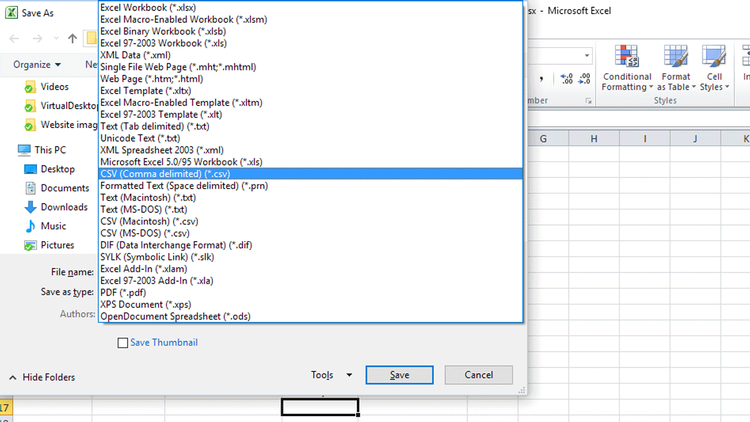
Импорт и экспорт данных: CSV, копирование таблиц, бэкапы
Импорт CSV-файлов
Импорт данных из файла
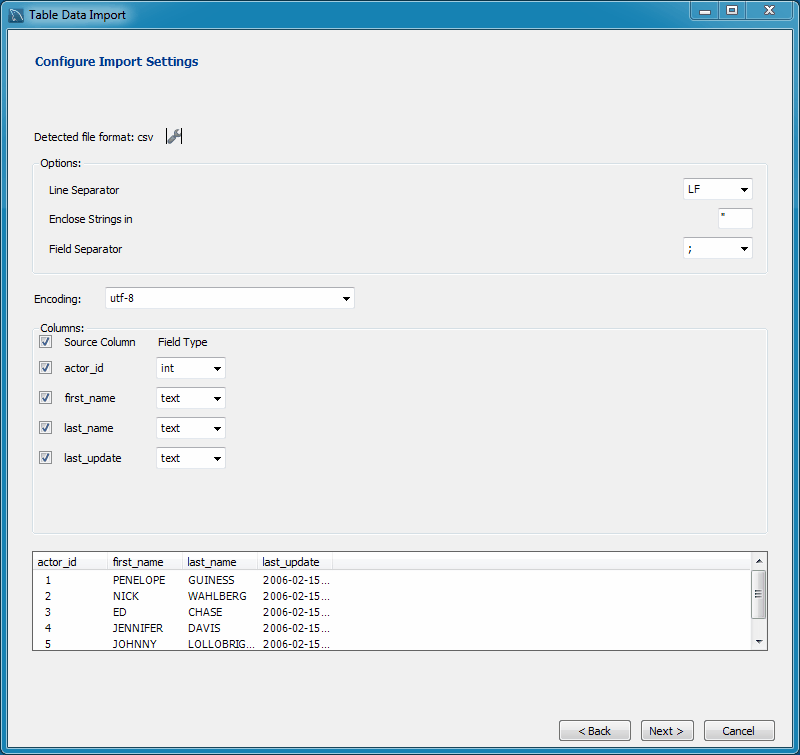
Для импорта CSV-файлов есть графический интерфейс. В контекстном меню схемы, в которую вы хотите импортировать, выберите пункт Import From File… Затем выберите сам CSV-файл.
Откроется диалоговое окно импорта. В левой панели опишите формат: укажите разделитель, префиксы, уточните наличие и формат заголовков.
В правой части окна опишите таблицу, в которую запишутся данные. Нажмите Delete на столбце, если не хотите его импортировать. Если вы хотите импортировать данные в существующую таблицу, кликните на Import From File…, используя контекстное меню этой таблицы.
В файле данных могут быть ошибки. По умолчанию включен флажок Write error records to file (Записывать ошибки в файл). Процесс импорта не прервется, но создастся журнал с информацией о строках, которые записать не удалось.
Вставка CSV в редактор данных
Вставляйте данные из экселевских таблиц. В общем случае это означает вставку в CSV формате. В DataGrip можно настроить формат, в котором будут записаны данные в буфере обмена. Но IDE может определить его и автоматически: нажмите на шестеренку и выберите значение Paste format.
Редактор CSV
DataGrip умеет редактировать CSV-файлы как таблицы. Для этого выберите Edit As Table из контекстного меню.
Затем укажите разделитель, уточните формат заголовка и т.д. Есть предпросмотр.
Экспорт данных
Что и куда
Таблица
Таблицу можно экспортировать в:
— Файл. Контекстное меню таблицы → Dump data to file.
— Другую таблицу. Контекстное меню таблицы → Copy Table to (или нажать F5 на таблице) → Выбрать существующую таблицу.
— Новую таблицу в любой СУБД. Контекстное меню таблицы → Copy
Table to (или нажать F5 на таблице) → Выбрать схему или базу данных. Или просто перетащите таблицу мышкой туда, куда хотите экспортировать! На видео показано, как скопировать таблицу из PostgreSQL в SQLite.
Или просто перетащите таблицу мышкой туда, куда хотите экспортировать! На видео показано, как скопировать таблицу из PostgreSQL в SQLite.
SQL-запрос
Запрос может быть экспортирован в файл, то есть результаты сразу запишутся на диск. Для этого вызовите контекстное меню на запросе, выберите Execute to file. Затем укажите формат экспорта. Это особенно полезно, если запрос медленный: для экспорта не нужно запускать его два раза.
Результат запроса
Результат можно экспортировать в:
— Файл. Кнопка экспорта → To
File.
— Буфер обмена. Кнопка экспорта → To Clipboard.
— Существующую таблицу. Кнопка копирования → Выберите таблицу.
Выделенную область данных
Выделенную область данных можно скопировать в буфер обмена: Ctrl+C или через контекстное меню Copy.
Форматы экспорта
Всякий раз, когда вы экспортируете в файл или буфер обмена, используется определенный формат экспорта. Часто это CSV, но можно использовать и другие, например: JSON, XML, HTML и Markdown. Выберите соответствующий формат в выпадающем списке на панели инструментов или создайте свой собственный.
SQL-запросы
Any table or result-set can be presented as a batch of INSERT statements. Для этого выберите формат SQL Inserts в выпадающем списке. В некоторых случаях это самый быстрый способ перенести данные из одной таблицы в другую. Генератор кода умеет учитывать столбцы с автоинкрементом.
It can be also can be also presented as a batch of UPDATE statements, which can help you to modify data.
CSV, TSV
There are two pre-built formats in the list: Comma Separated Values and Tab Separated Values. Вы можете создать свой формат с любым разделителем. For instance, it can be Confluence Wiki Markup.
HTML и XML
Один из форматов по умолчанию нельзя изменить: HTML table. Другие форматы описаны скриптами: HTML-Groovy.html.groovy, XML-Groovy.xml.groovy и т.д. Эти скрипты называются «экстракторами». Эти скрипты можно модифицировать.
JSON
Экстрактор JSON-Groovy.json.groovy экспортирует данные в формате JSON.
Создание собственных форматов
Для нетривиальных случаев можно писать свои экстракторы. CSV-Groovy.csv.groovy, HTML-Groove.html.groovy — это экстракторы, встроенные в DataGrip по умолчанию. В выпадающем списке выбора форматов/экстракторов выберите Go to scripts directory, чтобы открыть папку, в которой лежат экстракторы.
Экстракторы, то есть скрипты, можно писать на Groovy или JavaScript. Они расположены в Scratches and
Consoles/Extensions/Database Tools and
SQL/data/extractors. Изменяйте существующие экстракторы или добавляйте свои собственные.
Чтобы узнать больше о написании экстракторов, прочитайте эту статью.
Инструменты для бэкапа
DataGrip поддерживает работу с mysqldump и pg_dump. Чтобы создать копию базы, используйте пункт Dump with… из контекстного меню источника данных. Инструменты восстановления для MySQL и PostgreSQL тоже вызывайте из контекстного меню. Для PostgreSQL можно восстанавливать двумя утилитами: pg_dump или psql. Выберите нужную в диалоговом окне.
Импорт и экспорт файлов CSV и XML в PowerShell | Windows IT Pro/RE
Классическая оболочка Cmd.exe в операционных системах Windows предоставляет очень простые средства для обработки текстов. Например, команда For /f позволяет читать строки текста из файла и обрабатывать их как одну строку, а оператор > дает возможность писать выходные данные команды в текстовый файл.
Однако простой построчный анализ текста дает сбой в том случае, если вам нужно обработать структурированные данные. Например, файлы в формате CSV являются чрезвычайно распространенным форматом обмена данными. Я не могу даже сосчитать, сколько раз видел в онлайн-форумах вопрос: «как мне прочитать вводимые данные из файла формата CSV, используя пакетный файл (то есть набор команд оболочки Cmd.exe)»? Возможно, вам пришлось делать весь анализ вручную, а это крайне сложно. Например, если строка вводимых данных содержит специальные символы, такие как , вы не сможете выполнить анализ. Анализ файлов XML с помощью Cmd.exe даже более сложен. Если не сказать невозможен.
Например, файлы в формате CSV являются чрезвычайно распространенным форматом обмена данными. Я не могу даже сосчитать, сколько раз видел в онлайн-форумах вопрос: «как мне прочитать вводимые данные из файла формата CSV, используя пакетный файл (то есть набор команд оболочки Cmd.exe)»? Возможно, вам пришлось делать весь анализ вручную, а это крайне сложно. Например, если строка вводимых данных содержит специальные символы, такие как , вы не сможете выполнить анализ. Анализ файлов XML с помощью Cmd.exe даже более сложен. Если не сказать невозможен.
Windows PowerShell справляется с упомянутыми выше трудностями, предоставляя строку команд для импорта и экспорта структурированных данных. Все эти команды содержат в названии либо слово CSV, либо слово XML, поэтому вы можете получить их список, введя следующую команду в строке PowerShell:
Get-Command | Where-Object { ($_.Name -like "*csv*") или
($_.Name -like "*xml*") } | Select-Object Name Я расскажу о командах, которые содержат глаголы Export и Import.
Я расскажу о командах, которые содержат глаголы Export и Import.Импорт файлов CSV
Как уже говорилось выше, CSV – это весьма распространенный формат для обмена данными. файл CSV является открытым текстовым файлом, который представляет собой таблицу данных. Каждая строка файла — это одна запись (строка) данных. Первая строка файла обычно (хотя и не всегда) определяет имена полей (столбцов). Элементы данных внутри каждой строки разделены символом разделителя. В качестве разделителя часто используется запятая (особенно когда дело касается текстовых данных), поэтому элементы данных в файле CSV обычно заключены в двойные кавычки («) или в какие-либо другие символы. В таблице приведен пример таблицы данных.
На экране 1 показано, как эти данные будут представлены в файле CSV.
Экран 1. Пример данных файла CSV Пример данных файла CSV |
Import-Csv читает файл CSV и выводит список пользовательских объектов PowerShell: один для каждой строки вводимых данных. PowerShell воспринимает первую строку файла CSV как свойства объекта, а последующие строки файла являются выводимыми объектами. Например, если вы запускаете команду Import-Csv Sample.csv, то PowerShell выведет три объекта с двумя свойствами для каждого: DisplayName и Mail, как показано на экране 2.
| Экран 2. Вывод при использовании Import-Csv для чтения файла CSV |
Если файл CSV, который вы хотите импортировать, не имеет строки заголовка, вы можете использовать параметр –Header для наименования свойств объекта. Таким образом, если бы в Sample1.csv отсутствовала первая строка (заголовок), вы бы использовали команду, например:
Import-Csv Sample.csv -Header DisplayName,EmailAddress
 csv -Header DisplayName,EmailAddress
csv -Header DisplayName,EmailAddressImport-Csv использует символ запятой, так как это разделитель по умолчанию, но вы можете применить параметр –Delimiter для определения иного символа для разделителя. Например, если бы Sample.csv использовал символ «табуляции» в качестве разделителя, вы бы вводили такую команду:
Import-Csv Sample.csv -Delimiter "`t"
Поскольку Import-Csv выводит объекты PowerShell, вы можете задействовать другие команды PowerShell для обработки объектов. Например, предположим, что вы хотите рассортировать выводимые данные по критерию DisplayName, но вам нужно только свойство Mail для каждого объекта. Чтобы это сделать, вы используете команды Sort-Object и Select-Object:
Import-Csv Sample.csv | Sort-Object DisplayName | Select-Object Mail
Также вы можете передать эти объекты команде ForEach-Object для обработки:
Import-Csv Sample.Csv | ForEach-Object {
'»{0}«' -f $_.DisplayName,$_.Mail
} Эта команда использует символ –f для вывода форматированной строки для каждого объекта и производит вывод данных, показанный на экране 3.
| Экран 3. Чтение и обработка файла CSV командами Using?Import-Csv и ForEach-Object |
Экспорт файлов CSV
Иногда бывает необхоодимо создать файл CSV из выводимых данных объектов PowerShell. Чтобы это сделать, вы используете конвейер PowerShell для направления данных команде Export-Csv и указываете имя файла. PowerShell запишет выводимые данные объектов в файл CSV. Это просто, но есть одна небольшая хитрость. По умолчанию Export-Csv пишет строку, начинающуюся с символов #TYPE, в качестве первой строки файла CSV. Параметр –NoTypeInformation в Export-Csv опускает эту дополнительную строчку при выводе данных, поэтому я обычно указываю данный параметр.
Предположим, вы хотите создать копию Sample.csv, сортируя его по свойству DisplayName. Все, что вам нужно, — это импортировать файл, отправить его контент в команду Sort-Object, а затем экспортировать контент в новый файл CSV:
Import-Csv Sample.
 csv | Sort-Object DisplayName |
Export-Csv Sample-Sorted.csv –NoTypeInformation
csv | Sort-Object DisplayName |
Export-Csv Sample-Sorted.csv –NoTypeInformationЗаметьте, что Export-Csv может выводить данные любых объектов PowerShell, а не только объектов, созданных при помощи Import-Csv. Например, взгляните на такую команду:
Get-ChildItem | Sort-Object Length | Select-Object FullName,LastWriteTime,Length | Export-Csv Data.csv -NoTypeInformation
Эта команда создает файл CSV, содержащий в текущей папке файлы, отсортированные по критерию размера. Эта команда использует Select-Object для выбора полного файлового имени каждого файла, времени последнего изменения и размера файла (длины). Таким образом, эти три свойства будут являться столбцами в файле CSV.
Импорт файлов XML
XML представляет собой другой тип текстового файла, который хранит структурированные данные. В листинге 1 приведен пример представления в XML данных из таблицы.
Данные в документе XML организованы в иерархическом порядке. В Sample.xml (листинг 1) у вас есть корневой элемент () и три дочерних элемента (). Элементы располагаются в парах и содержат другие элементы. Открывающий элемент использует угловые скобки вокруг своего имени, а закрывающий элемент использует косую черту перед именем элемента. Когда вы работаете с данными XML в PowerShell, вы должны иметь единственный корневой элемент. Другие элементы содержатся внутри корневого элемента.
Элементы располагаются в парах и содержат другие элементы. Открывающий элемент использует угловые скобки вокруг своего имени, а закрывающий элемент использует косую черту перед именем элемента. Когда вы работаете с данными XML в PowerShell, вы должны иметь единственный корневой элемент. Другие элементы содержатся внутри корневого элемента.
В PowerShell есть команда Import-Clixml, но Import-Clixml не может импортировать Sample.xml, потому что Sample.xml не полностью соответствует формату, который требует cmdlet. Вместо него вы можете использовать Get-Content cmdlet и дополнительный тип обеспечения [Xml]: $Data = [Xml] (Get-Content Sample.xml).
После ввода команды переменная $Data содержит объект XmlDocument. Объект XmlDocument включает два свойства: xml (элемент в верхней части файла) и базу данных (корневой элемент). Вы можете вывести данные из файла XML так:
$Data.database.record
Эта команда производит точно такой же вывод данных, как показано на экране 2: выводит данные трех объектов с двумя свойствами для каждого (DisplayName и Mail).
Если данные файла XML, который вы хотите импортировать, были сохранены Export-Clixml, вам не нужен дополнительный акселератор типа [Xml] и команда Get-Content. Вместо них вы можете использовать Import-Clixml, о чем я расскажу в следующем разделе.
Экспорт Файлов XML
Вы можете экспортировать объект XmlDocument в файл, используя Export-Clixml. Как и Export-Csv, команда Export-Clixml требует имя файла. Рассмотрим такие команды:
$Data = [Xml] (Get-Content Sample.xml) $Data | Export-Clixml Data.xml
Первая команда импортирует Sample.xml (листинг 1) в качестве объекта XmlDocument. Вторая команда экспортирует объект XmlDocument в Data.xml.
Import-Clixml противоположна Export-Clixml. Import-Clixml возвращает файл XML, который был экспортирован Export-Clixml в качестве объекта XmlDocument. Например, в следующей команде Import-Clixml возвращает Data.xml:
$Data2 = Import-Clixml Data.xml
После запуска этой команды переменная $Data2 содержит копию того же объекта XmlDocument, который хранится в $Data.
Помните, что вы можете применять команду Import-Clixml для импорта только файла XML, созданного Export-Clixml. Это связано с тем, что файл XML должен содержать специфический набор элементов, чтобы Import-Clixml могла импортировать его. Если файл XML не в нужном формате, вам необходимо использовать дополнительный акселератор типа [Xml] и Get-Content, о чем говорилось в предыдущем разделе.
Управляйте файлами CVS и XML
Текстовые файлы CSV и XML представляют собой популярные форматы для обмена данными. Создатели PowerShell предоставили нам несколько весьма мощных и простых в использовании команд, которые помогают импортировать и экспортировать файлы в оба формата. Выполняемый вручную анализ файлов CSV и XML остался в прошлом.
Листинг 1. Sample.xml
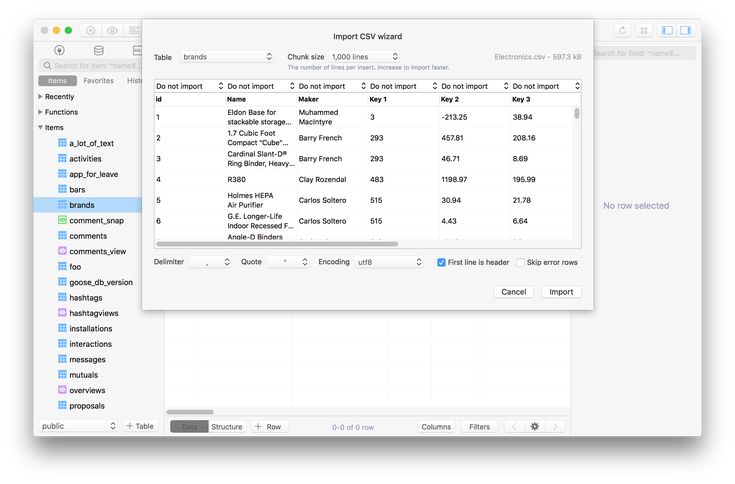
Импорт товаров из CSV | Инструкция Moguta.CMS
Обычно прайс-листы поставщиков предоставляются или в XLS или в CSV форматах. Moguta.CMS позволяет загружать прайсы поставщиков в форматах CSV и XLS/XLSX.
CSV - это текстовый формат файлов, предназначенный для представления табличных данных. Такие файлы можно открыть и редактировать не только в текстовом редакторе Notepad++, но и в знакомом всем табличном редакторе Excel от компании Micfosoft, с помощью которого можно легко переделать CSV в формат XSL и наоборот. Скорость импорта будет выше, при работе с форматом CSV.
Несмотря на то, что табличные файлы поставщиков имеют расширение CSV или XSL, необходимо убедиться, что таблицы внутри них соответствуют необходимой для Moguta.CMS структуре и содержат все необходимые колонки.
Пример работы с прайсом поставщика
Структура CSV и импорт каталога
Импорт изображений товаров
youtube.com/embed/5vm_jt7axZw?rel=0&hd=1">
Для того, чтобы импортировать товары из CSV файла в каталог интернет-магазина, выполните следющие действия:
- Перейдите в раздел "Товары", нажмите кнопку "Загрузить из Excel или CSV", затем "Загрузить файл Excel или CSV";
- Выберите прайслист вашего поставщика в формате CSV с вашего компьютера, кодировка файла должна быть Windows-1251.
На вашем хостинге может быть ограничение на размер загружаемого файла, что помешает загрузке больших каталогов. В таком случае файл CSV можно запаковать в zip-архив и загрузить его или сперва загрузить файл на сервер вручную.- В открывшемся окне выберите соответствия полей импорта. В столбце слева указаны названия полей в системе Moguta.CMS, в стоблце справа для каждого поля нужно выбрать соответствующее ему поле из вашего CSV файла.Обратите внимание, что в некоторых случаях важна последовательность полей и формат их названий.
- Убедитесь, что для каждого поля, которое нужно загрузить, выбрано соответствие, а для всех остальных отмечено «Не выбрано»;
- Если вам необходимо очистить каталог перед импортом, отметьте галочку «Удалить все имеющиеся товары, категории и свойства товаров». Это также удалить все переводы!
- Нажмите кнопку «Сохранить и начать импорт»;
- После импорта вам будет предложено загрузить архив с изображениями товаров. Если вы загружали изображения по ссылкам в CSV или хотите добавить их вручную, тогда пропустите этот пункт, импорт прайслиста из CSV для вас завершён, обновите страницу;
- Выберите с вашего компьютера ZIP-архив с изображениями, названия которых вы указывали в столбце Изображение в CSV файле;
- После загрузки обновите страницу, чтобы увидеть загруженные товары;
Назначение полей
Звездочкой * отмечены обязательные поля.
ID товара - уникальный идентификатор товара в Moguta.
Артикул - уникальный символьный код товара.
Категория* - название категории и подкатегорий через слешь.
Аксессуары/Головные уборы
URL категории - cодержит URL-адрес категории с учетом вложенностей. Следует заполнять, только, если вы хотите задать определённый URL, в противном случае URL для каждой категории будет заполнен автоматически транслитерацией из названия категории.
aksessuary/golovnye-ubory
Товар - название товара.
Вариант - нужно для создания вариантов, размеров и цветов товара. Позволяет задать название файла изображения, которое будет прикреплено к данному варианту товара.
Черный[:param:][src=image_name.jpg]
Краткое описание - содержит краткое описание товара, которое выводится в миникарточке. В данном поле имеется возможноть использовать HTML-разметку, но весь текст должен быть в одну строку и не нарушать целостность CSV файла.
Описание - содержит полное описание товара. В данном поле имеется возможноть использовать HTML-разметку, но весь текст должен быть в одну строку и не нарушать целостность CSV файла.
Цена* - содержит цену товара или его варианта. Указывается только числовое значение, без пробелов и валюты.
Изображение - позволяет загрузить изображения для товара. Изображения можно загрузить ZIP архивом с компьютера, либо по ссылкам со сторонних источников.
Загрузка изображений в архиве
Загрузка изображений по ссылке
Изображение варианта - позволяет загрузить изображения для варианта товара. Изображения можно загрузить ссылкой.
Количество - остаток (количество) товара в магазине.Активность - показывать или нет товар на сайте. Сменить активность можно будет вручную.
1 - товар будет отображаться в каталоге на сайте;
0 - товар будет скрыт;Заголовок [SEO] - текст, который будет подставляться в мета-теге Title на странице товара. Если не указать его в CSV, он будет сгенерирован автоматически из названия товара.
Ключевые слова [SEO] - текст, который будет подставляться в мета-теге Keywords на странице товара, если не указать его в CSV, он будет сгенерирован автоматически.
Бейсболка мужская Demix купить, CN32, Бейсболка, мужская, Demix
Описание [SEO] - текст, который будет подставляться в мета-теге Description на странице товара, если не указать его в CSV, он будет сгенерирован автоматически из описания товара.
Старая цена - позволяет установить старую цену для товаров, обычно используеться для установки скидки у товара.
Рекомендуемый 1 - Выводить товар в блоке «Рекомендуемые товары» (Хиты) на главной странице вашего интернет-магазина. 0 - не выводить.
Новый 1 - Выводить товар в блоке «Новинки» на главной странице вашего интернет-магазина. 0 - не выводить.
Сортировка - Позволяет вручную указать порядок вывода товаров путём присвоения порядкового номера каждому товару.
Вес - Позволяет указать вес товара. Данный параметр обычно необходим для интеграции с сервисами доставки. Указывается только числовое значение в килограммах, дробные значения указываются через точку.
Связанные артикулы
Указываются артикулы товаров, которые будут показываться в блоке «С этим товаром покупают» на странице товара.CN17,CN19,CN35,CN52,CN44
Смежные категории Указываются номера категорий, товары из которых будут показываться в блоке «С этим товаром покупают» на странице товара.
17,3,12
Ссылка на товар - Если вы собираетесь продавать электронные товары (книги, документы, музыку, любые другие файлы), то в этом поле необходимо указать ссылку на файл, который будет отправлен покупателю после оплаты. Сами файлы можно размещать в папке uploads в корне сайта, тогда ссылка будет иметь вид: http://site.ru/uploads/file.pdfВалюта - Позволяет установить валюту для определённого товара. Основная валюта магазина задаётся в разделе «Настроки» - «Валюта» в панели админстрирования сайта.
RUR
Единицы измерения - Устанавливает единицу измерения товара.
шт
Оптовые цены - в заголовке данного столбца нужно указать значение количества, от которого будет применяться цена, указанная в ячейках этого столбца.
Пример записи заголовка: Количество от 10 [оптовая цена]
Пример записи значения: 999
Обратите внимание на написания заголовков столбцов, текст в них должен быть такой же, изменять необходимо только число. Таких столбцов можно в CSV файле создать столько, сколько условий количества вам наобходимо, следовать они должны один за другим.
В ячейках указывается только числовое значение цены, без валюты и пробелов.Склады - В заголовке столбца указывается название склада и обязательный параметр [склад], в ячейках столбца указывается количество данного товара на складе.
Пример записи значения: 9
Пример записи заголовка: Слад №1 [склад]Таких столбцов можно в CSV файле создать столько, сколько складов вам наобходимо, следовать они должны один за другим.
Свойства начинаются с - в этом пукте необходимо указать с какого столбца у вас в CSV файле начинаются характеристики(свойства) товара, например:
В данном файле характеристики начинаются со столбца "Длина", именно его и следует указать в поле "Свойства начинаются с" при импорте.
Многостолбцовая структура. В заголовках вы указываете название свойства товара, а в самом поле указываете значение свойства. Если свойство является цветом или размером, в заголовке после названия свойства требуется прописать соответственно [size] или [color].
Если характеристика является текстовым полем, то аналогичным способом нужно приписать [textarea]. Если требуется задать несколько характеристик с одинаковым названием, необходимо у повторных характеристик указывать уникальный атрибут, например: Размер.
Примеры записи заголовка:
Производитель
Цвет [color]
Размер [size]
Размер [size]
Описание производства [textarea]В ячейках под заголовком нужно вписать значение свойства товара, если это свойство "цвет", то после названия цвета можно сразу прописать соответствующий ему HEX-код цвета в квадратных скобках, например так: Белый [#ffffff].
Если в вашем магазине уже заданы переводы, то после перезаписи характеристик через CSV переводы для них стираются!
Сложные характеристики Это поле не заполняется вручую, в него выгружаются сложные характеристики при экспорте каталога из магазина в CSV.
Изменение настройки импорта файла
Функционал изменения настройки импорта файла - позволяет обновить определенные товары. Определенные товары можно идентифицировать по артикулу или по категории и товару.
При выборе опции "Обновление конкретных товаров", с идентификацией по категории и товару, необходимо загружать csv файл, содержащий в себе все необходимые поля, с сохранением порядка.
При идентификации по артикулу, предоставляются поля на выбор, которые будут обновлены при импорте.
Например, если нам необходимо обновить только цену у определенных товаров, а искать определенные товары мы будем по артикулу, нам понадобится csv файл с 2 столбцами, а именно "Артикул" и "Цена".
После импорта таким способ, изменится только цена и только у определенного товара с соответствующим артикулом.Нулевая цена после импорта
Бывает при загрузке из CSV, пользователи сталкиваются с проблемой отображения нулевой цены.
Для решения проблемы заведите, в настройках, в разделе "Валюты" необходимое ISO обозначение или измените значения в столбце CSV на корректные.
Возможные ошибки при загрузке каталога разобраны здесь: http://wiki.moguta.ru/faq/oshibki/ne-zagrujaetsya-csv-fayl-s-tovarami-na-server
Import-Csv (Microsoft.PowerShell.Utility) — PowerShell | Microsoft Learn


 CMS.
CMS.
 В поле нужно указать число 1 или 0.
В поле нужно указать число 1 или 0. Товары, имеющие старую цену, будут отображаться в блоке «Акции» на главной странице вашего интернет-магазина.
Товары, имеющие старую цену, будут отображаться в блоке «Акции» на главной странице вашего интернет-магазина. Номера категорий можно посмотреть в разделе "Категории" в панели администратора.
Номера категорий можно посмотреть в разделе "Категории" в панели администратора.


 Связано это с тем, что в колонке "Валюта" указана несуществующая валюта.
Связано это с тем, что в колонке "Валюта" указана несуществующая валюта. - Справочник
- Модуль:
- Microsoft.PowerShell.Утилита
Создает табличные настраиваемые объекты из элементов файла со значениями, разделенными запятыми (CSV).
Синтаксис
Import-Csv
[[-Разделитель] ]
[-Путь] <Строка[]>
[-Заголовок <Строка[]>]
[-Кодировка <Кодировка>]
[<Общие параметры>] Импорт-CSV
[[-Разделитель] ]
-LiteralPath <Строка[]>
[-Заголовок <Строка[]>]
[-Кодировка <Кодировка>]
[] Import-Csv
[-Путь] <Строка[]>
-Использовать культуру
[-Заголовок <Строка[]>]
[-Кодировка <Кодировка>]
[] Import-Csv
-LiteralPath <Строка[]>
-Использовать культуру
[-Заголовок <Строка[]>]
[-Кодировка <Кодировка>]
[<Общие параметры>] Описание
Командлет Import-Csv создает табличные настраиваемые объекты из элементов в CSV-файлах. Каждый столбец
в файле CSV становится свойством пользовательского объекта, а элементы в строках становятся свойством
ценности.
Каждый столбец
в файле CSV становится свойством пользовательского объекта, а элементы в строках становятся свойством
ценности. Import-Csv работает с любым файлом CSV, включая файлы, созданные с помощью Export-Csv командлет.
Можно использовать параметры командлета Import-Csv , чтобы указать строку заголовка столбца и элемент
разделитель или прямая Import-Csv для использования разделителя списка для текущей культуры в качестве элемента
разделитель.
Вы также можете использовать командлеты ConvertTo-Csv и ConvertFrom-Csv для преобразования объектов в CSV
струны (и обратно). Эти командлеты аналогичны командлетам Export-CSV и Import-Csv , за исключением
что они не имеют дело с файлами.
Если запись строки заголовка в CSV-файле содержит пустое или нулевое значение, PowerShell вставляет значение по умолчанию.
имя строки заголовка и отображает предупреждающее сообщение.
Начиная с PowerShell 6.0, Import-Csv теперь поддерживает расширенный формат файла журнала W3C.
Примеры
Пример 1: Импорт объектов процесса
В этом примере показано, как экспортировать, а затем импортировать CSV-файл объектов процесса.
Процесс получения | Export-Csv -Путь .\Processes.csv $P = Импорт-CSV-Путь .\Processes.csv $П | Get-Member Имя Типа: System.Management.Automation.PSCustomObject Имя MemberType Определение ---- ---------- ---------- Метод Equals bool Equals (System.Object obj) Метод GetHashCode int GetHashCode() GetType Тип метода GetType() Строка метода ToString ToString() BasePriority NoteProperty string BasePriority=8 Строка Company NoteProperty Company=Microsoft Corporation ... $П | Таблица форматов Имя SI Обрабатывает VM WS PM NPM Путь ---- -- ------- -- -- -- --- ---- ApplicationFrameHost 4 407 2199293489152 15884288 15151104 23792 C:\WINDOWS\system32\ApplicationFrameHost.exe ... wininit 0 157 21904288 4591616 1630208 10376 winlogon 4 233 21949056 7659520 2826240 10992 C:\WINDOWS\System32\WinLogon.
 exe
WinStore.App 4 846 873435136 33652736 26607616 55432 C:\Program Files\WindowsApps\Microsoft.WindowsStore_11712.1001.13.0_x64__8weky...
WmiPrvSE 0 201 21919392 8830976 3297280 10632 C:\WINDOWS\system32\wbem\wmiprvse.exe
WmiPrvSE 0 407 2199157727232 18509824 12922880 16624 C:\WINDOWS\system32\wbem\wmiprvse.exe
WUDFHost 0 834 2199310204928 51945472 87441408 24984 C:\Windows\System32\WUDFHost.exe
exe
WinStore.App 4 846 873435136 33652736 26607616 55432 C:\Program Files\WindowsApps\Microsoft.WindowsStore_11712.1001.13.0_x64__8weky...
WmiPrvSE 0 201 21919392 8830976 3297280 10632 C:\WINDOWS\system32\wbem\wmiprvse.exe
WmiPrvSE 0 407 2199157727232 18509824 12922880 16624 C:\WINDOWS\system32\wbem\wmiprvse.exe
WUDFHost 0 834 2199310204928 51945472 87441408 24984 C:\Windows\System32\WUDFHost.exe Командлет Get-Process отправляет объекты процесса по конвейеру в Export-Csv .
Командлет Export-Csv преобразует объекты процесса в строки CSV и сохраняет строки в
Файл процессов.csv. Командлет Import-Csv импортирует строки CSV из файла Processes.csv.
Струны сохраняются в $P переменная. Переменная $P отправляется по конвейеру в Командлет Get-Member , отображающий свойства импортированных строк CSV. Переменная $P передается по конвейеру командлету Format-Table и отображает объекты.
Пример 2. Укажите разделитель
В этом примере показано, как использовать параметр Delimiter командлета Import-Csv .
Процесс получения | Export-Csv -Path .\Processes.csv -Delimiter : $P = Import-Csv -Путь .\Processes.csv -Разделитель: $П | Формат-Таблица
Командлет Get-Process отправляет объекты процесса по конвейеру на Export-Csv . Экспорт-CSV Командлет преобразует объекты процесса в строки CSV и сохраняет строки в файле Processes.csv.
Параметр Delimiter используется для указания разделителя двоеточия. Командлет Import-Csv импортирует
строки CSV из файла Processes.csv. Строки сохраняются в переменной $P . К $P переменная отправляется по конвейеру в 9Командлет 0027 Format-Table .
Пример 3. Укажите текущий язык и региональные параметры для разделителя
В этом примере показано, как использовать командлет Import-Csv с параметром UseCulture .
(Get-Culture).TextInfo.ListSeparator Get-процесс | Export-Csv -Путь .\Processes.csv -UseCulture Import-Csv -Path .\Processes.csv -UseCulture
Командлет Get-Culture использует вложенные свойства TextInfo и ListSeparator чтобы получить
разделитель списка по умолчанию для текущей культуры. Командлет Get-Process отправляет объекты процесса вниз по
трубопровод к Export-Csv . Командлет Export-Csv преобразует объекты процессов в строки CSV и
сохраняет строки в файле Processes.csv. Параметр UseCulture использует текущую
разделитель списка по умолчанию для культуры. Командлет Import-Csv импортирует строки CSV из
Файл процессов.csv.
Пример 4. Изменение имен свойств в импортированном объекте
В этом примере показано, как использовать параметр Header Import-Csv для изменения имен
свойства полученного импортированного объекта.
Start-Job -ScriptBlock { Get-Process } | Export-Csv -Путь .\Jobs.csv -NoTypeInformation
$Header = 'State', 'MoreData', 'StatusMessage', 'Location', 'Command', 'StateInfo', 'Finished', 'InstanceId', 'Id', 'Name', 'ChildJobs', 'BeginTime' , 'EndTime', 'JobType', 'Вывод', 'Ошибка', 'Ход выполнения', 'Подробный', 'Отладка', 'Предупреждение', 'Информация'
# Удалить заголовок по умолчанию из файла
$A = Get-Content-Path .\Jobs.csv
$A = $A[1..($A.Count - 1)]
$А | Out-File -FilePath .\Jobs.csv
$J = Import-Csv -Путь .\Jobs.csv -Заголовок $Заголовок
$J
Состояние: работает
Дополнительные данные: правда
Статус :
Местоположение: локальный хост
Команда: Получить-Процесс
Информация о состоянии: работает
Завершено: System.Threading.ManualResetEvent
Идентификатор экземпляра: a259eb63-6824-4b97-a033-305108ae1c2e
Идентификатор: 1
Имя: Работа1
Дочерние задания: System.Collections.Generic.List`1[System.Management.Automation.Job]
Время начала : 20.12.2018 18:59:57
Время окончания :
Тип задания: фоновое задание
Вывод: System. Management.Automation.PSDataCollection`1[System.Management.Automation.PSObject]
Ошибка: System.Management.Automation.PSDataCollection`1[System.Management.Automation.ErrorRecord]
Ход выполнения: System.Management.Automation.PSDataCollection`1[System.Management.Automation.ProgressRecord]
Verbose : System.Management.Automation.PSDataCollection`1[System.Management.Automation.VerboseRecord]
Отладка: System.Management.Automation.PSDataCollection`1[System.Management.Automation.DebugRecord]
Предупреждение: System.Management.Automation.PSDataCollection`1[System.Management.Automation.WarningRecord]
Информация : System.Management.Automation.PSDataCollection`1[System.Management.Automation.InformationRecord]  Management.Automation.PSDataCollection`1[System.Management.Automation.PSObject]
Ошибка: System.Management.Automation.PSDataCollection`1[System.Management.Automation.ErrorRecord]
Ход выполнения: System.Management.Automation.PSDataCollection`1[System.Management.Automation.ProgressRecord]
Verbose : System.Management.Automation.PSDataCollection`1[System.Management.Automation.VerboseRecord]
Отладка: System.Management.Automation.PSDataCollection`1[System.Management.Automation.DebugRecord]
Предупреждение: System.Management.Automation.PSDataCollection`1[System.Management.Automation.WarningRecord]
Информация : System.Management.Automation.PSDataCollection`1[System.Management.Automation.InformationRecord]
Management.Automation.PSDataCollection`1[System.Management.Automation.PSObject]
Ошибка: System.Management.Automation.PSDataCollection`1[System.Management.Automation.ErrorRecord]
Ход выполнения: System.Management.Automation.PSDataCollection`1[System.Management.Automation.ProgressRecord]
Verbose : System.Management.Automation.PSDataCollection`1[System.Management.Automation.VerboseRecord]
Отладка: System.Management.Automation.PSDataCollection`1[System.Management.Automation.DebugRecord]
Предупреждение: System.Management.Automation.PSDataCollection`1[System.Management.Automation.WarningRecord]
Информация : System.Management.Automation.PSDataCollection`1[System.Management.Automation.InformationRecord] Командлет Start-Job запускает фоновое задание, которое запускает Get-Process . Объект задания отправляется вниз
конвейер к командлету Export-Csv и преобразован в строку CSV. NoTypeInformation Параметр удаляет заголовок информации о типе из выходных данных CSV и является необязательным в PowerShell v6 и
выше.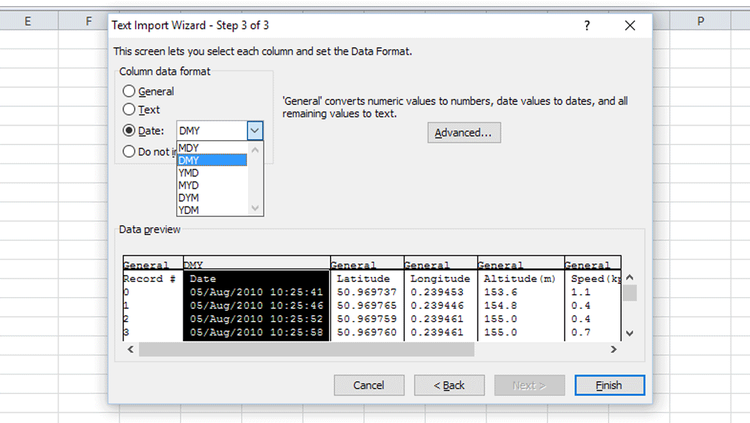 Переменная
Переменная $Header содержит настраиваемый заголовок, который заменяет следующие значения по умолчанию: Хасморедата , JobStateInfo , PSBeginTime , PSEndTime и PSJobTypeName . $A переменная использует командлет Get-Content для получения строки CSV из файла Jobs.csv. $A переменная используется для удаления заголовка по умолчанию из файла. Командлет Out-File сохраняет новый
версия файла Jobs.csv в переменной $A . Командлет Import-Csv импортирует файл Jobs.csv.
и использует параметр заголовка для применения Переменная $Header . Переменная $J содержит
импортировал PSCustomObject и отображает объект в консоли PowerShell.
Пример 5. Создание настраиваемого объекта с помощью CSV-файла
В этом примере показано, как создать настраиваемый объект в PowerShell с помощью CSV-файла.
Get-Content-Путь .\Links.csv 113207,about_Aliases 113208, about_Arithmetic_Operators 113209, about_Arrays 113210, about_Assignment_Operators 113212, about_Automatic_Variables 113213,about_Break 113214, about_Command_Precedence 113215, about_Command_Syntax 144309,about_Comment_Based_Help 113216, about_CommonParameters 113217, about_Comparison_Operators 113218,информация_Продолжить 113219, about_Core_Commands 113220, about_Data_Section $A = Import-Csv -Path .\Links.csv -Header 'LinkID', 'TopicTitle' $А | Get-Member Имя Типа: System.Management.Automation.PSCustomObject Имя MemberType Определение ---- ---------- ---------- Метод Equals bool Equals (System.Object obj) Метод GetHashCode int GetHashCode() GetType Тип метода GetType() Строка метода ToString ToString() LinkID NoteProperty string LinkID=113207 TopicTitle NoteProperty string TopicTitle=about_Aliases $А | Where-Object -Property TopicTitle -Like '*псевдоним*' LinkID Название темы ------ ---------- 113207 about_Aliases
Чтобы создать файл Links. csv, используйте значения, показанные в выходных данных
csv, используйте значения, показанные в выходных данных Get-Content .
Командлет Get-Content отображает файл Links.csv. Командлет Import-Csv импортирует файл Links.csv.
файл. Параметр Header указывает имена свойств LinkId и TopicTitle .
объекты хранятся в переменной $A . Командлет Get-Member показывает имена свойств из Заголовок параметр. Командлет Where-Object выбирает объекты со свойством TopicTitle .
который включает псевдоним .
Пример 6. Импорт CSV-файла, в котором отсутствует значение
В этом примере показано, как командлет Import-Csv в PowerShell реагирует на строку заголовка в CSV-файле.
файл содержит нулевое или пустое значение. Import-Csv заменяет отсутствующий заголовок именем по умолчанию.
строка, которая становится именем свойства объекта, который Import-Csv возвращает.
Get-Content-Путь .\Projects.csv ProjectID,ProjectName,Завершено 13, инвентарь, Редмонд, правда 440,Дальний Восток,Правда 469, Маркетинг, Европа, Ложь Import-Csv -Путь .\Projects.csv ПРЕДУПРЕЖДЕНИЕ. Один или несколько заголовков не указаны. Вместо отсутствующих заголовков использовались имена по умолчанию, начинающиеся с «H». ProjectID ProjectName h2 Завершено --------- ----------- -- --------- 13 Инвентарь Редмонд Правда 440 Дальний Восток Правда 469 Маркетинговая Европа Ложь (Импорт-Csv-Путь .\Projects.csv).h2 ПРЕДУПРЕЖДЕНИЕ. Один или несколько заголовков не указаны. Вместо отсутствующих заголовков использовались имена по умолчанию, начинающиеся с «H». Редмонд Дальний Восток Европа
Чтобы создать файл Projects.csv, используйте значения, показанные в выходных данных Get-Content примера .
Командлет Get-Content отображает файл Projects.csv. В строке заголовка отсутствует значение между ProjectName и Завершено . Командлет
Командлет Import-Csv импортирует файл Projects.csv и
отображает предупреждающее сообщение, поскольку h2 является именем заголовка по умолчанию. Команда (Import-Csv -Path .\Projects.csv).h2 получает h2 значений свойств и отображает предупреждение.
Параметры
-Delimiter
-Choding
-Header
-LiteralPath
-PATH
-USUCULTURE
. CSV
.Выходные данные
Объект
Этот командлет возвращает объекты, описанные в содержимом CSV-файла.
Примечания
Поскольку импортированные объекты являются CSV-версиями типа объекта, они не распознаются и отформатированы с помощью записей форматирования типа PowerShell, которые форматируют версии объекта, отличные от CSV. тип.
Результатом выполнения команды Import-Csv является набор строк, образующих пользовательский
объект. Каждая строка представляет собой отдельную строку, поэтому для подсчета можно использовать свойство объекта Count . строки таблицы. Столбцы — это свойства объекта, а элементы в строках — свойства.
ценности.
строки таблицы. Столбцы — это свойства объекта, а элементы в строках — свойства.
ценности.
Строка заголовка столбца определяет количество столбцов и имена столбцов. Имена столбцов также имена свойств объектов. Первая строка интерпретируется как столбец заголовки, если вы не используете параметр Заголовок для указания заголовков столбцов. Если в какой-либо строке больше значений, чем строка заголовка, дополнительные значения игнорируются.
Если в строке заголовка столбца отсутствует значение или содержится нулевое или пустое значение, Import-Csv использует Ч , за которым следует номер отсутствующего заголовка столбца и имя свойства.
В файле CSV каждый объект представлен списком значений свойств объекта, разделенных запятыми.
объект. Значения свойств преобразуются в строки с помощью метода ToString() класса
объекта, поэтому они представлены именем значения свойства. Export-Csv не экспортирует
методы объекта.
Import-Csv также поддерживает формат расширенного журнала W3C. Строки, начинающиеся с # рассматриваются как
комментарии и игнорируются, если комментарий не начинается с #Fields: и содержит список с разделителями
названия столбцов. В этом случае командлет использует эти имена столбцов. Это стандартный формат для
Windows IIS и другие журналы веб-сервера. Дополнительные сведения см. в разделе Расширенный формат файла журнала.
- ConvertFrom-Csv
- Преобразовать в CSV
- Экспорт-CSV
- Get-Культура
Как использовать Import-CSV в PowerShell — LazyAdmin
При работе с PowerShell мы можем использовать CSV-файлы для импорта данных в системы или использовать их в качестве справочного списка пользователей, например, для обновления или получения настроек. Для этого мы используем функцию Import-CSV в PowerShell.
Функция Import-CSV преобразует данные CSV в настраиваемый объект в PowerShell. Таким образом, мы можем легко просмотреть каждую строку CSV-файла и использовать данные в наших скриптах.
Таким образом, мы можем легко просмотреть каждую строку CSV-файла и использовать данные в наших скриптах.
В этой статье мы рассмотрим, как читать CSV-файл с помощью PowerShell, используя функцию Import-CSV, и как читать каждую строку с помощью командлета foreach. Я также дам вам несколько советов по использованию функции «Импорт CSV».
PowerShell Import-CSV
Командлет Import-CSV довольно прост и имеет лишь несколько полезных свойств:
- Путь — (обязательно) Расположение CSV-файла
- Разделитель , по умолчанию но это позволяет вам изменить его
- Заголовок — Позволяет вам определить пользовательские заголовки для столбцов. Используется в качестве имен свойств
- UseCulture — используйте разделитель по умолчанию вашей системы
- Кодировка — укажите кодировку импортируемого CSV-файла
Начнем с простого списка пользователей, которых мы можем импортировать в PowerShell. Я создал следующий файл CSV, который буду использовать в приведенных ниже примерах:
Я создал следующий файл CSV, который буду использовать в приведенных ниже примерах:
UserPrincipalName,"DisplayName","Title","UserType","IsLicensed" [email protected],"Ли Гу","младший инженер","Член","Правда" [email protected],"Меган Боуэн","рекрутер","Член","Правда" [email protected],"Грэйди Арчи","старший инженер","Член","Правда" [email protected],"Мириам Грэм","Директор","Член","Правда" [электронная почта защищена],"openmailbox","Член","False" [email protected],"Джоанна Лоренц","Старший инженер","Член","Правда" [электронная почта защищена],"Джони Шерман","рекрутер","Член","Ложь" [email protected],"Алекс Уилбер","Ассистент по маркетингу","Член","Правда" [email protected],"Исайя Лангер","Торговый представитель","Член","Настоящий"
В этом CSV-файле уже есть заголовки для каждого столбца, так что нам пока не нужно об этом беспокоиться. Чтобы импортировать этот файл CSV в PowerShell, мы можем просто использовать следующую команду:
Чтобы импортировать этот файл CSV в PowerShell, мы можем просто использовать следующую команду:
Import-CSV -Path c:\temp\test.csv | ft
В данном случае мы не сохраняем результаты в переменную, а сразу выводим в таблицу с ft . Как видите, теперь у нас есть все наши пользователи со всеми столбцами в PowerShell.
Если вы сохраняете результаты командлета импорта в переменную, вы можете ссылаться на каждый столбец как на свойство, используя имя столбца (заголовок):
$users = Import-Csv -Путь c:\temp\test.csv $users.DisplayName
Указание разделителя
Распространенная проблема при импорте CSV-файла с помощью PowerShell заключается в том, что разделитель не распознается. По умолчанию командлет Import-CSV использует
По умолчанию командлет Import-CSV использует , в качестве разделителя. Но здесь, в Нидерландах, например, разделитель по умолчанию в Excel для файлов CSV равен ; .
Поэтому, когда я создаю CSV-файл в Excel, который хочу использовать в PowerShell, мне нужно будет либо изменить разделитель в CSV-файле, либо указать правильный разделитель в PowerShell. Для этого есть два варианта.
Мы можем использовать параметр -delimiter , чтобы указать правильный разделитель:
$users = Import-Csv -Path c:\temp\test.csv -Delimiter ;
Или используйте системный разделитель по умолчанию с параметром -UseCulture :
$users = Import-Csv -Path c:\temp\test.
 csv -UseCulture
csv -UseCulture Если вы хотите узнать, какой разделитель по умолчанию компьютера, вы можете использовать следующую команду PowerShell для получения сведений о культуре:
(Get-Culture).TextInfo.ListSeparator
Powershell Import CSV ForEach
В большинстве случаев при импорте CSV-файла в PowerShell требуется просмотреть каждую строку CSV-файла. Например, чтобы получить разрешения для почтового ящика или размер папки OneDrive.
Для этого мы можем объединить команду Import CSV с ForEach. В этом случае внутри блока ForEach мы можем ссылаться на каждый столбец CSV-файла как на свойство объекта пользователя.
Взяв пример файла CSV, который я добавил в начале статьи, мы можем получить почтовый ящик каждого пользователя, используя UserPrincipalName следующим образом:
Import-CSV -Путь C:\temp\test.
 csv | Для каждого {
# Получить почтовый ящик каждого пользователя
Get-ExoMailbox-identity $_.UserPrincipalName
}
csv | Для каждого {
# Получить почтовый ящик каждого пользователя
Get-ExoMailbox-identity $_.UserPrincipalName
} Чтобы это работало, ваш CSV-файл должен иметь заголовки. Это не всегда так, иногда файлы CSV содержат только значения и вообще не содержат заголовков.
Чтобы по-прежнему можно было ссылаться на каждое значение в CSV-файле, вам потребуется добавить заголовки в командлет Import-CSV file.
Добавление заголовков в Import-CSV
Возьмем следующий CSV-файл с именами серверов и IP-адресом сервера:
la-ams-ad01,10.15.0.1 la-ams-file02,10.15.0.3 la-ams-db01,10.15.0.4 la-osl-ad01,10.12.0.1 la-osl-file01,10.12.0.5
Как видите, этот CSV-файл не имеет заголовков (имен столбцов). Поэтому, когда мы импортируем этот файл CSV непосредственно в PowerShell, вы увидите, что первая строка используется в качестве заголовка. Это не сработает.
Это не сработает.
Итак, нам нужно определить заголовки для CSV-файла. Нам нужно будет перечислить все заголовки в строке, разделенной запятыми, заключив имя каждого заголовка в одинарные кавычки ' .
Import-Csv -Path c:\temp\server.csv -Header 'ServerName', 'IpAddress'
Важно знать, что если вы не укажете все заголовки, остальные столбцы не будут импортированы. Итак, если мы расширим наш CSV-файл следующими столбцами:
la-ams-ad01,10.15.0.1,HP,DL365 G10 la-ams-file02,10.15.0.3,HP,DL380 G9 ла-амс-дб01, 10.15.0.4, HP, DL385 G10 ла-осл-ад01,10.12.0.1,HP,DL110 G8 la-osl-file01,10.
 12.0.5,HP,DL345 G10
12.0.5,HP,DL345 G10 И указать только три заголовка столбца, тогда последний столбец, в данном случае модель сервера, не будет импортирован:
Import-Csv -Path c:\temp\server.csv -Header 'ServerName', 'Ip', 'Бренд' # Результат: Имя сервера IP Марка ---------- -- ----- la-ams-ad01 10.15.0.1 HP la-ams-file02 10.15.0.3 HP ла-амс-дб01 10.15.0.4 HP ла-осл-ад01 10.12.0.1 HP la-osl-file01 10.12.0.5 HP
Если вы определяете больше заголовков, чем столбцов, то для каждого объекта создается дополнительное пустое свойство. Это может быть полезно, если вы хотите создать объект с дополнительными полями, которые вы хотите заполнить позже. Например, если вы хотите посмотреть дисковое пространство каждого сервера, мы уже можем добавить столбец дискового пространства к импортированным данным:
Import-Csv -Path c:\temp\server.
 csv -Header 'ServerName','Ip','Brand','Model','DiskSpace' | футов
# Результат
ServerName IP Марка Модель DiskSpace
---------- -- ----- ----- ---------
la-ams-ad01 10.15.0.1 HP DL365 G10
la-ams-file02 10.15.0.3 HP DL380 G9
la-ams-db01 10.15.0.4 HP DL385 G10
la-osl-ad01 10.12.0.1 HP DL110 G8
la-osl-file01 10.12.0.5 HP DL345 G10
csv -Header 'ServerName','Ip','Brand','Model','DiskSpace' | футов
# Результат
ServerName IP Марка Модель DiskSpace
---------- -- ----- ----- ---------
la-ams-ad01 10.15.0.1 HP DL365 G10
la-ams-file02 10.15.0.3 HP DL380 G9
la-ams-db01 10.15.0.4 HP DL385 G10
la-osl-ad01 10.12.0.1 HP DL110 G8
la-osl-file01 10.12.0.5 HP DL345 G10 Это позволяет сделать, например, следующее:
$servers = Import-Csv -Path c:\temp\server.csv -Header 'ServerName','Ip', «Бренд», «Модель», «DiskSpace»
$ серверы | Для каждого {
$_.DiskSpace = Invoke-Command -ComputerName $_.ServerName {Get-PSDrive C} | Выбор объекта бесплатно
} Как импортировать только определенные поля с помощью команды Import-CSV
При импорте файла CSV в PowerShell по умолчанию будут импортированы все столбцы. Но при работе с большими файлами бывает полезно выбирать только те данные, которые вам действительно нужны.
Но при работе с большими файлами бывает полезно выбирать только те данные, которые вам действительно нужны.
Есть два способа сделать это, если ваш CSV-файл имеет заголовки, то вы можете выбрать только тот столбец, который вам нужен:
Import-Csv -Path c:\temp\test.csv | выберите отображаемое имя, заголовок | Ft
Другой вариант — использовать -header , но это хорошо работает только тогда, когда вам нужен только первый столбец (или первая пара столбцов). Потому что вы не можете пропустить столбец с помощью этого метода:
Import-Csv -Path c:\temp\test.csv -Идентификатор заголовка # Результат я бы -- UserPrincipalName [электронная почта защищена] [электронная почта защищена] [электронная почта защищена] [электронная почта защищена] [электронная почта защищена] [электронная почта защищена] [электронная почта защищена] [электронная почта защищена] [email protected]
Подведение итогов
Командлет Import-CSV в PowerShell действительно полезен, когда вам нужно работать со списками или искать несколько объектов. Убедитесь, что вы проверили, содержит ли файл CSV заголовки и используете ли вы правильный разделитель.
Убедитесь, что вы проверили, содержит ли файл CSV заголовки и используете ли вы правильный разделитель.
Если у вас есть какие-либо вопросы, просто оставьте комментарий ниже.
csv — Чтение и запись файлов CSV — Документация по Python 3.10.8
Исходный код: Lib/csv.py
Так называемый формат CSV (значения, разделенные запятыми) является наиболее распространенным форматом импорта и
формат экспорта для электронных таблиц и баз данных. Формат CSV использовался для многих
лет до попыток стандартизированного описания формата в RFC 4180 . Отсутствие четко определенного стандарта означает, что тонкие различия
часто существуют в данных, производимых и потребляемых различными приложениями. Эти
различия могут затруднить обработку CSV-файлов из нескольких источников.
Тем не менее, хотя разделители и символы кавычек различаются, общий формат
достаточно похожи, чтобы можно было написать один модуль, который может
эффективно манипулировать такими данными, скрывая детали чтения и записи
данные от программатора.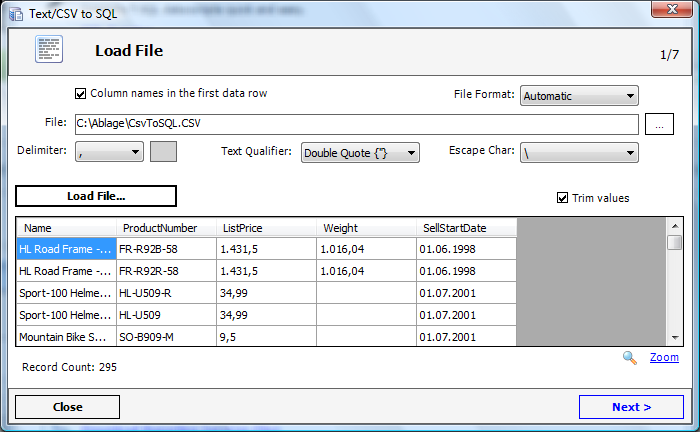
Модуль csv реализует классы для чтения и записи табличных данных в CSV.
формат. Это позволяет программистам сказать: «Запишите эти данные в предпочтительном формате».
Excel» или «прочитать данные из этого файла, созданного Excel», без
зная точные детали формата CSV, используемого Excel. Программисты могут
также опишите форматы CSV, понятные другим приложениям, или определите их
собственные специализированные форматы CSV.
Считыватель модуля и csv записи объектов чтение и
писать последовательности. Программисты также могут читать и записывать данные в словарной форме.
используя классы DictReader и DictWriter .
См. также
- PEP 305 — CSV File API
Предложение по улучшению Python, в котором предлагалось это дополнение к Python.
Содержание модуля
Модуль csv определяет следующие функции:
-
CSV. считыватель( csvfile , диалект='excel' , **fmtparams ) Возвращает объект чтения, который будет перебирать строки в заданном csvfile . csvfile может быть любым объектом, который поддерживает протокол итератора и возвращает string каждый раз, когда вызывается его метод
__next__()— подходят как файловые объекты, так и объекты списка. Если csvfile является файловым объектом, он должен быть открыт сновая строка = ''. 1 Дополнительный диалект параметр может быть задан, который используется для определения набора параметров характерные для конкретного диалекта CSV. Это может быть экземпляр подкласса классDialectили одна из строк, возвращаемыхфункция list_dialects(). Другие необязательные аргументы ключевого слова fmtparams может быть задан для переопределения отдельных параметров форматирования в текущем диалект. Полную информацию о диалекте и параметрах форматирования см.
раздел Диалекты и параметры форматирования.Каждая строка, прочитанная из CSV-файла, возвращается в виде списка строк. Нет автоматическое преобразование типа данных выполняется, если только формат
QUOTE_NONNUMERICуказана опция (в этом случае поля без кавычек преобразуются в числа с плавающей запятой).Краткий пример использования:
>>> импортировать csv >>> с open('eggs.csv', newline='') как csvfile: ... spamreader = csv.reader(csvfile, delimiter=' ', quotechar='|') ... для строки в программе чтения спама: ... печать (', '.join (строка)) Спам, Спам, Спам, Спам, Спам, Запеченная фасоль Спам, прекрасный спам, замечательный спам
 Полную информацию о диалекте и параметрах форматирования см.
раздел Диалекты и параметры форматирования.
Полную информацию о диалекте и параметрах форматирования см.
раздел Диалекты и параметры форматирования.-
CSV.писатель( csvfile , диалект='excel' , **fmtparams ) Возвращает объект записи, ответственный за преобразование данных пользователя в разделители строки в заданном файлоподобном объекте.
csvfile может быть любым объектом с метод write(). Если csvfile является файловым объектом, его следует открывать с помощьюnewline=''1. Необязательный диалект может быть задан параметр, который используется для определения набора параметров, специфичных для определенный диалект CSV. Это может быть экземпляр подклассаКласс диалектаили одна из строк, возвращенныхфункция list_dialects(). Другие необязательные аргументы ключевого слова fmtparams может быть задан для переопределения отдельных параметров форматирования в текущем диалект. Полную информацию о диалектах и параметрах форматирования см. раздел Диалекты и параметры форматирования. Сделать это как можно проще взаимодействовать с модулями, которые реализуют DB API, значениеНетзаписывается как пустая строка. Пока это не обратимое преобразование, упрощает вывод значений данных SQL NULL в CSV-файлы без предварительной обработки данных, возвращенных изcursor.вызов. Все остальные нестроковые данные преобразуются в строки с помощью fetch* str()перед записью.Краткий пример использования:
импорт CSV с open('eggs.csv', 'w', newline='') как csvfile: spamwriter = csv.writer (csvfile, разделитель = ' ', quotechar='|', quoting=csv.QUOTE_MINIMAL) spamwriter.writerow(['Спам'] * 5 + ['Запеченные бобы']) spamwriter.writerow(['Спам', 'Прекрасный спам', 'Чудесный спам'])
 csvfile может быть любым объектом с
csvfile может быть любым объектом с  fetch*
fetch* -
CSV.register_dialect( имя [ диалект [ **fmtparams ]]) Свяжите диалект с именем . имя должно быть строкой. диалект можно указать либо путем передачи подкласса
Dialect, либо по fmtparams аргументов ключевых слов или и то, и другое, с переопределением аргументов ключевых слов параметры диалекта. Для получения полной информации о диалектах и форматировании параметры, см. раздел Диалекты и параметры форматирования.
 раздел Диалекты и параметры форматирования.
раздел Диалекты и параметры форматирования.-
CSV.unregister_dialect( имя ) Удалите диалект, связанный с именем , из реестра диалектов. Ан
Ошибкавозникает, если имя не является зарегистрированным диалектным именем.
-
CSV.get_dialect( имя ) Вернуть диалект, связанный с именем . Ошибка
Диалект.
-
CSV.список_диалектов() Вернуть названия всех зарегистрированных диалектов.
-
CSV.field_size_limit([ new_limit ]) Возвращает текущий максимальный размер поля, разрешенный синтаксическим анализатором.
Если new_limit данный, это становится новым пределом.
 Если new_limit данный, это становится новым пределом.
Если new_limit данный, это становится новым пределом. Модуль csv определяет следующие классы:
- класс
csv.Dictreader( F , FieldNames = None , RESTKEY = NONE , RESTVAL = NONE , DIALECT = 'Excel' , *ARGS 656565656565656565656565656565656565656565656565656565656565656565656565656565656565656565656565656565656565656, .Создайте объект, который работает как обычный ридер, но отображает информация в каждой строке к
dict, чьи ключи даны опционально имена полей параметр.Параметр fieldnames представляет собой последовательность. Если имен полей опущены, значения в первой строке файла f будут использоваться в качестве имена полей. Независимо от того, как определяются имена полей, словарь сохраняет их первоначальный порядок.
Если в строке больше полей, чем имен полей, оставшиеся данные помещаются в список и сохраняется с именем поля, указанным ключом покоя (по умолчанию до
Нет). Если в непустой строке меньше полей, чем имен полей,
пропущенные значения заполняются значением restval (которое по умолчанию
до Нет).Все остальные необязательные или ключевые аргументы передаются базовому
считывательэкземпляр.Изменено в версии 3.6: возвращаемые строки теперь имеют тип
OrderedDict.Изменено в версии 3.8: возвращаемые строки теперь имеют тип
dict.Краткий пример использования:
>>> импортировать csv >>> с open('names.csv', newline='') как csvfile: ... читатель = csv.DictReader (csvfile) ... для строки в читателе: ... print(строка['first_name'], строка['last_name']) ... Эрик Айдл Джон Клиз >>> печать (строка) {'first_name': 'Джон', 'last_name': 'Клиз'}
 Если в непустой строке меньше полей, чем имен полей,
пропущенные значения заполняются значением restval (которое по умолчанию
до
Если в непустой строке меньше полей, чем имен полей,
пропущенные значения заполняются значением restval (которое по умолчанию
до - класс
csv.DictWriter( f , имена полей , restval='' , extrasaction='raise' , диалект='Excel' , *args , **kwds ) Создайте объект, который работает как обычный писатель, но сопоставляет словари на выходные строки.
Параметр 90 525 имен полей 90 526 представляет собой 90 027 последовательность 90 028 ключей, определяющих порядок, в котором значения в
словарь, переданный методу writerow(), записывается в файл ф . Необязательный параметр restval указывает значение, пишется, если в словаре отсутствует ключ в имена полей . Если словарь, переданный методуwriterow(), содержит ключ, не найденный в имена полей , необязательный параметр extrasaction указывает, какое действие следует брать. Если установлено значение'raise', значение по умолчанию,ValueErrorПоднялся. Если установлено значение'ignore', лишние значения в словаре игнорируются. Любые другие необязательные или ключевые аргументы передаются базовомуписательэкземпляр.Обратите внимание, что в отличие от класса
DictReaderпараметр имен полей классаDictWriterне является обязательным.Краткий пример использования:
импорт CSV с open('names.csv', 'w', newline='') как csvfile: имена полей = ['first_name', 'last_name'] писатель = csv.DictWriter (csvfile, имена полей = имена полей) писатель.writeheader() Writer.writerow({'first_name': 'Запеченный', 'last_name': 'Бобы'}) author.writerow({'first_name': 'Прекрасный', 'last_name': 'Спам'}) author.writerow({'first_name': 'Замечательно', 'last_name': 'Спам'})
 Параметр 90 525 имен полей 90 526 представляет собой 90 027 последовательность 90 028 ключей, определяющих порядок, в котором значения в
словарь, переданный методу
Параметр 90 525 имен полей 90 526 представляет собой 90 027 последовательность 90 028 ключей, определяющих порядок, в котором значения в
словарь, переданный методу 
- класс
csv.Диалект Класс
Dialect— это класс-контейнер, атрибуты которого содержат информация о том, как обрабатывать двойные кавычки, пробелы, разделители и т. д. Из-за отсутствия строгой спецификации CSV различные приложения производят слегка отличающиеся данные CSV.Экземпляры диалектаопределяют, какчитательиписательведут себя экземпляры.Все в наличии 9
- класс
csv. первенствовать Класс
excelопределяет обычные свойства файла CSV, созданного в Excel файл. Он зарегистрирован с диалектным именем'excel'.

- класс
csv.excel_tab Класс
excel_tabопределяет обычные свойства сгенерированного Excel Файл с разделителями TAB. Он зарегистрирован под диалектным названием 9.0027 ‘Excel-вкладка’ .
- класс
csv.unix_dialect Класс
unix_dialectопределяет обычные свойства файла CSV генерируется в системах UNIX, т. е. с использованием'\n'в качестве признака конца строки и заключения в кавычки все поля. Он зарегистрирован с именем диалекта'unix'.Новое в версии 3.2.
- класс
csv.Сниффер Класс
Snifferиспользуется для определения формата файла CSV.Класс
Snifferпредоставляет два метода:-
нюхать( образец , разделители=Нет ) Проанализируйте данный образец и верните подкласс
диалектаотражающие найденные параметры. Если необязательный параметр разделителей дан, он интерпретируется как строка, содержащая возможные допустимые символы-разделители.
Анализ образца текста (предположительно в формате CSV) и возврат
Истинно, если первая строка представляет собой серию заголовков столбцов. При проверке каждого столбца будет учитываться один из двух ключевых критериев. оценка, если образец содержит заголовок:Выбирается двадцать строк после первой строки; если больше половины столбцов + строки соответствуют критериям, возвращается
True.
Примечание
Этот метод является грубой эвристикой и может давать как ложные срабатывания, так и негативы.
-


Пример использования Sniffer :
с open('example.csv', newline='') как csvfile:
диалект = csv.Sniffer().sniff(csvfile.read(1024))
csvfile.seek(0)
читатель = csv.reader (csvfile, диалект)
# ... обработать содержимое файла CSV здесь ...
Модуль csv определяет следующие константы:
-
CSV.QUOTE_ALL Инструктирует
записывающих объектовзаключать в кавычки все поля.
-
CSV.QUOTE_MINIMAL Инструктирует
записывающихобъектов цитировать только те поля, которые содержат специальные символы, такие как разделитель , кавычка или любой из символов в терминатор линии .
-
CSV.QUOTE_NONNUMERIC Инструктирует
записывающих объектовзаключать в кавычки все нечисловые поля.Указывает читателю преобразовать все поля без кавычек в тип float .

-
CSV.QUOTE_NONE Инструктирует
записывающихобъектов никогда не заключать поля в кавычки. Когда текущий разделитель встречается в выходных данных, ему предшествует текущий управляющий символ персонаж. Если escapechar не установлен, модуль записи выдаст ошибкуError, если встречаются любые символы, требующие экранирования.Указывает
считывателюне выполнять специальную обработку символов кавычек.
Модуль csv определяет следующее исключение:
- исключение
csv.Ошибка Вызывается любой из функций при обнаружении ошибки.
Диалекты и параметры форматирования
Чтобы упростить задание формата входных и выходных записей,
параметры форматирования сгруппированы в диалекты. Диалект – это
подкласс класса
Диалект – это
подкласс класса Dialect , имеющий набор специфических методов и
единственный метод validate() . При создании считывателя или объектов записи , программист может указать строку или подкласс
класс Dialect в качестве параметра диалекта. В дополнение или вместо
из, диалект параметр, программист также может указать индивидуальный
параметры форматирования, которые имеют те же имена, что и атрибуты, определенные ниже
для класса Диалект .
Диалекты поддерживают следующие атрибуты:
-
Диалект.разделитель Односимвольная строка, используемая для разделения полей. По умолчанию это
','.
-
Диалект.двойная кавычка Управляет тем, как экземпляры quotechar , появляющиеся внутри поля, должны себя цитировать. Когда
True, символ удваивается. Когда False, escapechar используется в качестве префикса для кавычек . Это по умолчаниюTrue.На выходе, если двойная кавычка равна
Falseи escapechar не установлен,Ошибкавозникает, если в поле найдена кавычка .
 Когда
Когда -
Диалект.escapechar Строка из одного символа, используемая модулем записи для выхода из разделителя , если цитирует устанавливается в
QUOTE_NONEи кавычка , если двойная кавычкаЛожь. При чтении escapechar удаляет любое специальное значение из следующий персонаж. По умолчанию этоNone, что отключает экранирование.
-
Диалект.ограничитель линии Строка, используемая для завершения строк, созданных модулем записи
'\r\n'.Примечание
Считыватель
'\r', либо'\n'как конец строки и игнорирует признак конца строки . Это поведение может измениться в будущее.
 По умолчанию
до
По умолчанию
до -
Диалект.кавычка Односимвольная строка, используемая для заключения в кавычки полей, содержащих специальные символы, например как разделитель или кавычки , или которые содержат символы новой строки. Это по умолчанию
'"'.
-
Диалект.со ссылкой на Определяет, когда цитаты должны создаваться автором и распознаваться читатель. Он может принимать любую из констант
QUOTE_*(см. раздел Содержание модуля) и по умолчаниюQUOTE_MINIMAL.
-
Диалект.пропуск начального пространства Когда
True, пробелы сразу после разделителя игнорируются. По умолчанию Ложь.
 По умолчанию
По умолчанию -
Диалект.строгий Когда
True, возникает исключениеОшибкапри неправильном вводе CSV. По умолчаниюЛожь.
Объекты чтения
объектов Reader ( DictReader экземпляров и объектов, возвращенных функция reader() ) имеют следующие общедоступные методы:
-
csvreader.__следующий__() Вернуть следующую строку итерируемого объекта считывателя в виде списка (если объект был возвращен из
reader()) или dict (если этоDictReaderэкземпляр), проанализированный в соответствии с текущим диалектомследующий(читатель).
Объекты Reader имеют следующие общедоступные атрибуты:
-
csvreader.диалект Доступное только для чтения описание диалекта, используемого синтаксическим анализатором.

-
csvreader.номер_строки Количество строк, прочитанных из исходного итератора. Это не то же самое, что количество возвращаемых записей, так как записи могут занимать несколько строк.
Объекты DictReader имеют следующий общедоступный атрибут:
-
csvreader.имена полей Если этот атрибут не передается в качестве параметра при создании объекта, этот атрибут инициализируется при первом доступе или при чтении первой записи из файл.
Объекты записи
Writer объектов ( DictWriter экземпляров и объектов, возвращенных
функция Writer() ) имеют следующие общедоступные методы. А строка должна быть
итерация строк или чисел для объектов Writer и словарь
сопоставление имен полей со строками или числами (передавая их через str() первый) для объектов DictWriter . Обратите внимание, что комплексные числа записываются
в окружении скобок. Это может вызвать некоторые проблемы для других программ, которые
читать файлы CSV (при условии, что они вообще поддерживают комплексные числа).
Обратите внимание, что комплексные числа записываются
в окружении скобок. Это может вызвать некоторые проблемы для других программ, которые
читать файлы CSV (при условии, что они вообще поддерживают комплексные числа).
-
CSVWriter.запись строки( строка ) Запишите параметр строки в файловый объект устройства записи, отформатированный в соответствии с к текущему диалекту
Изменено в версии 3.5: Добавлена поддержка произвольных итераций.
-
CSVWriter.записей( строк ) Записать все элементы в строк (итерация ряд объектов как описано выше) в файловый объект писателя, отформатированный в соответствии с текущим диалект.
Объекты Writer имеют следующий общедоступный атрибут:
-
CSVWriter. диалект Доступное только для чтения описание диалекта, используемого писателем.

Объекты DictWriter имеют следующий общедоступный метод:
Напишите строку с именами полей (как указано в конструкторе) в файловый объект писателя, отформатированный в соответствии с текущим диалектом. Возвращаться возвращаемое значение
Вызов csvwriter.writerow()используется для внутреннего использования.Новое в версии 3.2.
Изменено в версии 3.8:
writeheader()теперь также возвращает значение, возвращаемое методcsvwriter.writerow(), который он использует внутри.
Примеры
Самый простой пример чтения файла CSV:
импорт CSV
с open('some.csv', newline='') как f:
читатель = csv.reader(f)
для строки в читателе:
печать (строка)
Чтение файла в альтернативном формате:
импорт CSV
с open('passwd', newline='') как f:
читатель = csv. reader(f, delimiter=':', quoting=csv.QUOTE_NONE)
для строки в читателе:
печать (строка)
 reader(f, delimiter=':', quoting=csv.QUOTE_NONE)
для строки в читателе:
печать (строка)
reader(f, delimiter=':', quoting=csv.QUOTE_NONE)
для строки в читателе:
печать (строка)
Соответствующий простейший пример написания:
импорт CSV
с open('some.csv', 'w', newline='') как f:
писатель = csv.writer (f)
писатель.writerows (некоторый вариант)
Поскольку open() используется для открытия файла CSV для чтения, файл
по умолчанию будет декодироваться в юникод с использованием системного значения по умолчанию
кодирование (см. locale.getpreferredencoding() ). Чтобы декодировать файл
используя другую кодировку, используйте аргумент encoding для open:
импорт CSV
с open('some.csv', newline='', encoding='utf-8') как f:
читатель = csv.reader(f)
для строки в читателе:
печать (строка)
То же самое относится к записи в чем-либо, отличном от системного по умолчанию кодировка: укажите аргумент кодировки при открытии выходного файла.
Регистрация нового диалекта:
импорт CSV csv.