Компиляция (программирование) | это… Что такое Компиляция (программирование)?
Компиля́тор —
- Программа или техническое средство, выполняющее компиляцию.[1][2]
- Машинная программа, используемая для компиляции.[3][2]
- Транслятор, выполняющий преобразование программы, составленной на исходном языке, в объектный модуль.[2]
- Программа, переводящая текст программы на языке высокого уровня, в эквивалентную программу на машинном языке.[4]
- Программа, предназначенная для трансляции высокоуровневого языка в абсолютный код или, иногда, в язык ассемблера. Входной информацией для компилятора (исходный код) является описание алгоритма или программа на проблемно-ориентированном языке, а на выходе компилятора — эквивалентное описание алгоритма на машинно-ориентированном языке (объектный код).[5]
Компиляция —
- Трансляция программы на язык, близкий к машинному.

- Трансляция программы, составленной на исходном языке, в объектный модуль. Осуществляется компилятором.[2]
Компилировать — проводить трансляцию машинной программы с проблемно-ориентированного языка на машинно-ориентированный язык.[3]
Содержание
|
Виды компиляторов
[2]- Векторизующий. Транслирует исходный код в машинный код компьютеров, оснащённых векторным процессором.
- Гибкий. Составлен по модульному принципу, управляется таблицами и запрограммирован на языке высокого уровня или реализован с помощью компилятора компиляторов.
- Диалоговый. См.: диалоговый транслятор.
- Инкрементальный. Повторно транслирует фрагменты программы и дополнения к ней без перекомпиляции всей программы.
- Интерпретирующий (пошаговый). Последовательно выполняет независимую компиляцию каждого отдельного оператора (команды) исходной программы.
- Компилятор компиляторов. Транслятор, воспринимающий формальное описание языка программирования и генерирующий компилятор для этого языка.
- Отладочный. Устраняет отдельные виды синтаксических ошибок.
- Резидентный. Постоянно находится в основной памяти и доступен для повторного использования многими задачами.
- Самокомпилируемый. Написан на том же языке, с которого осуществляется трансляция.
- Универсальный. Основан на формальном описании синтаксиса и семантики входного языка. Составными частями такого компилятора являются: ядро, синтаксический и семантический загрузчики.

Виды компиляции
[2]- Пакетная
- Построчная. То же, что и интерпретация.
- Условная. Компиляция, при которой транслируемый текст зависит от условий, заданных в исходной программе. Так, в зависимости от значения некоторой константы, можно включать или выключать трансляцию части текста программы.
 Компиляция нескольких исходных модулей в одном пункте задания.
Компиляция нескольких исходных модулей в одном пункте задания.Основы
Большинство компиляторов переводит программу с некоторого высокоуровневого языка программирования в машинный код, который может быть непосредственно выполнен центральным процессором. Как правило, этот код также ориентирован на исполнение в среде конкретной операционной системы, поскольку использует предоставляемые ею возможности (системные вызовы, библиотеки функций). Архитектура (набор программно-аппаратных средств), для которой производится компиляция, называется
Некоторые компиляторы (например, низкоуровневом языке. Такой язык — байт-код — также можно считать языком машинных команд, поскольку он подлежит интерпретации виртуальной машиной. Например, для языка Java это JVM (язык виртуальной машины Java), или так называемый байт-код Java (вслед за ним все промежуточные низкоуровневые языки стали называть байт-кодами). Для языков программирования на платформе .NET Framework (C#, Managed C++, Visual Basic .NET и другие) — это MSIL (Microsoft Intermediate Language).
Например, для языка Java это JVM (язык виртуальной машины Java), или так называемый байт-код Java (вслед за ним все промежуточные низкоуровневые языки стали называть байт-кодами). Для языков программирования на платформе .NET Framework (C#, Managed C++, Visual Basic .NET и другие) — это MSIL (Microsoft Intermediate Language).
Программа на байт-коде подлежит интерпретации виртуальной машиной, либо ещё одной компиляции уже в машинный код непосредственно перед исполнением. Последнее называется «Just-In-Time компиляция» (MSIL-код компилируется в код целевой машины также JIT-компилятором, а библиотеки .NET Framework компилируются заранее).
Для каждой целевой машины (Apple и т. д.) и каждой операционной системы или семейства операционных систем, работающих на целевой машине, требуется написание своего компилятора. Существуют также так называемые
 Кроме того, компиляторы могут быть оптимизированы под разные типы процессоров из одного семейства (путём использования специфичных для этих процессоров инструкций). Например, код, скомпилированный под процессоры семейства MMX, SSE2.
Кроме того, компиляторы могут быть оптимизированы под разные типы процессоров из одного семейства (путём использования специфичных для этих процессоров инструкций). Например, код, скомпилированный под процессоры семейства MMX, SSE2.Также существуют компиляторы, переводящие программу с языка высокого уровня на язык ассемблера.
Существуют программы, которые решают обратную задачу — перевод программы с низкоуровневого языка на высокоуровневый. Этот процесс называют декомпиляцией, а программы — декомпиляторами. Но поскольку компиляция — это процесс с потерями, точно восстановить исходный код, скажем, на C++, в общем случае невозможно. Более эффективно декомпилируются программы в байт-кодах — например, существует довольно надёжный декомпилятор для Flash. Сходным процессом является дизассемблирование машинного кода в код на языке ассемблера, который всегда выполняется успешно. Связано это с тем, что между кодами машинных команд и командами ассемблера имеется практически однозначное соответствие.
Структура компилятора
Процесс компиляции состоит из следующих этапов:
- Лексический анализ. На этом этапе последовательность символов исходного файла преобразуется в последовательность лексем.
- Синтаксический (грамматический) анализ. Последовательность лексем преобразуется в дерево разбора.
- Семантический анализ. Дерево разбора обрабатывается с целью установления его семантики (смысла) — например, привязка идентификаторов к их декларациям, типам, проверка совместимости, определение типов выражений и т. д. Результат обычно называется «промежуточным представлением/кодом», и может быть дополненным деревом разбора, новым деревом, абстрактным набором команд или чем-то ещё, удобным для дальнейшей обработки.
- Оптимизация. Выполняется удаление излишних конструкций и упрощение кода с сохранением его смысла. Оптимизация может быть на разных уровнях и этапах — например, над промежуточным кодом или над конечным машинным кодом.
- Генерация кода. Из промежуточного представления порождается код на целевом языке.
 Из промежуточного представления порождается код на целевом языке.
Из промежуточного представления порождается код на целевом языке.В конкретных реализациях компиляторов эти этапы могут быть раздельны или совмещены в том или ином виде.
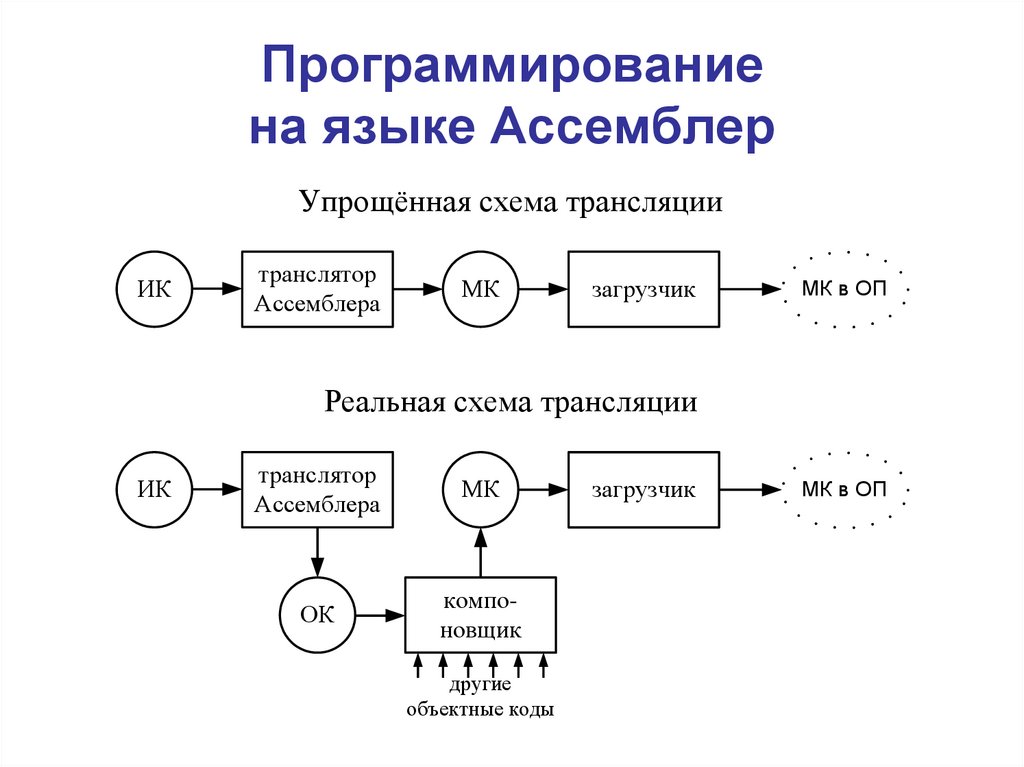
Трансляция и компоновка
Важной исторической особенностью компилятора, отражённой в его названии (англ. compile — собирать вместе, составлять), являлось то, что он мог производить и

Интересные факты
- На заре развития компьютеров первые компиляторы (трансляторы) называли «программирующими программами»[6] (так как в тот момент программой считался только машинный код, а «программирующая программа» была способна из человеческого текста сделать машинный код, то есть запрограммировать ЭВМ).
Примечания
- ↑ ГОСТ 19781-83 // Вычислительная техника. Терминология: Справочное пособие. Выпуск 1 / Рецензент канд. техн. наук Ю. П. Селиванов. — М.: Издательство стандартов, 1989. — 168 с. — 55 000 экз. — ISBN 5-7050-0155-X
- ↑ 1 2
- ↑ 1 2 3 СТ ИСО 2382/7-77 // Вычислительная техника. Терминология. Указ. соч.
- ↑ Борковский А. Б. Англо-русский словарь по программированию и информатике (с толкованиями). — М.: Русский язык, 1990. — 335 с. — 50 050 (доп.) экз. — ISBN 5-200-01169-3
- ↑ Толковый словарь по вычислительным системам = Dictionary of Computing / Под ред. В. Иллингуорта и др.: Пер. с англ. А. К. Белоцкого и др.; Под ред. Е. К. Масловского. — М.: Машиностроение, 1990. — 560 с. — 70 000 (доп.) экз. — ISBN 5-217-00617-X (СССР), ISBN 0-19-853913-4 (Великобритания)
- ↑ Н. А. Криницкий, Г. А. Миронов, Г. Д. Фролов. Программирование / Под ред. М. Р. Шура-Бура. — М.: Государственное издательство физико-математической литературы, 1963.
 — ISBN 5-279-00367-0
— ISBN 5-279-00367-0См. также
- Компилятор компиляторов
- «Книга дракона» — классический учебник о построении компиляторов.
- Синтаксический анализ
- Интерпретатор

- Реализации компиляторов
- GCC
- Free Pascal Compiler
- Sun Studio — компиляторы C, C++ и Fortran от Sun Microsystems Inc.
- Open Watcom — свободное продолжение компиляторов Watcom C/C++/Fortran.
- Intel C++/Fortran compiler
- ICC AVR
Литература
- Альфред В. Ахо, Моника С. Лам, Рави Сети, Джеффри Д. Ульман. Компиляторы: принципы, технологии и инструментарий = Compilers: Principles, Techniques, and Tools. — 2-е изд. — М.: Вильямс, 2008. — ISBN 978-5-8459-1349-4
- Робин Хантер. Основные концепции компиляторов = The Essence of Compilers. — М.: Вильямс, 2002. — С. 256. — ISBN 0-13-727835-7
- Хантер Р. Проектирование и конструирование компиляторов / Пер. с англ. С. М. Круговой. — М.: Финансы и статистика, 1984. — 232 с.
- Д. Креншоу. Давайте создадим компилятор!.
Компиляция (программирование) | это.
 .. Что такое Компиляция (программирование)?
.. Что такое Компиляция (программирование)?Компиля́тор —
- Программа или техническое средство, выполняющее компиляцию.[1][2]
- Машинная программа, используемая для компиляции.[3][2]
- Транслятор, выполняющий преобразование программы, составленной на исходном языке, в объектный модуль.[2]
- Программа, переводящая текст программы на языке высокого уровня, в эквивалентную программу на машинном языке.[4]
- Программа, предназначенная для трансляции высокоуровневого языка в абсолютный код или, иногда, в язык ассемблера. Входной информацией для компилятора (исходный код) является описание алгоритма или программа на проблемно-ориентированном языке, а на выходе компилятора — эквивалентное описание алгоритма на машинно-ориентированном языке (объектный код).[5]
Компиляция —
- Трансляция программы на язык, близкий к машинному. [3][2]
 [3][2]
[3][2]- Трансляция программы, составленной на исходном языке, в объектный модуль. Осуществляется компилятором.[2]
Компилировать — проводить трансляцию машинной программы с проблемно-ориентированного языка на машинно-ориентированный язык.[3]
Содержание
|
Виды компиляторов
[2]- Векторизующий. Транслирует исходный код в машинный код компьютеров, оснащённых векторным процессором.
- Гибкий. Составлен по модульному принципу, управляется таблицами и запрограммирован на языке высокого уровня или реализован с помощью компилятора компиляторов.
- Диалоговый. См.: диалоговый транслятор.
- Инкрементальный. Повторно транслирует фрагменты программы и дополнения к ней без перекомпиляции всей программы.
- Интерпретирующий (пошаговый). Последовательно выполняет независимую компиляцию каждого отдельного оператора (команды) исходной программы.
- Компилятор компиляторов. Транслятор, воспринимающий формальное описание языка программирования и генерирующий компилятор для этого языка.
- Отладочный. Устраняет отдельные виды синтаксических ошибок.
- Резидентный. Постоянно находится в основной памяти и доступен для повторного использования многими задачами.
- Самокомпилируемый. Написан на том же языке, с которого осуществляется трансляция.
- Универсальный. Основан на формальном описании синтаксиса и семантики входного языка. Составными частями такого компилятора являются: ядро, синтаксический и семантический загрузчики.

Виды компиляции
[2]- Пакетная. Компиляция нескольких исходных модулей в одном пункте задания.
- Построчная. То же, что и интерпретация.
- Условная. Компиляция, при которой транслируемый текст зависит от условий, заданных в исходной программе. Так, в зависимости от значения некоторой константы, можно включать или выключать трансляцию части текста программы.
 Компиляция нескольких исходных модулей в одном пункте задания.
Компиляция нескольких исходных модулей в одном пункте задания.Основы
Большинство компиляторов переводит программу с некоторого высокоуровневого языка программирования в машинный код, который может быть непосредственно выполнен центральным процессором. Как правило, этот код также ориентирован на исполнение в среде конкретной операционной системы, поскольку использует предоставляемые ею возможности (системные вызовы, библиотеки функций). Архитектура (набор программно-аппаратных средств), для которой производится компиляция, называется целевой машиной.
Некоторые компиляторы (например, низкоуровневом языке. Такой язык — байт-код — также можно считать языком машинных команд, поскольку он подлежит интерпретации виртуальной машиной. Например, для языка Java это JVM (язык виртуальной машины Java), или так называемый байт-код Java (вслед за ним все промежуточные низкоуровневые языки стали называть байт-кодами). Для языков программирования на платформе .NET Framework (C#, Managed C++, Visual Basic .NET и другие) — это MSIL (Microsoft Intermediate Language).
Например, для языка Java это JVM (язык виртуальной машины Java), или так называемый байт-код Java (вслед за ним все промежуточные низкоуровневые языки стали называть байт-кодами). Для языков программирования на платформе .NET Framework (C#, Managed C++, Visual Basic .NET и другие) — это MSIL (Microsoft Intermediate Language).
Программа на байт-коде подлежит интерпретации виртуальной машиной, либо ещё одной компиляции уже в машинный код непосредственно перед исполнением. Последнее называется «Just-In-Time компиляция» (MSIL-код компилируется в код целевой машины также JIT-компилятором, а библиотеки .NET Framework компилируются заранее).
Для каждой целевой машины (Apple и т. д.) и каждой операционной системы или семейства операционных систем, работающих на целевой машине, требуется написание своего компилятора. Существуют также так называемые кросс-компиляторы, позволяющие на одной машине и в среде одной ОС получать код, предназначенный для выполнения на другой целевой машине и/или в среде другой ОС. Кроме того, компиляторы могут быть оптимизированы под разные типы процессоров из одного семейства (путём использования специфичных для этих процессоров инструкций). Например, код, скомпилированный под процессоры семейства MMX, SSE2.
Кроме того, компиляторы могут быть оптимизированы под разные типы процессоров из одного семейства (путём использования специфичных для этих процессоров инструкций). Например, код, скомпилированный под процессоры семейства MMX, SSE2.
Также существуют компиляторы, переводящие программу с языка высокого уровня на язык ассемблера.
Существуют программы, которые решают обратную задачу — перевод программы с низкоуровневого языка на высокоуровневый. Этот процесс называют декомпиляцией, а программы — декомпиляторами. Но поскольку компиляция — это процесс с потерями, точно восстановить исходный код, скажем, на C++, в общем случае невозможно. Более эффективно декомпилируются программы в байт-кодах — например, существует довольно надёжный декомпилятор для Flash. Сходным процессом является дизассемблирование машинного кода в код на языке ассемблера, который всегда выполняется успешно. Связано это с тем, что между кодами машинных команд и командами ассемблера имеется практически однозначное соответствие.
Структура компилятора
Процесс компиляции состоит из следующих этапов:
- Лексический анализ. На этом этапе последовательность символов исходного файла преобразуется в последовательность лексем.
- Синтаксический (грамматический) анализ. Последовательность лексем преобразуется в дерево разбора.
- Семантический анализ. Дерево разбора обрабатывается с целью установления его семантики (смысла) — например, привязка идентификаторов к их декларациям, типам, проверка совместимости, определение типов выражений и т. д. Результат обычно называется «промежуточным представлением/кодом», и может быть дополненным деревом разбора, новым деревом, абстрактным набором команд или чем-то ещё, удобным для дальнейшей обработки.
- Оптимизация. Выполняется удаление излишних конструкций и упрощение кода с сохранением его смысла. Оптимизация может быть на разных уровнях и этапах — например, над промежуточным кодом или над конечным машинным кодом.
- Генерация кода. Из промежуточного представления порождается код на целевом языке.
 Из промежуточного представления порождается код на целевом языке.
Из промежуточного представления порождается код на целевом языке.В конкретных реализациях компиляторов эти этапы могут быть раздельны или совмещены в том или ином виде.
Трансляция и компоновка
Важной исторической особенностью компилятора, отражённой в его названии (англ. compile — собирать вместе, составлять), являлось то, что он мог производить и компоновку (то есть содержал две части — транслятор и компоновщик). Это связано с тем, что раздельная компиляция и компоновка как отдельная стадия сборки выделились значительно позже появления компиляторов, и многие популярные компиляторы (например, GCC) до сих пор физически объединены со своими компоновщиками. В связи с этим, вместо термина «компилятор» иногда используют термин «транслятор» как его синоним: либо в старой литературе, либо когда хотят подчеркнуть его способность переводить программу в машинный код (и наоборот, используют термин «компилятор» для подчёркивания способности собирать из многих файлов один).
Интересные факты
- На заре развития компьютеров первые компиляторы (трансляторы) называли «программирующими программами»[6] (так как в тот момент программой считался только машинный код, а «программирующая программа» была способна из человеческого текста сделать машинный код, то есть запрограммировать ЭВМ).
Примечания
- ↑ ГОСТ 19781-83 // Вычислительная техника. Терминология: Справочное пособие. Выпуск 1 / Рецензент канд. техн. наук Ю. П. Селиванов. — М.: Издательство стандартов, 1989. — 168 с. — 55 000 экз. — ISBN 5-7050-0155-X
- ↑ 1 2 3 4 5 6 7 Першиков В. И., Савинков В. М. Толковый словарь по информатике / Рецензенты: канд. физ.-мат. наук А. С. Марков и д-р физ.-мат. наук И. В. Поттосин. — М.: Финансы и статистика, 1991. — 543 с. — 50 000 экз. — ISBN 5-279-00367-0
- ↑ 1 2 3 СТ ИСО 2382/7-77 // Вычислительная техника. Терминология. Указ. соч.
- ↑ Борковский А. Б. Англо-русский словарь по программированию и информатике (с толкованиями). — М.: Русский язык, 1990. — 335 с. — 50 050 (доп.) экз. — ISBN 5-200-01169-3
- ↑ Толковый словарь по вычислительным системам = Dictionary of Computing / Под ред. В. Иллингуорта и др.: Пер. с англ. А. К. Белоцкого и др.; Под ред. Е. К. Масловского. — М.: Машиностроение, 1990. — 560 с. — 70 000 (доп.) экз. — ISBN 5-217-00617-X (СССР), ISBN 0-19-853913-4 (Великобритания)
- ↑ Н. А. Криницкий, Г. А. Миронов, Г. Д. Фролов. Программирование / Под ред. М. Р. Шура-Бура. — М.: Государственное издательство физико-математической литературы, 1963.
 — ISBN 5-279-00367-0
— ISBN 5-279-00367-0См. также
- Компилятор компиляторов
- «Книга дракона» — классический учебник о построении компиляторов.
- Синтаксический анализ
- Интерпретатор
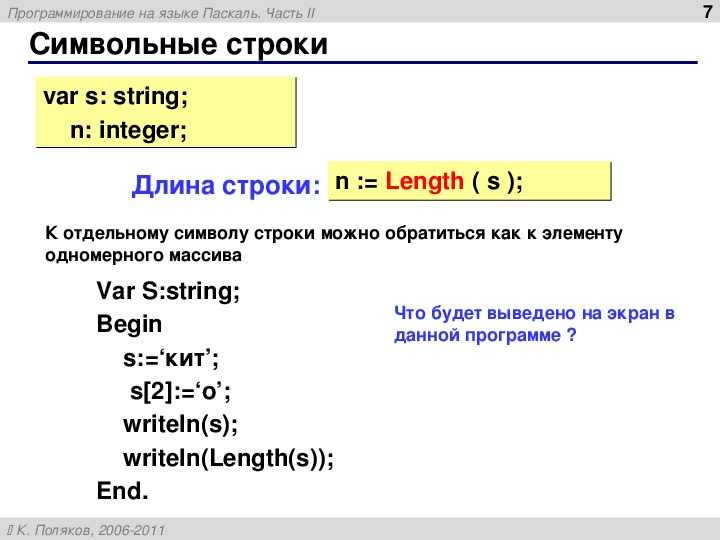
- Реализации компиляторов
- GCC
- Free Pascal Compiler
- Sun Studio — компиляторы C, C++ и Fortran от Sun Microsystems Inc.
- Open Watcom — свободное продолжение компиляторов Watcom C/C++/Fortran.
- Intel C++/Fortran compiler
- ICC AVR
Литература
- Альфред В. Ахо, Моника С. Лам, Рави Сети, Джеффри Д. Ульман. Компиляторы: принципы, технологии и инструментарий = Compilers: Principles, Techniques, and Tools. — 2-е изд. — М.: Вильямс, 2008. — ISBN 978-5-8459-1349-4
- Робин Хантер. Основные концепции компиляторов = The Essence of Compilers. — М.: Вильямс, 2002. — С. 256. — ISBN 0-13-727835-7
- Хантер Р. Проектирование и конструирование компиляторов / Пер. с англ. С. М. Круговой. — М.: Финансы и статистика, 1984. — 232 с.
- Д. Креншоу. Давайте создадим компилятор!.
Компиляция (программирование) | это.
 .. Что такое Компиляция (программирование)?
.. Что такое Компиляция (программирование)?Компиля́тор —
- Программа или техническое средство, выполняющее компиляцию.[1][2]
- Машинная программа, используемая для компиляции.[3][2]
- Транслятор, выполняющий преобразование программы, составленной на исходном языке, в объектный модуль.[2]
- Программа, переводящая текст программы на языке высокого уровня, в эквивалентную программу на машинном языке.[4]
- Программа, предназначенная для трансляции высокоуровневого языка в абсолютный код или, иногда, в язык ассемблера. Входной информацией для компилятора (исходный код) является описание алгоритма или программа на проблемно-ориентированном языке, а на выходе компилятора — эквивалентное описание алгоритма на машинно-ориентированном языке (объектный код).[5]
Компиляция —
- Трансляция программы на язык, близкий к машинному. [3][2]
 [3][2]
[3][2]- Трансляция программы, составленной на исходном языке, в объектный модуль. Осуществляется компилятором.[2]
Компилировать — проводить трансляцию машинной программы с проблемно-ориентированного языка на машинно-ориентированный язык.[3]
Содержание
|
Виды компиляторов
[2]- Векторизующий. Транслирует исходный код в машинный код компьютеров, оснащённых векторным процессором.
- Гибкий. Составлен по модульному принципу, управляется таблицами и запрограммирован на языке высокого уровня или реализован с помощью компилятора компиляторов.
- Диалоговый. См.: диалоговый транслятор.
- Инкрементальный. Повторно транслирует фрагменты программы и дополнения к ней без перекомпиляции всей программы.
- Интерпретирующий (пошаговый). Последовательно выполняет независимую компиляцию каждого отдельного оператора (команды) исходной программы.
- Компилятор компиляторов. Транслятор, воспринимающий формальное описание языка программирования и генерирующий компилятор для этого языка.
- Отладочный. Устраняет отдельные виды синтаксических ошибок.
- Резидентный. Постоянно находится в основной памяти и доступен для повторного использования многими задачами.
- Самокомпилируемый. Написан на том же языке, с которого осуществляется трансляция.
- Универсальный. Основан на формальном описании синтаксиса и семантики входного языка. Составными частями такого компилятора являются: ядро, синтаксический и семантический загрузчики.
Виды компиляции
[2]- Пакетная. Компиляция нескольких исходных модулей в одном пункте задания.
- Построчная. То же, что и интерпретация.
- Условная. Компиляция, при которой транслируемый текст зависит от условий, заданных в исходной программе. Так, в зависимости от значения некоторой константы, можно включать или выключать трансляцию части текста программы.
 Компиляция нескольких исходных модулей в одном пункте задания.
Компиляция нескольких исходных модулей в одном пункте задания.Основы
Большинство компиляторов переводит программу с некоторого высокоуровневого языка программирования в машинный код, который может быть непосредственно выполнен центральным процессором. Как правило, этот код также ориентирован на исполнение в среде конкретной операционной системы, поскольку использует предоставляемые ею возможности (системные вызовы, библиотеки функций). Архитектура (набор программно-аппаратных средств), для которой производится компиляция, называется целевой машиной.
Некоторые компиляторы (например, низкоуровневом языке. Такой язык — байт-код — также можно считать языком машинных команд, поскольку он подлежит интерпретации виртуальной машиной. Например, для языка Java это JVM (язык виртуальной машины Java), или так называемый байт-код Java (вслед за ним все промежуточные низкоуровневые языки стали называть байт-кодами). Для языков программирования на платформе .NET Framework (C#, Managed C++, Visual Basic .NET и другие) — это MSIL (Microsoft Intermediate Language).
Например, для языка Java это JVM (язык виртуальной машины Java), или так называемый байт-код Java (вслед за ним все промежуточные низкоуровневые языки стали называть байт-кодами). Для языков программирования на платформе .NET Framework (C#, Managed C++, Visual Basic .NET и другие) — это MSIL (Microsoft Intermediate Language).
Программа на байт-коде подлежит интерпретации виртуальной машиной, либо ещё одной компиляции уже в машинный код непосредственно перед исполнением. Последнее называется «Just-In-Time компиляция» (MSIL-код компилируется в код целевой машины также JIT-компилятором, а библиотеки .NET Framework компилируются заранее).
Для каждой целевой машины (Apple и т. д.) и каждой операционной системы или семейства операционных систем, работающих на целевой машине, требуется написание своего компилятора. Существуют также так называемые кросс-компиляторы, позволяющие на одной машине и в среде одной ОС получать код, предназначенный для выполнения на другой целевой машине и/или в среде другой ОС. Кроме того, компиляторы могут быть оптимизированы под разные типы процессоров из одного семейства (путём использования специфичных для этих процессоров инструкций). Например, код, скомпилированный под процессоры семейства MMX, SSE2.
Кроме того, компиляторы могут быть оптимизированы под разные типы процессоров из одного семейства (путём использования специфичных для этих процессоров инструкций). Например, код, скомпилированный под процессоры семейства MMX, SSE2.
Также существуют компиляторы, переводящие программу с языка высокого уровня на язык ассемблера.
Существуют программы, которые решают обратную задачу — перевод программы с низкоуровневого языка на высокоуровневый. Этот процесс называют декомпиляцией, а программы — декомпиляторами. Но поскольку компиляция — это процесс с потерями, точно восстановить исходный код, скажем, на C++, в общем случае невозможно. Более эффективно декомпилируются программы в байт-кодах — например, существует довольно надёжный декомпилятор для Flash. Сходным процессом является дизассемблирование машинного кода в код на языке ассемблера, который всегда выполняется успешно. Связано это с тем, что между кодами машинных команд и командами ассемблера имеется практически однозначное соответствие.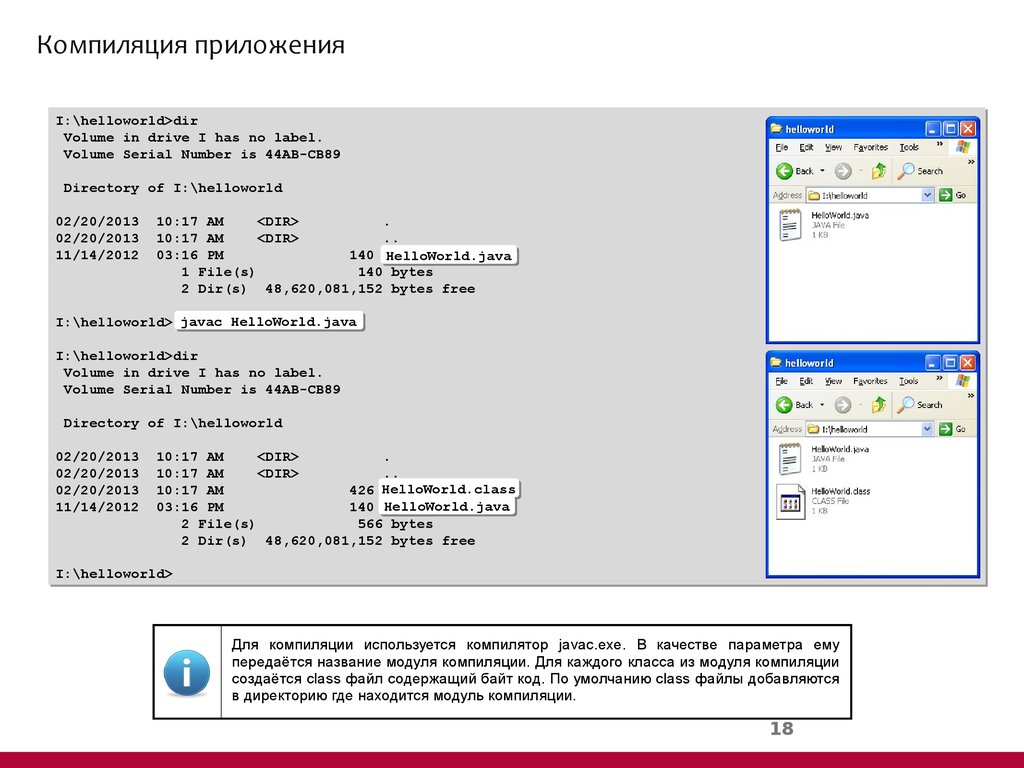
Структура компилятора
Процесс компиляции состоит из следующих этапов:
- Лексический анализ. На этом этапе последовательность символов исходного файла преобразуется в последовательность лексем.
- Синтаксический (грамматический) анализ. Последовательность лексем преобразуется в дерево разбора.
- Семантический анализ. Дерево разбора обрабатывается с целью установления его семантики (смысла) — например, привязка идентификаторов к их декларациям, типам, проверка совместимости, определение типов выражений и т. д. Результат обычно называется «промежуточным представлением/кодом», и может быть дополненным деревом разбора, новым деревом, абстрактным набором команд или чем-то ещё, удобным для дальнейшей обработки.
- Оптимизация. Выполняется удаление излишних конструкций и упрощение кода с сохранением его смысла. Оптимизация может быть на разных уровнях и этапах — например, над промежуточным кодом или над конечным машинным кодом.
- Генерация кода. Из промежуточного представления порождается код на целевом языке.
 Из промежуточного представления порождается код на целевом языке.
Из промежуточного представления порождается код на целевом языке.В конкретных реализациях компиляторов эти этапы могут быть раздельны или совмещены в том или ином виде.
Трансляция и компоновка
Важной исторической особенностью компилятора, отражённой в его названии (англ. compile — собирать вместе, составлять), являлось то, что он мог производить и компоновку (то есть содержал две части — транслятор и компоновщик). Это связано с тем, что раздельная компиляция и компоновка как отдельная стадия сборки выделились значительно позже появления компиляторов, и многие популярные компиляторы (например, GCC) до сих пор физически объединены со своими компоновщиками. В связи с этим, вместо термина «компилятор» иногда используют термин «транслятор» как его синоним: либо в старой литературе, либо когда хотят подчеркнуть его способность переводить программу в машинный код (и наоборот, используют термин «компилятор» для подчёркивания способности собирать из многих файлов один).
Интересные факты
- На заре развития компьютеров первые компиляторы (трансляторы) называли «программирующими программами»[6] (так как в тот момент программой считался только машинный код, а «программирующая программа» была способна из человеческого текста сделать машинный код, то есть запрограммировать ЭВМ).
Примечания
- ↑ ГОСТ 19781-83 // Вычислительная техника. Терминология: Справочное пособие. Выпуск 1 / Рецензент канд. техн. наук Ю. П. Селиванов. — М.: Издательство стандартов, 1989. — 168 с. — 55 000 экз. — ISBN 5-7050-0155-X
- ↑ 1 2 3 4 5 6 7 Першиков В. И., Савинков В. М. Толковый словарь по информатике / Рецензенты: канд. физ.-мат. наук А. С. Марков и д-р физ.-мат. наук И. В. Поттосин. — М.: Финансы и статистика, 1991. — 543 с. — 50 000 экз. — ISBN 5-279-00367-0
- ↑ 1 2 3 СТ ИСО 2382/7-77 // Вычислительная техника. Терминология. Указ. соч.
- ↑ Борковский А. Б. Англо-русский словарь по программированию и информатике (с толкованиями). — М.: Русский язык, 1990. — 335 с. — 50 050 (доп.) экз. — ISBN 5-200-01169-3
- ↑ Толковый словарь по вычислительным системам = Dictionary of Computing / Под ред. В. Иллингуорта и др.: Пер. с англ. А. К. Белоцкого и др.; Под ред. Е. К. Масловского. — М.: Машиностроение, 1990. — 560 с. — 70 000 (доп.) экз. — ISBN 5-217-00617-X (СССР), ISBN 0-19-853913-4 (Великобритания)
- ↑ Н. А. Криницкий, Г. А. Миронов, Г. Д. Фролов. Программирование / Под ред. М. Р. Шура-Бура. — М.: Государственное издательство физико-математической литературы, 1963.
 — ISBN 5-279-00367-0
— ISBN 5-279-00367-0См. также
- Компилятор компиляторов
- «Книга дракона» — классический учебник о построении компиляторов.
- Синтаксический анализ
- Интерпретатор

- Реализации компиляторов
- GCC
- Free Pascal Compiler
- Sun Studio — компиляторы C, C++ и Fortran от Sun Microsystems Inc.
- Open Watcom — свободное продолжение компиляторов Watcom C/C++/Fortran.
- Intel C++/Fortran compiler
- ICC AVR
Литература
- Альфред В. Ахо, Моника С. Лам, Рави Сети, Джеффри Д. Ульман. Компиляторы: принципы, технологии и инструментарий = Compilers: Principles, Techniques, and Tools. — 2-е изд. — М.: Вильямс, 2008. — ISBN 978-5-8459-1349-4
- Робин Хантер. Основные концепции компиляторов = The Essence of Compilers. — М.: Вильямс, 2002. — С. 256. — ISBN 0-13-727835-7
- Хантер Р. Проектирование и конструирование компиляторов / Пер. с англ. С. М. Круговой. — М.: Финансы и статистика, 1984. — 232 с.
- Д. Креншоу. Давайте создадим компилятор!.
Компиляция (программирование) | это.
 .. Что такое Компиляция (программирование)?
.. Что такое Компиляция (программирование)?Компиля́тор —
- Программа или техническое средство, выполняющее компиляцию.[1][2]
- Машинная программа, используемая для компиляции.[3][2]
- Транслятор, выполняющий преобразование программы, составленной на исходном языке, в объектный модуль.[2]
- Программа, переводящая текст программы на языке высокого уровня, в эквивалентную программу на машинном языке.[4]
- Программа, предназначенная для трансляции высокоуровневого языка в абсолютный код или, иногда, в язык ассемблера. Входной информацией для компилятора (исходный код) является описание алгоритма или программа на проблемно-ориентированном языке, а на выходе компилятора — эквивалентное описание алгоритма на машинно-ориентированном языке (объектный код).[5]
Компиляция —
- Трансляция программы на язык, близкий к машинному. [3][2]
 [3][2]
[3][2]- Трансляция программы, составленной на исходном языке, в объектный модуль. Осуществляется компилятором.[2]
Компилировать — проводить трансляцию машинной программы с проблемно-ориентированного языка на машинно-ориентированный язык.[3]
Содержание
|
Виды компиляторов
[2]- Векторизующий. Транслирует исходный код в машинный код компьютеров, оснащённых векторным процессором.
- Гибкий. Составлен по модульному принципу, управляется таблицами и запрограммирован на языке высокого уровня или реализован с помощью компилятора компиляторов.
- Диалоговый. См.: диалоговый транслятор.
- Инкрементальный. Повторно транслирует фрагменты программы и дополнения к ней без перекомпиляции всей программы.
- Интерпретирующий (пошаговый). Последовательно выполняет независимую компиляцию каждого отдельного оператора (команды) исходной программы.
- Компилятор компиляторов. Транслятор, воспринимающий формальное описание языка программирования и генерирующий компилятор для этого языка.
- Отладочный. Устраняет отдельные виды синтаксических ошибок.
- Резидентный. Постоянно находится в основной памяти и доступен для повторного использования многими задачами.
- Самокомпилируемый. Написан на том же языке, с которого осуществляется трансляция.
- Универсальный. Основан на формальном описании синтаксиса и семантики входного языка. Составными частями такого компилятора являются: ядро, синтаксический и семантический загрузчики.

Виды компиляции
[2]- Пакетная. Компиляция нескольких исходных модулей в одном пункте задания.
- Построчная. То же, что и интерпретация.
- Условная. Компиляция, при которой транслируемый текст зависит от условий, заданных в исходной программе. Так, в зависимости от значения некоторой константы, можно включать или выключать трансляцию части текста программы.
 Компиляция нескольких исходных модулей в одном пункте задания.
Компиляция нескольких исходных модулей в одном пункте задания.Основы
Большинство компиляторов переводит программу с некоторого высокоуровневого языка программирования в машинный код, который может быть непосредственно выполнен центральным процессором. Как правило, этот код также ориентирован на исполнение в среде конкретной операционной системы, поскольку использует предоставляемые ею возможности (системные вызовы, библиотеки функций). Архитектура (набор программно-аппаратных средств), для которой производится компиляция, называется целевой машиной.
Некоторые компиляторы (например, низкоуровневом языке. Такой язык — байт-код — также можно считать языком машинных команд, поскольку он подлежит интерпретации виртуальной машиной.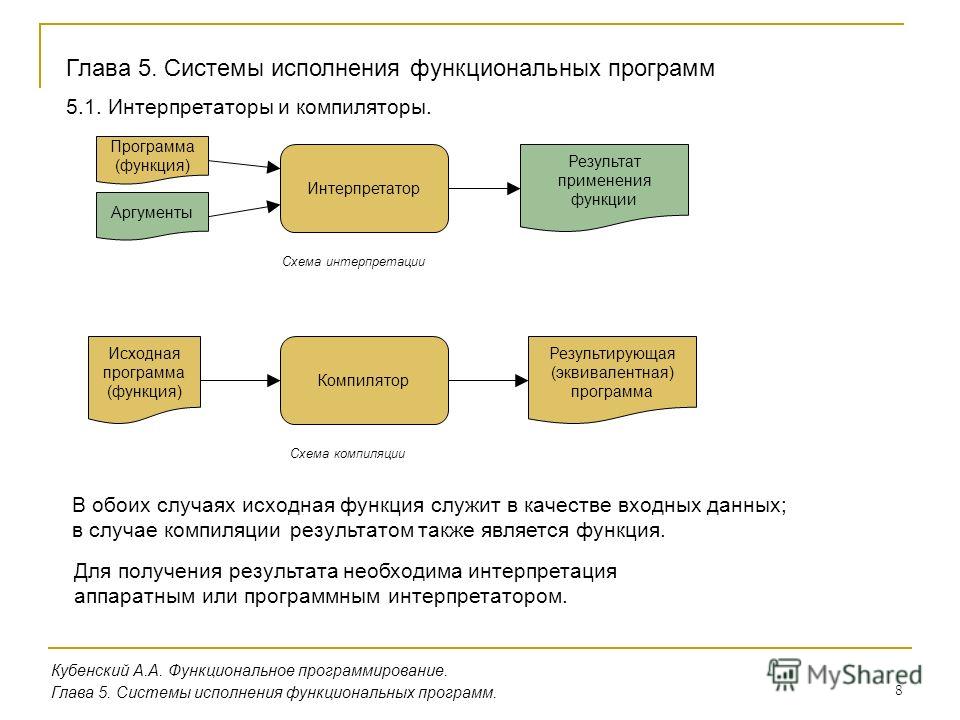 Например, для языка Java это JVM (язык виртуальной машины Java), или так называемый байт-код Java (вслед за ним все промежуточные низкоуровневые языки стали называть байт-кодами). Для языков программирования на платформе .NET Framework (C#, Managed C++, Visual Basic .NET и другие) — это MSIL (Microsoft Intermediate Language).
Например, для языка Java это JVM (язык виртуальной машины Java), или так называемый байт-код Java (вслед за ним все промежуточные низкоуровневые языки стали называть байт-кодами). Для языков программирования на платформе .NET Framework (C#, Managed C++, Visual Basic .NET и другие) — это MSIL (Microsoft Intermediate Language).
Программа на байт-коде подлежит интерпретации виртуальной машиной, либо ещё одной компиляции уже в машинный код непосредственно перед исполнением. Последнее называется «Just-In-Time компиляция» (MSIL-код компилируется в код целевой машины также JIT-компилятором, а библиотеки .NET Framework компилируются заранее).
Для каждой целевой машины (Apple и т. д.) и каждой операционной системы или семейства операционных систем, работающих на целевой машине, требуется написание своего компилятора. Существуют также так называемые кросс-компиляторы, позволяющие на одной машине и в среде одной ОС получать код, предназначенный для выполнения на другой целевой машине и/или в среде другой ОС. Кроме того, компиляторы могут быть оптимизированы под разные типы процессоров из одного семейства (путём использования специфичных для этих процессоров инструкций). Например, код, скомпилированный под процессоры семейства MMX, SSE2.
Кроме того, компиляторы могут быть оптимизированы под разные типы процессоров из одного семейства (путём использования специфичных для этих процессоров инструкций). Например, код, скомпилированный под процессоры семейства MMX, SSE2.
Также существуют компиляторы, переводящие программу с языка высокого уровня на язык ассемблера.
Существуют программы, которые решают обратную задачу — перевод программы с низкоуровневого языка на высокоуровневый. Этот процесс называют декомпиляцией, а программы — декомпиляторами. Но поскольку компиляция — это процесс с потерями, точно восстановить исходный код, скажем, на C++, в общем случае невозможно. Более эффективно декомпилируются программы в байт-кодах — например, существует довольно надёжный декомпилятор для Flash. Сходным процессом является дизассемблирование машинного кода в код на языке ассемблера, который всегда выполняется успешно. Связано это с тем, что между кодами машинных команд и командами ассемблера имеется практически однозначное соответствие.
Структура компилятора
Процесс компиляции состоит из следующих этапов:
- Лексический анализ. На этом этапе последовательность символов исходного файла преобразуется в последовательность лексем.
- Синтаксический (грамматический) анализ. Последовательность лексем преобразуется в дерево разбора.
- Семантический анализ. Дерево разбора обрабатывается с целью установления его семантики (смысла) — например, привязка идентификаторов к их декларациям, типам, проверка совместимости, определение типов выражений и т. д. Результат обычно называется «промежуточным представлением/кодом», и может быть дополненным деревом разбора, новым деревом, абстрактным набором команд или чем-то ещё, удобным для дальнейшей обработки.
- Оптимизация. Выполняется удаление излишних конструкций и упрощение кода с сохранением его смысла. Оптимизация может быть на разных уровнях и этапах — например, над промежуточным кодом или над конечным машинным кодом.
- Генерация кода. Из промежуточного представления порождается код на целевом языке.
В конкретных реализациях компиляторов эти этапы могут быть раздельны или совмещены в том или ином виде.
Трансляция и компоновка
Важной исторической особенностью компилятора, отражённой в его названии (англ. compile — собирать вместе, составлять), являлось то, что он мог производить и компоновку (то есть содержал две части — транслятор и компоновщик). Это связано с тем, что раздельная компиляция и компоновка как отдельная стадия сборки выделились значительно позже появления компиляторов, и многие популярные компиляторы (например, GCC) до сих пор физически объединены со своими компоновщиками. В связи с этим, вместо термина «компилятор» иногда используют термин «транслятор» как его синоним: либо в старой литературе, либо когда хотят подчеркнуть его способность переводить программу в машинный код (и наоборот, используют термин «компилятор» для подчёркивания способности собирать из многих файлов один).
Интересные факты
- На заре развития компьютеров первые компиляторы (трансляторы) называли «программирующими программами»[6] (так как в тот момент программой считался только машинный код, а «программирующая программа» была способна из человеческого текста сделать машинный код, то есть запрограммировать ЭВМ).
Примечания
- ↑ ГОСТ 19781-83 // Вычислительная техника. Терминология: Справочное пособие. Выпуск 1 / Рецензент канд. техн. наук Ю. П. Селиванов. — М.: Издательство стандартов, 1989. — 168 с. — 55 000 экз. — ISBN 5-7050-0155-X
- ↑ 1 2 3 4 5 6 7 Першиков В. И., Савинков В. М. Толковый словарь по информатике / Рецензенты: канд. физ.-мат. наук А. С. Марков и д-р физ.-мат. наук И. В. Поттосин. — М.: Финансы и статистика, 1991. — 543 с. — 50 000 экз. — ISBN 5-279-00367-0
- ↑ 1 2 3 СТ ИСО 2382/7-77 // Вычислительная техника. Терминология. Указ. соч.
- ↑ Борковский А. Б. Англо-русский словарь по программированию и информатике (с толкованиями). — М.: Русский язык, 1990. — 335 с. — 50 050 (доп.) экз. — ISBN 5-200-01169-3
- ↑ Толковый словарь по вычислительным системам = Dictionary of Computing / Под ред. В. Иллингуорта и др.: Пер. с англ. А. К. Белоцкого и др.; Под ред. Е. К. Масловского. — М.: Машиностроение, 1990. — 560 с. — 70 000 (доп.) экз. — ISBN 5-217-00617-X (СССР), ISBN 0-19-853913-4 (Великобритания)
- ↑ Н. А. Криницкий, Г. А. Миронов, Г. Д. Фролов. Программирование / Под ред. М. Р. Шура-Бура. — М.: Государственное издательство физико-математической литературы, 1963.
 — ISBN 5-279-00367-0
— ISBN 5-279-00367-0См. также
- Компилятор компиляторов
- «Книга дракона» — классический учебник о построении компиляторов.
- Синтаксический анализ
- Интерпретатор

- Реализации компиляторов
- GCC
- Free Pascal Compiler
- Sun Studio — компиляторы C, C++ и Fortran от Sun Microsystems Inc.
- Open Watcom — свободное продолжение компиляторов Watcom C/C++/Fortran.
- Intel C++/Fortran compiler
- ICC AVR
Литература
- Альфред В. Ахо, Моника С. Лам, Рави Сети, Джеффри Д. Ульман. Компиляторы: принципы, технологии и инструментарий = Compilers: Principles, Techniques, and Tools. — 2-е изд. — М.: Вильямс, 2008. — ISBN 978-5-8459-1349-4
- Робин Хантер. Основные концепции компиляторов = The Essence of Compilers. — М.: Вильямс, 2002. — С. 256. — ISBN 0-13-727835-7
- Хантер Р. Проектирование и конструирование компиляторов / Пер. с англ. С. М. Круговой. — М.: Финансы и статистика, 1984. — 232 с.
- Д. Креншоу. Давайте создадим компилятор!.
Компиляция — что это такое
Обновлено 21 июля 2021 Просмотров: 131 964 Автор: Дмитрий ПетровЗдравствуйте, уважаемые читатели блога KtoNaNovenkogo. ru. Компиляция – это слово многогранное, и в зависимости от сферы применения имеет разные, иногда непохожие значения.
ru. Компиляция – это слово многогранное, и в зависимости от сферы применения имеет разные, иногда непохожие значения.
Чаще всего этот термин используют в программировании, но так же он употребим в литературе, научных трудах, музыке и финансах.
Компиляция — это…
Слово образовано от латинского compilatio, и буквально переводится как «ограбление или кража». Но в отрицательном контексте его можно встретить всё же намного реже, чем в положительном.
Компиляция — это сочинительство (не обязательно литературное) на основе чужих работ и исследований. Она представляет пересказ написанного кем-то ранее, и поэтому ничего нового не даёт.
Но на самом деле, даже в таком виде она бывает полезной. Ведь если человек, создающий сие сочинение, хорошо разбирается в теме, и связывает чужие используемые отрывки своими рассуждениями и связками, с помощью которых легче отследить логическую цепочку. И это очень важно и полезно.
Такие известные писатели, как С. Цвейг, А.Моруа, были отличными компиляторами, произведениями которых зачитывалось не одно поколение любителей литературы.
Цвейг, А.Моруа, были отличными компиляторами, произведениями которых зачитывалось не одно поколение любителей литературы.
Компиляция текста — что это такое
Само понятие существует столько же, сколько талантливые книги, как научные, так и художественные.
Профессиональные компиляторы ставят в конце своего нового текста список материалов, которые они использовали. И то, что список, как правило, очень большой, уже говорит о серьёзной проделанной работе.
Количество источников — важное отличие от плагиата.
Использование множества источников создаёт информативный материал, в котором можно найти большое количество данных по заданной теме. В положительном контексте это служит популяризаторским и просветительским целям.
Но трактование слова компиляция в смысле «кража» тоже встречается.
Это, например, почти все газеты и журналы, которые очень часто вместо собственных мыслей и описаний событий, используют уже готовые, взятые в интернете, и только пересказанные своими словами, не исключено, что ещё и с искажением смысла. Случайным, или не очень, если издание ангажированное (это как?).
Случайным, или не очень, если издание ангажированное (это как?).
Компиляция в программировании — что это
Это трансляция программы, написанной на высокоуровневом языке, в программу с языком более низкого уровня, но с совпадающим или похожим машинным кодом. Для этого используются компиляторы.
Существует несколько категорий компиляции:
- условная, когда у транслируемого текста те же нормы, что и в первоначальном варианте;
- пакетная, с использованием нескольких модулей в задании;
- построчная — поочерёдная интерпретация завершённой грамматической конструкции.
Именно в программировании термин встречается особенно часто, в других сферах он чаще заменяется синонимами.
Другие примеры употребления термина
- В музыке это понятие распространено не меньше, чем в литературе, но означает несколько иное.
- Компиляцией можно назвать любое попурри.
По утверждению википедии, попурри, pot-pourri — мешанина.
В переводе с французского, музыкальная пьеса из популярных мотивов и музыкальных тем. Но попурри отличается тем, что часто является импровизацией, а не ранее оформленным альбомом. - Так же называются альбомы на определённую тему.
Они могут быть разными, например: составленные из узнаваемых работ одного автора, созданных им в разное время; хитпарады; музыка одного стиля, сборники одного автора или исполнителя.
Они не обязательно составляются из известных музыкальных произведений. Так называют альбомы редких записей, саундтреков к фильмам, просто жанровые сборники.
- Компиляцией можно назвать любое попурри.
- Аниме. Здесь у термина есть своё строго определённое значение. В этой области это фильм, чаще (но необязательно) короткометражный, основанный на материале из сериала и созданный в жанре японской анимации.
- Артрюньон, или компиляция в искусстве. Стиль в искусстве с эклектичным смешением жанров.
Классические танцы дополняет современный, балет (это что?) и брейк одновременно существуют на одной сцене.
Музыкальное сопровождение полностью эклектично. Представители стиля — канадский цирк Дюсалей, театр Моники (США), Театр Золотых фигур (Россия). - В аудите. Особая услуга в аудите: сбор и обобщение имеющейся финансовой информации, её трансформация, то есть преобразование имеющихся форм бухгалтерской отчётности уже подготовленных в соответствие с законодательством РФ в другие формы.
Например, если требуется подготовить консолидированную отчётность, или отчётность по МФСО.
 В переводе с французского, музыкальная пьеса из популярных мотивов и музыкальных тем. Но попурри отличается тем, что часто является импровизацией, а не ранее оформленным альбомом.
В переводе с французского, музыкальная пьеса из популярных мотивов и музыкальных тем. Но попурри отличается тем, что часто является импровизацией, а не ранее оформленным альбомом. Музыкальное сопровождение полностью эклектично. Представители стиля — канадский цирк Дюсалей, театр Моники (США), Театр Золотых фигур (Россия).
Музыкальное сопровождение полностью эклектично. Представители стиля — канадский цирк Дюсалей, театр Моники (США), Театр Золотых фигур (Россия).Удачи вам! До скорых встреч на страницах блога KtoNaNovenkogo.ru
Поделиться в соцсетяхКомпиляторы, интерпретаторы и байт-код | Computerworld Россия
Компиляторы — это программы, которые преобразуют исходные тексты программ, написанные на языке программирования высокого уровня, в программу на машинном языке, «понятную» компьютеру.
Определение
Компиляторы — это программы, которые преобразуют исходные тексты программ, написанные на языке программирования высокого уровня, в программу на машинном языке, «понятную» компьютеру. Полученный код, называемый исполняемой программой, можно устанавливать и запускать на нужном компьютере без дополнительных преобразований. Интерпретаторы выполняют аналогичную функцию, но делают это построчно всякий раз во время исполнения программы. Байт-код — это промежуточный подход, при котором программа преобразуется в промежуточный двоичный вид, интерпретируемый некой «виртуальной машиной» во время исполнения.
Причиной вновь вспыхнувшего интереса к компиляторам стало появление быстрых и сложных 64-разрядных микропроцессоров, типичным представителем которых можно считать Intel Itanium. Все усовершенствования в архитектуре процессоров, такие как распараллеливание и предсказание ветвления, а также возможность резкого увеличения производительности, окажутся бесполезны до тех пор, пока программисты не начнут их реально использовать.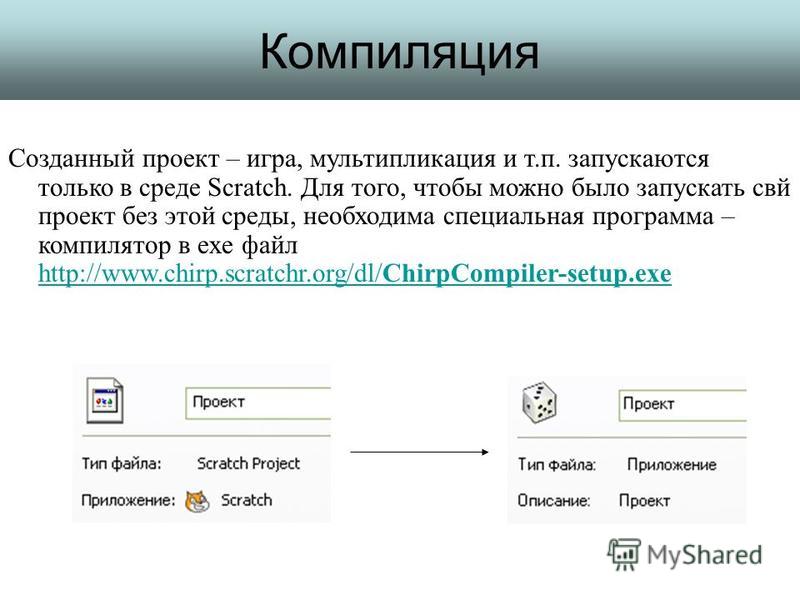
Забота о создании кода, ориентированного на эффективную параллельную обработку, серьезно усложняет и без того непростую задачу современного программирования. В итоге ответственность за увеличение производительности, на которое потенциально способны будущие 64-разрядные процессоры, ложится на компиляторы нового поколения.
Компиляторы, которым предстоит обеспечить значительное увеличение скорости вычислений, уже создаются в исследовательских лабораториях ряда компаний — Hewlett-Packard, Intel, MetaWare, Microsoft и других. В феврале прошлого года компания Silicon Graphics объявила о том, что ее оптимизированные компиляторы позволяют увеличить на 30-100% по сравнению с существующими продуктами производительность программ, работающих на компьютерах с процессорами Itanium и операционной системой Linux.
Как и их предшественники, оптимизированные компиляторы преобразуют программы на высокоуровневом языке в машинный код. Однако помимо этого они гарантируют максимально эффективное использование памяти (и в первую очередь процессорного кэша и механизма распараллеливания).
Например, процессоры Itanium предназначены для того, чтобы одновременно обрабатывать до шести команд на каждый такт процессора. Но для этого компилятор должен поддерживать стабильную передачу данных через конвейер команд.
Одна из возможных методик состоит в объединении часто используемых команд в группы, которые процессор может обрабатывать одновременно. Оптимизированные компиляторы также максимально используют свободные такты процессора за счет предсказания ветвления, пытаясь заранее определить результат команд наподобие GOTO и тем самым уберечь процессор от необходимости искать требуемые данные по всей программе. Метод спекулятивных вычислений предполагает, что оптимизированный компилятор загружает команды с некоторым упреждением.
Другие пути
Интерпретаторы также преобразуют код, написанный на языке программирования высокого уровня, но они делают это построчно всякий раз, когда программа запускается на выполнение. Для того чтобы программа была «понятна» компьютеру, на котором предполагается исполнять высокоуровневый код непосредственно, на нем также должна работать программа интерпретации.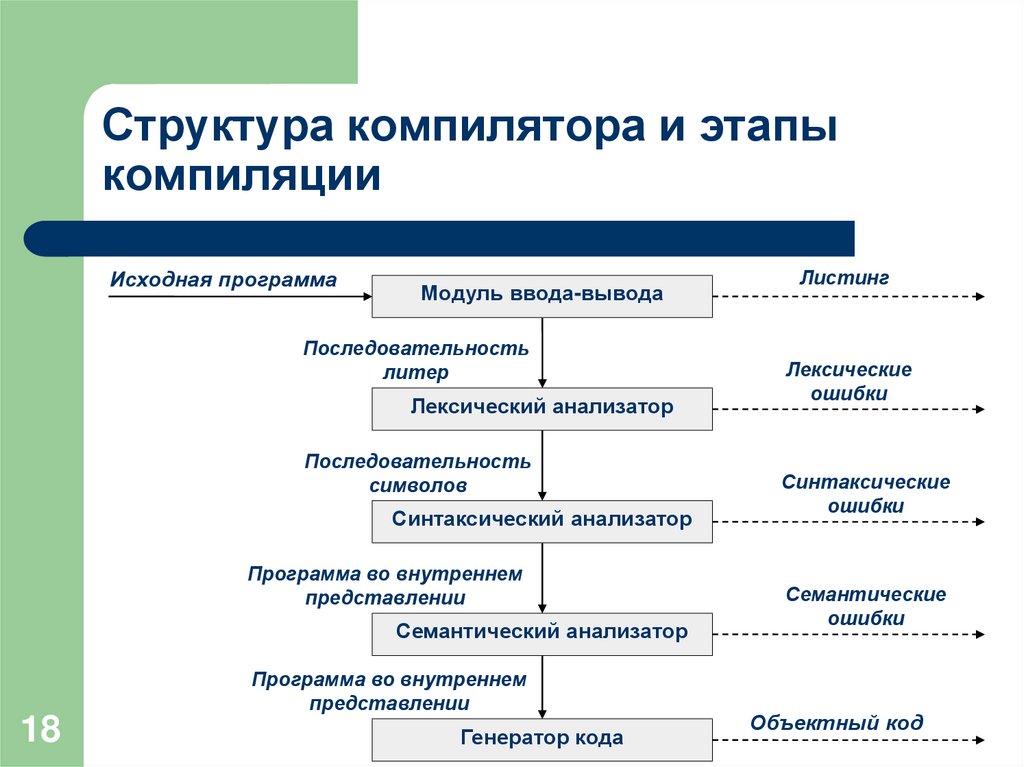 Интерпретаторы полезны для тестирования нового или модифицированного кода или при обучении программированию.
Интерпретаторы полезны для тестирования нового или модифицированного кода или при обучении программированию.
Заранее скомпилированное программное обеспечение работает быстрее, чем интерпретируемые программы, поэтому скомпилированные программы предпочтительны для крупных и устоявшихся приложений. За это приходится расплачиваться зависимостью исполняемого кода от конкретной аппаратной платформы. Но такой подход не всегда оправдывает себя в случае с Internet-апплетами, для которых нельзя сказать априори, в какой именно среде они будут работать.
Идеология Java опирается на третий, своего рода компромиссный подход — байт-код. При использовании байт-кода высокоуровневые программы преобразуются в промежуточный вид, способный исполняться на различных аппаратных платформах. Байт-код Java преобразуется в машинный код с помощью специального интерпретатора, называемого виртуальной машиной Java (Java Virtual Machine — JVM). JVM формирует выделенное пространство в памяти, которое отделено от памяти основной системы, для хранения байт-кода и порождаемых структур.
Использование динамических (just-in-time, JIT — «точно в срок») компиляторов увеличивает производительность Java-приложений. В этом случае не JVM исполняет байт-код, а JIT-компилятор преобразует его в «родной» для данной машины код. Таким образом, с одной стороны, повышается производительность скомпилированного кода, а с другой — сохраняется переносимость, свойственная Java.
Hewlett-Packard придерживается аналогичной тактики со своим TurboChai — средой Java для встроенных приложений. В TurboChai производительность увеличивается за счет преобразования наиболее часто используемого кода в данном встроенном приложении. С помощью выборочной компиляции в HP стараются оптимальным образом управлять использованием памяти, в то же время достигая скоростей, сравнимых с теми, которых позволяют добиться JIT-компиляторы. TurboChai использует байт-код Java в качестве входной информации и генерирует исходные тексты ANSI C, а затем использует любой компилятор для языка Си для получения оптимизированного «родного» машинного кода.
В прошлом году Microsoft анонсировала C#, объектно-ориентированный язык программирования, согласованный с XML. Корпорация подает новый язык как логическое продолжение Си и C++ для Web-приложений. Ключевыми модулями станут Common Language Runtime для C# и специальный компилятор, который преобразует текст, написанный на традиционных языках Кобол, Perl, Фортран или других, в промежуточный язык, который будет работать на новой платформе Microsoft .Net.
Конечные пользователи вряд ли будут уделять много внимания компиляторам. Тем не менее может появиться новое поколение компиляторов, позволяющих увеличить производительность до уровня, позволяющего убедить профессионалов в необходимости использовать 64-разрядные аппаратные архитектуры.
| Инструментарий | Что нового | Цели |
| Оптимизированные компиляторы | Обеспечивают высокую производительность процессорной обработки за счет распараллеливания, предсказания ветвлений и спекулятивных вычислений | Помогают реализовать потенциал 64-разрядных процессоров |
| JIT-компиляторы | В реальном времени компилируют код | Увеличивают производительность интерпретируемых языков, таких как Java |
| «Выборочные» компиляторы | Компилируют только часто используемый код | Увеличивают производительность, не тратя понапрасну дорогостоящие ресурсы памяти |
Компиляция программ | Изучите четырехэтапный процесс компиляции программы
Компиляция программы
Пошаговое объяснение процесса компиляции программы
Определение компиляции программы компилятор.
Компьютер из-за своей аппаратной архитектуры может выполнять только двоичные машинные инструкции. И поэтому все программы, написанные на любом языке, отличном от машинного кода, должны быть предварительно преобразованы в машинные инструкции.
Компиляция программы представляет собой многоэтапный процесс, который преобразует удобочитаемую компьютерную программу высокого уровня в машиночитаемый код низкого уровня в двоичном формате.
Стадии компиляции программ
Стадия компиляции | Принимает | Выход | 9003 | 9003 | 9003 | 9003 | 9003.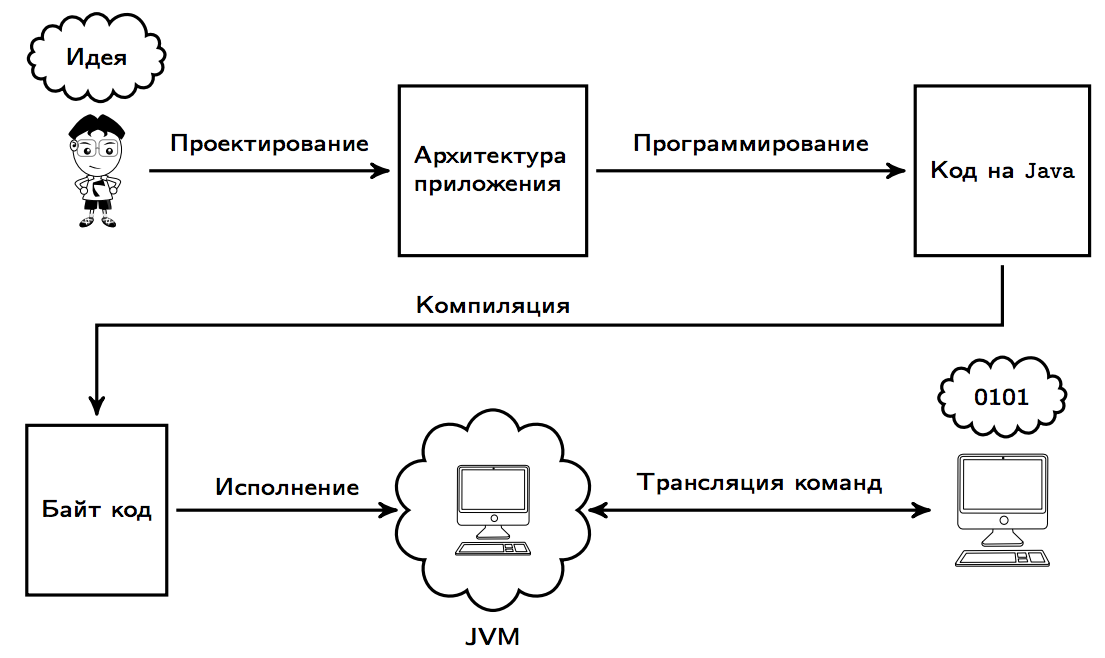 0030 0030 | Предварительно обработанный код | Resolve # Включите директивность Expand # Define Directive Удалить комментарии |
2. Компорт | Pro-Prococed Code 3030 | 9007 | 9007. | Сборочный код продукта компилятора | |||||
3. | Инструкции по сборке кода | Object Code File | Assembler Produce Object Code | ||||||
4. Linking | Object Code Files | Single Machine Code File | Linker Links And Produce Executable Machine Code |
 Сборка
Сборка Преобразование исходного кода программы в исполняемый файл (точка exe) происходит в четыре этапа. Эти четыре этапа компиляции – предварительная обработка, компиляция, сборка и, наконец, этап компоновки.
Однако в большинстве случаев все эти четыре этапа вместе называются процессом компиляции программы. В этом уроке мы подробно обсудим все четыре этапа.
Видеоруководство по компиляции программы
Процесс компиляции программы
Содержание
- Определение компиляции программы.
- Что такое компиляция программы?
- Процесс компиляции программы.
- Четыре этапа компиляции.
- Почему программы компилируются?
- Что такое компилятор?
- Интерпретатор и компилятор.
- Примеры компиляции.
Процесс компиляции программы
Объяснение четырех этапов компиляции программы
Составление программ высокого уровня представляет собой многоэтапный процесс.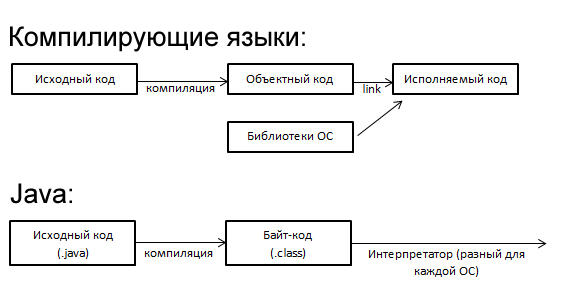 Программист пишет программный код в соответствии с синтаксисом языка программирования.
Программист пишет программный код в соответствии с синтаксисом языка программирования.
Компилятор — это особый тип системного программного обеспечения, который используется для преобразования файла исходного кода программы в машинный код. Машинный код состоит из машинных инструкций в двоичном виде.
Машинные инструкции кодируются компилятором в специальном формате, называемом форматом инструкций. ЦП декодирует машинную инструкцию в соответствии с форматом инструкции.
Компьютерные программы высокого уровня компилируются компилятором в четыре этапа. Каждый этап процесса компиляции берет входные данные с предыдущего этапа.
- 1. Предварительная обработка.
- 2. Компиляция.
- 3. Сборка.
- 4. Связывание.
Компиляция программы
ЭТАП — 1
Предварительная обработка
Что такое предварительная обработка?
Первый этап процесса компиляции называется этапом препроцессора.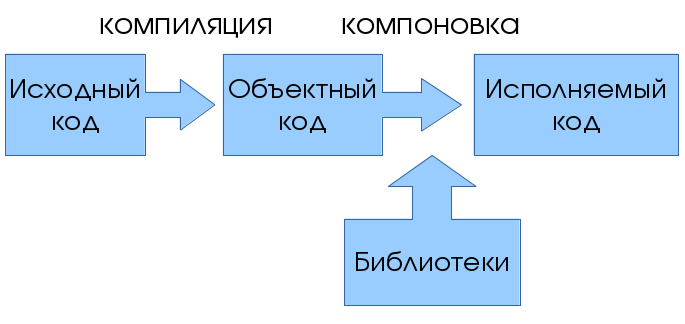 Альтернативно, этот этап также называют этапом лексического анализа.
Альтернативно, этот этап также называют этапом лексического анализа.
Стадия препроцессора принимает файл исходного кода программы в качестве входных данных и предоставляет предварительно обработанный файл в качестве вывода с расширением точка i.
Компилятор сканирует файл исходного кода на наличие всех директив препроцессора, которые содержат все коды # include и # define.
Этап предварительной обработки включает все заголовочные файлы, все макросы разрешаются путем замены их абсолютными значениями, а комментарии исключаются.
При программировании на C стандартные библиотечные функции хранятся в отдельном заголовочном файле с расширением точка h. Отдельный заголовочный файл помогает лучше организовать программный код и улучшает читабельность.
Программист может включить в программу стандартные файлы заголовков функций, а также другие файлы, содержащие определяемые пользователем функции, в зависимости от функциональности программы.
Компиляция программы
ЭТАП — 2
Компиляция
Что такое стадия компиляции?
Компиляция является вторым этапом процесса компиляции программы. Компилятор принимает предварительно обработанный файл в качестве входных данных и предоставляет ассемблерный код в качестве выходного файла с расширением точки s.
Компилятор принимает предварительно обработанный файл в качестве входных данных и предоставляет ассемблерный код в качестве выходного файла с расширением точки s.
Компилятор преобразует все высокоуровневые инструкции программы в эквивалентные инструкции ассемблерного кода. Эти инструкции зависят от платформы и скомпилированы для конкретной архитектуры.
Исходный код программы
Код сборки программы
Компиляция программы
ЭТАП — 3
Сборка
Что такое сборочный этап?
Компиляция является вторым этапом процесса компиляции программы. Компилятор принимает предварительно обработанный файл в качестве входных данных и предоставляет ассемблерный код в качестве выходного файла с расширением точки s.
Компилятор преобразует все высокоуровневые инструкции программы в эквивалентные инструкции ассемблерного кода. Эти инструкции зависят от платформы и скомпилированы для конкретной архитектуры.
Пример — код сборки
Пример — код объекта
Компиляция программы
ЭТАП — 4
Связывание
Что такое Связывание Этап?
Связывание является заключительным и четвертым этапом процесса компиляции. Основная функция связывания заключается в создании единого исполняемого файла (Sourcefile.exe) путем связывания всех файлов объектного кода.
Большие компьютерные программы организованы в несколько управляемых файлов. Пользовательские функции записываются в отдельный файл. Эти файлы привязаны к основному файлу программы в разделе заголовка, например # include на языке C .
Точно так же язык программирования также предоставляет стандартные библиотечные функции в формате предварительно скомпилированного объектного кода, которые программист может легко использовать для упрощения работы по программированию.
Программист может использовать эти определяемые пользователем функции и стандартные библиотеки функций, просто включив эти файлы в начало раздела заголовка программы.
Поскольку код стандартной библиотеки находится в форме объектного кода, которая является предварительно скомпилированным форматом и может быть непосредственно включена на этапе компоновки компоновщиком при создании исполняемого файла (исходный файл.exe для платформы Windows) в процессе компиляции программы .
Компиляция программы
Зачем компилируются компьютерные программы?
Студентам, изучающим информатику, важно понимать, зачем нам нужно компилировать программы высокого уровня.
Программы высокого уровня — это программы, разработанные на языках программирования высокого уровня, таких как язык C, C++, Python, точка Net и java.
Программы высокого уровня удобочитаемы для человека. Каждый язык программирования высокого уровня имеет свой собственный синтаксис и резервные ключевые слова, которые побуждают компьютер выполнять определенные задачи.
Языки программирования высокого уровня специально разработаны с учетом простоты программирования. В большинстве ключевых слов языка программирования высокого уровня используются общеупотребительные английские слова.
В большинстве ключевых слов языка программирования высокого уровня используются общеупотребительные английские слова.
Программист может использовать эти определяемые пользователем функции и стандартные библиотеки функций, просто включив эти файлы в начало раздела заголовка программы.
Поскольку код стандартной библиотеки находится в форме объектного кода, которая является предварительно скомпилированным форматом и может быть непосредственно включена на этапе компоновки компоновщиком при создании исполняемого файла (исходный файл.exe для платформы Windows) в процессе компиляции программы .
Компиляция программы
Что такое компилятор?
Студентам, изучающим информатику, важно понимать, зачем нам нужно компилировать программы высокого уровня.
Программы высокого уровня — это программы, разработанные на языках программирования высокого уровня, таких как язык C, C++, Python, точка Net и java.
Программы высокого уровня удобочитаемы для человека. Каждый язык программирования высокого уровня имеет свой синтаксис и резервные ключевые слова, которые побуждают компьютер выполнять определенные задачи.
Каждый язык программирования высокого уровня имеет свой синтаксис и резервные ключевые слова, которые побуждают компьютер выполнять определенные задачи.
Языки программирования высокого уровня специально разработаны с учетом простоты программирования. В большинстве ключевых слов языка программирования высокого уровня используются общеупотребительные английские слова.
Однако компьютерная система не может напрямую выполнять программный код высокого уровня. На аппаратном уровне процессор компьютера может декодировать и выполнять только машинные инструкции в двоичном виде.
И, следовательно, программный код высокого уровня, написанный на любом языке программирования, должен быть сначала преобразован в двоичный машинный код низкого уровня. Этот процесс преобразования называется компиляцией программы.
Компиляция программы
Присоединяйтесь к бестселлеру
Онлайн-курс по компьютерным наукам
Это наиболее полный и уникальный онлайн-курс C по компьютерным наукам и основам программирования , который даст вам глубокое понимание наиболее важных фундаментальных концепций информатики и программирования.
Получите скидку 90% на этот курс
Процесс компиляции. Многие из нас пишут коды и выполняют… | Сибасиш Гош | Coding Den
Многие из нас пишут коды и выполняют их. Но все ли мы (ну, думаю, в основном новички :P) знаем лежащий в основе процесс, который преобразует исходный код в исполняемую программу? Не многие, я думаю. Что ж, эта статья для всех тех Немногих, кто ищет секрет 😉
Источник изображения — worldcomputerarticle«Программисты пишут программы в форме, называемой исходным кодом. Исходный код должен пройти несколько этапов, прежде чем он станет исполняемой программой. Первый шаг — передать исходный код через компилятор , который переводит инструкции языка высокого уровня в объектный код. Компоновщик объединяет модули и присваивает действительные значения всем символическим адресам, тем самым создавая машинный код».
Приведенные выше строки объясняют весь процесс компиляции. Таким образом, у вас есть программа, называемая исходным кодом , , которая должна пройти процесс компиляции для создания вывода с помощью исполняемой программы .
Таким образом, у вас есть программа, называемая исходным кодом , , которая должна пройти процесс компиляции для создания вывода с помощью исполняемой программы .
Итак, если есть процесс «компиляции», должен быть инструмент для выполнения этой работы. Да, есть одна такая вещь, и она известна под названием 9Компилятор 0357. Теперь давайте посмотрим, что такое компилятор.
Источник изображения — CraftingInterpreters Компилятор — это специальная программа, которая обрабатывает операторы, написанные на определенном языке программирования, и преобразует их в машинный язык или «код», который использует процессор компьютера. Обычно программист пишет операторы языка на таком языке, как Pascal или C, по одной строке за раз, используя редактор . Созданный файл содержит так называемые исходные операторы 9.0358 . Затем программист запускает компилятор соответствующего языка, указывая имя файла, содержащего исходные операторы.
При выполнении (запуске) компилятор сначала анализирует (или анализирует) все операторы языка синтаксически один за другим, а затем, в один или несколько последовательных этапов или «проходов», строит выходной код, следя за тем, чтобы операторы, которые ссылаются на другие операторы, правильно ссылаются в окончательном коде. Традиционно выход компиляции получил название код объекта или иногда объектный модуль . Объектный код — это машинный код, который процессор может выполнять по одной инструкции за раз.
Традиционно в некоторых операционных системах после компиляции требовался дополнительный шаг — определение относительного расположения инструкций и данных, когда одновременно должно было выполняться более одного объектного модуля, и они ссылались на последовательности инструкций друг друга. или данные. Этот процесс иногда называли связывание редактирования и вывод, известный как загрузочный модуль .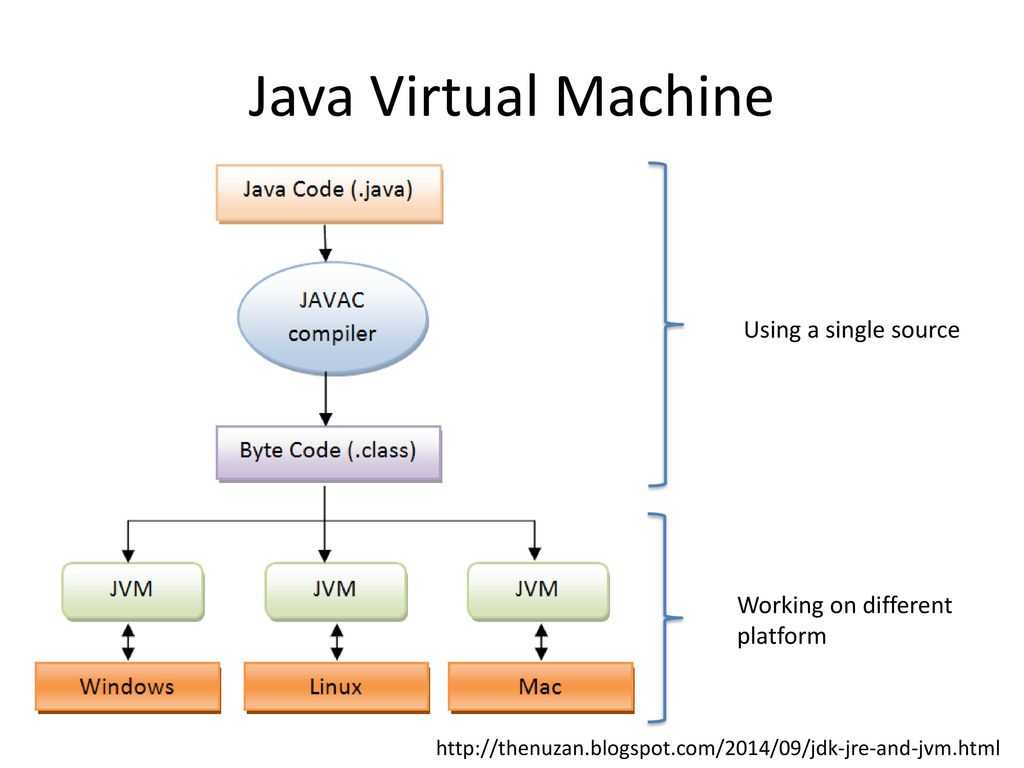
Компилятор работает с тем, что иногда называют 3GL и языками более высокого уровня. Ассемблер работает с программами, написанными на языке ассемблера процессора.
(Источник — WhatIs )
Некоторые языки программирования не компилируют исходный код. Так их можно казнить? К счастью или к сожалению, это вполне возможно. Ответ — с помощью переводчиков.
В компьютерных науках интерпретатор — это компьютерная программа, которая непосредственно выполняет, то есть выполняет инструкции, написанные на языке программирования или языке сценариев, без необходимости их предварительной компиляции в программу на машинном языке. Интерпретатор обычно использует одну из следующих стратегий выполнения программы:
1. Анализ исходного кода и непосредственное выполнение его поведения;
2. Преобразовать исходный код в некоторое эффективное промежуточное представление и немедленно выполнить его;
3. Явно выполнить сохраненный предварительно скомпилированный код, созданный компилятором, который является частью системы интерпретатора.
Явно выполнить сохраненный предварительно скомпилированный код, созданный компилятором, который является частью системы интерпретатора.
Ранние версии языка программирования Lisp и Dartmouth BASIC могут быть примерами первого типа. Perl, Python, MATLAB и Ruby являются примерами второго типа, а UCSD Pascal — примером третьего типа.
(Источник — Википедия )
Хорошо, я закончил большую часть теоретической части. Чтобы понять, как это на самом деле работает, давайте воспользуемся помощью известного языка программирования — 9.0357 С++.
Компиляция программы на C++ включает три этапа:
1. Предварительная обработка: препроцессор берет файл исходного кода C++ и обрабатывает #include’ s, #define’ s и другие директивы препроцессора. Результатом этого шага является «чистый» файл C++ без директив препроцессора.
2. Компиляция: компилятор берет выходные данные препроцессора и создает из них объектный файл.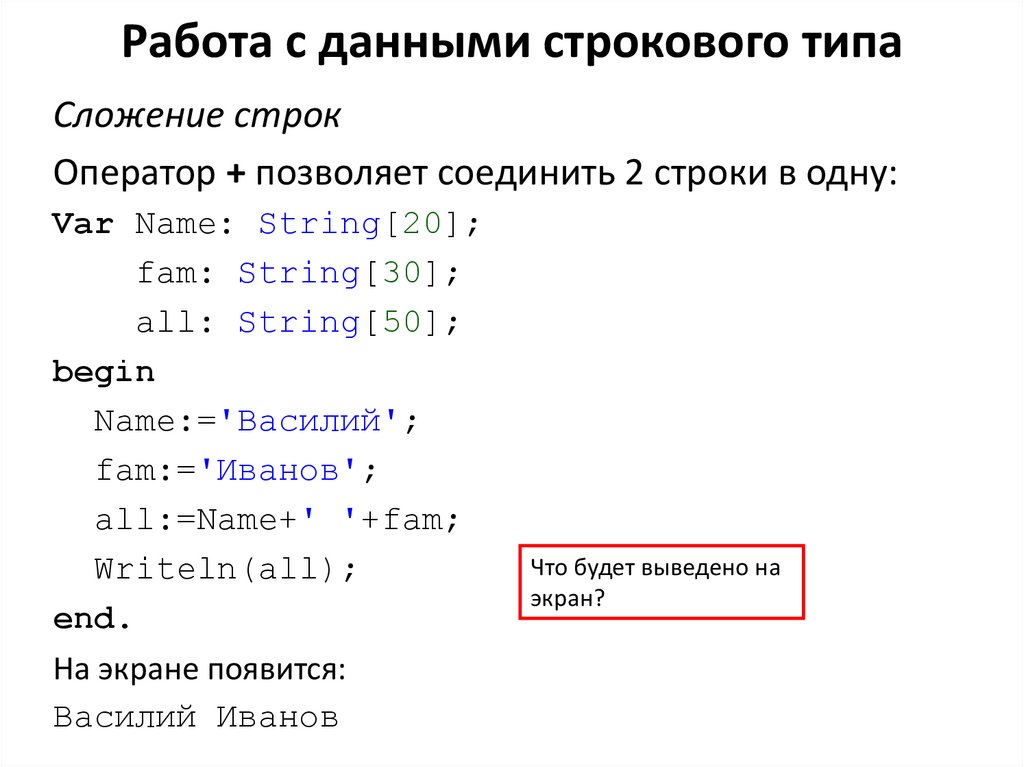
3. Связывание: компоновщик берет объектные файлы, созданные компилятором, и создает либо библиотеку, либо исполняемый файл.
1. Препроцессор Препроцессор обрабатывает директив препроцессора , например #include и #define . Он не зависит от синтаксиса C++, поэтому его следует использовать с осторожностью.
Он работает с одним исходным файлом C++ за раз, заменяя директивы #include содержимым соответствующих файлов (обычно это просто объявления), выполняя замену макросов ( #define ) и выбирая разные части текст в зависимости от #if , #ifdef и #ifndef директивы.
Препроцессор работает с потоком токенов предварительной обработки. Подстановка макросов определяется как замена токенов другими токенами (оператор ## позволяет объединить два токена, когда это имеет смысл).
После всего этого препроцессор выдает единственный результат — поток токенов, полученный в результате преобразований, описанных выше. Он также добавляет некоторые специальные маркеры, которые сообщают компилятору, откуда взялась каждая строка, чтобы он мог использовать их для создания разумных сообщений об ошибках.
Он также добавляет некоторые специальные маркеры, которые сообщают компилятору, откуда взялась каждая строка, чтобы он мог использовать их для создания разумных сообщений об ошибках.
На этом этапе могут возникнуть некоторые ошибки при грамотном использовании директив #if и #error .
2. Компиляция
Этап компиляции выполняется на каждом выходе препроцессора. Компилятор анализирует исходный код на чистом C++ (теперь без каких-либо директив препроцессора) и преобразует его в ассемблерный код. Затем вызывает базовый сервер (ассемблер в цепочке инструментов), который собирает этот код в машинный код, создавая фактический двоичный файл в некотором формате (ELF, COFF, a.out и т. д.). Этот объектный файл содержит скомпилированный код (в двоичной форме) символов, определенных во входных данных. Символы в объектных файлах упоминаются по имени.
Объектные файлы могут ссылаться на символы, которые не определены. Это тот случай, когда вы используете объявление и не предоставляете для него определения. Компилятор не возражает против этого и с радостью создаст объектный файл, если исходный код правильно сформирован.
Компилятор не возражает против этого и с радостью создаст объектный файл, если исходный код правильно сформирован.
Компиляторы обычно позволяют остановить компиляцию на этом этапе. Это очень полезно, потому что с его помощью вы можете скомпилировать каждый файл исходного кода отдельно. Преимущество, которое это дает, заключается в том, что вам не нужно перекомпилировать все , если вы изменяете только один файл.
Созданные объектные файлы можно поместить в специальные архивы, называемые статическими библиотеками, для более удобного повторного использования в дальнейшем.
Именно на этом этапе сообщается о «обычных» ошибках компилятора, таких как синтаксические ошибки или ошибки разрешения перегрузки.
3. Связывание
Компоновщик создает окончательный результат компиляции из объектных файлов, созданных компилятором. Этот вывод может быть либо разделяемой (или динамической) библиотекой (и хотя название похоже, у них мало общего со статическими библиотеками, упомянутыми ранее), либо исполняемым файлом.
Связывает все объектные файлы, заменяя ссылки на неопределенные символы правильными адресами. Каждый из этих символов может быть определен в других объектных файлах или в библиотеках. Если они определены в библиотеках, отличных от стандартной библиотеки, вам нужно сообщить о них компоновщику.
На этом этапе наиболее распространенными ошибками являются отсутствующие определения или повторяющиеся определения. Первое означает, что либо определения не существуют (т. е. они не написаны), либо объектные файлы или библиотеки, в которых они находятся, не были переданы компоновщику. Последнее очевидно: один и тот же символ был определен в двух разных объектных файлах или библиотеках.
(Источник — stackoverflow )
Итак, в следующий раз, когда вы будете запускать код, помните, что это чертовски много лежащего в его основе процесса! Добрый день, друзья 🙂
Что означает компиляция в программировании на C?
Программирование. Способность воплощать идеи в жизнь — не что иное, как сверхспособность. Языки программирования могут варьироваться от простых до сложных и от низкоуровневых до высокоуровневых. Однако компиляция написанного кода является обычным процессом для большинства языков высокого уровня.
Способность воплощать идеи в жизнь — не что иное, как сверхспособность. Языки программирования могут варьироваться от простых до сложных и от низкоуровневых до высокоуровневых. Однако компиляция написанного кода является обычным процессом для большинства языков высокого уровня.
Одним из наиболее широко используемых языков программирования во всем мире является язык C. Это машинно-независимый язык, представленный еще в 1972 году. С момента своего появления C использовался для написания всего, от сложных игр и приложений до полнофункциональных операционных систем, таких как Microsoft Windows.
Однако без компилятора языка «C» высокоуровневый код, написанный разработчиками для создания этих продуктов, не мог быть собран в машинный код. Так что можно с уверенностью сказать, что эти продукты не существовали бы без компиляции! Прежде чем мы углубимся в процесс компиляции для C, давайте подробно разберемся в этом термине.
Большая часть программирования или «кодирования» выполняется на языках, которые обычно имитируют тот или иной естественный язык мира, чаще всего — английский.
Их также называют языками программирования высокого уровня . Однако эти языки непонятны компьютерам, поскольку они понимают только язык битов, единиц и нулей, также известный как ассемблер или машинный язык.
Так что за волшебство превращает наш человеческий код в машинный язык? Вот где появляется компилятор! Большинство языков программирования имеют встроенные компиляторы. Они проверяют написанный код на наличие синтаксических, логических или структурных ошибок и преобразуют его в машинный язык, только если код равен 9.0538 без ошибок . Этот процесс называется Компиляция .
Процесс компиляции состоит из четырех основных этапов:
- Предварительная обработка
- Компиляция
- Сборка
- Связывание
Давайте рассмотрим каждый из них по порядку.
1. Предварительная обработка Код, который пишет человек, называется исходным кодом .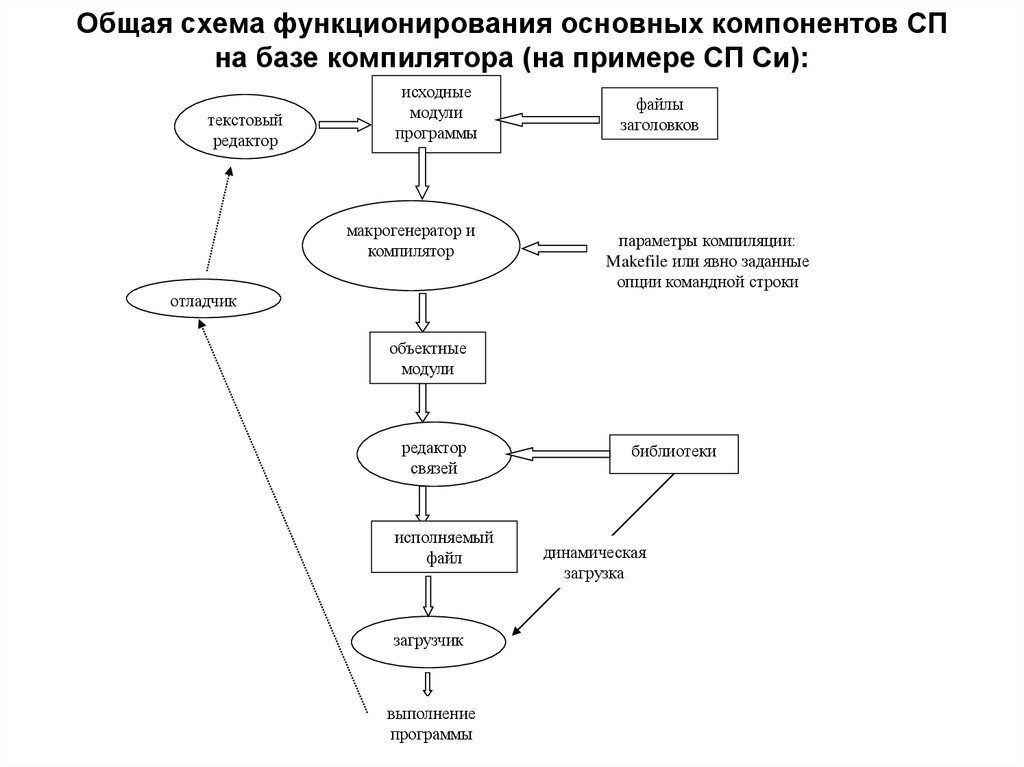 Файл исходного кода сохранен с расширением «.c». На первом этапе компиляции исходный код поступает на препроцессор, который выполняет над ним три основные функции:
Файл исходного кода сохранен с расширением «.c». На первом этапе компиляции исходный код поступает на препроцессор, который выполняет над ним три основные функции:
- Очистка кода
- Принятие директив
- Расширение кода
Одна из лучших практик кодирования для разработчиков — добавлять комментариев в свой код, чтобы его было легко понять другим программистам. Хотя эти комментарии полезны для людей, они не понятны машинам.
На первом этапе препроцессор берет файл исходного кода в качестве входных данных и очищает код, что просто означает удаление всех ненужных элементов, таких как комментарии. Это делает код легко расшифровываемым машинами.
Следующим действием препроцессора является передача директив препроцессора. Это просто строки кода в файле исходного кода, которые начинаются с символа «#». Вот некоторые примеры директив препроцессора:
- #include
- #определить
- #undef
- #если
- #ifelse
Препроцессор интерпретирует директивы и предпринимает соответствующие действия. Например, если в программе встречается директива #include
Например, если в программе встречается директива #include
Наконец, препроцессор расширяет код в файле исходного кода, и этот расширенный код затем передается компилятору.
Если вы хотите понять разницу между компилятором и интерпретатором, щелкните здесь.
2. КомпиляцияКак следует из названия, компилятор компилирует расширенный код, отправленный препроцессором, на язык ассемблера. Этот язык специфичен для целевого процессора и также удобочитаем.
3. АссемблированиеАссемблер преобразует скомпилированный код в чистый двоичный код или ассемблерный код (единицы и нули). Файл, который создает ассемблер, называется объектным файлом.
Он имеет то же имя файла, что и исходный файл, но имеет расширение «.obj» в DOS и «.o» в UNIX. Например, если исходный файл называется ‘Hello World.c’ , объектный файл будет называться ‘Hello World. obj’ .
obj’ .
Хотите узнать, что нужно, чтобы пройти путь от ученика до инженера-программиста, прочитайте здесь вдохновляющее путешествие Балджита.
4. СвязываниеЯзык программирования «C» имеет библиотеку предварительно скомпилированных функций. Все программы, написанные на языке C, используют одну или несколько из этих библиотечных функций. Собранный код этих файлов библиотеки хранится с расширением ‘.lib’ (или ‘.a’) .
В процессе компоновки компиляции ассемблерный код исходного файла объединяется с ассемблерным кодом используемых библиотечных файлов для беспрепятственного выполнения программы.
В некоторых случаях, когда программа использует несколько исходных файлов, один может вызвать функцию внутри другого. В таких случаях этап связывания становится наиболее важным этапом компиляции, поскольку он связывает ассемблерный код обоих файлов.
Полученный файл является полностью скомпилированным и готовым к выполнению. Он всегда имеет то же имя файла, что и исходный файл, но может иметь расширение ‘.exe’ в DOS или ‘a.out’ в UNIX.
Он всегда имеет то же имя файла, что и исходный файл, но может иметь расширение ‘.exe’ в DOS или ‘a.out’ в UNIX.
Давайте посмотрим на компиляцию в действии на примере простой программы, использующей директиву препроцессора и функцию printf.
#include
int main()
{
PRINTF ( «Hello CodeQuotient» )
return 0;;
}
Чтобы лучше понять, вот схема компиляции этой программы: Код файла > Сборка > Объектный файл ( Hello CodeQuotient.obj) > Связывание > Исполняемый файл ( Hello CodeQuotient.exe)
После успешной компиляции файл готов к выполнению. Однако компиляция завершится ошибкой для приведенной выше программы, так как наш синтаксис содержит ошибку. Точка с запятой отсутствует после вызова функции «printf».
Если вы учащийся и пропустили эту ошибку, не волнуйтесь. CodeQuotient предлагает известную в отрасли программу SuperCoders — трехмесячный онлайн-курс «полноценной разработки», который фокусируется на обучении на основе проектов, чтобы помочь вам стать опытным и логичным разработчиком полного стека и открыть в себе лучшего программиста!
CodeQuotient предлагает известную в отрасли программу SuperCoders — трехмесячный онлайн-курс «полноценной разработки», который фокусируется на обучении на основе проектов, чтобы помочь вам стать опытным и логичным разработчиком полного стека и открыть в себе лучшего программиста!
Хотите приступить к разработке программного обеспечения, но не знаете, с чего начать? Кликните сюда.
Компиляция программы
Компиляция программыC++, Visual Basic и другие языки программирования английский; компьютер — это электромагнитная машина, которая не непосредственно понимать либо английский, либо англоподобное программирование языки. Чтобы компьютер «выполнял» или «запускал» программу, программа должна быть переведена на электромагнитные переключатели что компьютер «понимает». Есть несколько способов сделать это, включая сборку, интерпретацию и компиляцию.
Языки ассемблера образованы одним англоподобным кодом для
каждая инструкция на родном языке машины, «машинный код». Перевод программы, написанной на языке ассемблера, в машину
код называется «сборкой» программы. Потому что язык ассемблера
карта инструкций (через ассемблирование) непосредственно в машинные инструкции,
получившийся машинный код, вероятно, будет чрезвычайно эффективным — запускается
быстро и экономит память. Это основные преимущества сборки
языковое программирование. Недостатки: с ним трудно работать,
и, так как каждая модель компьютера имеет свой вариант сборки
языке программы не являются «переносимыми» — их нужно переписывать, чтобы
для запуска на других моделях компьютеров. Например, программа, написанная
на языке ассемблера IBM PC должен работать на всех IBM PC-совместимых компьютерах,
но не на Macintosh в те дни, когда ПК и Mac были несовместимы.
Перевод программы, написанной на языке ассемблера, в машину
код называется «сборкой» программы. Потому что язык ассемблера
карта инструкций (через ассемблирование) непосредственно в машинные инструкции,
получившийся машинный код, вероятно, будет чрезвычайно эффективным — запускается
быстро и экономит память. Это основные преимущества сборки
языковое программирование. Недостатки: с ним трудно работать,
и, так как каждая модель компьютера имеет свой вариант сборки
языке программы не являются «переносимыми» — их нужно переписывать, чтобы
для запуска на других моделях компьютеров. Например, программа, написанная
на языке ассемблера IBM PC должен работать на всех IBM PC-совместимых компьютерах,
но не на Macintosh в те дни, когда ПК и Mac были несовместимы.
«Языки высокого уровня», такие как C++ и Visual Basic,
чтобы программисту было проще работать, чем с языками ассемблера, поскольку
инструкция на языке высокого уровня обычно эквивалентна
несколько инструкций на ассемблере или машинном языке. Язык высокого уровня
программы обычно либо интерпретируются, либо компилируются в машинный код.
Язык высокого уровня
программы обычно либо интерпретируются, либо компилируются в машинный код.
До 2000 года BASIC (не Visual Basic, хотя Visual Basic имеет корни в BASIC) был популярным языком программирования, который часто изучали в дошкольных учреждениях. ученики. BASIC обычно интерпретировался. Когда интерпретируемая программа запускается и управление внутри программы достигает данную инструкцию (такую как оператор LET), интерпретатор переводит инструкцию в машинный код и выполняет соответствующую машину инструкции, затем переходит к следующей инструкции программы БЕЗ ПОМНЯ машинный код, который он только что закончил выполнять. Таким образом, если инструкция повторяется, она должна быть повторно преобразована в машинный код, прежде чем его можно выполнить повторно.
C++, напротив, обычно компилируется.
компилятор переводит программу ПОЛНОСТЬЮ в машинный код, и
«запоминает» весь машинный код, сохраняя его в «исполняемом» файле,
перед запуском программы. Таким образом, при запуске программы перевод
инструкции исходного кода к машинному коду были сделаны заранее;
повторение инструкции исходного кода не требует повторного перевода
инструкции исходного кода к машинному коду; поэтому программа стремится
чтобы бежать быстрее. На некоторых компьютерах, где язык может быть скомпилирован
и интерпретируется, скомпилированная версия будет работать намного быстрее — это
обычно для частей программы, не требующих ввода или вывода
требовать в 1000 раз больше времени на интерпретацию, чем на компиляцию
версия.
Таким образом, при запуске программы перевод
инструкции исходного кода к машинному коду были сделаны заранее;
повторение инструкции исходного кода не требует повторного перевода
инструкции исходного кода к машинному коду; поэтому программа стремится
чтобы бежать быстрее. На некоторых компьютерах, где язык может быть скомпилирован
и интерпретируется, скомпилированная версия будет работать намного быстрее — это
обычно для частей программы, не требующих ввода или вывода
требовать в 1000 раз больше времени на интерпретацию, чем на компиляцию
версия.
ОК, это ясно указывает на важное преимущество компиляции
в отличие от интерпретации скорость выполнения. Что может быть недостатком
компиляции быть? Помните, мы говорили выше, что один язык высокого уровня
инструкция обычно эквивалентна нескольким инструкциям машинного кода.
Предположим, вы запускаете программу, скажем, на BASIC, которая имеет 500 символов BASIC.
инструкций, среднее значение которых эквивалентно 5 машинным кодам
инструкции, самая большая из которых эквивалентна 10 машинным кодам
инструкции. Если скомпилировано, это будет означать, что вам потребуется достаточно памяти
хранить 5*500 = 2500 инструкций машинного кода для запуска программы;
при интерпретации вам потребуется достаточно памяти для хранения 500 инструкций BASIC плюс
не более 10 инструкций машинного кода (для любой инструкции BASIC
выполняется в настоящее время). Таким образом, перевод использует меньше памяти. Это был
Чрезвычайно важный фактор для первых микрокомпьютеров — машины с
маленькие воспоминания — и, вероятно, объясняет, почему они обычно снабжались
интерпретируется Бейсик.
Если скомпилировано, это будет означать, что вам потребуется достаточно памяти
хранить 5*500 = 2500 инструкций машинного кода для запуска программы;
при интерпретации вам потребуется достаточно памяти для хранения 500 инструкций BASIC плюс
не более 10 инструкций машинного кода (для любой инструкции BASIC
выполняется в настоящее время). Таким образом, перевод использует меньше памяти. Это был
Чрезвычайно важный фактор для первых микрокомпьютеров — машины с
маленькие воспоминания — и, вероятно, объясняет, почему они обычно снабжались
интерпретируется Бейсик.
Обычно компилятор сканирует файл исходного кода на наличие «синтаксических ошибок». т.е. , ошибки в использовании правил языка программирования
по поводу формирования операторов в программе.
Часто одна фактическая ошибка
генерировать несколько сообщений об ошибках, так как первая ошибка может «запутать»
плохой компилятор. Следовательно, первое сообщение об ошибке имеет большое значение; другие
может быть, а может и не быть.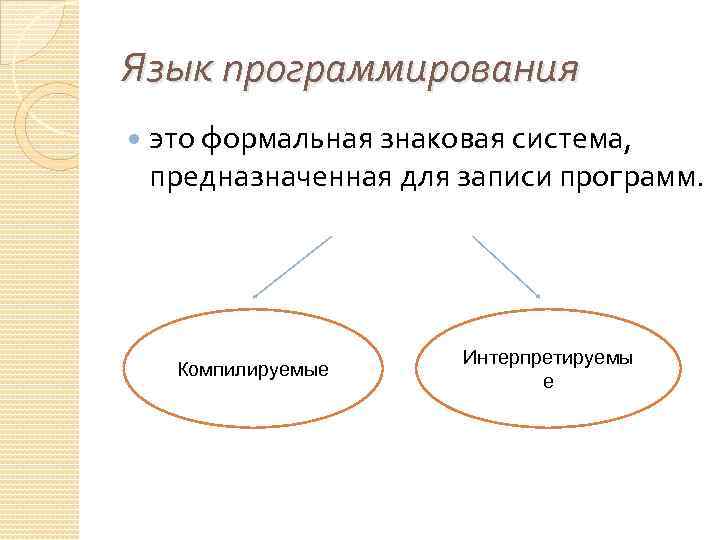
Если компилятор не находит «серьезных» синтаксических ошибок в вашей программе, он также обычно (детали различаются от одного компилятора к другому) создает файл, который является либо «исполняемой» версией вашей программы, либо почти исполняемый (это может быть «объектный» файл, который должен быть «слинкован» для создания исполняемый файл). Исполняемый файл представляет собой перевод машинного кода вашего исходный код, который компьютер использует для выполнения вашей программы, когда вы даете команду сделать это. Учащиеся должны отметить, что цель процесса не просто чтобы ваша программа работала. Он должен работать правильно и хорошо. Это может быть необходимые вам для наблюдения за поведением вашей программы, редактирования ее исходного кода, скомпилируйте снова и запустите снова много раз, прежде чем ваша программа заработает должным образом.
С другой стороны, если компилятор находит ошибки в вашей программе,
Вам необходимо отредактировать эти ошибки вне вашей программы (в редакторе). Ты
затем необходимо перекомпилировать. Цикл редактирования и компиляции часто приходится повторять несколько раз, прежде чем ваша программа будет готова к запуску.
Обратите также внимание на то, что вы, вероятно, еще не «готовы», когда ваша программа запускает
первый раз — успешная компиляция не гарантирует ни правильной логики
(необходимо для получения правильных «ответов») или красивого ввода/вывода. Это
ответственность программиста за проверку этих вопросов.
Ты
затем необходимо перекомпилировать. Цикл редактирования и компиляции часто приходится повторять несколько раз, прежде чем ваша программа будет готова к запуску.
Обратите также внимание на то, что вы, вероятно, еще не «готовы», когда ваша программа запускает
первый раз — успешная компиляция не гарантирует ни правильной логики
(необходимо для получения правильных «ответов») или красивого ввода/вывода. Это
ответственность программиста за проверку этих вопросов.
На домашнюю страницу боксера
L11: Компиляторы
Сегодня мы поговорим о том, как перевести языки высокого уровня в код, который могут выполнять компьютеры.
До сих пор мы видели бета-версию ISA, которая включает
инструкции, которые контролируют операции с путями данных, выполняемые на
32-битные данные хранятся в регистрах. Это также
инструкции по доступу к основной памяти и изменению программы
прилавок. Инструкции отформатированы как код операции, источник и
поля назначения, формирующие 32-битные значения в основной памяти.
Чтобы сделать нашу жизнь проще, мы разработали язык ассемблера как способ указания последовательности инструкций. Каждая сборка оператор языка соответствует одной инструкции. В качестве программисты на ассемблере, мы несем ответственность за управление тем, какие значения находятся в регистрах, а какие в main памяти, и нам нужно выяснить, как разбить сложные операции, например. , доступ к элементу массива, в правильная последовательность бета-операций.
Мы можем пойти еще дальше и использовать языки высокого уровня для
описать вычисления, которые мы хотим выполнить. Эти языки
использовать переменные и другие структуры данных, чтобы абстрагироваться от
сведения о распределении хранилища и перемещении данных в
из основной памяти. Мы можем просто обратиться к объекту данных по имени
и пусть языковой процессор обрабатывает детали. Сходным образом,
мы будем писать выражения и другие операторы, такие как
присваивание (=) для эффективного описания того, что потребовало бы многих
операторы на языке ассемблера.
Сегодня мы рассмотрим, как перевести программы на языке высокого уровня в код, который будет работать на Бета.
Здесь мы видим алгоритм Евклида для определения наибольший общий делитель двух чисел, в данном случае алгоритм написан на языке программирования C. Что ж использовать простое подмножество C в качестве нашего примера высокого уровня язык. См. краткий обзор C в раздаточных материалах. раздел, если вы хотите познакомиться с синтаксисом C и семантика. C был разработан Деннисом Ритчи в AT&T Bell Labs. в конце 60-х и начале 70-х для использования, когда внедрение операционной системы Unix. С того времени многие введены новые языки высокого уровня, обеспечивающие современные абстракции, такие как объектно-ориентированное программирование, наряду с полезными новые структуры данных и управления.
Использование C позволяет нам описать вычисление, не обращаясь к
любые детали бета-версии ISA, такие как регистры, конкретная бета-версия
инструкции и так далее.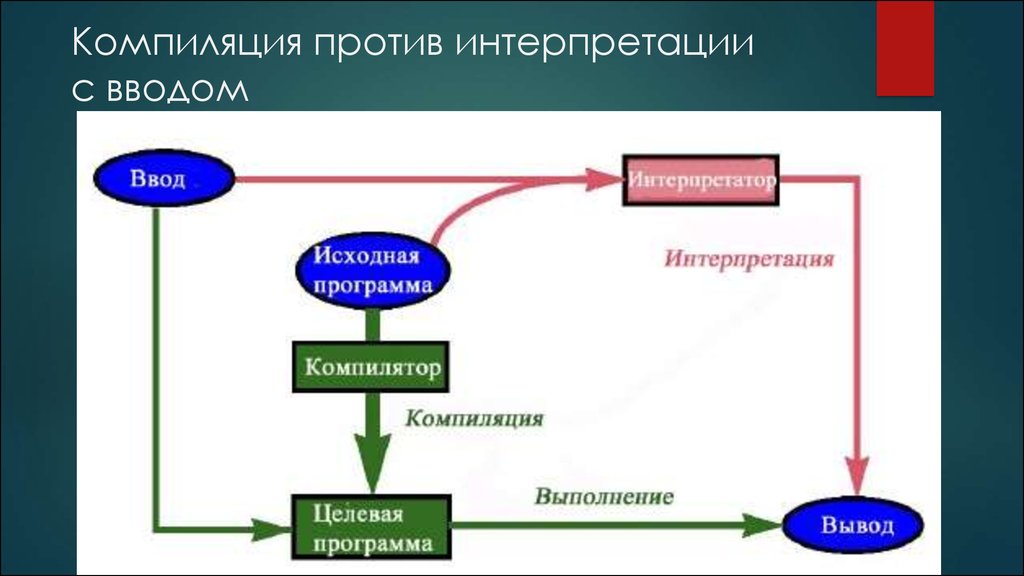 Отсутствие таких деталей означает
требуется меньше работы для создания программы и делает ее
другим легче читать и понимать алгоритм
реализуется программой.
Отсутствие таких деталей означает
требуется меньше работы для создания программы и делает ее
другим легче читать и понимать алгоритм
реализуется программой.
Использование языка высокого уровня дает множество преимуществ. Они позволяют программистам быть очень продуктивными, поскольку программы лаконично и читабельно. Эти атрибуты также облегчают поддерживать код. Часто труднее изготовить определенные типы ошибки, так как язык позволяет нам проверять глупые ошибки как сохранение строкового значения в числовой переменной. И более сложные задачи, такие как динамическое выделение и освобождение хранение может быть полностью автоматизировано. Результат в том, что он может потребуется гораздо меньше времени, чтобы создать правильную программу на высоком уровне языке, чем это было бы при написании на языке ассемблера.
Поскольку язык высокого уровня абстрагируется от деталей
конкретной ISA программы переносимы в том смысле, что
мы можем рассчитывать на запуск одного и того же кода на разных ISA без
приходится переписывать код.
Что мы теряем, используя язык высокого уровня? Можем ли мы беспокоиться, что мы заплатим цену с точки зрения эффективности и производительность, которую мы могли бы получить, создавая каждую инструкцию рука? Ответ зависит от того, как мы выбираем высокоуровневую языковые программы. Две основные стратегии исполнения: «интерпретация» и «компиляция».
Чтобы интерпретировать программу на языке высокого уровня, мы напишем специальная программа, называемая «интерпретатор», которая работает на собственно компьютер, M1. Интерпретатор имитирует поведение некоторая абстрактная легко программируемая машина M2 и для каждой M2 операция выполняет последовательности инструкций M1 для достижения желаемый результат. Мы можем думать об интерпретаторе вместе с M1 как реализация M2, т.е. , учитывая программу, написанную для M2, интерпретатор будет шаг за шагом эмулировать действие инструкций M2.
Мы часто используем несколько уровней интерпретации при решении
вычислительные задачи. Например, инженер может использовать свой ноутбук
с процессором Intel для запуска интерпретатора Python. В Питоне она
загружает набор инструментов SciPy, который предоставляет похожий на калькулятор
интерфейс для численного анализа матриц данных. Для каждого
команда SciPy, напр. , «найти максимальное значение набора данных»,
набор инструментов SciPy выполняет множество операторов Python, , например. ,
перебирать каждый элемент массива, запоминая наибольший
ценность. Для каждого оператора Python интерпретатор Python
выполняет множество инструкций x86, напр. , чтобы увеличить
индекс цикла и проверьте завершение цикла. Выполнение сингла
Команда SciPy может потребовать выполнения десятков Python
операторов, каждый из которых, в свою очередь, может потребовать выполнения сотен
инструкции для х86. Инженер очень рад, что она не
должна сама написать каждую из этих инструкций!
Например, инженер может использовать свой ноутбук
с процессором Intel для запуска интерпретатора Python. В Питоне она
загружает набор инструментов SciPy, который предоставляет похожий на калькулятор
интерфейс для численного анализа матриц данных. Для каждого
команда SciPy, напр. , «найти максимальное значение набора данных»,
набор инструментов SciPy выполняет множество операторов Python, , например. ,
перебирать каждый элемент массива, запоминая наибольший
ценность. Для каждого оператора Python интерпретатор Python
выполняет множество инструкций x86, напр. , чтобы увеличить
индекс цикла и проверьте завершение цикла. Выполнение сингла
Команда SciPy может потребовать выполнения десятков Python
операторов, каждый из которых, в свою очередь, может потребовать выполнения сотен
инструкции для х86. Инженер очень рад, что она не
должна сама написать каждую из этих инструкций!
Интерпретация является эффективной стратегией реализации, когда
выполнение вычислений один раз или при изучении того, какие
вычислительный подход является наиболее эффективным, прежде чем сделать более
значительные инвестиции в создание более эффективной
реализация.
Мы будем использовать стратегию реализации компиляции, когда будем есть вычислительные задачи, которые нам нужно выполнять неоднократно и следовательно, мы готовы инвестировать больше времени заранее для большего эффективность в долгосрочной перспективе.
При компиляции мы также начинаем с нашего реального компьютера M1. Затем мы возьмем нашу языковую программу высокого уровня P2 и пошагово переведите его в программу для M1. Примечание что на самом деле мы не запускаем программу P2. Вместо мы используем его как шаблон для создания эквивалентного P1 программа, которая может выполняться непосредственно на M1. Перевод процесс называется «компиляция», а программа, которая перевод называется «компилятором».
Мы компилируем программу P2 один раз, чтобы получить перевод P1, и
тогда мы будем запускать P1 на M1 всякий раз, когда захотим выполнить P2.
Запуск P1 позволяет избежать накладных расходов на обработку P2.
источник и затраты на выполнение любых промежуточных слоев
интерпретация. Вместо динамического определения
необходимые машинные инструкции для каждого оператора P2, как
с этим столкнулись, по сути, мы договорились
захватить этот поток машинных инструкций и сохранить их как
Программа P1 для последующего выполнения. Если мы готовы платить
первоначальные затраты на компиляцию, мы получим больше
эффективное исполнение.
Вместо динамического определения
необходимые машинные инструкции для каждого оператора P2, как
с этим столкнулись, по сути, мы договорились
захватить этот поток машинных инструкций и сохранить их как
Программа P1 для последующего выполнения. Если мы готовы платить
первоначальные затраты на компиляцию, мы получим больше
эффективное исполнение.
И, используя разные компиляторы, мы можем запустить P2 на многих разные машины — М2, М3 и т.д. — не имея переписать П2.
Теперь у нас есть два способа выполнить язык высокого уровня программа: интерпретация и компиляция. Оба позволяют нам изменить исходную программу. Оба позволяют абстрагироваться детали фактического компьютера, который мы будем использовать для запуска программа. И обе стратегии широко используются в современных Компьютерные системы!
Подытожим различия между интерпретацией и компиляция.
Предположим, что оператор «x+2» появляется в
программа высокого уровня. Когда интерпретатор обрабатывает это
оператор, он немедленно извлекает значение переменной x и
добавляет к нему 2.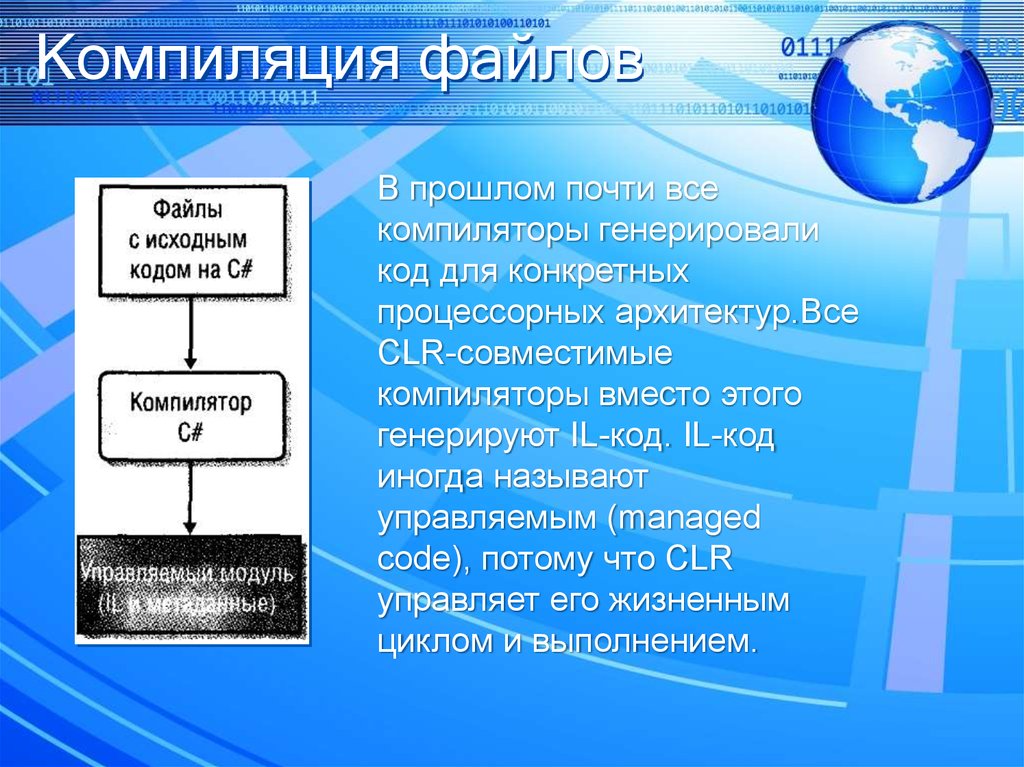 С другой стороны, компилятор сгенерирует
Бета-инструкции, которые записывают переменную x в регистр.
а затем ДОБАВЬТЕ 2 к этому значению.
С другой стороны, компилятор сгенерирует
Бета-инструкции, которые записывают переменную x в регистр.
а затем ДОБАВЬТЕ 2 к этому значению.
Интерпретатор выполняет каждую инструкцию по мере ее обрабатывается и, по сути, может обрабатывать и выполнять одно и то же заявление много раз, если, например. , это было в петле. компилятор просто генерирует инструкции, которые будут выполняться в определенное время. позднее время.
Интерпретаторы несут накладные расходы на обработку высокоуровневого исходный код во время выполнения, и могут возникнуть накладные расходы много раз в петлях. Компиляторы несут накладные расходы на обработку один раз, делая возможное выполнение более эффективным. Но во время разработки, программисту, возможно, придется скомпилировать и запустить программу много раз, часто неся затраты на компиляцию для только однократное выполнение программы. Итак цикл компиляции-запуска-отладки может занять больше времени.
Интерпретатор принимает решения о типе данных x
и тип операций, необходимых во время выполнения, т. е. ,
во время работы программы. Компилятор делает эти
решения в процессе компиляции.
е. ,
во время работы программы. Компилятор делает эти
решения в процессе компиляции.
Какой подход лучше? В общем, выполнение скомпилированного код выполняется намного быстрее, чем его интерпретация. Но поскольку интерпретатор принимает решения во время выполнения, он может менять свое поведение в зависимости, скажем, от типа данных в переменная X, обеспечивающая значительную гибкость в обработке различные типы данных с одним и тем же алгоритмом. Компиляторы берут отказаться от этой гибкости в обмен на быстрое выполнение.
Компилятор — это программа, которая транслирует язык высокого уровня программу в функционально эквивалентную последовательность машинных инструкции, т.е. , программа на ассемблере.
Сначала компилятор проверяет, что программа высокого уровня
правильно, т. е. , что утверждения правильно построены,
программист не требует бессмысленных вычислений
— напр. , добавив строковое значение и целое число
— или попытка использовать значение переменной перед ним
был правильно инициализирован. Компилятор также может предоставить
предупреждения, когда операции могут не дать ожидаемого
результаты, напр. , при преобразовании из числа с плавающей запятой
число в целое число, где значение с плавающей запятой может быть слишком
большой, чтобы соответствовать количеству битов, предоставляемых целым числом.
Компилятор также может предоставить
предупреждения, когда операции могут не дать ожидаемого
результаты, напр. , при преобразовании из числа с плавающей запятой
число в целое число, где значение с плавающей запятой может быть слишком
большой, чтобы соответствовать количеству битов, предоставляемых целым числом.
Если программа проходит проверку, компилятор переходит к генерировать эффективные последовательности инструкций, часто находя способы перестроить вычисления так, чтобы результирующие последовательности были короче и быстрее. Трудно превзойти современную оптимизацию компилятор при создании языка ассемблера, так как компилятор будет терпеливо исследовать альтернативы и делать выводы о свойствах программа, которая может быть не очевидна даже при тщательной сборке языковые программисты.
В этом разделе мы рассмотрим простую технику
компиляция программ на C в ассемблер. Затем, в следующем разделе,
мы углубимся в то, как современный компилятор
работает.
В нашем простом компиляторе есть две основные процедуры: compile_statement и compile_expr. Работа compile_statement должен скомпилировать один оператор из исходная программа. Поскольку исходная программа представляет собой последовательность операторы, мы будем вызывать compile_statement несколько раз.
Мы сосредоточимся на технике компиляции для четырех типов
заявлений. Безусловное утверждение — это просто
выражение, которое оценивается один раз. Составное утверждение — это
просто последовательность операторов, которые должны выполняться по очереди.
Условные операторы, иногда называемые «if
операторы», вычислить значение тестового выражения, напр. , такое сравнение, как «A < B». Если
тест верен, тогда выполняется оператор 1 ,
в противном случае выполняется оператор 2 . Итерация
Операторы также содержат тестовое выражение. В каждой итерации
если проверка верна, то оператор выполняется, и
процесс повторяется. Если тест неверен, итерация
прекращено.
Если тест неверен, итерация
прекращено.
Другой основной подпрограммой является compile_expr, задачей которой является генерировать код для вычисления значения выражения, оставляя привести к некоторому регистру. Выражения принимают различные формы:
простые постоянные значения
значения из скалярных или массивных переменных,
выражения присваивания, которые вычисляют значение, а затем сохраняют результат некоторой переменной,
унарных или бинарных операций, которые объединяют значения их операнды с указанным оператором. Комплексная арифметика выражения могут быть разложены на последовательности унарных и двоичных операции.
И, наконец, вызовы процедур, где именованная последовательность
операторы будут выполняться со значениями предоставленного
аргументы, назначенные в качестве значений формальных параметров
процедура. Компиляция процедур и вызовы процедур
тему, которой мы займемся на следующей лекции, так как есть некоторые
сложности, которые нужно понять и решить.
К счастью, компиляция других типов выражений и заявления просты, так что давайте начнем.
Какой код нам нужен, чтобы поместить значение константы в регистр? Если константа будет вписываться в 16-битную константу поле инструкции, мы можем использовать CMOVE для загрузки дополненная знаком константа в регистр. Этот подход работает для константы между -32768 и +32767. Если константа слишком большой, он хранится в ячейке основной памяти, и мы используем Инструкция LD для получения значения в регистр.
Загрузка значения переменной очень похожа на загрузку значение большой константы: мы используем инструкцию LD для доступа к ячейка памяти, в которой хранится значение переменной.
Доступ к массиву немного сложнее: массивы
хранятся в виде последовательных ячеек в основной памяти, начиная
с индексом 0. Каждый элемент массива занимает некоторое фиксированное число
байт. Итак, нам нужен код для преобразования индекса массива в
фактический адрес основной памяти для указанного элемента массива.
Сначала мы вызываем compile_expr для генерации кода, который оценивает индексное выражение и оставляет результат в Rx. Это будет значение между 0 и размером массива минус 1. Мы будем использовать инструкцию LD для доступа к соответствующему массиву. запись, но это означает, что нам нужно преобразовать индекс в байт смещение, которое мы делаем, умножая индекс на bsize, количество байтов в одном элементе. Если бы b был массивом целых чисел, bsize будет равен 4. Теперь, когда у нас есть смещение в байтах в регистр, мы можем использовать LD, чтобы добавить смещение к базовому адресу массив, вычисляющий адрес нужного элемента массива, затем загрузите значение памяти по этому адресу в регистр.
Выражения присваивания просты: вызовите compile_expr для сгенерировать код, который загружает значение выражения в регистр, затем сгенерируйте инструкцию ST для сохранения значения в указанная переменная.
Арифметические операции тоже довольно просты: используйте compile_expr для
генерировать код для каждого из операндных выражений, оставляя
результаты в реестрах. Затем сгенерируйте соответствующий ALU
инструкция объединить операнды и оставить ответ в
регистр.
Затем сгенерируйте соответствующий ALU
инструкция объединить операнды и оставить ответ в
регистр.
Давайте посмотрим на примере, как все это работает. Здесь есть выражение присваивания, которое требует вычитания, умножение и сложение для вычисления требуемого значения.
Проследим процесс компиляции от начала до конца когда мы вызываем compile_expr для генерации необходимого кода.
Следуя шаблону для выражений присваивания из предыдущей странице, мы рекурсивно вызываем compile_expr для вычисления значения правой части задания.
Это операция умножения, поэтому следуя Операциям шаблон, нам нужно скомпилировать левый операнд умножить.
Это операция вычитания, поэтому мы вызываем compile_expr снова, чтобы скомпилировать левый операнд вычитания.
Ага, мы знаем, как получить значение переменной в регистр. Итак, мы генерируем инструкцию LD для загрузки значения x. в р1.
Процесс, которому мы следуем, называется «рекурсивный
спуск». Мы использовали рекурсивные вызовы для
compile_expr для обработки каждого уровня дерева выражений. В
с каждым рекурсивным вызовом выражения упрощаются, пока мы не достигнем
переменная или константа, где мы можем сгенерировать соответствующий
инструкция без дальнейшего спуска. В этот момент
мы достигли листа дерева выражений, и мы
сделано с этой ветвью рекурсии.
Мы использовали рекурсивные вызовы для
compile_expr для обработки каждого уровня дерева выражений. В
с каждым рекурсивным вызовом выражения упрощаются, пока мы не достигнем
переменная или константа, где мы можем сгенерировать соответствующий
инструкция без дальнейшего спуска. В этот момент
мы достигли листа дерева выражений, и мы
сделано с этой ветвью рекурсии.
Теперь нам нужно получить значение правого операнда вычесть в регистр. В случае, если это небольшая константа, поэтому мы генерируем инструкцию CMOVE.
Теперь, когда значения обоих операндов находятся в регистрах, мы возвращаемся к вычесть шаблон и сгенерировать инструкцию SUB для выполнения вычитание. Теперь у нас есть значение левого операнда умножить на r1.
Проделываем тот же процесс для правого операнда
умножение, рекурсивный вызов compile_expr для обработки каждого уровня
выражения, пока мы не достигнем переменной или константы. затем
мы возвращаемся вверх по дереву выражений, генерируя соответствующий
инструкции, как мы идем, следуя диктату соответствующего
шаблон с предыдущего слайда.
Сгенерированный код отображается в левой части слайда. метод рекурсивного спуска позволяет быстро сгенерировать код даже для самых сложных выражений.
Есть даже возможность найти несколько простых оптимизации, глядя на соседние инструкции. Например, CMOVE, за которой следует арифметическая операция, часто может быть закорочена одной арифметической инструкции с константой в качестве второй операнд. Эти локальные преобразования называются «оптимизация глазка», поскольку мы только рассматривая только одну или две инструкции одновременно.
Теперь обратимся к compile_statement.
С первыми двумя типами операторов довольно легко работать. Безусловные операторы обычно представляют собой выражения присваивания или вызовы процедур. Мы просто попросим compile_expr сгенерировать соответствующий код.
Составные операторы одинаково просты. Мы будем рекурсивно
вызовите compile_statement для генерации кода для каждого оператора в
повернуть. Код для оператора_2 будет следовать сразу за кодом
создан для оператора_1. Выполнение будет продолжаться последовательно
через код для каждого оператора.
Код для оператора_2 будет следовать сразу за кодом
создан для оператора_1. Выполнение будет продолжаться последовательно
через код для каждого оператора.
Здесь мы видим простейшую форму условного оператора, где нам нужно сгенерировать код для оценки тестового выражения и затем, если значение в регистре FALSE, пропустить код который выполняет оператор в предложении THEN. Простой шаблон на языке ассемблера использует рекурсивные вызовы compile_expr и compile_statement для генерации кода для различных частей оператор ЕСЛИ.
Полноценный условный оператор включает предложение ELSE, который должен быть выполнен, если значение тестового выражения равно ЛОЖНЫЙ. Шаблон использует несколько ветвей и меток для обеспечения Ход исполнения соответствует задуманному.
Вы видите, что процесс компиляции на самом деле просто
применение множества мелких шаблонов, нарушающих код
задача генерации шаг за шагом на все меньшие и меньшие
задачи, генерируя необходимый код, чтобы склеить все кусочки
вместе соответствующим образом.
А вот и шаблон оператора WHILE, который очень похоже на шаблон оператора IF с ответвлением в конце, что приводит к повторному выполнению сгенерированного кода пока значение тестового выражения не станет FALSE.
Немного подумав, мы можем улучшить этот шаблон немного. Мы реорганизовали код таким образом, что только инструкция одиночного перехода (BT) выполняется на каждой итерации, вместо двух ветвей (BF, BR) на итерацию в оригинальный шаблон. Ничего страшного, но небольшая оптимизация для код внутри цикла может привести к значительной экономии в долгосрочной перспективе. программа.
Небольшой комментарий о другом распространенном операторе итерации, цикл FOR. Цикл FOR — это сокращенный способ выражения итераций, где индекс цикла («i» в примере показано) проходит через последовательность значений и тело Цикл FOR выполняется один раз для каждого значения индекса цикла.
Цикл FOR может быть преобразован в показанный оператор WHILE
здесь, который затем может быть скомпилирован с использованием показанных шаблонов
выше.
В этом примере мы применили наши шаблоны для создания код для итеративной реализации факториальной функции что мы видели раньше. Просмотрите сгенерированный код и вы сможете сопоставлять фрагменты кода с шаблоны из последних нескольких слайдов. это не самое эффективный код, но неплохой, учитывая простоту подход рекурсивного спуска для компиляции высокоуровневых программы.
Модифицировать рекурсивный спуск несложно. процесс для размещения значений переменных, которые хранятся в специальные регистры, а не в основной памяти. Оптимизация компиляторы довольно хорошо находят возможности сохранить значения в регистрах и, следовательно, избежать операций LD и ST требуется для доступа к значениям в основной памяти. С помощью этого простого оптимизация, количество инструкций в цикле ушло с 10 до 4. Теперь сгенерированный код выглядит красиво хороший!
Но вместо того, чтобы продолжать настраивать метод рекурсивного спуска,
давайте остановимся здесь. В следующем сегменте мы увидим, как
современные компиляторы используют более общий подход к генерации
код. Тем не менее, впервые я узнал о рекурсивном
спуска, побежал домой писать простенькую реализацию и
поразился тому, что написал свой собственный компилятор за полдня!
В следующем сегменте мы увидим, как
современные компиляторы используют более общий подход к генерации
код. Тем не менее, впервые я узнал о рекурсивном
спуска, побежал домой писать простенькую реализацию и
поразился тому, что написал свой собственный компилятор за полдня!
Современный компилятор начинает с анализа исходного текста программы
произвести эквивалентную последовательность операций, выраженную в
язык — и машинно-независимый промежуточный
представительство (ИР). Анализ, или внешний интерфейс, фазовые проверки
эта программа хорошо сформирована, т.е. , что синтаксис
каждое утверждение языка высокого уровня является правильным. Он понимает
смысл (семантика) каждого утверждения. Многие высокопоставленные
языки включают объявления типа — например. ,
целое число, с плавающей запятой, строка и т. д. — каждой переменной,
и интерфейс проверяет правильность всех операций
применяется, гарантируя, что числовые операции имеют числовой тип
операнды, строковые операции имеют операнды строкового типа, и поэтому
на. В основном фаза анализа преобразует текст
исходную программу во внутреннюю структуру данных, которая определяет
последовательность и вид выполняемых операций.
В основном фаза анализа преобразует текст
исходную программу во внутреннюю структуру данных, которая определяет
последовательность и вид выполняемых операций.
Часто существуют семейства внешних программ, которые переводят различные языки высокого уровня (например, C, C++, Java) в общий ИК.
На этапе синтеза или бэкэнда IR оптимизируется для
уменьшить количество операций, которые будут выполняться при
окончательный код запускается. Например, он может найти операции внутри
цикла, которые не зависят от индекса цикла и могут перемещаться
вне цикла, где они выполняются один раз вместо
несколько раз внутри цикла. После завершения IR
оптимизированная форма, серверная часть генерирует последовательности кода для
целевой ISA и ищет дальнейшие оптимизации, которые требуют
преимущества отдельных функций ISA. Например, для
в бета-версии ISA мы видели, как за CMOVE следует арифметическое
операция может быть сокращена до одной операции с константой
операнд.
Фаза анализа начинается со сканирования исходного текста и создание последовательности объектов маркеров, которые идентифицируют тип каждый фрагмент исходного текста. В то время как пробелы, вкладки, новые строки, и т. д. были необходимы для разделения токенов в исходном тексте, все они были удалены в процессе сканирования. К включить полезные отчеты об ошибках, объекты токенов также включают информация о том, где в исходном тексте находилась каждая лексема найдено, например. , имя файла, номер строки и столбец количество. Фаза сканирования сообщает о нелегальных токенах, напр. , токен «3x» вызовет ошибку, так как в C он не будет допустимым номером или допустимым именем переменной.
Фаза синтаксического анализа обрабатывает последовательность токенов для построения
синтаксическое дерево, которое отражает структуру оригинала
программу в удобной структуре данных. Операнды были
организованы для каждой унарной и бинарной операции.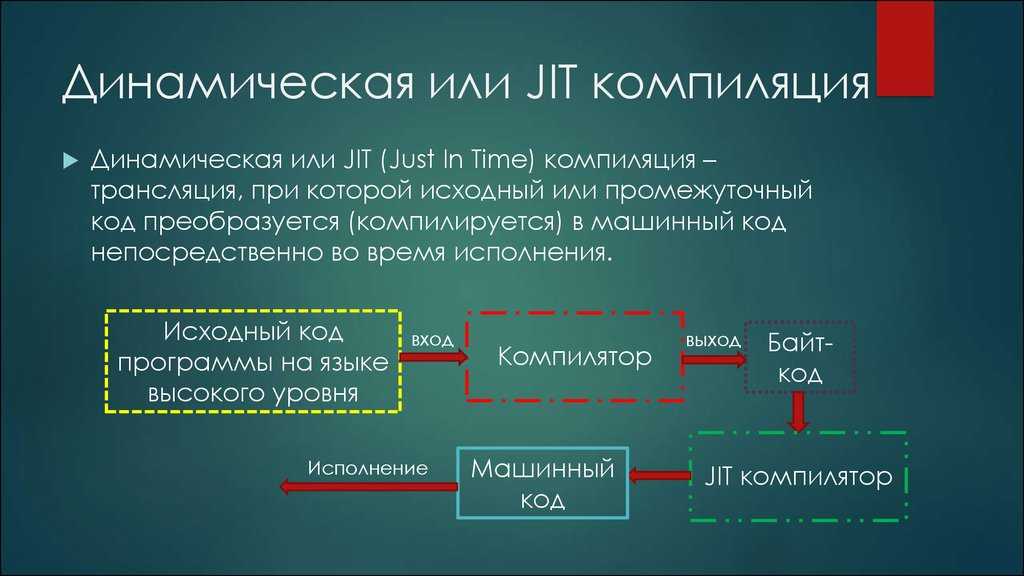 Компоненты
каждого утверждения были найдены и помечены. Роль каждого
исходный токен был определен, и информация, полученная в
синтаксическое дерево.
Компоненты
каждого утверждения были найдены и помечены. Роль каждого
исходный токен был определен, и информация, полученная в
синтаксическое дерево.
Сравните метки узлов дерева с шаблонами, которые мы обсуждалось в предыдущем сегменте. Мы видим, что это было бы легко написать программу, выполняющую обход дерева в глубину, используя метка каждого узла дерева для выбора соответствующего кода шаблон генерации. Мы пока не будем этого делать, так как еще предстоит проделать некоторую работу по анализу и преображение дерева.
Синтаксическое дерево позволяет легко проверить правильность программы. семантически правильно, напр. , чтобы проверить, что типы операнды совместимы с запрошенной операцией.
Например, рассмотрим оператор x =
«бананы». Синтаксис операции присваивания:
правильно: в левой части стоит переменная, а
выражение в правой части. Но семантика не
правильно, по крайней мере, на языке Си! Глядя в его символ
таблица для проверки объявленного типа переменной x (int) и
сравнивая его с типом выражения (строка),
семантическая проверка для узла дерева «op =»
обнаружить, что типы несовместимы, т.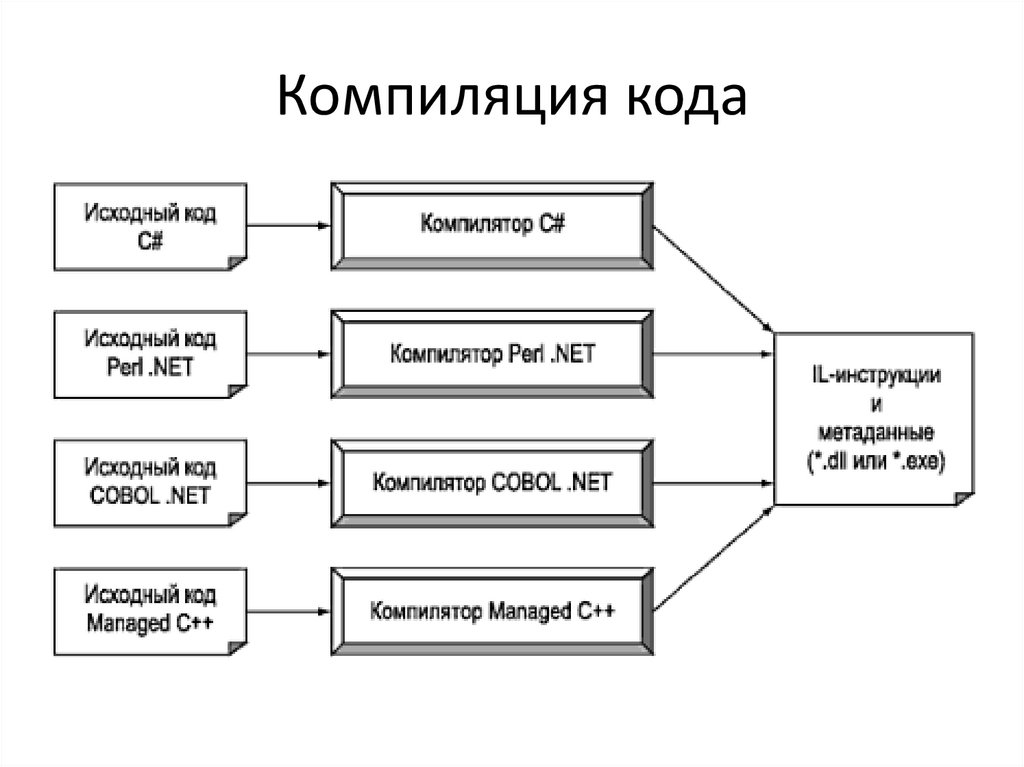 е. , что мы
не может сохранить строковое значение в целочисленной переменной.
е. , что мы
не может сохранить строковое значение в целочисленной переменной.
Когда семантический анализ завершен, мы знаем, что синтаксис дерево представляет собой синтаксически правильную программу с действительным семантику, и мы закончили преобразование исходного программу в эквивалентную, независимую от языка последовательность операции.
Синтаксическое дерево является полезным промежуточным представлением (IR)
который не зависит ни от исходного языка, ни от целевого
ЭТО. Он содержит информацию о последовательности и группировке
операций, которые не видны на отдельной машине
языковые инструкции. И это позволяет использовать интерфейсы для разных
исходные языки для совместного использования общего бэкенда, нацеленного на конкретный
ЭТО. Как мы увидим, внутреннюю обработку можно разделить
на две подфазы. Первый выполняет машинно-независимый
оптимизация в ИК. Затем оптимизированный IR преобразуется
этап генерации кода в последовательности инструкций для
целевой ИСА.
Обычный IR заключается в реорганизации синтаксического дерева в то, что называется графом потока управления (CFG). Каждый узел графа представляет собой последовательность вычислений присваивания и выражения, которая заканчивается филиал. Узлы называются «базовыми блоками» и представляют собой последовательности операций, которые выполняются как единое целое: после выполнения первой операции в базовом блоке остальные операции также будут выполняться без каких-либо других промежуточные операции. Эти знания позволяют рассматривать многие оптимизация, напр. , временное хранение значений переменных в регистрах, это было бы сложно, если бы возможность того, что другие операции вне блока также могут нужно получить доступ к значениям переменных, пока мы были в середине этого блока.
Ребра графа указывают ветви, которые ведут нас к еще один базовый блок.
Например, вот CFG для НОД.
Если базовый блок заканчивается условной ветвью, есть два
края, помеченные буквами «T» и «F», оставляя
блок, который указывает следующий блок для выполнения в зависимости от
итог теста. Другие блоки имеют только один исходящий
стрелка, указывающая на то, что блок всегда передает управление
блок указан стрелкой.
Другие блоки имеют только один исходящий
стрелка, указывающая на то, что блок всегда передает управление
блок указан стрелкой.
Обратите внимание, что если мы можем прийти к блоку только из одного предшествующий блок, то любые знания, которые у нас есть об операциях и переменные из предыдущего блока могут быть перенесены в блок назначения. Например, если «если (x > y)» сгенерировал код для загрузки значений x и y в регистры, оба блока назначения могут использовать эту информацию и использовать соответствующие регистры без необходимости генерировать свои собственные ЛД.
Но если блок имеет несколько предшественников, такие оптимизации более ограничены: мы можем использовать только общеизвестные знания. ко *всем* предшествующим блокам.
CFG очень похожа на диаграмму перехода состояний для ФМС высокого уровня!
Мы оптимизируем ИК, выполнив несколько проходов по
КФГ. Каждый проход выполняет конкретную простую оптимизацию.
Мы будем неоднократно применять простые оптимизации в
несколько проходов, пока мы не сможем найти дальше
оптимизации для выполнения. В совокупности простые
оптимизации могут сочетаться для достижения очень сложных
оптимизация.
В совокупности простые
оптимизации могут сочетаться для достижения очень сложных
оптимизация.
Вот несколько примеров оптимизации:
Мы можем отказаться от присвоений переменным, которые никогда не используются и основные блоки, которые никогда не достигаются. Это называется «устранение мертвого кода».
При постоянном распространении мы идентифицируем переменные, которые имеют постоянное значение и подставьте эту константу вместо ссылки на переменную.
Мы можем вычислить значение выражений, которые имеют константу операнды. Это называется «постоянное складывание».
Чтобы проиллюстрировать, как работают эти оптимизации, рассмотрим это немного глуповатая исходная программа и ее CFG. Обратите внимание, что мы разбили сложные выражения на простые бинарные операции с использованием имен временных переменных (например, «_t1»), чтобы назвать промежуточные результаты.
Начнем!
Проход устранения мертвого кода может удалить назначение Z
в первом базовом блоке, так как Z переназначается в последующих
блоки, а промежуточный код не ссылается на Z.
Далее мы ищем переменные с постоянными значениями. Здесь мы находим что X присваивается значение 3 и никогда не присваивается повторно, поэтому мы можем заменить все ссылки на X на константу 3.
Теперь выполните сворачивание констант, оценивая любую константу выражения.
Вот обновленный CFG, готовый к следующему раунду оптимизация.
Первое устранение мертвого кода.
Затем постоянное распространение.
И, наконец, постоянное складывание.
Итак, после двух циклов этих простых операций мы сократил количество заданий. На третий раунд!
Устранение мертвого кода. И здесь мы можем определить результат условная ветвь, исключающая целые базовые блоки из IR, либо потому, что они сейчас пусты, либо потому, что они могут больше не будет достигнуто.
Ух ты, ИК теперь значительно меньше.
Далее идет еще одно применение постоянного распространения.
А потом постоянное складывание.
Последующее удаление мертвого кода.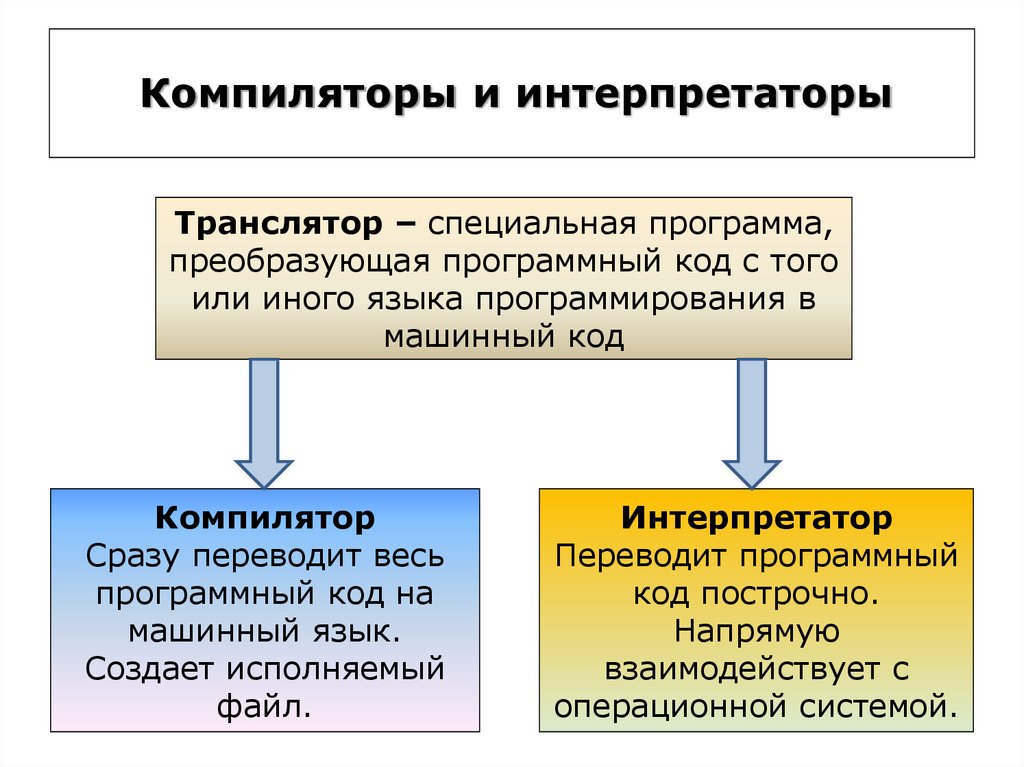
Проходы продолжаются до тех пор, пока мы не обнаружим, что больше нет оптимизации для выполнения, так что мы сделали!
Многократное применение этих простых преобразований преобразовать исходную программу в эквивалентную программу, которая вычисляет такое же конечное значение для Z.
Мы можем сделать больше оптимизации, добавив проходы: устранение избыточное вычисление общих подвыражений, перемещение циклонезависимые вычисления вне циклов, развертывание коротких циклы для выполнения эффекта, скажем, двух итераций за один выполнение цикла, экономя часть стоимости приращения и тестирования инструкции. Оптимизирующие компиляторы имеют сложный набор оптимизации, которые они используют, чтобы сделать их меньше и эффективнее код.
Хорошо, с оптимизацией покончено. Теперь пришло время генерировать инструкции для целевой ISA.
Сначала генератор кода назначает каждой переменной
регистр. Если у нас больше переменных, чем регистров, некоторые
переменные хранятся в памяти, и мы будем использовать LD и ST для
доступ к ним по мере необходимости. Но часто используемые переменные будут
почти наверняка живите как можно больше в регистрах.
Но часто используемые переменные будут
почти наверняка живите как можно больше в регистрах.
Используйте наши шаблоны для перевода каждого задания и операцию в одну или несколько инструкций.
Выдать код для каждого блока, добавив соответствующие метки и ветви.
Переупорядочить код базового блока, чтобы исключить безусловное отделения везде, где это возможно.
И, наконец, выполните любой глазок для конкретной цели оптимизация.
Вот исходная CFG для кода GCD вместе с немного оптимизирован CFG. GCD не так тривиален, как предыдущем примере, поэтому мы смогли сделать лишь немного постоянное распространение и постоянное сворачивание.
Обратите внимание, что мы не можем распространять информацию о переменной значения из верхнего базового блока в следующие блок «если», так как блок «если» имеет несколько предшественников.
Вот как генератор кода будет обрабатывать оптимизированный КФГ.
Во-первых, он выделяет регистры для хранения значений x и
у.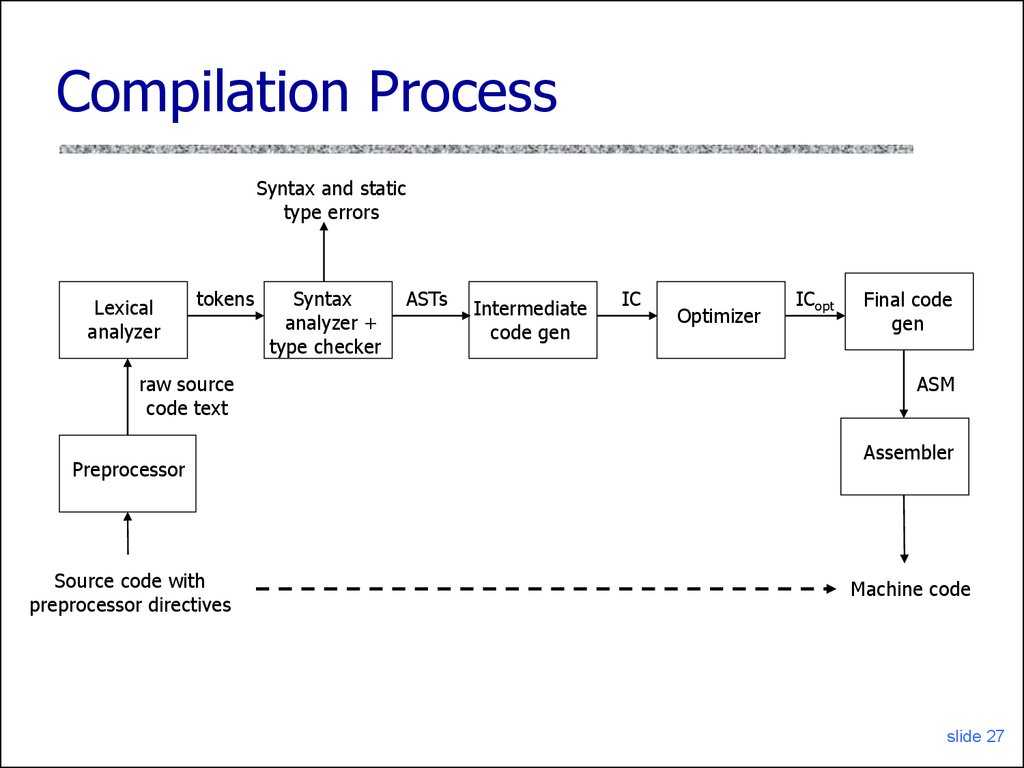
Затем он выдает код для каждого из основных блоков.
Затем измените порядок основных блоков, чтобы исключить безусловные переходы везде, где это возможно.
Полученный код довольно хорош. Явных изменений нет которые программист-человек мог бы сделать, чтобы сделать код быстрее или меньше. Хорошая работа, компилятор!
Здесь показаны все этапы компиляции по порядку вместе с их структуры входных и выходных данных. В совокупности они преобразовать оригинальный исходный код в качественную сборку код. Терпеливое применение оптимизации проходит часто производит код, который более эффективен, чем написание ассемблера язык вручную.
В настоящее время программисты могут сосредоточиться на получении исходного кода код для достижения желаемой функциональности и оставить детали перевода в инструкции в руках компилятора.
Руководство по компилируемым и интерпретируемым языкам программирования — GameDev Academy
Независимо от того, хотите ли вы улучшить свои навыки в области компьютерных наук или погрузиться в новый язык программирования, вы, вероятно, столкнетесь с одним вопросом: компилируемые или интерпретируемые языки.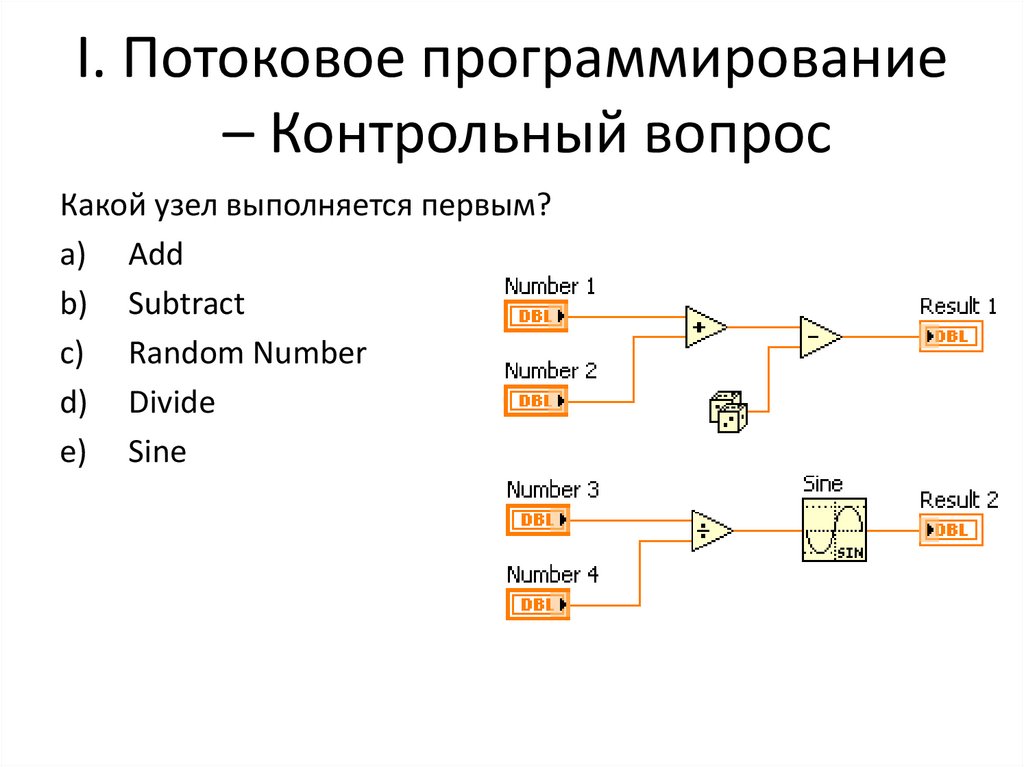 языки. Хотя эти термины часто используются, разница между ними не всегда передается — и почему это важно, когда вы начинаете заниматься программированием.
языки. Хотя эти термины часто используются, разница между ними не всегда передается — и почему это важно, когда вы начинаете заниматься программированием.
В этой статье мы собираемся демистифицировать компилируемые и интерпретируемые языки и помочь вам понять эти важные технические концепции с нуля в надежде, что эти идеи помогут вам выбрать правильный путь программирования для вас.
Содержание
Как работают компьютеры
Первым шагом к пониманию различий между компилируемыми и интерпретируемыми языками программирования является базовое понимание того, как работают компьютеры.
Машинный код и двоичный код
По сути, компьютеры — это просто набор электрических сигналов. Иногда мы отключаем эти сигналы, а иногда включаем их. В некотором смысле вы можете думать об этом как о более элементарной версии азбуки Морзе. И, подобно азбуке Морзе, мы можем присвоить этим электрическим сигналам значения.
В начале этой концепции мы решили присвоить простые значения 0 и 1, чтобы указать, был ли сигнал выключен или включен. Затем мы объединили эти 0 и 1 в последовательности и придали каждой из этих последовательностей значение. Для большинства людей это решение известно как двоичный код , и двоичный код является основной движущей силой машинного кода , который заставляет компьютеры работать на самом базовом уровне.
Затем мы объединили эти 0 и 1 в последовательности и придали каждой из этих последовательностей значение. Для большинства людей это решение известно как двоичный код , и двоичный код является основной движущей силой машинного кода , который заставляет компьютеры работать на самом базовом уровне.
В этот момент, однако, вы можете спросить, зачем проектировать компьютеры именно так? Ну, по сути, для того, чтобы компьютеры работали так же быстро, как они, нам нужны были как можно более простые числовые значения для подачи на ЦП. Без этого компьютеры, вероятно, вечно работали бы так же медленно, как коммутируемый доступ в Интернет, к которому вы пытаетесь получить доступ с удаленного острова. Таким образом, это чистое решение дало нам скорость, необходимую для выполнения всего, что мы делаем на компьютерах.
Что такое язык программирования?
При всем вышесказанном вы, возможно, знаете, что мы обычно не кодируем в двоичном коде. Конечно, вы определенно можете кодировать в двоичном коде (или шестнадцатеричных числах, которые легко преобразуются в двоичные), если вам так хочется. Однако знайте, что это будет большой проблемой!
Конечно, вы определенно можете кодировать в двоичном коде (или шестнадцатеричных числах, которые легко преобразуются в двоичные), если вам так хочется. Однако знайте, что это будет большой проблемой!
Вместо этого люди нашли более простой способ обойти это: языков программирования .
Языки программирования очень похожи на иностранные языки. Они предоставляют нам структурированный словарный запас и «грамматику» (т. Вместо нулей и единиц языки программирования были созданы с расчетом на человека, чтобы мы могли легко читать и писать с их помощью для достижения желаемой функциональности. Теперь здесь необходимы некоторые нюансы, поскольку нам все еще нужно сообщить об этой функциональности таким образом, чтобы он был совместим с компьютерами (то есть машинными инструкциями). Но написать цикл намного проще, чем написать 10 000 двоичных символов для достижения того же эффекта.
Однако, как вы могли догадаться, мы не можем передать этот удобочитаемый язык компьютеру, который действительно понимает только двоичный код.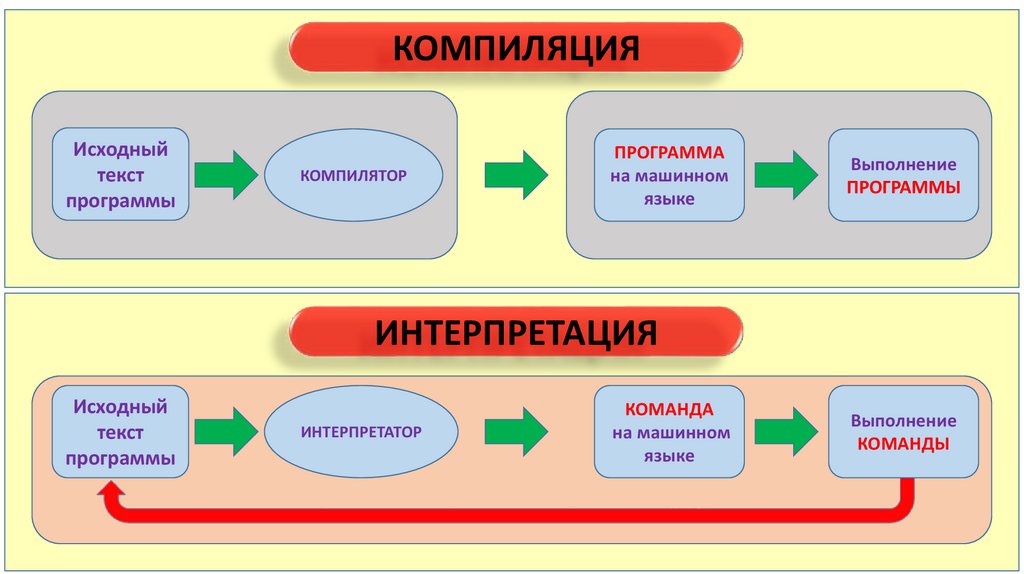 Итак, нам нужен какой-то способ перевести то, что говорит язык программирования, в двоичный формат, который может прочитать компьютер. Возможно, если бы у нас был какой-то способ составить этот перевод или, может быть, даже интерпретировать его на месте?
Итак, нам нужен какой-то способ перевести то, что говорит язык программирования, в двоичный формат, который может прочитать компьютер. Возможно, если бы у нас был какой-то способ составить этот перевод или, может быть, даже интерпретировать его на месте?
Итак, мы подошли к основной теме этой статьи: компилируемые и интерпретируемые языки.
Языки программирования для машинного кода
Вкратце, давайте теперь обрисуем в общих чертах, что такое компилируемый язык и что такое интерпретируемый язык. Имейте в виду, что во многих языках могут использоваться оба типа методов компиляции (пример: Python). Однако, как правило, большинство языков имеют метод псевдо-умолчания, поэтому полезно разделить языки на эти категории. Мы также рассмотрим здесь третью категорию, связанную с переводом кода на машинный язык, которая переплетается с двумя основными: компиляция точно в срок.
Что такое компилируемый язык?
Компилируемый язык программирования — это тот, который использует компилятор для перевода программы в машинный код до времени выполнения .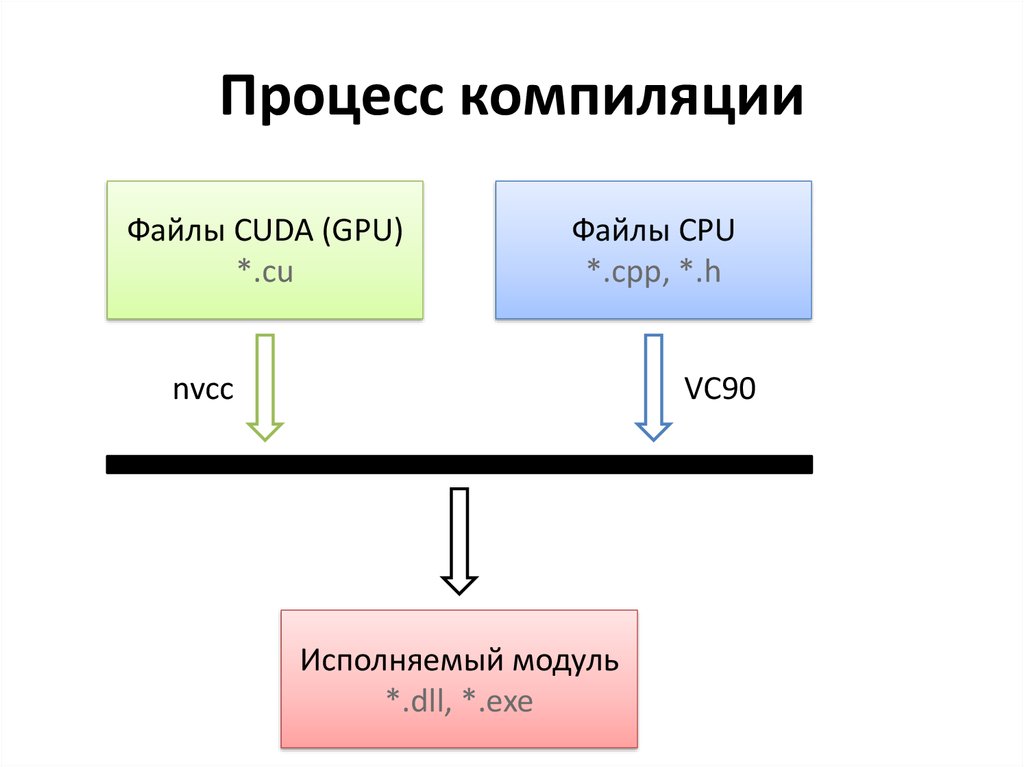 После того, как программа написана, скомпилированные языки проходят этап, который обычно называют «сборкой». Этот шаг сборки в основном инструктирует компилятор, у которого есть инструкции по переводу языка программирования, выполнить свою работу по переводу и создать, по сути, новый файл в двоичном формате. Затем, когда вы выполняете программу, компьютер переходит прямо к этому бинарному файлу и выполняет программу в соответствии с теми скомпилированными инструкциями, которые уже подготовлены для понимания компьютером.
После того, как программа написана, скомпилированные языки проходят этап, который обычно называют «сборкой». Этот шаг сборки в основном инструктирует компилятор, у которого есть инструкции по переводу языка программирования, выполнить свою работу по переводу и создать, по сути, новый файл в двоичном формате. Затем, когда вы выполняете программу, компьютер переходит прямо к этому бинарному файлу и выполняет программу в соответствии с теми скомпилированными инструкциями, которые уже подготовлены для понимания компьютером.
Примеры популярных компилируемых языков: C++, C#, F#, Go, Kotlin, Python (также можно интерпретировать), Rust, Swift
Что такое интерпретируемый язык?
Интерпретируемый язык программирования — это язык, который использует интерпретатор для перевода программы в машинный код во время выполнения . В отличие от скомпилированных языков, которые требуют дополнительного шага «сборки» для работы, интерпретаторы переводят вещи более или менее в режиме реального времени. Таким образом, в ту минуту, когда вы начинаете выполнять свою программу, интерпретатор приступает к работе, переводя вещи построчно прямо здесь и сейчас, без необходимости создавать для этого дополнительные файлы. Думайте об этом как о людях-переводчиках во время больших речей, которые слушают и переводят на язык жестов прямо здесь и сейчас для слабослышащих пользователей.
Таким образом, в ту минуту, когда вы начинаете выполнять свою программу, интерпретатор приступает к работе, переводя вещи построчно прямо здесь и сейчас, без необходимости создавать для этого дополнительные файлы. Думайте об этом как о людях-переводчиках во время больших речей, которые слушают и переводят на язык жестов прямо здесь и сейчас для слабослышащих пользователей.
Примеры популярных интерпретируемых языков: JavaScript, Lua, Perl, PHP, Python (также можно компилировать), Ruby, PowerShell
Что такое JIT-компилятор?
Хотя мы еще не упомянули об этом, существует один тип компиляции, тесно связанный как с компилируемыми, так и с интерпретируемыми языками, о котором стоит поговорить: JIT-компиляторы. Идея компиляторов «точно в срок» состоит в том, чтобы использовать преимущества как компиляторов, так и интерпретаторов (которые мы подробнее обсудим ниже). Такие компиляторы анализируют код во время выполнения и взять наиболее важные части и предварительно перевести их в машинный код. В то время как выполнение замедляется во время анализа, что может происходить часто, общее преимущество позволяет вам обойти некоторые проблемы регулярно интерпретируемых языков — в основном ту часть, где они в целом медленнее.
В то время как выполнение замедляется во время анализа, что может происходить часто, общее преимущество позволяет вам обойти некоторые проблемы регулярно интерпретируемых языков — в основном ту часть, где они в целом медленнее.
Примеры языков, которые могут использовать JIT-компиляторы: Java, C#, Scala, Visual Basic
Компилируемые и интерпретируемые: преимущества и недостатки
Итак, мы понимаем, что означает компилирование и интерпретация на самых фундаментальных уровнях. Однако зачем выбирать один тип языка/метода компиляции другому. В этом разделе мы обрисуем основные преимущества и недостатки между компилируемыми и интерпретируемыми языками.
Скорость выполнения
Чаще всего при обсуждении компилируемых и интерпретируемых языков это может быть первое, с чем вы сталкиваетесь. И на то есть веская причина, так как это обычно является основным решающим фактором для многих разных разработчиков.
Как объяснялось выше, компилируемые языки переводят код перед выполнением, а интерпретируемые языки делают это во время выполнения.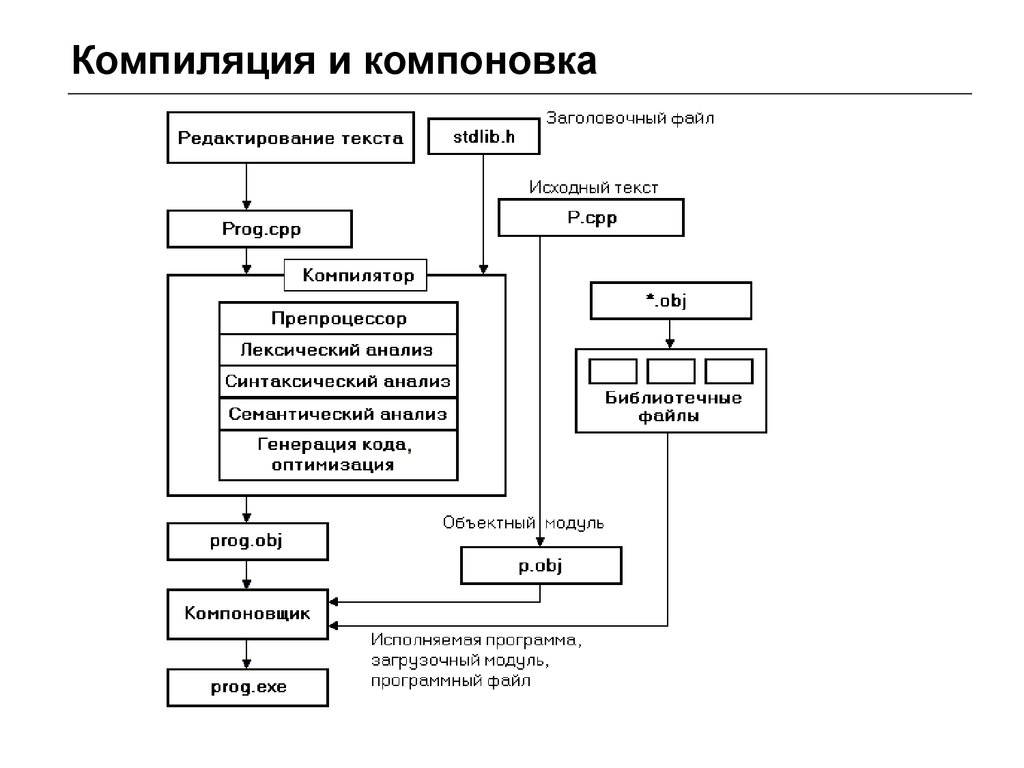 Вы можете думать об этом как об ученике, который делает домашнее задание накануне урока, и ученике, который делает это, пока все сдают свои работы учителю.
Вы можете думать об этом как об ученике, который делает домашнее задание накануне урока, и ученике, который делает это, пока все сдают свои работы учителю.
Поскольку учащийся, который делает это накануне, уже подготовлен, все испытания по сдаче домашнего задания проходят намного быстрее — и то же самое можно сказать о скомпилированном языке. Компьютер уже имеет встроенный машинный код, поэтому ему просто нужно посмотреть нужный файл, чтобы прочитать его. Это ускоряет работу программы, поскольку не нужно выполнять дополнительную работу. По этой же причине во многих играх, которым требуется сверхбыстрое время выполнения, для выполнения своей работы используются скомпилированные языки, такие как C++.
Тем временем ученик, пытающийся закончить домашнюю работу в классе, собирается медленно прокрасться в конец очереди и не сразу сдать работу. Интерпретируемые языки делают то же самое. Так что, по сути, они работают медленнее и просто не выполняют программы так быстро, поскольку переводят в реальном времени.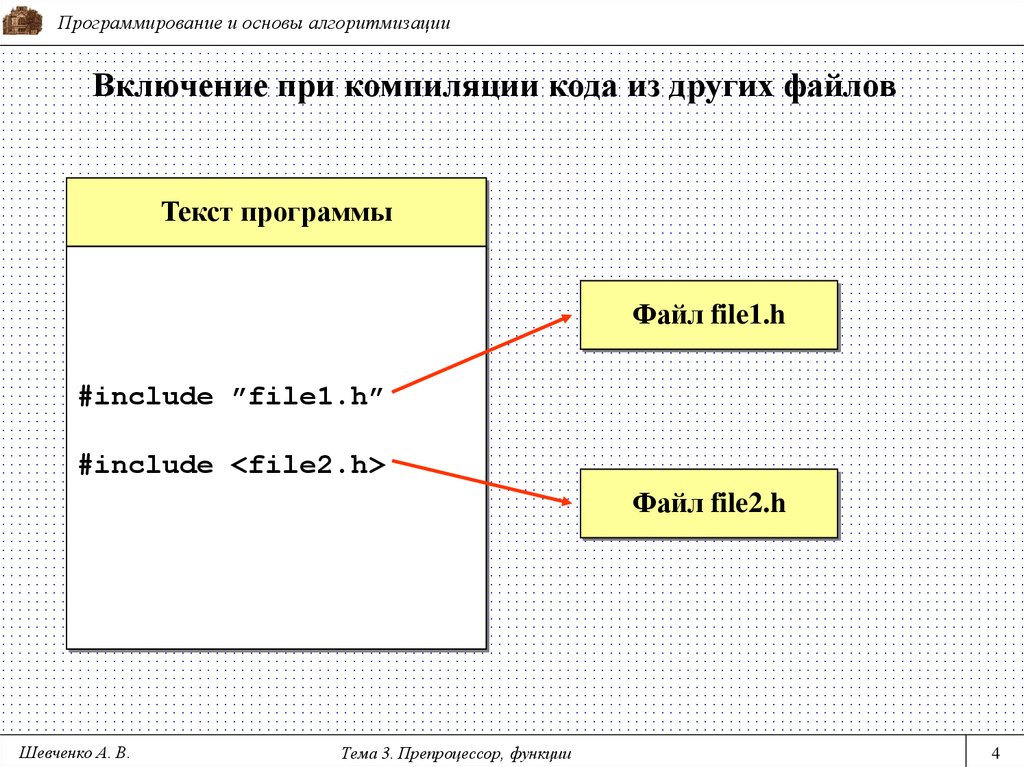 Теперь имейте в виду, что для небольших программ мы говорим о миллисекундах, которые на самом деле не имеют значения для среднего человека. Но для более крупных программ, особенно с большими базами данных, скорость является неотъемлемым условием максимально быстрого выполнения.
Теперь имейте в виду, что для небольших программ мы говорим о миллисекундах, которые на самом деле не имеют значения для среднего человека. Но для более крупных программ, особенно с большими базами данных, скорость является неотъемлемым условием максимально быстрого выполнения.
Шаги компиляции
Существует еще одно отличие «псевдоскорости» в обсуждении компиляции и интерпретации, которое выходит за рамки выполнения: шаги компиляции. Под этим мы подразумеваем, насколько быстро мы можем перейти от необработанного кода к тому, что нужно компьютеру для его выполнения как можно быстрее.
В этом отношении интерпретируемые языки действительно имеют преимущество. Поскольку интерпретируемые языки переводятся во время выполнения, вам как разработчику не нужно предпринимать никаких дополнительных шагов, чтобы перейти от кода к исполнению. Обычно все, что вам нужно сделать, это запустить выполнение, и бум, ваш код запускается и выполняется по команде.
Однако, как было установлено ранее, скомпилированные языки нуждаются в дополнительном шаге «сборки», чтобы перейти от кода к исполняемому приложению.![]() Продолжительность этого шага сборки сильно различается от программы к программе и во многом зависит от сложности. Например, ваш простой скрипт «Hello World», скорее всего, скомпилируется менее чем за 1 секунду. С другой стороны, ваша игра с открытым миром с сотнями персонажей и сценариями, вероятно, займет в лучшем случае несколько минут.
Продолжительность этого шага сборки сильно различается от программы к программе и во многом зависит от сложности. Например, ваш простой скрипт «Hello World», скорее всего, скомпилируется менее чем за 1 секунду. С другой стороны, ваша игра с открытым миром с сотнями персонажей и сценариями, вероятно, займет в лучшем случае несколько минут.
Обе «скорости» можно рассматривать как пару компромиссов. Компилируемые языки жертвуют «скоростью» компиляции ради более быстрого выполнения, а интерпретируемые языки жертвуют скоростью выполнения ради более быстрой компиляции.
Гибкость модификации
Для компилируемых и интерпретируемых языков этот пункт тесно связан с последним пунктом, касающимся компиляции. Когда мы говорим о гибкости модификации, мы говорим о том, как легко программисту отредактировать свой код, а затем повторно запустить его. Это крайне важно обсудить, так как вы будете много переписывать код, независимо от уровня ваших навыков.
Опять же, как и выше, интерпретируемые языки выигрывают здесь преимущество. Поскольку перевод происходит во время выполнения, а реального времени компиляции нет; вы можете отредактировать свой код в любой момент и сразу же вернуться к выполнению. На самом деле, вы даже можете редактировать код в то время как программа работает и не испытывает каких-либо серьезных побочных эффектов! Это действительно так просто.
Поскольку перевод происходит во время выполнения, а реального времени компиляции нет; вы можете отредактировать свой код в любой момент и сразу же вернуться к выполнению. На самом деле, вы даже можете редактировать код в то время как программа работает и не испытывает каких-либо серьезных побочных эффектов! Это действительно так просто.
С скомпилированными языками в любое время если вы измените свой код, даже если просто добавите отсутствующую точку с запятой, вам придется снова скомпилировать программу. Поскольку эта компиляция может занять некоторое время, вы можете себе представить, что это быстро складывается и делает модификацию не самой быстрой или самой гибкой задачей все время. Таким образом, вам нужно быть намного более внимательным, прежде чем снова скомпилировать свои программы, и вы не можете просто редактировать на лету.
Обработка ошибок компиляции
Еще одна проблема, связанная с компиляцией для компилируемых и интерпретируемых языков, — это ошибки. Другими словами, что делает ваш метод компиляции, когда он сталкивается с ошибками компиляции в коде? У этого сложнее сказать, у кого преимущество или недостаток, так как это будет зависеть от , когда вы захотите поймать эти ошибки.
Другими словами, что делает ваш метод компиляции, когда он сталкивается с ошибками компиляции в коде? У этого сложнее сказать, у кого преимущество или недостаток, так как это будет зависеть от , когда вы захотите поймать эти ошибки.
Компилируемые языки полностью не позволят вам скомпилировать что-либо, если есть ошибки кодирования, которые могут повлиять на компиляцию. Как правило, большинство компиляторов просто останавливают процесс трансляции и уведомляют вас о том, почему процесс компиляции не удался. С одной стороны, это делает так, что вы не выполняете программы, которые в любом случае имели бы критические ошибки. Таким образом, это позволяет решать проблемы до того, как они станут проблемами. Однако это может затруднить отладку программ, поскольку вы не можете протестировать выполнение, не исправив определенные ошибки — некоторые ошибки, которые вам может быть трудно найти без этого выполнения.
Интерпретируемые языки позволяют запускать программы с ошибками и просто регистрировать их появление. Таким образом, у него есть то преимущество, что вы можете выполнять всю отладку во время выполнения, и ваша программа будет продолжать работать так, как может в данных обстоятельствах. При этом это также означает, что вы не будете знать об этих ошибках компиляции, пока программа не столкнется с ними. Это может быть хорошо для небольшой программы, но если у вас есть тысячи строк и одна функция вызывается редко, вы можете никогда не увидеть эту ошибку до того, как программа будет запущена.
Таким образом, у него есть то преимущество, что вы можете выполнять всю отладку во время выполнения, и ваша программа будет продолжать работать так, как может в данных обстоятельствах. При этом это также означает, что вы не будете знать об этих ошибках компиляции, пока программа не столкнется с ними. Это может быть хорошо для небольшой программы, но если у вас есть тысячи строк и одна функция вызывается редко, вы можете никогда не увидеть эту ошибку до того, как программа будет запущена.
В общем, все зависит от того, чего вы хотите как разработчик!
Переносимость
Последнее важное преимущество/недостаток, которое следует обсудить для компилируемых и интерпретируемых языков, касается переносимости. В этом отношении мы говорим о том, как легко использовать программу с устройства на устройство.
Это раздел, в котором скомпилированные языки находятся в более невыгодном положении. Одна вещь, которую мы до сих пор не упомянули в этом посте, заключается в том, что при компиляции в машинный код компилятор делает это, ориентируясь на конкретную целевую платформу/процессор. Таким образом, вы не можете просто взять файл, предназначенный для запуска на мобильном телефоне, вставить его в компьютер, и компьютер без проблем выполнит тот же скомпилированный двоичный файл. Для каждой платформы требуется свой уникальный метод компиляции. Итак, если вы хотите, чтобы ваша программа работала на нескольких машинах, вам придется скомпилировать отдельный файл для на каждую целевую платформу — что, очевидно, требует времени.
Таким образом, вы не можете просто взять файл, предназначенный для запуска на мобильном телефоне, вставить его в компьютер, и компьютер без проблем выполнит тот же скомпилированный двоичный файл. Для каждой платформы требуется свой уникальный метод компиляции. Итак, если вы хотите, чтобы ваша программа работала на нескольких машинах, вам придется скомпилировать отдельный файл для на каждую целевую платформу — что, очевидно, требует времени.
Интерпретируемые языки лишены этого недостатка. Поскольку вещи переводятся во время выполнения, они очень независимы от платформы и на самом деле не требуют каких-либо дополнительных шагов для совместимости. Это основная причина, по которой такие языки, как JavaScript, широко используются в Интернете. Поскольку это интерпретируемый язык, он совместим с разными платформами независимо от того, как вы обращаетесь к программе JavaScript. Другие интерпретируемые языки имеют такой же опыт, поэтому для максимальной кроссплатформенности следует учитывать это направление.
Почему скомпилированное и интерпретированное имеет значение
Прежде чем мы закончим этот пост, мы хотим уделить короткое время обсуждению последней части скомпилированного и интерпретируемого пространства: почему это важно.
Разные программы требуют разной скорости выполнения
Мы немного коснулись этого выше, но этот момент стоит повторить. Как ни посмотри, скомпилированные языки выполняются быстрее, даже если процесс компиляции занимает больше времени. И, в зависимости от того, что вы пытаетесь запрограммировать, это может иметь огромные последствия.
Например, обратите внимание на разницу между играми, предназначенными только для браузера, и играми класса AAA, такими как Soulcalibur VI . Большинство браузерных игр создаются с помощью JavaScript, интерпретируемого языка, и поэтому имеют меньший масштаб. Во многом это связано с тем фактом, что интерпретируемые языки несколько ограничивают скорость работы этих игр. Таким образом, чтобы избежать задержек, разработчики должны уменьшить их размер — графически или программно.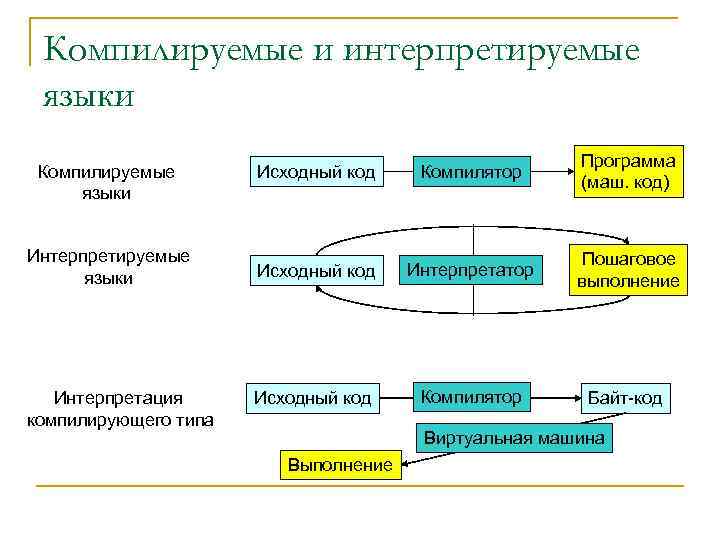
Однако с Soulcalibur VI , здесь гораздо больше возможностей для сложной графики и механики. Поскольку эта игра была основана на C++, скомпилированном языке, игра может использовать преимущества скорости, чтобы обеспечить более полный опыт с интенсивной 3D-графикой, чего вы не могли бы получить в браузерной игре.
В целом, для вас это означает, что вам нужно выбрать язык, который подходит для вашего проекта. Если вы хотите создать огромную MMORPG с открытым миром и 3D-графикой, вам не нужен интерпретируемый язык, поскольку вам нужна скорость. С другой стороны, если вы просто делаете простую викторину и скорость не имеет значения, интерпретируемый язык подойдет, а в некоторых ситуациях может быть даже лучше. Таким образом, это различие очень важно для правильного определения масштаба ваших проектов.
Редактирование кода должно быть быстрее или проще время компиляции. К сожалению, компилируемые языки делают именно это, даже если компиляция вашего проекта занимает менее 1 секунды.
 Иногда вам действительно нужно иметь возможность быстро протестировать определенные функции, строки кода и т. д., чтобы завершить его. А иногда вам может потребоваться выполнить тесты в реальном времени, чтобы убедиться, что определенные данные обрабатываются правильно.
Иногда вам действительно нужно иметь возможность быстро протестировать определенные функции, строки кода и т. д., чтобы завершить его. А иногда вам может потребоваться выполнить тесты в реальном времени, чтобы убедиться, что определенные данные обрабатываются правильно.Если вы чувствуете, что работаете над чем-то, что требует более легкого редактирования на лету, то интерпретируемые языки, вероятно, являются лучшим выбором — и почему важно знать разницу. При этом вы можете выбрать язык, который вы можете выполнить, и убедиться, что любая сложная программа, которую вы пытаетесь создать, действительно работает так, как задумано.
В целом, вы должны понимать разницу между двумя типами компиляции, чтобы сделать правильный выбор для своего проекта.
Кросс-платформенные соображения
Еще одна причина, по которой это различие имеет значение, связана с фактором переносимости, который мы объяснили выше. Если вам нужно что-то, к чему можно легко получить доступ с других устройств, вы можете использовать интерпретируемый код. Таким образом, вам не нужно беспокоиться об определенных факторах, связанных с компилятором, и вы можете сосредоточиться на своем проекте. Это может быть особенно актуально, если вы создаете что-то вроде веб-приложения, где вам нужно быть уверенным, что телефоны и ПК могут легко использовать его из коробки, и вы не засоряете свой сайт несколькими исполняемыми файлами.
Таким образом, вам не нужно беспокоиться об определенных факторах, связанных с компилятором, и вы можете сосредоточиться на своем проекте. Это может быть особенно актуально, если вы создаете что-то вроде веб-приложения, где вам нужно быть уверенным, что телефоны и ПК могут легко использовать его из коробки, и вы не засоряете свой сайт несколькими исполняемыми файлами.
В любом случае, в конце концов, гораздо проще заставить кроссплатформенную программу работать на нескольких устройствах с интерпретируемым языком, чем с компилируемым языком. При этом большинство скомпилированных языков также можно легко сделать кроссплатформенными, поскольку такие программы, как Unity и Unreal Engine (только для примера), поставляются с простыми решениями в один клик, которые позволяют вам создавать свои проекты без лишней суеты. Единственное соображение заключается в том, что это занимает больше времени, так как вам нужно делать отдельные сборки для каждого устройства.
Тем не менее, знание различий поможет вам принять еще одно обоснованное решение о том, какой язык лучше всего подходит для вашего проекта.
Ending Words
Понимание различий между компилируемыми и интерпретируемыми языками, безусловно, может быть важным. Это может повлиять не только на то, какой язык вы выберете для своего проекта в первую очередь, но и на то, как вы работаете с проектом в целом с фактической частью программирования. Кроме того, знание различий дает вам огромное преимущество в области компьютерных наук, поскольку эти ключевые понятия помогут вам погрузиться в другие аспекты работы компьютеров. При этом помните, что и компилируемые, и интерпретируемые языки — это всего лишь инструменты, которые помогут вам достичь определенной цели.
Прежде чем мы закончим, мы хотели бы предоставить вам еще несколько ресурсов ниже, чтобы помочь вам глубже погрузиться в изучение языка программирования и выбрать тот, который подходит именно вам. Однако, независимо от вашего выбора, мы надеемся, что вы лучше подготовлены для программирования проектов своей мечты!
- Лучшие языки программирования для разработки игр
- лучших языков программирования для изучения кода: издание 2021 г.
