Что такое запрос. Обработка баз данных на Visual Basic®.NET
Что такое запрос. Обработка баз данных на Visual Basic®.NETВикиЧтение
Обработка баз данных на Visual Basic®.NET
Мак-Манус Джеффри П
Содержание
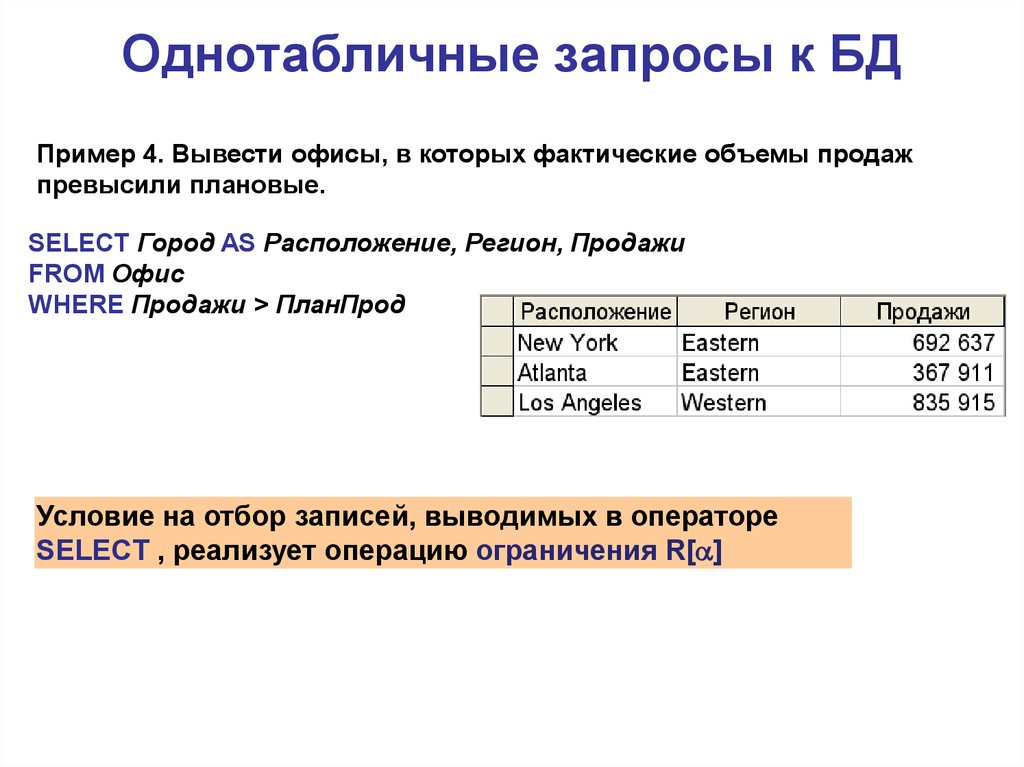
Что такое запрос
Запрос (query) — это команда базы данных, осуществляющая выборку записей. Используя запросы, можно получить данные из одного или нескольких полей, принадлежащих одной или нескольким таблицам. При этом данные можно отбирать в соответствии с определенными условиями, называемыми критериями, которые служат для ограничения общего объема отбираемых данных.
Запросы в Visual Basic .NET обычно основаны на SQL. Это стандартный язык для осуществления выборки информации и других операций над базами данных. Он прост в освоении и реализован во многих различных базах данных, поэтому при желании преобразовать свое приложение управления базой данных SQL Server, например, в Sybase или Oracle вам не придется заново изучать совершенно новый язык запросов.
Однако все это теория. А на практике каждый производитель базы данных имеет собственный способ реализации стандарта (так называемый промышленный стандарт), и Microsoft в этом смысле не является исключением. Хотя реализация SQL в СУБД SQL Server радикально не отличается от реализаций прочих производителей, вы должны знать, что существуют и другие диалекты языка SQL. В частности, разразработчику с опытом работы с Microsoft Access при знакомстве с СУБД SQL Server придется столкнуться с множеством различий в синтаксисе SQL, которые подробно рассматриваются далее.
11.3. Запрос и изменение информации inode
 Например, размер файла является
Например, размер файла является20.9.2 Запрос get и ответ на него
20.9.2 Запрос get и ответ на него На рис. 20.10 показаны запрос get-request и ответ на него (response), полученные в анализаторе Sniffer компании Network General. Запрос содержит список из пяти переменных, значения которых нужно получить. После каждого идентификатора переменной стоит заполнитель NULL.
20.9.3 Запрос get-next и ответ на него
20.9.3 Запрос get-next и ответ на него Сообщение get-next работает по-другому. Когда отсылается идентификатор объекта, возвращается значение следующего объекта. Например, если послать запрос:SNMP: Object = {1.3.6.1.2.1.5.1.0} (icmpInMsgs.0)SNMP: Value = NULLответ будет содержать имя и значение для следующей
20.9.4 Запрос set
 9.4 Запрос set
Запрос set позволяет записывать информацию в базу данных агента. Формат сообщения очень прост, он выглядит как get-request, но приводит к изменению указанных в запросе переменных. На рис. 20.11 показано отслеживание запроса set.SNMP: Version = 0SNMP: Community = xyzSNMP: Command = Set requestSNMP:
9.4 Запрос set
Запрос set позволяет записывать информацию в базу данных агента. Формат сообщения очень прост, он выглядит как get-request, но приводит к изменению указанных в запросе переменных. На рис. 20.11 показано отслеживание запроса set.SNMP: Version = 0SNMP: Community = xyzSNMP: Command = Set requestSNMP:Делаем запрос в поисковой системе
Делаем запрос в поисковой системе Начнем с простого примера. Откроем http://www.yandex.ru и в поисковой строке введем любой запрос, например новости пенсионной реформы, нажмем кнопку Найти, которая располагается справа от поисковой строки (рис. 3.20). Рис. 3.20. Поисковая система
Уточняем запрос в поисковой системе
Уточняем запрос в поисковой системе Скажем, вы решили приобрести мультиварку, о которой много уже наслышаны и о которой давно мечтали. Если указать в поисковой строке только одно слово мультиварка, то в выдаче окажется 13 миллионов ответов, где будут присутствовать ссылки
Запрос на удаление записей
Запрос на удаление записей
Базы данных не только используются по прямому назначению; часто возникает необходимость произвести в них некоторые вспомогательные, служебные операции.
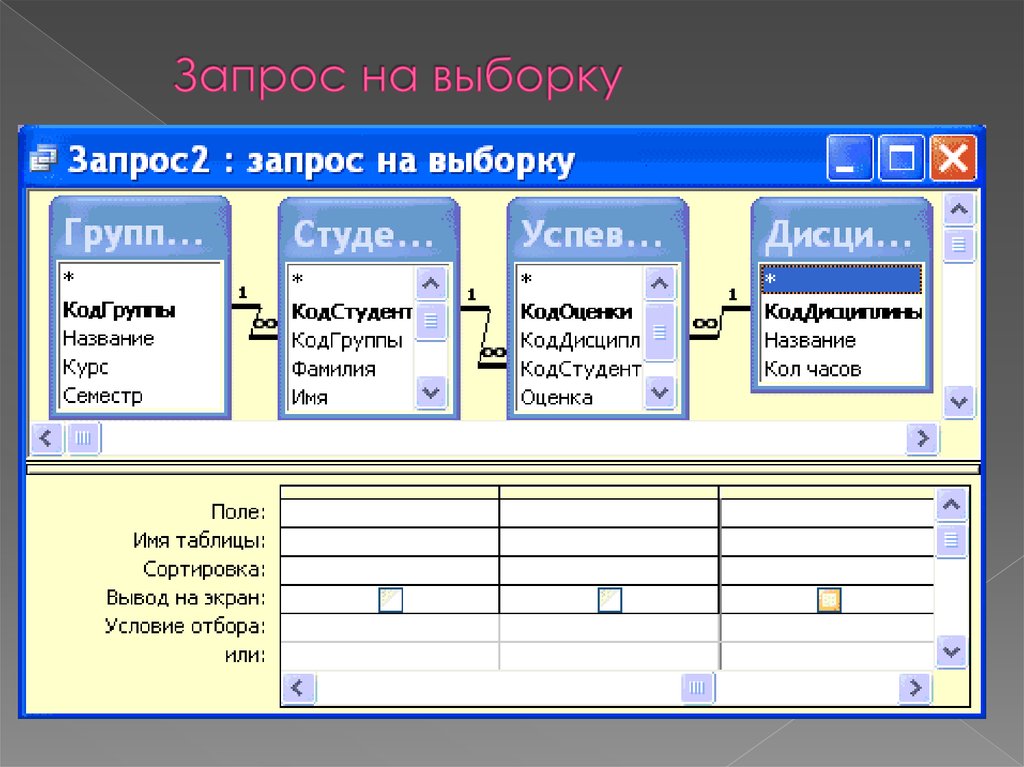
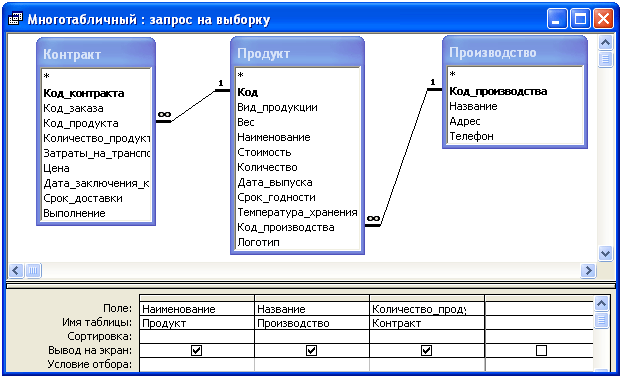
Перекрестный запрос
Перекрестный запрос Перекрестные запросы позволяют подсчитывать данные по двум и более переменным. В ситуациях, подобных нашей, перекрестные запросы компактнее, чем обычные.Как правило, при перекрестном запросе первый столбец получаемой в результате таблицы
АВАР/4 Запрос
АВАР/4 Запрос Конечные пользователи могут создавать простые отчеты с помощью АВАР/4 Query. С помощью удобного интерфейса пользователь может указать область или предмет, который его интересует, а также соответствующие таблицы, желаемые поля и оформление списка. Система
Аутентификация «запрос-ответ»
Аутентификация «запрос-ответ»
Как показано на рис. 2.2, сервер генерирует случайный запрос и отправляет его пользователю А [208]. Вместо того чтобы в ответ отправить серверу пароль, пользователь А шифрует запрос при помощи ключа, известного только ему самому и серверу.
2.2, сервер генерирует случайный запрос и отправляет его пользователю А [208]. Вместо того чтобы в ответ отправить серверу пароль, пользователь А шифрует запрос при помощи ключа, известного только ему самому и серверу.
Неявный запрос на базе времени
Что такое база данных и SQL. Как работают с базами и что в них хранят
Если сказать упрощённо, то база данных — это среда, в которой существуют таблицы с данными. Если вы когда-нибудь работали в офисной программе «Excel», в которой можно делать таблицы, то считайте что работали с базой данных.
В базах данных сайтов могут содержаться таблицы, в которых может быть записано всё что угодно:
- данные новостей, которые опубликованы на сайте
- данные пользователей, которые зарегистрированы на сайте
Продемонстрируем типичную таблицу из базы данных. Пускай эта таблица будет называться «Пользователи»:
+--------------------+ | Пользователи | +--------------------+ | Имя | Любимая еда | +------+-------------+ | Мышь | Сыр | +------+-------------+ | Кот | Молоко | +------+-------------+
Как можно заметить, это обычная таблица. Но в таком виде на сайте её увидеть нельзя. Сайт делает запрос к ней с помощью специального языка, который называется SQL (Structured Query Language — «язык структурированных запросов»). Эти запросы возвращают массив строк, которые подходят под параметр запроса. Разберём далее логику запросов.
Разберём далее логику запросов.
Представьте, что необходимо получить из примера выше все данные таблицы и вывести их на экран. Тогда нужно сделать запрос к базе данных на языке SQL:
SELECT 'Имя пользователя', 'Любимая еда' FROM 'Пользователи';
Как можно догадаться из этой строчки, к базе данных будет сделан запрос на получение данных. Об этом говорит слово SELECT, который переводится как «ВЫБРАТЬ». После слова SELECT стоят названия двух столбцов, значение которых необходимо получить из базы данных. Если название столбца не указать, то его значение не будет получено. Можно написать нужные столбцы через запятую, как это сделано в примере, а если нужно вывести все, то можно просто поставить значок звёздочки *.
Последняя часть запроса содержит слово FROM, которое дословно переводится как «из». После этого слова стоит таблица ИЗ которой надо получить данные.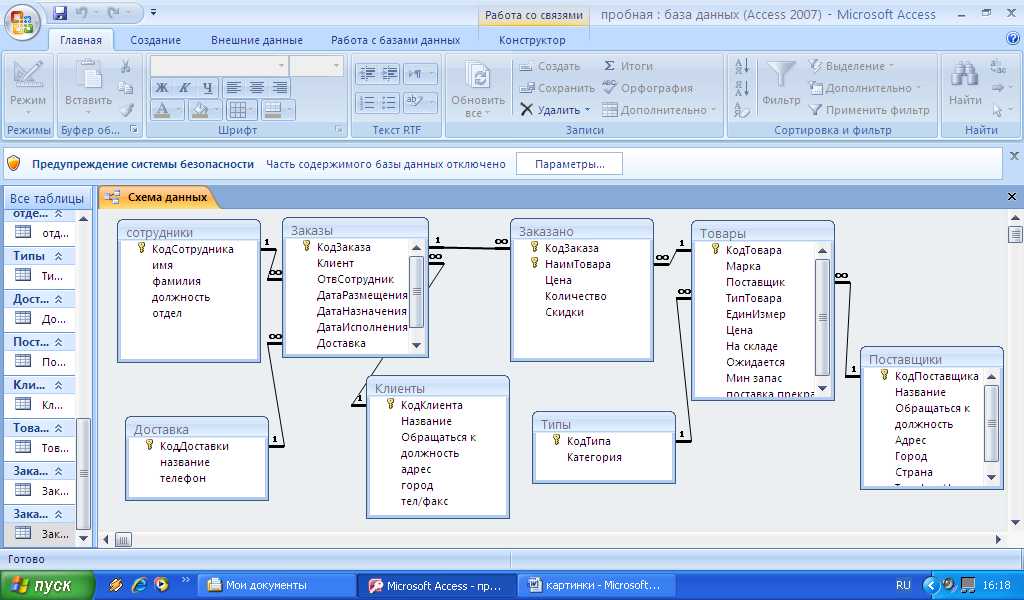
Пример SQL запроса, который приведён выше, сильно утрирован для большей наглядности и простоты. Потому что в базах данных крайне нежелательно создавать таблицы с кириллическими названиями таблиц и столбцов. А ещё названия столбцов и самой таблицы нужно заключать не в одинарную кавычку ‘ , а в наколнную `
Перейдём к обработке результатов выполнения запроса. Если утрировать, то после выполнения запроса из примера выше база данных вернёт такой массив:
Array
(
[0] => Array
(
[Имя] => Мышь
[Любимая еда] => Сыр
)
[1] => Array
(
[Имя] => Кот
[Любимая еда] => Молоко
)
)
После получения этого массива необходимо сделать цикл аналогичный foreach( ) по всем элементам полученного массива. Внутри цикла можно обернуть полученные значения в различные HTML теги, чтобы вывод был красивым, чтобы у страницы сайта был дизайн. Так и происходит взаимодействие сайтов с базами данных.
Внутри цикла можно обернуть полученные значения в различные HTML теги, чтобы вывод был красивым, чтобы у страницы сайта был дизайн. Так и происходит взаимодействие сайтов с базами данных.
Базы данных — это не лучшее хранилище информации. Конёк баз данных — это быстрый поиск информации и вывод с сортировкой. Поэтому базы данных целесообразно использовать далеко не везде. Если же нужно обрабатывать терабайты статичной информации без необходимости поиска и сортировки, то выгоднее использовать использовать простые файлы для хранения информации.
Базы данных используются для сайтов в основном потому, что с их помощью можно организовать уровни доступа к информации. И базы данных большинства сайтов в интернете очень редко когда превышают 10 Гигабайт (считая размеры всех таблиц в базе).
В следующих статьях мы разберём более сложные примеры обращения с базой данных: научимся создавать и удалять таблицы, объединять результаты выборки из нескольких разных таблиц и обновлять данные в таблицах. Если вам не терпится приступить к программированию, то рекомендуем ознакомиться со статьёй «Как сделать запрос из PHP к базе данных».
Если вам не терпится приступить к программированию, то рекомендуем ознакомиться со статьёй «Как сделать запрос из PHP к базе данных».
Была ли эта статья полезна? Есть вопрос?
Закажите недорогой хостинг Заказать
всего от 290 руб
Окно запросов к базе данных
Страница загрузки Окно запросов к базе данных.
Связанные страницы:
- Доступ к базе данных из представлений мониторинга приложений
- Добавление сборщиков базы данных
- Видимость базы данных
- Мониторинг баз данных и серверов баз данных
- Мониторинг производительности базы данных 9 которые занимают больше всего времени в базе данных. Вы можете сравнить веса запросов с другими показателями, такими как время ожидания SQL, чтобы определить SQL, который требует настройки.
- Чтобы просмотреть запросы к базе данных, щелкните имя базы данных.

- Перейдите на вкладку Запросы .
- Просмотр первых N запросов. Это запросы, на выполнение которых ушло наибольшее количество времени базы данных.
- Выберите отображение первых 5, 10, 100 или 200 запросов.
- Щелкните имя столбца, чтобы отсортировать список Query с помощью этого ключа.
Нажмите Фильтровать по состояниям ожидания , чтобы выбрать состояния ожидания для фильтрации списка Query . В отфильтрованном списке отображаются только запросы, вызвавшие выбранные состояния ожидания.
- Установите флажок Группировать похожие , чтобы сгруппировать запросы с одинаковым синтаксисом. Запросы с одинаковым синтаксисом, но разными параметрами предложения IN по-прежнему группируются вместе. Группировка запросов не зависит от регистра. Дважды щелкните группу запросов, чтобы перейти к сведениям о группе для получения дополнительных сведений об этой группе запросов. Группируются только запросы, о которых сообщают более новые агенты; запросы, о которых сообщают старые агенты, могут не отображаться при группировании.
- Поиск определенного запроса путем ввода текста в строку поиска, которая может отображаться в запросе. Это полезно, если вы обнаружили медленный запрос в окне «Медленные вызовы базы данных» мониторинга приложений AppDynamics.
- Дважды щелкните запрос или выберите запрос и щелкните View Query Details , чтобы перейти к Query Details для получения более подробной информации об этом конкретном запросе. Если вы видите сообщение о том, что сведения о запросе недоступны, вам может потребоваться обновить свои разрешения или продлить срок хранения запроса.
Щелкните стрелку вниз рядом с именем коллектора базы данных в верхней части страницы, чтобы просмотреть запросы к базе данных другого коллектора базы данных, выбрав коллектор базы данных из списка или выполнив поиск коллектора базы данных, введя текст в строке поиска, а затем щелкнуть значок обновления, чтобы отобразить только коллекторы баз данных, соответствующие этому критерию поиска.
- Нажмите Действия к:
- Экспортируйте данные в этом окне в файл в формате .csv, который автоматически загружается в указанный вами каталог загрузок.
- Переименуйте выбранный запрос, чтобы его было легче идентифицировать. Обратите внимание, что имя запроса связано с самим запросом. Таким образом, когда срок хранения запроса истекает, и запрос, и имя запроса исчезают.
- Идентификатор запроса : это уникальный идентификатор, присвоенный запросу внутри базы данных.
- Запрос : текст запроса, имя пользовательского запроса или, в случае вызова хранимой процедуры, имя хранимой процедуры. Если у пользователя нет ЛЮБОГО разрешения на просмотр имени хранимой процедуры, вместо имени хранимой процедуры отображается определение хранимой процедуры.
- Прошедшее время : Общее время, затраченное на все выполнения этого запроса. Статистика запросов, такая как количество выполнений, среднее время ответа и истекшее время, доступна для баз данных, поддерживающих индекс запросов, таких как SQL Server, Azure, Oracle, PostgreSQL и DB2. Для баз данных, в которых индекс запроса недоступен, истекшее время выводится из индекса или фаз состояния ожидания.
По умолчанию частота выборки запросов составляет один раз в секунду. Если запрос занимает менее одной секунды и возникает в промежутке времени между экземплярами выборки, его прошедшее время указывается как 0 секунд.
Вы можете настроить частоту выборки, добавив свойство-Ddbagent.для агента базы данных. Сведения о добавлении системных свойств см. в разделе Свойства конфигурации агента базы данных. sampling.interval= - Количество сеансов : (поддерживается для Oracle, MSSQL, PostgreSQL, MySQL, Sybase, DB2, MongoDB и Couchbase) Количество сеансов, в которых выполняется запрос.
- Количество выполнений : (поддерживается для SQL Server, Azure, Oracle, DB2, PostgreSQL) Количество запусков запроса в течение указанного периода времени. Если вы отслеживаете Greenplum, количество выполнений отображается как 0.
- Среднее время ответа (чч:мм:сс) : (поддерживается для SQL Server, Azure, Oracle, DB2, PostgreSQL) Среднее время, необходимое в течение указанного периода времени для ответа на запрос.
- Вес (%) : Процент от общего времени, затраченного на запрос.
- Что такое база данных NoSQL?
- Краткая история баз данных NoSQL
- Особенности базы данных NoSQL
- Типы баз данных NoSQL
- Разница между реляционной СУБД и NoSQL
- Почему NoSQL?
- Когда следует использовать NoSQL?
- Неправильные представления о базе данных NoSQL
- Учебное пособие по запросам NoSQL
- Резюме
- Часто задаваемые вопросы
- Гибкие схемы
- Горизонтальное масштабирование
- Быстрые запросы благодаря модели данных
- Простота использования для разработчиков
- Базы данных документов хранят данные в документах, аналогичных объектам JSON (JavaScript Object Notation). Каждый документ содержит пары полей и значений. Значения обычно могут быть различных типов, включая такие вещи, как строки, числа, логические значения, массивы или объекты.
- Базы данных «ключ-значение» — это более простой тип базы данных, где каждый элемент содержит ключи и значения.
- Хранилища с широкими столбцами хранят данные в таблицах, строках и динамических столбцах.
- Базы данных графов хранят данные в узлах и ребрах. Узлы обычно хранят информацию о людях, местах и вещах, а ребра хранят информацию об отношениях между узлами.
- Гибкость схемы
- Метод масштабирования
- Поддержка для сделок
- Зависимость от сопоставления данных с объектами
- Быстрая гибкая разработка
- Хранение структурированных и полуструктурированных данных
- Огромный объемы данных
- Требования к масштабируемой архитектуре
- Современные парадигмы приложений, такие как микросервисы и потоковая передача в реальном времени
- Реляционные данные лучше всего подходят для реляционных баз данных.
- Базы данных NoSQL не поддерживают транзакции ACID.
- Перейти к Атласу.
- Создайте учетную запись, если вы еще этого не сделали.
- Войдите в Атлас.
- Создать организацию и проект Atlas.
- Создайте бесплатный кластер, выполнив действия, описанные в официальной документации MongoDB.
- Загрузите образец набора данных, следуя инструкциям в официальной документации MongoDB.
- Серия блогов о шаблонах проектирования схемы MongoDB
- Серия блогов о шаблонах дизайна схемы MongoDB
- Бесплатный университетский курс MongoDB: Моделирование данных M320
Перейдите к обозревателю данных (вкладка «Коллекции»), если вы еще этого не сделали. См. официальную документацию MongoDB для получения информации о том, как перейти к обозревателю данных.
На левой панели проводника данных отображается список баз данных и коллекций в текущем кластере. На правой панели проводника данных отображается список документов в текущей коллекции.
Проводник данных отображает список документов в коллекции listingsAndReviews.
Разверните базу данных
sample_mflixна левой панели. Отображается список коллекций базы данных.Выберите коллекцию
фильмов. Представление поиска отображается на правой панели. Отображаются первые двадцать документов результатов.Теперь вы готовы запросить коллекцию
фильмов. Давайте запросим фильм Гордость и предубеждение. В строке запроса введите { title: "Гордость и предубеждение"}и нажмите Применить .
- Гибкие схемы
- Горизонтальное масштабирование
- Быстрые запросы благодаря модели данных
- Простота использования для разработчиков
Доступ к окну запросов к базе данных
Чтобы открыть окно запросов к базе данных:
Функции окна запросов к базе данных
Агент базы данных сообщает обо всех запросах со временем выполнения > 1 секунды. Он фиксирует запросы со временем выполнения <= 1 секунды, только если запрос выполняется во время выборки.
В окне запросов к базе данных вы можете:
 Запросы с одинаковым синтаксисом, но разными параметрами предложения IN по-прежнему группируются вместе. Группировка запросов не зависит от регистра. Дважды щелкните группу запросов, чтобы перейти к сведениям о группе для получения дополнительных сведений об этой группе запросов. Группируются только запросы, о которых сообщают более новые агенты; запросы, о которых сообщают старые агенты, могут не отображаться при группировании.
Запросы с одинаковым синтаксисом, но разными параметрами предложения IN по-прежнему группируются вместе. Группировка запросов не зависит от регистра. Дважды щелкните группу запросов, чтобы перейти к сведениям о группе для получения дополнительных сведений об этой группе запросов. Группируются только запросы, о которых сообщают более новые агенты; запросы, о которых сообщают старые агенты, могут не отображаться при группировании.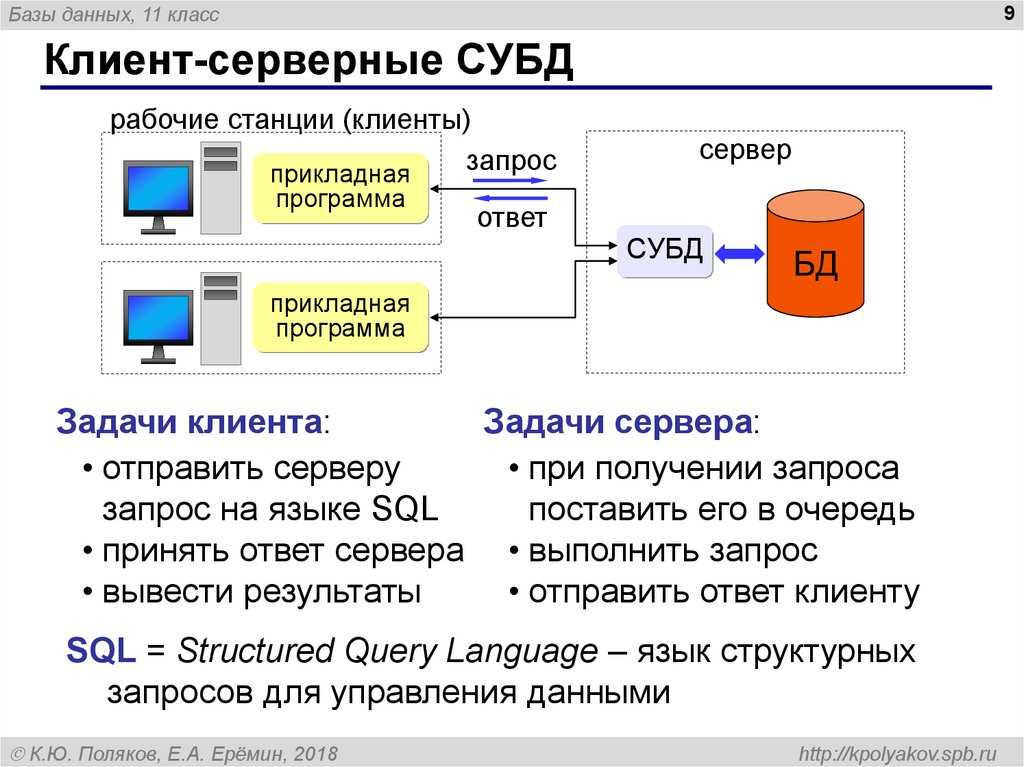
В окне запросов к базе данных можно просмотреть:

Для SQL Server, Azure, Oracle, PostgreSQL и DB2 показатели «Число выполнений», «Среднее время ответа» и «Истекшее время» выводятся из индекса запроса. Когда вы просматриваете запросы с установленным флажком Группа похожих, статистика отражает только те запросы, для которых собрана статистика запросов. Запросы, не имеющие статистики запросов, исключаются из статистических значений.
Для таких баз данных, как MySQL и MongoDB, у которых нет индекса запросов, данные в столбцах «Число выполнений» и «Среднее время ответа» отображаться не будут. Однако для баз данных MySQL и MongoDB можно определить прошедшее время с помощью индекса состояния ожидания. Прошедшее время также можно вывести с помощью индекса состояния ожидания, когда статистика запросов для запросов, выполняемых в базе данных SQL Server, Azure, Oracle, PostgreSQL или DB2, недоступна иным образом. Если статистика запроса недоступна для запроса, выполняемого в базе данных SQL Server, Azure, Oracle, PostgreSQL или DB2, статистика количества выполнений и среднего времени ответа не может быть представлена и помечена дефисом (-). Это означает, что база данных не предоставила статистику по этому запросу в выбранном временном диапазоне.
Если статистика запроса недоступна для запроса, выполняемого в базе данных SQL Server, Azure, Oracle, PostgreSQL или DB2, статистика количества выполнений и среднего времени ответа не может быть представлена и помечена дефисом (-). Это означает, что база данных не предоставила статистику по этому запросу в выбранном временном диапазоне.
 sampling.interval=
sampling.interval= После того, как вы определили операторы, которые потребляют больше всего ресурсов, вы можете углубиться в подробности, которые помогут вам настроить SQL-оператор. Чтобы получить более подробную информацию о запросе, щелкните оператор SQL, а затем нажмите Просмотр сведений о запросе . См. раздел Окно сведений о запросе к базе данных.
Чтобы получить более подробную информацию о запросе, щелкните оператор SQL, а затем нажмите Просмотр сведений о запросе . См. раздел Окно сведений о запросе к базе данных.
Что такое NoSQL? Описание баз данных NoSQL
Базы данных NoSQL (также известные как «не только SQL») не являются табличными базами данных и хранят данные иначе, чем реляционные таблицы. Базы данных NoSQL бывают разных типов в зависимости от их модели данных. Основными типами являются документ, ключ-значение, широкий столбец и график. Они обеспечивают гибкие схемы и легко масштабируются при больших объемах данных и высокой пользовательской нагрузке.
В этой статье вы узнаете что такое база данных NoSQL, почему (и когда!) вы должны ее использовать, и как начать работу.
Обзор
В этой статье рассматриваются:
Что такое база данных NoSQL?
Когда люди используют термин «база данных NoSQL», они обычно используют его для обозначения любой нереляционной базы данных. Некоторые говорят, что термин «NoSQL» означает «не SQL», в то время как другие говорят, что он означает «не только SQL». В любом случае, большинство согласны с тем, что базы данных NoSQL — это базы данных, которые хранят данные в формате, отличном от реляционных таблиц.
Некоторые говорят, что термин «NoSQL» означает «не SQL», в то время как другие говорят, что он означает «не только SQL». В любом случае, большинство согласны с тем, что базы данных NoSQL — это базы данных, которые хранят данные в формате, отличном от реляционных таблиц.
Краткая история баз данных NoSQL
Базы данных NoSQL появились в конце 2000-х, когда резко снизилась стоимость хранения. Прошли те времена, когда нужно было создавать сложную, трудноуправляемую модель данных, чтобы избежать дублирования данных. Разработчики (а не хранилище) становились основной статьей расходов при разработке программного обеспечения, поэтому базы данных NoSQL были оптимизированы для повышения производительности разработчиков.
Поскольку затраты на хранение быстро снижались, объем данных, которые приложения должны были хранить и запрашивать, увеличивался. Эти данные были самых разных форм и размеров — структурированные, полуструктурированные и полиморфные — и заранее определить схему стало практически невозможно. Базы данных NoSQL позволяют разработчикам хранить огромные объемы неструктурированных данных, что дает им большую гибкость.
Базы данных NoSQL позволяют разработчикам хранить огромные объемы неструктурированных данных, что дает им большую гибкость.
Кроме того, популярность Agile Manifesto росла, и инженеры-программисты переосмысливали свои методы разработки программного обеспечения. Они признавали необходимость быстрой адаптации к изменяющимся требованиям. Им нужна была возможность быстро выполнять итерации и вносить изменения в свой программный стек — вплоть до базы данных. Базы данных NoSQL предоставили им такую гибкость.
Популярность облачных вычислений также возросла, и разработчики начали использовать общедоступные облака для размещения своих приложений и данных. Им нужна была возможность распределять данные между несколькими серверами и регионами, чтобы сделать их приложения отказоустойчивыми, масштабировать, а не увеличивать, и интеллектуально распределять данные по географическому положению. Некоторые базы данных NoSQL, такие как MongoDB, предоставляют эти возможности.
Функции базы данных NoSQL
Каждая база данных NoSQL имеет свои уникальные функции. На высоком уровне многие базы данных NoSQL обладают следующими функциями:
На высоком уровне многие базы данных NoSQL обладают следующими функциями:
Ознакомьтесь с преимуществами баз данных NoSQL ? чтобы узнать больше о каждой из функций, перечисленных выше.
Типы баз данных NoSQL
Со временем появилось четыре основных типа баз данных NoSQL: базы данных документов, базы данных ключей-значений, хранилища с широкими столбцами и базы данных графов.
Дополнительные сведения см. на странице Общие сведения о различных типах баз данных NoSQL.
Разница между РСУБД и базами данных NoSQL
Несмотря на то, что между реляционными системами управления базами данных (RDBMS) и базами данных NoSQL существует множество различий, одно из ключевых различий заключается в способе моделирования данных в базе данных. В этом разделе мы рассмотрим пример моделирования одних и тех же данных в реляционной базе данных и базе данных NoSQL. Затем мы выделим некоторые другие ключевые различия между реляционными базами данных и базами данных NoSQL.
RDBMS vs NoSQL: пример моделирования данных
Рассмотрим пример хранения информации о пользователе и его увлечениях.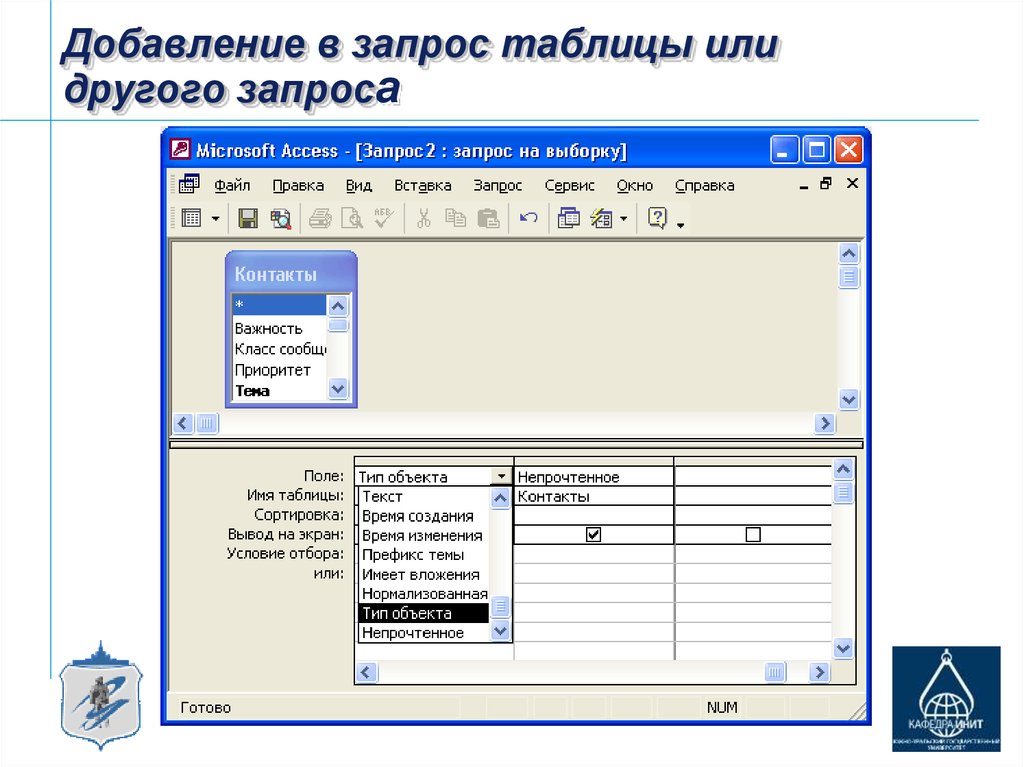 Нам нужно сохранить имя пользователя, фамилию, номер мобильного телефона, город и увлечения.
Нам нужно сохранить имя пользователя, фамилию, номер мобильного телефона, город и увлечения.
В реляционной базе данных мы, скорее всего, создадим две таблицы: одну для пользователей и одну для хобби.
Пользователи
| ID | имя | фамилия | сотовый | город |
|---|---|---|---|---|
| 1 | Leslie | Yepp | 8125552344 | Pawnee |
Hobbies
| ID | user_id | hobby |
|---|---|---|
| 10 | 1 | scrapbooking |
| 11 | 1 | Еда вафли |
| 12 | 1 | Работа | . таблицу нужно будет соединить вместе. Модель данных, которую мы разрабатываем для базы данных NoSQL, будет зависеть от типа выбранной нами базы данных NoSQL. {
"_id": 1,
"first_name": "Лесли",
"last_name": "Да",
"ячейка": "8125552344",
"город": "Пауни",
"хобби": ["скрапбукинг", "поедание вафель", "работа"]
} Чтобы получить всю информацию о пользователе и его увлечениях, из базы данных можно получить один документ. Соединения не требуются, что приводит к более быстрым запросам. Чтобы увидеть более подробную версию этого примера моделирования данных, прочитайте Сопоставление терминов и понятий из SQL в MongoDB. Другие различия между РСУБД и реляционными базами данныхХотя в приведенном выше примере показаны различия в моделях данных между реляционными базами данных и базами данных NoSQL, существует много других важных различий, в том числе: Дополнительные сведения о различиях между реляционными базами данных и базами данных NoSQL см. Почему NoSQL?Базы данных NoSQL используются практически во всех отраслях. Варианты использования варьируются от крайне важных (например, хранение финансовых данных и медицинских записей) до более забавных и легкомысленных (например, хранение показаний IoT из умного кошачьего туалета). В следующих разделах мы рассмотрим, когда следует использовать базу данных NoSQL, и распространенные заблуждения относительно баз данных NoSQL. Когда следует использовать NoSQL?При принятии решения о том, какую базу данных использовать, лица, принимающие решения, обычно обнаруживают, что один или несколько из следующих факторов приводят их к выбору базы данных NoSQL: Дополнительные сведения о причинах, перечисленных выше, см. Неправильные представления о базах данных NoSQLЗа прошедшие годы в сообществе разработчиков распространилось множество неправильных представлений о базах данных NoSQL. В этом разделе мы обсудим два наиболее распространенных заблуждения: Чтобы узнать больше о распространенных заблуждениях, прочитайте «Все, что вы знаете о MongoDB, неверно». Заблуждение: данные отношений лучше всего подходят для реляционных баз данныхРаспространенным заблуждением является то, что базы данных NoSQL или нереляционные базы данных плохо хранят данные о взаимосвязях. Базы данных NoSQL могут хранить данные об отношениях — просто они хранят их иначе, чем реляционные базы данных. На самом деле, по сравнению с реляционными базами данных, многие считают моделирование данных взаимосвязей в базах данных NoSQL проще, чем в реляционных базах данных, поскольку связанные данные не нужно разбивать между таблицами. Заблуждение: базы данных NoSQL не поддерживают транзакции ACIDДругое распространенное заблуждение состоит в том, что базы данных NoSQL не поддерживают транзакции ACID. Некоторые базы данных NoSQL, такие как MongoDB, действительно поддерживают транзакции ACID. Обратите внимание, что способ моделирования данных в базах данных NoSQL может устранить необходимость в транзакциях с несколькими записями во многих случаях использования. Рассмотрим предыдущий пример, в котором мы хранили информацию о пользователе и его увлечениях как в реляционной базе данных, так и в базе данных документов. Чтобы обеспечить совместное обновление информации о пользователе и его увлечениях в реляционной базе данных, нам потребуется использовать транзакцию для обновления записей в двух таблицах. Чтобы сделать то же самое в базе данных документов, мы могли бы обновить один документ — транзакция с несколькими записями не требуется. Руководство по запросам NoSQLСуществует множество баз данных NoSQL. Сегодня мы попробуем MongoDB, самую популярную в мире базу данных NoSQL по версии DB-Engines. В этом руководстве вы загрузите образец базы данных и научитесь делать запросы к ней, не устанавливая ничего на свой компьютер и ничего не платя. Аутентификация в MongoDB AtlasСамый простой способ начать работу с MongoDB — MongoDB Atlas. Atlas — это полностью управляемая база данных как услуга MongoDB. У Atlas есть бессрочный бесплатный уровень, который вы будете использовать сегодня. Для получения дополнительной информации о том, как выполнить описанные выше шаги, посетите официальную документацию MongoDB по созданию учетной записи Atlas. Создайте кластер и базу данных Кластер — это место, где вы можете хранить свои базы данных MongoDB. Когда у вас есть кластер, вы можете начать хранить данные в Atlas. Вы можете вручную создать базу данных в Atlas Data Explorer, в MongoDB Shell, в MongoDB Compass или с помощью вашего любимого языка программирования. Вместо этого в этом примере вы импортируете образец набора данных Atlas. Загрузка примера набора данных займет несколько минут. Хотя для этого руководства нам не нужно думать о проектировании базы данных, обратите внимание, что проектирование базы данных и моделирование данных являются основными факторами производительности MongoDB. Узнайте больше о передовых методах моделирования данных в MongoDB: Запрос к базе данных Теперь, когда у вас есть данные в кластере, давайте сделаем запрос! Точно так же, как у вас было несколько способов создать базу данных, у вас есть несколько вариантов запроса к базе данных: в Atlas Data Explorer, в оболочке MongoDB, в MongoDB Compass или с помощью вашего любимого языка программирования. В этом разделе вы будете запрашивать базу данных с помощью Atlas Data Explorer. Это хороший способ начать работу с запросами, так как он не требует настройки. Два документа с названием «Гордость и предубеждение» возвращены. Результаты поиска фильмов с названием «Гордость и предубеждение». Поздравляем! Вы успешно запросили базу данных NoSQL! Продолжить изучение ваших данных В этом руководстве мы лишь поверхностно рассмотрели, что вы можете делать в MongoDB и Atlas. Когда вы будете готовы попробовать более сложные запросы, объединяющие ваши данные, создайте конвейер агрегации. Платформа агрегации — невероятно мощный инструмент для анализа ваших данных. Чтобы узнать больше, пройдите бесплатный университетский курс MongoDB M121 The MongoDB Aggregation Framework. Если вы хотите визуализировать свои данные, ознакомьтесь с диаграммами MongoDB. Диаграммы — это самый простой способ визуализации данных, хранящихся в Atlas и Atlas Data Lake. Диаграммы позволяют создавать информационные панели, заполненные визуализацией ваших данных. РезюмеБазы данных NoSQL предоставляют множество преимуществ, включая гибкие модели данных, горизонтальное масштабирование, молниеносные запросы и простоту использования для разработчиков. Базы данных NoSQL бывают разных типов, включая базы данных документов, базы данных ключей и значений, хранилища с широкими столбцами и базы данных графов. MongoDB — самая популярная в мире база данных NoSQL. Узнайте больше о MongoDB Atlas и попробуйте бесплатный уровень. Хотите узнать больше, теперь у вас есть собственная учетная запись Atlas? Отправляйтесь в Университет MongoDB, где вы сможете пройти бесплатное онлайн-обучение у инженеров MongoDB и получить сертификат MongoDB. Учебники по быстрому запуску — еще одно отличное место для начала; они помогут вам быстро начать работу с вашим любимым языком программирования. Следуйте этому руководству с MongoDB AtlasОцените преимущества использования MongoDB, первоклассной базы данных NoSQL, в облаке.Каковы преимущества NoSQL?Многие базы данных NoSQL имеют следующие преимущества: Ознакомьтесь с преимуществами базы данных NoSQL? Больше подробностей. Что такое окончательная согласованность?Согласованность в конечном итоге является свойством распределенных баз данных. Согласованность в конечном счете гарантирует, что при обновлении базы данных все узлы в распределенной базе данных будут отражать это обновление. Что такое теорема CAP? Теорема CAP утверждает, что распределенная вычислительная система может обеспечить максимум два из следующих трех свойств: согласованность, доступность и устойчивость к разбиению. Для чего используется NoSQL?Базы данных NoSQL используются практически во всех отраслях для самых разных целей. Тип базы данных NoSQL определяет типичный вариант использования. Например, базы данных документов, такие как MongoDB, являются базами данных общего назначения. Базы данных «ключ-значение» идеально подходят для больших объемов данных с простыми поисковыми запросами. Хранилища с широкими столбцами хорошо подходят для случаев использования с большими объемами данных и предсказуемыми шаблонами запросов. Базы данных Graph отлично подходят для анализа и отслеживания взаимосвязей между данными. Дополнительную информацию см. в разделе Общие сведения о различных типах баз данных NoSQL. Что такое база данных NoSQL?База данных NoSQL — это база данных, в которой данные хранятся в формате, отличном от реляционных таблиц. Как написать запрос NoSQL? Каждая база данных NoSQL будет иметь собственный подход к написанию запросов. Трудно ли изучить NoSQL?Нет, базы данных NoSQL несложно изучить. Фактически, многие разработчики считают данные моделирования в базах данных NoSQL невероятно интуитивно понятными. Например, документы в MongoDB сопоставляются со структурами данных в большинстве популярных языков программирования, что делает программирование быстрее и проще. Обратите внимание, что тем, кто прошел обучение и имеет опыт работы с реляционными базами данных, скорее всего, придется немного поучиться, поскольку они приспосабливаются к новым способам моделирования данных в базах данных NoSQL. Является ли JSON NoSQL?Базы данных документов — это тип базы данных NoSQL, в которой данные хранятся в документах JSON или BSON. Какой язык используется для запросов NoSQL? Базы данных NoSQL охватывают множество типов и реализаций. В результате к базам данных NoSQL можно обращаться с помощью различных языков запросов и API. |
 Давайте рассмотрим, как хранить ту же информацию о пользователе и его увлечениях в базе данных документов, такой как MongoDB.
Давайте рассмотрим, как хранить ту же информацию о пользователе и его увлечениях в базе данных документов, такой как MongoDB. на странице Базы данных NoSQL и SQL.
на странице Базы данных NoSQL и SQL. в разделах «Когда использовать базы данных NoSQL» и «Изучение примеров баз данных NoSQL».
в разделах «Когда использовать базы данных NoSQL» и «Изучение примеров баз данных NoSQL». Модели данных NoSQL позволяют вкладывать связанные данные в единую структуру данных.
Модели данных NoSQL позволяют вкладывать связанные данные в единую структуру данных.
 В этом разделе вы создадите бесплатный кластер.
В этом разделе вы создадите бесплатный кластер.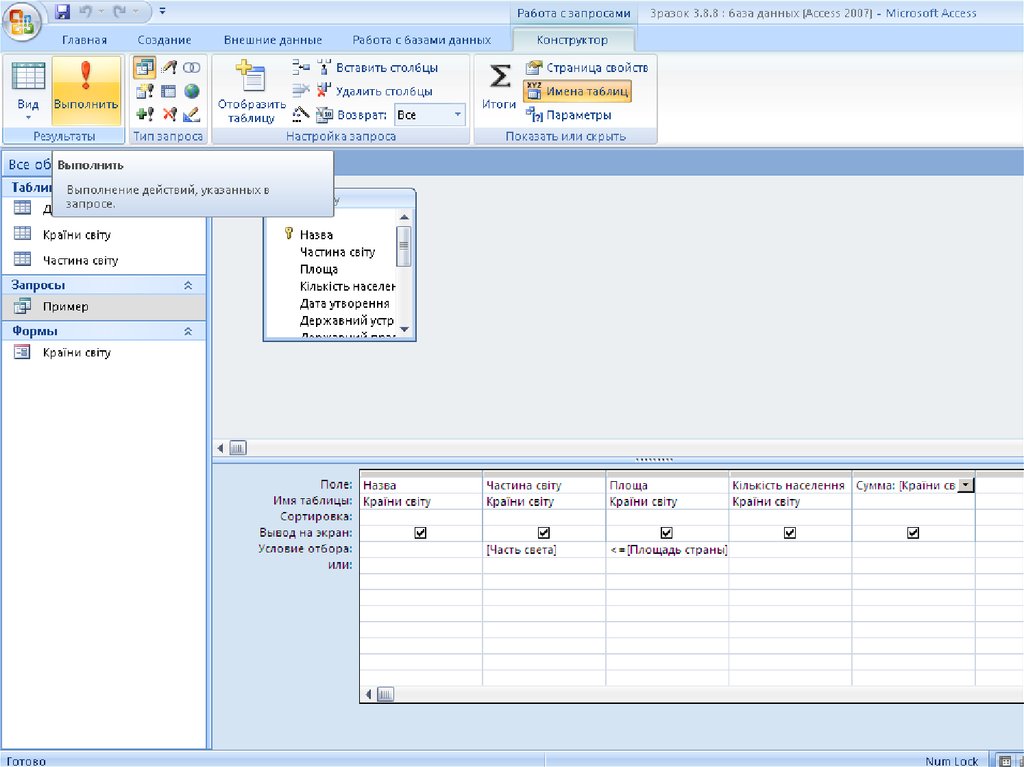
 Давайте запросим фильм Гордость и предубеждение. В строке запроса введите
Давайте запросим фильм Гордость и предубеждение. В строке запроса введите 

 Посетите интерактивную документацию MongoDB, чтобы узнать больше о запросах к базе данных MongoDB.
Посетите интерактивную документацию MongoDB, чтобы узнать больше о запросах к базе данных MongoDB.