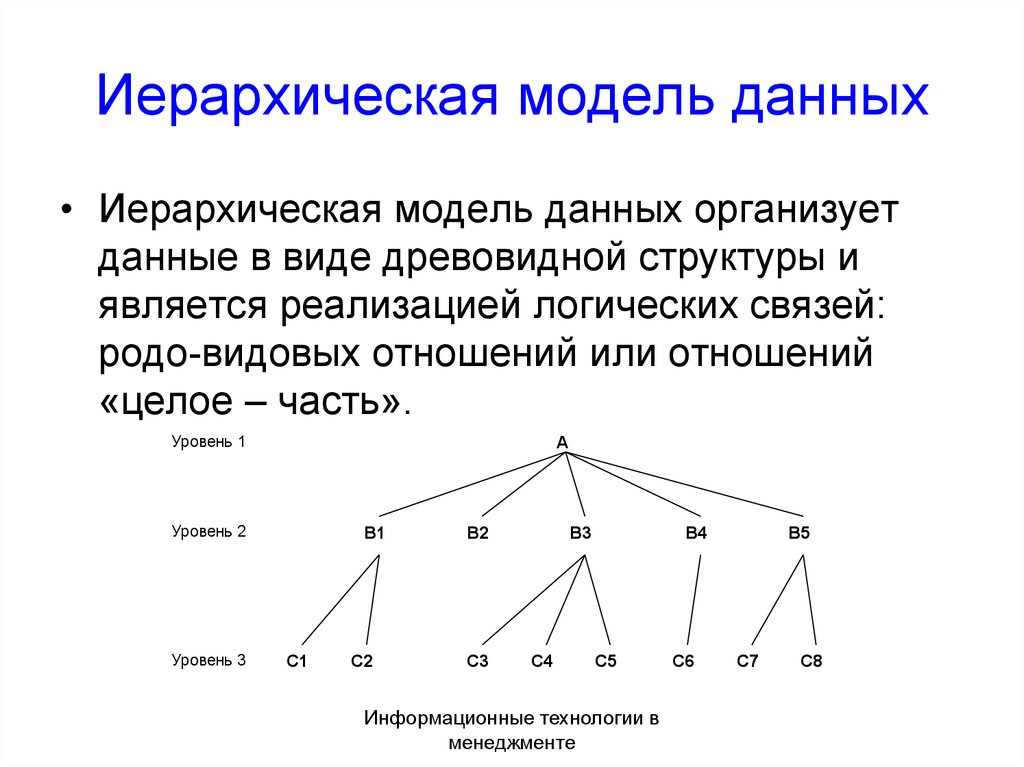
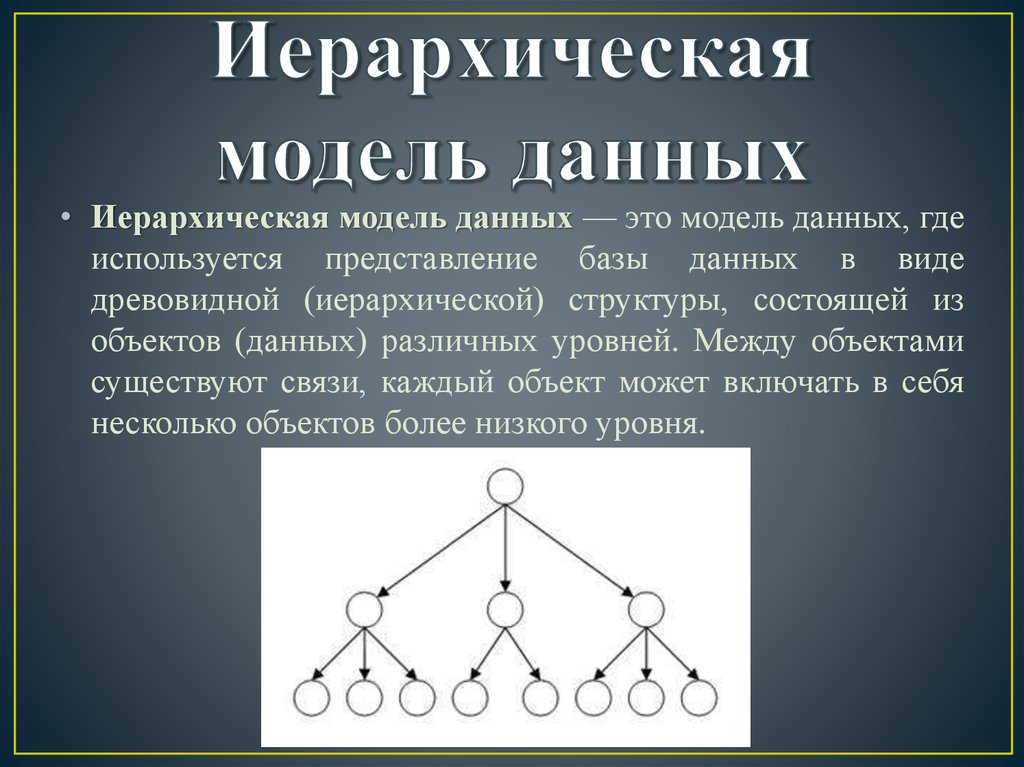
Известные иерархические СУБД. Иерархическая модель данных. Структуры данных
Многомерные статистические методы и их применение в экономике
1.1.4 Иерархические кластер — процедуры
Иерархические (деревообразные) процедуры являются наиболее распространенными алгоритмами кластерного анализа по их реализации на ЭВМ. Они бывают двух типов: агломеративные и дивизимные…
Модели данных, поддерживаемые СУБД. Концепция и разработка распределенных СУБД
1. Модели данных, поддерживаемые СУБД. Концепция и разработка распределенных СУБД
…
Модели данных, поддерживаемые СУБД. Концепция и разработка распределенных СУБД
1.1 Основные концепции распределенных СУБД. Распределенные СУБД: достоинства и недостатки
Системы управления базами данных (СУБД) стали сегодня общепризнанным инструментом создания прикладных программных систем…
Моделирование сети кластеризации данных в MATLAB NEURAL NETWORK TOOL
1.3.1 Иерархические алгоритмы
Результатом работы иерархических алгоритмов является дендограмма (иерархия), позволяющая разбить исходное множество объектов на любое число кластеров. Два наиболее популярных алгоритма…
Два наиболее популярных алгоритма…
Модель «черного ящика». Классификация вирусов. Пакет «Консультант плюс»
2. Дайте классификацию и описание вирусов. Охарактеризуйте известные типы антивирусных программ
На сегодняшний день одними из самых распространенных вирусов являются черви, которые независимо распространяются через Интернет. Они рассылают себя всем пользователям, записанным в адресной книге жертвы…
Организация работ по сопровождению и продвижению программного обеспечения в сфере телекоммуникационных услуг на примере программы для создания резервных копий Exilant Backup
1.2 Известные проблемы совместимости приложений
В этом разделе описаны технологии, изменения и улучшения ОС Windows 7, которые часто вызывают проблемы совместимости приложений. Важно Все приложения сторонних поставщиков необходимо протестировать на совместимость с Windows 7…
Программирование на языке delphi
1.4 Иерархические записи
Деревья представляют собой иерархическую структуру некой совокупности элементов.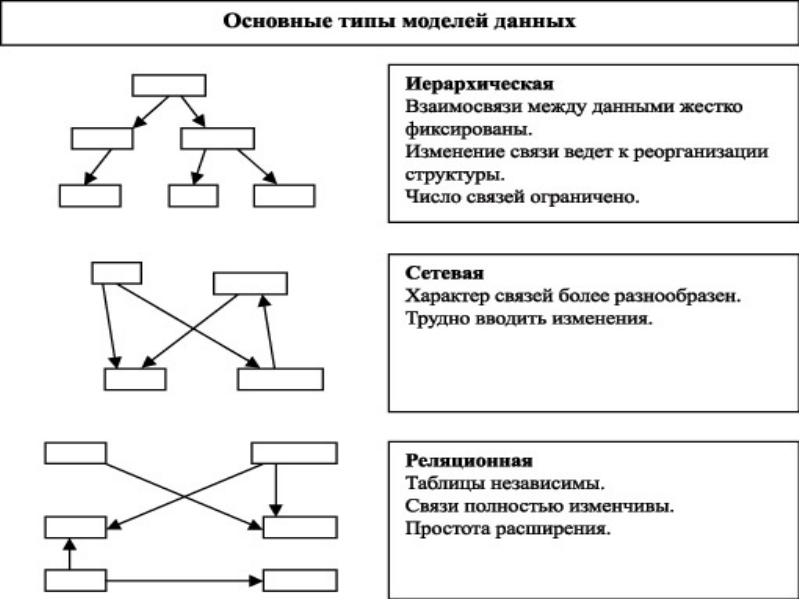 Деревья — это одна из наиболее важных нелинейных структур, которые встречаются при работе с компьютерными алгоритмами…
Деревья — это одна из наиболее важных нелинейных структур, которые встречаются при работе с компьютерными алгоритмами…
Проектирование «домашней» локальной сети
1.2 Одноранговые и иерархические сети
Компьютерные сети, в зависимости от роли каждого конкретного подключенного к сети компьютера, делятся на два вида: — одноранговые; — иерархические. В одноранговой сети все компьютеры имеют равные права…
Проектирование CRM-системы ОАО «Орбита-Сервис»
1.6.2 Иерархические структуры данных
Такая СУБД представляет данные в виде упорядоченного набора деревьев. При этом удобно оперировать терминами «потомок» и «предок». «Потомок» должен иметь только одного «предка», а «предок» может иметь несколько «потомков»…
Проектирование и разработка БД Oracle для информатизации объектов культуры
1.2.1 Иерархические базы данных
Иерархическая модель базы данных состоит из объектов с указателями от родительских объектов к потомкам, соединяя вместе связанную информацию.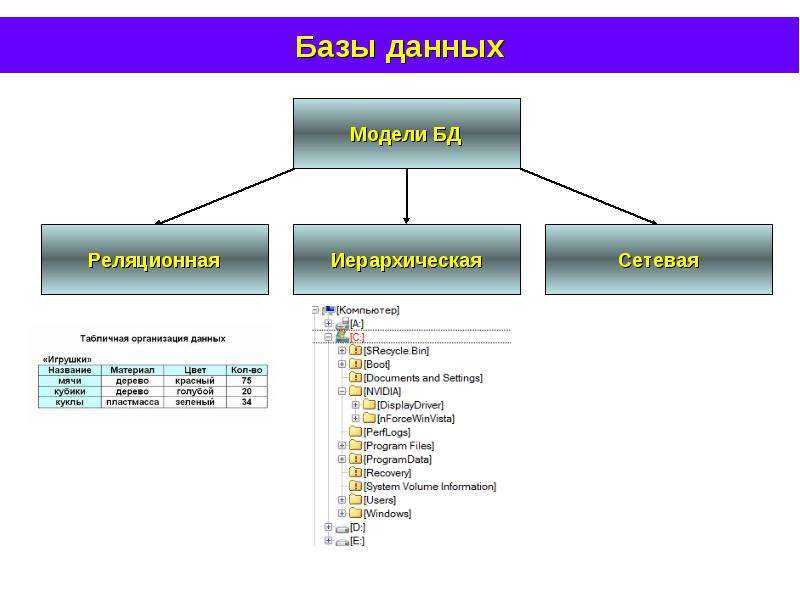 Иерархические базы данных могут быть представлены как дерево…
Иерархические базы данных могут быть представлены как дерево…
Проектирование локальных сетей
1.1 Одноранговые и иерархические сети
Компьютерные сети, в зависимости от роли каждого конкретного подключенного к сети компьютера, делятся на два вида: — одноранговые; — иерархические. В одноранговой сети все компьютеры имеют равные права…
Разработка и анализ эффективности средств отражения распределенных атак
2. ИЗВЕСТНЫЕ МЕТОДЫ ПРОТИВОДЕЙСТВИЯ TCP SYN АТАКЕ
В этом разделе рассматриваются существующие методы обнаружения и противодействия TCP SYN атаке, описываются их достоинства и недостатки…
Разработка и создание автоматизированной системы «АРМ ветеринарного врача колбасного предприятия»
4.2 Выбор методики СУБД. Сравнительная характеристика СУБД
СУБД — это программные средства, предназначенные для создания, наполнения, обновления и удаления баз данных. Пакеты СУБД дают возможность пользователям осуществлять непосредственное управление данными. ..
..
Разработка методики противодействия социальному инжинирингу на предприятиях БРО ООО «ВДПО» и ООО «Служба Мониторинга-Уфа»
1.3 Известные социальные инженеры
Одним из самых знаменитых социальных инженеров в истории является Кевин Митник. Будучи всемирно известным компьютерным хакером и консультантом по безопасности, Митник является автором книг по компьютерной безопасности, посвященным…
Экспертные системы
2. Некоторые известные ЭС
DENDRAL. Распознавания структуры сложных органических молекул по результатам их спектрального анализа (первая в мире ЭС). MOLGEN. Генерирование гипотез о структуре ДНК на основе экспериментов с ферментами. XCON…
Иерархическая база данных (ИБД)
Другие статьи
Что такое иерархическая база данных (ИБД)?
Иерархическая база данных (ИБД) представляет собой частный случай сетевой модели. При этом структура у неё более простая, а работа по такой схеме менее эффективна. И то, и другое создано на основе теории графов.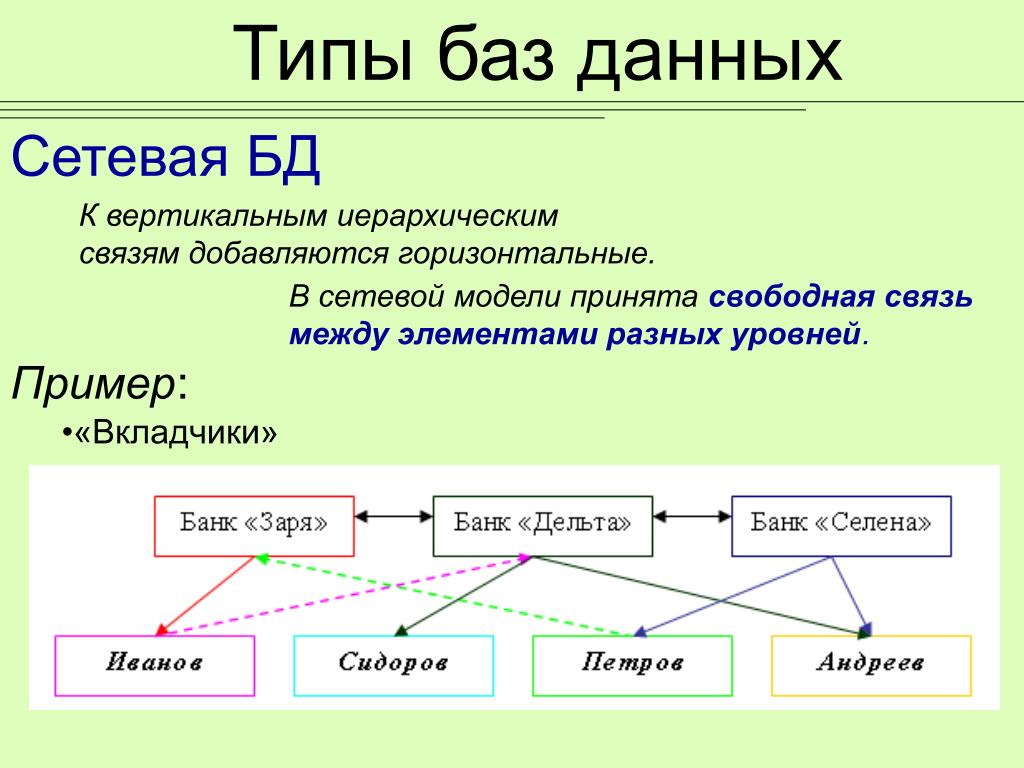
Ключевым для создания ИБД стал главный узел или элемент. Он называется корневым. В теории графов у него есть специальное название — корень дерева. Нетрудно разобраться, откуда появилось понятие «древовидная структура организации базы данных». В основе, по сути, находится корень. А всё, что расположено ниже, относится к его потомкам.
Иерархическая модель данных, аналогично сетевой, заточены на чтение из БД. Но запись не предполагается. Это обусловлено спецификой модели такого вида.
Узлы одного уровня соотносятся между собой как «братья». Те элементы, которые находятся ниже, называются «дочери». По сути, иерархическая модель была создана наподобие файловой системы у компьютера. И по логике организации иерархической модели получается, что операции с отдельным файлом или элементов производятся довольно быстро.
Но при возникновении задачи отыскать определённые данные это может потребовать время. С этим сталкивались все, кто когда-либо проверял ПК антивирусной программой.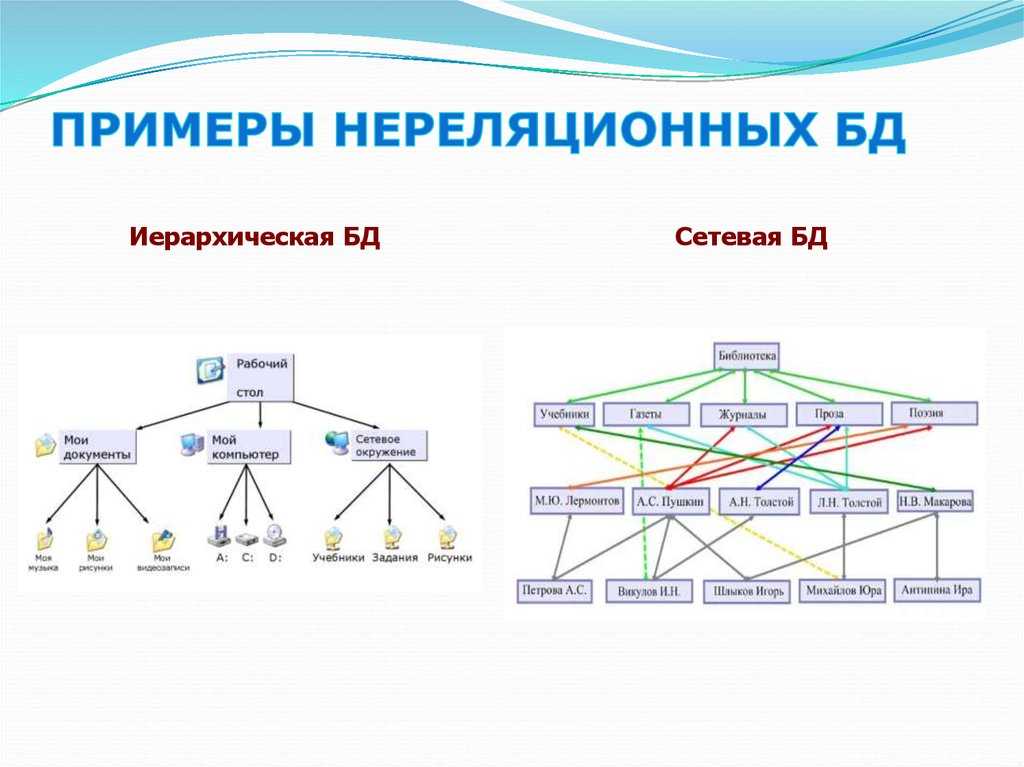 Дело в том, что поиск сведений и анализ происходит по цепочке иерархии. ПК в этом случае спускается от корневого элемента к дочерним всё ниже и ниже по структуре. Причём изучают не только каждый новый элемент, но и связи в цепи. А это требует времени, намного больше, чем просто операции с отдельно взятым файлом.
Дело в том, что поиск сведений и анализ происходит по цепочке иерархии. ПК в этом случае спускается от корневого элемента к дочерним всё ниже и ниже по структуре. Причём изучают не только каждый новый элемент, но и связи в цепи. А это требует времени, намного больше, чем просто операции с отдельно взятым файлом.
Что такое иерархическая система управления базами данных (СУБД)?
Иерархическая система управления базами данных (СУБД) организована по аналогичной структуре. Если связей несколько, то программа пойдёт в дочерний элемент, находящийся на позиции крайнего слева. ПО изучит его содержимое, после чего начнёт анализировать на предмет дочерних элементов. Если они будут обнаружены, программное обеспечение спустится для анализа дальше. При отсутствии таких элементов произойдёт возврат в родительскую часть, чтобы проверить другие элементы.
По описанной схеме действия будут повторяться и повторяться. То есть всё будет происходить по схеме: спуск, проверка, подъём, а потом снова спуск.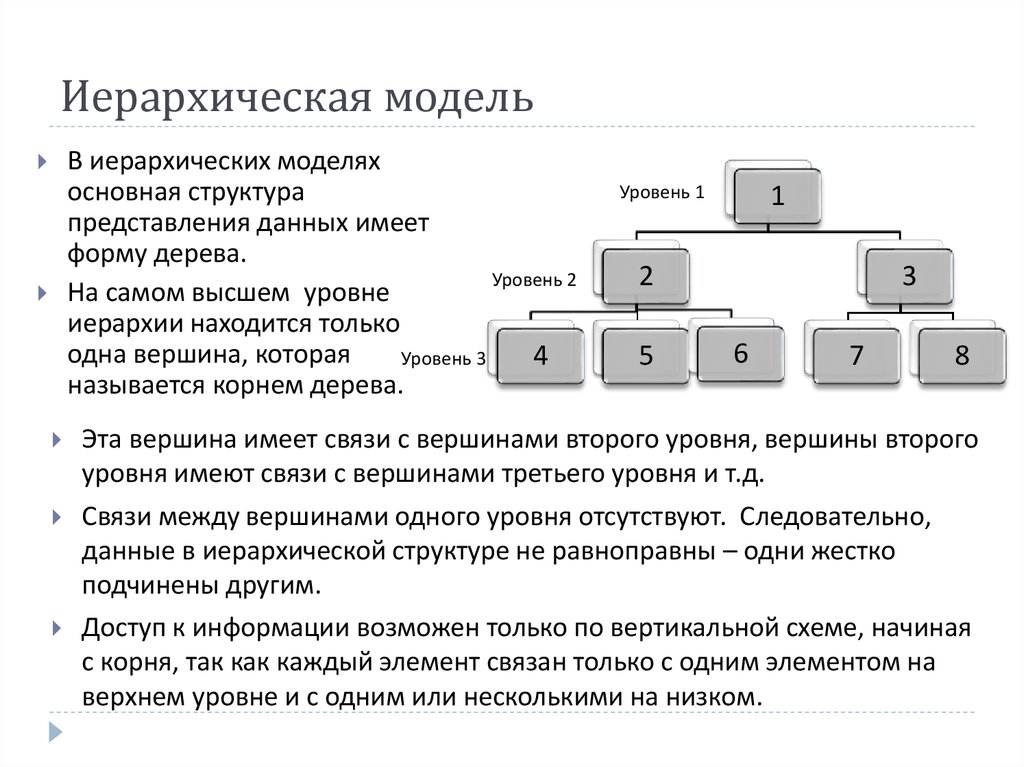 Таким образом происходит работа с данной структурой. И теперь можно понять, какая же у ИБД структура. Это облегчит работу с ней.
Таким образом происходит работа с данной структурой. И теперь можно понять, какая же у ИБД структура. Это облегчит работу с ней.
Структура ИБД
СУБД исторически начали первыми использовать иерархическую модель организации данных. Впоследствии, в результате развития появилась уже сетевая модель.
У ИБД есть ключевые информационные единицы. Это поле и сегмент. Поле — самая маленькая единица, которая является неделимой. Дальше идёт сегмент, у которого есть тип, плюс можно установить экземпляр.
Экземпляр сегмента создаётся заданными значениями полей данных. Непосредственно понятие «типа» возникло как сочетание типов полей, включённых в конкретный сегмент. Это означает, что тип сегмента представляет собой родительский сегмент.
Если внимательно изучить иерархическую структуру, то легко увидеть, что у любого потомка (дочерний элемент) есть только один корневой элемент. И это в некоторых случаях облегчает поиск, но при большом объёме данных может сделать его трудоёмким.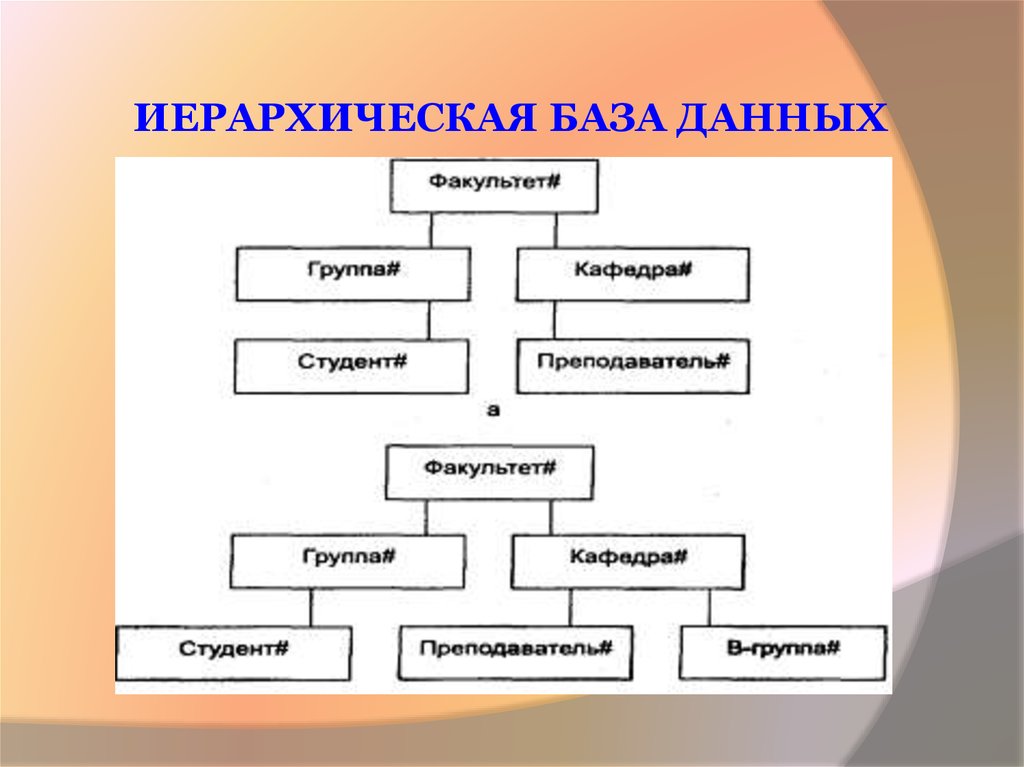
Каждый узел или элемент ИБД является сегментом. Между сегментами возможно установление связей.
Преобразование из концептуальной модели базы данных в иерархическую
Концептуальная модель может быть преобразована в иерархическую. В этом случае действия происходят по той же схеме, по которой преобразования осуществляются в сетевую модель. Но есть также ряд моментов, требующих уточнения. Они обусловлены древовидной структурой ИБД.
Между узлами, как и говорилось выше, могут быть связи. Они идут в форме 1 к 1, а также 1 к многим. Преобразование второго вида связи происходит автоматическим образом, если потомок иерархического дерева связан исключительно с 1 предком.
Все объекты с атрибутами, участвующие в формировании такой связи, становятся логическими сегментами. Между 2 подобными сегментами образуется связь по типу «1 к многим». И «один» выступает в роли «предок», а часть структуры, которая находится на позиции «много», будет «потомками». Такой принцип преобразования напоминает процесс с сетевой моделью.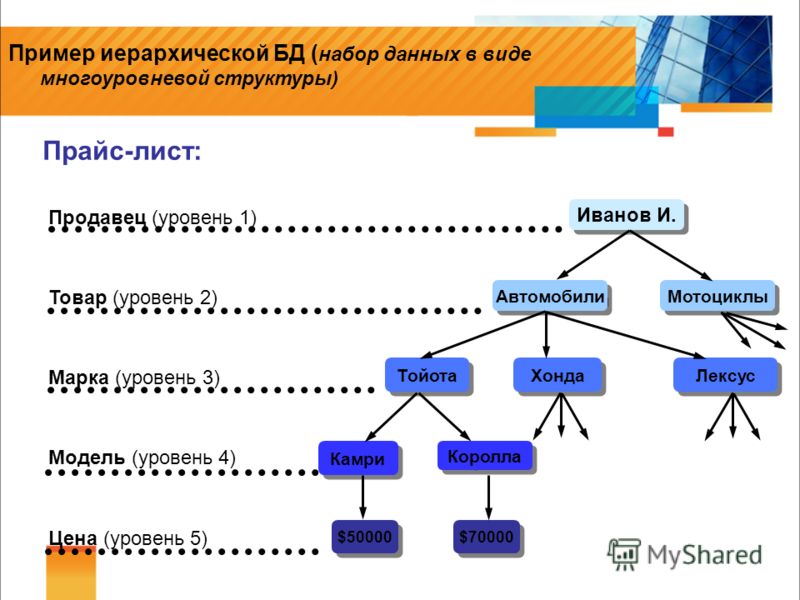
Ситуация может усложняться, когда родительских элементов — несколько. Для иерархической структуры такая ситуация априори невозможно. Поэтому её нужно разделять до тех пор, пока каждому элементу не будет соответствовать только один предок. В итоге у вас вместо одной конструкции может образоваться несколько деревьев, в основе у каждого — по одному корневому элементу. Но такие операции нужно осуществлять предельно внимательно, чтобы не перепутать части баз данных между собой. Надо понять, какой потомок к какому родительскому элементу относится. И при этом следует помнить, что не должно быть элемента без родительской части структуры.
Подобные манипуляции могут привести к избыточности. Так что единственно возможным выходом из ситуации становится дублирование.
Иерархические данные и управление
Управление иерархической моделью осуществляется с помощью 2 инструментов. Это языковые средства. Они нужны для манипулирования и описания данных.
Также в контексте решения вопросов управления необходимо принимать во внимание физическую структуру ИБД. Она описывает логическую структуру и структуру хранения БД.
Она описывает логическую структуру и структуру хранения БД.
Обозначенный способ доступа определяет то, каким образом будет организована связь между физическими записями. Есть несколько способов обеспечения доступа. Это иерархические:
- прямой способ;
- индексно-прямой;
- индексно-последовательный;
- последовательный.
Кроме того, в отдельную категорию обособлены индексные способы.
Чтобы управлять, нужно описание ИБД. У указанной структуры нужно установить имя. Также необходимо прописать способ доступа к каждому элементу. Плюс в описание необходимо внести определение типов сегментов данных, которые включены в БД по выстроенной иерархии. Делать описание начинают с корня.
Необходимо принять во внимание, что у каждой физической базы данных может быть только 1 корень. Однако у иерархической системы возможно несколько физических баз.
Если говорить об управлении, нужно выделить операторов манипулирования.
- поиск данных;
- поиск информации с возможностью модификации;
- модификация данных.
Указанный набор операций не назовёшь обширным. Но его достаточно, чтобы находить информацию и в целом управлять ИБД.
В контексте операторов поиска можно привести типичные примеры, которые помогут быстрее понять, о чём речь:
- отыскать конкретное дерево или элемент;
- перейти от одного дерева к другому;
- отыскать экземпляр по заданным параметрам.
- найти экземпляр сегмента и удержать для произведения модификации в последующем;
- отыскать экземпляр с удержанием для модификации, экземпляр будет от того же родителя.
Есть стандартные операторы модификации. Традиционно работа с ними идёт во второй группе. Это операции с экземпляром сегмента:
- добавление нового экземпляра в выбранную позицию;
- обновление уже имеющегося;
- удаление.


Иерархическая модель подразумевает поддержку на автоматическом уровне целостности структуры ссылок, которые соединяют предков и потомков в общую систему. Необходимо учитывать, что ни один потомок не может появиться в подобной системе без родителя. Соответственно, любые разрывы нельзя допускать. Именно по этой причине систему нужно проверять на целостность. В ней не должно возникать внутренних противоречий. В противном случае работа с подобной БД будет затруднена, а её устойчивость окажется под большим вопросом.
Получить помощь в работе с БД
Другие статьи
Hierarchical Edits
- Hierarchical Edits
- Hierarchical Edits Paths
- Редактирование вершин
- Краевые правки
- Редактирование лиц
Иерархические правки
Чтобы понять иерархический аспект подразделения, мы понимаем, что
само подразделение приводит к естественной иерархии: после первого уровня
подразделение, каждая грань в сетке подразделения подразделяется на четыре четырехугольника (в
Кэтмулла-Кларка), или четыре треугольника (в схеме Loop).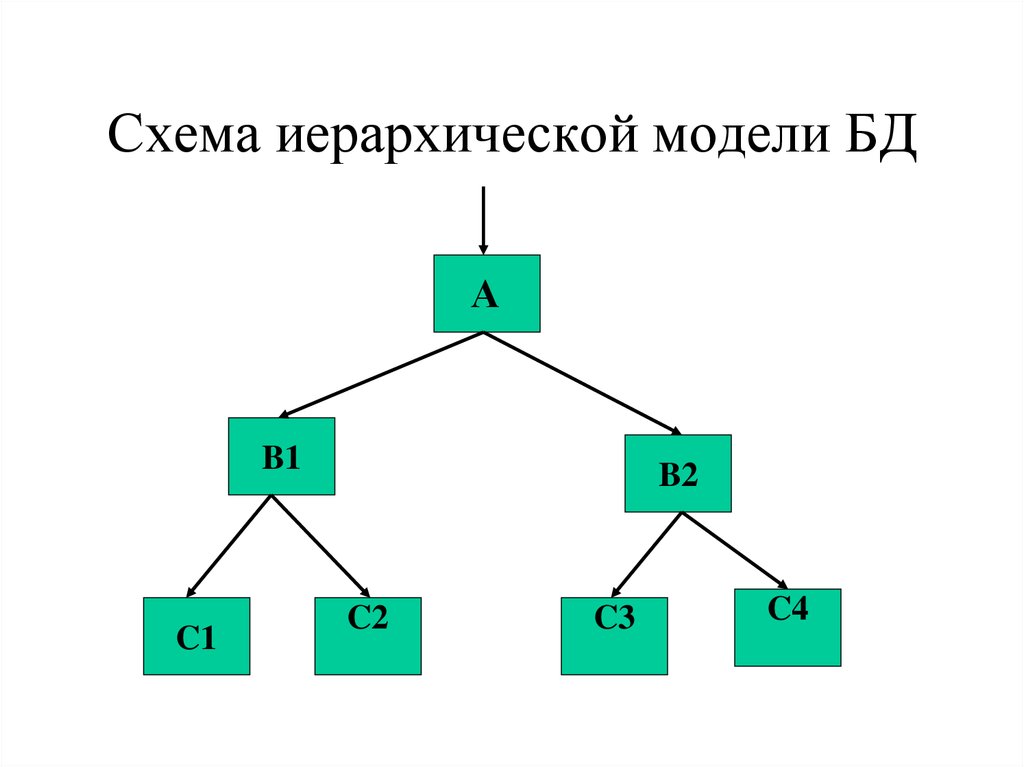 Это создает
родительские и дочерние отношения между исходным лицом и результирующими четырьмя
подразделенные лица, что, в свою очередь, приводит к иерархии подразделений, поскольку каждое
ребенок в свою очередь подразделяется. Иерархическое редактирование — это редактирование любого из
грани, ребра или вершины, возникающие в любом месте во время подразделения. Обычно
эти компоненты подразделения наследуют значения от своих родителей на основе набора
правил подразделения, которые зависят от схемы подразделения.
Это создает
родительские и дочерние отношения между исходным лицом и результирующими четырьмя
подразделенные лица, что, в свою очередь, приводит к иерархии подразделений, поскольку каждое
ребенок в свою очередь подразделяется. Иерархическое редактирование — это редактирование любого из
грани, ребра или вершины, возникающие в любом месте во время подразделения. Обычно
эти компоненты подразделения наследуют значения от своих родителей на основе набора
правил подразделения, которые зависят от схемы подразделения.
Иерархическое редактирование переопределяет эти значения. Это позволяет компактно спецификация локализованных деталей на поверхности подразделения, без необходимости выражать информацию об остальной поверхности подразделения на том же уровне деталей.
Примечания к выпуску (3.0.0)
Иерархические правки помечены как «расширенная спецификация» и поддержка
иерархические функции были удалены из версии 3.0. Это решение
позволяет значительно упростить многие области алгоритмов подразделения.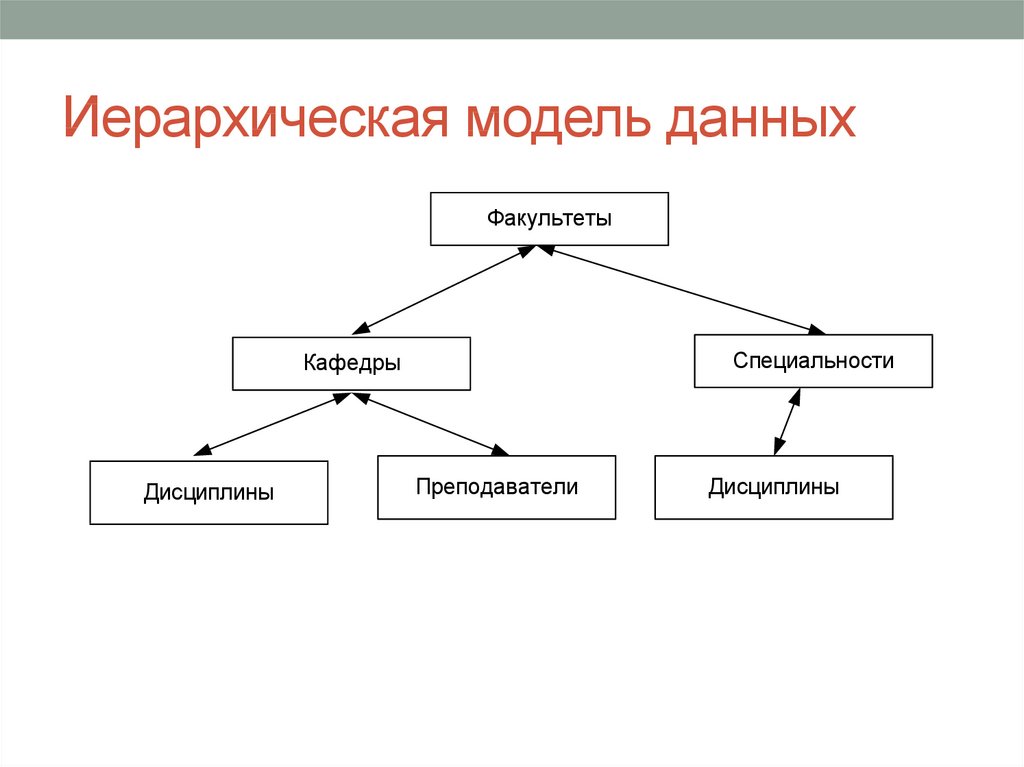
Пути иерархического редактирования
Чтобы выполнить иерархическое редактирование, мы должны иметь возможность назвать интересующий нас компонент подразделения, независимо от того, где он может встречаться в иерархия подразделений. Это приводит нас к спецификации иерархического пути для граней, так как когда у нас есть грань, мы можем перейти к инцидентному ребру или вершине по ассоциации. Заметим, что в сетке подразделения грань всегда имеет инцидентную вершины, которые помечены (относительно грани) целым индексом начиная с нуля и в последовательном порядке в соответствии с обычными правилами намотки для разделительных поверхностей. Грани также имеют инцидентные ребра, и это помечены в соответствии с исходной вершиной ребра.
На этой диаграмме индексы вершин базовой грани отмечены в
красный; Итак, слева у нас необычное лицо Кэтмулла-Кларка с
пять вершин (помеченных 0-4) и справа у нас есть обычная
Лицо Кэтмулла-Кларка с четырьмя вершинами (обозначено цифрами 0-3).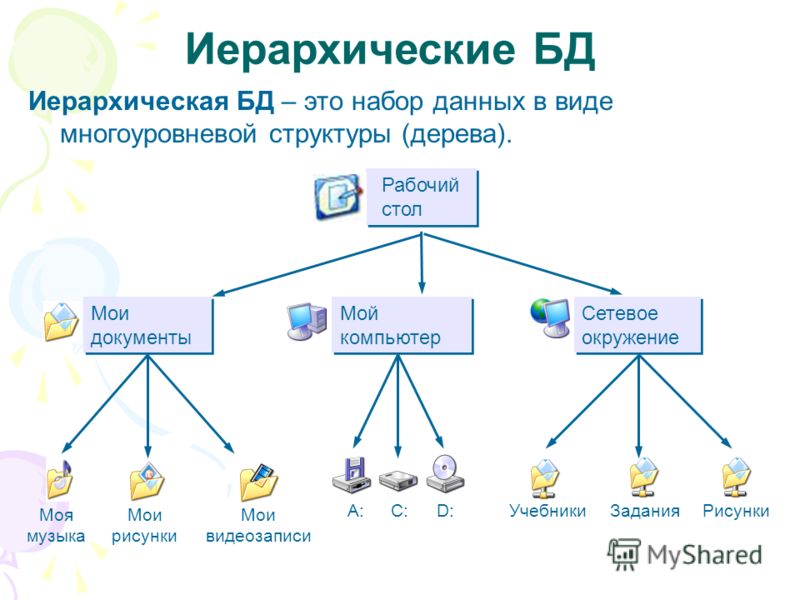
Индексы вершин дочерних граней помечены зеленым цветом, а
в этом заключается разница между экстраординарным и обычным случаем;
в экстраординарном случае деление от вершины к вершине всегда приводит к
вершина помечена 0, в то время как в обычном случае вершина к вершине
subdivision присваивает тот же индекс дочерней вершине. Опять же, конкретно мы
обратите внимание, что родительская вершина с индексом 1 в экстраординарном случае имеет
дочерняя вершина 0, в то время как в обычном случае индексированная родительская вершина
1 на самом деле имеет дочернюю вершину с индексом 1.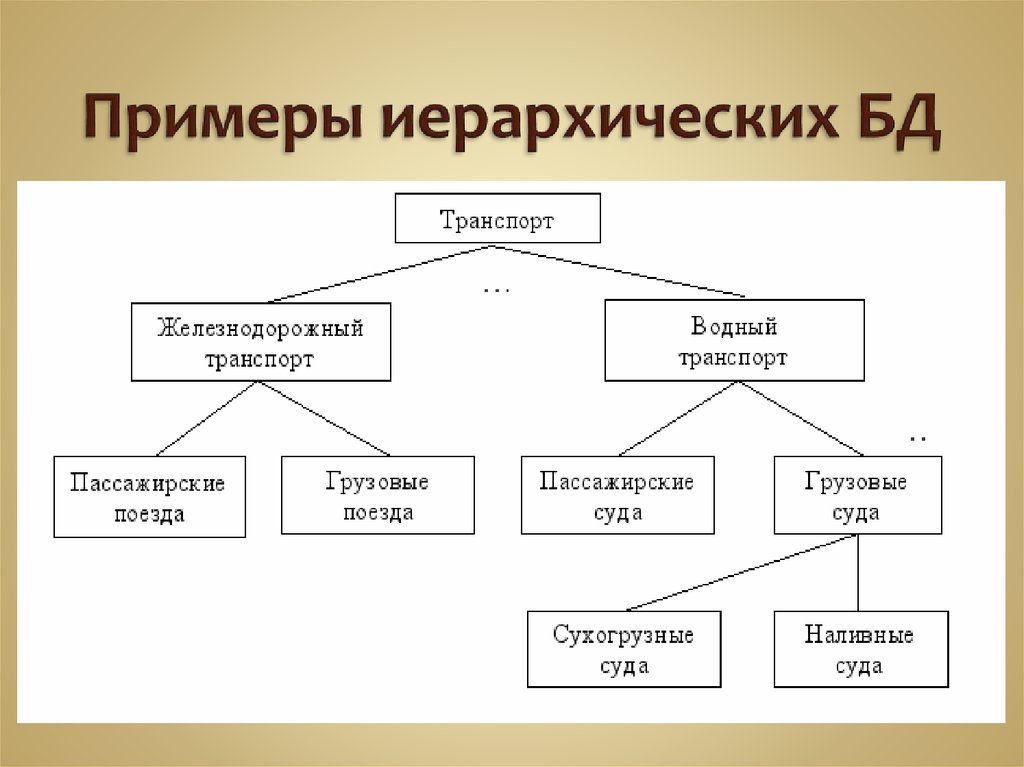
Добавляя индекс вершины к индексу грани, мы можем создать путь вершины Технические характеристики. Например, (655 2 3 0) определяет 1-й. вершина 3-го. детское лицо 2-го. детское лицо из 655-го. поверхность сетки подразделения.
Редактирование вершин
Редактирование иерархии вершин может изменять значение или резкость примитива. переменные для вершин и подвершин в любом месте иерархии подразделения.
Редактирование выполняется с помощью оператора «добавить» или «установить». «установлен»
указывает, что значение переменной примитива или резкость должны быть установлены непосредственно на
указанные значения. «добавить» добавляет значение к обычному результату, вычисленному с помощью
стандартные правила разделения. Другими словами, эта операция допускает смещения значений
применяться к сетке на любом уровне иерархии.
Редактирование краев
Иерархическое редактирование краев может изменять только резкость примитивных переменных для краев и подребра в любом месте иерархии подразделений.
Редактирование граней
Иерархические правки граней могут изменять некоторые свойства граней и подграней. в любом месте иерархии подразделений.
Изменяемые свойства включают:
- Операторы «установить» или «добавить» изменяют значение примитивных переменных связанные с лицами.
- Операция «отверстие» вводит отверстия (отсутствующие грани) в подразделение сетки на любом уровне иерархии подразделений. Лица будут удалены, и ни один из их дочерних элементов не появится (вы не можете «раскрыть» лицо, если оно есть). предок — «дыра»). Эта операция не принимает аргументов типа float или string.
Иерархическое подразделение кайнозойской эры: проверенное решение и критика текущих предложений
NASA/ADS
Иерархическое подразделение кайнозойской эры: почтенное решение и критика текущих предложений
- Уолш, Стивен Л.
Аннотация
Если формально определить и ранжировать третичный и четвертичный периоды, то только одна топология и два варианта ранжирования для основных подразделений кайнозойской эры согласуются с принципами иерархической классификации. Это: 1) причислить третичный и четвертичный периоды к суберам (с палеогеном и неогеном, причисленным к периодам третичного периода), или 2) приравнять третичный и четвертичный периоды к периодам (с палеогеном и неогеном, причисленным к подпериоды третичного периода). Однако первый вариант оставит ранг периода пустым для четвертичного времени, поэтому здесь предпочтительнее второй вариант. Ни в том, ни в другом случае не допускается продолжение неогена до настоящего времени. Однако при желании «ранний кайнозой» и «поздний кайнозой» можно определить как формальные хроны без ранжирования, причем последний термин обеспечивает однозначное выражение того же понятия, что и расширенный неоген.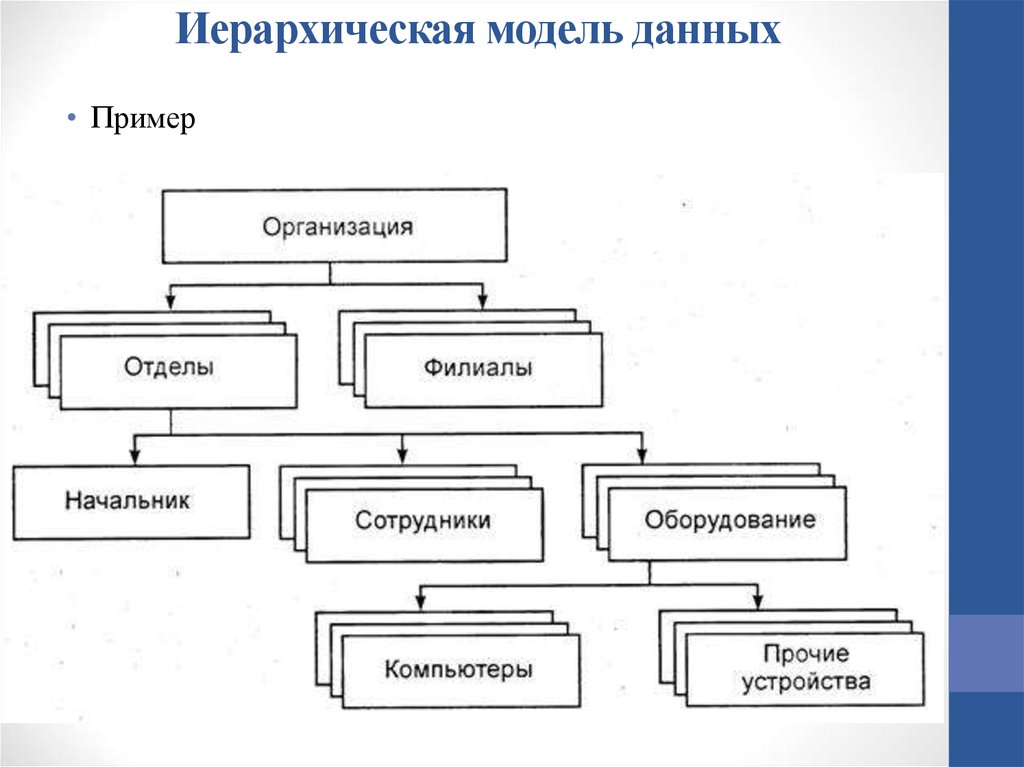 Попытки оправдать расширенный неоген ссылкой на утверждение, вытекающее из 1948 Международного геологического конгресса потерпят неудачу, потому что они основаны на неверном толковании этого заявления. Точно так же апелляция к предполагаемому первоначальному значению неогена терпит неудачу, потому что она фактически поверхностна и также имела бы неприемлемые последствия, если бы применялась в качестве общего принципа к остальной временной шкале. Четыре аргумента против ранжирования третичного и / или четвертичного включают статус этих названий как частей устаревшей классификации; несоответствие их продолжительности; аналогия между ними и неранжированным докембрием; и их предполагаемая двусмысленность. Эти аргументы легко опровергаются. Аргументы в пользу ранжирования третичного и четвертичного периодов включают продолжающееся широкое использование этих названий, их практическую значимость для геологических карт и их роль в чествовании пионеров стратиграфии. Недавняя рекомендация Международной комиссии по стратиграфии (ICS) предусматривает отделение начала четвертичного периода от начала плейстоцена, неоген и плиоцен перекрывают границу третичного и четвертичного периодов, а геласский век относится как к плиоцену, так и к позднему периоду.
Попытки оправдать расширенный неоген ссылкой на утверждение, вытекающее из 1948 Международного геологического конгресса потерпят неудачу, потому что они основаны на неверном толковании этого заявления. Точно так же апелляция к предполагаемому первоначальному значению неогена терпит неудачу, потому что она фактически поверхностна и также имела бы неприемлемые последствия, если бы применялась в качестве общего принципа к остальной временной шкале. Четыре аргумента против ранжирования третичного и / или четвертичного включают статус этих названий как частей устаревшей классификации; несоответствие их продолжительности; аналогия между ними и неранжированным докембрием; и их предполагаемая двусмысленность. Эти аргументы легко опровергаются. Аргументы в пользу ранжирования третичного и четвертичного периодов включают продолжающееся широкое использование этих названий, их практическую значимость для геологических карт и их роль в чествовании пионеров стратиграфии. Недавняя рекомендация Международной комиссии по стратиграфии (ICS) предусматривает отделение начала четвертичного периода от начала плейстоцена, неоген и плиоцен перекрывают границу третичного и четвертичного периодов, а геласский век относится как к плиоцену, так и к позднему периоду.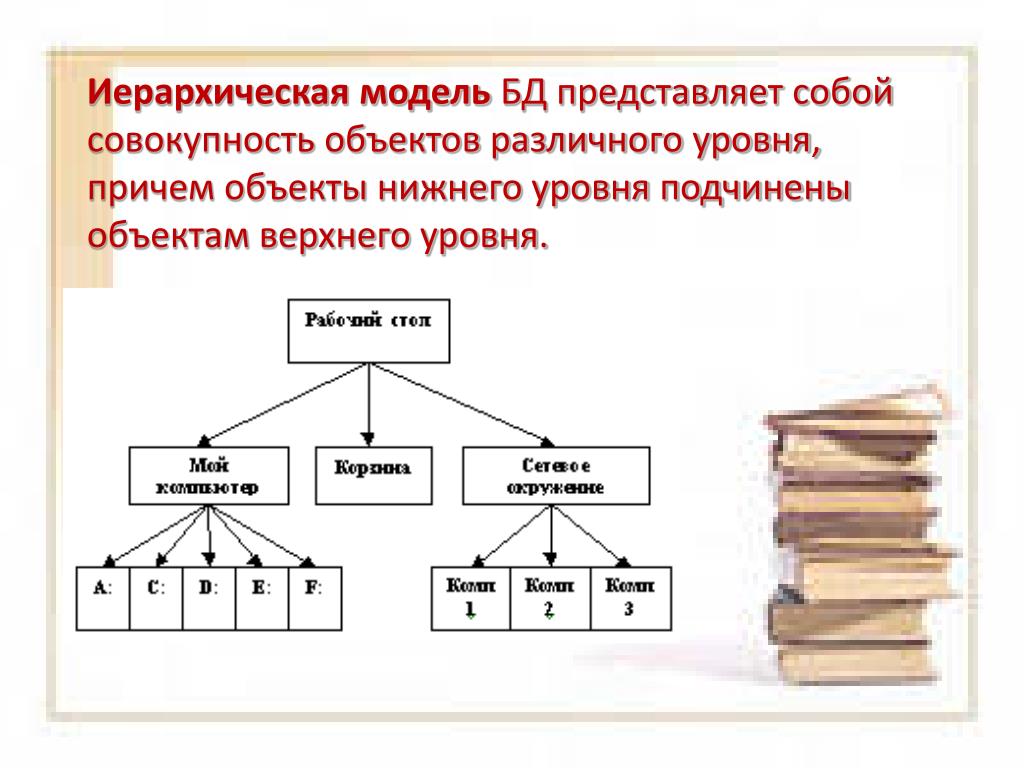 Четвертичный. Эти результаты нарушают существующие Руководящие принципы ICS. В этом же предложении четвертичный период также будет рассматриваться как субера в неогеновом периоде (последний продлен до настоящего времени). Однако такое расположение нарушает самое фундаментальное правило иерархической классификации, заключающееся в том, что единица более высокого ранга будет полностью включена в единицу более низкого ранга. Учитывая эти проблемы, Международный союз геологических наук (IUGS) должен отклонить рекомендацию ICS. Усовершенствованная версия предложения ICS (где четвертичный период оценивается как период, а палеоген и расширенный неоген оцениваются как суберы) по-прежнему запрещает ранжирование третичного периода и либо нарушает «правило Симпсона», либо требует нового названия для традиционного периода. концепции неогена. Поскольку отстаиваемая здесь классификация кайнозоя является строго иерархической, не нарушает ни одного из существующих руководящих принципов ICS, подчиняется правилу Симпсона, не требует новых названий, позволяет формально ранжировать третичный, четвертичный, палеогеновый и неогеновый периоды, общего использования в течение более века, это должно быть предпочтительным.
Четвертичный. Эти результаты нарушают существующие Руководящие принципы ICS. В этом же предложении четвертичный период также будет рассматриваться как субера в неогеновом периоде (последний продлен до настоящего времени). Однако такое расположение нарушает самое фундаментальное правило иерархической классификации, заключающееся в том, что единица более высокого ранга будет полностью включена в единицу более низкого ранга. Учитывая эти проблемы, Международный союз геологических наук (IUGS) должен отклонить рекомендацию ICS. Усовершенствованная версия предложения ICS (где четвертичный период оценивается как период, а палеоген и расширенный неоген оцениваются как суберы) по-прежнему запрещает ранжирование третичного периода и либо нарушает «правило Симпсона», либо требует нового названия для традиционного периода. концепции неогена. Поскольку отстаиваемая здесь классификация кайнозоя является строго иерархической, не нарушает ни одного из существующих руководящих принципов ICS, подчиняется правилу Симпсона, не требует новых названий, позволяет формально ранжировать третичный, четвертичный, палеогеновый и неогеновый периоды, общего использования в течение более века, это должно быть предпочтительным.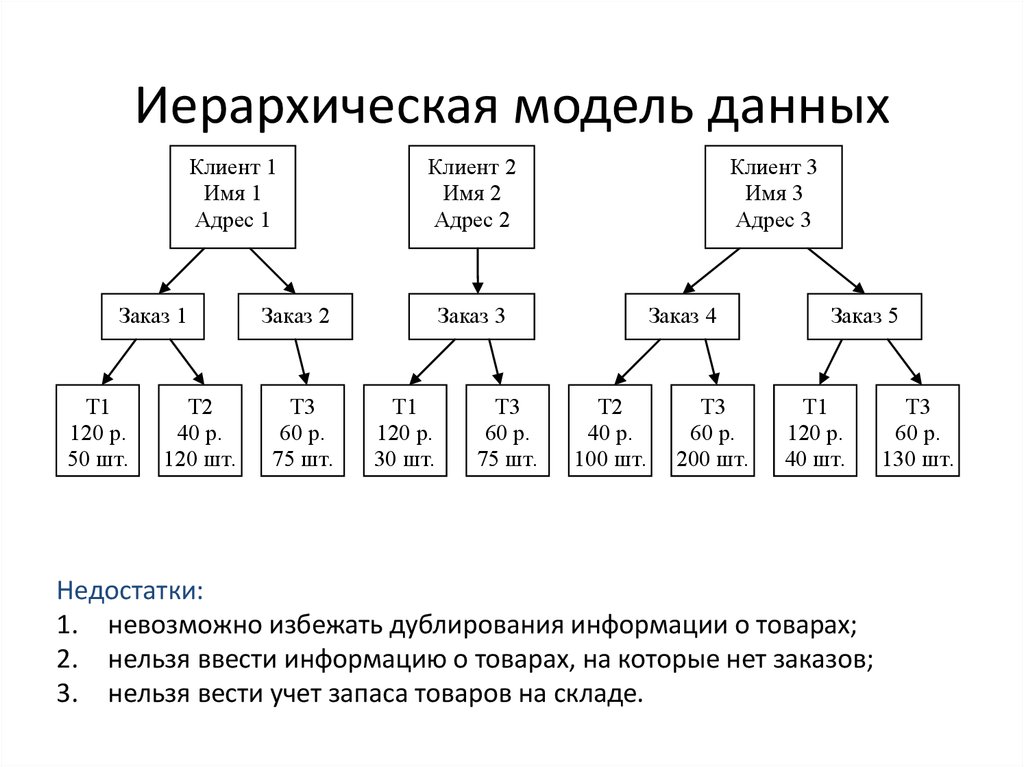 В настоящее время допустимы только два варианта определения четвертичного и плейстоценового периодов, а именно: оставить начала этих единиц там, где они находятся сейчас (GSSP Врица на 1,8 млн лет назад), или перенести оба на границу пьяченца и гелазии (GSSP Монте-Сан-Никола на 1,8 млн лет назад). 2,6 млн лет). Последний вариант не запрещен ни «типами» Лайелла для более раннего плиоцена, ни (после 2008 г.) существующими Руководящими принципами ICS, но если он будет принят, это может поставить под угрозу стабильность остальной части стандартной глобальной шкалы времени.
В настоящее время допустимы только два варианта определения четвертичного и плейстоценового периодов, а именно: оставить начала этих единиц там, где они находятся сейчас (GSSP Врица на 1,8 млн лет назад), или перенести оба на границу пьяченца и гелазии (GSSP Монте-Сан-Никола на 1,8 млн лет назад). 2,6 млн лет). Последний вариант не запрещен ни «типами» Лайелла для более раннего плиоцена, ни (после 2008 г.) существующими Руководящими принципами ICS, но если он будет принят, это может поставить под угрозу стабильность остальной части стандартной глобальной шкалы времени.
- Публикация:
Обзоры наук о Земле
- Дата публикации:
- октябрь 2006 г.
- DOI:
- 10.1016/j.earscirev.