Миграция на поисковый движок Manticore Search
Изначально в ELiS для полнотекстового поиска был использован отечественный поисковый движок Sphinx второй версии. Я собрал для него RPM-пакеты для CentOS7 и CentOS8 (пакеты доступны в открытом репозитории), но только для второй версии (актуальная — третья версия).
В результате внутренних проблем в 2017 году был создан форк Sphinx под названием Manticore Search.
И тот и другой поисковые движки развиваются под открытой лицензией GPL, но политика развития Manticore более открытая, исходный код доступен на GitHub, регулярно производятся релизы, есть RPM-пакеты для CentOS. Sphinx-же релизится раз в год, в открытом доступе исходников нет (предоставляются по запросу), RPM-пакетов нет, несколько хуже документация.
В целом и дальше можно было бы использовать Sphinx, но по историческим причинам в ELiS используется Sphinx без обновления индексов в реальном времени (т.е. чтобы изменения попали в поисковый индекс, необходимо переиндексировать полностью все документы и если вы хотите, чтобы изменения и добавления сущностей быстрее попадали в поиск надо чаще запускать полное переиндексирование).
Переиндексация требует перезаписи файлов больших объемов, что означает, что ее не выгодно производить слишком часто, а значит будет лаг между добавлением новых документов и тем как они появятся в индексе (обычно 1 час, но если индекс большой, то обновление индекса делается реже).
Второй отрицательный момент связан с механизмом резервного копирования виртуальных машин: есть средства, которые позволяют при резервном копировании производить копирование не всей виртуальной машины целиком, а только разницы того, что было записано за время последнего резервного копирования (дельта-диск). Но если регулярно делать переиндексацию, то даже за день дельта-диск будет составлять гигабайты информации, эффективность резервного копирования при этом резко падает. Можно, конечно, индекс хранить на диске, который исключается из резервного копирования, но это требует более сложной установки и более объемных инструкций, чего хотелось-бы избежать.
Эти два момента приводят к желанию изменить механизм поиска, отказавшись от переиндексирования и перейти на использование реалтаймовых индексов. Такие индексы позволяют сразу видеть новые документы в поиске без переиндексирования. Они на самом деле появились еще во второй версии Sphinx и можно было бы их включить не меняя и даже не обновляя сервер, но возникли некоторые проблемы с тем, что во второй версии имеются различные ошибки, которые уже не будут исправляться, а если мигрировать на третью версию Sphinx, то это потребует определенной ручной работы и тогда можно уже выбирать между Sphinx 3 и Manticore 3.
Такие индексы позволяют сразу видеть новые документы в поиске без переиндексирования. Они на самом деле появились еще во второй версии Sphinx и можно было бы их включить не меняя и даже не обновляя сервер, но возникли некоторые проблемы с тем, что во второй версии имеются различные ошибки, которые уже не будут исправляться, а если мигрировать на третью версию Sphinx, то это потребует определенной ручной работы и тогда можно уже выбирать между Sphinx 3 и Manticore 3.
Т.к. сборка RPM-пакета Sphinx 3 оказалась сложнее, чем вначале предполагалось, а Manticore продемонстрировала более высокий темп развития и лучшую открытость ПО, решено мигрировать поисковый движок на Manticore.
Итак, в результате миграции:
1) Появляется HTTP-интерфейс для поисковых запросов (на случай, если вы захотите использовать поисковый индекс напрямую, минуя API ELiS и HTTP-интерфейс для вас предпочтительнее SQL.
2) Используется новый генератор конфигурации поисковика, который теперь делает поисковыми полями не только те, что создаются при установке ELiS, но и те, которые вы добавите сами.
3) Атрибуты сущностей теперь будут храниться в формате JSON (rt_attr_json) в атрибуте с именем ‘fields’, что делает добавление атрибутов бессхемным. Теперь многие поля сущностей будут сохраняться в атрибуты просто при сохранении сущности и при этом ничего не надо настраивать!
4) Создаются три новых индекса: ‘node’, ‘user’, ‘term’, в которых хранятся соответствующие сущности Drupal. В будущем это позволит искать не только по документам, но и по терминам и по пользователям со всеми добавленными к ним полями!
5) Переиндексация теперь понадобится только при добавлении или изменении полей.
6) Изменения сущностей попадают в индекс сразу (реалтаймовая индексация) не дожидаясь запуска переиндексации.
7) Конфигурация поисковика теперь хранится в /etc/manticoresearch/manticore.conf и для реалтаймовых индексов ее теперь намного проще читать.
Миграция со Sphinx на Manticore[править]
Поддержка Manticore появилась в модуле ELiSsearch с 7.x-2.1
# dnf update drupal7-elis-mod-search
Остановите Sphinx:
# systemctl stop searchd
Установите репозитарий Manticore и из него соответствующий сервер (используйте вместо dnf пакетный менеджер yum на CentOS7):
# dnf install https://repo.manticoresearch.com/manticore-repo.noarch.rpm # dnf install manticore # mkdir -p /var/lib/manticore/binlog # chown -R manticore:manticore /var/lib/manticore
 manticoresearch.com/manticore-repo.noarch.rpm
# dnf install manticore
# mkdir -p /var/lib/manticore/binlog
# chown -R manticore:manticore /var/lib/manticore
manticoresearch.com/manticore-repo.noarch.rpm
# dnf install manticore
# mkdir -p /var/lib/manticore/binlog
# chown -R manticore:manticore /var/lib/manticore
Сгенерируйте конфигурацию для Manticore:
# chown manticore:elis /etc/manticoresearch/manticore.conf # chmod 0664 /etc/manticoresearch/manticore.conf # cd /var/www/vh/library # su elis $ drush cc drush $ drush elis-search-reconfigure $ exit
sudo -u sphinx /usr/bin/indexer --rotate --all# crontab /usr/share/elis/crontab
Запустите сервер Manticore:
# systemctl enable manticore # systemctl start manticore
Запустите индексирование:
# cd /var/www/vh/library # su elis $ drush cc drush $ drush elis-search-reindex $ exit
Переиндексирование[править]
После добавления или удаления любых полей требуется перестроить реалтаймовый индекс.
Для этого остановите сервер:
# systemctl stop manticore
Удалите существующие индексы и бинарные логи:
# rm -f /var/lib/manticore/node.* # rm -f /var/lib/manticore/user.* # rm -f /var/lib/manticore/term.* # rm -f /var/lib/manticore/binlog/*
Пересоздайте конфигурацию:
# chown manticore:elis /etc/manticoresearch/manticore.conf # chmod 0664 /etc/manticoresearch/manticore.conf # cd /var/www/vh/library # sudo -u elis /home/elis/drush/vendor/bin/drush elis-search-reconfigure
Запустите поисковый сервер:
# systemctl start manticore
Запустите переиндексацию:
# cd /var/www/vh/library # su elis $ drush elis-search-reindex
Если в процессе переиндексации произойдут ошибки и скрипт аварийно завершится из-за нехватки памяти, запустите переиндескацию несколько раз (прогресс запоминается) до корректного завершения работы.
Прогресс переиндексирования можно посмотреть в логах admin/reports/dblog, где через каждых 100 переиндексированных сущности пишется событие.
Команды drush для работы с поиском[править]
Модуль ELiS Search позволяет выполнять две команды:
elis-search-reindex[править]
$ drush elis-search-reindex
Команда полностью перестраивает индекс реального времени (обновляет все сущности в индексе). Выполняется долго и в случае нехватки оперативной памяти может аварийно завершаться. При аварийном завершении можно команду перезапустить, она запоминает прогресс импорта.
elis-search-reconfigure[править]
$ drush elis-search-reconfigure
Запускает генерацию конфигурации для Manticore Search. Чтобы конфигурация успешно сохранилась в /etc/manticoresearch/manticore.conf у пользователя под которым запущена команда (обычно это пользователь «elis»), должны быть права на запись в файл.
Чтобы поиск подхватил изменения, необходимо остановить сервер, удалить индексы и запустить сервер. Дальше необходимо провести повторное индексирование командой drush elis-search-reindex.
Яндекс, поисковая система.
 Яндекс — поисковый движок, принадлежащий российской корпорации Яндекс, основной продукт компании. Доля Яндекс.Поиска составляет 50.9
Яндекс — поисковый движок, принадлежащий российской корпорации Яндекс, основной продукт компании. Доля Яндекс.Поиска составляет 50.9Поисковая выдача для каждого пользователя формируется индивидуально на основе его местоположения, языковых запросов, интересов и предпочтений по результатам предыдущих и текущей поисковой сессии. Тем не менее, ключевым фактором при ранжировании поисковых результатов является их релевантность, соответствие поисковому запросу. Релевантность определяется на основе формулы ранжирования, которая постоянно обновляется на основе алгоритмов машинного обучения.
Долгое время ключевым фактором ранжирования у «Яндекса» было количество сторонних ссылок на конкретный сайт. Каждой странице в Интернете присваивался своеобразный индекс цитирования, аналогичный индексу для авторов научных статей: чем больше ссылок, тем лучше.
Поиск производится на русском, английском, французском, немецком, украинском, белорусском, татарском, казахском языках.
Результаты поиска можно отсортировать по релевантности и по дате кнопки снизу поисковой выдачи.
Страница с результатами поиска состоит из 10 ссылок с короткими аннотациями — «сниппетами». Последний включают в себя текстовый комментарий, ссылку, адрес, популярные разделы сайта, страницы в соцсетях и пр. В качестве альтернативы сниппетам «Яндекс» ввёл в 2014 году новый интерфейс под названием «Острова».
В качестве альтернативы сниппетам «Яндекс» ввёл в 2014 году новый интерфейс под названием «Острова».
В «Яндексе» реализован механизм «параллельных поисков», когда вместе поиском по вебу производится поиск по сервисам «Яндекса», таким, как Каталог, Новости, Маркет, Энциклопедии, Картинки и др. В результате в ответ на запрос пользователя система выдаёт не только текстовую информацию, но и ссылки на видеофайлы, картинки, словарные статьи и пр.
Отличительной особенностью поисковика являются также технологии «интентного поиска» от англ. intent — намерение, желание, то есть поиска, нацеленного на решение задачи. Среди элементов такого поиска — наличие диалоговых подсказок при неоднозначном запросе, автоматический перевод текста, показ информации о характеристиках автомобиля и т. д. Для примера, при запросе «Борис Гребенщиков — Город золотой» система покажет форму для онлайн-прослушивания музыки из сервиса «Яндекс.Музыка», при запросе «ул. Королёва,12» будет показан фрагмент карты с отмеченным на ней объектом.
Информационные блоки между строкой запроса и результатами называются «колдунщиками». Полный их список:
История поисковых систем от Arpa до Caffeine – статьи про интернет-маркетинг
1957 — проект ARPA
В ответ на запуск русскими спутника президент Дуайт Эйзенхауэр отдает указание о создании «Агентства высокотехнологичных исследовательских проектов» (Advanced Search Projects Agency, ARPA). На основе технологических разработок ARPA и американских университетов в 1969 году появилась компьютерная сеть ARPAnet. Она стала предшественником современного Интернета.
1960 – проект Xanadu
Тед Нельсон запустил проект Xanadu в 1960 году, а в 1963 ввел термин «гипертекст» как текст, состоящий из гиперссылок на другие тексты.
1980 – создана концепция World Wide Web
Работая в швецарском CERN («Европейский Центр Ядерных исследований», ныне – место разработки Большого Адронного Коллайдера), Тим Бернерс-Ли пишет программу, предназначенную для хранения информации путем использования рандомных ассоциаций. Программа была написана для его персональных нужд, названа Enquire и никогда не выпускалась массово.
1989 – Арчи
Поисковик Арчи – это первая в мире программа, индексирующая Интернет, благодаря чему и считается «дедушкой всех поисковиков». Он был изобретен Аланом Эмтеджем, студентом-компьютерщиком из Барбадоса, обучавшимся в университете МакГилл. До появления Арчи единственным способом найти что-то в Интернете или на FTP-серверах было спросить у кого-нибудь или получить email с указанием того, куда идти за информацией.
До появления Арчи единственным способом найти что-то в Интернете или на FTP-серверах было спросить у кого-нибудь или получить email с указанием того, куда идти за информацией.
1991 — World Wide Web становится онлайновым
с помощью Роберта Кальяу Тим Бернерс-Ли пишет первый www-вебсервер. Он выходит онлайн через компьютерную сеть под названием Интернет летом 1991 года
1993 – «Сетевой бродяга», World Wide Web Wanderer
Чтобы строить свои базы данных по сайтам, поисковые машины должны регулярно ходить по вебу. В 1993 году Мэтью Грей представил миру программу World Wide Web Wanderer. Изначально он хотел померять размеры Интернета и создал этот бот, чтобы посчитать активные веб-серверы. Вскоре он проапгрейдил его так, чтобы тот смог собирать URL-ы сайтов. Полученная им база данных стала называться Wandex.
Вскоре он проапгрейдил его так, чтобы тот смог собирать URL-ы сайтов. Полученная им база данных стала называться Wandex.
1993 – Aliweb
Aliweb – первая поисковая система по World Wide Web, созданная Мартином Костером. Владельцы сайтов должны были сами их добавлять в индекс Aliweb, чтобы они появлялись в поиске. Поскольку слишком мало вебмастеров это делали, Aliweb не стал популярным.
- 1994 — Джерри Янг и Дэвид Фило создали поисковую систему Yahoo
- 1994 — Майкл Лорен Молден создал поисковую систему Lycos
- 1995 – Луи Монье и Майкл Берроуз создали поисковую систему Altavista
- 1995 – Грэм Спенсер, Джо Краус, Марк ВанХарен, Райан МакИнтир, Бен Латч и Мартин Райнфрид создали поисковую систему Excite
- 1996 – Гаррет Грюнер и Дэвид Вартнер создали поисковую систему AskJeeves
- 1996 – Эрик Брюэр и Пол Готье создали поисковую систему Inktomi
1996 – BackRub
Студенты последнего курса компьютерного направления Стэнфордского университета Лари Пейдж и Сергей Брин начинают сотрудничество по разработке поисковой системы BackRub. Этот проект произведет революцию в веб-поиске, потому что BackRub будет учитывать ссылки на сайт и ранжировать сайты в соответствии с ними.
Этот проект произведет революцию в веб-поиске, потому что BackRub будет учитывать ссылки на сайт и ранжировать сайты в соответствии с ними.
1997 – Google
В 1997 году Пейдж и Брин переименовали BackRub в Google. Они произвели это имя от числительного «гугол», которое в математике используется для обозначения чисел с сотней нулей. Такое название отразило их миссию – организовать кажущееся бесконечным количество информации в вебе.
1998 – Goto.com
GoTo предложила рекламодателям возможность платить за показ сайта на первых местах своей поисковой выдачи в ответ на определенные запросы. Деньги снимались с рекламодателя каждый раз, когда ссылку в выдаче кликали. К июлю 1998 года рекламодатели платили до доллара за клик.
К июлю 1998 года рекламодатели платили до доллара за клик.
1998 – MSN
MSN.com запустилась в первой четверти 1998 года. Работала на поисковой выдаче Inktomi.В 2006 году появился свой поисковый движок и название Live Search. В 2009 году все поисковые бренды Microsoft уступили место Bing.
2000 – Google AdWords
Вдохновившись Goto.com, Google запустил AdWords, где было 350 рекламодателей. AdWords стала системой для размещения рекламных объявлений в квадратиках сбоку от поисковой выдачи.
2000 – Google на Yahoo!
Yahoo начинает использовать выдачу Google для YahooSearch
2003 – Google AdSense
Google запускает AdSense – сервис, позволяющий вебмастерам размещать на своих сайтах рекламу Google. Вебмастера получают плату за каждый клик по рекламе посетителя сайта.
Вебмастера получают плату за каждый клик по рекламе посетителя сайта.
- 2003 – Yahoo! приобретает Inktomi, Goto, AltaVista и AllTheWeb
- 2004 – у Yahoo появляется свой поиск
- 2006 – Google покупает YouTube. И до сих пор думает, как сделать его прибыльным.
2006 – Google Sitemaps.
Вебсайты становятся все больше и сложнее, все чаще поисковые индексаторы не могут получить доступ к части информации. Google позволяет разработчикам «скормить» себе карту сайта, которая описывает структуру последнего и сообщает Google об информации, по которой можно осуществлять поиск.
2009 — Bing от Microsoft
Запускается поисковая система Bing.:max_bytes(150000):strip_icc()/CustomSearchEngine-57240cbe5f9b589e34c6660f.png) Это название символизирует «звук, обозначающий момент какого-то открытия или принятия решения». В июле 2009 Microsoft и Yahoo объявляют о сделке сроком в 10 лет, в течение которых поиск Yahoo будет обеспечиваться движком Bing.
Это название символизирует «звук, обозначающий момент какого-то открытия или принятия решения». В июле 2009 Microsoft и Yahoo объявляют о сделке сроком в 10 лет, в течение которых поиск Yahoo будет обеспечиваться движком Bing.
2009 – борьба за пользователя
Google проиндексировал 8 млрд. вебсайтов, на него приходятся 70,24% поисков, совершаемых по всему Интернету. Однако, Bing стремительно набирает долю рынка, а вместе с Yahoo! у него будет 26,4%
2010 – Google Caffeine
В 2009 году Google предлагает поучаствовать в тестировании новой поисковой системы, которая выглядит так же, но выдает больше точных результатов за меньшее время. Специалисты пытаются проанализировать, в чем же новизна архитектуры и алгоритма Caffeine.
Рекомендуем прочесть
Businessinsider.com
пишет об «утечке мозгов из Google». По мнению издания, в истории Google еще не было такого периода, когда бы за короткое время компанию покинули столько ценных кадров. Один из бывших сотрудников Google сказал Businessinsider.com, что в компании не осталось возможностей роста. С другой стороны — «в Google собралось слишком много талантов, трудно их всех сохранить». Среди ушедших в 2009 году — Дэвид Розенблатт, президентотдела рекламы, бывший директор приобретенного Google DoubleClick; Тим Армстронг, вице-президент по рекламным продажам; Сухиндер Сингх Кассиди, президен латиноамерикано-азиатского департамента; Ларри Бриллиант, директор благотворительной организации Google.org; Дуг Бауман, ведущий дизайнер (теперь он занимает аналогичную должность в Twitter).
Определить, на какой CMS сделан сайт, можно по ряду признаков, в основном отображающихся в html-коде или URL страниц. Список признаков — на contorra.ru.
Илья Корнеев (рекламное агентство «Аффект») рассказал Mappr.ru о вирусном маркетинге, рекламе на форумах и в социальных сетях, способах измерения эффективности и проблемах интернет-рекламы.
Сайт об интернет-безопасности Securelist.com опубликовал обзор методов, используемых спаммерами. Среди них — трояны, ботнеты, эксплойты и так далее.Немного о поисковой оптимизации
Я не буду рассказывать про правильную расстановку ссылок, специальную обработку текста и другие серые методы оптимизации. Про это и так много написано, да и не сторонник я этих методов. Я расскажу немного о другом — как ускорить процесс индексации сайта поисковыми системами.
Это тема меня тронула во время настройки поисковой системы CNSearch, которую я использую для поиска по новгородскому региону. Оказывается, большую часть сайтов нельзя проиндексировать полностью — они содержат бесконечное количество страниц.
Оказывается, большую часть сайтов нельзя проиндексировать полностью — они содержат бесконечное количество страниц.
Как так получилось ?
Проблема тут в основном в некомпетентности программистов, разрабатывающих «движки» сайтов.
Для примера рассмотрим сайт: www.oldport.ru. Заходим в гостевую книгу и в блоке навигации по страницам гостевой книги нажимаем на ссылку «>>». Делать это можно бесконечно и каждый раз, загружается страница с уникальным адресом.
Точно так же ведут себя форумы на базе phpBB и vBulletin, сайты на базе Joomla и phpnuke. Кроме того, есть масса «движков» которые содержат большое количество страниц с дублирующейся информацией или просто страниц без информации. Про идентификаторы сессий (PHPSESSID, sid, ssid и пр.) я вообще молчу.
Решить эту проблему проще всего на стадии разработки «движка» сайта. Если сайт уже готов, или используется «движок» стороннего разработчика, то решить эту проблему на стадии разработки уже не получится. Но кое-что все равно можно исправить. Сделать это можно с помощью файлов robots.txt, мета тегов «noindex» и «nofollow». «Прятанья» ненужных ссылок.
Но кое-что все равно можно исправить. Сделать это можно с помощью файлов robots.txt, мета тегов «noindex» и «nofollow». «Прятанья» ненужных ссылок.
Например, в разы сократить количество индексируемых страниц в форуме, на базе vBulletin, можно добавив следующие строки в файл robots.txt
— robots.txt —————
User-Agent: *
Disallow: /forum/calendar.php
Disallow: /forum/misc.php
Disallow: /forum/external.php
Disallow: /forum/search.php
Disallow: /forum/vB.Sponsors
Disallow: /forum/showgroups.php
Disallow: /forum/online.php
Disallow: /forum/showthread.php?p=
Disallow: /forum/showpost.php
Disallow: /forum/printthread.php
Disallow: /forum/attachment.php
— robots.txt —————
Перечисленные страницы содержат либо несущественную, либо дублирующуюся информацию.
Для той же цели можно использовать мета теги «noindex» и «nofollow». Но помните, чтобы обнаружить теги, поисковая система должна сначала скачать страницу с вашего сайта. По этому вместо использования мета тега «noindex» лучше просто «спрятать» ссылку на несущественную страницу.
По этому вместо использования мета тега «noindex» лучше просто «спрятать» ссылку на несущественную страницу.
Следующий шаг — это проверка корректности индексации сайта с помощью собственной поисковой системы. При этом, решая эту задачу, можно убить еще одного зайца — создать Google Sitemap.
Для этих целей я использую все тот же CNSearch. Это платная система, но для нашей задачи подходит и незарегистрированная версия, так как фронтенд от нее не используется.
Для начала нужно положить фронтенд и индексатор в один каталог, настроить индексатор и фронтенд (об этом можно почитать в руководстве пользователя, которое есть на официальном сайте CNSearch).
После того как настройки поисковой системы выполнены, нужно создать простой shell скрипт:
— sitemap.sh ———————
#!/bin/sh
./indexer mike
export QUERY_STRING=»sitemap=1&password=парольнастатистику»
export REQUEST_METHOD=GET
./search.cgi | tail -n +3 > ../sitemap. xml
xml
rm ./docs.cns
rm ./files.cns
rm ./fulltxt.cns
rm ./index.cns
rm ./stats.log
— sitemap.sh ———————
Сначала запускается индексатор (indexer). Во время индексации выводится список индексируемых страниц. Визуально проверяем этот список. Если сайт содержит бесконечное количество страниц, то индексатор рано или поздно выдаст «To many files» (максимальное количество страниц — задается в настройках индексатора).
После того как произведена индексация, shell скрипт вызывает фронтенд (search.cgi), при этом, эмулируя Веб-сервер, так как фронтент является CGI приложением. После чего, с помощью tail удаляются http заголовки, которые вернул фронтенд. На этом этапе, на выходе мы имеем готовый файл sitemap.
Последний шаг — удаляем файлы поискового индекса — они нам не нужны.
Этот скрипт размещаем в отдельном каталоге и прописываем его в crontab.
После этого иногда заглядываем в файл sitemap.xml и смотрим нет ли там лишних страниц. Сам sitemap отправляем в Google, для ускорения процесса индексации сайта поисковым роботом Google.
Мой sitemap выглядит вот так: https://mikhail.krivyy.com/sitemap.xml. И я точно знаю, что поисковому роботы не понадобится много времени, чтобы произвести индексацию моего сайта.
Mail.ru ответила на почту «Яndex». С помощью Google
РОМАН ДОРОХОВ
Источник: «Ведомости» от 24 июля 2003 года
24.07.2003
На прошлой неделе компания Mail.ru, владеющая одноименной бесплатной службой электронной почты, начала предоставлять услуги поиска информации в Интернете с помощью «движка» крупнейшей мировой поисковой системы Google. Участники интернет-рынка уверены, что почтовая служба отреагировала на агрессию поискового портала «Яndex», активно «раскручивающего» свой почтовый сервис.
До недавних пор Mail.ru использовала поисковую систему Rambler, но в конце мая компания сменила ее на Google. А на прошлой неделе компания официально объявила о лицензировании технологии Google WebSearch. «Обновление нашей службы поиска предназначено в первую очередь для 4,5 млн владельцев почтовых ящиков Mail. ru», — говорит вице-президент Mail.ru Татьяна Желонкина. По ее словам, проведенное перед запуском нового поискового сервиса исследование показало, что пользователи Mail.ru хотели бы искать информацию через почтовый портал. Стоимость контракта с Google в Mail.ru не называют.
ru», — говорит вице-президент Mail.ru Татьяна Желонкина. По ее словам, проведенное перед запуском нового поискового сервиса исследование показало, что пользователи Mail.ru хотели бы искать информацию через почтовый портал. Стоимость контракта с Google в Mail.ru не называют.
Выбор технологии Google Желонкина объясняет относительной неизвестностью этого поисковика в России, при том что этот брэнд хорошо известен в мире. У Mail.ru весьма серьезные амбиции по поводу рынка интернет-поиска в Рунете. «Трафик на Mail.ru после запуска системы поиска вырос в полтора раза, при том что реклама сервиса началась совсем недавно», — говорит она.
Крупнейшие российские поисковые системы — «Яndex» и Rambler не слишком опасаются нового конкурента. Главный редактор портала «Яndex» Елена Колмановская говорит, что в поисковой системе «Яndex» не заметили падения числа обращений пользователей, если не учитывать традиционного летнего снижения активности в Рунете. Она сомневается, что владельцы почтовых ящиков на Mail. ru станут пользоваться и одноименным поисковиком. «Конечно, привязанность к брэндам существует и в Интернете, но ведь конкуренты находятся на расстоянии одного клика мышью», — поясняет она. Колмановская уверяет, что «Яndex» ищет информацию в Рунете лучше, чем Google: российская поисковая система учитывает морфологию русского языка и отслеживает близость слов в тексте.
ru станут пользоваться и одноименным поисковиком. «Конечно, привязанность к брэндам существует и в Интернете, но ведь конкуренты находятся на расстоянии одного клика мышью», — поясняет она. Колмановская уверяет, что «Яndex» ищет информацию в Рунете лучше, чем Google: российская поисковая система учитывает морфологию русского языка и отслеживает близость слов в тексте.
Не заметили перераспределения аудитории между порталами и в Rambler, говорит заместитель генерального директора холдинга Иван Засурский. По его мнению, Mail.ru начала продвигать собственный поисковый сервис в ответ на активную раскрутку почты «Яndex». «Об этом свидетельствуют рекламные баннеры Mail.ru, которые сравнивают результаты собственного поиска и поиска в «Яndex», — объясняет свою точку зрения Засурский.
Mail.ru после контракта с Google вставляет в результаты поиска контекстную рекламу, содержание которой подбирается в соответствии с пользовательскими запросами на поиск. За эту технологию и подбор клиентов для Mail. ru отвечает рекламное интернет-агентство «Бегун». Как считает исполнительный директор «Бегуна» Алексей Басов, контекстная реклама может помочь Mail.ru изменить ситуацию на рынке поисковых систем, который сегодня привлекает самые большие рекламные бюджеты в Рунете. «После подключения контекстной рекламы на Mail.ru количество посетителей, которые переходят по нашим ссылкам на сайты рекламодателей, выросло на 10% «, — говорит Басов. По его словам, договор с Mail.ru вызвал приток новых клиентов, желающих разместить контекстную рекламу.
ru отвечает рекламное интернет-агентство «Бегун». Как считает исполнительный директор «Бегуна» Алексей Басов, контекстная реклама может помочь Mail.ru изменить ситуацию на рынке поисковых систем, который сегодня привлекает самые большие рекламные бюджеты в Рунете. «После подключения контекстной рекламы на Mail.ru количество посетителей, которые переходят по нашим ссылкам на сайты рекламодателей, выросло на 10% «, — говорит Басов. По его словам, договор с Mail.ru вызвал приток новых клиентов, желающих разместить контекстную рекламу.
Mail.ru: переход на свой поисковый движок (02.07.2013) — «Фридом Финанс»
© 2011 – 2021 ООО ИК «Фридом Финанс»
ООО ИК «Фридом Финанс» оказывает финансовые услуги на территории Российской Федерации в соответствии с государственными бессрочными лицензиями профессионального участника рынка ценных бумаг на осуществление брокерской, дилерской и депозитарной деятельности, а также деятельности по управлению ценными бумагами. Государственное регулирование деятельности компании и защиту интересов ее клиентов осуществляет Центральный банк Российской Федерации.
Государственное регулирование деятельности компании и защиту интересов ее клиентов осуществляет Центральный банк Российской Федерации.
Владение ценными бумагами и прочими финансовыми инструментами всегда сопряжено с рисками: стоимость ценных бумаг и прочих финансовых инструментов может как расти, так и падать. Результаты инвестирования в прошлом не являются гарантией получения доходов в будущем. В соответствии с законодательством компания не гарантирует и не обещает в будущем доходности вложений, не дает гарантии надежности возможных инвестиций и стабильности размеров возможных доходов. Услуги по совершению сделок с зарубежными ценными бумагами доступны для лиц, являющихся в соответствии с действующим законодательством квалифицированными инвесторами, и производятся в соответствии с ограничениями, установленными действующим законодательством.
Информационно-аналитические услуги и материалы предоставляются ООО ИК «Фридом Финанс» в рамках оказания
указанных услуг и не являются самостоятельным видом деятельности. Компания оставляет за собой право
отказать в оказании услуг лицам, не удовлетворяющим предъявляемым к клиентам условиям или в отношении
которых установлен запрет/ограничения на оказание таких услуг в соответствии с законодательством Российской
Федерации или иных стран, где осуществляются операции. Также ограничения могут быть наложены внутренними
процедурами и контролем ООО ИК «Фридом Финанс».
Компания оставляет за собой право
отказать в оказании услуг лицам, не удовлетворяющим предъявляемым к клиентам условиям или в отношении
которых установлен запрет/ограничения на оказание таких услуг в соответствии с законодательством Российской
Федерации или иных стран, где осуществляются операции. Также ограничения могут быть наложены внутренними
процедурами и контролем ООО ИК «Фридом Финанс».
Поиск — Opera Help
Объединенная строка поиска и адресная строка
Объединенная строка поиска и адресная строка позволяет отправлять запросы в поисковые системы и вводить веб-адреса интересующих вас страниц в интернете.
Если вы не знаете адреса страницы или хотите увидеть результаты поисковиков, чтобы найти нужную информацию, пользуйтесь для поиска в интернете объединенной строкой. По умолчанию Opera отправляет запросы в поисковую систему.
Для поиска в Интернете выполните следующие действия:
- Нажмите в поле Search or enter address (Введите запрос для поиска или веб-адрес).
- Введите ключевые слова для информации, которую вы хотите найти. Например, введите
фильмы. - Нажмите один из вариантов, предложенных системой предиктивного поиска, нажмите клавишуВвод.

Предложения системы предиктивного поиска появляются по мере ввода вами текста. Если вы хотите просмотреть результаты из другой поисковой системы, например, Yahoo!, Amazon или Bing, нажмите соответствующую вкладку в нижней правой части окна с вариантами, предлагаемыми системой предиктивного поиска.
Если вы знаете адрес нужной страницы, введите адрес прямо в объединенной адресной строке и строке поиска и нажмите клавишуEnter Ввод, чтобы перейти на эту страницу. Например, введите www.opera.com и нажмите клавишу Enter Ввод, чтобы перейти на домашнюю страницу Opera Software.
Изменение поисковой системы по умолчанию
По умолчанию Opera использует поисковую систему Yandex или Google, но вы также можете выбрать Yahoo!, DuckDuckGo, Amazon или Wikipedia. Чтобы изменить поисковую систему по умолчанию, выполните следующие действия:
Чтобы изменить поисковую систему по умолчанию, выполните следующие действия:
- Перейдите в Settings (Настройки) (Preferences (Настройки) на Mac).
- Нажмите Basic (Основные) на боковой панели.
- В разделе Search engine (Служба поиска) выберите из выпадающего меню предпочтительную поисковую систему.
Настройка других поисковых систем
Вы можете использовать не только поисковые системы Opera по умолчанию, но и настроить другие системы в объединенной адресной строке и строке поиска. Для этого выполните следующие действия:
- Удерживая Ctrl,нажмите левой кнопкой мыши (Mac) или правой кнопкой мыши (Win/Lin) строку поиска сайта и выберите Edit Search Engine… (Редактировать поисковые системы…).
- В разделе Other search engines (Другие поисковые системы) нажмите Add (Добавить).
- Задайте имя и ключевое слово для поисковой системы.
- Нажмите OK.

Чтобы посмотреть результаты в настроенной вами поисковой системе, нажмите новую вкладку в объединенной адресной строке и строке поиска в браузере Opera. Или введите установленное для вашей поисковой системы ключевое слово, затем пробел и поисковый запрос.
Редактировать ключевые слова, управлять поисковыми системами и удалять их можно со страницы настроек.
- Перейдите в Settings (Настройки) (Preferences (Настройки) на Mac).
- Нажмите Basic (Основные) на боковой панели.
- В разделе Search engine (Служба поиска) нажмите кнопку Manage Search Engine (Управление поисковыми системами).
Всплывающее окно поиска
Всплывающее окно поиска – это небольшая панель инструментов Opera, которая позволяет вам искать, копировать или отправить в Мой Flow текст выделенный вами на веб-странице. Всего одним нажатием можно запустить поиск выделенного текста в новой вкладке с использованием поисковой системы по умолчанию. Вы также можете копировать текст в буфер обмена, чтобы использовать его позже.
Вы также можете копировать текст в буфер обмена, чтобы использовать его позже.
Этот инструмент также конвертирует незнакомые валюты, единицы измерения и часовые пояса при их выделении в выбранные вами единицы. Если вы хотите знать, сколько будет $44.50 в евро, 2.05 метра в футах или какому времени соответствует 7:00pm MST в Центральной Европе, всплывающее окно поиска Opera подскажет вам нужные ответы. Подробнее о конверторах можно прочитать здесь.
Как пользоваться всплывающим окном поиска:
- Выделите текст на странице.
- Над выделенным текстом появится всплывающий текст, включающий доступные функции Search (Поиск) и Copy (Копировать) и Send to My Flow (Отправить в Мой Flow). Если выделена валюта, единица измерения или часовой пояс, во всплывающем окне будет отображено конвертированное значение.
- Нажмите Search (Поиск) для запуска поиска выделенного текста с использованием поисковой системы по умолчанию.
- Нажмите Copy (Копировать), чтобы копировать выделенный текст в буфер обмена.
- Нажмите Send to My Flow (Отправить в Мой Flow) чтобы отправить сайт или нужные данные при помощи сервира Flow.
- При наличии во всплывающем окне конвертированного значения нажмите на это значение, чтобы копировать его в буфер обмена.

Чтобы отключить всплывающее окно поиска и все его функции, выполните следующие действия:
- Перейдите в Settings (Настройки) (Preferences (Настройки) на Mac).
- Нажмите Browser (Браузер) на боковой панели.
- В разделе User interface (Интерфейс пользователя) снимите флажок Enable search pop-up when selecting text (Включить всплывающее окно поиска при выборе текста).
Как работают поисковые системы | Поисковые запросы Google
При примерно 3,8 миллиона поисковых запросов Google в минуту мир вырос и теперь полагается на поисковых систем , таких как Google, Yahoo и Bing, чтобы дать им ответы на многие жизненные вопросы. Независимо от того, доставляют ли они ответы на повседневные или необычные вопросы, поисковые системы — это машины, которые сканируют Интернет (и его 1 миллиард веб-сайтов) по заданным ключевым словам и отвечают пользователям, предлагая наиболее релевантные веб-сайты или страницы для их поиска.
Независимо от того, доставляют ли они ответы на повседневные или необычные вопросы, поисковые системы — это машины, которые сканируют Интернет (и его 1 миллиард веб-сайтов) по заданным ключевым словам и отвечают пользователям, предлагая наиболее релевантные веб-сайты или страницы для их поиска.
Цель любой поисковой системы — облегчить пользователю поиск информации на веб-сайте или странице, потому что без помощи поисковой системы поиск ответа на вопрос длился бы дни, а не секунды. Поисковые системы, такие как Google и Bing, выполняют две основные функции: во-первых, сканирование и индексирование Интернета, а во-вторых, предоставление пользователям значимых результатов по их запросам.
Прежде чем предоставлять результаты пользователю, поисковая система должна сканировать Интернет и проиндексировать каждый уникальный документ в Интернете (который обычно является веб-страницей, но также может быть файлом PDF, JPG или другим), а затем найти лучший ссылка или путь к каждому документу. Эти ссылки / пути позволяют сканерам или паукам получать доступ к миллиардам взаимосвязанных документов в сети. Когда сканеры находят новые страницы, они расшифровывают их код, а затем сохраняют выбранные фрагменты в огромных базах данных, чтобы впоследствии вызывать их по поисковым запросам.
Эти ссылки / пути позволяют сканерам или паукам получать доступ к миллиардам взаимосвязанных документов в сети. Когда сканеры находят новые страницы, они расшифровывают их код, а затем сохраняют выбранные фрагменты в огромных базах данных, чтобы впоследствии вызывать их по поисковым запросам.
Поисковые системы — это машины ответов, поэтому, когда пользователь хочет решить вопрос с помощью Yahoo, Bing или Google, приоритетом любой поисковой системы является получение значимых и актуальных ответов. Для этого поисковые системы сначала возвращают только те результаты, которые релевантны или полезны для запроса пользователя, а затем ранжируют эти результаты в соответствии с популярностью и доверием к веб-сайтам, обслуживающим эту информацию.Сайты могут повышать свой рейтинг на страницах результатов поисковых систем или в результатах выдачи, применяя оптимизацию для поисковых систем (SEO), которая представляет собой процесс влияния на видимость веб-сайта или веб-страницы в естественных или бесплатных результатах поиска поисковой системы.
Поисковые системы также учитывают следующие факторы при ранжировании страницы:
Когда страница была опубликована
Если на странице есть текст, изображения или видео
Качество содержания
Насколько хорошо контент соответствует запросам пользователей
Как быстро загружается сайт
Сколько ссылок с других сайтов ведут на этот контент
Сколько людей поделились контентом сайта в Интернете
То, как каждая поисковая система определяет популярность, основано на их индивидуальном алгоритме и в значительной степени неизвестно, но известно их желание предоставлять пользователям точные, надежные и релевантные результаты.Основываясь на популярности сайта, страницы или документа, поисковые системы предполагают, что эта популярность коррелирует с тем, насколько ценной должна быть информация на странице.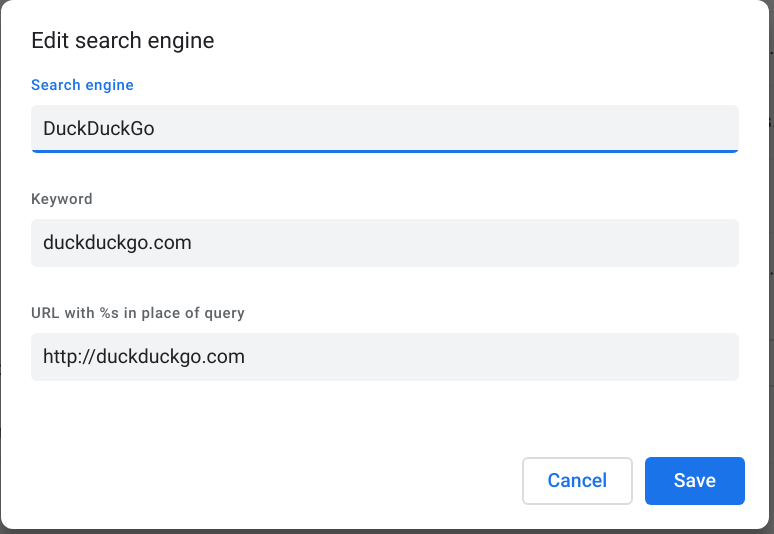 Их алгоритмы также учитывают удобочитаемость сайта, которую можно улучшить, добавив разметку Schema.
Их алгоритмы также учитывают удобочитаемость сайта, которую можно улучшить, добавив разметку Schema.
Поисковые системы, однако, не безупречны, потому что они не могут гарантировать надежность или правдивость для пользователей, просматривающих страницы результатов поисковых систем, или для компаний, публикующих свои местные списки в Интернете. Со стороны пользователя рекламные объявления в верхней части поисковой выдачи могут оплачиваться или спонсироваться компаниями, которые не принимают во внимание то, как поисковая система естественным образом оценивает их по степени достоверности.Это создает реальную ценность для естественных результатов в поисковой выдаче, и для компаний, публикующих сообщения в Интернете, любые попытки успокоить алгоритмы поисковых систем приведут к появлению списка в этих рядах.
Одним из способов улучшить локальное SEO для бизнеса является разметка Schema, которая кодирует страницу с использованием языка и словаря, которые легко распознаются основными алгоритмами поисковых систем. Другой метод повышения локального SEO — это добавление расширенного содержания в листинг в дополнение к данным NAP листинга. Расширенные списки контента включают информацию о местоположении, такую как меню, продукты и услуги, биографии, события и предложения.Дополняя страницу тегами схемы, расширенным контентом и изображениями, компания создает полезный, насыщенный информацией сайт, который дополнительно ясно и точно описывает свое содержание.
Другой метод повышения локального SEO — это добавление расширенного содержания в листинг в дополнение к данным NAP листинга. Расширенные списки контента включают информацию о местоположении, такую как меню, продукты и услуги, биографии, события и предложения.Дополняя страницу тегами схемы, расширенным контентом и изображениями, компания создает полезный, насыщенный информацией сайт, который дополнительно ясно и точно описывает свое содержание.
Yext помогает компаниям занять высокие позиции в поисковых системах, управляя тем, как списки компаний отображаются в экосистеме онлайн-поиска, обеспечивая точность и надежность во всей сети. Компании могут использовать Yext Knowledge Manager для управления цифровыми знаниями — от традиционной NAP до расширенного контента.Данные во всех нужных местах помогают компаниям занимать более высокие позиции на страницах результатов поисковых систем. Узнайте, как Yext Knowledge Manager может помочь вашему бизнесу.
 …. ….. …. …..
| ||
 directhit.com/
directhit.com/ Как работают поисковые системы?
Как работают поисковые системы?
Поисковые системы сканируют веб-сайты в поисках информации, индексируют и сохраняют данные, а затем получают наиболее релевантный и популярный результат, соответствующий поисковому запросу пользователя.
Ползать
Большинство поисковых систем просматривают огромное количество материалов в Интернете по ссылкам. «Ссылки позволяют автоматизированным роботам поисковых систем, называемым« сканерами »или« пауками », достигать многих миллиардов взаимосвязанных документов в сети», — говорится в руководстве Moz для начинающих по SEO.
Сканеры просматривают каждое доступное слово и фрагмент кода на каждой доступной веб-странице в Интернете. Они смотрят на веб-сайты так же, как и люди. Это имеет смысл, поскольку основные цели поисковых систем — попытаться «думать», как люди, чтобы обеспечить наилучшие результаты.
Индекс
После сканирования сканеры поисковых систем берут информацию и сохраняют ее в огромных базах данных, которые могут обрабатывать информацию практически мгновенно. Эти базы данных содержат информацию о свежести веб-сайта, всех словах на странице, контексте страницы, ссылках на страницу и с нее и многом другом. Согласно Google, «это похоже на указатель в конце книги — с записью для каждого слова, встречающегося на каждой веб-странице, которую мы индексируем».
Получить
Поисковые системыработают, получая наиболее релевантные и популярные результаты на основе запроса пользователя.Здесь задействовано довольно много алгоритмов, а также элементы машинного обучения и искусственного интеллекта. Однако, как правило, они сводятся к этим трем факторам.
Актуальность
Цель большинства поисковых систем — предоставить пользователю наилучший результат на основе того, что пользователь запрашивает у поисковой системы. Используя множество входных данных, поисковые системы пытаются представить список наиболее релевантных результатов для пользователя. Например, он пытается определить, ищет ли пользователь, выполняющий поиск «Пицца в Чикаго», пиццу в Чикаго или пиццерию в стиле Чикаго на основе контекстных подсказок, предыдущих поисков и других факторов ИИ.Отсюда он ранжирует наиболее релевантные результаты в списке по популярности.
Популярность
Популярность — это простой способ сказать, что поисковые системы ранжируют результаты на основе того, что другие пользователи считают лучшим результатом для других похожих запросов. Пользовательские сигналы, например, остается ли поисковик на первом выбранном сайте или возвращается на страницу поиска, помогают сообщить поисковым системам, действительно ли результат полезен для поисковика или нет.
Алгоритмы
Когда поисковые системы получают информацию, они принимают во внимание несколько факторов, касающихся запроса.Алгоритмы помогают им быстро сортировать информацию и представлять то, что их машины узнали, — лучший результат, основанный на том, что ищет пользователь. Согласно обзору Google, алгоритмы помогают во всех следующих случаях:
- анализировать слова искателя
- сопоставить запрос с релевантным контентом в Интернете
- ранжирует эти страницы на основе лучших результатов
- учитывает такие сигналы, как местоположение пользователя, а
- дает наилучшие результаты — всего за несколько миллисекунд.
Отслеживание трафика в поисковых системах
В Google Analytics легко отслеживать поисковый трафик. Здесь вы можете проверить источник перехода, включая прямой, платный, реферальный и обычный поиск. Это дает вам базовую базовую информацию о том, как идут ваши обычные поисковые запросы в Интернете.
Коллтрекинг также может помочь вам отслеживать офлайн-конверсии, которые происходят в результате обычного поиска. Это означает, что вы сможете определить, выполнил ли кто-то поиск по определенному ключевому слову, попал ли он на ваш сайт с помощью обычных результатов поиска, а затем снял трубку, чтобы позвонить из этого сеанса.
Подробнее об этом коллтрекинг на уровне ключевых слов и о том, как это работает. Если вы готовы, запросите бесплатную демоверсию CallRail или начните пользоваться 14-дневной бесплатной пробной версией , кредитная карта не требуется.
Интернет-ресурсов: поисковые системы и базы данных
ПОИСК ДВИГАТЕЛИ И БАЗЫ ДАННЫХ
• символ представляет сайт, который мы считаем особенно полезным.
• AlltheWeb
(БЫСТРО) (http://www.alltheweb.com)
AlltheWeb в настоящее время покрывает приблизительно
3,1 миллиарда веб-страниц, сотни тысяч мультимедийных материалов,
видео и загрузки программного обеспечения, а также новости в реальном времени от тысяч
источников. Расширенные функции включают возможность включать
или исключить слова или фразы из запроса и ограничить
результаты по дате.AlltheWeb автоматически попытается улучшить
ваши результаты, переписав ваши запросы. Преобразования
выполняется от вашего имени, включая добавление цитат
вокруг общих фраз, обнаруженных с AlltheWeb
словарь фраз.
Альта
Vista (http://www.altavista.com)
Нам нравится использовать Alta Vista для поиска информации о конкретных
термин или имя (например, человек или трудно найти компанию).Alta Vista часто показывает целую стопку релевантных ссылок
прямо вверху списка. Его источники включают правительство
и сайты, представляющие общественный интерес. Обязательно укажите свой конкретный
термин в кавычках.
• Коперник (http://www.copernic.com/desktop/products/agent/basic.html)
Copernic — популярная программа для мета-поиска, работающая на
рабочий стол вашего компьютера, либо как отдельное приложение
или в вашем браузере.Он предоставляет все преимущества
хорошая мета-поисковая система с дополнительными функциями
разрешение сортировки результатов поиска, проверки ссылок, сохранения
поиски и многое другое. Как бесплатные (базовые), так и платные (личные
и Professional) предлагаются версии программного обеспечения.
Собачья куча (http://www.dogpile.com)
Dogpile — наш любимый метапоисковый движок.
который запускает ваш поиск в нескольких поисковых системах в
один выстрел.Это хороший инструмент, если вы пришли с пустым
индивидуальные поисковые системы. Dogpile, как и многие поисковые системы,
также предлагает поиск в Usenet (дискуссионных группах в Интернете).
Опция Newscrawler ищет газеты и корпоративный поиск
доступен в настройках Business Wires. Ограничение:
методы поиска, которые работают в одной поисковой системе, не будут
обязательно хорошо работать на Dogpile из-за различий между
поисковые системы.
Федеральный
Веб-локатор (http://www.infoctr.edu/fwl)
Федеральный веб-локатор — услуга, предоставляемая Центром
для информационного законодательства и политики и предназначен для
универсальный магазин для федерального правительства США
информация во всемирной паутине. Также включает ссылки на
многосторонние организации и неправительственные федерально связанные
места.
• Найти Статьи (http://www.findarticles.com)
FindArticles.com — это обширный архив опубликованных статей.
которые можно искать и получать бесплатно. Каждый из
сотни тысяч статей, датируемых 1998 годом, из
более 300 журналов и журналов можно прочитать в его
целиком и бесплатно распечатывается.Бизнес и финансы
Раздел содержит множество отраслевых публикаций. Новости и
В разделе «Общество» представлены статьи из изданий с редакционной
точки обзора справа налево.
• Google (http://www.google.com)
Наш фаворит, Google отличается простотой использования и
быстро найти то, что вы ищете.
• Google
Новости (http://www.news.google.com)
Поиск и просмотр 4 000 постоянно обновляемых источников новостей
прямая ссылка на исходную публикацию. Ретроспектива
поиск ограничен политикой каждой публикации в отношении
бесплатный доступ, платный доступ и поддержание активных ссылок на
статьи.Для статей, отправляемых прямо на вашу электронную почту, создайте
Оповещения о новостях Google для отслеживания развития новостных сюжетов или
быть в курсе событий, личности, компании или отрасли
(http://www.google.com/newsalerts).
• Google
Группы (http://groups.google.com)
Компания Google приобрела и успешно интегрировала полную
Дежа.com в сервис Групп Google. Когда ты
поиск или просмотр в группах Google, теперь вы получаете доступ к Usenet
постов, датируемых 1995 годом. Этот архив — самый крупный из таких
хранилище сообщений в сети и содержит более
650 миллионов сообщений — более терабайта человеческого разговора,
многие из которых были недоступны в течение многих лет. Группы новостей Usenet
международные общественные дискуссионные форумы по широкому кругу вопросов
предметов; дежа.com архивирует около 45 000 групп новостей
восходит к марту 1995 года. Особенно полезно для отслеживания
информация о движении вниз, которая может не отображаться в Интернете.
Рекомендуется поиск в поле SUBJECT (Power Search).
Внимание: Usenet включает в себя полный спектр информации, идей,
и мнение. Обязательно проверьте свои источники перед подсчетом
о достоверности информации.
HotBot (http://www.hotbot.com)
HotBot был переработан для поисковика мощности,
доставка, скорость, контроль и единый интерфейс для четырех
из лучших поисковых систем в Интернете: HotBot, Google, Lycos
& Спросите Дживса. Вы выбираете, в каком каталоге хотите искать
с переключателями над формой поиска. После входа
ваши поисковые запросы и просмотр результатов выбранных вами
движок, вы можете легко просматривать результаты других
просто щелкнув соответствующие переключатели.
Публичная библиотека Интернета (http://www.ipl.org)
Этот сайт, разработанный и поддерживаемый библиотекарями, является
отличная отправная точка, а также предлагает очень хороший Ready Reference
Коллекция http://www.ipl.org/div/subject/browse/ref00.00.00/.
Подготовлено Школой информации Мичиганского университета.
НоуХ (http: // www.knowx.com)
Искать в публичных записях о компаниях или людях. Комиссия за поиск
варьируются от бесплатного до 1,50 доллара США за базу данных. Сборы за документы
варьируются от 1 до 7 долларов.
Библиотекарей
Индекс Интернета (http://lii.org)
Указатель библиотекарей в Интернете — это доступный для поиска, аннотированный
тематический справочник из более чем 5700 интернет-ресурсов
отобраны и оценены библиотекарями на предмет их полезности
пользователям публичных библиотек.Он предназначен для использования обоими
библиотекари и не библиотекари как надежные и эффективные
путеводитель по описанным и оцененным Интернет-ресурсам.
LexisNexis
AlaCarte! (http://alacarte.lexisnexis.com/)
После регистрации в этой службе вы можете свободно искать
более 3,8 миллиарда документов из более чем 20 000 источников
новостей, публичных записей и правительственной информации, в том числе
газеты, журналы и стенограммы, компания и отрасль
отчеты, документы, залоговые права, демографические данные, штатные и федеральные
законодательство еще в 1968 году.Страница расширенного поиска позволяет
поиск статей о человеке или компании,
выберите диапазон дат или сузьте результаты поиска.
Покупка документа за 3 доллара дает вам доступ на 90 дней.
Попробуйте этот сервис, когда пора копать глубже, чем Google
и услуги, которые предлагает ваша местная библиотека.
MSN
Поиск (http: // search.msn.com/)
Хотя индекс поисковой системы Microsoft меньше, чем
Google, он удобно предлагает доступ к Encarta,
онлайн-энциклопедия в дополнение к ссылкам на кешированные страницы,
объединение результатов из одного домена, похожего на Google
Страница настроек и автоматическое предложение альтернативного поиска
термины или варианты написания. Нажатие кнопки «Рядом со мной»
ранжирует результаты поиска по их удаленности от местоположения
вы указали на странице настроек.Щелчок по рабочему столу
ссылка вызывает модуль MSN Desktop Search на рабочем столе MSN
Найдите (или предложит установить его, если его нет). Поиск
Builder позволяет уточнить поиск без запоминания
специальные префиксы. Чтобы ограничить поиск определенным доменом,
например, вы просто нажимаете «Сайт / Домен»
кнопку, введите домен и нажмите кнопку «Добавить в поиск»
кнопка.
Найти
Советы по поиску в Интернете от Engine Watch (http://searchenginewatch.com/facts/)
В этом разделе Search Engine Watch даются советы по использованию
поисковые системы лучше, включая диаграмму функций поиска;
одностраничный обзор основных поисковых команд и операторов
в различных поисковых системах, а также сравнение специальных
функции поиска.
Topix http://www.topix.net/
Topix.net предоставляет пользователям возможность быстро и легко
находите целевые новости в Интернете, постоянно отслеживая
последние новости из более чем 3000 источников, создающих тематические
управляемые, конкретные новостные веб-страницы и заполнение каждой из них
страницы с новостями только по этой конкретной теме. Ли
вам интересно узнать все новости о вашем сообществе,
компания, отрасль или проблема, Topix.net обеспечивает легкий
способ найти целевые новости, которые имеют отношение к вам.
• Vivisimo (http://vivisimo.com)
Эта отличная метапоисковая машина запрашивает многие основные поисковые запросы.
движки, удобно группирует документы в подкатегории
папок и предоставляет результаты в удобном для просмотра формате,
тем не менее обеспечивает ненавязчивый доступ для тех, кто хочет
его расширенные функции.Варианты включают открытие результатов в
новое окно или «предварительный просмотр» страницы с помощью
он отображается встроенным в список результатов поиска. Хотя
Vivisimo теперь предоставляет платные объявления при выполнении по умолчанию.
поиск в Интернете, он отделяет их от результатов редактирования
он собирает данные из других поисковых систем и четко маркирует
их.
* Обратный путь
Машина (http: // www.archive.org/web/web.php)
Просмотрите 30 миллиардов веб-страниц, заархивированных с 1996 по
несколько месяцев спустя. Wayback Machine позволяет людям получить доступ
и использовать архивные версии сохраненных веб-сайтов; необходимо
инструмент для изучения прошлых выпусков электронных информационных бюллетеней и других
документы, представленные на компанию, организацию или личное
Веб-сайт. Введите URL-адрес, выберите дату и начните просмотр.
в заархивированной версии Интернета.
Yahoo (http://www.yahoo.com)
Обширный предметный указатель, хорошая отправная точка, если вы
ищу конкретную компанию, государственное учреждение или организацию
Веб-сайт. Информация о компании включает профиль, новости,
информация о запасах, должностные лица, количество сотрудников, контакты
информация, веб-сайт. Вы можете искать в Yahoo, если не можете
найдите то, что хотите, в предметных указателях.
Обновлено февр. 2005. Присылайте исправления на веб-сайте по адресу [email protected].
Что такое поисковая система и как она работает?
Понимание того, как работают поисковые системы, может помочь вашему бизнесу использовать SEO для привлечения потенциальных клиентов.
Что такое поисковая машина?
Поисковые системы позволяют пользователям искать в Интернете контент по ключевым словам. Хотя на рынке преобладают немногие, есть много поисковых систем, которые люди могут использовать.Когда пользователь вводит запрос в поисковую систему, возвращается страница результатов поисковой системы (SERP), ранжирующая найденные страницы в порядке их релевантности. Порядок выполнения этого ранжирования в разных поисковых системах различается.
Поисковые системы часто меняют свои алгоритмы (программы, оценивающие результаты), чтобы улучшить взаимодействие с пользователем. Они стремятся понять, как пользователи ищут, и дать им лучший ответ на их запрос. Это означает отдавать приоритет страницам высочайшего качества и большинству соответствующих страниц.
Как работают поисковые системы?
Есть три основных шага к тому, как работает большинство поисковых систем:
- Crawling — поисковые системы используют программы, называемые пауками, ботами или сканерами, для просмотра Интернета. Они могут делать это каждые несколько дней, поэтому контент может быть устаревшим до тех пор, пока они снова не просканируют ваш сайт.
- Индексирование — поисковая система попытается понять и классифицировать контент на веб-странице с помощью «ключевых слов».Следование передовой практике SEO поможет поисковой системе понять ваш контент, чтобы вы могли ранжироваться по правильным поисковым запросам.
- Рейтинг — результаты поиска ранжируются на основе ряда факторов. Они могут включать плотность ключевых слов, скорость и ссылки. Цель поисковой системы — предоставить пользователю наиболее релевантных результатов .
Хотя большинство поисковых систем предоставляют советы о том, как улучшить рейтинг вашей страницы, точные используемые алгоритмы тщательно охраняются и часто меняются во избежание злоупотреблений.Но следуя передовой практике поисковой оптимизации (SEO), вы можете гарантировать, что:
- Поисковые системы могут легко сканировать ваш сайт. Вы также можете предложить им сканировать новый контент.
- Ваш контент проиндексирован по правильным ключевым словам, поэтому он может отображаться при релевантном поиске.
- Ваш контент может занять высокие позиции в поисковой выдаче.
Справочник поисковых систем
Некоторые нишевые поисковые системы работают как каталоги для определенных типов контента.Это означает, что они показывают результаты только для контента, добавленного вручную. Они не лазят по Интернету. Тактику SEO все еще можно использовать для получения высоких позиций по релевантным запросам в этих поисковых системах каталогов. См. Типы поисковых систем.
Результаты поиска Rich Media
Универсальный или «смешанный» поиск — это то, как поисковые системы представляют пользователям различные типы контента в результатах поиска. Помимо результатов традиционных текстовых страниц, в поисковой выдаче также будет отображаться мультимедийный контент, такой как изображения, видео, карты, статьи и страницы покупок.
Наличие на вашем веб-сайте нескольких различных типов контента — например, обучающего видео о том, как использовать ваш продукт, или блога — может повлиять на ваши шансы появиться на страницах результатов и на то, насколько высоко вы занимаетесь.
Вы можете использовать «структурированные данные» на своем веб-сайте, чтобы помочь поисковым системам понимать и отображать определенные типы контента. Это код, добавленный в разметку HTML. Использование структурированных данных означает, что такая информация, как рейтинги отзывов, изображения, адреса и номера телефонов, могут отображаться на странице результатов поисковой системы.
Обзор поисковой системы
Что такое поисковая машина?
Поисковая система поможет вам найти вещи в Интернете. Каждый раз, когда кто-нибудь ищет что-нибудь в Интернете, там, где они начинают с нуля, они, вероятно, используют поисковую систему. Существуют отдельные поисковые системы, такие как Hotbot, MSN, AltaVista, Yahoo, Webcrawler и многие другие. Некоторые поисковые системы даже не работают самостоятельно списки, они просто ищут в других поисковых системах.
Непонятно?
Как работает поисковая система Работа?
Пару разных способов. Некоторый, как Yahoo, это гигантские каталоги, в которых каждый список тщательно помещен в его многоуровневую структуру каталогов.
Другие, такие как AltaVista, гигантские индексирующие машины. Они отправляют программы (часто называемые «пауками» или «роботы») через Интернет, чтобы добавить веб-сайты к своим индексы.
Тип индексации поисковых систем обычно работают одним из двух способов:
1. они индексируют все слова (или возможно только первые 250 слов) на одной или нескольких страницах веб-сайта.
2. они хватают за кадром информация, хранящаяся в «метатегах», которые находятся в верхней части каждого веб-страницу (если их туда поместил веб-мастер).
Как работают поисковые системы «Пауки» узнают о веб-сайтах?
1.Кто-то заходит в «Добавить URL «или» Отправить сайт «для определенной поисковой системы. и представляет свой сайт.
2. Поисковая машина «Паук» обнаруживает новый сайт, переходя по ссылкам с других сайтов.
3. Администрация сайта наняла Сервис (например, LinkExchange от Microsoft) для автоматической отправки своих сайт или страницы с него в список поисковых систем.
Как разместить сайт в поисковую систему
Каждый, у кого есть сайт, должен на по крайней мере, начните с индивидуальной отправки своей домашней страницы и / или других основных страниц в дюжину или около того основных поисковых систем.Техника, которую я использую это 1) перейдите на домашнюю страницу поисковой системы и найдите ссылку под названием «Добавить URL» или «Отправить сайт». 2) Щелкните по этой ссылке затем найдите ссылку на страницу справки. Сложность здесь в том, что каждый У поисковой системы есть свои правила. Они могут сбивать с толку, но не непостижимый. Вот несколько основных вопросов, на которые нужно найти ответы, прежде чем отправка в поисковую систему:
1.Требуется всего одна отправка домашней страницы или разрешит отправку других главных страниц или даже все страницы на сайте?
2. Индексирует ли он контент или мета теги? Перед отправкой в любую поисковую систему, которая использует метатеги, потратите какое-то время разрабатываю хорошие для ваших страниц.
3. Есть ли в вашем site и индексирует ли поисковая система сайты с фреймами? (Некоторые делают, большинство не надо)
4.Это поиск по каталогу Механизм (например, Yahoo), который требует, чтобы человек, делающий листинг, нашел правильные категории. К какой категории относится ваш сайт?
Как мы заносим в список Аляскул? сайт?
Периодически (если вы беспокоитесь о «хитах» и «листингах» это означает раз в месяц), Я перечислил основные страницы оглавления. В сентябре я создал каталог основных справочных страниц и перечислил все те, которые есть в паре поисковых систем что позволило осуществить такой массовый листинг.Мы работали над получением других сайты, которые нужно добавить в этот. Иногда это помогает сайту показываться выше в списках поисковых систем.
Это обзор, здесь гайки и болты
Что такое метатег?
Ниже приведен пример мета-тегов. для страницы карты сайта (http://www.alaskoo.org/alaska.htm)
Каждый из них входит в заголовок раздел документа.Откройте свою веб-страницу в текстовом редакторе и сделайте конечно, это где-то между
и. Слова вы используете эти метатеги, они должны появиться в тексте той же страницы. Вы не должны повторять любое слово более 2 раз в метатеге. Слова должны быть разделены запятыми, и вы можете использовать фразы из 2 слов. (Поиск двигатели бывают привередливыми.)Метатег Robots дает Разрешение поисковым роботам выполнять поиск на этой странице.Есть другие теги роботов, которые отказывают паукам в разрешении поиска на странице. Этот, тоже иногда бывает полезно.
Добавьте свой сайт
Теперь знайте, какой URL вы хотите list и посетите поисковые системы. Вот несколько ссылок для начала. По мере того, как вы добьетесь этого, вы найдете других.
альтависта
возбудить
гугл
хот-бот
ликеров
веб-краулер
северное сияние
MSN.ком
И, наконец, если ты еще запутались, зайдите в интернет и прочтите об этом. Ссылки много. Один, который я нашел одновременно интересным и занимательным, это: http://www.searchengineworld.com.
О рамах
И, наконец, если вы используете фреймы, убедитесь, что если кто-то зайдет на одну из ваших страниц без рамки друзья, что они могут найти остальную часть вашего сайта.Аляскул, с несколькими тысячи файлов, в настоящее время на каждой странице используется минималистичная ссылка, но a Щелкните по нему, чтобы вернуться на нашу домашнюю страницу.
Безопасность в поисковых системах: настройте вашу практику просмотра!
Благодаря тому, что доступ в Интернет всегда у нас под рукой, мы всего лишь на расстоянии ключевых слов от практически всего, о чем мы можем думать! Но используйте небезопасные методы просмотра, и вы можете оказаться на расстоянии одного ключевого слова от дорогостоящего компьютерного вируса или, что еще хуже, подвергнете риску свою личную информацию.Поэтому, прежде чем запускать поисковую систему, ознакомьтесь с этими простыми советами по безопасности:
ИСПОЛЬЗУЙТЕ НАДЕЖНЫЕ ПОИСКОВЫЕ ДВИГАТЕЛИ
Возможно, вы видели, как самозванцы поисковых систем маскируются под настоящие вещи. Остерегайтесь поисковых систем, которые визуально «громкие» — с частыми всплывающими окнами или мигающими и мигающими изображениями — это типично для мошенничества с поисковыми системами, которое может включать вредоносное программное обеспечение или «вредоносные программы» для нарушения работы компьютера или сбора конфиденциальной информации. Придерживайтесь основных брендов поисковых систем, таких как Bing, Google и Yahoo.Также неплохо использовать несколько уважаемых поисковых систем. Ваша полная история поиска не хранится в одном месте, поэтому кибер-мошенникам сложнее собрать все ваши данные одним махом.
ВЫБОР ПОИСКА
Вы когда-нибудь пробовали выполнить поиск в Интернете? Хотя хорошо знать, какая личная информация является общедоступной, будьте осторожны! Введите слишком много личных данных за один поиск, и вы можете их раскрыть. Когда вы включаете основные идентификационные данные в один поиск — полное юридическое имя, номер социального страхования, адрес и т. Д.- они будут отображаться вместе в строке поиска, которая потенциально может храниться в течение длительного времени, что подвергнет вас большему риску кражи личных данных. Играть безопасно! Избегайте поиска, который включает два или более легко идентифицируемых элемента информации.
ПРОВЕРИТЬ ЧИСТУЮ ПОДМЕТЬ
Регулярно очищайте историю просмотров и удаляйте «куки» — небольшие текстовые файлы, которые веб-сайты хранят на вашем ПК или мобильном устройстве, чтобы напоминать о ваших предпочтениях. «Отслеживающие файлы cookie» могут быть еще более инвазивным способом, которым мошенники отслеживают каждое действие в сети.Хорошая новость заключается в том, что в большинстве браузеров есть пункт меню, который позволяет одновременно очищать историю и файлы cookie.
ИСПОЛЬЗУЙТЕ ЗАПИСАННЫЕ СОЕДИНЕНИЯ
Это особенно важно, если вы выполняете поиск на мобильном устройстве или используете общедоступное соединение Wi-Fi.