Хеширование: разбираемся в деталях
Что это такое? Хеширование – это инструмент для обеспечения безопасности, который преобразовывает данные в зашифрованную строку. Также он применяется и для других задач, которые могут быть частично связаны с шифрованием.
Каким бывает? Существует несколько алгоритмов хеширования, каждый из которых имеет свои слабые стороны. В целом, идеальный процесс преобразования возможен только в теории, но это не значит, что к нему не нужно стремиться.
В статье рассказывается:
- Суть хеширования
- Схема работы хеширования
- Сферы применения хеширования
- Свойства и требования к криптографическому хешированию
- Стандарты хеширования
- Будущее хеширования
Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.Бесплатно от Geekbrains
Суть хеширования
Хеширование — это преобразование массива входных данных произвольной длины в выходную битовую строку установленной длины. В таком процессе генерации применяется набор методов хеширования с использованием математических формул (хеш-функций).
В таком процессе генерации применяется набор методов хеширования с использованием математических формул (хеш-функций).
Чтобы блокчейны и аналогичные системы, осуществляющие транзакции, могли сохранять целостность и надежную защиту данных, используются именно криптографические хеши. Следует заметить, что не каждый хеш-алгоритм применяет средства криптографии, а только криптографическая хеш-функция.
Также нужно учесть, что все хеш-процессы, защищенные криптографическими средствами, дают одинаковый результат при выводе данных, если входные остаются прежними. Данное свойство называется детерменированностью хеш-функции.
У алгоритмов хеширования биткоинов и других видов цифровой валюты есть уникальная особенность. Полученные строки с информацией нельзя вернуть назад в том же направлении, если только не потратить на это очень большое количество времени и ресурсов. Это связано с тем, что процессы, которые выполняются на криптовалютных платформах, осуществляются только в одностороннем порядке.
То есть, при транзакции, например, вывод изначальных данных производится достаточно быстро. Но получить их назад в обратной последовательности будет крайне трудно. Следовательно, надежность хеш-функции определяется сложностью поиска изначальных строк.
Схема работы хеширования
Посмотрим, как это работает на примере хеш-функции SHA-1, которая очень популярна при выборе защиты с помощью хеш (как и SHA-2 и MD5). Обратимся для этого к любому сервису, бесплатно предоставляющему услугу онлайн-хеширования. Предположим, у нас есть значение «Иван», которое нужно преобразовать в цифровой код. Результат всегда будет таким: «4D2902EB21DDE2404DE35677284A7DD4B44756D7». Но если допустить ошибку даже в написании одной буквы или поставить имя в другой падеж, код будет выглядеть совершенно по-другому.
Убедимся в этом и поставим слово в дательный падеж. Входные данные: «Ивану». Хеш-код: «4D13F6131C770A220BBF1BD34E3698D99DDD0CCB». Как мы видим, итоговый результат не имеет ничего общего с предыдущим, хотя к имени была добавлена лишь одна буква.
Единственное, что объединяет результаты выше, это одинаковая длина строки при выводе — 40 символов. Можно подумать, что такой объем определило количество букв у входных данных: в имени Иван их 5. На самом деле, даже если массив будет состоять из всего текста с этой страницы, длина строки с результатом получится такой же, взгляните: «DFB13520C775C03211EA5D41E767A0DD2BDF4840».
Топ-30 самых востребованных и высокооплачиваемых профессий 2023
Поможет разобраться в актуальной ситуации на рынке труда
Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
pdf 3,7mb
doc 1,7mb
Уже скачали 19925
Сорок символов хеш-кода вы получите и после размещения в исходных данных всех томов произведения Льва Толстого «Война и Мир».
Сферы применения хеширования
Помимо шифрования данных на блокчейнах и в различных платежных системах, функция хеширования применяется при составлении хеш-таблицы и декартова дерева.
Сравнение информации
Суть процесса заключается в том, что определенные данные проходят проверку на их соответствие оригиналу, причем сам подлинник в этом действии не участвует. При сравнении информации оценивается идентичность хеш-значений.
Тестирование на предмет ошибок
Рассмотрим один из способов проверки. Итоговая сумма может передаваться по определенному коммуникационному каналу вместе с остальными данными. В пункте получения контрольная сумма может быть пересчитана, а полученный результат проверен на соответствие оригиналу.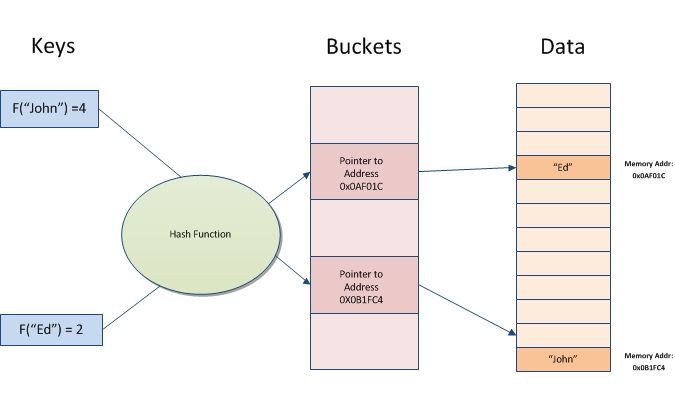 Если значения будут отличаться, функция это определит, что может привести к повторному запросу.
Если значения будут отличаться, функция это определит, что может привести к повторному запросу.
Приведем пример. При сложении чисел 2 и 5 образуется число 7. Контрольное значение передано программистом вместе с условиями его получения в компьютерную программу по обучению арифметике. Во время урока ученик решает задачу «5+2=?» за компьютером. Предположим, ребенок дает ответ «8». Хеш-алгоритм проверки определит, что итоговые данные не соответствуют оригиналу. В этом случае софт может предложить ребенку решить пример еще раз.
Контроль кодовой фразы
В настоящее время кодовые фразы (например, для авторизации на сайте) хранятся только в виде их хеш-значения. Размещать пароли в первоначальном виде небезопасно, ведь если захешированный файл будет взломан, защитный код станет известен хакеру и может быть использован в преступных целях.
А способ хранения в виде хеш подразумевает, что даже при хакерской атаке мошенники, в худшем случае, узнают только хеш-значение, которые они не смогут вернуть в первоначальное состояние. При аутентификации введенная информация преобразуется в хеш-значение, которое потом сравнивается с оригиналом.
При аутентификации введенная информация преобразуется в хеш-значение, которое потом сравнивается с оригиналом.
В качестве примера можно привести операционные системы Windows XP и Linux. Пароли для входа в учетную запись хранятся только в виде хеш-значений.
Ускорение поиска информации
При заполнении строк в информационной базе есть возможность создавать хеш-код из хранящихся названий, поэтому новые данные можно размещать в разделах, согласно с хеш-кодом. Тогда, чтобы найти нужную информацию, нужно просто преобразовать ее в хеш, после чего станет понятно, в каком разделе она находится. Таким образом сокращается время поиска: он уже будет осуществляться не по всем разделам, а только по тому, который соответствует хеш-коду искомой информации.
Сферы применения хешированияПример. У вас на компьютере есть каталог с различной продукцией. Она отсортирована по алфавиту. Первая буква каждого товара будет ее хеш-кодом. Для того чтобы быстро найти нужный продукт, вам не нужно искать его по всему каталогу — достаточно ввести первую букву наименования.
Свойства и требования к криптографическому хешированию
Особенности криптографических хеш-функций:
- Безвозвратность. Все попытки извлечь входные данные после хеширования обречены на провал, поскольку большая часть информации теряется в процессе преобразования в код (в отличие от обычного шифрования).
- Предопределенность. При вводе одной и той же информации для выполнения хеш-функции полученное значение всегда будет одинаковым. Это дает возможность проверять подлинность имеющихся данных с помощью хеш.
- Уникальность. Потенциально хеш-функция может всегда возвращать уникальный код. Но пока это не реализовано на практике, и изредка случаются «дубли» — одно и то же значение для разных данных. Тем не менее качество хеш сокращает риск образования копий до минимума.
- Многообразие. Даже при незначительном отличии двух отдельных данных (например, прописная и заглавная буквы) результатом будут два абсолютно разных кода.
- Большая скорость преобразования.
 Она характерна для всех хеш-функций: по сравнению со стандартным шифрованием файлов, хеширование генерирует значения гораздо быстрее, вне зависимости от объема исходных данных.
Она характерна для всех хеш-функций: по сравнению со стандартным шифрованием файлов, хеширование генерирует значения гораздо быстрее, вне зависимости от объема исходных данных.
 Она характерна для всех хеш-функций: по сравнению со стандартным шифрованием файлов, хеширование генерирует значения гораздо быстрее, вне зависимости от объема исходных данных.
Она характерна для всех хеш-функций: по сравнению со стандартным шифрованием файлов, хеширование генерирует значения гораздо быстрее, вне зависимости от объема исходных данных.Задача каждой хеш-функции заключается в защите пользователей от кражи личной информации. Авторизация в личных кабинетах и сверка введенных слов с оригиналом необходимы для сохранения конфиденциальности данных, которые в обычном виде уязвимы перед кибератаками. Поэтому эксперты рекомендуют пользоваться именно хешами, ведь они очень эффективны при хранении паролей и любых других данных.
Свойства и требования к криптографическому хешированиюВ потенциале криптографическая хеш-функция может соответствовать всем качествам, о которых мы расскажем ниже. В настоящее время методы хеш не всегда отвечают всем требованиям, поэтому каждый разработчик таких программ должен стремиться к стопроцентному результату.
- Устойчивость к коллизиям
Термин «коллизия» в рамках сферы информационных систем означает образование одинаковых хеш-кодов у двух разных входных данных. Это явление создает риск, что мошенник подменит реальную информацию на фальшивую.
Это явление создает риск, что мошенник подменит реальную информацию на фальшивую.
Точный инструмент «Колесо компетенций»
Для детального самоанализа по выбору IT-профессии
Список грубых ошибок в IT, из-за которых сразу увольняют
Об этом мало кто рассказывает, но это должен знать каждый
Мини-тест из 11 вопросов от нашего личного психолога
Вы сразу поймете, что в данный момент тормозит ваш успех
Регистрируйтесь на бесплатный интенсив, чтобы за 3 часа начать разбираться в IT лучше 90% новичков.
Только до 13 марта
Осталось 17 мест
Разумеется, следует избегать появления таких копий. Но пока, к сожалению, изредка могут случаться ошибки при хешированиии, которые приводят к появлению «дублей». Тем не менее вероятность, что хакер найдет коллизию, крайне мала, так как для этого ему могут потребоваться многие годы.
- Защита от восстановления информации
В какой-то мере это означает ту же безвозвратность. Теоретически, для установления исходных данных помимо обратной функции можно воспользоваться методом подбора.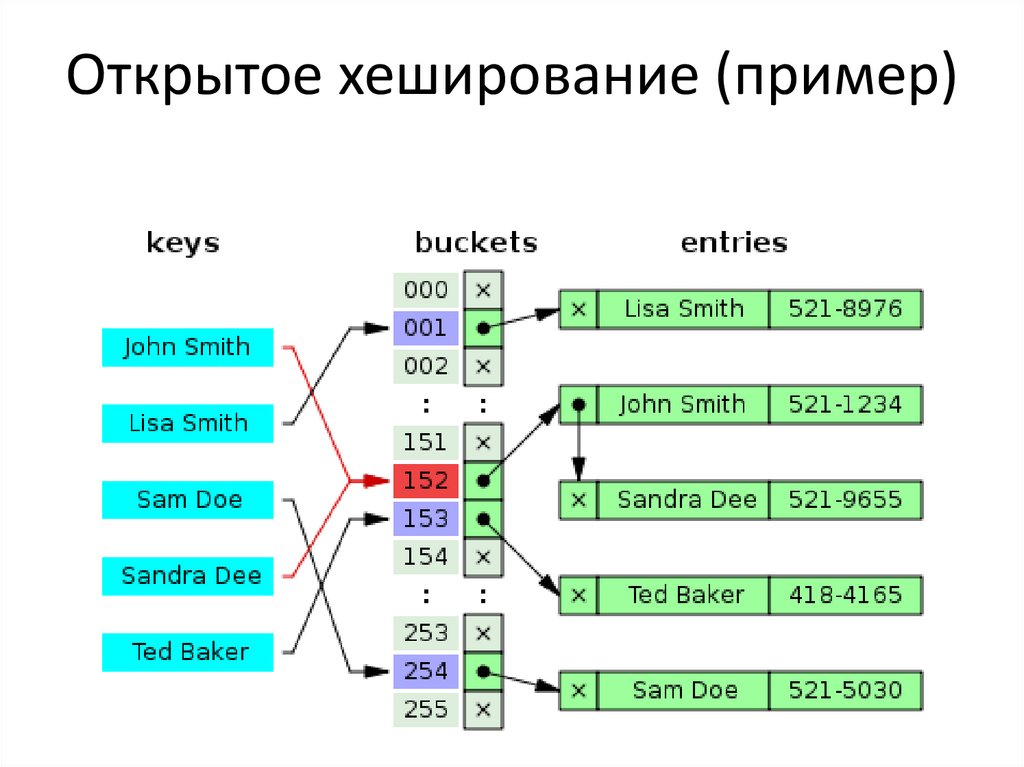
- Стойкость к выявлению 1-го и 2-го прообраза
Первый прообраз мог бы стать ключом для поиска обратной функции. Но отследить его не получится, так как криптографическая хеш-функция не оставляет следов. Второй прообраз очень похож на поиск коллизии. Он отличается лишь тем, что перед поиском второго прообраза хакеру известны и хеш-код, и оригинал, а при попытке найти копию он знает только код. Следовательно, хеш-функция не защищена от намерения обнаружить второй прообраз, поскольку знание исходника дает возможность изменить его.
Стандарты хеширования
Для лучшего понимания возможностей хеширования данных ознакомьтесь с небольшим обзором проверенных программ.
| Программа | Описание |
| CRC-32 | Приложение «Полином CRC». Работает на алгоритмах поиска контрольной суммы и предназначен для проверки целостности данных. Его процессы хеширования основаны на определенных математических свойствах циклического кода, обеспечивают надежную защиту информации и преобразуют вводные данные в 32-битный хеш-код. Программа стала востребованной благодаря очень высокому уровню обнаружения ошибок, низким затратам производительности и простоте использования. Работает на алгоритмах поиска контрольной суммы и предназначен для проверки целостности данных. Его процессы хеширования основаны на определенных математических свойствах циклического кода, обеспечивают надежную защиту информации и преобразуют вводные данные в 32-битный хеш-код. Программа стала востребованной благодаря очень высокому уровню обнаружения ошибок, низким затратам производительности и простоте использования. |
| MD5 | 128-битный алгоритм хеширования. Предназначен для создания «отпечатков» или дайджестов сообщения произвольной длины и последующего определения их подлинности. Также применяется для проверки целостности информации и хранения паролей после хеширования. Минус программы заключается в слабой защите перед кибератакой с целью найти коллизию. |
| SHA-1 | Данный софт производит хеш и кодирование посредством сжатия данных. Входы архивирования содержат информацию длиной 512 бит. Количество раундов – 80. В результате генерации получается 32-битный хеш-код. В программе было обнаружено 252 коллизии. В основном она применяется в информационных системах государственных структур США. В программе было обнаружено 252 коллизии. В основном она применяется в информационных системах государственных структур США. |
| SHA-2 | Представляет семейство однонаправленных хеш-функций. Размер блока может составлять 512 или 1024 бит. Количество раундов — 64 или 80. За время работы программы коллизий не было. Алгоритмы работают на 32 битах. |
| ГОСТ Р 34.11-2012(неофициальное название — Стрибог) | Российский криптографический стандарт на хеширование. Включает в себя 2 хеш-функции в 256 и 512 бит, которые имеют разные стартовые состояния и результаты вычисления. Устойчивость алгоритмов перед криптоанализом — 2128. Генерация значений строится на S-блоках, что сильно затрудняет обнаружение коллизий. |
Будущее хеширования
Изучая тему, может сложиться впечатление, что для обеспечения безопасности мы или просто
- делаем хеширование более сложным процессом,
- растягиваем длину значений на выходе, полагаясь на то, что компьютеры хакеров не обладают необходимой скоростью вычислений для поиска коллизии.
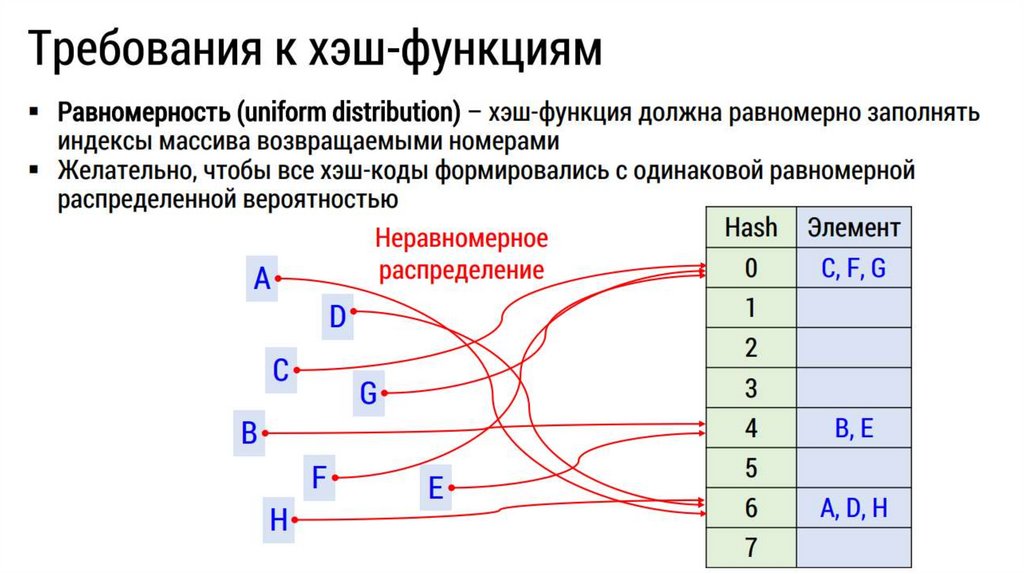
И действительно, сегодня защита информационных сетей основана на двусмысленности предварительных прообразов однонаправленных процессов. Защита алгоритмов хеш-функций состоит в создании трудностей тем, кто захочет найти два кода, отправленные к одному и тому же выводу, невзирая на бесчисленное количество несовпадений при поиске.
Смогут ли хеш-функции обеспечивать безопасность информации после распространения квантовых компьютеров? Исследуя данный вопрос, эксперты пришли к мнению, что процессы преобразования данных в хеш успешно пройдут испытание против квантовых методов взлома. Конечно, последние будут довольно эффективными, чтобы обходить разного рода защиты. Кибератаки нового уровня будут гораздо быстрее, а их алгоритмы станут использовать более сложные математические приемы.
Современные структуры хеш-функций не обладают ярко выраженными формами. А преимущество квантового компьютера заключается именно в скорости обнаружения неструктурированной информации. Только вот попытки взлома будут такими же однонаправленными, как и сегодня.
Только вот попытки взлома будут такими же однонаправленными, как и сегодня.
Вне зависимости от того, какие методы мы выбираем для защиты личной и корпоративной информации, очевидно, что цивилизация успешно развивается в сторону будущего, основанного на эффективности вычислительных процессов. И методы хеширования — это одно из важных достижений на этом пути.
( голосов 1 )
Поделиться статьей
Хеш-функция, что это такое? / Хабр
Приветствую уважаемого читателя!
Сегодня я хотел бы рассказать о том, что из себя представляет хеш-функция, коснуться её основных свойств, привести примеры использования и в общих чертах разобрать современный алгоритм хеширования SHA-3, который был опубликован в качестве Федерального Стандарта Обработки Информации США в 2015 году.
Общие сведения
Криптографическая хеш-функция — это математический алгоритм, который отображает данные произвольного размера в битовый массив фиксированного размера.
Результат, производимый хеш-функцией, называется «хеш-суммой» или же просто «хешем», а входные данные часто называют «сообщением».
Для идеальной хеш-функции выполняются следующие условия:
а) хеш-функция является детерминированной, то есть одно и то же сообщение приводит к одному и тому же хеш-значению
b) значение хеш-функции быстро вычисляется для любого сообщения
c) невозможно найти сообщение, которое дает заданное хеш-значение
d) невозможно найти два разных сообщения с одинаковым хеш-значением
e) небольшое изменение в сообщении изменяет хеш настолько сильно, что новое и старое значения кажутся некоррелирующими
Давайте сразу рассмотрим пример воздействия хеш-функции SHA3-256.
Число 256 в названии алгоритма означает, что на выходе мы получим строку фиксированной длины 256 бит независимо от того, какие данные поступят на вход.
На рисунке ниже видно, что на выходе функции мы имеем 64 цифры шестнадцатеричной системы счисления. Переводя это в двоичную систему, получаем желанные 256 бит.
Любой заинтересованный читатель задаст себе вопрос: «А что будет, если на вход подать данные, бинарный код которых во много раз превосходит 256 бит?»
Ответ таков: на выходе получим все те же 256 бит!
Дело в том, что 256 бит — это соответствий, то есть различных входов имеют свой уникальный хеш.
Чтобы прикинуть, насколько велико это значение, запишем его следующим образом:
Надеюсь, теперь нет сомнений в том, что это очень внушительное число!
Поэтому ничего не мешает нам сопоставлять длинному входному массиву данных массив фиксированной длины.
Свойства
Криптографическая хеш-функция должна уметь противостоять всем известным типам криптоаналитических атак.
В теоретической криптографии уровень безопасности хеш-функции определяется с использованием следующих свойств:
Pre-image resistance
Имея заданное значение h, должно быть сложно найти любое сообщение m такое, что
Second pre-image resistance
Имея заданное входное значение , должно быть сложно найти другое входное значение такое, что
Collision resistance
Должно быть сложно найти два различных сообщения и таких, что
Такая пара сообщений и называется коллизией хеш-функции
Давайте чуть более подробно поговорим о каждом из перечисленных свойств.
Collision resistance. Как уже упоминалось ранее, коллизия происходит, когда разные входные данные производят одинаковый хеш. Таким образом, хеш-функция считается устойчивой к коллизиям до того момента, пока не будет обнаружена пара сообщений, дающая одинаковый выход. Стоит отметить, что коллизии всегда будут существовать для любой хеш-функции по той причине, что возможные входы бесконечны, а количество выходов конечно. Хеш-функция считается устойчивой к коллизиям, когда вероятность обнаружения коллизии настолько мала, что для этого потребуются миллионы лет вычислений.
Несмотря на то, что хеш-функций без коллизий не существует, некоторые из них достаточно надежны и считаются устойчивыми к коллизиям.
Pre-image resistance. Это свойство называют сопротивлением прообразу. Хеш-функция считается защищенной от нахождения прообраза, если существует очень низкая вероятность того, что злоумышленник найдет сообщение, которое сгенерировало заданный хеш. Это свойство является важным для защиты данных, поскольку хеш сообщения может доказать его подлинность без необходимости раскрытия информации. Далее будет приведён простой пример и вы поймете смысл предыдущего предложения.
Это свойство является важным для защиты данных, поскольку хеш сообщения может доказать его подлинность без необходимости раскрытия информации. Далее будет приведён простой пример и вы поймете смысл предыдущего предложения.
Second pre-image resistance. Это свойство называют сопротивлением второму прообразу. Для упрощения можно сказать, что это свойство находится где-то посередине между двумя предыдущими. Атака по нахождению второго прообраза происходит, когда злоумышленник находит определенный вход, который генерирует тот же хеш, что и другой вход, который ему уже известен. Другими словами, злоумышленник, зная, что пытается найти такое, что
Отсюда становится ясно, что атака по нахождению второго прообраза включает в себя поиск коллизии. Поэтому любая хеш-функция, устойчивая к коллизиям, также устойчива к атакам по поиску второго прообраза.
Неформально все эти свойства означают, что злоумышленник не сможет заменить или изменить входные данные, не меняя их хеша.
Таким образом, если два сообщения имеют одинаковый хеш, то можно быть уверенным, что они одинаковые.
В частности, хеш-функция должна вести себя как можно более похоже на случайную функцию, оставаясь при этом детерминированной и эффективно вычислимой.
Применение хеш-функций
Рассмотрим несколько достаточно простых примеров применения хеш-функций:
• Проверка целостности сообщений и файлов
Сравнивая хеш-значения сообщений, вычисленные до и после передачи, можно определить, были ли внесены какие-либо изменения в сообщение или файл.
• Верификация пароля
Проверка пароля обычно использует криптографические хеши. Хранение всех паролей пользователей в виде открытого текста может привести к массовому нарушению безопасности, если файл паролей будет скомпрометирован. Одним из способов уменьшения этой опасности является хранение в базе данных не самих паролей, а их хешей. При выполнении хеширования исходные пароли не могут быть восстановлены из сохраненных хеш-значений, поэтому если вы забыли свой пароль вам предложат сбросить его и придумать новый.
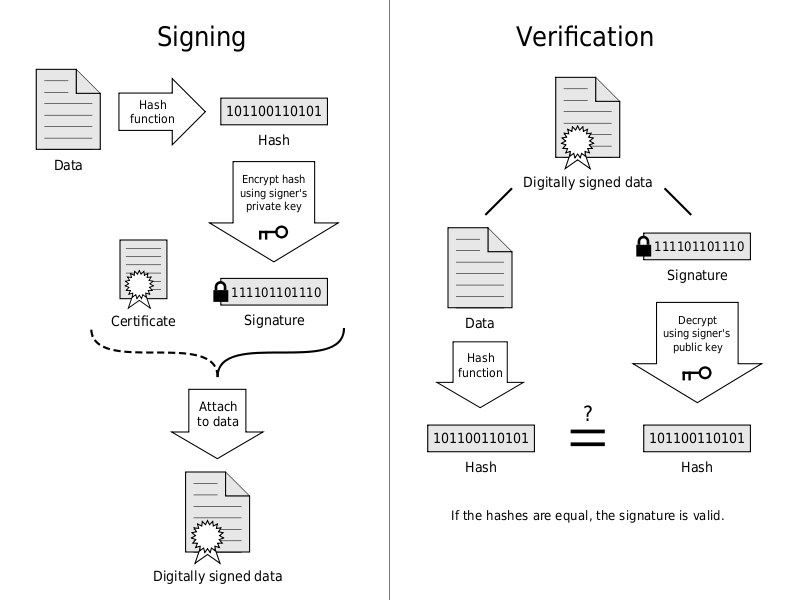
• Цифровая подпись
Подписываемые документы имеют различный объем, поэтому зачастую в схемах ЭП подпись ставится не на сам документ, а на его хеш. Вычисление хеша позволяет выявить малейшие изменения в документе при проверке подписи. Хеширование не входит в состав алгоритма ЭП, поэтому в схеме может быть применена любая надежная хеш-функция.
Предлагаю также рассмотреть следующий бытовой пример:
Алиса ставит перед Бобом сложную математическую задачу и утверждает, что она ее решила. Боб хотел бы попробовать решить задачу сам, но все же хотел бы быть уверенным, что Алиса не блефует. Поэтому Алиса записывает свое решение, вычисляет его хеш и сообщает Бобу (сохраняя решение в секрете). Затем, когда Боб сам придумает решение, Алиса может доказать, что она получила решение раньше Боба. Для этого ей нужно попросить Боба хешировать его решение и проверить, соответствует ли оно хеш-значению, которое она предоставила ему раньше.
Теперь давайте поговорим о SHA-3.
SHA-3
Национальный институт стандартов и технологий (NIST) в течение 2007—2012 провёл конкурс на новую криптографическую хеш-функцию, предназначенную для замены SHA-1 и SHA-2.
Организаторами были опубликованы некоторые критерии, на которых основывался выбор финалистов:
• Безопасность
Способность противостоять атакам злоумышленников
• Производительность и стоимость
Вычислительная эффективность алгоритма и требования к оперативной памяти для программных реализаций, а также количество элементов для аппаратных реализаций
• Гибкость и простота дизайна
Гибкость в эффективной работе на самых разных платформах, гибкость в использовании параллелизма или расширений ISA для достижения более высокой производительности
В финальный тур попали всего 5 алгоритмов:
• BLAKE
• Grøstl
• JH
• Keccak
• Skein
Победителем и новым SHA-3 стал алгоритм Keccak.
Давайте рассмотрим Keccak более подробно.
Keccak
Хеш-функции семейства Keccak построены на основе конструкции криптографической губки, в которой данные сначала «впитываются» в губку, а затем результат Z «отжимается» из губки.
Любая губчатая функция Keccak использует одну из семи перестановок которая обозначается , где
перестановки представляют собой итерационные конструкции, состоящие из последовательности почти одинаковых раундов. Число раундов зависит от ширины перестановки и задаётся как где
В качестве стандарта SHA-3 была выбрана перестановка Keccak-f[1600], для неё количество раундов
Далее будем рассматривать
Давайте сразу введем понятие строки состояния, которая играет важную роль в алгоритме.
Строка состояния представляет собой строку длины 1600 бит, которая делится на и части, которые называются скоростью и ёмкостью состояния соотвественно.
Соотношение деления зависит от конкретного алгоритма семейства, например, для SHA3-256
В SHA-3 строка состояния S представлена в виде массива слов длины бит, всего бит. В Keccak также могут использоваться слова длины , равные меньшим степеням 2.
Алгоритм получения хеш-функции можно разделить на несколько этапов:
• С помощью функции дополнения исходное сообщение M дополняется до строки P длины кратной r
• Строка P делится на n блоков длины
• «Впитывание»: каждый блок дополняется нулями до строки длиной бит (b = r+c) и суммируется по модулю 2 со строкой состояния , далее результат суммирования подаётся в функцию перестановки и получается новая строка состояния , которая опять суммируется по модулю 2 с блоком и дальше опять подаётся в функцию перестановки . Перед началом работы криптографической губки все элементыравны 0.
Перед началом работы криптографической губки все элементыравны 0.
• «Отжимание»: пока длина результата меньше чем , где — количество бит в выходном массиве хеш-функции, первых бит строки состояния добавляется к результату . После каждой такой операции к строке состояния применяется функция перестановок и данные продолжают «отжиматься» дальше, пока не будет достигнуто значение длины выходных данных .
Все сразу станет понятно, когда вы посмотрите на картинку ниже:
Функция дополнения
В SHA-3 используется следующий шаблон дополнения 10…1: к сообщению добавляется 1, после него от 0 до r — 1 нулевых бит и в конце добавляется 1.
r — 1 нулевых бит может быть добавлено, когда последний блок сообщения имеет длину r — 1 бит. В этом случае последний блок дополняется единицей и к нему добавляется блок, состоящий из r — 1 нулевых бит и единицы в конце.
Если длина исходного сообщения M делится на r, то в этом случае к сообщению добавляется блок, начинающийся и оканчивающийся единицами, между которыми находятся r — 2 нулевых бит. Это делается для того, чтобы для сообщения, оканчивающегося последовательностью бит как в функции дополнения, и для сообщения без этих бит значения хеш-функции были различны.
Это делается для того, чтобы для сообщения, оканчивающегося последовательностью бит как в функции дополнения, и для сообщения без этих бит значения хеш-функции были различны.
Первый единичный бит в функции дополнения нужен, чтобы результаты хеш-функции от сообщений, отличающихся несколькими нулевыми битами в конце, были различны.
Функция перестановок
Базовая функция перестановки состоит из раундов по пять шагов:
Шаг
Шаг
Шаг
Шаг
Шаг
Тета, Ро, Пи, Хи, Йота
Далее будем использовать следующие обозначения:
Так как состояние имеет форму массива , то мы можем обозначить каждый бит состояния как
Обозначим результат преобразования состояния функцией перестановки
Также обозначим функцию, которая выполняет следующее соответствие:
— обычная функция трансляции, которая сопоставляет биту бит ,
где — длина слова (64 бит в нашем случае)
Я хочу вкратце описать каждый шаг функции перестановок, не вдаваясь в математические свойства каждого.
Шаг
Эффект отображения можно описать следующим образом: оно добавляет к каждому биту побитовую сумму двух столбцов и
Схематическое представление функции:
Псевдокод шага:
Шаг
Отображение направлено на трансляции внутри слов (вдоль оси z).
Проще всего его описать псевдокодом и схематическим рисунком:
Шаг
Шаг представляется псевдокодом и схематическим рисунком:
Шаг
Шаг является единственный нелинейным преобразованием в
Псевдокод и схематическое представление:
Шаг
Отображение состоит из сложения с раундовыми константами и направлено на нарушение симметрии. Без него все раунды были бы эквивалентными, что делало бы его подверженным атакам, использующим симметрию. По мере увеличения раундовые константы добавляют все больше и больше асимметрии.
Ниже приведена таблица раундовых констант для бит
Все шаги можно объединить вместе и тогда мы получим следующее:
Где константы являются циклическими сдвигами и задаются таблицей:
Итоги
В данной статье я постарался объяснить, что такое хеш-функция и зачем она нужна
Также в общих чертах мной был разобран принцип работы алгоритма SHA-3 Keccak, который является последним стандартизированным алгоритмом семейства Secure Hash Algorithm
Надеюсь, все было понятно и интересно
Всем спасибо за внимание!
хэш-таблиц на C.
 Это HashTable на C — Поиск… | от J3 | Jungletronics
Это HashTable на C — Поиск… | от J3 | JungletronicsЭто хеш-таблица на C — Исследования алгоритмов поиска — #CSeries — Эпизод №02
Это реализация хеш-таблицы. Реализация
Hastable — добро пожаловать!Хэш-таблицы В хеш-таблице используется хеш-функция для вычисления индекса , также называемого хеш-кодом , в массив из сегментов или слотов , из которых можно найти желаемое значение. Во время поиска ключ хешируется, и полученный хэш указывает, где хранится соответствующее значение.
Это может быть довольно пугающе: есть много разных типов и множество различных оптимизаций, которые вы можете сделать. Однако, если вы используете простую хэш-функцию вместе с так называемым линейным зондированием , вы можете довольно легко создать приличную хеш-таблицу.
Если вы не знаете, как работает хэш-таблица, вот краткое напоминание. Хеш-таблица — это контейнерная структура данных, позволяющая быстро найти ключ (часто строку) и соответствующее ему значение (любой тип данных).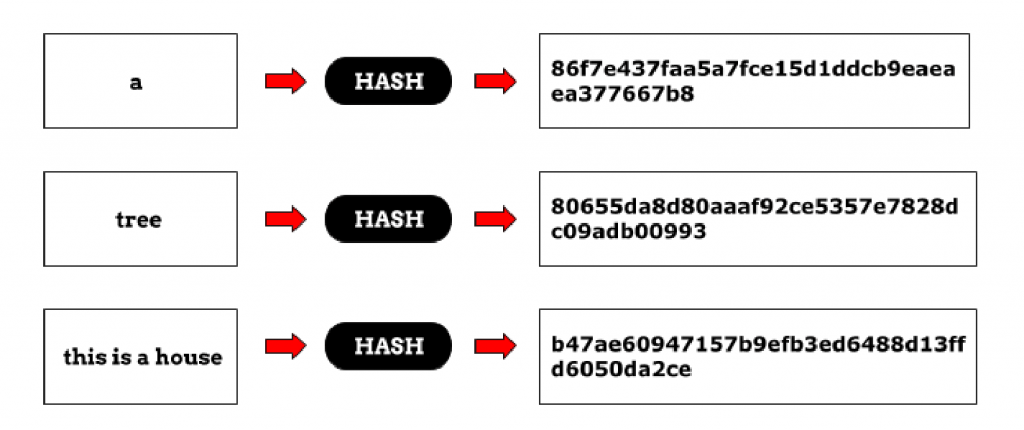 Под капотом это массивы, которые индексируются хэш-функцией ключа.
Под капотом это массивы, которые индексируются хэш-функцией ключа.
Хэш-функция превращает ключ в случайное число, и она всегда должна возвращать одно и то же число для одного и того же ключа.
Вот вывод этого кода, чтобы вы сразу поняли, о чем он:
******************************* ********************1. Вставить в хэш
2. Удалить из хэша
3. Поиск в хэше
4. Показать хэш
5. ВыходВыберите операцию: 1Введите число: 100 Вставка в позицию 0 таблицы… Нажмите, чтобы продолжить. . .Выберите операцию: 1Введите число: 110 Вставка в позицию 0 таблицы…1. Вставить в хеш
2. Удалить из хэша
3. Поиск в хэше
4. Показать хэш
5. ВыходВыберите операцию: по позиции 1 :Список ключей по позиции 2 :Список ключей по позиции 3 :Список ключей по позиции 4 :Список ключей по позиции 5 :Список ключей по позиции 6 :Список ключей по позиции 7 :Список ключей по позиции 8 :Список ключей по позиции 9 :Pressione qualquer tecla para continuar.
 . .*********************************************************
. .********************************************************* Вот код:
1. Используйте VSCode.
Ознакомьтесь с этим руководством, чтобы начать кодирование в VisualCode:
https://medium.com/jungletronics/vs-code-how-to-run-it-right-away-6fc9e569099a2. Загрузите этот файл на свой компьютер.3. Наслаждайся этим! Это бесплатно!
https://github.com/borinvini/EstruturaDeDados_AP4/tree/master/HashLista
Кредиты: https://br.linkedin.com/in/borinvini
Как работать с хеш-таблицей в C?
menu(): Предлагает пользователю опции;
HashingFunction(int): реализует простой хэш (модуль)
InsertHash(Table_t *, int, int): добавляет число в хеш-таблицу;
ShowHash(Table_t *): печатает каждый сегмент с данными внутри;
RemoveHash(Table_t *, int, int): удаляет число из хеш-таблицы;
SearchHash(Table_t *, int, int): Поиск вводимого числа.
В будущем (V1) мы также будем поддерживать следующие операции:
isEmpty() : Проверяет, пуста ли хэш-таблица.
isFull() : Проверяет, заполнен ли Deque.

При поиске номера и не нахождении системный сбой :/
Нужно улучшить функции удаления и поиска;
Не отображать пустой массив сегментов;
Удалить повторяющиеся элементы или Избегать ввода повторяющихся элементов;
Подтвердить входной файл;
При вводе данных разрешение на отказ от операции;
Обработка ошибок в целом;
Обработка коллизий.
Основным преимуществом хеш-таблиц по сравнению с другими табличными структурами данных является скорость. Это преимущество становится более очевидным при большом количестве записей. Хэш-таблицы особенно эффективны, когда можно предсказать максимальное количество записей, так что массив корзин может быть выделен один раз с оптимальным размером и никогда не изменяться.
1. Понять ** Обозначение в структуре: HashList_t **ListKey.
Небольшое напоминание: указатель может также указывать на другой указатель. Делая это, код разыменовывает указатель *ListKey и переносит его значение в код.
Это довольно сложно понять, особенно если вы никогда раньше не использовали указатели или множественную косвенность, и вам может понадобиться попробовать этот пример кода или написать свой собственный и, возможно, использовать отладчик, чтобы пройти его по одной строке за раз. Хотя это действительно стоит усилий! 2. В этом коде мы создаем таблицу Table типа struct, объявленную как Table_t , которая сохраняет размер сегментов и содержит список HashList. HashLists — это структуры, в которых хранится информация об указанном номере и следующей структуре HashList, *prox , которая формирует связанные списки в случае возникновения коллизий. 3. Большой трудностью было обнаружить, что метод поиска делает тот же запрос, что и метод удаления. Но отладка метода поиска стоила очень дорого! Здесь код заслуживает лучшего изучения! 4. Использование элемента сканирования и вспомогательного элемента следует той же схеме, что и предыдущий код (ищите этот пост, если вам интересно;)

Следующий шаг, следующий проект — повторное использование этого кода для выполнения академической работы!
Вот и все, ребята!
Ссылки и кредиты:
Vinicius Pozzobon Borin — Аспирант UTFPR (CPGEI/LABSC — Wireless Communications) и профессор UNINTER (очное и дистанционное издание)
https://en . wikipedia.org/wiki/Hash_table
wikipedia.org/wiki/Hash_table
https://benhoyt.com/writings/hash-table-in-c/
00 Episode#CSeries — Код VS — Как Запустить C Немедленно! Легкая IDE, наконец! — слава богу, пока приложение MS VS Community
01 Episode#CSeries — MUSIC ALBUM_V2.C — это Deque в C — исследования алгоритмов поиска
Hash#4 таблицы в C — это HashTable в C — исследования алгоритмов поиска (этот)
03 Эпизод#CSERIES — Университетский каталог V1 — Это хэштата — исследования алгоритмов. Простая сортировка — Изучение алгоритмов поиска
05 Episode#CSeries — Быстрая сортировка (Алгоритм возрастания) — Это быстрая сортировка — Изучение алгоритмов поиска
06 Episode#CSeries — Линейный поиск — This is a Linear — Изучение алгоритмов поиска
07 Episode#CSeries — Двойной связанный список — Изучение алгоритмов поиска (этот)
Вот и все, народ!
👉Code link (enjoy o/)
hash.
 h Ссылка на файл hash.h Ссылка на файл
h Ссылка на файл hash.h Ссылка на файл #include "хэш.c" Перейдите к исходному коду этого файла.
Compounds | |
| struct | hash_t |
Defines | |
| #define | HASH_FAIL -1 |
| #define | VMDEXTERNSTATIC |
Typedefs | |
| typedef hash_t | hash_t |
Functions | |
| void | hash_init (hash_t *, int) |
| int | hash_lookup (const hash_t *, const char *) |
| int | hash_insert (hash_t * , const char *, int) |
| int | hash_delete (hash_t *, const char *) |
| int | hash_entries (hash_t *) |
| void | hash_destroy (hash_t *) |
| char * | hash_stats (hash_t *) |
Определить документацию
|
Определение в строке 33 файла hash. |
 h.
h.
|
Определение в строке 40 файла hash.h. |
Типоопределение Документация
|
Структура данных верхнего уровня хеш-таблицы |
Документация по функциям
| ||||||||||||
удалить строку из хэш-таблицы, учитывая ее имя строки Определение в строке 183 файла hash. |
 c.
c.
|
полностью уничтожить хеш-таблицу, освободить память Определение в строке 234 файла hash.c. На него ссылаются read_mdf_bonds, write_js_structure, write_lammps_structure и write_lammpsyaml_structure. |
|
вернуть количество записей в таблице has Определение в строке 223 файла hash. На него ссылается write_js_structure. |
 c.
c.
| ||||||||||||
инициализировать хеш-таблицу для первого использования Определение в строке 63 файла hash.c. На него ссылаются read_mdf_bonds, reboot_table, write_js_structure, write_lammps_structure и write_lammpsyaml_structure. |
| ||||||||||||||||
вставить строку в хеш-таблицу вместе с целочисленным ключом Определение в строке 151 файла hash. На него ссылаются read_mdf_bonds, write_js_structure, write_lammps_structure и write_lammpsyaml_structure. |
 c.
c.
| ||||||||||||
искать строковый ключ в хеш-таблице, возвращая его целочисленный ключ Определение в строке 127 файла hash.c. На него ссылаются hash_insert, read_mdf_bonds, write_js_structure, write_lammps_structure и write_lammpsyaml_structure. |
