Тщательно разобраться в кодировке символов: разница между ASCII, Unicode, UTF-8, GBK
Я немедленно приступил к работе.При просмотре структуры файла класса сегодня в тексте упоминалась сокращенная кодировка UTF-8. Раньше кодирование ASCII, UTF-8, Unicode и т. Д. Находилось в нечетком состоянии. Сегодня я поделюсь своим опытом обучения. Напишите блог с простой и понятной идеей.
- Сначала узнайте, зачем нужна кодировка символов
Внутри компьютера вся информация представлена двоичными строками, такими как 0 и 1. Когда нам нужно сохранить символ «А» в компьютере, какому состоянию он должен соответствовать? При сохранении мы можем использовать символ «А» для представления символа «А» в виде двоичной строки 01000010 (это случайно скомпилировано) и сохранить его в компьютере; при чтении , А затем восстановите 01000010 до символа ‘A’. Итак, вопрос в том, какой строке двоичных чисел должен соответствовать символ «А» при сохранении, а это 01000010? Или это 10000000 11110101? Грубо говоря, нужно правило. Это правило может отображать символы только в одно состояние (двоичную строку), которое является кодировкой. Самым ранним правилом кодирования является кодирование ASCII. В правиле кодирования ASCII символ «A» не соответствует ни 01000010, ни 1000 0000 11110101, но соответствует 01000001.
Это правило может отображать символы только в одно состояние (двоичную строку), которое является кодировкой. Самым ранним правилом кодирования является кодирование ASCII. В правиле кодирования ASCII символ «A» не соответствует ни 01000010, ни 1000 0000 11110101, но соответствует 01000001.
Проще говоря, кодирование символов означает преобразование информации, которую компьютер не распознает, в двоичные символы, распознаваемые компьютером.
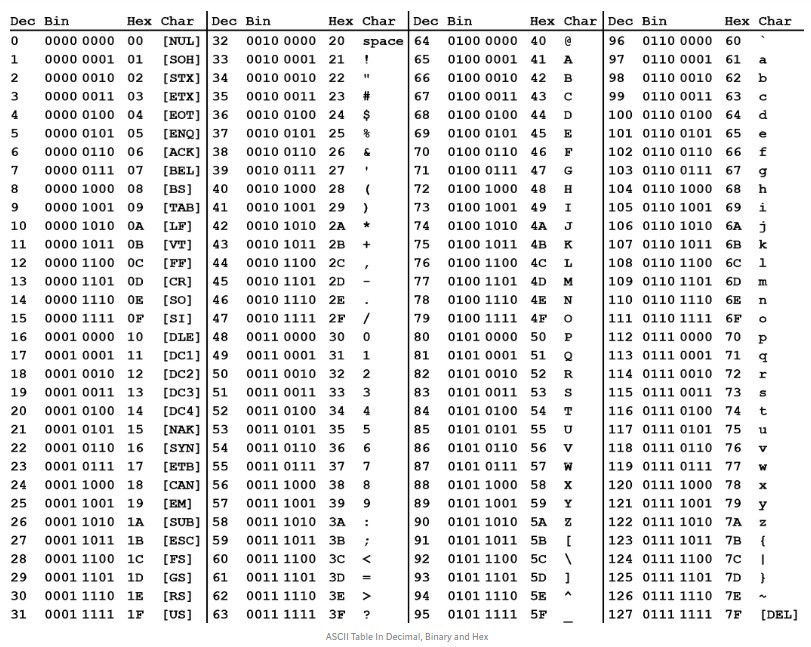
1. Код ASCIIМы знаем, что вся информация внутри компьютера в конечном итоге имеет двоичное значение. Каждый двоичный бит (бит) имеет0с участием1Два состояния, поэтому восемь двоичных битов могут объединять 256 состояний, что называется байтом. Другими словами, байт может использоваться для представления всего 256 различных состояний, и каждое состояние соответствует символу, который составляет 256 символов.00000000Чтобы11111111。
В 1960-х годах Соединенные Штаты сформулировали набор кодов символов для единообразного регулирования отношений между английскими символами и двоичными цифрами. Это называется кодом ASCII и используется до сих пор.
Это называется кодом ASCII и используется до сих пор.
Код ASCII определяет всего 128 символов, например пробелы.SPACE32 (двоичный00100000), заглавные буквыA65 (двоичный01000001). Эти 128 символов (включая 32 управляющих символа, которые не могут быть распечатаны) занимают только последние 7 бит байта, а первый бит всегда определяется как0。
Кодировки на английском языке 128 символов достаточно, но для других языков 128 символов недостаточно. Например, во французском языке, если над буквой есть фонетический символ, он не может быть представлен кодом ASCII. В результате некоторые европейские страны решили использовать старший бит неиспользуемого байта для программирования нового символа. Например, на французскомéКод 130 (двоичный10000010). Таким образом, система кодирования, используемая в этих европейских странах, может представлять до 256 символов.
Однако здесь возникли новые проблемы. В разных странах используются разные буквы, поэтому даже если все они используют методы кодирования 256 символов, они представляют разные буквы. Например, 130 во французском коде означаетé, Который представляет буквы в кодировке ивритаGimel (ג), который будет представлять другой символ в русской кодировке. Но в любом случае, во всех этих методах кодирования символы, представленные цифрами 0–127, одинаковы, и единственное отличие — это сегмент 128–255.
Что касается шрифтов азиатских стран, то здесь используется больше символов, насчитывающих до 100 000 китайских иероглифов. Один байт может представлять только 256 видов символов, что явно недостаточно, и для представления одного символа необходимо использовать несколько байтов. Например, распространенным методом кодирования для упрощенного китайского языка является GB2312, который использует два байта для представления китайского символа, поэтому теоретически он может представлять до 256 x 256 = 65536 символов.
Вопрос о китайской кодировке необходимо обсудить в специальной статье, которая не освещена в этой заметке. Здесь только указано, что, хотя для представления символа используется несколько байтов, китайская кодировка символов типа GB не имеет ничего общего с Unicode и UTF-8 ниже.
3. ЮникодКак упоминалось в предыдущем разделе, в мире существует несколько методов кодирования, и одно и то же двоичное число можно интерпретировать как разные символы. Следовательно, если вы хотите открыть текстовый файл, вы должны знать его метод кодирования, в противном случае будут отображаться искаженные символы, если вы декодируете его с помощью неправильного метода кодирования. Почему электронные письма часто выглядят искаженными? Это потому, что метод кодирования, используемый отправителем и получателем, отличается.
Вполне возможно, что если есть какой-то код, в него будут включены все символы мира. Каждому символу присваивается уникальный код, тогда искаженная проблема исчезнет. Это Unicode, как следует из названия, это кодировка всех символов.
Это Unicode, как следует из названия, это кодировка всех символов.
Unicode — это, конечно, большая коллекция, и текущий масштаб может содержать более 1 миллиона символов. Кодировка каждого символа разная, например,U+0639Представляет арабские буквыAin,U+0041Заглавные буквы, обозначающие английский языкA,U+4E25Представляет китайские иероглифыстрогий. Можно запросить конкретную таблицу соответствия символовunicode.org, Или специализированныйТаблица соответствия китайских иероглифов。
Следует отметить, что Unicode — это просто набор символов, он только указывает двоичный код символа, но не указывает, как этот двоичный код должен храниться.
Например, китайские иероглифыстрогийЮникод — это шестнадцатеричное число.4E25, Преобразуется в двоичное число с 15 битами (100111000100101), то есть для представления этого символа требуется не менее 2 байтов.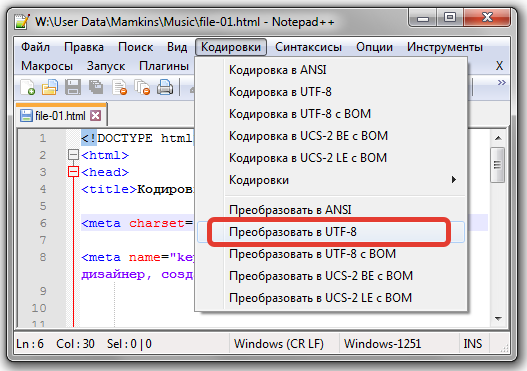 Представляет другие символы большего размера, для которых может потребоваться 3 или 4 байта или даже больше.
Представляет другие символы большего размера, для которых может потребоваться 3 или 4 байта или даже больше.
Здесь возникают два серьезных вопроса. Первый вопрос: как отличить Unicode от ASCII? Как компьютер узнает, что три байта представляют собой символ, а не три символа по отдельности? Вторая проблема заключается в том, что мы уже знаем, что английские буквы представлены только одним байтом.Если Unicode предусматривает, что каждый символ представлен тремя или четырьмя байтами, то перед каждой английской буквой должно стоять два. До трех байтов0, Это огромная трата памяти, размер текстового файла будет в два-три раза больше, что недопустимо.
Результатом этого является: 1) Существует несколько методов хранения Unicode, что означает, что существует множество различных двоичных форматов, которые могут использоваться для представления Unicode. 2) Юникод нельзя продвигать долго, до появления Интернета.
Пять, UTF-8Популярность Интернета настоятельно требует единого метода кодирования.![]() UTF-8 — наиболее широко используемая реализация Unicode в Интернете. Другие методы реализации включают UTF-16 (символы представлены двумя или четырьмя байтами) и UTF-32 (символы представлены четырьмя байтами), но они в основном не используются в Интернете.Повторюсь, здесь связь заключается в том, что UTF-8 является одной из реализаций Unicode.
UTF-8 — наиболее широко используемая реализация Unicode в Интернете. Другие методы реализации включают UTF-16 (символы представлены двумя или четырьмя байтами) и UTF-32 (символы представлены четырьмя байтами), но они в основном не используются в Интернете.Повторюсь, здесь связь заключается в том, что UTF-8 является одной из реализаций Unicode.
Одной из самых больших особенностей UTF-8 является то, что это метод кодирования переменной длины. Он может использовать от 1 до 4 байтов для представления символа, а длина байта зависит от разных символов.
Правила кодировки UTF-8 очень простые, их всего два:
1) Для однобайтовых символов первый бит байта устанавливается в0, Последние 7 бит — это код Unicode этого символа. Поэтому для английских букв кодировка UTF-8 и код ASCII одинаковы.
2) ДляnЗнак байта (n > 1), перед первым байтомnБиты установлены на1, Первоеn + 1Набор бит0, Первые две цифры следующих байтов устанавливаются равными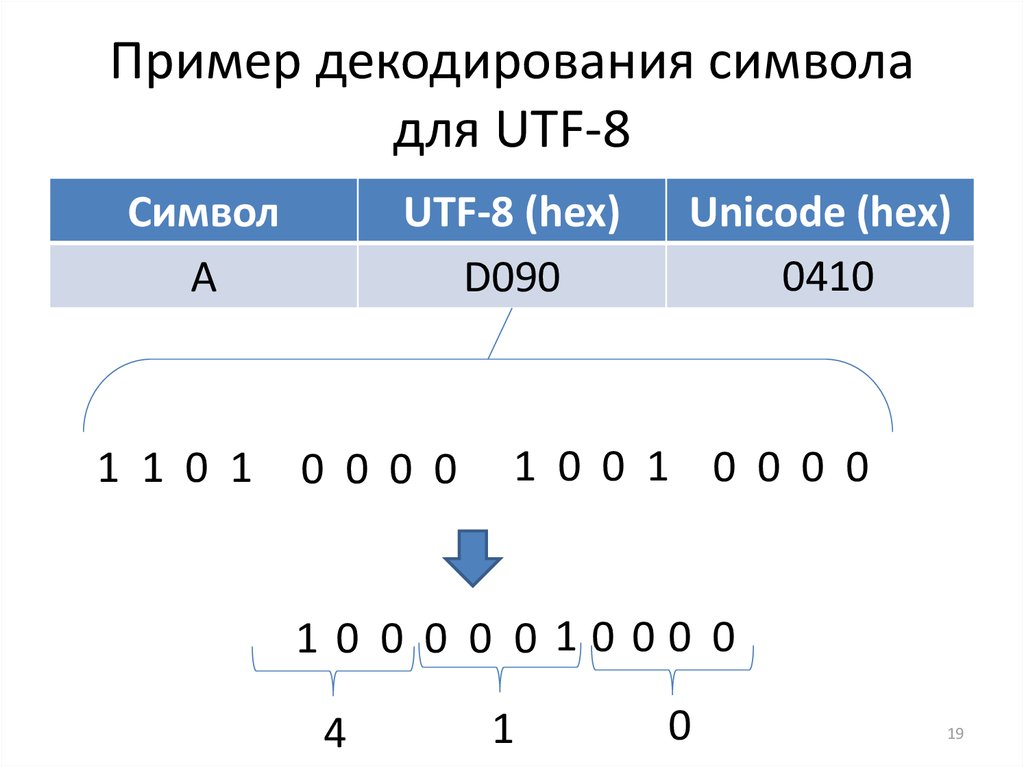 Остальные не упомянутые двоичные биты — это весь код Unicode этого символа.
Остальные не упомянутые двоичные биты — это весь код Unicode этого символа.
В следующей таблице приведены правила кодирования, буквыxПредставляет доступные закодированные биты.
Диапазон символов Unicode | метод кодирования UTF-8 (Шестнадцатеричный) | (Двоичный) ----------------------+--------------------------------------------- 0000 0000-0000 007F | 0xxxxxxx 0000 0080-0000 07FF | 110xxxxx 10xxxxxx 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Согласно приведенной выше таблице интерпретировать кодировку UTF-8 очень просто. Если первый бит байта0, Тогда только этот байт является символом; если первый бит1, Сколько подряд1, Это означает, сколько байтов занимает текущий символ.
Ниже по-прежнему используются китайские иероглифы.строгийРассмотрим пример, чтобы продемонстрировать, как реализовать кодировку UTF-8.
строгийЮникод — это4E25(100111000100101), согласно приведенной выше таблице можно найти4E25
0000 0800 - 0000 FFFF),следовательнострогийДля кодировки UTF-8 требуется три байта, то есть формат1110xxxx 10xxxxxx 10xxxxxx. Тогда изстрогийНачните с последней двоичной цифры и заполните формат вx, Дополнительное битовое дополнение0. Так понял,строгийКодировка UTF-811100100 10111000 10100101, В шестнадцатеричном форматеE4B8A5。- Итак, вот краткое изложение взаимосвязи между этими
ASCII завершает сопоставление только английских букв. Unicode — это просто набор символов. Он определяет двоичный код букв, но не указывает, как хранить символы.
UTF-8 — это кодировка переменной длины, которая может использовать 1–4 байта для представления символа. Для разных символов используются разные байтовые длины.
8 — разновидность кодировки Юникод. Экопарк Z
UTF-8UTF-8 (от англ. Unicode Transformation Format, 8-bit — «формат преобразования Юникода, 8-битный») — одна из общепринятых и стандартизированных кодировок текста, которая позволяет хранить символы Юникода, используя переменное количество байт (от 1 до 6).
Стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D. Кодировка нашла широкое применение в UNIX-подобных операционных системах и веб-пространстве.
Сам же формат UTF-8 был изобретён 2 сентября 1992 года Кеном Томпсоном и Робом Пайком и реализован в Plan 9. В качестве BOM использует последовательность байт EF16, BB16, BF16 (что у неё самой является трёх-байтовой реализацией символа FEFF16).
Одним из преимуществ является совместимость с ASCII — любые их 7-битные символы отображаются как есть, а остальные выдают пользователю мусор (шум).
Поэтому в случае, если латинские буквы и простейшие знаки препинания (включая пробел) занимают существенный объём текста, UTF-8 даёт выигрыш по объёму по сравнению с UTF-16.
Содержание
- 1 Принцип кодирования
- 2 Конвертирование в UTF-8
- 2.1 UTF-32LE в UTF-8
- 2.2 UTF-32BE в UTF-8
- 3 Максимальный потенциал
- 3.1 Кодирование битовых цепочек
- 4 Диапазоны Unicode
- 5 Отличительные значения байтов
- 6 UTF-8 и ошибки кодирования/декодирования
- 7 Самосинхронизация и UTF-16
Для номеров с U+0000 по U+007F кодировка UTF-8 полностью соответствует 7-битному US-ASCII c 0 в старшем бите и занимает один байт.
Алгоритм кодирования в UTF-8 стандартизирован в RFC 3629 и состоит из 3 пунктов:
1. Определить количество октетов (байт), требуемых для кодируемого номера символа в соответствии с таблицей:
| Диапазон символов | Количество байт |
|---|---|
00000000-0000007F | 1 |
00000080-000007FF | 2 |
00000800-0000FFFF | 3 |
00010000-001FFFFF | 4 |
00200000-03FFFFFF | 5 |
04000000-7FFFFFFF | 6 |
2.
| Количество байт | Значащих бит | Первый байт | Шаблон полностью |
|---|---|---|---|
| 1 | 7 | 0xxxxxxx | 0xxxxxxx |
| 2 | 11 | 110xxxxx | 110xxxxx 10xxxxxx |
| 3 | 16 | 1110xxxx | 1110xxxx 10xxxxxx 10xxxxxx |
| 4 | 21 | 11110xxx | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 5 | 26 | 111110xx | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 6 | 31 | 1111110x | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
3. Заполнить оставшиеся биты (в п.2 обозначены x) в октетах номером символа Юникода, выраженном в двоичном виде. Начать с младших битов номера символа, поставив их в младшие биты последнего октета кода. И так далее, пока все биты номера символа не будут перенесены в свободные биты октетов.
Заполнить оставшиеся биты (в п.2 обозначены x) в октетах номером символа Юникода, выраженном в двоичном виде. Начать с младших битов номера символа, поставив их в младшие биты последнего октета кода. И так далее, пока все биты номера символа не будут перенесены в свободные биты октетов.
Пример
Код BOM для UTF-8 = EF BB BF(16) = 1110 1111 1011 1011 1011 1111(2)
| 1 байт | 2 байт | 3 байт | |
|---|---|---|---|
| Шаблон | 1110 xxxx | 10xx xxxx | 10xx xxxx |
| BIN | 1110 1111 | 1011 1011 | 1011 1111 |
| HEX | EF | BB | BF |
В таблице ниже значения представлены в шестнадцатеричной системе счисления. На практике для каждого значения выбирается единственное верное представление по алгоритму, стандартизированному в RFC 3629 (с минимальной длиной байт, большие — не разрешены; и представлены для наглядности и тестов кодировщиков).
| Код символа | Имя символа | 1 байт | 2 байта | 3 байта | 4 байта | 5 байт | 6 байт |
|---|---|---|---|---|---|---|---|
0000 | NUL | 00 | C0 80 | E0 80 80 | F0 80 80 80 | F8 80 80 80 80 | FC 80 80 80 80 80 |
0073 | Малая латинская s | 73 | C1 B3 | E0 81 B3 | F0 80 81 B3 | F8 80 80 81 B3 | FC 80 80 80 81 B3 |
041A | Большая кириллическая К | D0 9A | E0 90 9A | F0 80 90 9A | F8 80 80 90 9A | FC 80 80 80 90 9A | |
0BF5 | Символ года на тамильском ௵ | E0 AF B5 | F0 80 AF B5 | F8 80 80 AF B5 | FC 80 80 80 AF B5 | ||
26218 | Китайский иероглиф | F0 A6 88 98 | F8 80 A6 88 98 | FC 80 80 A6 88 98 | |||
10FFFF | Максимальный код Unicode | F4 8F BF BF | F8 84 8F BF BF | FC 80 84 8F BF BF | |||
7FFFFFFF | Максимальный код UCS-4 | FD BF BF BF BF BF |
Схемой можете воспользоваться при кодировании и раскодировании.
Эта схема сделана так, чтобы Вы видели какие биты куда попадают как при кодировании, так и раскодировании. По ней видно, что при этих обоих процессах просто нужные биты выставляются на нужные позиции при нужных значениях контрольных бит.
Можно заметить что компоновка в больших байтовых последовательностях осуществляется по 6 бит (в так называемых лидирующих байтах). При этом старшие биты предусматриваемого кода будут в первых байтах (схоже с порядком Big-Endian).
UTF-32BE в UTF-8Значащие биты в форме записи UTF-32BE располагаются подряд, начиная с заполнения младшего байта. Задача преобразования UTF-32BE в UTF-8 сводится к выбору соответствующей формы UTF-8 и копированию значащих битов UTF-32BE без каких либо дополнительных преобразований.
- Очень часто требуется проверять наличие старших битов числа.
- Следующий код на языке Си исключает случайные описки при наборе маски
#define UTF8_MASK( bits ) ( ~(( int )0) << ( bits ) ) if ( !( value & UTF8_MASK( 7 ) ) ) // 7 - количество значащих бит.// Можно подставлять также: 11, 16, 21, 26, 31. { // Выполняется, если у числа нет битов, установленных в "1", кроме младших 7 }
 // Можно подставлять также: 11, 16, 21, 26, 31.
{
// Выполняется, если у числа нет битов, установленных в "1", кроме младших 7
}
// Можно подставлять также: 11, 16, 21, 26, 31.
{
// Выполняется, если у числа нет битов, установленных в "1", кроме младших 7
}
- Предыдущий код будет заменен препроцессором на этот:
if ( !( value & 0xFFFFFF80 ) )
{
}
Максимальный потенциалДо этого рассматривалось кодирование в UTF-8 лишь 32-битных целых без отрицательных значений. Следует отметить, что в стандарте Unicode используются символы лишь до кода 0010FFFF16 включительно. Поэтому даже 32-битных значений может вполне хватить, но этот раздел был включён для полноты изложения в случае использования UTF-8 для кодирования несимвольных данных.
Алгоритм UTF-8 технически позволяет записывать код любой длины. Но для эффективной и надёжной работы алгоритма необходимо ограничение длины кода. Действующий стандарт Unicode 6.х предполагает использование кода до 21-го бита, то есть до четырех байт в UTF-8.
Кодирование битовых цепочек| Занимает байт | Кодирует бит | Представление кода по алгоритму UTF-8 |
|---|---|---|
| 1 | 7 | 0xxx-xxxx |
| 2 | 11 | 110x-xxxx 10xx-xxxx |
| 3 | 16 | 1110-xxxx 10xx-xxxx 10xx-xxxx |
| 4 | 21 | 1111-0xxx 10xx-xxxx 10xx-xxxx 10xx-xxxx |
| 5 | 26 | 1111-10xx 10xx-xxxx 10xx-xxxx 10xx-xxxx 10xx-xxxx |
| 6 | 31 | 1111-110x 10xx-xxxx 10xx-xxxx 10xx-xxxx 10xx-xxxx 10xx-xxxx |
| 7 | 36 | 1111-1110 10xx-xxxx 10xx-xxxx 10xx-xxxx 10xx-xxxx 10xx-xxxx 10xx-xxxx |
| 8 | 41 | 1111-1111 100x-xxxx 10xx-xxxx … 10xx-xxxx |
| 9 | 46 | 1111-1111 1010-xxxx 10xx-xxxx … 10xx-xxxx |
| 10 | 51 | 1111-1111 1011-0xxx 10xx-xxxx … 10xx-xxxx |
| 11 | 56 | 1111-1111 1011-10xx 10xx-xxxx … 10xx-xxxx |
| 12 | 61 | 1111-1111 1011-110x 10xx-xxxx … 10xx-xxxx |
| 13 | 66 | 1111-1111 1011-1110 10xx-xxxx … 10xx-xxxx |
| 14 | 71 | 1111-1111 1011-1111 100x-xxxx 10xx-xxxx … 10xx-xxxx |
| 15 | 76 | 1111-1111 1011-1111 1010-xxxx 10xx-xxxx … 10xx-xxxx |
| 16 | 81 | 1111-1111 1011-1111 1011-0xxx 10xx-xxxx … 10xx-xxxx |
| 17 | 86 | 1111-1111 1011-1111 1011-10xx 10xx-xxxx … 10xx-xxxx |
| 18 | 91 | 1111-1111 1011-1111 1011-110x 10xx-xxxx … 10xx-xxxx |
| 19 | 96 | 1111-1111 1011-1111 1011-1110 10xx-xxxx … 10xx-xxxx |
| 20 | 101 | 1111-1111 1011-1111 1011-1111 100x-xxxx 10xx-xxxx … 10xx-xxxx |
В таблице ниже представлены диапазоны кодирования символов Unicode в UTF-8.
| Коды символов Unicode (HEX) | Размер в UTF-8 | Представленные классы символов |
|---|---|---|
00000000 — 0000007F | 1 байт | ASCII, в том числе латинский алфавит, простейшие знаки препинания и арабские цифры |
00000080 — 000007FF | 2 байта | кириллица, расширенная латиница, арабский, армянский, греческий, еврейский и коптский алфавит; сирийское письмо, тана, нко; МФА; некоторые знаки препинания |
00000800 — 0000FFFF | 3 байта | все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы |
00010000 — 001FFFFF | 4 байта | музыкальные символы, смайлы, редкие китайские иероглифы, вымершие формы письменности, 00110000 — 001FFFFF не используется в Unicode |
00200000 — 03FFFFFF | 5 байт | не используется в Unicode |
04000000 — 7FFFFFFF | 6 байт | не используется в Unicode |
Отличительные значения байтов представлены в первую очередь для использования в алгоритмах автоматического определения кодировки текста.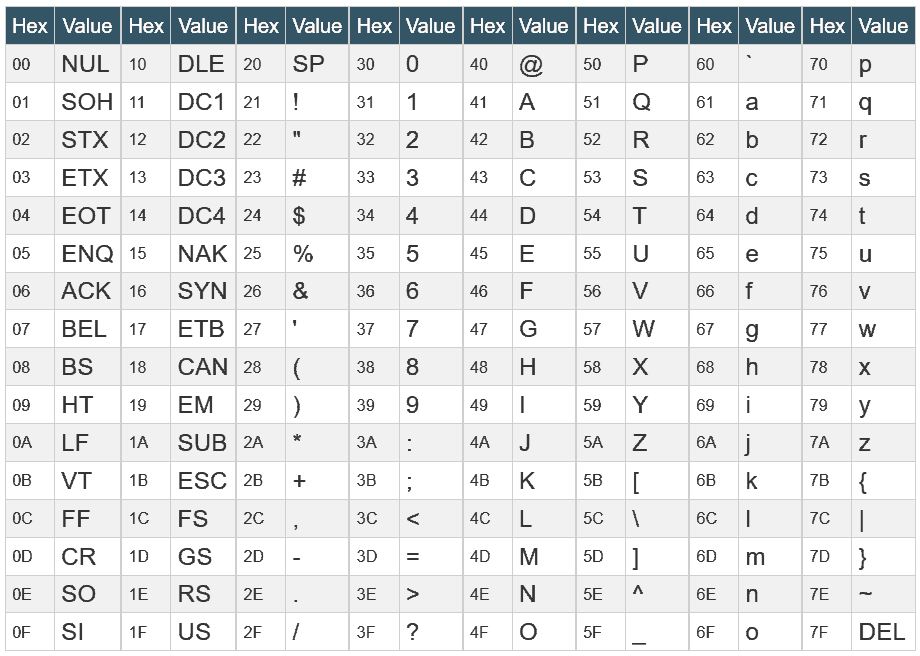 Первичным признаком можно считать BOM, которая повышает вероятность использования той или иной кодировки (см. отдельную статью). Другим признаком является обнаружение не валидных или сильно маловероятных байт, или же наоборот вероятных. Здесь же следует отметить, что UTF-8 поддерживает кодирование 31-битных кодов UCS-4. Если речь касается символов Unicode, то пяти- и шестибайтовые значения оказываются сильно маловероятными. И есть ещё один примечательный момент — в кодировке UTF-8 возможно избыточное кодирование, что порождает многозначность. Например, ASCII-символ можно закодировать шестью вариантами байтовых последовательностей, но это не означает не валидность избыточных байтовых последовательностей. И здесь можно впасть в заблуждение когда первый байт содержит только нулевые биты значения — для последовательностей выше двух байт исключительно это нормально.
Первичным признаком можно считать BOM, которая повышает вероятность использования той или иной кодировки (см. отдельную статью). Другим признаком является обнаружение не валидных или сильно маловероятных байт, или же наоборот вероятных. Здесь же следует отметить, что UTF-8 поддерживает кодирование 31-битных кодов UCS-4. Если речь касается символов Unicode, то пяти- и шестибайтовые значения оказываются сильно маловероятными. И есть ещё один примечательный момент — в кодировке UTF-8 возможно избыточное кодирование, что порождает многозначность. Например, ASCII-символ можно закодировать шестью вариантами байтовых последовательностей, но это не означает не валидность избыточных байтовых последовательностей. И здесь можно впасть в заблуждение когда первый байт содержит только нулевые биты значения — для последовательностей выше двух байт исключительно это нормально.
Все значения представлены в шестнадцатеричной системе счисления. Под значением «сильно маловероятен» в колонке «статус» следует рассматривать использование кодировщика, который не отбрасывает лидирующие нули.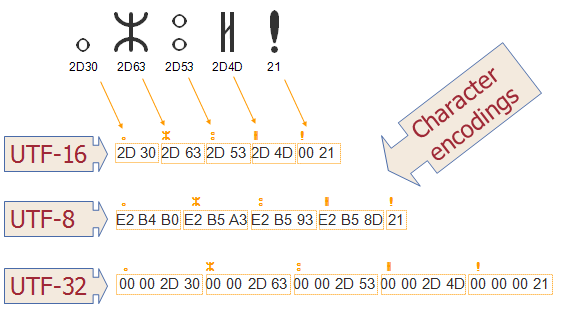
| Значение байта | Статус | Значение |
|---|---|---|
| 00..7F | без сомнений | ASCII-символы. |
| 80..BF | без сомнений | Любой не первый байт символа. |
| С0..C1 | избыточное кодирование | Первый байт двухбайтового символа, который содержит ASCII-код. |
| C2..DF | без сомнений | Первый байт двухбайтового символа. |
| E0 | небольшие сомнения | Первый байт трёхбайтового символа, но им же могут начинаться символы с избыточным кодированием (последовательности E0 80 и E0 81). |
| E1..EF | без сомнений | Первый байт трёхбайтового символа. |
| F0 | небольшие сомнения | Первый байт четырёхбайтового символа, но им же могут начинаться символы с избыточным кодированием (последовательности F0 80 A0 и ниже по последнему байту). |
| F1..F7 | без сомнений | Первый байт четырёхбайтового символа. |
| F8 | небольшие сомнения | Первый байт пятибайтового символа, но им же могут начинаться символы с избыточным кодированием (последовательности F0 80 и F0 87). |
| F9..FB | без сомнений | Первый байт пятибайтового символа, не используется для кодирования Unicode. |
| FC | небольшие сомнения | Первый байт шестибайтового символа, но им же могут начинаться символы с избыточным кодированием (последовательности FС 80 и F0 83). |
| FD | без сомнений | Первый байт шестибайтового символа, не используется для кодирования Unicode. |
| FE..FF | невозможны при кодировании вплоть до 31 бита | У первого байта символа устанавливается столько старших битов, сколько байтов отводится под символ. Их конец обозначается терминальным битом 0, а оставшиеся биты соответствуют старшим битам значения. Байты 254 и 255 в двоичной системе: 111111102 и 111111112 соответствуют длинам 7 и 8, а длина 31 бит может быть закодирован шестью байтами. |
Примеры ниже приведены для быстрой ориентации в случаях некорректного декодирования текста (так называемые кракозябры).
Так выглядит фраза «Человек сейчас увидит лишь то, что ожидает увидеть.» если она воспринята декодировщиком в кодировке Windows-1251, а не UTF-8:
Человек сейчас увидит лишь то, что ожидает увидеть.
Фраза «Человек сейчас увидит лишь то, что ожидает увидеть.» при двойном кодировании UTF-8 в UTF-8:
Самосинхронизация и UTF-16ЧеловеРѻ СЃРµРв»-час СѻРІРёРґРёС‚ лишь то, что ожидает Сѻвидеть.
Самосинхронизацию в UTF-8 можно рассмотреть когда вашей программе подаются случайные байты и вам нужно определить начало первого символа. Первичным признаком является сброшенный старший бит байта — это ASCII-символ. Если же он установлен, то пропускаем те байты, у которых сброшен бит перед старшим. В остальных случаях можно продолжать посимвольное поточное раскодирование.
Если же он установлен, то пропускаем те байты, у которых сброшен бит перед старшим. В остальных случаях можно продолжать посимвольное поточное раскодирование.
UTF-8 обладает свойством самосинхронизации при обработке 8-битными байтами. Альтернативной UTF-8 является кодировка UTF-16, которая уже обрабатывается 16-битными словами.
Возможно возникновение сомнения что UTF-16 не является самосинхронизирующейся. В настоящий момент передача данных в компьютере в подавляющем большинстве производится цельными октетами — 8 бит или ничего (см. IPv4, IPv6, SATA для современной аппаратуры и ATA с PATA для недавней).
В данных условиях UTF-8 имеет преимущество в характеристике самосинхронизации перед UTF-16, если речь касается аппаратной передачи данных или работы с байтовым потоком (чтение Unicode-данных с произвольной позиции).
Если же работа осуществляется в оперативной памяти одной машины, то UTF-16 так же является самосинхронизирующейся (если аппаратура способна подавать цельные 16-битные слова).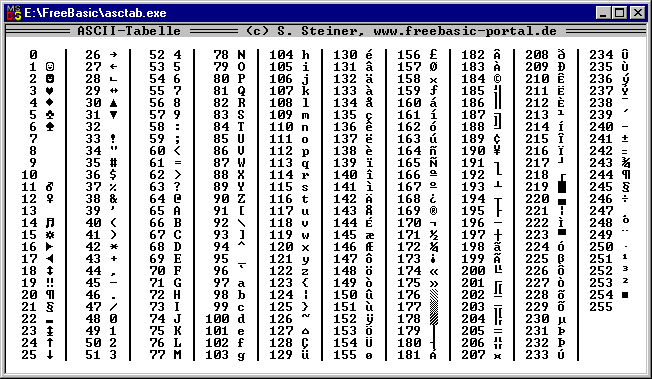
Можно считать, что UTF-8 является одной из основных современных кодировок, поэтому нужно знать её основные особенности, а кодировку и раскодировку поручать отлаженным программным функциям.
Приглашаю всех высказываться в Комментариях. Критику и обмен опытом одобряю и приветствую. В хороших комментариях сохраняю ссылку на сайт автора!
И не забывайте, пожалуйста, нажимать на кнопки социальных сетей, которые расположены под текстом каждой страницы сайта.
Продолжение тут…
полезная информация и краткая ретроспектива
Reg.ru: домены и хостинг
Крупнейший регистратор и хостинг-провайдер в России.
Более 2 миллионов доменных имен на обслуживании.
Продвижение, почта для домена, решения для бизнеса.
Более 700 тыс. клиентов по всему миру уже сделали свой выбор.
Перейти на сайт->
Бесплатный Курс «Практика HTML5 и CSS3»
Освойте бесплатно пошаговый видеокурс
по основам адаптивной верстки
на HTML5 и CSS3 с полного нуля.
Начать->
Фреймворк Bootstrap: быстрая адаптивная вёрстка
Пошаговый видеокурс по основам адаптивной верстки в фреймворке Bootstrap.
Научитесь верстать просто, быстро и качественно, используя мощный и практичный инструмент.
Верстайте на заказ и получайте деньги.
Получить в подарок->
Бесплатный курс «Сайт на WordPress»
Хотите освоить CMS WordPress?
Получите уроки по дизайну и верстке сайта на WordPress.
Научитесь работать с темами и нарезать макет.
Бесплатный видеокурс по рисованию дизайна сайта, его верстке и установке на CMS WordPress!
Получить в подарок->
*Наведите курсор мыши для приостановки прокрутки.
Данную статью я решил написать как небольшой обзор, касающийся вопроса кодировок.
Мы разберемся, что такое вообще кодировка и немного коснемся истории того, как они появились в принципе.
Мы поговорим о некоторых их особенностях а также рассмотрим моменты, позволяющие нам работать с кодировками более осознанно и избегать появления на сайте так называемых кракозябров, т. е. нечитаемых символов.
е. нечитаемых символов.
Итак, поехали…
Что такое кодировка?
Упрощенно говоря, кодировка — это таблица сопоставлений символов, которые мы можем видеть на экране, определенным числовым кодам.
Т.е. каждый символ, который мы вводим с клавиатуры, либо видим на экране монитора, закодирован определенной последовательностью битов (нулей и единиц). 8 бит, как вы, наверное, знаете, равны 1 байту информации, но об этом чуть позже.
Внешний вид самих символов определяется файлами шрифтов, которые установлены на вашем компьютере. Поэтому процесс вывода на экран текста можно описать как постоянное сопоставление последовательностей нулей и единиц каким-то конкретным символам, входящим в состав шрифта.
Прародителем всех современных кодировок можно считать ASCII.
Эта аббревиатура расшифровывается как American Standard Code for Information Interchange (американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов).
Это однобайтовая кодировка, в которую изначально заложено всего 128 символов: буквы латинского алфавита, арабские цифры и т.д.
Позже она была расширена (изначально она не использовала все 8 бит), поэтому появилась возможность использовать уже не 128, а 256 (2 в 8 степени) различных символов, которые можно закодировать в одном байте информации.
Такое усовершенствование позволило добавлять в ASCII символы национальных языков, помимо уже существующей латиницы.
Вариантов расширенной кодировки ASCII существует очень много по причине того, что языков в мире тоже немало. Думаю, что многие из вас слышали о такой кодировке, как KOI8-R — это тоже расширенная кодировка ASCII, предназначенная для работы с символами русского языка.
Следующим шагом в развитии кодировок можно считать появление так называемых ANSI-кодировок.
По сути это были те же расширенные версии ASCII, однако из них были удалены различные псевдографические элементы и добавлены символы типографики, для которых ранее не хватало «свободных мест».
Примером такой ANSI-кодировки является всем известная Windows-1251. Помимо типографических символов, в эту кодировку также были включены буквы алфавитов языков, близких к русскому (украинский, белорусский, сербский, македонский и болгарский).
ANSI-кодировка — это собирательное название. В действительности, реальная кодировка при использовании ANSI будет определяться тем, что указано в реестре вашей операционной системы Windows. В случае с русским языком это будет Windows-1251, однако, для других языков это будет другая разновидность ANSI.
Как вы понимаете, куча кодировок и отсутствие единого стандарта до добра не довели, что и стало причиной частых встреч с так называемыми кракозябрами — нечитаемым бессмысленным набором символов.
Причина их появления проста — это попытка отобразить символы, закодированные с помощью одной кодировочной таблицы, используя другую кодировочную таблицу.
В контексте веб-разработки, мы можем столкнуться с кракозябрами, когда, к примеру, русский текст по ошибке сохраняется не в той кодировке, которая используется на сервере.
Разумеется, это не единственный случай, когда мы можем получить нечитаемый текст — вариантов тут масса, особенно, если учесть, что есть еще база данных, в которой информация также хранится в определенной кодировке, есть сопоставление соединения с базой данных и т.д.
Возникновение всех этих проблем послужило стимулом для создания чего-то нового. Это должна была быть кодировка, которая могла бы кодировать любой язык в мире (ведь с помощью однобайтовых кодировок при всем желании нельзя описать все символы, скажем, китайского языка, где их явно больше, чем 256), любые дополнительные спецсимволы и типографику.
Одним словом, нужно было создать универсальную кодировку, которая решила бы проблему кракозябров раз и навсегда.
Юникод — универсальная кодировка текста (UTF-32, UTF-16 и UTF-8)
Сам стандарт был предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (Unicode Consortium, Unicode Inc. ), и первым результатом его работы стало создание кодировки UTF-32.
), и первым результатом его работы стало создание кодировки UTF-32.
Кстати, сама аббревиатура UTF расшифровывается как Unicode Transformation Format (Формат Преобразования Юникод).
В этой кодировке для кодирования одного символа предполагалось использовать аж 32 бита, т.е. 4 байта информации. Если сравнивать это число с однобайтовыми кодировками, то мы придем к простому выводу: для кодирования 1 символа в этой универсальной кодировке нужно в 4 раза больше битов, что «утяжеляет» файл в 4 раза.
Очевидно также, что количество символов, которое потенциально могло быть описано с помощью данной кодировки, превышает все разумные пределы и технически ограничено числом, равным 2 в 32 степени. Понятно, что это был явный перебор и расточительство с точки зрения веса файлов, поэтому данная кодировка не получила распространения.
На смену ей пришла новая разработка — UTF-16.
Как очевидно из названия, в этой кодировке один символ кодируют уже не 32 бита, а только 16 (т. е. 2 байта). Очевидно, это делает любой символ вдвое «легче», чем в UTF-32, однако и вдвое «тяжелее» любого символа, закодированного с помощью однобайтовой кодировки.
е. 2 байта). Очевидно, это делает любой символ вдвое «легче», чем в UTF-32, однако и вдвое «тяжелее» любого символа, закодированного с помощью однобайтовой кодировки.
Количество символов, доступное для кодирования в UTF-16 равно, как минимум, 2 в 16 степени, т.е. 65536 символов. Вроде бы все неплохо, к тому же окончательная величина кодового пространства в UTF-16 была расширена до более, чем 1 миллиона символов.
Однако и данная кодировка до конца не удовлетворяла потребности разработчиков. Скажем, если вы пишете, используя исключительно латинские символы, то после перехода с расширенной версии кодировки ASCII к UTF-16 вес каждого файла увеличивался вдвое.
В результате, была предпринята еще одна попытка создания чего-то универсального, и этим чем-то стала всем нам известная кодировка UTF-8.
UTF-8 — это многобайтовая кодировка с переменной длинной символа. Глядя на название, можно по аналогии с UTF-32 и UTF-16 подумать, что здесь для кодирования одного символа используется 8 бит, однако это не так. Точнее, не совсем так.
Точнее, не совсем так.
Дело в том, что UTF-8 обеспечивает наилучшую совместимость со старыми системами, использовавшими 8-битные символы. Для кодирования одного символа в UTF-8 реально используется от 1 до 4 байт (гипотетически можно и до 6 байт).
В UTF-8 все латинские символы кодируются 8 битами, как и в кодировке ASCII. Иными словами, базовая часть кодировки ASCII (128 символов) перешла в UTF-8, что позволяет «тратить» на их представление всего 1 байт, сохраняя при этом универсальность кодировки, ради которой все и затевалось.
Итак, если первые 128 символов кодируются 1 байтом, то все остальные символы кодируются уже 2 байтами и более. В частности, каждый символ кириллицы кодируется именно 2 байтами.
Таким образом, мы получили универсальную кодировку, позволяющую охватить все возможные символы, которые требуется отобразить, не «утяжеляя» без необходимости файлы.
C BOM или без BOM?
Если вы работали с текстовыми редакторами (редакторами кода), например Notepad++, phpDesigner, rapid PHP и т. д., то, вероятно, обращали внимание на то, что при задании кодировки, в которой будет создана страница, можно выбрать, как правило, 3 варианта:
д., то, вероятно, обращали внимание на то, что при задании кодировки, в которой будет создана страница, можно выбрать, как правило, 3 варианта:
— ANSI
— UTF-8
— UTF-8 без BOM
Сразу скажу, что выбирать всегда стоит именно последний вариант — UTF-8 без BOM.
Итак, что же такое BOM и почему нам это не нужно?
BOM расшифровывается как Byte Order Mark. Это специальный Unicode-символ, используемый для индикации порядка байтов текстового файла. По спецификации его использование не является обязательным, однако если BOM используется, то он должен быть установлен в начале текстового файла.
Не будем вдаваться в детали работы BOM. Для нас главный вывод следующий: использование этого служебного символа вместе с UTF-8 мешает программам считывать кодировку нормальным образом, в результате чего возникают ошибки в работе скриптов.
Поэтому, при работе с UTF-8 используйте именно вариант «UTF-8 без BOM». Также лучше не используйте редакторы, в которых в принципе нельзя указать кодировку (скажем, Блокнот из стандартных программ в Windows).
Также лучше не используйте редакторы, в которых в принципе нельзя указать кодировку (скажем, Блокнот из стандартных программ в Windows).
Кодировка текущего файла, открытого в редакторе кода, как правило, указывается в нижней части окна.
Обратите внимание, что запись «ANSI as UTF-8» в редакторе Notepad++ означает то же самое, что и «UTF-8 без BOM». Это одно и то же.
В программе phpDesigner нельзя сразу точно сказать, используется BOM, или нет. Для этого нужно кликнуть правой кнопкой мыши по надписи «UTF-8», после чего во всплывающем окне можно увидеть, используется ли BOM (опция Save with BOM).
В редакторе rapid PHP кодировка UTF-8 без BOM обозначается как «UTF-8*».
Как вы понимаете, в разных редакторах все выглядит немного по-разному, однако главную идею вы поняли.
После того, как документ сохранен в UTF-8 без BOM, нужно также убедиться, что верная кодировка указана в специальном метатэге в секции head вашего html-документа:
<meta charset = "utf-8" />
Соблюдение этих простых правил уже позволит вам избежать многих пробелем с кодировками.
На этом все, надеюсь, что данный небольшой экскурс и пояснения помогли вам лучше понять, что такое кодировки, какие они бывают и как работают.
Если вам интересна эта тема с более прикладной точки зрения, то рекомендую вам изучить мой видеоурок Полный UTF-8: чеклист для начинающих.
Дмитрий Науменко.
P.S. Присмотритесь к премиум-урокам по различным аспектам сайтостроения, а также к бесплатному курсу по созданию своей CMS-системы на PHP с нуля. Все это поможет вам быстрее и проще освоить различные технологии веб-разработки.
Понравился материал и хотите отблагодарить?
Просто поделитесь с друзьями и коллегами!
Смотрите также:
|
PHP: Получение информации об объекте или классе, методах, свойствах и наследовании |
|
|
CodeIgniter: жив или мертв? |
|
|
Функции обратного вызова, анонимные функции и механизм замыканий |
|
|
Применение функции к каждому элементу массива |
|
|
Слияние массивов. |
|
|
Деструктор и копирование объектов с помощью метода __clone() |
|
|
Эволюция веб-разработчика или Почему фреймворк — это хорошо? |
|
|
Магические методы в PHP или методы-перехватчики (сеттеры, геттеры и др.) |
|
|
PHP: Удаление элементов массива |
|
|
Ключевое слово final (завершенные классы и методы в PHP) |
|
|
50 классных сервисов, программ и сайтов для веб-разработчиков |
 Преобразование массива в строку
Преобразование массива в строкуНаверх
Кодировка UTF-8 | Справка Alchemer
Ведущая практика Кодирование файлов Excel в формат UTF (UTF-8 или UTF-16) может помочь обеспечить правильное чтение и отображение всего, что вы загружаете в Alchemer. Это особенно важно при работе с иностранными или специальными символами в кампаниях электронной почты, действиях с логином/паролем, списках контактов, импорте данных и тексте и переводах. Все эти функции имеют возможность получать загрузки файлов CSV.
Это особенно важно при работе с иностранными или специальными символами в кампаниях электронной почты, действиях с логином/паролем, списках контактов, импорте данных и тексте и переводах. Все эти функции имеют возможность получать загрузки файлов CSV.
Есть несколько различных способов получить правильную кодировку UTF, поэтому мы рассмотрим, как это сделать в старых версиях Microsoft Excel, OpenOffice, LibreOffice, Google Drive и даже как использовать для этого приложение Terminal!
Ниже приведены ссылки на видеоролики и пошаговые инструкции о том, как кодировать файлы Excel в UTF-8 и UTF-16. В Excel 2011 и более поздних версиях нет параметров для кодирования файлов UTF.
В зависимости от вашей версии Excel вы можете закодировать файл в UTF-8 в течение Сохранить как процесс . Это будет зависеть от вашей версии Excel, а также от того, используете ли вы Mac или ПК.
Версии Excel с 1999 по 2010
Посмотрите наше краткое пошаговое видео: Видео о кодировке UTF-8
- Перейдите к документу Excel.
- Нажмите Файл (или значок с цветным кругом, в зависимости от версии Excel).
- Выберите Сохранить как и выберите формат файла Excel, который вы хотите использовать.
- Назовите файл и при необходимости измените путь к файлу.
- Щелкните Инструменты , затем выберите Веб-параметры .
- Перейдите на вкладку Кодировка .
- В раскрывающемся списке для Сохраните этот документ как: выберите Unicode (UTF-8) .
- Нажмите Хорошо .
- Щелкните Сохранить .

Excel для Mac
Хотя в старых версиях Excel для Mac нет возможности кодирования UTF-8 для CSV, в последней версии Excel это делается довольно просто.
- Щелкните Файл > Сохранить как .
- Вы увидите диалоговое окно Сохранить . В раскрывающемся меню File Format выберите параметр CSV UTF-8.
- Щелкните Сохранить .
 В раскрывающемся меню File Format выберите параметр CSV UTF-8.
В раскрывающемся меню File Format выберите параметр CSV UTF-8. Open Office.org
Если у вас нет доступа к Excel, вы можете загрузить бесплатный пакет офисных программ с открытым исходным кодом под названием OpenOffice. Чтобы узнать больше, посетите: http://www.openoffice.org
Краткое пошаговое видео: UTF-8 Open Office Video
- Откройте OpenOffice и документ Excel.
- Щелкните Файл в верхнем левом углу панели инструментов.
- Выберите Сохранить как .
- Назовите файл и при необходимости измените путь к файлу.
- Сохраните свой Введите как CSV , а затем установите флажок Изменить настройки фильтра .
- Щелкните Сохранить .
Это займет мгновение, но Экспорт текстовых файлов Появится окно с дополнительными параметрами. - Рядом с набором символов выберите Unicode (UTF-8) .
- Нажмите OK , и все готово!
LibreOffice
Другой бесплатной альтернативой Microsoft Office с открытым исходным кодом является LibreOffice. Вы можете скачать его на http://www.libreoffice.org/.
- Откройте LibreOffice и нажмите Открыть файл слева. Выберите файл и Open .
- Нажмите Файл > Сохранить как… Появится следующее окно, измените Тип файла на Текстовый CSV и выберите параметр Изменить настройки фильтра , затем нажмите Сохранить .
- Появится окно с ошибкой, но не беспокойтесь об этом. Просто нажмите Использовать текстовый формат CSV .
- В следующем появившемся окне убедитесь, что набор символов Unicode (UTF-8) . Это должно быть по умолчанию.
- Появится последняя ошибка, говорящая о том, что сохранен только активный лист. Просто нажмите OK, и все готово!
 Просто нажмите OK, и все готово!
Просто нажмите OK, и все готово!Google Drive
Одним из широко доступных веб-решений для кодирования файлов XLS в UTF-8 CSV является Google Drive, также известный как Google Docs. Вы можете загрузить существующий файл и легко экспортировать его, выполнив следующие действия.
- На главном экране Google Диска нажмите Создать > Загрузка файла . Выберите файл XLS и нажмите Открыть .
- После загрузки файла дважды щелкните его в меню, чтобы открыть предварительный просмотр файла. Затем нажмите Открыть на верхней панели.
- Электронная таблица будет загружена, теперь вы можете нажать Файл > Загрузить как > Значения, разделенные запятыми (.csv, текущий лист) . Загрузка начнется немедленно.
Использование терминала
В крайнем случае вы можете легко преобразовать файлы в кодировку UTF-8 с помощью терминала. Вам может потребоваться загрузить эту библиотеку, чтобы использовать команду iconv.
Для начала сохраните файл CSV на рабочий стол с кратким именем.
Шаги Apple OSX
- Нажмите command + пробел, чтобы перейти к Spotlight, найдите «Терминал» и нажмите «Терминал», чтобы открыть.
- В командной строке введите ниже и нажмите Enter:
cd desktop
- Вставьте следующее:
iconv -c -t utf8 имя_файла.csv > имя_файла.utf8.csv
- Измените имена файлов, чтобы они соответствовали имени на ваш рабочий стол и нажмите Enter.
- И вуаля! Ваш файл имеет кодировку UTF-8. Не открывайте файл после конвертации!
Шаги Windows
- Перейдите в меню «Пуск», найдите «cmd» и щелкните cmd, чтобы открыть.
- В командной строке введите следующее (заменив имя пользователя на ваше имя пользователя Windows) и нажмите Enter:
cd C:\Users\(имя пользователя)\Desktop
- Вставьте следующее:
iconv -c -t utf8 filename.csv > filename.utf8.csv
- Измените имена файлов, чтобы они совпадали с именами на рабочем столе, и нажмите Enter.
- Теперь ваш файл имеет кодировку UTF-8. Не открывайте файл после конвертации, загрузите его в нашу систему.

Фильтр:
Базовый
Стандарт
Исследования рынка
HR-специалист
Полный доступ
Составление отчетов
Свободно
Индивидуальный
Команда и предприятие
| Особенность | Входит в |
|---|
НАЧАТЬ ПРОБНУЮ ПРОБНУЮ ВЕРСИЮ
- Автор: Бри Хиллмер
- Поделиться этой статьей: | Электронная почта
- Последнее обновление: 26.08.2022 8:56 MDT
Насколько полезна была эта статья?
Спасибо за отзыв!
Разница между кодировкой символов UTF-8, UTF-16 и UTF-32? Пример
Основное различие между кодировками символов UTF-8, UTF-16 и UTF-32 заключается в том, сколько байтов требуется для представления символа в памяти. UTF-8 использует минимум один байт, а UTF-16 использует минимум 2 байта. Кстати, если кодовая точка символа больше 127, максимальное значение байта тогда UTF-8 может занимать 2, 3 или 4 байта, но UTF-16 будет занимать только два или четыре байта. С другой стороны, UTF-32 представляет собой схему кодирования с фиксированной шириной и всегда использует 4 байта для кодирования кодовой точки Unicode. Теперь давайте начнем с того, что такое кодировка символов и почему это важно? Что ж, кодирование символов — важное понятие в процессе преобразования потоков байтов в символы, которые можно отобразить.
UTF-8 использует минимум один байт, а UTF-16 использует минимум 2 байта. Кстати, если кодовая точка символа больше 127, максимальное значение байта тогда UTF-8 может занимать 2, 3 или 4 байта, но UTF-16 будет занимать только два или четыре байта. С другой стороны, UTF-32 представляет собой схему кодирования с фиксированной шириной и всегда использует 4 байта для кодирования кодовой точки Unicode. Теперь давайте начнем с того, что такое кодировка символов и почему это важно? Что ж, кодирование символов — важное понятие в процессе преобразования потоков байтов в символы, которые можно отобразить.
Для преобразования байтов в символы важны две вещи: набор символов и кодировка . Поскольку в мире так много символов и символов, требуется набор символов для поддержки всех этих символов. Набор символов — это не что иное, как список символов, где каждый символ или символ сопоставлен с числовым значением, также известным как кодовые точки.
С другой стороны UTF-16, UTF-32 и UTF-8 являются схемами кодирования , которые описывают , как эти значения (кодовые точки) сопоставляются с байтами (с использованием различных битовых значений в качестве основы; например, 16-битный для UTF-16, 32-битный для UTF-32 и 8-битный для UTF-8). UTF означает преобразование Unicode, которое определяет алгоритм для сопоставления каждой кодовой точки Unicode с уникальной последовательностью байтов.
UTF означает преобразование Unicode, которое определяет алгоритм для сопоставления каждой кодовой точки Unicode с уникальной последовательностью байтов.
Например, для символа A, который представляет собой латинскую заглавную букву A, кодовая точка Unicode — U+0041, байты в кодировке UTF-8 — 41, кодировка UTF-16 — 0041, а символьный литерал Java — ‘\u0041’. Короче говоря, вам просто нужна схема кодировки символов для интерпретации потока байтов, при отсутствии кодировки символов вы не сможете их правильно показать. Язык программирования Java имеет обширную поддержку различных кодировок и кодировок символов, по умолчанию он использует UTF-8.
Как я уже говорил ранее, UTF-8, UTF-16 и UTF-32 — это всего лишь несколько способов хранения кодовых точек Unicode, то есть магических чисел U+, использующих 8, 16 и 32 бита в памяти компьютера. После преобразования символа Unicode в байты его можно легко сохранить на диске, передать по сети и воссоздать на другом конце.
Фундаментальное различие между UTF-32 и UTF-8, UTF-16 заключается в том, что первая является схемой кодирования с фиксированной шириной, а более поздняя дуэтом является кодировкой с переменной длиной. Кстати, несмотря на и UTF-8, и UTF-16 используют символы Unicode и кодировку переменной ширины , между ними также есть некоторые различия.
1. UTF-8 использует минимум один байт для кодирования символов, а UTF-16 использует минимум два байта.
В UTF-8 каждая кодовая точка от 0 до 127 хранится в одном байте. Только кодовые точки 128 и выше хранятся с использованием 2,3 или фактически до 4 байтов. Короче говоря, UTF-8 представляет собой кодировку переменной длины и занимает от 1 до 4 байтов, в зависимости от кодовой точки. UTF-16 также является кодировкой символов переменной длины, но занимает 2 или 4 байта. С другой стороны, UTF-32 имеет фиксированные 4 байта.
2. UTF-8 совместим с ASCII, а UTF-16 несовместим с ASCII
. UTF-8 имеет преимущество там, где чаще всего используются символы ASCII, в этом случае большинству символов требуется только один байт. Файл UTF-8, содержащий только символы ASCII, имеет ту же кодировку, что и файл ASCII, что означает, что текст на английском языке выглядит в UTF-8 точно так же, как и в ASCII. Учитывая доминирование ASCII в прошлом, это было основной причиной первоначального принятия Unicode и UTF-8.
UTF-8 имеет преимущество там, где чаще всего используются символы ASCII, в этом случае большинству символов требуется только один байт. Файл UTF-8, содержащий только символы ASCII, имеет ту же кодировку, что и файл ASCII, что означает, что текст на английском языке выглядит в UTF-8 точно так же, как и в ASCII. Учитывая доминирование ASCII в прошлом, это было основной причиной первоначального принятия Unicode и UTF-8.
Вот пример, который показывает, как разные символы сопоставляются с байтами в разных схемах кодирования символов, например. UTF-16, UTF-8 и UTF-32. Вы можете видеть, как разные схемы занимают разное количество байтов для представления одного и того же символа.
Резюме
1) UTF16 не имеет фиксированной ширины. Он использует 2 или 4 байта. Единственный UTF32 имеет фиксированную ширину и, к сожалению, его никто не использует. Кроме того, стоит знать, что строки Java представлены с использованием битовых символов UTF-16, ранее они использовали USC2, который имеет фиксированную ширину.
2) Вы можете подумать, что из-за того, что UTF-8 занимает меньше байтов для многих символов, потребуется меньше памяти, чем UTF-16, ну, это действительно зависит от того, на каком языке находится строка. Для неевропейских языков UTF-8 требует больше памяти, чем UTF-16.
3) ASCII строго быстрее, чем многобайтовая схема кодирования, потому что меньше данных для обработки = быстрее.
Это все о Unicode, UTF-8, UTF-32 и кодировке символов UTF-16 . Как мы узнали, Юникод — это набор различных символов, а UTF-8, UTF-16 и UTF-32 — это разные способы их представления в байтовом формате. И UTF-8, и UTF-16 являются кодировками переменной длины, где количество используемых байтов зависит от кодовых точек Unicode.
С другой стороны, UTF-32 — это кодировка с фиксированной шириной, где каждая кодовая точка занимает 4 байта. Unicode содержит кодовые точки почти для всех представляемых графических символов в мире и поддерживает все основные языки, например. Английский, японский, китайский или деванагари.
Английский, японский, китайский или деванагари.
Всегда помните, что UTF-32 — это кодировка с фиксированной шириной, всегда занимает 32 бита, но UTF-8 и UTF-16 — это кодировки с переменной длиной, где UTF-8 может занимать от 1 до 4 байтов, а UTF-16 — либо 2 или 4 байта.
Кодировка UTF-8 — преобразование текста в UTF-8 — онлайн
Самый простой в мире онлайн-кодировщик UTF8 для веб-разработчиков и программистов. Просто вставьте свой текст в форму ниже, нажмите кнопку Кодировка UTF8, и вы получите данные в кодировке UTF8. Нажимаешь кнопку — получаешь UTF8. Никакой рекламы, ерунды и мусора. Работает со строками ASCII и Unicode.
Объявление : Мы только что запустили TECHURLS — простой и интересный агрегатор технических новостей. Проверьте это!
(отменить)
Хотите декодировать текст UTF8?
Используйте декодер UTF8!
Кодировщик UTF8 может быть полезен, если вы проводите кроссбраузерное тестирование. Например, вы можете использовать его для обработки данных для тестирования форм ввода или проверки правильности данных. Если форма ввода имеет слабую проверку UTF8, вы можете обойти различные проверки безопасности. Точно так же вы можете использовать кодировщик UTF8, чтобы узнать, какие байты присутствуют во входных данных. Например, текст может иметь омоглифы, которые выглядят как обычные символы, но на самом деле являются похожими символами Unicode. Кодируя свои данные, вы сможете определить, из каких байтов состоит каждый символ. Кроме того, вы можете использовать кодировщик UTF8, чтобы проверить, сколько байтов занимает ввод. Если браузер проверяет длину данных, то, используя странные символы Unicode, вы можете передать ему больше байтов, чем он ожидает, что может привести к проблемам в вашем приложении.
Если форма ввода имеет слабую проверку UTF8, вы можете обойти различные проверки безопасности. Точно так же вы можете использовать кодировщик UTF8, чтобы узнать, какие байты присутствуют во входных данных. Например, текст может иметь омоглифы, которые выглядят как обычные символы, но на самом деле являются похожими символами Unicode. Кодируя свои данные, вы сможете определить, из каких байтов состоит каждый символ. Кроме того, вы можете использовать кодировщик UTF8, чтобы проверить, сколько байтов занимает ввод. Если браузер проверяет длину данных, то, используя странные символы Unicode, вы можете передать ему больше байтов, чем он ожидает, что может привести к проблемам в вашем приложении.
Ищете дополнительные инструменты веб-разработчика? Попробуйте это!
URL Encoder
URL Decoder
URL Parser
HTML Encoder
HTML Decoder
Base64 Encoder
Base64 Decoder
HTML Prettifier
HTML Minifier
JSON Prettifier
JSON Minifier
JSON Escaper
JSON Unescaper
JSON Validator
JS Prettifier
JS Minifier
JS Validator
CSS Prettify
Minifier CSS
XML Prettifier
XML Minifier
XML в JSON Converter
JSON TO CONTRETE Преобразователь XML
Преобразователь YAML в TSV
Преобразователь TSV в YAML
Преобразователь XML в TSV
Преобразователь TSV в XML
Преобразователь XML в текст
Преобразователь JSON в CSV
CSV в JSON Converter
JSON TO YAML Converter
YAML TO JSON Converter
JSON TO TSV Converter
TSV TO JSON Converter
YSON TOT TEXT CONTRETE Конвертер TSV в CSV
Конвертер CSV в TSV
Конвертер CSV в текстовые столбцы
Конвертер текстовых столбцов в CSV
Конвертер TSV в текстовые столбцы
Конвертер текстовых столбцов в TSV
CSV Transposer
Столбки CSV для строк преобразователя
CSV строки в столбцы преобразователь
CSV Clecver Swapper
CSV Column Export
CSV Column Column
CSV Prepender
CSV COBLACER
CSV CSV
CSV CSV COBLACER
CSV
CSV CSV. Средство удаления столбцов CSV
Средство удаления столбцов CSV
Средство смены разделителей CSV
Транспозитор TSV
Преобразователь столбцов в строки TSV
Преобразователь строк в столбцы TSV
Преобразователь столбцов TSV
TSV Column Exporter
TSV Column Replacer
TSV Column Prepender
TSV Column Appender
TSV Column Inserter
TSV Column Deleter
TSV Delimiter Changer
Delimited Column Exporter
Delimited Column Deleter
Delimited Column Replacer
Преобразователь текста
Преобразователь текстовых столбцов в строки
Преобразователь текстовых строк в столбцы
Преобразователь текстовых столбцов
Text Column Delimiter Changer
HTML to Markdown Converter
Markdown to HTML Converter
HTML to Jade Converter
Jade to HTML Converter
BBCode to HTML Converter
BBCode to Jade Converter
BBCode to Text Converter
HTML Преобразователь времени в текст
HTML Stripper
Преобразователь сущностей текста в HTML
Преобразователь времени UNIX в время UTC
Преобразователь времени UTC в время UNIX
IP в двоичный преобразователь
Двоирный в IP -преобразователь
IP в десятичный преобразователь
Октальный в IP -преобразователь
IP в восьмого преобразователя
Десятичный в IP -преобразователь
IP в Hex Converter
HEX в IP -конвертер
IP — Сортировщик адресов
Генератор паролей MySQL
Генератор паролей MariaDB
Генератор паролей Postgres
Генератор паролей Bcrypt
Средство проверки паролей Bcrypt
Scrypt Password Generator
Scrypt Password Checker
ROT13 Encoder/Decoder
ROT47 Encoder/Decoder
Punycode Encoder
Punycode Decoder
Base32 Encoder
Base32 Decoder
Base58 Encoder
Base58 Decoder
Ascii85 Encoder
Декодер Ascii85
Кодировщик UTF8
Декодер UTF8
Кодировщик UTF16
Декодер UTF16
Кодировщик Uuencoder
Uudecoder
Morse Code Encoder
Morse Code Decoder
XOR Encryptor
XOR Decryptor
AES Encryptor
AES Decryptor
RC4 Encryptor
RC4 Decryptor
DES Encryptor
DES Decryptor
Triple DES Encryptor
Triple DES Decryptor
Rabbit Encryptor
Rabbit Decryptor
NTLM Hash Calculator
MD2 Hash Calculator
MD4 Hash Calculator
MD5 Hash Calculator
MD6 Hash Calculator
RipeMD128 Hash Calculator
RipeMD160 Hash Calculator
RipeMD256 Hash Calculator
RipeMD320 Hash Calculator
SHA1 Hash Calculator
SHA2 Hash Calculator
SHA224 Hash Calculator
SHA256 Калькулятор хэша
SHA384 Калькулятор хэша
SHA512 Калькулятор хэша
SHA3 Калькулятор хэша
CRC16 Хэш -калькулятор
CRC32 Хэш -калькулятор
ADLER32 Хеш -калькулятор
Whirlpool Hash Calculator
Все хеш -калькулятор
секунды H: M: S Converter
H: M: S Converter
Seconds Secondable к человеку. Время
Время
Преобразователь двоичного кода в восьмеричный
Преобразователь двоичного кода в десятичный
Преобразователь двоичного кода в шестнадцатеричный
Преобразователь восьмеричного в двоичный
Преобразователь восьмеричного в десятичный
октября в шестнадцатеричном преобразователе
Десятичный в двоичный преобразователь
Десятичный в восьмовый преобразователь
Десятичный в шестнадцатеричный преобразователь
HEX в бинарный преобразователь
HEX в октальный конвертер
HEX к децимальному конвертеру
Decimal To BCD Converter
Decimal To BCD Converter
Decimal To BCD
Decimal To BCD
Decimal To BCD
9000 2Decimal To BCD
.
Преобразователь восьмеричных чисел в двоично-десятичные
Преобразование двоично-десятичных чисел в восьмеричные
Преобразование шестнадцатеричных чисел в двоично-десятичные
Преобразование двоично-десятичных чисел в шестнадцатеричные
Преобразование двоичных чисел в серые
от серого до бинарного преобразователя
октальный в серой преобразователь
от серого в октальный преобразователь
Десятичный в серой преобразователь
от серого до десятичного преобразователя
Гексадецимальный в серой конвертер
серо Калькулятор продукта
Калькулятор двоичного побитового И
Калькулятор двоичного побитового И-НЕ
Калькулятор двоичного побитового ИЛИ
Калькулятор двоичного побитового НЕ-ИЛИ
Бинарный бить калькулятор XOR
Бинарный бить калькулятор XNOR
Бинарный битевой битевой кубик.
Преобразователь числовой базы
Преобразователь римских чисел в десятичные
Преобразователь десятичных чисел в римские
Преобразователь чисел в слова
Преобразователь слов в числа
Круглые числа выше
Круглые номера вниз
UTF8 в шестнадцатеричный преобразователь
HEX в UTF8 преобразователь
Текст в коды ASCII
ASCII в текстовый преобразователь
Текст в бинарный преобразователь
Бинарный в текстовый преобразователь
Текст.
Преобразователь восьмеричного в текст
Преобразователь текста в десятичный
Преобразователь десятичного в текст
Преобразователь текста в шестнадцатеричный
Преобразователь шестнадцатеричного в текст
Текст в нижний конвертер
Текст в верхний конвертер
Текст в случайное преобразователь
Текст в Tittlecase Converter
Заглаживание слов в тексте
Текстовый чехол. Конвертер
Преобразователь табуляции в пробелы
Преобразователь пробелов в символы новой строки
Преобразователь новой строки в пробелы
Преобразователь символьного акцента
Extra WhiteSpaces Remover
All WhiteSpaces Remover
Партовая отметка
тысячи сепараторов Adder
Семовер Backslash
BackSlash Adder
Текст
Text Recaiter
Textclacer
Text REVERSER Text REVERSER Text REVERSER Text REVERSSER Text Reverser. Вращатель символов влево
Вращатель символов влевоВращатель текстовых символов вправо
Калькулятор длины текста
Сортировщик текста по алфавиту
Числовой текстовый сортировщик
Текст по длине сортировщик
Текст из генератора REGEX
Центральный текст
Правопрокат Текст
Текст левого столбца
Текст правой падки
Обоснованный текст
Текстовый столбец
Regex Match Extractor
Regex Match Replacer
Email Extractor
URL Extractor
Number Extractor
List Merger
List Zipper
List Intersection
List Difference
Printf Formatter
Text Grep
Text Head
Text Tail
Line Range Extractor
Word Sorter
Word Wrapper
Word Splitter
Add Line Numbers
Add Line Prefixes
Add Суффиксы строк
Добавление префикса и суффикса
Поиск самой длинной текстовой строки
Поиск самой короткой текстовой строки
Удаление повторяющихся строк
Удаление пустых строк
Текстовая линия Rampodizer
Letter Ramdigizer
Text Line Joiner
Строковой разветвитель
Text Line Reverser
Текстовая линия
Номер буквы в текстовом счетчике
Количество слов в текстовом счетчике
Номер строк в линии в буквах
Счетчик текста
Счетчик количества абзацев в тексте
Калькулятор частоты букв
Калькулятор частоты слов
Калькулятор частоты фраз
Text Statistics
Random Element Picker
Random JSON Generator
Random XML Generator
Random YAML Generator
Random CSV Generator
Random TSV Generator
Random Password Generator
Random String Generator
Random Number Generator
Генератор случайных дробей
Генератор случайных интервалов
Генератор случайных чисел
Генератор случайных чисел
Генератор случайных шестнадцатеричных чисел
Random Byte Generator
Random IP Generator
Random MAC Generator
Random UUID Generator
Random GUID Generator
Random Date Generator
Random Time Generator
Prime Number Generator
Fibonacci Number Generator
Pi Digit Generator
E Генератор цифр
Преобразователь десятичных чисел в научные
Преобразователь научных чисел в десятичные
Преобразователь JPG в PNG
PNG в JPG Converter
GIF TO PNG Converter
GIF для JPG Converter
BMP в PNG Converter
BMP в JPG Converter
Изображение BASE64
Файл Base64 Converter
JSON JONSON TOURTER
.