Как использовать условие 2 в запросе mysql?
Может ли кто-нибудь сказать мне, что не так с этим запросом ? Этот код не работает:
SELECT index_no FROM test_record_tbl WHERE year='2012' and year='2013';
Этот код работает:
SELECT index_no FROM test_record_tbl WHERE year='2012' or year='2013';
Поделиться Источник Amal Madawa 07 марта 2013 в 07:04
3 ответа
- Как сделать 2 UPDATE в одном запросе MySQL
в запросе MySQL Как сделать 2 UPDATE в одном запросе, запрос ниже: UPDATE `stats` SET `coin` = coin + 500 WHERE `player` = ‘userone’ UPDATE `stats` SET `coin` = coin — 500 WHERE `player` = ‘usertwo’
- Как использовать условие IF в запросе mysql
Проблема проста, но кажется, что каждый раз я делаю что-то не так в синтаксисе mysql.

3
Вы терпите неудачу, потому что год может (предположительно) никогда не быть одновременно 2012 AND 2013.
И является эксклюзивным оператором, что означает, что оба условия должны быть истинными, чтобы оператор оценивался как истинный.
OR означает одно, OR-другое, OR-оба
2
Если я правильно вас понял, вы хотите получить index_no , запись которого принадлежит году 2012 и 2013 .
Эта проблема часто называется Relational Division .
SELECT index_no
FROM test_record_tbl
WHERE year IN ('2012', '2013')
GROUP BY index_no
HAVING COUNT(DISTINCT year) = 2
Поделиться John Woo 07 марта 2013 в 07:16
0
Есть разница между and и or .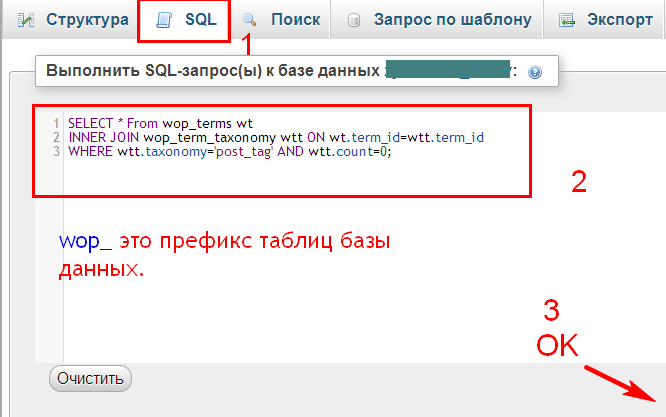
Вы никогда не можете иметь год 2012 и год 2013 одновременно, но год может упасть либо в 2012 году, либо в 2013 году.
Вот почему ваш первый запрос SQL не принес никакого результата, в то время как второй сделал.
Поделиться Buhake Sindi 07 марта 2013 в 07:10
- Как написать условие MySQL multilines с RubyOnRails?
Я хочу использовать ?char для поиска в запросе MySQL в запросе rails. Например, классический способ-это: Model.where(name = ?, ‘#{@search}’) Мой вопрос касается длинных запросов и условий многострочности. Если я хочу построить условие вручную: where = where << status = 1 where << …
- Как использовать условие Count в запросе sql
Как я могу использовать условие count в запросе sql. Вот мой вопрос SELECT COUNT(test=’maths’) FROM homework where id = 1;
Похожие вопросы:
условие в операторе mysql
Я пытаюсь написать условие в своем запросе mysql: SELECT g.
Условие использования в запросе mySQL
Мне нужно иметь условие в моей базе запросов mySQL на результат запроса. SELECT возвращает мне IVC_Recipient , и я хочу использовать эти данные, чтобы сделать условие. Но это не работает. Вот такой…
Если условие в запросе mysql
Я искал через google и здесь, но не нашел ответа на свой вопрос. Я пытаюсь использовать IF в запросе (не хранимая процедура) таким образом: IF EXISTS (SELECT * FROM TABLE WHERE COLUMN=VALUE) THEN DO…
в запросе MySQL Как сделать 2 UPDATE в одном запросе, запрос ниже: UPDATE `stats` SET `coin` = coin + 500 WHERE `player` = ‘userone’ UPDATE `stats` SET `coin` = coin — 500 WHERE `player` = ‘usertwo’
Как использовать условие IF в запросе mysql
Проблема проста, но кажется, что каждый раз я делаю что-то не так в синтаксисе mysql. Я хочу искать в таблице после строкового поля. Если это поле существует, я увеличу число видений. Если не…
Я хочу искать в таблице после строкового поля. Если это поле существует, я увеличу число видений. Если не…
Как написать условие MySQL multilines с RubyOnRails?
Я хочу использовать ?char для поиска в запросе MySQL в запросе rails. Например, классический способ-это: Model.where(name = ?, ‘#{@search}’) Мой вопрос касается длинных запросов и условий…
Как использовать условие Count в запросе sql
Как я могу использовать условие count в запросе sql. Вот мой вопрос SELECT COUNT(test=’maths’) FROM homework where id = 1;
Условие If else в запросе mysql
Как я могу использовать условие if и else в запросе mysql. Вот мой вопрос. SELECT CASE WHEN IDParent < 1 THEN ‘no’ ELSE ‘yes’ END AS ColumnName FROM tableName;
использовать вложенные IF в запросе выбрать mysql
Как я могу использовать вложенный IF в части select в запросе MySQL? Я делаю это, но это не работает это и есть код: SELECT *, IF(`view_price_trp` <= 0 ,IF(`view_price_sgl` > 0,.
Использование и & OR условие в MySQl с тем же запросом
Как использовать условие And, OR в том же запросе MySQL where. SELECT * FROM Table_name WHERE filed_name = 0 AND (field1 != » AND field2 =») OR (field1 = » AND field2 != ») AND filed3 = 1; Я…
Несколько SELECT COUNT в одном запросе MySQL « Блог вебмастера Романа Чернышова
В данной небольшой статье речь пойдет о базах данных в частности MySQL, выборке и подсчете. Работая с базами данных, часто требуется совершить подсчет количества строк COUNT() с определенным условием или без, это сделать крайне просто следующим запросом
Запрос вернет значение, с количеством строк в таблице.
Подсчет с условием
Запрос вернет значение, с количеством строк в таблице удовлетворяющих данному условию: var = 1
Для получения нескольких значений подсчета строк с разными условиями, можно поочередно выполнить несколько запросов, например
Но в ряде случаев, такой подход не практичен и не оптимален. По этому актуальным становится организация запроса, с несколькими подзапросами, для получения в одном запросе сразу несколько результатов. Например
По этому актуальным становится организация запроса, с несколькими подзапросами, для получения в одном запросе сразу несколько результатов. Например
Таким образом выполнив всего один запрос к базе данных, мы получаем результат с подсчетом количества строк по нескольким условиям, содержащий несколько значений подсчета, например
c1|c2|c3 -------- 1 |5 |8 |
Недостатком использования подзапросов, в сравнении с несколькими отдельными запросами, можно считать скорость выполнения и нагрузку на базу данных.
Следующий пример запроса, содержащего несколько COUNT в одном запросе MySQL, построен несколько иначе, в нем используются конструкции IF(условие, значение1, значение2), а также суммирование SUM(). Позволяющие произвести отбор данных по заданным критериям в рамках одного запроса, затем суммировать их, и вывести несколько значений в качестве результата.
Как видно из запроса, он построен достаточно лаконично, но скорость его выполнения тоже не порадовала, результат данного запроса будет следующий,
total|c1|c2|c3 -------------- 14 |1 |5 |8 |
Далее я приведу сравнительную статистику скорости выполнения трех вариантов запросов, для выборки нескольких COUNT(). Для тестирования скорости выполнения запросов, было выполнено по 1000 запросов каждого типа, с таблицей содержащей более трех тысяч записей. При этом каждый раз запрос содержал SQL_NO_CACHE для отключение кеширования результатов базой данных.
Для тестирования скорости выполнения запросов, было выполнено по 1000 запросов каждого типа, с таблицей содержащей более трех тысяч записей. При этом каждый раз запрос содержал SQL_NO_CACHE для отключение кеширования результатов базой данных.
Скорость выполнения
Три отдельных запроса: 0.9 сек
Один запрос с подзапросами: 0.95 сек
Один запрос с конструкцией IF и SUM: 1.5 сек
Вывод. И так, мы имеет несколько вариантов построения запросов к базе данных MySQL с несколькими COUNT(), первый вариант с отдельными запросами не очень удобен, но имеет наилучший результат по скорости. Второй вариант с подзапросами несколько удобнее, но при этом скорость его выполнение немного ниже. И наконец третий лаконичный вариант запроса с конструкциями IF и SUM, кажущийся самым удобным, имеет самую низкую скорость выполнения, которая почти в два раза ниже первых двух вариантов. По этому, при задаче оптимизации работы БД, я рекомендую использовать второй вариант запроса содержащий подзапросы с COUNT(), во первых его скорость выполнения близка к самому быстрому результату, во вторых такая организация внутри одного запроса достаточно удобна.
Похожие записи
Вложенные SQL запросы
Вложенный запрос — это запрос на выборку, который используется внутри инструкции SELECT, INSERT, UPDATE или DELETE или внутри другого вложенного запроса. Подзапрос может быть использован везде, где разрешены выражения.
Пример структуры вложенного запроса
SELECT поля_таблиц
FROM список_таблиц
WHERE конкретное_поле IN (
SELECT поле_таблицы FROM таблица
)Здесь, SELECT поля_таблиц FROM список_таблиц WHERE конкретное_поле IN (…) — внешний запрос, а SELECT поле_таблицы FROM таблица — вложенный (внутренний) запрос.
Каждый вложенный запрос, в свою очередь, может содержать один или несколько вложенных запросов. Количество вложенных запросов в инструкции не ограничено.
Подзапрос может содержать все стандартные инструкции, разрешённые для использования в обычном SQL-запросе: DISTINCT, GROUP BY, LIMIT, ORDER BY, объединения таблиц, запросов и т.д.
Подзапрос может возвращать скаляр (одно значение), одну строку, один столбец или таблицу (одну или несколько строк из одного или нескольких столбцов). Они называются скалярными, столбцовыми, строковыми и табличными подзапросами.
Они называются скалярными, столбцовыми, строковыми и табличными подзапросами.
Подзапрос как скалярный операнд
Скалярный подзапрос — запрос, возвращающий единственное скалярное значение (строку, число и т.д.).
Следующий простейший запрос демонстрирует вывод единственного значения (названия компании). В таком виде он не имеет большого смысла, однако ваши запросы могут быть намного сложнее.
SELECT (SELECT name FROM company LIMIT 1);Таким же образом можно использовать скалярные подзапросы для фильтрации строк с помощью WHERE, используя операторы сравнения.
SELECT *
FROM FamilyMembers
WHERE birthday = (SELECT MAX(birthday) FROM FamilyMembers);С помощью данного запроса возможно получить самого младшего члена семьи. Здесь используется подзапрос для получения максимальной даты рождения, которая затем используется для фильтрации строк.
Подзапросы с ANY, IN, ALL
ANY — ключевое слово, которое должно следовать за операцией сравнения (>, <, <>, = и т. д.), возвращающее TRUE, если хотя бы одно из значений столбца подзапроса удовлетворяет обозначенному условию.
д.), возвращающее TRUE, если хотя бы одно из значений столбца подзапроса удовлетворяет обозначенному условию.
SELECT поля_таблицы_1
FROM таблица_1
WHERE поле_таблицы_1 <= ANY (SELECT поле_таблицы_2 FROM таблица_2);ALL — ключевое слово, которое должно следовать за операцией сравнения, возвращающее TRUE, если все значения столбца подзапроса удовлетворяет обозначенному условию.
SELECT поля_таблицы_1
FROM таблица_1
WHERE поле_таблицы_1 > ALL (SELECT поле_таблицы_2 FROM таблица_2);IN — ключевое слово, являющееся псевдонимом ключевому слову ANY с оператором сравнения = (эквивалентность), либо <> ALL для NOT IN. Например, следующие запросы равнозначны:
...
WHERE поле_таблицы_1 = ANY (SELECT поле_таблицы_2 FROM таблица_2);...
WHERE поле_таблицы_1 IN (SELECT поле_таблицы_2 FROM таблица_2);Строковые подзапросы
Строковый подзапрос — это подзапрос, возвращающий единственную строку с более чем одной колонкой. Например, следующий запрос получает в подзапросе единственную строку, после чего по порядку попарно сравнивает полученные значения со значениями во внешнем запросе.
Например, следующий запрос получает в подзапросе единственную строку, после чего по порядку попарно сравнивает полученные значения со значениями во внешнем запросе.
SELECT поля_таблицы_1
FROM таблица_1
WHERE (первое_поле_таблицы_1, второе_поле_таблицы_1) =
(
SELECT первое_поле_таблицы_2, второе_поле_таблицы_2
FROM таблица_2
WHERE id = 10
);Данную конструкцию удобно использовать для замены логических операторов. Так, следующие два запроса полностью эквивалентны:
SELECT поля_таблицы_1 FROM таблица_1 WHERE (первое_поле_таблицы_1, второе_поле_таблицы_1) = (1, 1);
SELECT поля_таблицы_1 FROM таблица_1 WHERE первое_поле_таблицы_1 = 1 AND второе_поле_таблицы_1 = 1;Связанные подзапросы
Связанным подзапросом является подзапрос, который содержит ссылку на таблицу, которая была объявлена во внешнем запросе. Здесь вложенный запрос ссылается на внешюю таблицу «таблица_1»:
SELECT поля_таблицы_1 FROM таблица_1
WHERE поле_таблицы_1 IN
(
SELECT поле_таблицы_2 FROM таблица_2
WHERE таблица_2. поле_таблицы_2 = таблица_1.поле_таблицы_1
); поле_таблицы_2 = таблица_1.поле_таблицы_1
);
поле_таблицы_2 = таблица_1.поле_таблицы_1
);Подзапросы как производные таблицы
Производная таблица — выражение, которое генерирует временную таблицу в предложении FROM, которая работает так же, как и обычные таблицы, которые вы указываете через запятую. Так выглядит общий синтаксис запроса с использованием производных таблиц:
SELECT поля_таблицы_1 FROM (подзапрос) [AS] псевдоним_производной_таблицыОбратите внимание на то, что для производной таблицы обязательно должен указываться её псевдоним, для того, чтобы имелась возможность обратиться к ней в других частях запроса.
Обработка вложенных запросов
Вложенные подзапросы обрабатываются «снизу вверх». То есть сначала обрабатывается вложенный запрос самого нижнего уровня. Далее значения, полученные по результату его выполнения, передаются и используются при реализации подзапроса более высокого уровня и т.д.
| По-русски | По-английски |
| Вы замужем (женаты)? | Are you married (married)? |
Нет, я не женат (незамужем). |
No, I’m not married. |
| Я замужем (женат). | I’m married. |
| Я разведен/разведена. | I’m divorced / divorced. |
| Мой муж (моя жена) – учитель (предприниматель, строитель). | My husband (my wife) is a teacher (entrepreneur, builder). |
| У Вас есть дети (внуки)? | Do you have children (grandchildren)? |
| У Вас есть сёстры? Братья? | Do you have sisters? Brothers? |
| Сколько у них детей? | How many children do they have? |
| Ко мне приезжает племянник / племянница. | A nephew / niece is coming to see me. |
| У меня много родственников. | I have many relatives. |
| Они мои близкие (дальние) родственники. | They are my close (distant) relatives. |
Мой дядя (моя тётя) работает в России. |
My uncle (my aunt) works in Russia. |
| Мой сын (моя дочь) учится на программиста. | My son (my daughter) is studying for a programmer. |
| На свадьбу пригласим только самых близких родственников. | At the wedding we will invite only the closest relatives. |
| Мои родители не поймут (не простят) этого. | My parents will not understand (do not forgive) this. |
| Он (она) из уважаемого и древнего рода. | He (she) is from a respected and ancient family. |
| Распределение обязанностей внутри различных семьи могут быть различны. | The distribution of responsibilities within different families can be different. |
| Воспитание детей и отношение с ними довольно сложный вопрос. | Parenting and dealing with children is a rather difficult question. |
Порядок операций SQL — В каком порядке MySQL выполняет запросы?
Знание порядка битов и байтов операций SQL-запроса может быть очень полезным, поскольку оно может упростить процесс написания новых запросов, а также очень полезно при попытке оптимизировать SQL-запрос.
Если вы ищете короткую версию, это логический порядок операций, также известный как порядок выполнения, для SQL-запроса:
- FROM, включая JOINs
- WHERE
- GROUP BY
- HAVING
- Функции WINDOW
- SELECT
- DISTINCT
- UNION
- ORDER BY
- LIMIT и OFFSET
Но реальность не так проста и не прямолинейна. Как мы уже говорили, стандарт SQL определяет порядок выполнения для различных предложений SQL-запросов. Сказано, что современные базы данных уже проверяют этот порядок по умолчанию, применяя некоторые приемы оптимизации, которые могут изменить фактический порядок выполнения, хотя в конечном итоге они должны возвращать тот же результат, как если бы они выполняли запрос в порядке выполнения по умолчанию.
Почему они это сделали? Что ж, может быть глупо, если база данных сначала извлечет все данные, упомянутые в предложении FROM (включая JOIN), прежде чем заглядывать в предложение WHERE и его индексы. Эти таблицы могут содержать большое количество данных, поэтому вы можете представить, что произойдет, если оптимизатор базы данных будет придерживаться традиционного порядка операций SQL-запроса.
Давайте рассмотрим каждую из частей SQL-запроса в соответствии с порядком их выполнения.
FROM и JOINs
Таблицы, указанные в предложении FROM (включая JOIN), будут оцениваться первыми, чтобы определить весь рабочий набор, который имеет отношение к запросу. База данных будет объединять данные из всех таблиц в соответствии с предложениями JOINs ON, а также извлекать данные из подзапросов и даже может создавать некоторые временные таблицы для хранения данных, возвращаемых из подзапросов в этом разделе.
Во многих случаях, тем не менее, оптимизатор базы данных сначала выберет оценку части WHERE, чтобы увидеть, какая часть рабочего набора может быть пропущена (предпочтительно с использованием индексов), поэтому он не будет слишком сильно раздувать набор данных, если он действительно не нужен.
Класс WHERE
Предложение WHERE будет вторым, который будет оценен после предложения FROM. У нас есть набор рабочих данных, и теперь мы можем фильтровать данные в соответствии с условиями в предложении WHERE.
Эти условия могут включать ссылки на данные и таблицы из условия FROM, но не могут включать ссылки на псевдонимы, определенные в предложении SELECT, поскольку эти данные и эти псевдонимы могут еще не «существовать» в этом контексте, так как это предложение не было пока оценивается базой данных.
Кроме того, распространенной ошибкой для предложения WHERE является попытка отфильтровать агрегированные значения в предложении WHERE, например, с помощью этого предложения: WHERE sum (available_stock)> 0. Этот оператор не выполнит запрос, потому что агрегаты будут оцениваться позже в процессе (см. Раздел GROUP BY ниже). Чтобы применить условие фильтрации к агрегированным данным, вы должны использовать предложение HAVING, а не предложение WHERE.
Предложение GROUP BY
Теперь, когда мы отфильтровали набор данных с помощью предложения WHERE, мы можем объединить данные в соответствии с одним или несколькими столбцами, появляющимися в предложении GROUP BY. Группировка данных фактически разбивает их на разные порции или сегменты, где каждый сегмент имеет один ключ и список строк, соответствующих этому ключу. Отсутствие предложения GROUP BY похоже на помещение всех строк в одно большое ведро.
Группировка данных фактически разбивает их на разные порции или сегменты, где каждый сегмент имеет один ключ и список строк, соответствующих этому ключу. Отсутствие предложения GROUP BY похоже на помещение всех строк в одно большое ведро.
После того как вы агрегируете данные, вы можете теперь использовать функции агрегации, чтобы возвращать значение для каждой группы для каждого сегмента. Такие функции агрегации включают COUNT, MIN, MAX, SUM и другие.
Класс HAVING
Теперь, когда мы сгруппировали данные с помощью предложения GROUP BY, мы можем использовать предложение HAVING, чтобы отфильтровать некоторые сегменты. Условия в предложении HAVING могут ссылаться на функции агрегирования, поэтому пример, который не работал в приведенном выше предложении WHERE, будет прекрасно работать в предложении HAVING: HAVING sum (available_stock)> 0.
Поскольку мы уже сгруппировали данные, мы больше не можем получить доступ к исходным строкам на этом этапе, поэтому мы можем применять условия только для фильтрации целых сегментов, а не отдельных строк в сегменте.
Кроме того, как мы упоминали в предыдущих разделах, псевдонимы, определенные в предложении SELECT, также не могут быть доступны в этом разделе, поскольку они еще не были оценены базой данных (это верно для большинства баз данных).
Функции Window
Если вы используете функции Window , это точка, где они будут выполняться. Подобно механизму группировки, оконные функции также выполняют вычисления для набора строк. Основное отличие состоит в том, что при использовании оконных функций каждая строка будет сохранять свою идентичность и не будет сгруппирована в группу других похожих строк.
Оконные функции могут использоваться только в предложении SELECT или ORDER BY. Вы можете использовать функции агрегирования внутри оконных функций, например:
SUM(COUNT(*)) OVER ()
Предложение SELECT
Теперь, когда мы закончили отбрасывать строки из набора данных и группировать данные, мы можем выбрать данные, которые мы хотим получить из запроса на стороне клиента. Вы можете использовать имена столбцов, агрегаты и подзапросы внутри предложения SELECT. Имейте в виду, что если вы используете ссылку на функцию агрегации, например COUNT (*) в предложении SELECT, это просто ссылка на агрегацию, которая уже произошла, когда произошла группировка, поэтому сама агрегация не произойдет в предложении SELECT, но это только ссылка на его набор результатов.
Вы можете использовать имена столбцов, агрегаты и подзапросы внутри предложения SELECT. Имейте в виду, что если вы используете ссылку на функцию агрегации, например COUNT (*) в предложении SELECT, это просто ссылка на агрегацию, которая уже произошла, когда произошла группировка, поэтому сама агрегация не произойдет в предложении SELECT, но это только ссылка на его набор результатов.
Ключевое слово DISTINCT
Синтаксис ключевого слова DISTINCT немного сбивает с толку, потому что ключевое слово занимает свое место перед именами столбцов в предложении SELECT. Но фактическая операция DISTINCT происходит после SELECT. При использовании ключевого слова DISTINCT база данных отбрасывает строки с повторяющимися значениями из оставшихся строк, оставшихся после фильтрации и агрегирования.
Ключевое слово UNION
Ключевое слово UNION объединяет наборы результатов двух запросов в один набор результатов. В большинстве баз данных вы можете выбирать между UNION DISTINCT (который отбрасывает дублирующиеся строки из объединенного набора результатов) или UNION ALL (который просто объединяет наборы результатов без применения какой-либо проверки на дублирование).
Вы можете применить сортировку (ORDER BY) и ограничение (LIMIT) к набору результатов UNION, так же, как вы можете применить его к обычному запросу.
Предложение ORDER BY
Сортировка происходит после того, как в базе данных будет готов весь набор результатов (после фильтрации, группировки, удаления дубликатов). После этого база данных может теперь сортировать результирующий набор, используя столбцы, выбранные псевдонимы или функции агрегирования, даже если они не являются частью выбранных данных. Единственным исключением является использование ключевого слова DISTINCT, которое предотвращает сортировку по не выбранному столбцу, так как в этом случае порядок набора результатов будет неопределенным.
Вы можете выбрать сортировку данных по убыванию (DESC) или по возрастанию (ASC). Заказ может быть уникальным для каждой из частей заказа, поэтому действует следующее: ORDER BY firstname ASC, age DESC
LIMIT и OFFSET
В большинстве случаев использования (за исключением нескольких подобных отчетов) мы хотели бы отбросить все строки, кроме первых X строк результата запроса. Предложение LIMIT, которое выполняется после сортировки, позволяет нам сделать это. Кроме того, вы можете выбрать, с какой строки начинать извлекать данные и сколько исключать, используя комбинацию ключевых слов LIMIT и OFFSET. В следующем примере будет выбрано 50 строк, начиная с строки 100:
Предложение LIMIT, которое выполняется после сортировки, позволяет нам сделать это. Кроме того, вы можете выбрать, с какой строки начинать извлекать данные и сколько исключать, используя комбинацию ключевых слов LIMIT и OFFSET. В следующем примере будет выбрано 50 строк, начиная с строки 100: LIMIT 50 OFFSET 100
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
MySQL запросы для заполнения таблицы данными из других таблиц
При переносе сайта на другую CMS возникают проблемы c миграцией баз данных, структура как правило разная, универсальных решений нет. Поэтому приходится писать SQL запросы для переноса под конкретный случай. Далее несколько примеров таких запросов.
Если две таблицы одинаковы по структуре, все просто:
INSERT INTO `table_1` SELECT * FROM `table_2`Для таблиц с разными названиями полей придется делать «подгонку». В запросе данные из
В запросе данные из `table_2` добавляются `table_1`.
INSERT INTO `table_1` (`id`, `name`, `keywords`, `text`)
SELECT
NULL AS `id`,
`title` AS `name`,
`words` AS `keywords`,
`short_text` AS `text`
FROM
`table_2`Соединение полей
INSERT INTO `table_1` (`id`, `name`, `text`)
SELECT
NULL AS `id`,
`title` AS `name`,
CONCAT(`words`, `short_text`) AS `text`
FROM
`table_2`Соединение полей через разделитель.
INSERT INTO `table_1` (`id`, `name`, `text`)
SELECT
NULL AS `id`,
`title` AS `name`,
CONCAT_WS(' ', `words`, `short_text`) AS `text`
FROM
`table_2`Подзапросы из других таблиц
INSERT INTO `table_1` (`id`, `name`, `text`)
SELECT
NULL AS `id`,
`title` AS `name`,
(SELECT `full_text` FROM `table_3` WHERE `id` = `table_2`. `item_id`) AS `text`
FROM
`table_2` `item_id`) AS `text`
FROM
`table_2`
`item_id`) AS `text`
FROM
`table_2`Объединение таблиц
LEFT JOIN
INSERT INTO `table_1` (`id`, `name`, `keywords`, `text`)
SELECT
NULL AS `id`,
`table_2`.`title` AS `name`,
`table_2`.`words` AS `keywords`,
`table_3`.`full_text` AS `text
FROM
`table_2`
LEFT JOIN
`table_3`
ON
`table_2`.`id` = `table_3`.`item_id`UNION
INSERT INTO `table_1` (`id`, `name`, `text`)
(
SELECT
NULL AS `id`,
`title` AS `name`,
`short_text` AS `text`
FROM
`table_2`
)
UNION
(
SELECT
NULL AS `id`,
`title` AS `name`,
`short_text` AS `text`
FROM
`table_3`
)Оптимизация запросов к базе данных | Вопросы-ответы на Wiki
В данной статье объясняется логика оптимизации запросов к базе данных, так как большинство программистов тестируют свои программы при малом количестве записей в таблицах, а проблемы у владельца сайта начинаются позже, когда он наполнит товарные каталоги.
К примеру есть запрос:
SELECT p.product_id, (SELECT AVG(rating) AS total FROM mc_review r1 WHERE r1.product_id = p.product_id AND r1.STATUS ='1' GROUP BY r1.product_id) AS rating FROM mc_product p LEFT JOIN mc_product_description pd ON (p.product_id = pd.product_id) LEFT JOIN mc_product_to_store p2s ON (p.product_id = p2s.product_id) WHERE pd.language_id = '2' AND p.STATUS = '1' AND p.date_available <= NOW() AND p2s.store_id = '0' AND p.product_id IN (SELECT pt.product_id FROM mc_product_tag pt WHERE pt.language_id = '2' AND LOWER(pt.tag) LIKE '%роксолана%') ORDER BY rating ASC LIMIT 0,20
Если запрос выполнить с условием EXPLAIN в начале, то получим схему выполнения запроса:
| Тип выборки | Таблица | Тип | Возможные ключи | Ключ | Длина ключа | Ссылка | Строки | Доп. информация |
|---|---|---|---|---|---|---|---|---|
| PRIMARY | p | ALL | PRIMARY | 2907 | Using where; Using filesort | |||
| PRIMARY | pd | eq_ref | PRIMARY | PRIMARY | 8 | mebelnyc_db. p.product_id, const p.product_id, const | 1 | Using where; Using index |
| PRIMARY | p2s | eq_ref | PRIMARY | PRIMARY | 8 | mebelnyc_db.p.product_id, const | 1 | Using where; Using index |
| DEPENDENT SUBQUERY | pt | ALL | 6803 | Using where | ||||
| DEPENDENT SUBQUERY | r1 | ref | product_id | product_id | 4 | mebelnyc_db.p.product_id | 1 | Using where |
Если убрать из этого запроса условие
LIMIT, то он вернёт 2907 записей. Именно 2907 раз будет выполнен вложенный в условиеSELECTзапрос. Если эту часть запроса вынести в отдельный запрос, то это уменьшит нагрузку на базу данных в 2907/20=145 раз. Хотя, судя по названию запроса, можно сделать вывод относительно того, что таким интересным способом автор программы пытается при каждом заходе посетителя на сайт считать статистику товаров, которая может пересчитываться, к примеру, раз в сутки или ещё лучше — при добавлении отзыва к товару и добавляться в отдельную колонку таблицыmc_product, что позволит избавиться от этого вложенного запроса.В условии
WHEREмы видим вложенный запрос, который выполняется в условииIN. Если бы автор программы в условииINуказал не вложенный запрос, а просто статические значения, напримерIN (121, 1235, 43554), то MySQL использовал бы индекс и отработал быстро. Но с вложенными запросами дело обстоит совсем по другому — MySQL выполняет их без использования индексов, а точнее так —FIN_IN_SET(p.product_id, '121,1235,43554'). В таких случаях нужно писать запрос отдельно, а потом подставлять результат его выполнения в условиеIN.

MySQL :: Справочное руководство MySQL 8.0 :: 13.2.10 Оператор SELECT
select_expr можно присвоить псевдоним
с использованием AS . Псевдоним
используется в качестве имени столбца выражения и может использоваться в псевдоним ГРУППА ПО , ЗАКАЗ ПО , или ИМЕЕТ пунктов. Например:
Например:
SELECT CONCAT (last_name, ',', first_name) AS полное_имя
ИЗ mytable ORDER BY full_name; Ключевое слово AS необязательно при псевдониме select_expr с идентификатором.В
предыдущий пример можно было бы записать так:
SELECT CONCAT (last_name, ',', first_name) full_name
ИЗ mytable ORDER BY full_name; Однако, поскольку AS не является обязательным,
может возникнуть небольшая проблема, если вы забудете запятую между двумя select_expr выражений: MySQL
интерпретирует второе как псевдоним. Например, в
В следующем заявлении columnb рассматривается как
псевдоним:
ВЫБРАТЬ columna columnb ИЗ mytable; По этой причине рекомендуется иметь привычку
используя как явно при указании столбца
псевдонимы.
Недопустимо ссылаться на псевдоним столбца в WHERE , поскольку значение столбца
может еще не быть определено, когда WHERE оговорка выполнена. См. Раздел B.3.4.4, «Проблемы с псевдонимами столбцов».
ОТ пункт
указывает таблицу или таблицы, из которых нужно получить строки.Если
вы называете более одной таблицы, вы выполняете соединение. Для
информацию о синтаксисе соединения см. Раздел 13.2.10.2, «Предложение JOIN». Для
для каждой указанной таблицы вы можете дополнительно указать псевдоним. table_references
имя_таблицы [[AS] псевдоним ] [ index_hint ] Использование подсказок индексов предоставляет оптимизатору информацию
о том, как выбирать индексы при обработке запроса. Для
описание синтаксиса для указания этих подсказок см.
Раздел 8.9.4, «Указатели».
Для
описание синтаксиса для указания этих подсказок см.
Раздел 8.9.4, «Указатели».
Вы можете использовать SET
max_seeks_for_key = как альтернативный способ заставить MySQL предпочесть сканирование ключей
вместо сканирования таблицы. Увидеть
Раздел 5.1.8, «Системные переменные сервера». значение
Вы можете ссылаться на таблицу в базе данных по умолчанию как имя_таблицы , или как db_name . имя_таблицы явно указать базу данных. Вы можете ссылаться на столбец как имя_столбца , имя_таблицы . имя_столбца ,
или db_name . имя_таблицы . имя_столбца . Вам не нужно указывать
Вам не нужно указывать имя_таблицы или db_name . имя_таблицы префикс для ссылки на столбец, если ссылка не будет
неоднозначный.См. Раздел 9.2.2, «Квалификаторы идентификатора», для
примеры неоднозначности, требующие более явного столбца
справочные формы.
Ссылка на таблицу может быть псевдонимом, используя или имя_таблицы AS псевдоним имя_таблицы псевдоним_имя . Эти
утверждения эквивалентны:
ВЫБРАТЬ t1.имя, t2. зарплата ОТ сотрудника AS t1, информация AS t2
ГДЕ t1.name = t2.name;
ВЫБЕРИТЕ t1.name, t2.salary ОТ сотрудника t1, информация t2
ГДЕ t1.name = t2.name; Столбцы, выбранные для вывода, могут быть указаны в ЗАКАЗАТЬ ПО и ГРУППА ПО предложения с использованием имен столбцов, псевдонимов столбцов или столбцов
позиции. Позиции столбцов являются целыми числами и начинаются с 1:
Позиции столбцов являются целыми числами и начинаются с 1:
ВЫБЕРИТЕ колледж, регион, семя ИЗ турнира
ЗАКАЗАТЬ ПО региону, семя;
ВЫБЕРИТЕ колледж, регион AS r, seed AS s ИЗ турнира
ЗАКАЗАТЬ ПО r, s;
ВЫБЕРИТЕ колледж, регион, семя ИЗ турнира
ЗАКАЗАТЬ 2, 3; Для сортировки в обратном порядке добавьте DESC (по убыванию) к имени столбца в ORDER BY , по которому выполняется сортировка.По умолчанию используется возрастающий порядок; это можно указать
явно используя ключевое слово ASC .
Если ORDER BY находится в скобках
выражение запроса, а также применяется во внешнем запросе,
результаты не определены и могут измениться в будущей версии
MySQL.
Использование позиций столбцов не рекомендуется, поскольку в синтаксисе был удален из стандарта SQL.
До MySQL 8. 0.13 MySQL поддерживал нестандартный синтаксис.
расширение, разрешающее явное
0.13 MySQL поддерживал нестандартный синтаксис.
расширение, разрешающее явное ASC или DESC обозначения для GROUP
BY колонн. MySQL 8.0.12 и выше поддерживает ORDER BY с функциями группировки, чтобы
использование этого расширения больше не требуется. (Ошибка № 86312, Ошибка
# 26073525) Это также означает, что вы можете сортировать по произвольному столбцу
или столбцы при использовании GROUP BY , например:
ВЫБРАТЬ a, b, COUNT (c) AS t FROM test_table GROUP BY a, b ORDER BY a, t DESC; Начиная с MySQL 8.0.13, расширение GROUP BY больше не поддерживается: ASC или DESC обозначения для GROUP
BY столбцы не допускаются.
При использовании ORDER BY или GROUP
BY для сортировки столбца в SELECT , сервер сортирует значения
используя только начальное количество байтов, указанное max_sort_length система
переменная.
MySQL расширяет использование GROUP BY , чтобы разрешить
выбор полей, не упомянутых в ГРУППЕ BY пункт. Если вы не получаете результатов,
вы ожидаете от своего запроса, пожалуйста, прочтите описание GROUP BY найдено в
Раздел 12.20, «Агрегатные функции».
GROUP BY разрешает СО
Модификатор ROLLUP .Увидеть
Раздел 12.20.2, «Модификаторы GROUP BY».
Ранее было запрещено использовать ORDER
BY в запросе с WITH
Модификатор ROLLUP . Это ограничение снято с
MySQL 8.0.12. См. Раздел 12.20.2, «Модификаторы GROUP BY».
Предложение HAVING применяется почти последним,
непосредственно перед отправкой товаров клиенту, без
оптимизация. (
( LIMIT применяется после ИМЕЕТ .)
Стандарт SQL требует, чтобы ИМЕЕТ .
только ссылки на столбцы в GROUP BY предложение или столбцы, используемые в агрегатных функциях. Однако MySQL
поддерживает расширение этого поведения и разрешает ИМЕЕТ для ссылки на столбцы в ВЫБРАТЬ список и столбцы в
также внешние подзапросы.
Если предложение HAVING относится к столбцу
это неоднозначно, появляется предупреждение. В следующих
оператор, col2 неоднозначен, потому что он
используется как псевдоним и как имя столбца:
ВЫБРАТЬ СЧЕТЧИК (столбец1) КАК столбец2 ИЗ t ГРУППА ПО столбцу2 ИМЕЕТ столбец2 = 2; Предпочтение отдается стандартному поведению SQL, поэтому, если ИМЕЕТ имя столбца , которое используется как в GROUP BY и как столбец с псевдонимом в
список выходных столбцов, предпочтение отдается столбцу в ГРУППА ПО столбец.
Не используйте ИМЕЮЩИЙ для предметов, которые должны быть
в пункте WHERE . Например, не
напишите следующее:
ВЫБРАТЬ имя_столбца ИЗ имя_таблицы ИМЕЕТ имя_столбца > 0; Напишите вместо этого:
ВЫБРАТЬ имя_столбца ИЗ имя_таблицы ГДЕ имя_столбца > 0; Предложение HAVING может относиться к совокупному
функции, которые предложение WHERE не может:
ВЫБРАТЬ пользователя, МАКС. (Зарплата) ИЗ пользователей
ГРУППА ПО ПОЛЬЗОВАТЕЛЯМ С МАКС. (Зарплата)> 10; (Это не работало в некоторых старых версиях MySQL.)
MySQL допускает повторяющиеся имена столбцов. То есть может быть
более одного select_expr с
то же имя. Это расширение стандартного SQL. Поскольку MySQL
также разрешает
Это расширение стандартного SQL. Поскольку MySQL
также разрешает GROUP BY и ИМЕЕТ для обозначения select_expr значений, это может привести
в двусмысленности:
ВЫБРАТЬ 12 КАК a, a ИЗ t GROUP BY a; В этом заявлении оба столбца имеют имя а .Чтобы убедиться, что правильный столбец
используется для группировки, используйте разные имена для каждого select_expr .
Предложение WINDOW , если присутствует, определяет
именованные окна, на которые могут ссылаться оконные функции. Для
подробности см. в Раздел 12.21.4, «Именованные окна».
MySQL разрешает неквалифицированные ссылки на столбцы или псевдонимы в ORDER BY , выполнив поиск в select_expr значений, затем в
столбцы таблиц в разделе FROM .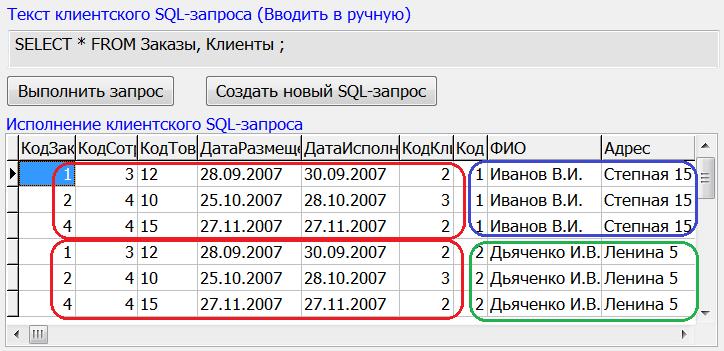 Для
Для GROUP BY или ИМЕЕТ предложений, он ищет предложение FROM перед
поиск в select_expr ценности. (Для GROUP BY и ИМЕЕТ , это отличается от версии до MySQL 5.0.
поведение, использующее те же правила, что и для ORDER
BY .)
Предложение LIMIT может использоваться для ограничения
количество строк, возвращаемых SELECT заявление. LIMIT принимает один или два числовых аргумента,
которые обе должны быть неотрицательными целыми константами, с этими
исключения:
В подготовленных отчетах
LIMITпараметры можно указать с помощью?маркеры-заполнители.Внутри сохраненных программ
LIMITпараметры могут быть указаны с помощью целочисленной подпрограммы параметры или локальные переменные.
С двумя аргументами первый аргумент указывает смещение первая строка для возврата, а вторая определяет максимум количество возвращаемых строк. Смещение начальной строки 0 (не 1):
ВЫБРАТЬ * ИЗ ТАБЛИЦЫ LIMIT 5,10; # Получить строки 6-15 Чтобы получить все строки от определенного смещения до конца набор результатов, вы можете использовать какое-то большое число для второго параметр.Этот оператор извлекает все строки из 96-й строки до конца:
ВЫБРАТЬ * ИЗ ТАБЛИЦЫ LIMIT 95,18446744073709551615; С одним аргументом значение указывает количество строк для возврат из начала набора результатов:
ВЫБРАТЬ * ИЗ ТАБЛИЦЫ LIMIT 5; # Получить первые 5 строк Другими словами, LIMIT эквивалентно
до row_count LIMIT 0, . row_count 
Для подготовленных операторов вы можете использовать заполнители. В
следующие операторы возвращают одну строку из табл. стол:
НАБОР @ a = 1;
ПОДГОТОВИТЬ STMT ИЗ 'SELECT * FROM tbl LIMIT?';
ВЫПОЛНИТЬ STMT, ИСПОЛЬЗУЯ @a; Следующие операторы возвращают строки со второй по шестую из
таблица tbl :
НАБОР @ skip = 1; НАБОР @ numrows = 5;
ПОДГОТОВИТЬ STMT ИЗ 'SELECT * FROM tbl LIMIT?,?';
ВЫПОЛНИТЕ STMT, ИСПОЛЬЗУЯ @skip, @numrows; Для совместимости с PostgreSQL MySQL также поддерживает LIMIT синтаксис. row_count OFFSET смещение
Если LIMIT встречается в скобках
выражение запроса, а также применяется во внешнем запросе,
результаты не определены и могут измениться в будущей версии
MySQL.
SELECT ...
ШТО форма ВЫБРАТЬ позволяет записать результат запроса в файл или сохранить в
переменные. Для получения дополнительной информации см.
Раздел 13.2.10.1, «Заявление SELECT … INTO».
Если вы используете FOR UPDATE с механизмом хранения
который использует блокировку страниц или строк, строки, проверенные запросом,
заблокирован от записи до конца текущей транзакции.
Вы не можете использовать FOR UPDATE как часть ВЫБЕРИТЕ в таком заявлении, как СОЗДАТЬ
ТАБЛИЦА . (Если ты
попытка сделать это, утверждение отклоняется с ошибкой
Не могу обновить таблицу
‘ new_table SELECT... ОТ старая_таблица ... old_table ‘, а
‘ new_table ‘ находится
создан. )
)
ДЛЯ АКЦИИ и БЛОКИРОВКА ДОЛИ
MODE устанавливает разделяемые блокировки, которые разрешают другие транзакции
читать исследуемые строки, но не обновлять или удалять их. ДЛЯ АКЦИИ и БЛОКИРОВКА ДОЛИ
MODE эквивалентны. Однако ДЛЯ
SHARE , как и FOR UPDATE , поддерживает NOWAIT , SKIP LOCKED и OF опции. имя_таблицы ДЛЯ АКЦИИ является заменой БЛОКИРОВКА В РЕЖИМЕ SHARE , но БЛОКИРОВКА
SHARE MODE остается доступным для обратной
совместимость.
NOWAIT вызывает FOR
UPDATE или FOR SHARE запрос на
выполнить немедленно, возвращая ошибку, если блокировка строки не может
быть полученным из-за блокировки, удерживаемой другой транзакцией.
ПРОПУСК ЗАБЛОКИРОВАН вызывает ДЛЯ
UPDATE или FOR SHARE запрос на
выполнить немедленно, исключая строки из набора результатов, которые
заблокированы другой транзакцией.
NOWAIT и ПРОПУСТИТЬ ЗАБЛОКИРОВАНО параметры небезопасны для репликации на основе операторов.
Заметка
Запросы, которые пропускают заблокированные строки, возвращают несогласованное представление
данные. ПРОПУСТИТЬ ЗАБЛОКИРОВАН поэтому не
подходит для общей транзакционной работы. Однако это может быть
используется для предотвращения конфликтов блокировок при доступе к нескольким сеансам
та же таблица, похожая на очередь.
OF применяет имя_таблицы ДЛЯ ОБНОВЛЕНИЯ и ДЛЯ
ПОДЕЛИТЬСЯ запросов к именованным таблицам. Например:
Например:
ВЫБРАТЬ * ИЗ t1, t2 ДЛЯ ДОЛЯ t1 ДЛЯ ОБНОВЛЕНИЯ t2; Все таблицы, на которые ссылается блок запроса, блокируются, когда OF есть
опущено. Следовательно, использование предложения блокировки без имя_таблицы OF дюйм
комбинация с другим предложением блокировки возвращает ошибку.Указание одной и той же таблицы в нескольких блокирующих предложениях возвращает
ошибка. Если псевдоним указан как имя таблицы в имя_таблицы SELECT , предложение блокировки может только
используйте псевдоним. Если оператор SELECT делает
не указывать псевдоним явно, предложение блокировки может только
укажите фактическое имя таблицы.
Для получения дополнительной информации о ДЛЯ ОБНОВЛЕНИЯ и ДЛЯ АКЦИИ см.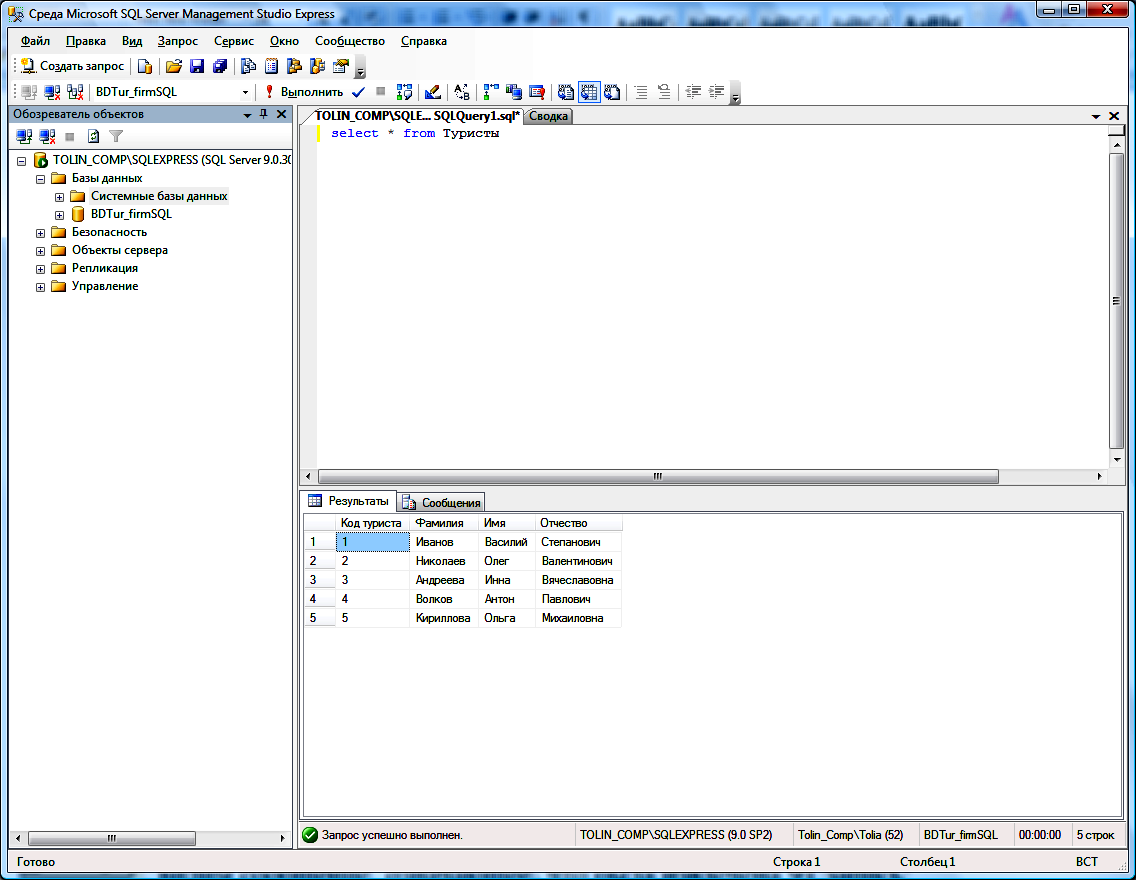 Раздел 15.7.2.4, «Блокировка чтения». Для дополнительных
информация о
Раздел 15.7.2.4, «Блокировка чтения». Для дополнительных
информация о NOWAIT и SKIP
ЗАБЛОКИРОВАНО варианты , см.
Блокировка параллелизма чтения с помощью NOWAIT и SKIP LOCKED.
phpMyAdmin Run MySQL Query Tutorial
В этом руководстве рассматриваются следующие темы:
В этом руководстве объясняется, как выполнять запросы MySQL с помощью инструмента phpMyAdmin. Есть два способа сделать это с помощью интерфейса phpMyAdmin.
Выполнение запросов MySQL с вкладкой SQL
Вы можете выполнить запрос MySQL к данной базе данных, открыв базу данных с помощью phpMyAdmin и затем щелкнув вкладку SQL .Загрузится новая страница, на которой вы можете ввести желаемый запрос. Когда будете готовы, щелкните Go , чтобы выполнить выполнение.
Страница обновится, и вы увидите результаты введенного вами запроса.
Создавайте и выполняйте запросы MySQL с вкладкой Query
Другой способ запросить базу данных MySQL с помощью инструмента phpMyAdmin — использовать вкладку Query . Здесь вы можете определить различные условия поиска, отсортировать результаты и запросить несколько таблиц.
Здесь вы можете определить различные условия поиска, отсортировать результаты и запросить несколько таблиц.
Столбцы, которые будут включены в оператор MySQL, должны быть выбраны из раскрывающихся меню Столбец . Также для каждого столбца должен быть установлен флажок Показать .
В раскрывающемся меню Сортировка можно визуализировать результат, отсортированный в порядке возрастания или убывания. В раскрывающемся списке Порядок сортировки вы можете выбрать столбец, в котором должны отображаться результаты.
В текстовом поле Criteria введите критерии, в соответствии с которыми будет завершен поиск.
Кроме того, вы можете использовать флажки Ins и Del для добавления или удаления текстовых строк для условий поиска. То же самое можно сделать с помощью раскрывающегося меню Добавить / удалить строку критериев .
В разделе Изменить определите отношения между полями (независимо от того, связаны ли они с помощью логических операторов И или ИЛИ ).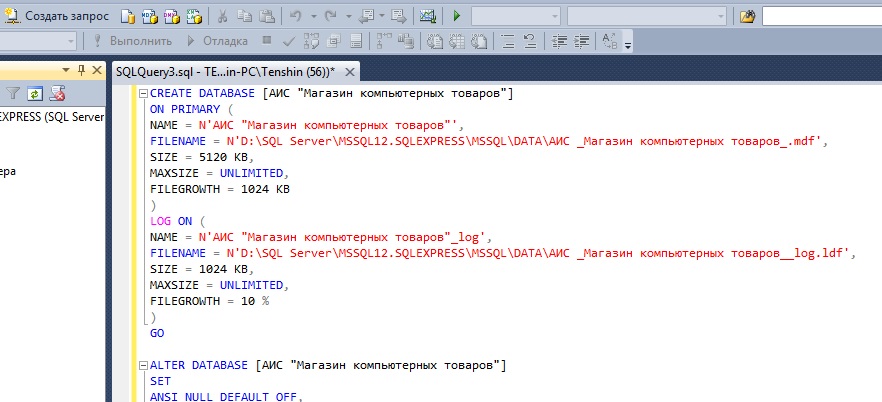
Вам нужно нажать на Update Query , чтобы завершить изменения.
Затем следует выбрать таблицы, используемые в запросе, из списка Использовать таблицы .
Чтобы запустить запрос, нажмите Отправить запрос .
Более подробную информацию о синтаксисе MySQL можно найти в официальной документации MySQL.
Понимание запросов MySQL с объяснением
Вы находитесь на новой работе в качестве администратора базы данных или инженера по данным и просто заблудились, пытаясь понять, что эти безумно выглядящие запросы должны означать и делать.Почему существует 5 объединений и почему в подзапросе используется ORDER BY до того, как произойдет одно из соединений? Помните, что вас наняли по какой-то причине — скорее всего, эта причина также связана со многими запутанными запросами, которые были созданы и отредактированы за последнее десятилетие.
Ключевое слово EXPLAIN используется в различных базах данных SQL и предоставляет информацию о том, как ваша база данных SQL выполняет запрос.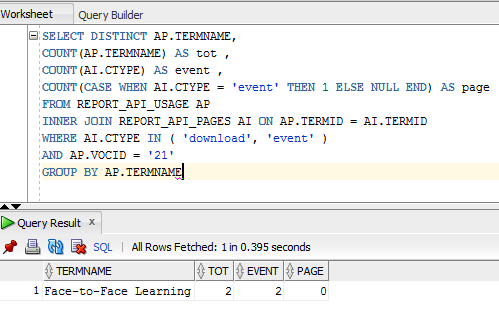 В MySQL
В MySQL EXPLAIN может использоваться перед запросом, начинающимся с SELECT , INSERT , DELETE , REPLACE и UPDATE .Для простого запроса это будет выглядеть так:
EXPLAIN SELECT * FROM foo WHERE foo.bar = 'инфраструктура как услуга' OR foo.bar = 'iaas';
Вместо обычного вывода результата MySQL затем покажет свой план выполнения оператора, объясняя, какие процессы и в каком порядке происходят при выполнении оператора.
Примечание: Если EXPLAIN не работает для вас, возможно, у пользователя вашей базы данных нет привилегии SELECT для таблиц или представлений, которые вы используете в своем операторе.
EXPLAIN — отличный инструмент для быстрого исправления медленных запросов. Хотя это, безусловно, может вам помочь, это не избавит вас от необходимости структурного мышления и хорошего обзора существующих моделей данных. Часто самым простым решением и самым быстрым советом является добавление индекса к столбцам конкретной таблицы, о которых идет речь, если они используются во многих запросах с проблемами производительности. Однако будьте осторожны, не используйте слишком много индексов, поскольку это может быть контрпродуктивным. Чтение индексов и таблицы имеет смысл только в том случае, если таблица имеет значительное количество строк и вам нужно только несколько точек данных.Если вы извлекаете огромный набор результатов из таблицы и часто запрашиваете разные столбцы, индекс для каждого столбца не имеет смысла и больше снижает производительность, чем помогает. Чтобы узнать больше о фактических расчетах индекса по сравнению с отсутствием индекса, прочтите «Оценка производительности» в официальной документации MySQL.
Часто самым простым решением и самым быстрым советом является добавление индекса к столбцам конкретной таблицы, о которых идет речь, если они используются во многих запросах с проблемами производительности. Однако будьте осторожны, не используйте слишком много индексов, поскольку это может быть контрпродуктивным. Чтение индексов и таблицы имеет смысл только в том случае, если таблица имеет значительное количество строк и вам нужно только несколько точек данных.Если вы извлекаете огромный набор результатов из таблицы и часто запрашиваете разные столбцы, индекс для каждого столбца не имеет смысла и больше снижает производительность, чем помогает. Чтобы узнать больше о фактических расчетах индекса по сравнению с отсутствием индекса, прочтите «Оценка производительности» в официальной документации MySQL.
Вещи, которые вы хотите избежать везде, где это возможно и применимо, — это сортировка и вычислений внутри запросов. Если вы думаете, что не можете избежать вычислений в своих запросах: да, вы можете.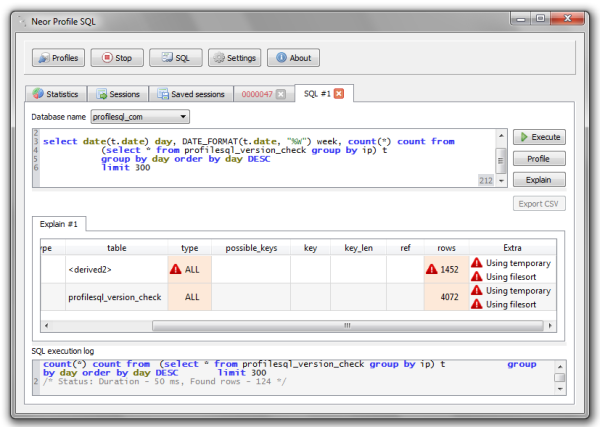 Напишите набор результатов в другом месте и вычислите точку данных вне запроса, это снизит нагрузку на базу данных и, следовательно, в целом будет лучше для вашего приложения. Просто убедитесь, что вы задокументировали, почему вы выполняете вычисления в своем приложении, а не сразу получаете результат в SQL. В противном случае следующий администратор или разработчик базы данных придет и у него возникнет великолепная идея использовать вычисление в запросе типа «о, смотрите, мой предшественник даже не знал, что вы можете сделать это в SQL!» Некоторые команды разработчиков, у которых еще не было неизбежной проблемы с умирающими базами данных, могут использовать вычисления в запросах для определения разницы между датами или аналогичными точками данных.
Напишите набор результатов в другом месте и вычислите точку данных вне запроса, это снизит нагрузку на базу данных и, следовательно, в целом будет лучше для вашего приложения. Просто убедитесь, что вы задокументировали, почему вы выполняете вычисления в своем приложении, а не сразу получаете результат в SQL. В противном случае следующий администратор или разработчик базы данных придет и у него возникнет великолепная идея использовать вычисление в запросе типа «о, смотрите, мой предшественник даже не знал, что вы можете сделать это в SQL!» Некоторые команды разработчиков, у которых еще не было неизбежной проблемы с умирающими базами данных, могут использовать вычисления в запросах для определения разницы между датами или аналогичными точками данных.
Общее практическое правило для SQL-запросов выглядит следующим образом:
Будьте точны и получайте только те результаты, которые вам нужны.
Давайте проверим более сложный запрос…
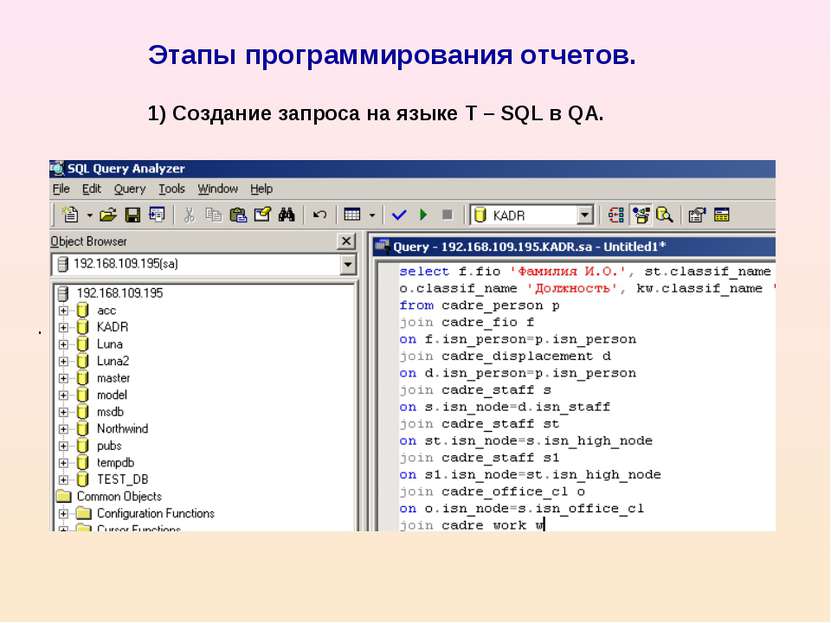
ВЫБЕРИТЕ site_options. domain, sites_users.user, site_taxes.monthly_statement_fee, site.name, AVG (цена) AS average_product_price FROM sites_orders_products, site_taxes, site, sites_users, site_options WHERE site_options.site_options.user_id И site_taxes.site_id = site.id И sites_orders_products.site_id = site.id ГРУППА ПО site.id ORDER BY site.date_modified desc LIMIT 5;
+ ----------------------------- + ------------------- ---------- + ----------------------- + --------------- --------------------------- + ---------------------- - +
| домен | пользователь | month_statement_fee | имя | average_product_price |
+ ----------------------------- + ------------------- ---------- + ----------------------- + --------------- --------------------------- + ---------------------- - +
| www.xxxxxxxxxxxxxxxxxxx.com | [email protected] | 0,50 | xxxxxxxxxxxxxxxxxxxxx | 3.254781 |
| www.xxxxxxxxxxx.com | [email protected] | 0,50 | xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx | 9.471022 |
| | [email protected] | 0. 00 | xxxxxxxxxxxxxxxxx | 8.646297 |
| | [email protected] | 0.00 | xxxxxxxxxxxxxxx | 9.042460 |
| | [email protected] | 0.00 | xxxxxxxxxxxxxxxxxx | 6.679182 |
+ ----------------------------- + ------------------- ---------- + ----------------------- + --------------- --------------------------- + ---------------------- - +
5 рядов в наборе (0,00 сек)
 00 | xxxxxxxxxxxxxxxxx | 8.646297 |
| |
00 | xxxxxxxxxxxxxxxxx | 8.646297 |
| | … и его выход EXPLAIN .
+ ------ + ------------- + -------------------------- ------- + -------- + ----------------- + --------------- + --------- + --------------------------------- + ----- - + ----------- +
| id | select_type | стол | тип | possible_keys | ключ | key_len | ref | строки | Экстра |
+ ------ + ------------- + ---------------------------- ----- + -------- + ----------------- + --------------- + - -------- + --------------------------------- + ------ + ----------- +
| 1 | ПРОСТО | сайты | индекс | ПЕРВИЧНЫЙ, user_id | ПЕРВИЧНЫЙ | 4 | NULL | 858 | Использование временных; Использование файловой сортировки |
| 1 | ПРОСТО | sites_options | ref | site_id | site_id | 4 | оказание услуг. sites.id | 1 | |
| 1 | ПРОСТО | sites_taxes | ref | site_id | site_id | 4 | service.sites.id | 1 | |
| 1 | ПРОСТО | sites_users | eq_ref | ПЕРВИЧНЫЙ | ПЕРВИЧНЫЙ | 4 | service.sites.user_id | 1 | |
| 1 | ПРОСТО | sites_orders_products | ref | site_id | site_id | 4 | service.sites.id | 4153 | | //
+ ------ + ------------- + ---------------------------- ----- + -------- + ----------------- + --------------- + - -------- + --------------------------------- + ------ + ----------- +
5 рядов в наборе (0.00 сек)
 sites.id | 1 | |
| 1 | ПРОСТО | sites_taxes | ref | site_id | site_id | 4 | service.sites.id | 1 | |
| 1 | ПРОСТО | sites_users | eq_ref | ПЕРВИЧНЫЙ | ПЕРВИЧНЫЙ | 4 | service.sites.user_id | 1 | |
| 1 | ПРОСТО | sites_orders_products | ref | site_id | site_id | 4 | service.sites.id | 4153 | | //
+ ------ + ------------- + ---------------------------- ----- + -------- + ----------------- + --------------- + - -------- + --------------------------------- + ------ + ----------- +
5 рядов в наборе (0.00 сек)
sites.id | 1 | |
| 1 | ПРОСТО | sites_taxes | ref | site_id | site_id | 4 | service.sites.id | 1 | |
| 1 | ПРОСТО | sites_users | eq_ref | ПЕРВИЧНЫЙ | ПЕРВИЧНЫЙ | 4 | service.sites.user_id | 1 | |
| 1 | ПРОСТО | sites_orders_products | ref | site_id | site_id | 4 | service.sites.id | 4153 | | //
+ ------ + ------------- + ---------------------------- ----- + -------- + ----------------- + --------------- + - -------- + --------------------------------- + ------ + ----------- +
5 рядов в наборе (0.00 сек)
Столбцы в выходных данных EXPLAIN с теми, которые требуют особого внимания для выявления проблем, выделены жирным шрифтом:
- id (идентификатор запроса)
- select_type (тип выписки)
- таблица (ссылка на таблицу) Тип
- (присоединительный)
- possible_keys (какие ключи могли быть использованы)
- ключ (ключ, который был использован)
- key_len (длина используемого ключа)
- ref (столбцы по сравнению с индексом)
- строк (количество найденных строк)
- Extra (дополнительная информация)
Чем выше количество строк, в которых выполняется поиск, тем лучше должен быть уровень оптимизации индексов и точности запроса, чтобы максимизировать производительность. В столбце Extra показаны возможные действия, на которых вы могли бы сосредоточиться, чтобы улучшить свой запрос, если это применимо.
В столбце Extra показаны возможные действия, на которых вы могли бы сосредоточиться, чтобы улучшить свой запрос, если это применимо.
Показать предупреждения;
Если запрос, который вы использовали с EXPLAIN , не разбирается правильно, вы можете ввести SHOW WARNINGS; в ваш редактор запросов MySQL, чтобы показать информацию о последнем операторе, который был запущен и не был диагностическим, т.е. он не будет отображать информацию для таких операторов, как SHOW FULL PROCESSLIST; . Хотя он не может дать надлежащий план выполнения запроса, как EXPLAIN , он может дать вам подсказки о тех фрагментах запроса, которые он может обработать.Допустим, мы используем запрос EXPLAIN SELECT * FROM foo WHERE foo.bar = 'Infrastructure as a service' OR foo.bar = 'iaas'; в любой данной базе данных, в которой фактически нет таблицы foo . Результат MySQL будет:
ОШИБКА 1146 (42S02): таблица db. foo не существует
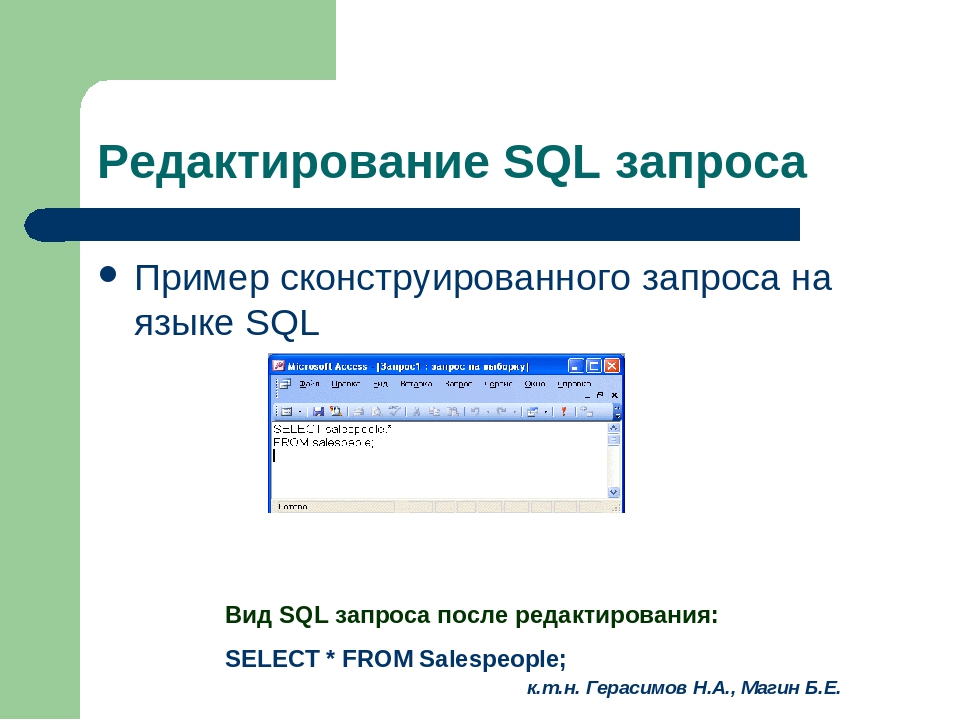 foo не существует
foo не существует
Если набрать ПОКАЗАТЬ ПРЕДУПРЕЖДЕНИЯ; вывод выглядит следующим образом:
+ ------- + ------ + -------------------------------- ----- +
| Уровень | Код | Сообщение |
+ ------- + ------ + ---------------------------------- --- +
| Ошибка | 1146 | Таблица 'db.foo 'не существует |
+ ------- + ------ + ---------------------------------- --- +
1 ряд в комплекте (0,00 сек)
Давайте попробуем это с намеренной синтаксической ошибкой.
EXPLAIN SELECT * FROM foo WHERE name = ///;
Это генерирует следующие предупреждения:
> ПОКАЗАТЬ ПРЕДУПРЕЖДЕНИЯ;
+ ------- + ------ + ---------------------------------- ----------------------------------- +
| Уровень | Код | Сообщение |
+ ------- + ------ + ---------------------------------- ----------------------------------- +
| Ошибка | 1064 | У вас есть ошибка в синтаксисе SQL; (...) рядом с '///' в строке 1 |
+ ------- + ------ + ---------------------------------- ----------------------------------- +
Этот вывод предупреждений довольно прост и сразу же отображается MySQL как вывод результата, но для более сложных запросов, которые не анализируются, все еще можно посмотреть, что происходит в тех фрагментах запроса, которые могут быть проанализированы.
ПОКАЗАТЬ ПРЕДУПРЕЖДЕНИЯ; включает специальные маркеры, которые могут предоставлять полезную информацию, например:
-
(фрагмент запроса) -
(условие, выражение1, выражение2) -
(фрагмент запроса) -
<временная таблица>: здесь будет создана внутренняя таблица для сохранения временных результатов, например, в подзапросах перед объединениями
Чтобы узнать больше об этих специальных маркерах, прочитайте Extended Explain Output Format в официальной документации MySQL.
Есть несколько способов устранить основную причину плохой работы базы данных. Первое, на что следует обратить внимание, — это модель данных, то есть как структурированы данные и правильно ли вы используете базу данных? Для многих продуктов вполне подойдет база данных SQL. Следует помнить одну важную вещь — всегда отделять журналы доступа от обычной производственной базы данных, что, к сожалению, не происходит во многих компаниях. Чаще всего в этих случаях компания начинала с малого, росла и по сути все еще использовала одну и ту же базу данных, что означает, что они обращаются к одной и той же базе данных как для функций ведения журнала, так и для других транзакций.Это значительно снижает общую производительность, особенно по мере роста компании. Следовательно, очень важно создать подходящую и устойчивую модель данных.
Следует помнить одну важную вещь — всегда отделять журналы доступа от обычной производственной базы данных, что, к сожалению, не происходит во многих компаниях. Чаще всего в этих случаях компания начинала с малого, росла и по сути все еще использовала одну и ту же базу данных, что означает, что они обращаются к одной и той же базе данных как для функций ведения журнала, так и для других транзакций.Это значительно снижает общую производительность, особенно по мере роста компании. Следовательно, очень важно создать подходящую и устойчивую модель данных.
Модель данных
Выбор модели данных, скорее всего, также откроет правильную форму базы данных (ов). Если ваш продукт не является очень простым, у вас, вероятно, будет несколько баз данных для нескольких вариантов использования — если вам нужно отображать числа почти в реальном времени для журналов доступа, вам, скорее всего, понадобится высокопроизводительное хранилище данных, тогда как обычные транзакции могут выполняться через SQL база данных, и у вас может быть база данных графов, в которой также накапливаются соответствующие точки данных обеих баз данных в механизм рекомендаций.
Программная архитектура продукта в целом так же важна, как и сама база данных, поскольку плохой дизайн здесь приведет к возникновению узких мест, которые идут в сторону базы данных и замедляют все как со стороны программного обеспечения, так и того, что база данных может выводить. Вам нужно будет выбрать, подходят ли контейнеры для вашего продукта, является ли монолит лучшим способом справиться с вещами, может ли вы иметь основной монолит с несколькими микросервисами, нацеленными на другие функции, распространенные в другом месте, и как вы получаете доступ, собираете, обрабатываете , и хранить данные.
Оборудование
Так же важно, как и ваша общая структура, ваше оборудование является ключевым компонентом производительности вашей базы данных. Exoscale предлагает вам различные варианты экземпляров, которые вы можете использовать в зависимости от вашей транзакции и объема хранилища, а также желаемого времени отклика.
Очень важно определить пиковые периоды вашего приложения и, следовательно, знать, когда, если возможно, опустить более медленные административные запросы. Дисковый ввод-вывод и сетевая статистика также должны быть приняты во внимание при проектировании времени транзакций и аналитики базы данных.
Дисковый ввод-вывод и сетевая статистика также должны быть приняты во внимание при проектировании времени транзакций и аналитики базы данных.
Резюме
В заключение, вот основные моменты для долгосрочной работы:
- создать устойчивую модель данных, соответствующую потребностям вашей компании
- выбрать правильную форму базы данных
- используйте программную архитектуру, соответствующую вашему продукту.
- регулярно проверяет структуру ваших запросов и использует
EXPLAINдля более сложных запросов, оптимизирует использование выбранных вами баз данных, а также в отношении обновлений баз данных и их влияния на вас. - выберите экземпляры, которые наилучшим образом соответствуют потребностям вашего приложения и базы данных в соответствии с производительностью и пропускной способностью
Запрос данных с сервера MySQL с помощью оператора SELECT
В этой серии статей мы узнаем об основах работы с сервером баз данных MySQL. В этой статье я собираюсь объяснить, как мы можем запрашивать данные с сервера MySQFL с помощью оператора SELECT.
В этой статье я собираюсь объяснить, как мы можем запрашивать данные с сервера MySQFL с помощью оператора SELECT.
Для демонстрации я установил MySQL 8.0 и MySQL Workbench на свою рабочую станцию, а также восстановил демонстрационную базу данных с именем sakila. Эта статья поможет вам установить сервер MySQL в Windows 10. Вы можете скачать базу данных sakila отсюда, а шаги по установке описаны в этой статье.
Теперь, чтобы понять архитектуру схемы таблиц сакилы, мы сгенерируем схему схемы путем обратного проектирования базы данных.
Создать схему схемы
Чтобы создать диаграмму схемы, откройте рабочую среду MySQL -> Подключиться к ядру базы данных MySQL -> В строке меню щелкните базу данных -> выберите Reverse Engineer . См. Следующее изображение:
На экране Reverse Engineer Database выберите имя соединения в раскрывающемся списке Сохраненное соединение , выберите соответствующий метод подключения ( TCP / IP ИЛИ именованная труба ) из раскрывающегося списка Метод подключения . Введите имя хоста или IP-адрес в текстовое поле Имя хоста. Введите соответствующий номер порта в текстовое поле Номер порта. И, наконец, введите соответствующее имя пользователя в текстовое поле Имя пользователя и нажмите Далее . См. Следующее изображение:
Введите имя хоста или IP-адрес в текстовое поле Имя хоста. Введите соответствующий номер порта в текстовое поле Номер порта. И, наконец, введите соответствующее имя пользователя в текстовое поле Имя пользователя и нажмите Далее . См. Следующее изображение:
Теперь сервер базы данных MySQL пытается установить соединение между мастером обратного проектирования и сервером и получить информацию о базе данных, размещенной на сервере. Если это не удается, то ошибка будет отображаться на Подключитесь к СУБД и вызовите информационный экран.Соединение успешно установлено. См. Следующее изображение. Щелкните Далее.
На экране Select Schemas to Reverse Engineer вы можете выбрать базу данных. Мастер сгенерирует схему выбранной базы данных. Мы хотим сгенерировать схему базы данных сакила; следовательно, щелкните sakila и щелкните Далее. См. Следующее изображение:
На экране извлечения и реинжиниринга объекта схемы мастер заполняет объект схемы в базе данных sakila.Если что-то происходит, при извлечении объекта, он отображается на экране. Схема получена успешно. Щелкните Далее. См. Следующее изображение:
На экране Select objects to Reverse Engineer вы можете выбрать объекты, которые хотите реконструировать. Мы хотим сгенерировать диаграмму таблиц, поэтому выбираем Import MySQL table object и нажимаем Execute . См. Следующее изображение:
Начнется процесс обратного проектирования базы данных.Если возникает какая-либо ошибка, она отображается на экране процесса обратного проектирования. Процесс завершился успешно. Щелкните Далее. См. Следующее изображение:
На экране Reverse Engineering Result вы можете увидеть подробную информацию о реконструированных объектах. Щелкните Готово, чтобы закрыть диалоговое окно. См. Следующее изображение:
Щелкните Готово, чтобы закрыть диалоговое окно. См. Следующее изображение:
После завершения процесса вы можете увидеть схему созданной базы данных sakila.Диаграмма находится на вкладке EER рабочей среды MySQL. Если вы захотите использовать его позже, вы можете сохранить эту диаграмму. См. Следующее изображение:
Теперь, когда диаграмма подготовлена, мы можем использовать ее, чтобы понять структуру схемы базы данных и использовать таблицы для понимания концепции программирования базы данных MySQL. Сначала позвольте мне объяснить оператор SELECT.
Введение в оператор SELECT
Оператор SELECT используется для заполнения данных из любой таблицы сервера базы данных MySQL.Это ни DML (язык модификации данных), ни DDL (язык определения данных). Это ограниченная форма оператора DML, которая используется только для заполнения данных из базы данных. Базовый синтаксис оператора SELECT следующий
Выбрать <столбец_1>, <столбец_2>, . из таблицы; |
 .
.В синтаксисе ключевое слово SELECT дает указание базе данных извлекать данные.Второй сегмент — это список столбцов или выражений, которые вы хотите получить в результирующем наборе. Здесь вы можете указать список столбцов или выражений или указать звездочку (*). Теперь, когда мы указываем звездочку (*), запрос заполняет все столбцы.
Наконец, в ключевом слове FROM вы можете указать имя таблицы или представления. Если вы хотите отфильтровать данные или отсортировать данные, ключевые слова будут помещены после имени таблицы или представления.
В синтаксисе точка с запятой используется в качестве разделителя операторов. Точка с запятой считается концом запроса. Если вы хотите получить результат нескольких запросов, вы должны указать точку с запятой в конце отдельного запроса. Когда мы указываем его в конце нескольких запросов, MySQL выполняет их индивидуально и генерирует для них отдельные наборы результатов.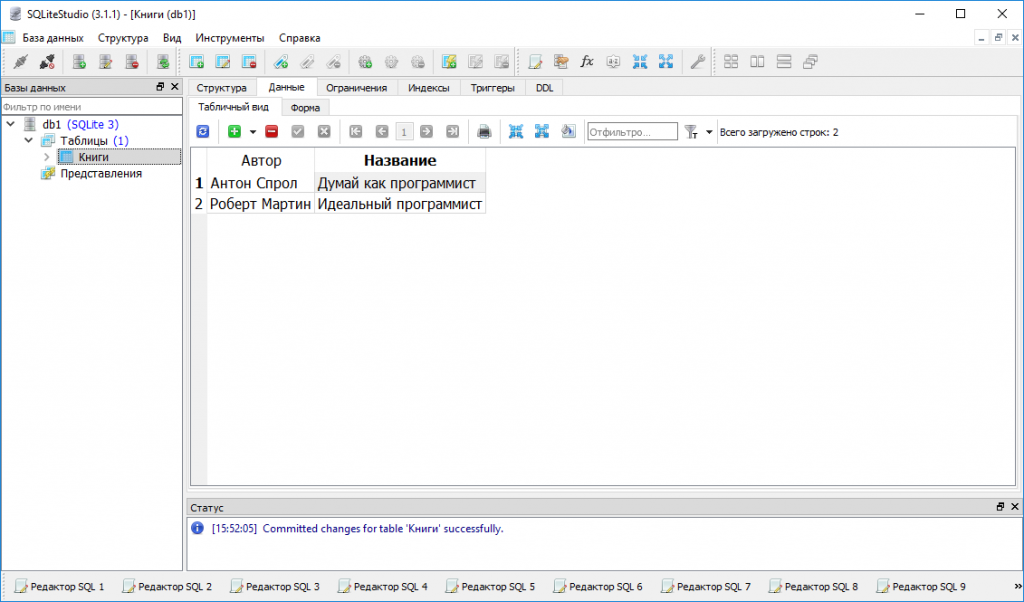
Примечание: Многие пользователи спрашивают, как мы можем запустить несколько операторов SELECT в MySQL Workbench.Если мы хотим использовать в запросе несколько операторов SELECT, вы должны указать точку с запятой в конце запроса. Набор результатов запросов будет отображаться на нескольких вкладках окна вывода.
Использование оператора SELECT для получения данных определенных столбцов таблицы
Например, я хочу заполнить только столбцы first_name, last_name и email таблицы клиентов базы данных sakila. Запрос должен быть записан следующим образом:
использовать сакила; выберите first_name, last_name, email от клиента; |
Результат ниже
Использование оператора SELECT для получения всех столбцов таблицы
Например, я хочу заполнить все столбцы таблицы клиентов базы данных sakila. Запрос должен быть записан следующим образом:
Запрос должен быть записан следующим образом:
использовать сакила; выбрать * от заказчика; |
Результат показан ниже:
Несколько замечаний об использовании start (*) в операторе Select
- Всегда помните, никогда не используйте таблицу SELECT * FROM , если в этом нет необходимости. SELECT * FROM всегда создает ненужные операции ввода-вывода в базе данных.Например, у вас есть таблица со столбцом, в котором хранятся данные BLOB, и когда вы используете SELECT * FROM для этой таблицы, запрос также заполняет столбец BLOB, который генерирует огромное количество операций ввода-вывода.
- Предположим, вы разработали приложение, и в нем вы сохраняете вывод запроса в наборе данных, и вы используете индекс столбцов. Теперь из-за бизнес-требований вам нужно добавить в таблицу больше столбцов. В таких случаях индекс столбцов будет изменен, поэтому в наборе данных вы получите неожиданный набор результатов
- Иногда он показывает конфиденциальную информацию пользователям.Например, индекс столбца user_id равен 0, индекс столбца first_name равен 2. Теперь кто-то добавляет столбец password в позицию индекса 1. Теперь на основе индекса столбцов, определенных в наборе данных. , приложение отображает данные в текстовых полях. Теперь, когда веб-страницы загружаются, в текстовом поле, в котором отображается имя пользователя, отображается пароль пользователя. Это одна из редких ошибок, но она может случиться с людьми, которые разрабатывают приложение впервые.
- Другой пример — это специальный запрос.Если вы используете в запросе SELECT * FROM , он также покажет столбец пароля. Это распространенная ошибка, но в настоящее время сервер базы данных MySQL достаточно умен, чтобы скрыть конфиденциальную информацию с помощью функции маскирования данных. Вы можете узнать больше об этом из этой статьи, Маскирование корпоративных данных в MySQL.
 В таких случаях индекс столбцов будет изменен, поэтому в наборе данных вы получите неожиданный набор результатов
В таких случаях индекс столбцов будет изменен, поэтому в наборе данных вы получите неожиданный набор результатов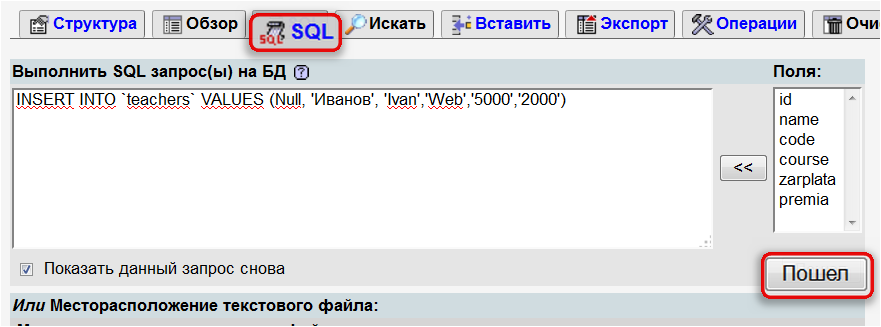 Вы можете узнать больше об этом из этой статьи, Маскирование корпоративных данных в MySQL.
Вы можете узнать больше об этом из этой статьи, Маскирование корпоративных данных в MySQL.Резюме
В этой статье я объяснил, как мы можем создать схему существующей базы данных MySQL с помощью MySQL Workbench. Более того, я также объяснил оператор SELECT на сервере базы данных MySQL.В следующей статье я расскажу, как мы можем фильтровать и сортировать данные из таблицы. Быть в курсе..!!
Содержание
Нисарг Упадхай — администратор баз данных SQL Server и сертифицированный специалист Microsoft, имеющий более 8 лет опыта администрирования SQL Server и 2 года администрирования баз данных Oracle 10g. Он имеет опыт проектирования баз данных, настройки производительности, резервного копирования и восстановления, настройки высокой доступности и аварийного восстановления, миграции и обновления баз данных.Он получил степень бакалавра технических наук Университета Ганпат. С ним можно связаться по nisargupadhyay87@outlook.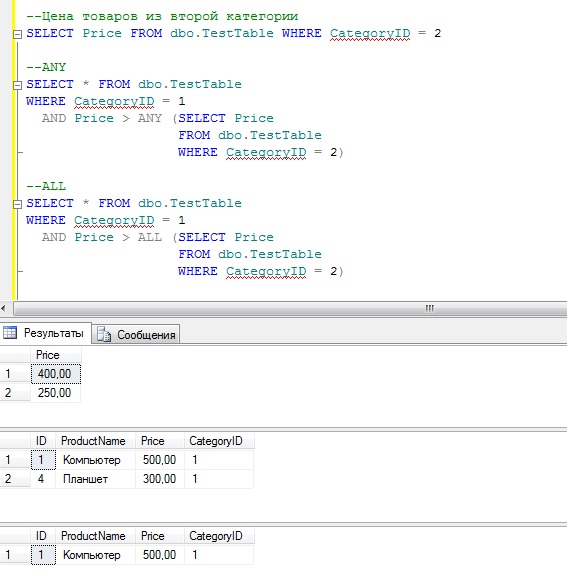 com
com
Query Store — База данных Azure для MySQL
- 7 минут на чтение
В этой статье
Применимо к: База данных Azure для MySQL 5.7, 8.0
Функция хранилища запросов в базе данных Azure для MySQL позволяет отслеживать производительность запросов с течением времени. Хранилище запросов упрощает устранение неполадок, связанных с производительностью, помогая быстро находить самые длительные и наиболее ресурсоемкие запросы. Хранилище запросов автоматически сохраняет историю запросов и статистику времени выполнения, а также сохраняет их для просмотра. Он разделяет данные по временным окнам, чтобы вы могли видеть шаблоны использования базы данных. Данные для всех пользователей, баз данных и запросов хранятся в базе данных схемы mysql в экземпляре База данных Azure для MySQL.
Данные для всех пользователей, баз данных и запросов хранятся в базе данных схемы mysql в экземпляре База данных Azure для MySQL.
Общие сценарии использования хранилища запросов
Хранилище запросов можно использовать в нескольких сценариях, включая следующие:
- Обнаружение регрессивных запросов
- Определение количества выполнений запроса в заданном временном окне
- Сравнение среднего времени выполнения запроса по временным окнам, чтобы увидеть большие отклонения
Включение хранилища запросов
Query Store является дополнительной функцией, поэтому по умолчанию он не активен на сервере.Хранилище запросов включено или отключено глобально для всех баз данных на данном сервере и не может быть включено или выключено для каждой базы данных.
Включить хранилище запросов с помощью портала Azure
- Войдите на портал Azure и выберите сервер базы данных Azure для MySQL.
- Выберите Параметры сервера в разделе меню Настройки .
- Найдите параметр query_store_capture_mode.
- Установите значение ВСЕ и Сохраните .

Чтобы включить статистику ожидания в хранилище запросов:
- Найдите параметр query_store_wait_sampling_capture_mode.
- Установите значение ВСЕ и Сохраните .
Подождите до 20 минут, пока первый пакет данных сохранится в базе данных mysql.
Информация в хранилище запросов
Query Store имеет два магазина:
- Хранилище статистики времени выполнения для сохранения информации статистики выполнения запроса.
- Хранилище статистики ожидания для сохраняющейся информации статистики ожидания.
Чтобы свести к минимуму использование пространства, статистика выполнения в хранилище статистики выполнения агрегируется за фиксированное настраиваемое временное окно. Информация в этих хранилищах отображается при запросе представлений хранилища запросов.
Следующий запрос возвращает информацию о запросах в хранилище запросов:
ВЫБРАТЬ * ИЗ mysql. query_store;
 query_store;
query_store;
Или этот запрос для статистики ожидания:
ВЫБРАТЬ * ИЗ mysql.query_store_wait_stats;
Поиск запросов ожидания
Примечание
Статистику ожидания нельзя включать в часы пиковой нагрузки или включать на неопределенный срок для чувствительных рабочих нагрузок.
Для рабочих нагрузок, выполняемых с высокой загрузкой ЦП или на серверах, настроенных с меньшим количеством виртуальных ядер, будьте осторожны при включении статистики ожидания. Его нельзя включать на неопределенный срок.
Типы событий ожидания объединяют различные события ожидания в сегменты по сходству. Хранилище запросов предоставляет тип события ожидания, конкретное имя события ожидания и рассматриваемый запрос.Возможность сопоставить эту информацию об ожидании со статистикой времени выполнения запроса означает, что вы можете получить более глубокое понимание того, что влияет на характеристики производительности запроса.
Вот несколько примеров того, как вы можете получить больше информации о своей рабочей нагрузке, используя статистику ожидания в Query Store:
| Наблюдение | Действие |
|---|---|
| Ожидание High Lock | Проверьте тексты запросов на наличие затронутых запросов и определите целевые сущности. Поищите в хранилище запросов другие запросы, изменяющие ту же сущность, которые часто выполняются и / или имеют большую продолжительность. После определения этих запросов рассмотрите возможность изменения логики приложения для улучшения параллелизма или использования менее строгого уровня изоляции. Поищите в хранилище запросов другие запросы, изменяющие ту же сущность, которые часто выполняются и / или имеют большую продолжительность. После определения этих запросов рассмотрите возможность изменения логики приложения для улучшения параллелизма или использования менее строгого уровня изоляции. |
| Ожидание ввода-вывода высокого буфера | Найдите запросы с большим количеством физических чтений в хранилище запросов. Если они соответствуют запросам с большим количеством ожидания ввода-вывода, рассмотрите возможность введения индекса для базового объекта, чтобы выполнять поиск вместо сканирования.Это минимизирует накладные расходы ввода-вывода запросов. Ознакомьтесь с рекомендациями по производительности для вашего сервера на портале, чтобы узнать, есть ли рекомендации по индексам для этого сервера, которые могли бы оптимизировать запросы. |
| Ожидание высокой памяти | Найдите запросы с наибольшим потреблением памяти в хранилище запросов. Эти запросы, вероятно, задерживают дальнейшее выполнение затронутых запросов. Проверьте Рекомендации по производительности для вашего сервера на портале, чтобы узнать, есть ли рекомендации по индексам, которые могут оптимизировать эти запросы. Эти запросы, вероятно, задерживают дальнейшее выполнение затронутых запросов. Проверьте Рекомендации по производительности для вашего сервера на портале, чтобы узнать, есть ли рекомендации по индексам, которые могут оптимизировать эти запросы. |
Варианты конфигурации
Когда включено хранилище запросов, данные сохраняются в 15-минутных окнах агрегации, до 500 отдельных запросов на окно.
Следующие параметры доступны для настройки параметров хранилища запросов.
| Параметр | Описание | По умолчанию | Диапазон |
|---|---|---|---|
| query_store_capture_mode | Включите / выключите функцию хранилища запросов в зависимости от значения.Примечание. Если performance_schema выключена, включение query_store_capture_mode включит performance_schema и подмножество инструментов схемы производительности, необходимых для этой функции. | ВСЕ | НЕТ, ВСЕ |
| query_store_capture_interval | Интервал захвата хранилища запросов в минутах. Позволяет указать интервал агрегирования показателей запроса | 15 | 5–60 |
| query_store_capture_utility_queries | Включение или выключение для захвата всех служебных запросов, выполняемых в системе. | НЕТ | ДА, НЕТ |
| query_store_retention_period_in_days | Временное окно в днях для хранения данных в хранилище запросов. | 7 | 1–30 |
Следующие параметры применяются специально для статистики ожидания.
| Параметр | Описание | По умолчанию | Диапазон |
|---|---|---|---|
| query_store_wait_sampling_capture_mode | Позволяет включить / выключить статистику ожидания.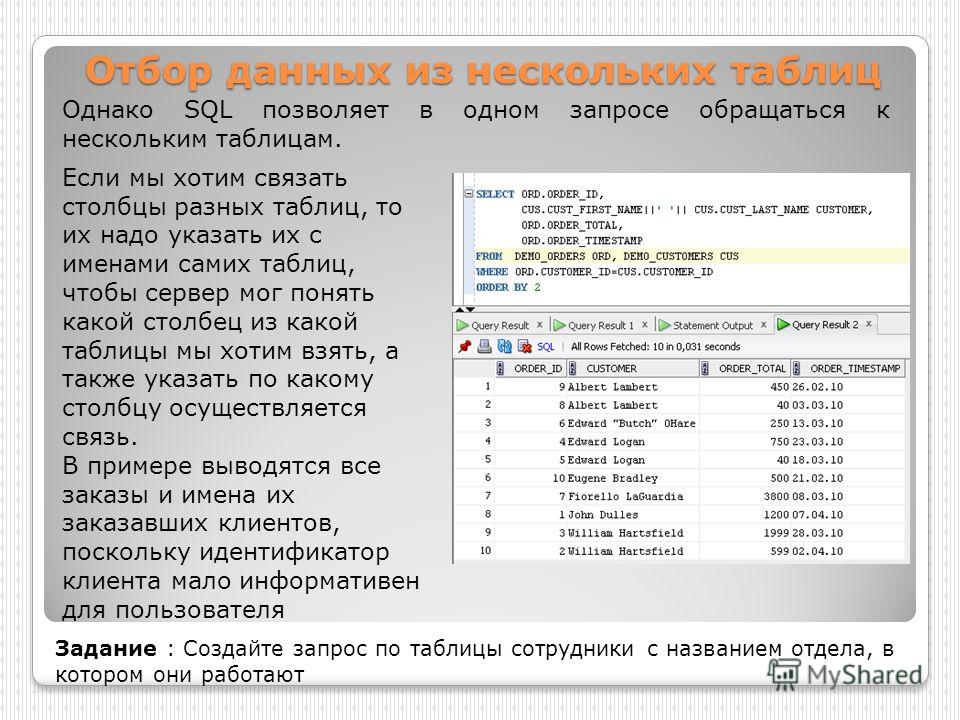 | НЕТ | НЕТ, ВСЕ |
| query_store_wait_sampling_frequency | Изменяет частоту ожидания выборки в секундах. От 5 до 300 секунд. | 30 | 5-300 |
Примечание
В настоящее время query_store_capture_mode заменяет эту конфигурацию, что означает, что и query_store_capture_mode и query_store_wait_sampling_capture_mode должны быть включены для ВСЕХ, чтобы статистика ожидания работала.Если query_store_capture_mode выключен, то статистика ожидания также отключается, поскольку статистика ожидания использует включенную performance_schema и query_text, захваченный хранилищем запросов.
Используйте портал Azure или Azure CLI, чтобы получить или установить другое значение для параметра.
Виды и функции
Просмотр и управление хранилищем запросов с помощью следующих представлений и функций. Любой человек с публичной ролью привилегий select может использовать эти представления для просмотра данных в хранилище запросов. Эти представления доступны только в базе данных mysql .
Эти представления доступны только в базе данных mysql .
Запросы нормализуются с учетом их структуры после удаления литералов и констант. Если два запроса идентичны, за исключением буквальных значений, они будут иметь одинаковый хэш.
mysql.query_store
Это представление возвращает все данные в хранилище запросов. Есть одна строка для каждого отдельного идентификатора базы данных, идентификатора пользователя и идентификатора запроса.
| Имя | Тип данных | IS_NULLABLE | Описание |
|---|---|---|---|
имя_схемы | varchar (64) | НЕТ | Имя схемы |
query_id | bigint (20) | НЕТ | Уникальный идентификатор, сгенерированный для конкретного запроса, если тот же запрос выполняется в другой схеме, будет сгенерирован новый идентификатор |
timestamp_id | метка времени | НЕТ | Отметка времени, в которой выполняется запрос. Это основано на конфигурации query_store_interval Это основано на конфигурации query_store_interval |
query_digest_text | длинный текст | НЕТ | Нормализованный текст запроса после удаления всех литералов |
query_sample_text | длинный текст | НЕТ | Первое появление фактического запроса с литералами |
query_digest_truncated | бит | ДА | Обрезан ли текст запроса.Значение будет Да, если запрос длиннее 1 КБ |
Execution_count | bigint (20) | НЕТ | Количество раз, когда запрос был выполнен для этого идентификатора временной метки / в течение заданного периода интервала |
warning_count | bigint (20) | НЕТ | Количество предупреждений, сгенерированных этим запросом во время внутреннего |
error_count | bigint (20) | НЕТ | Количество ошибок, сгенерированных этим запросом за интервал |
sum_timer_wait | двойной | ДА | Общее время выполнения этого запроса за интервал |
avg_timer_wait | двойной | ДА | Среднее время выполнения этого запроса за интервал |
min_timer_wait | двойной | ДА | Минимальное время выполнения этого запроса |
max_timer_wait | двойной | ДА | Максимальное время выполнения |
sum_lock_time | bigint (20) | НЕТ | Общее время, затраченное на все блокировки для выполнения этого запроса в течение этого временного окна |
sum_rows_affected | bigint (20) | НЕТ | Число затронутых строк |
sum_rows_sent | bigint (20) | НЕТ | Количество строк, отправленных клиенту |
sum_rows_examined | bigint (20) | НЕТ | Количество проверенных строк |
sum_select_full_join | bigint (20) | НЕТ | Количество полных соединений |
sum_select_scan | bigint (20) | НЕТ | Количество выбранных сканирований |
sum_sort_rows | bigint (20) | НЕТ | Количество отсортированных строк |
sum_no_index_used | bigint (20) | НЕТ | Количество раз, когда запрос не использовал индексы |
sum_no_good_index_used | bigint (20) | НЕТ | Количество раз, когда механизм выполнения запросов не использовал хорошие индексы |
sum_created_tmp_tables | bigint (20) | НЕТ | Общее количество созданных временных таблиц |
sum_created_tmp_disk_tables | bigint (20) | НЕТ | Общее количество временных таблиц, созданных на диске (генерирует ввод-вывод) |
first_seen | метка времени | НЕТ | Первое вхождение (UTC) запроса во время окна агрегирования |
last_seen | метка времени | НЕТ | Последнее вхождение (UTC) запроса во время этого окна агрегирования |
MySQL. query_store_wait_stats
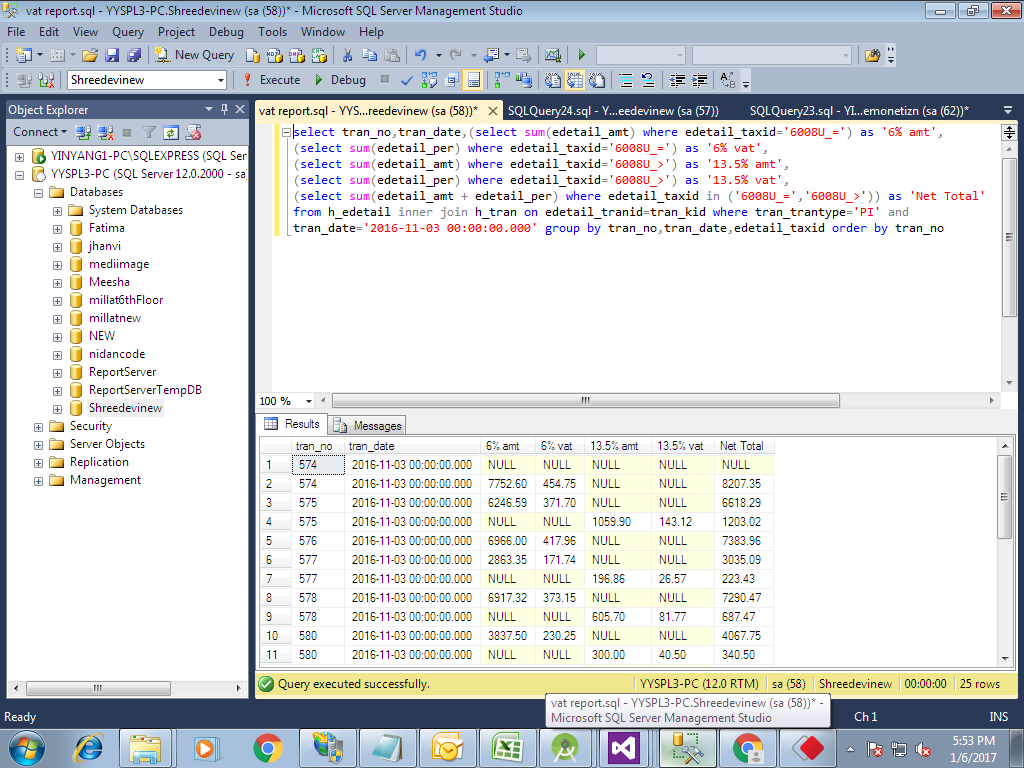 query_store_wait_stats
query_store_wait_stats Это представление возвращает данные событий ожидания в хранилище запросов. Есть одна строка для каждого отдельного идентификатора базы данных, идентификатора пользователя, идентификатора запроса и события.
| Имя | Тип данных | IS_NULLABLE | Описание |
|---|---|---|---|
interval_start | метка времени | НЕТ | Начало интервала (с шагом 15 минут) |
interval_end | метка времени | НЕТ | Конец интервала (с шагом 15 минут) |
query_id | bigint (20) | НЕТ | Сгенерированный уникальный идентификатор для нормализованного запроса (из хранилища запросов) |
query_digest_id | varchar (32) | НЕТ | Нормализованный текст запроса после удаления всех литералов (из хранилища запросов) |
query_digest_text | длинный текст | НЕТ | Первое появление фактического запроса с литералами (из хранилища запросов) |
event_type | varchar (32) | НЕТ | Категория события ожидания |
имя_события | varchar (128) | НЕТ | Имя события ожидания |
count_star | bigint (20) | НЕТ | Число событий ожидания, выбранных в течение интервала для запроса |
sum_timer_wait_ms | двойной | НЕТ | Общее время ожидания (в миллисекундах) этого запроса в интервале |
Функции
| Имя | Описание |
|---|---|
MySQL. | Удаляет все данные хранилища запросов до указанной отметки времени |
mysql.az_procedure_purge_querystore_event (TIMESTAMP) | Удаляет все данные событий ожидания до указанной отметки времени |
mysql.az_procedure_purge_recommendation (TIMESTAMP) | Удаляет рекомендации, срок действия которых предшествует указанной отметке времени |
 az_purge_querystore_data (TIMESTAMP)
az_purge_querystore_data (TIMESTAMP) Ограничения и известные проблемы
- Если на сервере MySQL включен параметр
default_transaction_read_only, хранилище запросов не может захватывать данные. Функциональность хранилища запросов - может быть прервана при обнаружении длинных запросов Unicode (> = 6000 байт).
- Срок хранения статистики ожидания составляет 24 часа.
- Статистика ожидания использует выборку для захвата части событий. Частоту можно изменить с помощью параметра
query_store_wait_sampling_frequency.
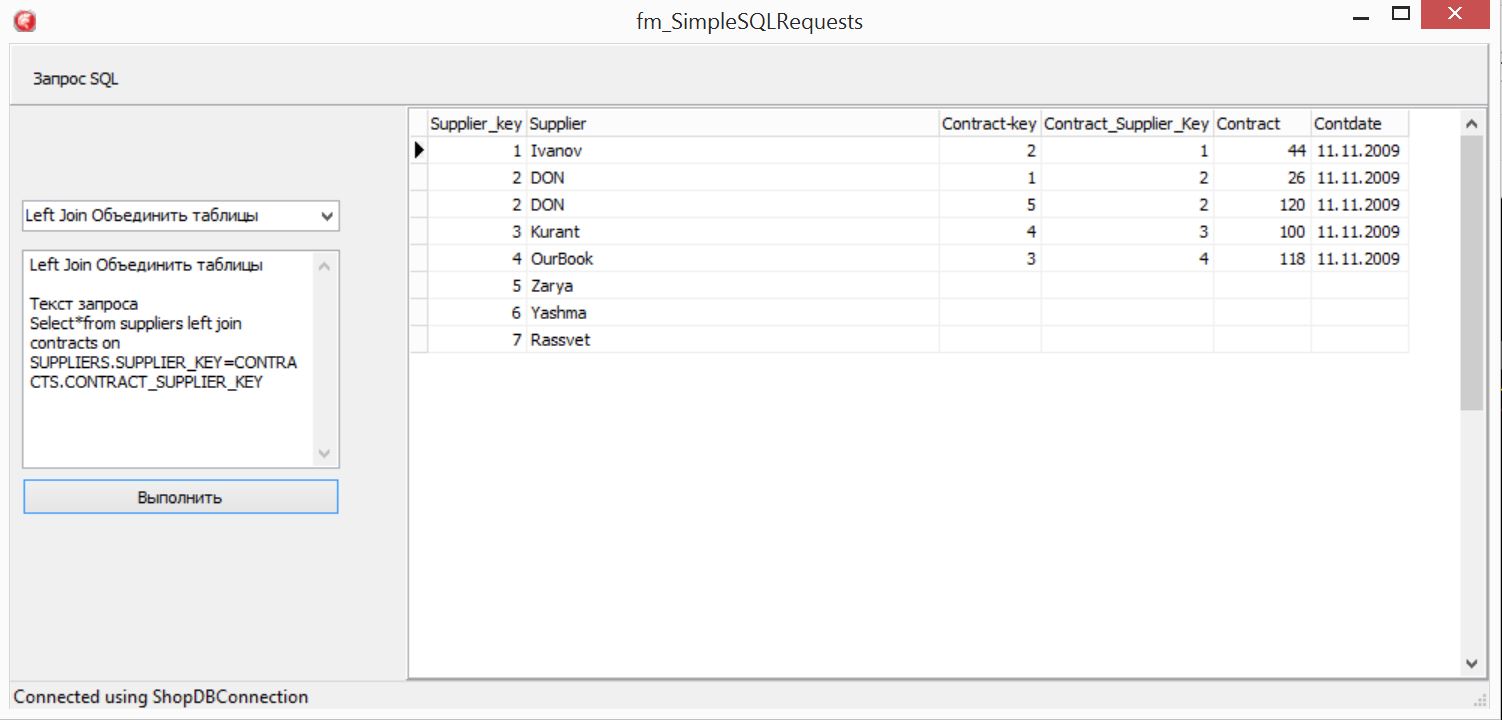
Следующие шаги
Identify and Kill Queries with MySQL Command-Line Tool
Длительные запросы MySQL не позволяют другим транзакциям обращаться к таблицам, необходимым для выполнения запроса, оставляя ваших пользователей на удержании.Чтобы убить эти запросы, вам потребуется доступ к базе данных MySQL среды.
Повышение производительности веб-сайта
Сделайте ваш сайт быстрее. Посетите наш бесплатный еженедельный семинар, где вы узнаете о кешировании страниц с помощью нашего Advanced CDN, нашего внутреннего кеша Redis и узнаете, как использовать New Relic для мониторинга производительности.
После успешного создания локального MySQL-соединения с базой данных сайта выполните следующую команду, чтобы отобразить список активных потоков:
Просмотрите поле Time , чтобы определить самый длинный выполняющийся запрос, и выполните следующую команду, чтобы завершить его.В приведенном ниже примере замените на идентификатор запроса, который вы хотите завершить:
Если большое количество неверных запросов блокирует допустимые запросы, вы можете очистить их, не выполняя kill каждый раз. индивидуальная резьба.
индивидуальная резьба.
Выполните следующее, чтобы сгенерировать kill команд из таблицы PROCESSLIST :
mysql> SELECT GROUP_CONCAT (CONCAT ('KILL', id, ';') SEPARATOR '') 'Вставьте следующий запрос, чтобы уничтожить все процессы 'FROM information_schema.processlist WHERE user <> 'system user' \ G Скопируйте предоставленный запрос в выходные данные и выполните его в соответствии с инструкциями.
Устранение неполадок с помощью New Relic
Чтобы лучше понять, что происходит с вашими запросами, взгляните на Устранение неполадок MySQL с помощью New Relic APM. Используя наши интегрированные службы отчетности с New Relic Pro, вы можете изолировать проблемы производительности MySQL на своих сайтах Drupal или WordPress.
Просмотр журналов медленных запросов
Используйте журнал медленных запросов MySQL вашего сайта для устранения неполадок MySQL и выявления серьезных проблем с производительностью.
Включить Redis
Большинство фреймворков веб-сайтов, таких как Drupal и WordPress, используют базу данных для кэширования внутренних «объектов» приложения, создание которых может быть дорогостоящим (деревья меню, результаты фильтрации и т. Д.), А также для хранения кэшированного содержимого страницы. Поскольку база данных также обрабатывает множество запросов для обычных запросов страниц, это наиболее частое узкое место, вызывающее увеличение времени загрузки.
Redis предоставляет альтернативный механизм кэширования, снимающий эту работу с базы данных, что имеет жизненно важное значение для масштабирования до большего числа вошедших в систему пользователей.Он также предоставляет ряд других полезных функций для разработчиков, которые хотят использовать его для управления очередями или для собственного кэширования.
Рассмотрите возможность репликации MySQL (WordPress)
Типичные сайты WordPress ограничены возможностями одной базы данных для обслуживания запросов на чтение и запись.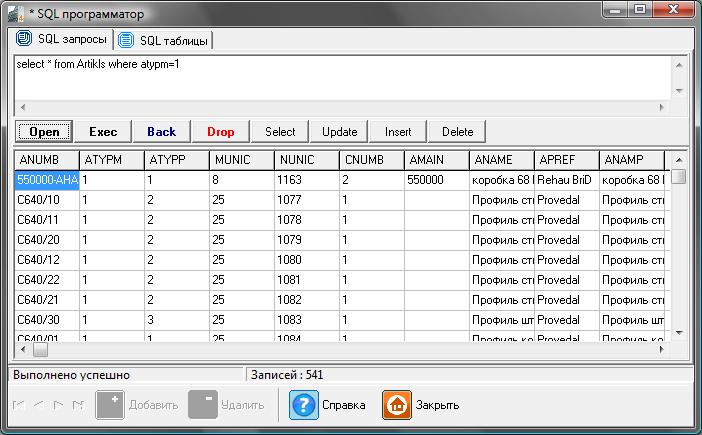 В результате на сайтах с высоким трафиком могут возникать задержки при выполнении запросов. Репликация MySQL быстро копирует контент из «главной» базы данных в одну или несколько «реплик» баз данных. Это позволяет распределять запросы по нескольким базам данных, чтобы улучшить производительность сайта и время загрузки.
В результате на сайтах с высоким трафиком могут возникать задержки при выполнении запросов. Репликация MySQL быстро копирует контент из «главной» базы данных в одну или несколько «реплик» баз данных. Это позволяет распределять запросы по нескольким базам данных, чтобы улучшить производительность сайта и время загрузки.
Понимание запросов MySQL с помощью EXPLAIN
Вы находитесь на новой работе в качестве администратора базы данных или инженера по данным и просто заблудились, пытаясь понять, что эти безумно выглядящие запросы должны означать и делать. Почему пять объединений и почему ORDER BY используется в подзапросе еще до того, как произойдет одно из соединений? Помните, что вас наняли по какой-то причине — скорее всего, эта причина также связана со многими запутанными запросами, которые были созданы и отредактированы за последнее десятилетие.
Объяснить
Ключевое слово EXPLAIN используется в различных базах данных SQL и предоставляет информацию о том, как ваша база данных SQL выполняет запрос. В MySQL
В MySQL EXPLAIN может использоваться перед запросом, начинающимся с SELECT , INSERT , DELETE , REPLACE и UPDATE . Для простого запроса это будет выглядеть так:
EXPLAIN SELECT * FROM foo WHERE foo.bar = 'инфраструктура как услуга' ИЛИ foo.бар = 'iaas'; Вместо обычного вывода результатов MySQL будет показывать план выполнения оператора, объясняя, какие процессы и в каком порядке происходят при выполнении оператора.
Примечание : Если EXPLAIN не работает для вас, возможно, у пользователя вашей базы данных нет привилегии SELECT для таблиц или представлений, которые вы используете в своем операторе.
EXPLAIN — отличный инструмент для быстрого исправления медленных запросов. Хотя это, безусловно, может вам помочь, это не избавит вас от необходимости структурного мышления и хорошего обзора существующих моделей данных. Часто самым простым решением и самым быстрым советом является добавление индекса к столбцам конкретной таблицы, о которых идет речь, если они используются во многих запросах с проблемами производительности. Однако будьте осторожны; не используйте слишком много индексов, так как это может быть контрпродуктивным. Чтение индексов и в таблице имеет смысл только в том случае, если таблица имеет значительное количество строк и вам нужно всего несколько точек данных. Если вы извлекаете огромный набор результатов из таблицы и часто запрашиваете разные столбцы, индекс для каждого столбца не имеет смысла и больше снижает производительность, чем помогает.Чтобы узнать больше о фактических расчетах индекса по сравнению с отсутствием индекса, прочтите «Оценка производительности» в официальной документации MySQL.
Часто самым простым решением и самым быстрым советом является добавление индекса к столбцам конкретной таблицы, о которых идет речь, если они используются во многих запросах с проблемами производительности. Однако будьте осторожны; не используйте слишком много индексов, так как это может быть контрпродуктивным. Чтение индексов и в таблице имеет смысл только в том случае, если таблица имеет значительное количество строк и вам нужно всего несколько точек данных. Если вы извлекаете огромный набор результатов из таблицы и часто запрашиваете разные столбцы, индекс для каждого столбца не имеет смысла и больше снижает производительность, чем помогает.Чтобы узнать больше о фактических расчетах индекса по сравнению с отсутствием индекса, прочтите «Оценка производительности» в официальной документации MySQL.
Вещи, которые вы хотите избежать везде, где это возможно и применимо, — это сортировка и вычислений внутри запросов. Если вы думаете, что не можете избежать вычислений в своих запросах: да, вы можете.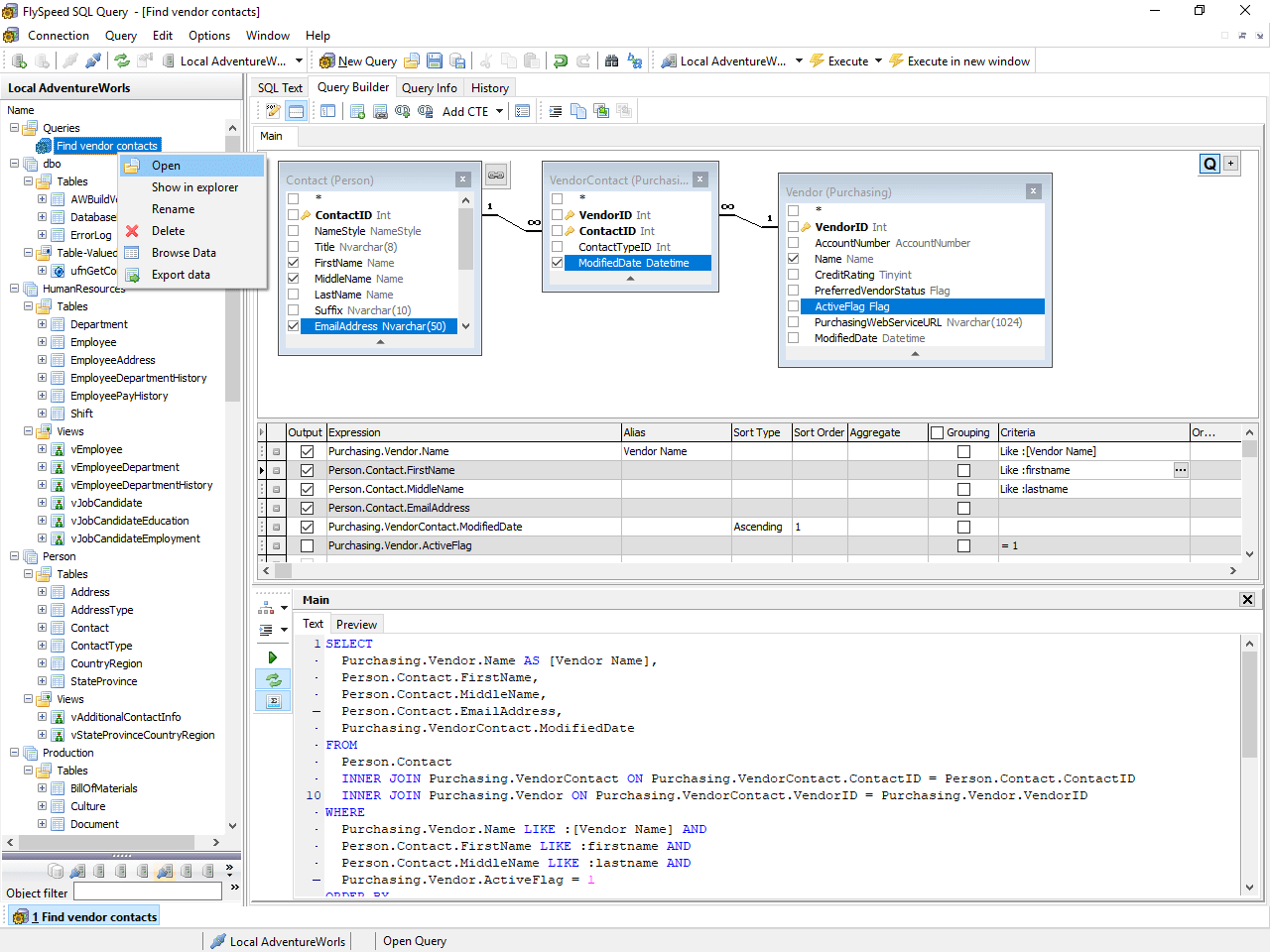 Запишите набор результатов в другом месте и вычислите точку данных вне запроса; это снизит нагрузку на базу данных и, следовательно, будет лучше для вашего приложения.Просто убедитесь, что вы задокументировали, почему вы выполняете вычисления в своем приложении, а не сразу получаете результат в SQL. В противном случае придет следующий администратор или разработчик базы данных, и у него возникнет великолепная идея использовать вычисление в запросе типа: «О, смотрите, мой предшественник даже не знал, что вы можете сделать это в SQL!» Некоторые команды разработчиков, у которых еще не было неизбежной проблемы с умирающими базами данных, могут использовать вычисления в запросах для определения разницы между датами или аналогичными точками данных.
Запишите набор результатов в другом месте и вычислите точку данных вне запроса; это снизит нагрузку на базу данных и, следовательно, будет лучше для вашего приложения.Просто убедитесь, что вы задокументировали, почему вы выполняете вычисления в своем приложении, а не сразу получаете результат в SQL. В противном случае придет следующий администратор или разработчик базы данных, и у него возникнет великолепная идея использовать вычисление в запросе типа: «О, смотрите, мой предшественник даже не знал, что вы можете сделать это в SQL!» Некоторые команды разработчиков, у которых еще не было неизбежной проблемы с умирающими базами данных, могут использовать вычисления в запросах для определения разницы между датами или аналогичными точками данных.
Общее практическое правило для запросов SQL выглядит следующим образом:
Будьте точны и получайте только те результаты, которые вам нужны.
Давайте проверим более сложный запрос…
ВЫБЕРИТЕ site_options. domain, sites_users.user, site_taxes.monthly_statement_fee, site.name, AVG (цена) AS average_product_price FROM sites_orders_products, site_taxes, site, sites_users, site_options WHERE site_options. user_id И site_taxes.site_id = site.id И sites_orders_products.site_id = site.id ГРУППА ПО site.id ORDER BY site.date_modified desc LIMIT 5;
+ ----------------------------- + ------------------- ---------- + ----------------------- + --------------- --------------------------- + ---------------------- - +
| домен | пользователь | month_statement_fee | имя | average_product_price |
+ ----------------------------- + ------------------- ---------- + ----------------------- + --------------- --------------------------- + ---------------------- - +
| www.xxxxxxxxxxxxxxxxxxx.com | [email protected] | 0,50 | xxxxxxxxxxxxxxxxxxxxx | 3.254781 |
| www.xxxxxxxxxxx.com | [email protected] | 0,50 | xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx | 9.471022 |
| | [email protected] | 0.00 | xxxxxxxxxxxxxxxxx | 8. 646297 |
| | [email protected] | 0.00 | xxxxxxxxxxxxxxx | 9.042460 |
| | [email protected] | 0.00 | xxxxxxxxxxxxxxxxxx | 6.679182 |
+ ----------------------------- + ------------------- ---------- + ----------------------- + --------------- --------------------------- + ---------------------- - +
5 рядов в комплекте (0,00 сек)  domain, sites_users.user, site_taxes.monthly_statement_fee, site.name, AVG (цена) AS average_product_price FROM sites_orders_products, site_taxes, site, sites_users, site_options WHERE site_options. user_id И site_taxes.site_id = site.id И sites_orders_products.site_id = site.id ГРУППА ПО site.id ORDER BY site.date_modified desc LIMIT 5;
+ ----------------------------- + ------------------- ---------- + ----------------------- + --------------- --------------------------- + ---------------------- - +
| домен | пользователь | month_statement_fee | имя | average_product_price |
+ ----------------------------- + ------------------- ---------- + ----------------------- + --------------- --------------------------- + ---------------------- - +
| www.xxxxxxxxxxxxxxxxxxx.com |
domain, sites_users.user, site_taxes.monthly_statement_fee, site.name, AVG (цена) AS average_product_price FROM sites_orders_products, site_taxes, site, sites_users, site_options WHERE site_options. user_id И site_taxes.site_id = site.id И sites_orders_products.site_id = site.id ГРУППА ПО site.id ORDER BY site.date_modified desc LIMIT 5;
+ ----------------------------- + ------------------- ---------- + ----------------------- + --------------- --------------------------- + ---------------------- - +
| домен | пользователь | month_statement_fee | имя | average_product_price |
+ ----------------------------- + ------------------- ---------- + ----------------------- + --------------- --------------------------- + ---------------------- - +
| www.xxxxxxxxxxxxxxxxxxx.com |  646297 |
| |
646297 |
| | … и его вывод EXPLAIN .
+ ------ + ------------- + -------------------------- ------- + -------- + ----------------- + --------------- + --------- + --------------------------------- + ----- - + ----------- +
| id | select_type | стол | тип | possible_keys | ключ | key_len | ref | строки | Экстра |
+ ------ + ------------- + ---------------------------- ----- + -------- + ----------------- + --------------- + - -------- + --------------------------------- + ------ + ----------- +
| 1 | ПРОСТО | сайты | индекс | ПЕРВИЧНЫЙ, user_id | ПЕРВИЧНЫЙ | 4 | NULL | 858 | Использование временных; Использование файловой сортировки |
| 1 | ПРОСТО | sites_options | ref | site_id | site_id | 4 | оказание услуг. sites.id | 1 | |
| 1 | ПРОСТО | sites_taxes | ref | site_id | site_id | 4 | service.sites.id | 1 | |
| 1 | ПРОСТО | sites_users | eq_ref | ПЕРВИЧНЫЙ | ПЕРВИЧНЫЙ | 4 | service.sites.user_id | 1 | |
| 1 | ПРОСТО | sites_orders_products | ref | site_id | site_id | 4 | service.sites.id | 4153 | | //
+ ------ + ------------- + ---------------------------- ----- + -------- + ----------------- + --------------- + - -------- + --------------------------------- + ------ + ----------- +
5 рядов в наборе (0.00 сек)  sites.id | 1 | |
| 1 | ПРОСТО | sites_taxes | ref | site_id | site_id | 4 | service.sites.id | 1 | |
| 1 | ПРОСТО | sites_users | eq_ref | ПЕРВИЧНЫЙ | ПЕРВИЧНЫЙ | 4 | service.sites.user_id | 1 | |
| 1 | ПРОСТО | sites_orders_products | ref | site_id | site_id | 4 | service.sites.id | 4153 | | //
+ ------ + ------------- + ---------------------------- ----- + -------- + ----------------- + --------------- + - -------- + --------------------------------- + ------ + ----------- +
5 рядов в наборе (0.00 сек)
sites.id | 1 | |
| 1 | ПРОСТО | sites_taxes | ref | site_id | site_id | 4 | service.sites.id | 1 | |
| 1 | ПРОСТО | sites_users | eq_ref | ПЕРВИЧНЫЙ | ПЕРВИЧНЫЙ | 4 | service.sites.user_id | 1 | |
| 1 | ПРОСТО | sites_orders_products | ref | site_id | site_id | 4 | service.sites.id | 4153 | | //
+ ------ + ------------- + ---------------------------- ----- + -------- + ----------------- + --------------- + - -------- + --------------------------------- + ------ + ----------- +
5 рядов в наборе (0.00 сек) Столбцы в выводе EXPLAIN вместе с столбцами, которые требуют особого внимания для выявления проблем, выделены жирным шрифтом:
-
id(идентификатор запроса) -
select_type(тип выписки) -
таблица(ссылка на таблицу) -
тип(соединительный тип) -
possible_keys(какие ключи могли быть использованы) -
ключ(ключ, который использовался) -
key_len(длина используемого ключа) -
ref(столбцы по сравнению с индексом) -
строк(количество найденных строк) -
Экстра(доп. Информация)
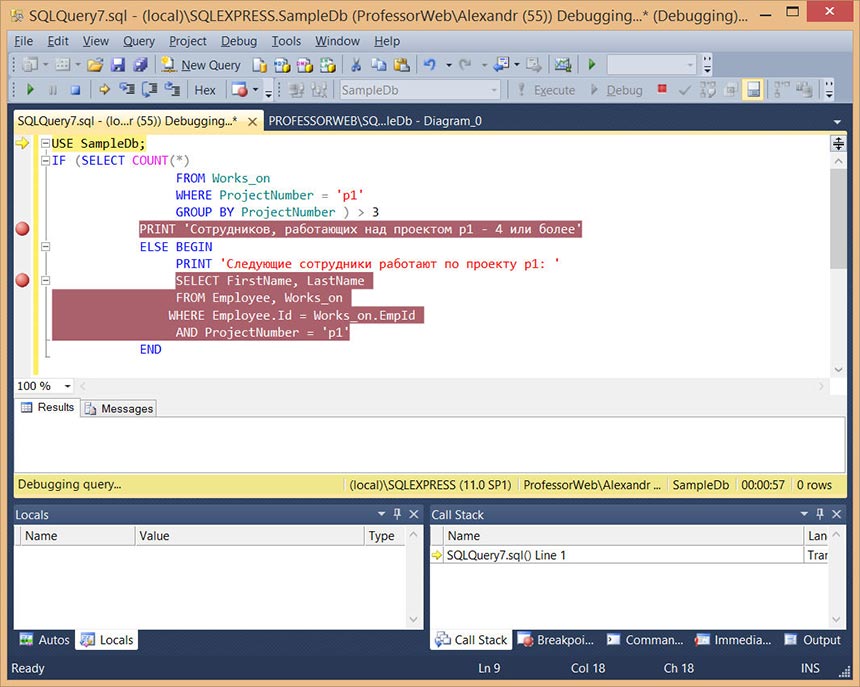 Информация)
Информация) Чем выше количество строк, в которых выполняется поиск, тем лучше должен быть уровень оптимизации индексов и точности запроса, чтобы максимизировать производительность.В столбце Extra показаны возможные действия, на которых вы могли бы сосредоточиться, чтобы улучшить свой запрос, если это применимо.
ПОКАЗАТЬ ПРЕДУПРЕЖДЕНИЯ;
Если запрос, который вы использовали с EXPLAIN , не разбирается правильно, вы можете ввести SHOW WARNINGS; в ваш редактор запросов MySQL, чтобы показать информацию о последнем операторе, который был запущен и не был диагностическим, т.е. он не будет отображать информацию для таких операторов, как SHOW FULL PROCESSLIST; . Хотя он не может дать надлежащий план выполнения запроса, как EXPLAIN , он может дать вам подсказки о тех фрагментах запроса, которые он может обработать.Допустим, мы используем запрос EXPLAIN SELECT * FROM foo WHERE foo. в любой данной базе данных, в которой фактически нет таблицы  bar = 'Infrastructure as a service' OR foo.bar = 'iaas';
bar = 'Infrastructure as a service' OR foo.bar = 'iaas'; foo . Результат MySQL будет:
ОШИБКА 1146 (42S02): Таблица «db.foo» не существует Если мы наберем ПОКАЗАТЬ ПРЕДУПРЕЖДЕНИЯ; вывод выглядит следующим образом:
+ ------- + ------ + -------------------------------- ----- +
| Уровень | Код | Сообщение |
+ ------- + ------ + ---------------------------------- --- +
| Ошибка | 1146 | Таблица 'db.foo 'не существует |
+ ------- + ------ + ---------------------------------- --- +
1 строка в комплекте (0,00 сек) Давайте попробуем это с намеренной синтаксической ошибкой.
EXPLAIN SELECT * FROM foo WHERE name = ///; Это генерирует следующие предупреждения:
> ПОКАЗАТЬ ПРЕДУПРЕЖДЕНИЯ;
+ ------- + ------ + ---------------------------------- ----------------------------------- +
| Уровень | Код | Сообщение |
+ ------- + ------ + ---------------------------------- ----------------------------------- +
| Ошибка | 1064 | У вас есть ошибка в синтаксисе SQL; (. ..) рядом с '///' в строке 1 |
+ ------- + ------ + ---------------------------------- ----------------------------------- + Этот вывод предупреждений довольно прост и сразу же отображается MySQL как вывод результата, но для более сложных запросов, которые не анализируются, все еще можно посмотреть, что происходит в тех фрагментах запроса, которые могут быть проанализированы. ПОКАЗАТЬ ПРЕДУПРЕЖДЕНИЯ; включает специальные маркеры, которые могут предоставлять полезную информацию, например:
-
(фрагмент запроса) -
(условие, выражение1, выражение2 ), если условиевстречается в этой конкретной части запроса. -
(фрагмент запроса) -
<временная таблица>: Здесь будет создана внутренняя таблица для сохранения временных результатов, например, в подзапросах перед объединениями.
Чтобы узнать больше об этих специальных маркерах, прочтите Extended Explain Output Format в официальной документации MySQL.
Долгосрочное решение
Есть несколько способов устранить основную причину плохой работы базы данных. Первое, на что следует обратить внимание, — это модель данных, то есть как структурированы данные и правильно ли вы используете базу данных? Для многих продуктов вполне подойдет база данных SQL. Следует помнить одну важную вещь — всегда отделять журналы доступа от обычной производственной базы данных, что, к сожалению, не происходит во многих компаниях. В большинстве случаев в этих случаях компания начинала с малого, росла и по сути все еще использовала одну и ту же базу данных, что означает, что они обращаются к одной и той же базе данных как для функций ведения журнала, так и для других транзакций.Это значительно снижает общую производительность, особенно по мере роста компании. Следовательно, очень важно создать подходящую и устойчивую модель данных.
Модель данных
Выбор модели данных, скорее всего, также покажет правильную форму базы данных (ов). Если ваш продукт не является очень простым, у вас, вероятно, будет несколько баз данных для нескольких вариантов использования — если вам нужно отображать числа, близкие к реальному времени, для журналов доступа, вам, скорее всего, понадобится высокопроизводительное хранилище данных, тогда как обычные транзакции могут происходить через SQL база данных, и у вас может быть база данных графов, которая также накапливает соответствующие точки данных обеих баз данных в механизм рекомендаций.
Программная архитектура всего продукта так же важна, как и сама база данных, так как плохой дизайн здесь приведет к возникновению узких мест, которые идут в сторону базы данных и замедляют все как со стороны программного обеспечения, так и того, что база данных может выводить. Вам нужно будет выбрать, подходят ли контейнеры для вашего продукта, является ли монолит лучшим способом справиться с вещами, может ли вы иметь основной монолит с несколькими микросервисами, нацеленными на другие функции, распространенные в другом месте, и как вы получаете доступ, собираете, обрабатываете , и хранить данные.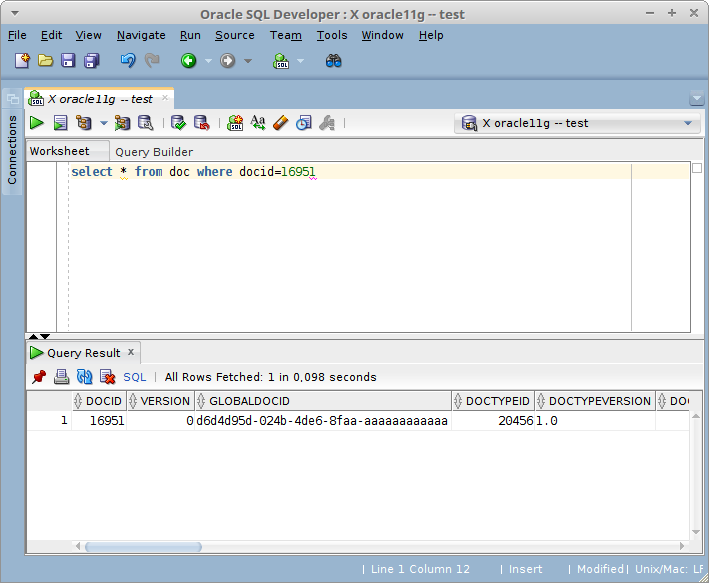
Оборудование
Так же важно, как и ваша общая структура, ваше оборудование является ключевым компонентом производительности вашей базы данных. Exoscale предлагает вам различные варианты экземпляров, которые вы можете использовать в зависимости от вашей транзакции и объема хранилища, а также желаемого времени отклика.
Крайне важно определить пиковые периоды вашего приложения и, следовательно, знать, когда по возможности опускать более медленные административные запросы. Дисковый ввод-вывод и сетевая статистика также должны быть приняты во внимание при проектировании времени транзакций и аналитики базы данных.
Резюме
В заключение кратко изложим основные моменты для долгосрочной работы:
- Создайте устойчивую модель данных, которая соответствует потребностям вашей компании.
- Выберите правильную форму базы данных.
- Используйте программную архитектуру, соответствующую вашему продукту.
