виды и функции — Самая полная в Рунете энциклопедия интернет-маркетинга
Материал из Самая полная в Рунете энциклопедия интернет-маркетинга
Поисковый паук (другие наименования — робот, веб-паук, краулер) — программа поисковой системы, сканирующая веб-ресурсы для отражения сведений о них в базе данных.
С какой целью создают поисковых пауков?
Приведём элементарный пример. Представим себе Иванова Валерия, который регулярно посещает сайт http://it-ebooks.info/, где ежедневно публикуются новые электронные книги. Заходя на ресурс, Валерий выполняет заданную последовательность действий:
1) открывает главную страницу;
2) заходит в раздел «Последние загруженные произведения»;
3) оценивает новинки из списка;
4) при появлении интересных заголовков, проходит по ссылкам;
5) читает аннотацию и, если она интересна, скачивает файл.
Указанные действия отнимают у Валерия 10 минут. Однако, если тратить на поиск 10 минут в день, в месяц это уже 5 часов. Вместо этого к задаче можно привлечь программу, отслеживающую новинки по расписанию. По механизму действия она будет представлять собой простейшего веб-паука, заточенного под выполнение определенных функций. Без краулеров не выживет никакая поисковая система, будь то лидеры Google и «Яндекс» или предприимчивые стартапы. Боты перемещаются по сайтам, отыскивая сырье для поисковой системы. При этом чем с большей отдачей трудится паук, тем актуальнее результаты выдачи
Функции веб-пауков
В зависимости от поисковой системы, функции, которые мы перечислим ниже, могут выполнять один или несколько роботов.
1. Сканирование контента сайта. Функция краулера первого порядка — обнаружение вновь созданных страниц и сбор размещенной текстовой информации.
2. Считывание графики. Если поисковая система подразумевает поиск графических файлов, для этой цели может быть введен отдельный веб-паук.
3. Сканирование зеркал. Робот находит идентичные по содержанию, но разные по адресу, ресурсы. «Работник», наделенный такими должностными полномочиями, есть у «Яндекса».
Виды поисковый роботов
У поисковых систем есть несколько пауков, каждый из которых поддерживает выполнение запрограммированных функций (рис. 2).
Пауки «Яндекс»
- Yandex/1.01.001 (compatible; Win16; I) — центральный поисковый продукт «Яндекса», который индексирует контент.
- Yandex/1.01.001 (compatible; Win16; P) — робот, который индексирует картинки и фотографии.
- Yandex/1.01.001 (compatible; Win16; H) — отыскивает зеркала и дубли ресурса.
- Yandex/1.03.003 (compatible; Win16; D) — первый паук, который приходит на ресурс после добавления его через раздел вебмастера. Его задачи — проверка добавленных параметров, указанных в панели, на соответствие.
- Yandex/1.03.000 (compatible; Win16; M) — краулер, который посещает страницу после ее загрузки по ссылке «Найденные слова» в поисковой выдаче.
- YaDirectBot/1.0 (compatible; Win16; I) — индексирует сайты из рекламной сети «Яндекса» (РСЯ).
- Yandex/1.02.000 (compatible; Win16; F) — бот сканирует фавиконы сайтов.
Пауки Google
- Googlebot — центральный робот.
- Googlebot News — бот, который находит и индексирует новости.
- Google Mobile — анализирует версии сайтов для смартфонов.
- Googlebot Images — веб-паук, индексирующий графику.
- Googlebot Video — сканирует видеоролики и индексирует их.
- Google AdsBot — оценивает страницу по качественным параметрам.
- Google Mobile AdSense и Google AdSense — индексируют сайты рекламной сети Google.
Вежливые пауки — как научить роботов правилам поведения
Вежливыми называют краулеров, которые действуют, придерживаясь существующих правил поведения на сайте. Эти правила пишут вебмастеры, размещая их в файле robots.txt
В robots.txt прописывают:
- разделы сайта, закрытые/открытые для ботов;
- интервалы, которые паук обязан выдерживать между запросами.
Правила адресуются всем краулерам или какому-то определенному. Открыв файл http://yandex.ru/robots.txt, мы увидим: User-agent: * … Disallow: /about.html … Disallow: /images/* Allow: /images/$
User-Agent: Twitterbot Allow: /images
Расшифруем эти данные:
- ни одному роботу не разрешено заходить на страницу /about.html;
- веб-пауку Twitterbot предоставляется возможность просматривать ресурсы с адресами типа /images;
- прочие боты могут посещать страницы, заканчивающиеся на /images/, погружение ниже уровня Disallow: /images/* запрещено.
Вежливый робот всегда представляется и указывает в заголовке запроса реквизиты, которые дают возможность вебмастеру связаться с владельцем. Для чего вводятся ограничения? Владельцы ресурсов заинтересованы в привлечении реальных пользователей и не желают, чтобы программы строили на их контенте свой бизнес. Для этих целей сайты часто настраивают на обслуживание браузерных HTTP-запросов и лишь за тем — запросов от программ.
Читайте другие статьи на тему «Поисковой паук»:
Полезные ссылки
для чего нужны веб-краулеры в системах Google и Yandex
Краулер (поисковый робот, бот, паук) — это программные модули поисковых систем, которые отвечают за поиск веб-сайтов их сканирование и добавление материалов в базу данных.
Поисковый паук без участия оператора посещает миллионы сайтов с гигабайтами текстов. Их принцип действия напоминает работу браузеров: на первом этапе оценивается содержимое документа, затем материал сохраняется в базе поисковика, после чего он переходит по линкам в другие разделы.
Какую работу выполняют роботы пауки поисковых машин
Малознакомые с принципом работы поисковых ботов вебмастера представляют их какими-то могущественными существами. Но, все гораздо проще. Каждый робот отвечает за выполнение своих функций.
Они не могут проникать как «шпионы» в запароленные разделы сайта, понимать работу фреймов, JavaScript или флеш-анимаций. Все зависит от того, какие функции в них были заложены разработчиками.
Скорость индексации и частота обходов сайта роботами во многом зависит от регулярности обновления контента и внешней ссылочной массы. Чтобы помочь боту проиндексировать все страницы, позаботьтесь о создании карт сайта в двух форматах .html и .xml.
Поисковая выдача формируется в 3 этапа:
- Сканирование — поисковые боты собирают содержимое сайтов (тексты, фото и видео).
- Индексация — робот вносит в базу данных собранную информацию и присваивает каждому документу определенный индекс. Материалы могут несколько дней находиться в быстровыдаче и получать трафик.
- Выдача результатов — каждая страница занимает определенную позицию по результатам ранжирования, заложенным в алгоритмах поисковых систем.
Специалисты Google и «Яндекс» часто вносят коррективы в работу поисковых роботов, например, ограничивают объем сканируемого текста или глубину проникновение паука внутрь сайта. Вебмастерам приходится адаптироваться под изменения при SEO-продвижении: выбирать оптимальные размеры текстов, ориентируясь на конкурентов в ТОП-10 выдаче, учитывать вложенность материалов, производить перелинковку материалов и так далее.
У каждой поисковой системы, будь то Google или «Яндекс», есть свои «пауки», отвечающие за разные функции. Их количество отличается, но задачи практически идентичные.
Как управлять поисковыми ботами?
Часто владельцы сайтов закрывают доступ некоторым поисковым роботам к определенному содержимому сайта, которое не должно принимать участие в поиске. Все команды паукам прописываются в специальном файле robots.txt.
Документ предоставляет краулерам список документов, которые нельзя индексировать (это может быть технические разделы сайта или личные данные пользователей). Ознакомившись с правилами, робот уходит с сайта или переходит на разрешенные для сканирования страницы.
Что указывать в robots.txt:
- Закрывать/открывать для индексации фрагменты контента или разделы сайта.
- Интервалы между запросами поисковых ботов.
Команды могут быть общими для всех роботов или отдельные для Yandex, Googlebot, Mail.Ru. Подробнее о работе с robots.txt читайте здесь.
Как узнать, что поисковый робот посещает сайт?
Существует несколько способов, позволяющих определить, как часто на ваш сайт заходят краулеры. Проще всего это отследить робота от «Яндекса». Для этого авторизуйтесь в сервисе «Яндекс.Вебмастер», откройте страницу «Индексирование» и «Статистика обхода»: 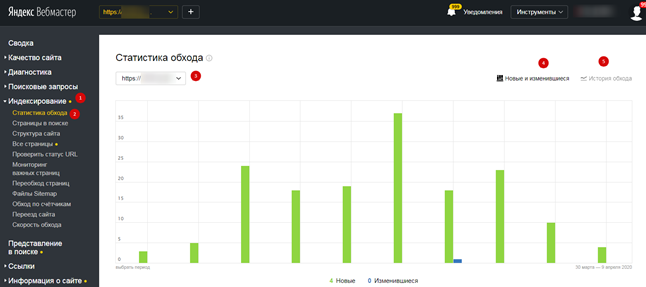
В этом разделе вы узнаете, какие страницы обошел робот, как часто обращался к вашему сайту («История обхода») и ошибки, случившиеся по причине перебоев со стороны сервера или неправильного содержимого документов.
Чтобы получить подробную информацию по конкретному разделу, найдите его в списке, где указан URL-сайта.
Рассказать поисковому роботу и направить на конкретную страницу можно с помощью инструмента «Переобход страниц». Добавьте урл-адреса в соответствующее поле: 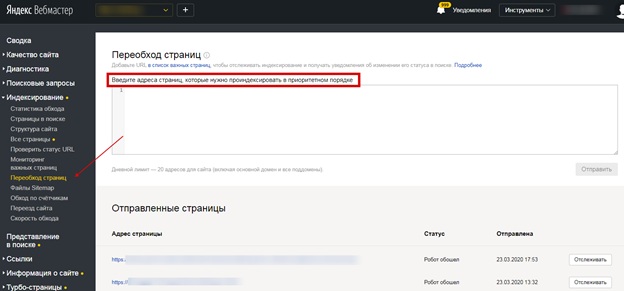
Точно также успешно можно отследить и посещение поискового робота Google. Для этого авторизуйтесь в Google Analytics. 
Появятся данные про обход страниц роботом: 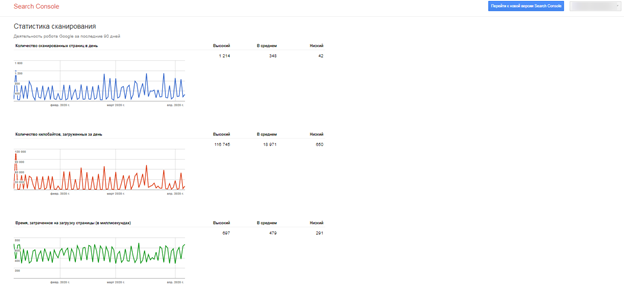
Выводы
Краулеры нужны не только поисковым системам для индексирования сайтов и добавления документов в базу данных, но и для SEO-специалистов, чтобы анализировать ресурсы, исправлять недочеты и успешно продвигать их в поиске.
Вебмастера будут всегда пытаться разгадать алгоритмы работы поисковых роботов, которые постоянно совершенствуются. Работа над качеством сайта — долгий и тернистый путь, направленный на долгосрочный результат.
А у вас не было проблем с индексацией сайта? Отслеживаете ли вы посещение сайта поисковыми роботами? Поделитесь свои опытом в комментариях.
Поиск под капотом Глава 1. Сетевой паук / Хабр
Умение искать информацию в Интернете является жизненно необходимым. Когда мы нажимаем на кнопку «искать» в нашей любимой поисковой системе, через доли секунды мы получаем ответ.
Большинство совершенно не задумывается о том, что же происходит «под капотом», а между тем поисковая система — это не только полезный инструмент, но еще и сложный технологический продукт. Современная поисковая система для своей работы использует практически все передовые достижения компьютерной индустрии: большие данные, теорию графов и сетей, анализ текстов на естественном языке, машинное обучение, персонализацию и ранжирование. Понимание того, как работает поисковая система, дает представление об уровне развития технологий, и поэтому разобраться в этом будет полезно любому инженеру.
В нескольких статьях я шаг за шагом расскажу о том, как работает поисковая система, и, кроме того, для иллюстрации я построю свой собственный небольшой поисковый движок, чтобы не быть голословным. Этот поисковый движок будет, конечно же, «учебным», с очень сильным упрощением того, что происходит внутри гугла или яндекса, но, с другой стороны, я не буду упрощать его слишком сильно.
Первый шаг — это сбор данных (или, как его еще называют, краулинг).
Веб — это граф
Та часть Интернета, которая нам интересна, состоит из веб-страниц. Для того чтобы поисковая система смогла найти ту или иную веб-страницу по запросу пользователя, она должна заранее знать, что такая страница существует и на ней содержится информация, релевантная запросу. Пользователь обычно узнает о существовании веб-страницы от поисковой системы. Каким же образом сама поисковая система узнает о существовании веб-страницы? Ведь никто ей не обязан явно сообщать об этом.
К счастью, веб-страницы не существуют сами по себе, они содержат ссылки друг на друга. Поисковый робот может переходить по этим ссылкам и открывать для себя все новые веб-страницы.
На самом деле структура страниц и ссылок между ними описывает структуру данных под названием «граф». Граф по определению состоит из вершин (веб-страниц в нашем случае) и ребер (связей между вершинами, в нашем случае — гиперссылок).
Другими примерами графов являются социальная сеть (люди — вершины, ребра — отношения дружбы), карта дорог (города — вершины, ребра — дороги между городами) и даже все возможные комбинации в шахматах (шахматная комбинация — вершина, ребро между вершинами существует, если из одной позиции в другую можно перейти за один ход).
Графы бывают ориентированными и неориентированными — в зависимости от того, указано ли на ребрах направление. Интернет представляет собой ориентированный граф, так как по гиперссылкам можно переходить только в одну сторону.
Для дальнейшего описания мы будем предполагать, что Интернет представляет собой сильно связный граф, то есть, начав в любой точке Интернета, можно добраться до любой другой точки. Это допущение — очевидно неверное (я могу легко создать новую веб-страницу, на которую не будет ссылок ниоткуда и соответственно до нее нельзя будет добраться), но для задачи проектирования поисковой системы его можно принять: как правило, веб-страницы, на которые нет ссылок, не представляют большого интереса для поиска.
Небольшая часть веб-графа:
Алгоритмы обхода графа: поиск в ширину и в глубину
Поиск в глубину
Существует два классических алгоритма обхода графов. Первый — простой и мощный — алгоритм называется поиск в глубину (Depth-first search, DFS). В его основе лежит рекурсия, и он представляет собой следующую последовательность действий:
- Помечаем текущую вершину обработанной.
- Обрабатываем текущую вершину (в случае поискового робота обработкой будет просто сохранение копии).
- Для всех вершин, в которые можно перейти из текущей: если вершина еще не обработана, рекурсивно обрабатываем и ее тоже.
Код на Python, имплементирующий данный подход буквально дословно:
seen_links = set()
def dfs(url):
seen_links.add(url)
print('processing url ' + url)
html = get(url)
save_html(url, html)
for link in get_filtered_links(url, html):
if link not in seen_links:
dfs(link)
dfs(START_URL)Полный код на github
Приблизительно таким же образом работает, например, стандартная линуксовая утилита wget с параметром -r, показывающим, что нужно выкачивать сайт рекурсивно:
wget -r habrahabr.ru
Метод поиска в глубину целесообразно применять для того, чтобы обойти веб-страницы на небольшом сайте, однако для обхода всего Интернета он не очень удобен:
- Содержащийся в нем рекурсивный вызов не очень хорошо параллелится.
- При такой реализации алгоритм будет забираться все глубже и глубже по ссылкам, и в конце концов у него, скорее всего, не хватит места в стеке рекурсивных вызовов и мы получим ошибку stack overflow.
В целом обе эти проблемы можно решить, но мы вместо этого воспользуемся другим классическим алгоритмом — поиском в ширину.
Поиск в ширину
Поиск в ширину (breadth-first search, BFS) работает схожим с поиском в глубину образом, однако он обходит вершины графа в порядке удаленности от начальной страницы. Для этого алгоритм использует структуру данных «очередь» — в очереди можно добавлять элементы в конец и забирать из начала.
- Алгоритм можно описать следующим образом:
- Добавляем в очередь первую вершину и в множество «увиденных».
- Если очередь не пуста, достаем из очереди следующую вершину для обработки.
- Обрабатываем вершину.
- Для всех ребер, исходящих из обрабатываемой вершины, не входящих в «увиденные»:
- Добавить в «увиденные»;
- Добавить в очередь.
- Перейти к пункту 2.
Код на python:
def bfs(start_url):
queue = Queue()
queue.put(start_url)
seen_links = {start_url}
while not (queue.empty()):
url = queue.get()
print('processing url ' + url)
html = get(url)
save_html(url, html)
for link in get_filtered_links(url, html):
if link not in seen_links:
queue.put(link)
seen_links.add(link)
bfs(START_URL)Полный код на github
Понятно, что в очереди сначала окажутся вершины, находящиеся на расстоянии одной ссылки от начальной, потом двух ссылок, потом трех ссылок и т. д., то есть алгоритм поиска в ширину всегда доходит до вершины кратчайшим путем.
Еще один важный момент: очередь и множество «увиденных» вершин в данном случае используют только простые интерфейсы (добавить, взять, проверить на вхождение) и легко могут быть вынесены в отдельный сервер, коммуницирующий с клиентом через эти интерфейсы. Эта особенность дает нам возможность реализовать многопоточный обход графа — мы можем запустить несколько одновременных обработчиков, использующих одну и ту же очередь.
Robots.txt
Прежде чем описать собственно имплементацию, хотелось бы отметить, что хорошо ведущий себя краулер учитывает запреты, установленные владельцем веб-сайта в файле robots.txt. Вот, например, содержимое robots.txt для сайта lenta.ru:
User-agent: YandexBot
Allow: /rss/yandexfull/turbo
User-agent: Yandex
Disallow: /search
Disallow: /check_ed
Disallow: /auth
Disallow: /my
Host: https://lenta.ru
User-agent: GoogleBot
Disallow: /search
Disallow: /check_ed
Disallow: /auth
Disallow: /my
User-agent: *
Disallow: /search
Disallow: /check_ed
Disallow: /auth
Disallow: /my
Sitemap: https://lenta.ru/sitemap.xml.gzВидно, что тут определены некоторые разделы сайта, которые запрещено посещать роботам яндекса, гугла и всем остальным. Для того чтобы учитывать содержимое robots.txt в языке python, можно воспользоваться реализацией фильтра, входящего в стандартную библиотеку:
In [1]: from urllib.robotparser import RobotFileParser
...: rp = RobotFileParser()
...: rp.set_url('https://lenta.ru/robots.txt')
...: rp.read()
...:
In [3]: rp.can_fetch('*', 'https://lenta.ru/news/2017/12/17/vivalarevolucion/')
Out[3]: True
In [4]: rp.can_fetch('*', 'https://lenta.ru/search?query=big%20data#size=10|sort=2|domain=1
...: |modified,format=yyyy-MM-dd')
Out[4]: FalseИмплементация
Итак, мы хотим обойти Интернет и сохранить его для последующей обработки.
Конечно, в демонстрационных целях обойти и сохранить весь Интернет не выйдет — это стоило бы ОЧЕНЬ дорого, но разрабатывать код мы будем с оглядкой на то, что потенциально его можно было бы масштабировать до размеров всего Интернета.
Это означает, что работать мы должны на большом количестве серверов одновременно и сохранять результат в какое-то хранилище, из которого его можно будет легко обработать.
В качестве основы для работы своего решения я выбрал Amazon Web Services, так как там можно легко поднять определенное количество машин, обработать результат и сохранить его в распределенное хранилище Amazon S3. Похожие решения есть, например, у google, microsoft и у яндекса.
Архитектура разработанного решения
Центральным элементом в моей схеме сбора данных является сервер очереди, хранящий очередь URL, подлежащих скачиванию и обработке, а также множество URL, которые наши обработчики уже «видели». В моей имплементации это они основаны на простейших структурах данных Queue и set языка python.
В реальной продакшн-системе, скорее всего, вместо них стоило бы использовать какое-нибудь существующее решение для очередей (например, kafka) и для распределенного хранения множеств (например, подошли бы решения класса in-memory key-value баз данных типа aerospike). Это позволило бы достичь полной горизонтальной масштабируемости, но в целом нагрузка на сервер очереди оказывается не очень большой, поэтому в таком масштабировании в моем маленьком демо-проекте смысла нет.
Рабочие серверы периодически забирают новую группу URL для скачивания (забираем сразу помногу, чтобы не создавать лишнюю нагрузку на очередь), скачивают веб-страницу, сохраняют ее на s3 и добавляют новые найденные URL в очередь на скачивание.
Для того чтобы снизить нагрузку на добавление URL, добавление тоже происходит группами (добавляю сразу все новые URL, найденные на веб-странице). Еще я периодически синхронизирую множество «увиденных» URL с рабочими серверами, чтобы осуществлять предварительную фильтрацию уже добавленных страниц на стороне рабочей ноды.
Скачанные веб-страницы я сохраняю на распределенном облачном хранилище (S3) — это будет удобно впоследствии для распределенной обработки.
Очередь периодически отправляет статистику по количеству добавленных и обработанных запросов в сервер статистики. Статистику отправляем суммарно и в отдельности для каждой рабочей ноды — это необходимо для того, чтобы было понятно, что скачивание происходит в штатном режиме. Читать логи каждой отдельной рабочей машины невозможно, поэтому следить за поведением будем на графиках. В качестве решения для мониторинга скачивания я выбрал graphite.
Запуск краулера
Как я уже писал, для того чтобы скачать весь Интернет, нужно огромное количество ресурсов, поэтому я ограничился только маленькой его частью — а именно сайтами habrahabr.ru и geektimes.ru. Впрочем, ограничение это довольно условное, и расширение его на другие сайты — просто вопрос количества доступного железа. Для запуска я реализовал простенькие скрипты, которые поднимают новый кластер в облаке amazon, копируют туда исходный код и запускают соответствующий сервис:
#deploy_queue.py
from deploy import *
def main():
master_node = run_master_node()
deploy_code(master_node)
configure_python(master_node)
setup_graphite(master_node)
start_urlqueue(master_node)
if __name__ == main():
main()#deploy_workers.py
#run as: http://<queue_ip>:88889
from deploy import *
def main():
master_node = run_master_node()
deploy_code(master_node)
configure_python(master_node)
setup_graphite(master_node)
start_urlqueue(master_node)
if __name__ == main():
main()Код скрипта deploy.py, содержащего все вызываемые функции
Использование в качестве инструмента статистики graphite позволяет рисовать красивые графики:
Красный график — найденные URL, зеленый — скачанные, синий — URL в очереди. За все время скачано 5.5 миллионов страниц.
Количество скрауленных страниц в минуту в разбивке по рабочим нодам. Графики не прерываются, краулинг идет в штатном режиме.
Результаты
Скачивание habrahabr и geektimes у меня заняло три дня.
Можно было бы скачать гораздо быстрее, увеличив количество экземпляров воркеров на каждой рабочей машине, а также увеличив количество воркеров, но тогда нагрузка на сам хабр была бы очень большой — зачем создавать проблемы любимому сайту?
В процессе работы я добавил пару фильтров в краулер, начав фильтровать некоторые явно мусорные страницы, нерелевантные для разработки поискового движка.
Разработанный краулер, хоть и является демонстрационным, но в целом масштабируется и может применяться для сбора больших объемов данных с большого количества сайтов одновременно (хотя, возможно, в продакшне есть смысл ориентироваться на существующие решения для краулинга, такие как heritrix. Реальный продакшн-краулер также должен запускаться периодически, а не разово, и реализовывать много дополнительного функционала, которым я пока пренебрег.
За время работы краулера я потратил примерно 60 $ на облако amazon. Всего скачано 5.5 млн страниц, суммарным объемом 668 гигабайт.
В следующей статье цикла я построю индекс по скачанным веб-страницам при помощи технологий больших данных и спроектирую простейший движок собственно поиска по скачанным страницам.
Код проекта доступен на github
Поисковые системы их роботы и пауки. Что такое поисковая машина или как работает поисковик Какую работу выполняют роботы пауки поисковых машин
Как функционируют роботы поисковых систем
Поисковый робот (паук, бот) представляет собой небольшую программу, способную без участия оператора посещать миллионы web-сайтов и сканировать гигабайты текстов. Считывание страниц и сохранение их текстовых копий – это первая стадия индексации новых документов. Следует отметить, что роботы поисковых систем не осуществляют какую-либо обработку полученных данных. В их задачу входит только сохранение текстовой информации.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA
Список поисковых роботов
Из всех поисковиков, занимающихся сканированием Рунета, самой большой коллекцией ботов располагает Яндекс. За индексацию отвечают следующие боты:
- главный индексирующий робот, собирающий данные со страниц web-сайтов;
- бот, способный распознавать зеркала;
- поисковый робот Яндекс, осуществляющий индексацию картинок;
- паук, просматривающий страницы сайтов, принятых в РСЯ;
- робот, сканирующий иконки favicon;
- несколько пауков, определяющих доступность страниц сайта.
Главный поисковый робот Google занимается сбором текстовой информации. В основном он просматривает html-файлы, с определенной периодичностью анализирует JS и CSS. Способен воспринимать любые типы контента, разрешенные к индексации. ПС Гугл располагает пауком, контролирующим индексацию изображений. Есть также поисковый робот – программа, поддерживающая функционирование мобильной версии поиска.
Увидеть сайт глазами поискового робота
Чтобы исправить погрешности кода и прочие недочеты, вебмастер может узнать, как видит сайт поисковый робот. Эту возможность предоставляет ПС Google. Потребуется перейти в инструменты для вебмастеров, а затем кликнуть на вкладку «сканирование». В открывшемся окне нужно выбрать строчку «просмотреть как Googlebot». Далее нужно завести адрес исследуемой страницы в поисковую форму (без указания домена и протокола http://).
Выбрав команду «получить и отобразить», вебмастер сможет визуально оценить состояние страницы сайта. Для этого понадобится кликнуть по галочке «запрос на отображение». Откроется окно с двумя версиями web-документа. Вебмастер узнает, как видит страницу обычный посетитель, и в каком виде она доступна для поискового паука.
Совет!Если анализируемый web-документ еще не проиндексирован, то можно воспользоваться командой «добавить в индекс» >> «сканировать только этот URL». Паук проанализирует документ через несколько минут, в ближайшем времени web-страница появится в выдаче. Месячный лимит запросов на индексацию составляет 500 документов.
Как повлиять на скорость индексирования
Выяснив, как работают поисковые роботы, вебмастер сможет гораздо результативнее продвигать свой сайт. Одной из основных проблем многих молодых web-проектов является плохая индексация. Роботы поисковых систем неохотно посещают неавторитетные интернет ресурсы.
Установлено, что скорость индексации напрямую зависит от того, с какой интенсивностью обновляется сайт. Регулярное добавление уникальных текстовых материалов позволит привлечь внимание поисковика.
Для ускорения индексации можно воспользоваться соцзакладками и сервисом twitter. Рекомендуется сформировать карту сайта Sitemap и загрузить ее в корневую директорию web-проекта.
Роботы поисковой системы, иногда их называют «пауки» или «кроулеры» (crawler) — это программные модули, занимающиеся поиском web-страниц. Как они работают? Что же они делают в действительности? Почему они важны?Учитывая весь шум вокруг поисковой оптимизации и индексных баз данных поисковиков, вы, наверное думаете, что роботы должно быть великие и могущественные существа. Неправда. Роботы поисковика обладают лишь базовыми функциями, похожими на те, которыми обладали одни из первых броузеров, в отношении того, какую информацию они могут распознать на сайте. Как и ранние броузеры, роботы попросту
Какую работу выполняют роботы пауки поисковых машин. Поисковые роботы — роботы поисковых систем. Разновидности поисковых роботов
Являющаяся составной частью поисковой системы и предназначенная для перебора страниц Интернета с целью занесения информации о них в базу данных поисковика. По принципу действия паук напоминает обычный браузер. Он анализирует содержимое страницы, сохраняет его в некотором специальном виде на сервере поисковой машины, которой принадлежит, и отправляется по ссылкам на следующие страницы. Владельцы поисковых машин нередко ограничивают глубину проникновения паука внутрь сайта и максимальный размер сканируемого текста, поэтому чересчур большие сайты могут оказаться не полностью проиндексированными поисковой машиной. Кроме обычных пауков, существуют так называемые «дятлы » — роботы, которые «простукивают» проиндексированный сайт, чтобы определить, что он доступен.
Порядок обхода страниц, частота визитов, защита от зацикливания, а также критерии выделения значимой информации определяются алгоритмами информационного поиска .
В большинстве случаев переход от одной страницы к другой осуществляется по ссылкам, содержащимся на первой и последующих страницах.
Также многие поисковые системы предоставляют пользователю возможность самостоятельно добавить сайт в очередь для индексирования . Обычно это существенно ускоряет индексирование сайта, а в случаях, когда никакие внешние ссылки не ведут на сайт, вообще оказывается практически единственной возможностью указать на его существование. Ещё одним способом быстрой индексации сайта является добавление на сайт систем веб-аналитики, принадлежащих поисковым сервисам. Например, таких как Google Analytics , Яндекс.Метрика и Рейтинг@Mail.ru от Google, Яндекса и Mail.Ru соответственно.
Ограничить индексацию сайта можно с помощью файла robots.txt . Полная защита от индексации может быть обеспечена другими механизмами, например установкой пароля на странице либо требованием заполнить регистрационную форму перед тем, как получить доступ к содержимому.
Энциклопедичный YouTube
1 / 3
Просмотров:
Тематические коллекции ссылок — это списки, составленные группой профессионалов или даже коллекционерами-одиночками. Очень часто узкоспециализированная тема может быть раскрыта одним специалистом лучше, чем группой сотрудников крупного каталога. Тематических коллекций в Сети так много, что давать конкретные адреса не имеет смысла.
Подбор доменного имени
Каталог — удобная система поиска, однако для того, чтобы попасть на сервер компании Microsoft или IBM , вряд ли имеет смысл обращаться к каталогу. Угадать название соответствующего сайта нетрудно: www.microsoft.com , www.ibm.com или www.microsoft.ru , www.ibm.ru — сайты российских представительств этих компаний.
Аналогично, если пользователю необходим сайт , посвященный погоде в мире, его логично искать на сервере www.weather.com . В большинстве случаев поиск сайта с ключевым словом в названии эффективнее, чем поиск документа, в тексте которого это слово используется. Если западная коммерческая компания (или проект) имеет односложное название и реализует в Сети свой сервер , то его имя с высокой вероятностью укладывается в формат www.name.com , а для Рунета (российской части Сети) — www.name.ru , где name — имя компании или проекта. Подбор адреса может успешно конкурировать с другими приемами поиска, поскольку при подобной системе поиска можно установить соединение с сервером, который не зарегистрирован ни в одной поисковой системе. Однако, если подобрать искомое имя не удается, придется обратиться к поисковой машине.
Поисковые машины
Скажи мне, что ты ищешь в Интернете, и я скажу, кто ты
Если бы компьютер был высокоинтеллектуальной системой, которой можно было легко объяснить, что вы ищете, то он выдавал бы два-три документа — именно те, которые вам нужны. Но, к сожалению, это не так, и в ответ на запрос пользователь обычно получает длинный список документов, многие из которых не имеют никакого отношения к тому, о чем он спрашивал. Такие документы называются нерелевантными (от англ. relevant — подходящий, относящийся к делу). Таким образом, релевантный документ — это документ, содержащий искомую информацию. Очевидно, что от умения грамотно выдавать запрос зависит процент получаемых релевантных документов. Доля релевантных документов в списке всех найденных поисковой машиной документов называется точностью поиска. Нерелевантные документы называют шумовыми. Если все найденные документы релевантные (шумовых нет), то точность поиска составляет 100%. Если найдены все релевантные документы, то полнота поиска — 100%.
Таким образом, качество поиска определяется двумя взаимозависимыми параметрами: точностью и полнотой поиска. Увеличение полноты поиска снижает точность , и наоборот.
Как работает поисковая машина
Поисковые системы можно сравнить со справочной службой, агенты которой обходят предприятия, собирая информацию в базу данных (рис. 4.21). При обращении в службу информация выдается из этой базы. Данные в базе устаревают, поэтому агенты их периодически обновляют. Некоторые предприятия сами присылают данные о себе, и к ним агентам приезжать не приходится. Иными словами, справочная служба имеет две функции: создание и постоянное обновление данных в базе и поиск информации в базе по запросу клиента.
Рис.
4.21.
Аналогично, поисковая машина состоит из двух частей: так называемого робота (или паука), который обходит серверы Сети и формирует базу данных поискового механизма.
База робота в основном формируется им самим (робот сам находит ссылки на новые ресурсы) и в гораздо меньшей степени — владельцами ресурсов, которые регистрируют свои сайты в поисковой машине. Помимо робота (сетевого агента, паука, червяка), формирующего базу данных, существует программа , определяющая рейтинг найденных ссылок.
Принцип работы поисковой машины сводится к тому, что она опрашивает свой внутренний каталог (базу данных) по ключевым словам, которые пользователь указывает в поле запроса, и выдает список ссылок, ранжированный по релевантности .
Следует отметить, что, отрабатывая конкретный запрос пользователя, поисковая система оперирует именно внутренними ресурсами (а не пускается в путешествие по Сети, как часто полагают неискушенные пользователи), а внутренние ресурсы, естественно, ограниченны. Несмотря на то что база данных поисковой машины постоянно обновляется, поисковая машина не может п
Какую работу выполняют пауки поисковых машин. Что такое роботы поисковики Яндекса и Google простыми словами. Поисковые роботы друзья и веб-мастерам и пользователям
Роботы поисковой системы, иногда их называют «пауки» или «кроулеры» (crawler) — это программные модули, занимающиеся поиском web-страниц. Как они работают? Что же они делают в действительности? Почему они важны?
Учитывая весь шум вокруг поисковой оптимизации и индексных баз данных поисковиков, вы, наверное думаете, что роботы должно быть великие и могущественные существа. Неправда. Роботы поисковика обладают лишь базовыми функциями, похожими на те, которыми обладали одни из первых броузеров, в отношении того, какую информацию они могут распознать на сайте. Как и ранние броузеры, роботы попросту не могут делать определенные вещи. Роботы не понимают фреймов, Flash анимаций, изображений или JavaScript. Они не могут зайти в разделы, защищенные паролем и не могут нажимать на все те кнопочки, которые есть на сайте. Они могут «заткнуться» в процессе индексирования динамических адресов URL и работать очень медленно, вплоть до остановки и безсилием над JavaScript-навигацией.
Как работают роботы поисковой машины?
Поисковые роботы стоит воспринимать, как программы автоматизированного получения данных, путешествующие по сети в поисках информации и ссылок на информацию.
Когда, зайдя на страницу «Submit a URL», вы регистрируете очередную web-страницу в поисковике — в очередь для просмотра сайтов роботом добавляется новый URL. Даже если вы не регистрируете страницу, множество роботов найдет ваш сайт, поскольку существуют ссылки из других сайтов, ссылающиеся на ваш. Вот одна из причин, почему важно строить ссылочную популярность и размещать ссылки на других тематических ресурсах.
Прийдя на ваш сайт, роботы сначала проверяют, есть ли файл robots.txt. Этот файл сообщает роботам, какие разделы вашего сайта не подлежат индексации. Обычно это могут быть директории, содержащие файлы, которыми робот не интересуется или ему не следовало бы знать.
Роботы хранят и собирают ссылки с каждой страницы, которую они посещают, а позже проходят по этим ссылкам на другие страницы. Вся всемирная сеть построена из ссылок. Начальная идея создания Интернет сети была в том, что бы была возможность перемещаться по ссылкам от одного места к другому. Вот так перемещаются и роботы.
«Остроумность» в отношении индексирования страниц в реальном режиме времени зависит от инженеров поисковых машин, которые изобрели методы, используемые для оценки информации, получаемой роботами поисковика. Будучи внедрена в базу данных поисковой машины, информация доступна пользователям, которые осуществляют поиск. Когда пользователь поисковой машины вводит поисковый запрос, производится ряд быстрых вычислений для уверенност
Поисковые системы их роботы и пауки
19 мая | Автор З. Владимир | 6 комментариев Как правило, поисковая машина представляет собой сайт, специализирующийся на поиске информации, соответствующей критериям запроса пользователя. Основная задача таких сайтов заключается в упорядочивании и структурировании информации в сети.
Как правило, поисковая машина представляет собой сайт, специализирующийся на поиске информации, соответствующей критериям запроса пользователя. Основная задача таких сайтов заключается в упорядочивании и структурировании информации в сети.
Большинство людей, пользуясь услугами поисковой системы, никогда не задаются вопросом как именно действует машина, отыскивая необходимую информацию из глубин Интернета.
Для рядового пользователя сети, само понятие принципов работы поисковых машин не является критичным, так как алгоритмы, которыми руководствуется система, способны удовлетворить запросы человека, который не знает как составлять оптимизированный запрос при поиске необходимой информации. Но для веб-разработчика и специалистов занимающихся оптимизацией сайтов, просто необходимо обладать, как минимум, начальными понятиями о структуре и принципах работы поисковых систем.
Каждая поисковая машина работает по точным алгоритмам, которые держатся под строжайшим секретом и известны лишь небольшому кругу сотрудников. Но при проектировании сайта или его оптимизации, обязательно нужно учитывать общие правила функционирования поисковых систем, которые рассматриваются в предлагаемой статье.
Невзирая на то, что каждая ПС имеет свою собственную структуру, после тщательного их изучения можно объединить в основные, обобщающие компоненты:
Модуль индексирования
Модуль индексирования — этот элемент включает три дополнительных компонента (программы-роботы):
1. Spider (робот-паук) — скачивает страницы, фильтрует текстовый поток извлекая из него все внутренние гиперссылки. Кроме того, Spider сохраняет дату скачивания и заголовок ответа сервера, а также URL — адрес страницы.
2. Crawler (ползающий робот-паук) — осуществляет анализ всех ссылок на странице, и на основе этого анализа, определяет какую страницу посещать, а какую не стоит. Таким же образом краулер находит новые ресурсы, которые должны быть обработаны ПС.
3. Indexer (Робот-индексатор) – занимается анализом скачанных пауком интернет-страниц. При этом сама страница разбивается на блоки и анализируется индексатором с помощью морфологических и лексических алгоритмов. Под разбор индексатора попадают различные части веб-страницы: заголовки, мета-теги, тексты и другая служебная информация.
Все документы, прошедшие обработку этим модулем, хранятся в базе данных поисковика, называемой индексом системы. Кроме самих документов, база данных содержит необходимые служебные данные – результат тщательной обработки этих документов, руководствуясь которыми, поисковая система выполняет запросы пользователя.
Поисковый сервер
Следующий, очень важный компонент системы – поисковый сервер, задача которого заключается в обработке запроса пользователя и генерации страницы результатов поиска.
Обрабатывая запрос пользователя, поисковый сервер рассчитывает рейтинг релевантности отобранных документов запросу пользователя. От этого рейтинга зависит позиция, которую займет веб-страница при выдаче поисковых результатов. Каждый документ, удовлетворяющий условиям поиска, отображается на странице выдачи результатов в виде сниппета.
Сниппет – это краткое описание страницы, включающее заголовок, ссылку, ключевые слова и краткую текстовую информацию. По сниппету пользователь может оценить релевантность отобранных поисковой машиной страниц своему запросу.
Важнейшим критерием, которым руководствуется поисковый сервер при ранжировании результатов запроса – является уже знакомый нам показатель тИЦ (тематический индекс цитирования).
Все описанные компоненты ПС требуют больших затрат и очень ресурсоемкие. Результативность поисковой системы напрямую зависит от эффективности взаимодействия этих компонентов.
На этом все. Если поделитесь своими наблюдениями о ПС , буду очень признателен.
С огромным Уважением, Vladimir Zadorozhnyuk
Понравилась статья? Подпишитесь на новости блога или поделитесь в социальных сетях, а я отвечу вам ВЗАИМНОСТЬЮ
Обратите внимание на другие интересные статьи:
Что такое паук поисковой машины?
Пауки поисковых систем, иногда называемые сканерами, используются поисковыми системами Интернета для сбора информации о веб-сайтах и отдельных веб-страницах. Поисковым системам нужна информация со всех сайтов и страниц; в противном случае они не знали бы, какие страницы отображать в ответ на поисковый запрос и с каким приоритетом.
«Пауки» поисковых систем ползают по Интернету и создают очереди веб-сайтов для дальнейшего исследования.Когда конкретный веб-сайт покрывается пауком, паук читает весь текст, гиперссылки, метатеги (метатеги — это ключевые слова в специальном формате, вставляемые в веб-страницу таким образом, чтобы он мог их найти и использовать) и код . Используя эту информацию, паук предоставляет поисковой системе профиль. Затем паук собирает дополнительную информацию, переходя по гиперссылкам на веб-странице, что дает ему лучший сбор данных об этих страницах. Это причина того, что наличие ссылок на вашей веб-странице — и, что еще лучше, на других веб-страницах, ведущих на вашу — так полезно для того, чтобы ваш веб-сайт был найден поисковыми системами.
Объявление
УSpiders есть четыре основных режима сбора информации. Один тип пауков используется только для создания очередей веб-страниц для поиска другими пауками. Этот паук, работающий в режиме «выбора», определяет приоритеты, какие страницы нужно просмотреть, и проверяет, была ли уже загружена более ранняя версия страницы. Второй режим — это паук, разработанный специально для просмотра страниц, которые уже были просмотрены пауком.Этот режим называется «повторное посещение». Некоторые поисковые системы обеспокоены тем, что страница была слишком тщательно просканирована другими пауками, поэтому они используют режим паука, называемый «вежливостью», который ограничивает сканирование перегруженных страниц. Наконец, «распараллеливание» позволяет пауку координировать свои усилия по сбору данных с другими пауками поисковых систем, которые просматривают ту же страницу.
.Что такое паук поисковой машины?
Паук поисковой системы , также известный как веб-сканер, представляет собой Интернет-бот, который сканирует веб-сайты и хранит информацию для индексации поисковой системы.
Подумайте об этом иначе. Когда вы ищете что-то в Google, эти страницы и страницы с результатами не могут появиться из воздуха. Фактически, все они взяты из индекса Google, который вы можете визуализировать как огромную, постоянно расширяющуюся библиотеку информации — текста, изображений, документов и т. Д.Он постоянно расширяется, потому что каждый день создаются новые веб-страницы!
Не отображение индекса поисковой системы.
Итак, как эти новые страницы попадают в индекс? Конечно, пауки поисковых систем.
Как работают пауки поисковых систем?
«Пауки», такие как робот Googlebot, посещают веб-страницы в поисках новых данных для добавления в индекс. Это очень важно, потому что бизнес-модель Google (привлечение потребителей и продажа рекламного места) зависит от предоставления высококачественных, релевантных и актуальных результатов поиска.
Пауки тоже довольно умные. Они распознают гиперссылки, по которым могут сразу перейти или записать их для последующего сканирования. В любом случае внутренние ссылки между страницами одного и того же сайта действуют аналогично ступеням, поскольку они прокладывают путь паукам для сканирования и хранения новой информации.
Кстати…
Почему я должен беспокоиться о пауках поисковых систем?
Поисковая оптимизация (SEO) — это повышение вашей видимости в обычных результатах поиска.Вы стремитесь получить авторитет домена и вывести свой сайт на первую страницу по как можно большему количеству ключевых слов.
Хороший первый шаг к первой странице: позволить поисковой системе действительно находить ваши веб-страницы. Если ваш материал не индексируется, вы даже не нюхаете страницу 13.
Хорошая новость: вам не нужно слишком много работать, чтобы сканировать и проиндексировать ваши новые страницы. По сути, пока вы ссылаетесь на свой новый контент из некоторого старого контента, пауки в конечном итоге будут переходить по этим ссылкам на новую страницу и сохранять ее для индексации.Как мы уже говорили ранее: внутренние ссылки имеют решающее значение.
Если вы хотите, чтобы ваш новый материал как можно скорее проиндексировался и появился в результатах поиска, вы можете напрямую отправить новый URL в Google и попросить паука сканировать его. После того, как вы нажмете «Отправить», это должно занять не более нескольких минут.
Могу ли я чем-нибудь помочь паукам поисковых систем?
Да, да. Да, ты можешь.
По сути, вы хотите, чтобы пауки видели как можно большую часть вашего сайта, и вы хотите, чтобы их навигация была максимально простой.Начните со скорости вашего сайта. Пауки стремятся работать как можно быстрее, не замедляя работу вашего сайта за счет взаимодействия с пользователем. Если ваш сайт начинает отставать или возникают ошибки сервера, пауки будут меньше сканировать.
Это, конечно, противоположно тому, что вы хотите: меньшее сканирование означает меньшее индексирование, что означает худшую производительность в результатах поиска. Скорость сайта — ключ к успеху.
Поддерживайте карту сайта XML для создания удобного каталога для поисковых систем. Это скажет им, какие URL-адреса требуют регулярного сканирования.
Основной принцип архитектуры сайта: сводите клики к минимуму. Если быть более точным, ни одна страница вашего сайта не должна находиться на расстоянии более 3–4 кликов от другой. Что-то большее делает навигацию громоздкой как для пользователей, так и для пауков.
Наконец, зарезервируйте уникальный URL для каждого отдельного фрагмента контента. Если вы назначите несколько URL-адресов одной и той же странице, паукам станет непонятно, что им следует использовать. Помните: фундаментальная часть SEO — облегчение работы пауков.Не терзай пауков, и все будет хорошо.
.Как работают поисковые системы
Как общество, мы стали зависимыми от поисковых систем. Сегодня проще, чем когда-либо, бежать в Интернет и найти ответ практически на любой вопрос, который нас беспокоит. От наших самых личных вопросов до самых простых — поисковые системы стали нашим основным источником информации. Но вы когда-нибудь задумывались, как они это делают? Как работают поисковые системы?
Crawling
Все начинается с паука поисковой системы. Чтобы доставлять информацию пользователям, поисковые системы сначала должны знать, какая информация там есть.У каждой поисковой системы есть собственный «паук», который представляет собой программу, которая позволяет поисковым системам «сканировать» или читать внутренний код веб-сайтов. (Вы можете увидеть код любого веб-сайта, щелкнув правой кнопкой мыши на веб-сайте и просмотрев источник.) Паук поисковой системы перемещается со страницы на страницу и с веб-сайта на веб-сайт посредством ссылок, так же, как если бы вы нажимали ссылки для навигации по веб-сайту. . Затем паук поисковой системы следует по этим ссылкам, чтобы перейти на другие страницы и другие веб-сайты.
TitanBOT, паук Titan Growth был создан, чтобы копировать способ, которым пауки поисковых систем ползают и извлекают данные.Посмотрите это видео, чтобы узнать больше о том, как TitanBOT и пауки поисковых систем в целом сканируют веб-сайты.
Индексирование
Когда паук просматривает страницы, он копирует код, а затем «индексирует» эту информацию. Индексирование по сути означает, что они сохраняют информацию в базах данных поисковой системы. Представьте, что база данных поисковой системы — это библиотека, а каждый веб-сайт — это книга. Если паук поисковой системы впервые сканирует веб-сайт, он добавит новую книгу в библиотеку.Кроме того, если текущий веб-сайт добавляет новые страницы, пауки найдут и добавят эти страницы в существующую книгу в библиотеке. Поскольку поисковые системы всегда хотят предоставлять самые свежие и наиболее релевантные данные, пауки поисковых систем постоянно ползают по сети в поисках новой информации и обновлений для добавления в библиотеку.
Из своей базы данных на ваш рабочий стол
Так как же поисковая система может сортировать свой арсенал данных, чтобы дать вам ответы, которые вы ищете? Ответ — алгоритмы.У поисковых систем есть расширенный набор алгоритмов, которые представляют собой условия, которые должны быть выполнены для того, чтобы определенный фрагмент данных был взят из библиотеки и показан вам. Когда вы вводите запрос в строку поиска, поисковая система просматривает свою огромную базу данных и использует алгоритмы для фильтрации того, что имеет отношение к вашему запросу. На основе своих алгоритмов поисковая система покажет вам, что, по их мнению, наиболее актуально для вашего вопроса.
Где подходит SEO?
SEO — это стратегия, которая помогает поисковым системам лучше определять веб-сайты и помогает веб-сайтам привлекать внимание релевантных поисковиков.Убедившись, что код веб-сайта читабелен, прост в навигации и функционален для пауков, оптимизатор поисковых систем может максимально увеличить количество проиндексированных страниц. Но то, что ваш сайт проиндексирован, не означает, что он обязательно будет отображаться в результатах поиска; вот где снова появляется SEO. SEO-агентства делают ряд вещей, чтобы показать релевантность сайта и убедить поисковые системы в том, что сайт должен занимать первую страницу. Это значительно упрощает поисковым системам понимание того, о чем страницы веб-сайта, чтобы они могли размещать результаты перед относительными запросами.
Вот как работают поисковые системы! Очень сжатая версия очень сложного процесса; но благодаря поисковой технологии и алгоритмам мы можем получать немедленные ответы на наши запросы в любой точке мира простым щелчком мыши. Ищите, искатели!
Представлено Эрикой Мачин, Titan Growth
.Веб-сканирование — Как работают поисковые системы в Интернете
Когда большинство людей говорят о поисковых машинах в Интернете, они на самом деле имеют в виду поисковые машины World Wide Web. Еще до того, как Интернет стал наиболее заметной частью Интернета, уже существовали поисковые системы, помогающие людям находить информацию в сети. Программы с именами вроде «gopher» и «Archie» хранят индексы файлов, хранящихся на серверах, подключенных к Интернету, и значительно сокращают время, необходимое для поиска программ и документов.В конце 1980-х годов получение серьезной выгоды от Интернета означало уметь пользоваться сусликом, Арчи, Вероникой и другими.
Сегодня большинство пользователей Интернета ограничивают поиск в Интернете, поэтому мы ограничим эту статью поисковыми системами, которые сосредоточены на содержании веб-страниц.
Прежде чем поисковая система сможет сказать вам, где находится файл или документ, он должен быть найден. Чтобы найти информацию на сотнях миллионов существующих веб-страниц, поисковая машина использует специальных программных роботов, называемых пауков , для создания списков слов, найденных на веб-сайтах.Когда паук составляет свои списки, процесс называется Поиск в Интернете . (Есть некоторые недостатки в том, чтобы называть часть Интернета Всемирной паутиной — одним из них является большой набор ориентированных на паукообразных имен инструментов.) Чтобы создать и поддерживать полезный список слов, пауки поисковой системы имеют посмотреть много страниц.
Как какой-либо паук начинает свое путешествие по сети? Обычно отправной точкой являются списки часто используемых серверов и очень популярных страниц.Паук начнет с популярного сайта, индексируя слова на своих страницах и переходя по каждой ссылке, найденной на сайте. Таким образом, система пауков быстро начинает перемещаться, распространяясь по наиболее широко используемым частям Интернета.
Google начинался как академическая поисковая система. В статье, описывающей, как была построена система, Сергей Брин и Лоуренс Пейдж приводят пример того, как быстро могут работать их пауки. Они построили свою первоначальную систему для использования нескольких пауков, обычно трех одновременно.Каждый паук мог одновременно поддерживать около 300 подключений к веб-страницам. При максимальной производительности с использованием четырех пауков их система могла сканировать более 100 страниц в секунду, генерируя около 600 килобайт данных каждую секунду.
Чтобы все работало быстро, нужно было создать систему для передачи необходимой информации паукам. В ранней системе Google был сервер, предназначенный для предоставления URL-адресов паукам. Вместо того, чтобы зависеть от интернет-провайдера для сервера доменных имен (DNS), который переводит имя сервера в адрес, у Google был свой собственный DNS, чтобы свести задержки к минимуму.
Когда паук Google просматривал HTML-страницу, он обращал внимание на две вещи:
- Слова на странице
- Где были найдены слова
слов, встречающихся в заголовке, субтитрах, метатегах и других позициях относительной важности были отмечены для особого рассмотрения во время последующего поиска пользователя. Паук Google был создан для индексации каждого значимого слова на странице, исключая статьи «a», «an» и «the.»Другие пауки используют другие подходы.
Эти разные подходы обычно пытаются заставить паука работать быстрее, позволить пользователям искать более эффективно или и то, и другое. Например, некоторые пауки будут отслеживать слова в заголовке, подзаголовках и ссылках, а также 100 наиболее часто используемых слов на странице и каждое слово в первых 20 строках текста. Сообщается, что Lycos использует этот подход для работы в Интернете.
Другие системы, такие как AltaVista, идут в другом направлении, индексируя каждое слово на странице, включая «a», «an», «the» и другие «незначительные» слова.Стремление к полноте в этом подходе согласуется с другими системами в отношении внимания, уделяемого невидимой части веб-страницы, метатегам. Узнайте больше о метатегах на следующей странице.
.