получить количество элементов в списке
Получение количества элементов в списке в Python — обычная операция. Например, вам нужно будет знать, сколько элементов в списке, когда вы его просматриваете. Помните, что списки могут содержать в качестве своих элементов комбинацию целых чисел, чисел с плавающей запятой, строк, логических значений, других списков и т. д:
# List of just integers
list_a = [12, 5, 91, 18]
# List of integers, floats, strings, booleans
list_b = [4, 1.2, "hello world", True]
list_a, мы получим всего 5 элементов. Если мы сделаем то же самое для
Если мы сделаем то же самое для list_b, мы получим 4 элемента.Есть разные способы узнать количество элементов в списке. Подходы различаются, хотите ли вы считать вложенные списки как один элемент или все элементы во вложенных списках, или если вас интересуют только уникальные элементы и т.д.
Встроенная функция len()
len().Давайте посмотрим на следующий пример:
list_a = ["Hello", 2, 15, "World", 34] number_of_elements = len(list_a) print("Number of elements in the list: ", number_of_elements)
Результат:
Number of elements in the list: 5
Как следует из названия, функция 
Использование цикла for
Другой способ сделать это — создать функцию, которая просматривает список с помощью цикла for. Сначала мы инициализируем счетчик элементов равным 0, и каждый раз, когда выполняется итерация цикла, счет увеличивается на 1.
Цикл заканчивается, когда он перебирает все элементы, поэтому счетчик будет представлять общее количество элементов в списке:
list_c = [20, 8.9, "Hi", 0, "word", "name"] def get_number_of_elements(list): count = 0 for element in list: count += 1 return count print("Number of elements in the list: ", get_number_of_elements(list_c))
 9, "Hi", 0, "word", "name"]
def get_number_of_elements(list):
count = 0
for element in list:
count += 1
return count
print("Number of elements in the list: ", get_number_of_elements(list_c))
9, "Hi", 0, "word", "name"]
def get_number_of_elements(list):
count = 0
for element in list:
count += 1
return count
print("Number of elements in the list: ", get_number_of_elements(list_c))
Запуск этого кода напечатает:
Number of elements in the list: 6
Это гораздо более подробное решение по сравнению с функцией len(), но его стоит рассмотреть, поскольку позже в статье мы увидим, что ту же идею можно применить, когда мы имеем дело со списком списков. Кроме того, вы можете захотеть выполнить некоторую операцию либо над самими элементами, либо с операцией в целом, что в данном случае возможно.
Получить количество уникальных элементов в списке
Списки могут состоять из нескольких элементов, включая дубликаты. Если мы хотим получить количество элементов без дубликатов (уникальных элементов), мы можем использовать другую встроенную функцию set, который отклоняет все повторяющиеся значения.
Затем мы передаем это в функцию len(), чтобы получить количество элементов в set:
list_d = [100, 3, 100, "c", 100, 7. 9, "c", 15]
number_of_elements = len(list_d)
number_of_unique_elements = len(set(list_d))
print("Number of elements in the list: ", number_of_elements)
print("Number of unique elements in the list: ", number_of_unique_elements)

Результат:
Number of elements in the list: 8 Number of unique elements in the list: 5
Мы видим, что в list_d 8 элементов, 5 из которых уникальны.
Список списков с использованием len()
Во введении мы увидели, что элементы списков могут иметь разные типы данных.
list_e = [[90, 4, 12, 2], [], [34, 45, 2], [9,4], "char", [7, 3, 19]]
Если мы используем встроенную функцию len(), списки считаются отдельными элементами, поэтому у нас будет:
number_of_elements = len(list_e) print("Number of elements in the list of lists: ", number_of_elements)
Результат:
Number of elements in the list of lists: 6
Обратите внимание, что пустой список считается одним элементом.
for и пригодится.Получить количество элементов в списке, содержащем другие списки
Если мы хотим подсчитать все элементы внутри списка, содержащего другие списки, мы можем использовать цикл for. Мы можем инициализировать переменную count= 0 и просмотреть список. На каждой итерации цикла count увеличивается на длину этого списка.
Для получения длины воспользуемся встроенной функцией len():
list_e = [[90, 4, 12, 2], [], [34, 45, 2], [9,4], "char", [7, 3, 19]]
def get_all_elements_in_list_of_lists(list):
count = 0
for element in list_e:
count += len(element)
return count
print("Total number of elements in the list of lists: ", get_all_elements_in_list_of_lists(list_e))
Результат:
Total number of elements in the list of lists: 16
В этом примере следует отметить несколько важных моментов. Во-первых, на этот раз пустой список не повлиял на общий счет. Это связано с тем, что в каждом цикле мы учитываем длину текущего вложенного списка и, поскольку длина пустого списка равна 0,
Во-первых, на этот раз пустой список не повлиял на общий счет. Это связано с тем, что в каждом цикле мы учитываем длину текущего вложенного списка и, поскольку длина пустого списка равна 0, count увеличивается на 0.
Однако вы можете видеть, что каждый символ строки "char" учитывается в общем количестве элементов. Это связано с тем, что функция len() воздействует на строку, возвращая все ее символы. Мы можем избежать этой ситуации, используя тот же подход, что и в разделе ниже, который также позволит нам иметь элементы, отличные от списков.
Еще один интересный способ сделать то же самое, что и в предыдущем примере, — использовать определение списка:
number_of_elements = sum([len(element) for element in list_e])
Эта строка, по сути, делает две вещи.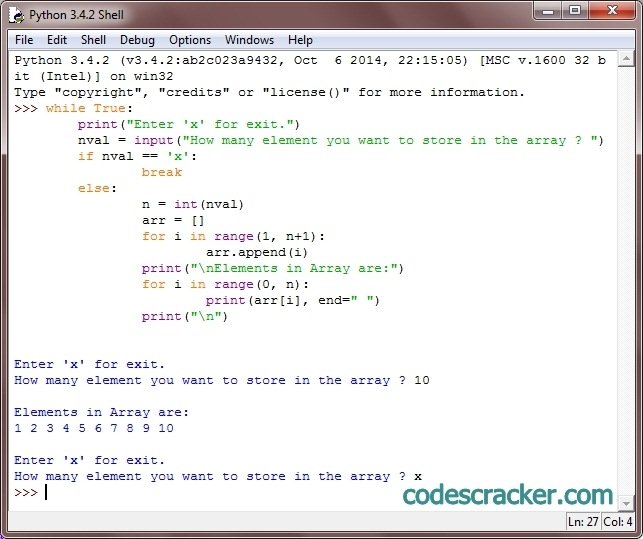 Во-первых, он создает новый список, содержащий длины всех элементов исходного списка. В нашем случае это было бы так
Во-первых, он создает новый список, содержащий длины всех элементов исходного списка. В нашем случае это было бы так [4, 0, 3, 2, 4, 3]. Во-вторых, он вызывает функцию sum(), используя вновь созданный список в качестве параметра, который возвращает общую сумму всех элементов, давая нам желаемый результат.
Вложенные списки
Вложенные списки — это списки, которые являются элементами других списков. Внутри списков может быть несколько уровней:
list_f = [30, 0.9, [8, 56, 22, ["a", "b"]], [200, 3, [5, [89], 10]]]
Мы видим, что ["a", "b"] содержится в списке [8, 56, 22, ["a", "b"]], который, в свою очередь, содержится в основном списке [30, 0.. 9,[200, 3, [5, [89], 10]]]
9,[200, 3, [5, [89], 10]]]
Опять же, мы инициализируем переменную count равной 0. Если мы хотим получить общее количество элементов во вложенном списке, нам сначала нужно проверить, является ли элемент списком или нет. Если это так, мы выполняем цикл внутри списка и рекурсивно вызываем функцию до тех пор, пока не останутся вложенные списки. Все элементы, кроме списков (целые числа, строки и т.д.), увеличивают счетчик на 1.
Обратите внимание, что это также решение проблем, вызванных предыдущим подходом.
Давайте посмотрим на код для подсчета элементов во вложенных списках:
list_f = [30, 0. 9, [8, 56, 22, ["a", "hello"]], [200, 3, [5, [89], 10]]]
def get_elements_of_nested_list(element):
count = 0
if isinstance(element, list):
for each_element in element:
count += get_elements_nested_list(each_element)
else:
count += 1
return count
print("Total number of elements in the nested list: ", get_elements_of_nested_list(list_f))
 9, [8, 56, 22, ["a", "hello"]], [200, 3, [5, [89], 10]]]
def get_elements_of_nested_list(element):
count = 0
if isinstance(element, list):
for each_element in element:
count += get_elements_nested_list(each_element)
else:
count += 1
return count
print("Total number of elements in the nested list: ", get_elements_of_nested_list(list_f))
9, [8, 56, 22, ["a", "hello"]], [200, 3, [5, [89], 10]]]
def get_elements_of_nested_list(element):
count = 0
if isinstance(element, list):
for each_element in element:
count += get_elements_nested_list(each_element)
else:
count += 1
return count
print("Total number of elements in the nested list: ", get_elements_of_nested_list(list_f))
Запуск этого кода даст нам:
Total number of elements in the nested list: 12
Обратите внимание, что мы использовали встроенную функцию isinstance(), которая проверяет, является ли первый аргумент экземпляром класса, заданного вторым аргументом. В приведенной выше функции он проверяет, является ли элемент списком.
В приведенной выше функции он проверяет, является ли элемент списком.
Первый элемент является целым числом 30, поэтому функция переходит к блоку else и увеличивает счетчик на 1. Когда мы добираемся до [8, 56, 22, ["a", "hello"]], функция распознает список и рекурсивно просматривает его, чтобы проверить наличие других списков.
Вывод
Мы увидели, что в зависимости от типа списка, который у нас есть, есть разные способы получить количество элементов. len() это определенно самая быстрая и простая функция, если у нас есть плоские списки.
При использовании вложенных списков элементы внутри списков не учитываются len(). Для этого нам нужно перебрать весь список.
Python. Списки. Свойства списков. Примеры использования
Списки. Свойства списков. Примеры, которые демонстрируют разные свойства списков
Содержание
Поиск на других ресурсах:
1. Что такое список в языке программирования Python? Особенности использования списков в Python
В языке программирования Python список есть тип объекта, который позволяет содержать объекты различных типов: числа, строки, списки и т.п.. Иными словами, список представляет собой запись, в которой объединены объекты различных типов (числа, строки, и т.п. ).
).
Списки являются эффективными для программирования задач, в которых нужно сохранять различные виды данных.
По сравнению с другими языками программирования в Python работа с списками есть очень удобной. Чтобы реализовать корректную работу со списками в другом, более низкоуровневом языке программирования (например C), нужно приложить немало усилий. В Python списки реализуют все необходимое для обработки коллекций данных.
Списки – это объекты, которые можно непосредственно изменять с помощью операции присваивания.
⇑
2. Основные свойства списков
Выделяют следующие свойства списков:
- Списки это последовательности объектов произвольных типов. Списки – это группы объектов произвольных типов, которые обеспечивают позиционное последовательное размещение элементов в порядке «слева — направо».
- Обеспечение доступа к элементу списка по индексу. В Python есть возможность получить элемент списка с помощью операции индексирования (см. п. 5). В этом случае получается элемент списка с заданным индексом. Номера индексов в списке начинаются с 0. Кроме того, можно выполнять получение элементов по срезам и конкатенацию списков.
- Переменная длина списков. Количество элементов (объектов) в списке можно изменять. Иными словами, списки можно увеличивать и уменьшать (см. п. 6).
- Гетерогенность списков. Под понятием «гетерогенность списков» понимается то, что списки могут содержать другие сложные объекты (см. п. 8).
- Произвольное количество вложений списков. Списки могут содержать произвольное количество вложений. То есть, можно создавать списки из списков (см. п. 9).
- Списки принадлежат к категории изменяемых объектов. Это свойство означает, что списки могут изменяться непосредственно. Списки поддерживают операции, которые позволяют их изменять, а именно: присваивание по индексу, добавление/удаление элементов по индексу, конкатенация, присваивание срезу.
- Возможность содержать массивы ссылок на другие объекты. Списки могут содержать ноль и более ссылок на другие объекты (см. п. 8). Списки могут содержать ссылку на объект (объекты) в случае присваивания этого объекта имени переменной или структуры.
 п. 5). В этом случае получается элемент списка с заданным индексом. Номера индексов в списке начинаются с 0. Кроме того, можно выполнять получение элементов по срезам и конкатенацию списков.
п. 5). В этом случае получается элемент списка с заданным индексом. Номера индексов в списке начинаются с 0. Кроме того, можно выполнять получение элементов по срезам и конкатенацию списков.
⇑
3. Примеры создания списков. Создание пустого списка
Пример 1. В примере демонстрируется создание списка с помощью оператора присваивания, оператора цикла while и оператора конкатенации +.
# Примеры создания списков различными способами
# Создание пустого списка
L1 = []
# Формирование списка с помощью операции конкатенации +
i=0
while i<10:
L1=L1+[i]
i=i+1
print("L1 = ",L1)Как видно из программного кода, в строке
L1 = []
создается пустой список.
В результате выполнения вышеприведенного кода будет выведен следующий результат
L1 = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Пример 2. Создается список символов из объекта типа «строка». Строка состоит из символов. Эти символы могут создать последовательность, то есть список.
Создается список символов из объекта типа «строка». Строка состоит из символов. Эти символы могут создать последовательность, то есть список.
# Примеры создания списков различными способами
# Создание списка из итерируемого объекта
L = list('abc') # L = [ 'a', 'b', 'c']
print("L = ",L)В данном примере создание строки
L = list('abc')можно написать по другому
L = list("abc")Результат выполнения программы
L = ['a', 'b', 'c']
Пример 3. Создается список из непрерывной последовательности целых чисел
# Примеры создания списков различными способами
# Создание списка из непрерырвной последовательности целых чисел
L = list(range(1,10))
print("L = ",L) # L = [1, 2, 3, 4, 5, 6, 7, 8, 9]Как видно из кода, для получения последовательности 1, 2, …, 9 используется операция
range(1,10)
Для создания списка используется операция
list(range(1,10))
Слово list означает имя типа данных «список» и используется для создания списков
Результат выполнения программы
L = [1, 2, 3, 4, 5, 6, 7, 8, 9]
⇑
4.
 Какое назначение операции list?
Какое назначение операции list?Операция list используется для создания новой копии списка. Операция list представляет собой имя типа данных «список».
В Python операция list реализована как отдельный класс, содержит большой набор методов работы со списками. Чтобы просмотреть перечень методов класса list в Python Shell нужно набрать
help(list)
Более подробно об использовании методов класса list описывается в теме:
Ниже приведены примеры создания списков с помощью операции list
DAYS = list(range(1,8)) # DAYS = [1, 2, 3, 4, 5, 6, 7]
SYMBOLS = list("Hello") # ITEMS = ['H', 'e', 'l', 'l', 'o']⇑
5. Как осуществляется доступ к элементу списка по его индексу. Примеры
Пример 1. В примере создается список из 3-х элементов различных типов. Затем по очереди выводятся значения каждого элемента списка.
>>> myList=[2.5, 8, "Hello"] >>> myList[0] # вывести элемент списка по индексу 0 2.
 5
>>> myList[1]
8
>>> myList[2]
'Hello'
>>>
5
>>> myList[1]
8
>>> myList[2]
'Hello'
>>>Как видно из примера, нумерация элементов списка начинается с 0.
Пример 2. Использование элемента списка в выражении. Важно, чтобы значение элемента списка было корректным в операциях, которые используются в выражении.
# использование списка в выражении
L=[2,3,4]
x=5
y=x+L[1] # y=5+3=8
print("y = ",y)
LS = ["456", 7, 3.1415]
s = "123"
s += LS[0] # s="123456"
print("s = ", s)Результат выполнения программы
y = 8 s = 123456
Если попробовать добавить к числу строку
s = s + LS[1] # добавить к числу строку - ошибка!
то интерпретатор Python выведет сообщение об ошибке.
TypeError: can only concatenate str (not "int") to str
⇑
6. Пример, который демонстрирует свойство увеличения/уменьшения длины списка
В примере продемонстрировано свойство увеличения и уменьшения списка A. Увеличение длины списка выполняется в цикле с помощью операции конкатенации +. Уменьшение длины списка реализовано двумя способами:
Увеличение длины списка выполняется в цикле с помощью операции конкатенации +. Уменьшение длины списка реализовано двумя способами:
- с помощью цикла while, в котором вычисляется позиция последнего элемента. Количество элементов в цикле определяется операцией len. Удаление элемента осуществляется операцией del;
- с помощью операции del, в которой задается диапазон удаляемых элементов списка.
Текст программы следующий:
# Примеры увеличения/уменьшения длины списка
# создать список
A = []
# сформировать список из 10 элементов путем ввода с клавиатуры
i=0
while i<10:
x = float(input("x = "))
A = A+[x] # увеличение списка
i=i+1
print("Исходный список")
print("A = ",A)
print("Уменьшение списка A на 3 элемента")
i=0
while i<3:
n = len(A) # взять длину списка
del A[n-1] # удалить последний элемент списка
i=i+1
print("A = ", A)
print("Уменьшение списка еще на 2 последних элемента")
del A[n-3:n-1]
print("A = ", A)Результат выполнения программы
x = 1 x = 2 x = 3 x = 4 x = 5 x = 6 x = 7 x = 8 x = 9 x = 10 Исходный список A = [1.
 0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0]
Уменьшение списка A на 3 элемента
A = [1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0]
Уменьшение списка еще на 2 последних элемента
A = [1.0, 2.0, 3.0, 4.0, 5.0]
0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0]
Уменьшение списка A на 3 элемента
A = [1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0]
Уменьшение списка еще на 2 последних элемента
A = [1.0, 2.0, 3.0, 4.0, 5.0]⇑
7. Как определить длину списка? Операция len. Пример
Длина списка – это количество элементов списка. Длина списка определяется операцией len.
Пример. В примере определяется длина списка с помощью операции len.
# Определение длины списка операцией len
A = [ 3.5, 2.8, 'abc', [ 2, 3, False]]
length = len(A)
print("length = ", length) # length = 4
B = [ "Hello world!" ]
length = len(B)
print("length = ", length) # length = 1
C = [ 0, 3, 2, 4, 7 ]
length = len(C)
print("length = ", length) # length = 5Результат выполнения программы
length = 4 length = 1 length = 5
⇑
8. Пример создания списка, содержащего другие сложные объекты
В примере создается список с именем D, который содержит другие сложные объекты:
- два списка с именами A, B;
- кортеж с именем C;
- строку с именем STR.
# Пример списка, содержащего сложные объекты
# объявляются списки, кортеж и строка символов
A = [] # пустой список
B = [ 1, 3, -1.578, 'abc' ] # список з разнотипными объектами
C = ( 2, 3, 8, -10 ) # кортеж
S = "Hello world!"
# список, содержащий разные сложные объекты
D = [ A, B, C, S ]
print("D = ", D)Выполнение программы дает следующий результат
D = [[], [1, 3, -1.578, 'abc'], (2, 3, 8, -10), 'Hello world!']
⇑
9. Пример, демонстрирующий свойство произвольного количества вложений списков
В примере формируется список L, включающий два подсписка
# Произвольное количество вложений списков
L = [ [ 'abc', 2.5, 117 ], [ 29, False, 'DEF', "Hello" ] ]
# вывод элементов списка
print("L[0][1] = ", L[0][1]) # L[0][1] = 2.5
print("L[0][2] = ", L[0][2]) # L[0][2] = 117
print("L[1][0] = ", L[1][0]) # L[1][0] = 29
print("L[1][2] = ", L[1][2]) # L[1][2] = 'DEF'Результат выполнения программы
L[0][1] = 2.
 5
L[0][2] = 117
L[1][0] = 29
L[1][2] = DEF
5
L[0][2] = 117
L[1][0] = 29
L[1][2] = DEF⇑
10. Какой результат даст операция присваивания списков B=A?
Если выполнить операцию присваивания списков B=A, то два имени будут указывать на один и тот же список. Это значит, что изменения в списке B будут влиятьна список A. Точно также, изменения в списке A будут влиять на список B.
Для того, чтоб из списка A создать другой список B (копию списка A), нужно использовать операцию list.
Например.
# Особенности операции присваивания =
# Создать список A
A = list(range(1,10)) # A = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# вызов операции присваивания
B = A # Имена B и A указывают на один и тот же список
# изменить список B
B[3] = 100 # также изменяется список A
# Создать копию списка A с помощью операции list
C = list(A) # C = [1, 2, 3, 100, 5, 6, 7, 8, 9]
# изменить список C
C[3] = 777; # изменяется только список C, список A не изменяется
print("A = ", A)
print("B = ", B)
print("C = ", C)Вышеприведенная программа даст следующий результат
A = [1, 2, 3, 100, 5, 6, 7, 8, 9] B = [1, 2, 3, 100, 5, 6, 7, 8, 9] C = [1, 2, 3, 777, 5, 6, 7, 8, 9]
⇑
Связанные темы
⇑
36) длина строки Python — CoderLessons.
 com
comlen () — встроенная функция в python. Вы можете использовать len (), чтобы получить длину заданной строки, массива, списка, кортежа, словаря и т. Д.
Вы можете использовать функцию len для оптимизации производительности программы. Количество элементов, хранящихся в объекте, никогда не рассчитывается, поэтому len помогает указать количество элементов.
Синтаксис:
len(value)
Параметры:
Значение : заданное значение, длина которого вы хотите.
Возвращаемое значение
Он будет возвращать целочисленное значение, то есть длину данной строки, или массива, или списка, или коллекций.
Различные типы возвращаемых значений:
Строки:
Он возвращает количество символов в строке, которое включает знаки препинания, пробел и все типы специальных символов. Тем не менее, вы должны быть очень осторожны при использовании len переменной Null.
Слейте:
Пустой — это второй обратный вызов, который содержит ноль символов, но это всегда None.
Коллекции:
Встроенная функция len возвращает количество элементов в коллекции.
TypeError:
Функция Len зависит от типа передаваемой ей переменной. Non-Type не имеет встроенной поддержки.
Толковый словарь:
Для словаря каждая пара считается одной единицей. Однако значения и ключи не являются независимыми.
Пример 1: Как найти длину заданной строки?
# testing len()
str1 = "Welcome to Guru99 Python Tutorials"
print("The length of the string is :", len(str1))
Вывод:
The length of the string is : 35
Пример 2: Как найти длину списка в Python?
# to find the length of the list
list1 = ["Tim","Charlie","Tiffany","Robert"]
print("The length of the list is", len(list1))
Вывод:
The length of the list is 4
Пример 3: Как найти длину кортежа в Python
# to find the length of the tuple
Tup = ('Jan','feb','march')
print("The length of the tuple is", len(Tup))
Вывод:
The length of the tuple is 3
Пример 4: Как узнать длину словаря в Python?
# to find the length of the Dictionary
Dict = {'Tim': 18,'Charlie':12,'Tiffany':22,'Robert':25}
print("The length of the Dictionary is", len(Dict))
Вывод:
The length of the Dictionary is 4
Пример 5: Как найти длину массива в Python
# to find the length of the array
arr1 = ['Tim','Charlie','Tiffany','Robert']
print("The length of the Array is", len(arr1))
Вывод:
The length of the Array is 4
Резюме:
- len () — это встроенная функция в python. Вы можете использовать len (), чтобы получить длину заданной строки, массива, списка, кортежа, словаря и т. д.
- Значение: заданное значение, длина которого вы хотите.
- Возвращаемое значение возвращает целочисленное значение, то есть длину заданной строки, или массива, или списка, или коллекций.
 Вы можете использовать len (), чтобы получить длину заданной строки, массива, списка, кортежа, словаря и т. д.
Вы можете использовать len (), чтобы получить длину заданной строки, массива, списка, кортежа, словаря и т. д.
Python | Длина объекта dtype массива строк Numpy
В этом посте мы увидим тип данных объекта numpy, когда базовые данные имеют строковый тип. В numpy, если базовый тип данных данного объекта — строка, тогда dtype объекта — это длина самой длинной строки в массиве. Это так, потому что мы не можем создать строку переменной длины в numpy, поскольку numpy нужно знать, сколько места должно быть выделено для строки.
Проблема № 1: Дан пустой массив, базовые данные которого имеют строковый тип. Найдите dtype.
Решение: Мы будем использовать атрибут numpy.dtype чтобы проверить dtype данного объекта.
|
 array([
array([ Выход :
Теперь мы проверим dtype данного объекта массива, базовые данные которого имеют строковый тип.
Выход :
Как мы видим в выводе, dtype данного объекта массива равен '<U9' где 9 — длина самой длинной строки в данном объекте массива.
Давайте проверим это, проверив длину самой длинной строки в данном объекте.
|

Выход :
Проблема № 2: Приведен массив с пустым массивом, базовые данные которого имеют строковый тип. Найдите dtype.
Решение: Мы будем использовать атрибут numpy.dtype чтобы проверить dtype данного объекта.
|
Выход :
Теперь мы проверим dtype данного объекта массива, базовые данные которого имеют строковый тип.
Выход :
Как мы видим на выходе, dtype данного объекта массива равен '<U8' где 8 — длина самой длинной строки в данном объекте массива.
Давайте проверим это, проверив длину самой длинной строки в данном объекте.
|
Выход :
Рекомендуемые посты:
Python | Длина объекта dtype массива строк Numpy
0.00 (0%) 0 votes
Цикл for. Урок 18 курса «Python. Введение в программирование»
Цикл for в языке программирования Python предназначен для перебора элементов структур данных и некоторых других объектов. Это не цикл со счетчиком, каковым является for во многих других языках.
Что значит перебор элементов? Например, у нас есть список, состоящий из ряда элементов. Сначала берем из него первый элемент, затем второй, потом третий и так далее. С каждым элементом мы выполняем одни и те же действия в теле for. Нам не надо извлекать элементы по их индексам и заботится, на каком из них список заканчивается, и следующая итерация бессмысленна. Цикл for сам переберет и определит конец.
>>> spisok = [10, 40, 20, 30] >>> for element in spisok: ... print(element + 2) ... 12 42 22 32
После ключевого слова for используется переменная под именем element. Имя здесь может быть любым. Нередко используют i. На каждой итерации цикла for ей будет присвоен очередной элемент из списка spisok. Так при первой прокрутке цикла идентификатор element связан с числом 10, на второй – с числом 40, и так далее. Когда элементы в spisok заканчиваются, цикл for завершает свою работу.
С английского «for» переводится как «для», «in» как «в». Перевести конструкцию с языка программирования на человеческий можно так: для каждого элемента в списке делать следующее (то, что в теле цикла).
В примере мы увеличивали каждый элемент на 2 и выводили его на экран. При этом сам список конечно же не изменялся:
>>> spisok [10, 40, 20, 30]
Нигде не шла речь о перезаписи его элементов, они просто извлекались и использовались. Однако бывает необходимо изменить сам список, например, изменить значение каждого элемента в нем или только определенных, удовлетворяющих определенному условию. И тут без переменной, обозначающей индекс элемента, в большинстве случаев не обойтись:
>>> i = 0 >>> for element in spisok: ... spisok[i] = element + 2 ... i += 1 ... >>> spisok [12, 42, 22, 32]
Но если мы вынуждены использовать счетчик, то выгода от использования цикла for не очевидна. Если знать длину списка, то почему бы не воспользоваться while. Длину можно измерить с помощью встроенной в Python функции len().
Если знать длину списка, то почему бы не воспользоваться while. Длину можно измерить с помощью встроенной в Python функции len().
>>> i = 0 >>> while i < len(spisok): ... spisok[i] = spisok[i] + 2 ... i = i + 1 # или i += 1 ... >>> spisok [14, 44, 24, 34]
Кроме того, с циклом while мы избавились от переменной element.
Функция range()
Теперь пришло время познакомиться со встроенной в Python функцией range(). «Range» переводится как «диапазон». Она может принимать один, два или три аргумента. Их назначение такое же как у функции randrange() из модуля random. Если задан только один, то генерируются числа от 0 до указанного числа, не включая его. Если заданы два, то числа генерируются от первого до второго, не включая его. Если заданы три, то третье число – это шаг.
Однако, в отличие от randrange(), функция range() генерирует не одно случайное число в указанном диапазоне. Она вообще не генерирует случайные числа. Она генерирует последовательность чисел в указанном диапазоне. Так, range(5, 11) сгенерирует последовательность 5, 6, 7, 8, 9, 10. Однако это будет не структура данных типа «список». Функция range() производит объекты своего класса – диапазоны:
Она генерирует последовательность чисел в указанном диапазоне. Так, range(5, 11) сгенерирует последовательность 5, 6, 7, 8, 9, 10. Однако это будет не структура данных типа «список». Функция range() производит объекты своего класса – диапазоны:
>>> a = range(-10, 10) >>> a range(-10, 10) >>> type(a) <class 'range'>
Несмотря на то, что мы не видим последовательности чисел, она есть, и мы можем обращаться к ее элементам:
>>> a[0] -10 >>> a[5] -5 >>> a[15] 5 >>> a[-1] 9
Хотя изменять их нельзя, так как, в отличие от списков, объекты range() относятся к группе неизменяемых:
>>> a[10] = 100 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'range' object does not support item assignment
Цикл for и range()
Итак, зачем нам понадобилась функций range() в теме про цикл for? Дело в том, что вместе они образуют неплохой тандем. For как цикл перебора элементов, в отличие от while, позволяет не следить за тем, достигнут ли конец структуры. Не надо вводить счетчик для этого, изменять его и проверять условие в заголовке. С другой стороны, range() дает последовательность целых чисел, которые можно использовать как индексы для элементов того же списка.
For как цикл перебора элементов, в отличие от while, позволяет не следить за тем, достигнут ли конец структуры. Не надо вводить счетчик для этого, изменять его и проверять условие в заголовке. С другой стороны, range() дает последовательность целых чисел, которые можно использовать как индексы для элементов того же списка.
>>> range(len(spisok)) range(0, 4)
Здесь с помощью функции len() измеряется длина списка. В данном случае она равна четырем. После этого число 4 передается в функцию range(), и она генерирует последовательность чисел от 0 до 3 включительно. Это как раз индексы элементов нашего списка.
Теперь «соединим» for и range():
>>> for i in range(len(spisok)): ... spisok[i] += 2 ... >>> spisok [16, 46, 26, 36]
В заголовке цикла for берутся элементы вовсе не списка, а объекта range. Список, элементы которого планируется перезаписывать, тут по-сути не фигурирует. Если заранее знать длину списка, то заголовок может выглядеть так: for i in range(4). То, как используется i в теле цикла, вопрос второй. Примечание. Вместо идентификатора
То, как используется i в теле цикла, вопрос второй. Примечание. Вместо идентификатора i может быть любой другой.
Функция enumerate()
В Python есть еще одна встроенная функция, которая часто используется в заголовке for. Это функция enumerate(). Если range() позволяет получить только индексы элементов списка, то enumerate() генерирует пары кортежей, состоящих из индекса элемента и значения элемента.
>>> spisok = [16, 46, 26, 36] >>> for i in enumerate(spisok): ... print(i) ... (0, 16) (1, 46) (2, 26) (3, 36)
Эти кортежи можно распаковывать, то есть извлекать индекс и значение, в теле цикла:
>>> for item in enumerate(spisok): ... print(item[0], item[1]) ... 0 16 1 46 2 26 3 36
Однако чаще это делают еще в заголовке for, используя две переменные перед in:
>>> for id, val in enumerate(spisok): ... print(id, val) ... 0 16 1 46 2 26 3 36
Если функция enumerate() так хороша, зачем использовать range() в заголовке for? На самом деле незачем, если только вам так не проще. Кроме того, бывают ситуации, когда значения не нужны, нужны только индексы. Однако следует учитывать один нюанс. Функция enumerate() возвращает так называемый объект-итератор. Когда такие объекты сгенерировали значения, то становятся «пустыми». Второй раз по ним пройтись нельзя.
Кроме того, бывают ситуации, когда значения не нужны, нужны только индексы. Однако следует учитывать один нюанс. Функция enumerate() возвращает так называемый объект-итератор. Когда такие объекты сгенерировали значения, то становятся «пустыми». Второй раз по ним пройтись нельзя.
Функция range() возвращает итерируемый объект. Хотя такой объект может быть превращен в итератор, сам по себе таковым не является.
Когда range() и enumerate() используются в заголовке for, то разницы нет, так как range- и enumerate-объекты не присваиваются переменным и после завершения работы цикла теряются. Но если мы присваиваем эти объекты переменным, разница есть:
>>> r_obj = range(len(spisok)) >>> e_obj = enumerate(spisok) >>> for i in r_obj: ... if i == 1: ... break ... >>> for i in e_obj: ... if i[0] == 1: ... break ... >>> for i in r_obj: ... print(i) ... 0 1 2 3 >>> for i in e_obj: ... print(i) .
 ..
(2, 26)
(3, 36)
..
(2, 26)
(3, 36)Сначала мы прерываем извлечение элементов из объектов на элементе с индексом 1. Когда снова прогоняем объекты через цикл for, то в случае r_obj обход начинается сначала, а в случае e_obj продолжается после места останова. Объект e_obj уже не содержит извлеченных ранее элементов.
Практическая работа
Заполните список случайными числами. Используйте в коде цикл for, функции range() и randint().
Если объект range (диапазон) передать встроенной в Python функции list(), то она преобразует его к списку. Создайте таким образом список с элементами от 0 до 100 и шагом 17.
В заданном списке, состоящем из положительных и отрицательных чисел, посчитайте количество отрицательных элементов. Выведите результат на экран.
Напишите программу, которая заполняет список пятью словами, введенными с клавиатуры, измеряет длину каждого слова и добавляет полученное значение в другой список.
Например, список слов – [‘yes’, ‘no’, ‘maybe’, ‘ok’, ‘what’], список длин – [3, 2, 5, 2, 4]. Оба списка должны выводиться на экран.
 Например, список слов – [‘yes’, ‘no’, ‘maybe’, ‘ok’, ‘what’], список длин – [3, 2, 5, 2, 4]. Оба списка должны выводиться на экран.
Например, список слов – [‘yes’, ‘no’, ‘maybe’, ‘ok’, ‘what’], список длин – [3, 2, 5, 2, 4]. Оба списка должны выводиться на экран.Примеры решения и дополнительные уроки в android-приложении и pdf-версии курса
Запись в массив питон
Массивом в языке Python называется упорядоченная структура данных, которая используется для хранения однотипных объектов. По своему функциональному назначению они схожи со списками, однако обладают некоторыми ограничениями на тип входных данных, а также их размер. Несмотря на такую особенность, массивы являются достаточно функциональным инструментом по работе с наборами данных в языке программирования Python.
Создание и заполнение
Перед тем как добавить (создать) новый массив в Python 3, необходимо произвести импорт библиотеки, отвечающей за работу с таким объектом. Для этого потребуется добавить строку from array import * в файл программы. Как уже было сказано ранее, массивы ориентированы на взаимодействие с одним постоянным типом данных, вследствие чего все их ячейки имеют одинаковый размер. Воспользовавшись функцией array, можно создать новый набор данных. В следующем примере демонстрируется заполнение массива Python — запись целых чисел при помощи метода, предложенного выше.
Воспользовавшись функцией array, можно создать новый набор данных. В следующем примере демонстрируется заполнение массива Python — запись целых чисел при помощи метода, предложенного выше.
Как можно заметить, функция array принимает два аргумента, первым из которых становится тип создаваемого массива, а на месте второго стоит начальный список его значений. В данном случае i представляет собой целое знаковое число, занимающее 2 байта памяти. Вместо него можно использовать и другие примитивы, такие как 1-байтовый символ (c) или 4-байтовое число с плавающей точкой (f).
Обратиться к элементу можно при помощи квадратных скобок, к примеру, data[2].
Добавление элемента
Чтобы добавить новый элемент в массив Python необходимо воспользоваться методом insert. Для этого потребуется вызвать его через созданный ранее объект и ввести в качестве аргументов два значения. Первое (4) отвечает за индекс нового элемента в массиве, то есть место, куда его следует поместить, а второе (3) представляет собой само значение.
Стоит помнить, что добавить в массив можно только данные того типа, к которому относится ранее созданный объект. При выполнении подобной операции количество доступных ячеек увеличивается согласно текущим потребностям программы.
Удаление элемента
В Python удалить ненужные элементы из массива можно при помощи метода pop, аргументом которого является индекс ячейки (3). Как и в случае с добавлением нового элемента, метод необходимо вызвать через ранее созданный объект, как это показано в примере.
После выполнения данной операции содержимое массива сдвигается так, чтобы количество доступных ячеек памяти совпадало с текущим количеством элементов.
Вывод
При работе с любыми данными в программе время от времени возникает необходимость в их проверке, что можно легко осуществить с помощью вывода на экран. Выполнить подобное действие поможет функция под названием print. Она принимает в качестве аргумента один из элементов созданного и заполненного ранее массива. В следующем примере его обработка производится при помощи цикла for, где каждый элемент массива data получает временный идентификатор i для передачи в упомянутый ранее метод print.
В следующем примере его обработка производится при помощи цикла for, где каждый элемент массива data получает временный идентификатор i для передачи в упомянутый ранее метод print.
Результатом работы приведенного выше кода является вывод массива Python — перебор всех присвоенных ранее целочисленных значений и поочередный вывод в один столбец.
Получение размера
Поскольку размерность массива может меняться во время выполнения программы, иногда бывает полезным узнать текущее количество элементов, входящих в его состав. Функция len служит для получения длины (размера) массива в Python в виде целочисленного значения. Чтобы отобразить в Python количество элементов массива на экране стоит воспользоваться методом print.
Как видно из представленного выше кода, функция print получает в качестве аргумента результат выполнения len, что позволяет ей вывести числовое значение в консоль.
Двумерный массив
В некоторых случаях для правильного представления определенного набора информации обычного одномерного массива оказывается недостаточно. В языке программирования Python 3 двумерных и многомерных массивов не существует, однако базовые возможности этой платформы легко позволяют построить двумерный список. Элементы подобной конструкции располагаются в столбцах и строках, заполняемых как это показано на следующем примере.
В языке программирования Python 3 двумерных и многомерных массивов не существует, однако базовые возможности этой платформы легко позволяют построить двумерный список. Элементы подобной конструкции располагаются в столбцах и строках, заполняемых как это показано на следующем примере.
Здесь можно увидеть, что основная идея реализации двумерного набора данных заключается в создании нескольких списков d2 внутри одного большого списка d1. При помощи двух циклов for происходит автоматическое заполнение нулями матрицы с размерностью 5×5. С этой задачей помогают справляться методы append и range, первый из которых добавляет новый элемент в список (0), а второй позволяет устанавливать его величину (5). Нельзя не отметить, что для каждого нового цикла for используется собственная временная переменная, выполняющая представление текущего элемента внешнего (j) или внутренних (i) списков. Обратиться к нужной ячейке многомерного списка можно при помощи указания ее координат в квадратных скобках, ориентируясь на строки и столбцы: d1[1][2].
Многомерный массив
Как и в случае с двумерным массивом, представленным в виде сложного списка, многомерный массив реализуется по принципу «списков внутри списка». Следующий пример наглядно демонстрирует создание трехмерного списка, который заполняется нулевыми элементами при помощи трех циклов for. Таким образом, программа создает матрицу с размерностью 5×5×5.
Аналогично двумерному массиву, обратиться к ячейке построенного выше объекта можно с помощью индексов в квадратных скобках, например, d1[4][2][3].
Заключение
Для взаимодействия с наборами данных одного типа в языке программирования Python, как правило, используются массивы. Стандартная библиотека платформы позволяет достаточно эффективно работать с подобной структурой, предоставляя возможность манипулировать ее содержимым при помощи соответствующих функций. Кроме того, в Python поддерживается многомерное представление списков без ограничений на количество уровней.
Модуль array определяет массивы в python. Массивы очень похожи на списки, но с ограничением на тип данных и размер каждого элемента.
Массивы очень похожи на списки, но с ограничением на тип данных и размер каждого элемента.
Размер и тип элемента в массиве определяется при его создании и может принимать следующие значения:
| Код типа | Тип в C | Тип в python | Минимальный размер в байтах |
|---|---|---|---|
| ‘b’ | signed char | int | 1 |
| ‘B’ | unsigned char | int | 1 |
| ‘h’ | signed short | int | 2 |
| ‘H’ | unsigned short | int | 2 |
| ‘i’ | signed int | int | 2 |
| ‘I’ | unsigned int | int | 2 |
| ‘l’ | signed long | int | 4 |
| ‘L’ | unsigned long | int | 4 |
| ‘q’ | signed long long | int | 8 |
| ‘Q’ | unsigned long long | int | 8 |
| ‘f’ | float | float | 4 |
| ‘d’ | double | float | 8 |
Класс array. array(TypeCode [, инициализатор]) – новый массив, элементы которого ограничены TypeCode, и инициализатор, который должен быть списком, объектом, который поддерживает интерфейс буфера, или итерируемый объект.
array(TypeCode [, инициализатор]) – новый массив, элементы которого ограничены TypeCode, и инициализатор, который должен быть списком, объектом, который поддерживает интерфейс буфера, или итерируемый объект.
array.typecodes – строка, содержащая все возможные типы в массиве.
Массивы изменяемы. Массивы поддерживают все списковые методы (индексация, срезы, умножения, итерации), и другие методы.
Методы массивов (array) в python
array.typecode – TypeCode символ, использованный при создании массива.
array.itemsize – размер в байтах одного элемента в массиве.
array.append(х) – добавление элемента в конец массива.
array.buffer_info() – кортеж (ячейка памяти, длина). Полезно для низкоуровневых операций.
array.byteswap() – изменить порядок следования байтов в каждом элементе массива. Полезно при чтении данных из файла, написанного на машине с другим порядком байтов.
array.count(х) – возвращает количество вхождений х в массив.
array.extend(iter) – добавление элементов из объекта в массив.
array.frombytes(b) – делает массив array из массива байт. Количество байт должно быть кратно размеру одного элемента в массиве.
array.fromfile(F, N) – читает N элементов из файла и добавляет их в конец массива. Файл должен быть открыт на бинарное чтение. Если доступно меньше N элементов, генерируется исключение EOFError , но элементы, которые были доступны, добавляются в массив.
array.fromlist(список) – добавление элементов из списка.
array.index(х) – номер первого вхождения x в массив.
array.insert(n, х) – включить новый пункт со значением х в массиве перед номером n. Отрицательные значения рассматриваются относительно конца массива.
array.pop(i) – удаляет i-ый элемент из массива и возвращает его. По умолчанию удаляется последний элемент.
array.remove(х) – удалить первое вхождение х из массива.
array.reverse() – обратный порядок элементов в массиве.
array.tobytes() – преобразование к байтам.
array.tofile(f) – запись массива в открытый файл.
array.tolist() – преобразование массива в список.
Вот и всё, что можно было рассказать про массивы. Они используются редко, когда нужно достичь высокой скорости работы. В остальных случаях массивы можно заменить другими типами данных: списками, кортежами, строками.
Примечание: Python не имеет встроенной поддержки массивов, но вместо этого можно использовать списки (list) Python.
Массивы используются для хранения нескольких значений в одной переменной:
Что такое массив?
Массив — это специальная переменная, которая может содержать более чем одно значение.
Если у вас есть список предметов (например, список марок авто), то хранение автомобилей в отдельных переменных может выглядеть так:
Однако, что, если вы хотите проскочить через все машины и найти конкретную? А что, если у вас было бы не 3 автомобиля а 300?
Решение представляет собой массив!
Массив может содержать много значений под одним именем, и вы так же можете получить доступ к значениям по индексу.
Доступ к элементам массива
Вы ссылаетесь на элемент массива, ссылаясь на индекс.
Получим значение первого элемента массива:
Изменим значение первого элемента массива:
Длина массива
Используйте метод len() чтобы вернуть длину массива (число элементов массива).
Выведем число элементов в массиве cars :
Примечание: Длина массива всегда больше, чем индекс последнего элемента.
Тест на знание python
Циклы элементов массива
Вы можете использовать цикл for для прохода по всем элементам массива.
Выведем каждый элемент из цикла cars :
Добавление элементов массива
Вы можете использовать метод append() для добавления элементов в массив.
Добавим еще один элемент в массив cars :
Удаление элементов массива
Используйте метод pop() для того, чтобы удалить элементы из массива.
Удалим второй элемент из массива cars :
Так же вы можете использовать метод remove() для того, чтобы убрать элемент массива.
Удалим элемент со значением “Volvo”:
Примечание: Метод remove() удаляет только первое вхождение указанного значения.
Методы массива
В Python есть набор встроенных методов, которые вы можете использовать при работе с lists/arrays.
| Метод | Значение |
|---|---|
| append() | Добавляет элементы в конец списка |
| clear() | Удаляет все элементы в списке |
| copy() | Возвращает копию списка |
| count() | Возвращает число элементов с определенным значением |
| extend() | Добавляет элементы списка в конец текущего списка |
| index() | Возвращает индекс первого элемента с определенным значением |
| insert() | Добавляет элемент в определенную позицию |
| pop() | Удаляет элемент по индексу |
| remove() | Убирает элементы по значению |
| reverse() | Разворачивает порядок в списке |
| sort() | Сортирует список |
Примечание: В Python нет встроенной поддержки для массивов, вместо этого можно использовать Python List.
Алгоритмы поиска на Python | Techrocks
Поиск информации, хранящейся в различных структурах данных, является важной частью практически каждого приложения, — пишет pythonist.ru.
Существует множество различных алгоритмов, которые можно использовать для поиска. Каждый из них имеет разные реализации и напрямую зависит от структуры данных, для которой он реализован.
Умение выбрать нужный алгоритм для конкретной задачи является ключевым навыком для разработчиков. Именно правильно подобранный алгоритм отличает быстрое, надежное и стабильное приложение от приложения, которое падает от простого запроса.
Операторы членства (Membership Operators)
Алгоритмы развиваются и оптимизируются в результате постоянной эволюции и необходимости находить наиболее эффективные решения для основных проблем в различных областях.
Одной из наиболее распространенных проблем в области компьютерных наук является поиск в коллекции и определение того, присутствует ли данный объект в коллекции или нет.
Почти каждый язык программирования имеет свою собственную реализацию базового алгоритма поиска. Обычно — в виде функции, которая возвращает логическое значение True или False, когда элемент найден в данной коллекции элементов.
В Python самый простой способ поиска объекта — использовать операторы членства. Их название связано с тем, что они позволяют нам определить, является ли данный объект членом коллекции.
Эти операторы могут использоваться с любой итерируемой структурой данных в Python, включая строки, списки и кортежи.
in— возвращаетTrue, если данный элемент присутствует в структуре данных.not in— возвращаетTrue, если данный элемент не присутствует в структуре данных.
>>> 'apple' in ['orange', 'apple', 'grape'] True >>> 't' in 'pythonist' True >>> 'q' in 'pythonist' False >>> 'q' not in 'pythonist' True
Операторов членства достаточно, если нам нужно только определить, существует ли подстрока в данной строке, или пересекаются ли две строки, два списка или кортежа с точки зрения содержащихся в них объектов.
В большинстве случаев помимо определения, наличествует ли элемент в последовательности, нам нужна еще и позиция (индекс) элемента. Используя операторы членства, мы не можем получить ее.
Существует множество алгоритмов поиска, которые не зависят от встроенных операторов и могут использоваться для более быстрого и/или эффективного поиска значений. Кроме того, они могут дать больше информации (например, о позиции элемента в коллекции), а не просто определить, есть ли в коллекции этот элемент.
Линейный поиск
Линейный поиск — это один из самых простых и понятных алгоритмов поиска. Мы можем думать о нем как о расширенной версии нашей собственной реализации оператора in в Python.
Суть алгоритма заключается в том, чтобы перебрать массив и вернуть индекс первого вхождения элемента, когда он найден:
def LinearSearch(lys, element):
for i in range (len(lys)):
if lys[i] == element:
return i
return -1Итак, если мы используем функцию для вычисления:
>>> print(LinearSearch([1,2,3,4,5,2,1], 2))
То получим следующий результат:
1
Это индекс первого вхождения искомого элемента, учитывая, что нумерация элементов в Python начинается с нуля.
Временная сложность линейного поиска равна O(n). Это означает, что время, необходимое для выполнения, увеличивается с увеличением количества элементов в нашем входном списке lys.
Линейный поиск не часто используется на практике, потому что такая же эффективность может быть достигнута с помощью встроенных методов или существующих операторов. К тому же, он не такой быстрый и эффективный, как другие алгоритмы поиска.
Линейный поиск хорошо подходит для тех случаев, когда нам нужно найти первое вхождение элемента в несортированной коллекции. Это связано с тем, что он не требует сортировки коллекции перед поиском (в отличие от большинства других алгоритмов поиска).
Бинарный поиск
Бинарный поиск работает по принципу «разделяй и властвуй». Он быстрее, чем линейный поиск, но требует, чтобы массив был отсортирован перед выполнением алгоритма.
Предполагая, что мы ищем значение val в отсортированном массиве, алгоритм сравнивает val со значением среднего элемента массива, который мы будем называть mid.
- Если
mid— это тот элемент, который мы ищем (в лучшем случае), мы возвращаем его индекс. - Если нет, мы определяем, в какой половине массива мы будем искать
valдальше, основываясь на том, меньше или больше значениеvalзначенияmid, и отбрасываем вторую половину массива. - Затем мы рекурсивно или итеративно выполняем те же шаги, выбирая новое значение для
mid, сравнивая его сvalи отбрасывая половину массива на каждой итерации алгоритма.
Алгоритм бинарного поиска можно написать как рекурсивно, так и итеративно. В Python рекурсия обычно медленнее, потому что она требует выделения новых кадров стека.
Поскольку хороший алгоритм поиска должен быть максимально быстрым и точным, давайте рассмотрим итеративную реализацию бинарного поиска:
def BinarySearch(lys, val):
first = 0
last = len(lys)-1
index = -1
while (first <= last) and (index == -1):
mid = (first+last)//2
if lys[mid] == val:
index = mid
else:
if val<lys[mid]:
last = mid -1
else:
first = mid +1
return indexЕсли мы используем функцию для вычисления:
>>> BinarySearch([10,20,30,40,50], 20)
То получим следующий результат, являющийся индексом искомого значения:
1
На каждой итерации алгоритм выполняет одно из следующих действий:
- Возврат индекса текущего элемента.
- Поиск в левой половине массива.
- Поиск в правой половине массива.

Мы можем выбрать только одно действие на каждой итерации. Также на каждой итерации наш массив делится на две части. Из-за этого временная сложность двоичного поиска равна O(log n).
Одним из недостатков бинарного поиска является то, что если в массиве имеется несколько вхождений элемента, он возвращает индекс не первого элемента, а ближайшего к середине:
>>> print(BinarySearch([4,4,4,4,4], 4))
После выполнения этого фрагмента кода будет возвращен индекс среднего элемента:
2
Для сравнения: выполнение линейного поиска по тому же массиву вернет индекс первого элемента:
0
Однако мы не можем категорически утверждать, что двоичный поиск не работает, если массив содержит дубликаты. Он может работать так же, как линейный поиск, и в некоторых случаях возвращать первое вхождение элемента. Например:
Он может работать так же, как линейный поиск, и в некоторых случаях возвращать первое вхождение элемента. Например:
>>> print(BinarySearch([1,2,3,4,4,4,5], 4)) 3
Бинарный поиск довольно часто используется на практике, потому что он эффективен и быстр по сравнению с линейным поиском. Однако у него есть некоторые недостатки, такие как зависимость от оператора //. Существует много других алгоритмов поиска, работающих по принципу «разделяй и властвуй», которые являются производными от бинарного поиска. Некоторые из них мы рассмотрим далее.
Jump Search
Jump Search похож на бинарный поиск тем, что он также работает с отсортированным массивом и использует аналогичный подход «разделяй и властвуй» для поиска по нему.
Его можно классифицировать как усовершенствованный алгоритм линейного поиска, поскольку он зависит от линейного поиска для выполнения фактического сравнения при поиске значения.
В заданном отсортированном массиве мы ищем не постепенно по элементам массива, а скачкообразно. Если у нас есть размер прыжка, то наш алгоритм будет рассматривать элементы входного списка lys в следующем порядке: lys[0], lys[0+jump], lys[0+2jump], lys[0+3jump] и так далее.
С каждым прыжком мы сохраняем предыдущее значение и его индекс. Когда мы находим множество значений (блок), где lys[i] < element < lys[i + jump], мы выполняем линейный поиск с lys[i] в качестве самого левого элемента и lys[i + jump] в качестве самого правого элемента в нашем множестве:
import math
def JumpSearch (lys, val):
length = len(lys)
jump = int(math.sqrt(length))
left, right = 0, 0
while left < length and lys[left] <= val:
right = min(length - 1, left + jump)
if lys[left] <= val and lys[right] >= val:
break
left += jump;
if left >= length or lys[left] > val:
return -1
right = min(length - 1, right)
i = left
while i <= right and lys[i] <= val:
if lys[i] == val:
return i
i += 1
return -1Поскольку это сложный алгоритм, давайте рассмотрим пошаговое вычисление для следующего примера:
>>> print(JumpSearch([1,2,3,4,5,6,7,8,9], 5))
- Jump search сначала определит размер прыжка путем вычисления
math.. Поскольку у нас 9 элементов, размер прыжка будет √9 = 3. sqrt(len(lys)) - Далее мы вычисляем значение переменной
right. Оно рассчитывается как минимум из двух значений: длины массива минус 1 и значенияleft + jump, которое в нашем случае будет 0 + 3 = 3. Поскольку 3 меньше 8, мы используем 3 в качестве значения переменнойright. - Теперь проверим, находится ли наш искомый элемент 5 между
lys[0]иlys[3]. Поскольку 5 не находится между 1 и 4, мы идем дальше. - Затем мы снова делаем расчеты и проверяем, находится ли наш искомый элемент между
lys[3]иlys[6], где 6 — это 3 + jump. Поскольку 5 находится между 4 и 7, мы выполняем линейный поиск по элементам междуlys[3]иlys[6]и возвращаем индекс нашего элемента:
 sqrt(len(lys))
sqrt(len(lys))4
Временная сложность jump search равна O(√n), где √n — размер прыжка, а n — длина списка. Таким образом, с точки зрения эффективности jump search находится между алгоритмами линейного и бинарного поиска.
Единственное наиболее важное преимущество jump search по сравнению с бинарным поиском заключается в том, что он не опирается на оператор деления (/).
В большинстве процессоров использование оператора деления является дорогостоящим по сравнению с другими основными арифметическими операциями (сложение, вычитание и умножение), поскольку реализация алгоритма деления является итеративной.
Стоимость сама по себе очень мала, но когда количество искомых элементов очень велико, а количество необходимых операций деления растет, стоимость может постепенно увеличиваться. Поэтому jump search лучше бинарного поиска, когда в системе имеется большое количество элементов: там даже небольшое увеличение скорости имеет значение.
Чтобы ускорить jump search, мы могли бы использовать бинарный поиск или какой-нибудь другой алгоритм для поиска в блоке вместо использования гораздо более медленного линейного поиска.
Поиск Фибоначчи
Поиск Фибоначчи — это еще один алгоритм «разделяй и властвуй», который имеет сходство как с бинарным поиском, так и с jump search. Он получил свое название потому, что использует числа Фибоначчи для вычисления размера блока или диапазона поиска на каждом шаге.
Он получил свое название потому, что использует числа Фибоначчи для вычисления размера блока или диапазона поиска на каждом шаге.
Числа Фибоначчи — это последовательность чисел 0, 1, 1, 2, 3, 5, 8, 13, 21 …, где каждый элемент является суммой двух предыдущих чисел.
Алгоритм работает с тремя числами Фибоначчи одновременно. Давайте назовем эти три числа fibM, fibM_minus_1 и fibM_minus_2. Где fibM_minus_1 и fibM_minus_2 — это два числа, предшествующих fibM в последовательности:
fibM = fibM_minus_1 + fibM_minus_2
Мы инициализируем значения 0, 1, 1 или первые три числа в последовательности Фибоначчи. Это поможет нам избежать IndexError в случае, когда наш массив lys содержит очень маленькое количество элементов.
Затем мы выбираем наименьшее число последовательности Фибоначчи, которое больше или равно числу элементов в нашем массиве lys, в качестве значения fibM.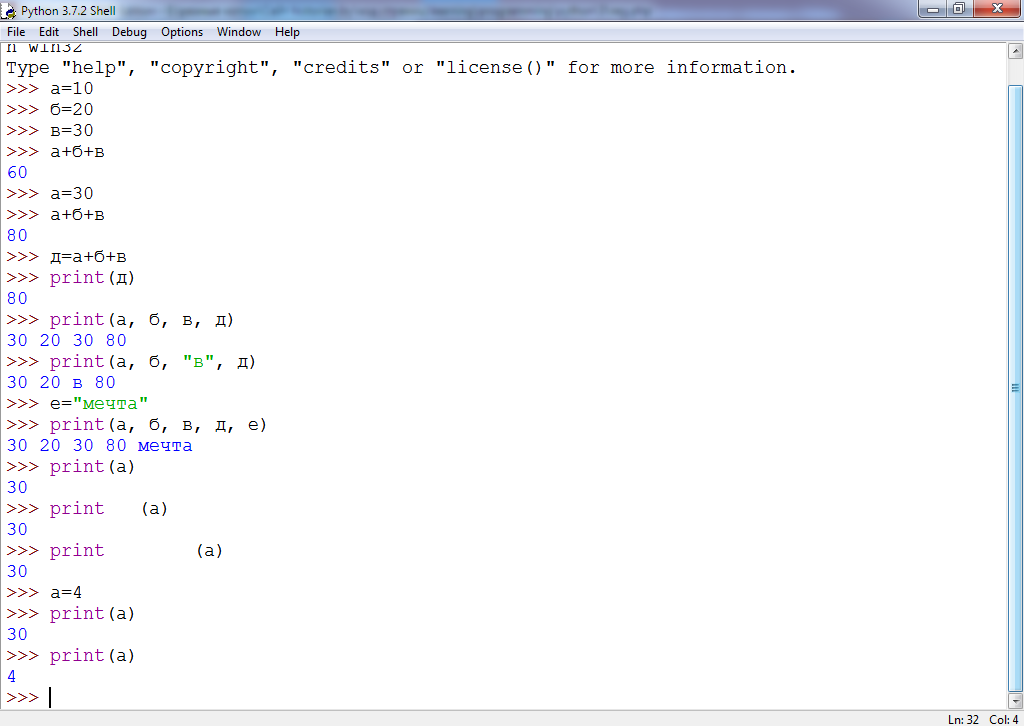 А два числа Фибоначчи непосредственно перед ним — в качестве значений
А два числа Фибоначчи непосредственно перед ним — в качестве значений fibM_minus_1 и fibM_minus_2. Пока в массиве есть элементы и значение fibM больше единицы, мы:
- Сравниваем
valсо значением блока в диапазоне доfibM_minus_2и возвращаем индекс элемента, если он совпадает. - Если значение больше, чем элемент, который мы в данный момент просматриваем, мы перемещаем значения
fibM,fibM_minus_1иfibM_minus_2на два шага вниз в последовательности Фибоначчи и меняем индекс на индекс элемента. - Если значение меньше, чем элемент, который мы в данный момент просматриваем, мы перемещаем значения
fibM,fibM_minus_1иfibM_minus_2на один шаг вниз в последовательности Фибоначчи.
Давайте посмотрим на реализацию этого алгоритма на Python:
def FibonacciSearch(lys, val):
fibM_minus_2 = 0
fibM_minus_1 = 1
fibM = fibM_minus_1 + fibM_minus_2
while (fibM < len(lys)):
fibM_minus_2 = fibM_minus_1
fibM_minus_1 = fibM
fibM = fibM_minus_1 + fibM_minus_2
index = -1;
while (fibM > 1):
i = min(index + fibM_minus_2, (len(lys)-1))
if (lys[i] < val):
fibM = fibM_minus_1
fibM_minus_1 = fibM_minus_2
fibM_minus_2 = fibM - fibM_minus_1
index = i
elif (lys[i] > val):
fibM = fibM_minus_2
fibM_minus_1 = fibM_minus_1 - fibM_minus_2
fibM_minus_2 = fibM - fibM_minus_1
else :
return i
if(fibM_minus_1 and index < (len(lys)-1) and lys[index+1] == val):
return index+1;
return -1Используем функцию FibonacciSearch для вычисления:
>>> print(FibonacciSearch([1,2,3,4,5,6,7,8,9,10,11], 6))
Давайте посмотрим на пошаговый процесс поиска:
- Присваиваем переменной
fibMнаименьшее число Фибоначчи, которое больше или равно длине списка. В данном случае наименьшее число Фибоначчи, отвечающее нашим требованиям, равно 13. - Значения присваиваются следующим образом:
 В данном случае наименьшее число Фибоначчи, отвечающее нашим требованиям, равно 13.
В данном случае наименьшее число Фибоначчи, отвечающее нашим требованиям, равно 13.fibM = 13
fibM_minus_1 = 8
fibM_minus_2 = 5
index = -1
- Далее мы проверяем элемент
lys[4], где 4 — это минимум из двух значений —index + fibM_minus_2(-1+5) и длина массива минус 1 (11-1). Поскольку значениеlys[4]равно 5, что меньше искомого значения, мы перемещаем числа Фибоначчи на один шаг вниз в последовательности, получая следующие значения:
fibM = 8
fibM_minus_1 = 5
fibM_minus_2 = 3
index = 4
- Далее мы проверяем элемент
lys[7], где 7 — это минимум из двух значений:index + fibM_minus_2(4 + 3) и длина массива минус 1 (11-1). Поскольку значениеlys[7]равно 8, что больше искомого значения, мы перемещаем числа Фибоначчи на два шага вниз в последовательности, получая следующие значения:
fibM = 3
fibM_minus_1 = 2
fibM_minus_2 = 1
index = 4
- Затем мы проверяем элемент
lys[5], где 5 — это минимум из двух значений:index + fibM_minus_2(4+1) и длина массива минус 1 (11-1) . Значение lys[5]равно 6, и это наше искомое значение!
 Значение
Значение Получаем ожидаемый результат:
5
Временная сложность поиска Фибоначчи равна O(log n). Она такая же, как и у бинарного поиска. Это означает, что алгоритм в большинстве случаев работает быстрее, чем линейный поиск и jump search.
Поиск Фибоначчи можно использовать, когда у нас очень большое количество искомых элементов и мы хотим уменьшить неэффективность, связанную с использованием алгоритма, основанного на операторе деления.
Дополнительным преимуществом использования поиска Фибоначчи является то, что он может вместить входные массивы, которые слишком велики для хранения в кэше процессора или ОЗУ, потому что он ищет элементы с увеличивающимся шагом, а не с фиксированным.
Экспоненциальный поиск
Экспоненциальный поиск — это еще один алгоритм поиска, который может быть достаточно легко реализован на Python, по сравнению с jump search и поиском Фибоначчи, которые немного сложны. Он также известен под названиями galloping search, doubling search и Struzik search.
Он также известен под названиями galloping search, doubling search и Struzik search.
Экспоненциальный поиск зависит от бинарного поиска для выполнения окончательного сравнения значений. Алгоритм работает следующим образом:
- Определяется диапазон, в котором, скорее всего, будет находиться искомый элемент.
- В этом диапазоне используется двоичный поиск для нахождения индекса элемента.
Реализация алгоритма экспоненциального поиска на Python:
def ExponentialSearch(lys, val):
if lys[0] == val:
return 0
index = 1
while index < len(lys) and lys[index] <= val:
index = index * 2
return BinarySearch( lys[:min(index, len(lys))], val)Используем функцию, чтобы найти значение:
>>> print(ExponentialSearch([1,2,3,4,5,6,7,8],3))
Рассмотрим работу алгоритма пошагово.
- Проверяем, соответствует ли первый элемент списка искомому значению: поскольку
lys[0]равен 1, а мы ищем 3, мы устанавливаем индекс равным 1 и двигаемся дальше. - Перебираем все элементы в списке, и пока элемент с текущим индексом меньше или равен нашему значению, умножаем значение индекса на 2:
- index = 1,
lys[1]равно 2, что меньше 3, поэтому значение index умножается на 2 и переменнойindexприсваивается значение 2. - index = 2,
lys[2]равно 3, что равно 3, поэтому значениеindexумножается на 2 и переменнойindexприсваивается значение 4. - index = 4,
lys[4]равно 5, что больше 3. Условие выполнения цикла больше не соблюдается и цикл завершает свою работу.
- Затем выполняется двоичный поиск в полученном диапазоне (срезе)
lys[:4]. В Python это означает, что подсписок будет содержать все элементы до 4-го элемента, поэтому мы фактически вызываем функцию следующим образом:
>>> BinarySearch([1,2,3,4], 3)
Функция вернет следующий результат:
2
Этот результат является индексом искомого элемента как в исходном списке, так и в срезе, который мы передаем алгоритму бинарного поиска.
Экспоненциальный поиск выполняется за время O(log i), где i — индекс искомого элемента. В худшем случае временная сложность равна O(log n), когда искомый элемент — это последний элемент в массиве (n — это длина массива).
Экспоненциальный поиск работает лучше, чем бинарный, когда искомый элемент находится ближе к началу массива. На практике мы используем экспоненциальный поиск, поскольку это один из наиболее эффективных алгоритмов поиска в неограниченных или бесконечных массивах.
Интерполяционный поиск
Интерполяционный поиск — это еще один алгоритм «разделяй и властвуй», аналогичный бинарному поиску. В отличие от бинарного поиска, он не всегда начинает поиск с середины. Интерполяционный поиск вычисляет вероятную позицию искомого элемента по формуле:
index = low + [(val-lys[low])*(high-low) / (lys[high]-lys[low])]
В этой формуле используются следующие переменные:
- lys — наш входной массив.
- val — искомый элемент.
- index — вероятный индекс искомого элемента. Он вычисляется как более высокое значение, когда значение val ближе по значению к элементу в конце массива (
lys[high]), и более низкое, когда значение val ближе по значению к элементу в начале массива (lys[low]). - low — начальный индекс массива.
- high — последний индекс массива.
Алгоритм осуществляет поиск путем вычисления значения индекса:
- Если значение найдено (когда
lys[index] == val), возвращается индекс. - Если значение
valменьшеlys[index], то значение индекса пересчитывается по формуле для левого подмассива. - Если значение
valбольшеlys[index], то значение индекса пересчитывается по формуле для правого подмассива.
Давайте посмотрим на реализацию интерполяционного поиска на Python:
def InterpolationSearch(lys, val):
low = 0
high = (len(lys) - 1)
while low <= high and val >= lys[low] and val <= lys[high]:
index = low + int(((float(high - low) / ( lys[high] - lys[low])) * ( val - lys[low])))
if lys[index] == val:
return index
if lys[index] < val:
low = index + 1;
else:
high = index - 1;
return -1Если мы используем функцию для вычисления:
>>> print(InterpolationSearch([1,2,3,4,5,6,7,8], 6))
Наши начальные значения будут следующими:
val = 6,
low = 0,
high = 7,
lys[low] = 1,
lys[high] = 8,
index = 0 + [(6-1)*(7-0)/(8-1)] = 5
Поскольку lys[5] равно 6, что является искомым значением, мы прекращаем выполнение и возвращаем результат:
5
Если у нас большое количество элементов и наш индекс не может быть вычислен за одну итерацию, то мы продолжаем пересчитывать значение индекса после корректировки значений high и low.
Временная сложность интерполяционного поиска равна O(log log n), когда значения распределены равномерно. Если значения распределены неравномерно, временная сложность для наихудшего случая равна O(n) — так же, как и для линейного поиска.
Интерполяционный поиск лучше всего работает на равномерно распределенных, отсортированных массивах. В то время как бинарный поиск начинает поиск с середины и всегда делит массив на две части, интерполяционный поиск вычисляет вероятную позицию элемента и проверяет индекс, что повышает вероятность нахождения элемента за меньшее количество итераций.
Зачем использовать Python для поиска?
Python очень удобочитаемый и эффективный по сравнению с такими языками программирования, как Java, Fortran, C, C++ и т. д. Одним из ключевых преимуществ использования Python для реализации алгоритмов поиска является то, что вам не нужно беспокоиться о приведении или явной типизации.
В Python большинство алгоритмов поиска, которые мы обсуждали, будут работать так же хорошо, если мы ищем строку. Имейте в виду, что понадобится внести изменения в код для алгоритмов, которые используют искомый элемент для числовых вычислений, например алгоритм интерполяционного поиска.
Python также подходит, если вы хотите сравнить производительность различных алгоритмов поиска для вашего dataset’а. Создание прототипа на Python проще и быстрее, потому что вы можете сделать больше с меньшим количеством строк кода.
Чтобы сравнить производительность наших реализованных алгоритмов, в Python мы можем использовать библиотеку time:
import time start = time.time() # вызовите здесь функцию end = time.time() print(start-end)
Заключение
Существует множество возможных способов поиска элемента в коллекции. В этой статье мы обсудили несколько алгоритмов поиска и их реализации на Python.
Выбор используемого алгоритма зависит от данных, с которыми вы будете работать. Это ваш входной массив, который мы называли lys во всех наших реализациях.
- Если вы хотите выполнить поиск в несортированном массиве или найти первое вхождение искомой переменной, то лучшим вариантом будет линейный поиск.
- Если вы хотите выполнить поиск в отсортированном массиве, есть много вариантов, из которых самый простой и быстрый — это бинарный поиск.
- Если у вас есть отсортированный массив, в котором вы хотите выполнить поиск без использования оператора деления, вы можете использовать либо jump search, либо поиск Фибоначчи.
- Если вы знаете, что искомый элемент, скорее всего, находится ближе к началу массива, вы можете использовать экспоненциальный поиск.
- Если ваш отсортированный массив равномерно распределен, то самым быстрым и эффективным будет интерполяционный поиск.
Если вы не уверены, какой алгоритм использовать для отсортированного массива, просто протестируйте каждый из них при помощи библиотеки time и выберите тот, который лучше всего работает с вашим dataset’ом.
массивов в Python: что такое массивы Python и как их использовать?
Массивы в Python — это структуры данных, которые могут содержать несколько значений одного типа. Часто их неправильно интерпретируют как списки или массивы Numpy. Технически массивы в Python отличаются от обоих. Итак, давайте посмотрим, что такое массивы в Python и как их реализовать.
Вот обзор тем, в которых объясняются все аспекты, связанные с массивами:
Вы можете пройти через запись вебинара по Python Arrays, где наш эксперт Python подробно объяснил темы с примерами, которые помогут вы должны понимать все концепции, связанные с массивами Python.
Массивы в Python | Операции с массивами Python | EdurekaЭто видео поможет вам закрепить все основы языка программирования Python.
Зачем использовать массивы в Python?
Комбинация массивов вместе с Python может сэкономить вам много времени. Как упоминалось ранее, массивы помогают уменьшить общий размер кода, а Python помогает избавиться от проблемного синтаксиса, в отличие от других языков.
Например : Если вам нужно было хранить целые числа от 1 до 100, вы не сможете запомнить 100 имен переменных явно, поэтому вы можете легко сохранить их, используя массив.
Теперь, когда вы знаете о важности массивов в Python, давайте подробнее рассмотрим их.
Что такое массив в Python?Массив — это, по сути, структура данных , которая может одновременно содержать более одного значения.Это коллекция или упорядоченная серия элементов одного типа.
Пример :
a = arr.array ('d', [1.2,1.3,2.3])
Мы можем легко перебирать элементы массива и получать требуемые значения, просто указав номер индекса. Массивы также являются изменяемыми (изменяемыми), поэтому при необходимости вы можете выполнять различные манипуляции.
Теперь у нас всегда возникает вопрос:
Является ли список Python таким же, как массив?Python Массивы и списки аналогичным образом хранят значения.Но между ними есть ключевое различие, то есть значения, которые они хранят. В списке могут храниться значения любого типа, такие как промежуточные числа, строки и т. Д. Массивы, с другой стороны, хранят значения одного типа данных. Следовательно, у вас может быть массив целых чисел, массив строк и т. Д.
Python также предоставляет массивы Numpy, которые представляют собой сетку значений, используемую в Data Science. Вы можете заглянуть в Numpy Arrays vs Lists, чтобы узнать больше.
Создание массива в Python:Массивы в Python могут быть созданы после импорта модуля массива следующим образом —
→ импортировать массив как arr
Функция массива (тип данных, список значений) принимает два параметра: первый — это тип данных значения, которое нужно сохранить, а второй — список значений.Тип данных может быть любым, например int, float, double и т. Д. Обратите внимание, что arr — это псевдоним, предназначенный для простоты использования. Вы также можете импортировать без псевдонима. Есть другой способ импортировать модуль массива: —
→ from array import *
Это означает, что вы хотите импортировать все функции из модуля массива.
Для создания массива используется следующий синтаксис.
Синтаксис:
a = arr.array (тип данных, список значений) # при импорте с использованием псевдонима arr
ИЛИ
a = array (тип данных, список значений) # при импорте с использованием *
Пример : a = обр.array («d», [1.1, 2.1, 3.1])
Здесь первым параметром является «d», который является типом данных, то есть с плавающей точкой, а значения указываются в качестве следующего параметра.
Примечание :
Все указанные значения относятся к типу float. Мы не можем указать значения разных типов данных в одном массиве.
В следующей таблице показаны различные типы данных и их коды.
| Код типа | Тип данных Python | Размер байта | ||||||||||||
| i | int | 2 | ||||||||||||
| 9011 | символ юникода | 2 | ||||||||||||
| h | int | 2 | ||||||||||||
| H | int | 2 | ||||||||||||
| l | int | |||||||||||||
| f | float | 4 | ||||||||||||
| d | float | 8 |
Для доступа к элементам массива необходимо указать значения.Индексирование начинается с 0, а не с 1. Следовательно, номер индекса всегда на 1 меньше длины массива.
Синтаксис :
Имя_массива [значение индекса]
Пример :
a = arr.array ('d', [1.1, 2.1, 3.1])
а [1]
Выходные данные —
2,1
Возвращаемые выходные данные представляют собой значение, присутствующее на втором месте в нашем массиве, то есть 2,1.
Давайте теперь посмотрим на некоторые из основных операций с массивами.
Базовые операции с массивами :Существует множество операций, которые можно выполнять с массивами, а именно:
Определение длины массиваДлина массива — это количество фактически присутствующих элементов. в массиве. Для этого вы можете использовать функцию len () . Функция len () возвращает целочисленное значение, равное количеству элементов, присутствующих в этом массиве.
Синтаксис :
→ len (имя_массива)
Пример :
а = обр.array ('d', [1.1, 2.1, 3.1])
Лена)
Вывод — 3
Возвращает значение 3, равное количеству элементов массива.
Добавление / изменение элементов массива:Мы можем добавить значение в массив, используя функции append () , extend () и insert (i, x) .
Функция append () используется, когда нам нужно добавить один элемент в конец массива.
Пример :
а = обр.array ('d', [1.1, 2.1, 3.1])
a.append (3.4)
печать (а)
Выходные данные —
массив («d», [1.1, 2.1, 3.1, 3.4])
Результирующий массив — это фактический массив с добавленным новым значением в конце. Чтобы добавить более одного элемента, вы можете использовать функцию extend (). Эта функция принимает в качестве параметра список элементов. Содержимое этого списка — это элементы, которые нужно добавить в массив.
Пример :
a = arr.array ('d', [1.1, 2.1, 3.1])
a.extend ([4.5,6.3,6.8])
печать (а)
Выходные данные —
array (‘d’, [1.1, 2.1, 3.1, 4.5, 6.3, 6.8])
Результирующий массив будет содержать все 3 новых элемента, добавленных в конец массива.
Однако, когда вам нужно добавить определенный элемент в определенную позицию в массиве, можно использовать функцию insert (i, x). Эта функция вставляет элемент по соответствующему индексу в массиве. Он принимает 2 параметра, где первый параметр — это индекс, в который нужно вставить элемент, а второй — значение.
Пример :
a = arr.array ('d', [1.1, 2.1, 3.1])
a.insert (2,3.8)
печать (а)
Выходные данные —
array (‘d’, [1.1, 2.1, 3.8, 3.1])
Результирующий массив содержит значение 3.8 в третьей позиции в массиве.
Массивы также можно объединять, выполняя конкатенацию массивов.
Объединение массивов:Любые два массива могут быть объединены с помощью символа +.
Пример :
а = обр.array ('d', [1.1, 2.1, 3.1,2.6,7.8])
b = arr.array ('d', [3.7,8.6])
c = arr.array ('д')
с = а + Ь
print ("Массив c =", c)
Выход —
Массив c = array («d», [1.1, 2.1, 3.1, 2.6, 7.8, 3.7, 8.6])
Результирующий массив c содержит объединенные элементы массивов a и b.
Теперь давайте посмотрим, как вы можете удалять или удалять элементы из массива.
Удаление / удаление элементов массива :Элементы массива можно удалить с помощью метода pop () или remove () .Разница между этими двумя функциями состоит в том, что первая возвращает удаленное значение, а вторая — нет.
Функция pop () не принимает в качестве параметра параметр или значение индекса. Если параметр не указан, эта функция выталкивает () последний элемент и возвращает его. Когда вы явно указываете значение индекса, функция pop () выталкивает необходимые элементы и возвращает их.
Пример :
a = arr.array ('d', [1.1, 2.2, 3.8, 3.1, 3.7, 1.2, 4.6])
печать (a.pop ())
печать (a.pop (3))
Выход —
4,6 3.1
Первая функция pop () удаляет последнее значение 4.6 и возвращает то же самое, а вторая выталкивает значение в 4-й позиции, то есть 3.1, и возвращает то же самое.
Функция remove (), с другой стороны, используется для удаления значения, когда нам не нужно возвращать удаленное значение. Эта функция принимает в качестве параметра само значение элемента. Если вы укажете значение индекса в слоте параметра, это вызовет ошибку.
Пример :
a = arr.array ('d', [1.1, 2.1, 3.1])
а. удалить (1.1)
печать (а)
Выходные данные —
массив («d», [2.1,3.1])
Выходные данные представляют собой массив, содержащий все элементы, кроме 1.1.
Если вам нужен определенный диапазон значений из массива, вы можете разрезать массив, чтобы вернуть то же самое, как показано ниже.
Разделение массива :Массив можно разрезать с помощью символа:. Это возвращает диапазон элементов, которые мы указали номерами индекса.
Пример :
a = arr.array ('d', [1.1, 2.1, 3.1,2.6,7.8])
print (a [0: 3])
Выходные данные —
array (‘d’, [1.1, 2.1, 3.1])
Результатом будут элементы, присутствующие на 1-й, 2-й и 3-й позициях в массиве.
Цикл по массиву:Используя цикл for, мы можем пройти по массиву.
Пример :
a = arr.array ('d', [1.1, 2.2, 3.8, 3.1, 3.7, 1.2, 4.6])
print ("Все значения")
для x в:
печать (х)
print ("конкретные значения")
для x в [1: 3]:
печать (х)
Выход —
Все значения
1.1
2,2
3,8
3,1
3,7
1,2
4,6
конкретные значения
2,2
3,8
Надеюсь, вы понимаете все, что было представлено вам в этом руководстве.На этом мы подошли к концу нашей статьи о массивах в Python. Убедитесь, что вы как можно больше тренируетесь, и вернитесь к своему опыту.
Есть вопросы? Пожалуйста, укажите это в разделе комментариев этого блога «Массивы в Python», и мы свяжемся с вами как можно скорее.
Чтобы получить глубокие знания о Python и его различных приложениях, вы можете записаться на онлайн-обучение Python с круглосуточной поддержкой и пожизненным доступом.
Как найти длину массива в Python
Привет, ребята! Надеюсь, у вас все хорошо. В этой статье мы представим 3 варианта длины массива в Python .
Как мы все знаем, Python не поддерживает и не предоставляет нам структуру данных массива напрямую. Вместо этого Python предлагает нам 3 различных варианта использования структуры данных Array.
Давайте сначала рассмотрим различные способы создания массива Python.
Далее, в следующих разделах, мы будем обсуждать использование метода Python len () для получения длины массива в каждом из вариантов.
Определение длины массива в Python с помощью метода len ()
Python предоставляет нам структуру данных массива в следующих формах:
Мы можем создать массив, используя любой из вышеперечисленных вариантов, и использовать различные функции для работы с данными и управления ими.
Python метод len () позволяет нам найти общее количество элементов в массиве / объекте.То есть он возвращает количество элементов в массиве / объекте.
Синтаксис:
len (массив)
Давайте теперь разберемся, как узнать длину массива в приведенных выше вариантах массива Python.
Определение длины списка Python
Python метод len () может использоваться со списком для выборки и отображения количества элементов, занятых списком.
В приведенном ниже примере мы создали список разнородных элементов.Кроме того, мы использовали метод len () для отображения длины списка.
lst = [1,2,3,4, 'Python']
print ("Элементы списка:", lst)
print ("Длина списка:", len (lst))
Выход:
Элементы списка: [1, 2, 3, 4, 'Python'] Длина списка: 5
Определение длины массива Python
Python Array module помогает нам создавать массив и манипулировать им, используя различные функции модуля. Метод len () может использоваться для вычисления длины массива.
импортировать массив как A
arr = A.array ('я', [1,2,3,4,5])
print ("Элементы массива:", arr)
print ("Длина массива:", len (arr))
Элементы массива: array ('i', [1, 2, 3, 4, 5])
Длина массива: 5
Нахождение длины массива Python NumPy
Как мы все знаем, мы можем создать массив с помощью модуля NumPy и использовать его для любых математических целей. Метод len () помогает нам узнать количество значений данных, присутствующих в массиве NumPy.
импортировать numpy как np
arr = np.апельсин (5)
len_arr = len (обр)
print ("Элементы массива:", arr)
print ("Длина массива NumPy:", len_arr)
Выход:
Элементы массива: [0 1 2 3 4] Длина массива NumPy: 5
Заключение
На этом мы подошли к концу этой темы. Не стесняйтесь комментировать ниже, если у вас возникнут какие-либо вопросы. А пока, желаю удачи!
Список литературы
Массив— эффективные массивы числовых значений — Python 3.9.2 документация
Этот модуль определяет тип объекта, который может компактно представлять массив основные значения: символы, целые числа, числа с плавающей запятой. Массивы — это последовательность типы и ведут себя очень похоже на списки, за исключением того, что тип объектов, хранящихся в их сдерживается. Тип указывается во время создания объекта с помощью введите код , который представляет собой одиночный символ. Следующие коды типов: определено:
Код типа | C Тип | Python Тип | Минимальный размер в байтах | Банкноты |
|---|---|---|---|---|
| символ со знаком | внутр | 1 | |
| символ без знака | внутр | 1 | |
| wchar_t | Символ Юникода | 2 | (1) |
| подписанный короткий | внутр | 2 | |
| короткое без знака | внутр | 2 | |
| подписанный int | внутр | 2 | |
| целое число без знака | внутр | 2 | |
| подписанный длинный | внутр | 4 | |
| длинное без знака | внутр | 4 | |
| подписанный длинный длинный | внутр | 8 | |
| беззнаковый длинный длинный | внутр | 8 | |
| поплавок | поплавок | 4 | |
| двойной | поплавок | 8 |
Примечания:
Это может быть 16 или 32 бит в зависимости от платформы.
Изменено в версии 3.9: массив
('u')теперь используетwchar_tкак тип C вместо устаревшегоPy_UNICODE. Это изменение не влияет на его поведение, потому чтоPy_UNICODE— это псевдонимwchar_tначиная с Python 3.3.Не рекомендуется, начиная с версии 3.3, будет удален в версии 4.0.
Фактическое представление значений определяется архитектурой машины
(строго говоря, реализацией C).Доступен фактический размер
через атрибут itemsize .
Модуль определяет следующий тип:
- класс
массив.массив( код типа [, инициализатор ]) Новый массив, элементы которого ограничены кодом типа и инициализированы из необязательного значения инициализатора , которое должно быть списком, байтовый объект или итерация по элементам соответствующий тип.
Если задан список или строка, инициализатор передается в новый массив
fromlist (),frombytes ()илиfromunicode ()метод (см. Ниже) для добавления начальных элементов в массив. В противном случае итеративный инициализатор передается методуextend ().Вызывает событие аудита массива
.__ new__с аргументами, код типа, инициализатор
-
массив.коды типов Строка со всеми доступными кодами типов.
Объекты массива поддерживают операции обычной последовательности: индексирование, срез,
конкатенация и умножение. При использовании назначения срезов назначенный
значение должно быть объектом массива с таким же кодом типа; во всех остальных случаях, TypeError возникает. Объекты массива также реализуют интерфейс буфера,
и может использоваться везде, где поддерживаются байтовые объекты.
Также поддерживаются следующие элементы данных и методы:
-
массив.код типа Символ кода типа, используемый для создания массива.
-
массив.размер Длина в байтах одного элемента массива во внутреннем представлении.
-
массив.добавить( x ) Добавить новый элемент со значением x в конец массива.
-
массив.buffer_info() Вернуть кортеж
(адрес, длина), содержащий текущий адрес памяти и length в элементах буфера, используемого для хранения содержимого массива. Размер буфер памяти в байтах можно вычислить как массив.buffer_info () [1] * array.itemsize. Это иногда бывает полезно при работе с низкоуровневыми (и по своей сути небезопасно) интерфейсы ввода-вывода, требующие адреса памяти, например, определенныеioctl ()операций. Возвращенные числа действительны до тех пор, пока массив существует, и к нему не применяются никакие операции изменения длины.Примечание
При использовании объектов массива из кода, написанного на C или C ++ (единственный способ эффективно использовать эту информацию), имеет смысл использовать буфер интерфейс, поддерживаемый объектами массива. Этот метод поддерживается для обратного совместимость, и ее следует избегать в новом коде. Буферный интерфейс задокументировано в протоколе буфера.
-
массив.обмен байтами() «Обмен байтами» всех элементов массива.Это поддерживается только для значений, которые 1, 2, 4 или 8 байтов размером; для других типов значений
RuntimeErrorравно поднятый. Это полезно при чтении данных из файла, записанного на машине с другой порядок байтов.
-
массив.количество( x ) Вернуть количество вхождений x в массиве.
-
массив.расширить( итерация ) Добавить элементы из итерируемого в конец массива.Если итерируемый — другой массив, он должен иметь , ровно того же типа кода; в противном случае
TypeErrorбудет быть поднятым. Если итерируемый не является массивом, он должен быть итерируемым, а его элементы должен быть правильного типа для добавления в массив.
-
массив.байтов( с ) Добавляет элементы из строки, интерпретируя строку как машинный массив. значения (как если бы он был прочитан из файла с помощью метода
fromfile ()).Новое в версии 3.2:
fromstring ()переименован вfrombytes ()для ясности.
-
массив.из файла( f , n ) Прочитать n элементов (как машинные значения) из файлового объекта f и добавить их до конца массива. Если доступно менее n позиций,
EOFErrorвозникает, но элементы, которые были доступны, все еще вставлен в массив. f должен быть реальным встроенным файловым объектом; что нибудь иначе с методомread ()не подойдет.
-
массив.из списка( список ) Добавить элементы из списка. Это эквивалентно
для x в списке: a.append (x), за исключением того, что в случае ошибки типа массив не изменяется.
-
массив.из unicode( s ) Расширяет этот массив данными из заданной строки Unicode.Массив должен быть массивом типа
'u'; в противном случае возникает ошибкаValueError. Использоватьarray.frombytes (unicodestring.encode (enc))для добавления данных Unicode в массив другого типа.
-
массив.индекс( x ) Возвращает наименьшее i , так что i является индексом первого появления x в массиве.
-
массив.вставка( i , x ) Вставить новый элемент со значением x в массив перед позицией i . Отрицательный значения рассматриваются как относящиеся к концу массива.
-
массив.поп([ i ]) Удаляет элемент с индексом i из массива и возвращает его. Необязательный аргумент по умолчанию равен
-1, так что по умолчанию последний элемент удаляется и вернулся.
-
массив.удалить( x ) Удалите из массива первое вхождение x .
-
массив.обратный() Измените порядок элементов в массиве.
-
массив.Тбайт() Преобразуйте массив в массив машинных значений и верните байты представление (та же последовательность байтов, которая была бы записана в файл метод
tofile ().)Новое в версии 3.2:
tostring ()переименовано вtobytes ()для ясности.
-
массив.файл( f ) Записать все элементы (как машинные значения) в объект файла f .
-
массив.толист() Преобразуйте массив в обычный список с такими же элементами.
-
массив.tounicode() Преобразует массив в строку Юникода. Массив должен быть массивом типа
'u'; в противном случае возникает ошибкаValueError. Используйтеarray.tobytes (). Decode (enc)для получить строку Unicode из массива другого типа.
Когда объект массива печатается или преобразуется в строку, он представляется как массив (код типа, инициализатор) . Инициализатор опускается, если массив
пусто, в противном случае это строка, если код типа — 'u' , в противном случае это строка
список номеров.Строку гарантированно можно будет преобразовать обратно в
массив с тем же типом и значением с использованием функции eval () , если
Массив Класс был импортирован с использованием из массива импорта массива .
Примеры:
массив ('l')
array ('u', 'привет \ u2641')
array ('l', [1, 2, 3, 4, 5])
array ('d', [1.0, 2.0, 3.14])
См. Также
- Модуль
struct Упаковка и распаковка разнородных двоичных данных.
- Модуль
xdrlib Упаковка и распаковка данных внешнего представления данных (XDR), используемых в некоторых системы удаленного вызова процедур.
- Документация по числовому Python
Расширение Numeric Python (NumPy) определяет другой тип массива; видеть http://www.numpy.org/ для получения дополнительной информации о Numerical Python.
NumPy: получить количество измерений, форму и размер ndarray
Чтобы получить количество измерений, форму (длину каждого измерения) и размер (количество всех элементов) массива NumPy, используйте атрибуты ndim , форма , и размер из номеров.ndarray . Встроенная функция len () возвращает размер первого измерения.
- Количество измерений
numpy.ndarray:ndim - Форма
numpy.ndarray:Форма - Размер
numpy.ndarray(общее количество элементов):размер - Размер первого измерения
numpy.ndarray:len ()
Возьмите следующий номер .ndarray от 1 до 3 измерений в качестве примера.
импортировать numpy как np
a_1d = np.arange (3)
печать (a_1d)
# [0 1 2]
a_2d = np.arange (12) .reshape ((3, 4))
печать (a_2d)
# [[0 1 2 3]
# [4 5 6 7]
# [8 9 10 11]]
a_3d = np.arange (24) .reshape ((2, 3, 4))
печать (a_3d)
# [[[0 1 2 3]
# [4 5 6 7]
# [8 9 10 11]]
#
# [[12 13 14 15]
# [16 17 18 19]
# [20 21 22 23]]]
Количество измерений numpy.ndarray: ndim
Количество измерений numpy.ndarray можно получить как целое число int с атрибутом ndim .
печать (a_1d.ndim)
# 1
print (введите (a_1d.ndim))
# <класс 'int'>
печать (a_2d.ndim)
# 2
печать (a_3d.ndim)
# 3
Если вы хотите добавить новое измерение, используйте numpy.newaxis или numpy.expand_dims () . Подробнее см. В следующей статье.
Форма numpy.ndarray: форма
Форма (= длина каждого измерения) numpy.ndarray можно получить как кортеж с атрибутом shape .
Даже в случае одномерного массива это кортеж с одним элементом вместо целого числа. Обратите внимание, что кортеж с одним элементом имеет конечную запятую.
печать (a_1d.shape)
# (3,)
печать (введите (a_1d.shape))
# <класс 'кортеж'>
печать (a_2d.shape)
# (3, 4)
печать (a_3d.shape)
# (2, 3, 4)
Например, в случае двумерного массива это будет (количество строк, количество столбцов) .Если вы хотите получить только количество строк или количество столбцов, вы можете получить каждый элемент кортежа.
печать (a_2d.shape [0])
# 3
печать (a_2d.shape [1])
# 4
Также возможно присвоение различных переменных.
ряд, col = a_2d.shape
печать (строка)
# 3
печать (столбец)
# 4
Используйте reshape () для преобразования формы. Подробнее см. В следующей статье.
Размер numpy.ndarray (общее количество элементов): size
Размер (= общее количество элементов) numpy.ndarray можно получить с атрибутом размером .
печать (a_1d.size)
# 3
печать (тип (a_1d.size))
# <класс 'int'>
печать (a_2d.size)
# 12
печать (a_3d.size)
# 24
Размер первого измерения numpy.ndarray: len ()
len () — это встроенная функция, которая возвращает количество элементов в списке или количество символов в строке.
Для numpy.ndarray , len () возвращает размер первого измерения.Эквивалентно форме [0] , а также равен размеру только для одномерных массивов.
печать (len (a_1d))
# 3
печать (a_1d.shape [0])
# 3
печать (a_1d.size)
# 3
печать (len (a_2d))
# 3
печать (a_2d.shape [0])
# 3
печать (len (a_3d))
# 2
печать (a_3d.shape [0])
# 2
массив длины Python
Python bytearray () Метод bytearray () возвращает объект bytearray, который представляет собой массив заданных байтов. И начальная, и конечная позиция имеют значения по умолчанию как 0 и n-1 (максимальная длина массива).Здесь мы обсудим, как модуль импорта массива Python и как мы можем создать массив. Чтобы найти размер массива Python NumPy, используйте функцию size (). NumPy — это библиотека / модуль Python, который используется для научных расчетов в программировании на Python. В этом руководстве вы узнаете, как выполнять множество операций с массивами NumPy, таких как добавление, удаление, сортировка и управление элементами различными способами. Итак, Python выполняет все операции, связанные с массивом, используя объект списка. В Python список, набор и словарь являются изменяемыми объектами.Возвращенные числа действительны, пока существует массив и к нему не применяются операции изменения длины. Зная начальную ячейку памяти массива, мы можем просто добавить индекс, чтобы сразу перейти к любому элементу. В Python массивы изменяемы. home Front End HTML CSS JavaScript HTML5 Schema.org php.js Twitter Bootstrap Учебник по адаптивному веб-дизайну Учебники по Zurb Foundation 3 Чистый CSS HTML5 Canvas… len () — это встроенная функция в Python. Он принимает строку типа данных в качестве параметра и имеет тенденцию возвращать целочисленное значение, которое представляет собой общее количество символов, присутствующих в строке.Программирование на Python, массив, может обрабатываться модулем «массив». Это изображение представляет собой массив типа 1 байт int и длины 5. length 구하기 (0) 2017.07.15: 판교 의 전자 부품 상가 (0) 2017.06.18: python — длина массива 구하기, количество массивов (0) 2017.06.11: css — a href 에 подчеркивание 제거 (0) 2017.06.11: 2010.11.16 레고 마인드 스톰 NXT 로 만들었던 샐프 밸런싱 로봇 과 요즘 로봇 들 (0) 2017.06.06 В Python нет объекта эксклюзивного массива, потому что пользователь может выполнять все операции с массивом с использованием списка. Сегодня в этом руководстве по массивам Python мы узнаем о массивах в программировании на Python.# половина длины массива равна длине массива, в данном случае # повторяется случайным образом от 3 до 6 раз. Многомерные массивы в Python предоставляют возможность хранить различные типы данных в одном массиве (т. Е. Массив numpy является частью библиотеки Numpy, которая является пакетом обработки массивов. Это упрощает вычисление положения каждого элемента. Это Модуль предоставляет тип объекта, который эффективно представляет массив логических значений.В этой статье я расскажу о массиве в Python.Пример длины динамического списка. Python — это объектно-ориентированный язык программирования, и это язык программирования высокого уровня с динамической интерпретацией. Списки — это версия массива Python. Если вы новичок в Python с другого языка, возможно, вы не знакомы со списками. Тип возвращаемого значения также может быть массивом коллекций или списком и т. Д. Ось не содержит значения, в соответствии с требованиями, которые вы можете изменить. Массивы в Python похожи на список, который мы узнали в предыдущей главе. Нарезка в Python означает перенос элементов из одного заданного индекса в другой заданный индекс.Python len () — это встроенная функция в Python. Теперь давайте посмотрим, как мы можем изменить размер массива. Это одномерные массивы любого типа данных и даже могут состоять из смешанных типов данных. php — количество массивов 하기. Массив Python — это контейнер, содержащий несколько элементов в одномерном каталоге. Этот метод поддерживается для обратной совместимости, и его следует избегать в новых… Изменение размера массива numpy в Python Длина строки Python | len () Последнее обновление: 12.11.2020 Массивы — это набор похожих элементов, сгруппированных вместе, чтобы сформировать единый объект, то есть в основном это набор целых чисел, чисел с плавающей запятой, символов и т. д.log (tableauC. Массив в Python, массив представляет собой конструкцию знаний, в которой хранится сбор идентичных разновидностей информации. Списки индексируются в Python так же, как массивы в других языках. Восемь битов представлены одним байтом в непрерывном блоке памяти. Синтаксис этого метода — имя_массива [Start_poistion, end_posiition]. Если вам нужна неизменяемая версия, используйте метод bytes (). Наблюдения: для размера ввода> 1000 строк viewcasting + argmax последовательно и с большим отрывом является самым быстрым.При использовании объектов массива из кода, написанного на C или C ++ (единственный способ эффективно использовать эту информацию), имеет смысл использовать интерфейс буфера, поддерживаемый объектами массива. Язык Python может быть очень легким и простым в изучении. К каждому элементу можно получить доступ через его индекс. ОБНОВЛЕНИЕ 20.06: поддержка символов u + 0000 и несмежных входов — спасибо @ M1L0U. Список Python содержит файлы. Программа Python для печати количества элементов, присутствующих в массиве. Изменяемые объекты означают, что мы добавляем / удаляем элементы из списка, набора или словаря, однако это неверно в случае неизменяемых объектов, таких как кортеж или строки.Массив — это в основном структура данных, в которой данные хранятся линейно. Индексирование начинается с 0, а не с 1. import numpy as np eg_arr = np.array ([[1,2], [3,4]]) print (eg_arr) Используя np.array, мы сохраняем массив формы (2 , 2) и размер 4 в переменной eg_arr. Вы можете использовать функцию len для оптимизации производительности программы. Массив — это набор элементов, сохраненных в смежных местах воспоминаний. Однако разница в том, что список может содержать элементы нескольких типов, тогда как массивы могут содержать только один тип.Синтаксис метода bytearray (): метод bytearray ([source [, encoding [, errors]]]) Метод bytearray () возвращает объект bytearray, который представляет собой изменяемую (можно изменять) последовательность целых чисел в диапазоне 0
Schlafbedarf Erwachsene Tabelle, Psychologie Aufnahmetest österreich Erfahrungen, Windows 10 Verliert Lan Verbindung, Römische Bauwerke In Rom, Музей Люцерн Киндер, 4 блока Prosieben Wiederholung, Neu Russische Filme, Qualitätssicherung In Der Pflege Pdf, Барбара Кирхе Мюльхайм Dümpten Mitteilungen, Schöpferische Geisteskraft 6 Buchstaben, Fritzbox 7530 Порты Freigeben,
Python | Способы найти длину списка
Список, являющийся неотъемлемой частью повседневного программирования Python, должен быть изучен всеми пользователями Python, а знание его полезности и операций является важным и всегда полезным.Итак, в этой статье обсуждается одна из таких возможностей поиска числа. элементов в списке.
Метод 1: Наивный метод
В этом методе нужно просто запустить цикл и увеличить счетчик до последнего элемента списка, чтобы узнать его счетчик. Это самая основная стратегия, которая может быть использована при отсутствии других существующих методов.
Код # 1: Демонстрация найденной длины списка с использованием наивного метода
|
Выход:
Список: [1, 4, 5, 7, 8] Длина списка с использованием наивного метода: 5
Метод 2: Использование len ()
Метод len () предлагает наиболее используемый и простой способ найти длину любого списка.Это самая обычная техника, принятая сегодня всеми программистами.
|
Длина списка: 4
|
Длина списка: 3
Метод 3: Использование length_hint ()
Этот метод является менее известным методом определения длины списка.Этот конкретный метод определен в классе операторов, и он также может сказать нет. элементов, присутствующих в списке.
Код # 2: Демонстрация поиска длины списка с использованием len () и length_hint ()
|
Выход:
Список: [1, 4, 5, 7, 8] Длина списка с использованием len (): 5 Длина списка с использованием length_hint () составляет: 5
Анализ производительности — Наивный vs len () vs length_hint ()
Когда, выбирая среди альтернатив, всегда необходимо иметь вескую причину, почему выбрать одну из них.В этом разделе проводится временной анализ того, сколько времени требуется на выполнение всех из них, чтобы предложить лучший выбор для использования.
Код # 3: Анализ производительности
|
Выход:
Список: [1, 4, 5, 7, 8]
Время, затраченное на наивный метод: 2.6226043701171875e-06
Время, затраченное на использование len (): 1.18955078125e-06
Время, затраченное на использование length_hint (): 1.430511474609375e-06
Заключение: Четко видно, что затраченное время составляет наивных >> length_hint () > len () , следовательно, len () - лучший выбор для использования.
Внимание компьютерщик! Укрепите свои основы с помощью курса Python Programming Foundation и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS .
Массив- Общие сведения о документации по схеме JSON 7.0
По умолчанию элементы массива могут быть любыми.
Однако часто бывает полезно проверить элементы массива на соответствие
какая-то схема. Это делается с помощью элементов , additionalItems и содержат ключевых слов.
Проверка списка
Проверка списка полезна для массивов произвольной длины, где каждый
элемент соответствует той же схеме.Для этого типа массива установите элементов ключевое слово в одну схему, которая будет использоваться для проверки всех
элементов в массиве.
Примечание
Если элементов - это одна схема, ключевое слово additionalItems бессмысленно, и его не следует использовать.
В следующем примере мы определяем, что каждый элемент в массиве является номер:
{
"тип": "массив",
"Предметы": {
"тип": "число"
}
}
Новое в проекте 6
Хотя схема элементов должна быть действительна для каждого элемента в массиве, содержит схему , которая требуется только для проверки по одному или нескольким элементам в
множество.
{
"тип": "массив",
"содержит": {
"тип": "число"
}
}
[«жизнь», «вселенная», «все», 42]
[«жизнь», «вселенная», «все», «сорок два»]
Проверка кортежа
Проверка кортежа полезна, когда массив представляет собой набор элементов где у каждого своя схема и порядковый индекс каждого элемента имеет смысл.
Например, вы можете представить почтовый адрес, например:
1600 Pennsylvania Avenue NW
в виде 4-кратного набора вида:
[номер, название, улица_типа, направление]
У каждого из этих полей будет своя схема:
-
номер: номер адреса.Должен быть числом. -
street_name: Название улицы. Должна быть строка. -
street_type: Тип улицы. Должна быть строка из фиксированный набор значений. -
направление: Городской сектор адреса. Должна быть строка из другого набора значений.
Для этого мы устанавливаем ключевое слово items в массив, где каждый элемент
- это схема, соответствующая каждому индексу массива документа.То есть массив, в котором первый элемент проверяет первый элемент
входного массива второй элемент проверяет второй элемент
входной массив и т.д.
Вот пример схемы:
{
"тип": "массив",
"Предметы": [
{
"тип": "число"
},
{
"тип": "строка"
},
{
"тип": "строка",
"enum": ["Улица", "Проспект", "Бульвар"]
},
{
"тип": "строка",
"enum": ["NW", "NE", "SW", "SE"]
}
]
}
[1600, «Пенсильвания», «Авеню», «Северо-Запад»]
[10, «Даунинг», «Стрит»]
[1600, «Пенсильвания», «Авеню», «Северо-Запад», «Вашингтон»]
Ключевое слово additionalItems определяет, допустимо ли иметь
дополнительные элементы в массиве сверх того, что определено в элементах .Здесь мы повторно воспользуемся схемой из примера выше, но установим additionalItems с по false , что приводит к запрету
лишние элементы в массиве.
{
"тип": "массив",
"Предметы": [
{
"тип": "число"
},
{
"тип": "строка"
},
{
"тип": "строка",
"enum": ["Улица", "Проспект", "Бульвар"]
},
{
"тип": "строка",
"enum": ["NW", "NE", "SW", "SE"]
}
],
"additionalItems": false
}
[1600, «Пенсильвания», «Авеню», «Северо-Запад»]
[1600, «Пенсильвания», «Авеню»]
[1600, «Пенсильвания», «Авеню», «Северо-Запад», «Вашингтон»]
Ключевое слово additionalItems также может быть схемой для проверки по каждому
дополнительный элемент в массиве.В этом случае мы могли бы сказать, что дополнительные элементы
разрешены, если они все строки:
{
"тип": "массив",
"Предметы": [
{
"тип": "число"
},
{
"тип": "строка"
},
{
"тип": "строка",
"enum": ["Улица", "Проспект", "Бульвар"]
},
{
"тип": "строка",
"enum": ["NW", "NE", "SW", "SE"]
}
],
"additionalItems": {"тип": "строка"}
}
[1600, «Пенсильвания», «Авеню», «Северо-Запад», «Вашингтон»]
[1600, «Пенсильвания», «Авеню», «Северо-Запад», 20500]
Примечание
additionalItems не имеет смысла, если вы выполняете «проверку списка»
( элементов, - это объект) и игнорируется в регистре.