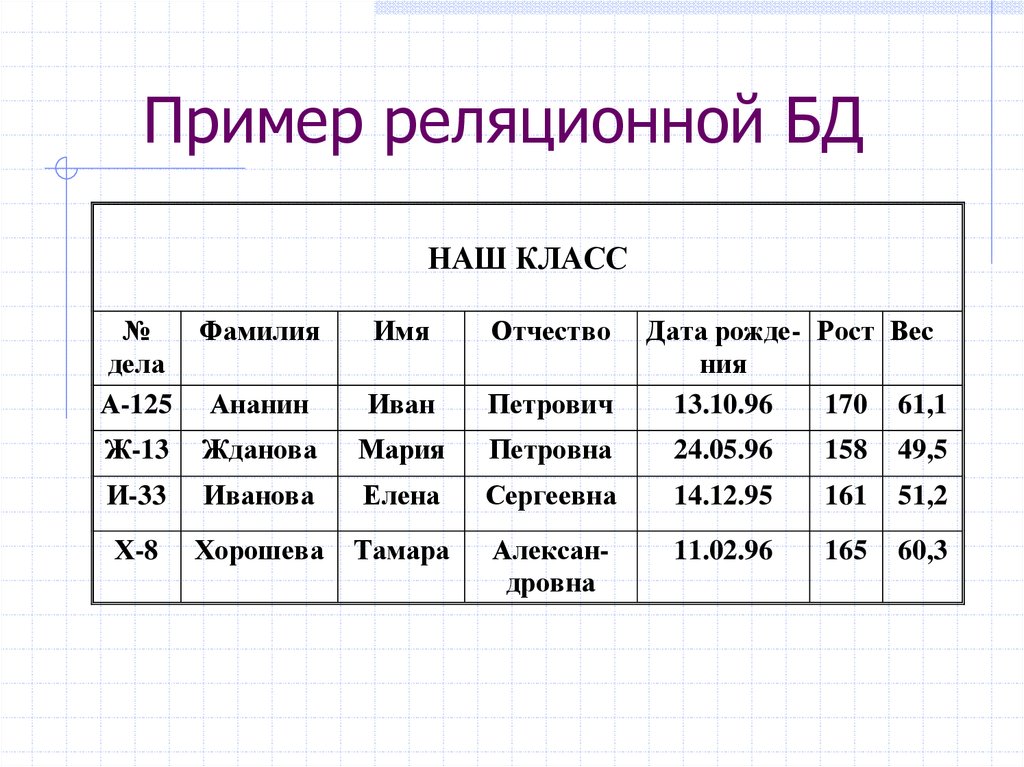
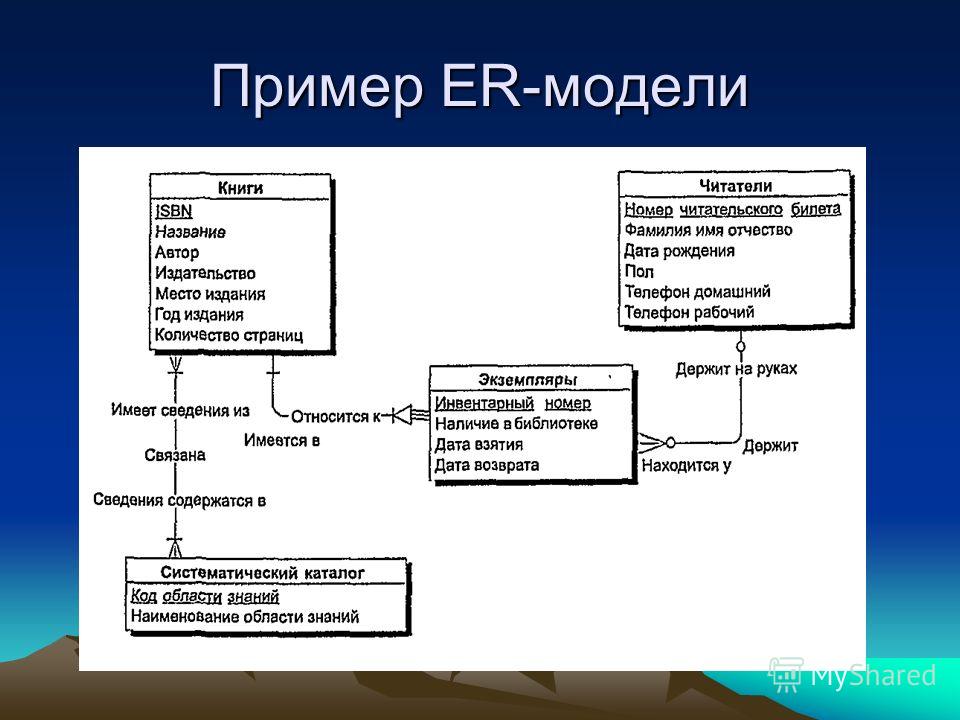
Контрольное тестирование 11 класс
Контрольный тест №1
1. Информационная система-это
1) Любая система обработки информации 2) Система обработки текстовой информации
3) Система обработки графической информации 4) Система обработки табличных данных 5) Нет верного варианта
2. Разновидность информационной системы, в которой реализованы функции централизованного хранения и накопления обработанной информации организованной в одну или несколько баз данных это
1) Банк данных 2) База данных 3) Информационная система 4) Словарь данных 5) Вычислительная система
3.Совокупность специальным образом организованных данных, хранимых в памяти вычислительной системы и отображающих состояние объектов и их взаимосвязей в рассматриваемой предметной области — это
1) База данных 2) СУБД 3) Словарь данных 4) Информационная система 5) Вычислительная система
4. Комплекс языковых и программных средств, предназначенный для создания, ведения и совместного использования БД многими пользователями — это
Комплекс языковых и программных средств, предназначенный для создания, ведения и совместного использования БД многими пользователями — это
1) Вычислительная система 2) База данных – 3) Словарь данных 4) СУБД 5) Информационная система
5. База данных – это?
набор данных, собранных на одной дискете;
данные, предназначенные для работы программы;
совокупность взаимосвязанных данных, организованных определенным образом;
данные, пересылаемые по коммуникационным сетям.
6.Лицо или группа лиц, отвечающих за выработку требований к БД, ее проектирование, создание, эффективное использование и сопровождение — это
1) Администратор базы данных 2) Диспетчер базы данных 3) Программист базы данных
4) Пользователь базы данных 5) Технический специалист
7.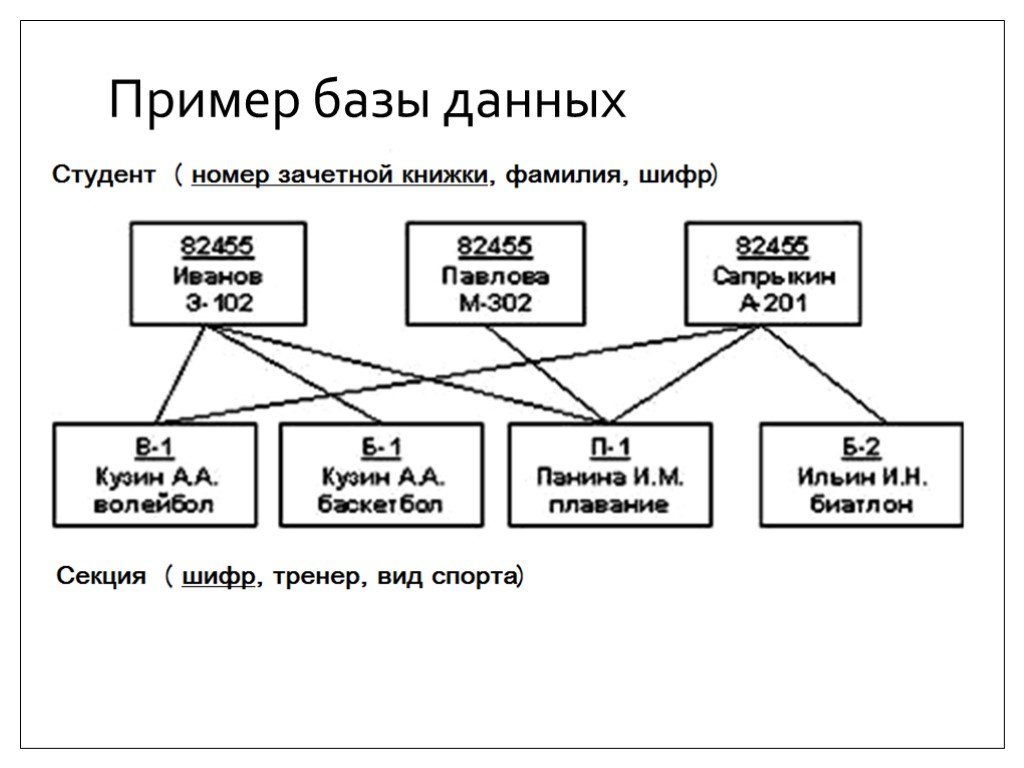 Совокупность взаимосвязанных и согласованно действующих ЭВМ или процессов и других устройств, обеспечивающих автоматизацию процессов приема, обработки и выдачи информации потребителям — это
Совокупность взаимосвязанных и согласованно действующих ЭВМ или процессов и других устройств, обеспечивающих автоматизацию процессов приема, обработки и выдачи информации потребителям — это
1) Словарь данных 2) Информационная система 3) Вычислительная система 4) СУБД 5) База данных
8. Отчеты в БД используются для:
отображения данных в удобном виде;
печати данных, содержащихся в таблицах и запросах;
хранения двумерных таблиц;
автоматизации повторяющихся операций.
9. Наиболее используемая (в большинстве БД) модель данных
1) Реляционная модель
2) Сетевая модель данных
3) Иерархическая модель данных
4) Системы инвертированных списков
5) Все вышеперечисленные варианты
10. |
|
|
|
|
 В число основных функций СУБД не входит
В число основных функций СУБД не входит11. Выберите правильный порядок действий при проектировании БД
а) Решение проблемы передачи данных б) Анализ предметной области, с учетом требования конечных пользователей в) Формализация представления данных в БД г) Обобщенное описание БД с использованием естественного языка, математических формул, графиков и других средств
1) б, г, в, а 2) а, б, г, в 3) а, б, в, г 4) г, б, в, а
5) Порядок действий значения не имеет
12. Основными составными частями клиент — серверной архитектуры являются
Основными составными частями клиент — серверной архитектуры являются
1) Сервер 2) Клиент 3) Сеть и коммуникационное программное обеспечение 4) Все выше перечисленное
5) Только варианты 1 и 2
13.Собственно СУБД и управление хранением данных, доступом, защитой, резервным копированием, отслеживанием целостности данных, выполнением запросов клиентов — это
1) Сервер базы данных 2) Клиенты 3) Сеть 4) Коммуникационное программное обеспечение
5) Нет правильного ответа
14.Различные приложения пользователей, которые формируют запросы к серверу, проверяют допустимость данных и получают ответы — это
1) Сервер базы данных 2) Клиенты 3) Сеть 4) Коммуникационное программное обеспечение
5) Нет правильного ответа
15. Система БД, где разделение вычислительной нагрузки происходит между двумя отдельными компьютерами, один — сервер, другой — клиент называется
1) Распространенной 2) Многофункциональной 3) Разветвленной 4) Централизованной 5) Многоцелевой
16. Реляционная модель представления данных — данные для пользователя передаются в виде
Реляционная модель представления данных — данные для пользователя передаются в виде
1) Таблиц 2) Списков 3) Графа типа дерева 4) Произвольного графа 5) Файлов
17. Сетевая модель представления данных — данные представлены с помощью
1) Таблиц 2) Списков 3) Упорядоченного графа 4) Произвольного графа 5) Файлов
18. Иерархическая модель представления данных — данные представлены в виде
1) Таблиц, 2) Списков 3) Упорядоченного графа 4) Произвольного графа 5) Файлов
19. Для отбора данных на основании заданных условий используются:
1) запросы; 2) отчеты; 3) таблицы; 4) формы; 5) макросы; 6) модули.
20. Отношением называют
1) Файл 2) Список 3) Таблицу 4) Связь между таблицами 5) Нет правильного варианта
21. Кортеж отношения — это
Кортеж отношения — это
1) Строка таблицы 2) Столбец таблицы 3) Таблица 4) Несколько связанных таблиц 6) Список
22. Атрибут отношения — это
1) Строка таблицы 2) Столбец таблицы 3) Таблица 4) Межтабличная связь 5) Нет правильного варианта
23. Один атрибут или минимальный набор из нескольких атрибутов, значения которых в одно и тоже время не бывают одинаковыми, то есть однозначно определяют запись таблицы — это
1) Первичный ключ 2) Внешний ключ 3) Индекс 4) Степень отношения 5) Нет правильного варианта
24. Ключ называется сложным, если состоит
1) Из одного атрибута 2) Из нескольких записей 3) Из нескольких атрибутов 4) Из одного атрибута, длина значения которого больше заданного количества символов 5) Нет правильного варианта
25.Таблица называется индексированной, если для неё используется
1) Индекс 2) Хеш-код 3) Первичный ключ 4) Внешний ключ 5) Нет верного варианта
26. Выберите соответствующий вид связи, если в каждый момент времени каждому элементу (кортежу) отношения А соответствует 0 или 1 кортеж отношения В
Выберите соответствующий вид связи, если в каждый момент времени каждому элементу (кортежу) отношения А соответствует 0 или 1 кортеж отношения В
1) Связь отсутствует 2) Связь один к одному 3) Связь один ко многим 4) Связь многие к одному
5) Связь многие ко многим
27. Выберите соответствующий вид связи, если в каждый момент времени множеству кортежей отношения А соответствует один кортеж отношения В.
1) Связь отсутствует 2) Связь один к одному 3) Связь один ко многим 4) Связь многие к одному
5) Связь многие ко многим
28. Выберите соответствующий вид связи, если в каждый момент времени единственному кортежу отношения А соответствует несколько кортежей отношения В.
1) Связь отсутствует 2) Связь один к одному 3) Связь один ко многим 4) Связь многие к одному
5) Связь многие ко многим
29. Выберите соответствующий вид связи, если в каждый момент времени множеству кортежей отношения А соответствует множество кортежей отношения В.
Выберите соответствующий вид связи, если в каждый момент времени множеству кортежей отношения А соответствует множество кортежей отношения В.
1) Связь отсутствует 2) Связь один к одному 3) Связь один ко многим
4) Связь многие к одному 5) Связь многие ко многим
30.Какая из перечисленных видов связи в реляционных СУБД непосредственно не поддерживается?
1) Связь отсутствует 2) Связь один к одному 3) Связь один ко многим 4) Связь многие к одному
5) Связь многие ко многим
31. Выберите из предложенных примеров тот, который иллюстрирует между указанными отношениями связь 1:1
1) Дом : Жильцы 2) Студент : Стипендия 3) Студенты : Группа 4) Студенты : Преподаватели
5) Нет подходящего варианта
32. Выберите из предложенных примеров тот, который между указанными отношениями иллюстрирует связь 1 :М
1) Дом : Жильцы 2) Студент : Стипендия Л- 3) Студенты : Группа
4) Студенты : Преподаватели 5) Нет подходящего варианта
33. Выберите из предложенных примеров тот, который между указанными отношениями иллюстрирует связь М: 1
Выберите из предложенных примеров тот, который между указанными отношениями иллюстрирует связь М: 1
1) Дом : Жильцы 2) Студент : Стипендия 3) Студенты : Группа
4) Студенты : Преподаватели 5) Нет подходящего варианта
34.Выберите из предложенных примеров тот, между указанными отношениями, который иллюстрирует связь М:М
1) Дом : Жильцы 2) Студент : Стипендия 3) Студенты : Группа
4) Студенты : Преподаватели 5) Нет подходящего варианта
35. Определите порядок действий при проектировании логической структуры БД:
а) формирование исходного отношения; б) определение всех объектов, сведения о которых будут включены в базу;
в) определение атрибутов; г) устанавливают связи между атрибутами;
д) определение характера информации, которую заказчик будет получать в процессе эксплуатации;
е) избавится от избыточного дублирования данных, являющихся причиной аномалий.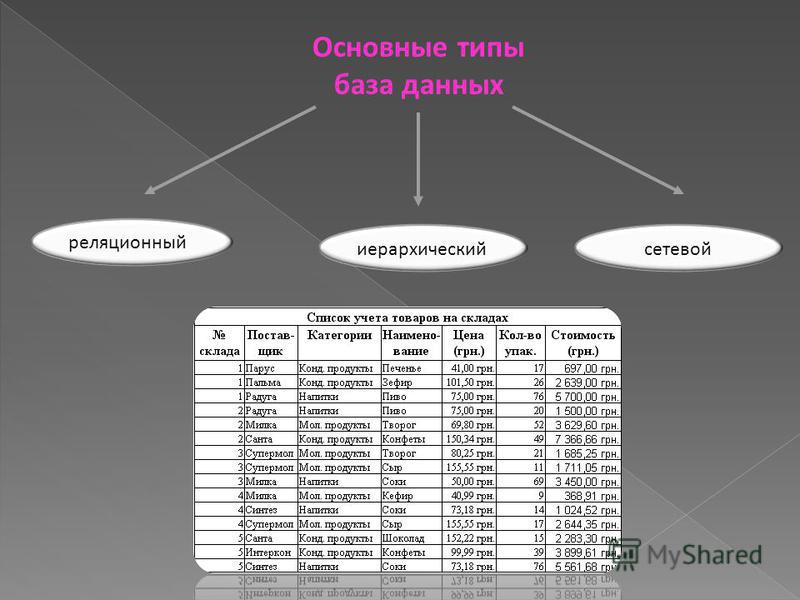
1) б, д, в, г, а, е 2) а, б, в, г, д, е 3) б, д, в, а, г, е 4) а, е, б, д, в, г 5) б, д, а, е, в, г
36. Клиент-серверная СУБД-это:
БД и СУБД располагаются централизованно на файл-сервере
серверная часть СУБД располагается на сервере вместе с БД
БД располагается на сервере, а СУБД -локально на компьютере
37. БД Аэрофлота имеет следующие поля: номер рейса, дата вылета, тип самолета, цена билетов, наличие билетов. Какое поле будет являться ключевым?
1) номер рейса, 2) дата вылета,3) тип самолета, 4) цена билетов, 5) наличие билетов
38. Может содержать длинный текст поле с типом…
1) числовым; 2) текстовым; 3) дата/время; 4) Мемо; 5) ОLE; 6) логическим
39. В фрагменте базы данных представлены сведения о родственных отношениях. На основании приведенных данных определите, сколько всего двоюродных братьев и сестер есть уСухорук П.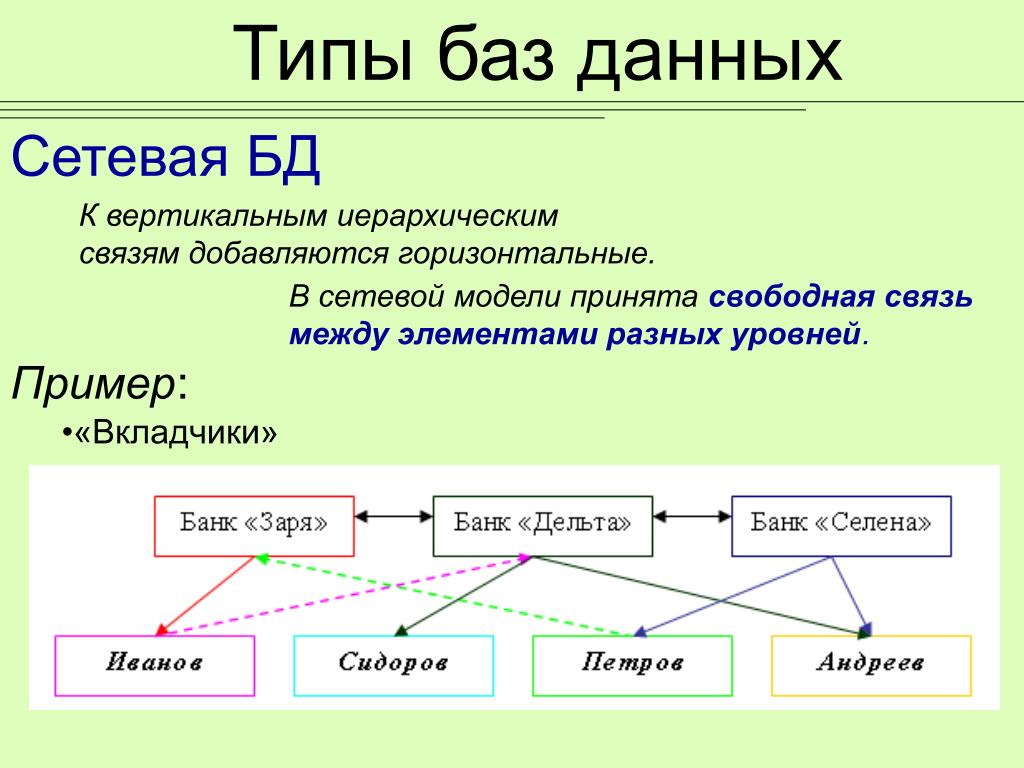 И. Двоюродный брат (сестра) – это сын (дочь) родного брата или сестры матери или отца.
И. Двоюродный брат (сестра) – это сын (дочь) родного брата или сестры матери или отца.
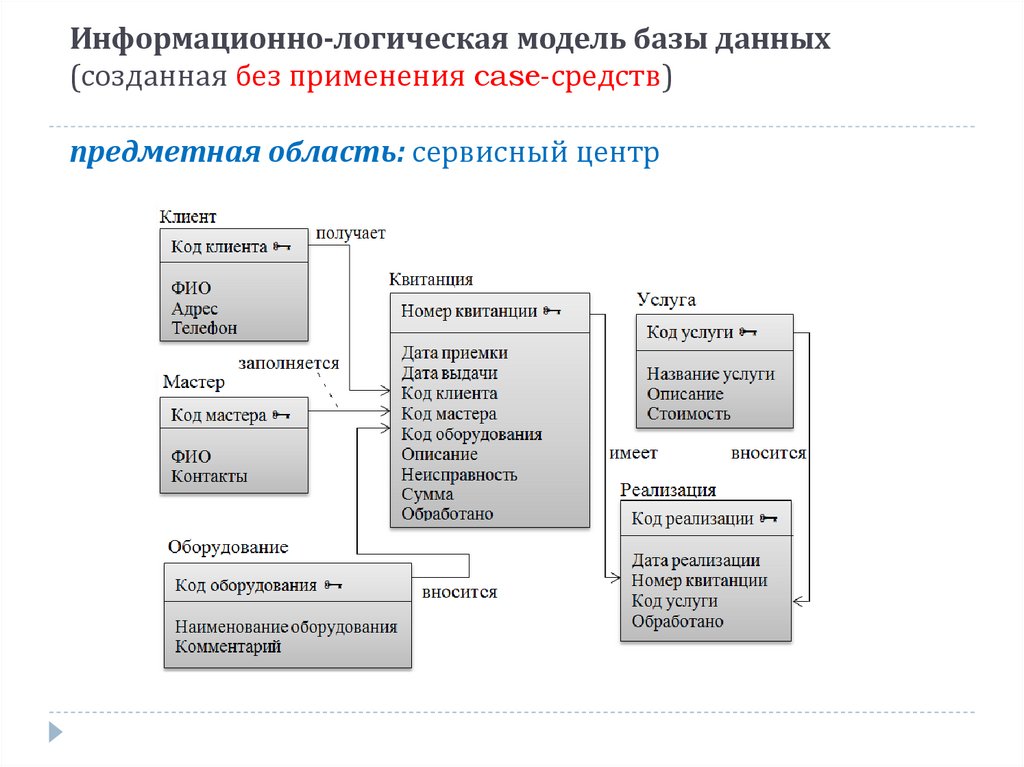
40. База данных службы доставки состоит из двух связанных таблиц:
Каков общий вес товаров, которые курьер должен доставить на ул. Цветочная?
1) 1500 грамм 2) 1900 грамм 3) 3750 грамм 4) 1300 грамм
41. Структура файла реляционной базы данных (БД) полностью определяется |
|
|
|
|
42. Сетевая база данных предполагает такую организацию данных, при которой |
|
|
|
|
43. Поддержание в любой момент времени взаимной непротиворечивости, правильности и точности данных, хранящихся в БД называется
Поддержание в любой момент времени взаимной непротиворечивости, правильности и точности данных, хранящихся в БД называется
а)целостностью данных б)ограничением модели данных в)избыточностью данных г)функциональной зависимостью данных
44.Какие из перечисленных объектов являются объектами базы данных MS ACCESS
а)сущности а)ключи б)таблицы в)конструктор г)отчеты
45. Какие существуют в СУБД способы создания таблиц
мастер таблиц б) конструктор в)ввод данных г)экспорт д)импорт
46. База данных «Расписание самолетов» задана таблицей:
Какие поля имеют тип «Дата/Время»?
День недели
Время вылета
День недели и время вылета
Время вылета и тип самолета
Тип самолета
47. Неверно утверждение:
Запись включает в себя несколько полей
Поле включает в себя несколько записей
Каждое поле БД имеет свой размер
БД имеет жесткую структуру
Каждое поле имеет имя
48. Если каждый элемент нижестоящего уровня связан одновременно с любыми элементами предыдущего уровня, такая модель называется …
Если каждый элемент нижестоящего уровня связан одновременно с любыми элементами предыдущего уровня, такая модель называется …
а) таблица; б) сеть; в) иерархическая структура; г) дерево.
49. Базы данных состоящие из связных двумерных таблиц называются …
а) реляционные; б) связные; в) обычные; г) комплектующие;
50. Строка таблицы, содержащая набор значений определенного свойства, называется…
а) полем; б) ключом; в) формой; г) записью.
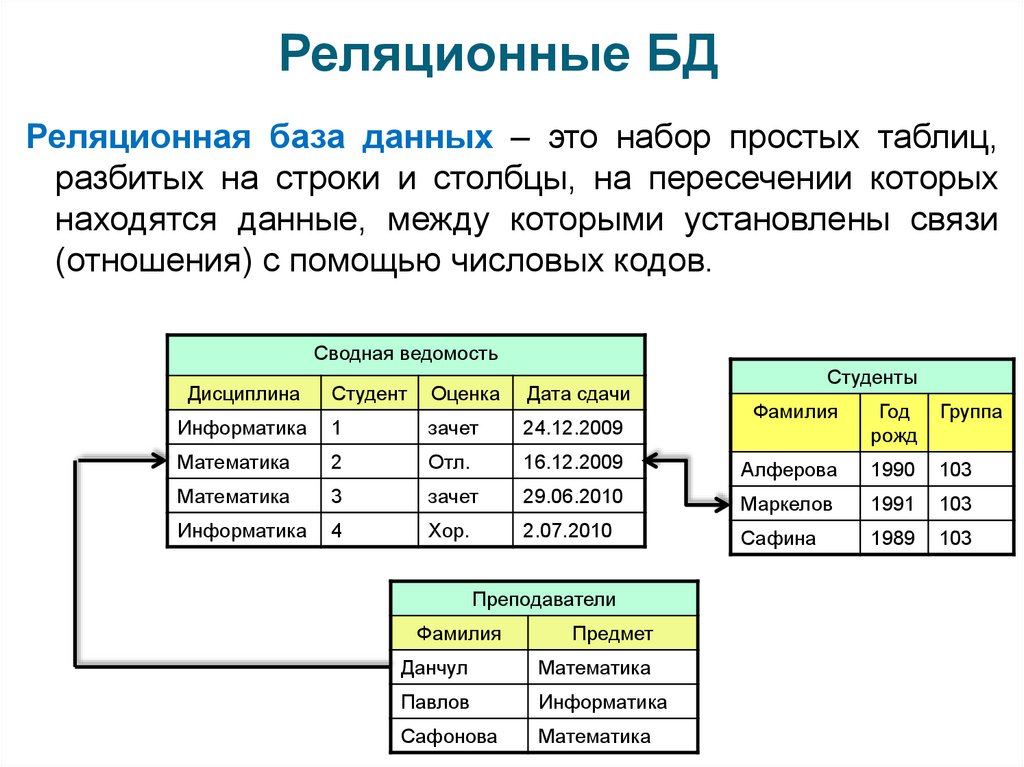
Сказки о СУБД / Хабр
Введение
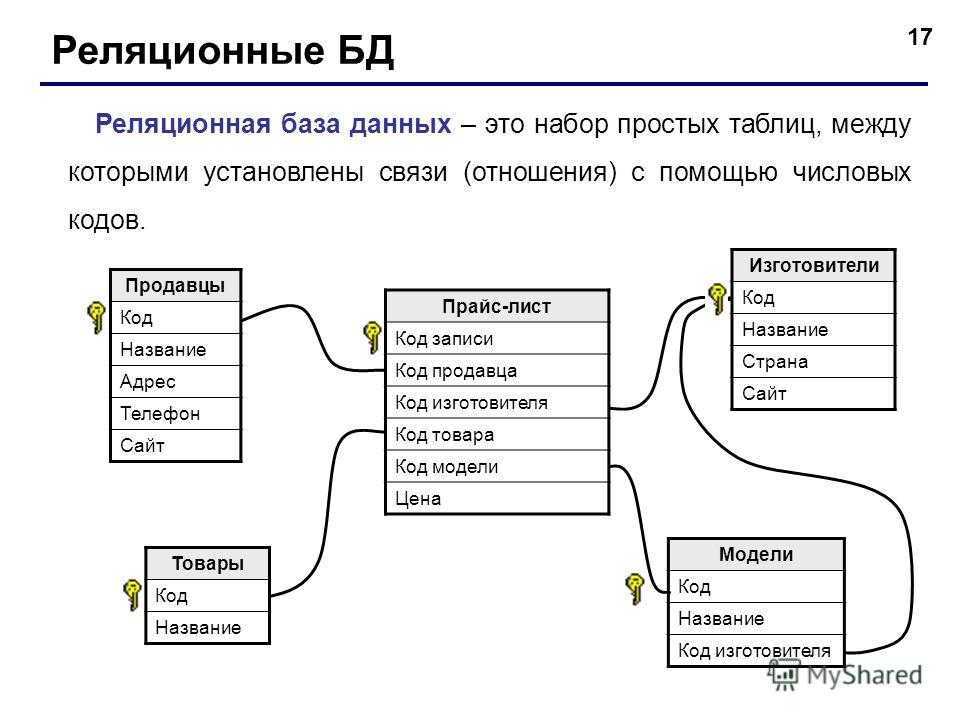
Часто, когда произносится термин «СУБД», под ним понимается только реляционная СУБД (здесь и далее по тексту будем считать термины синонимами) — это вызвано прежде всего тем, что большинство СУБД на рынке сейчас являются именно реляционными. Реляционная модель ориентирована на организацию данных в виде двумерных таблиц, а ее реализация опирается на работы Эдгара Кодда1. Реляционная модель — это хорошо и плохо: хорошо в следствии простоты реализации, плохо с точки зрения работы с объектно-ориентированными языками программирования.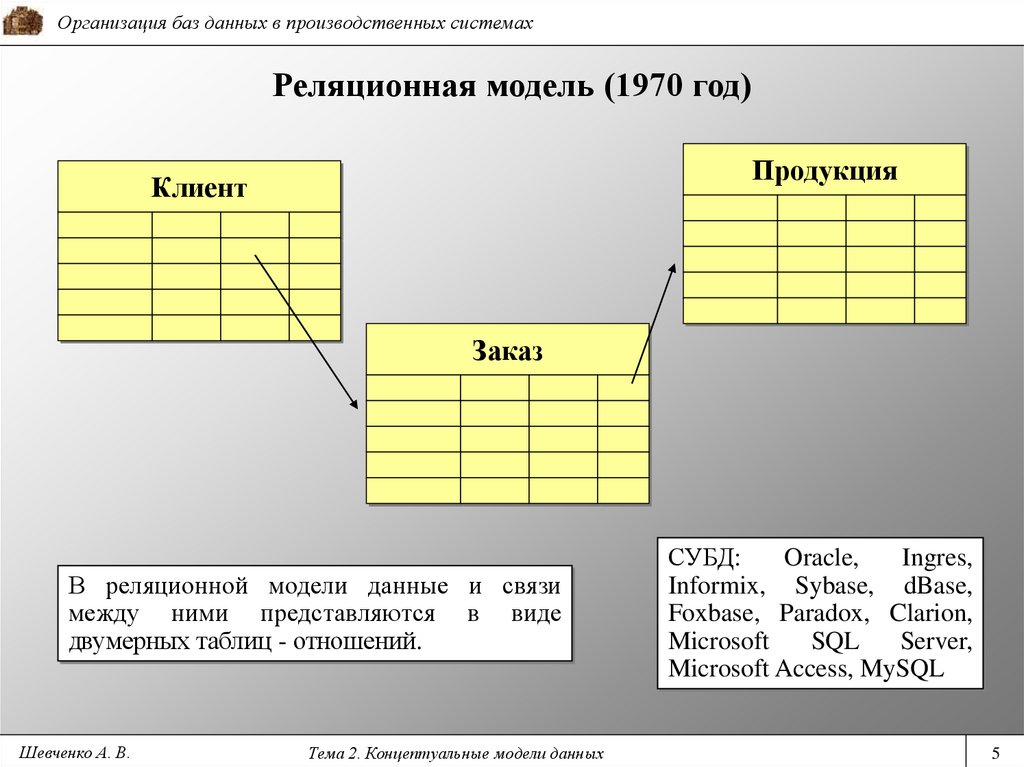
Сказка первая. «Объекты в БД»
Для решения проблем хранения объектов в БД создан целый класс новых систем — Объектно-ориентированные СУБД (и промежуточные Объектно-реляционные СУБД). Необходимость решения этой задачи вызвана тем, что объектно-ориентированное программирование (ООП) в настоящий момент — доминирующая парадигма программирования, в которой основными концепциями являются понятия объектов и классов. Объектно-ориентированное программирование — это методология программирования, основанная на представлении программы в виде совокупности объектов, каждый из которых является экземпляром определенного класса, а классы образуют иерархию наследования [Буч]. ООП ориентировано на реализацию крупных программных комплексов, которые разрабатываются командой программистов. ООП позволяет создать программные объекты, соответствующие объектам предметной области и повторно использовать объекты при разработке других программ, что значительно ускоряет процесс создания новых продуктов.
Объект обладает состоянием, поведением и идентичностью; структура и поведение схожих объектов определяет общий для них класс; термины «экземпляр класса» и «объект» взаимозаменяемы [Буч]. Важнейшими свойствами в контексте взаимодействия с СУБД является состояние (совокупное значение атрибутов объекта) и идентичность. «Идентичность — это такое свойство объекта, которое отличает его от всех других объектов» [Khoshafian].
Хошафян и Коуплэнд отмечают следующее: «в большинстве языков программирования и управления базами данных для различения временных объектов их именуют, тем самым путая адресуемость и идентичность. Большинство баз данных различают постоянные объекты по ключевому атрибуту, тем самым смешивая идентичность и значение данных».
Ряд проблем, связанных с обработкой объектов в БД, были решены в объектно-ориентированных СУБД, например, в Cache2. Использование таких СУБД пока не является повсеместным. Поэтому решение с использованием объектно-ориентированных СУБД в качестве основы для хранения данных следует считать скорее очередным «велосипедом», нежели промышленным стандартом.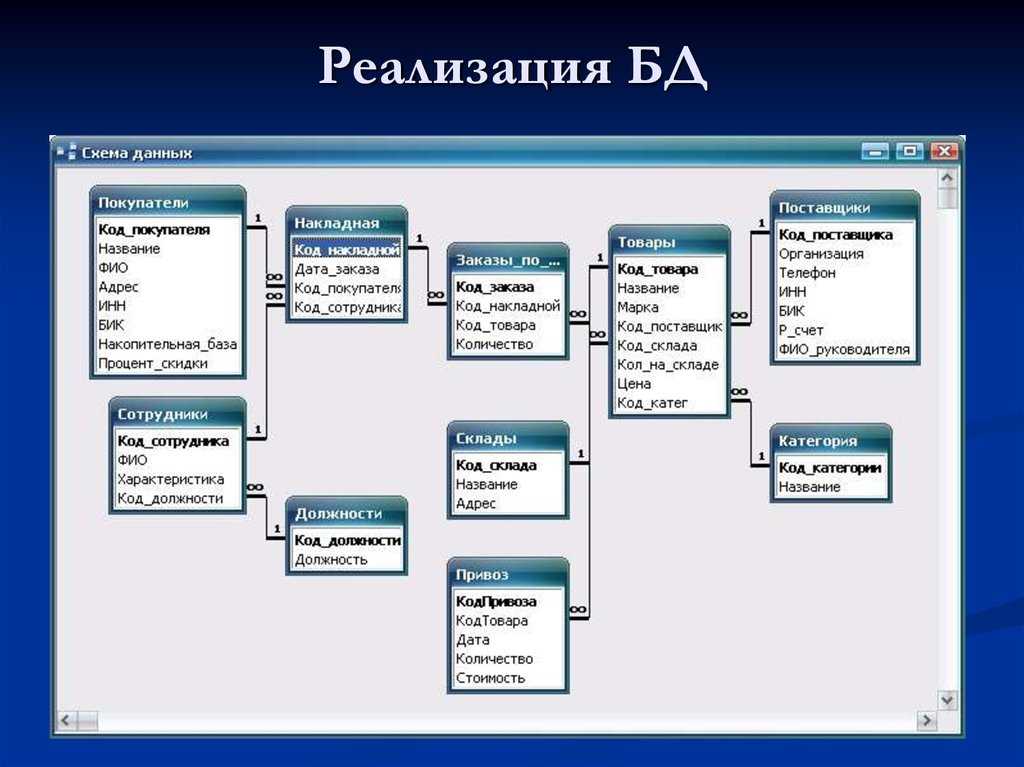
Сказка вторая. «Бизнес-логика»
Чтобы не быть голословным, приведу основные доводы в пользу подхода «Все в базу»:
- Безопасность.
- Скорость.
 Выполнение хранимых процедур происходит в адресном пространстве СУБД, что означает близость к хранимым данным, что в свою очередь, уменьшает время реакции системы.
Выполнение хранимых процедур происходит в адресном пространстве СУБД, что означает близость к хранимым данным, что в свою очередь, уменьшает время реакции системы. - Специализация языков для разработки хранимых процедур. Такие языки «заточены» на работу с данными в БД, что опять же положительно сказывается на скорости работы ХП.
- Локализация изменений. Изменение логики работы системы производится в единственном месте, и в большинстве случаев не требует перекомпиляции клиентского ПО и последующей его переинсталяции.
- Минимизация трафика. Уменьшение объемов трафика связано с тем, что пользователю возвращается результат выполнения ХП, а не сырые данные.
 Выполнение хранимых процедур происходит в адресном пространстве СУБД, что означает близость к хранимым данным, что в свою очередь, уменьшает время реакции системы.
Выполнение хранимых процедур происходит в адресном пространстве СУБД, что означает близость к хранимым данным, что в свою очередь, уменьшает время реакции системы. Спорить с данными утверждения бессмысленно, так как они в основе своей истинны. Однако, если конкретизировать вопрос, а именно, нужно ли хранить бизнес-логику в БД при использовании трехзвенной архитектуры с выделением полноценного «сервера приложения»? Если для стартапа создание такой инфраструктуры не всегда оправданно, то для корпоративного применения практически нет альтернативных решений, — монстры индустрии, естественно, предлагают собственные решения для промежуточного слоя.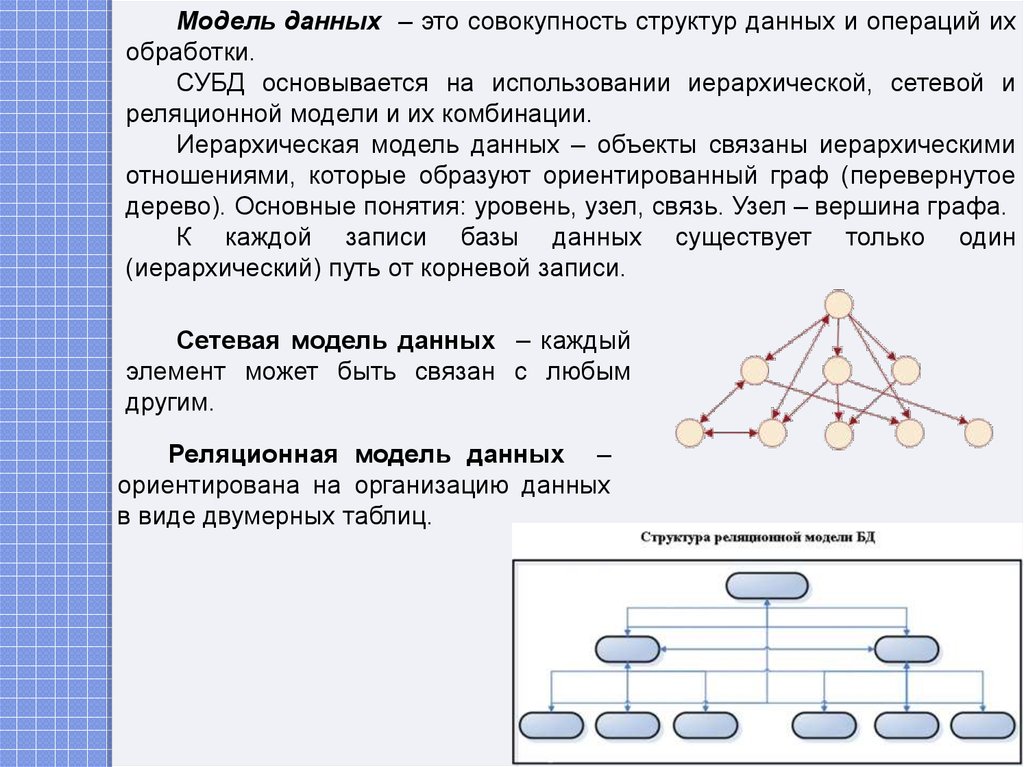
Исходя из вышесказанного, хочу напомнить одно из правил разработки приложений:
«Самое главное — это концентрация бизнес логики на одном уровне. А выбор уровня зависит от конкретной задачи.»
— Киселев Сергей, соучредитель и консультант по технологиям и разработке, ООО «Научно-производственная компания Ай-поинт рус».
Вынесение бизнес-логики на уровень БД — это концентрация ее в месте, где вы теряете контроль за производительностью, масштабированием и переносимостью и, в значительной степени, полагаетесь на производителя СУБД.
«Если переносить логику приложения в БД, то привязываешь себя к конкретной БД, а что еще точнее и хуже, к конкретной версии СУБД. Теряется гибкость. В то же время, если мы понимаем, что такое кросс-платформенная реализация, то перенесение логики в рамках реализации куда бы то ни было не составляет никаких проблем. И как этим управлять вполне известно.»
— Виктор Гамов, ведущий программист, учебно-научный центр МИИТ-Эксперт.
Еще одна, на мой взгляд, главная проблема связана со сложностью проведения ряда этапов разработки и сопровождения программного продукта, таких как отладка и тестирование. А также, использование подхода «Все в базу» в значительной степени усложняет проведение рефакторинга.
«Такая логика вендор-специфик, трудно отлаживаемая, неподвластна рефакторингу, тестирование возможно лишь статическим анализом. Однако, наверняка найдется дюжина аргументов за бизнес-логику на стороне СУБД. В их числе может оказаться, например, погоня за производительностью или необходимость хитрого управления блокировками на строках таблиц БД. В этих случаях все перечисленные минусы становятся неприятным следствием компромисса. А разработчики, в свою очередь, становятся жертвами этих минусов.»— Гура Андрей, менеджер проекта, Яндекс.
Конечно, принимать решение о месте нахождения бизнес-логики при реализации следует исходя из поставленной задачи. Исходя из того, что одни и те же действия по обработке данных возможно реализовать как в хранимой процедуре непосредсвенно на уровне СУБД, так и в приложении.
Исходя из того, что одни и те же действия по обработке данных возможно реализовать как в хранимой процедуре непосредсвенно на уровне СУБД, так и в приложении.
«Всю бизнес-логику условно можно разделить на «две части». Одна часть — «обслуживание данных», вторая «реализация прикладной задачи». Первую логичнее держать в СУБД, рядом с данными, вторую — на сервере приложений. Под «обслуживание данных» я понимаю поддержку непротиворечивости данных с точки зрения прикладной задачи и функции типа собрать из первичных данных прикладные-расчетные.»— Владимир Бормотов, системный админситратор, ЗАО «БиоХимМак».
В любом случае, принятие конкретного решения остается за разработчиками, которые должны как саперы понимать важность каждого их шага в данном вопросе.
Сказка третья. «Водопад подключений»
Если посмотреть во внутренности большинства CMS4 систем, несмотря на разный стиль написания и квалификацию разработчиков, можно заметить одну общую особенность — это то, как разработчики работают с подключениями к СУБД.
Если мы представим себе небольшой Web-проект, которым пользуются несколько сотен людей, и типовой процесс получения контента из БД, то мы получим удручающую картину. Часто при загрузке контента для каждого пользователя создается подключение, выгружаются данные и подключение закрывается — этот стройный с виду процесс на деле оборачивается тем, что если в час пик приходит неоправданно большое количество потребителей, то СУБД обеспечен отказ от обслуживания.
Вышеописанной ошибка — это анти-паттерн «Суета с подключениями» [Тейт]. Например, нескольким объектам во время выполнения бизнес-процесса требуется несколько раз подключиться к БД для получения и сохранения данных, причем на создание каждого подключения периодически может тратиться больше времени, чем на проведение транзакции. Для грамотной работы с СУБД достаточно использовать специальный паттерн ConnectionPool.
Суть данного паттерна заключается в обеспечении контроля количества подключений к БД (как правило, для работы ограничивают количество соединений с БД), что приводит к упрощению процесса получения данных. Для получения соединения с БД необходимо у объекта реализующего паттерн ConnectionPool вызвать метод getPooledConnection — в результате будет получено соединение для подключения к БД, и по завершению работы с БД, необходимо освободить соединение, вернув его в ConnectionPool.
Для получения соединения с БД необходимо у объекта реализующего паттерн ConnectionPool вызвать метод getPooledConnection — в результате будет получено соединение для подключения к БД, и по завершению работы с БД, необходимо освободить соединение, вернув его в ConnectionPool.
Обращаю ваше внимание, что ConnectionPool поддерживает выбранное количество подключений постоянно, что естественным образом минимизирует время получения данных.
Описанный механизм позволяет осуществлять более эффективное управление мощностью системы. При использовании подхода общая производительность системы, выраженная в количестве обслуживаемых запросов за единицу времени, становится гораздо более предсказуемой, поскольку не уменьшается из-за нехватки памяти [Ch].
Заключение
Скорость разработки программного обеспечения, а не его качество, во многих компаниях является главным приоритетом и, хоть это и неправильно, от этого никуда не деться. Так как большинство работ связанны с хранением и обработкой данных в СУБД, то компании от собственных «велосипедов» приходят к проверенным ORM-фреймворкам.
ЛИТЕРАТУРА
[Буч] Буч Г. Объектно-ориентированный анализ и проектирование с примерами приложений на С++ / Издательства: Бином, Невский Диалект, 1998 г., 560 стр.
[Khoshafian] Khoshafian, S. and Copeland, G. November 1986. Object Identity. SIGPLAN Notices vol.21(ll).p.406.
[Fa] Фаулер М. Рефакторинг. Улучшение существующего кода / М. Фаулер — СПб.: Символ-Плюс, 2004. — 432 с.: ил.
[Ki] Кериевски Д. Рефакторинг с использованием шаблонов / М.: ООО «И.Д. Вильямс», 2006. — 400 с.: ил.
[Тейт] Тейт Б. Горький вкус Java: Библиотека программиста / СП.: Питер, 2003. — 333 с.
[Ch] Черноусов А.В. ИТ-инфраструктура системных исследований в энергетике и технологии ее реализации / Л.В Массель, А.В. Черноусов // Моделювання та iнформацiйнi технологiï — КИÏВ, 2006.
_________
1 Эдгар Кодд (Edgar Codd) — британский ученый, основоположник теории реляционных баз данных. В 1970 издал работу «A Relational Model of Data for Large Shared Data Banks», которая считается первой работой по реляционной модели данных.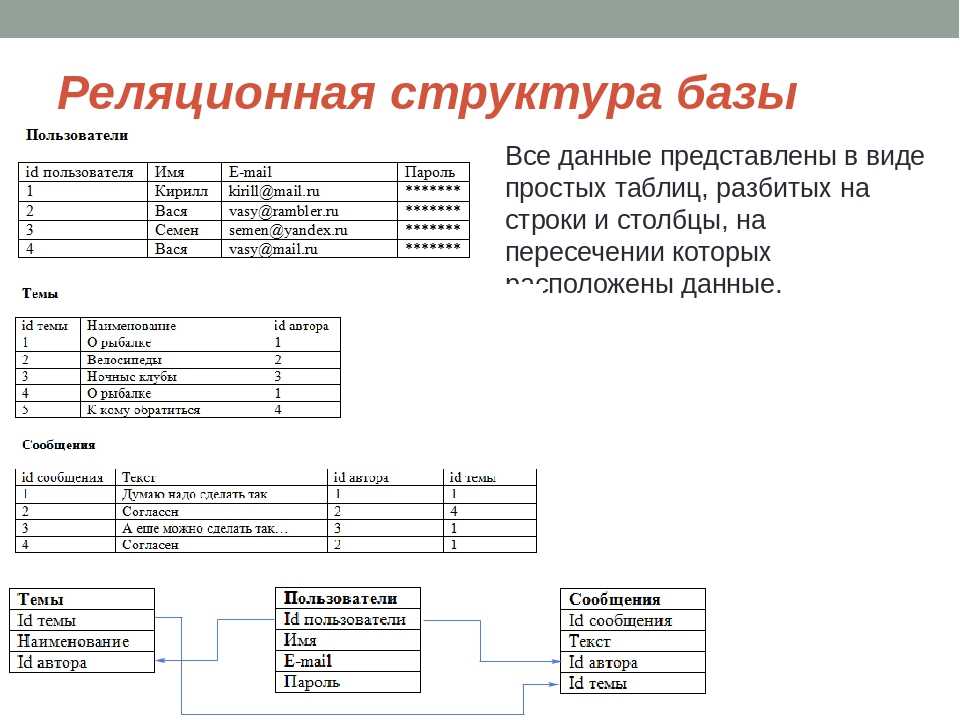
2 Официальный сайт InterSystems Caché www.intersystems.com/cache
3 Рефакторинг или Реорганизация — процесс полного или частичного переписывания компьютерной программы или другого материала, с целью добиться улучшения читаемости кода и общей внутренней структуры компонентов, при полном и точном сохранении изначального смысла и поведения (кроме случаев, когда при рефакторинге устраняется ошибка — неправильное поведение) [Fa, Ki].
4 CMS — (Content Management System) — компьютерная программа или система, используемая для обеспечения и организации совместного процесса создания, редактирования и управления текстовых и мультимедиа документов (содержимое или контента). Обычно это содержимое рассматривается как неструктурированные данные предметной задачи в противоположность структурированным данным, обычно находящимися под управлением СУБД. В данном случае рассматриваются Web-ориентированные CMS начального уровня.
6 Различные типы моделей
Во второй части серии статей «Как моделировать данные» мы отвечаем на вопрос «Каковы различные типы моделей данных?» Взгляните на различные логические модели , примеры моделей данных, их сильные и слабые стороны, плюсы и минусы.
В части 1 этой серии были рассмотрены три этапа моделирования данных: концептуальный, логический и физический.
Общие модели данныхПосле определения концептуальной модели следующим шагом будет создание логической модели данных. Еще слишком рано выбирать конкретную технологию или поставщика.
Логические модели данных, которые я считаю наиболее распространенными и популярными, включают: реляционную, JSON (документ), ключ-значение, граф, широкий столбец и текстовый поиск.
Реляционная модель данныхРеляционная модель данных была предложена в 1970 году Э. Ф. Коддом. Вообще говоря, реляционная модель данных состоит из таблиц, содержащих строки и столбцы, которые содержат данные, соответствующие заранее определенным схемам и ограничениям.
Термин «реляционный» означает не относится к отношениям между таблицами и сущностями, а скорее к теоретической концепции набора кортежей, которые являются членами домена данных, каждый из которых содержит атрибуты.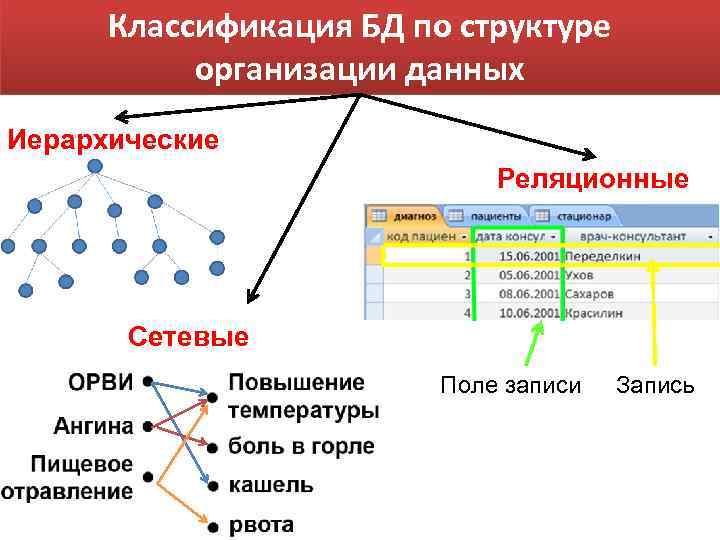
Реальные отношения не являются частью реляционной модели (или любой другой модели, кроме модели Graph, о которой будет сказано ниже), но обычно реализуются с несколькими таблицами и ограничениями внешнего ключа.
Реляционная модель — самый популярный тип логической модели данных в мире.
SQL не был частью первоначального предложения по реляционным базам данных, но тесно (но не исключительно) связан с реляционными базами данных. По сути, SQL — это вообще единственный способ взаимодействия с данными в реляционных базах данных.
Модель данных JSONБольшинство баз данных документов хранят данные в формате JSON (XML и другие представления гораздо менее популярны).
Высокомасштабируемые реализации NoSQL избегают реляционных ограничений в пользу независимых данных, которые могут быть распределены между несколькими серверами (путем кластеризации и сегментирования). JSON является популярным форматом для такого рода распределенных данных, потому что:
- Может предоставлять сложную структуру и «схему при чтении».
- Читается человеком.
- Существуют (де)сериализаторы для JSON практически на каждом языке программирования и на каждой платформе.
- Он может поддерживать SQL++, обратно совместимую реализацию SQL для моделей данных JSON.
- Может предоставлять сложную структуру и «схему при чтении».
Если вы пришли из реляционных систем, но хотите изучить преимущества «NoSQL» (масштабирование, гибкость, производительность, знакомство), то модель документа JSON — отличное место для начала.
Методы доступа к данным для баз данных документов обычно включают (но не ограничиваются) язык запросов (стандарт, такой как SQL++, или собственную реализацию поставщика, такую как MQL), который может фильтровать на основе отдельных значений JSON.
Модель данных «ключ-значение»Модель данных «ключ-значение» связывает каждый фрагмент данных с ключом. Фактическое значение может быть в любом формате. Это может быть JSON, XML, двоичный файл, текст или что-то еще.
Эти типы моделей баз данных великолепны, примерами являются определенные варианты использования, такие как кэширование, хранение сеансов, профиль пользователя, корзины покупок.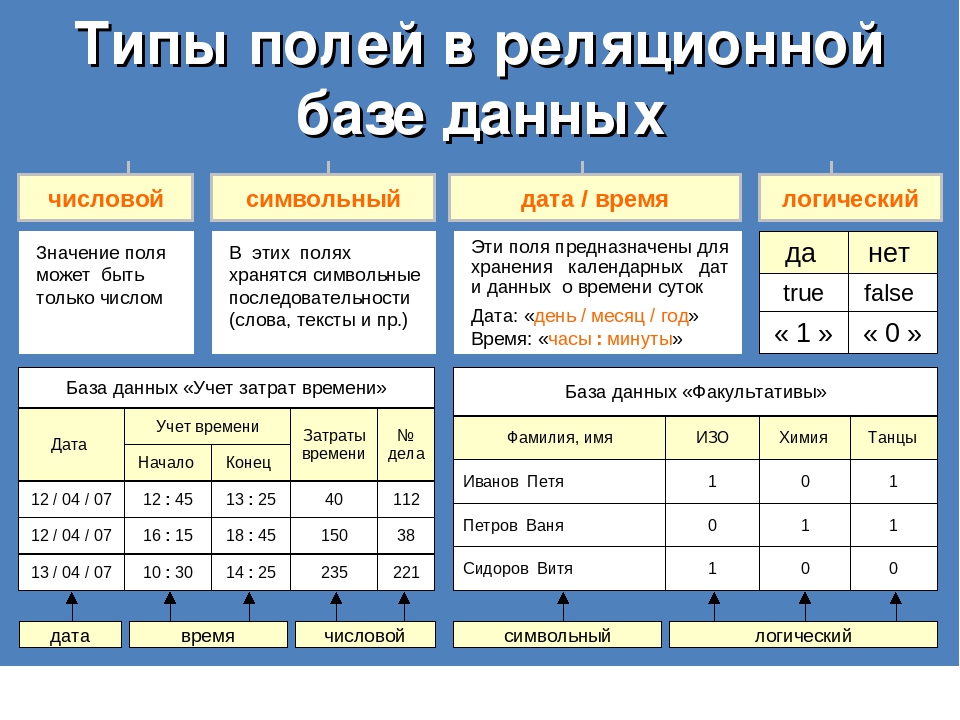
Помимо чтения и записи ключ-значение, такие функции, как «вложенный документ» и «сопоставление/уменьшение», добавляют дополнительные параметры доступа к данным, но использование чистой логической модели «ключ-значение» для данных со сложными отношениями может быть очень сложным.
Графовая модель данныхГрафовая модель данных — это единственная модель, в которую встроены как концепции данных, так и отношения. В графовой модели часть данных называется «узлом», а связь между двумя узлами называется «краем».
Графовая модель данных может быть полезна для моделирования сложной системы отношений. Например, моделирование физической компьютерной сети и компьютеров, находящихся в сети. Он часто используется для специальных случаев использования, таких как обнаружение мошенничества и рекомендации по покупкам.
Для запросов базы данных графов используют специализированный язык запросов графов, такой как Gremlin или Cypher.
Примечание.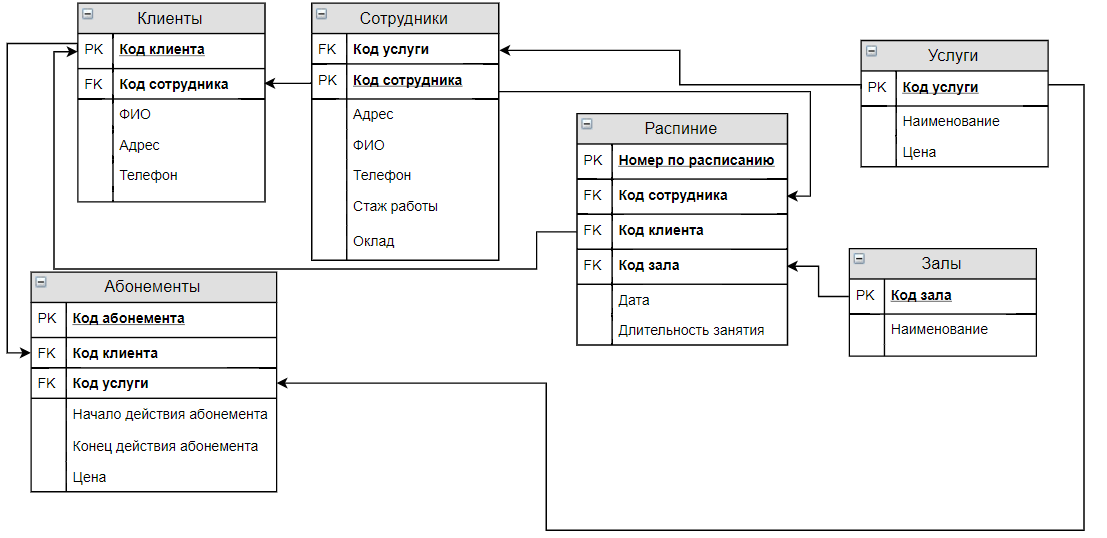 GraphQL и модель данных графа не связаны.
GraphQL и модель данных графа не связаны.
Модель данных с широкими столбцами содержит таблицы (иногда называемые «ключевыми семействами»), которые похожи на реляционные таблицы, но они основаны на столбцах, а не на строках.
Это означает, что любая данная строка может иметь произвольное количество столбцов, отличное от других строк. Кроме того, столбцы могут непрерывно добавляться к существующим строкам.
Каждая строка имеет ключ, поэтому вы также можете рассматривать эту модель как двумерную эволюцию хранилища значений ключа.
Языки запросов для моделей данных с широкими столбцами зависят от базы данных. Популярным примером является CQL (язык запросов Cassandra), который похож на SQL, но представляет собой очень ограниченное подмножество.
Модель данных текстового поиска Модель данных текстового поиска оптимизирована для хранения и поиска текста. Это включает в себя огранку и нечеткость, но также может включать географический поиск.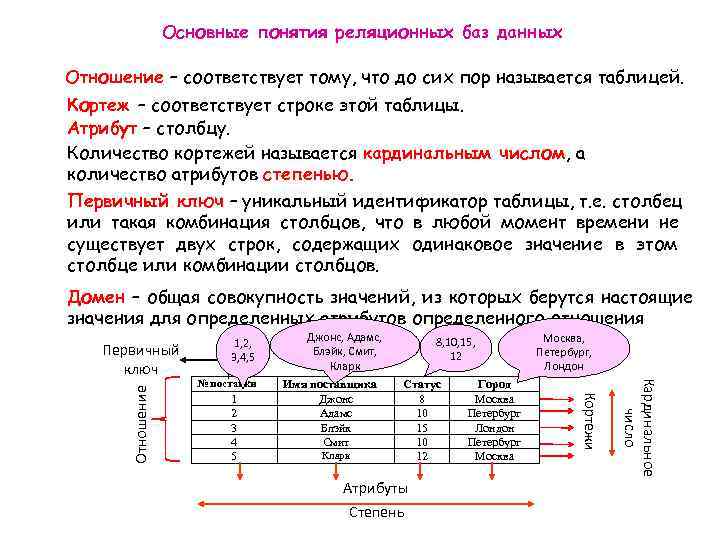
Создание индексов является ключевой частью взаимодействия с текстовым поиском. Поиск предоставляет параметры для активных индексов и часто выполняется с помощью запросов REST или специализированного SDK. Типы запросов, которые могут использоваться, включают строку, совпадение, фразу, составной запрос, диапазон и геопространственные запросы.
Примеры моделирования данныхБазы данных с несколькими моделями — это базы данных, которые могут поддерживать несколько типов моделей данных, перечисленных выше, с одним и тем же пулом данных. При этом, вот несколько примеров моделирования физических данных с инструментами реализации (базами данных) для каждой модели:
- Реляционный : SQL Server, Oracle, MySQL, MariaDB, PostgreSQL, SQLite, Microsoft Access, Snowflake.
- Документ JSON : Couchbase, CosmosDB*, DynamoDB, CouchDB (похожее название, но отличается от Couchbase), MongoDB.
- Ключ-значение : Существует очень мало баз данных с чистым ключом-значением , но есть примеры с хорошей поддержкой ключей-значений: Memcached, Redis, Couchbase.
- График : Neo4j, CosmosDB*, ArangoDB.
- Широкий столбец : Cassandra, HBase, CosmosDB*.
- Текст/Поиск : Elasticsearch и Solr (Lucene), Couchbase (Bleve)
*Обратите внимание, что вы должны заранее выбрать одну модель данных с CosmosDB.
Инструменты моделирования данныхМоделирование данных не требует никаких инструментов и может быть выполнено на доске для сухого стирания или с помощью карандаша и бумаги (конечно, за исключением моделирования физических данных). Однако существует множество инструментов моделирования данных, которые могут облегчить работу вашей команды. Вот некоторые популярные:
JetBrains DataGrip предоставляет инструмент построения диаграмм базы данных для построения модели из существующей базы данных. Эти диаграммы можно сохранить в формате UML или PNG. Это отлично подходит для моделирования физических данных .
Erwin Data Modeler — очень популярный инструмент, поддерживающий концептуальные, логические и физические модели данных. Quest, создатели Erwin, сотрудничают с Couchbase для моделирования и миграции.
Quest, создатели Erwin, сотрудничают с Couchbase для моделирования и миграции.
Hackolade — еще один инструмент моделирования данных, который поддерживает различные модели данных (включая все физические модели, упомянутые в этом посте), а также миграцию моделей данных.
Idera имеет полный набор инструментов для моделирования. Например, ER/Studio Business Architect обеспечивает концептуальное моделирование, а ER/Studio Data Architect обеспечивает логическое и физическое моделирование.
Если эти инструменты кажутся излишними для начала работы, помните, что вы можете использовать инструмент построения диаграмм более общего назначения, такой как Diagrams.net, чтобы ваша команда работала совместно.
Следующие шаги и ресурсы Концептуальное, логическое и физическое моделирование были представлены в предыдущий пост . В этом посте более подробно рассматриваются варианты логических моделей данных . Следующий (и последний) пост в этой серии посвящен физическому моделированию данных JSON.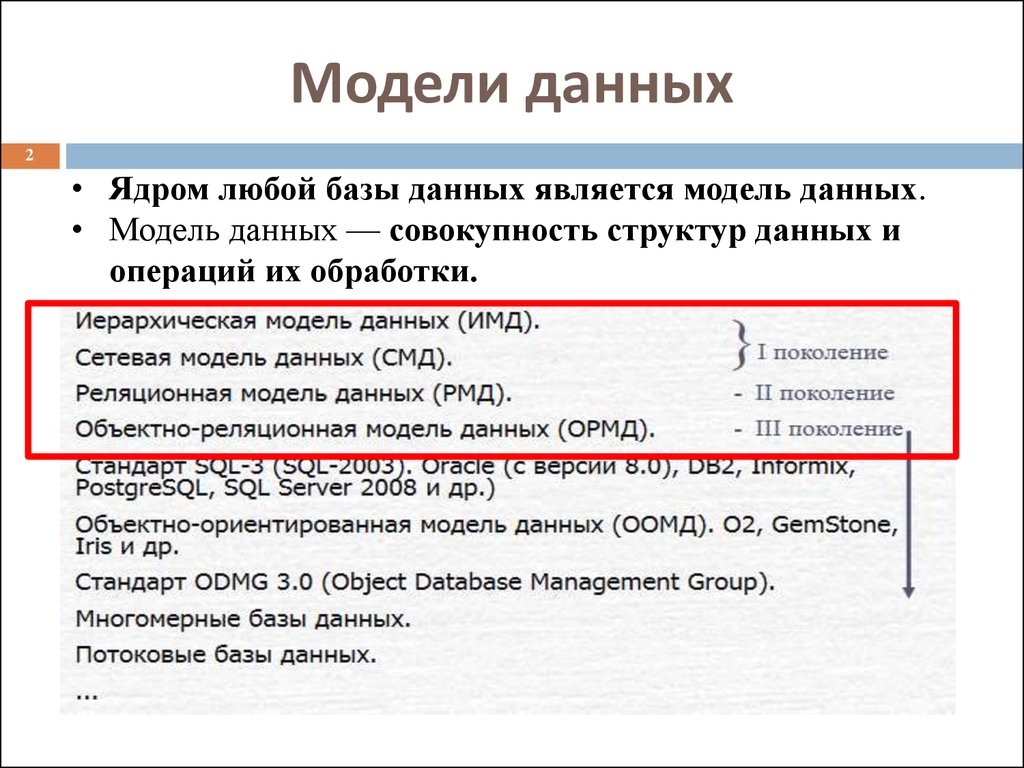
А пока ознакомьтесь с этими ресурсами для получения дополнительной информации:
- Сравнение баз данных документов и реляционных баз данных
- Прекращение реляционных и NoSQL дебатов раз и навсегда
- Другие записи в блогах о моделировании данных
Автор
- Мэтью Гроувс —
3 типа моделей данных и когда их использовать
Моделирование данных — это процесс организации ваших данных в структуру, чтобы сделать их более доступными и полезными. По сути, вы решаете, как данные будут перемещаться в вашу базу данных и из нее, и сопоставляете данные, чтобы они оставались чистыми и непротиворечивыми.
ThoughtSpot может использовать многие типы моделей данных, а также языки моделирования. Поскольку вы лучше всего знаете свои данные, обычно рекомендуется потратить некоторое время на настройку параметров моделирования .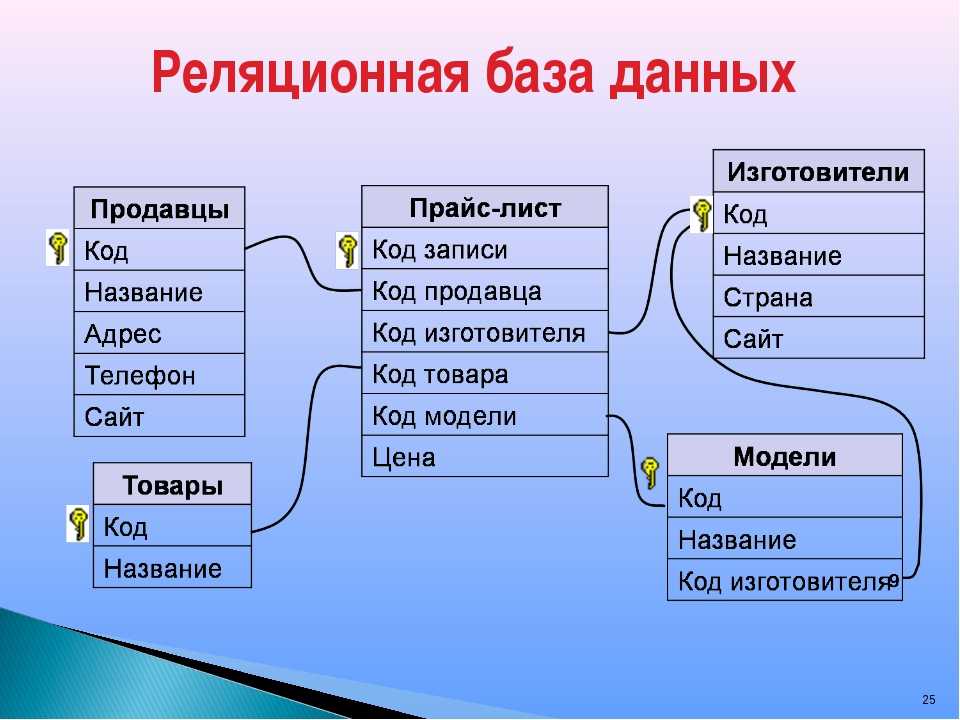 Это сделает данные более интуитивно понятными для поиска вашими конечными пользователями.
Это сделает данные более интуитивно понятными для поиска вашими конечными пользователями.
Существует 3 распространенных типа моделей данных: реляционная, иерархическая и сетевая база данных. В этой статье мы разберем каждый из них и рассмотрим плюсы и минусы, чтобы вы знали, когда вам следует использовать каждый тип для моделирования ваших данных.
Реляционная модель данных
Реляционная модель данных группирует данные в таблицы, называемые «отношениями», которые организованы в строки и столбцы. Каждая строка или «кортеж» содержит ряд связанных значений данных, а имя таблицы и имена столбцов или «атрибуты» говорят нам, что это за значения.
Пример реляционной модели данных
Вот пример базовой реляционной модели данных:
Здесь отношение (таблица) представляет собой жилье для студентов. Атрибуты — это столбцы, определяющие данные: STUD_NO, SURNAME и т. д.
Как видите, информация в столбце HOUSE_CODE имеет смысл только в том случае, если у вас также есть информация о том, что означает каждый код.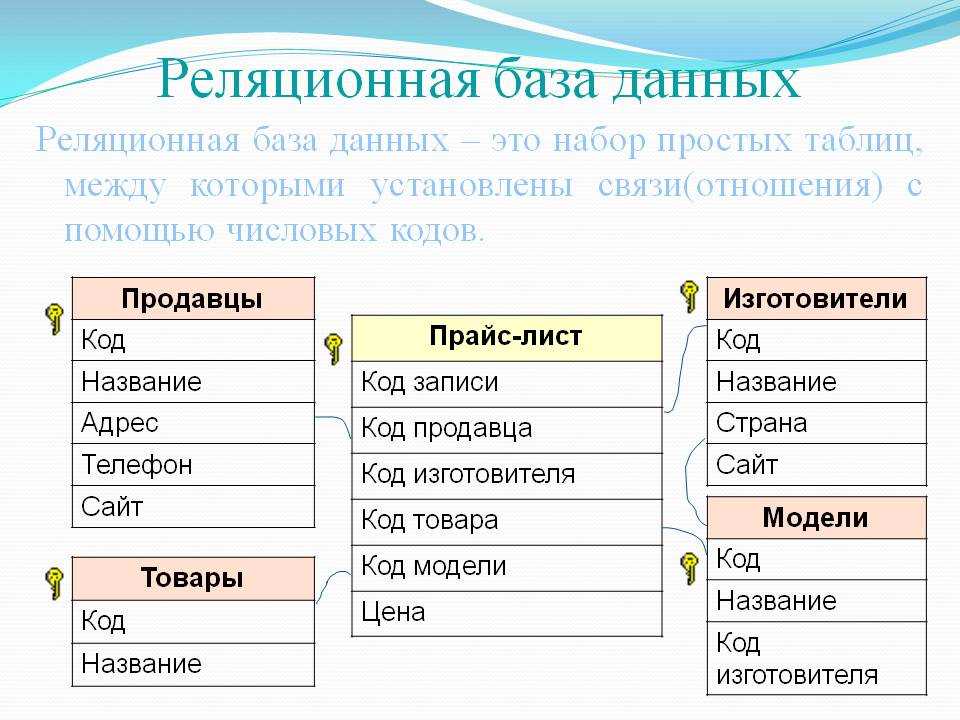 Это будет храниться в другой таблице:
Это будет храниться в другой таблице:
Тип данных, включенных в столбец, называется доменом. Думайте об этом как о типе столбца, который вы увидите в базе данных, — какую информацию содержит столбец.
Например, столбец ВОЗРАСТ может содержать любой возможный возраст. Столбец PHONE содержит номера телефонов. Это отличается от типа данных — столбцы AGE и PHONE содержат числа (это тип данных), но данные в этих столбцах относятся к двум разным доменам.
Компоненты реляционных моделей данных
Реляционные модели данных состоят из трех компонентов:
Структура данных : набор отношений и набор доменов, которые определяют, как данные могут быть представлены;
Обработка данных: Как вы можете работать с данными в модели, чтобы сделать их более удобными для чтения или более структурированными;
Целостность данных : Правила, которые определяют, как данные защищены и гарантируют, что сохраненные данные действительны.

Когда следует использовать реляционную модель данных?
Если ваши данные легко структурированы по категориям и вы можете определить отношения между точками данных, вам, вероятно, лучше всего использовать реляционную модель данных.
Например, если вы хотите смоделировать данные о результатах экзаменов учащихся, то реляционная модель имеет смысл, поскольку данные будут стандартизированы, легко организованы и непротиворечивы во времени.
Организуйте это так:
Связь: Результаты экзамена за июнь 2022
Столбцы : Название экзамена
Строки: Имя учащегося
Точки данных: Структура данных отсутствует, оценка5 получена 900 900 или организации, то он может сложно использовать реляционную модель, хотя, конечно, не невозможно .
Преимущества использования реляционной базы данных
Реляционные базы данных остаются одним из самых популярных подходов к моделированию данных, и на то есть веские причины:
Повышенная масштабируемость и эффективность : Реляционную базу данных можно легко увеличить или уменьшить по мере необходимости.
Например, если вам нужно добавить в таблицу дополнительные данные, вы можете добавить новый столбец. Реляционные базы данных также более эффективны, чем базы данных других типов, поскольку в них хранятся только данные, относящиеся к текущей задаче.Больше надежности и целостности : В реляционной базе данных применяются правила, обеспечивающие целостность, безопасность, согласованность и точность данных. Например, вы можете настроить такие правила, как:
 Например, если вам нужно добавить в таблицу дополнительные данные, вы можете добавить новый столбец. Реляционные базы данных также более эффективны, чем базы данных других типов, поскольку в них хранятся только данные, относящиеся к текущей задаче.
Например, если вам нужно добавить в таблицу дополнительные данные, вы можете добавить новый столбец. Реляционные базы данных также более эффективны, чем базы данных других типов, поскольку в них хранятся только данные, относящиеся к текущей задаче.Каждый клиент должен иметь уникальный идентификатор, чтобы исключить дублирование идентификаторов и обеспечить уникальную идентификацию каждого клиента.
Все имена клиентов должны быть введены в верхнем регистре, чтобы имена были согласованными и легко читаемыми.
Только авторизованные пользователи могут получить доступ к данным клиентов, что гарантирует безопасность конфиденциальных данных.
Недостатки использования реляционной базы данных
Негибкость: Реляционные базы данных могут быть негибкими, особенно когда речь идет об изменениях.
Например, добавление нового столбца в таблицу может потребовать от вас изменения нескольких других таблиц и написания сложных SQL-запросов для этого. Это занимает значительное время и может потребовать специальных знаний.Иногда медленно: При работе с большими объемами данных обработка реляционных баз данных может замедляться. Это связано с тем, что им необходимо обрабатывать несколько запросов SQL для получения нужной информации.
Комплекс: Реляционные базы данных могут включать сложные отношения данных. Например, если вы хотите связать две части данных, вам может понадобиться использовать несколько соединений таблиц и написать сложные SQL-запросы.
 Например, добавление нового столбца в таблицу может потребовать от вас изменения нескольких других таблиц и написания сложных SQL-запросов для этого. Это занимает значительное время и может потребовать специальных знаний.
Например, добавление нового столбца в таблицу может потребовать от вас изменения нескольких других таблиц и написания сложных SQL-запросов для этого. Это занимает значительное время и может потребовать специальных знаний.Иерархическая модель данных
Иерархическая модель данных – это способ организации данных в иерархию, немного напоминающую генеалогическое древо. Существует родительская запись, называемая «корневым узлом», с несколькими «дочерними узлами», соединяющимися с ней через ссылки.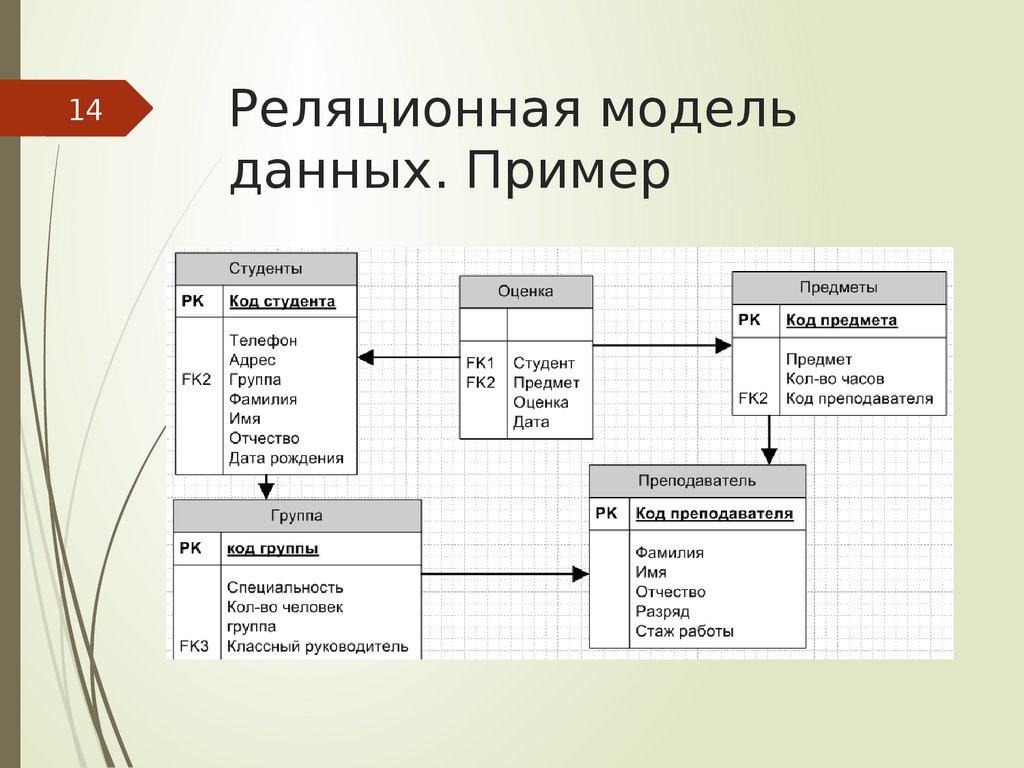 Для каждого дочернего узла существует только один родительский узел (хотя у родительского узла может быть несколько дочерних).
Для каждого дочернего узла существует только один родительский узел (хотя у родительского узла может быть несколько дочерних).
Пример иерархической модели данных
Хорошим примером иерархической модели данных может быть каталог. Например:
В этом примере корневым узлом является Электроника, которая имеет две подкатегории или «дочерние узлы» — Телевизоры и Портативная электроника. Эти категории или также родительские категории для своих собственных дочерних узлов — например, в разделе «Телевидение» мы видим Tube, LCD и Plasma. Однако все каталоги (записи) относятся к одному родительскому элементу — корневому узлу.
Наиболее целесообразно использовать иерархическую модель данных для данных, которые уже упорядочены по шаблону родитель-потомок, с одной корневой точкой, расходящейся на несколько ветвей. Например, подумайте об организационной диаграмме с несколькими отдельными сотрудниками, подчиняющимися одному менеджеру. Большинство из нас видели пример иерархической модели данных в действии — реестр Windows в операционной системе Microsoft Windows представляет собой иерархическую базу данных.
Преимущества иерархической модели
Иерархическая модель данных была популярна с момента ее создания, и легко понять, почему:
Простота понимания и использования: Иерархическая модель данных отражает то, как мы организуем информацию в нашем сознании. Это делает его естественным для многих приложений, таких как базы данных, файловые системы и системы управления документами.
Повышенная производительность: Когда данные хранятся в иерархической структуре, пользователи могут получить доступ к связанной информации с помощью одной операции, что намного эффективнее, чем извлечение данных из отдельных таблиц.
Простота обслуживания: Поддерживать этот тип модели просто, поскольку все данные хранятся в одной таблице, поэтому вам не нужно отслеживать несколько таблиц, чтобы обеспечить согласованность данных во всей системе. .
Упрощает сложную информацию: Иерархическая модель данных разбивает сложную информацию на более мелкие, более управляемые части.
Это упрощает работу с большими объемами данных.Поддерживает несколько представлений данных: Эта модель поддерживает несколько представлений данных, что важно для приложений, которым необходимо предоставить разным пользователям альтернативные представления одной и той же информации. Например, система базы данных может позволить менеджерам видеть данные о сотрудниках в иерархической структуре, в то время как сотрудники могут видеть те же данные в плоской структуре. Такая гибкость невозможна с другими моделями данных.
 Это упрощает работу с большими объемами данных.
Это упрощает работу с большими объемами данных.Недостатки иерархической модели
Ограниченная гибкость: Иерархическая модель данных является достаточно жесткой, поскольку данные организованы в виде строгой древовидной структуры. Если вы хотите добавить или удалить данные, вам может потребоваться переработать всю структуру. Это также может затруднить выполнение запроса, поскольку вам нужно пройти по иерархии, чтобы найти нужную информацию.
Избыточность данных: В иерархической модели данных дочерние узлы часто содержат дубликаты данных, хранящихся в их родительских узлах. Это может привести к нерациональному использованию места для хранения и несогласованности данных.

Сетевая модель данных
Сетевая модель данных представляет собой организацию данных в виде более гибкого ряда отношений. Это похоже на иерархическую модель данных, но дочерние узлы могут иметь несколько родительских узлов вместо одного.
Используемая терминология также отличается. Вместо родителей или корневых узлов у сетевых моделей данных есть владельцы. Точки данных, формирующие следующий уровень в иерархии, называются элементами.
Сетевые модели данных являются естественным развитием иерархических моделей данных. Они обеспечивают большую гибкость и сложность взаимосвязей между точками данных.
Пример сетевой модели данных
Преимущества сетевой модели
Сетевая модель представляет собой эволюцию иерархической модели и предлагает ряд существенных преимуществ:
Может представлять простые и сложные отношения: , сетевые модели могут выражать как простые, так и сложные отношения между точками данных.
Они могут собирать данные со структурой «один ко многим» (организационная диаграмма с одним начальником и несколькими прямыми подчиненными) и «многие ко многим» (скажем, матричная организационная диаграмма, где у каждого сотрудника может быть несколько начальников).Упрощенный дизайн и реализация базы данных: Как и иерархические модели, сетевые модели данных просты и логичны в разработке и реализации.
Более эффективный способ запроса, обновления и удаления данных: Любые изменения, внесенные в родительские данные, автоматически отражаются в дочерних данных, что позволяет быстрее вносить изменения в пакеты данных. (Однако стоит иметь в виду, что внесение структурных изменений в модель является сложной задачей. Все данные настолько взаимосвязаны, что, если вы хотите изменить набор данных, вам также придется отслеживать и изменять все данные, которые соединяют к этому тоже.)
Улучшенная производительность поиска данных: Эта модель имеет несколько путей связи между точками данных, что упрощает доступ к данным.
Простота использования и понимания: Сетевые модели данных позволяют разработчикам быстро и просто фиксировать отношения между точками данных интуитивно понятным и логичным образом.
 Они могут собирать данные со структурой «один ко многим» (организационная диаграмма с одним начальником и несколькими прямыми подчиненными) и «многие ко многим» (скажем, матричная организационная диаграмма, где у каждого сотрудника может быть несколько начальников).
Они могут собирать данные со структурой «один ко многим» (организационная диаграмма с одним начальником и несколькими прямыми подчиненными) и «многие ко многим» (скажем, матричная организационная диаграмма, где у каждого сотрудника может быть несколько начальников).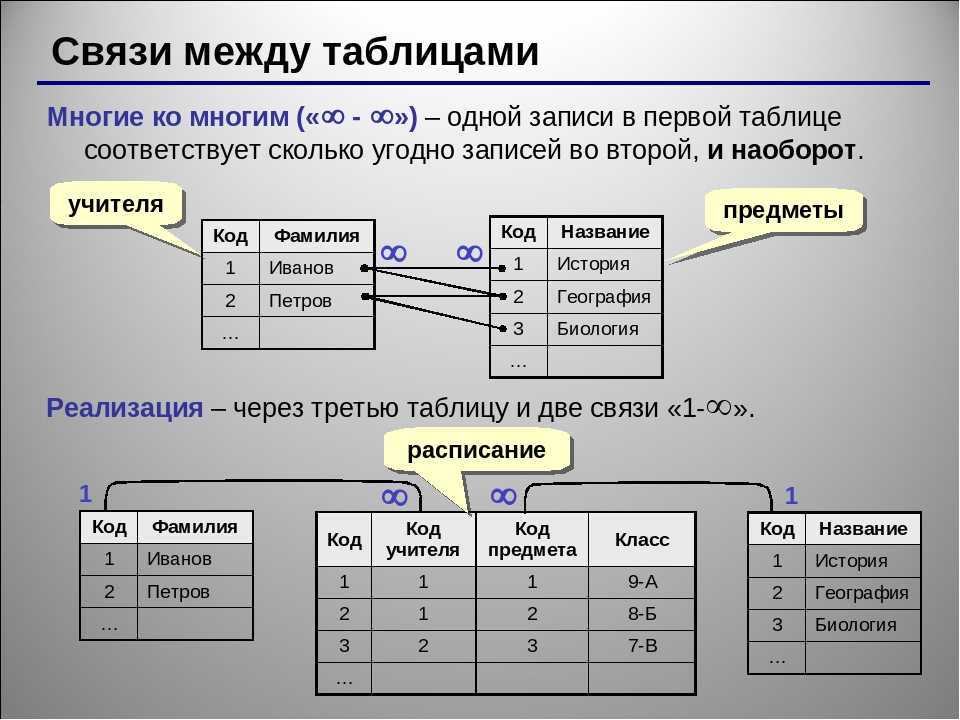
Недостатки сетевой модели
Ограниченная масштабируемость: Сетевая модель данных имеет меньшую масштабируемость, чем другие модели, поскольку отношения между элементами данных могут усложняться по мере роста базы данных.
Сложно выполнить запрос: В этой модели запрос к сетевой модели данных может быть сложным, поскольку отношения между элементами данных более сложны и трудны для понимания.
Отсутствие гибкости: Сетевая модель данных не так гибка, как другие модели, например реляционная модель. Это означает, что сложнее внести изменения в структуру данных, не затрагивая общую структуру базы данных.
Моделирование данных не должно быть (слишком) сложным.