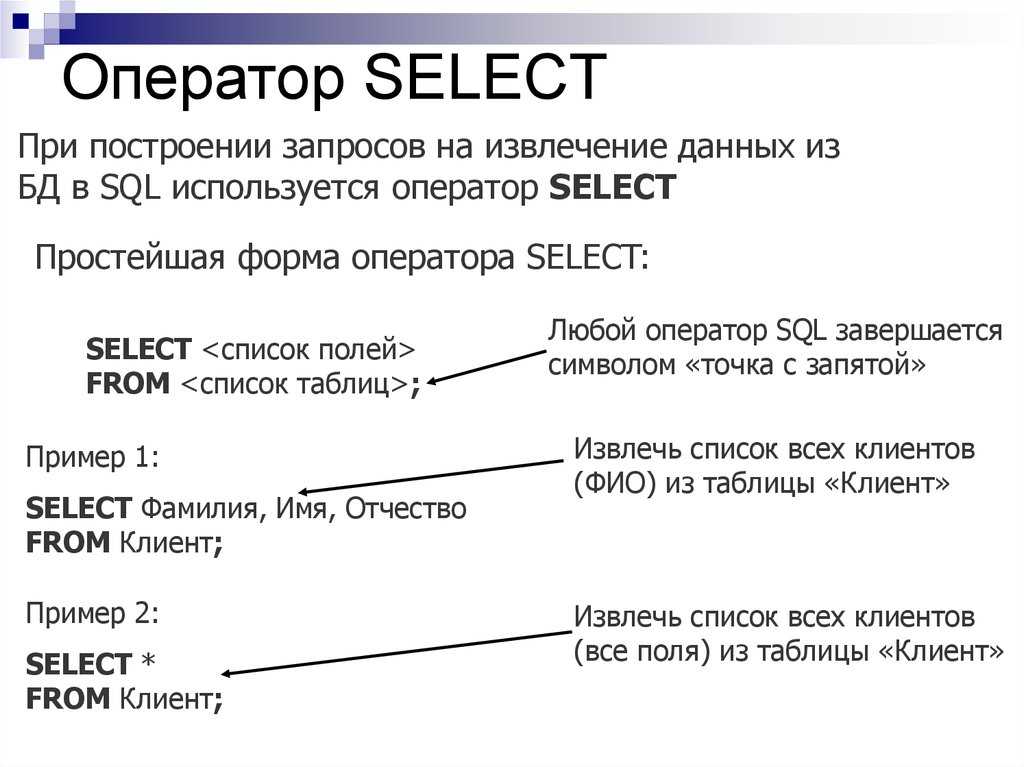
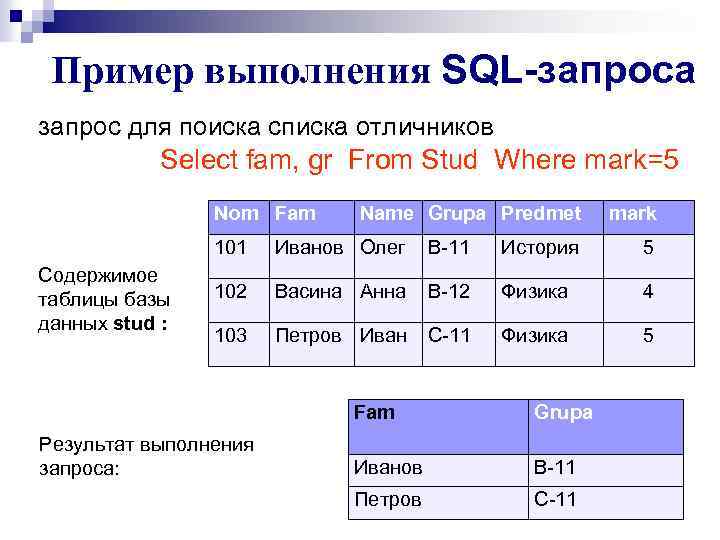
Создание запроса к серверу
Access
Миграция SQL Server
Миграция SQL Server
Создание запроса к серверу
Access для Microsoft 365 Access 2021 Access 2019 Access 2016 Access 2013 Access 2010 Еще…Меньше
Вы можете использовать Access как переднее приложение, а затем связывать таблицы на сервере, например с SQL Server. По умолчанию большинство запросов работают локально в ячеке баз данных Access ACE. В некоторых случаях в зависимости от синтаксиса SQL Server SQL и других факторов Access может выполнить запрос удаленно на SQL Server. Дополнительные сведения см. в документации по теме «ЯД БАЗ ДАННЫХ JET версии 3.0: подключение ODBC» в красных документах, открытых в jet и ODBC.
Однако часто необходимо явно выполнить запрос к серверу базы данных. Это помогает повысить производительность: серверы баз данных имеют большую вычислительную мощность, чем настольный компьютер, и вы можете возвращать меньшее подмножество данных по сетевому подключению.
Примечание Результаты запроса к проверке находятся только для чтения. Чтобы непосредственно редактировать данные в таблице или форме, создайте связанную таблицу в индексируемом представлении. Дополнительные сведения см. в теме «Создание индексных представлений».
-
Подключение к базе данных сервера.
Дополнительные сведения о связывание с SQL Server см. в дополнительных сведениях об импорте или связывание данных в базе данных SQL Server, а также связывание или импорт данных из базы данных Azure SQL Server.

На вкладке Создание нажмите кнопку Конструктор запросов.
-
При необходимости закройте диалоговое окно «Добавление таблиц»(добавление таблицы в Access 2013 ).
-
Выберите «>конструктора».
Access скроет сетку конструктора запросов и отобразит SQL представлении.
-
Если лист свойств запроса не отображается, нажмите F4, чтобы отобразить его.
-
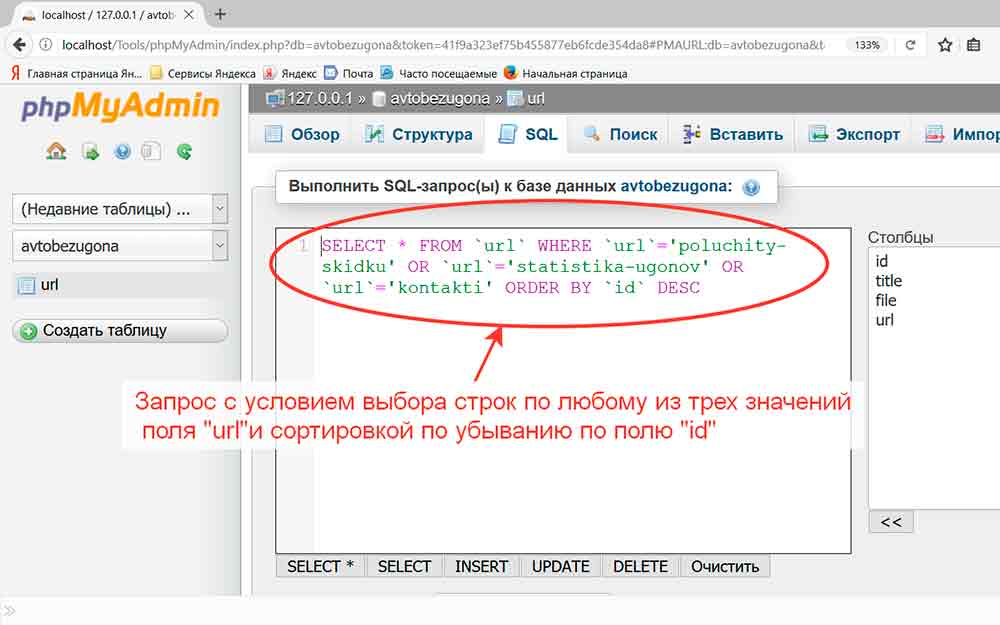
В области навигации щелкните правой кнопкой мыши таблицу, связанную с нужным источником данных, и выберите «Диспетчер связанных таблиц».
-
В диалоговом окне «Диспетчер связанных таблиц» выберите поле для источника данных и выберите «Изменить».
-
-
Выберите » «.
-
Следуйте запросам, чтобы создать файл DSN, содержащий сведения о строке подключения. Подробные инструкции см. в инструкциях по импорту или связываированию данных в базе данных SQL Server, а также связывать или импортировать данные из базы данных Azure SQL Server.
-
Нажмите CTRL+G. чтобы открыть окно VBA Immediate.
-
Введите следующий код:
?CurrentDb.TableDefs("<table name>").ConnectНо замените <имя таблицы> имя связанной таблицы из шага а.
-
Скопируйте строку, возвращаемую в свойство ODBC Connect Str.
-
Введите запрос в SQL представлении.
Примечание
Совет. Сначала постройте запрос TSQL в SQL Server Management Studio, а затем скопируйте его и в SQL в SQL View. Это гарантирует правильность синтаксиса запроса. Если у вас нет удобного доступа к базе данных SQL Server, вы можете установить на компьютере выпуск Microsoft SQL Server Express, который поддерживает до 10 ГБ, и это бесплатный и удобный способ проверить миграцию.
-
Возвращает записи. Некоторые SQL возвращают записи, например SELECT, а другие — нет, например UPDATE. Если запрос возвращает записи, установите для этого свойства для этого свойства конечное свойство «Да»; если запрос не возвращает записи, для этого свойства установите для этого свойства свойство
Примечание Запросы, которые передают данные, могут возвращать несколько наборов результатов, но в таблице, форме, отчете или переменной набора записей используется только первый набор результатов. Чтобы получить несколько наборов результатов, используйте запрос на таблицу, как показано в следующем примере:
SELECT <pass-through query name>.
*
INTO <local table name>
FROM < pass-through query name > -
Журнал сообщений Укажите, следует ли возвращать сообщения из базы SQL в таблице сообщений Access. Имя таблицы имеет формат «имя пользователя — nn», где имя пользователя — это имя для регистрации текущего пользователя, а «nn» — число, начиная с 00.
-
Max Records Укажите максимальное количество возвращаемых записей. Возможно, у вас мало ресурсов в системе или вы хотите протестировать результаты с небольшим объемом данных.
-
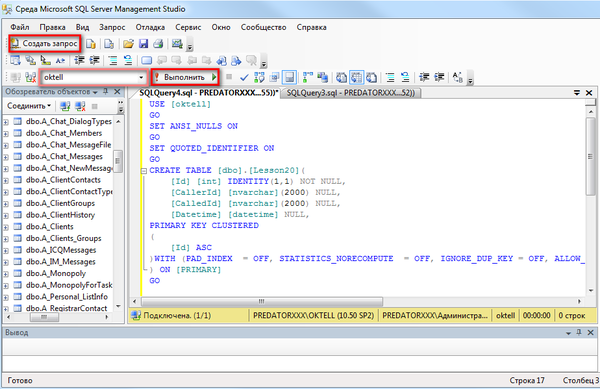
Завершив ввод запроса, выберите «Конструктор > Выполнить».
Запрос отправляется на сервер базы данных для обработки.

 org/ListItem»>
org/ListItem»>
На окне свойств щелкните поле свойства ODBC Connect Str и сделайте одно из следующего:
Получение строки подключения

После создания подключения к файлу DSN строка подключения ODBC будет храниться внутри базы данных Access. Вот как можно получить копию этой строки:
 org/ListItem»>
org/ListItem»>
Найдите имя связанной таблицы в области навигации, используя нужное подключение ODBC.


Вы также думайте о настройке дополнительных связанных свойств.
 *
INTO <local table name>
FROM < pass-through query name >
*
INTO <local table name>
FROM < pass-through query name > org/ListItem»>
org/ListItem»>
Время и времяообнабдения ODBC Укажите, в течение каких секунд произойдет ошибка времени ожидания при запуске запроса. По умолчанию установлен интервал 60 секунд. Могут возникнуть задержки из-за сетевого трафика или интенсивного использования сервера базы данных.
 Запрос отправляется на сервер базы данных для обработки.
Запрос отправляется на сервер базы данных для обработки.Transact-SQL referencehttps://docs.microsoft.com/en-us/sql/t-sql/language-reference?view=sql-server-2017
Запросы с помощью transact-SQL
🗄️ ✔️ 10 лучших практик написания SQL-запросов
Статья является переводом. Оригинал доступен по ссылке.
Я работаю с данными уже 3 года, и меня до сих пор удивляет, что есть люди, которые хотят стать аналитиками, практически не зная SQL. Хочу особо подчеркнуть, что SQL является фундаментальным языком независимо от того, кем вы будете работать в сфере анализа данных.
Конечно, я видел исключения, когда люди, обладающие впечатляющими знаниями в других областях, помимо SQL, получают работу, но при этом после получения оффера им все равно приходится изучать SQL. Я думаю, что почти невозможно быть профессионалом в сфере анализа данных без знаний SQL.
Я думаю, что почти невозможно быть профессионалом в сфере анализа данных без знаний SQL.
Данные советы предназначены для всех специалистов, независимо от опыта. Я перечислил самые распространенные случаи в моей практике, разместив в порядке возрастания сложности.
Для примеров я буду использовать базу данных SQLite: sql-practice.com
1. Проверка уникальных значений в таблице
SELECT count(*), count(distinct patient_id) FROM patients
В этом примере показано, как проверить, является ли ваш столбец первичным ключом в таблице. Конечно, это обычно используется в создаваемых вами таблицах, поскольку в большинстве баз данных есть возможность указать первичный ключ в метаданных информационной схемы.
Если числа из двух столбцов равны, то столбец, который вы подсчитали во второй части запроса, может быть первичным ключом. Это не всегда является гарантией, но иногда может помочь разобраться.
Это не всегда является гарантией, но иногда может помочь разобраться.
Однако становится немного сложнее, когда у вас есть несколько столбцов, которые создают первичный ключ. Чтобы решить эту проблему, просто объедините столбцы, составляющие первичный ключ, после ключевого слова DISTINCT. Простой пример — объединение имени и фамилии для создания первичного ключа.
SELECT count(*), count(distinct first_name || last_name) FROM patients
2. Поиск повторяющихся записей
SELECT
first_name
, count(*) as ct
FROM patients
GROUP BY
first_name
HAVING
count(*) > 1
ORDER BY
COUNT(*) DESC
;
Таблица из примера — это упрощенная версия баз данных, которые вы будете использовать в своей работе. В большинстве случаев вы захотите выяснить причины дублирования значений в базе данных. Для этого вам пригодится данный запрос.
Вы можете использовать ключевое слово HAVING для сортировки повторяющихся значений. В таком случае вы заметите, что чаще всего дублируется имя Джон. Затем вы запустите еще один запрос, чтобы увидеть причину повторяющихся значений, и увидите, что все пациенты имеют разные фамилии и ID.
Больше полезных материалов вы найдете на нашем телеграм-канале «Библиотека программиста»
Интересно, перейти к каналу
3. Обработка NULL с DISTINCT
with new_table as (
select patient_id from patients
UNION
select null
)
select
count(*)
, count(distinct patient_id)
, count(patient_id)
from new_table
Результатом запроса будет значение 4531 для столбца COUNT(*) и 4530 для двух оставшихся столбцов. Когда вы указываете столбец, ключевое слово COUNT исключает нулевые значения. Однако, при использовании звездочки в подсчет включаются значения
Однако, при использовании звездочки в подсчет включаются значения NULL. Это может сбивать с толку при проверке, является ли столбец первичным ключом, поэтому я посчитал нужным упомянуть об этом.
4. CTE > Подзапросы
-- Use of CTE
with combined_table as (
select
*
FROM patients p
JOIN admissions a
on p.patient_id = a.patient_id
)
, name_most_admissions as (
select
first_name || ' ' || last_name as full_name
, count(*) as admission_ct
FROM combined_table
)
select * from name_most_admissions
;
-- Use of sub-queries :(
select * from
(select
first_name || ' ' || last_name as full_name
, count(*) as admission_ct
FROM (select
*
FROM patients p
JOIN admissions a
on p.patient_id = a.patient_id
) combined_table
) name_most_admissions
;
Когда я впервые начал работать аналитиком данных 3 года назад, я писал SQL-запросы с большим количеством подзапросов, чем это было необходимо. Я быстро понял, что это не приводит к читабельному коду. В большинстве ситуаций вы хотите использовать общее табличное выражение вместо подзапроса. Зарезервируйте подзапросы для однострочников, которые вы хотите использовать.
Я быстро понял, что это не приводит к читабельному коду. В большинстве ситуаций вы хотите использовать общее табличное выражение вместо подзапроса. Зарезервируйте подзапросы для однострочников, которые вы хотите использовать.
5. Использование SUM и CASE WHEN вместе
select
sum(case when allergies = 'Penicillin' and city = 'Burlington' then 1 else 0 end) as allergies_burl
, sum(case when allergies = 'Penicillin' and city = 'Oakville' then 1 else 0 end) as allergies_oak
from patients
Предложение WHERE может работать, если вы хотите суммировать количество пациентов, отвечающих определенным условиям. Но если вы хотите проверить несколько условий, вы можете использовать ключевые слова SUM и CASE WHEN вместе. Это делает код лаконичным и легко читаемым.
Данную комбинацию также можно использовать в выражении WHERE, как в примере ниже.
select
*
FROM patients
WHERE TRUE
and 1 = (case when allergies = 'Penicillin' and city = 'Burlington' then 1 else 0 end)
6. Будьте осторожны с датами
with new_table as (
select
patient_id
, first_name
, last_name
, time(birth_date, '+1 second') as birth_date
from patients
where TRUE
and patient_id = 1
UNION
select
patient_id
, first_name
, last_name
, birth_date
from patients
WHERE TRUE
and patient_id != 1
)
select
birth_date
from new_table
where TRUE
and birth_date between '1953-12-05' and '1953-12-06'
В этой базе данных все даты сокращены до дня. Это означает, что все значения времени столбца Birthday_date в этом примере равны 00:00:00. Однако в реальных наборах данных это обычно не так.
В зависимости от среды разработки SQL ваши настройки могут скрыть отображение времени. Но то, что время скрыто, не означает, что оно не является частью данных.
Но то, что время скрыто, не означает, что оно не является частью данных.
В приведенном выше примере я искусственно добавил секунду к пациенту №1. Как видите, этой 1-й секунды было достаточно, чтобы исключить пациента из результатов при использовании ключевого слова BETWEEN.
Еще один распространенный пример, который чаще всего упускают из вида специалисты по работе с данными, — это присоединение к датам, в которых все еще есть временной компонент. В большинстве случаев они действительно пытаются присоединиться к столбцам с сокращенной датой и, в конечном итоге, не получают желаемого результата или, что еще хуже, они не осознают, что получили неправильный результат.
7. Не забывайте об оконных функциях
select
p.*
, MAX(weight) over (partition by city) as maxwt_by_city
from patients p
Оконные функции — отличный способ сохранить все строки данных, а затем добавить еще один столбец с важными агрегатными сведениями. В этом случае мы смогли сохранить все данные и добавить максимальный вес по столбцу города.
В этом случае мы смогли сохранить все данные и добавить максимальный вес по столбцу города.
Я видел, как некоторые аналитики пробовали обходные пути, когда оконная функция делала код короче и читабельнее и, скорее всего, также экономила им время.
Существует множество различных оконных функций, но приведенный выше пример является распространенным и простым вариантом использования.
8. По возможности избегайте DISTINCT
Последние 3 совета не содержат примеров программного кода, но они так же важны, как и приведенные выше. По моему опыту, специалисты по работе с данными слишком часто используют distinct, чтобы предотвратить дублирование, не разбираясь в причине.
Это ошибка. Если вы не можете с самого начала объяснить, почему в данных есть дубликаты, возможно, вы исключили из своего анализа какую-то полезную информацию. Вы всегда должны быть в состоянии объяснить, почему вы помещаете
Вы всегда должны быть в состоянии объяснить, почему вы помещаете distinct в таблицу и почему есть дубликаты. Использование WHERE обычно предпочтительнее, так как вы можете увидеть то, что исключается.
9. Форматирование SQL
Об этом сказано довольно много, но стоит повторить. Обязательно отформатируйте SQL. Лучше создать больше строк с хорошим форматированием, чем пытаться сжать весь код всего в несколько строк. Это позволит ускорить разработку.
Вы можете заметить, что в примерах я использовал TRUE в WHERE выражении. Это было сделано для того, чтобы все аргументы в выражении WHERE начинались с AND. Таким образом, аргументы начинаются с одного и того же места.
Еще один быстрый совет — добавить запятые в начале столбца в выражении SELECT. Это позволяет легко найти пропущенные запятые, поскольку все они будут упорядочены.
Это позволяет легко найти пропущенные запятые, поскольку все они будут упорядочены.
10. Совет по отладке
Некоторые SQL-запросы могут быть очень сложными для отладки. Что мне больше всего помогло, когда я сталкивался с этим в прошлом, так это то, что я очень усердно документировал свои шаги.
Чтобы задокументировать шаги, я пронумерую часть кода в комментариях перед запросом. Комментарий описывает, что я пытаюсь сделать в этом разделе запроса. Затем я напишу свой ответ под заголовком комментария после выполнения запроса.
Во время отладки действительно легко увидеть варианты, которые вы уже попробовали, и я обещаю, что с таким подходом вы решите эту проблему быстрее.
***
Надеюсь, вы узнали что-то полезное из приведенных выше советов. Какие из них вы нашли наиболее полезными? Мы также с нетерпением ждем ваших советов и, пожалуйста, дайте ссылки на любые другие полезные статьи в комментариях, спасибо!
Материалы по теме
- 📜 Основные SQL-команды и запросы с примерами, которые должен знать каждый разработчик
- 🐘 Руководство по SQL для начинающих. Часть 1: создание базы данных, таблиц и установка связей между таблицами
- 🐘 Руководство по SQL для начинающих. Часть 2: фильтрация данных, запрос внутри запроса, работа с массивами
- 🐘 Руководство по SQL для начинающих. Часть 3: усложняем запросы, именуем вложенные запросы, анализируем скорость запроса
 Часть 1: создание базы данных, таблиц и установка связей между таблицами
Часть 1: создание базы данных, таблиц и установка связей между таблицамиЧистый SQL код — Статьи : Персональный сайт Михаила Флёнова
05 Июля 2021 Базы данных
SQL тоже нужно писать красиво, чтобы этот код проще было впоследствии поддерживать. Если запрос состоит из выбора данных из одной таблицы, то можно и забить на чистоту, и оставить все как есть, но когда мы работаем над большим приложением, где много простых запросов или над одним запросом, но большим, очень важно написать код так, чтобы его проще было потом сопровождать.
Мне достаточно часто приходилось работать с большими по размеру запросами, в основном это были какие-то финансовые отчеты, но были и онлайн запросы, которые выполнялись регулярно.
Если запрос состоит из одного select из одной таблицы, то его можно записать как попало. Следующий запрос особо оформлять и не нужно, он легко читается:
select * from person
Печалька в том, что такие запросы в реальной жизни очень редко нужны.
Для начала нужно сказать, что выбирать все колонки с помощью звездочки можно ради тестов или когда вам действительно нужны все колонки, что бывает очень редко. В реальности рекомендуется или лучше все же приучать себя выбирать только колонки, которые вам действительно нужны и при этом указывать их в порядке, который вам необходим. В этом случае вы будете защищены от возможной смены структуры базы данных. Я конечно не рекомендую менять структуру, но сталкивался с таким уже много раз. Правда бывают и. случаи, когда наоборот, вы добавили колонку в запрос, а ее реально удалили и тут уже звездочка наоборот может спасти.
Перечисление колонок помогает в системах, где больше одного сервера приложений и нужен максимальный аптайм. Чтобы этого достигнуть желательно делать обновление базы данных не ломающим приложение, то есть вы должны иметь возможность добавить новые колонки и таблицы, но при этом старый код должен продолжать работать, а для этого нужно соблюдать два основных правила: не удалять колонки и не изменять на несовместимый тип.
Чтобы этого достигнуть желательно делать обновление базы данных не ломающим приложение, то есть вы должны иметь возможность добавить новые колонки и таблицы, но при этом старый код должен продолжать работать, а для этого нужно соблюдать два основных правила: не удалять колонки и не изменять на несовместимый тип.
Если вы будете выбирать в своих запросах только нужные колонки, то после наложения скриптов обновления код не увидит того, чего не должен видеть, для этого нужно будет обновить еще и код.
Надеюсь, я вас убедил, что не стоит использовать звездочку, а значит наш запрос должен выглядеть так:
select personid, teamid, firstname, lastname, positionid from person
Вот тут уже все не так все гладко читается. Если команды SQL написать большими буквами, что очень часто делают, то текст уже становиться чуть лучше:
SELECT personid, teamid, firstname, lastname, positionid FROM person
Это еще не все, можно разделить на строки, каждую секцию написать в своей строке:
SELECT personid, teamid, firstname, lastname, positionid FROM person
Тут даже если написать все маленькими буквами все тоже будет в принципе читаемым:
select personid, teamid, firstname, lastname, positionid from person
Да, это читаемо, но все же на мой вкус все писать большими буквами лучше.
Если код хранить в тексте программы, а текст программы находиться в GIT, то могут возникнуть проблемы со слиянием кода. Если два программиста изменят запрос и каждый из них добавит по одной колонке, то точно возникнет конфликт. Если вы используете ORM, то разрулить конфликт будет относительно просто, а если обращение идет через низкоуровневые функции и индексы колонок, то гореть вам в аду.
Если писать колонки в отдельной строке то можно снизить вероятность конфликтов:
SELECT personid,
teamid,
firstname,
lastname,
positionid
FROM person
Теперь конфликт возникнет только если два программиста добавят колонку в одно и то же место, к сожалению, это чаще всего и происходит, потому что программисты обычно добавляют колонки в конец запроса.
С другой стороны, такой вариант записи SQL удобная еще и тем, что проще убирать временно ненужные колонки. Можно удалить целую строку или поставить комментарии:
SELECT personid,
teamid,
-- firstname,
lastname,
positionid
FROM person
Теперь я отключил колонку firstname и это сделать было очень просто. В оформленном таким образом запросе проще сортировать колонки, если забыть про последнюю.
В оформленном таким образом запросе проще сортировать колонки, если забыть про последнюю.
SELECT personid,
firstname,
lastname,
teamid,
positionid
FROM person
Недостаток – перемещать удобно любую колонку, кроме последней. С конфликтами тоже была проблема с последней колонкой, причем чтобы добавить новую колонку программисты будут не только добавлять еще одну строку, но еще и трогать последнюю строку с колонками, туда придется добавить запятую после positioned. Эта запятая может стать проблемой, потому что она как раз усложняет слияние.
Запятую лучше писать вначале:
SELECT personid
, firstname
, lastname
, teamid
, positionid
FROM person
Теперь можно закомментировать любую колонку, кроме первой, а это первичный ключ и его редко отключают в запросе. И добавлять новую строку проще – просто добавляем в конец и добавляем одну единственную строку, а значит конфликты разрешать проще.
Да, для огромных запросов, которые возвращают более 20 колонок, такой запрос начинает занимать очень много места в файле и приходиться очень много скролить в коде. Скролить тоже плохо. И вот мы встаем перед выбором – что лучше? Зависит от ситуации и личных предпочтений, я же все же рекомендовал бы писать имена колонки каждую в своей строке.
Усложняем жизнь, добавляем объединение таблиц:
SELECT personid
, firstname
, lastname
, teamid
, p.positionid
, psn.Name
FROM person p
JOIN position psn on p.positionid = psn.positionid
Некоторые явно предпочитают писать INNER JOIN, чтобы указать, что перед нами именно INNER объединение. Я за счет лени не пишу лишние пять букв, а сокращаю все до JOIN, потому что привык, что именно это поведение по умолчанию. Тут у меня проблем с чтением нет.
Чуть другое дело, если что-то касается – где писать дополнительные фильтры. Например, следующие два запроса будут абсолютно идентичны:
Например, следующие два запроса будут абсолютно идентичны:
SELECT personid
, firstname
, lastname
, teamid
, p.positionid
, psn.Name
FROM person p
JOIN position psn on p.positionid = psn.positionid and psn.Name = 'Coach'
И
SELECT personid
, firstname
, lastname
, teamid
, p.positionid
, psn.Name
FROM person p
JOIN position psn on p.positionid = psn.positionid
WHERE psn.Name = 'Coach'
И даже этот запрос
SELECT personid
, firstname
, lastname
, teamid
, p.positionid
, psn.Name
FROM person p
JOIN position psn on 1=1
WHERE p.positionid = psn.positionid
AND psn.Name = 'Coach'
Вот реально все равно, где вы напишите проверку на Name = ‘Coach’, потому что в случае с INNER JOIN она не повлияет на результат и с точки зрения производительности я не видел разницы, потому что оптимизаторы обычно не смотрят, где вы пишите фильтры. Но проверка Name = ‘Coach’ логически не относится к объединению двух таблиц и поэтому не должна быть в JOIN, она должна быть в секции WHERE, потому что просто логически принадлежит этой секции.
Но проверка Name = ‘Coach’ логически не относится к объединению двух таблиц и поэтому не должна быть в JOIN, она должна быть в секции WHERE, потому что просто логически принадлежит этой секции.
Логическое расположение важно, и оно в будущем вам будет говорить, где искать определенный код. Например, если вы видите, что связь между двумя таблицами не работает, значит нужно идти, и проверять JOIN и что написано после ON. Если результат не совсем верный и отображаются только тренера, то скорей всего нужно смотреть на фильтры, а значит это секция WHERE. В реальной жизни бывает всякое, но по умолчанию именно логика поиска проблемы должна быть именно такой.
Посмотрим на секцию WHERE в последнем запросе:
WHERE p.positionid = psn.positionid AND psn.Name = 'Coach'
Обратите внимание, что каждый фильтр находиться в отдельной строке. Каждый AND должен быть отдельно. В одну строку можно помещать две проверки, только если они объединены с помощью OR, это удобно, чтобы не забыть поставить скобки:
WHERE p.
 positionid = psn.positionid
AND (psn.Name = 'Coach' OR psn.Name like 'P%')
positionid = psn.positionid
AND (psn.Name = 'Coach' OR psn.Name like 'P%')
Если две проверки в одной строке, это всегда должно быть сигналом, что они должны работать как одно целое и там есть скобки.
Секция WHERE одно из самых важных мест, где нужно правильно расставлять отступы. Не стесняйтесь ставить пробелы, чтобы текст запроса рос вправо. Если в каждой строке только одна проверка, то это норм, вы не заметите проблем. Слишком сильно вправо он не должен убежать.
В одном из видео Строим таблицу чемпионата на SQL — Проще некуда и в этой текстовой версии Практика — ищем победителей я написал запрос, в котором мы искали победителей чемпионата по какому-то командному спорту. Запрос получился вот такой:
select team, sum(points)
from (
select
case
when hometeamgoals > guestteamgoals then hometeamid
when hometeamgoals < guestteamgoals then guestteamid
end team,
3 as points
from game
where hometeamgoals != guestteamgoals
union all
select hometeamid, 1 as points
from game
where hometeamgoals = guestteamgoals
union all
select guestteamid, 1 as points
from game
where hometeamgoals = guestteamgoals
) p
group by team
order by 2 desc
Если вы не видели того видео или видели его очень давно, то понять и разобрать подобный запрос будет достаточно сложно. В секции FROM находиться три запроса и каждый из них выполняет что-то, а чтобы понять, что они делают, приходиться читать каждый из них и вдумываться.
В секции FROM находиться три запроса и каждый из них выполняет что-то, а чтобы понять, что они делают, приходиться читать каждый из них и вдумываться.
Можно было бы использовать комментарии, но я противник таких вещей. Если нужен комментарий, то код скорей всего плохой и читать его поддерживать будет сложно. Комментарии – это что-то, что должно быть в коде только в самом крайнем случае.
Запрос выше должен был бы выглядеть следующим образом:
select team, sum(points)
from (
select * from winners3points
union all
select * from hometies1point
union all
select * from guestties1point
) p
group by team
order by 2 desc
Вот такой запрос читать на много проще – здесь объединяются три выборки winners3points, hometies1point и guestties1point. По имени уже понятно, что это делает, а как. . . Вот тут есть два варианта, можно взять код, который был на этом месте и вынести в представления. Но я создаю представления только если код будет использоваться в нескольких местах. Если у вас нагруженная система с требованием обновления онлайн, то представления могут привести к проблемам и с ними нужно быть осторожнее.
Если у вас нагруженная система с требованием обновления онлайн, то представления могут привести к проблемам и с ними нужно быть осторожнее.
Если какой-то код только разово, то можно использовать CTE (в MySQL поддерживается с 8-й версии):
with
winners3points as (
select
case
when hometeamgoals > guestteamgoals then hometeamid
when hometeamgoals < guestteamgoals then guestteamid
end team,
3 as points
from game
where hometeamgoals != guestteamgoals
),
hometies1point as (
select hometeamid, 1 as points
from game
where hometeamgoals = guestteamgoals
),
guestties1point as (
select guestteamid, 1 as points
from game
where hometeamgoals = guestteamgoals
)
select team, sum(points)
from (
select * from winners3points
union all
select * from hometies1point
union all
select * from guestties1point
) p
group by team
order by 2 desc
CTE практически то же самое, что и псевдонимы для SQL запросов. Глядя на имена псевдонимов, мы без проблем можем понять, что делает запрос без дополнительных комментариев, а если мы хотим понять, как работает один из псевдонимов, мы можем взглянуть на него.
Глядя на имена псевдонимов, мы без проблем можем понять, что делает запрос без дополнительных комментариев, а если мы хотим понять, как работает один из псевдонимов, мы можем взглянуть на него.
CTE может помочь даже с точки зрения производительности. Из личного опыта – разбиение запросов на небольшие составляющие позволяет базе данных проще понять, что от него требуется.
Внимание!!! Если ты копируешь эту статью себе на сайт, то оставляй ссылку непосредственно на эту страницу. Спасибо за понимание
Лучшие практики написания SQL-запросов
- Корректность, удобочитаемость, затем оптимизация: в таком порядке
- Сделайте свои стога как можно меньше, прежде чем искать иголки
- Сначала узнайте свои данные
- Разработка вашего запроса
- Общий порядок выполнения запроса
- Некоторые рекомендации по запросам (не правила)
- Прокомментируйте свой код, особенно почему
- лучшие практики SQL для FROM
- Соединение таблиц с использованием ключевого слова ON
- Псевдоним нескольких таблиц
- лучшие практики SQL для WHERE
- Фильтр с WHERE до HAVING
- Избегайте функций для столбцов в предложениях WHERE
- Предпочтение
= отдоНРАВИТСЯ - Избегайте подстановочных знаков в операторах WHERE
- Предпочитаю СУЩЕСТВУЕТ вместо IN
- рекомендации SQL для GROUP BY
- Упорядочить несколько групп по убыванию мощности
- лучших практик SQL для HAVING
- Используйте только HAVING для агрегатов фильтрации
- рекомендации SQL для SELECT
- SELECT столбцы, а не звезды
- лучших практик SQL для UNION
- Предпочесть UNION All вместо UNION
- рекомендации SQL для ORDER BY
- По возможности избегайте сортировки, особенно в подзапросах
- рекомендации SQL для INDEX
- Добавление индексов
- Использовать частичные индексы
- Использовать составные индексы
- ОБЪЯСНИТЬ
- Поиск узких мест
- С
- Организуйте свои запросы с помощью Common Table Expressions (CTE)
- С метабазой вам даже не нужно использовать SQL
- Вопиющие ошибки или упущения?
В этой статье рассматриваются некоторые рекомендации по написанию SQL-запросов для аналитиков и специалистов по данным. Большая часть нашего обсуждения будет касаться SQL в целом, но мы включим некоторые заметки о функциях, специфичных для Metabase, которые упрощают написание SQL.
Большая часть нашего обсуждения будет касаться SQL в целом, но мы включим некоторые заметки о функциях, специфичных для Metabase, которые упрощают написание SQL.
Правильность, удобочитаемость, затем оптимизация: в таком порядке
Здесь применяется стандартное предупреждение о преждевременной оптимизации. Избегайте настройки SQL-запроса, пока не будете уверены, что ваш запрос возвращает нужные вам данные. И даже в этом случае оптимизируйте запрос в первую очередь только в том случае, если он выполняется часто (например, при включении популярной информационной панели) или если запрос проходит большое количество строк. В общем, прежде чем беспокоиться о производительности, отдайте предпочтение точности (выдает ли запрос ожидаемые результаты) и удобочитаемости (могут ли другие легко понять и изменить код).
Сделайте свои стога как можно меньше, прежде чем искать иголки
Возможно, здесь мы уже приступаем к оптимизации, но цель должна заключаться в том, чтобы указать базе данных сканировать минимальное количество значений, необходимых для получения ваших результатов.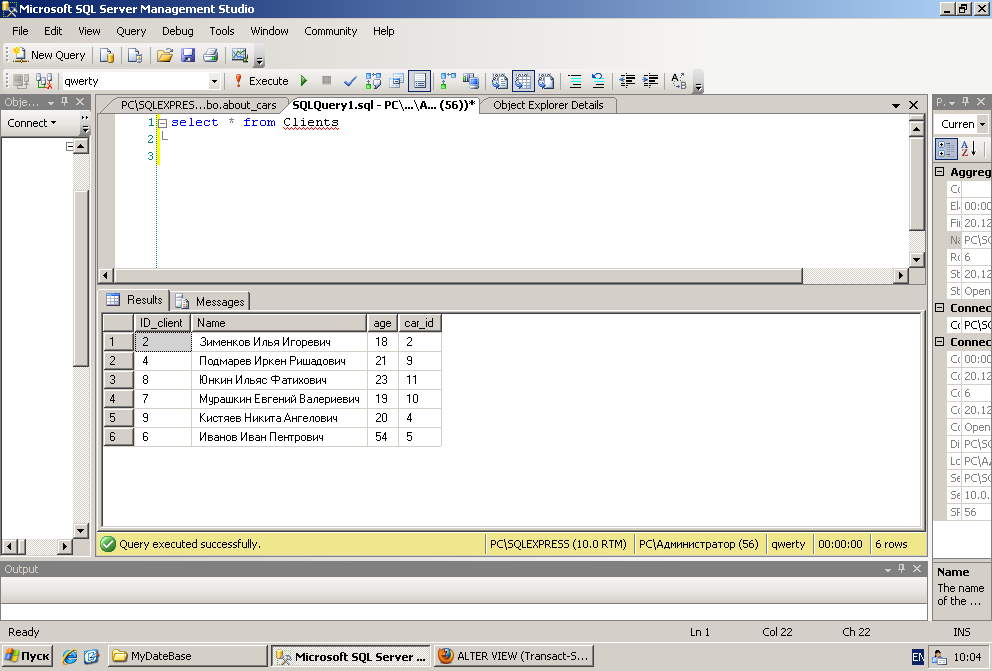
Частью красоты SQL является его декларативный характер. Вместо того, чтобы сообщать базе данных, как извлекать записи, вам нужно только сообщить базе данных, какие записи вам нужны, и база данных должна определить наиболее эффективный способ получения этой информации. Следовательно, большая часть советов по повышению эффективности запросов сводится просто к тому, чтобы показать людям, как использовать инструменты SQL для более точного формулирования своих потребностей.
Мы пересмотрим общий порядок выполнения запросов и добавим советы по сокращению пространства поиска. Затем мы поговорим о трех основных инструментах, которые можно добавить в пояс: INDEX, EXPLAIN и WITH.
Сначала узнайте свои данные
Прежде чем писать хоть одну строку кода, ознакомьтесь со своими данными, изучив метаданные, чтобы убедиться, что столбец действительно содержит ожидаемые данные. Редактор SQL в Metabase имеет удобную справочную вкладку данных (доступную через значок книги ), где вы можете просматривать таблицы в своей базе данных и просматривать их столбцы и соединения (рис. 1):
1):
Вы также можете просмотреть примеры значений для определенных столбцов (рис. 2).
Рис. 2 . Используйте боковую панель Data Reference , чтобы просмотреть образцы данных. Метабазапредоставляет вам множество различных способов изучения ваших данных: вы можете просматривать таблицы, составлять вопросы с помощью построителя запросов и редактора записной книжки, преобразовывать сохраненный вопрос в код SQL или создавать из существующего собственного запроса. Мы расскажем об этом в других статьях; а пока давайте рассмотрим общий рабочий процесс запроса.
Разработка запроса
Методы у всех разные, но вот пример рабочего процесса, которому нужно следовать при разработке запроса.
- Как и выше, изучите метаданные столбца и таблицы. Если вы используете собственный редактор запросов Metabase, вы также можете искать фрагменты SQL, содержащие код SQL для таблицы и столбцов, с которыми вы работаете. Фрагменты позволяют увидеть, как другие аналитики запрашивали данные. Или вы можете начать запрос из существующего вопроса SQL.
- Чтобы получить представление о значениях таблицы, ВЫБЕРИТЕ * из таблиц, с которыми вы работаете, и ОГРАНИЧЬТЕ результаты. Применяйте LIMIT по мере уточнения столбцов (или добавляйте дополнительные столбцы с помощью объединений).
- Сократите столбцы до минимального набора, необходимого для ответа на ваш вопрос.
- Применить любые фильтры к этим столбцам.
- Если вам нужно агрегировать данные, агрегируйте небольшое количество строк и убедитесь, что агрегирование соответствует вашим ожиданиям.
- Когда у вас есть запрос, возвращающий нужные вам результаты, найдите разделы запроса, чтобы сохранить их как Common Table Expression (CTE) для инкапсуляции этой логики.
- С помощью Metabase вы также можете сохранять код в виде фрагмента SQL для совместного использования и повторного использования в других запросах.
 Фрагменты позволяют увидеть, как другие аналитики запрашивали данные. Или вы можете начать запрос из существующего вопроса SQL.
Фрагменты позволяют увидеть, как другие аналитики запрашивали данные. Или вы можете начать запрос из существующего вопроса SQL.
Общий порядок выполнения запроса
Прежде чем мы перейдем к отдельным советам по написанию кода SQL, важно иметь представление о том, как базы данных будут выполнять ваш запрос. Это отличается от порядка чтения (слева направо, сверху вниз), который вы используете для составления запроса. Оптимизаторы запросов могут изменить порядок следующего списка, но этот общий жизненный цикл SQL-запроса следует помнить при написании SQL. Мы будем использовать порядок выполнения, чтобы сгруппировать следующие советы по написанию хорошего SQL.
Эмпирическое правило здесь таково: чем раньше в этом списке вы сможете удалить данные, тем лучше.
- FROM (и JOIN) получает(ют) таблицы, на которые есть ссылки в запросе. Эти таблицы представляют максимальное пространство поиска, указанное вашим запросом. По возможности ограничьте это пространство поиска, прежде чем двигаться дальше.
- ГДЕ фильтрует данные.
- GROUP BY объединяет данные.
- HAVING отфильтровывает агрегированные данные, которые не соответствуют критериям.
- SELECT захватывает столбцы (затем дедуплицирует строки, если вызывается DISTINCT).
- UNION объединяет выбранные данные в набор результатов.
- ORDER BY сортирует результаты.

И, конечно же, всегда будут случаи, когда оптимизатор запросов для вашей конкретной базы данных разработает другой план запроса, так что не зацикливайтесь на этом порядке.
Некоторые рекомендации по запросам (не правила)
Следующие советы являются рекомендациями, а не правилами, призванными уберечь вас от неприятностей. Каждая база данных обрабатывает SQL по-своему, имеет немного отличающийся набор функций и использует разные подходы к оптимизации запросов. И это еще до того, как мы приступим к сравнению традиционных транзакционных баз данных с аналитическими базами данных, которые используют форматы хранения столбцов, которые имеют совершенно разные характеристики производительности.
Помогите людям (включая себя через три месяца), добавив комментарии, поясняющие различные части кода. Самое важное, что здесь нужно уловить, — это «почему». Например, очевидно, что приведенный ниже код отфильтровывает заказы с
Самое важное, что здесь нужно уловить, — это «почему». Например, очевидно, что приведенный ниже код отфильтровывает заказы с ID больше 10, но это происходит потому, что первые 10 заказов используются для тестирования.
ВЫБЕРИТЕ я бы, товар ИЗ заказы -- отфильтровать тестовые заказы КУДА идентификатор заказа> 10
Загвоздка здесь в том, что вы вносите небольшие накладные расходы на обслуживание: если вы меняете код, вам нужно убедиться, что комментарий по-прежнему актуален и актуален. Но это небольшая цена за читаемый код.
Лучшие практики SQL для FROM
Соединение таблиц с помощью ключевого слова ON
Хотя можно «объединить» две таблицы с помощью предложения WHERE (то есть выполнить неявное соединение, например, SELECT * FROM a,b WHERE a.foo = b.bar ), вместо этого следует предпочесть явное ПРИСОЕДИНЕНИЕ:
ВЫБЕРИТЕ о.ид, о.общий, стр. поставщик ИЗ заказы КАК О ПРИСОЕДИНЯЙТЕСЬ к продуктам КАК p ON o.
 product_id = p.id
product_id = p.id
В основном для удобства чтения, так как JOIN + 9Синтаксис 0032 ON отличает объединения от предложений WHERE , предназначенных для фильтрации результатов.
Псевдоним нескольких таблиц
При запросе нескольких таблиц используйте псевдонимы и применяйте эти псевдонимы в своем операторе выбора, чтобы базе данных (и вашему читателю) не нужно было анализировать, какой столбец принадлежит какой таблице. Обратите внимание, что если у вас есть столбцы с одинаковыми именами в нескольких таблицах, вам нужно будет явно ссылаться на них либо по имени таблицы, либо по псевдониму.
Избегать
ВЫБЕРИТЕ заглавие, фамилия, Имя ИЗ художественных_книг ВЛЕВО ПРИСОЕДИНЯЙТЕСЬ ПО fiction_books.author_id = fiction_authors.id
Предпочтение
ВЫБЕРИТЕ книги.название, авторы.фамилия, авторы.first_name ИЗ художественных_книг КАК книги ВЛЕВО ПРИСОЕДИНЯЙТЕСЬ к авторам фикции КАК авторам ПО books.
 author_id = author.id
author_id = author.id
Это тривиальный пример, но когда количество таблиц и столбцов в вашем запросе увеличивается, вашим читателям не нужно будет отслеживать, какой столбец находится в какой таблице. Это и ваши запросы могут сломаться, если вы присоединитесь к таблице с неоднозначным именем столбца (например, обе таблицы включают поле с именем Создан_В .
Обратите внимание, что фильтры полей несовместимы с псевдонимами таблиц, поэтому вам потребуется удалить псевдонимы при подключении виджетов фильтров к вашим фильтрам полей.
Лучшие практики SQL для WHERE
Фильтр с WHERE перед HAVING
Используйте предложение WHERE для фильтрации лишних строк, чтобы вам не приходилось вычислять эти значения в первую очередь. Только после удаления ненужных строк, а также после объединения этих строк и их группировки следует включать Предложение HAVING для фильтрации агрегатов.
Избегайте функций для столбцов в предложениях WHERE
Использование функции для столбца в предложении WHERE может существенно замедлить ваш запрос, поскольку эта функция делает запрос недоступным для анализа (т. е. не позволяет базе данных использовать индекс для ускорения запроса). Вместо того, чтобы использовать индекс для перехода к соответствующим строкам, функция для столбца заставляет базу данных запускать функцию для каждой строки таблицы.
е. не позволяет базе данных использовать индекс для ускорения запроса). Вместо того, чтобы использовать индекс для перехода к соответствующим строкам, функция для столбца заставляет базу данных запускать функцию для каждой строки таблицы.
И помните, оператор конкатенации || — это тоже функция, так что не пытайтесь объединить строки для фильтрации нескольких столбцов. Вместо этого предпочесть несколько условий:
Избегать
ВЫБЕРИТЕ героя, помощника ОТ супергероев ГДЕ герой || помощник = 'БэтменРобин'
Предпочтение
ВЫБЕРИТЕ героя, помощника ОТ супергероев КУДА герой = «Бэтмен» А ТАКЖЕ помощник = 'Робин'
Предпочтение
= от до НРАВИТСЯ Это не всегда так. Приятно знать, что LIKE сравнивает символы и может сочетаться с операторами подстановки, такими как % , тогда как оператор = сравнивает строки и числа для точного совпадения.
= могут использовать индексированные столбцы. Это не относится ко всем базам данных, поскольку LIKE может использовать индексы (если они существуют для поля), если вы избегаете префикса поискового запроса с оператором подстановки, % . Что подводит нас к следующему пункту:
Избегайте подстановочных знаков в операторах WHERE
Использование подстановочных знаков для поиска может быть дорогостоящим. Предпочитаю добавлять подстановочные знаки в конец строк. Префикс строки с подстановочным знаком может привести к полному сканированию таблицы.
Избегать
ВЫБЕРИТЕ столбец ИЗ таблицы WHERE col LIKE "%wizar%"
Предпочтение
SELECT столбец FROM table WHERE col LIKE "wizar%"
Предпочитает СУЩЕСТВУЕТ, а не В
Если вам просто нужно проверить существование значения в таблице, выберите EXISTS 9От 0033 до IN , поскольку процесс EXISTS завершается, как только он находит искомое значение, тогда как IN просматривает всю таблицу.
IN следует использовать для поиска значений в списках.
Аналогично, предпочтите НЕ СУЩЕСТВУЕТ вместо НЕ В .
Рекомендации по SQL для GROUP BY
Упорядочить несколько групп по убыванию мощности
Где возможно, СГРУППИРОВАТЬ НА столбца в порядке убывания кардинальности. То есть сначала группируйте по столбцам с более уникальными значениями (например, идентификаторы или номера телефонов), а затем группируйте по столбцам с меньшим количеством различных значений (например, штат или пол).
Лучшие практики SQL для HAVING
Используйте только HAVING для агрегатов фильтрации
А до HAVING отфильтруйте значения с помощью предложения WHERE перед агрегированием и группировкой этих значений.
Рекомендации по SQL для SELECT
ВЫБЕРИТЕ столбцы, а не звезды
Укажите столбцы, которые вы хотите включить в результаты (хотя можно использовать * при первом просмотре таблиц — только не забудьте LIMIT ваши результаты).
Рекомендации по SQL для UNION
Предпочесть UNION All вместо UNION
Если дубликаты не являются проблемой, UNION ALL не будет отбрасывать их, а поскольку UNION ALL не занимается удалением дубликатов, запрос будет более эффективным.
Рекомендации по SQL для ORDER BY
По возможности избегайте сортировки, особенно в подзапросах
Сортировка стоит дорого. Если вам необходимо выполнить сортировку, убедитесь, что ваши подзапросы не сортируют данные без необходимости.
Рекомендации по SQL для INDEX
Этот раздел предназначен для администраторов баз данных в толпе (тема слишком велика, чтобы поместиться в этой статье). Одна из наиболее распространенных проблем, с которыми сталкиваются люди при возникновении проблем с производительностью в запросах к базе данных, — это отсутствие адекватной индексации.
То, какие столбцы следует индексировать, обычно зависит от столбцов, по которым вы фильтруете (т. е. от того, какие столбцы обычно заканчиваются в предложениях
е. от того, какие столбцы обычно заканчиваются в предложениях WHERE ). Если вы обнаружите, что всегда фильтруете по общему набору столбцов, вам следует подумать об индексации этих столбцов.
Добавление индексов
Индексация столбцов внешнего ключа и часто запрашиваемых столбцов может значительно сократить время запроса. Вот пример оператора для создания индекса:
CREATE INDEX product_title_index В продуктах (название)
Доступны различные типы индексов, наиболее распространенный тип индекса использует B-дерево для ускорения поиска. Ознакомьтесь с нашей статьей о том, как сделать информационные панели быстрее, и ознакомьтесь с документацией по вашей базе данных, чтобы узнать, как создать индекс.
Использовать частичные индексы
Для особенно больших наборов данных или неравномерных наборов данных, где определенные диапазоны значений появляются чаще, рассмотрите возможность создания индекса с предложением WHERE , чтобы ограничить количество индексируемых строк. Частичные индексы также могут быть полезны для диапазонов дат, например, если вы хотите индексировать данные только за последнюю неделю.
Частичные индексы также могут быть полезны для диапазонов дат, например, если вы хотите индексировать данные только за последнюю неделю.
Использовать составные индексы
Для столбцов, которые обычно используются вместе в запросах (например, last_name, first_name), рассмотрите возможность создания составного индекса. Синтаксис аналогичен созданию одного индекса. Например:
CREATE INDEX full_name_index ON клиентов (last_name, first_name)
ОБЪЯСНИТЬ
Поиск узких мест
Некоторые базы данных, такие как PostgreSQL, предлагают информацию о плане запроса на основе вашего кода SQL. Просто добавьте к своему коду префикс ключевых слов EXPLAIN ANALYZE . Эти команды можно использовать для проверки планов запросов и поиска узких мест или для сравнения планов одной версии запроса с другой, чтобы определить, какая версия более эффективна.
Вот пример запроса с использованием образца базы данных dvdrental , доступного для PostgreSQL.
EXPLAIN ANALYZE SELECT название, выпуск_год ИЗ фильма ГДЕ выпуск_год > 2000;
И вывод:
Seq Scan на пленке (стоимость=0,00..66,50 рядов=1000 ширина=19) (фактическое время=0,008..0,311 рядов=1000 петель=1) Фильтр: ((release_year)::integer > 2000) Время планирования: 0,062 мс Время выполнения: 0,416 мс
Вы увидите миллисекунды, необходимые для планирования времени, времени выполнения, а также стоимости, строк, ширины, времени, циклов, использования памяти и т. д. Чтение этих анализов — своего рода искусство, но вы можете использовать их для выявления проблемных областей в ваших запросах (таких как вложенные циклы или столбцы, индексация которых может быть полезна) по мере их уточнения.
Вот документация PostreSQL по использованию EXPLAIN.
С
Организуйте свои запросы с помощью общих табличных выражений (CTE)
Используйте предложение WITH для инкапсуляции логики в общем табличном выражении (CTE). Вот пример запроса, который ищет продукты с самым высоким средним доходом на единицу, проданную в 2019 году, а также максимальные и минимальные значения.
Вот пример запроса, который ищет продукты с самым высоким средним доходом на единицу, проданную в 2019 году, а также максимальные и минимальные значения.
С product_orders КАК (
ВЫБЕРИТЕ o.created_at AS order_date,
p.title КАК product_title,
(o.subtotal / o.quantity) КАК доход_на_единицу
ОТ заказов КАК o
LEFT JOIN products AS p ON o.product_id = p.id
-- Отфильтровывать заказы, размещенные службой поддержки клиентов, для взимания платы с клиентов.
ГДЕ о.количество > 0
)
ВЫБЕРИТЕ product_title КАК продукт,
AVG(доход_на_единицу) AS avg_revenue_per_unit,
MAX(доход_на_единицу) AS max_revenue_per_unit,
MIN(доход_на_единицу) AS min_revenue_per_unit
ОТ product_orders
ГДЕ order_date МЕЖДУ 2019 г.-01-01" И "31-12-2019"
СГРУППИРОВАТЬ ПО продукту
ЗАКАЗАТЬ ПО avg_revenue_per_unit DESC
Предложение WITH делает код читабельным, поскольку основной запрос (то, что вы на самом деле ищете) не прерывается длинным подзапросом.
Вы также можете использовать CTE, чтобы сделать ваш SQL более читабельным, если, например, в вашей базе данных есть поля с неудобными именами или которые требуют небольшой обработки данных для получения полезных данных. Например, CTE могут быть полезны при работе с полями JSON. Вот пример извлечения и преобразования полей из большого двоичного объекта JSON пользовательских событий.
С исходными_данными КАК (
ВЫБЕРИТЕ события->'данные'->>'имя' КАК событие_имя,
CAST(события->'данные'->>'ts' AS timestamp) AS event_timestamp
CAST(события->'данные'->>'cust_id' AS int) AS customer_id
ОТ пользовательской_активности
)
ВЫБЕРИТЕ имя_события,
event_timestamp,
Пользовательский ИД
ИЗ source_data
Кроме того, вы можете сохранить подзапрос как фрагмент SQL (рис. 3 — обратите внимание на круглые скобки вокруг фрагмента), чтобы легко повторно использовать этот код в других запросах.
Рис. 3 . Сохранение подзапроса во фрагменте и его использование в предложении FROM.
И да, как и следовало ожидать, аэродинамический кожаный тукан приносит самый высокий средний доход на проданную единицу.
С метабазой вам даже не нужно использовать SQL
SQL потрясающий. Но то же самое можно сказать и о построителе запросов Metabase и редакторе блокнотов. Вы можете составлять запросы с помощью графического интерфейса Metabase для объединения таблиц, фильтрации и суммирования данных, создания настраиваемых столбцов и многого другого. А с помощью пользовательских выражений вы можете справиться с подавляющим большинством аналитических вариантов использования, даже не прибегая к SQL. Вопросы, составленные с использованием Notebook Editor также имеет преимущества автоматической детализации, которая позволяет зрителям ваших диаграмм щелкать и исследовать данные, функция, недоступная для вопросов, написанных на SQL.
Вопиющие ошибки или упущения?
Существуют библиотеки книг по SQL, так что здесь мы коснемся только поверхности.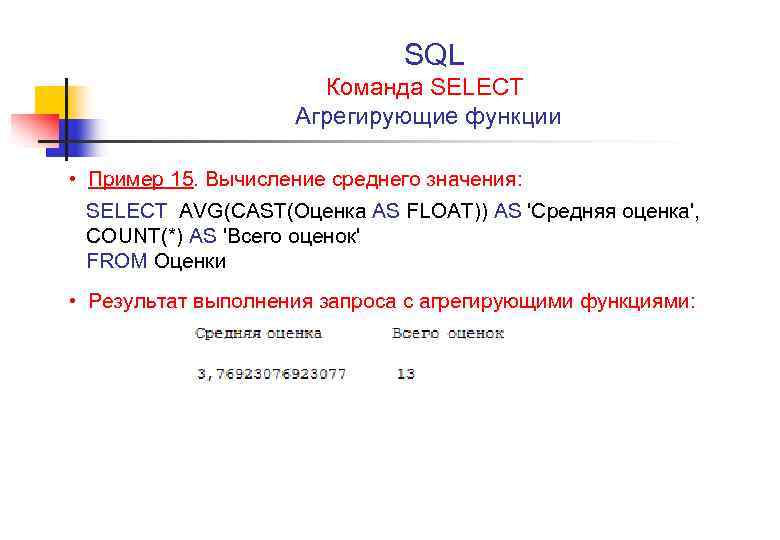 Вы можете поделиться секретами своего SQL-колдовства с другими пользователями метабазы на нашем форуме.
Вы можете поделиться секретами своего SQL-колдовства с другими пользователями метабазы на нашем форуме.
« Предыдущая Далее »
Вам помогла эта статья?
Спасибо за отзыв!
Использование SQL Runner для создания запросов и исследований | Looker
SQL Runner обеспечивает прямой доступ к вашей базе данных и использует этот доступ различными способами. Используя SQL Runner, вы можете легко перемещаться по таблицам в вашей схеме, использовать специальное исследование из SQL-запроса, запускать предварительно написанные описательные запросы к вашим данным, просматривать историю SQL Runner, загружать результаты, обмениваться запросами, добавлять в проект LookML как производную таблицу и выполнять другие полезные задачи.
На этой странице описывается, как выполнять запросы в SQL Runner, создавать специальные исследования и как использовать SQL Runner для отладки запросов. Дополнительные сведения см. на других страницах документации:
Дополнительные сведения см. на других страницах документации:
- Основы SQL Runner
- Использование SQL Runner для создания производных таблиц
- Управление функциями базы данных с помощью SQL Runner
Выполнение запросов в SQL Runner
Чтобы выполнить запрос к базе данных, вы можете написать запрос SQL с нуля, использовать Explore для создания запроса или выполнить запрос к модели LookML. Вы также можете использовать историю для повторного выполнения предыдущего запроса.
Написание SQL-запроса с нуля
Вы можете использовать SQL Runner для написания и запуска собственных SQL-запросов к вашей базе данных. Looker передает ваш запрос в вашу базу данных так, как вы его написали, поэтому убедитесь, что синтаксис вашего SQL-запроса действителен для вашего диалекта базы данных. Например, у каждого диалекта есть немного разные функции SQL с определенными параметрами, которые должны быть переданы в функцию.
- Щелкните в области запроса SQL и введите команду SQL.
- При необходимости дважды щелкните имя таблицы или поле в списке полей, чтобы включить его в запрос в том месте, где находится курсор.
- Щелкните Выполнить , чтобы выполнить запрос к вашей базе данных.
- Просмотрите результаты в области результатов. SQL Runner загрузит до 5000 строк набора результатов запроса. Для диалектов SQL, поддерживающих потоковую передачу, вы можете загрузить результаты, чтобы увидеть весь набор результатов.
Некоторые программы SQL позволяют выполнять несколько запросов подряд. Однако вы можете выполнять только один запрос за раз в SQL Runner. SQL Runner также имеет ограничение в 65 535 символов для запросов, включая пробелы.
Если у вас есть запрос, который вам нравится, вы можете добавить его в проект, получить LookML для производной таблицы или поделиться запросом.
Вы также можете использовать SQL Runner, чтобы поиграть с новыми запросами или протестировать существующие запросы. Подсветка ошибок SQL Runner помогает тестировать и отлаживать запросы.
Подсветка ошибок SQL Runner помогает тестировать и отлаживать запросы.
Использование Explore для создания SQL-запроса
Вы также можете использовать Explore для создания запроса, а затем получить команду SQL для этого запроса для использования в SQL Runner:
- В Исследовании щелкните вкладку SQL на панели Данные .
- Выберите текст SQL-запроса и скопируйте его в SQL Runner или
- Нажмите Открыть в SQL Runner или Объяснение в SQL Runner , чтобы открыть запрос в SQL Runner.
После добавления запроса в область SQL-запросов SQL Runner можно щелкнуть Выполнить , чтобы запросить базу данных. Кроме того, вы можете отредактировать запрос, а затем запустить новый запрос.
Создание визуализаций с помощью SQL Runner
Если ваш администратор Looker включил функцию SQL Runner Vis Labs, вы можете создавать визуализации непосредственно в SQL Runner.
При включении SQL Runner Vis панели SQL Runner реорганизованы. Панель визуализации отображается вверху, панель результатов — посередине, а панель запросов — внизу.
- После создания и выполнения SQL-запроса вы можете открыть Визуализация , чтобы просмотреть визуализацию и выбрать тип визуализации, как на странице Исследовать.
- Вы можете редактировать визуализацию с помощью меню Настройки .
- Вы можете поделиться визуализациями, созданными с помощью SQL Runner, поделившись URL-адресом. Любые настройки, сделанные с помощью меню Настройки визуализации , будут сохранены, а ссылка не изменится.
Следует помнить о том, как работают визуализации SQL Runner:
- Таблица результатов и визуализация интерпретируют любое числовое поле как меру.
- Полное имя поля всегда используется в таблице результатов и визуализации. Поэтому параметр Показать полное имя поля в меню Настройки неактивен.
- Чтобы использовать настраиваемые поля, табличные вычисления, сводные данные, итоги по столбцам и промежуточные итоги, изучите запрос SQL Runner.
- Визуализации статической карты (регионов) не поддерживаются визуализациями SQL Runner, однако поддерживаются карты, использующие данные широты и долготы (карта и статическая карта (точки) визуализации).
- Визуализации временной шкалы не поддерживаются визуализациями SQL Runner.
Сводные измерения
Вы можете отредактировать результаты запроса, чтобы свести их по одному или нескольким измерениям в визуализациях SQL Runner. Чтобы повернуть поле:
- Щелкните значок шестеренки столбца в области Результаты , чтобы открыть параметры столбца.
- Нажмите Сводная колонка .
Сводные результаты отображаются в визуализации SQL Runner:
Результаты в области Результаты не отображаются сводными.
Чтобы отменить сводку результатов , щелкните меню шестеренки сводного столбца и выберите Unpivot Column :
Изменение типа поля любое нечисловое поле в качестве измерения. Вы можете переопределить тип поля по умолчанию и преобразовать измерение в меру или наоборот:
- Щелкните значок шестеренки столбца в области Результаты , чтобы открыть параметры столбца.
- Нажмите Преобразовать в измерение или Преобразовать в меру , чтобы изменить тип поля.
В визуализации будет отображаться новый тип поля:
Выполнение запроса к модели LookML
Вы можете использовать SQL Runner для написания и выполнения SQL-запросов к модели LookML, а не непосредственно к вашей базе данных. При построении запроса к модели вы можете использовать операторы замены LookML, такие как ${view_name. или  field_name}
field_name} ${view_name.SQL_TABLE_NAME} . Это может сэкономить время при построении запроса, например, для устранения неполадок в производной таблице.
Looker разрешает любые замены LookML, а затем передает ваш запрос в вашу базу данных, поэтому запрос должен быть в допустимом SQL для вашего диалекта базы данных. Например, у каждого диалекта есть немного разные функции SQL с определенными параметрами, которые должны быть переданы в функцию.
Чтобы выполнить запрос к вашей модели LookML в SQL Runner:
- Перейдите на вкладку Модель .
- Выберите модель, которую вы хотите запросить.
- Щелкните в области SQL-запрос и введите свой SQL-запрос, используя поля LookML.
- При необходимости дважды щелкните представление в списке представлений, чтобы включить представление в запрос в том месте, где находится курсор.
- Чтобы просмотреть список полей в представлении, щелкните представление в разделе Представления . При желании вы можете дважды щелкнуть поле в списке полей, чтобы включить его в свой запрос в том месте, где находится курсор.
- В области Подготовленный SQL-запрос можно просмотреть результирующий SQL-запрос, созданный после преобразования любых замен LookML в SQL.
- Щелкните Выполнить , чтобы выполнить запрос для вашей модели.
- Просмотрите результаты в области Результаты . SQL Runner загружает до 5000 строк набора результатов запроса. Для диалектов SQL, поддерживающих потоковую передачу, вы можете загрузить результаты, чтобы увидеть весь набор результатов.
 При желании вы можете дважды щелкнуть поле в списке полей, чтобы включить его в свой запрос в том месте, где находится курсор.
При желании вы можете дважды щелкнуть поле в списке полей, чтобы включить его в свой запрос в том месте, где находится курсор.Когда у вас есть запрос, который вам нравится, вы можете добавить его в проект, получить LookML для производной таблицы или поделиться запросом.
Вы также можете использовать SQL Runner, чтобы играть с новыми запросами, тестировать существующие запросы или открывать новое исследование из результатов. Подсветка ошибок SQL Runner помогает тестировать и отлаживать запросы.
Просмотр поля LookML из SQL Runner
Из списка полей на вкладке Model можно также просмотреть LookML для поля. Наведите указатель мыши на поле в списке полей и щелкните значок Looker справа от имени поля:
Looker открывает IDE LookML и загружает файл, в котором определено поле.
История SQL Runner
Вы также можете просмотреть недавнюю историю всех запросов, которые вы выполняли в SQL Runner.
Чтобы просмотреть историю, щелкните вкладку История в верхней части панели навигации. SQL Runner отображает все запросы, выполняемые при подключении к базе данных. Красный цвет означает, что запрос не был выполнен из-за ошибки.
Щелкните запрос в истории, чтобы заполнить этот запрос в SQL Runner, затем щелкните Выполнить , чтобы повторно выполнить запрос:
Сортировка запроса
Порядок сортировки в таблице указывается стрелкой вверх или вниз рядом с именем отсортированного поля, в зависимости от того, в каком порядке находятся результаты: по возрастанию или по убыванию. Вы можете сортировать по нескольким столбцам, удерживая нажатой клавишу Shift, а затем щелкая заголовки столбцов в том порядке, в котором вы хотите их отсортировать. Порядок сортировки поля также обозначается числом, которое отличает его порядок сортировки по сравнению с другими полями, стрелкой рядом с именем поля, показывающей направление сортировки (по возрастанию или убыванию), и всплывающим окном, которое появляется при наведении курсора на имя поля.
Вы можете сортировать по нескольким столбцам, удерживая нажатой клавишу Shift, а затем щелкая заголовки столбцов в том порядке, в котором вы хотите их отсортировать. Порядок сортировки поля также обозначается числом, которое отличает его порядок сортировки по сравнению с другими полями, стрелкой рядом с именем поля, показывающей направление сортировки (по возрастанию или убыванию), и всплывающим окном, которое появляется при наведении курсора на имя поля.
Дополнительные сведения и примеры см. в разделе «Сортировка данных» на странице документации Изучение данных в Looker .
Совместное использование запросов
Вы можете поделиться запросом в SQL Runner с другим пользователем с доступом к SQL Runner. Чтобы поделиться запросом, просто скопируйте URL-адрес в адресную строку:
Загрузка результатов
После выполнения SQL-запроса вы можете загрузить результаты в различных форматах.
- Напишите запрос в Блок запроса SQL . (На данный момент вам не нужно запускать запрос в SQL Runner.)
- Выберите Загрузить из меню шестеренки в правом верхнем углу.
- Выберите формат загружаемого файла (текстовый файл, CSV, JSON и т. д.).
Щелкните Открыть в браузере , чтобы просмотреть результаты в новом окне браузера, или щелкните Загрузить , чтобы загрузить результаты в файл на свой компьютер.
При нажатии кнопки Открыть в браузере или Загрузить , Looker повторно запустит запрос, а затем выполнит загрузку.
Для диалектов SQL, поддерживающих потоковую передачу, параметр SQL Runner Загрузить загрузит весь набор результатов. Для диалектов SQL, не поддерживающих потоковую передачу, параметр SQL Runner Загрузить загрузит только те строки запроса, которые показаны в разделе Результаты (до 5000 строк).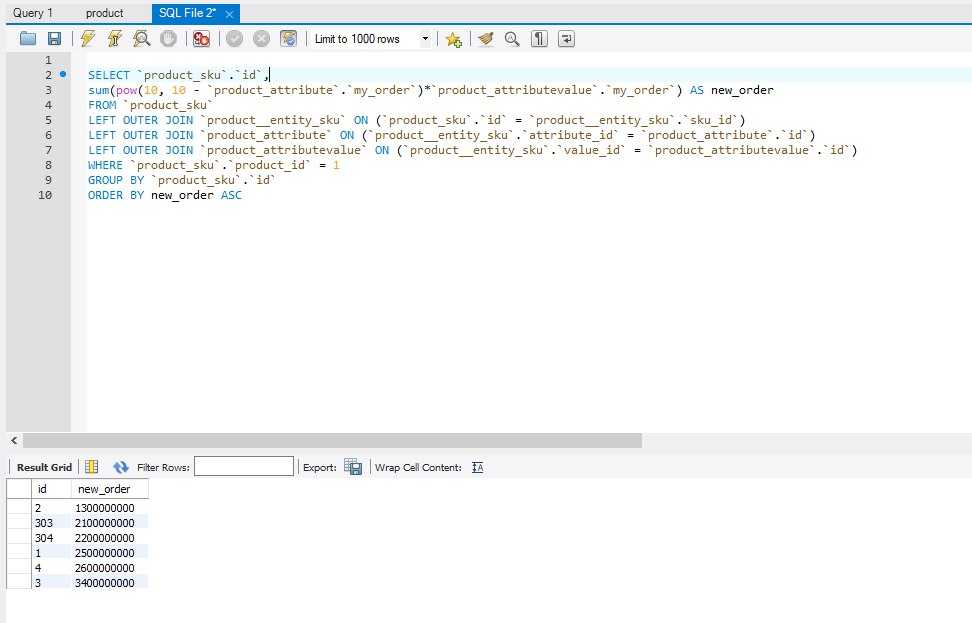
Копирование значений столбцов
Вы можете копировать значения столбцов из Раздел результатов в SQL Runner. Щелкните меню шестеренки столбца, чтобы скопировать значения в буфер обмена. Оттуда вы можете вставить значения столбца в текстовый файл, документ Excel или другое место.
Если ваш администратор Looker включил функцию SQL Runner Vis Labs, у вас также есть другие параметры в меню шестеренки столбца:
- Заморозить и разморозить
- Авторазмер всех столбцов
- Сбросить ширину всех столбцов
Вы также можете вручную перемещать, закреплять и изменять размер столбцов в таблице результатов.
Оценка стоимости запросов SQL Runner
Для подключений BigQuery, MySQL, Amazon RDS для MySQL, Snowflake, Amazon Redshift, Amazon Aurora, PostgreSQL, Cloud SQL для PostgreSQL и Microsoft Azure PostgreSQL SQL Runner предоставляет оценку стоимости запрос.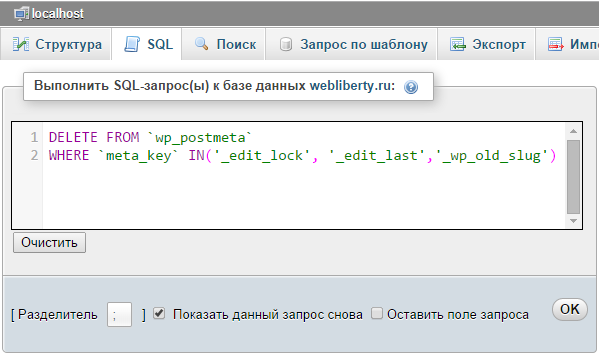 После того как вы введете SQL-запрос, SQL Runner рассчитает объем данных, которые потребуются для запроса, и отобразит информацию рядом с кнопкой Run .
После того как вы введете SQL-запрос, SQL Runner рассчитает объем данных, которые потребуются для запроса, и отобразит информацию рядом с кнопкой Run .
Для подключений BigQuery, MySQL и Amazon RDS для MySQL оценка затрат всегда включена. Для подключений к базам данных Snowflake, Amazon Redshift, Amazon Aurora, PostgreSQL, Cloud SQL для PostgreSQL и Microsoft Azure PostgreSQL необходимо включить Оценка стоимости вариант подключения. Вы можете включить Cost Estimate при создании соединения. Для существующих подключений вы можете редактировать подключение на странице Connections в разделе Database панели Looker Admin .
Создание специального исследования
С помощью SQL Runner вы можете быстро получить представление о данных, создав специальное исследование для запроса SQL или таблицы базы данных. Вы можете использовать Looker Explore для выбора полей, добавления фильтров, визуализации результатов и создания SQL-запросов.
Вы можете использовать Looker Explore для выбора полей, добавления фильтров, визуализации результатов и создания SQL-запросов.
Существует два способа открыть специальное исследование из SQL Runner:
- Исследование из результатов запроса SQL Runner
- Исследование из списка таблиц SQL Runner
Исследование из результатов запроса SQL Runner
SQL Runner позволяет открыть исследование из запроса SQL. Это создает временное исследование из запроса, написанного в SQL Runner. Это позволяет проверить, что возвращает запрос, а также визуализировать результаты. Это можно использовать для любого запроса, но особенно полезно для тестирования запросов, которые вы планируете использовать для производных таблиц.
Если ваш администратор Looker включил функцию SQL Runner Vis Labs, вы можете создавать визуализации непосредственно в SQL Runner.
- Используйте SQL Runner для создания SQL-запроса, который вы хотите использовать.
- Нажмите Исследуйте в меню шестеренки в правом верхнем углу. Это приведет вас к новому исследованию, где вы сможете исследовать SQL-запрос, как если бы это была сохраненная таблица в вашей модели.
- Вы можете скопировать URL-адрес этого обзора для совместного использования.
- Чтобы добавить этот запрос как производную таблицу в свой проект прямо отсюда, нажмите Добавить представление в проект .
Создание настраиваемых полей при изучении в SQL Runner
Если у вас есть доступ к функции настраиваемых полей, вы можете использовать настраиваемые поля для визуализации несмоделированных полей в SQL Runner. Как описано в предыдущем разделе, щелкните Исследовать в меню шестеренки. Затем в поле выбора:
- Щелкните раздел Пользовательские поля , чтобы открыть его, а затем щелкните Добавьте , чтобы начать создание пользовательского параметра, пользовательской меры или табличного расчета. (Если у вас нет раздела Custom Fields , то у вас нет доступа для создания настраиваемых полей.)
- Щелкните меню меры с тремя точками Options ](/exploring-data/exploring-data#three-dot_options_menu и выберите Filter Measure , чтобы создать отфильтрованную пользовательскую меру из существующей меры.
- Щелкните трехточечное меню измерения Параметры и выберите тип меры (например, сумма или количество), чтобы создать пользовательскую меру из измерения.
 (Если у вас нет раздела Custom Fields , то у вас нет доступа для создания настраиваемых полей.)
(Если у вас нет раздела Custom Fields , то у вас нет доступа для создания настраиваемых полей.)Изучение таблицы, указанной в SQL Runner
Используйте параметр Исследовать таблицу на вкладке База данных , чтобы создать нерегламентированное исследование для любой таблицы в соединении. Это позволяет вам использовать Looker для таблицы до того, как вы ее смоделировали, исследуя таблицу точно так же, как представление LookML.
После того, как вы откроете окно просмотра для таблицы, вы сможете решить, добавлять ли эту таблицу в свой проект. Вы также можете использовать вкладку Explorer SQL , чтобы просмотреть SQL-запросы, которые Looker отправляет в базу данных, а затем использовать Кнопка "Открыть в SQL Runner" , чтобы вернуть запрос обратно в SQL Runner.
Вы также можете использовать вкладку Explorer SQL , чтобы просмотреть SQL-запросы, которые Looker отправляет в базу данных, а затем использовать Кнопка "Открыть в SQL Runner" , чтобы вернуть запрос обратно в SQL Runner.
- Перейдите на вкладку База данных .
- В SQL Runner щелкните шестеренку для таблицы и выберите Исследовать таблицу .
- Looker создает временную модель с представлением для таблицы, а затем отображает файл Explore.
- Looker предоставляет поле измерения для каждого столбца в таблице. (Таким же образом Looker создает модель в начале проекта.)
- Looker автоматически включает временные рамки для любых полей даты.
- Looker также включает меру подсчета.
При использовании опции Explore Table файл LookML не связан с Explore — это просто специальное представление таблицы.
Отладка с помощью SQL Runner
SQL Runner также является полезным инструментом для проверки ошибок SQL в запросах.
Выделение ошибок SQL Runner
SQL Runner выделяет расположение ошибок в команде SQL и включает положение ошибки в сообщение об ошибке:
Предоставляемая информация о местоположении зависит от диалекта базы данных. Например, MySQL предоставляет номер строки, содержащей ошибку, а Redshift предоставляет позицию символа ошибки. Другие диалекты базы данных могут иметь один из этих или других вариантов поведения.
SQL Runner также выделяет расположение первой синтаксической ошибки в команде SQL, подчеркивая ее красным цветом и помечая строку знаком «x». Наведите указатель мыши на «x», чтобы просмотреть дополнительную информацию об ошибке. После устранения этой проблемы нажмите Запустите , чтобы проверить, есть ли еще какие-либо ошибки в запросе.
Использование SQL Runner для проверки ошибок в Explorer
Если вы столкнулись с синтаксическими ошибками SQL в Explore, вы можете использовать SQL Runner, чтобы определить место ошибки и тип ошибки, например орфографические ошибки или отсутствующие команды.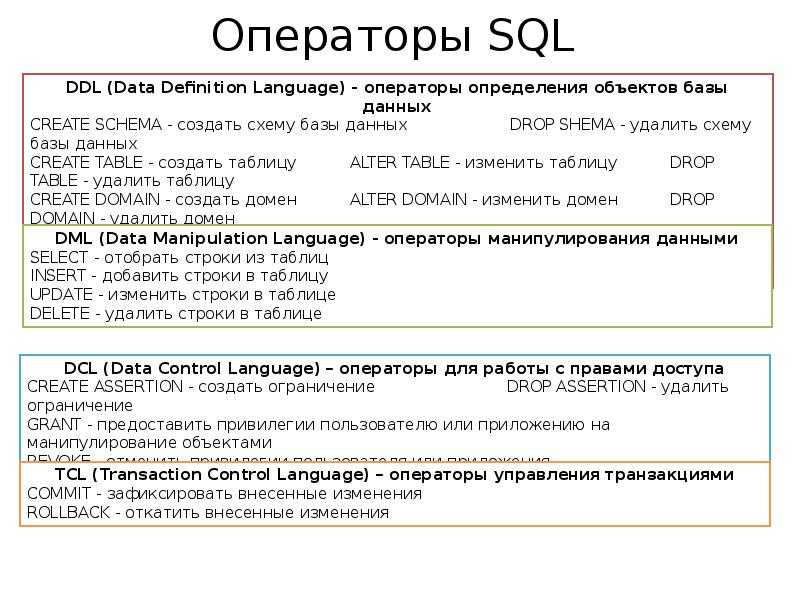
- В Исследовании щелкните вкладку SQL на панели данных.
- Щелкните Открыть в SQL Runner , чтобы открыть запрос в SQL Runner.
Это копирует сгенерированный SQL Explorer в SQL Runner. Как показано выше, SQL Runner выделяет расположение ошибок в команде SQL и включает положение ошибки в сообщение об ошибке. Затем вы можете внести изменения и повторно запустить запрос в SQL Runner, пока не исправите ошибки.
Использование SQL Runner для проверки ошибок в производных таблицах
Сведения об использовании SQL Runner для проверки ошибок SQL в производных таблицах см. в статье сообщества Looker Использование SQL Runner для проверки производных таблиц.
основные понятия, словарный запас и синтаксис
Когда вы хотите получить данные из базы данных, вы запрашиваете данные с помощью языка структурированных запросов или SQL. SQL — это компьютерный язык, очень похожий на английский, но понятный программам баз данных. Каждый выполняемый вами запрос использует SQL за кулисами.
SQL — это компьютерный язык, очень похожий на английский, но понятный программам баз данных. Каждый выполняемый вами запрос использует SQL за кулисами.
Понимание того, как работает SQL, может помочь вам создавать более качественные запросы и упростить понимание того, как исправить запрос, который не возвращает нужных вам результатов.
Это одна из статей о Access SQL. В этой статье описывается основное использование SQL для выбора данных и используются примеры для иллюстрации синтаксиса SQL.
В этой статье
Что такое SQL?
Основные предложения SQL: SELECT, FROM и WHERE.
Сортировка результатов: ORDER BY
Работа с суммированными данными: GROUP BY и HAVING
Объединение результатов запроса: UNION
Что такое SQL?
SQL — это компьютерный язык для работы с наборами фактов и отношениями между ними. Программы реляционных баз данных, такие как Microsoft Office Access, используют SQL для работы с данными. В отличие от многих компьютерных языков, SQL несложно читать и понимать даже новичку. Как и многие компьютерные языки, SQL является международным стандартом, признанным такими органами стандартизации, как ISO и ANSI.
Программы реляционных баз данных, такие как Microsoft Office Access, используют SQL для работы с данными. В отличие от многих компьютерных языков, SQL несложно читать и понимать даже новичку. Как и многие компьютерные языки, SQL является международным стандартом, признанным такими органами стандартизации, как ISO и ANSI.
Вы используете SQL для описания наборов данных, которые могут помочь вам ответить на вопросы. Когда вы используете SQL, вы должны использовать правильный синтаксис. Синтаксис — это набор правил, по которым правильно сочетаются элементы языка. Синтаксис SQL основан на синтаксисе английского языка и использует многие из тех же элементов, что и синтаксис Visual Basic для приложений (VBA).
Например, простой оператор SQL, который извлекает список фамилий для контактов, чье имя — Мэри, может выглядеть следующим образом:
ВЫБЕРИТЕ Фамилию
ИЗ Контактов
ГДЕ Имя = 'Мэри';
Примечание. SQL используется не только для управления данными, но также для создания и изменения структуры объектов базы данных, таких как таблицы. Часть SQL, используемая для создания и изменения объектов базы данных, называется языком определения данных (DDL). В этом разделе не рассматривается DDL. Дополнительные сведения см. в статье Создание или изменение таблиц или индексов с помощью запроса определения данных.
SQL используется не только для управления данными, но также для создания и изменения структуры объектов базы данных, таких как таблицы. Часть SQL, используемая для создания и изменения объектов базы данных, называется языком определения данных (DDL). В этом разделе не рассматривается DDL. Дополнительные сведения см. в статье Создание или изменение таблиц или индексов с помощью запроса определения данных.
Операторы SELECT
Чтобы описать набор данных с помощью SQL, вы пишете оператор SELECT. Оператор SELECT содержит полное описание набора данных, которые вы хотите получить из базы данных. В том числе:
Какие таблицы содержат данные.
Как связаны данные из разных источников.
Какие поля или вычисления будут создавать данные.
Критерии, которым должны соответствовать данные для включения.
Нужно ли и как сортировать результаты.

Предложения SQL
Как и предложение, оператор SQL имеет разделы. Каждое предложение выполняет функцию оператора SQL. Некоторые предложения необходимы в операторе SELECT. В следующей таблице перечислены наиболее распространенные предложения SQL.
Предложение SQL | Что он делает | Требуется |
ВЫБЕРИТЕ | Список полей, содержащих интересующие данные. | Да |
ИЗ | Список таблиц, содержащих поля, перечисленные в предложении SELECT. | Да |
ГДЕ | Указывает критерии поля, которым должна соответствовать каждая запись, чтобы быть включенной в результаты. | № |
ЗАКАЗАТЬ | Указывает способ сортировки результатов. | № |
ГРУППА ПО | В операторе SQL, содержащем агрегатные функции, перечислены поля, которые не суммируются в предложении SELECT. | Только при наличии таких полей |
ИМЕЮЩИЙ | В операторе SQL, содержащем агрегатные функции, указывает условия, которые применяются к полям, суммируемым в операторе SELECT. | № |


Термины SQL
Каждое предложение SQL состоит из терминов — сравнимых с частями речи. В следующей таблице перечислены типы терминов SQL.
В следующей таблице перечислены типы терминов SQL.
Термин SQL | Сопоставимая часть речи | Определение | Пример |
идентификатор | существительное | Имя, которое вы используете для идентификации объекта базы данных, например имя поля. | Клиенты. [Номер телефона] |
оператор | глагол или наречие | Ключевое слово, которое представляет действие или изменяет действие. | КАК |
постоянная | существительное | Неизменяемое значение, например число или NULL. | 42 |
выражение | прилагательное | Комбинация идентификаторов, операторов, констант и функций, результатом которой является одно значение. | >= Продукты.[Цена за единицу] |

Верх страницы
Основные предложения SQL: SELECT, FROM и WHERE
Оператор SQL имеет общий вид:
ВЫБЕРИТЕ поле_1
ИЗ таблицы_1
ГДЕ критерий_1
;
Примечания:
Access игнорирует разрывы строк в операторе SQL. Однако рассмотрите возможность использования строки для каждого предложения, чтобы улучшить читаемость ваших операторов SQL для себя и других.
Каждый оператор SELECT заканчивается точкой с запятой (;).
Точка с запятой может стоять в конце последнего предложения или в отдельной строке в конце оператора SQL.
 Точка с запятой может стоять в конце последнего предложения или в отдельной строке в конце оператора SQL.
Точка с запятой может стоять в конце последнего предложения или в отдельной строке в конце оператора SQL.Пример в Access
Ниже показано, как может выглядеть оператор SQL для простого запроса на выборку в Access:
1. Предложение SELECT
2. ИЗ статьи
3. ГДЕ пункт
Этот пример оператора SQL гласит: «Выберите данные, хранящиеся в полях с именами «Адрес электронной почты» и «Компания», из таблицы «Контакты», в частности те записи, в которых значением поля «Город» является Сиэтл».
Давайте рассмотрим пример, по одному предложению за раз, чтобы увидеть, как работает синтаксис SQL.
Предложение SELECT
ВЫБЕРИТЕ [Адрес электронной почты], Компания
Это предложение SELECT. Он состоит из оператора (SELECT), за которым следуют два идентификатора ([Адрес электронной почты] и Компания).
Он состоит из оператора (SELECT), за которым следуют два идентификатора ([Адрес электронной почты] и Компания).
Если идентификатор содержит пробелы или специальные символы (например, «Адрес электронной почты»), он должен быть заключен в квадратные скобки.
Предложение SELECT не должно указывать, какие таблицы содержат поля, и оно не может указывать какие-либо условия, которым должны соответствовать данные, подлежащие включению.
Предложение SELECT всегда появляется перед предложением FROM в операторе SELECT.
Пункт FROM
ОТ Контакты
Это предложение FROM. Он состоит из оператора (FROM), за которым следует идентификатор (Contacts).
В предложении FROM не указаны поля для выбора.
Пункт WHERE
ГДЕ Город="Сиэтл"
Это предложение WHERE. Он состоит из оператора (WHERE), за которым следует выражение (City="Seattle").
Он состоит из оператора (WHERE), за которым следует выражение (City="Seattle").
Примечание. В отличие от предложений SELECT и FROM, предложение WHERE не является обязательным элементом инструкции SELECT.
Многие действия, которые позволяет выполнять SQL, можно выполнять с помощью предложений SELECT, FROM и WHERE. Дополнительные сведения о том, как вы используете эти пункты, представлены в следующих дополнительных статьях:
.Доступ к SQL: предложение SELECT
Доступ к SQL: предложение FROM
 org/ListItem">
org/ListItem">Доступ к SQL: предложение WHERE
Верх страницы
Сортировка результатов: ПОРЯДОК ПО
Как и Microsoft Excel, Access позволяет сортировать результаты запроса в таблице. Вы также можете указать в запросе, как вы хотите сортировать результаты при выполнении запроса, используя предложение ORDER BY. Если вы используете предложение ORDER BY, это последнее предложение в операторе SQL.
Предложение ORDER BY содержит список полей, которые вы хотите использовать для сортировки, в том же порядке, в котором вы хотите применять операции сортировки.
Например, предположим, что вы хотите, чтобы результаты сначала были отсортированы по значению поля "Компания" в порядке убывания, а — если есть записи с таким же значением для "Компания " — затем отсортированы по значениям в поле "Адрес электронной почты" в порядке возрастания. заказ. Ваше предложение ORDER BY будет выглядеть следующим образом:
заказ. Ваше предложение ORDER BY будет выглядеть следующим образом:
ЗАКАЗАТЬ Компания DESC, [Адрес электронной почты]
Примечание. По умолчанию Access сортирует значения в порядке возрастания (от A до Z, от меньшего к большему). Вместо этого используйте ключевое слово DESC для сортировки значений в порядке убывания.
Дополнительные сведения о предложении ORDER BY см. в разделе Предложение ORDER BY.
Верх страницы
Работа со сводными данными: GROUP BY и HAVING
Иногда требуется работать со сводными данными, такими как общий объем продаж за месяц или самые дорогие товары в инвентаре. Для этого вы применяете агрегатную функцию к полю в предложении SELECT. Например, если вы хотите, чтобы ваш запрос отображал количество адресов электронной почты, перечисленных для каждой компании, ваше предложение SELECT может выглядеть следующим образом:
ВЫБЕРИТЕ COUNT([Адрес электронной почты]), Компания
Доступные для использования агрегатные функции зависят от типа данных в поле или выражении, которые вы хотите использовать. Дополнительные сведения о доступных агрегатных функциях см. в статье Агрегатные функции SQL.
Дополнительные сведения о доступных агрегатных функциях см. в статье Агрегатные функции SQL.
Указание полей, которые не используются в агрегатной функции: предложение GROUP BY
При использовании агрегатных функций обычно необходимо также создать предложение GROUP BY. В предложении GROUP BY перечислены все поля, к которым не применяется агрегатная функция. Если вы применяете агрегатные функции ко всем полям запроса, вам не нужно создавать предложение GROUP BY.
Предложение GROUP BY следует непосредственно за предложением WHERE или предложением FROM, если предложение WHERE отсутствует. Предложение GROUP BY перечисляет поля в том виде, в каком они появляются в предложении SELECT.
Например, продолжая предыдущий пример, если ваше предложение SELECT применяет агрегатную функцию к [Адрес электронной почты], но не к компании, ваше предложение GROUP BY будет выглядеть следующим образом:
ГРУППА КОМПАНИЙ
Дополнительные сведения о предложении GROUP BY см. в разделе Предложение GROUP BY.
в разделе Предложение GROUP BY.
Ограничение агрегированных значений с помощью групповых критериев: предложение HAVING
Если вы хотите использовать критерии для ограничения результатов, но поле, к которому вы хотите применить критерии, используется в агрегатной функции, вы не можете использовать предложение WHERE. Вместо этого вы используете предложение HAVING. Предложение HAVING работает так же, как предложение WHERE, но используется для агрегированных данных.
Например, предположим, что вы используете функцию AVG (которая вычисляет среднее значение) с первым полем в предложении SELECT:
ВЫБЕРИТЕ COUNT([Адрес электронной почты]), Компания
Если вы хотите, чтобы запрос ограничивал результаты на основе значения этой функции COUNT, вы не можете использовать критерий для этого поля в предложении WHERE.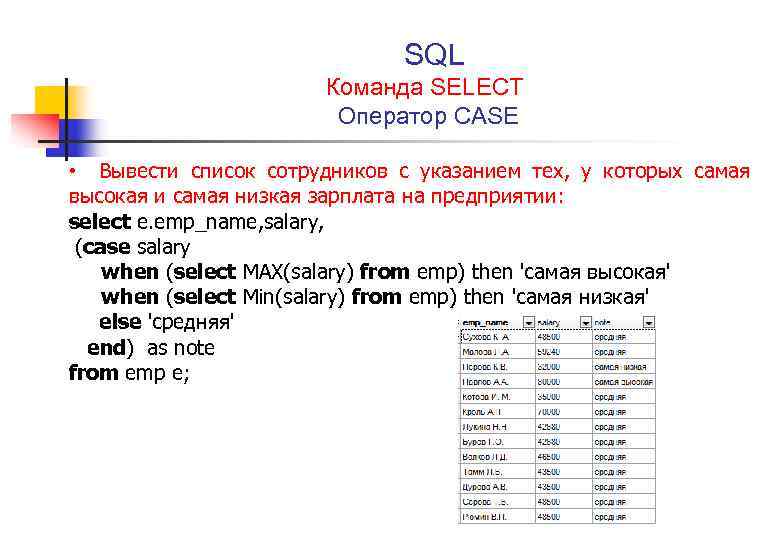 Вместо этого вы помещаете критерии в предложение HAVING. Например, если вы хотите, чтобы запрос возвращал строки только в том случае, если с компанией связано несколько адресов электронной почты, предложение HAVING может иметь следующий вид:
Вместо этого вы помещаете критерии в предложение HAVING. Например, если вы хотите, чтобы запрос возвращал строки только в том случае, если с компанией связано несколько адресов электронной почты, предложение HAVING может иметь следующий вид:
HAVING COUNT([Адрес электронной почты])>1
Примечание. Запрос может содержать предложение WHERE и предложение HAVING — критерии для полей, которые не используются в агрегатной функции, указываются в предложении WHERE, а критерии для полей, которые используются с агрегатными функциями, — в предложении HAVING.
Дополнительные сведения о предложении HAVING см. в разделе Предложение HAVING.
Верх страницы
Объединение результатов запроса: UNION
Если вы хотите просмотреть все данные, которые возвращаются несколькими похожими запросами на выборку вместе, как объединенный набор, вы используете оператор UNION.
Оператор UNION позволяет объединить два оператора SELECT в один. Объединяемые операторы SELECT должны иметь одинаковое количество выходных полей, в том же порядке и с одинаковыми или совместимыми типами данных. Когда вы запускаете запрос, данные из каждого набора соответствующих полей объединяются в одно выходное поле, так что выходные данные запроса имеют то же количество полей, что и каждый из операторов select.
Примечание. Для целей запроса на объединение типы данных Number и Text совместимы.
При использовании оператора UNION можно также указать, должны ли результаты запроса включать повторяющиеся строки, если они существуют, с помощью ключевого слова ALL.
Базовый синтаксис SQL для запроса на объединение, который объединяет две инструкции SELECT, выглядит следующим образом:
ВЫБЕРИТЕ поле_1
ИЗ таблицы_1
UNION [ALL]
SELECT field_a
FROM table_a
;
Например, предположим, что у вас есть таблица с именем «Продукты» и другая таблица с именем «Службы».