ASCII таблица / Программирование / stD
ASCII — AmericanStandardCode forInformationInterchange.
ASCII была разработана (1963 год) для кодирования символов, коды которых помещались в 7 бит (128 символов). Со временем кодировка была расширена до 8-ми бит (256 символов), коды первых 128-и символов не изменились.
Управляющие символы ASCII (код символа 0-31)
Первые 32 символа в ASCII-таблице не имеют печатных кодов и используются для управления периферийными устройствами, телетайпами, принтерами и т.д.
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description |
|---|---|---|---|---|---|---|---|
| 0 | 000 | 0x00 | 00000000 | NUL \0 | & #000; | Null char | |
| 1 | 001 | 0x01 | 00000001 | SOH | & #001; | Start of Heading | |
| 2 | 002 | 0x02 | 00000010 | STX | & #002; | Start of Text | |
| 3 | 003 | 0x03 | 00000011 | ETX | & #003; | End of Text | |
| 4 | 004 | 0x04 | 00000100 | EOT | & #004; | End of Transmission | |
| 5 | 005 | 0x05 | 00000101 | ENQ | & #005; | Enquiry | |
| 6 | 006 | 0x06 | 00000110 | ACK | & #006; | Acknowledgment | |
| 7 | 007 | 0x07 | 00000111 | BEL | & #007; | Bell | |
| 8 | 010 | 0x08 | 00001000 | BS | & #008; | Back Space | |
| 9 | 011 | 0x09 | 00001001 | HT \t | & #009; | Tab | |
| 10 | 012 | 0x0A | 00001010 | LF \n | & #010; | Новая строка | |
| 11 | 013 | 0x0B | 00001011 | VT | & #011; | Vertical Tab | |
| 12 | 014 | 0x0C | 00001100 | FF | & #012; | Form Feed | |
| 13 | 015 | 0x0D | 00001101 | CR \r | & #013; | Возврат каретки | |
| 14 | 016 | 0x0E | 00001110 | SO | & #014; | Shift Out / X-On | |
| 15 | 017 | 0x0F | 00001111 | SI | & #015; | Shift In / X-Off | |
| 16 | 020 | 0x10 | 00010000 | DLE | & #016; | Data Line Escape | |
| 17 | 021 | 0x11 | 00010001 | DC1 | & #017; | Device Control 1 (oft. XON) | |
| 18 | 022 | 0x12 | 00010010 | DC2 | & #018; | Device Control 2 | |
| 19 | 023 | 0x13 | 00010011 | DC3 | & #019; | Device Control 3 (oft. XOFF) | |
| 20 | 024 | 0x14 | 00010100 | DC4 | & #020; | Device Control 4 | |
| 21 | 025 | 0x15 | 00010101 | NAK | & #021; | Negative Acknowledgement | |
| 22 | 026 | 0x16 | 00010110 | SYN | & #022; | Synchronous Idle | |
| 23 | 027 | 0x17 | 00010111 | ETB | & #023; | End of Transmit Block | |
| 24 | 030 | 0x18 | 00011000 | CAN | & #024; | Cancel | |
| 25 | 031 | 0x19 | 00011001 | EM | & #025; | End of Medium | |
| 26 | 032 | 0x1A | 00011010 | SUB | & #026; | Substitute | |
| 27 | 033 | 0x1B | 00011011 | ESC | & #027; | Escape | |
| 28 | 034 | 0x1C | 00011100 | FS | & #028; | File Separator | |
| 29 | 035 | 0x1D | 00011101 | GS | & #029; | Group Separator | |
| 30 | 036 | 0x1E | 00011110 | RS | & #030; | Record Separator | |
| 31 | 037 | 0x1F | 00011111 | US | & #031; | Unit Separator | |
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description |
Печатные символы ASCII (код символа 32-127)
Буквы, цифры, знаки препинания и другие символы расположенные на клавиатуре (англ.).
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description |
|---|---|---|---|---|---|---|---|
| 32 | 040 | 0x20 | 00100000 | & #32; | Space | ||
| 33 | 041 | 0x21 | 00100001 | ! | & #33; | Exclamation mark | |
| 34 | 042 | 0x22 | 00100010 | « | & #34; | & quot; | Double quotes (or speech marks) |
| 35 | 043 | 0x23 | 00100011 | # | & #35; | Number | |
| 36 | 044 | 0x24 | 00100100 | $ | & #36; | Dollar | |
| 37 | 045 | 0x25 | 00100101 | % | & #37; | Procenttecken | |
| 38 | 046 | 0x26 | 00100110 | & | & #38; | & amp; | Ampersand |
| 39 | 047 | 0x27 | 00100111 | ‘ | & #39; | Single quote | |
| 40 | 050 | 0x28 | 00101000 | ( | & #40; | Open parenthesis (or open bracket) | |
| 41 | 051 | 0x29 | 00101001 | ) | & #41; | Close parenthesis (or close bracket) | |
| 42 | 052 | 0x2A | 00101010 | * | & #42; | Asterisk | |
| 43 | 053 | 0x2B | 00101011 | + | & #43; | Plus | |
| 44 | 054 | 0x2C | 00101100 | , | & #44; | Comma | |
| 45 | 055 | 0x2D | 00101101 | — | & #45; | Hyphen | |
| 46 | 056 | 0x2E | 00101110 | . | & #46; | Period, dot or full stop | |
| 47 | 057 | 0x2F | 00101111 | / | & #47; | Slash or divide | |
| 48 | 060 | 0x30 | 00110000 | 0 | & #48; | Zero | |
| 49 | 061 | 0x31 | 00110001 | 1 | & #49; | One | |
| 50 | 062 | 0x32 | 00110010 | 2 | & #50; | Two | |
| 51 | 063 | 0x33 | 00110011 | 3 | & #51; | Three | |
| 52 | 064 | 0x34 | 00110100 | 4 | & #52; | Four | |
| 53 | 065 | 0x35 | 00110101 | 5 | & #53; | Five | |
| 54 | 066 | 0x36 | 00110110 | 6 | & #54; | Six | |
| 55 | 067 | 0x37 | 00110111 | 7 | & #55; | Seven | |
| 56 | 070 | 0x38 | 00111000 | 8 | & #56; | Eight | |
| 57 | 071 | 0x39 | 00111001 | 9 | & #57; | Nine | |
| 58 | 072 | 0x3A | 00111010 | : | & #58; | Colon | |
| 59 | 073 | 0x3B | 00111011 | ; | & #59; | Semicolon | |
| 60 | 074 | 0x3C | 00111100 | < | & #60; | & lt; | Less than (or open angled bracket) |
| 61 | 075 | 0x3D | 00111101 | = | & #61; | Equals | |
| 62 | 076 | 0x3E | 00111110 | > | & #62; | & gt; | Greater than (or close angled bracket) |
| 63 | 077 | 0x3F | 00111111 | ? | & #63; | Question mark | |
| 64 | 100 | 0x40 | 01000000 | @ | & #64; | At symbol | |
| 65 | 101 | 0x41 | 01000001 | A | & #65; | A | |
| 66 | 102 | 0x42 | 01000010 | B | & #66; | B | |
| 67 | 103 | 0x43 | 01000011 | C | & #67; | C | |
| 68 | 104 | 0x44 | 01000100 | D | & #68; | D | |
| 69 | 105 | 0x45 | 01000101 | E | & #69; | E | |
| 70 | 106 | 0x46 | 01000110 | F | & #70; | F | |
| 71 | 107 | 0x47 | 01000111 | G | & #71; | G | |
| 72 | 110 | 0x48 | 01001000 | H | & #72; | H | |
| 73 | 111 | 0x49 | 01001001 | I | & #73; | I | |
| 74 | 112 | 0x4A | 01001010 | J | & #74; | J | |
| 75 | 113 | 0x4B | 01001011 | K | & #75; | K | |
| 76 | 114 | 0x4C | 01001100 | L | & #76; | L | |
| 77 | 115 | 0x4D | 01001101 | M | & #77; | M | |
| 78 | 116 | 0x4E | 01001110 | N | & #78; | N | |
| 79 | 117 | 0x4F | 01001111 | O | & #79; | O | |
| 80 | 120 | 0x50 | 01010000 | P | & #80; | P | |
| 81 | 121 | 0x51 | 01010001 | Q | & #81; | Q | |
| 82 | 122 | 0x52 | 01010010 | R | & #82; | R | |
| 83 | 123 | 0x53 | 01010011 | S | & #83; | S | |
| 84 | 124 | 0x54 | 01010100 | T | & #84; | T | |
| 85 | 125 | 0x55 | 01010101 | U | & #85; | U | |
| 86 | 126 | 0x56 | 01010110 | V | & #86; | V | |
| 87 | 127 | 0x57 | 01010111 | W | & #87; | W | |
| 88 | 130 | 0x58 | 01011000 | X | & #88; | X | |
| 89 | 131 | 0x59 | 01011001 | Y | & #89; | Y | |
| 90 | 132 | 0x5A | 01011010 | Z | & #90; | Z | |
| 91 | 133 | 0x5B | 01011011 | [ | & #91; | Opening bracket | |
| 92 | 134 | 0x5C | 01011100 | \ | & #92; | Backslash | |
| 93 | 135 | 0x5D | 01011101 | ] | & #93; | Closing bracket | |
| 94 | 136 | 0x5E | 01011110 | ^ | & #94; | Caret — circumflex | |
| 95 | 137 | 0x5F | 01011111 | _ | & #95; | Underscore | |
| 96 | 140 | 0x60 | 01100000 | ` | & #96; | Grave accent | |
| 97 | 141 | 0x61 | 01100001 | a | & #97; | a | |
| 98 | 142 | 0x62 | 01100010 | b | & #98; | b | |
| 99 | 143 | 0x63 | 01100011 | c | & #99; | c | |
| 100 | 144 | 0x64 | 01100100 | d | & #100; | d | |
| 101 | 145 | 0x65 | 01100101 | e | & #101; | e | |
| 102 | 146 | 0x66 | 01100110 | f | & #102; | f | |
| 103 | 147 | 0x67 | 01100111 | g | & #103; | g | |
| 104 | 150 | 0x68 | 01101000 | h | & #104; | h | |
| 105 | 151 | 0x69 | 01101001 | i | & #105; | i | |
| 106 | 152 | 0x6A | 01101010 | j | & #106; | j | |
| 107 | 153 | 0x6B | 01101011 | k | & #107; | k | |
| 108 | 154 | 0x6C | 01101100 | l | & #108; | l | |
| 109 | 155 | 0x6D | 01101101 | m | & #109; | m | |
| 110 | 156 | 0x6E | 01101110 | n | & #110; | n | |
| 111 | 157 | 0x6F | 01101111 | o | & #111; | o | |
| 112 | 160 | 0x70 | 01110000 | p | & #112; | p | |
| 113 | 161 | 0x71 | 01110001 | q | & #113; | q | |
| 114 | 162 | 0x72 | 01110010 | r | & #114; | r | |
| 115 | 163 | 0x73 | 01110011 | s | & #115; | s | |
| 116 | 164 | 0x74 | 01110100 | t | & #116; | t | |
| 117 | 165 | 0x75 | 01110101 | u | & #117; | u | |
| 118 | 166 | 0x76 | 01110110 | v | & #118; | v | |
| 119 | 167 | 0x77 | 01110111 | w | & #119; | w | |
| 120 | 170 | 0x78 | 01111000 | x | & #120; | x | |
| 121 | 171 | 0x79 | 01111001 | y | & #121; | y | |
| 122 | 172 | 0x7A | 01111010 | z | & #122; | z | |
| 123 | 173 | 0x7B | 01111011 | { | & #123; | Opening brace | |
| 124 | 174 | 0x7C | 01111100 | | | & #124; | Vertical bar | |
| 125 | 175 | 0x7D | 01111101 | } | & #125; | Closing brace | |
| 126 | 176 | 0x7E | 01111110 | ~ | & #126; | Equivalency sign — tilde | |
| 127 | 177 | 0x7F | 01111111 | & #127; | Delete | ||
| DEC | OCT | HEX | BIN | Symbol | HTML Number | HTML Name | Description |
Расширенные символы ASCII Win-1251 кириллица (код символа 128-255)
| DEC | OCT | HEX | BIN | Symbol |
|---|---|---|---|---|
| 128 | 200 | 0x80 | 10000000 | Ђ |
| 129 | 201 | 0x81 | 10000001 | Ѓ |
| 130 | 202 | 0x82 | 10000010 | ‚ |
| 131 | 203 | 0x83 | 10000011 | ѓ |
| 132 | 204 | 0x84 | 10000100 | „ |
| 133 | 205 | 0x85 | 10000101 | … |
| 134 | 206 | 0x86 | 10000110 | † |
| 135 | 207 | 0x87 | 10000111 | ‡ |
| 136 | 210 | 0x88 | 10001000 | € |
| 137 | 211 | 0x89 | 10001001 | ‰ |
| 138 | 212 | 0x8A | 10001010 | Љ |
| 139 | 213 | 0x8B | 10001011 | ‹ |
| 140 | 214 | 0x8C | 10001100 | Њ |
| 141 | 215 | 0x8D | 10001101 | Ќ |
| 142 | 216 | 0x8E | 10001110 | Ћ |
| 143 | 217 | 0x8F | 10001111 | Џ |
| 144 | 220 | 0x90 | 10010000 | Ђ |
| 145 | 221 | 0x91 | 10010001 | ‘ |
| 146 | 222 | 0x92 | 10010010 | ’ |
| 147 | 223 | 0x93 | 10010011 | “ |
| 148 | 224 | 0x94 | 10010100 | ” |
| 149 | 225 | 0x95 | 10010101 | • |
| 150 | 226 | 0x96 | 10010110 | – |
| 151 | 227 | 0x97 | 10010111 | — |
| 152 | 230 | 0x98 | 10011000 | |
| 153 | 231 | 0x99 | 10011001 | ™ |
| 154 | 232 | 0x9A | 10011010 | љ |
| 155 | 233 | 0x9B | 10011011 | › |
| 156 | 234 | 0x9C | 10011100 | њ |
| 157 | 235 | 0x9D | 10011101 | ќ |
| 158 | 236 | 0x9E | 10011110 | ћ |
| 159 | 237 | 0x9F | 10011111 | џ |
| 160 | 240 | 0xA0 | 10100000 | |
| 161 | 241 | 0xA1 | 10100001 | Ў |
| 162 | 242 | 0xA2 | 10100010 | ў |
| 163 | 243 | 0xA3 | 10100011 | Ј |
| 164 | 244 | 0xA4 | 10100100 | ¤ |
| 165 | 245 | 0xA5 | 10100101 | Ґ |
| 166 | 246 | 0xA6 | 10100110 | ¦ |
| 167 | 247 | 0xA7 | 10100111 | § |
| 168 | 250 | 0xA8 | 10101000 | Ё |
| 169 | 251 | 0xA9 | 10101001 | © |
| 170 | 252 | 0xAA | 10101010 | Є |
| 171 | 253 | 0xAB | 10101011 | « |
| 172 | 254 | 0xAC | 10101100 | ¬ |
| 173 | 255 | 0xAD | 10101101 | |
| 174 | 256 | 0xAE | 10101110 | ® |
| 175 | 257 | 0xAF | 10101111 | Ї |
| 176 | 260 | 0xB0 | 10110000 | ° |
| 177 | 261 | 0xB1 | 10110001 | ± |
| 178 | 262 | 0xB2 | 10110010 | І |
| 179 | 263 | 0xB3 | 10110011 | і |
| 180 | 264 | 0xB4 | 10110100 | ґ |
| 181 | 265 | 0xB5 | 10110101 | µ |
| 182 | 266 | 0xB6 | 10110110 | ¶ |
| 183 | 267 | 0xB7 | 10110111 | · |
| 184 | 270 | 0xB8 | 10111000 | ё |
| 185 | 271 | 0xB9 | 10111001 | № |
| 186 | 272 | 0xBA | 10111010 | є |
| 187 | 273 | 0xBB | 10111011 | » |
| 188 | 274 | 0xBC | 10111100 | ј |
| 189 | 275 | 0xBD | 10111101 | Ѕ |
| 190 | 276 | 0xBE | 10111110 | ѕ |
| 191 | 277 | 0xBF | 10111111 | ї |
| 192 | 300 | 0xC0 | 11000000 | А |
| 193 | 301 | 0xC1 | 11000001 | Б |
| 194 | 302 | 0xC2 | 11000010 | В |
| 195 | 303 | 0xC3 | 11000011 | Г |
| 196 | 304 | 0xC4 | 11000100 | Д |
| 197 | 305 | 0xC5 | 11000101 | Е |
| 198 | 306 | 0xC6 | 11000110 | Ж |
| 199 | 307 | 0xC7 | 11000111 | З |
| 200 | 310 | 0xC8 | 11001000 | И |
| 201 | 311 | 0xC9 | 11001001 | Й |
| 202 | 312 | 0xCA | 11001010 | К |
| 203 | 313 | 0xCB | 11001011 | Л |
| 204 | 314 | 0xCC | 11001100 | М |
| 205 | 315 | 0xCD | 11001101 | Н |
| 206 | 316 | 0xCE | 11001110 | О |
| 207 | 317 | 0xCF | 11001111 | П |
| 208 | 320 | 0xD0 | 11010000 | Р |
| 209 | 321 | 0xD1 | 11010001 | С |
| 210 | 322 | 0xD2 | 11010010 | Т |
| 211 | 323 | 0xD3 | 11010011 | У |
| 212 | 324 | 0xD4 | 11010100 | Ф |
| 213 | 325 | 0xD5 | 11010101 | Х |
| 214 | 326 | 0xD6 | 11010110 | Ц |
| 215 | 327 | 0xD7 | 11010111 | Ч |
| 216 | 330 | 0xD8 | 11011000 | Ш |
| 217 | 331 | 0xD9 | 11011001 | Щ |
| 218 | 332 | 0xDA | 11011010 | Ъ |
| 219 | 333 | 0xDB | 11011011 | Ы |
| 220 | 334 | 0xDC | 11011100 | Ь |
| 221 | 335 | 0xDD | 11011101 | Э |
| 222 | 336 | 0xDE | 11011110 | Ю |
| 223 | 337 | 0xDF | 11011111 | Я |
| 224 | 340 | 0xE0 | 11100000 | а |
| 225 | 341 | 0xE1 | 11100001 | б |
| 226 | 342 | 0xE2 | 11100010 | в |
| 227 | 343 | 0xE3 | 11100011 | г |
| 228 | 344 | 0xE4 | 11100100 | д |
| 229 | 345 | 0xE5 | 11100101 | е |
| 230 | 346 | 0xE6 | 11100110 | ж |
| 231 | 347 | 0xE7 | 11100111 | з |
| 232 | 350 | 0xE8 | 11101000 | и |
| 233 | 351 | 0xE9 | 11101001 | й |
| 234 | 352 | 0xEA | 11101010 | к |
| 235 | 353 | 0xEB | 11101011 | л |
| 236 | 354 | 0xEC | 11101100 | м |
| 237 | 355 | 0xED | 11101101 | н |
| 238 | 356 | 0xEE | 11101110 | о |
| 239 | 357 | 0xEF | 11101111 | п |
| 240 | 360 | 0xF0 | 11110000 | р |
| 241 | 361 | 0xF1 | 11110001 | с |
| 242 | 362 | 0xF2 | 11110010 | т |
| 243 | 363 | 0xF3 | 11110011 | у |
| 244 | 364 | 0xF4 | 11110100 | ф |
| 245 | 365 | 0xF5 | 11110101 | х |
| 246 | 366 | 0xF6 | 11110110 | ц |
| 247 | 367 | 0xF7 | 11110111 | ч |
| 248 | 370 | 0xF8 | 11111000 | ш |
| 249 | 371 | 0xF9 | 11111001 | щ |
| 250 | 372 | 0xFA | 11111010 | ъ |
| 251 | 373 | 0xFB | 11111011 | ы |
| 252 | 374 | 0xFC | 11111100 | ь |
| 253 | 375 | 0xFD | 11111101 | э |
| 254 | 376 | 0xFE | 11111110 | ю |
| 255 | 377 | 0xFF | 11111111 | я |
| DEC | OCT | HEX | BIN | Symbol |
Расширенные символы ASCII Win-1252 (код символа 128-255)
| DEC | OCT | HEX | BIN | Symbol |
|---|---|---|---|---|
| 128 | 200 | 0x80 | 10000000 | € |
| 129 | 201 | 0x81 | 10000001 | |
| 130 | 202 | 0x82 | 10000010 | ‚ |
| 131 | 203 | 0x83 | 10000011 | ƒ |
| 132 | 204 | 0x84 | 10000100 | „ |
| 133 | 205 | 0x85 | 10000101 | … |
| 134 | 206 | 0x86 | 10000110 | † |
| 135 | 207 | 0x87 | 10000111 | ‡ |
| 136 | 210 | 0x88 | 10001000 | ˆ |
| 137 | 211 | 0x89 | 10001001 | ‰ |
| 138 | 212 | 0x8A | 10001010 | Š |
| 139 | 213 | 0x8B | 10001011 | ‹ |
| 140 | 214 | 0x8C | 10001100 | Π|
| 141 | 215 | 0x8D | 10001101 | |
| 142 | 216 | 0x8E | 10001110 | Ž |
| 143 | 217 | 0x8F | 10001111 | |
| 144 | 220 | 0x90 | 10010000 | |
| 145 | 221 | 0x91 | 10010001 | ‘ |
| 146 | 222 | 0x92 | 10010010 | ’ |
| 147 | 223 | 0x93 | 10010011 | “ |
| 148 | 224 | 0x94 | 10010100 | ” |
| 149 | 225 | 0x95 | 10010101 | • |
| 150 | 226 | 0x96 | 10010110 | – |
| 151 | 227 | 0x97 | 10010111 | — |
| 152 | 230 | 0x98 | 10011000 | ˜ |
| 153 | 231 | 0x99 | 10011001 | ™ |
| 154 | 232 | 0x9A | 10011010 | š |
| 155 | 233 | 0x9B | 10011011 | › |
| 156 | 234 | 0x9C | 10011100 | œ |
| 157 | 235 | 0x9D | 10011101 | |
| 158 | 236 | 0x9E | 10011110 | ž |
| 159 | 237 | 0x9F | 10011111 | Ÿ |
| 160 | 240 | 0xA0 | 10100000 | |
| 161 | 241 | 0xA1 | 10100001 | ¡ |
| 162 | 242 | 0xA2 | 10100010 | ¢ |
| 163 | 243 | 0xA3 | 10100011 | £ |
| 164 | 244 | 0xA4 | 10100100 | ¤ |
| 165 | 245 | 0xA5 | 10100101 | ¥ |
| 166 | 246 | 0xA6 | 10100110 | ¦ |
| 167 | 247 | 0xA7 | 10100111 | § |
| 168 | 250 | 0xA8 | 10101000 | ¨ |
| 169 | 251 | 0xA9 | 10101001 | © |
| 170 | 252 | 0xAA | 10101010 | ª |
| 171 | 253 | 0xAB | 10101011 | « |
| 172 | 254 | 0xAC | 10101100 | ¬ |
| 173 | 255 | 0xAD | 10101101 | � |
| 174 | 256 | 0xAE | 10101110 | ® |
| 175 | 257 | 0xAF | 10101111 | ¯ |
| 176 | 260 | 0xB0 | 10110000 | ° |
| 177 | 261 | 0xB1 | 10110001 | ± |
| 178 | 262 | 0xB2 | 10110010 | ² |
| 179 | 263 | 0xB3 | 10110011 | ³ |
| 180 | 264 | 0xB4 | 10110100 | ´ |
| 181 | 265 | 0xB5 | 10110101 | µ |
| 182 | 266 | 0xB6 | 10110110 | ¶ |
| 183 | 267 | 0xB7 | 10110111 | · |
| 184 | 270 | 0xB8 | 10111000 | ¸ |
| 185 | 271 | 0xB9 | 10111001 | ¹ |
| 186 | 272 | 0xBA | 10111010 | º |
| 187 | 273 | 0xBB | 10111011 | » |
| 188 | 274 | 0xBC | 10111100 | ¼ |
| 189 | 275 | 0xBD | 10111101 | ½ |
| 190 | 276 | 0xBE | 10111110 | ¾ |
| 191 | 277 | 0xBF | 10111111 | ¿ |
| 192 | 300 | 0xC0 | 11000000 | À |
| 193 | 301 | 0xC1 | 11000001 | Á |
| 194 | 302 | 0xC2 | 11000010 | Â |
| 195 | 303 | 0xC3 | 11000011 | Ã |
| 196 | 304 | 0xC4 | 11000100 | Ä |
| 197 | 305 | 0xC5 | 11000101 | Å |
| 198 | 306 | 0xC6 | 11000110 | Æ |
| 199 | 307 | 0xC7 | 11000111 | Ç |
| 200 | 310 | 0xC8 | 11001000 | È |
| 201 | 311 | 0xC9 | 11001001 | É |
| 202 | 312 | 0xCA | 11001010 | Ê |
| 203 | 313 | 0xCB | 11001011 | Ë |
| 204 | 314 | 0xCC | 11001100 | Ì |
| 205 | 315 | 0xCD | 11001101 | Í |
| 206 | 316 | 0xCE | 11001110 | Î |
| 207 | 317 | 0xCF | 11001111 | Ï |
| 208 | 320 | 0xD0 | 11010000 | Ð |
| 209 | 321 | 0xD1 | 11010001 | Ñ |
| 210 | 322 | 0xD2 | 11010010 | Ò |
| 211 | 323 | 0xD3 | 11010011 | Ó |
| 212 | 324 | 0xD4 | 11010100 | Ô |
| 213 | 325 | 0xD5 | 11010101 | Õ |
| 214 | 326 | 0xD6 | 11010110 | Ö |
| 215 | 327 | 0xD7 | 11010111 | × |
| 216 | 330 | 0xD8 | 11011000 | Ø |
| 217 | 331 | 0xD9 | 11011001 | Ù |
| 218 | 332 | 0xDA | 11011010 | Ú |
| 219 | 333 | 0xDB | 11011011 | Û |
| 220 | 334 | 0xDC | 11011100 | Ü |
| 221 | 335 | 0xDD | 11011101 | Ý |
| 222 | 336 | 0xDE | 11011110 | Þ |
| 223 | 337 | 0xDF | 11011111 | ß |
| 224 | 340 | 0xE0 | 11100000 | à |
| 225 | 341 | 0xE1 | 11100001 | á |
| 226 | 342 | 0xE2 | 11100010 | â |
| 227 | 343 | 0xE3 | 11100011 | ã |
| 228 | 344 | 0xE4 | 11100100 | ä |
| 229 | 345 | 0xE5 | 11100101 | å |
| 230 | 346 | 0xE6 | 11100110 | æ |
| 231 | 347 | 0xE7 | 11100111 | ç |
| 232 | 350 | 0xE8 | 11101000 | è |
| 233 | 351 | 0xE9 | 11101001 | é |
| 234 | 352 | 0xEA | 11101010 | ê |
| 235 | 353 | 0xEB | 11101011 | ë |
| 236 | 354 | 0xEC | 11101100 | ì |
| 237 | 355 | 0xED | 11101101 | í |
| 238 | 356 | 0xEE | 11101110 | î |
| 239 | 357 | 0xEF | 11101111 | ï |
| 240 | 360 | 0xF0 | 11110000 | ð |
| 241 | 361 | 0xF1 | 11110001 | ñ |
| 242 | 362 | 0xF2 | 11110010 | ò |
| 243 | 363 | 0xF3 | 11110011 | ó |
| 244 | 364 | 0xF4 | 11110100 | ô |
| 245 | 365 | 0xF5 | 11110101 | õ |
| 246 | 366 | 0xF6 | 11110110 | ö |
| 247 | 367 | 0xF7 | 11110111 | ÷ |
| 248 | 370 | 0xF8 | 11111000 | ø |
| 249 | 371 | 0xF9 | 11111001 | ù |
| 250 | 372 | 0xFA | 11111010 | ú |
| 251 | 373 | 0xFB | 11111011 | û |
| 252 | 374 | 0xFC | 11111100 | ü |
| 253 | 375 | 0xFD | 11111101 | ý |
| 254 | 376 | 0xFE | 11111110 | þ |
| 255 | 377 | 0xFF | 11111111 | ÿ |
| DEC | OCT | HEX | BIN | Symbol |
istarik.ru
Кодирование символов
Кодировка символов (часто называемая также кодовой страницей) – это набор числовых значений, которые ставятся в соответствие группе алфавитно-цифровых символов, знаков пунктуации и специальных символов.
Для кодировки символов в Windows используется таблица ASCII (American Standard Code for Interchange of Information).
В ASCII первые 128 символов всех кодовых страниц состоят из базовой таблицы символов. Первые 32 кода базовой таблицы, начиная с нулевого, размещают управляющие коды.
| Символ | Код | Клавиши | Значение |
| nul | 0 | Ctrl + @ | Нуль |
| soh | 1 | Ctrl + A | Начало заголовка |
| stx | 2 | Ctrl + B | Начало текста |
| etx | 3 | Ctrl + C | Конец текста |
| eot | 4 | Ctrl + D | Конец передачи |
| enq | 5 | Ctrl + E | Запрос |
| ack | 6 | Ctrl + F | Подтверждение |
| bel | 7 | Ctrl + G | Сигнал (звонок) |
| bs | 8 | Ctrl + H | Забой (шаг назад) |
| ht | 9 | Ctrl + I | Горизонтальная табуляция |
| lf | 10 | Ctrl + J | Перевод строки |
| vt | 11 | Ctrl + K | Вертикальная табуляция |
| ff | 12 | Ctrl + L | Новая страница |
| cr | 13 | Ctrl + M | Возврат каретки |
| so | 14 | Ctrl + N | Выключить сдвиг |
| si | 15 | Ctrl + O | Включить сдвиг |
| dle | 16 | Ctrl + P | Ключ связи данных |
| dc1 | 17 | Ctrl + Q | Управление устройством 1 |
| dc2 | 18 | Ctrl + R | |
| dc3 | 19 | Ctrl + S | Управление устройством 3 |
| dc4 | 20 | Ctrl + T | Управление устройством 4 |
| nak | 21 | Ctrl + U | Отрицательное подтверждение |
| syn | 22 | Ctrl + V | Синхронизация |
| etb | 23 | Ctrl + W | Конец передаваемого блока |
| can | 24 | Ctrl + X | Отказ |
| em | 25 | Ctrl + Y | Конец среды |
| sub | 26 | Ctrl + Z | Замена |
| esc | 27 | Ctrl + [ | Ключ |
| fs | 28 | Ctrl + \ | Разделитель файлов |
| gs | 29 | Ctrl + ] | Разделитель группы |
| rs | 30 | Ctrl + ^ | Разделитель записей |
| us | 31 | Ctrl + _ | Разделитель модулей |
Базовая таблица кодировки ASCII
| 32 пробел | 48 0 | 64 @ | 80 P | 96 ` | 112 p |
| 33 ! | 49 1 | 65 A | 81 Q | 97 a | 113 q |
| 34 “ | 50 2 | 66 B | 82 R | 98 b | 114 r |
| 35 # | 51 3 | 67 C | 83 S | 99 c | 115 s |
| 36 $ | 52 4 | 68 D | 84 T | 100 d | 116 t |
| 37 % | 53 5 | 69 E | 85 U | 101 e | 117 u |
| 38 & | 54 6 | 70 F | 86 V | 102 f | 118 v |
| 39 ‘ | 55 7 | 71 G | 87 W | 103 g | 119 w |
| 40 ( | 56 8 | 72 H | 88 X | 104 h | 120 x |
| 41 ) | 57 9 | 73 I | 89 Y | 105 i | 121 y |
| 42 * | 58 : | 74 J | 90 Z | 106 j | 122 z |
| 43 + | 59 ; | 75 K | 91 [ | 107 k | 123 { |
| 44 , | 60 < | 76 L | 92 \ | 108 l | 124 | |
| 45 — | 61 = | 77 M | 93 ] | 109 m | 125 } |
| 46 . | 62 > | 78 N | 94 ^ | 110 n | 126 ~ |
| 47 / | 63 ? | 79 O | 95 _ | 111 o | 127 |
Символы с номерами от 128 до 255 представляют собой таблицу расширения и варьируются в зависимости от набора скриптов, представленных кодировкой символов. Набор символов таблицы расширения различается в зависимости от выбранной кодовой страницы:
1251 – кодовая страница Windows
| 128 Ђ | 144 Ђ | 160 | 176 ° | 192 А | 208 Р | 224 а | 240 р |
| 129 Ѓ | 145 ‘ | 161 Ў | 177 ± | 193 Б | 209 С | 225 б | 241 с |
| 130 ‚ | 146 ’ | 162 ў | 178 I | 194 В | 210 Т | 226 в | 242 т |
| 131 ѓ | 147 “ | 163 J | 179 i | 195 Г | 211 У | 227 г | 243 у |
| 132 „ | 148 ” | 164 ¤ | 180 ґ | 196 Д | 212 Ф | 228 д | 244 ф |
| 133 … | 149 • | 165 Ґ | 181 μ | 197 Е | 213 Х | 229 е | 245 х |
| 134 † | 150 – | 166 ¦ | 182 ¶ | 198 Ж | 214 Ц | 230 ж | 246 ц |
| 135 ‡ | 151 — | 167 § | 183 · | 199 З | 215 Ч | 231 з | 247 ч |
| 136 € | 152 □ | 168 Ё | 184 ё | 200 И | 216 Ш | 232 и | 248 ш |
| 137 ‰ | 153 ™ | 169 © | 185 № | 201 Й | 217 Щ | 233 й | 249 щ |
| 138 Љ | 154 љ | 170 Є | 186 є | 202 К | 218 Ъ | 234 к | 250 ъ |
| 139 < | 155 > | 171 « | 187 » | 203 Л | 219 Ы | 235 л | 251 ы |
| 140 Њ | 156 њ | 172 ¬ | 188 j | 204 М | 220 Ь | 236 м | 252 ь |
| 141 Ќ | 157 ќ | 173 | 189 S | 205 Н | 221 Э | 237 н | 253 э |
| 142 Ћ | 158 ћ | 174 ® | 190 s | 206 О | 222 Ю | 238 о | 254 ю |
| 143 Џ | 159 џ | 175 Ï | 191 ї | 207 П | 223 Я | 239 п | 255 я |
866 – кодовая страница DOS
| 128 А | 144 Р | 160 а | 176 ░ | 192 └ | 208 ╨ | 224 р | 240 ≡Ё |
| 129 Б | 145 С | 161 б | 177 ▒ | 193 ┴ | 209 ╤ | 225 с | 241 ±ё |
| 130 В | 146 Т | 162 в | 178 ▓ | 194 ┬ | 210 ╥ | 226 т | 242 ≥ |
| 131 Г | 147 У | 163 г | 179 │ | 195 ├ | 211 ╙ | 227 у | 243 ≤ |
| 132 Д | 148 Ф | 164 д | 180 ┤ | 196 ─ | 212 ╘ | 228 ф | 244 ⌠ |
| 133 Е | 149 Х | 165 е | 181 ╡ | 197 ┼ | 213 ╒ | 229 х | 245 ⌡ |
| 134 Ж | 150 Ц | 166 ж | 182 ╢ | 198 ╞ | 214 ╓ | 230 ц | 246 ¸ |
| 135 З | 151 Ч | 167 з | 183 ╖ | 199 ╟ | 215 ╫ | 231 ч | 247 » |
| 136 И | 152 Ш | 168 и | 184 ╕ | 200 ╚ | 216 ╪ | 232 ш | 248 ° |
| 137 Й | 153 Щ | 169 й | 185 ╣ | 201 ╔ | 217 ┘ | 233 щ | 249 · |
| 138 К | 154 Ъ | 170 к | 186 ║ | 202 ╩ | 218 ┌ | 234 ъ | 250 ∙ |
| 139 Л | 155 Ы | 171 л | 187 ╗ | 203 ╦ | 219 █ | 235 ы | 251 √ |
| 140 М | 156 Ь | 172 м | 188 ╝ | 204 ╠ | 220 ▄ | 236 ь | 252 ⁿ |
| 141 Н | 157 Э | 173 н | 189 ╜ | 205 ═ | 221 ▌ | 237 э | 253 ² |
| 142 О | 158 Ю | 174 о | 190 ╛ | 206 ╬ | 222 ▐ | 238 ю | 254 ■ |
| 143 П | 159 Я | 175 п | 191 ┐ | 207 ╧ | 223 ▀ | 239 я | 255 |
Русские названия основных спецсимволов:
| Символ | Название |
| ` | гравис, кавычка, обратный машинописный апостроф |
| ` | гравис, кавычка, обратный машинописный апостроф |
| ~ | тильда |
| ! | восклицательный знак |
| @ | |
| # | октоторп, решетка, диез |
| $ | знак доллара |
| % | процент |
| ^ | циркумфлекс, знак вставки |
| & | амперсанд |
| * | астериск, звездочка, знак умножения |
| ( | левая открывающая круглая скобка |
| ) | правая закрывающая круглая скобка |
| — | минус, дефис |
| _ | знак подчеркивания |
| = | знак равенства |
| + | плюс |
| [ | левая открывающая квадратная скобка |
| ] | правая закрывающая квадратная скобка |
| { | левая открывающая фигурная скобка |
| } | правая закрывающая фигурная скобка |
| ; | точка с запятой |
| : | двоеточие |
| ‘ | машинописный апостроф, одинарная кавычка |
| « | двойная кавычка |
| , | запятая |
| . | точка |
| / | слэш, косая черта, знак дроби |
| < | левая открытая угловая скобка, знак меньше |
| > | правая закрытая угловая скобка, знак больше |
| \ | обратный слэш, обратная косая черта |
| | | вертикальная черта |
Кодировка UNICODE
Юникод (Unicode) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода».
В Unicode используются 16-битовые (2-байтовые) коды, что позволяет представить 65536 символов.
Применение стандарта Unicode позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц.
Для представления символьных данных в кодировке Unicode используется символьный тип wchar_t.
| ASCII | UNICODE |
| char | wchar_t |
| 1 байт | 2 байта |
Тип кодировки задается в свойствах проекта Microsoft Visual Studio:
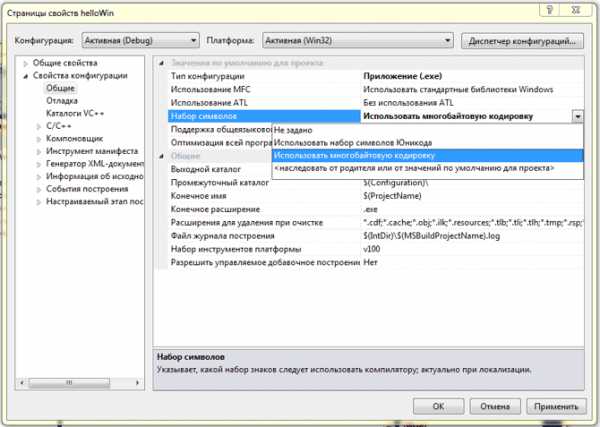
Многобайтовая кодировка предполагает использование кодировки ASCII.
При этом при построении проекта используется директива условной компиляции, переопределяющая тип TCHAR:
#ifdef _UNICODE
typedef wchar_t TCHAR;
#else
typedef char TCHAR;
#endif
Для перекодирования строки в формат Unicode без изменения кодировки файла используется макроопределение
_T(«строка»)
Прототип макроса содержится в файле tchar.h.
Назад: Представление данных и архитектура ЭВМ
prog-cpp.ru
Кодировка текста ASCII (Windows 1251, CP866, KOI8-R) и Юникод (UTF 8, 16, 32) — как исправить проблему с кракозябрами
Сегодня мы поговорим с вами про то, откуда берутся кракозябры на сайте и в программах, какие кодировки текста существуют и какие из них следует использовать. Подробно рассмотрим историю их развития, начиная от базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8. Оглавление:
Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (не читаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.
Оглавление:
Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (не читаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.ASCII — базовая кодировка текста для латиницы
Развитие кодировок текстов происходило одновременно с формированием отрасли IT, и они за это время успели претерпеть достаточно много изменений. Исторически все начиналось с довольно-таки не благозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами. Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую ASCII (American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания. Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы навроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их: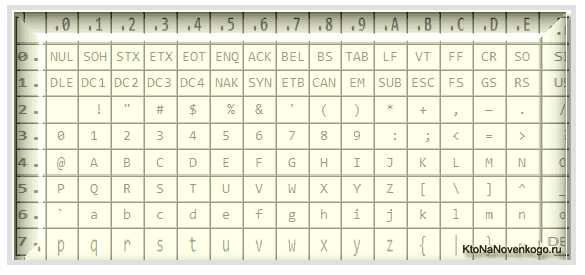 Именно эти 128 символов из первоначального вариант ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке. Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской). Тут, наверное, стоит еще немного сказать про системы счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет из себя двойку в степени, начиная с нулевой, и до двойки в седьмой: Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички. В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получает 233 в десятичной системе счисления. Как видите, все очень просто. Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать). Ну так вот, для
Именно эти 128 символов из первоначального вариант ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке. Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской). Тут, наверное, стоит еще немного сказать про системы счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет из себя двойку в степени, начиная с нулевой, и до двойки в седьмой: Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички. В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получает 233 в десятичной системе счисления. Как видите, все очень просто. Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать). Ну так вот, для Расширенные версии Аски — кодировки CP866 и KOI8-R с псевдографикой
Итак, мы с вами начали говорить про ASCII, которая являлась как бы отправной точкой для развития всех современных кодировок (Windows 1251, юникод, UTF 8). Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка. Тут нужно будет еще раз отвлечься, чтобы пояснить —
 Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом. На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье. Среди особенностей кодировки KOI8-R можно отметить то, что русские буквы в ее таблице идут не в алфавитном порядке, как это, например, сделали в CP866. Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом. На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье. Среди особенностей кодировки KOI8-R можно отметить то, что русские буквы в ее таблице идут не в алфавитном порядке, как это, например, сделали в CP866. Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).Windows 1251 — современная версия ASCII и почему вылезают кракозябры
Дальнейшее развитие кодировок текста было связано с тем, что набирали популярность графические операционные системы и необходимость использования псевдографики в них со временем пропала. В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики. Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251. Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):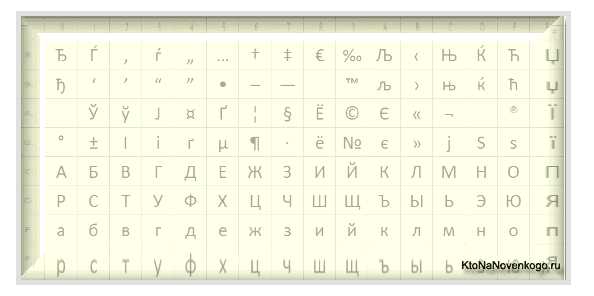 Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией. Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251. По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально. Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией. Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251. По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально. Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.  Аналогичная ситуация очень часто возникает при создании и настройке сайтов, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом. В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы, наконец, на корню проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Аналогичная ситуация очень часто возникает при создании и настройке сайтов, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом. В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы, наконец, на корню проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста. Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32. Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF. В результате чего, один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом). Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить. В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит. В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов. Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр: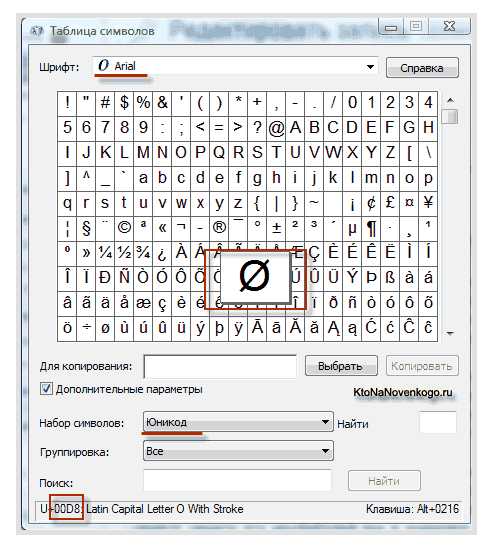 Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста. Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16). Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт. На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII. Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode. Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста. Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16). Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт. На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII. Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode. Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.Кракозябры вместо русских букв — как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста. Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов. Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++. Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке. В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию: В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM? Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов. В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров. Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры. Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств. В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация? Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка. После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название: Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы. Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM? Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов. В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров. Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры. Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств. В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация? Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка. После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название: Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы. Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.<?xml version="1.0" encoding="windows-1251"?><head>
...
<meta charset="utf-8">
...
</head>javarush.ru
Кодировка ASCII
ASCII обозначает «Американский Стандартный Кодекс для информационного Обмена» (American Standard Code for Information Interchange). Он был разработан в начале 60-х годов 20-го века как стандартная кодировка для компьютеров и аппаратных устройств.
ASCII это 7-битная кодировка, содержащая 128 символов.
Она состоит из цифр от 1 до 9, прописных и строчных латинских символов и некоторых специальных символов.
Кодировки, используемые в современных компьютерах, HTML и в интернете, основаны на кодексе ASCII.
В таблице ниже представлены все 128 символов ASCII и их аналоги в HTML.
| Символ ASCII | HTML кодировка | Описание |
|---|---|---|
|   | пробел | |
| ! | ! | восклицательный знак |
| « | " | компьютерные кавычка |
| # | # | номер |
| $ | $ | знак доллара |
| % | % | процент |
| & | & | амперсанд |
| ‘ | ' | апостроф |
| ( | ( | левая круглая скобка |
| ) | ) | правая круглая скобка |
| * | * | звездочка (астериск) |
| + | + | плюс |
| , | , | запятая |
| — | - | дефис |
| . | . | точка |
| / | / | слэш |
| 0 | 0 | цифра 0 |
| 1 | 1 | цифра 1 |
| 2 | 2 | цифра 2 |
| 3 | 3 | цифра 3 |
| 4 | 4 | цифра 4 |
| 5 | 5 | цифра 5 |
| 6 | 6 | цифра 6 |
| 7 | 7 | цифра 7 |
| 8 | 8 | цифра 8 |
| 9 | 9 | цифра 9 |
| : | : | двоеточие |
| ; | ; | точка с запятой |
| < | < | знак «меньше чем» |
| = | = | равно |
| > | > | знак «больше чем» |
| ? | ? | вопросительный знак |
| @ | @ | «собачка» |
| A | A | прописная A |
| B | B | прописная B |
| C | C | прописная C |
| D | D | прописная D |
| E | E | прописная E |
| F | F | прописная F |
| G | G | прописная G |
| H | H | прописная H |
| I | I | прописная I |
| J | J | прописная J |
| K | K | прописная K |
| L | L | прописная L |
| M | M | прописная M |
| N | N | прописная N |
| O | O | прописная O |
| P | P | прописная P |
| Q | Q | прописная Q |
| R | R | прописная R |
| S | S | прописная S |
| T | T | прописная T |
| U | U | прописная U |
| V | V | прописная V |
| W | W | прописная W |
| X | X | прописная X |
| Y | Y | прописная Y |
| Z | Z | прописная Z |
| [ | [ | левая квадратная скобка |
| \ | \ | обратный слэш |
| ] | ] | правая квадратная скобка |
| ^ | ^ | знак вставки |
| _ | _ | подчеркивание |
| ` | ` | градус |
| a | a | строчная a |
| b | b | строчная b |
| c | c | строчная c |
| d | d | строчная d |
| e | e | строчная e |
| f | f | строчная f |
| g | g | строчная g |
| h | h | строчная h |
| i | i | строчная i |
| j | j | строчная j |
| k | k | строчная k |
| l | l | строчная l |
| m | m | строчная m |
| n | n | строчная n |
| o | o | строчная o |
| p | p | строчная p |
| q | q | строчная q |
| r | r | строчная r |
| s | s | строчная s |
| t | t | строчная t |
| u | u | строчная u |
| v | v | строчная v |
| w | w | строчная w |
| x | x | строчная x |
| y | y | строчная y |
| z | z | строчная z |
| { | { | левая фигурная скобка |
| | | | | вертикальная черта |
| } | } | правая фигурная скобка |
| ~ | ~ | тильда |
URL коды символов ACSII
URL коды символов UTF-8 диапазон от U+0400 до U+04FF
HTML Кодирование URL
Таблица кодов символов кирилицы UTF-8
Таблица кодов символов Windows-1251
wm-school.ru
Кодировка ASCII. Таблица кодировки ASCII :: SYL.ru
Под кодированием информации в компьютере понимается процесс ее преобразования в форму, позволяющую организовать более удобную передачу, хранение или автоматическую переработку этих данных. С этой целью используются различные таблицы. Кодировка ASCII — это первая система, разработанная в Соединенных Штатах для работы с англоязычным текстом, которая получила впоследствии распространение во всем мире. Ее описанию, особенностям, свойствам и дальнейшему использованию посвящена статья, представленная ниже.

Отображение и хранение информации в ЭВМ
Символы на мониторе компьютера или того или иного мобильного цифрового гаджета формируются на основе наборов векторных форм всевозможных знаков и кода, позволяющего найти среди них тот символ, который необходимо вставить в нужное место. Он представляет собой последовательностей бит. Таким образом, каждому символу должен однозначно соответствовать набор нулей и единиц, которые стоят в определенном, уникальном порядке.
Как все начиналось
Исторически сложилось так, что первые ЭВМ были англоязычными. Для кодирования символьной информации в них было достаточно использовать всего лишь 7 бит памяти, тогда как для этой цели выделялся 1 байт, состоящий из 8 битов. Количество знаков, понимаемых компьютером в таком случае, было равно 128. В число таких символов входили английский алфавит с его знаками препинания, числа и некоторые специальные символы. Англоязычная семибитная кодировка с соответствующей таблицей (кодовой страницей), разработанная в 1963 году, была названа American Standard Code for Information Interchange. Обычно для ее обозначения использовалась и используется и по сей день аббревиатура «Кодировка ASCII».
Переход к мультиязычности
Со временем компьютеры стали широко использоваться и в неанглоговорящих странах. В связи с этим появилась нужда в кодировках, позволяющих использовать национальные языки. Было решено не изобретать велосипед, и взять за основу ASCII. Таблица кодировки в новой редакции значительно расширилась. Использование 8-го бита позволило переводить на компьютерный язык уже 256 символов.
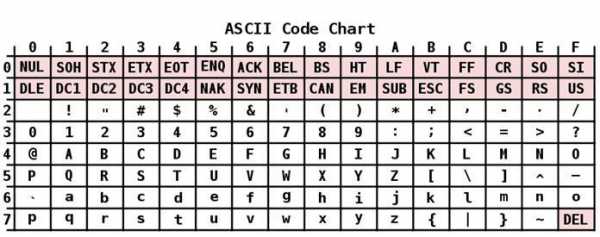
Описание
Кодировка ASCII имеет таблицу, которая делится на 2 части. Общепринятым международным стандартом принято считать лишь ее первую половину. В нее входят:
- Символы с порядковыми номерами от 0 до 31, кодируемые последовательностями от 00000000 до 00011111. Они отведены для управляющих символов, которые руководят процессом вывода текста на экран или принтер, подачей звукового сигнала и т. п.
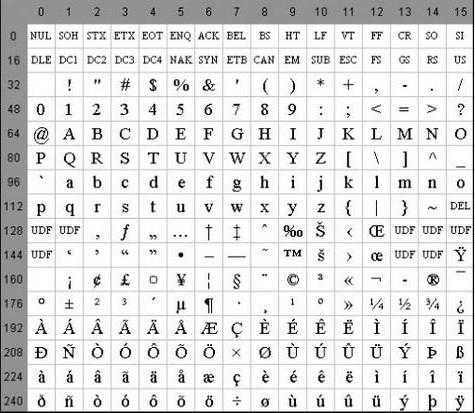
- Символы с NN в таблице от 32 до 127, кодируемые последовательностями от 00100000 до 01111111 составляют стандартную часть таблицы. В их число входят пробел (N 32), буквы латинского алфавита (строчные и прописные), десятизначные цифры от 0 до 9, знаки препинания, скобки разного начертания и другие символы.
- Символы с порядковыми номерами от 128 до 255, кодируемые последовательностями от 10000000 до 11111111. В их число включены буквы национальных алфавитов, отличные от латинского. Именно эта альтернативная часть таблицы кодировка ASCII используется для преобразования в компьютерную форму русских символов.
Некоторые свойства
К особенностям кодировки ASCII относится отличие букв «A» — «Z» нижнего и верхнего регистров только одним битом. Это обстоятельство значительно упрощает преобразование регистра, а также его проверку на принадлежность к заданному диапазону значений. Кроме того, все буквы в системае кодировки ASCII представляются собственными порядковыми номерами в алфавите, которые записаны 5 цифрами в двоичной системе счисления, перед которыми для букв нижнего регистра стоит 0112, а верхнего — 0102.
К числу особенностей кодировки ASCII можно причислить и представление 10 цифр — «0»-«9». Во второй системе счисления они начинаются с 00112, а заканчиваются 2-ми значениями чисел. Так, 01012 эквивалентно десятичному числу пять, поэтому символ «5» записывается как 0011 01012. Опираясь на сказанное, можно легко преобразовать двоично-десятичные числа в строку в кодировке ASCII посредством добавления слева битовой последовательности 00112 к каждому полубайту.

«Юникод»
Как известно, для отображения текстов на языках группы юго-восточной Азии требуются тысячи знаков. Такое их количество никак не описывается в одном байте информации, поэтому даже расширенные версии ASCII уже не могли удовлетворять возросшие потребности пользователей из разных стран.
Так, возникла необходимость создания универсальной кодировки текста, разработкой которой при сотрудничестве со многими лидерами мировой IT-индустрии занялся консорциум «Юникод». Его специалистами была создана система UTF 32. В ней для кодирования 1 символа выделялось 32 бита, составляющих 4 байта информации. Главным недостатком было резкое увеличение объема необходимой памяти в целых 4 раза, что влекло за собой множество проблем.
В то же время для большинства стран с официальными языками, относящимися к индоевропейской группе, количество знаков, равное 232, является более чем избыточным.
В результате дальнейшей работы специалистов из консорциума «Юникод» появилась кодировка UTF-16. Она стала тем вариантом преобразования символьной информации, которая устроила всех как по объему требуемой памяти, так и по числу кодируемых символов. Именно поэтому UTF-16 была принята по умолчанию и в ней для одного знака требуется зарезервировать 2 байта.
Даже эта достаточно продвинутая и удачная версия «Юникода» имела некоторые недостатки, и после перехода от расширенной версии ASCII к UTF-16 увеличивала вес документа в два раза.
В связи с этим было решено использовать кодировку переменной длины UTF-8. В таком случае каждый символ исходного текста кодируется последовательностью длиной от 1 до 6 байт.

Связь с American standard code for information interchange
Все знаки латинского алфавита в UTF-8 переменной длины кодируются в 1 байт, как в системе кодировки ASCII.
Особенностью ЮТФ-8 является то, что в случае текста на латинице без использования других символов, даже программы, не понимающие «Юникод», все равно позволят его прочитать. Иными словами, базовая часть кодировки текста ASCII просто переходит в состав новой UTF переменной длины. Кириллические знаки в ЮТФ-8 занимают 2 байта, а, например, грузинские — 3 байта. Созданием UTF-16 и 8 была решена основная проблема создания единого кодового пространства в шрифтах. С тех пор производителям шрифтов остается только заполнять таблицу векторными формами символов текста исходя из своих потребностей.
В различных операционных системах предпочтение отдается различным кодировкам. Чтобы иметь возможность читать и редактировать тексты, набранные в другой кодировке, применяются программы перекодировки русского текста. Некоторые текстовые редакторы содержат встроенные перекодировщики и позволяют читать текст вне зависимости от кодировки.

Теперь вы знаете, сколько символов в кодировке ASCII и, как и почему она была разработана. Конечно, сегодня наибольшее распространение в мире получил стандарт «Юникод». Однако нельзя забывать, что он создан на базе ASCII, поэтому следует по достоинству оценивать вклад его разработчиков в сферу IT.
www.syl.ru
ASCII – путеводитель для новичков
24.8KДля того, чтобы грамотно использовать ASCII, необходимо расширить знания в данной сфере и о возможностях кодирования.
ASCII представляет собой кодировочную таблицу печатных символов (см. скриншот №1), набираемых на компьютерной клавиатуре, для передачи информации и некоторых кодов. Иными словами происходит кодирование алфавита и десятичных цифр в соответствующие символы, представляющие и несущие в себе необходимую информацию.
Кодировка ASCII была разработана в Америке, поэтому стандартная кодировочная таблица обычно включает в себя английский алфавит с цифрами, что в общей сложности составляет около 128 символов. Но тогда возникает справедливый вопрос: что делать, если необходима кодировка национального алфавита?
Для решения подобных вопросов были разработаны другие версии таблицы ASCII. Например, для языков с иноязычной структурой были или убраны буквы английского алфавита, или к ним добавлялись дополнительные символы в виде национального алфавита. Так, в кодировке ASCII могут присутствовать русские буквы для национального использования (см. скриншот №2).
Данная кодировочная система необходима не только для набора текстовой информации на клавиатуре. Она также используется в графике. Например, в программе ASCII Art Maker графические изображения различных расширений состоят из спектра символов кодировки ASCII (см. скриншот №3).
Как правило, подобные программы можно разделить на те, что выполняют функцию графических редакторов, инвертируя изображение в текст, и на те, что конвертируют изображение в ASCII-графику. Всем известный смайлик (или как его еще называют «улыбающееся человеческое лицо») тоже является примером кодировочного символа.
Данный метод кодировки также может быть востребован во время написания или создания документа HTML. Например, вы вводите определённый и необходимый вам набор знаков, а при просмотре самой страницы на экран будет выведен символ, соответствующий данному коду.
Кроме всего прочего данный вид кодировки необходим при создании многоязычного сайта, потому что знаки, которые не входят в ту или иную национальную таблицу, нужно будет заменить ASCII кодами. Если читатель непосредственно связан с информационно-коммуникативными технологиями (ИКТ), то ему будет полезно ознакомиться и с такими системами как:
- Переносимый набор символов;
- Управляющие символы;
- EBCDIC;
- VISCII;
- YUSCII;
- Юникод;
- ASCII art;
- КОИ-8.
Как и любая систематизированная программа, ASCII обладает своими характерными свойствами. Так, например, десятеричная система исчисления (цифры от 0 до 9) преобразуется в двоичную систему исчисления (т.е. каждая десятеричная цифра преобразуется в двоичную 288=1001000 соответственно).
Буквы, располагающиеся в верхних и нижних колонках, отличаются друг от друга лишь битом, что существенно снижает уровень сложности проверки и редактирование регистра.
При всех этих свойствах кодировка ASCII работает как восьми битная, хотя изначально предусматривалась как семи битная.
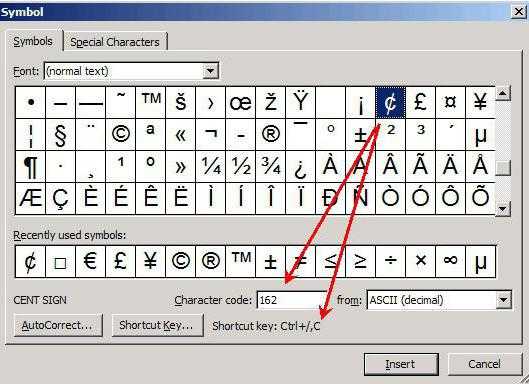
Применение ASCII в программах Microsoft Office:
В случае необходимости данный вариант кодирования информации может быть использован в Microsoft Notepad и Microsoft Office Word. В рамках этих приложений документ может быть сохранен в формате ASCII, но в этом случае при наборе текста невозможно будет использование некоторых функций.
В частности, будет недоступно выделение жирным и полужирным шрифтом, потому что кодирование сохраняет лишь смысл набранной информации, а не общий вид и форму. Добавить такие коды в документ вы можете с помощью следующих программных приложений:
- Microsoft Excel;
- Microsoft FrontPage;
- Microsoft InfoPath;
- Microsoft OneNote;
- Microsoft Outlook;
- Microsoft PowerPoint;
- Microsoft Project.
При этом стоит учитывать, что набирая код ASCII в этих приложениях необходимо удерживать нажатой клавиатурную клавишу ALT.
Конечно, все необходимые коды требует более длительного и обстоятельного изучения, но это выходит за пределы нашей сегодняшней статьи. Надеюсь, что она оказалась для Вас действительно полезной.
До новых встреч!
www.internet-technologies.ru
Кодировка ASCII (American standard code for information interchange)
По данным Международного Союза электросвязи, в 2016 году Интернетом с той или иной регулярностью пользовалось три с половиной миллиарда человек. Большинство из них даже не задумываются о том, что любые сообщения, посылаемые ими через ПК или мобильные гаджеты, а также тексты, которые отображаются на всевозможных мониторах, на самом деле представляют собой комбинации из 0 и 1. Такое представление информации называется кодированием. Оно обеспечивает и значительно облегчает осуществление ее хранения, обработки и передачи. В 1963 году была разработана американская кодировка ASCII, которой и посвящена данная статья.

Представление информации в компьютере
С точки зрения любой электронно-вычислительной машины текст представляет собой набор отдельных символов. К их числу принадлежат не только буквы, включая заглавные, но и знаки препинания, цифры. Кроме того, используются спецсимволы «=»,«&», «(» и пробелы.
Множество символов, из которых состоит текст, называется алфавитом, а их количество — мощностью (обозначается, как N). Для ее определения используется выражение N = 2^b, где b — число бит или информационный вес конкретного символа.
Доказано, что алфавит мощностью 256 символов позволяет представить все необходимые символы.
Так как 256 представляет собой 8 степень двойки, то вес каждого символа равен 8 бит.
Единица измерения 8 бит называется 1 байтом, поэтому принято говорить, что двоичный код любого символа в тексте, хранящемся на компьютере, занимает один байт памяти.
Как осуществляется кодирование
Любые тексты вводятся в память персонального компьютера посредством клавиш клавиатуры, на которых написаны цифры, буквы, знаки препинания и прочие символы. В оперативную память они передаются в двоичном коде, т. е. каждому символу сопоставляется привычный для человека десятеричный код, от 0 до 255, которому соответствует двоичный код — от 00000000 до 11111111.
Побайтовое кодирование символов позволяет процессору, выполняющему обработку текста, обращаться к каждому символу отдельно. В то же время 256 символов вполне достаточно для представления любой символьной информации.

Кодировка символов ASCII
Эта аббревиатура на английском расшифровывается как American standard code for information interchange.
Еще на заре компьютеризации стало очевидно, что можно придумать самые разнообразные способы кодировки информации. Однако для переноса информации с одной ЭВМ на другую требовалось разработать единый стандарт. Так, в 1963 году в США появилась таблица кодировки ASCII. В ней любому символу компьютерного алфавита поставлен в соответствие его порядковый номер в двоичном представлении. Изначально кодировка ASCII использовалась только в Соединенных Штатах, а затем стала международным стандартом для ПК.
Содержание таблицы
Коды ASCII делятся на 2 части. Международным стандартом считается лишь первая половина этой таблицы. В нее входят символы с порядковыми номерами от 0 (кодируется как 00000000) до 127 (код 01111111).
Порядковый номер N | Кодировка текста ASCII | Символ |
0 — 31 | 0000 0000 — 0001 1111 | Символы с N от 0 до 31 называют управляющими. Их функцией является «руководство» процессом вывода текста на монитор или печатающее устройство, подача звукового сигнала и т.п. |
32 — 127 | 0010 0000 — 0111 1111 | Символы с N от 32 до 127 (стандартная часть таблицы) — прописные и строчные буквы латинского алфавита, 10-ные цифры, знаки препинания, а также различные скобки, коммерческие и др. символы. Символом 32 обозначается пробел. |
128 — 255 | 1000 0000 — 1111 1111 | Символы с N от 128 до 255 (альтернативная часть таблицы или кодовая страница) могут иметь различные варианты, каждый из которых имеет свой номер. Кодовая страница используется для задания национальных алфавитов, которые отличны от латинского. В частности, именно с ее помощью осуществляется кодировка ASCII для русских символов. |
В таблице кодировки прописные и строчные буквы идут друг за другом в алфавитном порядке, а цифры — по возрастанию значений. Такой принцип сохраняется и для русского алфавита.
Управляющие символы
Таблица кодировки ASCII изначально создавалась для приема и передачи информации по такому уже давно не используемому устройству, как телетайп. В связи с этим в набор символов были включены непечатаемые, используемые в качестве команд для управления этим устройством. Подобные команды применялись и в таких докомпьютерных методах обмена сообщениями, как азбука Морзе, и пр.
Самым распространенным «телетайпным» символом является NUL (00, «нулевой»). Он и по сей день используется в большинстве языков программирования, обозначая признак конца строки.
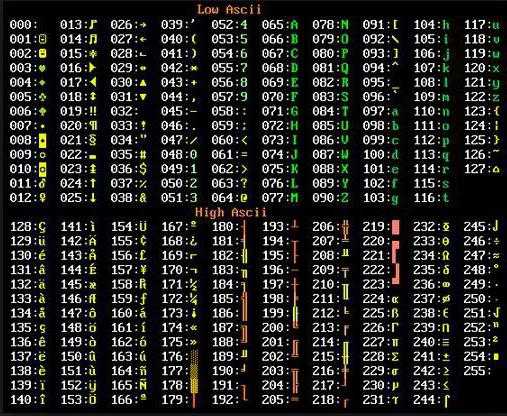
Где применяют кодировку ASCII
Американский стандартный код необходим не только для ввода текстовой информации с клавиатуры. Его также используют в графике. В частности, в программе ASCII Art Maker изображения различных расширений представляют собой спектр символов кодировки ASCII.
Подобные продукты бывают двух типов: выполняющие функцию графических редакторов путем преобразования изображения в текст и конвертирующие «рисунки» в ASCII-графику. Например, известный смайлик является ярким примером кодировочного символа.
ASCII может использоваться и при создании документа HTML. В таком случае вы можете вводить некий набор знаков, а при просмотре страницы на экране появится символ, который соответствует данному коду.
ASCII необходим и для создания многоязычных сайтов, так как знаки, которые не входят в конкретную национальную таблицу, заменяются ASCII-кодами.

Некоторые особенности
Для кодирования текстовой информации в кодировке ASCII изначально использовали 7 бит (один оставался пустым), однако сегодня она работает как 8-битная.
Буквы, располагающиеся в колонках, находящихся сверху и снизу, отличаются друг от друга только одним-единственным битом. Это значительно снижает степень сложности проверки.
Применение ASCII в Microsoft Office
При необходимости этот вид кодирования текстовой информации может использоваться в текстовых редакторах корпорации Microsoft, таких как Notepad и Office Word. Однако при наборе текста в таком случае будет невозможно использовать некоторые функции. Например, вы не сможете осуществлять выделение жирным шрифтом, так как кодировка ASCII сохраняет только смысл информации, игнорируя ее общий вид и форму.
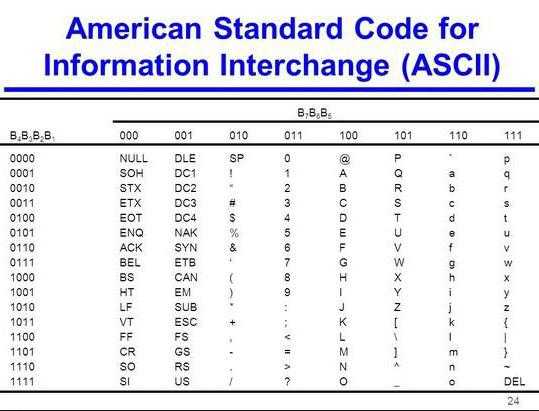
Стандартизация
Организация ISO приняла стандарты ISO 8859. Эта группа определяет восьмибитные кодировки для разных языковых групп. В частности, ISO 8859-1 — это Extended ASCII, представляющая собой таблицу для Соединенных Штатов и стран Западной Европы. А ISO 8859-5 — это таблица, применяемая для кириллицы, в том числе для русского языка.
По ряду исторических причин стандарт ISO 8859-5 использовался очень недолго.
Для русского языка на данный момент реально применяются кодировки:
- CP866 (Code Page 866) или DOS, которая часто называется альтернативной кодировкой ГОСТ. Она активно использовалась до середины 90-х годов прошлого века. На данный момент практически не используется.
- КОИ-8. Кодировка была разработана в 1970-80-е годы, и на данный момент это общепринятый стандарт для почтовых сообщений в Рунете. Она широко применяется и в ОС семейства Unix, в том числе Linux. «Русский» вариант КОИ-8 называется КОИ-8R. Кроме того, существуют версии и для других кириллических языков, например украинского.
- Code Page 1251 (CP 1251, Windows — 1251). Разработан корпорацией Microsoft для обеспечения поддержки русского языка в среде Windows.
Основным достоинством первого стандарта CP866 было сохранение псевдографических символов на тех же позициях, что и в Extended ASCII. Это позволяло запускать без изменений текстовые программы, зарубежного производства, такие как известный Norton Commander. На данный момент CP866 применяется для программ, разработанных под Windows, которые работают в полноэкранном текстовом режиме или в текстовых окнах, в том числе в FAR Manager.
Компьютерные тексты, написанные в кодировке CP866, в последнее время встречаются достаточно редко, однако именно она применяется для русских имен файлов в «Виндоус».
«Юникод»
На данный момент наиболее широкое распространение получила именно эта кодировка. Коды «Юникода» разделены на области. Первая (от U+0000 до U+007F) включает символы набора ASCII с кодами. Затем следуют области знаков различных национальных письменностей, а также пунктуационные знаки и технические символы. Кроме того, часть кодов «Юникода» зарезервирована на случай возникновения необходимости включить новые символы в будущем.

Теперь вы знаете, что в кодировке ASCII каждый символ представляется как комбинация 8 нулей и единиц. Неспециалистам эта информация может показаться ненужной и неинтересной, но разве вам не хочет знать, что происходит «в мозгах» вашего ПК?!
fb.ru