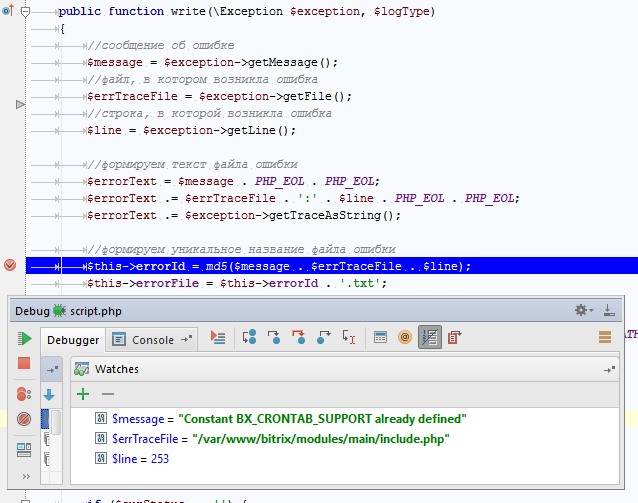
системный вызов write(), на самом деле, не такой уж и атомарный / Хабр
Недавно я читал материал Эвана Джонса «Устойчивое хранение данных и файловые API Linux». Я полагаю, что автор этой довольно хорошей статьи ошибается, говоря о том, чего можно ожидать от команды write() (и в том виде, в каком она описана в стандарте POSIX, и на практике). Начну с цитаты из статьи:
Системный вызов write() определён в стандарте IEEE POSIX как попытка записи данных в файловый дескриптор. После успешного завершения работы write() операции чтения данных должны возвращать именно те байты, которые были до этого записаны, делая это даже в том случае, если к данным обращаются из других процессов или потоков (вот соответствующий раздел стандарта POSIX). Здесь, в разделе, посвящённом взаимодействию потоков с обычными файловыми операциями, имеется примечание, в котором говорится, что если каждый из двух потоков вызывает эти функции, то каждый вызов должен видеть либо все обозначенные последствия, к которым приводит выполнение другого вызова, либо не видеть вообще никаких последствий.
Означает ли это, что операция write() является атомарной? С технической точки зрения — да. Операции чтения данных должны возвращать либо всё, либо ничего из того, что было записано с помощью write(). […].
К сожалению, то, что операции записи, в целом, атомарны — это не то, что говорится в стандарте POSIX, и даже если именно это и попытались выразить авторы стандарта — весьма вероятно то, что ни одна версия Unix этому стандарту не соответствует, и то, что ни одна из них не даёт нам полностью атомарных команд записи данных. Прежде всего, то, что в стандарте POSIX чётко сказано об атомарности, применяется лишь в двух ситуациях: когда что-то пишется в конвейер или в FIFO, или когда речь идёт о нескольких потоках одного и того же процесса, выполняющих некие действия. А то, что стандарт POSIX говорит об операциях записи, смешанных с операциями чтения, имеет гораздо более ограниченную область применения.
После того как произошёл успешный возврат из операции записи (write()) в обычный файл:
- Любая успешная операция чтения (read()) данных из каждой байтовой позиции файла, которая была модифицирована этой операцией записи, должна возвращать данные, установленные для этой позиции командой write() до тех пор, пока данные в таких позициях не будут снова модифицированы.
write()). Если выполнить подобную команду read(), POSIX позволяет этой команде вовсе не прочитать данные, записываемые write(), прочитать лишь некоторую часть этих данных, или прочитать их все. Подобная команда read() При таком подходе, определённо, не реализуется обычная, привычная всем, атомарная схема работы, когда либо видны все результаты работы некоей команды, либо результаты её работы не видны вовсе. Так как разрешено кросс-процессное выполнение команды
При таком подходе, определённо, не реализуется обычная, привычная всем, атомарная схема работы, когда либо видны все результаты работы некоей команды, либо результаты её работы не видны вовсе. Так как разрешено кросс-процессное выполнение команды read() во время выполнения команды write(), выполнение команды чтения может привести к возврату частичного результата работы команды записи. Мы не назвали бы «атомарной» SQL-базу данных, которая позволяет прочитать результаты незавершённой транзакции. Но именно это стандарт POSIX позволяет команде write()(Это, кроме того, именно то, что, почти гарантированно, дают нам реальные Unix-системы, хотя тут возможно много ситуаций, и Unix-системы я на предмет этого не тестировал. Например, меня бы не удивило, если бы оказалось, что выровненные операции записи фрагментов данных, размеры которых соответствуют размерам страниц (или блоков файловой системы), на практике, оказались бы атомарными во множестве Unix-систем.
Если подумать о том, что потребуется для реализации атомарных операций записи в файлы в многопроцессной среде, то сложившаяся ситуация не должна выглядеть удивительной. Так как Unix-программы не ожидают коротких сеансов записи в файлы, мы не можем упростить проблему, установив лимит размера данных, запись которых необходимо выполнять атомарно, а потом ограничив write() этим размером. Пользователь может запросить у системы запись мегабайтов или даже гигабайтов данных в одном вызове write() и эта операция должна быть атомарной. Во внутренний буфер ядра придётся собирать слишком много данных, а затем придётся менять видимое состояние соответствующего раздела файла, укладывая всё это в одно действие. Вместо этого подобное, вероятно, потребует блокировки некоего диапазона байтов, где read() блокируют друг друга при перекрытии захваченных ими диапазонов. А это означает, что придётся выполнять очень много блокировок, так как в этом процессе придётся принимать участие каждой операции write() и каждой операции read().
(Операцию чтения данных из файлов, которые никто не открывал для записи, можно оптимизировать, но при таком подходе, всё равно, придётся блокировать файл, делая так, чтобы его нельзя было бы открыть для записи до тех пор, пока не будет завершена операция
Но блокировать файлы лишь при выполнении команды read() в современных Unix-системах недостаточно, так как многие программы, на самом деле, читают данные, используя отображение файлов на память с помощью системного вызова mmap(). Если действительно требуется, чтобы операция write() была бы атомарной, нужно блокировать и операции чтения данных из памяти при выполнении команды записи. А это требует довольно-таки ресурсозатратных манипуляций с таблицей страниц. Если заботиться ещё и о mmap()
write() не обязательно будет атомарной даже на уровне отдельных страниц памяти. Тот, кто читает данные из памяти, на которую отображается файл, может столкнуться со страницей, находящейся в процессе копирования в неё байтов, записанных с помощью
Тот, кто читает данные из памяти, на которую отображается файл, может столкнуться со страницей, находящейся в процессе копирования в неё байтов, записанных с помощью write().(Это может произойти даже с read() и write(), так как и та и другая команды могут получить доступ к одной и той же странице данных из файла в буферном кеше ядра. Но тут, вероятно, легче применить механизм блокировки.)
Помимо проблем с производительностью тут наблюдаются и проблемы со справедливостью распределения системных ресурсов. Если команда write() является, по отношению к команде read(), атомарной, это значит, что длительная операция write() может остановить другую команду на значительное время. Пользователям не нравятся медленные и откладываемые на какое-то время операции read() и write(). Подобное, кроме того, даст удобный инструмент для DoS-атак путём записи данных в файлы, открываемые для чтения.
Правда, большая часть затрат системных ресурсов происходит из-за того, что мы рассуждаем о кросс-процессных атомарных операциях записи, так как это значит, что действия по выполнению блокировок должно выполнять ядро. Кросс-поточная атомарная операция write() может быть реализована полностью на уровне пользователя, в пределах отдельного процесса (при условии, что библиотека C перехватывает операции read() и write() при работе в многопоточном режиме). В большинстве случаев можно обойтись какой-нибудь простой системой блокировки всего файла, хотя тем, кто работает с базами данных, это, вероятно, не понравится. Вопросы справедливости распределения системных ресурсов и задержки операций из-за блокировок при работе в пределах одного процесса теряют остроту, так как единственным, кому это повредит, будет тот, кто запустил соответствующий процесс.
(Большинство программ не выполняют операции read() и write() над одним и тем же файлом в одно и то же время из двух потоков.)
P.S. Обратите внимание на то, что даже операции записи в конвейеры и в FIFO являются атомарными только если объём записываемых данных достаточно мал. Запись больших объёмов данных, очевидно, не должна быть атомарной (и в реальных Unix-системах она таковой обычно и не является). Если бы стандарт POSIX требовал бы атомарности при записи ограниченных объёмов данных в конвейеры, и при этом указывал бы на то, что запись любых объёмов данных в файлы так же должна быть атомарной, это выглядело бы довольно-таки необычно.
P.P.S. Я с осторожностью относился бы к принятию как данности того, что в некоем варианте Unix, в многопоточной среде, полностью реализованы атомарные операции read() и write(). Возможно, я настроен скептически, но я бы сначала это как следует проверил. Всё это похоже на излишне прихотливые требования POSIX, на которые разработчики систем закрывают глаза во имя простоты и высокой производительности своих решений.
Приходилось ли вам сталкиваться с проблемами, вызванными одновременным выполнением записи в файл и чтения из него?
Файловый ввод-вывод — Python documentation
Файловый ввод-вывод — Python documentationОбычно работа с файлами состоит из следующих этапов:
Открыть файл. При открытии следует указать режим: чтение или запись.
Выполнить чтение или запись данных.
Закрыть файл.
Рассмотрим функции для выполнения этих действий.
-
open(file_path, mode=’r’) Открыть файл
file_pathв режимеmode. Функция возвращаетfile object. Полная сигнатура функции приведена в официальной документации: open. Режим может принимать значения:'r'— read, чтение'w'— write, запись
-
f.
write(text) Записать строку
textв файл.

-
f.read() Прочитать все данные из файла
-
f.close() Закрыть файл
f.
Пример работы с файлом:
# Открываем файл для записи
out_file = open('data.txt', 'w')
# Пишем в файл две строки
out_file.write('Hello\n')
out_file.write('World\n')
# Закрываем файл
out_file.close()
# Снова открываем этот же файл, но уже для чтения
in_file = open('data.txt', 'r')
# Файл — итерируемый объект. Следовательно, для
# его построчного чтения можно использовать цикл for
for line in in_file:
print(f'Got line: {line}')
in_file.close()
Задачи
Написать программу, которая будет получать у пользователя строку и записывать её в файл “data.txt”
Разработать приложение, которое записывает в файл все строки, введенные пользователем.
Признак конца ввода — пустая строка. Пример:Введите имя файла: data.txt Начните вводить строки > one > two > three > Файл записан.
После выполнения программы должен появиться файл
data.txt, содержащий три строки:one two three
Написать программу, которая будет получать у пользователя путь к файлу и выводить его содержимое на экран
Доработать предыдущее приложение для нумерации строк в файле. Приложение принимает на вход имя файла и выводит его построчно, добавляя к каждой строке её номер. Если использовать файл, созданный в предыдущей задаче, то результат работы программы будет выглядеть так:
Введите имя файла: data.txt 1 one 2 two 3 three
Используйте метод строки
rstrip(), чтобы избавиться от лишних переносов сток. После этого результат работы программы примет вид:Введите имя файла: data.txt 1 one 2 two 3 three
Разработать приложение для разделения файла на части.
Приложение принимает
на вход имя файла для разделения и целое число N. На выходе у приложения
множество файлов, каждый из которых содержит не более, чем N строк из
исходного файла.Пусть на вход программе подается файл
data.txt, со следующим текстом:one two three four five six seven eight nine ten
Будем разделять его на несколько файлов, в каждом из которых окажется не более трех строк:
Введите имя входного файла: data.txt Введите максимальное количество строк: 3
После выполнения программы должны быть созданы файлы
1.txt,2.txtи так далее. В файле1.txtбудут сроки:one two three
В файле
2.txt:four five six
И так далее.
Разработать приложение для объединения файлов. Приложение принимает на вход имена файлов для объединения (можно использовать файлы, полученные из предыдущего задания) и имя выходного файла.
 Признак конца ввода — пустая строка. Пример:
Признак конца ввода — пустая строка. Пример: Приложение принимает
на вход имя файла для разделения и целое число N. На выходе у приложения
множество файлов, каждый из которых содержит не более, чем N строк из
исходного файла.
Приложение принимает
на вход имя файла для разделения и целое число N. На выходе у приложения
множество файлов, каждый из которых содержит не более, чем N строк из
исходного файла.Дополнительные задачи
Разработайте приложение, которое выводит
Nпервых строк файла.Разработайте приложение, которое выводит
Nпоследних строк файла.

- Versions
- latest
- Downloads
- html
- On Read the Docs
- Project Home
- Builds
Free document hosting provided by Read the Docs.
Как писать функции в R (с 18 примерами кода)
Функции — это важные инструменты в R. Вот что вам нужно знать о их создании и вызове — и многое другое.
Функция в R — один из наиболее часто используемых объектов. Очень важно понимать назначение и синтаксис функций R, а также знать, как их создавать и использовать. В этом руководстве мы узнаем все это и многое другое: что такое функция R, какие типы функций существуют в R, когда мы должны использовать функцию, самые популярные встроенные функции, как создать и вызвать пользователя -определенная функция, как вызывать одну функцию внутри другой и как вкладывать функции.
Что такое функция в R?
Функция в R — это объект, содержащий несколько взаимосвязанных операторов, которые выполняются вместе в предопределенном порядке каждый раз при вызове функции. Функции в R могут быть встроенными или создаваться пользователем (определяемые пользователем). Основная цель создания пользовательской функции — оптимизировать нашу программу, избежать повторения одного и того же блока кода, используемого для конкретной задачи, часто выполняемой в конкретном проекте, предотвратить неизбежные и трудноотлаживаемые ошибки. связанных с операциями копирования-вставки, и сделать код более читабельным. Хорошей практикой является создание функции всякий раз, когда мы должны запускать определенный набор команд более двух раз.
Встроенные функции R
В R существует множество полезных встроенных функций, используемых для различных целей. Некоторые из самых популярных:
-
min(),max(),mean(),median()— возвращают минимальное/максимальное/среднее/медианное значение числового вектора, соответственно -
sum()– возвращает сумму числового вектора -
range()— возвращает минимальное и максимальное значения числового вектора -
abs()– возвращает абсолютное значение числа -
str()— показывает структуру объекта R -
print()— отображает объект R на консоли -
ncol()— возвращает количество столбцов матрицы или кадра данных -
length()— возвращает количество элементов в объекте R (вектор, список и т. д.) -
nchar()— возвращает количество символов в символьном объекте -
sort()– сортирует вектор по возрастанию или убыванию (по убыванию=TRUE) в порядке -
exists()— возвращаетTRUEилиFALSEв зависимости от того, определена ли переменная в среде R
 д.)
д.)Давайте посмотрим на некоторые из вышеперечисленных функций в действии:
vector <- c(3, 5, 2, 3, 1, 4)
печать (мин (вектор))
печать (среднее (вектор))
печать (медиана (вектор))
печать (сумма (вектор))
печать (диапазон (вектор))
печать (ул (вектор))
печать (длина (вектор))
печать (сортировка (вектор, уменьшение = ИСТИНА))
print(exists('vector')) ## обратите внимание на кавычки [1] 1 [1] 3 [1] 3 [1] 18 [1] 1 5 число [1:6] 3 5 2 3 1 4 НУЛЕВОЙ [1] 6 [1] 5 4 3 3 2 1 [1] TRUE
Создание функции в R
В то время как применение встроенных функций облегчает многие общие задачи, часто нам нужно создать собственную функцию для автоматизации выполнения конкретной задачи. Чтобы объявить определяемую пользователем функцию в R, мы используем ключевое слово
Чтобы объявить определяемую пользователем функцию в R, мы используем ключевое слово function . Синтаксис следующий:
имя_функции <- функция(параметры){
тело функции
} Выше основные компоненты функции R: имя функции , параметры функции и тело функции . Давайте рассмотрим каждый из них отдельно.
Имя функции
Это имя объекта функции, который будет храниться в среде R после определения функции и использоваться для вызова этой функции. Оно должно быть кратким, но четким и осмысленным, чтобы пользователь, читающий наш код, мог легко понять, что именно делает эта функция. Например, если нам нужно создать функцию для вычисления длины окружности с известным радиусом, лучше назвать эту функцию окружность вместо function_1 или окружность_окружности . ( Примечание: Хотя обычно мы используем глаголы в именах функций, можно использовать только существительное, если это существительное является описательным и недвусмысленным. )
)
Параметры функции
Иногда их называют формальными аргументами . Параметры функции — это переменные в определении функции, помещенные в круглые скобки и разделенные запятой, которые будут установлены в фактические значения (называемые 9).0087 аргументов ) каждый раз, когда мы вызываем функцию. Например:
окружность <- function(r){
2*пи*р
}
print(circumference(2)) [1] 12,56637
Выше мы создали функцию для вычисления длины окружности с известным радиусом по формуле $C = 2\pi$$r$, поэтому функция имеет единственный параметр r . После определения функции мы вызвали ее с радиусом, равным 2 (следовательно, с аргументом 2).
Возможно, хотя и редко полезно, чтобы функция не имела параметров:
hello_world <- функция(){
'Привет, мир!'
}
print(hello_world()) [1] "Привет, мир!"
Кроме того, некоторые параметры могут быть установлены на значения по умолчанию (относящиеся к типичному случаю) внутри определения функции, которые затем могут быть сброшены при вызове функции. Возвращаясь к нашей функции
Возвращаясь к нашей функции окружности , мы можем установить радиус круга по умолчанию равным 1, поэтому, если мы вызовем функцию без переданного аргумента, она рассчитает длину окружности единичного круга (т. е. круга с радиусом 1 ). В противном случае он рассчитает длину окружности с заданным радиусом:
окружность <- функция (r=1){
2*пи*р
}
печать (окружность ())
печать(окружность(2)) [1] 6.283185 [1] 12.56637
Тело функции
Тело функции — это набор команд, заключенных в фигурные скобки, которые выполняются в заранее определенном порядке каждый раз, когда мы вызываем функцию. Другими словами, в теле функции мы размещаем то, что именно нам нужно от функции:
sum_two_nums <- function(x, y){
х + у
}
печать (sum_two_nums (1, 2)) [1] 3
Обратите внимание, что операторы в теле функции (в приведенном выше примере — единственный оператор x + y ) должны иметь отступ в 2 или 4 пробела, в зависимости от IDE, в которой мы запускаем код, но важно быть согласованным с отступом во всей программе. Хотя это не влияет на производительность кода и не является обязательным, он облегчает чтение кода.
Хотя это не влияет на производительность кода и не является обязательным, он облегчает чтение кода.
Фигурные скобки можно опустить, если тело функции содержит один оператор. Например:
sum_two_nums <- function(x, y) x + y print(sum_two_nums(1, 2))
[1] 3
Как мы видели из всех приведенных выше примеров, в R обычно нет необходимости явно включать оператор return при определении функции, поскольку функция R просто автоматически возвращает последнее оцененное выражение в теле функции. Однако мы по-прежнему можем добавить оператор return в тело функции, используя синтаксис return(expression_to_be_returned) . Это становится неизбежным, если нам нужно вернуть более одного результата функции. Например:
mean_median <- function(vector){
среднее <- среднее (вектор)
медиана <- медиана (вектор)
возврат (с (среднее, медиана))
}
print(mean_median(c(1, 1, 1, 2, 3))) [1] 1.6 1.0
Обратите внимание, что в операторе return выше мы фактически возвращаем вектор , содержащий необходимые результаты, а не просто переменные, разделенные запятой (поскольку функция return() может возвращать только один объект R). Вместо вектора мы могли бы также вернуть список, особенно если предполагается, что возвращаемые результаты будут иметь разные типы данных.
Вместо вектора мы могли бы также вернуть список, особенно если предполагается, что возвращаемые результаты будут иметь разные типы данных.
Вызов функции в R
Во всех приведенных выше примерах мы фактически уже много раз вызывали созданные функции. Для этого мы просто поместили имя пунктуации и добавили необходимые аргументы в круглые скобки. В R аргументы функции могут передаваться по позиции, по имени (так называемые именованные аргументы ), путем смешивания сопоставления на основе позиции и имени или вообще без аргументов.
Если мы передаем аргументы по позиции , нам нужно следовать той же последовательности аргументов, что определена в функции:
subtract_two_nums <- function(x, y){
х - у
}
print(subtract_two_nums(3, 1)) [1] 2
В приведенном примере x равно 3, а y – 1, а не наоборот.
Если мы передаем аргументы по имени , т. е. явно указываем, какое значение принимает каждый параметр, определенный в функции, то порядок аргументов не имеет значения:
subtract_two_nums <- function(x, y){
х - у
}
печать (вычесть_two_nums (x = 3, y = 1))
print(subtract_two_nums(y=1, x=3)) [1] 2 [1] 2
Поскольку мы явно присвоили x=3 и y=1 , мы можем передать их как x=3, y=1 или y=1, x=3 – результат будет то же самое.
Можно смешивать сопоставление аргументов на основе позиции и имени. Давайте рассмотрим пример функции для расчета BMR (базового метаболизма), или суточного потребления калорий, для женщин на основе их веса (в кг), роста (в см) и возраста (в годах). Формула, которая будет использоваться в функции, представляет собой уравнение Миффлина-Сент-Джора:
calculate_calories_women <- function(вес, рост, возраст){
(10 * вес) + (6,25 * рост) - (5 * возраст) - 161
} Теперь посчитаем калории для женщины 30 лет, весом 60 кг и ростом 165 см. Однако для параметра age мы передадим аргумент по имени, а для двух других параметров мы передадим аргументы по положению:
print(calculate_calories_women(age=30, 60, 165))
[1 ] 1320.25
В случае, подобном предыдущему (когда мы смешиваем сопоставление по имени и по положению), именованные аргументы извлекаются из всей последовательности аргументов и сопоставляются первыми, а остальные аргументы сопоставляются по положению, т. е. в том же порядке, в котором они появляются в определении функции. Однако эта практика не рекомендуется и может привести к путанице.
е. в том же порядке, в котором они появляются в определении функции. Однако эта практика не рекомендуется и может привести к путанице.
Наконец, мы можем вообще опустить некоторые (или все) аргументы. Это может произойти, если мы установим для некоторых (или всех) параметров значения по умолчанию внутри определения функции. Вернемся к нашей функции calculate_calories_women и установим возраст женщины по умолчанию 30 лет:
calculate_calories_women <- function(weight, height, age=30){
(10 * вес) + (6,25 * рост) - (5 * возраст) - 161
}
print(calculate_calories_women(60, 165)) [1] 1320,25
В приведенном выше примере мы передали функции только два аргумента, несмотря на то, что в ее определении было три параметра. Однако, поскольку одному из параметров присваивается значение по умолчанию, когда мы передаем функции два аргумента, R интерпретирует, что для третьего отсутствующего аргумента должно быть установлено значение по умолчанию, и выполняет соответствующие вычисления, не вызывая ошибки.
При вызове функции мы обычно присваиваем результат этой операции переменной, чтобы иметь возможность использовать ее позже:
окружность <- функция (r){
2*пи*р
}
окружность_радиус_5 <- окружность (5)
print(circumference_radius_5) [1] 31.41593
Использование функций внутри других функций
Внутри определения функции R мы можем использовать другие функции. Мы уже видели такой пример ранее, когда использовали встроенные функции mean() и median() внутри определяемой пользователем функции mean_median :
mean_median <- function(vector){
среднее <- среднее (вектор)
медиана <- медиана (вектор)
возврат (с (среднее, медиана))
} Также можно передать результат вызова одной функции непосредственно в качестве аргумента другой функции:
radius_from_diameter <- function(d){
д/2
}
окружность <- функция (г) {
2*пи*р
}
print(circumference(radius_from_diameter(4))) [1] 12.
 56637
56637 В приведенном выше фрагменте кода мы сначала создали две простые функции: для вычисления радиуса круга по его диаметру и для вычисления длины окружности. учитывая его радиус. Поскольку изначально мы знали только диаметр окружности (равный 4), мы назвали 9Функция 0016 radius_from_diameter внутри функции окружности для вычисления сначала радиуса из предоставленного значения диаметра, а затем вычисления длины окружности. Хотя этот подход может быть полезен во многих случаях, мы должны быть осторожны с ним и избегать передачи слишком большого количества функций в качестве аргументов другим функциям, поскольку это может повлиять на читабельность кода.
Наконец, функции могут быть вложенными , что означает, что мы можем определить новую функцию внутри другой функции. Допустим, нам нужна функция, которая суммирует площади окружностей 3-х непересекающихся окружностей: 92 } площадь_круга (r1) + площадь_круга (r2) + площадь_круга (r3) } print(sum_circle_ares(1, 2, 3))
[1] 43,9823
Выше мы определили функцию circle_area внутри функции sum_circle_ares . Затем мы вызвали эту внутреннюю функцию три раза (
Затем мы вызвали эту внутреннюю функцию три раза ( circle_area(r1) , circle_area(r2) и circle_area(r3) ) внутри внешней функции, чтобы вычислить площадь каждого круга для дальнейшего суммирования этих областей. Теперь, если мы попытаемся вызвать circle_area функция вне функции sum_circle_ares , программа выдает ошибку, потому что внутренняя функция существует и работает только внутри функции, где она была определена:
print(circle_area(10))
Ошибка в circle_area(10) : не удалось найти функцию "circle_area" Выслеживать: 1. print(circle_area(10))
При вложении функций мы должны помнить о двух вещах:
- Как и при создании любой функции, внутренняя функция должна использоваться внутри внешней функции не менее 3 раз. В противном случае создать его нецелесообразно. 92
}
sum_circle_ares <- функция (r1, r2, r3){
площадь_круга (r1) + площадь_круга (r2) + площадь_круга (r3)
}
печать (sum_circle_ares (1, 2, 3))
печать (круг_область (10))
[1] 43,9823 [1] 314.
1593 Здесь мы снова используем функцию
circle_areaвнутри функцииsum_circle_ares. Однако на этот раз мы также смогли вызвать его вне этой функции и получить результат, а не ошибку.Резюме
В этом уроке мы узнали довольно много аспектов, связанных с функциями в R. В частности, мы обсудили следующее:
- Типы функций в R
- Зачем и когда нам нужно создать функцию
- Некоторые из самых популярных встроенных функций в R и для чего они используются
- Как определить определяемую пользователем функцию
- Основные компоненты функции
- Лучшие методы именования функций
- Когда и как устанавливать для параметров функции значения по умолчанию
- Тело функции и особенности ее синтаксиса
- Когда мы должны явно включить оператор return в определение функции
- Как вызвать функцию R с именованными, позиционными или смешанными аргументами
- Что происходит, когда мы смешиваем позиционные и именованные аргументы — и почему это не рекомендуется
- Когда мы можем опустить некоторые (или все) аргументы
- Как применять функции внутри других функций
- Как передать вызов функции в качестве аргумента другой функции
- Когда и как вкладывать функции
Обладая этими навыками и информацией, вы готовы приступить к созданию и использованию функций в R.
Функция Write() в Python
Python — один из самых популярных языков программирования, используемых разработчиками во всем мире. Он известен своей простотой и легкостью использования, что делает его идеальным как для новичков, так и для экспертов. Одной из самых полезных функций в Python является функция записи, которая используется для записи данных в файл. В этой статье мы обсудим функцию записи в Python, ее синтаксис, параметры, возвращаемое значение и приведем несколько примеров.
Что такое функция Write() в Python?
В Python функция write() — это встроенная функция, позволяющая записывать данные в файл. Эта функция принимает на вход строку и записывает ее в указанный файл. Функция write() очень универсальна и может использоваться для записи в файл самых разных типов данных, включая текст, числа и двоичные данные.
Чтобы использовать функцию write(), вам сначала нужно открыть файл, в который вы хотите записать, используя функцию open().
Затем вы можете вызвать функцию write() для файлового объекта, чтобы записать ваши данные в файл. По умолчанию данные будут записаны в конец файла, но вы можете использовать функцию seek() для перемещения указателя файла в определенное место, если вам нужно записать данные в определенное место в файле.При работе с функцией write() важно помнить об обработке ошибок. Запись в файл иногда может завершаться сбоем по таким причинам, как нехватка места на диске, права доступа к файлу только для чтения или другие проблемы. Чтобы избежать потери или повреждения данных, рекомендуется обрабатывать любые ошибки, которые могут возникнуть при записи в файл.
В целом, функция write() — мощный и полезный инструмент для работы с файлами в Python. Независимо от того, пишете ли вы небольшой текстовый файл или большой двоичный файл, функция write() обеспечивает простой и эффективный способ записи данных в файл.
Синтаксис функции записи в Python
Синтаксис функции записи в Python следующий:
file.
write(str) строка или данные, которые вы хотите записать в файл.
Функция write() принимает единственный аргумент, представляющий собой строку или данные, которые вы хотите записать в файл. Этот аргумент должен быть строкового типа или объектом, который можно преобразовать в строку.
Параметры функции записи в Python
Функция записи в Python принимает один аргумент — строку или данные, которые вы хотите записать в файл. Аргумент должен иметь строковый тип или объект, который может быть преобразован в строку.
Важно отметить, что функция write() не добавляет автоматически символ новой строки в конец строки. Если вы хотите записать в файл несколько строк, вам нужно добавить символ новой строки ("\n") в конце каждой строки.
Возвращаемое значение функции записи в Python
Функция записи в Python возвращает количество символов, записанных в файл. Это значение представляет собой количество байтов, записанных в файл, которое может отличаться от количества символов в строке, переданной функции в качестве аргумента.
Вот пример того, как вы можете использовать функцию write() для записи строки в файл, а затем распечатать количество записанных байтов:
файл = открыть ("example.txt", "w") num_bytes_writing = file.write("Привет, PrepBytes!") print("Количество записанных байтов:", num_bytes_writing) file.close()Объяснение: В этом примере мы сначала открываем файл с именем "example.txt" в режиме записи с помощью функции open(). Затем мы вызываем функцию write() для записи строки «Hello, PrepBytes!» в файл. Функция write() возвращает количество байтов, записанных в файл, которое мы сохраняем в переменной num_bytes_writing. Наконец, мы выводим значение num_bytes_write на консоль.
Обратите внимание: если файл уже существует, функция write() перезапишет существующее содержимое файла. Если вы хотите добавить данные в конец файла, а не перезаписывать их, вы можете открыть файл в режиме добавления, передав флаг режима «a» в функцию open() вместо «w».
Примеры функции записи в Python
Вот несколько примеров использования функции записи в Python:
Пример — 1 Запись в текстовый файл
Вот пример записи в текстовый файл с помощью функции записи в питонеРеализация кода:
файл = открыть ("example. txt", "w")
file.write("Привет, PrepBytes!")
file.close() Объяснение: В этом коде мы сначала открываем файл с именем «example.txt» в режиме записи с помощью функции open(). Затем мы вызываем функцию write() для файлового объекта, чтобы записать строку «Hello, PrepBytes!» в файл. Наконец, мы закрываем файл с помощью функции close(), чтобы гарантировать, что любые буферизованные данные будут записаны в файл перед выходом из программы.
Пример – 2 Запись нескольких строк в текстовый файл
Вот пример записи нескольких строк в текстовый файл.Реализация кода:
= open("example.txt", "w") file.write("Строка 1\n") file.write("Строка 2\n") file.write("Строка 3\n") file.close()Объяснение: В этом примере мы сначала открываем файл с именем "example.txt" в режиме записи с помощью функции open(). Затем мы вызываем функцию write() несколько раз, чтобы записать каждую строку текста в файл, добавляя символ новой строки ("\n") в конце каждой строки.
Наконец, мы закрываем файл с помощью функции close().Пример — 3 Запись в двоичный файл
Вот пример записи в двоичный файл с помощью функции записи в Python.Реализация кода:
# Открытие файла в режиме записи файл = открыть('example.bin', 'wb') # Запись в файл файл.записать(b'\x41\x42\x43') # Закрытие файла file.close()Объяснение: В этом примере мы открываем файл с именем example.bin в режиме двоичной записи, используя функцию open() с параметром режима «wb». Затем мы записываем двоичную последовательность b’\x41\x42\x43’ в файл с помощью функции write(). Эта двоичная последовательность соответствует символам ASCII A, B и C. Наконец, мы закрываем файл с помощью функции close().
Временная и пространственная сложность функции записи в Python
Временная и пространственная сложность функции записи в Python может варьироваться в зависимости от нескольких факторов, таких как размер записываемых данных и тип используемого устройства хранения.
В общем случае временная сложность функции write() равна O(n), где n — количество записываемых байтов. Это означает, что функции требуется больше времени для записи больших объемов данных. Фактическое время, необходимое для записи данных, также зависит от скорости используемого устройства хранения (например, жесткого диска или твердотельного накопителя).
Объемная сложность функции write() равна O(1), что означает, что объем памяти, используемый функцией, является постоянным, независимо от размера записываемых данных. Это связано с тем, что функция write() не сохраняет данные в памяти; он просто записывает его непосредственно на запоминающее устройство.
Стоит отметить, что функция write() может также включать некоторые накладные расходы из-за вызовов операционной системы и дисковых операций ввода-вывода, которые могут увеличить общую сложность функции во времени и пространстве. Однако эти факторы в значительной степени находятся вне контроля интерпретатора Python и зависят от конкретного используемого оборудования и операционной системы.
Резюме
Вот краткое изложение того, что мы рассмотрели выше:- В Python вы можете писать в файл, используя метод write() для файлового объекта.
- Метод write() принимает в качестве аргумента строку и записывает ее в файл.
- По умолчанию данные записываются в конец файла.
- Временная сложность функции write() равна O(n), где n — количество символов, записываемых в файл.
- Объемная сложность функции write() также равна O(n), где n — размер данных, записываемых в файл.
- На фактическую временную и пространственную сложность функции write() могут влиять такие факторы, как скорость базовой файловой системы, размер записываемого файла и объем доступной памяти в системе.
Часто задаваемые вопросы
Вот некоторые часто задаваемые вопросы, связанные с функцией записи в Python:
В1: Можно ли использовать функцию записи для добавления данных в существующий файл?
A: Да, функцию записи можно использовать для добавления данных в существующий файл, открывая файл в режиме «дополнения» вместо режима «записи». Это можно сделать, передав аргумент «a» вместо «w» при открытии файла с помощью функции «open».Q2: Что произойдет, если файл, в который выполняется запись, не существует?
A: Если файл, в который выполняется запись, не существует, функция записи создаст новый файл с указанным именем и запишет в него данные.Q3: Можно ли использовать функцию записи для записи двоичных данных в файл?
A: Да, функцию записи можно использовать для записи двоичных данных в файл. Однако данные должны быть преобразованы в объект байтов с помощью функции «байты», прежде чем их можно будет записать в файл.Вопрос 4. Что произойдет, если файл, в который выполняется запись, доступен только для чтения или заблокирован другим процессом?
A: Если файл, в который выполняется запись, доступен только для чтения или заблокирован другим процессом, функция записи вызовет "IOError" с соответствующим сообщением об ошибке.
 1593
1593 
 Затем вы можете вызвать функцию write() для файлового объекта, чтобы записать ваши данные в файл. По умолчанию данные будут записаны в конец файла, но вы можете использовать функцию seek() для перемещения указателя файла в определенное место, если вам нужно записать данные в определенное место в файле.
Затем вы можете вызвать функцию write() для файлового объекта, чтобы записать ваши данные в файл. По умолчанию данные будут записаны в конец файла, но вы можете использовать функцию seek() для перемещения указателя файла в определенное место, если вам нужно записать данные в определенное место в файле. write(str)
write(str) 
 txt", "w")
file.write("Привет, PrepBytes!")
file.close()
txt", "w")
file.write("Привет, PrepBytes!")
file.close()  Наконец, мы закрываем файл с помощью функции close().
Наконец, мы закрываем файл с помощью функции close().

 Это можно сделать, передав аргумент «a» вместо «w» при открытии файла с помощью функции «open».
Это можно сделать, передав аргумент «a» вместо «w» при открытии файла с помощью функции «open».