Моделирование данных: обзор / Хабр
В работе мы с коллегами часто видим как компании сталкиваются с проблемой управления данными – когда таблиц и запросов становится сильно много и управлять всем этим очень сложно. В таких ситуациях мы рекомендуем моделировать данные. Чтобы разобраться, что это такое – я перевела статью-обзор про моделирование данных от Towards Data Science, в которой кроме основных терминов и понятий можно найти наглядный пример использования моделирования данных в ритейле. Вперед под кат!
Если вы посмотрите на любое программное приложение, то увидите, что на фундаментальном уровне оно занимается организацией, обработкой и представлением данных для выполнения бизнес-требований.
Модель данных — это концептуальное представление для выражения и передачи бизнес-требований. Она наглядно показывает характер данных, бизнес-правила, управляющие данными, и то, как данные будут организованы в базе данных.
Моделирование данных можно сравнить со строительством дома. Допустим, компании ABC необходимо построить дом для гостей (база данных). Компания вызывает архитектора (разработчик моделей данных) и объясняет требования к зданию (бизнес-требования). Архитектор (модельер данных) разрабатывает план (модель данных) и передает его компании ABC. Наконец, компания ABC вызывает инженеров-строителей (администраторов баз данных и разработчиков баз данных) для строительства дома.
Допустим, компании ABC необходимо построить дом для гостей (база данных). Компания вызывает архитектора (разработчик моделей данных) и объясняет требования к зданию (бизнес-требования). Архитектор (модельер данных) разрабатывает план (модель данных) и передает его компании ABC. Наконец, компания ABC вызывает инженеров-строителей (администраторов баз данных и разработчиков баз данных) для строительства дома.
Ключевые термины в моделировании данных
Сущности и атрибуты. Сущности — это «вещи» в бизнес-среде, о которых мы хотим хранить данные, например, продукты, клиенты, заказы и т.д. Атрибуты используются для организации и структурирования данных. Например, нам необходимо хранить определенную информацию о продаваемых нами продуктах, такую как отпускная цена или доступное количество. Эти фрагменты данных являются атрибутами сущности Product. Сущности обычно представляют собой таблицы базы данных, а атрибуты — столбцы этих таблиц.
Взаимосвязь.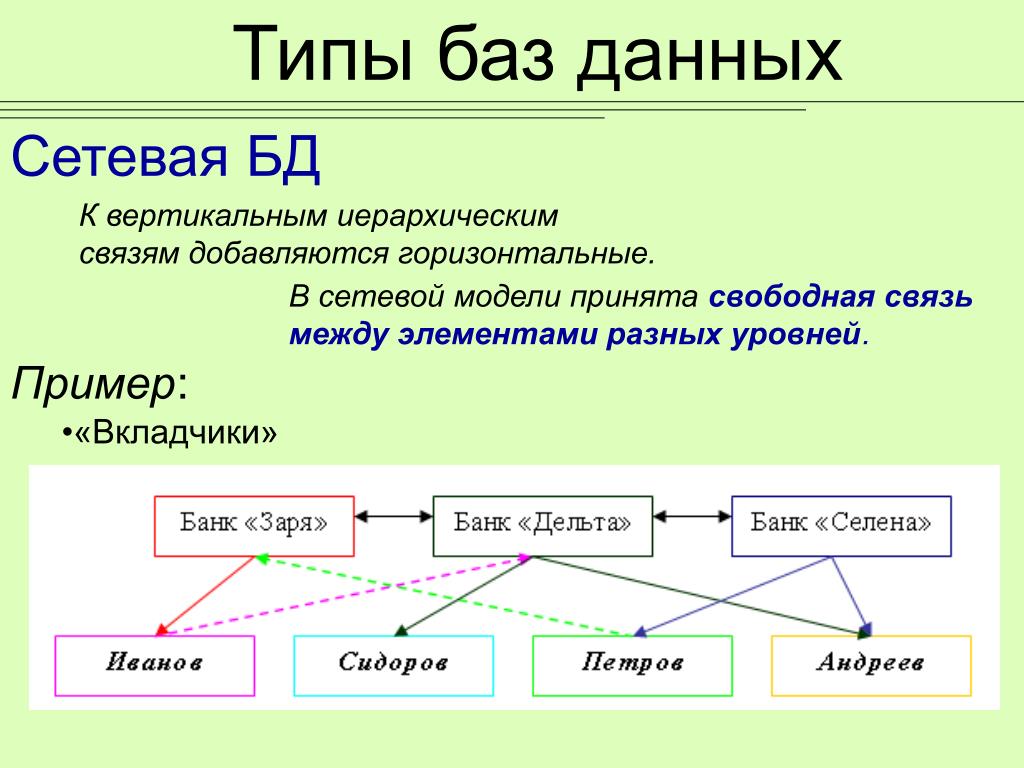 Взаимосвязь между сущностями описывает, как одна сущность связана с другой. В модели данных сущности могут быть связаны как: «один к одному», «многие к одному» или «многие ко многим».
Взаимосвязь между сущностями описывает, как одна сущность связана с другой. В модели данных сущности могут быть связаны как: «один к одному», «многие к одному» или «многие ко многим».
Сущность пересечения. Если между сущностями есть связь типа «многие ко многим», то можно использовать сущность пересечения, чтобы декомпозировать эту связь и привести ее к типу «многие к одному» и «один ко многим».
Простой пример: есть 2 сущности — телешоу и человек. Каждое телешоу может смотреть один или несколько человек, в то время как человек может смотреть одно или несколько телешоу.
Эту проблему можно решить, введя новую пересекающуюся сущность «Просмотр записи»:
ER диаграмма показывает сущности и отношения между ними. ER-диаграмма может принимать форму концептуальной модели данных, логической модели данных или физической модели данных.
Концептуальная модель данных включает в себя все основные сущности и связи, не содержит подробных сведений об атрибутах и часто используется на начальном этапе планирования. Пример:
Пример:
Логическая модель данных — это расширение концептуальной модели данных. Она включает в себя все сущности, атрибуты, ключи и взаимосвязи, которые представляют бизнес-информацию и определяют бизнес-правила. Пример:
Физическая модель данных включает в себя все необходимые таблицы, столбцы, связи, свойства базы данных для физической реализации баз данных. Производительность базы данных, стратегия индексации, физическое хранилище и денормализация — важные параметры физической модели. Пример:
Основные этапы моделирования данных:
Реляционное vs размерное моделирование
В зависимости от бизнес-требований ваша модель данных может быть реляционной или размерной. Реляционная модель — это метод проектирования, направленный на устранение избыточности данных. Данные делятся на множество дискретных сущностей, каждая из которых становится таблицей в реляционной базе данных. Таблицы обычно нормализованы до 3-й нормальной формы. В OLTP приложениях используется эта методология.
В размерной модели данные денормализованы для повышения производительности. Здесь данные разделены на измерения и факты и упорядочены таким образом, чтобы пользователю было легче извлекать информацию и создавать отчеты.
Кейс
Компания ABC имеет 200 продуктовых магазинов в восьми городах. В каждом магазине есть разные отделы, такие как «Товары повседневного спроса», «Косметика», «Замороженные продукты», «Молочные продукты» и т.д. В каждом магазине на полках находится около 20 000 отдельных товаров. Отдельные продукты называются складскими единицами (SKU). Около 6 000 артикулов поступают от сторонних производителей и имеют штрих-коды, нанесенные на упаковку продукта. Эти штрих-коды называются универсальными кодами продукта (UPC). Данные собираются POS-системой в 2 местах: у входной двери для покупателей, и у задней двери, где поставщики осуществляют доставку.
В продуктовом магазине менеджмент занимается логистикой заказа, хранением и продажами продуктов. Также продолжают расти рекламные активности, такие как временные скидки, реклама в газетах и т. д.
д.
Разработайте модель данных для анализа операций этой продуктовой сети.
Решение
Шаг 1. Сбор бизнес-требований
Руководство хочет лучше понимать покупки клиентов, фиксируемые POS-системой. Модель должна позволять анализировать, какие товары продаются, в каких магазинах, в какие дни и по каким акционным условиям. Кроме того, это складская среда, поэтому необходима размерная модель.
Шаг 2: Идентификация сущностей
В случае размерной модели нам необходимо идентифицировать наши факты и измерения. Перед разработкой модели необходимо уточнить объем требуемых данных. Согласно требованию, нам нужно видеть данные о конкретном продукте в определенном магазине в определенный день по определенной схеме продвижения. Это дает нам представление о необходимых сущностях:
Date Dimension
Product Dimension
Store Dimension
Promotion Dimension
Количество, которое необходимо рассчитать (например, объем продаж, прибыль и т. д), будет отражено в таблице с фактическими продажами.
д), будет отражено в таблице с фактическими продажами.
Шаг 3: Концептуальная модель данных
Предварительная модель данных будет создана на основе информации, собранной о сущностях. В нашем случае она будет выглядеть так:
Шаг 4: Доработка атрибутов и создание логической модели данных
Теперь необходимо завершить работу над атрибутами для сущностей. В нашем случае дорабатываются следующие атрибуты:
Date Dimension:
Product:
Store:
Promotion:
Sales Fact:
Номер транзакции.
Объем продаж (например, количество банок овощного супа с лапшой).
Сумма продаж в долларах: количество продаж * цена за единицу.
Стоимость в долларах: стоимость продукта, взимаемая поставщиком.
Сумма валовой прибыли в долларах: доход от продаж — затраты.
Логическая модель данных будет выглядеть так:
Шаг 5: Создание физических таблиц в базе данных
С помощью инструмента моделирования данных или с помощью кастомных скриптов теперь можно создавать физические таблицы в базе данных.
Думаю, теперь стало достаточно очевидно, что моделирование данных — одна из важнейших задач при разработке программного приложения. И оно закладывает основу для организации, хранения, извлечения и представления данных.
Модели баз данных
0 ∞- Основные виды баз данных и их модели
- Модели баз данных — иерархическая база данных
- Иерархическая база данных — пример
- Сетевая модель базы данных
- Реляционная модель базы данных
- Сравниваем три модели баз данных
- «Один к одному»
- «Один ко многим»
- «Многие ко многим»
- Другие модели баз данных (ООСУБД)
СУБД используют различные модели баз данных. Самые старые системы можно разделить на иерархические и сетевые базы данных — это пререляционные модели.
Иерархическая модель базы данных подразумевает, что элементы организованы в структуры, связанные между собой иерархическими или древовидными связями. Родительский элемент может иметь несколько дочерних элементов. Но у дочернего элемента может быть только один предок.
Родительский элемент может иметь несколько дочерних элементов. Но у дочернего элемента может быть только один предок.
«Система управления информацией» (Information Management System) компании IMB — пример иерархической СУБД.
Иерархическая модель данных организует их в форме дерева с иерархией родительских и дочерних сегментов. Такая модель подразумевает возможность существования одинаковых (преимущественно дочерних) элементов. Данные здесь хранятся в серии записей с прикреплёнными к ним полями значений. Модель собирает вместе все экземпляры определённой записи в виде «типов записей» — они эквивалентны таблицам в реляционной модели, а отдельные записи — столбцам таблицы. Для создания связей между типами записей иерархическая модель использует отношения типа «родитель-потомок» вида 1:N. Это достигается путём использования древовидной структуры — она «позаимствована» из математики, как и теория множеств, используемая в реляционной модели.
Будем считать, что в рамках данной статьи примером иерархической базы данных является организация, хранящая информацию о своём работнике: имя, номер сотрудника, отдел и зарплату.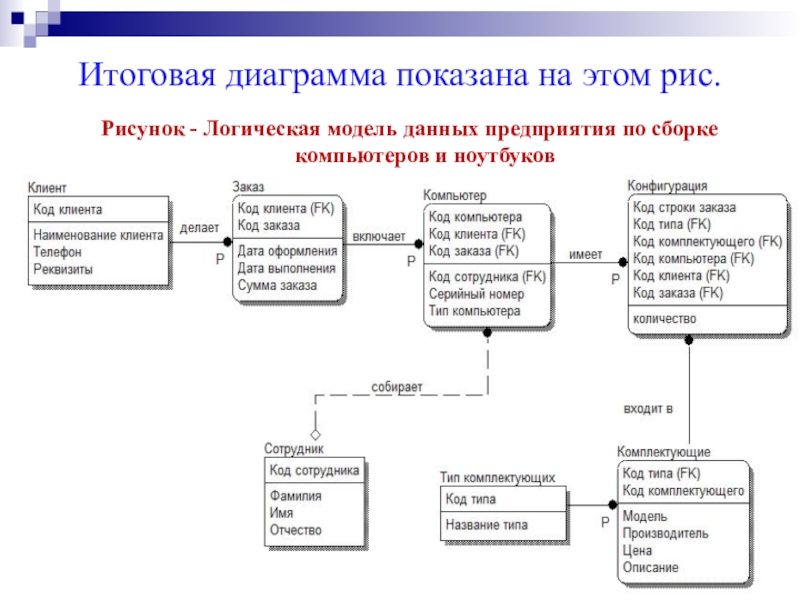 Организация также может хранить информацию о его детях, их имена и даты рождения.
Организация также может хранить информацию о его детях, их имена и даты рождения.
Данные о сотруднике и его детях формируют иерархическую структуру, где информация о сотруднике – это родительский элемент, а информация о детях — дочерний элемент. Если у сотрудника три ребёнка, то с родительским элементом будут связаны три дочерних. Иерархическая база данных подразумевает, что отношение «родитель-потомок» — это отношение «один ко многим». То есть у дочернего элемента не может быть больше одного предка.
Иерархические БД были популярны, начиная с конца 1960-х годов, когда компания IBM представила свою СУБД «Система управления информацией. Иерархическая схема состоит из типов записей и типов «родитель-потомок»:
- Запись — это набор значений полей.
- Записи одного типа группируются в типы записей.
- Отношения «родитель-потомок» — это отношения вида 1:N между двумя типами записей.
- Иерархическая база данных данных состоит из нескольких иерархических схем.


Сетевая модель базы данных подразумевает, что у родительского элемента может быть несколько потомков, а у дочернего элемента — несколько предков. Записи в такой модели связаны списками с указателями. IDMS («Интегрированная система управления данными») от компании Computer Associates international Inc. — пример сетевой СУБД.
Иерархическая модель данных структурирует данные в виде древа записей, где есть один родительский элемент и несколько дочерних. Сетевая модель позволяет иметь несколько предков и потомков, формирующих решётчатую структуру.
Сетевая модель позволяет более естественно моделировать отношения между элементами. И хотя эта модель широко применялась на практике, она так и не стала доминантной по двум основным причинам. Во-первых, компания IBM решила не отказываться от иерархической модели в расширениях для своих продуктов, таких как IMS и DL/I. Во-вторых, через некоторое время её сменила реляционная модель, предлагавшая более высокоуровневый, декларативный интерфейс.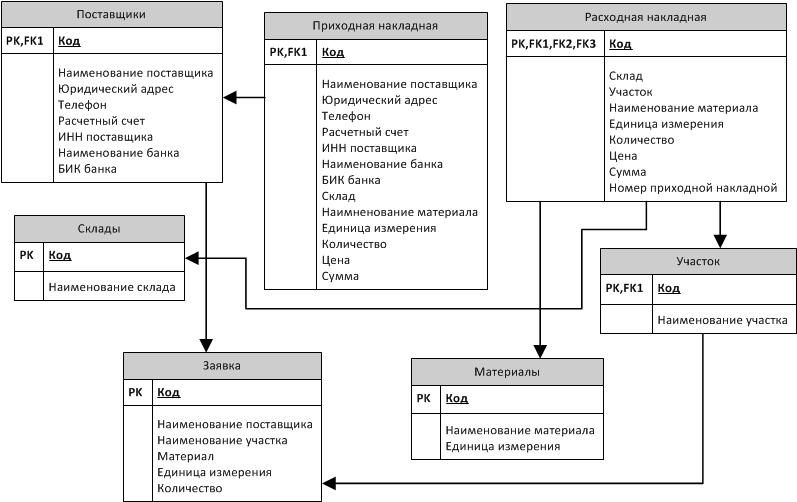
Популярность сетевой модели совпала с популярностью иерархической модели. Некоторые данные намного естественнее моделировать с несколькими предками для одного дочернего элемента. Сетевая модель как раз и позволяла моделировать отношения «многие ко многим». Её стандарты были формально определены в 1971 году на конференции по языкам систем обработки данных (CODASYL).
Основной элемент сетевой модели данных — набор, который состоит из типа «запись-владелец», имени набора и типа «запись-член». Запись подчинённого уровня («запись-член») может выполнять свою роль в нескольких наборах. Соответственно, поддерживается концепция нескольких родительских элементов.
Запись старшего уровня («запись-владелец») также может быть «членом» или «владельцем» в других наборах. Модель данных — это простая сеть, связи, типы пересечения записей (в IDMS они называются junction records, то есть «перекрёстные записи). А также наборы, которые могут их объединять. Таким образом, полная сеть представлена несколькими парными наборами.
В каждом из них один тип записи является «владельцем» (от него отходит «стрелка» связи), и один или более типов записи являются «членами» (на них указывает «стрелка»). Обычно в наборе существует отношение 1:М, но разрешено и отношение 1:1. Сетевая модель данных CODASYL основана на математической теории множеств.
Известные сетевые базы данных:
- TurboIMAGE;
- IDMS;
- Встроенная RDM;
- Серверная RDM.
В реляционной модели, в отличие от иерархической или сетевой, не существует физических отношений. Вся информация хранится в виде таблиц (отношений), состоящих из рядов и столбцов. А данные двух таблиц связаны общими столбцами, а не физическими ссылками или указателями. Для манипуляций с рядами данных существуют специальные операторы.
В отличие от двух других типов СУБД, в реляционных моделях данных нет необходимости просматривать все указатели, что облегчает выполнение запросов на выборку информации по сравнению с сетевыми и иерархическими СУБД.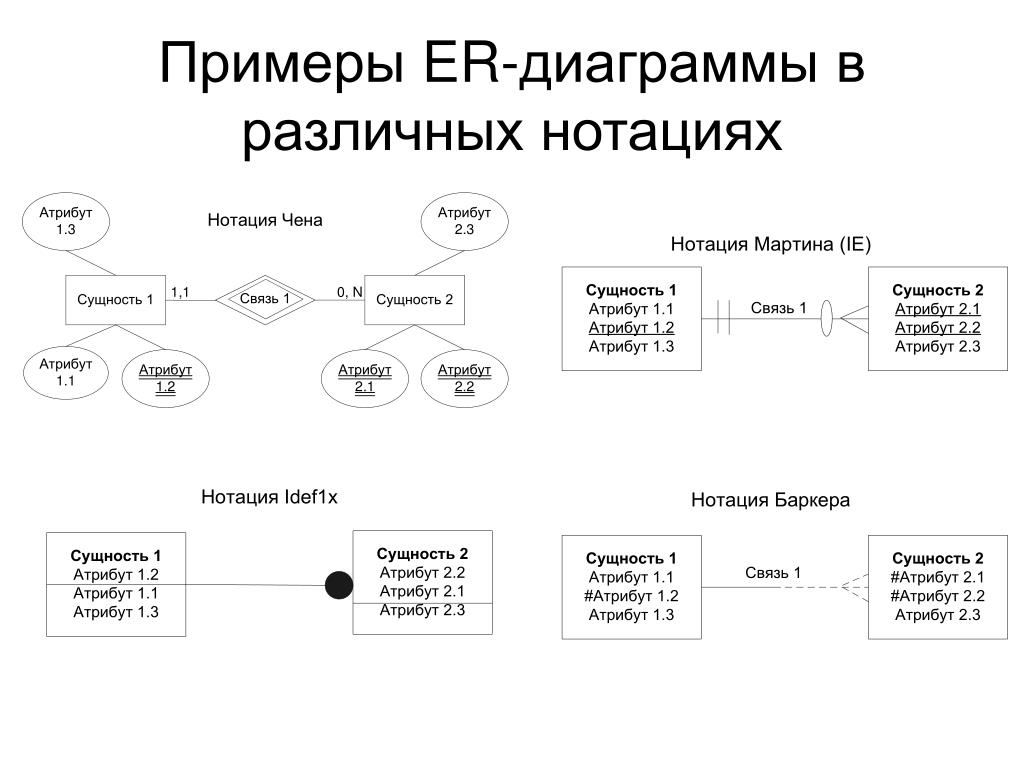 Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle, Sybase, DB2, Ingres, Informix и MS-SQL Server.
Это одна из основных причин, почему реляционная модель оказалась более удобна. Распространённые реляционные СУБД: Oracle, Sybase, DB2, Ingres, Informix и MS-SQL Server.
«В реляционной модели, как объекты, так и их отношения представлены только таблицами, и ничем более».
РСУБД — реляционная система управления базами данных, основанная на реляционной модели Э. Ф. Кодда. Она позволяет определять структурные аспекты данных, обработки отношений и их целостности. В такой базе информационное наполнение и отношения внутри него представлены в виде таблиц — наборов записей с общими полями.
Реляционные таблицы обладают следующими свойствами:
- Все значения атомарны.
- Каждый ряд уникален.
- Порядок столбцов не важен.
- Порядок рядов не важен.
- У каждого столбца есть своё уникальное имя.
Некоторые поля могут быть определены как ключевые. Это значит, что для ускорения поиска конкретных значений будет использоваться индексация. Когда поля двух различных таблиц получают данные из одного набора, можно использовать оператор JOIN для выбора связанных записей двух таблиц, сопоставив значения полей.
Часто у полей будет одно и то же имя в обеих таблицах. Например, таблица «Заказы» может содержать пары «ID-покупателя» и «код-товара». А в таблице «Товар» могут быть пары «код-товара» и «цена». Поэтому чтобы рассчитать чек для определённого покупателя, необходимо суммировать цену всех купленных им товаров, использовав JOIN в полях «код-товара» этих двух таблиц. Такие действия можно расширить до объединения нескольких полей в нескольких таблицах.
Поскольку отношения здесь определяются только временем поиска, реляционные базы данных классифицируются как динамические системы.
Первая, иерархическая модель данных, имеет древовидную структуру («родитель-потомок»), и поддерживает только отношения типа «один к одному» или «один ко многим». Эта модель позволяет быстро получать данные, но не отличается гибкостью. Иногда роль элемента (родителя или потомка) неясна и не подходит для иерархической модели.
Вторая, сетевая модель данных, имеет более гибкую структуру, чем иерархическая модель данных, и поддерживает отношения «многие ко многим». Но быстро становится слишком сложной и неудобной для управления.
Но быстро становится слишком сложной и неудобной для управления.
Третья модель — реляционная — более гибкая, чем иерархическая и проще для управления, чем сетевая. Реляционная модель сегодня используется чаще всего.
Объект в реляционной модели баз данных определяется как позиция информации, хранимой в базе данных. Объект может быть осязаемым или неосязаемым. Примером осязаемого объекта может быть сотрудник организации, а примером неосязаемой сущности — учётная запись покупателя. Объекты определяются атрибутами — информационным отображением свойств объекта. Эти атрибуты также известны как столбцы, а группа столбцов — как ряд. Ряд также можно определить как экземпляр объекта.
Объекты связываются отношениями, основные типы которых можно определить следующим образом:
В этом виде отношений один объект связан с другим. Например, Менеджер -> Отдел.
У каждого менеджера может быть только один отдел, и наоборот.
В моделях данных отношение одного объекта с несколькими. Например, Сотрудник -> Отдел.
Например, Сотрудник -> Отдел.
Каждый сотрудник может быть только в одном отделе, но в самом отделе может быть больше одного сотрудника.
В заданный момент времени объект может быть связан с любым другим. Например, Сотрудник -> Проект.
Сотрудник может участвовать в нескольких проектах, и каждый проект может объединять несколько сотрудников.
В реляционной модели объекты и их отношения представлены двухмерным массивом или таблицей.
Каждая таблица представляет объект.
Каждая таблица состоит из рядов и столбцов.
Отношения между объектами представлены столбцами.
Каждый столбец представляет атрибут объекта.
Значения столбцов выбираются из области или набора всех возможных значений.
Столбцы, которые используются для связи объектов, называются ключевыми. Есть два типа ключей — первичные и внешние.
Первичные служат для однозначного определения объекта. Внешний ключ — это первичный ключ одного объекта, существующий как атрибут в другой таблице.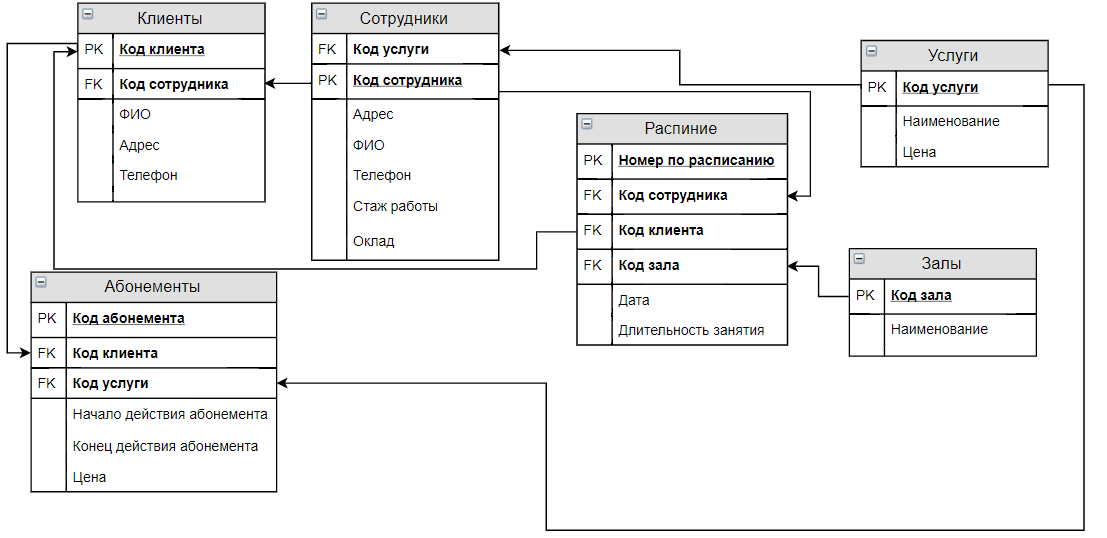
Преимущества реляционной модели данных:
- Простота использования.
- Гибкость.
- Независимость данных.
- Безопасность.
- Простота практического применения.
- Слияние данных.
- Целостность данных.
Недостатки:
- Избыточность данных.
- Низкая производительность.
В последнее время на рынке СУБД появились продукты, представленные объектными и объектно-ориентированной моделью данных, такие как Gem Stone и Versant ОСУБД. Также производятся исследования в области многомерных и логических моделей данных.
Особенности объектно-ориентированных систем управления базами данных (ООСУБД):
- При интеграции возможностей базы данных с объектно-ориентированным языком программирования получается объектно-ориентированная СУБД.
- ООСУБД представляет данные как объекты одного или нескольких языков программирования.
- Такая система должна отвечать двум критериям: являться СУБД и должна быть объектно-ориентированной. То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
- ООСУБД дают возможность моделирования данных в виде объектов.
 То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.
То есть должна насколько это возможно соответствовать современным объектно-ориентированным языкам программирования. Первый критерий подразумевает: длительное хранение данных, управление вторичным хранилищем, параллельный доступ к данным, возможность восстановления, а также поддержку нерегламентированных запросов. Второй критерий подразумевает: сложные объекты, идентичность объектов, инкапсуляцию, типы или классы, механизм наследования, переопределение в сочетании с динамическим связыванием, расширяемость и вычислительную полноту.А также поддержку классов объектов и наследование свойств и методов классов подклассами и их объектами.
На данный момент не существует общепринятого стандарта ООСУБД. Считается, что подобные модели данных находится на ранней стадии развития.
Примеры ООСУБД:
- D Gemstone;
- IRS;
- ORION;
- ONTOS.
Применение ООСУБД:
- В конструкторских и рассредоточенных базах данных, телекоммуникации, а также в таких научных областях, как физика высоких энергий и молекулярная биология.
- Используются в специализированных областях финансового сектора.
- Во встроенных системах, пакетном программном обеспечении и системах реального времени, чтобы у пользователей была возможность создавать объекты по своему выбору.

МКМихаил Кузнецовавтор-переводчик статьи «Types of Database Models | Database Management System»
Пожалуйста, опубликуйте свои отзывы по текущей теме материала. За комментарии, лайки, дизлайки, подписки, отклики огромное вам спасибо!
Что такое моделирование данных? | ИБМ
Что такое моделирование данных?
Моделирование данных — это процесс создания визуального представления либо всей информационной системы, либо ее частей для связи между точками данных и структурами. Цель состоит в том, чтобы проиллюстрировать типы данных, которые используются и хранятся в системе, отношения между этими типами данных, способы группировки и организации данных, а также их форматы и атрибуты.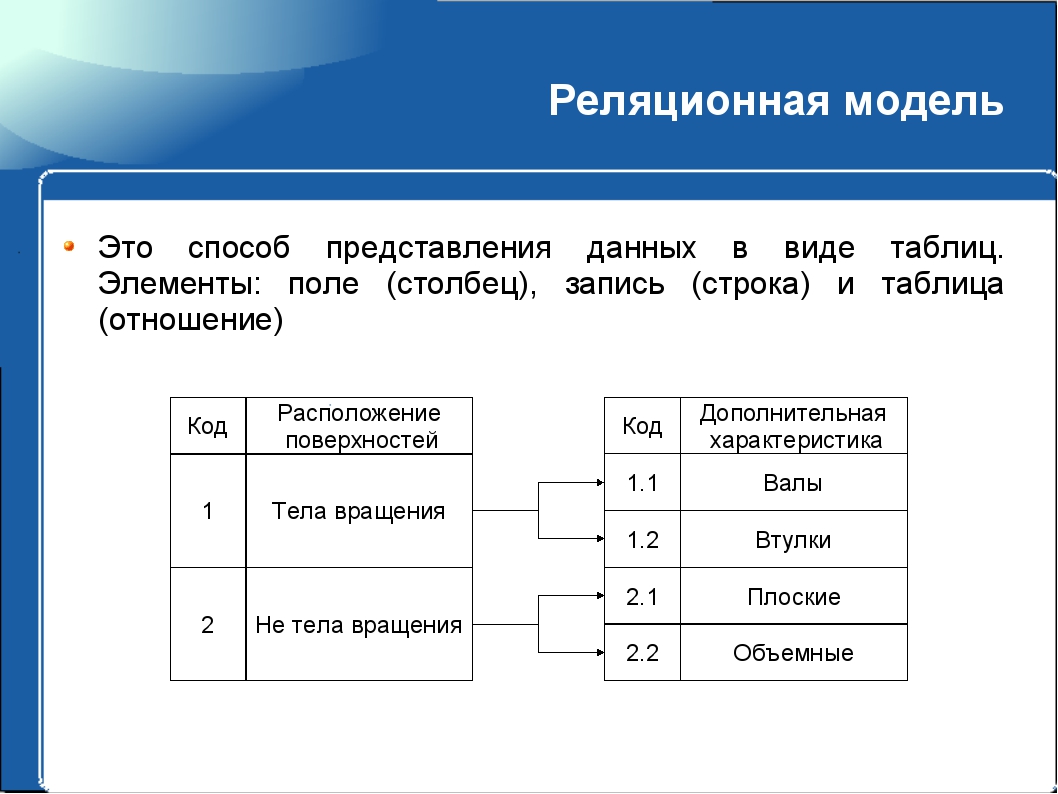
Модели данных строятся с учетом потребностей бизнеса. Правила и требования определяются заранее на основе отзывов заинтересованных сторон бизнеса, поэтому их можно включить в дизайн новой системы или адаптировать при итерации существующей.
Данные можно моделировать на различных уровнях абстракции. Процесс начинается со сбора информации о бизнес-требованиях от заинтересованных сторон и конечных пользователей. Затем эти бизнес-правила преобразуются в структуры данных, чтобы сформулировать конкретный проект базы данных. Модель данных можно сравнить с дорожной картой, планом архитектора или любой формальной диаграммой, которая способствует более глубокому пониманию того, что проектируется.
Моделирование данных использует стандартизированные схемы и формальные методы. Это обеспечивает общий, согласованный и предсказуемый способ определения и управления ресурсами данных в рамках организации или даже за ее пределами.
В идеале модели данных представляют собой живые документы, которые развиваются вместе с меняющимися потребностями бизнеса.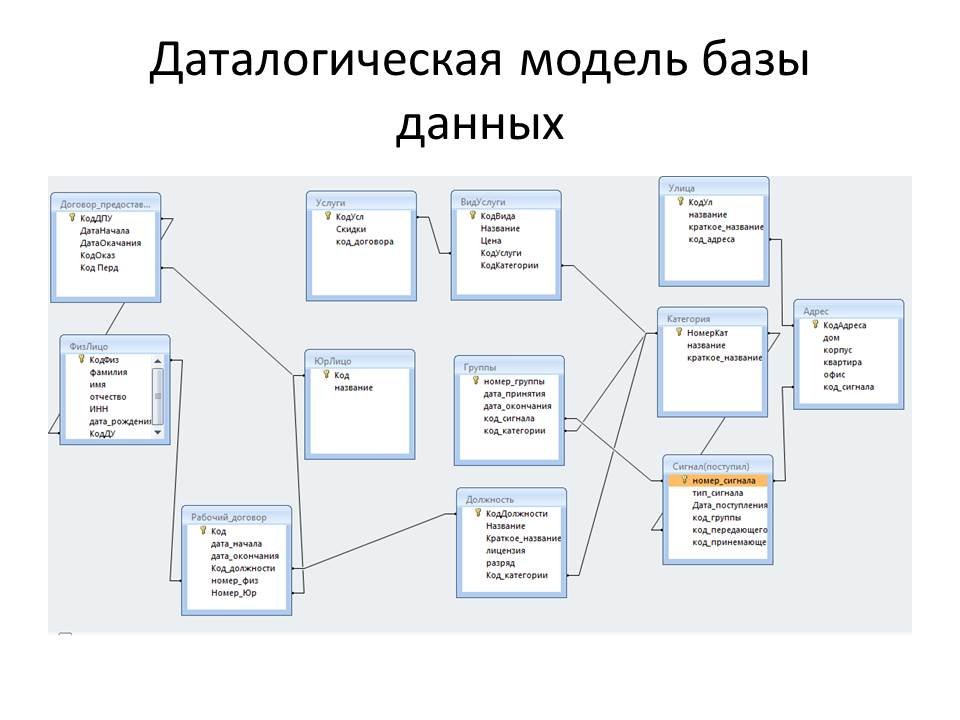
С легкостью обучайте, проверяйте, настраивайте и развертывайте базовые модели и модели машинного обучения
Смотри, что будетТипы моделей данных
Как и любой процесс проектирования, проектирование баз данных и информационных систем начинается с высокого уровня абстракции и становится все более конкретным и конкретным. Модели данных обычно можно разделить на три категории, которые различаются в зависимости от степени их абстракции. Процесс начнется с концептуальной модели, перейдет к логической модели и завершится физической моделью.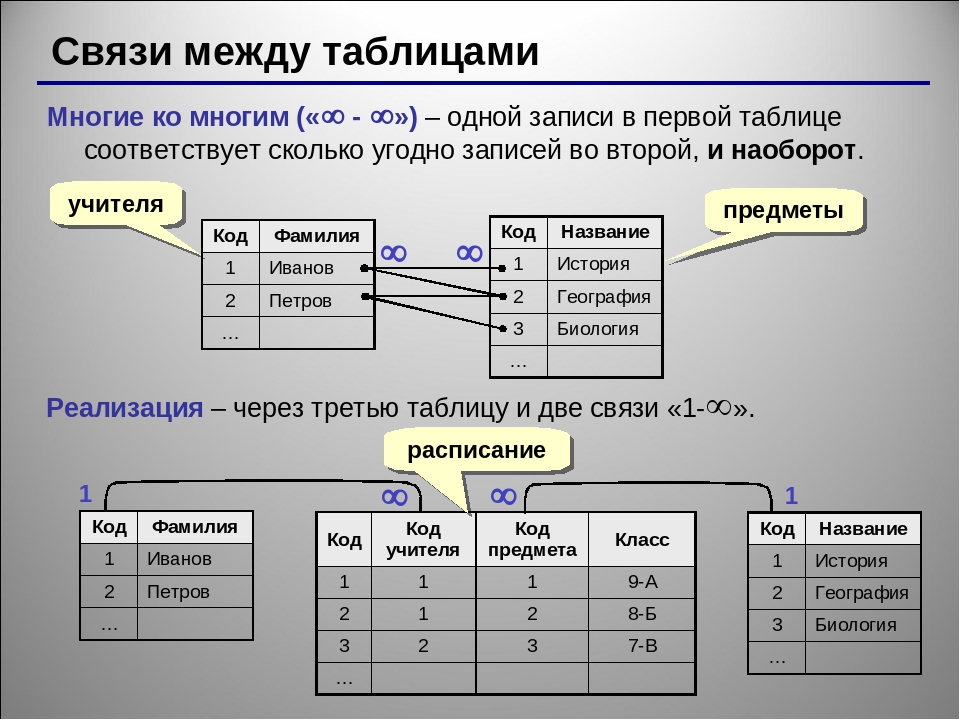
- Концептуальные модели данных. Их также называют моделями предметной области, и они дают общее представление о том, что будет содержать система, как она будет организована и какие бизнес-правила задействованы. Концептуальные модели обычно создаются как часть процесса сбора исходных требований к проекту. Как правило, они включают классы сущностей (определяющие типы вещей, которые важно для бизнеса представлять в модели данных), их характеристики и ограничения, отношения между ними и соответствующие требования безопасности и целостности данных. Любая нотация обычно проста.
- Логические модели данных. Они менее абстрактны и содержат более подробную информацию о концепциях и отношениях в рассматриваемой области. Используется одна из нескольких формальных систем записи моделирования данных. Они указывают атрибуты данных, такие как типы данных и их соответствующие длины, и показывают отношения между сущностями.
- Физические модели данных. Они предоставляют схему физического хранения данных в базе данных. Как таковые, они наименее абстрактны из всех. Они предлагают окончательный дизайн, который можно реализовать как реляционную базу данных, включая ассоциативные таблицы, иллюстрирующие отношения между сущностями, а также первичные и внешние ключи, которые будут использоваться для поддержания этих отношений. Физические модели данных могут включать свойства, характерные для системы управления базами данных (СУБД), включая настройку производительности.

Процесс моделирования данных
Моделирование данных как дисциплина предлагает заинтересованным сторонам тщательно оценить обработку и хранение данных.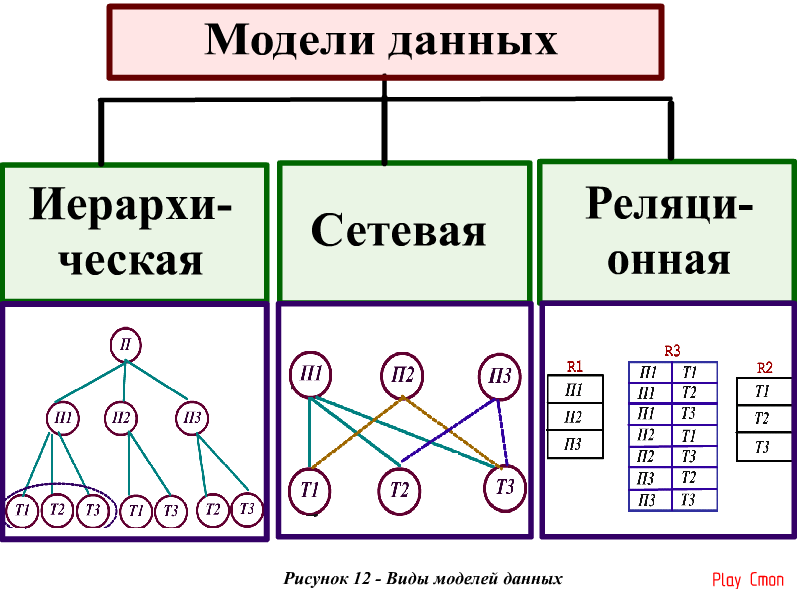
- Идентификация объектов. Процесс моделирования данных начинается с определения вещей, событий или концепций, представленных в наборе данных, который необходимо смоделировать. Каждая сущность должна быть связной и логически обособленной от всех остальных.
- Определение отношений между сущностями. Самый ранний проект модели данных будет определять характер отношений каждого объекта с другими. В приведенном выше примере каждый клиент «живет по адресу». Если бы эта модель была расширена, чтобы включить объект под названием «заказы», каждый заказ также был бы отправлен и выставлен счет по адресу. Эти отношения обычно документируются с помощью унифицированного языка моделирования (UML).
- Полностью сопоставить атрибуты объектам. Это гарантирует, что модель отражает то, как бизнес будет использовать данные. Широко используются несколько формальных шаблонов моделирования данных. Разработчики, ориентированные на объекты, часто применяют шаблоны анализа или шаблоны проектирования, в то время как заинтересованные стороны из других областей бизнеса могут обращаться к другим шаблонам.
- При необходимости назначьте ключи и определите степень нормализации, которая уравновешивает необходимость сокращения избыточности с требованиями к производительности. Нормализация – это метод организации моделей данных (и баз данных, которые они представляют), в котором числовые идентификаторы, называемые ключами, назначаются группам данных для представления взаимосвязей между ними без повторения данных. Например, если каждому клиенту назначен ключ, этот ключ может быть связан как с их адресом, так и с их историей заказов без необходимости повторять эту информацию в таблице имен клиентов. Нормализация, как правило, уменьшает объем дискового пространства, необходимого для базы данных, но это может сказаться на производительности запросов.
- Завершите и проверьте модель данных. Моделирование данных — это повторяющийся процесс, который следует повторять и уточнять по мере изменения потребностей бизнеса.
 .
. Нормализация – это метод организации моделей данных (и баз данных, которые они представляют), в котором числовые идентификаторы, называемые ключами, назначаются группам данных для представления взаимосвязей между ними без повторения данных. Например, если каждому клиенту назначен ключ, этот ключ может быть связан как с их адресом, так и с их историей заказов без необходимости повторять эту информацию в таблице имен клиентов. Нормализация, как правило, уменьшает объем дискового пространства, необходимого для базы данных, но это может сказаться на производительности запросов.
Нормализация – это метод организации моделей данных (и баз данных, которые они представляют), в котором числовые идентификаторы, называемые ключами, назначаются группам данных для представления взаимосвязей между ними без повторения данных. Например, если каждому клиенту назначен ключ, этот ключ может быть связан как с их адресом, так и с их историей заказов без необходимости повторять эту информацию в таблице имен клиентов. Нормализация, как правило, уменьшает объем дискового пространства, необходимого для базы данных, но это может сказаться на производительности запросов.Типы моделирования данных
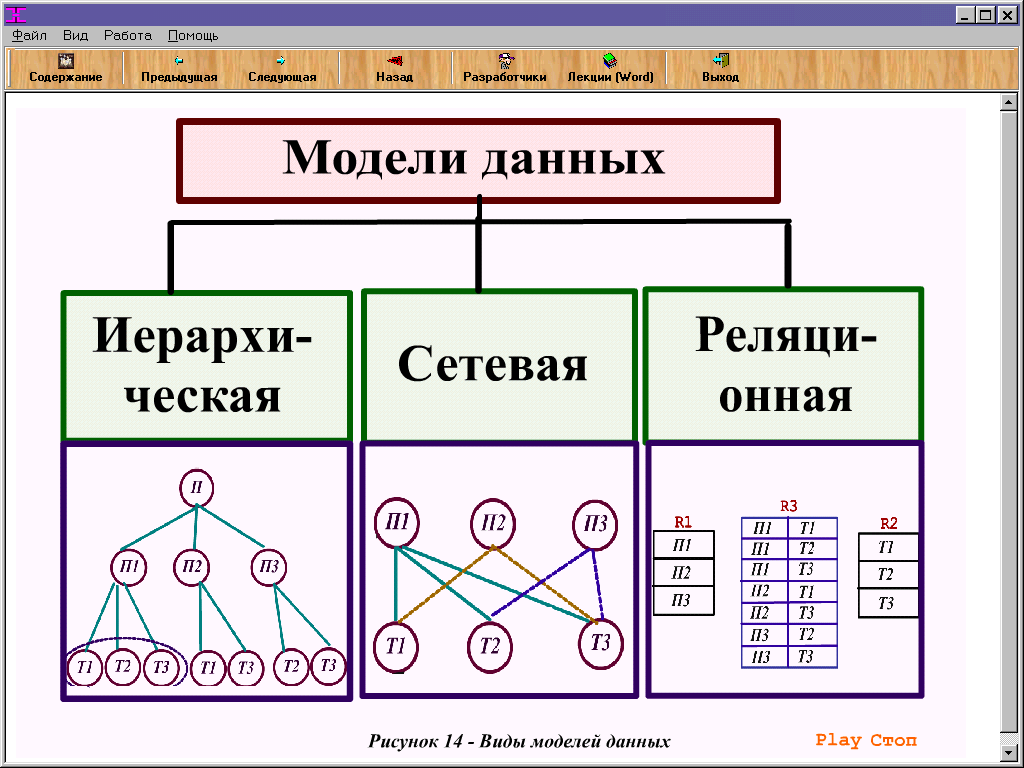
Моделирование данных развивалось вместе с системами управления базами данных, причем типы моделей усложнялись по мере роста потребностей бизнеса в хранении данных.
- Иерархические модели данных представляют отношения «один ко многим» в древовидном формате. В модели этого типа каждая запись имеет единственный корень или родитель, который сопоставляется с одной или несколькими дочерними таблицами. Эта модель была реализована в IBM Information Management System (IMS), которая была представлена в 1966 году и быстро нашла широкое применение, особенно в банковской сфере. Хотя этот подход менее эффективен, чем недавно разработанные модели баз данных, он все еще используется в системах расширяемого языка разметки (XML) и географических информационных системах (ГИС).
- Реляционные модели данных были первоначально предложены исследователем IBM Э. Ф. Коддом в 1970 году. Они до сих пор применяются во многих различных реляционных базах данных, обычно используемых в корпоративных вычислениях. Моделирование реляционных данных не требует детального понимания физических свойств используемого хранилища данных. В нем сегменты данных явно объединяются с помощью таблиц, что снижает сложность базы данных.
 В нем сегменты данных явно объединяются с помощью таблиц, что снижает сложность базы данных.
В нем сегменты данных явно объединяются с помощью таблиц, что снижает сложность базы данных.Реляционные базы данных часто используют язык структурированных запросов (SQL) для управления данными. Эти базы данных хорошо подходят для поддержания целостности данных и сведения к минимуму избыточности. Они часто используются в системах торговых точек, а также для других типов обработки транзакций.
- Модели данных «сущность-связь» (ER) используют формальные диаграммы для представления отношений между сущностями в базе данных. Архитекторы данных используют несколько инструментов моделирования ER для создания визуальных карт, передающих цели проектирования базы данных.
- Объектно-ориентированные модели данных получили распространение как объектно-ориентированное программирование и стали популярными в середине 1990-х годов. Вовлеченные «объекты» являются абстракциями сущностей реального мира. Объекты сгруппированы в иерархии классов и имеют связанные функции. Объектно-ориентированные базы данных могут включать таблицы, но также могут поддерживать более сложные отношения данных. Этот подход используется в мультимедийных и гипертекстовых базах данных, а также в других случаях.
- Многомерные модели данных были разработаны Ральфом Кимбаллом для оптимизации скорости извлечения данных в аналитических целях в хранилище данных. В то время как реляционные модели и модели ER подчеркивают важность эффективного хранения, многомерные модели увеличивают избыточность, чтобы упростить поиск информации для составления отчетов и поиска. Это моделирование обычно используется в системах OLAP.
 Объектно-ориентированные базы данных могут включать таблицы, но также могут поддерживать более сложные отношения данных. Этот подход используется в мультимедийных и гипертекстовых базах данных, а также в других случаях.
Объектно-ориентированные базы данных могут включать таблицы, но также могут поддерживать более сложные отношения данных. Этот подход используется в мультимедийных и гипертекстовых базах данных, а также в других случаях. Двумя популярными многомерными моделями данных являются звездообразная схема, в которой данные организованы в факты (измеряемые элементы) и измерения (справочная информация), где каждый факт окружен связанными с ним измерениями в виде звезды. Другая схема — это схема «снежинка», которая напоминает схему «звезда», но включает в себя дополнительные слои связанных измерений, что делает структуру ветвления более сложной.
Преимущества моделирования данных
Моделирование данных упрощает для разработчиков, архитекторов данных, бизнес-аналитиков и других заинтересованных сторон просмотр и понимание взаимосвязей между данными в базе данных или хранилище данных. Кроме того, он может:
- Уменьшить количество ошибок при разработке программного обеспечения и баз данных.
- Повысьте согласованность документации и проектирования систем на предприятии.
- Улучшить производительность приложения и базы данных.
- Упростите сопоставление данных во всей организации.
- Улучшите взаимодействие между разработчиками и группами бизнес-аналитики.
- Упростите и ускорьте процесс проектирования базы данных на концептуальном, логическом и физическом уровнях.
Средства моделирования данных
В настоящее время широко используются многочисленные коммерческие и открытые решения для автоматизированной разработки программного обеспечения (CASE), в том числе различные средства моделирования данных, построения диаграмм и визуализации. Вот несколько примеров:
Вот несколько примеров:
- erwin Data Modeler – это инструмент моделирования данных, основанный на языке моделирования данных Integration DEFinition для информационного моделирования (IDEF1X), который теперь поддерживает другие методологии записи, включая многомерный подход.
- Enterprise Architect – это инструмент визуального моделирования и проектирования, который поддерживает моделирование информационных систем и архитектур предприятия, а также программных приложений и баз данных. Он основан на объектно-ориентированных языках и стандартах.
- ER/Studio – это программное обеспечение для проектирования баз данных, совместимое с несколькими наиболее популярными на сегодняшний день системами управления базами данных. Он поддерживает как реляционное, так и многомерное моделирование данных.
- Бесплатные инструменты моделирования данных включают решения с открытым исходным кодом, такие как Open ModelSphere.

Полностью управляемое эластичное облачное хранилище данных, созданное для высокопроизводительной аналитики и искусственного интеллекта
Изучите IBM Db2 Warehouse в облаке Облачные решения IBMГибрид. Открыть. Устойчивый. Ваша платформа и партнер для цифровой трансформации.
Изучите облачные решения Облачные решенияГибридное облачное программное обеспечение на базе искусственного интеллекта.
Ознакомьтесь с решениями Cloud PakСделайте следующий шаг
Исследователи IBM были одними из первых, кто создал первые иерархические и реляционные модели данных, а также спроектировал базы данных, в которых эти модели были первоначально реализованы. Сегодня IBM Cloud предоставляет платформу с полным стеком, которая поддерживает обширный портфель баз данных SQL и NoSQL, а также инструменты разработчика, необходимые для эффективного управления ресурсами данных в них. IBM Cloud также поддерживает инструменты с открытым исходным кодом, которые помогают разработчикам управлять объектным, файловым и блочным хранилищем данных для оптимизации производительности и надежности.
Сегодня IBM Cloud предоставляет платформу с полным стеком, которая поддерживает обширный портфель баз данных SQL и NoSQL, а также инструменты разработчика, необходимые для эффективного управления ресурсами данных в них. IBM Cloud также поддерживает инструменты с открытым исходным кодом, которые помогают разработчикам управлять объектным, файловым и блочным хранилищем данных для оптимизации производительности и надежности.
Что такое модель данных? Определение и часто задаваемые вопросы
Модель данных Часто задаваемые вопросы
Что такое модель данных?
Модель данных определяет структуру элементов данных в информационной системе. Модель данных документирует отношения между элементами данных и то, как данные извлекаются и хранятся. Модели данных часто отображают поток данных с помощью графика или диаграммы модели данных. Это визуальное представление помогает упростить взаимодействие между программным обеспечением и бизнес-группами: бизнес-группы могут определять данные и форматы данных, необходимые для бизнес-функций, а группы разработчиков программного обеспечения могут создавать ответы, необходимые для этих запросов.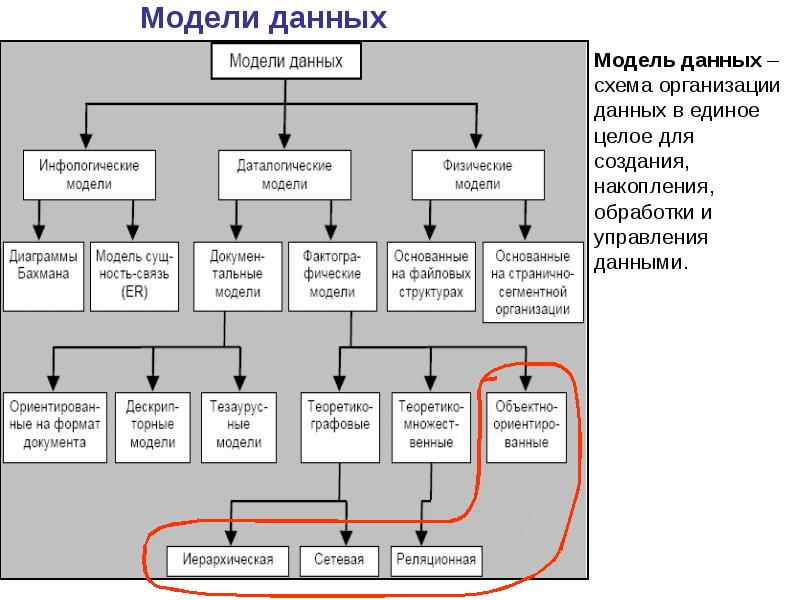
Чтобы ответить на вопрос «что такое модель данных», полезно понять несколько ключевых терминов, используемых в определении модели данных.
Модель данных идентифицирует:
- Объекты: компоненты данных, включая связанные метаданные, необработанные данные и обработанные данные
- Ассоциации: отношения между компонентами данных
- Требования: ожидаемое использование данных, особенно будущее использование
- Оценка технологии: сильные и слабые стороны аппаратного и программного обеспечения, используемого в проекте
Типы моделей данных
Концептуальная модель данных
Концептуальная модель данных идентифицирует объекты, которые описывают данные и отношения между ними. Концептуальные модели данных отображают только отношения самого высокого уровня между сущностями, а не атрибуты или первичные ключи в модели данных.
Физическая модель данных
Физическая модель данных определяет структуры таблиц, которые будут созданы в базе данных, включая все таблицы, столбцы, первичные ключи и внешние ключи, используемые для определения отношений между таблицами.
Реляционная модель данных
Реляционная модель данных является основой для баз данных SQL. Реляционные модели данных имеют фиксированную схему и работают со структурированными данными. В системе управления реляционными базами данных или РСУБД база данных является самым внешним контейнером, содержащим данные, связанные с приложением.
Нереляционная модель данных
Нереляционная модель данных предлагает гибкую структуру схемы и может обрабатывать неструктурированные данные — ее модель хранения можно оптимизировать в соответствии с требованиями типа хранимых данных. Нереляционные модели данных используются в нереляционных базах данных, также называемых базами данных NoSQL.
Многомерная модель данных
Многомерная модель данных используется при проектировании хранилища данных. Многомерные модели данных анализируют числовую информацию (например, балансы или значения) в хранилище данных. Напротив, реляционные модели данных обновляют, добавляют или удаляют данные в информационных системах реального времени.
Модель данных предприятия
Модель данных предприятия включает в себя отраслевую перспективу, чтобы дать непредвзятое представление о том, как данные хранятся, извлекаются и используются в организации. Модели корпоративных данных полезны для удовлетворения конкретных бизнес-потребностей предприятия.
Методы моделирования данных
Хотя методы моделирования данных могут различаться в зависимости от типа базы данных, которую использует ваша организация, существует несколько рекомендаций по моделированию данных, которые следует учитывать в процессе моделирования данных:
- Начните с основ моделирования данных : спросите бизнес-команды, какие результаты им нужны от данных, и организуйте модель данных вокруг этих требований .
- Создайте черновую модель данных с сущностями и отношениями и протестируйте модель в наилучшем и наихудшем сценариях
- Учитывайте запросы к базе данных: вы должны знать, как выглядят ваши данные и что они содержат, а также как вы собираетесь запрашивать их
- Оцените требования к оборудованию, поскольку серверы, работающие с огромными наборами данных, могут вскоре столкнуться с проблемами компьютерной памяти и скорости ввода-вывода.
- Проверка модели данных: проверьте каждое действие (например, выбор первичного ключа) перед переходом к следующему шагу

Какие существуют инструменты моделирования данных?
Доступен ряд инструментов моделирования данных. Популярное программное обеспечение для моделирования данных включает в себя:
- Toad Data Modeler
- Верстак MySQL
- МэджикДроу
- ERwin
- Архитектор предприятия
- Скорая помощь/Студия
- PowerDesigner
- Разработчик Oracle SQL
- Архитектор данных IBM InfoSphere
Моделирование данных для больших данных
ИТ-организации, которым необходимо управлять огромным количеством пользователей и данных, часто полагаются на базы данных NoSQL. Базы данных NoSQL — это нереляционные распределенные базы данных, предназначенные для обеспечения высокой доступности и рабочих нагрузок с большими данными. Базы данных NoSQL являются идеальной базой данных для моделирования больших данных, поскольку они позволяют приложениям больших данных архивировать огромные объемы данных любых типов, легко масштабироваться по горизонтали для обработки притока новых пользователей (например, приложений социальных сетей), а также оценивать и мгновенно реагировать на данные (например, в рекламе).
Моделирование данных NoSQL
Поскольку базы данных NoSQL поддерживают гибкие схемы, модели данных можно изменять после загрузки данных в базу данных. Любой тип неструктурированных данных можно загрузить в репозиторий NoSQL без предварительно определенной схемы и смоделировать позже. Для сравнения, моделирование данных происходит на этапе приема в реляционной базе данных. Гибкие схемы позволяют базам данных NoSQL поддерживать огромные объемы данных и адаптироваться к изменяющимся бизнес-требованиям в режиме реального времени. Поскольку разработчикам требуются новые функции базы данных, они могут добавлять их, не взаимодействуя с централизованными администраторами или операторами и не требуя полной реорганизации набора данных.
Предлагает ли ScyllaDB решения для моделирования больших данных?
ScyllaDB предлагает базу данных NoSQL с открытым исходным кодом. ScyllaDB — это невероятно быстрая и масштабируемая база данных NoSQL, простая замена Apache Cassandra, обеспечивающая более высокую производительность и меньшую задержку при стоимости большинства баз данных NoSQL.