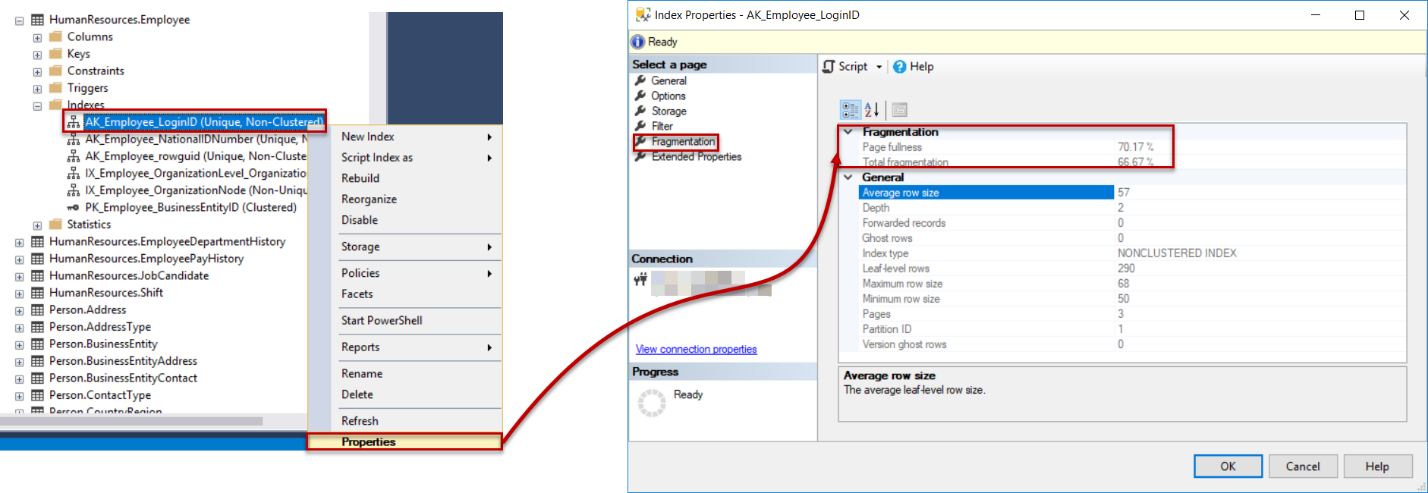
Различия индексов MySql, кластеризация, хранение данных в MyIsam и InnoDb / Хабр
Как устроены индексы в MySql, чем отличается индексирование в двух наиболее популярных движках MyISAM и InnoDb, чем первичные ключи отличаются от простого индекса, что такое кластерные индексы и покрывающие индексы, как с помощью них можно ускорить запросы. Вот как мне кажется наиболее интересные темы которые раскрою в этой статье. Тут же постараюсь подробно раскрыть тему с позиции того как работает этот механизм внутри. Буквально на пальцах и с позиции абстракций а не конкретики. В общем чтоб было минимум текста и максимум понятно.
Небольшое оглавление:
Вводная информация
Что представляет из себя индекс в MySql
Скорость чтения из индекса
Отличия в индексах MyISAM и InnoDb
Кластерный индекс
Первичные и «вторичные» индексы в чем отличия
Покрывающие индексы
Вводная информация
В MySql существует несколько типов индексов и каждый из них хорош для выполнения своих специализированных задач. Например Hash индекс хорош для хранения данных в виде ключ — значение в оперативной памяти, FULLTEXT индекс для поиска по текстовым документам, SPATIAL для хранения информации о гео-объектах, UNIQUE для уникальных значений. Но все же в подавляющем большинстве случаев мы используем индекс на основе B-дерева (BTREE) или Balanced-Tree. Сбалансированное оно потому что высота каждого поддерева с общим корневым элементом может отличаться, но всегда не более чем на константную величину. Далее в статье речь пойдет именно про BTREE индексы, по умолчанию под индексами буду подразумевать именно их.
Например Hash индекс хорош для хранения данных в виде ключ — значение в оперативной памяти, FULLTEXT индекс для поиска по текстовым документам, SPATIAL для хранения информации о гео-объектах, UNIQUE для уникальных значений. Но все же в подавляющем большинстве случаев мы используем индекс на основе B-дерева (BTREE) или Balanced-Tree. Сбалансированное оно потому что высота каждого поддерева с общим корневым элементом может отличаться, но всегда не более чем на константную величину. Далее в статье речь пойдет именно про BTREE индексы, по умолчанию под индексами буду подразумевать именно их.
Что представляет из себя индекс в MySql
ИндексНа рисунке изобразил схематично как устроен индекс. Имеются узловые элементы (квадраты) и листья (круги). Предположим у нас есть таблица с колонками «Val» и «ID» как на рисунке. В этой таблице индекс построен по числовому полю «ID». Тогда получается что в узловых элементах находятся значения индекса и ссылки на другой более нижний узел или лист. В листовых же элементах точно так же лежат значения индекса которые уже ссылаются непосредственно на данные из таблицы.
Тогда получается что в узловых элементах находятся значения индекса и ссылки на другой более нижний узел или лист. В листовых же элементах точно так же лежат значения индекса которые уже ссылаются непосредственно на данные из таблицы.
Процесс поиска происходит примерно следующим образом. Например нужно найти строку с индексом 11.
начинаем просмотр корневого (верхнего) узла
первое значение в нем 10
идем к следующему 19, оно уже больше чем нам нужно
по ссылке слева от 19 переходим к следующему нижнему узлу
там первое значение 13, оно больше чем нам нужно
опять по ссылке слева переходим к более нижнему элементу
это уже будет листовой элемент, в нем уже лежат непосредственно данные
просматриваем данные по порядку
находим 11
переходим по ссылке непосредственно к строке в таблице.
Скорость чтения из индекса
Такое устройство индекса позволяет обеспечить логарифмическую скорость поиска O(log n). Это очень быстро. Вот таблица где для наглядности посчитал сколько сравнений нужно сделать для поиска записи в таблице с разным количеством данных:
Это очень быстро. Вот таблица где для наглядности посчитал сколько сравнений нужно сделать для поиска записи в таблице с разным количеством данных:
Количество элементов в таблице | Количество сравнений |
10 | 3,3 |
100 | 6,6 |
1 000 | 9,9 |
10 000 | 13,2 |
100 000 | 16,6 |
1 000 000 | 19,9 |
Получается для поиска по миллиону значений нужно всего около 20 сравнений. Очень быстро. Одна небольшая ремарка — эти вычисления конечно же правдивы только для индексов с уникальными значениями. Построив индекс по значению, которое почти во всех строках одинаково, эффекта не будет так как все равно придется перебирать все эти строки с одинаковыми значениями.
Отличия в индексах MyISAM и InnoDb
MyIsam это более старый движок чем InnoDb и все описанное выше хорошо описывает устройство индекса именно в MyIsam. Более того для MyIsam можно сказать что первичный индекс и просто обычный индекс ни чем между собой не отличаются. В целом таблицы построенные на движке MyIsam вполне себе могут существовать даже без первичного ключа и без всякого индекса в целом. А вот InnoDb уже более свежий и продвинутый движок, и тут как раз есть отличия первичного ключа и просто индекса. Создать таблицу InnoDb тоже можно не указав первичный ключ, но в этом случае первичный ключ все равно создастся. Это называется суррогатный первичный ключ. InnoDb сам выберет поле по которому нужно этот ключ создать, если ни одно поле не подходит, то создаст новое числовое поле, которое конечно же будет скрыто и в структуре его не увидеть. Для разбора индексов InnoDb первым делом нужно начать с кластеризации.
Более того для MyIsam можно сказать что первичный индекс и просто обычный индекс ни чем между собой не отличаются. В целом таблицы построенные на движке MyIsam вполне себе могут существовать даже без первичного ключа и без всякого индекса в целом. А вот InnoDb уже более свежий и продвинутый движок, и тут как раз есть отличия первичного ключа и просто индекса. Создать таблицу InnoDb тоже можно не указав первичный ключ, но в этом случае первичный ключ все равно создастся. Это называется суррогатный первичный ключ. InnoDb сам выберет поле по которому нужно этот ключ создать, если ни одно поле не подходит, то создаст новое числовое поле, которое конечно же будет скрыто и в структуре его не увидеть. Для разбора индексов InnoDb первым делом нужно начать с кластеризации.
Кластерный индекс
Индекс в InnoDbКластерный индекс отличается тем, что в отличии от предыдущей картинки, где от листьев шли ссылки непосредственно на строки в таблице, тут все данные строк хранятся непосредственно в самом индексе. Проиллюстрировал это на примере листьев 10, 11, 12. Это хорошо тем что позволяет избежать лишнего чтения диска при переходе по ссылке от листа на данные в строке. Тут непосредственно вся строка лежит в индексе. То есть получается что в InnoDb при создании таблицы и указании первичного ключа будет построено такое дерево, в котором все данные таблицы будут продублированы в листья индекса. Если первичный ключ не задать то колонка для него будет выбрана или создана автоматически и все равно по ней будет построен кластерный индекс.
Проиллюстрировал это на примере листьев 10, 11, 12. Это хорошо тем что позволяет избежать лишнего чтения диска при переходе по ссылке от листа на данные в строке. Тут непосредственно вся строка лежит в индексе. То есть получается что в InnoDb при создании таблицы и указании первичного ключа будет построено такое дерево, в котором все данные таблицы будут продублированы в листья индекса. Если первичный ключ не задать то колонка для него будет выбрана или создана автоматически и все равно по ней будет построен кластерный индекс.
Более того, если мы говорим о таблицах на основе движка InnoDb, то в целом понятие таблица довольно абстрактное. На картинке она нарисована просто для наглядности. На самом деле ни какой таблицы по сути не существует, а все данные просто хранятся в кластерном индексе.
Первичные и «вторичные» индексы в чем отличия
Выше было оговорено что для MyIsam нет разницы между первичными и «вторичными» ключами.
Первичный и вторичный индекс в MyIsamНа картинке нарисован первичный и вторичный ключ в MyIsam. Первичный ключ построен по полю «ID», вторичный по полю «Val». Видно что их структура одинакова. И в том и в другом в листьях расположены значения индекса и ссылки на строки в таблице.
Первичный ключ построен по полю «ID», вторичный по полю «Val». Видно что их структура одинакова. И в том и в другом в листьях расположены значения индекса и ссылки на строки в таблице.
В InnoDb это устроено немного по другому.
Первичный и вторичный индекс в InnoDbКак уже говорил, таблица тут просто для наглядности. Все ее данные хранятся в первичном (кластерном ключе). Тут первичный ключ построен по полю «Id», вторичный по полю «Val». Видно что в листьях первичного ключа лежат значения индекса + все данные из строк таблицы. Во вторичном же ключе, в листьях лежат значения ключа + первичный ключ.
Можно резюмировать что для MyIsam нет различий между первичным и вторичными индексами. Для InnoDb первичный ключ содержит в себе все данные таблицы, вторичный же ключ содержит значения ключа плюс значение первичного ключа. Получается что при поиске по вторичному ключу, поиск будет произведен дважды. Первый раз непосредственно по самому индексу, будет найдено значение первичного индекса. И уже второй раз по найденому первичному индексу для поиска данных всей строки.
И уже второй раз по найденому первичному индексу для поиска данных всей строки.
Покрывающие индексы
Последнее о чем хотелось бы упомянуть — это покрывающие индексы и как с их помощью можно немного ускорить производительность.
Смысл покрывающих индексов в том, что MySql может вытаскивать данные непосредственно из самого индекса, не читая при этом всю строку и вовсе не читая строку. Для такой оптимизации нужно чтобы все поля указанные в SELECT имелись в индексе. То есть например у нас имеется таблица с полями «id», «name», «surname», «age», «address». И мы проиндексировали ее по полю «id». В запросе мы хотим получить например «id» и «name». При таком условии MySql найдет по первичному ключу нужную строку, прочитает ее и отбросит все поля не указанные в SELECT. Если же мы немного оптимизируем этот запрос и построим индкес по двум полям «id» и «name», то в таком случае MySql найдя нужную строку по этому индексу не пойдет читать всю эту строку, а просто возьмет данные, которые нужны непосредственно из индекса. Правда есть обратная сторона такого подхода, а именно размер индекса в этом случае будет больше, по этому нужно грамотно подходить к построению покрывающих индексов.
Правда есть обратная сторона такого подхода, а именно размер индекса в этом случае будет больше, по этому нужно грамотно подходить к построению покрывающих индексов.
Более подробно можно почитать в очень хорошей книге «MySQL по максимуму» Бэрон Шварц, Петр Зайцев, Вадим Ткаченко
sql — Что такое индекс mysql и как их использовать
Вопрос задан
Изменён 11 месяцев назад
Просмотрен 27k раза
Можете привести понятный пример индекса в таблицах? В документациях столько всего написано, это вводит в заблуждение. Индекс — это и есть первичный или внешний ключ?
mysql sql
6
Если в кратце, то индекс, это поле по которому оптимизирован(ускорен) поиск.
Поскольку индекс занимает место, то индексировать нужно только те поля, по которым происходит выборка.
Допустим есть таблица.
CREATE TABLE MyGuests (
id INT(6) UNSIGNED AUTO_INCREMENT PRIMARY KEY,
firstname VARCHAR(30) NOT NULL,
lastname VARCHAR(30) NOT NULL,
email VARCHAR(50),
reg_date TIMESTAMP
)
id — уже индекс
Допустим вам нужен поиск по имени (firstname).
SELECT * FROM MyGuests WHERE firstname = "Вася"
тогда есть смысл добавить индекс по данному полю.
CREATE INDEX firstname_index ON MyGuests (firstname) USING BTREE;
Будет созданна «карта» которая позволет легко находить записи в оригинальном списке.
https://ru.wikipedia.org/wiki/B-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE
Для одной небольшой таблицы приемущество не будет очевидно < 1000 записей, но только до тех пор, пока вы не попытаетесь объеденит  Убивает сервер на раз!
Убивает сервер на раз!
16
Вкратце, индексы создаются для повышения производительности поиска данных. Таблицы могут иметь огромное количество строк, которые хранятся в произвольном порядке. Без индекса поиск нужных строк идёт по порядку (последовательно), что на больших объемах данных отнимает много времени.
Индекс — обычно один или несколько столбцов таблицы и указателей на соответствующие строки таблицы, позволяет искать строки, удовлетворяющие критерию поиска. Ускорение работы с использованием индексов достигается в первую очередь за счёт того, что индекс имеет структуру, оптимизированную под поиск — например, в MySQL b-дерева. Индекс лучше использовать на тех столбцах таблицы, на которые вы чаще всего будете накладывать условия через
Индекс создаётся по правилу:
create index название_индекса on название_таблицы (название_столбца)
Например, у вас таблица называется test, где хранятся данные по городам России с улицами вида Город, Улица, Дом.
select * from test where city = 'Омск'
то, чтобы этот запрос отработал быстрее обычного, следует добавить индекс по вышеуказанному правилу:
create index city_index on test (city)
Тогда тот же самый запрос
select * from test where city = 'Омск'
отработает гораздо быстрее, если столбец city будет проиндексирован.
4
На пальцах можно объяснить так:
Когда Вы создаёте таблицу, добавляете в неё данные, то таблица разрастается и она выглядит как просто последовательный список, упорядоченный по тому как в неё данные добавлялись.
Когда данных мало, список маленький и все запросы к ней выполняются, почти, незаметно. Но когда количество записей в таблице начинает переваливать за миллион (в разных случаях по разном, но как пример миллион), то у Вас поиск уже идёт не так быстро и с добавлением всё новых и новых записей — ещё медленнее.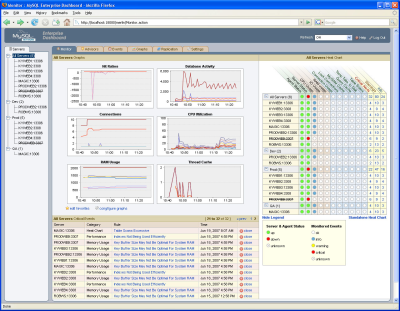
Это связано с тем, что когда Вы ищите какую-то запись, то просматриваются все записи, пока не дойдут до нужной.
Когда Вам это окончательно надоедает и Вы хотите что-нибудь сделать, то к Вам на помощь приходят индексы.
Индекс создаётся по какому-то определённому полю (можно по нескольким) по которому, обычно, выполняется поиск. Когда Вы создаёте индекс, то MySql (и любая другая БД) обходит все записи в таблице и строит дерево (скорее всего B-дерево или разновидность), в котором ключами выступает выбранное поле, а содержимым ссылки на записи в таблице.
И когда Вы делаете очередной свой select запрос по таблице, по полю для которого создали индекс MySql (и любая другая БД) знает что у неё есть индекс, по которому пройтись будет быстрее, нежели перебирать все записи и Ваш запрос будет направлен этому индексу и записи, удовлетворяющие условию, будут найдены гораздо быстрее, так как поиск по построенному дереву будет гораздо быстрее, нежели простой перебор всех записей.
Ваш ответ
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Типы индексов MySQL — Блог Lineate
ко всем статьям
< ко всем статьям
<
Автор: Татьяна Сергиенко, Software Engineer
В литературе встречается следующая терминология:
- кластеризованные — специальные индексы, Primary Key и Unique Index (Key и Index – это синонимы в данном случае)
- некластеризованные, или вторичные, индексы — все остальные индексы, которые не попадают под Primary и Unique
Кластеризованный индекс – это древовидная структура данных, при которой значения индекса хранятся вместе с данными, им соответствующими. И индексы, и данные при такой организации упорядочены. При добавлении новой строки в таблицу, она дописывается не в конец файла, не в конец плоского списка, а в нужную ветку древовидной структуры, соответствующую ей по сортировке.
И индексы, и данные при такой организации упорядочены. При добавлении новой строки в таблицу, она дописывается не в конец файла, не в конец плоского списка, а в нужную ветку древовидной структуры, соответствующую ей по сортировке.
В некластеризованном индексе на листьях древовидной структуры хранятся указатели (или ссылки) на соответствующие строки с данными в таблице. Каждая запись во вторичном индексе содержит столбцы первичного ключа для строки, а также столбцы, указанные в некластеризованном индексе.
Общие правила при создании индекса:
- Каждая таблица всегда имеет только один кластеризованный индекс.
- Когда вы определяете PRIMARY KEY для таблицы, MySQL использует PRIMARY KEY в качестве кластеризованного индекса.
- Если у вас нет PRIMARY KEY для таблицы, MySQL будет искать первый UNIQUE индекс, в котором находятся все ключевые столбцы, и будет использовать этот UNIQUE индекс в качестве кластеризованного индекса.
- В случае, если таблица не имеет PRIMARY KEY или подходящего UNIQUE индекса, MySQL внутренне генерирует скрытый кластерный индекс, названный GEN_CLUST_INDEX на синтетическом столбце, который содержит значения идентификатора строки.

Ключи в системе индексов MySQL
MySQL использует значение первичного ключа для поиска строк в некластеризованном индексе.
Следовательно, предпочтительно иметь короткий первичный ключ, иначе вторичные индексы будут использовать больше места. Обычно для столбца первичного ключа используется целочисленный столбец с автоинкрементом.
Primary key (первичный ключ)
Первичный ключ — это столбец или набор столбцов, которые однозначно идентифицируют каждую строку в таблице.
Первичный ключ следует следующим правилам:
- Первичный ключ должен содержать уникальные значения. Если первичный ключ состоит из нескольких столбцов, комбинация значений в этих столбцах должна быть уникальной.
- Столбец первичного ключа не может иметь NULL значений. Любая попытка вставить или обновить NULL столбцы первичного ключа приведет к ошибке.
Обратите внимание, что MySQL неявно добавляет NOT NULL ограничение к столбцам первичного ключа.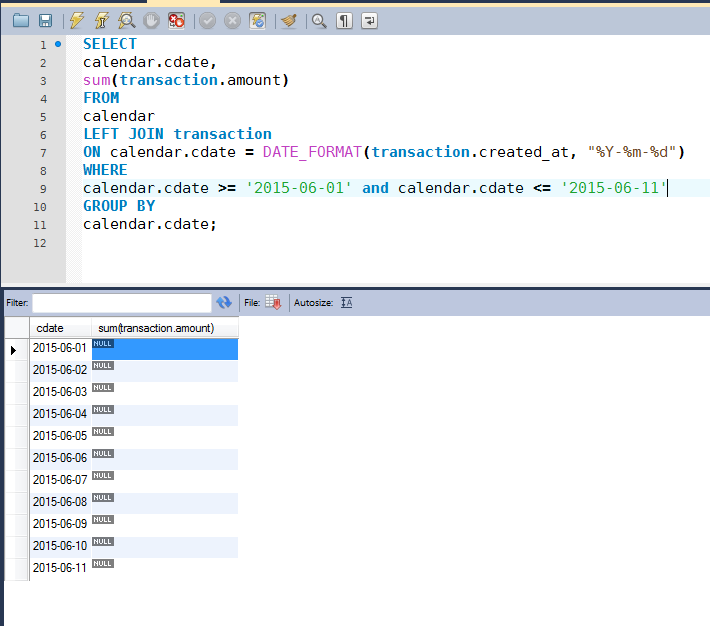
- Таблица может иметь один и только один первичный ключ.
Unique key
Чтобы обеспечить значение уникальности одного или нескольких столбцов, часто используют PRIMARY KEY. Однако каждая таблица может иметь только один первичный ключ.
UNIQUE index позволяет обеспечить уникальность значений в одном или нескольких столбцах. В отличие от PRIMARY KEY, вы можете создать более одного UNIQUE индекса для каждой таблицы.
Также, в отличие от PRIMARY key, MySQL допускает NULL значения в UNIQUE индексе.
Индекс префиксов
Если столбцы являются строковыми, при создании индекса, он будет занимать много места на диске и потенциально замедлять INSERT операции.
Чтобы решить эту проблему, MySQL позволяет создавать индекс для ведущей части значений столбцов строковых столбцов.
Невидимый индекс (только для MySQL 8. 0)
0)
По умолчанию индексы видимые (VISIBLE). Невидимые индексы (INVISIBLE) позволяют помечать индексы как недоступные для оптимизатора запросов.
MySQL поддерживает невидимые индексы в актуальном состоянии при изменении данных в столбцах, связанных с индексами.
Чтобы сделать индекс невидимым, с помощью ключевых слов VISIBLE и INVISIBLE, вы должны явно заявить о видимости индекса во время создания или с помощью ALTER TABLE команды.
Например, вы можете сделать индекс невидимым, чтобы увидеть, влияет ли он на производительность, и снова пометить индекс как видимый, если это так.
PRIMARY key оr UNIQUE index нельзя сделать невидимыми.
Составной индекс
Составной индекс — это индекс по нескольким столбцам. MySQL позволяет создавать составной индекс, состоящий до 16 столбцов.
Оптимизатор запросов использует составные индексы для запросов, которые проверяют все столбцы в индексе, или запросов, которые проверяют первые столбцы, первые два столбца и т. д.
д.
Если вы укажете столбцы в правильном порядке в определении индекса, единый составной индекс может ускорить выполнение таких запросов к одной и той же таблице.
ДРУГИЕ СТАТЬИ
>
ко всем статьям
Wednesday, August 18
Индексы MySQL: что это и зачем нужны — Блог Lineate
MySQL — это система управления реляционными базами данных с открытым исходным кодом с моделью клиент-сервер. Говоря совсем простым языком, база данных — набор структурированных данных. Чем их больше, тем труднее найти нужные. Для облегчения поиска информации и используются индексы MySQL.
Wednesday, August 18
Типы индексов MySQL — Блог Lineate
Кластеризованные — специальные индексы, Primary Key и Unique Index (Key и Index – это синонимы в данном случае). Некластеризованные, или вторичные, индексы — все остальные индексы, которые не попадают под Primary и Unique
Давайте работать вместе
Присоединяйтесь к нашей команде!
Смотреть вакансии
Использование индексов в СУБД MySQL
В СУБД MySQL индексы являются основным средством ускорения доступа к содержимому таблиц; особенное это касается запросов, включающих объединение нескольких таблиц.
СУБД MySQL использует индексы в нескольких аспектах:
- индексы используются для поиска строк, соответствующих условиям предложения
WHERE, или строк, имеющих соответствия в других таблицах при выполнении объединения. - для ускорения поиска максимального или минимального значения индексируемого столбца при работе с функциями
MAX(). - для ускорения сортировки с помощью конструкции
ORDER BYиGROUP BY. - иногда СУБД может избежать чтения из файла данных вообще, при выборке только индексированного столбца.
Существуют достаточно гибкие способы создания индексов:
- таблицу можно индексировать по одному или нескольким столбцам
- индексу может быть задан режим содержания повторяющихся или уникальных значений
- для оптимизации различных запросов одна таблица может иметь более одного индекса, опирающегося на различные столбцы (комбинации столбцов)
- любой строковый тип (кроме
ENUMиSETnсимволам слева (нельзя создавать индексы по столбцам типаBLOBиTEXT, пока не задана длина префикса). - для таблиц типа
InnoDBиндекс может строиться на внешних ключах, то есть значения в индексе должны соответствовать значениям, представленным в другой таблице.

При использовании индексов существуют ограничения, но по мере развития СУБД они сужаются. Свои особенности накладывают выбранные механизмы хранения, например, если применить индекс FULLTEXT, необходимо использовать только таблицы типа MyISAM, а если требуется установить внешние ключи, то необходимо работать с таблицами типа
Для создания индекса index_name по таблице table_name необходимо выполнить запрос:
CREATE [ UNIQUE | FULLTEXT | SPATIAL ] INDEX index_name [ USING = index_type ] ON table_name (index_columns)
Ключевые слова UNIQUE, FULLTEXT и SPATIAL могут добавляться для отображения специфический свойств индекса. Если ни одно из них не задано, создается не уникальный индекс. Оператор
Оператор CREATE INDEX не может быть использован для создания индекса ALTER TABLE.
ALTER TABLE table_name ADD PRIMARY KEY (index_columns) ALTER TABLE table_name ADD INDEX [index_name] (index_columns) ALTER TABLE table_name ADD FULLTEXT [KEY | INDEX] [index_name] (index_columns) ALTER TABLE table_name ADD UNIQUE (index_name) (index_columns) ALTER TABLE table_name ADD SPATIAL [KEY | INDEX] [index_name] (index_columns)
Если указано несколько столбцов, то из имена следует разделять запятыми. Если имя индекса index_name не определено, оно создается автоматически на основе первого индексируемого столбца. Кроме того, оператор ALTER TABLE позволяет удалять индексы:
ALTER TABLE table_name DROP [KEY | INDEX] index_name ALTER TABLE table_name DROP PRIMARY KEY
Индексы можно удалять с помощью оператора DROP INDEX:
DROP INDEX index_name ON table_name DROP INDEX `PRIMARY` ON table_name
Для определения алгоритма индексирования можно использовать оператор USING.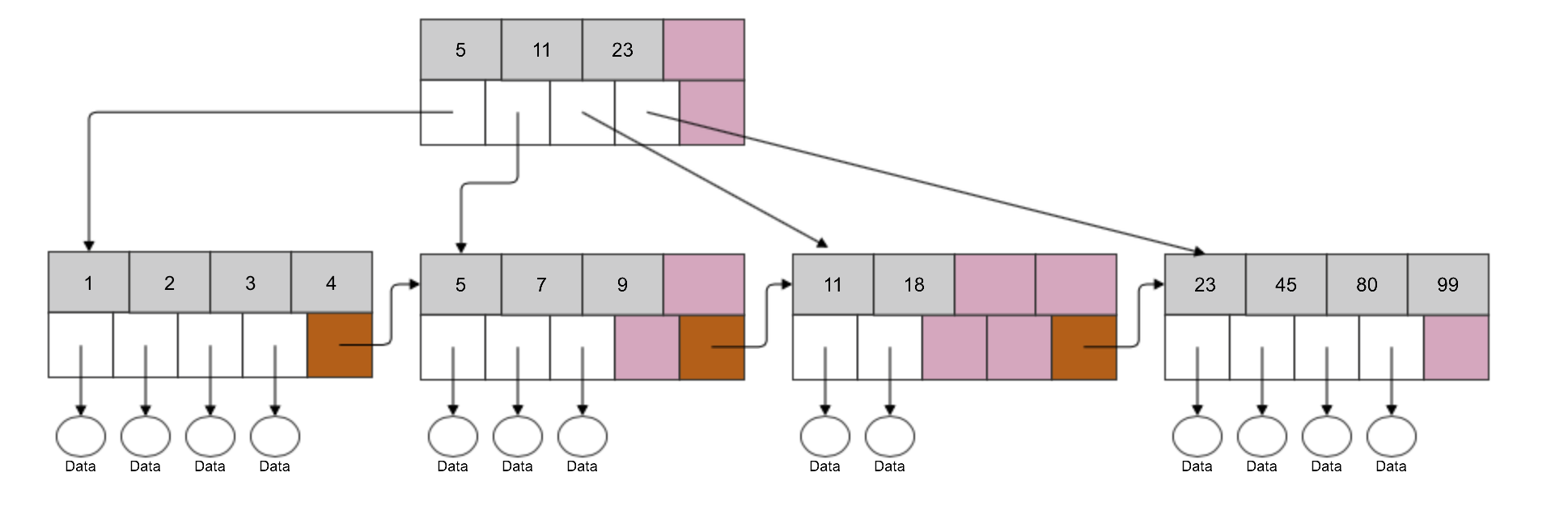
TYPE является синонимом USING, для таблиц типа MyISAM и InnoDB это может быть BTREE. Для таблиц типа MEMORY это может быть HASH или BTREE.
У составных индексов существует особенность использования, которая определяется тем, что при наличии такого индекса, например, для столбцов (col1, col2, col3), любой крайний левый префикс может быть использован для поиска. То есть нет необходимости дополнительно создавать индексы (col1) и (col1, col2).
Несмотря на все преимущества индексирования, эта операция имеет и недостатки. Во-первых, индексы ускорять поиск данных, но замедляют операции добавления, удаления и модификации в индексируемых столбцах. Это связано с тем, что чем больше индексов имеет таблица, тем больше замедление операций над записями. Во-вторых, индексных файл занимает определенное дисковое пространство. При создании большого количества индексов размер такого файла может быстро достичь максимально возможного (для современных систем максимальный размер файла может быть очень большим).
При создании большого количества индексов размер такого файла может быстро достичь максимально возможного (для современных систем максимальный размер файла может быть очень большим).
Список использованных источников:
- Поль Дюбуа, MySQL, 3-е издание.
- Официальный сайт MySQL
При полном или частичном использовании любых материалов с сайта вы обязаны явным образом указывать ссылку на handyhost.ru в качестве источника.
HighLoad Junior Блог
Темой моего доклада является индексирование в MySQL и расширенные возможности EXPLAIN, т.е. нашей задачей будет ответить на вопросы: что мы можем выяснить с помощью EXPLAIN’а, на что следует обращать внимание?
Многие ограничения EXPLAIN’а связаны с оптимизатором, поэтому мы предварительно посмотрим на архитектуру, чтобы понять, откуда следуют ограничения и что, в принципе, с помощью EXPLAIN’а можно сделать.
По индексам мы пройдемся очень кратко, исключительно в плане того, какие нюансы есть в MySQL, в отличие от общей теории.
Доклад, таким образом, состоит из 3х частей:
- Архитектура;
- Основы индексирования;
- EXPLAIN (примеры).
Архитектура MySQL.
Схематически сервер можно представить так:
Первый блок – клиенты, которые обращаются к серверу через функции соответствующего коннектора или C API по протоколу TCP/IP либо UNIX Socket, как правило. Они попадают на блок управления подключениями, где, собственно, происходит авторизация клиента в этот момент, и запуск процесса авторизации и исполнения. Каждый клиент работает в своем независимом потоке. Лишние потоки могут кэшироваться сервером и потом использоваться.
Про кэш запросов нужно отметить, что он представлен одним общим потоком для всех клиентов и в ряде случаев может оказаться узким местом, если у нас
многоядерная архитектура и очень простые запросы к базе. База их быстро выполняет, время обращения к кэшу может стать узким местом, поскольку это
единственный поток, и все к нему выстраиваются в очередь.
База их быстро выполняет, время обращения к кэшу может стать узким местом, поскольку это
единственный поток, и все к нему выстраиваются в очередь.
С управления подключениями запрос попадает на основной конвейер, который состоит их трех частей – парсер, оптимизатор и исполнитель. Собственно, эта часть и превращает полученный SQL-запрос в выборку данных. Эта часть общается с интерфейсом хранилищ, каждая по своим задачам:
- парсер проверяет синтаксис запроса, запрашивает у хранилищ наличие данных таблиц и полей, права доступа непосредственно к этим полям и проверяет наличие ответа в кэше запросов, после чего передает распарсенный запрос оптимизатору;
- оптимизатор запрашивает в интерфейсе хранилищ статистику по индексам, на основании которой он строит план запроса, который передает исполнителю;
-
исполнитель обращается по полученному плану непосредственно за данными в хранилище, передает ответ клиенту через интерфейс и, при необходимости, меняет в
кэше обновления (либо сам результат, либо обнуляет, если был запрос на обновления).
Здесь нужно отметить ключевую особенность, связанную с MySQL, – это интерфейс подключаемых хранилищ, т.е. вы можете в своей компании разработать свое собственное хранилище (интерфейс стандартный) и подключить его. Таким образом, вы можете сделать, чтобы данные хранились наиболее удобным вам образом с учетом различных нюансов.
Обратной особенностью является то, что оптимизатор очень слабо связан с хранилищами, он не знает и не учитывает отдельные нюансы исполнения части запроса тем или иным хранилищем. Причем, что странно, это так же плохо происходит для основных хранилищ, которые разрабатывают непосредственно разработчики MySQL, и данная ситуация стала улучшаться только в последних версиях. Этот момент нужно учитывать.
Еще тут стоит отметить то, что индексы в MySQL реализованы именно на уровне хранилищ, они не стандартизированы. Поэтому нужно следить за тем, какой тип
индекса – полнотекстовый, B-Tree, пространственный и др. – используется тем или иным хранилищем. И самое главное: один и тот же индекс в разных хранилищах
– это может быть совершенно разная структура. Например, B-Tree индекс в MyISAM хранит указатель на сами данные, а в InnoDB он хранит указатель на первичный
ключ; в MyISAM происходит сжатие префиксных индексов, а в InnoDB этого не происходит, но зато там есть кэширование и данных, и индексов.
– используется тем или иным хранилищем. И самое главное: один и тот же индекс в разных хранилищах
– это может быть совершенно разная структура. Например, B-Tree индекс в MyISAM хранит указатель на сами данные, а в InnoDB он хранит указатель на первичный
ключ; в MyISAM происходит сжатие префиксных индексов, а в InnoDB этого не происходит, но зато там есть кэширование и данных, и индексов.
Существует масса нюансов, которые нужно учитывать при работе, т.е. какие-то запросы будут быстрее выполняться в одном хранилище, какие-то – в другом, т.к. они по-разному хранят статистику. Например, запрос count (*) в случае MyISAM может выполняться очень быстро без обращения к самим данных, т.к. там хранится именно статистика в метаданных, это, правда, для частных случаев, но, тем не менее, такие нюансы есть.
Сразу скажем про план запроса. Его делает оптимизатор, и это не какой-то исполняемый код, а набор инструкций, который он передают исполнителю. Это некое
предположение о том, как запрос будет выполняться. После того, как исполнитель сделает запрос, могут появиться какие-то отличия и, в отличие от PostgreSQL,
MySQL не показывает то, что было сделано, т.е., когда мы смотрим EXPLAIN в MySQL, у нас нет EXPLAIN ANALYSE. Точнее, оно появилось совсем недавно в версии
10.1 Maria, которая еще beta, и, естественно, пока не используется. Поэтому нужно учитывать, что когда мы смотрим EXPLAIN в MySQL, это некие предположения.
Часто возникает такая ситуация, что у нас один и тот же план, но разная производительность. Тут надо отметить тот момент, что сам оптимизатор в плане
EXPLAIN дает очень мало вещей. Например, у нас запросы select (*) из таблицы и select пары полей из таблицы будут иметь одинаковый план, но в одном случае
у нас будет выбрано несколько Кб для каждой записи, а в другом – может быть несколько Мб, если у нас записи огромные. Естественно, производительность этих
запросов будет различаться на порядки, но план этого никак не покажет. Или же у нас может быть одинаковый план, один запрос, но выполняться на разных
машинах он будет по-разному, потому что в одном случае индекс читается из памяти, в другом, если буфер маленький, индекс берется с диска. Опять при
одинаковом плане производительность будет различаться. Поэтому в дополнение к EXPLAIN’у нужно на разные вещи смотреть, в первую очередь – на параметры
сервера (show status).
Или же у нас может быть одинаковый план, один запрос, но выполняться на разных
машинах он будет по-разному, потому что в одном случае индекс читается из памяти, в другом, если буфер маленький, индекс берется с диска. Опять при
одинаковом плане производительность будет различаться. Поэтому в дополнение к EXPLAIN’у нужно на разные вещи смотреть, в первую очередь – на параметры
сервера (show status).
Здесь уместно обратиться к прошедшей конференции РИТ++, на которой был доклад Григория Рубцова по ботаническому определителю MySQL – для тех, кто не умеет
гипнотизировать сервер и сразу навскидку определять узкое место, там выстроена целая последовательная схема: посмотрели на такой-то параметр – пошли туда.
Как в классическом ботаническом определителе, когда велся поиск определения растений, смотрели на количество листьев, на форму и т.д. и так пришли к
ответу. Там именно такая структура – куда последовательно смотреть, что делать, чтобы найти узкие места.
Перейдем к индексам в MySQL.
Мы не будем рассматривать и перечислять все типы индексов – они более-менее стандартны для каждой базы. Говоря о MySQL, нам нужно отметить следующее: MySQL никак не управляет дублированными индексами, т.е. если мы создаем таблицу так, как представлено, это не означает, что у нас будет создан primary index уникальный на колонку 1. Это означает, что у нас будет создано три одинаковых индекса на одну колонку. Они все три будут занимать место, будут обновляться, будут учитываться оптимизатором, и MySQL сам не выдаст никакого предупреждения, т.е. это нужно смотреть самостоятельно.
Говоря об индексах (в основном мы будем говорить о b-tree, как о наиболее используемых), чтобы не вдаваться в подробности и дерево не рисовать, индекс
очень удобно представлять в виде алфавитного указателя. Например, адресная книга – это таблица, алфавитный указатель к ней – это и есть индекс. Применив
такую аналогию, мы можем представить, как происходит работа с индексом, за счет чего там быстрее выбираются данные и пр. Но здесь есть некое отличие в
самом MySQL, поскольку MySQL всегда идет по индексу, он использует индекс только слева направо последовательно, без фокусов, это может вызвать вопросы.
Применив
такую аналогию, мы можем представить, как происходит работа с индексом, за счет чего там быстрее выбираются данные и пр. Но здесь есть некое отличие в
самом MySQL, поскольку MySQL всегда идет по индексу, он использует индекс только слева направо последовательно, без фокусов, это может вызвать вопросы.
Например, если нам нужно в алфавитном указателе найти какие-то имена. «Руками» мы будем искать следующим образом: посмотрим первую фамилию, найдем нужные имена, пролистнем до следующей фамилии. Это не ограничение b-tree дерева, это ограничение реализации b-tree дерева непосредственно в MySQL. Другие базы так умеют делать – использовать не первую колонку, например, в случае WHERE B=3 индекс в MySQL использоваться, вообще, не будет. Только в частном случае, если мы попросим минимум и максимум от этой колонки, но это, скорее, исключение.
На слайде выше представлены различные варианты, и стоит отметить, что индекс обрывается на первом же неравенстве, т. е. он используется последовательно
слева направо до первого неравенства. После неравенства дальнейшая часть индекса уже не используется. Т.е. в условии А – константа, В – диапазон, будут
использованы первые две части. Во втором случае будет использован целиком индекс. В третьем случае индекс тоже будет использован целиком, т.к. порядок
констант в условии не имеет значения, и сервер может их переставить местами. В случае В=3 индекс, вообще, использован не будет. В случае константы и
неравенства будет использован индекс только на первые две части, на третью часть индекс уже не сможет использоваться. В случае А – константа и сортировка
по последнему, будет только на первую часть использован индекс, потому что пропускается вторая часть, предпоследний индекс будет целиком использован. И в
последнем варианте, опять же, индекс будет использован только на первую часть, потому что для сортировки индекс может использоваться только лишь, когда в
одном направлении идет.
е. он используется последовательно
слева направо до первого неравенства. После неравенства дальнейшая часть индекса уже не используется. Т.е. в условии А – константа, В – диапазон, будут
использованы первые две части. Во втором случае будет использован целиком индекс. В третьем случае индекс тоже будет использован целиком, т.к. порядок
констант в условии не имеет значения, и сервер может их переставить местами. В случае В=3 индекс, вообще, использован не будет. В случае константы и
неравенства будет использован индекс только на первые две части, на третью часть индекс уже не сможет использоваться. В случае А – константа и сортировка
по последнему, будет только на первую часть использован индекс, потому что пропускается вторая часть, предпоследний индекс будет целиком использован. И в
последнем варианте, опять же, индекс будет использован только на первую часть, потому что для сортировки индекс может использоваться только лишь, когда в
одном направлении идет.
Это связано с тем, что составной индекс в MySQL – это, по сути, обычный b-tree индекс над конкатенацией входящих столбцов, соответственно, он может двигаться либо по возрастанию всего кортежа, либо по его убыванию. Поэтому сказать: «двигаемся по возрастанию В и по уменьшению С» по индексу мы не сможем. Это ограничение, характерное именно для MySQL.
Здесь есть такой нюанс. Например, A in (0,1) и А between 0 and 1 – это эквивалентные формы, это диапазон и там, и там, но в случае, когда это A in (0,1) – список, он понимает, что это не диапазон, а заменяет на множественное условие равенства. В этом случае он будет использовать индекс. Это еще один нюанс MySQL, т.е. нужно смотреть, как писать – либо списком, либо ставить <> . Он это различает.
Пара слов про избыточный синтаксис. Если у нас есть index(A) и index(A,B), то index(A) будет лишним, потому что в случае index(A,B) часть А может
использоваться в нем. Поэтому нам нужно следить, чтобы избыточных индексов не было и самостоятельно их удалять. Понятно, это относится и к случаю, когда
оба индекса b-tree, но, если, например, index(A) – это full-text, то, естественно, он может быть необходим.
Поэтому нам нужно следить, чтобы избыточных индексов не было и самостоятельно их удалять. Понятно, это относится и к случаю, когда
оба индекса b-tree, но, если, например, index(A) – это full-text, то, естественно, он может быть необходим.
Вернемся к нюансу на списке. Мы можем делать здесь более широкий индекс уникальным. Например, если мы сделаем index(A,B), то просто условие В использовать
не будем, но мы можем в приложении сделать так, чтобы оно самостоятельно подставляло пропущенное условие, если там небольшой возможный вариант списка. Но с
этой рекомендацией нужно быть очень осторожными, т.к., несмотря на то, что при наличии списка дальнейшее использование индекса не отбрасывается, он не
может быть использован для сортировки, т.е. только на равенство. Поэтому, если у нас есть запросы на сортировку, то нам придется запрос перестраивать через
union all, чтобы не было списков, дабы использовать сортировку. Естественно, это не всегда возможно и не всегда удобно. Если расширение индекса нам,
например, позволит сделать индекс покрывающим (имеется в виду, что все поля, которые выбираются и используются в запросе, присутствуют в индексе), тогда
сервер понимает, что лезть в таблицу за данными ему совсем не обязательно и он целиком обращается к индексу для формирования результата. Т.к. индекс более
упорядочен, компактен и хранится чаще всего в памяти кэшированной, это более удобно. Поэтому мы при составлении индекса смотрим всегда, можем ли мы как-то
подобрать покрывающий индекс для нашего запроса.
Естественно, это не всегда возможно и не всегда удобно. Если расширение индекса нам,
например, позволит сделать индекс покрывающим (имеется в виду, что все поля, которые выбираются и используются в запросе, присутствуют в индексе), тогда
сервер понимает, что лезть в таблицу за данными ему совсем не обязательно и он целиком обращается к индексу для формирования результата. Т.к. индекс более
упорядочен, компактен и хранится чаще всего в памяти кэшированной, это более удобно. Поэтому мы при составлении индекса смотрим всегда, можем ли мы как-то
подобрать покрывающий индекс для нашего запроса.
Далее рассмотрим случаи, когда индексы не используются.
Здесь есть общие нюансы с другими базами, например, когда индекс является частью выражения, как и в PostgreSQL, он не сможет его преобразовать, поэтому,
если у нас в запросе id + 1 = 3, индекс на id использован не будет. Мы должны сами переносить.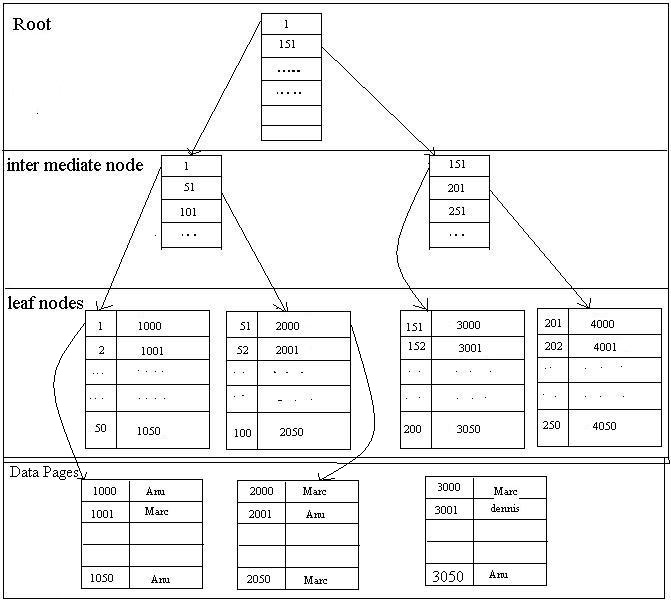 Если индекс является частью какого-то выражения, мы должны
смотреть, можем ли мы его преобразовать так, чтобы индекс вынести в левую часть в явном виде.
Если индекс является частью какого-то выражения, мы должны
смотреть, можем ли мы его преобразовать так, чтобы индекс вынести в левую часть в явном виде.
Аналогично, за счет того, что он не производит преобразований (это не только математические, это могут быть несоответствие кодировок, преобразование типов), индекс тоже не будет использован. Индекс не используется, когда пропускается первая часть, когда идет поиск по суффиксу. Ну и, естественно, индекс не будет использован, когда идет сравнение с полями сходной таблицы, потому что в этом случае ему сначала будет нужно прочитать запись из таблицы, чтобы сравнить.
До этого я упоминал покрывающие индексы, и чем они хороши. Вернемся к слайду с архитектурой:
Происходит так: исполнитель запрашивает данные (условие WHERE) у хранилища, соответственно, если у нас есть условие WHERE на несколько позиций, то они все
могут быть обработаны внутри самого хранилища.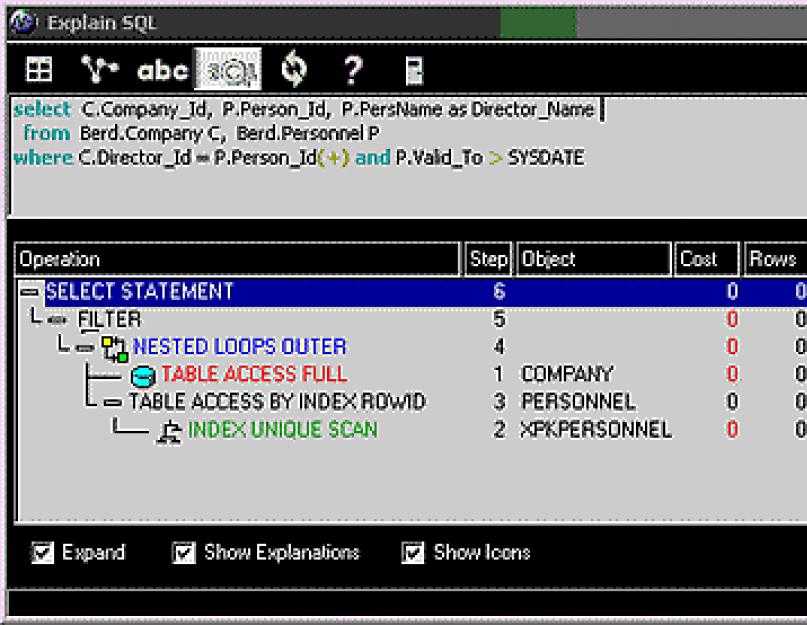 Это оптимальный вариант. Может быть вариант, когда часть условий будет обработано на уровне хранилищ по
индексу, строки, переданные на уровень вверх, сервер будет применять, а дальнейшие условия отбрасывать. Понятно, это будет медленнее, т.к. будет идти
передача самих записей из хранилища в исполнитель. Поэтому покрывающие индексы, если они у нас применяются только для тех полей, которые в запросе,
выгоднее, т.к. мы выбираем уже меньше строк.
Это оптимальный вариант. Может быть вариант, когда часть условий будет обработано на уровне хранилищ по
индексу, строки, переданные на уровень вверх, сервер будет применять, а дальнейшие условия отбрасывать. Понятно, это будет медленнее, т.к. будет идти
передача самих записей из хранилища в исполнитель. Поэтому покрывающие индексы, если они у нас применяются только для тех полей, которые в запросе,
выгоднее, т.к. мы выбираем уже меньше строк.
Вот, к примеру, подобная оптимизация, называемая index condition pushdown:
Имеется в виду следующее. У нас есть индекс на три поля – А, В, С. В таких условиях мы можем использовать только часть первого. Казалось бы, мы можем в
самом хранилище проверить индексы, но раньше (до версии MySQL 5.6, MariaDB 5.3) сервер этого не делал, поэтому нужно внимательно смотреть на конкретные
релизы – что умеет делать сервер. В новых версиях сервер производит поиск по первой части индекса, только по колонке А, выбирает данные и, прежде чем
передавать записи исполнителю, он проверяет условие на вторую и третью части и смотрит, нужно ли выбирать целиком записи или нет.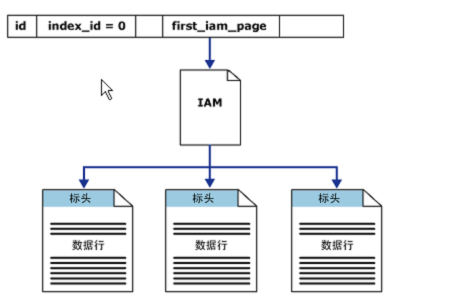 Это естественно уменьшает
количество тех записей, которые нужно считывать с диска.
Это естественно уменьшает
количество тех записей, которые нужно считывать с диска.
Особенность ключей в InnoDB – это то, что вторичные ключи ссылаются на первичный ключ, поэтому фактически вторичный ключ в InnoDB представляет собой вторичный ключ + указатель на первичный ключ.
Такой длинный индекс имеет невидимый «хвост». Невидимый в том смысле, что раньше оптимизатор его в своих действиях не учитывал.
Вот, у нас есть primary (A, B) составной, соответственно, вторичный ключ – это будет составной ключ на (C, A, B) и по нему уже можно проводить поиск.
Таким образом, когда вы работаете с таблицами InnoDB и делаете индексы, вы всегда должны учитывать, что длинный первичный ключ – это может быть либо хорошо, либо плохо в зависимости от того, какие у вас запросы, потому что он будет добавляться ко всем индексам.
Здесь следующий нюанс – эта оптимизация будет учитываться только для фильтрации строк. У нас в отсортированном виде хранятся только значения вторичного
ключа, а указатели на первичный ключ не отсортированы, поэтому такой длинный невидимый «хвост» сервер сможет использовать только для условий равенства
фильтрации строк. Это доступно в MariaDB 5.5, MySQL 5.6.
У нас в отсортированном виде хранятся только значения вторичного
ключа, а указатели на первичный ключ не отсортированы, поэтому такой длинный невидимый «хвост» сервер сможет использовать только для условий равенства
фильтрации строк. Это доступно в MariaDB 5.5, MySQL 5.6.
Ключевые ограничения оптимизатора – это то, что он исторически использует очень мало статистики. Он запрашивает у хранилищ данные. Вот здесь указано подробнее, что учитывает сервер:
Он может учитывать результаты вводимых команд, поля, количество строк, т.е. довольно-таки мало данных. Особенность в том, что изначально статистика
вычисляется следующим образом: мы запускаем сервер или делаем какую-то команду типа ALTER, у нас статистика обновляется, потом таблица живет некоторое
время, какой-то процесс вдруг меняется, потом статистика вновь обновляется. Т.е. бывает, что сама статистика не соответствует распределению данных.
Опять же, каждое хранилище выбирает статистику по-своему – где-то больше, где-то меньше. В последних версиях реализуется идея независимой статистики, т.е. статистики на уровне сервера – выделяются служебные таблицы, в которых единым образом уже независимо от механизмов хранения собирается статистика для всех таблиц, причем, если в Percona 5.6. это сделано только для индексов в InnoDB, то в Maria 10 пошли дальше и собирают ее даже для неиндексированных столбцов, за счет чего оптимизатор может выбирать более оптимальные планы выполнения, поскольку лучше понимает распределение данных.
Оптимизатор не учитывает особенности хранилищ – когда мы передаем запрос в хранилище, то, понятно, что в InnoDB поиск по вторичному ключу будет идти
дольше, потому что мы пройдемся по вторичному ключу, получим указатели на первичный ключ, возьмем эти указатели, пойдем за данными, т.е. у нас будет
двойной проход, а в MyISAM, например, будут сразу указатели непосредственно на сами строки. Вот подобных нюансов относительного быстродействия тех или иных
частей (у нас запрос может одновременно обращаться к разным хранилищам) оптимизатор и не учитывает. Он также не учитывает очень много вопросов, связанных с
оборудованием, т.е. какие данные у нас закэшированы, какие буферы…
Вот подобных нюансов относительного быстродействия тех или иных
частей (у нас запрос может одновременно обращаться к разным хранилищам) оптимизатор и не учитывает. Он также не учитывает очень много вопросов, связанных с
оборудованием, т.е. какие данные у нас закэшированы, какие буферы…
Метрика. Понятно, что оптимизатор выбирает самый дешевый план, но дешевый план с точки зрения оптимизатора – это план с наименьшей стоимостью, а вопрос стоимости – это некоторая условность, которая может не совпадать с нашими представлениями о ней. Опять же, сложность выбора – это когда много таблиц и нужно их по-разному перемещать и смотреть.
Еще он использует правила, т.е. если он, например, понимает, что нужно использовать full text index, то он использует его, даже несмотря на то, что у нас может быть условие на первичный ключ, которое однозначно выдаст одну колонку.
Есть еще такой нюанс – эти две записи с нашей точки зрения эквивалентны:
where a between 1 and 4
where a >0 and a < 5
но с точки зрения сервера MySQL – нет. В случае, когда а>0 и а<0 он будет использовать поиск по диапазону, а в случае, когда мы напишем то же самое
через «between», он может это преобразовать в список и использовать условие на множественные равенства.
В случае, когда а>0 и а<0 он будет использовать поиск по диапазону, а в случае, когда мы напишем то же самое
через «between», он может это преобразовать в список и использовать условие на множественные равенства.
Такие нюансы не позволяют писать запросы, опираясь на здравый смысл, но с другой стороны удобно тем, что повышает востребованность специально обученных людей по оптимизации MySQL. :)
Коротко о том, как работает оптимизатор.
Он проверяет запрос на тривиальность, т.е. может ли он, вообще, сделать запрос, опираясь только на статистику индексов. Может быть, мы запрашиваем отрицательные значения для колонки ID, которая определена положительно. Тогда он сразу понимает, что мы запрашиваем за пределами диапазона. Это очень эффективный вариант с точки зрения быстродействия – выбирает самый дешевый план.
Казалось бы, оптимизатор может делать очень мало вещей, на самом же деле при математическом преобразовании запроса он применяет различные техники,
например, подзапросы может либо ухудшить, как в старых версиях, сделав независимое зависимым, либо улучшить, как в новых. Список техник очень велик.
Список техник очень велик.
Это начало таблицы из документации на MariaDB:
Нужно знать, что скрывается за всеми этими словами, поэтому я рекомендую смотреть документацию на MariaDB, т.к. она снабжена понятными картинками-иллюстрациями, и по ним можно понять, что к чему относится.
Как мы можем влиять на оптимизатор:
- Переписать запрос – это либо использовать эквивалентную форму записи, т.е., например, подзапрос заменить на join, либо же переписать запрос кардинально, разбив на части, записывая какие-то данные во временные промежуточные таблицы, или же, вообще, денормализовать таблицу и избавиться от join’ов.
- Индексы – мы можем либо добавлять необходимые индексы, либо смотреть, может, нам достаточно обновить статистику.
-
Подсказки оптимизатору – use/force/ignore index – можем ему явно указать, какие индексы стоит использовать для каких операций – для сортировки,
группировки и пр.
- straight_join – мы можем задать жесткий порядок объединения таблиц, чтобы он не перебирал различные варианты. Нам известны особенности распределения данных и известно, в каком порядке нужно работать, поэтому явно на это указываем.
- @@optimizer_switch – включение/отключение всех конкретных добавочных методик оптимизации через эту переменную.
-
Переменные optimizer_prune_level и optimizer_search_depth определяют, как сервер выбирает оптимальный план – перебирает все возможные варианты или
отбрасывает. Понятно, что когда у нас много таблиц join’ится, и сервер будет несколько миллионов перестановок анализировать, он может уйти на четверть часа
в задумчивость, а потом за долю секунды выполнить. Такие ситуации встречаются, поэтому все эти переменные по умолчанию ограничивают время выполнения, что
приводит к тому, что план может быть выбран неоптимальный. Когда мы производим оптимизацию, в режиме тестирования мы можем изменить эти переменные, чтобы
сервер выбирал все варианты, и посмотреть, может, будет выбран более оптимальный план.
 Когда мы производим оптимизацию, в режиме тестирования мы можем изменить эти переменные, чтобы
сервер выбирал все варианты, и посмотреть, может, будет выбран более оптимальный план.
Когда мы производим оптимизацию, в режиме тестирования мы можем изменить эти переменные, чтобы
сервер выбирал все варианты, и посмотреть, может, будет выбран более оптимальный план.
SQL_CALC_FOUND_ROWS – это страшное слово, которое напрочь убивает оптимизацию. На практике идея состоит в том, что если у нас есть запрос LIMIT, мы можем
включить ключевое слово в запрос, и сервер нам при этом отдаст в ответе, в том числе, и общее число, которое было бы выбрано без лимита. Это удобно,
например, когда мы делаем пагинацию страниц, и этим грешат все автоматические системы. Это плохо, потому что запросы на COUNT MySQL умеет оптимизировать
очень хорошо, но в сложных случаях, когда у нас есть join’ы, группировки и пр., отдельно посчитать количество строк, мы можем переписать запрос так, что
часть объединений, join’ов нам не потребуется, часть группировок тоже, чтобы получить ответ об общем количестве страниц.
Сервер использует на один запрос только один метод. Когда мы добавляем FOUND_ROWS, он решает две задачи одним методом, т.е. он на самом деле выбирает все строки, как если бы не было LIMIT, из хранилища вытаскивает данные – все длинные записи, считает, отбрасывает лишние… Это очень плохо. Здесь нужно понимать, что тот же COUNT(*) не читает сами строки, он просто просматривает их на факт наличия, не передавая данные в читалку.
На таком уровне нужно знать детали, чтобы понимать, иначе просто смотреть на EXPLAIN будет не очень осмысленно.
Недостатки EXPLAIN следуют из недостатков оптимизатора. Бывают случаи, когда он, вообще, пишет не то, что делает, выдает очень мало информации, когда мы
говорим, что EXPLAIN не выполняет запрос, а просто составляет план. В старых версиях он выполнял from подзапросы, т.к. from подзапросы он материализовал во
временную подтаблицу и если они тяжелые, то выполнение этих from подзапросов занимало очень много времени.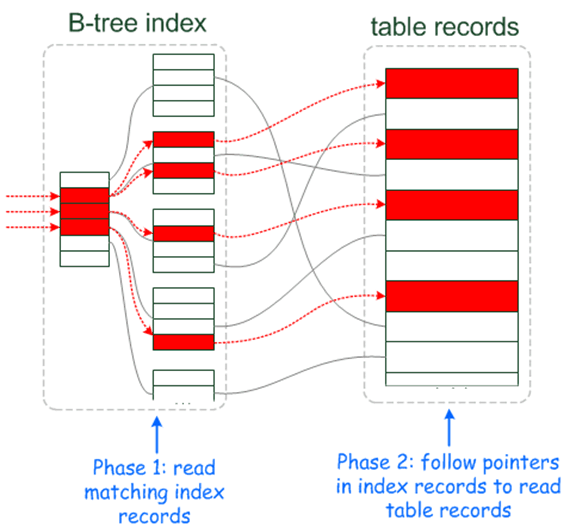 И была даже коллизия с тем, что from подзапрос
может содержать пользовательскую функцию, которая будет менять данные, тогда сам EXPLAIN тоже бы менял данные. Непонятно, зачем это нужно, но на практике
люди придумывают иногда очень странные вещи.
И была даже коллизия с тем, что from подзапрос
может содержать пользовательскую функцию, которая будет менять данные, тогда сам EXPLAIN тоже бы менял данные. Непонятно, зачем это нужно, но на практике
люди придумывают иногда очень странные вещи.
Виды EXPLAIN.
Если используем ключевое слово PARTITIONS, тогда он будет показывать, какие секции использует наш запрос.
Ключевое слово EXTENDED удобно тем, что он при этом формирует SQL-запрос, который восстанавливает из плана выполнения. Это не исходный SQL-запрос, исходный
SQL-запрос преобразован в план, а потом из плана уже оптимизатором синтезируется новый SQL-запрос, который содержит ряд подсказок, по которым мы можем
понять, что у нас происходит. Формирование временной таблицы с ключами, кэширование каких-то кусков запроса – все эти нюансы хорошо описаны в документации
и они помогают понять, что делает сервер, как преобразовывает наш запрос.
Это, собственно, EXPLAIN простейшего запроса.
Здесь нужно смотреть на следующее:
- тип доступа, который используется. В первом случае это ALL – идет сканирование всей таблицы. Во втором случае eq_ref – это поиск непосредственно по ключу, формирует одну запись.
- количество строк, которое ожидается, учитывая, что это некая условность.
-
possible_keys – это ключи, которые оптимизатор планирует использовать, а key – ключ, который он выбрал. Возможен вариант, если у вас, например,
possible_key: NULL, а в значении key стоит какой-то ключ. Это происходит в тех случаях, когда, например, SELECT FROM таблицы никаких условий WHERE нет.
Оптимизатор видит, что, вроде как, никаких ключей использовать не надо, а потом смотрит, что столбцы являются частью ключа и, в принципе, можно их выбрать
именно по индексу и тогда делать покрывающий индекс. Так может получиться, что possible_key: NULL, а key – покрывающий индекс, это значит, что он будет
использовать именно индекс.
- key_len – это длина индекса, которую он использует, т.е., если у нас составной индекс, то взглянув на key_len, мы можем понять, какую часть индекса он использует.
 Так может получиться, что possible_key: NULL, а key – покрывающий индекс, это значит, что он будет
использовать именно индекс.
Так может получиться, что possible_key: NULL, а key – покрывающий индекс, это значит, что он будет
использовать именно индекс.
Далее мы не будем рассматривать подробно все возможные варианты – это хорошо описано в документации.
Понятно, что он формирует по одной строке для каждой таблицы, которая встречается в запросе, и исполняет запрос в той последовательности, в какой выводится таблица, т.е. глядя на EXPLAIN, мы можем сразу понять, что был выбран следующий порядок доступа к таблицам – сначала выбирает таблицу city, потом выбирает таблицу country. Здесь все просто.
Но, когда у нас есть такой сложный навороченный EXPLAIN, который включает разные UNION, FROM подзапросы и пр. , и выводится длинная «простыня»:
, и выводится длинная «простыня»:
Возникает вопрос – как ее читать?
Идея очень проста: мы нумеруем все SELECT’ы, которые встречаются в запросе, и номер SELECT’а будет соответствовать номеру идентификатора, который в EXPLAIN’е.
Я выделили разными цветами для наглядности.
Второй нюанс – мы можем смотреть на номера. Например, номер 6 – DERIVED – это FROM подзапрос. Следующий идет с бОльшим идентификатором. Это означает, что он относится к тому же подзапросу FROM, т.е. пойдет в ту же временную таблицу. Таким образом, глядя только на идентификаторы, уже можно сделать много выводов.
Существует неудобство: я говорю, что строки выполняются последовательно, на самом же деле, когда есть такие вещи как производные таблицы, это не совсем
так. Т.е. запросы с UNION’ами удобно читать таким образом – один UNION у нас 4, и это означает, что строки с 1й по 4ю относятся к одной части UNION’а, а с
4й по последнюю – ко второй части. Т.е. мы можем посмотреть последнюю строчку и перейти вверх, и так разбивать запросы. Собственно, ничего сложного в этом
нет, нужен только навык.
Т.е. мы можем посмотреть последнюю строчку и перейти вверх, и так разбивать запросы. Собственно, ничего сложного в этом
нет, нужен только навык.
Есть утилиты, которые сразу строят графические представления EXPLAIN’а, но мы их не будем рассматривать, тем более, что в случае сложных запросов их тоже не так-то просто понять. Это на любителя.
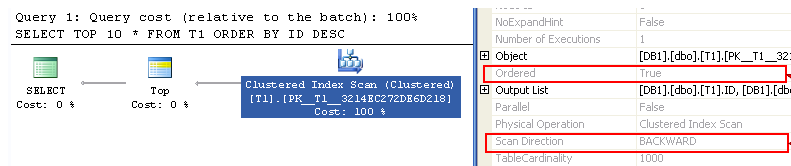
Пример, когда EXPLAIN врет.
У нас есть запрос с подзапросом в части in. Подзапрос независимый, тем не менее MySQL до MariaDB 5.3 и MySQL 5.6 эти запросы часто выполнял как зависимые. Мы видим тип запроса – зависимый, но с другой стороны мы видим type: index_subquery – это означает, что на самом деле подзапрос не выполняется, а заменяется на функцию просмотра индекса. Т.е. эти строчки между собой конфликтуют, они говорят о противоположных вещах.
Возникает вопрос – а что же на самом деле там происходит, т. к. EXPLAIN выдает противоречивую информацию?
к. EXPLAIN выдает противоречивую информацию?
Мы можем сделать профайлинг запроса и посмотреть:
В случае, когда запрос выполняется зависимый, как справа, у нас часть исполнения запроса – передача данных – будет многократна, будет дублирована. В случае, когда запрос выполняется независимо, эти значения дублироваться не будут.
Кроме того, профайлинг удобен для определения таких нюансов, как передача больших данных, подсчет статистики и др.
Сортировка.
Когда ORDER BY id LIMIT 10000, 10 – это плохо, т.к. сервер будет выбирать все 10 тыс. строк + еще 10, потом 1001-ю отбрасывать и только 10 выдавать. Такие вещи надо каким-то образом менять. Либо ID больше 10 000, LIMIT 10. Когда у нас offset большое число – с точки зрения того, что делает сервер, это плохо.
Нельзя использовать ORDER BY rand(), т. к. эта структура делает копию всех наших данных, загоняет во временную таблицу, добавляет туда еще один столбец,
куда записывает результат функции rand и потом файловую сортировку всего этого огромного массива. Поэтому, если мы хотим выбрать случайную строку, ORDER BY
rand() можно применять лишь на небольших объемах данных, на больших это сразу убьет всю производительность.
к. эта структура делает копию всех наших данных, загоняет во временную таблицу, добавляет туда еще один столбец,
куда записывает результат функции rand и потом файловую сортировку всего этого огромного массива. Поэтому, если мы хотим выбрать случайную строку, ORDER BY
rand() можно применять лишь на небольших объемах данных, на больших это сразу убьет всю производительность.
Группировка по умолчанию делает и сортировку, поэтому, если нам сортировка не нужна, то мы должны указать в явном виде – ORDER BY null.
Остальное мы уже выше рассмотрели.
Такой пример:
Есть таблица дисков и таблица шин в интернет-магазине автозапчастей. Мы хотим показать клиенту 10 наиболее дешевых комплектов, т.е. шины к каким дискам
подходят, и выбрать наиболее дешевый комплект. Понятно, что запрос “в лоб” мы просто join’им и сортировку производим по вычисляемому полю. Мы видим: полное
сканирование первой таблицы плюс выбираются данные из второй. Никаким добавлением индексов мы сделать здесь ничего не сможем. В таких случаях нужно
смотреть, как мы можем переписать запрос.
Мы видим: полное
сканирование первой таблицы плюс выбираются данные из второй. Никаким добавлением индексов мы сделать здесь ничего не сможем. В таких случаях нужно
смотреть, как мы можем переписать запрос.
Можем схитрить и сказать, что 10 самых дешевых комплектов – это 10 самых дешевых колес + соответствующие им диски, прибавить 10 самых дешевых шин + соответствующие им колеса. Это некая условность, т.к. это не совсем эквивалентно и можно подобрать такое распределение данных, когда это не будет выполняться. На практике это, как правило, не происходит. Если нам не очень важна точность, то мы можем усложнить запрос в явном виде, и мы увидим, что план, несмотря на то, что он стал гораздо больше, каждый раз он выбирает по индексу, и сортировки внутренние происходят не без Using filesort, файловой сортировки. А конечная строка Using filesort’а – небольшое число значений.
Основная стратегия, когда мы видим сортировку: смотрим, можем ли как-нибудь избавиться от файловой сортировки, загнав ее вглубь запроса. Если не можем, то
можем ли как-то ограничить количество строк, которые мы вынуждены делать файловой сортировкой.
Если не можем, то
можем ли как-то ограничить количество строк, которые мы вынуждены делать файловой сортировкой.
Здесь еще стоит обратить внимание на то, что в самих частях UNION’а еще делается вложенный from подзапрос и сортировка переносится вглубь. Если этого не сделать, то сервер ошибочно не будет использовать файловую сортировку, т.е. отдельно, без части UNION’а, диски+колеса сортировка сделает по индексу, а внутри он уже не понимает. Надо учитывать, что оптимизатор в таких сложных вещах может ошибаться, и следить за этим.
В продолжение про ORDER BY + LIMIT запрос, который делает WordPress.
Большинство проблеем с производительностью – это такие ужасные запросы, где сервер выбирает абсолютно все записи, т.е. все текстовые строки, сортирует этот
большой массив и в конце выдает только 3 записи. При этом, естественно, здесь будет Using filesort по огромному количеству записей. Т.к. мы не можем
использовать способ, аналогичный предыдущему, т.е. уменьшить количество строк для сортировки, мы можем уменьшить ширину записей для сортировки и сначала
отсортировать, выбрать на первом этапе не сами записи, а только их идентификаторы, т.е. разбить запрос на 2 части.
Т.к. мы не можем
использовать способ, аналогичный предыдущему, т.е. уменьшить количество строк для сортировки, мы можем уменьшить ширину записей для сортировки и сначала
отсортировать, выбрать на первом этапе не сами записи, а только их идентификаторы, т.е. разбить запрос на 2 части.
Мы делаем временную таблицу, где выбираем только идентификаторы. Глядя на этот запрос, мы увидим, что группировка в этом запросе совершенно не нужна, потому что возможное дублирование удаляется условием category_ID=1, поэтому, когда мы переписываем запрос, мы лишние группировки и пр. убираем. В этом случае у нас тоже будет файловая сортировка, но на меньшем объеме данных, а потом, выбрав 3 идентификатора, мы получим конкретные записи.
Когда у нас остается Using filesort, мы должны смотреть еще, где делается эта сортировка – в памяти или на диске. С помощью show status мы можем
определить, например, что в процессе файловой сортировки сервер 95 раз промежуточные результаты сбрасывал на диск. Естественно, это очень долго. Если мы
увеличим значение key bufer size, то увидим, что он делает. Таким образом, мы можем подобрать значение, его рекомендуют устанавливать в рамках сессии, а не
делать глобальным по умолчанию, потому что она выделяется для всех соединений.
Естественно, это очень долго. Если мы
увеличим значение key bufer size, то увидим, что он делает. Таким образом, мы можем подобрать значение, его рекомендуют устанавливать в рамках сессии, а не
делать глобальным по умолчанию, потому что она выделяется для всех соединений.
В случае, когда у нас есть несколько неравенств.
Мы можем использовать секционирование, т.е., например, если таблица разбита на партиции по значению поля А, то первое неравенство будет использовано сервером на этапе определения того, к какой секции обращаться, а уже к самой секции можем использовать индекс из 2х частей (С, В). Или же исключить одно из условий путем переписывания запроса каким-то образом.
Ну и, последнее – коротко об улучшениях EXPLAN’а, которые доступны в последних версиях.
Здесь можно отметить лишь ANALYZE statement – аналог того, что в PostgreSQL план после выполнения запроса, но это только в MariaDB 10. 1, которая еще beta.
1, которая еще beta.
Еще нас может заинтересовать SHOW EXPLAIN, который позволяет в стабильных версиях MariaDB записывать сам EXPLAIN в лог медленных запросов. Это удобно потом при анализе.
Любые вопросы вы мне можете задать на форуме SQLinfo.ru/forum/.
← HighLoad++ — это блюдо, которое подают высоконагруженным
Производительность запросов в PostgreSQL – шаг за шагом →
Как правильно строить составной индекс с поиском по диапазону значений
MySql
Fomenko Alexander
• 7 min read
Работая над повышением производительности одного из самых медленных запросов к MySQL, что выполнялся в нашей системе, мы столкнулись с интересным сценарием, который привел к ценным обсуждениям и размышлениям. В этой статье я рассмотрю этот пример и покажу решение, выделив некоторые детали, которые необходимо учитывать при построении индексов для сложных запросов.
В этой статье я рассмотрю этот пример и покажу решение, выделив некоторые детали, которые необходимо учитывать при построении индексов для сложных запросов.
Эта статья представляет собой обзор сложного случая, с которым мы столкнулись, где происходит индексации несколько полей, где осуществляется поиск по диапазону значений. Чтобы не затягивать, я объясню только основные концепции индексирования, непосредственно связанные с примером. Для дальнейшего изложения могут потребоваться некоторые базовые знания по индексированию MySQL.
В этой статье поговорим про составной индекс в Mysql, и как правильно его строить в различных случаях. На реальном примере запросе покажем подход к оптимизации с помощью индексов и выбора правильного порядка колонок составного индекса. А так же, разберемся, как работать с индексом по диапазону значений, и какие способы есть обойти ограничение такого индекса.
Проблема
Примеры в этой статье основаны на следующей таблице.
CREATE TABLE `blog_index_example_table` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `to_be_processed_at` datetime NOT NULL, `booking_confirmed_at` datetime DEFAULT NULL, `processed_at` datetime DEFAULT NULL, `canceled_at` datetime DEFAULT NULL, PRIMARY KEY (`id`), KEY `ready_to_be_processed_idx_1` (`processed_at`, `canceled_at`, `to_be_processed_at`), KEY `ready_to_be_processed_idx_2` (`processed_at`, `canceled_at`, `to_be_processed_at`, `booking_confirmed_at`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Представим, что blog_index_example_table — это большая таблица, содержащая миллионы строк. Мы стремимся сделать эффективный запрос к этой таблице, используя запрос:
SELECT blog_index_example_table.* FROM blog_index_example_table WHERE booking_confirmed_at IS NOT NULL AND to_be_processed_at
Для выполнения этого запроса к таблице, содержащей миллионы строк, определенно потребуется индекс. Но как нам структурировать этот индекс, по каким колонкам мы должны его создавать? Первая и очевидная идея для многих из нас, включая меня — это добавить четырех-колоночный составной индекс типа ready_to_be_processed_idx_2.
Этот индекс подходит для предложенного запроса и действительно позволяет выполнить его за несколько миллисекунд. Однако на самом деле этот индекс использует больше ресурсов, чем нам нужно. Позвольте мне объяснить, что с ним не так.
MySQL умна — но вы можете сделать ее умнее
Как многие из вас уже знают, порядок условий в запросе WHERE не имеет никакого значения. MySQL достаточно умна, чтобы найти лучший индекс для использования и соответствующим образом изменить порядок условий оператора WHERE.
Однако MySQL не меняет порядок самого индекса, чтобы выполнить его более эффективно в зависимости от ваших условий. Это стоило бы достаточно много ресурсов, и все равно не всегда было бы возможно правильно предсказать все сценарии. Другими словами: порядок столбцов во время создания индекса имеет значение (большое).
Однако оптимальный порядок столбцов в индексе не всегда одинаков. Это зависит от ваших данных и потребностей. В приведенном выше случае условие processed_at > фильтрует наибольшее количество строк. По этой причине мы выбрали его в качестве первого столбца нашего индекса. К сожалению, остальные три условия очень похожи по диапазону фильтрации. Как же выбрать правильный порядок индекса для остальных?
По этой причине мы выбрали его в качестве первого столбца нашего индекса. К сожалению, остальные три условия очень похожи по диапазону фильтрации. Как же выбрать правильный порядок индекса для остальных?
Что значит: фильтрует наибольшее количество строк?
Представим, что в нашем запросе не 4 условия WHERE, а 4 разных запроса с одним условием:
WHERE booking_confirmed_at IS NOT NULLWHERE booking_confirmed_at IS NOT NULLWHERE processed_at IS NULLWHERE canceled_at IS NULLИ какое из этих условий фильтрует большее количество строк (возвращает меньше всего записей), то такое условие нам и подходит больше всего.
Условия
В нашем запросе осталось три колонки, не попадающие в индекс. Нам нужно добавить эти столбцы в индекс, однако мы не уверены на 100%, в каком порядке их следует выбирать. Хорошим началом будет изучение типа условий. Это одиночные условия или условия диапазона? Я сейчас объясню почему это важно и в чем разница.
Одиночные условия
Давайте сначала рассмотрим условие canceled_at:
WHERE ... canceled_at IS NULL
На первый взгляд может показаться, что IS NULL — это критерий описания множества значений, поскольку NULL означает неопределенное значение. Но, если присмотреться внимательнее, NULL — это одиночное и конкретное значение, поэтому оно поддается подсчету и индексированию.
Другими словами, мы можем перечислить NULL так же как и конкретное значение: 10, 20, 500, 15, 0, NULL, 1, 10923… Исходя из этого, можно сделать вывод, что приведенный выше фрагмент запроса является одиночным условием, поскольку указывает на вполне определенное значение.
Условия диапазона
Теперь посмотрим на оставшиеся условие выборки по диапазону значений:
WHERE ... booking_confirmed_at IS NOT NULL ... to_be_processed_at
Вы заметили разницу? booking_confirmed_at и to_be_processed_at обозначают не единственное значение, а диапазон значений. После применения условия на диапазон значений, последующие поля, учавствующие в составном индексе, теряют эффективность, так как MySQL теперь нужно искать внутри этого подмножества значений, чтобы продолжить любой поиск в индексе.
После применения условия на диапазон значений, последующие поля, учавствующие в составном индексе, теряют эффективность, так как MySQL теперь нужно искать внутри этого подмножества значений, чтобы продолжить любой поиск в индексе.
То есть, после применения поиска по диапазону значений, составной индекс по последующим полям перестает работать. Важно добавлять в составной индекс сначала поля, с одиночным значением, а потом поля с диапазоном значений.
Золотое правило: всегда сначала индексируйте столбцы которые в запросе имеют только одно значение, а затем сосредоточьтесь на условиях диапазона.
Столбец для которого может быть задано условие по диапазону следует помещать в конец индекса, чтобы оптимизатор мог максимально использовать индекс.
Таким образом, мы выбрали canceled_at в качестве второго столбца индекса. Что дальше босс?
Условия диапазона это:
BETWEEN,<>,!=,IS NOT NULLи т.
Распространенным хаком обхода поиска по диапазону индекса — использование оператораIN(...).Например, вместо запроса:
WHERE age BETWEEN 10 AND 12мы можем выполнитьWHERE age IN(10, 11, 12), что позволит оптимизатору использовать остальные колонки индекса.
 д.
д.Условия по нескольких диапазонам
Осталось две колонки, которые мы хотим добавить в наш индекс. По обоим колонкам мы ищем диапазон значений с аналогичным диапазоном фильтрации. Какие из них мы должны использовать и в каком порядке? Инстинктивно вам может показаться, что можно добавить оба условия в любом, каком угодно порядке. Отдавая предпочтение условию, которое отфильтровывает немного больше или делает тот же составной индекс многократно используемым, вы можете оказаться полезным в других сценариях. Это справедливое предположение, но оно верно лишь наполовину.
На данный момент большинство решений, которые мы приняли здесь, приведут к аналогичным результатам. Настоятельно рекомендуется выбирать третий столбец этого индекса на основе условия, которое отфильтровывает больше строк. Также, если это применимо, хорошо построить составной индекс таким образом, чтобы его можно было использовать в других сценариях. Сокращение количества индексов и их размера — это хорошая оптимизация пространства и производительности.
Настоятельно рекомендуется выбирать третий столбец этого индекса на основе условия, которое отфильтровывает больше строк. Также, если это применимо, хорошо построить составной индекс таким образом, чтобы его можно было использовать в других сценариях. Сокращение количества индексов и их размера — это хорошая оптимизация пространства и производительности.
В данном случае у нас осталось несколько условий поиска по диапазону. Как мы уже объясняли, условие диапазона будет иметь свой собственный диапазон значений, которые нужно перебрать перед использованием индекса. Это основная концепция, необходимая для понимания нашего кейса:
Как только вы достигнете первого условия диапазона, любое последующее условие в вашем запросе не будет использовать дальнейшие индексы.
Таким образом, добавление обоих индексов не изменит производительность запроса. Просто потребуется больше дискового пространства для хранения индекса. Вы будете иметь абсолютно одинаковую скорость выполнения запроса с четвертым столбцом или без него, что я продемонстрирую на примере ниже. Лучшим выбором в нашем случае будет индекс с тремя столбцами, выбирая между оставшимися двумя столбцами наиболее подходящий для вашего сценария.
Вы будете иметь абсолютно одинаковую скорость выполнения запроса с четвертым столбцом или без него, что я продемонстрирую на примере ниже. Лучшим выбором в нашем случае будет индекс с тремя столбцами, выбирая между оставшимися двумя столбцами наиболее подходящий для вашего сценария.
Мы решили двигаться дальше с processed_at, canceled_at, to_be_processed_at. Он лучше подходит для наших сценариев, основываясь на диапазонах строк и потенциальном использовании этого индекса в других запросах.
Пример с книжным каталогом
Представьте себе каталог животных, индексированный по «имени» и «цвету». Его индекс организован примерно так:
Type, Color - Page ... Dog, Black - 11 Dog, Blue - 12 Dog, Brown - 13 Duck, Black - 14 Duck, White - 15 ... Rat, Black - 32 Rat, Gray - 33 Rat, White - 34 ...
Теперь давайте выполним несколько запросов к этому каталогу и посмотрим, как он будет использовать этот индекс страниц:
1.
 Одиночное условия
Одиночное условияSELECT * FROM catalog WHERE type = "Duck" AND color = "Black"; SELECT * FROM catalog WHERE type = "Rat" AND color = "Black"; SELECT * FROM catalog WHERE type = "Dog" AND color = "Brown"; SELECT * FROM catalog WHERE type = "Rat" AND color = "White";
Обратите внимание, что с помощью простого индексного поиска можно найти точные значения страниц для этих запросов. Для пары условий всегда найдется одно значение.
2. Условие поиска по диапазону после одиночного условия
SELECT * FROM catalog WHERE type = "Duck" AND color != "Black"; SELECT * FROM catalog WHERE type = "Rat" AND color != "Black"; SELECT * FROM catalog WHERE type = "Dog" AND color != "Brown"; SELECT * FROM catalog WHERE type = "Rat" AND color != "White";
Обратите внимание, что теперь есть дополнительный шаг для поиска страниц для наших значений. Это все еще очень просто, хотя и немного сложнее, чем в первом случае. Первая часть индекса сужает вашу выборку до одного типа. Затем нужно просто исключить ненужный цвет, и вы получите диапазон страниц, на которых находятся ваши результаты. Вам нужно было проверить несколько дополнительных индексов, но это не страшно. MySQL сделает это достаточно эффективно.
Затем нужно просто исключить ненужный цвет, и вы получите диапазон страниц, на которых находятся ваши результаты. Вам нужно было проверить несколько дополнительных индексов, но это не страшно. MySQL сделает это достаточно эффективно.
3. Условие поиска чисто по диапазону
SELECT * FROM catalog WHERE type != "Duck" AND color != "Black"; SELECT * FROM catalog WHERE type != "Rat" AND color != "Black"; SELECT * FROM catalog WHERE type != "Dog" AND color != "Brown"; SELECT * FROM catalog WHERE type != "Rat" AND color = "White";
Теперь все стало сложнее. Ваш диапазон индексов намного больше, чем раньше, и вы не можете использовать индексы должным образом. Для определения пар ключей, соответствующих вашему запросу, требуется почти полное сканирование индекса. Здесь MySQL также испытывает трудности. Чем больше у вас значений, тем больше становятся индексы, а значит, больше данных для сканирования. В итоге это не сильно отличается от сканирования таблицы, т.е. просмотра всей таблицы строка за строкой. Эффективность оказалась под угрозой.
Эффективность оказалась под угрозой.
Если посмотреть на наш исходный запрос, то этот пример показывает, почему добавление booking_confirmed_at не изменит поведение индекса и не ускорит запрос.
Теперь мы докажем вышесказанное, используя MySQL EXPLAIN.
Доказательство
Мы будем использовать EXPLAIN, чтобы проанализировать, как два разных индекса выполняют запрос, который мы обсуждали в этой статье. Оба индекса имеют одинаковые столбцы и порядок, но один из них имеет дополнительный четвертый столбец. Добавим индексы в существующую таблицу и проведем тесты:
KEY `ready_to_be_processed_idx_1` (`processed_at`, `canceled_at`, `to_be_processed_at`), KEY `ready_to_be_processed_idx_2` (`processed_at`, `canceled_at`, `to_be_processed_at`, `booking_confirmed_at`)
Выполнив запрос из начала этой статьи, мы получим следующие результаты:
Мы видим, что в обоих случаях использовался один и тот же ключевой диапазон (17). Это означает, что они использовали одну и ту же часть индекса и что дополнительный четвертый столбец был проигнорирован.
Это означает, что они использовали одну и ту же часть индекса и что дополнительный четвертый столбец был проигнорирован.
Вы можете внести небольшие изменения в свой запрос, которые позволят ему полностью использовать четырехколоночный индекс. Мы изменим условие to_be_processed_at на условие одного значения: to_be_processed_at = "2020-10-08 09:45:02". Таким образом, у нас теперь есть только одно условие диапазона.
Смотрите результаты ниже:
Вы должны были заметить, что теперь мы используем key_range равный 23, что означает, что теперь используется больший диапазон нашего индекса, как и ожидалось. Хотя это доказывает, что мы можем использовать четвертый индекс, он не подходит для нашего реального случая, поскольку нам нужен запрос с диапазоном дат.
Резюме
Все три возможности, представленные в этой статье, работают для нашего случая — и трехколоночный индекс, и четырехколоночный. Однако использование четырехколоночного индекса требует больше ресурсов: большее количество индексов приводит к увеличению размера таблиц и более медленному обновлению записей, но обеспечивает одинаковое время выполнения запроса. Выбор трехколоночного индекса оптимизирует наш запрос в наибольшей степени: как по производительности, так и по дисковому пространству.
Выбор трехколоночного индекса оптимизирует наш запрос в наибольшей степени: как по производительности, так и по дисковому пространству.
В итоге мы перешли от времени выполнения 6с к 17мс для того же запроса.
Индексы могут показаться простыми на первый взгляд, и их идея довольно проста. Однако, потратив некоторое время на оптимизацию использования индексов, можно добиться значительных улучшений в производительности и занимаемом дисковом пространстве.
Цель данного примера — продемонстрировать некоторые идеи, которые важно учитывать при создании или оптимизации индексов SQL.
8.3.1 Как MySQL использует индексы
8.3.1 Как MySQL использует индексы
Индексы используются для поиска строк с определенными значениями столбцов.
быстро. Без индекса MySQL должен начинаться с первой строки
а затем прочитайте всю таблицу, чтобы найти соответствующие
ряды. Чем больше стол, тем больше это стоит. Если таблица
имеет индекс для рассматриваемых столбцов, MySQL может быстро
определить позицию для поиска в середине файла данных
без просмотра всех данных. Это намного быстрее, чем
чтение каждой строки последовательно.
Это намного быстрее, чем
чтение каждой строки последовательно.
Большинство индексов MySQL ( PRIMARY KEY , УНИКАЛЬНЫЙ , ИНДЕКС и FULLTEXT ) хранятся в
B-деревья. Исключения: индексы
для пространственных типов данных используйте R-деревья; ПАМЯТЬ таблицы также поддерживают хэш
индексы; InnoDB использует инвертированные списки
для индексов FULLTEXT .
Как правило, индексы используются, как описано ниже.
обсуждение. Характеристики, специфичные для хеш-индексов (используемые в ПАМЯТЬ таблиц) описаны в
Раздел 8.3.9, «Сравнение индексов B-Tree и Hash».
MySQL использует индексы для этих операций:
Чтобы найти строки, соответствующие предложению
WHEREбыстро.Чтобы исключить ряды из рассмотрения.
Если есть выбор
между несколькими индексами, MySQL обычно использует индекс, который
находит наименьшее количество строк (самое
селективный индекс).Если таблица имеет индекс из нескольких столбцов, любой крайний левый префикс индекса может использоваться оптимизатором для поиска ряды. Например, если у вас есть индекс из трех столбцов на
(col1, col2, col3), вы проиндексировали возможности поиска по(col1),(столбец1, столбец2)и(столбец1, столбец2, столбец3). Для получения дополнительной информации см. Раздел 8.3.6, «Многостолбцовые индексы».Для извлечения строк из других таблиц при выполнении соединений. MySQL может более эффективно использовать индексы для столбцов, если они объявляются как одинаковые по типу и размеру.
В контексте, ВАРЧАРиCHARсчитаются одинаковыми если они объявлены как один размер. Например,VARCHAR(10)иCHAR(10)имеют одинаковый размер, ноVARCHAR(10)иCHAR(15)нет.Для сравнения столбцов недвоичных строк оба столбцы должны использовать один и тот же набор символов. Например, сравнение столбца
utf8mb4с Столбецlatin1исключает использование индекса.Сравнение непохожих столбцов (сравнение строкового столбца к временному или числовому столбцу, например) может предотвратить использование индексов, если значения нельзя сравнивать напрямую без преобразование. Для заданного значения, такого как
1в числовом столбце он может равняться любому числу значений в строковом столбце, например'1',' 1','00001'или'01.. Это исключает использование любых индексов для строкового столбца. e1' Чтобы найти
MIN()илиMAX()значение для конкретного индексированный столбецkey_col. Это оптимизирован препроцессором, который проверяет, используяГДЕна всех ключах части, которые встречаются доkey_part_N=постоянныйkey_colв индексе. В этом случае MySQL выполняет поиск одного ключа. для каждогоMIN()илиMAX()выражение и заменяет это с константой. Если все выражения заменить на константы, запрос возвращается сразу. Например:ВЫБЕРИТЕ МИН.( key_part2 ),MAX( key_part2 ) FROM tbl_name ГДЕ key_part1 =10;
Чтобы отсортировать или сгруппировать таблицу, если сортировка или группировка выполнены на крайний левый префикс используемого индекса (например,
ЗАКАЗ ПО).key_part1,key_part2 Если все ключевые
части следуют DESC, ключ читать в обратном порядке. (Или, если индекс является нисходящим индекс, ключ читается в прямом порядке.) См. Раздел 8.2.1.16, «ОПТИМИЗАЦИЯ В ОРЕНДЕ ПО», Раздел 8.2.1.17, «ГРУППИРОВКА ПО ОПТИМИЗАЦИИ» и Раздел 8.3.13, «Индексы по убыванию».В некоторых случаях запрос можно оптимизировать для извлечения значений. без обращения к строкам данных. (индекс, который обеспечивает все необходимые результаты для запроса называется индекс покрытия.) Если запрос использует из таблицы только включенные столбцы в некотором индексе выбранные значения могут быть получены из индексное дерево для большей скорости:
ВЫБЕРИТЕ key_part3 ИЗ имя_таблицы ГДЕ key_part1 =1
 Если есть выбор
между несколькими индексами, MySQL обычно использует индекс, который
находит наименьшее количество строк (самое
селективный индекс).
Если есть выбор
между несколькими индексами, MySQL обычно использует индекс, который
находит наименьшее количество строк (самое
селективный индекс). В контексте,
В контексте,  e1'
e1' 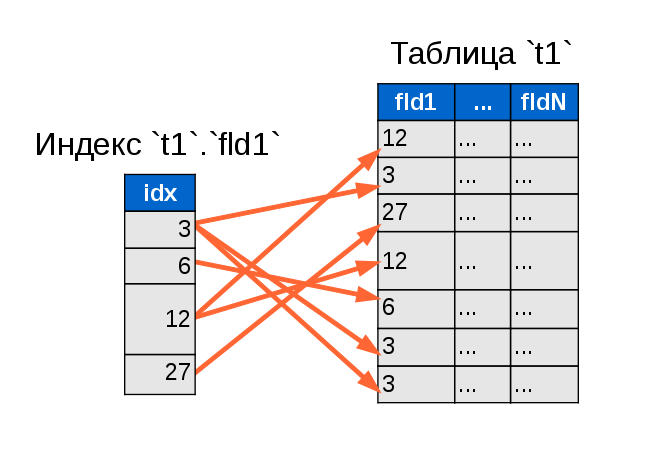 Если все ключевые
части следуют
Если все ключевые
части следуют Индексы менее важны для запросов к маленьким таблицам или к большим таблицам.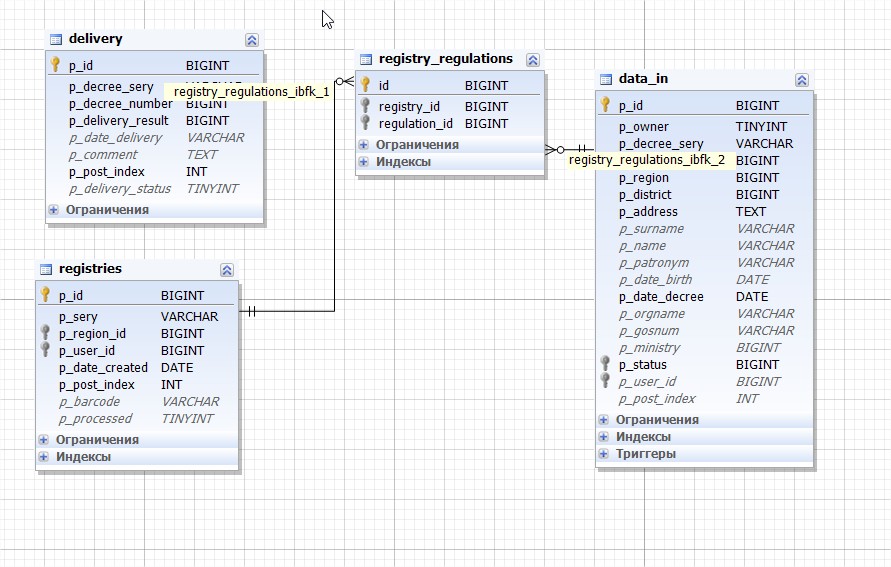 таблицы, в которых запросы отчетов обрабатывают большую часть или все строки.
Когда запросу требуется доступ к большинству строк, чтение
последовательно быстрее, чем работа через индекс. Последовательный
чтения минимизируют поиски на диске, даже если не все строки нужны
для запроса. См. раздел 8.2.1.23, «Как избежать сканирования полной таблицы».
Детали.
таблицы, в которых запросы отчетов обрабатывают большую часть или все строки.
Когда запросу требуется доступ к большинству строк, чтение
последовательно быстрее, чем работа через индекс. Последовательный
чтения минимизируют поиски на диске, даже если не все строки нужны
для запроса. См. раздел 8.2.1.23, «Как избежать сканирования полной таблицы».
Детали.
Понимание индексов в MySQL: часть первая
блог
Лукас Вилейкис
Индексы в MySQL — очень сложная штука. Мы рассматривали индексы MySQL в прошлом, но мы никогда не погружались в них глубже — мы сделаем это в этой серии сообщений в блоге. Этот пост в блоге должен служить очень общим руководством по индексам, в то время как в других частях этой серии эти темы будут рассмотрены немного глубже.
Что такое индексы?
В общем, как уже отмечалось в предыдущей записи блога об индексах, индекс — это алфавитный список записей со ссылками на страницы, на которых они упоминаются. В MySQL индекс — это структура данных, которая чаще всего используется для быстрого поиска строк. Вы также можете услышать термин «ключи» — он также относится к индексам.
В MySQL индекс — это структура данных, которая чаще всего используется для быстрого поиска строк. Вы также можете услышать термин «ключи» — он также относится к индексам.
Что делают индексы?
В MySQL индексы используются для быстрого поиска строк с определенными значениями столбцов и предотвращения чтения всей таблицы для поиска любых строк, относящихся к запросу. Индексы в основном используются, когда данные, хранящиеся в системе баз данных (например, MySQL), становятся больше, потому что чем больше таблица, тем выше вероятность того, что вы можете извлечь выгоду из индексов.
Типы индексов MySQL
Что касается MySQL, вы, возможно, слышали о наличии нескольких типов индексов:
ИНДЕКС B-дерева — такой индекс часто используется для ускорения запросов SELECT, соответствующих предложению WHERE. Такой индекс можно использовать в полях, значения которых не обязательно должны быть уникальными, он также принимает значения NULL.
A ПОЛНОТЕКСТНЫЙ ИНДЕКС – такой индекс используется для использования возможностей полнотекстового поиска. Этот тип индекса находит ключевые слова в тексте вместо прямого сравнения значений со значениями в индексе.
УНИКАЛЬНЫЙ ИНДЕКС часто используется для удаления повторяющихся значений из таблицы. Обеспечивает уникальность значений строки.
ПЕРВИЧНЫЙ КЛЮЧ также является индексом — он часто используется вместе с полями, имеющими атрибут AUTO_INCREMENT. Этот тип индекса не принимает значения NULL, и после установки значения в столбце, который имеет ПЕРВИЧНЫЙ КЛЮЧ, не могут быть изменены.
ИНДЕКС ПО УБЫВАНИЮ — это индекс, в котором строки хранятся в порядке убывания. Этот тип индекса был представлен в MySQL 8.
0 — MySQL будет использовать этот тип индекса, когда запросом запрашивается убывающий порядок.

 0 — MySQL будет использовать этот тип индекса, когда запросом запрашивается убывающий порядок.
0 — MySQL будет использовать этот тип индекса, когда запросом запрашивается убывающий порядок.Выбор оптимальных типов данных для индексов в MySQL
Что касается индексов, также необходимо помнить, что MySQL поддерживает широкий спектр типов данных, и некоторые типы данных нельзя использовать вместе с определенными типами индексов ( например, индексы FULLTEXT можно использовать только для текстовых столбцов (CHAR, VARCHAR или TEXT) — они не могут использоваться для любых других типов данных), поэтому, прежде чем выбирать индексы для своей базы данных, определитесь с типом данных. будет использоваться в рассматриваемом столбце (решите, какой класс данных вы собираетесь хранить: вы собираетесь хранить числа? строковые значения? как числа, так и строковые значения? и т. д.), затем определите диапазон значений, которые вы собираетесь хранить. которые вы собираетесь хранить (выберите тот, который, по вашему мнению, вы не превысите, потому что увеличение диапазона типов данных может оказаться трудоемкой задачей позже — мы рекомендуем вам использовать простой тип данных), и если вы не намереваетесь использовать значения NULL в своих столбцах, укажите ваши поля как NOT NULL всякий раз, когда вы можете — когда столбец, допускающий значение NULL, индексируется, для каждой записи требуется дополнительный байт.
Выбор оптимальных наборов символов и сопоставлений для индексов в MySQL
Помимо типов данных, также имейте в виду, что каждый символ в MySQL занимает место. Например, каждый символ UTF-8 может занимать от 1 до 4 байтов, поэтому вы можете не индексировать, например, 255 символов и использовать только, скажем, 50 или 100 символов для определенного столбца.
Преимущества и недостатки использования индексов в MySQL
Основным преимуществом использования индексов в MySQL является повышение производительности поисковых запросов, соответствующих предложению WHERE. Индексы ускоряют выполнение запросов SELECT, соответствующих предложению WHERE, поскольку MySQL не считывает всю таблицу, чтобы найти строки, относящиеся к запросу. Однако имейте в виду, что индексы имеют свои недостатки. Основные из них следующие:
Индексы занимают место на диске.
Индексы снижают производительность запросов INSERT, UPDATE и DELETE — при обновлении данных индекс необходимо обновлять вместе с ним.
MySQL не защищает вас от одновременного использования нескольких типов индексов. Другими словами, вы можете использовать PRIMARY KEY, INDEX и UNIQUE INDEX для одного и того же столбца — MySQL не защитит вас от такой ошибки.

Если вы подозреваете, что некоторые из ваших запросов становятся медленнее, подумайте о том, чтобы заглянуть на вкладку «Монитор запросов» в ClusterControl — включив монитор запросов, вы сможете увидеть, когда в последний раз выполнялся определенный запрос, а также его максимальное и среднее время выполнения, которые могут помочь вам выбрать лучшие индексы для вашей таблицы.
Как выбрать лучший индекс для использования?
Чтобы выбрать лучший индекс для использования, вы можете использовать встроенные механизмы MySQL. Например, вы можете использовать объяснитель запросов — запрос EXPLAIN. Он объяснит, какая таблица используется, есть ли в ней разделы или нет, какие индексы можно использовать и какой ключ (индекс) используется. Он также вернет длину индекса и количество строк, которые возвращает ваш запрос:
Он также вернет длину индекса и количество строк, которые возвращает ваш запрос:
mysql> EXPLAIN SELECT * FROM demo_table WHERE demo_field = ‘demo’G
*************************** 1-й ряд ********************** *******
идентификатор: 1
select_type: ПРОСТОЙ
таблица: demo_table
разделы: NULL
тип: ссылка
возможные_ключи: demo_field
ключ: demo_field
key_len: 1022
ссылка: константа
ряды: 1
отфильтровано: 100.00
Дополнительно: НОЛЬ
1 строка в наборе, 1 предупреждение (0,00 с) В этом случае имейте в виду, что индексы часто используются, чтобы помочь MySQL эффективно извлекать данные, когда наборы данных больше, чем обычно. Если ваша таблица небольшая, вам может не понадобиться использовать индексы, но если вы видите, что ваши таблицы становятся все больше и больше, скорее всего, вы можете извлечь выгоду из индекса.
Тем не менее, чтобы выбрать лучший индекс для вашего конкретного сценария, имейте в виду, что индексы также могут быть основной причиной проблем с производительностью. Имейте в виду, что будет ли MySQL эффективно использовать индексы или нет, зависит от нескольких факторов, включая дизайн ваших запросов, используемые индексы, типы используемых индексов, а также загрузку вашей базы данных во время выполнения запроса и другие вещи. Вот несколько вещей, которые следует учитывать при использовании индексов в MySQL:
Имейте в виду, что будет ли MySQL эффективно использовать индексы или нет, зависит от нескольких факторов, включая дизайн ваших запросов, используемые индексы, типы используемых индексов, а также загрузку вашей базы данных во время выполнения запроса и другие вещи. Вот несколько вещей, которые следует учитывать при использовании индексов в MySQL:
Сколько у вас данных? Возможно, что-то из этого лишнее?
Какие запросы вы используете? Будут ли в ваших запросах использоваться предложения LIKE? Что насчет заказа?
Какой тип индекса вам нужно использовать для повышения производительности ваших запросов?
Будут ли ваши индексы большими или маленькими? Вам нужно использовать индекс для префикса столбца, чтобы уменьшить его размер?
Стоит отметить, что вам, вероятно, следует избегать использования нескольких типов индексов (например, индекса B-Tree, UNIQUE INDEX и PRIMARY KEY) в одном и том же столбце.
Повышение производительности запросов с помощью индексов
Чтобы повысить производительность запросов с помощью индексов, вам нужно взглянуть на свои запросы — в этом может помочь оператор EXPLAIN. В целом, если вы хотите, чтобы ваши индексы повышали производительность ваших запросов, вам следует принять во внимание несколько вещей:
Запрашивайте у базы данных только то, что вам нужно. В большинстве случаев использование столбца SELECT будет быстрее, чем использование SELECT * (то есть без использования индексов)
Индекс B-дерева может подойти, если вы ищете точные значения (например, SELECT * FROM demo_table WHERE some_field = ‘x’) или если вы хотите искать значения с использованием подстановочных знаков (например, SELECT * FROM demo_table WHERE some_field LIKE ‘demo %’ — в этом случае имейте в виду, что использование запросов LIKE с чем-либо в начале может принести больше вреда, чем пользы — избегайте использования запросов LIKE со знаком процента перед текстом, который вы ищете — таким образом MySQL может не использовать индекс, потому что он не знает, с чего начинается значение строки) — хотя имейте в виду, что индекс B-дерева также может использоваться для сравнения столбцов в выражениях, которые используют равенство (=), больше, чем (> ), больше или равно (>=), меньше (
Полнотекстовый индекс может подойти, если вы обнаружите, что используете полнотекстовые поисковые запросы (MATCH … AGAINST()) или если ваша база данных спроектирована таким образом, что использует только текстовые столбцы — индексы FULLTEXT могут использовать TEXT, CHAR или столбцы VARCHAR, их нельзя использовать для столбцов любых других типов.
Покрывающий индекс может быть полезен, если вы хотите выполнять запросы без дополнительного чтения операций ввода-вывода для больших таблиц. Чтобы создать покрывающий индекс, закройте предложения WHERE, GROUP BY и SELECT, используемые в запросе.
Мы подробнее рассмотрим типы индексов в следующих частях этой серии блогов, но в целом, если вы используете такие запросы, как SELECT * FROM demo_table WHERE some_field = ‘x’, B-tree INDEX может подойти, если вы используете запросы MATCH() AGAINST(), вам, вероятно, следует изучить индекс FULLTEXT, если в вашей таблице очень длинные значения строк, вам, вероятно, следует изучить индексацию части столбца.
Сколько индексов нужно иметь?
Если вы когда-либо использовали индексы для повышения производительности ваших запросов SELECT, вы, вероятно, задавались вопросом: сколько индексов у вас должно быть на самом деле? Чтобы это понять, нужно помнить следующее: 9. 0006
0006
Индексы обычно наиболее эффективны при работе с большими объемами данных.
MySQL использует только один индекс для каждого оператора SELECT в запросе (подзапросы рассматриваются как отдельные операторы) — используйте запрос EXPLAIN, чтобы узнать, какие индексы наиболее эффективны для используемых вами запросов.
Индексы должны сделать все ваши операторы SELECT достаточно быстрыми без слишком большого ущерба для дискового пространства — однако «достаточно быстро» является относительным, поэтому вам нужно будет поэкспериментировать.
Индексы и механизмы хранения
При работе с индексами в MySQL также имейте в виду, что могут быть некоторые ограничения, если вы используете различные механизмы (например, если вы используете MyISAM, а не InnoDB).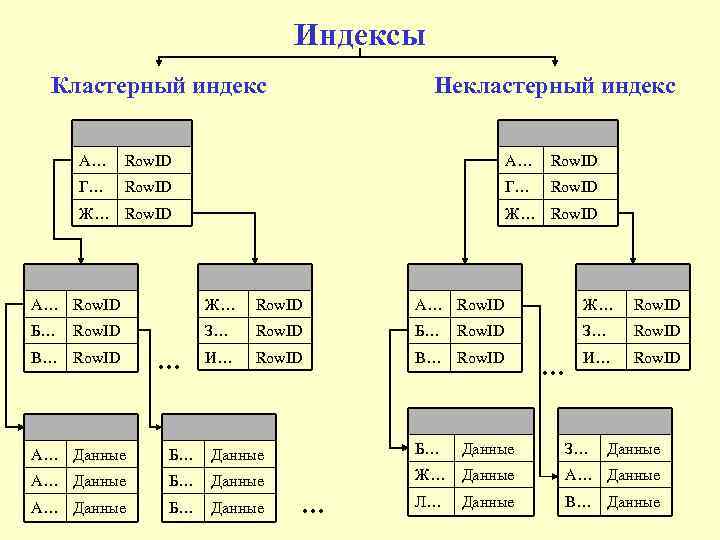 Более подробно мы расскажем в отдельном блоге, а вот некоторые идеи:
Более подробно мы расскажем в отдельном блоге, а вот некоторые идеи:
Максимальное количество индексов на таблицы MyISAM и InnoDB — 64, максимальное количество столбцов на индекс в обоих механизмах хранения — 16.
Максимальная длина ключа для InnoDB — 3500 байт, максимальная длина ключа для MyISAM — 1000 байт.
Полнотекстовые индексы имеют ограничения в некоторых механизмах хранения — например, полнотекстовые индексы InnoDB имеют 36 стоп-слов, список стоп-слов MyISAM немного больше и содержит 143 стоп-слова. InnoDB извлекает эти стоп-слова из переменной innodb_ft_server_stopword_table, а MyISAM извлекает эти стоп-слова из файла storage/myisam/ft_static.c — все слова, найденные в файле, будут рассматриваться как стоп-слова.
MyISAM был единственным механизмом хранения с поддержкой параметров полнотекстового поиска, пока не появился MySQL 5.
6 (точнее, MySQL 5.6.4), что означает, что InnoDB поддерживает полнотекстовые индексы, начиная с MySQL 5.6.4. Когда используется индекс FULLTEXT, он находит ключевые слова в тексте, а не сравнивает значения напрямую со значениями в индексе.Индексы играют очень важную роль для InnoDB — InnoDB блокирует строки при доступе к ним, поэтому уменьшение количества строк, к которым обращается InnoDB, может уменьшить количество блокировок.
MySQL позволяет использовать повторяющиеся индексы для одного и того же столбца.
Некоторые механизмы хранения имеют определенные типы индексов по умолчанию (например, для механизма хранения MEMORY тип индекса по умолчанию — хеш)
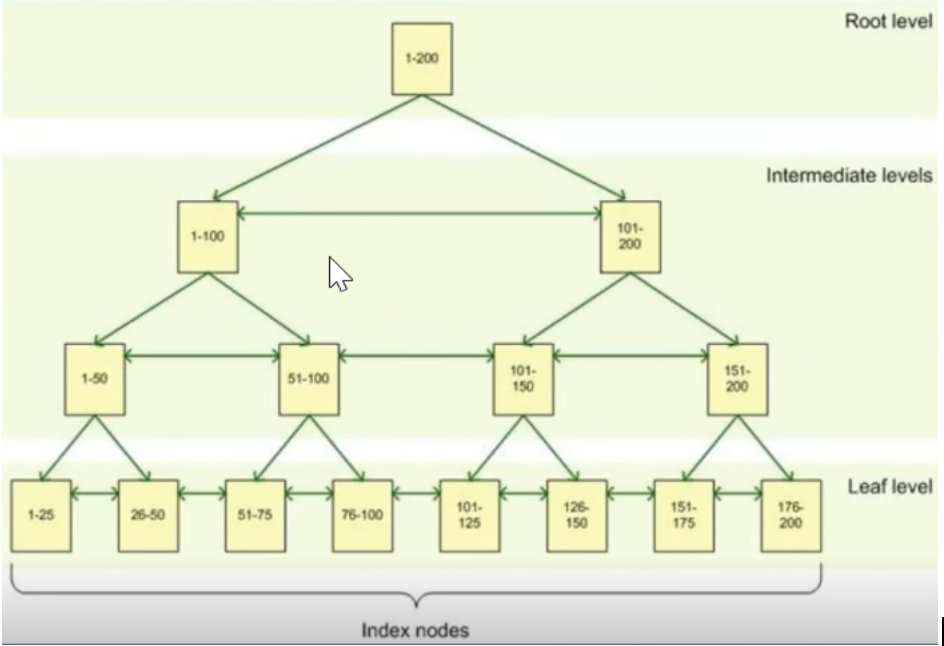 6 (точнее, MySQL 5.6.4), что означает, что InnoDB поддерживает полнотекстовые индексы, начиная с MySQL 5.6.4. Когда используется индекс FULLTEXT, он находит ключевые слова в тексте, а не сравнивает значения напрямую со значениями в индексе.
6 (точнее, MySQL 5.6.4), что означает, что InnoDB поддерживает полнотекстовые индексы, начиная с MySQL 5.6.4. Когда используется индекс FULLTEXT, он находит ключевые слова в тексте, а не сравнивает значения напрямую со значениями в индексе.Резюме
В этой части об индексах в MySQL мы рассмотрели некоторые общие моменты, связанные с индексами в этой системе управления реляционными базами данных. В следующих сообщениях блога мы рассмотрим несколько более подробных сценариев использования индексов в MySQL, включая использование индексов в определенных механизмах хранения и т. д., а также объясним, как можно использовать ClusterControl для достижения ваших целей производительности в MySQL.
В следующих сообщениях блога мы рассмотрим несколько более подробных сценариев использования индексов в MySQL, включая использование индексов в определенных механизмах хранения и т. д., а также объясним, как можно использовать ClusterControl для достижения ваших целей производительности в MySQL.
2 августа 2022 г. Сара Моррис
ClusterControl добавляет масштабирование для Redis, SQL Server и Elasticsearch в последнем выпуске
.8 июня 2022 г. Кайл Баззелл
Архитектуры частного облака и локальной базы данных с ClusterControl
19 мая 2022 г. Сара Моррис
Настоящая альтернатива Elastic Cloud для автоматизации операций Elasticsearch
Подпишитесь, чтобы получать наш лучший и самый свежий контент
Подписка на рассылку новостей
Скрытый
Государственный
CAPTCHA
Index WP MySQL For Speed – Плагин WordPress
Как использовать этот плагин?
После того, как вы установите и активируете этот подключаемый модуль, зайдите в Index MySQL Tool в меню Tools. Оттуда вы можете нажать кнопку Добавить ключи сейчас . Если у вас большие таблицы, используйте вместо этого WP-CLI, чтобы избежать тайм-аутов. См. раздел WP-CLI, чтобы узнать больше.
Оттуда вы можете нажать кнопку Добавить ключи сейчас . Если у вас большие таблицы, используйте вместо этого WP-CLI, чтобы избежать тайм-аутов. См. раздел WP-CLI, чтобы узнать больше.
Что он делает для моего сайта?
Этот плагин работает, чтобы сделать вашу базу данных MySQL более эффективной, добавляя высокопроизводительные ключи к выбранным вами таблицам. По запросу он отслеживает использование вашим сайтом базы данных MySQL, чтобы определить, какие операции базы данных выполняются медленнее всего. Это наиболее полезно для больших сайтов: сайтов с большим количеством пользователей, постов, страниц и/или продуктов.
Вы можете использовать его для восстановления ключей WordPress по умолчанию, если это необходимо.
О чем все это?
Где WordPress хранит все то, что делает ваш сайт замечательным? Где ваши страницы, сообщения, продукты, медиа, пользователи, настраиваемые поля, метаданные и весь ваш ценный контент? Все эти данные находятся в системе управления реляционными базами данных MySQL. (Многие хостинг-провайдеры и серверы используют форк программного обеспечения MySQL от MariaDB; он работает точно так же, как и сама MySQL.)
(Многие хостинг-провайдеры и серверы используют форк программного обеспечения MySQL от MariaDB; он работает точно так же, как и сама MySQL.)
По мере роста вашего сайта растут и ваши таблицы MySQL. Гигантские таблицы могут замедлить загрузку вашей страницы, расстроить ваших пользователей и даже повредить вашему рейтингу в поисковых системах. И массовый импорт может занять абсурдное количество времени. Что вы можете с этим поделать?
Вы можете установить и использовать подключаемый модуль очистки базы данных, чтобы избавиться от старых нежелательных данных и реорганизовать свои таблицы. Это делает их меньше и, следовательно, быстрее. Это хорошая и нужная задача. Это не задача этого плагина. Вы можете, если ваш хостинг-провайдер поддерживает это, установить и использовать подключаемый модуль Persistent Object Cache, чтобы уменьшить трафик к вашей базе данных. Это также не является задачей этого плагина.
Этот плагин добавляет ключи базы данных (также называемые индексами) в ваши таблицы MySQL, чтобы облегчить WordPress поиск необходимой информации. Все системы управления реляционными базами данных хранят вашу информацию в долгоживущих таблицы . Например, WordPress хранит ваши сообщения и другой контент в таблице с именем wp_posts , а настраиваемые поля сообщений — в другой таблице с именем wp_postmeta . Успешный сайт может иметь тысячи сообщений и сотни тысяч настраиваемых полей для сообщений. У MySQL есть две задачи:
Все системы управления реляционными базами данных хранят вашу информацию в долгоживущих таблицы . Например, WordPress хранит ваши сообщения и другой контент в таблице с именем wp_posts , а настраиваемые поля сообщений — в другой таблице с именем wp_postmeta . Успешный сайт может иметь тысячи сообщений и сотни тысяч настраиваемых полей для сообщений. У MySQL есть две задачи:
- Хранить все эти данные в порядке.
- Быстро найти нужные данные.
Для выполнения второй задачи MySQL использует ключи базы данных. Каждая таблица имеет один или несколько ключей. Например, wp_posts имеет ключ, позволяющий быстро находить сообщения, когда вы знаете автора. Без ключа post_author MySQL пришлось бы сканировать каждое из ваших сообщений в поисках совпадений с нужным вам автором. Наши пользователи знают, как это выглядит: медленно. С помощью ключа MySQL может перейти прямо к соответствующим сообщениям.
На новом сайте WordPress с парой пользователей и дюжиной сообщений ключи не имеют большого значения. По мере роста сайта ключи начинают иметь большое значение. Системы управления базами данных спроектированы так, чтобы их ключи обновлялись, настраивались и настраивались по мере роста их таблиц. Они предназначены для того, чтобы ключи могли развиваться без изменения содержимого базовых таблиц. В организациях с большими базами данных добавление, удаление или изменение ключей не изменяет базовые данные. Это рутинная задача обслуживания во многих центрах обработки данных. Если бы изменение ключей привело к потере данных в базах данных, разработчики MySQL и MariaDB услышали бы вой не только от вас и меня, но и от многих пользователей-тяжеловесов. (Конечно, вы все равно должны сделать резервную копию своего экземпляра WordPress.)
По мере роста сайта ключи начинают иметь большое значение. Системы управления базами данных спроектированы так, чтобы их ключи обновлялись, настраивались и настраивались по мере роста их таблиц. Они предназначены для того, чтобы ключи могли развиваться без изменения содержимого базовых таблиц. В организациях с большими базами данных добавление, удаление или изменение ключей не изменяет базовые данные. Это рутинная задача обслуживания во многих центрах обработки данных. Если бы изменение ключей привело к потере данных в базах данных, разработчики MySQL и MariaDB услышали бы вой не только от вас и меня, но и от многих пользователей-тяжеловесов. (Конечно, вы все равно должны сделать резервную копию своего экземпляра WordPress.)
Улучшенные ключи позволяют коду WordPress работать быстрее без каких-либо изменений кода . Опыт работы с крупными сайтами показывает, что многие замедления работы MySQL можно устранить с помощью лучших ключей. Код — это поэзия, данные — это сокровище, а ключи базы данных — это смазка, благодаря которой код и данные работают без сбоев.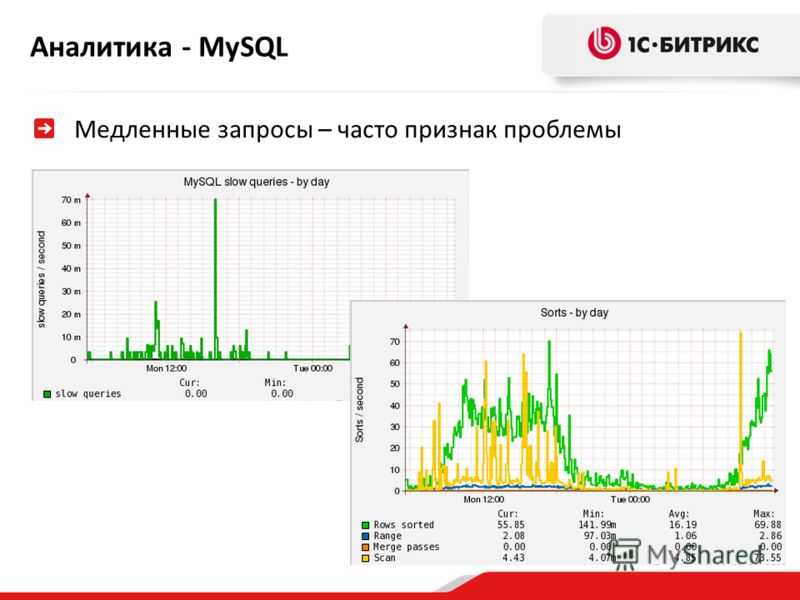
К каким таблицам подключаемый модуль добавляет ключи?
Этот плагин добавляет и обновляет ключи в этих таблицах WordPress.
- wp_comments
- wp_commentmeta
- wp_posts
- wp_postmeta
- wp_termmeta
- wp_users
- wp_usermeta
- wp_options
Вам нужно запустить этот плагин только один раз, чтобы воспользоваться его преимуществами.
Как я могу контролировать работу моей базы данных?
На странице Index MySQL (из меню «Инструменты» на панели инструментов) вы найдете вкладку «Мониторинг операций с базой данных». Используйте его, чтобы запросить мониторинг в течение выбранного вами количества минут.
Вы можете контролировать
- либо сайт (ваши страницы, видимые пользователям), либо панель инструментов, либо и то, и другое.
- все просмотры страниц или случайная выборка. (Случайные выборки полезны на очень загруженных сайтах для снижения затрат на мониторинг. )
 )
)После сбора информации мониторинга вы можете просмотреть захваченные запросы и отсортировать их по длительности выполнения. Или вы можете сохранить информацию о мониторе в файл и показать ее тому, кто разбирается в операциях с базой данных. Или вы можете загрузить монитор на серверы плагина, чтобы авторы могли его посмотреть.
Рекомендуется отслеживать пятиминутный интервал в то время дня, когда ваш сайт занят. После завершения мониторинга вы можете изучить его, чтобы определить, какие операции с базой данных замедляют работу больше всего.
Пожалуйста, рассмотрите возможность загрузки сохраненных мониторов на серверы плагина. Это то, как мы учимся на вашем опыте, чтобы продолжать совершенствоваться. Нажмите кнопку «Загрузить» на вкладке монитора.
Операция командной строки WP-CLI
Этот подключаемый модуль поддерживает WP-CLI. Когда ваши таблицы большие, это лучший способ добавить высокопроизводительные ключи: время ожидания не истекает.
Введите команду wp help index-mysql для подробностей. Несколько примеров:
-
wp index-mysql statusпоказывает текущий статус высокопроизводительных ключей. -
wp index-mysql enable --allдобавляет высокопроизводительные ключи ко всем таблицам, в которых их нет. -
wp index-mysql enable wp_postmetaдобавляет высокопроизводительные ключи в таблицу postmeta. -
wp index-mysql disable --allудаляет высокопроизводительные ключи из всех таблиц, в которых они есть, восстанавливает ключи WordPress по умолчанию. -
wp index-mysql enable --all --dryrunвыводит операторы SQL, необходимые для добавления высокопроизводительных ключей ко всем таблицам, но не запускает их. -
wp index-mysql enable --all --dryrun | wp db queryзаписывает операторы SQL и передает их в wp db для их запуска.
Примечание. Избегайте сохранения операторов вывода –dryrun для последующего запуска. Плагин генерирует их в соответствии с текущим состоянием ваших таблиц.
Плагин генерирует их в соответствии с текущим состоянием ваших таблиц.
Что нового в последней версии?
После первого релиза наши пользователи рассказали нам еще о нескольких возможностях ускорить работу WooCommerce и основных операций WordPress. Мы добавили ключи в метатаблицы , чтобы облегчить поиск контента, и в таблицу пользователей , чтобы искать людей по отображаемым именам. И теперь вы можете загружать сохраненные мониторы, чтобы мы могли видеть ваши самые медленные запросы. Мы будем использовать эту информацию для улучшения будущих версий. Спасибо, дорогие пользователи!
Плагин теперь правильно обрабатывает обновления версии WordPress: они не меняют ваши высокопроизводительные ключи.
Мы добавили переключатель –dryrun в интерфейс WP-CLI для тех, кто хочет увидеть используемые нами операторы SQL.
Кредиты
- Майкл Уно для платформы страницы администратора.
- Марко Чезарато для LiteSQLParser.
- Аллан Джардин для Datatables.net.
- Japreet Sethi за совет и за тестирование его большой установки.
- Рик Джеймс за все.
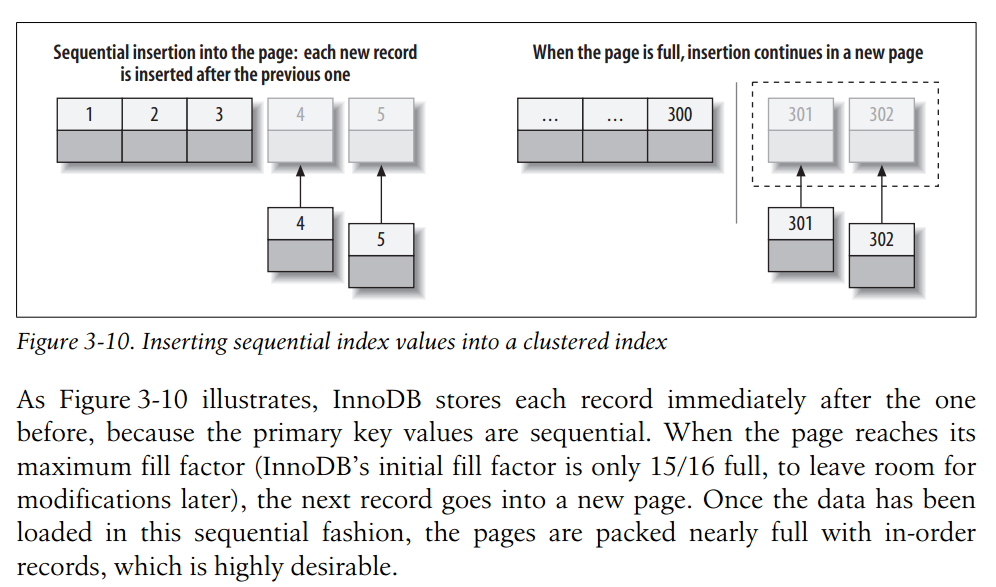
Как выбрать лучшие индексы для запросов MySQL и оптимизации базы данных
Содержание этого сообщения
- Какие индексы мне следует создать для оптимизации моего SQL-запроса?
- Чего нельзя делать при индексации (или написании SQL-запросов)?
- Индексация каждого столбца в таблице отдельно
- Оператор ИЛИ в условиях фильтрации
- Порядок столбцов в индексе важен
- Избыточные индексы
- Как автоматизировать создание индекса и оптимизацию SQL запросов?
Многие из наших пользователей, разработчиков и администраторов баз данных продолжают спрашивать нашу команду об алгоритме рекомендаций по индексированию EverSQL. Вот мы и решили написать об этом.
Первый вариант — использовать EverSQL для автоматического поиска индексов , которые лучше всего подходят для вашей базы данных.
Второй вариант – прочитать наше подробное руководство ниже и узнать больше о передовых методах индексирования.
В этом руководстве не будут подробно описываться все внутренности алгоритма, а вместо этого попытаемся простыми словами изложить основные и важные аспекты индексации.
Кроме того, что наиболее важно, мы представим практические примеры правильной индексации ваших таблиц и запросов, опираясь на набор правил.
В этом руководстве мы сосредоточимся на MySQL/MariaDB, хотя эта информация может быть актуальна и для других реляционных баз данных с аналогичными структурами индексирования.
Какие индексы следует создать для оптимизации моего SQL-запроса?
Прежде чем мы начнем, обратите внимание, что рекомендуется стремиться создавать индексы, которые «соответствуют» как можно большему количеству запросов в вашей рабочей нагрузке, поскольку это уменьшит общее количество индексов и нагрузку, которую их существование может создать на базу данных при вставке или обновлении данных (что также требует обновления индексов).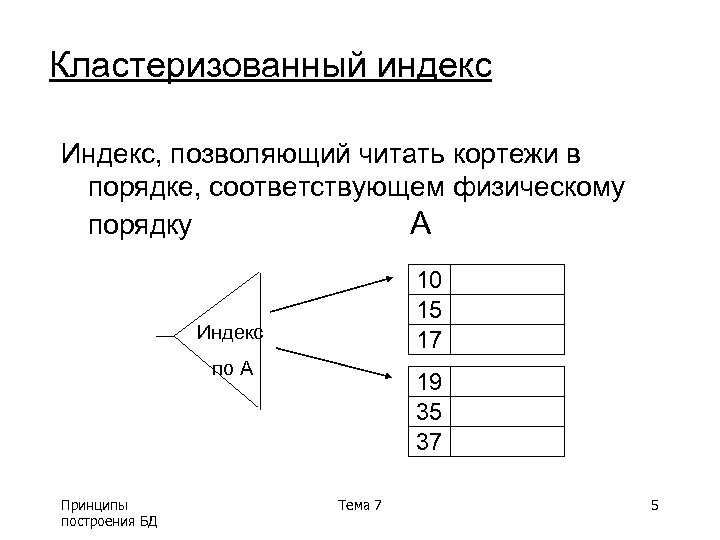 Кроме того, имейте в виду, что порядок столбцов в индексе имеет значение.
Кроме того, имейте в виду, что порядок столбцов в индексе имеет значение.
Как правило, MySQL может использовать только один индекс для каждой таблицы в запросе (исключая слияния индексов, которые мы не будем рассматривать в этом посте), поэтому вы должны начать с перечисления всех таблиц в вашем запросе и посмотреть если и какой индекс вы должны создать для него.
При создании индекса обычно следует начинать с условий равенства в условиях WHERE и JOIN. В большинстве случаев такие условия, как name = ‘John’ , позволят базе данных отфильтровать многие строки из таблицы и просмотреть небольшое количество строк, чтобы получить требуемые результаты. Следовательно, мы должны начать индексацию, добавив эти столбцы в индекс. Имейте в виду, что вам, вероятно, следует добавлять только те столбцы, которые являются частью выборочных условий, иначе они не внесут большого вклада в оптимизацию запроса.
Затем вам следует изучить условия диапазона, но вы должны добавить только одно из них для каждой таблицы — наиболее избирательное условие, поскольку MySQL может обрабатывать только один «диапазонный столбец» в каждом индексе. В некоторых случаях, когда нет условий диапазона, имеет смысл добавить столбцы GROUP BY/ORDER BY, предполагая упорядочение только в одном направлении (ASC/DESC).
В некоторых случаях, когда нет условий диапазона, имеет смысл добавить столбцы GROUP BY/ORDER BY, предполагая упорядочение только в одном направлении (ASC/DESC).
В некоторых случаях также имеет смысл создать отдельный индекс, содержащий столбцы предложения ORDER BY, поскольку MySQL иногда предпочитает его использовать. Обратите внимание, что для этого индекс должен содержать все столбцы из предложения ORDER BY, и все они должны быть указаны в одном и том же порядке (ASC / DESC). Это не гарантирует, что оптимизатор базы данных выберет именно этот индекс, а не другие составные индексы. Это произойдет только тогда, когда MySQL будет знать, что просмотр индекса сортировки будет более эффективным для быстрого отслеживания результата по сравнению с работой с другими индексами (или сканированием всей таблицы).
Кроме того, в некоторых случаях имеет смысл также добавить в индекс столбцы из предложения SELECT, чтобы создать покрывающий индекс. Это имеет значение только в том случае, если индекс еще не «слишком велик».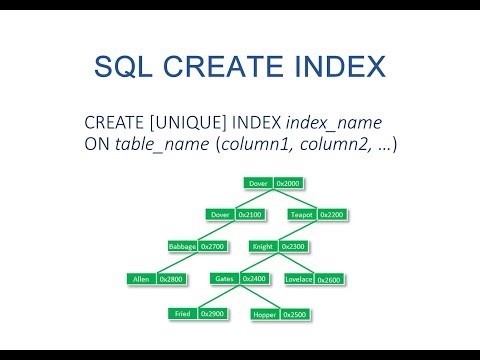 Что слишком большое? Ну, здесь нет официального эмпирического правила, но я обычно использую до 5 столбцов в индексе. Создание покрывающего индекса позволяет базе данных не только фильтровать с помощью индекса, но также извлекать информацию, требуемую предложением SELECT, непосредственно из индекса, что экономит драгоценные операции ввода-вывода для выборки данных отфильтрованных строк из данных таблицы. .
Что слишком большое? Ну, здесь нет официального эмпирического правила, но я обычно использую до 5 столбцов в индексе. Создание покрывающего индекса позволяет базе данных не только фильтровать с помощью индекса, но также извлекать информацию, требуемую предложением SELECT, непосредственно из индекса, что экономит драгоценные операции ввода-вывода для выборки данных отфильтрованных строк из данных таблицы. .
Давайте посмотрим на пример, чтобы пояснить:
SELECT
id, имя, фамилия, возраст
ИЗ
сотрудники
КУДА
first_name = 'Джон'
AND last_name = 'Брэк'
И возраст > 25
ЗАКАЗАТЬ ПО ВОЗРАСТУ ASC;
Для этого запроса мы начнем с добавления столбцов first_name и last_name , которые сравниваются с оператором равенства. Затем мы добавим столбец age , который сравнивается с условием диапазона. Здесь нет необходимости индексировать предложение ORDER BY, так как 9Столбец 0092 age уже находится в индексе. И последнее, но не менее важное: мы добавим id из предложения SELECT в индекс, чтобы иметь покрывающий индекс.
И последнее, но не менее важное: мы добавим id из предложения SELECT в индекс, чтобы иметь покрывающий индекс.
Таким образом, чтобы правильно проиндексировать этот запрос, вы должны создать индекс:
сотрудников (имя, фамилия, возраст, идентификатор).
Выше приведен очень упрощенный псевдоалгоритм, который позволит вам построить простые индексы для довольно простых SQL-запросов.
Определяя, какие столбцы из предложений JOIN ON индексировать, вы должны иметь в виду, что MySQL имеет алгоритм для определения, с какой таблицы вы должны начать в INNER JOIN, который также определяет, какой столбец индексировать первым. Дополнительную информацию и псевдоалгоритм можно найти в документации MySQL.
Если вы ищете способ автоматизировать создание индекса, а также воспользоваться собственным алгоритмом индексирования и рекомендациями по оптимизации запросов, вы можете попробовать EverSQL Index Advisor , который сделает всю тяжелую работу за вас.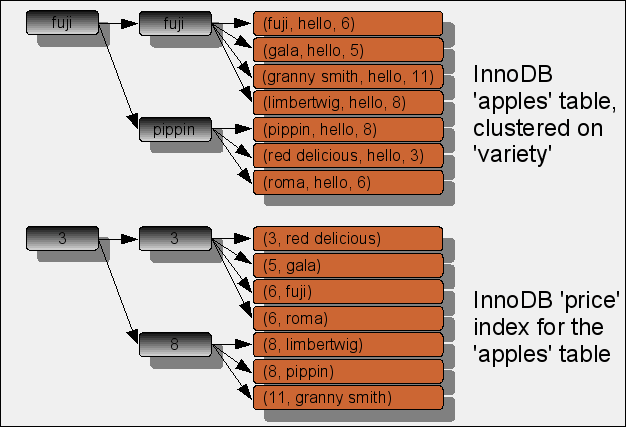
Чего нельзя делать при индексации (или написании SQL-запросов)?
Мы собрали некоторые из наиболее распространенных ошибок, с которыми сталкиваются программисты и администраторы баз данных при написании запросов и индексировании своих таблиц.
Индексирование каждого столбца в таблице отдельно
В большинстве случаев MySQL не сможет использовать более одного индекса для каждой таблицы в запросе (исключая очень специфические случаи слияния индексов).
Поэтому при создании отдельного индекса для каждого столбца в таблице база данных обязывает выполнять только одну из операций поиска по индексу, а остальные будут выполняться значительно медленнее, так как база данных не может использовать index для их выполнения.
Мы рекомендуем использовать составные (многостолбцовые) индексы везде, где это возможно, а не одностолбцовые индексы для каждого столбца в отдельности.
Оператор ИЛИ в условиях фильтрации
Рассмотрим этот запрос:
SELECT
а, б
ИЗ
стол
КУДА
а = 3 ИЛИ б = 8;
Во многих случаях MySQL не сможет использовать индекс для применения условия ИЛИ, и в результате этот запрос не может индексироваться.
Поэтому мы рекомендуем избегать таких условий ИЛИ и рассмотреть вопрос о разделении запроса на две части в сочетании с UNION DISTINCT (или, что еще лучше, UNION ALL, если вы знаете, что не будет повторяющихся результатов)
Порядок столбцов в указателе важен.
Допустим, я даю вам свою телефонную книгу контактов, которая упорядочена по имени контакта, и прошу вас подсчитать, сколько в книге людей с именем «Джон». Вы возьмете книгу обеими руками и скажете «нет проблем». Вы перейдете на страницу, содержащую все имена, начинающиеся с Джона, и начнете считать оттуда.
Теперь предположим, что я изменил назначение и вручил вам телефонную книгу, которая упорядочена по фамилии контакта, но попрошу вас по-прежнему считать все контакты с именем «Джон». Как бы вы подошли к этому? Ну и в этой ситуации база данных тоже ломает голову.
Теперь давайте посмотрим на запрос SQL, чтобы продемонстрировать такое же поведение с оптимизатором MySQL:
SELECT
имя Фамилия
ИЗ
контакты
КУДА
first_name = 'Джон';
Наличие индексных контактов (first_name, last_name) здесь идеально, потому что индекс начинается с нашего условия фильтрации и заканчивается другим столбцом в предложении SELECT.
Но иметь контакты с обратным индексом (last_name, first_name) довольно бесполезно, так как база данных не может использовать индекс для фильтрации, так как нужный нам столбец находится вторым в индексе, а не первым.
Из этого примера можно сделать вывод, что порядок столбцов в индексе очень важен.
Избыточные индексы
Индексы великолепно подходят для оптимизации SQL-запросов и могут значительно повысить производительность.
Но у них есть и обратная сторона. Каждый создаваемый вами индекс должен обновляться и синхронизироваться, когда в ваших базах данных происходят изменения. Таким образом, для каждого INSERT/UPDATE/DELETE в ваших базах данных должны обновляться все соответствующие индексы. Это обновление может занять некоторое время, особенно с большими таблицами/индексами.
Поэтому не создавайте индексы, если вы не знаете, что они вам понадобятся.
Кроме того, мы настоятельно рекомендуем время от времени анализировать вашу базу данных в поисках любых избыточных индексов, которые можно удалить.
Как автоматизировать создание индекса и оптимизацию SQL-запросов?
Если вы ищете способ автоматизировать создание индекса, а также воспользоваться собственным алгоритмом индексирования и рекомендациями по оптимизации запросов, попробуйте БЕСПЛАТНЫЙ EverSQL Index Advisor , который сделает всю тяжелую работу за вас.
Индексация MySQL для повышения производительности | Pluralsight
Перейти к содержимому- Дом
- Обзор
- Курсы
by Pinal Dave
Курс MySQL, посвященный стратегиям индексирования для высокопроизводительных баз данных
Предварительный просмотр этого курса
Попробуйте бесплатно
Получить это курс, а также лучшие подборки технических навыков и других популярных тем.
Начало работы
29,00 $
в месяц после 10-дневного пробного периода
Ваша 10-дневная бесплатная пробная версия Standard включает
Курсы под руководством экспертов
Идите в ногу с темпами изменений благодаря тысячам углубленных курсов под руководством экспертов.
Для команд
Предоставьте до 10 пользователям доступ к нашей полной библиотеке, включая этот курс бесплатно на 14 дней
Информация о курсе
Чему вы научитесь
Производительность — один из важнейших аспектов любого приложения. Каждый хочет, чтобы его сервер работал оптимально и с максимальной эффективностью. Индексы — это серебряные пули для производительности. В этом курсе мы познакомимся с основами индексов и дополнительно изучим практические советы и рекомендации по настройке производительности.
Содержание
Типы индексов
29 минут
Стратегии индексации для высокой производительности
55 минут
- Введение 1м
- Эффективность индекса 1м
- Демонстрация: список индексов 3м
- Демонстрация: основы индексов 6м
- Демонстрация: порядок столбцов в индексе 4м
- Демонстрация: оптимизация условий операции ИЛИ 7м
- Демонстрация: оптимизация условий ИЛИ — расширенный уровень 8м
- Демонстрация: оптимизация условий И 6м
- Демонстрация: оптимизация И условия — расширенный 2 м
- Демонстрация: указатель обложек 4м
- Демонстрация: кластеризованный индекс 8м
- Демонстрация: подсказки указателя 5м
- Резюме за шестьдесят секунд 0м
Ведение индекса
12 минут
- Введение 1м
- Оптимизатор запросов MySQL 1м
- Статистика 1м
- Статистика InnoDB 2 м
- Фрагментация данных и индексов 1м
- Ведение индекса 3м
- Другие советы по обслуживанию индекса 2 м
- Резюме за шестьдесят секунд 1м
Контрольные списки
3 минуты
- Контрольные списки 3м
Об авторе
Пинал Дэйв
Пинал Дэйв — эксперт по настройке производительности SQL Server и независимый консультант с более чем 21-летним практическим опытом.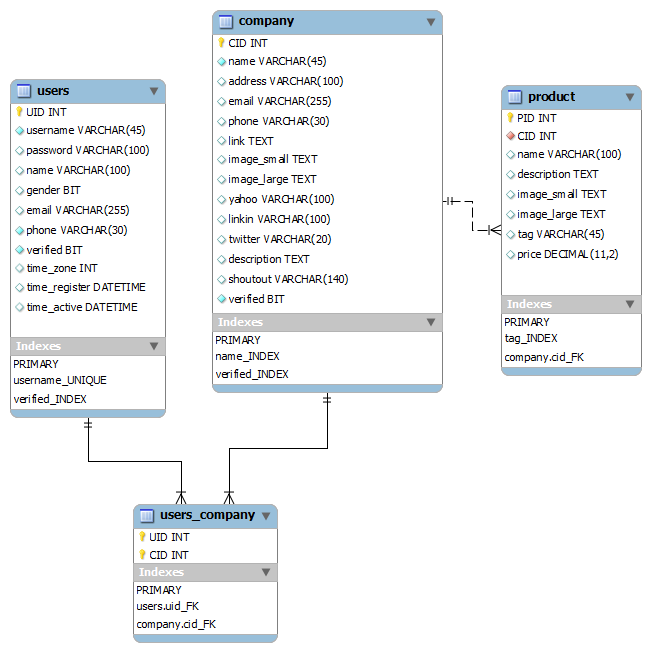 Он имеет степень магистра наук и многочисленные сертификаты по базам данных. Пинал является автором 14 книг по базам данных SQL Server и 42 курсов Pluralsight. Чтобы свободно делиться своими знаниями и помогать другим наращивать свой опыт, Пинал также написал более 5500 статей о технологиях баз данных в своем блоге по адресу https://blog.sqlauthority.com.
Он имеет степень магистра наук и многочисленные сертификаты по базам данных. Пинал является автором 14 книг по базам данных SQL Server и 42 курсов Pluralsight. Чтобы свободно делиться своими знаниями и помогать другим наращивать свой опыт, Пинал также написал более 5500 статей о технологиях баз данных в своем блоге по адресу https://blog.sqlauthority.com.
Посмотреть другие курсы от Pinal Dave
Попробовать бесплатно
Получить это курс, а также лучшие подборки технических навыков и других популярных тем.
Начало работы
29,00 $
в месяц после 10-дневного пробного периода
Ваша 10-дневная бесплатная пробная версия Standard включает
Курсы под руководством экспертов
Идите в ногу с темпами изменений благодаря тысячам углубленных курсов под руководством экспертов.
Для команд
Дайте до 10 пользователей доступ к нашей полной библиотеке, включая этот курс бесплатно на 14 дней
Информация о курсе
Получить доступ сейчас
Зарегистрируйтесь, чтобы получить немедленный доступ к этому курсу и тысячам других курсов, которые вы можете смотреть в любое время и в любом месте.
Отмена Начать бесплатную 10-дневную пробную версию Отменить
С помощью плана Pluralsight вы можете:
С помощью 14-дневного пилотного проекта вы можете:
- Получите доступ к тысячам видео для развития важнейших навыков
- Предоставьте до 10 пользователей доступ к тысячам видеокурсов
- Практика и применение навыков с интерактивными курсами и проектами
- Просмотр данных о навыках, использовании и тенденциях для ваших команд
- Подготовьтесь к сертификации с помощью лучших в отрасли практических экзаменов
- Измерение уровня владения навыками и ролями
- Согласуйте обучение с вашими целями с помощью путей и каналов
Готовы повысить уровень
всей своей команды?
10
Подписки
Нужно больше подписок? Свяжитесь с отделом продаж.
Продолжить оформление заказа
Отменить
С планом Pluralsight вы можете:
С 14-дневной пробной версией вы можете:
- Получите доступ к тысячам видео для развития важных навыков
- Предоставьте до 10 пользователей доступ к тысячам видеокурсов
- Практика и применение навыков с интерактивными курсами и проектами
- Просмотр данных о навыках, использовании и тенденциях для ваших команд
- Подготовьтесь к сертификации с помощью лучших в отрасли практических экзаменов
- Измерение уровня владения навыками и ролями
- Согласуйте обучение с вашими целями с помощью путей и каналов
Как посмотреть индексы для базы данных или таблицы в MySQL
1 ответ на этот вопрос.

0 голосов
Связанные вопросы в PHP
Я пытаюсь закодировать окно поиска… ПОДРОБНЕЕ
22 июля в PHP по нариккадан • 14 480 баллов • 54 просмотра
- PHP
- майскл
- linux-база данных
- линукс
- база данных
- фильтр
Как создать таблицу создания… ПОДРОБНЕЕ
4 августа в PHP по Китузз • 8 840 баллов • 17 просмотров
- MySQL
- linux-база данных
- линукс
- phpmyadmin
Привет @картик, Используйте этот запрос: ВЫБЕРИТЕ пользователя ИЗ mysql.user; Какие … ПОДРОБНЕЕ
ответил 18 августа 2020 г. в PHP по Нирой • 82 780 баллов • 551 просмотр
- HTML
- CSS
- JavaScript
- ларавель
- PHP
Привет @картик,
Вы можете использовать этот запрос, чтобы . .. ПОДРОБНЕЕ
.. ПОДРОБНЕЕ
ответил 18 августа 2020 г. в PHP по Нирой • 82 780 баллов • 343 просмотра
- HTML
- CSS
- JavaScript
- ларавель
- PHP
Привет @картик, Сначала вы должны пойти в … ПОДРОБНЕЕ
ответил 18 марта 2020 г. в Ларавеле по Нирой • 82 780 баллов • 15 205 просмотров
- HTML
- CSS
- JavaScript
- ларавель
- угловой
- PHP
Именованный маршрут используется для предоставления конкретных … ПОДРОБНЕЕ
ответил 18 марта 2020 г. в Ларавеле по Нирой • 82 780 баллов • 1720 просмотров
- HTML
- CSS
- JavaScript
- ларавель
- PHP
Привет, Это просто, вам просто нужно … ПОДРОБНЕЕ
ответил 23 марта 2020 г. в Ларавеле по
Нирой • 82 780 баллов • 1416 просмотров
в Ларавеле по
Нирой • 82 780 баллов • 1416 просмотров
- HTML
- CSS
- JavaScript
- ларавель
- PHP
Привет @картик, Именованная маршрутизация — еще одна замечательная особенность … ПОДРОБНЕЕ
ответил 23 марта 2020 г. в Ларавеле по Нирой • 82 780 баллов • 20 827 просмотров
- HTML
- CSS
- JavaScript
- ларавель
- PHP
Привет @картик, Если empName является столбцом VARCHAR(50): ИЗМЕНИТЬ … ПОДРОБНЕЕ
ответил 19 авг. 2020 г. в PHP по Нирой • 82 780 баллов • 559 просмотров
- HTML
- CSS
- JavaScript
- ларавель
- PHP
- майскл
- linux-база данных
- линукс
Картик привет, На самом деле есть много функций, которые … ПОДРОБНЕЕ
ответил
27 марта 2020 г.