Иерархическая база данных — это… Модели, примеры
Иерархическая база данных — это БД, основанная на древовидной структуре. По принципу построения она чем-то схожа с файловой системой компьютера. У использования такой модели есть свои достоинства и недостатки, которые будут рассмотрены в этой статье, вместе с подробными примерами.
Виды баз данных
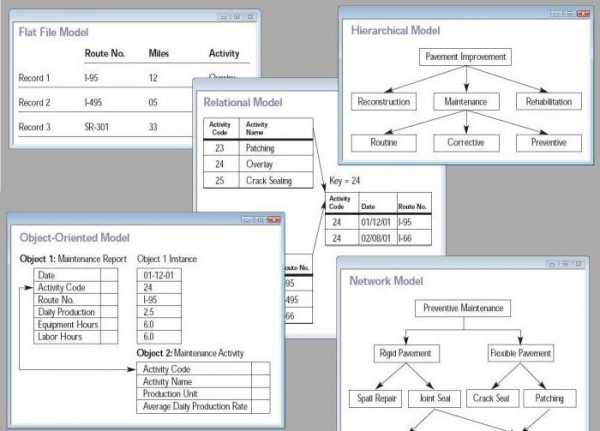
Как известно, различают четыре вида посторения БД:
- Реляционные — табличные СУБД, где информация представлена в виде строк-столбцов. По этому принципу строятся базы данных в «Аксесе», к примеру.
- Объектно-ориентированные — тесно связаны с ООП (программированием, в котором идет работа с объектами), и это их главный плюс, но, учитывая их небольшую производительность, они пока значительно уступают в распространенности реляционным.
- Гибридные — СУБД, вмещающие в себе сразу два указанных выше вида.
- Иерархические — объект внимания данной статьи. Это БД, характеризирующиеся древообразной структурой.
Наиболее известным примером иерархической базы данных является продукт, созданный компанией IBM («АйБиЭм»), под названием Information Management System (переводится как «Информационная система управления»), сокращенно IMS. Первая версия IMS вышла еще в прошлом, двадцатом веке, в шестьдесят восьмом году. Она используется для хранения и контроля данных и поныне.
Принцип построения иерархической модели
Иерархическая модель данных строится по следующему принципу:
- для каждого узла древовидной структуры ставится в соответствие некий сегмент;
- под сегментом понимаются поля данных с присвоенным каждому полю именем и выстроенные в один линейный кортеж;
- еще одно соответствие: один входной и несколько выходных сегментов для каждого исходного поля;
- для каждого структурного элемента существует одно и только одно место в системе иерархии;
- древовидная структура начинается с корневого элемента;
- у каждого подчиненного узла только один предок, но у каждого исходного может быть несколько потомков.
Применение иерархической структуры данных
Иерархическая база данных — это хранилище, применимое для тех систем, которым изначально свойственна древовидная структура. Для них выбирать подобное моделирование — логично.
Пример иерархической базы данных с изначально систематизированными степенями — воинское подразделение, в котором, как известно, четко определены ранги. Также это могут быть сложные механизмы, состоящие из все более упрощающихся к низу иерархии частичек. Для моделирования таких систем и приведения их к виду рассматриваемой БД нет необходимости в декомпозиции. Тем не менее такая ситуация складывается не всегда.
Кроме того, существует тенденция, при которой направленный вниз по структуре запрос проще, чем аналогичный вверх.
Основные операции над БД, построенными на иерархической модели
Структура иерархической базы данных позволяет успешно и практически беспроблемно (в зависимости от навыков и умений) совершать следующие операции (представлены самые основные, список всегда можно расширить мелкими дополнениями):
- поиск по базе данных того или иного элемента;
- переход по базе данных — от дерева к дереву;
- переход по дереву — от ветви к ветви;
- соответственно, переход по ветвям — поэлементно;
- работа с записями: вставка новой и/или удаление текущей, копирование, вырезание и т. д.
Обобщенное описание структуры
Термин «древовидная» для описания структуры упоминается в этой статье уже далеко не единожды. Пора рассказать, откуда он произошел. Все потому что иерархическая база данных — это такая БД, которая использует тип данных «дерево». Рассмотрим подробнее, что он из себя представляет.
Это составной тип: в каждый из элементов (узлов) вкладывается несколько последующих (один или более). А начинается все с одного корневого элемента. Суть в том, что каждый из кусочков типа «дерево», является подтипом, тоже «деревом». Много-много разветвленных, и все также упорядоченных структур.
Элементарные типы могут быть простыми и составными, но по существу это всегда записи. Но в простом записи присутствует один тип данных, а в составном — целая их совокупность.
Иерархической модели свойственен принцип потомков, когда каждый предыдущий сегмент является предком для последующего. Кроме того, потомок по отношению к вышестоящему типу является типом подчиненным, в то время как равнозначные один другому записи считаются близнецами.
Наполнение БД
Основными данными иерархической БД являются значения (числа или символы), которые хранятся в записях. Обходят такую базу данных обычно снизу вверх и слева направо.
Достоинства
Иерархическая база данных — это имеющая корневую папку БД, постепенно разветвляющаяся книзу. Учитывая, что подобная структура весьма схожа с файловой системой, такие базы успешно применяются для выполнения различных операций над данными ЭВМ. Итог: рациональное распределение ее памяти, а также весьма достойные показатели времени, затраченного на работу.
Иерархическая модель идеальна для применения ее для упорядоченной информации.
Недостатки
Однако те же особенности рассматриваемых СУБД, которые стали их основными достоинствами, определяют также и их недостатки. К примеру, громоздкость и сложность логических связей — опытному специалисту при работе с ранее неизвестной базой будет трудно разобраться, а простой пользователь и вовсе в ней «заблудится». Эта сложность понимания приводит к тому, что на самом деле не так много СУБД построены на иерархической модели. Примером иерархической базы данных является, кроме уже описанного продукта компании «АйБиЭм», «Ока» и МИРИС (производство России), а также Data Edge и Team-UP (от зарубежных корпораций).
Примеры
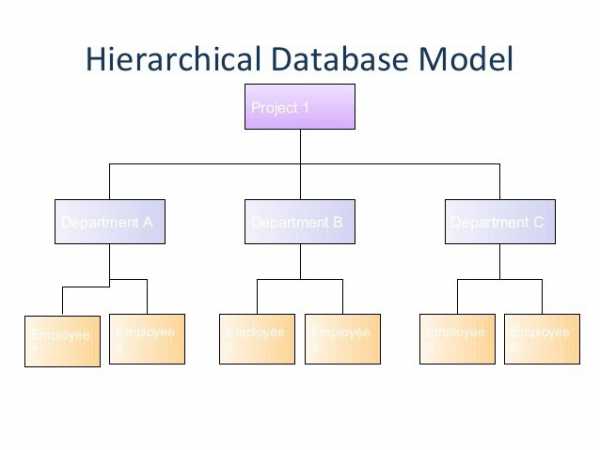
Иерархическая база данных — это многообразие различных уровней, на которых строятся взаимосвязи. Схематично она выглядит как перевернутый граф. Пример иерархической базы данных — любое государственное административное учреждение. Взять, допустим, школу.
На самом верхней уровне будет располагаться «лидер» администрации — директор. В его подчинении завучи, у завучей — преподаватели, который руководят параллелями классов. В каждой параллели энное их количество, а в каждом классе есть некоторое число учеников.
По такому же принципу можно расписать и управление какой-нибудь корпорацией. Глава компании или даже совет директоров на самом верху. Далее — все большее количество подразделений, в каждом из которых действует своя структура. Есть и общие черты: начальник в каждом отделе, его помощник, его секретарь, собственно, офисные сотрудники и так далее.
Применение в ЭВМ
Могут быть и более серьезные области применения. Яркий пример иерархической базы данных- это файловая система. Всем привычный «Проводник» строится в самом ядре операционной системы «Виндоус» именно по такой схеме, так же, как и многие другие файловые менеджеры.
Сетевые базы данных
Существуют:
- реляционные;
- иерархические;
- сетевые базы данных.
Почему мы вновь вспомнили о классификации? Поскольку, в отличие от реляционной, сетевая БД имеет с иерархической схожие черты.
Время вспомнить виды связей в базах данных. Есть связи «один-к-одному», «один-ко-многим» и «многие-ко-многим». Нас интересует последняя. В сетевой БД она проявляется следующим образом: у одного узла-наследника может быть сразу несколько предков. Свойство иметь несколько потомков также сохраняется. Можно сказать, что иерархические базы данных, сетевые базы данных сами по себе уже пример такого наследования. Предком в данном случае является именно иерархическая БД, так как принцип построения структуры в сетевых БД остается прежним.
Иерархия и реляционность
Название «реляционная» произошло от английского слова «отношение». Как уже упоминалось в начале статьи, они часто выражаются таблично. Но в предыдущем пункте мы указали, что иерархическая БД также может организовывать связи, значит ли это, что и между этими двумя типами есть некая объединяющая их тонкая ниточка?
Да. Помимо того, что и первый, и второй вид все еще относятся к базам данных, кроме этого признака есть еще одно общее свойство. Например, иерархическую БД (и сетевую заодно с ней) можно выразить в таблице. Суть здесь не в том, в каком виде представить информацию конечному пользователю (это уже вопрос юзабилити интерфейса), но по какому принципу была структурирована информация. Так, четкое деление на отделы со своими начальниками, подразделениями и прочим по-прежнему будет выражено в иерархии, но для удобства занесено в таблицу.
fb.ru
Иерархическая база данных. Иерархическая модель данных. Концептуальная модель и иерархическая структура данных.
Здравствуйте, уважаемые посетители моего скромного блога для начинающих вебразработчиков и web мастеров ZametkiNaPolyah.ru. Продолжаем рубрику Заметки о MySQL, в которой уже были публикации: Нормальные формы и транзитивная зависимость, избыточность данных в базе данных, типы и виды баз данных, настройка MySQL сервера и файл my.ini, MySQL сервер, установка и настройка, Архитектура СУБД и архитектура баз данных, Сетевая база данных, сетевая модель данных. Я продолжаю рассматривать различные модели данных, и сегодня мы поговорим про иерархическую модель данных или иначе – иерархическую базу данных.
Стоит сказать, что иерархическая база данных является частным случаем сетевой модели данных, о которой мы говорили в предыдущей публикации. Но дело все в том, что и иерархическая модель данных, и сетевые базы данных являются мало эффективными, и постепенно от их использования отказываются. Иерархические и сетевые СУБД остались только в некоторых крупных фирмах, которые наполняли такие базы годами. И сейчас основной проблемой для таких фирм является проблема совместимости иерархических и сетевых баз данных с реляционными базами данных. Ну а сегодня мы просто поговорим про
Не забываем подписываться на RSS-ленту и на публичную страницу Вконтакте.
Иерархическая модель данных
Содержание статьи:
Иерархическая модель данных является частным случаем сетевой модели данных, структура иерархической базы данных немного проще сетевой и, соответственно, иерархические базы данных даже менее эффективны, чем сетевые. Иерархическая модель данных, как и сетевые БД опирается на теорию графов.
Иерархическая база данных. Иерархическая модель данных.
В основе иерархической модели данных лежит один главный элемент (главный узел), с которого все и начинается, такой элемент называет корневым элементом, в теории графов это называется корнем дерева. Вообще, по сути, что сетевая база данных, что иерархическая база данных имеет древовидную структуру. Все элементы или узлы, которые находятся ниже корневого узла иерархической модели, являются потомками корня. Стоит сказать, что и иерархическая база данных, и сетевая база данных оптимизированы на чтение информации из БД, но не на запись информации в базу данных, эта особенность обусловлена самой моделью данных.
Узлы дерева, которые находятся на одном уровне, обычно называются братьями. Узлы, которые находятся ниже какого-то определенного уровня, являются дочерними узлами по отношению к нему. Иерархическую модель данных можно сравнить с файловой системой компьютера. Компьютер умеет очень быстро работать с отдельными файлами: удалять конкретный файл, редактировать файл, копировать или перемещать файл. Но операция проверки компьютера антивирусом может происходить достаточно длительное время.
Точно такие же особенности присуще иерархической СУБД, то есть базы данных, имеющие иерархическую структуру, умеют очень быстро находить и выбирать информацию и отдавать ее пользователю. Но структура иерархической модели данных не позволяет столь же быстро перебирать информацию. Ну, это видно из рисунка, представленного выше. Допустим, что нам необходимо найти все записи, содержащие слово «сотрудник». Как будет поступать иерархическая СУБД в этом случае? А поступать она будет следующим образом: свой поиск она начнет с корневого элемента иерархической модели данных, проверив его, она начнет проверять его связи, если связей будет несколько, то она пойдет проверять в крайний левый дочерний элемент, расположенный на уровень ниже.
Затем иерархическая СУБД проверит содержимое этого элемента и его связи, если связей опять будет несколько, то она отправится опять-таки в крайний левый дочерний элемент, чтобы проверить его содержимое, проверив его содержимое она увидит, что у этого узла нет дочерних элементов и вернется в родительский узел этого узла, чтобы проверить, есть ли у него еще дочерние элементы. И так постепенно, узел за узлом, спуская и поднимаясь по иерархии узлов СУБД переберет все узлы и выдаст нам все записи, в которых есть слово «сотрудник». Ну, думаю, что с иерархической моделью данных мы более-менее разобрались (если не разобрались, то пишите в комментарии), можно приступить к рассмотрению структуры иерархической базы данных.
Структура иерархической базы данных
Самые первые в мире СУБД использовали иерархическую модель данных, иерархические базы данных появились даже раньше, чем сетевая модель хранения данных. Поэтому структура иерархической базы данных немного проще, чем структура сетевой БД. И так, основными информационными единицами иерархической модели данных являются сегмент и поле. Поле данных является наименьшей неделимой информационной единицей иерархической базы данных, доступной пользователю. У сегмента данных можно определить его тип и экземпляр сегмента.
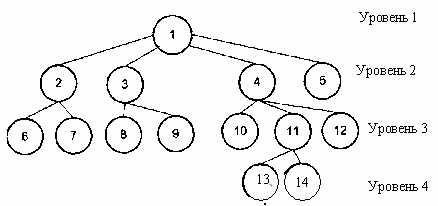
Иерархическая база данных. Иерархическая модель данных.
Экземпляр сегмента образуется из конкретных значений полей данных. Тип сегмента – это именованная совокупность всех типов полей данных, входящих в данный сегмент. Если ориентироваться по рисунку выше, то тип сегмента – это родительский элемент и все его дочерние элементы. Как я уже говорил: иерархическая модель данных базируется на теории графов, но если структура сетевой БД описывается ориентированным графом (графом со стрелочками), то структура иерархической базы данных описывается неориентированным графом. Характерной особенностью структуры иерархической модели данных является то, что у любого потомка или дочернего элемента может быть только один предок или родительский элемент.
Каждый узел иерархического дерева или каждый элемент иерархической базы данных является сегментом данных. Линии, соединяющие сегменты – это связи между информационными объектами иерархической базы данных. Рисунок должен внести дополнительную ясность:
На концептуальном уровне иерархическая база данных является частным случаем сетевой модели данных.
Преобразование концептуальной модели в иерархическую модель данных
Преобразование концептуальной модели в иерархическую модель данных происходит аналогично преобразованию в сетевую модель данных, но существую некоторые тонкости, о которых мы и поговорим. Эти тонкости связаны с тем, что структура иерархической базы данных должна быть представлена в виде дерева, то есть данные иерархической модели должны быть организованы в виде дерева.
Как вы помните: дуги, соединяющие узлы между собой, – это связи. Связи бывают один к одному и один ко многим. Преобразование связей один ко многим происходит автоматически в том случае, если потомок иерархического дерева имеет только одного предка. Происходит это следующим образом: Каждый объект с его атрибутами, участвующий в такой связи, становится логическим сегментом. Между двумя логическими сегментами устанавливается связь типа «один ко многим». Сегмент со стороны «много» становится потомком, а сегмент со стороны «один» становится предком. Согласитесь, что преобразование в иерархическую модель данных похоже на преобразование в сетевую модель.
Ситуация значительно усложняется, если потомок в связи имеет не одного, а двух и более предков. Так как подобное положение является невозможным для иерархической модели, то отражаемая структура данных нуждается в преобразованиях, которые сводятся к замене одного дерева, например, двумя (если имеется два предка). В результате такого преобразования в базе данных появляется избыточность, так как единственно возможный выход из этой ситуации — дублирование данных.
Управление иерархическими данными
У иерархической модели данных существует два средства управления данными: языковые средства описания данных (ЯОД) и языковые средства манипулирования данными (ЯМД). Физическая структура иерархической базы данных описывает: логическую структуру иерархической модели данных и саму структуру хранения базы данных.
При этом способ доступа устанавливает способ организации взаимосвязи физических записей. Определены следующие способы доступа:
- иерархически последовательный;
- иерархически индексно-последовательный;
- иерархически прямой;
- иерархически индексно-прямой;
- индексный.
Помимо того, что обязательно должно быть задано имя иерархической базы данных и способа доступа к каждому элементу иерархической модели данных, описание иерархической БД должно содержать определение типов каждого сегмента данных, входящих в базу данных, в соответствие с выстроенной иерархией. Описание типов сегмента следует начинать с корня иерархической модели. Особенностью иерархических баз данных является то, что каждая физическая база данных может содержать только один корень, но в одной
Среди операторов манипулирования данными для иерархической базы данных можно выделить операторы поиска данных, операторы поиска данных с возможностью модификации, операторы модификации данных. Набор операций манипулирования данными в иерархической модели данных не так уж обширен, но этого набора вполне достаточно для управления и поддержания иерархических баз данных. Примеры типичных операторов поиска данных:
- найти указанное дерево БД;
- перейти от одного дерева к другому;
- найти экземпляр сегмента, удовлетворяющий условию поиска;
- перейти от одного сегмента к другому внутри дерева;
- перейти от одного сегмента к другому в порядке обхода иерархии.
Примеры типичных операторов поиска данных с возможностью модификации:
- найти и удержать для дальнейшей модификации единственный экземпляр сегмента, удовлетворяющий условию поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр сегмента с теми же условиями поиска;
- найти и удержать для дальнейшей модификации следующий экземпляр для того же родителя.
Примеры типичных операторов модификации иерархически организованных данных, которые выполняются после выполнения одного из операторов второй группы (поиска данных с возможностью модификации):
- вставить новый экземпляр сегмента в указанную позицию;
- обновить текущий экземпляр сегмента;
- удалить текущий экземпляр сегмента.
В иерархической модели автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя. Надеюсь, что я достаточно просто и понятно описал структуру иерархической базы данных, как обычно, если что-то не понятно, то, пожалуйста, задавайте вопросы в комментариях под записью. На этом всё, спасибо за внимание, надеюсь, что был хоть чем-то полезен и до скорых встреч на страницах блога для начинающих вебразработчиков и вебмастеров ZametkiNaPolyah.ru. Не забываем комментировать и делиться с друзьями;)
zametkinapolyah.ru
Иерархическая модель данных — Национальная библиотека им. Н. Э. Баумана
Материал из Национальной библиотеки им. Н. Э. Баумана
Последнее изменение этой страницы: 20:29, 12 июня 2017.
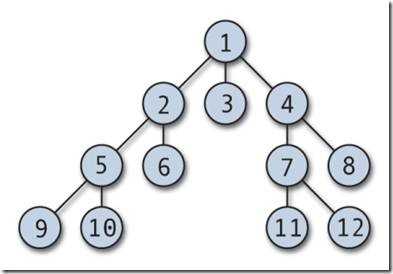
Иерархическая модель данных — логическая модель данных в виде древовидной структуры, представляющая собой совокупность элементов, расположенных в порядке их подчинения от общего к частному[1]. В иерархических моделях основная структура представления данных имеет форму дерева. На самом высшем (первом) уровне иерархии находится только одна вершина, которая называется корнем дерева. Эта вершина имеет связи с вершинами второго уровня, вершины второго уровня имеют связи с вершинами третьего уровня и т.д. Связи между вершинами одного уровня отсутствуют. Следовательно, данные в иерархической структуре не равноправны – одни жестко подчинены другим. Доступ к информации возможен только по вертикальной схеме, начиная с корня, так как каждый элемент связан только с одним элементом на верхнем уровне и с одним или несколькими на низком.
Основные понятия применяемые в иерархической модели данных
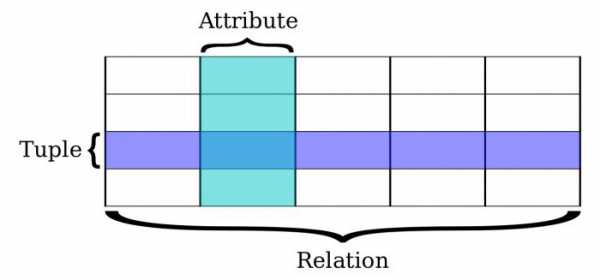
- Атрибут (элемент данных,поле) — определяется как наименьшая неделимая единица данных, доступная пользователю.. Обычно каждому элементу при описании базы данных присваивается уникальное имя. По этому имени к нему обращаются при обработке. Элемент данных также часто называют полем.
- Запись (сегмент) — именованная совокупность атрибутов. Использование записей позволяет за одно обращение к базе получить некоторую логически связанную совокупность данных. Именно записи изменяются, добавляются и удаляются. Тип сегмента — это поименованная совокупность входящих в него атрибутов.. Экземпляр записи — конкретная запись с конкретным значением элементов
- Групповое отношение — иерархическое отношение между записями двух типов. Родительская запись (владелец группового отношения) называется исходной записью, а дочерние записи (члены группового отношения) — подчиненными. Иерархическая база данных может хранить только такие древовидные структуры.
Сущность иерархической модели данных
Для описания структуры (схемы) иерархической БД на некотором языке программирования используется тип данных «дерево». Тип «дерево» является составным. Он включает в себя подтипы («поддеревья»), каждый из которых, в свою очередь, является типом «дерево». Корневым называется тип, который имеет подчиненные типы и сам не является подтипом. Подчиненный тип (подтип) является потомком по отношению к типу, который выступает для него в роли предка (родителя). Потомки одного и того же типа являются близнецами по отношению друг к другу.
В целом тип «дерево» представляет собой иерархически организованный набор типов «запись».
Иерархическая БД представляет собой упорядоченную совокупность экземпляров данных типа «дерево» (деревьев), содержащих экземпляры типа «запись» (записи). Поля записей хранят собственно числовые или символьные значения, составляющие основное содержание БД. Обход всех элементов иерархической БД обычно производится сверху вниз и слева направо.
Достоинства и недостатки
Основными достоинствами иерархической модели данных являются:
- эффективное использование памяти ЭВМ;
- высокая скорость выполнения основных операций над данными;
- удобство работы с иерархически упорядоченной информацией;
- простота при работе с небольшим объемом данных так как, иерархический принцип соподчиненности понятий является естественным для многих задач.
К недостаткам иерархической модели представления данных относятся:
- громоздкость такой модели для обработки информации с достаточно сложными логическими связями;
- трудность в понимании ее функционирования обычным пользователем.
- трудность в применении к данным со сложной внутренней взаимосвязью
- исключительно навигационный принцип доступа к данным
Операции над иерархически организованными данными
- Добавить в базу данных новую запись. Для корневой записи обязательно формирование значения ключа.
- Изменить значение данных предварительно извлеченной записи. Ключевые данные не должны подвергаться изменениям.
- Удалить некоторую запись и все подчиненные ей записи.
- Извлечь извлечение записи осуществляется в порядке левостороннего обхода дерева. В операции извлечь допускается задание условий выборки.
См. также
Источники
Ссылки
- http://www.bseu.by/it/tohod/lekcii2_2.htm
- http://citforum.ru/database/advanced_intro/6.shtml
- http://www.mstu.edu.ru/study/materials/zelenkov/ch_3_1.html
- http://wiki.mvtom.ru/index.php/%D0%98%D0%B5%D1%80%D0%B0%D1%80%D1%85%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%B0%D1%8F_%D0%BC%D0%BE%D0%B4%D0%B5%D0%BB%D1%8C_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85
ru.bmstu.wiki
Иерархическая СУБД
2010/05/23 00:13:23
Иерархическая СУБД (ИСУБД) — система управления базами данных, использующих в своей основе древовидную структуру.
Каталог СУБД-решений и проектов доступен на TAdviser.
Подробности
Типичным представителем (наиболее известным и распространенным) является Information Management System (IMS) фирмы IBM. Первая версия появилась в 1968 г. До сих пор существуют базы, которые поддерживаются этой СУБД. Иерархические модели имеют древовидную структуру, где каждому узлу соответствует один сегмент, представляющий собой поименованный линейный кортеж полей данных. Каждому сегменту соответствует один входной и несколько выходных сегментов. Каждый элемент структуры лежит на единственном иерархическом пути, начинающемся от корневого. Иерархические базы данных наиболее пригодны для моделирования структур, по своей природе являющихся иерархическими. В качестве примеров можно привести воинские подразделения или сложные механизмы, состоящие из более простых узлов, которые в свою очередь тоже можно подвергнуть декомпозиции. Тем не менее существует значительное количество организаций, не сводящихся к простой иерархии. В этой модели запрос, направленный вниз по иерархии, прост, однако запрос, направленный вверх по иерархии, более сложен. К достоинствам иерархической модели данных относятся эффективное использование памяти ЭВМ и неплохие показатели времени выполнения основных операций над данными. Иерархической базой данных является файловая система, состоящая из корневой директории, в которой имеется древовидная структура поддиректорий и файлов.
Иерархическая БД
Иерархические базы данных — самая ранняя модель представления сложной структуры данных. Информация в иерархической базе организована по принципу древовидной структуры, в виде отношений «предок-потомок». Каждая запись может иметь не более одной родительской записи и несколько подчиненных. Связи записей реализуются в виде физических указателей с одной записи на другую. Основной недостаток иерархической структуры базы данных — невозможность реализовать отношения «много-ко-многим», а также ситуации, когда запись имеет несколько предков.
Графически такую структуру можно изобразить в виде дерева, состоящего из объектов различных уровней. Верхний уровень занимает один объект, второй — объекты второго уровня и так далее.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможно, чтобы объект-предок не имел потомков или имел их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами.
Недостатки
К основным недостаткам иерархических моделей следует отнести: неэффективность, медленный доступ к сегментам данных нижних уровней иерархии, четкая ориентация на определенные типы запросов и др. Также недостатком иерархической модели является ее громоздкость для обработки информации с достаточно сложными логическими связями, а также сложность понимания для обычного пользователя. Иерархические СУБД быстро прошли пик популярности, которая обусловливалась их ранним появлением на рынке. Затем их недостатки сделали их неконкурентоспособными, и в настоящее время иерархическая модель представляет исключительно исторический интерес.
Ссылки
www.tadviser.ru
Иерархические БД
На этом уроке мы с вами вспомним, что такое иерархическая структура и из каких элементов она состоит. Также рассмотрим несколько примеров иерархической базы данных.
Начнём мы с вами с рассмотрения иерархической структуры базы данных.
Иерархическая структура – это многоуровневая форма организации объектов со строгой соотнесённостью объектов нижнего уровня определённому объекту верхнего уровня. Т. е. можно сказать, что иерархическая структура напоминает собой пирамиду, в которой объекты более низкого уровня подчиняются объектам более высокого уровня.
Из этого можно сделать вывод, что в иерархической структуре существуют отношения между её объектами (элементами).
Ещё иерархическую структуру называют древовидной. К примерам можно отнести содержание учебника.
А сейчас рассмотрим иерархическую структуру более подробно на примере.
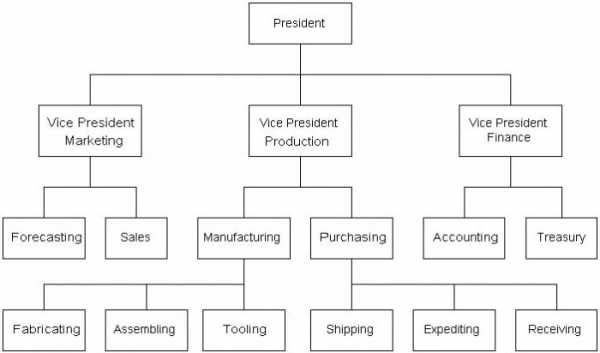
Давайте построим иерархическую структуру школы.
Во главе всегда находится директор школы. Далее будут идти завуч старших классов, завуч младших классов, заведующий хозяйственной деятельностью. После завучей идут учителя, которые, соответственно, делятся на преподавателей младших и старших классов. Не будем расписывать всех учителей, а возьмём по три учителя каждых классов. Заведующему по хозяйственной деятельности будет подчиняться весь технический персонал. Его мы расписывать не будем. Далее у каждого учителя есть свой класс, в котором он является классным руководителем, а в каждом классе – ученики. В свою очередь, учителя старших классов ведут уроки и в других классах. Давайте отобразим несколько таких классов в нашей структуре. Если же всю эту структуру расписывать более подробно, то нам понадобится очень много места, так как объектов в этой системе очень большое количество.
Итак, во главе любой иерархической структуры всегда находится один элемент (объект). В нашем случае – это директор школы. Он является корнем вершины и находится на верхнем (первом) уровне.
Далее идёт второй уровень, на котором находятся заместители.
На третьем уровне находятся учителя и технический персонал, на четвёртом – классы и на пятом – ученики.
Как говорилось ранее, между всеми объектами существуют связи. Каждый объект более высокого уровня может включать в себя несколько объектов более низкого уровня. Давайте снова обратимся к нашему примеру. Так, завуч старшей школы включает в себя всех учителей, которые ведут уроки в старших классах. А заведующий хозяйственной деятельностью управляет всем техническим персоналом школы. Такие объекты находятся в отношении предка (объект более высокого уровня) к потомку (объект более низкого уровня). То есть завуч старшей школы и заведующий хозяйственной деятельностью являются предками, а учителя и технический персонал – потомками.
Также мы можем видеть, что у объекта-предка может быть несколько потомков. Но в то же время у объекта-потомка может быть только один предок. Объекты, которые находятся на одном уровне и у которых один общий предок, называются близнецами.
Рассмотрим ещё один пример. Построить иерархическую структуру, исходя из следующего условия: на кафедре иностранных языков работают три преподавателя. Иванова Инна Сергеевна преподаёт английский язык, Кулибина Анна Васильевна преподаёт немецкий язык, а Рудков Игорь Сергеевич преподаёт французский язык.
Корневой вершиной в этой структуре будет являться кафедра. Изобразим её в виде круга. Она включает в себя трёх преподавателей. Также изобразим их схематично, а от кафедры к каждому преподавателю проведём стрелки.
Далее у каждого преподавателя есть свои предметы, которые он ведёт. Также изобразим их схематично и проведём стрелки.
Таким образом мы получили графическое отображение иерархической структуры кафедры.
Корневой вершиной является кафедра.
Учителя являются потомками по отношению к кафедре и предками по отношению к предметам, которые они преподают. Также они между собой являются близнецами, так как находятся на одном уровне структуры и имеют одного предка – кафедру.
У нас получилось несколько определений.
Корень – это единственный объект, который стоит на вершине иерархической системы и является её первым уровнем.
Предок – это объект, который стоит более близко к корню системы и у него может быть несколько потомков.
Потомок – это объект, который стоит на более низком уровне по отношению к предку и у него может быть только один предок.
Близнецы – это объекты, которые имеют одного предка и находятся на одном уровне.
А сейчас рассмотрим ещё несколько примеров.
Начнём с иерархической базы данных папки Windows.
Иерархической базой данных является каталог папок Windows. Перед вами рисунок системного диска. Для того, чтобы увидеть древовидную структуру в проводнике в Windows 7, необходимо выбрать кнопку «Упорядочить», далее из появившегося списка – «Представления», а затем «Область переходов». Это в том случае, если данная область не отображается.
А вот, например, в Windows 10 необходимо в проводнике, во вкладке «Вид», выбрать «Область навигации» и из списка снова «Область навигации».
На рисунке представлен проводник операционной системы Windows 10.
Итак, корневой является папка «Этот компьютер».
Далее, на втором уровне на представленном рисунке находится локальный диск С, который включает в себя несколько папок третьего уровня.
В нашем случае выбрана папка «Program Files». Она в себя включает несколько папок-потомков.
Исходя из этого можно сказать, что корнем является – «Этот компьютер». Далее и предком, и потомком является локальный диск С. Папка «Program Files» также является и потомком (по отношению к локальному диску С), и предком (по отношению к остальным папкам, которые она в себя включает). Файл «Rar.txt» является потомком папки «WinRAR». В свою очередь, мы можем видеть, что у файла «Rar.txt» нет своих потомков. Также, например, файлы «Rar.txt» и «Rar.exe» являются близнецами, так как находятся на одном уровне и у них один общий предок – папка «WinRAR».
Ещё одним примером иерархической базы данных является файловая система Linux.
Мы ранее её рассматривали. В ней существует одна корневая папка, все остальные папки являются потомками. В корневой папке содержатся все системные файлы. А вот, например, каталоги логических томов и запоминающих устройств содержатся в составе других каталогов. Директории томов жёсткого диска содержатся в папке «mnt». Другие запоминающие устройства находятся в папке «media». В свою очередь, папки «mnt» и «media» содержатся в одном системном корневом каталоге. Таким образом, папки «mnt» и «media» являются и потомками (по отношению к основному корневому каталогу), и предками (по отношению к каталогам логических томов и запоминающих устройств). Помимо этого, эти две папки являются близнецами, так как они находятся на одном уровне и имеют одного предка.
А сейчас давайте рассмотрим такую иерархическую базу данных, как «Системный реестр Windows».
В этой иерархической базе данных хранится вся информация, которая нужна для нормального функционирования компьютерной системы. То есть в этой базе данных содержится информация о настройках компьютера, установленных драйверах, настройках графического интерфейса, сведения о программах, которые установлены на компьютере, и многое другое.
Вся эта информация автоматически обновляется при установке нового оборудования, удалении или установке программ и так далее.
Давайте рассмотрим рисунок.
Корневым объектом является сам компьютер. Папка «Adobe» является потомком по отношению к папке «SOFTWARE» и предком для всех остальных папок, которые она в себя включает. Папки «7-Zip» и «Adobe» являются близнецами, так как они находятся на одном уровне и у них один предок – папка «SOFTWARE». Файл «UserID» является потомком папки «IAC». В свою очередь, мы можем видеть, что у файла «UserID» нет своих потомков.
В операционной же системе Linux как такового реестра нет. Вместо этого в ней существует папка «etc».
А сейчас мы с вами рассмотрим иерархическую базу данных «Доменная система имён». Эта система получила название DNS.
DNS – это распределённая база данных, которая поддерживает иерархическую систему имён для идентификации узлов сети Интернет.
Эта служба предназначена для автоматического поиска IP-адреса по известному символьному имени узла. То есть в этой базе данных содержится информация о всех компьютерах, подключённых к сети Интернет.
Корневой вершиной в этой системе является табличная база данных, которая содержит перечень доменов верхнего уровня.
Сам же корень управляется центром Internet Network Information Center. Домены верхнего уровня назначаются для каждой страны, а также на организационной основе. Для обозначения стран используются трёхбуквенные и двухбуквенные аббревиатуры.
Так, например, для русскоязычных сайтов доменом верхнего уровня является «.ru», для Казахстана – «.kz» и т. д. Для различных типов организаций также есть свои аббревиатуры.
На втором уровне находятся также табличные базы данных, но они уже в себя включают перечень доменов второго уровня для каждого домена первого уровня.
На третьем уровне содержатся табличные базы данных и таблицы. Табличные базы данных содержат перечень доменов третьего уровня для каждого домена второго уровня. Таблицы, в свою очередь, содержат IP-адреса компьютеров, которые находятся в домене второго уровня.
А теперь представьте, какой большой будет база данных, которая должна включать в себя информацию о всех компьютерах, подключенных к Интернету. Как вы думаете, много ли места она будет занимать?
Такая база данных огромна по своим размерам и соответственно она не будет умещаться в памяти одного компьютера, а если бы и можно было загрузить такую базу данных в один компьютер, то работа в Интернете была бы очень медленной. Представьте себе количество запросов, которые поступают от пользователей всего мира в течение, например, 1 минуты. Их количество огромно. А теперь представьте, что все эти запросы должен принять и обработать один компьютер. Это просто невозможно, так как приведёт не только к медленной работе компьютера, но также и к зависанию, если не к поломке. Таким образом, размещение базы данных доменной системы имён на одном компьютере неэффективно. Но решение этой проблемы было найдено. Вся база данных была разделена на части и размещена на различных DNS-серверах, которые связаны между собой. Такая иерархическая база данных является распределённой базой данных.
А сейчас давайте рассмотрим, как происходит поиск информации в такой огромной иерархической распределённой базе данных.
Например, вам нужно зайти на свою почту в Яндексе. Для этого вы вводите в адресную строку запрос.
Ваш запрос сначала отправляется на DNS-сервер вашего провайдера, с которого он переадресуется на DNS -сервер верхнего уровня базы данных.
На этом сервере, в таблице первого уровня, произойдёт поиск интересующего нас домена «ru», после чего запрос будет перенаправлен на DNS-сервер второго уровня, который содержит перечень доменов второго уровня, зарегистрированных в домене «ru».
На втором уровне будет происходить поиск среди доменов второго уровня. После того, как был найден интересующий нас домен «yandex», произойдёт перенаправление на DNS-сервер третьего уровня, на котором находится перечень доменов третьего уровня, зарегистрированных в домене «yandex».
В таблице третьего уровня будет найден домен «mail», и запрос будет переадресован на DNS-сервер четвёртого уровня.
В таблице четвёртого уровня будет найдена запись, которая соответствует доменному имени, содержащемуся в запросе. После этого поиск в самой базе данных «Доменная система имён» будет завершён и начнётся поиск компьютера в сети по его IP-адресу.
Пришла пора подвести итоги урока.
Сегодня мы с вами узнали, что такое иерархическая структура и построили такую структуру на примере. Более подробно познакомились с элементами иерархической базы данных: корнем, предком, потомком, близнецами.
Рассмотрели несколько иерархических баз данных на примере Windows и Linux, а также реестра Windows.
Узнали, как составлена и работает иерархическая база данных «Доменная система имён».
videouroki.net
Виды и типы баз данных. Структура реляционных БД. Проектирование БД.
Здравствуйте, уважаемые посетители моего скромного блога для начинающих вебразработчиков и web мастеров ZametkiNaPolyah.ru. Продолжаем рубрику Заметки о MySQL, в которой я уже успел рассмотреть установку и настройку MySQL сервера баз данных, а также рассмотрел способы изменения кодировок сервера MySQL при помощи команды SET NAMES и файла конфигураций my.ini. Сегодня будет краткая и если можно так сказать теоретическая статья, посвященная вопросу — что такое базы данных и какие базы данных бывают.

В этой статье я постараюсь изложить кратко какие виды и типы баз данных бывают и остановлюсь на некоторых из них более подробно. Мы поговорим о структуре иерархических баз данных, уделим внимание структуре сетевых баз данных, и более подробно остановимся на структуре реляционных базах данных, рассмотрим особенности реляционных баз данных. И в конце статьи немного затронем тему проектирования баз данных, естественно реляционных, так сервер MySQL это по сути математическая модель реляционных баз данных. Проектирование баз данных и типы данных, с которыми может работать MySQL сервер — это темы для последующих публикаций.
База данных. Математические модели, структура, определение.
Содержание статьи:
Я хоть и не собираюсь на своем блоге подробно рассказывать про математические законы и теории описывающие реляционные базы данных, но принцип того, как они устроены я рассказать должен, если вас заинтересует данная тема, то вы всегда можете посетить специализированный математический ресурс или почитать соответствующую литературу, а можете всегда задать вопрос в комментариях к данной публикации, и я по мере своих возможностей постараюсь вам ответить. Как я уже говорил, тема данной статьи – реляционные базы данных. Я постараюсь ответить на вопрос, что такое реляционные базы данных простым и понятным языком. Затрону основные понятия, относящиеся к реляционным базам данных, терминологию, историю возникновения баз данных вообще и реляционных в частности.
Наверное, самое простое определения баз данных, база данных – это упорядоченное хранение какой-либо информации. То есть, информация хранится в упорядоченном или систематизированном виде. Видов систематизации, упорядочивания и хранения информации может быть множество. Каждый из способов хранения информации отвечает каким-либо специфическим требованиям или предназначен для выполнения каких-либо определенных действий. На страницах своего блога я уже писал, про язык XML, данные в XML структурируются в виде дерева с разветвлениями, узлами и корнем. Но это лишь один из множества способов хранения информации. Более подробно обо всем этом читайте в рубрике Заметки о XML и XLST.
Виды и типы баз данных
Как я уже говорил, видов и типов баз данных очень и очень много и описать их все в данной публикации я просто не смогу, но самые распространенные виды хранения информации или виды баз данных я постараюсь описать. Понятно, что база данных хранит в себе информацию о каких-то объектах, например, информацию о товаре в интернет-магазине. Любой товар в базе данных – это объект с какими-то определенными параметрами и свойствами. Перейдем к конкретным примерам.
Иерархическая база данных, структура иерархических баз данных
Иерархическая база данных – каждый объект при таком хранение информации представляется в виде определенной сущности, то есть, у этой сущности могут быть дочерние элементы, родительские элементы, а у тех дочерних могут быть еще дочерние элементы, но есть один объект, с которого все начинается. Получается своеобразное дерево. Примером иерархической базы данных может быть, документ в формате XML или файловая система компьютера, пример с файловой системой компьютера я приводил, когда рассматривал структуру XML документа, в рубрике Заметки о XML.
Следует сказать, что базы данных подобного вида оптимизированы под чтение информации, то есть, базы данных, имеющие иерархическую структуру умеют очень быстро выбирать, запрашиваемую информацию и отдавать ее пользователям. Но такая структура не позволяет столь же быстро перебирать информацию, тут можно привести пример из жизни, компьютер может легко работать с каким-либо конкретным файлом или папкой (которые, по сути являются объектами иерархической структуры) но проверка компьютера антивирусам осуществляется очень долго. Второй пример – реестр Windows.
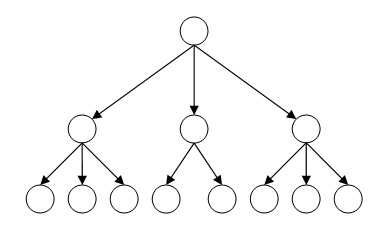
На рисунке вы можете увидеть структуру иерархической базы данных, в самом верху находится родитель или корневой элемент, ниже находятся дочерние элементы, элементы, находящиеся на одном уровне называются братьями, ну или соседними элементами. Соответственно чем ниже уровень элемента, тем вложенность этого элемента больше.
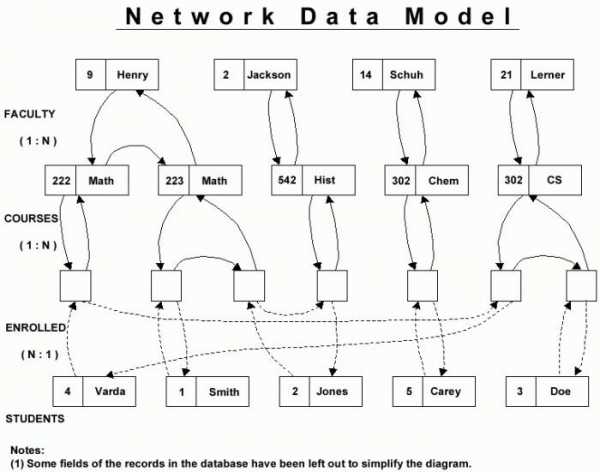
Сетевая база данных, структура сетевых баз данных
Сетевые базы данных, являются своеобразной модификацией иерархических баз данных. Если вы внимательно смотрели на рисунок выше, то наверное обратили внимание, что к каждому нижнему элементу идет только одна стрелочка от верхнего элемента. То есть у иерархических баз данных у каждого дочернего элемента может быть только один потомок. Сетевые базы данных отличаются от иерархических тем, что у дочернего элемента может быть несколько предков, то есть, элементов стоящих выше него. Для большей наглядности и понимания структуры сетевых баз данных обратите внимание на рисунок:
Стоит заметить, что сетевые базы данных обладают примерно теми же характеристиками, что и иерархические базы данных. Но, в данной рубрике нас не сильно интересуют иерархические и сетевые базы данных, данная тема больше относится к формату XML, и возможно в рубрике посвященной языку расширяемой разметки, я постараюсь более подробно рассмотреть эту тему. А в рубрике посвященной MySQL нас интересуют реляционные базы данных, на которых мы и остановимся более подробно.
Реляционные базы данных, структура реляционных баз данных
Реляционные базы данных получили очень широкое распространение и многие пытаются писать огромные статьи, посвященные вопросу – почему реляционные базы данных получили такое широкое распространение, делают глубокомысленные выводы и замечания. Но на самом деле все очень просто – реляционные базы данных очень легко описываются в математике, то есть, под них очень хорошо написана математика.
Был когда-то такой математик – Эдгар Франк Кодд, умерший в 2003 году, который в восьмидесятых годах очень подробно описал структуру реляционных баз данных математическим языком. А если есть хорошо написанная математика, то соответственно есть и программная реализация. Останавливаться на биографии Э.Ф. Кодда я не буду, для этого есть различные энциклопедии. Именно благодаря Кодду реляционные базы данных стали активно развиваться. Поэтому-то, когда мы говорим базы данных, чаще всего мы подразумеваем именно реляционные базы данных.
Особенности реляционных баз данных
Главной особенностью реляционных баз данных является, то, что объекты внутри таких баз данных хранятся в виде набора двумерных таблиц. То есть, таблица состоит из набора столбцов, в котором может указываться: название, тип данных(дата, число, строка, текст и т.д.). Еще одной важной особенность реляционных БД является, то, что число столбцов фиксировано, то есть, структура базы данных известна заранее, а вот число строк или рядов в реляционных базах данных ничем не ограничено, если говорить грубо, то строки в реляционных базах данных и есть объекты, которые хранятся в базе данных.
На самом деле, базы данных – это абстрактное понятие, таблица – это всего лишь способ хранения информации, набор таблиц может быть связан логически и этот набор называют база данных. Поэтому неправильно говорить, что MySQL это база данных, база данных – это хранящаяся информация. А вот такое понятие, как СУБД – система управления базами данных, это и есть MySQL сервер, именно при помощи него мы управляем хранящимися данными. Или иначе MySQL – это программное воплощение математических идей.
Самой трудной задачей при работе с реляционными базами данных, является проектирование структуры баз данных. Проектирование структуры базы данных, заключается не только в том, чтобы создать таблицу и указать тип данных и наименование столбцов. На самом деле проектирование – это самый сложный этап при работе с базами данных. Потому что мощности ваших компьютеров ограничены. Пока данных мало, мало таблиц и строк в этих таблицах, машина будет их обрабатывать очень и очень быстро. Но, со временем количество информации будет увеличиваться, и мы получим замедление, которое будет увеличиваться, поскольку машине необходимо время на обработку тех или иных запросов(обработка информации). В прошлой статье я уже писал, что реляционные БД прежде всего ориентированы на модификацию(OLTP), то есть, добавить новую запись в таблицу – это очень простая операция для реляционной СУБД, а вот сделать выборку данных, это уже трудоемкая операция. Также есть и изменение данных, это как бы промежуточное звено между чтением и добавлением. Хотя MySQL сервер всегда можно настроить.
Проектирование базы данных
Ну что же, мы немного поговорили о достоинствах и недостатках реляционных баз данных. И теперь, вкратце, я затрону вопрос проектирования баз данных. Под проектированием я понимаю следующее: садится человек за стол, берет бумагу и ручку, и исходя из поставленной задачи, а также, исходя из достоинств и недостатков той или иной системы, в нашем случае СУБД MySQL начинает составлять структуру будущей базы данных. Требование к проектируемой базе данных обычно ставятся следующее:
- База данных должна быть как можно более компактна, то есть, неизыбыточна.
- База данных должна быть простой с точки зрения обработки.
И как вы, наверное, поняли, данные требования противоречат друг другу. Проектирование — это самый важный аспект при работе с базами данных. Обычно, проектировщик – это опытный администратор сервера баз данных, либо архитектор баз данных, с большим опытом работы. В серьезных проектах может быть несколько десятков, а то и сотен таблиц, которые связаны между собой самыми замысловатыми способами связи. Конечно, я не собираюсь углубляться в проектирование баз данных, да и не смогу это сделать, но, кое какие основы проектирования баз данных я попытаюсь осветить на страницах своего блога. Прежде чем приступить к проектированию базы данных, нужно понять, а что мы вообще собираемся проектировать. То есть, должны понять, что у нас должно получиться на выходе.
А на выходе мы должны получить так называемую диаграмму или как ее еще называют схема. Диаграмма – это определение: какая информация будет храниться, в какой таблице она будет храниться, в каком столбце какой тип данных, как называется таблица, сколько столбцов в таблице и их тип, как связаны между собой таблицы. Да, типы данных в столбцах могут быть разными, например, номер телефона или индекс можно записать, как с помощью символов, так и с помощью числового типа данных. Но появляется вопрос: какой тип данных лучше для хранения номера телефона или почтового индекса? Чисто интуитивно на этот вопрос чаще всего отвечают правильно – номер телефона в базе данных должен иметь символьный тип, а вот объяснить, почему именно символьный тип могут немногие. Объяснение очень простое, например, нам потребовались все почтовые индексы, начинающиеся на 637 или номера телефонов начинающиеся на 952, так вот, сделать такую выборку из данных имеющих числовой тип задача довольно проблематичная, а сделать такую же выборку из данных символьного типа довольно легко.
При проектировании баз данных очень часто встречаются такие задачи и поверьте, от того, как вы будете их решать, будет зависеть, то, насколько быстро будет работать ваша система, в следующей статье я продолжу вопрос проектирования баз данных.
На этом всё, спасибо за внимание, надеюсь, что был хоть чем-то полезен и до скорых встреч на страницах блога для начинающих вебразработчиков и вебмастеров ZametkiNaPolyah.ru
zametkinapolyah.ru
Иерархическая модель данных что собой представляет? :: SYL.ru
В современное время построение распределительных информационных систем непосредственно связано с объектно-ориентированными реляционными СУБД. Последние утвердились в качестве основных средств для оперативной обработки данных в различных информационных системах, имеющих самые разные масштабы: от персональных систем на РС до крупных приложений по обработке транзакций преимущественно в банковских системах.
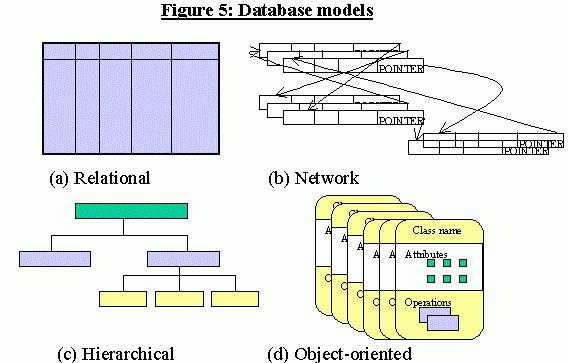
Сегодня существуют различные модели баз данных, других программ, которые выполняют аналогичные функции.
Классификация СУБД с точки зрения архитектуры
Известно, что они бывают:
- Локальными. Все части размещаются на 1-м компьютере.
- Распределительные. Все элементы распределены на нескольких компьютерах.

На протяжении нескольких десятилетий последовательно возникали системы, в основе которых были 3 модели баз данных:
- сетевая;
- иерархическая;
- реляционная.
Основные определения рассматриваемой сферы
Для удобства они сведены в таблицу ниже.
Основной термин | Трактовка |
СУБД – система управления базами данных | Ряд программных средств для создания, обновления, удаления, наполнения баз данных. |
СУБЗ – система управления базами знаний | Комплекс программных средств создания, обновления, удаления, наполнения баз знаний. |
БД – база данных | Электронные хранилища определенной информации, доступ к ним производится посредством 1-го (нескольких) компьютеров. |
БЗ – база знаний | Хранилища знаний, которые представлены в специальном форматизированном виде. |
Иерархическая модель данных: история создания, пример
Первые сетевые и иерархические СУБД появились в 60-х годах. Причиной этому послужила потребность в управлении миллионами записей, которые были связаны друг с другом определенном иерархическим образом, в частности, при поддержке (информационной) лунного проекта под названием «Аполлон». Пример иерархической модели данных — система IMS компании IBM. В современное время она выступает самой распространенной СУБД среди всех остальных данного типа. Другой пример иерархической модели данных – TDMS компании Development Corporation, а также Mark IV Multi компании Control Data Corporation и др.
Далее необходимо уделить внимание графическому представлению данной модели.
Что представляет собой иерархическая модель представления данных?
Здесь отношения организованы таким образом, что формируют совокупность деревьев. Каждое дерево выступает в качестве структуры данных, тип сегмента потомка в которой связан исключительно с 1-м типом сегмента предка.
Если рассматривать графически, то иерархическая модель данных представляет собой стрелку, где точка на ее конце – это предок, а точка на ее острие – потомок. Известно, что в БД установлено, что точками являются типы записей, стрелками же – взаимосвязи «один-ко-многим», «один-к-одному».
Совокупность ограничений рассматриваемой модели данных
Сюда можно отнести следующее:
- Если необходимо представить неиерархические отношения данных, то потребуются дополнительные манипуляции.
- Нет четкого разграничения физических и логических характеристик модели.
- В случае с непредвиденными запросами может потребоваться реорганизация базы данных.
Теперь для сравнения стоит рассмотреть все остальные модели.
Сетевая модель
Именно сети выступают единственным способом представления взаимосвязи между объектами. Их широко применяют в таких науках, как математика, химия, социология, физика, а также в исследованиях операций и в других сферах.
Сети чаще всего представляются математической структурой, именуемой как направляемый граф. Он оснащен простой структурой: состоит из узлов либо точек, которые соединены ребрами либо стрелками. В рамках контекста моделей данных точки могут быть представлены в виде типов записей данных, вышеупомянутые ребра – взаимосвязей «один-ко-многим», «один-к-одному». Графическая структура позволяет произвести простые представления отношений иерархии.
Реляционная модель
Все ранее существовавшие подходы к объединению записей из различных файлов применяли физические указатели (адреса на диске). Е. Ф. Кодд выделил внушительное ограничение числа типов манипуляций данных в такого рода базах. Более того, он доказал их чрезмерную чувствительность по отношению к переменам в физическом окружении. В ситуации, когда компьютерная система оснащалась новым накопителем, либо менялись адреса хранения определенных данных, всегда возникала необходимость дополнительного преобразования файлов. При добавлении в файле к формату записи новых полей их физические адреса изменялись. В связи с этим базы данных не давали возможность для манипуляции данными в такой степени, как это допускала логическая структура. Перечисленные проблемы были преодолены в рамках реляционной модели, основанной на логических взаимосвязях данных.
Известны два подхода к ее проектированию:
- На стадии концептуального проектирования выстраивается не концептуальная МД, а реляционная схема БД, которая состоит из определений специальных реляционных таблиц, постоянно подвергающихся нормализации.
- Механическая трансформация функциональной модели, которая была создана ранее, в реляционную (нормализованную). Данный подход, как правило, применяется в процессе проектирования масштабных, сложных схем БД, требуемых для информационных систем корпораций.
Отличительные особенности иерархической модели от сетевой
Сходство данных моделей – осуществление реализации наборов посредством указателей. Отличительной особенностью иерархической модели данных является, во-первых, то, что многочленные наборы устанавливают взаимосвязи соподчиненности. Там тип – владелец набора — именуется предком, а подчиненный тип – его потомком. Во-вторых, иерархия всегда начинается с единственного корневого узла. В-третьих, каждый узел соответствующего уровня присоединен к единственному узлу предыдущего уровня, а также, возможно, и с рядом узлов следующего. В-четвертых, доступ к всякому узлу, кроме корневого, возможен лишь посредством исходного узла. В-пятых, выборка узла, который представлен в иерархии, проводится с помощью цепи исходных узлов, формирующих путь, начиная от корня и заканчивая выбираемым узлом. В-шестых, число экземпляров узлов на каждом уровне не ограничено. В-седьмых, графа дерева не имеет циклов. И последнее. На самых низких уровнях могут присутствовать зависимые узлы. Тогда необходимо установить горизонтальные допсвязи между узлами разных уровней.
Недостатки и достоинства иерархической модели
Среди достоинств стоит отметить то, что программы, которые реализуют операции этой модели, значительно проще, чем аналоги сетевой. В ходе выполнений операций манипулирования перечнем данных в рассматриваемой модели рекомендуется учитывать то, что узел потомка не будет существовать, если удалить предка.
Что касается недостатков, то и иерархическая, и сетевая модели данных имеют идентичные недочеты, плюс в первой еще есть и те, которые связаны с ограниченностью связей.
Управление иерархическими данными
Иерархическая модель базы данных имеет 2 средства управления ими:
Физическая структура иерархической БД описывает, во-первых, логическую структуру рассматриваемой модели, а во-вторых, собственно структуру хранения БД. Способ доступа при этом определяет способ организации отношений физических записей.
Способ доступа может быть:
- индексным;
- иерархически прямым;
- иерархически последовательным:
- иерархически индексно-прямым;
- иерархически индексно-последовательным.
Помимо обязательного установления имени иерархической БД, а также способа доступа к любому из элементов, которые концентрирует в себе иерархическая модель данных, описание первой обязательно должно включать определение типов всех сегментов данных, вошедших в БД, согласно выстроенной иерархии.
Так, при описании типов сегментов рекомендуется начинать с главного корня рассматриваемой модели. Иерархическая модель данных имеет особенность: всякая физическая БД может включать лишь 1 корень. Однако в 1-й иерархической системе может быть расположено несколько физических БД.
Иерархическая модель данных среди всех своих операторов манипулирования последними выделяет операторов просто поиска данных (поиск указанного дерева БД, переход от 1-го дерева к другому, поиск экземпляра сегмента, который удовлетворяет условию, прочее) с возможностью их модификации (поиск и удержание в целях последующей модификации единственного экземпляра сегмента, который удовлетворяет условию и т. д.) и, соответственно, операторы модификации данных (помещение нового экземпляра сегмента в заданную позицию, удаление либо обновление текущего экземпляра соответствующего сегмента).
Здесь автоматически сохраняется единство ссылок между потомками и предками. Как уже было упомянуто ранее, существует правило касательно того, что потомок не может существовать без родителя.
Заключение
В статье были рассмотрены существующие на сегодняшний день модели данных: иерархическая, сетевая, реляционная. Более детально представлена первая модель.
www.syl.ru