Запросы — SQL Server | Microsoft Learn
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 2 мин
Применимо к: SQL Server Azure SQL DatabaseУправляемый экземпляр SQL AzureAzure Synapse AnalyticsAnalytics Platform System (PDW)
Язык обработки данных DML представляет словарь, используемый для получения данных и работы с ними в SQL Server и базе данных SQL. Большинство инструкций также работает в Azure Synapse Analytics и Система платформы аналитики (PDW) (см. сведения по каждой отдельно). Эти инструкции предназначены для добавления данных, изменения данных, запроса данных и удаления данных из базы данных SQL Server.
Большинство инструкций также работает в Azure Synapse Analytics и Система платформы аналитики (PDW) (см. сведения по каждой отдельно). Эти инструкции предназначены для добавления данных, изменения данных, запроса данных и удаления данных из базы данных SQL Server.
В следующей таблице перечислены инструкции DML, используемые SQL Server.
BULK INSERT (Transact-SQL)
SELECT (Transact-SQL)
DELETE (Transact-SQL)
UPDATE (Transact-SQL)
Инструкция INSERT (Transact-SQL)
UPDATETEXT (Transact-SQL)
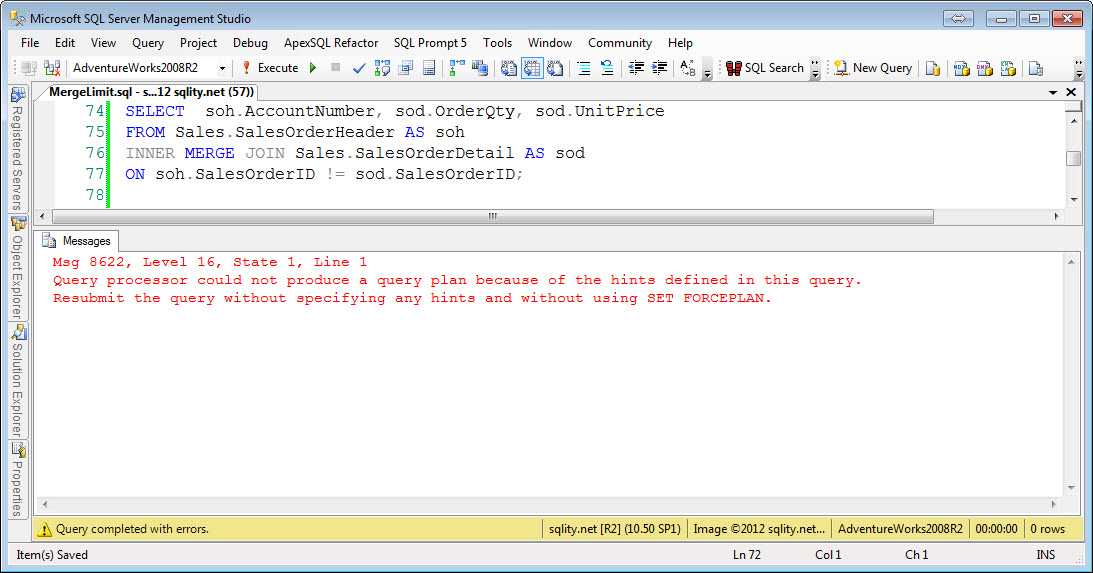
MERGE (Transact-SQL)
WRITETEXT (Transact-SQL)
READTEXT (Transact-SQL)
В следующей таблице перечислены предложения, используемые в нескольких инструкциях или предложениях DML.
| Предложение | Может использоваться в следующих инструкциях |
|---|---|
| FROM (Transact-SQL) | DELETE, SELECT, UPDATE |
| Указания (Transact-SQL) | DELETE, INSERT, SELECT, UPDATE |
| Предложение OPTION (Transact-SQL) | DELETE, SELECT, UPDATE |
| DELETE, INSERT, MERGE, UPDATE | |
| Условие поиска (Transact-SQL) | DELETE, MERGE, SELECT, UPDATE |
| Конструктор табличных значений (Transact-SQL) | FROM, INSERT, MERGE |
| TOP (Transact-SQL) | DELETE, INSERT, MERGE, SELECT, UPDATE |
| Предложение WHERE (Transact-SQL) | DELETE, SELECT, UPDATE, MATCH |
| WITH обобщенное_табличное_выражение (Transact-SQL) | DELETE, INSERT, MERGE, SELECT, UPDATE |
SQL Server.
 Оптимизация запросов SQL. MS SQL Медленно работают запросы SELECT
Оптимизация запросов SQL. MS SQL Медленно работают запросы SELECTВведение
В данном руководстве мы изложили некоторые рекомендации по оптимизации запросов SQL.
Оптимизация структуры таблиц SQL Server
Разбивайте сложные таблицы на несколько, помните, чем больше в вашей таблице столбцов и тяжелых типов (nvarchar(max)), тем тяжелее по ней проход. Если некоторые данные не всегда используются в select с ней, выносите большие столбцы в отдельные таблицы и связывайте через FK
Выберите правильные типы данных. Всегда выбирайте самый маленький тип для данных, которые Вы должны хранить в столбце.
Если текстовые данные в столбце имеют разную длину, используйте тип данных NVARCHAR вместо NCHAR.
Не используйте NVARCHAR или NCHAR типы данных, если Вы не должны сохранить 16-разрядные символьные данные (UNICODE). Они требуют в два раза больше места, чем CHAR и VARCHAR, что повышает расходы времени на ввод-вывод (но если у вас кириллица, то без NVARCHAR не обойтись).
Если Вы должны хранить большие строки данных и их длина меньше чем 8,000 символов, используют тип данных NVARCHAR вместо TEXT. Текстовые поля требуют больше ресурсов для обработки и снижают производительность.
Любое поле, в котором должны быть только отличные от нуля значения, нужно объявлять как NOT NULL
Для любого поля, которое должно содержать уникальные значения, стоит указать модификатор UNIQUE
Хранение изображений в БД нежелательно. Храните в таблице путь к файлу (локальный путь или URL), а сам файл помещайте в файловую систему сервера.
Оптимизация запросов SELECT
Не читайте больше данных, чем надо. Не используйте *
Если ваше приложение позволяет пользователям выполнять запросы, но вы не можете отсечь лишние тысячи возвращаемых строк, используйте оператор TOP внутри инструкции SELECT.
Не возвращайте клиенту большее количество столбцов или строк, чем действительно необходимо (Не используй * в Select).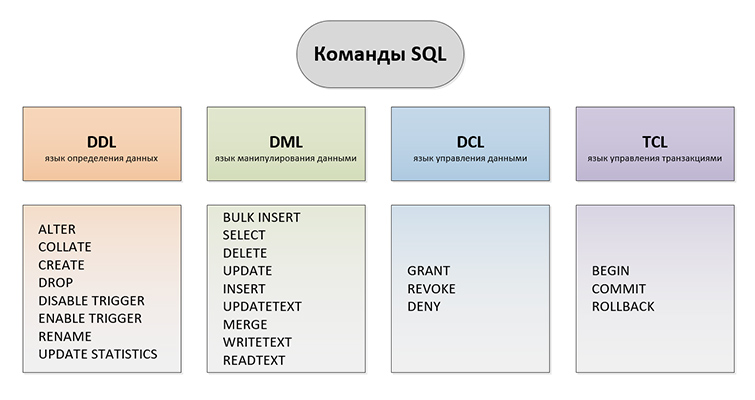
Как можно раньше отфильтруйте данные. Не нужно выполнять большой тяжелый подзапрос для всех строк таблицы. Сначала отфильтруйте нужные строки.
Корректно используйте JOIN
Если Вы имеете две или более таблиц, которые часто объединяются вместе, тогда столбцы, используемые для объединений должны иметь соответствующий индекс.
Для лучшей производительности, столбцы, используемые в объединениях должны иметь одинаковые типы данных. И если возможно, это должны быть числовые типы данных, вместо символьных типов.
Избегайте объединять таблицы по столбцам с малым числом уникальных значений. Если столбцы, используемые при объединениях, имеют мало уникальных значений, то SQL сервер будет просматривать всю таблицу, даже если по данному столбцу существует индекс. Для наилучшей производительности объединение таблиц должно производится по столбцам с уникальными индексами.
Если Вы должны регулярно объединять четыре или более таблиц, для получения recordset’а, попробуйте денормализовать таблицы так, чтобы число таблиц, участвующих в объединении уменьшилось.
Если вам нужно постоянно получать некоторые данные на лету (например, расчет бонусов клиента), попробуйте это поле хранить в отдельной колонке и обновлять по необходимости. В этом случае не нужно будет делать лишние join и подзапросы.
Тип JOIN используйте только тот, который вернет вам НЕОБХОДИМЫЕ данные без каких-либо дублей или лишней информации (или совсем отказаться от join). Т.е. не нужно получать всех пользователей таким образом:
select users.username from users inner join roles on users.roleID=roles.id
В этом случае вы получите много повторов пользователей
Сортировка в SELECT
Самой ресурсоемкой сортировкой является сортировка строк.
При объявлении полей всегда следует использовать размер, который нужен, и не выделять лишние байты про запас.
Если сортируете по дате создания, то попробуйте сортировать просто по id (первичный ключ с identity(1,1)).
Группирование в SELECT
Используйте как можно меньше колонок для группировки.
По возможности лучше использовать Where вместо Having, т.к. это уменьшает количество строк для группировки на ранней стадии.
Если требуется группирование, но без использования агрегатных функций (COUNT(), MIN(), MAX и т.д.), разумно использовать DISTINCT.
Не используйте множественные вложенные группировки через подзапросы.
Ограничить использование DISTINCT
Эта команда исключает повторяющиеся строки в результате. Команда требует повышенного времени обработки. Лучше всего комбинировать с LIMIT.
Ограничить использование SELECT для постоянно изменяющихся таблиц.
Возможно имеет смысл сохранять промежуточные агрегированные данные в какой-то другой таблице, которая обновляется менее часто чем таблица изменений (например, таблица логов).
Оптимизация WHERE в запросе SELECT
Если where состоит из условий, объединенных AND, они должны располагаться в порядке возрастания вероятности истинности данного условия.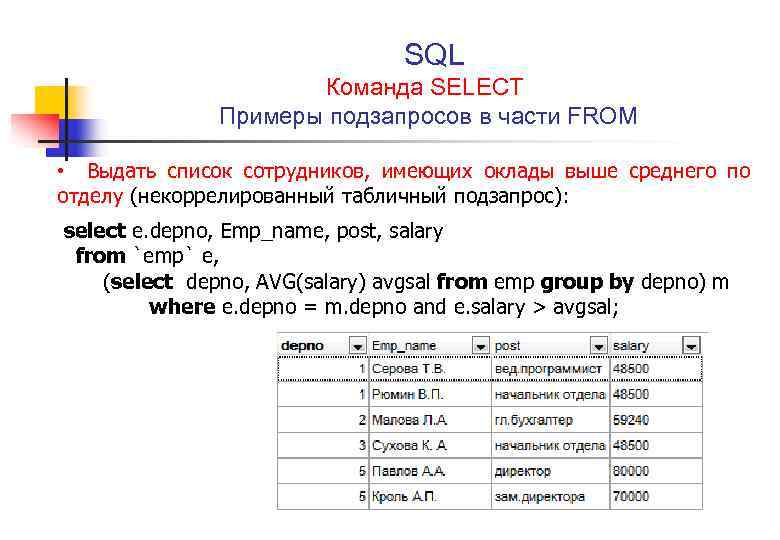 Чем быстрее мы получим false в одном из условий — тем меньше условий будет обработано и тем быстрее выполняется запрос.
Чем быстрее мы получим false в одном из условий — тем меньше условий будет обработано и тем быстрее выполняется запрос.
Если where состоит из условий, объединенных OR, они должны располагаться в порядке уменьшения вероятности истинности данного условия. Чем быстрее мы получим true в одном из условий — тем меньше условий будет обработано и тем быстрее выполняется запрос.
Исопльзуйте IN вместо OR. Операция IN работает гораздо быстрее, чем серия OR. Запрос «… WHERE column1 = 5 OR column1 = 6» медленнее чем «…WHERE column1 IN (5, 6)».
Используйте Exists вместо Count >0 в подзапросах. Используйте where exists (select id from t1 where id = t.id) вместо where count(select id from t1 where id=t.id) > 0
LIKE. Эту операцию следует использовать только при крайней необходимости, потому что лучше и быстрее использовать поиск, основанный на full-text индексах.
Советы по оптимизации хранимых процедур и SQL пакетов
Инкапсулируйте ваш код в хранимых процедурах
Для обработки данных используйте хранимые SQL процедуры.
Когда хранимая процедура выполняется в первый раз (и у нее не определена опция WITH RECOMPILE), она оптимизируется, для нее создается план выполнения запроса, который кешируется SQL сервером. Если та же самая хранимая процедура вызывается снова, она будет использовать кешированный план выполнения запроса, что экономит время и увеличивает производительность.
Всегда включайте в ваши хранимые процедуры инструкцию «SET NOCOUNT ON». Если Вы не включите эту инструкцию, тогда каждый раз при выполнении запроса SQL сервер отправит ответ клиенту, указывающему число строк, на которые воздействует запрос.
Избегайте использования курсоров
По возможности выбирайте быстрый forward-only курсор
При использовании серверного курсора, старайтесь использовать как можно меньший рекордсет. Для этого выбирайте только те столбцы и строки, которые необходимы клиенту для решения его текущей задачи.
Когда Вы закончили использовать курсор, как можно раньше не только ЗАКРОЙТЕ (CLOSE) его, но и ОСВОБОДИТЕ (DEALLOCATE).
Используйте триггеры c осторожностью
Триггеры — это усложнение логики работы приложения, неявное неожиданное выполнение дополнительных действий.
Триггеры усложняют интерфейс хранимых процедур. Поместите все необходимые проверки и действия в рамки хранимых процедур.
Временные таблицы для больших таблиц, табличные переменные — для малых (меньше 1000)
Если вам требуется хранить промежуточные данные в таблицах, то используйте табличные переменные (@t1) для малых таблиц, а временные таблицы (#t1) — для больших.
Подробнее:
http://sqlcom.ru/helpful-and-interesting/compare-temp-table-vs-table-variable-vs-cte/
https://coderoad.ru/27894/%D0%92-%D1%87%D0%B5%D0%BC-%D1%80%D0%B0%D0%B7%D0%BD%D0%B8%D1%86%D0%B0-%D0%BC%D0%B5%D0%B6%D0%B4%D1%83-%D0%B2%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%BD%D0%BE%D0%B9-%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%86%D0%B5%D0%B9-%D0%B8-%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%87%D0%BD%D0%BE%D0%B9-%D0%BF%D0%B5%D1%80%D0%B5%D0%BC%D0%B5%D0%BD%D0%BD%D0%BE%D0%B9-%D0%B2-SQL-Server
При определении временной таблицы имеет смысл проверить ее на существование:
IF OBJECT_ID('tempdb. .#eventIDs') IS NOT NULL begin
DROP TABLE #eventIDs
end
CREATE TABLE #eventIDs ( id int primary key,instanceID int )
.#eventIDs') IS NOT NULL begin
DROP TABLE #eventIDs
end
CREATE TABLE #eventIDs ( id int primary key,instanceID int )
 .#eventIDs') IS NOT NULL begin
DROP TABLE #eventIDs
end
CREATE TABLE #eventIDs ( id int primary key,instanceID int )
.#eventIDs') IS NOT NULL begin
DROP TABLE #eventIDs
end
CREATE TABLE #eventIDs ( id int primary key,instanceID int )
Также для улучшения быстродействия используйте для временной таблицы первичный ключ и индексы.
Как уменьшить вероятность дедлоков на базе
Дедлок — это взаимная блокировка 2 выполняющихся пакетов sql. Это самым негативным образом сказывается на быстродействии запросов.
Чтобы избежать deadlocks, пытайтесь разрабатывать ваше приложение с учетом следующих рекомендаций:
- Всегда получайте доступ к объектам в одном и том же порядке.
- Старайтесь делать транзакции короткими и заключайте их в один пакет (batch)
- Старайтесь использовать максимально низкий уровень изоляции для пользовательского соединения, которое работает с транзакцией.
Работа с индексами SQL Server
Советы по созданию кластерных индексов
- Первичный ключ не всегда должен быть кластерным индексом. Если Вы создаете первичный ключ, тогда SQL сервер автоматически делает первичный ключ кластерным индексом.
- Кластерные индексы идеальны для запросов, где есть выбор по диапазону или вы нуждаетесь в сортированных результатах. Так происходит потому, что данные в кластерном индексе физически отсортированы по какому-то столбцу. Запросы, получающие выгоду от кластерных индексов, обычно включают в себя операторы BETWEEN, <, >, GROUP BY, ORDER BY, и агрегативные операторы типа MAX, MIN, и COUNT.
- Кластерные индексы хороши для запросов, которые ищут запись с уникальным значением (типа номера служащего) и когда Вы должны вернуть большую часть данных из записи или всю запись. Так происходит потому, что запрос покрывается индексом.
- Кластерные индексы хороши для запросов, которые обращаются к столбцам с ограниченным числом значений, например столбцы, содержащие данные о странах или штатах. Но если данные столбца мало отличаются, например, значения типа «да/нет», «мужчина/женщина», то такие столбцы вообще не должны индексироваться.
- Кластерные индексы хороши для запросов, которые используют операторы GROUP BY или JOIN.
- Кластерные индексы хороши для запросов, которые возвращают много записей, потому что данные находятся в индексе, и нет необходимости искать их где-то еще.
- Избегайте помещать кластерный индекс в столбцы, в которых содержатся постоянно возрастающие величины, например, даты, подверженные частым вставкам в таблицу (INSERT). Так как данные в кластерном индексе должны быть отсортированы, кластерный индекс на инкрементирующемся столбце вынуждает новые данные быть вставленным в ту же самую страницу в таблице, что создает «горячую зону в таблице» и приводит к большому объему дискового ввода-вывода. Постарайтесь найти другой столбец, который мог бы стать кластерным индексом.


Советы по выбору некластерных индексов
- Некластерные индексы лучше подходят для запросов, которые возвращают немного записей (включая только одну запись) и где индекс имеет хорошую селективность (более чем 95 %).
- Если столбец в таблице не содержит по крайней мере 95% уникальных значений, тогда очень вероятно, что Оптимизатор Запроса SQL сервера не будет использовать некластерный индекс, основанный на этом столбце. Поэтому добавляйте некластерные индексы к столбцам, которые имеют хотя бы 95% уникальных записей. Например, столбец с «Да» или «Нет» не имеет 95% уникальных записей.
- Постарайтесь сделать ваши индексы как можно меньшего размера (особенно для многостолбцовых индексов). Это уменьшает размер индекса и уменьшает число чтений, необходимых, чтобы прочитать индекс, что увеличивает производительность.
- Если возможно, создавайте индексы на столбцах, которые имеют целочисленные значения вместо символов. Целочисленные значения имеют меньше потерь производительности, чем символьные значения.
- Если ваше приложение будет выполнять один и тот же запрос много раз на той же самой таблице, рассмотрите создание покрывающего индекса на таблице. Покрывающий индекс включает все столбцы, упомянутые в запросе. Из-за этого индекс содержит все данные, которые Вы ищете, и SQL сервер не должен искать фактические данные в таблице, что сокращает логический и/или физический ввод — вывод. С другой стороны, если индекс становится слишком большим (слишком много столбцов), это может увеличить объем ввода — вывода и ухудшить производительность.
- Индекс полезен для запроса только в том случае, если оператор WHERE запроса соответствует столбцу (столбцам), которые являются крайними левыми в индексе. Так, если Вы создаете составной индекс, типа «City, State», тогда запрос » WHERE City = ‘Хьюстон’ » будет использовать индекс, но запрос » WHERE State = ‘TX’ » не будет использовать индекс.
- Любая операция над полем в предикате поиска, которое лежит под индексом, сводит на нет его использование. where isnull(field,’’) = ‘’ здесь индекс не используется, where field = ‘’ and field is not null — здесь используется.
 Поэтому добавляйте некластерные индексы к столбцам, которые имеют хотя бы 95% уникальных записей. Например, столбец с «Да» или «Нет» не имеет 95% уникальных записей.
Поэтому добавляйте некластерные индексы к столбцам, которые имеют хотя бы 95% уникальных записей. Например, столбец с «Да» или «Нет» не имеет 95% уникальных записей.
Бывает ли слишком много индексов?
Да. Проблема с лишними индексами состоит в том, что SQL сервер должен изменять их при любых изменениях таблицы (INSERT, UPDATE, DELETE).
Лучшим решением ставить сомнительный индекс или нет, будет подождать и собрать статистику по работе индексов.
Лучшие кандидаты на установку индекса
- Это поля, по которым идет Join
- Поля связи, участвующие в подзапросах
- Поля, по которым идет фильтрация в where
- Поля, по которым выполняется сортировка.
Советы по использованию временных таблиц и табличных переменных
Если вы замечаете, что обращаетесь к одной и той же таблице несколько раз, то это явный знак необходимости использовать временную таблицу.
- Временная таблица храниться физически в tempdb, табличная переменная хранится в памяти SQL
- SQL может сам решить сохранить табличную переменную физически, если там будет много данных, это потеря ресурсов
- Временная таблица подходит для большого объема данных (полноценная выборка), табличная переменная — для малого объема данных (справочники или набор ID для чего-то)
- Временная таблица доступна из любой процедуры SQL, табличная переменная только в рамках запроса. Не забывайте очищать временные таблицы после их использования
Если вы SQL-разработчик или администратор MS SQL Server, и вы хотели бы разрабатывать веб-решения на SQL, то веб-платформа Falcon Space — это то, что вам нужно.
В ней SQL — это основной язык разработки, который позволяет реализовать систему личных кабинетов с формами, таблицами, дашбордами и другими компонентами.
Вводная статья по Falcon Space для SQL специалиста
 Все настраивается на SQL. Для поддержки решения надо иметь знания только по SQL и HTML.
Все настраивается на SQL. Для поддержки решения надо иметь знания только по SQL и HTML. Еще несколько советов по оптимизации SQL запросов (Февраль 2023)
- Обновлять только то, что необходимо в БД обновить.
- При больших загрузках отключайте ограничения и индексы
- В колонках с низкой избирательностью избегайте индексов (напр на булевы поля).
- Когда в следующий раз будете загружать данные в таблицу, подумайте о том, сколько информации будет запрашиваться, и отсортируйте так, чтобы индексы могли быстро сканировать диапазоны.
- Операции insert или обновления за 1 присест, а не много одиночных update
- Избегайте коррелирующих подзапросов (когда подзапрос зависит от родительского). Для больших таблиц.
- Используйте EXISTS() вместо Count() для проверки условия существованяи хотя бы одной записи.
Что почитать:
- https://habr.com/ru/company/vk/blog/513968/
- https://habr. com/ru/company/1cloud/blog/304642/
- https://stackoverflow.com/questions/761204/what-resources-exist-for-database-performance-tuning1
 com/ru/company/1cloud/blog/304642/
com/ru/company/1cloud/blog/304642/запросов — SQL Server | Microsoft Узнайте
Редактировать
Твиттер LinkedIn Фейсбук Электронная почта
- Статья
- 2 минуты на чтение
Применяется к: SQL Server Azure SQL База данных Azure SQL Управляемый экземпляр Azure Synapse Analytics Analytics Platform System (PDW)
Язык манипулирования данными (DML) — это словарь, используемый для извлечения и работы с данными в SQL Server и базе данных SQL. Большинство из них также работают в Azure Synapse Analytics и Analytics Platform System (PDW) (подробности см. в каждом отдельном заявлении). Используйте эти операторы для добавления, изменения, запроса или удаления данных из базы данных SQL Server.
в каждом отдельном заявлении). Используйте эти операторы для добавления, изменения, запроса или удаления данных из базы данных SQL Server.
В следующей таблице перечислены операторы DML, используемые SQL Server.
МАССОВАЯ ВСТАВКА (Transact-SQL)
ВЫБОР (Transact-SQL)
УДАЛИТЬ (Transact-SQL)
ОБНОВЛЕНИЕ(Transact-SQL)
ВСТАВКА (Transact-SQL)
ОБНОВЛЕНИЕТЕКСТ (Transact-SQL)
СЛИЯНИЕ (Transact-SQL)
ЗАПИСАТЬТЕКСТ (Transact-SQL)
READTEXT (транзакт-SQL)
В следующей таблице перечислены предложения, которые используются в нескольких операторах или предложениях DML.
| Пункт | Может использоваться в этих заявлениях |
|---|---|
| ОТ (Transact-SQL) | УДАЛИТЬ, ВЫБРАТЬ, ОБНОВИТЬ |
| Подсказки (Transact-SQL) | УДАЛИТЬ, ВСТАВИТЬ, ВЫБРАТЬ, ОБНОВИТЬ |
| Предложение OPTION (Transact-SQL) | УДАЛИТЬ, ВЫБРАТЬ, ОБНОВИТЬ |
| Пункт OUTPUT (Transact-SQL) | УДАЛИТЬ, ВСТАВИТЬ, ОБЪЕДИНИТЬ, ОБНОВИТЬ |
| Условие поиска (Transact-SQL) | УДАЛИТЬ, ОБЪЕДИНИТЬ, ВЫБРАТЬ, ОБНОВИТЬ |
| Конструктор табличных значений (Transact-SQL) | ИЗ, ВСТАВИТЬ, ОБЪЕДИНИТЬ |
| ВЕРХ (Transact-SQL) | УДАЛИТЬ, ВСТАВИТЬ, ОБЪЕДИНИТЬ, ВЫБРАТЬ, ОБНОВИТЬ |
| ГДЕ (Transact-SQL) | УДАЛИТЬ, ВЫБРАТЬ, ОБНОВИТЬ, СОВПАДАТЬ |
| С выражением common_table_expression (Transact-SQL) | УДАЛИТЬ, ВСТАВИТЬ, ОБЪЕДИНИТЬ, ВЫБРАТЬ, ОБНОВИТЬ |
Синтаксис SQL
❮ Назад Далее ❯
Таблицы базы данных
База данных чаще всего содержит одну или несколько таблиц. Каждая таблица идентифицируется
по имени (например, «Клиенты» или «Заказы»). Таблицы содержат записи (строки) с
данные.
Каждая таблица идентифицируется
по имени (например, «Клиенты» или «Заказы»). Таблицы содержат записи (строки) с
данные.
В этом руководстве мы будем использовать хорошо известную базу данных Northwind (входит в состав MS Access и MS SQL Server).
Ниже представлена выборка из таблицы «Клиенты»:
| CustomerID | ИмяКлиента | Имя контакта | Адрес | Город | Почтовый индекс | Страна |
|---|---|---|---|---|---|---|
| 1 | Альфред Футтеркисте | Мария Андерс | ул. Обере 57 | Берлин | 12209 | Германия |
| 2 | Ана Трухильо Emparedados y helados | Ана Трухильо | Авда. Конститусьон 2222 | Мексика Д.Ф. | 05021 | Мексика |
| 3 | Антонио Морено Такерия | Антонио Морено | Матадерос 2312 | Мексика Д. Ф. Ф. | 05023 | Мексика |
| 4 | Вокруг Рога | Томас Харди | Ганноверская площадь, 120 | Лондон | ВА1 1ДП | Великобритания |
| 5 | Берглундс снабжение | Кристина Берглунд | Бергувсвеген 8 | Лулео | С-958 22 | Швеция |
Таблица выше содержит пять записей (по одной для каждого клиента) и семь столбцов. (CustomerID, CustomerName, ContactName, Address, City, PostalCode и Country).
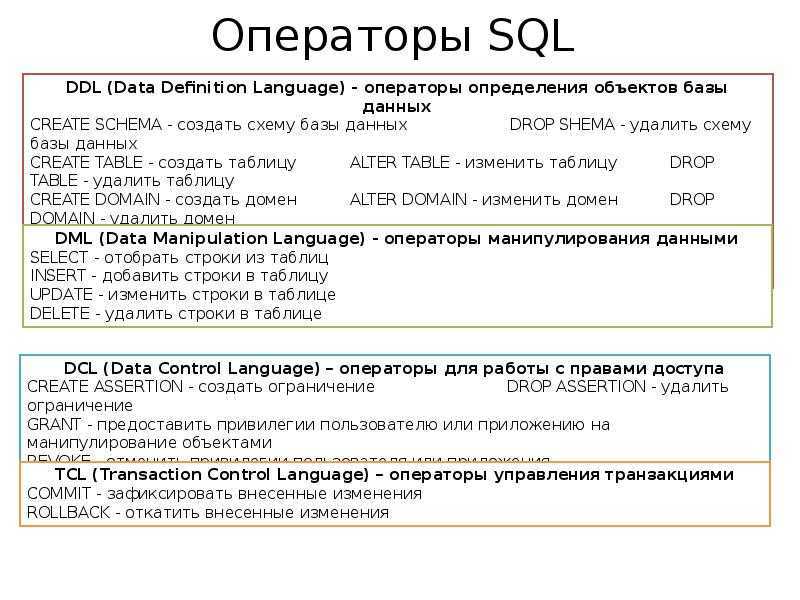
Операторы SQL
Большинство действий, которые необходимо выполнить с базой данных, выполняются с помощью SQL заявления.
Следующая инструкция SQL выбирает все записи в таблице «Клиенты»:
Пример
SELECT * FROM Customers;
Попробуйте сами »
В этом уроке мы научим вас всем, что касается различных операторов SQL.
Имейте в виду, что…
- Ключевые слова SQL НЕ чувствительны к регистру:
selectсовпадает сВЫБЕРИТЕ
В этом руководстве мы будем писать все ключевые слова SQL в верхнем регистре.
Точка с запятой после операторов SQL?
В некоторых системах баз данных требуется точка с запятой в конце каждого оператора SQL.
Точка с запятой — это стандартный способ разделения каждого оператора SQL в базе данных. системы, которые позволяют выполнять более одного оператора SQL в одном вызове на сервер.
В этом руководстве мы будем использовать точку с запятой в конце каждого оператора SQL.
Некоторые из наиболее важных команд SQL
-
SELECT— извлекает данные из базы данных -
ОБНОВЛЕНИЕ— обновляет данные в базе данных -
DELETE— удаляет данные из базы данных -
INSERT INTO— вставляет новые данные в базу данных -
CREATE DATABASE— создает новую базу данных -
ALTER DATABASE— изменяет базу данных -
CREATE TABLE— создает новую таблицу -
ALTER TABLE— изменяет таблицу -
DROP TABLE— удаляет таблицу -
CREATE INDEX— создает индекс (ключ поиска) -
DROP INDEX— удаляет индекс
❮ Предыдущий Следующий ❯
ВЫБОР ЦВЕТА
Лучшие учебники
Учебник HTMLУчебник CSS
Учебник JavaScript
Учебник How To
Учебник SQL
Учебник Python
Учебник W3.
 CSS
CSS Учебник Bootstrap
Учебник по PHP
Учебник по Java
Учебник по C++
Учебник по jQuery
Лучшие ссылки
Справочник по HTMLСправочник по CSS
Справочник по JavaScript
Справочник по SQL
Справочник по Python
Справочник по W3.CSS
Справочник по Bootstrap
Справочник по PHP
Цвета HTML
Справочник по Java
Справочник по Angular
Справочник по jQuery
90393 Top4 Examples
Примеры HTML
Примеры CSS
Примеры JavaScript
Как сделать Примеры
Примеры SQL
Примеры Python
Примеры W3.CSS
Примеры Bootstrap
Примеры PHP
Примеры Java
Примеры XML
Примеры jQuery
FORUM | О
W3Schools оптимизирован для обучения и обучения. Примеры могут быть упрощены для улучшения чтения и обучения.
Учебники, ссылки и примеры постоянно пересматриваются, чтобы избежать ошибок, но мы не можем гарантировать полную правильность всего содержания.