Особенности интерпретаторов OTUS
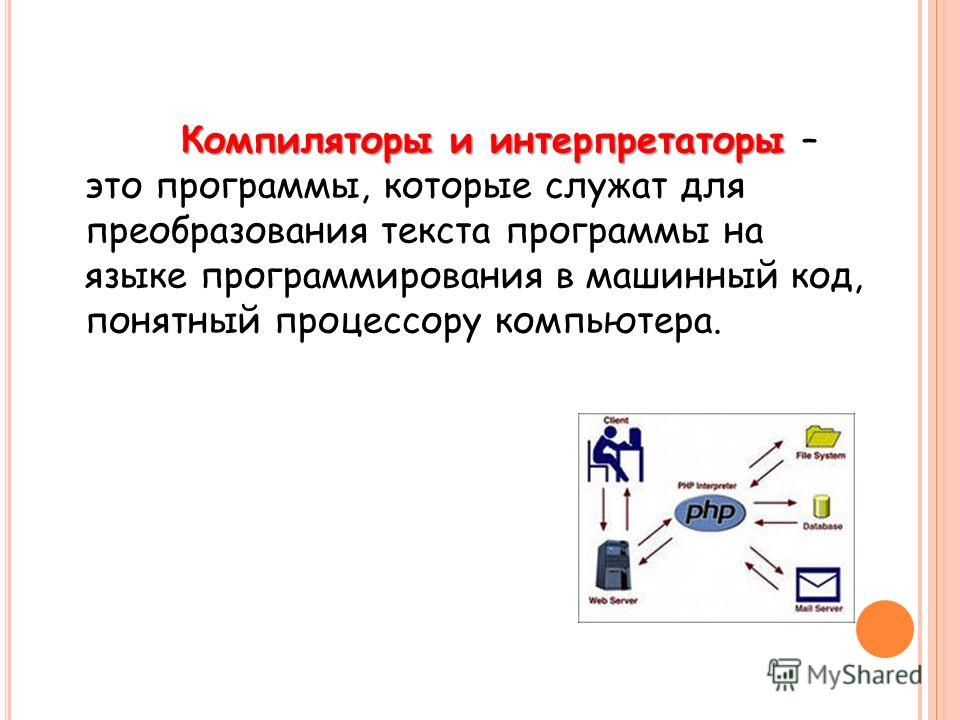
Интерпретатор и компилятор – два элемента, которые отвечают за непосредственное преобразование высокоуровневого языка программирования или сценария в машинный код. Несмотря на то, что данные компоненты выполняют одни и те же операции, они отличаются друг от друга.
Далее предстоит разобраться с тем, что собой представляют интерпретаторы и компиляторы. Рассмотрим ключевые особенности каждого «преобразователя» кода, наглядные примеры работы, а также их достоинства и недостатки. Все это пригодится как новичкам, так и опытным разработчикам.
Компиляция
Компилятор – это специальная программа на компьютере. Она переводит имеющийся код с одного языка разработки на другой. Популярный инструмент, без которого трудно представить современное программирование.
Компиляторы берут приложения целиком, а затем преобразовывают в исполняемый компьютерный код. Чтобы справиться с поставленной задачей, требуется целое программное обеспечение. Связано это с тем, что современные компьютеры понимают лишь то, что выражено при помощи двоичных кодов.
Связано это с тем, что современные компьютеры понимают лишь то, что выражено при помощи двоичных кодов.
У интерпретаторов и компиляторов языков есть одна цель – преобразовать исполняемое приложение в машинный код. После выполнения процедуры считывания устройство будет успешно распознавать имеющийся контент. Примеры – это приложения, интерпретация которых проведена через C или C++.
Здесь стоит обратить внимание на следующие моменты:
- Компиляторы применяются для программ, которые переводят исходное приложение с высокого уровня на язык разработки более низкого.
- Compiler выполняет различные функции. Он может организовывать предварительную обработку данных, семантический анализ, парсинг, а также оптимизацию контента. Это делает работу с приложением более удобным и простым.
Выше – пример того, как выглядит компиляция исходного кода той или иной программы.
Сильные стороны
Компиляторы имеют далеко не одно преимущество. К сильным сторонам соответствующих компонентов относят следующие моменты:
- Программный код уже переведен в машинный.
 На его обработку требуется намного меньше времени.
На его обработку требуется намного меньше времени. - Документы типа .exe выполняются быстрее, чем исходный код. Объектные программы сохраняются. Это делает приложение более удобным – оно может быть запущено в любое удобное пользователю время.
- Полученные объектные приложения сложнее скорректировать. Такие утилиты будут обладать надежной защитой.
 На его обработку требуется намного меньше времени.
На его обработку требуется намного меньше времени.А еще программирование с использованием компиляторов предусматривает проверку исходного кода на синтаксические ошибки. Это делает процесс написания софта более быстрым и удобным. Обнаруженная ошибка многими языками будет подчеркиваться. Устранить ее станет намного проще даже новичкам.
Слабые стороны
Несмотря на достоинства, рассматриваемый инструмент имеет недостатки. К ним относят такие моменты:
- Использование большого количества памяти на компьютере. Связано это с особенностями выполняемых преобразований.
- Затраты по времени. Процесс формирования объектного приложения производится не моментально.
- Толкования исходного кода должны быть 100% достоверными и однозначными. В противном случае сформировать объектное программное обеспечение не получится.

Это – только один из двух доступных вариантов преобразования исходного кода. Теперь можно рассмотреть интерпретаторы языков и их особенности.
Интерпретатор
Для преобразования приложений могут использоваться разные инструменты. Программы иногда используют интерпретаторы (interpreters). Так называют специальные компьютерные приложения, которые занимаются преобразованием каждого программного оператора высокого уровня. На выходе получается машинный код.
Сюда включены разные коды: исходные, предварительно скомпилированные, а также разнообразные сценарии.
Интерпретатор языка – машинная программа. Она непосредственно выполняет набор инструкций, а также отвечает за выполнение заданных функций. В ходе операций проводится интерпретация без компилирования. Примеры – языки Python, Matlab, Perl.
Интерпретаторы языков работают так же, как и compilers. Они отвечают за преобразование ЯП высокого уровня в более низкий. А именно – в машинный. Но interpretator выполняет функции при их непосредственном запуске.
Они отвечают за преобразование ЯП высокого уровня в более низкий. А именно – в машинный. Но interpretator выполняет функции при их непосредственном запуске.
Плюсы
Среди основных достоинств интерпретаторов выделяют:
- Облегчение работы с исходным кодом.
- Использование минимального объема памяти устройства. Связано это с тем, что у интерпретируемых программ используется принцип преобразования по одной инструкции раз за разом.
- Вы выполните отладку утилиты намного быстрее и комфортнее. Связано это с тем, что программа-интерпретатор выполняет связку обнаруженного сообщения об ошибке с обрабатываемым контентом.
Такой вариант помогает ускорить исходный исполняемый файл, а также делает работу написанного софта более комфортной на устройствах с небольшим объемом памяти.
Минусы
Интерпретаторы языков кроме преимуществ имеет ряд недостатков. О них должен помнить каждый разработчик.
Интерпретация может затянуть время исполнения программы. Связано это с тем, что каждый раз для запуска нужно поэтапно преобразовывать имеющиеся функции. А еще программы-интерпретаторы выполняются только там, где имеется соответствующий инструментарий. Если на устройстве отсутствует interpreter, воспользоваться приложением не получится.
Связано это с тем, что каждый раз для запуска нужно поэтапно преобразовывать имеющиеся функции. А еще программы-интерпретаторы выполняются только там, где имеется соответствующий инструментарий. Если на устройстве отсутствует interpreter, воспользоваться приложением не получится.
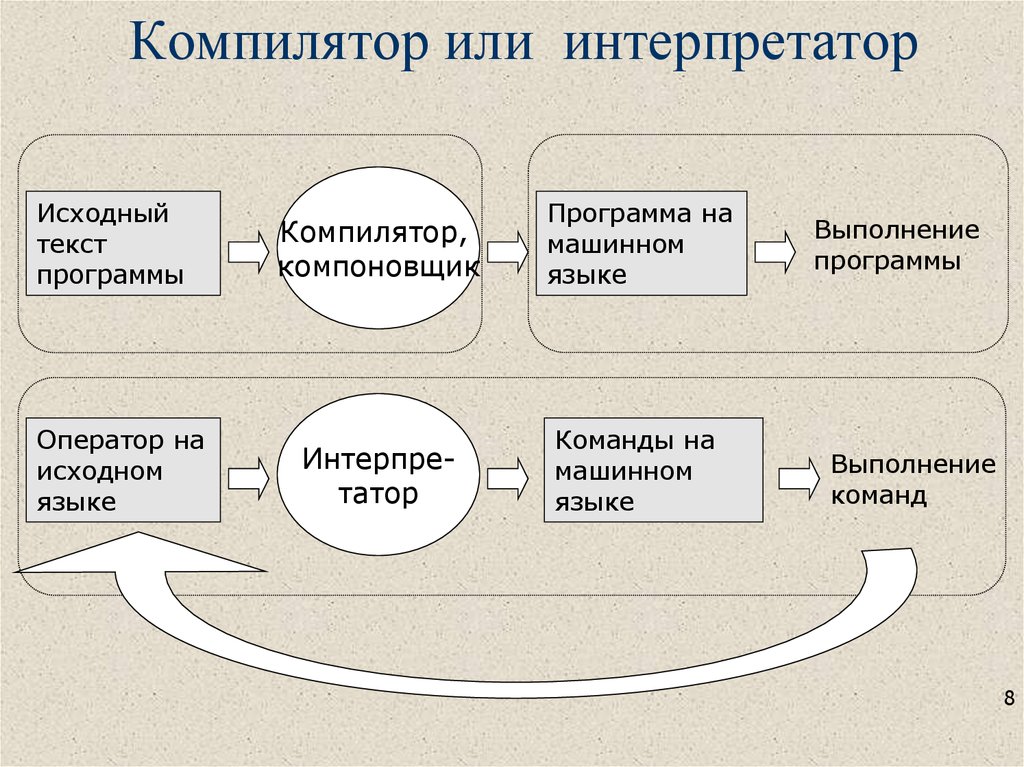
Как работают инструменты
Стоит обратить внимание на то, как работают рассматриваемые элементы. В случае с компилятором процессы проходят так:
- Компилятор создает программу.
- Проводится анализ всех операторов языка. На этом этапе сделаем проверку правильности.
- При обнаружении ошибок компилятор выдает соответствующее сообщение. В противном случае имеющийся контент переводится в машинный тип.
При компилировании допускается связывание различных кодовых файлов в программы, пригодные для запуска (пример – формат .exe). После этого имеющийся софт успешно запустится.
Интерпретатор работает иначе:
- Происходит создание программы.
- Построчно выполняются исходные операторы. Эти манипуляции реализовываются непосредственно во время исполнения программы.
- Связь файлов отсутствует. Машинного кода тоже не будет.
 Эти манипуляции реализовываются непосредственно во время исполнения программы.
Эти манипуляции реализовываются непосредственно во время исполнения программы.Выше – примеры того, как выглядит работа компиляторов и интерпретаторов. Использование этих инструментов обуславливается конкретным языком разработки.
Хотите освоить современную IT-специальность? Огромный выбор курсов по востребованным IT-направлениям есть в Otus!
|
Функциональная модель параллельных вычислений и язык программирования «Пифагор» |
|
[ <<< | Содержание | Предисловие | Введение | 1 | 2 | 3 | © 2002 А. Система интерпретации функциональных программ (СИФП) состоит из трех основных модулей:
Эти модули реализованы внутри монолитного исполняемого файла. Общая структура СИФП приведена на рис. 4.1.
При получении имени входного файла, содержащего текст функциональной программы, модуль управления проверяет наличие файла с введённым именем и посылает транслятору сигнал о готовности исходного текста программы. Первой задачей транслятора является проверка синтаксиса исходного текста программы и выявление синтаксических ошибок в тексте, допущенных программистом.
Сообщения об этих ошибках передаются модулю управления. Модуль управления
выдаёт сообщения об ошибках интерпретации в соответствующее окно сообщений.
Вторая задача транслятора — построение промежуточного представления программы
на ФЯПП. Промежуточное представление — это отражение структуры и информационных
связей между отдельными элементами программы. Обе эти задачи решаются
транслятором за один проход исходного текста программы. Если трансляция текста
программы была выполнена без ошибок, то промежуточное представление поступает в
интерпретатор, который может выполнить любую из оттранслированных функций. Необходимо отметить, что транслятор не записывает промежуточного представления в файл, который мог бы послужить исходным материалом для интерпретатора. Это связано с тем, что на данном этапе работ нет смысла хранить и отдельно использовать промежуточное представление. Основной упор был сделан на исследование принципов построения функционально-параллельных программ и возможностей языка.
|
 И. Легалов, Ф.А. Казаков, Д.А. Кузьмин, Д.В. Привалихин
И. Легалов, Ф.А. Казаков, Д.А. Кузьмин, Д.В. Привалихин

 1. Структура транслятора
1. Структура транслятора
 Под
промежуточным представлением понимается одна из внутренних форм представления
исходной программы — динамическая модель, с которой интерпретатору удобнее
работать, чем с текстовым представлением. Организация промежуточного
представления является одной из особенностей разрабатываемой системы. Оно
организовано в виде динамических структур данных, отображающих основные
конструкции языка: программы, функций, имен, операторов, выражений и пр.
Взаимосвязь между различными объектами промежуточного представления приведена
на рис. 4.3. Ниже описаны классы реализующие структуру промежуточного
представления.
Под
промежуточным представлением понимается одна из внутренних форм представления
исходной программы — динамическая модель, с которой интерпретатору удобнее
работать, чем с текстовым представлением. Организация промежуточного
представления является одной из особенностей разрабатываемой системы. Оно
организовано в виде динамических структур данных, отображающих основные
конструкции языка: программы, функций, имен, операторов, выражений и пр.
Взаимосвязь между различными объектами промежуточного представления приведена
на рис. 4.3. Ниже описаны классы реализующие структуру промежуточного
представления.
 Поле
NameOwner этого класса содержит значение NULL, поскольку он является владельцем
глобального пространства имён и, кроме того, это позволяет, при поиске
идентификатора в таблицах имён, проводить поиск по цепочке владельцев
пространств имён, прекращая поиск, как только в поле NameOwner одного из
объектов встретится значение NULL. Класс TProgram имеет метод, позволяющий
запускать на выполнение или отладку по имени одну из функций из его таблицы
имён функций.
Поле
NameOwner этого класса содержит значение NULL, поскольку он является владельцем
глобального пространства имён и, кроме того, это позволяет, при поиске
идентификатора в таблицах имён, проводить поиск по цепочке владельцев
пространств имён, прекращая поиск, как только в поле NameOwner одного из
объектов встретится значение NULL. Класс TProgram имеет метод, позволяющий
запускать на выполнение или отладку по имени одну из функций из его таблицы
имён функций.


 В качестве объектов — владельцев
пространства имён могут выступать только представители классов, содержащих
таблицу имен.
В качестве объектов — владельцев
пространства имён могут выступать только представители классов, содержащих
таблицу имен.




 .. :termn-1:termn.
.. :termn-1:termn.
 Фишка, выдаваемая блоком, является результатом операции интерпретации, где
аргументом выступает фишка — результат вычисления первого терма списка, а
функцией — результат вычисления второго.
Фишка, выдаваемая блоком, является результатом операции интерпретации, где
аргументом выступает фишка — результат вычисления первого терма списка, а
функцией — результат вычисления второго.
 Вся эта последовательность действий повторяется до тех
пор, пока все не будут произведены все операции интерпретации выражения.
Результирующая фишка последней операции интерпретации является результатом
вычисления выражения.
Вся эта последовательность действий повторяется до тех
пор, пока все не будут произведены все операции интерпретации выражения.
Результирующая фишка последней операции интерпретации является результатом
вычисления выражения.
 Создаются объекты класса
TObjectFishka, в поле Object которых записываются указатели на элементы
исходного списка. Эти указатели будут использованы в дальнейшем при раскрытии
задержанного списка. Полученные объекты становятся элементами результирующей
фишки — списка фишек.
Создаются объекты класса
TObjectFishka, в поле Object которых записываются указатели на элементы
исходного списка. Эти указатели будут использованы в дальнейшем при раскрытии
задержанного списка. Полученные объекты становятся элементами результирующей
фишки — списка фишек.
 При этом возникает задача поиска
идентификатора в таблицах локальных значений выражений, в таблицах локальных
идентификаторов, в таблице функций и таблице констант программы, а также
определение типа объекта, скрывающегося за этим идентификатором.
Последовательность действий при этом такова (рис. 4.8):
При этом возникает задача поиска
идентификатора в таблицах локальных значений выражений, в таблицах локальных
идентификаторов, в таблице функций и таблице констант программы, а также
определение типа объекта, скрывающегося за этим идентификатором.
Последовательность действий при этом такова (рис. 4.8):
 е. до объекта класса TProgram. В его
таблице имён идентификаторов происходит поиск рассматриваемого имени.
е. до объекта класса TProgram. В его
таблице имён идентификаторов происходит поиск рассматриваемого имени.
 Если выражение вычислено, то полученное значение заносится
в таблицу значений именованных выражений для дальнейшего использования.
Если выражение вычислено, то полученное значение заносится
в таблицу значений именованных выражений для дальнейшего использования.
 На его входы поступают две
фишки любого типа, одна из которых будет интерпретироваться как аргумент, а
другая — как функция. На выходе оператора, после окончания всех действий,
предусматриваемых моделью вычислений, появляется выходная фишка (в том числе,
возможно, и фишка ошибки), которая становится разметкой выходной.
На его входы поступают две
фишки любого типа, одна из которых будет интерпретироваться как аргумент, а
другая — как функция. На выходе оператора, после окончания всех действий,
предусматриваемых моделью вычислений, появляется выходная фишка (в том числе,
возможно, и фишка ошибки), которая становится разметкой выходной.


Написание интерпретатора с нуля
Некоторые говорят, что «все сводится к единицам и нулям» — но действительно ли мы понимаем, как наши программы преобразуются в эти биты?
И компиляторы, и интерпретаторы берут необработанную строку, представляющую программу, анализируют ее и анализируют. Хотя интерпретаторы являются более простыми из двух, написание даже очень простого интерпретатора (который выполняет только сложение и умножение) будет поучительным. Мы сосредоточимся на том, что общего у компиляторов и интерпретаторов: лексическом анализе и разборе входных данных.
Хотя интерпретаторы являются более простыми из двух, написание даже очень простого интерпретатора (который выполняет только сложение и умножение) будет поучительным. Мы сосредоточимся на том, что общего у компиляторов и интерпретаторов: лексическом анализе и разборе входных данных.
Что нужно и что нельзя делать при написании собственного интерпретатора
Читатели могут задаться вопросом Что не так с регулярным выражением? Регулярные выражения — это мощное средство, но грамматика исходного кода недостаточно проста для их анализа. Ни один из них не является доменно-ориентированным языком (DSL), и клиенту может потребоваться собственный DSL, например, для выражений авторизации. Но даже не применяя этот навык напрямую, написание интерпретатора значительно упрощает оценку усилий, стоящих за многими языками программирования, форматами файлов и DSL.
Правильное написание синтаксических анализаторов вручную может быть сложной задачей со всеми задействованными пограничными случаями. Вот почему существуют популярные инструменты, такие как ANTLR, которые могут генерировать синтаксические анализаторы для многих популярных языков программирования. Существуют также библиотеки, называемые комбинаторами синтаксических анализаторов , которые позволяют разработчикам писать синтаксические анализаторы непосредственно на предпочитаемых ими языках программирования. Примеры включают FastParse для Scala и Parsec для Python.
Вот почему существуют популярные инструменты, такие как ANTLR, которые могут генерировать синтаксические анализаторы для многих популярных языков программирования. Существуют также библиотеки, называемые комбинаторами синтаксических анализаторов , которые позволяют разработчикам писать синтаксические анализаторы непосредственно на предпочитаемых ими языках программирования. Примеры включают FastParse для Scala и Parsec для Python.
Мы рекомендуем читателям в профессиональном контексте использовать такие инструменты и библиотеки, чтобы не изобретать велосипед. Тем не менее, понимание проблем и возможностей написания интерпретатора с нуля поможет разработчикам более эффективно использовать такие решения.
Обзор компонентов интерпретатора
Интерпретатор — это сложная программа, поэтому она состоит из нескольких этапов:
- лексер — это часть интерпретатора, которая преобразует последовательность символов (обычный текст) в последовательность символов. жетоны.
- Анализатор , в свою очередь, берет последовательность токенов и создает абстрактное синтаксическое дерево (AST) языка. Правила, по которым работает синтаксический анализатор, обычно определяются формальной грамматикой.
- Интерпретатор — это программа, которая интерпретирует AST исходного кода программы на лету (без предварительной компиляции).
 жетоны.
жетоны.Здесь мы не будем создавать специальный интегрированный интерпретатор. Вместо этого мы рассмотрим каждую из этих частей и их общие проблемы на отдельных примерах. В итоге код пользователя будет выглядеть так:
val input="2*7+5" токены val = Lexer(input).lex() val ast = Parser(токены).parse() val res = Интерпретатор(ast).interpret() println(s"Результат: $res")
После трех этапов мы ожидаем, что этот код вычислит окончательное значение и напечатает Результат: 19 . В этом руководстве используется Scala, потому что он:
- Очень лаконичный, умещает большой объем кода на одном экране.
- Ориентирован на выражения, без необходимости использования неинициализированных/нулевых переменных.
- Надежный тип, с мощной библиотекой коллекций, перечислениями и классами case.

В частности, код здесь написан в синтаксисе необязательных фигурных скобок Scala3 (подобный Python синтаксис на основе отступов). Но ни один из подходов не является специфичным для Scala , а Scala похожа на многие другие языки: читатели найдут простым преобразование этих примеров кода в другие языки. За исключением этого, примеры можно запускать онлайн с помощью Scastie.
Наконец, секции Lexer, Parser и Interpreter содержат различных примера грамматик . Как показано в соответствующем репозитории GitHub, зависимости в более поздних примерах немного меняются для реализации этих грамматик, но общие концепции остаются прежними.
Компонент интерпретатора 1: Написание лексера
Допустим, мы хотим лексировать эту строку: "123 + 45 true * false1" . Он содержит различные типы токенов:
Он содержит различные типы токенов:
- Целочисленные литералы
- А
+оператор - А
*оператор - A
истинныйбуквальный - Идентификатор,
false1
В этом примере пробелы между токенами будут пропущены.
На данном этапе выражения не обязательно должны иметь смысл; лексер просто преобразует входную строку в список токенов. (Работа по «осмыслению токенов» возложена на синтаксический анализатор.)
Мы будем использовать этот код для представления токена:
case class Token(
tpe: Token.Type,
текст: строка,
startPos: Int
)
Токен объекта:
Тип перечисления:
случай Число
чехол Плюс
чехол раз
Идентификатор случая
случай Истинно
случай Ложь
случай EOF
Каждый токен имеет тип, текстовое представление и позицию в исходном вводе. Позиция может помочь конечным пользователям лексера с отладкой.
Маркер EOF — это специальный маркер, который отмечает конец ввода. Его нет в исходном тексте; мы используем его только для упрощения этапа парсера.
Его нет в исходном тексте; мы используем его только для упрощения этапа парсера.
Это будет вывод нашего лексера:
Ввод лексинга: 123 + 45 правда * ложь1 Токены: Список( Токен (tpe = число, текст = "123", tokenStartPos = 0), Токен (tpe = Плюс, текст = "+", tokenStartPos = 4), Токен (tpe = число, текст = "45", tokenStartPos = 6), Token(tpe = True, text = "true", tokenStartPos = 9), Токен (tpe = раз, текст = "*", tokenStartPos = 14), Токен (tpe = идентификатор, текст = "false1", tokenStartPos = 16), Token(tpe = EOF, text = "", tokenStartPos = 22) )
Давайте рассмотрим реализацию:
class Lexer(input: String):
def lex(): Список[Токен] =
val tokens = mutable.ArrayBuffer.empty[Token]
переменная текущая позиция = 0
в то время как currentPos < input.length делать
val tokenStartPos = currentPos
val lookahead = input (currentPos)
если lookahead.isWhitespace то
currentPos += 1 // игнорировать пробелы
иначе, если смотреть вперед == '+' тогда
текущийПос += 1
tokens += Token(Type. Plus, lookahead.toString, tokenStartPos)
иначе, если смотреть вперед == '*' тогда
текущийПос += 1
tokens += Token(Type.Times, lookahead.toString, tokenStartPos)
иначе если lookahead.isDigit тогда
переменный текст = ""
в то время как currentPos < input.length && input(currentPos).isDigit do
текст += ввод (currentPos)
текущийПос += 1
tokens += Token(Type.Num, text, tokenStartPos)
else if lookahead.isLetter then // сначала должна быть буква
переменный текст = ""
в то время как currentPos < input.length && input(currentPos).isLetterOrDigit do
текст += ввод (currentPos)
текущийПос += 1
val tpe = совпадение текста
case "true" => Type.True // специальные регистровые литералы
case "false" => Type.False
case _ => Type.Identifier
tokens += Token(tpe, text, tokenStartPos)
еще
error(s"Неизвестный символ $lookahead в позиции $currentPos")
tokens += Token(Type. EOF, "", currentPos) // специальный маркер конца
tokens.toList
 Plus, lookahead.toString, tokenStartPos)
иначе, если смотреть вперед == '*' тогда
текущийПос += 1
tokens += Token(Type.Times, lookahead.toString, tokenStartPos)
иначе если lookahead.isDigit тогда
переменный текст = ""
в то время как currentPos < input.length && input(currentPos).isDigit do
текст += ввод (currentPos)
текущийПос += 1
tokens += Token(Type.Num, text, tokenStartPos)
else if lookahead.isLetter then // сначала должна быть буква
переменный текст = ""
в то время как currentPos < input.length && input(currentPos).isLetterOrDigit do
текст += ввод (currentPos)
текущийПос += 1
val tpe = совпадение текста
case "true" => Type.True // специальные регистровые литералы
case "false" => Type.False
case _ => Type.Identifier
tokens += Token(tpe, text, tokenStartPos)
еще
error(s"Неизвестный символ $lookahead в позиции $currentPos")
tokens += Token(Type.
Plus, lookahead.toString, tokenStartPos)
иначе, если смотреть вперед == '*' тогда
текущийПос += 1
tokens += Token(Type.Times, lookahead.toString, tokenStartPos)
иначе если lookahead.isDigit тогда
переменный текст = ""
в то время как currentPos < input.length && input(currentPos).isDigit do
текст += ввод (currentPos)
текущийПос += 1
tokens += Token(Type.Num, text, tokenStartPos)
else if lookahead.isLetter then // сначала должна быть буква
переменный текст = ""
в то время как currentPos < input.length && input(currentPos).isLetterOrDigit do
текст += ввод (currentPos)
текущийПос += 1
val tpe = совпадение текста
case "true" => Type.True // специальные регистровые литералы
case "false" => Type.False
case _ => Type.Identifier
tokens += Token(tpe, text, tokenStartPos)
еще
error(s"Неизвестный символ $lookahead в позиции $currentPos")
tokens += Token(Type. EOF, "
EOF, "Мы начинаем с пустого списка токенов, затем просматриваем строку и добавляем токены по мере их поступления.
Мы используем упреждающий символ, чтобы определить тип следующего токена . Обратите внимание, что опережающий символ не всегда является самым дальним исследуемым символом. Основываясь на предварительном просмотре, мы знаем, как выглядит токен, и используем currentPos для сканирования всех ожидаемых символов в текущем токене, а затем добавляем токен в список:
Если опережение содержит пробелы, мы пропускаем его. Однобуквенные токены тривиальны; мы добавляем их и увеличиваем индекс. Для целых чисел нам нужно позаботиться только об индексе.
Теперь мы подошли к кое-чему немного сложному: идентификаторы против литералов. Правило состоит в том, что мы берем максимально длинное совпадение и проверяем, является ли оно литералом; если нет, то это идентификатор.
Будьте осторожны при работе с такими операторами, как < и <= . Там вы должны посмотреть вперед еще один символ и посмотреть, если это = , прежде чем сделать вывод, что это оператор <= . В противном случае это просто < .
После этого наш лексер создал список токенов.
Компонент интерпретатора 2: Написание синтаксического анализатора
Мы должны дать некоторую структуру нашим токенам — мы мало что можем сделать со списком. Например, нам нужно знать:
Какие выражения являются вложенными? Какие операторы применяются в каком порядке? Какие правила области применения применяются, если таковые имеются?
Древовидная структура поддерживает вложенность и порядок. Но сначала мы должны определить некоторые правила построения деревьев. Мы хотели бы, чтобы наш синтаксический анализатор был однозначным — всегда возвращал одну и ту же структуру для данного ввода.
Обратите внимание, что следующий синтаксический анализатор не использует предыдущий пример лексера . Это для добавления чисел, поэтому его грамматика имеет только две лексемы, '+' и NUM :
expr -> expr '+' expr выражение -> ЧИСЛО
Эквивалент с использованием вертикальной черты ( | ) как символ «или», как и в регулярных выражениях:
expr -> expr '+' expr | ЧИСЛО
В любом случае у нас есть два правила: одно говорит, что мы можем суммировать два expr s, а другое говорит, что expr может быть токеном NUM , что здесь будет означать неотрицательное целое число.
Правила обычно задаются формальной грамматикой . Формальная грамматика состоит из:
Сами правила, как показано выше
Начальное правило (первое указанное правило согласно соглашению)
Два типа символов для определения правил:
Терминалы: «буквы» (и другие символы) нашего языка — несократимые символы, из которых состоят токены. Нетерминалы: промежуточные конструкции, используемые для синтаксического анализа (т. е. символы, которые можно заменить)
Нетерминалы: промежуточные конструкции, используемые для синтаксического анализа (т. е. символы, которые можно заменить)
Слева от правила может находиться только нетерминал; правая часть может иметь как терминалы, так и нетерминалы. В приведенном выше примере терминалами являются 2 MethodOrFieldDecl '+' и NUM , а единственным нетерминалом является expr . Для более широкого примера, в языке Java у нас есть терминалы, такие как 'true' , '+' , Identifier и '[' , и нетерминалы, такие как BlockStatements , ClassBody 4, и .
Есть много способов реализовать этот синтаксический анализатор. Здесь мы будем использовать метод разбора «рекурсивный спуск». Это самый распространенный тип, потому что его проще всего понять и реализовать.
Анализатор рекурсивного спуска использует одну функцию для каждого нетерминала в грамматике. Он начинается с начального правила и спускается оттуда (отсюда «спуск»), выясняя, какое правило применить в каждой функции. «Рекурсивная» часть жизненно важна, потому что мы можем рекурсивно вкладывать нетерминалы! Регулярные выражения не могут этого сделать: они даже не могут обрабатывать сбалансированные скобки. Поэтому нам нужен более мощный инструмент.
Он начинается с начального правила и спускается оттуда (отсюда «спуск»), выясняя, какое правило применить в каждой функции. «Рекурсивная» часть жизненно важна, потому что мы можем рекурсивно вкладывать нетерминалы! Регулярные выражения не могут этого сделать: они даже не могут обрабатывать сбалансированные скобки. Поэтому нам нужен более мощный инструмент.
Парсер для первого правила будет выглядеть примерно так (полный код):
def expr() =
выражение()
есть('+')
выражение()
Функция eat() проверяет, соответствует ли предпросмотр ожидаемому токену, а затем перемещает упреждающий индекс. К сожалению, это пока не сработает, потому что нам нужно исправить некоторые проблемы с нашей грамматикой.
Неоднозначность грамматики
Первая проблема — неоднозначность нашей грамматики, которая может быть незаметна на первый взгляд:
выражение -> выражение '+' выражение | ЧИСЛО
Учитывая ввод 1 + 2 + 3 , наш синтаксический анализатор может сначала вычислить либо левое выражение , либо правое выражение в результирующем AST:

Вот почему нам нужно ввести некоторую асимметрию :
expr -> expr '+' NUM | ЧИСЛО
Набор выражений, которые мы можем представить с помощью этой грамматики, не изменился со времени ее первой версии. Только сейчас однозначно : Анализатор всегда идет влево. Как раз то, что нам было нужно!
Это делает нашу операцию + левой ассоциативной , но это станет очевидным, когда мы перейдем к разделу Интерпретатор.
Лево-рекурсивные правила
К сожалению, приведенное выше исправление не решает другую нашу проблему, левую рекурсию:
def expr() =
выражение()
есть('+')
есть(ЧИСЛО)
У нас есть бесконечная рекурсия здесь. Если бы мы вошли в эту функцию, то в конечном итоге получили бы ошибку переполнения стека. Но теория разбора может помочь!
Предположим, у нас есть такая грамматика, где альфа может быть любой последовательностью терминалов и нетерминалов:
A -> A альфа | Б
Мы можем переписать эту грамматику как:
A -> B A' А' -> альфа А' | эпсилон
Здесь эпсилон — пустая строка — ничего, нет токена.
Возьмем текущую версию нашей грамматики:
expr -> expr '+' NUM | ЧИСЛО
Следуя описанному выше методу перезаписи правил синтаксического анализа с alpha является нашим '+' токеном NUM , наша грамматика становится:
expr -> NUM exprOpt exprOpt -> '+' ЧИСЛО exprOpt | эпсилон
Теперь с грамматикой все в порядке, и мы можем разобрать ее с помощью анализатора рекурсивного спуска. Давайте посмотрим, как такой синтаксический анализатор будет искать эту последнюю итерацию нашей грамматики:
class Parser(allTokens: List[Token]):
импортировать Token.Type
частные токены var = allTokens
частный var lookahead = tokens.head
деф синтаксический анализ(): Единица измерения =
выражение()
если lookahead.tpe != Type.EOF, то
error(s"Неизвестный токен '${lookahead.text}' в позиции ${lookahead.tokenStartPos}")
частное выражение выражения(): Unit =
есть(Тип.Число)
exprOpt()
частная защита exprOpt(): Unit =
если lookahead. tpe == Type.Plus, то
есть(Тип.Плюс)
есть(Тип.Число)
exprOpt()
// иначе: конец рекурсии, эпсилон
частное определение (tpe: Type): Unit =
если lookahead.tpe != tpe, то
error(s"Ожидается: $tpe, получено: ${lookahead.tpe} в позиции ${lookahead.startPos}")
жетоны = жетоны.хвост
просмотр вперед = tokens.head
 tpe == Type.Plus, то
есть(Тип.Плюс)
есть(Тип.Число)
exprOpt()
// иначе: конец рекурсии, эпсилон
частное определение (tpe: Type): Unit =
если lookahead.tpe != tpe, то
error(s"Ожидается: $tpe, получено: ${lookahead.tpe} в позиции ${lookahead.startPos}")
жетоны = жетоны.хвост
просмотр вперед = tokens.head
tpe == Type.Plus, то
есть(Тип.Плюс)
есть(Тип.Число)
exprOpt()
// иначе: конец рекурсии, эпсилон
частное определение (tpe: Type): Unit =
если lookahead.tpe != tpe, то
error(s"Ожидается: $tpe, получено: ${lookahead.tpe} в позиции ${lookahead.startPos}")
жетоны = жетоны.хвост
просмотр вперед = tokens.head
Здесь мы используем токен EOF , чтобы упростить наш синтаксический анализатор. Мы всегда уверены, что в нашем списке есть хотя бы один токен, поэтому нам не нужно обрабатывать частный случай пустого списка.
Кроме того, если мы переключимся на потоковый лексер, у нас будет не список в памяти, а итератор, поэтому нам нужен маркер, чтобы знать, когда мы подошли к концу ввода. Когда мы подойдем к концу, токен EOF должен быть последним оставшимся токеном.
Просматривая код, мы видим, что выражение может быть просто числом. Если ничего не осталось, следующий жетон не будет Плюс , чтобы мы прекратили парсинг. Последним токеном будет
Последним токеном будет EOF , и мы закончим.
Если во входной строке больше токенов, то они должны выглядеть как + 123 . Вот где рекурсия по exprOpt() срабатывает!
Генерация AST
Теперь, когда мы успешно проанализировали наше выражение, трудно что-либо сделать с ним как есть. Мы могли бы поместить несколько обратных вызовов в наш парсер, но это было бы очень громоздко и нечитаемо. Вместо этого мы вернем AST, дерево, представляющее входное выражение:
класс случая Expr(num: Int, exprOpt: ExprOpt) перечисление Expropt: case Opt(num: Int, exprOpt: ExprOpt) чехол Эпсилон
Это похоже на наши правила, использующие простые классы данных.
Теперь наш синтаксический анализатор возвращает полезную структуру данных:
class Parser(allTokens: List[Token]):
импортировать Token.Type
частные токены var = allTokens
частный var lookahead = tokens.head
деф разбор(): Выражение =
val res = expr()
если lookahead. tpe != Type.EOF, то
error(s"Неизвестный токен '${lookahead.text}' в позиции ${lookahead.tokenStartPos}")
еще
разрешение
частное выражение выражения(): выражение =
val num = есть(Тип.Число)
Expr(num.text.toInt, exprOpt())
частная защита exprOpt(): ExprOpt =
если lookahead.tpe == Type.Plus, то
есть(Тип.Плюс)
val num = есть(Тип.Число)
ExprOpt.Opt(num.text.toInt, exprOpt())
еще
Экспроопт.Эпсилон
 tpe != Type.EOF, то
error(s"Неизвестный токен '${lookahead.text}' в позиции ${lookahead.tokenStartPos}")
еще
разрешение
частное выражение выражения(): выражение =
val num = есть(Тип.Число)
Expr(num.text.toInt, exprOpt())
частная защита exprOpt(): ExprOpt =
если lookahead.tpe == Type.Plus, то
есть(Тип.Плюс)
val num = есть(Тип.Число)
ExprOpt.Opt(num.text.toInt, exprOpt())
еще
Экспроопт.Эпсилон
tpe != Type.EOF, то
error(s"Неизвестный токен '${lookahead.text}' в позиции ${lookahead.tokenStartPos}")
еще
разрешение
частное выражение выражения(): выражение =
val num = есть(Тип.Число)
Expr(num.text.toInt, exprOpt())
частная защита exprOpt(): ExprOpt =
если lookahead.tpe == Type.Plus, то
есть(Тип.Плюс)
val num = есть(Тип.Число)
ExprOpt.Opt(num.text.toInt, exprOpt())
еще
Экспроопт.Эпсилон
Информацию о eat() , error() и других деталях реализации см. в соответствующем репозитории GitHub.
Упрощение правил
Наш нетерминал ExpOpt можно улучшить:
'+' NUM expOpt | эпсилон
Трудно распознать шаблон, который он представляет в нашей грамматике, просто взглянув на него. Оказывается, эту рекурсию можно заменить более простой конструкцией:
('+' NUM)*
Эта конструкция просто означает '+' NUM встречается ноль или более раз.
Теперь наша полная грамматика выглядит так:
expr -> NUM exprOpt* exprOpt -> '+' ЧИСЛО
И наш AST выглядит лучше:
case class Expr(num: Int, exprOpts: Seq[ExprOpt]) класс case ExprOpt (число: Int)
Полученный синтаксический анализатор такой же длины, но более простой для понимания и использования. Мы исключили Epsilon , что теперь подразумевается, если начать с пустой структуры.
Нам даже 9 не понадобилось0041 ExprOpt класс здесь. Мы могли бы просто указать case class Expr(num: Int, exprOpts: Seq[Int]) или в формате грамматики NUM ('+' NUM)* . Так почему же мы этого не сделали?
Учтите, что если бы у нас было несколько возможных операторов, таких как - или * , то у нас была бы такая грамматика:
expr -> NUM exprOpt* exprOpt -> [+-*] ЧИСЛО
В этом случае AST требуется ExpOpt для размещения типа оператора:
case class Expr(num: Int, exprOpts: Seq[ExprOpt]) класс case ExprOpt (op: String, num: Int)
Обратите внимание, что синтаксис [+-*] в грамматике означает то же самое, что и в регулярных выражениях: «один из этих трех символов».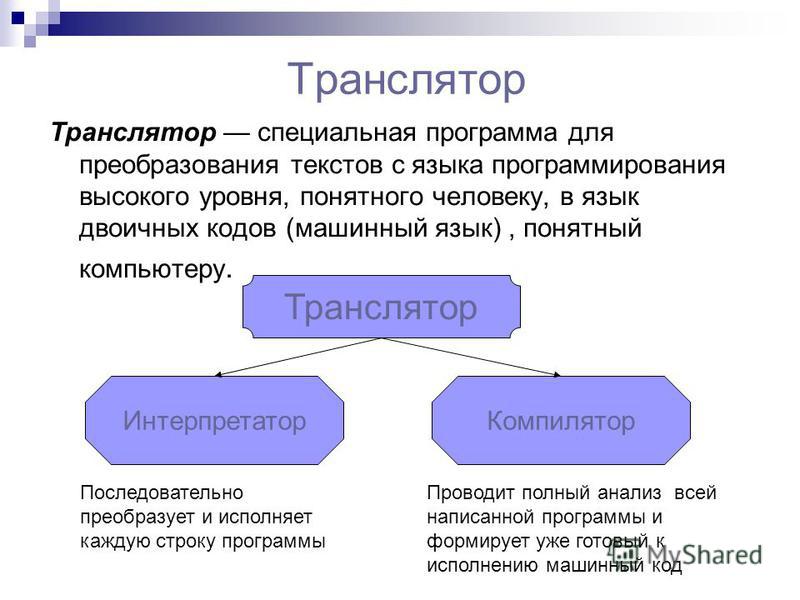 Мы скоро увидим это в действии.
Мы скоро увидим это в действии.
Компонент интерпретатора 3: Написание интерпретатора
Наш интерпретатор будет использовать наш лексер и синтаксический анализатор, чтобы получить AST нашего входного выражения, а затем оценить это AST любым удобным для нас способом. В данном случае мы имеем дело с числами и хотим вычислить их сумму.
В реализации нашего примера интерпретатора мы будем использовать эту простую грамматику:
expr -> NUM exprOpt* exprOpt -> [+-] ЧИСЛО
И этот AST:
case class Expr(num: Int, exprOpts: Seq[ExprOpt]) класс case ExprOpt (op: Token.Type, num: Int)
(Мы рассмотрели, как реализовать лексер и парсер для похожих грамматик, но любой читатель, который застрял, может просмотреть реализации лексера и парсера для этой грамматики в репозитории.)
Теперь посмотрим, как написать интерпретатор для приведенной выше грамматики:
class Interpreter(ast: Expr):
деф интерпретировать (): Int = eval (аст)
частная оценка (выражение: выражение): Int =
var tmp = expr. num
expr.exprOpts.foreach { exprOpt =>
если exprOpt.op == Token.Type.Plus
затем tmp += exprOpt.num
иначе tmp -= exprOpt.num
}
температура
 num
expr.exprOpts.foreach { exprOpt =>
если exprOpt.op == Token.Type.Plus
затем tmp += exprOpt.num
иначе tmp -= exprOpt.num
}
температура
num
expr.exprOpts.foreach { exprOpt =>
если exprOpt.op == Token.Type.Plus
затем tmp += exprOpt.num
иначе tmp -= exprOpt.num
}
температура
Если мы разобрали наши входные данные в AST без ошибок, мы уверены, что у нас всегда будет хотя бы одна ЧИСЛО . Затем мы берем необязательные числа и добавляем их к нашему результату (или вычитаем из него).
Замечание с самого начала о левой ассоциативности + теперь ясно: мы начинаем с крайнего левого числа и добавляем другие, слева направо. Это может показаться неважным для сложения, но рассмотрим вычитание: выражение 5 - 2 - 1 оценивается как (5 - 2) - 1 = 3 - 1 = 2 , а не как 5 - (2 - 1) = 5 - 1 = 4 !
Но если мы хотим выйти за рамки интерпретации операторов плюс и минус, нужно определить еще одно правило.
Приоритет
Мы знаем, как анализировать простое выражение, такое как 1 + 2 + 3 , но когда дело доходит до 2 + 3 * 4 + 5 , у нас возникает небольшая проблема.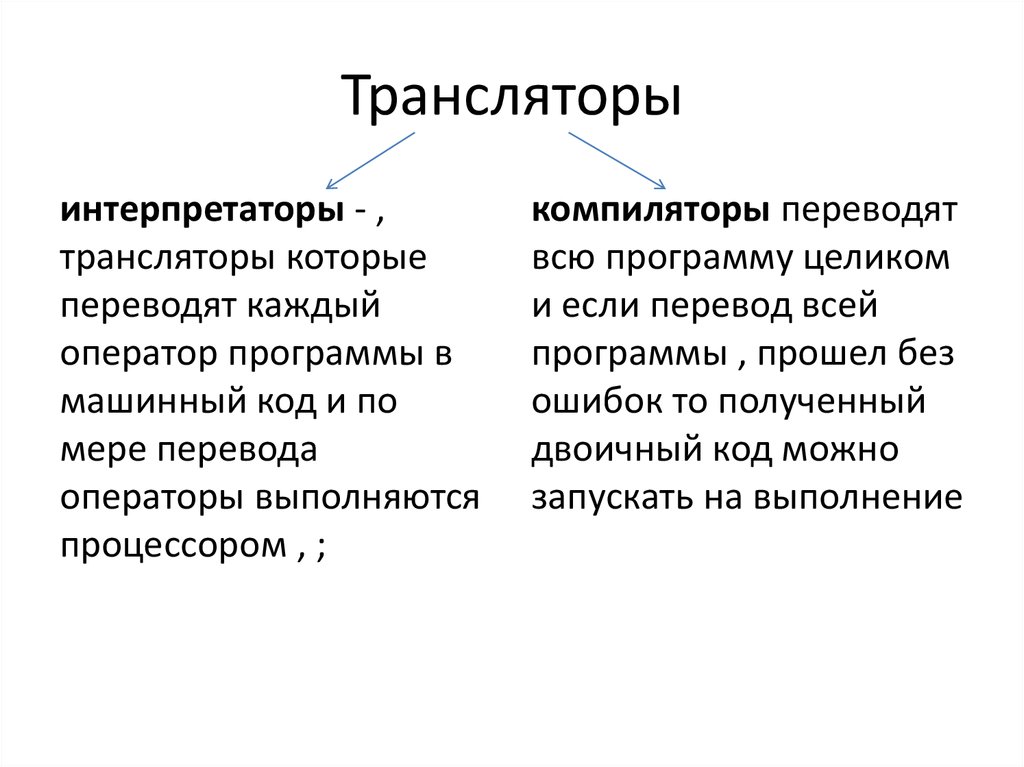
Большинство людей согласны с тем, что умножение имеет более высокий приоритет, чем сложение. Но парсер этого не знает. Мы не можем просто вычислить его как ((2 + 3) * 4) + 5 . Вместо этого нам нужно (2 + (3 * 4)) + 5 .
Это означает, что нам нужно сначала оценить умножение . Умножение должно быть на дальше от корня AST , чтобы принудительно оценить его перед добавлением. Для этого нам нужно ввести еще один уровень косвенности.
Исправление наивной грамматики от начала до конца
Это наша исходная леворекурсивная грамматика, не имеющая правил приоритета:
expr -> expr '+' expr | выражение '*' выражение | ЧИСЛО
Во-первых, мы даем ему правила приоритета и удаляем его неоднозначность :
выражение -> выражение '+' термин | срок термин -> термин '*' ЧИСЛО | ЧИСЛО
Затем он получает нелеворекурсивных правила :
expr -> term exprOpt* exprOpt -> '+' термин срок -> ЧИСЛО срокОпт* termOpt -> '*' ЧИСЛО
Результатом является красиво выразительный AST:
case class Expr(term: Term, exprOpts: Seq[ExprOpt]) класс случая ExprOpt(term: Term) класс case Term (число: Int, termOpts: Seq[TermOpt]) класс case TermOpt (число: Int)
Это дает нам краткую реализацию интерпретатора:
class Interpreter(ast: Expr):
деф интерпретировать (): Int = eval (аст)
частная оценка (выражение: выражение): Int =
var tmp = eval(expr. term)
expr.exprOpts.foreach { exprOpt =>
tmp += eval(exprOpt.term)
}
температура
частная оценка (срок: срок): Int =
var tmp = термин.номер
term.termOpts.foreach {termOpt =>
tmp *= termOpt.num
}
температура
 term)
expr.exprOpts.foreach { exprOpt =>
tmp += eval(exprOpt.term)
}
температура
частная оценка (срок: срок): Int =
var tmp = термин.номер
term.termOpts.foreach {termOpt =>
tmp *= termOpt.num
}
температура
term)
expr.exprOpts.foreach { exprOpt =>
tmp += eval(exprOpt.term)
}
температура
частная оценка (срок: срок): Int =
var tmp = термин.номер
term.termOpts.foreach {termOpt =>
tmp *= termOpt.num
}
температура
Как и прежде, идеи в отношении необходимого лексера и грамматики были рассмотрены ранее, но при необходимости читатели могут найти их в репозитории.
Следующие шаги в написании интерпретаторов
Мы не рассматривали это, но обработка ошибок и отчеты являются важными функциями любого синтаксического анализатора. Как разработчики, мы знаем, как неприятно, когда компилятор выдает запутанные или вводящие в заблуждение ошибки. Это область, в которой нужно решить много интересных проблем, таких как предоставление правильных и точных сообщений об ошибках, не отпугивание пользователя большим количеством сообщений, чем необходимо, и изящное восстановление после ошибок. Разработчики должны написать интерпретатор или компилятор, чтобы обеспечить их будущим пользователям лучший опыт.
В наших примерах лексеров, синтаксических анализаторов и интерпретаторов мы только поверхностно коснулись теорий, лежащих в основе компиляторов и интерпретаторов, которые охватывают такие темы, как:
- Области действия и таблицы символов
- Статические типы
- Оптимизация времени компиляции
- Статические анализаторы программ и линтеры
- Форматирование кода и красивая печать
- Доменные языки
Для дальнейшего чтения я рекомендую следующие ресурсы:
- Шаблоны языковой реализации Теренса Парра
- Бесплатная онлайн-книга, Crafting Interpreters , Боба Нистрома
- Введение в грамматику и синтаксический анализ Пола Клинта
- Написание хороших сообщений об ошибках компилятора Калеб Мередит
- Заметки из курса Университета Восточной Каролины «Перевод и компиляция программ»
Понимание основ
Как создать интерпретатор?
Чтобы сначала создать интерпретатор, вам нужно создать лексер для получения токенов вашей программы ввода.
Затем вы создаете синтаксический анализатор, который берет эти токены и, следуя правилам формальной грамматики, возвращает AST вашей входной программы. Наконец, интерпретатор берет этот AST и каким-то образом интерпретирует его.В чем разница между компилятором и интерпретатором?
Компилятор берет программу на языке более высокого уровня и преобразует ее в программу на языке более низкого уровня. Интерпретатор берет программу и запускает ее на лету. Он не создает никаких файлов.
На каком языке написан переводчик?
Интерпретаторы могут быть написаны на любом языке программирования. Популярным выбором являются функциональные языки, потому что они имеют отличные абстракции для преобразования данных.
Как работает переводчик?
Интерпретаторы в основном выполняют по одному оператору за раз. Они берут AST, возвращенный синтаксическим анализатором, и выполняют его. В этом процессе они обычно используют некоторые вспомогательные конструкции, такие как таблицы символов, генераторы и оптимизаторы.
Как работает лексер?
Лексер принимает строку символов и возвращает список токенов, которые в основном представляют собой сгруппированные символы. Токены обычно определяются с помощью регулярных выражений.
Как работают синтаксические анализаторы программирования?
Парсер программирования определяется формальной грамматикой, описывающей правила языка, который он анализирует. Наиболее распространенным видом является анализатор рекурсивного спуска, и он напоминает данную грамматику, имея одну функцию для каждого нетерминала. Он принимает последовательность токенов в качестве входных данных и возвращает AST в качестве выходных данных.
Что подразумевается под абстрактным синтаксическим деревом?
Абстрактное синтаксическое дерево (AST) представляет собой представление структуры исходного кода программы. Он содержит только те данные, которые важны для интерпретатора или компилятора. Он не содержит пробелов, фигурных скобок, точек с запятой и подобных частей входной программы.
Для чего используется абстрактное синтаксическое дерево?
Абстрактное синтаксическое дерево используется как промежуточное представление входной программы. Затем интерпретатор/компилятор может делать с ним все, что ему нужно: оптимизировать, упрощать, выполнять или что-то еще.
 Затем вы создаете синтаксический анализатор, который берет эти токены и, следуя правилам формальной грамматики, возвращает AST вашей входной программы. Наконец, интерпретатор берет этот AST и каким-то образом интерпретирует его.
Затем вы создаете синтаксический анализатор, который берет эти токены и, следуя правилам формальной грамматики, возвращает AST вашей входной программы. Наконец, интерпретатор берет этот AST и каким-то образом интерпретирует его.

Кто такой переводчик? - Определение из Techopedia
Что означает переводчик?
Интерпретатор — это компьютерная программа, которая используется для непосредственного выполнения программных инструкций, написанных с использованием одного из многих языков программирования высокого уровня.
Advertisements
Интерпретатор преобразует высокоуровневую программу в промежуточный язык, который затем выполняется, или он может анализировать высокоуровневый исходный код, а затем напрямую выполнять команды, что выполняется построчно или оператор за оператором.
Интерпретатор Techopedia объясняет
Люди могут понимать только языки высокого уровня, которые называются исходным кодом. Компьютеры, с другой стороны, могут понимать только программы, написанные на двоичных языках, поэтому требуется либо интерпретатор, либо компилятор.
Компьютеры, с другой стороны, могут понимать только программы, написанные на двоичных языках, поэтому требуется либо интерпретатор, либо компилятор.
Языки программирования реализуются двумя способами: интерпретацией и компиляцией. Как следует из названия, интерпретатор преобразует или интерпретирует программный код высокого уровня в код, понятный машине (машинный код), или в промежуточный язык, который также может быть легко выполнен.
Интерпретатор читает каждый оператор кода, а затем преобразует или выполняет его напрямую. Напротив, ассемблер или компилятор преобразует исходный код высокого уровня в собственный (скомпилированный) код, который может выполняться непосредственно операционной системой (например, путем создания программы .exe).
Как компиляторы, так и интерпретаторы имеют свои преимущества и недостатки и не исключают друг друга; это означает, что их можно использовать вместе, поскольку большинство интегрированных сред разработки используют как компиляцию, так и перевод для некоторых языков высокого уровня.
В большинстве случаев компилятор предпочтительнее, так как его вывод выполняется намного быстрее, чем построчная интерпретация. Вместо того, чтобы сканировать всю программу и переводить ее в машинный код, как это делает компилятор, интерпретатор переводит код по одному оператору за раз.
Хотя время анализа исходного кода сокращается, особенно особенно большого, время выполнения для интерпретатора сравнительно медленнее, чем для компилятора. Вдобавок ко всему, поскольку интерпретация выполняется для каждой строки или оператора, ее можно остановить в середине выполнения, чтобы разрешить либо модификацию кода, либо отладку.
Компиляторы должны генерировать промежуточный объектный код, который требует больше памяти для компоновки, в отличие от интерпретаторов, которые склонны более эффективно использовать память.
Поскольку интерпретатор читает и затем выполняет код в одном процессе, он очень удобен для сценариев и других небольших программ.