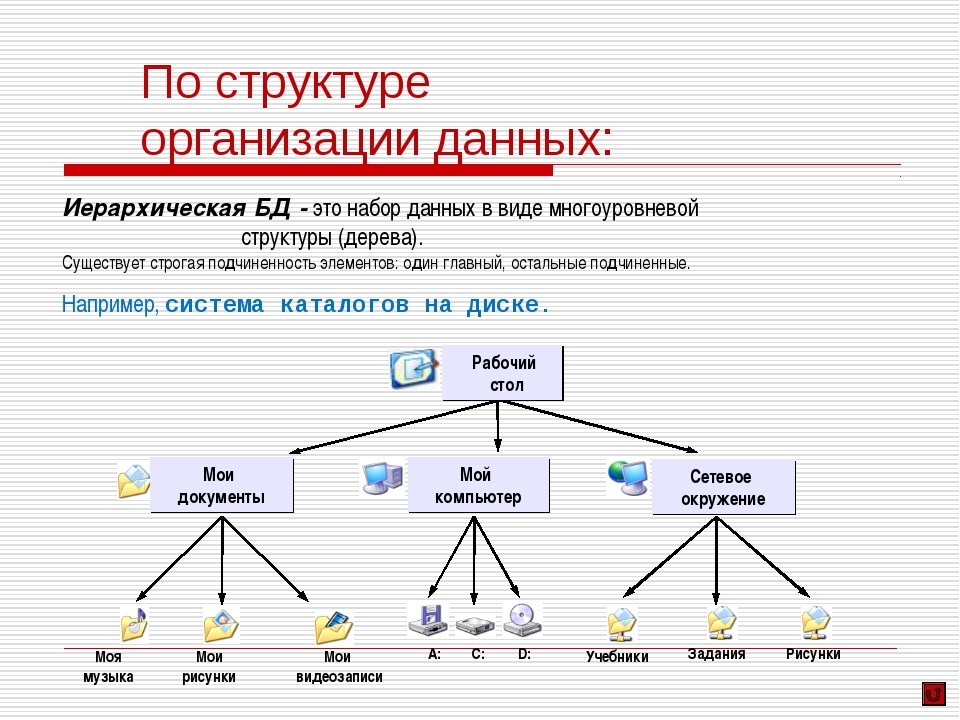
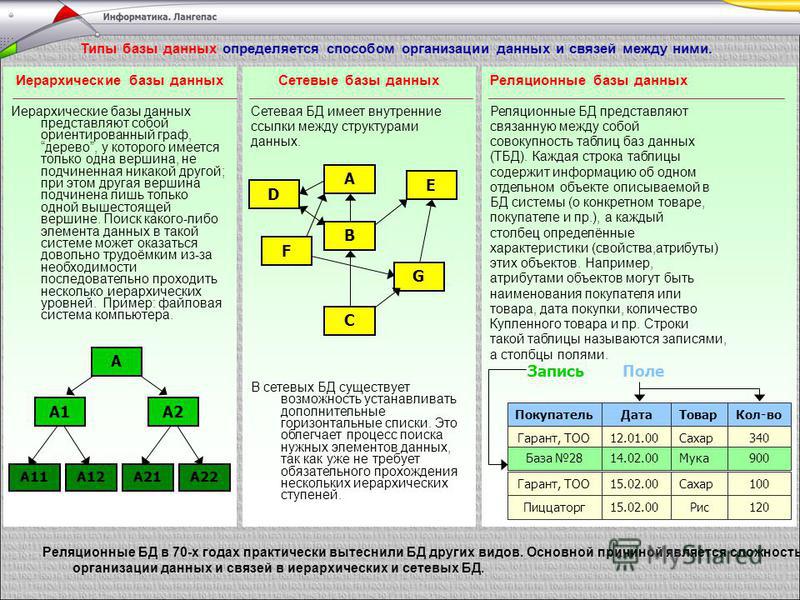
Основные структуры данных.
Необходимым условием хранения информации в памяти компьютера является возможность преобразования этой самой информации в подходящую для компьютера форму. В том случае, если это условие выполняется, следует определить структуру, пригодную именно для наличествующей информации, ту, которая предоставит требующийся набор возможностей работы с ней.
Здесь под структурой понимается способ представления информации, посредством которого совокупность отдельно взятых элементов образует нечто единое, обусловленное их взаимосвязью друг с другом. Скомпонованные по каким-либо правилам и логически связанные межу собой, данные могут весьма эффективно обрабатываться, так как общая для них структура предоставляет набор возможностей управления ими – одно из того за счет чего достигаются высокие результаты в решениях тех или иных задач.
Но не каждый объект представляем в произвольной форме, а возможно и вовсе для него имеется лишь один единственный метод интерпретации, следовательно, несомненным плюсом для программиста будет знание всех существующих структур данных.
Говоря о не вычислительной технике, можно показать ни один случай, где у информации видна явная структура. Наглядным примером служат книги самого разного содержания. Они разбиты на страницы, параграфы и главы, имеют, как правило, оглавление, то есть интерфейс пользования ими. В широком смысле, структурой обладает всякое живое существо, без нее органика навряд-ли смогла бы существовать.
Вполне вероятно, читателю приходилось сталкиваться со структурами данных непосредственно в информатике, например, с теми, что встроены в язык программирования. Часто они именуются типами данных. К таковым относятся: массивы, числа, строки, файлы и т. д.
Методы хранения информации, называемые «простыми», т. е. неделимыми на составные части, предпочтительнее изучать вместе с конкретным языком программирования, либо же глубоко углубляться в суть их работы.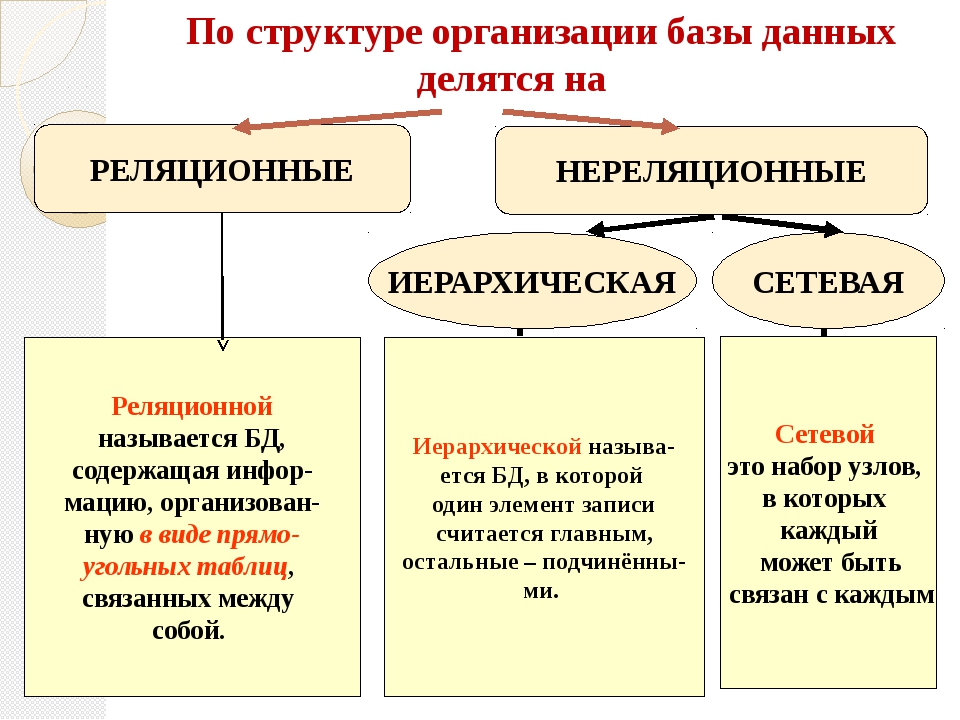 Поэтому здесь будут рассмотрены лишь «интегрированные» структуры, те которые состоят из простых, а именно: массивы, списки, деревья и графы.
Поэтому здесь будут рассмотрены лишь «интегрированные» структуры, те которые состоят из простых, а именно: массивы, списки, деревья и графы.
Массивы.
Массив – это структура данных с фиксированным и упорядоченным набором однотипных элементов (компонентов). Доступ к какому-либо из элементов массива осуществляется по имени и номеру (индексу) этого элемента. Количество индексов определяет размерность массива. Так, например, чаще всего встречаются одномерные (вектора) и двумерные (матрицы) массивы. Первые имеют один индекс, вторые – два.
Пусть одномерный массив называется A, тогда для получения доступа к его i-ому элементу потребуется указать название массива и номер требуемого элемента: A[i]. Когда A – матрица, то она представляема в виде таблицы, доступ к элементам которой осуществляется по имени массива, а также номерам строки и столбца, на пересечении которых расположен элемент: A[i, j], где i – номер строки, j – номер столбца.
В разных языках программирования работа с массивами может в чем-то различаться, но основные принципы, как правило, везде одни.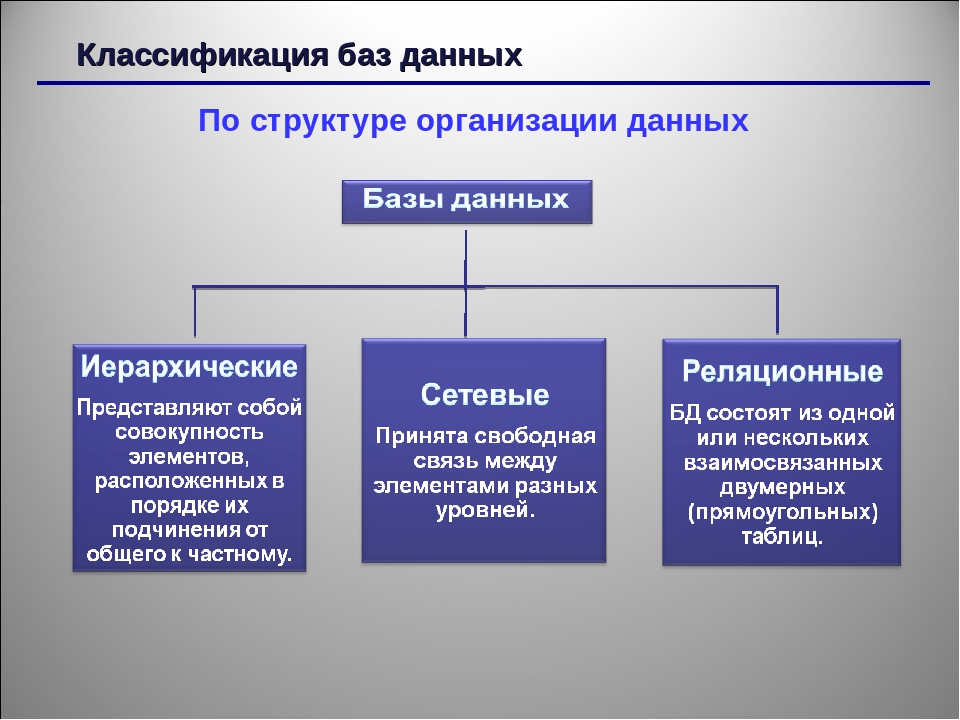 В языке Pascal, обращение к одномерному и двумерному массиву происходит точно так, как это показано выше, а, например, в C++ двумерный массив следует указывать так: A[i][j]. Элементы массива нумеруются поочередно. На то, с какого значения начинается нумерация, влияет язык программирования. Чаще всего этим значением является 0 или 1.
В языке Pascal, обращение к одномерному и двумерному массиву происходит точно так, как это показано выше, а, например, в C++ двумерный массив следует указывать так: A[i][j]. Элементы массива нумеруются поочередно. На то, с какого значения начинается нумерация, влияет язык программирования. Чаще всего этим значением является 0 или 1.
Массивы, описанного типа называются статическими, но существуют также массивы по определенным признакам отличные от них: динамические и гетерогенные. Динамичность первых характеризуется непостоянностью размера, т. е. по мере выполнения программы размер динамического массива может изменяться. Такая функция делает работу с данными более гибкой, но при этом приходится жертвовать быстродействием, да и сам процесс усложняется.
Обязательный критерий статического массива, как было сказано, это однородность данных, единовременно хранящихся в нем. Когда же данное условие не выполняется, то массив является гетерогенным. Его использование обусловлено недостатками, которые имеются в предыдущем виде, но оно оправданно во многих случаях.
Таким образом, даже если Вы определились со структурой, и в качестве нее выбрали массив, то этого все же недостаточно. Ведь массив это только общее обозначение, род для некоторого числа возможных реализаций. Поэтому необходимо определиться с конкретным способом представления, с наиболее подходящим массивом.
Списки.
Список – абстрактный тип данных, реализующий упорядоченный набор значений. Списки отличаются от массивов тем, что доступ к их элементам осуществляется последовательно, в то время как массивы – структура данных произвольного доступа. Данный абстрактный тип имеет несколько реализаций в виде структур данных. Некоторые из них будут рассмотрены здесь.
Список (связный список) – это структура данных, представляющая собой конечное множество упорядоченных элементов, связанных друг с другом посредствам указателей. Каждый элемент структуры содержит поле с какой-либо информацией, а также указатель на следующий элемент. В отличие от массива, к элементам списка нет произвольного доступа.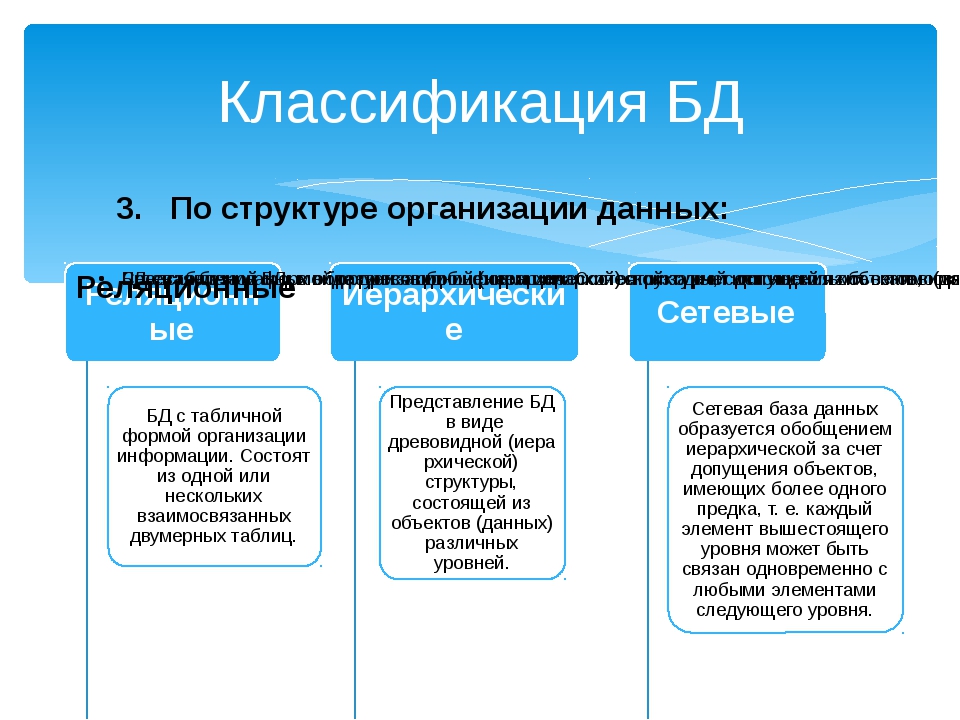
Односвязный список
В односвязном списке, приведенным выше, начальным элементом является Head list (голова списка [произвольное наименование]), а все остальное называется хвостом. Хвост списка составляют элементы, разделенные на две части: информационную (поле info) и указательную (поле next). В последнем элементе вместо указателя, содержится признак конца списка – nil.
Односвязный список не слишком удобен, т. к. из одной точки есть возможность попасть лишь в следующую точку, двигаясь тем самым в конец. Когда кроме указателя на следующий элемент есть указатель и на предыдущий, то такой список называется двусвязным.
Двусвязный список
Возможность двигаться как вперед, так и назад полезна для выполнения некоторых операций, но дополнительные указатели требуют задействования большего количества памяти, чем таковой необходимо в эквивалентном односвязном списке.
Для двух видов списков описанных выше существует подвид, называемый кольцевым списком.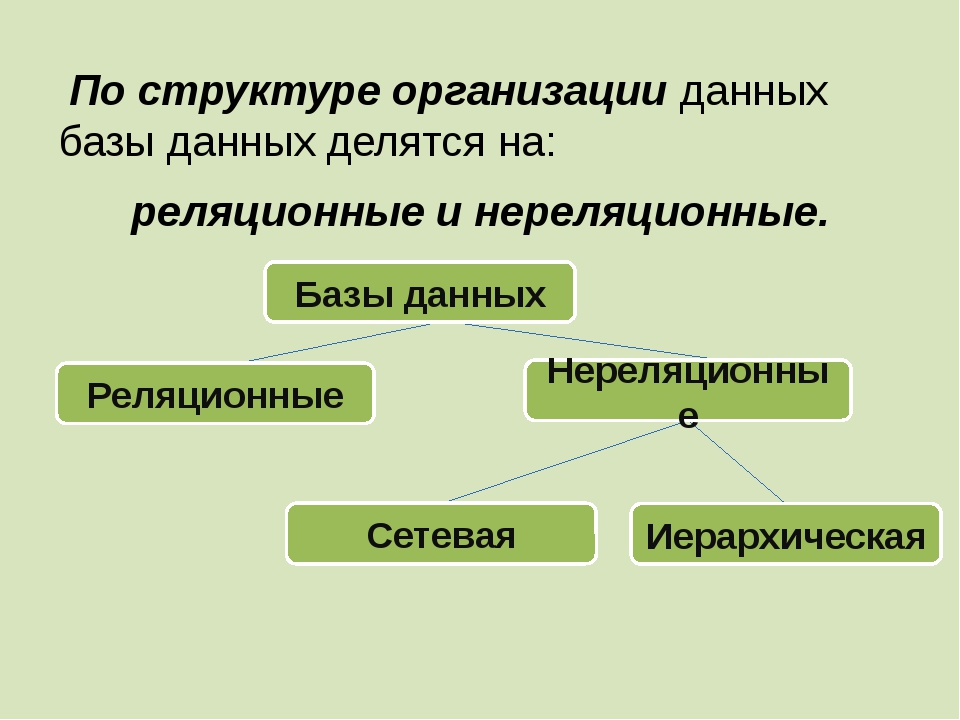 Сделать из односвязного списка кольцевой можно добавив всего лишь один указатель в последний элемент, так чтобы он ссылался на первый. А для двусвязного потребуется два указателя: на первый и последний элементы.
Сделать из односвязного списка кольцевой можно добавив всего лишь один указатель в последний элемент, так чтобы он ссылался на первый. А для двусвязного потребуется два указателя: на первый и последний элементы.
Кольцевой список
Помимо рассмотренных видов списочных структур есть и другие способы организации данных по типу «список», но они, как правило, во многом схожи с разобранными, поэтому здесь они будут опущены.
Кроме различия по связям, списки делятся по методам работы с данными. О некоторых таких методах сказано далее.
Стек
Стек.
Стек характерен тем, что получить доступ к его элементом можно лишь с одного конца, называемого вершиной стека, иначе говоря: стек – структура данных, функционирующая по принципу LIFO (last in — first out, «последним пришёл — первым вышел»).
Изобразить эту структуру данных лучше в виде вертикального списка, например, стопки каких-либо вещей, где чтобы воспользоваться одной из них нужно поднять все те вещи, что лежат выше нее, а положить предмет можно лишь на вверх стопки.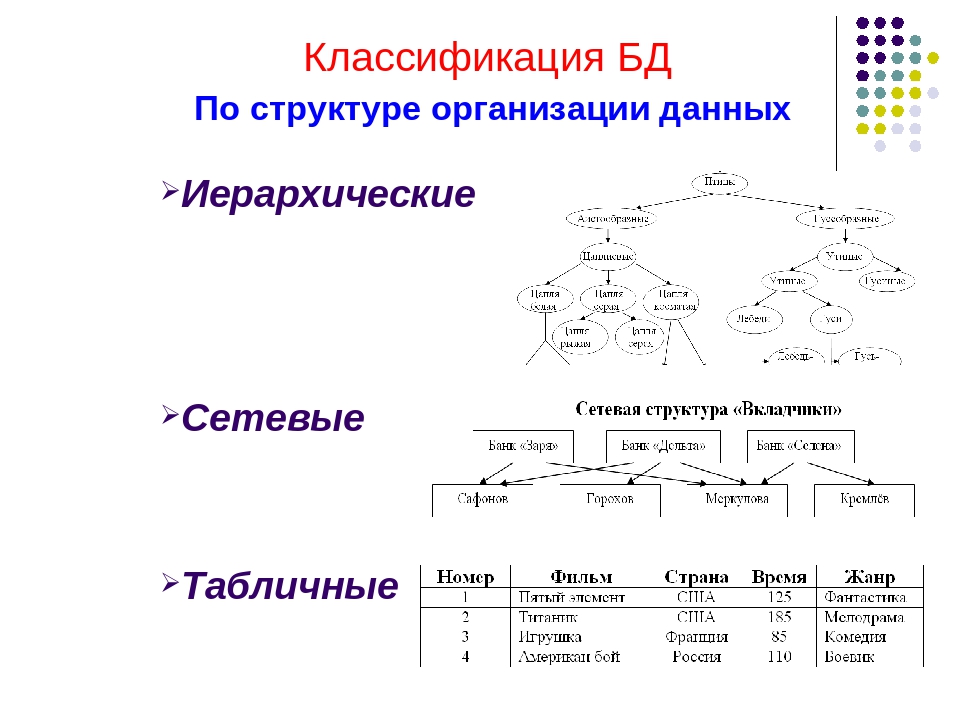
Если бы было, например 6 элементов, а вставить конкретный элемент требовалось также в пятую ячейку, то исключить бы пришлось уже два элемента.
Очередь.
Структура данных «Очередь» использует принцип организации FIFO (First In, First Out — «первым пришёл — первым вышел»). В некотором смысле такой метод более справедлив, чем тот, по которому функционирует стек, ведь простое правило, лежащее в основе привычных очередей в различные магазины, больницы считается вполне справедливым, а именно оно является базисом этой структуры.
Пусть данное наблюдение будет примером. Строго говоря, очередь – это список, добавление элементов в который допустимо, лишь в его конец, а их извлечение производиться с другой стороны, называемой началом списка.
Очередь
Дек.

Дек (deque — double ended queue, «двухсторонняя очередь») – стек с двумя концами. Действительно, несмотря конкретный перевод, дек можно определять не только как двухстороннюю очередь, но и как стек, имеющий два конца. Это означает, что данный вид списка позволяет добавлять элементы в начало и в конец, и то же самое справедливо для операции извлечения.
Дек
Эта структура одновременно работает по двум способам организации данных: FIFO и LIFO. Поэтому ее допустимо отнести к отдельной программной единице, полученной в результате суммирования двух предыдущих видов списка.
Графы.
Раздел дискретной математики, занимающийся изучением графов, называется теорией графов. В теории графов подробно рассматриваются известные понятия, свойства, способы представления и области применения этих математических объектов. Нас же интересует, лишь те ее аспекты, которые важны в программировании.
Граф – совокупность точек, соединенных линиями. Точки называются вершинами (узлами), а линии – ребрами (дугами).
Как показано на рисунке различают два основных вида графов: ориентированные и неориентированные. В первых ребра являются направленными, т. е. существует только одно доступное направление между двумя связными вершинами, например из вершины 1 можно пройти в вершину 2, но не наоборот. В неориентированном связном графе из каждой вершины можно пройти в каждую и обратно. Частный случай двух этих видов – смешанный граф. Он характерен наличием как ориентированных, так и неориентированных ребер.
Степень входа вершины – количество входящих в нее ребер, степень выхода – количество исходящих ребер.
Ребра графа необязательно должны быть прямыми, а вершины обозначаться именно цифрами, так как показано на рисунке. К тому же встречаются такие графы, ребрам которых поставлено в соответствие конкретное значение, они именуются взвешенными графами, а это значение – весом ребра. Когда у ребра оба конца совпадают, т. е. ребро выходит из вершины F и входит в нее, то такое ребро называется петлей.
Графы широко используются в структурах, созданных человеком, например в компьютерных и транспортных сетях, web-технологиях. Специальные способы представления позволяют использовать граф в информатике (в вычислительных машинах). Самые известные из них: «Матрица смежности», «Матрица инцидентности», «Список смежности», «Список рёбер». Два первых, как понятно из названия, для репрезентации графа используют матрицу, а два последних – список.
Деревья.
Неупорядоченное дерево
Дерево как математический объект это абстракция из соименных единиц, встречающихся в природе. Схожесть структуры естественных деревьев с графами определенного вида говорит о допущении установления аналогии между ними. А именно со связанными и вместе с этим ациклическими (не имеющими циклов) графами. Последние по своему строению действительно напоминают деревья, но в чем то и имеются различия, например, принято изображать математические деревья с корнем расположенным вверху, т. е. все ветви «растут» сверху вниз. Известно же, что в природе это совсем не так.
е. все ветви «растут» сверху вниз. Известно же, что в природе это совсем не так.
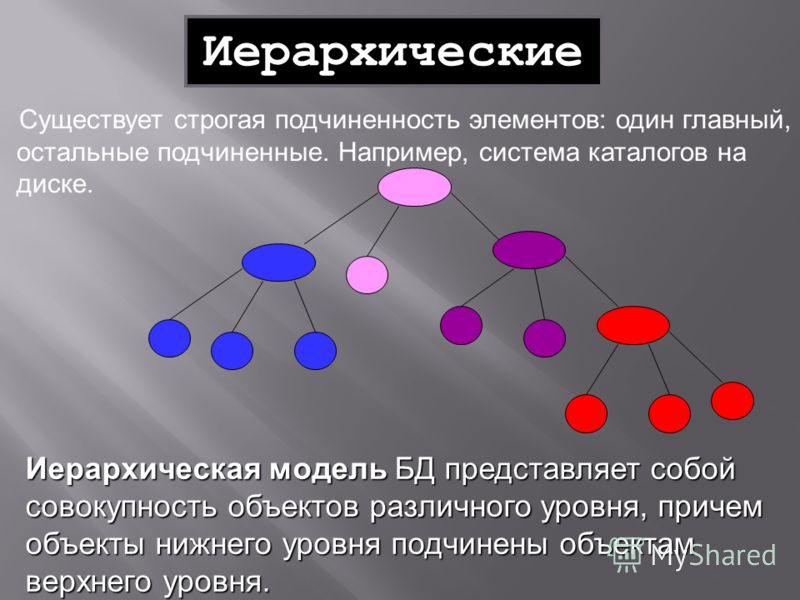
Поскольку дерево это по своей сути граф, у него с последним многие определения совпадают, либо интуитивно схожи. Так корневой узел (вершина 6) в структуре дерева – это единственная вершина (узел), характерная отсутствием предков, т. е. такая, что на нее не ссылается ни какая другая вершина, а из самого корневого узла можно дойти до любой из имеющихся вершин дерева, что следует из свойства связности данной структуры.
Узлы, не ссылающиеся ни на какие другие узлы, иначе говоря, ни имеющие потомков называются листьями (2, 3, 9), либо терминальными узлами. Элементы, расположенные между корневым узлом и листьями – промежуточные узлы (1, 1, 7, 8). Каждый узел дерева имеет только одного предка, или если он корневой, то не имеет ни одного.
Поддерево – часть дерева, включающая некоторый корневой узел и все его узлы-потомки. Так, например, на рисунке одно из поддеревьев включает корень 8 и элементы 2, 1, 9.
С деревом можно выполнять многие операции, например, находить элементы, удалять элементы и поддеревья, вставлять поддеревья, находить корневые узлы для некоторых вершин и др. Одной из важнейших операций является обход дерева. Выделяются несколько методов обхода. Наиболее популярные из них: симметричный, прямой и обратный обход. При прямом обходе узлы-предки посещаются прежде своих потомков, а в обратном обходе, соответственно, обратная ситуация. В симметричном обходе поочередно просматриваются поддеревья главного дерева.
Представление данных в рассмотренной структуре выгодно в случае наличия у информации явной иерархии. Например, работа с данными о биологических родах и видах, служебных должностях, географических объектах и т. п. требует иерархически выраженной структуры, такой как математические деревья.
Похожие записи:
Основные структуры данных. Матчасть. Азы / Хабр
Все чаще замечаю, что современным самоучкам очень не хватает матчасти. Все знают языки, но мало основы, такие как типы данных или алгоритмы. Немного про типы данных.
Все знают языки, но мало основы, такие как типы данных или алгоритмы. Немного про типы данных.Еще в далеком 1976 швейцарский ученый Никлаус Вирт написал книгу Алгоритмы + структуры данных = программы.
40+ лет спустя это уравнение все еще верно. И если вы самоучка и надолго в программировании пробегитесь по статье, можно по диагонали. Можно код кофе.
В статье так же будут вопросы, которое вы можете услышать на интервью.
Что такое структура данных?
Структура данных — это контейнер, который хранит данные в определенном макете. Этот «макет» позволяет структуре данных быть эффективной в некоторых операциях и неэффективной в других.
Какие бывают?
Линейные, элементы образуют последовательность или линейный список, обход узлов линеен. Примеры: Массивы. Связанный список, стеки и очереди.
Нелинейные, если обход узлов нелинейный, а данные не последовательны. Пример: граф и деревья.
Основные структуры данных.
- Массивы
- Стеки
- Очереди
- Связанные списки
- Графы
- Деревья
- Префиксные деревья
- Хэш таблицы
Массивы
Массив — это самая простая и широко используемая структура данных.
 Другие структуры данных, такие как стеки и очереди, являются производными от массивов.
Другие структуры данных, такие как стеки и очереди, являются производными от массивов.Изображение простого массива размера 4, содержащего элементы (1, 2, 3 и 4).
Каждому элементу данных присваивается положительное числовое значение (индекс), который соответствует позиции элемента в массиве. Большинство языков определяют начальный индекс массива как 0.
Бывают
Одномерные, как показано выше.
Многомерные, массивы внутри массивов.
Основные операции
- Insert-вставляет элемент по заданному индексу
- Get-возвращает элемент по заданному индексу
- Delete-удаление элемента по заданному индексу
- Size-получить общее количество элементов в массиве
Вопросы
- Найти второй минимальный элемент массива
- Первые неповторяющиеся целые числа в массиве
- Объединить два отсортированных массива
- Изменение порядка положительных и отрицательных значений в массиве
Стеки
Стек — абстрактный тип данных, представляющий собой список элементов, организованных по принципу LIFO (англ.
 last in — first out, «последним пришёл — первым вышел»).
last in — first out, «последним пришёл — первым вышел»).Это не массивы. Это очередь. Придумал Алан Тюринг.
Примером стека может быть куча книг, расположенных в вертикальном порядке. Для того, чтобы получить книгу, которая где-то посередине, вам нужно будет удалить все книги, размещенные на ней. Так работает метод LIFO (Last In First Out). Функция «Отменить» в приложениях работает по LIFO.
Изображение стека, в три элемента (1, 2 и 3), где 3 находится наверху и будет удален первым.
Основные операции
- Push-вставляет элемент сверху
- Pop-возвращает верхний элемент после удаления из стека
- isEmpty-возвращает true, если стек пуст
- Top-возвращает верхний элемент без удаления из стека
Вопросы
- Реализовать очередь с помощью стека
- Сортировка значений в стеке
- Реализация двух стеков в массиве
- Реверс строки с помощью стека
Очереди
Подобно стекам, очередь — хранит элемент последовательным образом.
 Существенное отличие от стека – использование FIFO (First in First Out) вместо LIFO.
Существенное отличие от стека – использование FIFO (First in First Out) вместо LIFO.Пример очереди – очередь людей. Последний занял последним и будешь, а первый первым ее и покинет.
Изображение очереди, в четыре элемента (1, 2, 3 и 4), где 1 находится наверху и будет удален первым
Основные операции
- Enqueue—) — вставляет элемент в конец очереди
- Dequeue () — удаляет элемент из начала очереди
- isEmpty () — возвращает значение true, если очередь пуста
- Top () — возвращает первый элемент очереди
Вопросы
- Реализовать cтек с помощью очереди
- Реверс первых N элементов очереди
- Генерация двоичных чисел от 1 до N с помощью очереди
Связанный список
Связанный список – массив где каждый элемент является отдельным объектом и состоит из двух элементов – данных и ссылки на следующий узел.
Принципиальным преимуществом перед массивом является структурная гибкость: порядок элементов связного списка может не совпадать с порядком расположения элементов данных в памяти компьютера, а порядок обхода списка всегда явно задаётся его внутренними связями.
Бывают
Однонаправленный, каждый узел хранит адрес или ссылку на следующий узел в списке и последний узел имеет следующий адрес или ссылку как NULL.
1->2->3->4->NULL
Двунаправленный, две ссылки, связанные с каждым узлом, одним из опорных пунктов на следующий узел и один к предыдущему узлу.
NULL<-1<->2<->3->NULL
Круговой, все узлы соединяются, образуя круг. В конце нет NULL. Циклический связанный список может быть одно-или двукратным циклическим связанным списком.
1->2->3->1
Самое частое, линейный однонаправленный список. Пример – файловая система.
Основные операции
- InsertAtEnd — Вставка заданного элемента в конец списка
- InsertAtHead — Вставка элемента в начало списка
- Delete — удаляет заданный элемент из списка
- DeleteAtHead — удаляет первый элемент списка
- Search — возвращает заданный элемент из списка
- isEmpty — возвращает True, если связанный список пуст
Вопросы
- Реверс связанного списка
- Определение цикла в связанном списке
- Возврат N элемента из конца в связанном списке
- Удаление дубликатов из связанного списка
Графы
Граф-это набор узлов (вершин), которые соединены друг с другом в виде сети ребрами (дугами).

Бывают
Ориентированный, ребра являются направленными, т.е. существует только одно доступное направление между двумя связными вершинами.
Неориентированные, к каждому из ребер можно осуществлять переход в обоих направлениях.
Смешанные
Встречаются в таких формах как
- Матрица смежности
- Список смежности
Общие алгоритмы обхода графа
- Поиск в ширину – обход по уровням
- Поиск в глубину – обход по вершинам
Вопросы
- Реализовать поиск по ширине и глубине
- Проверить является ли граф деревом или нет
- Посчитать количество ребер в графе
- Найти кратчайший путь между двумя вершинами
Деревья
Дерево-это иерархическая структура данных, состоящая из узлов (вершин) и ребер (дуг). Деревья по сути связанные графы без циклов.
Древовидные структуры везде и всюду. Дерево скилов в играх знают все.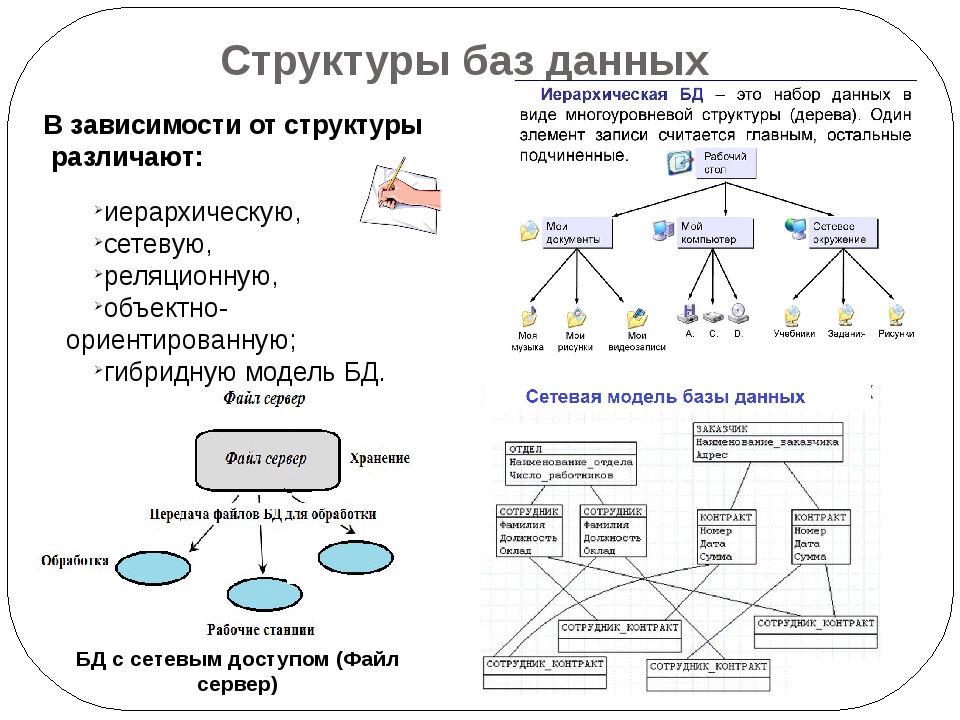
Простое дерево
Типы деревьев
Бинарное дерево самое распространенное.
«Бинарное дерево — это иерархическая структура данных, в которой каждый узел имеет значение (оно же является в данном случае и ключом) и ссылки на левого и правого потомка. » — Procs
Три способа обхода дерева
- В прямом порядке (сверху вниз) — префиксная форма.
- В симметричном порядке (слева направо) — инфиксная форма.
- В обратном порядке (снизу вверх) — постфиксная форма.
Вопросы
- Найти высоту бинарного дерева
- Найти N наименьший элемент в двоичном дереве поиска
- Найти узлы на расстоянии N от корня
- Найти предков N узла в двоичном дереве
Trie ( префиксное деревое )
Разновидность дерева для строк, быстрый поиск. Словари. Т9.
Вот как такое дерево хранит слова «top», «thus» и «their».
Слова хранятся сверху вниз, зеленые цветные узлы «p», «s» и «r» указывают на конец «top», «thus « и «their» соответственно.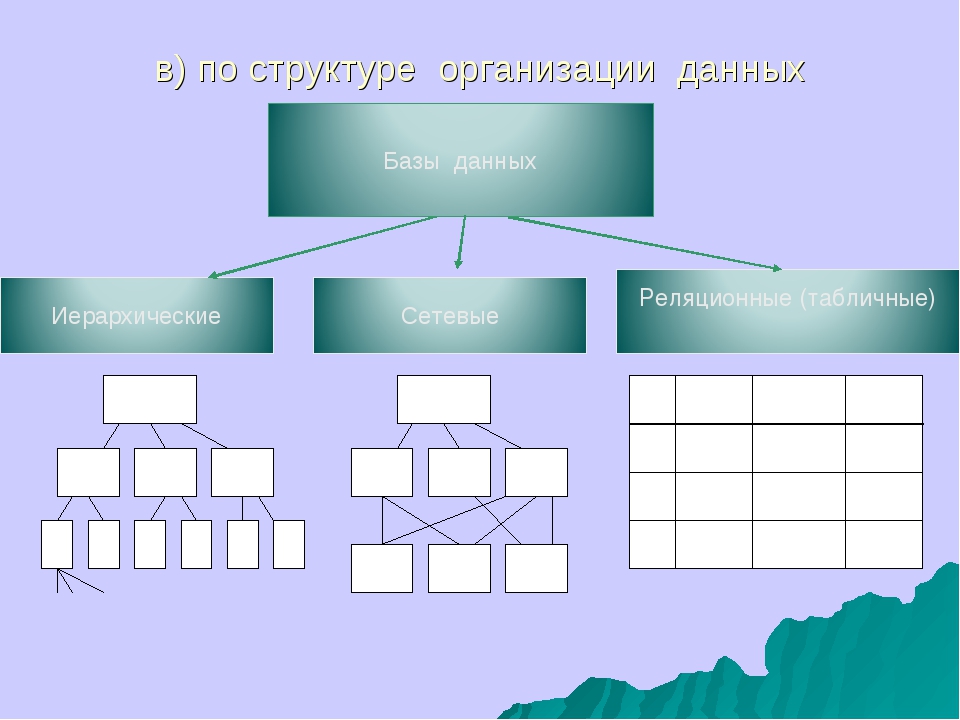
Вопросы
- Подсчитать общее количество слов
- Вывести все слова
- Сортировка элементов массива с префиксного дерева
- Создание словаря T9
Хэш таблицы
Хэширование — это процесс, используемый для уникальной идентификации объектов и хранения каждого объекта в заранее рассчитанном уникальном индексе (ключе).
Объект хранится в виде пары «ключ-значение», а коллекция таких элементов называется «словарем». Каждый объект можно найти с помощью этого ключа.
По сути это массив, в котором ключ представлен в виде хеш-функции.
Эффективность хеширования зависит от
- Функции хеширования
- Размера хэш-таблицы
- Метода борьбы с коллизиями
Пример сопоставления хеша в массиве. Индекс этого массива вычисляется через хэш-функцию.
Вопросы
- Найти симметричные пары в массиве
- Найти, если массив является подмножеством другого массива
- Описать открытое хеширование
Список ресурсов
Вместо заключения
Матчасть так же интересна, как и сами языки.
 Возможно, кто-то увидит знакомые ему базовые структуры и заинтересуется.
Возможно, кто-то увидит знакомые ему базовые структуры и заинтересуется.Спасибо, что прочли. Надеюсь не зря потратили время =)
PS: Прошу извинить, как оказалось, перевод статьи уже был тут и очень недавно, я проглядел.
Если интересно, вот она, спасибо Hokum, буду внимательнее.
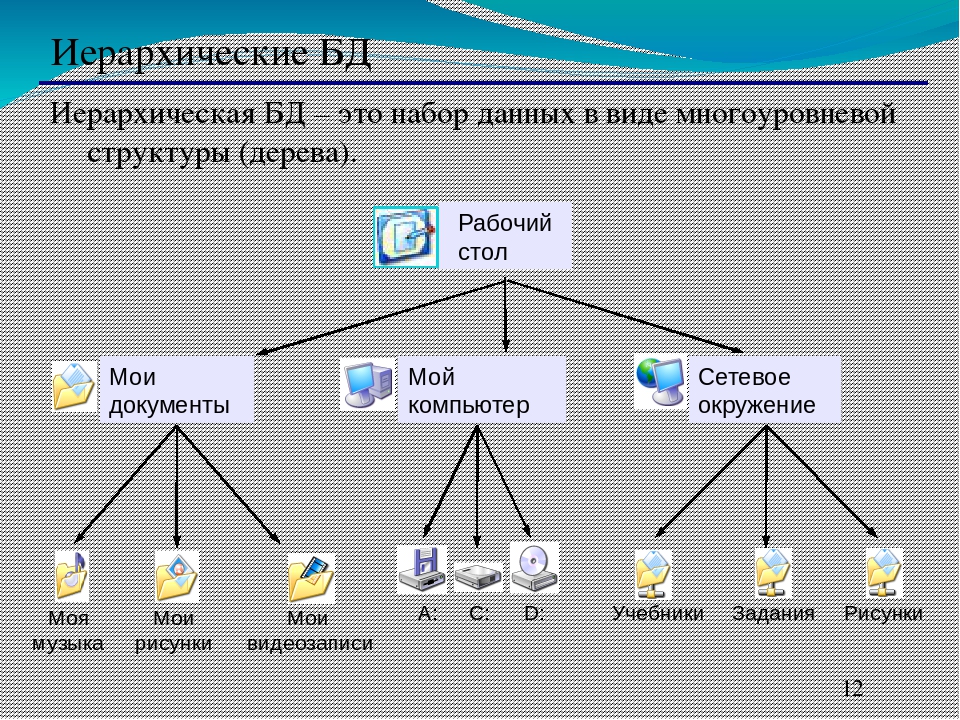
Структура базы данных, хранение и организация данных
Я создаю проект, который отслеживает кампании краудфандинга, чтобы конечный пользователь мог анализировать данные. Очевидно, я использую паука, чтобы регулярно соскребать все детали каждой кампании, которые затем буду хранить в базе данных.
Я просто не уверен, как мне следует проектировать базу данных. Проблема в том, что кампании могут иметь продолжительность жизни более месяца, и я могу очищать каждую кампанию несколько раз в день, чтобы проверить наличие изменений.
Объединять каждую кампанию в одну таблицу было бы нецелесообразно, так как там будут тысячи кампаний, и теоретически одна кампания может иметь сотни и сотни строк, если ее детали постоянно обновляются. Скорее всего, там тоже будут десятки и десятки колонок. Поэтому я решил создать отдельные таблицы для каждой кампании.
Скорее всего, там тоже будут десятки и десятки колонок. Поэтому я решил создать отдельные таблицы для каждой кампании.
В то же время наличие тысяч таблиц также кажется непрактичным, особенно если пользователь хочет сравнить несколько различных кампаний. Чтобы сравнить множество кампаний, мне пришлось бы запросить неопределенное количество таблиц.
Я никогда раньше не сталкивался с такой сложностью. Есть ли у кого-нибудь идеи, как подойти к этой проблеме?
Потенциальные Поля
CREATE TABLE campaign (
id INT(6) UNSIGNED AUTO_INCREMENT PRIMARY KEY,
campaign_url VARCHAR(255) NOT NULL,
campaign_phase VARCHAR(8) NOT NULL,
project_website VARCHAR(255) NOT NULL,
project_facebook_url VARCHAR(255) NULL,
project_linkedin_url VARCHAR (255) NULL,
project_twitter_url VARCHAR(255) NULL,
project_youtube_url VARCHAR(255) NULL,
product_title TEXT NOT NULL,
product_tagline TEXT NOT NULL,
product_phase VARCHAR(10) NULL,
product_overview TEXT NULL, # may be more columns derived from overview. ..
owner_name VARCHAR(255) NOT NULL,
owner_title VARCHAR(255) NOT NULL,
owner_description TEXT NULL,
owner_avatar_url VARCHAR(255) NULL,
owner_location VARCHAR(255) NOT NULL,
owner_campaign_count TINYINT NOT NULL,
owner_total_raised INT NOT NULL,
owner_other_campaign_urls TEXT NOT NULL, # this may have multiple values...
owner_contribution_count TINYINT NOT NULL,
owner_verified BIT NULL,
# info about team members...
# info about perks...
# info about/meta-analysis of campaign text, images, and videos...
# info about updates...
# info about backers...
crawled_on DATETIME NOT NULL
)
..
owner_name VARCHAR(255) NOT NULL,
owner_title VARCHAR(255) NOT NULL,
owner_description TEXT NULL,
owner_avatar_url VARCHAR(255) NULL,
owner_location VARCHAR(255) NOT NULL,
owner_campaign_count TINYINT NOT NULL,
owner_total_raised INT NOT NULL,
owner_other_campaign_urls TEXT NOT NULL, # this may have multiple values...
owner_contribution_count TINYINT NOT NULL,
owner_verified BIT NULL,
# info about team members...
# info about perks...
# info about/meta-analysis of campaign text, images, and videos...
# info about updates...
# info about backers...
crawled_on DATETIME NOT NULL
)
 ..
owner_name VARCHAR(255) NOT NULL,
owner_title VARCHAR(255) NOT NULL,
owner_description TEXT NULL,
owner_avatar_url VARCHAR(255) NULL,
owner_location VARCHAR(255) NOT NULL,
owner_campaign_count TINYINT NOT NULL,
owner_total_raised INT NOT NULL,
owner_other_campaign_urls TEXT NOT NULL, # this may have multiple values...
owner_contribution_count TINYINT NOT NULL,
owner_verified BIT NULL,
# info about team members...
# info about perks...
# info about/meta-analysis of campaign text, images, and videos...
# info about updates...
# info about backers...
crawled_on DATETIME NOT NULL
)
..
owner_name VARCHAR(255) NOT NULL,
owner_title VARCHAR(255) NOT NULL,
owner_description TEXT NULL,
owner_avatar_url VARCHAR(255) NULL,
owner_location VARCHAR(255) NOT NULL,
owner_campaign_count TINYINT NOT NULL,
owner_total_raised INT NOT NULL,
owner_other_campaign_urls TEXT NOT NULL, # this may have multiple values...
owner_contribution_count TINYINT NOT NULL,
owner_verified BIT NULL,
# info about team members...
# info about perks...
# info about/meta-analysis of campaign text, images, and videos...
# info about updates...
# info about backers...
crawled_on DATETIME NOT NULL
)
Примечательно, что я думаю об изоляции разделов, представленных комментариями, поскольку многие из этих разделов могут содержать или не содержать информацию в различных количествах. Кроме того, поля с VARCHAR(255) могут быть другого типа данных.
Поделиться Источник oldboy 17 июля 2018 в 04:26
2 ответа
- Структура базы данных-присоединяться или не присоединяться
Мы разрабатываем структуру базы данных с помощью mySQL Workbench для нового приложения, и количество соединений, необходимых для составления списка данных, резко увеличивается по мере увеличения отношений many-to-many.
Приложение будет довольно тяжелым для чтения и будет иметь пару сотен тысяч… - Эффективная структура базы данных для глубоких древовидных данных
Для очень большой базы данных (более миллиарда строк), где есть очень глубокое дерево данных, какая структура является наиболее эффективной? Загрузка чтения — это самое высокое использование, но есть также изменения в дереве на регулярной основе. Существует несколько стандартных алгоритмов…
 Приложение будет довольно тяжелым для чтения и будет иметь пару сотен тысяч…
Приложение будет довольно тяжелым для чтения и будет иметь пару сотен тысяч…
1
(Частичный ответ)
Сотни колонок, похожих на то, что вы показываете, скорее всего, будут проблематичными. Я рекомендую вам рассмотреть возможность разделения несколькими способами.
- «Team members» звучит как список людей, а не один человек. Итак, это обязательно отдельная таблица, соединенная 1:many. Точно так же «images» звучит как открытый список.
- Относительные статические данные должны (возможно) быть отделены от часто обновляемых данных.
- Выясните, как будет выглядеть ваш
SELECTs. Если некоторые из них смотрят, скажем, на «product» столбца, но не на «owner» столбца, то, вероятно, будет полезно разделить одну группу столбцов или другую.

Сотни, даже миллионы строк в одной таблице-это не проблема. Сотни колонок в одной таблице ступают по тонкому льду.
Слепое использование (255) , скорее всего, укусит вас.
Если вы просматриваете разные сайты, весьма вероятно, что формат и состав данных, которые вы получаете, будут отличаться от сайта к сайту. (Я делал это с новостными сайтами — это работа на полную ставку.)
Нижняя линия: На ваш вопрос нет простого, очевидного ответа. У вас будут проблемы.
Поделиться Rick James 18 июля 2018 в 22:22
0
Придерживайтесь нормализованной схемы. Одна таблица для содержания, которое вы описываете, хороша, если только мы не говорим о каких-то EXTREME объемах данных. IMHO, в последнем случае MySQL был бы не очень хорошим выбором в любом случае.
IMHO, в последнем случае MySQL был бы не очень хорошим выбором в любом случае.
Все просто: создайте одну таблицу, Выберите правильные типы данных, избегайте NULL-способных столбцов (вы упомянули «десятки и десятки столбцов», зачем?) и правильно индексируйте данные. Ты не можешь промахнуться.
Поделиться Boris Schegolev 18 июля 2018 в 12:14
Похожие вопросы:
Лучшая древовидная структура для многомерных данных
Для организации многомерных данных, Какова наиболее полезная и эффективная древовидная структура данных? (например, K-D-B дерево, область квадратичное дерево, R-дерево) Я хочу знать лучшее время…
MySQL Структура Базы Данных Статей?
Я хотел создать базу данных статей для своих пользователей, и мне было интересно, как должна выглядеть моя структура базы данных MySQL? Вот как выглядит моя структура таблиц базы данных до сих пор. …
…
Организация базы данных изображений
Мне любопытно, как я должен организовать хранение изображений в своем приложении. Они будут храниться где-то на диске, а путь / url-в базе данных, но мое приложение стало сложным, и организация…
Структура базы данных-присоединяться или не присоединяться
Мы разрабатываем структуру базы данных с помощью mySQL Workbench для нового приложения, и количество соединений, необходимых для составления списка данных, резко увеличивается по мере увеличения…
Эффективная структура базы данных для глубоких древовидных данных
Для очень большой базы данных (более миллиарда строк), где есть очень глубокое дерево данных, какая структура является наиболее эффективной? Загрузка чтения — это самое высокое использование, но…
Структура базы данных
У меня есть структура базы данных в следующем формате, таблица предметов subject_id subject_name 1 HTML 2 Java главам таблица chapter_id chapter_name subject_id 1 Doctype 1 2 Intro to Java 2 таблица. ..
..
Redmine-Структура Базы Данных / Нормализация
Я использую redmine для управления проектами и отслеживания проблем. Я смотрел на таблицы базы данных и лежащую в их основе структуру и задавался вопросом, Может ли кто-нибудь, кто имеет опыт работы…
Docker файлы базы данных: внутри или снаружи контейнера?
Мы изучаем возможность внедрения системы баз данных Oracle с использованием Docker на нашем сервере и рассматриваем две различные стратегии управления нашими данными: Хранение файлов базы данных (….
Безопасное хранение учетных данных безопасности базы данных в PHP
Безопасно ли хранить учетные данные базы данных на один относительный уровень выше в структуре каталогов ( ../dbconn_inc.php )? У нас есть базовая учетная запись общего хостинга через GoDaddy,…
Настраиваемая структура базы данных структура базы данных WordPress
У меня есть пользовательская структура базы данных, подобная этой Почта -сообщения дан -пост -categoryid Категория -categoryid -имя как сделать его wordpress постом и категорией ? это похоже на. ..
..
SPJ Россия / Статьи / База знаний / SAPLand — Мир решений SAP
Изучите технические спецификации для пользовательского инструмента синхронизации структуры организации и структуры бюджета для организаций, использующих функции бюджетирования SAP Enterprise Compensation Management в рамках управления компенсациями. Вы научитесь:
Создавать программу для выполнения сценариев создания, перемещения и ограничения
Выполнять проектирование на высоком уровне, а также создавать псевдокод программы
Описывать используемые функциональные модули, классы, таблицы, коды отношений и сообщения
Ключевое понятие
Структура бюджета состоит из единицы бюджета с видом бюджета, который определяет структуру, например, компанию или отдел. Иногда сотрудникам выплачивается вознаграждение сверх обычной заработной платы в качестве поощрения за определенные достижения или в целях мотивации. Администрирование такой компенсации осуществляется путем определения единицы бюджета. Бюджетирование предоставляет механизм контроля для управления вознаграждением в SAP Enterprise Compensation Management.
Бюджетирование предоставляет механизм контроля для управления вознаграждением в SAP Enterprise Compensation Management.
Структура организации постоянно изменяется. Система SAP Enterprise Compensation Management (ECM), в которой применяется интерфейс информационного сервиса для менеджера (MSS), позволяет разрабатывать и контролировать подробные бюджеты на основе данных организационной иерархии. Помимо структуры бюджета также существует структура организации. Структура бюджета создается на основе структуры организации за период и несет в себе информацию о бюджете. После создания изменить структуру бюджета невозможно. Можно создать новую структуру бюджета, но внести изменения – нет. Структура бюджета отражает организационную структуру на момент создания с видами бюджета и периодами. Структура бюджета состоит из единиц бюджета.
Различные факторы в организации могут вызывать сбои, влияющие на организационную структуру, в результате чего происходит изменение существующих или создание новых иерархий: изменения в организационной структуре, добавление нового отдела, перемещение сотрудника или менеджера внутри организационной структуры и т. д. Однако на структуру бюджета такие изменения не влияют.
д. Однако на структуру бюджета такие изменения не влияют.
В стандартной SAP-системе невозможно синхронизировать организационную структуру и структуру бюджета. Более того, администраторы и пользователи HR заметили, что это влияет на отчетность в ряде областей: планирование вознаграждений, анализ и взаимодействие менеджеров с сотрудниками. Здесь рассматривается процедура создания инструментального средства на базе ABAP, которое работает только с системами ECM и предназначено для процесса пересмотра размера окладов. С его помощью можно разрешить следующую ситуацию: Процесс пересмотра зарплаты настроен для года с января по декабрь. На основе организационной структуры в январе 2012 была создана структура бюджета. Далее бюджет был присвоен каждому отделу и всем менеджерам. В определенный момент в 2012 году организационная структура изменилась, допустим, был создан новый отдел. Необходимо соответствующим образом обновить сумму бюджета.
Динамические структуры данных. Организация данных в списковые структуры 3, Программирование
Пример готовой курсовой работы по предмету: Программирование
Содержание
Оглавление
Введение 2
Глава 1.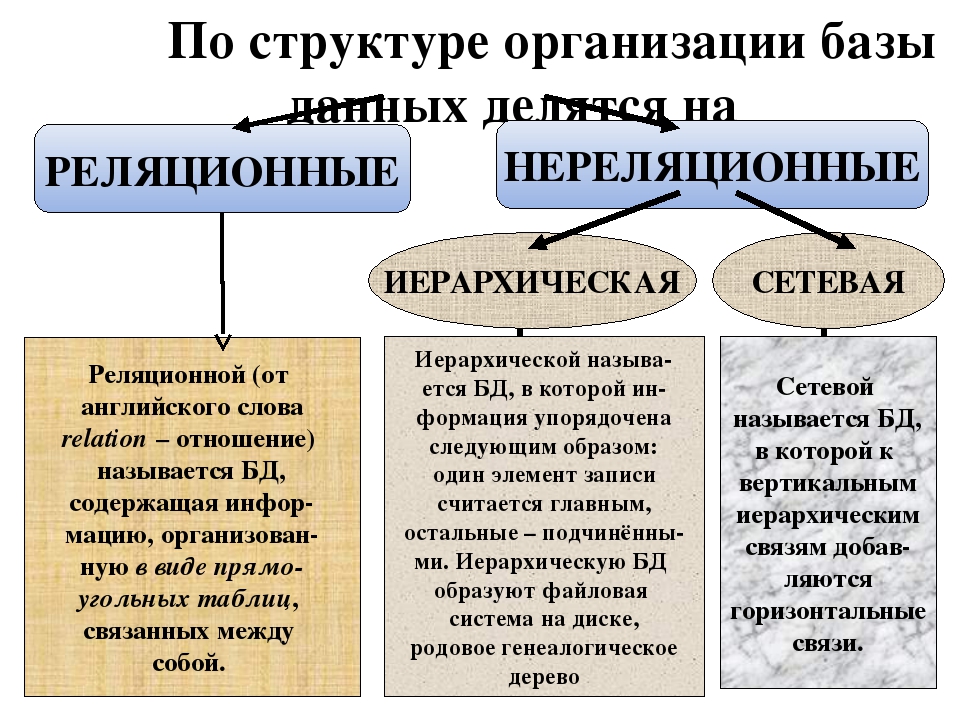 Динамические структуры данных 4
Динамические структуры данных 4
1.1 Общие понятия и определения динамических структур данных 4
1.2 Объявление динамических структур данных 10
Глава
2. Организация данных в списковые структуры 15
1. Однонаправленные (односвязные) списки 16
2. Двунаправленные (двусвязные) списки 25
ЗАКЛЮЧЕНИЕ 36
СПИСОК ЛИТЕРАТУРЫ 38
Приложение 1 39
Выдержка из текста
Введение
Актуальность выбранной темы. Актуальность выбранной для исследования очевидна. В наше время, когда информация имеет огромное значение, научиться правильно с ней работать и использовать различные инструменты для этой работы становиться архиважным. Компьютер, сейчас является универсальным помощником человеку во всех сферах деятельности. Использование динамических величин предоставляет целый ряд возможностей. Привлечение динамической памяти позволяет увеличить объем обрабатываемых данных. Если потребность в каких-то данных отпала до окончания программы, то занятую ими память можно освободить для другой информации.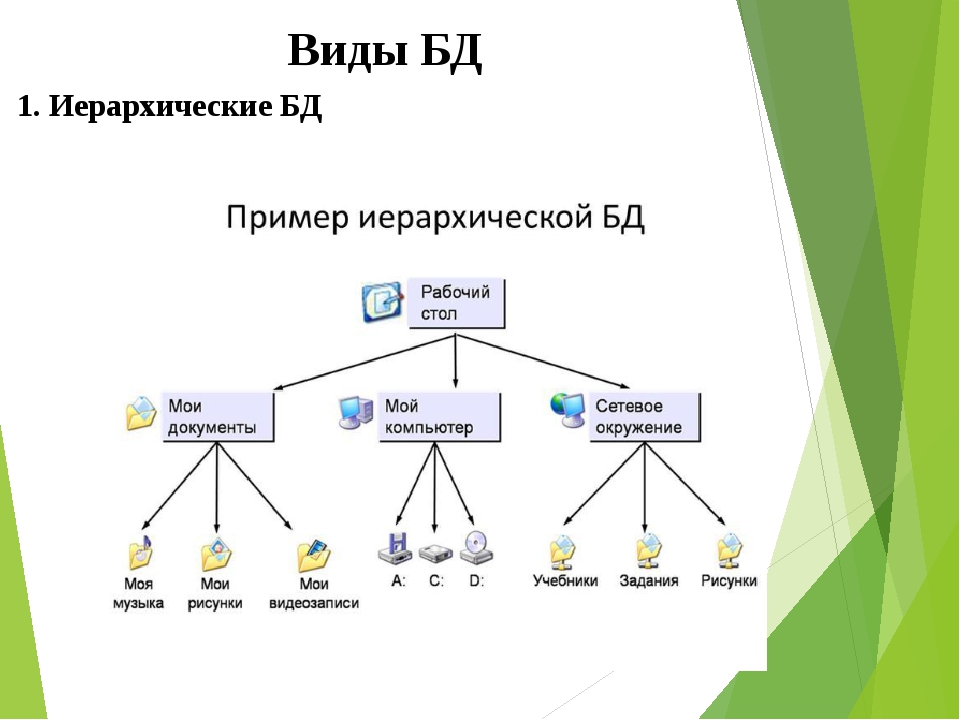 Использование динамической памяти позволяет создавать структуры данных переменного размера.
Использование динамической памяти позволяет создавать структуры данных переменного размера.
Важность использования динамических структур данных так же обусловлена необходимостью хранения большого объема данных во время разработки приложений.
Бывают случаи, когда до начала работы с данными нет возможности определить, какое количество памяти потребуется для их хранения. Что заставляет программистов, выделять память «с запасом». Но, даже «запас» ограничен, и кто может гарантировать, что и его будет достаточно. В тоже время, с другой стороны, «запаса» может хватить настолько, что большая часть отведенной программе памяти будет занята напрасно.
Данные проблемы решает такой тип хранения данных как динамический список. Компоненты добавляются и удаляются во время выполнения программы, и их количество зависит исключительно от размера доступной памяти. Тем не менее, за это преимущество приходится расплачиваться недостатком — в один момент времени нам доступны максимум 3 компонента.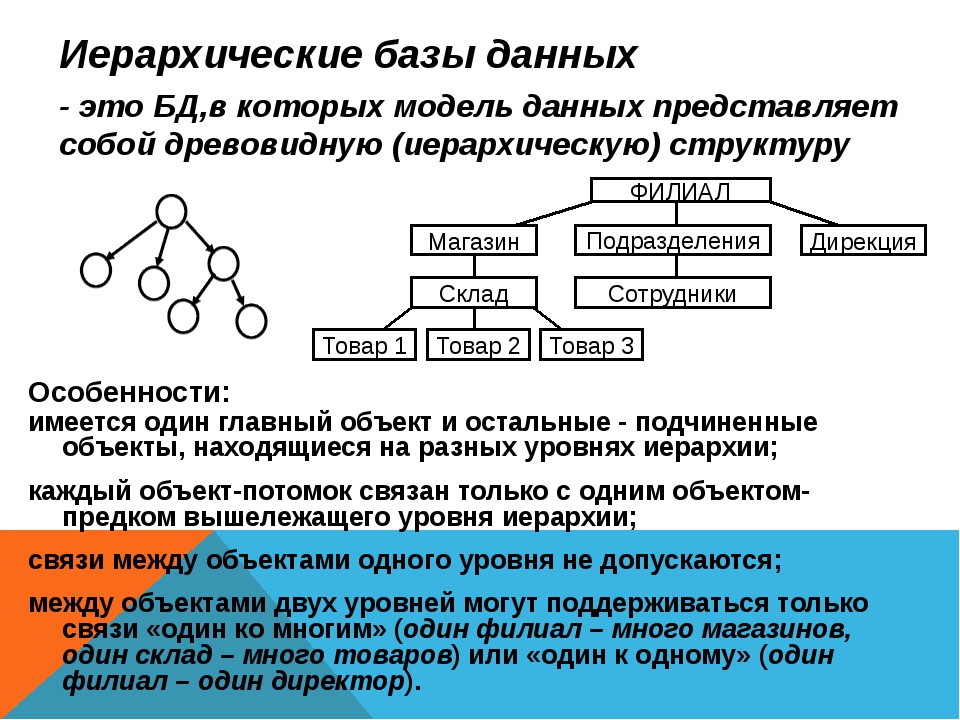
Память в программах где используются динамические структуры данных, следует распределять во время выполнения программы и по мере нужности отдельными блоками. Блоки нужно связывать друг с другом с помощью указателей. Динамическая структура данных это способ организации данных при котором структура данных размещается в динамической памяти и ее размер изменяется во время выполнения программы.
Теоретические основы организации динамических структур данных описаны в работах следующих авторов Кнут Д., Грисс Д., Танненбаум Э., Цикритзис Д., Бернстайн Ф., Bays С.А., Fenton I.S, Paim P.W., Campbell I.A., Shore J. и др.
Объектом исследования данной курсовой работы являются динамические структуры данных. Исследуются их виды, преимущества и недостатки.
Предметом исследования является организация данных в списковые структуры. Описываются способы объявления и алгоритмы создания при написании программ.
Цель курсовой работы: изучить понятия, классификацию, объявления и особенности доступа к данным в динамических структурах, работу с памятью при использовании структур в программе, а также понятия, классификацию и объявление списков, особенности доступа к данным и работу с памятью при использовании однонаправленных и двунаправленных списков, научиться решать задачи с использованием списков на языке C.
В языке C имеются средства создания динамических структур данных, которые позволяют во время выполнения программы образовывать объекты, выделять для них память, освобождать память, когда в них исчезает нужность.
Понятие списка хорошо известно из жизненных примеров: список студентов учебной группы, список призёров олимпиады, список документов для представления в приёмную комиссию, список почтовой рассылки, список литературы для самостоятельного чтения и т.п.
Для того чтобы изучение данной темы было успешным и для закрепления полученных данных необходимо решить ряд задач: рассмотреть основные понятия и определения динамических структур данных, способы их объявления, инициализацию динамических структур, методы доступа к данным динамических структур, размещение их в памяти, преимущества и недостатки использования динамических структур в программах. Во второй главе курсовой работы мы ознакомимся с определениями и видами списков, структурой и способами объявления однонаправленных и двунаправленных списков, основными операциями над элементами списков.
Так же в курсовой работе приведены примеры решения несложных задач, с целью продемонстрировать работу с динамическими списками.
Список использованной литературы
СПИСОК ЛИТЕРАТУРЫ
1. Айен Синклер «Большой толковый словарь компьютерных терминов», М.: 1998 г.
2. Архангельский А. Я. «Программирование в Delphi 4», М.: 1999 г.
3. Архангельский А. Я. «Программирование в C++», М.: 2000 г.
4. Бабушкина И.А., Бушмелева Н.А., Окулов С.М., Черных С.Ю. Конспекты по информатике. – Киров, 1997.
5. Вирт Н. «Алгоритмы и структуры данных», Москва Изд. Мир, 1989 г.
6. Вирт Н., Алгоритм + структура данных = программа.
7. Давыдов В.Г. Программирование и основы алгоритмизации.2-е изд., стер. — М.:Высш.шк.,2005.-447 с.: ил. ISDN 5-06-004432-7.
8. Грэхем Р., Кнут Д., Паташник О. Конкретная информатика. – М.: Мир, 1988.
9. Гудмэн Д. «Управление памятью для всех», Киев 1995 г.
10. Зубов В. С.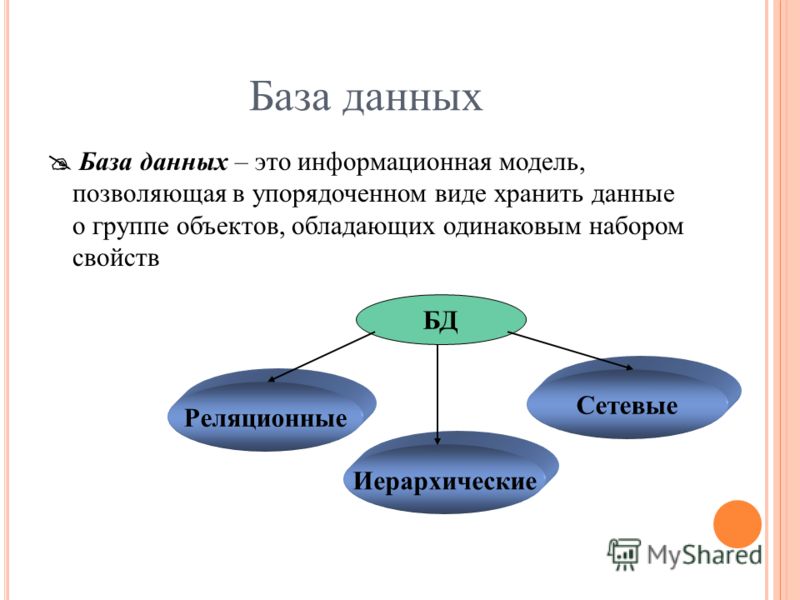 «Справочник программиста», М.: 1999 г.
«Справочник программиста», М.: 1999 г.
11. Информатика и образование, № 5 – 1999 г.
12. Кнут Д. «Искусство программирования для ЭВМ», т.1 Основные алгоритмы, Изд. Мир М.: 1976 г.
13. Кормен Т. и другие «Алгоритмы построения и анализ», М.: 2000 г.
14. Культин Н. Б. C++ Builder в задачах и примерах. Издательство Санкт-Петербург ХВ-Петербург. 2005 г.
15. Мюррей У., Паллас К. «VisualC++», М: BHV, 1996
16. Подласый И. П. Учебник для студентов высших педагогических учебных заведений, М.: Просвещение 1996 г.
17. Райнтли, Абстракция и структура данных.
18. Усова А. В. «Формирование у школьников понятий в процессе обучения», М.: Педагогика, 1986 г.
19. Уэйт М., Прата С. «Язык Си», М: МИР, 1988
20. Хабибуллин И.Ш. Программирование C++: Пер. с англ. — 3-е изд. — СПб.: БХВ-Петербург, 2006. — 512 с.
Ведение иерархической структуры организации > Добавление подразделений в структуру организации
В системе существует несколько способов добавления подразделения в структуру организации.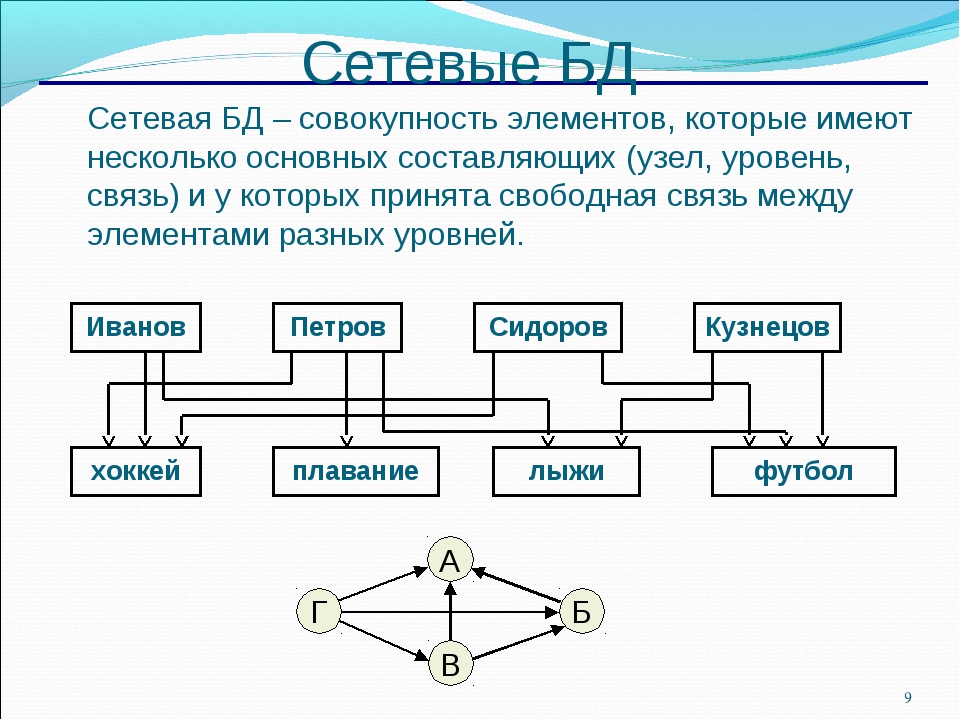
1. Добавление нового подразделения
Для добавления подразделения в структуру организации необходимо выбрать пункт меню Организация/Структура организации, в левой части открывшегося окна выбрать родительское подразделение, для которого будет добавлено новое подразделение, и нажать кнопку — Добавить. Пользователь имеет возможность создать новое подразделение в базе данных или выбрать уже существующее подразделение из другой структуры организации. Для создания нового подразделения необходимо выбрать закладку Новое подразделение.
Наименование подразделения — полное наименование подразделения, поле является обязательным для заполнения.
Краткое наименование подразделения — сокращённое наименование подразделения, поле является обязательным для заполнения.
Признак условного подразделения — позволяет создавать узлы, которые предназначены для формирования целостности структуры иерархических отношений подразделений. Условное подразделение отличается от структурного подразделения тем, что для него не может быть задан шаблон описания подразделения.
Шаблон описания подразделения — выбирается шаблон описания подразделения из списка существующих шаблонов описания. Выбор шаблона не является обязательным при регистрации нового подразделения.
2. Добавление существующего подразделения
Для добавления существующего подразделения в структуру организации из других структур организации необходимо выбрать закладку Выбрать существующее.
Структура — выбирается структура организации, из которой будет выбрано подразделение (в список не попадает текущая структура). Структура организации отображается с учётом разграничения доступа пользователя к конкретной структуре.
В выбранной структуре необходимо отметить подразделение, которое будет добавлено в текущую структуру.
После ввода данных необходимо подтвердить создание подразделения нажатием кнопки . После закрытия диалога новый узел будет отображён в текущей структуре организации.
3. Добавление нового подразделения путём копирования существующего
Необходимо выделить подразделение, копию которого необходимо создать в структуре, нажать правой кнопкой мыши и в контекстном меню выбрать «Создать копию организации с параметрами».
Откроется диалоговое окно «Копирование организации со всеми параметрами». По-умолчанию, в наименовании подразделения будет приписано «копия», для идентификации нового подразделения в структуре.
После нажатия кнопки , в структуре появится новое подразделение.
После добавления нового подразделения в структуру, необходимо сохранить изменения, нажав кнопку
Структура и органы управления образовательной организацией
Школа как многообразный живой организм немыслима без управляющей подсистемы. Системный характер нововведений, обеспечивший перевод целого ряда учебно-образовательных учреждений в качественно новое состояние, требует соответствующей реорганизации управления, а именно переход от командно-административной системы управления к горизонтальной системе профессионального сотрудничества, от функционирования — к развитию и саморазвитию управления педагогической системой.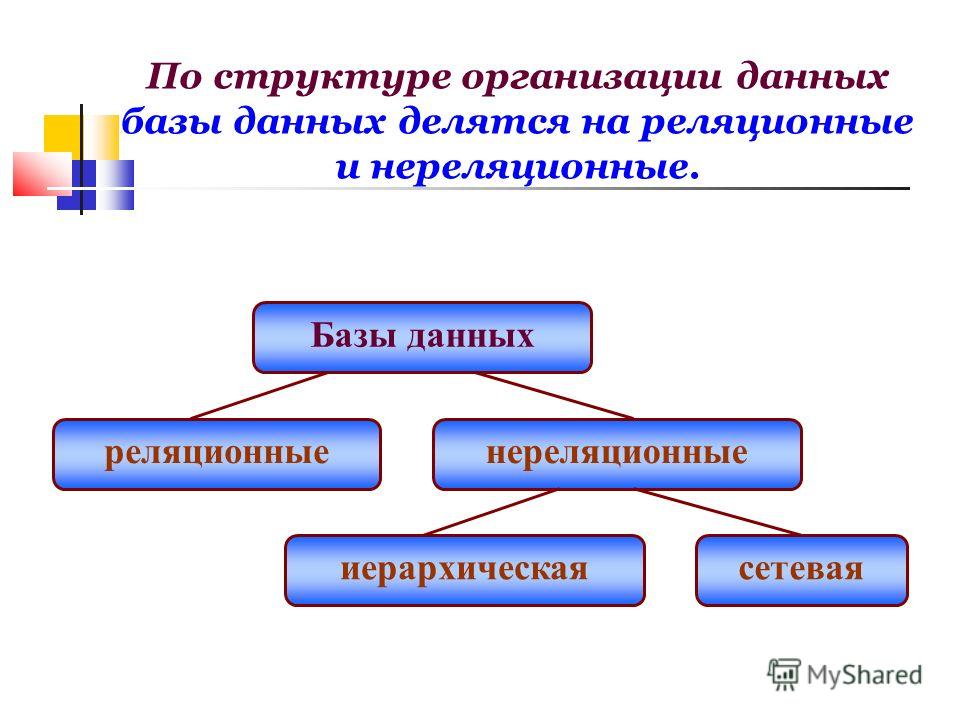
Линейно-функциональная структура управления школой.
Эта схема управления школой объединяет черты двух организационных моделей: наравне с линейной иерархией предусмотрено функционирование административных подразделений, уполномоченных влиять на общие показатели деятельности школы и вместе с тем отвечающих за определенные функции (управляющий совет, методический совет). Сильной стороной линейно-функциональной структуры является обеспечение принципов гласности, справедливости, равноправия, а основные риски заключается в возможности утраты четкости целевых установок из-за необходимости согласования стратегического решения с различными комитетами и внесения многочисленных правок для удовлетворения пожелания широкого круга поставщиков и потребителей образовательных услуг.
В школе используется четырехуровневая структура управления, в которой каждый наглядно видит свое место в иерархии управления и других ее субъектов, и понимает принципы и механизмы действия, связи и отношения между входящими в ее состав компонентами.
Первый уровень — (высший) в структуре занимают директор (Сухова Наталья Викторовна) учреждения и полномочные коллегиальные органы:
— общее собрание работников учреждения,
-управляющий совет школы,
— педагогический совет.
Второй уровень — представлен заместителями директора учреждения и такими службами, как методический совет, бухгалтерия, отдел кадров, библиотека, социально-психологическая служба.
Третий уровень — уровень руководителя методических объединений, временных творческих групп, учителей-предметников, организатора по внеклассной работе и других педагогических объединений.
Четвертый уровень — занимают ученический актив и подструктура самоуправления.
Каждой ступени отводится то или иное место не в соответствии со значительностью или значимостью субъектов, а по принципу их взаимодействия, подчиненности и соподчиненности, что объясняет некоторую условность принадлежности управленца к определенному уровню и что создает возможность различных модификаций структуры в зависимости от особенностей и статуса образовательного учреждения.
Уровни управления линейно-функциональной структуры рассмотрены ниже в таблице.
Уровни управления | Управленцы и их обязанности |
Первый | Руководитель МБОУ СОШ № 30 — главное управленческое лицо, несущее личную ответственность за порядок реализации всех видов деятельности в школе — от качества предоставления образовательных услуг до обеспечения условий по охране жизни и здоровья учеников и педагогов. Директор единолично отчитывается перед представителями вышестоящих организаций и находится в непосредственном подчинении учредителя. В первый уровень управления также входят органы, наравне с директором определяющие стратегические пути развития МБОУ СОШ № 30: Управляющий совет школы; Педагогический совет. Эти объединения наравне с руководителем представляют интересы учреждения в государственных и общественных организациях. |
Второй | В непосредственной подчиненности у директора находятся заместители (по административно-хозяйственной и учебно-воспитательной работе). Также в этот уровень подчиненности включены сотрудники, которые входят в сферу влияния управляющего или педагогического совета — члены методического совета, бухгалтерия, отдел кадров, библиотека, социально-психологическая служба. Задача заместителей и специалистов — обеспечение реализации целей и задач, озвученных директором школы, с их разбивкой на более мелкие задания, последующим делегированием полномочий и контролем выполнения, т.е. осуществление тактического выполнения стратегических целей администрации МБОУ СОШ № 30. |
Третий | Третий уровень структуры школы — оперативного управления — представляют педагоги, в т.ч. члены методических объединений и специальных служб. (МОП) |
Четвертый | Четвертую управленческую ступень представляет ученический коллектив. |
 Стратегически значимую позицию занимает Общее собрание трудового коллектива МБОУ СОШ № 30, определяющее Программу развития. Вместе с тем только директор несет персональную административную и юридическую ответственность за слаженность работы учреждения, безопасность педагогического коллектива и учеников.
Стратегически значимую позицию занимает Общее собрание трудового коллектива МБОУ СОШ № 30, определяющее Программу развития. Вместе с тем только директор несет персональную административную и юридическую ответственность за слаженность работы учреждения, безопасность педагогического коллектива и учеников. 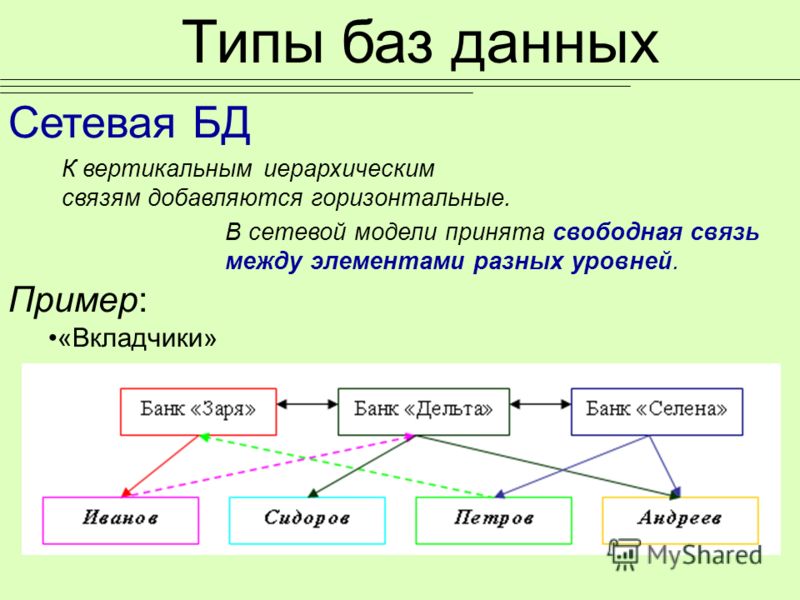
Особенности организации структуры управления школой
В связи с организационными особенностями структура управления современной школой, объединяющая административные органы разного типа, требует пояснений по каждому из звеньев.
Непосредственное управление образовательной организацией осуществляет руководитель (директор), прошедший процедуру аттестации и утвержденный учредительным органом. Круг ответственности директора составляют непосредственные управленческие обязанности, направленные на улучшение показателей образовательного процесса и эффективности педагогической работы, последовательное улучшение условий образования, обеспечения в учреждении норм противопожарной и антитеррористической безопасности. Стратегическое управление наравне с руководителем осуществляют самоуправленческие организации — управленческий, педагогический и методические советы, круг полномочий которых регламентируется актуальными нормативно-правовыми нормами и локальными актами школы, а также ученический совет, функционирующий на правах соуправления.
Стратегическое управление наравне с руководителем осуществляют самоуправленческие организации — управленческий, педагогический и методические советы, круг полномочий которых регламентируется актуальными нормативно-правовыми нормами и локальными актами школы, а также ученический совет, функционирующий на правах соуправления.
Формы школьного самоуправления | Особенности функционирования и круг полномочий |
Управляющий совет школы | Совет школы — высший коллегиальный орган ОУ, создание которого обосновано ФЗ № 273-ФЗ «Об образовании в РФ». Создание такой структуры в управленческой модели школы обеспечивает возможность реализации государственно-общественного порядка руководства, поскольку состав Совета формируют представители родительской общественности, ученического коллектива, педагогов (в равном количестве представителей). 1.Утверждение плана стратегического развития ОУ. 2.Представление интересов школы совместно с директором в государственных органах, общественных организациях с целью улучшения учебно-воспитательных условий, защиты прав несовершеннолетних, обеспечения материально-технических условий для удовлетворения широкого круга образовательных потребностей школьников. 3. Определение содержания, методов, средств и приемов организации образовательного процесса с учетом требований школьного методического совета и государственных нормативов. 4.Утверждение режима работы школы. 5.Поддержание административных и общественных инициатив, направленных на улучшение условий школьной жизни, совершенствованию показателей учебно-воспитательного процесса. 6.Мониторинг процесса расходования бюджетных средств, реализация инициатив по созданию собственного материально-технического фонда организации. 7.Заслушивание отчетов представителей школьной администрации, школьных методистов, учителей, при возникновении спорных ситуаций — принятие решений о продлении или окончании их полномочий. 8.Защищает сотрудников школы от необоснованного вмешательства в их профессиональную деятельность и предупреждение препятствованию выполнению ими должностных обязанностей. Функционирование школьного совета осуществляется в тесном сотрудничестве со школьной администрацией с соблюдением принципов толерантности, взаимоуважения и гласности, что реализуется через поиск компромисса при возникновении спорных ситуаций и широкое оповещение общественности о принятых решениях. |
Педагогический совет | Педагогический совет, в который входят все учителя школы, является консультативным органом, на который возложены функции координации методико-педагогической работы в ОУ. Педагогический совет уполномочен: 1.Координировать деятельность школьных методобъединений. 2. Разрабатывать новые направления и формы методической работы в ОУ. 3.Решать вопросы методического обеспечения, утверждать измененные, адаптированные и авторские учебные программы, разработанные учителями школы дидактические и наглядные пособия. 4. Организовывать проектную, исследовательскую, новаторскую педагогическую деятельность. 5.Обеспечивать систематическое консультирование педработников, особенно молодых специалистов, по вопросам пополнения личной методической копилки и повышения профессионального уровня, подготовки к аттестационному оцениванию. 6.Разработка и проведение мероприятий по распространению передового педагогического опыта. 8.Контроль внедрения передовых педагогический технологий в учебно-воспитательный процесс. |
Общее собрание трудового коллектива | Общее собрание трудового коллектива в структуре органов управления школой занимает особое место, поскольку его состав формируют все сотрудники учреждения без исключения. Заседание собрания считается правомочным при условии участия более половины работников школы и присутствия представителей профсоюзного органа. Решения принимаются путем отрытого голосования большинства членов собрания. В круг компетенций Общего собрания трудового коллектива входит: 1.Рассмотрение и утверждение Устава ОУ, а также дополнений и уточнений к этому локальному документу. |
Ученический совет | Школьный ученический совет — исполнительный орган самоуправлений, который выбирается сроком на год из числа наиболее инициативных, ответственных и дисциплинированных учащихся 5-11 классов. 1.Оказание посильной помощи педагогам и сотрудникам ОУ в вопросах обеспечения оптимальных условий ведения образовательного процесса. 2.Подготовка, организация и проведение мероприятий трудового, социально-коммуникативного, общественно полезного, экологического воспитания. 3.Участие в подготовке и проведении предметных олимпиад, конкурсов, творческих вечеров, торжественных линеек. 4. Контроль ученического самообслуживания в школе. |
 Функции Совета школы носят стратегический характер, к их числу относится:
Функции Совета школы носят стратегический характер, к их числу относится:
 Собрания органа созываются по мере необходимости (но не реже одного раза в четверть), решения принимаются путем голосования большинства (при условии присутствия на заседании не менее двух третей от общего числа педагогов).
Собрания органа созываются по мере необходимости (но не реже одного раза в четверть), решения принимаются путем голосования большинства (при условии присутствия на заседании не менее двух третей от общего числа педагогов).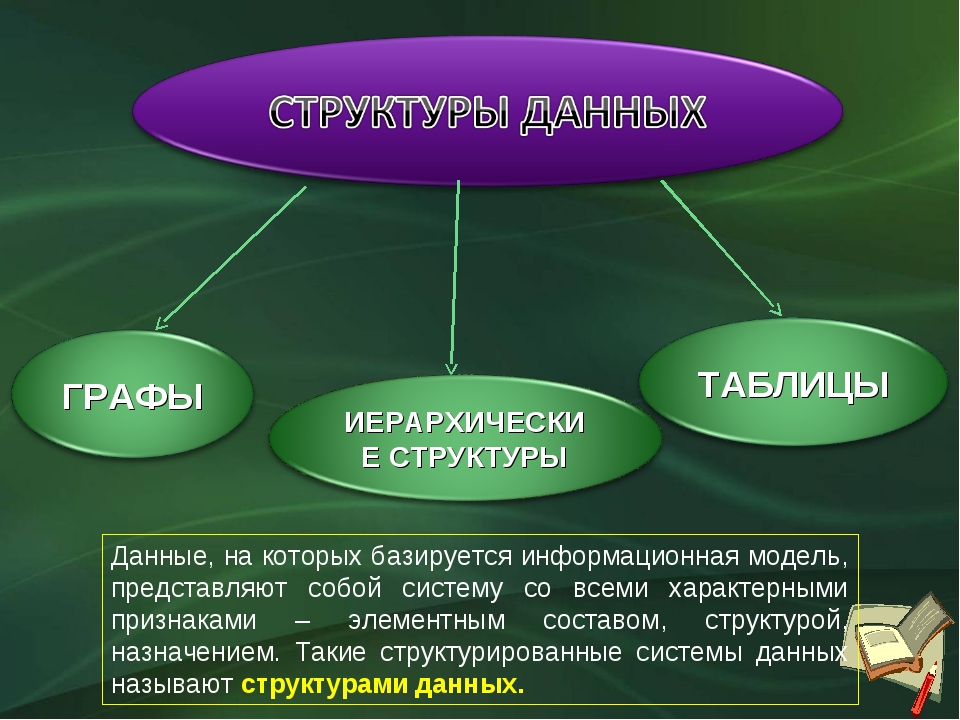 7.Налаживание связей с ведущими педагогами из других образовательных учреждений.
7.Налаживание связей с ведущими педагогами из других образовательных учреждений.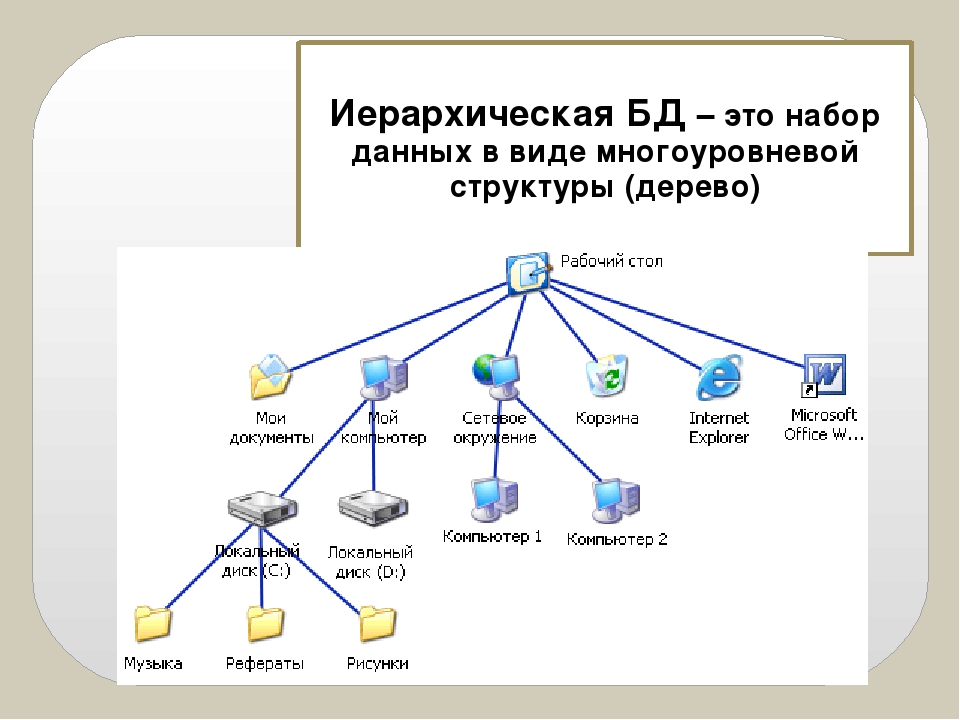 Полномочия ученического совета:
Полномочия ученического совета:Мы используем систему планирования, которая называется цикловым планированием. Она помогает нам управлять учебно-воспитательным процессом. При таком планировании значительно легче предусмотреть использование новых педагогических и информационных технологий в логике учебного процесса, заранее продумать общую стратегию и предусмотреть все необходимое для ее осуществления.
Алгоритм циклового планирования прост: исходя из своих функциональных обязанностей, администратор определяет, что ему придется делать один раз в год, в полгода, в триместр, в месяц, в неделю. Таким образом, складывается общая картина управленческих действий. Далее определяются связи: вертикальные — перед кем отчитываешься или на кого направлены твои управленческие действия, горизонтальные — с кем будешь сотрудничать, выполняя часть поставленной задачи сугубо по собственному функционалу или делегированному директором. Последнее, что необходимо решить в частоте управленческих действий — это время исполнения. Таким образом, управленец уже может видеть, насколько он в состоянии управлять своей подсистемой, насколько обеспечил ее функционирование и развитие. Нам наиболее удобна циклограмма работы по месяцам: циклограмма работы и распределения обязанностей между руководителями подразделений учреждения, ежемесячные совещания при директоре, циклограмма заместителя директора по УВР, циклограмма совещаний при завуче, календарный план работы школы.
Таким образом, складывается общая картина управленческих действий. Далее определяются связи: вертикальные — перед кем отчитываешься или на кого направлены твои управленческие действия, горизонтальные — с кем будешь сотрудничать, выполняя часть поставленной задачи сугубо по собственному функционалу или делегированному директором. Последнее, что необходимо решить в частоте управленческих действий — это время исполнения. Таким образом, управленец уже может видеть, насколько он в состоянии управлять своей подсистемой, насколько обеспечил ее функционирование и развитие. Нам наиболее удобна циклограмма работы по месяцам: циклограмма работы и распределения обязанностей между руководителями подразделений учреждения, ежемесячные совещания при директоре, циклограмма заместителя директора по УВР, циклограмма совещаний при завуче, календарный план работы школы.
Array
(
[PRICES] => Array
(
)
[PRICE_MATRIX] =>
[MIN_PRICE] =>
[ID] => 561
[~ID] => 561
[IBLOCK_ID] => 40
[~IBLOCK_ID] => 40
[CODE] => pologenie-ob-obem-sobranii
[~CODE] => pologenie-ob-obem-sobranii
[XML_ID] => 561
[~XML_ID] => 561
[NAME] => Положение об общем собрании работников
[~NAME] => Положение об общем собрании работников
[ACTIVE] => Y
[~ACTIVE] => Y
[DATE_ACTIVE_FROM] =>
[~DATE_ACTIVE_FROM] =>
[DATE_ACTIVE_TO] =>
[~DATE_ACTIVE_TO] =>
[SORT] => 10
[~SORT] => 10
[PREVIEW_TEXT] =>
[~PREVIEW_TEXT] =>
[PREVIEW_TEXT_TYPE] => text
[~PREVIEW_TEXT_TYPE] => text
[DETAIL_TEXT] =>
[~DETAIL_TEXT] =>
[DETAIL_TEXT_TYPE] => text
[~DETAIL_TEXT_TYPE] => text
[DATE_CREATE] => 11. 03.2019 17:58:53
[~DATE_CREATE] => 11.03.2019 17:58:53
[CREATED_BY] => 1
[~CREATED_BY] => 1
[TAGS] =>
[~TAGS] =>
[TIMESTAMP_X] => 11.03.2019 20:53:28
[~TIMESTAMP_X] => 11.03.2019 20:53:28
[MODIFIED_BY] => 1
[~MODIFIED_BY] => 1
[IBLOCK_SECTION_ID] => 100
[~IBLOCK_SECTION_ID] => 100
[DETAIL_PAGE_URL] => /documents/detail.php?ID=561
[~DETAIL_PAGE_URL] => /documents/detail.php?ID=561
[DETAIL_PICTURE] =>
[~DETAIL_PICTURE] =>
[PREVIEW_PICTURE] =>
[~PREVIEW_PICTURE] =>
[LANG_DIR] => /
[~LANG_DIR] => /
[EXTERNAL_ID] => 561
[~EXTERNAL_ID] => 561
[IBLOCK_TYPE_ID] => documents
[~IBLOCK_TYPE_ID] => documents
[IBLOCK_CODE] => new-documents
[~IBLOCK_CODE] => new-documents
[IBLOCK_EXTERNAL_ID] =>
[~IBLOCK_EXTERNAL_ID] =>
[LID] => s1
[~LID] => s1
[ACTIVE_FROM] =>
[ACTIVE_TO] =>
[IPROPERTY_VALUES] => Array
(
)
[PRODUCT] => Array
(
[TYPE] =>
[AVAILABLE] =>
[MEASURE] =>
[VAT_ID] =>
[VAT_RATE] =>
[VAT_INCLUDED] =>
[QUANTITY] =>
[QUANTITY_TRACE] =>
[CAN_BUY_ZERO] =>
[SUBSCRIPTION] =>
[BUNDLE] =>
)
[PROPERTIES] => Array
(
)
[DISPLAY_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES_FILL] => Array
(
)
[OFFERS] => Array
(
)
[OFFER_ID_SELECTED] => 0
[ITEM_PRICE_MODE] =>
[ITEM_PRICES] => Array
(
)
[ITEM_QUANTITY_RANGES] =>
[ITEM_MEASURE_RATIOS] =>
[ITEM_MEASURE] => Array
(
)
[ITEM_MEASURE_RATIO_SELECTED] =>
[ITEM_QUANTITY_RANGE_SELECTED] =>
[ITEM_PRICE_SELECTED] =>
[CAN_BUY] =>
[EDIT_LINK] =>
[DELETE_LINK] =>
[SECTION] => Array
(
[PATH] => Array
(
)
)
[~BUY_URL] => /about/structure/?action=BUY&id=561
[BUY_URL] => /about/structure/?action=BUY&id=561
[~ADD_URL] => /about/structure/?action=ADD2BASKET&id=561
[ADD_URL] => /about/structure/?action=ADD2BASKET&id=561
[~SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=561
[SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=561
[CATALOG_MEASURE_NAME] =>
[~CATALOG_MEASURE_NAME] =>
[CATALOG_MEASURE_RATIO] =>
)
 03.2019 17:58:53
[~DATE_CREATE] => 11.03.2019 17:58:53
[CREATED_BY] => 1
[~CREATED_BY] => 1
[TAGS] =>
[~TAGS] =>
[TIMESTAMP_X] => 11.03.2019 20:53:28
[~TIMESTAMP_X] => 11.03.2019 20:53:28
[MODIFIED_BY] => 1
[~MODIFIED_BY] => 1
[IBLOCK_SECTION_ID] => 100
[~IBLOCK_SECTION_ID] => 100
[DETAIL_PAGE_URL] => /documents/detail.php?ID=561
[~DETAIL_PAGE_URL] => /documents/detail.php?ID=561
[DETAIL_PICTURE] =>
[~DETAIL_PICTURE] =>
[PREVIEW_PICTURE] =>
[~PREVIEW_PICTURE] =>
[LANG_DIR] => /
[~LANG_DIR] => /
[EXTERNAL_ID] => 561
[~EXTERNAL_ID] => 561
[IBLOCK_TYPE_ID] => documents
[~IBLOCK_TYPE_ID] => documents
[IBLOCK_CODE] => new-documents
[~IBLOCK_CODE] => new-documents
[IBLOCK_EXTERNAL_ID] =>
[~IBLOCK_EXTERNAL_ID] =>
[LID] => s1
[~LID] => s1
[ACTIVE_FROM] =>
[ACTIVE_TO] =>
[IPROPERTY_VALUES] => Array
(
)
[PRODUCT] => Array
(
[TYPE] =>
[AVAILABLE] =>
[MEASURE] =>
[VAT_ID] =>
[VAT_RATE] =>
[VAT_INCLUDED] =>
[QUANTITY] =>
[QUANTITY_TRACE] =>
[CAN_BUY_ZERO] =>
[SUBSCRIPTION] =>
[BUNDLE] =>
)
[PROPERTIES] => Array
(
)
[DISPLAY_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES_FILL] => Array
(
)
[OFFERS] => Array
(
)
[OFFER_ID_SELECTED] => 0
[ITEM_PRICE_MODE] =>
[ITEM_PRICES] => Array
(
)
[ITEM_QUANTITY_RANGES] =>
[ITEM_MEASURE_RATIOS] =>
[ITEM_MEASURE] => Array
(
)
[ITEM_MEASURE_RATIO_SELECTED] =>
[ITEM_QUANTITY_RANGE_SELECTED] =>
[ITEM_PRICE_SELECTED] =>
[CAN_BUY] =>
[EDIT_LINK] =>
[DELETE_LINK] =>
[SECTION] => Array
(
[PATH] => Array
(
)
)
[~BUY_URL] => /about/structure/?action=BUY&id=561
[BUY_URL] => /about/structure/?action=BUY&id=561
[~ADD_URL] => /about/structure/?action=ADD2BASKET&id=561
[ADD_URL] => /about/structure/?action=ADD2BASKET&id=561
[~SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=561
[SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=561
[CATALOG_MEASURE_NAME] =>
[~CATALOG_MEASURE_NAME] =>
[CATALOG_MEASURE_RATIO] =>
)
03.2019 17:58:53
[~DATE_CREATE] => 11.03.2019 17:58:53
[CREATED_BY] => 1
[~CREATED_BY] => 1
[TAGS] =>
[~TAGS] =>
[TIMESTAMP_X] => 11.03.2019 20:53:28
[~TIMESTAMP_X] => 11.03.2019 20:53:28
[MODIFIED_BY] => 1
[~MODIFIED_BY] => 1
[IBLOCK_SECTION_ID] => 100
[~IBLOCK_SECTION_ID] => 100
[DETAIL_PAGE_URL] => /documents/detail.php?ID=561
[~DETAIL_PAGE_URL] => /documents/detail.php?ID=561
[DETAIL_PICTURE] =>
[~DETAIL_PICTURE] =>
[PREVIEW_PICTURE] =>
[~PREVIEW_PICTURE] =>
[LANG_DIR] => /
[~LANG_DIR] => /
[EXTERNAL_ID] => 561
[~EXTERNAL_ID] => 561
[IBLOCK_TYPE_ID] => documents
[~IBLOCK_TYPE_ID] => documents
[IBLOCK_CODE] => new-documents
[~IBLOCK_CODE] => new-documents
[IBLOCK_EXTERNAL_ID] =>
[~IBLOCK_EXTERNAL_ID] =>
[LID] => s1
[~LID] => s1
[ACTIVE_FROM] =>
[ACTIVE_TO] =>
[IPROPERTY_VALUES] => Array
(
)
[PRODUCT] => Array
(
[TYPE] =>
[AVAILABLE] =>
[MEASURE] =>
[VAT_ID] =>
[VAT_RATE] =>
[VAT_INCLUDED] =>
[QUANTITY] =>
[QUANTITY_TRACE] =>
[CAN_BUY_ZERO] =>
[SUBSCRIPTION] =>
[BUNDLE] =>
)
[PROPERTIES] => Array
(
)
[DISPLAY_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES_FILL] => Array
(
)
[OFFERS] => Array
(
)
[OFFER_ID_SELECTED] => 0
[ITEM_PRICE_MODE] =>
[ITEM_PRICES] => Array
(
)
[ITEM_QUANTITY_RANGES] =>
[ITEM_MEASURE_RATIOS] =>
[ITEM_MEASURE] => Array
(
)
[ITEM_MEASURE_RATIO_SELECTED] =>
[ITEM_QUANTITY_RANGE_SELECTED] =>
[ITEM_PRICE_SELECTED] =>
[CAN_BUY] =>
[EDIT_LINK] =>
[DELETE_LINK] =>
[SECTION] => Array
(
[PATH] => Array
(
)
)
[~BUY_URL] => /about/structure/?action=BUY&id=561
[BUY_URL] => /about/structure/?action=BUY&id=561
[~ADD_URL] => /about/structure/?action=ADD2BASKET&id=561
[ADD_URL] => /about/structure/?action=ADD2BASKET&id=561
[~SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=561
[SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=561
[CATALOG_MEASURE_NAME] =>
[~CATALOG_MEASURE_NAME] =>
[CATALOG_MEASURE_RATIO] =>
)
Array
(
[PRICES] => Array
(
)
[PRICE_MATRIX] =>
[MIN_PRICE] =>
[ID] => 562
[~ID] => 562
[IBLOCK_ID] => 40
[~IBLOCK_ID] => 40
[CODE] => polozhenie-ob-upravlyayushchem-sovete-shkoly
[~CODE] => polozhenie-ob-upravlyayushchem-sovete-shkoly
[XML_ID] => 562
[~XML_ID] => 562
[NAME] => Положение об управляющем совете школы
[~NAME] => Положение об управляющем совете школы
[ACTIVE] => Y
[~ACTIVE] => Y
[DATE_ACTIVE_FROM] =>
[~DATE_ACTIVE_FROM] =>
[DATE_ACTIVE_TO] =>
[~DATE_ACTIVE_TO] =>
[SORT] => 20
[~SORT] => 20
[PREVIEW_TEXT] =>
[~PREVIEW_TEXT] =>
[PREVIEW_TEXT_TYPE] => text
[~PREVIEW_TEXT_TYPE] => text
[DETAIL_TEXT] =>
[~DETAIL_TEXT] =>
[DETAIL_TEXT_TYPE] => text
[~DETAIL_TEXT_TYPE] => text
[DATE_CREATE] => 11. 03.2019 20:54:10
[~DATE_CREATE] => 11.03.2019 20:54:10
[CREATED_BY] => 1
[~CREATED_BY] => 1
[TAGS] =>
[~TAGS] =>
[TIMESTAMP_X] => 11.03.2019 20:54:10
[~TIMESTAMP_X] => 11.03.2019 20:54:10
[MODIFIED_BY] => 1
[~MODIFIED_BY] => 1
[IBLOCK_SECTION_ID] => 100
[~IBLOCK_SECTION_ID] => 100
[DETAIL_PAGE_URL] => /documents/detail.php?ID=562
[~DETAIL_PAGE_URL] => /documents/detail.php?ID=562
[DETAIL_PICTURE] =>
[~DETAIL_PICTURE] =>
[PREVIEW_PICTURE] =>
[~PREVIEW_PICTURE] =>
[LANG_DIR] => /
[~LANG_DIR] => /
[EXTERNAL_ID] => 562
[~EXTERNAL_ID] => 562
[IBLOCK_TYPE_ID] => documents
[~IBLOCK_TYPE_ID] => documents
[IBLOCK_CODE] => new-documents
[~IBLOCK_CODE] => new-documents
[IBLOCK_EXTERNAL_ID] =>
[~IBLOCK_EXTERNAL_ID] =>
[LID] => s1
[~LID] => s1
[ACTIVE_FROM] =>
[ACTIVE_TO] =>
[IPROPERTY_VALUES] => Array
(
)
[PRODUCT] => Array
(
[TYPE] =>
[AVAILABLE] =>
[MEASURE] =>
[VAT_ID] =>
[VAT_RATE] =>
[VAT_INCLUDED] =>
[QUANTITY] =>
[QUANTITY_TRACE] =>
[CAN_BUY_ZERO] =>
[SUBSCRIPTION] =>
[BUNDLE] =>
)
[PROPERTIES] => Array
(
)
[DISPLAY_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES_FILL] => Array
(
)
[OFFERS] => Array
(
)
[OFFER_ID_SELECTED] => 0
[ITEM_PRICE_MODE] =>
[ITEM_PRICES] => Array
(
)
[ITEM_QUANTITY_RANGES] =>
[ITEM_MEASURE_RATIOS] =>
[ITEM_MEASURE] => Array
(
)
[ITEM_MEASURE_RATIO_SELECTED] =>
[ITEM_QUANTITY_RANGE_SELECTED] =>
[ITEM_PRICE_SELECTED] =>
[CAN_BUY] =>
[EDIT_LINK] =>
[DELETE_LINK] =>
[SECTION] => Array
(
[PATH] => Array
(
)
)
[~BUY_URL] => /about/structure/?action=BUY&id=562
[BUY_URL] => /about/structure/?action=BUY&id=562
[~ADD_URL] => /about/structure/?action=ADD2BASKET&id=562
[ADD_URL] => /about/structure/?action=ADD2BASKET&id=562
[~SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=562
[SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=562
[CATALOG_MEASURE_NAME] =>
[~CATALOG_MEASURE_NAME] =>
[CATALOG_MEASURE_RATIO] =>
)
 03.2019 20:54:10
[~DATE_CREATE] => 11.03.2019 20:54:10
[CREATED_BY] => 1
[~CREATED_BY] => 1
[TAGS] =>
[~TAGS] =>
[TIMESTAMP_X] => 11.03.2019 20:54:10
[~TIMESTAMP_X] => 11.03.2019 20:54:10
[MODIFIED_BY] => 1
[~MODIFIED_BY] => 1
[IBLOCK_SECTION_ID] => 100
[~IBLOCK_SECTION_ID] => 100
[DETAIL_PAGE_URL] => /documents/detail.php?ID=562
[~DETAIL_PAGE_URL] => /documents/detail.php?ID=562
[DETAIL_PICTURE] =>
[~DETAIL_PICTURE] =>
[PREVIEW_PICTURE] =>
[~PREVIEW_PICTURE] =>
[LANG_DIR] => /
[~LANG_DIR] => /
[EXTERNAL_ID] => 562
[~EXTERNAL_ID] => 562
[IBLOCK_TYPE_ID] => documents
[~IBLOCK_TYPE_ID] => documents
[IBLOCK_CODE] => new-documents
[~IBLOCK_CODE] => new-documents
[IBLOCK_EXTERNAL_ID] =>
[~IBLOCK_EXTERNAL_ID] =>
[LID] => s1
[~LID] => s1
[ACTIVE_FROM] =>
[ACTIVE_TO] =>
[IPROPERTY_VALUES] => Array
(
)
[PRODUCT] => Array
(
[TYPE] =>
[AVAILABLE] =>
[MEASURE] =>
[VAT_ID] =>
[VAT_RATE] =>
[VAT_INCLUDED] =>
[QUANTITY] =>
[QUANTITY_TRACE] =>
[CAN_BUY_ZERO] =>
[SUBSCRIPTION] =>
[BUNDLE] =>
)
[PROPERTIES] => Array
(
)
[DISPLAY_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES_FILL] => Array
(
)
[OFFERS] => Array
(
)
[OFFER_ID_SELECTED] => 0
[ITEM_PRICE_MODE] =>
[ITEM_PRICES] => Array
(
)
[ITEM_QUANTITY_RANGES] =>
[ITEM_MEASURE_RATIOS] =>
[ITEM_MEASURE] => Array
(
)
[ITEM_MEASURE_RATIO_SELECTED] =>
[ITEM_QUANTITY_RANGE_SELECTED] =>
[ITEM_PRICE_SELECTED] =>
[CAN_BUY] =>
[EDIT_LINK] =>
[DELETE_LINK] =>
[SECTION] => Array
(
[PATH] => Array
(
)
)
[~BUY_URL] => /about/structure/?action=BUY&id=562
[BUY_URL] => /about/structure/?action=BUY&id=562
[~ADD_URL] => /about/structure/?action=ADD2BASKET&id=562
[ADD_URL] => /about/structure/?action=ADD2BASKET&id=562
[~SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=562
[SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=562
[CATALOG_MEASURE_NAME] =>
[~CATALOG_MEASURE_NAME] =>
[CATALOG_MEASURE_RATIO] =>
)
03.2019 20:54:10
[~DATE_CREATE] => 11.03.2019 20:54:10
[CREATED_BY] => 1
[~CREATED_BY] => 1
[TAGS] =>
[~TAGS] =>
[TIMESTAMP_X] => 11.03.2019 20:54:10
[~TIMESTAMP_X] => 11.03.2019 20:54:10
[MODIFIED_BY] => 1
[~MODIFIED_BY] => 1
[IBLOCK_SECTION_ID] => 100
[~IBLOCK_SECTION_ID] => 100
[DETAIL_PAGE_URL] => /documents/detail.php?ID=562
[~DETAIL_PAGE_URL] => /documents/detail.php?ID=562
[DETAIL_PICTURE] =>
[~DETAIL_PICTURE] =>
[PREVIEW_PICTURE] =>
[~PREVIEW_PICTURE] =>
[LANG_DIR] => /
[~LANG_DIR] => /
[EXTERNAL_ID] => 562
[~EXTERNAL_ID] => 562
[IBLOCK_TYPE_ID] => documents
[~IBLOCK_TYPE_ID] => documents
[IBLOCK_CODE] => new-documents
[~IBLOCK_CODE] => new-documents
[IBLOCK_EXTERNAL_ID] =>
[~IBLOCK_EXTERNAL_ID] =>
[LID] => s1
[~LID] => s1
[ACTIVE_FROM] =>
[ACTIVE_TO] =>
[IPROPERTY_VALUES] => Array
(
)
[PRODUCT] => Array
(
[TYPE] =>
[AVAILABLE] =>
[MEASURE] =>
[VAT_ID] =>
[VAT_RATE] =>
[VAT_INCLUDED] =>
[QUANTITY] =>
[QUANTITY_TRACE] =>
[CAN_BUY_ZERO] =>
[SUBSCRIPTION] =>
[BUNDLE] =>
)
[PROPERTIES] => Array
(
)
[DISPLAY_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES_FILL] => Array
(
)
[OFFERS] => Array
(
)
[OFFER_ID_SELECTED] => 0
[ITEM_PRICE_MODE] =>
[ITEM_PRICES] => Array
(
)
[ITEM_QUANTITY_RANGES] =>
[ITEM_MEASURE_RATIOS] =>
[ITEM_MEASURE] => Array
(
)
[ITEM_MEASURE_RATIO_SELECTED] =>
[ITEM_QUANTITY_RANGE_SELECTED] =>
[ITEM_PRICE_SELECTED] =>
[CAN_BUY] =>
[EDIT_LINK] =>
[DELETE_LINK] =>
[SECTION] => Array
(
[PATH] => Array
(
)
)
[~BUY_URL] => /about/structure/?action=BUY&id=562
[BUY_URL] => /about/structure/?action=BUY&id=562
[~ADD_URL] => /about/structure/?action=ADD2BASKET&id=562
[ADD_URL] => /about/structure/?action=ADD2BASKET&id=562
[~SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=562
[SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=562
[CATALOG_MEASURE_NAME] =>
[~CATALOG_MEASURE_NAME] =>
[CATALOG_MEASURE_RATIO] =>
)
Array
(
[PRICES] => Array
(
)
[PRICE_MATRIX] =>
[MIN_PRICE] =>
[ID] => 563
[~ID] => 563
[IBLOCK_ID] => 40
[~IBLOCK_ID] => 40
[CODE] => polozhenie-o-pedagogicheskom-sovete
[~CODE] => polozhenie-o-pedagogicheskom-sovete
[XML_ID] => 563
[~XML_ID] => 563
[NAME] => Положение о педагогическом совете
[~NAME] => Положение о педагогическом совете
[ACTIVE] => Y
[~ACTIVE] => Y
[DATE_ACTIVE_FROM] =>
[~DATE_ACTIVE_FROM] =>
[DATE_ACTIVE_TO] =>
[~DATE_ACTIVE_TO] =>
[SORT] => 30
[~SORT] => 30
[PREVIEW_TEXT] =>
[~PREVIEW_TEXT] =>
[PREVIEW_TEXT_TYPE] => text
[~PREVIEW_TEXT_TYPE] => text
[DETAIL_TEXT] =>
[~DETAIL_TEXT] =>
[DETAIL_TEXT_TYPE] => text
[~DETAIL_TEXT_TYPE] => text
[DATE_CREATE] => 11. 03.2019 20:54:41
[~DATE_CREATE] => 11.03.2019 20:54:41
[CREATED_BY] => 1
[~CREATED_BY] => 1
[TAGS] =>
[~TAGS] =>
[TIMESTAMP_X] => 11.03.2019 20:54:41
[~TIMESTAMP_X] => 11.03.2019 20:54:41
[MODIFIED_BY] => 1
[~MODIFIED_BY] => 1
[IBLOCK_SECTION_ID] => 100
[~IBLOCK_SECTION_ID] => 100
[DETAIL_PAGE_URL] => /documents/detail.php?ID=563
[~DETAIL_PAGE_URL] => /documents/detail.php?ID=563
[DETAIL_PICTURE] =>
[~DETAIL_PICTURE] =>
[PREVIEW_PICTURE] =>
[~PREVIEW_PICTURE] =>
[LANG_DIR] => /
[~LANG_DIR] => /
[EXTERNAL_ID] => 563
[~EXTERNAL_ID] => 563
[IBLOCK_TYPE_ID] => documents
[~IBLOCK_TYPE_ID] => documents
[IBLOCK_CODE] => new-documents
[~IBLOCK_CODE] => new-documents
[IBLOCK_EXTERNAL_ID] =>
[~IBLOCK_EXTERNAL_ID] =>
[LID] => s1
[~LID] => s1
[ACTIVE_FROM] =>
[ACTIVE_TO] =>
[IPROPERTY_VALUES] => Array
(
)
[PRODUCT] => Array
(
[TYPE] =>
[AVAILABLE] =>
[MEASURE] =>
[VAT_ID] =>
[VAT_RATE] =>
[VAT_INCLUDED] =>
[QUANTITY] =>
[QUANTITY_TRACE] =>
[CAN_BUY_ZERO] =>
[SUBSCRIPTION] =>
[BUNDLE] =>
)
[PROPERTIES] => Array
(
)
[DISPLAY_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES_FILL] => Array
(
)
[OFFERS] => Array
(
)
[OFFER_ID_SELECTED] => 0
[ITEM_PRICE_MODE] =>
[ITEM_PRICES] => Array
(
)
[ITEM_QUANTITY_RANGES] =>
[ITEM_MEASURE_RATIOS] =>
[ITEM_MEASURE] => Array
(
)
[ITEM_MEASURE_RATIO_SELECTED] =>
[ITEM_QUANTITY_RANGE_SELECTED] =>
[ITEM_PRICE_SELECTED] =>
[CAN_BUY] =>
[EDIT_LINK] =>
[DELETE_LINK] =>
[SECTION] => Array
(
[PATH] => Array
(
)
)
[~BUY_URL] => /about/structure/?action=BUY&id=563
[BUY_URL] => /about/structure/?action=BUY&id=563
[~ADD_URL] => /about/structure/?action=ADD2BASKET&id=563
[ADD_URL] => /about/structure/?action=ADD2BASKET&id=563
[~SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=563
[SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=563
[CATALOG_MEASURE_NAME] =>
[~CATALOG_MEASURE_NAME] =>
[CATALOG_MEASURE_RATIO] =>
)
 03.2019 20:54:41
[~DATE_CREATE] => 11.03.2019 20:54:41
[CREATED_BY] => 1
[~CREATED_BY] => 1
[TAGS] =>
[~TAGS] =>
[TIMESTAMP_X] => 11.03.2019 20:54:41
[~TIMESTAMP_X] => 11.03.2019 20:54:41
[MODIFIED_BY] => 1
[~MODIFIED_BY] => 1
[IBLOCK_SECTION_ID] => 100
[~IBLOCK_SECTION_ID] => 100
[DETAIL_PAGE_URL] => /documents/detail.php?ID=563
[~DETAIL_PAGE_URL] => /documents/detail.php?ID=563
[DETAIL_PICTURE] =>
[~DETAIL_PICTURE] =>
[PREVIEW_PICTURE] =>
[~PREVIEW_PICTURE] =>
[LANG_DIR] => /
[~LANG_DIR] => /
[EXTERNAL_ID] => 563
[~EXTERNAL_ID] => 563
[IBLOCK_TYPE_ID] => documents
[~IBLOCK_TYPE_ID] => documents
[IBLOCK_CODE] => new-documents
[~IBLOCK_CODE] => new-documents
[IBLOCK_EXTERNAL_ID] =>
[~IBLOCK_EXTERNAL_ID] =>
[LID] => s1
[~LID] => s1
[ACTIVE_FROM] =>
[ACTIVE_TO] =>
[IPROPERTY_VALUES] => Array
(
)
[PRODUCT] => Array
(
[TYPE] =>
[AVAILABLE] =>
[MEASURE] =>
[VAT_ID] =>
[VAT_RATE] =>
[VAT_INCLUDED] =>
[QUANTITY] =>
[QUANTITY_TRACE] =>
[CAN_BUY_ZERO] =>
[SUBSCRIPTION] =>
[BUNDLE] =>
)
[PROPERTIES] => Array
(
)
[DISPLAY_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES_FILL] => Array
(
)
[OFFERS] => Array
(
)
[OFFER_ID_SELECTED] => 0
[ITEM_PRICE_MODE] =>
[ITEM_PRICES] => Array
(
)
[ITEM_QUANTITY_RANGES] =>
[ITEM_MEASURE_RATIOS] =>
[ITEM_MEASURE] => Array
(
)
[ITEM_MEASURE_RATIO_SELECTED] =>
[ITEM_QUANTITY_RANGE_SELECTED] =>
[ITEM_PRICE_SELECTED] =>
[CAN_BUY] =>
[EDIT_LINK] =>
[DELETE_LINK] =>
[SECTION] => Array
(
[PATH] => Array
(
)
)
[~BUY_URL] => /about/structure/?action=BUY&id=563
[BUY_URL] => /about/structure/?action=BUY&id=563
[~ADD_URL] => /about/structure/?action=ADD2BASKET&id=563
[ADD_URL] => /about/structure/?action=ADD2BASKET&id=563
[~SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=563
[SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=563
[CATALOG_MEASURE_NAME] =>
[~CATALOG_MEASURE_NAME] =>
[CATALOG_MEASURE_RATIO] =>
)
03.2019 20:54:41
[~DATE_CREATE] => 11.03.2019 20:54:41
[CREATED_BY] => 1
[~CREATED_BY] => 1
[TAGS] =>
[~TAGS] =>
[TIMESTAMP_X] => 11.03.2019 20:54:41
[~TIMESTAMP_X] => 11.03.2019 20:54:41
[MODIFIED_BY] => 1
[~MODIFIED_BY] => 1
[IBLOCK_SECTION_ID] => 100
[~IBLOCK_SECTION_ID] => 100
[DETAIL_PAGE_URL] => /documents/detail.php?ID=563
[~DETAIL_PAGE_URL] => /documents/detail.php?ID=563
[DETAIL_PICTURE] =>
[~DETAIL_PICTURE] =>
[PREVIEW_PICTURE] =>
[~PREVIEW_PICTURE] =>
[LANG_DIR] => /
[~LANG_DIR] => /
[EXTERNAL_ID] => 563
[~EXTERNAL_ID] => 563
[IBLOCK_TYPE_ID] => documents
[~IBLOCK_TYPE_ID] => documents
[IBLOCK_CODE] => new-documents
[~IBLOCK_CODE] => new-documents
[IBLOCK_EXTERNAL_ID] =>
[~IBLOCK_EXTERNAL_ID] =>
[LID] => s1
[~LID] => s1
[ACTIVE_FROM] =>
[ACTIVE_TO] =>
[IPROPERTY_VALUES] => Array
(
)
[PRODUCT] => Array
(
[TYPE] =>
[AVAILABLE] =>
[MEASURE] =>
[VAT_ID] =>
[VAT_RATE] =>
[VAT_INCLUDED] =>
[QUANTITY] =>
[QUANTITY_TRACE] =>
[CAN_BUY_ZERO] =>
[SUBSCRIPTION] =>
[BUNDLE] =>
)
[PROPERTIES] => Array
(
)
[DISPLAY_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES_FILL] => Array
(
)
[OFFERS] => Array
(
)
[OFFER_ID_SELECTED] => 0
[ITEM_PRICE_MODE] =>
[ITEM_PRICES] => Array
(
)
[ITEM_QUANTITY_RANGES] =>
[ITEM_MEASURE_RATIOS] =>
[ITEM_MEASURE] => Array
(
)
[ITEM_MEASURE_RATIO_SELECTED] =>
[ITEM_QUANTITY_RANGE_SELECTED] =>
[ITEM_PRICE_SELECTED] =>
[CAN_BUY] =>
[EDIT_LINK] =>
[DELETE_LINK] =>
[SECTION] => Array
(
[PATH] => Array
(
)
)
[~BUY_URL] => /about/structure/?action=BUY&id=563
[BUY_URL] => /about/structure/?action=BUY&id=563
[~ADD_URL] => /about/structure/?action=ADD2BASKET&id=563
[ADD_URL] => /about/structure/?action=ADD2BASKET&id=563
[~SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=563
[SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=563
[CATALOG_MEASURE_NAME] =>
[~CATALOG_MEASURE_NAME] =>
[CATALOG_MEASURE_RATIO] =>
)
Array
(
[PRICES] => Array
(
)
[PRICE_MATRIX] =>
[MIN_PRICE] =>
[ID] => 564
[~ID] => 564
[IBLOCK_ID] => 40
[~IBLOCK_ID] => 40
[CODE] => polozhenie-o-sovete-starsheklassnikov1
[~CODE] => polozhenie-o-sovete-starsheklassnikov1
[XML_ID] => 564
[~XML_ID] => 564
[NAME] => Положение о Совете старшеклассников
[~NAME] => Положение о Совете старшеклассников
[ACTIVE] => Y
[~ACTIVE] => Y
[DATE_ACTIVE_FROM] =>
[~DATE_ACTIVE_FROM] =>
[DATE_ACTIVE_TO] =>
[~DATE_ACTIVE_TO] =>
[SORT] => 40
[~SORT] => 40
[PREVIEW_TEXT] =>
[~PREVIEW_TEXT] =>
[PREVIEW_TEXT_TYPE] => text
[~PREVIEW_TEXT_TYPE] => text
[DETAIL_TEXT] =>
[~DETAIL_TEXT] =>
[DETAIL_TEXT_TYPE] => text
[~DETAIL_TEXT_TYPE] => text
[DATE_CREATE] => 11. 03.2019 20:55:28
[~DATE_CREATE] => 11.03.2019 20:55:28
[CREATED_BY] => 1
[~CREATED_BY] => 1
[TAGS] =>
[~TAGS] =>
[TIMESTAMP_X] => 11.03.2019 20:55:28
[~TIMESTAMP_X] => 11.03.2019 20:55:28
[MODIFIED_BY] => 1
[~MODIFIED_BY] => 1
[IBLOCK_SECTION_ID] => 100
[~IBLOCK_SECTION_ID] => 100
[DETAIL_PAGE_URL] => /documents/detail.php?ID=564
[~DETAIL_PAGE_URL] => /documents/detail.php?ID=564
[DETAIL_PICTURE] =>
[~DETAIL_PICTURE] =>
[PREVIEW_PICTURE] =>
[~PREVIEW_PICTURE] =>
[LANG_DIR] => /
[~LANG_DIR] => /
[EXTERNAL_ID] => 564
[~EXTERNAL_ID] => 564
[IBLOCK_TYPE_ID] => documents
[~IBLOCK_TYPE_ID] => documents
[IBLOCK_CODE] => new-documents
[~IBLOCK_CODE] => new-documents
[IBLOCK_EXTERNAL_ID] =>
[~IBLOCK_EXTERNAL_ID] =>
[LID] => s1
[~LID] => s1
[ACTIVE_FROM] =>
[ACTIVE_TO] =>
[IPROPERTY_VALUES] => Array
(
)
[PRODUCT] => Array
(
[TYPE] =>
[AVAILABLE] =>
[MEASURE] =>
[VAT_ID] =>
[VAT_RATE] =>
[VAT_INCLUDED] =>
[QUANTITY] =>
[QUANTITY_TRACE] =>
[CAN_BUY_ZERO] =>
[SUBSCRIPTION] =>
[BUNDLE] =>
)
[PROPERTIES] => Array
(
)
[DISPLAY_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES_FILL] => Array
(
)
[OFFERS] => Array
(
)
[OFFER_ID_SELECTED] => 0
[ITEM_PRICE_MODE] =>
[ITEM_PRICES] => Array
(
)
[ITEM_QUANTITY_RANGES] =>
[ITEM_MEASURE_RATIOS] =>
[ITEM_MEASURE] => Array
(
)
[ITEM_MEASURE_RATIO_SELECTED] =>
[ITEM_QUANTITY_RANGE_SELECTED] =>
[ITEM_PRICE_SELECTED] =>
[CAN_BUY] =>
[EDIT_LINK] =>
[DELETE_LINK] =>
[SECTION] => Array
(
[PATH] => Array
(
)
)
[~BUY_URL] => /about/structure/?action=BUY&id=564
[BUY_URL] => /about/structure/?action=BUY&id=564
[~ADD_URL] => /about/structure/?action=ADD2BASKET&id=564
[ADD_URL] => /about/structure/?action=ADD2BASKET&id=564
[~SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=564
[SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=564
[CATALOG_MEASURE_NAME] =>
[~CATALOG_MEASURE_NAME] =>
[CATALOG_MEASURE_RATIO] =>
)
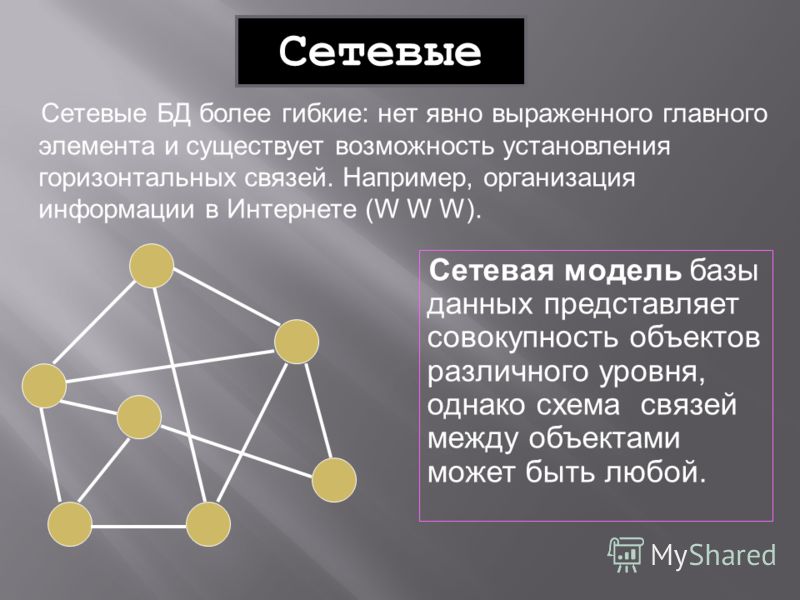 03.2019 20:55:28
[~DATE_CREATE] => 11.03.2019 20:55:28
[CREATED_BY] => 1
[~CREATED_BY] => 1
[TAGS] =>
[~TAGS] =>
[TIMESTAMP_X] => 11.03.2019 20:55:28
[~TIMESTAMP_X] => 11.03.2019 20:55:28
[MODIFIED_BY] => 1
[~MODIFIED_BY] => 1
[IBLOCK_SECTION_ID] => 100
[~IBLOCK_SECTION_ID] => 100
[DETAIL_PAGE_URL] => /documents/detail.php?ID=564
[~DETAIL_PAGE_URL] => /documents/detail.php?ID=564
[DETAIL_PICTURE] =>
[~DETAIL_PICTURE] =>
[PREVIEW_PICTURE] =>
[~PREVIEW_PICTURE] =>
[LANG_DIR] => /
[~LANG_DIR] => /
[EXTERNAL_ID] => 564
[~EXTERNAL_ID] => 564
[IBLOCK_TYPE_ID] => documents
[~IBLOCK_TYPE_ID] => documents
[IBLOCK_CODE] => new-documents
[~IBLOCK_CODE] => new-documents
[IBLOCK_EXTERNAL_ID] =>
[~IBLOCK_EXTERNAL_ID] =>
[LID] => s1
[~LID] => s1
[ACTIVE_FROM] =>
[ACTIVE_TO] =>
[IPROPERTY_VALUES] => Array
(
)
[PRODUCT] => Array
(
[TYPE] =>
[AVAILABLE] =>
[MEASURE] =>
[VAT_ID] =>
[VAT_RATE] =>
[VAT_INCLUDED] =>
[QUANTITY] =>
[QUANTITY_TRACE] =>
[CAN_BUY_ZERO] =>
[SUBSCRIPTION] =>
[BUNDLE] =>
)
[PROPERTIES] => Array
(
)
[DISPLAY_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES_FILL] => Array
(
)
[OFFERS] => Array
(
)
[OFFER_ID_SELECTED] => 0
[ITEM_PRICE_MODE] =>
[ITEM_PRICES] => Array
(
)
[ITEM_QUANTITY_RANGES] =>
[ITEM_MEASURE_RATIOS] =>
[ITEM_MEASURE] => Array
(
)
[ITEM_MEASURE_RATIO_SELECTED] =>
[ITEM_QUANTITY_RANGE_SELECTED] =>
[ITEM_PRICE_SELECTED] =>
[CAN_BUY] =>
[EDIT_LINK] =>
[DELETE_LINK] =>
[SECTION] => Array
(
[PATH] => Array
(
)
)
[~BUY_URL] => /about/structure/?action=BUY&id=564
[BUY_URL] => /about/structure/?action=BUY&id=564
[~ADD_URL] => /about/structure/?action=ADD2BASKET&id=564
[ADD_URL] => /about/structure/?action=ADD2BASKET&id=564
[~SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=564
[SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=564
[CATALOG_MEASURE_NAME] =>
[~CATALOG_MEASURE_NAME] =>
[CATALOG_MEASURE_RATIO] =>
)
03.2019 20:55:28
[~DATE_CREATE] => 11.03.2019 20:55:28
[CREATED_BY] => 1
[~CREATED_BY] => 1
[TAGS] =>
[~TAGS] =>
[TIMESTAMP_X] => 11.03.2019 20:55:28
[~TIMESTAMP_X] => 11.03.2019 20:55:28
[MODIFIED_BY] => 1
[~MODIFIED_BY] => 1
[IBLOCK_SECTION_ID] => 100
[~IBLOCK_SECTION_ID] => 100
[DETAIL_PAGE_URL] => /documents/detail.php?ID=564
[~DETAIL_PAGE_URL] => /documents/detail.php?ID=564
[DETAIL_PICTURE] =>
[~DETAIL_PICTURE] =>
[PREVIEW_PICTURE] =>
[~PREVIEW_PICTURE] =>
[LANG_DIR] => /
[~LANG_DIR] => /
[EXTERNAL_ID] => 564
[~EXTERNAL_ID] => 564
[IBLOCK_TYPE_ID] => documents
[~IBLOCK_TYPE_ID] => documents
[IBLOCK_CODE] => new-documents
[~IBLOCK_CODE] => new-documents
[IBLOCK_EXTERNAL_ID] =>
[~IBLOCK_EXTERNAL_ID] =>
[LID] => s1
[~LID] => s1
[ACTIVE_FROM] =>
[ACTIVE_TO] =>
[IPROPERTY_VALUES] => Array
(
)
[PRODUCT] => Array
(
[TYPE] =>
[AVAILABLE] =>
[MEASURE] =>
[VAT_ID] =>
[VAT_RATE] =>
[VAT_INCLUDED] =>
[QUANTITY] =>
[QUANTITY_TRACE] =>
[CAN_BUY_ZERO] =>
[SUBSCRIPTION] =>
[BUNDLE] =>
)
[PROPERTIES] => Array
(
)
[DISPLAY_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES] => Array
(
)
[PRODUCT_PROPERTIES_FILL] => Array
(
)
[OFFERS] => Array
(
)
[OFFER_ID_SELECTED] => 0
[ITEM_PRICE_MODE] =>
[ITEM_PRICES] => Array
(
)
[ITEM_QUANTITY_RANGES] =>
[ITEM_MEASURE_RATIOS] =>
[ITEM_MEASURE] => Array
(
)
[ITEM_MEASURE_RATIO_SELECTED] =>
[ITEM_QUANTITY_RANGE_SELECTED] =>
[ITEM_PRICE_SELECTED] =>
[CAN_BUY] =>
[EDIT_LINK] =>
[DELETE_LINK] =>
[SECTION] => Array
(
[PATH] => Array
(
)
)
[~BUY_URL] => /about/structure/?action=BUY&id=564
[BUY_URL] => /about/structure/?action=BUY&id=564
[~ADD_URL] => /about/structure/?action=ADD2BASKET&id=564
[ADD_URL] => /about/structure/?action=ADD2BASKET&id=564
[~SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=564
[SUBSCRIBE_URL] => /about/structure/?action=SUBSCRIBE_PRODUCT&id=564
[CATALOG_MEASURE_NAME] =>
[~CATALOG_MEASURE_NAME] =>
[CATALOG_MEASURE_RATIO] =>
)
Как мне структурировать свою группу данных?
Группа обработки данных — это нечто совершенно новое: это не ИТ, не финансы, это не какие-либо типичные бизнес-функции в действующем бизнесе. Итак … кому он подчиняется? Как он взаимодействует с остальной частью организации? Насколько это велико?
Итак … кому он подчиняется? Как он взаимодействует с остальной частью организации? Насколько это велико?
Это все вопросы, на которые в режиме реального времени получают ответы во всей отрасли. И это, вероятно, вопросы, которые возникают у вас, когда вы собираетесь построить или реконструировать свою команду данных.На сегодня нет однозначных ответов . Компании отвечают на эти вопросы по-разному, и все они адаптированы к их конкретному бизнесу.
Вот почему этот вопрос такой сложный. Поэтому вместо того, чтобы высказывать мнение о том, какие ответы мы считаем лучшими — а у нас есть собственное мнение! — мы решили, что было бы наиболее полезно собрать кучу «эталонных архитектур» от удивительных компаний. Просмотрите их и посмотрите, резонируют ли какие-либо из них с командой, которую вы пытаетесь создать.Мы выбрали следующие основные темы, которые, по-видимому, определяют структуру современной группы данных:
- Насколько централизовано / насколько распределено? Некоторые команды сильно централизованы, некоторые распределяют участников, чтобы они сидели и работали с организационными подразделениями.
- Где должна быть инженерия данных? Некоторые команды включают инженеров по обработке данных в группу по обработке данных, некоторые проводят пунктирную линию с инженерной организацией.
- Какова роль группы данных? Некоторые группы принимают данные как продукт, а некоторые используют данные как услугу.(Подробнее по этой теме здесь.)
- Под руководством какого руководителя живет группа данных? В некоторых командах есть руководители уровня вице-президента или высшего звена, которые подчиняются непосредственно генеральному директору. В других случаях данные попадают в функциональную головку.
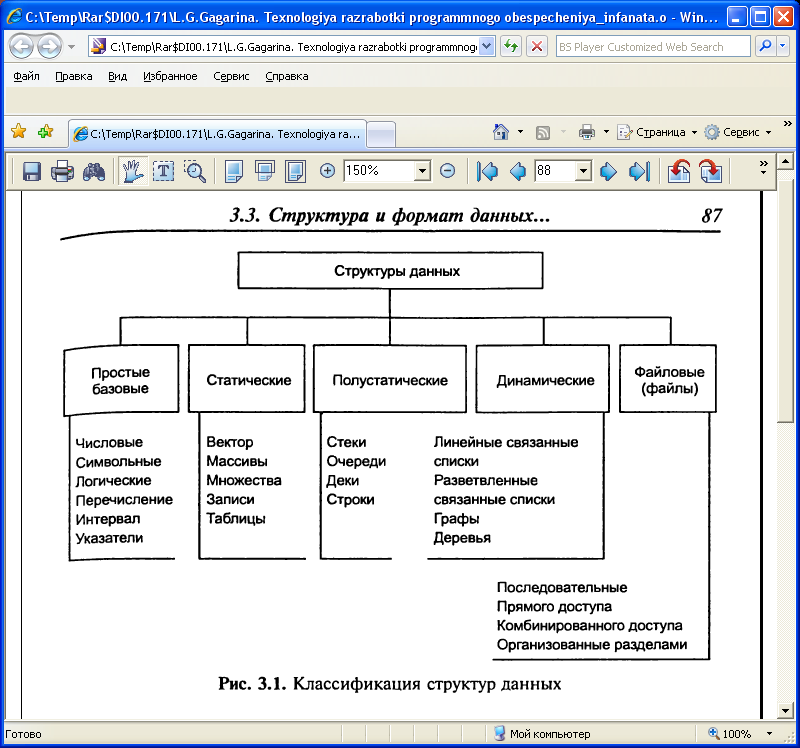
Последнее замечание перед тем, как мы углубимся: все лидеры, представленные ниже, являются членами dbt Slack и любезно вызвались ответить на конкретные вопросы по этой теме. Если вы проходите через этот процесс прямо сейчас, обратитесь к ним в Slack.Если вы еще не состоите в сообществе, сейчас хорошее время, чтобы присоединиться к нему!
Майк Берардо
Директор по данным и стратегии
Отрасль : Электронная торговля
Размер компании : 250 сотрудников
Цифры
⚡️3% организации, ориентированной на аналитику
🔎20% организации чувствуют себя комфортно с помощью инструмента BI
🔬1 специалист по данным (предоставляет и анализирует данные)
⚙️1 инженер по данным (обеспечивает данные)
📊5 аналитиков (в основном анализируют)
Организационная структура группы данных
Потребности в данных Away поддерживаются пятью людьми в группе аналитиков, и один человек в группе по анализу данных, обе группы подчиняются директору по данным и стратегии. Группа разработки данных, состоящая из одного человека, работает в тесном сотрудничестве с командой Data & Strategy, но подотчетна инженерам. Data & Strategy отчитывается перед генеральным директором, хотя Майк указывает, что это временная установка, долгосрочные данные будут переданы финансовому директору.
Группа разработки данных, состоящая из одного человека, работает в тесном сотрудничестве с командой Data & Strategy, но подотчетна инженерам. Data & Strategy отчитывается перед генеральным директором, хотя Майк указывает, что это временная установка, долгосрочные данные будут переданы финансовому директору.
Компания Away ожидает, что заинтересованные стороны смогут проводить собственный анализ, хотя опыт работы с клиентами, юридические вопросы и управление персоналом имеют специальную поддержку аналитиков.
Планы роста
«Мы только что наняли трех человек, — говорит Майк. — Итак, мы приближаемся, но на самом деле я думаю, что нам все еще нужно больше.В частности, нам нужен инженер-аналитик. Разрыв между разработкой данных и аналитикой становится слишком большим, и нам действительно нужен технический ресурс, связанный с аналитикой, чтобы помочь нам преодолеть этот разрыв ».
Гордон Вонг
Вице-президент по бизнес-данным
Отрасль : SaaS
Размер компании : ~ 3000
Цифры
5% организации, ориентированной на аналитику
🔎10% организации комфортно используют инструмент BI
⚙️10 поставщиков данных
📊120 анализаторов данных
Организационная структура группы обработки данных
В качестве вице-президента по бизнес-данным Гордон руководит разработкой данных, хранением данных и включением аналитики.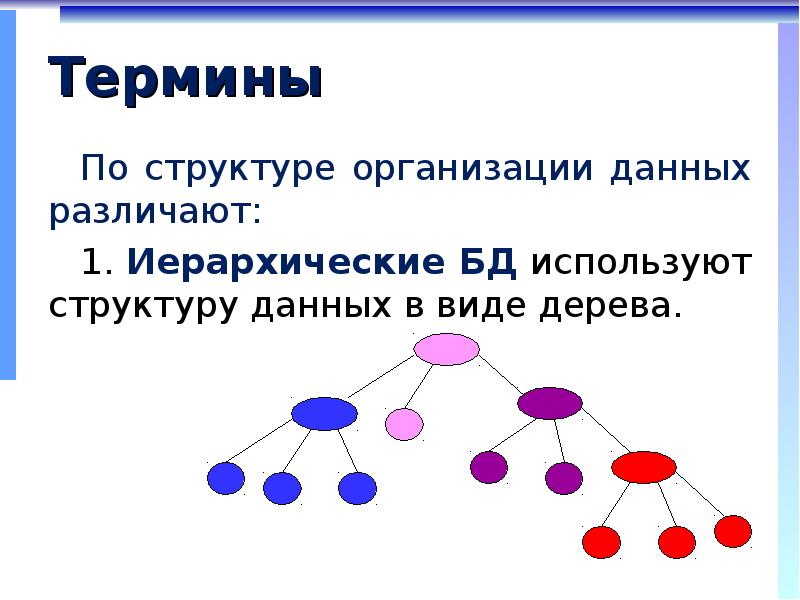 Как и многие компании SaaS, программное обеспечение HubSpot создает и перемещает огромные объемы данных о клиентах, которые могут быть непростыми для понимания. В то же время инженерия данных рассматривается как навык, отличный от инженерии полного стека. По этой причине команда инженеров данных укомплектована квалифицированными инженерами-программистами, но подчиняется бизнес-аналитике. Кластер инженерии данных в команде Гордона сосредоточен на создании инфраструктуры данных, которая поддерживает бизнес-аналитику и аналитику продуктов.
Как и многие компании SaaS, программное обеспечение HubSpot создает и перемещает огромные объемы данных о клиентах, которые могут быть непростыми для понимания. В то же время инженерия данных рассматривается как навык, отличный от инженерии полного стека. По этой причине команда инженеров данных укомплектована квалифицированными инженерами-программистами, но подчиняется бизнес-аналитике. Кластер инженерии данных в команде Гордона сосредоточен на создании инфраструктуры данных, которая поддерживает бизнес-аналитику и аналитику продуктов.
Гордон описывает свою команду сегодня как «инженеров тяжелого класса».«Они сосредоточены исключительно на включении аналитики, а не на аналитике. Функция аналитики полностью децентрализована, каждая бизнес-функция нанимает собственных аналитиков и специалистов по данным.
Планы роста
Гордон считает, что его собственная команда не сильно недоукомплектована для инженеров по обработке данных, но нуждается в гораздо большем количестве помощников.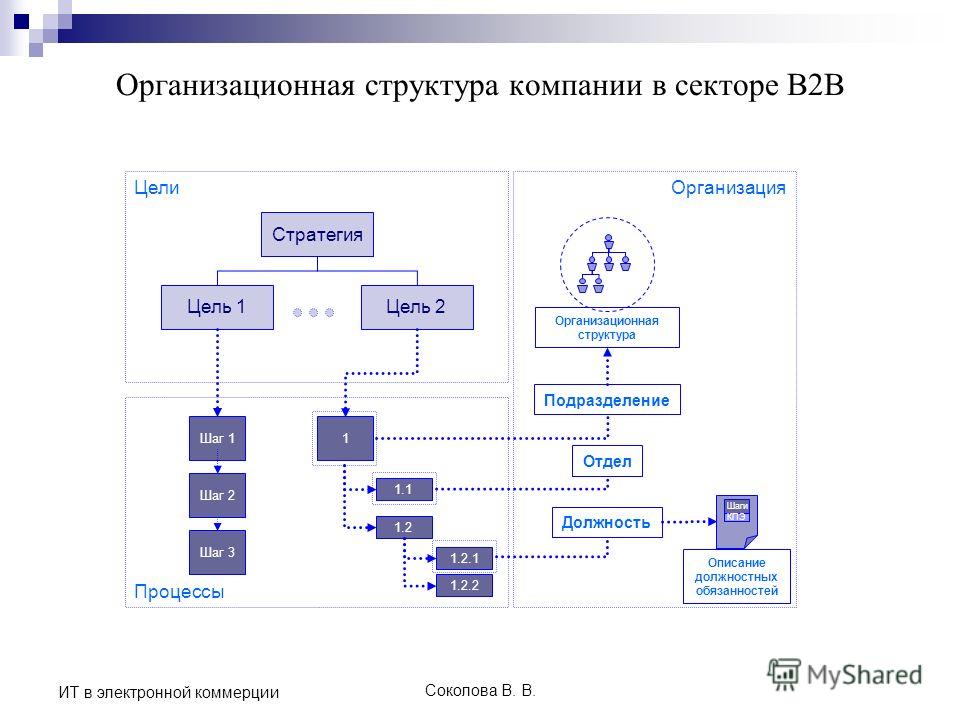 Он считает, что самым большим препятствием на пути к более глубокому пониманию бизнеса является не инженерия данных, а скорее «отсутствие аналитических инструментов, позволяющих преодолеть разрыв от атомарных данных к полезной информации».Он планирует сосредоточиться на добавлении инженеров-аналитиков, а также «аналитиков, которые могут обучать аналитиков».
Он считает, что самым большим препятствием на пути к более глубокому пониманию бизнеса является не инженерия данных, а скорее «отсутствие аналитических инструментов, позволяющих преодолеть разрыв от атомарных данных к полезной информации».Он планирует сосредоточиться на добавлении инженеров-аналитиков, а также «аналитиков, которые могут обучать аналитиков».
Кайлин Лу
Менеджер по аналитике
Отрасль : Электронная торговля
Размер компании : 100 сотрудников
Важные соотношения
2% организации, ориентированной на аналитику
🔎30% организации чувствуют себя комфортно с помощью инструмента BI
⚙️📊2 аналитика, которые отвечают как за предоставление данных, так и за анализ данных
Структура группы данных
«Мы небольшая, но мощная команда из двух человек», — говорит Кайлин.«Мы используем Stitch для передачи необработанных данных в наше хранилище и dbt для поддержки наших моделей данных и обеспечения наличия чистых и обновленных данных для работы».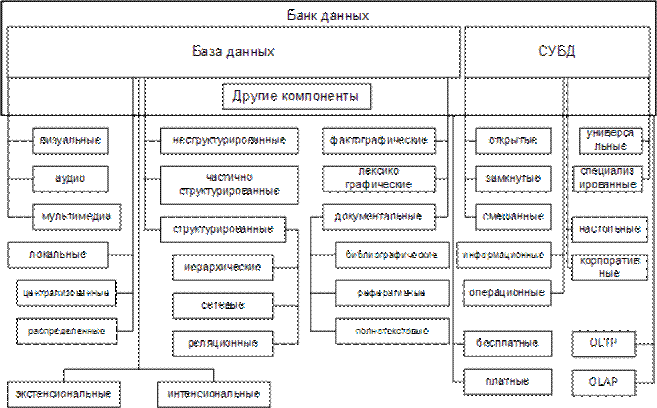 Один аналитик в первую очередь занимается поддержкой маркетинговой команды, а другой — поддержкой продаж и запасов. Оба аналитика подчиняются директору по продукту.
Один аналитик в первую очередь занимается поддержкой маркетинговой команды, а другой — поддержкой продаж и запасов. Оба аналитика подчиняются директору по продукту.
Помимо аналитиков, М. У LaFleur около пяти бизнес-пользователей, которые, по словам Кайлина, являются опытными пользователями и могут разрабатывать свои собственные отчеты на индивидуальной основе.
Кейтлин Мурман
Руководитель отдела аналитики
Отрасль : Розничная торговля
Размер компании : 75
Цифры
5% организации, ориентированной на аналитику
🔎40% организации комфортно используют инструмент BI
⚙️ ~ 1 поставщик данных
📊2 анализатора данных
Организационная структура группы обработки данных
Yerdle Recommerce в настоящее время претерпевает реорганизацию с полностью централизованного подхода к более гибридной структуре.«Полностью централизованная модель не работает!» — решительно говорит Кейтлин.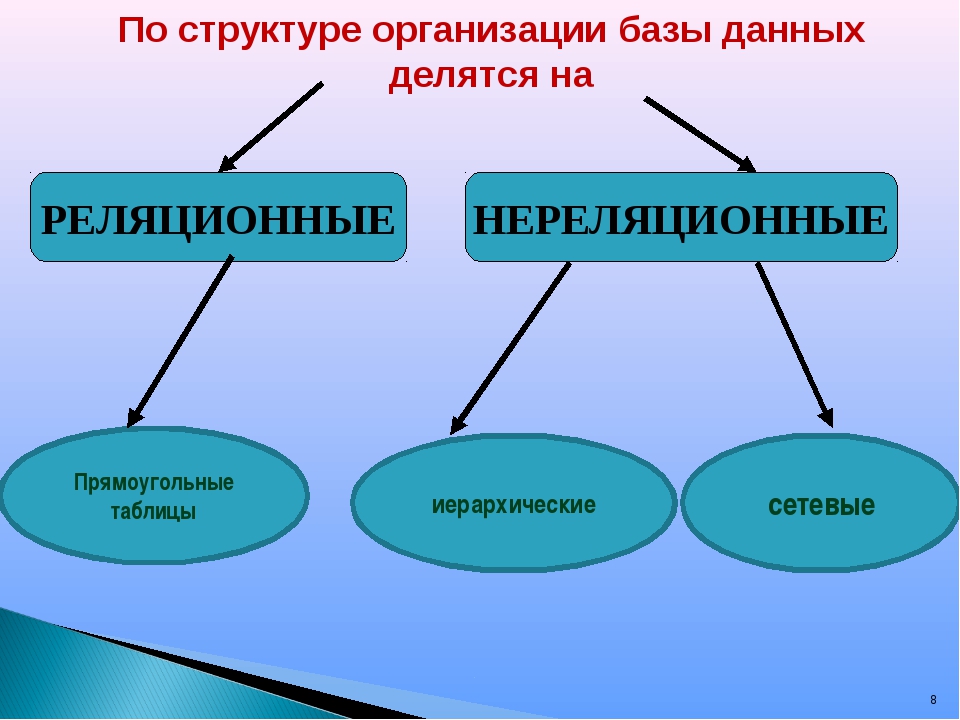 «Прямо сейчас у нас есть модель поставщика услуг для аналитики, но наборы навыков сильно разделены между ETL и визуализацией. Группа данных пытается обслуживать все команды в организации, но у нас огромные отставания и разрыв между аналитическими и функциональными группами ».
«Прямо сейчас у нас есть модель поставщика услуг для аналитики, но наборы навыков сильно разделены между ETL и визуализацией. Группа данных пытается обслуживать все команды в организации, но у нас огромные отставания и разрыв между аналитическими и функциональными группами ».
В гибридной модели группа данных Йердла будет состоять из руководителя группы и инженера по данным, действующих как централизованные ресурсы. Аналитики данных и специалисты по обработке данных будут четко обозначать линии операций, управления учетными записями и продуктовых групп, но они будут частью центральной команды.«Этот подход хорошо работал у меня в прошлом», — говорит Кейтлин. «Это помогает аналитикам почувствовать, что у них есть поддержка, в которой они нуждаются с точки зрения инструментов, методов и передовых практик, но дает им возможность стать экспертами в предметной области».
Планы роста
В настоящее время в команде Кейтлин открыто три должности аналитика. «Как только я заполню выдающиеся вакансии, мы окажемся в довольно хорошем месте для масштабирования вместе с компанией». Ее план состоит в том, чтобы иметь по одному аналитику для каждого направления бизнеса, но добавляет: «Мы находимся на ранней стадии, поэтому мы все еще выясняем, сколько текущих операций поддержки данных необходимо.”
Ее план состоит в том, чтобы иметь по одному аналитику для каждого направления бизнеса, но добавляет: «Мы находимся на ранней стадии, поэтому мы все еще выясняем, сколько текущих операций поддержки данных необходимо.”
Baran Toppare
Data Analyst
Отрасль : Потребительские услуги
Размер компании : 600 сотрудников
Цифры
⚡️2,50% организации, ориентированной на аналитику
🔎42% организации комфортно используют инструмент BI
🔬4 аналитика данных (анализ данных)
⚙️10 инженеров данных (предоставление данных)
6 специалистов по анализу данных (анализ данных)
Организационная структура группы данных
«Каждый аналитик входит в состав 1-2 миссионерских команд», — говорит Баран .«Мы поддерживаем продукты, поставки, маркетинг и финансы. Мы все подчиняемся нашему директору по аналитике ». По большей части специалисты по обработке данных не занимаются аналитикой, а сосредоточиваются на проектах машинного обучения в дорожной карте продукта.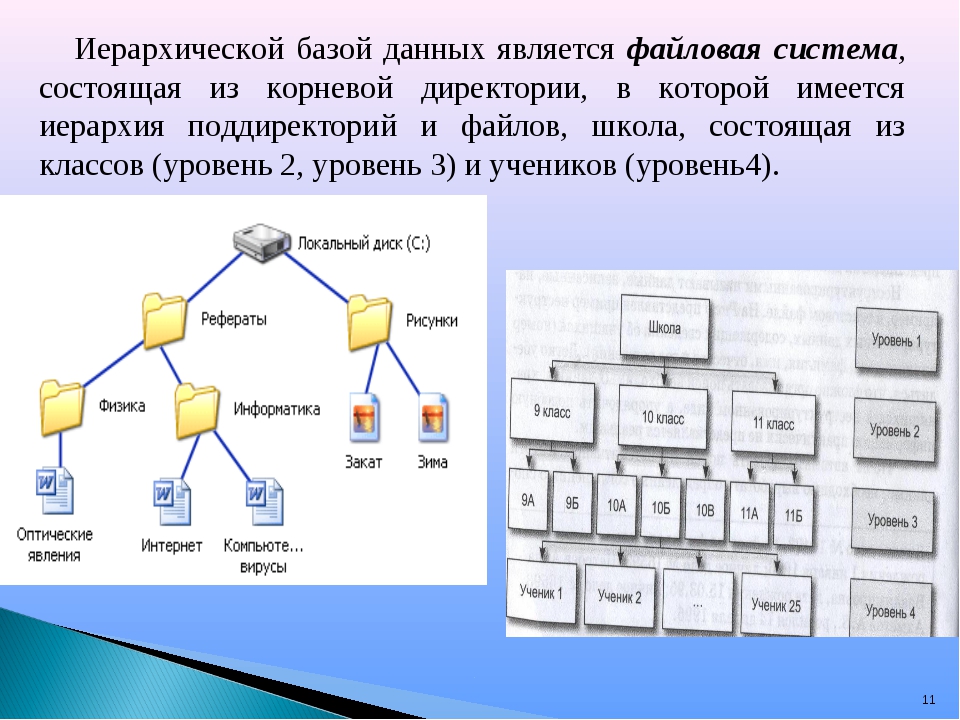
Питер Файн
Старший специалист по данным
Отрасль : SaaS
Размер компании : 45
Цифры
⚡️9% организации, ориентированной на аналитику
🔎100% организации комфортно используют инструмент BI
🔬3 аналитика данных
📊5 аналитика данных
Группа данных организационная структура
Группа данных 15Gifts включает трех специалистов по обработке данных и пять аналитиков, которые подчиняются руководителю отдела данных.
Планы роста
Питер не считает, что команда укомплектована должным образом, но добавляет: «В настоящее время мы нанимаем специального специалиста по обработке данных для управления производительностью инфраструктуры данных».
Чарли Мур
Вице-президент по финансам и операциям
Отрасль : Электронная торговля
Размер компании : 35 сотрудников
Цифры
⚡️3% организации, ориентированной на аналитику
🔎30% организации удобно использовать Инструмент бизнес-аналитики
🔬1 специалист по данным (анализ данных)
⚙️Консультант по аналитике (предоставление данных)
Организационная структура группы обработки данных
Сегодня группа специалистов по обработке данных Мака Велдона состоит из одного специалиста по данным и консультационной поддержки из Fishtown Analytics. Когда группе требуется новый тип анализа, они сами делают это, используя Looker, для запроса данных, которые были очищены и подготовлены с помощью dbt.
Когда группе требуется новый тип анализа, они сами делают это, используя Looker, для запроса данных, которые были очищены и подготовлены с помощью dbt.
Этой настройки было достаточно, чтобы довести их до сегодняшнего состояния, но Чарли планирует быстро расширить возможности внутренней аналитики: «Я бы хотел, чтобы к середине следующего года в нашей команде было 3-4 человека». Этот план исходит из внутреннего обдумывания того, как Мак Уэлдон хочет структурировать команду данных в долгосрочной перспективе. Они остановились на централизованной аналитической команде со специализированными аналитиками (первая из этих ролей сейчас открыта здесь).
Эта централизованная группа продолжит подчиняться отделам финансов и операций. «Мы хотели, чтобы наша группа по обработке данных была кросс-функциональной и не поддавалась влиянию какого-либо отдельного бизнес-подразделения», — сказал Чарли. «Мы хотели централизовать все наши инструменты обработки данных и иметь единый источник достоверных данных, которые передавались от нашей группы обработки данных к другим группам».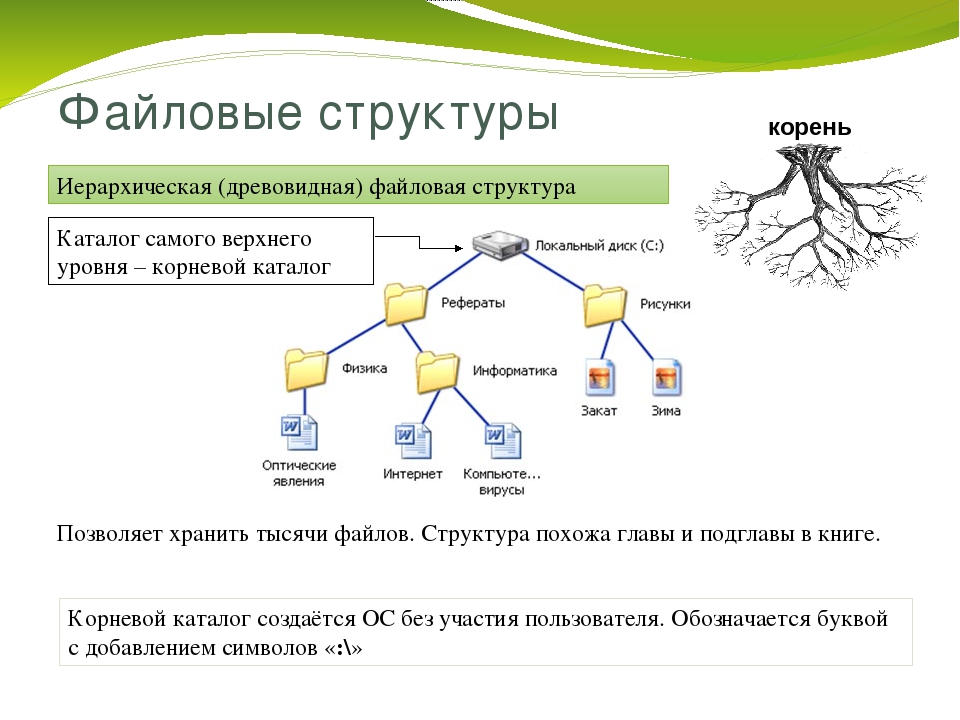
Управление данными с помощью организационной структуры
Организации должны взять на себя ответственность за данные из ИТ, как я утверждал в своем последнем посте.Большинство комментаторов согласились. Совершенно естественно, что некоторые задались вопросом, на что возложить эту ответственность. Я намекнул на федеративный подход, но не сообщил никаких подробностей. Вот несколько из них. В частности, я считаю, что управление людьми является хорошей моделью для начала.
Особенность управления людьми, которая меня больше всего поражает, — это то, как работа разделяется и вовлекает всех. У кадровых групп есть много собственных линейных обязанностей, таких как планирование преемственности, установка шкалы заработной платы и выбор пакета льгот.Они также работают с другими отделами, помогая нанимать и обучать нужные им человеческие способности. Тем не менее, большая часть управления людьми фактически осуществляется в ходе повседневной работы менеджерами и сотрудниками.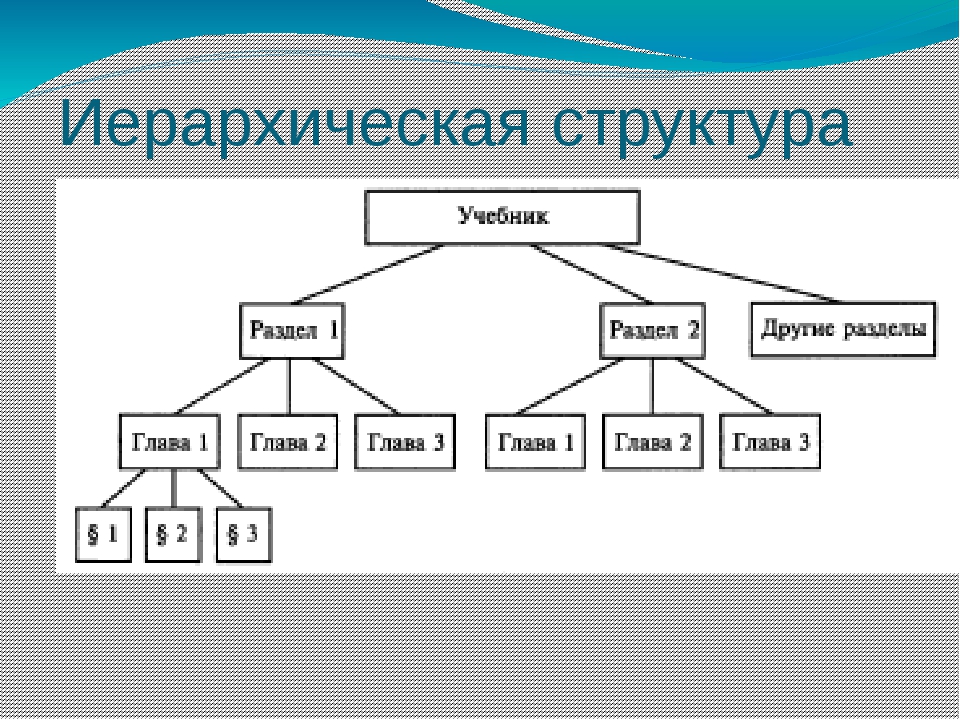 HR вполне может определить процесс полугодовой проверки эффективности, предоставить необходимые формы и убедиться, что он выполняется. Но оценка эффективности выполняется сотрудниками и руководителями.
HR вполне может определить процесс полугодовой проверки эффективности, предоставить необходимые формы и убедиться, что он выполняется. Но оценка эффективности выполняется сотрудниками и руководителями.
Этот последний пункт затрагивает самую суть федеративной модели. Корпоративный HR устанавливает политику; отдел HR может модифицировать его в соответствии с конкретными потребностями; и отделы, менеджеры и сотрудники проводят эту политику.У большинства есть определенная степень свободы в том, как они это делают.
Что предлагает разделение работы для данных? Как и в случае с управлением людьми, большая часть работы по созданию, хранению, управлению, использованию и доставке данных клиентам выполняется людьми в рамках процессов и отделов, и они должны быть полностью вовлечены. Практически каждый является одновременно создателем данных и покупателем. В этом заключается настоящая работа по управлению данными и их использованию. И именно здесь должна лежать большая ответственность за данные.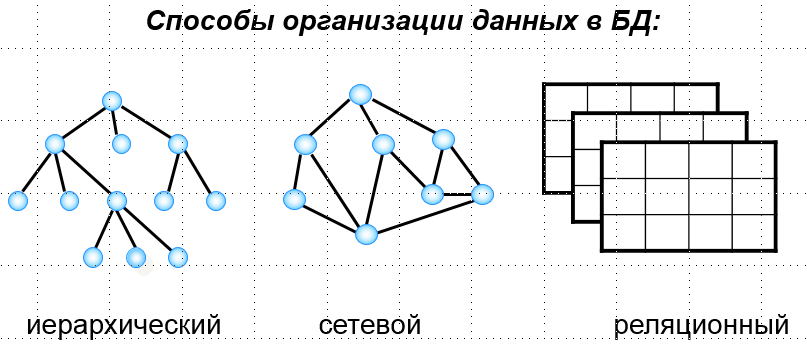
Корпоративные и ведомственные группы данных (ГД) должны устанавливать и администрировать политику, которая помогает отдельным лицам, процессам и отделам понимать и выполнять свои обязанности в соответствии с высокими стандартами. Например, политика качества данных должна предписывать создателям данных создавать данные в соответствии с потребностями тех, кто их использует, и чтобы заказчики данных разъясняли эти потребности.
Помимо своей роли по установлению политик, у корпоративного DG есть как минимум две важные функции.Некоторые данные имеют особое значение, потому что они принадлежат исключительно компании, что дает ей потенциал для устойчивого конкурентного преимущества. Корпоративный генеральный директор играет особую роль в выявлении, защите и обогащении этих данных.
Корпоративный DG также должен владеть процессами сквозных метаданных. Легко отвергнуть метаданные как технические тайны, но некоторые метаданные, включая определения данных, модели данных, некоторые стандарты, происхождение и ограничения использования, могут быть чрезвычайно важны. При правильном использовании метаданные упрощают понимание, доверие и обмен данными для всех остальных.
При правильном использовании метаданные упрощают понимание, доверие и обмен данными для всех остальных.
отделов помогают назначенному им отделу собирать и / или создавать разнообразие и глубину необходимых данных. Они могут работать напрямую с внешними поставщиками, измерять уровни качества в соответствии с требованиями политики, руководить проектами улучшения и помогать квалифицировать технологии, обеспечивающие доступ к данным.
В некоторых компаниях высокопоставленные специалисты по обработке данных, архитекторы и другие подчиняются таким отделам генерального директора.Это наиболее уместно, когда аналитическая работа должна быть «близкой к линии, но не в рамках». В других компаниях (и как я советовал) тем, кто стремится сделать открытия, меняющие отрасль, следует организовать своих специалистов по обработке данных подальше от линии, в их эквиваленте «лаборатории».
Понятно, что предстоит еще много работы. Основываясь на управлении качеством в производстве, усилиях ведущих информационных компаний, опыте работы в великих лабораториях Bell и полезности модели управления персоналом, я считаю, что около 2% сотрудников ведущей компании будут подчиняться корпоративной Генеральный директор, департаментский генеральный директор и лаборатория данных. Хотя специалисты по обработке данных привлекают наибольшее внимание, потребуются специалисты по разным специальностям, включая качество, моделирование, архитектуру, технологии управления данными и некоторые из них, которые мы еще не обозначили.
Хотя специалисты по обработке данных привлекают наибольшее внимание, потребуются специалисты по разным специальностям, включая качество, моделирование, архитектуру, технологии управления данными и некоторые из них, которые мы еще не обозначили.
Взятые вместе, эти моменты представляют собой кардинальные изменения в мышлении, особенно для тех, чьим старшим специалистом по работе с данными является технический архитектор, похороненный глубоко в недрах ИТ. Это не годится. Точно так же, как руководитель отдела кадров входит в число нескольких топ-менеджеров компании, данные требуют очень высокого руководства.Частично благодаря развитию больших данных назревает полномасштабная информационная революция. Люди и организации начинают более полно понимать, что все данные, а не только большие данные, являются активами с огромным потенциалом. Ускорение этого понимания, создание необходимых организационных возможностей, обсуждаемых здесь, и сосредоточение усилий — важная работа, которая мотивирует призыв к истинному руководителю данных уровня С.
Я думаю, что цифра 2%, да и весь этот пост, для многих шокирует.И после того, как они задумались, я надеюсь, они осознают, насколько остро эти темы требуют внимания. Во времена больших перемен удача благоволит смелым. Лови момент!
Пожалуйста, присоединяйтесь ко мне на вебинаре HBR, который я провожу, «Организационные императивы в эпоху больших данных», 5 декабря. Нажмите здесь, чтобы зарегистрироваться.
Какой должна быть организационная структура Google Analytics? | Жюльен Кервизич | Взлом Analytics
Каковы преимущества и недостатки разных структур?
Аналитические организации, как правило, создаются по-разному в зависимости от конкретных компаний, которые их создали, будь то с точки зрения линий отчетности, сегментированных или центральных групп или с точки зрения общей направленности (проект vs.продукт / бизнес). Каждый из этих атрибутов приносит свой собственный набор компромиссов, которые необходимо понимать и управлять ими.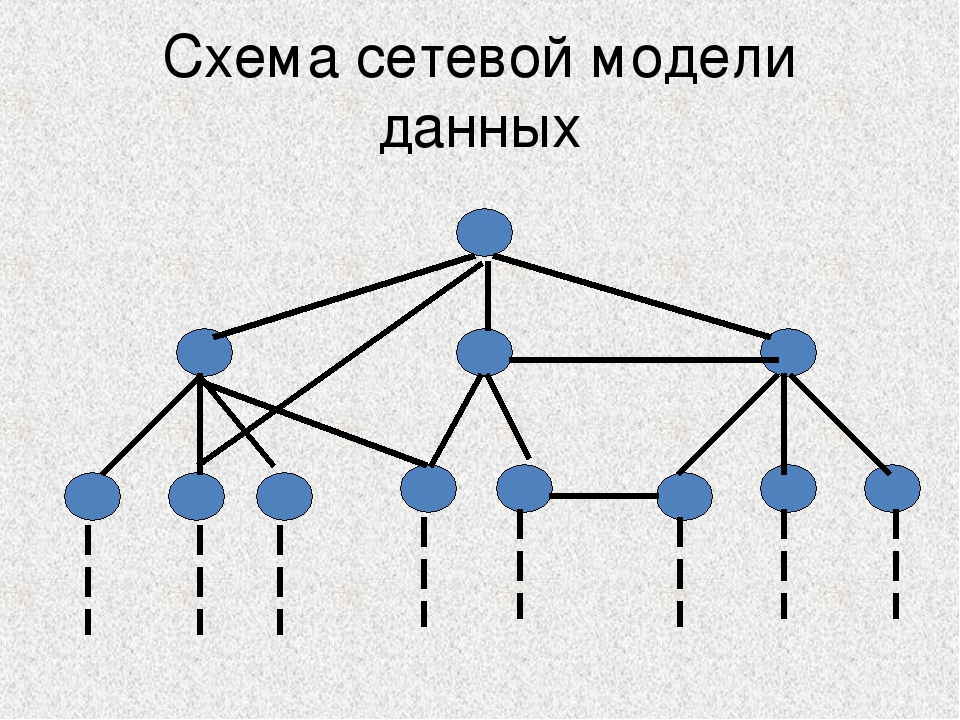
За годы работы в качестве специалиста-аналитика у меня была возможность поработать в различных отраслях и сферах бизнеса. Иногда аналитика относилась к бизнесу или продуктам, иногда — к финансам, а иногда — к технологиям. Amazon, например, имел тенденцию помещать аналитику и бизнес-аналитику в отдел финансов, а обработка данных — в технологический отдел, в то время как в Facebook была центральная аналитическая группа с подсегментами, отделенными от различных компонентов продукта.
Строки отчетности в значительной степени определяют приоритеты, которые в конечном итоге устанавливаются для аналитической группы. Финансы уделяют особое внимание контролю, продукты — расстановке приоритетов, а также бизнес-кейсам и технологиям для построения потоков данных.
Еще одно влияние линии отчетности — это процесс отбора специалистов по работе с данными, особенно в тех областях, где невозможно укомплектовать полную команду данных.
Существуют различные преимущества и недостатки сегментированных и центральных команд, которые необходимо учитывать. Структура влияет на прием на работу, обмен знаниями, сотрудничество, карьерный рост, фокус и объективность организации. Каждым из этих компромиссов необходимо управлять, чтобы обеспечить успешную организацию.
Структура влияет на прием на работу, обмен знаниями, сотрудничество, карьерный рост, фокус и объективность организации. Каждым из этих компромиссов необходимо управлять, чтобы обеспечить успешную организацию.
Наем персонала
Команда централизованной аналитики обычно использует более структурированный подход к найму, чем сегментированные команды. Они могут устанавливать и обеспечивать соблюдение стандартов найма в отношении выполняемых ими функций. Как правило, у них стандартный цикл собеседований, и они могут лучше набрать интервьюеров из разных аналитических специальностей.Сегментированные команды, как правило, будут уделять меньше внимания и способности проверять аналитические знания разных кандидатов и, таким образом, могут ценить более разный набор навыков.
Еще одно преимущество с точки зрения приема на работу — это возможность более легко назначить хороших кандидатов в другой сфере деятельности. Например, если хороший кандидат проходил собеседование на должность аналитика, которая тем временем была заполнена, ему / ей, возможно, придется повторно пройти собеседование на другую должность аналитика в компании с сегментированной аналитической командой, находясь в одной команде с центральной командой.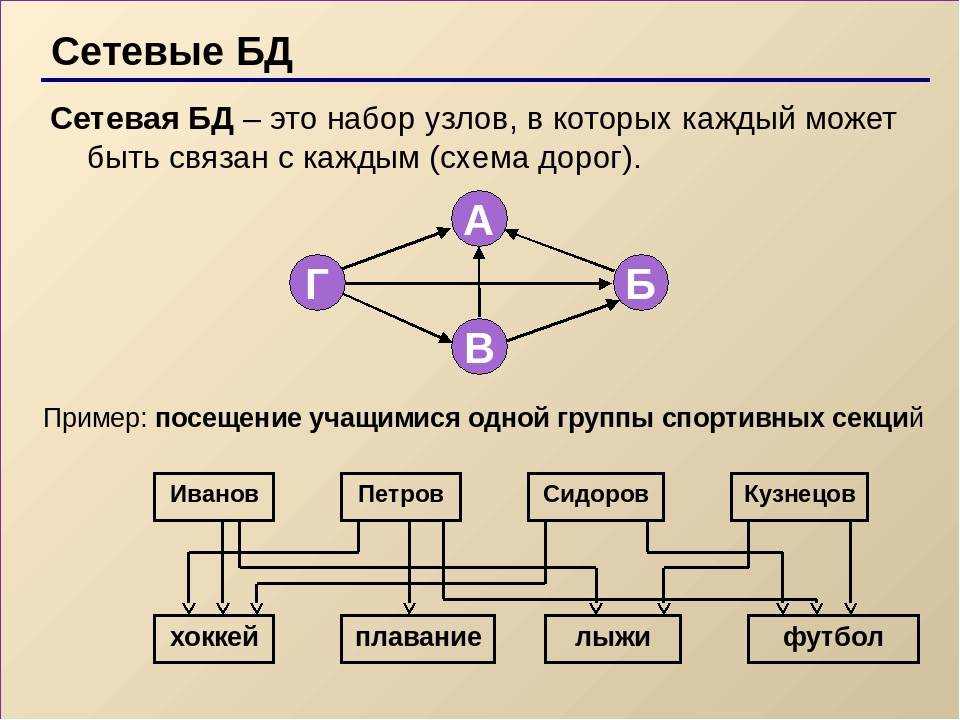 , до тех пор, пока существует общая численность персонала на уровне компании, ему / ей можно было бы напрямую предложить эту работу.
, до тех пор, пока существует общая численность персонала на уровне компании, ему / ей можно было бы напрямую предложить эту работу.
Обмен знаниями и совместная работа
Аспект, который отличает сегментированную команду от центральной — это подход к обмену знаниями и сотрудничеству внутри аналитических групп. В центральных аналитических группах обмен знаниями может происходить разными способами: через совместную работу над одним и тем же проектом, когда возникнет необходимость, через ротацию и передачу проектов, через наставничество или типичные презентации или проверки кода. В группах сегментированной аналитики обмен знаниями в рамках данных необходимо будет продвигать более быстрыми темпами, сегментированные команды, как правило, извлекают выгоду из более активного участия в конкретном бизнесе, которым они занимаются, за счет более широкого участия аналитиков.
Карьерный путь
Учитывая, что значительная часть роста в ролях данных происходит за счет практической работы над проектами с другими специалистами по данным и передачи сложных проектов в определенных аналитических областях, формат группы сегментированных данных препятствует росту по служебной лестнице аналитиков.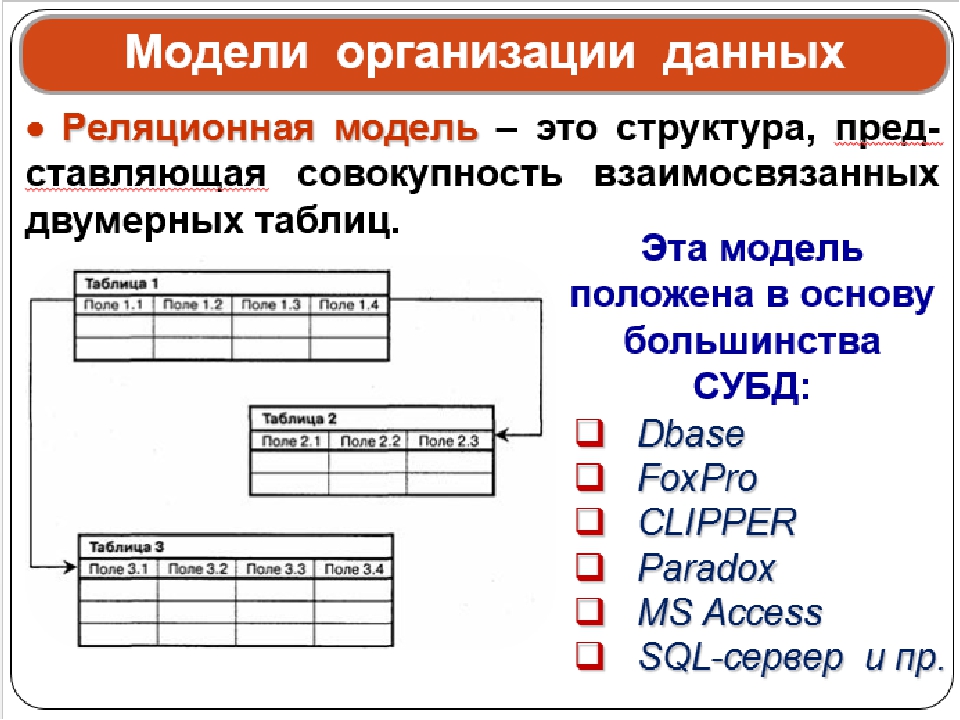 . Чаще всего для людей, сделавших свою карьеру в группах сегментированных данных, естественный карьерный рост происходит в сторону бизнес-ролей или продуктовых ролей, а не в сторону более высоких должностей аналитиков.
. Чаще всего для людей, сделавших свою карьеру в группах сегментированных данных, естественный карьерный рост происходит в сторону бизнес-ролей или продуктовых ролей, а не в сторону более высоких должностей аналитиков.
Focus
Команда сегментированной аналитики обычно нанимает на специалистов широкого профиля больше, чем группы центральной аналитики. Центральные группы выигрывают за счет экономии за счет масштаба и специализации и, следовательно, могут легче распределять обязанности между различными должностными инструкциями, такими как аналитики, инженеры по обработке данных, специалисты по обработке данных, … В то время как в сегментированных командах может быть только 1 или 2 специалиста по данным, поддерживающих данный бизнес не оставляет простора для специализации. Специалист по данным в этих командах должен быть мастером на все руки.
Команды сегментированных данных в силу сосредоточения на одной области бизнеса, как правило, имеют более глубокую направленность , чем центральная аналитическая группа, которая может легче перемещаться между проектами и сферами бизнеса. Более глубокая направленность дает преимущество в том, что позволяет специалисту-аналитику легче узнать, какое поведение ожидается и какие аномалии вы увидите в данных, а также позволяет специалисту-аналитику лучше избегать различных ловушек в данных. данные.Тем не менее, более широкий подход , предлагаемый центральной аналитической группой, дает также свой собственный набор преимуществ, таких как возможность использовать передовой опыт и возможность более простого переноса методов из других частей бизнеса.
Более глубокая направленность дает преимущество в том, что позволяет специалисту-аналитику легче узнать, какое поведение ожидается и какие аномалии вы увидите в данных, а также позволяет специалисту-аналитику лучше избегать различных ловушек в данных. данные.Тем не менее, более широкий подход , предлагаемый центральной аналитической группой, дает также свой собственный набор преимуществ, таких как возможность использовать передовой опыт и возможность более простого переноса методов из других частей бизнеса.
Объективность
Хотя сегментированные команды, подотчетные финансовым отделам, могут обладать определенной независимостью, приносящей определенную степень объективности, это не всегда так, когда специалисты по работе с данными отчитываются перед бизнесом. На специалистов-аналитиков может быть оказано давление, чтобы они сообщали числа определенным образом или высказывали мысли, которые им не нравятся.В таких случаях центральная аналитическая группа помогает обеспечить определенную независимость.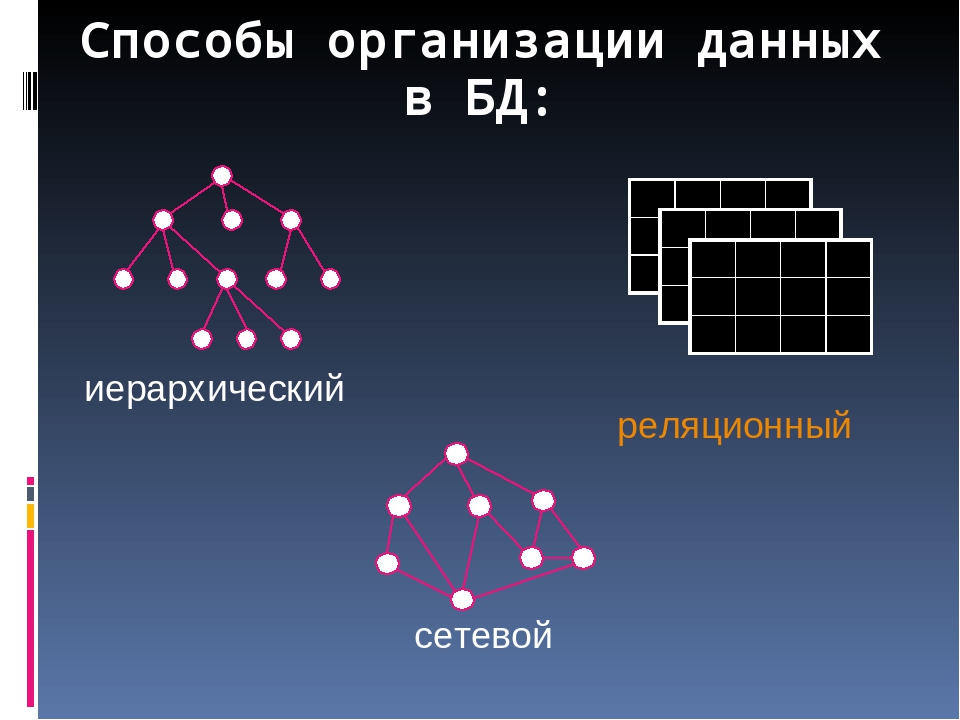
Матричная организация
Матричная организация помогает сочетать преимущества группы сегментированной аналитики и преимущества центральной группы, отделяя их членов от конкретных бизнес-задач. Специалисты-аналитики могут получить более глубокое понимание бизнеса, сохранив при этом все преимущества центральной аналитической группы с точки зрения найма, карьерного роста, обмена знаниями и объективности.
В некоторых организациях, помимо непосредственного линейного управления, есть также вопросы о том, как набрать специалистов-аналитиков.Будь то проект или назначение напрямую бизнесу или линейке продуктов.
Большая часть ценности аналитики достигается за счет настройки процесса измерения производительности и перевода процессов в состояние контроля. Таким образом, важно иметь по крайней мере владельца аналитики, который будет доступен для мониторинга производительности и выполнения таких действий, как обновление модели машинного обучения или непосредственное глубокое погружение в наборы данных, чтобы исправить данные или определить бизнес-проблему, нуждающуюся в исправлении.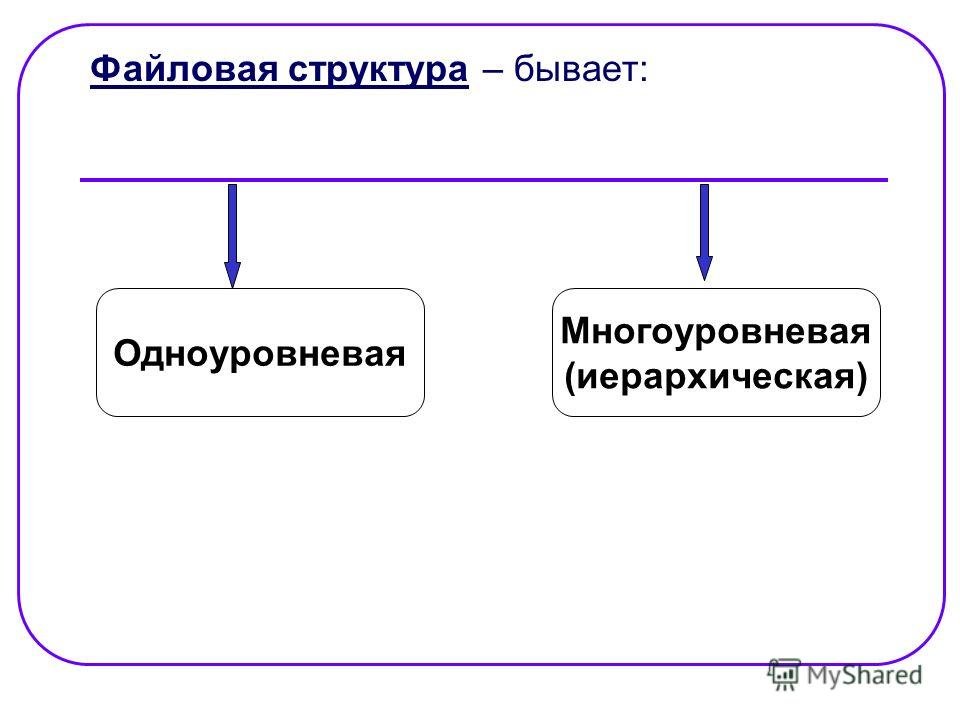
Тем не менее, фокус проекта может иметь значение для определенных аналитических задач, будь то предоставление временного облегчения в случае пиковой нагрузки или необходимости сначала доказать ценность инвестиций в определенные области. Эти типы проектной работы также могут быть полезны специалистам-аналитикам для открытия различных областей предметной области.
Существуют компромиссы, которые необходимо учитывать при создании аналитической организации. Обычно они упрощаются до степени сосредоточенности на данных или бизнеса.Однако есть несколько аспектов и способов смягчить определенные компромиссы. Выделенная центральная аналитическая организация может, например, иметь матричную структуру, чтобы помочь им лучше понять конкретный бизнес-образ мышления и приоритеты.
Как структурировать организацию данных — Бен Саллинс
Каков наиболее оптимальный способ структурировать организацию данных для максимального воздействия на ваш бизнес и ваших клиентов?
Я потратил несколько лет на организацию и развитие групп обработки данных, и у меня есть некоторые результаты, которыми я могу поделиться…
Сегодняшний деловой мир требует групп адаптивных данных, которые могут добиться результатов раньше, чем люди о них просят. Как группа данных, мы должны заранее продумать, какие запросы мы получим, и начать упреждающий сбор и структурирование данных для анализа. Таким образом, когда возникают вопросы, мы хорошо подготовлены к тому, чтобы дать рекомендации лицам, принимающим деловые решения.
Как группа данных, мы должны заранее продумать, какие запросы мы получим, и начать упреждающий сбор и структурирование данных для анализа. Таким образом, когда возникают вопросы, мы хорошо подготовлены к тому, чтобы дать рекомендации лицам, принимающим деловые решения.
В первую очередь вам нужна поддержка руководства. Без этого у вас будет мало шансов на успех, поскольку ресурсы и руководство, необходимые для любого бизнеса, существенны.
Давайте посмотрим, как данные преобразуются из необработанных битов в значимые идеи.
Данные создаются в нескольких местах, как правило, для большинства организаций. Оттуда данные поступают в промежуточную среду бэк-офиса, обычно некую форму базы данных, а затем преобразуются с помощью методов моделирования данных в пригодные для использования наборы данных для анализа.
После того, как данные собраны, организованы, очищены и структурированы в удобном для человека формате, ваши аналитики и специалисты по данным могут начать использовать их для решения бизнес-задач.
Это подводит нас к трем командам, которые, как я считаю, необходимы, чтобы дать вашей команде по обработке данных максимальные возможности для положительного влияния на бизнес.Вот эти три команды и их обязанности:
Разработка данных
- Создание платформы для сбора, организации и анализа всех данных
- Загрузка всех данных на эту платформу
- Очистить данные, загруженные в платформу данных
- Подготовка данных для анализа на основе указаний разработчиков моделей данных и аналитиков данных / ученых
- Обслуживание и поддержка этих сред для обеспечения надежности и производительности
Аналитика данных
- Работа с Data Engineering для обеспечения правильной структуры и полноты данных для анализа
- Поддержите лиц, принимающих деловые решения, предоставив простые в использовании инструменты для работы с данными и инструкции по их использованию
- Координировать с командой Data Science более глубокие исследования, которые необходимо провести, и любые предварительные выводы
- Разработка и предоставление аналитической платформы для бизнес-пользователей для поиска данных и взаимодействия с ними
Наука о данных
- Работа с группами разработки и анализа данных для обеспечения сбора и организации достаточного количества данных для надлежащего использования
- Работа с бизнес-пользователями для поддержки принятия стратегических решений, которые окажут большое влияние на бизнес или клиентов
- Работа с аналитикой данных, чтобы открывать более глубокие вопросы для изучения с помощью статистических методов и методов машинного обучения
- Создание интеллектуальных систем, которые могут улучшить бизнес-процессы и продукты
- Предоставлять рекомендации и наставничество бизнес-группам и группам по продуктам по правильной интерпретации данных и способам проверки гипотезы
С этими тремя командами, работающими вместе, вы настроитесь на успех. В следующих статьях я планирую более подробно остановиться на ключевых компонентах каждой из этих областей, чтобы вы могли понять, что на самом деле потребуется, чтобы стать организацией, управляемой данными.
В следующих статьях я планирую более подробно остановиться на ключевых компонентах каждой из этих областей, чтобы вы могли понять, что на самом деле потребуется, чтобы стать организацией, управляемой данными.
Что такое структура данных? Использование базовых структур данных для организации, как Марта Стюарт
Как Марта Стюарт может иметь какое-либо отношение к сообщению в блоге под названием «Что такое структура данных?» Оставайтесь с нами, и мы обещаем объяснить, как Марта может научить нас основным и расширенным структурам данных.
Думая о структуре данных, подумайте о ключах от машины. Предположим, вы теряли ключи от машины хотя бы раз в неделю, и, похоже, нет никакой закономерности, где они оказываются. Но, увы, ты немного накопитель: тебе приходится проскальзывать боком через дверные проемы из-за груд журналов, детских игрушек и коробок, сложенных до потолка. Как вы думаете, сколько времени потребуется, чтобы найти ключи?
Но что, если бы ваш дом был организован как у Марты Стюарт: предметы распределены по категориям; подобное хранится с подобным, выстраиваясь в приятном симметричном порядке.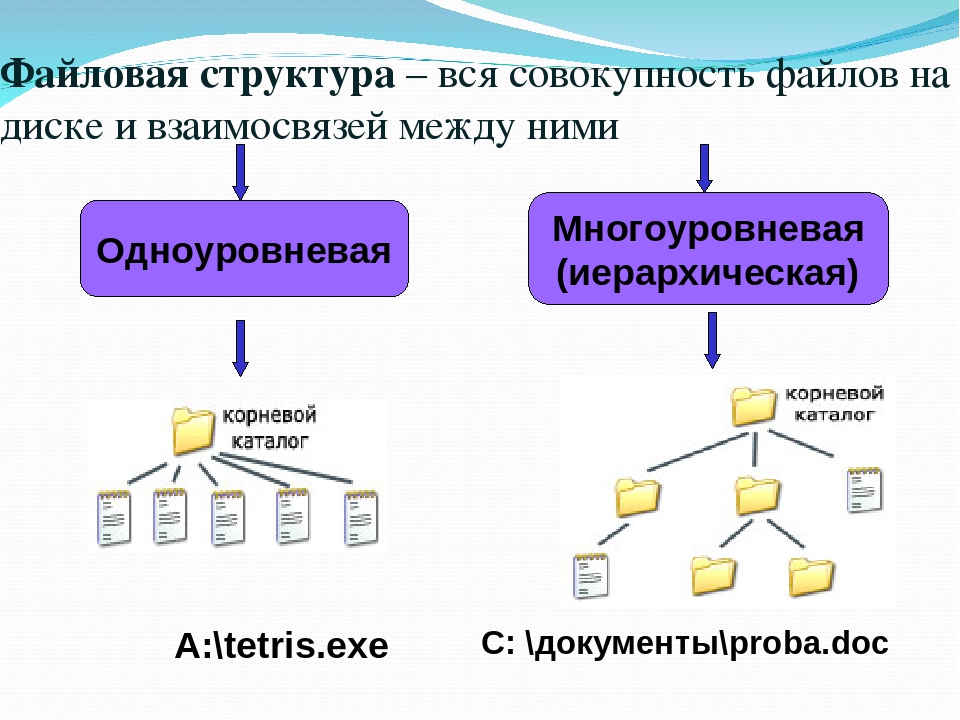 Насколько легко было бы найти там ключи от машины? Представьте себе структуру данных, как если бы она была компьютерной версией Марты Стюарт.
Насколько легко было бы найти там ключи от машины? Представьте себе структуру данных, как если бы она была компьютерной версией Марты Стюарт.
Почему важна структура данных
Когда вы имеете дело с терабайтами и петабайтами данных, которые вам так или иначе необходимо проанализировать и осмыслить, масштаб проблемы явно более сложен, чем поиск набора ключей от машины. Таким образом, основные структуры данных используются для следующих целей:
- Входная информация
- Информация о процессе
- Получение информации
- Ведение информации
Структуры данных — это средства, с помощью которых вы можете вводить и систематизировать данные, чтобы что-то делать. с этим.Алгоритм программы отвечает за часть «что-то с ним сделать» — это базовая логика, которая обрабатывает и выполняет операции с вашими данными, поэтому структуры данных и алгоритмы неразрывно связаны.
Когда вы что-то запрашиваете — например, вы хотите знать в режиме реального времени, как ваши клиенты говорят о вашем продукте во всех социальных сетях, — скорость и эффективность вашего поиска имеют первостепенное значение.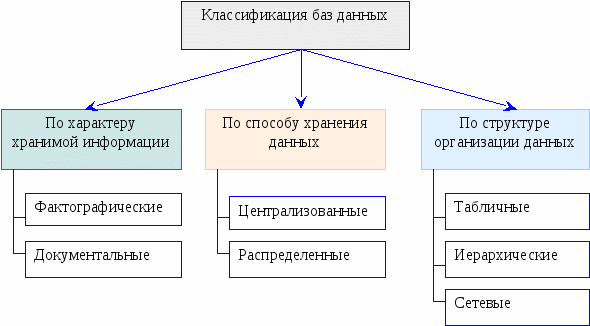 Структурирование данных является ключом к максимальной скорости и эффективности вашего поиска, чтобы вы могли как можно быстрее приступить к анализу.
Структурирование данных является ключом к максимальной скорости и эффективности вашего поиска, чтобы вы могли как можно быстрее приступить к анализу.
И со временем структуры данных становятся ключом к поддержанию данных. Структура данных является основой для добавления четких метаданных и основой для применения методов очистки данных, которые обеспечивают полезность и актуальность данных.
Примеры структур данных
Существует много типов структур данных, и знание того, какую из них использовать, является ключом к правильной организации. Чтобы иметь хорошо отлаженную машину, не всегда нужны сложные и продвинутые структуры данных. Часто простые решения оказываются наиболее эффективными.Вот несколько основных структур данных:
- Массивы — это список фиксированной длины, состоящий из набора объектов или значений; это самая основная структура данных. Массив позволяет определять положение каждого объекта или значения с помощью математической формулы. Пример: подсчет результатов гонок на поле из 300 бегунов.
- Очереди структурируют данные в порядке «первым пришел — первым ушел». Как и в реальной очереди (или очереди) людей в банке, первый прибывший также уходит первым.Пример: обслуживание запросов на печать на одном общем принтере.
- Стекирует структурных данных в порядке «последний пришел — первый ушел». Пример: отмена действия в компьютерной программе (один из наиболее распространенных примеров — кнопка «Назад» в вашем браузере).
- Деревья — это иерархическая структура данных, состоящая из одного или нескольких узлов данных. Первый узел называется корнем; каждый узел может иметь ноль или более дочерних узлов. Хотя деревья можно рассматривать как одну из основных структур данных, правильнее было бы сказать, что они являются фундаментальной структурой.Потому что древовидная иерархия часто используется при построении некоторых из наиболее сложных структур данных. Пример: хранение данных, которые естественным образом образуют иерархию, например организационную диаграмму.
 Пример: подсчет результатов гонок на поле из 300 бегунов.
Пример: подсчет результатов гонок на поле из 300 бегунов.
При выборе собственной структуры данных важно однозначно оценить имеющуюся информацию — не существует единой структуры данных, которая оказалась бы лучшей для всех ситуаций. Например, для чего предназначены данные? И подходят ли для этой цели определенные структуры данных? Как бы вы хотели искать свои данные? Что для вас важнее: вставка элементов в структуру данных или доступ к элементам?
Часто приходится идти на компромисс между созданием настраиваемой структуры данных, которая лучше всего подходит для ваших предполагаемых целей, и использованием более общей структуры, которую будет легче поддерживать с течением времени.В этом случае лучше всего посмотреть на долговечность проекта. Это то, что будет использоваться в течение многих лет или у него более короткий срок службы?
Однако во многих случаях вы не можете контролировать структуры данных, с которыми работаете. В частности, внешние данные могут поступать во всех различных структурах и форматах — если вы хотите использовать их, вы должны работать с особыми проблемами и ограничениями этой структуры.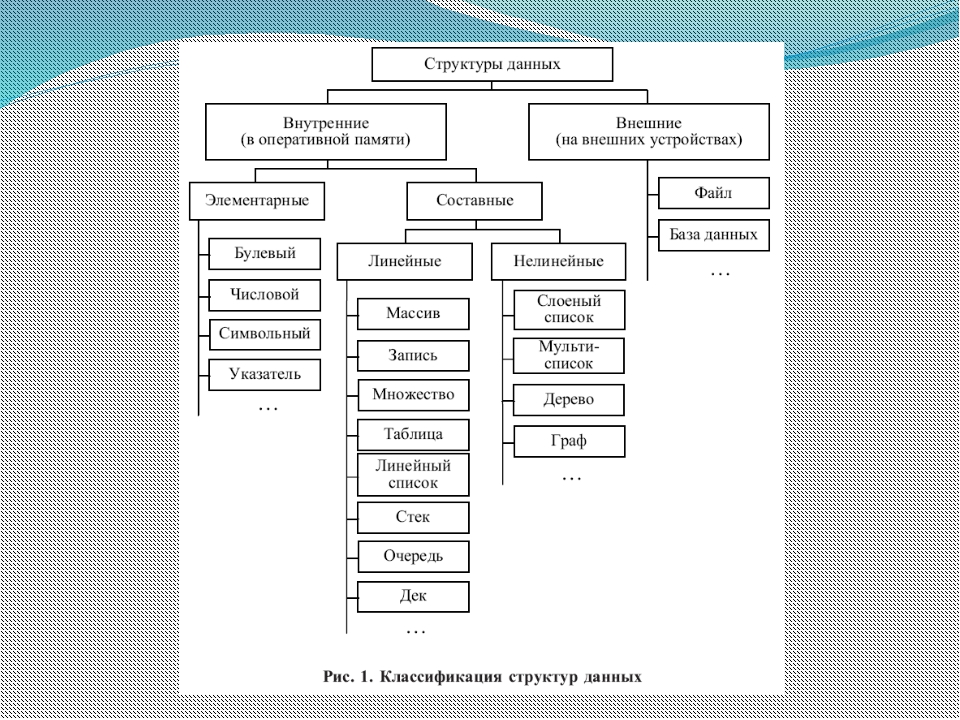 Важно оставаться гибким и иметь правильные инструменты для работы со всеми видами структур данных.
Важно оставаться гибким и иметь правильные инструменты для работы со всеми видами структур данных.
«Обработка данных» — это процесс получения данных в их исходном формате и их использования для анализа. Структурирование данных — только один из шести процессов, участвующих в обработке данных, но структурирование данных является неотъемлемой частью успеха ваших усилий по работе с большими данными:
«Если вы поговорите с любым специалистом по данным, который стоит их силы, он скажет вам, что первый Задача использования данных для вашего бизнеса заключается в том, чтобы преобразовать их в структурированный формат, чтобы вы могли анализировать, интерпретировать и принимать решения на основе своих данных.Это с любовью называется «борьба с данными», и это то, что поглощает большую часть непродуктивного (расточительного) времени (4 дня из 5, по мнению большинства пользователей). Это потому, что вместо того, чтобы тратить время на изучение данных, вы тратите время, пытаясь собрать все воедино в удобном формате. Это то, что обычно создает узкие места в любой организации ».
Это то, что обычно создает узкие места в любой организации ».
Что такое структура данных? Короче говоря, это первый важный шаг к тому, чтобы сделать что-то полезное с вашими данными.
Структура вашей группы данных.Поток данных в вашей организации.
У небольших компаний есть небольшие группы обработки данных (может быть, всего один человек), у более крупных компаний — большие. Хитрость в том, что несколько различных аспектов проекта данных требуют нескольких очень разных навыков.
Как вы должны создать команду по обработке данных, чтобы эти навыки лучше всего работали вместе? Я покажу вам вымышленный стартап.
Ваш выдуманный стартап летает! Ура.
Примечание. В качестве примера я попытался придумать стартап, которого определенно не существует. Но вы можете применить схему, которую я собираюсь показать вам, к любому онлайн-бизнесу.
Хорошо. Допустим, вы являетесь одним из основателей Adtrefa. io ( Ad opt tre es f rom A ustralia)! Вам пришла в голову замечательная идея помочь людям усыновить деревья из Австралии. Круто. Вы уже создали веб-приложение — и оно работает! За один месяц у вас их 10.000 пользователей. Затем в следующем месяце еще 10.000. Вы постоянно растете, мечта сбывается.
io ( Ad opt tre es f rom A ustralia)! Вам пришла в голову замечательная идея помочь людям усыновить деревья из Австралии. Круто. Вы уже создали веб-приложение — и оно работает! За один месяц у вас их 10.000 пользователей. Затем в следующем месяце еще 10.000. Вы постоянно растете, мечта сбывается.
Как мудрый основатель стартапа вы знаете, что:
- да, ваши инстинкты сработали, вы создали великое дело, о котором люди заботятся, а теперь
- пришло время понять ваших пользователей и привлечь к работе своего первого специалиста по обработке данных.
Но прежде чем вы начнете нанимать, стоит понять, как анализ данных и наука о данных работают в онлайн-бизнесе, подобном вашему. Ну вот!
Поток данных в разных группах данных.
Во-первых, давайте посмотрим, как уже существующие группы обработки данных делают это в более крупных компаниях.
Обычно весь процесс начинается с группы отслеживания , которая отвечает за сбор данных. Они передают данные группе Data Infrastructure Team , которая заботится о хранении данных. На основе сохраненных (а иногда уже очищенных, реструктурированных и / или агрегированных) данных группа Analytics / Data Science Team выбирает то, что ей нужно для анализа, и превращает данные в значимые идеи.В конце концов, эти идеи попадают в менеджеров и лиц, принимающих решения , которые принимают меры на основе результатов!
Они передают данные группе Data Infrastructure Team , которая заботится о хранении данных. На основе сохраненных (а иногда уже очищенных, реструктурированных и / или агрегированных) данных группа Analytics / Data Science Team выбирает то, что ей нужно для анализа, и превращает данные в значимые идеи.В конце концов, эти идеи попадают в менеджеров и лиц, принимающих решения , которые принимают меры на основе результатов!
Различные задачи — в ваших проектах данных
Параллельно с диаграммой выше — это поток данных между различными задачами:
Он также имеет четыре основных шага:
- Сбор необработанных данных. Как это правильно делать? Я уже писал об этом подробную статью: Как работает сбор данных
- Хранение данных.Для деловых людей этот шаг может показаться банальным, но это не так. В онлайн-бизнесе создание хорошей инфраструктуры данных непросто или самоочевидно. Это не обязательно сложно, но полезно знать, что может возникнуть много технических вопросов, особенно по поводу масштабирования (которое может быть наиболее важным фактором для стартапа).
- Анализ данных. Это этап, на котором ваши данные превращаются в значимую информацию после применения различных методов исследования (например, когортного анализа, анализа воронки, сегментации, прогнозной аналитики и т. Д.).
- Принятие делового решения. Никогда не забывайте, что первоначальная цель вашего проекта данных заключалась в том, чтобы понять ваших пользователей и преобразовать данные в действия (например, усилия по оптимизации).
Вы можете разбить этот поток данных на более мелкие задачи, но я не буду вдаваться в подробности в этой статье.
Кроме того, некоторые люди утверждают, что здесь следует упомянуть очистку данных. Я не упомянул об этом, потому что очистка данных может происходить либо в рамках инфраструктуры данных, либо в рамках анализа данных, поэтому я не хотел указывать, кто из вашей группы данных должен это делать.
Различные навыки для разных шагов
Как я описал во вступлении: , сложность состоит в том, что разные части проекта данных требуют разных навыков.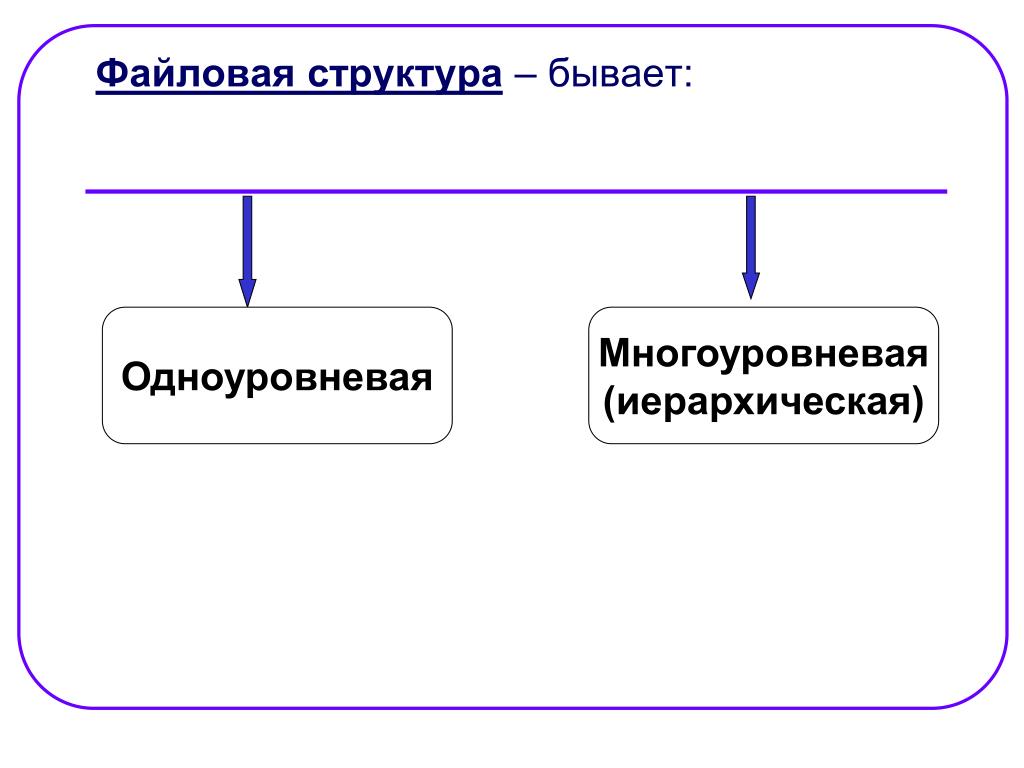
Часть сбора и хранения данных требует больших инженерных навыков. Аналитическая часть требует сочетания кодирования, статистики и бизнес-знаний. И, конечно же, для принятия решений нужен деловой настрой.
Но это не черное и не белое! Например. ни один из менеджеров не может принимать решения, не имея хотя бы высокого уровня понимания процесса проектирования.И ни один из инженеров не может построить значимую простую в использовании инфраструктуру, не зная бизнес-потребностей и аналитических потребностей.
Так кто чем занимается в вашей группе данных?
- На мой взгляд, сбор данных (он же отслеживание) должен выполняться теми же людьми, которые создают базу кода вашего продукта / веб-сайта. Почему? Скрипты отслеживания будут запущены в производство. Поскольку ваши разработчики лучше всех знают вашу кодовую базу, они смогут писать эти сценарии, ничего не нарушая.
- Хранилище данных должно быть создано экспертом по инфраструктуре данных. Наиболее распространенное название этой должности — Data Engineer .
- Аналитика и анализ данных выполняются экспертами по исследованию данных. Наиболее распространенные имена для этой должности: Data Analyst и / или Data Scientist . (Между ними есть небольшая разница. Подробнее читайте в моем видео на Youtube: Data Scientist или Data Analyst)
- И бизнес-решения принимаются руководством или другими лицами, принимающими решения.
 Наиболее распространенное название этой должности — Data Engineer .
Наиболее распространенное название этой должности — Data Engineer .Хорошо то, что у вас уже будет первый пузырь (разработчики) и последний пузырь (лица, принимающие решения) в вашей компании.Итак, вам нужно заполнить только позиции Data Engineering и Analytics…
Кого нанять первым? Аналитик данных или инженер данных?
Хороший вопрос! Вернемся к вымышленному стартап-проекту Adtrefa.io !
В компаниях среднего размера (~ 500 сотрудников) обычно есть не менее 3-4 инженеров по обработке данных в группе инфраструктуры данных и около 6-10 специалистов по обработке данных и аналитиков в группе аналитики (иногда специалисты по обработке данных и аналитики делятся на 2 команды). Конечно, точные цифры и точные структуры различаются от компании к компании.
Конечно, точные цифры и точные структуры различаются от компании к компании.
Ваша проблема — как стартапа — в том, что вы не можете и не хотите сразу нанять 10 человек для выполнения проектов по работе с данными.
В идеальном случае вы можете нанять двух человек:
- Инженер по данным, который отлично подходит вашим разработчикам с точки зрения инженерных навыков. (Свободно владеет языком программирования вашей платформы и общими языками данных.)
- И аналитик данных, который знает SQL и Python или R — и который очень талантлив в бизнес-мышлении.
Если вы можете нанять только одного человека, я бы сначала пошел с аналитиком данных — но в этом случае убедитесь, что он / она также имеет технические навыки выше среднего (желательно свободно владеет вышеуказанными языками: SQL + Python или Р). Если она хорошо разбирается в технических вещах, тогда она и ваши разработчики смогут построить «мост», пока вы не наймете своего первого инженера по данным. И с этим вы можете начать свой первый проект данных без хорошо налаженной инфраструктуры данных (команда).
И с этим вы можете начать свой первый проект данных без хорошо налаженной инфраструктуры данных (команда).
Если вы пойдете по этому пути, вашим вторым нанятым в группу данных определенно должен быть инженер по данным, который сможет сосредоточиться на создании инфраструктуры данных, которая будет масштабироваться вместе с вашей компанией, когда рост достигнет 1 или 10 млн пользователей.
Если вы правильно выполнили эти первые два приема данных, эти люди смогут посоветовать вам, как расширить вашу группу данных в будущем — исходя из своих потребностей.
Работаем вместе. Коммуникация через команду данных.
Связь является ключевым моментом.И это верно и для проектов данных. В ваших четырех командах данных — каждый должен говорить со всеми.
Когда разработчики передают данные группе инфраструктуры, они общаются и создают вещи вместе. В этом нет никаких сомнений.
Очевидно, что то же самое происходит, когда команда инфраструктуры передает данные группе аналитики и когда группа аналитики предоставляет аналитическую информацию менеджерам.
Но здесь я хотел бы подчеркнуть, что подгруппы, которые не находятся в ежедневном контакте друг с другом, также должны общаться! Например, менеджеры должны знать, чем занимаются инженеры данных.Это помогает им понять, например, почему серверы данных стоят так дорого и что это означает с точки зрения бюджета компании (чтобы они могли рассчитать рентабельность инвестиций проектов данных). Или другой пример: разработчики должны понимать, что делают аналитики / специалисты по данным, потому что это помогает им понять, какие данные нужно собирать. И так далее.
Заключение
Ваш поток данных проходит через эти четыре этапа:
- Коллекция
- Хранилище
- Анализ
- Решение.
И параллельно с этим над этим будут работать четыре подгруппы:
- Разработчики
- Команда инфраструктуры данных
- Аналитика данных / команда Data Science
- Менеджеры.
Каждый, кто участвует в этом процессе, должен иметь хотя бы общее представление обо всем этом процессе. Это единственный способ создать эффективную команду данных и превратить необработанные данные в значимые, полезные и успешные решения!
Это единственный способ создать эффективную команду данных и превратить необработанные данные в значимые, полезные и успешные решения!
Если вы хотите первым получать уведомления о новом контенте на Data36 (например, статьях, видео, справочниках и т. Д.)), Подпишитесь на мою рассылку!
Cheers,
Томи Местер
лучших практик для организационной структуры аналитики | Задайте вопросы эксперту | Весь контент MKC
30 сентября 2020 г.
Как я могу структурировать свою организацию, чтобы эффективно использовать свою аналитическую команду?
Создание успешной и эффективной команды маркетинговых аналитиков — непростая задача, особенно сейчас, когда технологии постоянно развиваются и развиваются, и за ними трудно успевать.Использование различных инструментов и подходов, когда дело доходит до сбора данных, их анализа и последующего создания действенных стратегий, — это многоуровневый процесс, который может улучшить измерения, аналитику, творческие и исследовательские способности бренда для взаимодействия с потребителями в нужное время. и место.
и место.
Однако речь идет не только о поиске правильных инструментов, но и о поиске правильной команды и поощрении неудач. Развитие культуры тестирования и обучения, а также культуры, в которой члены команды могут рисковать, имеет важное значение для роста.Ашиш Джоши, старший директор по глобальным данным, аналитике и науке о данных в The Clorox Co., объяснил на конференции ANA:
«У нас есть несколько докторов наук, несколько степеней магистра и несколько степеней бакалавра. Как правило, они связаны с количественными дисциплинами. Есть люди с опытом работы в области науки о данных, экономики и математики. Мы ищем несколько ключевых моментов. : количественные и технические навыки, деловая хватка, коммуникативные и межличностные навыки, а также креативность Многие проблемы, с которыми мы сталкиваемся ежедневно, требуют от нас поиска новых творческих решений.«
Джоши также отметил: «Что касается бизнес-идей, мы внедрили надежный процесс тестирования и провели около 50 рыночных экспериментов. Пятьдесят процентов были успешными; остальные 50 процентов потерпели неудачу. Наши менеджеры всегда говорил: «Ваш успех слишком высок. Вы недостаточно далеко продвигаетесь» ».
Пятьдесят процентов были успешными; остальные 50 процентов потерпели неудачу. Наши менеджеры всегда говорил: «Ваш успех слишком высок. Вы недостаточно далеко продвигаетесь» ».
Сначала создание прочного фундамента, а затем развитие аналитики было основным наблюдением в недавнем исследовании Gartner. Этот подход также означает, что компаниям необходимо сначала установить цели и ключевые показатели эффективности, чтобы понять, на что им обращать внимание и на чем сосредоточиться.Для многих компаний это означает инвестирование в возможности искусственного интеллекта для оптимизации процессов и экономии времени.
Эффективность — основная тема последних исследований и выбора технологий, которые однозначно соответствуют потребностям бренда. Отчет Deloitte за 2020 год показал, что 59 процентов респондентов глобального опроса ИТ-директоров Deloitte определили ИИ в качестве основной области инвестиций для своей организации, причем 70 процентов с вероятностью получат «возможности ИИ с помощью облачного корпоративного программного обеспечения», а 65 процентов с вероятностью создадут «приложения ИИ с облачные услуги разработки. «
«
Ниже приведены тематические исследования, примеры брендов и лучшие практики для структур аналитических организаций.
Тенденции и передовой опыт
- Развитие операционной модели аналитики может помочь продвинуть цифровые приоритеты компаний . Deloitte, 2020.
Пятьдесят девять процентов респондентов, опрошенных Deloitte Global CIO Survey, назвали искусственный интеллект и машинное обучение приоритетными областями для инвестиций своей организации. Облачные платформы данных и аналитика как услуга упростили и упростили доступ к аналитическим технологиям за счет гибких моделей потребления.«Делойт» проанализировал тенденции, обусловливающие растущую потребность организаций в расширенной аналитике и новой организационной структуре анализа данных, а также преимущества для организации в целом:
- Секрет гениальной организации маркетинговой аналитики . Gartner, 29 апреля 2019 г.
Исторически сложилось так, что большинство компаний были организованы и управлялись каналами и платформами. Но есть разница между тем, как вы организуете и как вы работаете. Однако сегодня современные организации движутся к индивидуальным сильным сторонам, расширению возможностей принятия решений и гибкой структуре.Изучив 10 000 объявлений о вакансиях, эксперты Gartner выяснили, как лучшие бренды создают успешные организации, занимающиеся маркетинговой аналитикой. Исследование данных также показало три набора новых навыков работы с данными и аналитикой: инженерия данных, наука о данных и передовая инженерия, визуализация и отчетность.

- Вот как получить максимальную отдачу от инвестиций в маркетинговую аналитику . Marketing Land, 19 апреля 2019 г.
Сегодня компании явно не демонстрируют стабильной окупаемости этих инвестиций — проблема, которая часто возникает из-за отсутствия лидеров в области маркетинговой аналитики и организационной структуры, необходимой для эффективного преобразования данных и идей в действия. Чтобы обсудить это более подробно, Marketing Land побеседовал с Gartner, чтобы узнать, что могут сделать директора по маркетингу и руководители маркетинга, чтобы опровергнуть прогнозы и добиться более высоких результатов в своих инвестициях в маркетинговую аналитику. В ходе беседы были обсуждены пять способов, с помощью которых директора по маркетингу могут повысить рентабельность инвестиций в маркетинговую аналитику, а также было подчеркнуто, почему это важно: - Постройте организационную структуру для применения более точных данных.
- Развивайте лидеров аналитики, которые объединяют науку о данных и маркетинговую стратегию.
- Наймите директора по аналитике или повысите важность аналитики.
- Сосредоточьтесь на лучших данных, а не на больших данных
- Отделите сигнал от шума для прогнозирования и оптимизации бизнес-результатов.
- Создайте команду мечты в области маркетинговых измерений . ANA, 5 сентября 2018 г.
Использование данных для реализации маркетинговой стратегии и установления связи с потребителями является одним из главных приоритетов директора по маркетингу. Но это непростое родео. Несмотря на то, что компании не страдают от недостатка данных, им часто не хватает таланта, необходимого для того, чтобы их заарканить.Сложная программа измерения и аналитики может добавить значительную мощность вашему маркетингу, от повышения качества обслуживания клиентов до создания конкурентного преимущества.Но если у команды нет навыков или времени, чтобы использовать идеи для разработки стратегии и принятия решений, она не сможет реализовать маркетинговые приоритеты. Что еще более важно, компания рискует отставать от более проницательных и ловких конкурентов. Тем не менее, чтобы работать в соответствии с высочайшими стандартами, каждая команда, занимающаяся измерением маркетинга, должна стремиться занять следующие должности с лучшими специалистами, которых они могут найти:
- Директор по науке о данных и аналитике.
- Переводчик данных или рассказчик
- Специалист по данным
- Маркетолог
- Системный интегратор
- Создание эффективной аналитической организации . McKinsey, 18 октября 2018 г.
Компания McKinsey провела обширный первичный опрос среди более чем 1000 организаций в разных отраслях и географических регионах, чтобы понять, как организации преобразуют данные расширенной аналитики в результаты и как компании смогли масштабировать аналитику на своем предприятии.В этой статье обсуждается, как спроектировать, внедрить и развить правильную организацию и таланты для трансформации расширенной аналитики. Для расширенного преобразования аналитики обычно требуются новые навыки, новые роли и новые организационные структуры.
 Чтобы обсудить это более подробно, Marketing Land побеседовал с Gartner, чтобы узнать, что могут сделать директора по маркетингу и руководители маркетинга, чтобы опровергнуть прогнозы и добиться более высоких результатов в своих инвестициях в маркетинговую аналитику. В ходе беседы были обсуждены пять способов, с помощью которых директора по маркетингу могут повысить рентабельность инвестиций в маркетинговую аналитику, а также было подчеркнуто, почему это важно:
Чтобы обсудить это более подробно, Marketing Land побеседовал с Gartner, чтобы узнать, что могут сделать директора по маркетингу и руководители маркетинга, чтобы опровергнуть прогнозы и добиться более высоких результатов в своих инвестициях в маркетинговую аналитику. В ходе беседы были обсуждены пять способов, с помощью которых директора по маркетингу могут повысить рентабельность инвестиций в маркетинговую аналитику, а также было подчеркнуто, почему это важно:
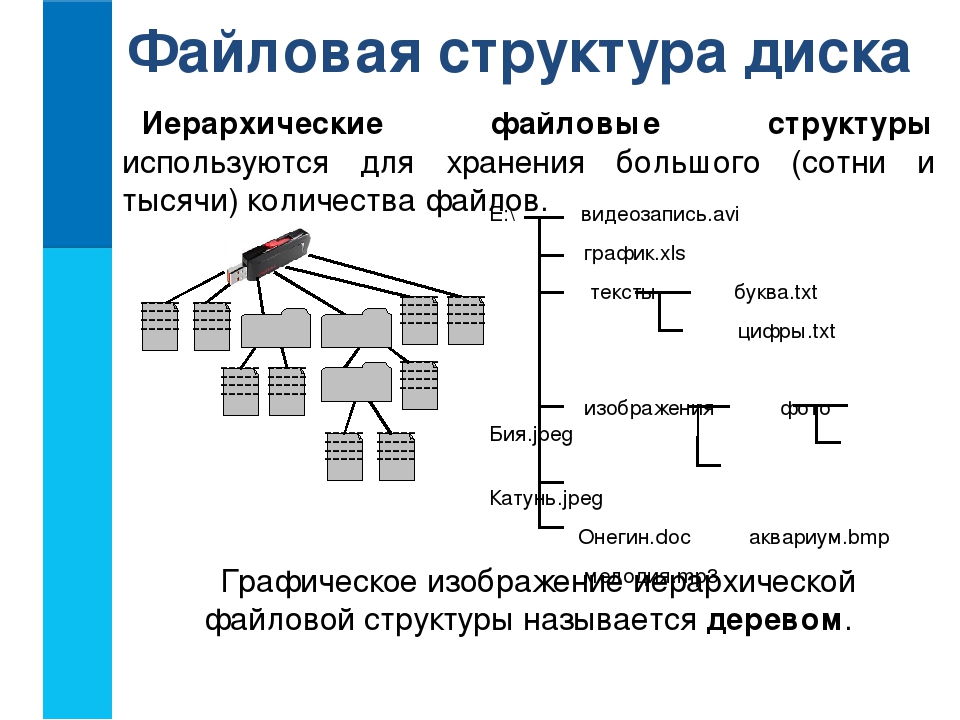
Случаи и примеры
- Джон Хэнкок: Управление потребительскими агентствами в John Hancock . ANA, 4 декабря 2019 г.
Джон Хэнкок объяснил свой подход к управлению широким спектром поставщиков средств измерений, аналитики и исследований.Команда маркетинговой аналитики организации играет важную роль в таких усилиях, как начало запроса предложений и измерение средств массовой информации, спонсорства, партнерских отношений с контентом, взаимодействия с пользователем, отношения и управления информационными панелями. - McCormick’s Analytics, Marketing Mix и оценка программы оптимизации в полете . ANA, 11 сентября 2019 г.
Маккормик обновил свое аналитическое подразделение и процедуры, чтобы стимулировать рост и оптимизировать бизнес-решения. Он использует оптимизацию на лету, платформы управления данными и моделирование комплекса маркетинга для повышения эффективности, затрат и прогнозирования.Они работают над оптимизацией ключевых факторов потребления и спроса, чтобы давать более точные прогнозы. Маккормик перешел от разрозненного медиапланирования к интегрированному подходу, который позволяет ему более эффективно масштабироваться. Его маркетинговый отдел теперь централизован и ориентирован на СМИ, что означает, что он выбирает максимальную отдачу от тактики СМИ и разрабатывает творческий подход, чтобы наполнить эту тактику, а медиаагентство является связующей тканью для всех партнеров. Цель состоит в том, чтобы достичь единого маркетингового измерения и максимизировать рентабельность медиа-затрат.
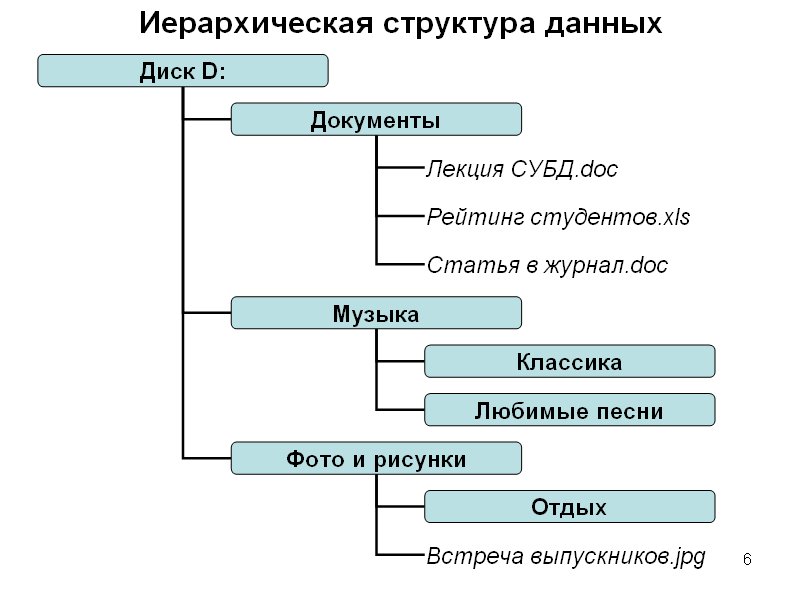
 Его маркетинговый отдел теперь централизован и ориентирован на СМИ, что означает, что он выбирает максимальную отдачу от тактики СМИ и разрабатывает творческий подход, чтобы наполнить эту тактику, а медиаагентство является связующей тканью для всех партнеров. Цель состоит в том, чтобы достичь единого маркетингового измерения и максимизировать рентабельность медиа-затрат.
Его маркетинговый отдел теперь централизован и ориентирован на СМИ, что означает, что он выбирает максимальную отдачу от тактики СМИ и разрабатывает творческий подход, чтобы наполнить эту тактику, а медиаагентство является связующей тканью для всех партнеров. Цель состоит в том, чтобы достичь единого маркетингового измерения и максимизировать рентабельность медиа-затрат.- Clorox: создание внутренней аналитической группы . ANA, 5 декабря 2018 г.
В этом ресурсе обсуждается команда аналитиков Clorox. В нем говорится: «Внутренняя аналитическая группа Clorox Co. состоит из 40 человек, включая аналитиков, специалистов по продвинутой аналитике и специалистов по обработке данных. В дополнение к своим обязанностям по основным аналитическим компетенциям, таким как данные, технологии, модели и идеи , группа также отвечает за взаимодействие с бизнес-группами, поставщиками и ИТ. - Как мне структурировать команду данных? Взгляд внутрь HubSpot, в гостях, M. M. LaFleur и More . DBT, 29 октября 2019 г.
Группа обработки данных — новая вещь: это не ИТ, это не финансы, и это не какие-либо типичные бизнес-функции в рамках действующего бизнеса. Итак, кому он подчиняется? Как он взаимодействует с остальной частью организации? Насколько это велико? Это все вопросы, на которые в режиме реального времени получают ответы во всей отрасли. DBT собрал «эталонные архитектуры» от своих компаний-членов, чтобы посмотреть, как, кто и что из их групп данных.Один пример из Away Travel:
 M. LaFleur и More . DBT, 29 октября 2019 г.
M. LaFleur и More . DBT, 29 октября 2019 г. У вас есть вопросы? Для информации пишите на [email protected].
Центр маркетинговых знаний активно предоставляет членам ANA ресурсы, необходимые им для достижения успеха в любой маркетинговой среде.
- Изучите контент, чтобы получить доступ к передовым методам, тематическим исследованиям и маркетинговым инструментам. Наш проприетарный контент включает в себя обзоры мероприятий, в которых делятся практическими выводами из презентаций конференций и комитетов.
