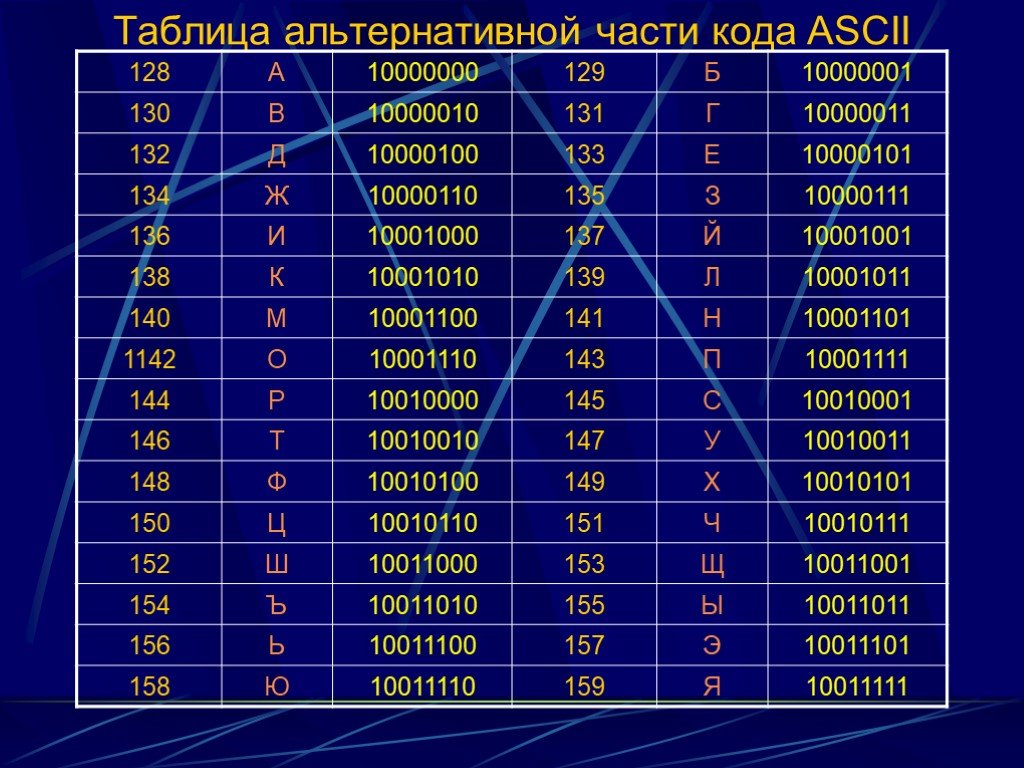
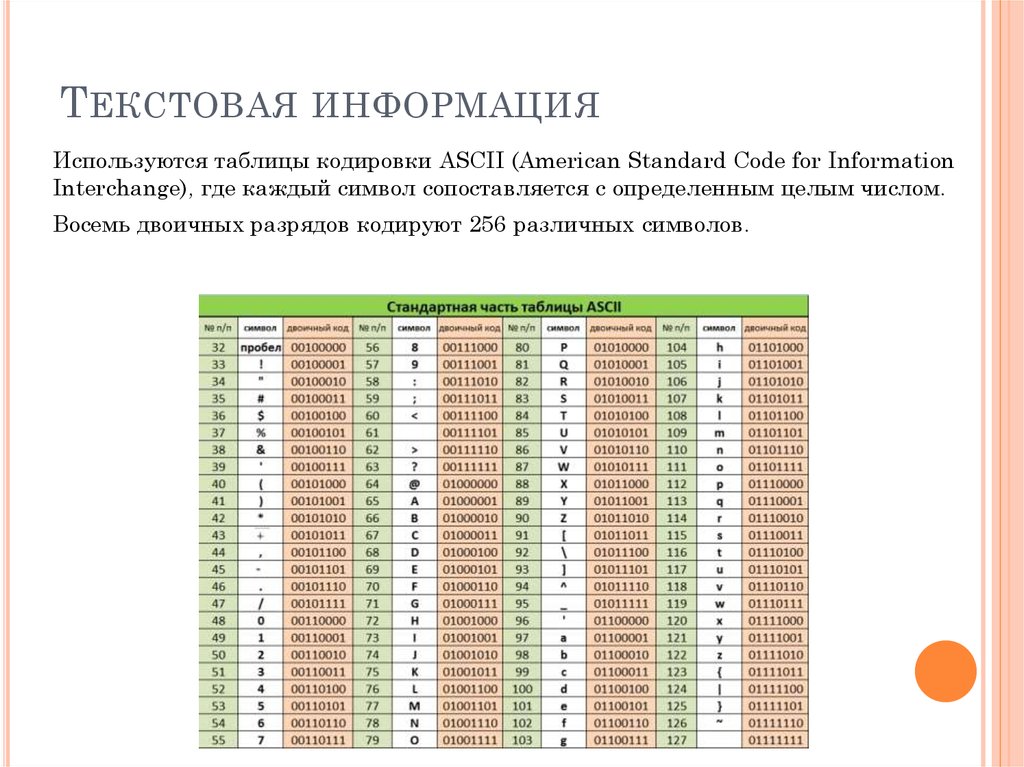
Кодирование текстовой информации с использованием таблицы символов ASCII или Unicode
Похожие презентации:
Пиксельная картинка
Информационная безопасность. Методы защиты информации
Электронная цифровая подпись (ЭЦП)
Этапы доказательной медицины в работе с Pico. Первый этап
История развития компьютерной техники
От печатной книги до интернет-книги
Краткая инструкция по CIS – 10 шагов
Информационные технологии в медицине
Информационные войны
Моя будущая профессия. Программист
Обсуждение в группе: Что означает данные цифры
99 111 109 112 117 116 101 114
2. Тема урока: Кодирование текстовой информации
Цели урока:• кодировать текстовую информацию с использованием таблицы
символов ASCII или Unicode
знать, как Unicode используется для обозначения специфических
букв казахского, английского и русского языков
3. Ожидаемые результаты (Критерии успеха):
• умеет закодировать с помощью кодировочнойтаблицы ASCII слово или выражение
• умеет кодировать и декодировать информацию
используя текстовые функции КОДСИМВ(текст),
СИМВОЛ(число) электронной таблицы Excel.

Множество
символов,
с
помощью
которых
записывается текст, называется алфавитом.
Число символов в алфавите – это его мощность.
Формула определения количества информации: N = 2b,
где N – мощность алфавита (количество символов),
b – количество бит (информационный вес символа).
В алфавит мощностью 256 символов можно поместить
практически все необходимые символы. Такой алфавит
называется достаточным.
Т.к. 256 = 28, то вес 1 символа – 8 бит.
Единице измерения 8 бит присвоили название 1 байт:
1 байт = 8 бит.
Двоичный код каждого символа в компьютерном
тексте занимает 1 байт памяти.
Каким же образом текстовая информация
представлена в памяти компьютера?
Тексты вводятся в память компьютера с помощью клавиатуры. На
клавишах написаны привычные нам буквы, цифры, знаки
препинания и другие символы. В оперативную память они
попадают в двоичном коде. Это значит, что каждый символ
представляется 8-разрядным двоичным кодом.
Кодирование заключается в том, что каждому символу ставится в
соответствие уникальный десятичный код от 0 до 255 или
соответствующий ему двоичный код от 00000000 до 11111111.
Таким образом, человек различает символы по их начертанию, а
компьютер — по их коду.
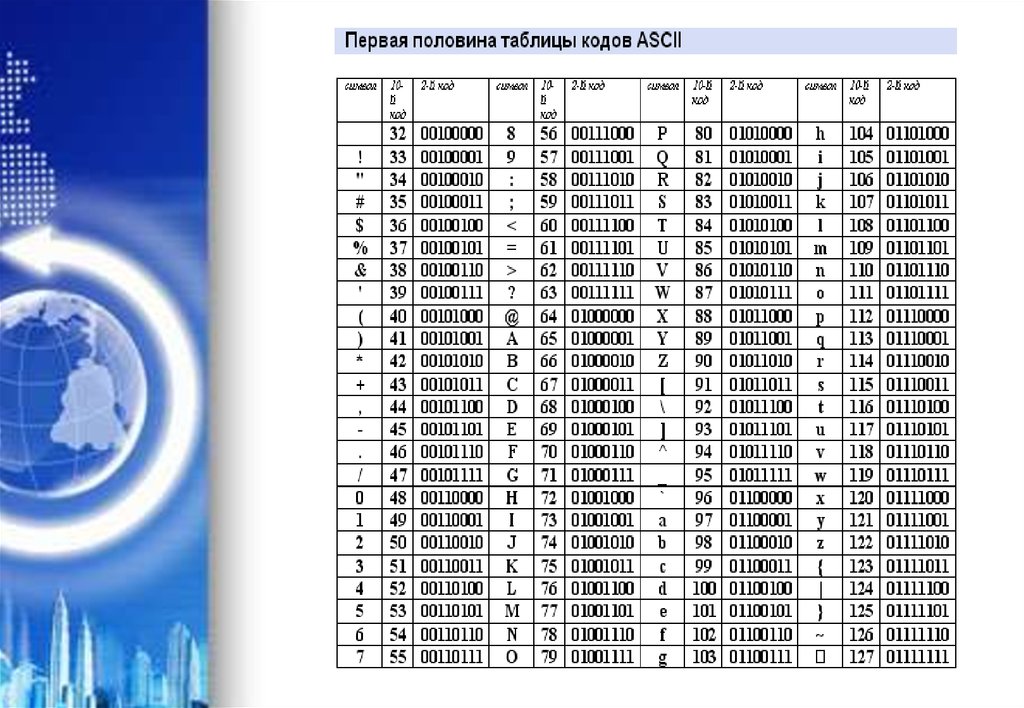
Таблица, в которой всем символам
компьютерного алфавита поставлены
в соответствие порядковые номера,
называется таблицей кодировки.
Для разных типов ЭВМ используются
различные таблицы кодировки.
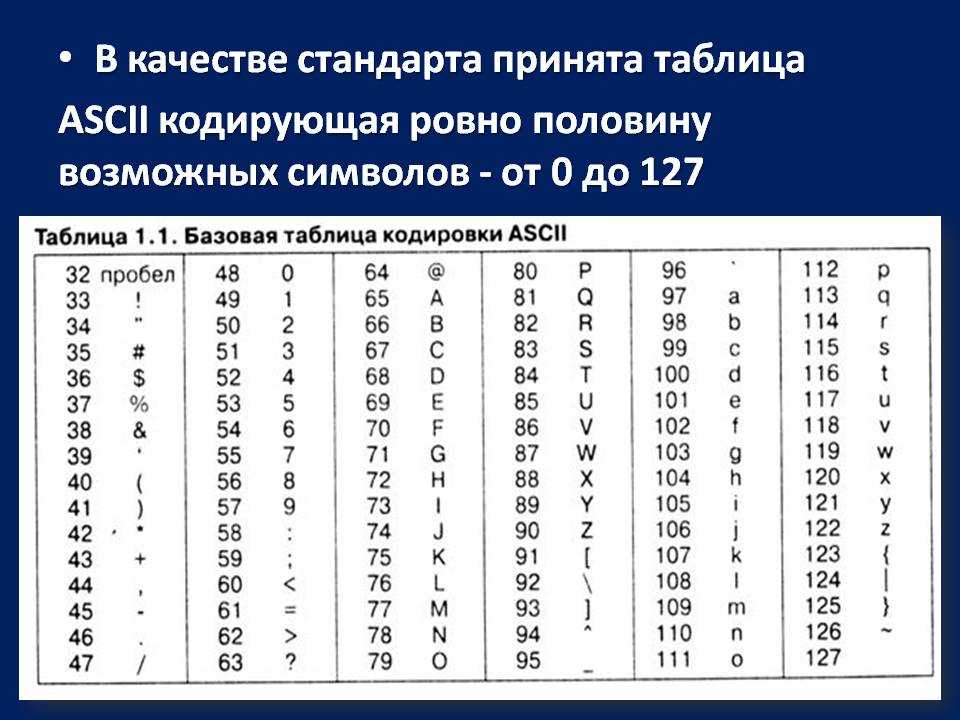
Международным стандартом для ПК стала
таблица ASCII (American Standard Code for
Information
Interchange
Американский
стандартный код для информационного
обмена).
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь
первая половина таблицы, т.е. символы с
номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
Для решения вышеизложенных проблем в начале 90-х
был разработан стандарт кодирования символов,
получивший название Unicode.
 Данный стандарт
Данный стандартпозволяет использовать в тексте почти любые языки и
символы.
Это 16-разрядная кодировка, т.е. в ней на
каждый символ отводится 2 байта памяти.
Конечно, при этом объем занимаемой
памяти увеличивается в 2 раза. Но зато
такая кодовая таблица допускает включение
до 65536 символов. Полная спецификация
стандарта Unicode включает в себя все
существующие, вымершие и искусственно
созданные алфавиты мира, а также
множество математических, музыкальных,
химических и прочих символов.
Буквы и цифры — это
обыкновенный код в
определённой
таблице символов.
14. Декодируйте следующие тексты, используя таблицу ASCII
Декодируйте следующие тексты,используя таблицу ASCII
А) 192 235 227 238 240 232 242 236
Б) 193 235 238 234 241 245 229 236 224
В) Таблица – закодировать в двоичной
и десятичной СЧ
возможности электронной таблицы для кодирования и декодирования по таблице ASCII
(текстовые функции КОДСИМВ(), СИМВОЛ()).

Функция СИМВОЛ и КОДСИМВ
Любой компьютер для представления символов использует
числовые коды. Наиболее распространенной системой
кодировки символов является ASCII. В этой системе
цифры, буквы и другие символы представлены числами от
0 до 127 (255). Функции СИМВОЛ (CHAR) и КОДСИМВ
(CODE) как раз и имеют дело с кодами ASCII. Функция
СИМВОЛ возвращает символ, который соответствует
заданному числовому коду ASCII, а функция КОДСИМВ
возвращает код ASCII для первого символа ее аргумента.
Синтаксис функций:
=СИМВОЛ(число)
=КОДСИМВ(текст)
Если в качестве аргумента текст вводится символ,
обязательно надо заключить его в двойные кавычки: в
противном случае Excel возвратит ошибочное значение.
С помощью электронной таблицы Excel
декодируйте данную пословицу
Работа в группе: Закодируйте короткую
фразу на русском языке. Обменяйтесь
полученными кодами с соседом и
декодируйте тексты друг друга.
Формативное оценивание:
http://goo.
 gl/forms/OAjH5zUl8a
gl/forms/OAjH5zUl8aПример 1. Сколько бит
необходимо для хранения на
диске слова «кабинет
информатики» в системе
кодирования ASCII?
Решение. Для хранения кода
символа в системе ASCII требуется 8
бит. Слово содержит 19 знаков,
следовательно, для хранения этого
слова на диске необходимо 19*8 =
Пример 2. Одна страница текста
формата А4 содержит 30 строк и
90 символов в строке (при шрифте
12 пунктов и полуторном
интервале). Определите
минимальный объем файла с этим
текстом в битах, байтах, Кб для
систем кодирования ASCII и
UNICODE.
• Решение. Количество символов на странице
равно 30*90=2700. В системе ASCII объем
файла составит
• 2700*8 = 21600 бит = 21600/8 байт = 2700
байт = 2700/1024 Кб ≈ 2,64 Кб.
• В системе UNICODE объем файла составит
• 2700*16 = 43200 бит = 43200/8 байт = 5400
байт = 5400/1024 Кб ≈ 5,27 Кб.
• Этот расчет показывает объем простейшего
текстового файла. В файле Word, например,
содержится
еще
информация
об
оформлении текста, т.
 е. свойствах каждого
е. свойствах каждогосимвола, абзаца, страницы.
23. Формативное оценивание
http://goo.gl/forms/Ev3QrzhCN9Домашнее задание
Просмотр видео
https://www.youtube.com/watch?v=gEpdBy5VC3Q
Почемучка. Машинные коды
English Русский Правила
§ 2. Представление текстовой информации в компьютере — ЗФТШ, МФТИ
Всякий текст состоит из символов — букв, цифр, знаков препинания и т. д., — которые человек различает по начертанию. Однако для компьютерного представления текстовой информации такой метод неудобен, а для компьютерной обработки текстов — и вовсе неприемлем. Используется другой способ: все символы кодируются числами, и текст представляется в виде набора чисел — 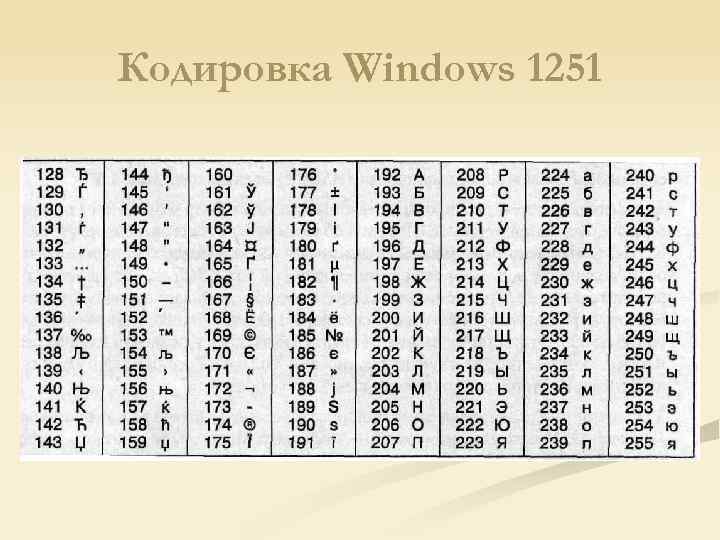 7=128`, из них первые `32` символа — «управляющие», а остальные — «изображаемые», т. е. имеющие графическое изображение. Управляющие символы должны восприниматься устройством вывода текста как команды, например:
7=128`, из них первые `32` символа — «управляющие», а остальные — «изображаемые», т. е. имеющие графическое изображение. Управляющие символы должны восприниматься устройством вывода текста как команды, например:
|
Cимвол |
Действие |
Английское название |
|
№7 |
Подача стандартного звукового сигнала |
Beep |
|
№8 |
Затереть предыдущий символ |
Back Space (BS) |
|
№13 |
Перевод строки |
Line Feed (LF) |
|
№26 |
Конец текстового файла |
End Of File (EOF) |
|
№27 |
Отмена предыдущего ввода |
Escape (ESC) |
К изображаемым символам в ASCII относятся буквы английского (латинского) алфавита (заглавные и прописные), цифры, знаки препинания и арифметических операций, скобки и некоторые специальные символы. Фрагмент кодировки ASCII приведён в таблице.
Фрагмент кодировки ASCII приведён в таблице.
|
Символ |
Десятичный код |
Двоичный код |
Символ |
Десятичный код |
Двоичный код |
|
Пробел |
`32` |
`00100000` |
`0` |
`48` |
`00110000` |
|
`!` |
|
`00100001` |
`1` |
`49` |
`00110001` |
|
# |
`35` |
`00100011` |
`2` |
`50` |
`00110010` |
|
$ |
`36` |
`00100100` |
`3` |
`51` |
`00110011` |
|
`**` |
|
`00101010` |
`4` |
`52` |
`00110100` |
|
`+` |
`43` |
00101011 |
5 |
53 |
`00110101` |
|
, |
`44` |
`00101100` |
`6` |
`54` |
`00110110` |
|
`–` |
`45` |
`00101101` |
`7` |
`55` |
`00110111` |
|
. |
`46` |
`00101110` |
`8` |
`56` |
`00111000` |
|
/ |
`47` |
`00101111` |
`9` |
`57` |
`00111001` |
|
`A` |
`65` |
`01000001` |
`N` |
`78` |
`01001110` |
|
`B` |
`66` |
`01000010` |
`O` |
`79` |
`01001111` |
|
`C` |
`67` |
`01000011` |
`P` |
`80` |
`01010000` |
|
`D` |
`68` |
`01000100` |
`Q` |
`81` |
`01010001` |
|
`E` |
`69` |
`01000101` |
`R` |
`82` |
`01010010` |
|
`F` |
`70` |
`01000110` |
`S` |
`83` |
`01010011` |
|
`G` |
`71` |
`01000111` |
`T` |
`84` |
`01010100` |
|
`H` |
`72` |
`01001000` |
`U` |
`85` |
`01010101` |
|
`I` |
`73` |
`01001001` |
`V` |
`86` |
`01010110` |
|
`J` |
`74` |
`01001010` |
`W` |
`87` |
`01010111` |
|
`K` |
`75` |
`01001011` |
`X` |
`88` |
`01011000` |
|
`L` |
`76` |
`01001100` |
`Y` |
`89` |
`01011001` |
|
`M` |
`77` |
`01001101` |
`Z` |
`90` |
`01011010` |
Хотя в ASCII символы кодируются `7`-ю битами, в памяти компьютера под каждый символ отводится ровно `1` байт (`8` бит). И получается, что один бит из каждого байта не используется.
И получается, что один бит из каждого байта не используется.
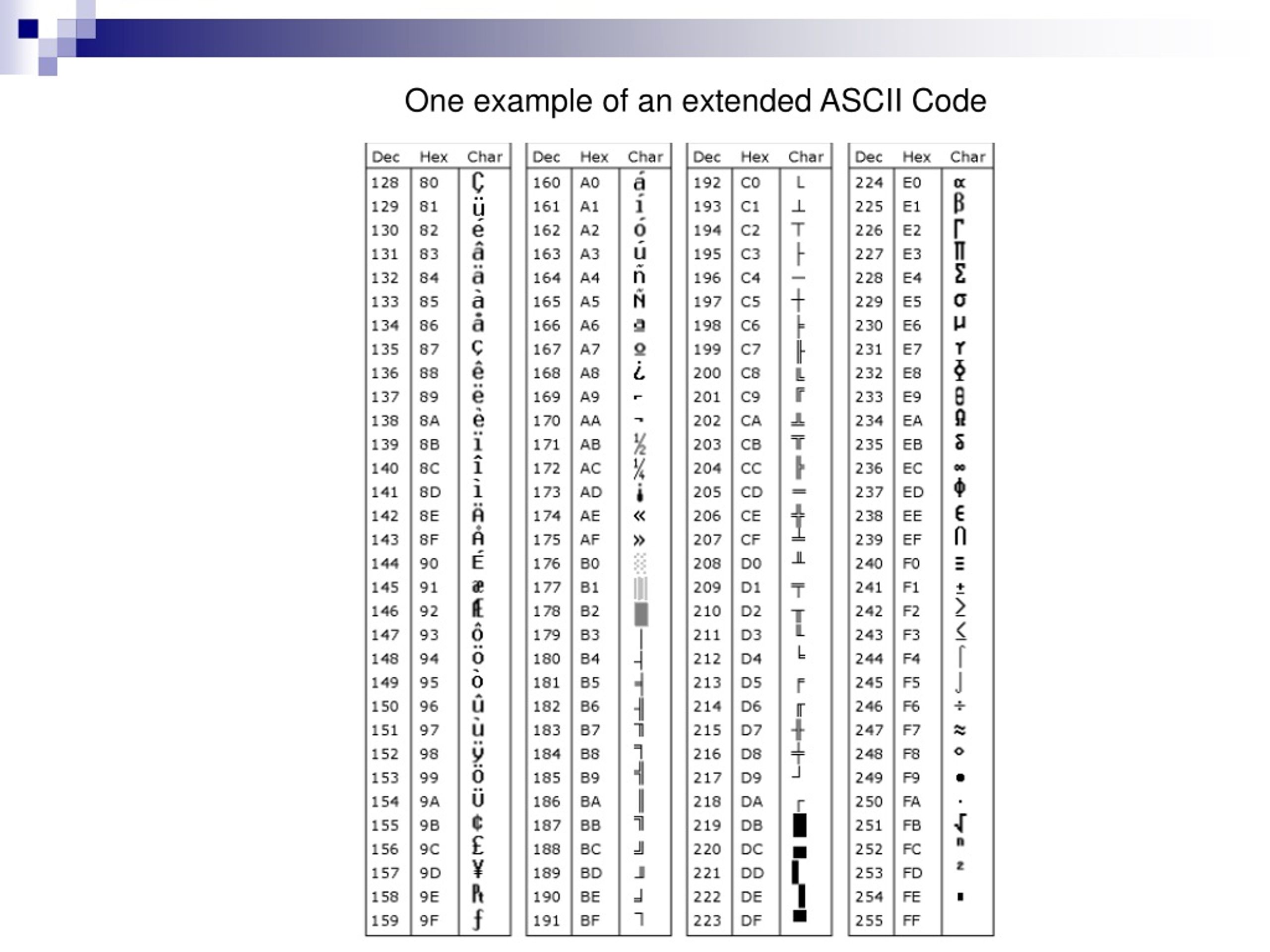
Главный недостаток стандарта ASCII заключается в том, что он рассчитан на передачу только текста, состоящего из английских букв. Со временем возникла необходимость кодирования и неанглийских букв. Во многих странах для этого стали разрабатывать расширения ASCII-кодировки, в которых применялись однобайтные коды символов; при этом первые `128` символов кодовой таблицы совпадали с кодировкой ASCII, а остальные (со `128`-го по `255`-й) использовались для кодирования букв национального алфавита, символов национальной валюты и т. п. Из-за несогласованности этих разработок для многих языков было создано по нескольку вариантов кодовых таблиц (например, для русского языка их около десятка).
Впоследствии использование кодовых таблиц было несколько упорядочено: каждой кодовой таблице было присвоено особое название и номер. Указав кодовую таблицу, автоматически выбирают и язык, которым можно пользоваться в дополнение к английскому; точнее, выбирается то, как будут интерпретироваться символы с кодами более `127`.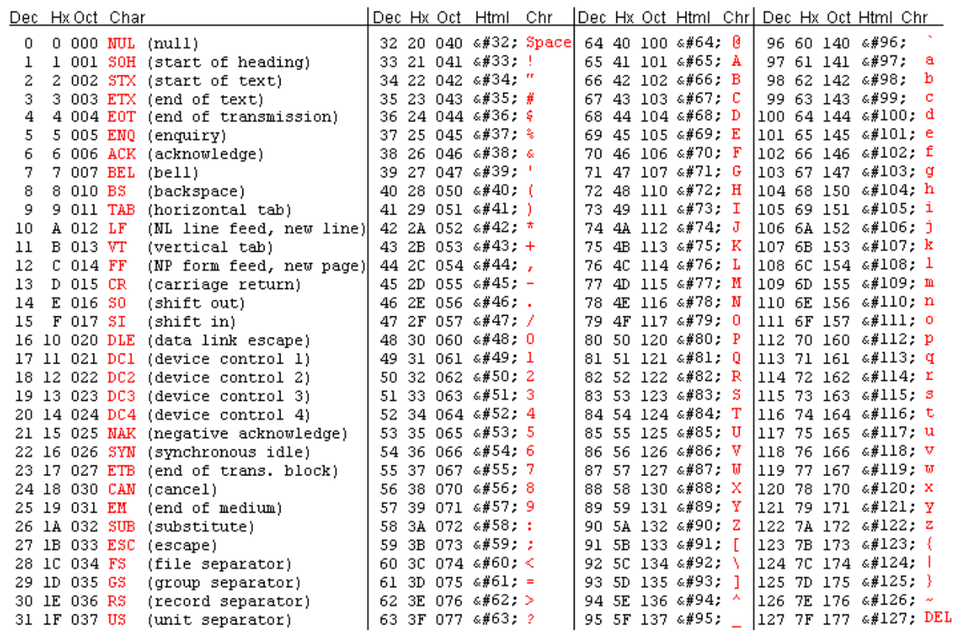
Для русского языка наиболее распространёнными являются однобайтовые кодовые таблицы СР-`866`, Windows-`1251`, ISO `8859-5` и КОИ-`8`. В них первые `128` символов совпадают с ASCII-кодировкой, а русские буквы помещены во второй части таблицы (с номерами `128-255`), однако коды русских букв в этих кодировках различны! Сравните, например, кодировки КОИ-`8` (Код Обмена Информацией `8`-битный, международное название «koi-`8`r») и Windows-`1251`, фрагменты которых приведены в таблицах на странице `13`.
Несовпадение кодовых таблиц приводит к ряду неприятных эффектов: один и тот же текст (неанглийский) имеет различное компьютерное представление в разных кодировках, соответственно, текст, набранный в одной кодировке, будет нечитабельным в другой!
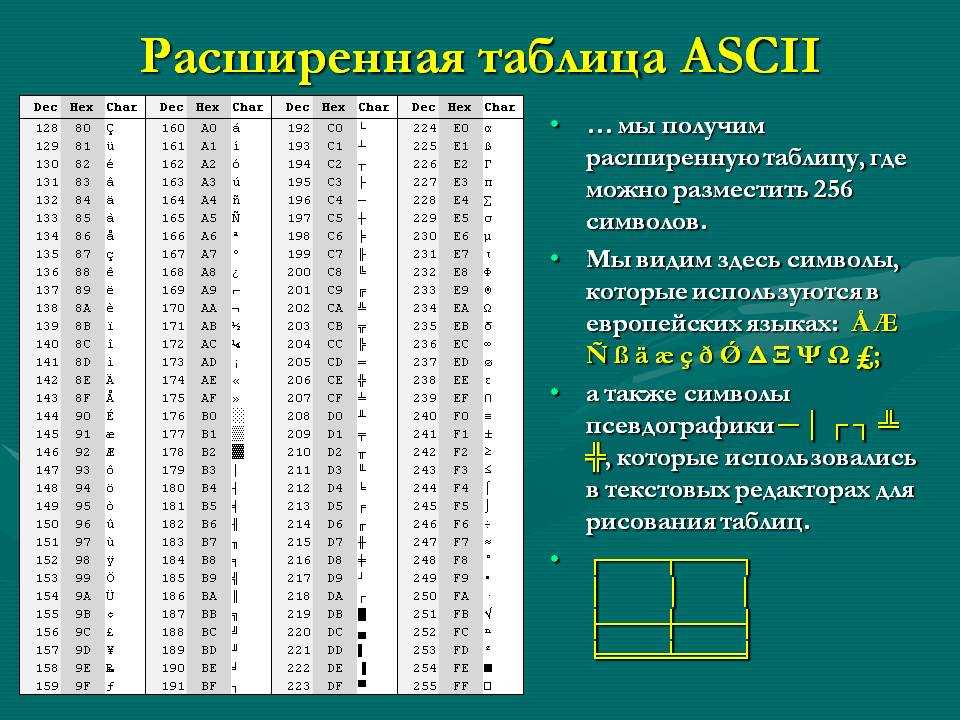
Однобайтовые кодировки обладают одним серьёзным ограничением: количество различных кодов символов в отдельно взятой кодировке недостаточно велико, чтобы можно было пользоваться одновременно несколькими языками. Для устранения этого ограничения в 1993-м году был разработан новый стандарт кодирования символов, получивший название Unicode, который, по замыслу его разработчиков, позволил бы использовать в текстах любые символы всех языков мира. 16`), а в целом стандарт Unicode описывает все алфавиты современных и мёртвых языков; для языков, имеющих несколько алфавитов или вариантов написания (например, японский и индийский), закодированы все варианты; внесены все математические и иные научные символьные обозначения, и даже — некоторые придуманные языки (например, письменности эльфов и Мордора из эпических произведений Дж.Р.Р. Толкиена). Потенциальная информационная ёмкость Unicode столь велика, что сейчас используется менее одной тысячной части возможных кодов символов!
16`), а в целом стандарт Unicode описывает все алфавиты современных и мёртвых языков; для языков, имеющих несколько алфавитов или вариантов написания (например, японский и индийский), закодированы все варианты; внесены все математические и иные научные символьные обозначения, и даже — некоторые придуманные языки (например, письменности эльфов и Мордора из эпических произведений Дж.Р.Р. Толкиена). Потенциальная информационная ёмкость Unicode столь велика, что сейчас используется менее одной тысячной части возможных кодов символов!
В современных компьютерах и операционных системах используется укороченная, `16`-битная версия Unicode, в которую входят все современные алфавиты; эта часть Unicode называется базовой многоязыковой страницей (Base Multilingual Plane, BMP).
Кодировка символов сейчас
FutureLearn использует куки-файлы, чтобы улучшить ваше взаимодействие с веб-сайтом. Все файлы cookie, кроме строго необходимых, в настоящее время отключены для этого браузера. Включите JavaScript, чтобы применить настройки файлов cookie для всех необязательных файлов cookie. Вы можете ознакомиться с политикой FutureLearn в отношении файлов cookie здесь.
Включите JavaScript, чтобы применить настройки файлов cookie для всех необязательных файлов cookie. Вы можете ознакомиться с политикой FutureLearn в отношении файлов cookie здесь.
ASCII и UTF-8 — две современные системы кодирования текста. Оба объясняются в этом видео с участием Кейтлин Мерри.
Просмотреть расшифровку
2.3
В 1963 году был принят Американский стандартный код для обмена информацией или ASCII, чтобы информацию можно было переводить между компьютерами. Он был разработан для создания международного стандарта кодирования латинского алфавита; превращая двоичные числа в текст на экране вашего компьютера. ASCII кодирует символы в семь битов двоичных данных. Поскольку каждый бит может быть либо 1, либо 0, всего получается 128 возможных комбинаций. Каждое из этих двоичных чисел можно преобразовать в десятичное число от 0 до 127. Например, 1000001 в двоичном формате равняется 65 в десятом.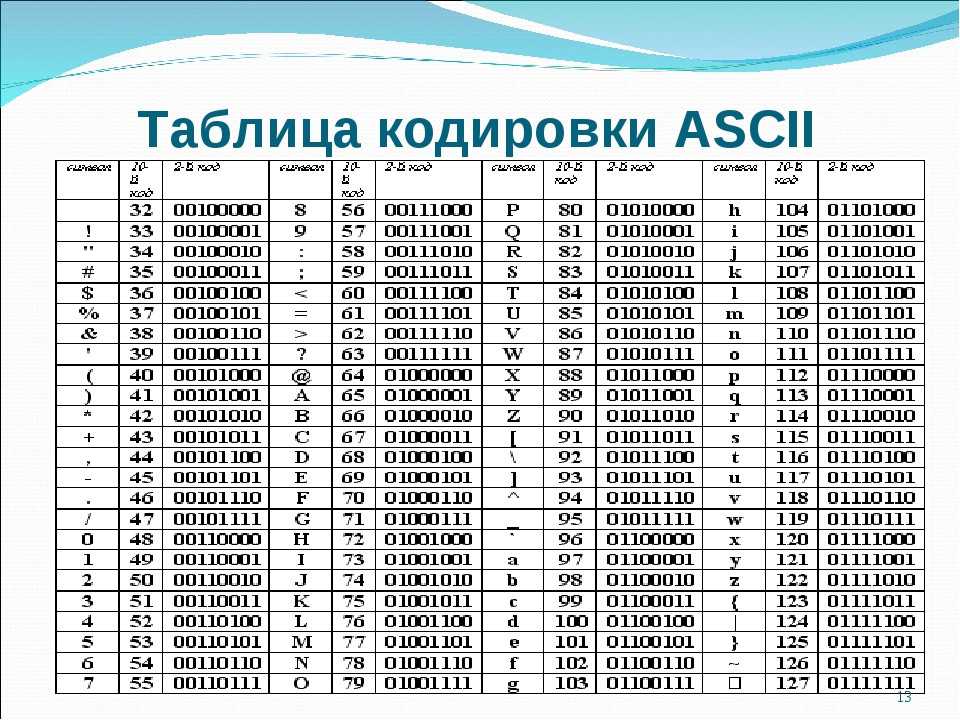 В ASCII каждое десятичное число соответствует символу, который мы хотим закодировать. От прописных и строчных букв до цифр, символов и компьютерных команд.
В ASCII каждое десятичное число соответствует символу, который мы хотим закодировать. От прописных и строчных букв до цифр, символов и компьютерных команд.
55.7
Например, 65 соответствует A в верхнем регистре. j в нижнем регистре равно 106 или 1101010 в двоичном формате. Или 0100001 равно 33, что кодирует символ восклицательного знака. Вот как hello кодируется в двоичный код с использованием ASCII. [H 1001000 E 1000101 L 1001100 L 1001100 O 1001111] Но что, если мы используем 8-битные байты? Мы просто ставим 0 перед двоичным числом. Итак, в 8-битном режиме привет выглядит так. Давайте посмотрим на все это на практике. На вашем компьютере откройте текстовый редактор Блокнот. Введите сообщение «Данные прекрасны» и сохраните его.
109.1
Посмотрите на размер файла. 18 байт. Теперь добавьте еще одно слово: Дейта такая красивая. Вы добавили три новых символа S, O и пробел. Если вы еще раз посмотрите на размер файла, то увидите, что он увеличился на 3 байта. Таким образом, ASCII использует 7 бит для представления 128 символов. Но когда были разработаны 8-битные компьютеры, дополнительная цифра означала, что теперь можно было закодировать 256 символов. Проблемы возникли, когда страны начали непоследовательно использовать эти дополнительные символы. Таким образом, разные числа представляли разные символы в разных языках. Япония создала несколько систем кодирования своего языка, которые различаются в зависимости от аппаратного обеспечения. Сообщения, отправляемые с одного японского компьютера на другой, становились искаженными и нечитаемыми, когда компьютер неправильно переводил данные.
Таким образом, ASCII использует 7 бит для представления 128 символов. Но когда были разработаны 8-битные компьютеры, дополнительная цифра означала, что теперь можно было закодировать 256 символов. Проблемы возникли, когда страны начали непоследовательно использовать эти дополнительные символы. Таким образом, разные числа представляли разные символы в разных языках. Япония создала несколько систем кодирования своего языка, которые различаются в зависимости от аппаратного обеспечения. Сообщения, отправляемые с одного японского компьютера на другой, становились искаженными и нечитаемыми, когда компьютер неправильно переводил данные.
161
Ошибки в преобразовании японских иероглифов стали такой проблемой, что у них даже есть название для этого, моджибаке. Эта проблема стала намного хуже с изобретением всемирной паутины. Для решения проблем, связанных с отправкой документов на разных языках по всему миру, был создан консорциум для создания всемирного стандарта Unicode. Как и в ASCII, в Unicode каждому символу присваивается определенный номер.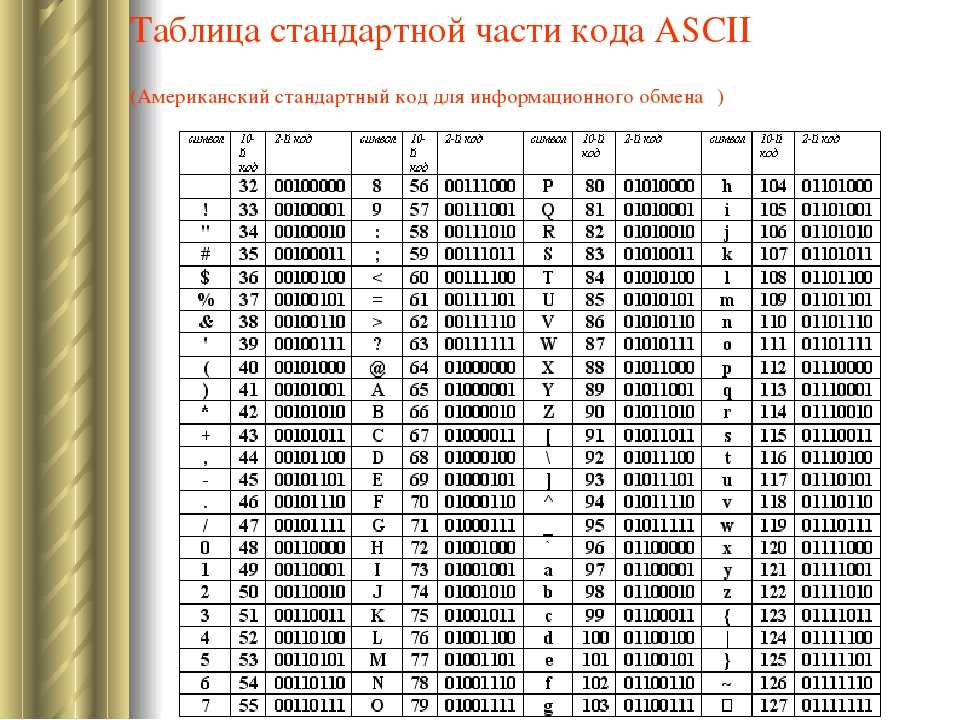 Unicode также использует старую кодировку ASCII для английского языка. Таким образом, A в верхнем регистре по-прежнему равен 65. Но Unicode кодирует гораздо больше, чем 100 000 символов в большинстве языков. Для этого он использует не 8 бит данных, а 32. Но 65, закодированные в 32 бита, выглядят так, что занимает много места.
Unicode также использует старую кодировку ASCII для английского языка. Таким образом, A в верхнем регистре по-прежнему равен 65. Но Unicode кодирует гораздо больше, чем 100 000 символов в большинстве языков. Для этого он использует не 8 бит данных, а 32. Но 65, закодированные в 32 бита, выглядят так, что занимает много места.
211.5
Также многие старые компьютеры интерпретируют восемь нулей подряд как конец строки символов, также называемой нулем. Это означает, что они не будут отправлять никаких символов, которые появятся позже. Метод кодирования Unicode, UTF8, решает эти проблемы. Вплоть до номера 127 значение ASCII остается неизменным. Так что A по-прежнему 01000001. Для всего, что выше 127, UTF8 разделяет код на два байта. Он добавляет 110 к первому байту и 10 ко второму байту. Затем вы просто заполняете двоичный код для промежуточных битов. Например, число 325 равно 00101000101, которое вставляется вот так. Это работает для первых 4,096 символов. После этого добавляется еще один байт.
268,2
И еще 1 добавляется в начале первого байта, вот так. Это дает вам 16 дополнительных битов для вашего двоичного кода. На самом деле вы можете получить до 7 байтов данных, которые выглядят так. Таким образом, UTF8 позволяет избежать проблемы с 8 нулями. И он обратно совместим со старой системой ASCII. И это краткое изложение ASCII и UTF8, двух важных стандартов, которые определяют, как символы кодируются из единиц и нулей в цифровой текст, который вы просматриваете каждый день.
Два стандарта кодирования символов определяют, как символы декодируются из единиц и нулей в текст, который вы видите на экране прямо сейчас, и в различные языки, просматриваемые каждый день во всемирной паутине. Этими двумя стандартами кодирования являются ASCII и Unicode.
ASCII
Американский стандартный код для обмена информацией (ASCII) был разработан для создания международного стандарта для кодирования латинского алфавита. В 1963 году был принят ASCII, чтобы информацию можно было интерпретировать между компьютерами; представляющие строчные и заглавные буквы, цифры, символы и некоторые команды.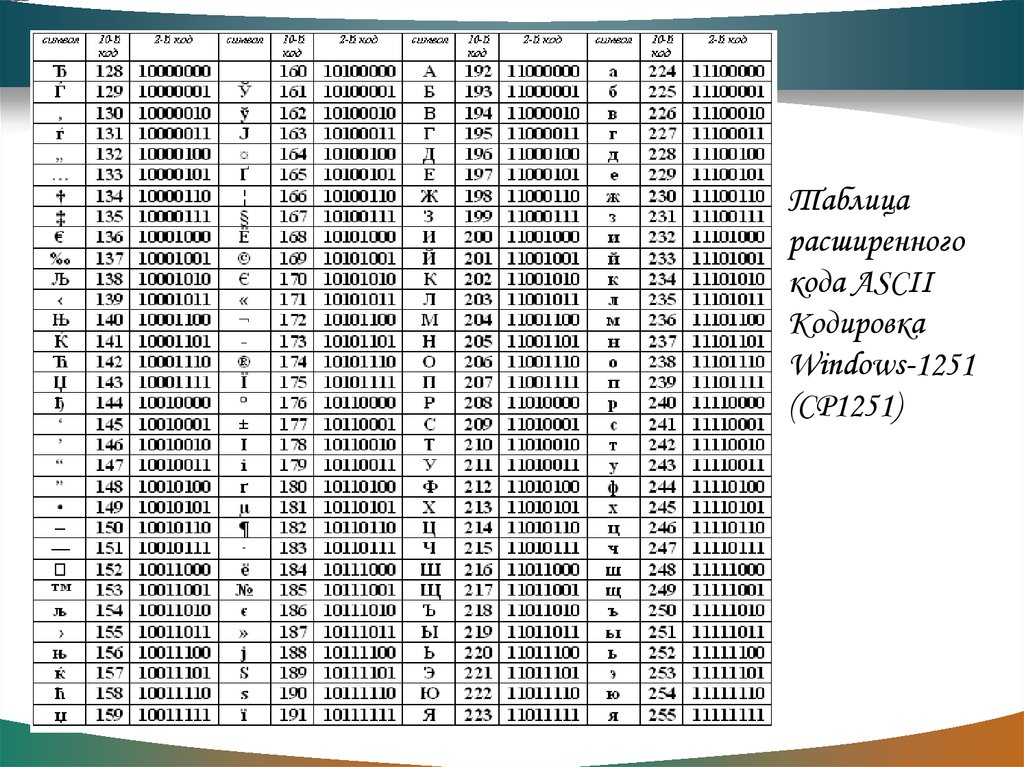 Поскольку ASCII кодируется с использованием единиц и нулей, системы счисления с основанием 2, он использует семь битов. Семь бит позволяют
Поскольку ASCII кодируется с использованием единиц и нулей, системы счисления с основанием 2, он использует семь битов. Семь бит позволяют 2 в степени 7 = 128 возможных комбинаций цифр для кодирования символа.
Таким образом,
ASCII обеспечил возможность кодирования 128 важных символов:
Как работает кодировка ASCII
- Вы уже знаете, как преобразовывать десятичные числа в двоичные
- Теперь вам нужно превратить буквы в двоичные числа
- Каждому символу соответствует десятичное число (например, A → 65)
- ASCII использует 7 бит
- Мы используем первые 7 столбцов таблицы преобразования, чтобы создать 128 различных чисел (от 0 до 127)
Например, 1000001 дает нам число 65 ( 64 + 1 ), которое соответствует букве «А».
| 64 | 32 | 16 | 8 | 4 | 2 | 1 |
|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 | 1 |
Вот как «HELLO» закодировано в ASCII в двоичном виде:
| Латинский символ | ASCII-код |
|---|---|
| Н | 1001000 |
| Е | 1000101 |
| Л | 1001100 |
| Л | 1001100 |
| О | 1001111 |
Применим эту теорию на практике:
- Откройте Блокнот или любой другой текстовый редактор, который вы предпочитаете
- Введите сообщение и сохраните его, например.
 «данные прекрасны»
«данные прекрасны» - Посмотрите на размер файла — у меня 18 байт
- Теперь добавьте еще одно слово, например. «данные такие красивые»
- Если вы еще раз посмотрите на размер файла, то увидите, что он изменился — теперь мой файл стал на 3 байта больше (SO[SPACE]: «S», «O» и пробел)
 «данные прекрасны»
«данные прекрасны»Unicode и UTF-8
Поскольку символы ASCII кодируются 7 битами, переход на 8-битную вычислительную технологию означал использование одного дополнительного бита. С этой дополнительной цифрой Расширенный код ASCII , закодированный до 256 символов. Однако возникшая проблема заключалась в том, что страны, использующие разные языки, по-разному использовали эту дополнительную возможность кодирования. Многие страны добавили свои собственные дополнительные символы, и разные числа представляли разные символы на разных языках. Япония даже создала несколько систем кодирования японского языка в зависимости от аппаратного обеспечения, и все эти методы были несовместимы друг с другом. Таким образом, когда сообщение было отправлено с одного компьютера на другой, полученное сообщение могло стать искаженным и нечитаемым; японские системы кодирования символов были настолько сложны, что даже когда сообщение было отправлено с одного типа японского компьютера на другой, происходило нечто, называемое «модзибаке»:
Таким образом, когда сообщение было отправлено с одного компьютера на другой, полученное сообщение могло стать искаженным и нечитаемым; японские системы кодирования символов были настолько сложны, что даже когда сообщение было отправлено с одного типа японского компьютера на другой, происходило нечто, называемое «модзибаке»:
Проблема несовместимых систем кодирования стала более актуальной с изобретением Всемирной паутины, поскольку люди обменивались цифровыми документами по всему миру, используя несколько языков. Чтобы решить эту проблему, Консорциум Unicode создал универсальную систему кодирования под названием Unicode . Юникод кодирует более 100 000 символов, охватывая все символы, которые вы найдете в большинстве языков. Unicode присваивает каждому символу определенное число, а не двоичную цифру. Но были некоторые проблемы с этим, например:
- Для кодирования 100 000 символов потребуется около 32 двоичных разрядов. Unicode использует ASCII для английского языка, поэтому A по-прежнему равно 65. Однако при 32-битной кодировке буква A будет двоичным представлением 00000000000000000000000000000000000001000001. Это тратит впустую много ценного пространства!
- Многие старые компьютеры интерпретируют восемь нулей подряд (ноль) как конец строки символов. Таким образом, эти компьютеры не будут отправлять символы, следующие за восемью нулями подряд (они не будут отправлять букву A, если она представлена как 00000000000000000000000000000000000001000001).
 Unicode использует ASCII для английского языка, поэтому A по-прежнему равно 65. Однако при 32-битной кодировке буква A будет двоичным представлением 00000000000000000000000000000000000001000001. Это тратит впустую много ценного пространства!
Unicode использует ASCII для английского языка, поэтому A по-прежнему равно 65. Однако при 32-битной кодировке буква A будет двоичным представлением 00000000000000000000000000000000000001000001. Это тратит впустую много ценного пространства! Метод кодирования Unicode UTF-8 решает следующие проблемы:
— до символа с номером 128 используется обычное значение ASCII (например, A равно 01000001)
— для любого символа после 128 UTF-8 разделяет код в два байта и добавление «110» к началу первого байта, чтобы показать, что это начальный байт, и «10» к началу второго байта, чтобы показать, что он следует за первым байтом.
Итак, для каждого символа после числа 128 у вас есть два байта:
[110xxxxx] [10xxxxxx]
И вы просто заполните двоичный код для числа между ними:
[11000101] [10000101] (это число 325 → 00101000101)
Это работает для первых 2048 символов.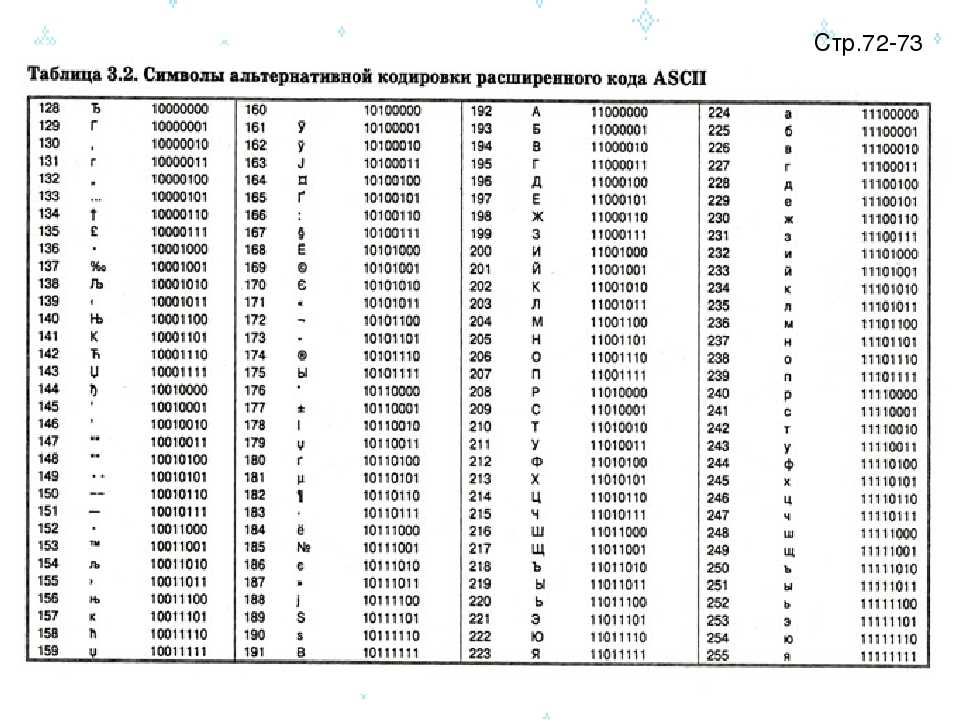 Для символов сверх этого добавляется еще одна «1» в начале первого байта, а также используется третий байт:
Для символов сверх этого добавляется еще одна «1» в начале первого байта, а также используется третий байт:
[1110xxxx] [10xxxxxx] [10xxxxxx]
Это дает вам 16 пробелов для двоичного кода. Таким образом, UTF-8 достигает четырех байтов:
[11110xxx] [10xxxxxx] [10xxxxxx] [10xxxxxx]
Таким образом, UTF-8 позволяет избежать проблем, упомянутых выше, а также необходимости индекса, и позволяет декодировать символы из двоичной формы в обратном направлении (т.е. имеет обратную совместимость).
Занятия в классе
Есть много занимательных занятий по обучению кодированию символов. Мы включили два упражнения ниже, чтобы вы могли попробовать их в своем классе. Какие у вас есть главные советы по обучению кодированию символов? Поделитесь ими в комментариях!
Перевод секретных сообщений : разместить короткое секретное сообщение в ASCII в разделе комментариев и перевести или ответить на ASCII-сообщения других участников
Бинарные браслеты : создавайте браслеты, используя разноцветные бусины для обозначения единиц и нулей и написания инициала или имени в ASCII.

Эта статья взята из бесплатного онлайн-ресурса
Представление данных в вычислениях: оживление данных
Создано
Присоединяйся сейчас
Достигните своих личных и профессиональных целей
Разблокируйте доступ к сотням экспертных онлайн-курсов и степеней от ведущих университетов и преподавателей, чтобы получить аккредитованные квалификации и профессиональные сертификаты для составления резюме.
Присоединяйтесь к более чем 18 миллионам учащихся, чтобы начать, сменить или развить свою карьеру в своем собственном темпе в широком диапазоне тем.
Начать обучение сейчас
Понимание таблицы ASCII
Если вы разбираетесь в компьютерах, вы, должно быть, сталкивались с таблицей ASCII. Это важная часть современных вычислений, даже если многие люди не знают об этом.
В этом уроке я расскажу
- Краткая история ASCII
- Кодировка символов
- Понимание содержимого таблицы ASCII
Корни ASCII
До появления ASCII каждый производитель компьютеров использовал свой собственный способ кодирования символов, что делало невозможным обмен данными при использовании двух машин разных производителей.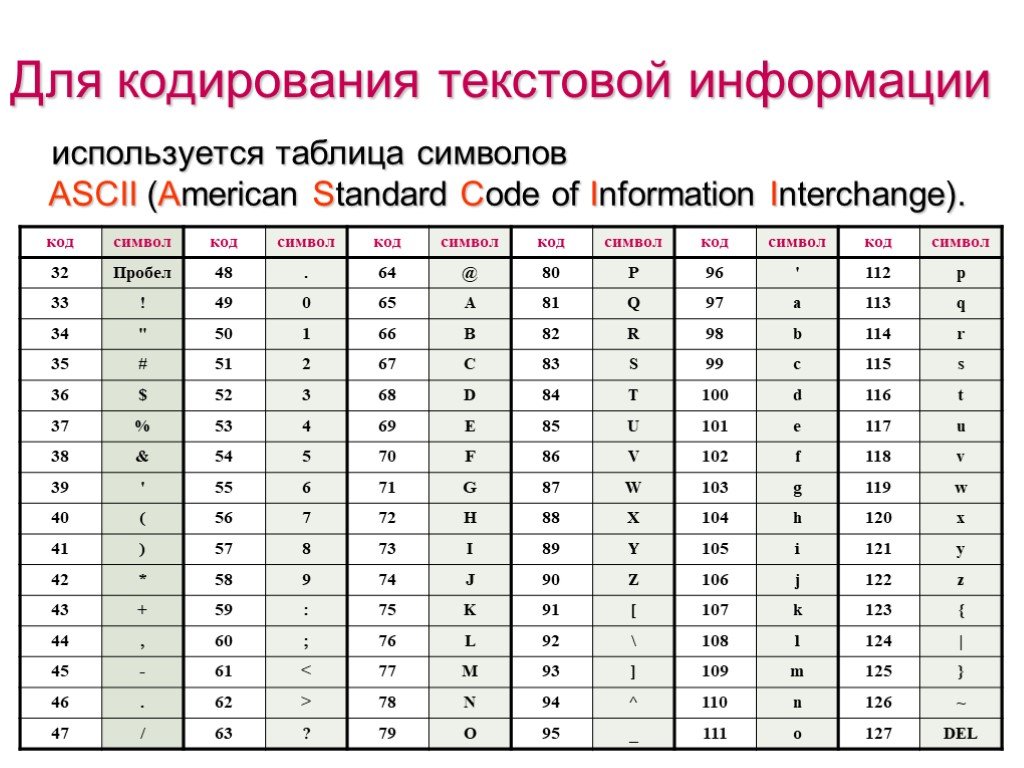
В то время IBM использовала только девять различных наборов символов!
Американская ассоциация стандартов (ASA), ныне известная как Американский национальный институт стандартов (ANSI), начала работу над ASCII в мае 1961 года. .
Первое издание было выпущено в 1963 г., оно не получило большой популярности в первые дни и было пересмотрено в 1967 г.
И все изменилось для ASCII 11 марта 1968 г., когда президент Линдон Б. Джонсон правительственный компьютер должен его поддерживать.
Теперь давайте перейдем к части кодировки символов.
Что такое кодировка символов?
Кодировка символов играет фундаментальную роль, если вы хотите понять таблицу ASCII.
Вы можете спросить, почему.
Ну, кодировка символов в основном означает присвоение цифр алфавиту.
Вы можете спросить, зачем кому-то заниматься нумерацией каждого символа.
Позвольте мне напомнить вам кое-что. Компьютеры — это не что иное, как мощные калькуляторы, работающие по основному принципу расчета.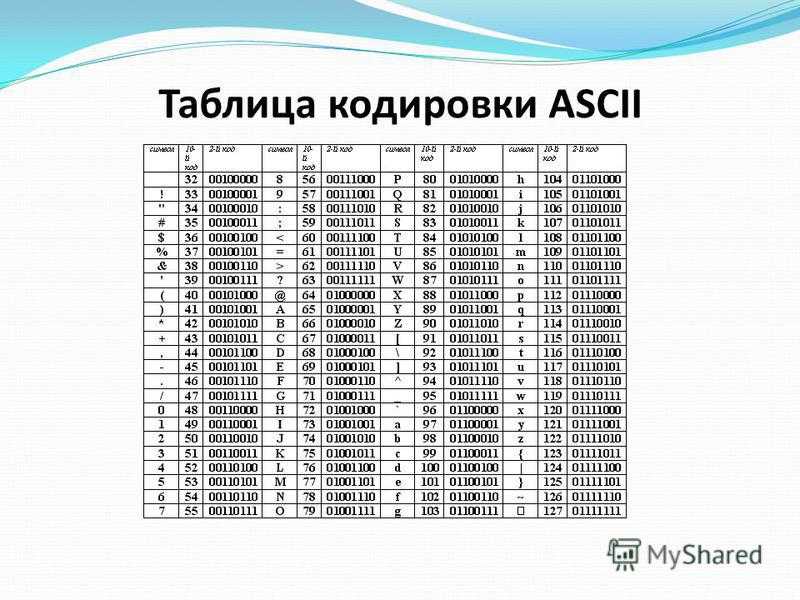
И когда вы присваиваете им номера, конвертировать их в двоичные файлы довольно просто.
В английском языке у нас есть 26 символов, поэтому, если мы присвоим им номера, это должно выглядеть так:
| Символ | Закодированный номер | Двоичное преобразование |
|---|---|---|
| Л | 12 | 00001100 |
| Н | 8 | 00001000 |
| Б | 2 | 00000010 |
Здесь я присвоил числа L, H и B, а затем преобразовал их в двоичные числа, что сделало все вычисления довольно простыми и эффективными.
Это была скорее базовая часть. Теперь давайте перейдем к таблице ASCII.
Доступ к таблице ASCII
Код ASCII S ASCII служит основным ориентиром, когда на вашем компьютере есть информация, которая должна быть переведена в удобочитаемую форму, поскольку компьютеры работают с двоичными числами (0 и 1).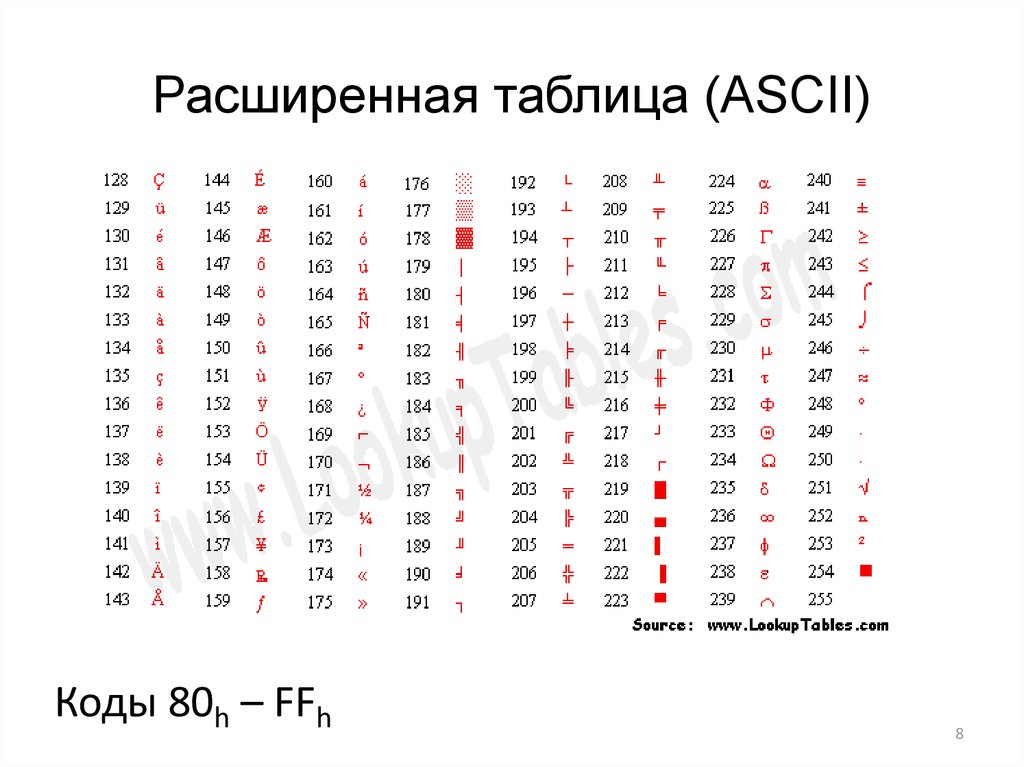
Вот полная таблица ASCII:
Полная таблица ASCIIИтак, для понимания, вы можете разделить таблицу ASCII на три основные части:
-
от 0 до 31 и 127: Управляющие символы (используются для таких клавиш, как backspace, escape и т. д.) -
от 32 до 126: Печатные символы (которые вы в основном используете для набора текста и выполнения основных задач). -
от 128 до 255: Расширенный ASCII.
Здесь расширенный ASCII представляет собой наиболее интересную часть, так как это расширение специальных символов исходной таблицы ASCII.
Изначально таблица ASCII состояла из 7-битных символов, что в общей сложности давало 128 возможных значений. Но ASCII был создан для расширения, и когда они перешли на 8-бит, было добавлено 127 специальных символов.
Всего 255 символов!
Но эту часть обсуждать не буду, так как она бесполезна для широкой публики, да и обсуждать, кроме спецсимволов, особо нечего.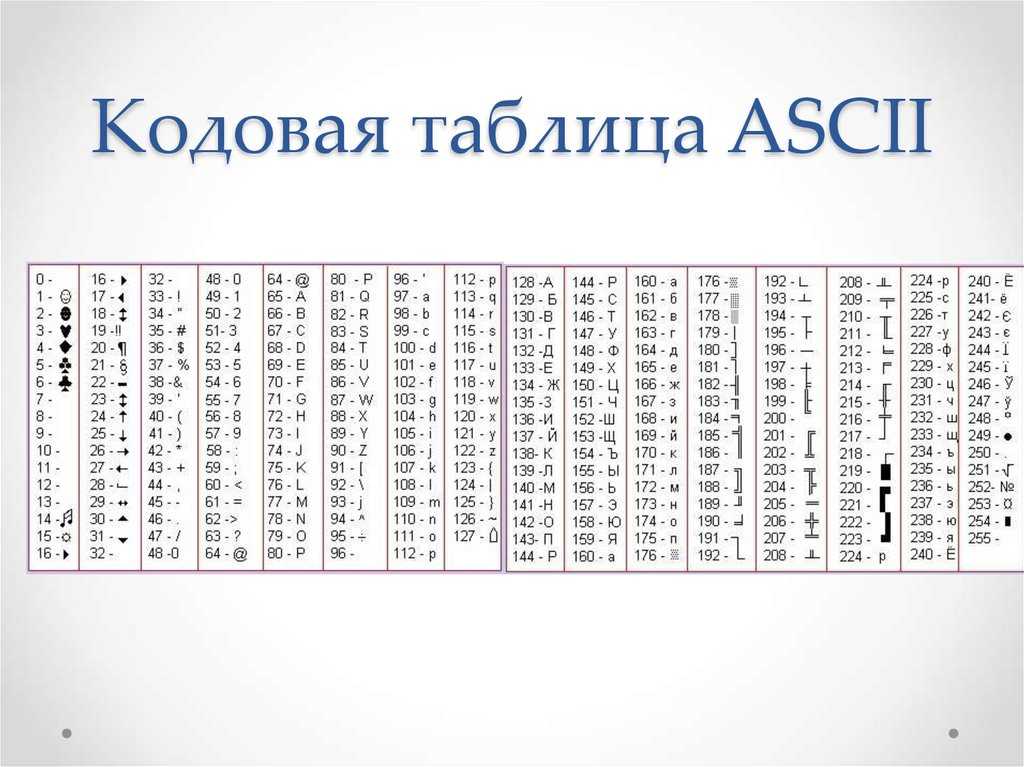
Теперь давайте рассмотрим быстрый пример того, как компьютеры будут обрабатывать символы на основе ASCII.
Вот что я использовал LINUX в качестве строки символов, чтобы объяснить, как это будет обрабатываться компьютером.
| Символ | л | я | Н | У | х |
|---|---|---|---|---|---|
| ASCII-код | 76 | 73 | 78 | 85 | 88 |
| Двоичный | 01001100 | 01001001 | 01001110 | 01010101 | 01011000 |
Таким образом, если вы сохраните LINUX в своей памяти, он будет сохранен как 01001100 01001001 01001110 01010101 01011000 и ASCII становится здесь связующим звеном между преобразованием.
Управляющие символы (от 0 до 31, 127)
Управляющие символы также известны как непечатаемые символы, которые используются для определенных действий и ничего не печатают.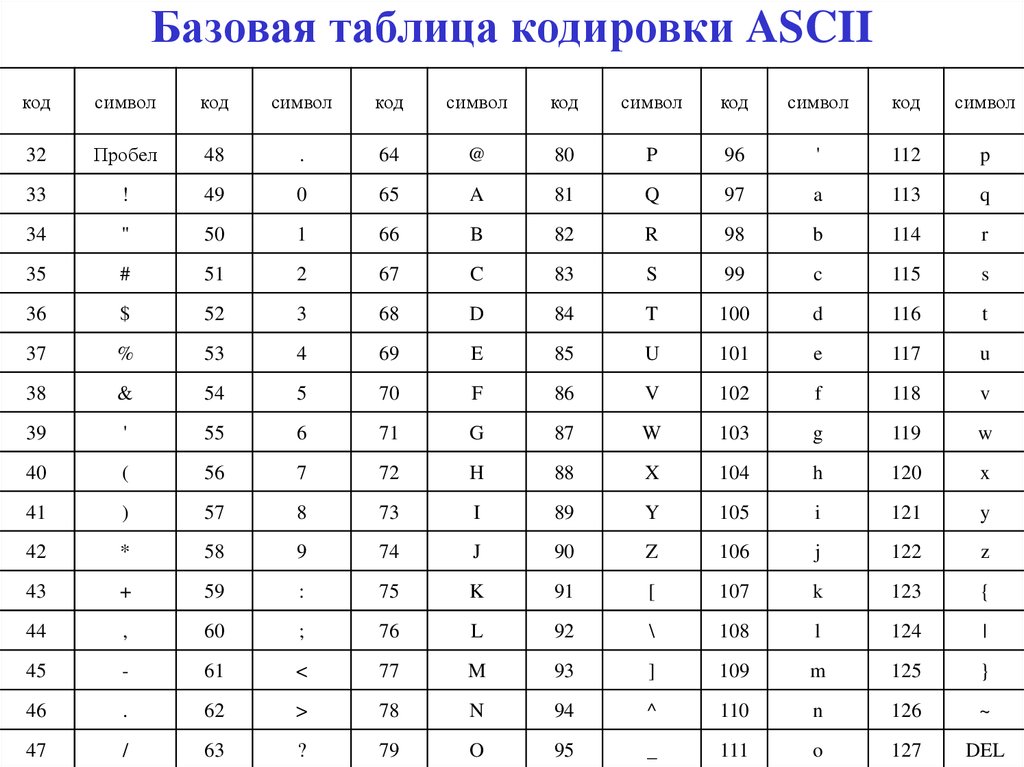
Например, когда вы нажимаете клавишу выхода, вы возвращаетесь на предыдущую страницу и ничего не печатаете на экране в качестве управляющего символа.
Печатные символы
Как следует из названия, печатные символы относятся к тем символам, которые визуально появляются на экране, например к буквам алфавита.
Печатные символы можно разделить на две части:
- Символы и цифры
- Алфавиты
Символы и цифры
Это не должна быть линейная последовательность, так как я разделил это для лучшего понимания.
Вы найдете символы и цифры в следующих диапазонах:
- От 32 до 64
- От 91 до 96
- И от 123 до 126
Алфавиты
В последней части таблицы ASCII вы найдете алфавит заглавными и строчными буквами.
- Прописные буквы будут в диапазоне от 65 до 90
- Тогда как строчные буквы будут в диапазоне от 97 до 122
