Вставка данных в таблицу MySQL на Python с использованием оператора INSERT INTO, метода execute, добавление данных
Оператор INSERT INTO используется для добавления записи в таблицу. В python мы можем упоминать спецификатор формата(%s) вместо значений.
Мы предоставляем фактические значения в виде кортежа в cursor execute() методе.
Рассмотрим следующий пример.
import mysql.connector
#Create the connection object
myconn = mysql.connector.connect(host = "localhost", user = "root",passwd = "google",database = "PythonDB")
#creating the cursor object
cur = myconn.cursor()
sql = "insert into Employee(name, id, salary, dept_id, branch_name) values(%s, %s, %s, %s, %s)"
#The row values are provided in the form of tuple
val =("John", 110, 25000.00, 201, "Newyork")
try:
#inserting the values into the table
cur.execute(sql,val)
#commit the transaction
myconn. commit()
except:
myconn.rollback()
print(cur.rowcount,"record inserted!")
myconn.close()
commit()
except:
myconn.rollback()
print(cur.rowcount,"record inserted!")
myconn.close()
 commit()
except:
myconn.rollback()
print(cur.rowcount,"record inserted!")
myconn.close()
commit()
except:
myconn.rollback()
print(cur.rowcount,"record inserted!")
myconn.close()
Выход:
1 record inserted!
Вставка нескольких строк
Мы также можем вставить сразу несколько строк, используя скрипт python. Несколько строк упоминаются как список различных кортежей.
Каждый элемент списка рассматривается как одна конкретная строка, тогда как каждый элемент кортежа рассматривается как одно конкретное значение столбца(атрибут).
Пример:
import mysql.connector
#Create the connection object
myconn = mysql.connector.connect(host = "localhost", user = "root",passwd = "google",database = "PythonDB")
#creating the cursor object
cur = myconn.cursor()
sql = "insert into Employee(name, id, salary, dept_id, branch_name) values(%s, %s, %s, %s, %s)"
val = [("John", 102, 25000. 00, 201, "Newyork"),("David",103,25000.00,202,"Port of spain"),("Nick",104,90000.00,201,"Newyork")]
try:
#inserting the values into the table
cur.executemany(sql,val)
#commit the transaction
myconn.commit()
print(cur.rowcount,"records inserted!")
except:
myconn.rollback()
myconn.close()

Выход:
3 records inserted!
Row ID
В SQL конкретная строка представлена идентификатором вставки, который известен как идентификатор строки – Row ID. Мы можем получить идентификатор последней вставленной строки, используя атрибут lastrowid объекта курсора.
Рассмотрим следующий пример.
import mysql.connector #Create the connection object myconn = mysql.connector.connect(host = "localhost", user = "root",passwd = "google",database = "PythonDB") #creating the cursor object cur = myconn.cursor() sql = "insert into Employee(name, id, salary, dept_id, branch_name) values(%s, %s, %s, %s, %s)" val =("Mike",105,28000,202,"Guyana") try: #inserting the values into the table cur.execute(sql,val) #commit the transaction myconn.commit() #getting rowid print(cur.rowcount,"record inserted! id:",cur.lastrowid) except: myconn.rollback() myconn.close()

Выход:
1 record inserted! Id: 0
Михаил Русаков
Изучаю Python вместе с вами, читаю, собираю и записываю информацию опытных программистов.
Еще для изучения:Как добавить данные в таблицу sql
SQL INSERT INTO: примеры вставки строк в таблицу БД MySQL
SQL оператор INSERT используется для вставки записей в существующую таблицу.
Синтаксис этого оператора следующий:
Создадим тестовую таблицу
Давайте создадим таблицу table1 со столбцами a, b, c в нашей MySQL базе данных:
Запрос на вставку строки
Простой запрос, который вставляет строку со столбцами 111, 222 и 333 выглядит так:
Еще один способ сделать то же самое:
Столбцы, которые вы не перечислите заполняются значениями по умолчанию, которые вы предусматриваете при создании таблицы, даже если это просто NULL.
У таблиц обычно есть поле id с первичным ключом (PRIMARY KEY) таблицы. Если этому полю установлено значение AUTOINCREMENT т.е. оно заполняется автоматически, то в таком случае вы не должны его перечислять в списке столбцов оператора INSERT.
Вставка без перечисления столбцов
Если количество значений, которые мы вставляем = количеству столбцов в таблице, то можно не перечислять столбцы, и наш запрос может выглядеть так:
Этот способ крайне не рекомендуется. Дело в том, что со временем вы можете менять таблицы, например добавлять в них новые столбцы, а это значит, что все запросы записанные таким способом просто перестанут работать и вам придется менять их по всему вашему приложению. Поэтому, навсегда забываем этот способ. Я его привел, только чтобы вы так не делали.
Вставка сразу нескольких строк с помощью INSERT INTO
Если нам нужно вставить несколько строк, то мы просто перечисляем группы значений через запятую выглядит это так:
Таким образом мы вставили 3 строки в нашу таблицу table1. Их может быть и больше. В MySQL четкого предела нет, однако он все таки существует и зависит от параметра max_allowed_packet который ограничивает размер запроса. Если вы установите SET GLOBAL max_allowed_packet=524288000; то размер запроса будет ограничен 500MB но делайте это в очень крайнем случае. Обычно всегда можно найти решение и разделить 1 большой запрос, на несколько более мелких и вставлять например не больше 1000 строк за один цикл.
Их может быть и больше. В MySQL четкого предела нет, однако он все таки существует и зависит от параметра max_allowed_packet который ограничивает размер запроса. Если вы установите SET GLOBAL max_allowed_packet=524288000; то размер запроса будет ограничен 500MB но делайте это в очень крайнем случае. Обычно всегда можно найти решение и разделить 1 большой запрос, на несколько более мелких и вставлять например не больше 1000 строк за один цикл.
Как вставить значение из другой таблицы INSERT INTO . SELECT .
Допустим у нас есть еще одна таблица table2 которая по структуре точно такая же как и первая. Нам в таблицу table2 нужно вставить все строки из table1.
Вставляем значения из table1 в таблицу table2:
Вам следует позаботиться об уникальности ключей, если они есть в таблице, в которую мы вставляем. Например при дублировании PRIMARY KEY мы получим следующее сообщение об ошибке:
Если вы делаете не какую-то единичную вставку при переносе данных, а где-то сохраните этот запрос, например в вашем PHP скрипте, то всегда перечисляйте столбцы.
Как не рекомендуется делать (без перечисления столбцов):
Если у вас со временем изменится количество столбцов в таблице, то запрос перестанет работать. При выполнении запроса MySQL в лучшем случае просто будет возвращать ошибку:
Либо еще хуже: значения вставятся не в те столбцы.
Вставка из другой таблицы с условием INSERT INTO . SELECT . WHERE .
А теперь представим, что нам нужно вставить только те строки из table1, у которых столбец «c» равен 333. Тогда наш запрос будет выглядеть так
То есть мы просто вставляем данные в таблицу, которые выбрали из другой таблицы при помощи обычного SELECT запроса
Теперь представим, что у нас в таблице table2 — 4 столбца, а в table1 — 3. При этом четвертый столбец в table2 обязательный. Чтобы выйти из этой ситуации, нужно передать какое-нибудь подходящее значение в этот лишний столбец. У нас чисто абстрактная задача, поэтому давайте передадим туда просто единицу.
Теперь в столбец d у нас записалась единица и проблема решена.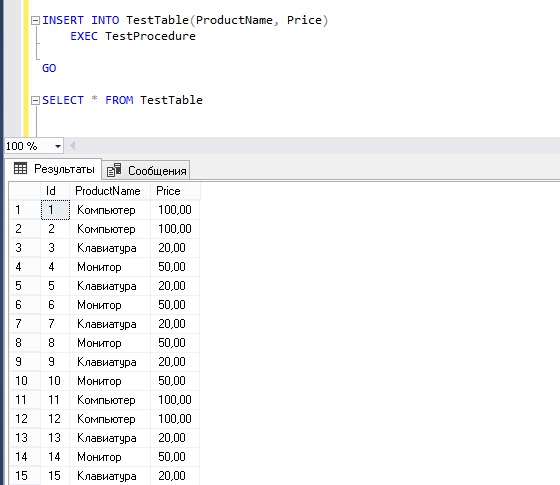
Вставка в определенный раздел INSERT INTO . PARTITION .
Если вам нужно вставить строки в определенный раздел таблицы, то нужно после таблицы указать PARTITION (название раздела), например так:
Вставка в несколько разделов. Первая строка вставляется в раздел p1, а вторая в p2
Вставка строк, некоторые из которых уже существуют в целевой таблице
Существование строк определяется по значению уникальных ключей. В зависимости от ситуации мы можем выбрать разные способы поведения при совпадении значений уникальных столбцов.
Игнорирование INSERT IGNORE INTO
Например если мы вставляем строку с PK = 1, и при этом в таблице уже есть PK = 1 то MySQL выдаст ошибку:
Выполнение запроса на этом прервется, однако нам в некоторых случаях хотелось бы просто вставить данные, игнорируя ошибки. В этом нам поможет INSERT IGNORE INTO:
Просто добавляем IGNORE в наш запрос и ошибки будут игнорироваться
Вставка с заменой существующих значений REPLACE INTO
REPLACE работает также INSERT, но если совпадают уникальные ключи, то старая строка (или строки!) удаляется до вставки новой.
В таком случае наш пример выглядит следующим образом:
Обновление некоторых полей, при существовании строк ON DUPLICATE KEY UPDATE
При совпадении ключей, мы можем также заменить некоторые или все поля в строке.
Наш запрос будет выглядеть так:
В данном примере если у нас какой-то уникальный ключ совпадает, то мы не производим вставку, а обновляем существующую строку или строки путем присваивания столбцу «c» значения, которое у нас перечислено в VALUES.
Иными словами, если ключ совпадает, то мы просто обновим данные столбца «с» а остальные столбцы трогать не будем.
Иногда нам нужно при совпадении ключей обновить все значения. Этом можно сделать просто перечислив все столбцы:
При обновлении столбцов мы также можем использовать разные выражения, например:
Выражения для вставляемых значений в VALUES
При вставке значений, мы можем использовать выражения и даже использовать в своих выражениях значения других столбцов.
Пример использования выражений:
Таким образом мы для формирования столбца «c» использовали столбцы «a» и «b».
Приоритет вставки INSERT LOW_PRIORITY / HIGH_PRIORITY
Установление приоритета нужно для решение проблем с конкурентными вставками. При вставках происходит блокировка строк и если 2 INSERT запроса требуют блокировки одних и тех же строк, для своего выполнения, то иногда может потребоваться повысить или понизить приоритет некоторых запросов, по отношению к другим. Это можно сделать указав приоритет LOW_PRIORITY или HIGH_PRIORITY
Как добавить данные в таблицу sql
INSERT inserts new rows into an existing table. The INSERT . VALUES , INSERT . VALUES ROW() , and INSERT . SET forms of the statement insert rows based on explicitly specified values. The INSERT . SELECT form inserts rows selected from another table or tables. You can also use INSERT . TABLE in MySQL 8.0.19 and later to insert rows from a single table. INSERT with an ON DUPLICATE KEY UPDATE clause enables existing rows to be updated if a row to be inserted would cause a duplicate value in a UNIQUE index or PRIMARY KEY . In MySQL 8.0.19 and later, a row alias with one or more optional column aliases can be used with ON DUPLICATE KEY UPDATE to refer to the row to be inserted.
In MySQL 8.0.19 and later, a row alias with one or more optional column aliases can be used with ON DUPLICATE KEY UPDATE to refer to the row to be inserted.
In MySQL 8.0, the DELAYED keyword is accepted but ignored by the server. For the reasons for this, see Section 13.2.6.3, “INSERT DELAYED Statement”,
Inserting into a table requires the INSERT privilege for the table. If the ON DUPLICATE KEY UPDATE clause is used and a duplicate key causes an UPDATE to be performed instead, the statement requires the UPDATE privilege for the columns to be updated. For columns that are read but not modified you need only the SELECT privilege (such as for a column referenced only on the right hand side of an col_name = expr assignment in an ON DUPLICATE KEY UPDATE clause).
When inserting into a partitioned table, you can control which partitions and subpartitions accept new rows. The PARTITION clause takes a list of the comma-separated names of one or more partitions or subpartitions (or both) of the table.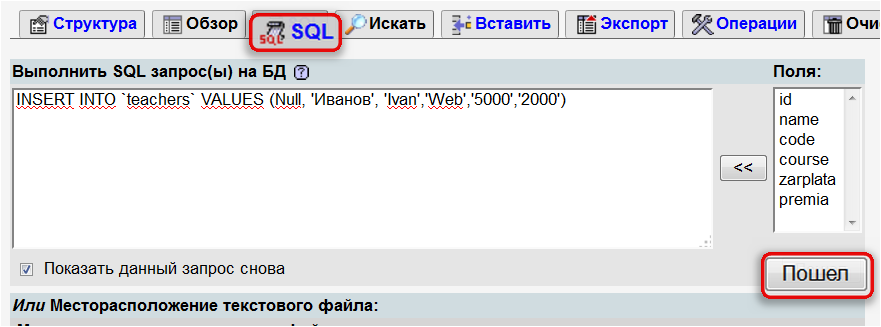 If any of the rows to be inserted by a given INSERT statement do not match one of the partitions listed, the INSERT statement fails with the error Found a row not matching the given partition set . For more information and examples, see Section 24.5, “Partition Selection”.
If any of the rows to be inserted by a given INSERT statement do not match one of the partitions listed, the INSERT statement fails with the error Found a row not matching the given partition set . For more information and examples, see Section 24.5, “Partition Selection”.
tbl_name is the table into which rows should be inserted. Specify the columns for which the statement provides values as follows:
Provide a parenthesized list of comma-separated column names following the table name. In this case, a value for each named column must be provided by the VALUES list, VALUES ROW() list, or SELECT statement. For the INSERT TABLE form, the number of columns in the source table must match the number of columns to be inserted.
If you do not specify a list of column names for INSERT . VALUES or INSERT . SELECT , values for every column in the table must be provided by the VALUES list, SELECT statement, or TABLE statement. If you do not know the order of the columns in the table, use DESCRIBE tbl_name to find out.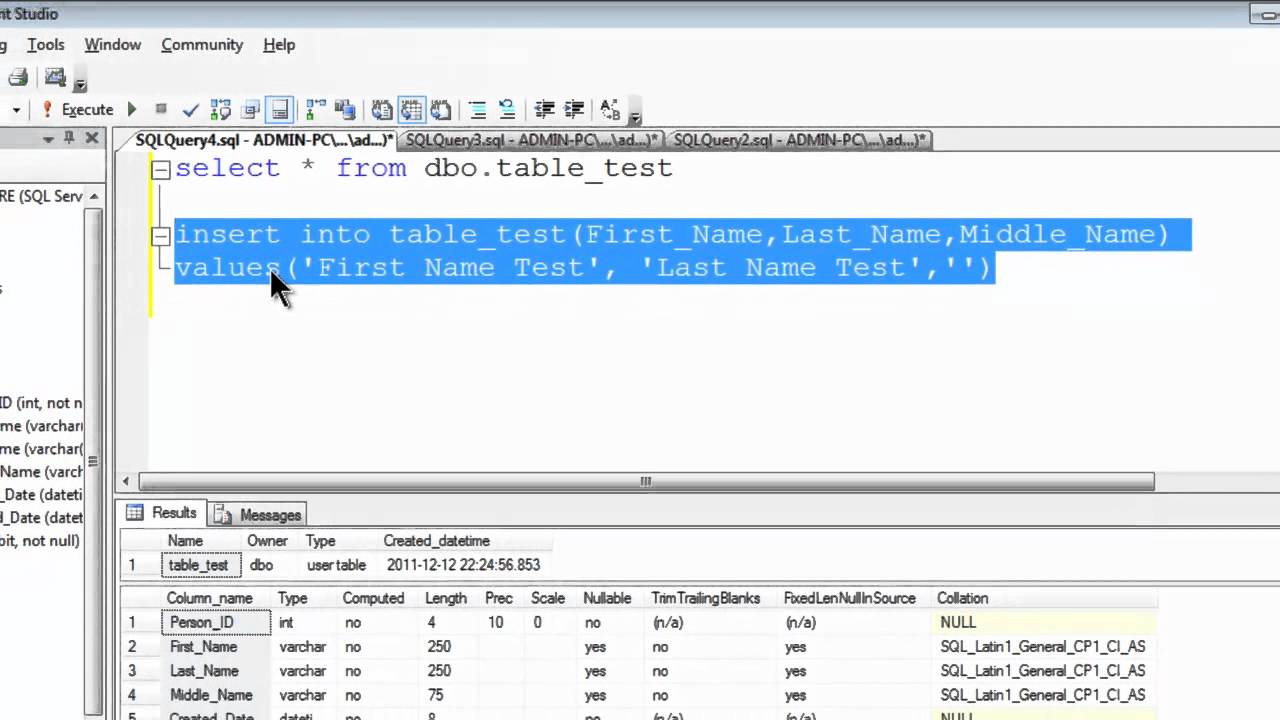
A SET clause indicates columns explicitly by name, together with the value to assign each one.
Column values can be given in several ways:
If strict SQL mode is not enabled, any column not explicitly given a value is set to its default (explicit or implicit) value. For example, if you specify a column list that does not name all the columns in the table, unnamed columns are set to their default values. Default value assignment is described in Section 11.6, “Data Type Default Values”. See also Section 1.7.3.3, “Enforced Constraints on Invalid Data”.
If strict SQL mode is enabled, an INSERT statement generates an error if it does not specify an explicit value for every column that has no default value. See Section 5.1.11, “Server SQL Modes”.
If both the column list and the VALUES list are empty, INSERT creates a row with each column set to its default value:
If strict mode is not enabled, MySQL uses the implicit default value for any column that has no explicitly defined default. If strict mode is enabled, an error occurs if any column has no default value.
If strict mode is enabled, an error occurs if any column has no default value.
Use the keyword DEFAULT to set a column explicitly to its default value. This makes it easier to write INSERT statements that assign values to all but a few columns, because it enables you to avoid writing an incomplete VALUES list that does not include a value for each column in the table. Otherwise, you must provide the list of column names corresponding to each value in the VALUES list.
If a generated column is inserted into explicitly, the only permitted value is DEFAULT . For information about generated columns, see Section 13.1.20.8, “CREATE TABLE and Generated Columns”.
In expressions, you can use DEFAULT( col_name ) to produce the default value for column col_name .
Type conversion of an expression expr that provides a column value might occur if the expression data type does not match the column data type. Conversion of a given value can result in different inserted values depending on the column type.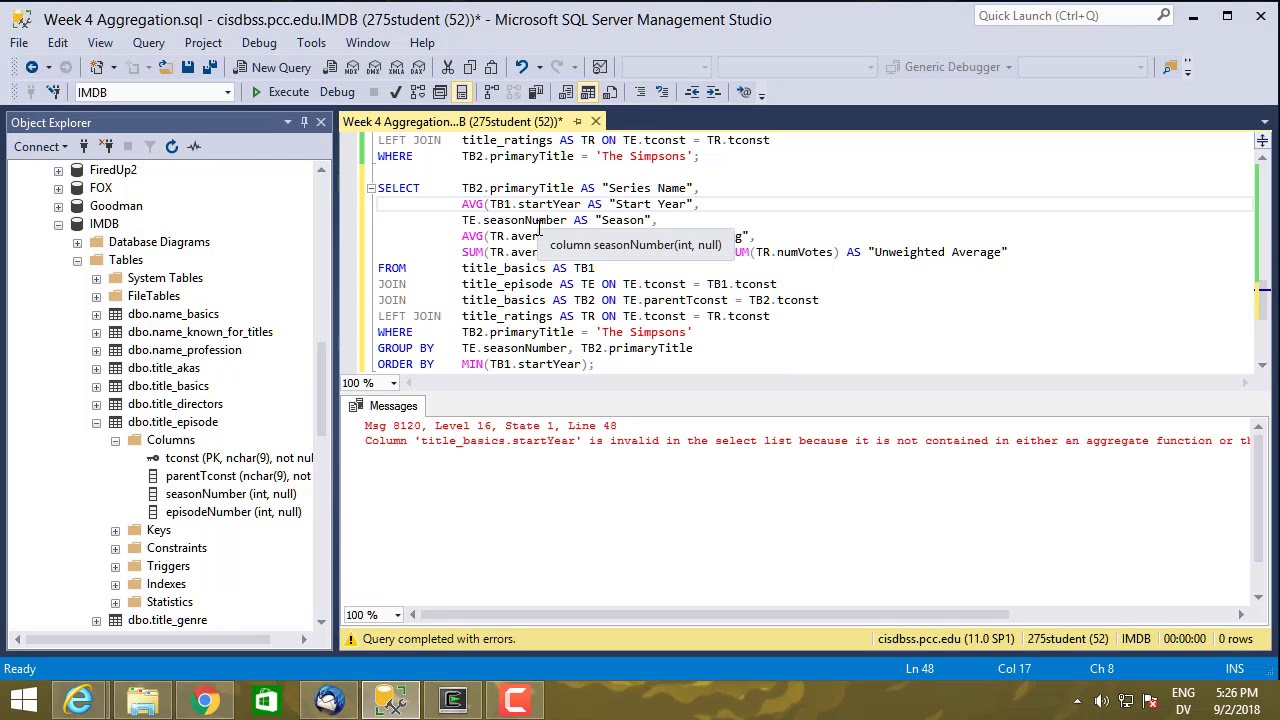 For example, inserting the string ‘1999.0e-2’ into an INT , FLOAT , DECIMAL(10,6) , or YEAR column inserts the value 1999 , 19.9921 , 19.992100 , or 1999 , respectively. The value stored in the INT and YEAR columns is 1999 because the string-to-number conversion looks only at as much of the initial part of the string as may be considered a valid integer or year. For the FLOAT and DECIMAL columns, the string-to-number conversion considers the entire string a valid numeric value.
For example, inserting the string ‘1999.0e-2’ into an INT , FLOAT , DECIMAL(10,6) , or YEAR column inserts the value 1999 , 19.9921 , 19.992100 , or 1999 , respectively. The value stored in the INT and YEAR columns is 1999 because the string-to-number conversion looks only at as much of the initial part of the string as may be considered a valid integer or year. For the FLOAT and DECIMAL columns, the string-to-number conversion considers the entire string a valid numeric value.
An expression expr can refer to any column that was set earlier in a value list. For example, you can do this because the value for col2 refers to col1 , which has previously been assigned:
But the following is not legal, because the value for col1 refers to col2 , which is assigned after col1 :
An exception occurs for columns that contain AUTO_INCREMENT values. Because AUTO_INCREMENT values are generated after other value assignments, any reference to an AUTO_INCREMENT column in the assignment returns a 0 .
INSERT statements that use VALUES syntax can insert multiple rows. To do this, include multiple lists of comma-separated column values, with lists enclosed within parentheses and separated by commas. Example:
Each values list must contain exactly as many values as are to be inserted per row. The following statement is invalid because it contains one list of nine values, rather than three lists of three values each:
VALUE is a synonym for VALUES in this context. Neither implies anything about the number of values lists, nor about the number of values per list. Either may be used whether there is a single values list or multiple lists, and regardless of the number of values per list.
INSERT statements using VALUES ROW() syntax can also insert multiple rows. In this case, each value list must be contained within a ROW() (row constructor), like this:
The affected-rows value for an INSERT can be obtained using the ROW_COUNT() SQL function or the mysql_affected_rows() C API function. See Section 12.16, “Information Functions”, and mysql_affected_rows().
See Section 12.16, “Information Functions”, and mysql_affected_rows().
If you use INSERT . VALUES or INSERT . VALUES ROW() with multiple value lists, or INSERT . SELECT or INSERT . TABLE , the statement returns an information string in this format:
If you are using the C API, the information string can be obtained by invoking the mysql_info() function. See mysql_info().
Records indicates the number of rows processed by the statement. (This is not necessarily the number of rows actually inserted because Duplicates can be nonzero.) Duplicates indicates the number of rows that could not be inserted because they would duplicate some existing unique index value. Warnings indicates the number of attempts to insert column values that were problematic in some way. Warnings can occur under any of the following conditions:
Inserting NULL into a column that has been declared NOT NULL . For multiple-row INSERT statements or INSERT INTO . SELECT statements, the column is set to the implicit default value for the column data type. This is 0 for numeric types, the empty string ( » ) for string types, and the “ zero ” value for date and time types. INSERT INTO . SELECT statements are handled the same way as multiple-row inserts because the server does not examine the result set from the SELECT to see whether it returns a single row. (For a single-row INSERT , no warning occurs when NULL is inserted into a NOT NULL column. Instead, the statement fails with an error.)
This is 0 for numeric types, the empty string ( » ) for string types, and the “ zero ” value for date and time types. INSERT INTO . SELECT statements are handled the same way as multiple-row inserts because the server does not examine the result set from the SELECT to see whether it returns a single row. (For a single-row INSERT , no warning occurs when NULL is inserted into a NOT NULL column. Instead, the statement fails with an error.)
Setting a numeric column to a value that lies outside the column range. The value is clipped to the closest endpoint of the range.
Assigning a value such as ‘10.34 a’ to a numeric column. The trailing nonnumeric text is stripped off and the remaining numeric part is inserted. If the string value has no leading numeric part, the column is set to 0 .
Inserting a string into a string column ( CHAR , VARCHAR , TEXT , or BLOB ) that exceeds the column maximum length. The value is truncated to the column maximum length.
Inserting a value into a date or time column that is illegal for the data type.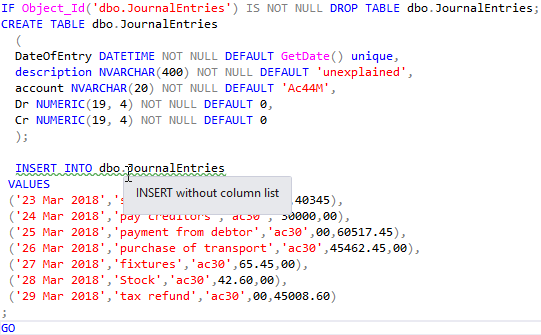 The column is set to the appropriate zero value for the type.
The column is set to the appropriate zero value for the type.
For INSERT examples involving AUTO_INCREMENT column values, see Section 3.6.9, “Using AUTO_INCREMENT”.
If INSERT inserts a row into a table that has an AUTO_INCREMENT column, you can find the value used for that column by using the LAST_INSERT_ID() SQL function or the mysql_insert_id() C API function.
These two functions do not always behave identically. The behavior of INSERT statements with respect to AUTO_INCREMENT columns is discussed further in Section 12.16, “Information Functions”, and mysql_insert_id().
The INSERT statement supports the following modifiers:
If you use the LOW_PRIORITY modifier, execution of the INSERT is delayed until no other clients are reading from the table. This includes other clients that began reading while existing clients are reading, and while the INSERT LOW_PRIORITY statement is waiting. It is possible, therefore, for a client that issues an INSERT LOW_PRIORITY statement to wait for a very long time.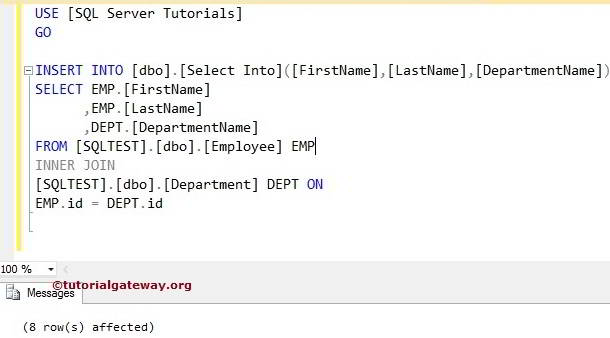
LOW_PRIORITY affects only storage engines that use only table-level locking (such as MyISAM , MEMORY , and MERGE ).
LOW_PRIORITY should normally not be used with MyISAM tables because doing so disables concurrent inserts. See Section 8.11.3, “Concurrent Inserts”.
If you specify HIGH_PRIORITY , it overrides the effect of the —low-priority-updates option if the server was started with that option. It also causes concurrent inserts not to be used. See Section 8.11.3, “Concurrent Inserts”.
HIGH_PRIORITY affects only storage engines that use only table-level locking (such as MyISAM , MEMORY , and MERGE ).
If you use the IGNORE modifier, ignorable errors that occur while executing the INSERT statement are ignored. For example, without IGNORE , a row that duplicates an existing UNIQUE index or PRIMARY KEY value in the table causes a duplicate-key error and the statement is aborted. With IGNORE , the row is discarded and no error occurs. Ignored errors generate warnings instead.
IGNORE has a similar effect on inserts into partitioned tables where no partition matching a given value is found. Without IGNORE , such INSERT statements are aborted with an error. When INSERT IGNORE is used, the insert operation fails silently for rows containing the unmatched value, but inserts rows that are matched. For an example, see Section 24.2.2, “LIST Partitioning”.
Data conversions that would trigger errors abort the statement if IGNORE is not specified. With IGNORE , invalid values are adjusted to the closest values and inserted; warnings are produced but the statement does not abort. You can determine with the mysql_info() C API function how many rows were actually inserted into the table.
You can use REPLACE instead of INSERT to overwrite old rows. REPLACE is the counterpart to INSERT IGNORE in the treatment of new rows that contain unique key values that duplicate old rows: The new rows replace the old rows rather than being discarded. See Section 13.2. 9, “REPLACE Statement”.
9, “REPLACE Statement”.
If you specify ON DUPLICATE KEY UPDATE , and a row is inserted that would cause a duplicate value in a UNIQUE index or PRIMARY KEY , an UPDATE of the old row occurs. The affected-rows value per row is 1 if the row is inserted as a new row, 2 if an existing row is updated, and 0 if an existing row is set to its current values. If you specify the CLIENT_FOUND_ROWS flag to the mysql_real_connect() C API function when connecting to mysqld , the affected-rows value is 1 (not 0) if an existing row is set to its current values. See Section 13.2.6.2, “INSERT . ON DUPLICATE KEY UPDATE Statement”.
INSERT DELAYED was deprecated in MySQL 5.6, and is scheduled for eventual removal. In MySQL 8.0, the DELAYED modifier is accepted but ignored. Use INSERT (without DELAYED ) instead. See Section 13.2.6.3, “INSERT DELAYED Statement”.
Добавление данных, оператор INSERT
Для добавления новых записей в таблицу предназначен оператор INSERT . Рассмотрим его общую структуру.
Общая структура запроса с оператором INSERT
В описанной структуре запроса необязательные параметры указаны в квадратных скобках. Вертикальной чертой обозначен альтернативный синтаксис.
Значения можно вставлять перечислением с помощью слова values , перечислив их в круглых скобках через запятую или c помощью оператора select . Таким образом, добавить новые записей можно следующими способами:
Первичный ключ при добавлении новой записи
Следует помнить, что первичный ключ таблицы является уникальным значением и добавление уже существующего значения приведет к ошибке.
При добавлении новой записи с уникальными индексами выбор такого уникального значения может оказаться непростой задачей. Решением может быть дополнительный запрос, направленный на выявление максимального значения первичного ключа для генерации нового уникального значения.
MySQL
В MySQL введен механизм его автоматической генерации. Для этого достаточно снабдить первичный ключ good_id атрибутом AUTO_INCREMENT . Тогда при создании новой записи в качестве значения good_id достаточно передать NULL или 0 — поле автоматически получит значение, равное максимальному значению столбца good_id, плюс единица.
Тогда при создании новой записи в качестве значения good_id достаточно передать NULL или 0 — поле автоматически получит значение, равное максимальному значению столбца good_id, плюс единица.
PostgreSQL
В PostgreSQL есть схожий механизм для автоматической генерации уникального идентификатора. Для этого он имеет типы SMALLSERIAL , SERIAL , BIGSERIAL , которые не являются настоящими типами, а скорее просто удобством записи столбцов с уникальным идентификатором. Столбец с одним из вышеперечисленных типов будет являться целочисленным и автоматически увеличиваться при добавление новой записи.
Изучение SQL: команды вставки нескольких строк
В этой статье объясняются различные подходы, используемые для вставки нескольких строк в таблицы SQL Server.
Вставка строк с помощью команды INSERT INTO VALUES
Самый простой подход к вставке нескольких строк в SQL — это использование команды INSERT INTO VALUES. Некоторые разработчики SQL считают, что эта команда предназначена для вставки только одной строки.
Команда INSERT INTO VALUES используется для вставки данных во все столбцы или определенные столбцы таблицы. Если данные вставляются в определенные столбцы, их следует указывать после имени таблицы. Кроме того, вставляемые значения должны быть указаны в двух круглых скобках после ключевого слова VALUES. Вставленные значения могут быть предоставлены вручную или с использованием переменных. Например:
ВСТАВИТЬ В [dbo].[Клиенты] ([имя], [отчество], [фамилия], [дата_рождения], [национальность]) VALUES(‘Уильям’, ‘Генри’, ‘Гейтс’, ‘19551028 ‘, ‘США’)
|
В приведенной выше команде SQL «[dbo].[Customers]» — это имя таблицы, «[имя], [отчество], [фамилия], [дата_рождения], [национальность]» — это имя столбца, и «Уильям», «Генри», «Гейтс», «19551028’,1”
Чтобы вставить данные во все столбцы, нет необходимости указывать их явно, но мы должны убедиться, что значения предоставлены в правильном порядке.
ВСТАВИТЬ В [dbo].[Клиенты] VALUES(‘Уильям’, ‘Генри’, ‘Гейтс’, ‘19551028’, ‘США’)
|
Чтобы вставить несколько строк в SQL, мы должны указать несколько групп значений, разделенных запятыми; каждая группа должна быть заключена в две круглые скобки, как показано ниже:
ВСТАВИТЬ В [dbo].[Клиенты] ([имя], [отчество], [фамилия], [дата_рождения], [национальность]) ЗНАЧЕНИЯ(‘Уильям’, ‘Генри’, ‘Гейтс’, ‘19551028’, ‘США’), («Марк», ‘Гленн’, ‘Каллауэй’, ‘19501020’, ‘США’), («Мехмет», ‘Фатех’, ‘Шоул’, ‘19601020’, ‘ТК ‘)
|
На следующем снимке экрана показано, как данные вставляются в таблицу клиентов:
Рисунок 1 – Вставка нескольких строк с помощью команды INSERT INTO VALUES
Вставка строк с помощью команды INSERT INTO SELECT
Команда INSERT INTO SELECT — это второй подход к вставке нескольких строк в SQL.
Вставка данных из одной таблицы или представления в другую
Чтобы вставить данные из одной таблицы в другую, мы должны указать целевую таблицу и столбцы аналогично командам INSERT INTO VALUES. Затем мы должны указать выбранный запрос, который считывает данные из исходной таблицы или представления.
1 2 3 4 5 6 7 8 |
ВСТАВИТЬ В [dbo].[Клиенты] ([имя],[отчество],[фамилия],[дата_рождения],[национальность]) SELECT DISTINCT [имя],[отчество],[фамилия],[дата_рождения],[национальность] ОТ [dbo].[Customers_] ГДЕ [национальность] IS NULL 90 003 |
На приведенном ниже снимке экрана показано, как несколько строк были вставлены из таблицы Customers_ в таблицу Customers.
Рисунок 2 – Вставка нескольких строк с помощью команды INSERT INTO SELECT
В случае, если обе таблицы имеют точное количество столбцов, типы и порядок. Мы можем использовать запрос SELECT * для вставки нескольких строк в SQL следующим образом:
1 2 3 4 5 6 |
INSERT INTO [dbo].[Customers] SELECT * FROM [dbo].[Customers_] WHERE [национальность] IS NULL 9 0002 |
Вставка данных из нескольких таблиц/представлений в одну таблицу
Команде SELECT не нужно читать из одной таблицы или представления. Мы можем использовать более сложный запрос с соединениями INNER и OUTER. Мы всегда должны следить за тем, чтобы столбцы назначения соответствовали столбцам, возвращаемым командой SQL, как показано на снимке экрана ниже:
Рисунок 3 – Вставка нескольких строк из нескольких таблиц
Вставка данных в представление
Вставка данных в представление означает, что данные вставляются в базовую таблицу. Чтобы проиллюстрировать это, мы создали представление vCustomers, используя запрос SELECT * из таблицы Customers. Затем мы визуализировали примерный план выполнения двух SQL-запросов; первый вставляет данные в представление vCustomers, а второй — в таблицу Customers. Как показано на скриншоте ниже, оба плана выполнения идентичны.
Чтобы проиллюстрировать это, мы создали представление vCustomers, используя запрос SELECT * из таблицы Customers. Затем мы визуализировали примерный план выполнения двух SQL-запросов; первый вставляет данные в представление vCustomers, а второй — в таблицу Customers. Как показано на скриншоте ниже, оба плана выполнения идентичны.
Рисунок 4 – Планы выполнения запросов
Вставка данных в представление действительна только тогда, когда нам нужно разрешить вставку данных в определенные столбцы, не позволяя пользователям вставлять их во все столбцы в целевой таблице.
Вставка данных из подзапроса в таблицу
Подзапросы — это еще один способ вставки нескольких строк в SQL. Их можно использовать в качестве источника данных в команде INSERT INTO SELECT. Подзапросы полезны, когда нам нужно более одного запроса для получения желаемого результата, и каждый подзапрос возвращает подмножество таблицы, связанной с запросом. Например:
Например:
ВСТАВИТЬ В [dbo].[Клиенты] SELECT * FROM (SELECT c.[имя],c.[отчество],c.[фамилия],c.[дата_рождения],ct.[CountryAlpha2] FROM [dbo].[Customers_] c INNER JOIN [dbo].[countries] ct on c.nationality = ct.[Id]) AS Table_1
|
Если вас интересуют подзапросы, вы можете обратиться к моей ранее опубликованной статье о SQL Shack: Как писать подзапросы в SQL.
Вставка данных из обычного табличного выражения в таблицу
Общее табличное выражение (CTE) также может использоваться в качестве источника данных. Поскольку многие разработчики считают, что они похожи, CTE отличаются от подзапросов, поскольку они являются рекурсивными, повторно используемыми и могут быть более удобочитаемыми.
Рисунок 5 – Вставка данных из рекурсивного общего табличного выражения
Вставка данных из таблицы значений в таблицу
Другой вариант вставки нескольких строк в SQL — использование команды SELECT для таблицы значений, предоставленной с помощью ключевого слова VALUES.+:.jpg) Имена столбцов должны быть указаны явно, а количество столбцов для каждой строки в конструкторе табличных значений должно быть одинаковым. Например:
Имена столбцов должны быть указаны явно, а количество столбцов для каждой строки в конструкторе табличных значений должно быть одинаковым. Например:
1 2 3 4 5 6 7 |
ВСТАВИТЬ В dbo.countries(id, country_name) SELECT DISTINCT * FROM ( ЗНАЧЕНИЯ (1, ‘США’), (1, ‘США’), ( 1, «США») (2, ‘LB’), (5, ‘Великобритания’), (1, ‘США’), (6, ‘IT’) ) AS X(id, страна)
|
В приведенной выше команде SQL четыре строки должны быть вставлены в таблицу стран, как показано на снимке экрана ниже.
Рисунок 6 – Вставка строк с помощью таблицы значений
Вставка данных из набора результатов хранимой процедуры в таблицу
Если хранимая процедура выводит набор результатов с помощью команды SELECT, этот набор результатов можно вставить в таблицу с помощью команды INSERT INTO EXEC. Например, рассмотрим следующую хранимую процедуру, которая возвращает продажи сотрудников с начала года.
Например, рассмотрим следующую хранимую процедуру, которая возвращает продажи сотрудников с начала года.
1 2 3 4 5 6 7 8 9 10 9 0003 11 12 |
СОЗДАТЬ ПРОЦЕДУРУ Sales.uspGetEmployeeSalesYTD AS SET NOCOUNT ON;
SELECT LastName, SalesYTD FROM Sales.SalesPerson AS sp ПРИСОЕДИНЯЙТЕСЬ к HumanResources.vEmployee AS e ON e.BusinessEntityID = sp.BusinessEntity удостоверение личности;
ВОЗВРАТ; GO
|
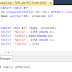
Чтобы вставить данные, полученные этой хранимой процедурой, в другую таблицу, мы должны использовать следующую команду SQL:
ВСТАВИТЬ В dbo.EmployeeSalesYTD EXEC Sales.uspGetEmployeeSalesYTD
|
Более того, мы можем изменить набор результатов хранимой процедуры в соответствии с определением, указанным в предложении WITH RESULT SETS, как показано ниже:
1 2 3 4 5 6 7 8 |
ВСТАВИТЬ В dbo. EXEC Sales.uspGetEmployeeSalesYTD С НАБОРАМИ РЕЗУЛЬТАТОВ (( 9000 3 LastName varchar(50), SalesYTD money ))
|
 EmployeeSalesYTD
EmployeeSalesYTDДополнительные сведения о команде EXEC см. в следующей статье: Обзор EXEC SQL и примеры.
Вставка данных из табличной функции в таблицу
Функцию с табличным значением также можно использовать для вставки нескольких строк в SQL с помощью оператора INSERT INTO SELECT, как показано в следующем примере:
ВСТАВИТЬ В dbo.Employees( PersonID, FirstName, LastName, JobTitle, BusinessEntityType) SELECT PersonID, FirstName, LastName, JobTitle, BusinessEntityType ОТ [dbo].[ufnGetContactInformation](@PersonID)
|
Чтобы узнать больше о функциях, возвращающих табличное значение, вы можете обратиться к следующим статьям:
- Встроенные табличные функции SQL Server
- Многооператорные табличные функции SQL Server
Вставка данных с помощью OPENQUERY
Чтобы вставить данные из удаленной базы данных, мы можем использовать оператор OPENQUERY. Например, следующая команда SQL считывает набор результатов запроса MDX, выполненного на связанном сервере, сопоставленном с экземпляром SSAS, а затем сохраняет результат во временной таблице.
Например, следующая команда SQL считывает набор результатов запроса MDX, выполненного на связанном сервере, сопоставленном с экземпляром SSAS, а затем сохраняет результат во временной таблице.
INSERT INTO #TBLTEMP SELECT * FROM OPENQUERY(SSAS_LINKEDSERVER, ‘SELECT NON EMPTY { [Меры].[Количество заказа], [Меры].[Сумма скидки]} ПО КОЛОНЦАМ, НЕ ПУСТЫЕ { ([ Product].[Ключ продукта].[Ключ продукта].ALLMEMBERS ) } СВОЙСТВА ИЗМЕРЕНИЙ MEMBER_CAPTION, MEMBER_UNIQUE_NAME ON ROWS FROM [Adventure Works DW2014]’)
|
Чтобы узнать больше об OPENQUERY и о том, как связать куб OLAP с реляционной базой данных, вы можете обратиться к следующей статье: Связывание реляционных баз данных с кубами OLAP.
Вставка данных с помощью OPENROWSET, OPENDATASOURCE
В SQL также возможно вставлять несколько строк из удаленной базы данных или внешнего источника данных, такого как файлы Microsoft Excel, текстовые файлы, разделенные запятыми, и другие источники, используя операторы OPENROWSET и OPENDATASOURCE. Например, в следующем примере данные считываются из базы данных Microsoft Access и вставляются в таблицу SQL с помощью оператора OPENROWSET:
Например, в следующем примере данные считываются из базы данных Microsoft Access и вставляются в таблицу SQL с помощью оператора OPENROWSET:
1 2 3 4 5 6 |
ВСТАВИТЬ В dbo.Customers ВЫБРАТЬ a.* FROM OPENROWSET(‘Microsoft.Jet.OLEDB.4.0′,’C:\SAMPLES\Northwind.mdb’;’admin ‘;’пароль’, Клиенты ) Как; Клиенты) AS a;
|
Более подробную информацию о командах OPENROWSET и OPENDATASOURCE можно найти в официальной документации:
- OPENROWSET (Transact-SQL) — SQL Server
- OPENDATASOURCE (Transact-SQL) — SQL Server
Вставка строк с помощью команды SELECT INTO
Распространенным подходом в SQL для вставки нескольких строк в новую таблицу является команда SELECT INTO FROM. Этот метод считается более быстрым, чем метод INSERT INTO, поскольку он минимально протоколируется при условии, что установлены правильные флаги трассировки. Как правило, этот метод обычно используется на этапе размещения данных или при создании временных таблиц.
Как правило, этот метод обычно используется на этапе размещения данных или при создании временных таблиц.
Мы должны указать имя таблицы, которую мы хотим создать, после ключевого слова INTO, а метаданные таблицы будут определены на основе вывода запроса SELECT.
SELECT TOP (1000) [BusinessEntityID],[PersonType],[NameStyle],[Title],[FirstName],[отчество],[LastName],[Suffix],[EmailPromotion], [AdditionalContactInfo],[ Демографические данные],[rowguid],[ModifiedDate] INTO #Temp_Persons ОТ [AdventureWorks2017].[Человек].[Человек]
|
Массовые операции вставки
Последним методом вставки нескольких строк в SQL является метод BULK INSERT, который используется для вставки данных из текстовых файлов в таблицу SQL. В случае, если массовая вставка правильно сконфигурирована, этот метод должен гарантировать более высокую производительность, чем другие методы.
В этом методе мы должны указать путь к файлу в предложении FROM, а параметры операции массовой вставки должны быть определены в предложении WITH, как показано в примере ниже:
1 2 3 4 5 6 7 8 9 9 0003 |
МАССОВАЯ ВСТАВКА dbo.StagingTable ИЗ ‘C:\PPE.txt’ С ( FIELDTERMINATOR = ‘;’, ROWTERMINATOR = ‘\n’ )
|
Вы можете узнать больше об операциях BULK INSERT в SQL Server в следующей статье: BULK INSERT (Transact-SQL) — SQL Server
Сводка
В этой статье мы кратко объяснили различные подходы, используемые для вставки нескольких строк в SQL. Мы объяснили операторы INSERT INTO VALUES, INSERT INTO SELECT, SELECT INTO FROM и BULK INSERT. Мы также перечислили различные источники данных, поддерживаемые в различных командах SQL.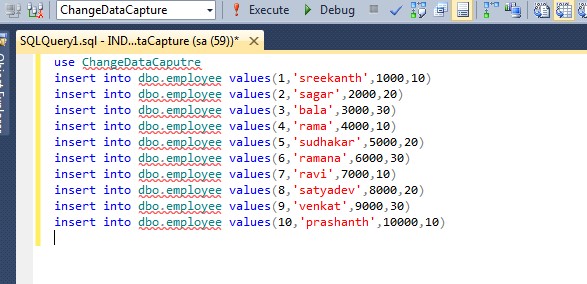
- Автор
- Последние сообщения
Хади Фадлаллах
Хади — профессионал SQL Server с более чем 10-летним опытом. Его основная специализация — интеграция данных. Он является одним из ведущих участников ETL и SQL Server Integration Services на Stackoverflow.com. Кроме того, он опубликовал несколько серий статей о Biml, функциях SSIS, поисковых системах, Hadoop и многих других технологиях.Помимо работы с SQL Server, он работал с различными технологиями обработки данных, такими как базы данных NoSQL, Hadoop, Apache Spark. Он сертифицированный профессионал MongoDB, Neo4j и ArangoDB.
На академическом уровне Хади имеет две степени магистра в области компьютерных наук и бизнес-вычислений. В настоящее время он является доктором философии. кандидат наук о данных, специализирующийся на методах оценки качества больших данных.
Хади действительно любит узнавать что-то новое каждый день и делиться своими знаниями. Вы можете связаться с ним на его личном сайте.
Просмотреть все сообщения от Hadi Fadlallah
Последние сообщения от Hadi Fadlallah (посмотреть все)
Вставка нескольких строк в таблицу SQL Использование Excel в качестве шаблона
Надеюсь, вы следовали предыдущему руководству, в котором мы проверяли Создали несколько новых таблиц базы данных используя Excel в качестве шаблона.
Давайте заполним эти таблицы значимыми данными. Хорошо, это может быть не самый значимый набор данных, поскольку я только что создал эти данные с помощью Mockaroo.com. (Невероятный сайт для создания примеров данных на лету.)
Для этого упражнения используйте данные из трех таблиц Excel для заполнения таблиц в Microsoft SQL Server.
Мы предоставили образцы данных, чтобы вам было проще следовать моим шаблонам или полностью украсть их и создавать собственные плавные SQL-запросы.
Вот образцы наших столов.
Таблица экспертов — хранит идентификатор, имя и дату рождения наших экспертов
Таблица технологий — сохраняет имена технологий и основную информацию о технологии
Таблица экспертных технологий — показывает, какими технологиями владеют эксперты. Вот наш шаблон.
Вот наш шаблон.
Строка зеленого цвета предназначена только для маркировки.
Чтобы увидеть, что происходит, переключитесь на представление формулы, сочетание клавиш (CTRL + `).
Преимущество использования Excel для форматирования заключается в том, что вам нужно настроить только один столбец данных, а затем вы можете перетащить формулу в конец набора данных.
Форматирование строки 5, строки 6 и ниже различается, поскольку строка 5 содержит заголовки, а строка 6 и ниже содержит импортированную информацию.
Вторая половина таблицы вставкиОбратите внимание, что эти поля метаданных также имеют разный формат.
Столбец N готов к вырезанию и вставке в Microsoft SQL Server.
Прежде чем вырезать и вставлять, вы заслуживаете объяснения того, что только что произошло.
Для лучшего понимания следуйте примерам данных.
Наша первая вкладка, вкладка «исходные данные», — это то, что мы хотим загрузить.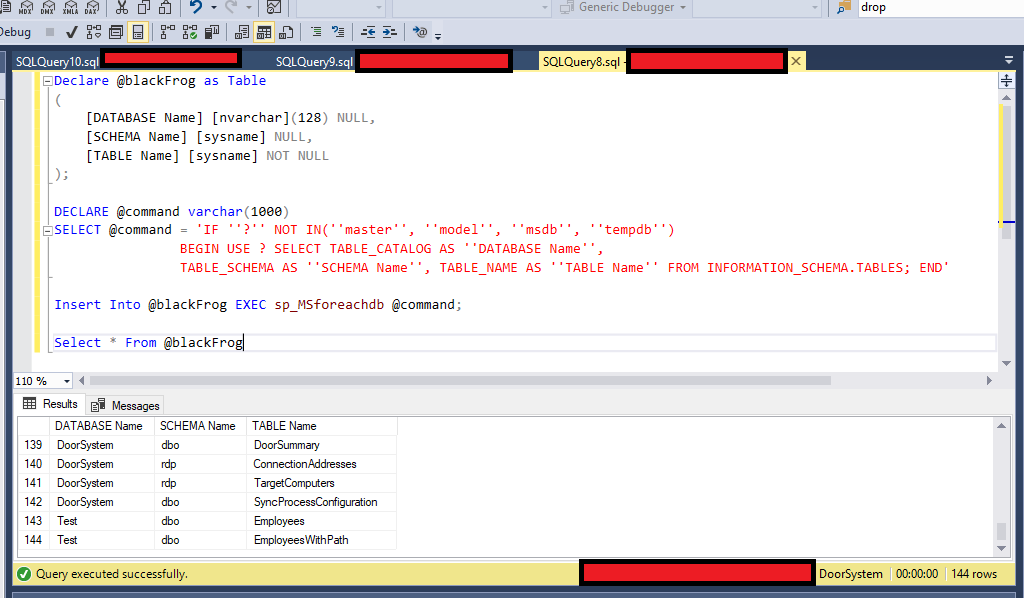 Вкладка «Insert Statement 1» выполняет следующие задачи:
Вкладка «Insert Statement 1» выполняет следующие задачи:
- Вызывает значения ячеек из исходных данных — Сначала, используя кавычки и символы &, мы форматируем каждый фрагмент данных, готовый к загрузке.
- Форматирование их как строки для нашей загрузки SQL — Затем мы используем формулу Concat, чтобы соединить все вместе.
Наш полезный друг, метаданные
Как упоминалось ранее, три столбца являются метаданными:
- Изменено — отслеживает последнего человека, редактировавшего столбец
- Отметка времени — отслеживает дату последнего редактирования столбца
- Rowversion — это поле используется несколькими способами. Сохраняйте повторяющиеся строки и полагайтесь на последнюю версию строки, чтобы указать самую новую запись, или замените старые строки, и пусть версия строки сигнализирует, сколько раз эта строка была изменена.

Теперь разместите этот сценарий в MSSQL и запустите эту присоску.
Сценарии наших операторов вставки, сформулированных в Excel, в Microsoft SQL
После успешного выполнения запроса в окне сообщения отображается 20 обновленных строк.
Поскольку первые сценарии отработаны, попробуйте тот же процесс с двумя другими сценариями вставки.
Таблица 2 Загружено.
Таблица 3 Загружено.
Проверьте свою работу
Пришло время перепроверить наши результаты.
Используйте сценарии ниже, чтобы проверить первые три результата из каждой таблицы, потому что мы не хотим просматривать каждую строку!
В этих сценариях используются подзапросы, что более интересно для последующего обсуждения.
– Получить первые 3 записи для каждой из вновь созданных таблиц ГДЕ Exp_TECH_ID IN (ВЫБЕРИТЕ ТОП 3 Exp_TECH_ID ИЗ testExpert.dbo.experttech)
ВЫБЕРИТЕ * ИЗ testExpert.dbo.technology
ГДЕ Technology_ID В (ВЫБЕРИТЕ ТОП 3 Technology_ID ИЗ testExpert.