MySQL | Группировка
Последнее обновление: 21.05.2018
Операторы GROUP BY и HAVING позволяют сгруппировать данные. Они употребляются в рамках команды SELECT:
SELECT столбцы FROM таблица [WHERE условие_фильтрации_строк] [GROUP BY столбцы_для_группировки] [HAVING условие_фильтрации_групп] [ORDER BY столбцы_для_сортировки]
GROUP BY
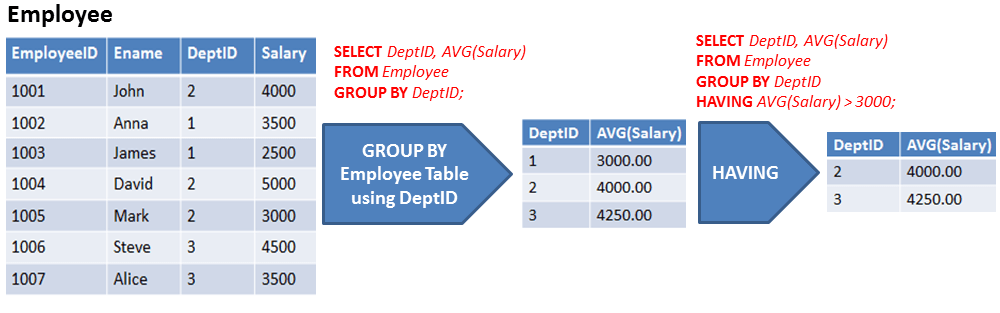
Оператор GROUP BY определяет, как строки будут группироваться.
Например, сгруппируем товары по производителю
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products GROUP BY Manufacturer
Первый столбец в выражении SELECT — Manufacturer представляет название группы, а второй столбец — ModelsCount представляет результат функции Count, которая вычисляет количество строк в группе.
И если в выражении SELECT производится выборка по одному или нескольким столбцам и также используются агрегатные функции, то необходимо использовать
выражение GROUP BY.
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products
Оператор GROUP BY может выполнять группировку по множеству столбцов. Так, добавим группировку по количеству товаров:
SELECT Manufacturer, ProductCount, COUNT(*) AS ModelsCount FROM Products GROUP BY Manufacturer, ProductCount
Следует учитывать, что выражение GROUP BY должно идти после выражения WHERE, но до выражения
ORDER BY:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products WHERE Price > 30000 GROUP BY Manufacturer ORDER BY ModelsCount DESC
Фильтрация групп. HAVING
Оператор HAVING позволяет выполнить фильтрацию групп, то есть определяет, какие группы будут включены в выходной результат.
Использование HAVING во многом аналогично применению WHERE. Только если WHERE применяется для фильтрации строк, то HAVING — для фильтрации групп.
Только если WHERE применяется для фильтрации строк, то HAVING — для фильтрации групп.
Например, найдем все группы товаров по производителям, для которых определено более 1 модели:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products GROUP BY Manufacturer HAVING COUNT(*) > 1
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products WHERE Price * ProductCount > 80000 GROUP BY Manufacturer HAVING COUNT(*) > 1;
То есть в данном случае сначала фильтруются строки: выбираются те товары, общая стоимость которых больше 80000. Затем выбранные товары группируются по производителям. И далее фильтруются сами группы — выбираются те группы, которые содержат больше 1 модели.
Если при этом необходимо провести сортировку, то выражение ORDER BY идет после выражения HAVING:
SELECT Manufacturer, COUNT(*) AS Models, SUM(ProductCount) AS Units FROM Products WHERE Price * ProductCount > 80000 GROUP BY Manufacturer HAVING SUM(ProductCount) > 2 ORDER BY Units DESC;
Здесь группировка идет по производителям, и также выбирается количество моделей для каждого производителя (Models)
и общее количество всех товаров по всем этим моделям (Units). В конце группы сортируются по количеству товаров по убыванию.
В конце группы сортируются по количеству товаров по убыванию.
НазадСодержаниеВперед
sql — Как работает GROUP BY в MySQL?
Привет.
Вопрос по sql по клаузуле GROUP BY.
Рассмотрим группировку по ОДНОМУ столбцу. Пример:
SELECT DEPARTMENT_ID, SUM(SALARY) FROM Employees GROUP BY DEPARTMENT_ID;
То есть, в столбце
DEPARTMENT_IDищется уникальное (похоже наDISTINCT) значение отдела, например, 30, затем ищутся все строки, где упоминается отдел 30 в данной таблице, из этих строк берутся значения из столбцаSALARYи суммируются (SUM). Потом ищется другой покупатель и все повторяется. В итоге я получаю сколько получил вообще денег каждый отдел.Не понимаю момент: у меня есть 6 строк, в которых есть столбец
DEPARTMENT_IDсо значением 30. Какая из строк пойдет в таблицу-SELECTи почему? То есть, в таблицеDEPARTMENT_ID30, а в таблице-SELECTтакая строка только одна. Как вообще эта группировка работает?
Как вообще эта группировка работает?Рассмотрим группировку по двум столбцам. Ее я вообще не понимаю. Даже картинки нормальной не нашел, из которой было бы понятно. Просмотрел кучу статей и книг по этому вопросу, но не понял ничего.
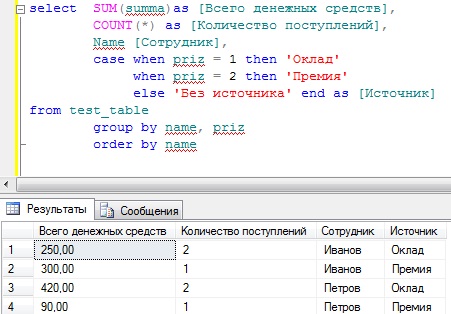 Как вообще эта группировка работает?
Как вообще эта группировка работает?- mysql
- sql
- group-by
4
В выборку после sum()), будет применена функция «первое попавшееся». Причем только в MySQL и только при выключенной опции ONLY_FULL_GROUP_BY. В остальных СУБД запрос, в котором хотя бы к одной колонке, не являющейся разрезом указанным в group by, «забыли» применить групповую функцию выдаст ошибку.
Как работает group by можно прикинуть в экселе. Запишите данные на лист, отсортируйте по тем полям, которые должны быть в
Запишите данные на лист, отсортируйте по тем полям, которые должны быть в group by отличается от значений в предыдущей — вставьте новую строку, скопируйте значения колонок group by, а в остальные поместите формулы вроде СУММ() ячеек группы под которой подводится итог. Результат group by — это именно эти вставленные итоговые записи. СУБД работает примерно по такому же алгоритму — сначала сортирует, потом суммирует идущие подряд одинаковые записи.
Добавлю про MySQL — он все таки слишком вольно к этому относится. Старайтесь всегда явно применять групповые функции ко всем колонкам, что бы самому понимать что именно в них окажется, ибо ‘первое попавшееся’ ни чем не стандартизировано и может меняться от версии к версии и в зависимости от физического расположения записей на диске и плана выполнения запроса.
0
Добавлю с примером запросов и вывода GROUP BY по двух полях. Смотреть можно по таблице в которую, например, сохраняеться какой пользователь (user_id) вносил деньги, на какой счет (account) и сколько (balance). Например, нужно узнать сколько каждый пользователь внес на каждый из своих счетов.
SELECT MIN(user_id), MIN(account), SUM(balance) FROM `t1` GROUP BY user_id, account;
Работает GROUP BY по двум полям так же как и по одному, сначала сортирует, а потом смотрит, если оба значения в строке такие же как и в предыдущей строке, тогда групирует эти строки. Если хотя бы одно значение не такое как в предыдущей строке, тогда групировки не будет. Для 3 и больше полей GROUP BY работает так же.
Результат:
0
Зарегистрируйтесь или войдите
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
sql — MySQL: группировка по выбору первых 2 строк в каждой группе
Задавать вопрос
спросил
Изменено 5 лет, 10 месяцев назад
Просмотрено 4к раз
Есть ли способ выбрать первые 2 ответа для каждого вопроса из таблицы ответов:
user_answers Структура таблицы:
id question_id user_id answer_id create_date 1 1 9 5 ноль 2 2 8 7 ноль 3 1 1 3 ноль 4 3 4 20 ноль 5 1 4 5 ноль 6 4 3 25 ноль 7 2 7 5 ноль 8 4 926 ноль 9 2 5 8 ноль 10 1 1 5 ноль
Мне нужно вернуть такие результаты:
id question_id user_id answer_id create_date 1 1 9 5 ноль 3 1 1 3 ноль 2 2 8 7 ноль 7 2 7 5 ноль 4 3 4 20 ноль 6 4 3 25 ноль 8 4 926 ноль
Это похоже на группу по «question_id», но выберите первые 2 строки из каждой группы,
спасибо,
- mysql
- sql
4
В одну сторону: (если вам нужно более 2 строк на группу, то это не решение)
выберите your_table.
 * from your_table
внутреннее соединение(
выберите min(id) в качестве идентификатора из группы your_table по question_id
союз всех
выберите min(id) в качестве идентификатора из your_table
где id нет (выберите min(id) из группы your_table по question_id)
группировать по question_id
) т
на your_table.id = t.id
порядок по your_table.question_id , your_table.id
* from your_table
внутреннее соединение(
выберите min(id) в качестве идентификатора из группы your_table по question_id
союз всех
выберите min(id) в качестве идентификатора из your_table
где id нет (выберите min(id) из группы your_table по question_id)
группировать по question_id
) т
на your_table.id = t.id
порядок по your_table.question_id , your_table.id
5
Это каноническая задача, в которой аналитическая функция ROW_NUMBER была бы чрезвычайно полезна. MySQL не поддерживает какие-либо функции нумерации строк из коробки, но мы можем имитировать их с помощью переменных сеанса:
SET @row_num = 0;
УСТАНОВИТЬ @q_id = 0;
ВЫБИРАТЬ
т.ид,
t.question_id,
t.user_id,
t.answer_id,
t.create_date
ОТ
(
ВЫБИРАТЬ
@row_num:=CASE WHEN @q_id = question_id THEN @row_num + 1 ELSE 1 END AS rn,
@q_id:=question_id как question_id,
идентификатор,
ID пользователя,
ответ_идентификатор,
create_date
ОТ
user_answers
ЗАКАЗАТЬ ПО question_id, id
) т
ГДЕ t. rn <= 2
ЗАКАЗАТЬ ПО t.question_id, t.id;
 rn <= 2
ЗАКАЗАТЬ ПО t.question_id, t.id;
rn <= 2
ЗАКАЗАТЬ ПО t.question_id, t.id;
Вывод:
Демо здесь:
2
Есть простое, но довольно медленное решение: считать записи.
выбрать * из ответов где ( выберите количество (*) из моей таблицы другое где др.вопросид = ответы.вопросид и др.идентификатор <= ответы.идентификатор ) <= 2 упорядочить по questionid, id;
1
пространственный - Как сгруппировать, чтобы получить MultiPoint/GeometryCollection в MySQL?
спросил
Изменено 9 месяцев назад
Просмотрено 766 раз
У меня есть такая таблица x:
Столбцы:
SubjectID int(11) Отметка времени bigint(20) точка fix_geom
Когда я пытаюсь сгруппировать свой столбец fix_geom в MultiPoint (или GeometryCollection) по SubjectID, например:
SELECT SubjectID, ST_AsText(MultiPoint(fix_geom)) ОТ х ГДЕ ИД субъекта = 100 СГРУППИРОВАТЬ ПО ИДЕНТИФИКАТОРу темы;
я получаю таблицу с многоточечной геометрией, но она содержит только одну точку вместо многих, которые я хотел бы там видеть. ..:
..:
Кто-нибудь может сказать мне, что я делаю неправильно?
С уважением и заранее большое спасибо, Олаф
- mysql
- пространственная
- геометрия
0
Как сказал Эван Кэрролл в комментарии: В отличие от PostGIS, пространственные агрегаты недоступны для MySQL.
Обходной путь, оставленный в комментарии danblack Works:
Похоже, вы хотите, чтобы
MultiPointбыла агрегатной функцией, а это не так. Вам, вероятно, понадобится что-то вродеST_GeomFromText(CONCAT('MultiPoint(', GROUP_CONCAT(...), ')')), где...получает строкуX Yизfix_geom.
Мы можем использовать агрегатную функцию ST_Collect() начиная с MySQL 8.0.24 .
Он поддерживает предложение DISTINCT и OVER и автоматически генерирует MULTIPOINT :
SELECT ALL Идентификатор субъекта, ST_Collect(fix_geom), ST_AsText(ST_Collect(fix_geom)) -- МНОГОТОЧЕЧНЫЙ((.
