Хеш-функция, что это такое? / Хабр
Приветствую уважаемого читателя!
Сегодня я хотел бы рассказать о том, что из себя представляет хеш-функция, коснуться её основных свойств, привести примеры использования и в общих чертах разобрать современный алгоритм хеширования SHA-3, который был опубликован в качестве Федерального Стандарта Обработки Информации США в 2015 году.
Общие сведения
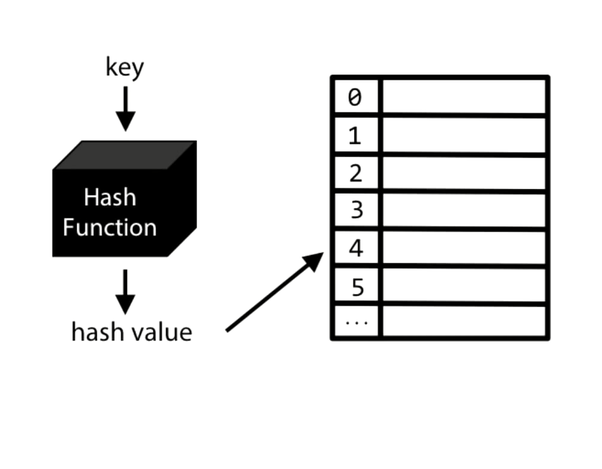
Криптографическая хеш-функция — это математический алгоритм, который отображает данные произвольного размера в битовый массив фиксированного размера.
Результат, производимый хеш-функцией, называется «хеш-суммой» или же просто «хешем», а входные данные часто называют «сообщением».
Для идеальной хеш-функции выполняются следующие условия:
а) хеш-функция является детерминированной, то есть одно и то же сообщение приводит к одному и тому же хеш-значению
b) значение хеш-функции быстро вычисляется для любого сообщения
c) невозможно найти сообщение, которое дает заданное хеш-значение
d) невозможно найти два разных сообщения с одинаковым хеш-значением
e) небольшое изменение в сообщении изменяет хеш настолько сильно, что новое и старое значения кажутся некоррелирующими
Давайте сразу рассмотрим пример воздействия хеш-функции SHA3-256.
Число 256 в названии алгоритма означает, что на выходе мы получим строку фиксированной длины 256 бит независимо от того, какие данные поступят на вход.
На рисунке ниже видно, что на выходе функции мы имеем 64 цифры шестнадцатеричной системы счисления. Переводя это в двоичную систему, получаем желанные 256 бит.
Любой заинтересованный читатель задаст себе вопрос: «А что будет, если на вход подать данные, бинарный код которых во много раз превосходит 256 бит?»
Ответ таков: на выходе получим все те же 256 бит!
Дело в том, что 256 бит — это соответствий, то есть различных входов имеют свой уникальный хеш.
Чтобы прикинуть, насколько велико это значение, запишем его следующим образом:
Надеюсь, теперь нет сомнений в том, что это очень внушительное число!
Поэтому ничего не мешает нам сопоставлять длинному входному массиву данных массив фиксированной длины.
Свойства
Криптографическая хеш-функция должна уметь противостоять всем известным типам криптоаналитических атак.
В теоретической криптографии уровень безопасности хеш-функции определяется с использованием следующих свойств:
Pre-image resistance
Имея заданное значение h, должно быть сложно найти любое сообщение m такое, что
Second pre-image resistance
Имея заданное входное значение , должно быть сложно найти другое входное значение такое, что
Collision resistance
Должно быть сложно найти два различных сообщения и таких, что
Такая пара сообщений и называется коллизией хеш-функции
Давайте чуть более подробно поговорим о каждом из перечисленных свойств.
Collision resistance. Как уже упоминалось ранее, коллизия происходит, когда разные входные данные производят одинаковый хеш. Таким образом, хеш-функция считается устойчивой к коллизиям до того момента, пока не будет обнаружена пара сообщений, дающая одинаковый выход. Стоит отметить, что коллизии всегда будут существовать для любой хеш-функции по той причине, что возможные входы бесконечны, а количество выходов конечно. Хеш-функция считается устойчивой к коллизиям, когда вероятность обнаружения коллизии настолько мала, что для этого потребуются миллионы лет вычислений.
Стоит отметить, что коллизии всегда будут существовать для любой хеш-функции по той причине, что возможные входы бесконечны, а количество выходов конечно. Хеш-функция считается устойчивой к коллизиям, когда вероятность обнаружения коллизии настолько мала, что для этого потребуются миллионы лет вычислений.
Несмотря на то, что хеш-функций без коллизий не существует, некоторые из них достаточно надежны и считаются устойчивыми к коллизиям.
Pre-image resistance. Это свойство называют сопротивлением прообразу. Хеш-функция считается защищенной от нахождения прообраза, если существует очень низкая вероятность того, что злоумышленник найдет сообщение, которое сгенерировало заданный хеш. Это свойство является важным для защиты данных, поскольку хеш сообщения может доказать его подлинность без необходимости раскрытия информации. Далее будет приведён простой пример и вы поймете смысл предыдущего предложения.
Second pre-image resistance.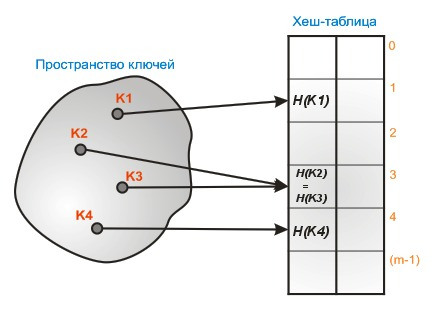 Это свойство называют сопротивлением второму прообразу. Для упрощения можно сказать, что это свойство находится где-то посередине между двумя предыдущими. Атака по нахождению второго прообраза происходит, когда злоумышленник находит определенный вход, который генерирует тот же хеш, что и другой вход, который ему уже известен. Другими словами, злоумышленник, зная, что пытается найти такое, что
Это свойство называют сопротивлением второму прообразу. Для упрощения можно сказать, что это свойство находится где-то посередине между двумя предыдущими. Атака по нахождению второго прообраза происходит, когда злоумышленник находит определенный вход, который генерирует тот же хеш, что и другой вход, который ему уже известен. Другими словами, злоумышленник, зная, что пытается найти такое, что
Отсюда становится ясно, что атака по нахождению второго прообраза включает в себя поиск коллизии. Поэтому любая хеш-функция, устойчивая к коллизиям, также устойчива к атакам по поиску второго прообраза.
Неформально все эти свойства означают, что злоумышленник не сможет заменить или изменить входные данные, не меняя их хеша.
Таким образом, если два сообщения имеют одинаковый хеш, то можно быть уверенным, что они одинаковые.
В частности, хеш-функция должна вести себя как можно более похоже на случайную функцию, оставаясь при этом детерминированной и эффективно вычислимой.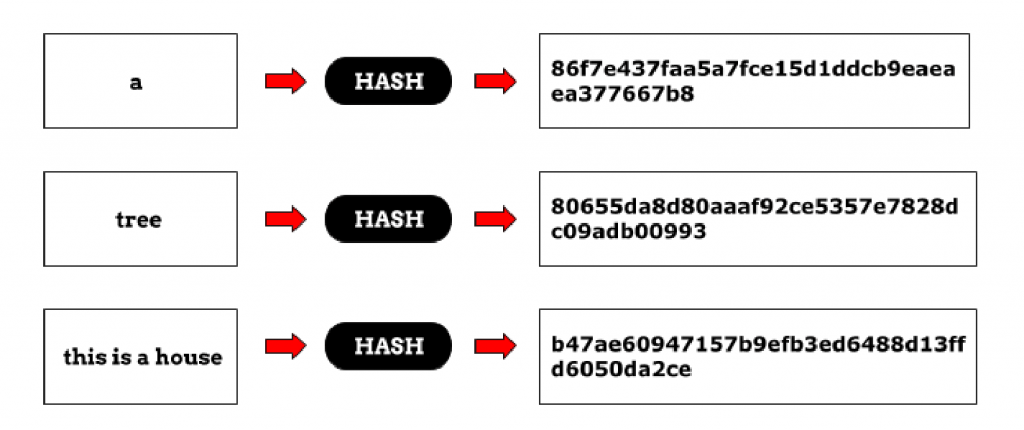
Применение хеш-функций
Рассмотрим несколько достаточно простых примеров применения хеш-функций:
• Проверка целостности сообщений и файлов
Сравнивая хеш-значения сообщений, вычисленные до и после передачи, можно определить, были ли внесены какие-либо изменения в сообщение или файл.
• Верификация пароля
Проверка пароля обычно использует криптографические хеши. Хранение всех паролей пользователей в виде открытого текста может привести к массовому нарушению безопасности, если файл паролей будет скомпрометирован. Одним из способов уменьшения этой опасности является хранение в базе данных не самих паролей, а их хешей. При выполнении хеширования исходные пароли не могут быть восстановлены из сохраненных хеш-значений, поэтому если вы забыли свой пароль вам предложат сбросить его и придумать новый.
• Цифровая подпись
Подписываемые документы имеют различный объем, поэтому зачастую в схемах ЭП подпись ставится не на сам документ, а на его хеш. Вычисление хеша позволяет выявить малейшие изменения в документе при проверке подписи. Хеширование не входит в состав алгоритма ЭП, поэтому в схеме может быть применена любая надежная хеш-функция.
Хеширование не входит в состав алгоритма ЭП, поэтому в схеме может быть применена любая надежная хеш-функция.
Предлагаю также рассмотреть следующий бытовой пример:
Алиса ставит перед Бобом сложную математическую задачу и утверждает, что она ее решила. Боб хотел бы попробовать решить задачу сам, но все же хотел бы быть уверенным, что Алиса не блефует. Поэтому Алиса записывает свое решение, вычисляет его хеш и сообщает Бобу (сохраняя решение в секрете). Затем, когда Боб сам придумает решение, Алиса может доказать, что она получила решение раньше Боба. Для этого ей нужно попросить Боба хешировать его решение и проверить, соответствует ли оно хеш-значению, которое она предоставила ему раньше.
Теперь давайте поговорим о SHA-3.
SHA-3
Национальный институт стандартов и технологий (NIST) в течение 2007—2012 провёл конкурс на новую криптографическую хеш-функцию, предназначенную для замены SHA-1 и SHA-2.
Организаторами были опубликованы некоторые критерии, на которых основывался выбор финалистов:
• Безопасность
Способность противостоять атакам злоумышленников
• Производительность и стоимость
Вычислительная эффективность алгоритма и требования к оперативной памяти для программных реализаций, а также количество элементов для аппаратных реализаций
• Гибкость и простота дизайна
Гибкость в эффективной работе на самых разных платформах, гибкость в использовании параллелизма или расширений ISA для достижения более высокой производительности
В финальный тур попали всего 5 алгоритмов:
• BLAKE
• Grøstl
• JH
• Keccak
• Skein
Победителем и новым SHA-3 стал алгоритм Keccak.
Давайте рассмотрим Keccak более подробно.
Keccak
Хеш-функции семейства Keccak построены на основе конструкции криптографической губки, в которой данные сначала «впитываются» в губку, а затем результат Z «отжимается» из губки.
Любая губчатая функция Keccak использует одну из семи перестановок которая обозначается , где
перестановки представляют собой итерационные конструкции, состоящие из последовательности почти одинаковых раундов. Число раундов зависит от ширины перестановки и задаётся как где
В качестве стандарта SHA-3 была выбрана перестановка Keccak-f[1600], для неё количество раундов
Далее будем рассматривать
Давайте сразу введем понятие строки состояния, которая играет важную роль в алгоритме.
Строка состояния представляет собой строку длины 1600 бит, которая делится на и части, которые называются скоростью и ёмкостью состояния соотвественно.
Соотношение деления зависит от конкретного алгоритма семейства, например, для SHA3-256
В SHA-3 строка состояния S представлена в виде массива слов длины бит, всего бит. В Keccak также могут использоваться слова длины , равные меньшим степеням 2.
В Keccak также могут использоваться слова длины , равные меньшим степеням 2.
Алгоритм получения хеш-функции можно разделить на несколько этапов:
• С помощью функции дополнения исходное сообщение M дополняется до строки P длины кратной r
• Строка P делится на n блоков длины
• «Впитывание»: каждый блок дополняется нулями до строки длиной бит (b = r+c) и суммируется по модулю 2 со строкой состояния , далее результат суммирования подаётся в функцию перестановки и получается новая строка состояния , которая опять суммируется по модулю 2 с блоком и дальше опять подаётся в функцию перестановки . Перед началом работы криптографической губки все элементыравны 0.
• «Отжимание»: пока длина результата меньше чем , где — количество бит в выходном массиве хеш-функции, первых бит строки состояния добавляется к результату . После каждой такой операции к строке состояния применяется функция перестановок и данные продолжают «отжиматься» дальше, пока не будет достигнуто значение длины выходных данных .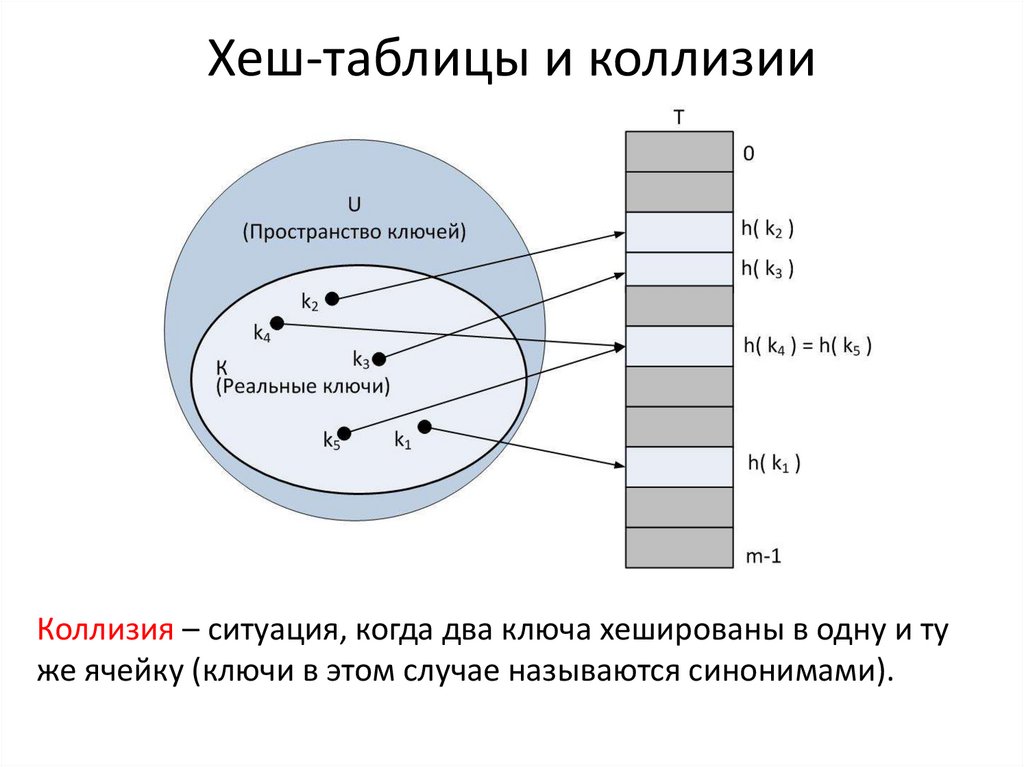
Все сразу станет понятно, когда вы посмотрите на картинку ниже:
Функция дополнения
В SHA-3 используется следующий шаблон дополнения 10…1: к сообщению добавляется 1, после него от 0 до r — 1 нулевых бит и в конце добавляется 1.
r — 1 нулевых бит может быть добавлено, когда последний блок сообщения имеет длину r — 1 бит. В этом случае последний блок дополняется единицей и к нему добавляется блок, состоящий из r — 1 нулевых бит и единицы в конце.
Если длина исходного сообщения M делится на r, то в этом случае к сообщению добавляется блок, начинающийся и оканчивающийся единицами, между которыми находятся r — 2 нулевых бит. Это делается для того, чтобы для сообщения, оканчивающегося последовательностью бит как в функции дополнения, и для сообщения без этих бит значения хеш-функции были различны.
Первый единичный бит в функции дополнения нужен, чтобы результаты хеш-функции от сообщений, отличающихся несколькими нулевыми битами в конце, были различны.
Функция перестановок
Базовая функция перестановки состоит из раундов по пять шагов:
Шаг
Шаг
Шаг
Шаг
Шаг
Тета, Ро, Пи, Хи, Йота
Далее будем использовать следующие обозначения:
Так как состояние имеет форму массива , то мы можем обозначить каждый бит состояния как
Обозначим результат преобразования состояния функцией перестановки
Также обозначим функцию, которая выполняет следующее соответствие:
— обычная функция трансляции, которая сопоставляет биту бит ,
где — длина слова (64 бит в нашем случае)
Я хочу вкратце описать каждый шаг функции перестановок, не вдаваясь в математические свойства каждого.
Шаг
Эффект отображения можно описать следующим образом: оно добавляет к каждому биту побитовую сумму двух столбцов и
Схематическое представление функции:
Псевдокод шага:
Шаг
Отображение направлено на трансляции внутри слов (вдоль оси z).
Проще всего его описать псевдокодом и схематическим рисунком:
Шаг
Шаг представляется псевдокодом и схематическим рисунком:
Шаг
Шаг является единственный нелинейным преобразованием в
Псевдокод и схематическое представление:
Шаг
Отображение состоит из сложения с раундовыми константами и направлено на нарушение симметрии. Без него все раунды были бы эквивалентными, что делало бы его подверженным атакам, использующим симметрию. По мере увеличения раундовые константы добавляют все больше и больше асимметрии.
Ниже приведена таблица раундовых констант для бит
Все шаги можно объединить вместе и тогда мы получим следующее:
Где константы являются циклическими сдвигами и задаются таблицей:
Итоги
В данной статье я постарался объяснить, что такое хеш-функция и зачем она нужна
Также в общих чертах мной был разобран принцип работы алгоритма SHA-3 Keccak, который является последним стандартизированным алгоритмом семейства Secure Hash Algorithm
Надеюсь, все было понятно и интересно
Всем спасибо за внимание!
Хеш — что это такое и как хэш-функция помогает решать вопросы безопасности в интернете
Обновлено 22 сентября 2022 Просмотров: 66 403 Автор: Дмитрий ПетровЗдравствуйте, уважаемые читатели блога KtoNaNovenkogo. ru. Хочу продолжить серию статей посвященных различным терминам, которые не всегда могут быть понятны без дополнительных пояснений. Чуть ранее я рассказывал про то, что значит слово кликбейт и что такое хост, писал про IP и MAC адреса, фишинг и многое другое.
ru. Хочу продолжить серию статей посвященных различным терминам, которые не всегда могут быть понятны без дополнительных пояснений. Чуть ранее я рассказывал про то, что значит слово кликбейт и что такое хост, писал про IP и MAC адреса, фишинг и многое другое.
Сегодня у нас на очереди хеш. Что это такое? Зачем он нужен? Почему это слово так часто используется в интернете применительно к совершенно разным вещам? Имеет ли это какое-то отношение к хештегам или хешссылкам? Где применяют хэш, как вы сами можете его использовать? Что такое хэш-функция и хеш-сумма? Причем тут коллизии?
Все это (или почти все) вы узнаете из этой маленькой заметки. Поехали…
Что такое хеш и хэширование простыми словами
Слово хеш происходит от английского «hash», одно из значений которого трактуется как путаница или мешанина. Собственно, это довольно полно описывает реальное значение этого термина. Часто еще про такой процесс говорят «хеширование», что опять же является производным от английского hashing (рубить, крошить, спутывать и т. п.).
п.).
Появился этот термин в середине прошлого века среди людей занимающихся обработках массивов данных. Хеш-функция позволяла привести любой массив данных к числу заданной длины. Например, если любое число (любой длинны) начать делить много раз подряд на одно и то же простое число (это как?), то полученный в результате остаток от деления можно будет называть хешем. Для разных исходных чисел остаток от деления (цифры после запятой) будет отличаться.
Для обычного человека это кажется белибердой, но как ни странно в наше время без хеширования практически невозможна работа в интернете. Так что же это такая за функция? На самом деле она может быть любой (приведенный выше пример это не есть реальная функция — он придуман мною чисто для вашего лучшего понимания принципа). Главное, чтобы результаты ее работы удовлетворяли приведенным ниже условиям.
Зачем нужен хэш
Смотрите, еще пример. Есть у вас текст в файле. Но на самом деле это ведь не текст, а массив цифровых символов (по сути число). Как вы знаете, в компьютерной логике используются двоичные числа (ноль и единица). Они запросто могут быть преобразованы в шестнадцатиричные цифры, над которыми можно проводить математические операции. Применив к ним хеш-функцию мы получим на выходе (после ряда итераций) число заданной длины (хеш-сумму).
Как вы знаете, в компьютерной логике используются двоичные числа (ноль и единица). Они запросто могут быть преобразованы в шестнадцатиричные цифры, над которыми можно проводить математические операции. Применив к ним хеш-функцию мы получим на выходе (после ряда итераций) число заданной длины (хеш-сумму).
Если мы потом в исходном текстовом файле поменяем хотя бы одну букву или добавим лишний пробел, то повторно рассчитанный для него хэш уже будет отличаться от изначального (вообще другое число будет). Доходит, зачем все это нужно? Ну, конечно же, для того, чтобы понять, что файл именно тот, что и должен быть. Это можно использовать в целом ряде аспектов работы в интернете и без этого вообще сложно представить себе работу сети.
Где и как используют хеширование
Например, простые хэш-функции (не надежные, но быстро рассчитываемые) применяются при проверке целостности передачи пакетов по протоколу TCP/IP (и ряду других протоколов и алгоритмов, для выявления аппаратных ошибок и сбоев — так называемое избыточное кодирование). Если рассчитанное значение хеша совпадает с отправленным вместе с пакетом (так называемой контрольной суммой), то значит потерь по пути не было (можно переходить к следующему пакету).
Если рассчитанное значение хеша совпадает с отправленным вместе с пакетом (так называемой контрольной суммой), то значит потерь по пути не было (можно переходить к следующему пакету).
А это, ведь на минутку, основной протокол передачи данных в сети интернет. Без него никуда. Да, есть вероятность, что произойдет накладка — их называют коллизиями. Ведь для разных изначальных данных может получиться один и тот же хеш. Чем проще используется функция, тем выше такая вероятность. Но тут нужно просто выбирать между тем, что важнее в данный момент — надежность идентификации или скорость работы. В случае TCP/IP важна именно скорость. Но есть и другие области, где важнее именно надежность.
Похожая схема используется и в технологии блокчейн, где хеш выступает гарантией целостности цепочки транзакций (платежей) и защищает ее от несанкционированных изменений. Благодаря ему и распределенным вычислениям взломать блокчен очень сложно и на его основе благополучно существует множество криптовалют, включая самую популярную из них — это биткоин. Последний существует уже с 2009 год и до сих пор не был взломан.
Последний существует уже с 2009 год и до сих пор не был взломан.
Более сложные хеш-функции используются в криптографии. Главное условие для них — невозможность по конечному результату (хэшу) вычислить начальный (массив данных, который обработали данной хеш-функцией). Второе главное условие — стойкость к коллизиями, т.е. низкая вероятность получения двух одинаковых хеш-сумм из двух разных массивов данных при обработке их этой функцией. Расчеты по таким алгоритмам более сложные, но тут уже главное не скорость, а надежность.
Так же хеширование используется в технологии электронной цифровой подписи. С помощью хэша тут опять же удостоверяются, что подписывают именно тот документ, что требуется. Именно он (хеш) передается в токен, который и формирует электронную цифровую подпись. Но об этом, я надеюсь, еще будет отдельная статья, ибо тема интересная, но в двух абзацах ее не раскроешь.
Для доступа к сайтам и серверам по логину и паролю тоже часто используют хеширование. Согласитесь, что хранить пароли в открытом виде (для их сверки с вводимыми пользователями) довольно ненадежно (могут их похитить). Поэтому хранят хеши всех паролей. Пользователь вводит символы своего пароля, мгновенно рассчитывается его хеш-сумма и сверяется с тем, что есть в базе. Надежно и очень просто. Обычно для такого типа хеширования используют сложные функции с очень высокой криптостойкостью, чтобы по хэшу нельзя было бы восстановить пароль.
Согласитесь, что хранить пароли в открытом виде (для их сверки с вводимыми пользователями) довольно ненадежно (могут их похитить). Поэтому хранят хеши всех паролей. Пользователь вводит символы своего пароля, мгновенно рассчитывается его хеш-сумма и сверяется с тем, что есть в базе. Надежно и очень просто. Обычно для такого типа хеширования используют сложные функции с очень высокой криптостойкостью, чтобы по хэшу нельзя было бы восстановить пароль.
Какими свойствами должна обладать хеш-функция
Хочу систематизировать кое-что из уже сказанного и добавить новое.
- Как уже было сказано, функция эта должна уметь приводить любой объем данных (а все они цифровые, т.е. двоичные, как вы понимаете) к числу заданной длины (по сути это сжатие до битовой последовательности заданной длины хитрым способом).
- При этом малейшее изменение (хоть на один бит) входных данных должно приводить к полному изменению хеша.
- Она должна быть стойкой в обратной операции, т.
 е. вероятность восстановления исходных данных по хешу должна быть весьма низкой (хотя последнее сильно зависит от задействованных мощностей)
е. вероятность восстановления исходных данных по хешу должна быть весьма низкой (хотя последнее сильно зависит от задействованных мощностей) - В идеале она должна иметь как можно более низкую вероятность возникновения коллизий. Согласитесь, что не айс будет, если из разных массивов данных будут часто получаться одни и те же значения хэша.
- Хорошая хеш-функция не должна сильно нагружать железо при своем исполнении. От этого сильно зависит скорость работы системы на ней построенной. Как я уже говорил выше, всегда имеется компромисс между скорость работы и качеством получаемого результата.
- Алгоритм работы функции должен быть открытым, чтобы любой желающий мог бы оценить ее криптостойкость, т.е. вероятность восстановления начальных данных по выдаваемому хешу.
 е. вероятность восстановления исходных данных по хешу должна быть весьма низкой (хотя последнее сильно зависит от задействованных мощностей)
е. вероятность восстановления исходных данных по хешу должна быть весьма низкой (хотя последнее сильно зависит от задействованных мощностей)Хеш — это маркер целостности скачанных в сети файлов
Где еще можно встретить применение этой технологии? Наверняка при скачивании файлов из интернета вы сталкивались с тем, что там приводят некоторые числа (которые называют либо хешем, либо контрольными суммами) типа:
CRC32: 7438E546 MD5: DE3BAC46D80E77ADCE8E379F682332EB SHA-1: 332B317FB97126B0F79F7AF5786EBC51E5CC82CF
Что это такое? И что вам с этим всем делать? Ну, как правило, на тех же сайтах можно найти пояснения по этому поводу, но я не буду вас утруждать и расскажу в двух словах. Это как раз и есть результаты работы различных хеш-функций (их названия приведены перед числами: CRC32, MD5 и SHA-1).
Это как раз и есть результаты работы различных хеш-функций (их названия приведены перед числами: CRC32, MD5 и SHA-1).
Зачем они вам нужны? Ну, если вам важно знать, что при скачивании все прошло нормально и ваша копия полностью соответствует оригиналу, то нужно будет поставить на свой компьютер программку, которая умеет вычислять хэш по этим алгоритмам (или хотя бы по некоторым их них).
После чего прогнать скачанные файлы через эту программку и сравнить полученные числа с приведенными на сайте. Если совпадают, то сбоев при скачивании не было, а если нет, то значит были сбои и есть смысл повторить закачку заново.
Популярные хэш-алгоритмы сжатия
- CRC32 — используется именно для создания контрольных сумм (так называемое избыточное кодирование). Данная функция не является криптографической. Есть много вариаций этого алгоритма (число после CRC означает длину получаемого хеша в битах), в зависимости от нужной длины получаемого хеша. Функция очень простая и нересурсоемкая. В связи с этим используется для проверки целостности пакетов в различных протоколах передачи данных.
- MD5 — старая, но до сих пор очень популярная версия уже криптографического алгоритма, которая создает хеш длиной в 128 бит. Хотя стойкость этой версии на сегодняшний день и не очень высока, она все равно часто используется как еще один вариант контрольной суммы, например, при скачивании файлов из сети.
- SHA-1 — криптографическая функция формирующая хеш-суммы длиной в 160 байт. Сейчас идет активная миграция в сторону SHA-2, которая обладает более высокой устойчивостью, но SHA-1 по-прежнему активно используется хотя бы в качестве контрольных сумм. Но она так же по-прежнему используется и для хранения хешей паролей в базе данных сайта (об этом читайте выше).
- ГОСТ Р 34.11-2012 — текущий российский криптографический (стойкий к взлому) алгоритм введенный в работу в 2013 году (ранее использовался ГОСТ Р 34.11-94). Длина выходного хеша может быть 256 или 512 бит. Обладает высокой криптостойкостью и довольно хорошей скоростью работы. Используется для электронных цифровых подписей в системе государственного и другого документооборота.
 В связи с этим используется для проверки целостности пакетов в различных протоколах передачи данных.
В связи с этим используется для проверки целостности пакетов в различных протоколах передачи данных. Обладает высокой криптостойкостью и довольно хорошей скоростью работы. Используется для электронных цифровых подписей в системе государственного и другого документооборота.
Обладает высокой криптостойкостью и довольно хорошей скоростью работы. Используется для электронных цифровых подписей в системе государственного и другого документооборота.HashTab — вычисление хеша для любых файлов на компьютере
Раз уж зашла речь о программе для проверки целостности файлов (расчета контрольных сумм по разным алгоритмам хеширования), то тут, наверное, самым популярным решением будет HashTab.
Она бесплатна для личного некоммерческого использования и покрывает с лихвой все, что вам может понадобиться от подобного рода софта. После ее скачивания и установки запускать ничего не надо. Просто кликаете правой кнопкой мыши по нужному файлу в Проводнике (или ТоталКомандере) и выбираете самый нижний пункт выпадающего меню «Свойства»:
В открывшемся окне перейдите на вкладку «Хеш-суммы файлов», где будут отображены контрольные суммы, рассчитанные по нужным вам алгоритмам хэширования (задать их можно нажав на кнопку «Настройки» в этом же окне).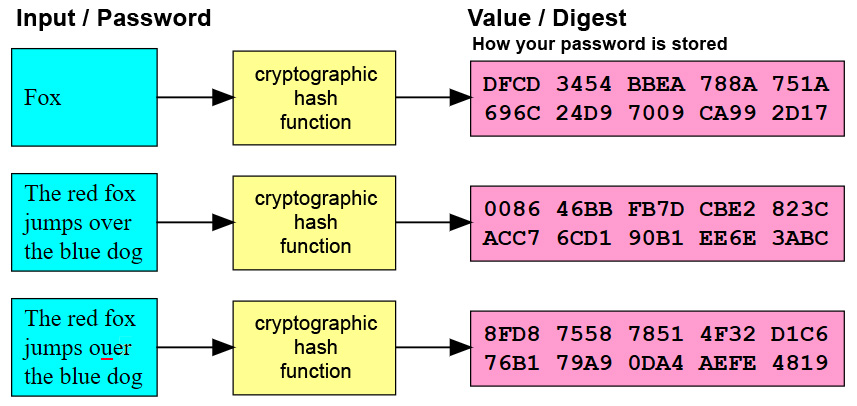 По умолчанию отображаются три самых популярных:
По умолчанию отображаются три самых популярных:
Чтобы не сравнивать контрольные суммы визуально, можно числа по очереди вставить в рассположенное ниже поле (со знаком решетки) и нажать на кнопку «Сравнить файл».
Как видите, все очень просто и быстро. А главное эффективно.
Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Хеш четкий и хеш нечеткий
Борис Осепов
Специалист Group-IB
Александр Мессерле
ИБтивист
На практике вирусописатели особо не заморачиваются с затратной по времени разработкой новых «качественных» вирусов: в большинстве случаев существующая база или ядро вредоноса повторно используется для создания новой разновидности малвари. Код может быть собран заново с помощью другого компилятора, из него могут быть удалены или, наоборот, в него могут быть добавлены новые функции, также обновляются некоторые библиотеки, меняется распределение кода внутри файла (при этом применяются новые компоновщики, пакеры, обфускация и так далее). Смысл таких преобразований — придать хорошо знакомой антивирусу вредоносной программе новый вид, чтобы она какое-то время осталась необнаруженной.
Смысл таких преобразований — придать хорошо знакомой антивирусу вредоносной программе новый вид, чтобы она какое-то время осталась необнаруженной.
Тем не менее существуют способы детектирования такого рода переупаковок и модификаций. Эти техники обнаружения зачастую используются для анализа большого массива данных и поиска в нем общих элементов. Практическими примерами использования похожих техник могут быть глобально распределенные базы знаний, такие как Virus Total и базы антивирусных компаний, а также подходы Threat Intelligence & Attribution. Ведущий пресейл-менеджер Group-IB Борис Осепов и ИБтивист Александр Мессерле на Хакере.ру рассказали, как работают продвинутые алгоритмы хеширования.
Хеш «четкий»
Ханс Петер Лун из IBM еще в 1940-е разрабатывал системы для анализа информации, в том числе исследовал вопросы хранения, передачи и поиска текстовых данных. Это привело его к созданию алгоритмов преобразования, а затем и к хешированию информации в качестве способа поиска телефонных номеров и текста.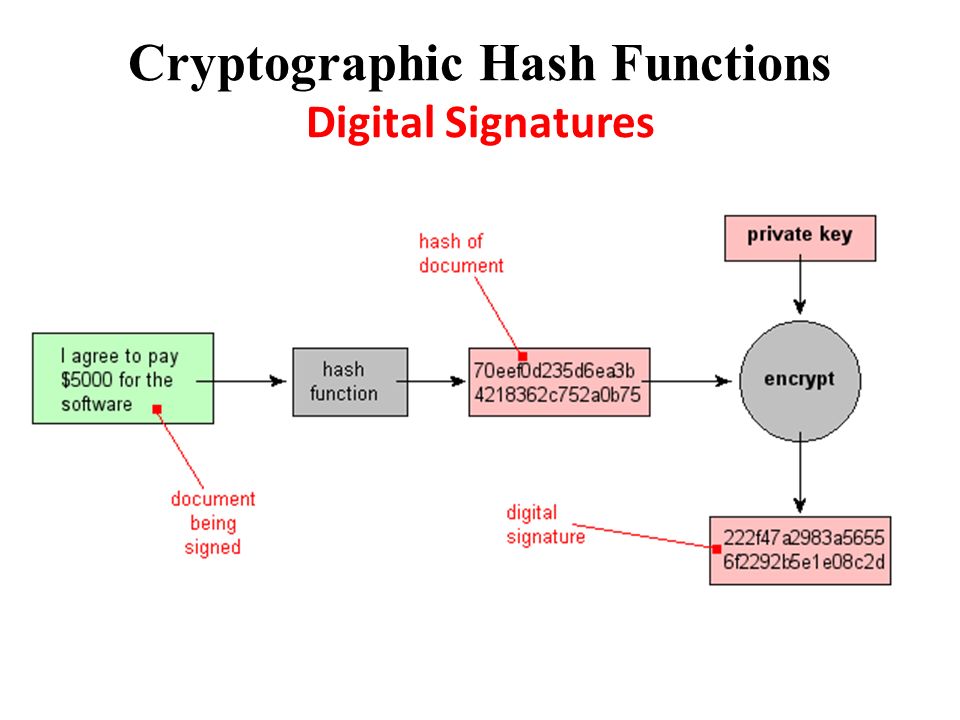 Так индексация и концепция «разделяй и властвуй» сделали свои первые шаги в области вычислительной техники.
Так индексация и концепция «разделяй и властвуй» сделали свои первые шаги в области вычислительной техники.
Сейчас существует множество алгоритмов хеширования, отличающихся криптостойкостью, скоростью вычисления, разрядностью и другими характеристиками.
Мы привыкли ассоциировать хеш-функции с криптографическими хеш-функциями. Это распространенный инструмент, который используется для решения целого ряда задач, таких как:
- аутентификация;
- электронная подпись;
- обнаружение вредоносного ПО (как файлов, так и их маркеров компрометации).
В сегодняшней статье речь пойдет о том, как различные алгоритмы хеширования помогают нам бороться с зловредным ПО.
Что такое хеш
Криптографическая хеш-функция, чаще называемая просто хешем, — это математическое преобразование, переводящее произвольный входной массив данных в состоящую из букв и цифр строку фиксированной длины. Хеш считается криптостойким, если справедливо следующее:
Хеш считается криптостойким, если справедливо следующее:
- по хешу нельзя восстановить исходные данные;
- выполняется устойчивость к коллизиям, то есть невозможно получить из различных входных последовательностей одинаковые хеши.
MD5, SHA-1 и SHA-256 — наиболее популярные криптографические алгоритмы вычисления хеша, которые часто используются в детектировании вредоносного ПО. Еще совсем недавно вредонос опознавали только по сигнатуре (хешу) исполняемого файла.
Но в современных реалиях недостаточно знать просто хеш объекта, так как это слабый индикатор компрометации (IoC). IoC — это все артефакты, на основе которых может быть выявлен вредонос. Например, используемые им ветки реестра, подгружаемые библиотеки, IP-адреса, байтовые последовательности, версии ПО, триггеры даты и времени, задействованные порты, URL.
Рассмотрим «пирамиду боли» для атакующего, придуманную аналитиком в области информационной безопасности Дэвидом Бьянко. Она описывает уровни сложности индикаторов компрометации, которые злоумышленники используют при атаках. Например, если ты знаешь MD5-хеш вредоносного файла, его можно довольно легко и при этом точно обнаружить в системе. Однако это принесет очень мало боли атакующему — достаточно добавить один бит информации к файлу вредоноса, и хеш изменится. Таким образом вирус может переселяться бесконечно, и каждая новая его копия будет иметь отличный от других экземпляров хеш.
Она описывает уровни сложности индикаторов компрометации, которые злоумышленники используют при атаках. Например, если ты знаешь MD5-хеш вредоносного файла, его можно довольно легко и при этом точно обнаружить в системе. Однако это принесет очень мало боли атакующему — достаточно добавить один бит информации к файлу вредоноса, и хеш изменится. Таким образом вирус может переселяться бесконечно, и каждая новая его копия будет иметь отличный от других экземпляров хеш.
«Пирамида боли» Дэвида Бьянко
Если ты имеешь дело с множеством вредоносных образцов, становится понятно, что большинство из них по сути своей не уникальны. Злоумышленники нередко заимствуют или покупают исходники друг у друга и используют их в своих программах. Очень часто после появления в паблике исходных кодов какого-либо вредоносного ПО в интернете всплывают многочисленные поделки, состряпанные из доступных фрагментов.
Как же определить схожесть между разными образцами малвари одного семейства?
Для поиска такого сходства существуют специальные алгоритмы подсчета хеша, например нечеткое (fuzzy) хеширование и хеш импортируемых библиотек (imphash). Эти два подхода используют разные методы обнаружения для поиска повторно встречающихся фрагментов вредоносных программ, принадлежащих к определенным семействам. Рассмотрим эти два метода подробнее.
Эти два подхода используют разные методы обнаружения для поиска повторно встречающихся фрагментов вредоносных программ, принадлежащих к определенным семействам. Рассмотрим эти два метода подробнее.
«Нечеткий» хеш — SSDeep
Если в криптографических хеш-функциях суть алгоритма состоит в том, что при малейшем изменении входных данных (даже одного бита информации) их хеш также значительно изменяется, то в нечетких хешах результат меняется незначительно или не изменяется вовсе. То есть нечеткие хеши более устойчивы к небольшим изменениям в файле. Поэтому подобные функции позволяют намного более эффективно обнаруживать новые модификации вредоносного ПО и не требуют больших ресурсов для расчета.
Нечеткое хеширование — это метод, при котором программа, такая как, например, SSDeep, вычисляет кусочные хеши от входных данных, то есть использует так называемое контекстно вызываемое кусочное хеширование. В англоязычных источниках этот метод называется context triggered piecewise hashing (CTPH aka fuzzy hashing).
На самом деле классификаций нечетких хешей довольно много. Например, по механизму работы алгоритмы делятся на piecewise hashing, context triggered piecewise hashing, statistically improbable features, block-based rebuilding. По типу обрабатываемой информации их можно разделить на побайтовые, синтаксические и семантические. Но если речь заходит о нечетких хешах, то это, как правило, CTPH.
Алгоритм SSDeep разработан Джесси Корнблюмом для использования в компьютерной криминалистике и основан на алгоритме spamsum. SSDeep вычисляет несколько традиционных криптографических хешей фиксированного размера для отдельных сегментов файла и тем самым позволяет обнаруживать похожие объекты. В алгоритме SSDeep используется механизм скользящего окна rolling hash. Его еще можно назвать рекурсивным кусочным хешированием.
Часто CTPH-подобные хеши лежат в основе алгоритмов локально чувствительных хешей — locality-sensitive hashing (LSH). В их задачи входит поиск ближайших соседей — approximate nearest neighbor (ANN), или, проще говоря, похожих объектов, но с чуть более высокоуровневой абстракцией. Алгоритмы LSH используются не только в борьбе с вредоносным ПО, но и в мультимедиа, при поиске дубликатов, поиске схожих генов в биологии и много где еще.
Алгоритмы LSH используются не только в борьбе с вредоносным ПО, но и в мультимедиа, при поиске дубликатов, поиске схожих генов в биологии и много где еще.
Алгоритм SSDeep
Как работает SSDeep? На первый взгляд, все довольно просто:
- он разделяет файл на более мелкие части и изучает их, а не файл в целом;
- он может определить фрагменты файлов, которые имеют последовательности одинаковых байтов, расположенных в схожем порядке, либо байты между двумя последовательностями, где они могут различаться как по значению, так и по длине.
Virus Total использует SSDeep, который выполняет нечеткое хеширование на загружаемых пользователями файлах. Пример — по ссылке.
Virus Total использует SSDeep
Итак, рубрика э-э-эксперименты! Возьмем по 18 образцов исполняемых файлов нашумевших вирусяк: среди них — MassLogger (имена образцов будут начинаться с аббревиатуры ML), Agent Tesla (AT) и Emotet (EMO). Только вот где мы найдем такое количество малвари? Да на базаре.
Только вот где мы найдем такое количество малвари? Да на базаре.
Теперь давай посмотрим, что же мы загрузили для испытаний. Agent Tesla — это .NET-кейлоггер и RAT, подробнее о нем рассказано вот в этой статье. Emotet — банковский троян с возможностью червеобразного распространения. При запуске сразу определяет, что работает не в виртуалке, иначе завершается. MassLogger, как и Agent Tesla, представляет собой кейлоггер. При этом он входит в топ-5 по популярности лета и осени 2020 года. Они оба используют механизм доставки вредоносных программ GuLoader, который загружает зашифрованную полезную нагрузку, лежащую на обычных платформах для обмена файлами.
Мы будем работать с .EXE-семплами, у каждого из испытуемых объектов уникальная криптографическая хеш-сумма SHA-1. Перечислим их все (команда для любителей Linux: shasum ML):
С использованием SSDeep рассчитаем кусочный хеш каждого из файлов и сохраним результат в файле командой ssdeep MassLogger/* > ML.ssd. На выходе получим следующее:
Выглядит пугающе, правда? Давай сравним объекты между собой (в выводе мы предварительно удалили дубли, оставив уникальные совпадения между семплами). Для этого используем следующую команду:
Для этого используем следующую команду:
ssdeep -m ML.ssd -s MassLogger/* > ML_COMPARE.txt
В выводе команды правый столбец — процент совпадения между семплами.
Получается, что в исследуемых семплах присутствуют стабильно кочующие участки кода, которые обеспечивают схожесть. Поскольку такой вывод, скажем честно, малоинформативен, для наглядности изобразим связи в виде графа.
Связи исследуемых семплов
Из 18 объектов оказалось всего восемь никак не связанных между собой образцов, но это пока… Тем не менее можно смело утверждать, что мы выявили целое семейство вредоносов. Теперь протестируем остальные объекты из других групп и сравним результаты.
Сразу изобразим граф связности для образцов Agent Tesla. Не будем перечислять хеш-суммы образцов, а сразу приступим к сравнению: сначала файлов между собой, затем с семплами MassLogger.
Граф связности для образцов Agent Tesla
Для Agent Tesla также обнаружено два семейства взаимосвязанных семплов и десять воинов-одиночек. Что дальше? Сравним SSDeep-хеши MassLogger с объектами Emotet. Пусто, нет совпадений. А если с Agent Tesla? Строим граф.
Что дальше? Сравним SSDeep-хеши MassLogger с объектами Emotet. Пусто, нет совпадений. А если с Agent Tesla? Строим граф.
Сравнение MassLogger с Agent Tesla
Бинго! Совпадения есть, и взаимопроникновение фрагментов кода семейств Agent Tesla и MassLogger доказано.
Однако не всегда у исследователя достаточно семплов и образцов вредоносов других семейств — например, для семейства Emotet. На графе видно, что из всех 18 объектов 13 так или иначе связаны между собой, а семплы EMO3, EMO9, EMO11, EMO15 и EMO18 не нашли «друзей», и их мы отражать на рисунке не станем.
Взаимосвязи объектов на графе
Итак, что же в итоге у нас получилось? У групп MassLogger есть пять объектов, связанных с объектами Agent Tesla. Почему так вышло? Во-первых, это два кейлоггера, у них есть пересечения в функциональности. Во-вторых, они оба используют один и тот же загрузчик. В каждом из тестов находились связи (то есть сходства) между объектами более чем на 50%. Иными словами, из 18 образцов так или иначе были связаны между собой как минимум девять. Среди семплов нашлись по меньшей мере две группы связанных объектов, а у Emotet — сразу три группы. Теперь давай рассмотрим другой тип хеш-функций, и, возможно, мы найдем новые взаимосвязи.
Иными словами, из 18 образцов так или иначе были связаны между собой как минимум девять. Среди семплов нашлись по меньшей мере две группы связанных объектов, а у Emotet — сразу три группы. Теперь давай рассмотрим другой тип хеш-функций, и, возможно, мы найдем новые взаимосвязи.
Хеш импортируемых библиотек — imphash
Imphash расшифровывается как import hash — «хеш импортов», то есть всех импортируемых программой библиотек, прописанных в исполняемом файле Windows Portable Executable (PE). Чтобы вычислить imphash, все импортированные библиотеки и связанные с ними функции выгружаются в строковом формате, объединяются, а затем криптографически хешируются. Virus Total также высчитывает по этому алгоритму хеш для PE-файлов.
Virus Total также использует imphash
Естественно, злоумышленники знают о таком алгоритме и могут его обойти, сделав свой вирус более модульным. Например, можно загружать каждый модуль в память только при необходимости или динамически загружать библиотеки, сохраняя объем импорта настолько малым, насколько позволяет компилятор. При этом любой импорт переносится в память только во время выполнения, а не транслируется в таблице импорта в PE-файле. Вирусы пишут люди, а люди — существа ленивые, нужно немного потрудиться, чтобы перевести работу программы в такой формат.
При этом любой импорт переносится в память только во время выполнения, а не транслируется в таблице импорта в PE-файле. Вирусы пишут люди, а люди — существа ленивые, нужно немного потрудиться, чтобы перевести работу программы в такой формат.
Перейдем к практике и найдем взаимосвязи среди наших исследуемых групп объектов. Начнем с MassLogger. Появились ли новые связи? Да, мы получили три группы связанных объектов — их imphash идентичны!
Три новые группы связанных объектов с общими imphash
Изобразим общие imphash файлов в виде графа. Тут со всеми объектами получается полносвязный граф, так что не суди строго, если какого-то ребра графа не будет!
Общие imphash файлов
Сравним с предыдущим графом из секции экспериментов с SSDeep.
Сравнение графов
Теперь объединим два получившихся графа в группы по их вершинам.
Объединим оба графа
Получается, что среди 18 образцов MassLogger не нашли себе «друзей» всего три объекта: ML1, ML2 и ML4, а это всего 17% от общего количества. Таким образом, используя две техники, мы выявили и подтвердили взаимосвязи вредоносных семплов и их «группировки».
Таким образом, используя две техники, мы выявили и подтвердили взаимосвязи вредоносных семплов и их «группировки».
Далее разберем остальные семейства вредоносных файлов. Agent Tesla по imphash разделился на две большие группы.
Деление Agent Tesla по imphash
Сравним с предыдущим графом из секции тестов с SSDeep.
Сравнение графа с предыдущим
Объединим два получившихся графа в группы по их вершинам.
Объединяем два графа в группы по их вершинам
Imphash дополнил связи, которые были выявлены на этапе тестирования с SSDeep, и продемонстрировал более целостную картину. Идентичный с левой группой imphash присутствует в образцах группы MassLogger — ML5, ML9, ML11 и ML14.
Далее рассмотрим группу малвари Emotet.
Группа Emotet
Сравни с предыдущим графом из секции тестов с SSDeep. Напомним, что семплы EMO3, EMO9, EMO11, EMO15 и EMO18 не нашли себе «друзей» в прошлом тесте.
Объединим два получившихся графа в группы по их вершинам.
Сравним графы, объединив их по вершинам
Опа! Недаром червь Emotet получил такое распространение. В наш тест попали довольно хитрые образцы, у которых, судя по всему, в явном виде не присутствует таблица импортов, а следовательно, отсутствует imphash. Скорее всего, в них используется одна из техник, которые мы перечисляли в разделе об этом типе хеширования.
Анализируя графы взаимосвязей, можно заметить, что благодаря комбинации imphash и SSDeep мы получили новые взаимосвязи между объектами, тем самым значительно расширив базу знаний об исследуемых образцах. И это знание позволяет с относительно малыми затратами эффективно дополнять сигнатурный анализ вредоносного ПО достаточно надежными отпечатками образцов по классу, семейству или типу малвари.
Источник: Хакер.ру
Что такое хеширование и как оно работает?
Одним из понятий, с которым вы снова и снова будете сталкиваться при обсуждении кибербезопасности, является понятие хэша. Эти длинные цепочки, по-видимому, случайных чисел и букв генерируются и используются несколькими важными способами. Некоторые устаревшие антивирусные решения полагаются на них почти исключительно в целях обнаружения, но даже несмотря на то, что это довольно ограниченный и легко нейтрализуемый способ обнаружения современных вредоносных программ, хэши по-прежнему имеют большое значение для установления личности и используются по-разному. В этом посте мы рассмотрим некоторые из них, изучая, что такое хэш и как он работает.
Эти длинные цепочки, по-видимому, случайных чисел и букв генерируются и используются несколькими важными способами. Некоторые устаревшие антивирусные решения полагаются на них почти исключительно в целях обнаружения, но даже несмотря на то, что это довольно ограниченный и легко нейтрализуемый способ обнаружения современных вредоносных программ, хэши по-прежнему имеют большое значение для установления личности и используются по-разному. В этом посте мы рассмотрим некоторые из них, изучая, что такое хэш и как он работает.
Что такое алгоритм хеширования?
Хэши — это результат алгоритма хеширования, такого как MD5 (5-й дайджест сообщения) или SHA (алгоритм безопасного хеширования). Эти алгоритмы по существу нацелены на создание уникальной строки фиксированной длины — хеш-значения или «дайджеста сообщения» — для любого заданного фрагмента данных или «сообщения». Поскольку каждый файл на компьютере — это, в конечном счете, просто данные, которые могут быть представлены в двоичной форме, алгоритм хеширования может взять эти данные и выполнить над ними сложные вычисления, а в результате вычислений вывести строку фиксированной длины.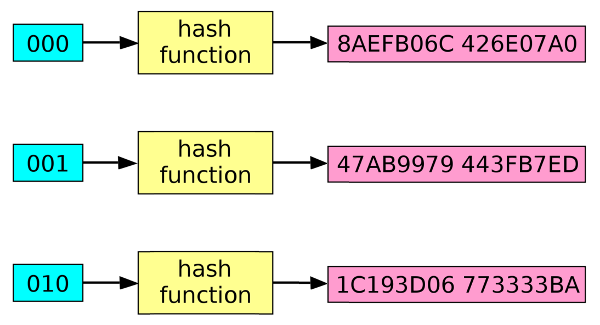 Результатом является хеш-значение файла или дайджест сообщения.
Результатом является хеш-значение файла или дайджест сообщения.
Чтобы вычислить хэш файла в Windows 10, используйте встроенный в PowerShell командлет Get-FileHash и укажите путь к файлу, хеш-значение которого вы хотите получить. По умолчанию будет использоваться алгоритм SHA-2 256:
Вы можете изменить его на другой алгоритм, указав его после пути к файлу с переключателем -Algorithm . Передача результата в Format-List также дает более удобный для чтения вывод:
Для пользователей Mac и Linux инструменты командной строки шасум и мд5 служат той же цели. Как мы вскоре увидим, независимо от того, используете ли вы Windows, Mac или Linux, значение хеш-функции будет одинаковым для любого заданного файла и алгоритма хеширования.
Как хэши устанавливают личность
Хэши не могут быть обращены, поэтому простое знание результата хеширования файла с помощью алгоритма хеширования не позволяет восстановить содержимое файла. Однако он позволяет вам определить, идентичны ли два файла или нет, ничего не зная об их содержимом.
Однако он позволяет вам определить, идентичны ли два файла или нет, ничего не зная об их содержимом.
По этой причине идея уникальности результата является фундаментальной для всей концепции хэшей. Если бы два разных файла могли создать один и тот же дайджест, мы бы столкнулись, и мы не смогли бы использовать хэш в качестве надежного идентификатора для этого файла.
Вероятность возникновения коллизии невелика, но не является чем-то неслыханным, и именно поэтому более безопасные алгоритмы, такие как SHA-2, заменили SHA-1 и MD5. Например, содержимое следующих двух файлов, ship.jpg и plane.jpg, как показывает простой визуальный осмотр, явно различается, поэтому они должны создавать разные дайджесты сообщений.
Однако, когда мы вычисляем значение с помощью MD5, мы получаем коллизию, ложно указывающую, что файлы идентичны. Здесь вывод из командной строки в macOS с использованием Terminal.app, но вы можете видеть, что значение хеш-функции ship.jpg такое же, как мы получили от PowerShell ранее:
Давайте посчитаем значение хэша с помощью SHA -2 256. Теперь мы получаем более точный результат, указывающий, что файлы действительно отличаются от ожидаемых:
Теперь мы получаем более точный результат, указывающий, что файлы действительно отличаются от ожидаемых:
Для чего используется хеширование?
Учитывая уникальный идентификатор файла, мы можем использовать эту информацию несколькими способами. Некоторые устаревшие антивирусные решения полностью полагаются на хеш-значения, чтобы определить, является файл вредоносным или нет, без проверки содержимого или поведения файла. Они делают это, сохраняя внутреннюю базу данных хеш-значений, принадлежащих известным вредоносным программам. При сканировании системы антивирусный движок вычисляет хеш-значение для каждого исполняемого файла на компьютере пользователя и проверяет, есть ли совпадение в его базе данных.
Должно быть, это казалось изящным решением на заре кибербезопасности, но нетрудно увидеть недостатки в использовании хеш-значений, если оглянуться назад.
Во-первых, из-за стремительного роста количества образцов вредоносных программ поддержание базы данных сигнатур стало задачей, которую просто невозможно масштабировать. По оценкам, каждый день появляется более 500 000 уникальных образцов вредоносных программ. Скорее всего, это во многом связано с тем, что авторы вредоносных программ осознали, что они могут обмануть антивирусные программы, которые полагаются на хэши, и заставить их не очень легко распознавать образец. Все, что нужно сделать злоумышленнику, это добавить лишний байт в конец файла, и он создаст другой хэш.
По оценкам, каждый день появляется более 500 000 уникальных образцов вредоносных программ. Скорее всего, это во многом связано с тем, что авторы вредоносных программ осознали, что они могут обмануть антивирусные программы, которые полагаются на хэши, и заставить их не очень легко распознавать образец. Все, что нужно сделать злоумышленнику, это добавить лишний байт в конец файла, и он создаст другой хэш.
Это настолько простой процесс, что авторы вредоносных программ могут автоматизировать его таким образом, что один и тот же URL-адрес будет доставлять жертвам одно и то же вредоносное ПО с другим хэшем каждые несколько секунд.
Во-вторых, недостатком устаревших антивирусов всегда было то, что для обнаружения требуется заранее знать об угрозе, поэтому изначально разработанное решение для защиты от вредоносных программ, которое опирается на базу данных известных хэш-значений, всегда находится на шаг впереди следующей атаки.
Ответом на этот вопрос, конечно же, является решение для обеспечения безопасности, использующее поведенческий ИИ и использующее подход глубокой защиты.
Однако это не означает, что хеш-значения не имеют значения! Напротив, возможность уникальной идентификации файла по-прежнему имеет важные преимущества. Вы увидите хеш-значения, предоставленные в цифровых подписях и сертификатах во многих контекстах, таких как подпись кода и SSL, чтобы помочь установить, что файл, веб-сайт или загрузка являются подлинными.
Хэш-значения также очень помогают исследователям безопасности, командам SOC, охотникам за вредоносными программами и обратным инженерам. Одним из наиболее распространенных способов использования хэшей, который вы увидите во многих технических отчетах здесь, на SentinelOne и в других местах, является обмен индикаторами компрометации. Используя хеш-значения, исследователи могут ссылаться на образцы вредоносных программ и делиться ими с другими через репозитории вредоносных программ, такие как VirusTotal, VirusBay, Malpedia и MalShare.
Преимущества хэшей при поиске угроз
Поиск угроз также упрощается благодаря хеш-значениям. Давайте рассмотрим пример того, как ИТ-администратор может искать угрозы в своем парке, используя хеш-значения в консоли управления SentinelOne.
Давайте рассмотрим пример того, как ИТ-администратор может искать угрозы в своем парке, используя хеш-значения в консоли управления SentinelOne.
Хэши очень полезны, когда вы идентифицируете угрозу на одном компьютере и хотите запросить всю вашу сеть на наличие этого файла. Щелкните значок «Видимость» в консоли управления SentinelOne и запустите новый запрос. В этом случае мы просто используем хеш SHA1 файла и будем искать его существование за последние 3 месяца.
Отлично, мы видим, что было несколько случаев, но волшебство на этом не заканчивается. Поиск по хешу привел нас к идентификатору TrueContext ID, который мы можем развернуть, чтобы действительно погрузиться в кроличью нору и точно увидеть, что делал этот файл: какие процессы он создал, какие файлы он изменил, с какими URL-адресами он связался и так далее. Короче говоря, мы можем построить всю сюжетную линию атаки всего за несколько кликов по хешу файла.
Заключение
Хеши — это фундаментальный инструмент компьютерной безопасности, поскольку они могут надежно сказать нам, когда два файла идентичны, если мы используем безопасные алгоритмы хеширования, которые избегают коллизий.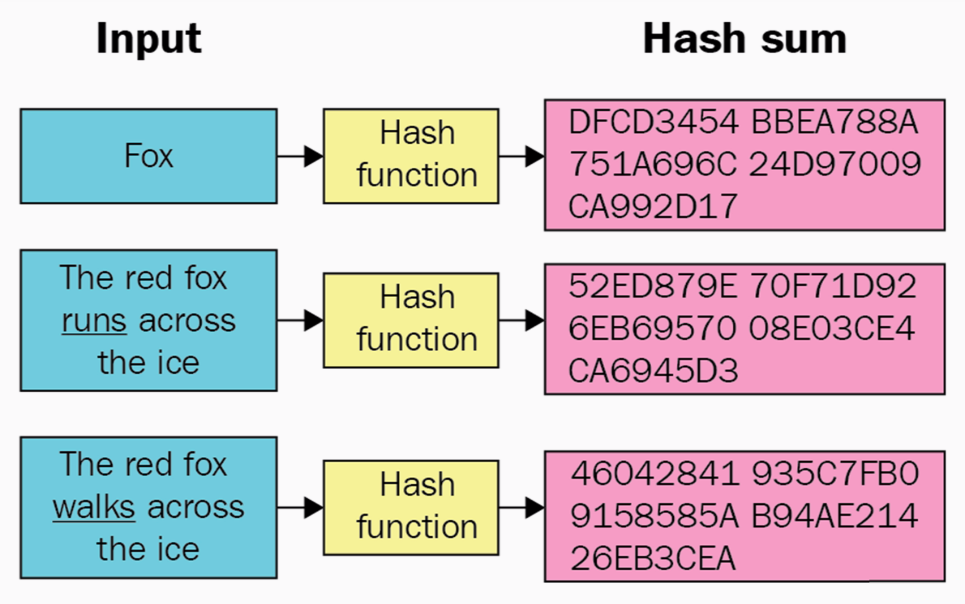 Тем не менее, как мы видели выше, два файла могут иметь одинаковое поведение и функциональность, не обязательно имея один и тот же хэш, поэтому полагаться на хеш-идентификацию для обнаружения антивируса — ошибочный подход.
Тем не менее, как мы видели выше, два файла могут иметь одинаковое поведение и функциональность, не обязательно имея один и тот же хэш, поэтому полагаться на хеш-идентификацию для обнаружения антивируса — ошибочный подход.
Несмотря на это, хэши по-прежнему полезны аналитикам безопасности для таких задач, как совместное использование IOC и поиск угроз, и вы, несомненно, будете сталкиваться с ними ежедневно, если будете работать где-либо в области компьютерной и сетевой безопасности.
Понравилась статья? Подпишитесь на нас в LinkedIn, Twitter, YouTube или Facebook, чтобы увидеть контент, который мы публикуем.
Подробнее о кибербезопасности
- Внутренний враг — 7 самых тревожных утечек данных в 2018 году
- 5 способов, которыми директор по информационной безопасности может решить проблему нехватки навыков кибербезопасности прямо сейчас
- Как вредоносное ПО может легко обойти систему безопасности macOS от Apple
- Что такое Windows PowerShell (и может ли он быть вредоносным)?
Что значит хэшировать данные и действительно ли это меня волнует?
хеширование
Что такое
хеширование ? Хэширование — это просто передача некоторых данных по формуле, которая дает результат, называемый хэшем. Этот хэш обычно представляет собой строку символов, а хэши, сгенерированные формулой, всегда имеют одинаковую длину, независимо от того, сколько данных вы вводите в него. Например, формула MD5 всегда выдает 32-символьные хэши. Независимо от того, вводите ли вы весь текст «МОБИ ДИКА» или только букву C, вы всегда получите 32 символа.
Этот хэш обычно представляет собой строку символов, а хэши, сгенерированные формулой, всегда имеют одинаковую длину, независимо от того, сколько данных вы вводите в него. Например, формула MD5 всегда выдает 32-символьные хэши. Независимо от того, вводите ли вы весь текст «МОБИ ДИКА» или только букву C, вы всегда получите 32 символа.
Наконец (и это важно) каждый раз, когда вы прогоняете эти данные через формулу, вы получаете один и тот же хэш. Так, например, формула MD5 для строки Dataspace возвращает значение e2d48e7bc4413d04a4dcb1fe32c877f6 . Каждый раз будет возвращаться одно и то же значение. Вот и попробуй сам.
Изменение даже одного символа приведет к совершенно другому результату. Например, MD5 для пространства данных с маленьким d дает 8e8ff9.250223973ebcd4d74cd7df26a7
Хеширование является односторонним
Хеширование работает только в одном направлении — для данного фрагмента данных вы всегда будете получать один и тот же хеш, НО вы не сможете превратить хеш обратно в исходные данные. Если вам нужно идти в двух направлениях, вам нужно шифровать , а не хэшировать.
Если вам нужно идти в двух направлениях, вам нужно шифровать , а не хэшировать.
При шифровании вы пропускаете некоторые данные через формулу шифрования и получаете результат, похожий на хэш, но с самым большим отличием в том, что вы можете взять зашифрованный результат, пропустить его через расшифровка формулы и вернуть исходные данные.
Помните, что хеширование — это другое — вы не можете вернуть свои исходные данные, просто запустив формулу на вашем хеше (однако, чуть позже о том, как это взломать).
Какие хеш-формулы доступны?
Существует огромное количество широко распространенных алгоритмов хеширования, доступных для общего использования. Например, MD5, SHA1, SHA224, SHA256, Snefru… Со временем эти формулы стали более сложными и производят более длинные хэши, которые труднее взломать.
Возможность хэширования доступна в стандартных библиотеках распространенных языков программирования. Вот краткий пример, написанный на Python (позвоните мне, если вы хотите пройтись по этому коду — я буду рад поболтать!):
import hashlib
hash = hashlib.
print(hash.hexdigest())
 md5(«Dataspace».encode(‘utf-8’))
md5(«Dataspace».encode(‘utf-8’)) Результат возвращается как: e2d48e7bc4413d04a4dcb1fe32c877f6
Обратите внимание, что это то же значение хеш-функции, которое мы создали ранее! По словам Бернадетт Питерс из THE JERK: «Это дерьмо действительно работает!»
Хэширование и пароли
Когда онлайн-система хранит ваши учетные данные, она обычно сохраняет и ваше имя пользователя, и пароль в базе данных. Однако здесь есть проблема: любой сотрудник, получивший доступ к базе данных, или любой хакер, взломавший систему, может увидеть имя пользователя и пароль каждого. Затем они могут выйти на экран входа в систему для этой системы, ввести это имя пользователя и пароль и получить доступ ко всему, что вам разрешено делать в этой системе.
Однако, если система хранит ваш пароль в виде хеша, то его просмотр не принесет хакеру никакой пользы. Он может видеть, что хэш равен, например, 5f4dcc3b5aa765d61d8327deb882cf99 , но он не может использовать это, чтобы войти в систему и выглядеть как вы. У него нет возможности узнать, что ваш пароль (то есть значение, которое вы вводите на экране входа в систему) на самом деле является словом password . Со стороны системы, всякий раз, когда вы входите в систему, она берет пароль, который вы ей даете, прогоняет его через свою хеш-формулу и сравнивает результат с тем, что есть в ее базе данных. Если они совпадают, вы участвуете!
У него нет возможности узнать, что ваш пароль (то есть значение, которое вы вводите на экране входа в систему) на самом деле является словом password . Со стороны системы, всякий раз, когда вы входите в систему, она берет пароль, который вы ей даете, прогоняет его через свою хеш-формулу и сравнивает результат с тем, что есть в ее базе данных. Если они совпадают, вы участвуете!
Могу ли я сломать хэш? Могу ли я удержать кого-то еще от его взлома?
Можно ли взломать хэши? Абсолютно. Один из самых простых способов — получить доступ к списку слов и хеш-сумме, полученному от каждого из них. Например, есть веб-сайты, которые публикуют миллионы слов и связанные с ними хэш-значения. Любой (как правило, хакер) может зайти на эти сайты, найти значение хеш-функции и мгновенно узнать, каким было значение до того, как оно было хешировано:
. Чтобы посолить хэш, просто добавьте к строке известное значение, прежде чем хешировать его. Например, если до того, как он будет сохранен в базе данных, каждый пароль равен с солью со строкой «собака», его, скорее всего, не найти в онлайн-базах.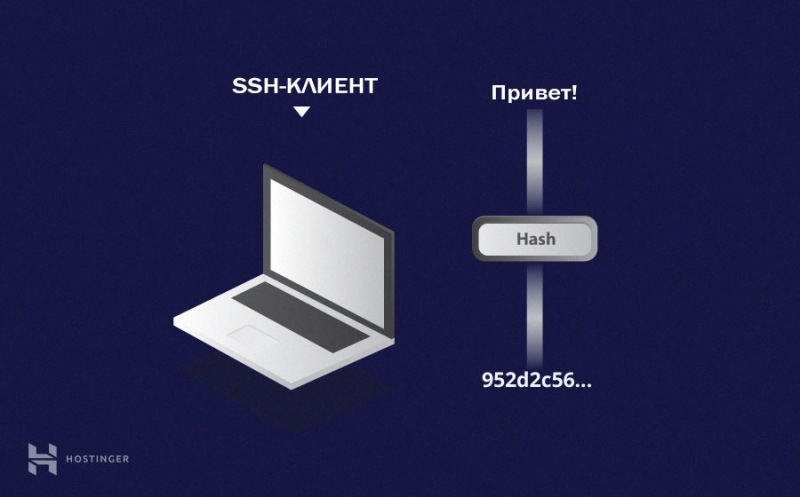 Итак, пароль соленый с dog (т.е. passworddog ) и затем прогоняемый через md5 калькулятор становится 854007583be4c246efc2ee58bf3060e6 .
Итак, пароль соленый с dog (т.е. passworddog ) и затем прогоняемый через md5 калькулятор становится 854007583be4c246efc2ee58bf3060e6 .
Чтобы использовать эти пароли при входе в систему, система берет введенный вами пароль, добавляет к нему слово «собака», пропускает эту строку через алгоритм хэширования и, наконец, ищет результат в своей базе данных, чтобы узнать, Вы действительно авторизованы, и если вы ввели правильный пароль.
Эй, Бен, ты знаешь другие интересные способы использования хеширования?
Ну да, помимо хранения паролей, у хеширования есть и другие полезные применения. Вот два:
- Борьба с компьютерными вирусами: когда компьютерный вирус «заражает» программу, он делает это, изменяя часть кода этой программы, заставляя ее делать что-то вредоносное. Таким образом, одним из способов защиты от вирусов является создание хеш-значения для программы при ее распространении среди пользователей (т. е. запуск компьютерного кода через алгоритм хеширования и получение хеш-функции).

- Сбор данных об изменениях. При чтении данных в хранилище данных мы часто хотим знать, изменились ли какие-либо записи в нашей исходной системе. Для этого мы иногда читаем каждое поле в каждой исходной записи и сравниваем его с каждым полем в связанной записи в нашем хранилище данных — сложный процесс, требующий большого количества компьютерных циклов. Однако мы можем ускорить его следующим образом:
- Прочитать все поля в исходной записи, объединить их вместе и создать хэш результата
- Сравните этот хэш со значением хеш-функции, которое было сохранено в связанной записи в хранилище данных при последнем обновлении
- Если они не совпадают, вы знаете, что исходная запись изменилась, и изменения должны быть перенесены в хранилище
- Создание смарт-ключей: Dataspace недавно выпустила продукт «программное обеспечение как услуга» (SaaS) под названием Golden Record.
Итак…
Хорошо, это немного вышло из-под контроля. Меня попросили написать короткий абзац для нашей ежемесячной электронной почты, и в итоге получилось четыре страницы текста. Спасибо, что выслушали меня. Я просто думаю, что концепция и использование хэшей намного круче, чем думает большинство людей.
Меня попросили написать короткий абзац для нашей ежемесячной электронной почты, и в итоге получилось четыре страницы текста. Спасибо, что выслушали меня. Я просто думаю, что концепция и использование хэшей намного круче, чем думает большинство людей.
Если вы хотите поговорить о хэшах, Python, науке о данных, больших данных или авиации времен Второй мировой войны, свяжитесь с нами — я буду рад пообщаться!
Бен
Хотите еще что-нибудь подобное? Подпишитесь на наши новости!
Имя *
Электронная почта *
Сообщение
Добавь меня!
6 + 0 = ?Пожалуйста, докажите, что вы человек, решив уравнение *
Что такое хэш? Хеш-функции и майнинг криптовалюты
Что такое хэш?
Хэш — это математическая функция, которая преобразует ввод произвольной длины в зашифрованный вывод фиксированной длины. Таким образом, независимо от исходного объема данных или размера файла, его уникальный хэш всегда будет одного размера. Более того, хэши нельзя использовать для «обратной разработки» входных данных из хешированных выходных данных, поскольку хеш-функции являются «односторонними» (как мясорубка: вы не можете положить говяжий фарш обратно в стейк). Тем не менее, если вы используете такую функцию для тех же данных, ее хэш будет идентичным, поэтому вы можете проверить, что данные те же (т. е. неизмененные), если вы уже знаете их хэш.
Более того, хэши нельзя использовать для «обратной разработки» входных данных из хешированных выходных данных, поскольку хеш-функции являются «односторонними» (как мясорубка: вы не можете положить говяжий фарш обратно в стейк). Тем не менее, если вы используете такую функцию для тех же данных, ее хэш будет идентичным, поэтому вы можете проверить, что данные те же (т. е. неизмененные), если вы уже знаете их хэш.
Хеширование также необходимо для управления блокчейном в криптовалюте.
Key Takeaways
- Хэш — это функция, которая отвечает зашифрованным требованиям, необходимым для решения вычислений в блокчейне.
- Хэши имеют фиксированную длину, поскольку практически невозможно угадать длину хэша, если кто-то пытается взломать блокчейн.
- Одни и те же данные всегда будут давать одно и то же хеш-значение.
- Хэш, как одноразовый номер или решение, является основой сети блокчейн.
- Хэш создается на основе информации, содержащейся в заголовке блока.

Как работают хэши
Типичные хэш-функции принимают входные данные переменной длины для возврата выходных данных фиксированной длины. Криптографическая хэш-функция сочетает в себе возможности передачи сообщений хэш-функции со свойствами безопасности.
Хеш-функции — это обычно используемые структуры данных в вычислительных системах для таких задач, как проверка целостности сообщений и аутентификация информации. Хотя они считаются криптографически «слабыми», поскольку могут быть решены за полиномиальное время, их нелегко расшифровать.
Криптографические хэш-функции добавляют функции безопасности к типичным хеш-функциям, что затрудняет обнаружение содержимого сообщения или информации о получателях и отправителях.
В частности, криптографические хэш-функции обладают следующими тремя свойствами:
- Они «без столкновений». Это означает, что никакие два входных хэша не должны сопоставляться с одним и тем же выходным хэшем.
- Их можно скрыть.
- Они должны подходить для решения головоломок. Должно быть сложно выбрать вход, который обеспечивает предопределенный выход. Таким образом, входные данные должны быть выбраны из как можно более широкого распределения.

Благодаря свойствам хэша они широко используются в онлайн-безопасности — от защиты паролей до обнаружения утечек данных и проверки целостности загруженного файла.
Хеширование и криптовалюты
Основой криптовалюты является блокчейн, представляющий собой глобальную книгу, образованную путем связывания отдельных блоков данных транзакций. Блокчейн содержит только проверенные транзакции, что предотвращает мошеннические транзакции и двойное расходование валюты. Полученное зашифрованное значение представляет собой ряд цифр и букв, не похожих на исходные данные, и называется хэшем. Майнинг криптовалют предполагает работу с этим хешем.
Хеширование требует обработки данных из блока с помощью математической функции, что приводит к выходу фиксированной длины. Использование вывода фиксированной длины повышает безопасность, поскольку любой, кто пытается расшифровать хэш, не сможет определить, насколько длинным или коротким является ввод, просто взглянув на длину вывода.
Использование вывода фиксированной длины повышает безопасность, поскольку любой, кто пытается расшифровать хэш, не сможет определить, насколько длинным или коротким является ввод, просто взглянув на длину вывода.
Решение хэша начинается с данных, доступных в заголовке блока, и, по сути, решает сложную математическую задачу. Заголовок каждого блока содержит номер версии, отметку времени, хэш, использованный в предыдущем блоке, хэш корня Меркла, одноразовый номер и целевой хэш.
Майнер фокусируется на одноразовом номере, строке чисел. Это число добавляется к хешированному содержимому предыдущего блока, которое затем хэшируется. Если этот новый хэш меньше или равен целевому хешу, то он принимается в качестве решения, майнер получает вознаграждение, и блок добавляется в цепочку блоков.
Процесс проверки транзакций в блокчейне основан на шифровании данных с использованием алгоритмического хеширования.
Особые указания
Решение хэша требует, чтобы майнер определил, какую строку использовать в качестве одноразового номера, что само по себе требует значительного количества проб и ошибок. Это связано с тем, что одноразовый номер представляет собой случайную строку. Крайне маловероятно, что майнер успешно найдет правильный одноразовый номер с первой попытки, а это означает, что майнер потенциально может протестировать большое количество вариантов одноразового номера, прежде чем получить его правильно. Чем выше сложность — мера того, насколько сложно создать хэш, отвечающий требованиям целевого хэша, — тем больше времени может потребоваться для создания решения.
Это связано с тем, что одноразовый номер представляет собой случайную строку. Крайне маловероятно, что майнер успешно найдет правильный одноразовый номер с первой попытки, а это означает, что майнер потенциально может протестировать большое количество вариантов одноразового номера, прежде чем получить его правильно. Чем выше сложность — мера того, насколько сложно создать хэш, отвечающий требованиям целевого хэша, — тем больше времени может потребоваться для создания решения.
Пример хэша
Хеширование слова «привет» приведет к получению вывода той же длины, что и хэш для «Я иду в магазин». Функция, используемая для генерации хэша, является детерминированной, что означает, что она будет давать один и тот же результат каждый раз, когда используется один и тот же ввод. Он может эффективно генерировать хэшированный ввод; это также усложняет определение входных данных (что приводит к майнингу), а также вносит небольшие изменения во входные данные, что приводит к неузнаваемому, совершенно другому хешу.
Обработка хеш-функций, необходимых для шифрования новых блоков, требует значительной вычислительной мощности компьютера, что может быть дорогостоящим. Чтобы побудить отдельных лиц и компании, называемые майнерами, инвестировать в необходимые технологии, криптовалютные сети вознаграждают их как новыми токенами криптовалюты, так и комиссией за транзакцию. Майнеры получают компенсацию только в том случае, если они первыми создадут хэш, соответствующий требованиям, изложенным в целевом хеше.
Что такое хеш-функция?
Хеш-функции — это математические функции, которые преобразуют или «отображают» заданный набор данных в битовую строку фиксированного размера, также известную как «хеш-значение».
Как вычисляется хеш-значение?
Хеш-функция использует сложные математические алгоритмы, которые преобразуют данные произвольной длины в данные фиксированной длины (например, 256 символов). Если вы измените один бит где-либо в исходных данных, изменится все значение хеш-функции, что делает его полезным для проверки точности цифровых файлов и других данных.