных, названный базами данных NewSQL.
Базы данных NewSQL следуют реляционной структуре и семантике, но построены с использованием более современных масштабируемых конструкций. Цель состоит в том, чтобы предложить большую масштабируемость, чем у реляционных баз данных, и более высокие гарантии согласованности , чем у альтернатив NoSQL.Они достигают этого, жертвуя определенной степенью доступности в случае сетевого раздела. Компромисс между согласованностью и доступностью - фундаментальная проблема распределенных баз данных, описываемая теоремой CAP .
Определение: теорема CAP
Теорема CAP - это утверждение о компромиссах, которые распределенные базы данных должны делать между доступностью и согласованностью. Он утверждает, что в случае сетевого раздела распределенная база данных может либо оставаться доступной, либо оставаться согласованной, но она не может делать и то, и другое.Члены кластера в разделенной сети могут продолжать работать, что приведет, по крайней мере, к временной несогласованности. В качестве альтернативы, по крайней мере, некоторые из отключенных членов должны отказаться изменять свои данные во время разделения, чтобы гарантировать согласованность данных.
Чтобы решить проблему доступности, были разработаны новые архитектуры, минимизирующие влияние разделов. Например, разделение наборов данных на более мелкие диапазоны, называемые фрагментами , , может минимизировать объем данных, которые недоступны во время разделов.Кроме того, механизмы автоматического изменения ролей различных членов кластера в зависимости от состояния сети позволяют им быстро восстановить доступность.
Благодаря этим качествам базы данных NewSQL лучше всего подходят для сценариев использования с большими объемами реляционных данных в распределенных облачных средах.
Хотя базы данных NewSQL предлагают большинство знакомых функций обычных реляционных баз данных, существуют некоторые важные отличия, которые не позволяют им быть однозначной заменой.Системы NewSQL обычно менее гибкие и универсальные, чем их более традиционные реляционные аналоги. Они также обычно предлагают только подмножество полных SQL и реляционных функций, что означает, что они могут быть не в состоянии обрабатывать определенные виды использования. Многие реализации NewSQL также хранят большую часть или весь набор данных в основной памяти компьютера. Это повышает производительность за счет большего риска нераспространенных изменений.
Базы данных NewSQL хорошо подходят для наборов реляционных данных, требующих масштабирования, превышающего возможности обычных реляционных баз данных.Поскольку они реализуют реляционную абстракцию и предоставляют интерфейсы SQL, переход к базе данных NewSQL часто оказывается более простым, чем переход к альтернативе NoSQL. Однако важно помнить, что, хотя они в основном стремятся воспроизвести обычные реляционные среды, существуют различия, которые могут повлиять на ваши развертывания. Обязательно исследуйте эти различия и определите ситуации, в которых сходство нарушается.
Примеры:
Многомодельные базы данных: объединение характеристик более чем одного типа баз данных
Рост популярности: 2010-е годы
Многомодельные базы данных - это базы данных, сочетающие в себе функциональность более чем одного типа баз данных.Преимущества этого подхода очевидны - одна и та же система может использовать разные представления для разных типов данных.
Совместное размещение данных из нескольких типов баз данных в одной системе позволяет выполнять новые операции, которые в противном случае были бы трудными или невозможными. Например, многомодельные базы данных могут позволить пользователям получать доступ и управлять данными, хранящимися в разных типах баз данных, в рамках одного запроса. Многомодельные базы данных также помогают поддерживать согласованность данных, что может быть проблемой при выполнении операций, изменяющих данные сразу во многих системах.
С точки зрения управления, многомодельные базы данных помогают уменьшить операционную нагрузку на ваши системы баз данных. Наличие многофункциональной системы позволяет вам изменять или расширять новые модели по мере изменения ваших потребностей без изменений базовой инфраструктуры или дополнительных затрат на изучение новой системы.
Трудно говорить о характеристиках многомодельных баз данных как о заданной категории, поскольку они в основном наследуют преимущества типов баз данных, которые они выбирают для поддержки.Важно помнить, что вы должны оценить, насколько хорошо отдельные реализации поддерживают требуемые вам конкретные типы баз данных. Некоторые системы могут поддерживать несколько моделей, но с разными наборами функций или с важными оговорками.
Какие бывают типы баз данных?
Базы данных - важная часть современной жизни. Без них большинство компьютерных функций перестало бы существовать. Если вы тот, кто полагается на хранение информации на компьютере, будь то индивидуальное лицо или ваша работа, то важно понимать различные типы существующих баз данных и то, как вы должны их использовать.В этом руководстве мы обсудим, что такое базы данных, включая наиболее распространенные типы баз данных, с которыми вы, вероятно, столкнетесь.
Что такое базы данных?
База данных - это набор информации, хранящейся в компьютере. Базы данных используются для всего, от хранения изображений на вашем компьютере до покупки товаров в Интернете и анализа фондового рынка. Базы данных позволяют компьютерам хранить важную информацию в организованном и удобном для поиска виде.
По мере того, как технология баз данных с годами улучшалась, менялись и различные типы баз данных.В настоящее время существует множество различных типов баз данных, каждая из которых имеет свои сильные и слабые стороны в зависимости от того, как они спроектированы. Для предприятий особенно важно понимать различные типы баз данных, чтобы убедиться, что они имеют наиболее эффективную настройку, однако некоторым людям может потребоваться изучить и это.
Типы баз данных
Во многих случаях люди обнаруживают, что им нужны разные типы баз данных для разных задач. Вы также заметите некоторое совпадение в разных типах баз данных.Узнав больше о различных типах, вы сможете принять лучшее решение о типах баз данных, которые вам нужны. Ниже приведены некоторые распространенные типы баз данных, с которыми вы можете столкнуться в личной жизни или в бизнесе:
- Централизованная база данных
- Облачная база данных
- Коммерческая база данных
- Распределенная база данных
- База данных конечных пользователей
- База данных Graph
- NoSQL база данных
- Объектно-ориентированная база данных
- База данных с открытым исходным кодом
- Оперативная база данных
- Персональная база данных
- Реляционная база данных
Централизованная база данных
Централизованная база данных - это база данных, которая работает полностью в одном месте.Централизованные базы данных обычно используются более крупными организациями, такими как бизнес или университет. Сама база данных находится на центральном компьютере или в системе баз данных. Пользователи могут получить доступ к базе данных через компьютерную сеть, но это центральный компьютер, который запускает и обслуживает базу данных.
Облачная база данных
Облачная база данных - это база данных, которая работает через Интернет. Данные хранятся на локальном жестком диске или сервере, но информация доступна в Интернете.Это упрощает доступ к вашим файлам из любого места, если у вас есть подключение к Интернету. Чтобы использовать облачную базу данных, пользователи могут либо создать ее сами, либо заплатить за услугу по хранению своих данных для них. Шифрование является неотъемлемой частью любой облачной базы данных, так как вся информация должна быть защищена, поскольку она передается в Интернете.
Связанные: Узнайте о том, как стать менеджером данных
Коммерческая база данных
Коммерческая база данных - это любая база данных, разработанная коммерческим предприятием.Компании разрабатывают многофункциональные базы данных, которые затем продают своим клиентам. Коммерческие базы данных могут различаться по составу или используемой технологии. Отличительной чертой коммерческих баз данных является то, что пользователи платят за их использование, в отличие от баз данных с открытым исходным кодом.
Распределенная база данных
Распределенная база данных - это база данных, распределенная по нескольким устройствам. Вместо того, чтобы хранить всю информацию на одном устройстве, как другие базы данных в этом списке, распределенные базы данных будут работать на нескольких машинах, например, на разных компьютерах в одном месте или в сети.Преимущества распределенной базы данных включают повышенную скорость, лучшую надежность и простоту расширения.
Связано: Узнайте, как стать специалистом по данным
База данных конечного пользователя
Конечный пользователь - это термин, используемый при разработке продукта, который относится к человеку, который использует продукт. Таким образом, база данных конечного пользователя - это база данных, которая в основном используется одним человеком. Хорошим примером этого типа базы данных является электронная таблица, хранящаяся на вашем локальном компьютере.
База данных Graph
База данных Graph - это базы данных, которые в равной степени сосредоточены на данных и связях между ними. В этой базе данных данные не ограничиваются предопределенными моделями. Большинство других баз данных могут находить связи между данными при выполнении поиска. В базе данных графов эти соединения хранятся внутри базы данных вместе с исходными данными. Это делает базу данных более эффективной и быстрой, когда вашей основной целью является управление соединениями между вашими данными.
База данных NoSQL
По сути, существует два основных типа баз данных: NoSQL и реляционные, все остальные являются разными версиями. База данных NoSQL имеет иерархию, аналогичную системе файловых папок, и данные в ней неструктурированы. Такое отсутствие структуры позволяет им быстро обрабатывать большие объемы данных и упрощает расширение в будущем. В облачных вычислениях регулярно используются базы данных NoSQL.
Объектно-ориентированная база данных
Объектно-ориентированная база данных - это базы данных, в которых данные представлены в виде объектов и классов.Объект - это предмет реального мира, такой как имя или номер телефона, а класс - это группа объектов. Объектно-ориентированные базы данных - это разновидность реляционной базы данных. Рассмотрите возможность использования объектно-ориентированной базы данных, когда у вас есть большой объем сложных данных, которые вы хотите быстро обработать.
База данных с открытым исходным кодом
База данных с открытым исходным кодом предназначена для бесплатного использования широкой публикой. В отличие от коммерческих баз данных, пользователи могут загружать или подписываться на базы данных с открытым исходным кодом без оплаты.Термин «открытый исходный код» относится к программе, в которой пользователи могут видеть, как это делается, и вносить свои собственные изменения в программу. Базы данных с открытым исходным кодом обычно намного дешевле коммерческих баз данных, но в них также могут отсутствовать некоторые из более продвинутых функций, имеющихся в коммерческих базах данных.
Оперативная база данных
Назначение оперативной базы данных - позволить пользователям изменять данные в реальном времени. Оперативные базы данных имеют решающее значение для бизнес-аналитики и хранилищ данных.Их можно настроить как реляционные базы данных или как NoSQL, в зависимости от потребностей. Обычные базы данных полагаются на пакетную обработку, при которой команды выполняются группами. С другой стороны, оперативные базы данных позволяют добавлять, редактировать и удалять данные в любой момент в режиме реального времени.
Связанные: Узнайте, как стать аналитиком данных
Персональная база данных
Персональная база данных предназначена для одного человека. Обычно он хранится на персональном компьютере и имеет очень простой дизайн, состоящий всего из нескольких таблиц.Персональные базы данных обычно не подходят для сложных операций, больших объемов данных или бизнес-операций.
Реляционная база данных
Реляционные базы данных - это другой основной тип баз данных, противоположный NoSQL. В реляционной базе данных информация хранится в структурированном виде и о других данных. Хорошим представлением реляционной базы данных может быть человек, делающий покупки в Интернете, и его корзина для покупок. Реляционные базы данных часто предпочтительнее, когда вы беспокоитесь о целостности ваших данных или когда вы не особо ориентируетесь на масштабируемость.
Типы систем баз данных | nibusinessinfo.co.uk
Система управления базами данных - это программный пакет для создания и управления базами данных. Существует множество различных типов систем баз данных в зависимости от того, как они управляют структурой базы данных.
Два типа структуры базы данных
Базы данных обычно имеют одну из двух основных форм:
- Однофайловая или однофайловая база данных
- Многофайловая реляционная или структурированная база данных
Плоская файловая база данных хранит данные в простой текстовый файл, в котором каждая строка текста обычно содержит одну запись.Поля разделяются разделителями, такими как запятые или табуляция. База данных с плоскими файлами использует простую структуру и, в отличие от реляционной базы данных, не может содержать несколько таблиц и отношений. Узнайте больше о базах данных с плоскими файлами.
Реляционная база данных содержит несколько таблиц данных со строками и столбцами, которые связаны друг с другом через специальные ключевые поля. Эти базы данных более гибкие, чем структуры плоских файлов, и предоставляют функции для чтения, создания, обновления и удаления данных.Реляционные базы данных используют язык структурированных запросов (SQL) - стандартное пользовательское приложение, которое обеспечивает простой программный интерфейс для взаимодействия с базой данных. Узнайте больше о реляционных базах данных.
Типы отношений в базе данных
В проекте реляционной базы данных существуют четыре типа отношений:
- один к одному - когда одна запись таблицы связана с другой записью в другой таблице
- один ко многим - где одна запись таблицы относится несколько записей в другой таблице
- многие к одному - где более одной записи таблицы относятся к другой записи таблицы
- многие ко многим - где несколько записей относятся к более чем одной записи в другой таблице
Эти отношения образуют функциональные зависимости внутри база данных.Некоторые общие примеры реляционных баз данных включают MySQL, Microsoft SQL Server, Oracle и т. Д.
Четыре типа систем управления базами данных
Система управления реляционными базами данных - это один из четырех распространенных типов систем , которые вы можете использовать для управления своими бизнес-данные. К другим трем относятся:
- иерархические системы баз данных
- сетевые системы баз данных
- объектно-ориентированные системы баз данных
Иерархическая база данных Модель напоминает древовидную структуру, аналогичную архитектуре папок в вашей компьютерной системе.Отношения между записями заранее определены один к одному, между «родительскими и дочерними» узлами. Они требуют, чтобы пользователь прошел иерархию, чтобы получить доступ к необходимым данным. Из-за ограничений такие базы данных могут быть ограничены конкретным использованием. Узнайте больше об иерархических базах данных.
Сетевая база данных Модели также имеют иерархическую структуру. Однако вместо использования иерархии дерева с одним родителем эта модель поддерживает отношения "многие ко многим", поскольку дочерние таблицы могут иметь более одного родителя.Подробнее о сетевых базах данных.
Наконец, в объектно-ориентированных базах данных , , информация представлена в виде объектов с различными типами отношений, возможными между двумя или более объектами. Такие базы данных используют для разработки объектно-ориентированный язык программирования. Узнайте больше об объектно-ориентированных базах данных.
NoSQL или нереляционные базы данных
Популярная альтернатива реляционным базам данных. Базы данных NoSQL принимают различные формы и позволяют хранить и обрабатывать большие объемы неструктурированных и полуструктурированных данных.Примеры включают хранилища "ключ-значение", хранилища документов и графические базы данных. Узнайте больше о базах данных NoSQL.
Какая база данных вам подходит?
Компании с простыми требованиями к базе данных часто используют стандартные офисные инструменты, такие как электронные таблицы. Однако, если вы используете большие объемы данных или имеете сложные бизнес-потребности, вам может потребоваться рассмотреть более мощные системы баз данных, которые предлагают лучшую функциональность. Найдите советы, которые помогут вам решить, какая база данных лучше всего подходит для вашего бизнеса.