Этапы компиляции. Общая схема работы компилятора — Студопедия
Поделись
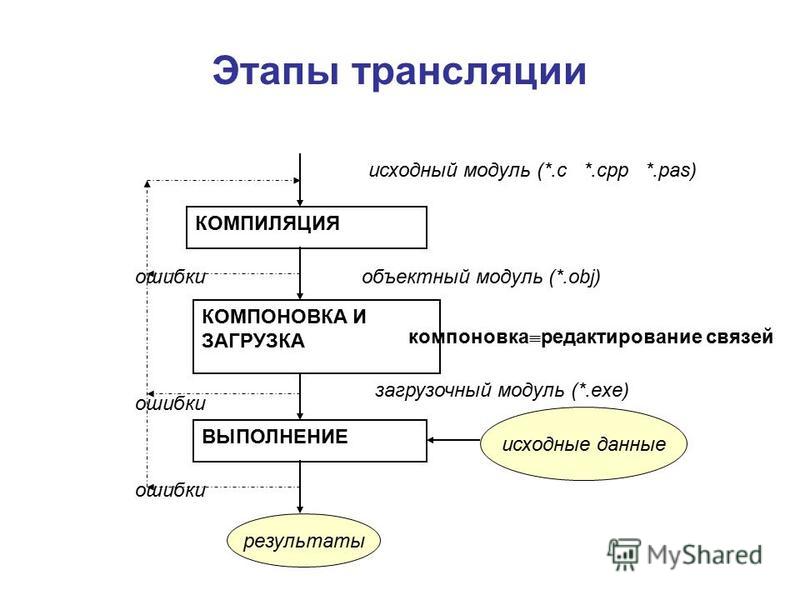
На рис. 1 представлена общая схема работы компилятора. Из нее видно, что в целом процесс компиляции состоит из двух основных этапов: анализа и синтеза.
На этапе анализа выполняется распознавание текста исходной программы, создание и заполнение таблиц идентификаторов. Результатом его работы служит некое внутреннее представление программы, понятное компилятору.
На этапе синтеза на основании внутреннего представления программы и информации, содержащейся в таблице идентификаторов, порождается текст результирующей программы. Результатом этого этапа является объектный код (модуль). Если программа обращалась к функциям и данным другого модуля, компилятор транслирует эти обращения во внешние ссылки (external reference). Если же программа предоставляет доступ к своим данным и функциям другим программам, каждый доступный элемент представляется как внешнее имя (external name). Объектные модули хранят эти внешние имена и ссылки в структуре данных, называемой таблицей имен (symbol table).
Объектные модули хранят эти внешние имена и ссылки в структуре данных, называемой таблицей имен (symbol table).
Кроме того, в составе компилятора присутствует часть, ответственная за анализ и исправление ошибок, которая при наличии ошибки в тексте исходной программы должна максимально полно информировать пользователя о типе ошибки и месте ее возникновения. В лучшем случае компилятор может предложить пользователю вариант исправления ошибки.
Эти этапы, в свою очередь, состоят из более мелких этапов, называемых фазами компиляции. Состав фаз компиляции на рис. 1 приведен в самом общем виде, их конкретная реализация и процесс взаимодействия могут, конечно, различаться в зависимости от версии компилятора. Однако в том или ином виде все представленные фазы практически всегда присутствуют в каждом конкретном компиляторе.
Компилятор в целом выполняет две основные функции. Во-первых, он является распознавателем для языка исходной программы. То есть он должен получить на вход цепочку символов входного языка, проверить ее принадлежность языку и, более того, выявить правила, по которым эта цепочка построена.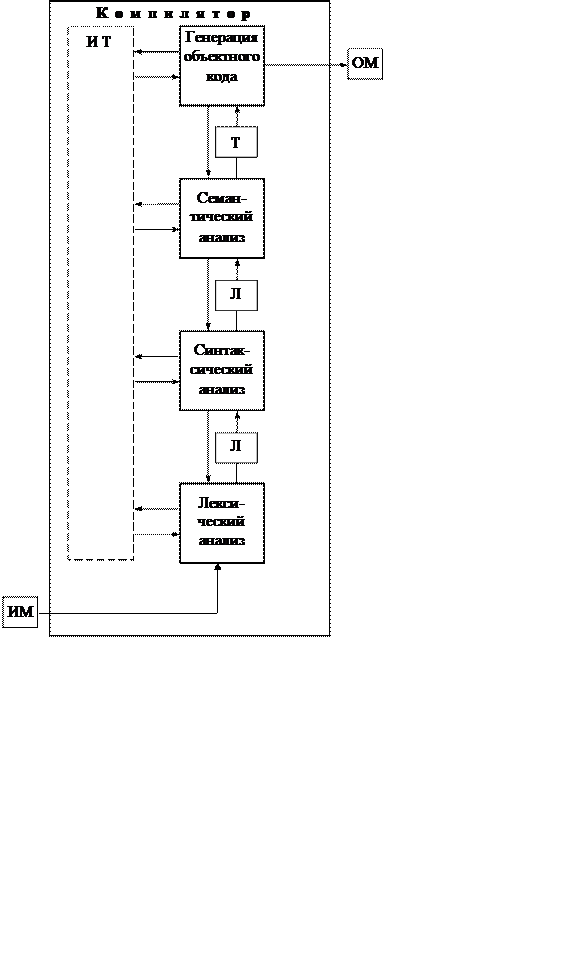 Во-вторых, компилятор является генератором для языка результирующей программы. Он должен построить на выходе цепочку выходного языка по определенным правилам, предполагаемым языком машинных команд или языком ассемблера. В случае машинных команд распознавателем этой цепочки будет выступать целевая вычислительная система, под которую создается результирующая программа.
Во-вторых, компилятор является генератором для языка результирующей программы. Он должен построить на выходе цепочку выходного языка по определенным правилам, предполагаемым языком машинных команд или языком ассемблера. В случае машинных команд распознавателем этой цепочки будет выступать целевая вычислительная система, под которую создается результирующая программа.
Рассмотрим основные фазы компиляции.
Лексический анализ (сканер) — это часть компилятора, которая читает литеры программы на исходном языке и строит из них слова (лексемы) исходного языка. На вход лексического анализатора поступает текст исходной программы, а выходная информация передается для дальнейшей обработки компилятором на этапе синтаксического разбора.
Синтаксический разбор — это основная часть компилятора на этапе анализа. Она выполняет выделение синтаксических конструкций в тексте исходной программы, обработанном лексическим анализатором. На этой же фазе компиляции проверяется синтаксическая правильность программы.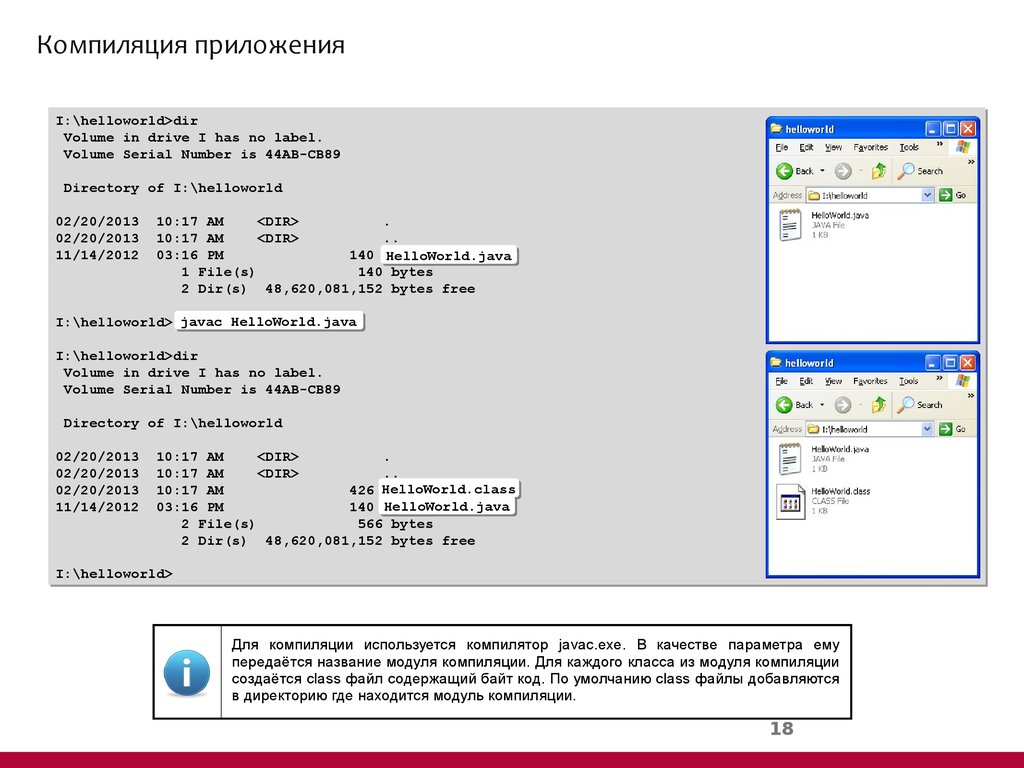
Семантический анализ — это часть компилятора, проверяющая правильность текста исходной программы с точки зрения семантики входного языка. Кроме непосредственно проверки, семантический анализ должен выполнять преобразования текста, требуемые семантикой входного языка (например, такие как добавление функций неявного преобразования типов). В различных реализациях компиляторов семантический анализ может частично входить в фазу синтаксического разбора, частично — в фазу подготовки к генерации кода.
Задачи семантического анализа:
· каждый используемый в программе идентификатор должен быть описан, но не более одного раза в одной зоне описания;
· При вызове функций число фактических параметров и их типы должны соответствовать числу и типам формальных параметров;
· Обычно в языке накладываются ограничения на типы операндов любой операции, определенной в этом языке, на типы левой и правой части в присваивании, на тип параметра цикла, на тип условия в операторе цикла и условном операторе, и т п.
Рис. 1. Общая схема работы компилятора.
Подготовка к генерации кода — это фаза, на которой компилятором выполняются предварительные действия, необходимые для синтеза результирующей программы, но не ведущие к порождению текста на выходном языке. Обычно в эту фазу входят действия, связанные с идентификацией элементов языка, распределением памяти и т. п.
Генерация кода — это фаза, непосредственно связанная с порождением текста результирующей программы. Это основная фаза на этапе синтеза результирующей программы. Кроме непосредственно порождения текста результирующей программы генерация обычно включает в себя также оптимизацию — процесс, связанный с обработкой уже порожденного текста. Иногда оптимизацию выделяют в отдельную фазу компиляции, так как она оказывает существенное влияние на качество и эффективность результирующей программы.
Таблицы идентификаторов (иногда «таблицы символов») — это специальным образом организованные структуры данных, служащие для хранения информации об элементах исходной программы, которые затем используются для порождения текста результирующей программы. В конкретной реализации компилятора может быть как одна, так и несколько таблиц идентификаторов. Элементами исходной программы, информацию о которых необходимо хранить в процессе компиляции, являются переменные, константы, функции и т. п. — конкретный состав этих элементов зависит от входного языка. Термин «таблицы» вовсе не предполагает, что это хранилище данных должно быть организовано именно в виде таблиц или массивов информации.
В конкретной реализации компилятора может быть как одна, так и несколько таблиц идентификаторов. Элементами исходной программы, информацию о которых необходимо хранить в процессе компиляции, являются переменные, константы, функции и т. п. — конкретный состав этих элементов зависит от входного языка. Термин «таблицы» вовсе не предполагает, что это хранилище данных должно быть организовано именно в виде таблиц или массивов информации.
С++ для начинающих. Урок 1. Компиляция
- Содержание
- Обзор компиляторов C++
- Этапы компиляции
- Препроцессинг
- Ассемблирование
- Компиляция
- Линковка
- Средства сборки проекта
- Простой пример компиляции
Обзор компиляторов
Существует множество компиляторов с языка C++, которые можно использовать для создания исполняемого кода под разные платформы. Проекты компиляторов можно классифицировать по следующим критериям.
- Коммерческие и некоммерческие проекты
- Уровень поддержки современных тенденций и стандартов языка
- Эффективность результирующего кода
Если на использование коммерческих компиляторов нет особых причин, то имеет смысл использовать компилятор с языка C++ из GNU коллекции компиляторов (GNU Compiler Collection). Этот компилятор есть в любом дистрибутиве Linux, и, он, также, доступен для платформы Windows как часть проекта MinGW (Minumum GNU for Windows). Для работы с компилятором удобнее всего использовать какой-нибудь дистрибутив Linux, но если вы твердо решили учиться программировать под Windows, то удобнее всего будет установить некоммерческую версию среды разработки QtCreator вместе с QtSDK ориентированную на MinGW. Обычно, на сайте производителя Qt можно найти инсталлятор под Windows, который сразу включает в себя среду разработки QtCreator и QtSDK. Следует только быть внимательным и выбрать ту версию, которая ориентирована на MinGW. Мы, возможно, за исключением особо оговариваемых случаев, будем использовать компилятор из дистрибутива Linux.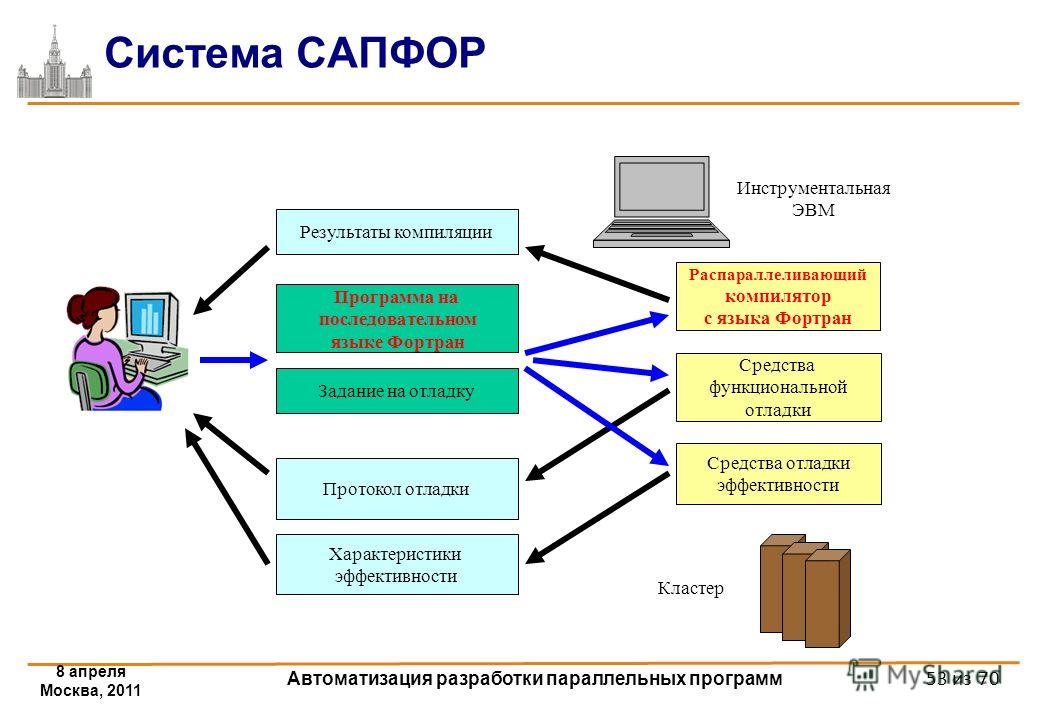
GNU коллекция компиляторов включает в себя несколько языков. Из них, группу языков Си составляет три компилятора.
- g++ — компилятор с языка C++.
- gcc — компилятор с языка C (GNU C Compiler).
- gcc -lobjc — Objective-C — это, фактически, язык C с некоторой макро-магией, которая доступна в объектной библиотеке objc. Ее следует поставить и указать через ключ компиляции -l.
Этапы компиляции
Процесс обработки текстовых файлов с кодом на языке C++, который упрощенно называют «компиляцией», на самом деле, состоит из четырех этапов.
- Препроцессинг — обработка текстовых файлов утилитой препроцессора, который производит замены текстов согласно правилам языка препроцессора C/C++. После препроцессора, тексты компилируемых файлов, обычно, значительно вырастают в размерах, но теперь в них содержится все, что потребуется компилятору для создания объектного файла.
- Ассемблирование — процесс превращения текста на языке C++ в текст на языке Ассемблера.
 Для компиляторов GNU используется синтаксис ассебмлера AT&T.
Для компиляторов GNU используется синтаксис ассебмлера AT&T. - Компилирование — процесс превращения текстов на языке Ассемблера в объектные файлы. Это файлы состоящие из кодов целевого процессора, но в которых еще не проставлены адреса объектов, которые находятся в других объектных файлах или библиотеках.
- Линковка — процесс объединения объектных файлов проекта и используемых библиотек в единую целевую сущность для целевой платформы. Это может быть исполняемая программа или библиотека статического или динамического типа.
 Для компиляторов GNU используется синтаксис ассебмлера AT&T.
Для компиляторов GNU используется синтаксис ассебмлера AT&T.Рассмотрим подробнее упомянутые выше стадии обработки текстовых файлов на языке C++.
Препроцессинг
Препроцессинг, это процедура ставшая традиционной для многих обработчиков разного рода описаний, в том числе и текстов с кодами программ. В общем случае, везде, где возникает необходимость в предварительной обработке текстов реализуется некоторый язык препроцессинга элементы которого ищутся препроцессором при обработке файла.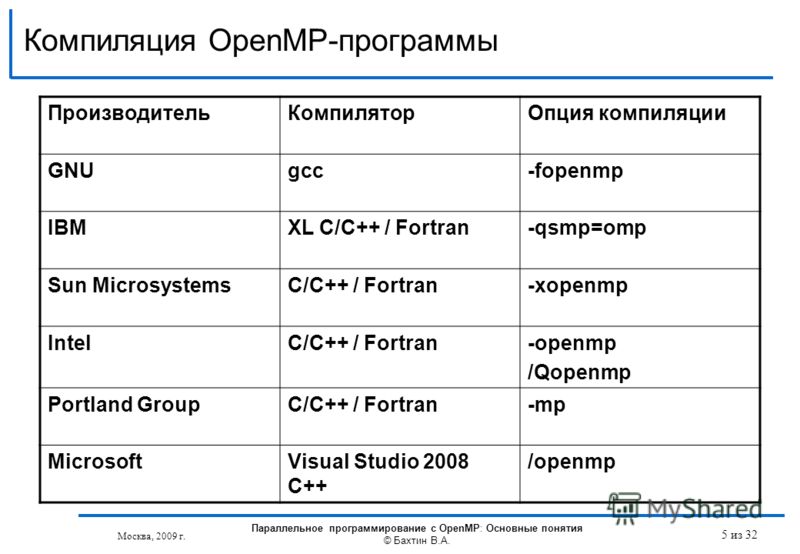
Основными элементами языка препроцессора являются директивы и макросимволы. Директивы вводятся с помощью символа «решетка» (#) в начале строки. Все, что следует за символом решетки и до конца строки считается директивой препроцессора. Директива препроцессора define вводит специальные макросимволы, которые могут быть использованы в следующих выражениях языка препроцессора.
На входе препроцессора мы имеем исходный файл с текстом на языке C++ включающим в себя элементы языка препроцессора.
На выходе препроцессора получаются так называемые компиляционные листы, состоящие исключительно из выражений языка C++, которых должно быть достаточно для создания объектных файлов на следующих этапах обработки. Последнее означает, что на момент использования каких-либо символов языка из других файлов, объявления этих символов должны присутствовать в компиляционном листе выше. Именно такие подстановки и призван осуществлять препроцессор. Часто, на вход препроцессора поступает файл размером в несколько десятков строк, а на выходе получается компиляционный лист из десятков тысяч строк.
Ассемблирование
Процесс ассемблирования с одной стороны достаточно прост для понимания и с другой стороны является наиболее сложным в реализации. По своей сути это процесс трансляции выражений одного языка в другой. Более конкретно, в данном случае, мы имеем на входе утилиты ассемблера файл с текстом на языке C++ (компиляционный лист), а на выходе мы получаем файл с текстом на языке Ассемблера. Язык Ассемблера это низкоуровневый язык который практически напрямую отображается на коды инструкций процессора целевой системы. Отличие только в том, что вместо числовых кодов инструкций используется англоязычная мнемоника и кроме непосредственно кодов инструкций присутствуют еще директивы описания сегментов и низкоуровневых данных, описываемых в терминологии байтов.
Ассемблирование не является обязательным процессом обработки файлов на языке C++. В данном случае, мы наблюдаем лишь общий подход в архитектуре проекта коллекции компиляторов GNU. Чтобы максимально объеденить разные языки в одну коллекцию, для каждого из языков реализуется свой транслятор на язык ассемблера и, при необходимости, препроцессор, а компилятор с языка ассемблера и линковщик делаются общими для всех языков коллекции.
Компиляция
В данном случае, мы имеем компилятор с языка ассемблера. Результатом его работы является объектный файл полученный на основе всего того текста, что был предоставлен в компиляционном листе. Поэтому можно говорить, что каждый объектный файл проекта соответствует одному компиляционному листу проекта.
Объектный файл — это бинарный файл, фактически состоящий из набора функций. Однако в исходном компиляционном листе не все вызываемые функции имели реализацию (или определение — definition). Не путайте с объявлением (declaration). Чтобы компиляционный лист можно было скомпилировать, необходимо, чтобы объявления всех вызываемых функций присутствовали в компиляционном листе до момента их использования. Однако, объявление, это не более чем имя функции и параметры ее вызова, которые позволяют во время компиляции правильно сформировать стек (передать переменные для вызова функции) и отметить, что тут надо вызвать функцию с указанным именем, адрес реализации которой пока не известен. Таким образом, объектные файлы сплошь состоят из таких «дыр» в которые надо прописать адреса из функций, которые реализованы в других объектных файлах или даже во внешних библиотеках.
Таким образом, объектные файлы сплошь состоят из таких «дыр» в которые надо прописать адреса из функций, которые реализованы в других объектных файлах или даже во внешних библиотеках.
Вообще, разница между объявлением (declaration) и определением (definition) состоит в том, что объявление (declaration) говорит об имени сущности и описывает ее внешний вид — например, тип объекта или параметры функции, в то время как определение (definition) описывает внутреннее устройство сущности: класс памяти и начальное значение объекта, тело функции и пр.
Исходя из этих определений, в компиляционном листе перед компиляцией должны существовать все объявления (declaration) всех тех сущностей, что используются в этом компиляционном листе. Причем их объявления должны находится до момента использования этих сущностей. Иначе, компилятор не сможет подготовить обращение к соответствующей сущности. Например, не сможет оформить передачу параметров через стек вызова функции и подготовиться к приему возвращаемого функцией значения.
Линковка
На этапе линковки выполняется объединение всех объектных файлов проекта, откомпилированных по соответствующим компиляционным листам проекта в единую сущность. Это может быть приложение, статическая или динамическая библиотека. Разница в бинарных заголовках целевых файлов и несколько различной внутренней организацией. Первичной задачей линковки следует назвать задачу по подстановке адресов вызова внешних объектов, которые были образованы в объектных файлах проекта. Соответствующие реализации сущностей с адресами их размещения должны находится в видимости линковщика. Эти сущности должны быть либо в объектных файлах, тогда они должны быть указаны в списке линковки, либо во внешних библиотеках функций, статических или динамических, тогда они должны быть указаны в списке внешних библиотек.
Средства сборки проекта
Традиционно, программа на языке C++ собирается средствами утилиты make исполняющей сценарий из файла Makefile. Сценарий сборки можно писать самостоятельно,
а можно создавать его автоматически с помощью всевозможных средств организации проекта. Среди наиболее известных средств организации проекта можно указать следующие.
Среди наиболее известных средств организации проекта можно указать следующие.
- GNU Toolchain — Старейшая система сборки проектов известная еще по сочетанию команд configure-make-«make install».
- CMake — Кроссплатформенная система сборки, которая позволяет не только создать кроссплатформенный проект но и создать сценарий компиляции под любые известные среды разработки, для которых написаны соответствующие генераторы сценариев.
- QMake — Достаточно простая система сборки, специально реализованная для фреймворка Qt и широко используемая именно для сборки Qt-проектов. Может быть использована и просто для сборки проектов на языке C++. Имеет некоторые проблемы с выявлением сложных зависимостей метакомпиляции, специфической для Qt, поэтому, даже в проектах Qt, рекомендуется использование системы сборки CMake.
Современные версии QtCreator могут работать с проектами, которые используют как систему сборки QMake, так и систему сборки CMake.
Простой пример компиляции
Рассмотрим простейший проект «Hello world» на языке C++. Для его компиляции мы будет использовать консоль, в которой будем писать прямые команды компиляции. Это позволит нам максимально прочувствовать описанные выше этапы компиляции. Создадим файл с именем main.cpp и поместим в него следующий текст программы.
01. #include <iostream>
02.
03. int main(int argc, char *argv[])
04. {
05. std::cout << "Hello world" << std::endl;
06.
07. return 0;
08. }В представленом примере выполнена нумерация строк, чтобы упростить пояснения по коду. В реальном коде нумерации не должно быть, так как она не входит в синтаксическое описание конструкций языка C++.
В первой строке кода записана директива включения файла с именем iostream в текст проекта. Как уже говорилось, все строки, которые начинаются со знака решетки (#) интерпретируются в языках C/C++ как директивы препроцессора. В данном случае, препроцессор, обнаружив директиву включения файла в текст программы, директиву include, выполнит включение всех строк указанного в директиве файла в то место программы, где стоит инструкция include. В результате этого у нас получится большой компиляционный лист, в котором будут присутствовать множество символов объявленных (declaration) в указанном файле. Включаемые файлы, содержащие объявления (declaration) называют заголовочными файлами. На языке жаргона можно услышать термины «header-файлы» или «хидеры».
В данном случае, препроцессор, обнаружив директиву включения файла в текст программы, директиву include, выполнит включение всех строк указанного в директиве файла в то место программы, где стоит инструкция include. В результате этого у нас получится большой компиляционный лист, в котором будут присутствовать множество символов объявленных (declaration) в указанном файле. Включаемые файлы, содержащие объявления (declaration) называют заголовочными файлами. На языке жаргона можно услышать термины «header-файлы» или «хидеры».
Чтобы увидеть результат препроцессинга можно воспользоваться опцией -E компилятора g++. По умолчанию, в этом случае, результат препроцессинга будет выведен в стандартный поток вывода. Чтобы можно было удобно рассмотреть его, следует перенаправить стандартный поток вывода в какой-нибудь текстовый файл. В представленном ниже примере это будет файл main.E.
g++ -E main.cpp > main.E
В третьей строке программы описана функция main(). В контексте операционной системы, каждое приложение должно иметь точку входа. Такой точкой входа в операционных системах *nix является функция main(). Именно с нее начинается исполнение приложения после его загрузки в память вычислительной системы. Так как операционная система Windows имеет корни тесно переплетенные с историей *nix, и, фактически, является далеким проприентарным клоном *nix, то и для нее справедливо данное правило. Поэтому, если вы пишете приложение, то начинается оно всегда с функции main().
В контексте операционной системы, каждое приложение должно иметь точку входа. Такой точкой входа в операционных системах *nix является функция main(). Именно с нее начинается исполнение приложения после его загрузки в память вычислительной системы. Так как операционная система Windows имеет корни тесно переплетенные с историей *nix, и, фактически, является далеким проприентарным клоном *nix, то и для нее справедливо данное правило. Поэтому, если вы пишете приложение, то начинается оно всегда с функции main().
При вызове функции main(), операционная система передает в нее два параметра. Первый параметр — это количество параметров запуска приложения, а второй — строковый массив этих параметров. В нашем случае, мы их не используем.
В пятой строке мы обращаемся к предопределенному объекту cout из пространства имен std, который связан с потоком вывода приложения. Используя синтаксис операций, определенных для указанного объекта, мы передаем в него строку «Hello world» и символ возврата каретки и переноса строки.
В седьмой строке мы возвращаем код 0, как код возврата функции main(). В организации процессов в операционной системы, это число будет восприниматься как код возврата приложения.
Следующим шагом проведения эксперимента выполним останов компиляции файла main.cpp после этапа ассемблирования. Для этого воспользуемся ключом -S для компилятора g++. Здесь и далее, знак доллара ($) обозначает стандартное приглашение к вводу команды в консоли *nix. Писать знак доллара не требуется.
$ g++ -S main.cpp
Выполнив остановку компиляции после этапа ассемблирование, возможно будет интересно выполнить остановку компиляции и после этапа, который собственно, и выполняет компиляцию, т.е. превращение ассемблерного кода в объектный файл, который впоследствии надо будет слинковать с библиотеками, в которых будет найдено реализация объекта cout, который используется в нашей программе как некий библиотечный объект.
Для остановки компиляции после, собственно, компиляции следует воспользоваться ключом -c для компилятора g++.
$ g++ -с main.cpp
Наконец, если нас не интересуют эксперименты с остановками компиляции на разных этапах и если мы просто хотим получить из нашего файла на языке C++ исполняемую программу, то следует выполнить следующую команду.
$ g++ main.cpp
В результате исполнения этой команды появится файл a.out который и представляет собой результат компиляции — исполняемый файл программы. Запустим его и посмотрим на результат выполнения. При работе в операционной системе Windows, результатом компиляции будет файл с расширением exe. Возможно, он будет называться main.exe.
$ ./a.out
Процесс выполнения управляемого кода | Microsoft Learn
- Статья
- Чтение занимает 6 мин
Процесс управляемого исполнения включает следующие шаги, которые подробно разбираются позднее в этом разделе:
Выбор компилятора.
Чтобы воспользоваться преимуществами среды CLR, необходимо использовать один или несколько языковых компиляторов, обращающихся к среде выполнения.
Компиляция кода в MSIL.
При компиляции исходный код преобразуется в MSIL и создаются необходимые метаданные.
Компиляция инструкций MSIL в машинный код.
Во время выполнения JIT-компилятор преобразует инструкции MSIL в машинный код. Во время этой компиляции выполняется проверка кода и метаданных MSIL с целью установить, можно ли для них определить, является ли код типобезопасным.
Выполнение кода.
Среда CLR предоставляет инфраструктуру, обеспечивающую выполнение кода, и ряд служб, которые можно использовать при выполнении.

Выбор компилятора
Чтобы воспользоваться преимуществами, предоставляемыми средой CLR, необходимо применить один или несколько языковых компиляторов, ориентированных на среду выполнения, например компилятор Visual Basic, C#, Visual C++, F# или один из многочисленных компиляторов от независимых разработчиков, например компилятор Eiffel, Perl или COBOL.
Поскольку среда выполнения является многоязычной, она поддерживает широкий набор разнообразных типов данных и языковых средств. Доступные средства среды выполнения определяются используемым языковым компилятором, и разработчики создают код с использованием этих средств. Используемый в коде синтаксис определяется компилятором, а не средой выполнения. Если компонент должен быть полностью доступен для компонентов, написанных на других языках, то экспортируемые этим компонентом типы должны предоставлять исключительно языковые функции, включенные в состав спецификации CLS. Атрибут CLSCompliantAttribute позволяет гарантировать, что код является CLS-совместимым. Дополнительные сведения см. в разделе Независимость от языка и независимые от языка компоненты.
Вверх
Компиляция в MSIL
При компиляции в управляемый код компилятор преобразует исходный код в промежуточный язык Microsoft (MSIL), представляющий собой независимый от процессора набор инструкций, который можно эффективно преобразовать в машинный код. Язык MSIL включает инструкции для загрузки, сохранения, инициализации и вызова методов для объектов, а также инструкции для арифметических и логических операций, потоков управления, прямого доступа к памяти, обработки исключений и других операций. Перед выполнением код MSIL необходимо преобразовать в код для конкретного процессора, обычно с помощью JIT-компилятора. Поскольку среда CLR предоставляет для каждой поддерживаемой компьютерной архитектуры один или несколько JIT-компиляторов, один набор инструкций MSIL можно компилировать и выполнять в любой поддерживаемой архитектуре.
Язык MSIL включает инструкции для загрузки, сохранения, инициализации и вызова методов для объектов, а также инструкции для арифметических и логических операций, потоков управления, прямого доступа к памяти, обработки исключений и других операций. Перед выполнением код MSIL необходимо преобразовать в код для конкретного процессора, обычно с помощью JIT-компилятора. Поскольку среда CLR предоставляет для каждой поддерживаемой компьютерной архитектуры один или несколько JIT-компиляторов, один набор инструкций MSIL можно компилировать и выполнять в любой поддерживаемой архитектуре.
Когда компилятор создает код MSIL, одновременно создаются метаданные. Метаданные содержат описание типов в коде, включая определение каждого типа, сигнатуры каждого члена типа, члены, на которые есть ссылки в коде, а также другие сведения, используемые средой выполнения во время выполнения. MSIL и метаданные содержатся в переносимом исполняемом (PE) файле, который основывается на форматах Microsoft PE и COFF, ранее использовавшихся для исполняемого контента, но при этом расширяет их возможности. Этот формат файлов, позволяющий размещать код MSIL или машинный код, а также метаданные, позволяет операционной системе распознавать образы среды CLR. Наличие в файле метаданных наряду с MSIL позволяет коду описывать себя. Это устраняет потребность в библиотеках типов и языке IDL. Среда выполнения находит и извлекает метаданные из файла по мере необходимости при выполнении.
Этот формат файлов, позволяющий размещать код MSIL или машинный код, а также метаданные, позволяет операционной системе распознавать образы среды CLR. Наличие в файле метаданных наряду с MSIL позволяет коду описывать себя. Это устраняет потребность в библиотеках типов и языке IDL. Среда выполнения находит и извлекает метаданные из файла по мере необходимости при выполнении.
Вверх
Компиляция инструкций MSIL в машинный код
Перед запуском MSIL его необходимо скомпилировать в машинный код в среде CLR для архитектуры конечного компьютера. Платформа .NET предоставляет два способа такого преобразования:
JIT-компилятор платформы .NET.
Ngen.exe (генератор образов в машинном коде).
Компиляция с помощью JIT-компилятора
При JIT-компиляции язык MSIL преобразуется в машинный код во время выполнения приложения по требованию, когда загружается и выполняется содержимое сборки. Поскольку среда CLR предоставляет JIT-компилятор для каждой поддерживаемой архитектуры процессора, разработчики могут создавать набор сборок MSIL, которые могут компилироваться с помощью JIT-компилятора и выполняться на разных компьютерах с разной архитектурой. Если управляемый код вызывает специфический для платформы машинный API или библиотеку классов, то он будет выполняться только в соответствующей операционной системе.
Если управляемый код вызывает специфический для платформы машинный API или библиотеку классов, то он будет выполняться только в соответствующей операционной системе.
При JIT-компиляции учитывается возможность того, что определенный код может никогда не вызываться во время выполнения. Чтобы не тратить время и память на преобразование всего содержащегося в PE-файле MSIL в машинный код, при компиляции MSIL преобразуется в машинный код по мере необходимости во время выполнения. Полученный таким образом машинный код сохраняется в памяти, что позволяет использовать его при дальнейших вызовах в контексте этого процесса. Загрузчик создает и присоединяет заглушки к каждому методу в типе, когда тип загружается и инициализируется. При первом вызове метода заглушка передает управление JIT-компилятору, который преобразует MSIL для этого метода в машинный код и заменяет заглушку на созданный машинный код. Поэтому последующие вызовы метода, скомпилированного с помощью JIT-компилятора, ведут непосредственно к машинному коду.
Создание кода во время установки с помощью NGen.exe
Тот факт, что JIT-компилятор преобразует MSIL-код сборки в машинный код при вызове отдельных методов, определенных в этой сборке, отрицательно сказывается на производительности во время выполнения. В большинстве случаев снижение производительности приемлемо. Что более важно, код, созданный JIT-компилятором, будет привязан к процессу, вызвавшему компиляцию. Его нельзя сделать общим для нескольких процессов. Чтобы созданный код можно было использовать в нескольких вызовах приложения или в нескольких процессах, которые совместно используют набор сборок, среда CLR предоставляет режим предварительной компиляции. В таком режиме компиляции для преобразования сборок MSIL в машинный код в стиле JIT-компилятора используется генератор образов в машинном коде (Ngen.exe). Однако, работа Ngen.exe отличается от JIT-компилятора в трех аспектах.
Ngen.exe выполняет преобразование из MSIL-кода в машинный код перед выполнением приложения, а не во время его выполнения.
При этом сборка компилируется целиком, а не по одному методу за раз.
Она сохраняет созданный код в кэше образа машинного кода в виде файла на диске.

Проверка кода
В процессе компиляции в машинный код MSIL-код должен пройти проверку, если только администратор не установил политику безопасности, разрешающую пропустить проверку кода. MSIL-код и метаданные проверяются на типобезопасность. Это подразумевает, что код должен обращаться только к тем адресам памяти, к которым ему разрешен доступ. Типобезопасность помогает изолировать объекты друг от друга и способствует их защите от непредумышленного или злонамеренного повреждения. Она также гарантирует надежное применение условий безопасности для кода.
Среда выполнения основывается на истинности следующих утверждений для поддающегося проверке типобезопасного кода:
ссылка на тип строго совместима с адресуемым типом;
для объекта вызываются только правильно определенные операции;
удостоверения являются подлинными.

В процессе проверки кода MSIL делается попытка подтвердить, что код может получать доступ к расположениям в памяти и вызывать методы только через правильно определенные типы. Например, код не должен разрешать доступ к полям объекта так, чтобы можно было выходить за границы расположения в памяти. Кроме того, проверка определяет, правильно ли был создан код MSIL, поскольку неверный код MSIL может приводить к нарушению правил строгой типизации. В процессе проверки передается правильно определенный типобезопасный код. Однако иногда типобезопасный код может не пройти проверку из-за ограничений процесса проверки, а некоторые языки по своей структуре не позволяют создавать поддающийся проверке типобезопасный код. Если в соответствии с политикой безопасности использование типобезопасного кода является обязательным и код не проходит проверку, то при выполнении кода создается исключение.
Вверх
Выполнение кода
Среда CLR предоставляет инфраструктуру, обеспечивающую управляемое выполнение кода, и ряд служб, которые можно использовать при выполнении. Перед выполнением метода его необходимо скомпилировать в код для конкретного процессора. Каждый метод, для которого создан MSIL-код, компилируется с помощью JIT-компилятора при первом вызове и затем запускается. При следующем вызове метода будет выполняться существующий JIT-скомпилированный код. Процесс JIT-компиляции и последующего выполнения кода повторяется до завершения выполнения.
Перед выполнением метода его необходимо скомпилировать в код для конкретного процессора. Каждый метод, для которого создан MSIL-код, компилируется с помощью JIT-компилятора при первом вызове и затем запускается. При следующем вызове метода будет выполняться существующий JIT-скомпилированный код. Процесс JIT-компиляции и последующего выполнения кода повторяется до завершения выполнения.
Во время выполнения для управляемого кода доступны такие службы, как сборка мусора, обеспечение безопасности, взаимодействие с неуправляемым кодом, поддержка отладки на нескольких языках, а также поддержка расширенного развертывания и управления версиями.
В Microsoft Windows Vista загрузчик операционной системы выполняет поиск управляемых модулей, анализируя бит в заголовке COFF. Установленный бит обозначает управляемый модуль. При обнаружении управляемых модулей загружается библиотека Mscoree.dll, а подпрограммы _CorValidateImage и _CorImageUnloading уведомляют загрузчик о загрузке и выгрузке образов управляемых модулей. Подпрограмма
Подпрограмма_CorValidateImage выполняет следующие действия:
Проверяет, является ли код допустимым управляемым кодом.
Заменяет точку входа в образе на точку входа в среде выполнения.
В 64-разрядных системах Windows _CorValidateImage изменяет образ, находящийся в памяти, путем преобразования его из формата PE32 в формат PE32+.
Вверх
См. также раздел
- Обзор
- Независимость от языка и независимые от языка компоненты
- Метаданные и компоненты с самоописанием
- Ilasm.exe (ассемблер IL)
- Security
- Взаимодействие с неуправляемым кодом
- Развертывание
- Сборки в .NET
- Домены приложений
Каковы основные этапы компиляции? [gcc, c, compilation, assembly, compiler-construction]
Каковы основные этапы компиляции программы на C? Под компиляцией я имею в виду (возможно, ошибочно) получение двоичного файла из простого текста, содержащего код C, с использованием gcc.
Я хотел бы понять некоторые ключевые моменты процесса:
К концу дня мне нужно преобразовать мой код C в язык, который должен понимать именно мой процессор. Итак, кому какое дело до моих инструкций для процессора? Операционная система?
Преобразует ли gcc какой-либо язык C в язык ассемблера?
Я знаю (фактически предполагаю), что для каждого типа процессора мне понадобится ассемблер, который будет интерпретировать (?) ассемблерный код и преобразовывать инструкции, специфичные для моего процессора. Где этот ассемблер (кто его поставляет)? Он идет с ОС?
Почему именно я не вижу 0 и 1, если я открываю двоичный файл в текстовом редакторе?
gcc c compilation assembly compiler-construction
person Pabluez
schedule 20. 11.2014
source источник
11.2014
source источник
Ответы (4)
arrow_upward
2
arrow_downward
К концу дня мне нужно преобразовать мой код C в язык, который должен понимать именно мой процессор. Итак, кого волнует знание моих конкретных инструкций для процессора? Операционная система?
Вы не очень ясно здесь. Если вы спрашиваете, какой инструмент знает конкретные инструкции вашего процессора, это ассемблер, дизассемблер, отладчик и, возможно, некоторые другие. Они могут генерировать машинный код или конвертировать его обратно в дизассемблированный.
Если вы спрашиваете, кого волнует, какие инструкции используются, то процессор должен их выполнять, поскольку каждый набор инструкций представляет даже такую распространенную инструкцию, как «сложить два целых числа», совершенно по-разному.
Преобразует ли gcc любой C в язык ассемблера?
Да, C (или программа на любом другом поддерживаемом языке) преобразуется в сборку с помощью GCC. Здесь задействовано много шагов, и в процессе используются по крайней мере два дополнительных внутренних представления. Подробности описаны в документе внутренние компоненты GCC. Наконец, «бэкенд» компилятора генерирует сборочное представление простых «шаблонов», сгенерированных предыдущими проходами компилятора. Вы можете попросить GCC вывести эту сборку, используя флаг -S. Если вы специально не попросите об этом, следующий шаг (сборка) будет выполнен автоматически, и вы увидите только свой окончательный исполняемый файл.
Здесь задействовано много шагов, и в процессе используются по крайней мере два дополнительных внутренних представления. Подробности описаны в документе внутренние компоненты GCC. Наконец, «бэкенд» компилятора генерирует сборочное представление простых «шаблонов», сгенерированных предыдущими проходами компилятора. Вы можете попросить GCC вывести эту сборку, используя флаг -S. Если вы специально не попросите об этом, следующий шаг (сборка) будет выполнен автоматически, и вы увидите только свой окончательный исполняемый файл.
Я знаю (фактически предполагаю), что для каждого типа процессора мне понадобится ассемблер, который будет интерпретировать (?) ассемблерный код и преобразовывать инструкции, специфичные для моего процессора. Где этот ассемблер (кто его поставляет)? Он идет с ОС?
Во-первых, обратите внимание, что языки ассемблера для каждого процессора различаются, поскольку предполагается, что они представляют машинный язык процессора 1:1. Затем ассемблер транслировал ассемблерный код в машинный код. Кто отправляет? Тот, кто строит. В наборе инструментов GNU он является частью пакета binutils и обычно устанавливается по умолчанию в большинстве дистрибутивов Linux. Доступен не только ассемблер. Также обратите внимание, что хотя GNU «suite» (GCC/binutils/gdb) поддерживает множество архитектур, вам необходимо использовать соответствующий порт для вашей архитектуры. Например, ассемблер по умолчанию вашего настольного ПК не может компилироваться/собираться в машинный код ARM.
Затем ассемблер транслировал ассемблерный код в машинный код. Кто отправляет? Тот, кто строит. В наборе инструментов GNU он является частью пакета binutils и обычно устанавливается по умолчанию в большинстве дистрибутивов Linux. Доступен не только ассемблер. Также обратите внимание, что хотя GNU «suite» (GCC/binutils/gdb) поддерживает множество архитектур, вам необходимо использовать соответствующий порт для вашей архитектуры. Например, ассемблер по умолчанию вашего настольного ПК не может компилироваться/собираться в машинный код ARM.
Почему именно я не вижу 0 и 1, если я открываю двоичный файл в текстовом редакторе?
Потому что текстовый редактор должен отображать текстовое представление этих 0 и 1. Предполагая, что каждый символ в файле занимает 8 бит, они интерпретируют каждые последующие 8 бит как один символ, вместо того, чтобы показывать отдельные биты. Если вы знаете, что в стандартном 8-битном ASCII буква «A» представлена значением 65, вы также можете преобразовать это обратно в двоичное: 01000001.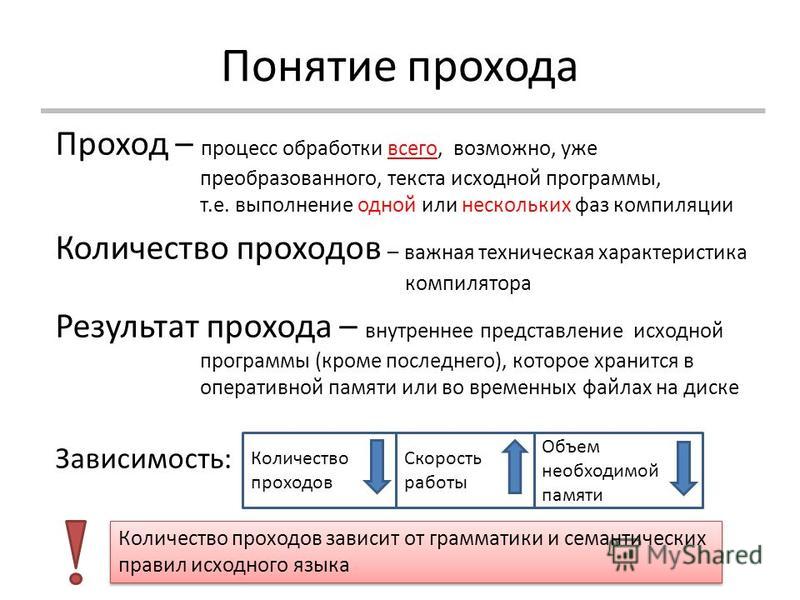 Немного проще преобразовать шестнадцатеричное представление обратно в двоичное. Для этого вы можете использовать hexdump (или аналогичный) инструмент.
Немного проще преобразовать шестнадцатеричное представление обратно в двоичное. Для этого вы можете использовать hexdump (или аналогичный) инструмент.
person dbrank0 schedule 20.11.2014
arrow_upward
9
arrow_downward
Много бывает 🙂
Вот некоторые из ключевых шагов (кстати, это то, как я думаю о компиляции, следующие шаги имеют только мимолетное сходство с шагами, определенными в стандарте).
Препроцессор работает с исходным файлом.
Препроцессор делает за нас все, что угодно, в том числе:
- It performs tri-glyph (special three character sequences that represented some of the special symbols that early keyboards didn’t have) replacement.
- Он выполняет замену макросов (например,
#define) простой текстовой заменой. - Он захватывает любые заголовочные файлы и копирует все их содержимое туда, где была строка
#include.
В Linux программа, которая делает это, называется
m4, и с помощьюgccвы можете остановиться после этого шага, используя флаг-E.После запуска препроцессора у нас есть файл, содержащий всю информацию, необходимую для запуска парсера, проверки нашего синтаксиса и создания ассемблера. Под Linux это, скорее всего, делает программа
cc1, а при использованииgccвы можете остановиться после этого шага, используя флаг-s.Сборка преобразуется в объектный код, скорее всего, программой
gas(GNU Assembler), а при использованииgccможно остановиться на этом шаге, установив флаг-c.Наконец, один или несколько объектных файлов вместе с библиотеками преобразуются исполняемым файлом в компоновщик.
Компоновщик под Linux обычно ld, и с использованиемgccбез каких-либо специальных флагов выполняется весь этот путь.

 Компоновщик под Linux обычно
Компоновщик под Linux обычно person thurizas schedule 20.11.2014
arrow_upward
6
arrow_downward
Поскольку вы специально упомянули: «К концу дня мне нужно преобразовать мой код C в язык, который должен понимать именно мой процессор», я немного объясню, как работают компиляторы.
Типичные компиляторы делают несколько вещей.
Во-первых, они делают то, что называется лексированием. На этом шаге отдельные символы объединяются в «токены», которые понимает следующий шаг. На этом шаге проводится различие между ключевыми словами языка (такими как «for» и «if» в C), операторами (такими как «+»), константами (такими как целые числа и строковые литералы) и другими вещами. Что именно он различает, зависит от самого языка.
Что именно он различает, зависит от самого языка.
Следующим шагом является синтаксический анализатор, который берет поток токенов, созданный лексером, и (обычно) преобразует его в нечто, называемое «Абстрактное синтаксическое дерево» или AST. AST представляет собой вычисления, выполняемые программой, со структурами данных, по которым может перемещаться компилятор. Обычно AST не зависит от языка, и такие компиляторы, как GCC, могут анализировать разные языки в общий формат AST, который может понять следующий шаг (генератор кода).
Наконец, генератор кода проходит через AST и выводит код, который представляет семантику AST, то есть код, который фактически выполняет вычисления, которые представляет AST.
В случае GCC и, возможно, других компиляторов компилятор фактически не создает машинный код. Вместо этого он выводит ассемблерный код, который передается ассемблеру. Ассемблер проходит аналогичный процесс лексирования, синтаксического анализа и генерации кода, чтобы фактически создать машинный код. В конце концов, ассемблер — это просто компилятор, который компилирует ассемблерный код.
В конце концов, ассемблер — это просто компилятор, который компилирует ассемблерный код.
В случае C (и многих других) ассемблер обычно не является последним шагом. Ассемблер создает вещи, называемые объектными файлами, которые содержат неразрешенные ссылки на функции в других объектных файлах или библиотеках (например, printf в стандартной библиотеке C или функции из других файлов C в вашем проекте). Эти объектные файлы передаются так называемому «компоновщику», чья работа заключается в объединении всех объектных файлов в один двоичный файл и разрешении всех неразрешенных ссылок в объектных файлах.
Наконец, после всех этих шагов у вас есть полный исполняемый двоичный файл.
Обратите внимание, что именно так работают GCC и многие другие компиляторы, но это не обязательно так. Любая программа, которую вы могли бы написать, которая точно принимает поток кода C и выводит поток какого-либо другого эквивалентного кода (ассемблера, машинного кода, даже javascript), является компилятором.
Кроме того, шаги не всегда полностью разделены. Вместо того, чтобы лексировать и весь файл, затем анализировать весь результат, а затем генерировать код для всего AST, компилятор может немного лексировать, затем начать синтаксический анализ, когда у него есть несколько токенов, а затем вернуться к лексическому анализу, когда синтаксическому анализатору нужно больше токенов. . Когда синтаксический анализатор чувствует, что знает достаточно, он может выполнить генерацию кода, прежде чем лексер создаст для него еще несколько токенов.
person jack_rabbit schedule 20.11.2014
arrow_upward
1
arrow_downward
К концу дня мне нужно преобразовать мой код C в язык, который должен понимать именно мой ЦП. Итак, кого волнует знание моих конкретных инструкций для процессора? Операционная система?
Процессор.
Но учтите, что на современном компьютере кажущийся единственным ЦП — всего лишь иллюзия.
Тем не менее, это достаточно хорошая концептуальная модель для простого программирования на C.
Преобразует ли gcc какой-либо язык C в язык ассемблера?
Если вы об этом попросите. Вариант -S создаст список сборки. Для ПК вы можете выбирать между синтаксисом AT&T, уродливым как грех, приправленным знаками процента, и обычным синтаксисом Intel. К сожалению, AT&T (выбирается через -masm=att IIRC) используется по умолчанию, но вы можете использовать -masm=intel для получения обычной сборки.
Если вы не попросите его произвести сборку, то gcc предположительно генерирует объектный код непосредственно из своего внутреннего абстрактного синтаксического дерева (AST).
Создание языка ассемблера в качестве промежуточной формы просто добавило бы сложности и неэффективности, поэтому я очень сомневаюсь, что это так.
Я знаю (фактически предполагаю), что для каждого типа процессора мне понадобится ассемблер, который будет интерпретировать (?) ассемблерный код и преобразовывать инструкции, специфичные для моего процессора. Где этот ассемблер (кто его поставляет)? Он идет с ОС?
Вам не нужен такой ассемблер. Но gcc поставляется с ассемблером as. Unix-подобные ОС обычно имеют в комплекте gcc и as, в то время как Windows не имеет в комплекте инструментов разработчика. Однако инструменты разработки Microsoft теперь можно загрузить бесплатно (примерно на прошлой неделе), включая полную среду разработки Visual Studio. Ассемблер Microsoft называется ml.exe и известен как MASM, Macro Assembler (как будто других ассемблеров макросов не существует).
Почему я не вижу 0 и 1 при открытии двоичного файла в текстовом редакторе?
Это зависит от текстового редактора, хотя я не знаю ни одного, который может отображать 0 и 1; текстовые редакторы предназначены для интерпретации байтов как текста.
Вы можете просто написать такой текстовый редактор, если хотите.
Справедливое предупреждение: я не могу придумать практического применения.
Наконец, что касается вопроса в заголовке,
Каковы основные этапы компиляции?
На практике есть два основных шага: компиляция и связывание. Этап компиляции далее подразделяется на предварительную обработку и компиляцию основного языка, т. е.
связывание компиляции
действительно
(предварительная обработка компиляции основного языка) связывание
Во время предварительной обработки файлы исходного кода объединяются с помощью директив #include. Это создает полную единицу перевода исходного кода. Компиляция основного языка переводит это в файл объектного кода, который содержит машинный код с некоторыми неразрешенными ссылками.
Затем, наконец, на этапе связывания файлы объектного кода объединяются (включая содержимое файлов объектного кода в библиотеках) для создания единого полного исполняемого файла.
person Cheers and hth. — Alf schedule 20.11.2014
Что такое компилятор c
Процесс компиляции программ на C++
В данной статье я хочу рассказать о том, как происходит компиляция программ, написанных на языке C++, и описать каждый этап компиляции. Я не преследую цель рассказать обо всем подробно в деталях, а только дать общее видение. Также данная статья — это необходимое введение перед следующей статьей про статические и динамические библиотеки, так как процесс компиляции крайне важен для понимания перед дальнейшим повествованием о библиотеках.
Все действия будут производиться на Ubuntu версии 16.04.
Используя компилятор g++ версии:
Состав компилятора g++
- cpp — препроцессор
- as — ассемблер
- g++ — сам компилятор
- ld — линкер
Мы не будем вызывать данные компоненты напрямую, так как для того, чтобы работать с C++ кодом, требуются дополнительные библиотеки, позволив все необходимые подгрузки делать основному компоненту компилятора — g++.
Зачем нужно компилировать исходные файлы?
Исходный C++ файл — это всего лишь код, но его невозможно запустить как программу или использовать как библиотеку. Поэтому каждый исходный файл требуется скомпилировать в исполняемый файл, динамическую или статическую библиотеки (данные библиотеки будут рассмотрены в следующей статье).
Этапы компиляции:
Перед тем, как приступать, давайте создадим исходный .cpp файл, с которым и будем работать в дальнейшем.
driver.cpp:
1) Препроцессинг
Самая первая стадия компиляции программы.
Препроцессор — это макро процессор, который преобразовывает вашу программу для дальнейшего компилирования. На данной стадии происходит происходит работа с препроцессорными директивами. Например, препроцессор добавляет хэдеры в код (#include), убирает комментирования, заменяет макросы (#define) их значениями, выбирает нужные куски кода в соответствии с условиями #if, #ifdef и #ifndef.
Хэдеры, включенные в программу с помощью директивы #include, рекурсивно проходят стадию препроцессинга и включаются в выпускаемый файл. Однако, каждый хэдер может быть открыт во время препроцессинга несколько раз, поэтому, обычно, используются специальные препроцессорные директивы, предохраняющие от циклической зависимости.
Получим препроцессированный код в выходной файл driver.ii (прошедшие через стадию препроцессинга C++ файлы имеют расширение .ii), используя флаг -E, который сообщает компилятору, что компилировать (об этом далее) файл не нужно, а только провести его препроцессинг:
Взглянув на тело функции main в новом сгенерированном файле, можно заметить, что макрос RETURN был заменен:
В новом сгенерированном файле также можно увидеть огромное количество новых строк, это различные библиотеки и хэдер iostream.
2) Компиляция
На данном шаге g++ выполняет свою главную задачу — компилирует, то есть преобразует полученный на прошлом шаге код без директив в ассемблерный код. Это промежуточный шаг между высокоуровневым языком и машинным (бинарным) кодом.
Это промежуточный шаг между высокоуровневым языком и машинным (бинарным) кодом.
Ассемблерный код — это доступное для понимания человеком представление машинного кода.
Используя флаг -S, который сообщает компилятору остановиться после стадии компиляции, получим ассемблерный код в выходном файле driver.s:
Мы можем все также посмотреть и прочесть полученный результат. Но для того, чтобы машина поняла наш код, требуется преобразовать его в машинный код, который мы и получим на следующем шаге.
3) Ассемблирование
Так как x86 процессоры исполняют команды на бинарном коде, необходимо перевести ассемблерный код в машинный с помощью ассемблера.
Ассемблер преобразовывает ассемблерный код в машинный код, сохраняя его в объектном файле.
Объектный файл — это созданный ассемблером промежуточный файл, хранящий кусок машинного кода. Этот кусок машинного кода, который еще не был связан вместе с другими кусками машинного кода в конечную выполняемую программу, называется объектным кодом.
Далее возможно сохранение данного объектного кода в статические библиотеки для того, чтобы не компилировать данный код снова.
Получим машинный код с помощью ассемблера (as) в выходной объектный файл driver.o:
Но на данном шаге еще ничего не закончено, ведь объектных файлов может быть много и нужно их всех соединить в единый исполняемый файл с помощью компоновщика (линкера). Поэтому мы переходим к следующей стадии.
4) Компоновка
Компоновщик (линкер) связывает все объектные файлы и статические библиотеки в единый исполняемый файл, который мы и сможем запустить в дальнейшем. Для того, чтобы понять как происходит связка, следует рассказать о таблице символов.
Таблица символов — это структура данных, создаваемая самим компилятором и хранящаяся в самих объектных файлах. Таблица символов хранит имена переменных, функций, классов, объектов и т.д., где каждому идентификатору (символу) соотносится его тип, область видимости. Также таблица символов хранит адреса ссылок на данные и процедуры в других объектных файлах.
Также таблица символов хранит адреса ссылок на данные и процедуры в других объектных файлах.
Именно с помощью таблицы символов и хранящихся в них ссылок линкер будет способен в дальнейшем построить связи между данными среди множества других объектных файлов и создать единый исполняемый файл из них.
Получим исполняемый файл driver:
5) Загрузка
Последний этап, который предстоит пройти нашей программе — вызвать загрузчик для загрузки нашей программы в память. На данной стадии также возможна подгрузка динамических библиотек.
Запустим нашу программу:
Заключение
В данной статье были рассмотрены основы процесса компиляции, понимание которых будет довольно полезно каждому начинающему программисту. В скором времени будет опубликована вторая статья про статические и динамические библиотеки.
Подбираем бесплатный компилятор для C / C++
C — это простой процедурный язык программирования общего назначения. Он достаточно прост в освоении. В то же время он мощный, чтобы его можно было использовать для создания любой компьютерной программы.
В то же время он мощный, чтобы его можно было использовать для создания любой компьютерной программы.
C++ — это объектно-ориентированный язык программирования, который изначально был создан как надмножество C . Языки C и C++ являются одними из самых популярных технологий, используемых для написания программ.
Эта статья призвана помочь вам выбрать бесплатный компилятор для C / C++ для различных операционных систем.
Open Watcom V2 Fork
Он может работать и создавать исполняемые файлы под Windows ( 16-разрядные, 32-разрядные и 64-разрядные версии ), Linux ( 32-разрядные и 64-разрядные версии ), OS / 2 и MS-DOS ( 16-разрядные и 32-разрядные режимы ). Стоит пояснить, что Watcom — это был известный коммерческий компилятор, пока первоначальные разработчики не прекратили его продажи и не опубликовали исходный код ( в соответствии с публичной лицензией Sybase Open Watcom ).
Microsoft Visual Studio Community
Для индивидуальных или начинающих программистов Microsoft Visual Studio Community включает в себя много важных инструментов из коммерческих версий проекта. Вы получите в свое распоряжение IDE , отладчик, оптимизирующий компилятор, редактор, средства отладки и профилирования. С помощью этого пакета можно разрабатывать программы для настольных и мобильных версий Windows , а также Android . Компилятор C++ поддерживает большинство функций ISO C++ 11 , некоторые из ISO C++ 14 и C++ 17 . В то же время компилятор C уже безнадежно устарел и не имеет даже надлежащей поддержки C99 .
Вы получите в свое распоряжение IDE , отладчик, оптимизирующий компилятор, редактор, средства отладки и профилирования. С помощью этого пакета можно разрабатывать программы для настольных и мобильных версий Windows , а также Android . Компилятор C++ поддерживает большинство функций ISO C++ 11 , некоторые из ISO C++ 14 и C++ 17 . В то же время компилятор C уже безнадежно устарел и не имеет даже надлежащей поддержки C99 .
Программное обеспечение также поставляется с поддержкой построения программ на C# , Visual Basic , F# и Python . В то время, когда я писал эту статью, на сайте проекта утверждалось, что Visual Studio Community 2015 « бесплатный инструмент для индивидуальных разработчиков, проектов с открытым исходным кодом, научных исследований, образовательных проектов и небольших профессиональных групп ».
Clang: Фронтенд языка программирования C для LLVM
Clang — компилятор C , C++ , Objective C и Objective C++ , разработанный под Apple . Это часть проекта LLVM . Clang реализует различные стандарты ISO C и C++ , такие как C11 , ISO C++ 11 , C++ 14 и частично C++ 1z .
Он также поддерживает расширения, которые можно найти в семействе компиляторов C GNU . Компилятор C для Windows выпущен под лицензией BSD . К сожалению, на момент написания этой статьи, он предоставляется только в исходной форме, и вам придется собирать его самостоятельно.
MinGW-w64
Проект MinGW-w64 предоставляет библиотеки, заголовки, необходимые компиляторам C и C++ GNU для работы в системе Windows . В случае MinGW-w64 эти файлы поддержки позволяют создавать 64-битные программы в дополнение к 32-битным . Проект также предоставляет кросс-компиляторы, так что можно скомпилировать программу Windows из системы Linux .
AMD x86 Open64 Compiler Suite
Это версия набора компиляторов Open64 ( описанного ниже ), которая была настроена для процессоров AMD и имеет дополнительные исправления ошибок. Компилятор C / C++ соответствует стандартам ANSI C99 и ISO C++ 98 , поддерживает межъязыковые вызовы ( так как он включает в себя компилятор Fortran ), 32-битный и 64-битный код x86 , векторную и скалярную генерацию кода SSE / SSE2 / SSE3, OpenMP 2. 5 для моделей с разделяемой памятью, MPICh3 для моделей с распределенной и разделяемой памятью; содержит оптимизатор, поддерживающий огромное количество оптимизаций ( глобальную, цикл-узел, межпроцедурный анализ, обратную связь ) и многое другое. Набор поставляется с оптимизированной AMD Core Math Library и документацией. Для этого набора компиляторов требуется Linux .
5 для моделей с разделяемой памятью, MPICh3 для моделей с распределенной и разделяемой памятью; содержит оптимизатор, поддерживающий огромное количество оптимизаций ( глобальную, цикл-узел, межпроцедурный анализ, обратную связь ) и многое другое. Набор поставляется с оптимизированной AMD Core Math Library и документацией. Для этого набора компиляторов требуется Linux .
Компилятор C/C++ Open Source Watcom / Open Watcom
Является бесплатным компилятором для Windows 7 с открытым исходным кодом. Он генерирует код для Win32 , Windows 3.1 (Win16) , OS / 2 , Netware NLM , MSDOS ( 16-битный и 32-битный режим ) и т. д. Watcom был очень популярным компилятором несколько лет назад до тех пор, пока Sybase не закрыла его. Он также включает в себя довольно известный STLport ( реализация библиотеки стандартных шаблонов C++ ). Обновление: этот проект, похоже, застопорился, и в настоящее время запущен новый проект Open Watcom V2 Fork ( описан выше ).
Компилятор Digital Mars C/C++ (замена Symantec C++)
Digital Mars C / C ++ является заменой Symantec C++ с поддержкой компиляции программ для Win32 , Windows 3. 1 , MSDOS и 32-разрядных расширенных MSDOS . Если используемый ПК не имеет процессора с плавающей запятой ( машины pre-Pentium ), можно связать эмуляцию с плавающей запятой в вашей программе. Компилятор поддерживает определение C++ из аннотированного руководства по C++ ( ARM ) и расширенные функции языка AT & T версии 3.0 , включая шаблоны, вложенные классы, вложенные типы, обработку исключений и идентификацию типа во время выполнения.
1 , MSDOS и 32-разрядных расширенных MSDOS . Если используемый ПК не имеет процессора с плавающей запятой ( машины pre-Pentium ), можно связать эмуляцию с плавающей запятой в вашей программе. Компилятор поддерживает определение C++ из аннотированного руководства по C++ ( ARM ) и расширенные функции языка AT & T версии 3.0 , включая шаблоны, вложенные классы, вложенные типы, обработку исключений и идентификацию типа во время выполнения.
UPS Debugger (интерпретатор C)
Это графический отладчик уровня исходного кода для X Window , который содержит встроенный интерпретатор языка C . Он может обрабатывать один или несколько исходных файлов. Можно использовать его для создания исполняемого файла с байтовым кодом и выполнения интерпретатора в этом исполняемом файле. Если вам нужен интерпретатор для отладки или создания прототипов программ, или просто для изучения языка, попробуйте этот инструмент. Он поддерживает следующие платформы: Solaris , SunOS , Linux , FreeBSD , BSD / OS и некоторые другие Unix-платформы .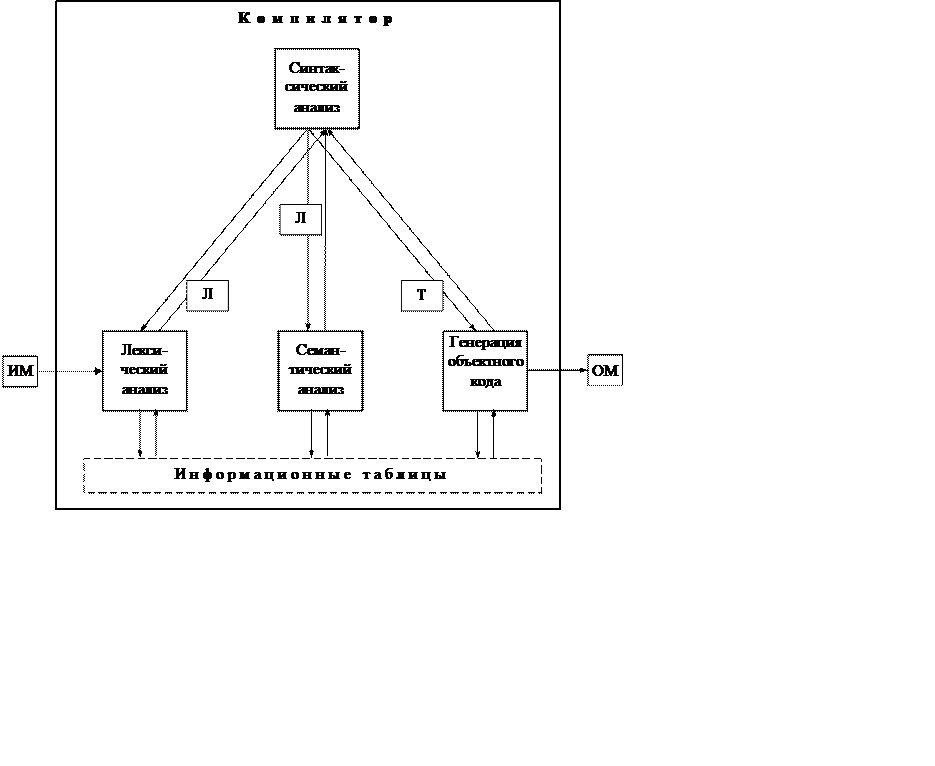
The BDS C Compiler
Помните старый ( популярный ) компилятор C BDS для систем CP / M 8080 / Z80 ? В настоящее время этот компилятор языка C находится в публичном доступе, в комплекте с исходным кодом языка ассемблера. Пакет представляет собой розничную версию компилятора с компоновщиком и руководством пользователя. Его можно использовать для простой генерации кода 8080/8085 / Z80 для встраиваемых систем ( то есть создавать собственные процедуры для замены любого кода библиотеки, который обращается к функциям операционной системы ).
Компилятор C / C++ Bloodshed Dev
Это интегрированная среда разработки Win32 , включающая в себя компилятор C++ egcs и отладчик GNU из среды Mingw32 . А также редактор и другие средства, облегчающие разработку программ с использованием компилятора Mingw32 gcc на платформе Windows . Он также содержит программу установки для приложений.
Компилятор C Orange
Он работает как в Windows , так и в DOS , имеет интегрированную среду разработки с редактором программ ( с подсветкой синтаксиса и автоматическим завершением кода ). Он может генерировать программы для Win32 и MSDOS , а также файлы Intel и Motorola hex ( что полезно, если вы пишете программы для встроенных систем ). Для вывода MSDOS ваши программы будут использовать расширитель DOS .
Он может генерировать программы для Win32 и MSDOS , а также файлы Intel и Motorola hex ( что полезно, если вы пишете программы для встроенных систем ). Для вывода MSDOS ваши программы будут использовать расширитель DOS .
DeSmet C
DeSmet C должен быть знаком тем, кто программировал на C в 1980-х годах. Это компилятор C для MSDOS . Он был выпущен под лицензией GNU GPL и поставляется с руководствами, редактором и сторонним оптимизатором.
Apple Xcode для Mac OS X
Xcode — это интегрированная среда разработки Apple , которая включает в себя редактор с подсветкой синтаксиса, систему управления сборкой, отладчик, компилятор C GNU ( gcc ), конструктор интерфейса, AppleScript Studio , поддержку разработки на Java , инструменты разработки WebObjects . Чтобы получить в свое распоряжение данные инструменты необходимо быть участником Apple Developer Connection ( ADC ) . Но онлайн-членство является бесплатным.
Tiny C Compiler — самый компактный Linux C компилятор
Этот небольшой компилятор C для Linux и Windows генерирует оптимизированные двоичные файлы x86 . Утверждается, что он собирает, компонует и связывает код в несколько раз быстрее, чем GCC . В настоящий момент разработчики стремятся обеспечить соответствие ISO C99 . Компилятор также включает необязательную проверку границ. Он обрабатывает файлы скриптов C ( просто добавьте в Linux shebang код #!/usr/local/bin/tcc -run в первую строку исходного кода на C , чтобы он выполнялся напрямую ). TCC распространяется под лицензией GNU General Public License .
Утверждается, что он собирает, компонует и связывает код в несколько раз быстрее, чем GCC . В настоящий момент разработчики стремятся обеспечить соответствие ISO C99 . Компилятор также включает необязательную проверку границ. Он обрабатывает файлы скриптов C ( просто добавьте в Linux shebang код #!/usr/local/bin/tcc -run в первую строку исходного кода на C , чтобы он выполнялся напрямую ). TCC распространяется под лицензией GNU General Public License .
Portable Object Compiler
Это набор библиотек классов и компилятор Objective C , который преобразует код Objective C в простой C-код . Работает на Windows , Linux , OS / 2 , Macintosh и т. д.
C & C++ компиляторы Mingw32
Эта система поставляется с компилятором GNU C / C++ , который можно использовать для создания исполняемых файлов Win32 . Она содержит собственный <windows.h>, который находится в открытом доступе. Предполагается, что приложения, созданные с использованием этой системы, будут быстрее, чем, те которые созданы с помощью Cygwin32 , и они не ограничиваются положениями лицензии GNU . Mingw32 поставляется с инструментами для обработки текста ( sed, grep ), генератором лексического анализатора ( flex ), генератором парсеров ( bison ) и т. д. Mingw32 также поставляется с компилятором ресурсов Windows .
Mingw32 поставляется с инструментами для обработки текста ( sed, grep ), генератором лексического анализатора ( flex ), генератором парсеров ( bison ) и т. д. Mingw32 также поставляется с компилятором ресурсов Windows .
Компилятор C / C++ GNU
На странице компилятора C GNU можно получить ссылки на бинарные файлы и исходный код для компилятора GNU C . Также можно использовать приведенные в этой статье ссылки на наиболее часто запрашиваемые бинарные версии ( MSDOS и Win32 ).
Компилятор C Pelles
Еще один компилятор C , основанный на LCC ( смотрите также LCC-Win32 ). Он включает в себя компилятор C , компоновщик, компилятор ресурсов, сообщений, утилиту make и другие инструменты. Он компилирует код для Windows и Pocket PC .
Компилятор C Compaq
Пользователи Linux / Alpha теперь могут бесплатно скачивать и использовать компилятор Compaq , просто заполнив форму и приняв лицензионное соглашение. Компилятор может использоваться для генерации любых программ, коммерческих или иных. Он включает в себя математическую библиотеку и отладчик ( ladebug ), перенесенный из True64 Unix . Он поставляется с обычными справочными страницами, а также справочником по языку и руководством программиста.
Он включает в себя математическую библиотеку и отладчик ( ladebug ), перенесенный из True64 Unix . Он поставляется с обычными справочными страницами, а также справочником по языку и руководством программиста.
Интерпретатор C / C++ Ch Embeddable (стандартная версия)
Интерпретатор C / C++ , поддерживающий стандарт ISO 1990 C ( C90 ), основные функции C99 , классы C++ , а также расширения к языку С , такие как вложенные функции, строковый тип и т. д. Он может быть встроен в другие приложения и аппаратные средства, использоваться в качестве языка сценариев. Код C / C++ интерпретируется напрямую без компиляции промежуточного кода. Поскольку этот интерпретатор поддерживает Linux , Windows , MacOS X , Solaris и HP-UX , созданный вами код можно перенести на любую из этих платформ. Стандартная версия бесплатна для личного, академического и коммерческого использования. Для загрузки пакета необходимо зарегистрироваться.
Компиляторы C и C++ DJGPP
Это система разработки, основанная на хорошо известном компиляторе C / C++ GNU . Она генерирует 32-разрядные исполняемые файлы MSDOS , которые являются файлами с длинными именами Windows 95 . Это очень функциональная система с IDE , графическими библиотеками, генераторами лексического анализатора ( flex ), генераторами парсеров ( bison ), утилитами обработки текста и так далее. Компилятор языка C , утилиты и библиотеки поставляются с исходным кодом.
Она генерирует 32-разрядные исполняемые файлы MSDOS , которые являются файлами с длинными именами Windows 95 . Это очень функциональная система с IDE , графическими библиотеками, генераторами лексического анализатора ( flex ), генераторами парсеров ( bison ), утилитами обработки текста и так далее. Компилятор языка C , утилиты и библиотеки поставляются с исходным кодом.
Cilk — ANSI компилятор на основе C
Cilk — это язык на основе ANSI C , который может использоваться для многопоточного параллельного программирования. Это особенно эффективно для использования динамического, высоко асинхронного параллелизма в стиле параллельных данных или передачи сообщений. На официальном сайте упоминается, что Cilk уже используется для разработки трех шахматных программ мирового класса: StarTech , Socrates и Cilkchess .
Sphinx — компилятор C—
Это своего рода сочетание компилятора C и ассемблера, который позволяет « создавать программы с возможностями и читабельностью C , сохраняя при этом эффективность языка ассемблера ». Он может создавать исполняемые файлы MSDOS или файлы .OBJ , которые можно применять вместе с другими компоновщиками для создания исполняемого файла. По приведенной выше ссылке можно найти исходный код и документацию для компилятора. Если вы хотите получить предварительно скомпилированный бинарный файл, это можно сделать на неофициальном сайте компилятора C— Sphinx .
Он может создавать исполняемые файлы MSDOS или файлы .OBJ , которые можно применять вместе с другими компоновщиками для создания исполняемого файла. По приведенной выше ссылке можно найти исходный код и документацию для компилятора. Если вы хотите получить предварительно скомпилированный бинарный файл, это можно сделать на неофициальном сайте компилятора C— Sphinx .
Компилятор C LSI C-86
Сайт этого компилятора написан на японском языке. Он выглядит как кросс-компилятор, позволяющий генерировать код для ROM . Старая версия компилятора ( 3.30c ) предоставляется бесплатно. Бесплатная версия работает только на MSDOS .
Кросс-компилятор C SDCC
Это кросс-компилятор C , предназначенный для микропроцессоров Intel 8051 , DS390, Z80, HC08 и PIC. Он также может быть переназначен для других 8-битных микроконтроллеров или ОСТО . SDCC поставляется с перенастраиваемым ассемблером и компоновщиком, отладчиком исходного уровня и симулятором. Библиотеки совместимы со стандартом C99 . Исходный код для компилятора доступен под лицензией GPL . Поддерживаются такие платформы, как Linux , Windows , Mac OS X , Alpha , Sparc и другие.
Исходный код для компилятора доступен под лицензией GPL . Поддерживаются такие платформы, как Linux , Windows , Mac OS X , Alpha , Sparc и другие.
Компилятор C LADSoft CC386
Это компилятор ANSI C для MSDOS / DPMI и Win32 , который поставляется с библиотекой среды выполнения, компоновщиком, отладчиком, DOS-расширителем ( версия MSDOS ), IDE ( версия Win32 ) и утилитой make . Также доступен исходный код. При работе в режиме совместимости с C99 он компилирует большинство конструкций C99 .
Проект Cygwin (компиляторы C и C ++)
Этот «проект» включает в себя коммерческий компилятор ( GNU C / C++ ), который генерирует графический интерфейс Win32 и консольные приложения. Предоставляется исходный код компилятора, библиотек и инструментов. Обратите внимание, что опция по умолчанию в этом пакете требует от вас распространять исходный код, если вы компилируете и связываетесь со своими библиотеками. Существует также специальная вызываемая опция, которая задает возможность связи с альтернативными библиотеками, позволяя распространять свои приложения без источников.
Компилятор C LCC-Win32
Это компилятор C для Windows , который генерирует графический интерфейс Win32 и консольные приложения. Он поставляется со своим собственным компоновщиком, IDE , отладчиком, редактором и компилятором ресурсов. LCC- Win32 основан на компиляторе LCC и является бесплатным только для некоммерческого использования.
LCC — перенанаправляемый компилятор для ANSI C
LCC — это компилятор C ( только исходный код ), который генерирует код для Alpha , Sparc , MIPS R3000 и Intel x86 . Он является основой как минимум для двух других компиляторов Win32 C ( также описанных выше ).
Cyclone C
Cyclone C не является компилятором ANSI C в строгом значении, а представляет собой компилятор « безопасного диалекта » C . Он обеспечивает безопасность типов, имеет множество проверок для защиты от переполнения буфера, связанных с массивами нарушений и т. д. В настоящее время он работает на Linux и Windows ( в последнем случае через Cygwin ), для него требуется наличие в системе инструментов компиляции GNU .
Leonardo IDE
Это IDE на базе Macintosh , компилятор и отладчик для программ на C . Он включает в себя редактор с подсветкой синтаксиса, ANSI C компилятор, компилятор для языка визуализации ALPHA , редактор графов, обратимый виртуальный процессор и т. д.
Обратите внимание, что программы в код, который будет выполняться для виртуального ЦПУ. Виртуальная машина и отладчик позволяют выполнять код вперед и назад и поддерживать многозадачность. IDE поставляется с анимированными алгоритмами, примерами исходного кода таких игр, как Tetris , Checkers и других. IDE полезна для проверки и отладки исходного кода, поиска процессов, неэффективно использующих память и т. д.
Примечание: этот проект был прекращен.
Turbo C 2.01
Старый, но проверенный Turbo C 2.01 для DOS доступен бесплатно по решению новых владельцев Borland . Это был популярный компилятор C во времена MSDOS , известный своей быстрой сборкой, интегрированной средой разработки (« IDE ») и графической библиотекой ( DOS ).
Дайте знать, что вы думаете по этой теме в комментариях. За комментарии, лайки, дизлайки, подписки, отклики огромное вам спасибо!
Что такое компилятор
В этом гайде вы узнаете о том, что такое компилятор и как он работает. Мы разберем этапы компиляции и от чего зависит выбор подходящего компилятора. Этот материал поможет лучше понять, как компьютер выполняет программный код и почему иногда код не компилируется.
Зачем нужен компилятор?
Процессор — самая важная часть компьютера. Он обрабатывает информацию, выполняет команды пользователя и следит за работой всех подключенных устройств. Но процессор может разобрать только машинный код — набор 0 и 1, которые записаны в определённом порядке.
Почему именно 0 и 1? В процессор поступают электрические сигналы. Сильный сигнал обозначается цифрой 1, а слабый — 0. Набор таких цифр обозначает какую-то команду. Процессор ее распознает и выполняет.
Программы для первых компьютеров выглядели как огромные наборы 0 и 1. Чтобы записать такую программу, инженеры пользовались гибкими картонными карточками — перфокартами. Цифры на перфокарте записывались поочередно, в несколько строк. Чтобы записать 1, программист делал отверстие в карте. Места без отверстия обозначали 0.
Чтобы записать такую программу, инженеры пользовались гибкими картонными карточками — перфокартами. Цифры на перфокарте записывались поочередно, в несколько строк. Чтобы записать 1, программист делал отверстие в карте. Места без отверстия обозначали 0.
Компьютер считывал перфокарту специальным устройством и выполнял записанную команду. Для одной программы составляли сотни перфокарт.
Писать их было долго и сложно, поэтому инженеры стали создавать языки программирования, обозначая команды словами и знаками. Для того, чтобы процессор понимал, какие команды записаны в программе, программисты создали компилятор — программу, которая преобразует программный код в машинный.
Как работает компилятор?
Преобразование программного кода в машинный называется компиляцией. Компиляция только преобразует код. Она не запускает его на исполнение. В этот момент он “статически” (то есть без запуска) транслируется в машинный код. Это сложный процесс, в котором сначала текст программы разбирается на части и анализируется, а затем генерируется код, понятный процессору.
Разберём этапы компиляции на примере вычисления периметра прямоугольника:
После запуска программы компилятору нужно определить, какие команды в ней записаны. Сначала компилятор разделяет программу на слова и знаки — токены, и записывает их в список. Такой процесс называется лексическим анализом. Его главная задача — получить токены.
Затем компилятор читает список и ищет токен-операторы. Это могут быть оператор присваивания( = ), арифметические операторы( + , — , * , / ), оператор вывода( printf() ) и другие операторы языка программирования. Такие операторы работают с числами, текстом и переменными.
Компилятор должен понять, какие токены в списке связаны с токен-оператором. Чтобы сделать это правильно, для каждого оператора строится специальная структура — логическое дерево или дерево разбора.
Так операция P = 2*(a + b) будет преобразована в логическое дерево:
Теперь каждое дерево нужно разобрать на команды, и каждую команду преобразовать в машинный код.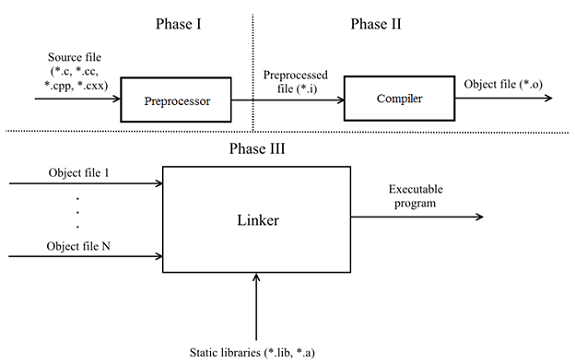 Компилятор начинает читать дерево снизу вверх и составляет список команд:
Компилятор начинает читать дерево снизу вверх и составляет список команд:
- Взять переменную a , взять переменную b , сложить их
- Взять результат сложения, взять число 2 и найти их произведение
- Результат произведения присвоить (записать) в переменную P
Компилятор еще раз проверяет команды, находит ошибки и старается улучшить код. При успешном завершении этого этапа, компилятор переводит каждую команду в набор 0 и 1. Наборы записываются в файл, который сможет прочитать и выполнить процессор.
На чем написан компилятор?
В 1950-е годы группа разработчиков IBM под руководством Джона Бэкуса разработала первый высокоуровневый язык программирования Fortran, который позволил писать программы на понятном человеку языке. Помимо языка, инженеры работали и над компилятором. Он представлял собой программу с набором исполняемых команд, которая могла компилировать другие программы на Fortran, в том числе и улучшенную версию себя.
В дальнейшем язык Fortran и его компилятор использовали, чтобы написать компиляторы для новых языков программирования. Такой подход используют программисты и в настоящее время. Писать машинный код долго и неудобно. К тому же, для современных процессоров он может отличаться. Придется писать несколько версий одного и того же компилятора для разных компьютеров. Быстрее и проще написать компилятор на существующем языке программирования. Для этого разработчики выбирают удобный язык и пишут на нем первую версию своего компилятора. Он будет более универсальным для компьютеров и легко скомпилирует улучшенную версию себя.
Такой подход используют программисты и в настоящее время. Писать машинный код долго и неудобно. К тому же, для современных процессоров он может отличаться. Придется писать несколько версий одного и того же компилятора для разных компьютеров. Быстрее и проще написать компилятор на существующем языке программирования. Для этого разработчики выбирают удобный язык и пишут на нем первую версию своего компилятора. Он будет более универсальным для компьютеров и легко скомпилирует улучшенную версию себя.
Какие бывают компиляторы?
Ни один компилируемый язык программирования не обходится без компилятора. Некоторые компиляторы работают с несколькими языками программирования. Но программист должен учитывать еще и параметры компьютера, на котором программа будет запускаться.
Дело в том, что современные процессоры отличаются друг от друга устройством, поэтому машинный код для одного процессора будет понятен, а для другого нет. Это касается и операционных систем: одна и та же программа будет работать на Windows, но не запустится на Linux или MacOS.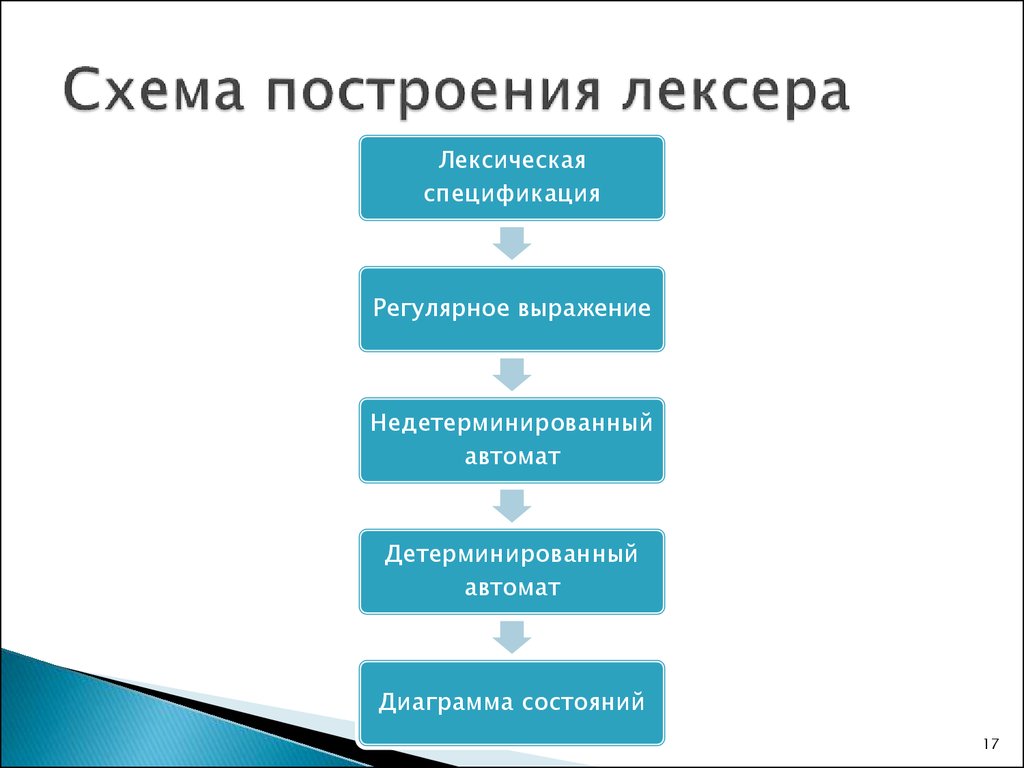 Поэтому нужно пользоваться тем компилятором, который работает с нужным процессором и операционной системой.
Поэтому нужно пользоваться тем компилятором, который работает с нужным процессором и операционной системой.
Если программа будет работать на нескольких операционных системах, то нужен кросс-компилятор — компилятор, который преобразует универсальный машинный код. Например, GNU Compiler Collection(сокращенно GCC) поддерживает C++, Objective-C, Java, Фортран, Ada, Go и поддерживает разную архитектуру процессоров.
Начинающие программисты даже не знают о наличии компилятора на компьютере. Они пишут программы в интегрированной среде разработки, в которую встроен компилятор, а иногда и не один. В этом случае, выбор компилятора делает среда, а не программист. Например, MS Visual Studio поддерживает компиляторы для операционных систем Windows, Linux, Android. Выбирая тип проекта, Visual Studio определяет процессор и операционную систему компьютера, и после этого выбирает подходящий компилятор.
Какие ошибки может определить компилятор?
Когда компилятор анализирует текст программы, он проверяет, соответствует ли запись оператора стандартам языка. Если найдено несоответствие, то компилятор выводит об этом информацию пользователю в виде ошибки. Когда вся программа разобрана, пользователь видит список ошибок, которые есть в коде, и может их исправить. Пока программист не исправит ошибки, компилятор не перейдет к следующему этапу — генерации машинного кода для процессора. Чаще всего компилятор показывает пользователю:
Если найдено несоответствие, то компилятор выводит об этом информацию пользователю в виде ошибки. Когда вся программа разобрана, пользователь видит список ошибок, которые есть в коде, и может их исправить. Пока программист не исправит ошибки, компилятор не перейдет к следующему этапу — генерации машинного кода для процессора. Чаще всего компилятор показывает пользователю:
- ошибки объявления переменных или отсутствие их начальных значений
- ошибки несоответствия типов
- ошибки неправильной записи операторов и функций
Иногда компилятор определяет код, который при выполнении дает неправильный результат. Но преобразовать такую программу в машинный код все-таки можно. В этом случае компилятор показывает пользователю предупреждение. Такая реакция компилятора больше похожа на рекомендации, но на них стоит обратить внимание. Программист сам решает оставить код с предупреждением или изменить программу. Анализируя текст программы, компилятор не только ищет ошибки, но еще и упрощает ее код.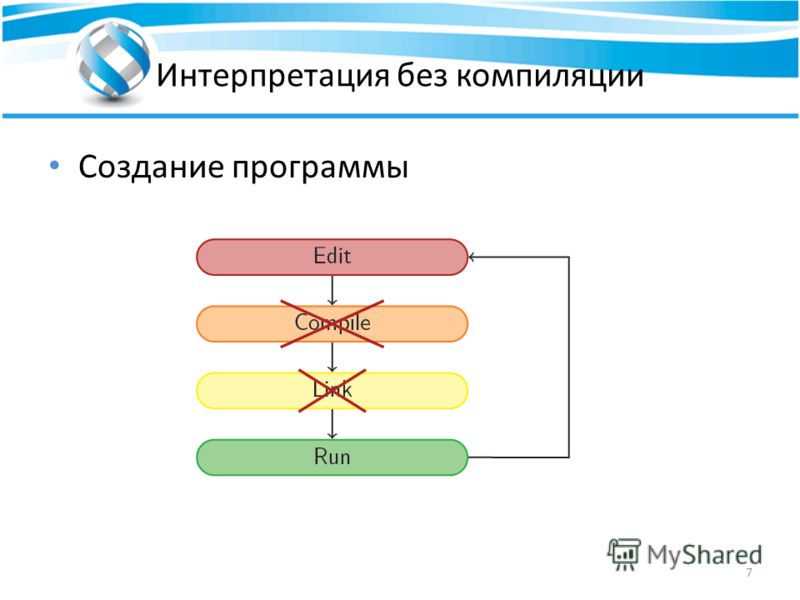 Такой процесс называется оптимизацией. Во время оптимизации компилятор изменяет программный код, но функции, которые выполняла программа, остаются прежними.
Такой процесс называется оптимизацией. Во время оптимизации компилятор изменяет программный код, но функции, которые выполняла программа, остаются прежними.
Выводы и рекомендации
Компилятор — переводчик между программистом и процессором. Он преобразует текст программы в машинный код, определяет ряд ошибок в программе и оптимизирует ее работу. Выбирая, где компилировать программу, важно помнить о том, что машинный код для процессоров и операционных систем будет разным, и подобрать правильный компилятор. Чем точнее компилятор определит команды, тем корректнее и быстрее будет работать программа. Для этого следуйте простым рекомендациям:
- использовать простые, понятные команды;
- помнить о соответствии типов данных;
- внимательно набирать код, избегая синтаксических ошибок;
- избегать повторяющихся действий и бесполезных переменных.
Частые вопросы
Чем компилятор отличается от интерпретатора?
Компилятор это программа, которая выполняет преобразование текста программы в другое представление, обычно машинный код, без его запуска, статически.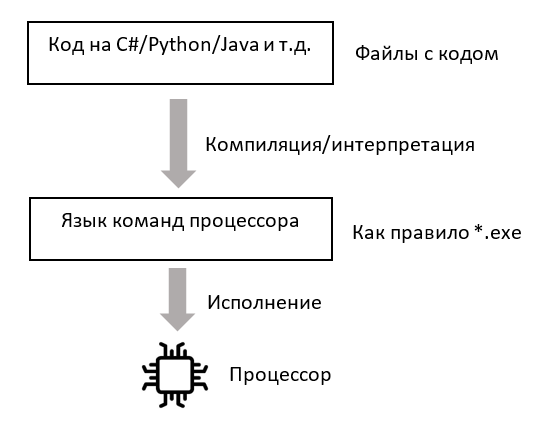 Затем эта программа уже может быть запущена на выполнение. Интерпретатор сразу запускает код и выполняет его в процессе чтения. Промежуточного этапа как в компиляции нет.
Затем эта программа уже может быть запущена на выполнение. Интерпретатор сразу запускает код и выполняет его в процессе чтения. Промежуточного этапа как в компиляции нет.
| Лекция 7. Языки и системы программирования. Структура данных. Языки программирования и их классификации. Понятие о системе программирования, ее основные функции и компоненты. Принципы работы сред программирования. «Операционные» и «модульные» среды программирования: достоинства и недостатки. Интерпретаторы и компиляторы. Трансляция программ и сопутствующие процессы. Данные и их обработка. Простые (неструктурированные типы данных). Структурированные типы данных. Язык программирования — формальная знаковая система, предназначенная для описания алгоритмов в форме, которая удобна для исполнителя (например, компьютера). Язык программирования определяет набор лексических, синтаксических и семантических правил, используемых при составлении компьютерной программы. 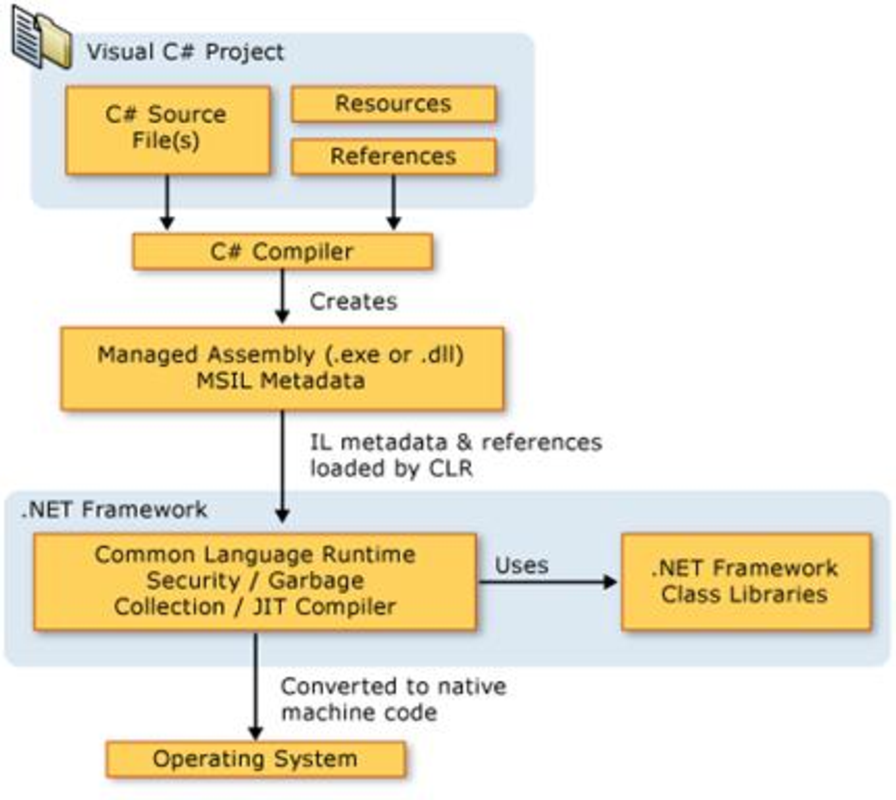 Он позволяет программисту точно определить то, на какие события будет реагировать компьютер, как будут храниться и передаваться данные, а также какие именно действия следует выполнять над этими при различных обстоятельствах. Он позволяет программисту точно определить то, на какие события будет реагировать компьютер, как будут храниться и передаваться данные, а также какие именно действия следует выполнять над этими при различных обстоятельствах.Со времени создания первых программируемых машин человечество придумало уже более двух с половиной тысяч языков программирования. Каждый год их число пополняется новыми. Некоторыми языками умеет пользоваться только небольшое число их собственных разработчиков, другие становятся известны миллионам людей. Профессиональные программисты иногда применяют в своей работе более десятка разнообразных языков программирования. Создатели языков по-разному толкуют понятие язык программирования. Среди общин мест, признаваемых большинством разработчиков, находятся следующие:
Первые языки программирования были очень примитивными и мало чем отличались от формализованных упорядоченных последовательностей единиц и нулей, понятных компьютеру. Использование таких языков было крайне неудобно с точки зрения программиста, так как он должен был знать числовые коды всех машинных команд, должен был сам распределять память под команды программы и данные. 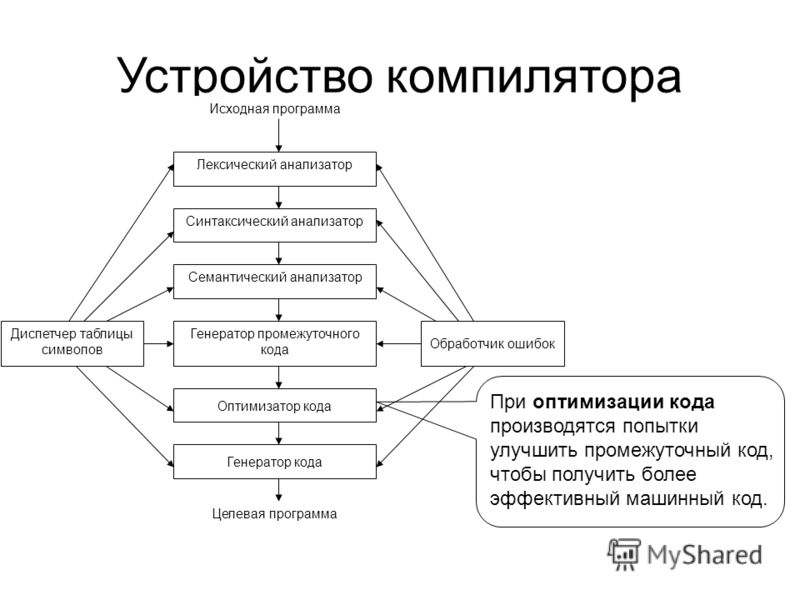 Для того, чтобы облегчить общение человека с ЭВМ были созданы языки программирования типа Ассемблер. Переменные величины стали изображаться символическими именами. Числовые коды операций заменились на мнемонические обозначения, которые легче запомнить. Язык программирования приблизился к человеческому языку, и отдалился от языка машинных команд. Языки программирования стали появляться уже с середины 50-х годов. Одним из первых языков такого типа стал язык Фортран (англ. FORTRAN от FORmula TRANslator – переводчик формул), разработанный в 1957 году. Фортран применяется для описания алгоритма решения научно-технических задач с помощью ЦВМ. Так же, как и первые вычислительные машины, этот язык предназначался, в основном, для проведения естественно-научных и математических расчётов. В усовершенствованном виде этот язык сохранился до нашего времени. Среди современных языков высокого уровня он является одним из наиболее используемых при проведении научных исследований. После Фортрана в 1958-1960 годах появился язык Алгол (Алгол-58, Алгол-60) (англ. ALGOL от ALGOrithmic Language – алгоритмический язык). Алгол был усовершенствован в 1964-1968 годах – Алгол-68. Алгол был разработан комитетом, в который входили европейские и американские учёные. Он относится к языкам высокого уровня (high-level language) и позволяет легко переводить алгебраические формулы в программные команды. Алгол был популярен в Европе, в том числе СССР, в то время как сравнимый с ним Фортран был распространен в США и Канаде. Алгол оказал заметное влияние на все разработанные позднее языки программирования, и, в частности, на язык Pascal. Этот язык так же, как и Фортран, предназначался для решения научно-технических задач. Кроме того, этот язык применялся как средство обучения основам программирования – искусства составления программ. Обычно под понятием Алгол подразумевается язык Алгол-60, в то время как Алгол-68 рассматривается как самостоятельный язык. В 1959 – 1960 годах был разработан язык Кобол (англ. COBOL от COmmom Business Oriented Language – общий язык, ориентированный на бизнес). Это язык программирования третьего поколения, предназначенный, в первую очередь, для разработки бизнес приложений. Также Кобол предназначался для решения экономических задач, обработки данных для банков, страховых компаний и других учреждений подобного рода. Разработчиком первого единого стандарта Кобола являлась Грейс Хоппер (бабушка Кобола). Кобол обычно критикуется за многословность и громоздкость, поскольку одной из целей создателей языка было максимально приблизить конструкции к английскому языку. (До сих пор Кобол считается языком программирования, на котором было написано больше всего строк кода). В то же время, Кобол имел прекрасные для своего времени средства для работы со структурами данных и файлами, что обеспечило ему долгую жизнь в бизнес приложениях, по крайней мере, в США. Почти одновременно с Коболом (1959 – 1960 гг.) в Массачусетском технологическом институте был создан язык Лисп (англ. LISP от LISt Processing – обработка списков). Лисп основан на представлении программы системой линейных списков символов, которые притом являются основной структурой данных языка. Лисп считается вторым после Фортрана старейшим высокоуровневым языком программирования. Этот язык широко используется для обработки символьной информации и применяется для создания программного обеспечения, имитирующего деятельность человеческого мозга. Любая программа на Лиспе состоит из последовательности выражений (форм). Результат работы программы состоит в вычислении этих выражений. Все выражения записываются в виде списков — одной из основных структур Лиспа, поэтому они могут легко быть созданы посредством самого языка. Это позволяет создавать программы, изменяющие другие программы или макросы, позволяющие существенно расширить возможности языка. Основной смысл Лисп-программы «жизнь» в символьном пространстве: перемещение, творчество, запоминание, создание новых миров и т. В середине 60-х годов (1963 г.) в Дартмутском колледже (США) был создан язык Бейсик (англ. BASIC от Beginner’s Allpurpose Instruction Code – всецелевой символический код инструкций для начинающих). Бейсик был спроектирован так, чтобы студенты могли писать программы, используя терминалы с разделением времени. Он создавался как решение для проблем, связанных со сложностью более старых языков. Он предназначался для более «простых» пользователей, не столько заинтересованных в скорости программ, сколько просто в возможности использовать компьютер для решения своих задач. В силу простоты языка Бейсик многие начинающие программисты начинают с него свой путь в программировании. В конце 60-х – начале 70-х годов появился язык Форт (англ. Ряд свойств, а именно интерактивность, гибкость и простота разработки делают Форт весьма привлекательным и эффективным языком в прикладных исследованиях и при создании инструментальных средств. Очевидными областями применения этого языка являются встраиваемые системы управления. Также находит применение при программировании компьютеров под управлением различных операционных систем. Появившийся в 1972 году язык Паскаль был назван так в честь великого французского математика XVII века, изобретателя первой в мире арифметической машины Блеза Паскаля. Этот язык был создан швейцарским учёным, специалистом в области информатики Никлаусом Виртом как язык для обучения методам программирования. Паскаль – это язык программирования общего назначения. Особенностями языка являются строгая типизация и наличие средств структурного (процедурного) программирования. Язык Паскаль учит не только тому, как правильно написать программу, но и тому, как правильно разработать метод решения задачи, подобрать способы представления и организации данных, используемых в задаче. С 1983 года язык Паскаль введён в учебные курсы информатики средних школ США. Для обучения младших школьников Самуэлем Пайпертом был разработан язык Лого. Он отличается простотой и богатыми возможностями. На основе языка Паскаль в конце 70-х годов был создан язык Ада, названный в честь одарённого математика Ады Лавлейс (Огасты Ады Байрон – дочери поэта Байрона). Именно она в 1843 году смогла объяснить миру возможности Аналитической машины Чарльза Бэббиджа. Ада — это структурный, модульный, объектно-ориентированный язык программирования, содержащий высокоуровневые средства программирования параллельных процессов. Синтаксис Ады унаследован от языков типа Algol или Паскаль, но расширен, а также сделан более строгим и логичным. Ада — язык со строгой типизацией, в нём исключена работа с объектами, не имеющими типов, а автоматические преобразования типов сведены к абсолютному минимуму. По утверждению Стефена Цейглера, разработка программного обеспечения на Аде в целом обходится на 60 % дешевле, а разработанная программа имеет в 9 раз меньше дефектов, чем при использовании языка Си. В настоящее время популярным среди программистов является язык Си (С – буква английского алфавита). Язык Си был разработан (на основе В) Деннисом Ритчи из Bell Laboratories и впервые был реализован в 1972 году на компьютере DEC PDP-11. Известность Си получил в качестве языка ОС UNIX. Сегодня практически все основные операционные системы были написаны на Си или С++. По прошествии двух десятилетий Си имеется в наличии на большинстве компьютеров. Он не зависит от аппаратной части. В конце 70-х годов Си превратился в то, что мы называем «традиционный Си». В 1983 году Американским комитетом национальных стандартов в области компьютеров и обработки информации был учрежден единый стандарт этого языка. Он является одним из универсальных языков программирования. В отличие от Паскаля, в нем заложены возможности непосредственного обращения к некоторым машинным командам и к определенным участкам памяти компьютера. Си широко используется как инструментальный язык для разработки операционных систем, трансляторов, баз данных и других системных и прикладных программ. Си – это язык программирования общего назначения, хорошо известный своей эффективностью, экономичностью, и переносимостью. Во многих случаях программы, написанные на Си, сравнимы по скорости с программами, написанными на языке Ассемблера. При этом они имеют лучшую наглядность и их более просто сопровождать. Си сочетает эффективность и мощность в относительно малом по размеру языке. Ещё один язык, который считается языком будущего, был создан в начале 70-х годов группой специалистов Марсельского университета. Это язык Пролог. Своё название он получил от слов «ПРОграммирование на языке ЛОГики». В последние десятилетия в программировании возник и получил существенное развитие объектно-ориентированный подход. Это метод программирования, имитирующий реальную картину мира: информация, используемая для решения задачи, представляется в виде множества взаимодействующих объектов. Каждый из объектов имеет свои свойства и способы поведения. Объектно-ориентированная идеология используется во всех современных программных продуктах, включая операционные системы. Первый объектно-ориентированный язык Simula—67 был создан как средство моделирования работы различных приборов и механизмов. Большинство современных языков программирования – объектно-ориентированные. Среди них последние версии языка Turbo—Pascal, C++, Ada и другие. В настоящее время широко используются системы визуального программирования Visual Basic, Visual C++, Delphi и другие. Существуют различные классификации языков программирования. По наиболее распространенной классификации все языки программирования делят на языки низкого, высокого и сверхвысокого уровня. В группу языков низкого уровня входят машинные языки и языки символического кодирования: (Автокод, Ассемблер). Операторы этого языка – это те же машинные команды, но записанные мнемоническими кодами, а в качестве операндов используются не конкретные адреса, а символические имена. Все языки низкого уровня ориентированы на определенный тип компьютера, т. е. являются машинно-зависимыми. Машинно-ориентированные языки – это языки, наборы операторов и изобразительные средства которых существенно зависят от особенностей ЭВМ (внутреннего языка, структуры памяти и т.д.). Следующую, существенно более многочисленную группу составляют языки программирования высокого уровня. К языкам сверхвысокого уровня можно отнести лишь Алгол-68 и APL. Повышение уровня этих языков произошло за счет введения сверхмощных операций и операторов. Алгол-68, при разработке которого сделана попытка формализовать описание языка, приведшая к появлению абстрактной и конкретной программ. Абстрактная программа создается программистом, конкретная — выводится из первой. Предполагается, что при таком подходе принципиально невозможно породить неверную синтаксически (а в идеале и семантически) конкретную программу. Язык APL относят к языкам сверхвысокого уровня за счет введения сверхмощных операций и операторов. Другая классификация делит языки на вычислительные и языки символьной обработки. К первому типу относят Фортран, Паскаль, Алгол, Бейсик, Си, ко второму типу — Лисп, Пролог, Снобол и др. В современной информатике можно выделить два основных направления развития языков программирования: процедурное и непроцедурное. Процедурное программирование возникло на заре вычислительной техники и получило широкое распространение. В процедурных языках программа явно описывает действия, которые необходимо выполнить, а результат задается только способом получения его при помощи некоторой процедуры, которая представляет собой определенную последовательность действий. Среди процедурных языков выделяют в свою очередь структурные и операционные языки. В структурных языках одним оператором записываются целые алгоритмические структуры: ветвления, циклы и т.д. В операционных языках для этого используются несколько операций. Непроцедрное (декларативное) программирование появилось в начале 70-х годов 20 века, но стремительное его развитие началось в 80-е годы, когда был разработан японский проект создания ЭВМ пятого поколения, целью которого явилась подготовка почвы для создания интеллектуальных машин. К непроцедурному программированию относятся функциональные и логические языки. В функциональных языках программа описывает вычисление некоторой функции. Обычно эта функция задается как композиция других, более простых, те в свою очередь разлагаются на еще более простые и т.д. Один из основных элементов в функциональных языках — рекурсия, то есть вычисление значения функции через значение этой же функции от других элементов. Присваивания и циклов в классических функциональных языках нет. В логических языках программа вообще не описывает действий. Можно выделить еще один класс языков программирования — объектно—ориентированные языки высокого уровня. На таких языках не описывают подробной последовательности действий для решения задачи, хотя они содержат элементы процедурного программирования. Объектно-ориентированные языки, благодаря богатому пользовательскому интерфейсу, предлагают человеку решить задачу в удобной для него форме. Примером такого языка может служить язык программирования визуального общения Object Pascal. Языки описания сценариев, такие как Perl, Python, Rexx, Tcl и языки оболочек UNIX, предполагают стиль программирования, весьма отличный от характерного для языков системного уровня. Они предназначаются не для написания приложения с нуля, а для комбинирования компонентов, набор которых создается заранее при помощи других языков. Развитие и рост популярности Internet также способствовали распространению языков описания сценариев. Так, для написания сценариев широко употребляется язык Perl, а среди разработчиков Web-страниц популярен JavaScript. жүктеу/скачать 218.5 Kb. Достарыңызбен бөлісу: |

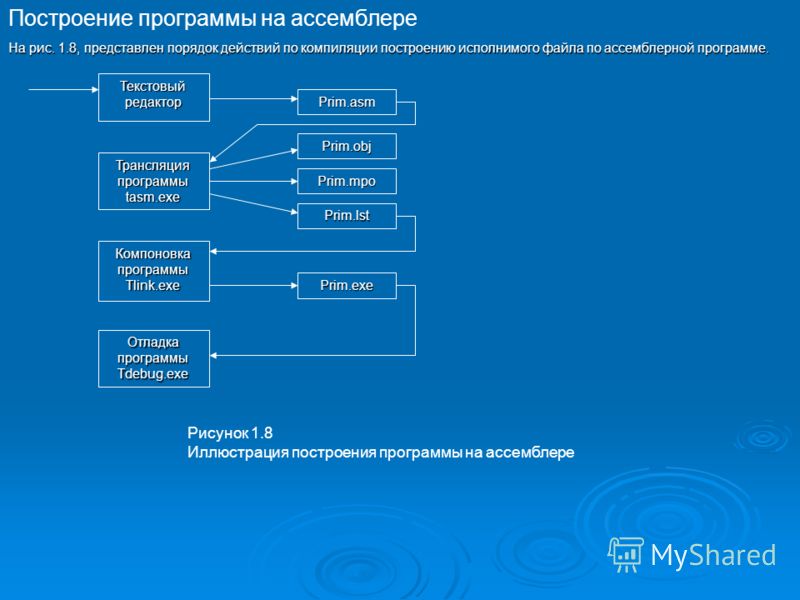 Наиболее распространены варианты Фортран-II, Фортран-IV, EASIC Fortran и их обобщения.
Наиболее распространены варианты Фортран-II, Фортран-IV, EASIC Fortran и их обобщения. Даже когда язык Алгол почти перестал использоваться для программирования, он ещё оставался официальным языком для публикации алгоритмов.
Даже когда язык Алгол почти перестал использоваться для программирования, он ещё оставался официальным языком для публикации алгоритмов.
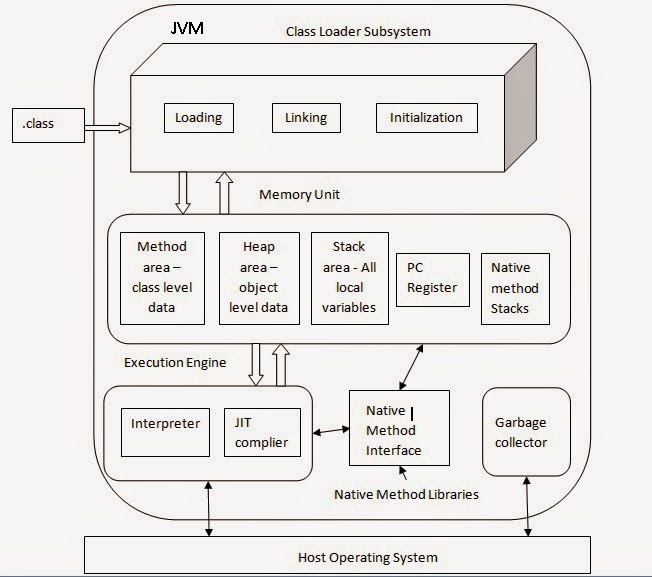 д. Лисп как метафора мозга, символ, метафора сигнала: «Как происходит биологический анализ сигналов мозгом, как внешний фактор — физическое и химическое воздействие, являющееся для организма раздражителем превращается в биологически значимый сигнал, зачастую жизненно важный, определяющий все поведение человека или животного; и как происходит разделение разных сигналов на положительные, отрицательные и безразличные, индифферентные. Сигнал это уже интегративное понятие. Он представляет собой опознавательный знак группы, комплексных раздражителей, связанных между собой общей историей и причинно следственными отношениями. В этом комплексе, системе раздражителей, сигнальный стимул сам является также составляющим элементом и при иных обстоятельствах его роль может принадлежать другому стимулу из комплекса. В сигнале концентрируется весь прошлый опыт животного или человека.»
д. Лисп как метафора мозга, символ, метафора сигнала: «Как происходит биологический анализ сигналов мозгом, как внешний фактор — физическое и химическое воздействие, являющееся для организма раздражителем превращается в биологически значимый сигнал, зачастую жизненно важный, определяющий все поведение человека или животного; и как происходит разделение разных сигналов на положительные, отрицательные и безразличные, индифферентные. Сигнал это уже интегративное понятие. Он представляет собой опознавательный знак группы, комплексных раздражителей, связанных между собой общей историей и причинно следственными отношениями. В этом комплексе, системе раздражителей, сигнальный стимул сам является также составляющим элементом и при иных обстоятельствах его роль может принадлежать другому стимулу из комплекса. В сигнале концентрируется весь прошлый опыт животного или человека.» Со временем, когда стали появляться другие диалекты, этот «изначальный» диалект стали называть Dartmouth BASIC. Язык был основан частично на Фортран II и частично на Алгол-60, с добавлениями, делающими его удобным для работы в режиме разделения времени и, позднее, обработки текста и матричной арифметики. Первоначально Бейсик был реализован на мейнфрейме GE-265 с поддержкой множества терминалов. Вопреки распространённому убеждению, в момент своего появления это был компилируемый язык.
Со временем, когда стали появляться другие диалекты, этот «изначальный» диалект стали называть Dartmouth BASIC. Язык был основан частично на Фортран II и частично на Алгол-60, с добавлениями, делающими его удобным для работы в режиме разделения времени и, позднее, обработки текста и матричной арифметики. Первоначально Бейсик был реализован на мейнфрейме GE-265 с поддержкой множества терминалов. Вопреки распространённому убеждению, в момент своего появления это был компилируемый язык.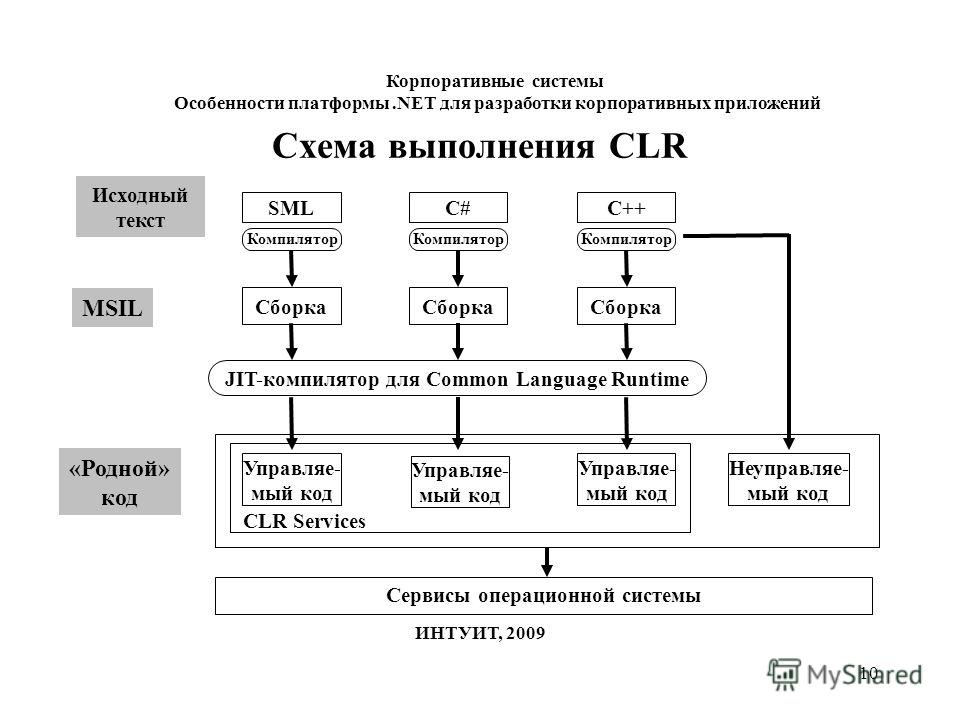 FOURTH – четвёртый). Этот язык стал применяться в задачах управления различными системами после того, как его автор Чарльз Мур написал на нём программу, предназначенную для управления радиотелескопом Аризонской обсерватории.
FOURTH – четвёртый). Этот язык стал применяться в задачах управления различными системами после того, как его автор Чарльз Мур написал на нём программу, предназначенную для управления радиотелескопом Аризонской обсерватории. Паскаль был одним из первых таких языков. По мнению Н. Вирта, язык должен способствовать дисциплинированию программирования, поэтому, наряду со строгой типизацией, в Паскале сведены к минимуму возможные синтаксические неоднозначности, а сам синтаксис интуитивно понятен даже при первом знакомстве с языком.
Паскаль был одним из первых таких языков. По мнению Н. Вирта, язык должен способствовать дисциплинированию программирования, поэтому, наряду со строгой типизацией, в Паскале сведены к минимуму возможные синтаксические неоднозначности, а сам синтаксис интуитивно понятен даже при первом знакомстве с языком.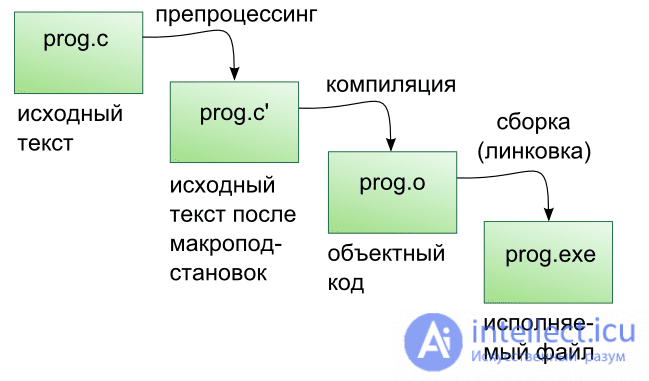 Язык Ада был разработан по заказу Министерства обороны США и первоначально предназначался для решения задач управления космическими полётами. Этот язык применяется в задачах управления бортовыми системами космических кораблей, системами обеспечения жизнедеятельности космонавтов в полёте, сложными техническими процессами.
Язык Ада был разработан по заказу Министерства обороны США и первоначально предназначался для решения задач управления космическими полётами. Этот язык применяется в задачах управления бортовыми системами космических кораблей, системами обеспечения жизнедеятельности космонавтов в полёте, сложными техническими процессами. Язык Си берёт своё начало от двух языков — BCPL и B. В 1967 году Мартин Ричардс разработал BCPL как язык для написания системного программного обеспечения и компиляторов. В 1970 году Кен Томпсон использовал В для создания ранних версий операционной системы UNIX на компьютере DEC PDP-7. Как в BCPL, так и в В переменные не разделялись на типы — каждое значение данных занимало одно слово в памяти и ответственность на различение, например, целых и действительных чисел целиком ложилась на плечи программиста.
Язык Си берёт своё начало от двух языков — BCPL и B. В 1967 году Мартин Ричардс разработал BCPL как язык для написания системного программного обеспечения и компиляторов. В 1970 году Кен Томпсон использовал В для создания ранних версий операционной системы UNIX на компьютере DEC PDP-7. Как в BCPL, так и в В переменные не разделялись на типы — каждое значение данных занимало одно слово в памяти и ответственность на различение, например, целых и действительных чисел целиком ложилась на плечи программиста.
 В основе этого языка лежат законы математической логики. Как и язык Лисп, Пролог применяется, в основном, при проведении исследований в области программной имитации деятельности мозга человека. В отличие от описанных выше языков, этот язык не является алгоритмическим. Он относится к так называемым дескриптивным (от англ. descriptive – описательный) – описательным языкам. Дескриптивный язык не требует от программиста разработки всех этапов выполнения задачи. Вместо этого, в соответствии с правилами такого языка, программист должен описать базу данных, соответствующую решаемой задаче, и набор вопросов, на которые нужно получить ответы, используя данные из этой базы.
В основе этого языка лежат законы математической логики. Как и язык Лисп, Пролог применяется, в основном, при проведении исследований в области программной имитации деятельности мозга человека. В отличие от описанных выше языков, этот язык не является алгоритмическим. Он относится к так называемым дескриптивным (от англ. descriptive – описательный) – описательным языкам. Дескриптивный язык не требует от программиста разработки всех этапов выполнения задачи. Вместо этого, в соответствии с правилами такого языка, программист должен описать базу данных, соответствующую решаемой задаче, и набор вопросов, на которые нужно получить ответы, используя данные из этой базы. Взаимодействие объектов осуществляется при помощи передачи сообщений: каждый объект может получать сообщения от других объектов, запоминать информацию и обрабатывать её определённым способом и, в свою очередь, посылать сообщения. Так же, как и в реальном мире, объекты хранят свои свойства и поведение вместе, наследуя часть из них от родительских объектов.
Взаимодействие объектов осуществляется при помощи передачи сообщений: каждый объект может получать сообщения от других объектов, запоминать информацию и обрабатывать её определённым способом и, в свою очередь, посылать сообщения. Так же, как и в реальном мире, объекты хранят свои свойства и поведение вместе, наследуя часть из них от родительских объектов.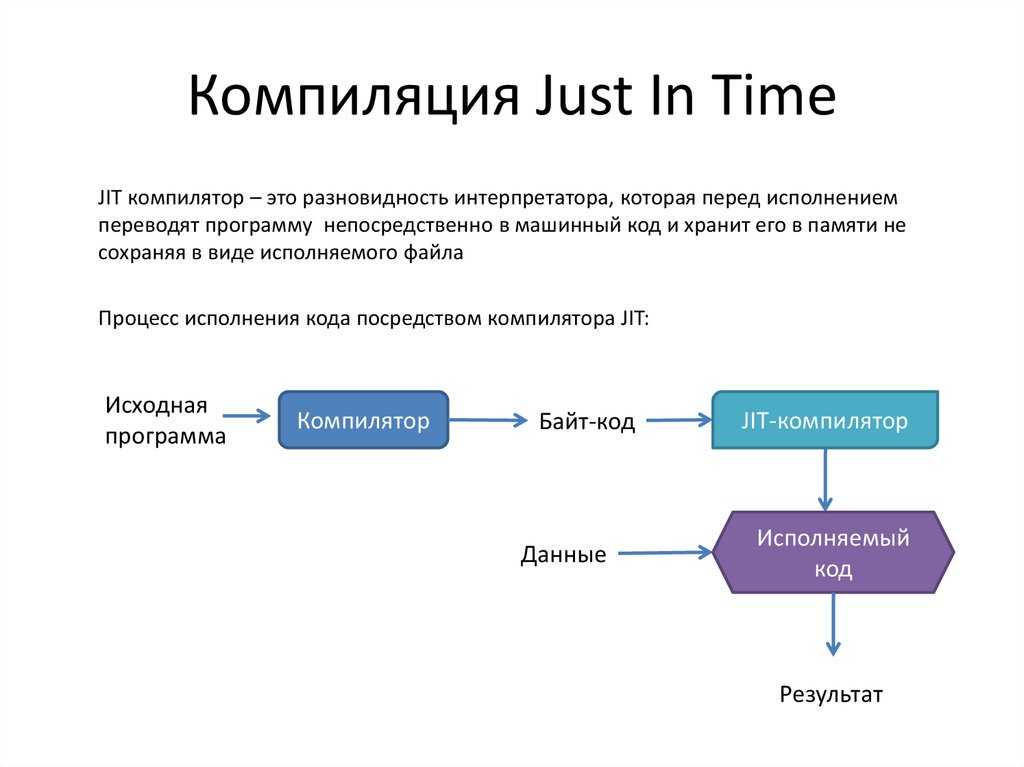 Они позволяют создавать сложные прикладные пакеты, обладающие простым и удобным пользовательским интерфейсом.
Они позволяют создавать сложные прикладные пакеты, обладающие простым и удобным пользовательским интерфейсом.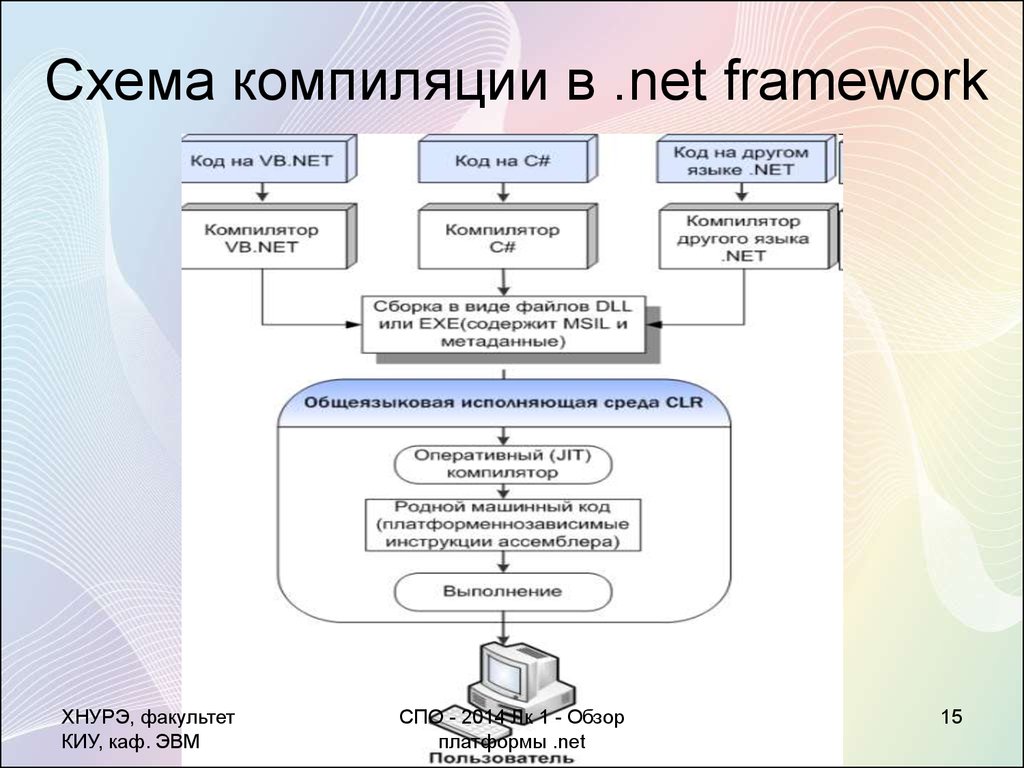 Это Фортран, Алгол, Кобол, Паскаль, Бейсик, Си, Пролог и т.д. Эти языки машинно-независимы, т.к. они ориентированы не на систему команд той или иной ЭВМ, а на систему операндов, характерных для записи определенного класса алгоритмов. Однако программы, написанные на языках высокого уровня, занимают больше памяти и медленнее выполняются, чем программы на машинных языках.
Это Фортран, Алгол, Кобол, Паскаль, Бейсик, Си, Пролог и т.д. Эти языки машинно-независимы, т.к. они ориентированы не на систему команд той или иной ЭВМ, а на систему операндов, характерных для записи определенного класса алгоритмов. Однако программы, написанные на языках высокого уровня, занимают больше памяти и медленнее выполняются, чем программы на машинных языках. Запись программ на таком языке получается компактной.
Запись программ на таком языке получается компактной. Широко распространены следующие структурные языки: Паскаль, Си, Ада, ПЛ/1. Среди операционных известны Фортран, Бейсик, Фокал.
Широко распространены следующие структурные языки: Паскаль, Си, Ада, ПЛ/1. Среди операционных известны Фортран, Бейсик, Фокал. Она задает данные и соотношения между ними. После этого системе можно задавать вопросы. Машина перебирает известные и заданные в программе данные и находит ответ на вопрос. Порядок перебора не описывается в программе, а неявно задается самим языком. Классическим языком логического программирования считается Пролог. Построение логической программы вообще не требует алгоритмического мышления, программа описывает статические отношения объектов, а динамика находится в механизме перебора и скрыта от программиста.
Она задает данные и соотношения между ними. После этого системе можно задавать вопросы. Машина перебирает известные и заданные в программе данные и находит ответ на вопрос. Порядок перебора не описывается в программе, а неявно задается самим языком. Классическим языком логического программирования считается Пролог. Построение логической программы вообще не требует алгоритмического мышления, программа описывает статические отношения объектов, а динамика находится в механизме перебора и скрыта от программиста.
Четыре этапа компиляции программы на языке C
Процесс компиляции программы на языке C Процесс компиляции исходного кода на языке C представляет собой многоэтапный процесс, включающий предварительную обработку, компиляцию кода, сборку, связывание библиотек и т. д.
д.
Процесс преобразования исходного кода, написанного на любом языке программирования — обычно языке среднего или высокого уровня — в язык машинного уровня, понятный компьютеру, называется компиляцией. Программное обеспечение, используемое для этого преобразования, известно как компилятор.
В процессе сборки компилятор проверяет исходный код на наличие синтаксических или структурных ошибок и, если все в порядке, создает объект кода.
В этой статье мы проследим за этапами процесса компиляции и узнаем, как в языке C посредством компиляции исходный код языка C преобразуется в объектный код — машинный код или двоичный код.
Конвейер компиляции программы C
Обычно файлы процесса сборки программы C занимают несколько секунд, но в течение этого короткого времени исходный код C входит в конвейер, и множество различных компонентов выполняют свою задачу.
Прежде чем продолжить, мы должны знать два правила:
Правило компиляции программ на C
- Компилируются только исходные файлы.
- Каждый файл компилируется отдельно.
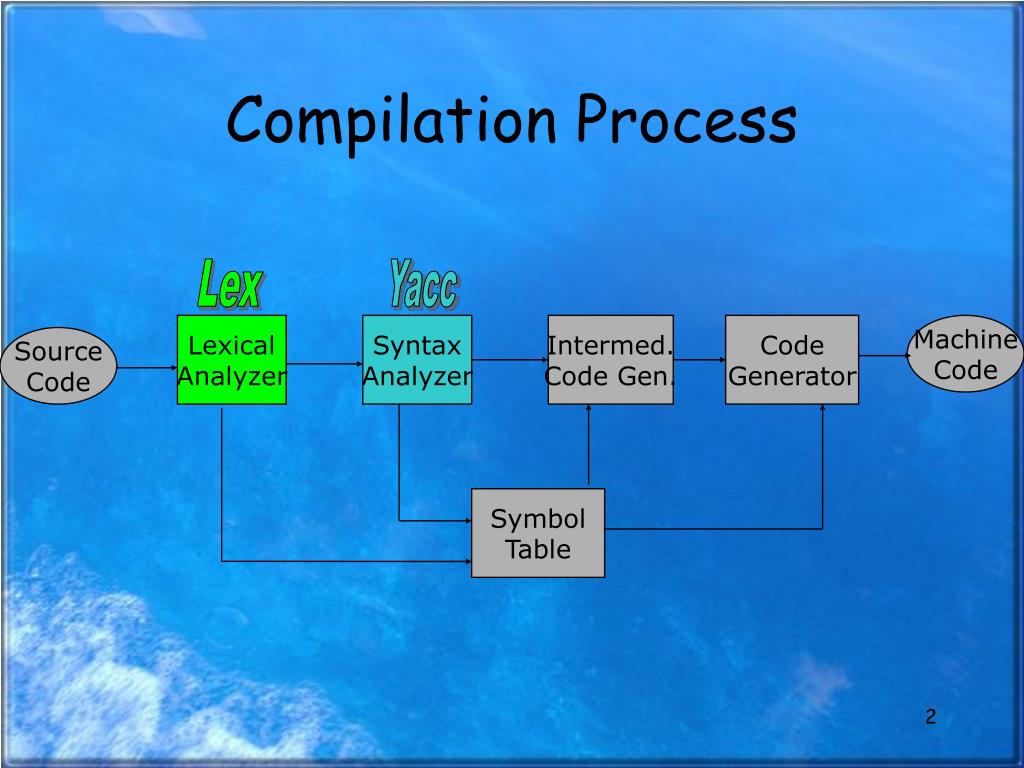
Компоненты строки компиляции программы C:
- Препроцессор.
- Компиляция
- Сборка
- Компоновщик
Каждый компонент в конвейере сборки принимает определенные входные данные от предыдущего компонента и создает определенный вывод для следующего компонента в конвейере сборки программы C.
Этот процесс продолжается до тех пор, пока последний компонент конвейера сборки не сгенерирует требуемый выходной файл, то есть двоичный файл. Одна вещь, которую нужно знать о конвейере сборки, заключается в том, что он будет генерировать выходные данные только тогда и только тогда, когда исходный файл успешно проходит через все компоненты в конвейере сборки. Даже небольшой сбой в любом из компонентов может привести к сбою компиляции или компоновки и вызвать сообщение об ошибке
1. Предварительная обработка
Предварительная обработка — это первый шаг в конвейере компиляции программы C.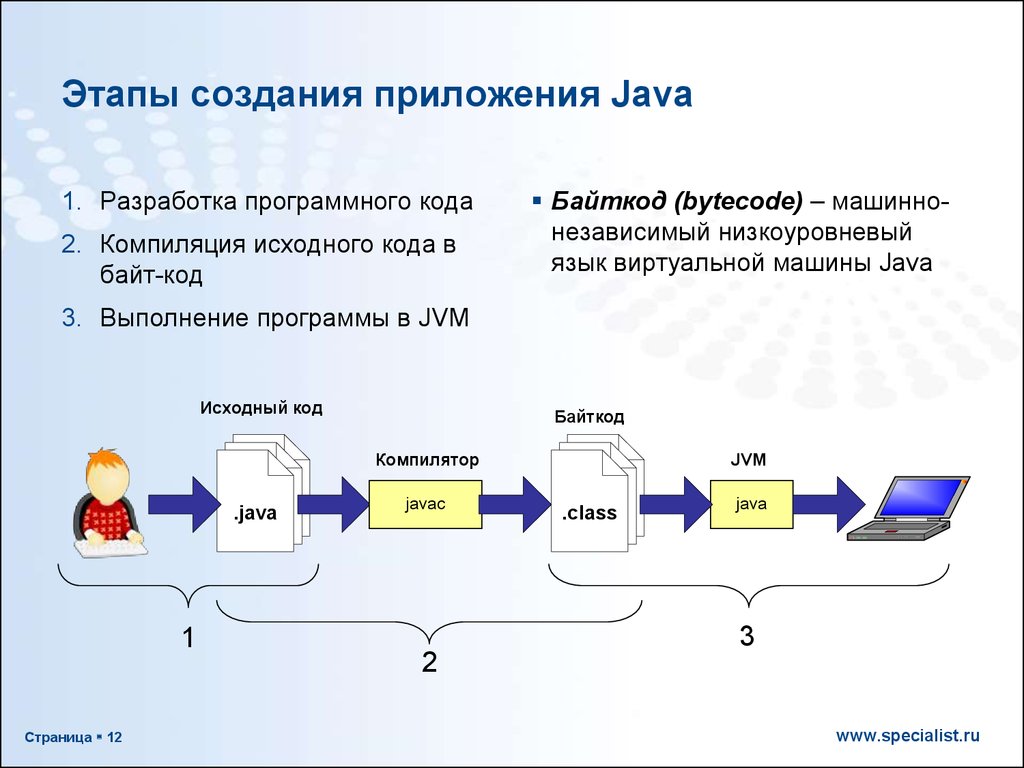 При написании программы на C мы подключаем библиотеки, определяем некоторые макросы и иногда даже выполняем условную компиляцию. Все они известны как директивы препроцессора.
При написании программы на C мы подключаем библиотеки, определяем некоторые макросы и иногда даже выполняем условную компиляцию. Все они известны как директивы препроцессора.
На этапе предварительной обработки в конвейере сборки программы C директивы предварительной обработки заменяются их исходными значениями.
2. Компиляция
На этапе сборки мы получаем ассемблерный код, уникальный для целевой архитектуры.
На этом этапе компилятор выполняет действие, беря предварительно обработанный файл, который проверяет синтаксические или структурные ошибки — в случае ошибок процесс компиляции останавливается и отображает соответствующие ошибки. После компиляции генерирует промежуточный код на языке ассемблера –file.s–.
Генерация ассемблерного кода из кода C — один из наиболее важных шагов в конвейере компиляции программы C, поскольку ассемблерный код — это язык низкого уровня, который можно преобразовать в объектный файл с помощью ассемблера.
3.
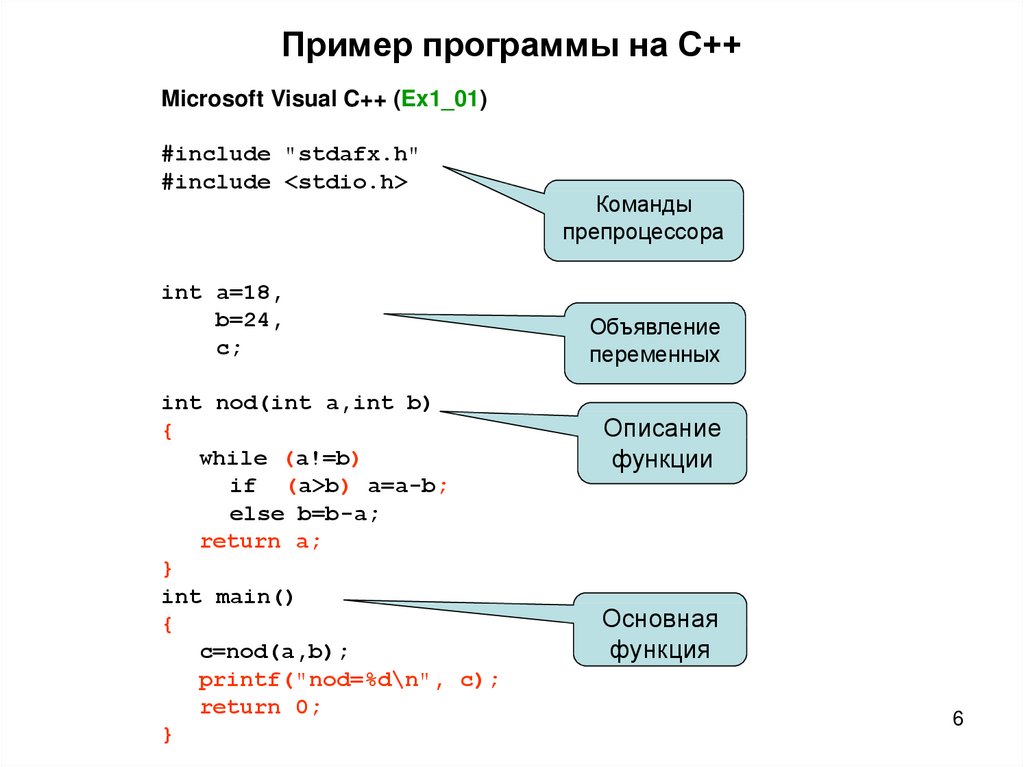 Сборка
СборкаТретий этап сборки. На этом этапе ассемблер используется для перевода ассемблерных инструкций в объектный код.
Ассемблер принимает скомпилированный исходный код на языке ассемблера и переводит его в низкоуровневый машинный код. Каждый файл имеет свой объектный файл. После успешной сборки он генерирует файл целевого кода –file.o–.
Объектный файл содержит «перемещаемый» машинный код, который не может выполняться напрямую, поскольку еще не сопоставлен с каким-либо конкретным адресом в памяти. Здесь важную роль играет компоновщик, который объединяет все объекты, разрешает ссылки между модулями и корректирует адреса.
4. Ссылка
Линкер выполняет две важные задачи: разрешение и перемещение символов. Объектный код, сгенерированный на этапе сборки, состоит из машинных инструкций, понятных процессору, но некоторые части программы вышли из строя или отсутствуют. Чтобы создать исполняемую программу, существующие части должны быть переставлены, а недостающие части должны быть завершены. Этот процесс называется склеиванием.
Этот процесс называется склеиванием.
Компоновщик организует части объектного кода таким образом, чтобы функции в одних частях могли успешно вызывать функции в других. Вы также добавите части, содержащие инструкции для библиотечных функций, используемых программой. В случае «Привет, мир!» программа, компоновщик добавит объектный код для функции puts.
Результатом этого этапа является исполняемый файл. Имя исполняемого файла совпадает с именем исходного файла, но отличается только расширением. в DOS исполняемый файл имеет расширение «.exe», а в UNIX исполняемый файл может называться «a.out». Например; если мы используем функцию printf() в программе, то компоновщик добавляет соответствующий код в выходной файл.
Компиляторы GNU (GCC)GCC — это набор компиляторов, созданных проектом GNU. Этот инструмент преобразует исходный код различных языков программирования на основе C, таких как C++ или Objective C, в машинный код.
gcc <файл.
 c>
c>
Это базовый состав команды gcc, она берет исходный файл и выполняет процесс сборки от предварительной обработки до связывания, возвращает исполняемый файл.
gcc -E <файл.c>
С опцией -E компилятор берет исходный файл и выполняет только предварительную обработку — первый шаг процесса — он не компилирует, не ассемблирует и не компонует и возвращает расширенный файл.gcc
-S <архив.с>
С опцией -S компилятор берет исходный файл и выполняет первые два шага — предварительную обработку и компиляцию — без сборки или компоновки и возвращает файл на языке ассемблера.
gcc -c <файл.c>
С опцией -c компилятор берет исходный файл и выполняет первые шаги дерева — предобработку, компиляцию и сборку — не компонует и возвращает файл в объектном коде.
Дополнительные сведения о команде gcc и ее параметрах см. на странице gcc man .
Это объяснение процесса компиляции, выполняемого на языке C перед запуском программы.
шагов компиляции
Этапы компиляцииИсполняемый файл получается путем перевода и компоновки как показано на рисунке 7.1.
Для начала предварительная обработка заменяет определенные фрагменты текста другим текстом в соответствии с система макросы. Далее компиляция переводит исходную программу в сборку. инструкции, которые затем преобразованы в машинные инструкции. Наконец, процесс связывания устанавливает подключение к операционной системе для примитивов. Это включает в себя добавление среды выполнения библиотека, которая в основном состоит из подпрограмм управления памятью.
Исходная программа предварительная обработка Исходная программа составление Программа сборки сборка Машинные инструкции соединение Исполняемый код Рисунок 7.
 1: Этапы создания исполняемого файла.
1: Этапы создания исполняемого файла.Компиляторы Objective CAML
Этапы генерации кода компилятора Objective CAML подробно показаны на рис. 7.2. Внутреннее представление сгенерированного кода компилятором называется промежуточным языком (ИЛ).Этап лексического анализа преобразует последовательность символов в последовательность лексический элементы. Эти лексические единицы в основном соответствуют целым числам с плавающей запятой. числа, символов, строк символов и идентификаторов. Сообщение Незаконно персонаж может быть сгенерированы этим анализом.
Последовательность символов лексический анализ Последовательность лексических элементов разбор Синтаксическое дерево семантический анализ Аннотированное синтаксическое дерево генерация промежуточного кода Последовательность IL оптимизация промежуточного кода Последовательность IL генерация псевдокода Программа сборки Рисунок 7.
 2: Этапы компиляции.
2: Этапы компиляции. Этап синтаксического анализа строит синтаксическое дерево и проверяет,
последовательность лексических
элементы правильны по отношению к грамматике языка. Сообщение Синтаксическая ошибка указывает на то, что анализируемая фраза не соответствует грамматике
язык.
Этап семантического анализа просматривает синтаксическое дерево, проверяя другой
аспект корректности программы. Анализ состоит в основном из типа
вывод, который в случае успеха дает самый общий тип выражения или объявления. Сообщения об ошибках типа могут появляться во время
эта фаза. На этом этапе также определяется, есть ли какие-либо члены последовательности
не относятся к типу блок . Могут появиться другие предупреждения, в том числе
анализ сопоставления с образцом (например, сопоставление с образцом не является исчерпывающим,
часть сопоставления с образцом не будет использоваться).
Могут появиться другие предупреждения, в том числе
анализ сопоставления с образцом (например, сопоставление с образцом не является исчерпывающим,
часть сопоставления с образцом не будет использоваться).
Генерация и оптимизация промежуточного кода не производит ошибки или предупреждающие сообщения.
Последним шагом в процессе компиляции является генерация программы двоичный. Детали отличаются от компилятора к компилятору.
Описание компилятора байт-кода
Виртуальная машина Objective CAML называется Цинк ( «Цинк не является каучуком» ). Первоначально созданный Xavier Leroy, Zinc описан в ([ Ler90 ]). Цинк Имя было выбрано для указать его отличие от первой реализации Caml на виртуальной машине CAM (Категориальная абстрактная машина, см. [ CCM87 ]). Рисунок 7.3 изображает
компилятор байт-кода. Первая часть этого рисунка показывает
Машинный интерпретатор Zinc, связанный с библиотекой времени выполнения. Вторая часть соответствует
Объективный компилятор байт-кода CAML
который производит инструкции для машины Zinc. Третья часть содержит
набор
библиотеки, поставляемые с компилятором. Они будут описаны в главе 8.
Вторая часть соответствует
Объективный компилятор байт-кода CAML
который производит инструкции для машины Zinc. Третья часть содержит
набор
библиотеки, поставляемые с компилятором. Они будут описаны в главе 8.
Для описания компонентов на рис. 7.3 используется стандартная графическая нотация компилятора. Простая коробка представляет собой файл написан на языке, указанном в поле. Двойной прямоугольник представляет собой интерпретация язык программой, написанной на другом языке. Тройной квадрат указывает что источник язык компилируется в машинный язык с помощью компилятора, написанного в третьем язык. На рис. 7.4 приведены легенды каждого поля.Рисунок 7.3: Виртуальная машина.
Обозначение рисунка 7.3 следующее:Рисунок 7.4: Графическая нотация для интерпретаторов и компиляторов.
- BC : байт-код цинка;
- C: код C;
- .o : код объекта
- : микропроцессор;
- OC (v1 или v2): Объективный код CAML.

Примечание
Большая часть компилятора Objective CAML написана на языке Objective CAML. вторая часть На рис. 7.3 показано, как перейти от версии v1 компилятора к версия v2.
Скомпилируйте и запустите первую программу на C (Пошаговое руководство)
Чтобы скомпилировать и запустить программу на языке C, вам понадобится компилятор C. Компилятор — это программное обеспечение, которое используется для компиляции и выполнения программ. Есть два способа установить компилятор языка C на вашем компьютере/ноутбуке:
Загрузите полноценную IDE, такую как Turbo C++, Microsoft Visual C++ или DevC++, которая поставляется вместе с компилятором языка C.
Или вы можете использовать любой текстовый редактор для редактирования файлов программы и скачать компилятор C отдельно, а затем запустить программу C с помощью командной строки.
Если вы еще не установили IDE для языка C — следуйте этому пошаговому руководству для Установка Turbo C++ для языка C
Использование IDE — Turbo C
Мы рекомендуем вам использовать Turbo C или Turbo C++ IDE, которая является старейшей IDE для программирования на C. Он находится в свободном доступе в Интернете и подходит для начинающих.
Он находится в свободном доступе в Интернете и подходит для начинающих.
Шаг 1: Откройте Turbo C IDE (интегрированная среда разработки), нажмите Файл и затем нажмите New
Шаг 2: Напишите программу Hello World, которую мы создали в предыдущей статье — Программа Hello World на C.
Шаг 3: Щелкните меню Compile , а затем пункт Compile или нажмите клавиши Alt + F9 , чтобы скомпилировать код.
Шаг 4: Нажмите Запустите или нажмите Ctrl + F9 , чтобы запустить код. Да, программы C сначала компилируются для генерации объектного кода, а затем этот объектный код запускается.
Шаг 5: Результат здесь.
Запуск программы на C без использования какой-либо IDE
Если вы не хотите настраивать IDE и предпочитаете старый способ, загрузите компилятор C под названием gcc с веб-сайта GCC https:/ /gcc.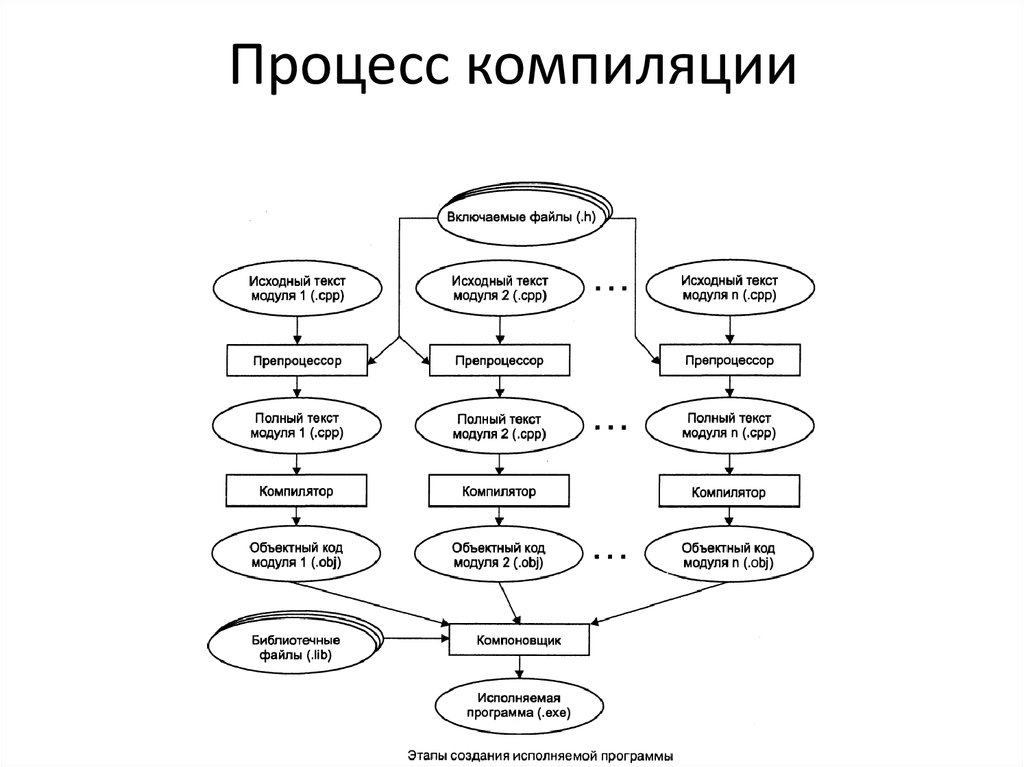 gnu.org/install/
gnu.org/install/
После того, как вы загрузили и установили компилятор gcc , все, что вам нужно сделать, это открыть любой текстовый редактор , скопировать и вставить код программы C для C Hello World Program и сохранить его под именем helloworld .c , как и любой другой файл, который вы сохраняете с именем.
Теперь откройте командную строку или терминал (если вы используете Ubuntu или Mac OS) и перейдите в каталог, в котором вы сохранили программный файл helloworld.c .
Введите команду gcc hello.c для компиляции кода. Это скомпилирует код, и если ошибок нет, он создаст выходной файл с именем a.out (имя по умолчанию)
Теперь, чтобы запустить программу, введите ./a.out , и вы на экране появится Hello, World .
$ gcc hello.c $ ./a.out
Hello, World
Разница между компиляцией и запуском в C?
Вы, должно быть, думаете, почему это двухэтапный процесс: сначала мы компилируем код, а затем запускаем его. Мы сделали то же самое с Turbo C, и то же самое с командной строкой или Терминалом.
Мы сделали то же самое с Turbo C, и то же самое с командной строкой или Терминалом.
Ну, компиляция — это процесс, в котором компилятор проверяет правильность синтаксиса программы и отсутствие ошибок в синтаксисе, и, если код в порядке, преобразует исходный код на языке C в машинно-понятный код объекта.
Когда мы запускаем скомпилированную программу , запускается только уже скомпилированный код.
Эта разница очевидна, когда мы запускаем программу на языке C с помощью командной строки. Когда вы компилируете код, 9Создается файл 0003 .out , который затем запускается для выполнения программы.
После создания файла .out и внесения изменений в вашу программу в файле исходного кода вам придется снова скомпилировать код , в противном случае файл .out будет иметь старый исходный код и продолжит работу самой старой программы.
Часто задаваемые вопросы (FAQ)
1. Что вы понимаете под процессом компиляции?
Это процесс, при котором компилятор проверяет, является ли программа синтаксически правильной или нет. Если в синтаксисе обнаружена какая-либо ошибка, она выдаст ошибки. Ошибка, возникающая во время компиляции, называется Ошибка времени компиляции .
2. Назовите ключи, используемые в Turbo C для компиляции кода.
ALT + F9 используется в Turbo C для компиляции кода.
3. Как выполняется программа на C?
Во время компиляции и выполнения программы C компилятор генерирует выходные файлы с тем же именем, что и у Файл программы C , но с другими расширениями. Файл с расширением .c называется исходным файлом, в котором хранится код программы . Теперь, когда мы компилируем файл, то компилятор C ищет ошибки.
4. Где я могу написать и запустить программу C?
Вы можете использовать IDE для написания и запуска программы C, выполнив следующие действия:
Шаг 1: Откройте Turbo C IDE (интегрированная среда разработки), нажмите Файл , а затем нажмите Новый .
Шаг 2: Напишите код программы на C.
Шаг 3: Щелкните Compile или нажмите Alt + F9 , чтобы скомпилировать код.
Шаг 4: Нажмите Запустите или нажмите Ctrl + F9 , чтобы запустить код.
Шаг 5: И turbo C откроет консоль, чтобы показать вам вывод программы.
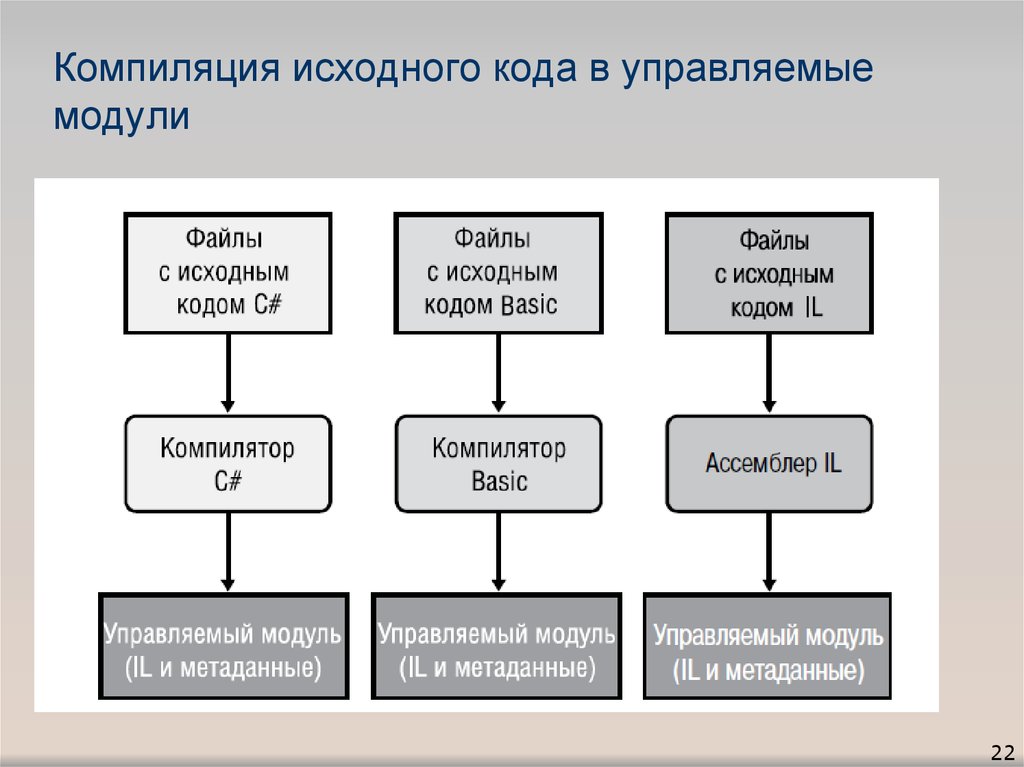
Заключение
Это руководство посвящено тому, как запускать и компилировать любую программу на языке C, используя имя IDE Turbo C. Мы также рассмотрели, как это можно сделать без использования какой-либо IDE.
- ← Назад
- Далее →
Фазы компилятора с примером: процесс и шаги компиляции
Автор John Smith
ЧасовОбновлено
Каковы этапы разработки компилятора?
Компилятор работает в различных фазах, каждая фаза преобразует исходную программу из одного представления в другое.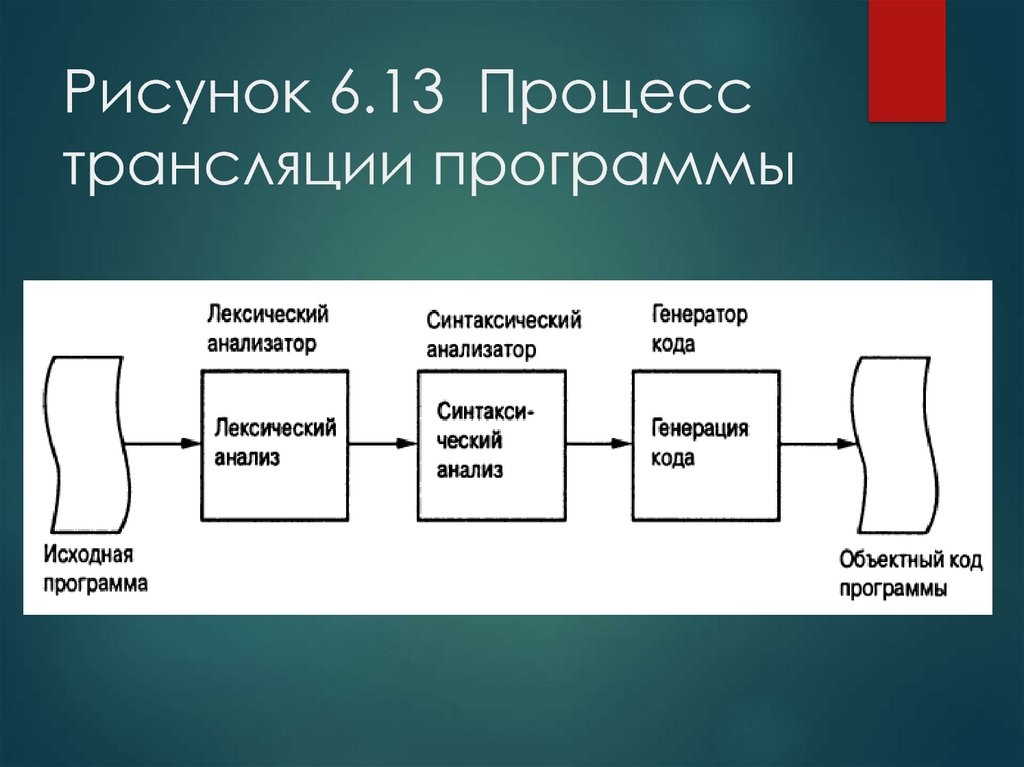 Каждая фаза берет входные данные с предыдущей стадии и передает свои выходные данные на следующую фазу компилятора.
Каждая фаза берет входные данные с предыдущей стадии и передает свои выходные данные на следующую фазу компилятора.
В компиляторе 6 фаз. Каждый из этих этапов помогает преобразовать язык высокого уровня в машинный код. Фазы компилятора:
- Лексический анализ
- Синтаксический анализ
- Семантический анализ
- Генератор промежуточного кода
- Оптимизатор кода
- Генератор кодов
Все эти этапы преобразовывают исходный код путем разделения на токены, создания деревьев синтаксического анализа и оптимизации исходного кода на разных этапах.
В этом уроке вы узнаете:
- Какие этапы разработки компилятора?
- Фаза 1: Лексический анализ
- Фаза 2: анализ синтаксиса
- Фаза 3: Семантический анализ
- Фаза 4: Генерация промежуточного кода
- Этап 5: Оптимизация кода
- Фаза 6: Генерация кода
- Управление таблицей символов
- Процедура обработки ошибок:
Фаза 1: Лексический анализ
Лексический анализ — это первая фаза, когда компилятор сканирует исходный код. Этот процесс можно выполнять слева направо, символ за символом, и группировать эти символы в токены.
Этот процесс можно выполнять слева направо, символ за символом, и группировать эти символы в токены.
Здесь поток символов из исходной программы сгруппирован в осмысленные последовательности путем идентификации токенов. Он вносит соответствующие билеты в таблицу символов и передает этот токен на следующую фазу.
Основные функции этой фазы:
- Идентификация лексических единиц в исходном коде
- Классифицировать лексические единицы по классам, таким как константы, зарезервированные слова, и вносить их в разные таблицы. Он будет игнорировать комментарии в исходной программе
- Идентифицировать токен, который не является частью языка
Пример :
x = y + 10
Жетоны
| X | идентификатор |
| = | Оператор присваивания |
| Д | идентификатор |
| + | Оператор сложения |
| 10 | Номер |
Этап 2: Анализ синтаксиса
Анализ синтаксиса заключается в обнаружении структуры кода.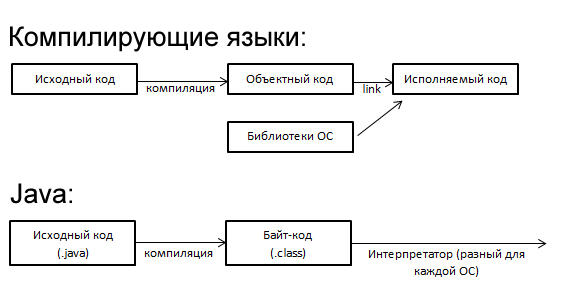 Он определяет, соответствует ли текст ожидаемому формату. Основная цель этого этапа — убедиться, что исходный код был написан программистом правильно или нет.
Он определяет, соответствует ли текст ожидаемому формату. Основная цель этого этапа — убедиться, что исходный код был написан программистом правильно или нет.
Анализ синтаксиса основан на правилах, основанных на конкретном языке программирования, путем построения дерева синтаксического анализа с помощью токенов. Он также определяет структуру исходного языка и грамматику или синтаксис языка.
Вот список задач, выполняемых на этом этапе:
- Получить токены из лексического анализатора
- Проверяет, является ли выражение синтаксически правильным или нет
- Сообщить обо всех синтаксических ошибках
- Построить иерархическую структуру, известную как дерево синтаксического анализа
Пример
Любой идентификатор/число является выражением
Если x является идентификатором, а y+10 является выражением, то x= y+10 является оператором.
Рассмотрим дерево синтаксического анализа для следующего примера
(a+b)*c
В дереве разбора
- Внутренний узел: запись с оператором filed и два файла для детей
- Leaf: записи с 2 и более полями; один для токена и другая информация о токене
- Убедитесь, что компоненты программы осмысленно сочетаются друг с другом
- Собирает информацию о типе и проверяет совместимость типов
- Проверяет, разрешены ли операнды исходным языком
Фаза 3: семантический анализ
Семантический анализ проверяет семантическую согласованность кода.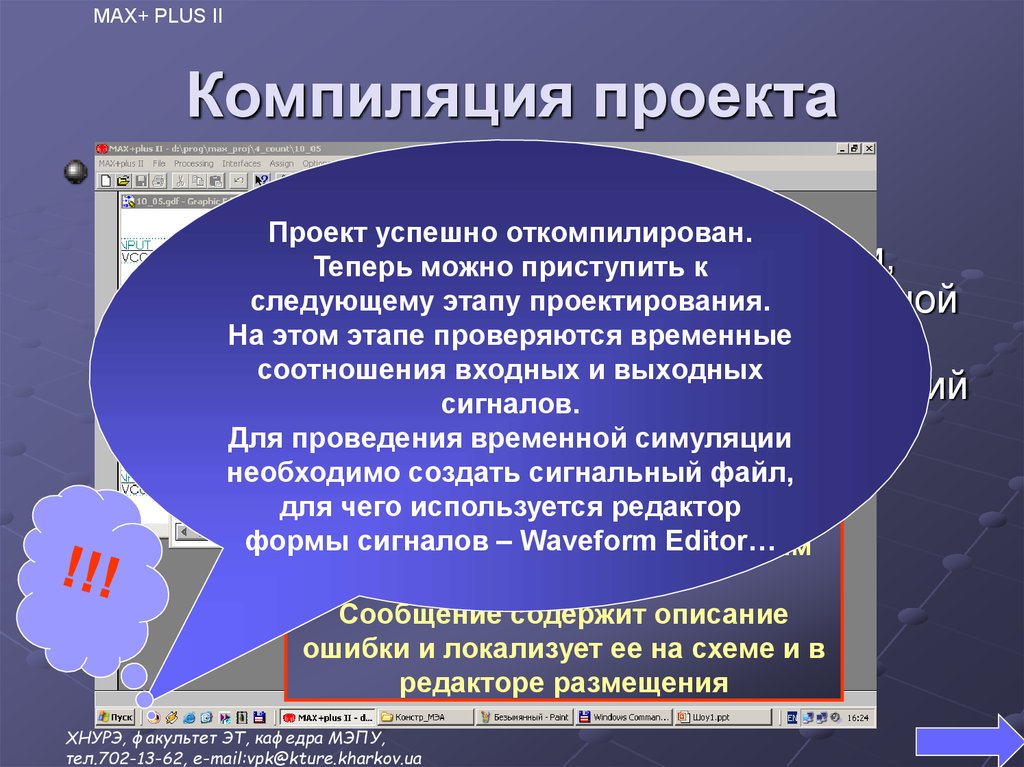 Он использует синтаксическое дерево предыдущей фазы вместе с таблицей символов, чтобы убедиться, что данный исходный код семантически непротиворечив. Он также проверяет, передает ли код соответствующее значение.
Он использует синтаксическое дерево предыдущей фазы вместе с таблицей символов, чтобы убедиться, что данный исходный код семантически непротиворечив. Он также проверяет, передает ли код соответствующее значение.
Semantic Analyzer проверит несоответствие типов, несовместимые операнды, вызов функции с неправильными аргументами, необъявленную переменную и т. д.
Функции этапа семантического анализа:
- Помогает хранить собранную информацию о типах и сохранять ее в таблице символов или синтаксическом дереве
- Позволяет выполнять проверку типов
- В случае несоответствия типов, когда нет точных правил исправления типов, удовлетворяющих требуемой операции, отображается семантическая ошибка
- Собирает информацию о типе и проверяет совместимость типов
- Проверяет, разрешает ли исходный язык операнды или нет
Пример
float x = 20,2; поплавок у = х*30;
В приведенном выше коде семантический анализатор преобразует целое число 30 в число с плавающей запятой 30,0 перед умножением
Фаза 4: Генерация промежуточного кода
По завершении фазы семантического анализа компилятор генерирует промежуточный код для целевой машины. Он представляет собой программу для некоторой абстрактной машины.
Он представляет собой программу для некоторой абстрактной машины.
Промежуточный код находится между языком высокого уровня и языком машинного уровня. Этот промежуточный код должен быть сгенерирован таким образом, чтобы его можно было легко преобразовать в целевой машинный код.
Функции на промежуточном этапе Генерация кода:
- Должен быть сгенерирован из семантического представления исходной программы
- Содержит значения, вычисленные в процессе преобразования
- Помогает вам перевести промежуточный код на целевой язык
- Позволяет поддерживать порядок приоритета исходного языка
- Содержит правильное количество операндов инструкции
Пример
Например,
всего = количество + скорость * 5
Промежуточный код методом адресного кода:
t1 := int_to_float(5) t2 := скорость * t1 t3 := количество + t2 всего := t3
Этап 5: Оптимизация кода
Следующий этап — оптимизация кода или промежуточный код.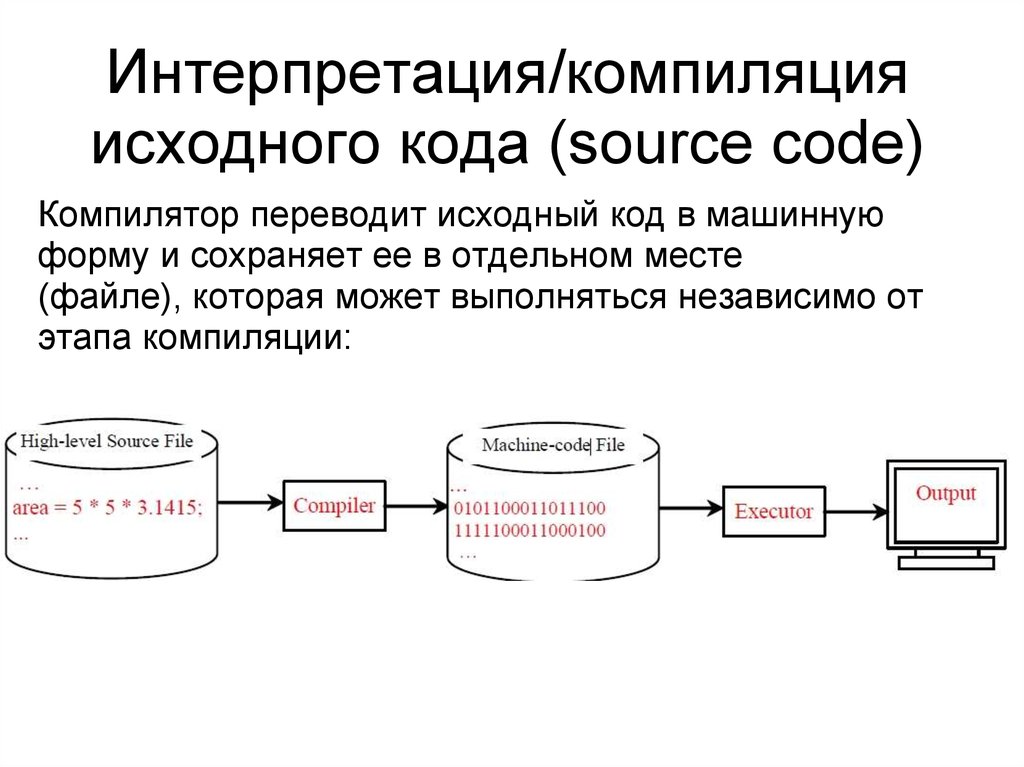 На этом этапе удаляются ненужные строки кода и упорядочивается последовательность операторов, чтобы ускорить выполнение программы без потери ресурсов. Основная цель этого этапа — улучшить промежуточный код, чтобы сгенерировать код, который работает быстрее и занимает меньше места.
На этом этапе удаляются ненужные строки кода и упорядочивается последовательность операторов, чтобы ускорить выполнение программы без потери ресурсов. Основная цель этого этапа — улучшить промежуточный код, чтобы сгенерировать код, который работает быстрее и занимает меньше места.
Основные функции этой фазы:
- Она помогает найти компромисс между скоростью выполнения и компиляции
- Увеличивает время работы целевой программы
- Генерирует упрощенный код, все еще в промежуточном представлении
- Удаление недостижимого кода и избавление от неиспользуемых переменных
- Удаление операторов, которые не были изменены, из цикла
Пример:
Рассмотрим следующий код
а = плавает(10) б = с * а д = е + б ж = д
Может стать
b =c * 10,0 ф = е+б
Этап 6: Генерация кода
Генерация кода — это последний и завершающий этап компилятора. Он получает входные данные на этапах оптимизации кода и в результате создает код страницы или объектный код. Целью этого этапа является выделение памяти и создание перемещаемого машинного кода.
Целью этого этапа является выделение памяти и создание перемещаемого машинного кода.
Он также выделяет ячейки памяти для переменной. Инструкции в промежуточном коде преобразуются в машинные инструкции. На этом этапе оптимизированный или промежуточный код преобразуется в целевой язык.
Целевой язык — машинный код. Следовательно, все ячейки памяти и регистры также выбираются и распределяются на этом этапе. Код, сгенерированный на этом этапе, выполняется для получения входных данных и генерации ожидаемых выходных данных.
Пример:
a = b + 60.0
Возможно, будет преобразовано в регистры.
МОВФ а, R1 МУЛЬФ #60.0, R2 АДДФ R1, R2
Управление таблицей символов
Таблица символов содержит запись для каждого идентификатора с полями для атрибутов идентификатора. Этот компонент облегчает компилятору поиск записи идентификатора и ее быстрое извлечение. Таблица символов также поможет вам в управлении областью действия. Таблица символов и обработчик ошибок взаимодействуют со всеми фазами и обновлением таблицы символов соответственно.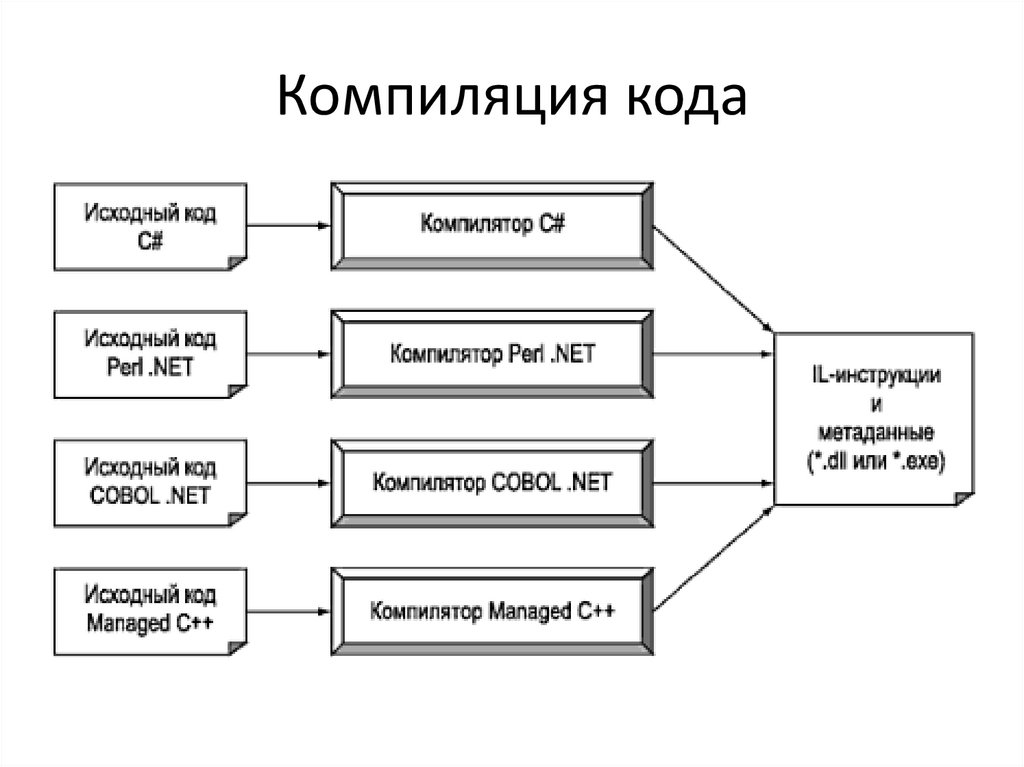
Подпрограмма обработки ошибок:
В процессе проектирования компилятора ошибка может возникнуть на всех нижеприведенных этапах:
- Лексический анализатор: Неправильно написанные токены
- Анализатор синтаксиса: Отсутствует скобка
- Генератор промежуточного кода: Несовпадение операндов для оператора
- Оптимизатор кода: когда оператор недоступен
- Генератор кода: когда память заполнена или нужные регистры не выделены
- Таблицы символов: ошибка нескольких объявленных идентификаторов
Наиболее распространенными ошибками являются недопустимая последовательность символов при сканировании, недопустимая последовательность токенов в типе, ошибка области и синтаксический анализ при семантическом анализе.
Ошибка может возникнуть на любом из вышеуказанных этапов. После обнаружения ошибок на этапе необходимо устранить ошибки, чтобы продолжить процесс компиляции. Об этих ошибках необходимо сообщать обработчику ошибок, который обрабатывает ошибку для выполнения процесса компиляции. Как правило, об ошибках сообщается в виде сообщения.
Как правило, об ошибках сообщается в виде сообщения.
Сводка
- Компилятор работает в различных фазах, каждая фаза преобразует исходную программу из одного представления в другое
- Шесть этапов разработки компилятора: 1) Лексический анализ 2) Синтаксический анализ 3) Семантический анализ 4) Генератор промежуточного кода 5) Оптимизатор кода 6) Генератор кода
- Лексический анализ — это первая фаза, когда компилятор сканирует исходный код
- Синтаксический анализ заключается в обнаружении структуры в тексте
- Семантический анализ проверяет семантическую согласованность кода
- После завершения фазы семантического анализа компилятор сгенерирует промежуточный код для целевой машины
- Фаза оптимизации кода удаляет ненужную строку кода и упорядочивает последовательность операторов
- Фаза генерации кода получает входные данные из фазы оптимизации кода и в результате создает код страницы или объектный код
- Таблица символов содержит запись для каждого идентификатора с полями для атрибутов идентификатора
- Процедура обработки ошибок обрабатывает ошибки и создает отчеты на многих этапах
Как компилируется C#? — Мэннинг
Из Code Like Pro in C# Йорта Роденбурга В этой статье дается обзор того, как именно компилируется код C#. |

Получите скидку 40% на Code like a Pro в C# , введя fccrodenburg в поле кода скидки при оформлении заказа на сайте manning.com.
Как компилируются CLI-совместимые языки
В этой статье вы подробно узнаете, как компилируется C# (и другие языки, совместимые с Common Language Infrastructure). Знание всей истории компиляции подготовит вас к использованию всех возможностей C# с пониманием некоторых подводных камней, связанных с памятью и выполнением. Процесс компиляции C# имеет три состояния (C#, промежуточный язык и машинный код) и два этапа: переход от C# к общему промежуточному языку и переход от промежуточного языка к машинному коду.
ПРИМЕЧАНИЕ. Собственный код иногда называют машинным кодом.
Глядя на то, что нужно, чтобы перейти от одного шага к другому и следовать методу, когда компилятор и CLR компилируют высокоуровневый код C# до работоспособного машинного кода, мы получаем представление о сложной машине, которой является C#. и .NET 5. Хорошее понимание этого процесса часто является пробелом в ресурсах для начинающих, но продвинутые ресурсы требуют от вас понимания этого.
и .NET 5. Хорошее понимание этого процесса часто является пробелом в ресурсах для начинающих, но продвинутые ресурсы требуют от вас понимания этого.
Рисунок 1. Полный процесс компиляции C#. Он переходит от кода C# к общему промежуточному языку и к машинному коду. Понимание процесса компиляции дает нам представление о некоторых внутренних решениях, сделанных в отношении C# и .NET.
Мы используем комбинацию статической компиляции и JIT-компиляции для компиляции C# в машинный код:
- После того, как разработчик напишет код C#, он или она компилирует свой код. Это приводит к тому, что Common Intermediate Language хранится в переносимых исполняемых файлах (PE для 32-разрядных, PE+ для 64-разрядных), таких как файлы «.exe» и «.dll» для Windows. Эти файлы распространяются среди пользователей.
- Когда мы запускаем программу .NET, операционная система вызывает среду CLR. JIT среды Common Language Runtime компилирует CIL в собственный код, соответствующий платформе, на которой он работает. Это позволяет CLI-совместимым языкам работать на множестве платформ и типов компиляторов. Однако было бы неправильным не упомянуть о главном негативном последствии использования виртуальной машины и JITter для запуска вашего кода: производительности.
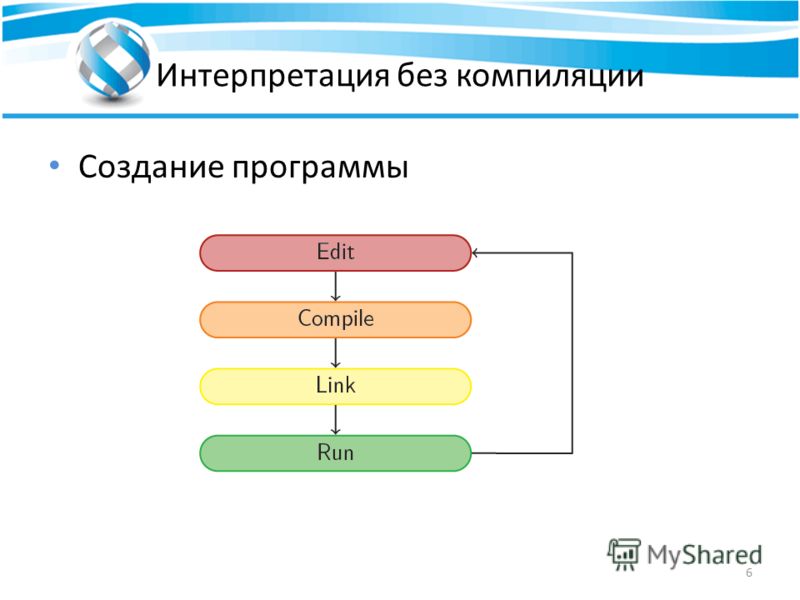 Это позволяет CLI-совместимым языкам работать на множестве платформ и типов компиляторов. Однако было бы неправильным не упомянуть о главном негативном последствии использования виртуальной машины и JITter для запуска вашего кода: производительности.
Это позволяет CLI-совместимым языкам работать на множестве платформ и типов компиляторов. Однако было бы неправильным не упомянуть о главном негативном последствии использования виртуальной машины и JITter для запуска вашего кода: производительности.Статически скомпилированная программа имеет преимущество во время выполнения, так как нет ожидания во время выполнения для компиляции кода.
ОПРЕДЕЛЕНИЕ Статическая компиляция и JIT-компиляция — два наиболее часто используемых способа компиляции кода. C# использует комбинацию статической компиляции и JIT-компиляции. Это означает, что код компилируется в байт-код в последний возможный момент. Статическая компиляция заранее компилирует весь исходный код.
Шаг 1: Код C# (высокоуровневый)
Впервые я столкнулся с теоремой Пифагора в 2008 году. Теорема того года. Через пару дней, поздно ночью, я был в машине с отцом. Мы ехали какое-то время, так что разговор естественно замедлился. В совершенно не характерный момент я спросил его: «Что такое теорема Пифагора?» Вопрос явно застал его врасплох, поскольку в то время я не проявлял особого академического интереса, особенно к математике. В течение следующих десяти минут он пытался объяснить мне, человеку с математическими способностями грейпфрута, что такое теорема Пифагора. Я был удивлен, что действительно понял, о чем он говорил, и теперь, годы спустя, он оказался отличным ресурсом, чтобы показать вам первый шаг в процессе компиляции C#.
В совершенно не характерный момент я спросил его: «Что такое теорема Пифагора?» Вопрос явно застал его врасплох, поскольку в то время я не проявлял особого академического интереса, особенно к математике. В течение следующих десяти минут он пытался объяснить мне, человеку с математическими способностями грейпфрута, что такое теорема Пифагора. Я был удивлен, что действительно понял, о чем он говорил, и теперь, годы спустя, он оказался отличным ресурсом, чтобы показать вам первый шаг в процессе компиляции C#.
В этом разделе мы рассмотрим первый шаг процесса компиляции C#: компиляцию кода C#. Программа, которой мы следуем в процессе компиляции, — это Теорема Пифагора. Причина использования программы, представляющей теорему Пифагора, для обучения процессу компиляции C# проста: мы можем сжать теорему Пифагора до пары строк кода, понятных на уровне математических знаний средней школы. Это позволяет нам сосредоточиться на истории компиляции, а не на деталях реализации.
ПРИМЕЧАНИЕ.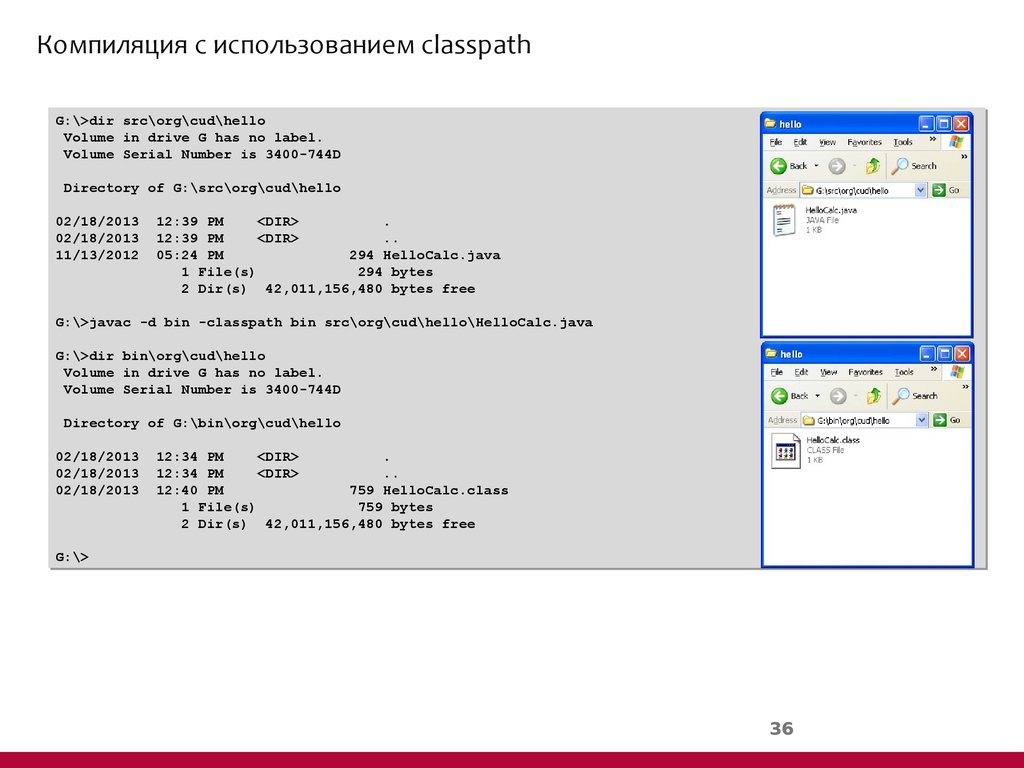 Если вам нужно быстро напомнить, теорема Пифагора утверждает, что в треугольнике с одним прямым углом, обычно называемом прямоугольным треугольником, квадрат длины гипотенузы ( c ) равен сумме квадраты длин двух других сторон ( a и b ), или a 2 + b 2 = c 2 .
Если вам нужно быстро напомнить, теорема Пифагора утверждает, что в треугольнике с одним прямым углом, обычно называемом прямоугольным треугольником, квадрат длины гипотенузы ( c ) равен сумме квадраты длин двух других сторон ( a и b ), или a 2 + b 2 = c 2 .
Рис. 2. Процесс компиляции C#, шаг 1: код C#. Это статическая фаза компиляции.
Начнем с написания простого метода, вычисляющего результат теоремы Пифагора при наличии двух аргументов.
Листинг 1. Теорема Пифагора (высокий уровень)
общедоступный двойной Пифагор (двойная длина стороны A, двойная длина стороны B) { # A
удвоенная длина в квадрате = длина стороны A * длина стороны A + длина стороны B * длина стороны B; #Б
вернуть квадратную длину;
}
#A Мы объявляем метод с модификатором открытого доступа, возвращающий число с плавающей запятой, называемое «Pythagoras», которое ожидает два аргумента с плавающей запятой (двойные): «sideLengthA» и «sideLengthB».
#B Мы применяем теорему Пифагора и присваиваем результат переменной с именем «squaredLength».
Если мы запустим этот код и зададим ему аргументы [3, 8], мы увидим, что результат равен 73, что правильно. В качестве альтернативы, поскольку мы используем 64-битные числа с плавающей запятой (двойные числа), мы также можем протестировать наборы аргументов, такие как [47.21, 99.04]. Результат 12037,7057.
Модификаторы доступа, сборки и пространства имен
Модификаторы доступа C# с открытого на ограниченный. Использование правильного модификатора доступа помогает инкапсулировать наши данные и защитить наши классы.
Теперь компилируем код. Предположим, что метод в листинге 1 является частью класса Pythagoras, , который является частью проекта и решения HelloPythagoras . Чтобы скомпилировать .NET 5 (или решение .NET Framework/.NET Core) в промежуточный язык, хранящийся в файле PE/PE+, вы можете либо использовать кнопку сборки или компилятора в своей среде IDE, либо выполнить следующую команду в командной строке:
сборка dotnet [путь к файлу решения]
Файл решения имеет расширение «.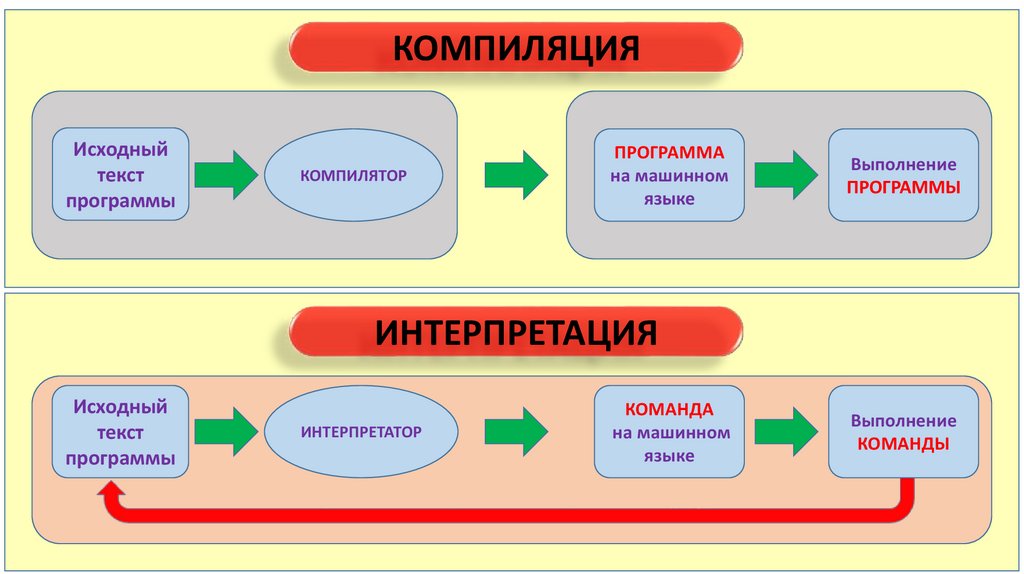 sln». Команда для создания нашего решения:
sln». Команда для создания нашего решения:
сборка dotnet HelloPythagoras.sln
После выполнения команды запускается компилятор. Сначала компилятор восстанавливает все необходимые пакеты зависимостей через диспетчер пакетов NuGet. Затем инструмент командной строки компилирует проект и сохраняет результат в новой папке с именем «bin». В папке «bin» есть два возможных варианта дополнительных папок: «Debug» и «Release». Это зависит от режима, который мы установили для компилятора (вы можете определить свои собственные режимы, если хотите). По умолчанию компилятор компилирует в режиме «Отладка». Режим «Отладка» содержит всю отладочную информацию (хранящуюся в файлах .pdb), необходимую для пошагового выполнения приложения с точками останова.
Для компиляции в режиме «Release» через командную строку добавьте к команде флаг --Configuration release . Кроме того, в Visual Studio есть раскрывающийся список для выбора режима «Отладка» или «Выпуск». Это самый простой, быстрый и наиболее вероятный способ компиляции кода.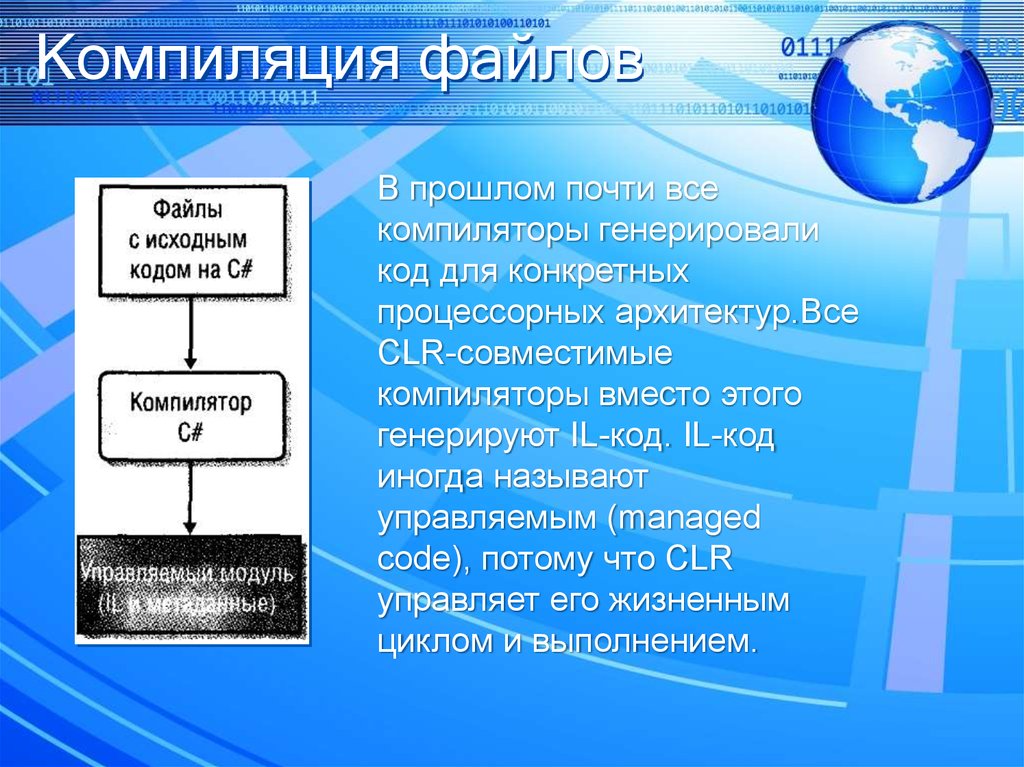
Режимы сборки «Отладка» и «Релиз»
На этом этапе высокоуровневый код C# компилируется в исполняемый файл, содержащий код промежуточного языка.
Шаг 2: Общий промежуточный язык (уровень ассемблера)
С повседневной точки зрения ваша работа выполнена. Код находится в исполняемой форме, и вы можете завершить свой тикет или пользовательскую историю. С технологической точки зрения путешествие только начинается. Код C# статически скомпилирован до Common Intermediate Language, но CIL не может быть запущен операционной системой.
Рис. 3. Процесс компиляции C#, шаг 2: промежуточный язык. Здесь мы переходим от статической компиляции к JIT-компиляции.
Так как же перейти от CIL к машинному коду? Недостающая часть — это Common Language Runtime. Эта часть .NET 5 переводит Common Intermediate Language в машинный код. Это «среда выполнения» .NET. Мы можем сравнить CLR с чем-то вроде виртуальной машины Java (JVM), если смотреть на показатели сложности и использования. CLR была частью .NET с самого начала (начиная с версии 1.0 в феврале 2002 г.). Также полезно отметить, что с переходом на .NET Core и .NET 5 место старой CLR занимает новая реализация CLR: CoreCLR. В этой статье термин CLR используется как для обычной среды CLR, так и для CoreCLR.
CLR была частью .NET с самого начала (начиная с версии 1.0 в феврале 2002 г.). Также полезно отметить, что с переходом на .NET Core и .NET 5 место старой CLR занимает новая реализация CLR: CoreCLR. В этой статье термин CLR используется как для обычной среды CLR, так и для CoreCLR.
Любой код, реализующий технический стандарт под названием Common Language Infrastructure (CLI), может быть скомпилирован до Common Intermediate Language. CLI описывает инфраструктуру, лежащую в основе экосистемы .NET, специфическими разновидностями которой являются реализации самого CLI, и дает языкам основу для формирования своей системы типов. Поскольку CLR может принимать любую часть промежуточного языка, а компилятор .NET может генерировать этот CIL из любого языка, совместимого с CLI, мы можем сгенерировать код CIL из кода смешанного исходного кода. C#, Visual Basic и F# — наиболее распространенные языки программирования .NET, но есть и другие языки.
До 2017 года Microsoft также поддерживала J#, реализацию Java, совместимую с CLI. Теоретически вы можете загрузить совместимый компилятор и использовать J#, но вы упустите некоторые современные функции Java в обмен на разработку на платформе .NET. Также полезно отметить, что .NET 5 включает новые функции совместимости с Java, которые не используют J#.
Теоретически вы можете загрузить совместимый компилятор и использовать J#, но вы упустите некоторые современные функции Java в обмен на разработку на платформе .NET. Также полезно отметить, что .NET 5 включает новые функции совместимости с Java, которые не используют J#.
ПРИМЕЧАНИЕ. CLR — чрезвычайно сложная программа. Если вы хотите узнать больше о (традиционной, основанной на Windows) среде CLR, см. статью Джеффри Рихтера 9.0300 CLR через C# (четвертое издание; Microsoft Press, 2012 г.).
Поскольку компилятор встраивает CIL в исполняемые файлы, нам нужно использовать дизассемблер для просмотра CIL. Все варианты .NET поставляются с таким инструментом, который называется IL DASM (что означает Intermediate Language Disassembler). Чтобы использовать IL DASM, нам нужно запустить «Командную строку разработчика для Visual Studio», которая устанавливается вместе с Visual Studio. Это среда командной строки, которая дает нам доступ к инструментам .NET.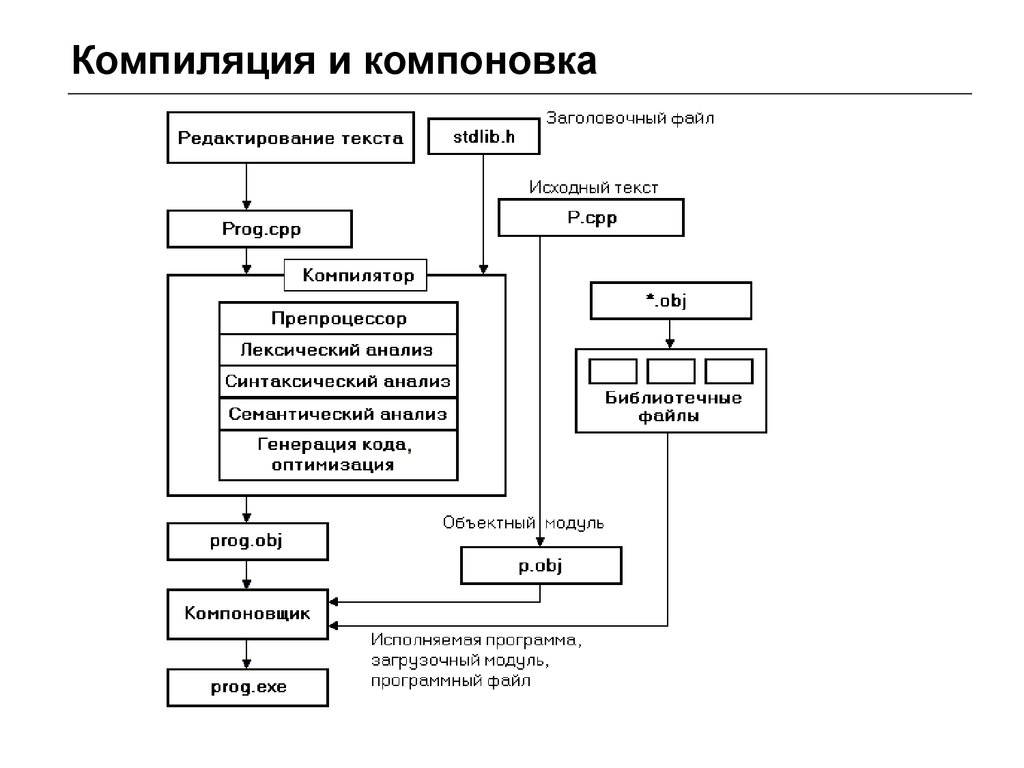 Имейте в виду, что IL DASM доступен только для Windows.
Имейте в виду, что IL DASM доступен только для Windows.
В командной строке разработчика мы можем вызвать IL DASM для нашего скомпилированного файла и указать выходной файл:
>\ ildasm HelloPythagoras.dll /output:HelloPythagoras.il
Если мы не указываем выходной файл, инструмент командной строки запускает графический интерфейс для IL DASM. Там вы также можете просмотреть IL-код дизассемблированного исполняемого файла. Выходной файл может иметь любое расширение файла, которое вы хотите, так как это простой двоичный текстовый файл. Обратите внимание, что в .NET Framework ildasm работает с файлом .exe, а не с .dll. .NET 5 и .NET Core используют файл .dll.
Когда мы открываем файл HelloPythagoras.il в текстовом редакторе или смотрим на графический интерфейс IL DASM, открывается файл, наполненный таинственным кодом. Это CIL-код. Мы сосредоточимся на CIL для метода Пифагора (если он скомпилирован в «режиме отладки»), как показано в листинге 1.
Листинг 2.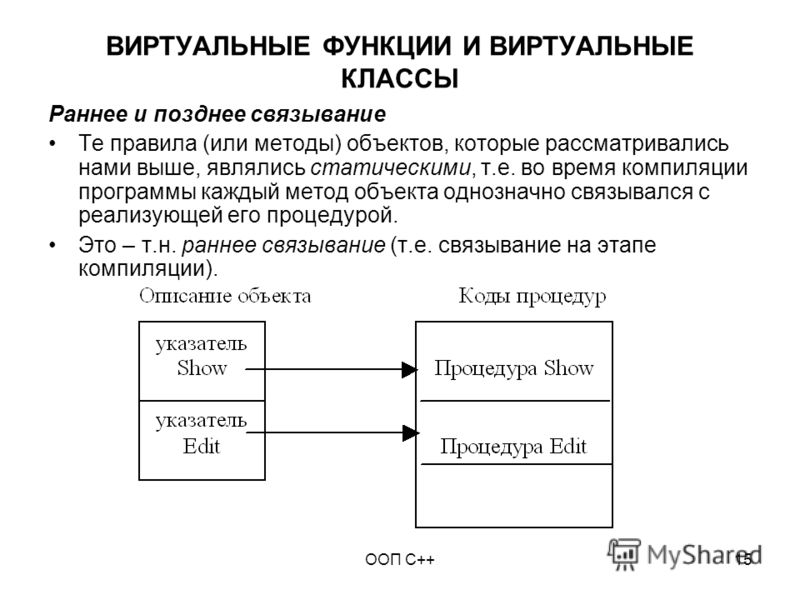 Теорема Пифагора (Common Intermediate Language)
Теорема Пифагора (Common Intermediate Language)
.method public hidebysig static float64
Пифагор(float64 sideLengthA,
float64 sideLengthB) cil управляемый {
.maxstack 3
.locals init([0] float64, длина в квадрате,
[1] float64 V_1)
IL_0000: нет
IL_0001: ldarg.0
IL_0002: ldarg.0
IL_0003: мул.
IL_0004: ldarg.1
IL_0005: ldarg.1
IL_0006: мул.
IL_0007: добавить
IL_0008: stloc.0
ИЛ_0009: ldloc.0
IL_000a: stloc.1
IL_000b: кр.с IL_000d
IL_000c: ldloc.1
IL_000e: возврат
}
Если вы когда-либо работали или видели программирование на уровне ассемблера, вы могли заметить некоторые сходства. Common Intermediate Language определенно сложнее читать и он более «близок к железу», чем обычный код C#, но он не так загадочен, как может показаться. Проходя по CIL построчно, вы видите, что это просто другой синтаксис для уже известных вам концепций программирования. Код CIL, сгенерированный компилятором на вашем компьютере, может немного отличаться (особенно числа, используемые с ldarg код операции), но функциональность и типы кодов операций должны быть одинаковыми.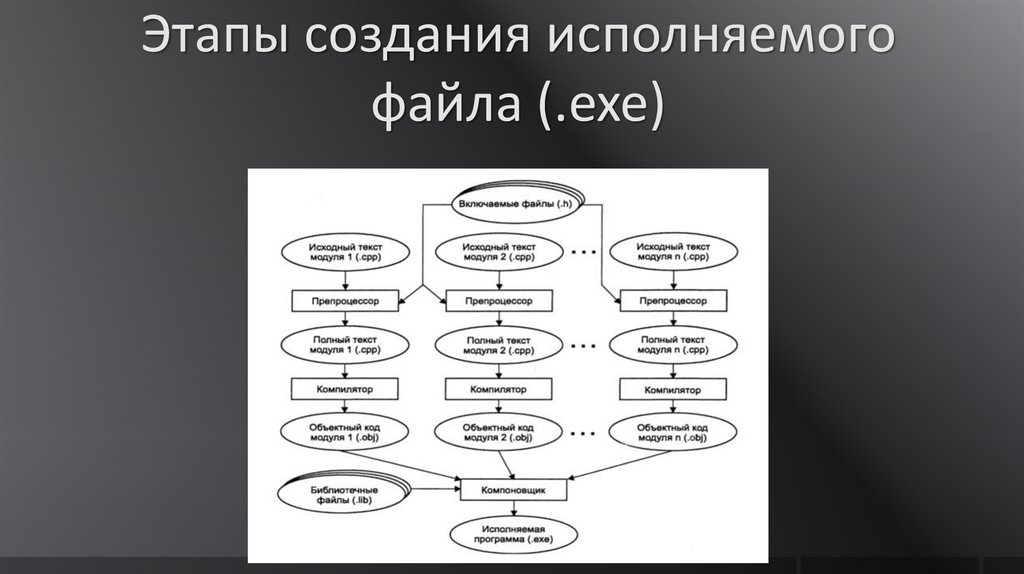
Самое первое, что мы видим, это объявление метода:
.method private hidebysig static float64 Пифагор(float64 sideLengthA, float64 sideLengthB) cil управляемый
Мы можем легко сделать вывод, что метод является общедоступным, статическим и возвращает 64-битное число с плавающей запятой (известное как double в C#). Мы также можем видеть, что метод называется Pythagoras и принимает 2 аргумента с именами sideLengthA и sideLengthB , оба 64-битные числа с плавающей запятой. Два термина, которые кажутся странными, это hidebysig и cil управляемый .
Во-первых, термин hidebysig говорит нам о том, что метод Пифагора скрывает все остальные методы с такой же сигнатурой. Если он опущен, метод скрывает все методы с тем же именем (не ограничиваясь совпадением подписи). Во-вторых, цил управлял означает, что этот код является общим промежуточным языком и что мы работаем в управляемом режиме. Другая сторона медали будет неуправляемой. Это относится к тому, может ли CLR выполнять метод, возможно ли ручное управление памятью и есть ли все метаданные, которые требуются CLR. По умолчанию весь ваш код выполняется в управляемом режиме, если вы явно не укажете ему не делать этого, включив флаг «небезопасности» компилятора и обозначив код как «небезопасный».
Другая сторона медали будет неуправляемой. Это относится к тому, может ли CLR выполнять метод, возможно ли ручное управление памятью и есть ли все метаданные, которые требуются CLR. По умолчанию весь ваш код выполняется в управляемом режиме, если вы явно не укажете ему не делать этого, включив флаг «небезопасности» компилятора и обозначив код как «небезопасный».
Переходя к самому методу, мы можем разделить его на две части: настройку (конструктор) и выполнение (логика). Во-первых, давайте посмотрим на конструктор:
.maxstack 3 .locals init([0] float64, длина в квадрате, [1] float64 V_1)
Здесь есть незнакомые термины. Для начала .maxstack 3 сообщает нам, что максимально допустимое количество элементов в стеке памяти во время выполнения равно 3. Статический компилятор автоматически генерирует это число и сообщает CLR JITter, сколько элементов нужно зарезервировать для метода. Это очень важная часть кода метода. Представьте, что вы не можете сообщить CLR, сколько памяти нам нужно. Он может решить зарезервировать все доступное пространство стека в системе или вообще не резервировать его. Любой сценарий был бы катастрофическим.
Он может решить зарезервировать все доступное пространство стека в системе или вообще не резервировать его. Любой сценарий был бы катастрофическим.
инициализация .locals (…)
Когда мы объявляем переменную на языке программирования, совместимом с CLI, компилятор назначает переменной область действия и инициализирует значение переменной значением по умолчанию во время компиляции. Ключевое слово locals сообщает нам, что область действия переменных, объявленных в этом блоке кода, является локальной по области действия (привязана к методу, а не к классу), в то время как init означает, что мы инициализируем объявленные переменные их значениями по умолчанию. Компилятор присваивает ему null или обнуленное значение, в зависимости от того, является ли переменная ссылочным или типом значения.
Расширение блока кода .locals init (…) показывает переменные, которые мы объявляем и инициализируем:
.locals инициализация ( [0] float64 длина в квадрате, [1] float64 V_1
CIL объявляет две локальные переменные и инициализирует их нулевыми значениями: squaredLength и V_1 .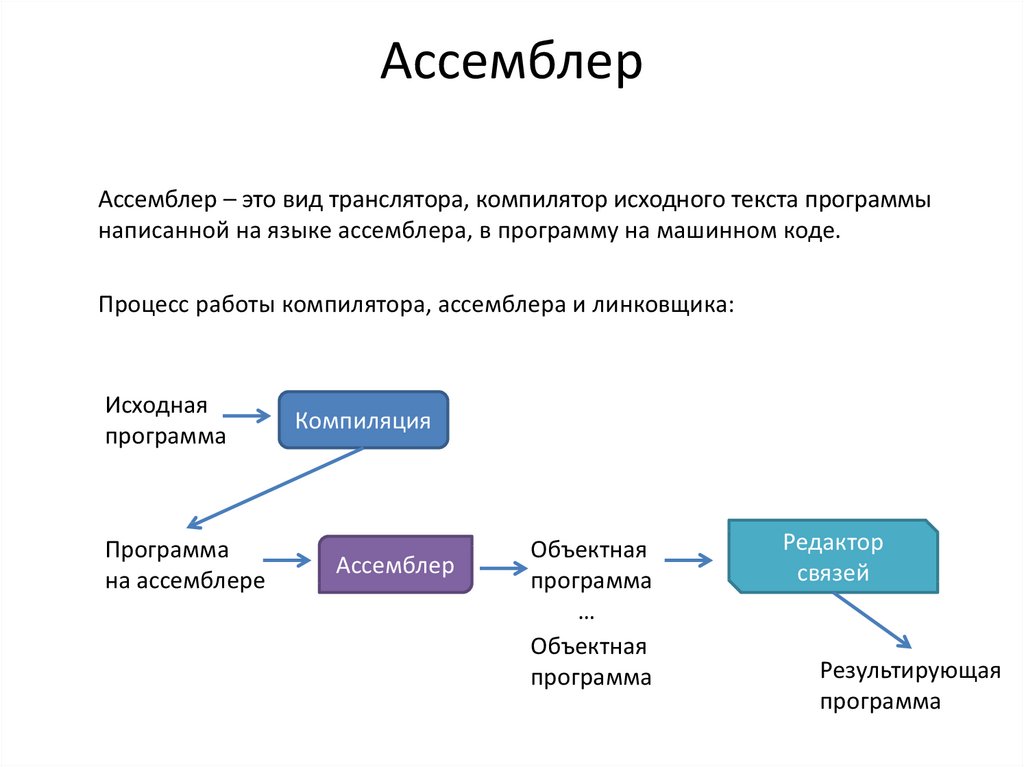
Теперь вы можете сказать, подождите секунду! В нашем коде C# мы объявили только одну локальную переменную: кв.Длина. Что это за V_1 дело? Еще раз взгляните на код C#:
.
публичный двойной Пифагор (двойная длина стороны A, двойная длина стороны B) {
удвоенная длина в квадрате = длина стороныA* длина стороныA+ длина стороныB* длина стороныAB;
вернуть квадратную длину;
}
Мы явно объявили только одну локальную переменную. Однако мы возвращаем squaredLength по значению, а не по ссылке. Это означает, что под капотом объявляется новая переменная, инициализируется и ей присваивается значение 9.0296 в квадратеДлина . Это V_1 .
Подводя итог, мы рассмотрели сигнатуру метода и настройку. Теперь мы можем погрузиться в дебри логики. Давайте также разделим эту часть на две части: вычисление теоремы Пифагора и возврат результирующего значения.
IL_0000: нет IL_0001: ldarg.
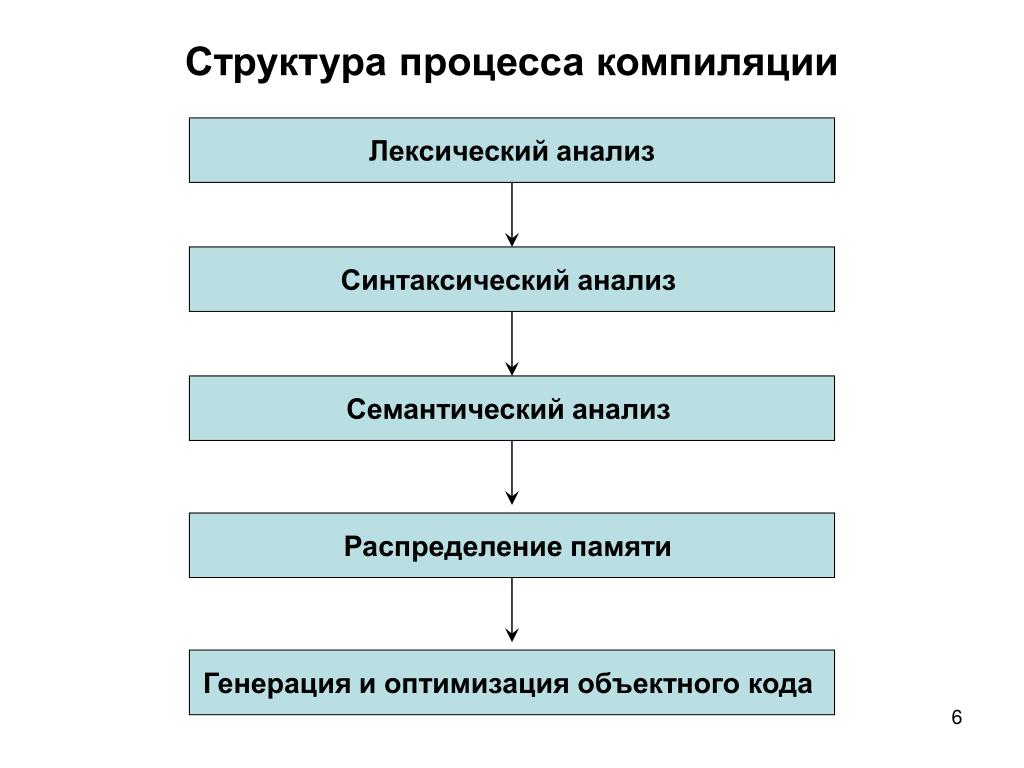 0
IL_0002: ldarg.0
IL_0003: мул.
IL_0004: ldarg.1
IL_0005: ldarg.1
IL_0006: мул.
IL_0007: добавить
IL_0008: stloc.0
0
IL_0002: ldarg.0
IL_0003: мул.
IL_0004: ldarg.1
IL_0005: ldarg.1
IL_0006: мул.
IL_0007: добавить
IL_0008: stloc.0
Для начала мы видим операцию (мы также называем эти операции кодами операций) с именем nop . Это также называется «ничего не делать» или «без операции», потому что сама по себе операция nop ничего не делает. Они широко используются в коде CIL и ассемблере для обеспечения отладки точек останова. Наряду с файлом PDB, созданным в сборках отладки, среда CLR может вводить инструкции для остановки выполнения программы в операции nop . Это позволяет нам «проходить» код во время выполнения.
Далее мы рассмотрим оценку самой теоремы Пифагора:
удвоенная длина в квадрате = длина стороны A * длина стороны A + длина стороны B * длина стороны B;
Следующие две операции являются двойным заголовком: две ldarg.0 операции. Первая операция ( IL_0001 ) загружает в стек первое вхождение sideLengthA . Вторая операция (
Вторая операция ( IL_0002 ) также загружает в стек второе вхождение sideLengthA .
После того, как мы загрузили аргументы первой математической оценки в стек, код CIL вызывает операцию умножения:
IL_0003: мул.
Это приводит к тому, что два аргумента, загруженные во время IL_0001 и IL_0002 , перемножаются и сохраняются в новом элементе стека. Теперь сборщик мусора удаляет из стека предыдущие (теперь неиспользуемые) элементы стека.
Повторяем этот процесс для возведения в квадрат числа 9.0296 sideLengthB аргументы:
IL_0004: ldarg.1 IL_0005: ldarg.1 IL_0006: мул.
Итак, теперь у нас есть элементы в стеке, содержащие значения sidelengthA 2 и sidelengthB 2 . Чтобы выполнить теорему Пифагора и наш код, мы должны сложить эти два значения и сохранить их в sqedLength. Это делается в IL_0007 и IL_0008 .
IL_0007: добавить IL_0008: stloc.0
Подобно операциям mul ( IL_0003 и IL_0006 ), операция add ( IL_0007 ) оценивает добавление ранее сохраненных аргументов и помещает полученное значение в стек. CIL берет этот элемент и сохраняет его в переменной squaredLength , которую мы инициализировали в настройках ( [0] float64 squaredLength ) через команду stloc.0 ( IL_0008 ). Операция stloc.0 извлекает значение из стека и сохраняет его в переменной с индексом 0.
Теперь мы полностью оценили и сохранили результат теоремы Пифагора в переменной. Остается только вернуть значение из метода, как мы и обещали в нашей исходной сигнатуре метода.
IL_0009: ldloc.0 IL_000a: stloc.1 IL_000b: кр.с IL_000d IL_000c: ldloc.1 IL_000e: возврат
Сначала мы загружаем значение переменной в ячейке 0 в память (IL_0009). В предыдущем сегменте мы закончили сохранением значения теоремы Пифагора в переменной по адресу 0, так что это должно быть 
squaredLength . Но, как упоминалось ранее, мы передаем переменную по значению, а не по ссылке, поэтому мы создаем копию squaredLength для возврата из метода. К счастью, именно для этой цели мы объявили и инициализировали переменную с индексом 1:9029.6 V_1 ([1] float64 V_1 ). Мы сохраняем значение в индексе 1 с помощью операции (IL_000a) stdloc.1.
Далее мы видим еще одну странную операцию: бр.с IL_000d (IL_000b) . Это оператор ветвления, который означает, что возвращаемое значение вычисляется и сохраняется для возврата. CIL использует оператор ветвления для целей отладки. Оператор ветвления аналогичен операции nop . Все различные ветки вашего кода (условные операторы с другими возвращаемыми значениями) переходят к бр.с оператор при вызове возврата. Оператор br.s занимает два байта и поэтому имеет два местоположения IL (IL_000b и IL_000d) , поскольку один код операции обычно занимает один байт.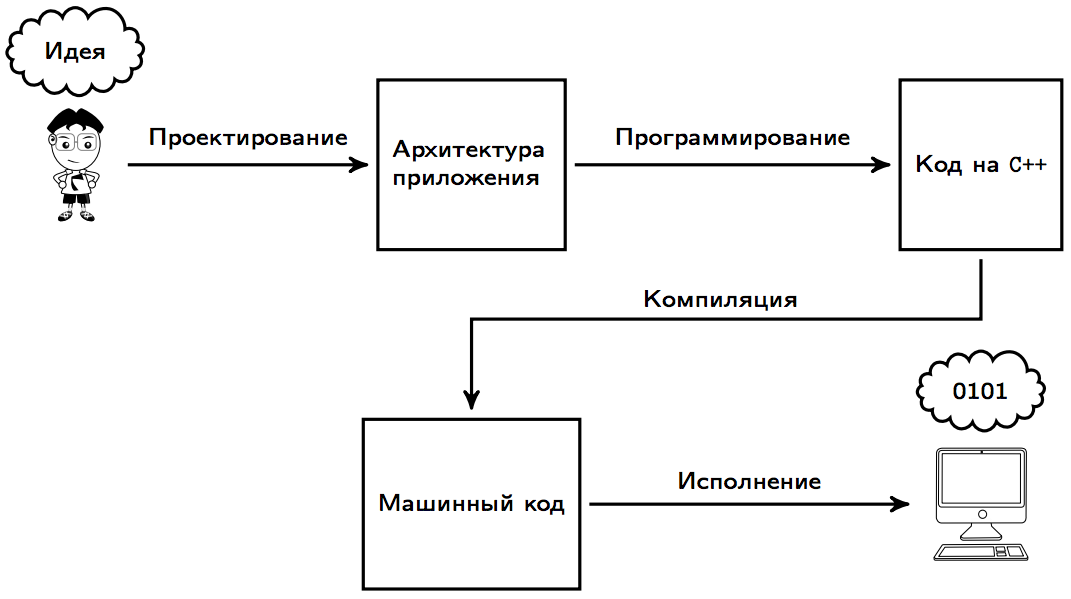 Поскольку оператор
Поскольку оператор br.s имеет размер два байта, IL_000c ( ldloc.1 ) заключен в оператор ветвления. Это позволяет отладчику прекратить выполнение при загрузке сохраненного возвращаемого значения и манипулировать им при необходимости.
Наконец, мы готовы вернуться из метода через IL_000c и IL_000e:
IL_000c: ldloc.1 IL_000e: возврат
Операция ldloc.1 (IL_000c) загружает ранее сохраненное возвращаемое значение. Затем следует оператор ret, который берет значение, которое мы загрузили по адресу IL_000c , и возвращает его из метода.
Это подводит нас к концу раздела. Надеюсь, теперь вы немного освоились с мельчайшими деталями шага статической компиляции C# и .NET.
Листинг 3. Исходный код CIL метода теоремы Пифагора
.method private hidebysig static float64 #A
Пифагор(float64 sideLengthA, #B
float64 sideLengthB) cil управляемый { #C
. максстек 3 #D
.locals init ([0] float64, квадратная длина, #E
[1] float64 V_1)
IL_0000: нет #F
IL_0001: ldarg.0 #G
IL_0002: ldarg.0
IL_0003: мул #H
IL_0004: ldarg.1 #I
IL_0005: ldarg.1
IL_0006: мул #J
IL_0007: добавить #K
IL_0008: stloc.0 #L
ИЛ_0009: ldloc.0 #M
IL_000a: stloc.1 #N
IL_000b: кр.с IL_000d #O
IL_000c: ldloc.1 #P
IL_000e: повтор #Q
}
 максстек 3 #D
.locals init ([0] float64, квадратная длина, #E
[1] float64 V_1)
IL_0000: нет #F
IL_0001: ldarg.0 #G
IL_0002: ldarg.0
IL_0003: мул #H
IL_0004: ldarg.1 #I
IL_0005: ldarg.1
IL_0006: мул #J
IL_0007: добавить #K
IL_0008: stloc.0 #L
ИЛ_0009: ldloc.0 #M
IL_000a: stloc.1 #N
IL_000b: кр.с IL_000d #O
IL_000c: ldloc.1 #P
IL_000e: повтор #Q
}
максстек 3 #D
.locals init ([0] float64, квадратная длина, #E
[1] float64 V_1)
IL_0000: нет #F
IL_0001: ldarg.0 #G
IL_0002: ldarg.0
IL_0003: мул #H
IL_0004: ldarg.1 #I
IL_0005: ldarg.1
IL_0006: мул #J
IL_0007: добавить #K
IL_0008: stloc.0 #L
ИЛ_0009: ldloc.0 #M
IL_000a: stloc.1 #N
IL_000b: кр.с IL_000d #O
IL_000c: ldloc.1 #P
IL_000e: повтор #Q
}
#A Начало метода, который является приватным, статическим, возвращает двойник и скрывает другие методы с такой же сигнатурой.
#B Метод называется «Пифагор». Он ожидает два аргумента типа float64 (двойной).
#C Это метод CIL (Common Intermediate Language), который работает в управляемом режиме.
#D Максимальное количество одновременных элементов, необходимых в стеке, равно 3.
#E Объявлены и инициализированы две локальные переменные типа float64: squaredLength с индексом 0 и V_1 с индексом 1.
#F Операция «Ничего не делать». Используется отладчиками для точек останова.
#G Первый аргумент «sideLengthA» загружается в память.
#H Два загруженных в память значения «sideLengthA» перемножаются и сохраняются в элементе стека.
#I Первый аргумент «sideLengthB» загружается в память.
#J Два загруженных в память значения «sideLengthB» перемножаются и сохраняются в элементе стека.
#K Квадраты значений sideLengthA и sideLengthB сложены вместе и сохранены в элементе стека.
#L Возведенные в квадрат значения, ранее сохраненные в элементе стека, сохраняются в новом элементе стека, предназначенном для переменной с индексом 0: «squaredLength».
#M Значение для «squaredLength» загружается в память.
#N Ранее загруженное в память значение «squaredLength» сохраняется в элементе стека для переменной с индексом 1: «V_1».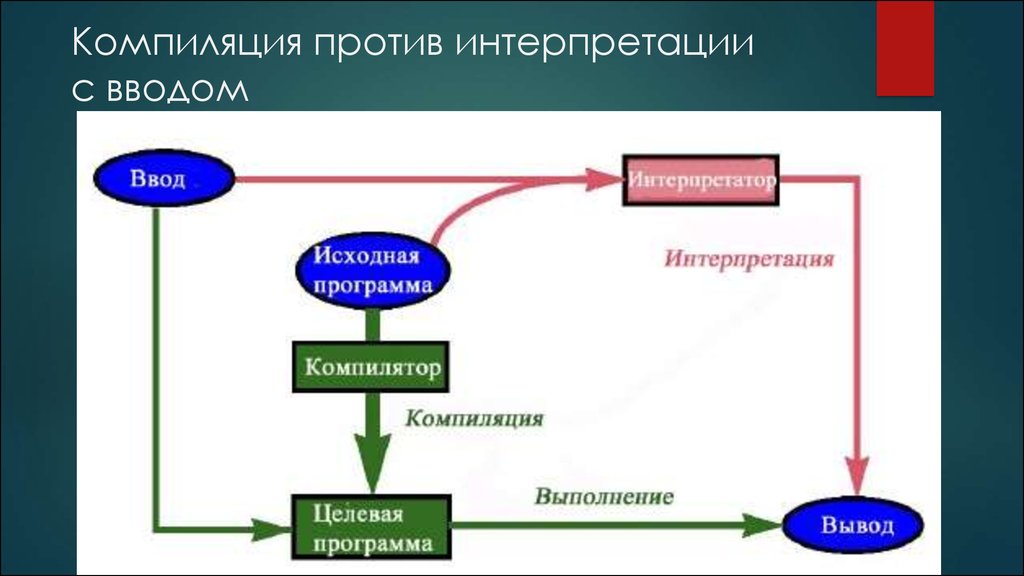
#O Оператор ветвления. Означает завершение метода и сохранение возвращаемого значения.
#P Возвращаемое значение (переменная V_1) загружается в память.
#Q Возвращаемся из метода со значением V_1.
Шаг 3: Собственный код (уровень процессора)
Последним шагом в процессе компиляции является преобразование Общего промежуточного языка в собственный код, который процессор действительно может выполнять. До сих пор код компилировался статически, но здесь все изменилось. Когда .NET 5 выполняет приложение, CLR запускает и сканирует исполняемые файлы на наличие CIL-кода. Затем CLR вызывает JIT-компилятор для преобразования CIL в машинный код во время его выполнения. Нативный код — это самый низкий уровень кода, который (в некоторой степени) удобочитаем. Процессор может выполнять этот код напрямую благодаря включению предопределенных операций (кодов операций), аналогично тому, как Common Intermediate Language включает коды операций CIL.
Рис. 4. Процесс компиляции C#, шаг 3: машинный код. Это этап JIT.
JIT-обработка нашего кода снижает производительность, но также означает, что мы можем выполнять код на основе .NET на любой платформе, поддерживаемой CLR и компилятором. Мы можем увидеть это на практике с .NET Core и новым CoreCLR. CoreCLR может JIT Intermediate Language для Windows, macOS и Linux.
Рисунок 5. CoreCLR поддерживает JIT для таких целевых систем, как Linux, Windows и macOS. Это позволяет кроссплатформенное выполнение кода C#.
Из-за JIT-характера этого шага компиляции просмотр фактического машинного кода немного сложен. Единственный способ просмотреть собственный код, сгенерированный на вашем промежуточном языке, — это использовать инструмент командной строки под названием ngen , который предустановлен с .NET 5. Этот инструмент позволяет создавать так называемые собственные образы, содержащие собственный код. из общего промежуточного языка, заранее сохраненного в PE-файле.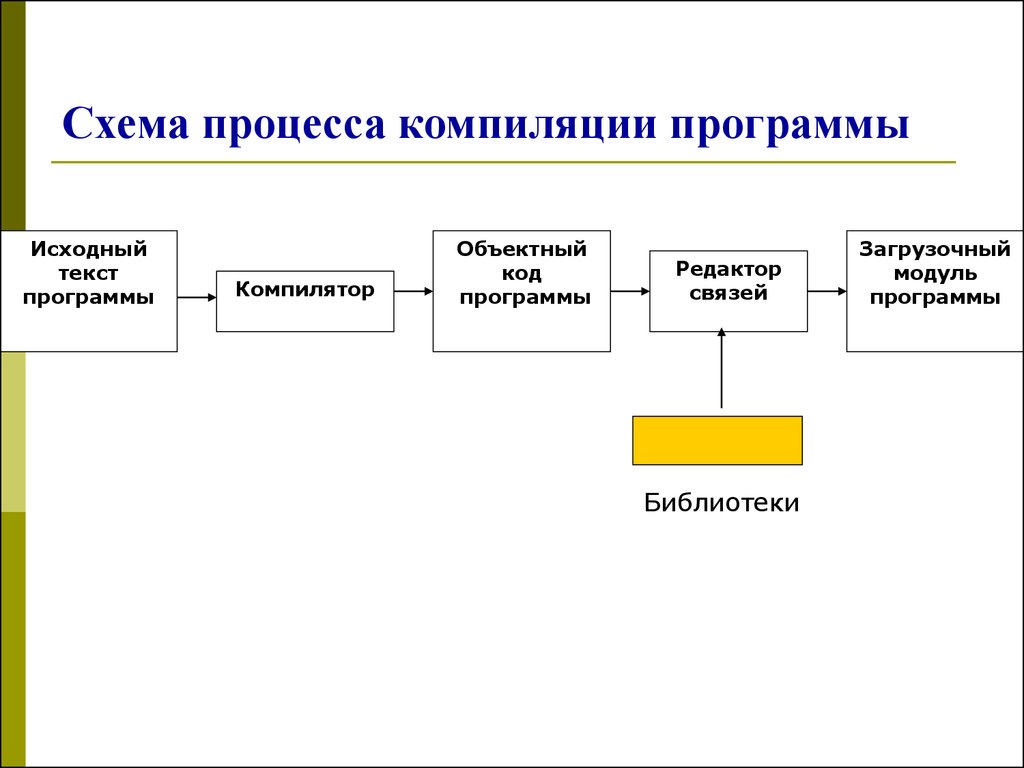 CLR сохраняет выходные данные собственного кода в подпапке «%SystemRoot%/Assembly/NativeAssembly» (доступно только в Windows). Имейте в виду, однако, что вы не можете использовать обычный проводник для навигации здесь, и полученный результат не будет разборчивым. После запуска
CLR сохраняет выходные данные собственного кода в подпапке «%SystemRoot%/Assembly/NativeAssembly» (доступно только в Windows). Имейте в виду, однако, что вы не можете использовать обычный проводник для навигации здесь, и полученный результат не будет разборчивым. После запуска ngen CLR видит, что CIL уже скомпилирован (статически) в собственный код, и выполняется на его основе. Это связано с ожидаемым повышением производительности; однако собственный код и код CIL могут рассинхронизироваться при выпуске новой сборки и иметь неожиданные побочные эффекты, если CLR решит использовать старый статически скомпилированный собственный образ вместо повторной компиляции нового обновленного кода.
В повседневных операциях вы, скорее всего, не так много касаетесь CIL или слишком беспокоитесь о компиляции CIL в машинный код. Тем не менее, понимание процесса компиляции является фундаментальным блоком знаний, поскольку оно проливает свет на проектные решения в .NET 5.
Пока это все.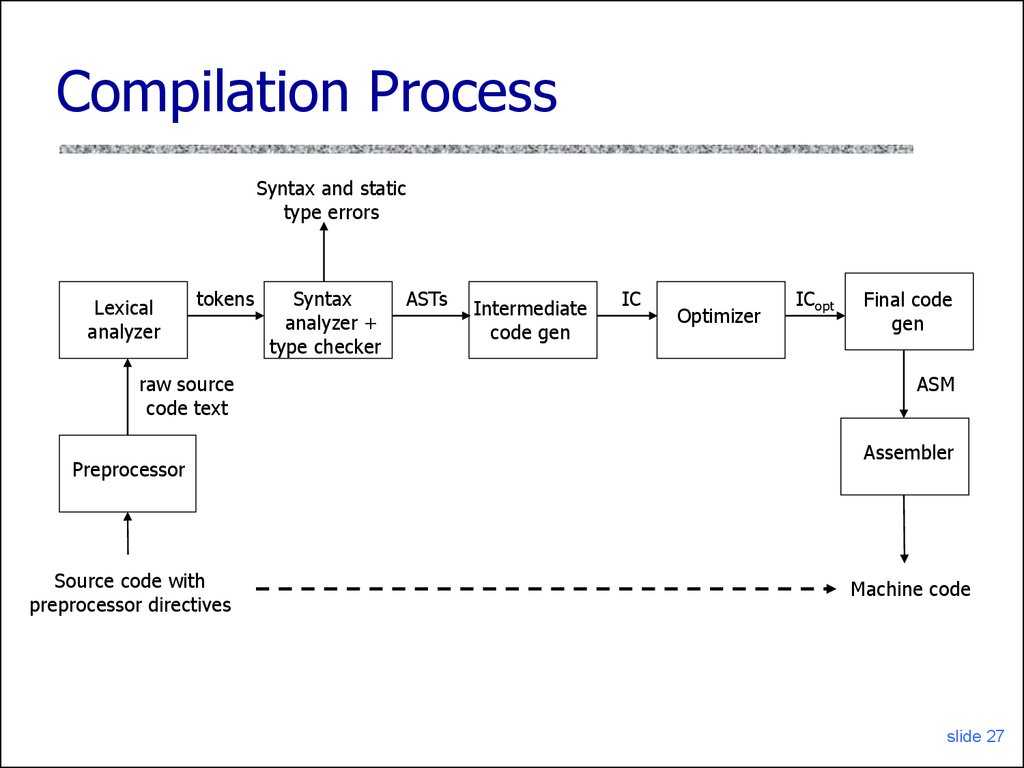
Если вы хотите узнать больше о книге, вы можете ознакомиться с ней на нашей браузерной платформе liveBook здесь.
Процессы компиляции и связывания – ПРОГРАММИРОВАНИЕ НА ЭВМ
Процесс компиляции и выполнения C можно разделить на несколько этапов:
Вот простая таблица, показывающая ввод и вывод каждого шага в процессе компиляции и выполнения: Ввод Программа Вывод
источник code > Препроцессор > расширенный исходный код расширенный исходный код > Компилятор > исходный код сборки сборкакод > Ассемблер > код объекта объект code > Linker > исполняемый код исполняемый код > загрузчик > выполнение Вот примеры часто используемых программы для различных этапов компиляции и выполнения в системе Linux: «cpp hello.c -o hello.i» — Препроцессор предварительно обрабатывает hello.c и сохраняет вывод в hello.i. «cc1 привет.и -о привет.с» —
Компилятор компилирует hello.i и сохраняет вывод в hello. «привет.с -о привет.о» — Ассемблер собирает hello.s и сохраняет вывод в hello.o. «лд привет.о -о привет» — Линкер, связывающий hello.o и сохраняющий выходные данные в hello. «загрузить привет» — Загрузчик загружаем привет и запускаем привет.
Предварительная обработка, Компиляция, связывание и выполнение С тех пор предварительная обработка, компиляция и компоновка обычно рассматриваются как шаги одного попытаться создать исполняемый файл, их можно вместе назвать процесс «строительства». Обычно, если один из шагов не удается, здание останавливается, а описания ошибок выводятся либо в командное окно, либо в выходное окно IDE.
Следующая диаграмма последовательности демонстрирует типичные успешные события, циркулирующие между компонентами построить в порядке их появления: препроцессор А
файл является традиционной единицей хранения в файловой системе. Точно так же файл
также традиционная единица компиляции программы. Наличие полная программа в одном файле обычно невозможна. Код стандарта C++ библиотеки или библиотеки программ, специфичных для операционной системы, обычно предоставляется директивами #include в нашем исходном файле. Набросок выглядит следующим образом:
КомпиляторКомпилятор это программа-переводчик, которая преобразует программу на языке высокого уровня в машинную язык. ЦП (центральный процессор) может напрямую понимать свои собственные машинный язык. Типичная схема выглядит так:
компоновщик — это программа, которая связывает воедино все отдельно скомпилированные части. А компоновщик связывает код объекта с кодом недостающих функций для создания исполняемый образ и создает исполняемый файл на диске. C++ и работа библиотеки системных объектов предоставляют недостающие функции. Программа теперь может быть загружается в память и выполняется. Загрузка и запуск программ Один раз
программа готова ее можно запустить из командного окна. Наша программа загружается вместе с другими пользовательскими программами в память следующим образом: Операционная система занимает слой между пользовательскими программами и центральный процессор, или сокращенно ЦП. Между пользовательскими программами, операционной системой и ЦП могут существовать другие уровни. Типичными уровнями являются отладчики пользовательского режима и режима ядра: Отладчик пользовательского режима — это тип процесса,
указывает ЦП выполнять инструкции процессора в одношаговом режиме.
отладчик загружает пользовательскую программу в отдельный процесс. В этой настройке
отладчик является родителем, а пользовательская программа — дочерним процессом. Отладчик может
выполнять пользовательскую программу по одному оператору за раз, помогая программистам обнаруживать и
исследовать «баги». Отладчики режима ядра (KD) аналогичны отладчики пользовательского режима, но когда KD прекращает выполнение, вся операционная система останавливается. Отладчики KD часто поддерживают интерфейс, который позволяет программисту дистанционно управлять его функциями с другого компьютера, подключенного через нуль-модемный кабель. Отладчики KD позволяют разработчикам обнаруживать ошибки в компонентах операционная система, например драйверы устройств. Хотя ЦП выполняет отдельные
инструкции программы, операционная система имеет механизм прерывания
выполнения пользовательской программы и передать квант времени выполнения другому
программа. Такой тип планирования задач создает у пользователя впечатление, что
все программы работают параллельно. |
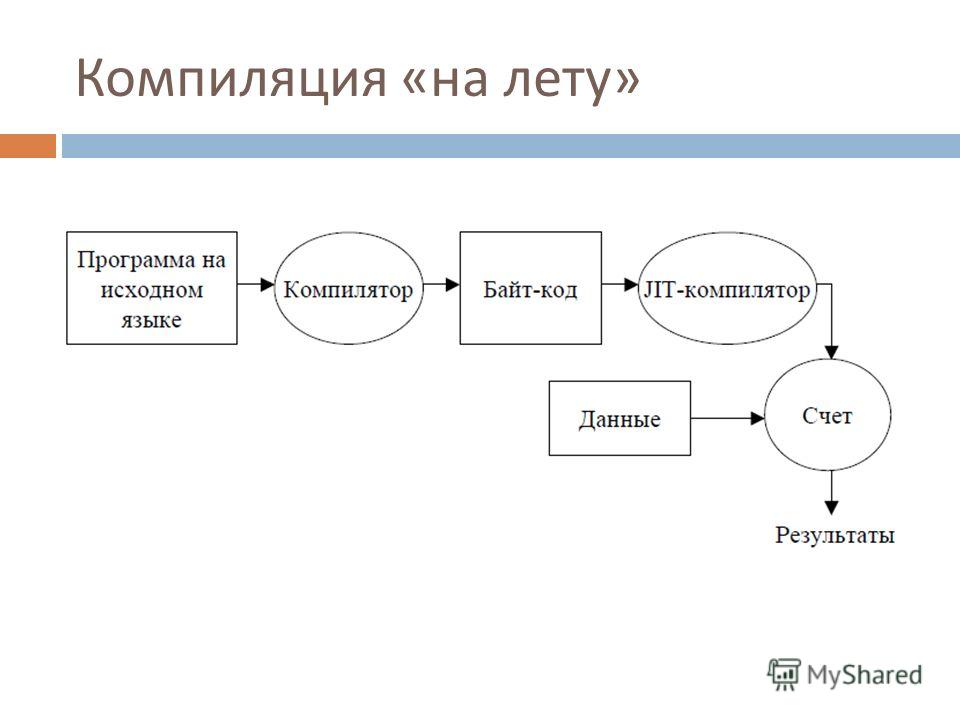 Несколько единиц объектных кодов связаны друг с другом
на этом шаге.
Несколько единиц объектных кодов связаны друг с другом
на этом шаге. s.
s.

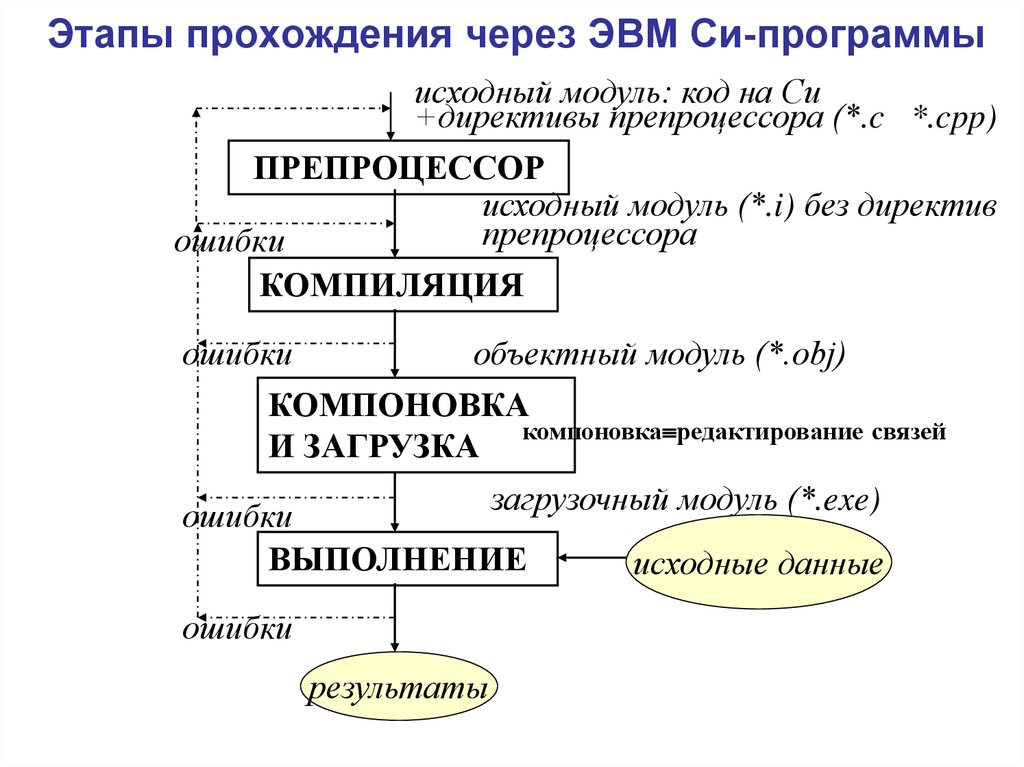 Компонент загрузчика
операционная система берет исполняемый образ с диска и передает его на
память для выполнения:
Компонент загрузчика
операционная система берет исполняемый образ с диска и передает его на
память для выполнения: Отладчики являются ценными инструментами времени выполнения для обнаружения
и убрать логические ошибки. Microsoft VC++ имеет собственный отладчик с графическим интерфейсом.
пользовательский интерфейс.
Отладчики являются ценными инструментами времени выполнения для обнаружения
и убрать логические ошибки. Microsoft VC++ имеет собственный отладчик с графическим интерфейсом.
пользовательский интерфейс.