PostgreSQL : Документация: 10: 23.3. Поддержка кодировок : Компания Postgres Professional
RU
EN
RU EN
- 23.3.1. Поддерживаемые кодировки
- 23.3.2. Настройка кодировки
- 23.3.3. Автоматическая перекодировка между сервером и клиентом
- 23.3.4. Дополнительные источники информации
- 23.3.2. Настройка кодировки
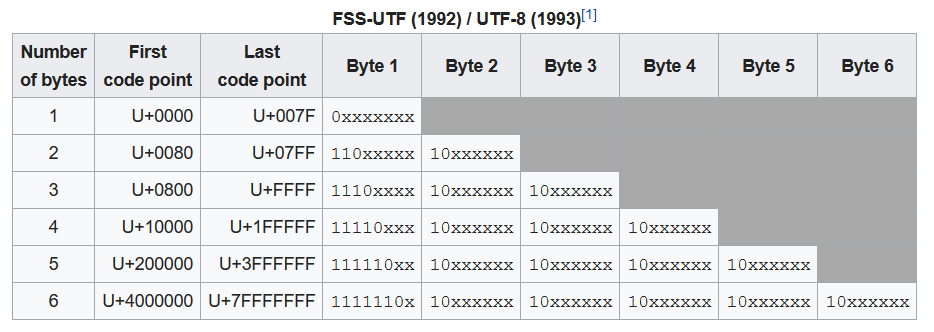
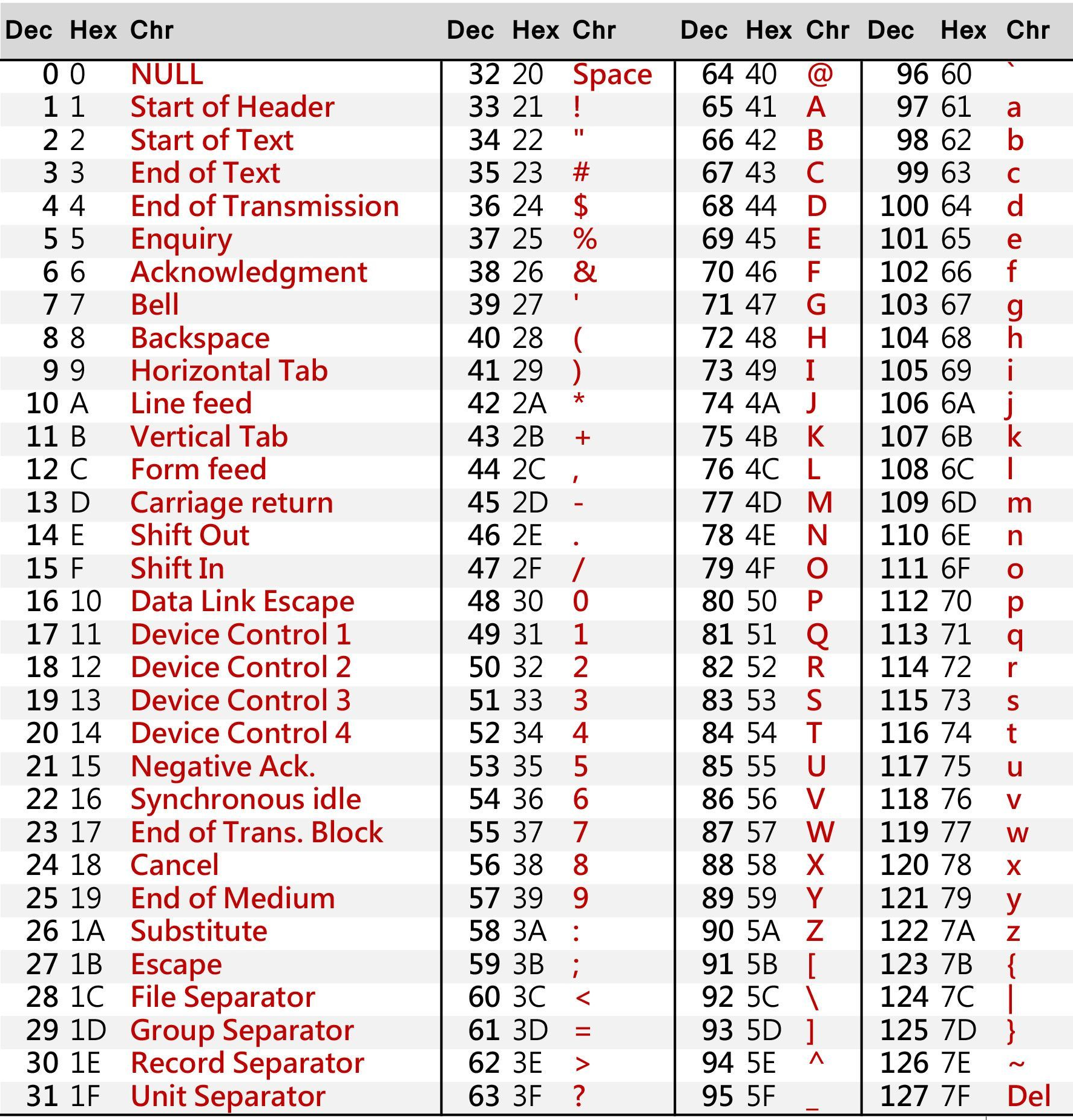
Поддержка кодировок в PostgreSQL позволяет хранить текст в различных кодировках, включая однобайтовые кодировки, такие как входящие в семейство ISO 8859 и многобайтовые кодировки, такие как EUC (Extended Unix Code), UTF-8 и внутренний код Mule. Все поддерживаемые кодировки могут прозрачно использоваться клиентами, но некоторые не поддерживаются сервером (в качестве серверной кодировки). Кодировка по умолчанию выбирается при инициализации кластера базы данных PostgreSQL при помощи initdb. Она может быть переопределена при создании базы данных, что позволяет иметь несколько баз данных с разными кодировками.
Важным ограничением, однако, является то, что кодировка каждой базы данных должна быть совместима с параметрами локали базы данных LC_COLLATE (порядок сортировки строк). Для локали C или POSIX подойдёт любой набор символов, но для других локалей, предоставляемых библиотекой libc, есть только один набор символов, который будет работать правильно. (Однако в среде Windows кодировка UTF-8 может использоваться с любой локалью.) Если у вас включена поддержка ICU, локали, предоставляемые библиотекой ICU, можно использовать с большинством (но не всеми) кодировками на стороне сервера.
23.3.1. Поддерживаемые кодировки
Таблица 23.1 показывает кодировки, доступные для использования в PostgreSQL.
Таблица 23.1. Кодировки PostgreSQL
| Имя | Описание | Язык | Поддержка на сервере | ICU? | Байтов на символ | Псевдонимы |
|---|---|---|---|---|---|---|
BIG5 | Big Five | Традиционные китайские иероглифы | Нет | Нет | 1-2 | WIN950, Windows950 |
EUC_CN | Extended UNIX Code-CN | Упрощённые китайские иероглифы | Да | Да | 1-3 | |
EUC_JP | Extended UNIX Code-JP | Японский | Да | Да | 1-3 | |
EUC_JIS_2004 | Extended UNIX Code-JP, JIS X 0213 | Японский | Да | Нет | 1-3 | |
EUC_KR | Extended UNIX Code-KR | Корейский | Да | Да | 1-3 | |
EUC_TW | Extended UNIX Code-TW | Традиционные китайские иероглифы, тайваньский | Да | Да | 1-3 | |
GB18030 | Национальный стандарт | Китайский | Нет | Нет | 1-4 | |
GBK | Расширенный национальный стандарт | Упрощённые китайские иероглифы | Нет | Нет | 1-2 | WIN936, Windows936 |
ISO_8859_5 | ISO 8859-5, ECMA 113 | Латинский/Кириллица | Да | Да | 1 | |
ISO_8859_6 | ISO 8859-6, ECMA 114 | Латинский/Арабский | Да | Да | 1 | |
ISO_8859_7 | ISO 8859-7, ECMA 118 | Латинский/Греческий | Да | Да | 1 | |
ISO_8859_8 | ISO 8859-8, ECMA 121 | Латинский/Иврит | Да | Да | 1 | |
JOHAB | JOHAB | Корейский (Хангыль) | Нет | Нет | 1-3 | |
KOI8R | KOI8-R | Кириллица (Русский) | Да | Да | 1 | KOI8 |
KOI8U | KOI8-U | Кириллица (Украинский) | Да | Да | 1 | |
LATIN1 | ISO 8859-1, ECMA 94 | Западноевропейские | Да | Да | 1 | ISO88591 |
LATIN2 | ISO 8859-2, ECMA 94 | Центральноевропейские | Да | Да | 1 | ISO88592 |
LATIN3 | ISO 8859-3, ECMA 94 | Южноевропейские | Да | Да | 1 | ISO88593 |
LATIN4 | ISO 8859-4, ECMA 94 | Североевропейские | Да | Да | 1 | ISO88594 |
LATIN5 | ISO 8859-9, ECMA 128 | Турецкий | Да | Да | 1 | ISO88599 |
LATIN6 | ISO 8859-10, ECMA 144 | Скандинавские | Да | Да | 1 | ISO885910 |
LATIN7 | ISO 8859-13 | Балтийские | Да | Да | 1 | ISO885913 |
LATIN8 | ISO 8859-14 | Кельтские | Да | Да | 1 | ISO885914 |
LATIN9 | ISO 8859-15 | LATIN1 c европейскими языками и диалектами | Да | Да | 1 | ISO885915 |
LATIN10 | ISO 8859-16, ASRO SR 14111 | Румынский | Да | Нет | 1 | ISO885916 |
MULE_INTERNAL | Внутренний код Mule | Мультиязычный редактор Emacs | Да | Нет | 1-4 | |
SJIS | Shift JIS | Японский | Нет | Нет | 1-2 | Mskanji, ShiftJIS, WIN932, Windows932 |
SHIFT_JIS_2004 | Shift JIS, JIS X 0213 | Японский | Нет | Нет | 1-2 | |
SQL_ASCII | не указан (см. текст) текст) | any | Да | Нет | 1 | |
UHC | Унифицированный код Хангыль | Корейский | Нет | Нет | 1-2 | WIN949, Windows949 |
UTF8 | Unicode, 8-bit | все | Да | Да | 1-4 | Unicode |
WIN866 | Windows CP866 | Кириллица | Да | Да | 1 | ALT |
WIN874 | Windows CP874 | Тайский | Да | Нет | 1 | |
WIN1250 | Windows CP1250 | Центральноевропейские | Да | Да | 1 | |
WIN1251 | Windows CP1251 | Кириллица | Да | Да | 1 | WIN |
WIN1252 | Windows CP1252 | Западноевропейские | Да | Да | 1 | |
WIN1253 | Windows CP1253 | Греческий | Да | Да | 1 | |
WIN1254 | Windows CP1254 | Турецкий | Да | Да | 1 | |
WIN1255 | Windows CP1255 | Иврит | Да | Да | 1 | |
WIN1256 | Windows CP1256 | Арабский | Да | Да | 1 | |
WIN1257 | Windows CP1257 | Балтийские | Да | Да | 1 | |
WIN1258 | Windows CP1258 | Вьетнамский | Да | Да | 1 | ABC, TCVN, TCVN5712, VSCII |
Не все клиентские API поддерживают все перечисленные кодировки. Например, драйвер интерфейса JDBC PostgreSQL не поддерживает
Например, драйвер интерфейса JDBC PostgreSQL не поддерживает MULE_INTERNAL, LATIN6, LATIN8 и LATIN10.
Поведение кодировки SQL_ASCII существенно отличается от других. Когда набором символов сервера является SQL_ASCII, сервер интерпретирует значения от 0 до 127 байт согласно кодировке ASCII, тогда как значения от 128 до 255 воспринимаются как незначимые. Перекодировка не будет выполнена при выборе SQL_ASCII. Таким образом, этот вариант является не столько объявлением того, что используется определённая кодировка, сколько объявлением того, что кодировка игнорируется. В большинстве случаев, если вы работаете с любыми данными, отличными от ASCII, не стоит использовать SQL_ASCII, так как PostgreSQL не сможет преобразовать или проверить символы, отличные от ASCII.
23.3.2. Настройка кодировки
initdb определяет кодировку по умолчанию для кластера PostgreSQL.
initdb -E EUC_JP
настраивает кодировку по умолчанию на EUC_JP (Расширенная система кодирования для японского языка). Можно использовать --encoding вместо -E в случае предпочтения более длинных имён параметров. Если параметр -E или --encoding не задан, initdb пытается определить подходящую кодировку в зависимости от указанной или заданной по умолчанию локали.
При создании базы данных можно указать кодировку, отличную от заданной по умолчанию, если эта кодировка совместима с выбранной локалью:
createdb -E EUC_KR -T template0 --lc-collate=ko_KR.euckr --lc-ctype=ko_KR.euckr korean
Это создаст базу данных с именем korean, которая использует кодировку EUC_KR и локаль ko_KR. Также, получить желаемый результат можно с помощью данной SQL-команды:
CREATE DATABASE korean WITH ENCODING 'EUC_KR' LC_COLLATE='ko_KR.euckr' LC_CTYPE='ko_KR.euckr' TEMPLATE=template0;
 euckr' TEMPLATE=template0;
euckr' TEMPLATE=template0; Заметьте, что приведённые выше команды задают копирование базы данных template0. При копировании любой другой базы данных, параметры локали и кодировку исходной базы изменить нельзя, так как это может привести к искажению данных. Более подробное описание приведено в Разделе 22.3.
Кодировка базы данных хранится в системном каталоге pg_database. Её можно увидеть при помощи параметра psql -l или команды \l.
$psql -lList of databases Name | Owner | Encoding | Collation | Ctype | Access Privileges -----------+----------+-----------+-------------+-------------+------------------------------------- clocaledb | hlinnaka | SQL_ASCII | C | C | englishdb | hlinnaka | UTF8 | en_GB.UTF8 | en_GB.UTF8 | japanese | hlinnaka | UTF8 | ja_JP.UTF8 | ja_JP.UTF8 | korean | hlinnaka | EUC_KR | ko_KR.euckr | ko_KR.euckr | postgres | hlinnaka | UTF8 | fi_FI.UTF8 | fi_FI.UTF8 | template0 | hlinnaka | UTF8 | fi_FI.UTF8 | fi_FI.UTF8 | {=c/hlinnaka,hlinnaka=CTc/hlinnaka} template1 | hlinnaka | UTF8 | fi_FI.UTF8 | fi_FI.UTF8 | {=c/hlinnaka,hlinnaka=CTc/hlinnaka} (7 rows)

Важно
На большинстве современных операционных систем PostgreSQL может определить, какая кодировка подразумевается параметром LC_CTYPE, что обеспечит использование только соответствующей кодировки базы данных. На более старых системах необходимо самостоятельно следить за тем, чтобы использовалась кодировка, соответствующая выбранной языковой среде. Ошибка в этой области, скорее всего, приведёт к странному поведению зависимых от локали операций, таких как сортировка.
PostgreSQL позволит суперпользователям создавать базы данных с кодировкой SQL_ASCII, даже когда значение LC_CTYPE не установлено в C или POSIX. Как было сказано выше,
Как было сказано выше, SQL_ASCII не гарантирует, что данные, хранящиеся в базе, имеют определённую кодировку, и таким образом, этот выбор чреват сбоями, связанными с локалью. Использование данной комбинации устарело и, возможно, будет полностью запрещено.
23.3.3. Автоматическая перекодировка между сервером и клиентом
PostgreSQL поддерживает автоматическую перекодировку между сервером и клиентом для определённых комбинаций кодировок. Информация, касающаяся перекодировки, хранится в системном каталоге pg_conversion. PostgreSQL включает в себя некоторые предопределённые кодировки, как показано в Таблице 23.2. Есть возможность создать новую перекодировку при помощи SQL-команды CREATE CONVERSION.
Таблица 23.2. Клиент-серверные перекодировки наборов символов
| Серверная кодировка | Доступные клиентские кодировки |
|---|---|
BIG5 | не поддерживается как серверная кодировка |
EUC_CN | EUC_CN, MULE_INTERNAL, UTF8 |
EUC_JP | EUC_JP, MULE_INTERNAL, SJIS, UTF8 |
EUC_JIS_2004 | EUC_JIS_2004, SHIFT_JIS_2004, UTF8 |
EUC_KR | EUC_KR, MULE_INTERNAL, UTF8 |
EUC_TW | EUC_TW, BIG5, MULE_INTERNAL, UTF8 |
GB18030 | не поддерживается как серверная кодировка |
GBK | не поддерживается как серверная кодировка |
ISO_8859_5 | ISO_8859_5, KOI8R, MULE_INTERNAL, UTF8, WIN866, WIN1251 |
ISO_8859_6 | ISO_8859_6, UTF8 |
ISO_8859_7 | ISO_8859_7, UTF8 |
ISO_8859_8 | ISO_8859_8, UTF8 |
JOHAB | не поддерживается как серверная кодировка |
KOI8R | KOI8R, ISO_8859_5, MULE_INTERNAL, UTF8, WIN866, WIN1251 |
KOI8U | KOI8U, UTF8 |
LATIN1 | LATIN1, MULE_INTERNAL, UTF8 |
LATIN2 | LATIN2, MULE_INTERNAL, UTF8, WIN1250 |
LATIN3 | LATIN3, MULE_INTERNAL, UTF8 |
LATIN4 | LATIN4, MULE_INTERNAL, UTF8 |
LATIN5 | LATIN5, UTF8 |
LATIN6 | LATIN6, UTF8 |
LATIN7 | LATIN7, UTF8 |
LATIN8 | LATIN8, UTF8 |
LATIN9 | LATIN9, UTF8 |
LATIN10 | LATIN10, UTF8 |
MULE_INTERNAL | MULE_INTERNAL, BIG5, EUC_CN, EUC_JP, EUC_KR, EUC_TW, ISO_8859_5, KOI8R, LATIN1 to LATIN4, SJIS, WIN866, WIN1250, WIN1251 |
SJIS | не поддерживается как серверная кодировка |
SHIFT_JIS_2004 | не поддерживается как серверная кодировка |
SQL_ASCII | любая (перекодировка не будет выполнена) |
UHC | не поддерживается как серверная кодировка |
UTF8 | все поддерживаемые кодировки |
WIN866 | WIN866, ISO_8859_5, KOI8R, MULE_INTERNAL, UTF8, WIN1251 |
WIN874 | WIN874, UTF8 |
WIN1250 | WIN1250, LATIN2, MULE_INTERNAL, UTF8 |
WIN1251 | WIN1251, ISO_8859_5, KOI8R, MULE_INTERNAL, UTF8, WIN866 |
WIN1252 | WIN1252, UTF8 |
WIN1253 | WIN1253, UTF8 |
WIN1254 | WIN1254, UTF8 |
WIN1255 | WIN1255, UTF8 |
WIN1256 | WIN1256, UTF8 |
WIN1257 | WIN1257, UTF8 |
WIN1258 | WIN1258, UTF8 |
Чтобы включить автоматическую перекодировку символов, необходимо сообщить PostgreSQL кодировку, которую вы хотели бы использовать на стороне клиента. Это можно выполнить несколькими способами:
Это можно выполнить несколькими способами:
Использование команды
\encodingв psql.\encodingпозволяет оперативно изменять клиентскую кодировку. Например, чтобы изменить кодировку наSJIS, введите:\encoding SJIS
libpq (Раздел 33.10) имеет функции, для управления клиентской кодировкой.
Использование
SET client_encoding TO. Клиентская кодировка устанавливается следующей SQL-командой:SET CLIENT_ENCODING TO '
value';Также, для этой цели можно использовать стандартный синтаксис SQL
SET NAMES:SET NAMES '
value';Получить текущую клиентскую кодировку:
SHOW client_encoding;
Вернуть кодировку по умолчанию:
RESET client_encoding;
Использование
PGCLIENTENCODING. Если установлена переменная окруженияPGCLIENTENCODING, то эта клиентская кодировка выбирается автоматически при подключении к серверу. (В дальнейшем это может быть переопределено при помощи любого из методов, указанных выше.)Использование переменной конфигурации client_encoding. Если задана переменная
client_encoding, указанная клиентская кодировка выбирается автоматически при подключении к серверу. (В дальнейшем это может быть переопределено при помощи любого из методов, указанных выше.)
 (В дальнейшем это может быть переопределено при помощи любого из методов, указанных выше.)
(В дальнейшем это может быть переопределено при помощи любого из методов, указанных выше.)Если перекодировка определённого символа невозможна (предположим, выбраны EUC_JP для сервера и LATIN1 для клиента, и передаются некоторые японские иероглифы, не представленные в LATIN1), возникает ошибка.
Если клиентская кодировка определена как SQL_ASCII, перекодировка отключается вне зависимости от кодировки сервера. Что же касается сервера, не стоит использовать SQL_ASCII, если только вы не работаете с данными, которые полностью соответствуют ASCII.
23.3.4. Дополнительные источники информации
Рекомендуемые источники для начала изучения различных видов систем кодирования.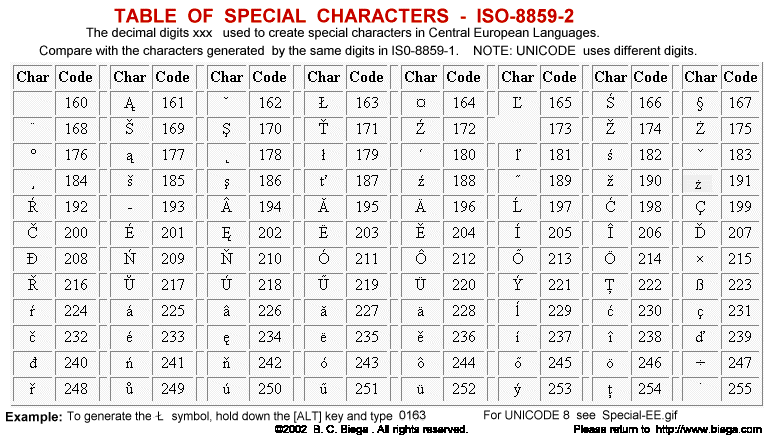
- Обработка информации на китайском, японском, корейском & вьетнамском языках.
Содержит подробные объяснения по
EUC_JP,EUC_CN,EUC_KR,EUC_TW.- http://www.unicode.org/
Сайт Unicode Consortium.
- RFC 3629
UTF-8 (формат преобразования 8-битного UCS/Unicode) определён здесь.
что это такое и как установить ее
Что такое кодировка сайта. Как узнать и как установить кодировку страницы сайта. Разбираемся вместе с экспертами Ingate.
Кодировка сайта
Этот атрибут веб-ресурса объединяет в себе его коды и основанное на них экранное отображение печатных символов.
Назначение и принцип работы кодировки
Независимо от вида и места размещения (в текстовом контенте, файлах, письмах на email и на сайтах), целью кодирования всегда является сохранение данных в двоичном формате, то есть на языке компьютеров.
Как это работает?
Для наглядности рассмотрим такой пример. Допустим, ваш друг воспринимает только два символа: единицу и ноль. С другими цифрами и буквами он не знаком и может прочитать только те тексты, которые состоят из известных ему элементов. Поэтому возникает масса вопросов: как с таким другом общаться, доносить до него смысл слов и понимать, что он отвечает. Выход из ситуации – разработать систему, по которой каждой цифре, букве и другому символу будет соответствовать определенная комбинация единиц и нулей. Это позволит рассказать что-то другу, заменив слова двоичным кодом, и узнать, что он отвечает.
Допустим, ваш друг воспринимает только два символа: единицу и ноль. С другими цифрами и буквами он не знаком и может прочитать только те тексты, которые состоят из известных ему элементов. Поэтому возникает масса вопросов: как с таким другом общаться, доносить до него смысл слов и понимать, что он отвечает. Выход из ситуации – разработать систему, по которой каждой цифре, букве и другому символу будет соответствовать определенная комбинация единиц и нулей. Это позволит рассказать что-то другу, заменив слова двоичным кодом, и узнать, что он отвечает.
Что может пойти не так?
Если непонятливый друг один, всё более-менее понятно. Но как быть, когда таких людей десятки или даже сотни? У каждого из них собственные друзья и таблицы с кодами, поэтому при встрече никто никого не сможет понять. Один решил заменить «А» на 111000, а на другом табличном языке – это цифра 5. В результате все путаются, и разговор никак не складывается. Но пора вернуться к реальности. Компьютеры – это те друзья, о которых мы говорили, а кодировки – таблицы с заменой символов.
Виды кодировок
Из всех существующих языков кодирования мы выбрали несколько самых востребованных и удобных, о которых расскажем подробнее.
UTF-8
Этот вид кодирования, полное название которого – «Unicode Transformation Format», представляет собой восьмибитный «Юникод». Он появился в 1992 году и с тех пор по всему миру остаётся эталоном программного обеспечения. В UTF-8 есть два раздела, выделенных под кириллицу: Cyrillic Supplement и Cyrillic.
Таблица кодировки UTF-8 для букв русского алфавита
Коды UTF-8 для кириллических буквWindows-1251
Это вторая по популярности восьмибитная кодировка, разработанная для русификаторов Windows еще в 1990 году. Она рассчитана на кириллический шрифт.
Таблица кодировки Windows-1251
Коды Windows-1251KOI8-R
Такой стандартный язык предназначен специально для кодирования кириллицы. Убирая восьмой бит у каждого из его символов, получаем латинскую транскрипцию кириллических букв. С его помощью можно, например, закодировать письмо для отправки на email, но сегодня этот вид кодировки можно встретить редко.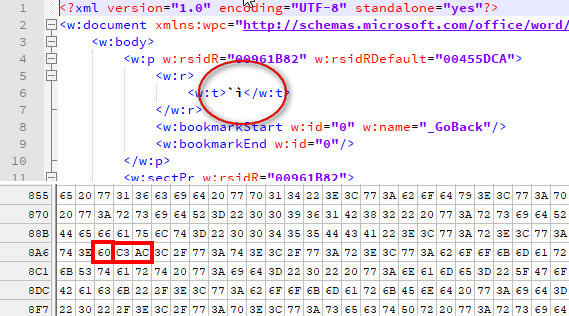
Таблица кодировки KOI8-R
Коды KOI8-RСпособы определения кодировки
Когда на сайте возникают ошибки, чтобы исправить их, иногда необходимо установить, как закодирована страница. Как именно это можно сделать, расскажем дальше.
1-й способ – по метатегу
Будем действовать по такому алгоритму.
- Открываем исходный код. Для этого в открытом окне кликаем правой клавишей мышки по свободному месту. Появится меню, в котором нужно выбрать «Исходный код страницы».
- Находим тег в директории .
- Дальше ищем в нём строчку с реквизитом charset. Именно его значение отражает кодировку страницы.
2-й способ – при помощи инструментов браузера
В этом случае, чтобы проверить, какой вид кодирования выбран для сайта, нужно придерживаться такой схемы действий.
- Ищем в настройках браузера раздел с информацией о странице или пункт «Подробнее» в зависимости от выбранного программного обеспечения.
- Откроется окно, в котором нам нужно выбрать вкладку с ключевыми сведениями о странице.
- Здесь одним из пунктов будет кодировка

Установка кодировки для разных браузеров
Если при открытии сайта невозможно ничего прочитать, потому что видны не буквы кириллицы, а какие-то крючки, цифры или символы на латинице, для приведения страницы в стандартный вид необходимо выставить кодировку вручную. Рассмотрим по шагам, как это сделать в самых популярных браузерах.
Firefox от Mozilla
- Открываем меню. Это можно сделать, кликнув по значку в виде трех горизонтальных полосок.
- Переходим в раздел «Ещё».
- Откроется окно, где нужно выбрать пункт «Кодировка текста».
- Из появившегося списка выбираем подходящий вариант.
Opera
- Запускаем настройку браузера.
- Находим в меню раздел «Веб-сайты»..
- Здесь нужно выбрать «Отображение».
- Из доступных команд нам пригодится «Настроить шрифты».
- Теперь остаётся только выбрать кодировку.
Chrome от Google
- Заходим в меню. В этом браузере это можно сделать, кликнув по троеточию в правом верхнем углу.
- Выбираем раздел «Дополнительные инструменты»
- Здесь нам нужен пункт «Кодировка».
- В открывшемся окне появится список языков кодирования, из которых выбираем нужный.
 В этом браузере это можно сделать, кликнув по троеточию в правом верхнем углу.
В этом браузере это можно сделать, кликнув по троеточию в правом верхнем углу.Настройка кодировки
Если с вашим сайтом постоянно возникают проблемы, поступают жалобы от посетителей по поводу неправильно закодированных страниц, есть смысл настроить всё заново. Чтобы наладить работу ресурса, нужно закодировать сервер, базы данных, скрипты и файлы одинаково. Для этого мы пройдёмся по таким пунктам.
- Все размещённые на сайте файлы приводим к единой кодировке. Если есть необходимость её поменять, используем специальные приложения. Как вариант, можно выбрать Notepad++.
- Устанавливаем теги кодировок в html.
- Настраиваем заголовки серверов таким образом, чтобы они кодировались по умолчанию. Иначе браузер не будет воспринимать даже метатеги.
- В файле httpd.conf находим команду AddDefaultCharset и устанавливаем нужное значение.
- Если доступ к корневым настройкам сервера отсутствует, есть другой способ изменения кодировки. Вводим необходимые параметры в файл .htaccess, размещённый в папке нашего ресурса.
- Заголовки можно отправить при помощи скриптов. Это важная операция, и прежде чем выводить контент, прежде всего нужно выполнить её.

Нам придётся выставить для подключаемых модулей правильную кодировку вручную. Если закодировать сайт неправильно, можно причинить вред аудитории. В результате посещаемость и доходность значительно снизятся. Попав на ваш ресурс, посетители увидят не тексты, а непонятные символы. Вряд ли кто-то из них займётся ручной настройкой кодировки, и практически все просто покинут страницу. Нужно решать эту задачу максимально ответственно, так как от правильного кодирования во многом зависит судьба вашего проекта.
ЧИТАЙ ТАКЖЕ
Вики-разметка ВКонтакте для чайников
Гид по API Google Maps: разбираем по шагам
Исходный код сайта: что это такое и как посмотреть HTML-код страницы
(Рейтинг: 5, Голосов: 6) |
У тебя есть нерешенные задачи?
В этом блоге мы делимся знаниями, но если у тебя есть серьезные цели, которые требуют вмешательства настоящих профи, сообщи! Перезвоним, расскажем, решим любые задачи из области digital
Находи клиентов. Быстрее!
Быстрее!
Работаем по будням с 9:30 до 18:30. Заявки, отправленные в выходные, обрабатываем в первый рабочий день до 10:30.
Приложи файл или ТЗ
Нажимая кнопку, ты разрешаешь обработку персональных данных и соглашаешься с политикой конфиденциальности.
Работаем по будням с 9:30 до 18:30. Заявки, отправленные в выходные, обрабатываем в первый рабочий день до 10:30.
Нажимая кнопку, ты разрешаешь обработку персональных данных и соглашаешься с политикой конфиденциальности.
наверх
Использовать кодовые страницы UTF-8 в приложениях для Windows — Приложения для Windows
Редактировать Твиттер LinkedIn Фейсбук Электронная почта- Статья
Используйте кодировку символов UTF-8 для оптимальной совместимости между веб-приложениями и другими платформами на основе *nix (Unix, Linux и варианты), минимизируйте ошибки локализации и уменьшите затраты на тестирование.
UTF-8 — это универсальная кодовая страница для интернационализации, которая может кодировать весь набор символов Unicode. Он широко используется в Интернете и используется по умолчанию для платформ на основе * nix.
Установите для кодовой страницы процесса значение UTF-8
Начиная с версии Windows 1903 (обновление за май 2019 г.) вы можете использовать свойство ActiveCodePage в appxmanifest для упакованных приложений или манифест fusion для неупакованных приложений, чтобы заставить процесс используйте UTF-8 в качестве кодовой страницы процесса.
Примечание
В настоящее время GDI не поддерживает настройку свойства ActiveCodePage для каждого процесса. Вместо этого GDI по умолчанию использует кодовую страницу активной системы. Чтобы настроить приложение для отображения текста UTF-8 через GDI, перейдите в раздел «Параметры Windows » > «Время и язык» > «Язык и регион» > «Параметры административного языка» > «Изменить язык системы» и установите флажок «Бета-версия: использовать». Unicode UTF-8 для поддержки языков во всем мире . Затем перезагрузите компьютер, чтобы изменения вступили в силу.
Unicode UTF-8 для поддержки языков во всем мире . Затем перезагрузите компьютер, чтобы изменения вступили в силу.
Вы можете объявить свойство ActiveCodePage и использовать его в более ранних сборках Windows, но вы должны выполнять обнаружение и преобразование устаревших кодовых страниц как обычно. При минимальной целевой версии Windows версии 1903 кодовая страница процесса всегда будет UTF-8, поэтому можно избежать обнаружения и преобразования устаревшей кодовой страницы.
Примечание
Закодированный символ занимает от 1 до 4 байтов. Кодировка UTF-8 поддерживает более длинные последовательности байтов, до 6 байтов, но самая большая кодовая точка Unicode 6.0 (U+10FFFF) занимает всего 4 байта.
Примеры
Манифест Appx для упакованного приложения:
<Пакет xmlns="http://schemas.microsoft.com/appx/manifest/foundation/windows10"
...
xmlns:uap7="http://schemas. microsoft.com/appx/manifest/uap/windows10/7"
xmlns:uap8="http://schemas.microsoft.com/appx/manifest/uap/windows10/8"
...
IgnorableNamespaces="... uap7 uap8 ...">
<Приложения>
<Приложение...>
UTF-8
 microsoft.com/appx/manifest/uap/windows10/7"
xmlns:uap8="http://schemas.microsoft.com/appx/manifest/uap/windows10/8"
...
IgnorableNamespaces="... uap7 uap8 ...">
<Приложения>
<Приложение...>
microsoft.com/appx/manifest/uap/windows10/7"
xmlns:uap8="http://schemas.microsoft.com/appx/manifest/uap/windows10/8"
...
IgnorableNamespaces="... uap7 uap8 ...">
<Приложения>
<Приложение...>
Манифест Fusion для неупакованного приложения Win32:
<приложение> <настройки окна> UTF-8
Примечание
Добавьте манифест к существующему исполняемому файлу из командной строки с помощью mt.exe -manifest .
-A и -W API
Win32 API часто поддерживают оба варианта -A и -W.
Варианты -A распознают кодовую страницу ANSI, настроенную в системе, и поддерживают char* , а варианты -W работают в UTF-16 и поддерживают WCHAR .
До недавнего времени Windows делала упор на варианты «Unicode» -W, а не на -A API. Однако в недавних выпусках использовалась кодовая страница ANSI и API-интерфейсы -A в качестве средства внедрения поддержки UTF-8 в приложения. Если кодовая страница ANSI настроена для UTF-8, то API-интерфейсы -A обычно работают в UTF-8. Преимущество этой модели заключается в поддержке существующего кода, созданного с помощью API-интерфейсов -A, без каких-либо изменений кода.
Преобразование кодовой страницы
Поскольку Windows изначально работает в UTF-16 ( WCHAR ), вам может потребоваться преобразовать данные UTF-8 в UTF-16 (или наоборот) для взаимодействия с Windows API.
MultiByteToWideChar и WideCharToMultiByte позволяют выполнять преобразование между UTF-8 и UTF-16 ( WCHAR ) (и другими кодовыми страницами). Это особенно полезно, когда устаревший API Win32 может понимать только
Это особенно полезно, когда устаревший API Win32 может понимать только WCHAR . Эти функции позволяют преобразовать ввод UTF-8 в 9.0063 WCHAR для передачи в -W API и последующего преобразования любых результатов обратно, если это необходимо.
Используйте dwFlags из 0 или MB_ERR_INVALID_CHARS при использовании этих функций с CodePage , установленным на CP_UTF8 (в противном случае 9006 3 ERROR_INVALID_FLAGS ).
Примечание
CP_ACP соответствует CP_UTF8 только при работе в Windows версии 1903 (обновление за май 2019 г.) или более поздней версии, а для описанного выше свойства ActiveCodePage установлено значение UTF-8. В противном случае он учитывает кодовую страницу устаревшей системы. Мы рекомендуем использовать CP_UTF8 явно.
- Кодовые страницы
- Идентификаторы кодовых страниц
Обратная связь
Просмотреть все отзывы о странице
asp classic — кодовая страница 65001 и utf-8 — это одно и то же?
спросил
Изменено 3 года, 1 месяц назад
Просмотрено 119 тысяч раз
<%@LANGUAGE="VBSCRIPT" CODEPAGE="65001"%> <голова>
Верен ли приведенный выше код?
- asp-classic
- кодовые страницы
Да.
UTF-8 — это CP65001 в Windows (это просто способ указать UTF-8 в устаревшей кодовой странице). Насколько я читал, ASP может обрабатывать UTF-8, если указано таким образом.
9Ваш код правильный, хотя я предпочитаю устанавливать CharSet в коде, а не использовать метатег: —
<% Response.CharSet = "UTF-8" %>
Кодовая страница 65001 относится к набору символов UTF-8. Вам нужно будет убедиться, что ваша страница asp (и любые включения) сохранены как UTF-8, если они содержат какие-либо символы за пределами стандартного набора символов ASCII.
Указав атрибут CODEPAGE в блоке <%@, вы указываете, что все, что пишется с помощью Response.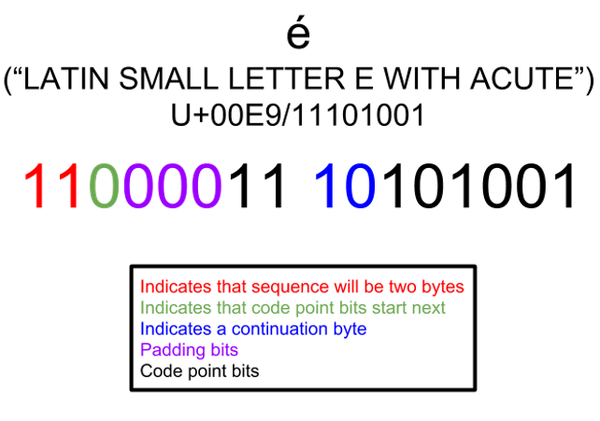 Write, должно быть закодировано с указанной кодовой страницей, в данном случае 65001 (utf-8). Стоит иметь в виду, что это не влияет на статический контент, который дословно отправляется байт за байтом в ответ. Следовательно, причина, по которой файл должен быть фактически сохранен с использованием указанной кодовой страницы.
Write, должно быть закодировано с указанной кодовой страницей, в данном случае 65001 (utf-8). Стоит иметь в виду, что это не влияет на статический контент, который дословно отправляется байт за байтом в ответ. Следовательно, причина, по которой файл должен быть фактически сохранен с использованием указанной кодовой страницы.
Свойство CharSet ответа устанавливает значение CharSet заголовка Content-Type. Это не влияет на то, как контент может быть закодирован, он просто сообщает клиенту, какая кодировка принимается. Опять же важно, чтобы его значение соответствовало фактической отправленной кодировке.
3Да, 65001 — это идентификатор кодовой страницы Windows для UTF-8, как указано на веб-сайте Microsoft. Википедия предполагает, что кодовая страница IBM 128 и кодовая страница SAP 4110 также являются индикаторами для UTF-8.
1ответ.кодовая страница = 65001
, кажется, дает плохой результат, когда физический файл сохраняется как utf-8
В противном случае он работает так, как должен.