Интерпретация и компиляция в программировании
Одной из ключевых характеристик PHP является то, что это интерпретируемый язык программирования. С другой стороны, языки программирования наподобие C, изначально разрабатывались для компиляции. Что это значит?
Компилируется ли язык программирования или интерпретируется, на самом деле это не зависит от природы языка программирования. Любой язык программирования может интерпретироваться так называемым интерпретатором или компилироваться с помощью так называемого компилятора.
- Рабочий цикл программы
- Интерпретация программы
- Природа интерпретатора
- За и против
- Заключение
При использовании любого языка программирования существует определенный рабочий цикл создания кода. Вы пишете его, запускаете, находите ошибки и отлаживаете. Таким образом, вы переписываете и дописываете программу, проверяете ее. То, о чем пойдет речь в этой статье, это «запускаемая» часть программы.
Вы пишете его, запускаете, находите ошибки и отлаживаете. Таким образом, вы переписываете и дописываете программу, проверяете ее. То, о чем пойдет речь в этой статье, это «запускаемая» часть программы.
Когда пишете программу, вы хотите, чтобы ее инструкции работали на компьютере. Компьютер обрабатывает информацию с помощью процессора, который поэтапно выполняет инструкции, закодированные в двоичном формате. Как из выражения «a = 3;» получить закодированные инструкции, которые процессор может понять?
Мы делаем это с помощью компиляции. Существует специальные приложения, известные как компиляторы. Они принимают программу, которую вы написали. Затем анализируют и разбирают каждую часть программы и строят машинный код для процессора. Часто его также называют объектным кодом.
На одном из этапов процесса обработки задействуется компоновщик, принимающий части программы, которые отдельно были преобразованы в объектный код, и связывает их в один исполняемый файл. Вот схема, описывающая данный процесс:
Конечным элементом этого процесса является исполняемый файл. Когда вы запускаете или сообщаете компьютеру, что это исполняемый файл, он берет первую же инструкцию из него, не фильтрует, не преобразует, а сразу запускает программу и выполняет ее без какого-либо дополнительного преобразования. Это ключевая характеристика процесса компиляции — его результат должен быть исполняемым файлом, не требующим дополнительного перевода, чтобы процессор мог начать выполнять первую инструкцию и все следующие за ней.
Когда вы запускаете или сообщаете компьютеру, что это исполняемый файл, он берет первую же инструкцию из него, не фильтрует, не преобразует, а сразу запускает программу и выполняет ее без какого-либо дополнительного преобразования. Это ключевая характеристика процесса компиляции — его результат должен быть исполняемым файлом, не требующим дополнительного перевода, чтобы процессор мог начать выполнять первую инструкцию и все следующие за ней.
Первые компиляторы были написаны непосредственно через машинный код или с использованием ассемблеров. Но цель компилятора очевидна: перевести программу в исполняемый машинный код для конкретного процессора.
Некоторые языки программирования разрабатывались с учетом компиляции. C, например, предназначался для того, чтобы дать возможность программистам с легкостью реализовать разные вещи. Но в итоге он разрабатывался таким образом, чтобы его можно было легко перевести на машинный код. Компиляция в программировании это серьезно!
Не все языки программирования учитывают это в своей концепции. Например, Java предназначался для запуска в «интерпретирующей» среде, а Python всегда должен интерпретироваться.
Например, Java предназначался для запуска в «интерпретирующей» среде, а Python всегда должен интерпретироваться.
Альтернативой компиляции является интерпретация. Чем отличаются компиляторы и интерпретаторы? Основная разница между компилятором и интерпретатором заключается в том, как они работают. Компилятор берет всю программу и преобразует ее в машинный код, который понимает процессор.
Интерпретатор — это исполняемый файл, который поэтапно читает программу, а затем обрабатывает, сразу выполняя ее инструкции.
Другими словами, программа-интерпретатор выполняет программу поэтапно как часть собственного исполняемого файла. Объектный код не передается процессору, интерпретатор сам является объектным кодом, построенным таким образом, чтобы его можно было вызвать в определенное время.
Это ломает рабочий цикл, который был приведен на диаграмме выше. Теперь у нас есть новая диаграмма:
На ней мы видим, что в отличии от компилятора, интерпретатор всегда должен быть под рукой, чтобы мы могли вызвать его и запустить нашу программу. В некотором смысле интерпретатор становится процессором. Программы, написанные для интерпретации, называются «скриптами», потому что они являются сценариями действий для другой программы, а не прямым машинным кодом.
В некотором смысле интерпретатор становится процессором. Программы, написанные для интерпретации, называются «скриптами», потому что они являются сценариями действий для другой программы, а не прямым машинным кодом.
Например, так работают такие языки программирования, как Python. Вы пишете программу. Затем вводите код в интерпретатор Python, и он выполняет все описанные вами шаги. В командной строке вы можете ввести примерно следующее:
C:>python myprogram.py
В этой команде Python — это исполняемый файл. Вы вводите в него все, что находится в файле myprogram.py, и он выполняет эти инструкции. Компьютер не запустит myprogram.py без Python. Это не машинный код, который понимает процессор. Можно скомпилировать программы Python в объектный или машинный код и запустить его непосредственно в процессоре. Но эта процедура включает в себя компиляцию кода и добавление в качестве ее части всего интерпретатора Python.
Интерпретаторы могут создаваться по-разному. Существуют интерпретаторы, которые читают исходную программу и не выполняют дополнительной обработки. Они просто берут определенное количество строк кода за раз и выполняют его.
Они просто берут определенное количество строк кода за раз и выполняют его.
Некоторые интерпретаторы выполняют собственную компиляцию, но обычно преобразуют программу байтовый код, который имеет смысл только для интерпретатора. Это своего рода псевдо машинный язык, который понимает только интерпретатор.
Такой код быстрее обрабатывается, и его проще написать для исполнителя (части интерпретатора, которая исполняет), который считывает байтовый код, а не код источника.
Есть интерпретаторы, для которых этот вид байтового кода имеет более важное значение. Например, язык программирования Java «запускается» на так называемой виртуальной машине. Она является исполняемым кодом или частью программы, которая считывает конкретный байтовый код и эмулирует работу процессора. Обрабатывая байтовый код так, как если бы процессор компьютера был виртуальным процессором.
У меня есть эмулятор для игровой приставки NIntendo. Когда я загружаю ROM-файл Dragon Warrior, он форматируется в машинный код, который понимает только процессор NES. Но если я создаю виртуальный процессор, который интерпретирует байтовый код во время работы на другом процессоре, я могу запустить Dragon Warrior на любой машине с эмулятором.
Но если я создаю виртуальный процессор, который интерпретирует байтовый код во время работы на другом процессоре, я могу запустить Dragon Warrior на любой машине с эмулятором.
Это использует концепция компиляции Java, а также все интерпретаторы. На любом процессоре, для которого я могу создать интерпретатор / эмулятор, можно запускать мои интерпретируемые программы / байтовый код. В этом заключается основное преимущество интерпретатора над компилятором.
Основным аргументом за использование процесса компиляции является скорость. Возможность компилировать любой программный код в машинный, который может понять процессор ПК, исключает использование промежуточного кода. Можно запускать программы без дополнительных шагов, тем самым увеличивая скорость обработки кода.
Но наибольшим недостатком компиляции является специфичность. Когда компилируете программу для работы на конкретном процессоре, вы создаете объектный код, который будет работать только на этом процессоре. Если хотите, чтобы программа запускалась на другой машине, вам придется перекомпилировать программу под этот процессор. А перекомпиляция может быть довольно сложной, если процессор имеет ограничения или особенности, не присущие первому. А также может вызывать ошибки компиляции.
А перекомпиляция может быть довольно сложной, если процессор имеет ограничения или особенности, не присущие первому. А также может вызывать ошибки компиляции.
Основное преимущество интерпретации — гибкость. Можно не только запускать интерпретируемую программу на любом процессоре или платформе, для которых интерпретатор был скомпилирован. Написанный интерпретатор может предложить дополнительную гибкость. В определенном смысле интерпретаторы проще понять и написать, чем компиляторы.
С помощью интерпретатора проще добавить дополнительные функции, реализовать такие элементы, как сборщики мусора, а не расширять язык.
Другим преимуществом интерпретаторов является то, что их проще переписать или перекомпилировать для новых платформ.
Написание компилятора для процессора требует добавления множества функций, или полной переработки. Но как только компилятор написан, можно скомпилировать кучу интерпретаторов и на выходе мы имеем перспективный язык. Не нужно повторно внедрять интерпретатор на базовом уровне для другого процессора.
Самым большим недостатком интерпретаторов является скорость. Для каждой программы выполняется так много переводов, фильтраций, что это приводит к замедлению работы и мешает выполнению программного кода.
Это проблема для конкретных real-time приложений, таких как игры с высоким разрешением и симуляцией. Некоторые интерпретаторы содержат компоненты, которые называются just-in-time компиляторами (JIT). Они компилируют программу непосредственно перед ее исполнением. Это специальные программы, вынесенные за рамки интерпретатора. Но поскольку процессоры становятся все более мощными, данная проблема становится менее актуальной.
Всегда июмейте всегда в виду, что некоторые языки программирования специально предназначены для компиляции кода, например, C. В то время как другие языки всегда должны интерпретироваться, например Java.
Для меня не имеет значения, скомпилировано что-то или интерпретировано, если оно может выполнить задачу эффективно.
Некоторые системы не предлагают технические условия для эффективного использования интерпретаторов. Поэтому вы должны запрограммировать их с помощью чего-то, что может быть непосредственно скомпилировано, например C. Иногда нужно выполнить вычисления настолько интенсивно, насколько это возможно. Например, при точном распознавании голоса роботом. В других случаях скорость или вычислительная мощность могут быть не столь критичными, и написать эмулятор на оригинальном языке может быть проще.
Поэтому вы должны запрограммировать их с помощью чего-то, что может быть непосредственно скомпилировано, например C. Иногда нужно выполнить вычисления настолько интенсивно, насколько это возможно. Например, при точном распознавании голоса роботом. В других случаях скорость или вычислительная мощность могут быть не столь критичными, и написать эмулятор на оригинальном языке может быть проще.
Сообщите мне, что бы вы предпочли: интерпретацию или компиляцию? Спасибо за уделенное время!
Пожалуйста, опубликуйте ваши комментарии по текущей теме материала. Мы крайне благодарны вам за ваши комментарии, отклики, подписки, дизлайки, лайки!
Вадим Дворниковавтор-переводчик статьи «Interpretation Versus Compilation»
MexBIOS — интерпретатор графически-разработанных программ
Введение
Применение систем программирования в свое время произвело настоящую революцию среди электронных устройств. За счет того, что стало возможным наращивать количество разнообразных функций посредством смены программного кода и без изменения аппаратной части, микропроцессорная техника быстро вошла во все сферы нашей повседневной жизни.
В настоящее время компании — флагманы электротехнической промышленности все чаще оснащают свои специализированные электронные устройства управления встроенными системами программирования, посредством которых пользователь может устанавливать собственные алгоритмы работы устройств промышленного применения — преобразователей частоты, сервоконтроллеров, модулей управления движением, блоков диагностики и сигнализации. Целесообразность интеграции функции программирования внутрь устройства очевидна и положительно оценена пользователями: не нужен дополнительный внешний контроллер, а значит, нет необходимости и в его программировании, отсутствуют проблемы совмещения габаритов и кабельных соединений, и пользователь в соответствии с конкретными требованиями может изменить логику работы своего устройства. Все это снижает стоимость запуска конечного оборудования, обслуживающего технологический процесс.
С помощью встроенной системы программирования, работающей, как правило, на языках программирования BASIC и Си, пользователь без привлечения разработчика может изменить алгоритм функционирования устройства для адаптации его к требованиям собственного технологического процесса. Осуществляется это посредством написанного пользователем программного кода, для которого в качестве входных данных принимается состояние дискретных и аналоговых входов, а также логических состояний и значений внутренних переменных, а в качестве выходных данных — задания на отработку технологической величины и значения коэффициентов и параметров настроек. При этом базовое (системное) программное обеспечение устройства остается неизменным, меняется только логический «интерфейс» взаимодействия с внешней средой.
Осуществляется это посредством написанного пользователем программного кода, для которого в качестве входных данных принимается состояние дискретных и аналоговых входов, а также логических состояний и значений внутренних переменных, а в качестве выходных данных — задания на отработку технологической величины и значения коэффициентов и параметров настроек. При этом базовое (системное) программное обеспечение устройства остается неизменным, меняется только логический «интерфейс» взаимодействия с внешней средой.
В связи с тем, что встраивание систем программирования внутрь устройства практически не ведет к изменению аппаратной части и, более того, такие системы могут быть интегрированы в уже выпускающиеся устройства, для увеличения конкурентных преимуществ проектируемой и выпускаемой продукции определенную перспективу представляет создание универсальной системы исполнения программ пользователя на микроконтроллере.
Компания «НПФ Мехатроника-Про», участник Texas Instruments Developer Network, разработала систему MexBIOS, которая является интерпретатором программ пользователя и может быть интегрирована в проекты встроенного программного обеспечения различных микроконтроллерных устройств.
Описание системы программирования
Система МехBIOS предназначена для интеграции в 16‑ и 32‑разрядные микроконтроллеры, она позволяет создавать программное обеспечение микроконтроллеров графическим и текстовым методом, в том числе формировать события, формулы, алгоритмы, объявлять переменные и обращаться к ячейкам памяти. Система ориентирована на решение прикладных задач, в то время как обслуживание коммуникаций и периферийных устройств решается разработчиком на уровне системного программного обеспечения микроконтроллера. Система состоит из двух частей: аппаратно зависимой (ядро интерпретатора и библиотека функций) и среды программирования MexBIOS Development Studio.
Ядро интерпретатора и библиотека, содержащая скомпилированные функции, загружаются в память микроконтроллера и являются аппаратно зависимыми. Адаптация для конкретного типа микроконтроллера выполняется с помощью его стандартного компилятора. Вызов ядра интерпретатора осуществляется из системного ПО микроконтроллера, а вызов функций библиотеки осуществляет интерпретатор исходя из программы пользователя. В качестве функций библиотеки выступают операции арифметики и логики, вычисления цифровых регуляторов и фильтров, координатные и тригонометрические преобразования и т. д. (всего более ста стандартных функций). Следует отметить, что при этом обеспечивается высокая скорость исполнения интерпретатором программного кода за счет запуска уже предварительно скомпилированных функций.
В качестве функций библиотеки выступают операции арифметики и логики, вычисления цифровых регуляторов и фильтров, координатные и тригонометрические преобразования и т. д. (всего более ста стандартных функций). Следует отметить, что при этом обеспечивается высокая скорость исполнения интерпретатором программного кода за счет запуска уже предварительно скомпилированных функций.
Среда программирования MexBIOS Development Studio предназначена для создания графических программ пользователя с возможностью последующей загрузки в микроконтроллер. MexBIOS Development Studio запускается на персональном компьютере, эта среда позволяет предварительно моделировать работу проектируемого алгоритма совместно с моделями объектов управления и проводить визуализацию управляемых процессов. При моделировании на персональном компьютере будет исполняться та же программа, которая затем будет загружена в микроконтроллер, при этом учитываются типы данных используемых переменных и ограничения на точность представления значений. В качестве моделей объектов, которыми должен управлять разрабатываемый код, могут выступать как имеющиеся в системе модели различных типов электродвигателей и механизмов, так и самостоятельно разработанные пользователем модели.
В качестве моделей объектов, которыми должен управлять разрабатываемый код, могут выступать как имеющиеся в системе модели различных типов электродвигателей и механизмов, так и самостоятельно разработанные пользователем модели.
Внешний вид среды программирования показан на рис. 1, где продемонстрированы фрагменты проекта по созданию встроенного программного обеспечения для станции управления лифтами.
Рис. 1. Экран работы по созданию системы управления лифтовой станцией:
1 — панель визуализации;
2 — поле алгоритмов;
3 — корневое поле для объявления переменных, событий и используемых протоколов коммуникаций;
4 — поле блок-диаграмм;
5 — поле машины состояний;
6 — окно структуры проекта;
7 — панель меню
Среда программирования кодирует разработанные алгоритмы и блок-схемы в специальный файл, содержащий условия запуска требуемых функций библиотеки и направления передачи данных между функциями. Этот файл с программой загружается в микроконтроллер и выполняется интерпретатором.
Подключение системы к проекту
Для запуска системы на имеющемся микроконтроллере необходимо провести минимальное количество действий, позволяющее вызвать ядро системы и осуществлять коммуникации с компьютером, на котором установлена система MexBIOS. Для этого необходимо:
- Подключить библиотеку к имеющемуся проекту программного обеспечения устройства (системному ПО). Размер библиотеки зависит от количества блоков, которое может быть откорректировано разработчиком. Предоставляются возможности по добавлению в библиотеку собственных блоков.
- Сконфигурировать интерфейс коммуникаций устройства для связи с компьютером для обеспечения процесса загрузки программы пользователя и последующей отладки программы.
- Настроить драйвер работы с EEPROM-микросхемой для сохранения программы пользователя в устройстве.
- Установить вызов интерпретатора по требуемому событию (например, прерыванию таймера).
Более детально действия описаны в документации к системе, где также приведены примеры подключения системы для различных типов микроконтроллеров.
После загрузки исполняемого файла в микроконтроллер пользователь связывается с ним посредством персонального компьютера, на котором создаются программы пользователя в графическом виде, после предварительного моделирования они загружаются на исполнение в микропроцессор.
Использование системы
Применение визуального программирования позволяет инженерам, не являющимся специалистами в области программирования, разрабатывать интеллектуальную «начинку» встроенной системы управления. Проектирование на уровне блок-схем, алгоритмов, машин состояний является признанной тенденцией, упрощающей процесс разработки и документирования проекта.
Проектирование ПО в системе начинается с объявления переменных, используемых разрабатываемыми алгоритмами. Объявление переменных осуществляется путем выноса на рабочее поле системного блока VAR. На экране (рис. 2) находится алгоритм, вызывающий последовательно основные модули системы. Здесь показано, что используются протоколы коммуникаций (Modbus_RTU для связи с системой управления электродвигателем главного движения, TCP/CLIENT1 и TCP/SERVER1 для связи по Ethernet с компьютером диспетчера), в центре рабочего поле объявлены переменные. Переменные допускается выносить только на корневое поле проекта. В автоматически открывающемся окне инспектора необходимо задать имя переменной и тип. (Можно выбрать из списка: «плавающая запятая» либо «фиксированная запятая» заданного формата.)
Переменные допускается выносить только на корневое поле проекта. В автоматически открывающемся окне инспектора необходимо задать имя переменной и тип. (Можно выбрать из списка: «плавающая запятая» либо «фиксированная запятая» заданного формата.)
Рис. 2. Корневое поле для проекта системы управления лифтовой станцией
В дальнейшем к переменной можно обращаться посредством блоков In и Out (соответственно — считать и записать значение), предварительно указав в инспекторе свойств данного блока привязку к требуемой переменной.
Для прямого обращения в память существуют специальные блоки: RD_MEM (для считывания значения ячейки памяти) и WR_MEM (для записи). При их использовании необходимо в окне инспектора свойств блока указать адрес в памяти данных, с которым будет работать этот блок.
Для удобства при обмене информации между основным (системным) ПО и интерпретатором можно подключить map-файл, образованный при компиляции проекта встроенного программного обеспечения. Этот файл уже содержит информацию об адресах всех глобальных переменных, и список переменных будет отражен в инспекторе свойств в поле Address блоков RD_MEM и WR_MEM, через которые значения требуемых переменных становятся доступны для программы пользователя, что позволяет ему обращаться к переменным системного ПО.
Этот файл уже содержит информацию об адресах всех глобальных переменных, и список переменных будет отражен в инспекторе свойств в поле Address блоков RD_MEM и WR_MEM, через которые значения требуемых переменных становятся доступны для программы пользователя, что позволяет ему обращаться к переменным системного ПО.
Проектирование системы в среде осуществляется за счет прорисовки алгоритмов, в которых необходимо указать условия запуска формул, которые осуществляют изменение значения переменных, либо следующих вложенных алгоритмов.
Формулы создаются путем прорисовывания блок-схем за счет использования готовых блоков, являющихся графическим отображением функции, запрограммированной в микроконтроллер библиотеки. Пользователь должен установить требуемый набор блоков и соединить между собой их входы и выходы, обеспечивающие необходимые потоки данных. Пример блок-схемы цифрового ПИД-регулятора показан на рис. 3. Блок мультиплексора A_MUX определяет источник получения сигнала обратной связи и задания его на основе состояния внешних переменных.
Рис. 3. Блок-схема цифрового ПИД-регулятора
Каждый блок изначально создан с помощью текстового программирования. Пользователь может просмотреть текст и при необходимости его модифицировать. (Для этого потребуется перепрограммировать микроконтроллер в связи с изменением библиотеки либо воспользоваться блоком текстового интерпретатора.) На рис. 4 показано окно текстового редактора утилиты конструктора блоков среды MexBIOS Development Studio, демонстрирующее создание блока нелинейной зависимости.
Рис. 4. Конструктор блоков системы, позволяющий задавать количество и тип входов/выходов и прописывать программный код в текстовом виде
Алгоритмы могут быть вложены друг в друга согласно иерархии исполнения. Кроме условий запуска, можно организовать и циклическое исполнение выбранных участков (блок While). Фактически алгоритмы определяют условия запуска и порядок выполнения формул, в свою очередь выполняющих непосредственные действия над данными. Элементы условного ветвления if (ромбы) на основании своих условий запускают другую ветку алгоритма (рис. 5) или требуемую формулу (прямоугольник).
Элементы условного ветвления if (ромбы) на основании своих условий запускают другую ветку алгоритма (рис. 5) или требуемую формулу (прямоугольник).
Рис. 5. Пример алгоритма в среде MexBIOS Development Studio
Машина состояний — это метод создания программ (автоматное программирование), который набирает все бóльшую популярность. Пользователь должен определить основные логические состояния, в которых может находиться управляемая система (например, «Стоп», «Движение вверх», «Движение вниз» и т. д.), определить действия, характерные для каждого состояния (включить контактор, установить скорость и т. д.), и указать направления и условия перехода между состояниями. Этот метод позволяет легко наращивать функциональность алгоритма, он прост и нагляден. Система может создать любое количество состояний (ограничение только по максимально свободной памяти микроконтроллера), с установлением индивидуальных условий перехода и детализацией действий для каждого состояния.
Для создания машины состояний необходимо вынести на рабочее поле нужное количество блоков состояний, соединить состояния между собой стрелками, указывающими направления перехода, разместить на стрелках условия перехода и в каждом состоянии установить соответствующие блок-схемы. На рис. 6 показана машина состояний для управления перемещением лифта.
Рис. 6. Пример машины состояний, описывающей логику управления лифтом
Следует отметить, что MexBIOS Development Studio предоставляет множество дополнительных возможностей, позволяющих говорить о ней как о полномасштабной системе автоматизированного проектирования программного обеспечения. Большинство из них продемонстрированы в видеоуроках, прилагающихся к системе. Перечислим лишь некоторые из них:
- Генерация кода — позволяет на основе графически сформированной программы создать ее текстовое представление на языке Си, с последующим применением в системном ПО микроконтроллера.
- Вывод графиков — позволяет визуализировать изменение значения наблюдаемой переменной за заданный промежуток времени.

- Блоки драйверов — позволяют напрямую конфигурировать периферийные блоки микроконтроллеров (АЦП, ШИМ, дискретные пины процессора и т. д.).
- Создание интерфейсов управления — позволяет создавать графические (в том числе анимированные) интерфейсы управления для персональных компьютеров.
- Поддержка протоколов коммуникаций — позволяет непосредственно из среды MexBIOS Development Studio связываться по стандартным протоколам коммуникации типа Ethernet, Modbus и т. д. с устройствами, поддерживающими эти протоколы.
- Подключение внешних приложений — позволяет среде обмениваться данными с другими приложениями.
- Готовые шаблоны распространенных систем управления — позволяют быстро запустить управление электродвигателем требуемого типа.

Заключение
Рассмотренная система дает возможность эффективно программировать как в текстовом виде (задачи системного програм-много обеспечения и создания блоков), так и в различных парадигмах графического программирования, причем одновременно. Встраивание системы в существующие проекты программного обеспечения позволяет значительно повысить функциональные свойства устройств. Пользователь получает возможность настраивать не только параметры устройства управления, но и логику его работы. Наглядное графическое представление алгоритмов значительно упрощает их понимание и позволяет проводить дальнейшие работы по оптимизации работы устройства при изменении объекта управления или требований технологического процесса. Система прежде всего рассчитана для устройств, чьи пользователи обладают минимально достаточной квалификацией для создания собственных алгоритмов управления, которые разработчики устройства не могут заложить изначально из-за отсутствия знаний об особенностях его применения для конкретных целей.
Встраивание системы в существующие проекты программного обеспечения позволяет значительно повысить функциональные свойства устройств. Пользователь получает возможность настраивать не только параметры устройства управления, но и логику его работы. Наглядное графическое представление алгоритмов значительно упрощает их понимание и позволяет проводить дальнейшие работы по оптимизации работы устройства при изменении объекта управления или требований технологического процесса. Система прежде всего рассчитана для устройств, чьи пользователи обладают минимально достаточной квалификацией для создания собственных алгоритмов управления, которые разработчики устройства не могут заложить изначально из-за отсутствия знаний об особенностях его применения для конкретных целей.
Литература
- Систему можно скачать с сайта производителя www.mexbios.com.
Выбор и установка интерпретаторов Python — Visual Studio (Windows)
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 3 мин
Область применения:Visual StudioVisual Studio для Mac Visual Studio Code
По умолчанию при установке рабочей нагрузки Python для разработки в Visual Studio 2017 и более поздних версий также устанавливается Python 3 (64-разрядная версия). При необходимости вы можете установить 32-разрядную и 64-разрядную версии Python 2, Python 3 вместе с Miniconda (Visual Studio 2019) или Anaconda 2/Anaconda 3 (Visual Studio 2017), как описано в руководстве по установке.
При необходимости вы можете установить 32-разрядную и 64-разрядную версии Python 2, Python 3 вместе с Miniconda (Visual Studio 2019) или Anaconda 2/Anaconda 3 (Visual Studio 2017), как описано в руководстве по установке.
Кроме того, вы можете установить стандартные интерпретаторы из диалогового окна Add Environment (Добавление среды). Выберите команду Add Environment (Добавление среды) в окне Python Environments (Среды Python) или в панели инструментов Python, выберите вкладку Python installation (Установка Python), укажите интерпретаторы для установки и нажмите Install (Установить).
Кроме того, любой интерпретатор из приведенной ниже таблицы можно установить вручную, не используя Visual Studio Installer. Например, если вы установили Anaconda 3 еще до установки Visual Studio, нет необходимости снова устанавливать этот дистрибутив с помощью Visual Studio Installer. Вы также можете установить интерпретатор вручную, если, например, доступна новая версия, которая пока что не отображается в установщике Visual Studio.
Примечание
Visual Studio поддерживает Python 3.7. Visual Studio можно использовать для редактирования кода, написанного на языке Python других версий, но эти версии официально не поддерживаются, а функции, такие как IntelliSense и отладка, могут не работать.
Для Visual Studio 2015 и более ранних версий нужно вручную установить один из интерпретаторов.
Примечание
Хотя в Visual Studio предлагается установить дистрибутив Anaconda, на использование дистрибутива и дополнительных пакетов из Anaconda Repository распространяются условия предоставления услуг Anaconda. Согласно этим условиям, некоторым организациям может потребоваться приобрести коммерческую лицензию Anaconda или настроить средства для доступа к другому репозиторию. Дополнительные сведения см. в документации по каналам Conda.
Visual Studio (любой версии) автоматически обнаруживает все установленные интерпретаторы Python и окружения для них, проверяя значения в реестре (согласно описанию регистрации Python в реестре Windows 514 PEP). Установки Python обычно находятся в разделе HKEY_LOCAL_MACHINE\SOFTWARE\Python (32-разрядная версия) и HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Python (64-разрядная версия), затем в узлах для распределения, таких как PythonCore (CPython) и ContinuumAnalytics (Anaconda).
Установки Python обычно находятся в разделе HKEY_LOCAL_MACHINE\SOFTWARE\Python (32-разрядная версия) и HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\Python (64-разрядная версия), затем в узлах для распределения, таких как PythonCore (CPython) и ContinuumAnalytics (Anaconda).
Если Visual Studio не сможет обнаружить установленное окружение, см. раздел Указание существующего окружения вручную.
Visual Studio отображает все известные окружения в окне Окружения Python и автоматически обнаруживает обновления для существующих интерпретаторов.
| Интерпретатор | Описание |
|---|---|
| CPython | Собственный и самый используемый интерпретатор доступен в 32- и 64-разрядных версиях (рекомендуется 32-разрядная). Он предоставляет последние возможности языка, максимальную совместимость пакета Python, полную поддержку отладки и взаимодействие с IPython. См. также статью о сравнении Python 2 и Python 3. Visual Studio 2015 и более ранние версии не поддерживают Python 3.6+, и в них может появиться ошибка Неподдерживаемая версия Python 3.6. Используйте Python 3.5 или более раннюю версию. Visual Studio 2015 и более ранние версии не поддерживают Python 3.6+, и в них может появиться ошибка Неподдерживаемая версия Python 3.6. Используйте Python 3.5 или более раннюю версию. |
| IronPython | Реализация .NET для Python (доступна 32- и 64-разрядная версия), обеспечивающая взаимодействие с C#, F# и Visual Basic, доступ к API-интерфейсам .NET, стандартную отладку Python (но не отладку в смешанном режиме C++) и отладку в смешанном режиме IronPython и C#. Однако IronPython не поддерживает виртуальные среды. |
| Anaconda | Открытая платформа для анализа и обработки данных на базе Python, которая включает в себя последнюю версию CPython и большинство пакетов со сложной установкой. Если вы не можете сделать выбор, рекомендуется использовать Anaconda. |
| PyPy | Реализация JIT для Python с высокопроизводительной трассировкой, которая хорошо подходит для долго выполняющихся программ и ситуаций, когда вы обнаружили проблемы с производительностью, которые не удается устранить другими способами. Работает с Visual Studio, но имеет ограниченную поддержку расширенных возможностей отладки. Работает с Visual Studio, но имеет ограниченную поддержку расширенных возможностей отладки. |
| Jython | Реализация Python на виртуальной машине Java (JVM). Как и в IronPython, код, выполняемый в Jython, может взаимодействовать с классами и библиотеками Java. Однако многие библиотеки, предназначенные для CPython, могут быть недоступны. Работает с Visual Studio, но имеет ограниченную поддержку расширенных возможностей отладки. |
Сведения о новых способах обнаружения сред Python см. в статье PTVS Environment Detection (Обнаружение среды PTVS) на сайте github.com.
Перемещение интерпретатора
Если вы переместите существующий интерпретатор в новое расположение с помощью средств файловой системы, Visual Studio не сможет отследить изменение автоматически.
Если изначально вы указали расположение интерпретатора в окне Окружения Python, укажите новое расположение, изменив параметры окружения на вкладке Настройка в этом же окне.
См. раздел Указание существующего окружения вручную.Если вы установили интерпретатор с помощью установщика, выполните следующие действия для переустановки интерпретатора в новом расположении:
- Верните интерпретатор Python в исходное расположение.
- Удалите интерпретатор с помощью установщика, который очистит записи в реестре.
- Повторно установите интерпретатор в новом расположении.
- Перезапустите Visual Studio. Вместо старого расположения должно автоматически определиться новое.
 См. раздел Указание существующего окружения вручную.
См. раздел Указание существующего окружения вручную.Такой процесс позволяет гарантировать, что в реестре правильно обновятся записи о расположении интерпретатора, которое использует Visual Studio. Также установщик устраняет все возможные побочные эффекты.
См. также
- Управление средами Python
- Выбор интерпретатора для проекта
- Использование файла requirements.txt для зависимостей
- Пути поиска
- Справочная информация по окну «Окружения Python»
4 Интерпретатор функций
← пред вверх следующая →
4 Интерпретатор функций
В этом задании вы реализуете расширение Paret для поддержки списков и
функции более высокого порядка.
4.1 Определения данных
Вы будете реализовывать расширенный Парет с функциями и списками более высокого порядка. Его конкретный синтаксис:
exp := ( | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (let (( | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (if | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| правда | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ложь | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
# Для создания функций | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 90 006| (lam ( | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
# Для вызова функций | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ( | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
# Для списков | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 9000| ( | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (ссылка | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| пустой | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
оп := + | — | * | / | < | > | == | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
unop := первый | отдых | IS-EMPTY | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
ID: = любой символ, отличный от OP или UnoP, | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
или TRUE, Fals программы:
0003
В основном это сопоставления один к одному с фрагментами конкретного синтаксиса. Программы Паре могут привести к значениям или вызвать ошибки, которые описываются двумя Структуры данных Pyret:
Наконец, ваш интерпретатор будет основан на среде, а не на
4.2 Семантика ParetВы определите вычислитель для Paret с помощью одной функции:
Однако семантика выражений из оригинального Парета не изменилась.
они должны быть реализованы с помощью среды, а не замены (как
отмечено ниже). В вашей реализации не должно быть функции subst.
4.3 ЛогистикаВам предоставлены два файла:
Файлы находятся по адресу: Код: https://code.pyret.org/editor#share=0B32bNEogmncOZUFCTGh5eFpZWk0&v=v0.5r790 Тесты: https://code.pyret.org/editor#share=0B32bNEogmncOVFRJMGduZ1ZqOVU&v=v0.5r790 Оба файла импортируют модуль fun-interp-defs.arr, который определяет определения данных и вспомогательная функция, используемая eval для разбора строк на АСТ: https://code. 4.3.1 Использование модулейВот подходящий шаблон привязки для этого задания, если хотите. использовать его:
4.4 Этапы тестирования и отправкиК полуночи воскресенья (15 февраля) вы должны отправить 5–10 из того, что вы думаете самые интересные тесты для капитана Тича по ссылке cs91-basic-interp от: https://www.captain-teach.org/swarthmore-cs091/assignments/ Отправьте один файл Pyret с заполненными тестовыми примерами в контрольный блок в файл шаблона. Если вы планируете свое время на выходные, вы не нужно тратить больше часа, играя с интерпретатором, чтобы придумать интересные случаи. К полуночи понедельника (16 февраля) вы должны отправить все отзывы, которые вы
назначенный. Вы можете свободно заполнять обзоры в любое время до
затем, и они будут назначены по мере поступления материалов (поэтому, если несколько человек
представить в субботу, рассмотрение может начаться тогда). Во вторник будет выпущен набор различных реализаций, с инструкции по добавлению строки импорта для доступа и тестирования различных реализации. Обновление : теперь вы можете включить интерпретаторы для тестирования с помощью:
Все интерпретаторы можно найти на B.bad-interps. Их имена являются:
К полуночи четверга (19 февраля) вы должны отправить заполненный реализация интерпретатора и окончательный набор тестов. Используйте тот же ссылка на отправку, как указано выше, но отправьте на шаг кода, который разблокируется после Вы завершаете свои обзоры. 4.5 Обращение за помощьюВы получите от меня более эффективную обратную связь, если зададите свой вопрос в одном одним из следующих способов (постановка вопроса может даже решить вашу проблему):
Конечно, вы можете спрашивать все, что хотите, но такие вопросы, как правило, быть самым эффективным. 4.6 ОценкаВаша оценка будет состоять из нескольких частей:
Рецензии коллег не влияют на вашу оценку, хотя вы можете копировать тесты от других, которые вы видите во время просмотра. Пожалуйста, не делитесь тестами с одним другое, помимо того, что было предоставлено во время проверки теста. Написание интерпретатора с нуляНекоторые говорят, что «все сводится к единицам и нулям» — но действительно ли мы понимаем, как наши программы преобразуются в эти биты? И компиляторы, и интерпретаторы берут необработанную строку, представляющую программу, анализируют ее и анализируют. Хотя интерпретаторы являются более простыми из двух, написание даже очень простого интерпретатора (который выполняет только сложение и умножение) будет поучительным. Мы сосредоточимся на том, что общего у компиляторов и интерпретаторов: лексическом анализе и разборе входных данных. Что нужно и что нельзя делать при написании собственного интерпретатора Читатели могут задаться вопросом Что не так с регулярным выражением? Регулярные выражения обладают мощными возможностями, но грамматика исходного кода недостаточно проста для их анализа. Правильное написание синтаксических анализаторов вручную может быть сложной задачей со всеми задействованными пограничными случаями. Вот почему существуют популярные инструменты, такие как ANTLR, которые могут генерировать синтаксические анализаторы для многих популярных языков программирования. Существуют также библиотеки, называемые комбинаторами синтаксических анализаторов , которые позволяют разработчикам писать синтаксические анализаторы непосредственно на предпочитаемых ими языках программирования. Примеры включают FastParse для Scala и Parsec для Python. Мы рекомендуем читателям в профессиональном контексте использовать такие инструменты и библиотеки, чтобы не изобретать велосипед. Обзор компонентов интерпретатораИнтерпретатор — это сложная программа, поэтому она состоит из нескольких этапов:
Здесь мы не будем создавать специальный интегрированный интерпретатор. Вместо этого мы рассмотрим каждую из этих частей и их общие проблемы на отдельных примерах. В итоге код пользователя будет выглядеть так: val input="2*7+5" токены val = Lexer(input). После трех этапов мы ожидаем, что этот код вычислит окончательное значение и напечатает
В частности, код здесь написан в синтаксисе необязательных фигурных скобок Scala3 (синтаксис на основе отступов, подобный Python). Но ни один из подходов не является специфичным для Scala , а Scala похожа на многие другие языки: читатели найдут простым преобразование этих примеров кода на другие языки. За исключением этого, примеры можно запускать онлайн с помощью Scastie. Наконец, разделы Lexer, Parser и Interpreter содержат различных примеров грамматик . Компонент интерпретатора 1: Написание лексера Допустим, мы хотим лексировать эту строку:
В этом примере пробелы между токенами будут пропущены. На данном этапе выражения не обязательно должны иметь смысл; лексер просто преобразует входную строку в список токенов. (Работа по «осмыслению токенов» возложена на синтаксический анализатор.) Мы будем использовать этот код для представления токена: case class Token(
tpe: Token.Type,
текст: строка,
startPos: Int
)
Токен объекта:
Тип перечисления:
случай Число
чехол Плюс
чехол раз
Идентификатор случая
случай Истинно
случай Ложь
случай EOF
Каждый токен имеет тип, текстовое представление и положение в исходном вводе. Маркер Это будет вывод нашего лексера: Ввод лексинга: 123 + 45 правда * ложь1 Токены: Список( Токен (tpe = число, текст = "123", tokenStartPos = 0), Токен (tpe = Плюс, текст = "+", tokenStartPos = 4), Токен (tpe = число, текст = "45", tokenStartPos = 6), Token(tpe = True, text = "true", tokenStartPos = 9), Токен (tpe = раз, текст = "*", tokenStartPos = 14), Токен (tpe = идентификатор, текст = "false1", tokenStartPos = 16), Token(tpe = EOF, text = " Давайте рассмотрим реализацию: class Lexer(input: String):
def lex(): Список[Токен] =
val tokens = mutable.ArrayBuffer.empty[Token]
переменная текущая позиция = 0
в то время как currentPos < input.length делать
val tokenStartPos = currentPos
val lookahead = input (currentPos)
если lookahead.Мы начинаем с пустого списка токенов, затем просматриваем строку и добавляем токены по мере их поступления. Мы используем упреждающий символ, чтобы определить тип следующего токена . Обратите внимание, что опережающий символ не всегда является самым дальним исследуемым символом. Основываясь на предварительном просмотре, мы знаем, как выглядит токен, и используем Если опережение содержит пробелы, мы пропускаем его. Однобуквенные токены тривиальны; мы добавляем их и увеличиваем индекс. Для целых чисел нам нужно позаботиться только об индексе. Теперь мы подошли к чему-то более сложному: идентификаторы против литералов. Будьте осторожны при работе с такими операторами, как После этого наш лексер создал список токенов. Компонент интерпретатора 2: Написание синтаксического анализатораМы должны придать нашим токенам некоторую структуру — мы мало что можем сделать с одним списком. Например, нам нужно знать: Какие выражения являются вложенными? Какие операторы применяются в каком порядке? Какие правила области применения применяются, если таковые имеются? Древовидная структура поддерживает вложенность и порядок. Но сначала мы должны определить некоторые правила построения деревьев. Обратите внимание, что следующий синтаксический анализатор не использует предыдущий пример лексера . Это для добавления чисел, поэтому его грамматика имеет только две лексемы, expr -> expr '+' expr выражение -> ЧИСЛО Эквивалент с использованием вертикальной черты ( expr -> expr '+' expr | ЧИСЛО В любом случае у нас есть два правила: одно говорит, что мы можем суммировать два Правила обычно определяются формальной грамматикой . Формальная грамматика состоит из:
Сами правила, как показано выше
Начальное правило (первое указанное правило согласно соглашению)
Два типа символов для определения правил:
Терминалы: «буквы» (и другие символы) нашего языка — несократимые символы, из которых состоят токены. Слева от правила может находиться только нетерминал; правая часть может иметь как терминалы, так и нетерминалы. В приведенном выше примере терминалами являются Есть много способов реализовать этот синтаксический анализатор. Здесь мы будем использовать метод разбора «рекурсивный спуск». Это самый распространенный тип, потому что его проще всего понять и реализовать. Анализатор рекурсивного спуска использует одну функцию для каждого нетерминала в грамматике. Парсер для первого правила будет выглядеть примерно так (полный код): def expr() =
выражение()
есть('+')
выражение()
Функция Неоднозначность грамматикиПервая проблема — двусмысленность нашей грамматики, которая может быть незаметна на первый взгляд: выражение -> выражение '+' выражение | ЧИСЛО Учитывая ввод Левосторонние и правосторонние AST. Вот почему нам нужно ввести некоторую асимметрию : expr -> expr '+' NUM | ЧИСЛО Набор выражений, которые мы можем представить с помощью этой грамматики, не изменился со времени ее первой версии. Только сейчас однозначно : Анализатор всегда идет влево. Как раз то, что нам было нужно! Это делает нашу операцию Лево-рекурсивные правилаК сожалению, приведенное выше исправление не решает другую нашу проблему, левую рекурсию: def expr() =
выражение()
есть('+')
есть(ЧИСЛО)
У нас есть бесконечная рекурсия здесь. Если бы мы вошли в эту функцию, то в конечном итоге получили бы ошибку переполнения стека. Но теория разбора может помочь! Предположим, у нас есть такая грамматика, где A -> A альфа | Б Мы можем переписать эту грамматику как: A -> B A' А' -> альфа А' | эпсилон Здесь Возьмем текущую версию нашей грамматики: expr -> expr '+' NUM | ЧИСЛО Следуя методу перезаписи правил синтаксического анализа, описанному выше, с expr -> NUM exprOpt exprOpt -> '+' ЧИСЛО exprOpt | эпсилон Теперь с грамматикой все в порядке, и мы можем разобрать ее с помощью анализатора рекурсивного спуска. Давайте посмотрим, как такой синтаксический анализатор будет искать эту последнюю итерацию нашей грамматики: class Parser(allTokens: List[Token]):
импортировать Token.Type
частные токены var = allTokens
частный var lookahead = tokens.head
деф синтаксический анализ(): Единица измерения =
выражение()
если lookahead.tpe != Type.EOF, то
error(s"Неизвестный токен '${lookahead.text}' в позиции ${lookahead.tokenStartPos}")
частное выражение выражения(): Unit =
есть(Тип.Число)
exprOpt()
частная защита exprOpt(): Unit =
если lookahead. Здесь мы используем токен Кроме того, если мы переключимся на потоковый лексер, у нас будет не список в памяти, а итератор, поэтому нам нужен маркер, чтобы знать, когда мы подошли к концу ввода. Когда мы подойдем к концу, токен Просматривая код, мы видим, что выражение может быть просто числом. Если ничего не осталось, следующий жетон не будет Если во входной строке больше токенов, то они должны выглядеть как Генерация ASTТеперь, когда мы успешно проанализировали наше выражение, трудно что-либо сделать с ним как есть. Мы могли бы поместить несколько обратных вызовов в наш парсер, но это было бы очень громоздко и нечитаемо. Вместо этого мы вернем AST, дерево, представляющее входное выражение: класс случая Expr(num: Int, exprOpt: ExprOpt) перечисление Expropt: case Opt(num: Int, exprOpt: ExprOpt) чехол Эпсилон Это похоже на наши правила, использующие простые классы данных. Теперь наш синтаксический анализатор возвращает полезную структуру данных: class Parser(allTokens: List[Token]):
импортировать Token.Type
частные токены var = allTokens
частный var lookahead = tokens.head
деф разбор(): Выражение =
val res = expr()
если lookahead. Информацию о Упрощение правил Наш нетерминал '+' NUM expOpt | эпсилон Трудно распознать шаблон, который он представляет в нашей грамматике, просто взглянув на него. Оказывается, эту рекурсию можно заменить более простой конструкцией: ('+' NUM)*
Эта конструкция просто означает Теперь наша полная грамматика выглядит так: expr -> NUM exprOpt* exprOpt -> '+' ЧИСЛО И наш AST выглядит лучше: case class Expr(num: Int, exprOpts: Seq[ExprOpt]) класс case ExprOpt (число: Int) Полученный синтаксический анализатор такой же длины, но более простой для понимания и использования. Мы исключили Нам даже 9 не понадобилось0417 ExprOpt класс здесь. Мы могли бы просто поместить Учтите, что если бы у нас было несколько возможных операторов, таких как expr -> NUM exprOpt* exprOpt -> [+-*] ЧИСЛО В этом случае AST требуется case class Expr(num: Int, exprOpts: Seq[ExprOpt]) класс case ExprOpt (op: String, num: Int) Обратите внимание, что синтаксис Компонент интерпретатора 3: Написание интерпретатораНаш интерпретатор будет использовать наш лексер и синтаксический анализатор, чтобы получить AST нашего входного выражения, а затем оценить это AST любым удобным для нас способом. В данном случае мы имеем дело с числами и хотим вычислить их сумму. В реализации нашего примера с интерпретатором мы будем использовать следующую простую грамматику: expr -> NUM exprOpt* exprOpt -> [+-] ЧИСЛО И этот AST: case class Expr(num: Int, exprOpts: Seq[ExprOpt]) класс case ExprOpt (op: Token.Type, num: Int) (Мы рассмотрели, как реализовать лексер и парсер для похожих грамматик, но любой читатель, который застрял, может просмотреть реализации лексера и парсера для этой грамматики в репозитории.) Теперь посмотрим, как написать интерпретатор для приведенной выше грамматики: class Interpreter(ast: Expr):
деф интерпретировать (): Int = eval (аст)
частная оценка (выражение: выражение): Int =
var tmp = expr. Если мы проанализировали наши входные данные в AST без ошибок, мы уверены, что у нас всегда будет хотя бы один Замечание с самого начала о левой ассоциативности Но если мы хотим выйти за рамки интерпретации операторов плюс и минус, нужно определить еще одно правило. Приоритет Мы знаем, как анализировать простое выражение, такое как Большинство людей согласны с тем, что умножение имеет более высокий приоритет, чем сложение. Но парсер этого не знает. Мы не можем просто вычислить его как Это означает, что нам нужно сначала оценить умножение 904:30 . Умножение должно быть на 90 429 дальше от корня AST 90 430, чтобы принудительно оценить его перед сложением. Для этого нам нужно ввести еще один уровень косвенности. Исправление наивной грамматики от начала до концаЭто наша исходная леворекурсивная грамматика, не имеющая правил приоритета: expr -> expr '+' expr | выражение '*' выражение | ЧИСЛО Во-первых, мы даем ему правила приоритета и удаляем его неоднозначность : выражение -> выражение '+' термин | срок термин -> термин '*' ЧИСЛО | ЧИСЛО Затем он получает нелеворекурсивных правил : expr -> term exprOpt* exprOpt -> '+' термин срок -> ЧИСЛО срокОпт* termOpt -> '*' ЧИСЛО В результате получается прекрасно выразительный AST: case class Expr(term: Term, exprOpts: Seq[ExprOpt]) класс случая ExprOpt(term: Term) класс case Term (число: Int, termOpts: Seq[TermOpt]) класс case TermOpt (число: Int) Это дает нам краткую реализацию интерпретатора: class Interpreter(ast: Expr):
деф интерпретировать (): Int = eval (аст)
частная оценка (выражение: выражение): Int =
var tmp = eval(expr.Как и прежде, идеи в отношении необходимого лексера и грамматики были рассмотрены ранее, но при необходимости читатели могут найти их в репозитории. Следующие шаги в написании интерпретаторов Мы не рассматривали это, но обработка ошибок и отчеты являются важными функциями любого синтаксического анализатора. Как разработчики, мы знаем, как неприятно, когда компилятор выдает запутанные или вводящие в заблуждение ошибки. Это область, в которой нужно решить много интересных проблем, таких как предоставление правильных и точных сообщений об ошибках, не отпугивание пользователя большим количеством сообщений, чем необходимо, и изящное восстановление после ошибок. Разработчики должны написать интерпретатор или компилятор, чтобы обеспечить их будущим пользователям лучший опыт. В наших примерах лексеров, синтаксических анализаторов и интерпретаторов мы коснулись только поверхности теорий, лежащих в основе компиляторов и интерпретаторов, которые охватывают такие темы, как:
Для дальнейшего чтения я рекомендую следующие ресурсы:
Бюро трудовой статистики СШАДЛЯ ПРИНТЕРА
Резюме Пожалуйста, включите JavaScript для воспроизведения этого видео. Стенограмма видео доступна по адресу https://www.youtube.com/watch?v=QQ7xfQqRhKk.
Чем занимаются устные и письменные переводчикиУстные и письменные переводчики переводят информацию с одного языка на другой. Рабочая средаУстные и письменные переводчики работают в школах, больницах, залах судебных заседаний, конференц-залах и конференц-центрах. Неполный рабочий день является обычным явлением, и график работы может варьироваться. Как стать устным или письменным переводчиком Устным и письменным переводчикам обычно требуется как минимум степень бакалавра, чтобы начать работать. Они также должны владеть английским языком и, по крайней мере, еще одним языком, а также услугами устного или письменного перевода, которые они намерены предоставлять. ОплатаСредняя годовая заработная плата устных и письменных переводчиков в мае 2021 года составляла 49 110 долларов США. Ежегодно в среднем в течение десятилетия прогнозируется около 9 200 вакансий для устных и письменных переводчиков. Ожидается, что многие из этих вакансий будут вызваны необходимостью замены работников, которые переходят на другую профессию или выходят из состава рабочей силы, например, в связи с уходом на пенсию. Данные по штатам и районамИзучите ресурсы по трудоустройству и заработной плате устных и письменных переводчиков по штатам и районам. Аналогичные профессииСравните должностные обязанности, образование, карьерный рост и оплату устных и письменных переводчиков с аналогичными занятиями. Дополнительная информация, включая ссылки на O*NET Узнайте больше о устных и письменных переводчиках, посетив дополнительные ресурсы, включая O*NET, источник основных характеристик работников и профессий. Чем занимаются устные и письменные переводчики Об этом разделеУстные и письменные переводчики свободно говорят, читают и пишут как минимум на двух языках. Устные и письменные переводчики переводят информацию с одного языка на другой язык. Переводчики работают на разговорном или жестовом языке; переводчики работают на письменном языке. ОбязанностиУстные и письменные переводчики обычно делают следующее:
Устные и письменные переводчики помогают общаться, переводя сообщения или текст с одного языка (обычно называемого исходным языком) на другой язык (целевой язык). Переводчики переводят информацию с одного разговорного языка на другой или, в случае сурдопереводчиков, между разговорным языком и языком жестов. Цель переводчика состоит в том, чтобы люди воспринимали целевой язык так же легко, как если бы это был исходный язык. Переводчики, как правило, должны свободно говорить на обоих языках или подписываться на них, потому что они общаются между людьми, которые не говорят на одном языке. Переводчики могут предоставлять свои услуги удаленно, а также лично. Три общих способа перевода:
Переводчики переводят письменные материалы с одного языка на другой. Цель переводчика состоит в том, чтобы люди читали целевой язык так, как если бы он был исходным языком письменного материала. Для этого переводчик должен быть в состоянии сохранить или воспроизвести письменную структуру и стиль исходного текста, сохраняя при этом точность идей и фактов. Переводчики должны свободно читать исходный язык. Целевой язык, на который они переводят, обычно является их родным языком. Они адаптируют ряд продуктов, включая веб-сайты, маркетинговые материалы и пользовательскую документацию. Почти все переводчики используют в своей работе программное обеспечение. Инструменты автоматизированного перевода (CAT), которые используют компьютерную базу данных ранее переведенных предложений или сегментов (называемую «памятью переводов») для перевода нового текста, позволяют переводчикам быть эффективными и последовательными. Программное обеспечение для машинного перевода автоматически генерирует текст с исходного языка на целевой язык, который переводчики затем просматривают в процессе, называемом постредактированием. Переводы часто проходят несколько редакций, прежде чем стать окончательными. Хотя большинство устных и письменных переводчиков специализируются в определенной области или отрасли, многие из них имеют более чем одну область специализации. Ниже приведены примеры типов устных и письменных переводчиков: Устные переводчики работают в различных общественных учреждениях, предоставляя устные переводы индивидуально или в группах. Общественные переводчики часто требуются на собраниях родителей и учителей, общественных мероприятиях, деловых и общественных встречах, в социальных и государственных учреждениях, при покупке нового дома и во многих других рабочих и общественных условиях. Переводчики конференций работают на мероприятиях, на которых присутствуют неанглоязычные участники. Работа часто связана с международным бизнесом или дипломатией, хотя синхронные переводчики могут предоставлять услуги для любой организации, которая работает с носителями иностранных языков. Работодатели обычно предпочитают опытных переводчиков, которые могут перевести два языка на один родной язык, например, способность переводить с испанского и французского на английский. Конференц-переводчики часто выполняют синхронный перевод. Участники конференции или собрания, которые не понимают языка говорящего, носят наушники, настроенные на переводчика, говорящего на том языке, на котором они хотят слышать. Медицинские или медицинские устные и письменные переводчики обычно работают в медицинских учреждениях и помогают пациентам общаться с врачами, медсестрами, техниками и другим медицинским персоналом. Устные и письменные переводчики должны владеть медицинской терминологией на обоих языках. Они могут переводить документы о согласии пациентов, истории болезни пациентов, фармацевтические и информационные брошюры, нормативную информацию и исследовательские материалы с одного языка на другой. Медицинские или медицинские переводчики должны учитывать личные обстоятельства пациентов и соблюдать конфиденциальность и соблюдать этические стандарты. Переводчики для связи или сопровождения сопровождают либо посетителей из США за границей, либо иностранных гостей в Соединенных Штатах, которые плохо владеют английским языком. Переводя как в официальной, так и в неформальной обстановке, эти специалисты гарантируют, что посетители смогут общаться во время своего пребывания. Юридические или судебные устные и письменные переводчики обычно работают в судах и других судебных инстанциях. При предъявлении обвинений, даче показаний, слушаниях и судебных процессах они помогают людям с ограниченным знанием английского языка. Соответственно, они должны понимать юридическую терминологию. Судебные переводчики иногда должны читать вслух исходные документы на целевом языке, что называется переводом с листа. Литературные переводчики переводят книги, стихи и другие опубликованные произведения с исходного языка на целевой язык. Когда это возможно, литературные переводчики тесно сотрудничают с авторами, чтобы уловить предполагаемый смысл, а также литературные и культурные отсылки к оригинальной публикации. Локализаторы участвуют в комплексном процессе адаптации текста и графики с исходного языка на целевой язык. Цель перевода локализаторов — сделать так, чтобы продукт или услуга были созданы в стране, где они будут продаваться. Они должны не только знать оба языка, но и понимать техническую информацию, с которой они работают, и культуру людей, которые будут использовать продукт или услугу. Локализаторы обычно работают в командах. Переводчики жестового языка облегчают общение между глухими или слабослышащими людьми и людьми, которые могут слышать. Переводчики языка жестов должны свободно владеть английским языком и американским языком жестов (ASL), который сочетает в себе жесты, написание пальцев и особый язык тела. ASL — это отдельный от английского язык, и у него своя грамматика. Некоторые переводчики специализируются на других видах устного перевода для глухих или слабослышащих. Некоторые глухие или слабослышащие люди читают по губам по-английски вместо или в дополнение к жестам на ASL. Другие способы перевода включают речь по сигналу, в которой используются формы рук, помещенные рядом со ртом, чтобы дать людям, читающим по губам, больше информации; подписание на точном английском языке; и тактильные жесты, которые переводят как для слепых, так и для глухих людей, делая знаки рукой в руке человека. Трехъязычные переводчики облегчают общение между англоговорящим, говорящим на другом языке и пользователем ASL. Они должны обладать универсальностью и культурным пониманием, необходимыми для перевода на все три языка без изменения основного смысла сообщения. Юридические переводчики иногда должны читать вслух документы на языке, отличном от того, на котором они были написаны. Устные и письменные переводчики занимали около 69 400 рабочих мест в 2021 году.
Переводчики работают в самых разных условиях, включая школы, больницы, залы судебных заседаний, места содержания под стражей и конференц-центры; они также могут работать удаленно. Некоторые устные переводчики, например переводчики связи или сопровождающие, часто путешествуют. В зависимости от обстановки и типа задания устный перевод может вызвать стресс. Переводчики обычно работают в офисах, что может включать удаленные настройки. График работыРабота на неполный рабочий день распространена среди устных и письменных переводчиков, и графики работы могут различаться. У устных и письменных переводчиков могут быть периоды ограниченной работы и периоды продолжительного ненормированного рабочего дня. Устные и письменные переводчики, работающие не по найму, могут устанавливать свой собственный график. Как стать переводчиком Об этом разделеНекоторые устные и письменные переводчики получают степень бакалавра по определенному языку или американскому языку жестов. Устным и письменным переводчикам обычно требуется как минимум степень бакалавра, чтобы начать работать. Они также должны владеть как минимум двумя языками (английским и еще одним языком), а также услугами устного или письменного перевода, которые они намерены предоставлять. ОбразованиеУстным и письменным переводчикам обычно требуется степень бакалавра; общие области степени включают иностранный язык, бизнес и коммуникации. Студенты, изучающие технические предметы, такие как инженерное дело или медицина, могут обеспечить более высокий уровень устного и письменного перевода. Устные и письменные переводчики также должны владеть как минимум двумя языками, одним из которых обычно является английский, и навыками письменного или устного перевода, которые они планируют предоставить. Учащиеся старших классов, желающие стать устными или письменными переводчиками, должны пройти широкий спектр занятий, в том числе по иностранным языкам и английскому языку. Через общественные организации учащиеся, заинтересованные в переводе жестового языка, могут посещать вводные занятия по американскому языку жестов (ASL) и искать возможности волонтеров для работы с глухими или слабослышащими людьми. Стажировки предлагают потенциальным устным и письменным переводчикам возможность узнать о работе. Лицензии, сертификаты и регистрацииОбщая сертификация устных и письменных переводчиков обычно не требуется. Однако работники могут продемонстрировать свою квалификацию, сдав различные необязательные сертификационные тесты. Например, Американская ассоциация переводчиков (АТА) проводит сертификацию по множеству языковых комбинаций. Работодатели могут потребовать или предпочесть сертификацию для некоторых типов устных и письменных переводчиков. Например, в большинстве штатов требуется сертификация судебных переводчиков. Федеральные суды предлагают сертификацию судебных переводчиков на несколько языков, включая испанский, навахо и гаитянский креольский. На государственном уровне суды предлагают сертификацию на нескольких языках. Комиссия по сертификации медицинских переводчиков (CCHI) предлагает два типа сертификации для медицинских переводчиков: Core Certification Healthcare Interpreter (CoreCHI) для переводчиков любого языка, предоставляющих услуги в США; и Certified Healthcare Interpreter (CHI) для переводчиков испанского, арабского и китайского языков. Национальный совет по сертификации медицинских переводчиков (NBCMI) предлагает два типа сертификации для медицинских переводчиков: сертификат Hub-CMI, сертификат, не зависящий от языка, доступный для всех переводчиков независимо от целевого языка; и сертификат CMI для переводчиков испанского, кантонского, китайского, русского, корейского и вьетнамского языков. Непрерывное образование требуется для большинства государственных судебных и медицинских сертификатов переводчика. Его предлагают профессиональные ассоциации устных и письменных переводчиков, такие как ATA и Национальная ассоциация судебных переводчиков (NAJIT). Национальная ассоциация глухих (NAD) и Реестр переводчиков глухих (RID) совместно предлагают сертификацию для переводчиков общего жестового языка. Кроме того, реестр предлагает специальные тесты по юридическому переводу, чтению речи и переводу глухих на глухие, включая перевод глухих, говорящих на разные родные языки, и от ASL до тактильного жеста. Государственный департамент США предлагает тесты на пригодность для устных и письменных переводчиков различных уровней, от начального до продвинутого. Хотя эти тесты не считаются аттестацией, они являются обязательным шагом для добавления кандидатов в список для внештатных заданий. Другие федеральные агентства могут предложить аналогичные тесты на квалификацию. Другой опытОпыт работы обычно не требуется, но он может быть особенно полезен переводчикам и фрилансерам, занимающимся самозанятостью. Будущим устным и письменным переводчикам могут быть полезны такие мероприятия, как пребывание в другой стране, непосредственное взаимодействие с иностранными культурами и изучение различных предметов на английском и, по крайней мере, еще на одном языке. Работа на дому в переводческой компании или выполнение внештатных или волонтерских заданий может помочь людям получить непосредственные знания о навыках, которые необходимы устным или письменным переводчикам. Развивая отношения с опытными работниками в этой области, устные и письменные переводчики укрепляют свои навыки и уверенность и устанавливают сеть контактов. Наставничество может быть формальным, например, через профессиональную ассоциацию; например, и Американская ассоциация переводчиков (ATA), и Реестр переводчиков для глухих (RID) предлагают официальные программы наставничества. Наставничество также может быть неформальным, например, с коллегой или знакомым, имеющим опыт устного или письменного перевода. РазвитиеОпытные устные и письменные переводчики продвигаются вперед, выполняя все более сложные задания, получая сертификаты и получая редакционные полномочия. Некоторые устные и письменные переводчики продвигаются вперед, работая не по найму. Они могут отправлять резюме и образцы в различные бюро письменных и устных переводов, которые соответствуют своим навыкам выполнению заданий. Важные качестваДеловые навыки . Устные и письменные переводчики, работающие не по найму, должны уметь управлять своими финансами. Им необходимо устанавливать цены за свою работу, выставлять счета клиентам, вести учет и продавать свои услуги, чтобы создать свою клиентскую базу. Коммуникабельность. Устные и письменные переводчики должны уметь читать, четко говорить и эффективно писать на всех языках, на которых они работают. Концентрация . Устные и письменные переводчики должны иметь возможность сосредоточиться, пока другие говорят или перемещаются вокруг них. Культурная чувствительность . Устные и письменные переводчики должны знать об ожиданиях людей, которым они помогают облегчить общение. Ловкость . Переводчики языка жестов должны уметь делать быстрые и скоординированные движения руками, пальцами и руками при переводе. Навыки межличностного общения . Устные и письменные переводчики должны уметь успокаивать клиентов и других лиц. Переводчики могут работать в группах и должны ладить с коллегами, чтобы добиться успеха. Навыки слушания . Переводчики должны обращать внимание при переводе для аудитории, чтобы убедиться, что они правильно слышат и интерпретируют. Interpreters and TranslatorsMedian annual wages, May 2021
Средняя годовая заработная плата устных и письменных переводчиков составляла 49 долларов. В мае 2021 года средняя годовая заработная плата устных и письменных переводчиков в ведущих отраслях, в которых они работали, была следующей:
Эти данные о заработной плате не включают самозанятых. Работа на неполный рабочий день распространена среди устных и письменных переводчиков, и графики работы могут различаться. У устных и письменных переводчиков могут быть периоды ограниченной работы и периоды продолжительного ненормированного рабочего дня. Устные и письменные переводчикиПроцентное изменение занятости, прогнозируемое на 2021-31 гг.1269 Прогнозируется, что занятость устных и письменных переводчиков вырастет на 20 процентов с 2021 по 2031 год, что намного быстрее, чем в среднем по всем профессиям. Ежегодно в среднем в течение десятилетия прогнозируется около 9 200 вакансий для устных и письменных переводчиков. ЗанятостьРост занятости отражает растущую глобализацию и более разнообразное население США, что, как ожидается, потребует больше устных и письменных переводчиков. Спрос на переводчиков часто переводимых языков, таких как французский, немецкий, португальский, русский и испанский, скорее всего, останется высоким. Спрос также должен быть высоким на переводчиков арабского и других ближневосточных языков; для основных азиатских языков, включая китайский, японский, хинди и корейский; и для языков коренных народов Мексики и Центральной Америки, таких как микстек, сапотек и языки майя. Ожидается, что спрос на переводчиков американского языка жестов будет расти из-за более широкого использования услуг видеоретрансляции, которые позволяют людям проводить онлайн-видеозвонки и использовать переводчика языка жестов. Кроме того, растущая международная торговля и расширение глобальных связей должны потребовать большего количества устных и письменных переводчиков, особенно на развивающихся рынках, таких как Азия и Африка. Постоянная потребность в устных и письменных переводчиках для вооруженных сил и национальной безопасности также должна привести к увеличению числа рабочих мест. Компьютеры сделали работу переводчиков и специалистов по локализации более эффективной. Однако многие из этих работ не могут быть полностью автоматизированы, потому что компьютеры еще не могут выполнять работу, сравнимую с работой, которую в большинстве случаев выполняют люди-переводчики.
Программа статистики занятости и заработной платы (OEWS) ежегодно производит оценки занятости и заработной платы для более чем 800 профессий. Эти оценки доступны для страны в целом, для отдельных штатов, а также для столичных и неметропольных территорий.
Прогнозы профессиональной занятости разрабатываются для всех штатов отделом информации о рынке труда (LMI) или отделами прогнозов занятости отдельных штатов. Все данные прогнозов штата доступны на сайте www.projectionscentral.com. Информация на этом сайте позволяет сравнивать прогнозируемый рост занятости по профессии между штатами или в пределах одного штата. Кроме того, штаты могут составлять прогнозы по районам; есть ссылки на веб-сайты каждого штата, где эти данные могут быть получены. CareerOneStop CareerOneStop включает в себя сотни профессиональных профилей с данными, доступными по штатам и городам. В левом боковом меню есть ссылки для сравнения профессиональной занятости по штатам и профессиональной заработной платы по местности или городскому району. В этой таблице приведен список профессий с должностными обязанностями, аналогичными обязанностям устных и письменных переводчиков.
Для получения дополнительной информации о переводчиках посетите Откройте для себя устный перевод Для получения дополнительной информации о специальностях устных и литературных переводчиков, включая профессиональную сертификацию, посетите Американская ассоциация переводчиков (ATA) Комиссия по сертификации медицинских переводчиков (CCHI) Международная ассоциация переводчиков конференций Национальная ассоциация судебных переводчиков (NAJIT) Национальная ассоциация глухих (НАД) Национальный совет по сертификации медицинских переводчиков Национальный совет по устному переводу в здравоохранении (NCIHC) Реестр переводчиков для глухих (RID) Для получения дополнительной информации о том, как стать устным или письменным переводчиком по федеральному контракту, посетите .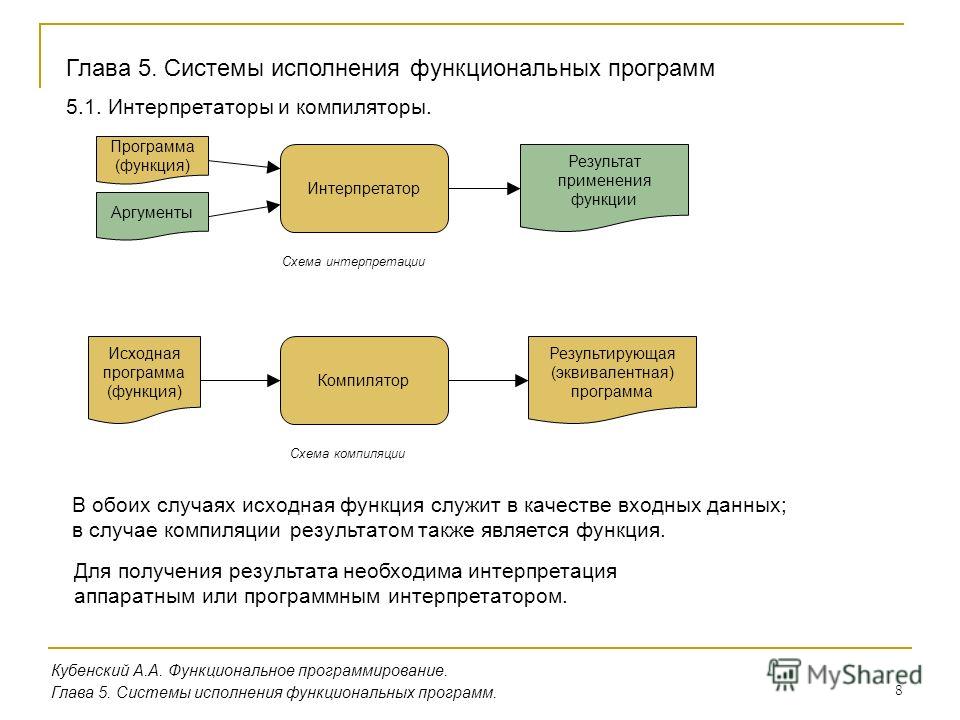 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

 Новые формы описаны здесь:
Новые формы описаны здесь: Затем оцените аргументы слева направо.
порядок и оценить тело замыкания в соответствующем расширенном
Окружающая среда.
Затем оцените аргументы слева направо.
порядок и оценить тело замыкания в соответствующем расширенном
Окружающая среда. pyret.org/editor#share=0B32bNEogmncOMERfaE1VRTQ1M3M&v=v0.5r790
pyret.org/editor#share=0B32bNEogmncOMERfaE1VRTQ1M3M&v=v0.5r790 v-bool
is-v-bool = I.is-v-bool
v-закрыть = I.v-закрыть
is-v-clos = I.is-v-clos
v-пусто = I.v-пусто
is-v-пусто = I.is-v-пусто
v-ссылка = I.v-ссылка
is-v-ссылка = I.is-v-ссылка
v-bool
is-v-bool = I.is-v-bool
v-закрыть = I.v-закрыть
is-v-clos = I.is-v-clos
v-пусто = I.v-пусто
is-v-пусто = I.is-v-пусто
v-ссылка = I.v-ссылка
is-v-ссылка = I.is-v-ссылка 
 »
»
 Ни один из них не является доменно-ориентированным языком (DSL), и клиенту может потребоваться собственный DSL, например, для выражений авторизации. Но даже не применяя этот навык напрямую, написание интерпретатора значительно упрощает оценку усилий, стоящих за многими языками программирования, форматами файлов и DSL.
Ни один из них не является доменно-ориентированным языком (DSL), и клиенту может потребоваться собственный DSL, например, для выражений авторизации. Но даже не применяя этот навык напрямую, написание интерпретатора значительно упрощает оценку усилий, стоящих за многими языками программирования, форматами файлов и DSL. Тем не менее, понимание проблем и возможностей написания интерпретатора с нуля поможет разработчикам более эффективно использовать такие решения.
Тем не менее, понимание проблем и возможностей написания интерпретатора с нуля поможет разработчикам более эффективно использовать такие решения. lex()
val ast = Parser(токены).parse()
val res = Интерпретатор(ast).interpret()
println(s"Результат: $res")
lex()
val ast = Parser(токены).parse()
val res = Интерпретатор(ast).interpret()
println(s"Результат: $res")
 Как показано в соответствующем репозитории GitHub, зависимости в более поздних примерах немного меняются для реализации этих грамматик, но общие концепции остаются прежними.
Как показано в соответствующем репозитории GitHub, зависимости в более поздних примерах немного меняются для реализации этих грамматик, но общие концепции остаются прежними. Позиция может помочь конечным пользователям лексера с отладкой.
Позиция может помочь конечным пользователям лексера с отладкой. isWhitespace то
currentPos += 1 // игнорировать пробелы
иначе, если смотреть вперед == '+' тогда
текущийПос += 1
tokens += Token(Type.Plus, lookahead.toString, tokenStartPos)
иначе, если смотреть вперед == '*' тогда
текущийПос += 1
tokens += Token(Type.Times, lookahead.toString, tokenStartPos)
иначе если lookahead.isDigit тогда
переменный текст = ""
в то время как currentPos < input.length && input(currentPos).isDigit do
текст += ввод (currentPos)
текущийПос += 1
tokens += Token(Type.Num, text, tokenStartPos)
else if lookahead.isLetter then // сначала должна быть буква
переменный текст = ""
в то время как currentPos < input.length && input(currentPos).isLetterOrDigit do
текст += ввод (currentPos)
текущийПос += 1
val tpe = совпадение текста
case "true" => Type.True // специальные регистровые литералы
case "false" => Type.
isWhitespace то
currentPos += 1 // игнорировать пробелы
иначе, если смотреть вперед == '+' тогда
текущийПос += 1
tokens += Token(Type.Plus, lookahead.toString, tokenStartPos)
иначе, если смотреть вперед == '*' тогда
текущийПос += 1
tokens += Token(Type.Times, lookahead.toString, tokenStartPos)
иначе если lookahead.isDigit тогда
переменный текст = ""
в то время как currentPos < input.length && input(currentPos).isDigit do
текст += ввод (currentPos)
текущийПос += 1
tokens += Token(Type.Num, text, tokenStartPos)
else if lookahead.isLetter then // сначала должна быть буква
переменный текст = ""
в то время как currentPos < input.length && input(currentPos).isLetterOrDigit do
текст += ввод (currentPos)
текущийПос += 1
val tpe = совпадение текста
case "true" => Type.True // специальные регистровые литералы
case "false" => Type. False
case _ => Type.Identifier
tokens += Token(tpe, text, tokenStartPos)
еще
error(s"Неизвестный символ $lookahead в позиции $currentPos")
tokens += Token(Type.EOF, "
False
case _ => Type.Identifier
tokens += Token(tpe, text, tokenStartPos)
еще
error(s"Неизвестный символ $lookahead в позиции $currentPos")
tokens += Token(Type.EOF, " Правило состоит в том, что мы берем максимально длинное совпадение и проверяем, является ли оно литералом; если нет, то это идентификатор.
Правило состоит в том, что мы берем максимально длинное совпадение и проверяем, является ли оно литералом; если нет, то это идентификатор. Мы хотели бы, чтобы наш синтаксический анализатор был однозначным — всегда возвращал одну и ту же структуру для данного ввода.
Мы хотели бы, чтобы наш синтаксический анализатор был однозначным — всегда возвращал одну и ту же структуру для данного ввода. Нетерминалы: промежуточные конструкции, используемые для синтаксического анализа (т. е. символы, которые можно заменить)
Нетерминалы: промежуточные конструкции, используемые для синтаксического анализа (т. е. символы, которые можно заменить) Он начинается с начального правила и спускается оттуда (отсюда «спуск»), выясняя, какое правило применить в каждой функции. «Рекурсивная» часть жизненно важна, потому что мы можем рекурсивно вкладывать нетерминалы! Регулярные выражения не могут этого сделать: они даже не могут обрабатывать сбалансированные скобки. Поэтому нам нужен более мощный инструмент.
Он начинается с начального правила и спускается оттуда (отсюда «спуск»), выясняя, какое правило применить в каждой функции. «Рекурсивная» часть жизненно важна, потому что мы можем рекурсивно вкладывать нетерминалы! Регулярные выражения не могут этого сделать: они даже не могут обрабатывать сбалансированные скобки. Поэтому нам нужен более мощный инструмент.

 tpe == Type.Plus, то
есть(Тип.Плюс)
есть(Тип.Число)
exprOpt()
// иначе: конец рекурсии, эпсилон
частное определение (tpe: Type): Unit =
если lookahead.tpe != tpe, то
error(s"Ожидается: $tpe, получено: ${lookahead.tpe} в позиции ${lookahead.startPos}")
жетоны = жетоны.хвост
просмотр вперед = tokens.head
tpe == Type.Plus, то
есть(Тип.Плюс)
есть(Тип.Число)
exprOpt()
// иначе: конец рекурсии, эпсилон
частное определение (tpe: Type): Unit =
если lookahead.tpe != tpe, то
error(s"Ожидается: $tpe, получено: ${lookahead.tpe} в позиции ${lookahead.startPos}")
жетоны = жетоны.хвост
просмотр вперед = tokens.head
 Последним токеном будет
Последним токеном будет  tpe != Type.EOF, то
error(s"Неизвестный токен '${lookahead.text}' в позиции ${lookahead.tokenStartPos}")
еще
разрешение
частное выражение выражения(): выражение =
val num = есть(Тип.Число)
Expr(num.text.toInt, exprOpt())
частная защита exprOpt(): ExprOpt =
если lookahead.tpe == Type.Plus, то
есть(Тип.Плюс)
val num = есть(Тип.Число)
ExprOpt.Opt(num.text.toInt, exprOpt())
еще
Экспроопт.Эпсилон
tpe != Type.EOF, то
error(s"Неизвестный токен '${lookahead.text}' в позиции ${lookahead.tokenStartPos}")
еще
разрешение
частное выражение выражения(): выражение =
val num = есть(Тип.Число)
Expr(num.text.toInt, exprOpt())
частная защита exprOpt(): ExprOpt =
если lookahead.tpe == Type.Plus, то
есть(Тип.Плюс)
val num = есть(Тип.Число)
ExprOpt.Opt(num.text.toInt, exprOpt())
еще
Экспроопт.Эпсилон

 Мы скоро увидим это в действии.
Мы скоро увидим это в действии. num
expr.exprOpts.foreach { exprOpt =>
если exprOpt.op == Token.Type.Plus
затем tmp += exprOpt.num
иначе tmp -= exprOpt.num
}
температура
num
expr.exprOpts.foreach { exprOpt =>
если exprOpt.op == Token.Type.Plus
затем tmp += exprOpt.num
иначе tmp -= exprOpt.num
}
температура

 term)
expr.exprOpts.foreach { exprOpt =>
tmp += eval(exprOpt.term)
}
температура
частная оценка (срок: срок): Int =
var tmp = термин.номер
term.termOpts.foreach {termOpt =>
tmp *= termOpt.num
}
температура
term)
expr.exprOpts.foreach { exprOpt =>
tmp += eval(exprOpt.term)
}
температура
частная оценка (срок: срок): Int =
var tmp = термин.номер
term.termOpts.foreach {termOpt =>
tmp *= termOpt.num
}
температура




 Хотя некоторые люди занимаются и тем, и другим, устный и письменный перевод — это разные навыки: устные переводчики работают с устной речью, а переводчики — с письменной.
Хотя некоторые люди занимаются и тем, и другим, устный и письменный перевод — это разные навыки: устные переводчики работают с устной речью, а переводчики — с письменной. Из-за связанной с этим умственной усталости синхронные переводчики могут работать парами или небольшими группами, если они переводят в течение длительного периода времени, например, в суде или на конференции.
Из-за связанной с этим умственной усталости синхронные переводчики могут работать парами или небольшими группами, если они переводят в течение длительного периода времени, например, в суде или на конференции. Переводчики должны правильно передавать культурные отсылки, включая сленг и другие выражения, которые не переводятся буквально.
Переводчики должны правильно передавать культурные отсылки, включая сленг и другие выражения, которые не переводятся буквально.
 Для некоторых должностей, например, в Организации Объединенных Наций, требуется эта квалификация.
Для некоторых должностей, например, в Организации Объединенных Наций, требуется эта квалификация.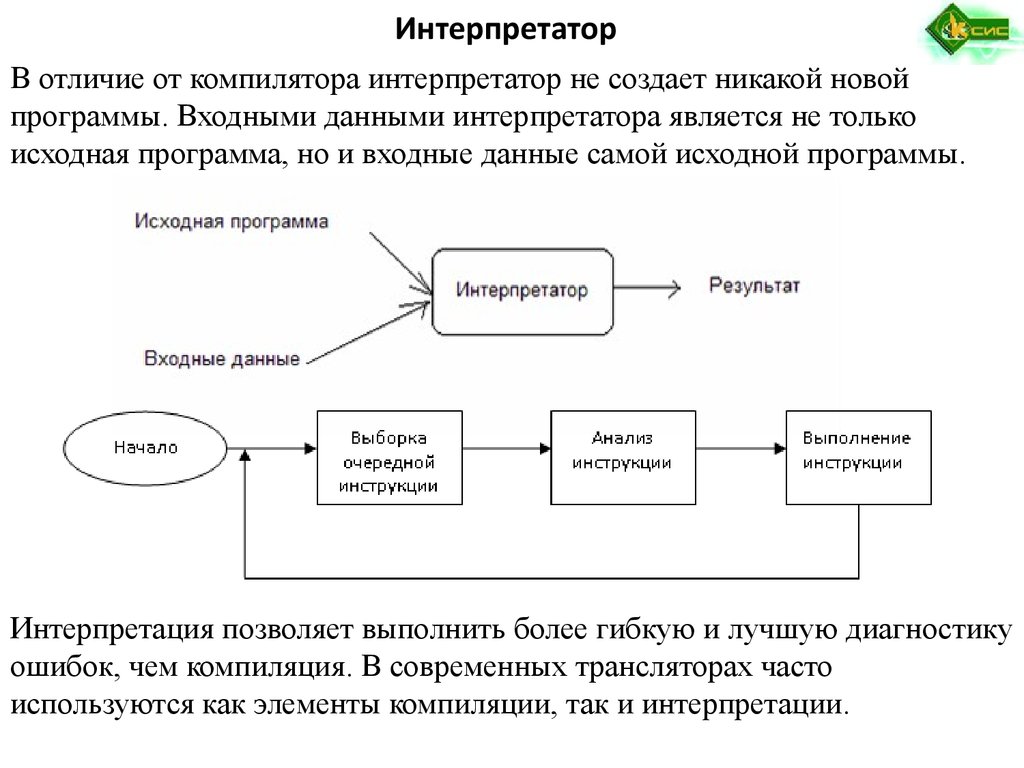

 Переводчики, работающие с этими людьми, выполняют «устный перевод», произнося речь молча и осторожно. Они также могут использовать мимику и жесты, чтобы помочь читающему по губам понять.
Переводчики, работающие с этими людьми, выполняют «устный перевод», произнося речь молча и осторожно. Они также могут использовать мимику и жесты, чтобы помочь читающему по губам понять. Крупнейшими работодателями устных и письменных переводчиков были следующие:
Крупнейшими работодателями устных и письменных переводчиков были следующие: Обычно они получают и представляют свою работу в электронном виде, и иногда им приходится сталкиваться с давлением сроков и жестких графиков.
Обычно они получают и представляют свою работу в электронном виде, и иногда им приходится сталкиваться с давлением сроков и жестких графиков.
 Например, стажеры могут заменить опытного переводчика или начать работать в отраслях с особенно высоким спросом на лингвистические услуги, таких как судебный или медицинский перевод.
Например, стажеры могут заменить опытного переводчика или начать работать в отраслях с особенно высоким спросом на лингвистические услуги, таких как судебный или медицинский перевод.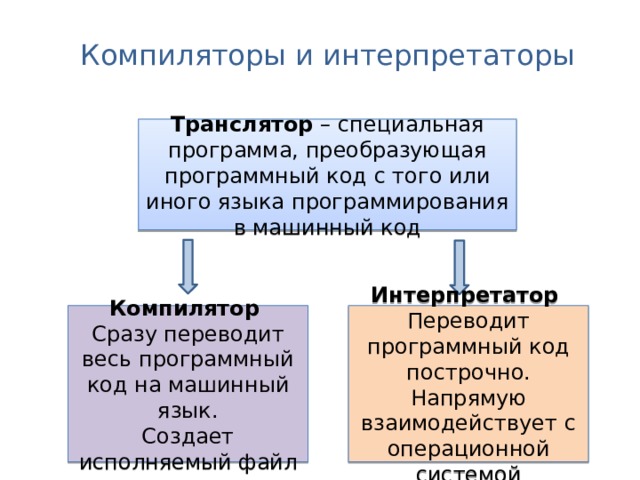

 Волонтерские возможности для переводчиков могут быть доступны через общественные организации, больницы и спортивные мероприятия, такие как футбол, в которых участвуют международные спортсмены.
Волонтерские возможности для переводчиков могут быть доступны через общественные организации, больницы и спортивные мероприятия, такие как футбол, в которых участвуют международные спортсмены. Они могут получить работу, основываясь на своей репутации или по рекомендации клиентов или коллег. Те, кто начинает свой собственный бизнес, также могут нанимать письменных и устных переводчиков для работы на них.
Они могут получить работу, основываясь на своей репутации или по рекомендации клиентов или коллег. Те, кто начинает свой собственный бизнес, также могут нанимать письменных и устных переводчиков для работы на них. Они должны понимать не только язык, но и культуру.
Они должны понимать не только язык, но и культуру. ,110 в мае 2021 года.
Медианная заработная плата — это заработная плата, при которой половина работающих по профессии зарабатывает больше этой суммы, а половина — меньше. Самые низкие 10 процентов заработали менее 29 360 долларов, а самые высокие 10 процентов заработали более 97 760 долларов.
,110 в мае 2021 года.
Медианная заработная плата — это заработная плата, при которой половина работающих по профессии зарабатывает больше этой суммы, а половина — меньше. Самые низкие 10 процентов заработали менее 29 360 долларов, а самые высокие 10 процентов заработали более 97 760 долларов. Оплата устных и письменных переводчиков может зависеть от ряда переменных, включая язык, специальность, опыт, образование и сертификацию устного или письменного переводчика.
Оплата устных и письменных переводчиков может зависеть от ряда переменных, включая язык, специальность, опыт, образование и сертификацию устного или письменного переводчика. Ожидается, что многие из этих вакансий будут вызваны необходимостью замены работников, которые переходят на другую профессию или выходят из состава рабочей силы, например, в связи с уходом на пенсию.
Ожидается, что многие из этих вакансий будут вызваны необходимостью замены работников, которые переходят на другую профессию или выходят из состава рабочей силы, например, в связи с уходом на пенсию.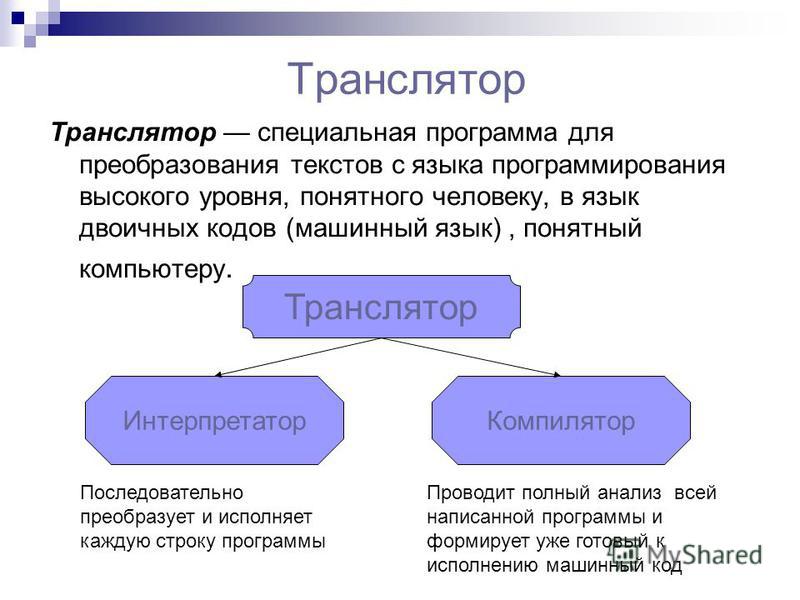

 Ссылки ниже ведут на карты данных OEWS по занятости и заработной плате по штатам и районам.
Ссылки ниже ведут на карты данных OEWS по занятости и заработной плате по штатам и районам. Существует также инструмент информации о зарплате для поиска заработной платы по почтовому индексу.
Существует также инструмент информации о зарплате для поиска заработной платы по почтовому индексу.



