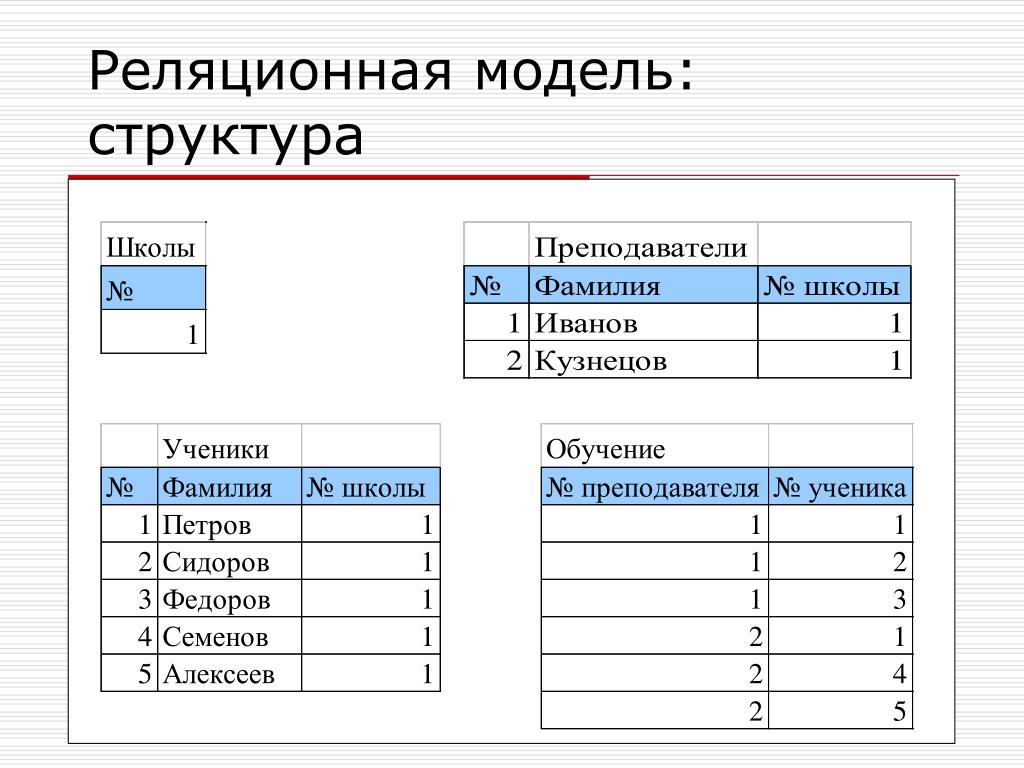
2.3. Реляционная модель
Реляционная модель данных предложена сотрудником фирмы IBM Эдгаром Коддом и основывается на понятии отношение(relation).
Отношрншпредставляет < обой множество элементов, называемых кортежами. Подробно теоретическая основа реляционной модели данных рассматривается в следующем разделе. Наглядной формой представления отношения является привычная для человеческого восприятия двумерная таблица.
Таблица имоет строки (записи) и столоны (колонки). Каждая строка таблицы имеет одинаковую структуру и состоит из полей. Строкам таблицы со ответствуют кортежи, а столбцам — атрибуты отношения.
С
помощью одной таблицы удобно описывать
простейший вид связей между данными,
а именно деление одно1 о объекта (явления,
сущности, системы и проч.), информация
о котором хранится в таблице, на множество
подобъектов, каждому из которых
соответствует строка или запись
таблицы.
Физическое размещение дачных в реляционных базах на внешних носителях легко осуществляется с помощью обычных файлов.
Достоит твореляционной модели данных заключаете я в простоте, понят ности и удобст ве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной их широкого иснользова ния. Проблемы же эффективности обраоотки данных этого типа оказались технически вполне разрешимыми.
Основными недостаткамиреляционной модели ивляютс я следу
ющие: отсутствие стандартных средств
идентификации отдельных записей и
сложность описания иерархических
и сетевых связей.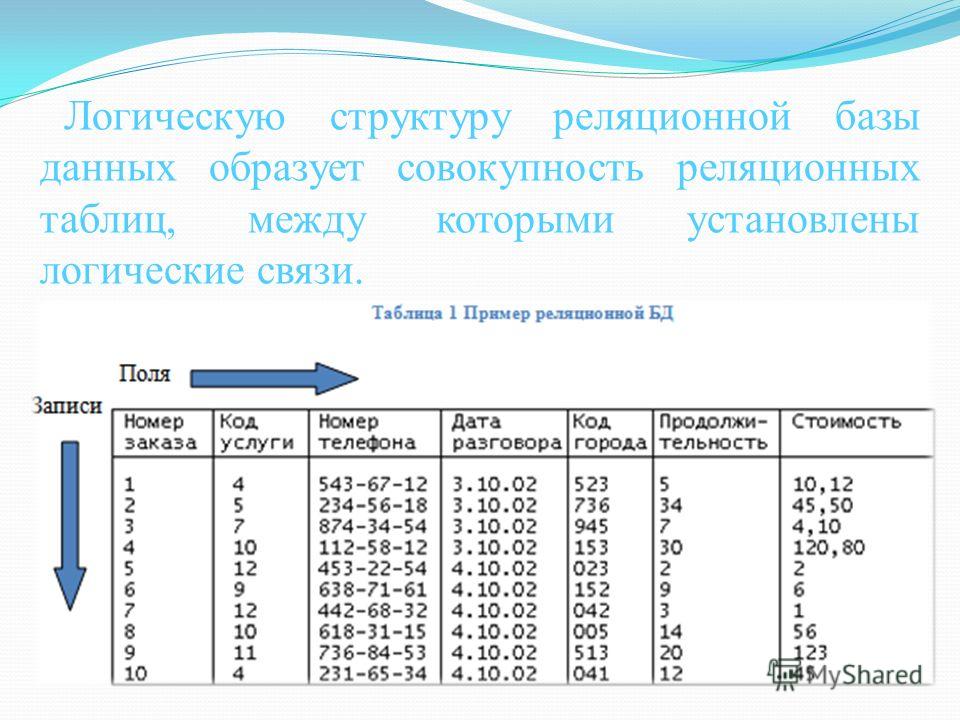
Примерами зарубежных реляционных СУБД для ПЭВМ являются следующие: dBaselliPlusиdBaseIY(фирмаAshtnn-Tate),DB2 (IBM),RBASH(Microrim),FoxProранних версий иFoxBase(FoxSoftware),ParadoxиdBASEforWindows(Borland»),FoxPro60.ieeпоздних версий,VisualFoxProиAccess(Microsoft),Clarion(ClarionSoftware),Ingres(ASKComputerSystems) иOracle(Oracle).
К отечественным СУБД релчционною тига относятся системы ПАЛЬМА (ИК АН УССР), а также система IlyTech (МИФИ).
Заметим, что последние версии реляционных СУБД имеют некоторые свойства объектно -ориентиров шных систем. Такие СУБД часто называют объектно-реляционными. Примером такой системы можно считать продукты Oracle 8.x. Системы предыдущих версий вплоть цоOracle 7 х считаются *чисто» реляционными.
 р нак тадной(INYNO).
название товара(GOODS)
и количество товара(QTY).
ТаблицаINVOICES
связана с таблицейINVOICE.ITEMS
по полюINVNO.
р нак тадной(INYNO).
название товара(GOODS)
и количество товара(QTY).
ТаблицаINVOICES
связана с таблицейINVOICE.ITEMS
по полюINVNO.Как видно из рисунка, по < равнению с реляционной моделью в постреля- нионной модели данные хранят ся более эффективно, а при обработке не
2 Чак.474
INVNO | CUSTNO | GOODS | QTY |
0373 | 8723 | Сыр | 3 |
Рыба | 2 | ||
8232 | Лимонад | 1 | |
Сок | 6 | ||
Печенье | 2 | ||
7364 | 8723 | Йогурт | 1 |
Риг.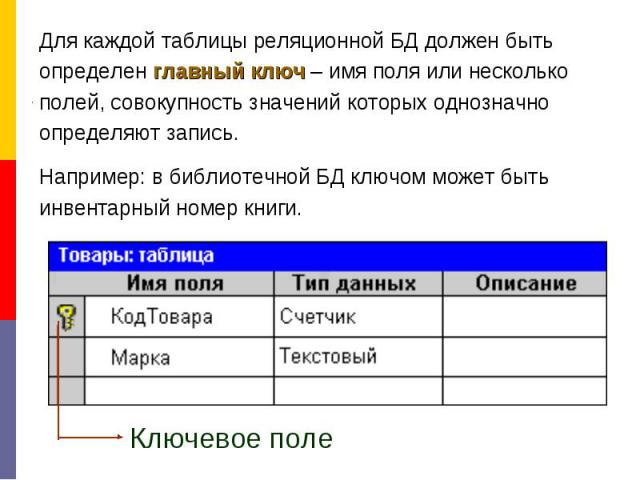 2.6. ( груктуры данных реляционной и пос
греляционной моделей
2.6. ( груктуры данных реляционной и пос
греляционной моделей
требуется выполнять операцию соединения данных из двух таблиц. Для доказательства на рис. 2.7 приводятся примеры операторов SELECT выбора данных из всех полей базы на языкеSQL для реляционной (а) и постреляционной (б) моделей.
Помимо обеспечения влож< нности полей постреляционная модель поддерживает ассоциированные многозначные поля (множественные группы). Совокупность ассоциированных полей называется ассоциациейПри этом в строке первое значение одного столбца ассоциации соответствует первым значениям всех других столбцов ассоциации. А налогичным образом связаны все вторые значения столбцов и т. д.
а)
SELECT
INVOICES.INVNO, CUSTNO, GOODS, QTY
FROM
INVOICES, INVOICE.ITEMS
WHERE
INVOICES.INVNO=INVOICE. ITEMS.INVNO;
ITEMS.INVNO;
б)
SELECT
INVNO, CUSTNO, GOODS, QTY
FROM
INVOICES;
Рис. 2.7. Операторы SQL для реляционной и поп реляционной моделей
На длину полей и количество полей в записях таблицы не накладывается требование постоянства. Это означает, что структура данных и таблиц имеет большую гибкость.
Поскольку постреляционная модель допускает хранение в таблицах ненормализованных данных, возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается включением в СУБД механизмов, подобных хранимым процедурам в клиент серверных системах.
Для
описания функций контроля значений в
полях имеется возможность (оздавать
процедуры (коды конверсии и коды
корреляции), автома гически вызываемые
до или после обращения к данным. Коды
корреляции выполняются сразу после
чтения данных, перед их обработкой.
Дог.тоинстпвомпостреляционной модели является возможность представления совокупности свя 1анных реляционных таблиц одной постреляционной таблицей. Это обеспечивав , зысокую наглядность представления информации и повышение гффективности ее обработки.
Недостаткомпостркляционной модели является сложность решения проблемы обеспечения целостности и нещ ютиворечивост и хранимых данных.
Рассмотренная нами постреляционная модель данных поддерживается СУБД uniVers. К числу других СУБД, основанных на пострсляционной модели данных, относятся также системыBubba иDasdb.
Организация баз данных и знанийТема 5
5 РЕЛЯЦИОННАЯ МОДЕЛЬ ДАННЫХ
5.1 Реляционная структура данных
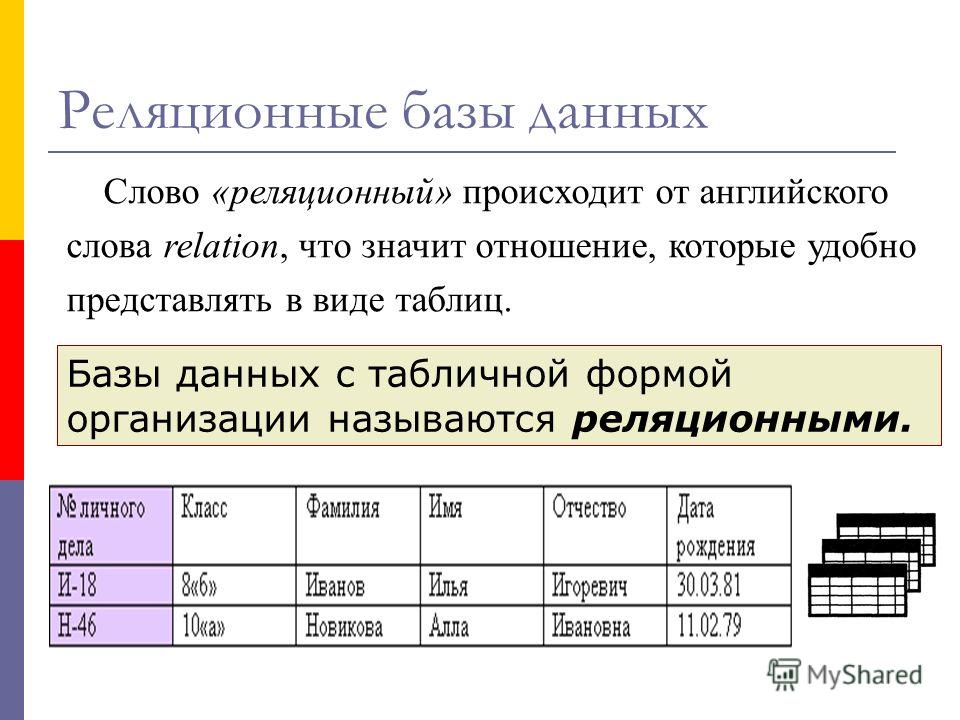
Теоретические основы реляционной модели баз данных были заложены Э. Коддом в начале 70- х годов XX века. В отличие от распространенных в то время систем с иерархическими или сетевыми типами структур данных, реляционный подход предложил упрощенные структуры данных — реляции, или таблицы, и расширил возможности языка манипулирования данными.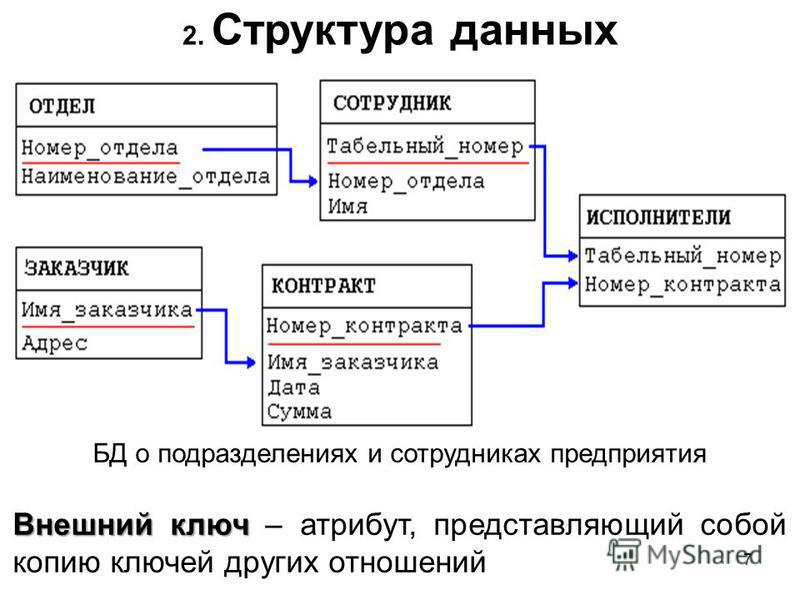 В научной литературе, посвященной реляционным базам данных, для определения того, что было названо выше реляцией или таблицей, часто применяется термин отношения. Каждый из этих терминов имеет свои преимущества и недостатки. Термином «отношения» в математической теории отношений сказывается несколько другое понятие и поэтому толкование этого термина в контексте теории баз данных является неоднозначным. Недостаток термина «реляция» заключается в его недавнем иноязычном происхождении. Поэтому для теоретических разработок будем употреблять термин «реляционное отношение», а в примерах — «отношение» или «таблица».
В научной литературе, посвященной реляционным базам данных, для определения того, что было названо выше реляцией или таблицей, часто применяется термин отношения. Каждый из этих терминов имеет свои преимущества и недостатки. Термином «отношения» в математической теории отношений сказывается несколько другое понятие и поэтому толкование этого термина в контексте теории баз данных является неоднозначным. Недостаток термина «реляция» заключается в его недавнем иноязычном происхождении. Поэтому для теоретических разработок будем употреблять термин «реляционное отношение», а в примерах — «отношение» или «таблица».
Рассмотрим пример. Таблица расписания движения поездов или самолетов, условно говоря, состоит из двух частей: наполнение и описания структуры таблицы. Наполнение – это те номера рейсов поездов или самолетов и время их отправки, занесенных в соответствующие ячейки таблицы и периодически меняются, а структура таблицы описывается заголовками столбцов. Согласно терминологии баз данных и реляционного подхода, наполнение таблиц называют данными.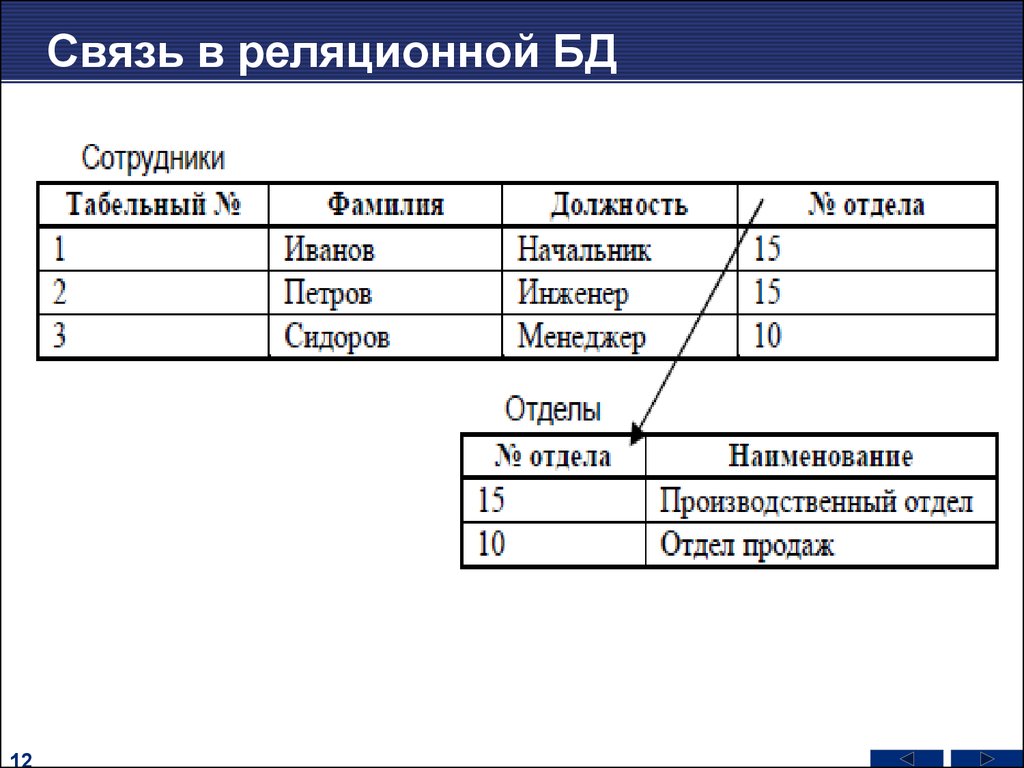 Иногда бывает так, что таблица расписания содержит только пустые столбцы. Такой объект специалист по базам данных мог бы назвать схеме.
Иногда бывает так, что таблица расписания содержит только пустые столбцы. Такой объект специалист по базам данных мог бы назвать схеме.
Реляционное отношение в реляционной модели данных изображается через схему и экземпляр отношения. Схема записывается в видеили просто R(A1, A2,…, Ak), если связь атрибутов с доменами известна априори.
Совокупность схем реляционных отношений называют схемой базы данных, или реляционной схемой. Схема реляционного отношения обладает следующими свойствами:
Реляционное отношение имеет имя;
Имена атрибутов в пределах схемы одного реляционного отношения должны быть уникальными;
Порядок атрибутов в схеме реляционного отношения не является существенным, поскольку обращение к атрибуту осуществляется по имени, а не по телефону.
Пример схемы реляционного отношения:
EDUCATION (#Id_Person, Id_School, Date_enter, Date_left)
Здесь EDUCATION — это имя реляционного отношения, а # Id_Person, Id_School, Date_enter, Date_left — имена его атрибутов.
Экземпляр реляционного отношения это его наполнение. Точнее, экземпляр является множеством кортежей, а кортеж это множество значений . Экземпляр отношение имеет такие свойства.
порядок кортежей произвольный;
кортежи, как элементы множества должны быть уникальными в пределах реляционного отношения.
Реляционное отношение может быть изображено в виде таблицы. Пример табличного отображения реляционного отношения приведены на рис. 5.1.
Рисунок 5.1 — Расписание автобусов как отношение
Таблица это поименованное двумерное изображение отношения, она состоит из одного или более поименованных столбцов и нуля или более строк. Название таблицы соответствует имени реляционного отношения, имена столбцов именам атрибутов, а строки кортежам.
Табличная форма представления отношения была введена с целью популяризации модели среди неподготовленных пользователей БД. Трактовка реляционной теории на уровне таблиц скрывают ряд определений, важных для понимания как теории реляционных БД, так и языка манипулирования данными.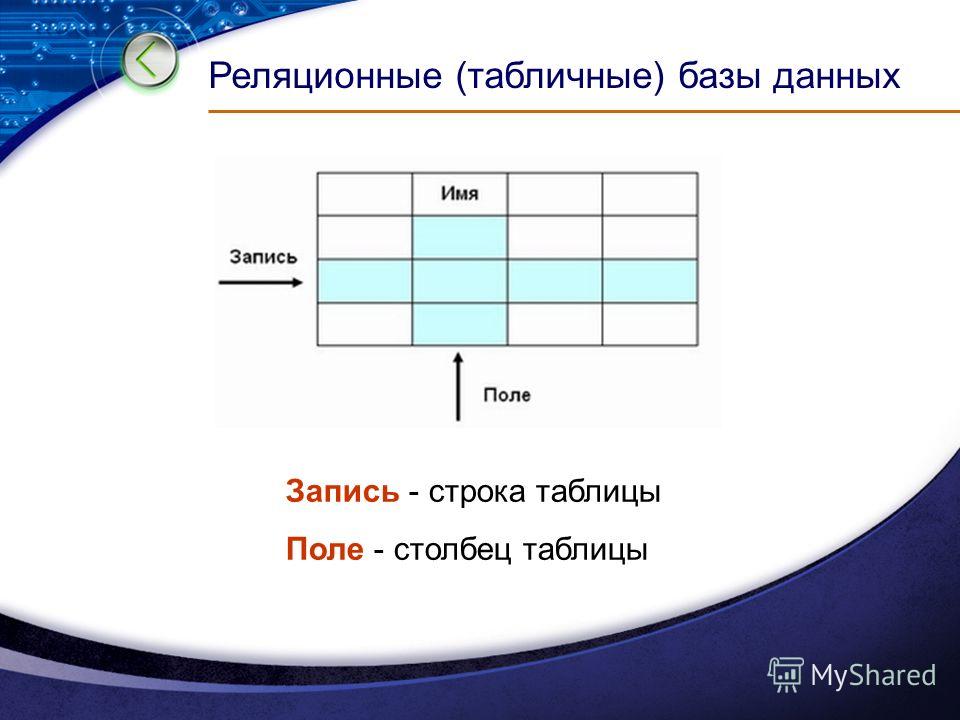
Во-первых, атрибуты различных отношений могут быть определены на одном домене, так же как и атрибуты одного отношения. Это очень важное обстоятельство, что позволяет устанавливать связи по значению между отношениями. Во-вторых, множество математически по своему определению не может иметь совпадающих элементов, и, следовательно, кортежи в отношении можно различить только по значению их компонентов. Это тоже очень важно для модели: никакие два кортежа не могут иметь полностью совпадающих компонентов. Таким образом, в реляционной модели полностью исключается дублирование данных о сущности реального мира. В-третьих, отметим, что схема отношения также множество, позволяет работать с ними с помощью теоретико — множественных операций. Это является важным моментом для построения теории проектирования реляционных схем БД.
Ключом или ключевым полем называется уникальное значение, позволяющее тем или иным способом идентифицировать сущность или часть сущности ПО, т.е. ключ — это значения некоторого атрибута или атрибутов в кортеже отношения, представляет экземпляр сущности в реляционной модели данных.
Принято различать первичные ключи и частичные ключи. Математически первичным ключом отношения является подмножество сужения декартового произведения, которое позволяет однозначно идентифицировать кортеж. Если первичный ключ состоит из нескольких атрибутов, то он называется составным ключом, в противном случае атомарным. Частичным ключом называется атрибут составного ключа, если он однозначно определяет совокупность неключевых атрибутов отношения. Атрибут кортежа, является первичным ключом другого отношения, называется внешним (иногда посторонним) ключом. Из определения отношения вытекает следующее важное свойство реляционной модели данных: каждое отношение должно иметь первичный ключ. Отметим, что ключ в контексте модели ПО БД всегда отражает ту или иную степень связи между атрибутами сущностей ПО, т.е. семантически ключ есть средство моделирования связей в модели.
Пример: рассмотрим предложения «Гражданин Иванов проживал в городе Москве 10 лет». Возможными атрибутами в отношении Место_проживания является фамилия гражданина, название города проживания и время проживания. Фамилия гражданина может выступать в качестве первичного ключа этого отношения, потому что личность однозначно определяет время его проживания в конкретном городе. Таким образом, в этом моделируется связь «проживал» между атрибутами «фамилия» и «город».
Фамилия гражданина может выступать в качестве первичного ключа этого отношения, потому что личность однозначно определяет время его проживания в конкретном городе. Таким образом, в этом моделируется связь «проживал» между атрибутами «фамилия» и «город».
Пример. Представление связи отношением. Представим связь между личностью и местом его обитания через отношение
ЖИВЕТ (Кл. личность, Кл. Населенного_пункта, Время) Описание личности:
ЛИЧНОСТЬ (Кл. личность, ФИО, Возраст, Пол) Описание населенного пункта:
НАСЕЛЕННЫЙ_ПУНКТ (Кл.населенного_пункта, География, Население)
Однако наибольшее распространение получило представление отношений в виде графических диаграмм, например ER-диаграмм, о которых мы говорили раньше. Преимуществами такого представления является наглядность диаграмм и возможность их построения в ряде CASE-средств проектирования БД.
В итоге сформулируем основные свойства реляционной модели данных, вытекающих из понятия отношения как множества:
Все кортежи одного отношения должны иметь то же количество атрибутов.
Значение каждого из атрибутов должно принадлежать некотором определенном домена.
Каждое отношение должно иметь первичный ключ.
Никакие два кортежа не могут иметь полностью совпадающих наборов значений.
Каждое значение атрибутов должно быть атомарными, то является не должно иметь внутренней структуры и содержать как компонент другое отношение.
Реляционная модель данных должна быть непротиворечивой, в частности должно выполняться 1) принцип ссылочной целостности — связи между отношениями должны быть замкнутыми, 2) значение колонок должны принадлежать тому же определенном для них домена.
Порядок следования кортежей в отношении не имеет значения. Порядок в большей степени свойством хранения данных, чем свойством непосредственно самой реляционной модели данных.
5.2 Реляционная алгебра
5.2.1 Общие сведения
В состав реляционной модели данных, кроме структуры данных, должны входить операции манипулирования данными. Из всех таких операций состоитязык запросов. Наиболее известными языками запросов в реляционной модели является реляционная алгебра и реляционное исчисление.
Наиболее известными языками запросов в реляционной модели является реляционная алгебра и реляционное исчисление.
В классическом понимании алгебра определяется как пара, состоящая из основной множества и множества операций (сигнатуры), при этом аргументы и результат каждой операции относятся основной множестве.
Реляционная алгебра является алгеброй в строгом классическом понимании ее определения. Элементами основной множества является реляционные отношения. В связи с этим операции алгебры могут вкладываться друг в друга, то является аргументом определенной операции может быть результат выполнения другой операции. Это дает возможность записывать запросы произвольного уровня сложности в виде выражений, содержащих вложенные друг в друга операции.
5.5.2 Операции реляционной алгебры
Сигнатура реляционной алгебры Кодда состоит из восьми операций. Прежде чем подробно рассмотреть эти операции, введем понятие совместимости реляционных отношений. Это понятие необходимо, поскольку некоторые операции (а именно: теоретико-множественные операции объединения, пересечения и разности) определены только для совместимых реляционных отношений.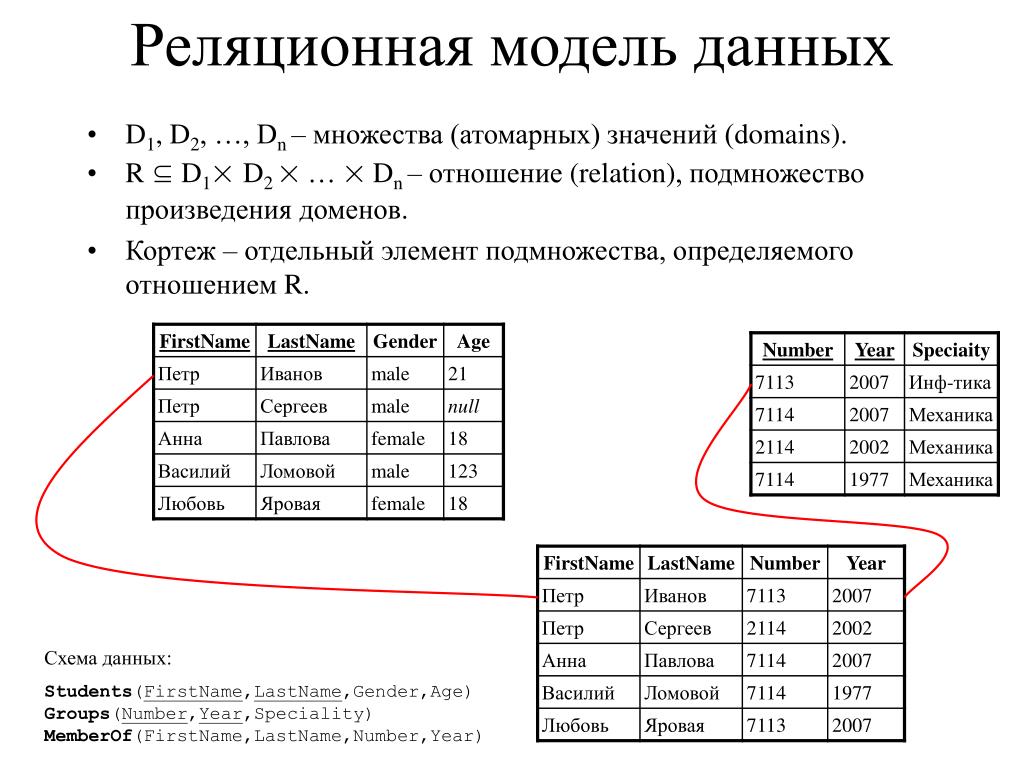
Реляционные отношения R1(A1,…, An) і R2(B1,…, Bk) называются совместимыми, если:
У них одинаковое количество атрибутов, то является k = n;
Можно установить взаимно однозначное соответствие между доменами атрибутов первой и второй реляций, т.е. существует такое биективне отображения
То является домены сопоставленных атрибутов одинаковы. Для удобства будем считать, что сопоставимые атрибуты совместимых отношений должны иметь одинаковые имена.
Дадим также определения нескольких свойств бинарных операций:
Операция φ является коммутативной, если А φ В = В φ А;
Операция φ является ассоциативной, если (А φ В) φ С = А φ (В φ С) ;
Операция φ является дистрибутивной с операцией θ, если А φ (В θ С) = (А φ В) θ (А φ С).
Давая определение бинарным операциям реляционной алгебры, мы будем указывать, какие из этих свойств они имеют.
Поскольку различные отношения могут содержать атрибуты с одинаковыми именами. то при выполнении бинарных операций в конечном отношении могут повторяться имена атрибутов. Для обеспечения уникальности имен атрибутов они уточняются именами соответствующих отношений согласно таким синтаксисом:
Для обеспечения уникальности имен атрибутов они уточняются именами соответствующих отношений согласно таким синтаксисом:
<имя отношения>. <имя атрибута>
При рассмотрении операций реляционной алгебры атрибуты обозначать большими буквами с начала латинского алфавита: А, В,… а множества атрибутов — большими буквами с середины латинского алфавита: L, М,….
Отметим некоторые особенности теоретико -множественных операций.
В реляционной алгебре, в отличие от алгебры множеств, еще не используется операция дополнения, поскольку определенные домены могут быть бесконечными или содержать очень много значений и в результате операции дополнения можно получить или бесконечное отношение, или отношение с очень большим количеством кортежей
Требование совместимости операндов обусловлены тем, что без этого ограничения результатом теоретико -множественных операций могли бы быть разноструктурные кортежи, а не реляционные отношения.
Объединения.
Пусть L — некоторое множество атрибутов.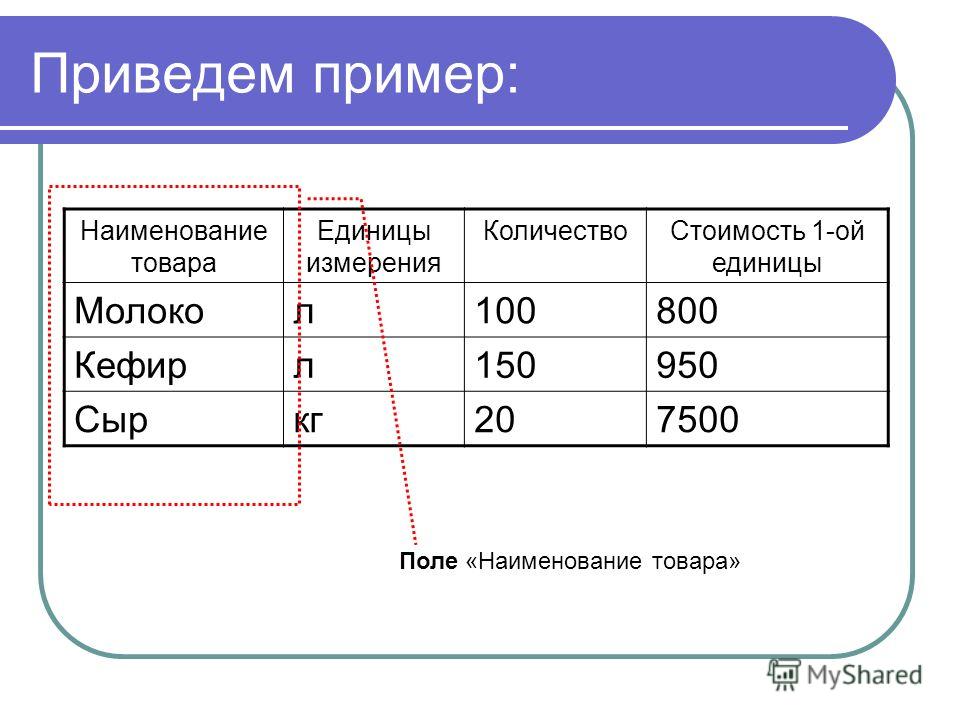 Объединением совместимых реляционных отношений R1 и R2 со схемами R1 (L) и R2 (L) (обозначается R1∪R2) называется такое реляционное отношение R схеме R (L), содержащий кортежи обоих объединяемых отношений, но без повторений (рис. 4.2).
Объединением совместимых реляционных отношений R1 и R2 со схемами R1 (L) и R2 (L) (обозначается R1∪R2) называется такое реляционное отношение R схеме R (L), содержащий кортежи обоих объединяемых отношений, но без повторений (рис. 4.2).
Операция коммутативна, ассоциативна и дистрибутивная относительно пересечения.
Рисунок 5.2 — Операция объединения отношений
Пересечение.
Предположим, что L — некоторое множество атрибутов. Сечением совместимых реляционных отношений R1 и R2 со схемами R1 (L) и R2 (L) (обозначается R1 ∩ R2) называется такое реляционное отношение R схеме R (L), которое содержит кортежи, входящие в состав обоих операндов (рис. 5.3).:
Операция коммутативна, ассоциативна и дистрибутивная относительно объединения.
Рисунок 5.3 — Операция пересечения отношений
Разница
Пусть L — некоторое множество атрибутов. Разницей совместимых реляционных отношений R1 и R2 со схемами R1 (L) и R2 (L) (обозначается R1- R2) называется такое реляционное отношение R схеме R (L), содержащий кортежи с первого операнда R1, которых нет во втором операнде R2 (рис. 5.4): .
5.4): .
Операция не коммутативна, НЕ ассоциативная и не дистрибутивная с другими операциями.
Рисунок 5.4 — Операция разницы отношений
Декартовое произведение.
Декартовым произведением реляционных отношений R и S со схемами и соответственно, что сказывается RxS, называется отношение Q схеме , которое содержит все возможные соединения кортежей отношения R с кортежами отношения S (рис. 5.5):
Операция коммутативна и ассоциативна.
Рисунок 5.5 — Операция декартового произведения отношений
Специальные операции.
Селекция – выборка по критеряим, которые выполняються построчно.
Проекция – выборка по колонкам. елекція – вибірка по критеріям, що виконується по рядкам.
Естественное объединение изображено на рис. 5.6 , деление – рис. 5.7
Рисунок 5.6 Операция естественного обїединения отношений
Рисунок 5.7 Операция деления отношений
5.3 Понятие функциональной зависимости
На стадии логического проектирования реляционной БД разработчик определяет и выстраивает схемы отношения в рамках некоторой ПО, а именно − представляет сущности, группирует их атрибуты, выявляет основные связи между сущностями. Так, в самом общем смысле проектирования реляционной БД состоит в обоснованном выборе конкретных схем отношений из множества различных альтернативных вариантов схем.
Так, в самом общем смысле проектирования реляционной БД состоит в обоснованном выборе конкретных схем отношений из множества различных альтернативных вариантов схем.
На практике построение логической модели БД, независимо от модели данных, выполняется с учетом двух основных требований: исключить избыточность и максимально повысить надежность данных. Эти требования вытекают из требования коллективного использования данных группой пользователей.
Поэтому любое априорное знание об ограничении ПО, накладывают на взаимосвязи между данными и значения данных, и знания об их свойствах и взаимоотношения между ними может сыграть определенную роль в соблюдении указанных выше требований. Формализация таких априорных знаний о свойствах данных ПО БД нашла свое отражение в концепции функциональной зависимости данных, то есть ограничений на возможные взаимосвязи между данными, которые могут быть текущими значениями схемы отношений.
Кортежи отношения могут представлять экземпляры сущности ПО или фиксировать их взаимосвязь. Но даже если эти кортежи соответствуют схеме отношений и выбраны из допустимых доменов, не всякий из них может быть текущим значением некоторого отношения. Например, возраст человека редко бывает больше 120 лет, или тот же пилот не может одновременно выполнять два разных рейса. Такие ограничения семантики домена практически не влияют на выбор той или иной схемы отношений. Они представляют собой ограничения на типы данных.
Но даже если эти кортежи соответствуют схеме отношений и выбраны из допустимых доменов, не всякий из них может быть текущим значением некоторого отношения. Например, возраст человека редко бывает больше 120 лет, или тот же пилот не может одновременно выполнять два разных рейса. Такие ограничения семантики домена практически не влияют на выбор той или иной схемы отношений. Они представляют собой ограничения на типы данных.
Поскольку функциональную зависимость можно задать в виде таблицы, а таблица является формой представления отношений, то становится очевидной связь между функциональной зависимостью и отношением. Отношение может задавать функциональную зависимость. Это утверждение является первой конструктивной идеей, которая положена в основу теории проектирования реляционных БД.
Пример. Понятие функциональной зависимости
Проиллюстрируем понятие функциональной зависимости на примере графика полетов аэропорта.
ГРАФИК_ПОЛЁТОВ (Пилот, Рейс, Дата_вылета, Время_вылета)
Иванов 100 8.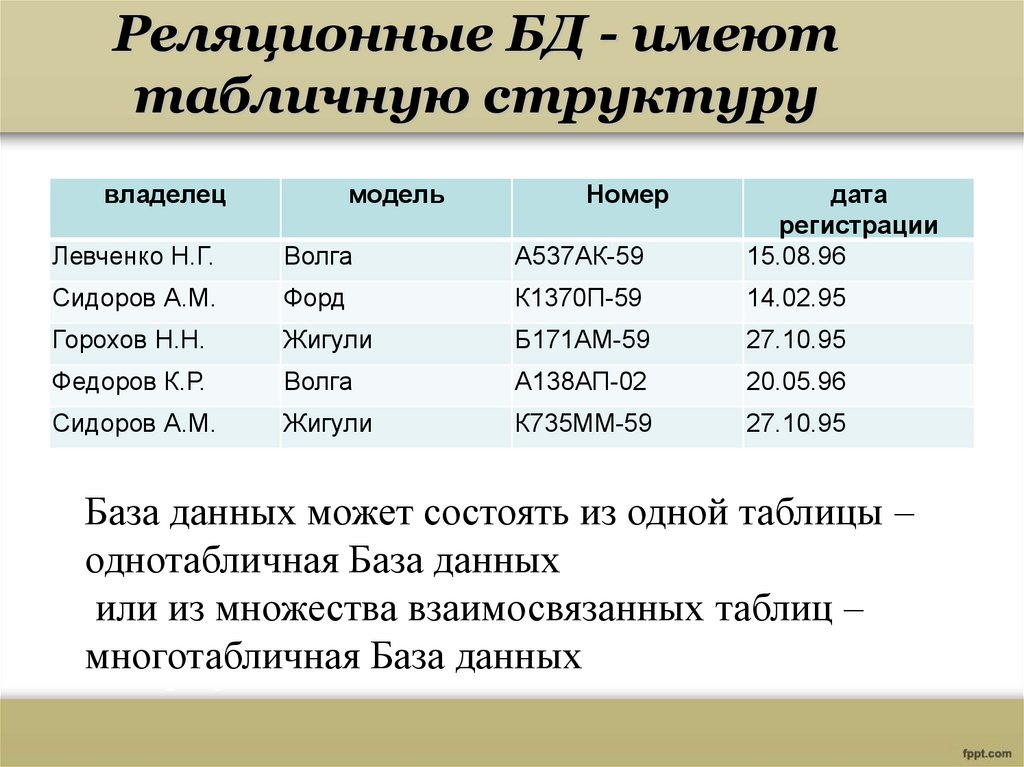 07 10:20
07 10:20
Иванов 2 9.07 13:30
Исаев 90 7.07 6:00
Исаев 103 10.07 19:30
Петров 100 12.07 10:20
Петров 102 11.07 13:30
Фролов 90 8.07 6:00
Фролов 90 12.07 6:00
Известно, что: каждому рейсу соответствует определенное время вылета, для каждого пилота, даты и времени вылета возможен только один рейс, на определенный день и рейс назначается определенный пилот.
Итак: » Время_вылета» функционально зависит от {» Рейс» }, » Рейс» функционально зависит от {» Пилот», » Дата_вылета «, » Время_вылета «}, » Пилот» функционально зависим от {» Рейс», » Дата_вылета «}.
Важной задачей при выявлении функциональных зависимостей на атрибутах отношений, по определению является множеством, необходимо выяснить, какой из атрибутов выступает как аргумент, а какой — как значение функциональная зависимость. Наиболее подходящими кандидатами в аргументы функциональной зависимости является возможные ключи, потому что кортежи представляют экземпляры сущности, которые идентифицируются значениями атрибутов своего ключа
Выводы
В итоге сформулируем основные свойства реляционной модели данных, вытекающих из понятия отношения как множества:
Все кортежи одного отношения должны иметь то же количество атрибутов.
Значение каждого из атрибутов должно принадлежать некотором определенном домена.
Каждое отношение должно иметь первичный ключ.
Никакие два кортежа не могут иметь полностью совпадающих наборов значений.
Каждое значение атрибутов должно быть атомарными, то является не должно иметь внутренней структуры и содержать как компонент другое отношение.
Реляционная модель данных должна быть непротиворечивой, в частности должно выполняться 1) принцип ссылочной целостности — связи между отношениями должны быть замкнутыми, 2) значение колонок должны принадлежать тому же определенном для них домена.
Порядок следования кортежей в отношении не имеет значения. Порядок в большей степени свойством хранения данных, чем свойством непосредственно самой реляционной модели данных.
Вопросы для самоконтроля
1. Назовите преимущества реляционной БД?
2. Объясните понятие «отношение».
3. Какие компоненты составляют отношения?
4. Что такое ключевое поле? Назначение и разновидности.
Что такое ключевое поле? Назначение и разновидности.
5. Объясните понятие «целостность данных».
6. Что такое категориальная целостность?
7. Что такое целостность по ссылке
8. Какие основные операции реляционной алгебры относятся к операциям над отношением БД?
9. Назовите основные свойства реляционной БД.
10.Назовите основные принципы при определении функциональных зависимостей.
Нереляционные данные и базы данных NoSQL — Azure Architecture Center
Нереляционная база данных — это база данных, в которой в отличие от большинства традиционных систем баз данных не используется табличная схема строк и столбцов. В этих базах данных применяется модель хранения, оптимизированная под конкретные требования типа хранимых данных. Например, данные могут храниться как простые пары «ключ — значение», документы JSON или граф, состоящий из ребер и вершин.
Все эти хранилища данных не используют реляционную модель. Кроме того, они, как правило, поддерживают определенные типы данных. Процесс запроса данных также специфический. Например, хранилища данных временных рядов рассчитаны на запросы к последовательностям данных, упорядоченных по времени. В свою очередь хранилища данных графов рассчитаны на анализ взвешенных связей между сущностями. Ни один из форматов не подходит в полней мере при выполнении задач управления данными о транзакциях.
Процесс запроса данных также специфический. Например, хранилища данных временных рядов рассчитаны на запросы к последовательностям данных, упорядоченных по времени. В свою очередь хранилища данных графов рассчитаны на анализ взвешенных связей между сущностями. Ни один из форматов не подходит в полней мере при выполнении задач управления данными о транзакциях.
Термин NoSQL применяется к хранилищам данных, которые не используют язык запросов SQL. Вместо этого они запрашивают данные с помощью других языков программирования и конструкций. На практике NoSQL означает «нереляционная база данных», даже несмотря на то, что многие из этих баз данных под держивают запросы, совместимые с SQL. Однако базовая стратегия выполнения запросов SQL обычно значительно отличается от применяемой в системе управления реляционной базой данных (реляционная СУБД).
В разделах ниже описаны основные категории нереляционных баз данных или баз данных NoSQL.
Хранилища данных документов
Хранилище данных документов управляет набором значений именованных строковых полей и данных объекта в сущности, которая называется документом. Обычно данные в этих хранилищах содержатся в виде документов JSON. Каждое значение поля может представлять собой скалярный элемент, например число, или сложный объект, например список или коллекция типа «родитель — потомок». Данные в полях документа можно закодировать разными способами, например в формате XML, YAML, JSON, BSON, или хранить в виде обычного текста. Поля документов доступны системе управления хранилищем, что позволяет приложению выполнять запросы и применять фильтры, основанные на значениях этих полей.
Обычно данные в этих хранилищах содержатся в виде документов JSON. Каждое значение поля может представлять собой скалярный элемент, например число, или сложный объект, например список или коллекция типа «родитель — потомок». Данные в полях документа можно закодировать разными способами, например в формате XML, YAML, JSON, BSON, или хранить в виде обычного текста. Поля документов доступны системе управления хранилищем, что позволяет приложению выполнять запросы и применять фильтры, основанные на значениях этих полей.
Как правило, документ содержит все данные для сущности. Элементы, составляющие сущность, зависят от конкретного приложения. Например, сущность может содержать сведения о клиенте, заказе или их сочетание. Один документ может содержать сведения, которые в реляционной СУБД обычно распределяются по нескольким реляционным таблицам. Хранилище документов не требует, чтобы все документы имели одинаковую структуру. Такой свободный подход к форме обеспечивает большую гибкость. Например, приложения могут хранить в документах разные данные в соответствии с текущими требованиями компании.
Приложение может получать документы по ключу документа. Ключ — это уникальный идентификатор документа. Часто к нему применяется хэширование для равномерного распределения данных. Некоторые базы данных документов автоматически создают ключ документа. Другие позволяют указать атрибут документа, который будет использоваться в качестве ключа. Приложение также может запрашивать документы на основе значения одного или нескольких полей. Некоторые базы данных документов поддерживают индексирование, чтобы облегчить быстрый поиск документов по одному или нескольким индексированным полям.
Многие базы данных документов поддерживают обновления «на месте», то есть позволяют приложению изменять значения отдельных полей без перезаписи всего документа. Операции чтения и записи в нескольких полях одного документа обычно являются атомарными.
Соответствующие службы Azure:
- Azure Cosmos DB
Столбчатые хранилища данных
Столбчатое хранилище данных или хранилище семейств столбцов упорядочивает данные по столбцам и строкам. Столбчатое хранилище данных в простейшей форме почти неотличимо от реляционной базы данных, по крайней мере организационно. Настоящее преимущество столбчатого хранилища данных заключается в способности денормализованно структурировать разреженные данные, что связано со столбцово-ориентированным методом хранения данных.
Столбчатое хранилище данных в простейшей форме почти неотличимо от реляционной базы данных, по крайней мере организационно. Настоящее преимущество столбчатого хранилища данных заключается в способности денормализованно структурировать разреженные данные, что связано со столбцово-ориентированным методом хранения данных.
Столбчатое хранилище данных можно представить как набор табличных данных со строками и столбцами, в которых столбцы разделяются на определенные группы или семейства столбцов. Каждое семейство столбцов включает набор логически связанных столбцов, которые обычно извлекаются или управляются как единое целое. Другие данные, которые используются в других процессах, хранятся отдельно в других семействах столбцов. В семейство столбцов можно динамически добавить новые столбцы, а строки могут быть разреженными (то есть строки не обязаны иметь значение для каждого столбца).
На следующей диаграмме представлен пример таблицы с двумя семействами столбцов: Identity и Contact Info. Данные одной сущности имеют одинаковые ключи строк во всех семействах столбцов. Такая структура, в которой строки любого объекта в семействе столбцов могут динамически изменяться, определяет важное преимущество этой категории хранилищ. Семейства столбцов очень хорошо подходят для хранения данных с различными схемами.
Данные одной сущности имеют одинаковые ключи строк во всех семействах столбцов. Такая структура, в которой строки любого объекта в семействе столбцов могут динамически изменяться, определяет важное преимущество этой категории хранилищ. Семейства столбцов очень хорошо подходят для хранения данных с различными схемами.
В отличие от хранилища пар «ключ — значение» и баз данных документов, большинство столбчатых баз данных упорядочивают хранимые данные с помощью самих значений ключей, а не хэш-кодов от них. Ключ строки рассматривается как первичный индекс и обеспечивает доступ на основе определенного ключа или их диапазона. Некоторые реализации позволяют создавать вторичные индексы по определенным столбцам в семействе столбцов. Вторичные индексы позволяют получать данные по значениям столбцов, а не ключам строки.
Все столбцы одного семейства хранятся на диске в одном файле. Каждый файл содержит определенное число строк. При использовании больших наборов данных этот подход позволяет повысить производительность за счет снижения объема данных, которые необходимо считывать с диска, когда отправляется запрос на получение нескольких столбцов за раз.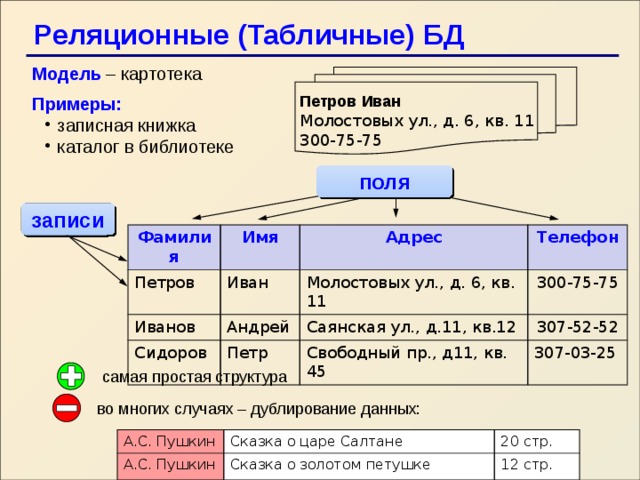
Чтение и запись строки из одного семейства столбцов — это обычно атомарные операции. Однако некоторые реализации поддерживают атомарность всей строки, распределенной по нескольким семействам столбцов.
Соответствующие службы Azure:
- API Cassandra для Cosmos DB
- Использование HBase в HDInsight
Хранилище пар «ключ — значение»
Хранилище пар «ключ — значение» по сути представляет собой большую хэш-таблицу. Каждое значение сопоставляется с уникальным ключом, и хранилище ключей использует этот ключ для хранения данных, применяя к нему некоторую функцию хэширования. Выбор функции хэширования должен обеспечить равномерное распределение хэшированных ключей по хранилищу данных.
Большинство хранилищ пар «ключ — значение» поддерживают только самые простые операции запроса, вставки и удаления. Чтобы частично или полностью изменить значение, приложение всегда перезаписывает существующее значение целиком. В большинстве реализаций атомарной операцией считается чтение или запись одного значения.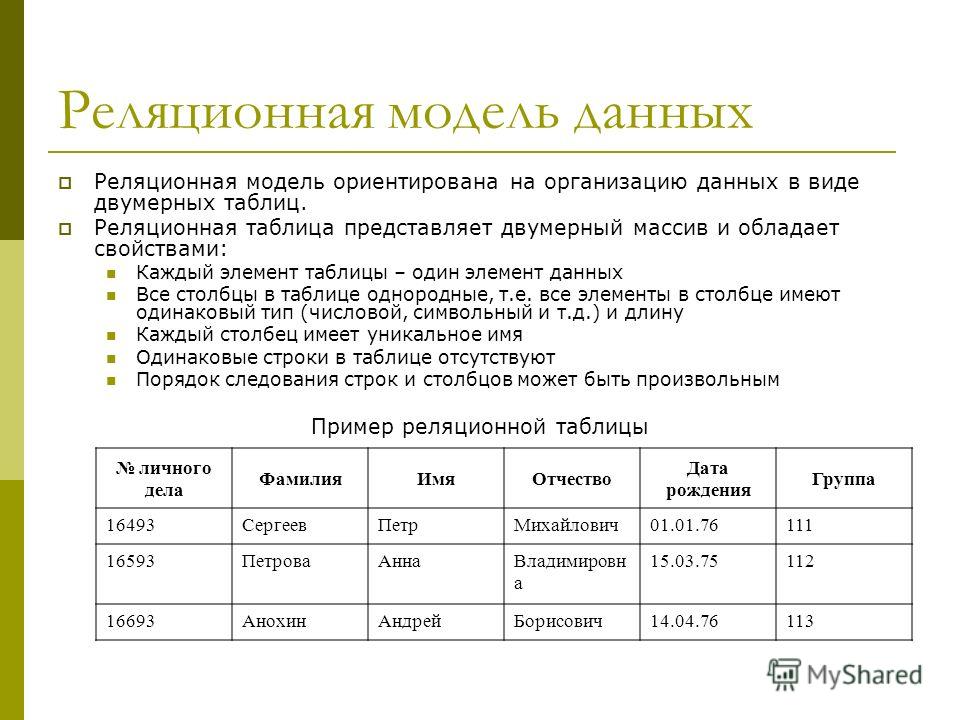 Запись больших значений занимает относительно долгое время.
Запись больших значений занимает относительно долгое время.
Приложение может хранить в наборе значений произвольные данные, но некоторые хранилища пар «ключ — значение» накладывают ограничения на максимальный размер значений. Программное обеспечение хранилища ничего не знает о значениях, которые в нем хранятся. Все сведения о схеме поддерживаются и применяются на уровне приложения. Эти значения по существу являются большими двоичными объектами, которые хранилище извлекает и сохраняет по соответствующему ключу.
Хранилища пар «ключ — значение» рассчитаны на приложения, выполняющие простые операции поиска на основе значения ключа или диапазона ключей, но не очень подходят для систем, которым нужно запрашивать данные из нескольких таблиц хранилищ пар «ключ — значение», например присоединенные данные в нескольких таблицах.
Кроме того, хранилища пар «ключ — значение» неудобны в сценариях, где могут выполняться запросы или фильтрация по значению, а не только по ключам. Например, в реляционной базе данных вы можете найти определенную запись с помощью предложения WHERE и отфильтровать ее по неключевым столбцам, но хранилища пар «ключ-значение» обычно не поддерживают такую возможность поиска значений или же этот процесс выполняется медленно.
Например, в реляционной базе данных вы можете найти определенную запись с помощью предложения WHERE и отфильтровать ее по неключевым столбцам, но хранилища пар «ключ-значение» обычно не поддерживают такую возможность поиска значений или же этот процесс выполняется медленно.
Одно хранилище пар «ключ — значение» очень легко масштабируется, поскольку позволяет удобно распределить данные среди нескольких узлов на разных компьютерах.
Соответствующие службы Azure:
- API таблиц Azure Cosmos DB
- Кэш Azure для Redis
- хранилище таблиц Azure
Хранилища данных графов
Хранилища данных графов управляют сведениями двух типов: узлами и ребрами. Узлы в этом случае представляют сущности, а ребра определяют связи между ними. Узлы и грани имеют свойства, которые предоставляют сведения о конкретном узле или грани, примерно как столбцы в реляционной таблице. Грани могут иметь направление, указывающее на характер связи.
Хранилища данных графов позволяют приложениям эффективно выполнять запросы, которые проходят через сеть узлов и ребер, а также анализировать связи между сущностями.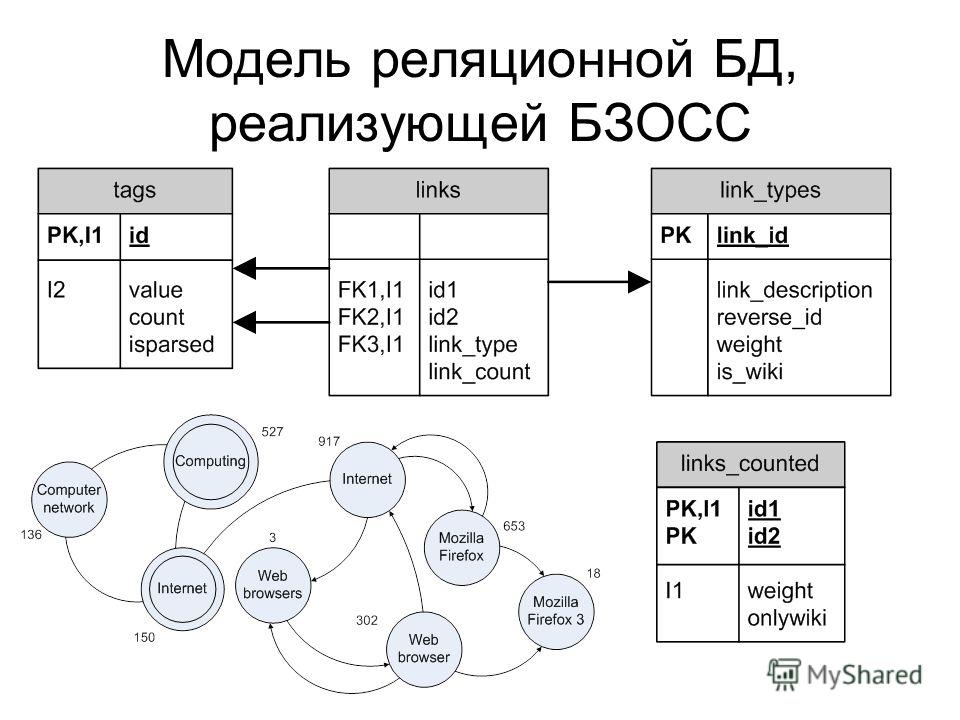 На схеме ниже представлены данные персонала организации, структурированные в виде графа. Сущностями здесь являются сотрудники и отделы, а грани определяют отношения подчинения и отдел, в котором работает каждый сотрудник. Стрелки на ребрах этого графа показывают направление связей.
На схеме ниже представлены данные персонала организации, структурированные в виде графа. Сущностями здесь являются сотрудники и отделы, а грани определяют отношения подчинения и отдел, в котором работает каждый сотрудник. Стрелки на ребрах этого графа показывают направление связей.
Такая структура позволяет легко выполнять такие запросы, как «найти всех сотрудников, которые прямо или косвенно подчиняются Светлане» или «найти всех, кто работает в одном отделе с Дмитрием». Процессы сложного анализа выполняются быстро даже на больших графах с большим количеством сущностей и связей. Многие базы данных графов предоставляют язык запросов, который можно использовать для эффективного обхода сети связей.
Соответствующие службы Azure:
- API Graph в Azure Cosmos DB
Хранилища данных временных рядов
Данными временных рядов называются наборы значений, которые упорядочены по времени. Соответственно хранилища данных временных рядов оптимизированы для хранения данных именно такого типа. Хранилища данных временных рядов должны поддерживать очень большое число операций записи, так как обычно в них в режиме реального времени собирается большой объем данных из большого количества источников. Эти хранилища также хорошо подходят для хранения данных телеметрии. Например, для сбора данных от датчиков Интернета вещей или счетчиков в приложениях или системах. Обновления в таких базах данных выполняются редко, а удаление чаще всего является массовой операцией.
Хранилища данных временных рядов должны поддерживать очень большое число операций записи, так как обычно в них в режиме реального времени собирается большой объем данных из большого количества источников. Эти хранилища также хорошо подходят для хранения данных телеметрии. Например, для сбора данных от датчиков Интернета вещей или счетчиков в приложениях или системах. Обновления в таких базах данных выполняются редко, а удаление чаще всего является массовой операцией.
Размер отдельных записей в базе данных временных рядов обычно невелик, но их очень много, а значит общий размер данных быстро увеличивается. Хранилища данных временных рядов также обрабатывают данные, полученные вне очереди или несвоевременно, автоматически индексируют точки данных и оптимизируют запросы, полученные в течение определенного промежутка времени. Эта последняя возможность позволяет быстро выполнять запросы к миллионам точек данных и нескольким потокам данных, что, в свою очередь, обеспечивает поддержку визуализации временных рядов (стандартный способ потребления данных временных рядов).
Дополнительные сведения см. в статье Решения для временных рядов.
Соответствующие службы Azure:
- Аналитика временных рядов Azure
- OpenTSDB с HBase в HDInsight
Хранилище данных объектов
Хранилища данных объектов оптимизированы для хранения и извлечения больших двоичных объектов, например изображений, текстовых файлов, видео- и аудиопотоков, объектов данных и документов приложений большого размера, образы дисков виртуальных машин. Объект состоит из сохраненных данных, метаданных и уникального идентификатора доступа к объекту. Хранилища объектов поддерживают отдельные большие файлы, а также позволяют управлять всеми файлами за счет внушительного общего объема хранилища.
Некоторые хранилища данных объектов реплицируют определенный большой двоичный объект между несколькими узлами кластера, что обеспечивает быстрое параллельное чтение. Этот процесс, в свою очередь, позволяет реализовать масштабируемую архитектуру запроса данных, хранящихся в больших файлах, так как несколько процессов, обычно выполняющихся на разных серверах, могут одновременно запрашивать большие файлы данных.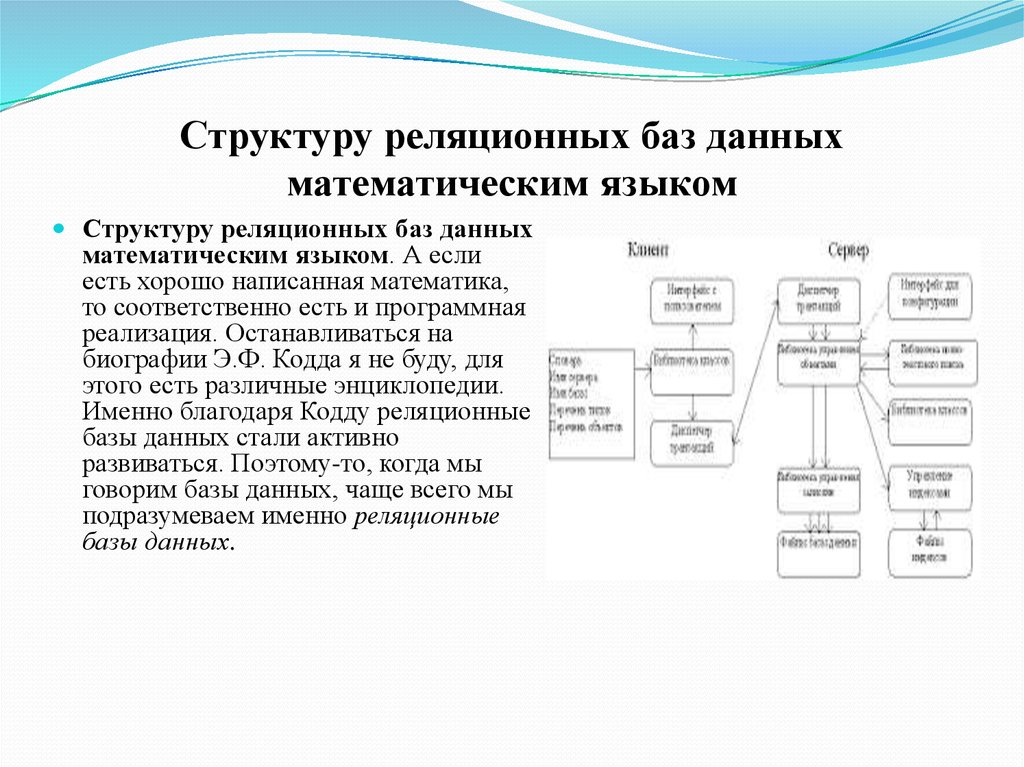
Часто хранилища данных объектов используют как сетевые общие папки. Доступ к файлам, хранящимся в этих папках, можно получить через компьютерную сеть с использованием стандартных сетевых протоколов, например SMB. Если созданы необходимые механизмы поддержки безопасности и одновременного доступа, такое совместное использование данных позволяет распределенным службам с высокой степенью масштабируемости предоставлять доступ к данным для базовых низкоуровневых операций, то есть для простых запросов на чтение и запись.
Соответствующие службы Azure:
- Хранилище BLOB-объектов Azure
- Azure Data Lake Storage
- Хранилище файлов Azure
Хранилища данных внешних индексов
Хранилища данных внешних индексов позволяют искать информацию, содержащуюся в других хранилищах данных и службах. Внешний индекс выступает в роли вторичного индекса любого хранилища данных. Кроме того, с его помощью можно индексировать большие объемы данных и предоставлять доступ к этим индексам почти в реальном времени.
Например, в файловой системе могут храниться текстовые файлы. По пути файл можно найти быстро, но поиск на основе содержимого выполняется медленно, так как сканируются все файлы. Внешний индекс позволяет создавать вторичные индексы, а затем быстро искать путь к файлам, соответствующим заданным условиям. Рассмотрим еще один пример использования внешнего индекса. Предположим, что хранилища пар «ключ — значение» поддерживают индексирование только по ключу. Вы можете создать вторичный индекс на основе значений данных и быстро найти ключ, однозначно определяющий каждый соответствующий элемент.
Индексы создаются в процессе индексирования, который может выполняться по модели извлечения, то есть по требованию хранилища данных, или по модели передачи, то есть по команде из кода приложения. В некоторых системах поддерживаются многомерные индексы и полнотекстовый поиск по большим объемам текстовых данных.
Часто хранилища данных внешних индексов используют для реализации полнотекстового поиска и поиска в Интернете. В этих случаях поддерживается точный или нечеткий поиск. Нечеткий поиск находит документы, которые соответствуют набору условий, и вычисляет для них коэффициент совпадения с этим набором. Некоторые внешние индексы также поддерживают лингвистический анализ, который возвращает соответствия с учетом синонимов, категорий (например, при поиске по запросу «собаки» соответствием считается «питомцы») и морфологии (например, при поиске по запросу «бег» соответствием считается «бегущий»).
В этих случаях поддерживается точный или нечеткий поиск. Нечеткий поиск находит документы, которые соответствуют набору условий, и вычисляет для них коэффициент совпадения с этим набором. Некоторые внешние индексы также поддерживают лингвистический анализ, который возвращает соответствия с учетом синонимов, категорий (например, при поиске по запросу «собаки» соответствием считается «питомцы») и морфологии (например, при поиске по запросу «бег» соответствием считается «бегущий»).
Соответствующие службы Azure:
- Поиск Azure
Стандартные требования
Часто архитектура нереляционных хранилищ данных отличается от архитектуры реляционных баз данных. В частности эти хранилища, как правило, не имеют фиксированной схемы, а также не поддерживают транзакции или ограничивают их область. Из соображений масштабируемости они обычно не включают вторичные индексы.
В таблице ниже приведено сравнение требований каждого нереляционного хранилища данных.
| Требование | Хранилище данных документов | Столбчатое хранилище данных | Хранилище данных пар «ключ — значение» | Хранилище данных графов |
|---|---|---|---|---|
| Нормализация | Денормализированные данные | Денормализированные данные | Денормализированные данные | Нормализированные данные |
| схема | Схема при чтении | Семейства столбцов, определенные при записи, схема столбца при чтении | Схема при чтении | Схема при чтении |
| Согласованность (между параллельными транзакциями) | Настраиваемый уровень согласованности, гарантии на уровне документа | Гарантии на уровне семейства столбцов | Гарантии на уровне ключей | Гарантии на уровне графа |
| Атомарность (область транзакции) | Коллекция | Таблица | Таблица | График |
| Стратегия блокировки | Оптимистичная (без блокировки) | Пессимистичная (блокировка строк) | Оптимистичная (ETag) | |
| Шаблон доступа | Прямой доступ | Статистические выражения на основе данных большого формата | Прямой доступ | Прямой доступ |
| Индексация | Первичный и вторичные индексы | Первичный и вторичные индексы | Только первичный индекс | Первичный и вторичные индексы |
| Форма представления данных | Документ | Таблица с семействами столбцов | Ключ и значение | Граф с ребрами и вершинами |
| разреженные; | Да | Да | Да | Нет |
| Масштабность (большое количество столбцов и атрибутов) | Да | Да | Нет | Нет |
| Размер данных | От малого (КБ) до среднего (несколько МБ) | От среднего (МБ) до большого (несколько ГБ) | Небольшой (КБ) | Небольшой (КБ) |
| Общий максимальный масштаб | Очень большой (ПБ) | Очень большой (ПБ) | Очень большой (ПБ) | Большой (ТБ) |
| Требование | Данные временных рядов | Хранилище данных объектов | Хранилище данных внешних индексов |
|---|---|---|---|
| Нормализация | Нормализированные данные | Денормализированные данные | Денормализированные данные |
| схема | Схема при чтении | Схема при чтении | Схема при записи |
| Согласованность (между параллельными транзакциями) | Н/Д | Н/Д | Н/Д |
| Атомарность (область транзакции) | Н/Д | Объект | Н/Д |
| Стратегия блокировки | Н/Д | Пессимистичная (блокировка больших двоичных объектов) | Н/Д |
| Шаблон доступа | Прямой доступ и агрегирование | Последовательный доступ | Прямой доступ |
| Индексация | Первичный и вторичные индексы | Только первичный индекс | Н/Д |
| Форма представления данных | Таблица | Большой двоичный объект и метаданные | Документ |
| разреженные; | нет | Н/Д | Нет |
| Масштабность (большое количество столбцов и атрибутов) | Нет | Да | Да |
| Размер данных | Небольшой (КБ) | От большого (ГБ) до очень большого (ТБ) | Небольшой (КБ) |
| Общий максимальный масштаб | Большой (несколько ТБ) | Очень большой (ПБ) | Большой (несколько ТБ) |
Соавторы
Эта статья поддерживается корпорацией Майкрософт.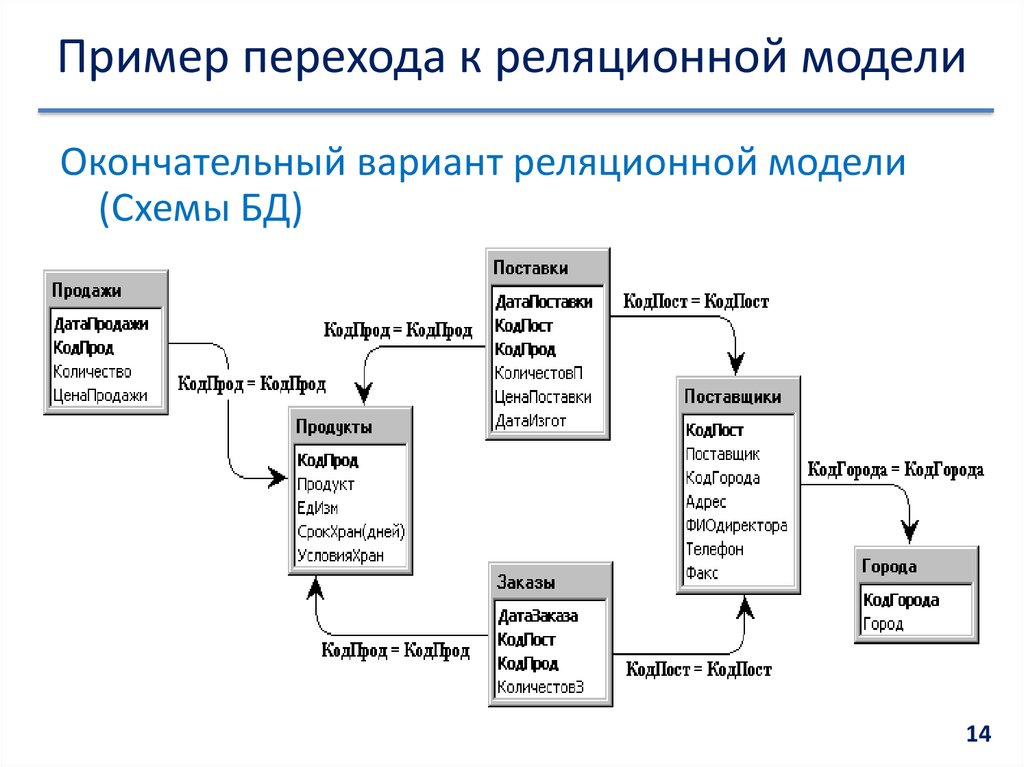 Первоначально он был написан следующими участниками.
Первоначально он был написан следующими участниками.
Автор субъекта:
- Зоинер Тейада | Генеральный директор и архитектор
Реляционная модель
В реляционная модель (RM) за база данных менеджмент — это подход к управлению данные используя структуру и язык, соответствующие логика предикатов первого порядка, впервые описанный в 1969 году английским ученым-компьютерщиком Эдгар Ф. Кодд,[1][2] где все данные представлены в виде кортежи, сгруппированы в связи. База данных, организованная в терминах реляционной модели, является реляционная база данных.
Цель реляционной модели — предоставить декларативный Метод для указания данных и запросов: пользователи напрямую указывают, какую информацию содержит база данных и какую информацию они хотят от нее, и позволяют программному обеспечению системы управления базами данных заботиться об описании структур данных для хранения данных и процедур поиска для ответов на запросы.
Большинство реляционных баз данных используют SQL определение данных и язык запросов; эти системы реализуют то, что можно рассматривать как инженерное приближение к реляционной модели. А стол в SQL схема базы данных соответствует предикатной переменной; содержимое таблицы для отношения; ключевые ограничения, другие ограничения и запросы SQL соответствуют предикатам. Однако базы данных SQL отклоняться от реляционной модели во многих деталях, и Кодд яростно выступал против отклонений, которые ставят под угрозу исходные принципы.[3]
Содержание
- 1 Обзор
- 1.1 Альтернативы
- 1.2 Выполнение
- 2 История
- 2.1 Споры
- 3 Темы
- 3.1 Интерпретация
- 3.2 Приложение к базам данных
- 3.3 SQL и реляционная модель
- 3.4 Реляционные операции
- 3.5 Нормализация базы данных
- 4 Примеры
- 4.1 База данных
- 4.2 Отношения с клиентами
- 5 Теоретико-множественная формулировка
- 5.
 1 Ключевые ограничения и функциональные зависимости
1 Ключевые ограничения и функциональные зависимости - 5.2 Алгоритм получения ключей-кандидатов из функциональных зависимостей
- 5.
- 6 Смотрите также
- 7 Рекомендации
- 8 дальнейшее чтение
- 9 внешняя ссылка
 1 Ключевые ограничения и функциональные зависимости
1 Ключевые ограничения и функциональные зависимостиОбзор
Центральная идея реляционной модели — описать базу данных как набор предикаты над конечным набором предикатных переменных, описывающих ограничения о возможных значениях и комбинациях значений. Содержимое базы данных в любой момент времени является конечным (логическим) модель базы данных, то есть набор связи, по одному на каждую переменную предиката, так что все предикаты удовлетворяются. Запрос информации из базы данных ( запрос к базе данных ) также является предикатом.
Понятия реляционной модели.
Альтернативы
Другой модели включить иерархическая модель и сетевая модель. Немного системы использование этих старых архитектур все еще используется сегодня в дата-центры с потребностями в большом объеме данных или в тех случаях, когда существующие системы настолько сложны и абстрактны, что переход на системы, использующие реляционную модель, был бы дорогостоящим.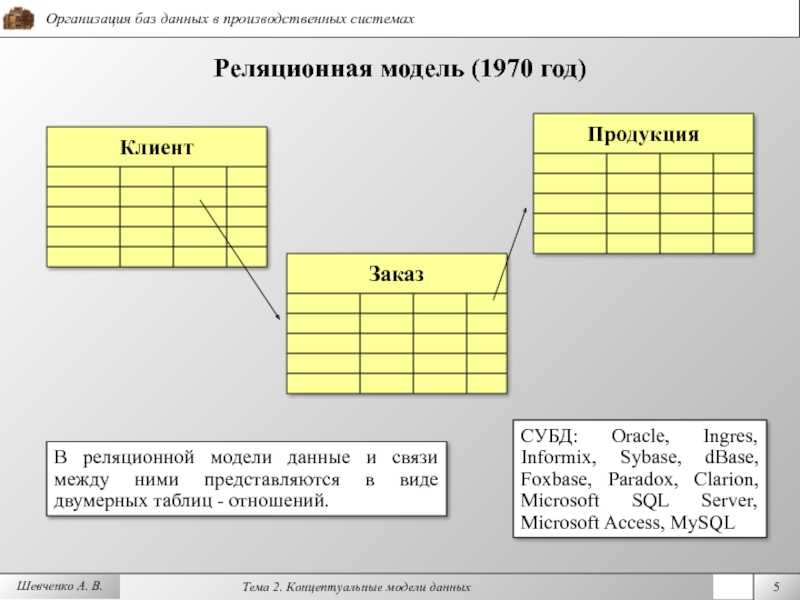 Также следует отметить новее объектно-ориентированные базы данных.
Также следует отметить новее объектно-ориентированные базы данных.
Выполнение
Было предпринято несколько попыток создать истинную реализацию модели реляционной базы данных, как первоначально определено Кодд и объяснил Дата, Дарвен и другие, но до сих пор ни один из них не пользовался популярностью. По состоянию на октябрь 2015 г.Rel это одна из самых недавних попыток сделать это.
Реляционная модель была первой моделью базы данных, описанной в формальных математических терминах. Иерархические и сетевые базы данных существовали до реляционных баз данных, но их спецификации были относительно неформальными. После определения реляционной модели было много попыток сравнить и сопоставить разные модели, что привело к появлению более строгих описаний более ранних моделей; хотя процедурный характер интерфейсов управления данными для иерархических и сетевых баз данных ограничивал возможности для формализации.[нужна цитата ]
Структурная аналитика баз данных, использующая протоколы реляционной модальности, часто использует дифференциацию последовательностей данных для поддержки обозначений иерархической архитектуры с включением новых входных данных. Эти системы функционально схожи по концепции с альтернативными алгоритмами ретрансляции, которые составляют основу инфраструктуры облачных баз данных.[4]
Эти системы функционально схожи по концепции с альтернативными алгоритмами ретрансляции, которые составляют основу инфраструктуры облачных баз данных.[4]
История
Реляционная модель была изобретена Эдгар Ф. Кодд в качестве общей модели данных и впоследствии продвигаемой Крис Дата и Хью Дарвен среди прочего. В Третий манифест (впервые опубликовано в 1995 г.) Дэйт и Дарвен пытаются показать, как реляционная модель якобы может приспособиться к определенным «желаемым» объектно-ориентированный Особенности.
Споры
Через несколько лет после публикации своей модели 1970 года Кодд предложил трехзначная логика (Верно, Неверно, Отсутствует /НОЛЬ ) его версия для работы с недостающей информацией, а в его Реляционная модель для управления базами данных версии 2 (1990) он пошел дальше, предложив версию с четырехзначной логикой (Верно, Ложно, Отсутствует, но применимо, Отсутствует, но неприменимо).[5] Они никогда не были реализованы, по-видимому, из-за сложности обслуживания.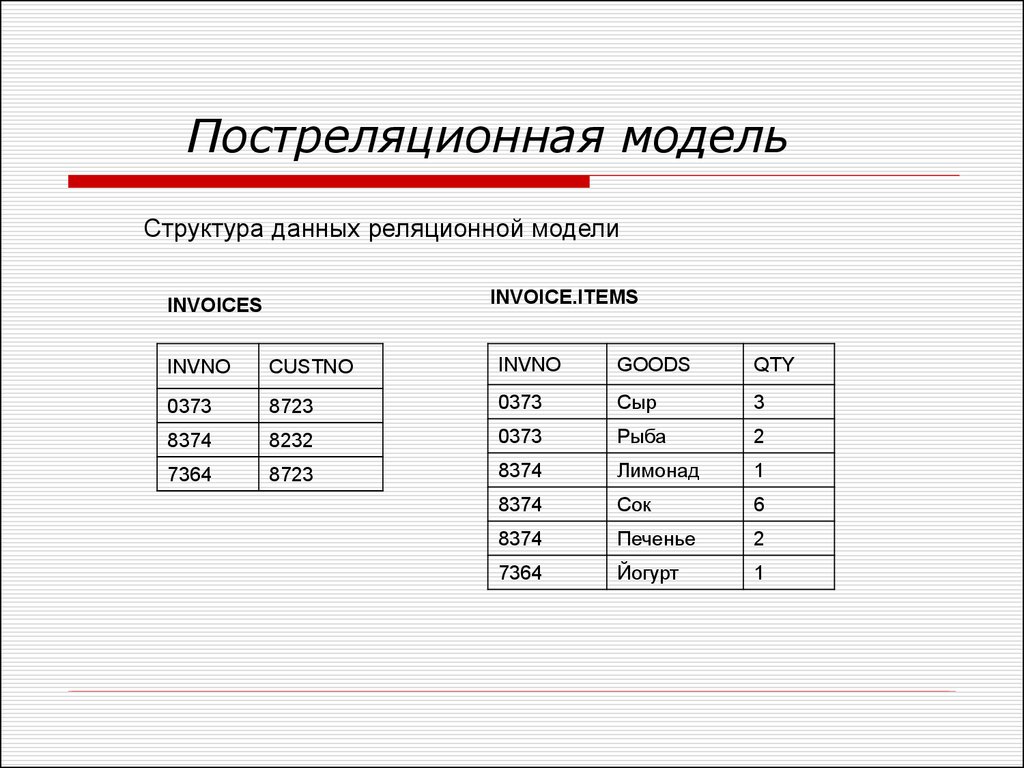 Конструкция SQL NULL должна была быть частью трехзначной логической системы, но не соответствовала этому из-за логических ошибок в стандарте и его реализациях.[6]
Конструкция SQL NULL должна была быть частью трехзначной логической системы, но не соответствовала этому из-за логических ошибок в стандарте и его реализациях.[6]
Темы
Основное предположение реляционной модели состоит в том, что все данные представлен как математический п-арый связи, п-арное отношение, являющееся подмножество из Декартово произведение из п домены. В математической модели рассуждение о таких данных делается в двузначном логика предикатов, то есть есть два возможных оценки для каждого предложение: либо истинный или же ложный (и, в частности, нет третьего значения, такого как неизвестный, или же непригодный, любой из которых часто ассоциируется с концепцией НОЛЬ ). Данные обрабатываются с помощью реляционное исчисление или же реляционная алгебра, они эквивалентны в выразительная сила.
Реляционная модель данных позволяет разработчику базы данных создавать согласованное, логическое представление Информация. Последовательность достигается за счет включения заявленных ограничения в дизайне базы данных, который обычно называют логическая схема. Теория включает в себя процесс нормализация базы данных посредством чего дизайн с определенными желаемыми свойствами может быть выбран из набора логически эквивалентный альтернативы. В планы доступа и другие детали реализации и работы обрабатываются СУБД двигателя, и не отражены в логической модели. Это контрастирует с обычной практикой для СУБД SQL, в которых настройка производительности часто требует изменения логической модели.
Последовательность достигается за счет включения заявленных ограничения в дизайне базы данных, который обычно называют логическая схема. Теория включает в себя процесс нормализация базы данных посредством чего дизайн с определенными желаемыми свойствами может быть выбран из набора логически эквивалентный альтернативы. В планы доступа и другие детали реализации и работы обрабатываются СУБД двигателя, и не отражены в логической модели. Это контрастирует с обычной практикой для СУБД SQL, в которых настройка производительности часто требует изменения логической модели.
Основным строительным блоком отношений является домен или же тип данных, обычно сокращенно в настоящее время тип. А кортеж заказанный набор из значения атрибутов. An атрибут упорядоченная пара имя атрибута и имя типа. Значение атрибута — это конкретное допустимое значение для типа атрибута. Это может быть скалярное значение или более сложный тип.
Отношение состоит из Заголовок и тело. Заголовок — это набор атрибутов. Тело (из п-арное отношение) представляет собой набор п— пары. Заголовок отношения также является заголовком каждого из его кортежей.
Отношение определяется как набор из п— пары. И в математике, и в модели реляционной базы данных набор — это неупорядоченный сбор уникальных, не повторяющихся элементов, хотя некоторые СУБД устанавливают порядок для своих данных. В математике кортеж имеет заказ и допускает дублирование. Э. Ф. Кодд первоначально определенные кортежи с использованием этого математического определения.[2] Позже это был один из Э. Ф. Кодд отличное понимание того, что использование имен атрибутов вместо упорядочивания было бы более удобным (в целом) на компьютерном языке, основанном на отношениях[нужна цитата ]. Это понимание все еще используется сегодня. Хотя концепция изменилась, название «кортеж» не осталось.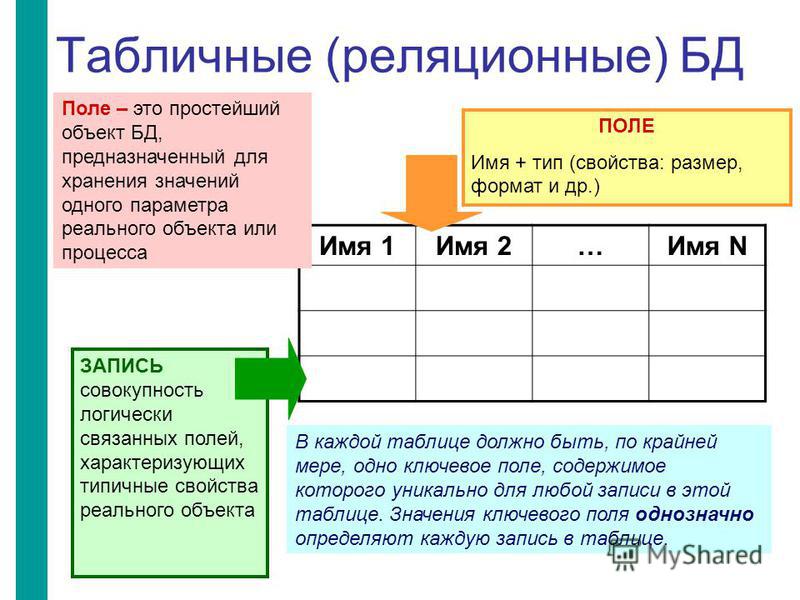 Непосредственным и важным следствием этой отличительной черты является то, что в реляционной модели Декартово произведение становится коммутативный.
Непосредственным и важным следствием этой отличительной черты является то, что в реляционной модели Декартово произведение становится коммутативный.
А стол это общепринятое визуальное представление отношения; кортеж похож на концепцию ряд.
А relvar — это именованная переменная определенного типа отношения, которой всегда присваивается какое-либо отношение этого типа, хотя отношение может содержать нулевые кортежи.
Основной принцип реляционной модели — это Информационный принцип: все Информация представлен значениями данных в отношениях. В соответствии с этим Принципом реляционная база данных представляет собой набор relvar, и результат каждого запроса представлен в виде отношения.
Согласованность реляционной базы данных обеспечивается не правилами, встроенными в приложения, которые ее используют, а скорее ограничения, объявленный как часть логической схемы и обеспечиваемый СУБД для всех приложений. В общем, ограничения выражаются с помощью операторов сравнения отношений, из которых только один, «является подмножеством» (), теоретически достаточно[нужна цитата ]. На практике ожидается, что будет доступно несколько полезных сокращений, из которых наиболее важными являются кандидат ключ (В самом деле, суперключ ) и иностранный ключ ограничения.
На практике ожидается, что будет доступно несколько полезных сокращений, из которых наиболее важными являются кандидат ключ (В самом деле, суперключ ) и иностранный ключ ограничения.
Интерпретация
Чтобы полностью оценить реляционную модель данных, важно понимать предполагаемый интерпретация из связь.
Тело отношения иногда называют его расширением. Это потому, что его следует интерпретировать как представление расширение некоторых предикат, это набор истинных предложения который может быть сформирован заменой каждого свободная переменная в этом предикате по имени (термин, который что-то обозначает).
Существует индивидуальная переписка между свободными переменными предиката и именами атрибутов заголовка отношения. Каждый кортеж тела отношения предоставляет значения атрибутов для создания экземпляра предиката путем подстановки каждой из его свободных переменных. Результатом является предложение, которое считается истинным из-за появления кортежа в теле отношения. И наоборот, каждый кортеж, заголовок которого соответствует заголовку отношения, но не появляется в теле, считается ложным. Это предположение известно как предположение о закрытом мире: это часто нарушается в практических базах данных, где отсутствие кортежа может означать, что истинность соответствующего предложения неизвестна. Например, отсутствие кортежа («Джон», «Испанский») в таблице языковых навыков не обязательно может рассматриваться как свидетельство того, что Джон не говорит по-испански.
И наоборот, каждый кортеж, заголовок которого соответствует заголовку отношения, но не появляется в теле, считается ложным. Это предположение известно как предположение о закрытом мире: это часто нарушается в практических базах данных, где отсутствие кортежа может означать, что истинность соответствующего предложения неизвестна. Например, отсутствие кортежа («Джон», «Испанский») в таблице языковых навыков не обязательно может рассматриваться как свидетельство того, что Джон не говорит по-испански.
Формальное изложение этих идей см. В разделе Теоретико-множественная формулировка, ниже.
Приложение к базам данных
А тип данных в типичной реляционной базе данных может быть набор целых чисел, набор символьных строк, набор дат или два логических значения истинный и ложный, и так далее. Соответствующие имена типов для этих типов могут быть строки «int», «char», «date», «boolean» и т. д. Однако важно понимать, что теория отношений не диктует, какие типы должны поддерживаться; действительно, в настоящее время ожидается наличие резервов для определяемые пользователем типы в дополнение к встроенный предоставленные системой.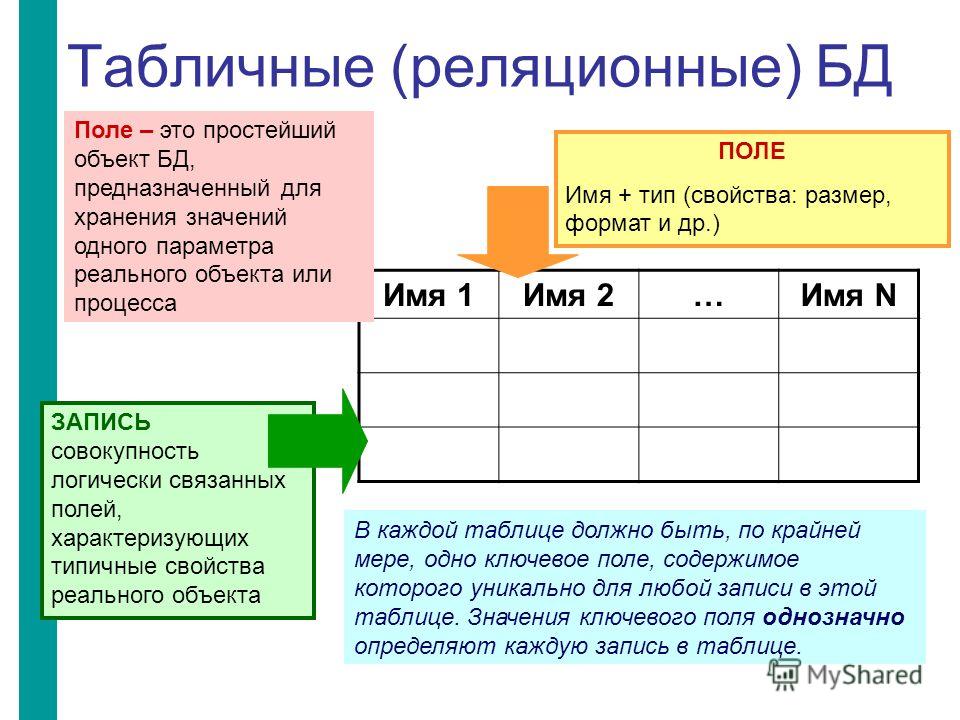
Атрибут — термин, используемый в теории для обозначения того, что обычно называют столбец. По аналогии, стол обычно используется вместо теоретического термина связь (хотя в SQL этот термин ни в коем случае не является синонимом отношения). Структура данных таблицы определяется как список определений столбцов, каждое из которых указывает уникальное имя столбца и тип значений, разрешенных для этого столбца. An атрибут ценить — это запись в определенном столбце и строке, например «Джон Доу» или «35».
А кортеж в основном то же самое, что и ряд, за исключением СУБД SQL, где значения столбцов в строке упорядочены. (Кортежи не упорядочиваются; вместо этого каждое значение атрибута идентифицируется исключительно имя атрибута и никогда — по порядковому номеру в кортеже.) Имя атрибута может быть «name» или «age».
А связь это стол определение структуры (набор определений столбцов) вместе с данными, появляющимися в этой структуре.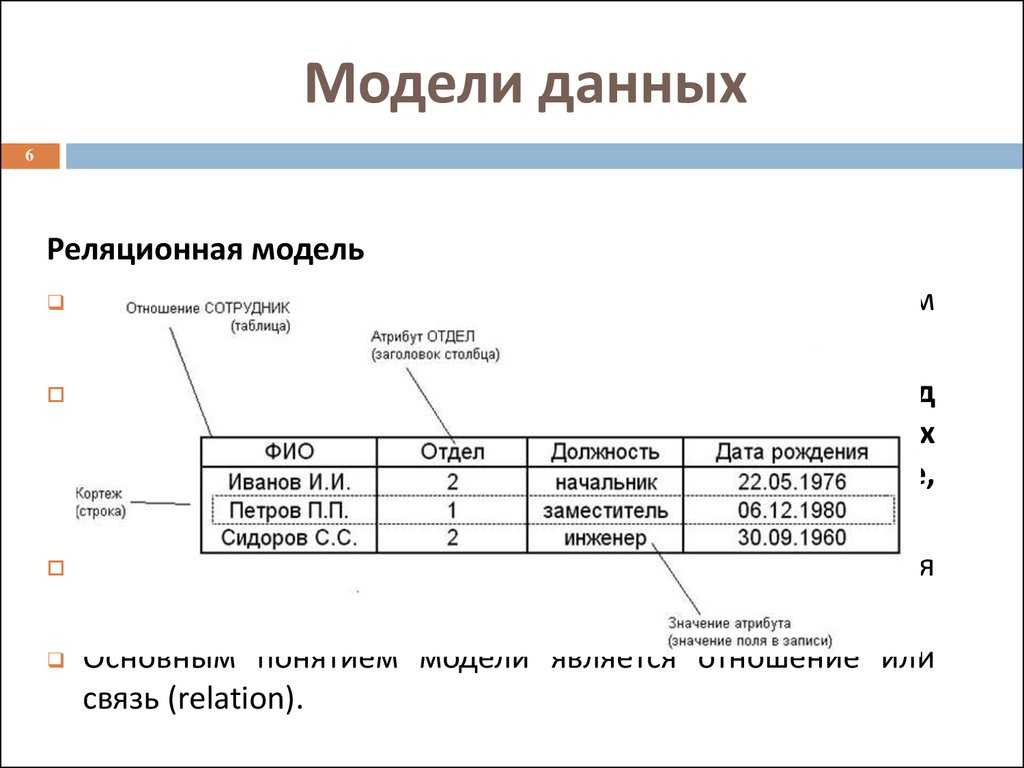 Определение структуры — это Заголовок и данные, появляющиеся в нем, являются тело, набор строк. База данных relvar (переменная отношения) широко известна как базовый стол. Заголовок присвоенного ему значения в любое время соответствует указанному в объявлении таблицы, а его тело — это то, что было присвоено ему последним путем вызова некоторых оператор обновления (обычно INSERT, UPDATE или DELETE). Заголовок и тело таблицы, полученной в результате оценки некоторого запроса, определяются определениями операторов, используемых в выражении этого запроса. (Обратите внимание, что в SQL заголовок не всегда является набором определений столбцов, как описано выше, потому что столбец может не иметь имени, а также иметь одно и то же имя для двух или более столбцов. Кроме того, тело не всегда набор строк, потому что в SQL одна и та же строка может появляться более одного раза в одном теле.)
Определение структуры — это Заголовок и данные, появляющиеся в нем, являются тело, набор строк. База данных relvar (переменная отношения) широко известна как базовый стол. Заголовок присвоенного ему значения в любое время соответствует указанному в объявлении таблицы, а его тело — это то, что было присвоено ему последним путем вызова некоторых оператор обновления (обычно INSERT, UPDATE или DELETE). Заголовок и тело таблицы, полученной в результате оценки некоторого запроса, определяются определениями операторов, используемых в выражении этого запроса. (Обратите внимание, что в SQL заголовок не всегда является набором определений столбцов, как описано выше, потому что столбец может не иметь имени, а также иметь одно и то же имя для двух или более столбцов. Кроме того, тело не всегда набор строк, потому что в SQL одна и та же строка может появляться более одного раза в одном теле.)
SQL и реляционная модель
SQL, изначально заданный как стандарт язык для реляционные базы данных, отклоняется от реляционной модели в нескольких местах. Электрический ток ISO Стандарт SQL не упоминает реляционную модель и не использует реляционные термины или концепции. Однако можно создать базу данных, соответствующую реляционной модели, с использованием SQL, если не используются определенные функции SQL.
Электрический ток ISO Стандарт SQL не упоминает реляционную модель и не использует реляционные термины или концепции. Однако можно создать базу данных, соответствующую реляционной модели, с использованием SQL, если не используются определенные функции SQL.
Отмечены следующие отклонения от реляционной модели[ВОЗ? ] в SQL. Обратите внимание, что некоторые серверы баз данных реализуют весь стандарт SQL и, в частности, не допускают некоторых из этих отклонений. В то время как NULL встречается повсеместно, например, разрешение дублирования имен столбцов в таблице или анонимных столбцов встречается редко.
- Повторяющиеся строки
- Одна и та же строка может появляться в таблице SQL более одного раза. Один и тот же кортеж не может появляться более одного раза в связь.
- Анонимные столбцы
- Столбец в таблице SQL может быть безымянным, поэтому на него нельзя ссылаться в выражениях. Реляционная модель требует, чтобы каждый атрибут был назван и на него можно было ссылаться.
- Повторяющиеся имена столбцов
- Два или более столбца одной и той же таблицы SQL могут иметь одно и то же имя, и поэтому на них нельзя ссылаться из-за очевидной неоднозначности. Реляционная модель требует, чтобы на каждый атрибут можно было ссылаться.
- Значение порядка столбцов
- Порядок столбцов в таблице SQL определен и важен, одним из следствий которого является то, что реализации декартова произведения и объединения в SQL являются некоммутативными. Реляционная модель требует, чтобы какой-либо порядок атрибутов отношения не имел значения.
- Просмотры без CHECK OPTION
- Обновления до Посмотреть определенное без CHECK OPTION может быть принято, но результирующее обновление базы данных не обязательно окажет выраженное влияние на его цель. Например, вызов INSERT может быть принят, но не все вставленные строки могут отображаться в представлении, или вызов UPDATE может привести к исчезновению строк из представления. Реляционная модель требует, чтобы обновления представления имели такой же эффект, как если бы представление было базовой относительной переменной.
- Таблицы без столбцов не распознаны
- SQL требует, чтобы каждая таблица имела хотя бы один столбец, но есть два отношения нулевой степени ( мощность единица и ноль), и они необходимы для представления расширений предикатов, не содержащих свободных переменных.
- НОЛЬ
- Эта специальная метка может появляться вместо значения везде, где значение может появляться в SQL, в частности, вместо значения столбца в некоторой строке. Отклонение от реляционной модели возникает из-за того, что реализация этого для этого случая концепция в SQL предполагает использование трехзначная логика, при котором сравнение NULL с самим собой не дает истинный но вместо этого дает третий значение истины, неизвестный; аналогично сравнение NULL с чем-то другим, кроме самого себя, не дает ложный но вместо этого дает неизвестный. Именно из-за такого поведения при сравнении NULL описывается как отметка, а не как значение. Реляционная модель зависит от закон исключенного среднего при котором все, что не является ложным, является ложным, а все, что не является ложным, является истинным; он также требует, чтобы каждый кортеж в теле отношения имел значение для каждого атрибута этого отношения. Некоторые оспаривают это конкретное отклонение хотя бы потому, что Э. Сам Ф. Кодд в конечном итоге выступал за использование специальных знаков и четырехзначной логики, но это было основано на его наблюдении о том, что есть две различные причины, по которым можно использовать специальный знак вместо значения, что привело противников использование такой логики для обнаружения более отчетливых причин, и было отмечено по крайней мере 19, что потребовало бы 21-значной логики.[нужна цитата ] Сам SQL использует NULL для нескольких целей, кроме представления «неизвестного значения». Например, сумма пустого набора равна NULL, что означает ноль, среднее значение пустого набора равно NULL, что означает undefined, а NULL, появляющийся в результате LEFT JOIN, может означать «нет значения, потому что нет соответствующей строки в правый операнд «. Есть способы создавать таблицы, чтобы избежать необходимости в NULL, обычно это может рассматриваться или напоминать высокие степени нормализация базы данных, но многие находят такое непрактичным. Это может быть горячо обсуждаемая тема.


 Некоторые оспаривают это конкретное отклонение хотя бы потому, что Э. Сам Ф. Кодд в конечном итоге выступал за использование специальных знаков и четырехзначной логики, но это было основано на его наблюдении о том, что есть две различные причины, по которым можно использовать специальный знак вместо значения, что привело противников использование такой логики для обнаружения более отчетливых причин, и было отмечено по крайней мере 19, что потребовало бы 21-значной логики.[нужна цитата ] Сам SQL использует NULL для нескольких целей, кроме представления «неизвестного значения». Например, сумма пустого набора равна NULL, что означает ноль, среднее значение пустого набора равно NULL, что означает undefined, а NULL, появляющийся в результате LEFT JOIN, может означать «нет значения, потому что нет соответствующей строки в правый операнд «. Есть способы создавать таблицы, чтобы избежать необходимости в NULL, обычно это может рассматриваться или напоминать высокие степени нормализация базы данных, но многие находят такое непрактичным.
Некоторые оспаривают это конкретное отклонение хотя бы потому, что Э. Сам Ф. Кодд в конечном итоге выступал за использование специальных знаков и четырехзначной логики, но это было основано на его наблюдении о том, что есть две различные причины, по которым можно использовать специальный знак вместо значения, что привело противников использование такой логики для обнаружения более отчетливых причин, и было отмечено по крайней мере 19, что потребовало бы 21-значной логики.[нужна цитата ] Сам SQL использует NULL для нескольких целей, кроме представления «неизвестного значения». Например, сумма пустого набора равна NULL, что означает ноль, среднее значение пустого набора равно NULL, что означает undefined, а NULL, появляющийся в результате LEFT JOIN, может означать «нет значения, потому что нет соответствующей строки в правый операнд «. Есть способы создавать таблицы, чтобы избежать необходимости в NULL, обычно это может рассматриваться или напоминать высокие степени нормализация базы данных, но многие находят такое непрактичным.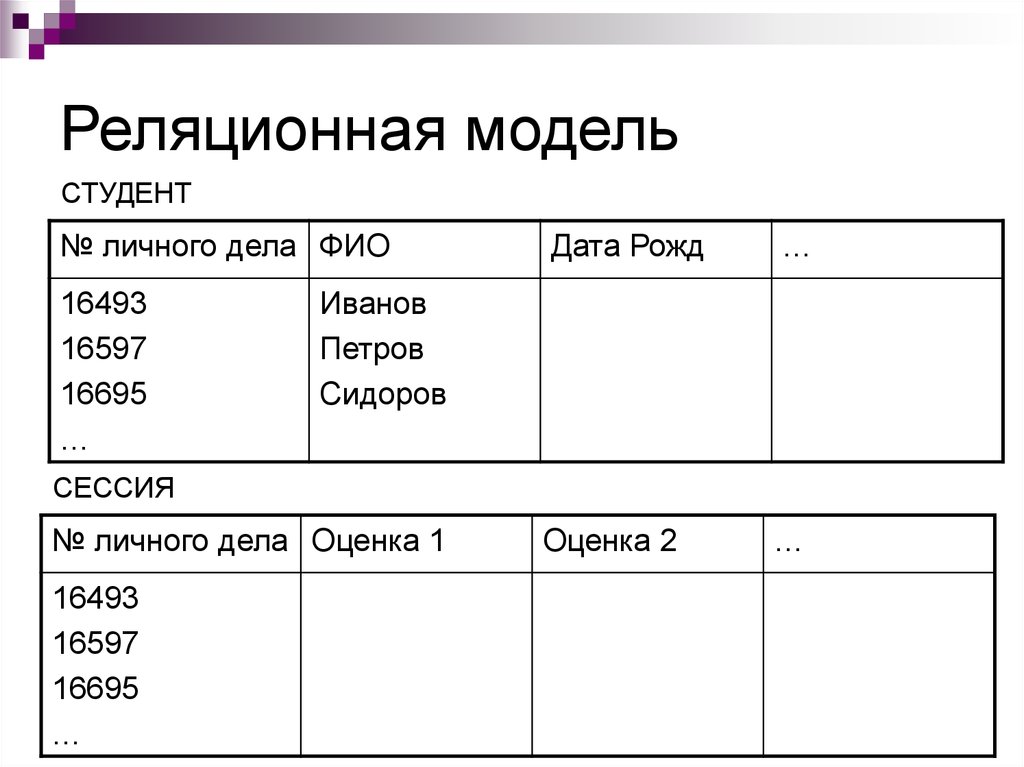 Это может быть горячо обсуждаемая тема.
Это может быть горячо обсуждаемая тема.Реляционные операции
Пользователи (или программы) запрашивают данные из реляционной базы данных, отправляя ей запрос который написан на специальном языке, обычно диалекте SQL. Хотя изначально SQL был предназначен для конечных пользователей, гораздо чаще запросы SQL встраиваются в программное обеспечение, обеспечивающее более простой пользовательский интерфейс. Многие веб-сайты, такие как Википедия, при создании страниц выполняют запросы SQL.
В ответ на запрос база данных возвращает набор результатов, который представляет собой просто список строк, содержащих ответы. Самый простой запрос — просто вернуть все строки из таблицы, но чаще строки каким-то образом фильтруются, чтобы вернуть только нужный ответ.
Часто данные из нескольких таблиц объединяются в одну, выполняя присоединиться. Концептуально это делается путем взятия всех возможных комбинаций строк ( Декартово произведение ), а затем отфильтровав все, кроме ответа.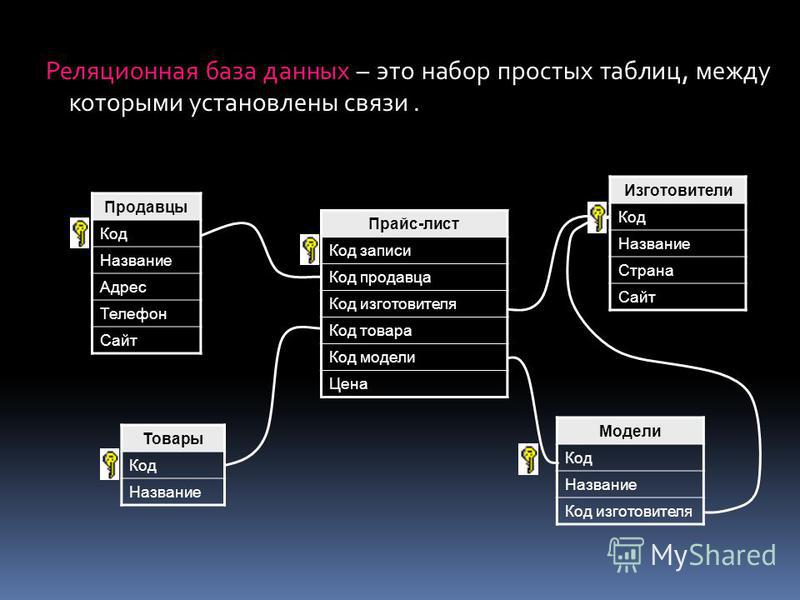 На практике системы управления реляционными базами данных переписывают («оптимизировать «) запросы для более быстрого выполнения с использованием различных методов.
На практике системы управления реляционными базами данных переписывают («оптимизировать «) запросы для более быстрого выполнения с использованием различных методов.
В дополнение к соединению существует ряд реляционных операций. К ним относятся проект (процесс удаления некоторых столбцов), ограничение (процесс удаления некоторых строк), объединение (способ объединения двух таблиц с похожими структурами), разность (который перечисляет строки в одной таблице, которые являются не найдено в другой), пересечение (в котором перечислены строки, найденные в обеих таблицах) и продукт (упомянутый выше, который объединяет каждую строку одной таблицы с каждой строкой другой). В зависимости от того, с какими другими источниками вы обращаетесь, существует ряд других операторов, многие из которых могут быть определены в терминах тех, что перечислены выше. К ним относятся полусоединение, внешние операторы, такие как внешнее соединение и внешнее объединение, а также различные формы разделения. Затем есть операторы для переименования столбцов, а также операторы суммирования или агрегирования, и если вы разрешите связь значения как атрибуты (атрибут со значением отношения), затем такие операторы, как группировка и разгруппировка. Оператор SELECT в SQL служит для обработки всего этого, за исключением операторов группировки и разгруппировки.
Оператор SELECT в SQL служит для обработки всего этого, за исключением операторов группировки и разгруппировки.
Гибкость реляционных баз данных позволяет программистам писать запросы, которые не ожидались разработчиками баз данных. В результате реляционные базы данных могут использоваться несколькими приложениями способами, не предусмотренными первоначальными разработчиками, что особенно важно для баз данных, которые могут использоваться в течение длительного времени (возможно, несколько десятилетий). Это сделало идею и реализацию реляционных баз данных очень популярными в бизнесе.
Нормализация базы данных
Основная статья: Нормализация базы данных
связи классифицируются по типам аномалий, которым они уязвимы. База данных, которая находится в первая нормальная форма уязвима для всех типов аномалий, в то время как база данных в нормальной форме домен / ключ не имеет аномалий модификации. Нормальные формы имеют иерархический характер. То есть самый нижний уровень — это первая нормальная форма, и база данных не может удовлетворить требования для нормальных форм более высокого уровня, не выполнив сначала все требования меньших нормальных форм.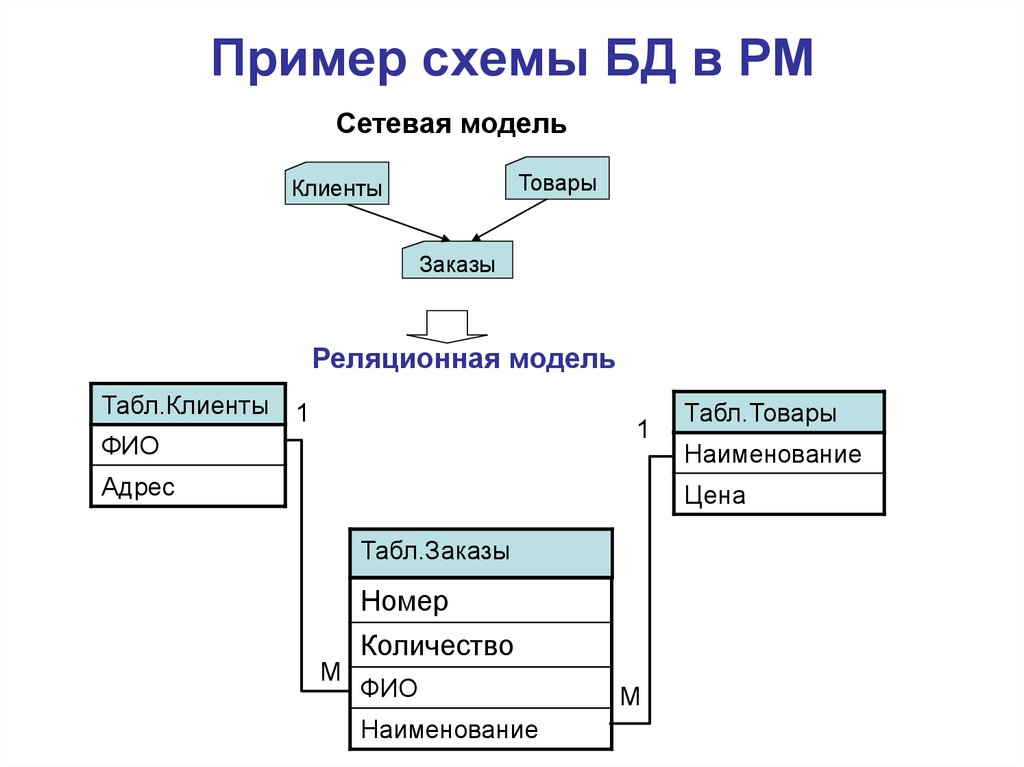 [7]
[7]
Примеры
База данных
Идеализированный, очень простой пример описания некоторых relvar (связь переменные) и их атрибуты:
- Покупатель (Пользовательский ИД, Налоговый номер, имя, адрес, город, штат, почтовый индекс, телефон, электронная почта, пол)
- Заказ (№ заказа, Пользовательский ИД, Счет-фактура №, Дата размещения, дата обещания, условия, статус)
- Строка заказа (№ заказа, Номер строки заказа, Код продукта, Кол-во)
- Выставленный счет (Счет-фактура №, Пользовательский ИД, № заказа, Дата, Статус)
- Строка счета-фактуры (Счет-фактура №, Номер строки счета-фактуры, Код продукта, Количество отправлено)
- Товар (Код продукта, Описание товара)
В этом дизайн у нас есть шесть релеваров: клиент, заказ, строка заказа, счет-фактура, строка счета-фактуры и продукт.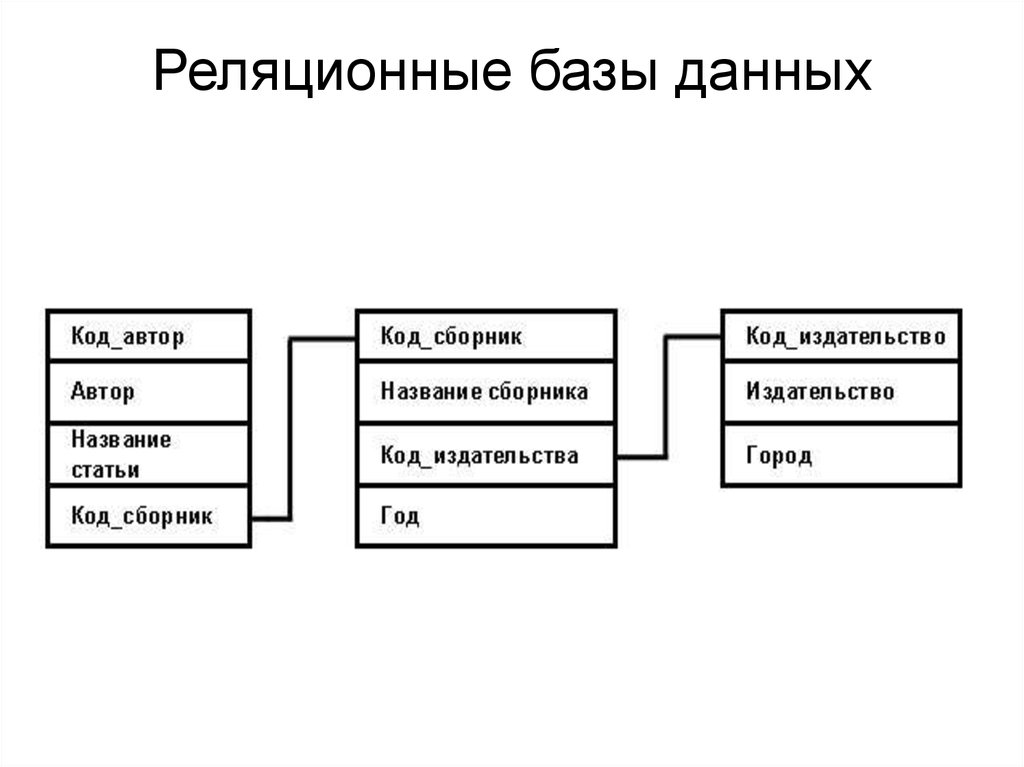 Атрибуты, выделенные жирным шрифтом, подчеркнуты ключи-кандидаты. Атрибуты, не выделенные жирным шрифтом, подчеркнуты: внешние ключи.
Атрибуты, выделенные жирным шрифтом, подчеркнуты ключи-кандидаты. Атрибуты, не выделенные жирным шрифтом, подчеркнуты: внешние ключи.
Обычно один кандидат ключ выбран, чтобы называться первичный ключ и используется в предпочтение над другими ключами-кандидатами, которые затем вызываются альтернативные ключи.
А кандидат ключ уникальный идентификатор обеспечение того, что нет кортеж будет продублирован; это сделало бы связь во что-то другое, а именно мешок, нарушая основное определение набор. И внешние ключи, и суперключи (включая ключи-кандидаты) могут быть составными, то есть состоять из нескольких атрибутов. Ниже приводится табличное изображение отношения нашего примера Customer relvar; отношение можно рассматривать как значение, которое может быть приписано relvar.
Отношения с клиентами
| Пользовательский ИД | ИНН | Имя | Адрес | [Дополнительные поля…] |
|---|---|---|---|---|
| 1234567890 | 555-5512222 | Рамеш | Южный проспект, 323 | … |
| 2223344556 | 555-5523232 | Адам | 1200 Main Street | … |
| 3334445563 | 555-5533323 | Светлана | 871 Rani Jhansi Road | … |
| 4232342432 | 555-5325523 | Сарфараз | 123 Маулана Азад Сарани | … |
Если бы мы попытались вставлять новый клиент с идентификатором 1234567890, это нарушило бы конструкцию relvar, поскольку Пользовательский ИД это первичный ключ и у нас уже есть заказчик 1234567890. В СУБД должен отклонить сделка такие как это, что сделало бы база данных несовместимы с нарушением ограничение целостности.
В СУБД должен отклонить сделка такие как это, что сделало бы база данных несовместимы с нарушением ограничение целостности.
Внешние ключи находятся ограничения целостности обеспечение того, чтобы ценить из набор атрибутов взят из кандидат ключ в другой связь. Например, в отношении «Порядок» атрибут Пользовательский ИД это внешний ключ. А присоединиться это операция это опирается на Информация сразу от нескольких родственников. Объединив relvar из приведенного выше примера, мы могли бы запрос база данных для всех клиентов, заказов и счетов-фактур. Если бы нам нужны были только кортежи для определенного клиента, мы бы указали это, используя условие ограничения.
Если бы мы хотели получить все заказы для клиента 1234567890, мы могли бы запрос база данных для возврата каждой строки в таблице заказов с Пользовательский ИД 1234567890 и присоедините таблицу заказов к таблице строки заказов на основе № заказа.
В нашем дизайн базы данных над. Относительная переменная Invoice содержит атрибут Order No. Таким образом, каждый кортеж в relvar Invoice будет иметь один номер заказа, что означает, что существует ровно один заказ для каждого счета-фактуры. Но на самом деле счет-фактура может быть выставлен по многим заказам или даже по любому конкретному заказу. Кроме того, relvar «Заказ» содержит атрибут «Номер счета-фактуры», подразумевающий, что каждому Заказу соответствует соответствующий счет-фактура. Но опять же, это не всегда верно в реальном мире. Иногда заказ оплачивается несколькими счетами, а иногда — без счета. Другими словами, может быть много счетов-фактур на заказ и много заказов на счет-фактуру. Это многие-ко-многим связь между Заказом и Счетом-фактурой (также называемая неспецифические отношения). Чтобы представить эту взаимосвязь в базе данных, необходимо ввести новую относительную переменную, чья роль — указать соответствие между Заказами и Счетами:
Счет-фактура (№ заказа, Счет-фактура №)
Теперь у relvar Order есть отношения один ко многим в таблицу OrderInvoice, как и относительная переменная Invoice. Если мы хотим получить каждый счет-фактуру для определенного заказа, мы можем запросить все заказы, где № заказа в отношении порядка равно № заказа в OrderInvoice, а где Счет-фактура № в OrderInvoice равно Счет-фактура № в счете-фактуре.
Если мы хотим получить каждый счет-фактуру для определенного заказа, мы можем запросить все заказы, где № заказа в отношении порядка равно № заказа в OrderInvoice, а где Счет-фактура № в OrderInvoice равно Счет-фактура № в счете-фактуре.
Теоретико-множественная формулировка
Основные понятия в реляционной модели: связь имена и имена атрибутов. Мы будем представлять их в виде строк, таких как «Человек» и «имя», и обычно будем использовать переменные р,s,т,…{displaystyle r, s, t, ldots} и а,б,c{displaystyle a, b, c} пробегать по ним. Еще одно базовое понятие — это набор атомарные значения который содержит такие значения, как числа и строки.
Наше первое определение касается понятия кортеж, который формализует понятие строки или записи в таблице:
- Кортеж
- Кортеж — это частичная функция от имен атрибутов до атомарных значений.
- Заголовок
- Заголовок — это конечный набор имен атрибутов.
- Проекция
- Проекция кортежа т{displaystyle t} на конечный набор атрибутов А{displaystyle A} является т[А]={(а,v):(а,v)∈т,а∈А}{displaystyle t [A] = {(a, v) 🙁 a, v) in t, ain A}}.

Следующее определение определяет связь который формализует содержимое таблицы, как оно определено в реляционной модели.
- Связь
- Отношение — это кортеж (ЧАС,B){displaystyle (H, B)} с ЧАС{displaystyle H}, заголовок и B{displaystyle B}, тело, набор кортежей, каждый из которых имеет домен ЧАС{displaystyle H}.
Такое отношение близко соответствует тому, что обычно называют расширением предиката в логика первого порядка за исключением того, что здесь мы идентифицируем места в предикате с именами атрибутов. Обычно в реляционной модели a схема базы данных как говорят, состоит из набора имен отношений, заголовков, связанных с этими именами, и ограничения это должно выполняться для каждого экземпляра схемы базы данных.
- Вселенная отношений
- Вселенная отношений U{displaystyle U} над заголовком ЧАС{displaystyle H} непустой набор отношений с заголовком ЧАС{displaystyle H}.
- Схема отношения
- Схема отношения (ЧАС,C){displaystyle (H, C)} состоит из заголовка ЧАС{displaystyle H} и предикат C(р){displaystyle C (R)} что определено для всех отношений р{displaystyle R} с заголовком ЧАС{displaystyle H}. Отношение удовлетворяет схеме отношения (ЧАС,C){displaystyle (H, C)} если у него есть заголовок ЧАС{displaystyle H} и удовлетворяет C{displaystyle C}.
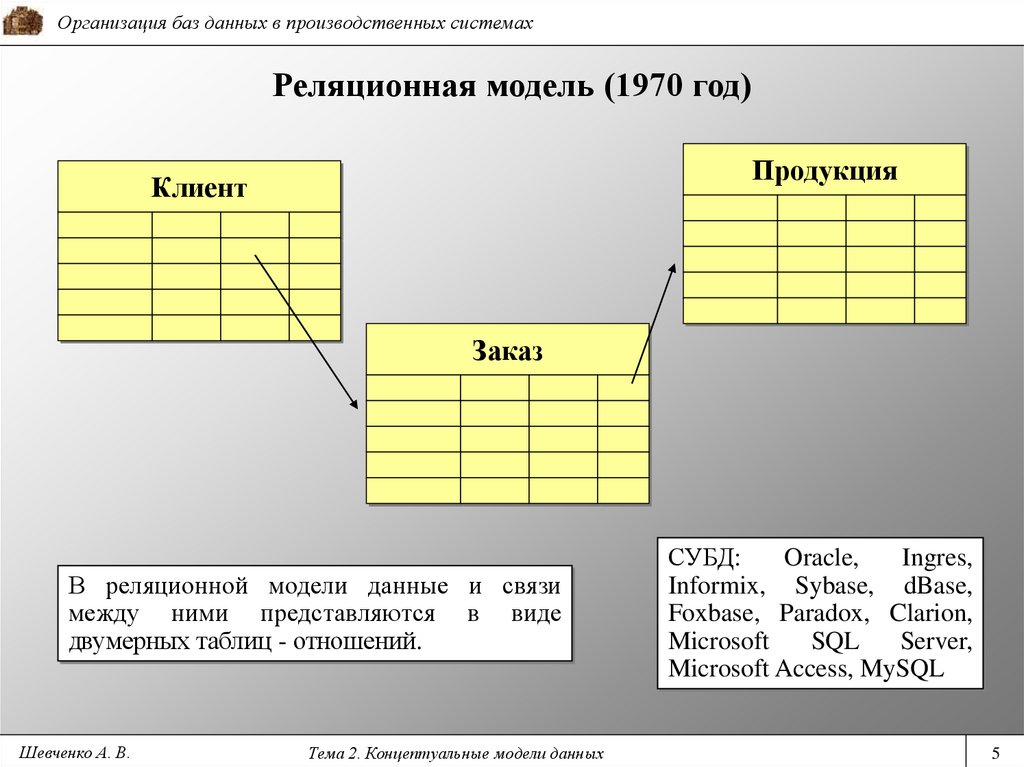
Ключевые ограничения и функциональные зависимости
Один из самых простых и важных типов отношений ограничения это ключевое ограничение. Он сообщает нам, что в каждом экземпляре определенной реляционной схемы кортежи можно идентифицировать по их значениям для определенных атрибутов.
- Суперключ
Суперключ — это набор заголовков столбцов, для которых значения этих объединенных столбцов уникальны для всех строк. Формально:
- Суперключ записывается как конечный набор имен атрибутов.
- Супер ключ K{displaystyle K} выполняется в отношении (ЧАС,B){displaystyle (H, B)} если:
- K⊆ЧАС{displaystyle Ksubseteq H} и
- не существует двух разных кортежей т1,т2∈B{displaystyle t_ {1}, t_ {2} в B} такой, что т1[K]=т2[K]{displaystyle t_ {1} [K] = t_ {2} [K]}.
- Суперключ держится во вселенной отношений U{displaystyle U} если это верно во всех отношениях в U{displaystyle U}.
- Теорема: Супер ключ K{displaystyle K} имеет место во вселенной отношений U{displaystyle U} над ЧАС{displaystyle H} если и только если K⊆ЧАС{displaystyle Ksubseteq H} и K→ЧАС{displaystyle Kightarrow H} держит в U{displaystyle U}.
- Ключ кандидата

Ключ-кандидат — это суперключ, который не может быть далее подразделен для формирования другого суперключа.
- Супер ключ K{displaystyle K} используется как кандидатный ключ для вселенной отношений U{displaystyle U} если он используется как суперключ для U{displaystyle U} и нет правильное подмножество из K{displaystyle K} который также является суперключом для U{displaystyle U}.
- Функциональная зависимость
Функциональная зависимость — это свойство, согласно которому значение в кортеже может быть получено из другого значения в этом кортеже.
- Функциональная зависимость (сокращенно FD) записывается как Икс→Y{displaystyle Xightarrow Y} за Икс,Y{displaystyle X, Y} конечные наборы имен атрибутов.
- Функциональная зависимость Икс→Y{displaystyle Xightarrow Y} выполняется в отношении (ЧАС,B){displaystyle (H, B)} если:
- Икс,Y⊆ЧАС{displaystyle X, Ysubseteq H} и
- ∀{displaystyle forall} кортежи т1,т2∈B{displaystyle t_ {1}, t_ {2} в B}, т1[Икс]=т2[Икс] ⇒ т1[Y]=т2[Y]{displaystyle t_ {1} [X] = t_ {2} [X] ~ Стрелка вправо ~ t_ {1} [Y] = t_ {2} [Y]}
- Функциональная зависимость Икс→Y{displaystyle Xightarrow Y} держится во вселенной отношений U{displaystyle U} если это верно во всех отношениях в U{displaystyle U}.
- Тривиальная функциональная зависимость
- Функциональная зависимость тривиальна под заголовком ЧАС{displaystyle H} если это верно во всех взаимосвязанных вселенных над ЧАС{displaystyle H}.
- Теорема: ФД Икс→Y{displaystyle Xightarrow Y} тривиально под заголовком ЧАС{displaystyle H} если и только если Y⊆Икс⊆ЧАС{displaystyle Ysubseteq Xsubseteq H}.
- Закрытие
- Аксиомы Армстронга: Замыкание набора ФД S{displaystyle S} под заголовком ЧАС{displaystyle H}, записанный как S+{displaystyle S ^ {+}}, является наименьшим надмножеством S{displaystyle S} такой, что:
- Y⊆Икс⊆ЧАС ⇒ Икс→Y∈S+{displaystyle Ysubseteq Xsubseteq H ~ Rightarrow ~ Xightarrow Yin S ^ {+}} (рефлексивность)
- Икс→Y∈S+∧Y→Z∈S+ ⇒ Икс→Z∈S+{displaystyle Xightarrow Yin S ^ {+} land Yightarrow Zin S ^ {+} ~ Rightarrow ~ Xightarrow Zin S ^ {+}} (транзитивность) и
- Икс→Y∈S+∧Z⊆ЧАС ⇒ (Икс∪Z)→(Y∪Z)∈S+{displaystyle Xightarrow Yin S ^ {+} land Zsubseteq H ~ Rightarrow ~ (Xcup Z) ightarrow (Ycup Z) in S ^ {+}} (увеличение)
- Теорема: Аксиомы Армстронга верны и полны; учитывая заголовок ЧАС{displaystyle H} и набор S{displaystyle S} FD, которые содержат только подмножества ЧАС{displaystyle H}, Икс→Y∈S+{displaystyle Xightarrow Yin S ^ {+}} если и только если Икс→Y{displaystyle Xightarrow Y} имеет место во всех отношениях вселенных над ЧАС{displaystyle H} в котором все ФД в S{displaystyle S} держать. {+}}.
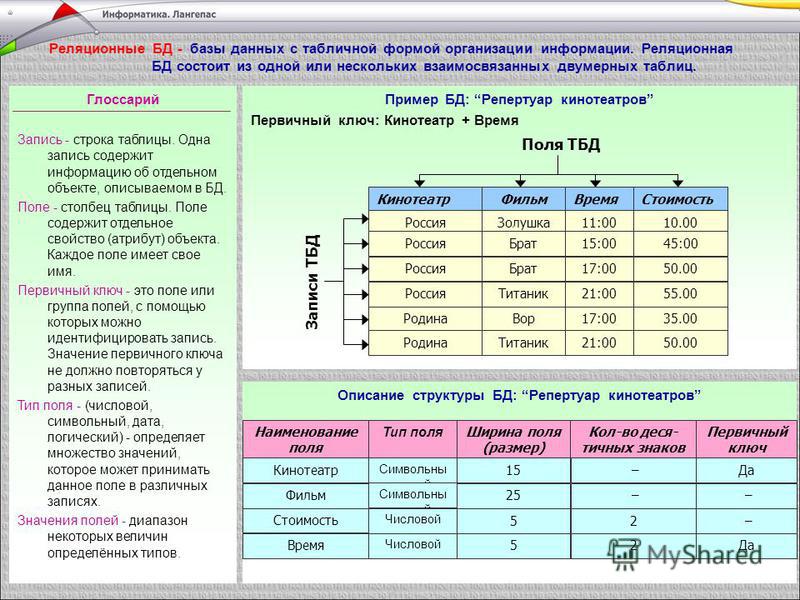
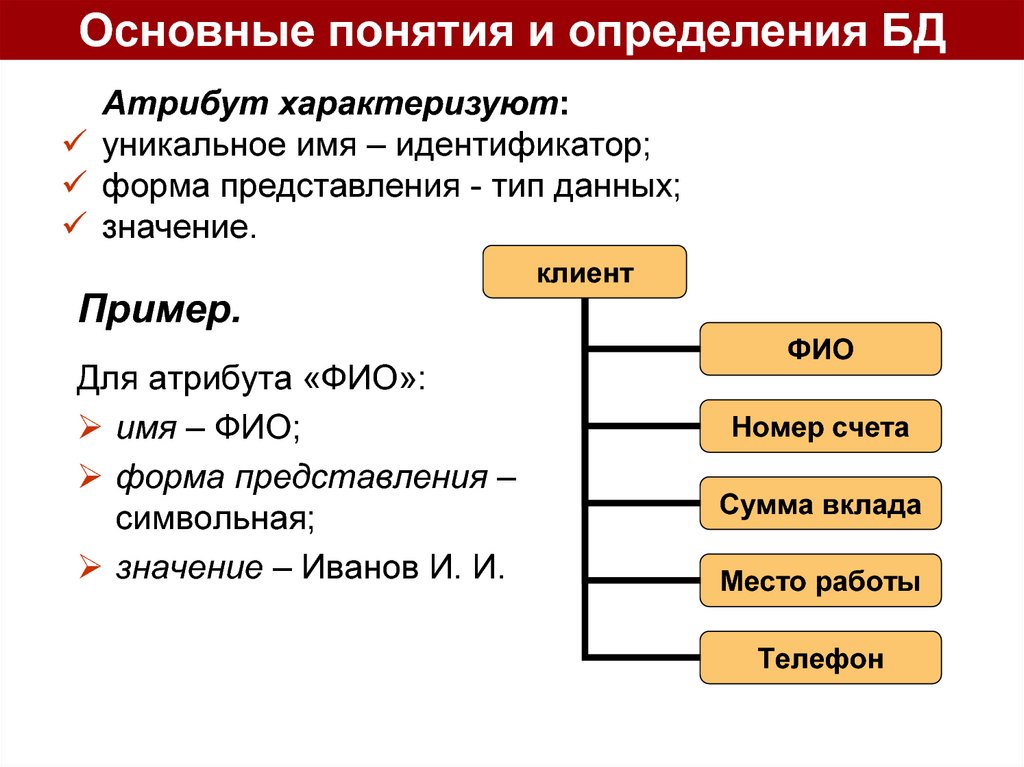 {+}}.
{+}}.Алгоритм получения ключей-кандидатов из функциональных зависимостей
алгоритм получить ключи-кандидаты из функциональных зависимостей является Вход: множество S FD, которые содержат только подмножества заголовка ЧАС выход: набор C суперключей, которые используются в качестве ключей-кандидатов во всех взаимосвязанных вселенных ЧАС в котором все ФД в S держать C : = ∅ // найдены ключи-кандидаты Q := { ЧАС } // суперключи, содержащие ключи-кандидаты пока Q <> ∅ делать позволять K быть каким-то элементом из Q Q := Q – { K } минимальный := истинный для каждого X-> Y в S делать K ' := (K – Y) ∪ Икс // получить новый суперключ если K ' ⊂ K тогда минимальный := ложный Q := Q ∪ { K ' } конец, если конец для если минимальный и нет подмножества K в C тогда удалить все надмножества K из C C := C ∪ { K } конец, если конец покаСмотрите также
|
|
Рекомендации
- ^ Кодд, E. Дэвид М. Кроенке, Обработка базы данных: основы, проектирование и реализация (1997), Prentice-Hall, Inc., стр. 130–144.
 Дэвид М. Кроенке, Обработка базы данных: основы, проектирование и реализация (1997), Prentice-Hall, Inc., стр. 130–144.
Дэвид М. Кроенке, Обработка базы данных: основы, проектирование и реализация (1997), Prentice-Hall, Inc., стр. 130–144.дальнейшее чтение
- Date, C.J .; Дарвен, Хью (2000). Основа для будущих систем баз данных: третий манифест; подробное исследование влияния теории типов на реляционную модель данных, включая комплексную модель наследования типов (2-е изд.). Чтение, MA: Аддисон-Уэсли. ISBN 978-0-201-70928-5.
- ——— (2007). Введение в системы баз данных (8-е изд.). Бостон: образование Пирсона. ISBN 978-0-321-19784-9.
внешняя ссылка
- Чайлдс (1968), Возможности теоретико-множественной структуры данных: общая структура, основанная на восстановленном определении отношения (исследование), ручка, HDL:2027.42/4164 цитируется в статье Кодда 1970 года.
- Дарвен, Хью, Третий манифест (ТТМ).
- Реляционные базы данных в Керли
- «Реляционная модель», C2.
- Бинарные отношения и кортежи по сравнению с семантической сетью (Всемирная паутина журнал), вс.
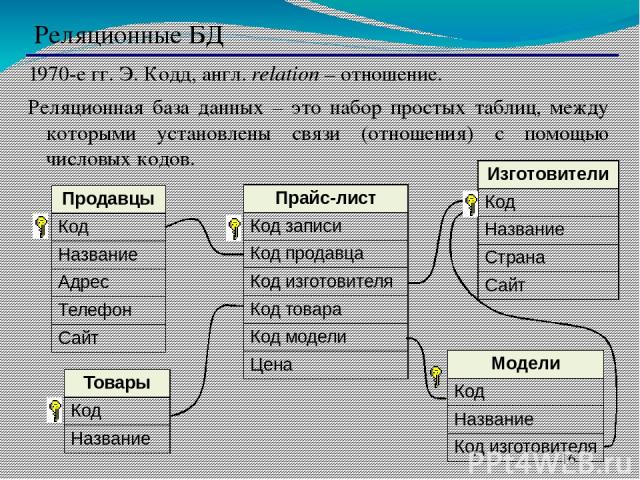
|
 ........................ 8
1.1.1 Основные типы данных ................................ 8
1.1.2 Обобщенные структуры или модели данных .............. 9
1.2 Методы доступа к данным ................................... 10
1.2.1 Методы поиска по дереву ............................ 11
1.2.2 Хеширование ........................................ 14
2 Модели представления данных ............................... 15
2.1 Представление данных с помощью модели «сущность - связь» .. 15
2.1.1 Назначение модели .................................. 15
2.1.2 Элементы модели .................................... 15
2.2 Диаграмма «сущность - связь» .............................. 21
2.3 Целостность данных ........................................ 26
2.4 Обзор нотаций, используемых при построении диаграмм
«сущность - связь» ........................................ 28
2.4.1 Нотация Чэня .
........................ 8
1.1.1 Основные типы данных ................................ 8
1.1.2 Обобщенные структуры или модели данных .............. 9
1.2 Методы доступа к данным ................................... 10
1.2.1 Методы поиска по дереву ............................ 11
1.2.2 Хеширование ........................................ 14
2 Модели представления данных ............................... 15
2.1 Представление данных с помощью модели «сущность - связь» .. 15
2.1.1 Назначение модели .................................. 15
2.1.2 Элементы модели .................................... 15
2.2 Диаграмма «сущность - связь» .............................. 21
2.3 Целостность данных ........................................ 26
2.4 Обзор нотаций, используемых при построении диаграмм
«сущность - связь» ........................................ 28
2.4.1 Нотация Чэня .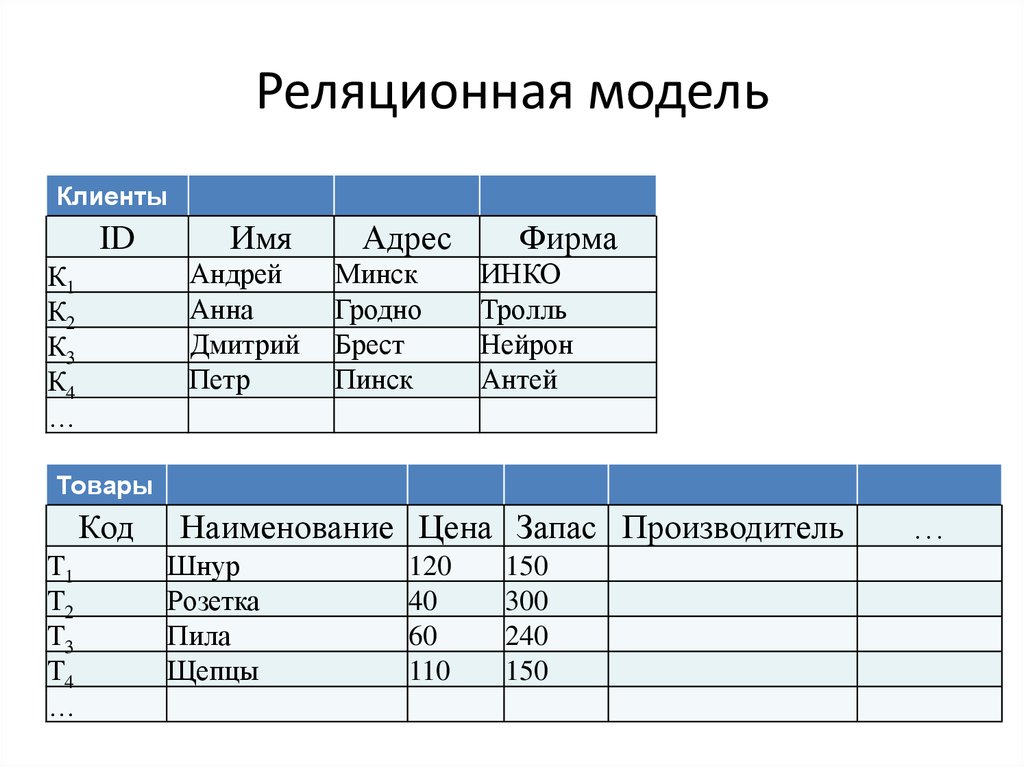 ...................................... 28
2.4.2 Нотация Мартина .................................... 29
2.4.3 Нотация IDEF1X ..................................... 30
2.4.4 Нотация Баркера .................................... 31
3 Дореляционные модели представления данных ................. 33
3.1 Иерархическая модель данных ............................... 33
3.1.1 Структура данных ................................... 33
3.1.2 Операции над данными, определенные в
иерархической модели ............................... 34
3.1.3 Ограничения целостности ............................ 35
3.2 Сетевая модель данных ..................................... 36
3.2.1 Структура данных ................................... 36
3.2.2 Операции над данными ............................... 38
3.2.3 Ограничения целостности ............................ 38
4 Реляционные базы данных .
...................................... 28
2.4.2 Нотация Мартина .................................... 29
2.4.3 Нотация IDEF1X ..................................... 30
2.4.4 Нотация Баркера .................................... 31
3 Дореляционные модели представления данных ................. 33
3.1 Иерархическая модель данных ............................... 33
3.1.1 Структура данных ................................... 33
3.1.2 Операции над данными, определенные в
иерархической модели ............................... 34
3.1.3 Ограничения целостности ............................ 35
3.2 Сетевая модель данных ..................................... 36
3.2.1 Структура данных ................................... 36
3.2.2 Операции над данными ............................... 38
3.2.3 Ограничения целостности ............................ 38
4 Реляционные базы данных . .................................. 39
4.1 Основные понятия реляционных баз данных ................... 39
4.1.1 Тип данных ......................................... 39
4.1.2 Домен .............................................. 40
4.1.3 Схема отношения, схема базы данных ................. 40
4.1.4 Кортеж, отношение .................................. 40
4.2 Целостность реляционных баз данных ........................ 41
4.3 Основные свойства отношений реляционных баз данных ........ 42
4.3.1 Отсутствие кортежей-дубликатов ..................... 43
4.3.2 Отсутствие упорядоченности кортежей ................ 43
4.3.3 Отсутствие упорядоченности атрибутов ............... 43
4.3.4 Атомарность значений атрибутов ..................... 44
4.4 Операции с таблицами реляционных баз данных ............... 44
4.4.1 Ограничение отношения .............................. 44
4.4.
.................................. 39
4.1 Основные понятия реляционных баз данных ................... 39
4.1.1 Тип данных ......................................... 39
4.1.2 Домен .............................................. 40
4.1.3 Схема отношения, схема базы данных ................. 40
4.1.4 Кортеж, отношение .................................. 40
4.2 Целостность реляционных баз данных ........................ 41
4.3 Основные свойства отношений реляционных баз данных ........ 42
4.3.1 Отсутствие кортежей-дубликатов ..................... 43
4.3.2 Отсутствие упорядоченности кортежей ................ 43
4.3.3 Отсутствие упорядоченности атрибутов ............... 43
4.3.4 Атомарность значений атрибутов ..................... 44
4.4 Операции с таблицами реляционных баз данных ............... 44
4.4.1 Ограничение отношения .............................. 44
4.4. 2 Проекция отношения ................................. 45
4.4.3 Объединение отношений .............................. 45
4.4.4 Пересечение отношений .............................. 46
4.4.5 Разность отношений ................................. 48
4.4.6 Произведение отношений ............................. 50
4.4.7 Деление отношений .................................. 51
4.4.8 Соединение отношений ............................... 53
4.5 Нормализация отношений реляционных баз данных ............. 53
4.5.1 Пример декомпозиции исходной «универсальной»
таблицы на простые отношения ....................... 55
4.5.2 Проблемы, возникающие при использовании
универсального отношения ........................... 55
4.5.3 Первая нормальная форма (1NF) ...................... 59
4.5.4 Вторая нормальная форма (2NF) ...................... 60
4.5.5 Третья нормальная форма (3NF) .
2 Проекция отношения ................................. 45
4.4.3 Объединение отношений .............................. 45
4.4.4 Пересечение отношений .............................. 46
4.4.5 Разность отношений ................................. 48
4.4.6 Произведение отношений ............................. 50
4.4.7 Деление отношений .................................. 51
4.4.8 Соединение отношений ............................... 53
4.5 Нормализация отношений реляционных баз данных ............. 53
4.5.1 Пример декомпозиции исходной «универсальной»
таблицы на простые отношения ....................... 55
4.5.2 Проблемы, возникающие при использовании
универсального отношения ........................... 55
4.5.3 Первая нормальная форма (1NF) ...................... 59
4.5.4 Вторая нормальная форма (2NF) ...................... 60
4.5.5 Третья нормальная форма (3NF) .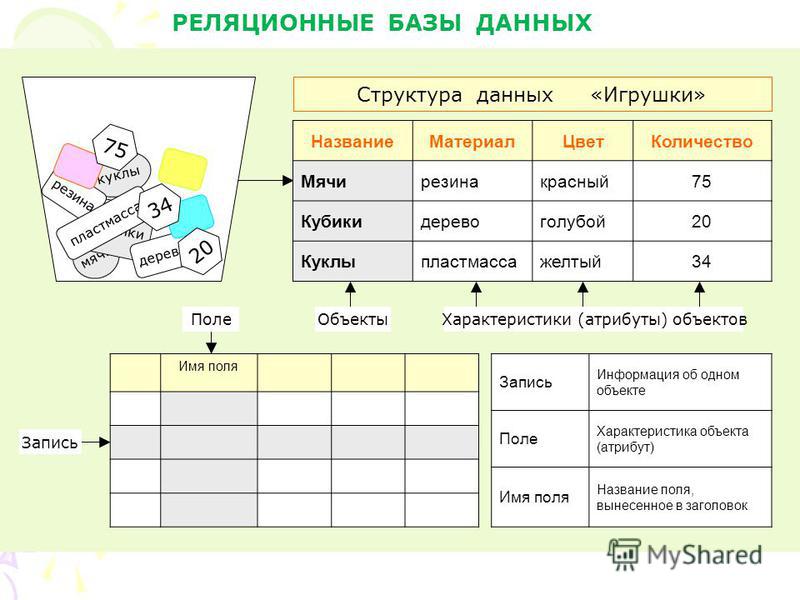 ..................... 62
4.5.6 Нормальная форма Бойса-Кодда (BCNF) ................ 64
4.5.7 Четвертая нормальная форма (4NF). Пятая
нормальная форма проекции-соединения (5NF или
PJ/NF) ............................................. 65
4.6 Ограничения целостности ................................... 65
4.6.1 Целостность сущностей .............................. 66
4.6.2 Целостность ссылок ................................. 66
5 Язык SQL .................................................. 68
5.1 Общие сведения о языке SQL ................................ 68
Из истории SQL ............................................ 68
5.1.1 Типы данных SQL .................................... 69
5.1.2 DDL: Операторы создания схемы базы данных .......... 71
5.1.3 DDL: Операторы создания индексов ................... 72
5.1.4 DDL: Операторы управления правами доступа .
..................... 62
4.5.6 Нормальная форма Бойса-Кодда (BCNF) ................ 64
4.5.7 Четвертая нормальная форма (4NF). Пятая
нормальная форма проекции-соединения (5NF или
PJ/NF) ............................................. 65
4.6 Ограничения целостности ................................... 65
4.6.1 Целостность сущностей .............................. 66
4.6.2 Целостность ссылок ................................. 66
5 Язык SQL .................................................. 68
5.1 Общие сведения о языке SQL ................................ 68
Из истории SQL ............................................ 68
5.1.1 Типы данных SQL .................................... 69
5.1.2 DDL: Операторы создания схемы базы данных .......... 71
5.1.3 DDL: Операторы создания индексов ................... 72
5.1.4 DDL: Операторы управления правами доступа .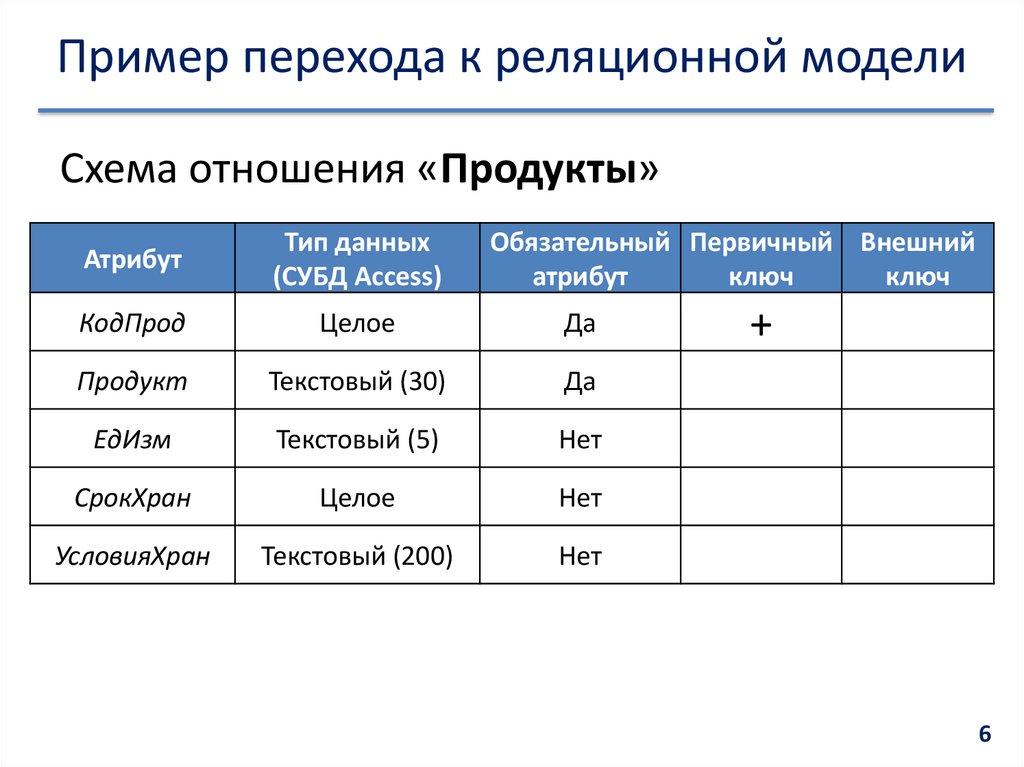 ......... 74
5.1.5 DML: Команды модификации данных .................... 75
5.1.6 DML: Выборка данных ................................ 77
5.1.7 DML: Выборка из нескольких таблиц .................. 79
5.1.8 DML: Вычисления внутри SELECT ...................... 81
5.1.9 DML: Группировка данных ............................ 82
5.1.10 DML: Сортировка данных ............................. 83
5.1.11 DML: Операция объединения .......................... 83
5.1.12 Использование представлений ........................ 83
5.1.13 Другие возможности SQL ............................. 85
5.2 Вопросы практического програмирования ..................... 87
5.2.1 Использование специализированных библиотек
и встраиваемого SQL ................................ 88
5.2.2 CLI - интерфейс уровня вызовов ..................... 91
5.2.3 ODBC - открытый интерфейс к базам данных на
платформе MS Windows .
......... 74
5.1.5 DML: Команды модификации данных .................... 75
5.1.6 DML: Выборка данных ................................ 77
5.1.7 DML: Выборка из нескольких таблиц .................. 79
5.1.8 DML: Вычисления внутри SELECT ...................... 81
5.1.9 DML: Группировка данных ............................ 82
5.1.10 DML: Сортировка данных ............................. 83
5.1.11 DML: Операция объединения .......................... 83
5.1.12 Использование представлений ........................ 83
5.1.13 Другие возможности SQL ............................. 85
5.2 Вопросы практического програмирования ..................... 87
5.2.1 Использование специализированных библиотек
и встраиваемого SQL ................................ 88
5.2.2 CLI - интерфейс уровня вызовов ..................... 91
5.2.3 ODBC - открытый интерфейс к базам данных на
платформе MS Windows .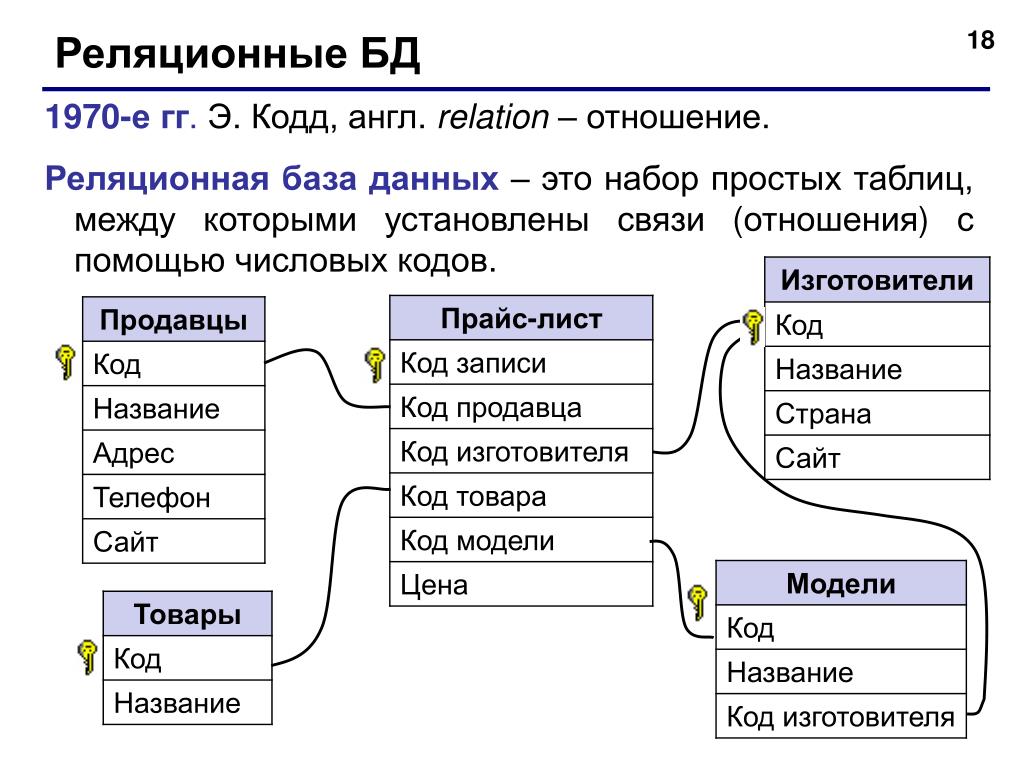 .............................. 91
5.2.4 Технология ADO.NET ................................. 93
5.2.5 JDBC - мобильный интерфейс к базам данных на
платформе Java ..................................... 94
5.3 Навигационный подход к манипулированию данными
и персональные СУБД ....................................... 96
5.4 Транзакции, блокировки и многопользовательский доступ
к данным .................................................. 97
5.5 Как определить степень соответствия СУБД реляционной
модели ................................................... 102
6 Проектирование реляционных баз данных .................... 105
6.1 Этапы проектирования данных .............................. 105
6.2 Инструментальные средства проектирования информационных
систем ................................................... 107
6.3 Методологии функционального моделирования ......
.............................. 91
5.2.4 Технология ADO.NET ................................. 93
5.2.5 JDBC - мобильный интерфейс к базам данных на
платформе Java ..................................... 94
5.3 Навигационный подход к манипулированию данными
и персональные СУБД ....................................... 96
5.4 Транзакции, блокировки и многопользовательский доступ
к данным .................................................. 97
5.5 Как определить степень соответствия СУБД реляционной
модели ................................................... 102
6 Проектирование реляционных баз данных .................... 105
6.1 Этапы проектирования данных .............................. 105
6.2 Инструментальные средства проектирования информационных
систем ................................................... 107
6.3 Методологии функционального моделирования ......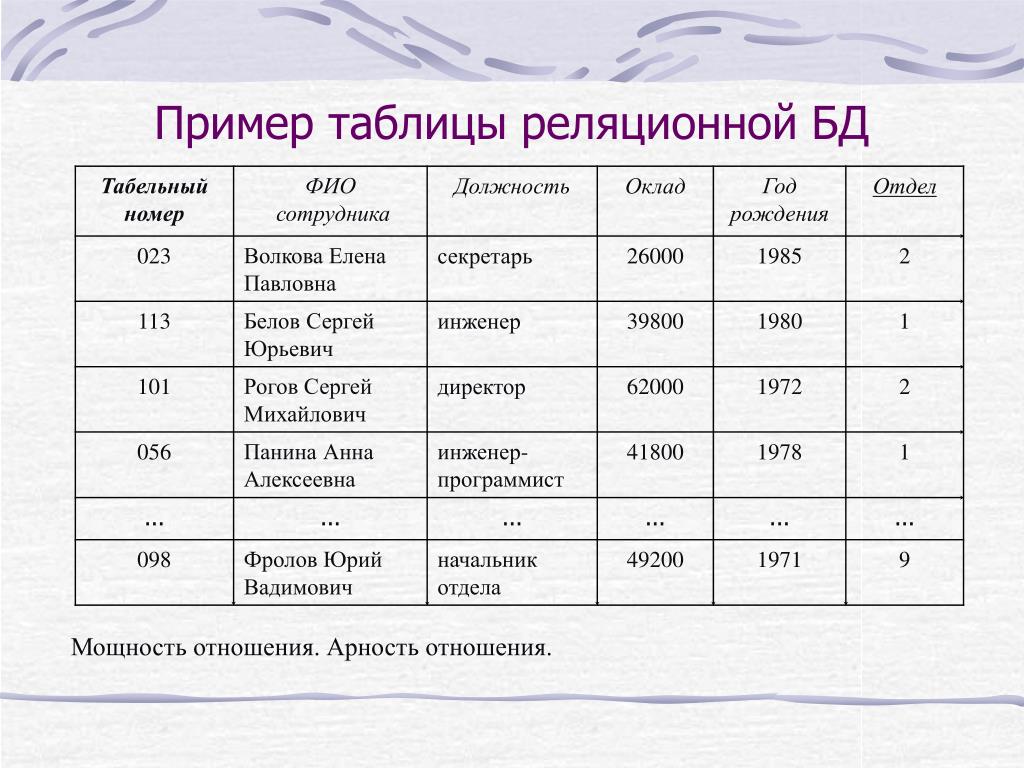 .......... 109
6.3.1 Диаграммы потоков данных. Нотация Йордона-Де
Марко ............................................. 109
6.3.2 Другие нотации, используемые при построении
диаграмм потоков данных ........................... 111
6.3.3 Методология SADT (IDEF0) .......................... 112
6.3.4 Сравнительный анализ методологий функционального
моделирования ..................................... 113
6.4 Концептуальное моделирование. Пример построения модели
«сущность - связь» ....................................... 114
6.5 Правила порождения реляционных отношений из модели
«сущность - связь» ....................................... 117
6.5.1 Бинарные связи .................................... 117
6.5.2 N-арные связи ..................................... 117
6.5.3 Иерархические связи ............................... 119
6.6 Проектирование реляционной базы данных на основе
декомпозиции универсального отношения .
.......... 109
6.3.1 Диаграммы потоков данных. Нотация Йордона-Де
Марко ............................................. 109
6.3.2 Другие нотации, используемые при построении
диаграмм потоков данных ........................... 111
6.3.3 Методология SADT (IDEF0) .......................... 112
6.3.4 Сравнительный анализ методологий функционального
моделирования ..................................... 113
6.4 Концептуальное моделирование. Пример построения модели
«сущность - связь» ....................................... 114
6.5 Правила порождения реляционных отношений из модели
«сущность - связь» ....................................... 117
6.5.1 Бинарные связи .................................... 117
6.5.2 N-арные связи ..................................... 117
6.5.3 Иерархические связи ............................... 119
6.6 Проектирование реляционной базы данных на основе
декомпозиции универсального отношения . ................... 122
7 Физическая организация СУБД .............................. 125
7.1 Архитектура «клиент - сервер» ............................ 125
7.1.1 Основные понятия .................................. 125
7.1.2 Модели взаимодействия «клиент - сервер» ........... 125
7.1.3 Мониторы транзакций ............................... 127
7.2 Обработка распределенных данных .......................... 128
7.3 Структура сервера базы данных ............................ 129
8 Базы знаний .............................................. 131
8.1 Основные понятия и определения ........................... 131
8.1.1 Интеллект ......................................... 131
8.1.2 Интеллектуальные задачи ........................... 132
8.1.3 Знания ............................................ 132
8.1.4 Свойства знаний ................................... 134
8.
................... 122
7 Физическая организация СУБД .............................. 125
7.1 Архитектура «клиент - сервер» ............................ 125
7.1.1 Основные понятия .................................. 125
7.1.2 Модели взаимодействия «клиент - сервер» ........... 125
7.1.3 Мониторы транзакций ............................... 127
7.2 Обработка распределенных данных .......................... 128
7.3 Структура сервера базы данных ............................ 129
8 Базы знаний .............................................. 131
8.1 Основные понятия и определения ........................... 131
8.1.1 Интеллект ......................................... 131
8.1.2 Интеллектуальные задачи ........................... 132
8.1.3 Знания ............................................ 132
8.1.4 Свойства знаний ................................... 134
8. 1.5 Граница между данными и знаниями .................. 135
8.2 Модели представления знаний .............................. 136
8.2.1 Логическая модель ................................. 136
8.2.2 Продукционная модель (или модель, основанная
на правилах) ...................................... 137
8.2.3 Фреймовая модель .................................. 138
8.2.4 Модель семантической сети ......................... 140
8.3 Современные подходы к управлению корпоративными
знаниями ................................................. 140
9 Принципы построения систем, ориентированных на анализ
данных ................................................... 142
9.1 Хранилища данных ......................................... 142
9.2 Модели данных, используемые при построении хранилищ
данных ................................................... 143
9.2.1 Многомерная модель .
1.5 Граница между данными и знаниями .................. 135
8.2 Модели представления знаний .............................. 136
8.2.1 Логическая модель ................................. 136
8.2.2 Продукционная модель (или модель, основанная
на правилах) ...................................... 137
8.2.3 Фреймовая модель .................................. 138
8.2.4 Модель семантической сети ......................... 140
8.3 Современные подходы к управлению корпоративными
знаниями ................................................. 140
9 Принципы построения систем, ориентированных на анализ
данных ................................................... 142
9.1 Хранилища данных ......................................... 142
9.2 Модели данных, используемые при построении хранилищ
данных ................................................... 143
9.2.1 Многомерная модель . ............................... 144
9.2.2 Реляционная модель хранилища ...................... 145
9.2.3 Комбинация многомерного и реляционного подходов ... 146
10 Защита данных ............................................ 149
10.1 Общие вопросы защиты данных .............................. 149
10.2 Основные методы и приемы защиты данных ................... 150
10.2.1 Идентификация пользователя ........................ 150
10.2.2 Управление доступом ............................... 151
10.2.3 Защита данных при статической обработке ........... 152
10.2.4 Физическая защита ................................. 152
10.3 Практика защиты данных .................................. 153
11 Системы хранения и обработки больших данных .............. 157
11.1 Характеристики больших данных ....................... 157
11.2 NoSQL системы ..................................
............................... 144
9.2.2 Реляционная модель хранилища ...................... 145
9.2.3 Комбинация многомерного и реляционного подходов ... 146
10 Защита данных ............................................ 149
10.1 Общие вопросы защиты данных .............................. 149
10.2 Основные методы и приемы защиты данных ................... 150
10.2.1 Идентификация пользователя ........................ 150
10.2.2 Управление доступом ............................... 151
10.2.3 Защита данных при статической обработке ........... 152
10.2.4 Физическая защита ................................. 152
10.3 Практика защиты данных .................................. 153
11 Системы хранения и обработки больших данных .............. 157
11.1 Характеристики больших данных ....................... 157
11.2 NoSQL системы ..................................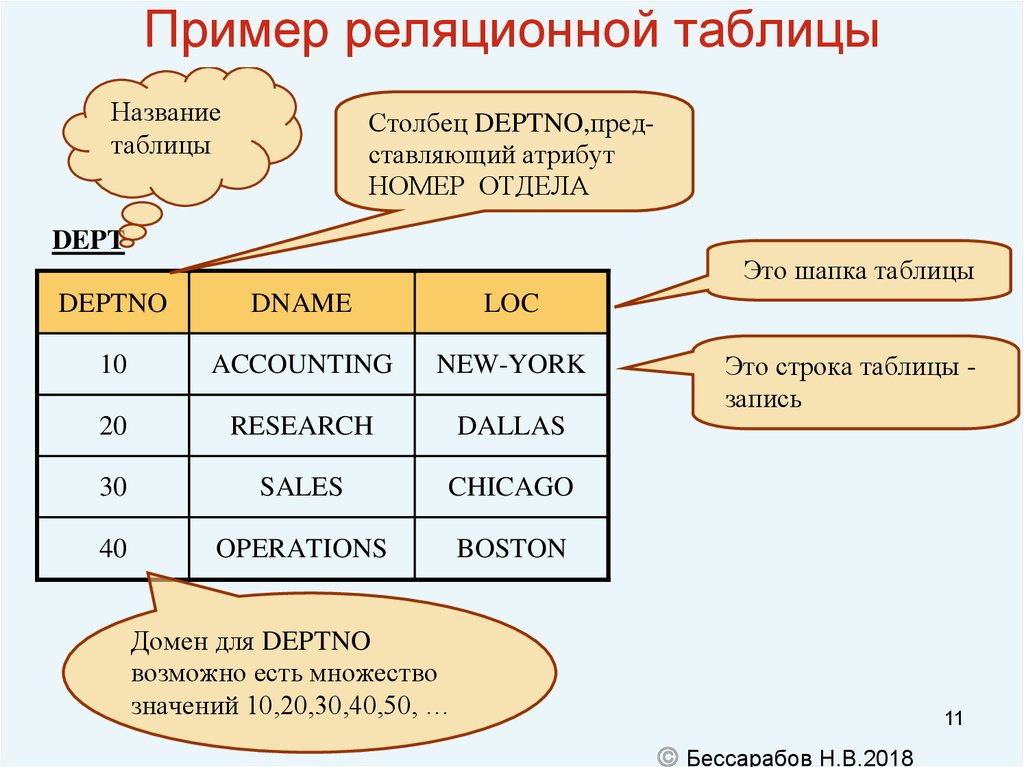 ..... 159
11.3 Модель распределенных вычислений MapReduce .......... 160
11.4 Разработка и выполнение распределенных программ ..... 161
Заключение .................................................... 163
Список литературы ............................................. 164
..... 159
11.3 Модель распределенных вычислений MapReduce .......... 160
11.4 Разработка и выполнение распределенных программ ..... 161
Заключение .................................................... 163
Список литературы ............................................. 164
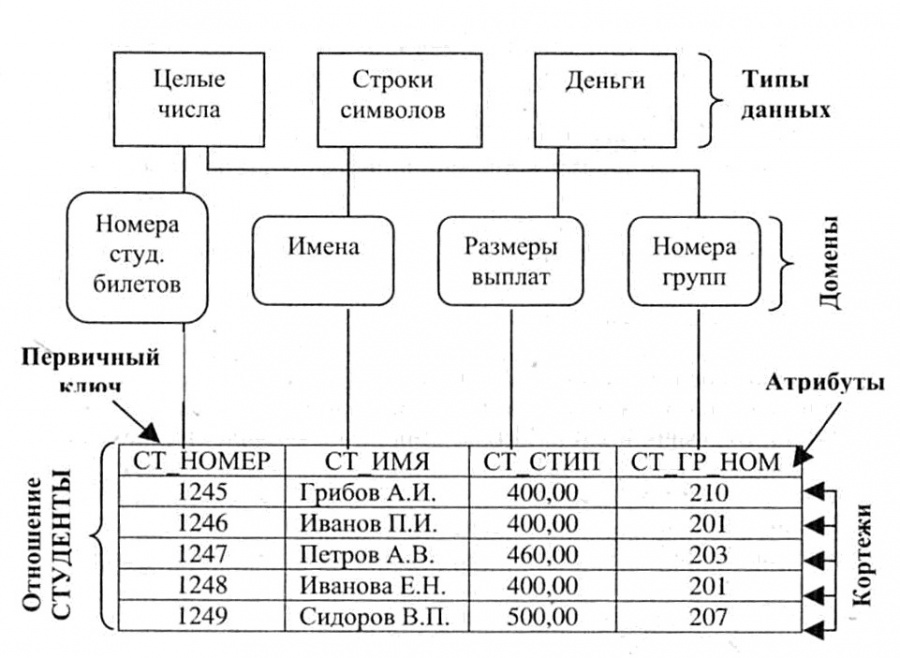 Рассмотрены основные вопросы защиты данных, обеспечения их безопасности и секретности, а также системы хранения и обработки больших данных.
Рассмотрены основные вопросы защиты данных, обеспечения их безопасности и секретности, а также системы хранения и обработки больших данных.
1. Требования к табличной форме представления отношений. Базы данных: конспект лекций
1. Требования к табличной форме представления отношений. Базы данных: конспект лекцийВикиЧтение
Базы данных: конспект лекций
Автор неизвестен
Содержание
1. Требования к табличной форме представления отношений
1.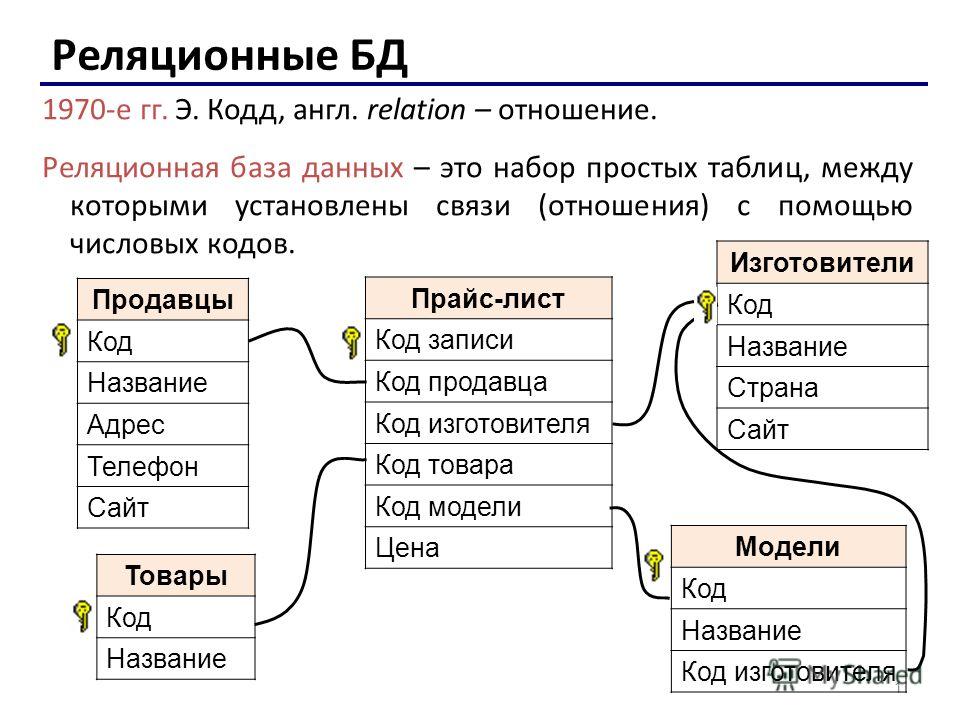 Самое первое требование, предъявляемое к табличной форме представления отношений, – это конечность. Работать с бесконечными таблицами, отношениями или любыми другими представлениями и организациями данных неудобно, редко оправдываются затраченные усилия, и, кроме того, подобное направление имеет малое практическое приложение.
Самое первое требование, предъявляемое к табличной форме представления отношений, – это конечность. Работать с бесконечными таблицами, отношениями или любыми другими представлениями и организациями данных неудобно, редко оправдываются затраченные усилия, и, кроме того, подобное направление имеет малое практическое приложение.
Но помимо этого, вполне ожидаемого, существуют и другие требования.
2. Заголовок таблицы, представляющей отношение, должен обязательно состоять из одной строки – заголовка столбцов, причем с уникальными именами. Многоярусных заголовков не допускается. Например, таких:
Все многоярусные заголовки заменяются одноярусными путем подбора подходящих заголовков. В нашем примере таблица после указанных преобразований будет выглядеть следующим образом:
Мы видим, что имя каждого столбца уникально, поэтому их можно как угодно менять местами, т. е. их порядок становится несущественным.
А это очень важно, поскольку является третьим свойством.
3.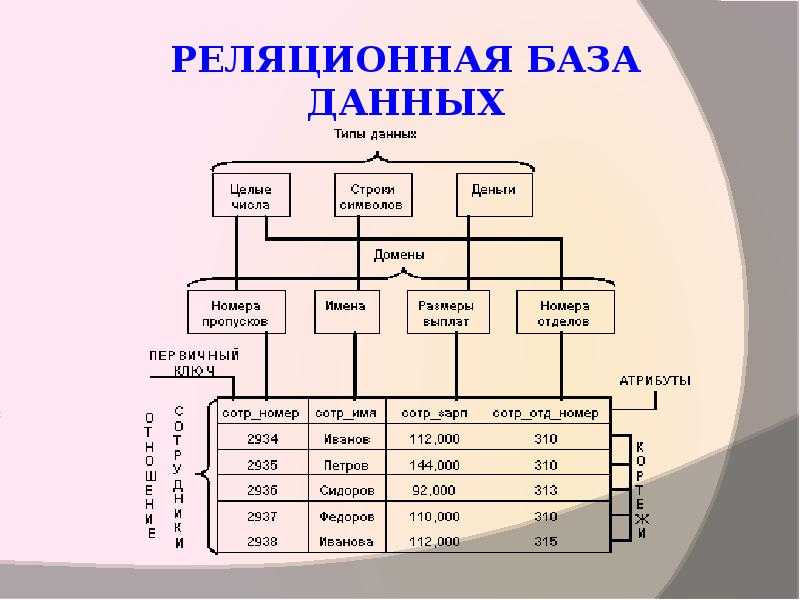 Порядок строк должен быть несущественным. Однако это требование также не является строго ограничительным, так как можно без труда привести любую таблицу к требуемому виду. Например, можно ввести дополнительный столбец, который будет определять порядок строк. В этом случае от перестановки строк тоже ничего не изменится. Вот пример такой таблицы:
Порядок строк должен быть несущественным. Однако это требование также не является строго ограничительным, так как можно без труда привести любую таблицу к требуемому виду. Например, можно ввести дополнительный столбец, который будет определять порядок строк. В этом случае от перестановки строк тоже ничего не изменится. Вот пример такой таблицы:
4. В таблице, представляющей отношение, не должно быть строк-дубликатов. Если же в таблице встречаются повторяющиеся строки, это можно легко исправить введением дополнительного столбца, отвечающего за количество дубликатов каждой строки, например:
Следующее свойство также является вполне ожидаемым, потому что лежит в основе всех принципов программирования и проектирования реляционных баз данных.
5. Данные во всех столбцах должны быть одного и того же типа. И кроме того они должны быть простого типа.
Поясним, что такое простой и сложный типы данных.
Простой тип данных – это такой тип, значения данных которого не являются составными, т.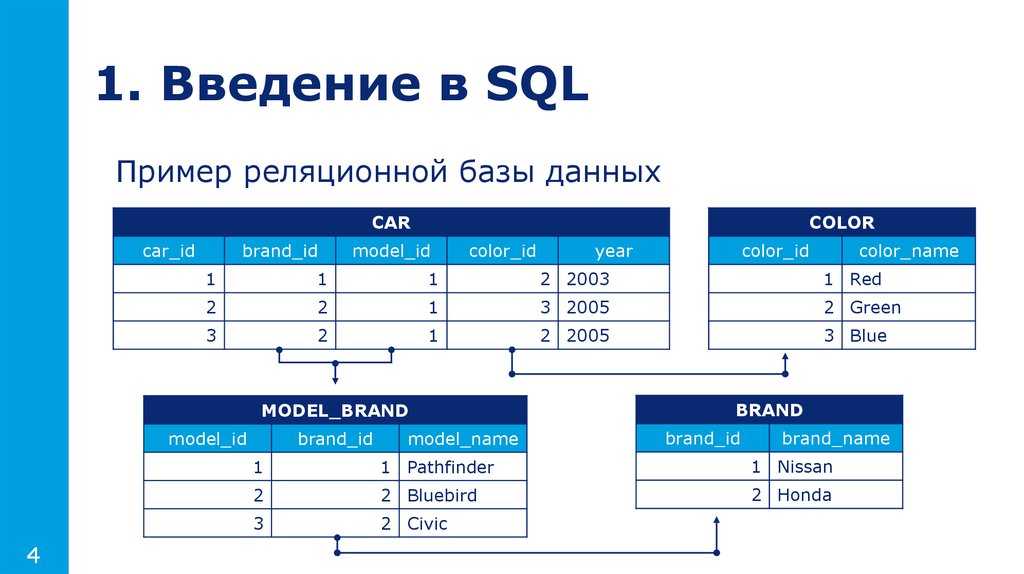 е. не содержат составных частей. Таким образом, в столбцах таблицы не должны присутствовать ни списки, ни массивы, ни деревья, ни подобные названным составные объекты.
е. не содержат составных частей. Таким образом, в столбцах таблицы не должны присутствовать ни списки, ни массивы, ни деревья, ни подобные названным составные объекты.
Такие объекты – составной тип данных – в реляционных системах управления базами данных сами представляются в виде самостоятельных таблиц-отношений.
Данный текст является ознакомительным фрагментом.
Глава 6. Определение отношений
Глава 6. Определение отношений Необходимость отношенийСистема состоит из большого количества классов и объектов. Ее поведение обеспечивается взаимодействием объектов. Например, студент добавляется к курсу, когда на курс поступает сообщение добавить студента. В этом
10.
 2. Приведение формул к стандартной форме
2. Приведение формул к стандартной форме10.2. Приведение формул к стандартной форме Как было показано в предыдущем разделе, формулы исчисления предикатов, записанные с использованием связок -› (импликация) и ‹-› (эквивалентность), могут быть переписаны лишь с использованием связок& (конъюнкция), # (дизъюнкция) и
Компоновка виджетов на форме
Компоновка виджетов на форме Существует три основных способа управления компоновкой дочерних виджетов формы: абсолютное позиционирование, ручная компоновка и применение менеджеров компоновки. Мы рассмотрим по очереди каждый из этих методов, используя в качестве
Представление данных в табличной форме
Представление данных в табличной форме
Во многих случаях табличное представление является самым простым представлением набора данных для пользователей.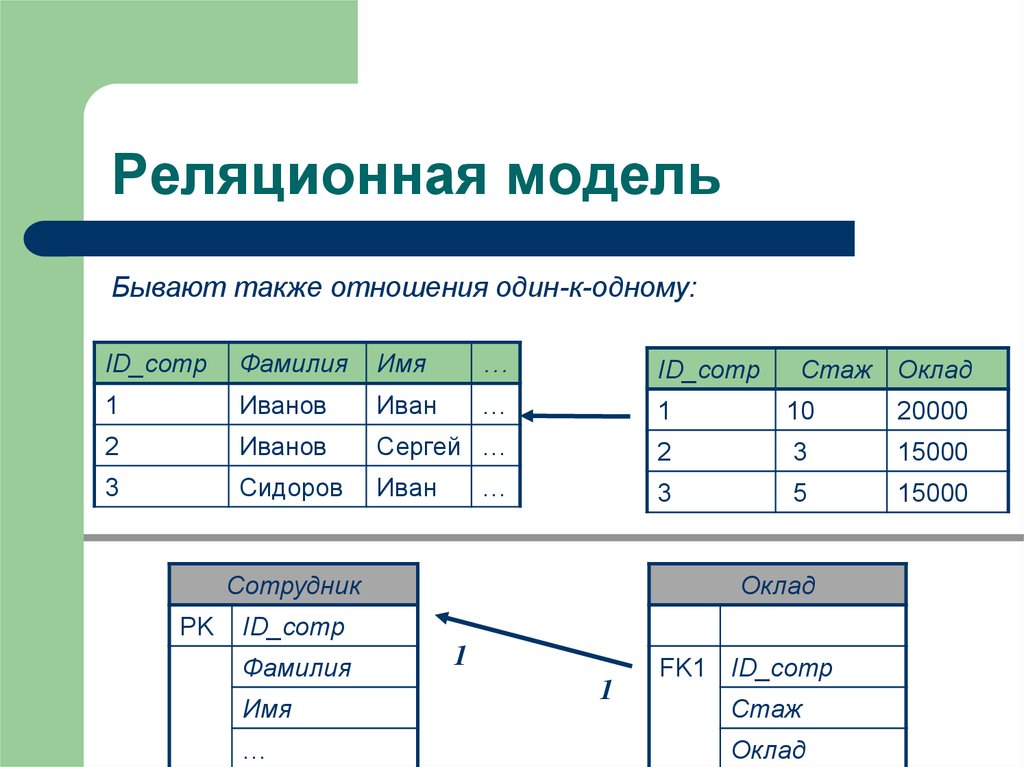 В этом и последующих разделах мы рассмотрим простое приложение CD Collection (Коллекция компакт-дисков), в котором модель
В этом и последующих разделах мы рассмотрим простое приложение CD Collection (Коллекция компакт-дисков), в котором модель
Операторы отношений
Операторы отношений Итак, предполагая что вы захотите принять грамматику, которую я показал здесь, мы теперь имеем синтаксические правила и для арифметики и для булевой алгебры. Сложность возникает когда мы должны объединить их. Почему мы должны сделать это? Ну, эта тема
Создание новых записей в форме, связанной с данными
Создание новых записей в форме, связанной с данными Для создания новой записи в связанном с данными приложении на основе Windows Forms нужно использовать метод AddNew объекта BindingContext. При выполнении этого метода любые связанные с данными элементы управления очищаются для ввода
Проверка введенных данных в форме, связанной с данными
Проверка введенных данных в форме, связанной с данными
В программировании баз данных проверка введенных данных (validation) гарантирует, что эти данные отвечают правилам, определенным при проектировании приложения.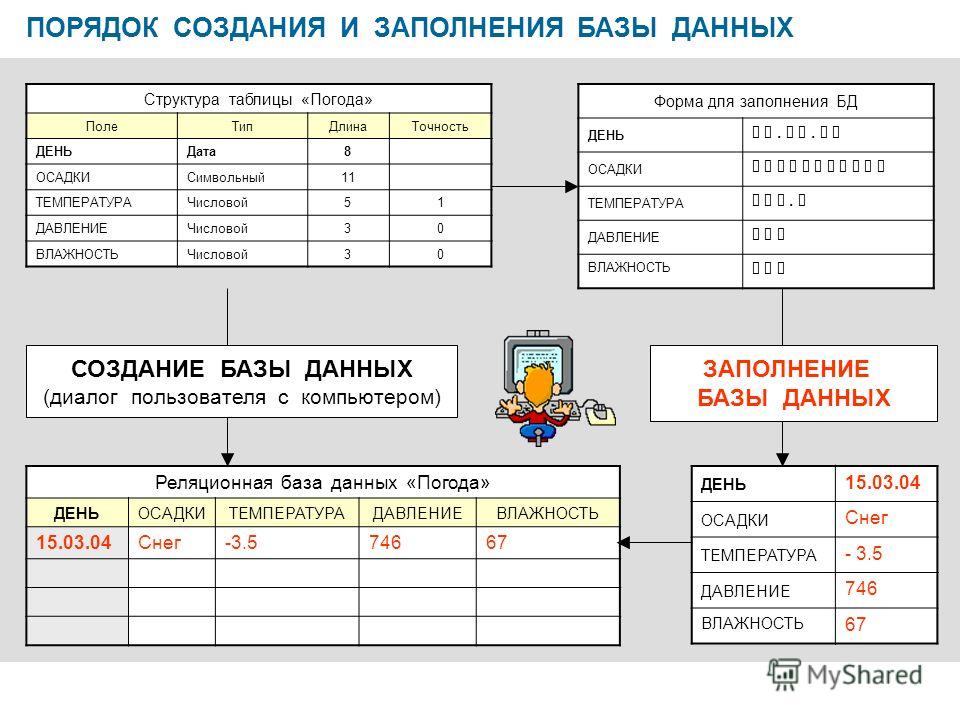 Эти правила называются правилами проверки данных (validation
Эти правила называются правилами проверки данных (validation
3.5. Лексический анализ строки, содержащей число в экспоненциальной форме
3.5. Лексический анализ строки, содержащей число в экспоненциальной форме ПроблемаИмеется строка, содержащая число в экспоненциальной форме, и требуется сохранить значение числа в переменной типа double.РешениеНаиболее простым способом анализа числа в экспоненциальной
5. Отношения. Типы отношений
5. Отношения. Типы отношений И наконец дадим определение отношению, как некой вершине пирамиды, состоящей из всех предыдущих понятий. Итак, отношение (обозначается r, от англ. relation – «отношение») со схемой отношений S определяется как обязательно конечное множество
6. Модификация базовых отношений
6. Модификация базовых отношений
Для успешной и продуктивной работы с различными базовыми отношениями очень часто разработчикам необходимо каким-либо образом модифицировать это базовые отношения.Какие основные необходимые варианты модификации встречаются чаще всего
Модификация базовых отношений
Для успешной и продуктивной работы с различными базовыми отношениями очень часто разработчикам необходимо каким-либо образом модифицировать это базовые отношения.Какие основные необходимые варианты модификации встречаются чаще всего
Модели отношений доверия
Модели отношений доверия В относительно закрытых системах, таких как небольшие организации и фирмы, можно без труда отследить путь сертификата назад к корневому ЦС. Однако, пользователям зачастую приходится связываться с людьми за пределами их корпоративной среды,
Кафедра Ваннаха: Инновации в изощренной форме Ваннах Михаил
Кафедра Ваннаха: Инновации в изощренной форме
Ваннах Михаил
Опубликовано 19 мая 2010 года
Май 2010 года. Под свежей листвой каштанов мелькает яркое пятно жакетика. Носительница его бредёт по проспекту в полной прострации. Нет, её не терзают страсти,
Носительница его бредёт по проспекту в полной прострации. Нет, её не терзают страсти,
Описание отношений и структурирование ПО
Описание отношений и структурирование ПО Другой вопрос связан с тем, какие отношения допустимы между типами объектов. В рафинированной объектной технологии имеются только два отношения: «быть клиентом» и наследование. Они соответствуют различным видам возможных
Описание нормализации базы данных — Office
- Статья
- 5 минут на чтение
- Применимо к:
- Microsoft Office Access 2007, Microsoft Office Access 2003
Исходный номер базы знаний: 283878
В этой статье объясняется терминология нормализации базы данных для начинающих. Базовое понимание этой терминологии полезно при обсуждении дизайна реляционной базы данных.
Базовое понимание этой терминологии полезно при обсуждении дизайна реляционной базы данных.
Описание нормализации
Нормализация — это процесс организации данных в базе данных. Это включает в себя создание таблиц и установление отношений между этими таблицами в соответствии с правилами, предназначенными как для защиты данных, так и для повышения гибкости базы данных за счет устранения избыточности и непоследовательной зависимости.
Избыточные данные занимают место на диске и создают проблемы с обслуживанием. Если необходимо изменить данные, которые существуют более чем в одном месте, данные должны быть изменены одинаково во всех местах. Изменить адрес клиента гораздо проще, если эти данные хранятся только в таблице «Клиенты» и больше нигде в базе данных.
Что такое «несогласованная зависимость»? Хотя для пользователя интуитивно понятно искать в таблице «Клиенты» адрес конкретного клиента, может не иметь смысла искать там зарплату сотрудника, который звонит этому клиенту.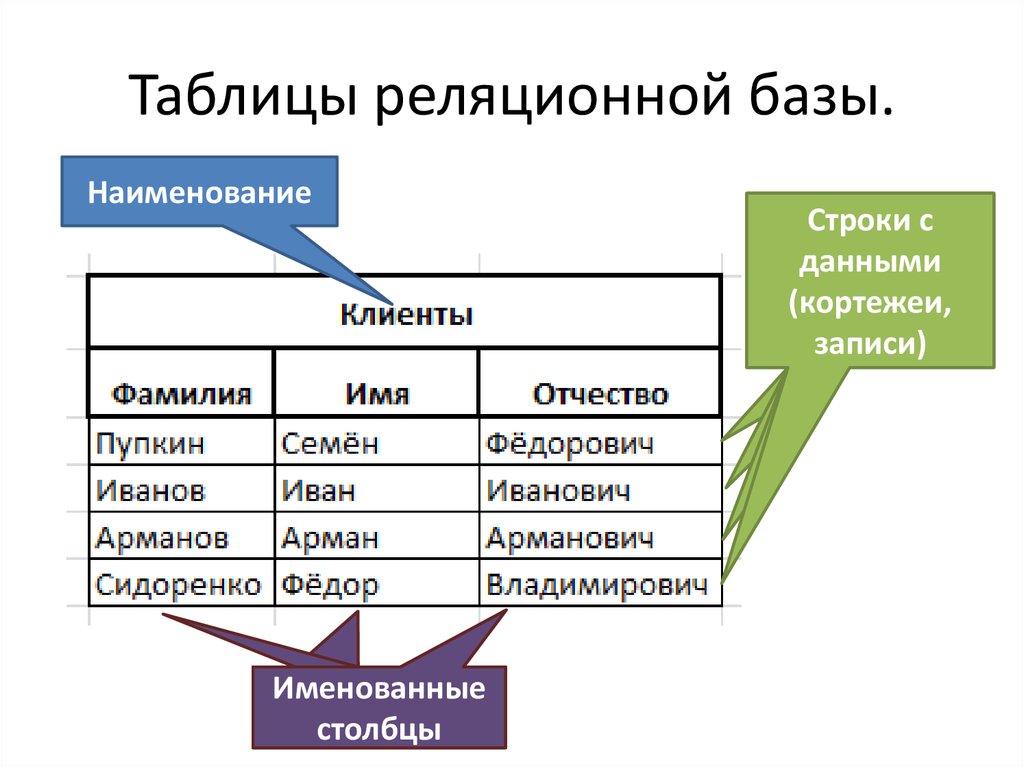 Зарплата сотрудника связана с сотрудником или зависит от него и поэтому должна быть перемещена в таблицу «Сотрудники». Несогласованные зависимости могут затруднить доступ к данным, поскольку путь для поиска данных может отсутствовать или быть нарушен.
Зарплата сотрудника связана с сотрудником или зависит от него и поэтому должна быть перемещена в таблицу «Сотрудники». Несогласованные зависимости могут затруднить доступ к данным, поскольку путь для поиска данных может отсутствовать или быть нарушен.
Существует несколько правил нормализации базы данных. Каждое правило называется «нормальной формой». Если первое правило соблюдается, говорят, что база данных находится в «первой нормальной форме». Если соблюдаются первые три правила, считается, что база данных находится в «третьей нормальной форме». Хотя возможны и другие уровни нормализации, третья нормальная форма считается наивысшим уровнем, необходимым для большинства приложений.
Как и многие формальные правила и спецификации, реальные сценарии не всегда обеспечивают идеальное соответствие. Как правило, для нормализации требуются дополнительные таблицы, и некоторые клиенты считают это громоздким. Если вы решите нарушить одно из первых трех правил нормализации, убедитесь, что ваше приложение предвидит любые проблемы, которые могут возникнуть, такие как избыточные данные и несогласованные зависимости.
Следующие описания включают примеры.
Первая нормальная форма
- Устранение повторяющихся групп в отдельных таблицах.
- Создайте отдельную таблицу для каждого набора связанных данных.
- Определите каждый набор связанных данных с помощью первичного ключа.
Не используйте несколько полей в одной таблице для хранения похожих данных. Например, для отслеживания элемента инвентаря, который может поступать из двух возможных источников, запись инвентаризации может содержать поля для кода поставщика 1 и кода поставщика 2.
Что происходит, когда вы добавляете третьего поставщика? Добавление поля — это не ответ; он требует модификации программы и таблиц и не может плавно приспосабливаться к постоянно меняющемуся количеству поставщиков. Вместо этого поместите всю информацию о поставщиках в отдельную таблицу с именем Поставщики, а затем свяжите запасы с поставщиками с помощью ключа номера товара или поставщиков с запасами с помощью ключа кода поставщика.
Вторая нормальная форма
- Создайте отдельные таблицы для наборов значений, которые применяются к нескольким записям.
- Свяжите эти таблицы с помощью внешнего ключа.
Записи не должны зависеть ни от чего, кроме первичного ключа таблицы (при необходимости составного ключа). Например, рассмотрим адрес клиента в системе учета. Адрес необходим таблице Customers, а также таблицам Orders, Shipping, Invoices, Accounts Receivable и Collections. Вместо того, чтобы хранить адрес клиента как отдельную запись в каждой из этих таблиц, сохраните его в одном месте, либо в таблице «Клиенты», либо в отдельной таблице «Адреса».
Третья нормальная форма
- Исключить поля, не зависящие от ключа.
Значения в записи, которые не являются частью ключа этой записи, не принадлежат таблице. Как правило, каждый раз, когда содержимое группы полей может относиться к нескольким записям в таблице, рассмотрите возможность размещения этих полей в отдельной таблице.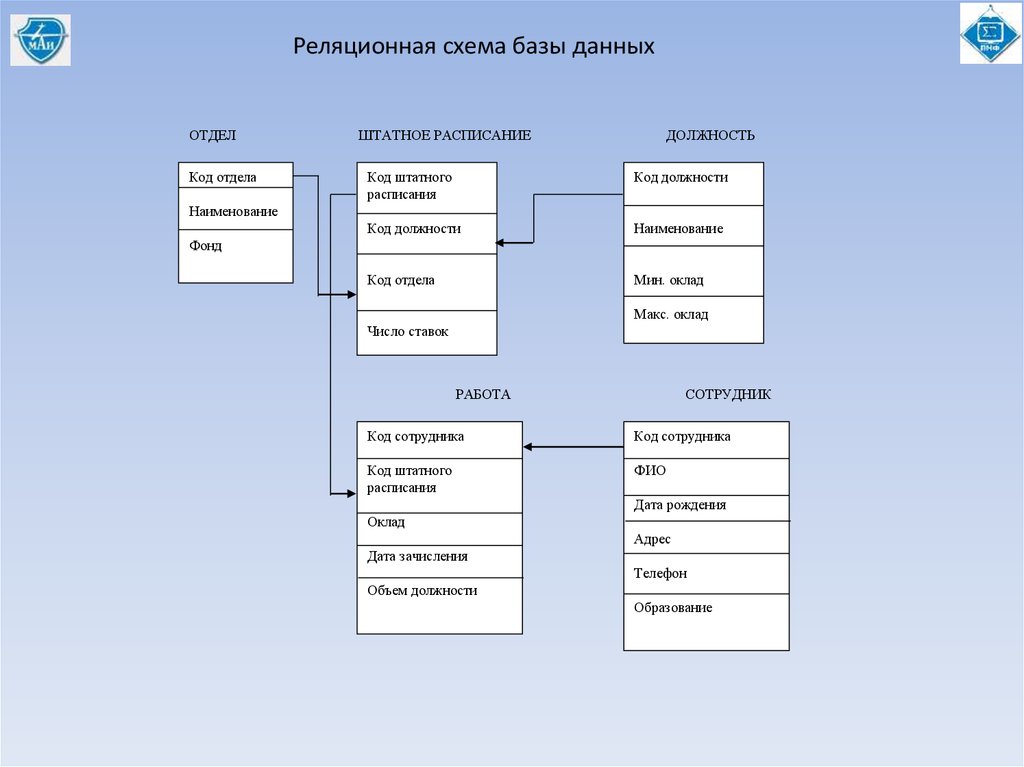
Например, в таблицу подбора сотрудников могут быть включены название университета и адрес кандидата. Но нужен полный список вузов для групповых рассылок. Если информация об университете хранится в таблице «Кандидаты», невозможно составить список университетов, в которых нет текущих кандидатов. Создайте отдельную таблицу Universities и свяжите ее с таблицей Candidates с ключом кода университета.
ИСКЛЮЧЕНИЕ: Соблюдение третьей нормальной формы, хотя и желательно теоретически, не всегда практично. Если у вас есть таблица «Клиенты» и вы хотите устранить все возможные зависимости между полями, вы должны создать отдельные таблицы для городов, почтовых индексов, торговых представителей, классов клиентов и любых других факторов, которые могут дублироваться в нескольких записях. Теоретически нормализация стоит того. Однако многие небольшие таблицы могут снизить производительность или превысить объем открытых файлов и памяти.
Может оказаться более целесообразным применять третью нормальную форму только к часто изменяющимся данным. Если некоторые зависимые поля остаются, спроектируйте приложение таким образом, чтобы пользователь проверял все связанные поля при изменении любого из них.
Если некоторые зависимые поля остаются, спроектируйте приложение таким образом, чтобы пользователь проверял все связанные поля при изменении любого из них.
Другие формы нормализации
Четвертая нормальная форма, также называемая нормальной формой Бойса-Кодда (BCNF), и пятая нормальная форма существуют, но редко учитываются при практическом проектировании. Несоблюдение этих правил может привести к далеко не идеальному дизайну базы данных, но не должно влиять на функциональность.
Нормализация примера таблицы
Эти шаги демонстрируют процесс нормализации вымышленной таблицы учеников.
Ненормализованная таблица:
Студент# Советник Adv-комната Класс 1 Класс 2 Класс 3 1022 Джонс 412 101-07 143-01 159-02 4123 Смит 216 101-07 143-01 179-04 Первая нормальная форма: нет повторяющихся групп
Таблицы должны иметь только два измерения.
Так как у одного студента несколько классов, эти классы должны быть указаны в отдельной таблице. Поля Class1, Class2 и Class3 в приведенных выше записях указывают на проблемы проектирования.В электронных таблицах часто используется третье измерение, а в таблицах — нет. Другой способ взглянуть на эту проблему — использовать отношение «один ко многим», не помещать одну сторону и многие стороны в одну и ту же таблицу. Вместо этого создайте другую таблицу в первой нормальной форме, удалив повторяющуюся группу (Class#), как показано ниже:
Студент# Советник Adv-комната Класс# 1022 Джонс 412 101-07 1022 Джонс 412 143-01 1022 Джонс 412 159-02 4123 Смит 216 101-07 4123 Смит 216 143-01 4123 Смит 216 179-04 Вторая нормальная форма: удаление избыточных данных
Обратите внимание на несколько значений Class# для каждого значения Student# в приведенной выше таблице.
Class# функционально не зависит от Student# (первичный ключ), поэтому эта связь не находится во второй нормальной форме.Следующие таблицы демонстрируют вторую нормальную форму:
Студенты:
Студент# Советник Adv-комната 1022 Джонс 412 4123 Смит 216 Регистрация:
Студент# Класс# 1022 101-07 1022 143-01 1022 159-02 4123 101-07 4123 143-01 4123 179-04 Третья нормальная форма: исключить данные, не зависящие от ключа
В последнем примере Adv-Room (номер кабинета советника) функционально зависит от атрибута Advisor.
Решение состоит в том, чтобы переместить этот атрибут из таблицы «Студенты» в таблицу «Преподаватель», как показано ниже:0025Студенты:
Студент# Советник 1022 Джонс 4123 Смит Факультет:
Имя Комната Отдел Джонс 412 42 Смит 216 42
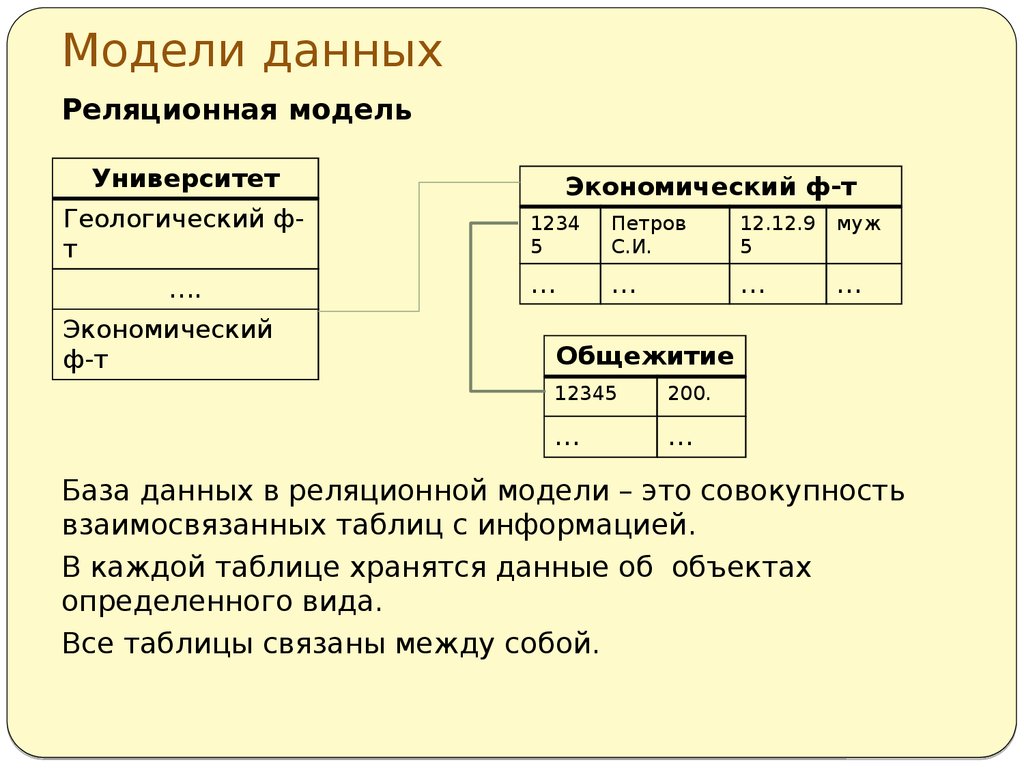 Так как у одного студента несколько классов, эти классы должны быть указаны в отдельной таблице. Поля Class1, Class2 и Class3 в приведенных выше записях указывают на проблемы проектирования.
Так как у одного студента несколько классов, эти классы должны быть указаны в отдельной таблице. Поля Class1, Class2 и Class3 в приведенных выше записях указывают на проблемы проектирования.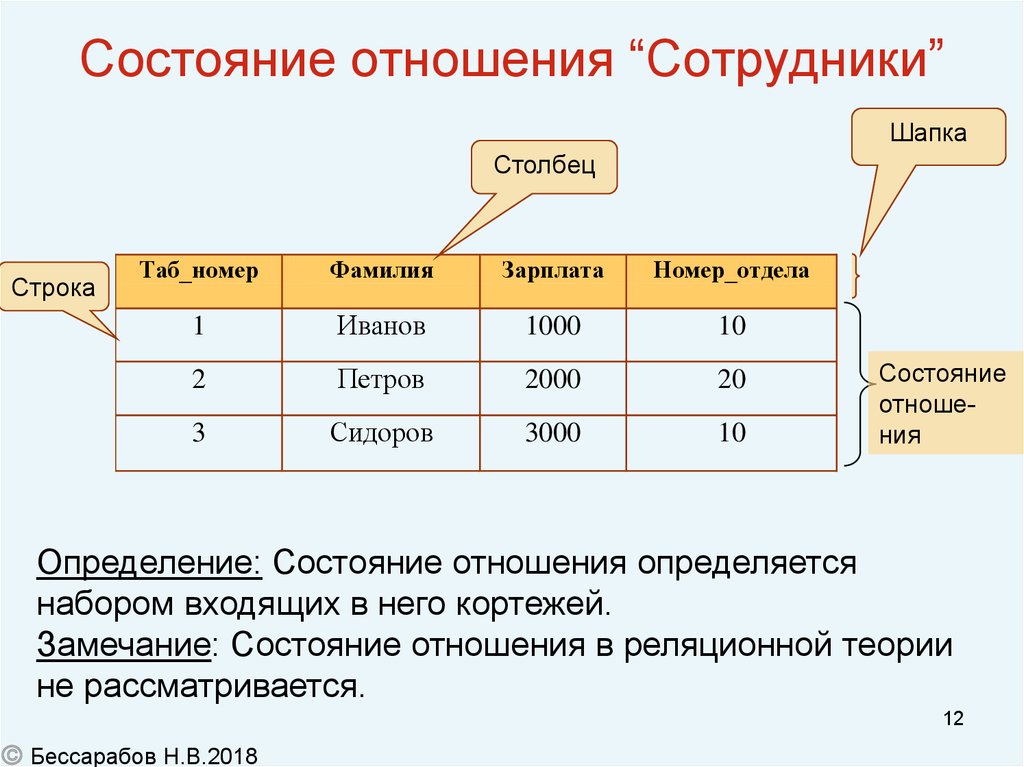 Class# функционально не зависит от Student# (первичный ключ), поэтому эта связь не находится во второй нормальной форме.
Class# функционально не зависит от Student# (первичный ключ), поэтому эта связь не находится во второй нормальной форме. Решение состоит в том, чтобы переместить этот атрибут из таблицы «Студенты» в таблицу «Преподаватель», как показано ниже:0025
Решение состоит в том, чтобы переместить этот атрибут из таблицы «Студенты» в таблицу «Преподаватель», как показано ниже:0025Что такое нормализация в СУБД (SQL)? 1NF, 2NF, 3NF Пример
Что такое нормализация базы данных?
Нормализация — это метод проектирования базы данных, который уменьшает избыточность данных и устраняет нежелательные характеристики, такие как аномалии вставки, обновления и удаления. Правила нормализации делят большие таблицы на меньшие и связывают их с помощью отношений.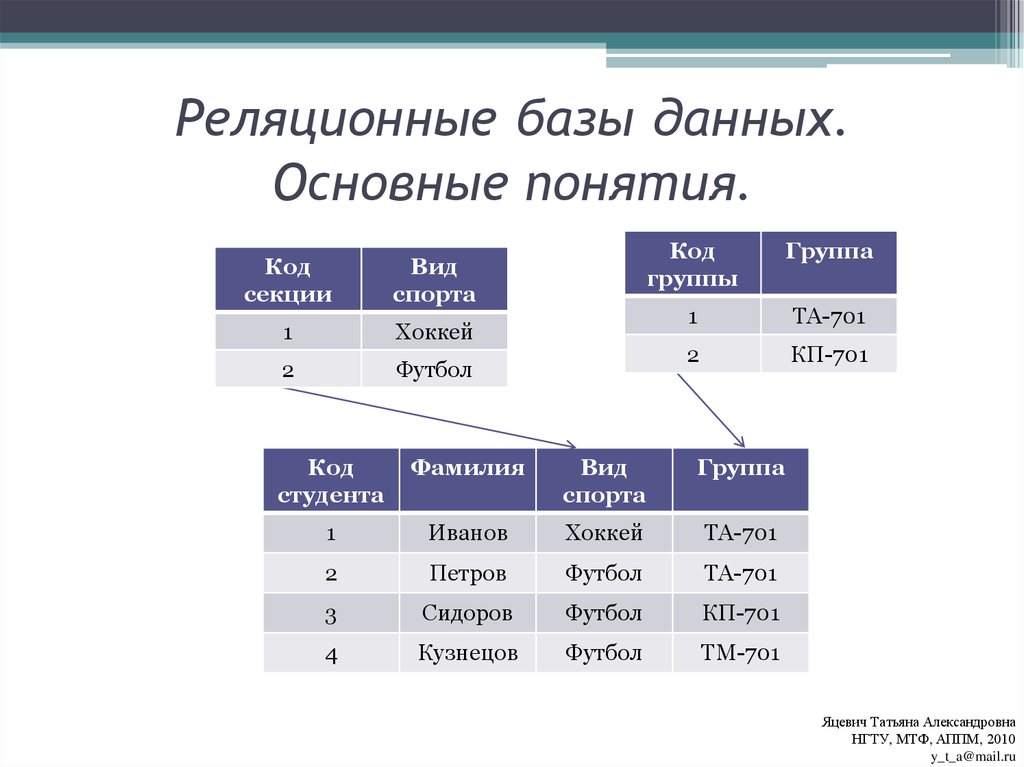 Целью нормализации в SQL является устранение избыточных (повторяющихся) данных и обеспечение логического хранения данных.
Целью нормализации в SQL является устранение избыточных (повторяющихся) данных и обеспечение логического хранения данных.
Изобретатель реляционной модели Эдгар Кодд предложил теорию нормализации данных с введением первой нормальной формы и продолжил расширять теорию второй и третьей нормальными формами. Позже он присоединился к Рэймонду Ф. Бойсу для разработки теории нормальной формы Бойса-Кодда.
Нормальные формы базы данных
Вот список нормальных форм в SQL:
- 1NF (первая нормальная форма)
- 2NF (вторая нормальная форма)
- 3NF (Третья нормальная форма)
- BCNF (нормальная форма Бойса-Кодда)
- 4NF (Четвертая нормальная форма)
- 5NF (пятая нормальная форма)
- 6NF (Шестая нормальная форма)
Теория нормализации данных в сервере MySQL все еще развивается. Например, есть обсуждения даже на 6 й Нормальной Форме. Однако в большинстве практических приложений нормализация достигает своего наилучшего результата в 3 rd Normal Form . Эволюция нормализации в теориях SQL показана ниже.0025
Эволюция нормализации в теориях SQL показана ниже.0025
Нормализация базы данных с примерами
База данных Нормализация Пример можно легко понять с помощью тематического исследования. Предположим, видеотека поддерживает базу данных фильмов, взятых напрокат. Без какой-либо нормализации в базе данных вся информация хранится в одной таблице, как показано ниже. Давайте разберемся с базой данных нормализации с примером нормализации с решением:
Здесь вы видите столбец Взятые напрокат фильмы имеет несколько значений. Теперь перейдем к 1-м нормальным формам:
Правила 1NF (первая нормальная форма)- Каждая ячейка таблицы должна содержать одно значение.
- Каждая запись должна быть уникальной.
Приведенная выше таблица в 1NF-
Пример 1NF
Пример 1НФ в СУБД
Прежде чем мы продолжим, давайте разберемся в нескольких вещах —
Что такое KEY в SQL?
КЛЮЧ в SQL — это значение, используемое для уникальной идентификации записей в таблице. Ключ SQL — это один столбец или комбинация нескольких столбцов, используемых для уникальной идентификации строк или кортежей в таблице. Ключ SQL используется для выявления повторяющейся информации, а также помогает установить связь между несколькими таблицами в базе данных.
Ключ SQL — это один столбец или комбинация нескольких столбцов, используемых для уникальной идентификации строк или кортежей в таблице. Ключ SQL используется для выявления повторяющейся информации, а также помогает установить связь между несколькими таблицами в базе данных.
Примечание. Столбцы в таблице, которые НЕ используются для уникальной идентификации записи, называются неключевыми столбцами.
Что такое первичный ключ?
Первичный ключ в СУБД
Первичный — это значение одного столбца, используемое для уникальной идентификации записи базы данных.
Имеет следующие атрибуты
- Первичный ключ не может быть NULL
- Значение первичного ключа должно быть уникальным
- Значения первичного ключа следует редко изменять
- При вставке новой записи первичному ключу должно быть присвоено значение.
Что такое составной ключ?
Составной ключ — это первичный ключ, состоящий из нескольких столбцов, используемых для уникальной идентификации записи.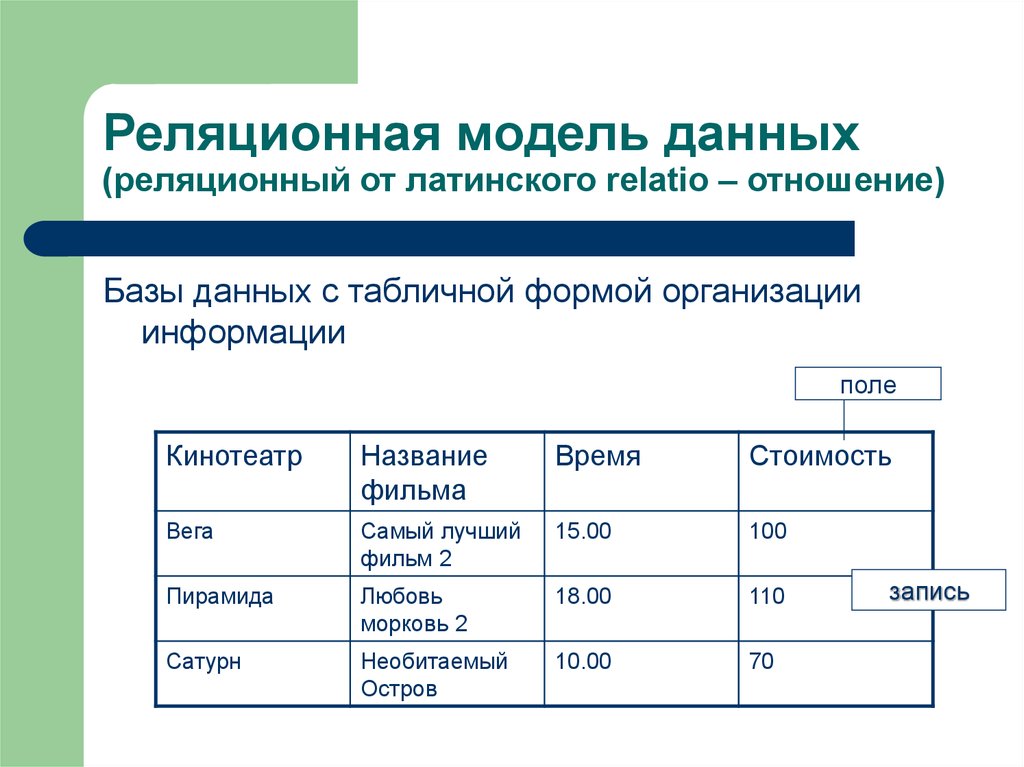
В нашей базе данных есть два человека с одинаковым именем Роберт Фил, но они живут в разных местах.
Составной ключ в базе данных
Следовательно, для однозначной идентификации записи требуются как Полное имя, так и Адрес. Это составной ключ.
Давайте перейдем ко второй нормальной форме 2NF
2NF (Вторая нормальная форма) Правила
- Правило 1 – Быть в 1NF
- Правило 2. Одностолбцовый первичный ключ, который функционально не зависит ни от какого подмножества потенциального ключевого отношения
Понятно, что мы не можем двигаться дальше, чтобы сделать нашу простую базу данных в форме нормализации 2 nd , если мы не разделим таблицу выше.
Мы разделили нашу таблицу 1NF на две таблицы, а именно. Таблица 1 и Таблица 2. Таблица 1 содержит информацию об участниках. Таблица 2 содержит информацию о фильмах, взятых напрокат.
Мы ввели новый столбец Membership_id, который является первичным ключом для таблицы 1.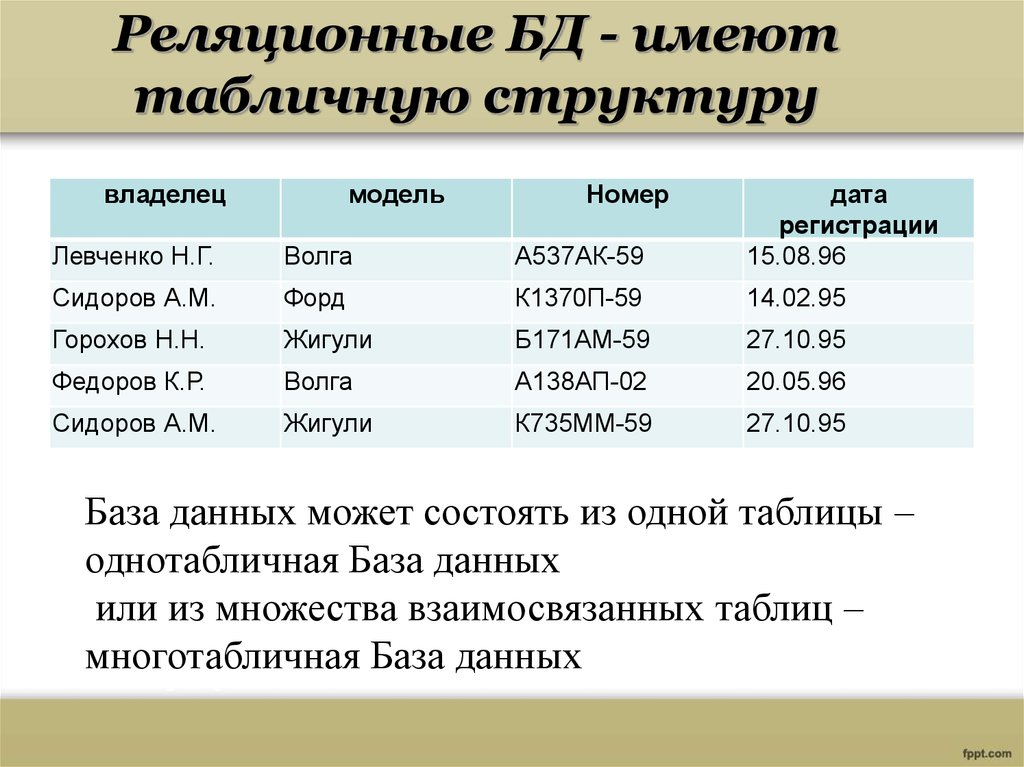 Записи в таблице 1 можно однозначно идентифицировать с помощью идентификатора членства
Записи в таблице 1 можно однозначно идентифицировать с помощью идентификатора членства
База данных — внешний ключ
В таблице 2 Membership_ID — это внешний ключ
Внешний ключ в СУБД
Внешний ключ ссылается на первичный ключ другой таблицы! Это помогает соединить ваши таблицы
- Внешний ключ может иметь имя, отличное от его первичного ключа
- Гарантирует, что строки в одной таблице имеют соответствующие строки в другой
- В отличие от первичного ключа, они не обязательно должны быть уникальными. Чаще всего это не
- Внешние ключи могут быть нулевыми, даже если первичные ключи не могут быть
Зачем нужен внешний ключ?
Предположим, новичок вставляет запись в таблицу B, например
. Вы сможете вставлять в свой внешний ключ только те значения, которые существуют в уникальном ключе родительской таблицы.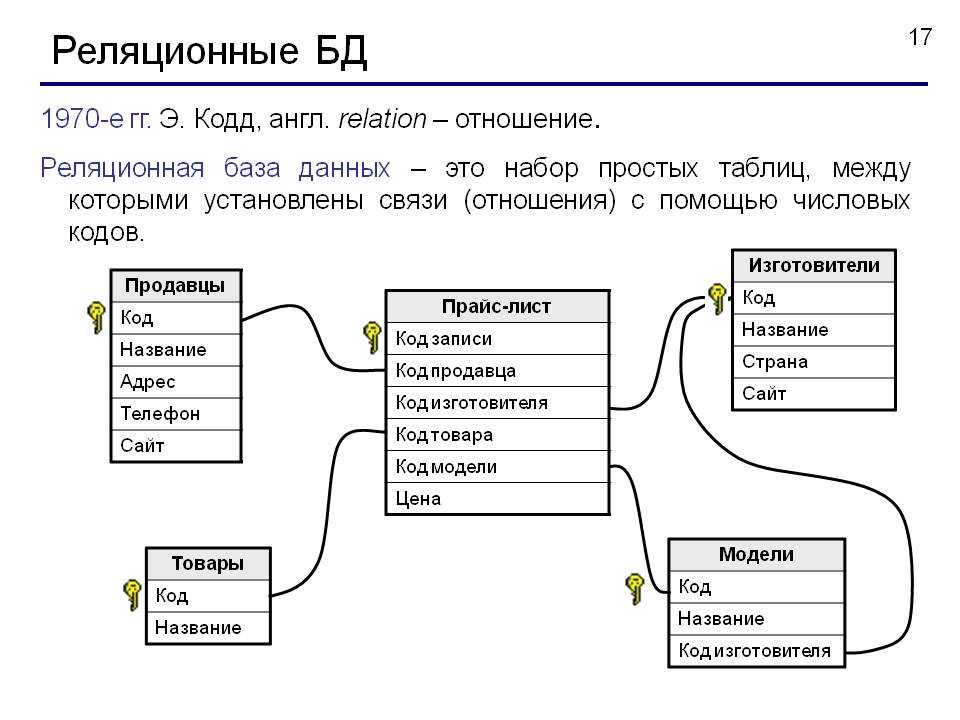 Это помогает в ссылочной целостности.
Это помогает в ссылочной целостности.
Описанную выше проблему можно решить, объявив идентификатор членства из таблицы 2 в качестве внешнего ключа идентификатора членства из таблицы 1.
Теперь, если кто-то попытается вставить значение в поле идентификатора членства, которого нет в родительской таблице, возникнет ошибка показать!
Что такое транзитивные функциональные зависимости?
Транзитивная функциональная зависимость заключается в том, что изменение неключевого столбца может привести к изменению любого из других неключевых столбцов
Рассмотрим таблицу 1. Изменение Полного имени неключевого столбца может изменить Приветствие.
Переходим в 3NF
Правила 3NF (Третья нормальная форма)
- Правило 1 – Быть во 2NF
- Правило 2. Не имеет транзитивных функциональных зависимостей
Чтобы перевести нашу таблицу 2NF в 3NF, нам снова нужно снова разделить нашу таблицу.
Пример 3NF
Ниже приведен пример 3NF в базе данных SQL:
Мы снова разделили наши таблицы и создали новую таблицу, в которой хранятся приветствия.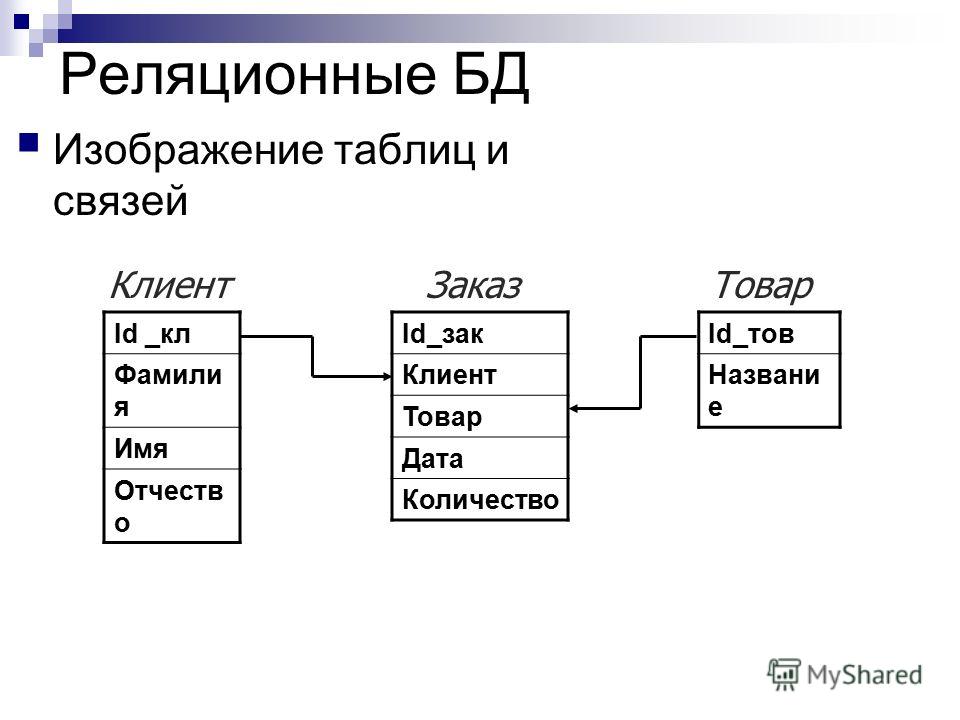
Нет транзитивных функциональных зависимостей, поэтому наша таблица находится в 3NF
В таблице 3 идентификатор приветствия является первичным ключом, а в таблице 1 идентификатор приветствия является внешним для первичного ключа в таблице 3 уровень, который не может быть подвергнут дальнейшей декомпозиции для достижения типов нормализации в более высоких нормальных формах в СУБД. На самом деле он уже находится в более высоких формах нормализации. В сложных базах данных обычно требуются отдельные усилия для перехода на следующие уровни нормализации данных. Однако далее мы кратко обсудим следующие уровни нормализации в СУБД.
BCNF (нормальная форма Бойса-Кодда)
Даже если база данных находится в нормальной форме 3 rd , все равно могут возникнуть аномалии, если она имеет более одного ключа Candidate .
Иногда BCNF также упоминается как 3.5 Нормальная форма.
Правила 4NF (четвертая нормальная форма)
Если ни один экземпляр таблицы базы данных не содержит двух или более независимых и многозначных данных, описывающих соответствующий объект, то он находится в 4-й -й -й нормальной форме.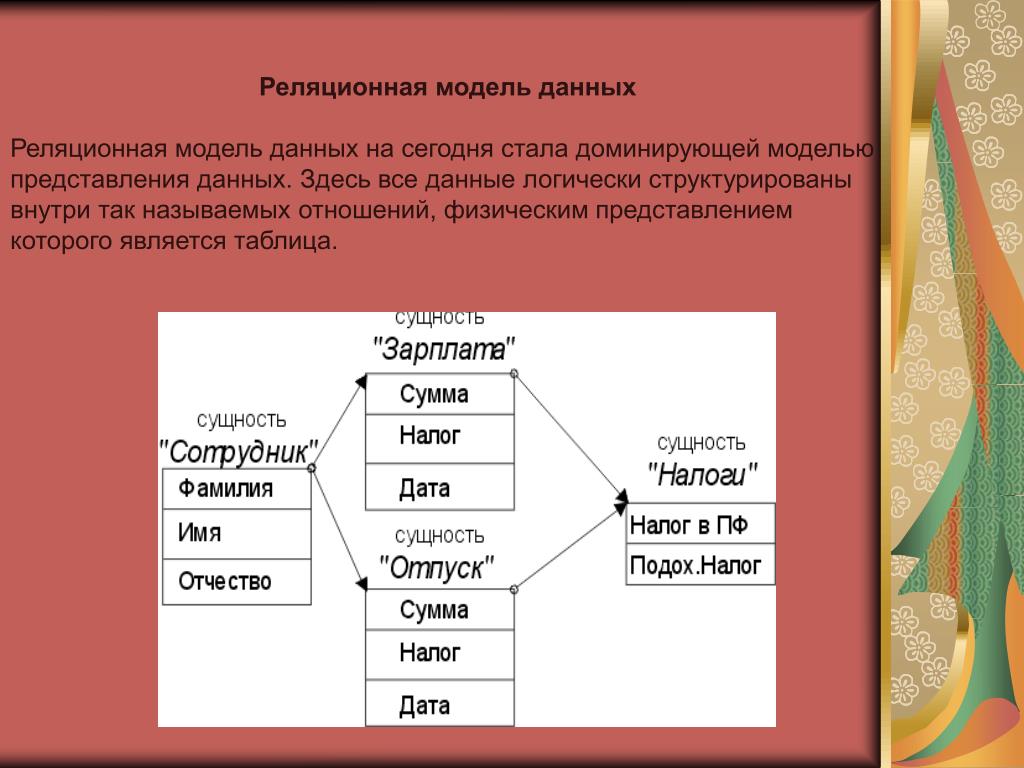
5NF (Пятая нормальная форма) Правила
Таблица находится в 5 th нормальной форме только в том случае, если она находится в 4NF и не может быть разложена на любое количество меньших таблиц без потери данных.
6NF (Шестая нормальная форма) Предложено
6 th Нормальная форма не стандартизирована, однако она уже некоторое время обсуждается экспертами по базам данных. Будем надеяться, что в ближайшем будущем у нас будет четкое и стандартизированное определение для 6 th Normal Form…
Вот и все для нормализации SQL!!!
Резюме
- Проектирование базы данных имеет решающее значение для успешного внедрения системы управления базами данных, отвечающей требованиям к данным корпоративной системы.
- Нормализация в СУБД — это процесс, помогающий создавать экономичные системы баз данных с лучшими моделями безопасности.
- Функциональные зависимости являются очень важным компонентом процесса нормализации данных
- Большинство систем баз данных являются нормализованными базами данных до третьей нормальной формы в СУБД.
- Первичный ключ однозначно идентифицирует запись в таблице и не может быть нулевым
- Внешний ключ помогает соединить таблицу и ссылается на первичный ключ

Реляционные базы данных: использование обычных форм для создания баз данных
Реляционные базы данных: использование обычных форм для создания баз данных
Хотя вы можете создать базу данных, не понимая никакой теории проектирования, лучше немного узнать о нормализации и о том, как нормальные формы являются ключом к хорошо спроектированным базам данных.
Теория реляционных баз данных, возможно, была спасением пионеров систем хранения в 60-х и 70-х годах, но с тех пор она стала проклятием для многих разработчиков баз данных именно потому, что современные системы баз данных стали так хорошо скрывать свои реляционные основы от разработчика. Хорошо спроектированная реляционная база данных проста в использовании, гибка и обеспечивает достоверность данных.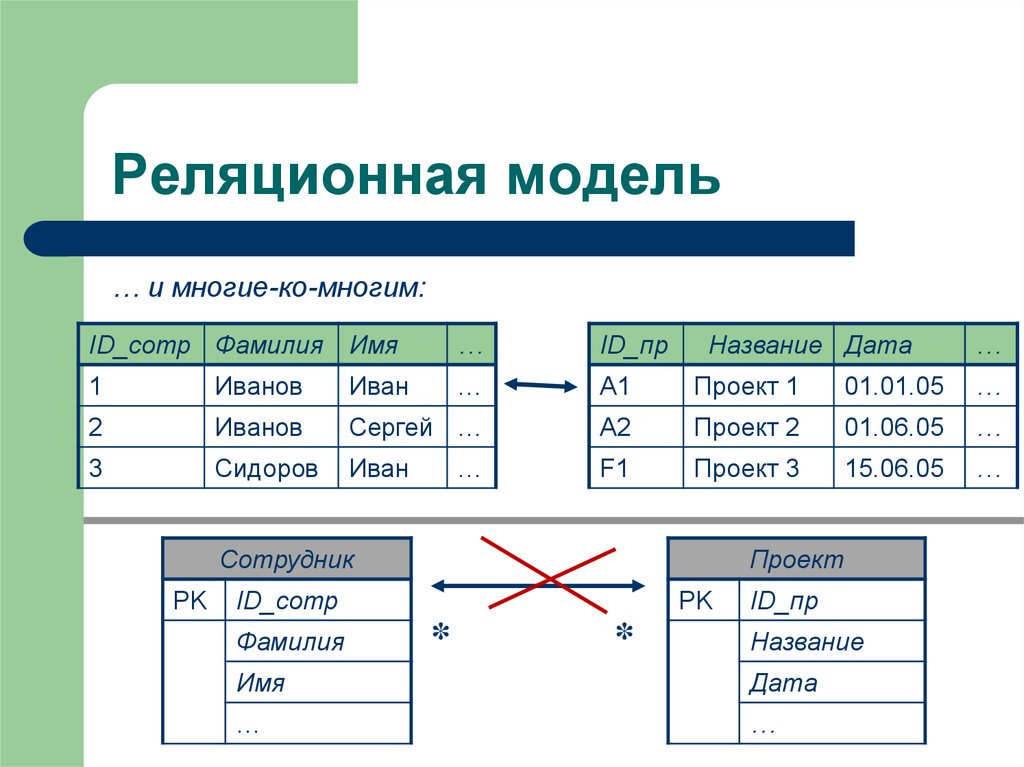 С другой стороны, плохой дизайн все еще будет достаточно функциональным, но в конечном итоге приведет к разочарованию и, возможно, к ошибочным или отсутствующим данным.
С другой стороны, плохой дизайн все еще будет достаточно функциональным, но в конечном итоге приведет к разочарованию и, возможно, к ошибочным или отсутствующим данным.
У разработчиков есть определенные правила, известные как нормальные формы, которым они следуют для создания хорошо спроектированных баз данных. Здесь я рассмотрю обычные формы путем создания простой базы данных для хранения информации о коллекции книг.
Вторая часть серии
Это вторая часть серии статей Builder.com, посвященных проектированию реляционных баз данных. Если вы пропустили это, вы можете ознакомиться с первой частью, в которой объясняются мотивы развития реляционной теории.
Определение сущностей и элементов
Первый шаг к проектированию базы данных — выполнить домашнее задание и определить, какие сущности вам понадобятся. Сущность — это концептуальная коллекция данных одного типа. Нет ничего необычного в том, чтобы начать с одной или двух сущностей и расширять список по мере нормализации данных.
 Похоже, что для нашего образца базы данных нам понадобится только один объект, книги.
Похоже, что для нашего образца базы данных нам понадобится только один объект, книги.После определения списка необходимых вам сущностей вам нужно будет создать список элементов данных (т. е. информацию, которую вы будете хранить) для каждой сущности. Есть несколько способов собрать эту информацию, но наиболее эффективным, вероятно, будет полагаться на ваших пользователей. Спросите своих пользователей об их текущей рутине и попросите показать любые формы и отчеты, которые они в настоящее время используют для выполнения своей работы. Например, в форме заказа может быть перечислено множество элементов данных, необходимых для размещения в приложении для закупок.
Для нашей книжной сущности нет бумажных форм или отчетов, но хорошим началом будет следующий список элементов:
{Название, Автор, ISBN, Цена, Издатель, Категория}
Важно отметить, что процесс перехода от объекта к элементу, который мы использовали здесь, работает не во всех ситуациях. Сущности, которые вам потребуются, не всегда будут такими четкими, как в нашем примере с коллекцией книг, поэтому вам, возможно, придется начать с длинного списка элементов данных, который вы позже разделите по сущности.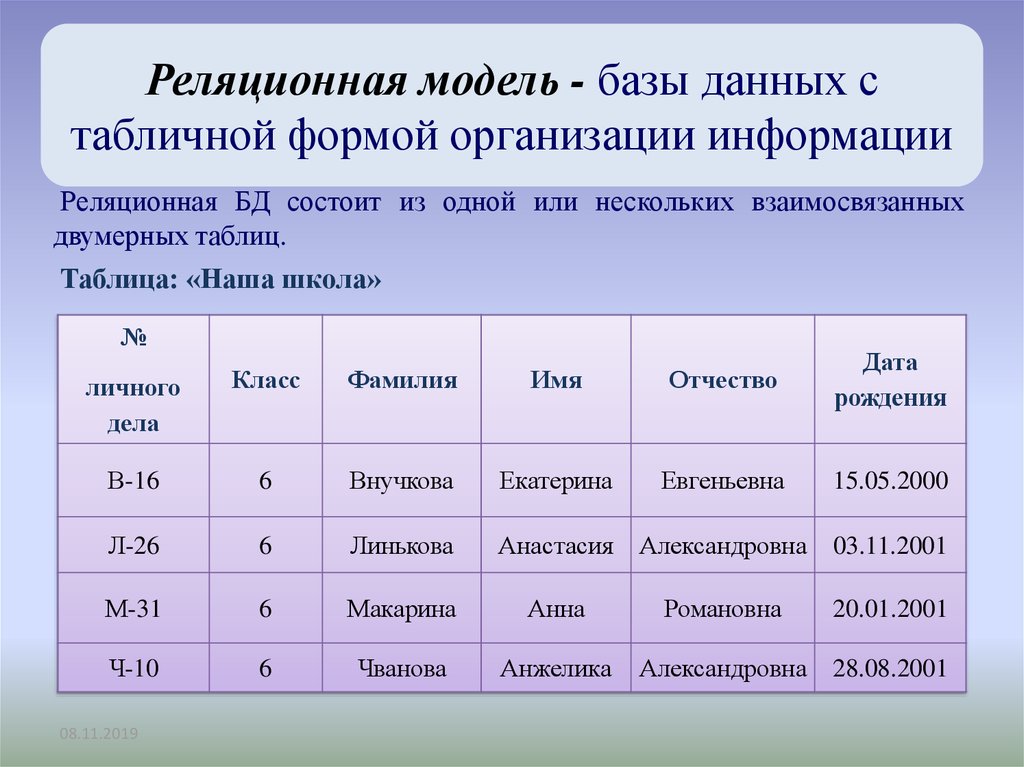
Первые шаги нормализации
Когда у вас есть список сущностей (таблиц) и элементов данных (полей), вы готовы применить реляционную теорию к работе. Основное направление теории — нормализация — процесс удаления любых повторяющихся групп и избыточных данных и помещения их в две или более связанных таблиц. Не обязательно, чтобы у вас было более одной таблицы, но вероятность того, что ваши данные настолько просты, что у вас будет только одна таблица, невелика.
Вам следует внимательно просмотреть свои списки сущностей и элементов на наличие данных, встречающихся в нескольких записях, и несоответствующих зависимостей, а также переместить проблемное поле в другую таблицу. Например, вы можете перечислить несколько книг одного и того же автора, повторяя имя этого автора в своей базе данных. Если вы считаете, что одно и то же значение данных будет появляться снова и снова, вам следует подумать о переносе этого поля в другую таблицу.
Имейте в виду, что на данный момент вы работаете только со списками потенциальных таблиц.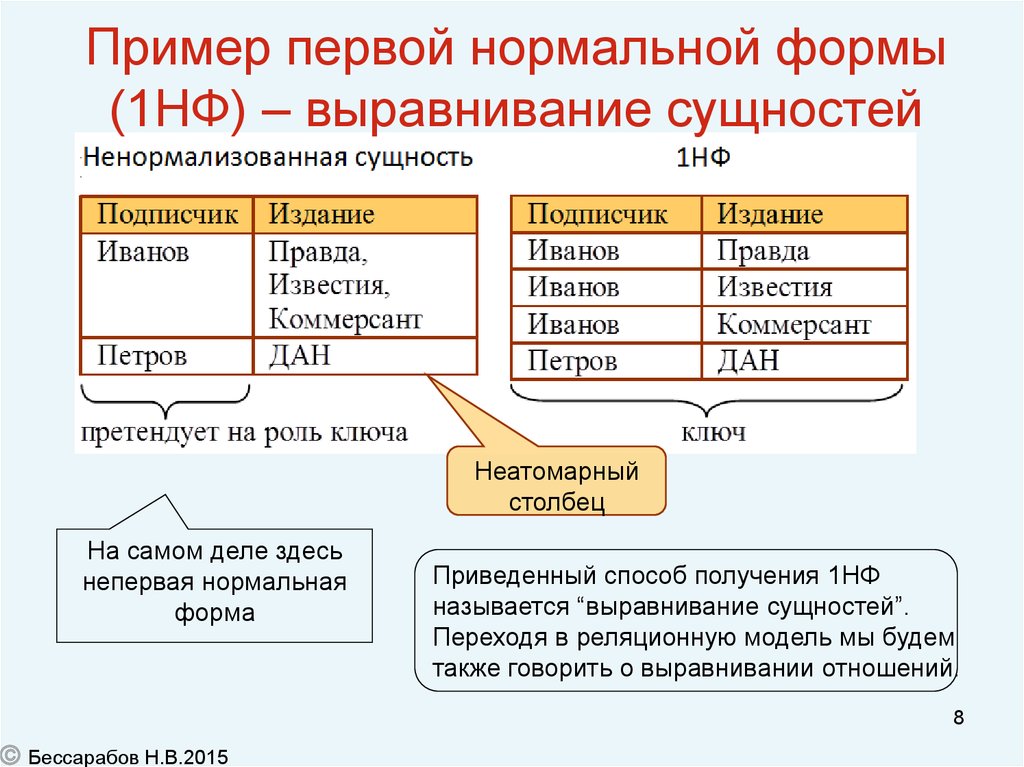 Вы не должны на самом деле создавать эти таблицы: пока придерживайтесь ручных и бумажных списков.
Вы не должны на самом деле создавать эти таблицы: пока придерживайтесь ручных и бумажных списков.
Знакомство с нормальными формами
Процесс нормализации базы данных настолько хорошо известен, что существуют формальные правила, регулирующие структуру нормализованной базы данных. Всего существует семь таких правил, известных как нормальные формы, но в большинстве случаев подходят первые четыре:
- Первая нормальная форма (1NF) — Это правило имеет несколько требований, включая отсутствие многозначных элементов или повторяющихся групп; что каждое поле является атомарным, то есть каждое поле должно содержать наименьший возможный элемент данных; и что таблица содержит ключ.
- Вторая нормальная форма (2NF) — Таблица должна быть нормализована до 1NF. Все поля должны ссылаться (или описывать) на значение первичного ключа. Если первичный ключ основан на нескольких полях, каждое неключевое поле должно зависеть от сложного ключа, а не только от одного поля в ключе. Неключевые поля, не поддерживающие первичный ключ, следует переместить в другую таблицу.
- Третья нормальная форма (3NF) — Таблица должна соответствовать требованиям 1NF и 2NF. Все поля должны быть взаимно независимыми. Любое поле, описывающее неключевое поле, должно быть перемещено в другую таблицу.
- Нормальная форма Бойса-Кодда (BCNF) — Не должно быть возможности появления поля, не зависящего от ключа. Это правило на самом деле является субправилом 3NF и предположительно улавливает зависимости, которые в противном случае могли бы проскользнуть через процесс. Это довольно абстрактно, и поначалу его может быть трудно применить.
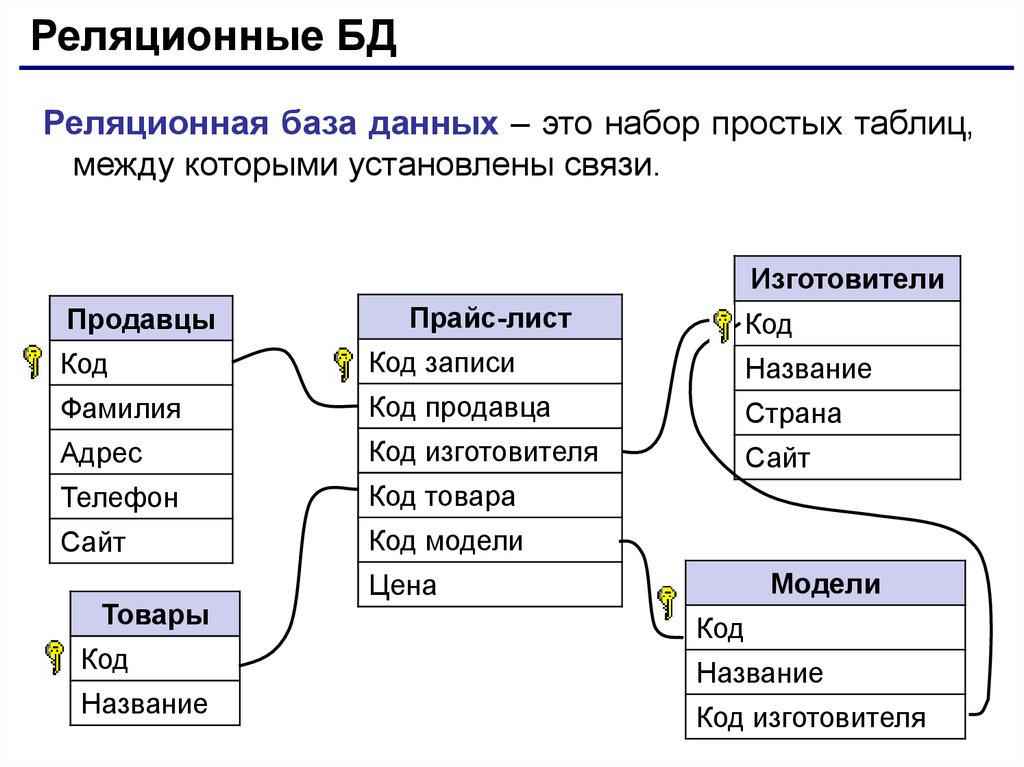 Неключевые поля, не поддерживающие первичный ключ, следует переместить в другую таблицу.
Неключевые поля, не поддерживающие первичный ключ, следует переместить в другую таблицу.Хотя приведенные выше правила являются точными, техническими определениями, правила нормализации можно упростить до следующего:
- Каждое поле должно быть как можно меньше.
- Каждое поле может содержать только один элемент данных.
- Каждая запись должна быть уникальной.
- Следите за повторяющимися записями.
- Каждое поле должно полностью поддерживать первичный ключ и только первичный ключ.
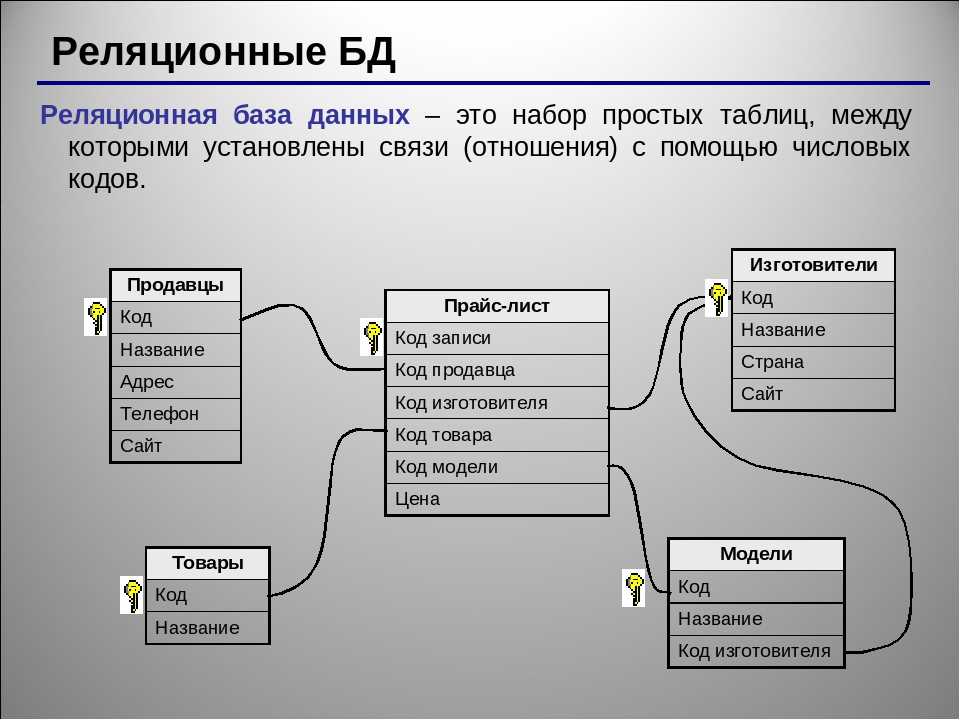
Что дальше?
Применение правил нормализации, особенно составной 1НФ, может оказаться сложным процессом. Как вы увидите в следующем выпуске, где я фактически начну применять нормальные формы к образцу базы данных, вы можете вернуться к 1NF после выполнения других шагов нормализации.
Сьюзен Харкинс
Опубликовано: . Изменено: Увидеть больше Управление данными Поделиться: Реляционные базы данных: использование обычных форм для создания баз данных- Управление данными
Выбор редактора
- Изображение: Rawpixel/Adobe Stock
ТехРеспублика Премиум
906:40
Редакционный календарь TechRepublic Premium: ИТ-политики, контрольные списки, наборы инструментов и исследования для загрузки
Контент TechRepublic Premium поможет вам решить самые сложные проблемы с ИТ и дать толчок вашей карьере или новому проекту.
Персонал TechRepublic
Опубликовано: Изменено: Читать далее Узнать больше - Изображение: diy13/Adobe Stock
Программного обеспечения
Виндовс 11 22х3 уже здесь
Windows 11 получает ежегодное обновление 20 сентября, а также ежемесячные дополнительные функции. На предприятиях ИТ-отдел может выбирать, когда их развертывать.
Мэри Бранскомб
Опубликовано: Изменено: Читать далее Увидеть больше Программное обеспечение - Изображение: Кто такой Дэнни/Adobe Stock
Край
ИИ на переднем крае: 5 трендов, за которыми стоит следить
Edge AI предлагает возможности для нескольких приложений. Посмотрите, что организации делают для его внедрения сегодня и в будущем.
Меган Краус
Опубликовано: Изменено: Читать далее Увидеть больше - Изображение: яблоко
Программного обеспечения
Шпаргалка по iPadOS: все, что вы должны знать
Это полное руководство по iPadOS от Apple.
Узнайте больше об iPadOS 16, поддерживаемых устройствах, датах выпуска и основных функциях с помощью нашей памятки.Персонал TechRepublic
Опубликовано: Изменено: Читать далее Увидеть больше Программное обеспечение - Изображение: Worawut/Adobe Stock
- Изображение: Bumblee_Dee, iStock/Getty Images
Программного обеспечения
906:40
108 советов по Excel, которые должен усвоить каждый пользователь
Независимо от того, являетесь ли вы новичком в Microsoft Excel или опытным пользователем, эти пошаговые руководства принесут вам пользу.
Персонал TechRepublic
Опубликовано: Изменено: Читать далее Увидеть больше Программное обеспечение

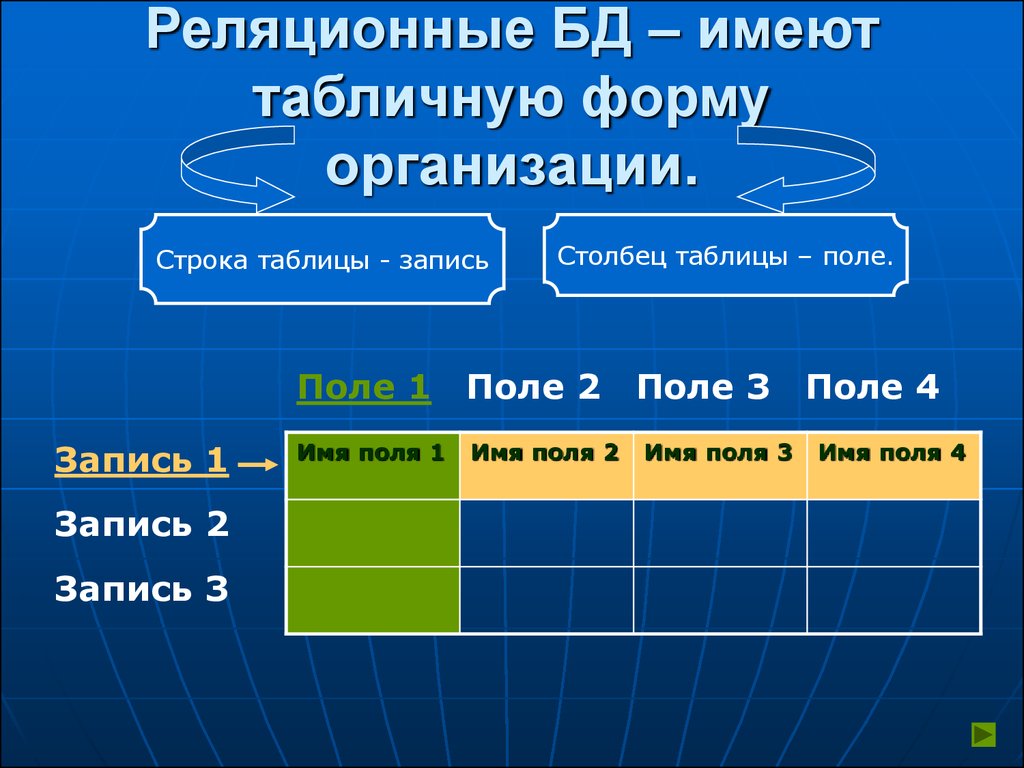 Узнайте больше об iPadOS 16, поддерживаемых устройствах, датах выпуска и основных функциях с помощью нашей памятки.
Узнайте больше об iPadOS 16, поддерживаемых устройствах, датах выпуска и основных функциях с помощью нашей памятки.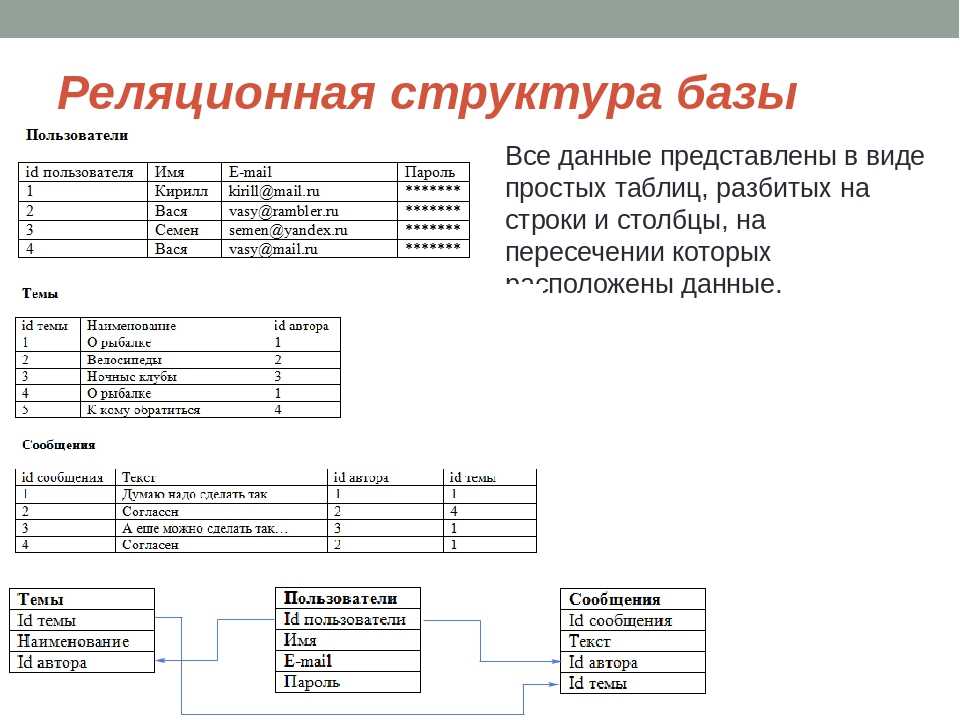
Нормальные формы в СУБД — GeeksforGeeks
Предварительное условие – Нормализация базы данных и концепция функциональной зависимости.
Нормализация — это процесс минимизации избыточности отношения или набора отношений. Избыточность в отношении может вызвать аномалии вставки, удаления и обновления. Таким образом, это помогает свести к минимуму избыточность в отношениях. Обычные формы используются для устранения или уменьшения избыточности в таблицах базы данных.
1. Первая нормальная форма –
Если отношение содержит составной или многозначный атрибут, оно нарушает первую нормальную форму или отношение находится в первой нормальной форме, если оно не содержит составного или многозначного атрибута. Отношение находится в первой нормальной форме, если каждый атрибут в этом отношении является однозначным атрибутом .
- Пример 1 – Отношение STUDENT в таблице 1 не находится в 1NF из-за многозначного атрибута STUD_PHONE. Его разложение в 1НФ показано в таблице 2.
- Пример 2 –
Курсы по идентификационным именам ------------------ 1 А с1, с2 2 Э c3 3 М С2, с3
В приведенной выше таблице курс является многозначным атрибутом, поэтому он не входит в 1NF.
Таблица ниже приведена в 1NF, так как нет многозначного атрибута
Идентификационное имя Курс ------------------ 1 А с1 1 А с2 2 Э c3 3 М с2 3 М с3
2.
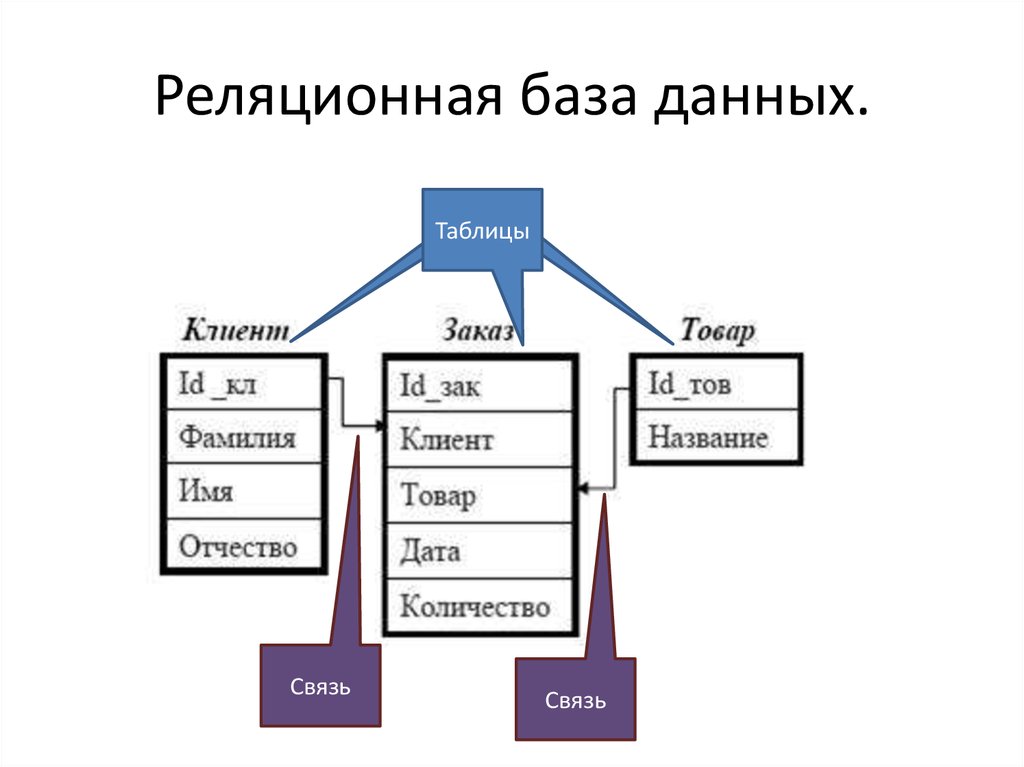 Вторая нормальная форма —
Вторая нормальная форма —Чтобы быть во второй нормальной форме, отношение должно быть в первой нормальной форме и отношение не должно содержать частичных зависимостей. Отношение находится во 2НФ, если оно имеет Нет частичной зависимости, т. е. , ни один непервичный атрибут (атрибуты, которые не являются частью какого-либо ключа-кандидата) не зависит ни от какого надлежащего подмножества любого ключа-кандидата таблицы.
Частичная зависимость — Если правильное подмножество ключа-кандидата определяет неосновной атрибут, это называется частичной зависимостью.
- Пример 1 – Рассмотрим таблицу 3, как показано ниже.
STUD_NO COURSE_NO COURSE_FEE 1 С1 1000 2 С2 1500 1 С4 2000 4 С3 1000 4 С1 1000 2 С5 2000 г.
{Обратите внимание, что многие курсы имеют одинаковую стоимость. }
Здесь
COURSE_FEE не может сам по себе определить значение COURSE_NO или STUD_NO;
COURSE_FEE вместе с STUD_NO не может определить значение COURSE_NO;
COURSE_FEE вместе с COURSE_NO не может определить значение STUD_NO;
Следовательно,
COURSE_FEE будет атрибутом, отличным от простого, поскольку он не принадлежит единственному ключу-кандидату {STUD_NO, COURSE_NO} ;
Но COURSE_NO -> COURSE_FEE, т. е. COURSE_FEE зависит от COURSE_NO, который является правильным подмножеством ключа-кандидата. Непервичный атрибут COURSE_FEE зависит от надлежащего подмножества ключа-кандидата, который является частичной зависимостью, и поэтому это отношение не находится во 2NF.Чтобы преобразовать приведенное выше отношение во 2NF,
нам нужно разделить таблицу на две таблицы, например:
Таблица 1: STUD_NO, COURSE_NO
Таблица 2: COURSE_NO, COURSE_FEEТаблица 1 Таблица 2 STUD_NO COURSE_NO COURSE_NO COURSE_FEE 1 С1 С1 1000 2 С2 С2 1500 1 С4 С3 1000 4 С3 С4 2000 4 С1 С5 2000
2 C5
ПРИМЕЧАНИЕ. 2NF пытается уменьшить количество избыточных данных, сохраняемых в памяти. Например, если курс C1 посещают 100 студентов, нам не нужно хранить его плату как 1000 для всех 100 записей, вместо этого мы можем сохранить ее во второй таблице, поскольку плата за курс для C1 составляет 1000.
- Пример 2 – Рассмотрим следующие функциональные зависимости в отношении R (A, B , C, D )
AB -> C [A и B вместе определяют C] BC -> D [B и C вместе определяют D]
В приведенном выше отношении AB является единственным ключом-кандидатом, и частичная зависимость отсутствует, т.
е. любое правильное подмножество AB не определяет какой-либо непростой атрибут.
 е. COURSE_FEE зависит от COURSE_NO, который является правильным подмножеством ключа-кандидата. Непервичный атрибут COURSE_FEE зависит от надлежащего подмножества ключа-кандидата, который является частичной зависимостью, и поэтому это отношение не находится во 2NF.
е. COURSE_FEE зависит от COURSE_NO, который является правильным подмножеством ключа-кандидата. Непервичный атрибут COURSE_FEE зависит от надлежащего подмножества ключа-кандидата, который является частичной зависимостью, и поэтому это отношение не находится во 2NF. е. любое правильное подмножество AB не определяет какой-либо непростой атрибут.
е. любое правильное подмножество AB не определяет какой-либо непростой атрибут.3. Третья нормальная форма –
Отношение находится в третьей нормальной форме, если нет транзитивной зависимости для не простых атрибутов, а также находится во второй нормальной форме.
Отношение находится в 3НФ, если выполняется хотя бы одно из следующих условий в каждой нетривиальной функциональной зависимости X -> Y
- X — суперключ.
- Y является первичным атрибутом (каждый элемент Y является частью некоторого ключа-кандидата).
Транзитивная зависимость – Если A->B и B->C являются двумя FD, то A->C называется транзитивной зависимостью.
- Пример 1 – Для отношения STUDENT, указанного в таблице 4,
FD set: {STUD_NO -> STUD_NAME, STUD_NO -> STUD_STATE, STUD_STATE -> STUD_COUNTRY, STUD_NO -> STUD_AGE}
Ключ кандидата: {STUD_NO}Для этого отношения в таблице 4 значения STUD_NO -> STUD_STATE и STUD_STATE -> STUD_COUNTRY верны.
Таким образом, STUD_COUNTRY транзитивно зависит от STUD_NO. Нарушает третью нормальную форму. Чтобы преобразовать его в третью нормальную форму, мы разложим отношение STUDENT (STUD_NO, STUD_NAME, STUD_PHONE, STUD_STATE, STUD_COUNTRY_STUD_AGE) как: Пример 2 – Рассмотрим соотношение R(A, B, C, D, E)
A -> BC,
CD -> E,
B -> D,
E -> A
Все возможные ключи-кандидаты в приведенном выше отношении: {A, E, CD, BC} Все атрибуты находятся справа от всех функциональных зависимости являются простыми. - Пример 1 – Найти высшую нормальную форму отношения R(A,B,C,D,E) с FD, установленным как {BC->D, AC->BE, B->E}
Шаг 1. Как видим, (AC)+ = {A,C,B,E,D}, но ни одно из его подмножеств не может определить все атрибуты отношения, поэтому AC будет потенциальным ключом. A или C не могут быть получены из любого другого атрибута отношения, поэтому будет только 1 ключ-кандидат {AC}.
Шаг 2. Основные атрибуты — это те атрибуты, которые являются частью ключа-кандидата {A, C} в этом примере, а другие в этом примере не будут простыми {B, D, E}.
Шаг 3. Отношение R находится в 1-й нормальной форме, поскольку реляционная СУБД не допускает многозначных или составных атрибутов.
Отношение находится во 2-й нормальной форме, поскольку BC->D находится во 2-й нормальной форме (BC не является правильным подмножеством ключа-кандидата AC), а AC->BE находится во 2-й нормальной форме (AC является ключом-кандидатом), а B-> E находится во 2-й нормальной форме (B не является правильным подмножеством ключа-кандидата AC).
Отношение не находится в 3-й нормальной форме, поскольку в BC->D (ни BC не является суперключом, ни D не является первичным атрибутом) и в B->E (ни B не является суперключом, ни E не является первичным атрибутом), но чтобы удовлетворить 3-й нормали, либо левая часть FD должна быть суперключом, либо правая часть должна быть первичным атрибутом.
Таким образом, высшей нормальной формой отношений будет 2-я нормальная форма. - Пример 2 – Например, рассмотрим отношение R(A, B, C)
A -> BC,
B ->
A и B оба являются суперключами, поэтому приведенное выше отношение находится в BCNF.
 Таким образом, STUD_COUNTRY транзитивно зависит от STUD_NO. Нарушает третью нормальную форму. Чтобы преобразовать его в третью нормальную форму, мы разложим отношение STUDENT (STUD_NO, STUD_NAME, STUD_PHONE, STUD_STATE, STUD_COUNTRY_STUD_AGE) как: Пример 2 – Рассмотрим соотношение R(A, B, C, D, E)
Таким образом, STUD_COUNTRY транзитивно зависит от STUD_NO. Нарушает третью нормальную форму. Чтобы преобразовать его в третью нормальную форму, мы разложим отношение STUDENT (STUD_NO, STUD_NAME, STUD_PHONE, STUD_STATE, STUD_COUNTRY_STUD_AGE) как: Пример 2 – Рассмотрим соотношение R(A, B, C, D, E) 4. Нормальная форма Бойса-Кодда (BCNF) –
Отношение R находится в BCNF, если R находится в третьей нормальной форме и для каждого FD LHS является суперключом. Отношение находится в НФБК тогда и только тогда, когда в каждой нетривиальной функциональной зависимости X -> Y X является суперключом.
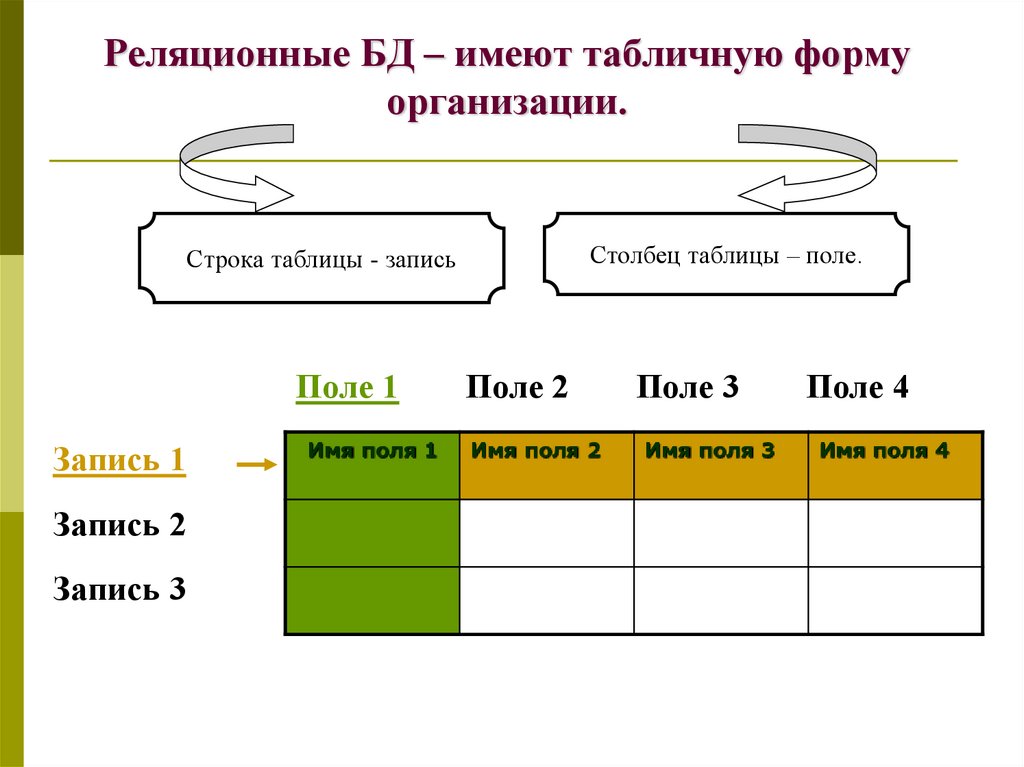 A или C не могут быть получены из любого другого атрибута отношения, поэтому будет только 1 ключ-кандидат {AC}.
A или C не могут быть получены из любого другого атрибута отношения, поэтому будет только 1 ключ-кандидат {AC}. 
Ключевые точки –
- BCNF не имеет избыточности.
- Если отношение находится в НФБК, то также выполняется 3НФ.
- Если все атрибуты отношения являются первичными атрибутами, то отношение всегда находится в 3НФ.
- Отношение в реляционной базе данных всегда и как минимум в форме 1NF.
- Каждое бинарное отношение (отношение только с двумя атрибутами) всегда находится в BCNF.
- Если отношение имеет только одноэлементные ключи-кандидаты (т. е. каждый ключ-кандидат состоит только из 1 атрибута), то отношение всегда находится во 2NF (поскольку частичная функциональная зависимость невозможна).
- Иногда переход на форму BCNF может не сохранить функциональную зависимость. В этом случае переходите к BCNF, только если потерянные FD не требуются, в противном случае нормализуйте только до 3NF.
- Есть много других нормальных форм, которые существуют после BCNF, например, 4NF и другие. Но в реальных системах баз данных обычно не требуется выходить за пределы BCNF.
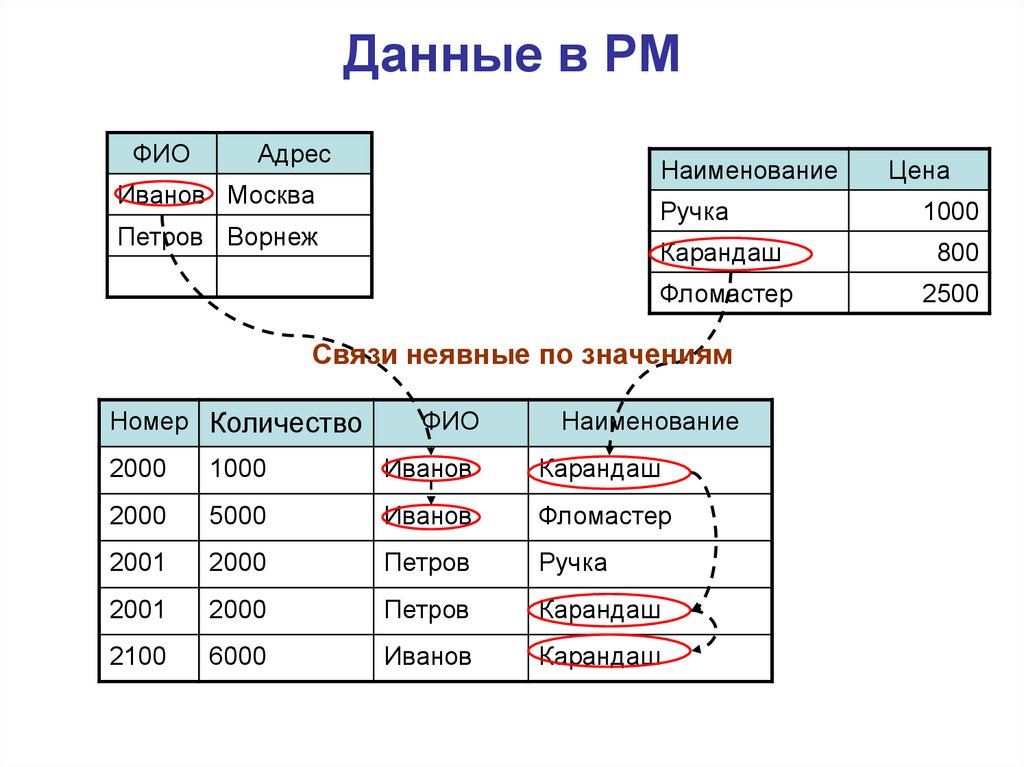 В этом случае переходите к BCNF, только если потерянные FD не требуются, в противном случае нормализуйте только до 3NF.
В этом случае переходите к BCNF, только если потерянные FD не требуются, в противном случае нормализуйте только до 3NF.
Упражнение 1 : Найдите высшую нормальную форму в R (A, B, C, D, E) при следующих функциональных зависимостях.
азбука --> д CD --> AE
Важные моменты для решения вышеуказанного типа вопросов.
1) Всегда рекомендуется начинать проверку с BCNF, затем с 3 NF и так далее.
2) Если какая-либо функциональная зависимость удовлетворяет нормальной форме, то нет необходимости проверять более низкую нормальную форму. Например, ABC -> D находится в BCNF (обратите внимание, что ABC — это суперключ), поэтому нет необходимости проверять эту зависимость на наличие более низких нормальных форм.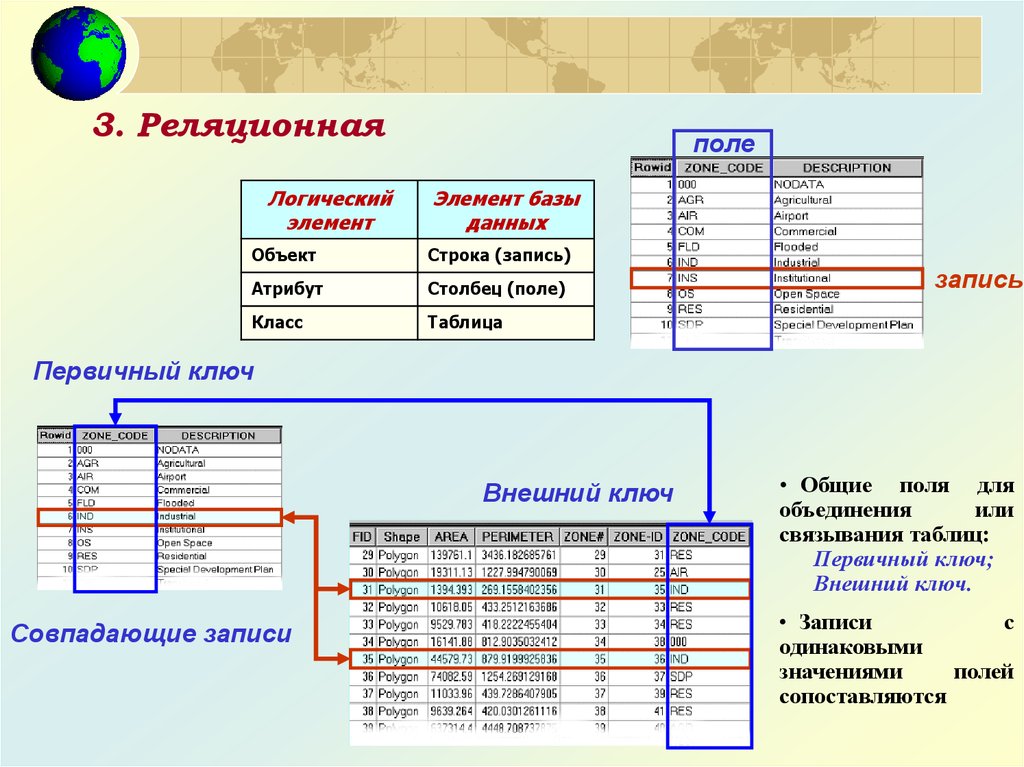
Ключи-кандидаты в данном отношении: {ABC, BCD}
BCNF: ABC -> D находится в BCNF. Давайте проверим CD -> AE, CD не является суперключом, поэтому этой зависимости нет в BCNF. Итак, R не находится в НФБК.
3NF: ABC -> D нам не нужно проверять эту зависимость, так как она уже удовлетворяет BCNF. Рассмотрим CD -> AE. Поскольку E не является простым атрибутом, отношение не находится в 3NF.
2NF: В 2NF нам нужно проверить частичную зависимость. CD является правильным подмножеством ключа-кандидата и определяет E, который не является простым атрибутом. Значит, данное отношение тоже не во 2 НФ. Итак, высшая нормальная форма равна 1 NF.
Угловые вопросы GATE CS
Ответив на следующие вопросы, вы сможете проверить свои знания. Все вопросы были заданы в GATE в предыдущие годы или в пробных тестах GATE. Настоятельно рекомендуется их практиковать.
- GATE CS 2012, Вопрос 2
- GATE CS 2013, Вопрос 54
- GATE CS 2013, Вопрос 55
- GATE CS 2005, Вопрос 29
- GATE CS 2002, Вопрос 23
- CS 2002, Вопрос 50 000444.
- Gate CS 2001, Вопрос 48
- Gate CS 1999, вопрос 32
- Gate IT 2005, вопрос 22
- Gate IT 2008, вопрос 60
- Gate CS 2016 (SET 1), Вопрос 31
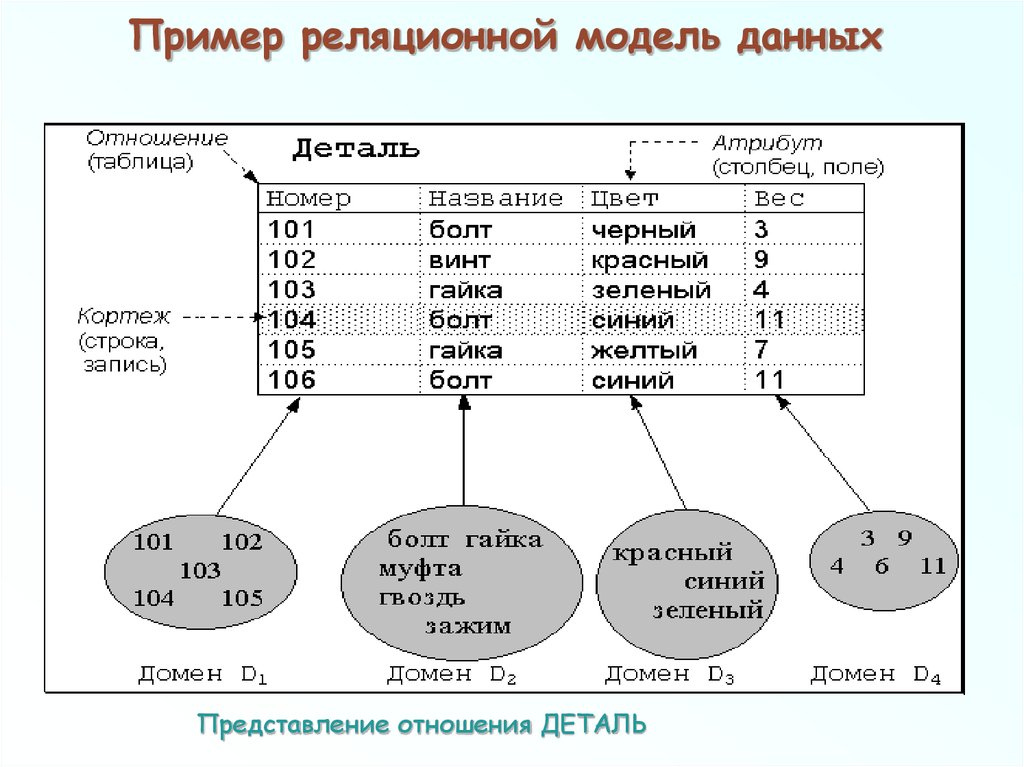
См. Викторина на DataBase Обычные формы для всех вопросов предыдущего года.
Эта статья предоставлена Sonal Tuteja . Если вам нравится GeeksforGeeks и вы хотите внести свой вклад, вы также можете написать статью с помощью write.geeksforgeeks.org или отправить ее по адресу [email protected]. Посмотрите, как ваша статья появится на главной странице GeeksforGeeks, и помогите другим гикам.
Пожалуйста, пишите комментарии, если вы обнаружите что-то неправильное, или вы хотите поделиться дополнительной информацией по теме, обсуждаемой выше.
1НФ. Изучите первую нормальную форму отношений… | Александр Данилович | Явапосетил
Изучите первую нормальную форму проектирования реляционных баз данных
Фото Яна Антонина Колара на Unsplash В этом рассказе мы начнем говорить о проектировании реляционных баз данных. Весь сериал будет включать в себя 1NF, 2NF и 3NF, но главным героем этой истории будет так называемая 1NF (First Normalization Form).
Весь сериал будет включать в себя 1NF, 2NF и 3NF, но главным героем этой истории будет так называемая 1NF (First Normalization Form).
Как вы знаете, реляционные базы данных, основанные на SQL, наиболее часто используются в современных системах. Они сильны из-за своих КИСЛОТНЫХ свойств.
За свою профессиональную карьеру я повидал множество реляционных баз данных. Я должен вам сказать одну вещь, у них часто был плохой дизайн. Многие программисты не имеют достаточного образования или вообще не заинтересованы в проектировании баз данных.
Из-за этого можно увидеть много плохих вещей. В базах данных много избыточности, поэтому довольно часто возникают несоответствия между базами данных. Затем люди начинают вручную вмешиваться в базы данных с помощью сценариев SQL и т. д. Много ошибок в производстве из-за несоответствий в базе данных, много ручного обслуживания базы данных.
Правильно спроектированная база данных должна пройти процесс нормализации. Обычно достаточно, если база данных проходит 3 нормальные формы: 1NF, 2NF и 3NF. Или почти 3 нормальные формы. Обычно 1NF и 2NF являются обязательными. 3NF — это хорошо, но иногда мы не так строги и где-то (на какой-то таблице) допускаем его нарушение из-за выигрыша в производительности.
Процесс нормализации завершится с увеличением количества таблиц в базе данных, однако это снизит избыточность данных, и благодаря этому целостность данных будет поддерживаться намного проще. Минимизация избыточности данных — одна из ключевых целей нормализации.
Давайте начнем с одного примера. Представим, что у нас есть какая-то ИТ-школа, в которой много студентов, курсов и инструкторов (инструкторы придут в следующих историях). Допустим, какой-то младший программист начал его проектировать. И таблица STUDENT была создана.
Исходная таблица STUDENTЭта таблица содержит список курсов для каждого студента. Столбец ID является первичным ключом таблицы STUDENT.
Таблица находится в 1НФ, если она удовлетворяет следующим условиям:
- В таблице нет повторяющихся строк
- Записи в столбце одного типа
- Содержит только атомарные значения
- Нет повторяющихся групп
Атомарное значение — это значение, которое нельзя разделить. Повторяющаяся группа означает, что таблица содержит два или более тесно связанных столбца. Например, если в таблице STUDENT есть столбцы COURSE_1, COURSE_2 и COURSE_3 (вместо столбца COURSES), то это нарушит правило повторяющихся групп.
Если все таблицы в базе данных не находятся хотя бы в 1NF, это считается очень плохим дизайном, и тогда мы вообще не должны использовать реляционную базу данных! Базы данных, не требующие 1NF, часто называют базами данных NoSQL. Тогда вам следует использовать какую-нибудь базу данных NoSQL, и вы, вероятно, потеряете лучшее из реляционных баз данных: свойства ACID.
Давайте теперь изменим таблицу STUDENT и поместим ее в 1NF. Мы переименуем столбец КУРСЫ в КУРС (имя в единственном числе) и поместим курс каждого студента в отдельную строку. Кроме того, столбец NAME будет разделен на 2 столбца: FIRST_NAME и LAST_NAME. Возможно, иногда нам понадобится имя ученика отдельно от фамилии, и наоборот. А что тогда делать, например, с Аной-Марией Джонсон? Как программно решить, что такое имя, а что фамилия? У некоторых людей может быть имя из 1 слова, а фамилия из 2 слов. Мы застряли. Кроме того, использование всех трех столбцов: NAME, FIRST_NAME и LAST_NAME — не решение. Потому что это нарушает правило 1NF о повторяющихся группах. Таким образом, 1NF таблицы STUDENT может быть:
Переработанная таблица теперь находится в 1NF. Однако 1NF недостаточно, здесь много проблем.
Какие проблемы с текущим дизайном таблицы STUDENT? Что ж, с этим дизайном у нас есть так называемая вставка, обновление и удаление аномалий.
Что такое аномалия вставки ? Если мы хотим добавить нового студента, то у этого студента должен быть хотя бы один зачисленный курс. В противном случае мы не сможем вставить нового студента (при условии, что столбец COURSE не может принимать значения NULL). Или, если столбец COURSE допускает значение NULL, мы должны установить для него значение NULL.
Что такое аномалия обновления ? Предположим, студентка с ID 1 (Ана Мария Джонсон) выходит замуж. И она получает фамилию своего мужа. Теперь нам нужно обновить все строки, в которых фигурирует Ана-Мария. Таким образом, поддерживать целостность данных сложнее.
Что такое удаление аномалии ? Например, если мы удалим студента с идентификатором 1 (Ана Мария Джонсон), то у нас не будет ни одного студента, который записался на курс JavaScript. Таким образом, мы потеряем данные, говорящие о том, что курс JavaScript существует.
Кроме того, при таком дизайне каждый раз, когда существующий учащийся записывается на новый курс, мы будем повторять общие данные учащегося (ID, FIRST_NAME, LAST_NAME). Таким образом, у нас будет много избыточных данных, которые увеличат размер базы данных, и производительность базы данных будет снижена.
Еще одна проблема — первичный ключ. Каждая таблица в реляционной базе данных должна иметь первичный ключ. Мы уже говорили, что столбец ID является здесь первичным ключом (может быть автоматически сгенерированным ID из базы данных). Теперь у нас есть строки с повторяющимися идентификаторами. Итак, нам нужен новый первичный ключ на столе. Что здесь должно быть? Все 4 столбца (ID, FIRST_NAME, LAST_NAME, COURSE) должны быть частью нового первичного ключа! Не очень оптимально.
Нормализация нашей базы данных должна продолжаться с 2NF и 3NF. Почему же тогда 1НФ так фундаментальна? Потому что это граница использования реляционной базы данных вообще! SQL не предназначен для эффективного запроса столбцов с умноженными значениями. Если ваша база данных не находится в 1NF, вам следует использовать базу данных NoSQL!
За свою карьеру я встречал реляционные базы данных, которые не относятся к 1NF. Даже эти базы данных были созданы опытными программистами. Как это случилось? Ответ — отсутствие образования! Обычно они не знают, как реализовать отношение «многие ко многим» между сущностями базы данных. Что такое отношение «многие ко многим»? Ну, 1 студент может записаться на многие курсы. И 1 курс может посещать много студентов. Это отношение многие ко многим. Из-за отсутствия образования они строят эти отношения примерно так:
Плохой дизайн связи «многие ко многим» Значит, у них как-то получается. Обычно они используют много кода на программном языке. Разбор значений столбцов с перемноженными значениями, разделение их по разделителю и т. д. Кроме того, как вы сделаете SQL-запрос, который, например, получит всех студентов, записавшихся на какой-то конкретный курс? Нелегко! Не говоря уже о производительности этого запроса.
Между прочим, правильный способ представления связи «многие ко многим» в реляционной базе данных — это ввести новую таблицу. Так называемая сводная таблица. Это мы увидим в историях, которые станут продолжением. Мы также увидим силу нормализации базы данных и познакомимся с 2NF и 3NF.
1NF недостаточно. Мы должны пойти дальше в процессе нормализации базы данных. Но это фундаментальная форма, потому что это граница между базами данных SQL и NoSQL!
Что такое нереляционная база данных?
Обзор
- Что такое нереляционная база данных?
- Реляционные базы данных
- Нереляционные базы данных
- Преимущества нереляционных баз данных
- Нереляционные базы данных и разработка приложений
Большинство баз данных можно разделить на реляционные и нереляционные. Нереляционные базы данных иногда называют «NoSQL», что означает не только SQL. Основное различие между ними заключается в том, как они хранят свою информацию.
Нереляционная база данных хранит данные в нетабличной форме и имеет тенденцию быть более гибкой, чем традиционная структура реляционной базы данных на основе SQL. Он не следует реляционной модели, предоставляемой традиционными системами управления реляционными базами данных.
Чтобы более подробно объяснить нереляционные базы данных, давайте сначала рассмотрим, что такое традиционная реляционная база данных.
Реляционные базы данных
Реляционная база данных обычно хранит информацию в таблицах, содержащих определенные части и типы данных. Например, магазин может хранить информацию об именах и адресах своих клиентов в одной таблице, а информацию об их заказах — в другой. Эту форму хранения данных часто называют структурированными данными.
Пример таблицы реляционной базы данных клиентов.
Реляционные базы данных используют язык структурированных запросов (SQL). В реляционной базе данных база данных обычно содержит таблицы, состоящие из столбцов и строк. При добавлении новых данных новые записи вставляются в существующие таблицы или добавляются новые таблицы. Затем можно установить отношения между двумя или более таблицами.
Реляционные базы данных работают лучше всего, когда данные, которые они содержат, меняются не очень часто и когда важна точность. Реляционные базы данных, например, часто используются в финансовых приложениях.
Нереляционные базы данных
Нереляционные базы данных (часто называемые базами данных NoSQL) отличаются от традиционных реляционных баз данных тем, что они хранят свои данные в нетабличной форме. Вместо этого нереляционные базы данных могут быть основаны на таких структурах данных, как документы. Документ может быть очень подробным, но содержать ряд различных типов информации в разных форматах. Эта способность усваивать и упорядочивать различные типы информации рядом друг с другом делает нереляционные базы данных гораздо более гибкими, чем реляционные базы данных.
Пример документа MongoDB для пациента в системе здравоохранения.
Нереляционные базы данных часто используются, когда необходимо организовать большие объемы сложных и разнообразных данных. Например, большой магазин может иметь базу данных, в которой у каждого покупателя есть собственный документ, содержащий всю его информацию, от имени и адреса до истории заказов и информации о кредитной карте. Несмотря на разные форматы, каждая из этих частей информации может храниться в одном и том же документе.
Нереляционные базы данных часто работают быстрее, потому что запросу не нужно просматривать несколько таблиц, чтобы получить ответ, как это часто бывает с реляционными наборами данных. Поэтому нереляционные базы данных идеально подходят для хранения данных, которые могут часто изменяться, или для приложений, обрабатывающих множество различных типов данных. Они могут поддерживать быстро развивающиеся приложения, требующие динамической базы данных, способной быстро изменяться и вмещать большие объемы сложных неструктурированных данных.
При запуске проекта стоит рассмотреть реляционные и нереляционные базы данных с точки зрения их различий, чтобы лучше понять правильное решение для проекта. Вы также можете рассмотреть различные примеры использования обоих, и когда вы можете выбрать один из них.
Преимущества нереляционной базы данных
Современные приложения собирают и хранят все больше и больше все более сложных данных о клиентах и пользователях. Преимущества этих данных для бизнеса, конечно же, заключаются в их потенциале для анализа. Использование нереляционной базы данных может выявить закономерности и ценность даже в массе разнородных данных.
Использование нереляционных баз данных имеет несколько преимуществ, в том числе:
Массивная организация набора данных
В эпоху больших данных нереляционные базы данных могут не только хранить огромные объемы информации, но и запрашивать эти наборы данных с легкостью. Масштаб и скорость являются решающими преимуществами нереляционных баз данных.
Гибкое расширение базы данных
Данные не статичны. По мере сбора дополнительной информации нереляционная база данных может поглощать эти новые точки данных, обогащая существующую базу данных новыми уровнями детализации, даже если они не соответствуют типам данных ранее существовавшей информации.
Множественные структуры данных
Данные, которые теперь собираются от пользователей, принимают множество форм, от чисел и строк до фото- и видеоконтента и истории сообщений. Базе данных необходима возможность хранить эти различные информационные форматы, понимать отношения между ними и выполнять подробные запросы. Независимо от того, в каком формате находится ваша информация, нереляционные базы данных могут сопоставлять различные типы информации в одном документе.
Создано для облака
Нереляционная база данных может быть огромной. И поскольку в некоторых случаях они могут расти в геометрической прогрессии, им нужна среда хостинга, которая может расти и расширяться вместе с ними.
Присущая облаку масштабируемость делает его идеальным домом для нереляционных баз данных.
Нереляционные базы данных и разработка приложений
Приложения должны иметь возможность эффективно запрашивать данные и практически мгновенно выдавать результаты. Нереляционные базы данных — естественный выбор для такой среды. Они обеспечивают как безопасность, так и гибкость, позволяя быстро разрабатывать приложения в гибкой среде. Более простые и менее сложные в управлении, чем реляционные базы данных, они также могут обеспечить более низкие затраты на управление данными, обеспечивая при этом превосходную производительность и скорость.
Нереляционные базы данных, естественно подходящие для гибкой разработки, могут более эффективно обрабатывать сложные входные данные, чем структурированные базы данных. В эпоху возрастающей сложности данных нереляционные базы данных обеспечивают гибкость проектирования баз данных, которая становится все более необходимой. Особенно в сочетании с облаком нереляционные базы данных снимают ограничения на сбор, организацию и анализ ваших данных, позволяя вам получить максимальную отдачу от ваших данных.