3 способа удалить страницу из поиска Google
Если вы хотите избавиться от низкокачественных, неактуальных, конфиденциальных страниц или дублей в результатах поиска Google, предлагаем ознакомиться с тремя популярными способами удаления URL из выдачи мирового поисковика.
Способ #1: С помощью Google Search Console
Старый метод
Страницы принадлежащие вашему сайту можно легко удалить с помощью Google Search Console. Сайт должен быть авторизован в сервисе Google для Вебмастеров.
Инструкция по удалению URL с помощью Google Search Console:
- Обратитесь к инструменту для удаления URL от Google, он находится здесь
- Выберите подтвержденный ресурс
- Нажмите на кнопку
Временно скрыть, введите URL и нажмитеПродолжить - Подтвердите операцию с помощью кнопки
Отправить запрос
По умолчанию, Google временно удалит URL из кеша и исключит его из поиска.
Страница пропадет из Google поиска примерно на 90 дней. Каждый новый URL-адрес будет иметь статус «Ожидающий удаления», но вы легко можете отменить этот запрос нажав кнопку Отмена.
Имейте ввиду, что этот способ — временный. Если страница продолжает находится на вашем сайте спустя 90 дней, возможно, Google снова начнет показывать ее в результатах поиска.
Новый метод
В новой версии Google Search Console появился инструмент для удаления URL. Его можно найти в левой колонке в разделе «Индекс». Примечательно, что временное скрытие страниц из Google было расширено до 6 месяцев или 180 дней, что вдвое больше предыдущей квоты.
Чтобы удалить URL через обновленную консоль, выполните:
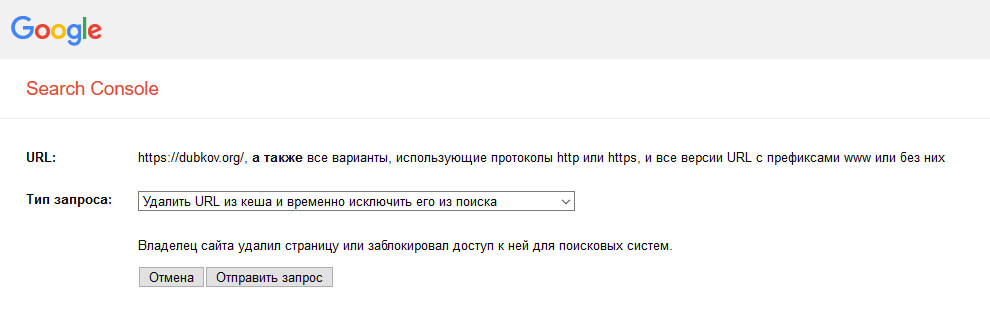
- Обратитесь к инструменту для удаления URL, теперь он находится здесь
- Выберите сайт
- Создайте запрос для удаления страницы во вкладке «Временные удаления» с помощью кнопки
Создать запрос - Введите URL страницы или раздела, который хотите скрыть и нажмите
След. - Подтвердите действие кнопкой
Отправить запрос
Мета-тег noindex самый простой способ удалить страницу из результатов поиска или запретить ей индексироваться. Мета-тег это маленький отрывок кода в заголовке HTML-файла вашей страницы. Он запрещает Google и другим поисковым системам ее индексировать.
Вот как он выглядит:
<meta name="robots" content="noindex" />Иногда можно встретить комбинацию noindex, follow вместо noindex — оба варианта имеют одинаковый эффект.
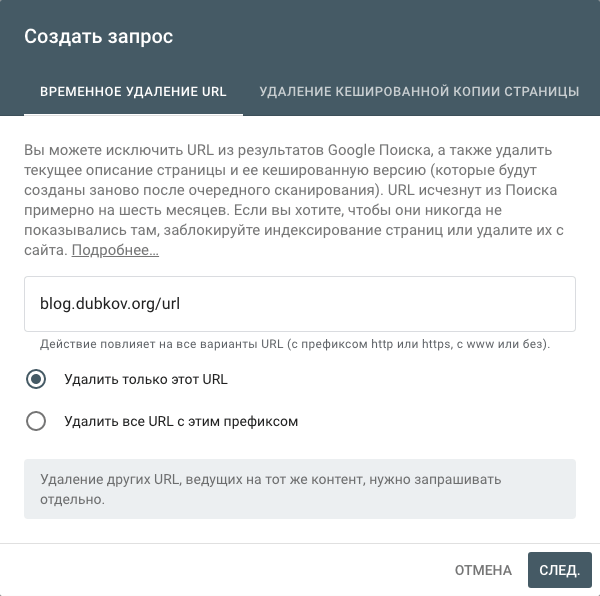
Вы можете добавить такой код вручную на ваш сайт, если имеете доступ к редактированию разметки HTML. Если вы используете WordPress, то большинство SEO-плагинов предоставляют опции запрета индексации отдельных постов, страниц и категорий.
Например, в популярном плагине Yoast SEO для WordPress это можно сделать во вкладке «Разрешить поисковым системам показывать запись в результатах поиска?», изменив статус «По умолчанию» на «Нет». Так, вы добавите мета-тег noindex в заголовок страницы.
Страницы должны исчезнуть из поиска, когда поисковой робот вновь обойдет их. Ускорить процесс можно с помощью инструмента по удалению устаревшего контента Google. Это лучший способ запрета индексирования контента или удаления ненужных URL.
Пока тег noindex присутствует на страницах, они не попадут в поле зрения краулера и не будут показываться в результатах поиска. Мета-тег noindex также поможет исключить страницы из других поисковых систем, включая Яндекс, Bing и Yahoo.
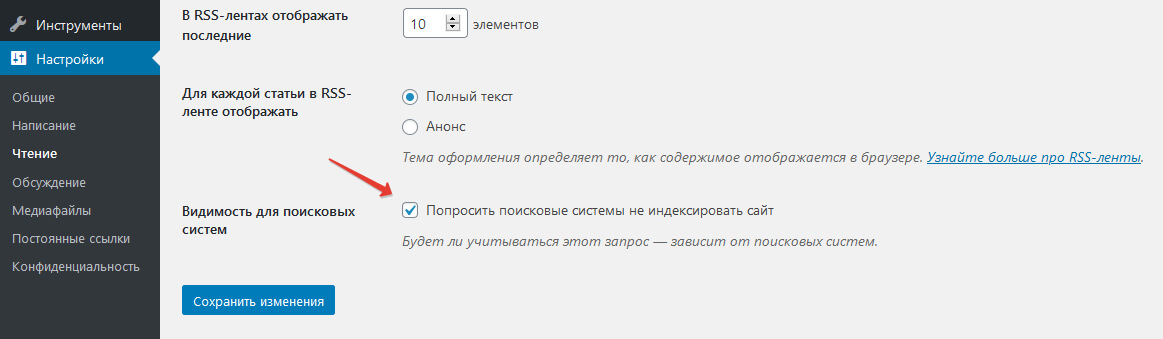
Вы также можете применить мета-тег noindex ко всему сайту, чтобы убрать все ваши страницы из результатов поиска. В WordPress это можно сделать в панели управления: Настройки > Чтение. Установите флажок «Попросить поисковые системы не индексировать сайт» в блоке «Видимость для поисковых систем».
Не используйте этот прием на работающем сайте, если не хотите потерять поисковой трафик.
Способ #3: Удаление URL навсегда
Если страница не преследует никакой цели, вы можете просто удалить ее с сайта навсегда. В момент сканирования страницы роботом, сервер сообщит ему о том, что такая страница не найдена (404) или удалена навсегда (410).
Отметим, что лучше использовать вызов серверной ошибки 410, так как стандартная ошибка 404 Not Found в дальнейшем может привести к повторному индексированию URL, подробнее об этом можно узнать из справки Google.
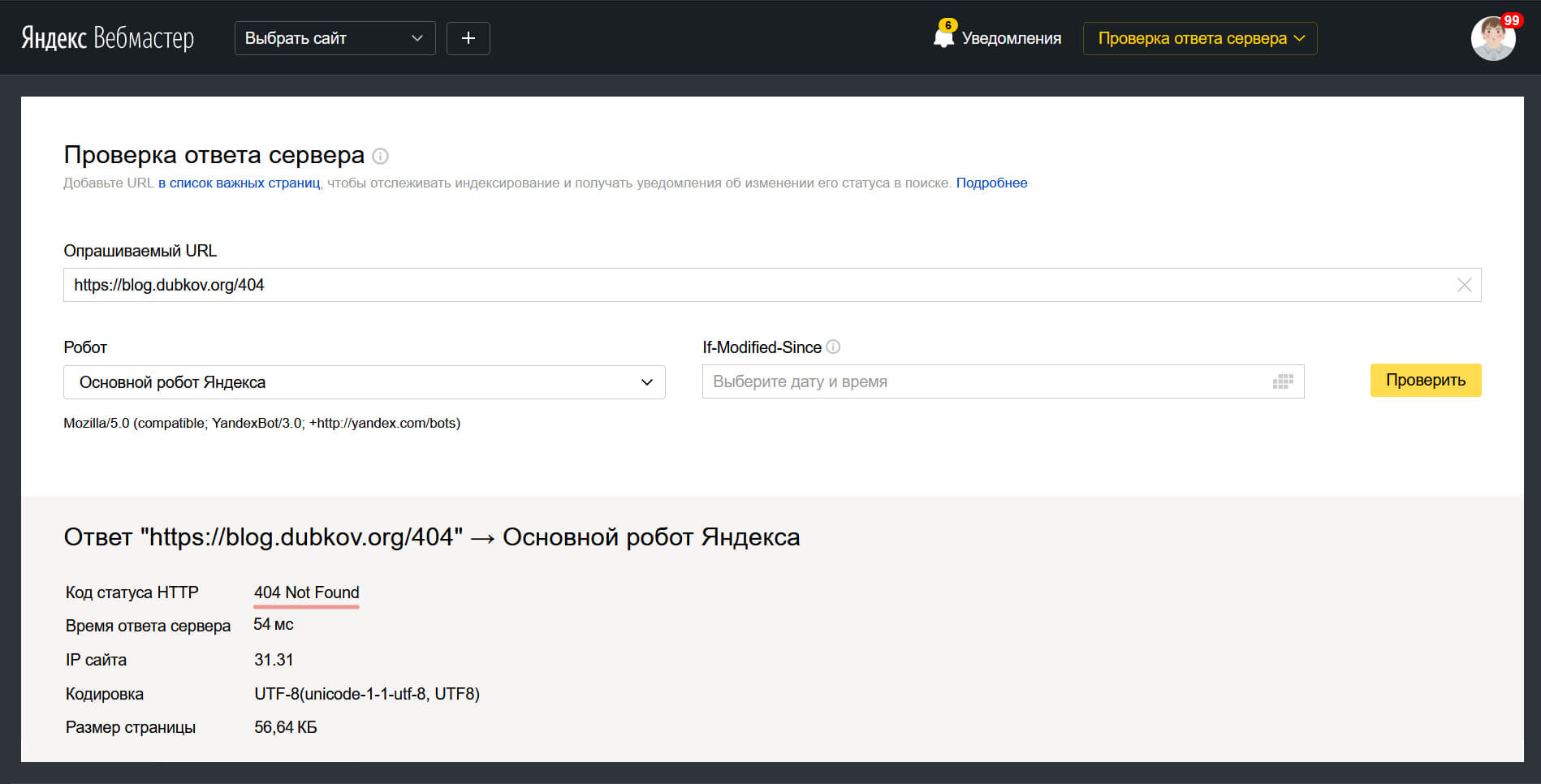 Проверка ответа от сервера с помощью инструмента от сервиса Яндекс Вебмастер
Проверка ответа от сервера с помощью инструмента от сервиса Яндекс ВебмастерИногда, страница которую вы хотите убрать из поиска может иметь устойчивый трафик или входящие ссылки, которые несут ценность для SEO. В таком случае, для удобства пользователей лучше использовать 301 редирект для перенаправления новых посетителей и поискового робота на другую релевантную страницу или раздел.
Не расcчитывайте на Robots.txt
Robots.txt — специальный файл, который используется для регулирования процесса индексации сайта поисковыми системами. Например, с его помощью вы можете ограничить доступ робота Google к конкретным страницам и разделам вашего сайта. Как показывает практика, полностью полагаться на этот файл не совсем правильно.
Если у страницы, которую вы хотите удалить из поиска есть трастовые входящие ссылки, Google может проигнорировать требования Robots.txt и показать страницу в поиске с ограниченным сниппетом.
Как удалить весь сайт из Google
Лучший способ удалить сайт из Google это добавить тег noindex к каждой странице. Вы также можете использовать плагин для ограничения доступа к контенту с помощью серверной авторизации, если проще — установить пароль для скачивания и просмотра документа пользователями.
Кроме того, вы можете заблокировать сайт от обхода роботов, указав в robots.txt следующее:
User-agent: *Disallow: /Как удалить URL-адреса с сайтов, которыми вы не владеете
Гораздо сложнее удалить страницы из Google если они не принадлежат сайту, который вы контролируете. Тем не менее, если кто-то скопировал ваш контент, то у вас есть возможность удалить его из Google заполнив форму о нарушении авторских прав (DMCA).
Лучше всего начать с отправки запроса о нарушении авторских прав хостинговой компании в которой обслуживается нарушитель.
Также вы можете отправить запрос о нарушении прав непосредственно в Google, используя инструменты поддержки. Кроме того, Google сделал детальный гид о удалении стороннего контента.
Но, если для удаления страницы нет надлежащей юридической причины это, как правило, невозможно. Лучший способ удаления таких страниц это отправка письма вебмастеру напрямую с просьбой удалить ворованный или конфиденциальный контент.
Переходим сразу от слов к делу. Для того, чтобы удалить URL адреса из поисковой выдачи в Google необходимо обратиться к сервису вебмастер и выяснить в каких случаях нужно пользоваться сервисом — удалить URL адреса, а в каких не следует:
Прежде всего хочу предупредить о том, что если у Вас присутствуют древовидные комментарии, необходимо обратить внимание на удаление внутренних ссылок. Прежде, чем удалять параметры URL и полностью запрещать поисковому роботу обращаться к внутренним ссылкам страниц содержащих: /?replytocom=, следует обязательно удалить из поисковой выдачи — эти страницы содержащие /?replytocom= .
Для удаления URL адреса из поисковой выдачи Google необходимо перейти по адресу https://www.google.com/webmasters/tools/, выбрать значение — оптимизация -> удалить URL адреса:
Далее создаете запрос на удаление, вводите URL (например: https://abisab.com/?replytocom=53) и нажимаете кнопку продолжить, тем самым создав запрос на удаление URL адреса. Через некоторое время URL будет удален.
Если же Вы сначала удалите Параметры URL, то при обращении в сервис удалить URL адреса из поисковой выдачи Google, будет появляться следующее окно, тем самым говоря, что Вы уже внесли replytocom в Параметры URL. Нажимаем — отправить запрос и удаляем необходимый URL страницы:
После удаления URL адреса, можно посмотреть список удаленных страниц:
Там, где стрелка указывает на кнопку «ожидание», при нажатии на нее — появится список вариантов, в котором есть «удаленные» — проверить удалился ли адрес, можете вставив данный URL в строчку браузера.
Когда НЕ следует использовать инструмент удаления URL
Инструмент удаления URL предназначен для срочного удаления страниц, например в тех случаях, если на них случайно оказались конфиденциальные данные. Использование этого инструмента не по назначению может привести к негативным последствиям для вашего сайта.
Не используйте инструмент удаления URL в следующих случаях:
- Для удаления «мусора», например старых страниц, отображающих ошибку 404. Если вы изменили структуру своего сайта и некоторые URL в индексе Google устарели, поисковые роботы обнаружат это и повторно просканируют их, а старые страницы постепенно будут исключены из результатов поиска. Вам не нужно запрашивать срочное удаление.
- Для удаления ошибок сканирования из аккаунта Инструментов для веб-мастеров. Инструмент удаления URL исключает URL из результатов поиска Google, а не из вашего аккаунта Инструментов для веб-мастеров. Вам не нужно вручную удалять URL из этого отчета. Со временем они будут исключены автоматически.
- Для создания сайта «с чистого листа». Если вы обеспокоены тем, что к вашему сайту могут быть применены штрафные санкции, или хотите начать все сначала после покупки домена у прежнего владельца, рекомендуем подать запрос на повторную проверку, в котором нужно описать, какие изменения вы внесли и в чем состоит причина вашего беспокойства.
- Для перевода сайта в автономный режим после взлома. Если ваш сайт был взломан и вы хотите удалить из индекса страницы с вредоносным кодом, используйте инструмент удаления URL для удаления новых URL, созданных злоумышленником, например http://www.example.com/buy-cheap-cialis-skq3w598.html. Однако мы не рекомендуем удалять все страницы сайта или те URL, которые нужно будет проиндексировать в будущем. Вместо этого удалите вредоносный код, чтобы роботы Google могли повторно просканировать ваш сайт. Подробнее о работе со взломанными сайтами…
- Для индексации правильной версии своего сайта. На многих сайтах одно и то же содержание можно найти по разным URL. Если вы не хотите, чтобы дублирующееся содержание отображалось в результатах поиска, ознакомьтесь с рекомендуемыми методами назначения канонических версий страниц. Не используйте инструмент удаления URL для удаления нежелательных версий URL. Это вам не поможет сохранить предпочтительную версию страницы. Ведь при удалении одной из версий URL (http/https, с префиксом www или без него) будут удалены и все остальные.
Для удаления URL адреса из Яндекса, набираем в поисковой строке http://webmaster.yandex.ua/delurl.xml, вводим адрес и действуем по интуитивно понятным инструкциям:
Надеюсь, данная статья помогла Вам лучше понять тему удаления URL адреса.
SEO-специалисты стремятся ускорить индексацию целевых страниц сайта, Google идёт на встречу, но также легко добавляет в поиск и нежелательные для нас страницы.
SearchEngineJournal опубликовали актуальные методы деиндексации, их влияние на SEO и почему меньшее количество страниц в поиске может привести к увеличению трафика. Давайте посмотрим!
Что такое «раздутый» индекс?
Index Bloat (раздутый индекс) возникает, когда в поиск попадает большее количество малополезных страниц сайта с небольшим количеством уникального контента или вовсе без него. Такие URL в индексе могут оказывать негативный каскадный эффект на SEO, примеры документов:
-
Страницы результатов фильтрации.
-
Неупорядоченные архивные страницы с неактуальным контентом.
-
Неограниченные страницы тегов.
-
Страницы с GET-параметрами.
-
Неоптимизированные страницы результатов поиска по сайту.
-
Автоматически сгенерированные страницы.
-
Трекинг-URL с метками для отслеживания.
-
http / https или www / non-www страницы без переадресации.
В чём вред? Googlebot обходит бесполезные для привлечения трафика страницы, тратит на них краулинговый бюджет и замедляет сканирование целевых URL. Повышается вероятность дублирование контента, каннибализации по запросам, релевантные страницы теряют позиции и вообще на сайте начинает царить плохо контролируемый беспорядок.
Кроме того, URL ранжируются в контексте репутации всего сайта и Google Webmaster Center недвусмысленно заявляет:
Низкокачественный контент на отдельных страницах веб-сайта может повлиять на рейтинг всего сайта, и, следовательно, удаление некачественных страниц… может помочь ранжированию высококачественного контента.
В Google Search Console на вкладке Индекс > Покрытие:
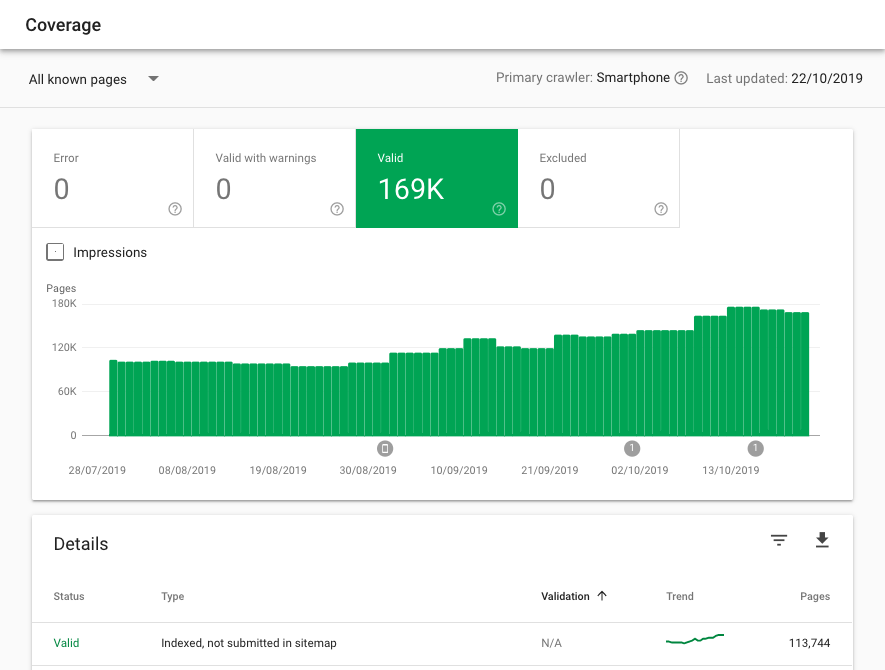
С помощью отдельных инструментов, например в «Модуле ведения проектов» на вкладке «Аудит»
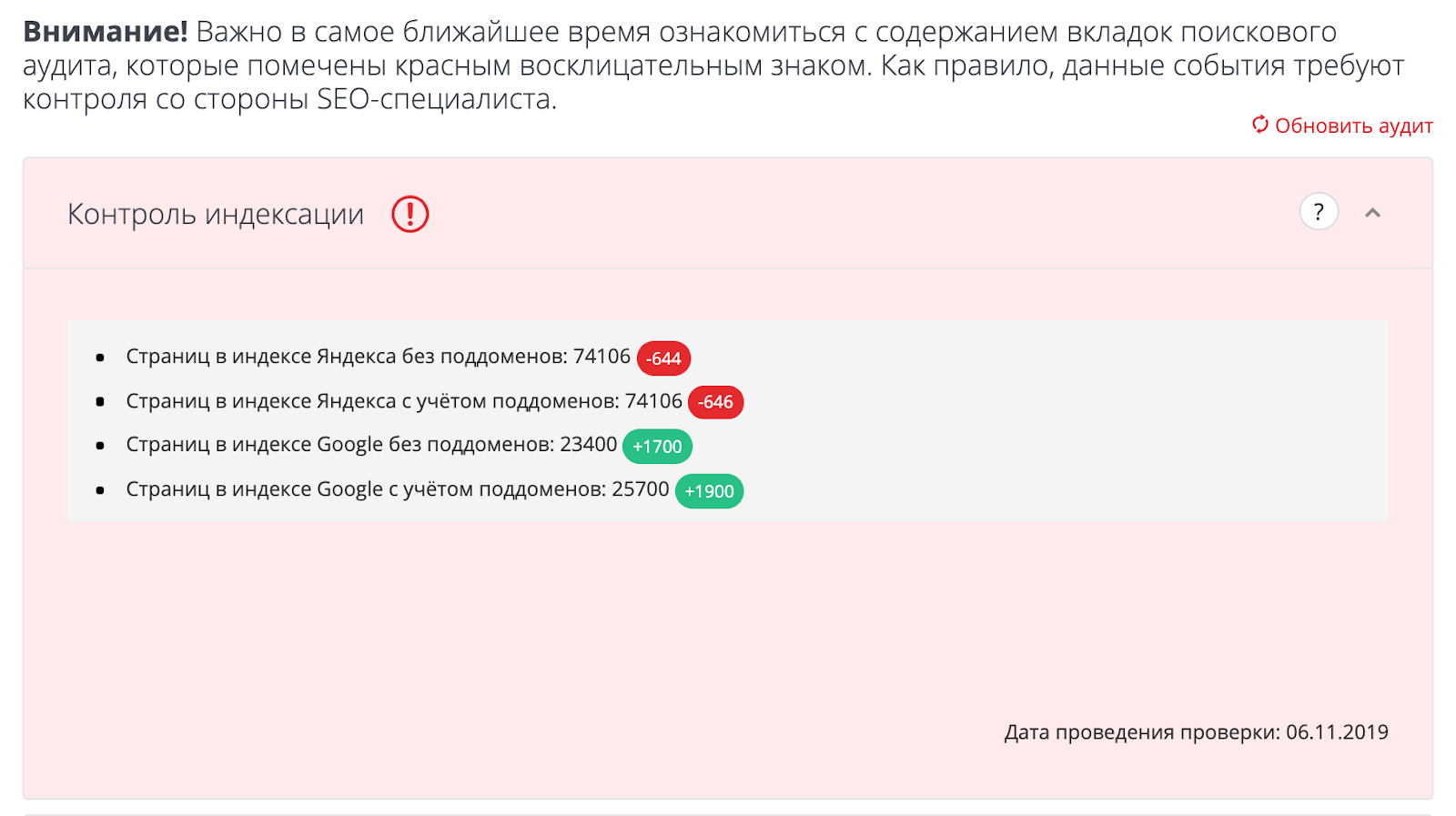
Или, используя оператор site: в поиске Google (не самый надёжный и не очень точный способ):

Если количество страниц в индексе превышает число URL, которое вы хотели отдать на индексацию (скажем, из файла Sitemap.xml), вероятно имеет место проблема «раздутого» индекса и пора освежить правила запрета на сканирование.
-
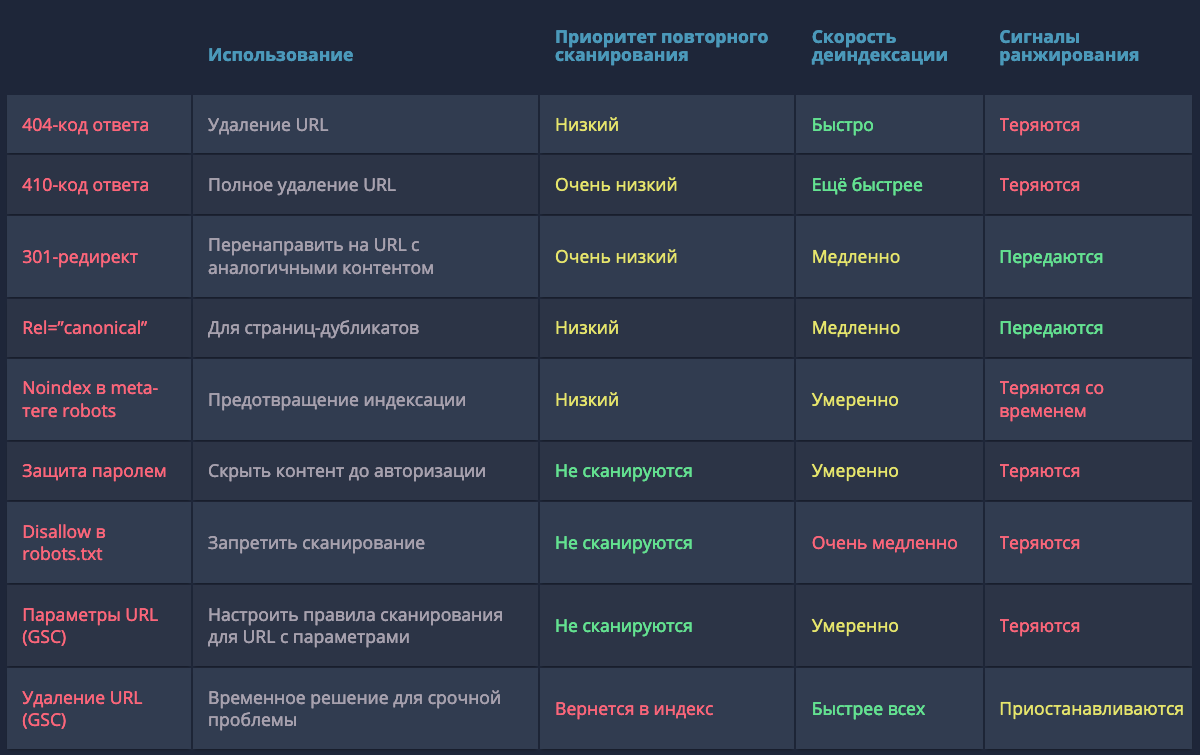
410 Gone — быстрый способ сообщить Google о том, что страница была намеренно удалена, и вы не планируете её заменить.
-
404-код ответа («страница не найдена») указывает на то, что страница может быть восстановлена, поэтому Googlebot может вернуться и проверить страницу на доступность через некоторое время.
При проверках в Search Console Google 410-код ответа помечается как 404-й. Джон Мюллер подтвердил, что это сделано с целью «упрощения», но разница всё-таки есть.
Также специалисты Google успокаивают — количество 4xx-ошибок на сайте не вредит вашему сайту. Проверить код ответа и размер документа для списка URL можно с помощью бесплатного инструмента.
Предотвращение «раздувания» индекса: 1/5
Борьба с последствиями «раздувания»: 4/5
301-редирект
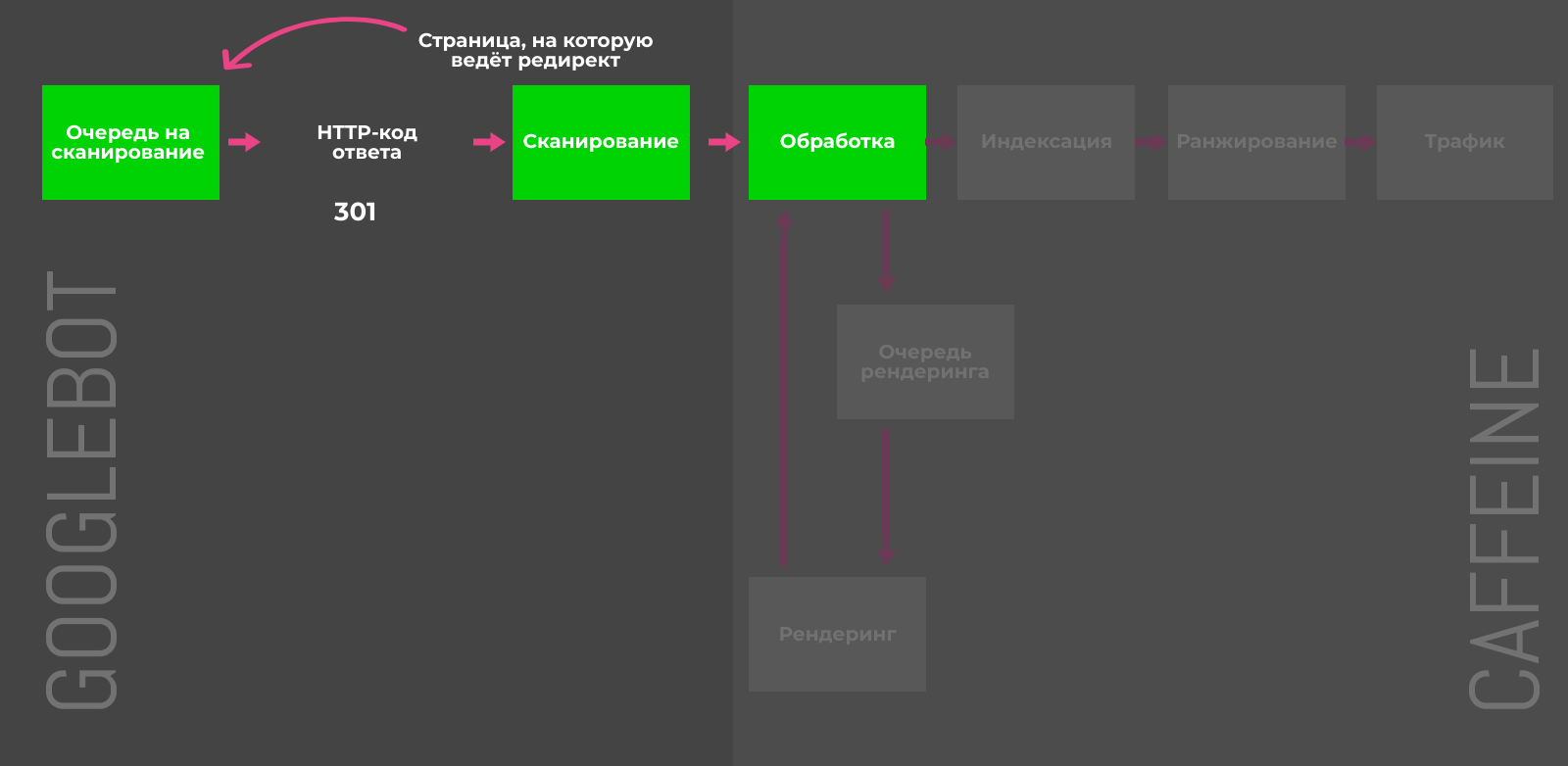
Если множество малополезных страниц можно переадресовать на целевой URL с похожим контентом и таким образом объединить их сигналы ранжирования, то 301-редирект самое верное решение. Например, в случае удалённых товаров или неактуальных новостей, можно перенаправить пользователя на схожие позиции или свежие посты по теме.
Деиндексирование перенаправляемых страниц требует времени: сначала Googlebot должен дойти до исходного URL, добавить целевой адрес в очередь для сканирования и затем обработать контент, чтобы убедиться в его тематической связи с первичным документом. В обратном случае (например, редирект на главную страницу сайта) 301-код ответа будет расцениваться Google как SOFT-404 и никаких сигналов для ранжирования (например, ссылочная масса) передано не будет.
Предотвращение «раздувания» индекса: 1/5
Борьба с последствиями «раздувания»: 3/5
Атрибут rel=”canonical” тега link
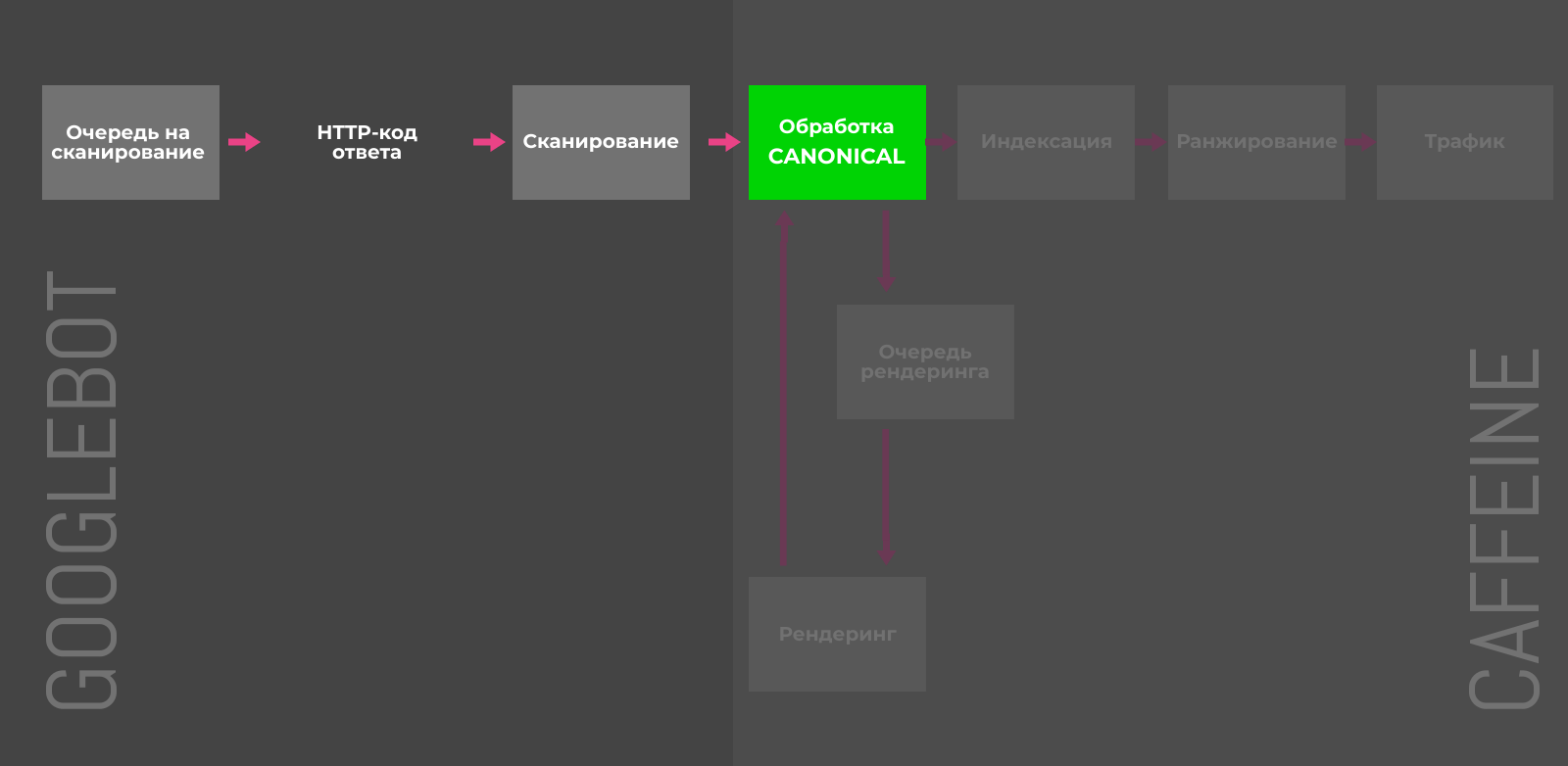
В случае дубликатов, атрибут rel=”canonical” сообщает краулеру какую именно страницу нужно индексировать. Альтернативные версии будут сканироваться, но гораздо реже и постепенно исчезнут из индекса. Чтобы учитывались и передавались сигналы ранжирования, контент на дубликатах и оригинальных страницах должен быть почти идентичным.
Предотвращение «раздувания» индекса: 4/5
Борьба с последствиями «раздувания»: 2/5
GSC-инструмент «Параметры URL»
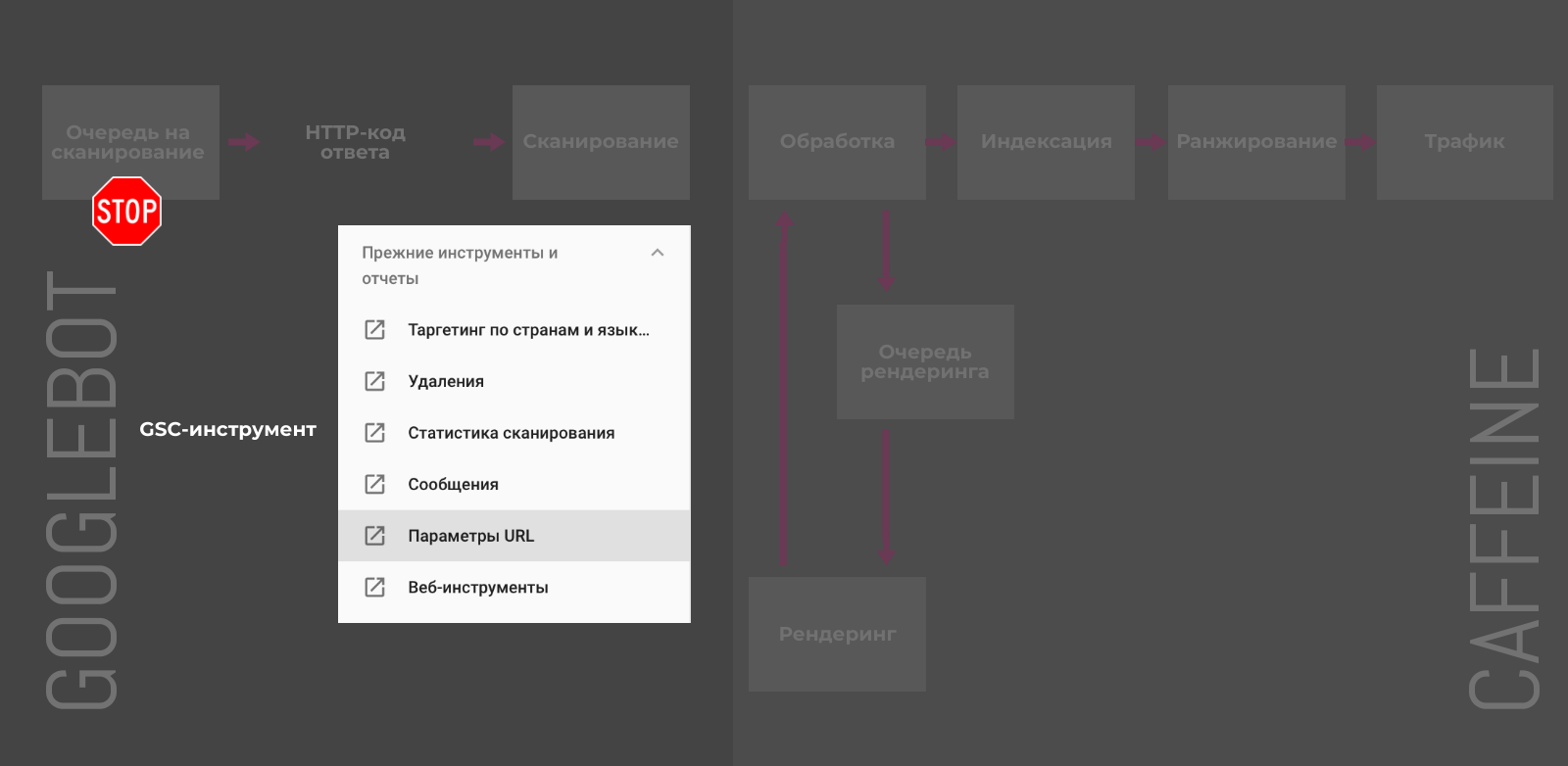
В старой версии Google Search Console можно настроить обработку и задать правила сканирования для URL с различными параметрами.
У этого способа есть несколько недостатков:
-
Работает только для URL с наличием параметров в адресе.
-
Актуально только для Googlebot и не повлияет на сканирование другими поисковыми роботами.
-
Позволяет контролировать только краулинг и не управляет индексацией напрямую.
Хотя Джон Мюллер уверяет, что в конечном счёте, попавшие под исключения, URL также будут удалены из индекса. Не самый быстрый, но также способ деиндексации.
Предотвращение «раздувания» индекса: 3/5
Борьба с последствиями «раздувания»: 1/5
Robots.txt
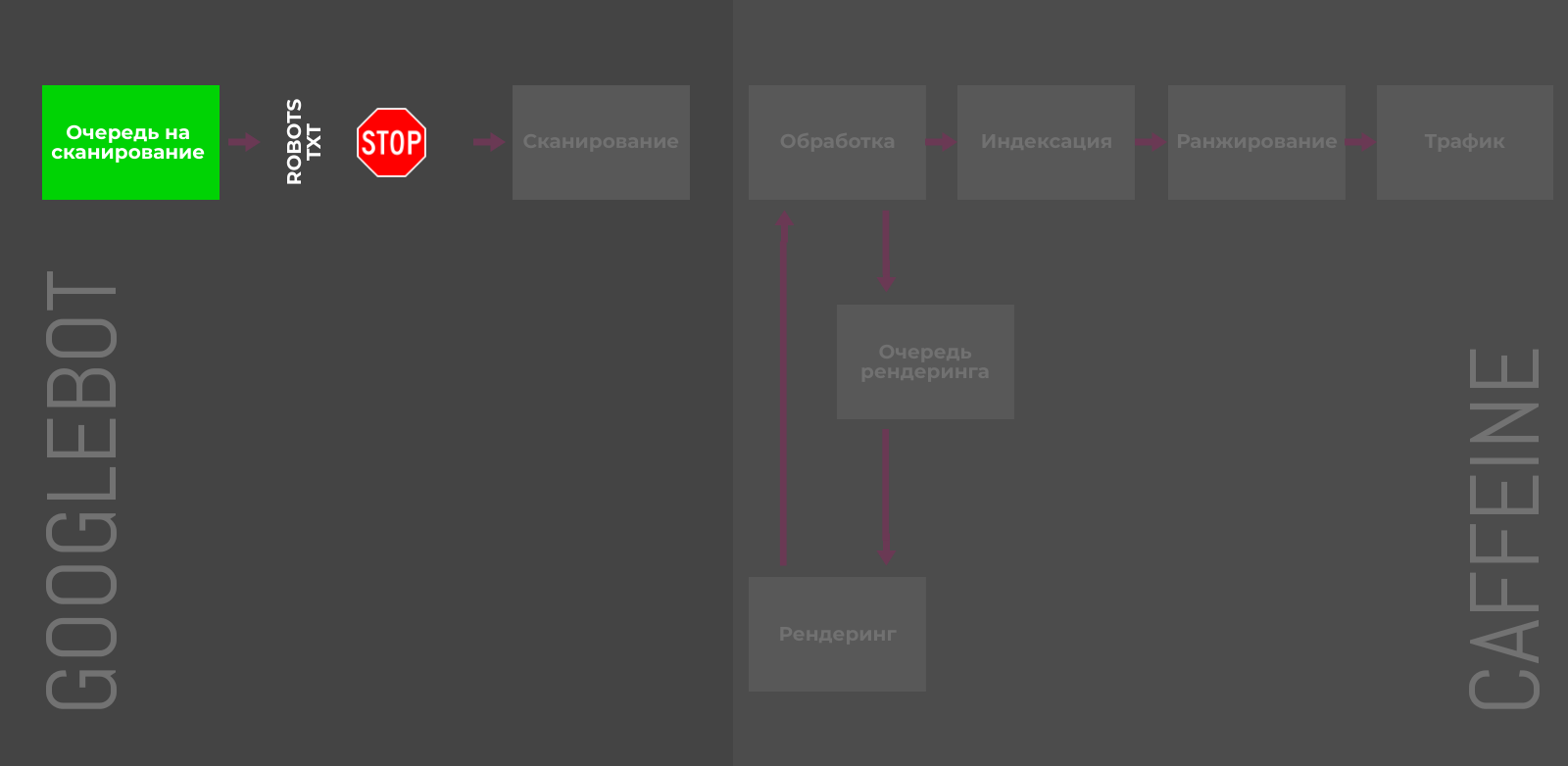
Директива Disallow в файле robots.txt позволяет блокировать отдельные страницы, разделы или полностью весь сайт. Пригодятся для закрытия служебных, временных или динамических страниц.
Тем не менее, директива не управляет индексацией напрямую, и некоторые адреса Google может отправить в индекс, если на них ссылаются сторонние ресурсы. Более того, правило не даёт четких инструкций краулерам, как поступать со страницами, которые уже попали в индексе, что замедляет процесс деиндексации.
Предотвращение «раздувания» индекса: 2/5
Борьба с последствиями «раздувания»: 1/5
Noindex в meta-теге robots
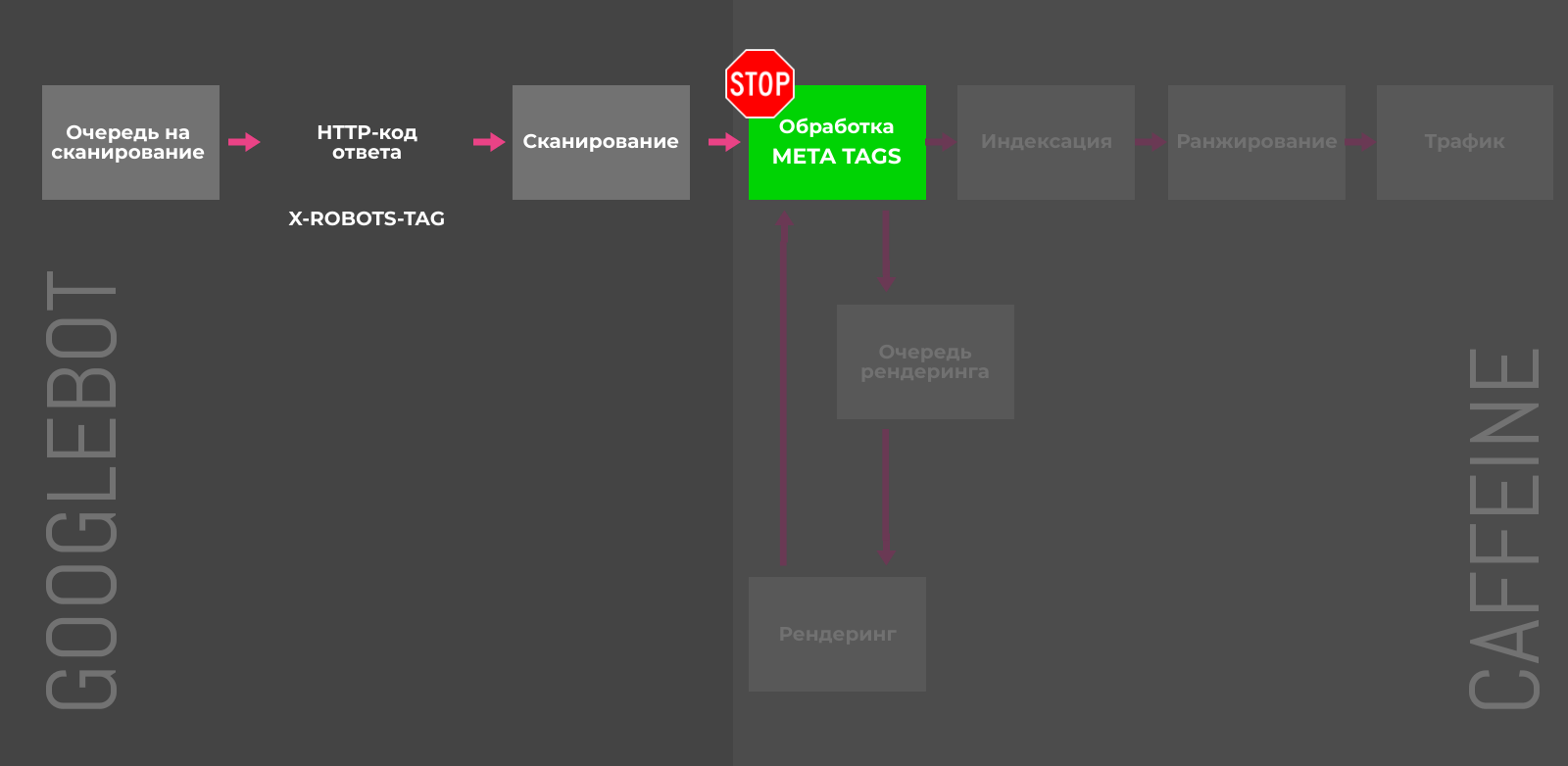
Для полной блокировки индексации отдельных страниц можно использовать мета-тег robots с атрибутом content=»noindex» или HTTP-заголовок X-Robots-Tag с директивой noindex. Напомним, что noindex, прописанный в robots.txt, игнорируется поисковыми краулерами.
X-Robots-Tag и мета-тег robots на страницах имеют каскадный эффект и возможны следующие последствия:
-
Предотвращают индексацию или исключают страницу из индекса в случае добавления постфактум.
-
Сканирование таких URL будет происходить реже.
-
Любые факторы ранжирования перестают учитываться для заблокированных страниц.
-
Если параметры используются продолжительное время, ссылки на страницах обретают статус «nofollow».
Предотвращение «раздувания» индекса: 4/5
Борьба с последствиями «раздувания»: 4/5
Защита с помощью пароля / авторизации
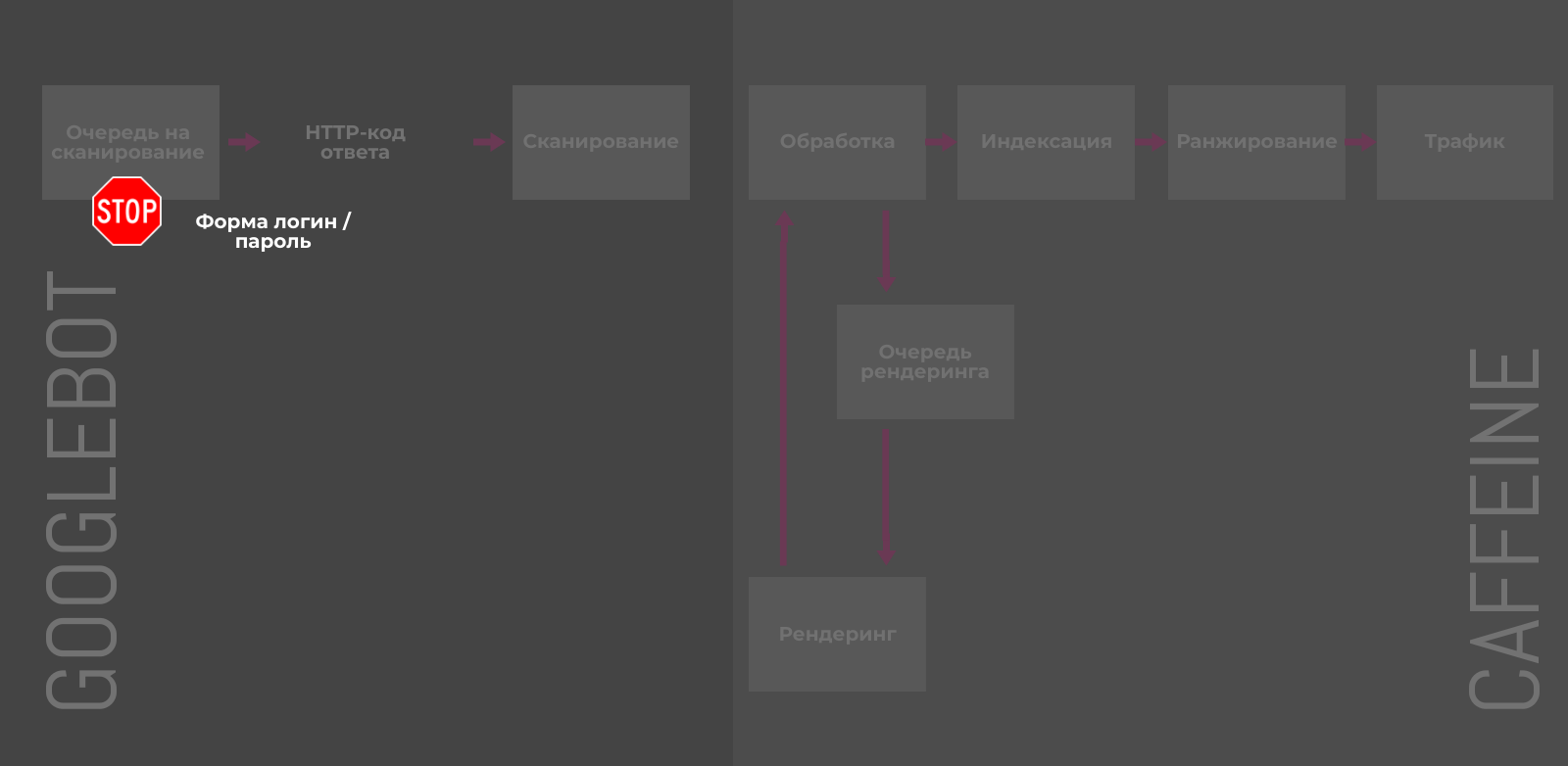
Все файлы на вашем сервере, защищенные паролем и требующие авторизации, будут недоступны для поисковых систем. Такие URL нельзя просканировать и проиндексировать. Очевидно, для пользователей контент на закрытых паролем страницах также будет недоступен до авторизации.
Предотвращение «раздувания» индекса: 2/5
Борьба с последствиями «раздувания»: 1/5
Инструмент Google для удаления URL
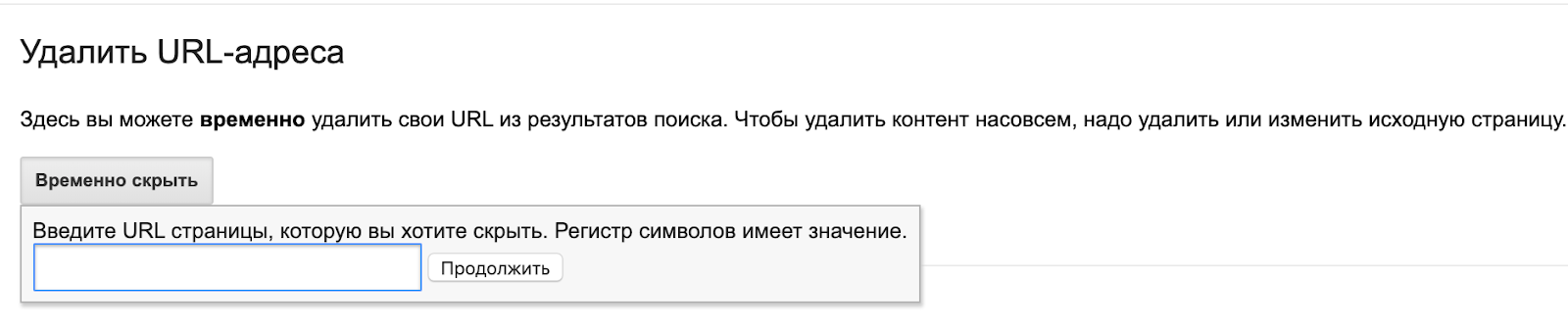
Если необходимо срочно удалить из индекса какую-либо страницу, можно использовать инструмент в старой версии Search Console. Как правило, запросы обрабатываются в день заявки. Главное, нужно понимать — это временная блокировка. По истечении 90 дней URL снова может оказаться в поисковой выдаче, если не будут применены способы для блокировки индексации, описанные выше.
Предотвращение «раздувания» индекса: 1/5
Борьба с последствиями «раздувания»: 3/5
Краткие выводы
Как всегда, профилактика гораздо эффективнее лечения. У Google слишком хорошая память и деиндексации может занять неприлично много времени. Всем терпения и целевых страниц в индексе!
При вводе адреса сайта адресую строку браузера мы можем видеть предлагаемые адреса, на которые вы уже заходили, то есть вы можете стрелочками сразу перейти на этот ресурс и сразу оказаться на нужно сайте. Это, конечно, убыстряет процесс ввода и перехода, но иногда могут показаться такие сайты из вашей истории, которые не должны видеть ваши знакомые. Есть еще один случай, когда вы однажды ввели сайт неверно и теперь о будет постоянно выскакивать при вводе. Естественно, надоедливые адреса можно удалить, чтобы они вас не беспокоили.
В данной статьей я не буду разбирать браузер Microsoft Edge, потому что в нем нет функции удаления URL. Но все необходимые функции в будущем должны быть реализованы.
Автозаполнение URL адресов в Google Chrome
Огромное количество пользователей пользуется браузером Chrome. Чтобы очистить адреса, которые предлагаются после ввода каких букв или фраз, то всё, что вам нужно сделать – дойти стрелочками до этого адреса и нажать комбинацию Shift+Delete. Нежелательный адрес мгновенно удалится.

Как удалить автозаполнение URL-адресов в Firefox?
При пользовании браузеров Mozilla Firefox удалить адреса сайтов, появляющихся в адресной строке при вводе можно удалить точно так же, как и в Google Chrome. Набираете несколько букв интересующего вас адреса, стрелками переходите на появившейся нежелательный и нажимаете Shift+Delete.

Как удалить автозаполнение URL-адресов в Internet Explorer?
Пока еще есть пользователи, которые пользуются Internet Explorer, поэтому я буду во многих статьях упоминать этот браузер.
Когда вы начинаете набирать URL-адрес, ниже появляются предложения. Чтобы какое-то из них удалить направляете на него мышкой, и справа появляется красный крестик, отвечающий за удаление.

Таким же образом вы можете работать и с другими браузерами. При возникновении трудностей у вас есть возможность обратиться к автору через комментарии.
Похожее:
Как отключить в браузере запрос местоположения?
9 Способов ускорить Google Chrome
Internet Explorer для Windows 10 находим браузер в системе
Как очистить куки браузера (Cookie)?
Есть проблемы с ранжированием, проект не растет, хотите проверить работу своих специалистов по продвижению? Закажите профессиональный аудит в Семантике

Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Способов убрать URL из Google несколько. Какой использовать — зависит от обстоятельств.
И цель не убрать сам адрес, а понять, какой способ выбрать. Неправильный выбор приведет к проблемам с поисковым продвижением. Вот простая блок-схема, которая поможет определиться:
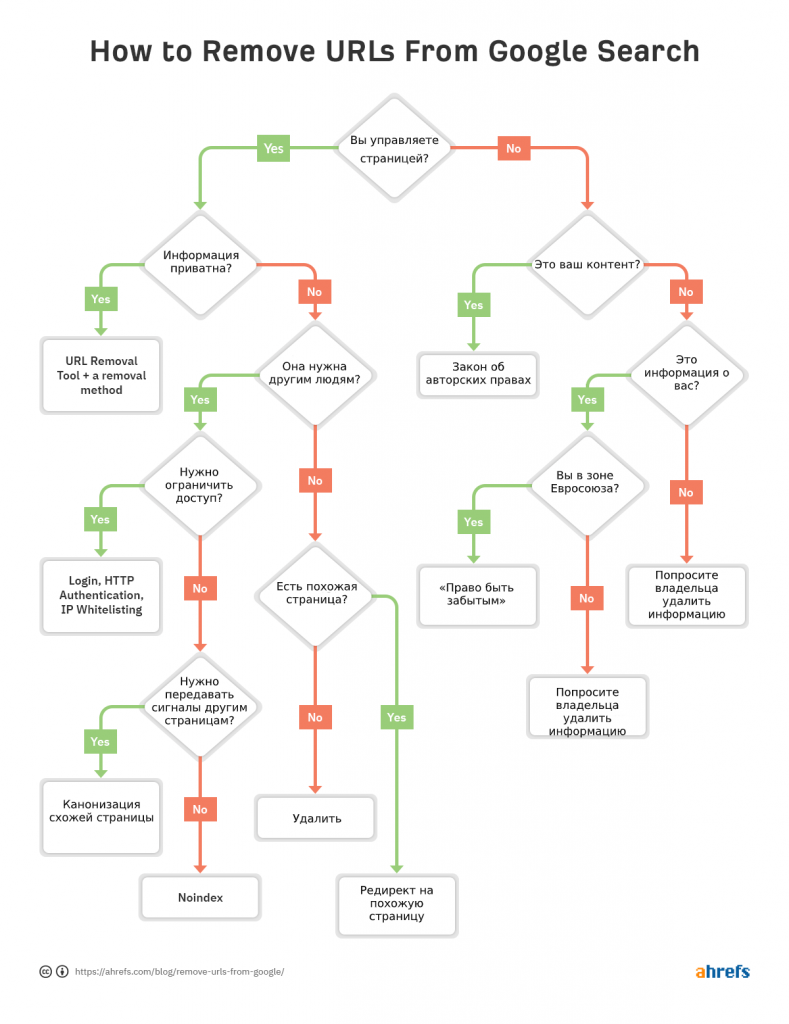
В этой статье вы узнаете:
Как проверить индексацию URL
Чтобы понять, есть ли адрес в индексе системы, специалист обычно просто вводит в строке нужный адрес. Проблема оператора поиска «site:» в том, что это специфический запрос. Он не даст точной информации об индексации урла. Он может показать адреса страниц, которые известны Google, но не отображаются в результатах поиска по обычному запросу.
Например, этот оператор все равно покажет в выдаче страницы с редиректом или являющиеся каноническими для других. Когда вы ищете конкретный сайт, Google может показать страницу искомого домена с контентом, заголовком и описанием другого ресурса.
Например, привычный moz.com раньше располался на seomoz.com. Обычные пользователи увидят в выдаче адрес moz.com. Если искать seomoz.com, несмотря на адрес сайта в выдаче, человек все равно попадет на moz.com:
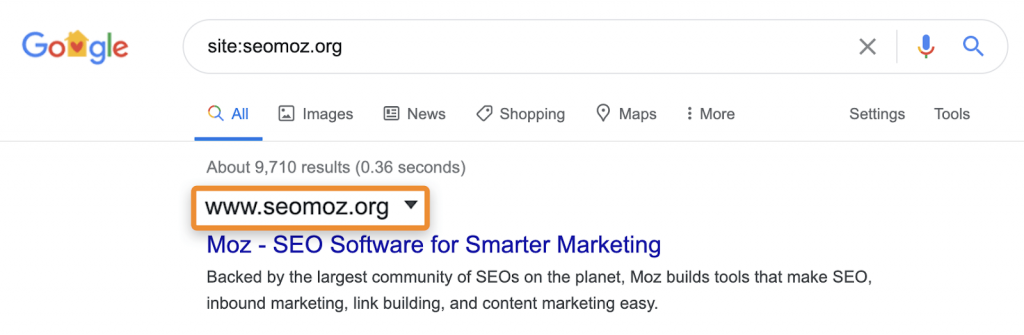
Причина, по которой это важно. Специалисты могу удалить из индекса URL для старого сайта, а это приведет к уменьшению сигналов для поисковика. Есть много примеров, когда при переносе сайта на новый домен в выдаче присутствуют адреса старого сайта. Оптимизатор начинает вычищать якобы ненужное и вредит новому сайту.
Лучший способ проверить индексацию — Отчет об индексировании в GSC или инструмент для проверки отдельного адреса. Вы узнаете, проидексирована ли страницы, и как Google ее обрабатывает.
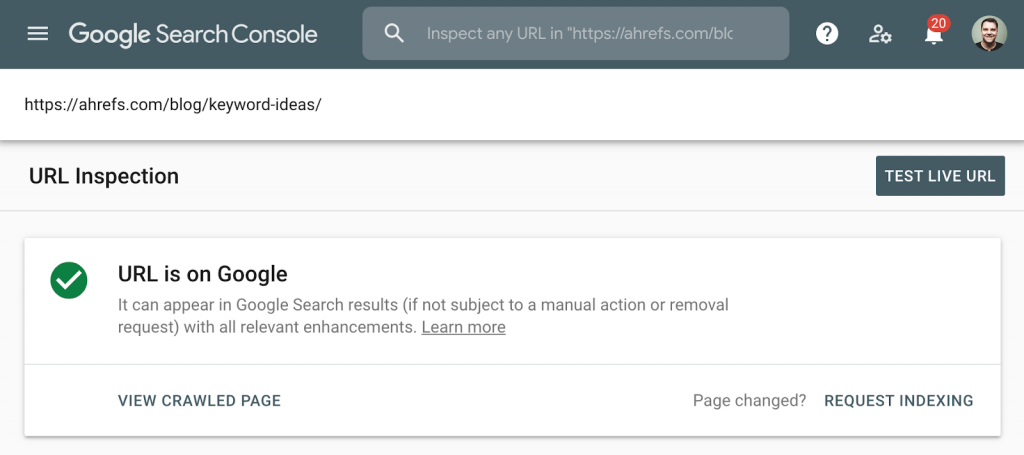
Если в инструменте Ahrefs вы найдете страницу в «Top Pages» или сводке о ранжировании ключевых слов, это означает, что наши роботы видели ее в выдаче по обычным запросам, следовательно, страница в индексе. Уточните дату, к которой относятся данные — могли произойти изменения, о которых в сервисе пока нет информации.

Если есть проблема с определенным адресом, и его нужно удалить из индекса, изучите блок-схему, а потом выберите нужный вариант удаления ниже.
Вариант 1. Удаление контента
Если вы удалите страницу, появится код ответа 404, либо 410. При следующем обходе сайта роботом, удаленная страница пропадет из индекса. До этого момента она останется в результатах поиска. Возможно, человек попадет на ее кэшированную версию.
Когда нужно выбрать другой метод:
- Необходимо мгновенное удаление: воспользоваться специальными инструментами.
- Нужно сохранить сигналы, например, ссылки: воспользоваться канонизацией.
- Хочется оставить доступ пользователей к странице: закрыть страницу от индексации.
Вариант 2. Noindex
Метатег сообщает роботам, что страницу не нужно индексировать. Работает для обычных страниц и дополнительных типов, например, для pdf-файлов. Чтобы теги были видны, у поисковика должен быть доступ к сканированию. Убедитесь, что они не заблокированы в robots.txt. Обратите внимание: удаление страницы из индекса может помешать передаче сигналов.
Как выглядит тег:
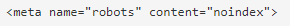
Для x-robots:
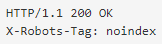
Когда нужно выбрать другой метод:
- Не нужен доступ к странице: см. следующий раздел про ограничение доступа.
- Нужно оставить все сигналы страницы: см. раздел про канонизацию.
Вариант 3. Ограничение доступа
Если хотите, чтобы страница осталось доступной для некоторых пользователей, но не для поисковиков, нужен один из трех вариантов:
- какой-то механизм входа в систему;
- HTTP-аутентификация, когда требуется пароль для входа;
- белый список IP-адресов — доступ будет только у пользователей с IP из списка.
Такой вариант подойдет для внутренних сетей, для тестирования и разработки сайтов, когда контент предназначен только для определенных людей (например, участников рабочей группы).
Группа пользователей сможет заходить на страницу, но поисковые системы к ней доступ не получат.
Когда нужно выбрать другой метод:
- Нужно немедленно удалить страницу: см. следующий раздел про инструмент удаление URL. Подойдет, когда нужно удалить контент, который уже есть в кэше, но вы не хотите, чтобы пользователи его увидели.
Вариант 4. Инструмент удаления URL
Речь про инструмент Google.
Следует сказать, что его применять стоит в экстренных ситуациях — когда произошла утечка личных данных, или информации, которая угрожает чьей-либо безопасности. При использовании инструмента Google продолжает видеть страницу и распознавать на ней контент. Просто сама страница не отображается в выдаче у пользователей.
Вариант 5. Тег canonical
У нас есть большое руководство по использованию этого тега.
Если есть несколько версий страницы, вам нужно объединить сигналы — например, ссылки на одну версию, нужна форма, по которой страницу можно канонизировать. Это предотвращает дублирование контента при объединении версий в один проиндексированный URL.
Несколько вариантов канонизации:
- Canonical. Указывает адрес как канонический, который вы хотите показывать. Если другие страницы являются полными дублями или похожи, все сработает. Если страницы разные, тег может не сработать. Это подсказка, а не директива.
- Редиректы. Самый популярный — 301. Гугл считает страницу, на которую он указывает, желательной для отображения в результатах. Для нее он учитывает все сигналы. 302 или временный редирект показывает поисковику, что вы хотите оставить в индексе первоначальный адрес страницы, и учитывать сигналы для нее.
- Обработка параметров URL. Параметр в адресе может указывать на разные версии страницы. Инструмент от Google позволяет указывать, как именно обрабатывать конкретные параметры, например, изменяют ли они контент на странице или просто нужны для отслеживания событий.
Как расставить приоритетность
Если у вас есть несколько страниц, которые нужно удалить из индекса, нужно расставить приоритеты.
Высокий приоритет: страницы, связанные с безопасностью или приватными данными — информации с личными данными человека, клиентские сводки и т. д.
Средний приоритет: контент, предназначенный для определенной группы пользователей — внутренние корпоративные порталы, регламенты, инструкции.
Низкий приоритет: страницы с дублирующимся контентом, доступные по нескольким адресам, по параметрическим URL, тестовые или необходимые для разработки.
Как избежать распространенных ошибок
Здесь поговорим о нескольких способах удаления страницы, которые приводят к грустным последствиям и покажем сценарий того, что происходит. Так вы поймете, что именно неверно.
Noindex в robots.txt
Хотя раньше Google поддерживает такое сочетание, оно никогда не было официальным стандартом. Многие сайты, которые запрещали индексирование в robots постоянно, сейчас находятся на 4 странице выдачи.
Блокировка обхода в robots.txt
Сканирование и индексирование — разные процессы. Даже если заблокировать сканирование страницы, при наличии внутренних или внешних ссылок поисковик все равно сможет ее проиндексировать.
Google не будет знать, что находится на странице, потому что он ее не просканирует. Но он в курсе, что страница существует, даже укажет ее заголовок в выдаче на основе анкорного текста в ссылке.
Nofollow
Его часто путают с noindex. На самом деле это подсказка, которую раньше успешно применяли для запрета индексирования. Сейчас это не работает, и Гугл все равно может индексировать страницы. Чтобы найти все ссылки nofollow, используйте фильтр в отчете Ahrefs:
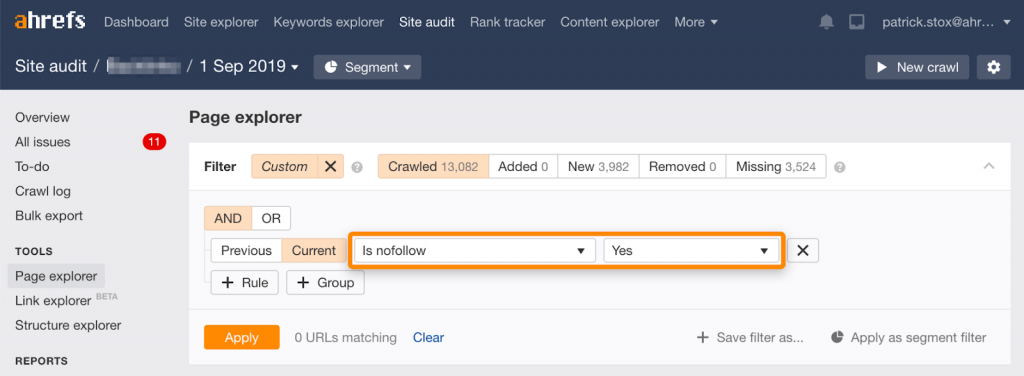
Смысла указывать все ссылки на странице почти нет, поэтому число должно быть близким к нулю.
Отдельные ссылки можно найти в этом фильтре для Link Explorer:
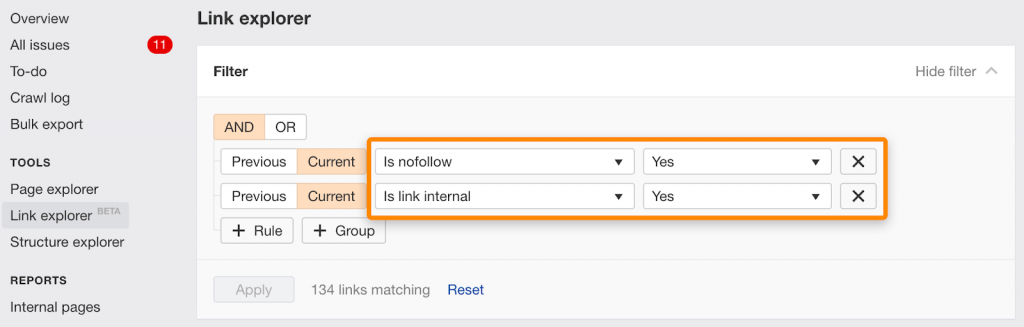
Noindex и канонизация для другого URL одновременно
Сигналы противоречат друг другу. Первый говорит об удалении страницы из индекса, второй — что это версия, которую нужно проиндексировать. Это может работать для консолидации, потому что Google предпочитает игнорировать noindex и вместо него использует канонизацию в качестве основной директивы. Однако это не всегда именно так. Есть риск, что страницы неправильно объединятся друг с другом.
Вы можете найти неиндексированные страницы с каноническими ссылками, используя такой набор фильтров:
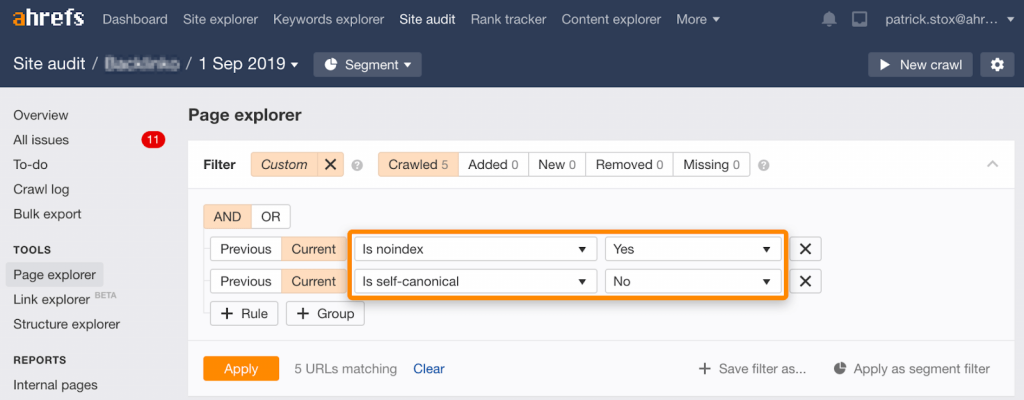
Запрет индексирования и ограничение сканирования
Два варианта, почему такое происходит:
- Страницы уже заблокированы, но проиндексированы. Оптимизатор может запретить индексирование и разблокировать поисковику возможность обхода, чтобы он считает запрет индексирования. Затем повторно блокируют обход.
- Оптимизаторы добавляют noindex для страниц, которые хотят удалить после того, как Гугл сканирует и обрабатывает тег, блокируют обход страниц.
В любом случае, итоговое состояние — блокировка обхода страницы. Если вы помните, ранее мы говорили, что сканирование и индексирование — разные процессы. И заблокированная от обхода страница все равно может оказаться в индексе.
Что делать, если ваш контент на чужом сайте?
Если вы — автор текста, который используется на чужом сайте, можно попытаться защитить свои авторские права. Можно использовать инструмент от Google, который запрашивает удаление любого материала, который защищен авторским правом.
Что делать, если информация о вас есть на чужом сайте?
Если вы в зоне ЕС, вы можете удалить контент, в котором есть информация о вас, согласно «праву быть забытым». Вы можете запросить удаление личной информации через эту форму.
Как удалить изображение
Для удаления изображений из Google проще использовать robots.txt. Хотя неофициальная возможность удалить картинку более в нем не присутствует, можно запретить сканирование изображения.
Для одного изображения:

Для всех:

Заключение
Удаление URL ситуативно. Для каждой причины — свой метод. Мы говорили о нескольких вариантах, если что-то непонятно — вернитесь к блок-схеме из начала статьи.
Источник.
Удаляем URL’ы из дополнительного индекса Google
 Ведя борьбу с дублями страниц, провела настоящую «чистку» блога. Настроила редиректы, прописала noindex для технических дублей своего сайта. Довольная своей работой, стала ждать, когда же наконец все дубли вылетят из индекса.
Ведя борьбу с дублями страниц, провела настоящую «чистку» блога. Настроила редиректы, прописала noindex для технических дублей своего сайта. Довольная своей работой, стала ждать, когда же наконец все дубли вылетят из индекса.
Однако, хоть их число заметно сократилось, значительная часть их так и осталась «болтаться». Время от времени проверяя дополнительный индекс Google, убедилась, что ждать придется очень долго, пока поисковик сам все это удалит. Конечно, в вебмастере есть инструмент «Удалить URL-адреса», однако при этом возникает проблема: как узнать эти самые урлы?
Как узнать URL-адреса дублей?
Если вбить комбинацию site:incomeeasily.ru (для каждого сайта конечно же свой домен), можно узнать количество страниц в индексе Гугла. Пройдя в конец списка и нажав «показать скрытые результаты», мы увидим, что же там в Supplemental results, или как уже многие говорят, в «соплях».
А у меня там болтались удаленные давно страницы, дубли комментариев к ним, даже страницы админки(!), файлы темы, копии мобильной версии сайта (кстати давно удаленные) и прочий мусор. Некоторые адреса я могла узнать, пройдя по ссылке и открыв сам сайт. Но большинство не открывалось благодаря настроенным редиректам.
Вот тут и возник вопрос: что же делать? Как всегда ответ пришел сам собой. «Метод научного тыка» — самый лучший метод для ленивых. Я себя отношу к числу лентяев. Болея последнюю неделю, не нашла в себе силы писать новые статьи, но вот поковыряться в этих каверзах почему-то захотелось. Стала отправлять запросы на удаление тех адресов, которые смогла определить.
Потом пришла идея посмотреть исходный код ссылки, которую дает поисковик. Если кто не знает, для этого достаточно клацнуть по ссылке правой кнопкой мыши и в выпавшем меню выбрать «просмотр кода элемента».
После чего увидим «развернутую картину», как переадресовывается ссылка из архива поисковика на нашу страницу. Но вот беда: как я не пыталась ее выделить, никак не получалось, а перепечатывать длиннющую ссылку — это очень долго. Промучившись с полчаса, все же «методом тыка» обнаружила: ссылка выделяется двойным щелчком левой кнопки. Элементарно! 
Как удалить URL-адреса
Теперь достаточно сделать запросы на удаление URL-адресов в вебмастере Гугла (Инструменты для веб-мастеров — Индекс Google — Удалить URL-адреса). Пару вечеров по полчаса «скопировал-вставил-подтвердил» — и никаких дублей в индексе Google больше не будет! При условии конечно, что вы поработали над тем, чтобы они не создавались заново.  Думаю, информация очень доступная и даже школьник разберется, как удалить URL-адреса из дополнительного индекса Google!
Думаю, информация очень доступная и даже школьник разберется, как удалить URL-адреса из дополнительного индекса Google!
Удалить URL:Mal (Инструкции по удалению)
Пользователи могут столкнуться с фальшивым предупреждением Avast — URL:Mal

URL:Mal — это код обнаружения антивирусного программного обеспечения Avast, который запрещает пользователям посещать вредоносный веб-сайт. Это полностью законно и должно выполняться. Однако недавно люди сообщают, что каждая страница, которую они пытаются посетить, обозначена как опасная. Аналогичным образом, существует возможность того, что преступники маскируют свои вредоносные программы в соответствии с этим предупреждением безопасности.
URL:Mal вирус может выглядеть идентично оригиналу. Поскольку дополнительные надстройки и плагины могут блокировать вас от входа на предположительно вредоносный веб-сайт, существует высокий риск, что вы думаете, что всплывающее сообщение правдиво. Тем не менее, это просто рекламное ПО, пытающееся выманить у вас деньги .
Обратите внимание, что поддельное URL:Mal обнаружение также может привести к предложениям по обновлению текущего антивирусного программного обеспечения или установке нового. Однако, если у вас есть какие-либо сомнения относительно легитимности сообщения, не загружайте/устанавливайте какие-либо программы или их обновления и не платите за них деньги.
Если вы заражены URL:Mal, сканируйте свой компьютер с помощью Reimage Reimage Cleaner Intego или другого профессионального антивирусного программного обеспечения. Оно обнаружит все потенциально нежелательные программы, которые вызывают ложное обнаружение и устранят паразита с вашего компьютера.

Кроме того, вы должны как можно скорее завершить удаление URL:Mal, поскольку эти типы вирусов могут вызывать проникновение других опасных компьютерных инфекций, таких как троянские кони, шпионские программы и т.д. По данным Virusi.hr экспертов вы не должны пытаться устранять паразита самостоятельно.
Аналогично, для удаления URL:Mal вируса вам следует либо использовать антивирусное программное обеспечение, либо приведенные ниже инструкции. Они не только проведут вас через этот процесс, но также покажут, как сбросить ваш браузер после заражения рекламным ПО и избавиться от всех фальшивых всплывающих окон.
Методы какими распространяется рекламное ПО
Наиболее распространенный способ проникновения потенциально нежелательной программы в вашей системе — комплектация программного обеспечения. Обычно люди не знают, что, загрузив бесплатное приложение, они могут тайно установить дополнительное. Эта маркетинговая стратегия широко используется разработчиками ПНП .
Тем не менее, вы можете легко избежать рекламных программ, если обратите внимание во время процедуры загрузки/установки. Во-первых, вы должны выбрать расширенную или пользовательскую установку. Они покажут ранее выбранные галочки, которые позволяют установить потенциально нежелательную программу. Не забудьте отменить их.
Кроме того, мы рекомендуем вам держаться подальше от онлайн-рекламы. После нажатия она может даже помочь проникнуть рекламному ПО или другим компьютерным инфекциям высокого риска. Поэтому используйте надежное программное обеспечение любого шпионского ПО для защиты вашего компьютера и ценной информации, хранящейся на нем.
Самое простое руководство по удалению URL:Mal вируса
Поскольку может быть сложно определить, действительно ли предупреждение Avast URL:Mal является реальным, вам следует дважды проверить свою систему с помощью профессионального программного обеспечения безопасности. Сканируйте компьютер и убедитесь, что рекламное ПО не присутствует на нем. Если это угрожает вашему ПК, антивирусное средство устранит его.
Кроме того, имейте в виду, что рекламные программы не путешествуют в одиночку – их компоненты могут также повредить вашу систему. Поэтому очень важно не только удалить URL:Mal, но и все элементы. Для этого используйте одно из средств защиты от вредоносных программ из приведенного ниже списка.
Если вы хотите вручную удалить URL:Mal, не забудьте проверить приведенные ниже инструкции. Они помогут вам обнаружить компоненты, связанные с рекламным ПО, и устранить скрытую опасность.
Вы можете устранить повреждения вируса с помощью Reimage Reimage Cleaner Intego. SpyHunter 5Combo Cleaner and Malwarebytes рекомендуются для обнаружения потенциально нежелательных программ и вирусов со всеми их файлами и записями реестра, связанными с ними.
Reimage Intego имеет бесплатный ограниченный сканер. Reimage Intego предлагает дополнительную проверку при покупке полной версии. Когда бесплатный сканер обнаруживает проблемы, вы можете исправить их с помощью бесплатного ручного ремонта или вы можете приобрести полную версию для их автоматического исправления.
: preg_match(): Compilation failed: regular expression is too large at offset 75 in
.htaccess — Как удалить .html из URL?
Переполнение стека- Товары
- Клиенты
- Случаи использования
- Переполнение стека Публичные вопросы и ответы
- Команды Частные вопросы и ответы для вашей команды
- предприятие Частные вопросы и ответы для вашего предприятия
- работы Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимать технический талант
- Товары
- Клиенты
- Случаи использования
- Переполнение стека Публичные вопросы и ответы
- Команды Частные вопросы и ответы для вашей команды
- предприятие Частные вопросы и ответы для вашего предприятия
- работы Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимать технический талант
- реклама Связаться с разработчиками по всему миру
У вас есть контент, который вы хотите удалить из результатов поиска Google & Bing , который вы хотите, , но вы не знаете, как это сделать? Вот пошаговое руководство по удалению вашего контента и URL-адресов из результатов поиска.
Во-первых, удалите контент из видимости поисковой системы.
Первый шаг к удалению контента из поисковой системы — сделать его невидимым для поисковых систем.Это может произойти несколькими способами:
- само содержание и URL удаляются
- вы устанавливаете страницу без индекса для поисковых систем
- вы 301 перенаправляете страницу
Давайте рассмотрим эти ситуации более подробно ,
Содержимое и URL удалены
На веб-сайте была страница, которая теперь была удалена (возможно, содержала контент, который больше не был полезен). Это обычная ситуация, хотя, если ваша страница была в течение некоторого времени, вероятно, есть другие страницы в Интернете, ссылающиеся на вашу страницу.Если это так, вы должны рассмотреть возможность перенаправления 301 для этой страницы.
Вы установили страницу без индекса для поисковых систем
Допустим, вы хотите, чтобы у вас была страница, которая является благодарностью за заполнение формы. Вы действительно не хотите, чтобы поисковые системы проиндексировали эту страницу, поскольку она не имеет полезного контента для широкой публики. Однако страница должна быть общедоступной, чтобы можно было поблагодарить людей, заполняющих ваши формы. Страницы с благодарностью также часто используются для отслеживания конверсий в Google Analytics.
Вы можете установить для этой страницы тег «без индекса». Обычно это делается с помощью такого инструмента, как Yoast SEO for WordPress, или через ваш файл robots.txt, или вручную добавляя метатег в заголовок.
You 301 Перенаправьте страницу
Если вы удалили контент и заменили его на что-то более качественное, или если вы изменили свой URL-адрес, или если ваш контент был в течение некоторого времени, то вы должны 301 перенаправить ваш URL. Это может быть сделано с помощью плагина Redirection для WordPress или путем редактирования вашего.htaccess файл для веб-серверов Linux.
У вас есть контент, который вы хотите удалить
Если вы владеете контентом — например, он принадлежит вашему веб-сайту — вы можете использовать Инструменты для веб-мастеров для удаления контента. Если у вас нет настроек сайта для инструментов для веб-мастеров, ознакомьтесь с разделами Настройка веб-сайта Google и Инструменты для веб-мастеров, Инструменты для отправки веб-сайтов Bing и Инструменты для веб-мастеров.
Консоль поиска Google Инструмент удаления URL-адресов
Перейдите в консоль поиска Google (ранее называвшуюся Инструментами Google для веб-мастеров) и выберите свою собственность, затем Google Index, а затем URL-адреса для удаления или просто нажмите здесь и выберите свою собственность.
Отсюда вы сможете временно скрывать URL-адреса. Просто нажмите Временно скрыть и затем введите свой URL. Содержимое будет удалено из результатов поиска Google.

Это будет работать, даже если в настоящее время контент доступен и доступен в Интернете . Хорошим примером того, как это может быть полезно, является то, что если вы опубликовали страницу, а затем поняли, что ей нужно еще несколько обновлений, прежде чем вы захотите, чтобы люди приходили на нее. Вы можете разрешить людям вернуться на эту страницу позже, просто повторно посетив поисковую консоль.
Bing
Перейдите на панель инструментов Bing для веб-мастеров, а затем настройте Мой сайт и заблокируйте URL-адреса.
Здесь вы можете выбрать, хотите ли вы заблокировать каталог (например, удаляете целую группу URL-адресов) или отдельную страницу. Затем введите URL-адрес каталога или страницы и нажмите на URL-адреса блоков и кэш.

Опять же, здесь, , у вас есть контроль над блокировкой, и контент не должен быть удален из видимости поисковой системы. Вы можете закончить или расширить блок по своему усмотрению.
Вам не принадлежит контент
Если вам не принадлежит контент, или у вас нет инструментов для веб-мастеров, настроенных для вашего веб-сайта, вы можете использовать опцию удаления контента.
Google инструмент для удаления устаревшего контента
Начните с перехода к инструменту Google для удаления устаревшего контента.
Если в данный момент вы не вошли в систему с учетной записью Google, вам необходимо выполнить вход. Цель входа — отслеживать ваши запросы на удаление.
Введите URL-адрес в поле URL-адреса и нажмите «Запрос на удаление».

Google проанализирует URL-адрес и либо подтвердит, что контент больше не существует, либо сообщит вам, что Google по-прежнему может получить доступ к контенту. Если Google по-прежнему может получить доступ к контенту, вам придется вернуться к описанным выше шагам, чтобы удалить видимость вашего контента поисковыми системами (см. Шаги выше).
Если вы видите ниже сообщение о том, что ваш контент исчез, просто нажмите «Запрос на удаление».

После того, как вы нажмете на «Запрос на удаление», URL появится в вашем списке как ожидающие. Обычно он переключается на удаление в течение 24 часов.
Инструмент удаления контента Bing
Начните с перехода к инструменту удаления контента Bing.
Так же, как инструмент Google, вы должны войти в систему с учетной записью Bing.
Введите свой URL-адрес в поле «URL-адрес содержимого» и нажмите «Отправить».

Если вы получили следующее сообщение об ошибке, ваша отправка не удалась:
Мы не смогли проверить, что URL больше не существует в Интернете или устарел.Пожалуйста, проверьте URL на наличие ошибок или повторите попытку позже. Ваш запрос не будет отправлен.
Важно отметить, что Bing гораздо более проблематичен для удаления URL-адресов, чем Google . Запросы, которые проходят без проблем в Google, могут не выполняться на Bing. Например, если ваш домен больше не существует, Google удалит ваш URL без каких-либо проблем, однако Bing откажется это сделать.
Если вы не можете заставить Bing удалить свой URL-адрес, я рекомендую настроить его как перенаправление 301, следуя этому руководству или проверив свой сайт с помощью Bing и выполнив действия, описанные в предыдущем разделе, если вы являетесь владельцем контента ,
Если Bing согласится удалить ваш URL, это обычно происходит в течение 24 часов. Вы можете вернуться на эту страницу через день, чтобы проверить статус удаления.
- Товары
- Клиенты
- Случаи использования
- Переполнение стека Публичные вопросы и ответы
- Команды Частные вопросы и ответы для вашей команды
- предприятие Частные вопросы и ответы для вашего предприятия
- работы Программирование и связанные с ним технические возможности карьерного роста
- Талант Нанимать технический талант
- реклама Связаться с разработчиками по всему миру