2.3. Реляционная модель
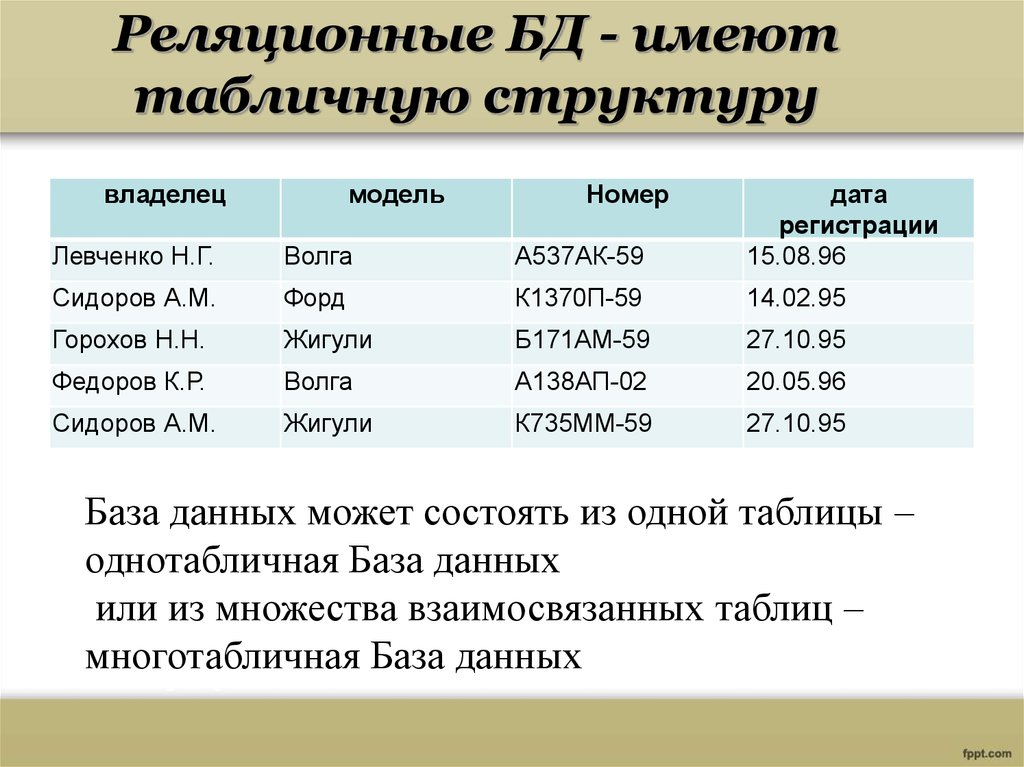
Реляционная модель данных предложена сотрудником фирмы IBM Эдгаром Коддом и основывается на понятии отношение(relation).
Отношрншпредставляет < обой множество элементов, называемых кортежами. Подробно теоретическая основа реляционной модели данных рассматривается в следующем разделе. Наглядной формой представления отношения является привычная для человеческого восприятия двумерная таблица.
Таблица имоет строки (записи) и столоны (колонки). Каждая строка таблицы имеет одинаковую структуру и состоит из полей. Строкам таблицы со ответствуют кортежи, а столбцам — атрибуты отношения.
С
помощью одной таблицы удобно описывать
простейший вид связей между данными,
а именно деление одно1 о объекта (явления,
сущности, системы и проч.), информация
о котором хранится в таблице, на множество
подобъектов, каждому из которых
соответствует строка или запись
таблицы.
Физическое размещение дачных в реляционных базах на внешних носителях легко осуществляется с помощью обычных файлов.
Достоит твореляционной модели данных заключаете я в простоте, понят ности и удобст ве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной их широкого иснользова ния. Проблемы же эффективности обраоотки данных этого типа оказались технически вполне разрешимыми.
Основными недостаткамиреляционной модели ивляютс я следу
ющие: отсутствие стандартных средств
идентификации отдельных записей и
сложность описания иерархических
и сетевых связей.
Примерами зарубежных реляционных СУБД для ПЭВМ являются следующие: dBaselliPlusиdBaseIY(фирмаAshtnn-Tate),DB2 (IBM),RBASH(Microrim),FoxProранних версий иFoxBase(FoxSoftware),ParadoxиdBASEforWindows(Borland»),FoxPro60.ieeпоздних версий,VisualFoxProиAccess(Microsoft),Clarion(ClarionSoftware),Ingres(ASKComputerSystems) иOracle(Oracle).
К отечественным СУБД релчционною тига относятся системы ПАЛЬМА (ИК АН УССР), а также система IlyTech (МИФИ).
Заметим, что последние версии реляционных СУБД имеют некоторые свойства объектно -ориентиров шных систем. Такие СУБД часто называют объектно-реляционными. Примером такой системы можно считать продукты Oracle 8.x. Системы предыдущих версий вплоть цоOracle 7 х считаются *чисто» реляционными.
 р нак тадной(INYNO).
название товара(GOODS)
и количество товара(QTY).
ТаблицаINVOICES
связана с таблицейINVOICE.ITEMS
по полюINVNO.
р нак тадной(INYNO).
название товара(GOODS)
и количество товара(QTY).
ТаблицаINVOICES
связана с таблицейINVOICE.ITEMS
по полюINVNO.Как видно из рисунка, по < равнению с реляционной моделью в постреля- нионной модели данные хранят ся более эффективно, а при обработке не
2 Чак.474
INVNO | CUSTNO | GOODS | QTY |
0373 | 8723 | Сыр | 3 |
Рыба | 2 | ||
8232 | Лимонад | 1 | |
Сок | 6 | ||
Печенье | 2 | ||
7364 | 8723 | Йогурт | 1 |
Риг. 2.6. ( груктуры данных реляционной и пос
греляционной моделей
2.6. ( груктуры данных реляционной и пос
греляционной моделей
требуется выполнять операцию соединения данных из двух таблиц. Для доказательства на рис. 2.7 приводятся примеры операторов SELECT выбора данных из всех полей базы на языкеSQL для реляционной (а) и постреляционной (б) моделей.
Помимо обеспечения влож< нности полей постреляционная модель поддерживает ассоциированные многозначные поля (множественные группы). Совокупность ассоциированных полей называется ассоциациейПри этом в строке первое значение одного столбца ассоциации соответствует первым значениям всех других столбцов ассоциации. А налогичным образом связаны все вторые значения столбцов и т. д.
а)
SELECT
INVOICES.INVNO, CUSTNO, GOODS, QTY
FROM
INVOICES, INVOICE.ITEMS
WHERE
INVOICES.INVNO=INVOICE. ITEMS.INVNO;
ITEMS.INVNO;
б)
SELECT
INVNO, CUSTNO, GOODS, QTY
INVOICES;
Рис. 2.7. Операторы SQL для реляционной и поп реляционной моделей
На длину полей и количество полей в записях таблицы не накладывается требование постоянства. Это означает, что структура данных и таблиц имеет большую гибкость.
Поскольку постреляционная модель допускает хранение в таблицах ненормализованных данных, возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается включением в СУБД механизмов, подобных хранимым процедурам в клиент серверных системах.
Для
описания функций контроля значений в
полях имеется возможность (оздавать
процедуры (коды конверсии и коды
корреляции), автома гически вызываемые
до или после обращения к данным. Коды
корреляции выполняются сразу после
чтения данных, перед их обработкой.
Дог.тоинстпвомпостреляционной модели является возможность представления совокупности свя 1анных реляционных таблиц одной постреляционной таблицей. Это обеспечивав , зысокую наглядность представления информации и повышение гффективности ее обработки.
Недостаткомпостркляционной модели является сложность решения проблемы обеспечения целостности и нещ ютиворечивост и хранимых данных.
Рассмотренная нами постреляционная модель данных поддерживается СУБД uniVers. К числу других СУБД, основанных на пострсляционной модели данных, относятся также системыBubba иDasdb.
НОУ ИНТУИТ | Лекция | Нормальные формы отношений. Создание логической модели реляционной базы данных
< Лекция 5 || Лекция 6: 123456 || Лекция 7 >
Аннотация: В данной лекции вводится понятие нормальных форм отношений и логической модели реляционной базы данных. Эти понятия составляют теоретическую основу для процедур проектирования реляционных баз данных.
Эти понятия составляют теоретическую основу для процедур проектирования реляционных баз данных.
Ключевые слова: операции, определение, реляционная база данных, схема отношения, схема реляционной базы данных, логическая модель реляционная база данных, базы данных, физические модели данных, модель данных, логическая модель данных, физическая модель, СУБД, третья нормальная форма, предметной области, нормализация, представление данных, процесс нормализации, значение, множества, надежность, эквивалентное преобразование, информационная модель предметной области, логическая модель реляционной базы данных, первичный ключ отношения, операция включения, состояние предметной области, избыточность, логическая структура, БД, отношение, адрес, товар, стоимость, теория реляционных баз данных, производительность, запрос, функциональные зависимости, нормальная форма, разбиение, минимальные покрытия, синтез отношений, ключ отношения, целостность, реляционная модель данных, реляционные операции, схема базы данных, первая нормальная форма, домен, атрибут, дублирование данных, массив, 1НФ, вторая нормальная форма, составной ключ, shipping, capacity, registration number, транзитивность, место, ограничение целостности, связь, пункт, нормальная форма Бойса-Кодда, ключ, кортеж, работ, руководитель команды, аномалия удаления, информация, команда, четвертая нормальная форма, семантика, декомпозиция схемы отношения, логическая модель реляционной базы данных, пятая нормальняа, многие-ко-многим, многозначная зависимость, степень связи, поиск, CAR, color, model
Понятие о логической модели реляционной базы данных
 intuit.ru/2010/edi»>Теперь, когда определены понятия отношения и операции над отношениями, уточним интуитивно используемое определение реляционной базы данных и ее схемы.
intuit.ru/2010/edi»>Теперь, когда определены понятия отношения и операции над отношениями, уточним интуитивно используемое определение реляционной базы данных и ее схемы.Определение 1. Под реляционной базой данных принято понимать совокупность экземпляров конечных отношений. Совокупность схем отношений образует схему реляционной базы данных.
Схема реляционной базы данных является логической моделью реляционной базы данных.
Как уже было сказано в
«Предметная область базы данных и ее модели»
— «Предметная область базы данных и ее модели», — на основе информационной модели в процессе проектирования создаются логическая и физическая модели данных. Информационная модель данных отражает потребности системы в данных и связи между данными с точки зрения их потребителей — пользователей; логическая модель данных является независимым логическим представлением данных; физическая модель данных содержит определения всех реализуемых объектов в конкретной базе данных для конкретной СУБД.
На практике часто рассматривают только две модели — логическую и физическую модели данных. При этом информационная и логическая модели данных не различаются и считаются синонимами. В рамках такого подхода некоторые специалисты в области баз данных считают, что информационная модель данных должна быть нормализована. Это означает, что проектировщики баз данных должны требовать от аналитиков, чтобы они приводили информационную модель данных к третьей нормальной форме! Такой подход имеет ряд недостатков. Во-первых, аналитики, являясь экспертами в предметной области, как правило, не представляют, что такое нормализация данных. Во-вторых, информационная модель данных должна быть независимой от физической модели данных, в рамках которой она будет реализовываться. Для реализации информационной модели данных может быть выбрана не реляционная, а, например, сетевая (СУБД ADABAS ) или многомерная (СУБД Teradata ) модели данных, тогда нормализация отношений модели не столь актуальна. В-третьих, проектировщики базы данных должны иметь логическое представление данных, посредством которого, с одной стороны, общаться с аналитиками и пользователями в понятных для них терминах, и, с другой стороны, превращать полученные логические отношения в физические объекты базы данных.
В-третьих, проектировщики базы данных должны иметь логическое представление данных, посредством которого, с одной стороны, общаться с аналитиками и пользователями в понятных для них терминах, и, с другой стороны, превращать полученные логические отношения в физические объекты базы данных.
Поэтому в настоящем курсе рассматривается три уровня моделей данных, а процесс нормализации информационной модели данных считается составной частью процесса создания логической модели данных, которую предполагается реализовать на реляционной СУБД.
На практике при построении логической модели реляционной базы данных особое значение для решения задачи формирования отношений базы данных имеет понятие функциональной зависимости (ФЗ). Установление ФЗ и получение наилучшего с точки зрения минимальности представления множества ФЗ позволят построить наиболее оптимальный вариант базы данных, обеспечивающий надежность хранения и обработки данных на основе методов эквивалентных преобразований схем отношений реляционной базы данных.
Процесс решения такой задачи называется нормализацией отношений информационной модели предметной области и заключается в превращении ее объектов в логические таблицы базы данных.
Дальше >>
< Лекция 5 || Лекция 6: 123456 || Лекция 7 >
Описание нормализации базы данных — Office
- Статья
- 5 минут на чтение
- Применимо к:
- Microsoft Office Access 2007, Microsoft Office Access 2003
Исходный номер базы знаний: 283878
В этой статье объясняется терминология нормализации базы данных для начинающих. Базовое понимание этой терминологии полезно при обсуждении дизайна реляционной базы данных.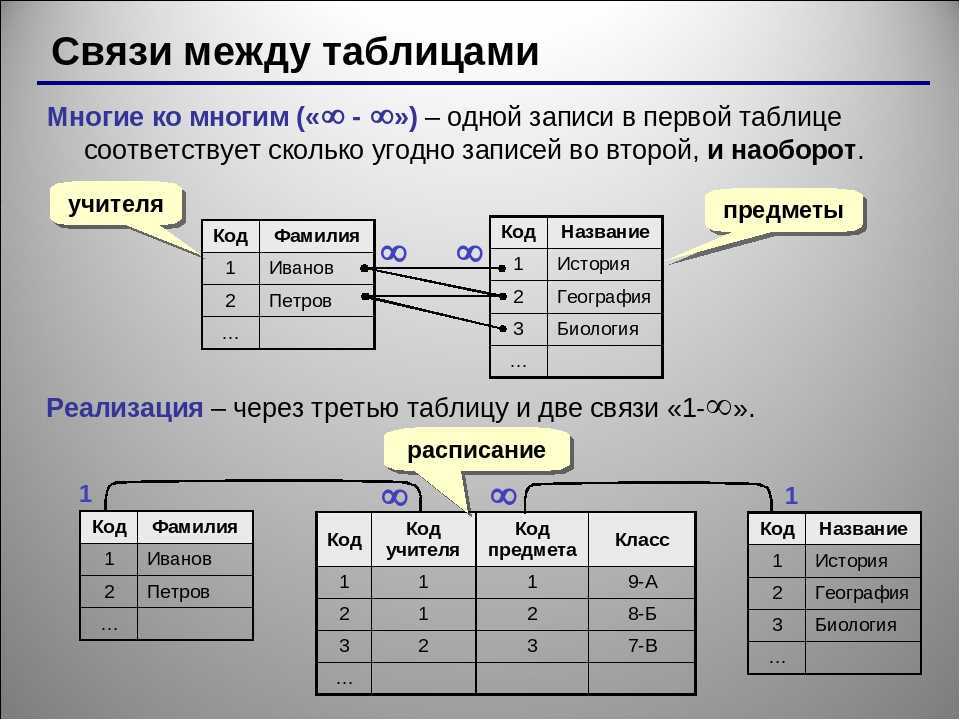
Описание нормализации
Нормализация — это процесс организации данных в базе данных. Это включает в себя создание таблиц и установление отношений между этими таблицами в соответствии с правилами, предназначенными как для защиты данных, так и для повышения гибкости базы данных за счет устранения избыточности и непоследовательной зависимости.
Избыточные данные занимают место на диске и создают проблемы с обслуживанием. Если необходимо изменить данные, которые существуют более чем в одном месте, данные должны быть изменены одинаково во всех местах. Изменить адрес клиента гораздо проще, если эти данные хранятся только в таблице «Клиенты» и больше нигде в базе данных.
Что такое «несогласованная зависимость»? Хотя для пользователя интуитивно понятно искать в таблице «Клиенты» адрес конкретного клиента, может не иметь смысла искать там зарплату сотрудника, который звонит этому клиенту. Зарплата сотрудника связана с сотрудником или зависит от него и поэтому должна быть перемещена в таблицу «Сотрудники». Несогласованные зависимости могут затруднить доступ к данным, поскольку путь для поиска данных может отсутствовать или быть нарушен.
Несогласованные зависимости могут затруднить доступ к данным, поскольку путь для поиска данных может отсутствовать или быть нарушен.
Существует несколько правил нормализации базы данных. Каждое правило называется «нормальной формой». Если первое правило соблюдается, говорят, что база данных находится в «первой нормальной форме». Если соблюдаются первые три правила, считается, что база данных находится в «третьей нормальной форме». Хотя возможны и другие уровни нормализации, третья нормальная форма считается наивысшим уровнем, необходимым для большинства приложений.
Как и многие формальные правила и спецификации, реальные сценарии не всегда обеспечивают идеальное соответствие. Как правило, для нормализации требуются дополнительные таблицы, и некоторые клиенты считают это громоздким. Если вы решите нарушить одно из первых трех правил нормализации, убедитесь, что ваше приложение предвидит любые проблемы, которые могут возникнуть, такие как избыточные данные и несогласованные зависимости.
Следующие описания включают примеры.
Первая нормальная форма
- Устранение повторяющихся групп в отдельных таблицах.
- Создайте отдельную таблицу для каждого набора связанных данных.
- Определите каждый набор связанных данных с помощью первичного ключа.
Не используйте несколько полей в одной таблице для хранения похожих данных. Например, для отслеживания элемента инвентаря, который может поступать из двух возможных источников, запись инвентаризации может содержать поля для кода поставщика 1 и кода поставщика 2.
Что происходит, когда вы добавляете третьего поставщика? Добавление поля — это не ответ; он требует модификации программы и таблиц и не может плавно приспосабливаться к постоянно меняющемуся количеству поставщиков. Вместо этого поместите всю информацию о поставщиках в отдельную таблицу с именем Поставщики, а затем свяжите запасы с поставщиками с помощью ключа номера товара или поставщиков с запасами с помощью ключа кода поставщика.
Вторая нормальная форма
- Создайте отдельные таблицы для наборов значений, которые применяются к нескольким записям.
- Свяжите эти таблицы с помощью внешнего ключа.
Записи не должны зависеть ни от чего, кроме первичного ключа таблицы (при необходимости составного ключа). Например, рассмотрим адрес клиента в системе учета. Адрес необходим таблице Customers, а также таблицам Orders, Shipping, Invoices, Accounts Receivable и Collections. Вместо того, чтобы хранить адрес клиента как отдельную запись в каждой из этих таблиц, сохраните его в одном месте, либо в таблице «Клиенты», либо в отдельной таблице «Адреса».
Третья нормальная форма
- Исключить поля, не зависящие от ключа.
Значения в записи, которые не являются частью ключа этой записи, не принадлежат таблице. Как правило, в любое время, когда содержимое группы полей может относиться к нескольким записям в таблице, рассмотрите возможность размещения этих полей в отдельной таблице.
Например, в таблицу подбора сотрудников могут быть включены название университета и адрес кандидата. Но нужен полный список вузов для групповых рассылок. Если информация об университете хранится в таблице «Кандидаты», невозможно составить список университетов, в которых нет текущих кандидатов. Создайте отдельную таблицу Universities и свяжите ее с таблицей Candidates с ключом кода университета.
ИСКЛЮЧЕНИЕ: Соблюдение третьей нормальной формы, хотя и желательно теоретически, не всегда практично. Если у вас есть таблица «Клиенты» и вы хотите устранить все возможные зависимости между полями, вы должны создать отдельные таблицы для городов, почтовых индексов, торговых представителей, классов клиентов и любого другого фактора, который может дублироваться в нескольких записях. Теоретически нормализация стоит того. Однако многие небольшие таблицы могут снизить производительность или превысить объем открытых файлов и памяти.
Может оказаться более целесообразным применять третью нормальную форму только к часто изменяющимся данным. Если некоторые зависимые поля остаются, спроектируйте приложение таким образом, чтобы пользователь проверял все связанные поля при изменении любого из них.
Если некоторые зависимые поля остаются, спроектируйте приложение таким образом, чтобы пользователь проверял все связанные поля при изменении любого из них.
Другие формы нормализации
Четвертая нормальная форма, также называемая нормальной формой Бойса-Кодда (BCNF), и пятая нормальная форма существуют, но редко учитываются при практическом проектировании. Несоблюдение этих правил может привести к далеко не идеальному дизайну базы данных, но не должно влиять на функциональность.
Нормализация примера таблицы
Эти шаги демонстрируют процесс нормализации вымышленной таблицы учеников.
Ненормализованная таблица:
Студент# Советник Adv-комната Класс 1 Класс 2 Класс 3 1022 Джонс 412 101-07 143-01 159-02 4123 Смит 216 101-07 143-01 179-04 Первая нормальная форма: нет повторяющихся групп
Таблицы должны иметь только два измерения.
 Так как у одного студента несколько классов, эти классы должны быть указаны в отдельной таблице. Поля Class1, Class2 и Class3 в приведенных выше записях указывают на проблемы проектирования.
Так как у одного студента несколько классов, эти классы должны быть указаны в отдельной таблице. Поля Class1, Class2 и Class3 в приведенных выше записях указывают на проблемы проектирования.В электронных таблицах часто используется третье измерение, а в таблицах — нет. Другой способ взглянуть на эту проблему — использовать отношение «один ко многим», не помещать одну сторону и многие стороны в одну и ту же таблицу. Вместо этого создайте другую таблицу в первой нормальной форме, удалив повторяющуюся группу (Class#), как показано ниже:
Студент# Советник Adv-комната Класс# 1022 Джонс 412 101-07 1022 Джонс 412 143-01 1022 Джонс 412 159-02 4123 Смит 216 101-07 4123 Смит 216 143-01 4123 Смит 216 179-04 Вторая нормальная форма: удаление избыточных данных
Обратите внимание на несколько значений Class# для каждого значения Student# в приведенной выше таблице.
Class# функционально не зависит от Student# (первичный ключ), поэтому эта связь не находится во второй нормальной форме.Следующие таблицы демонстрируют вторую нормальную форму:
Студенты:
Студент# Советник Adv-комната 1022 Джонс 412 4123 Смит 216 Регистрация:
Студент# Класс# 1022 101-07 1022 143-01 1022 159-02 4123 101-07 4123 143-01 4123 179-04 Третья нормальная форма: исключить данные, не зависящие от ключа
В последнем примере Adv-Room (номер кабинета советника) функционально зависит от атрибута Advisor.
Решение состоит в том, чтобы переместить этот атрибут из таблицы «Студенты» в таблицу «Преподаватель», как показано ниже:0025Студенты:
Студент# Советник 1022 Джонс 4123 Смит Факультет:
Имя Комната Отдел Джонс 412 42 Смит 216 42
 Так как у одного студента несколько классов, эти классы должны быть указаны в отдельной таблице. Поля Class1, Class2 и Class3 в приведенных выше записях указывают на проблемы проектирования.
Так как у одного студента несколько классов, эти классы должны быть указаны в отдельной таблице. Поля Class1, Class2 и Class3 в приведенных выше записях указывают на проблемы проектирования. Class# функционально не зависит от Student# (первичный ключ), поэтому эта связь не находится во второй нормальной форме.
Class# функционально не зависит от Student# (первичный ключ), поэтому эта связь не находится во второй нормальной форме. Решение состоит в том, чтобы переместить этот атрибут из таблицы «Студенты» в таблицу «Преподаватель», как показано ниже:0025
Решение состоит в том, чтобы переместить этот атрибут из таблицы «Студенты» в таблицу «Преподаватель», как показано ниже:0025Что такое нормализация в СУБД (SQL)? 1NF, 2NF, 3NF Пример
Ричард Петерсон
часовОбновлено
Что такое нормализация базы данных?
Нормализация — это метод проектирования базы данных, который уменьшает избыточность данных и устраняет нежелательные характеристики, такие как аномалии вставки, обновления и удаления. Правила нормализации делят большие таблицы на меньшие и связывают их с помощью отношений. Целью нормализации в SQL является устранение избыточных (повторяющихся) данных и обеспечение логического хранения данных.
Правила нормализации делят большие таблицы на меньшие и связывают их с помощью отношений. Целью нормализации в SQL является устранение избыточных (повторяющихся) данных и обеспечение логического хранения данных.
Изобретатель реляционной модели Эдгар Кодд предложил теорию нормализации данных с введением первой нормальной формы и продолжил расширять теорию второй и третьей нормальными формами. Позже он присоединился к Рэймонду Ф. Бойсу для разработки теории нормальной формы Бойса-Кодда.
Нормальные формы базы данных
Вот список нормальных форм в SQL:
- 1NF (первая нормальная форма)
- 2NF (вторая нормальная форма)
- 3NF (Третья нормальная форма)
- BCNF (нормальная форма Бойса-Кодда)
- 4NF (Четвертая нормальная форма)
- 5NF (пятая нормальная форма)
- 6NF (Шестая нормальная форма)
Теория нормализации данных в сервере MySQL все еще развивается. Например, есть обсуждения даже на 6 th Normal Form. Однако в большинстве практических приложений нормализация достигает своего наилучшего результата в 3 rd Normal Form . Эволюция нормализации в теориях SQL показана ниже.0025
Однако в большинстве практических приложений нормализация достигает своего наилучшего результата в 3 rd Normal Form . Эволюция нормализации в теориях SQL показана ниже.0025
Нормализация базы данных с примерами
База данных Нормализация Пример можно легко понять с помощью тематического исследования. Предположим, видеотека поддерживает базу данных фильмов, взятых напрокат. Без какой-либо нормализации в базе данных вся информация хранится в одной таблице, как показано ниже. Давайте разберемся с базой данных нормализации с примером нормализации с решением:
Здесь вы видите столбец Взятые напрокат фильмы имеет несколько значений. Теперь перейдем к 1-м нормальным формам:
Правила 1NF (первая нормальная форма)- Каждая ячейка таблицы должна содержать одно значение.
- Каждая запись должна быть уникальной.

Приведенная выше таблица в 1NF-
Пример 1NF
Пример 1НФ в СУБД
Прежде чем мы продолжим, давайте разберемся в нескольких вещах —
Что такое KEY в SQL?
КЛЮЧ в SQL — это значение, используемое для уникальной идентификации записей в таблице. Ключ SQL — это один столбец или комбинация нескольких столбцов, используемых для уникальной идентификации строк или кортежей в таблице. Ключ SQL используется для выявления повторяющейся информации, а также помогает установить связь между несколькими таблицами в базе данных.
Примечание. Столбцы в таблице, которые НЕ используются для уникальной идентификации записи, называются неключевыми столбцами.
Что такое первичный ключ?
Первичный ключ в СУБД
Первичный — это значение одного столбца, используемое для уникальной идентификации записи базы данных.
Имеет следующие атрибуты
- Первичный ключ не может быть NULL
- Значение первичного ключа должно быть уникальным
- Значения первичного ключа следует редко изменять
- При вставке новой записи первичному ключу должно быть присвоено значение.

Что такое составной ключ?
Составной ключ — это первичный ключ, состоящий из нескольких столбцов, используемых для уникальной идентификации записи.
В нашей базе данных есть два человека с одинаковым именем Роберт Фил, но они живут в разных местах.
Составной ключ в базе данных
Следовательно, мы требуем, чтобы и полное имя, и адрес однозначно идентифицировали запись. Это составной ключ.
Давайте перейдем ко второй нормальной форме 2NF
2NF (Вторая нормальная форма) Правила
- Правило 1 – Быть в 1NF
- Правило 2. Одностолбцовый первичный ключ, который функционально не зависит ни от какого подмножества потенциального ключевого отношения
Понятно, что мы не можем двигаться вперед, чтобы сделать нашу простую базу данных в форме нормализации 2 и , если мы не разделим таблицу выше.
Мы разделили нашу таблицу 1NF на две таблицы, а именно. Таблица 1 и Таблица 2. Таблица 1 содержит информацию об участниках. Таблица 2 содержит информацию о фильмах, взятых напрокат.
Таблица 1 и Таблица 2. Таблица 1 содержит информацию об участниках. Таблица 2 содержит информацию о фильмах, взятых напрокат.
Мы ввели новый столбец Membership_id, который является первичным ключом для таблицы 1. Записи в таблице 1 можно однозначно идентифицировать с помощью идентификатора членства
База данных — внешний ключ
В таблице 2 Membership_ID — это внешний ключ
Внешний ключ в СУБД
Внешний ключ ссылается на первичный ключ другой таблицы! Это помогает соединить ваши таблицы
- Внешний ключ может иметь имя, отличное от его первичного ключа
- Гарантирует, что строки в одной таблице имеют соответствующие строки в другой
- В отличие от первичного ключа, они не обязательно должны быть уникальными. Чаще всего это не
- Внешние ключи могут быть нулевыми, даже если первичные ключи не могут быть
Зачем нужен внешний ключ?
Предположим, новичок вставляет запись в таблицу B, например
. Вы сможете вставлять в свой внешний ключ только те значения, которые существуют в уникальном ключе родительской таблицы. Это помогает в ссылочной целостности.
Вы сможете вставлять в свой внешний ключ только те значения, которые существуют в уникальном ключе родительской таблицы. Это помогает в ссылочной целостности.
Описанную выше проблему можно решить, объявив идентификатор членства из таблицы 2 в качестве внешнего ключа идентификатора членства из таблицы 1.
Теперь, если кто-то попытается вставить значение в поле идентификатора членства, которого нет в родительской таблице, возникнет ошибка показать!
Что такое транзитивные функциональные зависимости?
Транзитивная функциональная зависимость заключается в том, что изменение неключевого столбца может привести к изменению любого из других неключевых столбцов
Рассмотрите таблицу 1. Изменение Полного имени неключевого столбца может изменить Приветствие.
Переходим в 3NF
Правила 3NF (Третья нормальная форма)
- Правило 1 – Быть во 2NF
- Правило 2. Не имеет транзитивных функциональных зависимостей
Чтобы перевести нашу таблицу 2NF в 3NF, нам снова нужно снова разделить нашу таблицу.
Пример 3NF
Ниже приведен пример 3NF в базе данных SQL:
Мы снова разделили наши таблицы и создали новую таблицу, в которой хранятся приветствия.
Нет транзитивных функциональных зависимостей, поэтому наша таблица находится в 3NF
В таблице 3 идентификатор приветствия является первичным ключом, а в таблице 1 идентификатор приветствия является внешним для первичного ключа в таблице 3 уровень, который не может быть подвергнут дальнейшей декомпозиции для достижения типов нормализации в более высоких нормальных формах в СУБД. На самом деле он уже находится в более высоких формах нормализации. В сложных базах данных обычно требуются отдельные усилия для перехода на следующие уровни нормализации данных. Однако далее мы кратко обсудим следующие уровни нормализации в СУБД.
BCNF (нормальная форма Бойса-Кодда)
Даже если база данных находится в нормальной форме 3 rd , все равно могут возникнуть аномалии, если она имеет более одного ключа кандидата .
Иногда BCNF также упоминается как 3.5 Нормальная форма.
Правила 4NF (четвертая нормальная форма)
Если ни один экземпляр таблицы базы данных не содержит двух или более независимых и многозначных данных, описывающих соответствующий объект, то он находится в 4 -й -й нормальной форме.
5NF (Пятая нормальная форма) Правила
Таблица находится в 5 th нормальной форме только в том случае, если она находится в 4NF и не может быть разложена на любое количество меньших таблиц без потери данных.
6NF (Шестая нормальная форма) Предложено
6 th Нормальная форма не стандартизирована, однако она некоторое время обсуждается экспертами по базам данных. Будем надеяться, что в ближайшем будущем у нас будет четкое и стандартизированное определение для 6 th Normal Form…
Вот и все для нормализации SQL!!!
Резюме
- Проектирование базы данных имеет решающее значение для успешного внедрения системы управления базами данных, отвечающей требованиям к данным корпоративной системы.