Python: String (Строки)
Статья проплачена кошками — всемирно известными производителями котят.
Если статья вам понравилась, то можете поддержать проект.
format
F-strings: новый способ форматирования
Байтовые строки
В Python строки относятся к классу str вместо привычных String в других языках. Полный список методов класса можно узнать через команду:
print(str)
Строки можно обрамлять одинарными или двойными кавычками. Два варианта позволяют вставлять в литералы строк символы кавычек или апострофов, не используя экранирование. В обычных случаях проще использовать одинарные кавычки, которые проще набрать с клавиатуры без использования клавиши Shift.
print("Мурзик")
print('Барсик')
print('Рыжик любил полежать на крыше автомобиля "Жигули"')
Экранированные последовательности позволяют вставить служебные символы, как и во многих языках программирования. Если перед открывающей кавычкой стоит символ
 Но следите за тем, чтобы строка не заканчивалась на символ обратного слеша, иначе потребуется дополнительная обработка.
Но следите за тем, чтобы строка не заканчивалась на символ обратного слеша, иначе потребуется дополнительная обработка.
print("Мурзик\t5 лет") # табуляция
print('Рыжик любил полежать \nна крыше автомобиля "Жигули"') # перевод строки
print(r'D:\cats.txt') # отключение экранирования
Для многострочного текста можно использовать тройные кавычки или апострофы. Внутри строки возможно наличие кавычек и апострофов, но они не должные встречаться три раза подряд.
pushkin = """У лукоморья дуб зелёный; Златая цепь на дубе том: И днём и ночью кот учёный Всё ходит по цепи кругом; Идёт направо - песнь заводит, Налево - сказку говорит.""" print(pushkin)
Длину строки можно узнать через метод len().
str = "cat" print(len(str)) # 3
Склеиваем две строки
Склейка двух строк (concatinate) происходит очень просто через сложение.
str1 = "Hello" str2 = "Kitty" concat = str1 + " " + str2 print(concat)
Метод split(): разбить строку
Разбить строку по указанному разделителю можно через функцию split(). По умолчанию в качестве разделителя используется пробел.
По умолчанию в качестве разделителя используется пробел.
terminator = "I\'ll be back." list = terminator.split() print(list[0]) # I'll
Укажем разделитель явно.
myString = "one|two|three"
list = myString.split("|")
print(list[1])
Можно указать количество учитываемых разделителей.
myString = "one|two|three"
list = myString.split("|", 1)
print(list[1]) # two|three
«Умножаем» строку (повтор)
Довольно неожиданный оператор, который не встречал в других языках. Оказывается, строку можно «умножить». На самом деле, оператор позволяет повторить строку указанное число раз.
str = "cat" repeatedStr = str * 3 print(repeatedStr)
Доступ к отдельному символу можно получить по индексу.
cat = "кот" print(cat[0]) print(cat[1]) print(cat[2])
Можно указывать отрицательные значения, тогда отсчёт пойдёт с конца строки, начиная с -1.
cat = "кот" print(cat[-1]) # т print(cat[-2]) # о print(cat[-3]) # к
Можно получить срез строки, указав начало индекса и конец, который не входит в срез.
cat = "скотина" print(cat[1:4]) # кот
Возможные другие варианты среза. Смотрите примеры.
cat = "скотина" print(cat[1:-3]) # кот print(cat[:4]) # скот print(cat[3:]) # тина print(cat[:]) # скотина
Можно задать шаг, с которым нужно извлекать срез.
cat = "скотина" print(cat[::-1]) # анитокс print(cat[1:6:2]) # ктн print(cat[2::2]) # оиа
Для удаления символов новой строки в конце строки можно использовать метод rstrip(«\r\n») без удаления конечных пробелов:
>>> lines = ("line 1 \r\n"
... "\r\n"
... "\r\n")
>>> lines.rstrip("\r\n")
'line 1 '
Также есть всевозможные функции перевода в верхний/нижний регистр, проверок на наличие цифр и т.
format
Мощная функция с большими возможностями для форматирования строк.
Если для подстановки требуется только один аргумент, то значение — сам аргумент:
print('Hello, {} !'.format('Kitty'))
Другие варианты.
print('{1}, {0}, {2}'.format('Кошка', 'Кот', 'Котёнок')) # Кот, Кошка, Котёнок
print('{}, {}, {}'.format('Кошка', 'Кот', 'Котёнок')) # Кошка, Кот, Котёнок
На самом деле функцию следует изучить по документации, слишком много вариантов.
Во всех примерах мы использовали функцию print() с параметрами по умолчанию. В частности, строка завершается символом перевода строки. Если мы не хотим добавлять этот символ в нашу строку, то используем именованный аргумент
print('Барсик')
print('Мурзик', end='')
print('Васька')
# Результат
Барсик
МурзикВаська
F-strings: новый способ форматирования
Всё же format() не слишком читабелен и удобен при большом количестве параметров. Гораздо приятнее использовать новый способ. Нужно всего лишь подставить символ f перед кавычками и затем просто подставлять имена переменных в фигурных скобках.
Гораздо приятнее использовать новый способ. Нужно всего лишь подставить символ f перед кавычками и затем просто подставлять имена переменных в фигурных скобках.
catName = 'Рыжик'
age = 7
print(f"Моего кота зовут {catName}, ему {age} лет")
Байтовые строки
Байтовые строки очень похожи на обычные строки, но с небольшими отличиями.
Создадим байтовую строку.
b'bytes'
# b'bytes'
'Байты'.encode('utf-8')
# b'\xd0\x91\xd0\xb0\xd0\xb9\xd1\x82\xd1\x8b'
bytes('bytes', encoding = 'utf-8')
# b'bytes'
bytes([50, 100, 76, 72, 41]) # числам от 0 до 255 соответствуют символы как у chr()
# b'2dLH)'
Байтовые строки используют для записи в файл или чтения из него.
Для преобразования в обычную строку используют метод decode().
b'\xd0\x91\xd0\xb0\xd0\xb9\xd1\x82\xd1\x8b'.decode('utf-8')
# 'Байты'
Реклама
22 сниппета на Python для повседневных задач — Разработка на vc.
 ru
ru1686 просмотров
В этой статье хотелось бы поделиться 22 фрагментами кода на Python, которые помогут вам в решении повседневных задач.
1. Прием нескольких входных значений, разделенных пробелами
Этот фрагмент кода позволяет принимать сразу несколько значений вводимых данных, которые разделены пробелами. Он пригодится при решении задач на соревнованиях по программированию.
## Прием двух целых чисел в качестве входных данных a,b = map(int,input().split()) print(«a:»,a) print(«b:»,b) ## Прием списка в качестве входных данных arr = list(map(int,input().split())) print(«Input List:»,arr)
2. Одновременный доступ к индексу и значению
Одновременный доступ к индексу и значению в цикле позволяет получить встроенная функция enumerate():
arr = [2,4,6,3,8,10] for index,value in enumerate(arr): print(f»At Index {index} The Value Is -> {value}») »’Output At Index 0 The Value Is -> 2 At Index 1 The Value Is -> 4 At Index 2 The Value Is -> 6 At Index 3 The Value Is -> 3 At Index 4 The Value Is -> 8 At Index 5 The Value Is -> 10 »’
3. Проверка использования памяти
Проверка использования памяти
Этот фрагмент используется для проверки использования памяти объекта:
import sys a = 20 print(sys.getsizeof(a)) #28
4. Проверка существования файла
Важно знать, существуют ли используемые в коде файлы. Python здорово облегчает управление файлами благодаря встроенному синтаксису для чтения и записи файлов:
# Метод перебора import os.path from os import path def check_for_file(): print(«File exists: «,path.exists(«data.txt»)) if __name__==»__main__»: check_for_file() »’ File exists: False »’
5. Вывод уникального идентификатора переменной
Уникальный идентификатор переменной находится с помощью метода id(). Для этого нужно просто передать в метод имя переменной:
a = 20 name = ‘Karl’ deci = 5.5 print(id(a)) # 2557830785936 print(id(name)) # 2557830785956 print(id(deci)) # 2557830785996
6. Вычисление времени выполнения в оболочке
Иногда важно знать время выполнения в оболочке или в блоке кода для получения лучшего алгоритма с минимальным количеством затраченного им времени:
# МЕТОД 1
import datetime
start = datetime. datetime.now()
«»»
CODE
«»»
print(datetime.datetime.now()-start)
# МЕТОД 2
import time
start_time = time.time()
main()
print(f»Total Time To Execute The Code is {(time.time() — start_time)}» )
# МЕТОД 3
import timeit
code = »’
## Фрагмент кода, чье время выполнения подлежит измерению
[2,6,3,6,7,1,5,72,1].sort()
»’
print(timeit.timeit(stmy = code,number = 1000))
datetime.now()
«»»
CODE
«»»
print(datetime.datetime.now()-start)
# МЕТОД 2
import time
start_time = time.time()
main()
print(f»Total Time To Execute The Code is {(time.time() — start_time)}» )
# МЕТОД 3
import timeit
code = »’
## Фрагмент кода, чье время выполнения подлежит измерению
[2,6,3,6,7,1,5,72,1].sort()
»’
print(timeit.timeit(stmy = code,number = 1000))
7. Цепочка вызовов функций
В Python есть возможность вызывать несколько функций в одной строке:
def add(a,b): return a+b def sub(a,b): return a-b a,b = 9,6 print((sub if a > b else add)(a, b))
8. Перестановка значений
Быстрый способ поменять местами две переменные без использования дополнительной:
a,b = 5,7 # Метод 1 b,a = a,b # Метод 2 def swap(a,b): return b,a swap(a,b)
9. Калькулятор без if-else
Этот фрагмент кода показывает, как просто написать калькулятор без использования каких-либо условных операторов if-else:
import operator
action = {
«+» : operator. add,
«-» : operator.sub,
«/» : operator.truediv,
«*» : operator.mul,
«**» : pow
}
print(action[‘*’](5, 5)) # 25
add,
«-» : operator.sub,
«/» : operator.truediv,
«*» : operator.mul,
«**» : pow
}
print(action[‘*’](5, 5)) # 25
10. Обработка ошибок
В Python, как и в языках Java и C++, имеется способ обработки исключений с помощью блоков try, except и finally:
# Пример 1 try: a = int(input(«Enter a:»)) b = int(input(«Enter b:»)) c = a/b print(c) except: print(«Can’t divide with zero») # Пример 2 try: #если файл не существует, будет выброшено исключение. fileptr = open(«file.txt»,»r») except IOError: print(«File not found») else: print(«The file opened successfully») fileptr.close() # Пример 3 try: fptr = open(«data.txt»,’r’) try: fptr.write(«Hello World!») finally: fptr.close() print(«File Closed») except: print(«Error»)
11. Проверка наличия анаграммы
Анаграмма — это слово, которое образуется путем перестановки букв другого слова, причем каждая буква используется только один раз.
def check_anagram(first_word, second_word): return sorted(first_word) == sorted(second_word) print(check_anagram(«silent», «listen»)) # True print(check_anagram(«ginger», «danger»)) # False
12. Проверка наличия подстрок в строке списка
А вот и задача, с которой мне обычно приходится иметь дело ежедневно: проверять, есть ли в строке подстрока. В отличие от других языков программирования, в Python имеется для этого хорошее ключевое слово:
addresses = [ «12/45 Elm street», ’34/56 Clark street’, ‘56,77 maple street’, ’17/45 Elm street’ ] street = ‘Elm street’ for i in addresses: if street in i: print(i) »’output 12/45 Elm street 17/45 Elm street »’
13. Форматирование строки
Самые важные части кода — это входные данные, логика и выходные данные. Все три части требуют некоторого форматирования при написании кода для получения лучших и более удобных для восприятия человеком выходных данных. В Python имеется целый ряд методов форматирования строки.
name = «Abhay» age = 21 ## МЕТОД 1: конкатенация print(«My name is «+name+», and I am «+str(age)+ » years old.») ## МЕТОД 2: форматированные строки (F-строки в Python 3+) print(f»My name is {name}, and I am {age} years old») ## МЕТОД 3: join print(».join([«My name is «, name, «, and I am «, str(age), » years old»])) ## МЕТОД 4: оператор модуля print(«My name is %s, and I am %d years old.» % (name, age)) ## МЕТОД 5: format (Python 2 и 3) print(«My name is {}, and I am {} years old».format(name, age))Списки
14. Сортировка списка строк
Этот фрагмент кода пригодится, например при упорядочении всех имен студентов в списке:
list1 = [«Karl»,»Larry»,»Ana»,»Zack»] # Метод 1: sort() list1.sort() # Метод 2: sorted() sorted_list = sorted(list1) # Метод 3: метод перебора size = len(list1) for i in range(size): for j in range(size): if list1[i] < list1[j]: temp = list1[i] list1[i] = list1[j] list1[j] = temp print(list1)
15. Генератор списков с If и Else
Генератор списков с If и Else
А этот фрагмент кода будет очень полезен при проведении фильтрации структуры данных на основе некоторых условий:
## List Comprehension with if and else [«Divided by 5″ if i%5=0 else i for i in range(1,20)] ### FizzBuzz Implementation Threw the same [‘FizzBuzz’ if i%3=0 and i%5=0 else ‘Fizz’ if i%3=0 else ‘Buzz’ if i%5=0 else i for i in range(1,20)] »’output [1, 2, ‘Fizz’, 4, ‘Buzz’, ‘Fizz’, 7, 8, ‘Fizz’, ‘Buzz’, 11, ‘Fizz’, 13, 14, ‘FizzBuzz’, 16, 17, ‘Fizz’, 19] »’
16. Сложение элементов двух списков
Допустим, у вас есть два списка, которые надо объединить в один, суммировав их элементы. Это пригодится, например в таком сценарии:
maths = [59, 64, 75, 86]
physics = [78, 98, 56, 56]
# Метод перебора
list1 = [
maths[0]+physics[0],
maths[1]+physics[1],
maths[2]+physics[2],
maths[3]+physics[3]
]
# Генератор списков
list1 = [x + y for x,y in zip(maths,physics)]
# Использование методов map
import operator
all_devices = list(map(operator. add, maths, physics))
# Использование библиотеки Numpy
import numpy as np
list1 = np.add(maths,physics)
»’Output
[137 162 131 142]
»’
add, maths, physics))
# Использование библиотеки Numpy
import numpy as np
list1 = np.add(maths,physics)
»’Output
[137 162 131 142]
»’
17. Самые часто встречающиеся в списке
Этот метод возвращает элементы, появляющиеся в списке наиболее часто:
def most_frequent(nums): return max(set(nums), key = nums.count)
18. Возведение в квадрат всех чисел в заданном диапазоне
В этом фрагменте для нахождения квадрата каждого целого числа в заданном диапазоне прибегнем к помощи встроенной функции itertools:
# МЕТОД 1 from itertools import repeat n = 5 squares = list(map(pow, range(1, n+1), repeat(2))) print(squares) # МЕТОД 2 n = 6 squares = [i**2 for i in range(1,n+1)] print(squares) «»»Output [1, 4, 9, 16, 25] «»»
19. Поиск дублей
Эти фрагменты кода позволяют проверить, есть ли в списке повторяющиеся значения:
def has_duplicates(lst): return len(lst) ≠ len(set(lst)) x = [1,2,2,4,3,5] y = [1,2,3,4,5] has_duplicates(x) # True has_duplicates(y) # False
20. Преобразование двух списков в словарь
Преобразование двух списков в словарь
Здесь используются следующие методы:
list1 = [‘karl’,’lary’,’keera’] list2 = [28934,28935,28936] # Метод 1: zip() dictt0 = dict(zip(list1,list2)) # Метод 2: генераторы словарей dictt1 = {key:value for key,value in zip(list1,list2)} # Метод 3: использование цикла For (не рекомендуется) tuples = zip(list1, list2) dictt2 = {} for key, value in tuples: if key in dictt2: pass else: dictt2[key] = value print(dictt0, dictt1, dictt2, sep = «\n»)
21. Сортировка списка словарей
Бывают задачи, в которых требуется упорядочить список словарей, чтобы получить с помощью ключа отсортированный в определенном порядке список:
dict1 = [
{«Name»:»Karl»,
«Age»:25},
{«Name»:»Lary»,
«Age»:39},
{«Name»:»Nina»,
«Age»:35}
]
## Использование sort()
dict1.sort(key=lambda item: item.get(«Age»))
# Сортировка списка с помощью itemgetter
from operator import itemgetter
f = itemgetter(‘Name’)
dict1. sort(key=f)
# Функция sorted для итерируемых элементов
dict1 = sorted(dict1, key=lambda item: item.get(«Age»))
»’Output
[{‘Age’: 25, ‘Name’: ‘Karl’},
{‘Age’: 35, ‘Name’: ‘Nina’},
{‘Age’: 39, ‘Name’: ‘Lary’}]
»’
sort(key=f)
# Функция sorted для итерируемых элементов
dict1 = sorted(dict1, key=lambda item: item.get(«Age»))
»’Output
[{‘Age’: 25, ‘Name’: ‘Karl’},
{‘Age’: 35, ‘Name’: ‘Nina’},
{‘Age’: 39, ‘Name’: ‘Lary’}]
»’
22. Объединение двух словарей
А этот фрагмент кода пригодится при работе с базами данных и файлами JSON, когда нужно объединить данные из разных файлов или таблиц в общий файл. Объединение двух словарей таит в себе ряд опасностей, например возможность появления повторяющихся ключей. К счастью, у нас есть решения и для этого:
basic_information = {«name»:[‘karl’,’Lary’],»mobile»:[«0134567894″,»0123456789»]}
academic_information = {«grade»:[«A»,»B»]}
details = dict() ## Объединяет словари
## Метод генераторов словарей
details = {key: value for data in (basic_information, academic_information) for key,value in data.items()}
print(details)
## Распаковывание словарей
details = {**basic_information ,**academic_information}
print(details)
## Метод копирования и обновления
details = basic_information. copy()
details.update(academic_information)
print(details)
copy()
details.update(academic_information)
print(details)
В конце статьи хочу сказать, что еще больше полезной и нужной информации вы найдете в моём Telegram-канале. Подпишитесь, мне будет очень приятно.
Оригинал на английском: Abhay Parashar: 22 Python Code Snippets for Everyday Problems
Программа C++ для разделения строки
Обзор
Когда мы разделяем или делим строку, мы делим группу слов или наборов строк на отдельные слова. Однако разделение строк возможно только с определенными разделителями, такими как пробел (), запятая (,), дефис (-) и т. д., что приводит к отдельным словам. Кроме того, не существует предопределенной функции разделения для разделения набора строк на отдельные строки. Итак, в этой статье мы изучим различные способы разделения строк в C++.
Введение
В любом языке программирования работа со строковыми данными является необходимым компонентом. В целях программирования мы иногда разбиваем строковые данные. Многие языки программирования включают функцию split() для разделения строки на несколько частей. В C++ нет встроенной функции split() для разделения строк, но есть множество способов выполнить одну и ту же задачу, например, с помощью функции getline(), функции strtok(), функций find() и erase() и так далее. В этой статье объясняется, как использовать эти функции для разделения строк в C++.
Многие языки программирования включают функцию split() для разделения строки на несколько частей. В C++ нет встроенной функции split() для разделения строк, но есть множество способов выполнить одну и ту же задачу, например, с помощью функции getline(), функции strtok(), функций find() и erase() и так далее. В этой статье объясняется, как использовать эти функции для разделения строк в C++.
Программа для преобразования массива символов в строку с использованием временной строки
Давайте возьмем программу, которая использует временную строку для разбиения данного символа на строки.
Ввод
Вывод
Объяснение
В этой программе мы сохраняем каждый символ arr во временной строке s, пока не найдем разделитель (в данном случае пробел). Как только мы находим разделитель, мы печатаем строку s, а затем используем функцию clear(), чтобы очистить строку s. Мы повторяем процесс, пока не найдем \0.
Программа для преобразования массива символов в строку с использованием API строкового потока C++
Объекты строкового потока могут быть инициализированы строковым объектом, и он автоматически размечает строки символами пробела. Поток строк, как и поток cin, позволяет читать строку как поток слов. Наиболее часто используемые операторы строкового потока следующие:
- Оператор<< :- помещает строковый объект в поток.
- Оператор>> :- извлекает слово из потока.
Примечание: Токенизация строки означает ее разделение по разделителю.
Синтаксис
Программа
Вывод
Объяснение
В этой программе мы создаем объект stringstream ss и запускаем цикл, пока мы не сможем извлечь слово из потока. В каждой итерации цикла мы печатаем слово, извлеченное с помощью оператора >> из потока.
Программа для преобразования массива символов в строку с использованием функции strtok()
Функция strtok() делит исходную строку на фрагменты или токены на основе переданного разделителя. Функция strtok() изменяет исходную строку при каждом вызове, вставляя символ NULL (\0) в позиции разделителя. Это позволяет легко отслеживать статус токена.
Синтаксис
Функция strtok() принимает два параметра:
- string :- Это исходная строка, к которой мы применяем функцию strtok() для разделения.
- разделитель :- Это параметр или символ, на основе которого мы разделяем строку.
- Возврат :- Возвращает указатель на следующие токены символов. Первоначально он указывает на первый токен строк.
Программа
Ввод
Вывод
Объяснение
В этой программе мы создаем указатель char p, указывающий на токен символа, возвращаемый функцией strtok(). После этого мы запускаем цикл до тех пор, пока указатель char не станет равным NULL. На каждой итерации мы печатаем указатель.
После этого мы запускаем цикл до тех пор, пока указатель char не станет равным NULL. На каждой итерации мы печатаем указатель.
Программа для преобразования массива символов в строку с использованием пользовательской функции split()
В этой программе мы настраиваем функцию разделения, которая принимает строку и разделитель для разделения заданной строки.
Программа
Выходные данные
Объяснение
В этой программе мы стремимся создать функцию, которая принимает два параметра, то есть строку и разделитель, на основе которых мы разделить входную строку. В этой программе мы запускаем цикл и проверяем разделитель (мы используем пробел). Когда мы находим разделитель, мы добавляем эту часть строки во временную временную строку. После этого мы соответствующим образом обновляем startIndex и endIndex и помещаем временную строку в вектор строки.
Программа для преобразования массива символов в строку с помощью функции std::getline()
Функция getline() — это функция стандартной библиотеки C++, которая считывает строку из входного потока и вставляет ее в векторную строку до тех пор, пока не будут найдены символы-разделители. Импортируя заголовочный файл
Импортируя заголовочный файл
Синтаксис
Функция getline() принимает три параметра;
- строка :- Это переменная, в которой хранится исходная строка;
- токен : — Сохраняет извлеченные строковые токены из исходной строки.
- разделитель :- Это параметр или символ, на основе которого мы разделяем строку.
Программа
Вывод
Объяснение
В этой программе мы создаем две строки, str и s, и объект stringstream, ss. Объект stringstream ss, строка str и разделитель (пробел) передаются в качестве параметра функции getline, а строка s является входной строкой. На каждой итерации цикла функция getline() возвращает строку в строке str, и мы печатаем эту строку.
Программа для преобразования массива символов в строку с использованием функций find(), substr() и erase()
Substr() — это предопределенная функция в C++, используемая для обработки строковых операций. Эта функция принимает два аргумента, pos и len, и возвращает вновь созданный строковый объект со значением, равным копии подстроки этого объекта. Копирование строки начинается с pos и продолжается до pos+len, что означает [pos, pos+len).
Эта функция принимает два аргумента, pos и len, и возвращает вновь созданный строковый объект со значением, равным копии подстроки этого объекта. Копирование строки начинается с pos и продолжается до pos+len, что означает [pos, pos+len).
Синтаксис
Функция substr() принимает два параметра:
- позиция :- Это позиция первой переменной.
- length :- Длина подстроки, которую мы хотим сгенерировать.
Примечание: substr() возвращает строковый объект, а size_t — целочисленный тип без знака.
Программа
Вывод
Объяснение
В этой программе мы используем функцию find() для поиска первого появления разделителя во входной строке s. Найдя позицию разделителя, мы печатаем подстроку строки s до позиции разделителя. Теперь, используя функцию erase(), мы удаляем эту подстроку из строки и устанавливаем end в качестве следующей позиции разделителя для следующей итерации. Мы запускаем этот цикл до тех пор, пока в строке не останется разделителя.
Мы запускаем этот цикл до тех пор, пока в строке не останется разделителя.
Программа для преобразования массива символов в строку с помощью функции std::regex_token_iterator
Доступный только для чтения LegacyForwardIterator std::regex_token_iterator получает доступ к отдельным подсовпадениям каждого совпадения регулярного выражения в базовой последовательности символов. Его также можно использовать для доступа к сегментам последовательности, которые не соответствуют заданному регулярному выражению (например, в качестве токенизатора). Для разделения строки используется std::sregex_token_iterator, который является подклассом std::regex token iterator
Примечание: Регулярное выражение, также известное как регулярное выражение, представляет собой выражение, содержащее ряд символов, определяющих конкретный шаблон поиска, который можно использовать в алгоритмах поиска строк, алгоритмах поиска или поиска/замены и т. д.
д.
Программа
Вывод
Объяснение
В этой программе мы создаем вектор строк v с помощью функции sregex_token_iterator(). Этот вектор хранит необходимые разделенные строки. Наконец, мы повторяем вектор v, используя цикл for, и печатаем строки на каждой итерации.
Программа для преобразования массива символов в строку с использованием функции find_first_not_of() с функцией find()
Функция find_first_not_of() ищет первый символ в строке, который не соответствует символам, указанным в ее аргументах. В случае успеха возвращается индекс первого несопоставленного символа или string::npos, если такой символ не найден.
Синтаксис
Функция find_first_not_of() принимает два параметра.
- стр :- Другая строка, содержащая символы, которые будут использоваться при поиске.
- idx :- Это номер индекса, из которого мы должны искать первый несопоставленный символ.

Примечание: Константа после функции-члена указывает, что функция find_first_not_of() является константной функцией-членом, и в этой функции-члене никакие элементы данных не изменяются.
Программа
Выход
Объяснение
В этой программе мы используем функцию find_first_not_of(), чтобы найти первую позицию, где разделитель не соответствует символу в строке str. Эта позиция считается начальной позицией подстроки и сохраняется в начальной переменной. Теперь мы используем функцию find(), чтобы найти первую позицию разделителя. Эта позиция будет действовать как конечный индекс подстроки и будет храниться в конечной переменной. Разница между начальной и конечной переменными даст нам длину необходимой подстроки. Используя функцию substr(), мы сохраняем подстроку в векторе v. Повторяем этот процесс до тех пор, пока начальная переменная не будет равна string::npos.
Заключение
- В C++ нет встроенной функции split() для разделения строк, но есть множество способов выполнить одну и ту же задачу, например, используя функцию getline(), функцию strtok(), функции find() и erase() и т. д.
- Функция strtok() делит исходную строку на фрагменты или токены в зависимости от переданного разделителя.
- Функция getline() — это функция стандартной библиотеки C++, которая считывает строку из входного потока и вставляет ее в векторную строку до тех пор, пока не будут найдены символы-разделители.
- Функция substr() возвращает подстроку заданной строки, принимая два параметра.
- Доступный только для чтения LegacyForwardIterator std::regex_token_iterator обращается к отдельным вложенным совпадениям каждого совпадения регулярного выражения в базовой последовательности символов.
- Функция find_first_not_of() ищет первый символ в строке, который не соответствует символам, указанным в ее аргументах.
- Чтобы разбить строку, лучше и проще всего использовать временную строку. Если входная строка имеет длину n, то:
- Временная сложность: O(n)O(n)O(n)
- Вспомогательное пространство: O(n)O(n)O(n)
 д.
д.Читайте также:
- Сравнение двух строк в C++.
- Вектор в C++.

Метод разделения строки Visual Basic
В Visual Basic метод разделения строки полезен для разделения строки на подстрок на основе символов в массиве. Метод split возвращает массив строк, содержащий подстроки, разделенные указанными символами в массиве.
Ниже приведено графическое представление функциональности метода Split на визуальном базовом языке программирования.
Если вы наблюдаете приведенную выше диаграмму, мы разбиваем строку « Суреш-Рохини-Тришика » с разделителем « — », используя 9001 5 Метод разделения . После завершения разделения строки метод split вернет массив строк, как показано на диаграмме выше.
Синтаксис метода разделения строк Visual Basic
Ниже приведен синтаксис определения метода Split в языке программирования Visual Basic.
Открытая функция Split(ByVal separator As Char()) As String()
Если вы соблюдаете приведенный выше синтаксис, мы используем массив символов ( Char() ) для определения разделителей, чтобы разделить данную строку на подстрок и вернуть ее в виде массива строк .
Пример метода разделения строк Visual Basic
Ниже приведен пример разделения заданной строки с разделителем-запятой («,») с использованием метода Split() на визуальном базовом языке программирования.
Module Module1
Sub Main()
Dim msg As String = «Suresh,Rohini,Trishika»
Dim strarr As String () = msg.Split(«,»c)
For i As Integer = 0 To strarr.Length — 1
Console.WriteLine(strarr(i))
Next
Console.WriteLine(«Нажмите клавишу Enter для выхода..»)
Console.ReadLine()
End Sub
End Module
Если вы заметили приведенный выше пример, мы использовали Split () метод для разделения заданной строки («Суреш, Рохини, Тришика») с разделителем-запятой (‘,’) и возврата подстрок в виде массива строк.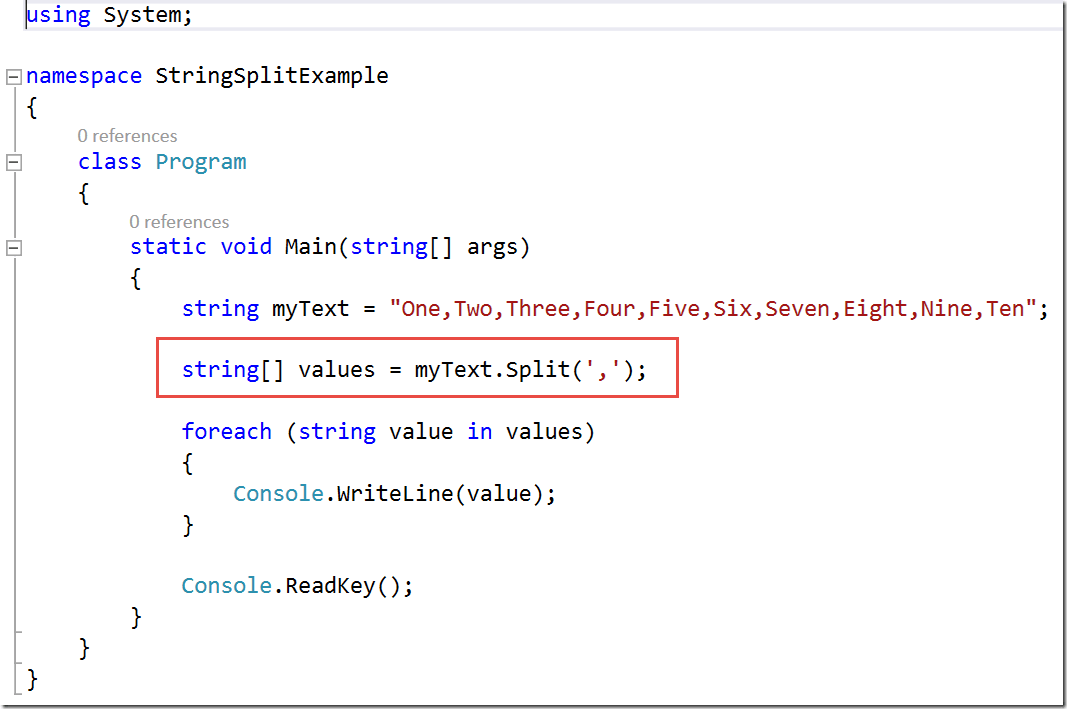 Здесь мы использовали цикл for для перебора массива строк для отображения элементов массива.
Здесь мы использовали цикл for для перебора массива строк для отображения элементов массива.
Когда мы выполним приведенную выше программу Visual Basic, мы получим результат, как показано ниже.
Вот как мы можем разделить строку с необходимыми разделителями, используя метод Split() в визуальном базовом языке программирования.
Visual Basic Разделить строку с несколькими разделителями
В приведенном выше примере мы использовали только один разделитель-запятую с методом Split() для разделения заданной строки. Мы также можем использовать несколько разделителей с помощью метода Split() , чтобы разделить заданную строку, и мы можем удалить пустые индексы в массиве строк.
Ниже приведен пример разделения заданной строки несколькими разделителями на визуальном базовом языке программирования.
Module Module1
Sub Main()
Dim msg As String = «Suresh,Rohini,Trishika,-Praven%Sateesh»
Dim strarr As String() = msg. Split(New Char() {«,»c, «-«c, «%»c}, StringSplitOptions.RemoveEmptyEntries)
Split(New Char() {«,»c, «-«c, «%»c}, StringSplitOptions.RemoveEmptyEntries)
For i As Integer = 0 To strarr.Length — 1
Console.WriteLine (страрр (я))
Next
Console.WriteLine(«Нажмите клавишу Enter для выхода..»)
Console.ReadLine()
End Sub
End Module 900 05
Если вы наблюдаете приведенный выше пример, мы использовали метод Split() с несколькими разделителями для разделения данной строки на массив строк.
Здесь свойство StringSplitOptions.RemoveEmptyEntries полезно для удаления пустых строковых элементов при возврате результирующего массива.
Когда мы выполним приведенную выше программу Visual Basic, мы получим результат, как показано ниже.
Вот как мы можем разделить данную строку с несколькими разделителями, используя метод Split() в языке программирования Visual Basic.
Visual Basic Разделить строку на список
Как правило, метод Разделить в Visual Basic возвращает результат в виде массива строк. В случае, если мы хотим вернуть результат в виде списка, мы можем преобразовать массив строк в список, используя Список объектов.
Ниже приведен пример возврата результата метода разделения в виде списка на визуальном базовом языке программирования.
Module Module1
Sub Main()
Dim msg As String = «Suresh,Rohini,Trishika,-Praven%Sateesh»
Затемнить список As IList(Of String) = New List(Of String)(msg.Split(New Char() {«,»c, «-«c, «%»c}, StringSplitOptions.RemoveEmptyEntries))
For i As Integer = 0 To list.Count — 1
Console.WriteLine(list(i))
Next
Console.WriteLine(«Нажмите клавишу Enter для выхода..»)
Console.ReadLine() 9000 5
End Sub
End Module
Если вы наблюдаете приведенный выше пример, мы преобразуем результат массива строк метода Split в список list с использованием объекта List .