Библиотека Requests Python 3 — GET-запросы
В этой статье мы рассмотрим библиотеку Python Requests, которая позволяет отправлять HTTP-запросы в Python.
Работа API основана на отправке HTTP-запросов и получение ответов. Библиотека Requests позволяет использовать API в Python. В качестве примера я продемонстрирую принцип работы Translate API.
- Краткий обзор HTTP-запросов
- Requests Python 3 — установка
- Наш первый запрос
- Коды состояния
- Заголовки
- Response Text
- Используем Translate API
- Виды ошибок Translate API
- Заключение
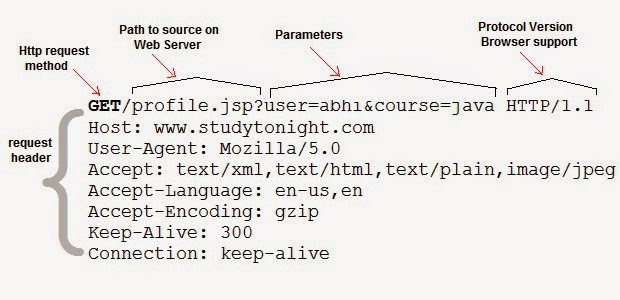
Каждый раз, когда вы переходите на веб-страницу, браузер отправляет несколько запросов на сервер. В ответ он отсылает данные для рендеринга страницы, которые браузер использует для ее отображения.
Механизмы работает следующим образом: клиент (например, браузер или скрипт Python, использующий библиотеку Requests) отправляет данные на сервер, расположенный по указанному URL. Сервер обрабатывает полученную информацию и возвращает ответ клиенту.
В запросе клиент также указывает, какой метод будет использован для передачи. Самые распространенные методы: GET, POST и PUT.
GET-запросы предназначены только для чтения данных без внесения каких-либо изменений. POST и PUT-запросы предназначены для изменения данных на сервере. Так, например, Stripe API применяет POST-запросы для создания новых платежей, чтобы пользователь мог что-то купить в вашем приложении.
В этой статье рассматриваются только запросы GET, потому что мы не будем изменять отправляемые данные на сервере.
Прежде всего, установим библиотеку Python Requests, используя менеджер пакетов pip. Сначала создайте виртуальную среду.
pip install requests
Для начала используем библиотеку Python Requests для чего-то простого: отправим запрос на сайт Scotch. io. Создайте файл script.py и добавьте в него приведенный ниже код.
io. Создайте файл script.py и добавьте в него приведенный ниже код.
import requests
res = requests.get('https://scotch.io')
print(res)
Приведенный выше код отправляет запрос GET на Scotch.io. Это тот же тип запроса, который браузер отправляет для просмотра веб-страницы. Отличие заключается в том, что эти запросы не могут передать HTML. Поэтому вместо него приходит необработанный HTML и другая информация из ответа, предоставленного сервером.
В данном случае мы используем функцию .get(). Но библиотека Requests содержит и другие подобные функции: .post() и .put().
Запустите файл script.py.
python script.py
В ответ придет следующее:
Проверим код состояния ответа. Коды состояния HTTP варьируются от 1XX до 5XX. Скорее всего, вы сталкивались с кодами состояния 200, 404 и 500.
Что обозначает каждый из них:
- 1XX – информация.
- 2XX – успешно.
- 3XX – перенаправление.
- 4XX — Ошибка клиента.
- 5XX — Ошибка сервера.


Обычно при выполнении запросов приходят коды состояния 2ХХ. Коды 4XX и 5XX являются ошибками. При их получении ответ расценивается как False.
Вы можете проверить результативность запроса с помощью следующего кода:
if res:
print('Response OK')
else:
print('Response Failed')
Чтобы увидеть ответ с ошибкой 404, измените URL-адрес на произвольные знаки. Можно проверить код состояния, выполнив:
print(res.status_code)
Также можно проверить код состояния самостоятельно.
Кроме этого ответ сервера содержит заголовки. На них можно взглянуть, используя словарь HTTP-заголовков.
print(res.headers)
Заголовки отправляются вместе с запросом и возвращаются в ответе. Они сообщают клиенту и серверу, как интерпретировать отправляемые и получаемые данные.
Важно знать тип содержимого ответа сервера, поскольку оно указывает на формат отправляемых данных. Например, HTML, JSON, PDF, text и т. д. Но тип содержимого обычно обрабатывается библиотекой Requests. Это обеспечивает простой доступ к полученным данным.
Это обеспечивает простой доступ к полученным данным.
Свойство res.text позволяет получить весь HTML-код, необходимый для создания домашней страницы Scotch. Если сохранить этот HTML как веб-страницу и открыть ее, то мы увидим нечто похожее на сайт Scotch.
Чтобы загрузить изображения, скрипты и таблицы стилей совершается множество запросов к одной веб-странице. Поэтому, если сохранить в файле только HTML-код, он не будет выглядеть так, как страница Scotch.io, открытая в браузере.
print(res.text)
Мы будем использовать Yandex Translate API. После регистрации перейдите в Translate API и создайте ключ API. Получив ключ API, добавьте его в свой файл. Вот ссылка на сайт, где это можно сделать: https://yandex.ru/dev/translate/
API_KEY = 'your yandex api key'
Ключ API нужен, чтобы Яндекс мог аутентифицировать нас. Ключ API добавляется в конец URL-адреса запроса при отправке.
https://yandex. ru/dev/translate/doc/dg/reference/translate-docpage/
ru/dev/translate/doc/dg/reference/translate-docpage/
Здесь доступна вся информация по использованию Translate API для перевода текста.
Если в документации указан URL с амперсандами (&), вопросительными знаками (?) и знаками равенства (=), значит он предназначен для отправки GET- запросов
Параметры, размещенные в квадратных скобках ([]), не является обязательными. В данном случае format, options и callback являются необязательными. Но key, text и lang обязательны для запроса.
Добавим код для отправки на этот URL. Можно заменить созданный нами запрос следующим образом:
url = 'https://translate.yandex.net/api/v1.5/tr.json/translate' res = requests.get(url)
Параметры можно добавить в конец URL-адреса. Но библиотека Requests может сделать это за нас. Причем второй вариант гораздо проще.
Для его реализации создадим словарь для параметров. Понадобятся только key, text и language. Создадим словарь, используя следующие значения: API key, «Hello» для текста и «en-es» для lang (для перевода с английского на испанский).
Передадим функции dict() нужные ключи и значения:
params = dict(key=API_KEY, text='Hello', lang='en-es')
Теперь передаем словарь параметров в функцию .get().
res = requests.get(url, params=params)
После этого библиотека Requests добавит параметры к URL-адресу. Теперь используем оператор print для response text и посмотрим, что вернется в ответе.
print(res.text)
Мы получили code (код состояния), совпадающий с кодом состояния ответа. А также language (язык), который мы указали, и перевод. Поэтому вы должны увидеть переведенный текст «Hola».
Попробуйте еще раз со значением кода языка en-fr и получите «Bonjour».
params = dict(key=API_KEY, text='Hello', lang='en-fr')
Посмотрим на заголовки этого ответа:
print(res.headers)
Заголовки отличаются, потому что мы обращаемся к другому серверу. Но в этом случае тип контента будет application/json вместо text/html. Это означает, что данные могут быть интерпретированы как JSON.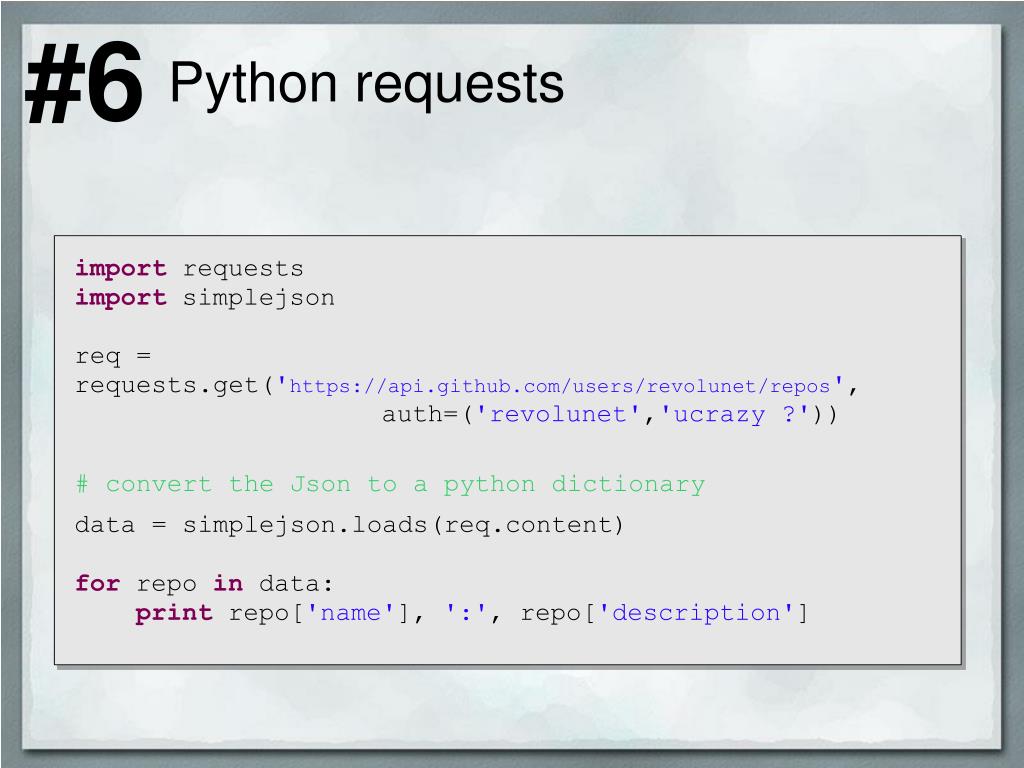
Когда application/json является типом содержимого ответа, Requests может преобразовать ответ в словарь и список.
Чтобы данные были идентифицированы как JSON, используем метод .json() для объекта ответа. Если вывести результат его работы, то будет видно, что данные выглядят одинаково, но формат отличается.
json = res.json() print(json)
Причина этого заключается в том, что теперь это не обычный текст из res.text. Теперь это печатная версия словаря.
Допустим, что нужно получить доступ к тексту. Поскольку теперь это словарь, мы можем использовать текстовый ключ.
print(json['text'])
Теперь мы видим только данные этого ключа. Чтобы получить этот текст, можно использовать индекс.
print(json['text'][0])
Теперь единственное, что мы видим, это переведенное слово. Поэтому если изменить значения параметров, то получим разные результаты. Давайте изменим текст для перевода с Hello на Goodbye, целевой язык на испанский и отправим запрос снова.
params = dict(key=API_KEY, text='Goodbye', lang='en-es')
Попробуйте изменить API KEY, удалив один символ. После этого ключ API не будет работать. Затем попробуйте отправить запрос.
Вот что будет в коде состояния:
print(res.status_code)
При использовании API необходимо проверять, все ли правильно работает, чтобы вовремя устранять возникающие ошибки.
Конечно, можно сделать гораздо больше. Но то, о чем я рассказал в этой статье, является основой большинства запросов.
Чтобы получить больше информации, зайдите на https://apilist.fun/ и увидите множество доступных API. Попробуйте использовать их совместно с Python Requests.
Пожалуйста, оставляйте свои мнения по текущей теме материала. Мы крайне благодарны вам за ваши комментарии, подписки, отклики, дизлайки, лайки!
Ангелина Писанюкавтор-переводчик статьи «Getting Started With Python Requests — GET Requests»
Отправка запроса GET на API REST | Руководство по REST API
Для команды rpc общий формат оконечных точек:
scheme://device-name:port/rpc/method[@attributes]/params
scheme:httpилиhttpsmethod: Имя любойrpcJunos OS. Имя methodидентично элементу тега. Дополнительные сведения см. в справочнике Junos разработчиков XML API.params: Необязательные значения параметровname[=value]().
 Имя
Имя Для аутентификации запроса отправьте имя пользователя и пароль, закодированный базой 64, в задатке авторизации:
curl -u "username:password" http://device-name:port/rpc/get-interface-information
Чтобы указать данные в качестве строки запроса в URI для запросов GET, можно использовать следующий URI с разделиатором, отделяющий несколько аргументов, или использовать разделиатор, как показано в этих эквивалентных rpc ? & / вызовах cURL:
Например:
curl -u "username:password" http://device-name:port/rpc/get-interface-information?interface-name=cbp0&snmp-index=1
curl -u "username:password" http://device-name:port/rpc/get-interface-information/interface-name=cbp0/snmp-index=1Для указания формата возврата с использованием одного из следующих значений типа содержимого можно использовать заглавныедеры HTTP Accept:
Например, следующий вызов cURL определяет формат вывода JSON:
curl -u "username:password" http://device-name:port/rpc/get-interface-information?interface-name=cbp0 –header "Accept: application/json"
Можно также указать формат вывода с помощью дополнительного format параметра.
Например, элемент <get-software-information> тега извлекает уровни версий процессов программного обеспечения. Следующая httpS GET-запрос выполняет эту команду и извлекает результаты в формате JSON:
https://device-name:3000/rpc/get-software-information@format=json
Следующая программа Python использует интерфейс REST для выполнения RPC, извлекает данные из ответа и составляет график get-route-engine-information средней загрузки ЦП:
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
import requests
temp_y = 1
def update_line(num, data, line):
if num == 0:
return line,
global temp_y
x_data.append(num)
if num is not 0 and num%8 == 1:
r = requests.get('scheme://device:port/rpc/get-route-engine-information@format=json', auth=('username', 'password'))
if r: temp_y = r.json()["route-engine-information"][0]["route-engine"][0]["load-average-one"][0]["data"]
y_data. append(temp_y)
line.set_data(x_data, y_data)
return line,
fig1 = plt.figure()
x_data = []
y_data = []
l, = plt.plot([], [])
plt.xlim(0, 80)
plt.ylim(0, 1.5)
plt.xlabel('Time in seconds')
plt.ylabel('CPU utilization (load average)')
plt.title('REST-API test')
line_ani = animation.FuncAnimation(fig1, update_line, 80, fargs=(0, l), interval=1000, blit=True)
plt.show() append(temp_y)
line.set_data(x_data, y_data)
return line,
fig1 = plt.figure()
x_data = []
y_data = []
l, = plt.plot([], [])
plt.xlim(0, 80)
plt.ylim(0, 1.5)
plt.xlabel('Time in seconds')
plt.ylabel('CPU utilization (load average)')
plt.title('REST-API test')
line_ani = animation.FuncAnimation(fig1, update_line, 80, fargs=(0, l), interval=1000, blit=True)
plt.show()
append(temp_y)
line.set_data(x_data, y_data)
return line,
fig1 = plt.figure()
x_data = []
y_data = []
l, = plt.plot([], [])
plt.xlim(0, 80)
plt.ylim(0, 1.5)
plt.xlabel('Time in seconds')
plt.ylabel('CPU utilization (load average)')
plt.title('REST-API test')
line_ani = animation.FuncAnimation(fig1, update_line, 80, fargs=(0, l), interval=1000, blit=True)
plt.show()Быстрый старт — Запросы документации 2.28.2
Хотите начать? Эта страница дает хорошее представление о том, как начать работу с запросами.
Во-первых, убедитесь, что:
Давайте начнем с нескольких простых примеров.
Сделать запрос
Сделать запрос с помощью Requests очень просто.
Начните с импорта модуля «Запросы»:
>>> запросы на импорт
Теперь давайте попробуем получить веб-страницу. Для этого примера давайте получим общедоступный GitHub временная шкала:
>>> r = request.get('https://api.github.com/events')
Теперь у нас есть объект Response с именем r . Мы можем
получить всю необходимую нам информацию от этого объекта.
Мы можем
получить всю необходимую нам информацию от этого объекта.
Requests означает, что все формы HTTP-запросов очевидны. Для например, вот как вы делаете запрос HTTP POST:
>>> r = request.post('https://httpbin.org/post', data={'key': 'value'})
Красиво, правда? А как насчет других типов HTTP-запросов: PUT, DELETE, HEAD и ПАРАМЕТРЫ? Все так же просто:
>>> r = request.put('https://httpbin.org/put', data={'key': 'value'})
>>> r = request.delete('https://httpbin.org/delete')
>>> r = request.head('https://httpbin.org/get')
>>> r = request.options('https://httpbin.org/get')
Это все хорошо, но это только начало того, что могут сделать Запросы. делать.
Передача параметров в URL-адресах
Вы часто хотите отправить какие-то данные в строке запроса URL. Если
вы создавали URL-адрес вручную, эти данные будут представлены как ключ/значение
пары в URL-адресе после вопросительного знака, например. httpbin. .
Запросы позволяют вам предоставлять эти аргументы в виде словаря строк,
используя аргумент ключевого слова  org/get?key=val
org/get?key=val params . Например, если вы хотите пройти key1=value1 и key2=value2 to httpbin.org/get , вы должны использовать
следующий код:
>>> полезная нагрузка = {'key1': 'value1', 'key2': 'value2'}
>>> r = request.get('https://httpbin.org/get', params=payload)
Вы можете убедиться, что URL-адрес был правильно закодирован, распечатав URL-адрес:
>>> print(r.url) https://httpbin.org/get?key2=value2&key1=value1
Обратите внимание, что любой ключ словаря, значение которого равно None , не будет добавлен в
Строка запроса URL.
Вы также можете передать список элементов как значение:
>>> полезная нагрузка = {'ключ1': 'значение1', 'ключ2': ['значение2', 'значение3']}
>>> r = request.get('https://httpbin.org/get', params=payload)
>>> напечатать(r. url)
https://httpbin.org/get?key1=value1&key2=value2&key2=value3
 url)
https://httpbin.org/get?key1=value1&key2=value2&key2=value3
url)
https://httpbin.org/get?key1=value1&key2=value2&key2=value3
Содержание ответа
Мы можем прочитать содержимое ответа сервера. Рассмотрите временную шкалу GitHub еще раз:
>>> запросы на импорт
>>> r = request.get('https://api.github.com/events')
>>> р.текст
'[{"репозиторий":{"open_issues":0,"url":"https://github.com/...
Запросы будут автоматически декодировать контент с сервера. Самый юникод кодировки легко декодируются.
Когда вы делаете запрос, Requests делает обоснованные предположения о кодировке
ответ на основе заголовков HTTP. Кодировка текста, угадываемая Requests
используется при доступе к р.текст . Вы можете узнать, что такое кодировка Requests
using и измените его, используя свойство r.encoding :
>>> р.кодировка 'утф-8' >>> r.encoding = 'ISO-8859-1'
Если вы измените кодировку, запросы будут использовать новое значение r.encoding всякий раз, когда вы звоните r. . Вы можете сделать это в любой ситуации, когда
вы можете применить специальную логику, чтобы выяснить, какая кодировка контента будет
быть. Например, HTML и XML имеют возможность указать свою кодировку в
их тело. В таких ситуациях вы должны использовать 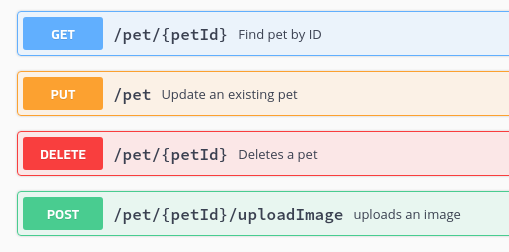 text
text r.content найти
кодировку, а затем установите r.encoding . Это позволит вам использовать r.text с
правильная кодировка.
также будут использовать пользовательские кодировки, если они вам нужны. Если
вы создали свою собственную кодировку и зарегистрировали ее с кодеками модуль, вы можете просто использовать имя кодека в качестве значения r.encoding и
Запросы будут обрабатывать декодирование для вас.
Содержимое двоичного ответа
Вы также можете получить доступ к телу ответа в виде байтов для нетекстовых запросов:
>>> р.содержимое
b'[{"репозиторий":{"open_issues":0,"url":"https://github.com/...
Кодирование передачи gzip и deflate автоматически декодируется для вас.
Кодирование передачи br автоматически декодируется для вас, если библиотека Brotli
например, brotli или brotlicffi.
Например, чтобы создать образ из бинарных данных, возвращаемых запросом, вы можете используйте следующий код:
>>> из изображения импорта PIL >>> из io импортировать BytesIO >>> i = Image.open(BytesIO(r.content))
Содержимое ответа JSON
Также имеется встроенный декодер JSON, если вы имеете дело с данными JSON:
>>> запросы на импорт
>>> r = request.get('https://api.github.com/events')
>>> р.json()
[{'репозиторий': {'open_issues': 0, 'url': 'https://github.com/...
В случае сбоя декодирования JSON r.json() вызывает исключение. Например, если
ответ получает 204 (нет содержимого), или если ответ содержит недопустимый JSON,
попытка r.json() вызывает request.exceptions.JSONDecodeError . Это исключение оболочки
обеспечивает взаимодействие для нескольких исключений, которые могут быть вызваны разными
версии python и библиотеки сериализации json.
Следует отметить, что успех вызова r.json() делает не указать успешность ответа. Некоторые серверы могут возвращать объект JSON в
неудачный ответ (например, сведения об ошибке с HTTP 500). Такой JSON будет декодирован
и вернулся. Чтобы проверить успешность запроса, используйте r.raise_for_status() или проверка r.status_code — это то, что вы ожидаете.
Необработанное содержимое ответа
В редких случаях, когда вы хотите получить необработанный ответ сокета от
сервер, вы можете получить доступ к r.raw . Если вы хотите сделать это, убедитесь, что вы установили stream = True в вашем первоначальном запросе. Как только вы это сделаете, вы можете сделать это:
>>> r = request.get('https://api.github.com/events', stream=True)
>>> r.raw
>>> r.raw.read(10)
б'\x1f\x8b\x08\x00\x00\x00\x00\x00\x00\x03'
В целом, однако, вы должны использовать подобный шаблон, чтобы сохранить то, что передано в файл:
с открытым (имя файла, 'wb') как fd:
для чанка в r. iter_content(chunk_size=128):
fd.write(чанк)
 iter_content(chunk_size=128):
fd.write(чанк)
iter_content(chunk_size=128):
fd.write(чанк)
Использование Response.iter_content будет обрабатывать многое из того, что вы сделали бы в противном случае.
приходится обрабатывать при использовании Response.raw напрямую. При потоковой передаче
загрузки, указанный выше способ является предпочтительным и рекомендуемым способом получения
содержание. Обратите внимание, что chunk_size можно свободно настроить на число, которое
может лучше соответствовать вашим вариантам использования.
Note
Важное примечание об использовании Response.iter_content по сравнению с Response.raw . Response.iter_content автоматически декодирует gzip и deflate трансфер-кодировки. Response.raw — необработанный поток байтов.
преобразовать содержимое ответа. Если вам действительно нужен доступ к байтам, поскольку они
были возвращены, используйте Ответ. . raw
raw
Более сложные запросы POST
Как правило, вы хотите отправить некоторые данные, закодированные в форме — очень похоже на HTML-форму.
Для этого просто передайте словарь в аргумент data . Твой
словарь данных будет автоматически закодирован в форме при запросе:
>>> полезная нагрузка = {'key1': 'value1', 'key2': 'value2'}
>>> r = request.post('https://httpbin.org/post', data=payload)
>>> печать (р.текст)
{
...
"форма": {
"ключ2": "значение2",
"ключ1": "значение1"
},
...
}
Аргумент данных также может иметь несколько значений для каждого ключа. Это может быть
делается путем создания данных либо списка кортежей, либо словаря со списками
как ценности. Это особенно полезно, когда форма содержит несколько элементов,
используйте тот же ключ:
>>> payload_tuples = [('ключ1', 'значение1'), ('ключ1', 'значение2')]
>>> r1 = request.post('https://httpbin.org/post', data=payload_tuples)
>>> payload_dict = {'key1': ['value1', 'value2']}
>>> r2 = request. post('https://httpbin.org/post', data=payload_dict)
>>> печать(r1.текст)
{
...
"форма": {
"ключ1": [
"значение1",
"значение2"
]
},
...
}
>>> r1.текст == r2.текст
Истинный
 post('https://httpbin.org/post', data=payload_dict)
>>> печать(r1.текст)
{
...
"форма": {
"ключ1": [
"значение1",
"значение2"
]
},
...
}
>>> r1.текст == r2.текст
Истинный
post('https://httpbin.org/post', data=payload_dict)
>>> печать(r1.текст)
{
...
"форма": {
"ключ1": [
"значение1",
"значение2"
]
},
...
}
>>> r1.текст == r2.текст
Истинный
В некоторых случаях вам может потребоваться отправить данные, не закодированные в форме. Если
вы передаете строку вместо dict , эти данные будут отправлены напрямую.
Например, GitHub API v3 принимает данные POST/PATCH в формате JSON:
>>> импортировать json
>>> url = 'https://api.github.com/some/endpoint'
>>> полезная нагрузка = {'некоторые': 'данные'}
>>> r = request.post(url, data=json.dumps(полезная нагрузка))
Обратите внимание, что приведенный выше код НЕ добавит Заголовок Content-Type (поэтому, в частности, он НЕ будет устанавливать его на application/json ).
Если вам нужен этот набор заголовков и вы не хотите самостоятельно кодировать dict ,
вы также можете передать его напрямую, используя параметр json (добавлен в версии 2. 4.2)
и он будет закодирован автоматически:
4.2)
и он будет закодирован автоматически:
>>> url = 'https://api.github.com/some/endpoint'
>>> полезная нагрузка = {'некоторые': 'данные'}
>>> r = request.post(url, json=полезная нагрузка)
Обратите внимание, что параметр json игнорируется, если передается либо данные , либо файлы .
POST файл, закодированный из нескольких частей
Запросы упрощают загрузку файлов с кодировкой Multipart:
>>> URL = 'https://httpbin.org/post'
>>> files = {'файл': open('report.xls', 'rb')}
>>> r = request.post(url, files=файлы)
>>> р.текст
{
...
"файлы": {
"file": "<цензурированные...бинарные...данные>"
},
...
}
Вы можете указать имя файла, тип содержимого и заголовки явно:
>>> URL = 'https://httpbin.org/post'
>>> files = {'file': ('report.xls', open('report.xls', 'rb'), 'application/vnd.ms-excel', {'Expires': '0'}) }
>>> r = request.post(url, files=файлы)
>>> р. текст
{
...
"файлы": {
"file": "<цензурированные...бинарные...данные>"
},
...
}
 текст
{
...
"файлы": {
"file": "<цензурированные...бинарные...данные>"
},
...
}
текст
{
...
"файлы": {
"file": "<цензурированные...бинарные...данные>"
},
...
}
При желании вы можете отправить строки для получения в виде файлов:
>>> URL = 'https://httpbin.org/post'
>>> files = {'file': ('report.csv', 'some,data,to,send\nanother,row,to,send\n')}
>>> r = request.post(url, files=файлы)
>>> р.текст
{
...
"файлы": {
"file": "некоторые,данные,кому,отправить\\nanother,строка,кому,отправить\\n"
},
...
}
Если вы публикуете очень большой файл как multipart/form-data запрос, вы можете захотеть передать запрос. По умолчанию запрашивает не
поддерживают это, но есть отдельный пакет, который делает — запрашивает пояс с инструментами . Вы должны прочитать документацию по поясу инструментов для получения более подробной информации о том, как его использовать.
Для отправки нескольких файлов в одном запросе обратитесь к расширенным раздел.
Предупреждение
Настоятельно рекомендуется открывать файлы в двоичном формате
режим. Это связано с тем, что запросы могут пытаться предоставить
Это связано с тем, что запросы могут пытаться предоставить Content-Length заголовок для вас, и если он делает это значение
будет установлено число байт в файле. Могут возникать ошибки
если открыть файл в текстовом режиме .
Коды состояния ответа
Мы можем проверить код состояния ответа:
>>> r = request.get('https://httpbin.org/get')
>>> r.status_code
200
Requests также поставляется со встроенным объектом поиска кода состояния для легкого ссылка:
>>> r.status_code == request.codes.ok Истинный
Если мы сделали неверный запрос (ошибка клиента 4XX или ответ об ошибке сервера 5XX), мы
может поднять его с Ответ.raise_for_status() :
>>> bad_r = request.get('https://httpbin.org/status/404')
>>> bad_r.status_code
404
>>> bad_r.raise_for_status()
Traceback (последний последний вызов):
Файл "requests/models.py", строка 832, в raise_for_status
поднять http_error
запросы. исключения.HTTPError: 404 Ошибка клиента
 исключения.HTTPError: 404 Ошибка клиента
исключения.HTTPError: 404 Ошибка клиента
Но, так как наши status_code для r было 200 , когда мы звоним raise_for_status() получаем:
>>> r.raise_for_status() Никто
Все хорошо.
Печенье
Если ответ содержит несколько файлов cookie, вы можете быстро получить к ним доступ:
>>> url = 'http://example.com/some/cookie/setting/url' >>> r = запросы.get(url) >>> r.cookies['example_cookie_name'] 'example_cookie_value'
Чтобы отправить собственные файлы cookie на сервер, вы можете использовать печенье параметр:
>>> URL = 'https://httpbin.org/cookies'
>>> cookies = dict(cookies_are='working')
>>> r = request.get(url, cookies=cookies)
>>> р.текст
'{"cookies": {"cookies_are": "рабочие"}}'
куки возвращаются в RequestsCookieJar ,
который действует как dict , но также предлагает более полный интерфейс,
подходит для использования в нескольких доменах или путях.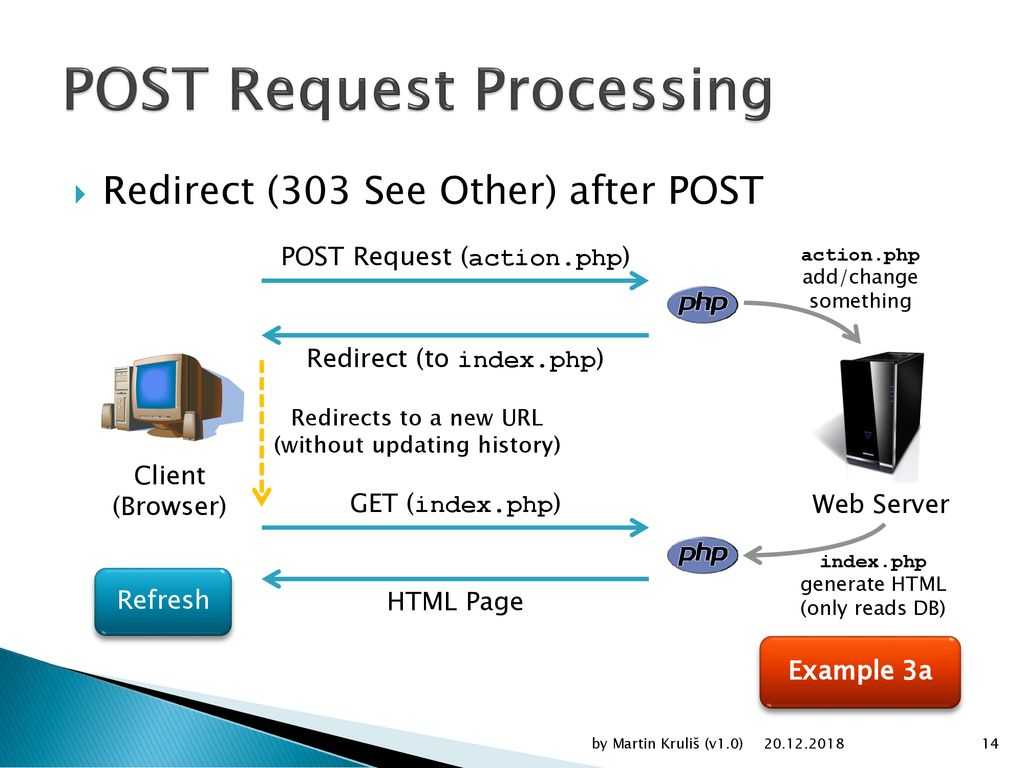 Баночки для печенья могут
также передаваться в запросы:
Баночки для печенья могут
также передаваться в запросы:
>>> jar = запросы.cookies.RequestsCookieJar()
>>> jar.set('tasty_cookie', 'ням', domain='httpbin.org', path='/cookies')
>>> jar.set('gross_cookie', 'blech', domain='httpbin.org', path='/в другом месте')
>>> URL = 'https://httpbin.org/cookies'
>>> r = request.get(url, cookies=jar)
>>> р.текст
'{"cookies": {"tasty_cookie": "ням"}}'
Перенаправление и история
По умолчанию запросы будут выполнять перенаправление местоположения для всех команд, кроме ГОЛОВА.
Мы можем использовать свойство history объекта Response для отслеживания перенаправления.
Список Response.history содержит Ответ объектов, созданных для
завершить запрос. Список отсортирован от самого старого к самому последнему
ответ.
Например, GitHub перенаправляет все HTTP-запросы на HTTPS:
>>> r = request.get('http://github.com/')
>>> р.url
'https://github. com/'
>>> r.status_code
200
>>> р.история
[<Ответ [301]>]
 com/'
>>> r.status_code
200
>>> р.история
[<Ответ [301]>]
com/'
>>> r.status_code
200
>>> р.история
[<Ответ [301]>]
Если вы используете GET, OPTIONS, POST, PUT, PATCH или DELETE, вы можете отключить
обработка перенаправления с параметром allow_redirects :
>>> r = request.get('http://github.com/', allow_redirects=False)
>>> r.status_code
301
>>> р.история
[]
Если вы используете HEAD, вы также можете включить перенаправление:
>>> r = request.head('http://github.com/', allow_redirects=True)
>>> р.url
'https://github.com/'
>>> р.история
[<Ответ [301]>]
Тайм-ауты
Вы можете указать Requests прекратить ожидание ответа после заданного количества
секунд с параметром timeout . Почти весь производственный код должен использовать
этот параметр почти во всех запросах. Невыполнение этого требования может привести к тому, что ваша программа
висеть на неопределенный срок:
>>> request.get('https://github.com/', timeout=0.001)
Traceback (последний последний вызов):
Файл "", строка 1, в
request. exceptions.Timeout: HTTPConnectionPool (host = 'github.com', port = 80): время ожидания запроса истекло. (время ожидания = 0,001)
 exceptions.Timeout: HTTPConnectionPool (host = 'github.com', port = 80): время ожидания запроса истекло. (время ожидания = 0,001)
exceptions.Timeout: HTTPConnectionPool (host = 'github.com', port = 80): время ожидания запроса истекло. (время ожидания = 0,001)
Примечание
тайм-аут не является ограничением по времени на загрузку всего ответа;
скорее, исключение возникает, если сервер не выдал
ответ на тайм-аут секунды (точнее, если ни один байт не был
получено на базовом сокете в течение тайм-аута секунд). Если тайм-аут не указан явно, запросы
не тайм-аут.
Ошибки и исключения
В случае проблемы с сетью (например, сбой DNS, отказ в подключении и т. д.)
Запросы поднимут Исключение ConnectionError .
Response.raise_for_status() будет
поднять HTTPError , если HTTP-запрос
вернул неудачный код состояния.
Если время ожидания запроса истекает, возникает исключение Timeout .
поднятый.
Если запрос превышает настроенное максимальное количество перенаправлений, Возникает исключение TooManyRedirects .
Все исключения, явно вызываемые Requests, наследуются от запросы.исключения.RequestException .
Готовы к большему? Загляните в расширенный раздел.
Если вы находитесь на рынке труда, подумайте над тем, чтобы пройти этот тест по программированию. Существенное пожертвование будет сделано этому проекту, если вы найдете работу через эту платформу.
тел запросов в запросах GET
12 лет назад я спросил в Stack Overflow: разрешены ли запросы HTTP GET для есть запрос тел?. Это получило 2626 голосов и колоссальные 1,6 миллиона голосов. просмотров, поэтому очевидно, что многие люди все еще интересуются этим, и в некоторых случаях не согласен с принятым ответом.
Потому что он продолжает появляться в моих уведомлениях о переполнении стека (и
навязчиво захожу на сайт) вопрос поселился в голове
Аренда бесплатно. Я продолжаю добавлять контекст в своей голове, и я собирался написать
часть из этого вниз в течение нескольких лет теперь и, надеюсь, выселить его.
В любом случае, если вы просто ищете быстрый ответ, это «Нет, вы не должны делать
this.’, вам, вероятно, следует использовать QUERY .
Неопределенное поведение
Некоторые люди (наиболее известный ElasticSearch) ошиблись, но почему? Я думаю, это из-за этого предложения в спецификации HTTP:
Полезная нагрузка в сообщении запроса GET не имеет определенной семантики
Из этого предложения легко можно предположить, что нет никакого определенного поведения, связанного с
запрашивать тела с запросами GET , и что поведение оставлено на усмотрение
разработчик.
Реальность такова, что это больше похоже на неопределенное поведение языков
как С/С++. Насколько я понимаю, оставляя некоторые аспекты языка C
undefined (вместо того, чтобы, например, требовать выдачи ошибки) оставляет место для
реализации компилятора для выполнения определенных оптимизаций. Некоторые компиляторы также
получайте удовольствие от этого; GCC весело запускает видеоигру в конкретном случае
неопределенного поведения, которое действительно подтверждает этот момент.
Если бы вы написали программу на C, которая зависит от того, как компилятор обрабатывает специфическое неопределенное поведение, это означает, что ваша программа больше не является переносимой. Программа на C, но она написана на варианте C, который работает только на некоторых компиляторах.
То же самое относится и к HTTP. Это правда, что неопределенное поведение означает что ты как разработчик сервера можешь это определить, но ты не остров!
При работе с HTTP есть серверы, а также балансировщики нагрузки, прокси,
браузеры и другие клиенты, которые должны работать вместе. Поведение не
просто undefined на стороне сервера, балансировщик нагрузки может выбрать тихое удаление
тела или выдавать ошибки. Тому есть множество реальных примеров. выборка() например выдаст ошибку.
Это все равно не остановило людей от этого. OpenAPI удален
поддержка описания тела запроса GET в версии 3.0 (и DELETE ,
который имеет ту же проблему!), но был добавлен еще в 3. 1, чтобы не
запретить людям документировать свои, возможно, неработающие API.
1, чтобы не
запретить людям документировать свои, возможно, неработающие API.
Почему это не определено
Лучший источник, который у меня есть, это цитата Роя Филдинга в 2007 году. Рой Филдинг придумал REST и является одним из основных авторов HTTP/1.1 RFC.
Да. Другими словами, любое сообщение HTTP-запроса может содержать тело сообщения и, следовательно, должно анализировать сообщения с учетом этого. Однако семантика сервера для GET ограничена таким образом, что тело, если оно есть, не имеет семантического значения для запроса. Требования к синтаксическому анализу отделены от требований к семантике метода. Итак, да, вы можете отправить тело с помощью GET, и нет, это никогда не полезно. Это часть многоуровневого дизайна HTTP/1.1, который снова прояснится после того, как спецификация будет разделена (работа в процессе).
….Рой
( Его сообщение изначально было отправлено на покойный покой-обсудить group на Yahoo Groups, но нашел архив в формате JSON )
Однако этот ответ меня всегда не устраивал. Я понимаю, что вы можете
нужен низкоуровневый протокол, который просто передает сообщения, содержащие заголовки,
тела, URL-адреса, методы и статусы и не касаются конкретных методов
поведение.
Я понимаю, что вы можете
нужен низкоуровневый протокол, который просто передает сообщения, содержащие заголовки,
тела, URL-адреса, методы и статусы и не касаются конкретных методов
поведение.
Эта цель разработки не исключает GET от конкретного отклонения запроса
тела, и это также не мешает спецификации упомянуть, что
тела запроса не должны быть испущены.
Итак, если для этого нет другой причины, я должен предположить что это было сделано из лучших побуждений, но просто недостаточно ясно написано.
Несмотря на это объяснение одного из авторов самой спецификации HTTP, Я заметил, что некоторые люди по-прежнему претендуют на другую интерпретацию, делая своего рода аргумент «смерти автора». Немного смешно думать о «смерти автора» в технических характеристиках, но я думаю, что они имеют точка. Я считаю, что определение такого стандарта, как HTTP, не написанный RFC, это то, как все на самом деле его реализуют.
Цель спецификации — точно описать стандарт, а не определить
это. Если то, что делают все, отличается от замысла автора,
спецификация не смогла точно описать стандарт, а не наоборот.
Если то, что делают все, отличается от замысла автора,
спецификация не смогла точно описать стандарт, а не наоборот.
Команда разработчиков HTTP-спецификаций тоже так думает, поэтому мы
видел новые релизы HTTP/1.1 без повышения версии.
В каждой итерации предпринимаются важные шаги, чтобы зафиксировать реальное использование,
иногда даже в конфликте с исходным RFC2616.
Впрочем, в данном случае это не имеет значения. Многие популярные реализации HTTP
выдает ошибки при просмотре тел GET , например fetch() . Использование ПОЛУЧИТЬ тела дадут вам такую плохую совместимость, что стоит продолжать
не делай этого.
В 2019 году я открыл тикет, чтобы попросить исправить это, и они слушал. Предстоящий HTTP/1.1 будет включать следующий текст:
.Хотя кадрирование сообщения запроса не зависит от используемого метода, контент, полученный в GET-запросе, не имеет общепринятой семантики, не может изменить смысл или цель запроса и может привести к некоторые реализации для отклонения запроса и закрытия соединения из-за его потенциальной возможности атаки контрабандой запросов (раздел 11.
Клиент НЕ ДОЛЖЕН генерировать содержимое в GET запрос, если только он не направлен непосредственно на исходный сервер, который ранее указывалось внутри или вне диапазона, что такой запрос имеет цели и будет адекватно поддерживаться.>Исходный сервер ДОЛЖЕН НЕ полагайтесь на частные соглашения для получения контента, поскольку участники в HTTP-коммуникациях часто не знают о посредниках на цепочка запросов.
 2
HTTP/1.1).
2
HTTP/1.1).Источник.
Зачем
GET иметь тело?Думаю, мы так себя чувствуем, потому что нам снова и снова говорили, что рекомендуется использовать протоколы «семантически правильным» способом.
Но зачем заботиться о семантике? 2 причины:
- Если вы делаете что-то семантически правильно, другие системы могут
предположения о том, как он должен себя вести. Например: запрос
PUT. может быть автоматически повторено, если оно не удалось в первый раз из-за сети сбой или ошибка 5xx. ЗапросGETможет быть кэширован, если он содержитЗаголовок Cache-Control. - Самодокументируемое поведение. Если вы видите запрос
GET, это говорит разработчик что-то извлекается.

Таким образом, хотя пункт 1 здесь не применим (нет технических преимуществ, потому что это неопределенное поведение), но № 2 имеет смысл.
Итак, если мы решили использовать GET для нашего сложного поиска, что мы можем сделать?
Тело явно не разрешено; наши единственные варианты — это заголовки и URL.
С этим есть ряд проблем: кодировка UTF-8 неясна, нет реального
поддержка типов документов/мин, ограничения по длине. Это немного беспорядок!
Большинство разработчиков работают с HTTP и изучают его в контексте API, но это не первоначальный вариант использования.
Все начинается с HTML, браузеров и URL-адресов. Всемирная паутина была спроектирован как распределенная система гипертекстовых документов, где каждый документ имеет глобальный уникальный идентификатор, называемый URL-адресом.
Чтобы получить гипертекстовый документ, вы должны сделать GET по этому URL-адресу, чтобы
заменить или создать документ PUT и удалить документ УДАЛИТЬ . ( Обратите внимание, что создание доступной для записи сети заняло больше времени, но я хотел
проиллюстрировать, что я думаю о предполагаемом дизайне, не будучи обремененным
по фактам ).
( Обратите внимание, что создание доступной для записи сети заняло больше времени, но я хотел
проиллюстрировать, что я думаю о предполагаемом дизайне, не будучи обремененным
по фактам ).
С этой точки зрения идея «параметров» теряет смысл. GET означает не просто «Выполните безопасный запрос и прочитайте что-нибудь из
server», это означает: «Дайте мне документ с этим именем».
Эта особенность отчасти объясняет успех сети. При условии
URL-адрес всесторонне описывает клиенту, как именно подключиться к
сервер и получить документ, он сделал HTML работает. Это также позволяет
люди делают закладки, делятся ссылками по электронной почте/чату и рисуют их на
витрины.
URL — это суперзвезда и убойная функция Интернета. HTTP просто позволит вам найти документы, связанные с URL. HTTP/0.9 не имел даже заголовков и можно читать во время перерыва в ванной.
Наши потребности изменились, HTTP?
Я по-прежнему утверждаю, что даже если вы создаете REST API, хорошо подумать
ваших конечных точек в виде документов, а ПОЛУЧИТЬ , ПОСТАВИТЬ и УДАЛИТЬ как наиболее
важные методы HTTP для управления ими, используя URL-адрес в качестве первичного ключа.
Но, иногда нужно сделать что-то посложнее и было бы неплохо если бы HTTP имел предписанный способ обработки случаев, когда мы хотим описать поисковый запрос как документ.
Традиционно ответом было просто использовать POST . POST вроде твой
метод без гарантий поймать все. Часто также используется для туннелирования других протоколов.
которые на самом деле плохо говорят по HTTP, такие как SOAP, XMLRPC и совсем недавно
ГрафQL.
Но появился новый соперник. Теперь я думаю, что ваш лучший вариант — QUERY .
Это новый метод, еще не совсем стандартный, но любой совместимый с HTTP
клиент и сервер уже должны его поддерживать. Целью ЗАПРОСА является
специально для решения этого варианта использования.
QUERY решает следующие проблемы:
- Это в основном «безопасный»
POST. Это означает, что подразумевается, что это для чтения и безопасного повторения. - Это также говорит само за себя.
