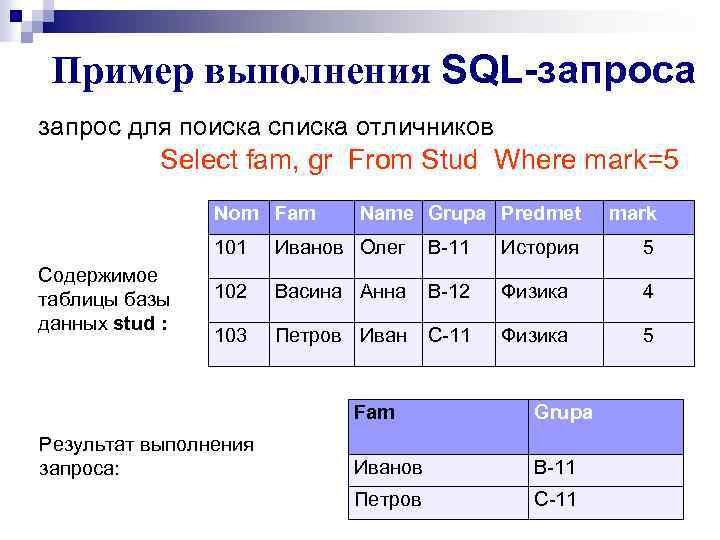
Основы SQL для выражений запроса, применяемых в ArcGIS—Справка
- Поля
- Строки
- Числа
- Даты и время
- Подзапросы
- Операторы
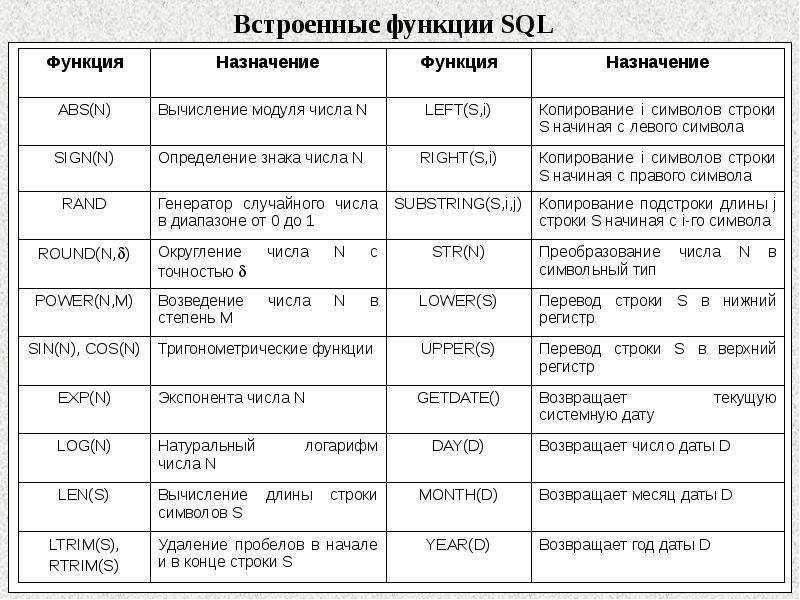
- Функции
В этом разделе описываются элементы обычных запросов, используемых в выражениях выборки в ArcGIS. Выражения запросов в ArcGIS используют общепринятый синтаксис SQL.
Внимание:
Синтаксис SQL не работает при вычислении полей при помощи Калькулятора поля (Field Calculator).
Поля
Чтобы указать поле в выражении SQL, поставьте разделитель, в противном случае имя поля может быть истолковано двусмысленно, например если оно такое же, как резервное ключевое слово SQL.
Так как существует немало резервных ключевых слов, а новые слова могут появляться с каждой последующей версией, рекомендуется всегда заключать имена полей в разделители.
Разделители имени поля зависят от СУБД. При запросе к любым файловым данным – файловой базе геоданных, данным из базы геоданных ArcSDE, данным из класса пространственных объектов ArcIMS или подслоёв сервиса изображений, вы можете заключать имена полей в двойные кавычки:
"AREA"
При запросе к данным персональной базы геоданных, поля заключаются в квадратные скобки:
[AREA]
Для наборов растровых данных в персональной базе геоданных имена полей заключаются в двойные кавычки:
"AREA"
Для данных файловой базы геоданных вы можете заключить имена полей в двойные кавычки, но обычно это не требуется.
AREA
Строки
Строковые значения всегда заключаются в выражениях в одинарные кавычки. Например:
STATE_NAME = 'California'
Используемые вами групповые символы для выполнения поиска по части строки также зависят от того, к какому источнику данных выполняется запрос. Например в файловом источнике данных или базе геоданных ArcSDE, для поиска Mississippi и Missouri в названиях штатов США используется выражение:
STATE_NAME LIKE 'Miss%'
Символ процента (%) означает, что на этом месте может быть что угодно – один символ или сотня, или ни одного. Групповые символы, используемые при запросах к персональным базам геоданных:звездочка (*) для любого количества символов, и вопросительный знак (?) для одного символа.
Строковые функции могут использоваться для форматирования строк. Например функция LEFT вернет определенное количество символов начиная с левого края строки. Данный запрос вернет все штаты, начинающиеся на букву A:
LEFT(STATE_NAME,1) = 'A'
Список поддерживаемых функций вы найдете в документации по своей СУБД.
Числа
Точка (.) всегда используется в качестве десятичного разделителя, независимо от региональных настроек. В выражениях в качестве разделителя десятичных знаков нельзя использовать запятую.
Вы можете запрашивать цифровые значения, используя операторы равно (=), не равно (<>), больше (>), меньше (<), больше или равно (>=) и меньше или равно (<=), а также BETWEEN (между). Например:
POPULATION >= 5000
Числовые функции можно использовать для форматирования чисел. Например функция ROUND округлит до заданного количества десятичных знаков данные в файловой базе геоданных:
ROUND(SQKM,0) = 500
Список поддерживаемых числовых функций вы найдете в документации по своей СУБД.
Даты и время
Общие правила
В таких источниках данных, как база геоданных, даты хранятся в полях даты–времени. А в покрытиях ArcInfo и шейп-файлах этого нет.
Поэтому большинство из примеров синтаксиса запроса, представленных ниже, содержит ссылки на время. В некоторых случаях часть запроса, касающаяся времени, может быть без всякого вреда пропущена, когда известно, что поле содержит только даты; в других случаях её необходимо указывать, или запрос вернет синтаксическую ошибку.
В некоторых случаях часть запроса, касающаяся времени, может быть без всякого вреда пропущена, когда известно, что поле содержит только даты; в других случаях её необходимо указывать, или запрос вернет синтаксическую ошибку.
Основное назначение формата даты в ArcMap – хранение дат, а не времени. Можно хранить в поле только время, когда связанная база данных на самом деле использует формат дата–время, но это не рекомендуется. Запросы по времени будут несколько громоздкими, например 12:30:05 p.m. будет храниться как ‘1899-12-30 12:30:05’.
Примечание:
Даты хранятся в исходной базе данных относительно 30 декабря 1899 года, 00:00:00. Это действительно для всех источников данных, перечисленных здесь.
Цель этого подраздела – помочь вам в построении запросов по датам, но не по значениям времени. Когда со значением даты хранится не нулевое значение (например January 12, 1999, 04:00:00), то запрос по дате не возвратит данную запись, поскольку если вы задаете в запросе только дату для поля в формате дата–время, недостающие поля времени заполняются нулями, и выбраны будут только записи, время которых соответствует 12:00:00 полуночи.
Таблица атрибутов отображает дату и время в удобном для пользователя формате, согласно вашим региональным установкам, а не в формате исходной базы данных. В большинстве случаев это хорошо, но также имеются и некоторые недостатки такого способа отображения:
- Строка, отображаемая в SQL-запросе, может иметь только небольшое сходство со значением, показанным в таблице, особенно когда в нее входит время. Например время, введенное как 00:00:15, будет отображаться в атрибутивной таблице как 12:00:15 AM с региональными настройками Соединённых Штатов, а сопоставимый синтаксис запроса должен быть Datefield= ‘1899-12-30 00:00:15’.
- Атрибутивная таблица не имеет сведений об исходных данных, пока вы не сохраните изменения. Она сначала попытается отформатировать значения для соответствия её собственному формату, затем, поверх сохраненных изменений, она попытается подогнать получившиеся результаты для соответствия базе данных. По этой причине, вы можете вводить время в шейп-файл, но обнаружите, что оно удаляется при сохранении ваших изменений.
 Поле будет содержать значение ‘1899-12-30’, которое будет отображаться как 12:00:00 AM или как-то подобно, в зависимости от ваших региональных настроек.
Поле будет содержать значение ‘1899-12-30’, которое будет отображаться как 12:00:00 AM или как-то подобно, в зависимости от ваших региональных настроек.
 Поле будет содержать значение ‘1899-12-30’, которое будет отображаться как 12:00:00 AM или как-то подобно, в зависимости от ваших региональных настроек.
Поле будет содержать значение ‘1899-12-30’, которое будет отображаться как 12:00:00 AM или как-то подобно, в зависимости от ваших региональных настроек.Синтаксис даты-времени для баз геоданных ArcSDE
Informix
Datefield = 'yyyy-mm-dd hh:mm:ss'
Часть запроса hh:mm:ss не может быть опущена, даже если она равна 00:00:00.
Oracle
Datefield = date 'yyyy-mm-dd'
Имейте в виду, что здесь записи, где время не равно нулю, не будут возвращены.
Альтернативный формат при запросах к датам в Oracle следующий:
Datefield = TO_DATE('yyyy-mm-dd hh:mm:ss','YYYY-MM-DD Hh34:MI:SS')Второй параметр ‘YYYY-MM-DD Hh34:MI:SS’ описывает используемый при запросах формат. Актуальный запрос будет выглядеть так:
Datefield = TO_DATE('2003-01-08 14:35:00','YYYY-MM-DD Hh34:MI:SS')Вы можете использовать более короткую версию:
TO_DATE('2003-11-18','YYYY-MM-DD')И снова записи, где время не равно нулю, не будут возвращены.
SQL Server
Datefield = 'yyyy-mm-dd hh:mm:ss'
Часть запроса hh:mm:ss может быть опущена, когда в записях не установлено время.
Альтернативный формат следующий:
Datefield = 'mm/dd/yyyy'
IBM DB2
Datefield = TO_DATE('yyyy-mm-dd hh:mm:ss','YYYY-MM-DD Hh34:MI:SS')Часть запроса hh:mm:ss не может быть опущена, даже если время равно 00:00:00.
PostgreSQL
Datefield = TIMESTAMP 'YYYY-MM-DD Hh34:MI:SS' Datefield = TIMESTAMP 'YYYY-MM-DD'
Вы должны указать полностью временную метку при использовании запросов типа «равно», в противном случае не будет возвращено никаких записей. Вы можете успешно делать запросы со следующими выражениями, если запрашиваемая таблица содержит записи дат с точными временными метками (2007-05-29 00:00:00 или 2007-05-29 12:14:25):
select * from table where date = '2007-05-29 00:00:00';
или
select * from table where date = '2007-05-29 12:14:25';
При использовании других операторов, таких как больше, меньше, больше или равно, или меньше или равно, вам не надо указывать время, хотя и можно, для точности.
select * from table where date < '2007-05-29';
select * from table where date < '2007-05-29 12:14:25';
Файловые базы геоданных, шейп-файлы, покрытия и прочие файловые источники данных
Перед датами в файловых базах геоданных, шейп-файлах и покрытиях должно стоять date.
"Datefield" = date 'yyyy-mm-dd'
Файловые базы геоданных поддерживают использование времени в поле даты, поэтому его можно добавить в выражение:
"Datefield" = date 'yyyy-mm-dd hh:mm:ss'
Шейп-файлы и покрытия не поддерживают использование времени в поле даты.
Примечание:
SQL, используемый в файловой базе геоданных, базируется на стандарте SQL-92.
Персональная база геоданных
Даты в персональных базах геоданных отделены при помощи знака решетки (#).
Например:
[Datefield] = #mm-dd-yyyy hh:mm:ss#
Это может быть сокращено до [Datefield] = #mm-dd-yyyy#.
Альтернативный формат
[Datefield] = #yyyy/mm/dd#
Известные ограничения
Построение запросов к датам, находящимся в левой части (первой таблице) соединения, работает только для файловых источников данных, таких как файловые базы геоданных, шейп-файлы и таблицы DBF. Однако, возможен обходной путь при работе с другими, не файловыми, источниками, такими как персональная база геоданных и данные ArcSDE, как описано ниже.
Однако, возможен обходной путь при работе с другими, не файловыми, источниками, такими как персональная база геоданных и данные ArcSDE, как описано ниже.
Запрос к датам левой части соединения будет выполнен успешно, если использовать ограниченную версию SQL, разработанную для файловых источников данных. Если вы не используете такой источник данных, можете перевести выражение для использования этого формата. Нужно обеспечить, чтобы выражение запроса включало поля из более чем одной присоединенной таблицы. Например если соединены класс пространственных объектов и таблица (FC1 и Table1), и оба они из персональной базы геоданных, следующее выражение или вернет данные, или не выполнится:
FC1.date = date #01/12/2001# FC1.date = date '01/12/2001'
Чтобы запрос был выполнен успешно, можно создать вот такой запрос:
FC1.date = date '01/12/2001' and Table1.OBJECTID > 0
Так как запрос включает поля из обеих таблиц, будет использована ограниченная версия SQL.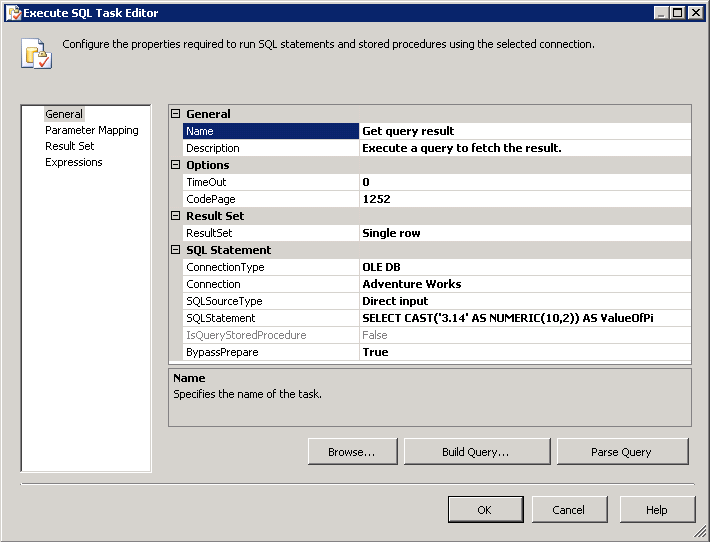 В этом выражении Table1.OBJECTID всегда > 0 для записей, которые сопоставлены в процессе создания соединения, поэтому это выражение всегда верно для всех строк, содержащих сопоставления соединения.
В этом выражении Table1.OBJECTID всегда > 0 для записей, которые сопоставлены в процессе создания соединения, поэтому это выражение всегда верно для всех строк, содержащих сопоставления соединения.
Чтобы быть уверенным, что каждая запись с FC1.date = date ’01/12/2001′ выбрана, используйте следующий запрос:
FC1.date = date '01/12/2001' and (Table1.OBJECTID IS NOT NULL OR Table1.OBJECTID IS NULL)
Такой запрос будет выбирать все записи с FC1.date = date ’01/12/2001′, независимо от того, есть ли сопоставление при соединении для каждой отдельной записи.
Подзапросы
Примечание:
Покрытия, шейп-файлы и прочие файловые источники данных, не относящиеся к базам геоданных, не поддерживают подзапросы. Подзапросы, выполняемые на версионных классах ArcSDE и таблицах не возвращают объекты, которые хранятся в дельта-таблицах. Файловые базы геоданных предоставляют ограниченную поддержку подзапросов, описанных в данном разделе, а базы геоданных персональные и ArcSDE предоставляют полную поддержку. Информацию обо всех возможностях подзапросов к базам геоданных персональным и ArcSDE ищите в документации по своей СУБД.
Информацию обо всех возможностях подзапросов к базам геоданных персональным и ArcSDE ищите в документации по своей СУБД.
Подзапрос – это запрос, вложенный в другой запрос. Подзапросы могут использоваться в SQL-выражении для применения предикативных или агрегирующих функций, или для сравнения данных со значениями, хранящимися в другой таблице и т.п. Это может быть сделано с помощью ключевых слов IN или ANY. Например этот запрос выберет только те страны, которых нет в таблице indep_countries:
"COUNTRY_NAME" NOT IN (SELECT "COUNTRY_NAME" FROM indep_countries)
Этот запрос возвратит объекты, где GDP2006 больше, чем GDP2005 любых объектов, содержащихся в countries (странах):
"GDP2006" > (SELECT MAX("GDP2005") FROM countries)Для каждой записи в таблице, подзапросу может понадобиться проанализировать все данные целевой таблицы. Это может очень сильно замедлить выполнение запроса при больших объёмах данных.
Поддержка подзапросов в файловых базах геоданных ограничена следующим:
- IN предикат. Например:
"COUNTRY_NAME" NOT IN (SELECT "COUNTRY_NAME" FROM indep_countries)
- Скалярные подзапросы с операторами сравнения. Скалярный подзапрос возвращает одно значение. Например:
"GDP2006" > (SELECT MAX("GDP2005") FROM countries)Для файловых баз геоданных, набор функций AVG, COUNT, MIN, MAX и SUM может использоваться лишь в скалярных подзапросах. - EXISTS предикат. Например:
EXISTS (SELECT * FROM indep_countries WHERE "COUNTRY_NAME" = 'Mexico')
 Например:
Например:Операторы
Ниже приведен полный список операторов, поддерживаемых файловыми базами геоданных, шейп-файлами, покрытиями и прочими файловыми источниками данных. Они также поддерживаются в персональных и ArcSDE базах геоданных, хотя для этих источников данных может требоваться иной синтаксис. Кроме нижеперечисленных операторов, персональные и ArcSDE базы геоданных поддерживают дополнительные возможности. Более подробную информацию см. в документации по своей СУБД.
Арифметические операторы
Для сложения, вычитания, умножения и деления числовых значений можно использовать арифметические операторы.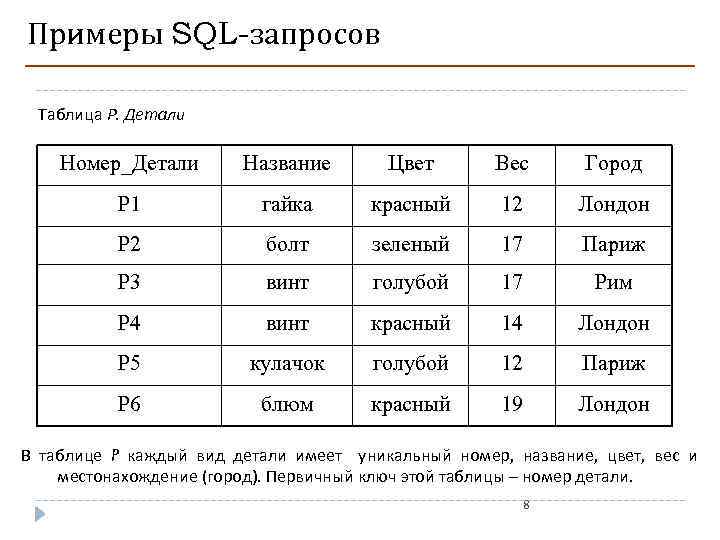
| Оператор | Описание |
|---|---|
* | Арифметический оператор умножения |
/ | Арифметический оператор деления |
+ | Арифметический оператор сложения |
— | Арифметический оператор вычитания |
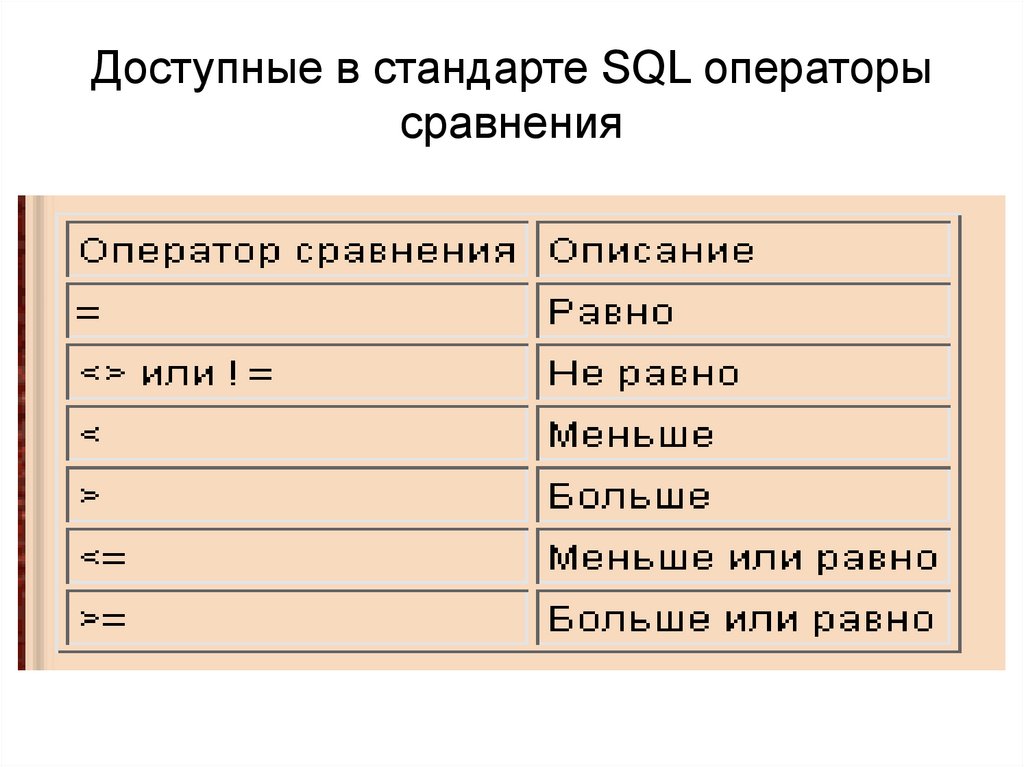
Операторы сравнения
Операторы сравнения используются для сравнения одного выражения с другим.
| Оператор | Описание |
|---|---|
< | Меньше . Может использоваться со строками (сравнение основывается на алфавитном порядке) и для числовых вычислений, а также дат. |
<= | Меньше или равно. Может использоваться со строками (сравнение основывается на алфавитном порядке) и для числовых вычислений, а также дат. |
<> | Не равно . Может использоваться со строками (сравнение основывается на алфавитном порядке) и для числовых вычислений, а также дат. |
> | Больше . Может использоваться со строками (сравнение основывается на алфавитном порядке) и для числовых вычислений, а также дат. |
>= | Больше или равно. Может использоваться со строками (сравнение основывается на алфавитном порядке) и для числовых вычислений, а также дат. Например это запрос возвратит все города, названия которых начинаются на буквы от M до Z: "CITY_NAME" >= 'M' |
[NOT] BETWEEN x AND y | Выбирает запись, если её значение больше или равно x и меньше или равно y. "OBJECTID" BETWEEN 1 AND 10Вот эквивалент этого выражения: "OBJECTID" >= 1 AND OBJECTID <= 10Однако, выражение с оператором BETWEEN обрабатывается быстрее, если у вас поле проиндексировано. |
[NOT] EXISTS | Возвращает TRUE (истинно), если подзапрос возвращает хотя бы одну запись; в противном случае возвращает FALSE (ложно). Например, данное выражение вернет TRUE, если поле OJBECTID содержит значение 50: EXISTS (SELECT * FROM parcels WHERE "OBJECTID" = 50)EXISTS поддерживается только в файловых, персональных и ArcSDE базах геоданных. |
[NOT] IN | Выбирает запись, если она содержит одну из нескольких строк или значений в поле. "STATE_NAME" IN ('Alabama', 'Alaska', 'California', 'Florida')Для файловых, персональных и ArcSDE баз геоданных этот оператор также может применяться в подзапросе:"STATE_NAME" IN (SELECT "STATE_NAME" FROM states WHERE "POP" > 5000000) |
IS [NOT] NULL | Выбирает запись, если там в определенном поле есть нулевое значение. Если перед NULL стоит NOT, выбирает запись, где в определенном поле есть какое-то значение. Например данное выражение выбирает все записи с отсутствующим значением численности населения: "POPULATION" IS NULL |
x [NOT] LIKE y [ESCAPE ‘escape-character‘] | Используйте оператор LIKE (вместо оператора = ) с групповыми символами, если хотите построить запрос по части строки. "STATE_NAME" LIKE 'Miss%'Символ процента (%) означает, что на этом месте может быть что угодно – один символ или сотня, или ни одного. Если вы хотите использовать групповой символ, обозначающий один любой символ, используйте символ подчёркивания (_). Следующий пример показывает выражение для выбора имен Catherine Smith и Katherine Smith: "OWNER_NAME" LIKE '_atherine Smith'Групповые символы (%) и(_) работают для любых данных на основе файлов или в многопользовательских базах геоданных. LIKE работает с данными символов с обеих сторон выражения. Если вам нужен доступ к несимвольным данным, используйте функцию CAST. Например, этот запрос возвращает числа, начинающиеся на 8, из целочисленного поля SCORE_INT: CAST ("SCORE_INT" AS VARCHAR) LIKE '8%'Для включения символа (%) или (_) в вашу строку поиска, используйте ключевое слово ESCAPE для указания другого символа вместо escape, который в свою очередь обозначает настоящий знак процента или подчёркивания. Например данное выражение возвращает все строки, содержащие 10%, такие как 10% DISCOUNT или A10%: Например данное выражение возвращает все строки, содержащие 10%, такие как 10% DISCOUNT или A10%:"AMOUNT" LIKE '%10$%%' ESCAPE '$'Групповые символы, используемые при запросах к персональным базам геоданных:звездочка (*) для любого количества символов, и вопросительный знак (?) для одного символа. Знак решётки (#) также используется в качестве группового для замены одного символа (числовое значение). Например, данный запрос возвращает земельные участки с номерами A1, A2 и т.д. из персональной базы геоданных: [PARCEL_NUMBER] LIKE 'A#' |

 Если впереди стоит отрицание NOT, выбирает записи, значения которых находятся за пределами указанного диапазона. Например это выражение выбирает все записи со значениями, которые больше или равны 1 и меньше или равны 10:
Если впереди стоит отрицание NOT, выбирает записи, значения которых находятся за пределами указанного диапазона. Например это выражение выбирает все записи со значениями, которые больше или равны 1 и меньше или равны 10: Если впереди стоит NOT, выбирает запись, где нет таких строк или значений. Например, это выражение будет искать четыре разных названия штатов:
Если впереди стоит NOT, выбирает запись, где нет таких строк или значений. Например, это выражение будет искать четыре разных названия штатов: В этом примере из названий штатов США запрос выберет Mississippi и Missouri:
В этом примере из названий штатов США запрос выберет Mississippi и Missouri:Логические операторы
| Оператор | Описание |
|---|---|
AND | Соединяет вместе два условия и выбирает запись, в которой оба условия являются истинными. Например, выполнение следующего запроса выберет все дома с площадью более 1 500 квадратных футов и гаражом на две и более машины: "AREA" > 1500 AND "GARAGE" > 2 |
OR | Соединяет вместе два условия и выбирает запись, где истинно хотя бы одно условие. "AREA" > 1500 OR "GARAGE" > 2 |
NOT | Выбирает записи, не соответствующие указанному выражению. Например это выражение выберет все штаты, кроме Калифорнии (California): NOT "STATE_NAME" = 'California' |
 Например выполнение следующего запроса выберет все дома с площадью более 1,500 квадратных футов или гаражом на две и более машины:
Например выполнение следующего запроса выберет все дома с площадью более 1,500 квадратных футов или гаражом на две и более машины:Операторы строковой операции
| Оператор | Описание |
|---|---|
|| | Возвращает символьную строку, являющуюся результатом конкатенации двух или более строковых выражений. FIRST_NAME || MIDDLE_NAME || LAST_NAME |
Функции
Ниже приведен полный список функций, поддерживаемых файловыми базами геоданных, шейп-файлами, покрытиями и прочими файловыми источниками данных.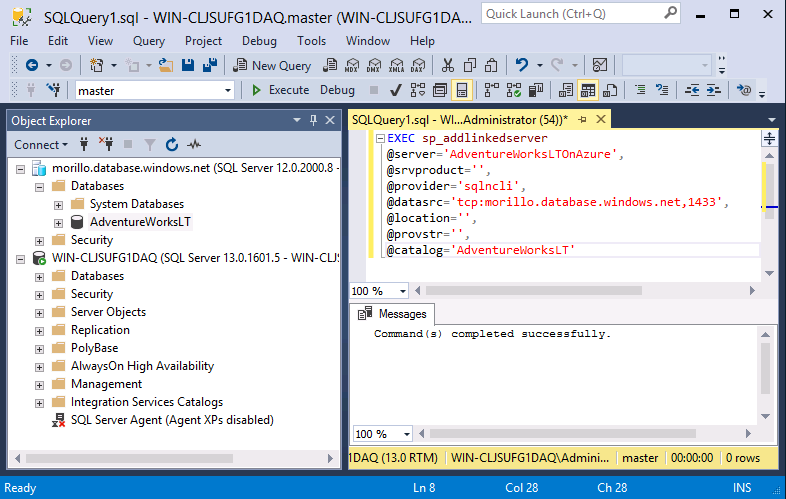 Они также поддерживаются в персональных базах геоданных и базах геоданных ArcSDE, хотя в этих источниках данных может использоваться иной синтаксис или имена функций. Помимо этих функций, персональные базы геоданных и базы геоданных ArcSDE поддерживают дополнительные возможности. Более подробную информацию см. в документации по своей СУБД.
Они также поддерживаются в персональных базах геоданных и базах геоданных ArcSDE, хотя в этих источниках данных может использоваться иной синтаксис или имена функций. Помимо этих функций, персональные базы геоданных и базы геоданных ArcSDE поддерживают дополнительные возможности. Более подробную информацию см. в документации по своей СУБД.
Функции дат
| Функция | Описание |
|---|---|
CURRENT_DATE | Возвращает текущую дату. |
EXTRACT (extract_field FROM extract_source) | Возвращает extract_fieldчасть из extract_source. Аргумент extract_source является выражением даты–времени. Аргументом extract_field может быть одно из следующих ключевых слов: YEAR (ГОД), MONTH (МЕСЯЦ), DAY (ДЕНЬ), HOUR (ЧАС), MINUTE (МИНУТА) или SECOND (СЕКУНДА). |
CURRENT TIME | Возвращает текущую дату. |
Строковые функции
Аргументы, указанные как string_exp, могут быть названиями столбцов, символьными строковыми постоянными или результатом другой скалярной функции, где исходные данные представлены символьным типом.
Аргументы, указанные как character_exp, являются символьными строками переменной длины.
Аргументы, указанные как start или length могут быть числовыми постоянными или результатами других скалярных функций, где исходные данные представлены числовым типом.
Строковые функции, перечисленные здесь, базируются на 1; то есть, первым символом в строке является символ 1.
| Функция | Описание |
|---|---|
CHAR_LENGTH(string_exp) | Возвращает длину строкового выражения в символах. |
LOWER(string_exp) | Возвращает строку, идентичную string_exp, в которой все символы верхнего регистра изменены на символы нижнего регистра. |
POSITION(character_exp IN character_exp) | Возвращает место первого символьного выражения во втором символьном выражении. Результат – число с точностью, определяемой реализацией и коэффициентом кратности 0. |
SUBSTRING(string_exp FROM start FOR length) | Возвращает символьную строку, извлекаемую из string_exp, начинающуюся с символа, номер которого определяется аргументом start, а длина строки составляет столько символов, сколько указано в аргументе length . |
TRIM(BOTH | LEADING | TRAILING trim_character FROM string_exp) | Возвращает строку string_exp укороченную на количество символов, указанное в аргументе trim_character, с начала, с конца или с обоих концов строки. |
UPPER(string_exp) | Возвращает строку, идентичную string_exp, в которой все символы нижнего регистра изменены на символы верхнего регистра. |
Числовые функции
Все числовые функции возвращают числовые значения.
Аргументы, обозначенные numeric_exp, float_exp или integer_exp могут быть именем столбца, результатом другой скалярной функции или числовой константой, где исходные данные могут быть представлены числовым типом.
| Функция | Описание |
|---|---|
ABS(numeric_exp) | Возвращает абсолютное значение numeric_exp. |
ACOS(float_exp) | Возвращает угол в радианах, равный арккосинусу float_exp. |
ASIN(float_exp) | Возвращает угол в радианах, равный арксинусу float_exp. |
ATAN(float_exp) | Возвращает угол в радианах, равный арктангенсу float_exp. |
CEILING(numeric_exp) | Возвращает наименьшее целое значение, большее или равное numeric_exp. |
COS(float_exp) | Возвращает косинус float_exp, где float_exp как угол, выраженный в радианах. |
FLOOR(numeric_exp) | Возвращает наибольшее целое значение, меньшее или равное numeric_exp. |
LOG(float_exp) | Возвращает натуральный логарифм float_exp. |
LOG10(float_exp) | Возвращает логарифм по основанию 10 float_exp. |
MOD(integer_exp1, integer_exp2) | Возвращает остаток от деления integer_exp1 на integer_exp2. |
POWER(numeric_exp, integer_exp) | Возвращает значение numeric_exp в степени integer_exp. |
ROUND(numeric_exp, integer_exp) | Возвращает numeric_exp, округленное до integer_exp знаков справа от десятичной точки. Если integer_exp отрицательное, numeric_exp округляется до |integer_exp| знаков слева от десятичной запятой. |
SIGN(numeric_exp) | Возвращает указатель знака numeric_exp. |
SIN(float_exp) | Возвращает синус float_exp, где float_exp – угол, выраженный в радианах. |
TAN(float_exp) | Возвращает тангенс float_exp, где float_exp – угол в радианах. |
TRUNCATE(numeric_exp, integer_exp) | Возвращает numeric_exp , усеченное до integer_exp знаков справа от десятичной запятой. Если integer_exp является отрицательным, numeric_exp усекается до |integer_exp| знаков слева от десятичной точки. |

 Если numeric_exp меньше нуля, возвращается –1. Если numeric_exp равно нулю, возвращается 0. Если numeric_exp больше нуля, возвращается 1.
Если numeric_exp меньше нуля, возвращается –1. Если numeric_exp равно нулю, возвращается 0. Если numeric_exp больше нуля, возвращается 1.Функция CAST
Функция CAST конвертирует значение в определенный тип данных. Синтаксис выглядит так:
Синтаксис выглядит так:
CAST(exp AS data_type)
Аргумент exp может быть названием столбца, результатом другой скалярной функции или буквенным. Data_type может быть любым и указываться строчными или заглавными буквами: CHAR, VARCHAR, INTEGER, SMALLINT, REAL, DOUBLE, DATE, TIME, DATETIME, NUMERIC, или DECIMAL.
Более подробно о функции CAST см. CAST and CONVERT.
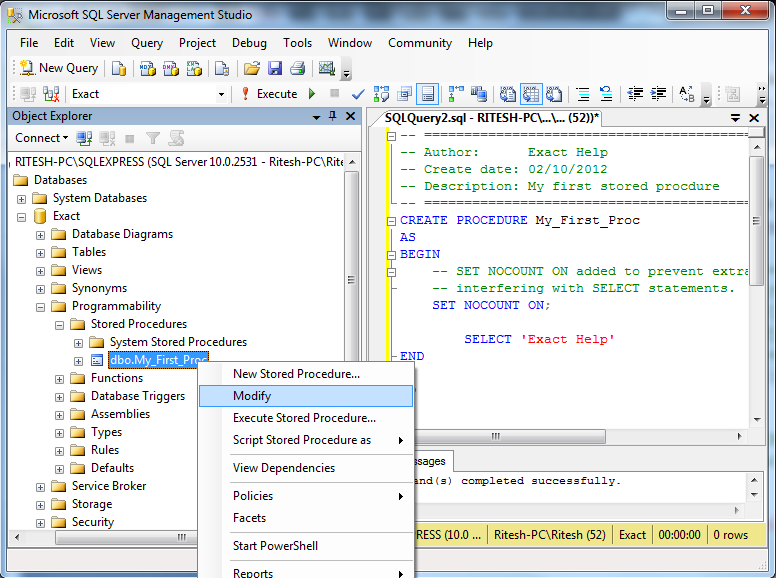
Связанные разделы
SQL Query Analyzer – интерактивное графическое средство, которое позволяет администратору базы данных или разработчику писать запросы, выполнять различные запросы одновременно, просматривать результаты, анализировать план запроса и получать поддержку для улучшения плана выполнения. Опция просмотра плана выполнения графически показывает методы получения данных, используемые оптимизатором запроса Microsoft SQL Server 2000. Иконки, изображенные в графическом плане исполнения, представляют физические операторы, которые используются MS SQL Server для выполнения запроса, и представлены ниже: Assert – логический и физический оператор проверки условия. Например, он проверяет ссылочную целостность данных или проверку ограничений или гарантирует, что скалярный подзапрос возвращает одну строку. The Bookmark Lookup – это физическая или логическая операция использования закладки (указателя строки или ключа кластерного индекса) для поиска соответствующей строки в таблице или кластерном индексе. Колонка Argument содержит значение закладки, используемое для поиска строки в таблице или кластерном индексе. Также содержит имя таблицы или кластерного индекса, в котором будет осуществляться поиск. Если используется выражение WITH PREFETH, то обработчик запроса считает, что в данном случае выгодно использовать асинхронное предварительное считывание данных (опережающее чтение). Clustered Index Delete – физический оператор, удаляет строки из кластерного индекса, заданного в колонке Argument. Если есть параметр WHERE:() в колонке Argument, то удаляются только те строки, которые соответствуют условию. Clustered Index Insert — физический оператор, который вставляет строки из ввода в кластеризованный индекс, соответствующий в колонке Argument. В этой колонке будет также параметр SET:(), указывающий на значение, которое будет присвоено каждой из соответствующих колонок. Clustered Index Scan – логический и физический оператор сканирует кластеризованный индекс, определенный в колонке Argument. Если есть опциональный параметр WHERE:(), то возвращаются только те строки, которые соответствуют параметру. Если колонка Argument содержит параметр ORDERED, процессор запроса предложит вывод строк в том порядке, в котором они отсортированы в кластерном индексе. Если упорядочения нет, индекс будет отсканирован самым оптимальным образом (но не гарантируется, что вывод будет отсортирован). Clustered Index Seek (поиск) – логическая и физическая операция, использующая поисковую способность индексов извлекать хранимые строки из кластеризованного индекса. Колонка Argument содержит название использованного кластеризованного индекса, и параметр SEEK:(). Clustered Index Update – физический оператор, обновляющий исходные строки в кластеризованном индексе, указанные в колонке Argument. Если есть параметр WHERE:(), обновляются только те строки, которые соответствуют этому параметру. Если есть указатель SET:(), то он указывает значение, устанавливаемое для каджой из колонок. Collapse – логический и физический оператор, оптимизирующий процесс обновления. Когда выполняется обновление, оно может быть разделено на удаление и вставку. Если колонка Argument содержит указатель обновляются и перечень группировочных колонок, процессор запроса группирует колонки по наборам ключей с целью оптимизировать операцию обновления, избавляясь от временных ненужных операций обновления на каждой строке. Compute Scalar – логический и физический оператор, вычисляющий выражение с целью предоставления скалярного значения, которое может быть возвращено пользователю или представлено в виде таблицы в запросе, например в условии или в объединении (JOIN). Concatenation – логический и физический оператор, сканирующий многочисленные источники, возвращая каждую отсканированную строку. Constant Scan – логический и физический оператор, вводящий постоянную строку в запрос. Она будет возвращена либо нулем, либо одной строкой, которая обычно не содержит колонки. Оператор Compute Scalar часто используется, чтобы добавить колонки в строке, созданные Constant Scan Deleted Scan – логический и физический оператор, сканирующий таблицу Deleted в рамках триггера. Filter (clsColumn) — свойство обьекта ClassType clsColumn. Определяет условие фильтра, которое применяется к запросу SQL, который возвращает папки для извлекаемой модели. Обратите внимание, что эта особенность применяется только к колонкам, которые принадлежат извлекаемой модели объектов Subclass Type sbclsRegular. Читать/записывать для колонок с Subclass Type sbclsNested, только читать для всех остальных. Примечания Для колонок с Subclass Type sbclsRegular, эта особенность возвращает собственность Фильтра родительского объекта. Колонки могут быть вставлены, так что родительский объект может быть или объект clsMiningModel или объект clsColumn. Hash Match — физический оператор, создающий хэш таблицу путем вычисления значения hash-функции для каждой строки из построенного входа. Параметр HASH:() с перечнем колонок, использованных для создания Hash-значения, появляется в колонке Argument. Затем для каждой подходящей строки он высчитывает Hash-значение (используя ту же Hash- функцию) и показывает в Hash-таблице для пар. Если есть параметр RESIDUAL:() в колонке Argument, то указатель должен также соответствовать строкам, которые рассматриваются как пара. Образ действия мало отличается, основываясь на уже выполненной логической операции:
Hash Match Root – физический оператор, согласующий действие всех операторов Hash Match Team сразу напрямую. Оператор The Hash Match Root и операторы Hash Match Team напрямую за ним отражают общую hash-функцию и разделяют общую стратегию. Оператор Hash March Root всегда возвращает вывод оператору, который не является членом цепочки (группы). Hash Match Team Team – физический оператор, который является частью цепочки (группы) объединенных hash-операторов, отображающих общую hash- функцию и разделяющих общую стратегию. Index Delete – физический оператор, который удаляет строки ввода из некластеризованного индекса, указанного в колонке Argument. Index Insert – физический оператор, который вставляет строки из своего ввода в некластеризованный индекс, указанный в колонке Argument. Колонка Argument может также содержать указатель SET:(), который указывает на значение, определяемое для каждой из колонок. Index Scan – логический и физический оператор, который извлекает все строки из некластеризованного индекса, указанного в колонке Argument. Если появляется дополнительный параметр WHERE:() в колонке Argument, возвращаются только те строки, которые соответствуют этому параметру. Если колонка Argument содержит ORDERED — оператор, то процессор запроса определяет, что строки должны быть возвращены в порядке сортировки некластерного индекса. Если нет ORDERED-оператора, то искать индекс будет обрабатываться самым оптимальным способом, но без гарантии отсортированности вывода. Index Seek — логический и физический оператор, который использует возможность поиска индексов с целью извлечения строк из некластеризованного индекса. Index Spool– физический оператор содержит указатель SEEK:() в колонке Argument. Оператор Index Spool сканирует свои строки ввода, размещая копию каждой строки в скрытом файле спулинга – файл, в который в процессе спулинга сбрасывается копия каждой строки (сохраняется в базе данных tempdb и существует только в течение существования запроса) и создает индекс по всем строкам. Index Update – физический оператор, обновляющий строки из его ввода в некластеризованном индексе, соответствующему в колонке Argument. Если есть параметр WHERE:(), то обновляются только те строки, которые соответствуют этому параметру. Если есть параметр SET: (), то он указывает на значение, определяемое для каждой из колонок. Если есть параметр DEFINE:(), он составляет список тех значений, которые определяет оператор. Эти значения могут быть предоставлены в виде таблиц в SET — операторе, или где-нибудь в рамках оператора или запроса. Inserted Scan – логический и физический оператор, сканирующий таблицу inserted в триггер. Log Row Scan – логический и физический оператор, сканирующий журнал транзакций. Merge Join – физический оператор, представляющий Inner Join, Left Outer Join, Left Semi Join, Left Anti Semi Join, Right Outer Join, Right Semi Join, Right Anti Semi Join, and Union логические операции. Nested Loops – физический оператор, представляющий Inner Join, Left Outer Join, Left Semi Join, и Left Anti Semi Join операции. Соединения nested Loops представляют поиск по внутренней таблице для каждой строки внешней таблицы, обычно использующий какой-то индекс. Parallelism– физический оператор, представляющий распределенные потоки, собранные потоки и перераспределенные потоки логических операций. Колонка Argument может содержать указатель PARTITION COLUMNS: () с перечнем колонок, разделенных запятой. Колонка Argument также может содержать указатель ORDERED BY:() с перечнем колонок, для которых порядок сортировки сохраняется в течение разделения. Parameter Table Scan – логический и физический оператор, сканирующий таблицу, которая выступает в качестве параметра в текущем запросе. Обычно это используется для запросов INSERT в рамках хранимой процедуры. Remote Delete – логический и физический оператор, удаляющий строки ввода из дистанционного объекта. Remote Insert — логический и физический оператор, вставляющий строки ввода в дистанционный объект. Remote Query – логический и физический оператор, предлагающий запрос дистанционному ресурсу. Текст запроса, посланный на дистанционный сервер, появляется в колонке Argument. Remote Scan – логический и физический оператор, который отсканирует дистанционный объект. Название дистанционного объекта появится в колонке Argument. Remote Update – логический и физический оператор, обновляющий строки ввода в дистанционном объекте. Row Count Spool – физический оператор, сканирующий ввод, подсчитывает сколько строк существует и возвращаются, поскольку много строк может быть без данных в них. Этот оператор используется, когда важней провести проверку на существование строк, чем на данные, содержащиеся в этих строках. Например, если оператор Nested Loops представляет собой левую полусоединенную операцию и объединенный показатель используется для внутреннего ввода, Row Count Spool может быть перемещен наверх внутреннего ввода оператора Nested Loops. Sequence – логический и физический оператор, управляющий большими планами обновления. Функционально, он выполняет каждый ввод в последовательности (сверху вниз). Каждый ввод – обычно обновление различных объектов. Он возвращает только те строки, которые поступают с последнего ввода. Sort – логический и физический оператор, сортирующий все строки ввода. Колонка Argument содержит указатель DISTINCT ORDER BY: (), если дублирующиеся строки удаляются или указатель ORDER BY:() если нет, с перечнем рассортированных колонок, разделенных запятой. Колонки имеют префикс ASC, если колонки рассортированы в порядке возрастания, или префикс DESC, если колонки рассортированы в порядке убывания. Stream Aggregate – физический оператор, опционально группирующий набор колонок и высчитывающий один или несколько агрегирующих выражений, возвращенных запросом и/или ссылающиеся на что-либо в рамках запроса. Table Delete – физический оператор, удаляющий строки из таблицы, соответствующие колонке Argument. Если есть указатель WHERE:() в колонке Argument, будут удалены только те строки, которые соответствуют указателю. Table Insert – физический оператор, вставляющий строки из своего ввода в таблицу в колонке Argument. Эта колонка также может содержать параметр SET:(), который указывает на значение, устанавливаемой для каждой из колонок. Table Scan – логический и физический оператор, возвращающий все строки из таблицы, указанной в колонке Argument. Если параметр WHERE:() появляется в колонке Argument, то возвращаются только те строки, которые соответствуют параметру. Table Spool – физический оператор, сканирующий ввод и помещающий копию каждой строки в скрытой таблице спулинга (сохраняемой в базе данных tempdb и существующей только в течение существования запросов). Если оператор повторяется заново (например, в цикле Nested Loops), то вместо повторного сканирования входа используется spool-таблица. Table Update – физический оператор, обновляющий строки ввода в таблице, соответствующие в колонке Argument. Если есть указатель WHERE:(), то обновляются только те строки, которые соответствуют этому указателю. Если есть указатель SET:(), он указывает устанавливаемое значение для каждой из колонок. Если есть указатель DEFINE:(), то составляется список значений, который определяет этот оператор. Эти значения могут быть представлены в виде таблиц в SET-операторе или где-то еще в рамках оператора или запроса. Top — логический или физический оператор, который будет сканировать ввод, возвращая только первое указанное количество или процентное соотношение строк. Иконки, представленные ниже, используются для отображения в планах выполнения операций, связанных с курсорами. Dynamic Динамический курсор. Этот курсор может просматривать все изменения, сделанные другими пользователями. Fetch Query – возвращает прочитанные данные из курсора. Keyset — этот курсор может просматривать обновления, сделанные другими пользователями, но не вставки, сделанные ими. Population Query – Это запрос заполняет рабочую таблицу курсора при открытии курсора. Refresh Query – этот запрос получает текущие данные для строк в буфере. Snapshot – этот курсор не видит изменений, сделанные другими пользователями. Чтение графического вывода плана выполнения. Вывод графического плана исполнения MS-SQL Query Analyzer читается слева направо и сверху вниз.
T-SQL и хранимые процедуры: Если инструкция это текст T-SQL или хранимая процедура, то она становится основой графического плана исполнения древовидной структуры. Язык манипулирования данными (DML): Если выполняется инструкция языка манипулирования данными, такая как SELECT, INSERT, DELETE или UPDATE, положение языка манипулирования данных – корень дерева. Инструкции языка манипулирования данных могут иметь дочерних уровня. Первый уровень – выполнение плана для инструкции языка манипулирования данных. Второй уровень представляет собой триггер, если он использован в результате выполнения инструкции. Условия: Графическое исполнение плана условных инструкций, таких как IF…ELSE делятся на трех детей. Инструкция IF…ELSE становится корнем. Условие IF становится узлом поддерева. Условия THEN и ELSE представлены как положения блоков. WHILE и DO_UNTIL положения представлены по такому же принципу. Реляционные операторы: Выполненные операции, такие как сканирование таблицы, соединения и агрегации представлены узлами на дереве. DECLARE CURSOR: Объявление курсора является корнем графического плана выполнения, а его соответствующий текст представлен как дочерний уровень или узел. Каждый узел показывает контекстную справку, когда курсор указывает на него:
Статья написана по материалам BOL и MSDN.
Перепечатка, воспроизведение в любой форме, распространение, в том числе в переводе, любых материалов с сайта www.softpoint.ru возможны только с письменного разрешения компании «СофтПоинт». Это правило действует для всех без исключения случаев, кроме тех, когда в материале прямо указано разрешение на копирование (основание: Закон Российской Федерации «Об авторском праве и смежных правах»).
|
 Для каждого ввода строки, Assert – оператор вычисляет выражение колонки Argument. Если это выражение является NULL, строка проходит оператор Assert. Если выражение NOT NULL, появится соответствующая ошибка.
Для каждого ввода строки, Assert – оператор вычисляет выражение колонки Argument. Если это выражение является NULL, строка проходит оператор Assert. Если выражение NOT NULL, появится соответствующая ошибка.
 SQL server использует индекс, чтобы обрабатывать только те строки, которые соответствуют параметру SEEK:(). Дополнительно может указываться параметр WHERE:(), который SQL server применяет к каждой из найденных строк диапазона удовлетворяющего параметру SEEK:(). Если колонка Argument содержит парметр ORDERED, процессор запроса определяет, что строки должны выдаваться в том порядке, в котором они отсортированы в кластерном индексе. Если упорядочения нет, индекс будет отсканирован самым оптимальным образом (но не гарантируется, что вывод будет отсортирован). Позволить , чтобы вывод был отсортирован может быть менее эффективно, чем если бы вывод был неотсортированным.
SQL server использует индекс, чтобы обрабатывать только те строки, которые соответствуют параметру SEEK:(). Дополнительно может указываться параметр WHERE:(), который SQL server применяет к каждой из найденных строк диапазона удовлетворяющего параметру SEEK:(). Если колонка Argument содержит парметр ORDERED, процессор запроса определяет, что строки должны выдаваться в том порядке, в котором они отсортированы в кластерном индексе. Если упорядочения нет, индекс будет отсканирован самым оптимальным образом (но не гарантируется, что вывод будет отсортирован). Позволить , чтобы вывод был отсортирован может быть менее эффективно, чем если бы вывод был неотсортированным.

 Когда хэш таблица создана, сканируется таблица и выводятся все вхождения.
Когда хэш таблица создана, сканируется таблица и выводятся все вхождения. Если есть указатель WHERE:(), то удаляются только те строки, которые соответствуют указателю.
Если есть указатель WHERE:(), то удаляются только те строки, которые соответствуют указателю. Колонка Argument содержит название используемого некластеризованного индекса. Она также содержит параметр SEEK:(). Использует индекс для поиска только тех строк, которые соответствуют параметру SEEK:(). Он может содержать параметр WHERE:(), который будет проверяться по отношению ко всем строкам, которые соответствуют параметру SEEK:() (индексы для этого не используются). Если колонка Argument содержит ORDERED-оператор, процессор запроса определяет, что строки должны быть возвращены в порядке сортировки некластерного индекса. Если нет ORDERED-оператора, то искать индекс будет обрабатываться самым оптимальным способом, но без гарантии отсортированности вывода. Если позволить выходу сохранять свой порядок, то это будет менее эффективней, нежели создание несортированного выхода.
Колонка Argument содержит название используемого некластеризованного индекса. Она также содержит параметр SEEK:(). Использует индекс для поиска только тех строк, которые соответствуют параметру SEEK:(). Он может содержать параметр WHERE:(), который будет проверяться по отношению ко всем строкам, которые соответствуют параметру SEEK:() (индексы для этого не используются). Если колонка Argument содержит ORDERED-оператор, процессор запроса определяет, что строки должны быть возвращены в порядке сортировки некластерного индекса. Если нет ORDERED-оператора, то искать индекс будет обрабатываться самым оптимальным способом, но без гарантии отсортированности вывода. Если позволить выходу сохранять свой порядок, то это будет менее эффективней, нежели создание несортированного выхода. Это позволяет использовать возможность поиска индексов для вывода только тех строк, которые соответствуют указателю SEEK: (). Если оператор повторяется заново (например, в цикле Nested Loops), то вместо повторного сканирования входа используется spool-таблица.
Это позволяет использовать возможность поиска индексов для вывода только тех строк, которые соответствуют указателю SEEK: (). Если оператор повторяется заново (например, в цикле Nested Loops), то вместо повторного сканирования входа используется spool-таблица. В колонке Argument оператор Merge Join содержит указатель MERGE:(), если операция представлена типом соединения «один ко многим», или MANY-TO-MANY MERGE:(), если операция представлена типом соединения «множество-множество». Колонка Argument может также содержать перечень колонок, отделенных запятой, использованные для выполнения операции. Оператор Merge Join требует двух вводов, отсортированных по своим колонкам соответственно, возможно путем добавления лишней операции сортировки в план запроса. Эта операция особенно эффективна, если добавление сортировки не требуется, например, если существует подходящий индекс в базе данных или если порядок сортировки может быть использован для многочисленных операций, таких как объединение и группировка со сворачиванием (roll up).
В колонке Argument оператор Merge Join содержит указатель MERGE:(), если операция представлена типом соединения «один ко многим», или MANY-TO-MANY MERGE:(), если операция представлена типом соединения «множество-множество». Колонка Argument может также содержать перечень колонок, отделенных запятой, использованные для выполнения операции. Оператор Merge Join требует двух вводов, отсортированных по своим колонкам соответственно, возможно путем добавления лишней операции сортировки в план запроса. Эта операция особенно эффективна, если добавление сортировки не требуется, например, если существует подходящий индекс в базе данных или если порядок сортировки может быть использован для многочисленных операций, таких как объединение и группировка со сворачиванием (roll up). MS SQL Server решает, основываясь на предугадывании стоимости, стоит ли рассортировывать внешний выход с целью улучшения положения поисков индекса над (по) внутреннему входу. Возвращаются любые строки, которые соответствуют дополнительному указателю в колонке Argument, (основываясь на представленной логической операции).
MS SQL Server решает, основываясь на предугадывании стоимости, стоит ли рассортировывать внешний выход с целью улучшения положения поисков индекса над (по) внутреннему входу. Возвращаются любые строки, которые соответствуют дополнительному указателю в колонке Argument, (основываясь на представленной логической операции).
 Затем этот оператор может просматривать как много строк на выходе, благодаря Row Count Spool (поскольку реальные данные не нужны из внутренней стороны), чтоб определить, нужно ли возвращать внешнюю строку.
Затем этот оператор может просматривать как много строк на выходе, благодаря Row Count Spool (поскольку реальные данные не нужны из внутренней стороны), чтоб определить, нужно ли возвращать внешнюю строку. Этот оператор требует того, чтобы ввод располагался в определенном порядке колонками в рамках группы. Если оператор Stream Aggregate группирует по колонками, то указатель GROUP BY: () и перечень колонок появляется в колонке Argument. Если оператор Stream Aggregate вычисляет любые выражения, их перечень появится в колонке вывода Defined Values из отчета SNOWPLAN_ALL или в колонке графического плана исполнения.
Этот оператор требует того, чтобы ввод располагался в определенном порядке колонками в рамках группы. Если оператор Stream Aggregate группирует по колонками, то указатель GROUP BY: () и перечень колонок появляется в колонке Argument. Если оператор Stream Aggregate вычисляет любые выражения, их перечень появится в колонке вывода Defined Values из отчета SNOWPLAN_ALL или в колонке графического плана исполнения.
 Колонка Argument может опционально содержать перечень колонок, которые проверяются на связи. В планах запросов на обновление, оператор — Top используется для ограничения количества обрабатываемых строк.
Колонка Argument может опционально содержать перечень колонок, которые проверяются на связи. В планах запросов на обновление, оператор — Top используется для ограничения количества обрабатываемых строк. Каждый запрос в группе, проходя анализ, появляется, включая стоимость каждого запроса в процентном отношении общей стоимости группы.
Каждый запрос в группе, проходя анализ, появляется, включая стоимость каждого запроса в процентном отношении общей стоимости группы. Хранимая процедура может иметь многочисленные дочерние уровни, которые представляют собой инструкции, вызванные хранимой процедурой. Каждый дочерний уровень – узел или ветвь дерева.
Хранимая процедура может иметь многочисленные дочерние уровни, которые представляют собой инструкции, вызванные хранимой процедурой. Каждый дочерний уровень – узел или ветвь дерева.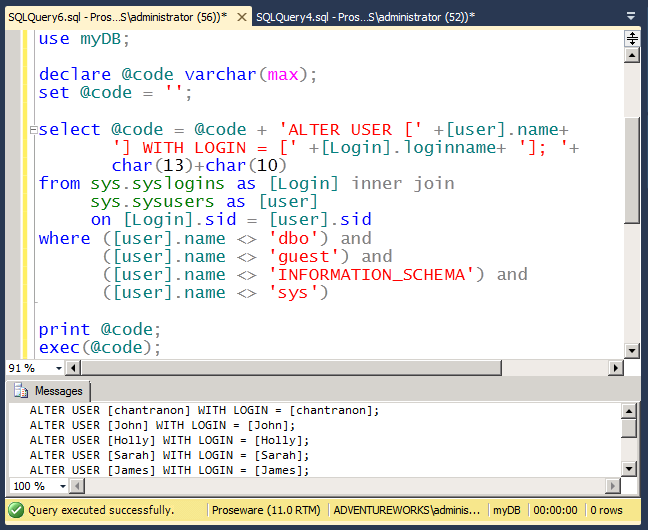
 Логический оператор, если отличается от физического, регистрируется после физического в начале контекстной подсказки и отделяется косой чертой (/).
Логический оператор, если отличается от физического, регистрируется после физического в начале контекстной подсказки и отделяется косой чертой (/).
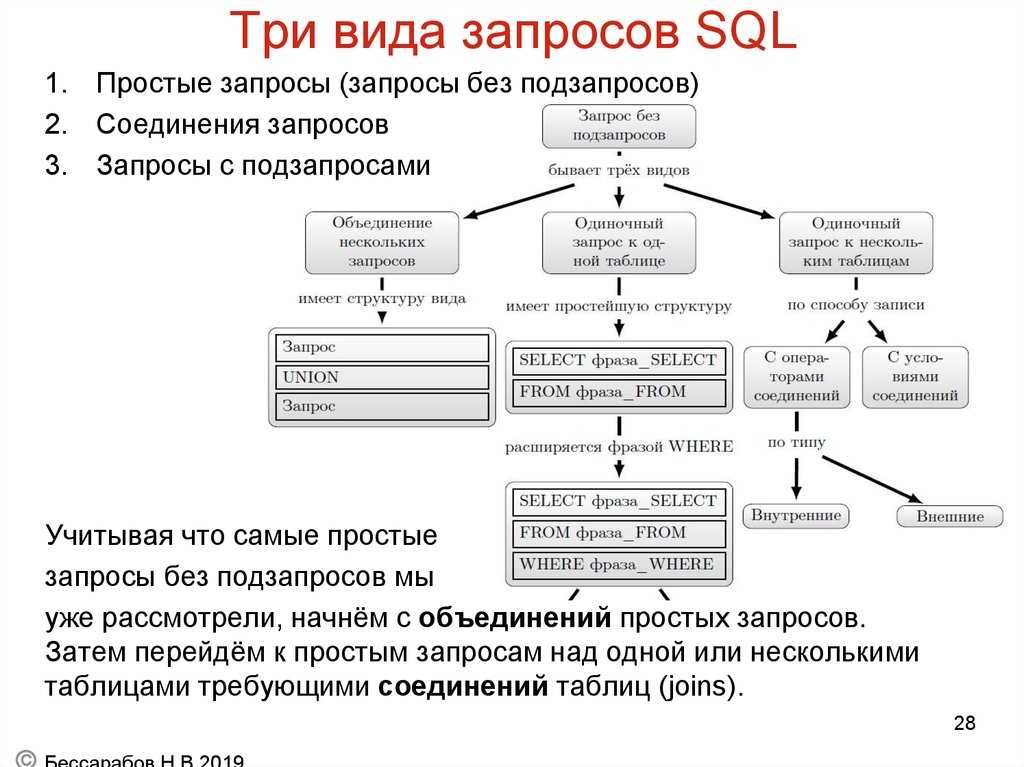
Команда SQL для выборки из базы данных часть 2 (ORDER BY, LIMIT, SELECT AS, COUNT)
При запросе к базе данных существует возможность ограничить выборку по количеству возвращаемых строк. А ещё можно запросить отсортированный по какому-либо параметру результат.
Сортировка (ORDER BY)
С помощью команды ORDER BY можно сделать сортировку результата, который будет выдан из базы данных. Результат можно сортировать по значению поля. Либо в прямом направлении «ASC», либо в обратном направлении «DESC». Приведём пример использования:
Результат можно сортировать по значению поля. Либо в прямом направлении «ASC», либо в обратном направлении «DESC». Приведём пример использования:
SELECT * FROM `USERS` WHERE `ID` > 2 ORDER BY `ID` DESC;
В конце этого запроса можно увидеть конструкцию «ORDER BY `ID` DESC», которая говорит о том, что выборка будет отсортирована по убыванию значения столбца ID. Если нужно сделать по возрастанию, то будет такой запрос:
SELECT * FROM `USERS` WHERE `ID` > 2 ORDER BY `ID` ASC;
Можно сделать две сортировки. Для этого после «ORDER BY» необходимо написать через запятую название столбца и направление сортировки. К примеру, отсортируем выборку по возрастанию ID но по убыванию даты (столбец DATE):
SELECT * FROM `USERS` ORDER BY `ID` ASC, `DATE` DESC;
Ограничение (LIMIT)
При работе с базой надо всегда помнить, что база данных — это довольно медленный инструмент. Поэтому необходимо минимизировать не только количество запросов к ней, но и количество выбранных из неё данных. Это можно сделать тремя способами. И лучше использовать их все одновременно:
Поэтому необходимо минимизировать не только количество запросов к ней, но и количество выбранных из неё данных. Это можно сделать тремя способами. И лучше использовать их все одновременно:
- Делать выборку определённых полей, а не всех полей таблицы. Для этого после команды SELECT необходимо ставить не *, а название выбираемых полей через запятую.
- Использовать условия WHERE, которые ограничивают размер выборки.
- Использовать LIMIT (лимит) на количество выбираемых строк.
О последнем способе поговорим отдельно. Лимит задаётся числом. К примеру, если написать «LIMIT 1;», то в результате SQL запроса будут возвращены не более 10 строк из таблицы. Чтобы установить лимит, напишите его в самом конце запроса:
SELECT * FROM `USERS` LIMIT 10;
Установка лимита на выборку может значительно ускорить некоторые запросы к базе. Не забывайте, что чем медленнее загружаются страницы Вашего сайта, тем меньше посетителей на нём будет. Потому что люди не любят ждать загрузки страницы. Загрузка длительностью более 2 секунд отталкивает от сайта более 60% его аудитории.
Потому что люди не любят ждать загрузки страницы. Загрузка длительностью более 2 секунд отталкивает от сайта более 60% его аудитории.
Переименовывание столбца при запросе (AS)
Бывают случаи, когда необходимо переименовать столбец в результатах выборки. Зачастую это делается для упрощения последующего программирования обработки выборки. Представьте, что у нас есть таблица со столбцом, который называется «SECTION_FULL_NUMBER»:
+---------------------+ | SECTION_FULL_NUMBER | +---------------------+ | 6 | +---------------------+ | 118 | +---------------------+ | 21 | +---------------------+
Использовать такое длинное имя не хочется, поэтому попробуем его укоротить до слова «NAME». Сделать это нам поможет команда «AS», которую необходимо поставить после называния выбираемого поля, вот так:
SELECT `SECTION_FULL_NUMBER` AS 'SECTION' FROM `USERS`;
В результате выполнения такого SQL запроса мы получим таблицу, но название столбца будет заменено на ‘SECTION’:
+---------+ | SECTION | +---------+ | 6 | +---------+ | 118 | +---------+ | 21 | +---------+
При переименовании в SELECT нельзя указать новое название столбца, которое будет совпадать с названием другого столбца.
Количесво строк в выборке (COUNT)
Одной из самых частых необходимостей является подсчёт количества строк вы вборке. Но как было сказано ранее, получение большого количества строк и столбцов из базы происходит довольно долго, что замедляет сайт. Поэтому не стоит пытаться подсчитывать количество строк после получения выборки. Лучше получить количество строк непосредственно из запроса. Для этого исопльзуется команда «COUNT(*)» (по английски «count» переводится как «количество»). Попробуем использовать её в SQL запросе:
SELECT COUNT(*) FROM `USERS`;
В результате выполнения такого запроса будет получен один столбце с одной строкой:
+----------+ | COUNT(*) | +----------+ | 3 | +----------+
Цифра «3» в примере означает, что в таблице было всего 3 записи (3 строчки).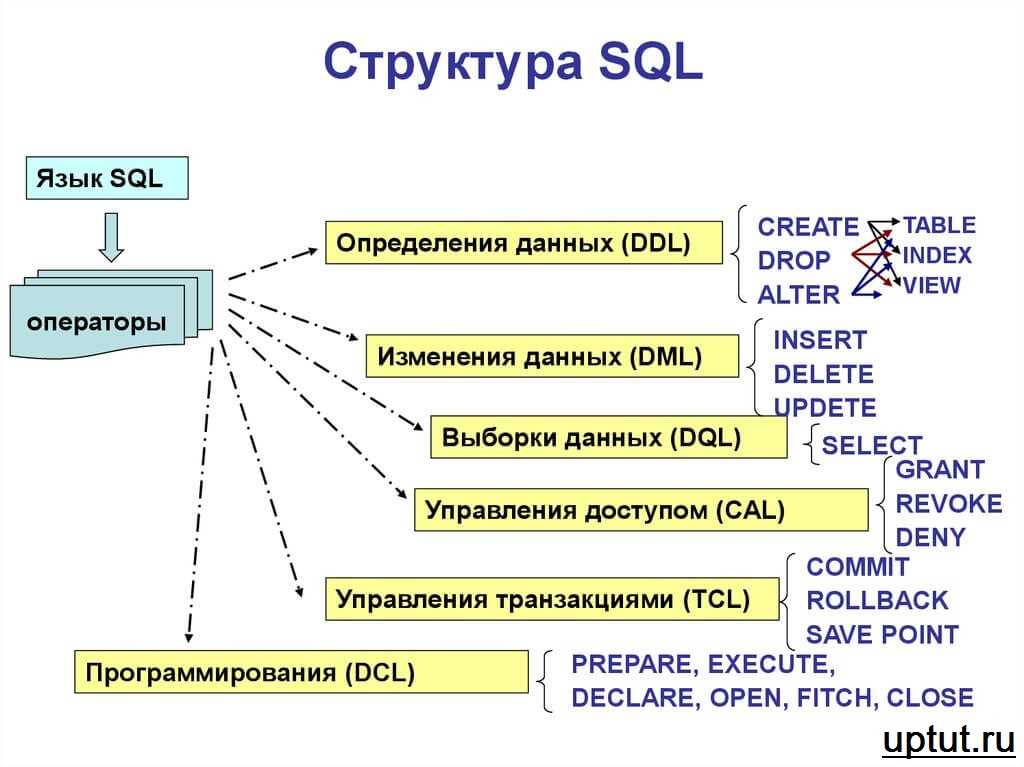 Если попробовать обработать данные, возвращённые базой, то может возникнуть проблема с названием столбца (в нём есть скобки и звёздочка). Поэтому воспользуемся рекомендацией из предыдущего параграфа и переименуем столбец в «CNT»:
Если попробовать обработать данные, возвращённые базой, то может возникнуть проблема с названием столбца (в нём есть скобки и звёздочка). Поэтому воспользуемся рекомендацией из предыдущего параграфа и переименуем столбец в «CNT»:
SELECT COUNT(*) AS 'CNT' FROM `USERS`;
Теперь результат будет легче обработать благодаря лаконичному названию столбца, содержащему только латинские буквы:
+-----+ | CNT | +-----+ | 2 | +-----+
Была ли эта статья полезна? Есть вопрос?
Закажите недорогой хостинг Заказать
всего от 290 руб
Описание операторов плана выполнения запроса в Microsoft SQL Server. Какая иконка, что обозначает | Info-Comp.ru
Приветствую Вас на сайте Info-Comp.ru! Продолжаем рассматривать план выполнения запроса и сегодня мы поговорим об операторах, которые наиболее часто встречаются в плане запроса, узнаем, что означает тот или иной оператор и как обозначается, т. е. как он выглядит в плане.
е. как он выглядит в плане.
Напомню, ранее мы уже рассматривали план выполнения запроса, например, в следующих статьях:
- План выполнения запроса в Microsoft SQL Server – что это такое и для чего он нужен
- Как посмотреть план выполнения запроса в Microsoft SQL Server
Чтобы создать план выполнения запроса, который показывает, как именно будет достигнут результат выполнения SQL инструкции, оптимизатор запросов использует операторы, которые описывают конкретные действия.
Операторы плана запроса делятся на логические и физические:
- Логические операторы – описывают операции реляционной алгебры, используемые для обработки инструкции. Другими словами, логические операторы описывают на концептуальном уровне, какие действия следует совершить;
- Физические операторы – реализуют действия, описанные логическими операторами. Иными словами, физический оператор является действием или процедурой, которая выполняет операцию. Например, некоторые физические операторы обращаются к данным в таблицах, а другие физические операторы выполняют соединения данных, вычисления, статистическую обработку, проверку целостности и другие действия.
 Например, некоторые физические операторы обращаются к данным в таблицах, а другие физические операторы выполняют соединения данных, вычисления, статистическую обработку, проверку целостности и другие действия.
Например, некоторые физические операторы обращаются к данным в таблицах, а другие физические операторы выполняют соединения данных, вычисления, статистическую обработку, проверку целостности и другие действия.Результатом плана выполнения запроса является дерево физических операторов, которое как раз и описывает, как именно SQL Server будет выполнять SQL инструкцию, т.е. как именно будет достигнут результат этой SQL инструкции.
План запроса можно посмотреть графически в SQL Server Management Studio, как это делается, я показывал в статье – Как посмотреть план запроса в SQL Server.
Ну а сейчас давайте рассмотрим конкретные операторы, которые наиболее часто мы будем видеть в плане выполнения запроса.
| Иконка | Оператор | Описание |
| Assert | Данный оператор предназначен для проверки условий. Например, он проверяет целостность ссылок или гарантирует, что скалярный вложенный запрос возвращает одну строку. Для каждой входной строки оператор Assert вычисляет выражение в столбце «Аргумент» плана запроса:
| |
| Clustered Index Scan | Оператор сканирует кластеризованный индекс. Если существуют условия, то возвращаются только строки, удовлетворяющие условию. Подробно о том, какие существуют индексы в SQL Server мы разговаривали в статье – Основы индексов в Microsoft SQL Server. | |
| Clustered Index Seek | Этот оператор использует поисковые возможности индексов для получения строк из кластеризованного индекса, т.е. выполняет поиск в кластеризованном индексе. Argument содержит имя кластеризованного индекса и предикат SEEK. Подсистема хранилища использует этот индекс для обработки только тех строк, которые удовлетворяют данному предикату. | |
| Clustered Index Delete | Оператор удаляет строки из кластеризованного индекса. Если в Argument есть предикат WHERE, то удаляются только строки, удовлетворяющие условиям предиката. | |
| Clustered Index Insert | Оператор вставляет в кластеризованный индекс новые строки. Argument содержит предикат SET, который указывает значение, устанавливаемое для каждого столбца. | |
| Index Scan | Оператор Index Scan предназначен для сканирования всех записей некластеризованного индекса. Если в Argument присутствует необязательный предикат WHERE, то возвращаются только те строки, которые удовлетворяют условию, указанному в этом предикате. | |
| Index Seek | Данный оператор выполняет поиск в некластеризованном индексе. Argument содержит имя некластеризованного индекса и предикат SEEK. Подсистема хранилища использует этот индекс для обработки только тех строк, которые удовлетворяют данному предикату. Также может включаться предикат WHERE, в котором подсистема хранилища вычисляет выражение для всех строк, удовлетворяющих предикату SEEK. Поиск в индексе является более эффективной операцией, чем сканирование индекса, однако если в запросе запрашивается большая часть данных индекса, то гораздо быстрее будет один раз просканировать индекс, чем осуществлять поиск каждого значения. Таким образом, Index Seek не всегда эффективнее, чем Index Scan, SQL Server сам определяет, что выбрать в том или ином случае на основе внутреннего порогового значения. | |
| Key Lookup | Данный оператор выполняет поиск данных в кластеризованном индексе. Возникает он, например, тогда, когда происходит получение данных из некластеризованного индекса, однако один из столбцов, указанных в запросе, отсутствует в этом некластеризованном индексе, т. Заметка! Проектирование индексов для оптимизации запросов в Microsoft SQL Server. | |
| RID Lookup | Этот оператор похож на Key Lookup, однако он выполняет поиск данных не в кластеризованном индексе, а в таблице «куче». Иными словами, если Вы видите данный оператор, значит у Вас есть таблица «куча», что в большинстве случаев является менее эффективным способом хранения данных, чем их хранение в кластеризованном индексе. | |
| Compute Scalar | Данный оператор вычисляет выражение и выдает скалярную величину. Затем эту величину можно вернуть в качестве результата или использовать в запросе, например, в предикате фильтра или соединения. | |
| Constant Scan | Этот оператор вводит в запрос одну или несколько константных строк. Он возникает, например, когда мы используем конструктор табличных значений VALUES. Он возникает, например, когда мы используем конструктор табличных значений VALUES. | |
| Concatenation | Данный оператор принимает данные с нескольких входов, объединяет их, и возвращает один общий результат. Оператор Concatenation мы можем встретить в плане запроса, когда используем конструкцию UNION ALL. | |
| Filter | Этот оператор принимает входные данные и возвращает только те строки, которые удовлетворяют критерию фильтрации (предикату). | |
| Nested Loops | Это оператор вложенных циклов. Он выполняет логические операции соединения. Иными словами, данный оператор возникает, когда мы соединяем несколько таблиц, при этом один набор данных соединения имеет небольшой размер (обычно менее десяти строк), а другой набор данных сравнительно большой и индексирован по соединяемым столбцам. Nested Loops встречается достаточно часто, так как является самой быстрой операцией соединения на небольшом объеме данных. Если оба набора данных будут достаточно большие, то данный способ соединения будет крайне неэффективен. Заметка! Что нужно знать и уметь разработчику T-SQL. Технологии, языки, навыки. | |
| Hash Match | Данный оператор также возникает при соединении таблиц, однако здесь используется другой алгоритм. Оператор Hash Match строит хэш-таблицу при помощи вычисления хэш-значения для каждой строки одного набора данных. Затем для каждой строки другого набора данных, с помощью той хэш-функции, он вычисляет хэш-значение и осуществляет поиск совпадений по хэш-таблице. Такой способ физического соединения данных возникает тогда, когда мы обрабатываем большие, несортированные и неиндексированные наборы данных, при этом он делает это достаточно эффективно. | |
| Merge Join | Еще один способ соединения таблиц. Однако в данном случае требуется, чтобы оба набора данных были отсортированы. Данный способ соединения наиболее эффективен в тех случаях, когда два набора данных достаточно велики, при этом они отсортированы по соединяемым столбцам (например, если они были получены просмотром отсортированных индексов). Если оба набора данных велики и имеют сходные размеры, но не отсортированы, то соединение слиянием с предварительной сортировкой и хэш-соединение (Hash Match) имеют примерно одинаковую производительность. Однако хэш-соединения часто выполняются быстрее, если наборы данных значительно отличаются по размеру. Принцип работы данного оператора следующий: он получает строку из каждого набора входных данных и сравнивает их. Например, для операций внутреннего соединения строки возвращаются в том случае, если они равны. Если они не равны, строка с меньшим значением не учитывается, и из этого набора входных данных берется следующая строка и снова происходит сравнение. Этот процесс повторяется, пока не будет выполнена обработка всех строк, т.е. пока этот, назовем его курсор, не дойдет до конца. | |
| Adaptive Join | Данный оператор появился относительно недавно, и он также предназначен для соединения таблиц. Однако Adaptive Join откладывает выбор метода соединения до завершения сканирования первых входных данных, в результате у SQL Server более точные сведения о том, какой способ соединения будет эффективней: Nested Loops или Hash Match. Таким образом, во время выполнения план запроса может динамически переключаться на более эффективный алгоритм соединения без перекомпиляции. Заметка! Статистика в Microsoft SQL Server – что это такое и для чего она нужна. | |
| Index Spool | Оператор Index Spool сканирует входные данные, и помещает их в буфер, который хранится в базе данных tempdb, этот буфер существует только в течение выполнения запроса. При этом для этих временных данных создается некластеризованный индекс, который позволяет использовать поддерживаемый индексами механизм поиска для вывода только строк, отвечающих требованиям предиката SEEK. Примечание! В большинстве случаев задействование tempdb в запросе отрицательно сказывается на его скорости выполнения, т.е. желательно проанализировать и переписать запрос так, чтобы исключить Spool в tempdb (во всех его проявлениях). | |
| Table Spool | Оператор Table Spool сканирует входную таблицу и помещает копию каждой строки в буфер, который находится в базе данных tempdb и существует только в течение времени жизни запроса. | |
| Spool | Оператор Spool сохраняет промежуточные результаты запроса в базе данных tempdb. | |
| Table Scan | Данный оператор получает строки из таблицы, указанной в столбце Аргумент плана выполнения запроса. Если предикат WHERE присутствует в столбце Argument, возвращаются только строки, удовлетворяющие условию, указанному в этом предикате. | |
| Sort | Оператор Sort сортирует входящие строки. Сортировка является достаточно трудоемкой операцией, поэтому лучше ее избегать, например, это можно достигнуть путем создания индекса с ключевыми столбцами, перечисленными в том же самом порядке, который использует оператор сортировки. Сортировка является достаточно трудоемкой операцией, поэтому лучше ее избегать, например, это можно достигнуть путем создания индекса с ключевыми столбцами, перечисленными в том же самом порядке, который использует оператор сортировки. | |
| Top | Оператор Top просматривает входные данные и возвращает только указанное число или процент строк. | |
| Stream Aggregate | Это оператор — статистическое выражение потока, он группирует строки в один или несколько столбцов и вычисляет одно или несколько агрегатных выражений, возвращенных запросом. Данный оператор возникает, когда мы используем GROUP BY и агрегатные выражения. | |
| Parallelism | Оператор Parallelism делит данные на несколько частей для параллельной обработки, тем самым сокращая общее время выполнения запроса. В большинстве случаев параллельная обработка является эффективной операцией, однако это создает дополнительную нагрузку на процессоры и в некоторых случаях, например, когда большинство запросов на сервере используют параллелизм, она может вызвать снижение общей производительности сервера. |
 Также может включаться предикат WHERE, в котором подсистема хранилища вычисляет выражение для всех строк, удовлетворяющих предикату SEEK, но это не является обязательным.
Также может включаться предикат WHERE, в котором подсистема хранилища вычисляет выражение для всех строк, удовлетворяющих предикату SEEK, но это не является обязательным.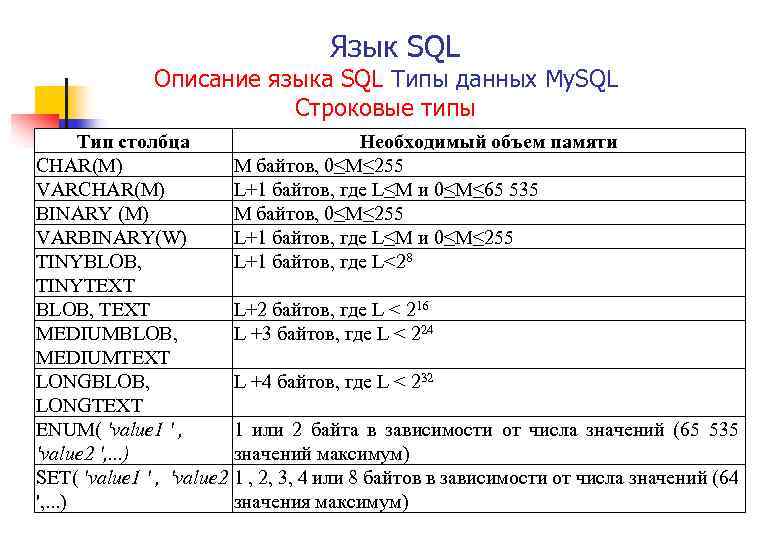
 е. в данном случае SQL Server по ключу обращается в кластеризованный индекс за недостающими данными. В большинстве случаев можно выиграть в производительности, избавившись от этого оператора, например, создав покрывающий индекс.
е. в данном случае SQL Server по ключу обращается в кластеризованный индекс за недостающими данными. В большинстве случаев можно выиграть в производительности, избавившись от этого оператора, например, создав покрывающий индекс.



Заметка! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код» – это самоучитель по языку SQL для начинающих программистов. В ней очень подробно рассмотрены основные конструкции языка.
На сегодня это все, надеюсь, материал был Вам полезен, пока!
Введение в SQL-запросы (часть 1)
введение
Язык SQL — это простой, легкий в освоении, но мощный язык, который позволяет быстро приступить к работе и писать более сложные запросы. Но для большинства разработчиков не существует абстрактного процесса и разумного шага в использовании SQL для запроса к базе данных. Это может заставить их «застрять» при написании некоторых конкретных запросов SQL для решения конкретных проблем. В серии статей в основном описываются некоторые основные теории запросов SQL и абстрактные идеи для написания операторов запросов.
Введение в SQL-запросы
Язык SQL возник на основе теории реляционных баз данных, опубликованной Э. Дж. Коддом в 1970 году, поэтому SQL служит реляционной базой данных. А для SQL-запросовОтносится к подмножеству данных, полученных из базы данных., Это предложение звучит непонятно, правда? Давайте вкратце объясним это с помощью нескольких картинок:
Если в базе данных только одна таблица, то если все данные следующие (взяты из образца базы данных AdventureWork):
Чтобы понять концепцию подмножеств, посмотрите на следующую картинку:
Наконец, подмножество выглядит следующим образом:
Фактически, каким бы сложным ни был запрос в SQL, его можно абстрагировать в описанный выше процесс.
Предварительные условия для точного запроса
Для правильного получения необходимого подмножества данных, в дополнение к правильному мышлению и правильному преобразованию мышления в соответствующий оператор SQL-запроса. Еще один очень важный момент — необходимостьБаза данных имеет хороший дизайн. Под хорошим дизайном здесь я подразумеваю, что дизайн базы данных соответствует бизнес-логике и, по крайней мере,Третья нормальная форма, Что касается реализации третьей парадигмы, это только мое личное мнение. Краткое введение в парадигму см. В моем блоге:Парадигма базы данныхЕсли проект базы данных плохой, существует большая избыточность и много отклонений от нормы в информации в базе данных, даже если SQL написан правильно, точные результаты не могут быть получены.
Еще один очень важный момент — необходимостьБаза данных имеет хороший дизайн. Под хорошим дизайном здесь я подразумеваю, что дизайн базы данных соответствует бизнес-логике и, по крайней мере,Третья нормальная форма, Что касается реализации третьей парадигмы, это только мое личное мнение. Краткое введение в парадигму см. В моем блоге:Парадигма базы данныхЕсли проект базы данных плохой, существует большая избыточность и много отклонений от нормы в информации в базе данных, даже если SQL написан правильно, точные результаты не могут быть получены.
Два пути, тот же результат
В SQL для получения одного и того же подмножества данных могут использоваться разные идеи или разные операторы SQL, поскольку SQL происходит из теории реляционных баз данных, а теория реляционных баз данных берет свое начало в математике. Когда вы думаете о том, как построить операторы запроса, их можно абстрагировать на две части. Методы:
1.
 Реляционная алгебра
Реляционная алгебраИдея реляционной алгебры состоит в том, чтобы выполнять пошаговые операции с базой данных и, наконец, получить желаемый результат.
Например, следующее предложение:
Select Name,Department,Age From Employee where Age>20
Идея реляционной алгебры описана выше. Приведенное выше предложение: Проект (выберите столбцы) в таблице «Сотрудник», затем отфильтруйте результаты и получите результаты только для возраста старше 20.
2. Алгоритм взаимоотношений
По сравнению с реляционной алгеброй, реляционные алгоритмы уделяют больше внимания условиям получения данных. Вышеупомянутый SQL можно описать реляционными алгоритмами следующим образом: Я хочу получить имена, отделы и возраст всех сотрудников старше 20 лет.
Зачем нужны два метода
Для простых запросов-запросов не нужен ни один из двух вышеперечисленных методов. Вы можете понять это самостоятельно. Проблема в том, что многие запросы очень сложные. Для реляционных алгоритмов больше внимания уделяется условиям, которым удовлетворяет извлеченная информация, в то время как для реляционной алгебры больше внимания уделяется тому, как извлекать конкретную информацию. Проще говоря, реляционный алгоритм означает «Что», а реляционная алгебра выражает «как». Идеи, раскрытые в операторах SQL, иногда представляют собой реляционную алгебру, иногда реляционные алгоритмы, а некоторые представляют собой смесь двух идей.
Для реляционных алгоритмов больше внимания уделяется условиям, которым удовлетворяет извлеченная информация, в то время как для реляционной алгебры больше внимания уделяется тому, как извлекать конкретную информацию. Проще говоря, реляционный алгоритм означает «Что», а реляционная алгебра выражает «как». Идеи, раскрытые в операторах SQL, иногда представляют собой реляционную алгебру, иногда реляционные алгоритмы, а некоторые представляют собой смесь двух идей.
Для некоторых ситуаций запроса метод реляционной алгебры может быть проще, в то время как для других ситуаций реляционный алгоритм более прямолинейный.В некоторых случаях нам нужно смешать две идеи. Итак, эти два образа мышления необходимы при написании SQL-запросов.
Запрос одной таблицы
Однотабличный запрос — это промежуточное состояние всех запросов. Даже сложные запросы из нескольких таблиц могут быть абстрагированы в запросы из одной таблицы после того, как это соединение будет окончательно установлено. Итак, начнем с запроса одной таблицы.
Итак, начнем с запроса одной таблицы.
Выберите подмножество столбцов
Согласно утверждению вышеупомянутого подмножества данных, выбор столбца достигается путем добавления имени столбца, который будет выбран после оператора select:
Например, в следующей базе данных выбор достигается путем выбора соответствующего имени столбца после выбораПодмножество столбцов.
Соответствующий оператор sql выглядит следующим образом:
SELECT [Name]
,[GroupName]
FROM [AdventureWorks].[HumanResources].[Department]Выберите подмножество строк
Выбор подмножества строк заключается в добавлении соответствующих условий ограничения после предложения where оператора SQL. Когда выражение после предложения where имеет значение «true», то есть когда удовлетворяется так называемое «условие», соответствующееПодмножество строкБыл возвращен.
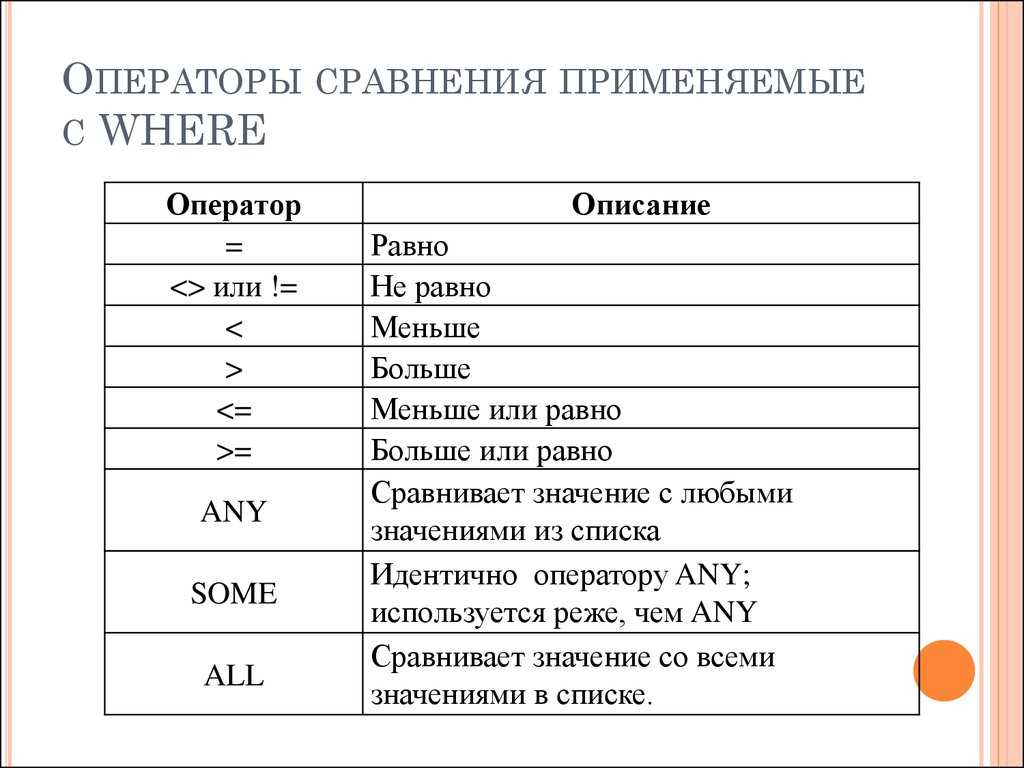
Операторы, следующие за предложением where, делятся на две категории, а именноОператор сравненияс участиемЛогические операторы.
Оператор сравнения сравнивает два данных одного и того же типа, а затем возвращает оператор логического типа (bool). В SQL есть шесть операторов сравнения, которые равны (=), меньше (<) и больше, чем (>), меньше или равно (<=), больше или равно (> =) и не равно (<>), из которых меньше или равно и больше или равно могут рассматриваться как комбинация операторов сравнения и логических операторов.
Логический оператор соединяет два логических типа и возвращает новый оператор логического типа.В SQL логический оператор обычно соединяет логический тип, возвращаемый оператором сравнения, чтобы определить конец предложения where. Верно или неверно, что соответствует условиям. Есть три типа логических операторов: (И) или (ИЛИ), а не (НЕ).
Например, выше я хочу выбрать второй и шестой элементы. Чтобы проиллюстрировать операторы сравнения и логические операторы, вы можете использовать следующий оператор SQL:
SELECT [Name]
,[GroupName]
FROM [AdventureWorks]. [HumanResources].[Department]
WHERE DepartmentID>1 and DepartmentID<3 or DepartmentID>5 and DepartmentID<7Из этого видно, что эти типы операторов имеют приоритет. Порядок приоритета в порядке убывания — это оператор сравнения> (And)> (Or)
Конечно, операторы также могут использовать круглые скобки для изменения своего приоритета. Для таблицы выше
Когда скобки не добавлены:
SELECT * FROM [AdventureWorks].[HumanResources].[Department] WHERE DepartmentID>=1 and DepartmentID<=3 and DepartmentID>=5 or DepartmentID<=7
После добавления круглых скобок для изменения порядка операций:
SELECT * FROM [AdventureWorks].[HumanResources].[Department] WHERE DepartmentID>=1 and DepartmentID<=3 and (DepartmentID>=5 or DepartmentID<=7)
Очень особенный NULL
Если в таблице, зарегистрированной пользователем, некоторая дополнительная информация не должна заполняться пользователем, она сохраняется в базе данных как null. Эти нулевые значения могут вызвать потерю данных при использовании оператора после предложения where выше, например Необязательная информация — пол (Gender), предполагая следующие два условных предложения:
where Gender="M"
where NOT (Gender="M")
Из-за наличия нулевого значения строки данных, возвращаемые этими двумя операторами, не суммируются со всеми данными во всей таблице. Следовательно, когда принимается во внимание значение null, условное предложение после where имеет возможные значения от true и false до true, false и unknown (null). Это возможные ответы, когда мы думаем о некоторых вопросах из реального мира — правда, ложь, я не знаю.
Итак, как нам не потерять данные в этом случае? В приведенном выше примере, как мы можем предотвратить потерю данных всей таблицы? Здесь необходимо выбрать параметр «unknown», кроме «true» и «false». Включенный SQL предоставляет IS NULL, чтобы указать, что эта опция неизвестна:
where Gender IS NULL
Добавьте приведенный выше оператор, и вы больше не потеряете данные.
Сортировать результаты
Вышеупомянутые методы предназначены для извлечения данных, а следующие — для извлеченияПодмножествоСортировать. SQL использует предложение Order by для сортировки. Предложение Order by является последним предложением оператора запроса Sql, что означает, что никакие предложения не могут быть добавлены после предложения Order by.
Предложение Order By разделено на возрастающий (ASC) и убывающий (DESC). Если возрастающий или убывающий порядок не указан, по умолчанию используется возрастающий (от малого к большему), а Order by определяется в соответствии с типом данных основы сортировки, и существует 3 типа соответственно Типы данных можно сортировать:
- персонаж
- цифровой
- Дата и время
Символы сортируются по алфавиту, числа сортируются по размеру чисел, а время и дата сортируются в соответствии с порядком времени.
Некоторые другие связанныеПосмотреть
Представление можно рассматривать как сохраненную виртуальную таблицу или просто как сохраненный оператор запроса. Преимущество представления состоит в том, что представление может быть изменено в соответствии с изменением содержимого таблицы, запрашиваемого представлением. Аналогия для понимания этого предложения:
Преимущество использования представлений заключается в том, что они могут шифровать запросы и облегчать управление, а также говорят, что они могут также оптимизировать производительность (я не согласен с этим).
Предотвратить дублирование
Иногда мы не хотим повторять подмножество полученных данных. Например, вы хотите знать, к скольким отделам принадлежит определенный сотрудник.
SELECT [EmployeeID]
,[DepartmentID]
FROM [AdventureWorks].[HumanResources].[EmployeeDepartmentHistory]Этот результат не имеет смысла, SQL предоставляет ключевое слово Distinct для этого:
SELECT distinct DepartmentID FROM [AdventureWorks].[HumanResources].[EmployeeDepartmentHistory]
Агрегатная функция
Так называемая функция агрегации предназначена для агрегирования нескольких значений в одном столбце в одно для определенных целей. Например, я хочу знать максимальный возраст группы людей, и я могу использовать MAX (возраст). Например, я хочу узнать средний результат теста класса. Используйте AVG (Результат) …
подводить итоги
В статье кратко излагаются принципы SQL-запроса и простого однотабличного запроса. Это основные концепции запроса к базе данных. Важно понимать эти концепции для сложных запросов.
SQL UNION — оператор для объединения результатов запросов
Оглавление
Связанные темы
Оператор языка SQL UNION предназначен для объединения результирующих таблиц базы данных, полученных
с применением слова SELECT. SELECT ИМЕНА_СТОЛБЦОВ (1..N) FROM ИМЯ_ТАБЛИЦЫ UNION SELECT ИМЕНА_СТОЛБЦОВ (1..N) FROM ИМЯ_ТАБЛИЦЫ В этой конструкции объединяемые запросы могут иметь условия в секции WHERE, а могут не иметь их. При помощи оператора UNION можно объединить запросы на извлечение данных как из одной таблицы, так и из разных. При использовании оператора UNION без слова ALL результат не содержит дубликатов, а со словом ALL — содержит дубликаты. Одним запросом можно вывести из таблицы индивидуальные значения столбцов, например, число лет, проработанных
сотрудниками фирмы, размеры их заработной платы и другие. Другим запросом — с использованием агрегатных функций — можно получить,
например, сумму заработных плат, получаемых сотрудниками отделов или занимающих те или иные должности, или
среднее число лет трудового стажа
(в таких запросах применяется группировка с помощью оператора GROUP BY). А если нам требуется получить в одной таблице и сводку всех индивидуальных значений, и итоговые значения? Здесь на помощь приходит оператор SQL UNION, с помощью которого два запроса объединяются. К результату объединения требуется применить упорядочение, используя оператор ORDER BY. Для чего это необходимо, будет лучше понятно из примеров. Если вы хотите выполнить запросы к базе данных из этого урока на MS SQL Server, но эта СУБД не установлена на вашем компьютере, то ее можно установить, пользуясь инструкцией по этой ссылке. Пример 1. В базе данных фирмы есть таблица Staff, содержащая данные о сотрудниках фирмы. В ней есть столбцы Salary (размер заработной платы), Job (должность) и Years (длительность трудового стажа). Первый запрос возвращает индивидуальные размеры заработной платы, упорядоченные по должностям: SELECT Name, Job, Salary FROM STAFF ORDER BY Job Результатом выполнения запроса будет следующая таблица:
Второй запрос вернёт суммарную заработную плату по должностям. Мы уже готовим этот запрос для соединения с первым, поэтому будем помнить, что условием соединения является равное число столбцов, совпадение их названий, порядка следования и типов данных. Поэтому включаем в таблицу с итогами также столбец Name с произвольным значением ‘Z-TOTAL’: SELECT ‘Z-TOTAL’ AS Name, Job, SUM(Salary) AS Salary FROM STAFF GROUP BY Job Результатом выполнения запроса будет следующая таблица:
Теперь объединим запросы при помощи оператора UNION и применим оператору ORDER BY
к результату объединения. (SELECT Name, Job, Salary FROM STAFF) UNION (SELECT ‘Z-TOTAL’ AS Name, Job, SUM(Salary) AS Salary FROM STAFF GROUP BY Job) ORDER BY Job, Name Результатом выполнения запроса с оператором UNION будет следующая таблица, в которой каждая первая строка в каждой группе должностей будет содержать суммарную заработную плату сотрудников, работающих на этой должности:
Написать запросы с использованием UNION самостоятельно, а затем посмотреть решениеПример 2. Данные — те же, что в примере 1, но задача немного посложнее. Требуется вывести в одной таблице не только индивидуальные размеры заработной платы, упорядоченные по должностям и суммарную заработную плату по должностям, но суммарную заработную плату по всем сотрудникам. Правильное решение. Пример 3. В базе данных фирмы есть таблица Staff, содержащая данные о сотрудниках фирмы. В ней есть столбцы Name (фамилия), Dept (номер отдела), и Years (длительность трудового стажа).
Вывести в одной таблице
средний трудовой стаж по отделам и индивидуальные значения длительности трудового стажа сотрудников,
сгруппированных по номерам отделов. Правильное решение.
Пример 4. В базе данных фирмы есть таблица Staff, содержащая данные о сотрудниках фирмы. В ней есть столбцы Salary (размер заработной платы), Job (должность) и Years (длительность трудового стажа). Первый запрос нужен для получения данных о сотрудниках, заработная плата которых более 21000: SELECT ID, Name FROM STAFF WHERE SALARY > 21000 Результатом выполнения запроса будет следующая таблица:
Второй запрос возвращает имена сотрудников, должность которых «менеждер», а число лет трудового стажа — менее 8: SELECT ID, Name FROM STAFF WHERE Job = ‘Mgr’ AND Years Результатом выполнения запроса будет следующая таблица:
Теперь требуются данные, в которых объединены критерии отбора, применённые в двух
запросах. SELECT ID, Name FROM STAFF WHERE SALARY > 21000 UNION SELECT ID, Name FROM STAFF WHERE Job = ‘Mgr’ AND Years Результатом выполнения запроса с оператором UNION будет следующая таблица:
Запрос с оператором UNION может возвращать и большее количество столбцов, важно, повторимся, чтобы в объединяемых запросах число столбцов, порядок их следования и типы данных совпадали. Теперь работаем с базой данных «Портал объявлений — 1». Скрипт для создания этой базы данных, её таблицы и заполения таблицы данных — в файле по этой ссылке Пример 5. Пусть сначала требуется получить данные о категориях и частях категорий объявлений, в которых подано более 100 объявлений в неделю. Пишем следующий запрос: SELECT Category, Part, Units, Money FROM ADS WHERE Units > 100 Результатом выполнения запроса будет следующая таблица:
Теперь требуется извлечь данные о категориях и частях категорий объявлений, за
которые выручено более 10000 денежных единиц в неделю. SELECT Category, Part, Units, Money FROM ADS WHERE Money > 10000 Результатом выполнения запроса будет следующая таблица:
Теперь требуется извлечь данные, которые соответствуют критериям и первого, и второго запросов. Объединяем запросы при помощи оператора UNION: SELECT Category, Part, Units, Money FROM ADS WHERE Units > 100 UNION SELECT Category, Part, Units, Money FROM ADS WHERE Money > 10000 Результатом выполнения запроса будет следующая таблица:
Примеры запросов к базе данных «Портал объявлений-1» есть также в уроках об
операторах INSERT, UPDATE, DELETE, HAVING.
До сих пор мы рассматривали запросы с оператором UNION, в которых объединялись результаты из одной таблицы. Теперь будем объединять результаты из двух таблиц. Пример 6. Есть база данных склада строительных материалов. В ней есть таблицы, содержащая данные об обоях. Таблица Vinil содержит данные о виниловых обоях, таблица Paper — о бумажных обоях. Требуется узнать данные о ценах обоев из одной и другой таблицы. Чтобы извлечь не повторяющиеся данные о ценах на виниловые обои, составим запрос со словом DISTINCT: SELECT DISTINCT Price FROM VINIL Результатом выполнения запроса будет следующая таблица:
Чтобы извлечь не повторяющиеся данные о ценах на бумажные обои, составим следующий запрос, также со словом DISTINCT: SELECT DISTINCT Price FROM PAPER Результатом выполнения запроса будет следующая таблица:
Теперь составим объединённый запрос с оператором UNION: SELECT DISTINCT Price FROM VINIL UNION SELECT DISTINCT Price FROM PAPER Так как мы не используем
слово ALL, дубликаты значений 400, 500 и 530 выводиться не будут.
Пример 7. База данных и таблицы — те же, что и в предыдущем примере. Требуется получить все данные о ценах, в том числе повторяющиеся. Запрос на объединение результатов с использованием оператора UNION будет аналогичен запросу в предыдущем примере, но вместо просто UNION пишем UNION ALL: SELECT DISTINCT Price FROM VINIL UNION ALL SELECT DISTINCT Price FROM PAPER Результатом выполнения запроса будет следующая таблица:
При помощи оператора SQL UNION можно объединить как простые запросы, так и запросы,
содержащие подзапросы (вложенные запросы). Пример 8. Есть база данных «Театр». В её таблице Play содержатся данные о постановках (названия — в столбце Name), в таблице Director — даные о режиссёрах (в столбце Fname — имя, в столбце Lname — фамилия). Первичный ключ таблицы Director — dir_id — идентификационный номер режиссёра. Dir_id также — внешний ключ таблицы Play, он ссылается на первичный ключ таблицы Director. Требуется вывести спектакли режиссеров John Barton и Trevor Nunn. Решение. Объединим результаты двух запросов — один возвращает спектакли режиссёра John Barton, другой — режиссёра Trevor Nunn. А каждый из этих объединяемых запросов к таблице Play делаем с подзапросом к таблице Director, который возвращает dir_id по имени и фамилии режиссёра. Каждый внешний запрос принимает из вложенного запроса значение ключа dir_id и возвращает названия постановок (Name): SELECT NAME FROM PLAY WHERE dir_id = (SELECT dir_id FROM DIRECTOR WHERE fname = ‘John’ AND lname = ‘Barton’) UNION SELECT NAME FROM PLAY WHERE dir_id = (SELECT dir_id FROM DIRECTOR WHERE fname = ‘Trevor’ AND lname = ‘Nunn’)
Поделиться с друзьями
|
Что такое SQL в SQL Server?
Что такое SQL в контексте SQL Server — распространенный вопрос, который задают новички. Эта статья призвана ответить на этот вопрос, предоставив некоторую историю, контекст и обзор основ языка.
Значение и определение
SQL расшифровывается как Structured Query Language, язык для манипулирования и обсуждения данных в базах данных. Впервые он был использован в 1970 году и стал стандартом IBM в 1986 году в сочетании с несколькими проектами для правительства США, и в течение многих лет он оставался проектом только для правительства. Это язык программирования, который используется для доступа к данным, хранящимся в базе данных.
Слово «SQL» является аббревиатурой, которая сегодня ассоциируется с «языком структурированных запросов». Первоначально он назывался SEQUEL с немного другим значением. Некоторые люди до сих пор произносят аббревиатуру как SEQUEL, а некоторые люди произносят каждую отдельную букву как S-Q-L. Они означают одно и то же.
SQL как язык поиска данных является отраслевым стандартом; Во всех продуктах реляционных баз данных SQL — это механизм, язык и синтаксис, используемые для извлечения данных из базы данных ar.
Согласно Википедии …
- «SQL разработан на основе реляционной алгебры и реляционного исчисления кортежей, SQL состоит из многих типов операторов, которые можно неофициально классифицировать как подъязыки, обычно: язык запросов данных (DQL), [a ] язык определения данных (DDL), [b] язык управления данными (DCL) и язык манипулирования данными (DML). Область применения SQL включает запрос данных, манипулирование данными (вставка, обновление и удаление), определение данных ( создание и изменение схемы) и контроль доступа к данным. Хотя SQL часто называют декларативным языком (4GL) и в значительной степени таковым и является, он также включает в себя процедурные элементы.
- SQL был одним из первых коммерческих языков для реляционной модели Эдгара Ф. Кодда, как описано в его влиятельной статье 1970 года «Реляционная модель данных для больших общих банков данных» [11]. Несмотря на то, что он не полностью придерживался реляционной модели, описанной Коддом, он стал наиболее широко используемым языком баз данных. Это отличает его от других языков, таких как C, C++, JavaScript или Java, которые являются языками программирования общего назначения. Это означает, что у SQL есть очень конкретная цель — манипулировать наборами данных. Мы манипулируем наборами данных, используя реляционное исчисление.
Как правило, мы можем использовать SQL для любых баз данных или источников данных, и даже если мы не можем использовать SQL напрямую для некоторых источников данных, большинство современных языков запросов имеют какое-то отношение к SQL. В общем, после того, как вы изучили SQL, довольно легко освоить другие языки запросов.
SQL имеет ряд стандартов. Он соответствует стандартам ANSI и ISO. Эти стандарты жизненно важны, потому что каждый поставщик реляционных баз данных должен реализовать стандарт, по крайней мере, как наименьший общий знаменатель, чтобы вы знали, что если вы изучите стандарт SQL, вы сможете применить эти знания к другим продуктам баз данных.
Интересные факты:
- Первый общедоступный продукт, использующий язык SQL, был выпущен в 1979 году вместе с Oracle, версии 2, и сегодня Oracle остается одной из ведущих систем баз данных.
- Большинство баз данных имеют некоторые дополнительные функции, не являющиеся частью стандарта. Если вы хотите изучить конкретный продукт базы данных, вам придется его изучить. Но базовый SQL, основанный на стандартах, всегда будет одним и тем же.
- SQL, как правило, не зависит от пробелов, а это означает, что если вы хотите добавить пробел между предложениями или выражениями, чтобы облегчить чтение оператора, вы можете это сделать.
- глаголы, т. е. ВЫБРАТЬ, ВСТАВИТЬ, ОБНОВИТЬ и УДАЛИТЬ.
SQL стандартизирован таким образом, что задает определенные вопросы объекту базы данных в форме структурированного запроса, на который база данных знает, как ответить. SQL использует интерпретатор команд для разбора SQL. Поскольку это такой мощный способ представления данных, SQL был адаптирован во многих продуктах баз данных. Некоторые продукты поддерживают стандарт SQL и добавляют к нему другие функции, а некоторые поддерживают часть, хотя и не все, стандарта SQL.
Операторы DML
Прежде чем мы начнем создавать операторы SQL в SQL Server, нам нужно понять, каковы основные части оператора. В целом, «оператор» — это то, что вы пишете на SQL, чтобы получить ответ от базы данных или внести в нее изменения.
DML означает операторы языка манипулирования данными. Это операторы, которые считывают, добавляют, редактируют или удаляют данные.
Операторы DDL
DDL означает операторы языка определения данных. Это операторы, относящиеся к объектам, таким как таблицы, в SQL Server и к данным. Например, чтобы создать таблицу, вы должны использовать оператор CREATE TABLE, указав имя и другие атрибуты вашей таблицы. Позже вы можете использовать операторы DML для добавления к ним данных, обновления или удаления этих данных и чтения данных.
Примечание. Подробное объяснение оператора SQL Create можно найти здесь: Обзор оператора SQL create
Операторы Create, Read (Select), Update (Update) и Delete (Delete) упоминаются вместе, аббревиатурой CRUD.
Подробное объяснение операций SQL CRUD можно найти здесь: Создание и использование хранимых процедур CRUDПредложения
Предложения — это основные компоненты операторов SQL, меньшие строительные блоки, составляющие целое. Эти предложения состоят из ключевых слов, которые сообщают базе данных о необходимости выполнить определенное действие. Есть также имена полей, которые сообщают базе данных, где искать и что искать. Есть также предикаты, которые позволяют указать, с какой информацией мы работаем. Предикаты включают значение или условие, называемое выражением. Предложение может быть утверждением, если вы пишете действительно основное. Существуют также операторы, как мы увидим позже, которые позволяют нам сравнивать равенство или диапазоны данных или обрабатывать информацию другими способами.
- Примечание. Ключевые слова и операторы обычно пишутся в верхнем регистре, хотя обычно это не обязательно. Но это помогает с первого взгляда отличить SQL от ваших выражений и имен полей
Сводка
Используя SQL, вы можете просмотреть некоторые данные; выбирать данные только из определенных таблиц; добавить фильтрацию к данным; манипулировать данными.
Все это можно сделать с помощью языка SQL. Итак, думайте о SQL как об API или интерфейсе прикладного программирования, основном языке, который вы используете для взаимодействия с вашей базой данных.Во-вторых, вы можете изменять данные; вставить новые данные; обновить или удалить существующие данные.
В-третьих, язык SQL позволяет изменять объекты в базе данных. Это создание новых таблиц. Или измените структуру существующих таблиц, например, добавьте столбцы в таблицы или удалите столбцы из таблиц.
Сильные стороны
Некоторые из сильных сторон SQL включают фильтрацию, особенно при выполнении инструкции SELECT. У нас есть простые и мощные инструменты для фильтрации возвращаемых нам результатов. Сортировка любых результатов, возвращаемых из SQL-запроса, может быть легко отсортирована по возрастанию или убыванию в любом столбце.
- Подробное объяснение оператора СККЛ, как , можно найти здесь: Обзор SQL, такой как Operator
. Функция часто используемой функции обработки данных можно найти здесь: Использование функции SQL Coalesce в SQL Server - Первый общедоступный продукт, использующий язык SQL, был выпущен в 1979 году вместе с Oracle, версии 2, и сегодня Oracle остается одной из ведущих систем баз данных.
- Подробное объяснение Порядок SQL по пункту можно найти здесь: Обзор заказа SQL по пункту
- Подробное объяснение соединения SQL можно найти здесь: Обзор соединения SQL и руководство
- Автор
- Последние сообщения
- SQL 86
- SQL 89
- SQL 92
- SQL 99
- SQL 2003
- SQL 2006
- SQL 2008
- SQL 2011
- SQL 2016
- Обзор типов соединений SQL и руководство
- Обзор объединения SQL, использование и примеры
- Автор
- Последние сообщения
В SQL уровень сложности работы с двумя и более таблицами аналогичен уровню сложности работы с одной таблицей.
Слабые стороны
Самым большим недостатком SQL является структурированный поток управления. В базовом стандарте SQL на самом деле нет никаких структур принятия решений, таких как операторы IF-ELSE, и при этом в нем нет много циклических структур, таких как For, While и Do-While, где мы хотим выполнить итерацию по некоторому предложению условия для выполнения некоторого SQL снова и снова. над.
Поэтому некоторые поставщики предлагают определенные решения. Эти языковые дополнения включают в себя все стандартные команды SQL для управления данными. Microsoft реализует T-SQL. T означает «Транзакция». Точно так же Oracle поддерживает расширение программирования PLSQL, также известное как Procedural Language SQL 9.0003
Пока это все…
Надеюсь, вам понравилась эта статья. Не стесняйтесь комментировать ниже.
Прашант Джаярам
Я технолог баз данных, обладающий более чем 11-летним богатым практическим опытом работы с технологиями баз данных. Я сертифицированный специалист Microsoft и имею степень магистра компьютерных приложений.
Моя специальность заключается в разработке и внедрении решений высокой доступности и межплатформенной миграции БД. В настоящее время работают над такими технологиями, как SQL Server, PowerShell, Oracle и MongoDB.
Просмотреть все сообщения Прашанта Джаярама
Последние сообщения Прашанта Джаярама (посмотреть все)
Определение SQL
Введение
В этой статье мы дадим определение SQL и объясним, что это такое, а также поговорим о
Расширения SQL. Мы также приведем несколько примеров синтаксиса SQL.
Определение SQL
По сути, SQL означает язык структурированных запросов , который в основном является языком, используемым базами данных. Этот язык позволяет обрабатывать информацию с помощью таблиц и показывает язык для запросов к этим таблицам и другим связанным объектам (представлениям, функциям, процедурам и т. д.). Большинство баз данных, таких как SQL Server, Oracle, PostgreSQL, MySQL, MariaDB, используют этот язык (с некоторыми расширениями и вариациями) для обработки данных.
С помощью SQL вы можете вставлять, удалять и обновлять данные. Вы также можете создавать, удалять или изменять объекты базы данных.
Кто изобрел SQL?
Эдгар Фрэнк Кодд, работавший в IBM, изобрел реляционную базу данных в 70-х годах. На основе этой работы Дональд
Чемберлин и Рэймонд Бойс разработали SQL для управления данными. Первоначально он назывался SEQUEL, но из-за торговой марки
проблема, он был изменен на SQL. Тем не менее, многие люди все еще говорят SEQUEL.
Определение ANSI SQL и определение ISO SQL
Американский национальный институт стандартов (ANSI) сделал SQL стандартом в 1986 году, а Международный Организация по стандартизации (ISO) делает SQL стандартом базы данных. Теперь все самые популярные базы данных следуют этим стандартам с некоторыми расширениями. Определение SQL — это язык для определения объектов базы данных и управления данными.
Было несколько изменений для определения того, каким будет SQL, включая типы данных, уровни изоляции, логические операторы, синтаксис, синтаксис языка определения данных, определения языка обработки данных, процедуры, функции и т. д.
Названия ревизий содержат год, когда она была сделана. Вот вам ревизии:
Синтаксис определения SQL
Допустим, у нас есть небольшая таблица с именем студентов и некоторыми данными:
Я БЫ | Имя | Фамилия |
1 | Джон | Рэмбо |
2 | Люк | Ходящий по небу |
3 | Питер | Чубакка |
4 | Джон | Матрица |
Если мы хотим увидеть все данные, SQL-запрос будет таким:
Выберите * среди студентов |
По сути, мы говорим, покажите мне все столбцы (*) из таблицы студентов. Если мы хотим получить только столбец ID
и имя, запрос будет выглядеть следующим образом:
Выберите ID, имя от студентов
В этом примере SQL-запрос получает идентификатор столбца Name из таблицы ученика. Важно отметить, что мы можем указывать имена столбцов в любом порядке. Я не буду говорить о производительности и индексах при использовании запросов, но порядок столбцов может повлиять на производительность в таблицах с несколькими миллионами строк или с соединениями с другими столбцами.
Для получения дополнительной информации о выбранных предложениях в T-SQL перейдите по ссылке Microsoft.
Отличительной чертой SQL является то, что вы можете запрашивать несколько таблиц. Например, если у меня есть оценки студенты, я мог запросить информацию из обеих таблиц. Допустим, у нас есть оценка студента в таблице:
Я БЫ | Счет |
1 | 52 |
2 | 63 |
1 | 57 |
3 | 69 |
ID — это студенческий билет. Это общий столбец между учеником и таблицей баллов. Нам нужен общий столбец
чтобы создать отношения. Если нам нужны имя, фамилия и оценка студента, запрос будет таким:
Выберите имя, фамилию, оценку От студента Внутреннее соединение Оценка ON student.ID=score.ID |
Первая строка проста. Мы вызываем столбцы с требуемыми данными. Вторая строка — это просто первая таблица, а внутреннее соединение должно использовать вторую таблицу с именем score. Наконец, нам нужно указать в запросе, какие общие столбцы соответствуют данным. В этом примере идентификаторы. Чтобы отличить столбец ID от других таблиц, нам нужно указать имена таблиц, за которыми следует точка, а затем имя столбца.
Полное руководство по объединениям см. по следующей ссылке:
Определение SQL для UNION, INTERSECT, ЗА ИСКЛЮЧЕНИЕМ
SQL определил стандартный синтаксис для создания объединения между двумя таблицами или для получения общих строк (пересечения) или строк
которые не являются общими (кроме). В следующей статье объясняется, как их использовать:
Расширения определения SQL
Каждая система баз данных имеет собственное расширение SQL. Например, SQL Server использует T-SQL, который является расширением SQL. Оракул использует PL-SQL, MySQL и MariaDB используют SQL/PSM (SQL и постоянный хранимый модуль). PSM — это стандарт ISO для хранимых процедуры. Teradata и Informix используют SPL, и существует несколько разных расширений, используемых разными системами. Базы данных.
Заключение
В этой статье мы объяснили определение SQL. По сути, это язык для обработки данных. Это было изначально
созданы для обработки структурированных данных, но даже базы данных NoSQL (нереляционные базы данных) обычно используют
Расширение SQL для получения данных. Платформы больших данных также используют расширения SQL для обработки своих данных, поэтому SQL
определение будет полезно в течение длительного времени.
Даниэль Кальбимонте
Даниэль Кальбимонте — Microsoft Most Valuable Professional, Microsoft Certified Trainer и Microsoft Certified IT Professional for SQL Server. Он опытный автор SSIS, преподаватель ИТ-академий и имеет более чем 13-летний опыт работы с различными базами данных.
Он работал на правительство, нефтяные компании, веб-сайты, журналы и университеты по всему миру. Дэниел также регулярно выступает на конференциях и в блогах, посвященных SQL Server. Он пишет учебные материалы по SQL Server для сертификационных экзаменов.
Он также помогает с переводом статей SQLShack на испанский язык
Просмотреть все сообщения Daniel Calbimonte
Последние сообщения Daniel Calbimonte (посмотреть все)
Что такое SQL? Изучите основы SQL, полную форму SQL и как использовать
Ричард Петерсон
ЧасовОбновлено
Что такое SQL?
SQL — это стандартный язык для работы с реляционными базами данных. SQL можно использовать для вставки, поиска, обновления и удаления записей базы данных. SQL может выполнять множество других операций, включая оптимизацию и обслуживание баз данных.
Полная форма SQL
SQL означает язык структурированных запросов, произносится как «S-Q-L» или иногда как «See-Quel»… Реляционные базы данных, такие как MySQL Database, Oracle, MS SQL Server, Sybase и т. д., используют ANSI SQL.
Как использовать SQL
Пример кода SQL:
SELECT * FROM Members WHERE Возраст > 30
Синтаксисы SQL, используемые в разных базах данных, почти одинаковы, хотя немногие СУБД используют несколько разных команд и даже проприетарные синтаксисы SQL.
Щелкните здесь, если видео недоступно
Для чего используется SQL?
Вот важные причины для использования SQL
- Это помогает пользователям получать доступ к данным в системе СУБД.
- Это поможет вам описать данные.
- Это позволяет вам определять данные в базе данных и управлять этими конкретными данными.
- С помощью SQL вы можете создавать и удалять базы данных и таблицы.
- SQL предлагает вам использовать функцию в базе данных, создать представление и хранимую процедуру.
- Вы можете установить разрешения для таблиц, процедур и представлений.
Краткая история SQL
Вот важные вехи из истории SQL:
- 1970 — Доктор Эдгар Ф. «Тед» Кодд описал реляционную модель для баз данных.
- 1974 – Появился язык структурированных запросов.
- 1978 — IBM выпустила продукт под названием System/R.
- 1986 — IBM разработала прототип реляционной базы данных, которая стандартизирована ANSI.
- 1989 г. — выпущена первая версия SQL .
- 1999 г. — запущен SQL 3 с такими функциями, как триггеры, объектная ориентация и т. д.
- SQL 2003 — оконные функции, функции, связанные с XML, и т. д.
- SQL 2006 — поддержка языка запросов XML
- SQL 2011 — улучшенная поддержка временных баз данных
Типы операторов SQL
Вот пять типов широко используемых запросов SQL.
- Язык определения данных (DDL)
- Язык обработки данных (DML)
- Язык управления данными (DCL)
- Язык управления транзакциями (TCL)
- Язык запросов данных (DQL)
Список команд SQL
Вот список некоторых наиболее часто используемых команд SQL :
- CREATE — определяет схему структуры базы данных
- INSERT — вставляет данные в строку таблицы
- ОБНОВЛЕНИЕ — обновляет данные в базе данных
- DELETE — удаляет одну или несколько строк из таблицы
- SELECT — выбирает атрибут на основе условия, описанного в предложении WHERE .
- DROP — удаляет таблицы и базы данных
Процесс SQL
Если вы хотите выполнить команду SQL для какой-либо системы СУБД, вам нужно найти наилучший метод для выполнения вашего запроса, а механизм SQL определяет, как интерпретировать эту конкретную задачу.
Важными компонентами, включенными в этот процесс SQL, являются:
- Механизм запросов SQL
- Механизмы оптимизации
- Диспетчер запросов
- Классический механизм запросов
Классический механизм запросов позволяет управлять всеми запросами, отличными от SQL.
Стандарты SQL
SQL — это язык для работы с базами данных. Он включает в себя создание базы данных, удаление, выборку строк, изменение строк и т. д. SQL — это стандартный язык ANSI (Американский национальный институт стандартов). Стандарты SQL разделены на несколько частей.
Вот некоторые важные части стандартов SQL:
| Часть | Описание |
|---|---|
| Часть 1 — SQL/Framework | Предлагает логические концепции. |
| Часть 2 — SQL/Основа | Он включает в себя основные элементы SQL. |
| Часть 3 — SQL/CLI | Этот стандарт включает основные элементы SQL. |
| Часть 4. Постоянно сохраняемые модули | Сохраненные подпрограммы, внешние подпрограммы и расширения процедурного языка для SQL. |
| Часть 9. Управление внешними данными | Добавляет синтаксис и определения в SQL/Foundation, которые разрешают доступ SQL к источникам данных, отличным от SQL (файлам). |
| Часть 10. Привязки объектного языка | Связи объектного языка: Эта часть определяет синтаксис и семантику внедрения SQL в Java™. |
| Часть 11 — SQL/схема | Схемы информации и определений |
| Часть 12 — SQL/Репликация | Этот проект начался в 2000 году. Эта часть помогает определить синтаксис и семантику, позволяющие определить схемы и правила репликации. |
| Часть 13 – Подпрограммы Java и тип | Подпрограммы и типы Java: эта часть подпрограмм, использующая язык программирования Java. |
| Часть 14 — SQL/XML | SQL и XML |
| Часть 15 — SQL/MDA | Обеспечить поддержку SQL для многомерных массивов |
Элементы языка SQL
Вот важные элементы языка SQL:
- Ключевые слова: Каждое выражение SQL содержит одно или несколько ключевых слов.
- Идентификаторы: Идентификаторы — это имена объектов в базе данных, таких как идентификаторы пользователей, таблицы и столбцы.
- Строки: Строки могут быть литеральными строками или выражениями с типами данных VARCHAR или CHAR.
- Выражения: Выражения формируются из нескольких элементов, таких как константы, операторы SQL, имена столбцов и подзапросы.
- Условия поиска: Условия используются для выбора подмножества строк из таблицы или используются для управляющих операторов, таких как оператор IF, для определения управления потоком.
- Специальные значения: Специальные значения следует использовать в выражениях и в качестве значений по умолчанию для столбцов при построении таблиц.
- Переменные: Sybase IQ поддерживает локальные переменные, глобальные переменные и переменные уровня соединения.
- Комментарии: Комментарий — это еще один элемент SQL, который используется для присоединения пояснительного текста к операторам SQL или блокам операторов. Сервер базы данных не выполняет никаких комментариев.
- Значение NULL: Используйте значение NULL, которое помогает указать неизвестное, отсутствующее или неприменимо значение.
Что такое база данных в SQL?
База данных состоит из набора таблиц, в которых хранится подробный набор структурированных данных. Это таблица, содержащая набор строк, называемых записями или кортежами, и столбцы, также называемые атрибутами.
Каждый столбец в таблице предназначен для хранения определенного типа информации, например, имен, дат, сумм в долларах и чисел.
Что такое NoSQL?
NoSQL — новая категория систем управления базами данных. Его основной характеристикой является несоблюдение концепций реляционных баз данных. NoSQL означает «Не только SQL». Концепция баз данных NoSQL выросла вместе с интернет-гигантами, такими как Google, Facebook, Amazon и т. д., которые имеют дело с гигантскими объемами данных.
Когда вы используете реляционную базу данных для больших объемов данных, система начинает замедляться с точки зрения времени отклика. Чтобы преодолеть это, мы могли бы «расширить» наши системы, обновив существующее оборудование. Альтернативой вышеуказанной проблеме было бы распределение нагрузки нашей базы данных на несколько хостов по мере увеличения нагрузки. Это известно как «масштабирование».
База данных NoSQL — это нереляционные базы данных , которые масштабируются лучше, чем реляционные базы данных, и разработаны с учетом веб-приложений. Они не используют SQL для запроса данных и не следуют строгим схемам, таким как реляционные модели. При использовании NoSQL функции ACID (атомарность, согласованность, изоляция, долговечность) не всегда гарантируются.
Почему имеет смысл изучать SQL после NoSQL?
Учитывая преимущества баз данных NoSQL, которые масштабируются лучше, чем реляционные модели, вы можете подумать, почему все еще нужно изучать базу данных SQL? Что ж, базы данных NoSQL являются узкоспециализированными системами и имеют свои особенности использования и ограничения. NoSQL больше подходит для тех, кто работает с огромными объемами данных. Подавляющее большинство используют реляционные базы данных и связанные с ними инструменты.
Реляционные базы данных имеют следующие преимущества перед базами данных NoSQL.
- Базы данных SQL (реляционные) имеют зрелую модель хранения данных и управления. Это очень важно для корпоративных пользователей. База данных SQL
- поддерживает понятие представлений, которые позволяют пользователям видеть только те данные, на просмотр которых у них есть права. Данные, которые им не разрешено просматривать, скрыты от них. Базы данных
- SQL поддерживают хранимую процедуру SQL, которая позволяет разработчикам баз данных реализовывать часть бизнес-логики в базе данных. Базы данных
- SQL имеют лучшие модели безопасности по сравнению с базами данных NoSQL.
Мир не отказался от использования реляционных баз данных. Растет спрос на специалистов, умеющих работать с реляционными базами данных. Таким образом, изучение баз данных и основ SQL по-прежнему заслуживает внимания.
Лучшая книга для изучения SQL
Вот пять лучших книг по SQL:
- Учебное пособие по SQL для начинающих
такие темы, как объединение SQL, создание, добавление и удаление таблицы и т. д. КУПИТЬ - SQL за 10 минут:
Эта книга по SQL предлагает полноцветные примеры кода, которые помогут вам понять, как устроены операторы SQL. Вы также получите знания о ярлыках и решениях. КУПИТЬ - SQL Cookbook: В этой книге по SQL вы сможете изучить технику обхода строки, позволяющую использовать SQL для анализа символов, слов или элементов строки с разделителями. КУПИТЬ
- SQL: полный справочник Эта книга включает важные темы Microsoft SQL, такие как функции окна, преобразование строк в столбцы, обратное преобразование столбцов в строки. КУПИТЬ
- Карманный справочник по SQL: руководство по использованию SQL В книге рассказывается, как системы используют функции SQL, синтаксис регулярных выражений и функции преобразования типов. КУПИТЬ
Дополнительные книги по SQL — Щелкните здесь
Резюме/Ключевые выводы
- Язык SQL используется для запросов к базе данных
- Что означает SQL или SQL означает: язык структурированных запросов
- SQL Используется для:
- Система РСУБД
- Описывать, определять и управлять данными
- Создание и удаление баз данных и таблицы
- Типы операторов SQL: DDL, DML, DCL, TCL, DQL
- Список команд SQL: CREATE, INSERT, UPDATE, DELETE, SELECT, DROP
- Элементы языка SQL: ключевые слова, идентификаторы, строки, выражения, переменные и т. д.
- NoSQL: означает, что «Не только SQL» относится к будущей категории систем управления базами данных .
- Подход к базе данных имеет много преимуществ, когда речь идет о хранении данных по сравнению с традиционными системами на основе плоских файлов
Что означает SQL? Определение стандарта SQL
SQL5 месяцев назад
от John Otieno
Язык структурированных запросов, или сокращенно SQL, является популярным и стандартным языком для взаимодействия и запроса информации в реляционной базе данных.
Базы данных есть везде, от небольших портативных устройств до крупных приложений, работающих в облаке. Хотя существует множество систем баз данных, реляционные базы данных являются наиболее популярными и влиятельными.
Используя язык SQL, вы можете выполнять такие операции, как добавление данных, выборка информации, поиск, обновление, оптимизация и удаление записей.
Как работает SQL?
Как администраторы баз данных, нам редко нужно понимать, что происходит под капотом, когда мы запускаем SQL-запрос. Хотя этот тип абстракции обычно используется, он может ограничивать тех, кому необходимо понимать внутреннюю работу базы данных.
ПРИМЕЧАНИЕ. Существуют различные вариации языка SQL, и, следовательно, сложно объяснить, как он работает в целом.
Однако после выполнения SQL-запроса он оценивается в следующих четырех простых шагах:
- Анализатор компиляции/запроса : Первый — это анализатор запросов. Этот шаг гарантирует, что выполняемый SQL-запрос соответствует определенному синтаксису.
- Компиляция/связывание : SQL-запрос проверяется на наличие схем, и для оператора в процессе связывания создается план запроса. План содержит двоичное представление шагов, которые необходимо выполнить во время выполнения указанного запроса.
- Оптимизация : После того, как план запроса был сгенерирован на этапе привязки, он переносится на этап оптимизации. Здесь для предоставленного плана запроса выбирается лучший алгоритм.
- Выполнение : Последний шаг — запустить инструкцию SQL, выполнив план запроса.
На следующей блок-схеме показаны четыре шага:
ПРИМЕЧАНИЕ. Имейте в виду, что это общий обзор работы SQL Engine. Различные механизмы баз данных могут по-разному реализовывать эти процессы.
Типы операторов SQL
SQL — это язык запросов, использующий формат, подобный операторам. Например, чтобы получить все таблицы в таблице, вы можете использовать следующий оператор:
SELECT * FROM TABLE_NAME;
В SQL существуют различные типы запросов. Они организованы следующим образом:
- Языки определения данных — запросы DDL
- Язык обработки данных — запросы DML
- Запросы управления транзакциями
- Запросы управления сеансом
- Запросы управления системой
- Язык управления данными
- Язык запроса данных
Хотя ранее упомянутые запросы являются общими типами запросов SQL, они могут различаться в зависимости от реализации ядра. Не стесняйтесь обращаться к документации по движку базы данных, чтобы узнать больше.
Общая терминология SQL
При работе с SQL и базами данных, связанными с SQL, вы услышите следующие общие термины:
- База данных — база данных относится к набору таблиц, представлений, индексов, операторов, функций и т. д.
- Запрос — запрос — это команда, которая воздействует на данные SQL. Эти типы запросов классифицируются по типам, упомянутым выше.
- Клиент — SQL-клиент — это любое приложение или соединение, взаимодействующее с базой данных в рамках независимой функции.
- Сервер — SQL-сервер — это программа, которая размещает базу данных и обрабатывает все входящие SQL-запросы от подключенных клиентов.
- Транзакция — транзакция SQL представляет собой набор большего количества запросов SQL, которые обрабатываются и выполняются как единое целое. В большинстве случаев транзакции атомарны. Это означает, что если один из запросов завершается ошибкой, вся транзакция завершается ошибкой. Однако эта функция может различаться в зависимости от ядра базы данных.
- Результат или набор результатов — Результат — это просто результат запроса к базе данных.
- РСУБД – Система управления реляционными базами данных. Относится к программе, которая предлагает SQL Server, позволяющий хранить, управлять, запрашивать и извлекать данные, хранящиеся в базе данных SQL. Популярные СУБД включают MySQL, SQL Server, PostgreSQL, Oracle и т. д.
Термины, включенные в предыдущий список, являются самыми основными и стандартными терминами в мире SQL. Однако имейте в виду, что это лишь минимальный список. SQL обширен и содержит множество других терминов.
Заключение
В этой статье мы познакомили вас с теоретической частью языка SQL. Следовательно, используя наши учебные пособия по SQL, вы изучите, как работает SQL, различные функции и как его использовать. Мы надеемся, что вы нашли эту статью полезной. Прочтите другие статьи Linux Hint, чтобы узнать больше советов и руководств.
Об авторе
Джон Отиено
Меня зовут Джон, и я такой же гик, как и вы. Я увлечен всеми вещами компьютеров от аппаратного обеспечения, операционных систем до программирования. Моя мечта — поделиться своими знаниями с миром и помочь другим гикам. Следите за моим контентом, подписавшись на список рассылки LinuxHint
.Просмотреть все сообщения
Что означает SQL?
Аббревиатура » Термин
Термин » Аббревиатура
Слово в термине
#ABCDEFGHIJKLMNOPQRSTUVWXYZ НОВЫЙ
Сокр. » Термин
Срок » Сокр.
Слово в термине
Фильтровать по: Выберите категорию из списка…──────────AllComputing (1)Любительское радио (1)Язык и литература (7)Символы NASDAQ (1)Образовательные (3)Новости и СМИ (1) Базы данных (2) Расширения файлов (2) Общие вычисления (1) ИТ (2) Сети (1) Программное обеспечение (1) FDA (1) Военные (2) НАСА (2) Правительство США (1) Чат (2) Автомобильная (1)Неклассифицированная (1)Коды аэропортов (1) Сортировать по: ПопулярностиВ алфавитном порядкеКатегории
Термин | Определение | Опции | Рейтинг |
| SQL | Язык структурированных запросов Governmental » Military — and more. | Rate it: | |||
| SQL | Sound Quality Loud Community » News & Media | Оценить: | |||
| SQL | База сообщений Squish указатели последнего чтения Компьютеры » Расширения файлов1030 | Rate it: | |||
| SQL | SQL report or query Computing » File Extensions | Rate it: | |||
| SQL | Strong Question Язык Интернет » Чат | Оценить: | |||
| SQL | Структурированный вопрос3Community » Educational | Rate it: | |||
| SQL | Simulated Quest For Learning Community » Educational | Rate it: | |||
| SQL | Стандартные вопросы0043 | ||||
| SQL | Simple Quantum Leptons Miscellaneous » Unclassified | Rate it: | |||
| SQL | School Internet » Chat | Оценить: | |||
| SQL | Язык структурированных запросов (для баз данных) Компьютеры » Базы данных | Rate it: | |||
| SQL | Sequenced Query Language Academic & Science » Language & Literature | Rate it: | |||
| SQL | SQueLch Правительственный » НАСА — и не только. | ||||
| SQL | Search and Query Language Academic & Science » Language & Literature | Rate it: | |||
| SQL | Server Query Line Business » Символы NASDAQ | Оценить: | |||
| SQL | String & Litature Query Language 9 Академический язык и литература 9000 003 | Rate it: | |||
| SQL | Scalable Query Language Academic & Science » Language & Literature | Rate it: | |||
| SQL | Стандартизированный язык запросов Академический и научный язык » Язык и литература | Rate it: | |||
| SQL | simple Query Language Academic & Science » Language & Literature | Rate it: | |||
| SQL | San Carlos Airport Региональный » Коды аэропортов | Оценить: | |||
| Стандарт SQL | 60003 Rate it: | ||||
| SQL | Square Left Miscellaneous » Automotive | Оценить: |
Что означает
SQL ?- SQL
- SQL — это язык программирования специального назначения, предназначенный для управления данными, хранящимися в системе управления реляционными базами данных.
Первоначально основанный на реляционной алгебре и реляционном исчислении кортежей, SQL состоит из языка определения данных и языка обработки данных. Область применения SQL включает в себя вставку данных, запрос, обновление и удаление, создание и изменение схемы, а также управление доступом к данным. Хотя SQL часто называют декларативным языком и в значительной степени таковым и является, он также включает процедурные элементы.
SQL был одним из первых коммерческих языков для реляционной модели Эдгара Ф. Кодда, как описано в его влиятельном 1970 статья «Реляционная модель данных для больших общих банков данных». Несмотря на то, что он не полностью придерживался реляционной модели, описанной Коддом, он стал наиболее широко используемым языком баз данных.
SQL стал стандартом Американского национального института стандартов в 1986 г. и Международной организации по стандартам в 1987 г. С тех пор стандарт несколько раз дорабатывался, добавлялись новые функции. Но код не полностью переносим между различными системами баз данных, что может привести к привязке к поставщику. Различные производители не полностью следуют стандарту, они добавляют расширения, и стандарт иногда неоднозначен.
подробнее »
Знаете что такое
SQL ? Есть еще одно хорошее объяснение SQL ? Не держите это в себе! Все еще не можете найти искомое определение аббревиатуры? Используйте нашу технологию Power Search , чтобы искать более уникальные определения в Интернете!Цитата
Используйте приведенные ниже параметры цитирования, чтобы добавить эти сокращения в свою библиографию.
Самый большой ресурс в Интернете для
Сокращения и сокращения
Член сети STANDS4
Изображение или иллюстрация
SQL
Аэропорт Сан-Карлос
SQL
Кредит »
Просмотреть Abbreviations.com
#ABCDEFGHIJKLMNOPQRSTUVWXYZ
Бесплатно, регистрация не требуется:
Добавить в Chrome
Получите мгновенное объяснение любой аббревиатуры или аббревиатуры, которая попадется вам в любом месте в Интернете!
Бесплатно, регистрация не требуется:
Добавить в Firefox
Получите мгновенное объяснение любой аббревиатуры или аббревиатуры, которая попадется вам в любом месте в Интернете!
Викторина
Окончательный тест аббревиатуры
»
СССР
A.
Университет Социалистических Студенческих РеспубликБ. Союз Советских Социалистических Республик
C. Союз советских социалистов России
Д. Союз Советских Стандартных Республик
Встроить
Общий доступ к образу SQL
»Нажмите, чтобы просмотреть:
SQL | Предложение WITH — GeeksforGeeks
Предложение SQL WITH было представлено Oracle в базе данных Oracle 9i выпуска 2. Предложение SQL WITH позволяет дать блоку подзапроса имя (этот процесс также называется рефакторингом подзапроса), на который можно ссылаться в нескольких местах в основном SQL-запросе.
- Предложение используется для определения временного отношения таким образом, что выходные данные этого временного отношения доступны и используются запросом, связанным с предложением WITH.
- Запросы со связанным предложением WITH также могут быть написаны с использованием вложенных подзапросов, но это усложняет чтение/отладку SQL-запроса.
- Предложение WITH не поддерживается всеми системами баз данных.
- Имя, присвоенное подзапросу, рассматривается как встроенное представление или таблица.
- Предложение SQL WITH было введено Oracle в базу данных Oracle 9i выпуска 2.
Синтаксис:
С временной таблицей (среднее значение) как
(ВЫБЕРИТЕ среднее (Атрибут1)
ИЗ таблицы)
ВЫБЕРИТЕ Атрибут1
ИЗ таблицы, временная таблица
ГДЕ Table.Attr1 > временноеTable.averageValue;
В этом запросе предложение WITH используется для определения временной связи временной таблицы, которая имеет только 1 атрибут mediumValue. mediumValue содержит среднее значение столбца Attr1, описанного в таблице отношения. Оператор SELECT, следующий за предложением WITH, создаст только те кортежи, в которых значение атрибута Attr1 в таблице отношения больше, чем среднее значение, полученное из оператора предложения WITH.
Примечание. При выполнении запроса с предложением WITH сначала оценивается запрос, упомянутый в предложении, а результат этой оценки сохраняется во временном отношении. После этого наконец выполняется основной запрос, связанный с предложением WITH, который будет использовать созданное временное отношение.
Запросы
Пример 1: Найдите всех сотрудников, чья зарплата больше, чем средняя зарплата всех сотрудников.
Name of the relation: Employee
| EmployeeID | Name | Salary |
|---|---|---|
| 100011 | Smith | 50000 |
| 100022 | Bill | 94000 |
| 100027 | Сэм | 70550 |
| 100845 | Walden | 80000 |
| 115585 | Erik | 60000 |
| 1100070 | Kate | 69000 |
SQL Query:
WITH temporaryTable (среднее значение) как
(ВЫБЕРИТЕ сред. (зарплата)
от работника)
ВЫБЕРИТЕ ID сотрудника, имя, зарплата
ОТ сотрудника, временная таблица
ГДЕ Сотрудник.Зарплата > временнаяТаблица.среднееЗначение; Output :
| EmployeeID | Name | Salary |
|---|---|---|
| 100022 | Bill | 94000 |
| 100845 | Walden | 80000 |
Explanation : Средняя заработная плата всех работников равна 70591. Следовательно, все работники, чья заработная плата больше полученной средней, лежат в отношении выхода.
Пример 2: Найдите все авиакомпании, в которых общая зарплата всех пилотов больше, чем средняя общая зарплата всех пилотов в базе данных.
Name of the relation: Pilot
| EmployeeID | Airline | Name | Salary |
|---|---|---|---|
| 70007 | Airbus 380 | Kim | 60000 |
| 70002 | Boeing | Laura | 20000 |
| 10027 | Airbus 380 | Will | 80050 |
| 10778 | Airbus 380 | Warren | 80780 |
| 115585 | Boeing | Smith | 25000 |
| 114070 | Airbus 380 | Кэти | 78000 |
SQL-запрос: 3 900 Суммарный SQL-запрос: 3 900
(ВЫБЕРИТЕ авиакомпанию, сумма(Зарплата)
ОТ Пилота
ГРУППА ПО Авиакомпаниям),
авиакомпанияСредняя (средняя зарплата) как
(ВЫБЕРИТЕ сред. (зарплата)
ОТ Пилота)
ВЫБЕРИТЕ авиакомпанию
ОТ ИтогоЗарплата, авиакомпанияСредняя
ГДЕ totalSalary.total > авиакомпанияAverage.avgSalary;
Output :
| Airline |
|---|
| Airbus 380 |
Explanation: The total salary of all pilots of Airbus 380 = 298,830 and that of Boeing = 45000. Average salary всех пилотов в таблице Pilot = 57305. Поскольку только общая заработная плата всех пилотов Airbus 380 больше, чем полученная средняя заработная плата, поэтому Airbus 380 лежит в выходном отношении.
Важные моменты:
- Предложение SQL WITH удобно использовать со сложными операторами SQL, а не с простыми.
- Оно также позволяет разбивать сложные запросы SQL на более мелкие, что упрощает отладку и обработку сложных запросов.
- Предложение SQL WITH в основном является заменой обычного подзапроса.