Основы репликации в MySQL / Хабр
С репликацией серверов MySQL я познакомился относительно недавно, и по мере проведения разных опытов с настройкой, записывал, что у меня получалось. Когда материала набралось достаточно много, появилась идея написать эту статью. Я постарался собрать советы и решения по некоторым самым основным вопросам, с которыми я столкнулся. По ходу дела я буду давать ссылки на документацию и другие источники. Не могу претендовать на полноту описания, но надеюсь, что статья будет полезной.Небольшое введение
Репликация (от лат. replico -повторяю) — это тиражирование изменений данных с главного сервера БД на одном или нескольких зависимых серверах. Главный сервер будем называть мастером, а зависимые — репликами.
Изменения данных, происходящие на мастере, повторяются на репликах (но не наоборот). Поэтому запросы на изменение данных (INSERT, UPDATE, DELETE и т. д.) выполняются только на мастере, а запросы на чтение данных (проще говоря, SELECT) могут выполняться как на репликах, так и на мастере. Процесс репликации на одной из реплик не влияет на работу других реплик, и практически не влияет на работу мастера.
При репликации содержимое БД дублируется на нескольких серверах. Зачем необходимо прибегать к дублированию? Есть несколько причин:
- производительность и масштабируемость. Один сервер может не справляться с нагрузкой, вызываемой одновременными операциями чтения и записи в БД. Выгода от создания реплик будет тем больше, чем больше операций чтения приходится на одну операцию записи в вашей системе.
- отказоустойчивость. В случае отказа реплики, все запросы чтения можно безопасно перевести на мастера. Если откажет мастер, запросы записи можно перевести на реплику (после того, как мастер будет восстановлен, он может принять на себя роль реплики).
- резервирование данных
- отложенные вычисления. Тяжелые и медленные SQL-запросы можно выполнять на отдельной реплике, не боясь помешать нормальной работе всей системы.
Кроме того, есть некоторые другие интересные возможности. Поскольку на реплики передаются не сами данные, а запросы, вызывающие их изменения, мы можем использовать различную структуру таблиц на мастере и репликах. В частности, может отличаться тип таблицы (engine) или набор индексов. Например, для осуществления полнотекстового поиска мы можем на реплике использовать тип таблицы MyISAM, несмотря на то, что мастер будет использовать InnoDB.
Настройка репликации
- IP-адрес мастера 192.168.1.101, реплики — 192.168.1.102.
- MySQL установлен и настроен
- требуется настроить репликацию БД testdb
- мы можем приостановить работу мастера на некоторое время
- у нас, разумеется, есть root на обеих машинах
Настройки мастера
Обязательно укажем уникальный ID сервера, путь для бинарных логов и имя БД для репликации в секции [mysqld]:
server-id = 1
log-bin = /var/lib/mysql/mysql-bin
replicate-do-db = testdbУбедитесь, что у вас достаточно места на диске для бинарных логов.
Добавим пользователя replication, под правами которого будет производится репликация. Будет достаточно привилегии «replication slave «:
mysql@master> GRANT replication slave ON "testdb".* TO "replication"@"192.168.1.102" IDENTIFIED BY "password";
Перезагрузим MySQL, чтобы изменения в конфиге вступили в силу:
root@master# service mysqld restart
Если все прошло успешно, команда «show master status » должна показать примерно следующее:
mysql@master> SHOW MASTER STATUS\G
Position: 98
Binlog_Do_DB:
Binlog_Ignore_DB:
Значение position должно увеличиваться по мере того, как вносятся изменения в БД на мастере.
Настройки реплики
Укажем ID сервера, имя БД для репликации и путь к relay-бинлогам в секции [mysqld] конфига, затем перезагрузим MySQL:
server-id = 2
relay-log = /var/lib/mysql/mysql-relay-bin
relay-log-index = /var/lib/mysql/mysql-relay-bin.index
replicate-do-db = testdbroot@replica# service mysqld restart
Переносим данные
Здесь нам придется заблокировать БД для записи. Для этого можно либо остановить работу приложений, либо воспользоваться установкой флажка read_only на мастере (внимание: на пользователей с привилегией SUPER этот флаг не действует). Если у нас есть таблицы MyISAM, сделаем также «flush tables»:
mysql@master> FLUSH TABLES WITH READ LOCK;
mysql@master> SET GLOBAL read_only = ON;Посмотрим состояние мастера командой «show master status» и запомним значения File и Position (после успешной блокировки мастера они не должны изменятся):
File: mysql-bin.000003
Position: 98
Делаем дамп БД, и после завершения операции снимаем блокировку мастера:
mysql@master> SET GLOBAL read_only = OFF;
Переносим дамп на реплику и восстанавливаем из него данные.
mysql@replica> CHANGE MASTER TO MASTER_HOST = "192.168.1.101 ", MASTER_USER = "replication ", MASTER_PASSWORD = "password ", MASTER_LOG_FILE = "mysql-bin.000003 ", MASTER_LOG_POS = 98;
mysql@replica> start slave;Значения MASTER_LOG_FILE и MASTER_LOG_POS мы берем с мастера.
Посмотрим, как идет репликация командой «show slave status «:
mysql@replica> SHOW SLAVE STATUS\G
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.1.101
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000003
Read_Master_Log_Pos: 98
Relay_Log_File: mysql-relay-bin.001152
Relay_Log_Pos: 235
Relay_Master_Log_File: mysql-bin.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB: testdb,testdb
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 98
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 5
Наиболее интересные сейчас значения я выделил. При успешном начале репликации их значения должны быть примерно такими, как в листинге (см. описание команды «show slave status » в документации). Значение Seconds_Behind_Master может быть любым целым числом.
Если репликация идет нормально, реплика будет следовать за мастером (номер лога в Master_Log_File и позиция Exec_Master_Log_Pos будут расти). Время отставания реплики от мастера (Seconds_Behind_Master), в идеале, должно быть равно нулю. Если оно не сокращается или растет, возможно, что нагрузка на реплику слишком высока — она просто не успевает повторять изменения, происходящие на мастере.
mysql@replica> start slave;
Путем этих нехитрых действий мы получаем реплику, данные которой идентичны данным на мастере.
Кстати, время блокировки мастера — это время создания дампа. Если он создается недопустимо долго, можно попробовать поступить так:
- заблокировать запись в мастер флагом read_only, запомнить позицию и остановить MySQL.
- после этого скопировать файлы БД на реплику и включить мастер.
- начать репликацию обычным способом.
Существует несколько способов создать реплику без остановки мастера вообще, но они срабатывают не всегда.
Добавляем реплики
Пусть у нас уже есть работающие мастер и реплика, и нам нужно добавить к ним еще одну. Сделать это даже проще, чем добавить первую реплику к мастеру. И гораздо приятнее то, что нет необходимости останавливать для этого мастер.
Для начала настроим MySQL на второй реплике и убедимся, что мы внесли нужные параметры в конфиг:
server-id = 3
replicate-do-db = testdbТеперь остановим репликацию на первой реплике:
mysql@replica-1> stop slave;
Реплика продолжит работать нормально, однако данные на ней уже не будут актуальными. Посмотрим статус и запомним позицию мастера, до которой реплика дошла перед остановкой репликации:
mysql@replica-1> SHOW SLAVE STATUS\G
Нам нужные будет значения Master_Log_File и Exec_Master_Log_Pos:
Master_Log_File: mysql-bin.000004
Exec_Master_Log_Pos: 155
Создадим дамп БД и продолжим репликацию на первой реплике:
mysql@replica-1> START SLAVE;
Восстановим данные из дампа на второй реплике. Затем включим репликацию:
mysql@replica-2> CHANGE MASTER TO MASTER_HOST = "192.168.1.101 ", MASTER_USER = "replication ", MASTER_PASSWORD = "password ", MASTER_LOG_FILE = "mysql-bin.000004 ", MASTER_LOG_POS = 155;
mysql@replica-2> START SLAVE;
Значения MASTER_LOG_FILE и MASTER_LOG_POS — это соответственно значения Master_Log_File и Exec_Master_Log_Pos из результата команды «show slave status » на первой реплике.
Репликация должна начаться с той позиции, на которой была остановлена первая реплика (и соответственно, создан дамп). Таким образом, у нас будет две реплики с идентичными данными.
Объединяем реплики
Иногда возникает такая ситуация: на мастере существует две БД, одна из которых реплицируется на одной реплике, а вторая — на другой. Как настроить репликацию двух БД на обеих репликах, не делая их дампы на мастере и не выключая его из работы? Достаточно просто, с использованием команды «start slave until «.
Итак, у нас имеется master с базами данных testdb1 и testdb2, которые реплицируются соответственно на репликах replica-1 и replica-2. Настроим репликацию обеих БД на replica-1 без остановки мастера.
Остановим репликацию на replica-2 командой и запомним позицию мастера:
mysql@replica-2> STOP SLAVE;
mysql@replica-2> SHOW SLAVE STATUS\G
Master_Log_File: mysql-bin.000015
Exec_Master_Log_Pos: 231Создадим дамп БД testdb2 и возобновим репликацию (на этом манипуляции с replica-2 закончились). Дамп восстановим на replica-1.
Ситуация на replica-1 такая: БД testdb1 находится на одной позиции мастера и продолжает реплицироваться, БД testdb2 восстановлена из дампа с другой позиции. Синхронизируем их.
Остановим репликацию и запомним позицию мастера:
mysql@replica-1> STOP SLAVE;
mysql@replica-1> SHOW SLAVE STATUS\G
Master_Log_File: mysql-bin.000016
Exec_Master_Log_Pos: 501
Убедимся, что в конфиге на replica-1 в секции [mysqld] указано имя второй БД:
replicate-do-db = testdb2
Перезагрузим MySQL, чтобы изменения в конфиге вступили в силу. Кстати, можно было просто перезагрузить MySQL, не останавливая репликацию — из лога мы бы узнали, на какой позиции мастера репликация остановилась.
Теперь проведем репликацию с позиции, на которой была приостановлена replica-2 до позиции, на которой мы только что приостановили репликацию:
mysql@replica-1> CHANGE MASTER TO MASTER_HOST = "192.168.1.101 ", MASTER_USER = "replication ", MASTER_PASSWORD = "password ", MASTER_LOG_FILE = "mysql-bin.000015 ", MASTER_LOG_POS = 231;
mysql@replica-1> start slave until MASTER_LOG_FILE = "mysql-bin.000016 ", MASTER_LOG_POS = 501;
Репликация закончится, как только реплика дойдет до указанной позиции в секции until, после чего обе наши БД будут соответствовать одной и той же позиции мастера (на которой мы остановили репликацию на replica-1). Убедимся в этом:
mysql@replica-1> SHOW SLAVE STATUS\G
mysql@replica-1> START SLAVE;
Master_Log_File: mysql-bin.000016
Exec_Master_Log_Pos: 501
Добавим в конфиг на replica-1 в секции [mysqld] имена обеих БД:
replicate-do-db = testdb1
replicate-do-db = testdb2
Важно: каждая БД должна быть указана на отдельной строке.
Перезагрузим MySQL и продолжим репликацию:
mysql@replica-1> CHANGE MASTER TO MASTER_HOST = "192.168.1.101 ", MASTER_USER = "replication ", MASTER_PASSWORD = "password ", MASTER_LOG_FILE = "mysql-bin.000016 ", MASTER_LOG_POS = 501;
После того, как replica-1 догонит мастер, содержание их БД будет идентично. Объединить БД на replica-2 можно или подобным образом, или сделав полный дамп replica-1.
Рокировка мастера и реплики
Переключить реплику в режим мастера бывает необходимо, например, в случае отказа мастера или при проведении на нем технических работ. Для возможности такого переключения необходимо настроить реплику подобно мастеру, или сделать её пассивным мастером.
Включим ведение бинарных логов (дополнительно к relay-бинлогам) в конфиге в секции [mysqld]:
log-bin = /var/lib/mysql/mysql-bin
И добавим пользователя для ведения репликации:
mysql@master> GRANT replication slave ON ’testdb’.* TO ’replication’@’192.168.1.101′ IDENTIFIED BY "password ";
Пассивный мастер ведет репликацию как и обычная реплика, но кроме этого создает бинарные логии — то есть, мы можем начать репликацию с него. Убедимся в этом командой «show master status «:
mysql@replica> SHOW MASTER STATUS\G
File: mysql-bin.000001
Position: 61
Binlog_Do_DB:
Binlog_Ignore_DB:
Теперь, чтобы перевести пассивный мастер в активный режим, необходимо остановить репликацию на нем и включить репликацию на бывшем активном мастере. Чтобы в момент переключения данные не были утеряны, активный мастер необходимо заблокировать на запись.
mysql@master> FLUSH TABLES WITH READ LOCK
mysql@master> SET GLOBAL read_only = ON;
mysql@replica> STOP SLAVE;
mysql@replica> SHOW MASTER STATUS;
File: mysql-bin.000001
Position: 61
mysql@master> CHANGE MASTER TO MASTER_HOST = "192.168.1.102 ", MASTER_USER = "replication ", MASTER_PASSWORD = "password ", MASTER_LOG_FILE = "mysql-bin.000001 ", MASTER_LOG_POS = 61;
mysql@master> start slave;
Все, так мы поменяли активный мастер. Можно снять с бывшего мастера блокировку.
Заключение
Мы немного разобрались в том, как настраивать репликацию в MySQL и выполнять некоторые основные операции. К сожалению, за рамками статьи остались следующие важные вопросы:
- устранение единичных точек отказа (SPF, Single Points of Failure). При использовании единственного сервера MySQL, его отказ приводил к отказу всей системы. При использовании нескольких серверов, отказ любого из них приведет к отказу системы, если только мы специально не позаботимся об этом. Нам нужно предусмотреть обработку ситуации с отказом мастера и реплики. Одно из существующих средств — MMM, однако, требует доработки напильником.
- балансировка нагрузки. При использовании нескольких реплик нам было бы удобно использовать прозрачный механизм балансировки, особенно если производительность реплик неодинакова. Под Linux возможно использовать стандартное решение — LVS.
- изменение логики работы приложения. В идеальной ситуации, запросы на чтение данных надо направлять на реплики, а на изменение — на мастер. Однако, из-за возможного отставания реплик, такая схема часто неработоспособна и необходимо выявлять такие запросы на чтение, которые все же должны выполнятся на мастере.
Надеюсь осветить эти вопросы в дальнейших статьях.
Спасибо за внимание!
Репликация MySQL | Losst
В наши дни база данных MySQL используется уже практически везде, где только можно. Невозможно представить сайта, который бы работал без MySQL. Конечно, есть некоторые исключения, но основную часть рынка занимает именно эта система баз данных. И самая популярная из реализаций — MariaDB. Когда проект небольшой, для его работы достаточно одного сервера, на котором расположены все службы: веб-сервер, сервер баз данных и почтовый сервер. Но когда проект становится более большим может понадобится выделить для каждой службы отдельный сервер или даже разделить одну службу на несколько серверов, например, MySQL.
Для того чтобы поддерживать синхронное состояние баз данных на всех серверах одновременно нужно использовать репликацию. В этой статье мы рассмотрим как настраивается репликация MySQL с помощью MariaDB Galera Cluster.
ЧТО ТАКОЕ MARIADB GALERA?
MariaDB Galera — это кластерная система для MariaDB типа master-master. Начиная с MariaDB 10.1 программное обеспечение Galera Server и MariaDB Server поставляются в одном пакете, так что вы получаете все необходимое программное обеспечение сразу. На данный момент MariaDB Galera может работать только с движками баз данных InnoDB и XtraDB. Из преимуществ использования репликации можно отметить добавление избыточности для базы данных сайта. Если одна из баз данных, даст сбой, то вы сразу же сможете переключиться на другой. Все сервера поддерживают синхронизированное состояние между собой и гарантируют отсутствие потерянных транзакций.
Основные возможности MariaDB Galera:
- Репликация с постоянной синхронизацией;
- Автоматическое объединение узлов;
- Возможность подключения нескольких узлов master;
- Поддержка записи на любой из узлов;
- Прозрачная параллельная репликация;
- Масштабируемость чтения и записи, минимальные задержки;
- Давшие сбой ноды автоматически отключаются от кластера;
- Нельзя блокировать доступ к таблицам.
Дальше перейдем ближе к настройке MariaDB Galera.
НАСТРОЙКА РЕПЛИКАЦИИ MYSQL
В этой инструкции мы будем использовать для примера Ubuntu 16.04 и MariaDB версии 10.1. Перед тем, как начать полностью обновите систему:
sudo apt-get update -ysudo apt-get upgrade -y
Поскольку мы будем развертывать нашу конфигурацию на нескольких узлах, нужно выполнить операции обновления на всех них. Если сервер баз данных MariaDB еще не установлен, его нужно установить. Сначала добавьте репозиторий и его ключ:
sudo apt-key adv --recv-keys --keyserver hkp://keyserver.ubuntu.com:80 0xF1656F24C74CD1D8
sudo add-apt-repository 'deb [arch=amd64,i386,ppc64el] http://ftp.utexas.edu/mariadb/repo/10.1/ubuntu xenial main'
sudo apt-get update -y

Когда обновление списка пакетов завершено, установите MariaDB командой:
sudo apt install mariadb-server rsync -y
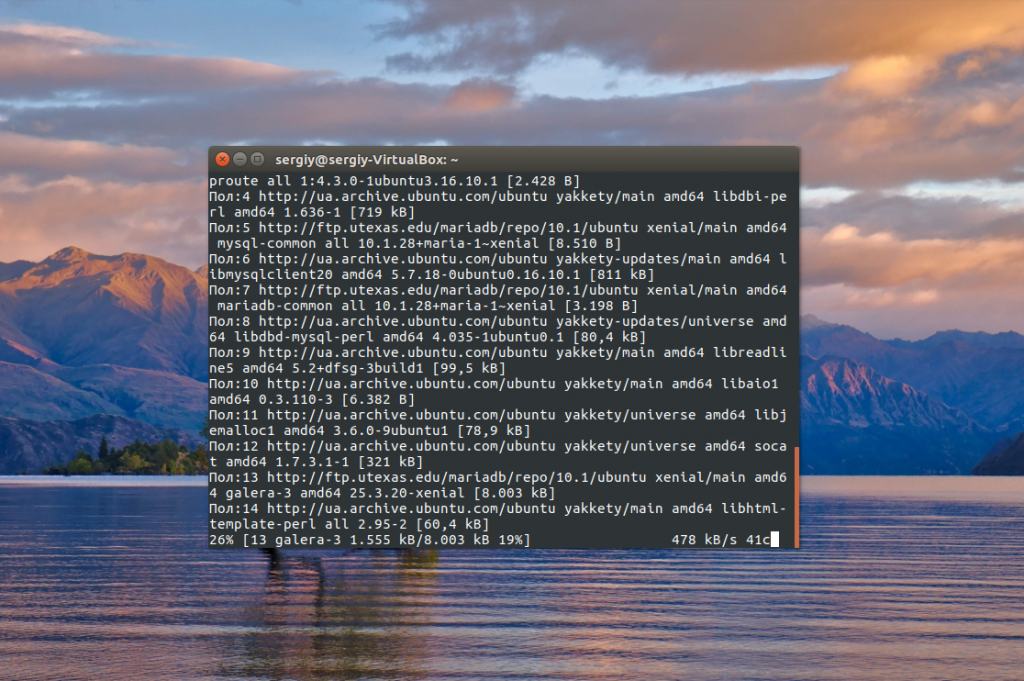
Пакет rsync нам понадобится для выполнения непосредственно синхронизации. Когда установка будет завершена, вам необходимо защитить базу данных с помощью скрипта mysql_secure_installation:
sudo mysql_secure_installation

По умолчанию разрешен гостевой вход, есть тестовая база данных, а для пользователя root не задан пароль. Все это надо исправить. Читайте подробнее в статье установка MariaDB в Ubuntu. Если кратко, то вам нужно будет ответить на несколько вопросов:
Enter current password for root (enter for none):
Change the root password? [Y/n] n
Remove anonymous users? [Y/n] Y
Disallow root login remotely? [Y/n] Y
Remove test database and access to it? [Y/n] Y
Reload privilege tables now? [Y/n] Y
Когда все будет готово, можно переходить к настройке нод, между которыми будет выполняться репликация баз данных mysql. Сначала рассмотрим настройку первой ноды. Можно поместить все настройки в my.cnf, но лучше будет создать отдельный файл для этих целей в папке /etc/mysql/conf.d/.
sudo vi /etc/mysql/conf.d/galera.cnf
Добавьте такие строки:
[mysqld]
binlog_format=ROW
default-storage-engine=innodb
innodb_autoinc_lock_mode=2
bind-address=0.0.0.0
# Galera Provider Configuration
wsrep_on=ON
wsrep_provider=/usr/lib/galera/libgalera_smm.so
# Galera Cluster Configuration
wsrep_cluster_name="galera_cluster"
wsrep_cluster_address="gcomm://192.168.56.101,192.168.56.102"
# Galera Synchronization Configuration
wsrep_sst_method=rsync
# Galera Node Configuration
wsrep_node_address="192.168.56.101"
wsrep_node_name="Node1"

Здесь адрес 192.168.56.101 — это адрес текущей ноды. Дальше перейдите на другой сервер и создайте там такой же файл:
sudo vi /etc/mysql/conf.d/galera.cnf
[mysqld]
binlog_format=ROW
default-storage-engine=innodb
innodb_autoinc_lock_mode=2
bind-address=0.0.0.0
# Galera Provider Configuration
wsrep_on=ON
wsrep_provider=/usr/lib/galera/libgalera_smm.so
# Galera Cluster Configuration
wsrep_cluster_name="galera_cluster"
wsrep_cluster_address="gcomm://192.168.56.101,192.168.56.102"
# Galera Synchronization Configuration
wsrep_sst_method=rsync
# Galera Node Configuration
wsrep_node_address="192.168.56.102"
wsrep_node_name="Node2"
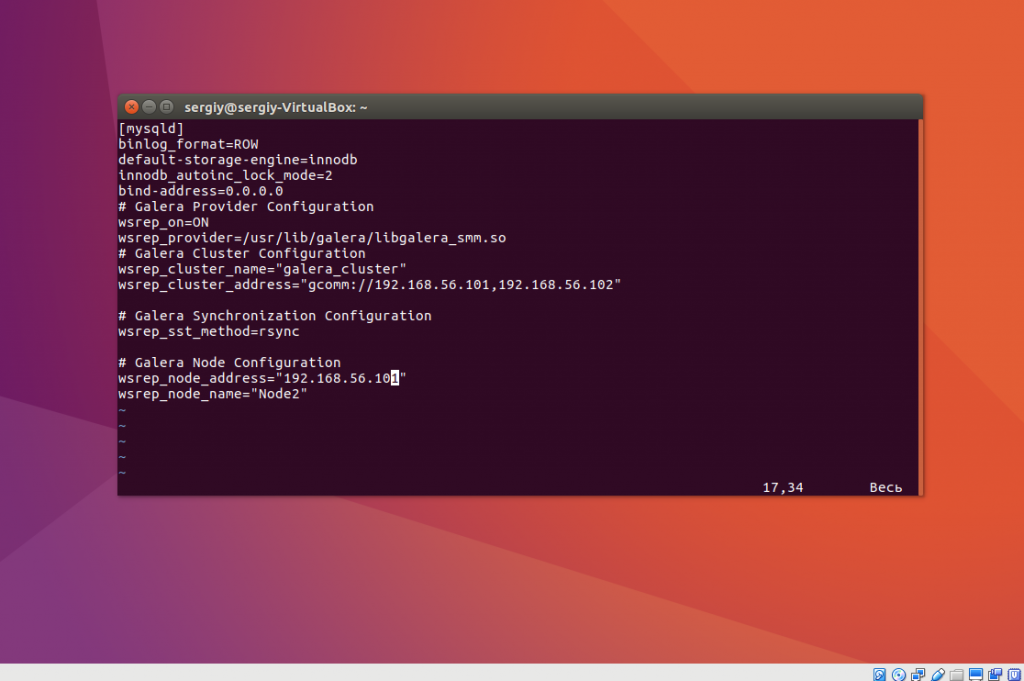
Аналогично тут адрес ноды — 192.168.0.103. Остановимся на примере с двумя серверами, так как этого достаточно чтобы продемонстрировать работу системы, а добавить еще один сервер вы можете, прописав дополнительный IP адрес в поле wsrep_cluster_address. Теперь рассмотрим что означают значения основных параметров и перейдем к запуску:
- binlog_format — формат лога, в котором будут сохраняться запросы, значение row сообщает, что там будут храниться двоичные данные;
- default-storage-engine — движок SQL таблиц, который мы будем использовать;
- innodb_autoinc_lock_mode — режим работы генератора значений AUTO_INCREMENT;
- bind-address — ip адрес, на котором программа будет слушать соединения, в нашем случае все ip адреса;
- wsrep_on — включает репликацию;
- wsrep_provider — библиотека, с помощью которой будет выполняться репликация;
- wsrep_cluster_name — имя кластера, должно соответствовать на всех нодах;
- wsrep_cluster_address — список адресов серверов, между которыми будет выполняться репликация баз данных mysql, через запятую;
- wsrep_sst_method — транспорт, который будет использоваться для передачи данных;
- wsrep_node_address — ip адрес текущей ноды;
- wsrep_node_name — имя текущей ноды.
Настройка репликации MySQL почти завершена. Остался последний штрих перед запуском — это настройка брандмауэра. Сначала включите инструмент управления правилами iptables в Ubuntu — UFW:
sudo ufw enable

Затем откройте такие порты:
sudo ufw allow 3306/tcpsudo ufw allow 4444/tcpsudo ufw allow 4567/tcpsudo ufw allow 4568/tcpsudo ufw allow 4567/udp

ЗАПУСК MARIADB GALERA
После успешной настройки всех нод нам останется только запустить кластер Galera на первой ноде. Перед тем как мы сможем запустить кластер, вам нужно убедиться, что сервис MariaDB остановлен на всех серверах:
sudo systemctl stop mysql
Дальше запустите скрипт создания нового кластера:
sudo galera_new_cluster
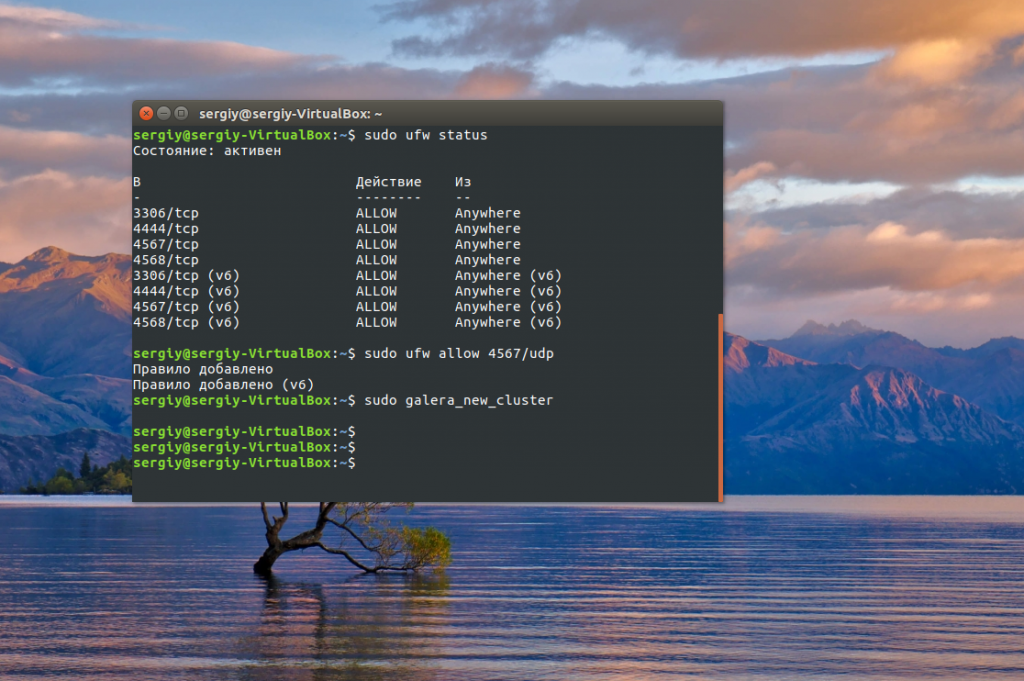
Проверить запущен ли кластер и сколько к нему подключено машин можно командой:
mysql -u root -p -e "show status like 'wsrep_cluster_size'"

Сейчас там только одна машина, теперь перейдите на другой сервер и запустите ноду там:
sudo systemctl start mysql
Вы можете проверить прошел ли запуск успешно и были ли какие-либо ошибки командой:
sudo systemctl status mysql

Затем, выполнив ту же команду, вы убедитесь, что новая нода была автоматически добавлена к кластеру:
mysql -u root -p -e "show status like 'wsrep_cluster_size'"

Чтобы проверить как работает репликация просто создайте базу данных на первой ноде и посмотрите действительно ли она была добавлена на всех других:
mysql -u root -p
MariaDB [(none)]> create database test_db;
MariaDB [(none)]> show databases;

mysql -u root -p
MariaDB [(none)]> show databases;

Как видите, действительно база данных автоматически появляется на другой машине. Репликация данных mysql работает.
ВЫВОДЫ
В этой статье мы рассмотрели как настраивается репликация MySQL, или точнее MariaDB для резервного копирования и создания более отказоустойчивой базы данных. Теперь вы можете добавлять неограниченное количество нод, как только в этом возникнет необходимость. Надеюсь, эта информация была полезной для вас.
Оцените статью:
 Загрузка…
Загрузка…Как настроить MySQL Master-Slave репликацию?
MySQL репликация типа Master-Slave часто используется для обеспечения отказоустойчивости приложений. Кроме этого, она позволяет распределить нагрузку на базу данных между несколькими серверами (репликами). Читайте подробнее о применении репликации.

Настройка репликации происходит в несколько шагов. Мы будем использовать два сервера с адресами:
- Master сервер, 10.10.0.1
- Slave сервер, 10.10.0.2
Шаг 1. Настройка Мастера
На сервере, который будет выступать мастером, необходимо внести правки в my.cnf:
# выбираем ID сервера, произвольное число, лучше начинать с 1
server-id = 1
log_bin = /var/log/mysql/mysql-bin.log
binlog_do_db = newdatabaseПерезапускаем Mysql:
/etc/init.d/mysql restart
Шаг 2. Права на репликацию
Далее необходимо создать профиль пользователя, из под которого будет происходить репликация. Для этого запускаем консоль:
mysql -u root -p
Далее создаем и назначаем права пользователю для реплики:
GRANT REPLICATION SLAVE ON *.* TO 'slave_user'@'%' IDENTIFIED BY 'password';
FLUSH PRIVILEGES;Далее блокируем все таблицы в нашей базе данных:
USE newdatabase;
FLUSH TABLES WITH READ LOCK;Проверяем статус Мастер-сервера:
SHOW MASTER STATUS;Мы увидим что-то похожее на:
mysql> SHOW MASTER STATUS; +------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000001 | 107 | newdatabase | | +------------------+----------+--------------+------------------+ 1 row in set (0.00 sec)
Шаг 3. Дамп базы
Теперь необходимо сделать дамп базы данных:
mysqldump -u root -p newdatabase > newdatabase.sql
Разблокируем таблицы в консоли mysql:
UNLOCK TABLES;Шаг 4. Создание базы на слейве
В консоли mysql на Слейве создаем базу с таким же именем, как и на Мастере:
CREATE DATABASE newdatabase;После этого загружаем дамп (из bash):
mysql -u root -p newdatabase < newdatabase.sql
Шаг 5. Настройка Слейва
В настройках my.cnf на Слейве необходимо указать такие параметры:
# ID Слейва, удобно выбирать следующим числом после Мастера
server-id = 2
relay-log = /var/log/mysql/mysql-relay-bin.log
log_bin = /var/log/mysql/mysql-bin.log
binlog_do_db = newdatabaseШаг 6. Запуск Слейва
Нам осталось включить репликацию, для этого необходимо указать параметры подключения к мастеру. В консоли mysql на Слейве необходимо выполнить запрос:
CHANGE MASTER TO MASTER_HOST='10.10.0.1', MASTER_USER='slave_user', MASTER_PASSWORD='password',
MASTER_LOG_FILE = 'mysql-bin.000001', MASTER_LOG_POS = 107;После этого запускаем репликацию на Слейве:
START SLAVE;Статус репликации
Проверить работу репликации на Слейве можно запросом:
mysql> SHOW SLAVE STATUS\G
Slave_IO_State: Waiting for master to send event
Master_Host: localhost
Master_User: root
Master_Port: 3306
Connect_Retry: 3
Master_Log_File: gbichot-bin.005
Read_Master_Log_Pos: 79
Relay_Log_File: gbichot-relay-bin.005
Relay_Log_Pos: 548
Relay_Master_Log_File: gbichot-bin.005
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 79
Relay_Log_Space: 552
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 8
Читайте также как настроить Master-Master репликацию на MySQL.
#mysql #репликация ID: 208
MySQL & PostgreSQL: Часть 6. Репликация MySQL
MySQL & PostgreSQL

Сергей Яковлев
Опубликовано 19.01.2012
Серия контента:
Этот контент является частью # из серии # статей: MySQL & PostgreSQL
https://www.ibm.com/developerworks/ru/library/?series_title_by=**auto**
Следите за выходом новых статей этой серии.
Этот контент является частью серии:MySQL & PostgreSQL
Следите за выходом новых статей этой серии.
MySQL имеет встроенную репликацию, которая может послужить основой для нагруженных распределенных приложений.
Основная проблема, решаемая при репликации – синхронизация данных между серверами. Возможны различные топологии: один мастер (master) – много слэйвов (slave), много мастеров и т.д. Реплицировать можно весь сервер целиком, одну базу, одну таблицу. MySQL поддерживает на данный момент один тип репликаций: логическую репликацию (statement) . Построчная репликация (row-based) появится начиная с версии 5.1. Обе репликации имеют асинхронный характер, т.е. нет никаких гарантий, что процесс может длиться строго фиксированный промежуток времени. Репликация не работает вниз, т.е. база версии 5.0 не может быть реплицирована на версию 4.0. Основным условием репликации является включение бинарного логирования на мастере.
Что достигается с помощью репликации?
- Распределение данных: данные можно копировать по разным дата-центрам.
- Распределение нагрузки: запросы можно разносить между разными серверами с помощью простого базового round-robin DNS или используя Linux Virtual Server (LVS).
- Бэкапы: репликация упрощает архивацию.
- Устойчивость: наличие слэйвов позволяет уменьшить риск отказов системы.
1. Как работает репликация MySQL
Процесс репликации состоит из трех основных фаз:
- происходит добавление записи в бинарный лог на мастере;
- добавленные записи копируются из лога мастера слэйв-сервером в свой лог;
- слэйв реплицирует свой лог в свою базу данных.
Во время этого процесса на мастере и на слэйве два отдельных треда устанавливают между собой коннект и передают репликационные данные.
2. Как конфигурировать master/slave
Для настройки репликации необходимо:
- на каждом сервере настроить репликационный аккаунт;
- сконфигурировать мастер и слэйв;
- настроить на слэйве коннект и репликацию.
На мастере и на слэйве нужно выполнить команду:
mysql> GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.*
-> TO repl@'192.168.0.%' IDENTIFIED BY 'p4ssword';На мастере нужно сделать изменения в конфиге my.cnf:
log_bin = mysql-bin server_id = 10
Перезапускаем мастера и выполняем команду SHOW MASTER STATUS:
mysql> SHOW MASTER STATUS; +------------------+----------+ | File | Position | +------------------+----------+ | mysql-bin.000001 | 98 | ...
На слэйве делаем аналогичные настройки в конфиге:
log_bin = mysql-bin server_id = 2 relay_log = mysql-relay-bin log_slave_updates = 1 read_only = 1
Здесь relay_log – промежуточный репликационный лог. log_slave_updates включает обмен данными между промежуточным и основным логами.
3. Запуск slave
Для запуска процесса репликации на слэйве нужно запустить команду:
mysql> CHANGE MASTER TO MASTER_HOST='server1',
-> MASTER_USER='repl',
-> MASTER_PASSWORD='p4ssword',
-> MASTER_LOG_FILE='mysql-bin.000001',
-> MASTER_LOG_POS=0;После этого нужно сделать проверку:
mysql> SHOW SLAVE STATUS\G
********************* 1. row *******************
Slave_IO_State:
Master_Host: server1
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 4
Relay_Log_File: mysql-relay-bin.000001
Relay_Log_Pos: 4
Relay_Master_Log_File: mysql-bin.000001Теперь запускаем репликацию:
mysql> START SLAVE;
Проверка:
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: server1
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 164
Relay_Log_File: mysql-relay-bin.000001
Relay_Log_Pos: 164
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Yes
Slave_SQL_Running: YesЗапущен реплицирующий тред, который ждет сообщений от мастера. Если на мастере произойдут изменения, мы это увидим, запустив повторно команду SHOW SLAVE STATUS.
На мастере и на слэйве можно запустить команду, которая покажет информацию о тредах:
mysql> SHOW PROCESSLIST\G
Для мастера рекомендуется в конфиге поставить параметр:
sync_binlog=1
Это синхронизирует изменения закешированного бинарного лога с его копией на диске, что предотвращает потери данных. Отключение этого параметра повышает производительность, но снижает надежность репликации.
В качестве основного движка базы данных рекомендуется InnoDB. Что касается MyISAM, то он может вести себя некорректно при остановках на слэйве. Для InnoDB рекомендуются следующие конфигурационные настройки мастера:
innodb_flush_logs_at_trx_commit=1 # синхронизация всех коммитов на диск innodb_support_xa=1 # начиная с версии MySQL 5.0 innodb_safe_binlog # только для версии MySQL 4.1
Для слэйва рекомендуется установить следующие конфигурационные параметры: первая опция предотвращает автоматический рестарт слэйва после остановки, вторая не дает возможности обычным пользователям делать изменения на слэйве:
skip_slave_start read_only
4. Различия в репликации
MySQL, включая версию 5.0, поддерживает только логическую (statement-based) репликацию. Когда слэйв реплицирует данные, фактически он выполняет тот же самый SQL-запрос, который выполнял мастер. У этого метода есть свои преимущества – он прост в реализации, размер лога при этом компактен. Но есть и недостатки: время выполнения запросов на мастере и на слэйве может сильно различаться. Некоторые выражения не реплицируются корректно, например функция CURRENT_USER(). Есть также проблемы с триггерами и хранимыми процедурами.
В версии 5.1 появится поддержка построчной (row-based) репликации. Преимущество этого варианта в том, что каждое выражение может быть реплицировано корректно и эффективно. При этом может возрасти размер лога, который уже нельзя будет инспектировать с помощью утилиты mysqlbinlog.
Почему построчная репликация эффективней? Возьмем пример для инсерта, который выбирает суммарный итог из очень большой таблицы:
mysql> INSERT INTO global_table(col1, col2, sum_col3)
-> SELECT col1, col2, sum(col3)
-> FROM my_table
-> GROUP BY col1, col2;Будет просканировано огромное количество строк в исходной таблице, а результат уместится всего в три строки. Логический репликатор запустит на слэйве эту команду целиком, а построчный просто добавит результат.
Зато, с другой стороны, если взять выражение:
mysql> UPDATE enormous_table SET col1 = 0;
то в этом случае для очень большой таблицы построчная репликация приведет к очень большому росту лога и будет неэффективной.
В версии 5.1 будет динамическое переключение между логической и построчной репликациями. По умолчанию будет применяться логическая репликация, это можно настраивать с помощью параметра binlog_format.
5. Топологии репликации
В MySQL для репликации есть несколько правил, независимо от их топологии: мастер может иметь несколько слэйвов; у каждого слэйва может быть только один мастер, т.е. multimaster не поддерживается.
Существует несколько топологических вариантов.
- Мастер и несколько слэйвов.
- Мастер-мастер в режиме active-active.
- Мастер-мастер в режиме active-passive.
- Мастер-мастер и несколько слэйвов.
- Кольцо.
- Дерево или пирамида.
Мастер и несколько слэйвов: этот вариант мы уже рассмотрели детально. Вместо одного слэйва здесь их будет несколько, при этом они не будут общаться друг с другом. Эта схема хороша в том случае, когда писать будет мастер, а основная нагрузка на чтение будет приходиться на слэйвы. В этой схеме слэйвы можно наращивать постепенно.
Тут можно реализовать следующие идеи:
- – каждый слэйв исполняет свою роль – например, выборочное индексирование;
- использовать слэйв для аварийного восстановления;
- использовать слэйв для бэкапа или разработки.
Мастер-мастер в режиме active-active: этот вариант известен как двунаправленная репликация. Каждый из двух серверов выступает одновременно в качестве мастера и в качестве слэйва. В этом варианте есть проблема с разрешением конфликтов, когда, например, два запроса начинают одновременно менять одну и ту же строку или когда происходит одновременная автоинкрементная вставка в таблицу на оба сервера. В версии 5.0 появились специальные параметры конфига: auto_increment_increment, auto_increment_offset, которые генерируют неконфликтные инсерты. Вообще говоря, в этой схеме можно придумать логику апдейтов, которая разрушает синхронизацию между серверами или создает между ними конфликты.
Мастер-мастер и несколько слэйвов: здесь можно назначить один или более слэйвов на каждый мастер. Эта схема уменьшает трафик между мастером и слэйвом.
Кольцо – это вторая схема, в которой участвуют три и более мастера. Если в этой схеме одна нода выйдет из строя, это приведет к зависанию репликации. Это хрупкая схема, и ее лучше избегать.
Древовидная структура может иметь место для очень большого числа слэйвов. На вершине находится мастер, а каждый последующий слэйв может быть родителем для других слэйвов. Управлять такой структурой сложнее в силу ее природы – все зависит от уровня слэйва, который может остановиться, и от числа его зависимостей.
Заключение
Подведем итог: реализация репликаций в MySQL имеет ряд недостатков, над которыми активно ведется работа. Google выпустил несколько патчей, улучшающих возможности репликации. Ведется работа над multimaster и построчной репликациями, которые появятся в будущих версиях. Имеются планы по автоматической конфигурации слэйвов. Все это вселяет уверенность в том, что одна из самых востребованных на сегодняшний день open-source баз данных MySQL станет еще продуктивнее, еще быстрее, еще надежнее.
Последнюю статью цикла мы посвятим обобщению предыдущих материалов и подведению итогов.
Ресурсы для скачивания
Multi-Master репликация в MySQL / Хабр
В данной статье будет рассмотрен процесс развертывания отказоустойчивой подсистемы баз данных на базе MySQL сервера.Перед прочтением советую прочитать эту статью.
На работе встал вопрос по созданию зеркала сайта для другого региона (Азия). Т.к. время прохождения пакетов туда довольно большое, сказывается географическая удалённость, да и Великий Китайский Файервол тоже еще не отменили, то было решено создать зеркало в азиатском регионе. С переносом движка проблем не предвиделось, файлы пользователей можно спокойно синхронизировать через rsync, а вот с базой данных наметилась проблема. Как быть если пользователь добавил объект в Азии? Надо, чтобы этот объект был виден не только пользователям локального зеркала, но и всем остальным.
Изучение вопроса я начал с кластеризации MySQL. Выяснилось много интересных подробностей. Например, то, что версия сервера входящая в дистрибьютив Ubuntu(её я использую на тестовом стенде) не поддерживает NDB(Network Data Base) Storage Engine. Необходимо поставить либо версию mysql-max, которая по слухам поддерживает NDB, либо mysql-cluster. Самое интересно что deb-пакетов для них нет, так что надо либо ставить из бинарников, либо из исходников. Установка из бинарноков у меня не получилась. Я никак не мог удалить старый сервер (пакет удаляется, а файлы все на месте). Честно прокулупавшись с этим два дня я бросил сию затею. Из исходников компилировать не пробовал, но думаю это самый лучший вариант.
Master-Master replication
Вообщем следующим этапом изысканий была репликация. Тут то я и понял, что это то, что мне нужно. Есть центральный сервер, и есть реплика в регионе, которая будет таскать с него обновления. Но надо сделать так, чтобы и обновления с реплики попадали в основную базу. Получается, необходимо сделать master-master репикацию. Т.е. первый сервер будет мастером для второго(второй подключапется к нему как слейв), а второй будет мастером для первого(первый подключается к нему как слейв). Испытания проводил на виртуалках на базе Ubuntu Server 9.10
Итак, сервер ubuntu1(192.168.0.21), конфиг mysql:
[mysqld]
# номер сервера, у всех реплицируемых серверов они должны быть уникальными
server-id = 1
# конфигурация серера, как мастера
log-bin = /var/lib/mysql/mysql-bin
# конфигурация сервера, как слейва
relay-log = /var/lib/mysql/mysql-relay-bin
relay-log-index = /var/lib/mysql/mysql-relay-bin.index
replicate-do-db = test_db
master-host=192.168.0.22 #ubuntu2
master-user=replication
master-password=password_of_user_replication
master-port=3306
Для второго аналогично, только другой ip мастера и номер сервера.
Теперь перезапускаем сервера. Потом создаем юзера replication, даем ему права на репликацию:
mysql@ubuntu1> GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'replication'@'192.168.0.22' IDENTIFIED BY 'password';
mysql@ubuntu2> GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'replication'@'192.168.0.21' IDENTIFIED BY 'password';
Дальше необходимо привязать слейвов к своим мастерам. Делается это так:
Привязка ubuntu1 как мастера к ubuntu2:
Сначала блокируем запись в базу.
mysql@ubuntu1> SET GLOBAL read_only = OFF;
Подробнее об этом можно прочитать здесь
mysql@ubuntu1> show master status;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000006 | 7984 | | |
+------------------+----------+--------------+------------------+
1 row in set (0,00 sec)
Берем оттуда значение File и position и осуществляем подключение мастера.
mysql@ubuntu2> slave stop; # на всякий случай
mysql@ubuntu2> CHANGE MASTER TO MASTER_HOST = "192.168.0.22", MASTER_USER = "replication", MASTER_PASSWORD = "password_of_user_replication", MASTER_LOG_FILE = "mysql-bin.000006", MASTER_LOG_POS = 7984;
mysql@ubuntu2> slave start;
После этого проверить подключение можно либо через
mysql@ubuntu2>load data from master;
либо через
mysql@ubuntu2> show slave status;
Если ошибок нет, мастер подключен.
Теперь подключаем этот сервер в качестве мастера для первого (делается точно также).
В итоге мы имеем систему из двух серверов, вносим изменение на любой сервер и оно реплицируется на второй.
Multi-Master replication
Но этого мне показалось мало. А если захочется добавить третий сервер? Сначала я думал про линейную топологию
ubuntu1 ubuntu2 ubunt3 и даже топологию звезда. Но увы, это было далеко от реальности. MySQL не позволяет одному слейву иметь несколько мастеров. А в линейной топологии таким будет ubuntu2. Если кто-то знает, как можно прявязать один слейв к нескольким мастерам буду благодарен за информацию.
Звезда не подходит, линейная тоже, остается кольцо. А попробую, подумал я.
Получается что в данной схеме каждый сервер имеет только одного мастера, а благодаря тому, что кольцо замкнуто, обновления дойдут до всех серверов из любой точки кольца. Тут важно упомянуть, что чтобы мастер передавал на слейв не только свои собственные обновления, но и обновления своего мастера надо добавить в [mysqld] секцию my.cnf строку:
log-slave-updates
соответственно в конфиг каждого сервера.
Проверил, и был приятно удивлен, что схема заработала. Где бы не меняли базу, изменения реально реплицируются на остальные сервера.
Автоинкрементные поля
При одновременном добавлении новых строк, содержащих автоинкрементные поля, на разные мастер-сервера может возникнуть конфликт. Чтобы такого не происходило, надо изменить шаг последовательности автоинкрементов на серверах БД.
- auto_increment_increment определяет шаг изменения AUTO_INCREMENT .
- auto_increment_offset определяет начальное значение инкремента
Подобрав правильные(не конфликтующие) значения этих параметров на разных мастерах, сервера, используемые в мульти-мастер конфигурации будут использовать неконфликтующие значения AUTO_INCREMENT при вставки записей. Например для N мастер-серверов, установим такие значения:
- Установим auto_increment_increment в N на каждом мастере.
- На каждом из N мастеров ставим разные значения auto_increment_offset, используя 1, 2,…, N.
Например, используя auto_increment_increment = 10 и auto_increment_offset=3, будут сгенерированы следующие значения поля 3, 13, 23. А используя 10, 7, будут такие 7, 17, 27, и т.д.
Отказоусточивость
После всего этого не мог не попробовать уронить один из серверов. Выдергиваем питание из ubuntu2. Потом загружаем его. Что же получается?
При последующих изменениях на ubnutu2 они без проблем тиражируются на ubuntu3 и ubuntu1. Но изменения вносимые на ubuntu2 на остальные сервера не тиражируеются. Смотрим show slave status на ubuntu3 и видим, что он потерял своего мастера.
В качестве рецепта, могу предложить следующее:
После старта сервера БД выполнять отвязывание мастера от слейва текущего сервера, и привязывание его вновь. Т.к. в топологии кольцо слейв у любого сервера один, это упрощает задачу. Алгоритм будет примерно такой:
1. ubuntu2 выключился по питанию и загрузился вновь
2. ubuntu2 у себя:
— блокирует реплицируемую базу на запись:
mysql@ubuntu2> SET GLOBAL read_only = OFF;— смотрит название и позицию в логе:
mysql@ubuntu2> show master status;2. ubuntu2 через mysql клиент заходит на своего слейва (ubuntu3)
— отвязывает себя от слейва
mysql@ubuntu3> slave stop;— объявляет себя мастером:
mysql@ubuntu3> CHANGE MASTER TO MASTER_HOST = "192.168.0.22", MASTER_USER = "replication", MASTER_PASSWORD = "password_of_user_replication", MASTER_LOG_FILE = "mysql-bin.000006", MASTER_LOG_POS = 5161; с полученными на предыдущем шаге названием лога и позицией.— вновь привязывает слейва:
mysql@ubuntu3> slave start;Пока реализация данного скрипта не готова, думаю на чем его писать perl/php/python/bash…
Буду рад услышать мысли хабрасообщества на эту тему. Пишите если статья оказалась полезной, в планах всё-таки разобраться с кластеризацией и сделать репликацию кластеров.
MySQL MASTER SLAVE репликация, настройка репликации БД
Репликация — прием, применяемый в архитектуре систем работающих под нагрузкой, результатом которого является распределение нагрузки при работе с одной базой данных на несколько серверов. MySQL MASTER SLAVE репликация используется чаще, но применяется и второй тип репликации — Master-Master.
Репликация Master-Slave предполагает дублирование данных на подчиненный сервер MySQL, производится подобное дублирование большей частью с целью обеспечения надежности. В случае выхода из строя Master сервера его функции переключаются на Slave.
Репликация может осуществляться и с целью повышения производительности системы, однако производительность здесь практически всегда вторична.
При работе приложения с БД самыми частыми операциями являются операции SELECT — запросы на считывание данных, модификация данных — запросы DELETE, INSERT, UPDATE, ALTER статистически происходит гораздо реже.
Чтобы в случае выхода из строя одного из серверов не произошло потери данных операции на изменение информации в таблицах всегда обрабатываются Master-сервером. Затем изменения реплицируются на Slave. Считывание же можно производить с сервера играющего роль Slave.
За счет этого можно получить выигрыш в производительности вместе с надежностью.
Решение популярно, но не всегда применимо поскольку при репликации могут наблюдаться задержки — если такое случается считывать информацию также приходится с Master-сервера.

Направление запросов определенного типа к тому или иному серверу баз данных в любом случае реализуется на уровне приложения.
Если выполнять разделение SELECT запросов и всех остальных на программном уровне отправляя их на нужный сервер при выходе из строя одного из них приложение, которое обслуживает инфраструктура окажется неработоспособно. Чтобы это работало нужно предусматривать более сложную схему и резервировать каждый из серверов.
Репликация служит для отказоустойчивости, не для масштабирования.
MySQL MASTER SLAVE репликация — настройка на Debian
Будем использовать два сервера с адресами:
- Master сервер 192.168.0.1
- Slave сервер 192.168.0.2
Для демонстрации используются VDS объединенные в локальную сеть.
Чтобы всегда наверняка знать на каком сервере мы выполняем ту или иную команду отредактируем файлы /etc/hosts на обоих серверах
mcedit /etc/hosts
192.168.0.1 master
192.168.0.2 slave
Заменим существующие значения в /etc/hostname на master и slave соответственно, чтобы изменения вступили в силу сервера перезагрузим.
1. Производим настройки на мастер сервере.
root@master:/#
Редактируем основной конфигурационный файл сервера баз данных
mcedit /etc/mysql/my.cnf
Выбираем ID сервера — число можно указать любое, по умолчанию стоит 1 — строку достаточно раскомментировать
server-id = 1
Задаем путь к бинарному логу — также указано по умолчанию, раскомментируем
log_bin = /var/log/mysql/mysql-bin.log
Задаем название базы данных, которую будем реплицировать на другой сервер
binlog_do_db = db1
Перезапускаем Mysql чтобы конфигурационный файл перечитался и изменения вступили в силу:
/etc/init.d/mysql restart
2. Задаем пользователю необходимые права
Заходим в консоль сервера баз данных:
mysql -u root -p
Даем пользователю на подчиненном сервере необходимые права:
GRANT REPLICATION SLAVE ON *.* TO ‘slave_user’@’%’ IDENTIFIED BY ‘123’;
FLUSH PRIVILEGES;
Блокируем все таблицы в БД
USE db1;
FLUSH TABLES WITH READ LOCK;
Проверяем статус Master-сервера:
SHOW MASTER STATUS;
+——————+———-+—————+——————+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+——————+———-+—————+——————+
| mysql-bin.000001 | 327 | db1 | |
+——————+———-+—————+——————+
1 row in set (0.00 sec)
3. Создаем дамп базы данных на сервере
Создаем дамп базы данных:
mysqldump -u root -p db1 > db1.sql
Разблокируем таблицы в консоли mysql:
mysql -u root -p
UNLOCK TABLES;
4. Переносим дамп базы на Slave-сервер
scp db1.sql [email protected]:/home
Дальнейшие действия производим на Slave-сервере
root@slave:/#
5. Созданием базу данных
mysql -u root -p
CREATE DATABASE db1;
Загружаем дамп:
cd /home
mysql -u root -p db1 < db1.sql
6. Вносим изменения в my.cnf
mcedit /etc/mysql/my.cnf
Назначаем ID инкрементируя значение установленное на Мастер сервере
server-id = 2
Задаем путь к relay логу
relay-log = /var/log/mysql/mysql-relay-bin.log
и путь bin логу на Мастер сервере
log_bin = /var/log/mysql/mysql-bin.log
Указываем базу
binlog_do_db = db1
Перезапускаем сервис
/etc/init.d/mysql restart
7. Задаем подключение к Master серверу
mysql -u root -p
CHANGE MASTER TO MASTER_HOST=’192.168.0.1′, MASTER_USER=’slave_user’, MASTER_PASSWORD=’123′, MASTER_LOG_FILE = ‘mysql-bin.000001’, MASTER_LOG_POS = 327;
Запускаем репликацию на подчиненном сервере:
START SLAVE;
Проверить работу репликации на Слейве можно запросом:
SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.0.1
Master_User: slave_user
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000002
Read_Master_Log_Pos: 107
Relay_Log_File: mysql-relay-bin.000003
Relay_Log_Pos: 253
Relay_Master_Log_File: mysql-bin.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 107
Relay_Log_Space: 555
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
1 row in set (0.00 sec)
Поскольку каких-либо ошибок не возникло можно сделать вывод о том, что репликация настроена корректно.
MySQL MASTER SLAVE репликация является хорошим инструментом масштабирования, но в качестве главного минуса имеет рассинхронизацию копирования данных и задержки, которые могут быть критичны.
Полностью их избежать позволяет использование более современного решения Galera Cluster. Он отличается простой настройкой, надежностью и отсутствием необходимости вручную копировать дампы баз данных.
Master-slave репликация MySQL 5.7 — Блог Антона Аксенова
Введение
Это мой рецепт, который я использую на проектах. В сети можно найти разные другие инструкции. Но они различаются только командами, которые по сути своей выполняют одно и то же. Например, чтобы заблокировать запись в БД, можно использовать как эти команды:
SET GLOBAL read_only = ON; # вкл только чтение SET GLOBAL read_only = OFF; # выкл только чтение
так и эти:
FLUSH TABLES WITH READ LOCK; # вкл только чтение UNLOCK TABLES; # выкл только чтение
Либо импортирование БД из дампа на слейве можно выполнить и так:
$ mysql -u root -p > USE mydb; > SOURCE ~/mydb.sql
и эдак:
$ mysql -u root -p mydb < mydb.sql
Я считаю так. Чтобы выполнить задачу по сабжу, особо можешь не заморачиваться — главное понимать что происходит в целом. Но фундаментальное понимание сути этих команд будет только в плюс.
Здесь же я собрал универсальный рецепт как поднять и восстановить репликацию. Поехали.
Первоначальная установка
Master
- Настраиваем кофиг (my.cnf)
[mysqld] # ... bind-address = 0.0.0.0 # чтобы можно было достучаться до базы извне server-id = 1 # уникальный ИД сервера expire_logs_days = 2 # время жизни бинлогов в днях max_binlog_size = 100M # макс размер бинлогов binlog_do_db = mydb # БД для реплицирования ("экспорта" в бинлог) log_bin = /var/log/mysql/mydb-bin.log # путь к бинлогу # ... - Лезем в консоль
root@master# service mysql restart # перезапускаем mysql user@master$ mysql -u root -p # заходим в mysql mysql> SHOW MASTER STATUS\G # проверяем статус репликации # запоминаем значения File и Position из результата # далее создаём пользователя для репликации с нужными правами mysql> CREATE USER 'repl_user'@'%' IDENTIFIED WITH mysql_native_password AS 'password'; GRANT REPLICATION SLAVE ON *.* TO 'repl_user'@'%'; mysql> USE mydb; # выбираем нашу реплицируемую БД mysql> FLUSH TABLES WITH READ LOCK; # блокируем запись во все таблицы mysql> \q # пока выходим user@master$ mysqldump -u root -p mydb > mydb.sql # делаем полный дамп БД в файл # чтобы файл дампа был легче, можно сжать его через tar: user@master$ tar -czf mydb.tar.gz mydb.sql # сливаем этот дамп на slave и возвращаемся сюда в консоль user@master$ mysql -u root -p # заходим в mysql mysql> USE mydb; # выбираем нашу реплицируемую БД mysql> UNLOCK TABLES; # снимаем блокировки с таблиц, пусть пишется дальше mysql> \q # выходим
Slave
- Настраиваем кофиг (my.cnf)
[mysqld] # ... server-id = 2 # уникальный ИД сервера master-host = <Master-IP> # адрес мастера master-user = repl_user # юзер БД master-password = password # пароль юзера БД master-port = 3306 # порт mysql мастера expire_logs_days = 2 # время жизни логов в днях replicate_do_db = mydb # БД для реплицирования ("импорта" из лога) relay-log = /var/lib/mysql/mydb-relay-bin # путь к логу relay-log-index = /var/lib/mysql/mydb-relay-bin.index # путь к индексу лога # ... - Лезем в консоль
root@slave# service mysql reload # перезапускаем mysql # если дамп был запакован, распечатываем: user@slave$ tar -xzf mydb.tar.gz # на выходе будет только mydb.sql user@slave$ mysql -u root -p # заходим в mysql mysql> CREATE DATABASE mydb; # создаём БД mysql> USE mydb; # переходим к ней mysql> SOURCE ~/mydb.sql # импорт БД из дампа (допустим, он лежит в дом. папке) mysql> CHANGE MASTER TO MASTER_LOG_FILE = '<File>', MASTER_LOG_POS = <Position>; # указываем настройки мастера и доступа к нему mysql> START SLAVE; # стартуем репликацию mysql> \q # выходим из мускуля
Как понять, что слейв работает нормально?
В консоли MySQL запустить:
mysql> SHOW SLAVE STATUS\G
Если всё порядке, то:
- Параметр Slave_IO_State = Waiting for master to send event
- Параметр Slave_IO_Running = Yes
- Параметр Slave_SQL_Running = Yes
- Параметр Last_Errno = 0
- Параметр Last_Error пустой
- Чем ближе Seconds_Behind_Master к нулю, тем лучше.
- Position на мастере значительно увеличивается по мере работы и может быть каким угодно большим.
Если будут какие-то ошибки, нужно обратиться к параметрам Last_Errno, Last_Error, а также к логам mysql.
Что если при репликации возникла ошибка?
Смотря что за ошибка. Я рассмотрю парочку. В конце статьи есть ещё пачка ссылок, можешь обратиться туда.
1. Расхождение слейва с мастером
История:
- На слейве в одну таблицу были внесены изменения вручную, мимо репликации
- В процессе репликации слейву надо выполнить операцию над этой таблицей
- Из-за расхождения возникает ошибка выполнения запроса
- Репликация продолжается, логи на слейве появляются и ротируются, но запросы не выполняются. Выглядит это так:
mysql> SHOW SLAVE STATUS\G ... Slave_IO_Running = Yes Slave_SQL_Running = No Last_Errno = <код ошибки> Last_Error = <текст ошибки> ...
Решение:
mysql> STOP SLAVE; # стопаем слейв mysql> RESET SLAVE; # сбрасываем состояние репликации на слейве (позиция, логи) mysql> RESET MASTER; # ...и на мастере
- Повторяем шаги, описанные выше:
- блокировка мастера
- снимаем дамп БД
- смотрим SHOW MASTER STATUS\G, запоминаем позицию (File и Position)
- разблокировка мастера
- заливка дампа на слейв
- установка позиции на слейве (File и Position)
- старт слейва
При этом перезапускать mysql нет необходимости ни на мастере, ни на слейве. На слейве нужно будет установить свежие параметры File и Position:
mysql> CHANGE MASTER TO MASTER_LOG_FILE = '<File>', MASTER_LOG_POS = <Position>;
2. Закончилось место на мастере/слейве
История:
- Из-за неоптимальной настройки либо небольшого размера жёсткого диска его свободное место быстро иссякло
- Логи репликации некуда писать, mysql отказывается работать в принципе либо выдаёт ошибки
Решение:
- Остановить репликацию на слейве: если там ещё не возникли проблемы, то они обязательно возникнут
- Удалить все бинлоги в директориях, указанных в конфигах, на том сервере, где нехватает места
- Освободить максимум места на всём сервере, пересмотреть и оптимизировать использование места (ротация логов другого софта, удаление ненужных проектов, сжатие всего, что сжимается, и пр.)
- Обратиться к конфигам: убедись, что параметры expire_logs_days и expire_logs_days нигде больше не переопределяются значениями, больше необходимого
- Восстановить репликацию также, как в прошлой проблеме
Необходимо поменять местами Master и Slave
В теории, если обе базы идентичны и актуальны:
- Остановить слейв и мастер
- Отключить запись в реплицируемые базы
- Поменять местами параметры репликации, заданные в конфигах мастера и слейва, закомментировать лишние, обратить внимание на значения
- Следовать инструкциям как поднять репликацию с нуля, описанным выше, исключая шаг с созданием дампа
Использованные и другие полезные материалы
Некоторые из них я использовал и уже пересказал выше, но там же можно найти ответ по другим вопросам можно найти ответы.
- Документация MySQL
- Основы репликации в MySQL (habr)
- Как настроить MySQL Master-Slave репликацию? (ruhighload)
- Оптимизация репликации в Mysql (ruhighload)
- Как восстановить MySQL репликацию без выключения? (ruhighload)
- Mysql 1062 Duplicate entry for key PRIMARY при репликации
- НАСТРОЙКА РЕПЛИКАЦИИ MASTER-SLAVE В MYSQL (handyhost)
- Репликация MySQL в виде Master/Slave
- Битрикс: Настройка репликации MySQL, аварийное переключение slave->master
Как на самом деле работает репликация MySQL?
Хотя в нашем блоге есть много сообщений о репликации, например, об однопоточной репликации, о полусинхронной репликации или об оценке емкости репликации, я не думаю, что у нас есть статья, которая охватывает самые основы того, как Репликация MySQL действительно работает на высоком уровне. Или это было так давно, что я даже не могу его найти. Итак, я решил написать его сейчас.
Конечно, существует множество аспектов репликации MySQL, но мое основное внимание будет сосредоточено на логистике — как события репликации записываются на ведущем устройстве, как они передаются ведомому устройству репликации, а затем как они там применяются.Заметьте, что это НЕ репликация установки HOWTO, а скорее, как все работает.
События репликации MySQL
В этой статье я говорю событий репликации , потому что я хочу избежать обсуждения различных форматов репликации. Они довольно хорошо описаны в руководстве по MySQL здесь. Проще говоря, события могут быть одного из двух типов:
- На основе операторов — в этом случае это запросы на запись
- На основе строк — в данном случае это изменения записей, вид строки отличается от , если вы будете
Но кроме этого, я не буду возвращаться к различиям в репликации с разными форматами репликации, в основном потому, что очень мало отличается, когда дело доходит до переноса изменений данных.
На мастере
Итак, позвольте мне начать с того, что происходит на мастере. Для работы репликации, прежде всего, ведущему устройству необходимо записывать события репликации в специальный журнал, называемый двоичным журналом . Обычно это очень легкое действие (при условии, что события не синхронизируются с диском), потому что записи буферизуются и потому что они являются последовательными. В двоичном файле журнала хранятся данные, которые ведомое устройство репликации будет читать позже.
Всякий раз, когда подчиненное устройство репликации подключается к мастеру, мастер создает новый поток для соединения (аналогичный тому, который используется практически для любого другого клиента сервера), а затем выполняет все, что запрашивает клиент — подчиненное устройство репликации в данном случае -.Большая часть этого будет (а) снабжать подчиненное устройство репликации событиями из двоичного журнала и (б) уведомлять подчиненное устройство о вновь записанных событиях в его двоичный журнал.
Ведомые, которые обновлены, в основном будут читать события, которые все еще кэшируются в кеше ОС на ведущем устройстве, поэтому на ведущем устройстве не будет операций чтения с физического диска для передачи событий двоичного журнала ведомым устройствам , Однако, когда вы подключаете подчиненное устройство репликации, которое отстает на несколько часов или даже дней, оно сначала начнет читать двоичные журналы, которые были записаны несколько часов или дней назад — мастер может больше не кэшировать их, поэтому будет происходить чтение с диска.Если у мастера нет свободных ресурсов ввода-вывода, вы можете почувствовать удар в этот момент.
На реплике
Теперь посмотрим, что происходит на ведомом устройстве. Когда вы запускаете репликацию, два потока запускаются на ведомом устройстве:
1. Поток ввода-вывода
Этот процесс, называемый поток ввода-вывода , подключается к ведущему, считывает события двоичного журнала от ведущего устройства по мере их поступления и просто копирует их в локальный файл журнала с именем relay log . Вот и все.
Несмотря на то, что существует только один поток, считывающий двоичный журнал с ведущего устройства, и один записывающий журнал реле на ведомом устройстве, очень редко копирование событий репликации является более медленным элементом репликации. Возможна задержка в сети, вызывающая постоянную задержку в несколько сотен миллисекунд, но это все.
Если вы хотите увидеть, где в данный момент находится поток ввода-вывода, проверьте следующее в «show slave statusG»:
- Master_Log_File — последний файл, скопированный с главного устройства (в большинстве случаев это будет то же самое, что и последний двоичный журнал записано мастером)
- Read_Master_Log_Pos — двоичный журнал от ведущего копируется в журнал реле на ведомом до этой позиции.
И затем вы можете сравнить его с выводом «show master statusG» от мастера.
2. Поток SQL
Второй процесс — поток SQL — считывает события из журнала реле, хранящегося локально на ведомом устройстве репликации (файл, который был записан потоком ввода-вывода), а затем применяет их как можно быстрее.
Эту ветку часто обвиняют в однопоточности. Вернувшись к «show slave statusG», вы можете получить текущий статус потока SQL по следующим переменным:
- Relay_Master_Log_File — двоичный журнал от мастера, этот поток SQL «работает» (на самом деле он работает над релейный журнал, так что это просто удобный способ отображения информации)
- Exec_Master_Log_Pos — какая позиция из главного двоичного журнала выполняется потоком SQL.
Запаздывание репликации
Теперь я хочу вкратце коснуться вопроса запаздывания репликации в этом контексте. Когда вы имеете дело с задержкой репликации, первое, что вам нужно знать, — какой из двух потоков репликации отстает. В большинстве случаев это будет поток SQL, но все же имеет смысл дважды проверить. Вы можете сделать это, сравнив переменные состояния репликации, упомянутые выше, с состоянием главного двоичного журнала из вывода «show master statusG» главного.
Если это поток ввода-вывода, который, как я уже много раз упоминал, встречается очень редко, одна вещь, которую вы можете попытаться исправить, — это включить протокол сжатия ведомого устройства.
В противном случае, если вы уверены, что это поток SQL, тогда вы хотите понять, в чем причина и что вы обычно можете наблюдать с помощью vmstat. Отслеживайте активность сервера с течением времени и посмотрите, является ли столбец «r» или «b» чаще всего «оцениваемым». Если это «r», репликация зависит от ЦП, иначе — IO. Если это не окончательно, mpstat предоставит вам лучшую видимость по потоку ЦП.
Обратите внимание, это предполагает, что на сервере не происходит никакой другой активности. Если есть какая-то активность, вы также можете посмотреть diskstats или даже сделать обзор запроса для потока SQL, чтобы получить хорошую картину.
Если вы обнаружите, что репликация связана с ЦП, это может быть очень полезно.
Если это связано с вводом-выводом, то исправить это может быть не так просто (или, скорее, так дешево). Позволь мне объяснить. Если репликация связана с вводом-выводом, в большинстве случаев это означает, что поток SQL не может читать достаточно быстро, поскольку чтение является однопоточным. Да, вы правильно поняли — именно читает , а не записывает, ограничивает производительность репликации. Позвольте мне объяснить это дальше.
Предположим, у вас есть RAID10 с кучей дисков и кешем обратной записи. Записи , даже если они сериализованы, будут быстрыми, потому что они буферизуются в кэше контроллера и потому, что внутренняя карта RAID может распараллеливать записи на диски. Следовательно, ведомое устройство репликации с аналогичным оборудованием может писать так же быстро, как и ведущее устройство.
Сейчас Читает . Если ваш рабочий набор не умещается в памяти, то данные, которые собираются изменить, должны быть сначала прочитаны с диска, и именно здесь это ограничено однопоточным характером репликации, потому что один поток будет только когда-либо читал с одного диска за раз.
При этом одно из решений для исправления репликации с привязкой к вводу-выводу — увеличить объем памяти, чтобы рабочий набор поместился в памяти. Другой вариант — получить устройство ввода-вывода, которое может выполнять гораздо больше операций ввода-вывода в секунду даже с одним потоком — самые быстрые традиционные диски могут выполнять до 250 операций ввода-вывода в секунду, твердотельные накопители — порядка 10 000 операций ввода-вывода в секунду.
Вопросы? Комментарии? Опасения?
Дополнительные ресурсы
Сообщения в блогах
Вебинары
Бесплатная электронная книга
Связанные
.различных типов решений для репликации MySQL
В этом сообщении блога я рассмотрю некоторые концепции репликации MySQL, которые являются частью среды MySQL (и в частности Percona Server для MySQL). Я также попытаюсь прояснить некоторые заблуждения людей о репликации.
С тех пор, как я работал в группе разработки решений, я заметил, что — хотя информации много, — репликацию часто неправильно понимают или не до конца понимают.
Итак, что такое репликация MySQL?
Репликация гарантирует, что информация будет скопирована и намеренно помещена в другую среду, а не хранится только в одном месте (на основе транзакций исходной среды).
Идея состоит в том, чтобы использовать вторичные серверы в вашей инфраструктуре для чтения или других административных решений. На схеме ниже показан пример среды репликации MySQL.

Хорошо, но какие варианты выбора есть в MySQL?
На самом деле у вас есть несколько различных вариантов:
Стандартная асинхронная репликация
Асинхронная репликация означает, что транзакция полностью завершается в локальной среде и не зависит от самих ведомых устройств репликации.
После завершения своих изменений мастер заполняет двоичный журнал модификацией данных или фактическим оператором (разница между репликацией на основе строк или репликацией на основе операторов — подробнее об этом позже). Этот поток дампа считывает двоичный журнал и отправляет его подчиненному потоку ввода-вывода. Подчиненное устройство помещает его в свою собственную очередь предварительной обработки (называемую журналом реле), используя свой поток ввода-вывода.
Ведомое устройство выполняет каждое изменение в базе данных ведомого устройства, используя поток SQL.

Полусинхронная репликация
Полусинхронная репликация означает, что ведомое устройство и ведущее устройство связываются друг с другом, чтобы гарантировать правильную передачу транзакции.Ведущее устройство заполняет бинарный журнал и продолжает сеанс только в том случае, если одно из ведомых устройств предоставляет подтверждение того, что транзакция была правильно помещена в один из журналов реле ведомого устройства.
Полусинхронная репликация гарантирует правильное копирование транзакции, но не гарантирует, что фиксация на ведомом устройстве действительно имеет место.

Важно отметить, что полусинхронная репликация гарантирует, что ведущее устройство ожидает продолжения обработки транзакций в конкретном сеансе, пока хотя бы одно из ведомых устройств не подтвердит прием транзакции (или не истечет время ожидания).Это отличается от асинхронной репликации, поскольку полусинхронизация обеспечивает дополнительную целостность данных.
Имейте в виду, что полусинхронная репликация влияет на производительность, потому что ей нужно дождаться передачи фактического ACK от ведомого устройства туда и обратно.
Групповая репликация
Это новая концепция, представленная в MySQL Community Edition 5.7, и была GA в MySQL 5.7.17. Это довольно новый плагин для виртуальной синхронной репликации.
Каждый раз, когда транзакция выполняется на узле, плагин пытается достичь консенсуса с другими узлами, прежде чем вернуть завершенную транзакцию обратно клиенту.Хотя решение представляет собой совершенно другую концепцию по сравнению со стандартной репликацией MySQL, оно основано на генерации и обработке событий журнала с помощью binlog.
Ниже приведен пример архитектуры групповой репликации.

Если вас интересует групповая репликация, прочтите следующие сообщения в блоге:
На конференции Percona Live Open Source Database Conference в Санта-Кларе в апреле 2017 года будет учебное пособие.
Percona XtraDB Cluster / Galera Cluster
Еще одно решение, которое позволяет реплицировать информацию на другие узлы, — Percona XtraDB Cluster.Это решение направлено на обеспечение согласованности, а также использует процесс сертификации, чтобы гарантировать, что транзакции избегают конфликтов и выполняются правильно.
В данном случае речь идет о кластерном решении. Каждая среда подчиняется одним и тем же данным, и между узлами существует связь, чтобы гарантировать согласованность.
Percona XtraDB Cluster состоит из нескольких компонентов:
- Percona Server для MySQL
- Percona XtraBackup для создания моментальных снимков работающего кластера (при восстановлении или добавлении узла).
- wsrep patches / Библиотека Galera
Это решение практически синхронно, что сравнимо с групповой репликацией. Однако он также может использовать репликацию с несколькими мастерами. Такие решения, как Percona XtraDB Cluster, являются компонентом повышения доступности инфраструктуры вашей базы данных.

Учебное пособие по Percona XtraDB Cluster будет представлено на конференции Percona Live Open Source Database Conference в Санта-Кларе в апреле 2017 года.
Репликация на основе строк Vs.Репликация на основе операторов
При репликации на основе операторов сам запрос SQL записывается в двоичный журнал. Например, подчиненное устройство выполняет те же самые инструкции INSERT / UPDATE / DELETE.
У этой системы много преимуществ и недостатков:
- Аудит базы данных намного проще, поскольку фактические отчеты регистрируются в двоичном журнале
- Меньше данных передается по сети
- Недетерминированные запросы могут создать настоящий хаос в подчиненной среде
- Могут быть проблемы с производительностью, некоторые запросы используют репликацию на основе операторов (INSERT на основе SELECT)
- Репликация на основе операторов медленнее из-за оптимизации и выполнения SQL
Репликация на основе строк является выбором по умолчанию, начиная с MySQL 5.7.7, и у него много преимуществ. Изменения строк регистрируются в двоичном журнале и не требуют контекстной информации. Это устраняет влияние недетерминированных запросов.
Некоторые дополнительные преимущества:
- Повышение производительности при запросах с высоким уровнем параллелизма, содержащих несколько изменений строк
- Значительное улучшение согласованности данных
И, конечно, некоторые недостатки:
- Сетевой трафик может быть значительно больше, если у вас есть запросы, которые изменяют большое количество строк
- Сложнее контролировать изменения в базе данных
- Репликация на основе строк в некоторых случаях может быть медленнее, чем репликация на основе операторов
Некоторые заблуждения о репликации
Репликация — это кластер ,
Стандартная асинхронная репликация не является синхронным кластером. Имейте в виду, что стандартная и полусинхронная репликация не гарантирует, что среды обслуживают один и тот же набор данных. Это отличается от использования Percona XtraDB Cluster, где каждый сервер фактически должен обрабатывать каждое изменение. В противном случае затронутый узел удаляется из кластера. В асинхронной репликации этого нет. Он по-прежнему принимает чтения, пока находится в несогласованном состоянии.
Репликация звучит идеально, я могу использовать это как решение ручного аварийного переключения.
Теоретически среды должны быть сопоставимы. Однако существует множество параметров, влияющих на эффективность и согласованность передачи данных. Пока вы используете асинхронную репликацию, нет гарантии, что транзакция прошла правильно. Вы можете обойти это, увеличив надежность конфигурации, но за это придется платить за производительность. Вы можете проверить согласованность вашего ведущего и ведомых устройств с помощью инструмента контрольной суммы pt-table.
У меня есть репликация, поэтому резервные копии мне вообще не нужны.
Репликация — отличное решение для получения доступной копии набора данных (например, для создания отчетов о проблемах, чтения запросов, создания резервных копий). Однако это не решение для резервного копирования. Наличие внешнего резервного копирования дает вам уверенность в том, что вы сможете восстановить свою среду в случае каких-либо серьезных бедствий, ошибки пользователя или других причин (помните комикс Bobby Tables). Некоторые люди используют отложенных рабов. Однако даже отложенные ведомые устройства не заменяют надлежащие процедуры аварийного восстановления.
У меня есть репликация, поэтому теперь среда будет балансировать нагрузку транзакций.
Хотя вы потенциально повысили доступность своей среды, запустив вторичный экземпляр с тем же набором данных, вам все равно может потребоваться направить запросы чтения на ведомые устройства, а запросы записи на ведущее устройство. Вы можете использовать прокси-инструменты или определить эту функцию в собственном приложении.
Репликация значительно замедлит работу моего мастера.
Репликация лишь незначительно влияет на производительность вашего мастера.У Петра Зайцева есть интересный пост по этому поводу, в котором обсуждается потенциальное влияние рабов на хозяина. Имейте в виду, что запись в двоичный журнал может потенциально повлиять на производительность, особенно если у вас много небольших транзакций, которые затем сбрасываются и принимаются несколькими ведомыми устройствами.
Конечно, существует множество других параметров, которые могут повлиять на производительность фактической настройки главного и подчиненного устройства.