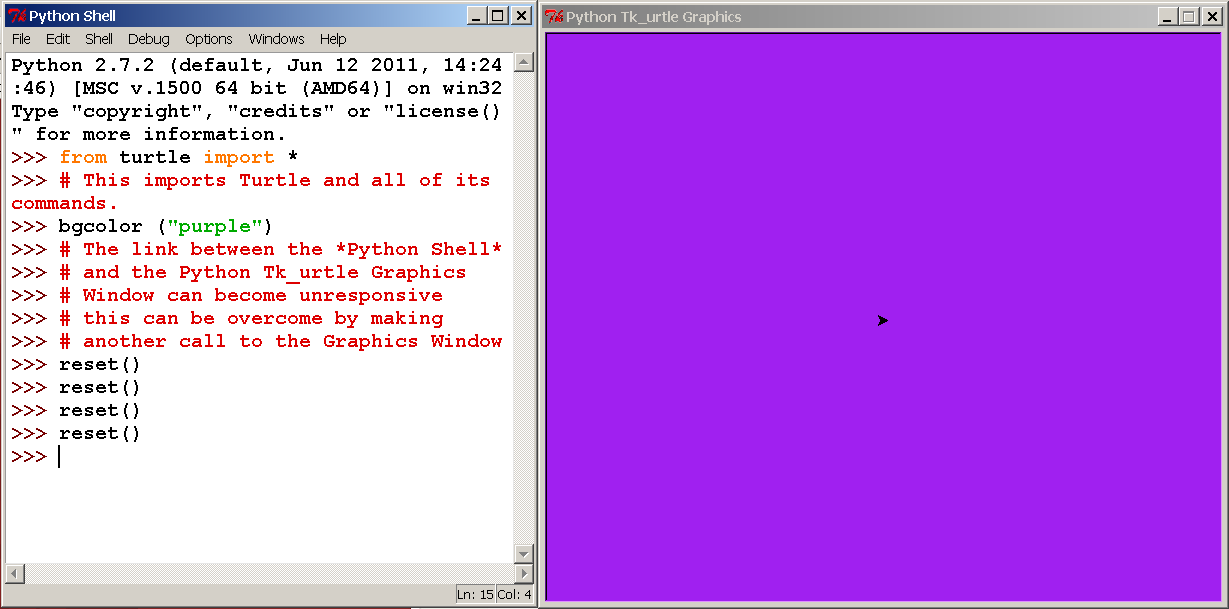
Основы работы с файлами в Python
Михаил Свинцов
автор курса «Full-stack веб-разработчик на Python»
Взаимодействие с файловой системой позволяет хранить информацию, полученную в результате работы программы. Михаил Свинцов из SkillFactory расскажет о базовой функциональности языка программирования Python для работы с файлами.
Встроенные средства Python
Основа для работы с файлами — built-in функция open()
open(file, mode="rt")
Эта функция имеет два аргумента. Аргумент file принимает строку, в которой содержится путь к файлу. Второй аргумент, mode, позволяет указать режим, в котором необходимо работать с файлом. По умолчанию этот аргумент принимает значение «rt», с которым, и с некоторыми другими, можно ознакомиться в таблице ниже
Эти режимы могут быть скомбинированы. Например, «rb» открывает двоичный файл для чтения. Комбинируя «r+» или «w+» можно добиться открытия файла в режиме и чтения, и записи одновременно с одним отличием — первый режим вызовет исключение, если файла не существует, а работа во втором режиме в таком случае создаст его.
Начать саму работу с файлом можно с помощью объекта класса io.TextIOWrapper, который возвращается функцией open(). У этого объекта есть несколько атрибутов, через которые можно получить информацию
name— название файла;mode— режим, в котором этот файл открыт;closed— возвращаетTrue, если файл был закрыт.
По завершении работы с файлом его необходимо закрыть при помощи метода close()
f = open("examp.le", "w")
// работа с файлом
f.close()Однако более pythonic way стиль работы с файлом встроенными средствами заключается в использовании конструкции with .. as .., которая работает как менеджер создания контекста. Написанный выше пример можно переписать с ее помощью
with open("examp.le", "w") as f:
// работа с файломГлавное отличие заключается в том, что python самостоятельно закрывает файл, и разработчику нет необходимости помнить об этом. И бонусом к этому не будут вызваны исключения при открытии файла (например, если файл не существует).
И бонусом к этому не будут вызваны исключения при открытии файла (например, если файл не существует).
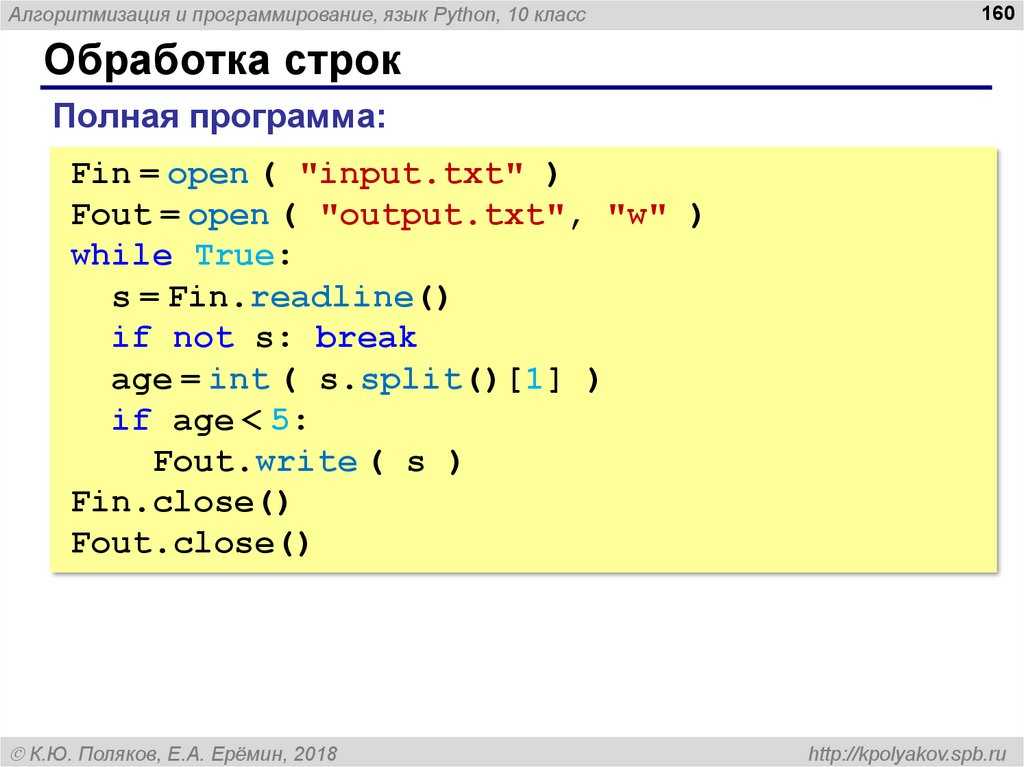
Чтение из файла
При открытии файла в режимах, допускающих чтение, можно использовать несколько подходов.
Для начала можно прочитать файл целиком и все данные, находящиеся в нем, записать в одну строку.
with open("examp.le", "r") as f:
text = f.read()Используя эту функцию с целочисленным аргументом, можно прочитать определенное количество символов.
with open("examp.le", "r") as f:
part = f.read(16)При этом будут получены только первые 16 символов текста. Важно понимать, что при применении этой функции несколько раз подряд будет считываться часть за частью этого текста — виртуальный курсор будет сдвигаться на считанную часть текста. Его можно сдвинуть на определенную позицию, при необходимости воспользовавшись методом
with open("examp.le", "r") as f: # 'Hello, world!'
first_part = f. read(8) # 'Hello, w'
f.seek(4)
second_part = f.read(8) # 'o, world'
read(8) # 'Hello, w'
f.seek(4)
second_part = f.read(8) # 'o, world' read(8) # 'Hello, w'
f.seek(4)
second_part = f.read(8) # 'o, world'
read(8) # 'Hello, w'
f.seek(4)
second_part = f.read(8) # 'o, world'Другой способ заключается в считывании файла построчно. Метод readline() считывает строку и, также как и с методом read(), сдвигает курсор — только теперь уже на целую строку. Применение этого метода несколько раз будет приводить к считыванию нескольких строк. Схожий с этим способом, другой метод позволяет прочитать файл целиком, но по строкам, записав их в список. Этот список можно использовать, например, в качестве итерируемого объекта в цикле.
with open("examp.le", "r") as f:
for line in f.readlines():
print(line)Однако и здесь существует более pythonic way. Он заключается в том, что сам объект io.TextIOWrapper имеет итератор, возвращающий строку за строкой. Благодаря этому нет необходимости считывать файл целиком, сохраняя его в список, а можно динамически по строкам считывать файл. И делать это лаконично.
with open("examp.le", "r") as f:
for line in f:
print(line)Запись в файл
Функциональность внесения данных в файл не зависит от режима — добавление данных или перезаписывание файла. В выполнении этой операции также существует несколько подходов.
Самый простой и логичный — использование функции write()
with open("examp.le", "w") as f:
f.write(some_string_data)Важно, что в качестве аргумента функции могут быть переданы только строки. Если необходимо записать другого рода информацию, то ее необходимо явно привести к строковому типу, используя методы __str__(self) для объектов или форматированные строки.
Есть возможность записать в файл большой объем данных, если он может быть представлен в виде списка строк.
with open("examp.le", "w") as f:
f.writelines(list_of_strings)Здесь есть еще один нюанс, связанный с тем, что функции write() и writelines() автоматически не ставят символ переноса строки, и это разработчику нужно контролировать самостоятельно.
Существует еще один, менее известный, способ, но, возможно, самый удобный из представленных. И как бы не было странно, он заключается в использовании функции print(). Сначала это утверждение может показаться странным, потому что общеизвестно, что с помощью нее происходит вывод в консоль. И это правда. Но если передать в необязательный аргумент io.TextIOWrapper, каким и является объект файла, с которым мы работаем, то поток вывода функции print() перенаправляется из консоли в файл.
with open("examp.le", "w") as f:
print(some_data, file=f)Сила такого подхода заключается в том, что в print() можно передавать не обязательно строковые аргументы — при необходимости функция сама их преобразует к строковому типу.
На этом знакомство с базовой функциональностью работы с файлами можно закончить. Вместе с этим стоит сказать, что возможности языка Python им не ограничивается. Существует большое количество библиотек, которые позволяют работать с файлами определенных типов, а также допускают более тесное взаимодействие с файловой системой.
Работа с файлами в python. Чтение и запись в файл ~ PythonRu
Эта статья посвящена работе с файлами (вводу/выводу) в Python: открытие, чтение, запись, закрытие и другие операции.
Файлы Python
Файл — это всего лишь набор данных, сохраненный в виде последовательности битов на компьютере. Информация хранится в куче данных (структура данных) и имеет название «имя файла» (filename).
В Python существует два типа файлов:
- Текстовые
- Бинарные
Текстовые файлы
Это файлы с человекочитаемым содержимым. В них хранятся последовательности символов, которые понимает человек. Блокнот и другие стандартные редакторы умеют читать и редактировать этот тип файлов.
Текст может храниться в двух форматах: (.txt) — простой текст и (.rtf) — «формат обогащенного текста».
Бинарные файлы
В бинарных файлах данные отображаются в закодированной форме (с использованием только нулей (0) и единиц (1) вместо простых символов). В большинстве случаев это просто последовательности битов.
В большинстве случаев это просто последовательности битов.
Они хранятся в формате .bin.
Любую операцию с файлом можно разбить на три крупных этапа:
- Открытие файла
- Выполнение операции (запись, чтение)
- Закрытие файла
Открытие файла
Метод open()
В Python есть встроенная функция open(). С ее помощью можно открыть любой файл на компьютере. Технически Python создает на его основе объект.
Синтаксис следующий:
f = open(file_name, access_mode)
Где,
file_name= имя открываемого файлаaccess_mode= режим открытия файла. Он может быть: для чтения, записи и т. д. По умолчанию используется режим чтения (r), если другое не указано. Далее полный список режимов открытия файла
| Режим | Описание |
|---|---|
| r | Только для чтения. |
| w | Только для записи. Создаст новый файл, если не найдет с указанным именем. Создаст новый файл, если не найдет с указанным именем. |
| rb | Только для чтения (бинарный). |
| wb | Только для записи (бинарный). Создаст новый файл, если не найдет с указанным именем. |
| r+ | Для чтения и записи. |
| rb+ | Для чтения и записи (бинарный). |
| w+ | Для чтения и записи. Создаст новый файл для записи, если не найдет с указанным именем. |
| wb+ | Для чтения и записи (бинарный). Создаст новый файл для записи, если не найдет с указанным именем. |
| a | Откроет для добавления нового содержимого. Создаст новый файл для записи, если не найдет с указанным именем. |
| a+ | Откроет для добавления нового содержимого. Создаст новый файл для чтения записи, если не найдет с указанным именем. |
| ab | Откроет для добавления нового содержимого (бинарный). Создаст новый файл для записи, если не найдет с указанным именем.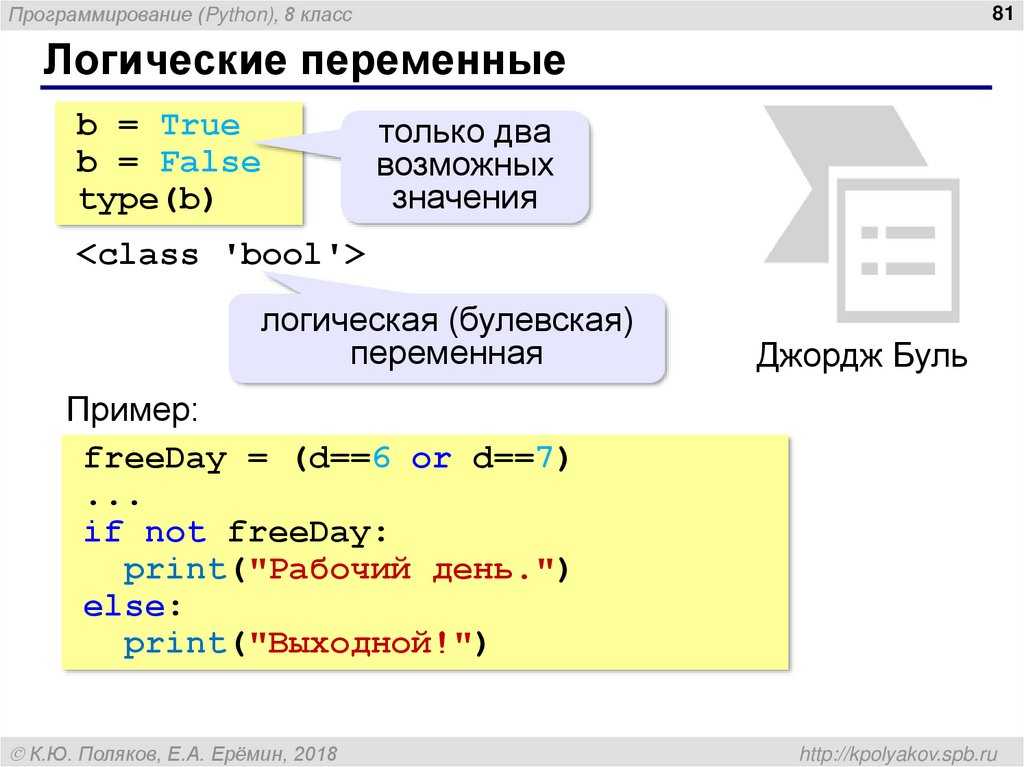 |
| ab+ | Откроет для добавления нового содержимого (бинарный). Создаст новый файл для чтения записи, если не найдет с указанным именем. |
Пример
Создадим текстовый файл example.txt и сохраним его в рабочей директории.
Следующий код используется для его открытия.
f = open('example.txt','r') # открыть файл из рабочей директории в режиме чтения
fp = open('C:/xyz.txt','r') # открыть файл из любого каталога
В этом примере f — переменная-указатель на файл
Следующий код используется для вывода содержимого файла и информации о нем.
>>> print(*f) # выводим содержимое файла This is a text file. >>> print(f) # выводим объект <_io.TextIOWrapper name='example.txt' mode='r' encoding='cp1252'>
Стоит обратить внимание, что в Windows стандартной кодировкой является cp1252, а в Linux — utf-08.
Закрытие файла
Метод close()
После открытия файла в Python его нужно закрыть. Таким образом освобождаются ресурсы и убирается мусор. Python автоматически закрывает файл, когда объект присваивается другому файлу.
Таким образом освобождаются ресурсы и убирается мусор. Python автоматически закрывает файл, когда объект присваивается другому файлу.
Существуют следующие способы:
Способ №1
Проще всего после открытия файла закрыть его, используя метод close().
f = open('example.txt','r')
# работа с файлом
f.close()
После закрытия этот файл нельзя будет использовать до тех пор, пока заново его не открыть.
Способ №2
Также можно написать try/finally, которое гарантирует, что если после открытия файла операции с ним приводят к исключениям, он закроется автоматически.
Без него программа завершается некорректно.
Вот как сделать это исключение:
f = open('example.txt','r')
try:
# работа с файлом
finally:
f.close()
Файл нужно открыть до инструкции
try, потому что если инструкцияopenсама по себе вызовет ошибку, то файл не будет открываться для последующего закрытия.

Этот метод гарантирует, что если операции над файлом вызовут исключения, то он закроется до того как программа остановится.
Способ №3
Инструкция with
Еще один подход — использовать инструкцию with, которая упрощает обработку исключений с помощью инкапсуляции начальных операций, а также задач по закрытию и очистке.
В таком случае инструкция close не нужна, потому что with автоматически закроет файл.
Вот как это реализовать в коде.
with open('example.txt') as f:
# работа с файлом
Чтение и запись файлов в Python
В Python файлы можно читать или записывать информацию в них с помощью соответствующих режимов.
Функция read()
Функция read() используется для чтения содержимого файла после открытия его в режиме чтения (r).
Синтаксис
file.read(size)
Где,
file= объект файлаsize= количество символов, которые нужно прочитать. Если не указать, то файл прочитается целиком.
 Если не указать, то файл прочитается целиком.
Если не указать, то файл прочитается целиком.Пример
>>> f = open('example.txt','r')
>>> f.read(7) # чтение 7 символов из example.txt
'This is '
Интерпретатор прочитал 7 символов файла и если снова использовать функцию read(), то чтение начнется с 8-го символа.
>>> f.read(7) # чтение следующих 7 символов ' a text'
Функция readline()
Функция readline() используется для построчного чтения содержимого файла. Она используется для крупных файлов. С ее помощью можно получать доступ к любой строке в любой момент.
Пример
Создадим файл test.txt с нескольким строками:
This is line1. This is line2. This is line3.
Посмотрим, как функция readline() работает в test.txt.
>>> x = open('test.txt','r')
>>> x.readline() # прочитать первую строку
This is line1.
>>> x. readline(2) # прочитать вторую строку
This is line2.
>>> x.readlines() # прочитать все строки
['This is line1.','This is line2.','This is line3.']
 readline(2) # прочитать вторую строку
This is line2.
>>> x.readlines() # прочитать все строки
['This is line1.','This is line2.','This is line3.']
readline(2) # прочитать вторую строку
This is line2.
>>> x.readlines() # прочитать все строки
['This is line1.','This is line2.','This is line3.']
Обратите внимание, как в последнем случае строки отделены друг от друга.
Функция write()
Функция write() используется для записи в файлы Python, открытые в режиме записи.
Если пытаться открыть файл, которого не существует, в этом режиме, тогда будет создан новый.
Синтаксис
file.write(string)
Пример
Предположим, файла xyz.txt не существует. Он будет создан при попытке открыть его в режиме чтения.
>>> f = open('xyz.txt','w') # открытие в режиме записи
>>> f.write('Hello \n World') # запись Hello World в файл
Hello
World
>>> f.close() # закрытие файла
Переименование файлов в Python
Функция rename()
Функция rename() используется для переименовывания файлов в Python. Для ее использования сперва нужно импортировать модуль os.
Для ее использования сперва нужно импортировать модуль os.
Синтаксис следующий.
import os os.rename(src,dest)
Где,
src= файл, который нужно переименоватьdest= новое имя файла
Пример
>>> import os
>>> # переименование xyz.txt в abc.txt
>>> os.rename("xyz.txt","abc.txt")
Текущая позиция в файлах Python
В Python возможно узнать текущую позицию в файле с помощью функции tell(). Таким же образом можно изменить текущую позицию командой seek().
Пример
>>> f = open('example.txt') # example.txt, который мы создали ранее
>>> f.read(4) # давайте сначала перейдем к 4-й позиции
This
>>> f.tell() # возвращает текущую позицию
4
>>> f.seek(0,0) # вернем положение на 0 снова
Методы файла в Python
file. | закрывает открытый файл |
file.fileno() | возвращает целочисленный дескриптор файла |
file.flush() | очищает внутренний буфер |
file.isatty() | возвращает True, если файл привязан к терминалу |
file.next() | возвращает следующую строку файла |
file.read(n) | чтение первых n символов файла |
file.readline() | читает одну строчку строки или файла |
file.readlines() | читает и возвращает список всех строк в файле |
| file.seek(offset[,whene]) | устанавливает текущую позицию в файле |
file.seekable() | проверяет, поддерживает ли файл случайный доступ. Возвращает True, если да |
file.tell() | возвращает текущую позицию в файле |
file. | уменьшает размер файл. Если n указала, то файл обрезается до n байт, если нет — до текущей позиции |
file.write(str) | добавляет строку str в файл |
file.writelines(sequence) | добавляет последовательность строк в файл |
 close()
close() truncate(n)
truncate(n)- ТЕГИ
- для начинающих
Максим
Я создал этот блог в 2018 году, чтобы распространять полезные учебные материалы, документации и уроки на русском. На сайте опубликовано множество статей по основам python и библиотекам, уроков для начинающих и примеров написания программ.
Python Q https://yandex.ru/q/loves/python Online
Python QCEO [email protected]://secure.gravatar.com/avatar/b16f253879f7349f64830c64d1da4415?s=96&d=mm&r=gCEO PythonruPythonАлександрРедакторhttps://t.me/cashncarryhttps://pythonru.com/https://yandex.ru/q/profile/cashnc/[email protected] Zabrodin2018-10-26OnlinePython, Programming, HTML, CSS, JavaScriptФункция open.
 Чтение и запись текстовых файлов в Python. Урок 24
Чтение и запись текстовых файлов в Python. Урок 24Большие объемы данных хранят не в списках или словарях, а в файлах и базах данных. В этом уроке изучим особенности работы с текстовыми файлами в Python. Такие файлы рассматриваются как содержащие символы и строки.
Бывают еще байтовые (бинарные) файлы, которые рассматриваются как потоки байтов. Побайтово считываются, например, файлы изображений. Работа с бинарными файлами несколько сложнее. Нередко их обрабатывают с помощью специальных модулей Python (pickle, struct).
Функция open
Связь с файлом на жестком диске выполняется с помощью встроенной в Python функции open(). Обычно ей передают один или два аргумента. Первый – имя файла или имя с адресом, если файл находится не в том каталоге, где находится сама программа. Второй аргумент – режим, в котором открывается файл.
Обычно используются режимы чтения ('r') и записи ('w'). Если файл открыт в режиме чтения, то запись в него невозможна. Можно только считывать данные. Если файл открыт в режиме записи, то в него можно только записывать данные, считывать нельзя.
Можно только считывать данные. Если файл открыт в режиме записи, то в него можно только записывать данные, считывать нельзя.
Если файл открывается в режиме 'w', то все данные, которые в нем были до этого, стираются. Файл становится пустым. Если не надо удалять существующие в файле данные, тогда следует использовать вместо режима записи, режим дозаписи ('a').
Если файл отсутствует, то открытие его в режиме 'w' создаст новый файл. Бывают ситуации, когда надо гарантировано создать новый файл, избежав случайной перезаписи данных существующего. В этом случае вместо режима 'w' используется режим 'x'. В нем всегда создается новый файл для записи. Если указано имя существующего файла, то будет выброшено исключение. Потери данных в уже имеющемся файле не произойдет.
Если при вызове open() второй аргумент не указан, то файл открывается в режиме чтения как текстовый файл. Чтобы открыть файл как байтовый, дополнительно к букве режима чтения/записи добавляется символ 'b'. Буква
Буква 't' обозначает текстовый файл. Поскольку это тип файла по умолчанию, то обычно ее не указывают.
Нельзя указывать только тип файла, то есть open("имя_файла", 'b') есть ошибка, даже если файл открывается на чтение. Правильно – open("имя_файла", 'rb'). Только текстовые файлы мы можем открыть командой open("имя_файла"), потому что и 'r' и 't' подразумеваются по-умолчанию.
Функция open() возвращает объект файлового типа. Его надо либо сразу связать с переменной, чтобы не потерять, либо сразу прочитать.
Чтение файла
С помощью файлового метода read() можно прочитать файл целиком или только определенное количество байт. Пусть у нас имеется файл data.txt с таким содержимым:
one - 1 - I two - 2 - II three - 3 - III four - 4 - IV five - 5 - V
Откроем его и почитаем:
>>> f1 = open('data. txt')
>>> f1.read(10)
'one - 1 - '
>>> f1.read()
'I\ntwo - 2 - II\nthree - 3 - III\n
four - 4 - IV\nfive - 5 - V\n'
>>> f1.read()
''
>>> type(f1.read())
<class 'str'> txt')
>>> f1.read(10)
'one - 1 - '
>>> f1.read()
'I\ntwo - 2 - II\nthree - 3 - III\n
four - 4 - IV\nfive - 5 - V\n'
>>> f1.read()
''
>>> type(f1.read())
<class 'str'>
txt')
>>> f1.read(10)
'one - 1 - '
>>> f1.read()
'I\ntwo - 2 - II\nthree - 3 - III\n
four - 4 - IV\nfive - 5 - V\n'
>>> f1.read()
''
>>> type(f1.read())
<class 'str'>Сначала считываются первые десять символов. Последующий вызов read() считывает весь оставшийся текст. После этого объект файлового типа f1 становится пустым.
Заметим, что метод read() возвращает строку, и что конец строки считывается как '\n'.
Для того, чтобы читать файл построчно существует метод readline():
>>> f1 = open('data.txt')
>>> f1.readline()
'one - 1 - I\n'
>>> f1.readline()
'two - 2 - II\n'
>>> f1.readline()
'three - 3 — III\n'Метод readlines() считывает сразу все строки и создает список:
>>> f1 = open('data.txt')
>>> f1.readlines()
['one - 1 - I\n', 'two - 2 - II\n',
'three - 3 - III\n',
'four - 4 - IV\n', 'five - 5 - V\n']Объект файлового типа относится к итераторам. Из таких объектов происходит последовательное извлечение элементов. Элементами в данном случае являются строки-линии файла. Поэтому считывать данные из них можно сразу в цикле без использования методов чтения:
Из таких объектов происходит последовательное извлечение элементов. Элементами в данном случае являются строки-линии файла. Поэтому считывать данные из них можно сразу в цикле без использования методов чтения:
>>> for i in open('data.txt'):
... print(i)
...
one - 1 - I
two - 2 - II
three - 3 - III
four - 4 - IV
five - 5 - V
>>> Здесь выводятся лишние пустые строки, потому что функция print() преобразует '\n' в переход на новую строку. К этому добавляет свой переход на новую строку. Создадим список строк файла без '\n':
>>> nums = []
>>> for i in open('data.txt'):
... nums.append(i[:-1])
...
>>> nums
['one - 1 - I', 'two - 2 - II',
'three - 3 - III',
'four - 4 - IV', 'five - 5 - V']Переменной i присваивается очередная строка файла. Мы берем ее срез от начала до последнего символа, не включая его. Следует иметь в виду, что '\n' это один символ, а не два.
Запись в файл
Запись в файл выполняется с помощью методов write() и writelines(). Во второй можно передать структуру данных:
>>> l = ['tree', 'four']
>>> f2 = open('newdata.txt', 'w')
>>> f2.write('one')
3
>>> f2.write(' two')
4
>>> f2.writelines(l)Метод write() возвращает количество записанных символов.
Закрытие файла
После того как работа с файлом закончена, важно не забывать его закрыть, чтобы освободить место в памяти. Делается это с помощью файлового метода close(). Свойство файлового объекта closed позволяет проверить закрыт ли файл.
>>> f1.close() >>> f1.closed True >>> f2.closed False
Если файл открывается в заголовке цикла (for i in open('fname')), то видимо интерпретатор его закрывает при завершении работы цикла или через какое-то время.
Практическая работа
Создайте файл data.
txt по образцу урока. Напишите программу, которая открывает этот файл на чтение, построчно считывает из него данные и записывает строки в другой файл (dataRu.txt), заменяя английские числительные русскими, которые содержатся в списке (["один", "два", "три", "четыре", "пять"]), определенном до открытия файлов.Создайте файл nums.txt, содержащий несколько чисел, записанных через пробел. Напишите программу, которая подсчитывает и выводит на экран общую сумму чисел, хранящихся в этом файле.
 txt по образцу урока. Напишите программу, которая открывает этот файл на чтение, построчно считывает из него данные и записывает строки в другой файл (dataRu.txt), заменяя английские числительные русскими, которые содержатся в списке (
txt по образцу урока. Напишите программу, которая открывает этот файл на чтение, построчно считывает из него данные и записывает строки в другой файл (dataRu.txt), заменяя английские числительные русскими, которые содержатся в списке (Примеры решения и дополнительные уроки в android-приложении и pdf-версии курса
Файлы в Python OTUS
Статья расскажет о работе с файлами в Python: о вводе и выводе, открытии, чтении, записи, закрытии и выполнении других не менее важных операций.
Файл представляет собой набор данных, сохраненных на компьютере, причем каждый файл имеет название — filename (имя файла, name of file).
В языке программирования Python выделяют 2 вида файлов:
— текстовые;
— бинарные.
Поговорим о каждом из типов подробнее.
Текстовые файлы. Формат .txtСодержимое таких файлов вполне понятно человеку. То есть речь идет об обычных общепринятых символах, тексте, цифрах и т. п. Такие документы можно без проблем создавать, открывать, читать и редактировать Блокнотом и прочими простейшими редакторами.
Также важно отметить, что текст хранят не только в форме .txt, но и в формате.rtf (так называемом «формате обогащенного текста»).
Бинарные файлы. Формат .binВ бинарных файлах отображение данных осуществляется в кодированной форме (применяются лишь нули и единицы). То есть речь идет уже о последовательности битов. Как следует из подзаголовка, для хранения используется формат .bin.
Основные операции
По сути, практически любую операцию с файлом мы можем разделить на 3 главных этапа:
- Открытие.
- Непосредственно выполнение операции (чтение, запись).
- Закрытие.
В «Питоне» существует встроенная функция open. Используя ее, вы сможете открыть файл на персональном компьютере. Технически, речь идет о создании на основе файла объекта.
Синтаксис относительно прост:
f = open(file_name, access_mode)
Что здесь что:
- file_name — это имя файла, который надо открыть;
- access_mode — это режим открытия файла. Это может быть чтение, запись и так далее. Если ничего не указать, будут справедливы настройки по умолчанию, те есть станет использоваться режим чтения (r).
Полный список режимов открытия смотрите в таблице ниже:
В качестве примера давайте выполним создание текстового файла test.txt с последующим сохранением его в рабочей директории.
Открыть созданный документ можно в режиме чтения из рабочей директории:
f = open('test. txt','r')
txt','r')
Здесь f представляет собой переменную-указатель на файл test.txt.
Идем далее. Код ниже выведет содержимое файла и информацию об этом файле.
>>> print(*f) # вывод содержимого
Hello, Otus!
>>> print(f) # вывод объекта
<_io.TextIOWrapper name='test.txt' mode='r' encoding='cp1252'>
Учтите, что в операционной системе «Виндовс» стандартная кодировка — это cp1252, в то время как в Linux — utf-08.
Закрытие. Метод closeРаз открыли, надо и закрыть — это высвободит ресурсы. Язык программирования Python автоматически закроет файл в том случае, если объект будет присвоен другому файлу.
Для закрытия есть несколько вариантов действий.
Вариант №1
Один из наиболее простых способов. Открытый файл закрываем с помощью метода close.
f = open('test.txt','r')
# работаем с файлом
f.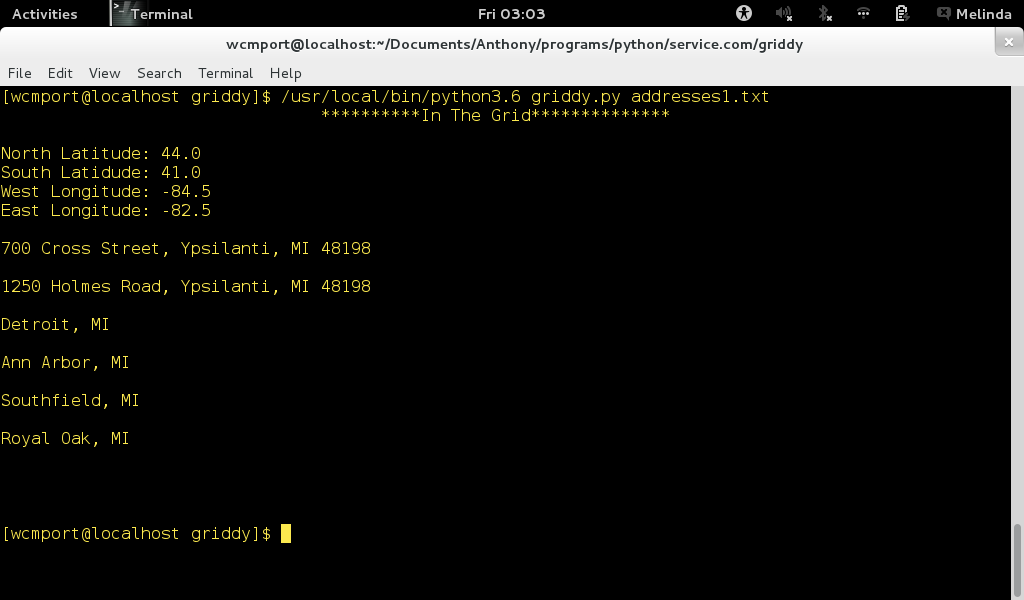 close()
close()
Все, документ закрыт (closed). Закрыв его таким образом, вы не сможете его использовать, пока не откроете по новой.
Вариант №2
Можно прописать try/finally. В результате файл закроется автоматически, если операции с ним приведут к исключениям. Закрытие произойдет до того, как остановится программа.
Синтаксис создания исключения следующий:
f = open('test.txt','r')
try:
# работаем с файлом
finally:
f.close()
Важно отметить, что файл следует открыть до срабатывания инструкции try.
Вариант №3
В третьем случае пригодится инструкция with, упрощающая обработку исключений посредством инкапсуляции начальных операций, а также задач по очистке и закрытию.
Тут уже инструкция close нужна не будет, так как with закроет файл автоматически.
Реализация в коде относительно проста:
with open('test. txt') as f:
txt') as f:
# работаем с документом
Используя соответствующие режимы, можно выполнять чтение информации и ее сохранение (save) в буфер памяти.
Функция readПрименяется для чтения содержимого после открытия документа в режиме чтения (r).
Вот, как это выглядит:
file.read(size)
Что здесь что:
- file — это объект файла;
- size — это число символов, которые необходимо прочесть. Если конкретное число не указывать, документ будет прочитан полностью.
>>> f = open('test.txt','r')
>>> f.read(7) # читаем семь символов из test.txt
Это функция обеспечивает построчное чтение (считывание) содержимого. Ее используют для работы с большими файлами, так как она позволяет получать доступ к конкретной строке, причем любой.
Для примера создадим test. txt со следующими строками:
txt со следующими строками:
This is Otus for developers 1.
This is Otus for developers 2.
This is Otus for developers 3.
И воспользуемся readline:
x = open('test.txt','r')
x.readline() # читаем первую строку
This is Otus for developers 1.
>>> x.readline(2) # читаем 2-ю строку
This is Otus for developers 2.
>>> x.readlines() # читаем все строки сразу
['This is Otus for developers 1.','This is Otus for developers 2.','This is Otus for developers 3.']
Чтобы выполнить сохранение, нужно использовать функцию write. Сохранение в буфер памяти возможно только в те документы, которые открыты для записи (их можно сохранять, когда они находятся в соответствующем режиме).
Синтаксис несложен:
file.write(string)
Если вы попытаетесь открыть в данном режиме файл, несуществующий в буфере, будет создан новый. Представим, что файла supertest.txt у нас нет. Однако при попытке его открыть в режиме чтения, он появится:
Представим, что файла supertest.txt у нас нет. Однако при попытке его открыть в режиме чтения, он появится:
f = open('supertest.txt','w') # открываем в режиме записи
f.write('Hello \n Otus') # пишем Hello Otus в документ
Hello
Otus
f.close() # закрываем документ
Может возникнуть необходимость в переименовании имен файлов (filenames). Вопрос можно решить посредством функции rename. Но чтобы это сделать, сначала надо импортировать модуль os.
Синтаксис:
import os
os.rename(src,dest)
Что здесь что:
- src — это файловый документ, которому надо изменить name;
- dest — это новое имя.
Вот, как это выглядит в коде:
import os
# переименовываем otus1.txt в otus2.txt
>>> os. rename("otus1.txt","otus2.txt")
rename("otus1.txt","otus2.txt")
В таблице ниже вы увидите основные методы, которые используются при работе с файлами (files) в «Пайтон»:
Источник
Как открыть файлы в Python
Автор оригинала: Pankaj Kumar.
Python дает нам методы обработки файлов в своей стандартной библиотеке. Это действительно удобно, как разработчик, поскольку вам действительно не нужно импортировать дополнительные модули для обработки файлов.
Ключевые методы, предоставленные нам Python для обработки файлов, являются Открыть () , Закрыть () , Написать () , Читать () , Ищите () и Добавить () Отказ
Давайте перейдем на Открыть () Метод, который позволяет нам открывать файлы в Python в разных режимах.
Открытые файлы в Python
Чтобы открыть файл, все, что нам нужно, это путь к каталогу, в котором находится файл. Если он находится в том же каталоге, то это, в том числе только полное имя файла будет достаточно.
Я создал файл с некотором образец текста в нем, который мы будем использовать в качестве образца для изучения метода открытого файла.
1. Открытие файла с помощью метода Open ()
Чтобы открыть OpenFile.txt и прочитайте текстовое содержимое файла, давайте использовать Открыть () и Читать () методы.
file = open('OpenFile.txt')
print(file.read())
file.close()
Читать () Метод будет прочитать все содержимое файла.
По умолчанию Открыть () Метод открывает файл в режиме только для чтения. Чтобы написать в файл, нам нужно указать, что файл должен быть открыт в режиме записи.
2. Разные режимы для Open () метода
Давайте попробуем написать файл с режимом по умолчанию.
file = open('OpenFile.txt')
print(file.read())
file.write("testing write")
file.close()
Мы будем держать операцию чтения, так как это так, чтобы мы могли видеть, где код останавливается.
Так что, что такое режимы, и как мы их добавляем? Ниже приведен список режимов при использовании метода Open ().
- R : Режим только для чтения.
- R +: Режим прочитанного и записи. Не будет создавать новый файл и открыть не удастся, если файл не существует
- RB : Двоичный режим только для чтения для чтения изображений, видео и т. Д.
- W: Режим только для записи. Перезаписывает существующий файл содержимого. Это создаст новый файл, если указанное имя файла не существует.
- W +: Режим прочитанного и записи.
- WB: Двоичный режим только для записи в Media файлы.
- WB +: Двоичный режим чтения и записи.
- A: Режим добавления. Не перезаписывает существующий контент
- A +: Присоединяйтесь и читайте режим. Он создаст новый файл, если имя файла не существует.
- AB: Добавьте двоичный режим для изображений, видео и т. Д.
- AB +: Добавьте и читайте двоичный режим.
 Д.
Д.3. Открытие файлов в режиме записи в Python
Есть несколько способов открыть файл в режиме записи в Python. В зависимости от того, как вы хотите, чтобы методы обработки файлов писать в файл, вы можете использовать один из режимов ниже.
file = open('OpenFile. txt', 'w')
print(file.read())
file.close()
 txt', 'w')
print(file.read())
file.close()
txt', 'w')
print(file.read())
file.close()
Добавляя «W» при открытии файла в первой строке, мы указываем, что файл должен быть открыт в режиме записи. Но Эта операция потерпит неудачу ТОО Потому что файл – только для записи И не позволит нам использовать метод чтения ().
file = open('OpenFile.txt', 'w')
file.write('New content\n')
file.close()
Приведенный выше код полностью очистит все содержимое текстового файла и вместо этого просто сказать «новый контент».
Если вы не хотите перезаписать файл, Вы можете использовать А + или R + Режимы.
Режим R + напишет любой контент, переданный на Написать () метод.
file = open('OpenFile.txt', 'r+')
print(file.read())
file.write('r+ method, adds a line\n')
file.close()
Режим A или A + будет выполнять то же действие, что и режим R + с одним главным отличием.
В случае метода R +, Новый файл не будет создан Если указанное имя файла не существует. Но с помощью режима A + новый файл будет создан, если указанный файл недоступен.
4. Открытие файлов с использованием предложения
При чтении файлов с Открыть () Метод, вам всегда нужно убедиться, что Закрыть () Метод называется, чтобы избежать утечек памяти. Как разработчик, вы можете пропустить при добавлении Закрыть () Метод, вызывающий вашу программу утечку памяти файла из-за открытия файла.
С меньшими файлами, на системных ресурсах не очень заметное влияние, но он будет отображаться при работе с большим файлами.
with open('OpenFile.txt', 'r+') as file:
print(file.read())
В приведенном выше примере вывод будет таким же, как те, которые мы видели в начале, но нам не нужно закрывать файл.
А с Блок получает блокировку, как только он выполняется и выпускает блокировку после окончания блока.
Вы также можете запустить другие методы на данных во время пребывания в с код кода. Я отредактировал OpenFile.txt, в этом случае и добавил еще несколько текстов для лучшего понимания.
with open('OpenFile. txt', 'r+') as file:
lines = file.readlines()
for line in lines:
print(line.split())
 txt', 'r+') as file:
lines = file.readlines()
for line in lines:
print(line.split())
txt', 'r+') as file:
lines = file.readlines()
for line in lines:
print(line.split())
с Заявление делает память для нас, пока мы продолжаем работать в его объеме. Это еще один, но лучший способ работать с файлами в Python.
Заключение
Теперь вы должны понять, как открыть файл в Python и обрабатывать различные режимы для открытия файла с помощью метода Open (). Мы рассмотрим дополнительные методы обработки файлов в предстоящих учебных пособиях.
Python | Текстовые файлы
Последнее обновление: 21.06.2017
Запись в текстовый файл
Чтобы открыть текстовый файл на запись, необходимо применить режим w (перезапись) или a (дозапись). Затем для записи применяется метод write(str), в который передается записываемая строка. Стоит отметить, что записывается именно строка, поэтому, если нужно записать числа, данные других типов, то их предварительно нужно конвертировать в строку.
Запишем некоторую информацию в файл «hello. txt»:
txt»:
with open("hello.txt", "w") as file:
file.write("hello world")
Если мы откроем папку, в которой находится текущий скрипт Python, то увидем там файл hello.txt. Этот файл можно открыть в любом текстовом редакторе и при желании изменить.
Теперь дозапишем в этот файл еще одну строку:
with open("hello.txt", "a") as file:
file.write("\ngood bye, world")
Дозапись выглядит как добавление строку к последнему символу в файле, поэтому, если необходимо сделать запись с новой строки, то можно использовать эскейп-последовательность «\n». В итоге файл hello.txt будет иметь следующее содержимое:
hello world good bye, world
Еще один способ записи в файл представляет стандартный метод print(), который применяется для вывода данных на консоль:
with open("hello.txt", "a") as hello_file:
print("Hello, world", file=hello_file)
Для вывода данных в файл в метод print в качестве второго параметра передается название файла через параметр file. А первый параметр представляет записываемую
в файл строку.
А первый параметр представляет записываемую
в файл строку.
Чтение файла
Для чтения файла он открывается с режимом r (Read), и затем мы можем считать его содержимое различными методами:
readline(): считывает одну строку из файла
read(): считывает все содержимое файла в одну строку
readlines(): считывает все строки файла в список
Например, считаем выше записанный файл построчно:
with open("hello.txt", "r") as file:
for line in file:
print(line, end="")
Несмотря на то, что мы явно не применяем метод readline() для чтения каждой строки, но в при переборе файла этот метод автоматически вызывается
для получения каждой новой строки. Поэтому в цикле вручную нет смысла вызывать метод readline. И поскольку строки разделяются символом перевода строки «\n», то чтобы исключить излишнего переноса на другую строку в функцию
print передается значение end="".
Теперь явным образом вызовем метод readline() для чтения отдельных строк:
with open("hello.txt", "r") as file:
str1 = file.readline()
print(str1, end="")
str2 = file.readline()
print(str2)
Консольный вывод:
hello world good bye, world
Метод readline можно использовать для построчного считывания файла в цикле while:
with open("hello.txt", "r") as file:
line = file.readline()
while line:
print(line, end="")
line = file.readline()
Если файл небольшой, то его можно разом считать с помощью метода read():
with open("hello.txt", "r") as file:
content = file.read()
print(content)
И также применим метод readlines() для считывания всего файла в список строк:
with open("hello.txt", "r") as file:
contents = file.readlines()
str1 = contents[0]
str2 = contents[1]
print(str1, end="")
print(str2)
При чтении файла мы можем столкнуться с тем, что его кодировка не совпадает с ASCII. В этом случае мы явным образом можем указать кодировку с помощью
параметра encoding:
В этом случае мы явным образом можем указать кодировку с помощью
параметра encoding:
filename = "hello.txt"
with open(filename, encoding="utf8") as file:
text = file.read()
Теперь напишем небольшой скрипт, в котором будет записывать введенный пользователем массив строк и считывать его обратно из файла на консоль:
# имя файла
FILENAME = "messages.txt"
# определяем пустой список
messages = list()
for i in range(4):
message = input("Введите строку " + str(i+1) + ": ")
messages.append(message + "\n")
# запись списка в файл
with open(FILENAME, "a") as file:
for message in messages:
file.write(message)
# считываем сообщения из файла
print("Считанные сообщения")
with open(FILENAME, "r") as file:
for message in file:
print(message, end="")
Пример работы программы:
Введите строку 1: hello Введите строку 2: world peace Введите строку 3: great job Введите строку 4: Python Считанные сообщения hello world peace great job Python
НазадСодержаниеВперед
Чтение и запись файлов в Python
В этом руководстве вы узнаете об операциях с файлами Python. В частности, открытие файла, чтение из него, запись в него, закрытие и различные методы работы с файлами, о которых вам следует знать.
В частности, открытие файла, чтение из него, запись в него, закрытие и различные методы работы с файлами, о которых вам следует знать.
Файлы
Файлы — это именованные места на диске для хранения связанной информации. Они используются для постоянного хранения данных в энергонезависимой памяти (например, на жестком диске).
Поскольку оперативная память (ОЗУ) является энергозависимой (которая теряет свои данные при выключении компьютера), мы используем файлы для будущего использования данных, сохраняя их постоянно.
Когда мы хотим прочитать файл или записать в него, нам нужно сначала его открыть. Когда мы закончим, его нужно закрыть, чтобы освободить ресурсы, которые завязаны с файлом.
Следовательно, в Python файловая операция выполняется в следующем порядке:
- Открыть файл
- Чтение или запись (выполнение операции)
- Закрыть файл
Открытие файлов в Python
Python имеет встроенную функцию open() для открытия файла. Эта функция возвращает файловый объект, также называемый дескриптором, поскольку он используется для чтения или изменения файла соответствующим образом.
Эта функция возвращает файловый объект, также называемый дескриптором, поскольку он используется для чтения или изменения файла соответствующим образом.
>>> f = open("test.txt") # открыть файл в текущем каталоге
>>> f = open("C:/Python38/README.txt") # указание полного пути Мы можем указать режим при открытии файла. В режиме мы указываем, хотим ли мы читать r , записывать w или добавлять к в файл. Мы также можем указать, хотим ли мы открыть файл в текстовом или двоичном режиме.
По умолчанию чтение в текстовом режиме. В этом режиме мы получаем строки при чтении из файла.
С другой стороны, двоичный режим возвращает байты, и этот режим следует использовать при работе с нетекстовыми файлами, такими как изображения или исполняемые файлы.
| Режим | Описание |
|---|---|
р | Открывает файл для чтения. (по умолчанию) |
ш | Открывает файл для записи. Создает новый файл, если он не существует, или усекает файл, если он существует. Создает новый файл, если он не существует, или усекает файл, если он существует. |
х | Открывает файл для монопольного создания. Если файл уже существует, операция завершится ошибкой. |
и | Открывает файл для добавления в конец файла без его усечения. Создает новый файл, если он не существует. |
т | Открывается в текстовом режиме. (по умолчанию) |
б | Открывается в двоичном режиме. |
+ | Открывает файл для обновления (чтения и записи) |
f = open("test.txt") # эквивалентно 'r' или 'rt'
f = open("test.txt",'w') # запись в текстовом режиме
f = open("img.bmp",'r+b') # чтение и запись в двоичном режиме В отличие от других языков, символ a не подразумевает число 97, пока он не будет закодирован с использованием ASCII (или другие эквивалентные кодировки).
Более того, кодировка по умолчанию зависит от платформы. В винде cp1252 , но utf-8 в Linux.
Таким образом, мы не должны также полагаться на кодировку по умолчанию, иначе наш код будет вести себя по-разному на разных платформах.
Поэтому при работе с файлами в текстовом режиме настоятельно рекомендуется указывать тип кодировки.
f = open("test.txt", mode='r', encoding='utf-8') Закрытие файлов в Python
Когда мы закончим выполнение операций над файлом, нам нужно правильно закрыть файл.
Закрытие файла освобождает ресурсы, которые были связаны с файлом. Это делается с помощью метода close() , доступного в Python.
В Python есть сборщик мусора для очистки объектов, на которые нет ссылок, но мы не должны полагаться на него при закрытии файла.
f = открыть ("test.txt", кодировка = 'utf-8')
# выполняем файловые операции
f.close() Этот метод не совсем безопасен.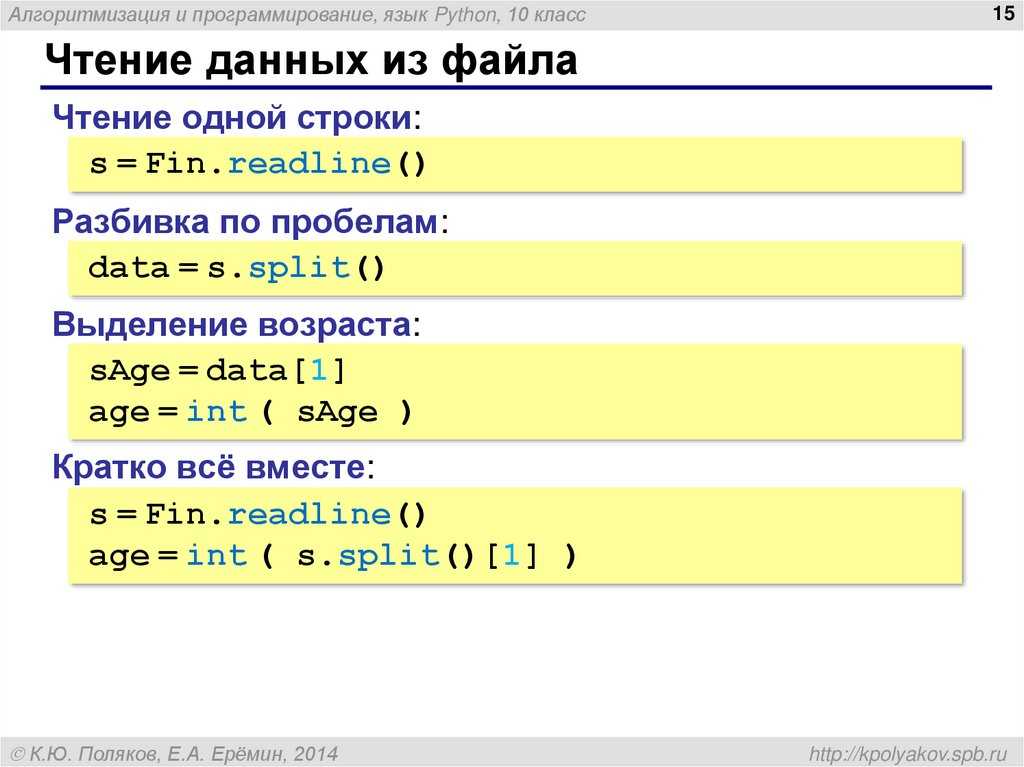 Если возникает исключение, когда мы выполняем какую-либо операцию с файлом, код завершает работу, не закрывая файл.
Если возникает исключение, когда мы выполняем какую-либо операцию с файлом, код завершает работу, не закрывая файл.
Безопаснее использовать блок try…finally.
попробуйте:
f = открыть ("test.txt", кодировка = 'utf-8')
# выполняем файловые операции
в конце концов:
f.close() Таким образом, мы гарантируем правильное закрытие файла, даже если возникает исключение, которое приводит к остановке выполнения программы.
Лучший способ закрыть файл — использовать оператор with . Это гарантирует, что файл будет закрыт при выходе из блока внутри оператора with .
Нам не нужно явно вызывать метод close() . Это делается внутри.
с открытым ("test.txt", encoding = 'utf-8') как f:
# выполнять операции с файлами Запись в файлы на Python
Чтобы записать в файл на Python, нам нужно открыть его в режиме записи w , добавить к или эксклюзивном режиме создания x .
Нам нужно быть осторожными с режимом w , так как он перезапишет файл, если он уже существует. Благодаря этому все предыдущие данные стираются.
Запись строки или последовательности байтов (для двоичных файлов) выполняется с помощью метода write() . Этот метод возвращает количество символов, записанных в файл.
с открытым("test.txt",'w',encoding = 'utf-8') как f:
f.write("мой первый файл\n")
f.write("Этот файл\n\n")
f.write("содержит три строки\n") Эта программа создаст новый файл с именем test.txt в текущем каталоге, если он не существует. Если он существует, он перезаписывается.
Мы должны сами включать символы новой строки, чтобы различать разные строки.
Чтение файлов в Python
Чтобы прочитать файл в Python, мы должны открыть файл в режиме чтения r .
Для этой цели доступны различные методы. Мы можем использовать метод read(size) для чтения данных размера . Если параметр размер не указан, он считывает и возвращает до конца файла.
Если параметр размер не указан, он считывает и возвращает до конца файла.
Мы можем прочитать файл text.txt , который мы написали в предыдущем разделе, следующим образом:
>>> f = open("test.txt",'r',encoding = 'utf-8')
>>> f.read(4) # прочитать первые 4 данных
'Этот'
>>> f.read(4) # прочитать следующие 4 данных
' является '
>>> f.read() # прочитать остаток до конца файла
'мой первый файл\nЭтот файл\nсодержит три строки\n'
>>> f.read() # дальнейшее чтение возвращает пустую строку
'' Мы видим, что Метод read() возвращает новую строку как '\n' . Как только конец файла достигнут, мы получаем пустую строку при дальнейшем чтении.
Мы можем изменить текущий файловый курсор (положение), используя метод seek() . Точно так же метод tell() возвращает нашу текущую позицию (в байтах).
>>> f.tell() # получить текущую позицию в файле 56 >>> f.seek(0) # установить файловый курсор в исходное положение 0 >>> print(f.
 read()) # прочитать весь файл
это мой первый файл
Этот файл
состоит из трех строк
read()) # прочитать весь файл
это мой первый файл
Этот файл
состоит из трех строк Мы можем читать файл построчно, используя цикл for. Это и эффективно, и быстро.
>>> для строки в f: ... печать (строка, конец = '') ... это мой первый файл Этот файл содержит три строки
В этой программе строки в самом файле содержат символ новой строки \n . Итак, мы используем конечный параметр функции print() , чтобы избежать двух новых строк при печати.
Кроме того, мы можем использовать метод readline() для чтения отдельных строк файла. Этот метод читает файл до новой строки, включая символ новой строки.
>>> f.readline() 'Это мой первый файл\n' >>> f.readline() 'Этот файл\n' >>> f.readline() 'содержит три строки\n' >>> f.readline() ''
Наконец, метод readlines() возвращает список оставшихся строк всего файла. Все эти методы чтения возвращают пустые значения при достижении конца файла (EOF).
>>> f.readlines() ['Это мой первый файл\n', 'Этот файл\n', 'содержит три строки\n']
Файловые методы Python
Существуют различные методы, доступные с файловым объектом. Некоторые из них использовались в приведенных выше примерах.
Вот полный список методов в текстовом режиме с кратким описанием:
| Метод | Описание |
|---|---|
| закрыть() | Закрывает открытый файл. Это не имеет никакого эффекта, если файл уже закрыт. |
| отсоединить() | Отделяет базовый двоичный буфер от TextIOBase и возвращает его. |
| файлно() | Возвращает целое число (дескриптор файла) файла. |
| смыв() | Очищает буфер записи файлового потока. |
| isatty() | Возвращает True , если файловый поток является интерактивным. |
| чтение( n ) | Читает не более n символов из файла. Читает до конца файла, если он отрицательный или Читает до конца файла, если он отрицательный или Нет . |
| читаемый() | Возвращает True , если файловый поток доступен для чтения. |
| readline( n =-1) | Читает и возвращает одну строку из файла. Считывает не более n байт, если указано. |
| строки чтения( n =-1) | Читает и возвращает список строк из файла. Считывает не более n байт/символов, если указано. |
поиск ( смещение , от = SEEK_SET ) | Изменяет позицию файла на со смещением байт относительно с (начало, текущая, конец). |
| поиск() | Возвращает True , если файловый поток поддерживает произвольный доступ. |
| рассказать() | Возвращает целое число, представляющее текущую позицию объекта файла. |
усечение (размер = Нет ) | Изменяет размер файлового потока до размера байт. Если размер не указан, размер изменяется в соответствии с текущим местоположением. Если размер не указан, размер изменяется в соответствии с текущим местоположением. |
| запись() | Возвращает True , если файловый поток может быть записан. |
| запись( с ) | Записывает строку s в файл и возвращает количество записанных символов. |
| строки записи( строк ) | Записывает в файл список из строк . |
Чтение и запись файлов CSV
В этом руководстве мы научимся читать и записывать файлы CSV в Python с помощью примеров.
Формат CSV (значения, разделенные запятыми) — один из самых простых и распространенных способов хранения табличных данных. Чтобы представить файл CSV, он должен быть сохранен с расширением .csv .
Возьмем пример:
Если вы откроете указанный выше файл CSV с помощью текстового редактора, такого как возвышенный текст, вы увидите:
SN, Имя, Город 1, Майкл, Нью-Джерси 2, Джек, Калифорния
Как видите, элементы файла CSV разделены запятыми. Здесь
Здесь , — разделитель.
Вы можете использовать любой символ в качестве разделителя в соответствии с вашими потребностями.
Примечание: Модуль csv также можно использовать для других расширений файлов (например: .txt ), если их содержимое имеет правильную структуру.
Работа с файлами CSV в Python
Хотя мы могли бы использовать встроенную функцию open() для работы с файлами CSV в Python, существует специальный модуль csv , который значительно упрощает работу с файлами CSV.
Прежде чем мы сможем использовать методы модуля csv , нам нужно сначала импортировать модуль, используя:
import csv
Чтение файлов CSV с помощью csv.reader()
Чтобы прочитать файл CSV в Python, мы можем использовать функцию csv.reader() . Предположим, у нас есть файл csv с именем people.csv в текущем каталоге со следующими записями.
| Имя | Возраст | Профессия |
| Домкрат | 23 | Доктор |
| Миллер | 22 | Инженер |
Давайте прочитаем этот файл, используя csv.reader() :
Пример 1: Чтение CSV с разделителем-запятой
import csv
с open('people.csv', 'r') в виде файла:
читатель = csv.reader (файл)
для строки в читателе:
печать (строка)
Выход
['Имя', 'Возраст', 'Профессия'] ['Джек', '23', 'Доктор'] ['Миллер', '22', 'Инженер']
Здесь мы открыли файл people.csv в режиме чтения, используя:
с файлом open('people.csv', 'r'):
.. .. ...
Чтобы узнать больше об открытии файлов в Python, посетите: Python File Input/Output
Затем для чтения файла используется csv.reader() , который возвращает повторяемый объект reader .
Объект считывателя затем повторяется с использованием цикла for для печати содержимого каждой строки.
В приведенном выше примере мы используем функцию csv.reader() в режиме по умолчанию для файлов CSV с разделителем-запятой.
Однако эта функция гораздо более настраиваема.
Предположим, что наш CSV-файл использует в качестве разделителя вкладку . Чтобы прочитать такие файлы, мы можем передать необязательные параметры в функцию csv.reader() . Возьмем пример.
Пример 2: чтение CSV-файла с разделителем табуляции
импорт CSV
с open('people.csv', 'r',) в виде файла:
читатель = csv.reader (файл, разделитель = '\ t')
для строки в читателе:
печать (строка)
Обратите внимание на необязательный параметр разделитель = '\t' в приведенном выше примере.
Полный синтаксис функции csv.reader() :
Как видно из синтаксиса, мы также можем передать параметр диалекта в функцию csv. reader() . Параметр диалект позволяет сделать функцию более гибкой. Чтобы узнать больше, посетите: Чтение файлов CSV в Python.
Запись файлов CSV с помощью csv.writer()
Чтобы записать файл CSV в Python, мы можем использовать функцию csv.writer () .
Функция csv.writer() возвращает объект Writer , который преобразует данные пользователя в строку с разделителями. Позже эту строку можно будет использовать для записи в CSV-файлы с помощью функции writerow(). Возьмем пример.
Пример 3. Запись в файл CSV
импорт csv
с open('protagonist.csv', 'w', newline='') в виде файла:
писатель = csv.writer (файл)
Writer.writerow(["SN", "Фильм", "Главный герой"])
author.writerow([1, "Властелин колец", "Фродо Бэггинс"])
author.writerow([2, "Гарри Поттер", "Гарри Поттер"])
Когда мы запускаем указанную выше программу, создается файл protagonist.csv со следующим содержимым:
SN, фильм, главный герой 1, Властелин колец, Фродо Бэггинс 2, Гарри Поттер, Гарри Поттер
В приведенной выше программе мы открыли файл в режиме записи.
Затем мы передали каждую строку как список. Эти списки преобразуются в строку с разделителями и записываются в файл CSV.
Пример 4. Запись нескольких строк с помощью writerows()
Если нам нужно записать содержимое двумерного списка в файл CSV, вот как мы можем это сделать.
импорт CSV
csv_rowlist = [["SN", "Фильм", "Главный герой"], [1, "Властелин колец", "Фродо Бэггинс"],
[2, «Гарри Поттер», «Гарри Поттер»]]
с open('protagonist.csv', 'w') в виде файла:
писатель = csv.writer (файл)
писатель.writerows (csv_rowlist)
Вывод программы такой же, как и в Пример 3 .
Здесь наш двумерный список передается в write.writerows() метод для записи содержимого списка в файл CSV.
Пример 5. Запись в файл CSV с разделителем табуляции
import csv
с open('protagonist.csv', 'w') в виде файла:
писатель = csv.writer (файл, разделитель = '\ t')
Writer.writerow(["SN", "Фильм", "Главный герой"])
author. writerow([1, "Властелин колец", "Фродо Бэггинс"])
author.writerow([2, "Гарри Поттер", "Гарри Поттер"])
Обратите внимание на необязательный параметр delimiter = '\t' в функции csv.writer() .
Полный синтаксис функции csv.writer() :
Подобно csv.reader() , вы также можете передать диалектный параметр функции csv.writer() , чтобы сделать функцию более настраиваемой. Чтобы узнать больше, посетите: Написание файлов CSV в Python
Python csv.DictReader() Class
Объекты Класс csv.DictReader() можно использовать для чтения файла CSV в качестве словаря.
Пример 6: Python csv.DictReader()
Предположим, у нас есть тот же файл people.csv , что и в Примере 1 .
| Имя | Возраст | Профессия |
| Домкрат | 23 | Доктор |
| Миллер | 22 | Инженер |
Давайте посмотрим, как можно использовать csv.. DictReader()
импорт CSV
с open("people.csv", 'r') в виде файла:
csv_file = csv.DictReader(файл)
для строки в csv_file:
печать (дикт (строка))
Выход
{'Имя': 'Джек', 'Возраст': '23', 'Профессия': 'Доктор'}
{'Имя': 'Миллер', 'Возраст': '22', 'Профессия': 'Инженер'}
Как мы видим, записи первой строки являются ключами словаря. И записи в других строках являются значениями словаря.
Здесь csv_file — это объект csv.DictReader() . Объект можно перебирать с помощью цикла for . csv.DictReader() возвратил тип OrderedDict для каждой строки. Вот почему мы использовали dict() для преобразования каждой строки в словарь.
Обратите внимание, что мы явно использовали метод dict() для создания словарей внутри цикла for .
печать (дикт (строка))
Примечание : Начиная с Python 3. 8, csv.DictReader() возвращает словарь для каждой строки, и нам не нужно явно использовать dict() .
Полный синтаксис класса csv.DictReader() : )
Чтобы узнать об этом подробнее, посетите: Python csv.DictReader() class
Python csv.DictWriter() Class
Объекты Класс csv.DictWriter() можно использовать для записи в файл CSV из словаря Python.
Минимальный синтаксис класса csv.DictWriter() :
csv.DictWriter(file, fieldnames)
Здесь,
-
файл— CSV файл куда мы хотим записать -
имена полей— объект списка
Пример 7: Python csv.DictWriter()
импорт csv
с open('players.csv', 'w', newline='') в виде файла:
fieldnames = ['player_name', 'fide_rating']
писатель = csv. DictWriter (файл, имена полей = имена полей)
писатель.writeheader()
Writer.writerow({'player_name': 'Магнус Карлсен', 'fide_rating': 2870})
Writer.writerow({'player_name': 'Фабиано Каруана', 'fide_rating': 2822})
Writer.writerow({'player_name': 'Дин Лижэнь', 'fide_rating': 2801})
Программа создает Файл player.csv со следующими записями:
player_name,fide_rating Магнус Карлсен, 2870 Фабиано Каруана, 2822 г. Дин Лижэнь, 2801
Полный синтаксис класса csv.DictWriter() :
csv.DictWriter(f, fieldnames, restval='', extrasaction='raise', dialect='excel', *args, * *kwds)
Чтобы узнать больше об этом, посетите: Python csv.DictWriter() class
Использование библиотеки Pandas для обработки файлов CSV
Pandas — это популярная библиотека данных на Python для обработки и анализа данных. Если мы работаем с огромными объемами данных, для простоты и эффективности лучше использовать pandas для обработки CSV-файлов.
Прежде чем мы сможем использовать pandas, нам нужно установить его. Чтобы узнать больше, посетите: Как установить Pandas?
После установки мы можем импортировать Pandas как:
импортировать pandas как pd
Чтобы прочитать файл CSV с помощью pandas, мы можем использовать read_csv() 9Функция 0027.
импортировать панд как pd
pd.read_csv("люди.csv")
Здесь программа считывает people.csv из текущего каталога.
Для записи в файл CSV нам нужно вызвать функцию to_csv() DataFrame.
импортировать панд как pd
# создание фрейма данных
df = pd.DataFrame([['Джек', 24], ['Роза', 22]], columns = ['Имя', 'Возраст'])
# запись фрейма данных в файл CSV
df.to_csv('person.csv')
Здесь мы создали DataFrame, используя Метод pd.DataFrame() . Затем вызывается функция to_csv() для этого объекта, чтобы записать в person.csv .
Чтобы узнать больше, посетите:
- Python pandas. read_csv (официальный сайт)
- Python pandas.pandas.DataFrame.to_csv (официальный сайт)
Чтение, запись, анализ JSON (с примерами)
В этом руководстве вы научитесь анализировать, читать и писать JSON в Python с помощью примеров. Кроме того, вы научитесь преобразовывать JSON в dict и красиво печатать его.
JSON ( J ava S cript O bject N otation) — популярный формат данных, используемый для представления структурированных данных. Обычно данные между сервером и веб-приложением передаются и получаются в формате JSON.
В Python JSON существует в виде строки. Например:
p = '{"имя": "Боб", "языки": ["Python", "Java"]}'
Также обычно объект JSON хранится в файле.
Модуль импорта json
Для работы с JSON (строка или файл, содержащий объект JSON) вы можете использовать модуль Python json . Вам необходимо импортировать модуль, прежде чем вы сможете его использовать.
import json
Анализ JSON в Python
Модуль json упрощает анализ строк и файлов JSON, содержащих объект JSON.
Пример 1: Python JSON для dict
Вы можете проанализировать строку JSON, используя метод json.loads() . Метод возвращает словарь.
импорт json
человек = '{"имя": "Боб", "языки": ["английский", "французский"]}'
person_dict = json.loads (человек)
# Вывод: {'имя': 'Боб', 'языки': ['английский', 'французский']}
печать(человек_дикт)
# Вывод: ['Английский', 'Французский']
print(person_dict['languages']) Здесь person — это строка JSON, а person_dict — словарь.
Пример 2: Python читает файл JSON
Вы можете использовать метод json.load() для чтения файла, содержащего объект JSON.
Предположим, у вас есть файл с именем person.json , который содержит объект JSON.
{"имя": "Боб",
"языки": ["английский", "французский"]
}
Вот как вы можете разобрать этот файл:
импортировать json
с open('path_to_file/person. json', 'r') как f:
данные = json.load(f)
# Вывод: {'имя': 'Боб', 'языки': ['английский', 'французский']}
печать (данные)
Здесь мы использовали функцию open() для чтения файла json. Затем файл анализируется с использованием json.load() , который дает нам словарь с именем data .
Если вы не знаете, как читать и записывать файлы в Python, мы рекомендуем вам проверить файловый ввод-вывод Python.
Преобразование Python в строку JSON
Вы можете преобразовать словарь в строку JSON, используя метод json.dumps() .
Пример 3. Преобразование dict в JSON
импортировать json
person_dict = {'имя': 'Боб',
'возраст': 12,
«дети»: нет
}
person_json = json.dumps(person_dict)
# Вывод: {"name": "Боб", "возраст": 12, "дети": null}
печать (person_json)
Вот таблица, показывающая объекты Python и их эквивалентное преобразование в JSON.
| Питон | JSON Эквивалент |
|---|---|
дикт | объект |
список , кортеж | массив |
ул | строка |
целое число , число с плавающей запятой , целое число | номер |
Правда | правда |
Ложь | ложь |
Нет | ноль |
Запись JSON в файл
Чтобы записать JSON в файл на Python, мы можем использовать метод json.. dump()
Пример 4. Запись JSON в файл
импортировать json
person_dict = {"имя": "Боб",
"языки": ["английский", "французский"],
"замужем": Правда,
"возраст": 32
}
с open('person.txt', 'w') как json_file:
json.dump(person_dict, json_file)
В приведенной выше программе мы открыли файл с именем person.txt в режиме записи, используя 'w' . Если файл еще не существует, он будет создан. Затем json.dump() преобразует person_dict в строку JSON, которая будет сохранена в файле person.txt .
При запуске программы будет создан файл person.txt . Файл имеет следующий текст внутри него.
{"имя": "Боб", "языки": ["английский", "французский"], "замужем": правда, "возраст": 32} Python pretty print JSON
Для анализа и отладки данных JSON нам может потребоваться распечатать их в более читаемом формате. Это можно сделать, передав дополнительные параметры indent и sort_keys в методы json. и dumps() json.dump() .
Пример 5: красивая печать Python JSON
импортировать json
person_string = '{"name": "Боб", "languages": "English", "numbers": [2, 1.6, null]}'
# Получение словаря
person_dict = json.loads(person_string)
# Красивая печать строки JSON назад
печать (json.dumps (person_dict, отступ = 4, sort_keys = True))
Когда вы запустите программу, вывод будет:
{
"языки": "английский",
"имя": "Боб",
"числа": [
2,
1,6,
нулевой
]
}
В приведенной выше программе мы использовали 4 пробелов для отступов. И ключи сортируются в порядке возрастания.
Кстати, значение по умолчанию для отступа равно Нет . И значение по умолчанию sort_keys равно False .
Рекомендуемые чтения:
- Python JSON в CSV и наоборот
- Python XML в JSON и наоборот
- Простой Python
Обработка файлов в Python — GeeksforGeeks
Python также поддерживает работу с файлами и позволяет пользователям обрабатывать файлы, т. е. читать и записывать файлы, наряду со многими другими вариантами обработки файлов, чтобы работать с файлами. Концепция обработки файлов распространена на многие другие языки, но ее реализация либо сложна, либо длинна, но, как и другие концепции Python, здесь эта концепция также проста и кратка. Python по-разному обрабатывает файлы как текстовые или двоичные, и это важно. Каждая строка кода включает в себя последовательность символов, и они образуют текстовый файл. Каждая строка файла завершается специальным символом, называемым EOL или символами конца строки, такими как запятая {,} или символ новой строки. Он заканчивает текущую строку и сообщает интерпретатору, что началась новая. Начнем с чтения и записи файлов.
Прежде чем выполнять какие-либо операции с файлом, такие как чтение или запись, сначала мы должны открыть этот файл. Для этого мы должны использовать встроенную функцию Python open(), но во время открытия мы должны указать режим, который представляет цель открытия файла.
f = open(имя файла, режим)
Если поддерживается следующий режим:
- r: открыть существующий файл для операции чтения.
- w: открыть существующий файл для операции записи. Если файл уже содержит некоторые данные, он будет переопределен.
- a: открыть существующий файл для операции добавления. Он не будет переопределять существующие данные.
- r+: Для чтения и записи данных в файл. Предыдущие данные в файле будут переопределены.
- w+: Для записи и чтения данных. Он переопределит существующие данные.
- a+: Для добавления и чтения данных из файла. Он не будет переопределять существующие данные.
Take a look at the below example:
Python3
|
|
Другой способ прочитать файл - вызвать определенное количество символов, как в следующем коде, интерпретатор прочитает первые пять символов сохраненных данных и return it as a string:
Python3
|
режим работает, поэтому для управления файлом напишите в среде Python следующее:
Python3
|
Команда close() завершает использование всех ресурсов и освобождает систему этой конкретной программы.
Давайте посмотрим, как работает режим приложения:
Python3
rstrip(): Эта функция удаляет пробелы с правой стороны каждой строки файла. lstrip(): эта функция удаляет пробелы с левой стороны каждой строки файла. Он предназначен для более чистого синтаксиса и обработки исключений при работе с кодом. Это объясняет, почему рекомендуется использовать их с оператором там, где это применимо. Это полезно, потому что при использовании этого метода любые открытые файлы будут автоматически закрыты после того, как один из них будет завершен, поэтому выполняется автоматическая очистка. Пример: Python3
Мы также можем использовать функцию записи вместе с функцией with(): Python3
Мы также можем разделить строки с помощью обработки файлов в Python. Это разбивает переменную, когда встречается пробел. Вы также можете разделить, используя любые символы, как мы хотим. Python3
Существуют также различные другие функции, которые помогают управлять файлами и содержимым. Эту статью предоставил Чинмой Ленка . Если вам нравится GeeksforGeeks и вы хотите внести свой вклад, вы также можете написать статью с помощью write.geeksforgeeks.org или отправить ее по адресу [email protected]. Посмотрите, как ваша статья появится на главной странице GeeksforGeeks, и помогите другим гикам. Пожалуйста, пишите в комментариях, если вы обнаружите что-то неправильное или если вы хотите поделиться дополнительной информацией по обсуждаемой выше теме. Работа с файлами в Python — Real PythonСмотреть сейчас Это руководство содержит соответствующий видеокурс, созданный командой Real Python. Посмотрите его вместе с письменным учебным пособием, чтобы углубить свое понимание: Практические рецепты для работы с файлами в Python Python имеет несколько встроенных модулей и функций для работы с файлами. Эти функции распределены по нескольким модулям, таким как В этом руководстве вы узнаете, как:
Бесплатный бонус: 5 Thoughts On Python Mastery, бесплатный курс для разработчиков Python, который показывает вам дорожную карту и образ мышления, которые вам понадобятся, чтобы вывести свои навыки Python на новый уровень. Паттерн Python «с открытым(…) как…»Чтение и запись данных в файлы с помощью Python довольно просты. Для этого необходимо сначала открыть файлы в соответствующем режиме. Вот пример использования шаблона Python «with open(…) as…», чтобы открыть текстовый файл и прочитать его содержимое: с open('data.txt', 'r') как f:
данные = f.read()
с open('data.txt', 'w') как f:
data = 'некоторые данные для записи в файл'
f.запись (данные)
В приведенных выше примерах Удалить рекламу Получение списка каталогов Предположим, что в вашем текущем рабочем каталоге есть подкаталог с именем мой_каталог/ | ├── sub_dir/ | ├── bar.py | └── foo.py | ├── sub_dir_b/ | └── файл4.txt | ├── sub_dir_c/ | ├── config.py | └── файл5.txt | ├── file1.py ├── файл2.csv └── файл3.txt Встроенный модуль Список каталогов в устаревших версиях Python В версиях Python до Python 3 метод >>> >>> импорт ОС
>>> записи = os.listdir('my_directory/')
>>> >>> os.listdir('my_directory/')
['sub_dir_c', 'file1.py', 'sub_dir_b', 'file3.txt', 'file2.csv', 'sub_dir']
Такой список каталогов нелегко читать. Распечатка вывода вызова >>> >>> записи = os.listdir('мой_каталог/')
>>> для записи в записи:
... печать (ввод)
...
...
sub_dir_c
файл1.py
sub_dir_b
файл3.txt
файл2.csv
sub_dir
Список каталогов в современных версиях Python В современных версиях Python альтернативой >>> >>> импорт ОС
>>> записи = os.scandir('my_directory/')
>>> записи
<объект posix.ScandirIterator по адресу 0x7f5b047f3690>
импорт ОС
с os.scandir('my_directory/') в качестве записей:
для записи в записи:
печать (запись.имя)
Здесь sub_dir_c файл1.py sub_dir_b файл3.txt файл2.csv sub_dir Другой способ получить список каталогов — использовать модуль из пути импорта pathlib
записи = Путь ('мой_каталог/')
для записи в entry.itertir():
печать (запись.имя)
Объекты, возвращаемые В приведенном выше примере вы вызываете Выполнение приведенного выше кода приводит к следующему результату: sub_dir_c файл1.py sub_dir_b файл3.txt файл2.csv sub_dir Использование Вот снова функции вывода списка каталогов:
Эти функции возвращают список всего в каталоге, включая подкаталоги. Это может не всегда быть тем поведением, которое вам нужно. В следующем разделе будет показано, как фильтровать результаты из списка каталогов. Удаление рекламы Список всех файлов в каталоге В этом разделе показано, как распечатать имена файлов в каталоге, используя импорт ОС
# Список всех файлов в каталоге с помощью os.listdir
базовый путь = 'мой_каталог/'
для записи в os.listdir(базовый путь):
если os.path.isfile(os.path.join(базовый путь, запись)):
печать (ввод)
Здесь вызов файл1.py файл3.txt файл2.csv Более простой способ вывести список файлов в каталоге — использовать импорт ОС
# Список всех файлов в каталоге с помощью scandir()
базовый путь = 'мой_каталог/'
с os.scandir(basepath) в качестве записей:
для записи в записи:
если запись.is_file():
печать (запись.имя)
Использование файл1.py файл3.txt файл2.csv Вот как составить список файлов в каталоге с помощью из пути импорта pathlib
базовый путь = Путь('мой_каталог/')
files_in_basepath = базовый путь.iterdir()
для элемента в files_in_basepath:
если item. Здесь вы вызываете файл1.py файл3.txt файл2.csv Приведенный выше код можно сделать более кратким, если объединить цикл Модифицированная версия выглядит так: из пути импорта pathlib
# Список всех файлов в каталоге с помощью pathlib
базовый путь = Путь('мой_каталог/')
files_in_basepath = (запись для записи в basepath.itrdir(), если entry.is_file())
для элемента в files_in_basepath:
печать (элемент.имя)
Это дает точно такой же результат, как и в предыдущем примере. В этом разделе показано, что фильтрация файлов или каталогов с использованием Список подкаталогов Чтобы отобразить подкаталоги вместо файлов, используйте один из приведенных ниже способов. Вот как использовать импорт ОС
# Список всех подкаталогов с помощью os.listdir
базовый путь = 'мой_каталог/'
для записи в os.listdir(базовый путь):
если os.path.isdir(os.path.join(базовый путь, запись)):
печать (ввод)
Манипулирование путями файловой системы таким образом может быстро стать громоздким, если у вас есть несколько вызовов sub_dir_c sub_dir_b sub_dir Вот как использовать импорт ОС
# Список всех подкаталогов с помощью scandir()
базовый путь = 'мой_каталог/'
с os.scandir(basepath) в качестве записей:
для записи в записи:
если entry.is_dir():
печать (запись. Как и в примере со списком файлов, здесь вы вызываете sub_dir_c sub_dir_b sub_dir Вот как использовать из пути импорта pathlib
# Список всех подкаталогов с помощью pathlib
базовый путь = Путь('мой_каталог/')
для записи в basepath.itertir():
если entry.is_dir():
печать (запись.имя)
Вызов sub_dir_c sub_dir_b sub_dir Удаление рекламы Получение атрибутов файла Python упрощает получение атрибутов файла, таких как размер файла и время изменения. В приведенных ниже примерах показано, как получить время последнего изменения файлов в >>> >>> импорт ОС
>>> с os.scandir('my_directory/') как dir_contents:
... для записи в dir_contents:
... информация = запись.stat()
... печать (info.st_mtime)
...
15399.0052035
153 |
| Функция | Описание |
|---|---|
os.mkdir() | Создает один подкаталог |
pathlib.Path.mkdir() | Создает один или несколько каталогов |
os.makedirs() | Создает несколько каталогов, включая промежуточные каталоги |
Создание единого каталога
Чтобы создать один каталог, передайте путь к каталогу в качестве параметра os.mkdir() :
импорт ОС
os.mkdir('example_directory/')
Если каталог уже существует, os.mkdir() вызывает FileExistsError . Кроме того, вы можете создать каталог, используя pathlib :
из пути импорта pathlib
p = Путь ('example_directory/')
p.mkdir()
Если путь уже существует, mkdir() вызывает FileExistsError :
>>>
>>> p.', строка 1, в Файл '/usr/lib/python3.5/pathlib.py', строка 1214, в mkdir self._accessor.mkdir(я, режим) Файл '/usr/lib/python3.5/pathlib.py', строка 371, в упаковке вернуть strfunc(str(pathobj), *args) FileExistsError: [Errno 17] Файл существует: '.' [Errno 17] Файл существует: '.'
Чтобы избежать подобных ошибок, поймайте ошибку, когда она произойдет, и сообщите об этом пользователю:
из пути импорта pathlib
p = Путь ('example_directory')
пытаться:
p.mkdir()
кроме FileExistsError как exc:
печать (отл.)
Кроме того, вы можете игнорировать FileExistsError , передав аргумент exists_ok=True в .mkdir() :
из пути импорта pathlib
p = Путь ('example_directory')
p.mkdir(exist_ok=Истина)
Это не приведет к ошибке, если каталог уже существует.
Удаление рекламы
Создание нескольких каталогов
os. аналогичен makedirs() os.mkdir() . Разница между ними заключается в том, что os.makedirs() может не только создавать отдельные каталоги, но и использоваться для создания деревьев каталогов. Другими словами, он может создавать любые необходимые промежуточные папки, чтобы обеспечить наличие полного пути.
os.makedirs() аналогичен запуску mkdir -p в Bash. Например, чтобы создать группу каталогов, таких как 2018/10/05 , все, что вам нужно сделать, это следующее:
импорт ОС
os.makedirs('2018/10/05')
Это создаст вложенную структуру каталогов, содержащую папки 2018, 10 и 05:
. .
|
└── 2018/
└── 10/
└── 05/
.makedirs() создает каталоги с разрешениями по умолчанию. Если вам нужно создать каталоги с разными правами доступа, вызовите .makedirs() и укажите режим, в котором вы хотите создать каталоги:
импорт ОС os.
Это создает структуру каталогов 2018/10/05 и предоставляет владельцу и пользователям группы разрешения на чтение, запись и выполнение. Режим по умолчанию — 0o777 , а биты прав доступа к файлам существующих родительских каталогов не изменяются. Дополнительные сведения о правах доступа к файлам и о том, как применяется режим, см. в документации.
Запустите дерево , чтобы убедиться, что были применены правильные разрешения:
$ дерево -p -i . . [drwxrwx---] 2018 [drwxrwx---] 10 [drwxrwx---] 05
Это распечатывает дерево каталогов текущего каталога. дерево обычно используется для отображения содержимого каталогов в древовидном формате. Передача аргументов -p и -i выводит имена каталогов и их информацию о правах доступа к файлам в вертикальном списке. -p выводит права доступа к файлу, а -i заставляет tree создавать вертикальный список без линий отступа.
Как видите, все каталоги имеют права доступа 770 . Альтернативный способ создания каталогов — использовать .mkdir() из pathlib.Path :
импортировать библиотеку путей
p = pathlib.Path('2018/10/05')
p.mkdir (родители = Истина)
Передача parents=True в Path.mkdir() приводит к созданию каталога 05 и любых родительских каталогов, необходимых для того, чтобы сделать путь допустимым.
По умолчанию os.makedirs() и Path.mkdir() вызывают OSError , если целевой каталог уже существует. Это поведение можно переопределить (начиная с Python 3.2), передав exists_ok=True в качестве аргумента ключевого слова при вызове каждой функции.
Запуск приведенного выше кода создает структуру каталогов, подобную приведенной ниже, за один раз:
.
|
└── 2018/
└── 10/
└── 05/
Я предпочитаю использовать pathlib при создании каталогов, потому что я могу использовать одну и ту же функцию для создания отдельных или вложенных каталогов.
Соответствие шаблону имени файла
После получения списка файлов в каталоге одним из описанных выше способов вы, скорее всего, захотите найти файлы, соответствующие определенному шаблону.
Вам доступны следующие методы и функции:
-
endwith()иstartwith()строковые методы -
fnmatch.fnmatch() -
глоб.глоб() -
pathlib.Path.glob()
Каждый из них обсуждается ниже. Примеры в этом разделе будут выполняться в каталоге с именем some_directory , который имеет следующую структуру:
. | ├── sub_dir/ | ├── file1.py | └── file2.py | ├── admin.py ├── data_01_backup.txt ├── data_01.txt ├── data_02_backup.txt ├── data_02.txt ├── data_03_backup.txt ├── data_03.txt └──tests.py
Если вы используете оболочку Bash, вы можете создать указанную выше структуру каталогов, используя следующие команды:
$ mkdir некоторый_каталог $ cd некоторый_каталог/ $ mkdir sub_dir $ touch sub_dir/file1.
Это создаст каталог some_directory/, перейдет в него, а затем создаст sub_dir . Следующая строка создает file1.py и file2.py в sub_dir , а последняя строка создает все остальные файлы, используя расширение. Чтобы узнать больше о расширении оболочки, посетите этот сайт.
Удаление рекламы
Использование строковых методов
Python имеет несколько встроенных методов для изменения строк и управления ими. Два из этих методов, .startswith() и .endswith() , полезны при поиске шаблонов в именах файлов. Для этого сначала получите список каталогов, а затем выполните итерацию по нему:
>>>
>>> импорт ОС
>>> # Получить файлы .txt
>>> для f_name в os.listdir('some_directory'):
. .. если f_name.endswith('.txt'):
... печать (f_name)
Приведенный выше код находит все файлы в some_directory/ , перебирает их и использует .endswith() для вывода имен файлов с расширением .txt . Запуск этого на моем компьютере дает следующий вывод:
data_01.txt data_03.txt data_03_backup.txt data_02_backup.txt data_02.txt data_01_backup.txt
Сопоставление простого шаблона имени файла с использованием
fnmatch Строковые методы ограничены в возможностях сопоставления. fnmatch имеет более продвинутые функции и методы для сопоставления с образцом. Мы рассмотрим fnmatch.fnmatch() , функцию, которая поддерживает использование подстановочных знаков, таких как * и ? для соответствия именам файлов. Например, чтобы найти все файлы .txt в каталоге с использованием fnmatch , вы должны сделать следующее:
>>>
>>> импорт ОС >>> импортировать fnmatch >>> для имени файла в os.
Это выполняет итерацию по списку файлов в some_directory и использует .fnmatch() для поиска файлов с подстановочными знаками, которые имеют расширение .txt .
Более расширенное сопоставление шаблонов
Предположим, вы хотите найти файлов .txt , соответствующих определенным критериям. Например, вас может интересовать только поиск .txt файлов, которые содержат слово data , число между набором символов подчеркивания и слово резервная копия в их имени файла. Что-то похожее на data_01_backup , data_02_backup или data_03_backup .
Используя fnmatch.fnmatch() , вы можете сделать это следующим образом:
>>>
>>> для имени файла в os.listdir('.'):
... если fnmatch. fnmatch(имя файла, 'data_*_backup.txt'):
... печать (имя файла)
Здесь вы печатаете только имена файлов, которые соответствуют шаблону data_*_backup.txt . Звездочка в шаблоне будет соответствовать любому символу, поэтому при запуске будут найдены все текстовые файлы, имена файлов которых начинаются со слова 9.0026 data и заканчиваться backup.txt , как видно из вывода ниже:
data_03_backup.txt data_02_backup.txt data_01_backup.txt
Сопоставление шаблона имени файла с использованием
glob Еще один полезный модуль для сопоставления с образцом — glob .
.glob() в модуле glob работает так же, как fnmatch.fnmatch() , но в отличие от fnmatch.fnmatch() обрабатывает файлы, начинающиеся с точки ( . ) как особенный.
UNIX и родственные системы переводят шаблоны имен с помощью подстановочных знаков, таких как ? и * в список файлов. Это называется глобированием.
Например, ввод mv *.py python_files/ в оболочке UNIX перемещает ( mv ) все файлы с расширением .py из текущего каталога в каталог python_files . Символ * — это подстановочный знак, означающий «любое количество символов», а *.py — шаблон глобуса. Эта возможность оболочки недоступна в операционной системе Windows. Модуль glob добавляет эту возможность в Python, что позволяет программам Windows использовать эту функцию.
Вот пример использования glob для поиска всех исходных файлов Python ( .py ) в текущем каталоге:
>>>
>>> импортировать глобус
>>> glob.glob('*.py')
['admin.py', 'tests.py']
glob.glob('*.py') ищет все файлы с расширением .py в текущем каталоге и возвращает их в виде списка. glob также поддерживает подстановочные знаки в стиле оболочки для соответствия шаблонам:
>>>
>>> импортировать глобус >>> для имени в glob.
Это находит все текстовые ( .txt ) файлы, которые содержат цифры в имени файла:
data_01.txt data_03.txt data_03_backup.txt data_02_backup.txt data_02.txt data_01_backup.txt
glob упрощает рекурсивный поиск файлов и в подкаталогах:
>>>
>>> импортировать глобус
>>> для файла в glob.iglob('**/*.py', recursive=True):
... распечатать файл)
В этом примере используется glob.iglob() для поиска файлов .py в текущем каталоге и подкаталогах. Передача recursive=True в качестве аргумента .iglob() заставляет искать .py файлов в текущем каталоге и любых подкаталогах. Разница между glob.iglob() и glob.glob() заключается в том, что .iglob() возвращает итератор вместо списка.
Запуск указанной выше программы приводит к следующему результату:
admin.
pathlib содержит аналогичные методы для создания гибких списков файлов. Пример ниже показывает, как вы можете использовать .Path.glob() для списка типов файлов, начинающихся с буквы p :
>>>
>>> из пути импорта pathlib
>>> p = Путь('.')
>>> для имени в p.glob('*.p*'):
... печать (имя)
admin.py
скребок.py
документы.pdf
Вызов p.glob('*.p*') возвращает объект генератора, который указывает на все файлы в текущем каталоге, которые начинаются с буквы p в их расширении.
Path.glob() аналогично os.glob() обсуждалось выше. Как видите, pathlib сочетает в себе многие из лучших функций модулей os , os.path и glob в одном модуле, что делает его использование приятным.
Напомню, вот таблица функций, которые мы рассмотрели в этом разделе:
| Функция | Описание |
|---|---|
начинается с() | Проверяет, начинается ли строка с указанного шаблона и возвращает Верно или Ложно |
заканчивается с() | Проверяет, заканчивается ли строка заданным шаблоном, и возвращает True или False |
fnmatch. | Проверяет, соответствует ли имя файла шаблону, и возвращает True или False |
глоб.глоб() | Возвращает список имен файлов, соответствующих шаблону |
pathlib.Path.glob() | Находит шаблоны в именах путей и возвращает объект генератора |
Удаление рекламы
Обход каталогов и обработка файлов
Распространенной задачей программирования является обход дерева каталогов и обработка файлов в дереве. Давайте рассмотрим, как для этого можно использовать встроенную функцию Python os.walk() . os.walk() используется для создания имени файла в дереве каталогов путем обхода дерева сверху вниз или снизу вверх. Для целей этого раздела мы будем манипулировать следующим деревом каталогов:
. | ├── папка_1/ | ├── file1.
В следующем примере показано, как составить список всех файлов и каталогов в дереве каталогов с помощью os.walk() .
os.walk() по умолчанию обход каталогов сверху вниз:
# Обходим дерево каталогов и печатаем имена каталогов и файлов
для dirpath, dirnames, файлов в os.walk('.'):
print(f'Найден каталог: {dirpath}')
для file_name в файлах:
печать (имя_файла)
os.walk() возвращает три значения на каждой итерации цикла:
Имя текущей папки
Список папок в текущей папке
Список файлов в текущей папке
На каждой итерации он выводит имена найденных подкаталогов и файлов:
Найден каталог: . test1.txt test2.txt Найден каталог: ./folder_1 файл1.py файл3.py файл2.py Найден каталог: .
Чтобы просмотреть дерево каталогов снизу вверх, передайте аргумент ключевого слова topdown=False в os.walk() :
для путей каталогов, имен каталогов, файлов в os.walk('.', topdown=False):
print(f'Найден каталог: {dirpath}')
для file_name в файлах:
печать (имя_файла)
Передача аргумента topdown=False заставит os.walk() распечатать файлы, найденные в подкаталогах сначала:
Найден каталог: ./folder_1 файл1.py файл3.py файл2.py Найден каталог: ./folder_2 файл4.py файл5.py файл6.py Найден каталог: . test1.txt test2.txt
Как видите, программа запустилась с вывода содержимого подкаталогов перед выводом содержимого корневого каталога. Это очень полезно в ситуациях, когда вы хотите рекурсивно удалить файлы и каталоги. Вы узнаете, как это сделать, в следующих разделах. По умолчанию os.walk не переходит по символическим ссылкам, которые разрешаются в каталоги. Это поведение можно переопределить, вызвав его с помощью followlinks=Аргумент True .
Создание временных файлов и каталогов
Python предоставляет удобный модуль для создания временных файлов и каталогов под названием tempfile .
tempfile можно использовать для открытия и временного хранения данных в файле или каталоге во время работы вашей программы. tempfile обрабатывает удаление временных файлов, когда ваша программа завершает работу с ними.
Вот как создать временный файл:
из временного файла импорта TemporaryFile
# Создаем временный файл и записываем в него данные
fp = временный файл ('w + t')
fp.write('Привет, вселенная!')
# Вернуться к началу и прочитать данные из файла
fp.seek(0)
данные = fp.read()
# Закрыть файл, после чего он будет удален
fp.close()
Первым шагом является импорт TemporaryFile из модуля tempfile . Затем создайте файл, подобный объекту, используя метод TemporaryFile() , вызвав его и передав режим, в котором вы хотите открыть файл. Это создаст и откроет файл, который можно использовать в качестве области временного хранения.
В приведенном выше примере режим равен 'w+t' , что заставляет tempfile создавать временный текстовый файл в режиме записи. Нет необходимости давать временному файлу имя файла, поскольку он будет уничтожен после завершения работы скрипта.
После записи в файл вы можете прочитать его и закрыть, когда закончите его обработку. Как только файл будет закрыт, он будет удален из файловой системы. Если вам нужно назвать временные файлы, созданные с использованием tempfile , используйте tempfile.NamedTemporaryFile() .
Временные файлы и каталоги, созданные с помощью tempfile , хранятся в специальном системном каталоге для хранения временных файлов. Python просматривает стандартный список каталогов, чтобы найти тот, в котором пользователь может создавать файлы.
В Windows это каталоги C:\TEMP , C:\TMP , \TEMP и \TMP в указанном порядке. На всех остальных платформах каталогов /tmp , /var/tmp и /usr/tmp , именно в таком порядке. В крайнем случае, tempfile сохранит временные файлы и каталоги в текущем каталоге.
.TemporaryFile() также является диспетчером контекста, поэтому его можно использовать вместе с оператором with . Использование контекстного менеджера обеспечивает автоматическое закрытие и удаление файла после его прочтения:
с TemporaryFile('w+t') как fp:
fp.write('Привет, вселенная!')
fp.seek(0)
fp.read()
# Файл теперь закрыт и удален
Создает временный файл и считывает из него данные. Как только содержимое файла прочитано, временный файл закрывается и удаляется из файловой системы.
tempfile также можно использовать для создания временных каталогов. Давайте посмотрим, как это можно сделать с помощью tempfile.TemporaryDirectory() :
>>>
>>> импорт временного файла >>> с tempfile.
Вызов tempfile.TemporaryDirectory() создает временный каталог в файловой системе и возвращает объект, представляющий этот каталог. В приведенном выше примере каталог создается с помощью менеджера контекста, а имя каталога сохраняется в tmpdir . Третья строка выводит имя временного каталога, а os.path.exists(tmpdir) подтверждает, действительно ли каталог был создан в файловой системе.
После того, как менеджер контекста выходит из контекста, временный каталог удаляется, а вызов os.path.exists(tmpdir) возвращает False , что означает, что каталог был успешно удален.
Удаление рекламы
Удаление файлов и каталогов
Вы можете удалять отдельные файлы, каталоги и целые деревья каталогов, используя методы, найденные в модулях os , Shutil и pathlib . В следующих разделах описано, как удалить файлы и каталоги, которые вам больше не нужны.
Удаление файлов в Python
Чтобы удалить один файл, используйте pathlib.Path.unlink() , os.remove() . или os.unlink() .
os.remove() и os.unlink() семантически идентичны. Чтобы удалить файл с помощью os.remove() , сделайте следующее:
импорт ОС data_file = 'C:\\Users\\vuyisile\\Desktop\\Test\\data.txt' os.remove (файл_данных)
Удаление файла с помощью os.unlink() аналогично тому, как вы делаете это с помощью os.remove() :
импорт ОС data_file = 'C:\\Users\\vuyisile\\Desktop\\Test\\data.txt' os.unlink (файл_данных)
Вызов .unlink() или .remove() для файла удаляет файл из файловой системы. Эти две функции выдают OSError , если переданный им путь указывает на каталог, а не на файл. Чтобы избежать этого, вы можете либо проверить, что то, что вы пытаетесь удалить, на самом деле является файлом, и удалить его только в том случае, если это так, либо вы можете использовать обработку исключений для обработки Ошибка ОС :
импорт ОС
data_file = 'дом/data.txt'
# Если файл существует, удаляем его
если os.path.isfile(data_file):
os.remove (файл_данных)
еще:
print(f'Ошибка: {data_file} недопустимое имя файла')
os.path.isfile() проверяет, действительно ли data_file является файлом. Если да, то он удаляется вызовом os.remove() . Если data_file указывает на папку, сообщение об ошибке выводится на консоль.
В следующем примере показано, как использовать обработку исключений для обработки ошибок при удалении файлов:
импорт ОС
data_file = 'дом/data.txt'
# Использовать обработку исключений
пытаться:
os.remove (файл_данных)
кроме OSError как e:
print(f'Ошибка: {data_file}: {e. strerror}')
Приведенный выше код сначала пытается удалить файл перед проверкой его типа. Если data_file на самом деле не является файлом, выданная ошибка OSError обрабатывается в предложении , кроме , и на консоль выводится сообщение об ошибке. Распечатываемое сообщение об ошибке форматируется с использованием f-строк Python.
Наконец, вы также можете использовать pathlib.Path.unlink() для удаления файлов:
из пути импорта pathlib
data_file = Путь('дом/data.txt')
пытаться:
data_file.unlink()
кроме IsADirectoryError как e:
print(f'Ошибка: {data_file}: {e.strerror}')
Это создает объект Path с именем data_file , который указывает на файл. Вызов .remove() для data_file удалит home/data.txt . Если файл_данных указывает на каталог, возникает ошибка IsADirectoryError . Стоит отметить, что приведенная выше программа Python имеет те же права, что и пользователь, который ее запускает. Если у пользователя нет разрешения на удаление файла, возникает ошибка PermissionError .
Удаление каталогов
Стандартная библиотека предлагает следующие функции для удаления каталогов:
-
os.rmdir() -
pathlib.Path.rmdir() -
шутил.rmtree()
Чтобы удалить один каталог или папку, используйте os.rmdir() или pathlib.rmdir() . Эти две функции работают только в том случае, если каталог, который вы пытаетесь удалить, пуст. Если каталог не пуст, возникает ошибка OSError . Вот как удалить папку:
импорт ОС
trash_dir = 'мои_документы/плохой_каталог'
пытаться:
os.rmdir(trash_dir)
кроме OSError как e:
print(f'Ошибка: {trash_dir}: {e.strerror}')
Здесь каталог trash_dir удаляется путем передачи его пути в os.rmdir() . Если каталог не пуст, на экран выводится сообщение об ошибке:
>>>
Трассировка (последний последний вызов): Файл '', строка 1, в OSError: [Errno 39] Каталог не пуст: 'my_documents/bad_dir'
Кроме того, вы можете использовать pathlib для удаления каталогов:
из пути импорта pathlib
trash_dir = Путь('my_documents/bad_dir')
пытаться:
trash_dir.rmdir()
кроме OSError как e:
print(f'Ошибка: {trash_dir}: {e.strerror}')
Здесь вы создаете объект Path , указывающий на удаляемый каталог. Вызов .rmdir() для объекта Path удалит его, если он пуст.
Удаление рекламы
Удаление целых деревьев каталогов
Чтобы удалить непустые каталоги и целые деревья каталогов, Python предлагает Shutil.rmtree() :
импортный шутил
trash_dir = 'мои_документы/плохой_каталог'
пытаться:
Shutil.rmtree(trash_dir)
кроме OSError как e:
print(f'Ошибка: {trash_dir}: {e. strerror}')
Все в trash_dir удаляется, когда на нем вызывается Shutil.rmtree() . Могут быть случаи, когда вы хотите рекурсивно удалить пустые папки. Вы можете сделать это, используя один из методов, описанных выше, в сочетании с os.walk() :
импорт ОС
для каталогов, имен каталогов, файлов в os.walk('.', topdown=False):
пытаться:
os.rmdir(путь к каталогу)
кроме OSError как например:
проходить
Просматривает дерево каталогов и пытается удалить каждый найденный каталог. Если каталог не пуст, Возникает ошибка OSError , и этот каталог пропускается. В таблице ниже перечислены функции, описанные в этом разделе:
| Функция | Описание |
|---|---|
os.remove() | Удаляет файл и не удаляет каталоги |
os.unlink() | Идентичен os.remove() и удаляет один файл |
pathlib. | Удаляет файл и не может удалять каталоги |
os.rmdir() | Удаляет пустой каталог |
pathlib.Path.rmdir() | Удаляет пустой каталог |
шутил.rmtree() | Удаляет все дерево каталогов и может использоваться для удаления непустых каталогов |
Копирование, перемещение и переименование файлов и каталогов
Python поставляется с модулем Shutil . Shutil — сокращение от утилит оболочки. Он предоставляет ряд высокоуровневых операций с файлами для поддержки копирования, архивирования и удаления файлов и каталогов. В этом разделе вы узнаете, как перемещать и копировать файлы и каталоги.
Копирование файлов в Python
Shutil предлагает несколько функций для копирования файлов. Наиболее часто используемые функции: , Shutil.copy() и Shutil. . Чтобы скопировать файл из одного места в другое с помощью copy2() Shutil.copy() , сделайте следующее:
импортный шутил src = 'путь/к/файлу.txt' dst = 'путь/к/dest_dir' Shutil.copy(src, dst)
Shutil.copy() аналогичен команде cp в системах на основе UNIX. Shutil.copy(src, dst) скопирует файл src в место, указанное в dst . Если dst является файлом, содержимое этого файла заменяется содержимым источник . Если dst является каталогом, то src будет скопирован в этот каталог. Shutil.copy() копирует только содержимое файла и права доступа к файлу. Другие метаданные, такие как время создания и изменения файла, не сохраняются.
Чтобы сохранить все метаданные файла при копировании, используйте Shutil.copy2() :
импортный шутил src = 'путь/к/файлу.txt' dst = 'путь/к/dest_dir' Shutil.
Использование .copy2() сохраняет сведения о файле, такие как время последнего доступа, биты разрешений, время последнего изменения и флаги.
Копирование каталогов
В то время как Shutil.copy() копирует только один файл, Shutil.copytree() копирует весь каталог и все, что в нем содержится. Shutil.copytree(src, dest) принимает два аргумента: исходный каталог и целевой каталог, в который будут скопированы файлы и папки.
Вот пример того, как скопировать содержимое одной папки в другое место:
>>>
>>> импортный шутил
>>> Shutil.copytree('data_1', 'data1_backup')
'data1_backup'
В этом примере .copytree() копирует содержимое data_1 в новое место data1_backup и возвращает целевой каталог. Целевой каталог не должен уже существовать. Он будет создан так же, как и отсутствующие родительские каталоги. Shutil.copytree() — хороший способ сделать резервную копию ваших файлов.
Удалить рекламу
Перемещение файлов и каталогов
Чтобы переместить файл или каталог в другое место, используйте Shutil.move(src, dst) .
src — файл или каталог для перемещения, а dst — место назначения:
>>>
>>> импортный шутил
>>> Shutil.move('dir_1/', 'резервная копия/')
'резервное копирование'
Shutil.move('dir_1/', 'backup/') перемещает dir_1/ в backup/ , если существует резервная копия /. Если backup/ не существует, dir_1/ будет переименован в backup .
Переименование файлов и каталогов
Python включает os.rename(src, dst) для переименования файлов и каталогов:
>>>
>>> os.
Строка выше переименует first.zip в first_01.zip . Если путь назначения указывает на каталог, он поднимет Ошибка ОС .
Другой способ переименовать файлы или каталоги — использовать rename() из модуля pathlib :
>>>
>>> из пути импорта pathlib
>>> data_file = Путь('data_01.txt')
>>> data_file.rename('data.txt')
Чтобы переименовать файлы с помощью pathlib , вы сначала создаете объект pathlib.Path() , который содержит путь к файлу, который вы хотите заменить. Следующим шагом будет звонок rename() в объекте пути и передайте новое имя файла для файла или каталога, который вы переименовываете.
Архивирование
Архивы — это удобный способ упаковать несколько файлов в один. Двумя наиболее распространенными типами архивов являются ZIP и TAR. Программы Python, которые вы пишете, могут создавать, читать и извлекать данные из архивов. В этом разделе вы узнаете, как читать и записывать в оба формата архивов.
Чтение ZIP-файлов
Модуль zipfile — это модуль низкого уровня, который является частью стандартной библиотеки Python. zipfile имеет функции, облегчающие открытие и распаковку ZIP-файлов. Чтобы прочитать содержимое ZIP-файла, первое, что нужно сделать, это создать объект ZipFile . Объекты ZipFile аналогичны файловым объектам, созданным с помощью open() . ZipFile также является менеджером контекста и поэтому поддерживает оператор with :
импортировать zip-файл
с zipfile.ZipFile('data.zip', 'r') как zipobj:
Здесь вы создаете ZipFile , передавая имя ZIP-файла для открытия в режиме чтения. После открытия ZIP-файла доступ к информации об архиве можно получить с помощью функций, предоставляемых модулем zipfile . Архив data.zip в приведенном выше примере был создан из каталога с именем data , который содержит в общей сложности 5 файлов и 1 подкаталог:
. | ├── sub_dir/ | ├── bar.py | └── foo.py | ├── file1.py ├── file2.py └── файл3.py
Чтобы получить список файлов в архиве, позвоните по номеру namelist() в объекте ZipFile :
импортировать zip-файл
с zipfile.ZipFile('data.zip', 'r') как zipobj:
zipobj.namelist()
Это создает список:
['file1.py', 'file2.py', 'file3.py', 'sub_dir/', 'sub_dir/bar.py', 'sub_dir/foo.py']
.namelist() возвращает список имен файлов и каталогов в архиве. Чтобы получить информацию о файлах в архиве, используйте .getinfo() :
импортировать zip-файл
с zipfile.ZipFile('data.zip', 'r') как zipobj:
bar_info = zipobj.getinfo('sub_dir/bar.py')
bar_info.file_size
Вот результат:
. возвращает объект getinfo() ZipInfo , в котором хранится информация об одном члене архива. Чтобы получить информацию о файле в архиве, вы передаете его путь в качестве аргумента функции .getinfo() . Используя getinfo() , вы можете получить информацию об элементах архива, такую как дата последнего изменения файлов, их сжатые размеры и полные имена файлов. Доступ к .file_size возвращает исходный размер файла в байтах.
В следующем примере показано, как получить дополнительные сведения об архивных файлах в Python REPL. Предположим, что модуль zipfile был импортирован, а bar_info — это тот же объект, который вы создали в предыдущих примерах:
>>>
>>> bar_info.date_time (2018, 10, 7, 23, 30, 10) >>> bar_info.compress_size 2856 >>> bar_info.имя_файла 'sub_dir/bar.py'
bar_info содержит сведения о bar.py , такие как его размер при сжатии и полный путь.
В первой строке показано, как получить дату последнего изменения файла. В следующей строке показано, как получить размер файла после сжатия. В последней строке указан полный путь к bar.py в архиве.
ZipFile поддерживает протокол диспетчера контекста, поэтому вы можете использовать его с оператором with . Это автоматически закроет ZipFile после завершения работы с ним. Попытка открыть или извлечь файлы из закрытого объекта ZipFile приведет к ошибке.
Удаление рекламы
Создание новых ZIP-архивов
Чтобы создать новый ZIP-архив, вы открываете объект ZipFile в режиме записи ( w ) и добавляете файлы, которые хотите заархивировать:
>>>
>>> импортировать zip-файл >>> file_list = ['file1.py', 'sub_dir/', 'sub_dir/bar.py', 'sub_dir/foo.py'] >>> с zipfile.
В примере new_zip открывается в режиме записи и каждый файл из file_list добавляется в архив. Когда пакет операторов с завершен, new_zip закрывается. Открытие ZIP-файла в режиме записи стирает содержимое архива и создает новый архив.
Чтобы добавить файлы в существующий архив, откройте объект ZipFile в режиме добавления, а затем добавьте файлы:
>>>
>>> # Открытие объекта ZipFile в режиме добавления
>>> с zipfile.ZipFile('new.zip', 'a') как new_zip:
... new_zip.write('data.txt')
... new_zip.write('latin.txt')
Здесь вы открываете архив new.zip , созданный в предыдущем примере, в режиме добавления. Открытие объекта ZipFile в режиме добавления позволяет добавлять новые файлы в ZIP-файл, не удаляя его текущее содержимое. После добавления файлов в ZIP-файл оператор с выходит из контекста и закрывает ZIP-файл.
Открытие архивов TAR
Файлы TAR представляют собой несжатые файловые архивы, такие как ZIP. Их можно сжать с помощью методов сжатия gzip, bzip2 и lzma. Класс TarFile позволяет читать и записывать архивы TAR.
Сделайте это, чтобы прочитать из архива:
импортировать tar-файл
с tarfile.open('example.tar', 'r') как tar_file:
печать (tar_file.getnames())
tarfile объекты открываются как большинство файловоподобных объектов. У них есть функция open() , которая принимает режим, определяющий способ открытия файла.
Используйте режимы 'r' , 'w' или 'a' , чтобы открыть несжатый файл TAR для чтения, записи и добавления соответственно. Чтобы открыть сжатые файлы TAR, передайте аргумент режима в tarfile.open() , то есть в форме filemode[:compression] . В таблице ниже перечислены возможные режимы открытия файлов TAR:
| Режим | Действие |
|---|---|
р | Открывает архив для чтения с прозрачным сжатием |
р:гз | Открывает архив для чтения со сжатием gzip |
р:бз2 | Открывает архив для чтения со сжатием bzip2 |
р:хз | Открывает архив для чтения со сжатием lzma |
ш | Открывает архив для несжатой записи |
ш:гз | Открывает архив для записи сжатым gzip |
ш:хз | Открывает архив для сжатой записи lzma |
а | Открывает архив для добавления без сжатия |
.open() по умолчанию используется режим 'r' . Чтобы прочитать несжатый файл TAR и получить имена файлов в нем, используйте .getnames() :
>>>
>>> импортировать tar-файл
>>> tar = tarfile.open('example.tar', mode='r')
>>> tar.getnames()
['CONTRIBUTING.rst', 'README.md', 'app.py']
Возвращает список с именами содержимого архива.
Примечание: Чтобы показать вам, как использовать различные методы объекта tarfile , файл TAR в примерах открывается и закрывается вручную в интерактивном сеансе REPL.
Взаимодействие с файлом TAR таким образом позволяет вам видеть результат выполнения каждой команды. Обычно вы хотите использовать диспетчер контекста для открытия файловоподобных объектов.
Доступ к метаданным каждой записи в архиве можно получить с помощью специальных атрибутов:
>>>
>>> для записи в tar.getmembers():
... print(entry.name)
... print('Изменено:', time. ctime(entry.mtime))
... print('Размер:', entry.size, 'байты')
... Распечатать()
CONTRIBUTING.rst
Изменено: Сб 1 ноября 09:09:51 2018
Размер : 402 байта
README.md
Изменено: Сб 3 ноября 07:29:40 2018
Размер : 5426 байт
app.py
Изменено: Сб 3 ноября 07:29:13 2018
Размер : 6218 байт
В этом примере вы просматриваете список файлов, возвращенных .getmembers() и распечатайте атрибуты каждого файла. Объекты, возвращаемые .getmembers() , имеют атрибуты, к которым можно получить программный доступ, такие как имя, размер и время последнего изменения каждого из файлов в архиве. После чтения или записи в архив его необходимо закрыть, чтобы освободить системные ресурсы.
Создание новых архивов TAR
Вот как это сделать:
>>>
>>> импортировать tar-файл
>>> file_list = ['app.py', 'config.py', 'CONTRIBUTORS.md', 'tests.py']
>>> с tarfile.open('packages.tar', mode='w') как tar:
... для файла в списке_файлов:
. .. tar.add(файл)
>>> # Прочитать содержимое только что созданного архива
>>> с tarfile.open('package.tar', mode='r') as t:
... для члена в t.getmembers():
... печать (имя_члена)
app.py
config.py
CONTRIBUTORS.md
тесты.py
Сначала вы составляете список файлов, которые нужно добавить в архив, чтобы вам не приходилось добавлять каждый файл вручную.
Следующая строка использует менеджер контекста с для открытия нового архива с именем packages.tar в режиме записи. Открытие архива в режиме записи ( 'w' ) позволяет записывать в архив новые файлы. Все существующие файлы в архиве удаляются и создается новый архив.
После создания и заполнения архива с контекстным менеджером автоматически закрывает его и сохраняет в файловой системе. Последние три строки открывают только что созданный архив и выводят имена содержащихся в нем файлов.
Чтобы добавить новые файлы в существующий архив, откройте архив в режиме добавления ( 'a' ):
>>>
>>> с tarfile.
Открытие архива в режиме добавления позволяет добавлять в него новые файлы, не удаляя уже находящиеся в нем.
Работа со сжатыми архивами
tarfile также может читать и записывать архивы TAR, сжатые с использованием сжатия gzip, bzip2 и lzma. Чтобы прочитать или записать в сжатый архив, используйте tarfile.open() , передав соответствующий режим для типа сжатия.
Например, для чтения или записи данных в архив TAR, сжатый с помощью gzip, используйте ключ 'r:gz' или 'w:gz' режимов соответственно:
>>>
>>> файлы = ['app.py', 'config.py', 'tests.py']
>>> с tarfile.open('packages.tar.gz', mode='w:gz') как tar:
... tar.add('app. py')
... tar.add('config.py')
... tar.add('tests.py')
>>> с tarfile.open('packages.tar.gz', mode='r:gz') как t:
... для члена в t.getmembers():
... печать (имя_члена)
app.py
config.py
тесты.py
'w:gz' 9Режим 0027 открывает архив для записи сжатым gzip, а 'r:gz' открывает архив для чтения сжатого gzip.
Открытие сжатых архивов в режиме добавления невозможно. Чтобы добавить файлы в сжатый архив, необходимо создать новый архив.
Более простой способ создания архивов
Стандартная библиотека Python также поддерживает создание архивов TAR и ZIP с использованием методов высокого уровня в модуле Shutil . Утилиты архивации в шутил позволяют создавать, читать и извлекать архивы ZIP и TAR. Эти утилиты основаны на модулях нижнего уровня tarfile и zipfile .
Работа с архивами с помощью Shutil.make_archive()
Shutil.make_archive() принимает как минимум два аргумента: имя архива и формат архива.
По умолчанию сжимает все файлы в текущем каталоге в формат архива, указанный в формат аргумент. Вы можете передать необязательный аргумент root_dir для сжатия файлов в другом каталоге. .make_archive() поддерживает форматы архивов zip , tar , bztar и gztar .
Вот как создать TAR-архив с помощью Shutil :
импортный шутил
# Shutil.make_archive(base_name, format, root_dir)
Shutil.make_archive('данные/резервная копия', 'tar', 'данные/')
Это копирует все в data/ и создает в файловой системе архив с именем backup.tar и возвращает его имя. Чтобы извлечь архив, вызовите .unpack_archive() :
Shutil.unpack_archive('backup.tar', 'extract_dir/')
Вызов .unpack_archive() и передача имени архива и каталога назначения извлекает содержимое backup.tar в extract_dir/ . Таким же образом можно создавать и распаковывать ZIP-архивы.
Чтение нескольких файлов
Python поддерживает чтение данных из нескольких входных потоков или из списка файлов через модуль fileinput . Этот модуль позволяет быстро и легко просматривать содержимое одного или нескольких текстовых файлов.
Вот типичный способ использования fileinput :
ввод файла импорта
для строки в fileinput.input()
процесс (строка)
fileinput получает ввод из аргументов командной строки, переданных в sys.argv по умолчанию.
Использование fileinput для зацикливания нескольких файлов
Давайте воспользуемся fileinput для создания грубой версии обычной UNIX-утилиты cat . Утилита cat читает файлы последовательно, записывая их в стандартный вывод. Если в аргументах командной строки задано более одного файла, cat объединит текстовые файлы и отобразит результат в терминале:
# Файл: fileinput-example.
Запуск этого на двух текстовых файлах в моем текущем каталоге приводит к следующему выводу:
$ python3 fileinput-example.py bacon.txt cupcake.txt --- Чтение bacon.txt --- -> Пряный бекон халапеньо ipsum dolor amet in in aute est qui enim aliquip, -> голень irure cillum elit. -> Doner Jowl Shank ea Exercitation landjaeger incididunt ut porchetta. -> Вырезка бекон aliquip cupidatat куриный цыпленок quis anim et swine. -> Tri-tip doner kevin cillum ham veniam коровий гамбургер. -> Корейка свинины индейки купидат филе миньон капикола грудинка купим в. -> Шариковый наконечник dolor do magna Laboris nisi pancetta nostrud doner. --- Чтение cupcake.txt --- -> Кекс ipsum dolor sit amet candy Я люблю чизкейк с фруктами. -> Посыпать сладкую вату маффинов.
fileinput позволяет получить дополнительную информацию о каждой строке, например, является ли она первой строкой ( .isfirstline() ), номер строки ( .lineno() ) и имя файла (. имя файла() ). Вы можете прочитать больше об этом здесь.
Заключение
Теперь вы знаете, как использовать Python для выполнения наиболее распространенных операций с файлами и группами файлов. Вы узнали о различных встроенных модулях, используемых для чтения, поиска и управления ими.
Теперь вы можете использовать Python для:
- Получить содержимое каталога и свойства файла
- Создание каталогов и деревьев каталогов
- Поиск шаблонов в именах файлов
- Создание временных файлов и каталогов
- Перемещение, переименование, копирование и удаление файлов или каталогов
- Чтение и извлечение данных из разных типов архивов
- Одновременное чтение нескольких файлов с помощью
fileinput
Смотреть сейчас Это руководство содержит связанный с ним видеокурс, созданный командой Real Python. Посмотрите его вместе с письменным руководством, чтобы углубить свое понимание: Практические рецепты по работе с файлами в Python
Чтение и запись файлов в Python (Руководство) — Real Python
Смотреть сейчас Это руководство содержит соответствующий видеокурс, созданный командой Real Python. Посмотрите его вместе с письменным учебным пособием, чтобы углубить свое понимание: Чтение и запись файлов в Python
Одной из наиболее распространенных задач, которые вы можете выполнять с помощью Python, является чтение и запись файлов. Будь то запись в простой текстовый файл, чтение сложного журнала сервера или даже анализ необработанных байтовых данных, во всех этих ситуациях требуется чтение или запись файла.
Из этого руководства вы узнаете:
- Из чего состоит файл и почему это важно в Python
- Основы чтения и записи файлов в Python
- Некоторые базовые сценарии чтения и записи файлов
Это руководство в основном предназначено для начинающих и опытных программистов Python, но здесь есть несколько советов, которые могут быть полезны и более продвинутым программистам.
Бесплатный бонус: Нажмите здесь, чтобы получить нашу бесплатную памятку по Python, которая покажет вам основы Python 3, такие как работа с типами данных, словарями, списками и функциями Python.
Примите участие в викторине: Проверьте свои знания с помощью нашей интерактивной викторины «Чтение и запись файлов в Python». По завершении вы получите балл, чтобы вы могли отслеживать свой прогресс в обучении с течением времени:
Пройдите тест »
Что такое файл?
Прежде чем мы приступим к работе с файлами в Python, важно понять, что такое файл и как современные операционные системы обрабатывают некоторые из его аспектов.
По своей сути файл представляет собой непрерывный набор байтов, используемый для хранения данных. Эти данные организованы в определенном формате и могут быть как простыми, как текстовый файл, так и сложными, как исполняемый файл программы. В конце концов, эти байтовые файлы затем транслируются в двоичные 9. 0026 1 и 0 для упрощения обработки на компьютере.
Файлы в большинстве современных файловых систем состоят из трех основных частей:
- Заголовок: метаданные о содержимом файла (имя файла, размер, тип и т. д.)
- Данные: содержимое файла, написанное создателем или редактором
- Конец файла (EOF): специальный символ, указывающий конец файла
То, что представляют эти данные, зависит от используемой спецификации формата, которая обычно представлена расширением. Например, файл с расширением .gif , скорее всего, соответствует спецификации формата обмена графикой. Существуют сотни, если не тысячи расширений файлов. В этом руководстве вы будете иметь дело только с расширениями файлов .txt или .csv .
Удалить рекламу
Пути к файлам
При доступе к файлу в операционной системе требуется путь к файлу. Путь к файлу — это строка, представляющая расположение файла. Он разбит на три основные части:
- Путь к папке: расположение папки с файлами в файловой системе, где последующие папки разделяются косой чертой
/(Unix) или обратной косой чертой\(Windows) - Имя файла: фактическое имя файла
- Расширение: конец пути к файлу с предшествующей точкой (
.), используемой для указания типа файла
Вот простой пример. Допустим, у вас есть файл, расположенный в файловой структуре, подобной этой:
/ │ ├── путь/ | │ │ ├── к/ │ │ └── коты.gif │ │ │ └── dog_breeds.txt | └── Животные.csv
Допустим, вы хотели получить доступ к файлу cats.gif , и ваше текущее местоположение было в той же папке, что и путь . Чтобы получить доступ к файлу, вам нужно пройти через папку path , а затем через папку to , и, наконец, вы получите файл cats.. Путь к папке: gif path/to/. Имя файла котов . Расширение файла .gif . Таким образом, полный путь равен path/to/cats.gif .
Теперь предположим, что ваше текущее местоположение или текущий рабочий каталог (cwd) находится в папке с по в нашей примерной структуре папок. Вместо ссылки на cats.gif по полному пути path/to/cats.gif на файл можно просто ссылаться по имени файла и расширению cats.gif .
/ │ ├── путь/ | │ | ├── to/ ← Здесь находится ваш текущий рабочий каталог (cwd) | │ └──cats.gif ← Доступ к этому файлу | │ | └── dog_breeds.txt | └── Животные.csv
А как насчет dog_breeds.txt ? Как бы вы получили доступ к этому, не используя полный путь? Вы можете использовать специальные символы с двумя точками ( .. ) для перемещения на один каталог вверх. Это означает, что ../dog_breeds.txt будет ссылаться на файл dog_breeds. из каталога с txt по :
/ │ ├── путь/ ← Ссылка на эту родительскую папку | │ | ├── в/ ← Текущий рабочий каталог (cwd) | │ └── коты.gif | │ | └── dog_breeds.txt ← Доступ к этому файлу | └── Животные.csv
Двойная точка ( .. ) может быть объединена в цепочку для обхода нескольких каталогов над текущим каталогом. Например, чтобы получить доступ к animals.csv из папки to , вы должны использовать ../../animals.csv .
Концы строк
Одной из проблем, часто возникающих при работе с файлами данных, является представление новой строки или окончания строки. Окончание строки восходит к эпохе азбуки Морзе, когда для обозначения конца передачи или конца строки использовался специальный про-знак.
Позже это было стандартизировано для телетайпов как Международной организацией по стандартизации (ISO), так и Американской ассоциацией стандартов (ASA). Стандарт ASA указывает, что в конце строки должна использоваться последовательность символов возврата каретки ( CR или \r ) и перевода строки ( LF или \n ) ( CR+LF или \).). Однако стандарт ISO допускал либо р\п символов CR+LF , либо только 9 символов.0026 LF символов.
Windows использует символы CR+LF для обозначения новой строки, в то время как Unix и более новые версии Mac используют только символ LF . Это может вызвать некоторые сложности при обработке файлов в операционной системе, отличной от источника файла. Вот простой пример. Допустим, мы изучаем файл dog_breeds.txt , созданный в системе Windows:
Мопс\r\n Джек-рассел-терьер\r\n Английский спрингер-спаниель\r\n Немецкая овчарка\r\n Стаффордширский бультерьер\r\n Кавалер-кинг-чарльз-спаниель\r\n Золотистый ретривер\r\n Вест-хайленд-уайт-терьер\r\n Боксёр\r\n Бордер-терьер\r\n
Этот же вывод будет интерпретироваться на устройстве Unix иначе:
Мопс\r \n Джек-рассел-терьер\r \n Английский спрингер-спаниель\r \n немецкая овчарка\r \n Стаффордширский бультерьер\r \n Кавалер-кинг-чарльз-спаниель\r \n Золотистый ретривер\r \n Вест-хайленд-уайт-терьер\r \n Боксёр\r \n Бордер-терьер\r \n
Это может сделать повторение каждой строки проблематичным, и вам может потребоваться учитывать подобные ситуации.
Кодировки символов
Другой распространенной проблемой, с которой вы можете столкнуться, является кодировка байтовых данных. Кодировка — это перевод байтовых данных в символы, понятные человеку. Обычно это делается путем присвоения числового значения символу. Двумя наиболее распространенными кодировками являются форматы ASCII и UNICODE. ASCII может хранить только 128 символов, а Unicode может содержать до 1 114 112 символов.
ASCII на самом деле является подмножеством Unicode (UTF-8), что означает, что ASCII и Unicode имеют одни и те же числовые и символьные значения. Важно отметить, что синтаксический анализ файла с неправильной кодировкой символов может привести к сбоям или искажению символа. Например, если файл был создан с использованием кодировки UTF-8, и вы пытаетесь проанализировать его с помощью кодировки ASCII, если есть символ, который находится за пределами этих 128 значений, будет выдано сообщение об ошибке.
Удалить рекламу
Открытие и закрытие файла в Python
Если вы хотите работать с файлом, первое, что нужно сделать, это открыть его. Это делается путем вызова встроенной функции open() . open() имеет единственный обязательный аргумент — путь к файлу. open() имеет один возврат, файловый объект:
файл = открыть('dog_breeds.txt')
После того, как вы откроете файл, вам нужно научиться его закрывать.
Важно помнить, что вы несете ответственность за закрытие файла. В большинстве случаев после завершения работы приложения или скрипта файл в конечном итоге будет закрыт. Однако нет никакой гарантии, когда именно это произойдет. Это может привести к нежелательному поведению, включая утечку ресурсов. В Python (Pythonic) также рекомендуется убедиться, что ваш код ведет себя четко определенным образом и уменьшает любое нежелательное поведение.
При работе с файлом есть два способа убедиться, что файл закрыт правильно, даже при возникновении ошибки. Первый способ закрыть файл — использовать блок try-finally :
читатель = открыть('dog_breeds. txt')
пытаться:
# Здесь идет дальнейшая обработка файла
в конце концов:
читатель.close()
Если вы не знакомы с блоком try-finally , ознакомьтесь с Исключения Python: введение.
Второй способ закрыть файл — использовать кнопку 9.0026 с оператором :
с open('dog_breeds.txt') в качестве читателя:
# Здесь идет дальнейшая обработка файла
Оператор с автоматически обеспечивает закрытие файла после выхода из блока с , даже в случае ошибки. Я настоятельно рекомендую вам как можно чаще использовать оператор with , так как он обеспечивает более чистый код и упрощает обработку любых непредвиденных ошибок.
Скорее всего, вы также захотите использовать второй позиционный аргумент, режим . Этот аргумент представляет собой строку, содержащую несколько символов, которые представляют, как вы хотите открыть файл. По умолчанию и наиболее часто используется 'r' , что означает открытие файла в режиме только для чтения в виде текстового файла:
с open('dog_breeds. txt', 'r') в качестве читателя:
# Здесь идет дальнейшая обработка файла
Другие параметры режимов полностью задокументированы в Интернете, но наиболее часто используемые из них следующие:
| Символ | Значение |
|---|---|
"р" | Открыто для чтения (по умолчанию) |
'ш' | Открыть для записи, сначала усекая (перезаписывая) файл |
"рб" или "вб" | Открыть в двоичном режиме (чтение/запись с использованием байтовых данных) |
Давайте вернемся и поговорим немного о файловых объектах. Файловый объект:
«объект, предоставляющий файловый API (с такими методами, как
read()илиwrite()) в базовый ресурс». (Источник)
Существует три различных категории файловых объектов:
- Текстовые файлы
- Буферизованные двоичные файлы
- Необработанные двоичные файлы
Каждый из этих типов файлов определен в модуле io . Вот краткое изложение того, как все выстраивается.
Удалить рекламу
Типы текстовых файлов
Текстовый файл является наиболее распространенным файлом, с которым вы столкнетесь. Вот несколько примеров того, как эти файлы открываются:
открыть('abc.txt')
открыть('abc.txt', 'р')
открыть('abc.txt', 'ш')
С этими типами файлов open() вернет объект файла TextIOWrapper :
>>>
>>> файл = open('dog_breeds.txt')
>>> тип(файл)
<класс '_io.TextIOWrapper'>
Это файловый объект по умолчанию, возвращаемый open() .
Типы буферизованных двоичных файлов
Тип буферизованного двоичного файла используется для чтения и записи двоичных файлов. Вот несколько примеров того, как эти файлы открываются:
открыть('abc.txt', 'рб')
открыть('abc.txt', 'wb')
Для этих типов файлов open() вернет объект файла BufferedReader или BufferedWriter :
>>>
>>> файл = open('dog_breeds. txt', 'rb')
>>> тип(файл)
<класс '_io.BufferedReader'>
>>> файл = открыть('dog_breeds.txt', 'wb')
>>> тип(файл)
<класс '_io.BufferedWriter'>
Необработанные типы файлов
Тип необработанного файла:
«обычно используется как низкоуровневый строительный блок для двоичных и текстовых потоков». (Источник)
Поэтому обычно не используется.
Вот пример открытия этих файлов:
открыть('abc.txt', 'rb', буферизация=0)
С этими типами файлов open() вернет файловый объект FileIO :
>>>
>>> file = open('dog_breeds.txt', 'rb', буферизация=0)
>>> тип(файл)
<класс '_io.FileIO'>
Чтение и запись открытых файлов
После того, как вы открыли файл, вы захотите его прочитать или записать. Прежде всего, давайте рассмотрим чтение файла. Существует несколько методов, которые можно вызвать для файлового объекта, чтобы помочь вам:
| Метод | Что он делает |
|---|---|
. | Это чтение из файла на основе числа размером байт. Если аргумент не передан или Нет или -1 передается, затем считывается весь файл. |
.readline(размер=-1) | Это считывает не более размеров количества символов из строки. Это продолжается до конца строки, а затем возвращается обратно. Если аргумент не передается или передается None или -1 , то считывается вся строка (или оставшаяся часть строки). |
.readlines() | Это читает оставшиеся строки из файлового объекта и возвращает их в виде списка. |
Используя тот же файл dog_breeds.txt , который вы использовали выше, давайте рассмотрим несколько примеров использования этих методов. Вот пример того, как открыть и прочитать весь файл, используя .read() :
>>>
>>> с open('dog_breeds. txt', 'r') в качестве читателя:
>>> # Прочитать и распечатать весь файл
>>> печать(читатель.читать())
Мопс
Джек Рассел терьер
Английский спрингер-спаниель
Немецкая овчарка
Стаффордширский бультерьер
Кавалер-кинг-чарльз-спаниель
Золотистый ретривер
Вест-хайленд-уайт-терьер
Боксер
Бордер-терьер
Вот пример того, как каждый раз читать 5 байтов строки с помощью метода Python .readline() :
>>>
>>> с open('dog_breeds.txt', 'r') в качестве читателя:
>>> # Прочитать и напечатать первые 5 символов строки 5 раз
>>> печать (читатель.readline (5))
>>> # Обратите внимание, что строка длиннее 5 символов и продолжается
>>> # далее по строке, читая каждый раз по 5 символов до конца строки
>>> # строка, а затем "обтекает"
>>> печать (читатель.readline (5))
>>> печать (читатель.readline (5))
>>> печать (читатель.readline (5))
>>> печать (читатель.readline (5))
Мопс
Джек
русский
лл те
рьер
Вот пример чтения всего файла в виде списка с помощью метода Python .: readlines()
>>>
>>> f = open('dog_breeds.txt')
>>> f.readlines() # Возвращает объект списка
['Мопс\n', 'Джек-рассел-терьер\n', 'Английский спрингер-спаниель\n', 'Немецкая овчарка\n', 'Стаффордширский бультерьер\n', 'Кавалер-кинг-чарльз-спаниель\n', 'Золотистый ретривер \n', 'Вест-хайленд-уайт-терьер\n', 'Боксер\n', 'Бордер-терьер\n']
Приведенный выше пример также можно выполнить, используя list() для создания списка из файлового объекта:
>>>
>>> f = open('dog_breeds.txt')
>>> список(ф)
['Мопс\n', 'Джек-рассел-терьер\n', 'Английский спрингер-спаниель\n', 'Немецкая овчарка\n', 'Стаффордширский бультерьер\n', 'Кавалер-кинг-чарльз-спаниель\n', 'Золотистый ретривер \n', 'Вест-хайленд-уайт-терьер\n', 'Боксер\n', 'Бордер-терьер\n']
Удаление рекламы
Перебор каждой строки в файле
Обычно при чтении файла выполняется повторение каждой строки. Вот пример того, как использовать метод Python .readline() для выполнения этой итерации:
>>>
>>> с open('dog_breeds.txt', 'r') в качестве читателя:
>>> # Читать и печатать весь файл построчно
>>> строка = читатель.readline()
>>> while line != '': # Символ EOF представляет собой пустую строку
>>> печать (строка, конец = '')
>>> строка = читатель.readline()
Мопс
Джек Рассел терьер
Английский спрингер-спаниель
Немецкая овчарка
Стаффордширский бультерьер
Кавалер-кинг-чарльз-спаниель
Золотистый ретривер
Вест-хайленд-уайт-терьер
Боксер
Бордер-терьер
Еще один способ перебора каждой строки в файле — использовать метод Python .readlines() файлового объекта. Помните, .readlines() возвращает список, в котором каждый элемент списка представляет строку в файле:
>>>
>>> с open('dog_breeds.txt', 'r') в качестве читателя:
>>> для строки в reader. readlines():
>>> печать (строка, конец = '')
Мопс
Джек Рассел терьер
Английский спрингер-спаниель
Немецкая овчарка
Стаффордширский бультерьер
Кавалер-кинг-чарльз-спаниель
Золотистый ретривер
Вест-хайленд-уайт-терьер
Боксер
Бордер-терьер
Однако приведенные выше примеры можно еще больше упростить, перебирая сам файловый объект:
>>>
>>> с open('dog_breeds.txt', 'r') в качестве читателя:
>>> # Читать и печатать весь файл построчно
>>> для строки в читателе:
>>> печать (строка, конец = '')
Мопс
Джек Рассел терьер
Английский спрингер-спаниель
Немецкая овчарка
Стаффордширский бультерьер
Кавалер-кинг-чарльз-спаниель
Золотистый ретривер
Вест-хайленд-уайт-терьер
Боксер
Бордер-терьер
Этот последний подход больше похож на Python и может быть быстрее и эффективнее с точки зрения использования памяти. Поэтому рекомендуется использовать это вместо этого.
Примечание: Некоторые из приведенных выше примеров содержат print('some text', end='') . end='' предназначен для предотвращения добавления Python дополнительной новой строки к печатаемому тексту и печати только того, что читается из файла.
Теперь приступим к записи файлов. Как и при чтении файлов, файловые объекты имеют несколько методов, полезных для записи в файл:
| Метод | Что он делает |
|---|---|
.write(string) | Это записывает строку в файл. |
.writelines(seq) | Это записывает последовательность в файл. К каждому элементу последовательности не добавляются окончания строк. Вам решать, как добавить соответствующее окончание строки. |
Вот краткий пример использования .write() и .writelines() :
с open('dog_breeds.txt', 'r') в качестве читателя:
# Примечание: readlines не обрезает концы строк
dog_breeds = читатель.readlines()
с open('dog_breeds_reversed. txt', 'w') в качестве автора:
# В качестве альтернативы вы можете использовать
# Writer.writelines(обратный(dog_breeds))
# Записываем породы собак в файл в обратном порядке
для породы в обратном порядке (dog_breeds):
писатель.написать (порода)
Работа с байтами
Иногда вам может понадобиться работать с файлами, используя байтовые строки. Это делается путем добавления 'b' символов в аргумент режима . Применяются все те же методы для файлового объекта. Однако каждый из методов ожидает и вместо этого возвращает объект размером байт :
>>>
>>> с open('dog_breeds.txt', 'rb') в качестве читателя:
>>> напечатать(читатель.readline())
б'Мопс\n'
Открытие текстового файла с использованием флага b не так интересно. Допустим, у нас есть эта милая фотография джек-рассел-терьера ( jack_russell.png ):
0 (https://creativecommons.org/licenses/by/3.0)], из Wikimedia Commons. Вы действительно можете открыть этот файл в Python и изучить его содержимое! Поскольку формат файла .png хорошо определен, заголовок файла состоит из 8 байт, разбитых следующим образом:
| Значение | Интерпретация |
|---|---|
0x89 | «Волшебное» число, указывающее, что это начало числа 9.0026 PNG |
0x50 0x4E 0x47 | PNG в ASCII |
0x0D 0x0A | Строка в стиле DOS, заканчивающаяся \r\n |
0x1A | Символ EOF в стиле DOS |
0x0A | Строка в стиле Unix, заканчивающаяся \n |
Конечно же, когда вы открываете файл и читаете эти байты по отдельности, вы можете видеть, что это действительно . Заголовочный файл: png
>>>
>>> с open('jack_russell.png', 'rb') как byte_reader:
>>> печать (byte_reader.read (1))
>>> печать (byte_reader.read (3))
>>> печать (byte_reader.read (2))
>>> печать (byte_reader.read (1))
>>> печать (byte_reader.read (1))
б'\х89'
б'PNG'
б'\г\п'
б'\х1а'
б'\п'
Удалить рекламу
Полный пример:
dos2unix.py Давайте вернемся домой и посмотрим на полный пример того, как читать и писать в файл. Далее идет dos2unix подобный инструмент, который преобразует файл, содержащий окончания строки \r\n в \n .
Этот инструмент разбит на три основных раздела. Первый — str2unix() , который преобразует строку из \r\n окончаний строк в \n . Второй — dos2unix() , который преобразует строку, содержащую \r\n символов, в \n . dos2unix() вызывает str2unix() внутренне. Наконец, есть __main__ блок, который вызывается только тогда, когда файл выполняется как скрипт. Думайте об этом как о основной функции , которую можно найти в других языках программирования.
"""
Простой скрипт и библиотека для преобразования файлов или строк из DOS, например
окончания строк с Unix-подобными окончаниями строк.
"""
импортировать аргументы
импорт ОС
def str2unix (input_str: str) -> str:
р"""
Преобразует строку из окончаний строк \r\n в \n
Параметры
----------
input_str
Строка, концы строк которой будут преобразованы
Возвращает
-------
Преобразованная строка
"""
r_str = input_str.replace('\r\n', '\n')
вернуть r_str
def dos2unix (исходный_файл: ул, целевой_файл: ул):
"""
Преобразует файл, содержащий Dos-подобные окончания строк, в Unix-подобные
Параметры
----------
исходный файл
Путь к исходному файлу, который нужно преобразовать
целевой_файл
Путь к сконвертированному файлу для вывода
"""
# ПРИМЕЧАНИЕ. Можно добавить проверку существования файла и перезапись файла.
# защита
с open(source_file, 'r') в качестве читателя:
dos_content = читатель.read()
unix_content = str2unix(dos_content)
с open(dest_file, 'w') в качестве записи:
писатель.write(unix_content)
если __name__ == "__main__":
# Создадим наш парсер аргументов и зададим его описание
синтаксический анализатор = argparse.ArgumentParser(
description="Сценарий, который преобразует файл, подобный DOS, в файл, подобный Unix",
)
# Добавьте аргументы:
# - source_file: исходный файл, который мы хотим преобразовать
# - файл_назначения: место назначения, куда должны поступать выходные данные
# Примечание: использование типа аргумента argparse.FileType может
# упростить некоторые вещи
parser.add_argument(
'исходный файл',
help='Расположение источника'
)
parser.add_argument(
'--dest_file',
help='Расположение целевого файла (по умолчанию: исходный_файл с добавлением `_unix`',
по умолчанию = нет
)
# Разобрать аргументы (argparse автоматически получает значения из
# sys. argv)
аргументы = парсер.parse_args()
s_file = аргументы.исходный_файл
d_file = args.dest_file
# Если целевой файл не был передан, то предположим, что мы хотим
# создать новый файл на основе старого
если d_file равен None:
путь_к_файлу, расширение_файла = os.path.splitext(s_file)
d_file = f'{путь_к_файлу}_unix{расширение_файла}'
dos2unix(s_file, d_file)
Советы и рекомендации
Теперь, когда вы освоили основы чтения и записи файлов, вот несколько советов и приемов, которые помогут вам улучшить свои навыки.
__файл__ Атрибут __file__ — это специальный атрибут модулей, аналогичный __name__ . Это:
«путь к файлу, из которого был загружен модуль, если он был загружен из файла». (Источник
Примечание: Повторяю, __file__ возвращает путь относительно того места, где был вызван исходный скрипт Python. Если вам нужен полный системный путь, вы можете использовать os.getcwd() , чтобы получить текущий рабочий каталог вашего исполняемого кода.
Вот реальный пример. На одной из своих прошлых работ я провел несколько тестов аппаратного устройства. Каждый тест был написан с использованием сценария Python с именем файла тестового сценария в качестве заголовка. Затем эти сценарии выполнялись и могли печатать свой статус, используя __file__ специальный атрибут. Вот пример структуры папок:
проект/ | ├── тесты/ | ├── test_commanding.py | ├── test_power.py | ├── test_wireHousing.py | └── test_leds.py | └── main.py
Запуск main.py выдает следующее:
>>> python main.py тесты/test_commanding.py Запущено: тесты/test_commanding.py Пройдено! тесты/test_power.py Запущено: тесты/test_power.py Пройдено! тесты/test_wireHousing.py Запущено: test/test_wireHousing.py Ошибка! тесты/test_leds.py Запущено: тесты/test_leds.py Пройдено!
Мне удалось запустить и динамически получить статус всех моих тестов с помощью специального атрибута __file__ .
Добавление к файлу
Иногда может потребоваться добавить в файл или начать запись в конце уже заполненного файла. Это легко сделать, используя символ 'a' для аргумента режима :
с open('dog_breeds.txt', 'a') в качестве a_writer:
a_writer.write('\nБигль')
При осмотре dog_breeds.txt снова, вы увидите, что начало файла не изменилось, а Beagle теперь добавлено в конец файла:
>>>
>>> с open('dog_breeds.txt', 'r') в качестве читателя:
>>> печать(читатель.читать())
Мопс
Джек Рассел терьер
Английский спрингер-спаниель
Немецкая овчарка
Стаффордширский бультерьер
Кавалер-кинг-чарльз-спаниель
Золотистый ретривер
Вест-хайленд-уайт-терьер
Боксер
Бордер-терьер
бигль
Удалить рекламу
Работа с двумя файлами одновременно
Бывают случаи, когда вы можете одновременно читать файл и записывать в другой файл. Если вы используете пример, который был показан, когда вы учились писать в файл, его на самом деле можно объединить в следующее:
d_path = 'dog_breeds.txt'
d_r_path = 'dog_breeds_reversed.txt'
с open(d_path, 'r') в качестве читателя, open(d_r_path, 'w') в качестве писателя:
dog_breeds = читатель.readlines()
писатель.writelines (обратный (dog_breeds))
Создание собственного контекстного менеджера
Может наступить время, когда вам потребуется более точное управление файловым объектом, поместив его в пользовательский класс. Когда вы делаете это, использование оператора with больше не может использоваться, если вы не добавите несколько магических методов: __enter__ и __exit__ . Добавив их, вы создадите так называемый контекстный менеджер.
__enter__() вызывается при вызове оператора with . __exit__() вызывается при выходе из блока операторов с .
Вот шаблон, который вы можете использовать для создания собственного класса:
класс my_file_reader():
def __init__(я, путь_к_файлу):
self.__path = путь_к_файлу
self.__file_object = Нет
защита __enter__(сам):
self.__file_object = открыть (self.__path)
вернуть себя
def __exit__(self, type, val, tb):
self.__file_object.close()
# Дополнительные методы, реализованные ниже
Теперь, когда у вас есть собственный класс, который теперь является менеджером контекста, вы можете использовать его аналогично встроенному open() :
с my_file_reader('dog_breeds.txt') в качестве читателя:
# Выполнение пользовательских операций класса
проходить
Вот хороший пример. Помните милое изображение Джека Рассела, которое у нас было? Возможно, вы хотите открыть другие файлы .png , но не хотите каждый раз анализировать файл заголовка. Вот пример того, как это сделать. В этом примере также используются пользовательские итераторы. Если вы не знакомы с ними, посмотрите Python Iterators:
класс PngReader():
# Каждый файл .png содержит это в заголовке. Используйте его для проверки
# файл действительно имеет формат .png.
_expected_magic = b'\x89PNG\r\n\x1a\n'
def __init__(я, путь_к_файлу):
# Убедитесь, что файл имеет правильное расширение
если не file_path.endswith('.png'):
поднять NameError("Файл должен иметь расширение '.png'")
self.__path = путь_к_файлу
self.__file_object = Нет
защита __enter__(сам):
self.__file_object = открыть (self.__path, 'rb')
магия = self.__file_object.read(8)
если магия != self._expected_magic:
поднять TypeError («Файл не является правильно отформатированным файлом .png!»)
вернуть себя
def __exit__(self, type, val, tb):
self.__file_object.close()
защита __iter__(я):
# Это и __next__() используются для создания пользовательского итератора
# См. https://dbader.org/blog/python-iterators
вернуть себя
деф __следующий__(сам):
# Прочитать файл в "Chunks"
# См. https://en.wikipedia.org/wiki/Portable_Network_Graphics#%22Chunks%22_within_the_file
начальные_данные = self.__file_object.read(4)
# Файл не был открыт или достиг EOF. Это означает, что мы
# дальше идти нельзя, поэтому остановите итерацию, подняв
# Остановить итерацию.
если self.__file_object имеет значение None или initial_data == b'':
поднять StopIteration
еще:
# Каждый фрагмент имеет длину, тип, данные (на основе длины) и crc
# Получить эти значения и вернуть их в виде кортежа
chunk_len = int.from_bytes (начальные_данные, порядок байтов = 'большой')
chunk_type = self.__file_object.read(4)
chunk_data = self.__file_object.read(chunk_len)
chunk_crc = self.__file_object.read(4)
вернуть chunk_len, chunk_type, chunk_data, chunk_crc
Теперь вы можете открывать файлы . и правильно анализировать их с помощью вашего пользовательского менеджера контекста: png
>>>
>>> с PngReader('jack_russell.png') в качестве читателя:
>>> для l, t, d, c в считывателе:
>>> print(f"{l:05}, {t}, {c}")
00013, b'IHDR', b'v\x121k'
00001, b'sRGB', b'\xae\xce\x1c\xe9'
00009, b'pHYs', b'(<]\x19'
00345, b'iTXt', b"L\xc2'Y"
16384, б'ИДАТ', б'i\x99\x0c('
16384, б'ИДАТ', б'\хб3\хфа\х9а$'
16384, б'ИДАТ', б'\xff\xbf\xd1\n'
16384, б'ИДАТ', б'\хс3\х9с\xb1}'
16384, б'ИДАТ', б'\xe3\x02\xba\x91'
16384, б'ИДАТ', б'\xa0\xa99='
16384, б'ИДАТ', б'\xf4\x8b.\x92'
16384, б'ИДАТ', б'\x17i\xfc\xde'
16384, б'ИДАТ', б'\x8fb\x0e\xe4'
16384, б'ИДАТ', б')3={'
01040, б'ИДАТ', б'\xd6\xb8\xc1\x9f'
00000, b'IEND', b'\xaeB`\x82'
Не изобретайте змею
Существуют распространенные ситуации, с которыми вы можете столкнуться при работе с файлами. Большинство из этих случаев могут быть обработаны с помощью других модулей. Два распространенных типа файлов, с которыми вам может понадобиться работать: . и csv .json . Real Python уже собрал несколько замечательных статей о том, как с ними справиться:
- Чтение и запись файлов CSV в Python
- Работа с данными JSON в Python
Кроме того, существуют встроенные библиотеки, которые могут вам помочь:
-
волна: чтение и запись файлов WAV (аудио) -
aifc: чтение и запись файлов AIFF и AIFC (аудио) -
sunau: чтение и запись файлов Sun AU -
tarfile: чтение и запись архивных файлов tar -
zipfile: работа с ZIP архивами -
configparser: легко создавать и анализировать файлы конфигурации -
xml.etree.ElementTree: создание или чтение файлов на основе XML -
msilib: чтение и запись файлов установщика Microsoft -
plistlib: создание и анализ файлов Mac OS X. plist
Есть еще много других. Кроме того, на PyPI доступно еще больше сторонних инструментов. Некоторые популярные из них следующие:
-
PyPDF2: Инструментарий PDF -
xlwings: чтение и запись файлов Excel -
Подушка: чтение изображений и обработка
Удалить рекламу
Ты файловый волшебник Гарри!
Ты сделал это! Теперь вы знаете, как работать с файлами в Python, включая некоторые передовые методы. Работа с файлами в Python теперь должна быть проще, чем когда-либо, и это приятное чувство, когда вы начинаете это делать.
В этом уроке вы узнали:
- Что такое файл
- Как правильно открывать и закрывать файлы
- Как читать и записывать файлы
- Некоторые продвинутые методы работы с файлами
- Некоторые библиотеки для работы с распространенными типами файлов
Если у вас есть какие-либо вопросы, напишите нам в комментариях.