Universal online Cyrillic decoder — recover your texts
Universal online Cyrillic decoder — recover your texts Version: 20230216 By the same author: Virtour.fr — visites virtuelles Հայերեն —
Башҡорт — Беларуская — Български —
Иронау —
Қазақша —
Кыргызча — Македонски —
Монгол
Нохчийн — O’zbek — Русский — Slovensky — Српски — Татарча — Тоҷикӣ — Українська — Чaваш — Français — English
Output
The resulting text will be displayed here…
| Guestbook Please link to this site! | Custom Work For a small fee I can help you quickly recode/recover large pieces of data — texts, databases, websites… or write custom functions you can use (invoice available).  FAQ and contact information. |
About the program
Welcome! You may find this site useful, if you have recieved some texts that you believe are written in the Cyrillic alphabet, but instead are displayed in some strange combination of bizarre characters. This program will try to guess the encoding, and if it does not, it will show samples, examples of all encoding-combinations, so as you will be able to select the good one.
How to
- Paste the text to decode in the big text area. The first few words will be analyzed so they should be (scrambled) in supposed Cyrillic.
- The program will try to decode the text and will print the result below.
- If the translation is successful, you will see the text in Cyrillic characters and will be able to copy it and save it if it’s important.
- If the translation isn’t successful (still the text is not in Cyrillic but in the same or other unintelligible characters), you can choose from the newly created select-listbox the variant that is in Cyrillic (if there are more than one, select the longest).
 By pressing the button OK you will have the correct text converted.
By pressing the button OK you will have the correct text converted. - If the text is not totally converted, try all other variants in Cyrillic from the select-listbox.
 By pressing the button OK you will have the correct text converted.
By pressing the button OK you will have the correct text converted.Limits
- If your text contains question marks «???? ?? ??????», the problem is with the sender and no recovery will be possible. Ask them to resend the text, eventually as an ordinary text file or in LibreOffice/OpenOffice/MSOffice format.
- There is no claim that every text is recoverable, even if you are certain that the text is in Cyrillic.
- The analyzed and converted text is limited to 100 KiB.
- A 100% precision is not always achieved — in a conversion from a codepage to another code page, some characters may be lost, like the Bulgarian quotes or rarely some single letters. Some of this depends on your Windows Clipboard character handling.
- The program will try a maximum of 8280 variants in two or three levels: if there had been a multiple encoding like koi8(utf(cp1251(utf))), it will not be detected or tested. Usually the possible and displayed correct variants are between 32 and 255.
- If a part of the text is encoded with one code page, and another part — with another code page, the program could recognize only one of the parts at a time.
 Usually the possible and displayed correct variants are between 32 and 255.
Usually the possible and displayed correct variants are between 32 and 255.Terms of use
Please notice that this freeware program is created with the hope that it would be useful, but has no warranty, not even an implied warranty for fitness for any particular use
If you have very long texts to translate, please make sure you have a backup copy.
What’s new
- March 2021 : After a server upgrade, the program stopped working and some parts of it had to be rewritten.
- May 2020 : Added Тоҷикӣ/Tajik translation, thanks to Анвар/Anvar.
- October 2017 : Added «Select all / Copy» button.
- July 2016 : SSL Certificate installed, you can now access the Decoder on a secure connection.
- October 2013 : I am trying different optimizations for the system which should make the decoder run faster and handle more text.
- March 2013 : My hosting provider sent me a warning that the Decoder is using too much server CPU power and its processes were killed more than 100 times. I am making some changes so that the program will use less CPU, especially when reposting a previously sampled text, however, the decoded form may load somewhat slower. Please contact me if you have some difficulties using the program.
- 2012-08-09 : Added French translation, thanks to Arnaud D.
- 2011-03-06 : Added Belorussian translation, thanks to Зыль and Aliaksandr Hliakau.
- 31.07.10 : Added Serbian translation, thanks to Miodrag Danilovic (Boston — Beograd).
- 07.05.09 : Raised limit of MAX text size to 50 kiB.
- may 2009 : Added Ukrainian interface thanks to Barmalini.
- 2008-2009 : A number of small fixes and tweaks of the detection algorithm. Changed interface to default to automatic decoding.
- 12.08.07 : Fixed Russian language translation, thanks to Petr Vasilyev. This page will be significantly restructured in the near future.
- 10.11.06 : Three new postfilters added: «base64», «unix-to-unix» и «bin-to-hex», theoretically the tested combinations are 4725. Changes to the frequency analysis function (testing).
- 11.10.06 : The main site is on a new hardware server, should run faster.
- 11.09.06 : The program now uses PHP5 and should run times faster.
- 19.08.06 : Because of a broken DNS entry, this site was inaccessible from 06:00 on 15 august up to 15:00 on 18 august. That was the reason for me to set two «mirror» sites (5ko.free.fr/decode and www.accent.bg/decode) with the same program. If the original has a problem, you can find the copies in Google and recover your texts.
- 17.06.06
- 03.03. 06 : Added Slovak translation, thanks to Martin from KPR Slovakia.
- 15.02.06 : More encodings added and tested.
- 20.10.05 : Small improvement to the frequency-analysis function: for texts, written in all-capital letters.
- 14.10.05 : Two more gmail-Cyrillic encodings were added. Theoretically the tested combinations are 2112.
- 15.06.05 : Russian language interface was added. Big thanks to chAlx!
- 16.02.05 : One more postfilter decoding is added, for strings like this: «%u043A%u0438%u0440%u0438%u043B%u0438%u0446%u0430».
- 05.02.05 : More encodings tests added, the number of tested encodings is doubled, but thus the program may work slightly slower.
- 03.02.05 : The frequency analysis function that detects the original encoding works much better now. Currently the program recognises most of the encodings if the first few words are not too weird. It although still needs some improvement.
- 15.01.05 : The input text limit is raised from 10 to 20 kB.
- 01.12.04 : First public release.


 06 : Added Slovak translation, thanks to Martin from KPR Slovakia.
06 : Added Slovak translation, thanks to Martin from KPR Slovakia.
Back to the Latin to Cyrillic convertor.
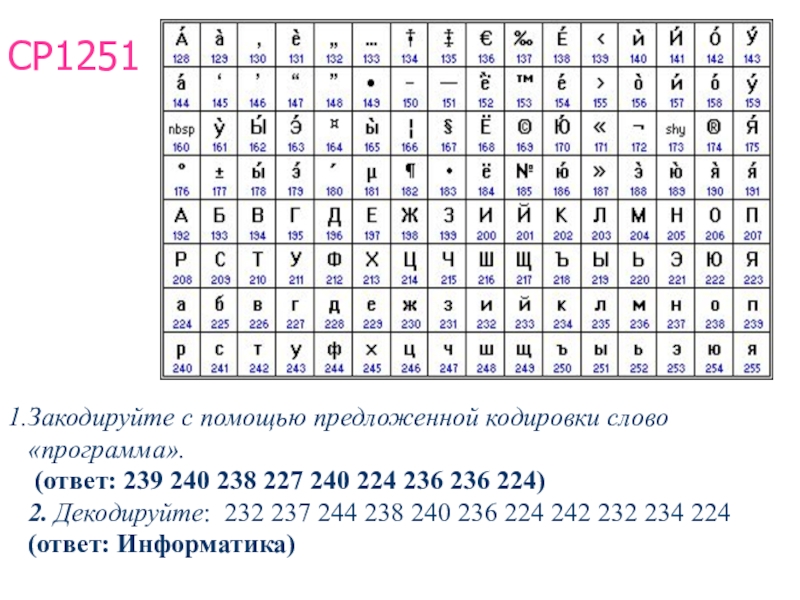
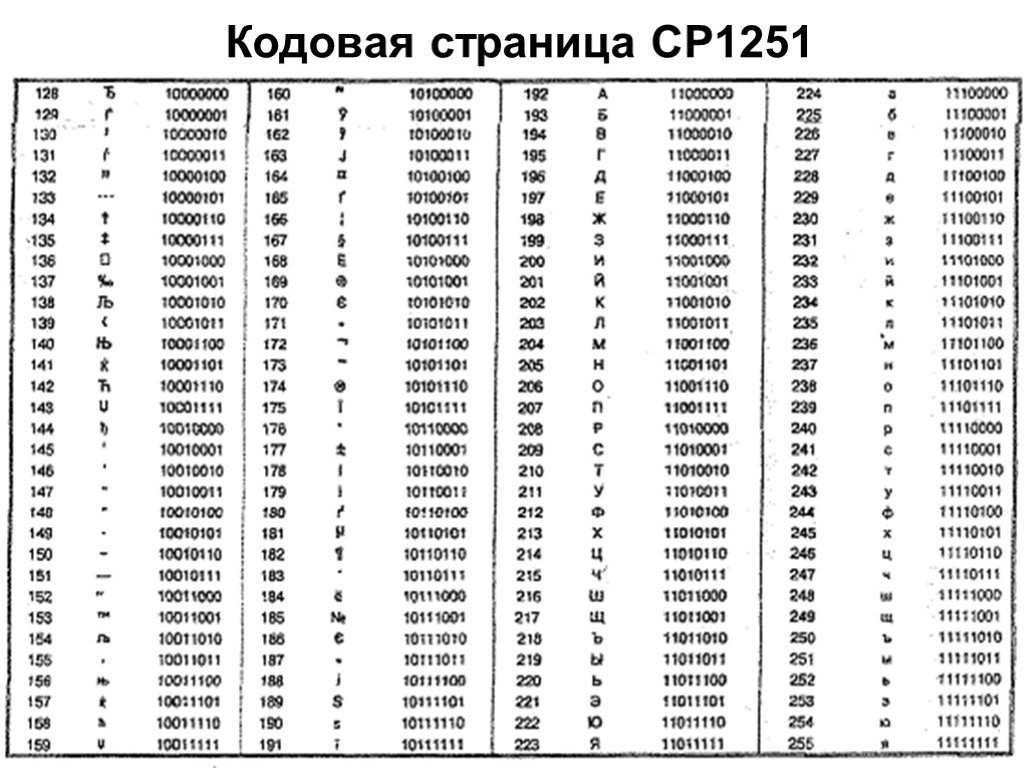
Кодировка CP1251 вместо UTF-8 при функции «Поиск файлов»…
Your browser does not seem to support JavaScript. As a result, your viewing experience will be diminished, and you may not be able to execute some actions.
Please download a browser that supports JavaScript, or enable it if it’s disabled (i.e. NoScript).
- Home
- BrowserAutomationStudio
- Поддержка
 org/Breadcrumb»>
Кодировка CP1251 вместо UTF-8 при функции «Поиск файлов»…
org/Breadcrumb»>
Кодировка CP1251 вместо UTF-8 при функции «Поиск файлов»…
This topic has been deleted. Only users with topic management privileges can see it.
-
Здравствуйте!
Запускаю на сервере «Поиск файлов» в папке.
Там, где английские названия папок — все хорошо.
НО там где русские названия — идут проблемы с кодировкой, т.е. в txt сохраняется в неправильной кодировке. Скажите, как это можно исправить?
Вот пример того что оно извлекает: (т.е. часто нормально, а часть в подпорченной кодировке).
Виндовс сервер 2019 стоит.c://1/Professionhair/3000.csv,c://1/Professionhair/3500.csv,c://1/Professionhair/4000.csv,c://1/Professionhair/4500.csv,c://1/Professionhair/500.csv,c://1/Professionhair/5000.csv,c://1/Professionhair/5500.csv,c://1/Professionhair/6000.csv,c://1/Professionhair/6500.csv,c://1/Professionhair/7000.csv,c://1/Professionhair/7500.csv,c://1/Professionhair/8000.csv,c://1/Professionhair/8500.csv,c://1/Professionhair/9000.csv,c://1/Professionhair/9500.csv,c://1/Sifo,c://1/Sifo/1.csv,c://1/Sifo/1000.csv,c://1/Sifo/1500.csv,c://1/Sifo/2000.csv,c://1/Sifo/2500.csv,c://1/Sifo/3000.csv,c://1/Sifo/3500.csv,c://1/Sifo/500.csv,c://1/VICHY,c://1/VICHY/1.csv,c://1/vremypodarkov,c://1/vremypodarkov/1.csv,c://1/Л'Ðтуаль,c://1/Л'Ðтуаль/1.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/1.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/1000.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/10000.
csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/10500.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/11000.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/11500.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/12000.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/12500.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/13000.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/13500.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и
-
@brotok said in Кодировка CP1251 вместо UTF-8 при функции «Поиск файлов»…:
пример файла с ошибочной кодировкой где?
в какой кодировке он определяется и отображается вашим текстовым редактором?
вы используете нотепад++ для открытия текстовых файлов или то, что там в винде встроено? -
@Fox в «темной теме» на фоне остальных текстов дата блеклая и 14 ноября мне показалось недавней

 csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/10500.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/11000.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/11500.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/12000.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/12500.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/13000.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/13500.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и
csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/10500.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/11000.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/11500.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/12000.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/12500.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/13000.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и ЗдоровьÑ/13500.csv,c://1/Ð›Ð°Ð±Ð¾Ñ€Ð°Ñ‚Ð¾Ñ€Ð¸Ñ ÐšÑ€Ð°Ñоты и
 org/Comment»>
org/Comment»>
@SotkaDaily said in Кодировка CP1251 вместо UTF-8 при функции «Поиск файлов»…:
@brotok said in Кодировка CP1251 вместо UTF-8 при функции «Поиск файлов»…:
пример файла с ошибочной кодировкой где?
в какой кодировке он определяется и отображается вашим текстовым редактором?
вы используете нотепад++ для открытия текстовых файлов или то, что там в винде встроено?
Вы опоздали с этим ответом почти ровно на год
 org/Comment»>
org/Comment»>
ещё круче — это блок рекламы:
5
Posts
234
Views
-
36
0
Votes36
Posts593
Views -
8
0
Votes8
Posts588
Views -
5
0
Votes5
Posts114
Views -
3
0
Votes3
Posts44
Views -
4
0
Votes4
Posts65
Views -
2
0
Votes2
Posts267
Views -
1
1
Votes1
Posts328
Views -
3
0
Votes3
Posts120
Views
python — Как преобразовать строку из cp1251 в UTF-8 в Python3?
спросил
Изменено 4 года, 9 месяцев назад
Просмотрено 3к раз
Нужна помощь с довольно простым скриптом Python 3. 6.
6.
Во-первых, он загружает HTML-файл со старомодного сервера, использующего кодировку cp1251.
Затем мне нужно поместить содержимое файла в строку в кодировке UTF-8.
Вот что я делаю:
запросов на импорт
импортировать кодеки
#получение файла
ri = request.get('http://old.moluch.ru/_python_test/0.html')
# проверяем, что это в cp1251
печать (ri.encoding)
#кодирование с использованием cp1251
текст = ри.текст
текст = codecs.encode (текст, 'cp1251')
# декодирование с использованием utf-8 - ЗДЕСЬ ОШИБКА!
текст = codecs.decode (текст, 'utf-8')
печать (текст)
Вот ошибка:
Трассировка (последний последний вызов): Файл «main.py», строка 15, втекст = codecs.decode (текст, 'utf-8') Файл "/var/lang/lib/python3.6/encodings/utf_8.py", строка 16, в декодировании вернуть codecs.utf_8_decode (ввод, ошибки, True) UnicodeDecodeError: кодек utf-8 не может декодировать байт 0xca в позиции 43: недопустимый байт продолжения
Буду очень признателен за любую помощь.
- python
- python-3.x
- utf-8
- cp1251
Не знаю, что вы пытаетесь сделать.
.text — это текст ответа, строка Python. Кодировки не играют никакой роли в строках Python.
Кодировки играют роль только тогда, когда у вас есть поток байтов, который вы хотите преобразовать в строка (или наоборот). И модуль запросов уже делает это за вас.
запросов на импорт
ri = request.get('http://old.moluch.ru/_python_test/0.html')
печать (ри.текст)
Например, предположим, что у вас есть текстовый файл (то есть: байты). Затем вы должны выбрать кодировку, когда вы open() файл — выбор кодировки определяет, как байты в файле преобразуются в символы. Этот ручной шаг необходим, потому что open() не может знать, в какой кодировке находятся байты файла.0005
HTTP, с другой стороны, отправляет это в заголовках ответа ( Content-Type ), поэтому запросы могут знать эту информацию. Будучи высокоуровневым модулем, он просматривает заголовки HTTP и преобразует для вас входящие байты. (Если бы вы использовали гораздо более низкоуровневую
Будучи высокоуровневым модулем, он просматривает заголовки HTTP и преобразует для вас входящие байты. (Если бы вы использовали гораздо более низкоуровневую urllib , вам пришлось бы выполнять собственное декодирование.)
Свойство .encoding является чисто информационным, когда вы используете .text ответа. Это может быть актуально, если вы используете 9Однако свойство 0041 .raw . Для работы с серверами, которые возвращают обычные текстовые ответы, использование .raw требуется редко.
Когда многие люди уже ответили, что вы получаете расшифрованное сообщение, когда делаете запросов. Получите . Я отвечу на ошибку, с которой вы столкнулись прямо сейчас.
Эта строка:
текст = codecs.encode(текст,'cp1251')
Кодирует текст в cp1251, затем вы пытаетесь декодировать его с помощью utf-8, что дает вам ошибку здесь:
текст = codecs.decode(текст,'utf-8')
Для определения типов, которые вы можете использовать:
import chardet текст = codecs.
 encode (текст, 'cp1251')
chardet.detect(текст) . #output {'кодировка': 'windows-1251', 'доверие': 0,99, 'язык': 'русский'}
#ИЛИ
текст = codecs.encode (текст, 'utf-8')
chardet.detect(текст) . #output {'кодировка': 'utf-8', 'доверие': 0,99, 'язык': ''}
encode (текст, 'cp1251')
chardet.detect(текст) . #output {'кодировка': 'windows-1251', 'доверие': 0,99, 'язык': 'русский'}
#ИЛИ
текст = codecs.encode (текст, 'utf-8')
chardet.detect(текст) . #output {'кодировка': 'utf-8', 'доверие': 0,99, 'язык': ''}
Таким образом, кодирование в одном формате и последующее декодирование в другом вызывает ошибку.
Кодировать/декодировать не нужно.
«Когда вы делаете запрос, Requests делает обоснованные предположения о кодировке ответа на основе заголовков HTTP. При доступе к r.text используется текстовая кодировка, предполагаемая Requests»
Итак, это будет работать:
запросов на импорт
#получение файла
ri = request.get('http://old.moluch.ru/_python_test/0.html')
текст = ри.текст
печать (текст)
Вы также можете получить доступ к телу ответа в виде байтов для нетекстовых запросов:
ri.content
Пожалуйста, ознакомьтесь с документацией по запросам
вы можете просто проигнорировать ошибку, добавив настройку в функцию декодирования:
text = codecs.
 decode(text,'utf-8',errors='ignore')
decode(text,'utf-8',errors='ignore')
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя адрес электронной почты и парольОпубликовать как гость
Электронная почтаОбязательно, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Кодировкасимволов. Как просмотреть текстовый файл cp1251 в консоли UTF-8?
спросил
Изменено 5 лет, 2 месяца назад
Просмотрено 7к раз
Попытка 1:
$ меньше subs....
 srt
«subs.srt» может быть двоичным файлом. Все равно видишь?
srt
«subs.srt» может быть двоичным файлом. Все равно видишь?
Попытка 2:
$ LANG=ru_RU.CP1251 меньше subs.srt ������ ������, ���� ������. �� �������� �������������! ...
Обходной путь:
$ iconv -f cp1251 < subs.srt | меньше
Как это сделать удобно?
- консоль
- кодировка символов
- меньше
- текст
Чтобы заставить меньше работать в кодировке, отличной от кодировки терминала, используйте luit (который входит в набор утилит X11).
LANG=ru_RU.CP1251 луит без саб.срт
Если вы хотите автоматически определять кодировку, это сложнее, потому что текстовый файл не содержит указаний на его кодировку. Программное обеспечение Enca пытается распознать кодировку файла, исходя из его языка:
$ enca -L russian subs.srt Кодовая страница MS-Windows 1251 $ iconv -f "$(enca -iL russian subs.
