MSSQL — получить список JOB с помощью SQL запроса
- 8 ноября 2018
Пример вывода списка заданий JOB с помощью запроса из системных таблиц. Запрос выводит только те задания, которые созданы в Database Maintenance. Если вам нужны все, то уберите «AND [sCAT].[name] = N’Database Maintenance'» из запроса:
USE msdb
GO
SELECT
[sJOB].[name] AS [JobName]
, [sDBP].[name] AS [JobOwner]
, [sCAT].[name] AS [JobCategory]
, [sJOB].[description] AS [JobDescription]
, [sJSTP].[step_id] AS [JobStartStepNo]
, [sJSTP].[step_name] AS [JobStartStepName]
, [sJOB].[date_created] AS [JobCreatedOn]
, [sJOB].[date_modified] AS [JobLastModifiedOn]
, CASE [sJOB].[enabled]
WHEN 1 THEN 'Yes'
WHEN 0 THEN 'No'
END AS [IsEnabled]
, CASE
WHEN [sSCH].[schedule_uid] IS NULL THEN 'No'
ELSE 'Yes'
END AS [IsScheduled]
, CASE
WHEN [freq_type] = 64 THEN 'Start automatically when SQL Server Agent starts'
WHEN [freq_type] = 128 THEN 'Start whenever the CPUs become idle'
WHEN [freq_type] IN (4, 8, 16, 32) THEN 'Recurring'
WHEN [freq_type] = 1 THEN 'One Time'
END [ScheduleType]
, CASE [freq_type]
WHEN 1 THEN 'One Time'
WHEN 4 THEN 'Daily'
WHEN 8 THEN 'Weekly'
WHEN 16 THEN 'Monthly'
WHEN 32 THEN 'Monthly - Relative to Frequency Interval'
WHEN 64 THEN 'Start automatically when SQL Server Agent starts'
WHEN 128 THEN 'Start whenever the CPUs become idle'
END [Occurrence]
, CASE [freq_type]
WHEN 4 THEN 'Occurs every ' + CAST([freq_interval] AS VARCHAR(3)) + ' day(s)'
WHEN 8 THEN 'Occurs every ' + CAST([freq_recurrence_factor] AS VARCHAR(3))
+ ' week(s) on '
+ CASE WHEN [freq_interval] & 1 = 1 THEN 'Sunday' ELSE '' END
+ CASE WHEN [freq_interval] & 2 = 2 THEN ', Monday' ELSE '' END
+ CASE WHEN [freq_interval] & 4 = 4 THEN ', Tuesday' ELSE '' END
+ CASE WHEN [freq_interval] & 8 = 8 THEN ', Wednesday' ELSE '' END
+ CASE WHEN [freq_interval] & 16 = 16 THEN ', Thursday' ELSE '' END
+ CASE WHEN [freq_interval] & 32 = 32 THEN ', Friday' ELSE '' END
+ CASE WHEN [freq_interval] & 64 = 64 THEN ', Saturday' ELSE '' END
WHEN 16 THEN 'Occurs on Day ' + CAST([freq_interval] AS VARCHAR(3))
+ ' of every '
+ CAST([freq_recurrence_factor] AS VARCHAR(3)) + ' month(s)'
WHEN 32 THEN 'Occurs on '
+ CASE [freq_relative_interval]
WHEN 1 THEN 'First'
WHEN 2 THEN 'Second'
WHEN 4 THEN 'Third'
WHEN 8 THEN 'Fourth'
WHEN 16 THEN 'Last'
END
+ ' '
+ CASE [freq_interval]
WHEN 1 THEN 'Sunday'
WHEN 2 THEN 'Monday'
WHEN 3 THEN 'Tuesday'
WHEN 4 THEN 'Wednesday'
WHEN 5 THEN 'Thursday'
WHEN 6 THEN 'Friday'
WHEN 7 THEN 'Saturday'
WHEN 8 THEN 'Day'
WHEN 9 THEN 'Weekday'
WHEN 10 THEN 'Weekend day'
END
+ ' of every ' + CAST([freq_recurrence_factor] AS VARCHAR(3))
+ ' month(s)'
END AS [Recurrence]
, CASE [freq_subday_type]
WHEN 1 THEN 'Occurs once at '
+ STUFF(STUFF(RIGHT('000000' + CAST([active_start_time] AS VARCHAR(6)), 6), 3, 0, ':'), 6, 0, ':')
WHEN 2 THEN 'Occurs every '
+ CAST([freq_subday_interval] AS VARCHAR(3)) + ' Second(s) between '
+ STUFF(STUFF(RIGHT('000000' + CAST([active_start_time] AS VARCHAR(6)), 6), 3, 0, ':'), 6, 0, ':')
+ ' & '
+ STUFF(STUFF(RIGHT('000000' + CAST([active_end_time] AS VARCHAR(6)), 6), 3, 0, ':'), 6, 0, ':')
WHEN 4 THEN 'Occurs every '
+ CAST([freq_subday_interval] AS VARCHAR(3)) + ' Minute(s) between '
+ STUFF(STUFF(RIGHT('000000' + CAST([active_start_time] AS VARCHAR(6)), 6), 3, 0, ':'), 6, 0, ':')
+ ' & '
+ STUFF(STUFF(RIGHT('000000' + CAST([active_end_time] AS VARCHAR(6)), 6), 3, 0, ':'), 6, 0, ':')
WHEN 8 THEN 'Occurs every '
+ CAST([freq_subday_interval] AS VARCHAR(3)) + ' Hour(s) between '
+ STUFF(STUFF(RIGHT('000000' + CAST([active_start_time] AS VARCHAR(6)), 6), 3, 0, ':'), 6, 0, ':')
+ ' & '
+ STUFF(STUFF(RIGHT('000000' + CAST([active_end_time] AS VARCHAR(6)), 6), 3, 0, ':'), 6, 0, ':')
END [Frequency]
, [sSCH].
[name] AS [JobScheduleName]
, LastRun = CONVERT(DATETIME, RTRIM(run_date)
+ ' '
+ STUFF(STUFF(REPLACE(STR(RTRIM(h.run_time),6,0),' ','0'),3,0,':'),6,0,':'))
, CASE [sJSTP].Last_run_outcome
WHEN 0 THEN 'Failed'
WHEN 1 THEN 'Succeeded'
WHEN 2 THEN 'Retry'
WHEN 3 THEN 'Canceled'
WHEN 5 THEN 'Unknown'
END AS LastRunStatus
, LastRunDuration = STUFF(STUFF(REPLACE(STR([sJSTP].last_run_duration,7,0),' ','0'),4,0,':'),7,0,':')
, MaxDuration = STUFF(STUFF(REPLACE(STR(l.run_duration,7,0),' ','0'),4,0,':'),7,0,':')
, NextRun = CONVERT(DATETIME, RTRIM(NULLIF([sJOBSCH].next_run_date, 0))
+ ' '
+ STUFF(STUFF(REPLACE(STR(RTRIM([sJOBSCH].next_run_time),6,0),' ','0'),3,0,':'),6,0,':'))
, CASE [sJOB].[delete_level]
WHEN 0 THEN 'Never'
WHEN 1 THEN 'On Success'
WHEN 2 THEN 'On Failure'
WHEN 3 THEN 'On Completion'
END AS [JobDeletionCriterion]
, [sSVR].[name] AS [OriginatingServerName]
, [sJSTP].subsystem AS Subsystem
, [sJSTP].command AS Command
, h.message AS Message
FROM
[msdb]. [dbo].[sysjobs] AS [sJOB]
LEFT JOIN [msdb].[sys].[servers] AS [sSVR]
ON [sJOB].[originating_server_id] = [sSVR].[server_id]
LEFT JOIN [msdb].[dbo].[syscategories] AS [sCAT]
ON [sJOB].[category_id] = [sCAT].[category_id]
LEFT JOIN [msdb].[dbo].[sysjobsteps] AS [sJSTP]
ON [sJOB].[job_id] = [sJSTP].[job_id] AND [sJOB].[start_step_id] = [sJSTP].[step_id]
LEFT JOIN [msdb].[sys].[database_principals] AS [sDBP]
ON [sJOB].[owner_sid] = [sDBP].[sid]
LEFT JOIN [msdb].[dbo].[sysjobschedules] AS [sJOBSCH]
ON [sJOB].[job_id] = [sJOBSCH].[job_id]
LEFT JOIN [msdb].[dbo].[sysschedules] AS [sSCH]
ON [sJOBSCH].[schedule_id] = [sSCH].[schedule_id]
LEFT JOIN (
SELECT job_id, instance_id = MAX(instance_id), MAX(run_duration) AS run_duration
FROM msdb.dbo.sysjobhistory
GROUP BY job_id
) AS l
ON sJOB.job_id = l.job_id
LEFT JOIN
msdb.dbo.sysjobhistory AS h
ON h.job_id = l.job_id AND h.instance_id = l.instance_id
ORDER BY [JobName]
- [JobName]: название задания агента SQL Server.
- [JobOwner]: владелец задания.
- [JobCategory]: категория, к которой относится задание, например моментальный снимок репликации, обслуживание базы данных, отправка журналов и т.д.
- [JobDescription]: описание задания.
- [JobStartStepNo]: номер шага, из которого задано задание для запуска.
- [JobStartStepName]: имя шага, с которого задание начинается.
- [JobCreatedOn]: дата и время создания задания.
- [JobLastModifiedOn]: дата и время последнего изменения задания.
- [IsEnabled]: индикатор, показывающий, включено ли задание.
- [IsScheduled]: индикатор, указывающий, запланировано ли задание или нет.
- [ScheduleType]: тип расписания.
- [Occurrence]: график задания, такого как Ежедневный, Еженедельный, Ежемесячный и т.д.
- [Recurrence]: повторение графика.
- [Frequency]: как часто задание должно выполняться.
- [JobScheduleName]: имя расписания, связанного с заданием.
- [LastRun]: дата и время выполнения задания в последний раз (соответствует самому последнему запуску).
- [LastRunStatus]: состояние или результат последнего запуска задания.
- [LastRunDuration]: Продолжительность последнего выполнения задания.
- [MaxDuration]: максимальная продолжительность задания.
- [NextRun]: дата и время следующего запуска.
- [JobDeletionCriterion]: критерий для удаления задания.
- [OriginatingServerName]: сервер, с которого выполнялось задание.
- [Subsystem]: тип операции, например, интеграция с SQL Server Пакет услуг, Transact-SQL Script (T-SQL), ActiveX Script и т.д.
- [Command]: фактическая команда, которая будет выполнена.
- [Message]: информация о успехе/неудаче работы и т.д.


Теги
- sql
Настройка MSSQL для работы с 1С — мифы и реальность
Оптимизируем Microsoft SQL Server 2014 для работы с 1С. ОС — Windows Server 2012 R2. Напишу что нужно сделать, а что не нужно.
Определяю мифичность очень просто, если мне пришлось применить настройку — реальность, не пришлось — миф.
Статья по оптимизация сервера Microsoft SQL Server 2019 для работы с 1С
Устанавливаем последний Service Pack и Cumulative Update — реальность
На текущий момент нужно обновиться до SP3.
MSSQL — устанавливаем Service Pack 3
Обязательно нужно сделать.
Выравнивание разделов — миф
Рекомендуют выравнивать сектора дисков по границе 1024Кб. Не заморачивайтесь, эта рекомендация устарела. Операционная система теперь сама выравнивает раздел как нужно для дисков более 4 ГБ.
HKLM\SYSTEM\CurrentControlSet\Services\VDS\Alignment
Эту настройку не применяем.
Форматирование с размером блока 64Кб
А вот здесь всё очень неявно. Есть статья Best Practice от Microsoft:
https://docs.microsoft.com/ru-ru/archive/blogs/docast/operating-system-best-practice-configurations-for-sql-server
В ней явно говорится:
Partition the Disk volumes hosting SQL databases (Data and log) with 64 KB allocation unit size:
A drive can be formatted with different sizes ranging from 512 bytes to 64K sizes with the default being 4KB (4096 bytes).This setting is also called as “Bytes Per Cluster”. The atomic unit of storage in SQL Server is a page which is 8KB in size. Extents are groups of eight 8 KB pages that are physically contiguous to each other for a total of 64 KB. SQL Server uses extents to store data. Hence, on a SQL Server machine the NTFS Allocation unit size hosting SQL database files (Including tempdb files) should be 64K.
Кстати, обратите внимание на другие разделы статьи, возможно, там тоже найдёте для себя что-то полезное.
Казалось бы всё ясно, 64 килобайта — наше всё. Но… Откуда ноги растут? Есть рекомендация от Microsoft с 2008 года:
https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008/dd758814(v=sql.100)
Здесь аргументированно с указанием конкретного железа, на котором производились испытания, пишут:
Note that file allocation unit (cluster) size commonly correlates with common stripe unit sizes. The performance question here is usually not one of correlation per the formula, but whether the cluster size is the NTFS default of 4,096 bytes or has been explicitly defined at 64 KB, which is a best practice for SQL Server.

Снова 64 килобайта — наше всё. Читаем дальше:
An appropriate value for most installations should be 65,536 bytes (that is, 64 KB) for partitions on which SQL Server data or log files reside. In many cases, this is the same size for Analysis Services data or log files, but there are times where 32 KB provides better performance. To determine the right size, you will need to do performance testing with your workload comparing the two different block sizes.
Получается, что SQL сервер ведёт себя лучше при размере кластера 64 килобайта, однако, в некоторых случаях, максимальной производительности удавалось достигать при размере кластера в 32 килобайта.
А теперь добавляем переменных:
- Появились новые типы массивов типа SSD и NVMe.
- Всё чаще SQL сервер устанавливается виртуально или в облаке, где файловая система виртуальной машины живёт внутри файловой системы гипервизора.
- Производители жёстких дисков и RAID контроллеров используют кеширование и дополнительные технологии ускорения работы дисков.

Ещё следует учитывать, что NTFS для разных размеров диска создаёт разные размеры блока. Стандартный размер кластера (лучше использовать это название) в файловой системе NTFS:
- ёмкость до 16 Тб — 4 килобайта
- ёмкость от 16 до 32 Тб — 8 килобайт
- ёмкость от 32 до 64 Тб — 16 килобайт
- ёмкость от 64 до 128 Тб — 32 килобайта
- ёмкость от 128 до 256 Тб — 64 килобайта
Так что если вы не хотите заморачиваться, то ставьте размер блока (кластера) при форматировании 64 килобайта. Однако не факт, что при этом ваш SQL сервер будет работать быстрее. Правильный ответ можно получить только при тестировании производительности.
Присылайте ссылки на статьи, где проводились исследования производительности для разных размеров кластера. Истина где-то там.
Database instant file initialization — частично миф, частично реальность
Рекомендуют включить возможность Database instant file initialization для пользователя, от которого запущена служба Microsoft SQL Server.
Что это за штука?
Во-первых, эта настройка влияет только на файл данных. Когда файл автоматически вырастает, то новый кусок заполняется нулями, в этот момент 1С может тормозить. Instant File Initialization (IFI) позволяет отключить это зануление.
Делается так.
- Запускаем Local Group Policy Editor:
gpedit.msc
- Слева выбираем Local Computer Policy, Computer Configuration, Windows Settings, Security Settings, Local Policies, User Rights Assigment.
- Тыкаем в Perform volume maintenance tasks.
- Сюда добавляем юзера, от имени которого запускается SQL Server.
Однако, у меня там уже прописана группа Administrators, а пользователь, под которым работает служба SQL Server уже в этой группе.
Так что у меня ничего не пришлось настраивать. Но вы у себя проверьте.
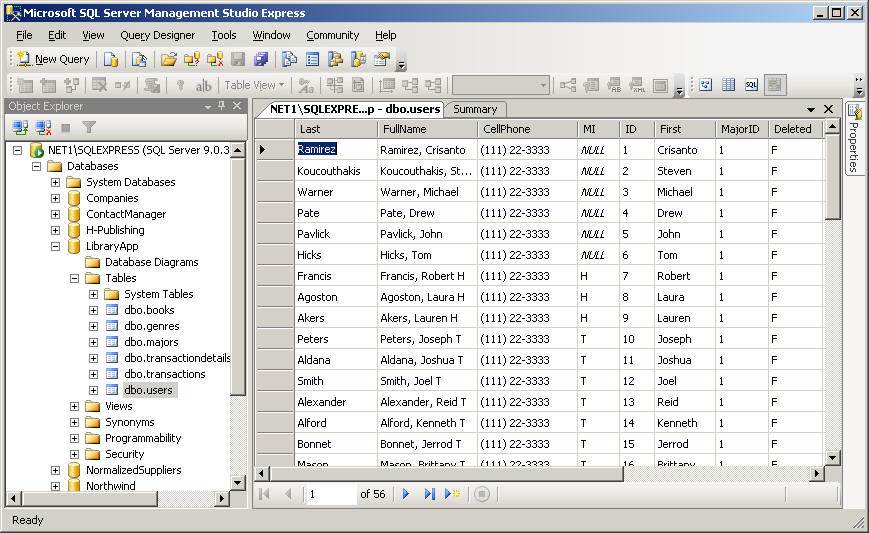
Давайте проверим, что всё работает. Рекомендуют создать новую БД размером 5 Гб и логом 1 Мб. Вот тут тоже нужно быть внимательным, нужно создавать под тем же пользователем, от которого запускается сервис SQL. Я создам от имени другого пользователя, который тоже в группе Administrators.
Я создам от имени другого пользователя, который тоже в группе Administrators.
База создалась мгновенно. На всякий случай попробую создать базу размером 50 Гб, место есть. Да, моментально на диске пропало 50 Гб и БД создалась быстро.
Вывод:
Instant File Initialization (IFI) работает из коробки, если пользователь, под которым работает сервис SQL входит в группу Administrators сервера.
Эту настройку применяем только при необходимости.
Lock pages in memory — реальность
Рекомендуют установить разрешение на Lock pages in memory (блокировку страниц в памяти) для пользователя, от которого запущена служба Microsoft SQL Server. Эта политика Windows определяет, какие учетные записи могут сохранять данные в физической памяти, чтобы система не отправляла страницы данных в виртуальную память на диске.
- Запускаем Local Group Policy Editor:
gpedit.msc
- Слева выбираем Local Computer Policy, Computer Configuration, Windows Settings, Security Settings, Local Policies, User Rights Assignment.
- Тыкаем в Lock pages in memory.
- Видим, что политика не настроена. Можно добавить сюда пользователя, от имени которого работает SQL Server, я просто добавляю сюда группу Administrators.

Эту настройку применяем. Нужно учитывать, что потребление оперативки возрастёт.
Power Option: High performance — реальность
Да, это реальность. По умолчанию план электропитания в Windows Server 2012 R2 — Balanced.
https://support.microsoft.com/en-au/help/2207548/slow-performance-on-windows-server-when-using-the-balanced-power-plan
В некоторых случаях, Microsoft не уточняет в каких, на сервере может из-за этого снижаться производительность. Переключаем план на High performance.
Эту настройку применяем.
Сжатие содержимого — миф
Рекомендуют проверить, что галка, отмеченная на картинке выше, снята. Имеется в виду папка, где лежат файлы БД. По умолчанию она снята — рекомендация миф.
Индексация файлов — миф
По умолчанию галка Allow files in this folder to have contents indexed in addition to the file properties стоит:
Казалось бы, надо снимать. Подумаем, эта галка указывает службе индексации, что содержимое нужно обработать. Зачем на сервере индексировать содержимое? А стоит ли вообще служба индексации по умолчанию? Проверяем:
Подумаем, эта галка указывает службе индексации, что содержимое нужно обработать. Зачем на сервере индексировать содержимое? А стоит ли вообще служба индексации по умолчанию? Проверяем:
А служба поиска не установлена! Ну и забиваем на все эти галки. Эту настройку не применяем.
Исключить файлы БД из систем резервного копирования — миф
Это классика, не нужно ничего исключать, нужно просто нормально резервирование делать.
Во-первых, не отделяйте мух от котлет. Не держите приложение 1С и SQL Server на одном сервере. MSSQL должен жить отдельно. И резервироваться он должен средствами MSSQL. И зеркалироваться.
Эту настройку не применяем.
Резервирование и обслуживание — реальность
Ссылки:
Maintenance Plans — резервное копирование и обслуживание баз данных в Microsoft SQL Server 2014
Настройка зеркалирования в Microsoft SQL Server 2014
Эту настройку применяем.
Настройка памяти — реальность
Да, память для MSSQL нужно настраивать. По умолчанию сиквел жрёт всё что может, системе начинает не хватать. Как итог — тормоза. Нужно выделить SQL серверу строго определённое количество памяти и пусть не рыпается.
По умолчанию сиквел жрёт всё что может, системе начинает не хватать. Как итог — тормоза. Нужно выделить SQL серверу строго определённое количество памяти и пусть не рыпается.
Повторюсь:
Не держите приложение 1С и SQL Server на одном сервере. MSSQL должен жить отдельно.
Это позволить избежать конкуренции за ресурсы.
MSSQL — настройка памяти
Эту настройку применяем.
Настройка процессора — реальность
Настроим проц.
MSSQL — настройка процессора
Эту настройку применяем.
Расположение файлов данных — реальность
Файлы данных и файлы журналов транзакций желательно размещать на разных дисковых массивах. Если один из массивов быстрее, то лог нужно разместить там.
Эту настройку по возможности применяем.
Разбить tempdb на несколько файлов по количеству процессоров — миф
Миф обыкновенный:
Эту настройку не применяем.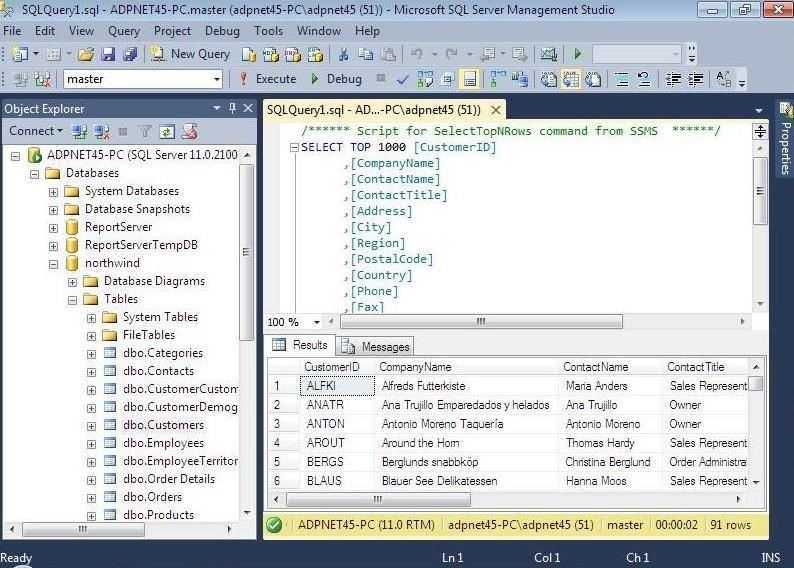
Перенести tempdb в RAM — реальность
Сам протестировал, добился 10-кратного прироста скорости чтения-запись для tempdb.
MSSQL — переносим tempdb на RAM диск
Эту настройку по возможности применяем.
Установить параметр Max degree of parallelism = 1 — частично миф, частично реальность
В закладке Advanced есть возможность установить параметр Max degree of parallelism. Кто-то рекомендует ставить 1, чтобы запретить параллельные запросы. Смысл в том, что один толстый запрос может сожрать все процессоры и помешать другим пользователям. С другой стороны, запущенная на ночь обработка могла бы выполняться быстрее при использовании нескольких процессоров. Давайте поступим иначе — ограничим половиной процессоров. У меня их 8, ставлю 4.
https://docs.microsoft.com/ru-ru/sql/database-engine/configure-windows/configure-the-max-degree-of-parallelism-server-configuration-option?view=sql-server-2014
Эту настройку применяем только при необходимости и в зависимости от количества процессоров.
Прирост файлов БД — реальность
Меняем дефолтные настройки прироста размера файлов данных и лога.
По умолчанию прирост 10%, это никуда не годится. Если база 500 гигабайт, то одномоментно отобранные 50 Гб места могут негативно сказаться на работе.
Ставим прирост 200 Мб.
Эту настройку применяем.
Флаги трассировки — реальность
4199 — включает исправления оптимизатора из фиксов.
https://blogs.msdn.microsoft.com/psssql/2015/06/16/identifying-sql-server-2014-new-cardinality-estimator-issues-and-service-pack-1-improvement/
1118 — использовать разные страницы памяти.
Запускаем SQL Server Configuration Manager. SQL Server Services. SQL Server — правой кнопкой свойства. Вкладка Startup Parameters. Добавляем -T1118 и -T4199.
Для применения потребуется перезапустить SQL сервер.
Эту настройку применяем.
Сетевые протоколы — реальность
Протокол «Named pipes» необходимо отключить.
Запускаем SQL Server Configuration Manager. SQL Server Network Connfiguration. Protocols for MSSQLSERVER (наш инстанс). Делаем Named Pipes — Disabled.
SQL Server Network Connfiguration. Protocols for MSSQLSERVER (наш инстанс). Делаем Named Pipes — Disabled.
Эту настройку применяем.
Отключение DFSS — миф
DFSS по умолчанию устанавливается на терминальный сервер. При чём тут SQL? Отключать нечего.
Эту настройку не применяем.
SQL Server 2019 — ресурсы | Microsoft
Независимо от того, являются ли ваши данные структурированными или неструктурированными, запрашивайте и анализируйте их с помощью платформы данных с лучшей в отрасли производительностью и безопасностью.
Получить справку по SQL Server
Найти поддержку SQL Server
Техническая поддержка
Поддержка сообщества
Начните работу с SQL Server 2019
Подписывайтесь на нас
Поделиться этой страницей
Что такое MSSQL? О Microsoft SQL Server
- Домашний
- /
- Хостинг VPS
- /
- Что такое MSSQL?
Что такое MSSQL?
MySQL — это система управления реляционными базами данных (RDBMS) с открытым исходным кодом, основанная на языке структурированных запросов (SQL). MySQL доступен во всех основных операционных системах, включая Windows, Linux и Solaris. Его можно использовать бесплатно для частных лиц и непроизводственных сред в соответствии с Стандартной общественной лицензией GNU; однако при коммерческом использовании требуется коммерческая лицензия.
MySQL доступен во всех основных операционных системах, включая Windows, Linux и Solaris. Его можно использовать бесплатно для частных лиц и непроизводственных сред в соответствии с Стандартной общественной лицензией GNU; однако при коммерческом использовании требуется коммерческая лицензия.
MySQL, как и другие реляционные базы данных, хранит данные в таблицах, столбцах и строках. Каждая запись определяется уникальным идентификатором. Смысл ее существования всегда заключался в производительности и надежности базы данных. MySQL был разработан и оптимизирован для веб-разработки; возможно, это самая распространенная база данных, используемая при развертывании веб-серверов. MySQL очень хорошо работает с Apache и PHP и часто является базой данных для развертывания стека LAMP. Сегодня MySQL поддерживает 9 из 10 веб-сайтов в Интернете, и эта база данных выбрана Facebook, Twitter и Wikipedia. и
Microsoft SQL Server (MSSQL) широко используется в корпоративных средах. MSSQL — это масштабируемая платформа данных, которая включает в себя несколько инструментов ETL (извлечение, преобразование и загрузка) и служб отчетов, где данные можно добавлять, изменять и запрашивать с помощью стандартизированного структурированного языка запросов (SQL). MSSQL — это развивающаяся платформа данных, используемая для критически важных бизнес-решений и решений для данных в помещении, в облаке и на гибридных платформах. i
MSSQL — это масштабируемая платформа данных, которая включает в себя несколько инструментов ETL (извлечение, преобразование и загрузка) и служб отчетов, где данные можно добавлять, изменять и запрашивать с помощью стандартизированного структурированного языка запросов (SQL). MSSQL — это развивающаяся платформа данных, используемая для критически важных бизнес-решений и решений для данных в помещении, в облаке и на гибридных платформах. i
Краткая история MSSQL
Синтаксис SQL и MSSQL связаны, но различны. Синтаксис SQL — это язык, используемый для запросов к базам данных, а MSSQL — это пакет продуктов Microsoft для баз данных, использующий синтаксис SQL. Самые первые версии SQL-сервера были разработаны Ashton Tate, Sybase и Microsoft в период с 1988 по 1993 год и были созданы для операционных систем на базе Unix. Когда в начале 1990-х Microsoft стала доминировать в операционных системах для настольных ПК, основное внимание было смещено на разработку SQL Server для Windows. В 1993 году был выпущен SQL Server 4.21, и это была первая платформа базы данных SQL, созданная для Microsoft Windows, которая использовала преимущества графического пользовательского интерфейса.
В 1993 году был выпущен SQL Server 4.21, и это была первая платформа базы данных SQL, созданная для Microsoft Windows, которая использовала преимущества графического пользовательского интерфейса.
До сих пор Sybase лицензировала свою технологию базы данных Dbase для Microsoft; эта технология широко использовалась в SQL Server, но условия лицензии не позволяли Microsoft изменять исходный код без явного согласия Sybase. В 1994 году пути компаний разошлись, и Microsoft сместила фокус разработки на выпуск SQL Server 6.0 (SQL95). Они быстро последовали в 1996 году с SQL Server 6.5, который представил поддержку Интернета и хранилищ данных для молодой Всемирной паутины. ii
В 1998 году Microsoft полностью переписала SQL Server 7.0, удалив все устаревшие функции Sybase и добавив огромное количество новых возможностей. SQL Server 2000 был выпущен одновременно с Windows Server 2000. iii Это начало знакомого сегодня цикла выпуска пакета SQL Server, все последующие версии SQL были обновлены с добавлением дополнительных функций и служб и обычно совпадают с датой выпуска операционной системы.
Почему стоит выбрать MSSQL
Сервер MSSQL — невероятно популярное решение для баз данных, используемое сегодня, и одним из его самых сильных преимуществ является простота использования. MSSQL поставляется с множеством отличных инструментов, которые делают разработку базы данных быстрым и гибким процессом. Студия управления SQL Server позволяет любому утвержденному пользователю управлять базами данных и обслуживать их, выполнять SQL-запросы, выполнять резервное копирование и анализировать диаграммы производительности. MSSQL интегрируется с Visual Studio, чтобы предоставить вашей команде DevOps мощную знакомую платформу для создания пользовательских приложений и управления ими, которые легко интегрируются с MSSQL Server.
Основные характеристики MSSQL
Существует множество продуктов, составляющих платформу баз данных SQL Server, но в MSSQL встроены 4 ключевых службы, которые определяют ее и делают ее популярной в качестве системы управления базами данных (СУБД).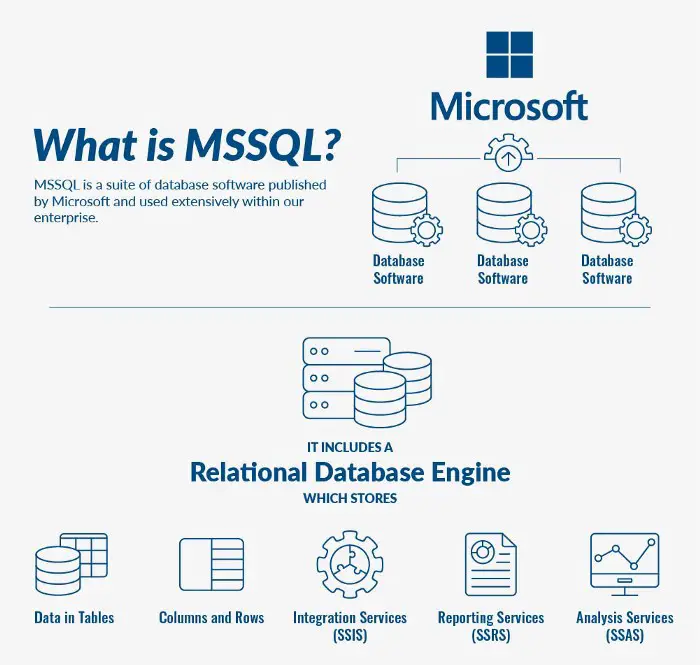 Эти параметры доступны для установки при развертывании экземпляра MSSQL. Последние выпуски MSSQL не только совместимы с Windows; совсем недавно Microsoft предложила SQL для Linux (Red Hat и SUSE), а также контейнерные платформы Docker.
Эти параметры доступны для установки при развертывании экземпляра MSSQL. Последние выпуски MSSQL не только совместимы с Windows; совсем недавно Microsoft предложила SQL для Linux (Red Hat и SUSE), а также контейнерные платформы Docker.
Механизм базы данных
Механизм базы данных SQL является ядром набора продуктов MSSQL. Это был оригинальный продукт, который используется для хранения, обработки и защиты данных. Данные хранятся в одном или нескольких экземплярах базы данных. Некоторые из ключевых функций ядра базы данных включают хранение данных в таблицах экземпляров и возможность импорта данных XML, управление данными больших двоичных объектов (большие двоичные объекты), триггеры БД, журналы транзакций, сжатие данных, поиск данных и планы обслуживания, чтобы назвать немного.
Integration Services (SSIS)
SSIS — это средство перемещения данных, которое может импортировать и экспортировать данные из базы данных. Он широко используется для разработки процессов ETL (извлечение, преобразование, загрузка). Вы можете извлекать данные практически из любого источника (например, других баз данных, текстовых файлов или документов Excel), преобразовывать их путем слияния, фильтрации, сортировки полей или агрегирования данных iv , и вы можете загружать эти данные в место назначения, часто в общую папку или даже в другую базу данных/приложение. v
Вы можете извлекать данные практически из любого источника (например, других баз данных, текстовых файлов или документов Excel), преобразовывать их путем слияния, фильтрации, сортировки полей или агрегирования данных iv , и вы можете загружать эти данные в место назначения, часто в общую папку или даже в другую базу данных/приложение. v
Службы отчетов (SSRS)
SSRS — это комплексная платформа отчетов для SQL Server, которая используется для создания и развертывания нескольких типов отчетов с разбивкой на страницы. SSRS может сообщать о любых данных в базе данных и отображать их либо в виде простых диаграмм, либо в виде сложных визуализаций данных. SSRS может создавать отчеты практически по любым исходным данным базы данных. Отчеты можно отображать на веб-сайте служб отчетности или интегрировать в любое приложение, поддерживающее .NET. Отчеты SSRS обычно используются компаниями для отображения ключевых показателей эффективности, таких как данные о продажах или количество заказов, обрабатываемых в час, и, таким образом, являются одной из функций, наиболее востребованных исполнительными командами. vi
vi
Analysis Services (SSAS)
SSAS — это сервер многомерной оперативной аналитической обработки (OLAP) и интеллектуального анализа данных. vii SSAS — это отдельная база данных, в которую через службы SSIS подаются данные из любого другого источника данных для создания кубов реляционных данных в хранилище данных. Это высокоэффективная база данных, позволяющая выполнять глубокие запросы практически мгновенно по огромному объему данных. Примером типичных отчетов SSAS может быть анализ всех продаж в регионе EMEA за конкретный месяц; SSAS позволит вам сделать это с помощью выражений MDX. viii
Резюме
MSSQL Server — одно из лучших решений для баз данных, доступных сегодня на рынке SQL. Если вы ищете безопасную, простую в управлении и высокопроизводительную систему управления базой данных для вашей совместимой базы данных, то MSSQL должен стать серьезным вариантом для рассмотрения. Это позволяет пользователям анализировать данные, прогнозировать продажи и даже предсказывать поведение клиентов с помощью аналитики бизнес-аналитики.
Ссылки
i Microsoft SQL Server — США (английский). (2018). SQL Server 2017 для Windows и Linux | Майкрософт. [онлайн] Доступно по адресу: https://www.microsoft.com/en-us/sql-server/sql-server-2017 [По состоянию на 8 мая 2018 г.].
ii Спеник, М; Сани О (2000). Руководство по выживанию администраторов баз данных Microsoft SQL Server 2000. САМС. Глава 2. ISBN 0672324687.
iii Харрис, Скотт; Кертис Престон (2007). Резервное копирование и восстановление: недорогие решения для резервного копирования для открытых систем. О’Райли. п. 562. ISBN 0596102461.
iv Docs.microsoft.com. (2018). Установите ядро базы данных SQL Server. [онлайн] Доступно по адресу: https://docs.microsoft.com/en-us/sql/database-engine/install-windows/install-sql-server-database-engine?view=sql-server-2017 [Доступ 8 май 2018].
v Docs.microsoft.com. (2018). Службы интеграции SQL Server. [онлайн] Доступно по адресу: https://docs.