Что такое URL адрес | ИТ Блог. Администрирование серверов на основе Linux (Ubuntu, Debian, CentOS, openSUSE)
Что такое URL
URL – это обозначение индивидуального адреса веб-сайта или другого ресурса, который записывают и формируют по особой форме. Сама аббревиатура URL обозначает «Universal Resource Locator», что можно перевести как «Универсальный Указатель Местоположения». Рекомендуем интересную статью про URL адреса – a-round.com.ua/seo-url-sajta-chpu.
Говоря простым языком – чтобы найти нужный дом нам потребуется знать город, улицу и его номер (иными словами – адрес), то в случае с веб-сайтом нам достаточно знать его URL, который представляет собой аналогичный адрес, только в интернете – он может состоять из букв латиницы, цифр и некоторых других символов.
Из чего состоит URL адрес
Рассмотрим для примера URL http://www.site.ru/category/page. Данный веб адрес URL состоит из таких компонентов:
Протокол
«http://» – это указание на используемый протокол, который будет маршрутизировать данные через интернет-соединение. Некоторые браузеры не отображают протокол в адресной строке, но это не значит, что его нет. Сейчас часто можно встретить протокол «https», где буква «s» в названии обозначает передачу информации по защищённому протоколу.
Доменное имя
Адрес www.site.ru состоит из таких компонентов:
«ru» – домен первого (верхнего) уровня
«site» – домен второго уровня, который предпочитают регистрировать большинство владельцев веб-сайтов
«www» – домен третьего уровня; корректно настроенный сайт также должен работать без ввода «www».

Каталог
В элементе адреса – /category/page, приведен путь к определённой странице на самом домене. Иногда URL адрес написан только в такой сокращенной форме, и тогда он называется относительным адресом URL. Термин «относительный» означает, что даже если вы перемещаете веб-сайт на другой домен, указанная вами ссылка будет по-прежнему работать внутри сайта.
Иногда URL адреса веб-сайтов, построенных на некоторых системах управления контентом, труднопонятны для человека, потому что они не являются конкретным путем к определенной странице, а представляют собой техническую команду. Такие адреса неудобны пользователям, поэтому с помощью специальных команд их заменяют на так называемые «человекопонятные URL» или «SEO URL».
История
URL адрес был изобретён в далёком 1990 году и использовался для указания на расположение определенных файлов в сети интернет. Затем его создатели пришли к выводу, что такой адрес можно применять и для доступа пользователей на веб-сайты в еще только зарождавшемся на тот момент интернете.
Правильно подобранный адрес для сайта значит очень многое. Краткое и емкое имя позволяет клиентам и посетителям легко запомнить это обозначение, что позволит зайти на требуемый сайт, просто введя его адрес по памяти. Также большое значение URL имеет и для продвижения веб-сайта в поисковых системах. Так, например, Яндекс и Google рекомендуют делать адреса понятными и информативными, что позволит улучшить пользовательский опыт, а пользователи, вероятнее всего, будут чаще переходить по таким ссылкам.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
andreyex.ru
Что такое URL адрес? Виды и назначение
URL – неотъемлемая часть, один из столпов Интернета, каким мы его знаем. Цель данного материала – познакомить вас с этим термином как можно ближе, но в то же время объяснить доступным языком. Мы рассмотрим наиболее часто встречаемые разновидности URL-адресов и узнаем, чем и кому они бывают полезны.
Если объяснять в «двух словах», то URL – это ссылка на любую страницу или файл. http://vk.com – это URL-адрес; эта страница – тоже адрес; ссылка, по которой вы скачали любой документ – тоже. Аббревиатура означает Uniform Resource Locator (переводится как «Единый указатель ресурсов»), в русскоязычном сегменте интернета часто называется «Урл».
URL отличаются по протоколу. Протокол – это то, что пишется перед любой ссылкой, и оканчивается знаками «://».
http://
Этот протокол предназначен для интернет-ресурсов и используется в браузерах. Наверняка вы замечали, что он есть у любого сайта, на который вы заходите. Даже если сами вы его и не набирали, браузер, чтобы установить соединение с ресурсом, автоматически добавляет http:// в начало ссылки. Это легко проверить: наберите в адресной строке браузера любой адрес (тот же vk.com) и вы увидите, что когда страница будет загружена, то адрес будет начинаться с «http://».
Отсутствие пробелов
Особенность всех URL-адресов в том, что они не могут содержать пробелы.
Поэтому разделителями в URL выступают знаки «-», «_» и конструкция «%20».
Это легко проверить, просто введя любой запрос из двух и более слов в том же Яндекс.
GET
Очень грубо, но сайты можно разделить на 2 группы:
- Простые
- Сложные
Простые – это сайты, где вся информация, которую вы читаете, содержится в страничках вида .html. Т.е. одна страница – один файл.
Сложные же имеют более запутанную систему хранения и выдачи информации, но это плата за количество возможностей, которые на таких ресурсах можно реализовать.
Сложный сайт может выдавать одну (псевдо)страницу, но с разным содержимым. Пример – поиск Яндекса.
Любой запрос, который вы вводите, отправляет вас к одной и той же страничке (yandex.ru/search/). Всё начинается с момента, когда добавляется вопросительный знак.
http://yandex.ru/search/?text=как%20купить%20панду&lr=51
Всё, что идёт после него – и есть GET-запрос, в котором может быть сколько угодно атрибутов. Они «подключаются» через знак «&».
Якорь
Приём с якорем используется на сайтах для навигации в пределах одной страницы. Так можно создать своего рода оглавление, позволяя читателю не листать всю страницу в поисках нужной части, а просто нажать на ссылку и переместиться, куда требовалось.
Это конструкция вида «http://домен/ссылка#якорь»
Проверить, как это работает, можно прямо здесь: нажмите на любую ссылку в оглавлении и увидите, что все ссылки идентичны, не считая того, что добавлено к ним после символа «#».
https://
Чтобы не вдаваться в технические подробности, скажем просто: это защищённый вариант соединения http://. Актуален там, где речь идёт о хранении важной информации о пользователях. Например, если сайт связан с покупкой/оплатой или паспортными данными. Как пример – тот же Яндекс.
Но как именно такой протокол помогает уберечь пользователя? У него есть несколько степеней защиты, каждый из которых предоставляется владельцу сайта после предъявления личных данных. В каждом браузере, в адресной строке (место, где пишется URL-адрес), есть небольшая картинка.
При обычном (http), или защищённом первой степени (https) она остаётся неприметной:
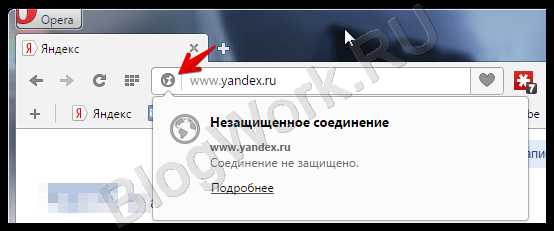
Если же владелец ресурса подтвердил достаточно данных, мы увидим зелёный значок, а иногда и название компании.
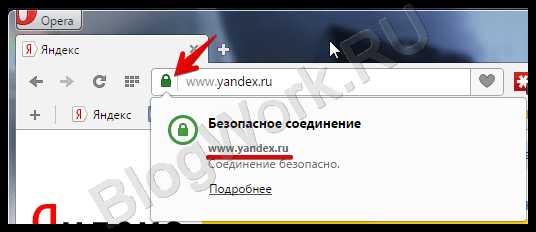
Таким образом, находясь на таком «зелёном» сайте можно не беспокоиться о том, что вы каким-либо образом могли попасть на сайт мошенников, замаскированный под официальный.
FTP (ftp://)
Он, хоть и относится к сайтам, не предназначен для их просмотра. FTP – это протокол передачи данных (File Transfer Protocol), с помощью которого можно загружать файлы на сайт, и скачивать их оттуда.
У него, несмотря на схожесть с http:// есть масса отличий. Вот те, что легче всего заметить:
Поддержка авторизации
При попытке войти на FTP какого-либо сайта, браузер может запросить логин и пароль от этого соединения. Это логично, т.к. не позволяет каждому желающему вносить изменения в файлы сайта.
Отличный от домена адрес
Далеко не всегда ftp-адрес копирует http-адрес одного и того же ресурса. К примеру, если к vk.com дописать ftp://, то мы получим ошибку, т.к. такого адреса не существует. Но FTP у этого сайта (как и любого другого) есть, просто он скрыт от посторонних глаз.
Подключение через программы-клиенты
Существует немалое количество специальных программ, призванных помочь владельцам интернет-ресурсов удобно взаимодействовать с этим протоколом.
Подключение через Проводник Windows
Если вы не знали, то в Проводнике тоже есть адресная строка. Выглядит она так:
Если нажать на ней левой кнопкой мыши, то красиво оформленный путь до текущей папки пример вид, похожий на http. Что будет, если здесь просто вписать адрес любого сайта? Проводник передаст эту информацию в браузер, используемый по умолчанию и сайт откроется именно в браузере. А вот с FTP всё иначе:
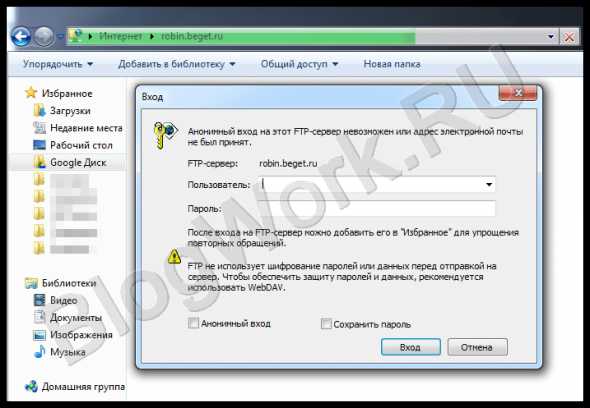
В случае с открытым подключением, прямо в Проводнике отобразятся все доступные файлы и папки, которые можно скачать на компьютер простым перетаскиванием. Если подключение защищено, то при простом наборе ftp-адреса, нас попросят ввести логин и пароль.
mailto:
Протокол, отвечающий за e-mail. Нажатие на такую ссылку отправляет запрос в почтовый клиент, который считается основным в системе. Если клиента нет, то эту функцию берут на себя браузер и почтовые сервисы. Например, у меня после клика по mailto-адресу открывается страничка Gmail.
Заключение
Как говорилось в начале, здесь – далеко не полный список возможных URL-адресов. Существует немало программ, давших жизнь разновидностям URL; например, «magnet:» — тип ссылок, преимущественно для торрент-клиентов. Примеров много, но чаще всего на сайтах, где используется специфический протокол, есть и пояснение, какая программа его понимает.
blogwork.ru
адрес — что это такое и где его взять?
Таинственный урл сайта – открываем завесу
Почти любой юзер интернета слышал о таком понятии, как URL адрес, но не каждый знает зачем он нужен. Давайте же рассмотрим пару пунктов, связанных с этим тезисом.
URL – адрес любого ресурса во всемирной паутине интернет. Впервые об URL услышали благодаря великобританскому изобретателю Тиму Бернерсу-Ли, который в 1990 году создал единообразный локатор ресурса. Изначально он обозначал места отдельных файлов.
На данный момент URL применятся для определения адресов чуть ли не для каждого ресурсав Интернете. То есть он показывает нам, где именно лежит то, что мы ищем. У каждого ресурса в глобальной сети есть своя уникальная совокупность символов, которые помогает идентифицировать его, будь то картинка, сайт и тому подобное.
Из чего же он состоит?
В браузере URL выглядит так: https://index.ru/
Она состоит из отдельных блоков, и в действительности выглядит так:<схема>:[//[ <логин:<>;<пароль>@]<хост>[:<порт>]][/][?<параметры>][#<якорь>]
Теперь же рассмотрим эти блоки отдельно.
- Схема показывает то, как к ресурсу будут обращаться, то есть сетевой протокол.
- Логин – имя юзера, который обращается к данному ресурсу.
- Пароль – пароль данного юзера.
- Хост – это IP или имя хоста в структуре DNS.
- Порт – порт при подключении.
- URL – путь определяет сведения об интересующем нам ресурсе.
- Параметры – особые параметры сайта, отвечающие за файлы внутри этого ресурса.
- Якорь нужен для указания заголовок внутри документа. Многие профессионалы считают, что он не нужен.
Наиболее важным в приведенной конструкции является блок<схема> или сетевой протокол. Одним из популярных протоколов является http. Как говорилось ранее, это свод правил при доступе к ресурсам. И таких схем очень много. Например, https – тот же самый http, только со специальной защитой.
Протокол ftp, созданный для передачи информации по сети TCP. Mailto обозначаются адреса электронных почт. Именно такой вид имеет URL адрес во всем мире.
Теперь узнаем как его взять
Если мы рассматриваем сайт, то найти URL очень просто, следует навести курсор на адресную строку и просто кликнуть. Бывает так, что иногда браузер скрывает протокол ресурса, но после того, как URL адрес будет находиться в буфере обмена, его будет видно.
Как мы уже знаем протокол бывает не только у страниц, но и у файлов. Так как же узнать их URL?
Рассмотрим пример с картинкой. Следует нажать на данное изображение правой кнопкой мыши и в высветившемся окне выбрать нужный нам пункт “Копировать адрес картинки”. Если же мы хотим узнать адрес документа, действовать стоит точно также, нажать на документ правой кнопкой мыши и выбрать соответствующий раздел в меню. Все очень легко и ясно.
Часто можно увидеть такую часть в URL: “B%0С%”. Что же это значит? Это всего лишь шифрование. Происходит это из-за того, что все адреса представляются в виде специального набора символов, а кириллица туда не входит, и чтобы аппарат смог понять куда ей переходить, он шифрует данный адрес.
Данное кодирование происходит в 2 этапа.
- Адрес кодируется в Юникод, в итоге мы получаем двух байтный порядок (в более новых
браузерах происходит шифровка в BASE58). - Перекодировка в шестнадцатеричную систему счисления.
Тогда для чего нужен знак процента? Этим знаком разделяется каждый байт.
На данный момент у URL существует большое количество недостатков.
- Иногда шифрование проходит не совсем верно.
- URL почти никак не возможно изменить.
- Нестабильная работа с гипертекстом.
Именно поэтому была предложена новая система адресов под названием PURL. Здесь используется немного другой подход. В определенной базе данных хранятся все адреса, которые постоянно проверяются, и если один из них не прошел проверку, он удаляется из этой базы. На данный момент разрабатываются еще несколько решений по разрешению данных проблем.
Со временем на замену URL пришел URI – унифицированный идентификатор ресурса. URI также обозначает символьное представление различных ресурсов.
URI состоит из двух частей:
- уже известный нам URL, он дает информацию о местонахождении ресурсов;
- URN, определяющий ресурсы в какой – либо зоне имен, но не показывающий его местонахождение.
Было выдвинуто предложение о замене термина URL на термин URI, так как прошлый адрес считается устаревшим. Ресурсы, которые не возможно получить через всемирную паутину, в URI имеют возможность описываться с помощью PDF, так как URI лишь идентифицирует их.
Но и он имеет свои изъяны, так как URL является фундаментом всей глобальной сети, URI должен быть полностью совместим с ним. Отсюда и пришли все недостатки, как преемство от URL.
Одним из них является шифровка, так как в URI, как и в URL, входит небольшой пакет символов. Иначе говоря, если мы захотим использовать буквы русского алфавита, то все символы нам придется кодировать таким же образом, как и URL.
bystriy-zaym.ru
Что такое url адрес.

Любой документ в сети Интернет имеет свой адрес. Его имеют веб-страницы, аудио, видео-файлы и любые другие документы, которые могут храниться на компьютере.
Для того, чтобы привести все адреса в сети Интернет к единому виду, был разработан специальный стандарт, который определяет, каким образом должен выглядеть адрес к любому документу.
Этому адресу присвоили название URL (англ. URL — Uniform Resource Locator) единый указатель ресурсов.
Произошло это относительно недавно в 1990 году.
Давайте разберемся, каким образом, согласно этому стандарту нужно указывать адреса к веб-ресурсам.
Общая схема или структура URL-адреса выглядит следующим образом:
<схема>://<логин>:<пароль>@<хост>:<порт>/<URL‐путь>?<параметры>#<якорь>
Давайте разберемся, что обозначает каждый параметр, который здесь указывается:
Схема – это тот протокол передачи данных, по которому, мы хотим обратиться к ресурсу.
логин и пароль — имя пользователя и пароль, используемые для доступа к ресурсу. Далеко не всегда эти параметры будут использоваться. Например, для доступа к какой-либо веб-странице, по протоколу http – как правило, эти данные не указывают.
@ — разделитель между хостом и парой логин-пароль. В случае, если логин-пароль не указывается, то разделитель можно точно также не указывать.
хост – доменное имя или IP-адрес (ссылки) того ресурса, к которому нужно обратиться.
Порт – уникальный номер, который выделяется тому приложению, которое будет обрабатывать ваш запрос. При работе по протоколу http, чаще всего задается автоматически и равен 80 или 8080.
URL — путь – здесь мы указываем уточняющую информацию о местонахождении ресурса. Зависит от используемого протокола. В случае с протоколом HTTP задается путь с указанием каталогов и подкаталогов, где лежит ресурс.
параметры — строка запроса с передаваемыми на сервер методом GET параметрами.
Разделитель параметров — знак &.
Пример: ?параметр_1=значение_1&параметр_2=значение_2&параметр3=значение_3
якорь – уникальная строка, набор букв И(ИЛИ) цифр, которая ссылается на определенную уникальную область (раздел) того веб-документа, который вы собираетесь открыть.
Т.е. переходя по url адресу с якорем можно сделать так, чтобы документ открылся не с самого начала, а с конкретного места или раздела.
Мы с вами рассмотрели общую структуру URL адреса. Чаще всего при обращении к веб-страницам и документам, которые лежат на веб-сервере, многие параметры являются необязательными для указания и могут задаваться автоматически.
Когда вы хотите просто посмотреть какую-то страницу в Интернете, с помощью своего браузер, то структура url адреса выглядит намного проще:
<схема>:// <хост>/<URL‐путь>
Например, это может быть записано в виде:
http://yandex.ru
Это сделано для того, чтобы упростить жизнь простым рядовым пользователям.
Вот несколько книг, которые могут быть полезны:


webgyry.info
Мой URL — это не ваш URL / Habr

Когда давным-давно в 1996 году я приступил к работе над программой httpget, предшественницей проекта Curl, я написал свой первый синтаксический анализатор URL. Как раз тогда этот универсальный адрес получил название URL: Uniform Resource Locator (единый указатель ресурсов). Его спецификация была опубликована IETF в 1994 году. Аббревиатура «URL» была затем использована как источник вдохновения для названия инструмента и проекта Curl.
Термин «URL» был позднее изменён; его стали называть URI (Uniform Resource Identifier — единый идентификатор ресурсов), согласно спецификации, опубликованной в 2005 году, однако основное сохранилось: синтаксис для строки, задающей онлайн-ресурс и указывающей протокол для получения этого ресурса. Мы требуем, чтобы curl принимал указатели URL, как определено данной спецификацией RFC 3986. Ниже я расскажу, почему на самом деле это не совсем так.
Был ещё родственный RFC, описывающий IRI: Internationalized Resource Identifier (международный идентификатор ресурсов). IRI, по существу, то же самое, что URI, но IRI позволяют использовать символы, не входящие в ASCII.
Консорциум WHATWG позднее создал свою собственную спецификацию URL, в основном, сведя вместе форматы и идеи от URI и IRI с сильным упором на браузеры (что неудивительно). Одна из объявленных ими целей — «Модернизировать RFC 3986 и RFC 3987 в соответствии с современными реализациями и постепенно вывести их из употребления». Они хотят вернуться к использованию термина «URL», справедливо заявляя, что термины URI и IRI просто запутывают ситуацию и что люди так и не поняли их (или часто даже не знают, что эти термины существуют).
Спецификация WHATWG написана в духе старой доброй мантры браузеров: быть как можно более либеральными с пользователями, всегда пытаться угадать, что они имеют в виду, и выворачиваться наизнанку, пытаясь сделать это. Хотя при этом мы все знаем сейчас, что закон Постеля — не самый лучший подход к делу. На деле это значит, что спецификация позволяет использовать в URL слишком много слэшей, пробелы и символы, не входящие в ASCII.
С моей точки зрения, такую спецификацию также очень трудно читать и соблюдать, поскольку она не очень подробно описывает синтаксис или формат, но при этом навязывает обязательный алгоритм парсинга. Чтобы проверить моё утверждение: посмотрите, что это спецификация говорит о концевой точке после имени хоста в URL.
Вдобавок ко всем этим стандартам и спецификациям, в интерфейсе всех браузеров есть адресная строка (которую часто называют и по-другому), которая позволяет пользователям вводить какие угодно забавные строки и преобразовывает их в URL. Если ввести «http://localhost/%41» в адресную строку, то участок с процентом будет преобразован в «A» (поскольку 41 в шестнадцатеричном исчислении является заглавной буквой A в ASCII), но если ввести «http://localhost/A A«, то фактически в исходящий HTTP-запрос GET будет отправлено «/A%20A» (с пробелом в URL-кодировке). Я говорю об этом, так как люди часто думают, что всё, что можно ввести в эту строку — и есть URL.
Указанное выше — в основном моё (искаженное) представление, с какими спецификациями и стандартами нам пока приходится работать. Теперь давайте добавим реальности и посмотрим, какие проблемы мы получаем, когда мой URL — это не ваш URL.
Так что же такое URL?
Или более конкретно — как мы пишем их? Какой синтаксис используем?
Думаю, одна из самых больших ошибок в спецификации WHATWG (и в ней причина, почему я выступаю против этой спецификации в её текущей форме с твёрдым убеждением, что они неправы) состоит в том, что они полагают, будто только им позволено работать с URL и давать им определение; они ограничивают свое представление об URL исключительно браузерами, HTML и адресными строками. Конечно, WHATWG создан большими компаниями, представляющими браузеры, которые использует почти каждый, а в этих браузерах широко работают указатели URL, но сами URL — явление значительно большее.
Представление об URL, существующее у WHATWG, не слишком широко принимается за пределами браузеров.
Двоеточие-слэш-слэш
Если спросить пользователей — обычных людей без какого-либо особого знания протоколов или сети — о том, что такое URL, то что они ответят? Последовательность «://» (двоеточие-слэш-слэш) была бы в начале списка ответов; несколько лет назад, когда браузеры показывали URL более полно, это было бы еще заметнее. Увидев эту последовательность, мы сразу понимаем, что перед нами именно URL.
Однако давайте отойдём от пользователей и оглядимся — в мире существуют почтовые клиенты, эмуляторы терминалов, текстовые редакторы, Perl-скрипты и многое-многое другое, что способно распознавать URL и работать с ними. Например, открыть URL в браузере, превратить в активную ссылку в сгенерированном HTML и так далее. Огромное количество названных скриптов и программ будет использовать именно последовательность «двоеточие-слэш-слэш» как главный признак.
Спецификация WHATWG говорит, что должен быть как минимум один слэш и что парсер при этом обязан принимать какое угодно количество слэшей. Это значит, что «http:/example.com» и «http:///////////////example.com» — полностью подходящие варианты. RFC 3986 и многие другие с этим не согласны. Ну, действительно, большинство из людей, с которыми я спорил последние несколько дней, даже те, кто работает в вебе, говорит, думает и убеждено, что URL имеет два слэша. Просто посмотрите внимательнее на скриншот результата поиска картинок в Гугл по запросу «URL» выше в этой статье.
Мы просто знаем, что у URL есть два слэша (хотя, да, URL типа file: обычно имеют три слэша, но давайте пока проигнорируем это). Не один. Не три. Два. Но WHATWG с этим не согласен.
«Есть хоть одна настоящая причина принимать более двух слэшей для не-файловых URL?» (спрашиваю я раздраженно у членов WHATWG)
«Факт в том, что это делают все браузеры.»
Спецификация говорит это, потому что браузеры реализовали её именно так.
Никакое лучшее объяснение не было дано даже после того, как я указал, что это утверждение неправильное и далеко не все браузеры делают так. Возможно, эта ветка обсуждения покажется вам весьма познавательной.
В проекте Curl мы как раз недавно начали обсуждать, как обращаться с указателями URL, имеющими число слэшей, отличное от двух, потому что, оказывается, уже есть серверы, передающие обратно такие URL в заголовке “Location:”, и некоторые браузеры без возражений принимают их. Curl — нет, так же как и большинство из множества других библиотек и инструментов командной строки. Кого нам поддержать?
Пробелы
Символ пробела (код 32 в ASCII, шестнадцатеричный код 0x20) не может быть частью URL. Если требуется отправить его, то следует использовать URL-кодировку, как это делают с любым другим недопустимым символом, который надо сделать частью URL. URL-кодировка — это байтовое значение в шестнадцатеричном исчислении со знаком процента перед ним. Таким образом, «%20» означает пробел. Это также означает, что синтаксический анализатор, например, сканирующий текст на предмет указателей URL, узнаёт, что достиг конца URL, когда он обнаруживает недопустимый символ. Например, пробел.
Браузеры обычно преобразовывают все %20 в своих адресных строках в символ пробела, чтобы ссылки выглядели прилично. При копировании адреса в буфер и вставке его в текстовый редактор мы видим пробелы как %20, что и требуется.
Я не уверен, в этом ли причина, но браузеры также принимают пробелы как часть URL, получая, например, переадресацию в HTTP-ответе. Такие URL передаются от сервера к клиенту в заголовке «Location:». Браузеры без проблем допускают пробелы в них URL, кодируя их в виде %20 и отправляя следующий запрос. Это заставляет curl принимать пробелы в перенаправляемых «URL».
Не-ASCII
Поддержка в URL языков, включающих символы, не входящие в ASCII, конечно, важно, особенно для незападных сообществ, и я согласен, что спецификация IRI никогда не была достаточно хороша. Я лично далёко не эксперт в интернационализации, поэтому я руководствуюсь тем, что слышал от других. Но, конечно, пользователи нелатинских алфавитов и систем печати должны иметь возможность записывать свои «интернет-адреса» в ресурсы и использовать их как ссылки.
В идеальном случае у нас была бы интернационализированная версия для показа пользователю, и версия в кодировке ASCII для внутреннего использования в сетевых запросах.
Для международных доменных имён имя преобразуется в кодировку punycode так, чтобы оно могло быть прочитано обычными серверами DNS, которые ничего не знают об именах в кодировке, отличной от ASCII. Идентификаторы URI не имеют IDN-имён; IRI и URL по версии WHATWG — имеют. Сurl поддерживает IDN-имена хостов.
WHATWG заявляет, что URL могут использовать UTF-8, тогда как URI — только ASCII. Curl не воспринимает не-ASCII-символы в части адреса, задающей путь, но кодирует их процентом в исходящих запросах; это порождает “интересные» побочные эффекты, когда не-ASCII-символы представлены в коде, отличном от UTF-8, что является, например, стандартным для Windows.
Подобно тому, что я написал выше, это приводит к серверам, отправляющим назад не-ASCII-коды в HTTP-заголовках, которые браузеры охотно принимают, и не-браузерам тоже приходится работать с ними.
Стандарта URL не существует
Я не пытался представить полный список проблем или несоответствий — здесь просто некоторая подборка трудностей, с которыми я недавно столкнулся. «URL», выданный в одном месте, конечно, совсем необязательно будет принят или понят в другом месте как «URL».
В наши дни даже curl уже не следует строго ни одной опубликованной спецификации — мы медленно деградируем в угоду “веб-совместимости”.
Единый стандарт URL отсутствует, и какая-либо работа в этом направлении не ведётся. Я не могу считать, что WHATWG прилагает настоящие усилия к этому, поскольку она пишет спецификацию закрытой группой без серьёзных попыток привлечь более широкое сообщество.
habr.com
Что такое url-адрес: определение и структура

Приветствую всех читателей блога Александра Сергиенко! Сегодняшняя тема нашей статьи будет посвящена URL-адресам, собственно тому, что такое url-адрес сайта какую структуру имеет и ещё кое-что.
Эта статья будет первой в рубрике «Вопросы новичков», в которой я буду писать о наиболее простых вопросах, которые возникают у новичков. Ну, а эта статья может быть полезна не только новичкам, кое-что новое может узнать и «бывалый» блоггер.
Если подробно разбирать тему формирования урл-адресов, а тем более их более расширенную версию URI, можно встретить много сложностей в плане понимания, которые, в принципе, рядовому блоггеру и не нужно знать, разве что для общего развития.
data-ad-client=»ca-pub-8243622403449707″
data-ad-slot=»1319308473″
data-ad-format=»auto»>
Нам же главное понять, на данном этапе, структуру создания урлов, что мы и будем делать в данной статье.
Определение
Как вы уже знаете поисковые системы индексируют страницы сайты по некоторому принципу, в результате данную страницу сайта можно найти при помощи поисковой системы по некоторому запросу.Но это можно сделать, набрав, в строке браузера url-адрес страницы сайта. В общем, любая вебстраница (документ) любого Интернет-ресурса имеет свой уникальный адрес, который называют аббревиатурой URL (урл), а расшифровывается она как Uniform Resource Locator (определитель местонахождения ресурса). Разработал URL-адрес Тим Бернерс — Ли.
URL-адрес — это частный случай идентификатора URI (Uniform Resource Identifier — унифицированный идентификатор ресурса). Но об этом мы подробно разговаривать не будем, так как нам все эти тонкости на данном этапе не нужны.
Итак, урл-адрес — это способ в Интернете указать на какой-либо Интернет-ресурс (его страницу, документ). Этот URL-адрес используется не только для работы по протоколу http и https, которые нас будут интересовать в данной статье.
Вот как будет выглядеть c протоколом передачи данных http:
http://int-net-partner.ru/papka/fail.html
После протокола передачи данных http следует «int-net-partner.ru» или же это может быть «www.int-net-partner.ru». Доменное имя входит в обозначение URL-адреса и оно может быть как с WWW, так и без него.
Если говорить о поисковиках, то сайты с WWW и без него для них являются абсолютно разными для них. И если не произвести склейку зеркал, то ссылочная масса будет делится на два этих зеркала.Обычно склейку зеркал производит хостер, но это нужно обязательно проверить. Главное, что нужно сделать — это определить главное зеркало, которое будет индексироваться поисковиками, а также участвовать в ранжировании. Это можно сделать при помощи Гугл или Яндекс Вебмастер или прописыванием директивы Host в файле robots.txt.
На моём блоге главное зеркало — «int-net-partner.ru», «без WWW». Если же добавить к этому URL-адресу «WWW», то произойдёт автоматическое перенаправление на адрес «без WWW».
http://www.int-net-partner.ru/papka/fail.html
Хочу заметить, что склеить можно любые доменные имена. Но давайте рассмотрим Урл — адрес, расположенный выше. Путь до документа или файла (конкретного объекта) будет расположен за третьим слешем, в данном случае это «papka/fail.html«. В вышеприведённом примере в роли документа выступает «fail.html«, который находится в каталоге «papka«, который находится в корневой папке.
Также через урлы различные системы управления контентом передают GET параметры, которые добавляются в конец URL-адреса, после знака вопроса:
http://www.int-net-partner.ru/papka/fail.html?print=yes
Дело в том, что документы с GET параметром и без него, являются абсолютно разными для поисковиков, поэтому нужно вводить запрет в robots.txt, во избежание дублирования контента, за которое поисковики могут наложить определённые санкции.
К главной странице моего сайта можно обратиться по трём URL-адресам:
- http://int-net-partner.ru
- http://www.int-net-partner.ru
- http://www.int-net-partner.ru/index.php
И это опять же в плане дублирования контента очень и очень плохо. У меня же, при любом вводе Урла перенаправление идёт на URL-адрес такого вида: «http://int-net-partner.ru«
Как я уже говорил, перенаправление можно сделать при помощи 301 редиректа в файле .htaccess, или в настройках сервера вами или вашим хостером.
Структура URL-адреса
Вот так выглядет полный вид URL-адреса (блок-схема):
Обычно не используют логин, пароль и порт, хотя на некоторые сайты они могут понадобиться:
http://login:[email protected]/platniy-dostup.html
Иногда для входа на ftp-сервер может быть использован не стандартный порт, который отличается от используемого «по умолчанию» протокола. Тогда для доступа к такому ftp-серверу придётся вводить подобный урл:
ftp://login:[email protected]:6789/samoe-nujnoe/cimus
Кроме вышепреведённых примеров, в состав урл — адреса может добавляться якорь, который ставиться после символа «#» в конце урла. URL-адреса, которые содержат якоря, называют хеш-ссылками.
Якоря нужны для того, чтобы можно было перейти в нужное место страницы (там где проставлен якорь). Это удобно делать, если вы хотите сделать содержание своей статьи, тогда посетитель может перейти в нужную ему часть статьи, не просматривая её полностью. Чтобы это осуществить, нужно заранее проставить якоря (в нужных местах) внутри Html кода страницы (документа), затем нужно добавить название самого якоря к урлу страницы через знак решётки «#».
Перекодировка
А теперь давайте ещё поговорим о перекодировке URL-адресов. Вот, например, использование русских символов допустимо, но в этом случае произойдёт перекодировка этих символов, URL Encoding.
Вот пример:
http://int-net-partner.ru/оптимизация сайта/
А вот, что получилось после перекодировки:
http//int-net-partner.ru/%BA%B1%82%D0%BE%20%D0%BD%D0% B0%20%D0%BD%D0%BE%D0%B2%D0%B5%D0%BD%D1%8C%B0%BA%D0 %BE%D0%B3%D0%BE
Вот видите, не очень удобоваримый вариант. Поэтому, по мнению многих оптимизаторов, лучше использовать транслитерацию, так как это будет намного лучше в плане SEO оптимизации под поисковики.
P.S.
Как вам статья? Рекомендую получать свежие статьи блога на e-mail, чтобы не пропустить много новой интересной информации!
С уважением, Александр Сергиенко
int-net-partner.ru
Что такое URL адрес? :: SYL.ru
В сети очень часто происходит обмен различной информацией, которая находится на разных порталах. Как вы понимаете, в интернете сейчас существует огромное количество сайтов, картинок, музыки и т.д. У каждого элемента есть свой личный идентификатор, который выглядит как отдельный URL адрес. Перейдя по нему, вы получите желаемую информацию. В этой статье мы разберем самые распространенные вопросы про URL адрес, которые тревожат современных пользователей интернета.

Определение
URL адрес — это аббревиатура от английских слов «Uniform Resource Locator», что в переводе значит «Унифицированный адрес ресурса». Ранее использовалась запись Universal Resource Locator. URL можно считать универсальным локатором определенного ресурса, с помощью которого происходит определение местонахождения элемента. В процессе развития интернета такой адрес стал стандартным и единственным способом указания расположения порталов.
История
В самом начале своего существования URL адрес предназначался только для определения нахождения элементов, и чаще всего это были файлы. С момента изобретения данный локатор стал приобретать более широкое применение. Тим Бернерс-Ли – так зовут человека, который, собственно, и является изобретателем URL адреса. Именно он в 1990 году представил всеобщему вниманию универсальное средство для распознавания местонахождения элемента. Сам Тим Бернерс-Ли является изобретателем не только URL, но и HTTP, HTML, UTI. Сейчас он занимает пост главы W3C (Консорциум Всемирной паутины).
Структура
URL адрес состоит из максимально точных указаний местонахождения элемента. То есть, если вам нужно сослаться на стартовую страницу сайта, достаточно будет ввести его непосредственный адрес. Если речь идет о файле, находящемся на этом портале, то нужно указывать более подробное описание. Давайте разберем пример с адресом на отдельный сайт. В этом случае ссылка будет состоять из следующих частей:

- Протокол. Вы наверняка видели такую запись, как HTTP или HTTPS. Это и есть протокол, через который происходит соединение к серверу сайта. Есть еще FTP, который встречается в файловых архивах. Протокол разделяется специальным обозначением — это двоеточие и два слеша — ://.
- Доменное имя. По-другому можно сказать, что это личный идентификатор сайта, который является уникальным. При создании портала резервируется индивидуальное имя. В конце такого индивидуального идентификатора ставится домен, который определяет принадлежность к определенной стране. Например, в российских порталах ставится «ru». Домен отделяется от основной части имени сайта точкой.
- Дополнительные каталоги. Если ссылка будет состоять только из протокола и доменного имени, то вы попадете на стартовую страницу сайта. Но можно сразу указывать дополнительные каталоги, которые имеются на сервере. От основной части адреса они отделяются знаком слеш «/». Таким образом, можно выбирать картинки либо другие файлы, которые находятся на сервера сайта. Достаточно указать правильное расположение и конечное имя элемента.
Заключение
Адрес URL встречается нам каждый день, когда мы пользуемся своими компьютерами, телефонами и т.д. Данная статья помогла вам получить поверхностные знания об идентификаторах, которые имеются у каждого элемента, расположенного в интернете.
www.syl.ru