Моделирование данных · Loginom Wiki
Моделирование данных заключается в определении и анализе требований к данным, необходимым для поддержки бизнес-процессов в компании.
Требования к данным первоначально записываются в виде концептуальной модели, которая представляет собой набор спецификаций данных и используется для обсуждения начальных требований заинтересованными сторонами. Затем концептуальная модель преобразуется в логическую, которая описывает структуры данных. Реализация одной концептуальной модели может потребовать использования нескольких логических моделей. И наконец, последний шаг в моделировании данных — преобразование логической модели в физическую. Моделирование данных определяет не только элементы данных, но также их структуры и отношения между ними.
Главная цель моделирования данных — дать возможность компании управлять ими как ресурсом. К основным задачам моделирования данных относятся:
- помочь бизнес-аналитикам и IT-специалистам использовать единую информационную модель компании при решении стоящих перед ними задач;
- осуществлять интеграцию ресурсов в информационную систему компании;
- разрабатывать и проектировать базы и хранилища данных.
Окончательных, завершенных моделей данных не существует, поскольку они должны изменяться вместе с изменениями в бизнесе. Для хранения различных версий модели данных обычно используют специальные репозитории, из которых модель можно извлекать, расширять и редактировать.
Различают два уровня моделирования данных: стратегический и аналитический:
- Стратегическое моделирование — это часть создания стратегии информационной системы компании, которая определяет ее общее представление и архитектуру.
- Аналитическое моделирование — моделирование данных в процессе системного анализа, когда логические модели данных создаются как часть разработки новых баз данных.
Существует ряд проблем, которые необходимо учитывать при моделировании данных:
- Бизнес-правила, специфичные для определенного периода или процесса, жестко фиксируются в модели данных. Это означает, что даже небольшие изменения в бизнесе ведут к значительным изменениям в информационной системе компании. Поэтому модель данных должна быть достаточно гибкой, чтобы изменения в бизнесе могли быть отражены в ней относительно быстро и эффективно.
- Типы сущностей в концептуальной модели компании не идентифицируются или идентифицируются неправильно. Это может привести к репликации данных и соответствующим затратам. Поэтому определения данных должны быть как можно более явными и понятными, чтобы минимизировать неправильное толкование и дублирование.
- Модели данных для различных подсистем информационной системы компании могут существенно различаться. В результате для обмена данными между ними потребуются сложные интерфейсы, затраты на создание и поддержку которых могут достигать 25-70% от стоимости системы в целом. Поэтому модели данных должны разрабатываться с учетом минимизации стоимости организации их взаимодействия.
- Игнорирование стандартов, которые обеспечивают соответствие моделей данных бизнес-потребностям, может привести к тому, что данные нельзя будет передать в электронном виде клиентам, поставщикам или партнерам, потому что структура и форматы данных не были стандартизированы.
Как стать моделью: советы и инструкция
Многие девушки во всем мире, листая гламурные журналы, мечтают оказаться на одной из обложек популярного издания. Для девушек, которые всерьез задумались о том, чтобы попробовать свои силы в этом бизнесе, стоит заранее ознакомиться с базовыми требованиями. Они увеличивают шанс успешного прохождения кастинга. Давайте узнаем, как стать моделью, с чего стоит начать и какие советы помогут достичь вершин Клаудии Шиффер и Синди Кроуфорд.
Фото: pixabay.com: UGC
Как стать моделью: с чего начать?
Перед началом стоит тщательно взвесить свое решение. Понятие «работа моделью» формируется из двух слов. Модель вызывает ассоциации со вспышками фотокамер, восхищением людей и пристальным общественным вниманием. Но многие забывают, что это только одна сторона медали. Работа — основная составляющая, без которой невозможно достичь подиумных выступлений и восхищения. Девушкам, мечтающим о карьере модели, нужно настроиться на ежедневный труд, постоянные кастинги и поддержание идеальной внешности.
Вот советы, которые дадут понять, как стать моделью «Шанель» и других крупных брендов:
- Реальная оценка собственной внешности.
Необходимо трезво проанализировать собственные параметры, ведь в модельном бизнесе существуют определенные нормы. Низкий рост означает отсутствие карьеры. Тело должно быть красивым, подтянутым, без крупных и заметных шрамов, татуировок. Волосы создают характерное отличие от других моделей, особенно если они длинные, натурального оттенка, не посечены и не повреждены. Обязательно следите за состоянием ногтей и пяток.
- Моральная подготовка.
Когда внешние показатели в норме, переходим к оценке внутреннего состояния. Для модели очень важны целеустремленность, трудолюбие, коммуникабельность, скромность и способность преподнести себя в наилучшем свете. Вы будете получать много отказов в начале, поэтому важно не сдаваться, адекватно воспринимать критику и двигаться только вперед.
- Модельная школа.
Именно в этом заведении вы получите все знания о том, как правильно держать осанку, краситься (это касается и парней), ухаживать за телом и волосами. Учителя расскажут об основах дефиле и прочих важных вещах в модельном бизнесе.
Фото: pixabay.com: UGC
Как стать моделью парню или девушке? Начать карьеру стоит с подготовки портфолио. Первым делом подготовьте 2–3 фотографии, которые покажут вас со всех ракурсов и представят агентам многогранность. На этих снимках обязательно продемонстрируйте игру эмоций:
- красивую улыбку;
- расслабленность;
- ярость;
- злость;
- радость.
Девушкам фотографироваться нужно на однотонном фоне в купальнике, черных туфлях на высокой шпильке, а парням в нижнем белье и майке или шортах. Снимки должны подчеркнуть естественную красоту и выгодные стороны.
Помните, что перед началом работы моделью стоит избегать эротических фотосессий. Это поможет в дальнейшем сохранить карьеру, чтобы пикантные снимки не использовали против вас.
Фото: pixabay.com: UGC
Далее переходим к модельным агентствам, благодаря которым девушки получают возможность сотрудничать с известными брендами. Тут стоит тоже знать основные правила подбора. Выбираем модельное агентство по таким критериям:
- обращаемся только в те компании, которые присутствуют на рынке больше двух лет;
- ищем реальные отзывы об услугах агентства;
- изучаем базу данных манекенщиц и их успехи в модельном бизнесе;
- проверяем, с какими брендами сотрудничают представители агентства, если нет ни одного известного, стоит отказаться от работы;
- если изначально от вас требуют заплатить деньги за какой-то курс для обучения — этот вариант сразу вычеркиваем из списка;
- агент обещает великую славу и всемирную популярность — еще один повод отказаться от работы с такими людьми;
- нормальные компании не выставляют счета за свои услуги заранее, но берут конкретно оговоренный процент с заработков модели.
Обращайтесь только в проверенные и рейтинговые модельные агентства, которые зарекомендовали себя с положительной стороны и имеют большой опыт работы. В дальнейшем показываем портфолио в выбранной компании и ждем результатов. В случае успешного прохождения представители компании сами свяжутся с вами.
Читайте также: Неделя моды в Париже: итоги, чем удивляли дизайнеры
Как стать моделью: необходимые параметры и навыки
Поговорим более детально о требованиях и критериях, которые помогут ответить на вопрос: «Как стать моделью?». Параметры, играющие важную роль при приеме на работу:
- рост;
- возраст;
- вес;
- объем груди.
Фото: pixabay.com: UGC
Хотите стать моделью мирового уровня? В этом бизнесе имеются правила, которые необходимо соблюдать с максимальной строгостью. Давайте определимся с будущей специализацией и параметрами:
- Подиумная модель.
Идеальное описание таких девушек есть в романе Владимира Набокова «Лолита»: «мальчишеские бедра» и «полуразвитая грудь». Как стать моделью «Гуччи» и других крупных брендов? Основополагающие параметры для девушки 90–60–90 сменились на 86–61–86. Один лишний сантиметр — потеря работы. Именно подобный случай произошел с моделью Коко Роша. Девушка не смогла вписаться в нулевой размер, поэтому ей пришлось сойти с дистанции.
Вторым важным параметром является рост. Он должен быть в диапазоне от 175 до 185 см. Практически половина разрушенных карьер связана с ростом. Но даже тут есть исключения, например, Кейт Мосс со своими 169 см показывает себя на высоком уровне.
- Бельевая модель.
Девушки из Victoria’s Secret — идеальные представительницы этой категории. Как стать моделью в США и Европе? Параметры могут не соответствовать приведенным выше. Например, тут допускают объем груди 86–91, талии —58–63 и бедер — 86–90. Главное правило — красивая фигура: не сильное худощавое и не перекаченное тело. Возрастной моделью становятся только с 21 года.
В этой категории открываются возможности для девушек с более аппетитными формами. В модели берут с размером одежды от 46 до 54.
Оптимальный вариант для девушек, которые выделяются одной частью тела. Обычно в бизнесе требуются обладательницы красивых и ухоженных рук, волос, ног, мочек ушей. Эти части тела используют в рекламных кампаниях косметики, часов, обуви и дорогих ювелирных изделий.
Основное правило — красивая и широкая улыбка. Выбор отдают доброжелательным и терпеливым девушкам.
- Гламурная модель.
К этой категории относят девушек возрастом от 18 до 25 лет, которые должны позировать в бикини или даже без для мужских журналов. Основные требования: объем груди — 86–91, талия — 56–61, бедра — 86–91.
Отдельно стоит рассмотреть возраст моделей. Идеальным считается, когда девушке 13–15 лет. Это самый подходящий возраст для старта, ведь главным товаром в модельной индустрии является молодость. Когда девушке за 20, ее шансы автоматически сокращаются вдвое. Далеко не каждое модельное агентство будет с вами работать. Однако если присутствует харизма, выдающаяся внешность и красивая фигура — эти параметры сыграют на руку. Поэтому даже во взрослом возрасте не стоит сдаваться.
В модельной индустрии существует младшая возрастная категория, куда входят дети до 13 лет. В этой сфере другие правила, так как девочки и мальчики не могут совершать перелеты за границу и постоянно работать, как взрослые модели. Обычно агентства подписывают контракты с детьми на будущее. Они наблюдают за их развитием, изменениями в фигуре и внешности. Если модели оправдывают ожидания, то компания способна поднять крупную сумму денег. Все зависит исключительно от дальновидности агента.
Как стать моделью: советы
Фото: pixabay.com: UGC
Модель — интересная и сложная профессия. Все претенденты проходят жесткие кастинги, где представители агентств смотрят на внешность, фигуру и харизму. Чтобы получить мировую славу и понять, как стать моделью в Корее, Европе, Австралии и США, ознакомьтесь с советами специалистов:
- Учим иностранные языки.
То, что модель должна знать английский на разговорном уровне — даже не обсуждается. Иначе у вас не получится прочесть условия контракта с зарубежным работодателем или понять, что от вас хочет фотограф.
- Разбираемся в основах модной индустрии.
Моделям не нужно заниматься созданием одежды, но они должны знать, что такое оверсайз или кюлоты. Для получения этих навыков можно отравиться в модельную школу или самостоятельно изучить книги об истории моды. Регулярно проверяйте специализированные порталы, чтобы постоянно быть в курсе современных тенденций.
- Следим за тем, что едим.
Правильное питание — основа сохранения стройной фигуры. Убираем из рациона сладости, мучные изделия и алкоголь. Это касается даже тех девушек, которые планируют стать моделью плюс-сайз. Для снимков и показов наличие целлюлита и обвисшей кожи — нонсенс. Модель должна иметь красивую здоровую кожу, ухоженные волосы и отличное самочувствие, чтобы выкладываться на 100%.
- Регулярно посещаем фитнес-центр.
Систематические физические упражнения сделают тело идеальным и повысят здоровье. Спорт поможет воспитать в себе выносливость, целеустремленность и силу воли. Вы поймете, о чем мы говорим, если будете каждый день вставать в 6 утра и отправляться на пробежку. Специалисты советуют обратить внимание на занятия йогой, стретчингом или танцами. Эти виды фитнеса научат девушку быть более грациозной и женственной.
- Приводим в порядок зубы.
Устраняем имеющиеся проблемы, если они есть, а потом регулярно посещаем стоматолога для контроля общего состояния. На подиуме моделям не нужно выражать эмоции, а вот для фотосессий от вас потребуется улыбаться, злиться и даже кричать.
- Изучаем базовые правила этикета.
Научитесь грамотно себя вести и преподносить во время кастингов, на публике или светском мероприятии. Какой бы красотой не обладала модель, если она не может адекватно поздороваться, поддержать беседу или уточнить график работы — никто не будет с ней работать.
- Выглядим естественно.
Моделям нужно с особой осторожностью относиться к украшению собственного тела. В 2020 году в моде остается натуральная красота и естественность, а такие черты очень трудно увидеть за обилием накладных ресниц, волос или татуировок. Главная задача модели — предстать в образе сказочной феи, которая умывается росой, чтобы оставаться свежей и нежной.
Придерживайтесь этих правил, чтобы стать настоящей моделью, с которой приятно работать. Вас не пугают сложности, присутствующие на пути в этой индустрии? Вы не боитесь критики? Подходите по всем параметрам? Тогда не упустите свой шанс. Станьте самой популярной моделью не только у себя в стране, но и во всем мире!
Читайте также: Модные туфли 2020: какие модели в моде
Модели жизненного цикла программного обеспечения / Хабр
Здравствуйте, уважаемые хабровчане! Думаю будет кому-то интересно вспомнить какие модели разработки, внедрения и использования программного обеспечения существовали ранее, какие модели в основном используются сейчас, зачем и что это собственно такое. В этом и будет заключаться моя небольшая тема.Собственно, что же такое жизненный цикл программного обеспечения — ряд событий, происходящих с системой в процессе ее создания и дальнейшего использования. Говоря другими словами, это время от начального момента создания какого либо программного продукта, до конца его разработки и внедрения. Жизненный цикл программного обеспечения можно представить в виде моделей.
Эти модели можно разделить на 3 основных группы:
- Инженерный подход
- С учетом специфики задачи
- Современные технологии быстрой разработки
Модель кодирования и устранения ошибок
Совершенно простая модель, характерная для студентов ВУЗов. Именно по этой модели большинство студентов разрабатывают, ну скажем лабораторные работы.
- Постановка задачи
- Выполнение
- Проверка результата
- При необходимости переход к первому пункту
Каскадная модель жизненного цикла программного обеспечения (водопад)
Алгоритм данного метода, который я привожу на схеме, имеет ряд преимуществ перед алгоритмом предыдущей модели, но также имеет и ряд весомых недостатков.
Преимущества:
- Позволяет оценивать качество продукта на каждом этапе
- Отсутствие обратных связей между этапами
- Не соответствует реальным условиям разработки программного продукта
Каскадная модель с промежуточным контролем (водоворот)
Данная модель является почти эквивалентной по алгоритму предыдущей модели, однако при этом имеет обратные связи с каждым этапом жизненного цикла, при этом порождает очень весомый недостаток: 10-ти кратное увеличение затрат на разработку. Относится к первой группе моделей.
V модель (разработка через тестирование)
Данная модель имеет более приближенный к современным методам алгоритм, однако все еще имеет ряд недостатков. Является одной из основных практик экстремального программирования.
Модель на основе разработки прототипа
Данная модель основывается на разработки прототипов и прототипирования продукта.
Прототипирование используется на ранних стадиях жизненного цикла программного обеспечения:
- Прояснить не ясные требования (прототип UI)
- Выбрать одно из ряда концептуальных решений (реализация сцинариев)
- Проанализировать осуществимость проекта
- Горизонтальные и вертикальные
- Одноразовые и эволюционные
- бумажные и раскадровки
Вертикальные прототипы — проверка архитектурных решений.
Одноразовые прототипы — для быстрой разработки.
Эволюционные прототипы — первое приближение эволюционной системы.
Модель принадлежит второй группе.
Спиральная модель жизненного цикла программного обеспечения
Спиральная модель представляет собой процесс разработки программного обеспечения, сочетающий в себе как проектирование, так и постадийное прототипирование с целью сочетания преимуществ восходящей и нисходящей концепции.
Преимущества:
- Быстрое получение результата
- Повышение конкурентоспособности
- Отсутствие регламентации стадий
Большое спасибо за внимание!
Концептуальная модель базы данных: наглядная диаграмма связи
Содержание статьи:
Концептуальная модель базы данных это
Концептуальная модель базы данных это некая наглядная диаграмма, нарисованная в принятых обозначениях и подробно показывающая связь между объектами и их характеристиками. Создается концептуальная модель для дальнейшего проектирования базы данных и перевод ее, например, в реляционную базу данных. На концептуальной модели в визуально удобном виде прописываются связи между объектами данных и их характеристиками.
Принятые определения в концептуальной базе данных
Для единообразия программирования баз данных введены следующие понятия для концептуальных баз данных:
- Объект или сущность. Это фактическая вещь или объект (для людей) за которой пользователь (заказчик) хочет наблюдать. Например, Иванов Иван Иванович;
- Атрибут это характеристика объекта, соответствующая его сущности. Например. Задаем себе вопрос: Какую информацию нужно хранить об Иванове Иване Ивановиче? Ответы на этот вопрос и будут атрибуты объекта Иванов Иван Иванович;
- Третье понятие в проектировании концептуальной базы данных это
Лексически более правильно говорить связь между объектами КБД и отношения между сущностями КБД (концептуальная база данных), но встретить можно самые различные сочетания сущности, объекта, связи и отношения (огрехи переводов).
Концептуальная модель базы данных условные обозначенияКонцептуальная модель базы данных: принятые графические обозначения
Диаграмма сущность/отношения (объект/связь) называют ER-диаграммой или EDR (entity-relationship diagram). Сама модель сущность-связь была предложена профессором Peter Pin-Shen Chen (Питер Чен) в 1976 году. Правила написания и условные обозначения ER-диаграммы называют нотацией. Распространены две основные нотации ER-диаграмм:
- Нотация Питера Чена;
- Нотация Gordon Everest (Гордона Эверста). Под назаванием Crow’s Foot или Fork (вилка).
Обозначения ER-диаграммы по Питеру Чену
Чен предложил и это приняли следующие условные обозначения для ER-диаграмм:
- Сущность или объект обозначать прямоугольником;
- Отношения обозначать ромбом;
- Атрибуты объектов, обозначаются овалом;
- Если сущность связана с отношением, то их связь обозначается прямой линией со стрелкой. Необязательная связь обозначается пунктирной линией. Мощная связь обозначается двойной линией.
Каждый атрибут может быть связан с одним объектом (сущностью).

Нотация Gordon Everest
Gordon Everest ввел новое обозначение связей, которые получили название вилка или воронья лапа. Также он ввел, что объект должен обозначаться прямоугольником с названием типа объекта в виде имени существительного внутри прямоугольника. Причем, это имя должно быть уникальным в пределах создаваемой базы данных.
Атрибуты не выделяются в отдельную фигуру, а вписываются в прямоугольник объекта именем существительным с уточняющим словом.
Связь между объектами обозначается прямой линией. Множественные связи обозначаются вилкой на конце. Сама связь подписывается глаголом, типа «Включает» или «Принадлежит».
 концептуальная модель базы данных ERD Fork
концептуальная модель базы данных ERD ForkДополнения
Атрибуты в ER диаграмме, могут иметь свои собственные атрибуты (композитный) атрибут.
Как нарисовать ER-диаграмму-советы
Простую ER диаграмму нарисовать достаточно просто. Другое дело насыщенная, объемная ER диаграмма. Ниже приведены некоторые советы, которые помогут вам построить эффективные ER схемы:
- Определите все объекты в данной системе и определите отношения между этими объектами;
- Объект должен появиться только один раз в определенном месте схемы;
- Определите точное и подходящее имя для каждого объекта, атрибута и отношений в диаграмме. Выберите простые и понятные слова. Условия, которые просты и знакомы всегда побеждает смутные, технические звучащие слова. Для объектов имена существительные, для связей глаголы (можно с пояснениями). Не забываем про уникальность имен объектов;
- Удалите неявные, избыточные или ненужные отношения между объектами;
- Никогда не подключайте отношения к другим отношениям;
- Используйте цвета, чтобы классифицировать однотипные объекты или выделить ключевые области в диаграмме.
©WebOnTo.ru
Другие статьи раздела: СУБД
Поделиться ссылкой:
Похожие статьи
Как стать моделью: модельные агенствта, параметры, гонорары
Еще 10 лет назад на вопрос «Какими данными нужно обладать, чтобы стать моделью?» был конкретный ответ: «Высокий рост (желательно от 175 см), длинные ноги, соответствие параметрам». Сегодня все изменилось — в мире, где одновременно можно называться моделью, инфлюенсером и активистом, строгие рамки уже неактуальны.
Благодаря социальным сетям модель стала не просто лицом с обложки модного журнала или «вешалкой для одежды». Теперь это самодостаточная личность с собственной историей и мнением. Внешние данные, считающиеся синонимом красоты, для этой профессии порой не имеют никакого значения. Возьмем, например, топ-модель и активистку Адвоа Абоа, которая стал обладательницей награды «Модель года» 2017 от Британского модного совета. Ее изюминка — необычная внешность вкупе с непростой историей о борьбе с зависимостями и депрессией.
Чтобы понять, какие требования предъявляет к кандидатам модельная индустрия сегодня, как начать карьеру и чего ожидать от моделинга, Vogue встретился с одним из руководителей популярного британского модельного агентства Models 1 Ханной Джоуит и топ-моделью Алексиной Грэм.
С чего начать
«Для начала советую изучить сайт Models.com, где вы найдете всю информацию касательно официально зарегистрированных агентств по всему миру, — говорит Ханна Джоуит. — Выберите те, которые вам нравятся и которым, как вам кажется, вы могли бы подойти. Лучше всего представить себя на личной встрече, по возможности советую хотя бы на день поехать в город, где находится нужное агентство. После того как менеджер сможет оценить вас вживую, он, возможно, предложит контракт. Но даже если это не случилось, опускать сразу руки не стоит. Посетите два-три разных агентства, послушайте разные мнения и изучите предложения. Если вам отказали сразу несколько агентств, просто попробуйте себя в каком-то другом деле.
Кроме того, будьте бдительны, если агентство предлагает вам заплатить некую сумму за то, чтобы начать сотрудничество, уходите сразу. Также есть множество недобросовестных агентств, которые берут деньги за создание портфолио, а в итоге даже не занимаются поиском работы для моделей».
Необходимые параметры
По словам Джоуит, интернет и социальные сети оказали большое влияние на список требований, предъявляемый к моделям. «Безусловно, есть определенные модельные параметры, но иметь стройное тело, длинные ноги и симпатичную внешность не достаточно, чтобы стать моделью, — уверяет Ханна. — Сегодня для успешной карьеры требуется гораздо большее: трудолюбие, приятный характер, жизнерадостность, общительность и готовность в любой момент выйти на работу. Модель не может позволить себе выходной, если ее забукировали на съемку.
Девочкам с ростом ниже стандартных параметров расстраиваться не стоит. Они также могут построить успешную карьеру в моделинге и много зарабатывать. Если раньше такие модели подходили разве что для бьюти-съемок, то с популярностью онлайн-шопинга у них появилось больше возможностей для работы. Тем более сегодня актуальна тенденция на нестандартных моделей. Не сказать, что журналы и показы пестрят такими манекенщицами, но многие дизайнеры приглашают и моделей plus size, и взрослых женщин. Растущий рынок инфлюенсеров также дает нетипичным моделям зеленый свет — если у вас много подписчиков и высокая активность в социальных сетях, это будет одним из решающих факторов для клиента».
Сколько получают модели
Конечно, все мы помним знаменитую фразу Линды Евангелисты: «Меньше чем за 10 тысяч долларов я даже с кровати не встану» и внушительные гонорары ее коллег по цеху в 1990-е, но, как говорит Алексина Грэм, с современной реальностью это имеет мало общего. «Я начала карьеру модели, когда мне было 18, и первые пять лет зарабатывала очень мало, — рассказывает она. — Только на шестой год мои гонорары стали более существенными, и к тому моменту я уже была готова все бросить. Секрет успеха в трудолюбии. Нужно много работать, верить в себя и не сдаваться на полпути. И еще мне очень повезло с букером, что тоже немаловажно».
Совет начинающим моделям
Джоуит считает, что понимание того, как работает индустрия — первый шаг к успеху. Изучайте модные съемки, следите за хорошими фотографами и другими моделями. Смотрите, как они двигаются в кадре, позируют, ходят по подиуму. Она также советует всегда быть в форме и вести здоровый образ жизни. «Профессия модели — тяжелый труд, который требует большой самоотдачи. Те, кто сегодня находится в топе, — это усовершенствованные версии самих себя, так же как спортсмены или танцоры. И все усилия стоят того — вы будете знакомиться с талантливыми людьми, путешествовать, хорошо зарабатывать. Каждый день будет отличаться от предыдущего. Да, бывают трудные периоды, но когда все хорошо, работа модели — это работа мечты».
Читайте также:
Разработка метамодели с помощью Eclipse Modeling Framework (и немного про моделирование данных)
Это вторая статья цикла, посвященного разработке, управляемой моделями. Сегодня мы создадим метамодель, основанную на метаметамодели Ecore. Вскользь затронем моделирование данных, а именно Anchor, 6НФ и концептуальное моделирование.
Введение
Вы можете пролистать предыдущую статью про OCL и метамоделирование, но это не обязательно. Достаточно только этих тезисов:
- Есть различные объекты реального мира (люди, организации, события, здания, банковские счета, звезды, планеты, деревья, музыкальные произведения и т.д.).
- В некоторой информационной системе мы можем обрабатывать различные сведения об этих объектах.
- Сведения соответствуют некоторой модели. Модель может быть более или менее формализованная, явная или неявная, может описывать различные аспекты объектов реального мира, сама является объектом реального мира. Например, некоторая диаграмма классов UML – это модель.
- Модель строится в соответствии с некоторой метамоделью, языком моделирования (например, UML).
- Метамодели строятся в соответствии с метаметамоделями (например, Ecore, MOF).
Более развернуто эти тезисы описал консорциум OMG (Object Management Group) в архитектуре, управляемой моделями (Model-driven architecture).
После прочтения данной статьи вы научитесь создавать собственные метамодели (языки моделирования).
Выбор метамодели для реализации
Сначала нужно решить какую метамодель мы будем реализовывать.
Искусственные метамодели, созданные исключительно для примера, слишком бесполезные.
Модели сущность-связь, сети Петри и т.п. слишком простые и неинтересные.
Какой-нибудь PMML интересный, но слишком сложный.
Можно было бы реализовать Charity с помощью EMF. Наверное, это было бы очень интересно (представьте себе язык программирования, в котором всё описывается с помощью коммутативных диаграмм), но бесполезно.
На мой взгляд, золотая середина – это Anchor. На примере этого языка мы поймаем сразу множество зайцев:
- Научимся создавать метамодели.
- Познакомимся с одной из альтернатив диаграммам сущность-связь.
- Может быть сломаем некоторые стереотипы о нормализации данных.
- Вскользь затронем концептуальное моделирование.
Отступление про то зачем нужны ещё какие-то языки моделирования данных
Когда я устраивался на последнюю работу, на собеседовании я рассказывал какое замечательное хранилище и кубы я сделал на предыдущей работе, рассказывал, что это практически полностью избавило людей от ручных расчетов. А меня спросили: что будет с этим хранилищем и кубами, если схема данных изменится? Ведь если менять при этом структуру хранилища и кубы, то мы не сможем получать отчеты за прошлые периоды, основанные на старой схеме данных. Я ответил что-то типа того, что мы очень тщательно продумывали схему данных и существенных изменений в ней не будет, максимум в неё что-то добавится, ну, а если будут более серьезные изменения, то с этим ничего не поделать.
Спустя некоторое время я понял, что эта задача безболезненного изменения схемы данных совершенно тривиальна. Достаточно просто выбрать правильную методику моделирования данных. Если строить хранилище на основе 3НФ-5НФ, то, действительно, малейшие изменения в схеме данных всё ломают. Если же нормализовывать данные до 6НФ, то никакие изменения не затронут уже хранящиеся в базе данные.
На идеях нормализации данных до 6НФ в той или иной степени основаны Data Vault и Anchor. Надеюсь, этого отступления достаточно, чтобы заинтересовать вас Anchor.
ПримечаниеНа самом деле, и это не вершина моделирования данных, есть некоторые вещи, которые не учтены в этих подходах. Но учтены, например, в нашей методике моделирования, но об этом вы узнаете, если устроитесь к нам работать 😉
Отступление про историю моделирования данных
Прежде чем наконец перейти к Anchor немного истории (пожалуйста, отнеситесь к ней критически и с иронией).
В 1970-х было много исследований в области моделирования данных. Один из не плохих подходов, который был придуман в те годы – это объектно-ролевое моделирование. Это была альфа и омега моделирования данных, практически вершина, после которой началась история деградации в этой области. Не буду детально описывать этот подход. В двух словах, данные там описываются в виде фактов, но не «субъект-предикат-объект» как в RDF, а в виде кортежей с произвольным количеством объектов.
К сожалению, не все в те годы осознали гениальность OR-моделирования, поэтому в 1976 Питер Чен опубликовал статью, в которой описал модель сущность-связь. ER-модели отличаются от OR-моделей тем, что в них нет фактов, но есть атрибуты. Это очень существенное отличие.
«ER Diagram MMORPG» by TheMattrix at English Wikipedia. Licensed under CC BY-SA 3.0 via Commons.
В OR-модели набор фактов, относящихся к объекту может быть достаточно произвольным. Например, мы можем сформулировать факты «Сотрудник №1 – имеет имя – Иван» или «Сотрудник №1 – родился в – 1990 год». Или даже более сложные: «Сотрудник №1 – получил степень – доктор наук – в – 2010 год». Но это совершенно не значит, что мы всегда должны для сотрудника указывать имя и год рождения, причем, именно в этом порядке, как и не значит, что мы не можем сформулировать ещё какие-то факты о сотруднике.
В ER-модели при переходе от фактов к атрибутам такая гибкость/открытость модели исчезает, мы начинаем моделировать фиксированные структуры, описывающие фиксированный набор фактов, зашитый в атрибуты, упорядоченные определенным образом.
Обратите внимание на то, что в ER-моделях в нотации Питера Чена связи изображаются ромбиками, а атрибуты овалами. Причём, связи могут быть не только бинарными.
В 1981 в рамках предложенной ВВС США программы дальнейшей деградации моделирования данных компьютеризации промышленности (ICAM) был разработан IDEF1, в котором атрибуты перешли внутрь сущностей, а связи из ромбиков превратились просто в линии. Причем, в результате коварного заговора американских военных у многих людей модель сущность-связь ассоциируется именно с IDEF1, а не с ER-моделью Питера Чена.
«B 5 1 IDEF1X Diagram» by itl.nist.gov — Integration Definition for Information Modeling (IDEFIX) — 93 Dec 21. Licensed under Public Domain via Commons.
Позже возникло ещё множество языков и методов, позволяющих моделировать данные, включая UML, RDF, XSD, Anchor, всякие NoSQL. Но чего-то революционно нового во всём этом нет. Это, кстати, хороший пример того, что в ИТ не нужно гоняться за какими-то модными свистелками, большая часть вещей уже давно придумана и просто оборачивается маркетологами в новую обертку.
Отступление про Anchor
Итак, мы дошли до Anchor. Хотя этот язык и отличается от привычного всем IDEF1X или диаграмм классов UML, фактически это просто калька с более древней ER-модели Питера Чена, о которой, возможно, многие уже забыли. Перечислим основные отличия.
«Anchor Modeling Example» by Lars Rönnbäck — http://www.anchormodeling.com. Licensed under MIT via Commons.
В Anchor сущности (entity) переименованы в якори (anchor), связи (relationship) переименованы в скрепы (tie – наверное их тоже можно называть связями, но слово «скрепа» добавляет этой модели шарма), атрибуты (attribute) оставлены без изменений.
В ER-модели у атрибутов есть представления (representation). В Anchor их называют более привычно – тип данных (data type).
В ER-модели у представлений можно дополнительно ограничивать область допустимых значений (allowable values). В Anchor тоже можно ограничивать область значений, но не произвольным образом, а перечисляя допустимые значения. Такие перечислимые типы в Anchor называют узлами (knot). Забегая вперед, далее мы немного разовьем Anchor в этом плане.
Вряд ли перечисленные отличия между ER-моделью и Anchor можно считать существенными. Пока Anchor напоминает ребрендированную идею 40-летней давности.
Пожалуй, более существенное отличие – это атрибуты и связи с сохранением истории (historized attribute и historized tie). Хотя в ER-модели они отсутствуют, но вообще в них тоже нет чего-то принципиально нового.
Может возникнуть вопрос: если Anchor на столько вторичен, то зачем он вообще нужен, в чём его преимущества по сравнению с другими подходами?
Ответ очень простой. Anchor позволяет немного иначе взглянуть на нормализацию данных. Раньше нормальные формы рассматривались в основном с точки зрения аномалий в данных. При этом 6НФ выглядела каким-то сферическим конём в вакууме, который возможно представляет интерес с теоретической точки зрения, но практически бесполезен. С появлением подходов типа Anchor или Data Vault стало ясно, что нормализация данных важна не только с точки зрения устранения аномалий, но и с точки зрения эволюции схемы данных. В такие схемы проще вносить изменения, ничего при этом не ломая.
Создание проекта
На сайте есть замечательный редактор Anchor-моделей. Мы попробуем сделать аналогичный редактор, основанный на Eclipse Modeling Framework.
ПримечаниеТочнее, в этой статье мы сделаем упрощенный (древовидный) редактор. В следующей статье сделаем уже полноценный редактор диаграмм. А из совсем следующих статей станет ясно зачем мы всё это делаем. Конечно, чтобы научиться создавать языки моделирования, но не только.
Итак, если хотите попробовать всё на практике, то скачайте и распакуйте Eclipse Modeling Tools.
Создайте новый «Ecore Modeling Project». Назовите его «anchor». На вкладке «Select viewpoints» выберите «Design».
В ecore-файле будет храниться наша метамодель. В aird-файле будет храниться диаграмма для метамодели. Если вы прочитали предыдущую статью, то должны понимать, что модель и диаграмма модели – это разные вещи. Наконец, в genmodel-файле хранится модель генерации исходного кода из нашей метамодели. В ней задаются различные правила генерации кода, в частности, в какую папку его нужно складывать и т.п.
ПримечаниеЗдесь и далее я иногда буду называть метамодель моделью. В этом нет никакого противоречия, метамодель сама является моделью. Равно как и метаклассы являются классами с точки зрения метаметамодели.
Если лень создавать проект, можете взять готовый.
Создание основных метаклассов
Теперь необходимо описать метаклассы (виды сущностей, которые могут быть в наших Anchor-моделях). Добавьте на диаграмму класс и назовите его Anchor. Добавьте ему атрибут name с типом данных EString. В поле Lower Bound укажите 1.
Добавьте ещё один класс, назовите его Attribute. Скопипастьте ему атрибут name.
В Anchor-моделях якоря и атрибуты можно связывать друг с другом. Поэтому в нашей метамодели мы должны создать связь между якорем и атрибутом. Связь должна быть композицией (composition), потому что атрибуты не могут существовать сами по себе, они всегда принадлежат якорю и причём одному.
ПримечаниеЕсть разные подходы к именованию отношений. Данное отношение между якорем и атрибутом можно назвать: attribute, attributes, ownedAttribute или ownedAttributes. Отношение один-к-одному нужно однозначно называть в единственном числе. Отношение один-ко-многим иногда называют в единственном, иногда во множественном числе. Если отношение является композицией, то иногда к имени добавляют префикс owned. Это значит, что атрибут принадлежит якорю.
Важно, чтобы в модели использовалась одна схема именования. Я буду использовать вторую.
Генерация редактора модели
Итак, упрощенный набросок метамодели у нас уже есть. Теперь создадим модель в соответствии с этой метамоделью. Для этого необходимо сгенерировать исходный код для плагина, который мы запустим в Eclipse и который позволит нам работать с моделью.
Откройте anchor.genmodel. В свойствах множество разных настроек. Можно оставить их без изменений, но обычно папка для сгенерированного кода изменяется с src на src-gen, чтобы разделять код написанный вручную от сгенерированного. К слову, в нашем проекте вообще не будет кода, написанного вручную.
В контекстном меню выберите «Generate Model Code», после чего в папке src (или src-gen) появится Java API для работы с нашими Anchor-моделями. В рамках данной и последующих статей нам не потребуется ни заглядывать в этот код, ни править его.
Запустите «Generate Edit Code» и «Generate Editor Code». Таким образом вы создадите два дополнительных проекта: 1) некоторую прослойку между объектной моделью нашего языка моделирования и редактором и 2) древовидный редактор моделей.
До кучи создайте тестовый проект с помощью команды «Generate Test Code». Мы не будем писать модульные тесты, однако в этом проекте вы можете увидеть примеры использования API, сгенерированного для нашей метамодели. Также в этом проекте мы будем создавать тестовые модели.
Переключитесь на Java-перспективу (Window -> Perspective -> Open Perspective).
Выберите Run -> Run Configurations… В разделе Eclipse Application создайте новую конфигурацию и запустите её.
Импортируйте в запущенный экземпляр Eclipse проект anchor.tests (File -> Import… -> General -> Existing Projects into Workspace). Откройте перспективу моделирования (Window -> Perspective -> Open Perspective -> Modeling). Создайте в проекте новую папку model (File -> New -> Folder). Создайте в папке Anchor-модель (File -> New -> Other…).
На последней вкладке мастер создания модели спросит какой объект использовать в качестве корневого (поле Model Object). Корневой объект мы пока не создали, поэтому выберите Anchor.
На вкладке свойств укажите какое-нибудь имя якоря, добавьте атрибуты.
Создание корневого объекта модели
Пока наш редактор позволяет описывать только один якорь с атрибутами. Чтобы в модели могло быть несколько якорей, сделайте следующее.
Закройте второй экземпляр Eclipse, в первом экземпляре откройте перспективу Modeling. Откройте файл anchor.ecore. Добавьте в метамодель метакласс Model.
Добавьте созданному метаклассу EReference с именем anchors. В поле EType выберите Anchor. Lower Bound задайте 1, Upper Bound задайте -1 (произвольное количество). В поле Containment укажите истинное значение (это значит, что якори будут принадлежать модели).
Теперь создайте обратную ссылку от якоря к модели. Это не обязательно, но понадобится в следующей статье. Для этого у метакласса Anchor создайте ссылку с именем model и типом Model. В поле EOpposite выберите обратную ссылку anchors. В поле Lower Bound укажите 1.
ПримечаниеНаверняка вы заметили, что древовидный редактор метамодели очень похож на редактор, который вы только что сгенерировали. Разве что выглядит немного симпатичнее благодаря иконкам. Дефолтные иконки лежат в проекте anchor.edit в папке icons. Другие иконки можно взять отсюда. Они немного кривые, потому что сгенерированы из svg, но идею вы поняли.
Сохраните метамодель. Откройте диаграмму в файле anchor.aird. Добавьте на диаграмму метакласс Model (на палитре инструментов справа в разделе Existing Elements выберите Add). Обратите внимание на то, что на диаграмму также добавилась двунаправленная связь с метаклассом Anchor, которую вы создали в древовидном редакторе.
Генерация плагина
После изменения метамодели не забудьте перегенерировать исходные коды во всех проектах. Теперь вместо запуска второго экземпляра Eclipse сделайте следующее. В меню выберите File -> Export… -> Deployable plugin-ins and fragments.
Отметьте все созданные проекты (по крайней мере, все кроме anchor.tests). Выберите Install into host. Repository. После развертывания плагина перезапустите Eclipse. Теперь редактор Anchor-модели будет доступен в этой рабочей области без запуска второго экземпляра Eclipse.
Также вы можете экспортировать плагин в какую-нибудь папку. Затем полученные jar-файлы можно скопировать в папку $ECLIPSE_HOME/dropins. После перезапуска Eclipse, в нём будет доступен ваш плагин.
Завершение создания метамодели
В общем-то, это всё, что необходимо знать о EMF для создания своих метамоделей. Теперь остаётся только добавить недостающие метаклассы.
Узнать какие ещё нужны метаклассы можно либо просто глядя на примеры Anchor-моделей, либо из статьи M. Bergholtz, P. Johannesson, P. Wohed «Anchor Modeling – Agile Information Modeling in Evolving Data Environments».
Если вы попробуете реализовать эту метамодель, то увидите, что некоторые вещи в ней можно сделать более оптимально, чем изображено на рисунке. Мы улучшим две вещи:
- Дублирующиеся свойства и отношения вынесем в отдельные классы.
- Немного усовершенствуем систему типов.
ПримечаниеНа рисунке не изображён интерфейс Named, потому что с ним диаграмма станет совсем нечитаемой.
Для некоторых свойств используется тип EDoubleObject, а не просто EDouble, потому что эти свойства опциональные. Если задать для них тип данных EDouble, то по умолчанию для них будет устанавливаться значение 0, и будет невозможно понять действительно ли они установлены в 0 или они просто не указаны.
Рассмотрим наши усовершенствования подробнее.
Дополнение про абстрактные классы и интерфейсы
На исходной диаграмме классов выше видно, что для всех атрибутов и скреп с сохранением истории определено отношение с метаклассом TIME TYPE. Некоторые метаклассы связаны аналогичным отношением с метаклассом DATA TYPE. Также у многих метакслассов есть атрибут name, хотя он и не показан на рисунке.
Все эти одинаковые свойства и отношения можно вынести в соответствующие метаклассы Historized, Typed, Named и т.д. В Anchor-моделях не могут существовать экземпляры этих метаклассов, поэтому их нужно отметить как абстрактные.
Ecore допускает множественное наследование. И, например, HistorizedAttribute вполне может наследоваться от метаклассов Attribute, Typed и Historized. Однако, если вы загляните в Java API, которое сгенерировано для Ecore-метамодели с использованием множественного наследования, то увидите, что только один из базовых метаклассов будет реализован как Java-класс, а остальные будут реализованы как Java-интерфейсы (т.к. Java не поддерживает множественное наследование). Поэтому для однозначности желательно сразу в Ecore-метамодели отметить некоторые метаклассы как интерфейсы.
Дополнение про типы данных
Если вы посмотрите примеры Anchor-моделей на сайте, то обнаружите там типы данных вида varchar(42), money и т.п. Увидите, что в модели явно заданы типы данных для ключей. Лично меня такая привязка к физике очень удивила. Изначально Anchor производил впечатление достаточно концептуального языка моделирования, а оказалось, что модели привязаны к конкретной СУБД.
Мы устраним эту недоработку, добавив несколько абстрактных типов данных (вы видите их на рисунке выше), которые в последующих статьях будем транслировать в типы данных конкретной СУБД. Ну, в общем-то, забегая вперед, мы и создавали эту метамодель ради того, чтобы в следующих статьях показать возможности преобразования моделей. А то в комментариях на сайте Anchor я даже читал какой-то ад про генерацию SQL-запросов с помощью XSLT – это плохо.
Заключение
После прочтения этой статьи вы должны уметь создавать языки моделирования с помощью Eclipse Modeling Framework. Также, возможно, вы узнали что-то интересное из области моделирование данных.
В следующей статье я опишу как сделать уже не просто древовидный редактор, а редактор диаграмм.
модель базы данных — Database model
 Коллаж из пяти типов моделей баз данных
Коллаж из пяти типов моделей баз данныхМодель базы данных представляет собой тип модели данных , которая определяет логическую структуру базы данных и фундаментально определяет , в каком порядке данные могут быть сохранены, организованы и манипулировать. Самый популярный пример модели базы данных является реляционная модель , которая использует формат на основе таблиц.
Примеры
Общие логические модели данных для баз данных включают в себя:
- Это самый старый вид базы данных модели. Она была разработана IBM для IMS (система управления информацией). Он представляет собой набор организованных данных в древовидной структуре. БД запись представляет собой дерево, состоящее из множества групп, называемых сегментами. Он использует один ко многим отношений. Доступ к данным также предсказуем.
Объектно-реляционная база данных объединяет в себе две взаимосвязанные структуры.
Физические модели данных включают в себя:
Другие модели включают в себя:
Отношения и функции
Данная система управления базами данных может предоставить одну или несколько моделей. Оптимальная структура зависит от естественной организации данных приложения, а также от требований приложения, которые включают в себя скорость транзакций (скорость), надежность, ремонтопригодность, масштабируемость и стоимость. Большинство систем управления базами данных построены вокруг одной конкретной модели данных, хотя возможно для продуктов , чтобы предложить поддержку для более чем одной модели.
Различные физические модели данных можно реализовать любую заданную логическую модель. Большинство программного обеспечения базы данных будет предлагать пользователю определенный уровень контроля при настройке физической реализации, так как выборы, которые сделаны оказывают существенное влияние на производительность.
Модель не только способ структурирования данных: он также определяет набор операций , которые могут быть выполнены над данными. Реляционная модель, например, определяет операции , такие как выбор ( проект ) и присоединиться . Хотя эти операции не могут быть явными в конкретном языке запросов , они обеспечивают основу , на которой строится язык запросов.
Плоская модель
 Плоская Модель файла
Плоская Модель файлаПлоская (или таблица) Модель состоит из одного двумерного массива данных элементов, где предполагаются все члены данного столбца , чтобы быть аналогичные ценности, и все члены ряда предполагаются связанными друг с другом. Например, столбцы для имени и пароля , которые могут быть использованы в качестве части базы данных безопасности системы. Каждая строка будет иметь специальный пароль , связанный с отдельным пользователем. Столбцы таблицы часто имеют типа , связанный с ними, определяя их как данные, дата или время информации, целые числа, или числа с плавающей точкой. Этот табличный формат является предшественником реляционной модели.
Ранние модели данных
Эти модели были популярны в 1960 — х, 1970 — х годах, но в настоящее время можно найти в основном в старых унаследованных системах . Они характеризуется в первую очередь, будучи судовождение с сильными связями между их логическими и физическими представлениями, а также недостатками в независимости данных .
Иерархическая модель
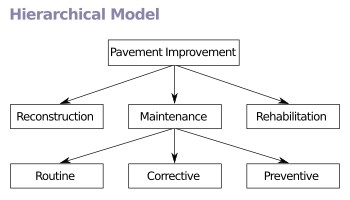 Иерархическая модель
Иерархическая модельВ иерархической модели , данные организованы в древовидной структуре , подразумевая одного родителя для каждой записи. Поле сортировки сохраняет одноуровневые записи в определенном порядке. Иерархические структуры широко использовались в ранних системах управления базами данных мэйнфреймов, такие как информационная система управления (ИСА) на IBM , и теперь описывают структуру XML — документы. Эта структура позволяет одному один-ко-многим между двумя типами данных. Эта структура является очень эффективной для описания отношений в реальном мире; рецепты, оглавление, порядок пунктов / стихов, любой вложенной и отсортированной информация.
Эта иерархия используется в качестве физического порядка записей в хранилище. Доступ к записи осуществляется путем перехода вниз по структуре данных с использованием указателей в сочетании с последовательным ACCESSING. Из — за этого, иерархическая структура неэффективна для некоторых операций с базой данных , когда полный путь (в противоположность восходящей линии связи и поля сортировки) не включены также для каждой записи. Такие ограничения были компенсированы в более поздних версиях IMS с помощью дополнительных логических иерархий , наложенных на базовую физической иерархии.
модель сети

Сетевая модель расширяет иерархическую структуру, что позволяет многие-ко-многим в виде древовидной структуры , что позволяет несколько родителей. Он был самым популярным , прежде чем заменить реляционную модель, и определяется CODASYL спецификации.
Сетевая модель организует данные с использованием двух основных концепций, которые называются записями и наборы . Записи содержат поля (которые могут быть организованы иерархически, как и в языке программирования COBOL ). Наборы (не следует путать с математическими множествами) определяют один-ко-многим отношений между записями: один владелец, много членов. Запись может быть владельцем в любом количестве наборов, и член в любом количестве наборов.
Набор состоит из круговых связанных списков , где один типа записи, владелец набора или один из родителей, появляется один раз в каждом круге, а второй типа записи, подчиненные или ребенка, может появляться несколько раз в каждом круге. Таким образом , иерархия может быть установлена связь между любыми двумя типами записей, например, тип А является владельцем В. В то же время другой набор может быть определено , где В является владельцем А. Таким образом , все наборы содержат общий ориентированный граф (форма собственности определяет направление), или сетевую конструкцию. Доступ к записям либо последовательный ( как правило , в каждом типе записи) или навигация в круговых связанные списках.
Сетевая модель может представлять избыточность данных более эффективно, чем в иерархической модели, и может быть больше, чем один путь от узла-предка к потомку. Операции сетевой модели являются навигационными в стиле: программа поддерживает текущую позицию и переходит от одной записи к другой, следуя отношения, в которых запись участвует. Записи также могут быть размещены путем подачи ключевых значений.
Хотя это не является существенным признаком модели, сетевые базы данных обычно реализуют заданные отношения с помощью указателей , непосредственно связанных местоположение записи на диске. Это дает отличную производительность извлечения, за счет таких операций, как загрузка базы данных и реорганизация.
Популярные продукты СУБД , которые использовали это были Cincom Systems «Total и Cullinet » s IDMS . IDMS получила значительную клиентскую базу; в 1980 году она приняла реляционную модель и SQL в дополнение к оригинальным инструментов и языков.
Большинство баз данных объектов (изобретены в 1990 — х годах) используют навигационную концепцию для обеспечения быстрой навигации по сети объектов, как правило , с использованием идентификаторов объектов , как «умные» указатели на соответствующие объекты. Объективность / DB , например, реализует названный один-к-одному, один-ко-многим, многие-к-одному и многие-ко-многим именованных отношений , которые могут пересекать базы данных. Многие объектные базы данных поддерживают SQL , сочетающий в себе сильные стороны обеих моделей.
Перевернутый файл модели
В инвертированном файле или инвертированный индексе , содержимые данных используются в качестве ключей в таблице поиска, а значения в таблице являются указателями на местоположение каждого экземпляра данного элемента контента. Это также логическая структура современных индексов базы данных , которые могут использовать только содержимое из конкретных столбцов в таблице. Перевернутая модель данных файла можно поместить индексы в виде набора файлов рядом с существующими плоскими файлами баз данных, для того , чтобы эффективно получить быстрый доступ к необходимым записям в этих файлах.
Примечательные для использования этой модели данных является ADABAS СУБД Software AG , введенная в 1970 году ADABAS приобрел значительную клиентскую базу и существует и не поддерживаются до сих пор. В 1980 — х годах она была принята реляционная модель и SQL в дополнение к оригинальным инструментов и языков.
База данных документов , ориентированные на Clusterpoint использует перевернутую модель индексации , чтобы обеспечить быстрый полнотекстовый поиск по XML или JSON данных объектов, например.
Реляционная модель
Две таблицы с отношениямиРеляционная модель была представлена EF Коддом в 1970 году как способ сделать системы управления базами данных более независимыми от какого — либо конкретного применения. Это математическая модель определяется в терминах логики предикатов и теории множеств , а также реализации в ней были использованы мэйнфреймов, средних и микрокомпьютеров систем.
Продукты , которые , как правило , упоминаются как реляционные базы данных на самом деле реализовать модель , которая является лишь приближением к математической модели , определенной Кодд. Три ключевые термины широко используются в реляционных моделей баз данных: отношения , атрибуты и домены . Отношение представляет собой таблицу со столбцами и строками. Названные столбцы отношений называются атрибутами, а область является набором значений атрибутов разрешено брать.
Базовая структура данных реляционной модели является таблицей, где информация о конкретных организациях (например, работник) представлена в строках (называемые также кортежи ) и столбцах. Таким образом, « отношение » в «реляционной базе данных» относится к различным таблицам в базе данных; отношение есть множество кортежей. Столбцы перечисляются различные атрибуты объекта (имя, адрес работника или номер телефона, например), и ряд является фактическим экземпляром объекта (конкретного сотрудника) , который представлен соотношением. В результате, каждый кортеж таблицы служащих представляет различные атрибуты одного работника.
Все отношения (и, таким образом, таблица) в реляционной базе данных должны придерживаться некоторых основных правил, чтобы квалифицировать в качестве отношений. Во-первых, порядок столбцов не имеет значения в таблице. Во-вторых, не может быть одинаковые кортежи или строки в таблице. И третье, каждый кортеж будет содержать одно значение для каждого из его атрибутов.
Реляционная база данных содержит несколько таблиц, каждая из которых похож на тот , в «плоской» модели базы данных. Одним из достоинств реляционной модели является то , что, в принципе, любое значение , происходит в двух различных записях (принадлежащих к одной и той же таблице или разным таблицам), предполагает связь между этими двумя записями. Тем не менее, в целях обеспечения соблюдения явных ограничений целостности , отношения между записями в таблицах также могут быть определены в явном виде, путем идентификации или не идентификации родитель-потомок , характеризующиеся назначая мощность (1: 1, (0) 1: М, М: М ). Таблицы могут также иметь назначенный один атрибут или набор атрибутов , которые могут выступать в качестве «ключа», который может быть использован для однозначной идентификации каждого кортежа в таблице.
Ключ , который может быть использован для однозначной идентификации строки в таблице, называется первичным ключом. Ключи обычно используются для соединения или объединить данные из двух или более таблиц. Например, сотрудник таблица может содержать столбец с именем Расположения , который содержит значение , которое соответствует тональности Location таблицы. Клавиши также имеют важное значение в создании индексов, которые облегчают быстрое извлечение данных из больших таблиц. Любой столбец может быть ключевым или несколько столбцов могут быть сгруппированы вместе в ключ соединения. Не нужно , чтобы определить все ключи заранее; столбец может быть использован в качестве ключа , даже если он не был изначально предназначен , чтобы быть один.
Ключ , который имеет внешний, в реальном мире смысл (например, имя человека, книгу в ISBN , или серийный номер автомобиля в) иногда называют «естественной» ключ. Если нет естественного ключа не подходит (думает , из многих людей по имени Брауна ), произвольный или суррогатный ключ может быть назначен (например, путем предоставления номера сотрудников ID). На практике, большинство баз данных имеют как сгенерированные и естественные ключи, потому что сгенерированные ключи могут быть использованы внутри для создания связей между строками , которые не могут сломаться, в то время как естественные ключи могут быть использованы, менее надежно, для поиска и интеграции с другими базами данных. (Например, записи в двух самостоятельно разработанных базах данных могут быть подобраны по номеру социального страхования , за исключением случаев, когда номер социального страхования является неправильным, не хватают, или изменить).
Наиболее распространенный язык запросов , используемый в реляционной модели является язык структурированных запросов ( SQL ).
Размерный модель
Одномерная модель является специализированной адаптацией реляционной модели , используемой для представления данных в хранилищах данных таким образом , что данные могут быть легко обобщены с помощью оперативного аналитической обработки данных или OLAP — запросы. В одномерной модели, схема базы данных состоит из одной большой таблицы фактов, которые описаны с помощью измерений и мер. Размерность обеспечивает контекст факта (например, кто принимал участие, когда и где это произошло, и его типа) и используются в запросах к группе связанных фактам вместе. Размеры , как правило, быть дискретным и часто являются иерархическими; например, расположение может включать в себя здание, состояние и страну. Мера является величина , описывающая тот факт, например, доход. Важно , что меры могут быть осмысленно агрегируются, например, доходы от различных мест могут быть добавлены вместе.
В запросе OLAP, размеры выбраны и факты, группируются и объединяются вместе, чтобы создать резюме.
Трехмерная модель часто реализуется поверх реляционной модели с использованием звездообразной схемы , состоящей из одного высоко нормализованной таблицы , содержащей факты, и окружающая денормализованная таблицу , содержащей каждое измерение. Альтернатива физическая реализация, называемая снежинка схемой , нормализует иерархии многоуровневых в измерении в нескольких таблиц.
Хранилище данных может содержать несколько размерных схемы , которые разделяют таблицы размеров, что позволяет использовать их вместе. Далее с стандартным набором размеров является важной частью многомерного моделирования .
Его высокая производительность сделала одномерная модель самой популярной структуры базы данных для OLAP.
Пост-реляционные модели баз данных
Продукты , предлагающие более общая модель данных , чем реляционная модель, иногда классифицируются как постреляционные . Альтернативные термины включают «гибридную базу данных», «объект повышенного RDBMS» и другие. Модель данных в таких продуктах , включает в себя отношения , но не ограничивается EF Кодда информационного принципа «s, который требует , чтобы
вся информация в базе данных должны быть отлиты явно с точки зрения ценностей в отношениях и никак иначе
-
Некоторые из этих расширений реляционной модели интеграции концепции из технологий , которые предшествуют реляционную модель. Например, они позволяют представление ориентированного графа с деревьев на узлах. Немецкая компания Sones реализует эту концепцию в своем GraphDB .
Некоторые пост-реляционные продукты распространяются реляционные системы с нереляционными функциями. Другие прибыли в основном так же место, добавив реляционные предварительно реляционные системы. Как это ни парадоксально, это позволяет продукты, которые исторически пре-реляционная, такие как PICK и MUMPS , чтобы сделать правдоподобным утверждают, что пост-реляционная.
Пространства модель ресурса (РСМ) не является реляционной моделью данных на основе многомерной классификации.
Graph модель
базы данных Graph позволяют еще более общую структуру, чем базы данных сети; любой узел может быть соединен с любым другим узлом.
модель многозначного
Многозначные базы данных «кусковой» данные, в том, что они могут хранить точно так же, как реляционные базы данных, но они также позволяют уровень глубины, который реляционная модель может только аппроксимировать с помощью вложенных таблиц. Это почти идентично тому, как XML выражающего данных, где данное поле / атрибут может иметь несколько правильных ответов, в то же время. Многозначный можно рассматривать как сжатый вид XML.
Примером является счет-фактура, который в любом многозначными или реляционных данных можно рассматривать как (A) счета-фактуры заголовка таблицы — одна запись в счете-фактуре, и (Б) Деталь счета-фактуры Таблица — одна запись для каждой позиции. В многозначной модели, мы имеем возможность сохранения данных, как на столе, со встроенной таблицей, чтобы представить деталь: (А) Счета Таблица — одна записи на счета, никаких других таблиц, необходимых.
Преимущество состоит в том, что атомарность счета-фактуры (концептуальной) и счета-фактуры (представления данных) являются один-к-одному. Это также приводит к менее читает вопросы ссылочной целостности меньше, и резкое снижение аппаратных средств, необходимых для поддержания заданного объема транзакций.
моделей баз данных объектно-ориентированных
 Объектно-ориентированная модель
Объектно-ориентированная модельВ 1990 — х, объектно-ориентированном программировании парадигма была применена к технологии баз данных, создание новой модели базы данных , известную как объектные базы данных . Это имеет целью избежать объектно-реляционного несоответствия импеданса — накладные расходы преобразования информации между ее представлением в базе данных (например , в виде строк в таблицах) и его представление в прикладной программе ( как правило , в качестве объектов). Еще дальше, то система типов используются в конкретном приложении может быть определена непосредственно в базе данных, что позволяет в базе данных для обеспечения одних и те же инвариантов целостности данных. Объектные базы данных также ввести ключевые идеи объектного программирования, такие как инкапсуляция и полиморфизм , в мире баз данных.
Разнообразие этих способов было triedfor хранения объектов в базе данных. Некоторые продукты подошли к проблеме с конца программирования приложений, делая объекты , которыми манипулируют программы постоянная . Это , как правило , требует добавления какого — то языка запросов, так как обычные языки программирования не имеют возможности найти объекты на основе их информационного содержания. Другие напали на проблему с конца базы данных, определяя модель данных объектно-ориентированных для базы данных, и определение языка программирования баз данных , что позволяет в полной мере возможности программирования, а также традиционные средства запроса.
Объектные базы данных пострадали из — за отсутствия стандартизации: хотя стандарты были определены ODMG , они никогда не были реализованы достаточно хорошо , чтобы обеспечить совместимость между продуктами. Тем не менее, объектные базы данных были успешно использованы во многих приложениях: как правило , специализированные приложения , такие как инженерные базы данных или базы данных молекулярной биологии , а не основной обработки коммерческих данных. Однако идеи баз данных объектов были подхвачены реляционными поставщиками и под влиянием расширения , сделанные на эти продукты и действительно к SQL языка.
Альтернатива перевод между объектами и реляционных баз данных является использование объектно-реляционного отображения библиотеки (ОРМ).
Рекомендации
php — Что значит $ this-> model = $ model; означает в MVC
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- работы Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимайте технических специалистов и создавайте свой бренд работодателя
- реклама Обратитесь к разработчикам и технологам со всего мира
- О компании
backbone.js — Backbone JS — this.model.models вместо this.collection?
Переполнение стека- Около
- Товары
- Для команд
- Переполнение стека Общественные вопросы и ответы
- Переполнение стека для команд Где разработчики и технологи делятся частными знаниями с коллегами
- работы Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимайте технических специалистов и создавайте свой бренд работодателя
- реклама Обратитесь к разработчикам и технологам со всего мира
- О компании
Загрузка…
.Учебник по классификации изображений: модели обучения — Машинное обучение Azure
- 13 минут на чтение
В этой статье
ПРИМЕНЯЕТСЯ К: Базовая версия Enterprise (предварительная версия) Edition (Обновление до версии Enterprise)
В этом руководстве вы обучаете модель машинного обучения на удаленных вычислительных ресурсах.Вы будете использовать рабочий процесс обучения и развертывания для машинного обучения Azure в записной книжке Python Jupyter. Затем вы можете использовать записную книжку в качестве шаблона для обучения собственной модели машинного обучения с использованием собственных данных. Этот учебник является первой частью серии руководств , состоящей из двух частей.
В этом руководстве обучается простая логистическая регрессия с использованием набора данных MNIST и scikit-learn с машинным обучением Azure. MNIST — популярный набор данных, состоящий из 70 000 изображений в оттенках серого. Каждое изображение представляет собой рукописную цифру размером 28 x 28 пикселей, представляющую число от нуля до девяти.Цель состоит в том, чтобы создать мульти-классификатор для идентификации цифры, которую представляет данное изображение.
Узнайте, как выполнять следующие действия:
- Настройте среду разработки.
- Получите доступ к данным и проверьте их.
- Обучите простую модель логистической регрессии на удаленном кластере.
- Просмотрите результаты обучения и зарегистрируйте лучшую модель.
Вы узнаете, как выбрать модель и развернуть ее во второй части этого руководства.
Если у вас нет подписки Azure, прежде чем начать, создайте бесплатную учетную запись.Попробуйте бесплатную или платную версию Машинного обучения Azure уже сегодня.
Предварительные требования
Завершите руководство: приступите к созданию своего первого эксперимента по машинному обучению Azure на:
- Создать рабочее пространство
- Клонируйте записную книжку с обучающими материалами в свою папку в рабочей области.
- Создайте экземпляр облачных вычислений.
В клонированной папке tutorials / image-Classification-mnist-data откройте файл img-classification-part1-training.ipynb ноутбук.
Учебное пособие и сопровождающий его файл utils.py также доступны на GitHub, если вы хотите использовать его в своей локальной среде. Запустите pip install azureml-sdk [notebooks] azureml-opendatasets matplotlib , чтобы установить зависимости для этого руководства.
Важно
Остальная часть этой статьи содержит то же содержание, что и в записной книжке.
Переключитесь на записную книжку Jupyter сейчас, если хотите читать во время выполнения кода.Чтобы запустить одну ячейку кода в записной книжке, щелкните ячейку кода и нажмите Shift + Enter . Или запустите всю записную книжку, выбрав Запустить все на верхней панели инструментов.
Настройте среду разработки
Все настройки для вашей разработки могут быть выполнены в записной книжке Python. Настройка включает в себя следующие действия:
- Импортировать пакеты Python.
- Подключитесь к рабочей области, чтобы ваш локальный компьютер мог связываться с удаленными ресурсами.
- Создайте эксперимент для отслеживания всех ваших пробежек.
- Создайте целевой объект удаленных вычислений для обучения.
Импортные пакеты
Импортируйте пакеты Python, необходимые в этом сеансе. Также отобразите версию пакета SDK для машинного обучения Azure:
% встроенный matplotlib
импортировать numpy как np
импортировать matplotlib.pyplot как plt
импортировать azureml.core
из azureml.core import Workspace
# проверить номер версии основного SDK
print («Версия пакета SDK для Azure ML:», azureml.core.ВЕРСИЯ)
Подключиться к рабочей области
Создайте объект рабочего пространства из существующего рабочего пространства. Workspace.from_config () читает файл config.json и загружает детали в объект с именем ws :
# загрузить конфигурацию рабочего пространства из файла config.json в текущую папку.
ws = Workspace.from_config ()
print (ws.name, ws.location, ws.resource_group, sep = '\ t')
Создать эксперимент
Создайте эксперимент для отслеживания пробежек в вашем рабочем пространстве.В рабочем пространстве может быть несколько экспериментов:
из эксперимента по импорту azureml.core
эксперимент_имя = 'sklearn-mnist'
exp = эксперимент (рабочая область = ws, name = имя_эксперимента)
Создать или присоединить существующую цель вычислений
Используя Azure Machine Learning Compute, управляемую службу, специалисты по данным могут обучать модели машинного обучения на кластерах виртуальных машин Azure. Примеры включают виртуальные машины с поддержкой графического процессора. В этом руководстве вы создадите вычислительную среду машинного обучения Azure в качестве учебной среды.Вы отправите код Python для запуска на этой виртуальной машине позже в руководстве.
Приведенный ниже код создает для вас вычислительные кластеры, если они еще не существуют в вашей рабочей области. Он устанавливает кластер, который будет масштабироваться до 0, когда он не используется, и может масштабироваться максимум до 4 узлов.
Создание целевого объекта вычислений занимает около пяти минут. Если вычислительный ресурс уже находится в рабочей области, код использует его и пропускает процесс создания.
от azureml.core.compute импорт AmlCompute
из azureml.core.compute import ComputeTarget
импорт ОС
# выберите имя для вашего кластера
compute_name = os.environ.get ("AML_COMPUTE_CLUSTER_NAME", "cpucluster")
compute_min_nodes = os.environ.get ("AML_COMPUTE_CLUSTER_MIN_NODES", 0)
compute_max_nodes = os.environ.get ("AML_COMPUTE_CLUSTER_MAX_NODES", 4)
# В этом примере используется ЦП ВМ. Для использования виртуальной машины с графическим процессором установите для SKU значение STANDARD_NC6.
vm_size = os.environ.get ("AML_COMPUTE_CLUSTER_SKU", "STANDARD_D2_V2")
если compute_name в ws.compute_targets:
compute_target = ws.compute_targets [compute_name]
если compute_target и тип (compute_target) - AmlCompute:
print ('найден целевой объект вычислений. Просто используйте его.' + compute_name)
еще:
print ('создание новой цели вычислений ...')
provisioning_config = AmlCompute.provisioning_configuration (vm_size = vm_size,
min_nodes = compute_min_nodes,
max_nodes = compute_max_nodes)
# создаем кластер
compute_target = ComputeTarget.Создайте(
ws, compute_name, provisioning_config)
# может опрашивать минимальное количество узлов и определенный тайм-аут.
# если минимальное количество узлов не указано, будут использоваться настройки масштаба для кластера
compute_target.wait_for_completion (
show_output = True, min_node_count = None, timeout_in_minutes = 20)
# Для более подробного просмотра текущего статуса AmlCompute используйте get_status ()
печать (compute_target.get_status (). serialize ())
Теперь у вас есть необходимые пакеты и вычислительные ресурсы для обучения модели в облаке.
Посмотреть данные
Прежде чем обучать модель, вам необходимо понять, какие данные вы используете для ее обучения. В этом разделе вы узнаете, как:
- Загрузите набор данных MNIST.
- Покажите несколько образцов изображений.
Загрузите набор данных MNIST
Используйте открытые наборы данных Azure, чтобы получить файлы необработанных данных MNIST. Открытые наборы данных Azure — это тщательно отобранные общедоступные наборы данных, которые можно использовать для добавления функций для конкретных сценариев в решения машинного обучения для получения более точных моделей.У каждого набора данных есть соответствующий класс, в данном случае MNIST , для получения данных разными способами.
Этот код извлекает данные как объект FileDataset , который является подклассом Dataset . FileDataset ссылается на один или несколько файлов любого формата в ваших хранилищах данных или общедоступных URL. Класс предоставляет вам возможность загружать или подключать файлы к вашему вычислению, создавая ссылку на расположение источника данных. Кроме того, вы регистрируете набор данных в своей рабочей области для облегчения поиска во время обучения.
Следуйте инструкциям, чтобы узнать больше о наборах данных и их использовании в SDK.
из набора данных импорта azureml.core
из azureml.opendatasets импортировать MNIST
data_folder = os.path.join (os.getcwd (), 'данные')
os.makedirs (data_folder, exist_ok = True)
mnist_file_dataset = MNIST.get_file_dataset ()
mnist_file_dataset.download (data_folder, overwrite = True)
mnist_file_dataset = mnist_file_dataset.register (рабочая область = ws,
name = 'mnist_opendataset',
description = 'обучающий и тестовый набор данных',
create_new_version = True)
Показать образцы изображений
Загрузить сжатые файлы в массивы numpy .Затем используйте matplotlib для построения 30 случайных изображений из набора данных с их метками над ними. Для этого шага требуется функция load_data , которая включена в файл util.py . Этот файл находится в папке с образцами. Убедитесь, что он находится в той же папке, что и этот блокнот. Функция load_data просто разбирает сжатые файлы в массивы numpy.
# убедитесь, что utils.py находится в том же каталоге, что и этот код
из утилит import load_data
импортный глобус
# обратите внимание, что мы также уменьшаем значения интенсивности (X) с 0-255 до 0-1.Это помогает модели быстрее сходиться.
X_train = load_data (glob.glob (os.path.join (data_folder, "** / train-images-idx3-ubyte.gz"), рекурсивный = True) [0], False) / 255,0
X_test = load_data (glob.glob (os.path.join (data_folder, "** / t10k-images-idx3-ubyte.gz"), рекурсивный = True) [0], False) / 255.0
y_train = load_data (glob.glob (os.path.join (data_folder, "** / train-labels-idx1-ubyte.gz"), рекурсивный = True) [0], True) .reshape (-1)
y_test = load_data (glob.glob (os.path.join (data_folder, "** / t10k-labels-idx1-ubyte.gz"), рекурсивный = True) [0], True).изменить форму (-1)
# а теперь покажем несколько случайно выбранных изображений из обучающего набора.
count = 0
sample_size = 30
plt.figure (figsize = (16, 6))
для i в np.random.permutation (X_train.shape [0]) [: sample_size]:
count = count + 1
plt.subplot (1, размер_элемента, количество)
plt.axhline ('')
plt.axvline ('')
plt.text (x = 10, y = -10, s = y_train [i], fontsize = 18)
plt.imshow (X_train [i] .reshape (28, 28), cmap = plt.cm.Greys)
plt.show ()
Отображается случайная выборка изображений:
Теперь у вас есть представление о том, как выглядят эти изображения и ожидаемый результат прогноза.
Обучить на удаленном кластере
Для этой задачи вы отправляете задание на выполнение в кластере удаленного обучения, который вы настроили ранее. Чтобы отправить вакансию вам:
- Создать каталог
- Создать сценарий обучения
- Создание объекта оценки
- Отправить задание
Создать каталог
Создайте каталог для доставки необходимого кода с вашего компьютера на удаленный ресурс.
импорт ОС
script_folder = os.path.join (os.getcwd (), "sklearn-mnist")
os.makedirs (script_folder, exist_ok = True)
Создать сценарий обучения
Чтобы отправить задание в кластер, сначала создайте сценарий обучения. Выполните следующий код, чтобы создать обучающий сценарий с именем train.py в только что созданном каталоге.
%% writefile $ script_folder / train.py
import argparse
импорт ОС
импортировать numpy как np
импортный глобус
из sklearn.linear_model import LogisticRegression
импорт joblib
из azureml.основной импорт Выполнить
из утилит import load_data
# разрешить пользователю вводить 2 параметра: набор данных для монтирования или загрузки и скорость регуляризации модели логистической регрессии
parser = argparse.ArgumentParser ()
parser.add_argument ('- папка данных', type = str, dest = 'папка_данных', help = 'точка подключения папки данных')
parser.add_argument ('- регуляризация', type = float, dest = 'reg', по умолчанию = 0,01, help = 'скорость регуляризации')
args = parser.parse_args ()
data_folder = args.data_folder
print ('Папка данных:', папка_данных)
# загружаем поезд и набор тестов в массивы numpy
# обратите внимание, что мы масштабируем значения яркости пикселей до 0-1 (делением на 255.0), чтобы модель могла сойтись быстрее.
X_train = load_data (glob.glob (os.path.join (data_folder, '** / train-images-idx3-ubyte.gz'), recursive = True) [0], False) / 255,0
X_test = load_data (glob.glob (os.path.join (data_folder, '** / t10k-images-idx3-ubyte.gz'), рекурсивный = True) [0], False) / 255.0
y_train = load_data (glob.glob (os.path.join (data_folder, '** / train-labels-idx1-ubyte.gz'), рекурсивный = True) [0], True) .reshape (-1)
y_test = load_data (glob.glob (os.path.join (data_folder, '** / t10k-labels-idx1-ubyte.gz'), recursive = True) [0], True).изменить форму (-1)
print (X_train.shape, y_train.shape, X_test.shape, y_test.shape, sep = '\ n')
# получить текущий запуск
run = Run.get_context ()
print ('Обучите модель логистической регрессии со скоростью регуляризации', args.reg)
clf = LogisticRegression (C = 1.0 / args.reg, solver = "liblinear", multi_class = "auto", random_state = 42)
clf.fit (X_train, y_train)
print ('Предсказать набор тестов')
y_hat = clf.predict (X_test)
# вычислить точность прогноза
acc = np.average (y_hat == y_test)
print ('Точность', соотв.)
запустить.log ('уровень регуляризации', np.float (args.reg))
run.log ('точность', np.float (согласно))
os.makedirs ('выходы', exist_ok = True)
# файл заметки, сохраненный в папке выходов, автоматически загружается в запись эксперимента
joblib.dump (значение = clf, filename = 'output / sklearn_mnist_model.pkl')
Обратите внимание, как сценарий получает данные и сохраняет модели:
Сценарий обучения считывает аргумент, чтобы найти каталог, содержащий данные. Когда вы отправляете задание позже, вы указываете на хранилище данных для этого аргумента:
парсер.add_argument ('- папка данных', type = str, dest = 'папка_данных', help = 'точка подключения каталога данных')Сценарий обучения сохраняет вашу модель в каталоге с именем , выводит . Все, что написано в этом каталоге, автоматически загружается в ваше рабочее пространство. Вы получите доступ к своей модели из этого каталога позже в руководстве.
joblib.dump (значение = clf, filename = 'output / sklearn_mnist_model.pkl')Для обучающего скрипта требуется файл
utils.py, чтобы правильно загрузить набор данных. Следующий код копируетutils.pyвscript_folder, чтобы к файлу можно было получить доступ вместе со сценарием обучения на удаленном ресурсе.импортный шутиль shutil.copy ('utils.py', папка_скрипта)
Создать оценщик
Объект оценки используется для отправки прогона. Машинное обучение Azure имеет предварительно настроенные оценщики для распространенных платформ машинного обучения, а также общий оценщик.Создайте оценщик, указав
- Имя объекта оценщика,
est. - Каталог, содержащий ваши сценарии. Все файлы в этом каталоге загружаются в узлы кластера для выполнения.
- Цель вычислений. В этом случае вы используете созданный вами вычислительный кластер Машинного обучения Azure.
- Имя обучающего скрипта, train.py .
- Среда, содержащая библиотеки, необходимые для запуска сценария.
- Параметры, необходимые для обучающего сценария.
В данном руководстве это AmlCompute. Все файлы в папке сценария загружаются в узлы кластера для запуска. data_folder настроен на использование набора данных. «Сначала создайте среду, которая содержит: библиотеку scikit-learn, azureml-dataprep, необходимую для доступа к набору данных, и azureml-defaults, которая содержит зависимости для регистрации метрик. Azureml-defaults также содержит зависимости, необходимые для развертывания модели как веб-сервис позже во второй части руководства.
После того, как среда определена, зарегистрируйте ее в Рабочей области, чтобы повторно использовать ее в части 2 руководства.
из azureml.core.environment import Environment
из azureml.core.conda_dependencies импорт CondaDependencies
# для установки необходимых пакетов
env = Среда ('учебник-env')
cd = CondaDependencies.create (pip_packages = ['azureml-dataprep [pandas, fuse]> = 1.1.14', 'azureml-defaults'], conda_packages = ['scikit-learn == 0.22.1'])
env.python.conda_dependencies = cd
# Зарегистрируйте среду для повторного использования позже
окр.зарегистрироваться (рабочая область = WS)
Затем создайте оценщик с помощью следующего кода.
из оценщика импорта azureml.train.estimator
script_params = {
# для монтирования файлов, на которые ссылается набор данных mnist
'--data-folder': mnist_file_dataset.as_ named_input ('mnist_opendataset'). as_mount (),
'--регуляризация': 0,5
}
est = Оценщик (source_directory = script_folder,
script_params = параметры_сценария,
compute_target = compute_target,
environment_definition = env,
entry_script = 'поезд.ру ')
Отправить задание в кластер
Запустите эксперимент, отправив объект оценки:
запустить = exp.submit (config = est)
бегать
Поскольку вызов является асинхронным, он возвращает состояние Подготовка или Выполняется , как только задание запускается.
Мониторинг удаленного запуска
В общей сложности первый прогон занимает около 10 минут . Но для последующих запусков, пока зависимости скрипта не изменяются, то же изображение используется повторно.Таким образом, время запуска контейнера намного быстрее.
Что происходит, пока вы ждете:
Создание образа : создается образ Docker, соответствующий среде Python, заданной оценщиком. Изображение загружено в рабочую область. Создание и загрузка изображения занимает около пяти минут .
Этот этап выполняется один раз для каждой среды Python, поскольку контейнер кэшируется для последующих запусков. Во время создания образа журналы передаются в журнал запусков.Вы можете отслеживать процесс создания образа с помощью этих журналов.
Масштабирование : Если удаленному кластеру требуется больше узлов для выполнения, чем доступно в настоящее время, дополнительные узлы добавляются автоматически. Масштабирование обычно занимает около пяти минут.
Запуск : на этом этапе необходимые сценарии и файлы отправляются в целевой объект вычислений. Затем подключаются или копируются хранилища данных. Затем запускается entry_script .Во время выполнения задания stdout и каталог ./logs передаются в журнал выполнения. Вы можете отслеживать ход выполнения с помощью этих журналов.
Постобработка : Каталог ./outputs цикла копируется в журнал запусков в вашем рабочем пространстве, поэтому вы можете получить доступ к этим результатам.
Проверить ход выполнения задания можно несколькими способами. В этом руководстве используется виджет Jupyter и метод wait_for_completion .
Виджет Jupyter
Наблюдайте за ходом выполнения с помощью виджета Jupyter. Как и отправка запуска, виджет является асинхронным и предоставляет обновления в реальном времени каждые 10–15 секунд до завершения задания:
из azureml.widgets import RunDetails
RunDetails (запустить) .show ()
В конце обучения виджет будет выглядеть следующим образом:
Если вам нужно отменить запуск, вы можете следовать этим инструкциям.
Получить результаты журнала по завершении
Обучение и мониторинг модели происходят в фоновом режиме.Подождите, пока модель завершит обучение, прежде чем запускать новый код. Используйте wait_for_completion , чтобы показать, когда обучение модели завершено:
run.wait_for_completion (show_output = False) # укажите True для подробного журнала
Показать результаты выполнения
Теперь у вас есть модель, обученная на удаленном кластере. Получить точность модели:
печать (run.get_metrics ())
Выходные данные показывают, что удаленная модель имеет точность 0.9204:
{'уровень регуляризации': 0,8, 'точность': 0,9204}
В следующем руководстве вы исследуете эту модель более подробно.
Регистровая модель
На последнем этапе обучающего сценария был записан файл output / sklearn_mnist_model.pkl в каталог с именем output в виртуальной машине кластера, в котором выполняется задание. выводит — это специальный каталог, в котором все содержимое этого каталога автоматически загружается в вашу рабочую область.Это содержимое отображается в записи запуска эксперимента в вашей рабочей области. Таким образом, файл модели теперь также доступен в вашем рабочем пространстве.
Вы можете увидеть файлы, связанные с этим запуском:
печать (run.get_file_names ())
Зарегистрируйте модель в рабочей области, чтобы вы или другие соавторы могли позже запросить, изучить и развернуть эту модель:
# зарегистрировать модель
model = run.register_model (model_name = 'sklearn_mnist',
model_path = 'выходы / sklearn_mnist_model.пкл ')
print (имя модели, идентификатор модели, версия модели, sep = '\ t')
Очистить ресурсы
Важно
Созданные вами ресурсы можно использовать в качестве предварительных условий для других руководств по машинному обучению Azure и статей с практическими рекомендациями.
Если вы не планируете использовать созданные вами ресурсы, удалите их, чтобы не платить за вас:
На портале Azure выберите Группы ресурсов в крайнем левом углу.
Из списка выберите созданную вами группу ресурсов.
Выберите Удалить группу ресурсов .
Введите имя группы ресурсов. Затем выберите Удалить .
Вы также можете удалить только вычислительный кластер машинного обучения Azure. Однако автомасштабирование включено, и минимум кластера равен нулю. Таким образом, этот конкретный ресурс не требует дополнительных затрат на вычисления, когда он не используется:
# При желании удалите вычислительный кластер машинного обучения Azure
compute_target.Удалить()
Следующие шаги
В этом руководстве по машинному обучению Azure вы использовали Python для следующих задач:
- Настройте среду разработки.
- Получите доступ к данным и проверьте их.
- Обучите несколько моделей в удаленном кластере с помощью популярной библиотеки машинного обучения scikit-learn
- Просмотрите подробности обучения и зарегистрируйте лучшую модель.
Вы готовы развернуть эту зарегистрированную модель, используя инструкции в следующей части серии руководств:
.