Сколько весит один символ в UTF-8?
Сколько весит один символ в UTF-8?
2 либо 4 байта, смотря какой юникод. Текст, состоящий только из символов Юникода с номерами меньше 128, при записи в UTF—8 превращается в обычный текст ASCII. И наоборот, в тексте UTF—8 любой байт со значением меньше 128 изображает символ ASCII с тем же кодом.
Для чего выбирается кодировка UTF-8?
Unicode Transformation Format, 8-bit — «формат преобразования Юникода, 8-бит») — распространённый стандарт кодирования символов, позволяющий более компактно хранить и передавать символы Юникода, используя переменное количество байт (от 1 до 4), и обеспечивающий полную обратную совместимость с 7-битной кодировкой ASCII.
Что можно сказать о таблице символов ascii?
ASCII (англ. American Standard Code for Information Interchange) — американский стандартный код для обмена информацией. ASCII представляет собой кодировку для представления десятичных цифр, латинского и национального алфавитов, знаков препинания и управляющих символов.
Какой символ имеет код 49 в таблице ascii?
Печатные символы
| DEC | OCT | HTML код |
|---|---|---|
| 48 | 060 | 0 |
| 49 | 061 | 49; |
| 50 | 062 | 2 |
| 51 | 063 | 3 |
Как кодируются буквы?
Тексты вводятся в память компьютера с помощью клавиатуры. На клавишах написаны привычные нам буквы, цифры, знаки препинания и другие символы. … Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от до
Что представляют собой расширения ascii кодировки?
к. представляется последовательностью отдельных символов. … Расширения ASCII — кодировки, в которых первые 128 символов кодовой таблицы совпадают с кодировкой ASCII, а остальные (со 128-го по 255-й) используются для кодирования букв национального алфавита, символов национальной валюты и т. п.
п.
Сколько бит в кодировке ascii?
Символ ASCII в 8-битной кодировке ASCII составляет 8 бит (1 байт), хотя он может поместиться в 7 бит. Символ ISO-8895-1 в кодировке ISO-8859-1 составляет 8 бит (1 байт). Символ Unicode в кодировке UTF-8 находится между 8 битами (1 байт) и 32 битами (4 байта).
Что такое таблица кодировки какие таблицы кодировки вы знаете?
Ответ:Таблицы кодировки — таблицы, где каждому символу, буквам, цифрам, а также специальным знакам присвоен уникальный номер — код символа. … Также существуют такие таблицы, как ASCII, UNICODE и многие другие.
Чем отличается стандарт Unicode от кодировки ascii?
Основное различие между ними заключается в том, как они кодируют символ и количество битов, которые они используют для каждого. ASCII первоначально использовал семь битов для кодирования каждого символа. … Unicode практически устраняет эту проблему, поскольку все кодовые точки символов были стандартизированы.
Сколько символов можно закодировать в кодировке ascii?
Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII , в которых можно было кроме 128 основных знаков закодировать еще и символы …
Как найти таблицу символов?
Используем горячие клавиши, то есть:
- нажимаем одновременно две клавиши «Win+R».
- Появится окно “Выполнить”, в котором набираем без кавычек «charmap.exe».
- После чего щелкаем “ОК”, и откроется «Таблица символов».
Сколько различных символов можно использовать при 10 битном коде?
2. Сколько различных символов можно использовать при 10—битном коде (на каждый символ отводится 10 бит)? Ответ: 3.
Какое минимальное количество бит на символ надо выделить в памяти?
Ответ, проверенный экспертом 1 бит это самая маленькая информационная единица. Бит это значение 0 или 1. Чтобы закодировать 2 возможных варианта, достаточно 1 бита. Если нужно закодировать 3 варианта, то нужно будет уже 2 бита.
Бит это значение 0 или 1. Чтобы закодировать 2 возможных варианта, достаточно 1 бита. Если нужно закодировать 3 варианта, то нужно будет уже 2 бита.
Как открыть символы на клавиатуре?
Выход есть, и он всегда под рукой! – нажмите и удерживайте клавишу Alt; – на дополнительной цифровой клавиатуре (цифровой блок расположен в правой части клавиатуры) наберите код символа; – когда вы отпустите клавишу Alt, в текст будет вставлен нужный символ.
Объём памяти текстовой информации — что это, определение и ответ
В компьютере все символы представляются в виде кода из 0 и 1. Для работы с кодированием цифр, букв и других символов, таких как знаки препинания, пробелы, арифметические операции и т.д. были придуманы таблицы кодировок.
Количество символов необходимое нам для набора текста, состоящего из этих специальных символов, цифр и букв английского алфавита было закодировано с помощью таблицы ASCII (American Standard Code for Information Interchange). В этом наборе вес одного символа имеет 7 бит (27 — ближайшая максимальная степень двойки). Но в рамках этой таблицы создание многоязычных документов оказалось очень проблематичным. Эту кодировку пытались расширять, и это получалось, но программное обеспечение должно было следить за кодовыми страницами, и смешивать языки оказалось невозможным.
В этом наборе вес одного символа имеет 7 бит (27 — ближайшая максимальная степень двойки). Но в рамках этой таблицы создание многоязычных документов оказалось очень проблематичным. Эту кодировку пытались расширять, и это получалось, но программное обеспечение должно было следить за кодовыми страницами, и смешивать языки оказалось невозможным.
Позже появилась еще одна кодировка Unicode, которая позволяла закодировать 1 114 112 символов. Стандарт Unicode поддерживается тремя формами:
32-битной (UTF-32) – вес символа – 32 бита
16-битной (UTF-16) – вес символа – 16 бит
8-битной (UTF-8). – вес символа – 8 бит.
Для экзамена нужно только понимать, что 32 битной кодировке Unicode один символ весит 32 бита, а в 16 битной — 16 бит, а в 8 битной — 8 бит.
Также существуют кодировки КОИ, которые широко использовались до 2010 года как русскоязычные кодировки. С распространением кодировок Unicod их использование стало очень редким.
С точки зрения информационного объёма документа подобный принцип кодирования прост – каждый символ несёт в себе определённое количество бит, итоговый информационный объём текста определяется как: Вес одного символа* на количество символов в тексте.
Например: пусть часть текста стихотворения «Я к вам пишу – чего же боле? Что я могу ещё сказать?» записана с использованием кодировки UTF – 16, тогда размер этой фразы будет равен:16 бит (вес одного символа) * 52 (количество символов, учитывая пробелы и знаки препинания) = 832 бита.
Единицы измерения информации.
Для работы с объёмом памяти полезно вспомнить перевод единиц измерения количества информации.
Один двоичный знак — 0 или 1 — называется бит (англ. bit — сокращение от английских слов binary digit, что означает двоичная цифра).
Бит представляет наименьшую единицу информации. Однако компьютер имеет дело не с отдельными битами, а с байтами.
Однако компьютер имеет дело не с отдельными битами, а с байтами.
Байтом называется единица, равная 8 (23) бит.
Ее выделили и назвали отдельно, потому что она имеет важное значение для компьютерной памяти.
В информатике принято получать новые единицы измерения умножением на 2 в различных степенях — 10 (кило-), 20 (мега-), 30 (гига-) и т.д.
1 байт = 8 бит = 23 бит
1 Кбайт (Килобайт) = 210 байт = 213 бит
1 Мбайт (Мегабайт) = 220 байт = 223 бит
1 Гбайт (Гигабайт) = 230 байт = 233 бит
Рассмотрим примеры заданий экзамена, связанных с определением объёма текстовой информации.
Пример 1.
Задание.В одной из кодировок Unicode каждый символ кодируется 16 битами. Ученик написал текст (в нём нет лишних пробелов):
«Ёж, лев, слон, олень, тюлень, носорог, крокодил, аллигатор – дикие животные».
Ученик вычеркнул из списка название одного из животных. Заодно он вычеркнул ставшие лишними запятые и пробелы – два пробела не должны идти подряд.
При этом размер нового предложения в данной кодировке оказался на 16 байт меньше, чем размер исходного предложения. Напишите в ответе вычеркнутое название животного.
Решение.
Для начала определим количество удалённых из текста символов. Для этого поделим 16 байт (то, на сколько уменьшился текст) на вес одного символа – 16 бит.
\(\frac{16\ байт}{16\ бит} = \ \frac{16*8\ бит}{16\ бит} = 8\ символов\)
Так как по условию задания слово удалялось вместе со ставшими лишними запятой и пробелами, то длинна самого слова – 6 символов (при удалении слова уйдут 1 запятая и 1 пробел).
Название животного длинной 6 символов в тексте одно – это «тюлень».
Ответ: ТЮЛЕНЬ
Пример 2.
Задание.Статья, набранная на компьютере, содержит 48 страниц, на каждой странице 40 строк, в каждой строке 64 символа. {3}Кбайт = 120\ Кбайт\)
{3}Кбайт = 120\ Кбайт\)
Получаем, что правильный вариант ответа – первый – 120 Кбайт.
Ответ: 1
Простая в использовании таблица ASCII — быстрый поиск кода символа
© дизайн / Shutterstock.com
В компьютерных науках программисты должны иметь доступ к стандартизированным представлениям часто используемых символов, чтобы они могли работать эффективно и точно. Кроме того, компьютеры должны иметь возможность эффективно обрабатывать текстовую информацию независимо от ее источника. Из этих потребностей родился ASCII. Эта система кодирования почти так же стара, как сами компьютеры, но мы все еще широко используем ее сегодня. Мы расскажем, что такое ASCII, и предоставим вам таблицу ASCII, чтобы вы могли быстро и легко найти нужные коды символов.
Что такое ASCII и для чего он используется?
ASCII означает Американский стандартный код для обмена информацией, что звучит довольно сложно. Однако основные принципы довольно просты. Используя 7-битную систему кодирования, ASCII отображает символы в числовое представление, которое называется кодом ASCII.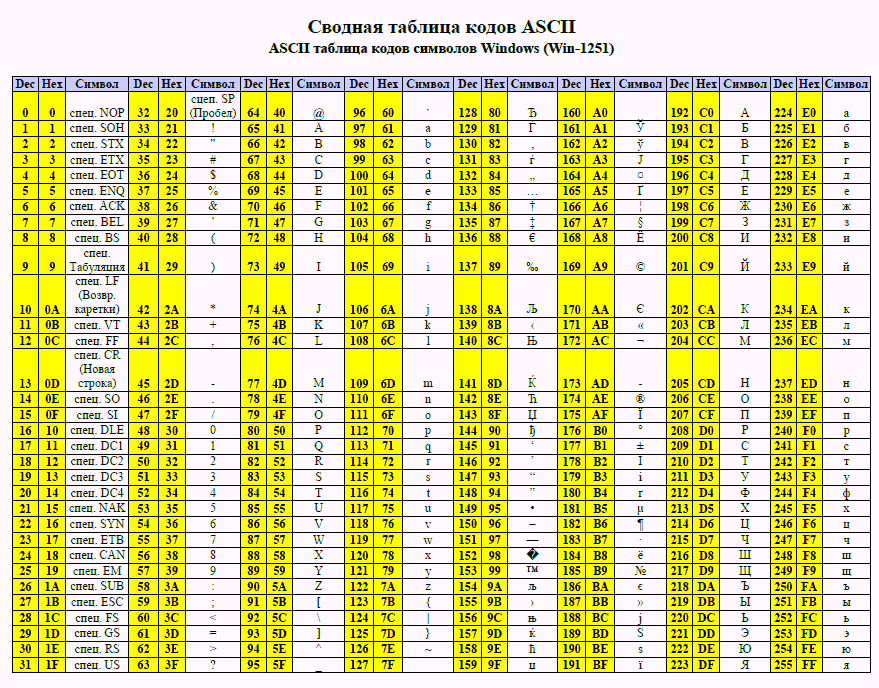 Стандарт ASCII представляет 128 символов, включая строчные и прописные буквы, знаки препинания, цифры и специальные символы. Они часто отображаются в формате сетки в порядке возрастания, чтобы вы могли быстро найти нужный символ.
Стандарт ASCII представляет 128 символов, включая строчные и прописные буквы, знаки препинания, цифры и специальные символы. Они часто отображаются в формате сетки в порядке возрастания, чтобы вы могли быстро найти нужный символ.
Стандарт ASCII упорядочивает символы в десятичном представлении, но также обеспечивает шестнадцатеричное и двоичное представление.
Наиболее известен десятичный формат, в котором значения представлены цифрами от 0 до 9.
Шестнадцатеричный формат использует буквы от A до F и цифры от 0 до 9, где от A до F представляют значения от 10 до 15. Каждая цифра имеет вес что является степенью 16. Крайняя правая цифра равна 0 и увеличивается на 1 по мере продвижения влево. Например, FF означает 255, так как (15 * 161) + (15 * 160) = 240 + 15 = 255,
Двоичный, с другой стороны, использует только цифры 0 и 1. Каждая цифра указывает вес, равный степени 2, начиная с 0 справа, как и раньше. Например, 1010 представляет собой (1 * 23) + (0 * 22) + (1 * 21) + (0 * 20).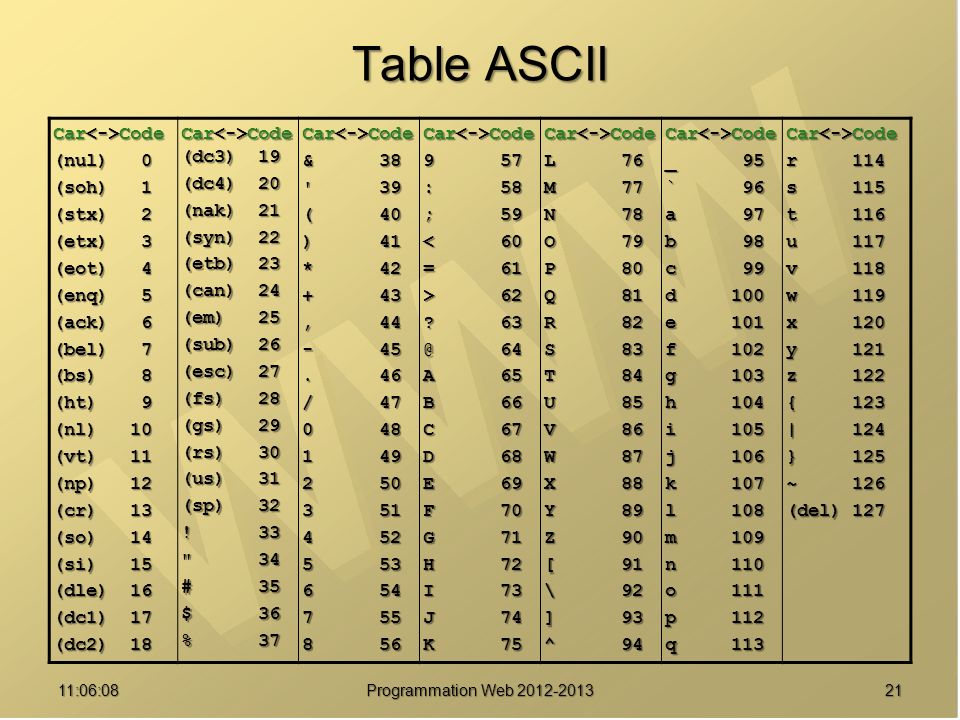 Это упрощается до (1 * 8) + (0 * 4) + (1 * 2) + (0 * 1) = 10.
Это упрощается до (1 * 8) + (0 * 4) + (1 * 2) + (0 * 1) = 10.
ASCII имеет множество применений. Но его основная цель — создавать представления, которые могут использовать разные системы и языки программирования. Стандартизированные коды символов помогают компьютерам эффективно взаимодействовать друг с другом, а программистам — преобразовывать текст и манипулировать им. ASCII также помогает в криптографии, где числа часто заменяют символы.
Простая диаграмма ASCII
Эта диаграмма ASCII показывает десятичные, шестнадцатеричные и двоичные значения для каждого символа.© History-Computer.com
Вот простая стандартная таблица ASCII со 128 символами, расположенными в порядке возрастания десятичного числа. Он также дает шестнадцатеричные и двоичные представления. Обратите внимание, что нумерация символов начинается с 0, а первые 32 символа являются управляющими. Их нельзя распечатать, и они в основном используются для форматирования.
Подведение итогов
В заключение отметим, что диаграммы ASCII очень полезны в компьютерных науках. Они служат стандартизированными ссылками для представления символов в десятичном, шестнадцатеричном и двоичном форматах. Эти уникальные числовые коды позволяют программистам легко манипулировать текстовой информацией. ASCII также помогает различным компьютерам и операционным системам общаться и передавать данные, используя стандартный язык.
Они служат стандартизированными ссылками для представления символов в десятичном, шестнадцатеричном и двоичном форматах. Эти уникальные числовые коды позволяют программистам легко манипулировать текстовой информацией. ASCII также помогает различным компьютерам и операционным системам общаться и передавать данные, используя стандартный язык.
Простая в использовании таблица ASCII — быстрый поиск кода символа Часто задаваемые вопросы (часто задаваемые вопросы)
Что такое ASCII?
ASCII расшифровывается как Американский стандартный код для обмена информацией и обеспечивает простой для понимания стандартизированный справочник для часто используемых текстовых символов. Каждый символ имеет соответствующее числовое представление в десятичном, шестнадцатеричном и двоичном виде.
Сколько символов представляет ASCII?
Стандарт ASCII представляет 128 символов с использованием 7-битной системы кодирования. Однако существует расширенный ASCII, который использует 8 бит для представления 256 символов.
Какие типы символов включает ASCII?
ASCII представляет множество типов символов, таких как буквы, цифры, специальные символы, управляющие символы и знаки препинания.
Каков диапазон символов ASCII?
В стандартном ASCII символы начинают нумероваться с 0 и доходят до 127, всего 128 символов. Первые 32 являются управляющими символами и представляют собой функции, которые нельзя распечатать визуально.
Для чего используется ASCII?
ASCII используется в качестве стандартного языка, чтобы компьютеры и операционные системы могли взаимодействовать и передавать данные, а также помогает программистам выполнять манипуляции с текстом независимым от платформы способом.
Когда был изобретен ASCII?
ASCII был разработан в 1963 году и сначала был известен как ASCII-63. Используемая сегодня версия также известна как ASCII-1977, так как она была представлена 14 лет спустя.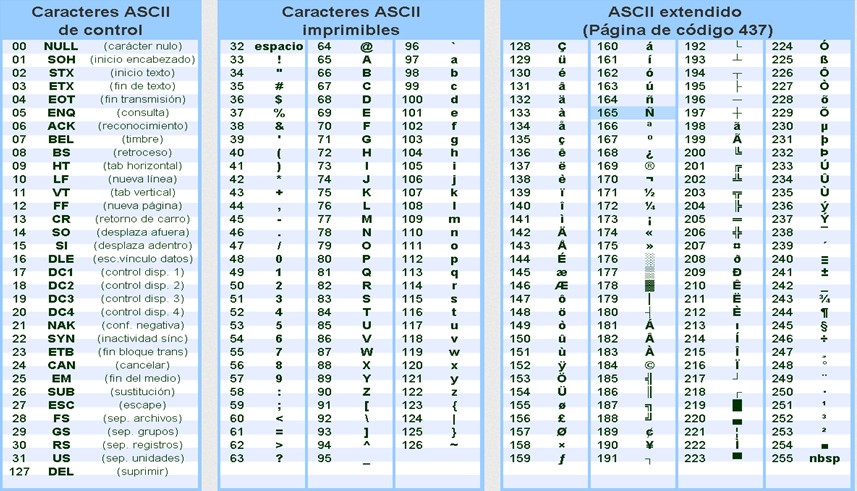
Что такое диаграммы ASCII?
Диаграммы ASCII обеспечивают представление символов ASCII и представлены в формате сетки в порядке возрастания. Это делается для того, чтобы вы могли легко найти персонажа, которого ищете.
Является ли ASCII универсальным?
Да, коды ASCII поддерживаются множеством различных систем и устройств. Большинство современных компьютеров используют ASCII в качестве основы для кодирования символов.
Какие существуют альтернативы ASCII?
Unicode является широко используемой альтернативой ASCII. Unicode поддерживает намного больше символов, чем ASCII, в настоящее время более 140 000. Unicode также использует различные системы кодирования, от 8 до 16 и 32 бит, и поддерживает языки, отличные от английского.
Что такое UTF-8?
Unicode, набор символов , отображает человеческие символы в натуральные числа, а UTF-8, кодировка символов , отображает строки этих чисел в строки байтов.
Старый набор символов ASCII содержит 128 символов, которые представляются с использованием значений байтов 0–127. Например, символ «а» принимает число 97, и это просто кодируется с использованием байта со значением 97 ).
Набор символов Unicode является надмножеством ASCII: код символа в ASCII совпадает с его кодом в Unicode. Например, символ ASCII «a» по-прежнему соответствует 97, а символ «😊», не относящийся к ASCII, соответствует 55357.
UTF-8 обладает важным свойством, состоящим в том, что текст ASCII (текст, использующий набор символов ASCII) имеет такое же значение. кодировка байта в UTF-8, как и в кодировке ASCII. Например, строка «hello world» кодируется теми же байтами, что и выше. Это означает, что новые программы могут взаимодействовать со старыми программами, если они используют только набор символов ASCII.
Например, строка «hello world» кодируется теми же байтами, что и выше. Это означает, что новые программы могут взаимодействовать со старыми программами, если они используют только набор символов ASCII.
Каждое число, отличное от ASCII (символьный код), имеет размер от 2 до 6 байтов. Первый байт содержит префикс, указывающий количество байтов. Например, четырехбайтная кодировка имеет пятибитный префикс 10 . Например, один шаблон 11110___ 10______ 10______ 10______ . Остальные биты (здесь показаны как символы подчеркивания) содержат двоичную кодировку кода символа.
Таким образом, глядя на битовый префикс любого байта, мы можем определить его тип: байт, начинающийся с 1 является символом ASCII, байт, начинающийся с 10 , является продолжением символа, отличного от ASCII, а остальные байты (начинающиеся с 1..10 ) являются началом символа, отличного от ASCII.
Сколько битов доступно в шаблоне UTF-8 для кодирования символа? В n-байтовом символе используется n+1 бит для указания длины байта и 2 бита в каждом оставшемся n-1 байте, в результате чего общие служебные данные составляют 3n-1 бит.
| # байт | накладные расходы | осталось |
|---|---|---|
| 2 байта | 5 бит | 11 бит |
| 3 байта | 8 бит | 16 бит |
| 4 байта | 11 бит | 21 бит |
| 5 байт | 14 бит | 26 бит |
| 6 байт | 17 бит | 31 бит |
Чтобы закодировать код символа, мы сначала находим, сколько битов требуется коду, а затем выбираем наименьшую кодировку, которая будет его содержать. Например, 121579 в двоичном виде равно
Например, 121579 в двоичном виде равно 11101101011101011 , что требует 17 бит, поэтому мы выбираем 4-байтовую кодировку, которая дает нам 21 бит.
Что могут компьютеры?
Каковы пределы математики?
И насколько занятым может быть занятой бобр?
В этом году я пишу
Это всего 19 долларов, и вы можете получить со скидкой 50% на , если найдете код скидки … Не совсем так. Хакеры используют консоль!
После месяцев тайного труда,
Я и Эндрю Карр выпустили  Вы похудеете с помощью дифференциальных уравнений.
И вы могли бы просто претендовать на Олимпийские игры с небольшим количеством статистики!
Вы похудеете с помощью дифференциальных уравнений.
И вы могли бы просто претендовать на Олимпийские игры с небольшим количеством статистики!
Это 29 долларов, но вы можете получить со скидкой 50% на , если найдете код скидки … Не совсем так. Хакеры используют консоль!
Еще от Джима
- У вас неправильная подсветка синтаксиса
- Сегодня умер дедушка
- Три Т: время, мысль и набор текста: измерение затрат в Интернете
- точки имеют значение: как обмануть пользователя Gmail
- Мои родители плоскоземельцы
- Как Hacker News остаются интересными
- Проект C-43: утерянные истоки асимметричной криптографии
- Цикл хакерской шумихи
- Стартовая панель: новый метод фишинга
- Время на обнаружение COVID-19 истекает
- Вероятностная викторина в пабе для ботаников
- Обманный фишинг: новая уязвимость Android
Отмечен .